В книге рассмотрены все важнейшие навыки работы с JavaScript, HTML5 и CSS3, требующиеся разработчику, чтобы преуспеть в создании современного клиентского кода. Изучая эту книгу, вы напишете четыре веб-приложения. Каждому приложению посвящена отдельная часть книги, а каждая глава добавляет в создаваемое приложение новые функциональные возможности. Создание этих четырех веб-приложений даст вам возможность изучить все технологии, требуемые для создания клиентской части.
• Ottergram. Наш первый проект посвящен веб-фотогалерее. Создание Ottergram научит вас основам программирования для браузеров с помощью языка разметки HTML, таблиц стилей CSS и языка программирования JavaScript. Вы вручную создадите пользовательский интерфейс и узнаете, как браузер загружает и визуализирует контент.
• CoffeeRun. Частично форма заказа кофе, частично — список заказов. CoffeeRun познакомит вас с множеством методов языка программирования JavaScript, включая написание модульного кода, использование преимуществ замыканий и взаимодействие с удаленным сервером с помощью технологии Ajax.
Далее под катом...
• Chattrbox. Часть, описывающая приложение Chattrbox, — самая короткая, и это приложение больше всего отличается от остальных. В нем будет использоваться язык программирования JavaScript для создания системы общения в Интернете, включая написание сервера чата с помощью платформы Node.js, а также браузерного клиента для чата.
• Tracker. Последний проект использует Ember.js — один из самых функциональных фреймворков для разработки клиентской части. Мы напишем приложение для каталогизации случаев наблюдения редких, экзотических и мифических существ. По ходу дела вы узнаете, как использовать возможности богатейшей экосистемы, лежащей в основе фреймворка Ember.js.
По мере создания этих приложений вы познакомитесь с множеством инструментов, включая:
— Текстовый редактор Atom и некоторые полезные плагины для работы с кодом;
— Источники документации, например Mozilla Developer Network;
— Командную строку с использованием приложения терминала OS X или командной строки Windows;
— Утилиту browser-sync;
— Инструменты разработчика браузера Google Chrome (Google Chrome’s Developer Tools);
— Файл normalize.css;
— Фреймворк Bootstrap;
— Библиотеки jQuery, crypto-js и moment;
— Платформу Node.js, систему управления пакетами Node (npm) и модуль nodemon;
— Протокол WebSockets и модуль wscat;
— Компилятор Babel и модули Babelify, Browserify и Watchify;
— Фреймворк Ember.js и такие дополнения к нему, как интерфейс командной строки Ember CLI, плагин для Chrome Ember Inspector, дополнение Ember CLI Mirage и шаблонизатор Handlebars;
— Систему управления пакетами Bower;
— Систему управления пакетами Homebrew;
— Утилиту Watchman.
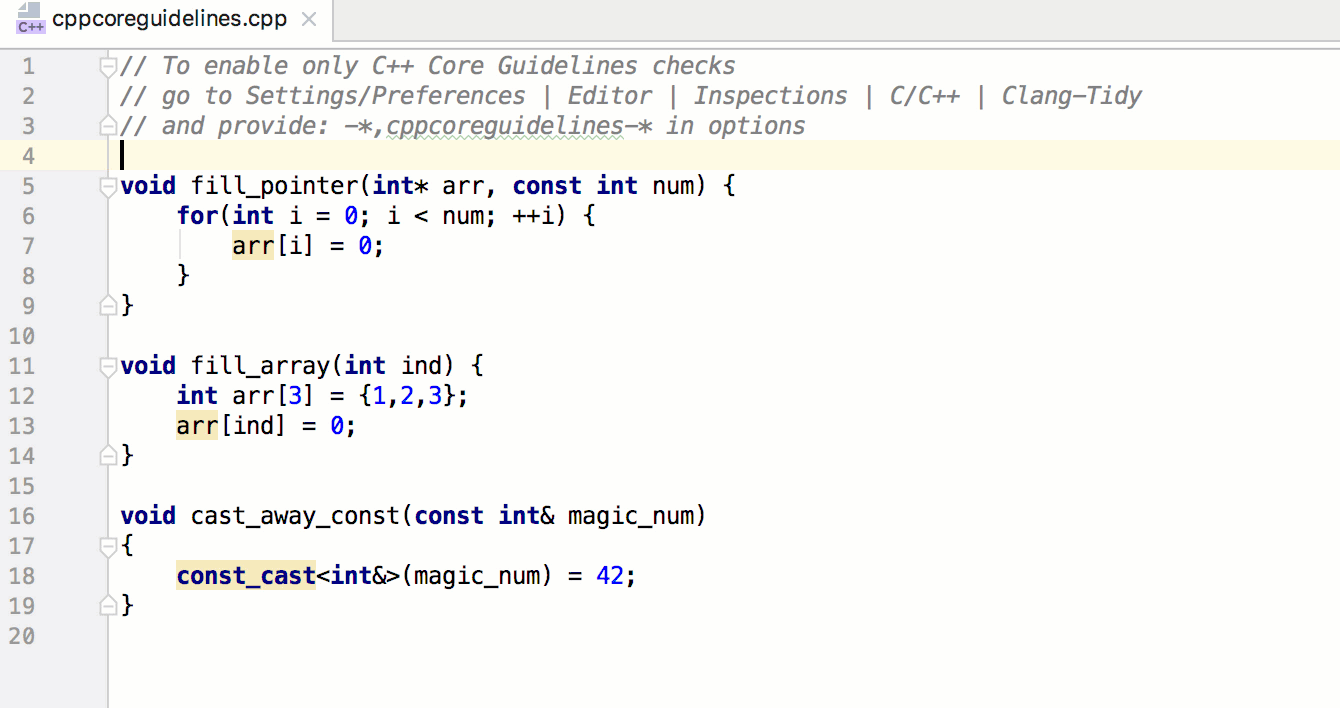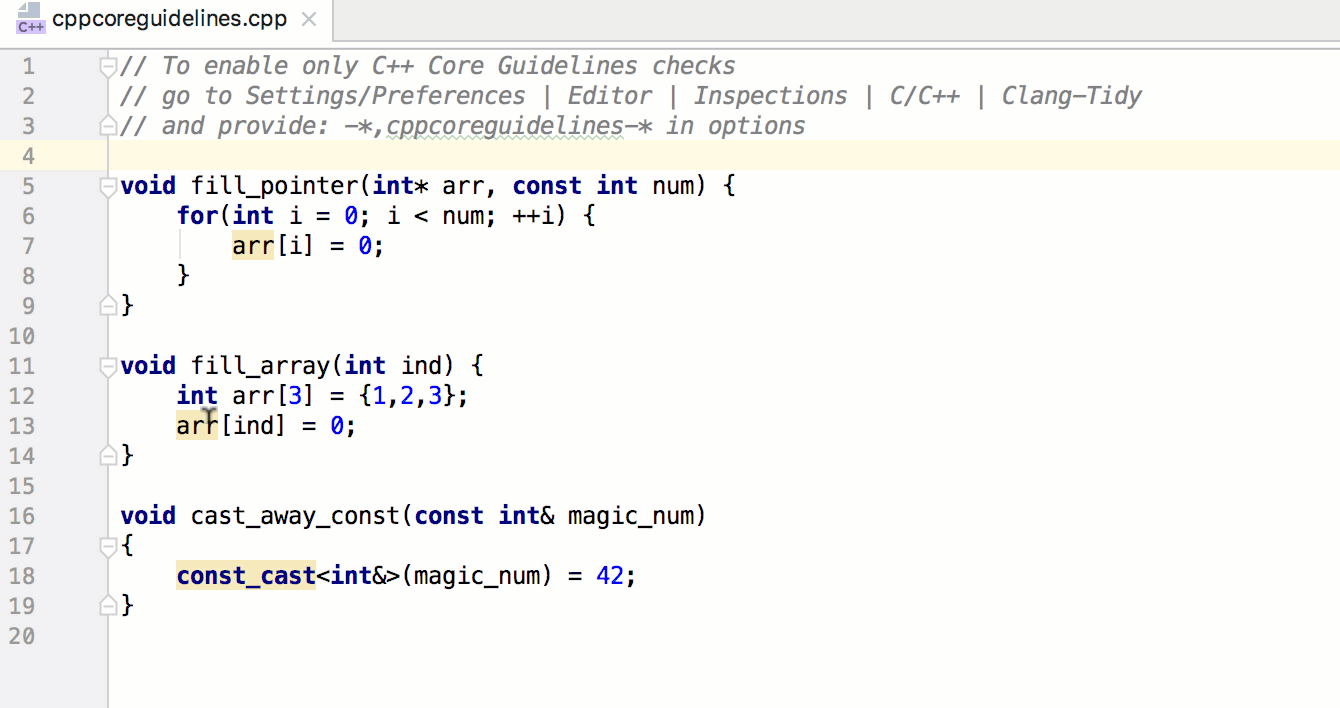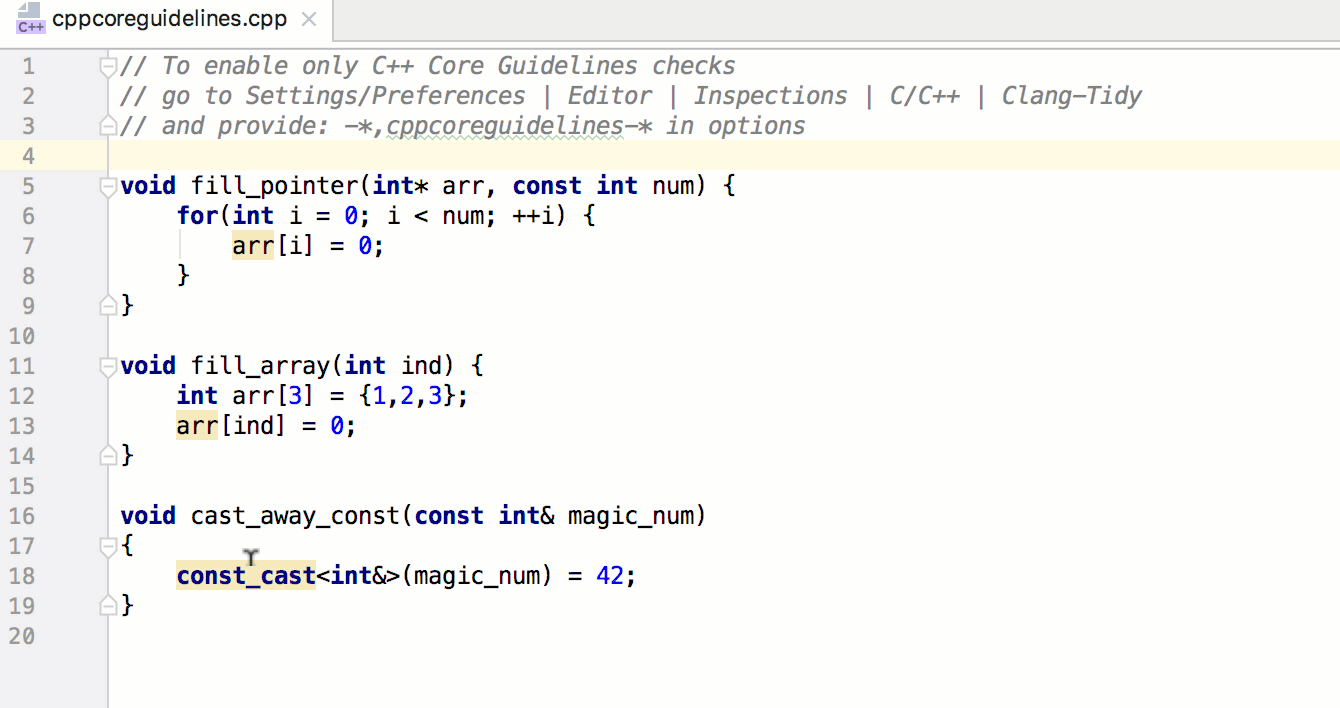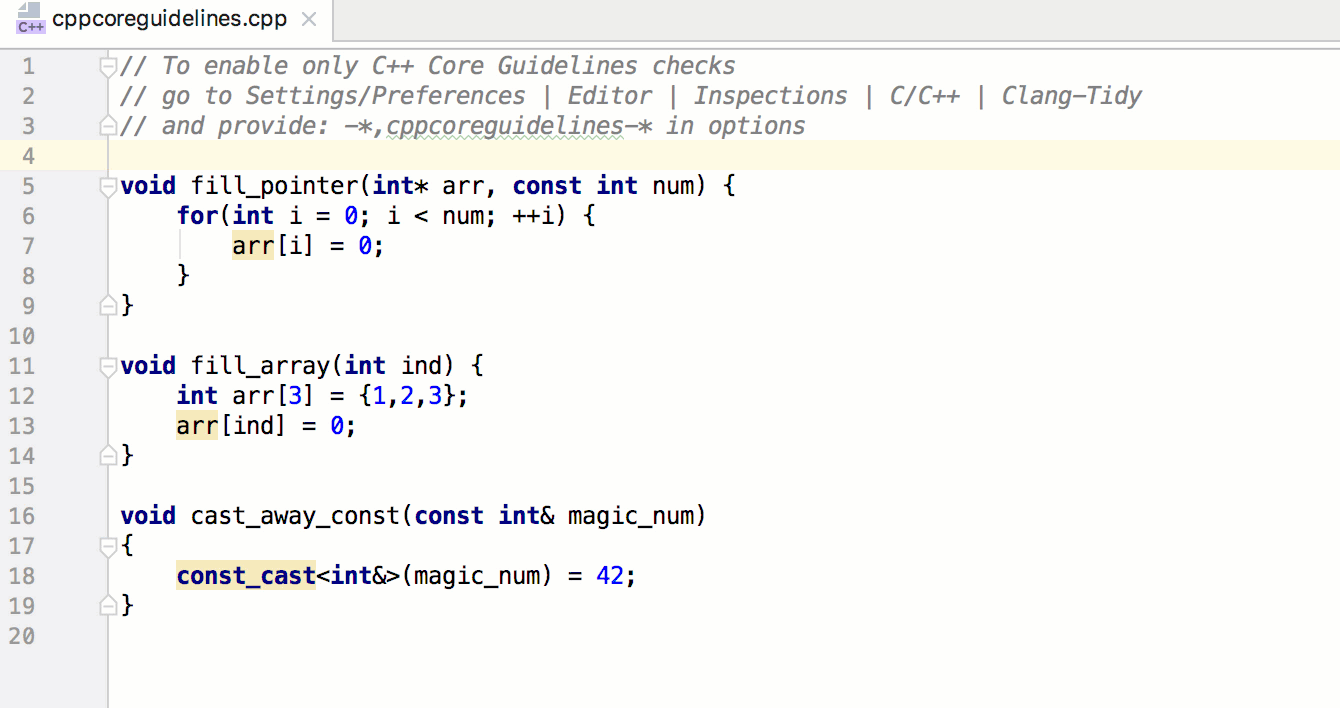
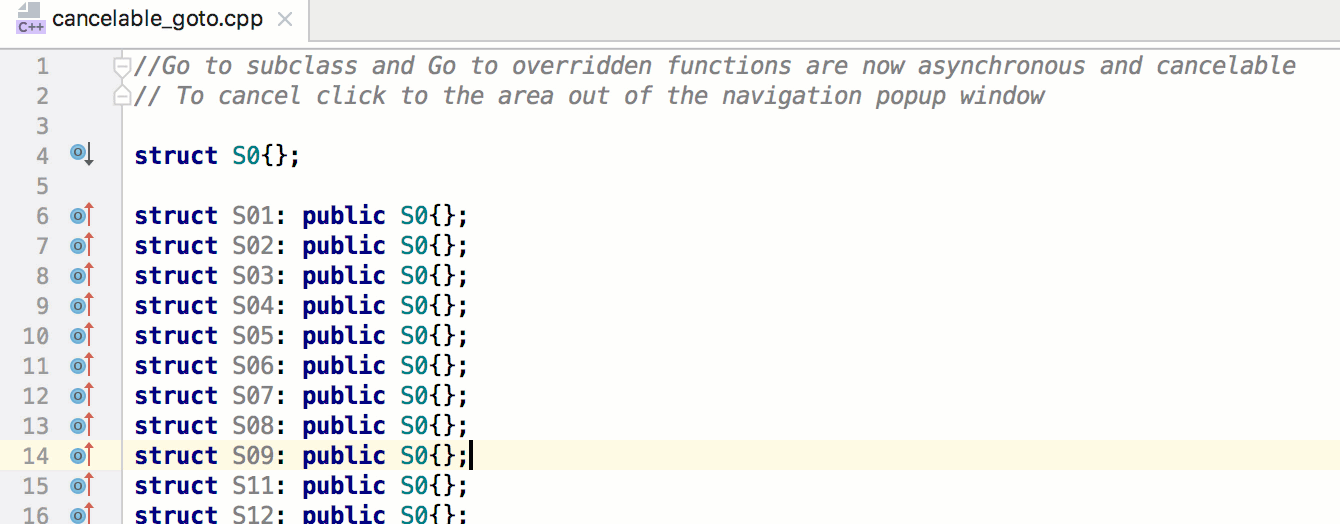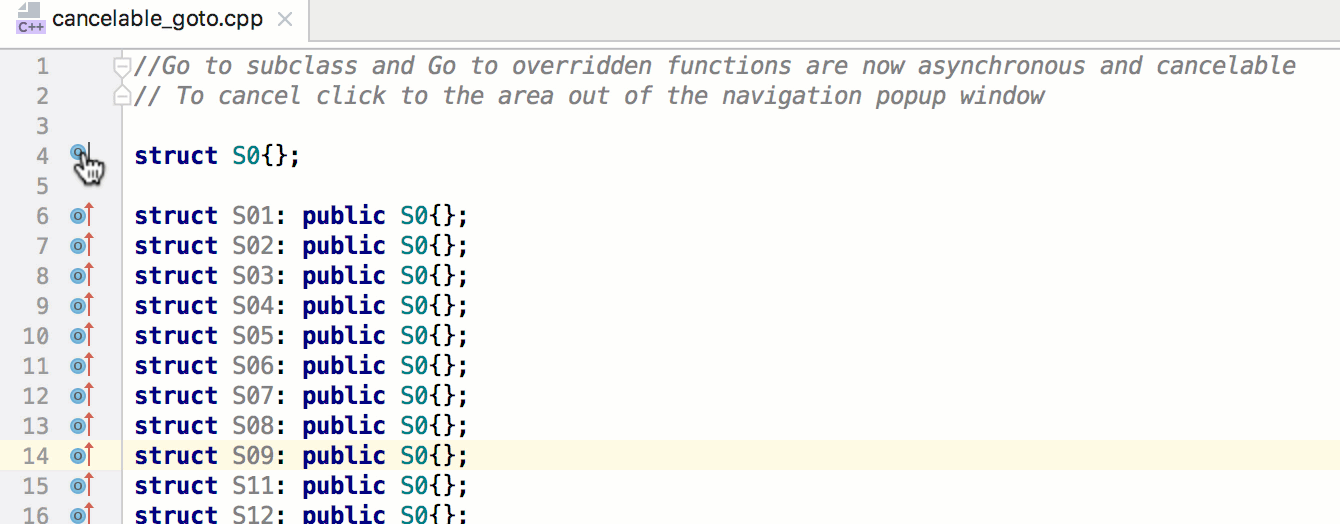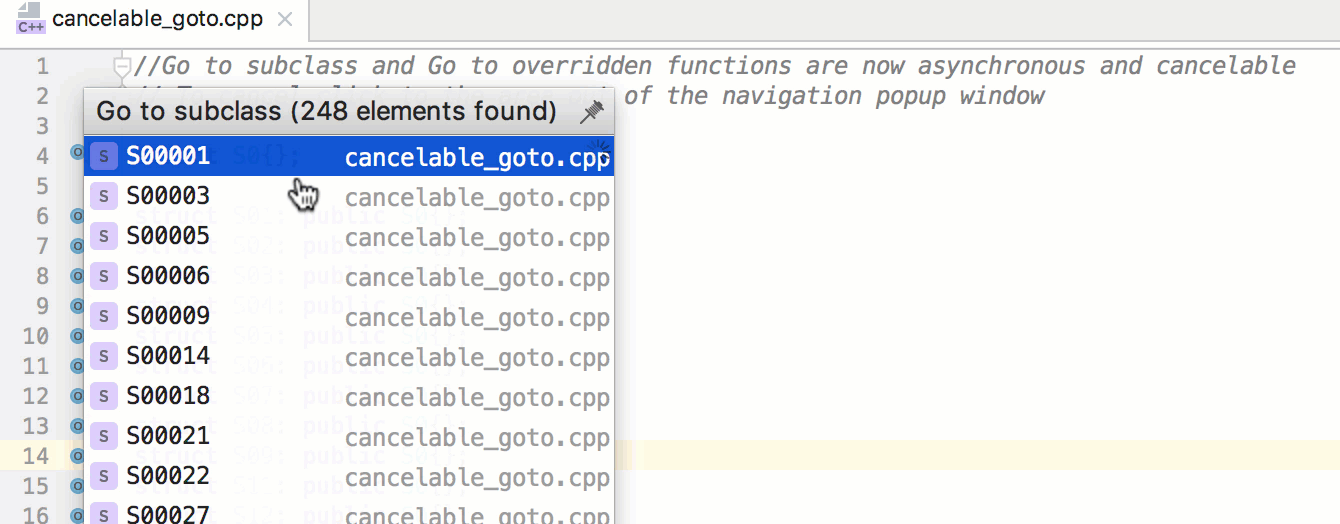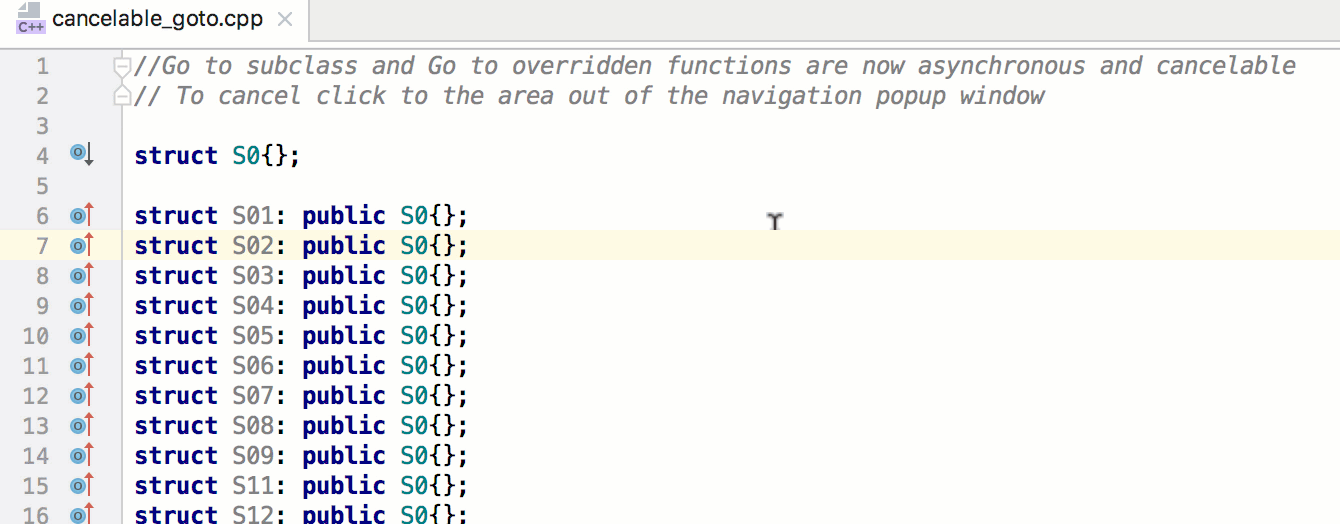
Отрывок. Организация цикла по массиву миниатюр
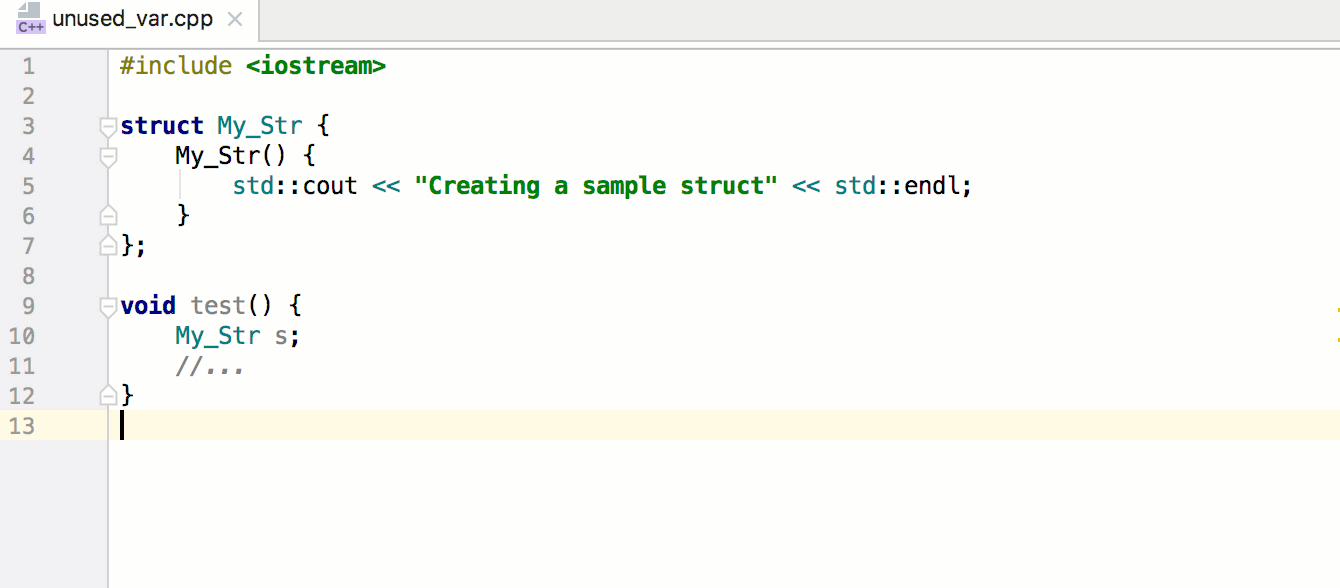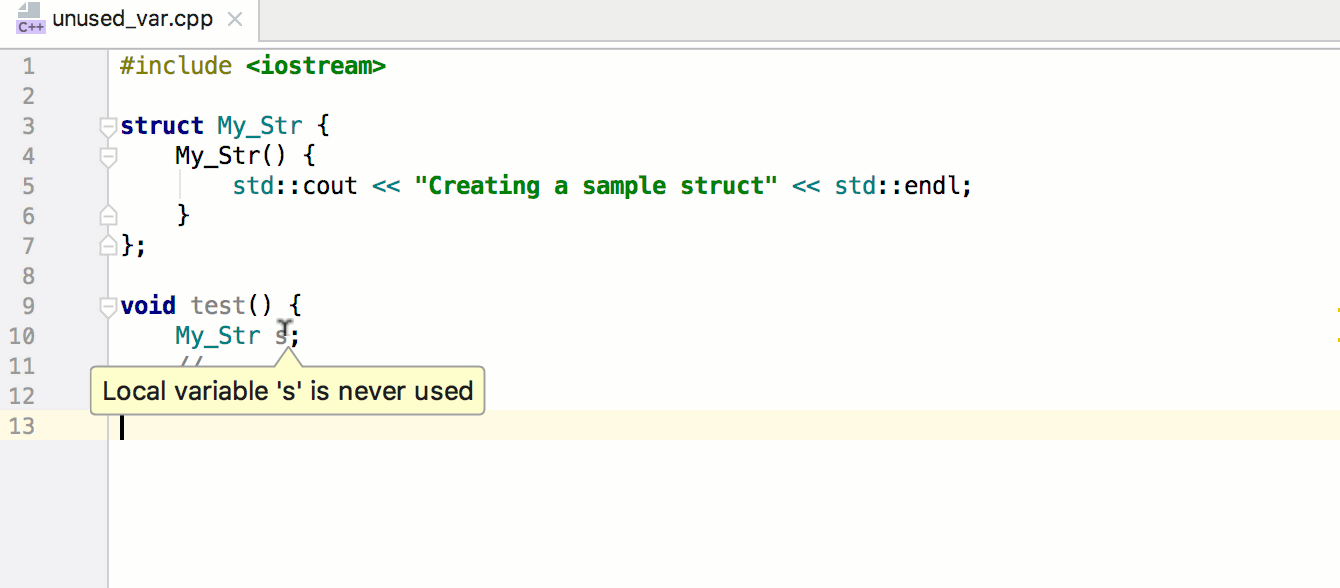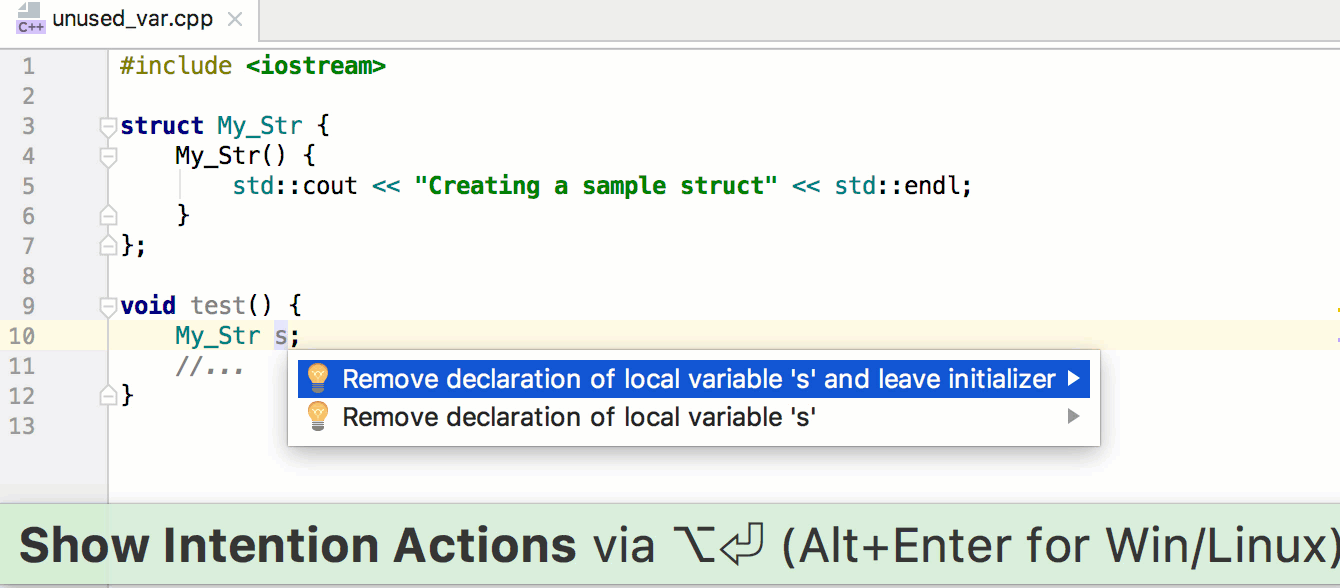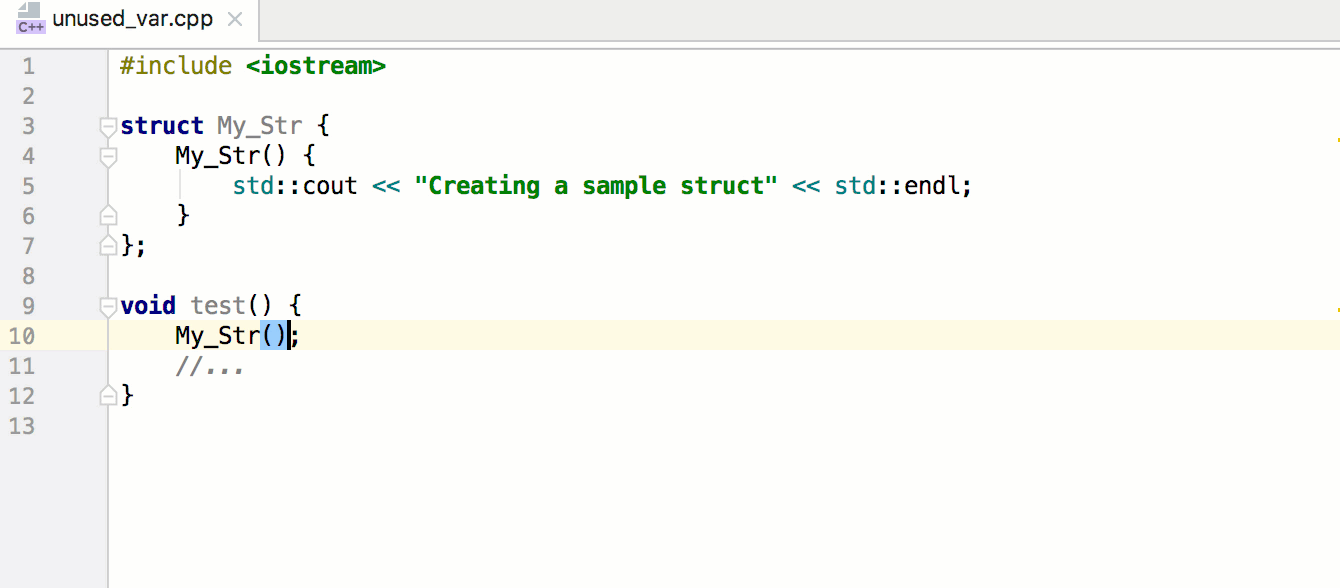
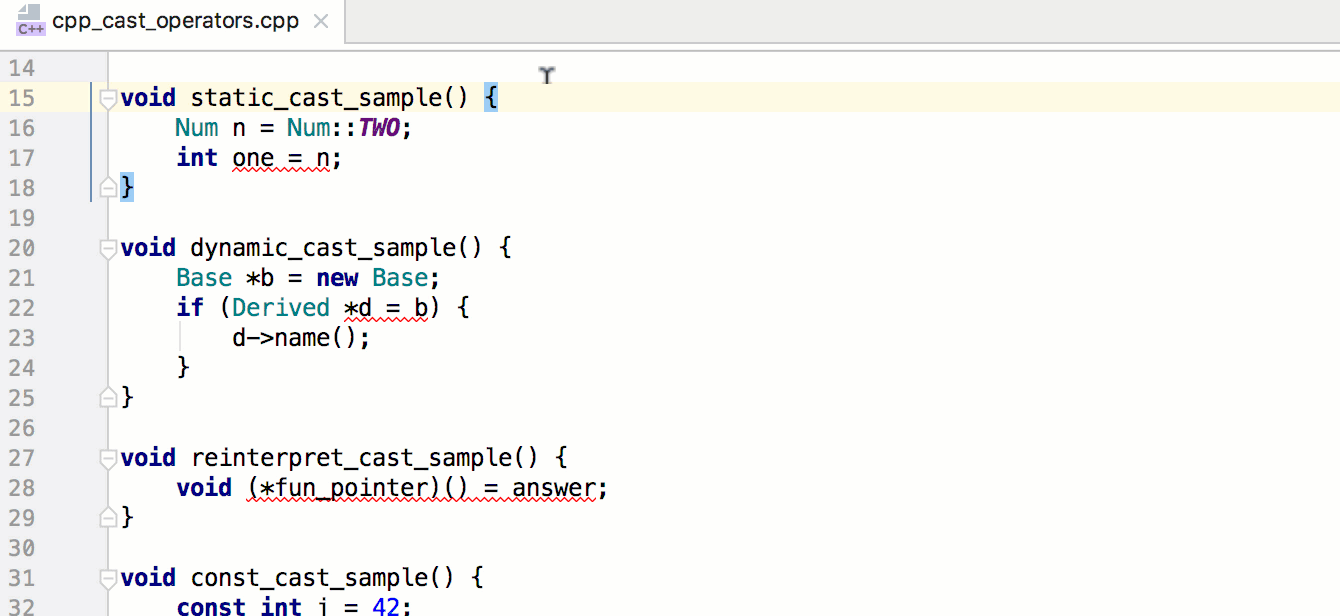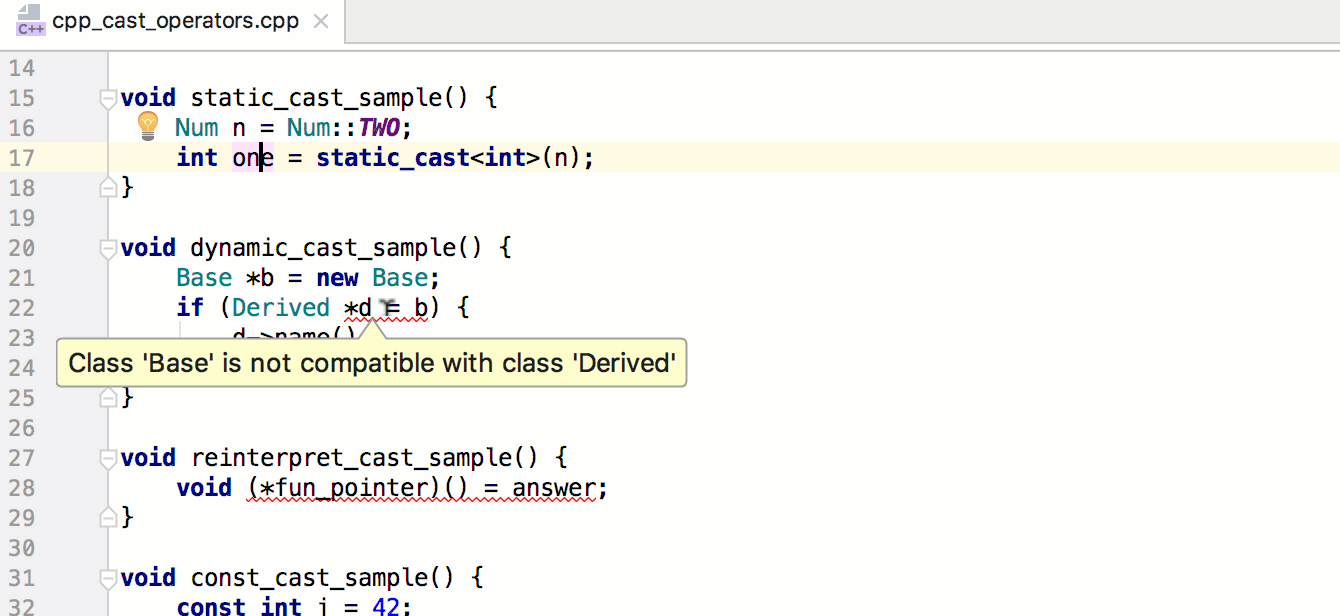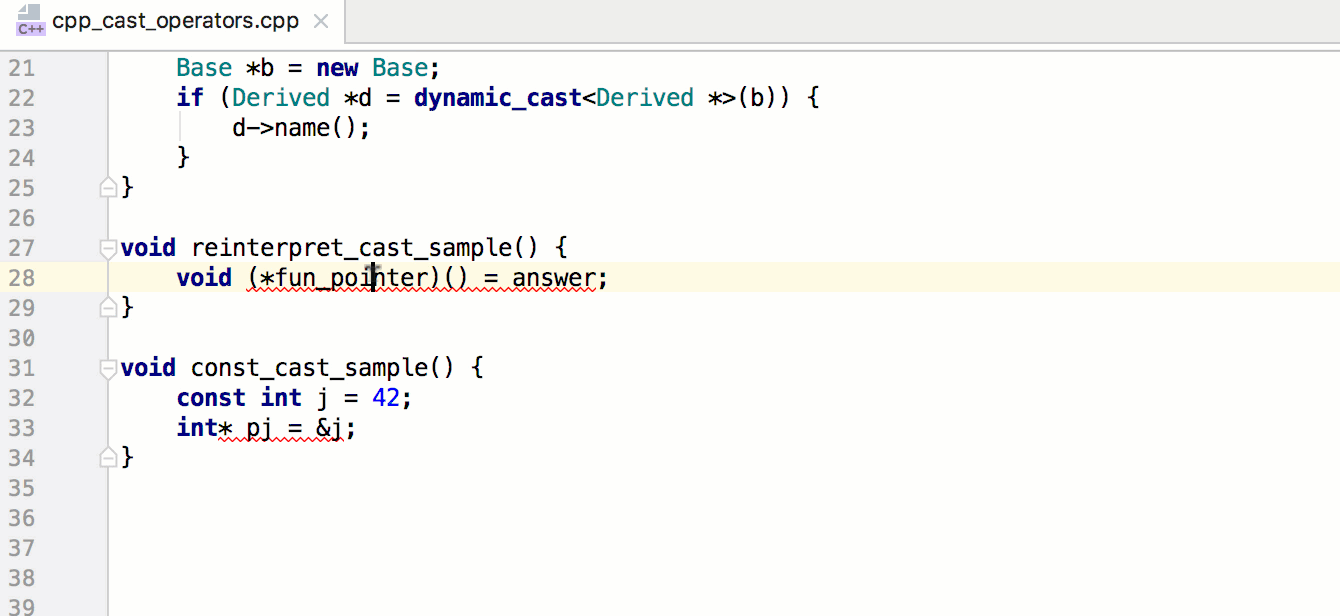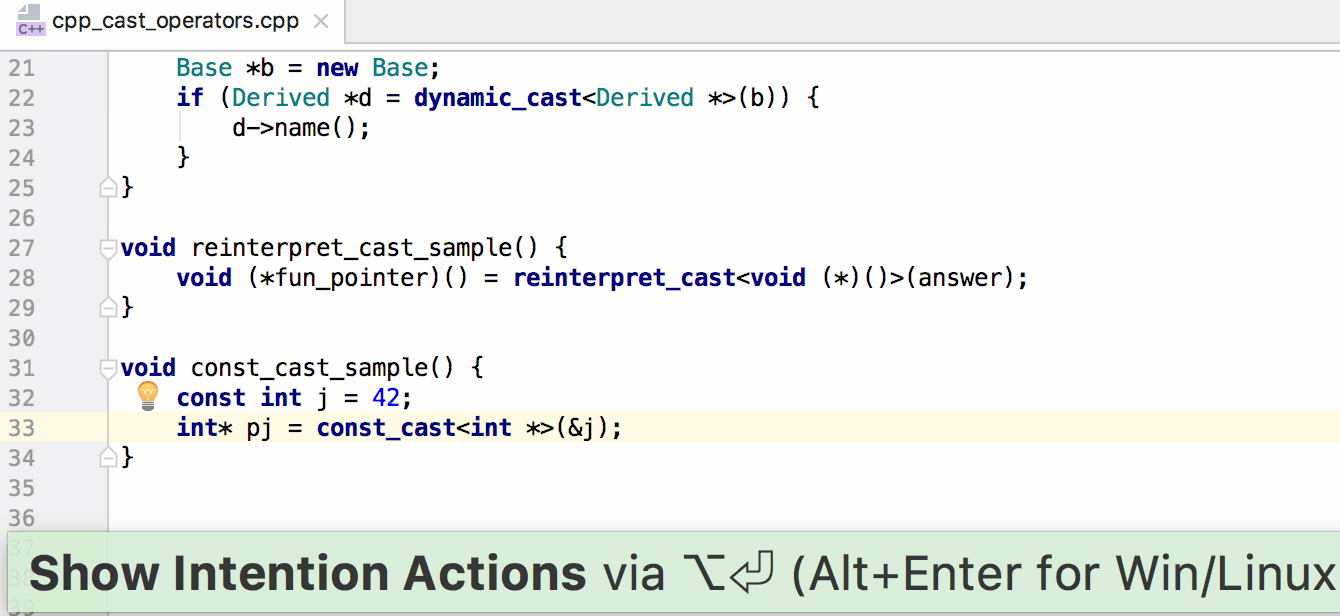
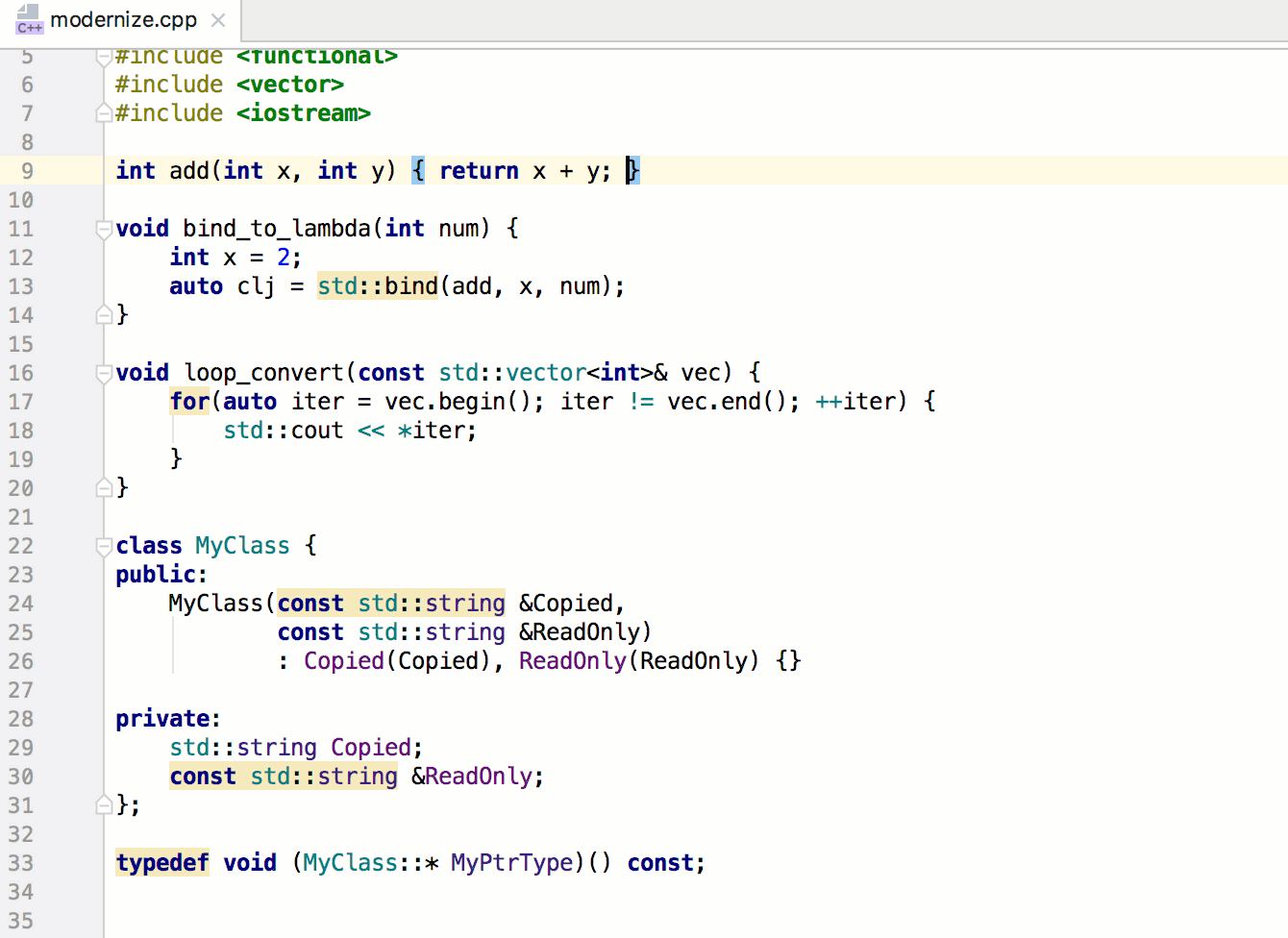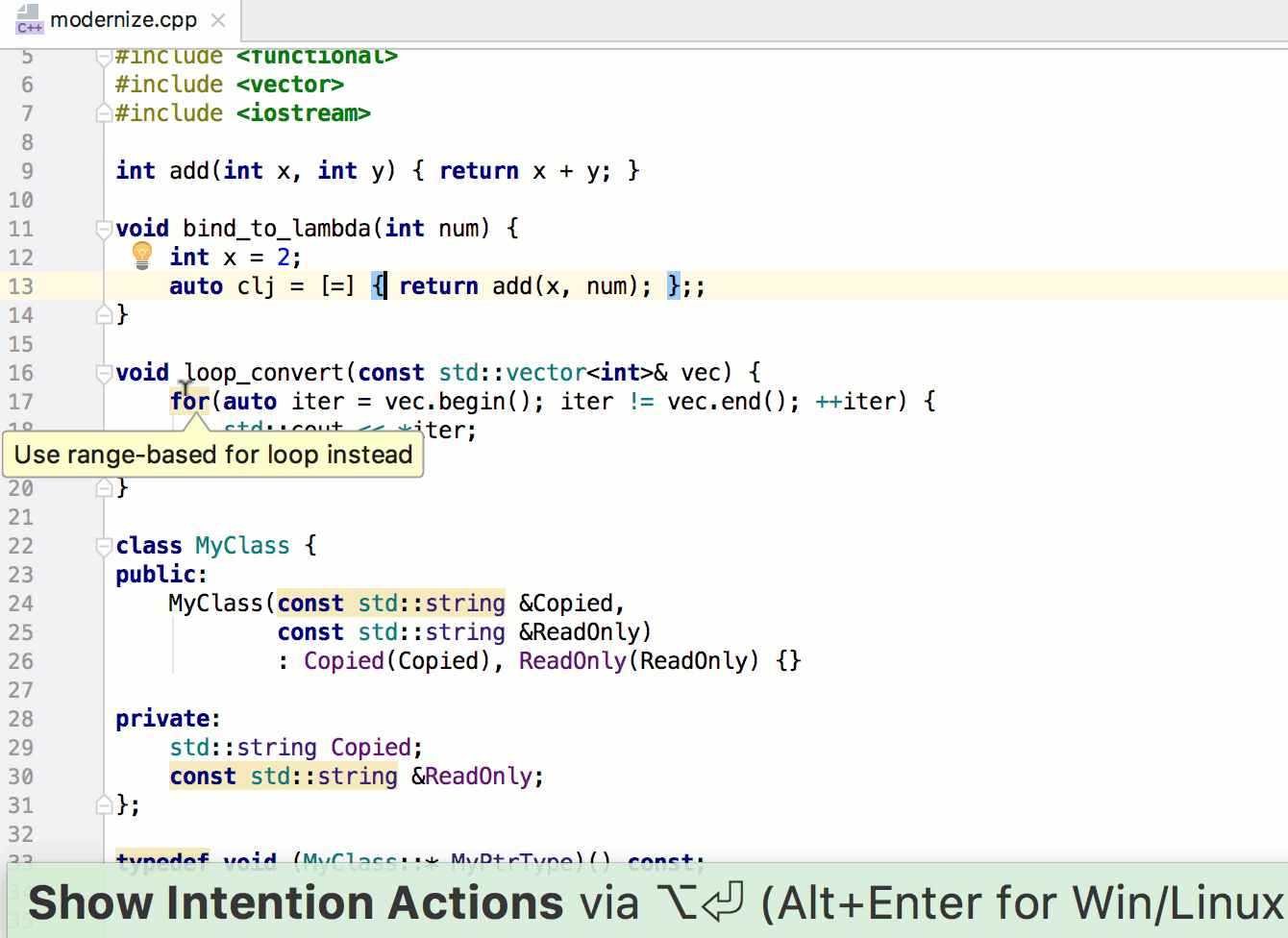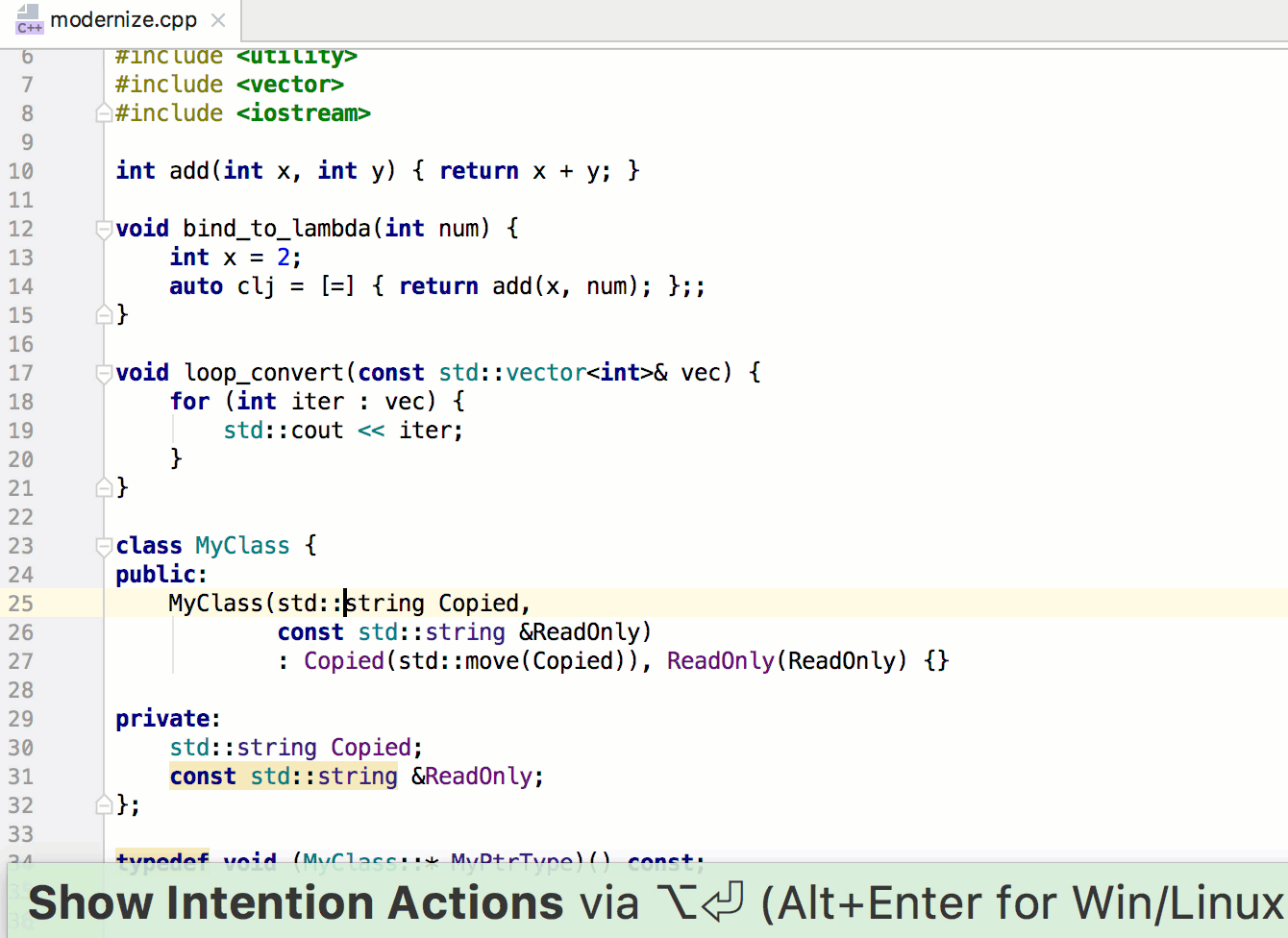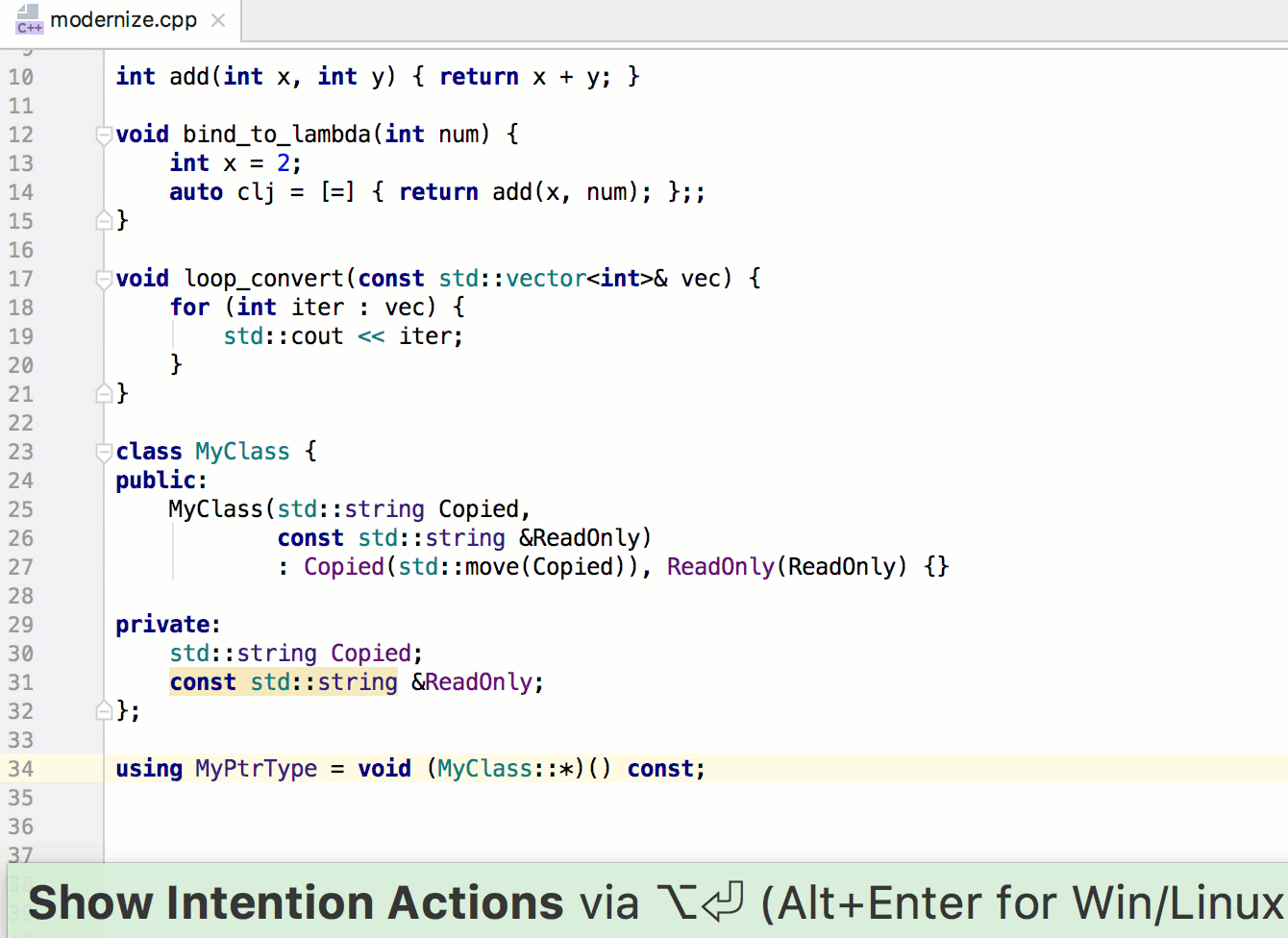
Связывание миниатюр с кодом обработки событий будет быстрым и несложным делом. Мы напишем функцию, которая станет отправной точкой всей логики Ottergram. В других языках программирования, в отличие от JavaScript, есть встроенный механизм запуска приложения. Но не волнуйтесь — его достаточно легко можно реализовать вручную.
Начнем с добавления функции initializeEvents в конец файла main.js. Этот метод свяжет воедино все шаги по превращению Ottergram в интерактивное приложение. Во-первых, он получит массив миниатюр. Далее он пройдет в цикле по массиву, добавляя обработчик нажатий для каждой из них. После написания этой функции мы добавим вызов функции initializeEvents в самый конец файла main.js для ее запуска.
В теле нашей новой функции добавьте вызов функции getThumbnailsArray и присвойте результат (массив миниатюр) переменной thumbnails:
...
function getThumbnailsArray() {
...
}
function initializeEvents() {
'use strict';
var thumbnails = getThumbnailsArray();
}
Далее нам нужно пройти в цикле по массиву миниатюр, по одному элементу за раз. При обращении к каждому из них мы будем вызывать метод addThumbClickHandler и передавать ему элемент миниатюры. Это может показаться несколькими шагами, но поскольку thumbnails — настоящий массив, сделать все это можно с помощью вызова одного-единственного метода.
Добавьте вызов метода thumbnails.forEach в файл main.js и передайте его функции addThumbClickHandler в качестве обратного вызова.
...
function initializeEvents() {
'use strict';
var thumbnails = getThumbnailsArray();
thumbnails.forEach(addThumbClickHandler);
}
Обратите внимание, что вы передаете в качестве обратного вызова поименованную функцию. Как вы прочтете далее, это не всегда хорошее решение. Однако в данном случае оно сработает как надо, поскольку функции addThumbClickHandler требуется только та информация, которая будет ей передаваться, когда ее будет вызывать метод forEach, — элемент массива thumbnails.
Наконец, чтобы увидеть все это в действии, добавьте вызов функции initializeEvents в самый конец файла main.js:
...
function initializeEvents() {
'use strict';
var thumbnails = getThumbnailsArray();
thumbnails.forEach(addThumbClickHandler);
}
initializeEvents();
Помните, браузер выполняет код по мере чтения каждой строки вашего JavaScript. На протяжении большей части файла main.js он просто выполняет объявления переменных и функций. Но когда он дойдет до строки initializeEvents();, он выполнит эту функцию. Сохраните и вернитесь в браузер. Нажмите на несколько различных миниатюр и полюбуйтесь на плоды своих трудов (рис. 6.28).
Откиньтесь на спинку кресла, расслабьтесь и наслаждайтесь щелчками на фото выдр! Вы немало потрудились и усвоили много нового во время создания интерактивного слоя нашего сайта. В следующей главе мы завершим создание Ottergram, добавив для пущей красоты визуальные эффекты.
Серебряное упражнение: взлом ссылок
DevTools браузера Chrome предоставляют немало возможностей для развлечений с посещаемыми страницами. Следующее упражнение будет заключаться в том, чтобы поменять все ссылки на странице результатов поиска так, чтобы они вели в никуда.
Зайдите в вашу любимую поисковую систему и выполните поиск по ключевому слову выдры. Откройте консоль DevTools. Используя написанные для Ottergram функции в качестве образца, подключите прослушиватели событий ко всем ссылкам и отключите имеющуюся по умолчанию функциональность перехода по щелчку кнопкой мыши.
Золотое упражнение: случайные выдры
Напишите функцию для изменения атрибута data-image-url случайно выбранной миниатюры выдры так, чтобы увеличенное изображение более не соответствовало миниатюре. Используйте URL изображения по вашему выбору (хотя можно отыскать неплохое путем поиска в Интернете по слову tacocat). В качестве дополнительного упражнения напишите функцию, возвращающую миниатюрам выдр исходные значения атрибута data-image-url и меняющую одну из них, выбранную случайным образом.
Для самых любознательных: строгий режим
Что такое строгий режим и для чего он существует? Он был создан в качестве более «чистого» режима JavaScript, позволяет перехватывать определенные виды ошибок программирования (например, опечатки в именах переменных), удерживая разработчиков от использования некоторых подверженных ошибкам частей языка и отключая возможности языка, которые попросту явно неудачны.
У строгого режима есть немало преимуществ:
• Заставляет использовать ключевое слово var
• Не требует использования операторов with
• Ограничивает способы использования функции eval
• Рассматривает дублирующиеся имена параметров функций как синтаксическую ошибку
Все это можно получить всего лишь за счет размещения директивы 'use strict' наверху функции. В качестве бонуса директива 'use strict' игнорируется не поддерживающими ее старыми версиями браузеров (эти браузеры просто рассматривают эту директиву как строку).
Прочесть больше о строгом режиме можно на MDN по адресу.
Всем привет! В нескольких статьях я хотел бы поделиться опытом создания подобия ММО игры используя Unreal Engine и Netty. Возможно архитектура и мой опыт кому-то пригодится и поможет начать создавать свой игровой сервер в противовес unreal dedicated server, который слегка прожорлив или заменить собой фреймворки для разработки многопользовательских игр такие как Photon.
В конечном итоге у нас будет клиент, который логиниться или регистрируется в игре, может создавать игровые комнаты, пользоваться чатом и начинать игры, соединение будет зашифровано, клиенты будут синхронизироваться через сервер, в игре будет присутствовать одно оружие — лазер, выстрел будет проверяться на проверочном сервере. Я не стремился сделать красивую графику, тут будет только необходимый минимум, дальнейший функционал добавляется по аналогии. Логику можно легко расширить на сервере, добавить например случайные игры и балансер. Для меня было важно создать ММО базу и разобраться с тем что понадобится для создания полноценной мобильной ММО игры.
Часть 1. Общая картина, сборка библиотек, подготовка клиента и сервера к обмену сообщениями
Часть 2. Наращивание игрового функционала
Часть 3. Бонус материал. HLSL шейдеры в Unreal Engine, генерация ландшафтной сетки с помощью алгоритма Diamond Square, динамическая подгрузка моделей из сети
Общая архитектура, как всё работает
В начале я опишу в общих чертах, а затем мы напишем всё шаг за шагом. Общение клиент сервер построено на сокетах, формат обмена сообщениями Protobuf, каждое сообщение после входа в игру шифруется с помощью алгоритма AES используя библиотеку OpenSSL на клиенте и javax.crypto* на сервере, обмен ключами происходит с помощью протокол Диффи — Хеллмана. В качестве асинхронного сервера используется Netty, данные будем хранить в MySQL и использовать для выборки Hibernate. Я ставил целью поддержку игры на Android, поэтому мы уделим немного внимания портированию под эту платформу. Я назвал проект Spiky — колючий, и не с проста:
Начнем с того как происходит общение между клиентом и сервером. Оба обладают MessageDecoder и DecryptHandler, это точки входа для сообщений, после чтения пакета, сообщения дешифруются, определяется их тип и по типу отправляются на какой-то обработчик. Точка выхода MessageEncoder и EncryptHandler, клиента и сервера соответственно. Когда мы в Netty отправляем сообщение, оно будет проходить через EncryptHandler. Тут принимается решение нужно ли шифровать, и как обёртывать.
Каждое сообщение, обёртывается в протобаф Wrapper, получатель проверяет что внутри Wrapper, для выбора обработчика, это может быть CryptogramWrapper — шифрованные байты или открытые сообщения. Сообщение Wrapper будет выглядеть примерно так (часть его):
Весь обмен сообщениями построен на принципе Decoder-Encoder, если нам надо добавить новую команду в игру, нужно обновить условия. Например клиент хочет зарегистрироваться, сообщение попадает в MessageEncoder, где шифруется, обёртывается и отправляется на сервер. На сервере сообщение поступает на DecryptHandler, дешируется если надо, читается тип по наличию у сообщения полей и отправляется на обработку
if(wrapper.hasCryptogramWrapper())
{
if(wrapper.getCryptogramWrapper().hasField(registration_cw))
{
byte[] cryptogram = wrapper.getCryptogramWrapper().getRegistration().toByteArray();
byte[] original = cryptography.Decrypt(cryptogram, cryptography.getSecretKey());
RegModels.Registration registration = RegModels.Registration.parseFrom(original);
new Registration().saveUser(ctx, registration);
}
else if (wrapper.getCryptogramWrapper().hasField(login_cw)) {}
}
Для того чтобы найти поле в сообщении используя .hasField, нам понадобится набор дескрипторов (registration_cw, login_cw) мы их будем хранить отдельно в классе Descriptors.
Итак, если нам нужен новый функционал, то мы
1. Создаём новый тип Protobuf сообщения, вкладываем его в Wrapper/CryptogramWrapper
2. Объявляем поля к которым нужен доступ в дескрипторах клиента и сервера
3. Создаём класс логики в который после определения типа отправляем сообщение
4. Добавляем условие определяющее новый тип в Decode-Encoder клиента и сервера
5. Обрабатываем
Эта ключевой момент который придётся повторять множество раз.
В этом проекте я использовал протокол TCP, конечно лучше писать свою надстроку над UDP, что я и пробовал делать вначале, но всё что у меня выходило, было похоже на TCP единственный минус которого, в моей ситуации, невозможность отключить подтверждение пакетов, TCP ждёт подтверждения, прежде чем продолжить отправку, это создаёт задержки, и добиться пинга меньше 100 будет сложно, если пакет будет потерян при передаче по сети, игра останавливается и ждет, пока пакет не будет доставлен повторно. К сожалению, изменить такое поведение TCP никак нельзя, да и не надо, так как в нем и заключается смысл TCP. Выбор типа сокетов полностью зависит от жанра игры, в играх жанра action важно не то что происходило секунду назад, а важно наиболее актуальное состояние игрового мира. Нам нужно, чтобы данные доходили от клиента к серверу как можно быстрее, и мы не хотим ждать повторной отправки данных. Вот почему не следует использовать TCP для многопользовательских игр.
Но если мы хотим сделать reliable udp нас ждут трудности, нам нужно реализовать упорядоченность, возможность включения отключения подтверждения доставки, контроль загруженности канала, отправку больших сообщений, больше 1400 байт. Action игры должны использовать UDP для тех кто хочет почитать про это подробнее советую начать с этих статей и книги:
Мне нужно было надёжное, последовательное соединение, для передачи команд, зашифрованных сообщений и файлов (капча). TCP даёт мне такие возможности из коробки. Для передачи игровых данных, часто обновляемых и не очень важных, таких как перемещение игроков, UDP лучший вариант, я добавил возможность отправки UDP сообщений для полноты и чтобы было с чего начать, но в этом проекте всё общение будет происходить посредством TCP. Возможно стоит использовать TCP и UDP совместно? Однако тогда увеличивается количество потерянных UDP пакетов, так как TCP приоритетнее. UDP остался в области дальнейших улучшений. В этой статье я следую принципу «Done in better when pefect»
В основе сервера лежит Netty, он берет на себя работу с сокетами, реализуя удобную архитектуру. Можно подключить несколько обработчиков для входящих данных. В первом обработчике мы десериализируем входящее сообщение используя ProtobufDecoder, а далее обрабатываем непосредственно игровые данные. При этом можно гибко управлять настройками самой библиотеки, выделять ей необходимое число потоков или памяти. C помощью Netty можно быстро и просто написать любое клиент-серверное приложение, которое будет легко расширяться и масштабироваться. Если для обработки клиентов не хватает одного потока, следует всего лишь передать нужное число потоков в конструктор EventLoopGroup. Если на какой-то стадии развития проекта понадобится дополнительная обработка данных, не нужно переписывать код, достаточно добавить новый обработчик в ChannelPipeline, что значительно упрощает поддержку приложения.
Общая архитектура при использовании Netty у нас выглядит так:
public class ServerInitializer extends ChannelInitializer {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
/* отладка */
//pipeline.addLast(new LoggingHandler(LogLevel.INFO));
/* разворачиваем сообщения */
// Decoders protobuf
pipeline.addLast(new ProtobufVarint32FrameDecoder());
pipeline.addLast(new ProtobufDecoder(MessageModels.Wrapper.getDefaultInstance()));
/* оборачиваем сообщения */
// Encoder protobuf
pipeline.addLast(new ProtobufVarint32LengthFieldPrepender());
pipeline.addLast(new ProtobufEncoder());
/* Соединение закрывается если не было входящих сообщений в течении 30 секунд */
pipeline.addLast(new IdleStateHandler(30, 0, 0));
/* зашифруем исходящее сообщение */
pipeline.addLast(new EncryptHandler());
/* расшифруем входящее сообщение */
pipeline.addLast(new DecryptHandler());
}
}
Плюс такого подхода в том что сервер и обработчики можно разнести по разным машинам получив кластер для расчетов игровых данных, получаем довольно гибкую структуру. Пока нагрузки маленькие можно держать все на одном сервере. При возрастании нагрузки логику можно выделить в отдельную машину.
Для проверки попаданий я создал специальный Unreal Engine клиент, задача которого принимать параметры выстрела, размещать объект в мире, на основе того где он был в момент выстрела, симулировать выстрел возвращая основному серверу информацию о попадании, имя объекта перекрытия, кость если есть, или же что промахнулись.
Начнём с нуля
Я старался писать подробно, но многое вынес под спойлер.
Создадим пустой проект с кодом назовём его Spiky. Первым делом удалим созданный по умолчанию GameMode (это класс, определяющий правила текущей игры, может быть переопределен для каждого конкретного уровня, чем мы далее воспользуемся, существует только один экземпляр GameMode) – удалим Spiky_ClientGameModeBase созданный автоматически. Далее откроем Spiky_Client.Build.cs, это часть Unreal Build System в котором мы подключаем различные модули, сторонние библиотеки а так же настраиваем различные сборочные переменные, по умолчанию начиная с версии 4.16 используется режим SharedPCH (Sharing precompiled headers), а так же Include-What-You-Use (IWYU), позволяющий не включать тяжелые заголовки Engine.h. В предыдущих версиях Unreal Engine большая часть функциональности движка была включена через файлы с заголовком модуля, такие как Engine.h и UnrealEd.h, а время компиляции зависело от того, как быстро эти файлы могли быть скомпилированы через Precompiled Header (PCH). По мере роста движка это стало узким местом.
Работает хорошо на быстрых машинах с ssd (для работы с unreal – must have иначе головная боль, еще советую отключить IntelliSense и использовать вместо него VisualAssist) но не обладающим ssd машинам, для удобства и скорости я посоветовал бы переключиться на другой режим, который меньше пишет на диск, что мы и сделаем, включив PCHUsageMode.Default тем самым отключив генерацию Precompiled Header.
using UnrealBuildTool;
public class Spiky_Client : ModuleRules
{
public Spiky_Client(ReadOnlyTargetRules Target) : base(Target)
{
PCHUsage = PCHUsageMode.Default;
PublicDependencyModuleNames.AddRange(new string[] { "Core", "CoreUObject", "Engine", "InputCore" });
PrivateDependencyModuleNames.AddRange(new string[] { });
}
}
В чем отличие PublicDependencyModuleNames от PrivateDependencyModuleNames? В Unreal проектах желательно использовать Source/Public и Source/Private для заголовков-интерфейсов и исходного кода, тогда PublicDependencyModuleNames будут доступны в Public и Private папках, но PrivateDependencyModuleNames будет доступен только в папке Private. Разные другие параметры сборки можно изменить переопределив BuildConfiguration.xml, все параметры можно узнать тут:
Включим мелкие иконки, отображение frame rate и потребление памяти:
General->Miscellaneous->Performance->Show Frame Rate and Memory
General->User Interface->Use Small Tool Bar Icons
Двигаемся дальше, добавим вне игровой GameMode для экранов логина, регистрации и главного меню.
Добавление SpikyGameMode
File->New C++ Class->Game Mode Base назовём SpikyGameMode, выберем public и создадим папку GameModes. Конечный путь должен выглядеть так:
Задачей SpikyGameMode будет создание верной ссылки на мир. Мир это объект верхнего уровня, представляющий карту в которой акторы и компоненты будут существовать и визуализироваться. Позже мы создадим класс DiffrentMix унаследованный от UObject в котором будем управлять интерфейсом, для создания виджетов нужна ссылка на текущий мир, которую из классов UObject получить нельзя, поэтому мы создадим GameMode через который инициализируем DiffrentMix и передадим ему ссылку на мир.
Отдельное слово об интерфейсе, это относится к архитектуре клиента. У нас доступ ко всем виджетам, происходит через синглтон DifferentMix, все виджеты размещаются внутри WidgetsContainer, который нам понадобится чтобы размещать виджеты слоями глубину которых можно задать, корень WidgetsContainer это Canvas к сожалению я не нашел способ изменять порядок виджетов используя Viewport. Это удобно когда нужно например чтобы чат гарантированно был поверх всего остального. Для этого выставляем его виджету максимальную глубину (приоритет) у нас в программе mainMenuChatSlot->SetZOrder(10), однако приоритет может быть любой.
Добавим класс DifferentMix, родитель UObject базовый класс для всех объектов, разместим в новой папке Utils Здесь мы будем хранить ссылки на виджеты, редкие функции для которых создавать свои классы было бы лишним, это синглтон через который мы будем управлять пользовательским интерфейсом.
Добавим SpikyGameInstance производный от UGameInstance класс, универсального UObject, который может хранить любые данные переносимые между уровнями. Он создается при создании игры, и существует до тех пор, пока игра не будет закрыта. Мы будем его использовать для хранения уникальных игровых данные, таких как логин игрока, id игровой сессии, ключ шифрования, так же тут мы запускаем и останавливаем потоки слушающие сокеты, и через него мы будем получать доступ к функциям DifferentMix.
Земетьте, возможно из редактора игра после добавления новых классов откажется собираться, это из-за того что мы переключились на режим который требует наличие #include «Spiky_Client.h» во всех исходных файлах, добавим его вручную и соберем через студию, дальше я не добавляю новый код через редактор, я копирую, редактирую вручную и нажимаю на Spiky_Client.uproject пкм Generate Visual Studio project files.
Вернёмся к редактору, создадим папку Maps и сохраним в ней стандартную карту, назовём её MainMap позже мы разместим на ней вращающегося меха (или выбор игрового персонажа как во многих ММО).
Откроем Project Settings -> Maps & Modes и выставим созданные GameMode/GameInstance/Map как на снимке:
Сетевая часть
С подготовкой всё, начнём писать проект с сетевой части реализуем подключение к серверу, восстановление соединения при его потере, слушатели входящих сообщений и поток проверяющий доступность сервера. Главный объект на клиенте через который мы работаем с сетью, обслуживаем сокеты, будет называться SocketObject производный от UObject, добавим его в папку Net. Так как мы используем сеть, нужно добавить модули «Networking», «Sockets» в Spiky_Client.Build.cs
Добавим в заголовок SocketObject деструктор, ряд самоописуемых статических функций и нужные нам инклуды SocketSubsystem и Networking.
SocketObject.h
// Copyright (c) 2017, Vadim Petrov - MIT License
#pragma once
#include "CoreMinimal.h"
#include "UObject/NoExportTypes.h"
#include "Networking.h"
#include "SocketSubsystem.h"
#include "SocketObject.generated.h"
/**
* Главный сетевой объект, создаёт сокет, отвечает за подключение-отключение и т.п
*/
UCLASS()
class SPIKY_CLIENT_API USocketObject : public UObject
{
GENERATED_BODY()
~USocketObject();
public:
// tcp
static FSocket* tcp_socket;
// tcp адрес сервера
static TSharedPtr tcp_address;
// состояние соединения
static bool bIsConnection;
// переподключиться если соединение потерянно
static void Reconnect();
// проверить онлайн ли сервер
static bool Alive();
// udp
static FSocket* udp_socket;
// udp адрес сервера
static TSharedPtr udp_address;
// мы не создаём отдельный поток для UDP сокет слушателя, у unreal имеется FUdpSocketReceiver, создадим и делегируем входящие сообщения на ф-ю
static FUdpSocketReceiver* UDPReceiver;
static void Recv(const FArrayReaderPtr& ArrayReaderPtr, const FIPv4Endpoint& EndPt);
static void RunUdpSocketReceiver();
static int32 tcp_local_port;
static int32 udp_local_port;
// инициализируем сокеты когда запускаем игру, в GameInstance
static void InitSocket(FString serverAddress, int32 tcp_local_p, int32 tcp_server_port, int32 udp_local_p, int32 udp_server_port);
};
Теперь в исходниках, начнём с создания сокетов в InitSocket, выделим буфер, назначим локальные порты, мне известны два способа создания сокетов, один из них билдером:
Это базовые абстракции различных сокет интерфейсов, специфичных для конкретной платформы. Так как мы задаём адрес где-то в файле конфигурации или коде строкой нам следует привести его в нужный вид, для этого используем FIPv4Address::Parse, после чего подключаемся и вызываем bIsConnection = Alive(); Метод отправляет пустые сообщения серверу, если доходят значит связь есть. Напоследок создадим UDP сокет с помощью FUdpSocketBuilder, итоговый вид InitSocket должен быть таким:
Займемся методом отправкой Alive сообщений, форматом сообщений и сервером. В основе сервера я использовал ассинхронный фреймворк Netty написанный на java. Основное преимущество которого проста чтения и записи в сокеты. Netty поддерживает неблокирующий асинхронный ввод-вывод, легко масштабируется, что важно для онлайн игры, если ваша система должна иметь возможность обрабатывать многие тысячи соединений одновременно. И что тоже важно — Netty легко использовать.
Создадим сервер, тут пользуемся IntelliJ IDEA, создаём Maven проект:
com.spiky.serverSpiky server
Добавляем необходимые нам зависимости, Netty
io.nettynetty-all4.1.8.Final
Теперь разберёмся с форматом сериализации сообщений. Мы используем Protobuf. Размер сообщения выходит предельно малым, и судя по графикам он во всем превосходит JSON.
У протобафа хорошая документация которая лучше поможет понять значение каждого поля.
Протобаф реализован для Java и C++ используемым нашим проектом. Добавим еще одну зависимость:
com.google.protobufprotobuf-java3.0.0-beta-4
Теперь нужно добавить поддержку протобафа в Unreal это уже не так просто, для начала получаем ветку с github. Теперь нужно правильно собрать, инструкцию как собрать через Visual Studio можно найти тут. Выставить тип линковки для анриала «Filter through to Configuration Properties > C/C++ > Code Generation > Runtime Library, from the drop down list select Multi-threaded DLL (/MD)» смотрите Linking Static Libraries Using The Build System и собрать libprotobuf.lib. После добавим в проект, создадим в корне папку ThirdParty/Protobuf в которой нужно создать Libs и Includes. Поместить /protobuf-3.0.0-beta-4/cmake/build/solution/Release/libprotobuf.lib в Libs. Поместить /proto-install/include/google в Includes.
Так как моя цель была в поддержке мобильных устройств, нам понадобится собрать библиотеку еще и для Android с помощью Android NDK, список файлов для компиляции можно взять тут, в начале lite, потом остальное. Сам процесс выглядит так, установите Android NDK, создайте папку jni поместите в них два файла Android.mk и Application.mk, там же создайте src в которую скопируйте src из protobuf-3.0.0-beta-4/src и воспользуйтесь ndk-build. Готовые файлы Application.mk и Android.mk:
В случае успеха мы получим «сошку» /android/proto/libs/armeabi-v7a — libprotobuf.so. Скопируем её в проект /Spiky/Spiky_Client/Source/Spiky_Client/armv7.
Возможные трудности и ошибки
Если появляется ошибка:
ThirdParty/Protobuf/Includes\google/protobuf/arena.h(635,25) : error: cannot use typeid with -fno-rtti
откройте arena.h и напишите в самом вверху
#define GOOGLE_PROTOBUF_NO_RTTI
Если после включения в заголовков наших сообщений, возникает конфликт имён протобафа и анриала — error: "error C3861: 'check': identifier not found, проблема в совпадении имён макроса check в анриал (AssertionMacros.h), и check в протобафе (type_traits.h), к счастью check в протобафе используется очень мало и проблему легко решить подредактировав исходники, переименовав check в check_UnrealFix, например, и закомментировать #undef check. Решение подсказал вопрос на unreal answers — Error C3861 (identifier not found) when including protocol buffers.
template
struct is_base_of {
typedef char (&yes)[1];
typedef char (&no)[2];
// BEGIN GOOGLE LOCAL MODIFICATION -- check is a #define on Mac.
#undef check
// END GOOGLE LOCAL MODIFICATION
static yes check(const B*);
static no check(const void*);
enum {
value = sizeof(check(static_cast(NULL))) == sizeof(yes),
};
};
Исправленный вариант type_traits.h выглядит так:
template
struct is_base_of {
typedef char (&yes)[1];
typedef char (&no)[2];
// BEGIN GOOGLE LOCAL MODIFICATION -- check is a #define on Mac.
//#undef check
// END GOOGLE LOCAL MODIFICATION
static yes check_UnrealFix(const B*);
static no check_UnrealFix(const void*);
enum {
value = sizeof(check_UnrealFix(static_cast(NULL))) == sizeof(yes),
};
};
Вообще часто встречаются проблемы совместимости, мы еще с ними столкнёмся когда будем добавлять поддержку OpenSSL и компилировать под андроид. к примеру Android NDK не полностью поддерживает С++ 11, мне нужно было получить миллисекунды я хотел использовать chrono но увы, нужно часто проводить проверки, здесь куча подводных камней.
Советую тестировать функционал внешних библиотек, перед добавлением в проект, отдельно, вне Unreal, это значительно быстрее.
Пока отложим подключение protobuf, скомпилируем OpenSSL чтобы больше не возвращаться к этой теме и не повторяться. Я использую OpenSSL-1.0.2k. Чтобы собрать библиотеку, воспользуйтесь этим руководством (Building the 64-bit static libraries with debug symbols). Пару советов если возникнут трудности:
Найди в папке со студией ml64.exe и скопировать в папку с OpenSSL, не пользуемся NASM — это только для х32
Используйте чистые исходники (без попыток сборки)
openssl fatal error LNK1112: module machine type 'x64' conflicts with target machine type 'X86' — откройте Developer Command Prompt for VS2015, перейдите E:\Program Files (x86)\Microsoft Visual Studio 14.0\VC и выполните vcvarsall.bat x64 (источник)
Конфликт имён с Unreal закомментируйте 172 строчку: openssl/ossl_typ.h(172): error C2365: 'UI': redefinition; previous definition was 'namespace'
Что до компиляции под андроид, проще всего это делать из под Ubuntu, воспользовавшись скриптами для armv7 и x86 которые вы можете найти в исходниках проекта.
После того как мы получили сошку, с ней нужно немного поработать, надо изменить номер версии иначе будем получать ошибку:
E/AndroidRuntime( 1574): java.lang.UnsatisfiedLinkError: dlopen failed: could not load library "libcrypto.so.1.0.0" needed by "libUE4.so"; caused by library "libcrypto.so.1.0.0" not found
Где то внутри зашит номер версии, воспользуемся улитой Ubuntu для переименования: rpl -R -e .so.1.0.0 "_1_0_0.so" /path/to/libcrypto.so
Скопируем сошку в Source/Spiky_Client/armv7, библиотеки, заголовки в ThirdParty/OpenSSL и скомпилируем.
Подключаем библиотеки в Spiky_Client.Build.cs. Для удобства добавим две функциии ModulePath и ThirdPartyPath, первая возвращает путь к проекту, вторая к папке с подключаемыми библиотеками.
public class Spiky_Client : ModuleRules
{
private string ModulePath
{
get { return ModuleDirectory; }
}
private string ThirdPartyPath
{
get { return Path.GetFullPath(Path.Combine(ModulePath, "../../ThirdParty/")); }
}
...
}
Специфично для каждой платформы мы добавляем библиотеку и заголовки. При компиляции выбирается необходимая платформе библиотека:
Чтобы добавить сошки в сборку нужно создать APL.xml (AndroidPluginLanguage) файл в папке с исходниками, в котором описывается откуда и куда должны быть скопированы библиотеки, и под какую платформу armv7, x86. Примеры и другие параметры можно глянуть тут.
APL
Можно протестировать работу OpenSSL для windows и android создав тестовый hud и вывести в него hash (в исходниках отсутствует)
Когда мы добавляем скомпилированные .proto сообщения, анриал выдаёт различные предупреждения, отключить которые можно либо разбираясь с исходникам движка, либо подавить их. Для этого создадим DisableWarnings.proto и скомпилируем ./protoc --cpp_out=. --java_out=. DisableWarnings.proto затем в полученном заголовке DisableWarnings.pb.h подавим предупреждения, будем включать DisableWarnings в каждый прото файл. В DisableWarnings.proto всего три строчки, версия протобафа, имя java пакета и имя генерируемого класса.
// Generated by the protocol buffer compiler. DO NOT EDIT!
// source: DisableWarnings.proto
#define PROTOBUF_INLINE_NOT_IN_HEADERS 0
#pragma warning(disable:4100)
#pragma warning(disable:4127)
#pragma warning(disable:4125)
#pragma warning(disable:4267)
#pragma warning(disable:4389)
#ifndef PROTOBUF_DisableWarnings_2eproto__INCLUDED
#define PROTOBUF_DisableWarnings_2eproto__INCLUDED
#include
#include protobuf/stubs/common.h>
#if GOOGLE_PROTOBUF_VERSION < 3000000
#error This file was generated by a newer version of protoc which is
#error incompatible with your Protocol Buffer headers. Please update
#error your headers.
#endif
#if 3000000 < GOOGLE_PROTOBUF_MIN_PROTOC_VERSION
#error This file was generated by an older version of protoc which is
#error incompatible with your Protocol Buffer headers. Please
#error regenerate this file with a newer version of protoc.
#endif
#include protobuf/arena.h>
#include protobuf/arenastring.h>
#include protobuf/generated_message_util.h>
#include protobuf/metadata.h>
#include protobuf/repeated_field.h>
#include protobuf/extension_set.h>
// @@protoc_insertion_point(includes)
// Internal implementation detail -- do not call these.
void protobuf_AddDesc_DisableWarnings_2eproto();
void protobuf_AssignDesc_DisableWarnings_2eproto();
void protobuf_ShutdownFile_DisableWarnings_2eproto();
// ===================================================================
// ===================================================================
// ===================================================================
#if !PROTOBUF_INLINE_NOT_IN_HEADERS
#endif // !PROTOBUF_INLINE_NOT_IN_HEADERS
// @@protoc_insertion_point(namespace_scope)
// @@protoc_insertion_point(global_scope)
#endif // PROTOBUF_DisableWarnings_2eproto__INCLUDED
Все наши протобафы мы помещаем в папку Protobufs (Source/Spiky_Client/Protobufs), но лучше настроить автоматичекое размещение сгенерированных файлов, указав полные пути в --cpp_out=. --java_out=.
Едем дальше, настроим Spiky сервер!
Создаём пакет com.spiky.server и добавляем класс ServerMain, входная точка нашего сервера, тут мы будем хранить глобальные переменные, инициализируем и запустим два Netty сервера для tcp и udp соединений (но напомню в проекте используется только tcp). Нам определённо понадобится файл конфигурации, где мы могли бы хранить порты серверов (сервера логики – Netty и проверочного на Unreal), а так же возможность включать отключать криптографию. В папке Recources создадим configuration.properties.
Добавим в ServerMain инициализацию сервера, и чтение файла настроек:
/* файл конфигурации */
private static final ResourceBundle configurationBundle = ResourceBundle.getBundle("configuration", Locale.ENGLISH);
/* серверные порты */
private static final int tcpPort = Integer.valueOf(configurationBundle.getString("tcpPort"));
private static final int udpPort = Integer.valueOf(configurationBundle.getString("udpPort"));
private static void run_tcp() {
EventLoopGroup bossGroup = new NioEventLoopGroup(); // 1
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap(); // 2
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class) // 3
.childHandler(new com.spiky.server.tcp.ServerInitializer()) // 4
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.TCP_NODELAY, true);
ChannelFuture f = b.bind(tcpPort).sync(); // 5
f.channel().closeFuture().sync(); // 6
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
Полный файл, с инициализацией udp и main()
/*
* Copyright (c) 2017, Vadim Petrov - MIT License
*/
package com.spiky.server;
import io.netty.bootstrap.Bootstrap;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelOption;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioDatagramChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import java.util.Locale;
import java.util.ResourceBundle;
public class ServerMain {
/* файл конфигурации */
private static final ResourceBundle configurationBundle = ResourceBundle.getBundle("configuration", Locale.ENGLISH);
/* серверные порты */
private static final int tcpPort = Integer.valueOf(configurationBundle.getString("tcpPort"));
private static final int udpPort = Integer.valueOf(configurationBundle.getString("udpPort"));
private static void run_tcp() {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new com.spiky.server.tcp.ServerInitializer())
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.TCP_NODELAY, true);
ChannelFuture f = b.bind(tcpPort).sync();
f.channel().closeFuture().sync();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
}
}
private static void run_udp() {
final NioEventLoopGroup group = new NioEventLoopGroup();
try {
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(group).channel(NioDatagramChannel.class)
.handler(new com.spiky.server.udp.ServerInitializer());
bootstrap.bind(udpPort).sync();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
new Thread(ServerMain::run_tcp).start();
new Thread(ServerMain::run_udp).start();
}
}
NioEventLoopGroup — это многопоточный цикл, который обрабатывает операции ввода-вывода. Netty предоставляет различные реализации EventLoopGroup для разных видов транспорта. В этом примере мы реализуем серверное приложение, и поэтому будет использоваться две NioEventLoopGroup. Первый, часто называемое «босс», принимает входящее соединение. Второй, часто называемый «рабочий», обрабатывает трафик принятого соединения, босс принимает соединение и регистрирует принятое соединение с работником. Сколько потоков используется и как они сопоставляются с создаваемыми каналами, зависит от реализации EventLoopGroup и может настраиваться через конструктор
ServerBootstrap — это вспомогательный класс, который устанавливает сервер. Вы можете настроить сервер напрямую с помощью канала. Однако учтите, что это утомительный процесс, и вам не нужно делать это в большинстве случаев
Здесь мы указываем использовать класс NioServerSocketChannel, который используется для создания нового канала приема входящих соединений
Специальный Handler, который предоставляет простой способ инициализации канала после его регистрации в EventLoop. В нем мы добавляем обработчики входящих сообщений, декодеры, инкодеры и логику,
Привязываем и начнинаем принимать входящие соединения
Подождём, пока серверный сокет не будет закрыт
Как работает Netty, на простых примерах эхо сервера, с объясненями можно найти в документации. Еще очень советую прочитать книгу Netty in Action, она небольшая.
Наш сервер почти готов к запуску, добавим ServerInitializer для обоих протоколов:
/* Для UDP и TCP*/
public class ServerInitializer extends ChannelInitializer
public class ServerInitializer extends ChannelInitializer
Создадим два пакета com.spiky.server.tcp и com.spiky.server.udp в каждом из которых создадим класс ServerInitializer (с отличными NioDatagramChannel/SocketChannel) с таким содержимым:
Pipeline это то через что проходит каждое сообщение, содержит список ChannelHandlers, который обрабатывают входящие и исходящие сообщения. Например один из обработчиков может принимать только строковые данные, другой протобаф, если мы вызовем write(string) то вызовется обработчик для строк, в котором мы решим обрабатывать сообщение дальше, отправить в другой обработчик соответствующий новому типу или отправить клиенту. У каждого обработчика есть тип определяющий для каких он сообщений — входящих или исходящих.
Добавим стандартный обработчик отладки в ServerInitializer, который весьма полезен, можно посмотреть размер входящих сообщений и в каком виде они представлены, так же адресат:
Обработка протобаф сообщений присланных по TCP отличается от присланных по UDP, у Netty есть заготовленные обработчики для протобафа, но работают они только для потоковых соединений таких как TCP, когда мы отправляем сообщение мы должны знать где закончить читать, поэтому в начале каждого сообщения должна идти его длина, затем само тело. Начнём с UDP, добавим и протестируем прием и отправку сообщений сервером и клиентом. Добавим обработчик отладки в ServerInitializer, затем создадим пакет com.spiky.server.udp.handlers. Добавим в него public class ProtoDecoderHandler extends SimpleChannelInboundHandler. ChannelInboundHandlerAdapter, позволяет явным образом обрабатывать только определенные типы входящих сообщений. Например ProtoDecoderHandler обрабатывает только сообщения типа DatagramPacket.
Добавим сюда же PackageHandler — класс с логикой, после декодирования (а далее нам надо будет декодировать и расшифровать) сюда приходят сообщения используемого нами протобаф формата public class PackageHandler extends SimpleChannelInboundHandler
MessageModels это класс-обёртка верхнего уровня, который будет содержать шифрованные и нешифрованные данные. Все сообщения обёртывается в него, вот его конечный вид, некоторые типы нам еще не знакомы:
Когда мы отправляем сообщение, принимающая сторона читает обёртку и смотрит какие у неё есть поля. Логина, регистрация? А может зашифрованные байты cryptogramWrapper? Тем самым выбирая поток исполнения.
Давайте определим и опишем все протобаф модели в нашем проекте чтобы больше на это не отвлекаться.
DisableWarnings — пустой протобаф, задача которого лишь в том чтобы отключать предупреждения.
MessageModels — содержит в себе главную обёртку Wrapper, внутри которой могут быть нешифрованные сообщения Utility, InputChecking, Registration, Login и шифрованные CryptogramWrapper. CryptogramWrapper содержит зашифрованные байты, например после того как мы обменялись ключами и начали шифровать данные, эти данные присваиваются как одно из полей CryptogramWrapper. Получатель получил, проверил есть ли зашифрованные данные, расшифровал, определил тип по имени поля и отправил дальше на обработку.
Все модели вы можете найти в Spiky/Spiky_Protospace.
Чтобы определить тип сообщения и как оно должно обрабатываться, мы узнаём что в нем по наличию именованных полей:
// java
if(wrapper.getCryptogramWrapper().hasField(registration_cw)) //сделать что-то
// cpp
if (wrapper->cryptogramwrapper().GetReflection()->HasField(wrapper->cryptogramwrapper(), Descriptors::registration_cw)) //сделать что-то
И чтобы не захламлять код создадим отдельные классы с набором дескрипторов, добавьте на клиенте и на сервере в Utils класс Descriptors.
Descriptors.java
// Copyright (c) 2017, Vadim Petrov - MIT License
package com.spiky.server.utils;
import com.spiky.server.protomodels.*;
/**
* Разные дескрипторы для того чтобы определить содержимое сообщений
* */
public class Descriptors {
public static com.google.protobuf.Descriptors.FieldDescriptor registration_cw = MessageModels.CryptogramWrapper.getDefaultInstance().getDescriptorForType().findFieldByName("registration");
public static com.google.protobuf.Descriptors.FieldDescriptor login_cw = MessageModels.CryptogramWrapper.getDefaultInstance().getDescriptorForType().findFieldByName("login");
public static com.google.protobuf.Descriptors.FieldDescriptor initialState_cw = MessageModels.CryptogramWrapper.getDefaultInstance().getDescriptorForType().findFieldByName("initialState");
public static com.google.protobuf.Descriptors.FieldDescriptor room_cw = MessageModels.CryptogramWrapper.getDefaultInstance().getDescriptorForType().findFieldByName("room");
public static com.google.protobuf.Descriptors.FieldDescriptor mainMenu_cw = MessageModels.CryptogramWrapper.getDefaultInstance().getDescriptorForType().findFieldByName("mainMenu");
public static com.google.protobuf.Descriptors.FieldDescriptor gameModels_cw = MessageModels.CryptogramWrapper.getDefaultInstance().getDescriptorForType().findFieldByName("gameModels");
public static com.google.protobuf.Descriptors.FieldDescriptor getCaptcha_ich = RegistrationLoginModels.InputChecking.getDefaultInstance().getDescriptorForType().findFieldByName("getCaptcha");
public static com.google.protobuf.Descriptors.FieldDescriptor login_ich = RegistrationLoginModels.InputChecking.getDefaultInstance().getDescriptorForType().findFieldByName("login");
public static c
— Нам нужно срочно поговорить! Примерно так начинаются 90% всех разговоров про увольнение. Причем кто бы не начинал разговор первым, результат обычно предсказуем. Что делать, если от вас уходит нужный человек? Под катом мнениевице-президента ParallelsНиколая Добровольского.
Я обычно собеседую всех сотрудников приходящих в нашу компанию. Учитывая, что нас во всем мире всего около 300 человек, уход любого из «300 спартанцев» вызывает определенное внутреннее волнение. С некоторыми коллегами мы работаем вместе около двадцати лет. За эти годы накопились определенные мысли относительно того, что делать, если бесценный для команды человек внезапно решил сойти с корабля на берег.
Держите его крепче
Часто слышу мнение, что сотрудник решивший покинуть компанию рано или поздно уйдет, поэтому не стоит за него держаться, или что незаменимых людей нет. Я с этим категорически не согласен. Увольнение – это стресс. По своей воле человек, если с ним все в порядке, вряд ли захочет сознательно выходить из зоны комфорта. Вероятно есть причины, толкнувшие его к этому. Узнайте о них. Постарайтесь помочь. Опыт подсказывает, что неразрешимых ситуаций практически не бывает. Если человек реально ценен для команды, стоит наступить на горло самолюбию и постараться его удержать. Причем, далеко не всегда речь идет о деньгах. Элементарное переключение на новые задачи может повлиять на принятое ранее решение. Вероятно возникает вопрос, а как же быть с прежними обязанностями сотрудника? Кто будет делать его работу? Поверьте, это менее критично. Если ценный специалист от вас уйдет, вам все равно придется как-то распределить его задачи и, скорее всего, рано или поздо искать ему замену. Важно понимать, что ценный профессионал – это хранитель знаний, культуры, традиций, авторитет и лидер мнений. Это как лишиться пальца на руке или ноге, прожить можно, но функциональность снижается.
Разговаривайте
О чем люди сожалеют на смертном одре? Судя по рассказам находившихся на грани жизни и смерти, неисполненные рабочие обязательства находятся где-то далеко в конце списка. Больше всего люди сетовали на отсутствие времени для общения с родными и близкими. По сути, увольнение – это маленькая смерть. Конечно, слава богу, все остаются живы и здоровы, но устойчивая связь обрывается. Человек сходит с орбиты, вы перестаете общаться. В вашей власти этого избежать. Говорите с людьми. Вы удивитесь, насколько часто в качестве причины к увольнению фигурирует отсутствие позитивной оценки работы со стороны прямого руководителя. Люди хотят быть нужными и чувствовать свою значимость. Например, в больших компаниях, таких как Intel, у менеджеров есть обязанность не менее часа в месяц проводить с каждым из своих прямых подчиненных в беседе на не связанные с работой темы. Считается, что так можно почувствовать настроение своего сотрудника относительно его положения в компании. Кстати, во-многом, этим отличается отечетвенный менеджмент от американского, например. Что происходит с сотрудником допустившим рабочую ошибку в России? Жесткая реакция со стороны начальства, “ковер”, “головомойка”, “намыленная шея”, топор и веревка в придачу. На Западе все выглядит иначе. Оступившегося сотрудника благодарят за работу, оказывают всяческую моральную поддержку и напутствуют к дальнейшим трудовым подвигам. Менеджмент понимает, что бизнес благодаря допущенной ошибке уже заплатил дорогую цену за обучение этого конкретного специалиста и будет глупо прощаться с ним прямо сейчас. Вероятнее всего полученный опыт позволит компании избежать аналогичных провалов в будущем.
Ждите обратно
Представим, что ваши усилия остались без результата. Человек уходит. Мое стойкое убеждение, что бы ни происходило, расставаться нужно всегда по-хорошему. Не сжигайте мосты. Кроме того, как ни странно, увольнение это далеко еще не конец вашей совместной работы. Во-первых, стоит получить от уходящего специалиста максимальную обратную связь. Что нравилось в работе? Что не нравилось? Что бы он изменил? Кого он видит на своем месте и почему? Человеку нечего терять и он готов в этой ситуации делиться своим опытом и знаниями. Не пренебрегайте этой информацией. Подумайте о тех, кто остался с вами. Стоит внимательно отнестись к переопределению зон ответственности между членами команды. Вероятно нагрузка возрастет. Нужно подготовить людей. Мы в Parallels дорожим своей командой и стремимся сохранять здоровую атмосферу в коллективе.
Не раз встречал мнение, что однажды ушедших обратно в компанию принимать нельзя. Это бред, миф и глупость. Вспомним Стива Джобса, со скандалом уволенного из собственной компании и триумфально вернувшегося через несколько лет. Возвращаются те, кого ждут. Скажу больше, не только ждите ушедшего обратно, но и готовьте для этого почву. Например, от меня уходили люди в другие компании, на позиции выше, на большую зарплату, но многие из тех, кому я от всей души предлагал вернуться, возвращались. Даже на те же условия, с которых уходили. Мне знакомы случаи, когда в крупных ИТ-корпорациях специалисты уходили и возвращались по несколько раз. Если по-настоящему ценный сотрудник покидает компанию, вы обязаны уверить его, что будете всегда рады возобновить сотрудничество. Важно понимать, что часто уход блестящего специалиста – это следствие вашей невнимательности.
В общем, если подвести итог, то удерживайте талантливых людей. Иногда через преодоление собственной гордыни, через общение, уважение и поддержку. Будьте мудрее. Старайтесь делать жизнь сотрудников комфортной и счастливой. Ведь программист – своего рода художник. А счастливый человек способен творить и создавать шедевры.
В этой статье мы хотим рассказать о том, какая модель работы с данными выбрана в платформе 1С:Предприятия и почему.
Для бизнес-приложений работа с данными — это очень важный архитектурный вопрос. Так или иначе, но вся работа приложения строится вокруг данных. При чем, если в некоторых классах программных систем данные носят вспомогательный характер, то в бизнес-приложениях данные являются основным содержанием решаемых задач.
Причем здесь (в этой статье) мы говорим не о техническом аспекте хранения и манипулирования данными, а об описании данных как способе проектирования приложения. Почему данные так важны для бизнес-приложений?
Потому, что они описывают саму предметную область. Какие сущности имеются в бизнесе, как они связаны между собой. Данные очень хорошо описывают и саму решаемую задачу. Ведь при проектировании приложений нас не интересуют абсолютно все данные, а интересуют те данные (и их взаимосвязи), которые тем или иным способом влияют на решаемую задачу (включая некоторый запас развития системы в потенциально интересных направлениях). Например, если мы автоматизируем процесс развития персонала, то нас будет интересовать по сотрудникам образование, история работы. Но мы не будем отражать информацию по размерам одежды и обуви. Но, если, например, мы хотим автоматизировать учет спецодежды, то это становится уже интересным. Хотя, пытливый проектировщик может и тут поставить вопрос. Где развитие персонала, там и мотивация. А где мотивация, там и, возможно, изготовление одежды с фирменной символикой. Здесь видно, что количество данных в природе бесконечно, и искусство моделирования данных во многом определяет искусство проектирования приложений.
Конечно, очень важное место в бизнес-приложениях занимают и процессы. Хотя очень хочется (и нам, и разработчикам других платформ для разработки бизнес приложений) больший вес в проектировании приложений возложить на процессы, но данные все равно остаются наиболее значимым аспектом предметной области. И именно на отражении данных строится основная модель приложений.
Сделаем только небольшую оговорку. Под данными здесь понимаются и данные, сопровождающие процессы. То есть, получается, что процессы тоже косвенно выражаются через модель данных.
В платформе 1С:Предприятие есть и механизмы для отражения именно процессов, но это тема отдельной статьи.
Существует несколько традиционных парадигм работы с данными.
Прежде всего – есть классическая реляционная модель. В ней данные описываются в виде реляционных таблиц (обычно хранимых в реляционных DBMS). Эта парадигма хотя и совсем не новая, но вполне актуальная.
Есть объектная парадигма. В ней данные описываются в виде объектов языка программирования и каким-то образом сохраняются в базе данных. Это может быть реляционная или объектная база данных. В первом случае возможности моделирования определяются DBMS, во втором случае — используемым ORM.
Есть еще методики и подходы, которые применяются реже (при создании бизнес-приложений). Например, подход, основанный на слабоструктурированных данных.
Теперь, собственно, о том подходе, который мы выбрали для платформы 1С:Предприятия. Для него нет официально принятого названия. Назовем его «модель типов прикладных объектов». Суть подхода в том, что платформа предлагает разработчику некоторый набор типов прикладных объектов. Каждый тип предназначен для отражения в модели приложения некоторой категории сущностей предметной области. Разработчик приложения при отражении предметной области решаемой задачи в модели приложения должен выбрать подходящие типы объектов и с помощью них описать модель данных. На самом деле при этом он описывает не только модель данных, но и, во многом, модель самого приложения. Но об этом чуть позже.
Что представляет собой тип прикладных объектов?
Это некоторый заложенный в платформу шаблон (можно еще считать его абстрактным классом), определяющий множество различных аспектов работы с сущностью предметной области.
Типы прикладных объектов проявляются и при разработке (в design-time) и при работе системы (в run-time). В design-time это мета-модель описания объектов в метаданных и классы для манипулирования данными в программной модели. В run-time это различные аспекты поведения системы при работе с объектами этого типа. Например, поведение механизма блокировок.
В 1С:Предприятии существует несколько типов прикладных объектов.
Для примера возьмем три типа:
Справочники
Документы
Регистры накопления
Справочники предназначены для отражения в системе некоторой условно постоянной информации (списков сотрудников, товаров, клиентов…).
Документы отражают некоторые события предметной области (продажу, прием сотрудника на работу, перечисление денег в банк). Иногда они называются по названиям печатных форм («платежное поручение», «приказ о приеме на работу», …). Но это только для удобства понимания. По сути, это именно тип события, а не печатной формы.
Регистры накопления предназначены для отражения в приложении некоторой системы учета. Например, учета хранения денежных средств или товаров на складах.
Посмотрим, что все-таки входит в «комплект» возможностей, предоставляемый типами прикладных объектов
Прежде всего, конечно, тип прикладного объекта описывает модель данных и обеспечивает отображение данных на реляционную модель хранения. Но это только небольшая часть того, что он определяет.
Например, для справочника:
существует несколько стандартных реквизитов (полей), заложенных сразу в платформу (ссылка-идентификатор, код, наименование, ссылка на родителя для иерархического справочника, …)
можно описать свои (произвольные) реквизиты (поля)
можно описать табличные части, которые представляют собой тесно связанные сущности (containment) или еще их можно считать вложенными таблицами
Для документа — похоже, но есть стандартный реквизит Дата, отражающий положение события относительно других событий на оси времени, а также признак «Проведен», определяющий, отражается документ в системе учета или является черновиком.
Для регистра накопления поля делятся на измерения, ресурсы и реквизиты. Измерения описывают систему координат модели учета (например, товар, склад), ресурсы – показатели (например, количество, сумма), реквизиты – просто дополнительные поля (не влияющие на модель учета, но комментирующие записи движений).
Почему мы оперируем типами прикладных объектов, а не оперируем, например, просто таблицами (или просто сущностями – entity)?
Это очень важный момент. Таблицы имеют много преимуществ. Они ближе к простейшему моделированию в реляционной модели, они не ограничивают разработчика рамками заложенных типов. Но таблицы и не дают тех возможностей, которые дает выбранный нами подход.
Суть выбранного нами подхода в том (если говорить простыми словами), что в нашем подходе сама система (платформа) «много чего знает» про описанные объекты и «много чего умеет с ними делать». На основании этих знаний и умений система автоматически обеспечивает работу более десятка разных механизмов, работающих прямо или косвенно с этими объектами. То есть, получается, что разработчик приложения выбирает тип объекта и описывает конкретный объект, а платформа, зная тип и описание конкретного объекта, сама обеспечивает множество различных полезных функций и механизмов. Это достигается за счет того, что на уровне типа объекта определена семантика объектов данного типа (назначение объекта «по крупному»), а модель метаданных позволяет уточнить семантику конкретного объекта за счет различных свойств и специализированных моделей, описывающих различные аспекты жизнедеятельности.
Перечислим только некоторые из них:
Прежде всего, конечно, это создание структур данных для хранения и автоматическое преобразование структуры при изменении модели
Набор классов в объектной модели для манипулирования данными (чтения, записи, поиска)
Механизм объектно-реляционного преобразования
Набор типичных процедур обработки данных. Например, для документов это автоматическая нумерация, для регистра это расчет итогов, получение среза остатков на конкретный момент времени, и т.д.
Отражение в системе прав. Так как система знает о назначении объекта, то знает и какие права для него будут актуальны
Визуализация (отражение в интерфейсе). Опять же, зная о назначении и роли объектов, система сама конструирует и команды в интерфейсе приложения для доступа к объектам этого типа, и формы для просмотра и редактирования, и команды для различных действий с объектом.
Обмен данными. На основании знания семантики данных платформа предоставляет стандартный механизм для асинхронного обмена измененными данными как среди родственных приложений (узлов распределенной базы), так и между разнородными приложениями (написанными как на 1С:Предприятии, так и на других технологиях)
Объектные и транзакционные блокировки. Для правильного построения системы блокировки нужно знание о назначении данных и о взаимосвязях.
Механизм характеристик (дополнительных полей, определяемых пользователем)
Автоматически предоставляемый REST интерфейс (по стандарту OData)
Выгрузку-загрузку данных в XML, JSON
Кроме того, автоматически работают такие механизмы как: полнотекстовый поиск, журналирование доступа к данным, и т.д.
На схеме изображены далеко не все механизмы платформы, которые работают на основе прикладных объектов, а только некоторые.
В каком-то смысле типы прикладных объектов пересекаются с аспектно-ориентированным подходом. Так как все перечисленные возможности — это некоторые предопределенные аспекты, в которых отражаются типы прикладных объектов. Можно сказать, что типы прикладных объектов это не просто шаблоны, а параметризованные шаблоны. Параметризация осуществляется за счет набора свойств метаданных. Выбрав значение свойства, разработчик параметризует шаблон выбранного типа прикладного объекта и уточняет тем поведение объекта в конкретном аспекте. Например, он может выбрать тип нумерации документа (в пределах года, квартала, месяца…) и система будет автоматически обеспечивать присвоение и контроль номеров с заданной периодичностью.
Типы прикладных объектов обеспечивают знание о семантике не только самих сущностей, но и о семантике их взаимосвязей. Например, существует стандартная связь между документами и регистрами, отражающая то, как в предметной области события отражаются в модели учета. Определив такую связь, разработчик сразу получает готовую функциональность по совместному времени жизни документа и связанных с ним записей регистра.
Отдельно стоит сказать о важных предметно ориентированных аспектах.
Например, для справочников есть возможность одним флажком включить поддержку иерархии. При этом система обеспечит поддержку иерархических справочников во всем: в пользовательском интерфейсе, в отчетах, в объектной модели.
Установка одного свойства справочника «Иерархический справочник» сразу поддерживает иерархию в пользовательском интерфейсе, в отчетах, в объектной модели.
Для документов существуют такие возможности, как журналы, объединяющие несколько типов документов, сквозная нумерация в разрезе периодов и т.д.
Для регистров накопления наиболее важной возможностью является автоматическое хранение рассчитанных итогов и готовые виртуальные таблицы для доступа к итогам в различных разрезах и с учетом периодичности.
То есть, по сути, в типы прикладных объектов заложена существенная часть универсальных (типовых) механизмов бизнес-логики приложения, характерных для соответствующей категории данных предметной области.
Получается, что разработчик собирает приложение из объектов выбранных типов, как из деталей конструктора. Причем, если бывают конструкторы с «абстрактными» деталями, то в нашем конструкторе детали уже с «назначением» — колеса, окна, двери… На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.
Еще стоит сказать про методологическую ценность такого подхода. Все разработчики оперируют некоторым набором понятий, который помогает им лучше понимать суть приложений, упрощает общение. Открыв незнакомый проект 1С:Предприятия разработчик сразу видит знакомые понятия и может быстро разобраться в том какую роль в системе играет тот или иной объект. Например, чтобы понять суть приложения стоит посмотреть на состав регистров – обычно она отражает основное назначение приложения. Если открыть структуру таблиц или, тем более, структуру классов незнакомого приложения написанного на инструментах, оперирующих таблицами и классами, то понимания будет существенно меньше.
Но, что еще важно, такой подход сближает язык разработчиков и представителей бизнеса (или аналитиков). Про необходимость наличия такого языка хорошо сказано в книге «Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем» Эрика Эванса. Типы прикладных объектов достаточно быстро становятся понятными не-программистам и это позволяет обсуждать аналитикам, заказчикам и разработчикам основную функциональность проекта на одном языке. Часто можно встретить представителей бизнеса или аналитиков, которые не владеют программированием, но могут поставить задачу в терминах типов прикладных объектов 1С:Предприятия.
Что еще интересно. Этот подход обеспечивает постоянное развитие системы. Мы добавляем в платформу новые механизмы, и они сразу начинают работать для уже существующих объектов (без усилий разработчика приложений или с минимальными усилиями). Например, недавно мы разработали механизм хранения истории данных (версионирования). Так как система знает в общем виде о семантике данных, то разработчику достаточно поставить флажок, что он хочет хранить историю данных конкретного объекта, и платформа обеспечивает все, что нужно, от хранения истории, до визуализации — отображения пользователю истории изменений в виде различных отчетов. Когда ранее мы разработали механизм стандартного REST интерфейса (на основе стандарта OData), то во всех приложения сразу появился готовый REST интерфейс. Разработчикам ничего не пришлось для этого дорабатывать.
Почему мы не делаем еще и «просто таблицы» (в дополнение к готовым типам прикладных объектов)? Это непростой вопрос. Мы сами себе его периодически задаем.
С одной стороны это кажется заманчивым. Так мы бы закрыли все спорные случаи, когда предметная область не идеально ложится в заготовленный нами набор типов прикладных объектов. Можно было сказать разработчикам – «ну вот тебе просто таблица – и делай в ней все, как сам хочешь». Но с другой стороны это приведет к тому, что все наши стандартные механизмы будут пребывать «в растерянности» — как им обходиться с этими таблицами? Ведь они не будут знать семантику этих данных и не смогут понять, как с ними правильно работать. Ну, то есть с ними можно работать «как-то». Строго говоря, у нас есть такой опыт в части внешних источников. Для внешних источников мы описываем у себя именно таблицы (не указывая предметную направленность). И система с ними работает некоторым универсальным образом – при этом не поддерживается часть функциональности.
Пока мы все-таки стараемся удержаться от введения «просто таблиц», чтобы обеспечить чистоту модели и возможность добавлять новую функциональность, опираясь на знание о семантике всех данных. Если каких-то возможностей не будет хватать, то вначале мы все-таки будем рассматривать то, как можно развить состав типов прикладных объектов. Но, конечно, это вопрос дискуссионный и мы будем продолжать про него думать.
Таким образом, возможности, которые предоставляет в готовом виде платформа 1С:Предприятия и то повышение уровня абстракции, которое ценится прикладными разработчиками, во многом опираются именно на набор типов прикладных объектов. Это является одним из наиболее существенных отличий 1С:Предприятия от других средств разработки и одним из главных инструментов, обеспечивающих быструю и унифицированную разработку.
Ни для кого не секрет, что 2017 год выдался весьма “жарким” для всех специалистов по информационной безопасности. WannaCry, Petya, NotPetya, утечки данных и многое другое. На рынке ИБ сейчас небывалый ажиотаж и многие компании в ускоренном порядке ищут средства защиты. При этом многие забывают про самое главное — человеческий фактор.
Согласно отчетам компании Gartner за 2016 год, 95% всех успешных атак можно было предотвратить при грамотной настройке существующих средств защиты. Т.е. компании уже обладали всеми средствами для отражения атак, однако серьезно пострадали из-за невнимательности или халатности сотрудников. В данном случае компания теряет деньги дважды:
В результате атаки;
Выброшены деньги на средства защиты, которые не используются даже на 50%.
Если вспомнить тот же WannaCry, то жертвами данного шифровальщика стали компании, которые вовремя не обновили операционные системы и не закрыли “лишние” порты на межсетевых экранах. На самом деле здесь много и других факторов, такие как отсутствие централизованного управления, системы централизованного мониторинга, сбора и корреляции событий (т.е. SIEM, который тоже нужно “правильно” настроить). Подобных примеров можно привести очень много. Взять то же сетевое оборудование. По работе мне часто приходилось участвовать в очень крупных проектах, где ставилась задача по защите сети в 5-10 тысяч пользователей. Закупалось огромное количество дорого оборудования — межсетевые экраны, системы предотвращения вторжений, прокси-сервера и т.д. Бюджет проектов исчислялся десятками миллионов рублей. Представьте мое удивление, когда после внедрения таких “дорогущих” проектов обнаруживалось, что на обычном сетевом оборудовании использовались пароли вроде “admin” или “1234” (и эти пароли не менялись годами, даже после смены системных администраторов). Для подключения к коммутаторам использовался незащищенный протокол “Telnet”. В офисах стояли хабы, которые принесли сами пользователи, “потому что им так удобнее”. В корпоративную сеть подключались личные ноутбуки сотрудников. В ИТ инфраструктуре была полная анархия. Т.е. несмотря на потраченные миллионы, такую сеть мог бы “положить” даже школьник в течении 5 минут.
Что уж говорить о настройке таких “сложных” средств защиты как межсетевые экраны следующего поколения (NGFW) или UTM-устройства. И не важно на сколько дорогой фаервол вы купили и какое место он занимает в ежегодном рейтинге того же Gartner.
Нужна грамотная настройка и администрирование! Довольно часто можно встретить жесткую критику того или иного решения со стороны администраторов. Однако, при проверке конфигурации понимаешь, что кроме списка доступа “permit ip any any” ничего больше и не настраивалось. Результат в таком случае закономерен. Cisco, Fortinet, Check Point, Palo Alto, без разницы. Без правильной настройки это деньги на ветер (и зачастую весьма большие деньги). Кроме того, нужно понимать, что информационная безопасность это непрерывный процесс, а не результат. Выполнив настройку один раз, вам обязательно придется вернуться к ее актуализации через какое-то время.
В связи со всем выше описанным, мы анонсируем новый мини-курс по настройке Check Point, в котором мы постараемся показать, как “выжать” из него максимум защиты. Да, наличие Check Point-а не гарантирует хорошую защиту без адекватной настройки, собственно как и для любых других решений. Это всего лишь инструмент, которым нужно правильно пользоваться. Ранее мы уже публиковали статью по лучшим практикам в части настройки блейда Firewall, теперь же мы сосредоточимся на таких блейдах как Anti-Virus, IPS, Threat Emulation, Application Control, Content Awareness и т.д. Также мы обязательно рассмотрим блейд Compliance, который призван минимизировать ошибки и опасности в конфигурации Check Point-а (т.е. уменьшить влияние человеческого фактора).
При этом мы не будем ограничиваться лишь теоретическими данными и опробуем все на практике. Все настройки мы осуществим в новейшей версии Check Point — R80.10. Уроки будут в формате “Оружие — Защита”. В целом, наш макет будет выглядеть следующим образом:
Для тестов мы будем использовать дистрибутив Kali Linux (Hacker PC), генерируя вирусы различных видов и пытаясь “протащить” их через Check Point различными способами (доставка почтой или через браузер). Мы рассмотрим способы обхода антивирусов и систем предотвращения вторжений с помощью различных механизмов обфускации кода. Т.е. по сути мы будем заниматься чем-то вроде pentest-а, что в принципе и является лучшим методом проверки качества защиты и качества настройки.
Как вы понимаете, в рамках одного мини-курса невозможно объять необъятное, поэтому мы рассмотрим защиту от атак только на примере Check Point (возможно в будущем затронем и других вендоров). Однако, даже если вы не используете Check Point, то с помощью данных уроков, в последствии вы сможете самостоятельно протестировать эффективность своих текущих средств защиты. Мы сформируем некий чек-лист обязательных проверок. В крайнем же случае (если вам лень) воспользуйтесь хотя бы базовыми проверками, которые мы публиковали ранее.
На этом наше введение заканчивается. Надеюсь что данный курс вас действительно заинтересовал, а в следующем уроке мы поговорим о https инспекции.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Себастьян ван Элвердинге рассказывает о своём подходе к созданию потрясающих трёхмерных камней и скал с помощью множества фотографий. Более подробно о нём можно узнать в туториале на gumroad.com/sebvhe.
Введение
Привет, меня зовут Себастьян, я живу в Брюсселе, на родине лучшего картофеля фри, пива и шоколада! Сейчас я работаю художником по окружениям в Starbreeze Studios (Стокгольм). раньше я работал в Playground Games над игрой Forza Horizon 3, которая стала для меня отличной возможностью применения фотограмметрии в игре AAA-класса.
За последние четыре года я много экспериментировал с фотограмметрией. Довольно быстро я начал заниматься текстурами и материалами, о которых тогда мало знал. Примерно год назад я выпустил туториал о том, как создавать текстуры с помощью фотограмметрии.
Хотя с момента написания мой рабочий процесс немного поменялся, туториал всё равно применим к тому, что собираюсь рассказать. Если вам будет что-то непонятно в этом интервью, то, скорее всего, вы найдёте подробное объяснение в туториале. Мой самый первый бесшовный скан 2014 года (слева) и один из последних сканов (справа)
Фотограмметрия
Обычно люди воспринимают фотограмметрию как способ переноса в игру статичных отсканированных сеток (mesh). При работе со сканированием окружений они всегда имеют дело с огромными уникальными текстурами со стороной по 4-16 килопикселей на уникальных, неповторяющихся сетках. Хорошим примером может служить демо UE4 Kite. Но то, что подходит для кинематографических роликов типа Kite, будет совсем неприменимо для использования в реальном времени, особенно на больших поверхностях.
Это было важно для меня, когда я работал над набором текстур UE4 Marketplace Rock Texture Set. Представим, что мы делаем небольшой скалистый каньон. Ошибкой будет сканирование набора из 4-8 крупных скал, из которых вы затем попробуете собрать каньон. В результате у вас скорее всего получится четыре уникальных текстуры со стороной в 4 килопикселя. Вместо этого я стремлюсь создать одну очень хорошую бесшовную текстуру камня, записывая красивые формы в её карту высот. Затем я просто создаю очень простую сетку каньона, для которой применяю смещение (displacement) на основании полученной текстуры. Таким образом я получаю целую сцену, в которой для скал используется только одна текстура на 4k.
Быстро созданная «огибающая сетка» каньона со смещением в UE4, используется одна бесшовная текстура камня и немного снега для красоты.
Можно без всяких проблем выполнить смещение заранее в 3D-редакторе на основе карты высот, а потом импортировать оптимизированную сетку вместо использования тесселяции. Выбор зависит от важности окружения и имеющихся ресурсов.
Я считаю, что этот метод занимает гораздо меньше памяти, требует невероятно мало времени (по сравнению со сканированием нескольких сеток) и позволяет выполнять итерации дизайна намного быстрее. Если вы хотите превратить сцену в пустынный каньон, то достаточно будет просто отсканировать одну текстуру пустынной скалы.
Просто представьте, сколько сеток пришлось бы отсканировать для замены биома, а в нашем случае требуется всего одна текстура (плюс снег, песок или мох)
Однако стоит с умом подходить к сокрытию или удалению швов. Мой материал тесселяции позволяет удалять 100% швов.
В конце концов, фотограмметрия может быть очень гибкой, стоит только задуматься о ней за пределами традиционного «жёсткого» использования.
Техника
На самом деле, кроме камеры и компьютера вам больше ничего не понадобится. Хорошая аналогия: чтобы играть на гитаре, вам не нужен Gibson за 2000 долларов, с простой гитарой за 100 долларов можно добиться очень многого. В конечном итоге мастерство значит больше, чем оборудование. При работе с фотограмметрией я использую очень простое оборудование. Я с удовольствием бы «проапгрейдился», но пока я думаю, что ограничения плохого оборудования помогали мне находить хитрые способы улучшения низкого качества сканов.
Все мои работы по сканированию я провожу с помощью Canon 100D/Rebel SL1, одной из самых дешёвых зеркалок на рынке, она стоит всего около 400 долларов.
Тем не менее, для улучшения качества сканов потребуются некоторые усилия.
Ручная выдержка: хотя технически можно использовать и плохую камеру с автоматическими настройками, на самом деле отсутствие ручной выдержки очень ограничивает. Нужно, чтобы все снимки имели одинаковые настройки, иначе камера начнёт компенсировать более тёмные снимки и программному обеспечению будет гораздо сложнее привязать снимки друг к другу, а вам — удалить информацию об освещении. Почти во всех камерах и телефонах сегодня есть функция ручной выдержки.
Хорошая SD-карта/высокая скорость записи: сначала это не так очевидно, но это может изменить ваш мир. Долгое время я пользовался медленной SD-картой и мне приходилось ждать примерно по 5 секунд между снимками (как только заполнялась буферная память карты). Когда делаешь сотни кадров, 5 секунд между снимками — это много.
Файлы в формате RAW: это самая главная причина, по которой я рекомендую DSLR. Формат файлов RAW содержит гораздо больше информации и динамического диапазона, чем обычный JPG (который, к тому же имеет артефакты сжатия). Он позволяет предварительно обрабатывать снимки, добиваясь, среди прочего, лучшего качества, цветового баланса и устранения виньеток.
Кроме того, он позволяет уменьшать информацию об освещении перед обработкой сканов, что упрощает удаление этой информации после процесса. Файлы RAW могут быть огромными, так что стоит учесть это при выборе SD-карты.
А теперь про оборудование, которое я не использую:
Штатив: совершенно верно, я редко использую штатив, по крайней мере, при съёмках на улице. Это мой личный выбор. Для меня приоритетнее большая скорость затвора, чем большая диафрагма (подробнее об этом позже). Не поймите меня неправильно, использование штатива вне всяких сомнений улучшает качество сканов, но тут есть недостаток — на установку штатива для каждого снимка тратится время, много времени (а ведь даже несколько секунд на кадр в сумме дают очень очень много). При съёмке на улице условия освещения редко бывают идеальными, поэтому я обычно стремлюсь быть как можно быстрее (но без суеты), чтобы избежать постепенной смены условий освещения при сканировании. Повторюсь, если вы сканируете в помещении или условия освещения стабильные, то нет никаких причин не использовать штатив! Более того, возможно, для вас хорошим компромиссом между потраченным временем и качеством может быть монопод.
Калибровщик цветов (color checker): нет ни одной достойной причины не использовать их, кроме дороговизны — примерно 100 долларов за X-Rite Passport. Калибровщик цветов обеспечивает правильную калибровку цветов. Скоро я его себе куплю.
Хромированные шары и всё оборудование для удаления информации об освещении HDR: по-моему, это просто трата времени и денег, по крайней мере, для текстур, но может быть и пригодится для больших сканов на 360 градусов. По умолчанию, если вы сканируете текстуры, то снимаемая поверхность чаще всего смотрит в одном направлении и освещение всего скана практически одинаково. Можно избавиться от остатков освещения за несколько минут работы в Photoshop и не тратить время на возню с удалением информации об освещении HDRI.
Поговорим о компьютерах: если у вас есть стандартный игровой настольный компьютер, то проблем с обработкой не будет. Рекомендую иметь не менее 16 ГБ ОЗУ и приличную видеокарту. Я использую GTX670 и 16 ГБ ОЗУ, довольно стандартный набор. Вероятно, «узким местом» будет память.
Освещение
Хорошего освещения добиться очень трудно, потому что на улице вы не можете им управлять и нет других вариантов, кроме как ждать нужного момента. В целом, нужно избегать двух моментов:
Дождя: при сканировании должно быть сухо. В зависимости от материала дождь может сделать его более отражающим или тёмным.
Изменения условий: если вам не удаётся застать хорошего равномерного облачного неба, по крайней мере стремитесь к чему-то стабильному, даже если солнечно, в таком случае можно будет отсканировать что-нибудь в тени. Надо любой ценой избегать движущихся облаков, потому что они могут буквально за секунды значительно изменять освещённость.
Вот это один из наихудших примеров.
Ваша цель — облачное небо, одновременно и равномерное, и очень яркое. Не ждите слишком долго, вероятность получить его не очень велика!
Сколько снимков обычно нужно делать, чтобы получить хороший материал?
Количество снимков сильно зависит от используемого ПО (о нём чуть позже), размера сканируемой поверхности и нужного уровня детализации. Всегда лучше сделать больше снимков, чем нужно.
Разумеется, критически важно наложение. Фотограмметрическое ПО сопоставляет характерные черты на разных снимках для определения пространственного положения кадров. Поэтому на нескольких снимках должны быть одинаковые части, чем больше, тем лучше.
Итак, вы хотите отсканировать найденную поверхность, с чего же начать?
Помните, я говорил, что могу отказаться от штатива, потому что меняю узкую диафрагму на высокую скорость затвора? Я могу позволить себе узкую глубину поля резкости почти без размывания, потому что я всегда снимаю сверху вниз (но тут надо быть аккуратным, чтобы не залезть в кадр обувью!). Это не только обеспечивает наилучшие результаты, но и означает, что объект будет почти на одном расстоянии от камеры во всём кадре, снижая количество размывания глубины поля резкости. Разумеется, это относится к сканированию относительно плоских поверхностей.
Источник: руководство пользователя Agisoft
А теперь о наложении: представьте себя картографом Google Earth, сначала вы хотите запечатлеть всю Землю, весь объект в первых снимках, а потом добавить различные уровни детализации. Сначала делайте глобальные снимки, не меньше восьми, лучше больше. Возможно, их не удастся сделать сверху вниз, не волнуйтесь, просто двигайтесь по объекту, и аккуратнее с глубиной поля резкости. Теперь у вас на каждом снимке есть все характерные черты поверхности, к которым будут привязываться следующие, более точные снимки.
Далее вам нужно создать первый уровень масштабирования: сделайте снимки сверху вниз, размером примерно в 1/4 поверхности. Сделайте так, чтобы они перекрывали друг друга больше чем на 50%. Повторите снова для 1/8 поверхности, 1/16, и т.д… Всё зависит от нужного вам уровня детализации.
Такой алгоритм работы гарантирует, что близкие снимки не смешаются со своими соседями, для привязки они смогут полагаться на предыдущий уровень детализации.
Конечно же, в реальности вы делаете всё на глазок, не нужно носить с собой рулетку. Более того, этот принцип срабатывает не всегда, например, если вы сканируете песок, то на него нельзя наступать в процессе сканирования. Но неплохо всегда помнить об этом принципе.
В этом примере общие снимки выделены синим, первый уровень снимков сверху вниз показан зелёным, а другой подробный вид сверху вниз — красным.
Программное обеспечение
Есть два основных конкурента, Agisoft Photoscan и довольно новый пакет Reality Capture. Я в основном использовал Photoscan, но недавно стал пользоваться Reality Capture. Не скажу, что один в чём-то намного лучше другого, но в последнее время индустрия, похоже, склоняется к Reality Capture.
Вот мои плюсы и минусы каждого пакета. Не забывайте, я ещё довольно неопытен в Reality Capture и могу в чём-то ошибаться.
Agisoft Photoscan
Reality Capture
Плюсы
Хорошая документация и онлайн-туториалы
Безумно быстрый в обработке, иногда даже не успеваешь выпить кофе!
Хорошие инструменты фильтрации для удаления нежелательных точек после привязки.
Похоже, не делает так много дыр, как Reality Capture
Может обрабатывать тысячи снимков на простом компьютере
На мой взгляд, качество текстур в Agisoft немного лучше
Программа ни разу не вываливалась, это бывает так редко, что стоит упомянуть
Лицензия Standalone довольно дешёвая, 179 долларов, в долговременной перспективе дешевле, чем у Reality Capture.
Минусы
Довольно медленный и использует КУЧУ ОЗУ, при посредственном компьютере разрешение сканов может быть довольно сильно урезано
Создаёт больше дыр и требует немного больше ручной привязки. Однако здесь проблема может быть в моих настройках, которые пока неидеальны.
Нужно аккуратно подбирать снимки, потому что компьютер, возможно, не сможет их все обработать.
Большинство параметров очень загадочно, не хватает документации и примеров.
По тем же причинам скорее всего не получится добиться сеток сверхвысокого разрешения.
Слишком похож на подход «решение одним нажатием». Удобно, когда это работает, но когда не получается, то при исправлении возникает куча проблем.
Система подписки делает его более дорогим в долгосрочной перспективе (от шести месяцев)
Думаю, стоит посоветовать новичкам начать с Reality Capture, он более терпим к плохим снимкам, кроме того, вы можете компенсировать некачественные снимки хорошим качеством изображений, чего Agisoft, возможно, не обеспечит на вашем компьютере.
Однако если вы планируете работать с фотограмметрией только время от времени, то наверно дешевле будет выбрать standalone-лицензию Agisoft.
Особенности
Потрясающий сверхдетализированный скан может и не выглядеть в игре красиво, если заранее не позаботиться о хорошем художественном видении.
Самое важное и трудное — это замощение (tiling). О нём стоит помнить всегда, особенно при поиске поверхности для сканирования. Многие спрашивают меня: «Есть ли более быстрый способ размещения текстур и можно ли его автоматизировать, например, с помощью Substance?»
В 90% случаев такого способа нет.
Думаю, вера в существование такого способа возникла из-за убеждения, что замощение — это удаление швов. Да, наверно так и есть, но это меньше 10% процесса соединения текстур. Реальная работа заключается в балансировке частотности и характерных черт вашей поверхности, в том, чтобы текстура выглядела хорошо даже при многократном повторении. В большинстве случаев это пока нельзя автоматизировать.
Возможно, этот процесс стоит называть не «размещением», а «соединением».
Не фокусируйтесь только на швах, перемещайте фрагменты текстуры, удаляйте слишком заметные камешки, и т.д…
Невозможно перейти от протяжённой скалы (слева) к квадратной бесшовной текстуре (справа), просто «удалив швы»
Способ, которым я делаю текстуры бесшовными в Photoshop, позволяет довольно просто двигать объекты по сравнению с 3D-редакторами, особенно когда работаешь с сетками в 50 миллионов полигонов.
Я почти не пользуюсь ZBrush, за исключением смещения текстуры для запекания всех нужных мне карт. Иногда я могу быстро исправить некоторые артефакты, но обычно этого не бывает, и я ничего не делаю в ZBrush.
Удаление информации об освещении
Избавление от освещения — это очень большая проблема при сканировании 3D-объектов. Для текстур же… оно не слишком важно. Чаще всего эта проблем решается быстро и прямолинейно. Важнее всего иметь при сканировании равномерное освещение. Если удалось его добиться, то дело остаётся за использованием карты AO (Ambient occlusion) для удаления затемнения из диффузной карты. Затем, возможно, придётся исправить несколько фрагментов вручную.
Я почти никогда не трачу на удаление информации об освещении больше тридцати минут.
Карты нормалей
Карты нормалей создаются достаточно просто, однако стоит обратить внимание на два момента:
Любой ценой избегайте нависания: об этом нужно помнить даже во время съёмки, разберитесь, какая область может выглядеть неправильно при смещении на плоскости, и знайте, как исправить это, если всё равно решите снимать. Как я объяснил в своём туториале, большинство проблем можно решить созданием специальной низкополигональной модели. Однако это хитрая проблема, потому что вы можете не заметить её, пока уже не заберётесь в процессе очень далеко. На моих первых сканах было много растяжений из-за нависаний.
Пример растяжения из-за нависаний в одном из моих первых сканов. Специальная низкополигональная сетка, которую я теперь использую, исправило бы это.
Не ожидайте, что скан будет достаточно детальным для сверхчёткой карты нормалей. Потребуется регенерировать высокочастотные детали, преобразовав albedo в карту нормалей и наложив мелкие детали поверх нормалей скана.
Почему вы думаете, что использование карт отражений важно для подбора правильных типов материалов?
Очень хитрый вопрос!
Поскольку в играх широко используется PBR, мнения художников разделились. Одни хотят, чтобы система была точной на 100%, а потому заявляют, что никогда не стоит использовать карты отражений. Другие говорят, что некоторые объекты выглядят с ними лучше, хотя и технически неверно. Могу сказать, что правы обе стороны, однако я склоняюсь к использованию в определённых случаях карт отражений. Более того, возможно, они не так неточны, как вы думаете. Давайте я объясню:
При запекании органических текстур на плоскость вы слишком упрощаете чрезвычайно сложные формы, листья, небольшие камешки, и т.д… Осознавали ли вы когда-нибудь, насколько сложным может быть мох?
Все эти неровности невозможно имитировать простыми roughness и картой нормалей. Основная причина этого в том, что все эти мелкие детали отбрасывают друг на друга тени. Свет «запутывается» в сложном рисунке мха, и не может просто так отразиться обратно.
Тесселяцией можно вернуть обратно эти мелкие тени, но для маленьких деталей её недостаточно.
Можно ли решить эту проблему с помощью карты AO?
Да, может быть, но проблема с картами AO в том, что они по-настоящему работают только в затенённых частях сетки, а все освещённые прямым светом части остаются очень плоскими и «пластмассовыми».
Использование карты отражений — это простой способ для имитации сложного поведения сложных органических форм.
Без карты отражений (слева) и с картой отражений (справа). Заметьте, что грязь и очень мелкие камешки выглядят менее пластмассовыми с картой отражений.
При этом стоит аккуратно обращаться с картой отражений. Всегда понимайте, зачем вы её делаете, какая логика за этим стоит. Потребность в карте отражений также сильно зависит от используемого движка.
При использовании карты отражений я передаю на вход с помощью линейной интерполяции только её часть, чтобы управлять количеством изменяемого отражения.
Я всегда создаю карты отражений для моих текстур, потому что это занимает всего несколько минут, но в результате я использую их только в особых случаях, в основном для травы и мха.
Привет! Это моя новая статья, посвященная Selenium. Ранее я уже подробно рассказал об организации масштабируемого кластера Selenium (часть I, часть II). Затем мы рассмотрели вопрос использования Selenium в качестве инструмента отладки автотестов (раз, два), Наконец, нам удалось создать порядок из хаоса на Windows (ссылка). Сегодня мы будем иметь дело с яблоками, точнее с одним большим Яблоком (т.е. с Apple).
Хотя Selenium является относительно простым инструментом, жизнь усложняется, когда мы пытаемся запускать автоматические тесты в браузерах из Купертино: Safari под MacOS и мобильный Safari под iOS. Чтобы полностью разобраться с браузерами для настольных операционных систем, давайте сегодня поговорим о Safari под MacOS. Сегодня свежие версии Safari разрабатываются только под MacOS. Исторически работа с Safari была реализована в Selenium при помощи браузерного расширения, которое транслировало команды Selenium во внутренние команды браузера. Изначально расширение загружалось в Safari автоматически. Позже из-за изменения правил безопасности в Safari нужно было установить расширение один раз вручную. Наконец, с выходом Safari X все значительно поменялось. Теперь Safari использует отдельно стоящий процесс веб-драйвера — safaridriver, аналогично chromedriver у Chrome и geckodriver у Firefox. Чтобы запустить тесты в Safari нужно:
Запустить safaridriver (обычно устанавливаемый вместе с Safari и расположенный в /usr/bin/safaridriver) на свободном порту, например, 4444. Команда для запуска будет такая:
$ /usr/bin/safaridriver --port 4444
Запустить тесты, используя следующий Selenium URL:
http://localhost:4444/
Остановить запущенный процесс драйвера.
Звучит легко, не правда ли? И так оно и есть! Тем не менее есть проблема — safaridriver умеет работать только с одной копией Safari параллельно. Как преодолеть это ограничение? — Запустить драйвер несколько раз на разных портах и запустить тесты на разных URL с этими портами. Просто, но требует много ручной работы. Давайте автоматизируем этот процесс! Как это могло бы работать? А вот как:
Вы запускаете сервер, предоставляющий Selenium API и указываете ему при старте, где расположен safaridriver.
Когда приходит запрос на новую сессию — запущенный сервер ищет свободный порт и занимает его. Затем он запускает процесс safaridriver на этом порту и проксирует все последующие запросы туда же.
Когда поступает запрос на закрытие сессии — процесс safaridriver также останавливается.
Описанный алгоритм очень прост, поэтому он не должен требовать разработки сложного сервера, не так ли? Если вы возьмете в качестве сервера сегодняший стандарт — Selenium сервер, то будете использовать чересчур сложный инструмент для такой просто задачи. Почему это так:
Selenium server — огромный как слон! Размер дистрибутива начинается от 20 Мб.
Он требует установки Java — еще одного гигантского существа в ваш зоопарк. Со всякими всплывающими окнами об обновлении и графическим интерфейсом из 90-х.
Он всегда голоден и есть память без причины.
Он довольно плохо документирован и не работает из коробки. Нужно быть волшебником, чтобы заставить его заработать.
Короче говоря, позвольте мне показать вам более подходящий инструмент — Selenoid. Selenoid — это легковесный демон, созданный полностью заменить тучный Selenium сервер. Завести Selenoid с Safari очень просто:
Скопировать кусочек JSON, приведенный ниже, в файл (например, в ~/browsers.json):
Больше не нужно устанавливать Java и компанию! Но если вы, как я, не хотите делать руками и это, то можете получить аналогичный результат, используя однострочный скрипт:
В данной статье мы расскажем, как эксплуатировать ShellShock на клиенте DHCP и получить на нем полноценный reverse или bind shell. Интернет пестрит статьями, повествующими о возможностях эксплуатации shellshock на DHCP-клиентах. Есть даже статьи о том, как получить reverse shell на DHCP-клиенте. Однако, стабильно и повсеместно работающего инструмента для получения shell мы еще не встречали. Те, кто в теме, возможно, нового здесь не увидят, но не исключено, что вам будет интересно узнать, как нам удалось автоматизировать получение reverse и bind shell в условиях фильтрации и экранирования символов на стороне DHCP-клиента. Кроме того, мы расскажем и о том, чем вообще может быть интересен протокол DHCP.
Протокол DHCP применяется для автоматического назначения IP-адреса, шлюза по умолчанию, DNS-сервера и т.д. В качестве транспорта данный протокол использует UDP, а это значит, что мы можем без особых проблем подменять все интересующие нас поля в сетевом пакете, начиная с канального уровня: MAC-адрес источника, IP-адрес источника, порты источника — то есть все, что нам хочется.
Работает DHCP, в двух словах, примерно так:
DHCPDISCOVER Клиент отправляет широковещательный сетевой пакет с целью найти DHCP-сервер в сети, при этом с канальным уровнем все понятно и о нем писать дальше не будем, сетевой — исходя из собственного опыта, здесь может быть всякое — зависит от клиента, но должно быть: SRC IP: 0.0.0.0, DST IP: 255.255.255.255.
На транспортном уровне все запросы отправляются так: SRC PORT: 68, DST PORT: 67
Соответственно, когда сервер отвечает клиенту: SRC PORT: 67, DST PORT: 68
Контрольную сумму UDP можно не считать. Мы не встречали ни одного DHCP-сервера, который бы ее проверял, да и сетевое оборудование пропускает пакеты с нулевым значением UDP checksum без проблем. В первом байте прикладного уровня (поле op — тип сообщения) клиент выставляет значение — 0х01 (BOOTREQUEST — запрос от клиента к серверу). На остальных полях пакета не будем останавливаться, поскольку их описание, длина и значения есть в RFC и в WIKI. В запросе от клиента нам также интересно поле xid (Transaction ID — рандомное число размером 4 байта по смещению 0х04 от начала прикладного уровня в пакете). Если сервер в ответе выставит поле xid не равным xid клиента, то клиент отбросит ответ от сервера, поскольку посчитает, что этот ответ в другой транзакции. Остановимся на DHCP-опциях пакета. Всего их 256, а полный список можно найти здесь или тут. Клиент обязательно выставляет опцию с кодом 53 (DHCP message type тип DHCP сообщения) равной 0х01, это значит, что данный пакет предназначен для нахождения DHCP-сервера, и опцию 55 (Parameter Request List список запрашиваемых у сервера параметров, например адрес шлюза, маска подсети, DNS-серверы и т.д.).
Вот так выглядит этот запрос в WireShark:
DHCPOFFER Сервер получает запрос от клиента и отправляет ему предложение. На сетевом уровне в качестве SRC IP сервер выставляет свой IP-адрес, в DST IP должно быть: 255.255.255.255, но это не всегда так. В DST IP также может быть выставлен IP-адрес, выделенный клиенту, или IP-адрес ретранслятора, если тот участвует в процессе. Вы спросите, а как же пакет доходит до клиента, если у него еще нет IP-адреса? Все просто: в DHCPDISCOVER- и DHCPREQUEST-запросах, в поле chaddr (Сlient MAC address) клиент указывает свой MAC-адрес. Таким образом, сервер или ретранслятор знают, куда доставлять пакет на канальном уровне, поскольку сервер или ретранслятор всегда находятся в пределах одного широковещательного домена с клиентом, а что происходит на сетевом уровне, не так уж и важно UDP магия. В типе сообщения значение 0х02 (BOOTREPLY — ответ сервера клиенту). В поле xid выставляется значение, равное значению поля xid в запросе клиента. В поле yiaddr (Your (client) IP address) выставляется IP-адрес клиента, предложенный сервером. Что появляется в DHCP-опциях: в опции с кодом 53 (DHCP message type) значение — 0х02 (DHCPOFFER), код 51 (IP Address Lease Time) — время аренды IP-адреса, код 54 (Server Identifier) — IP-адрес DHCP-сервера. Все остальные опции предложения зависят от того, какие параметры запросил клиент, их список клиент указал в DHCPDISCOVER-запросе в опции с кодом 55 (Parameter Request List).
DHCPREQUEST Клиент отправляет серверу запрос на получение сетевых параметров. На сетевом уровне должно быть так: SRC IP: 0.0.0.0 DST IP: 255.255.255.255 но может быть и так: в SRC IP выставляется IP-адрес, который назначил сервер в своем предложении (поле yiaddr), а в DST IP выставляется IP-адрес, который расположен в опции предложения сервера с кодом 54 (Server Identifier). DHCP-опции в этом запросе не отличаются от DHCPDISCOVER-запроса, за исключением опции с кодом 53 (DHCP message type тип DHCP сообщения), равной 0х03 — это значит, что данный пакет предназначен для запроса параметров от DHCP-сервера. И еще клиент добавляет в запрос опцию с кодом 54 (Server Identifier), поскольку уже знает IP-адрес сервера, а также опцию с кодом 50 (Requested IP address). Кроме того, клиент может выставить опцию 12(Host Name Option свое имя хоста) и т.п.
DHCPACK Сервер отправляет клиенту подтверждение. На сетевом уровне должно быть так: SRC IP: DST IP: 255.255.255.255. Опции и поля этого пакета не отличаются от DHCPOFFER, за исключением опции с кодом 53 (DHCP message type тип DHCP-сообщения), равной 0х05 — это значит, что данный пакет — подтверждение от DHCP-сервера.
Далее, клиент с помощью протокола ARP пытается обнаружить конфликт IP-адресов в локальной сети (Address Conflict Detection). Если конфликт не найден, клиент выставляет полученные из DHCPACK параметры сетевому интерфейсу. Если обнаружен, клиент рассылает широковещательное сообщение отказа DHCP DHCPDECLINE, после чего процедура получения IP-адреса повторяется.
Также у протокола DHCP есть еще одна особенность: если клиент ранее отправлял запрос DHCPDISCOVER, то при повторном подключении к той же сети клиент сразу отправляет DHCPREQUEST; при этом в DHCP-опции с кодом 50 (Requested IP address) выставляется IP-адрес, полученый ранее.
Остановимся на упомянутом DHCPDECLINE подробнее. На практике это выглядит так:
Клиент отправляет DHCPREQUEST, поскольку уже подключался к этой сети. Transaction ID: 0x825b824a; Requested IP: 192.168.1.171; Client MAC address: 08:00:27:ce:7a:64
Клиент с помощью протокола ARP узнает MAC-адрес шлюза, а далее, через тот же ARP, пытается обнаружить конфликт IP-адресов в локальной сети (Address Conflict Detection). Запрос выглядит так: sender mac: 08:00:27:ce:7a:64; sender ip: 0.0.0.0; target mac: 00:00:00:00:00:00; target ip: 192.168.1.171
Хост с IP-адресом 192.168.1.171 отвечает на ARP-запрос.
Клиент выявил конфликт IP-адресов в сети и отправляет широковещательный DHCPDECLINE. Transaction ID: 0x825b824a; Requested IP: 192.168.1.171; ciaddr: 192.168.1.171
Процедура получения IP-адреса повторяется, но уже с другим Transaction ID: 0x713a0fe7. Вы обратили внимание на пакеты с номерами 89, 101, 106, 136 и 151? Если да, то наверняка поняли, что на этот раз сервер выделил клиенту IP-адрес 192.168.1.172 и перед этим DHCP-сервер сам с помощью того же ARP (пакеты с номерами 89, 101, 106: Who has 192.168.1.172? Tell 192.168.1.1) убедился, что IP-адрес 192.168.1.172 свободен, и только потом отправил DHCPOFFER. После этого клиент еще раз попытался выявить конфликт IP-адресов (пакеты с номерами 136, 151: Who has 192.168.1.172? Tell 0.0.0.0).
Мы уже знаем, что клиент, подключившись хотя бы раз к сети, будет отправлять только DHCPREQUEST-запрос, выставляя при этом в Requested IP адрес, который получил ранее. Но что если DHCP-сервер уже выделил этот IP-адрес, поменялась конфигурация или адресация, и сервер не может дать клиенту этот адрес? Для этого существует тип сообщения DHCPNAK. Работает он следующим образом:
В настройках сервера указан диапазон, в котором он может выделять IP-адрес, но тот, который запросил клиент, не входит в данный диапазон, поэтому сервер отправляет DHCPNAK. Transaction ID: 0xa7ddc5cb; Message: address not available
Процедура получения IP-адреса повторяется, но уже с другим Transaction ID: 0xcfbf77a9.
Перейдем к shellshock
Про то, как и почему работает shellshock, писать нет никакого смысла, ведь эта уязвимость — одна из самых популярных, и о ней есть великое множество статей. Лучше остановимся на моменте, как получить shell на клиенте DHCP, в случае, если мы выступим в роли DHCP-сервера.
В нашем PoC мы будем использовать DHCP-опцию с кодом 114 (URL). Почему? Потому, что ее длина — вариативна (максимальная длина — 256 байт), а также потому, что ее все используют. Ее описание еще есть здесь. Существует даже статья о том, как с помощью этой опции обновить уязвимые к shellshock системы :)
Какие у нас ограничения?
Ответ: их много, слишком много!
Длина — 256 байт
Возможно использовать только команды интерпретатора
Большое ограничение на используемые символы: некоторые фильтруются, некоторые экранируются. Это зависит от клиента DHCP. Вот набор символов, которые не везде получится использовать: "';&|
После выполнения команды, IPv4-адрес может не присвоиться, в таком случае возможно использовать IPv6 link-local-адрес, если на интерфейсе не включено игнорирование IPv6
Необходимо использовать абсолютные пути, иначе команда может не выполниться
И что тогда делать?
Ответ: обходить ограничения!
Для обхода фильтра мы должны выполнить все одной командой. Сделаем это так:
/bin/sh <(/usr/bin/base64 -d <<< Base64String)
Здесь на вход интерпретатора /bin/sh мы подаем вывод /usr/bin/base64, которая декодирует строку Base64String. Таким образом, мы использовали уже 34 байта, длина Base64String не должна превышать 222 байтов.
А что будет в Base64String? Не забываем про четвертое ограничение, поэтому в первую очередь выставим IP-адрес интерфейсу командой:
/bin/ip addr add / dev eth0;
Эта команда накладывает на нас еще одно ограничение: мы должны знать имя интерфейса, которому выставляем IP-адрес. По умолчанию, в старых версиях Linux, на которых еще есть shellshock, первый сетевой интерфейс называется eth0, так что ориентируемся на него. Еще в эту строку мы должны поместить reverse shell или bind shell.
Для reverse shell будем использовать стандартный shell с использованием nc:
Ни в коем случае DHCP нельзя рассматривать исключительно как метод получения RCE на клиентах, потому что, во-первых, мы должны ответить быстрее реального DHCP-сервера в сети, и, во-вторых, на клиенте должен быть shellshock, а это маловероятно. Протокол DHCP в первую очередь необходимо рассматривать как метод осуществления MITM.
Поговорим о том, как ответить на любой запрос быстрее DHCP-сервера. Самый очевидный вариант — быть ближе к клиенту по расположению в сети, и еще наше железо и алгоритм должны работать быстрее. Однако, в большинстве случаев это не так.
Есть второй вариант: нужно нагрузить сервер, но при этом не занимать новые IP-адреса в сети, чтобы не исчерпать весь пул свободных адресов (такая атака называется DHCP starvation). Как вы уже поняли, необходимо отправлять большое количество запросов DHCPDISCOVER, поскольку сервер должен обработать каждый из них и отправить в ответ DHCPOFFER. Однако, в рамках данной транзакции DHCPREQUEST мы отправлять не будем, поэтому сервер будет его ждать. IP-адрес не будет считаться выделенным, потому что процедура получения IP не завершена.
Давайте посмотрим, как это выглядит на практике.
Графы нагрузки и процессы до отправки DHCPDISCOVER-запросов:
На рисунках видно, что load average роутера колеблется от 0.1 до 0.3, и процесс dnsmasq занимает 0% CPU.
Графы нагрузки, процессы и список DHCP-клиентов во время отправки DHCPDISCOVER-запросов:
Load average роутера повысился до 1.96, и он уже не успевает отвечать на все запросы DHCPDISCOVER, процесс dnsmasq занимает целых 64% CPU, но при этом в списке DHCP клиентов только наш хост.
В результате, мы и сервер немного нагрузили, и IP-адреса не заняли. Если мы отфильтруем все сгенерированные нами же запросы DHCPDISCOVER, вероятнось того, что мы ответим быстрее реального DHCP-сервера, значительно увеличится. Задача выполнена, идем дальше.
Первые шесть типов сообщений мы уже разобрали, осталось всего два: седьмой (DHCPRELEASE) и восьмой (DHCPINFORM). Остановимся на них подробнее.
Клиент может явным образом прекратить аренду IP-адреса. Для этого он отправляет сообщение освобождения аренды адреса DHCPRELEASE тому серверу, который предоставил адрес ранее. В отличие от других сообщений, это не рассылается широковещательно.
Сообщение информации DHCPINFORM предназначено для определения дополнительных сетевых параметров теми клиентами, у которых IP-адрес настроен вручную. Исходя из своего опыта, можем сказать, что такие сообщения отправляют только Windows хосты :(. Сервер отвечает на подобный запрос DHCPACK без выделения IP-адреса. Для этих сообщений существует свой проект rfc. Вы уже поняли, что мы можем выставить в DHCPACK свой шлюз, DNS, и т.д. Главное — ответить раньше реального DHCP сервера, а эта проблема уже решена выше.
DHCP starvation & DHCP relay agent
В данной статье мы упоминали про атаку DHCP starvation — исчерпание пула свободных IP-адресов. Бытует мнение, что провести данную атаку возможно, отправляя лишь большое количество DHCPDISCOVER или DHCPREQUEST запросов с рандомных MAC-адресов, и тогда на каждый такой запрос DHCP-сервер выделит и зарезервирует IP-адрес, но это не всегда так. Как мы уже знаем, процедура получения и резервирования IP-адреса заканчивается тогда, когда DHCP-сервер отправляет сообщение DHCPACK. Наиболее корректно производить данную атаку, представляясь как DHCP relay agent.
Приведем пример:
Наш сетевой интерфейс enp0s3 с MAC-адресом: 08:00:27:6a:82:5f и IP-адресом: 192.168.1.2. В качестве DHCP-сервера будет выступать Dnsmasq/2.73 из состава OpenWrt Chaos Calmer 15.05.1 IP-адрес: 192.168.1.1
Начинаем отправку запросов:
Таким образом, мы забъем весь пул свободных IP-адресов, а легитимный DHCP-клиент сможет получить IP-адрес от этого DHCP-сервера только через 12 часов. Пока легитимный DHCP-сервер не может отправить ответы клиентам, это можем сделать мы!
Как это работает:
Формируем и отправляем широковещательный DHCPDISCOVER-запрос, при этом представлемся как DHCP relay agent. В поле giaddr (Relay agent IP) указываем свой IP-адрес 192.168.1.2, в поле chaddr (Client MAC address) — рандомный MAC 00:19:bb:f5:e7:a8, при этом на канальном уровне в SRC MAC выставляем свой MAC-адрес.
Сервер отвечает сообщением DHCPOFFER агенту ретрансляции (нам), и предлагает клиенту с MAC-адресом 00:19:bb:f5:e7:a8 IP-адрес 192.168.1.232
После получения DHCPOFFER, отправляем широковещательный DHCPREQUEST-запрос, при этом в DHCP-опции с кодом 50 (Requested IP address) выставляем предложеный клиенту IP-адрес 192.168.1.232, в опции с кодом 12 (Host Name Option) — рандомную строку. Важно: значения полей xid (Transaction ID) и chaddr (Client MAC address) в DHCPREQUEST и DHCPDISCOVER должны быть одинаковыми, иначе сервер отбросит запрос, ведь это будет выглядеть, как другая транзакция от того же клиента, либо другой клиент с той же транзакцией.
Сервер отправляет агенту ретрансляции сообщение DHCPACK. С этого момента IP-адрес 192.168.1.232 считается зарезервированным за клиентом с MAC-адресом 00:19:bb:f5:e7:a8 на 12 часов (время аренды по умолчанию).
Выводы
Способы противодействия:
DHCP snooping — функция коммутатора, предназначенная для защиты от атак с использованием протокола DHCP. Например, атаки с подменой DHCP-сервера в сети;
Port security — функция коммутатора, позволяющая указать MAC-адреса хостов, которым разрешено передавать данные через порт. После этого порт не передает пакеты, если MAC-адрес отправителя не указан как разрешенный;
Настройка сетевого оборудования с целью ограничения количества DHCPDISCOVER и DHCPREQUEST запросов с одного MAC-адреса и/или IP-адреса;
Запись и анализ трафика в сети для отслеживания аномалий. Например, обычное количество DHCP-запросов в вашей сети не превышает 100-200 в день, а во время атаки DHCP starvation их число увеличивается многократно. Еще один пример: обычно в вашей сети количество DHCP-ответов не превышает количества DHCP-запросов, а теперь количество DHCP-ответов стало вдвое больше DHCP-запросов. Это значит, что кто-то производит атаку с подменой DHCP-сервера;
Использование IDS, IPS, SIEM и систем мониторинга оборудования типа Zabbix;
Непрерывное обновления программного обеспечения. Обновить хосты можно и так :)
На просторах сети Интернет можно найти немало полезных утилит для Docker. Многие из них принадлежат к разряду Open Source и доступны на Github. В последние два года я достаточно активно использую Docker в большинстве своих проектов по разработке программного обеспечения. Однажды начав работать с Docker, вы осознаете, что он оказывается полезен для гораздо более широкого круга задач, нежели вы изначально предполагали. Вам захочется сделать с Docker еще больше, и он не разочарует!
Docker-сообщество живет активной жизнью, ежедневно производя новые полезные инструменты. За этой бурной деятельностью достаточно сложно уследить. Поэтому я решил выбрать несколько наиболее интересных и полезных из ежедневно используемых мной Docker-утилит. Они делают работу более продуктивной, автоматизируя операции, которые пришлось бы выполнять вручную.
Давайте посмотрим на утилиты, которые помогают мне в процессе докеризации всего и вся.
Watchtower мониторит выполняющиеся контейнеры и отслеживает изменения в образах, на основе которых они были созданы. Если образ изменился, Watchtower автоматически перезапускает контейнер, используя новый образ. Это удобно при локальной разработке, если есть желание работать с самыми новыми версиями используемых инструментов.
Утилита Watchtower также поставляется в виде Docker-образа и выполняется в контейнере. Для ее запуска введите следующую команду:
Мы запустили Watchtower с примонтированным файлом /var/run/docker.sock. Это нужно для того, чтобы Watchtower мог взаимодействовать с демоном Docker через соответствующий API. Мы также передали опцию interval, равную 30 секундам, которая определяет интервал опроса. У Watchtower есть и другие опции, которые описаны в документации.
Давайте запустим контейнер и помониторим его с помощью Watchtower.
Теперь Watchtower начнет мониторинг контейнера friendlyhello. Если я размещу новый образ на Docker Hub, Watchtower во время очередного запуска это обнаружит. Затем она корректно остановит контейнер и перезапустит его из нового образа. Также контейнеру будут переданы указанные нами в команде run опции, то есть он будет запущен с -p 4000:80.
По умолчанию Watchtower будет искать новые версии образов в реестре Docker Hub. При этом Watchtower может опрашивать закрытые реестры, используя для входа учетные данные из переменных окружения REPO_USER и REPO_PASS.
Более подробную информацию о Watchtower вы можете найти в документации.
2. Docker-gc — удаление ненужных контейнеров и образов
Утилита docker-gc помогает очистить Docker-хост, удалив более не нужные образы и контейнеры. Удаляются контейнеры, завершенные более часа назад, а также образы, не принадлежащие ни одному из оставшихся контейнеров.
Docker-gc может запускаться в виде скрипта или контейнера. Мы воспользуемся вторым вариантом. Запустим docker-gc, чтобы узнать, какие контейнеры и образы можно удалить.
Чтобы docker-gc мог взаимодействовать с Docker через его API, мы подмонтировали сокет-файл Docker. Для поиска контейнеров и образов, которые можно удалить, запустим docker-gc с переменной окружения DRY_RUN=1. При этом никаких изменений на диске сделано не будет. Всегда лучше сначала убедиться, что docker-gc не собирается удалить ничего лишнего. Вот вывод этой команды:
Если вы согласны с предложенным docker-gc планом очистки, запустите ту же команду, но теперь уже без DRY_RUN.
В выводе будут перечислены удаленные docker-gc контейнеры и образы.
У docker-gc есть еще несколько опций. Чтобы получить более подробную информацию об этой утилите, рекомендую почитать соответствующую документацию.
3. Docker-slim — волшебная пилюля, которая поможет вашим контейнерам похудеть
Обеспокоены размером ваших Docker-образов? Вам поможет docker-slim!
Эта утилита использует статический и динамический анализ для создания легковесных вариантов Docker-образов. Чтобы поработать с docker-slim, загрузите бинарник с Github (доступны версии для Linux и Mac), а затем добавьте путь к исполняемому файлу в переменную окружения PATH.
Для очень простого приложения нам пришлось загрузить 194 МБ! Посмотрим, сколько мегабайт можно скинуть с docker-slim.
Инспектируя исходный образ, docker-slim выполнит несколько шагов, а затем создаст его облегченную версию. Посмотрим, какой в итоге получился размер:
На иллюстрации видно, что размер образа уменьшился до 24.9 МБ. Если запустить контейнер, то он будет работать точно так же, как и его предыдущая версия. Docker-slim хорошо справляется с приложениями на Java, Python, Ruby и Node.js.
Попробуйте docker-slim сами, и, возможно, это позволит вам освободить немало места. Эта утилита корректно отработала практически во всех моих проектах. Получить более подробную информацию о docker-slim можно из соответствующей документации.
Большинство разработчиков для сборки образов предпочитают использовать Dockerfile. Dockerfile — это декларативный способ определения команд по созданию образа, которые пользователь мог бы выполнить в командной строке.
Rocker добавляет в Dockerfile набор новых инструкций. Rocker был создан в Grammarly для решения проблем, с которыми эта компания столкнулась при использовании Dockerfile. В Grammarly написали содержательную статью, объясняющую причины создания Rocker. Если у вас есть желание лучше разобраться с Rocker, рекомендую эту статью к прочтению. В ней отмечены две проблемы:
Размер образов.
Скорость сборки.
Там также упоминается несколько добавленных Rocker инструкций. Для получения информации о всех поддерживаемых Rocker инструкциях см. документацию.
MOUNT — позволяет настроить совместное использование томов различными сборками, что удобно, например, для инструментов управления зависимостями.
FROM — эта инструкция существует и в стандартном Dockerfile. При этом Rocker позволяет добавить несколько FROM в один файл. Это значит, что с помощью одного Rockerfile можно сделать несколько образов, например, один для сборки, а другой для выполнения приложения. Первый набор инструкций соберет артефакт, используя все необходимые зависимости. Второй набор инструкций может использовать артефакт, созданный на первом шаге. С помощью этого приема достигается значительное уменьшение размера образа.
TAG позволяет на разных этапах сборки создавать метки образа, то есть вручную это делать больше не нужно.
PUSH используется для загрузки образов в реестр.
ATTACH позволяет интерактивно подключаться к контейнеру на промежуточных этапах сборки, что очень удобно для отладки.
Rocker требует установки. Для пользователей Mac команды следующие:
Rockerfile выглядит вот так:
Для сборки образа и загрузки его на Docker Hub выполните:
У Rocker очень интересная функциональность. Чтобы узнать больше, обратитесь к его документации.
5. Ctop — top-подобная утилита для вывода информации о контейнерах
Я начал пользоваться ctop сравнительно недавно. Эта утилита в реальном времени отображает метрики сразу нескольких контейнеров. Если вы используете Mac, то для установки ctop можете воспользоваться следующей командой:
Для работы ctop требуется установка переменной окружения DOCKER_HOST.
Выполните ctop, чтобы отобразить состояние всех контейнеров.
Для вывода информации только о запущенных контейнерах выполните ctop -a.
Ctop проста в использовании и при этом весьма полезна. Более подробную информацию вы можете найти в документации.
Умоляю перестань мне сниться Я люблю тебя моя невеста Белый иней на твоих ресницах Поцелуй на теле бессловесном
Когда-то в школе мне казалось, что писать стихи просто: нужно всего лишь расставлять слова в нужном порядке и подбирать подходящую рифму. Следы этих галлюцинаций (или иллюзий, я их не различаю) встретили вас в эпиграфе. Только это стихотворение, конечно, не результат моего тогдашнего творчества, а продукт обученной по такому же принципу нейронной сети.
Вернее, нейронная сеть нужна лишь для первого этапа — расстановки слов в правильном порядке. С рифмовкой справляются правила, применяемые поверх предсказаний нейронной сети. Хотите узнать подробнее, как мы это реализовывали? Тогда добро пожаловать под кат.
Языковые модели
Определение
Начнем с языковой модели. На Хабре я встречал не слишком-то много статей про них — не лишним будет напомнить, что это за зверь.
Языковые модели определяют вероятность появления последовательности слов в данном языке: . Перейдём от этой страшной вероятности к произведению условных вероятностей слова от уже прочитанного контекста:
.
В жизни эти условные вероятности показывают, какое слово мы ожидаем увидеть дальше. Посмотрим, например, на всем известные слова из Пушкина:
Языковая модель, которая сидит у нас (во всяком случае, у меня) в голове, подсказывает: после честных навряд ли снова пойдёт мой. А вот и, или, конечно, правил — очень даже.
N-граммные языковые модели
Кажется, самым простым способом построить такую модель является использование N-граммной статистики. В этом случае мы делаем аппроксимацию вероятности — отбрасывая слишком далекие слова, как не влияющие на вероятность появления данного.
Такая модель легко реализуется с помощью Counter’ов на Python — и оказывается весьма тяжелой и при этом не слишком вариативной. Одна из самых заметных её проблем — недостаточность статистики: большая часть 5-грамм слов, в том числе и допустимых языком, просто не встретится в сколько-то ни было большом корпусе.
Для решения такой проблемы используют обычно сглаживание Kneser–Ney или Katz’s backing-off. За более подробной информацией про методы сглаживания N-грамм стоит обратиться к известной книге Кристофера Маннинга “Foundations of Statistical Natural Language Processing”.
Хочу заметить, что 5-граммы слов я назвал не просто так: именно их (со сглаживанием, конечно) Google демонстрирует в статье “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling” — и показывает результаты, весьма сопоставимые с результатами у рекуррентных нейронных сетей — о которых, собственно, и пойдет далее речь.
Нейросетевые языковые модели
Преимущество рекуррентных нейронных сетей — в возможности использовать неограниченно длинный контекст. Вместе с каждым словом, поступающим на вход рекуррентной ячейки, в неё приходит вектор, представляющий всю предыдущую историю — все обработанные к данному моменту слова (красная стрелка на картинке).
Возможность использования контекста неограниченной длины, конечно, только условная. На практике классические RNN страдают от затухания градиента — по сути, отсутствия возможности помнить контекст дальше, чем на несколько слов. Для борьбы с этим придуманы специальные ячейки с памятью. Самыми популярными являются LSTM и GRU. В дальнейшем, говоря о рекуррентном слое, я всегда буду подразумевать LSTM.
Рыжей стрелкой на картинке показано отображение слова в его эмбеддинг (embedding). Выходной слой (в простейшем случае) — полносвязный слой с размером, соответствующим размеру словаря, имеющий softmax активацию — для получения распределения вероятностей для слов словаря. Из этого распределения можно сэмплировать следующее слово (или просто брать максимально вероятное).
Уже по картинке виден минус такого слоя: его размер. При словаре в несколько сотен тысяч слов его он легко может перестать влезать на видеокарту, а для его обучения требуются огромные корпуса текстов. Это очень наглядно демонстрирует картинка из блога torch:
Для борьбы с этим было придумано весьма большое количество различных приемов. Наиболее популярными можно назвать иерархический softmax и noise contrastive estimation. Подробно про эти и другие методы стоит почитать в отличной статье Sebastian Ruder.
Оценивание языковой модели
Более-менее стандартной функцией потерь, оптимизируемой при многоклассовой классификации, является кросс-энтропийная (cross entropy) функция потерь. Вообще, кросс-энтропия между вектором и предсказанным вектором записывается как . Она показывает близость распределений, задаваемый и .
При вычислении кросс-энтропии для многоклассовой классификации — это вероятность -ого класса, а — вектор, полученный с one-hot-encoding (т.е. битовый вектор, в котором единственная единица стоит в позиции, соответствующей номеру класса). Тогда при некотором .
Кросс-энтропийные потери целого предложения получаются усреднением значений по всем словам. Их можно записать так: . Видно, что это выражение соответствует тому, чего мы и хотим достичь: вероятность реального предложения из языка должна быть как можно выше.
Кроме этого, уже специфичной для языкового моделирования метрикой является перплексия (perplexity):
.
Чтобы понять её смысл, посмотрим на модель, предсказывающую слова из словаря равновероятно вне зависимости от контекста. Для неё , где N — размер словаря, а перплексия будет равна размеру словаря — N. Конечно, это совершенно глупая модель, но оглядываясь на неё, можно трактовать перплексию реальных моделей как уровень неоднозначности генерации слова.
Скажем, в модели с перплексией 100 выбор следующего слова также неоднозначен, как выбор из равномерного распределения среди 100 слов. И если такой перплексии удалось достичь на словаре в 100 000, получается, что удалось сократить эту неоднозначность на три порядка по сравнению с “глупой” моделью.
Реализация языковой модели для генерации стихов
Построение архитектуры сети
Вспомним теперь, что для нашей задачи языковая модель нужна для выбора наиболее подходящего следующего слова по уже сгенерированной последовательности. А из этого следует, что при предсказании никогда не встретится незнакомых слов (ну откуда им взяться). Поэтому число слов в словаре остается целиком в нашей власти, что позволяет регулировать размер получающейся модели. Таким образом, пришлось забыть о таких достижениях человечества, как символьные эмбеддинги для представления слов (почитать про них можно, например, здесь).
Исходя из этих предпосылок, мы начали с относительно простой модели, в общих чертах повторяющей ту, что изображена на картинке выше. В роли желтого прямоугольника с неё выступали два слоя LSTM и следующий за ними полносвязный слой.
Решение ограничить размер выходного слоя кажется вполне рабочим. Естественно, словарь надо ограничивать по частотности — скажем, взятием пятидесяти тысяч самых частотных слов. Но тут возникает ещё вопрос: какую архитектуру рекуррентной сети лучше выбрать.
Очевидных варианта тут два: использовать many-to-many вариант (для каждого слова пытаться предсказать следующее) или же many-to-one (предсказывать слово по последовательности предшествующих слов).
Чтобы лучше понимать суть проблемы, посмотрим на картинку:
Здесь изображен many-to-many вариант со словарем, в котором не нашлось места слову “чернил”. Логичным шагом является подстановка вместо него специального токена — незнакомое слово. Проблема в том, что модель радостно выучивает, что вслед за любым словом может идти незнакомое слово. В итоге, выдаваемое ею распределение оказывается смещено в сторону именно этого незнакомого слова. Конечно, это легко решается: нужно всего лишь сэмплировать из распределение без этого токена, но всё равно остается ощущение, что полученная модель несколько кривовата.
Альтернативным вариантом является использование many-to-one архитектуры:
При этом приходится нарезать всевозможные цепочки слов из обучающей выборки — что приведет к заметному её разбуханию. Зато все цепочки, для которых следующее слов — неизвестное, мы сможем просто пропускать, полностью решая проблему с частым предсказанием токена.
Такая модель имела у нас следующие параметры (в терминах библиотеки keras):
Как видно, в неё включено 60000 + 1 слово: плюс первый токен это тот самый .
Проще всего повторить её можно небольшой модификацией примера. Основное её отличие в том, что пример демонстрирует посимвольную генерацию текста, а вышеописанный вариант строится на пословной генерации.
Полученная модель действительно что-то генерирует, но даже грамматическая согласованность получающихся предложений зачастую не впечатляет (про смысловую нагрузку и говорить нечего). Логичным следующим шагом является использование предобученных эмбеддингов для слов. Их добавление упрощает обучение модели, да и связи между словами, выученные на большом корпусе, могут придать осмысленность генерируемому тексту.
Основная проблема: для русского (в отличие от, например, английского) сложно найти хорошие словоформенных эмбеддингов. С имеющимися результат стал даже хуже.
Попробуем пошаманить немного с моделью. Недостаток сети, судя по всему — в слишком большом количестве параметров. Сеть просто-напросто не дообучается. Чтобы исправить это, следует поработать с входным и выходным слоями — самыми тяжелыми элементами модели.
Доработка входного слоя
Очевидно, имеет смысл сократить размерность входного слоя. Этого можно добиться, просто уменьшив размерность словоформенных эмебедингов — но интереснее пойти другим путём.
Вместо того, чтобы представлять слово одним индексом в высокоразмерном пространстве, добавим морфологическую разметку:
Каждое слово будем описывать парой: его лемма и грамматическое значение. Использование лемм вместо словоформ позволяет очень сильно сократить размер эмбеддингов: первым тридцати тысячам лемм соответствует несколько сотен тысяч различных слов. Таким образом, серьёзно уменьшив входной слой, мы ещё и увеличили словарный запас нашей модели.
Как видно из рисунка, лемма имеет приписанную к ней часть речи. Это сделано для того, чтобы можно было использовать уже предобученные эмбеддинги для лемм (например, от RusVectores). С другой стороны, эмбеддинги для тридцати тысяч лемм вполне можно обучить и с нуля, инициализируя их случайно.
При подаче грамматического значения на вход модели оно переводится в битовую маску: для каждой грамматической категории выделяются позиции по числу граммем в этой категории — плюс одна позиция для отсутствия данной категории в грамматическом значении (Undefined). Битовые вектора для всех категорий склеиваются в один большой вектор.
Вообще говоря, грамматическое значение можно было бы, так же как лемму, представлять индексом и обучать для него эмбеддинг. Но битовой маской сеть показала более высокое качество.
Этот битовый вектор можно, конечно, подавать в LSTM непосредственно, но лучше пропускать его предварительно через один или два полносвязных слоя для сокращения размерности и, одновременно — обнаружения связей между комбинациями граммем.
Доработка выходного слоя
Вместо индекса слова можно предсказывать всё те же лемму и грамматическое значение по отдельности. После этого можно сэмплировать лемму из полученного распределения и ставить её в форму с наиболее вероятным грамматическим значением. Небольшой минус такого подхода в том, что невозможно гарантировать наличие такого грамматического значения у данной леммы.
Эта проблема легко исправляется двумя способами. Честный путь — сэмплировать именно слово из действительно реализуемых пар лемма + грамматическое значение (вероятностью этого слова, конечно, будет произведение вероятностей леммы и грамматического значения). Более быстрый альтернативный способ — это выбирать наиболее вероятное грамматическое значение среди возможных для сэмплированной леммы.
Кроме того, softmax-слой можно было заменить иерархическим softmax’ом или вообще утащить реализацию noise contrastive estimation из tensorflow. Но нам, с нашим размером словаря, оказалось достаточно и обыкновенного softmax. По крайней мере, вышеперечисленные ухищрения не принесли значительного прироста качества модели.
Итоговая модель
В итоге у нас получилась следующая модель:
Обучающие данные
До сих пор мы никак не обсудили важный вопрос — на чём учимся. Для обучения мы взяли большой кусок stihi.ru и добавили к нему морфологическую разметку. После этого отобрали длинные строки (не меньше пяти слов) и обучались на них.
Каждая строка рассматривалась как самостоятельная — таким образом мы боролись с тем, что соседние строки зачастую слабо связаны по смыслу (особенно на stihi.ru). Конечно, можно обучаться сразу на полном стихотворении, и это могло дать улучшение качества модели. Но мы решили, что перед нами стоит задача построить сеть, которая умеет писать грамматически связный текст, а для такой цели обучаться лишь на строках вполне достаточно.
При обучении ко всем строкам добавлялся завершающий символ , а порядок слов в строках инвертировался. Разворачивать предложения нужно для упрощения рифмовки слов при генерации. Завершающий же символ нужен, чтобы именно с него начинать генерацию предложения.
Кроме всего прочего, для простоты мы выбрасывали все знаки препинания из текстов. Это было сделано потому, что сеть заметно переобучалась под запятые и прочие многоточия: в выборке они ставились буквально после каждого слова. Конечно, это сильное упущение нашей модели и есть надежда исправить это в следующей версии.
Схематично предобработка текстов может быть изображена так:
Стрелки означают направление, в котором модель читает предложение.
Реализация генератора
Правила-фильтры
Перейдём, наконец-то, к генератору поэзии. Мы начали с того, что языковая модель нужна только для построения гипотез о следующем слове. Для генератора необходимы правила, по которым из последовательности слов будут строиться стихотворения. Такие правила работают как фильтры языковой модели: из всех возможных вариантов следующего слова остаются только те, которые подходят — в нашем случае по метру и рифмовке.
Метрические правила определяют последовательность ударных и безударных слогов в строке. Записываются они обычно в виде шаблона из плюсов и минусов: плюс означает ударный слог, а минусу соответствует безударный. Например, рассмотрим метрический шаблон + — + — + — + — (в котором можно заподозрить четырёхстопный хорей):
Генерация, как уже упоминалось, идёт справа налево — в направлении стрелок на картинке. Таким образом, после мглою фильтры запретят генерацию таких слов как метель (не там ударение) или ненастье (лишний слог). Если же в слове больше 2 слогов, оно проходит фильтр только тогда, когда ударный слог не попадает на “минус” в метрическом шаблоне.
Второй же тип правил — ограничения по рифме. Именно ради них мы генерируем стихотворения задом наперед. Фильтр применяется при генерации самого первого слова в строке (которое окажется последним после разворота). Если уже была сгенерирована строка, с которой должна рифмоваться данная, этот фильтр сразу отсечёт все нерифмующиеся слова.
Также применялось дополнительное правило, запрещающее считать рифмами словоформы с одинаковой леммой.
У вас мог возникнуть вопрос: а откуда мы взяли ударения слов, и как мы определили какие слова рифмуются с какими? Для работы с ударениями мы взяли большой словарь и обучили на этом словаре классификатор, чтобы предсказывать ударения незнакомых слов (история, заслуживающая отдельной статьи). Рифмовка же определяется несложной эвристикой на основе расположения ударного слога и его буквенного состава.
Лучевой поиск
В результате работы фильтров вполне могло не остаться ни одного слова. Для решения этой проблемы мы делаем лучевой поиск (beam search), выбирая на каждом шаге вместо одного сразу N путей с наивысшими вероятностями.
Итого, входные параметры генератора — языковая модель, метрический шаблон, шаблон рифмы, N в лучевом поиске, параметры эвристики рифмовки. На выходе же имеем готовое стихотворение. В качестве языковой модели в этом же генераторе можно использовать и N-граммную модель. Система фильтров легко кастомизируется и дополняется.
Примеры стихов
Так толку мне теперь грустить Что будет это прожито Не суждено кружить в пути Почувствовав боль бомжика
Затерялся где то на аллее Где же ты мое воспоминанье Я люблю тебя мои родные Сколько лжи предательства и лести Ничего другого и не надо За грехи свои голосовые
Скучаю за твоим окном И нежными эфирами Люблю тебя своим теплом Тебя стенографируя
Пост был написан совместно с Гусевым Ильёй. В проекте также принимали участие Ивашковская Елена, Карацапова Надежда и Матавина Полина.
Работа над генератором была проделана в рамках курса “Интеллектуальные системы” кафедры Компьютерной лингвистики ФИВТ МФТИ. Хотелось бы поблагодарить автора курса, Константина Анисимовича, за советы, которые он давал в процессе.
Большое спасибо atwice за помощь в вычитке статьи.
Вышла новая версия де-факто стандартного компилятора Haskell — GHC 8.2.1! Этот релиз является скорее итеративным улучшением, но вместе с тем имеет и ряд новых интересных фич, относящихся к удобству написания кода, выразительности языка и производительности скомпилированных программ. Рассмотрим же наиболее интересные, на мой взгляд, изменения!
Compact regions
Как раз одно из изменений, напрямую влияющих на производительность. Теперь можно пометить некоторый набор данных как один большой объект (region), единожды прогнать по нему сборщик мусора (compact) и считать его живым до тех пор, пока есть хотя бы одна ссылка внутрь этого региона, не залезая внутрь и не бегая по графу объектов при последующих сборках.
Это полезно, например, если программа в самом начале своей работы создаёт большой набор данных, который затем используется большую часть её последующей жизни. Например, официальное описание приводит в пример словарь для спеллчекера с выигрышем времени сборки мусора в полтора раза, а в некоторых из моих тестов время, проведённое в GC, сокращается в 2-3 раза. Папир с описанием формальной логики и реализации приводит (вероятно, на чуть более синтетических бенчмарках) вообще какие-то сумасшедшие числа (стр. 9, графики 7-8), где выигрыш иногда составляет примерно порядок, и хаскелевский GC начинает обгонять такого production-ready-монстра, как Oracle JVM с её затюненным GC.
Пользоваться этим довольно просто: для создания региона из некоторого значения предназначена функция compact :: a -> IO (Compact a) из модуля Data.Compact, после чего можно получить исходное (но уже «сжатое») значение через getCompact :: Compact a -> a. Суммарно это может выглядеть как-то так:
Естественно, при создании compact region'а объект вычисляется практически целиком (конкретнее — достаточно, чтобы доказать замкнутость региона), поэтому, например, компактифицировать бесконечный список — не очень хорошая идея.
Кроме того, полученный compact region можно сериализовать и десериализовать. Правда, с оговорками: десериализующая программа должна быть, в общем, точно такой же, как сериализующая, вплоть до адресного пространства, поэтому даже ASLR всё сломает.
Небольшая отсылка к Франклину
Если внимательно почитать вышеприведённую статью, то можно заметить, что в статье добавляется тайпкласс Compactable a, и функция compact имеет сигнатуру Compactable a => a -> IO (Compact a). В реальном же API этот констрейнт отсутствует, а приписка в документации к функции говорит, что в случае наличия в регионе мутабельных данных и тому подобных некомпактифицируемых бяк будет брошено исключение. Так что, похоже, в этом случае авторы пожертвовали типобезопасностью в угоду удобству использования.
Deriving strategies
У GHC есть как минимум три с половиной механизма вывода инстансов тайпклассов:
1. Вывод стандартных классов (таких, как Show, Read и Eq) и тех, которые GHC умеет выводить сам (всякие Functor и Traversable, а также Data, Typeable и Generic).
2. Вывод через реализации методов по умолчанию, включаемый через расширение DeriveAnyClass
пример
В этом случае объявление
{-# LANGUAGE DeriveAnyClass #-}
class Foo a where
doFoo :: a -> b
doFoo = defaultImplementation
data Bar = Bar deriving(Foo)
разворачивается в
data Bar = Bar
instance Foo Bar
что полезно в случае, если Foo может выводиться через механизм Generics (как, скажем, инстансы для конвертации в JSON у Aeson или CSV у Cassava), либо если минимальное определение Foo не обязано иметь какие-либо методы вообще (что полезно при написании более академического кода, когда тайпкласс используется, скажем, как свидетель условия теоремы).
3. В случае алиасов типов, созданных через newtype, также возможно использовать реализации тайпклассов для базового типа напрямую через расширение GeneralizedNewtypeDeriving:
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
newtype WrappedInt = WrappedInt { unwrap :: Int } deriving(Unbox)
Так вот, проблема в том, что до GHC 8.2 не было возможности указать, какой из механизмов должен использоваться в случае, если включено сразу несколько расширений — скажем, при одновременном включении DeriveAnyClass и GeneralizedNewtypeDeriving первое расширение имело приоритет, что не всегда желательно и, по факту, мешало использованию обоих расширений в одном и том же модуле.
Указывать стратегию можно и в standalone deriving-декларациях:
data Foo = Foo
deriving anyclass instance C Foo
Интересно, что в ранних версиях пропозала предлагалось использовать {-# прагмы #-}, но в итоге был реализован указанный выше подход.
Другие улучшения автовывода инстансов
DeriveAnyClass поумнел. Во-первых, теперь он не ограничен тайпклассами с сигнатурой * либо * -> *. Во-вторых, теперь instance constraint'ы выводятся на базе констрейнтов реализаций по умолчанию. Так, например, такой код раньше не тайпчекался:
{-# LANGUAGE DeriveAnyClass, DefaultSignatures #-}
class Foo a where
bar :: a -> String
default bar :: Show a => a -> String
bar = show
baz :: a -> a -> Bool
default baz :: Ord a => a -> a -> Bool
baz x y = compare x y == EQ
data Option a = None | Some a deriving (Eq, Ord, Show, Foo)
так как инстанс для Foo не имел констрейнтов (Ord a, Show a), и компилятор предлагал добавить их руками. Теперь же соответствующие констрейнты автоматически добавляются к выводимому инстансу.
GeneralizedNewtypeDeriving тоже поумнел. В некоторых случаях (на самом деле, в большинстве из практически интересных) ассоциированные с тайпклассом типы также выводятся автоматически. Так, например, для типов
class HasRing a where
type Ring a
newtype L1Norm a = L1Norm a deriving HasRing
компилятор сгенерирует инстанс
instance HasRing (L1Norm a) where
type Ring (L1Norm a) = Ring a
Backpack
Теперь у приверженцев OCaml чуть меньше поводов троллить хаскелистов: в GHC 8.2 появилась существенно более продвинутая система модулей (по сравнению с тем, что было раньше) — Backpack. Это само по себе довольно большое и сложное изменение, заслуживающее отдельной статьи, поэтому я просто сошлюсь на диссертацию автора реализации с формальным описанием и на более краткий пример.
Прочее
Перечислим избранные прочие изменения:
Во внутренностях самого компилятора формализовано понятие join points — блоков кода, всегда выполняющихся после данного ветвления. Даёт несущественный, но статистически значимый прирост производительности скомпилированного кода и открывает простор для дальнейших оптимизаций.
Улучшена производительность на NUMA-системах.
Добавлена возможность выделять для сборщика мусора меньше потоков, чем непосредственно для мутатора самой программы. Simon Marlow описывает, как и зачем это было реализовано в контексте использования Haskell в Facebook в этом посте.
Улучшения в поддержке levity-полиморфизма, ответственного за возможность написания функций, работающих как с типами, обитающими в * (более-менее обычные типы, которые мы так любим), так и с обитающими в # (неленивые unboxed-типы).
Улучшения в типобезопасности рефлексии.
Возможность использовать ld.gold либо ld.lld вместо стандартного линкера ld.
Сообщения об ошибках теперь сделаны цветными и с указателями на позицию ошибки в стиле clang.
Привет, хабровчане! В прошлой теме я рассказывал, как мы с командой производили (и дальше производим) ромхакинг такой игры, как Xenoblade Chronicles на Nintendo Wii. Я бы хотел рассказать о менее простой, но интересной теме – устройство хранения файловой системы у Nintendo GameCube. Так уж вышло, что я полюбил данную консоль и никак не мог упустить шанс рассказать о её технической стороне, хоть и малой. Не будем затягивать, начнём!
Введение
Как понятно по названию темы, речь пойдёт о том, как устроена файловая система Nintendo GameCube, а если быть точнее, то как устроена файловая система дисков. Давайте поговорим о том, какие всё такие диски использовались на Nintendo GameCube. Прошу Вас выйти из дома в гараж, сесть в DeLorean и отправиться в начало нулевых. На дворе 2001 год, на рынке игровых консолей уже как год властвует Sony PlayStation 2 и выходит оно – Nintendo GameCube. Мощнее начинка, больше потенциал, но почему продажи не так высоки, как у PlayStation 2? Крикнем “Спасибо!” Nintendo и их политике от пиратства и тому чудовищу, которое они решили использовать в своей консоле в качестве носителя информации – собственно разработанный miniDVD диск. Что он из себя представлял и почему смог погубить такую потенциальную консоль, спросите Вы? А я отвечу, представлял он из себя по размеру половину DVD диска, а вот проблемой стал малый объем в размере 1,5ГБ (против 4,7ГБ у DVD диска на PlayStation 2). Это чисто моё личное мнение, но именно данный диск и погубил продажи данной консоли. Об этом можно говорить много, но всё же вернёмся к основной теме. Да, Nintendo изобрели для GameCube свой собственный диск объёмом в 1,5ГБ, что категорически не хватало крупным играм, из-за чего их разделяли на несколько дисков (привет 90-е). Приходилось использовать кучу разных алгоритмов сжатия, как-то сокращать игры, чтобы они влезли на диск. Ладно, хватит о грустном, пора вернуться к основной теме.
Техническая составляющая
Как я сказал выше, диск имел объем в 1,5ГБ. С таким объёмом использовать всем прижившуюся ISO9660 или её модификацию было явно нерентабельно. Nintendo пошли другим путем – они разработали свою технологию описывания файловой системы, её основой стал блок FST (FileStringTable). Данный блок компактный и хранит всю нужную информацию о файлах, о нём я ещё расскажу побольше, но об этом чуть позже.
Весь игровой образ можно разделить на 6 блоков:
Основная информация (boot.bin)
Дополнение к основной информации (bi2.bin)
Apploader (apploader.img)
FileStringTable (fst.bin)
DOL (main.dol)
Основные данные
Предлагаю рассмотреть каждый блок отдельно.
Для примера использовался первый диск европейской версии Resident Evil Code Veronica X (GCDP08).
Основная информация, блок boot.bin
Данный блок находится в самом начале файла и содержит информацию, которая позволяет опознать, что это за диск и что с ним делать дальше. Он имеет фиксированный размер в 0x440 байт. Есть байты, значения которых мне до сих пор не понятны, но их трогать мы и не будем, я расскажу только о том, что более важно:
class gcmBoot
{
public uint gameCode;
public ushort makerCode;
public byte diskID;
public byte version;
//seek to 0x1C
public uint DVDMagicWord; //0xC2339F3D
public string gameName;
//seek to 0x420
public uint offsetMainDol;
public uint offsetFST;
public uint sizeFST;
}
Как видно по коду выше, данный блок содержит в себе код диска, его номер (используется, когда игра содержит несколько дисков), название игры, указатель на блок DOL, указатель и размер на блок FST. В данном блоке есть и другие данные, но они используются для debug режима, что в гражданском режиме вовсе не используется.
Дополнение к основной информации, блок bi2.bin
Данный блок, как и прошлый, имеет фиксированный размер, правда на этот раз его размер 0x2000 байт, а начинается он строго после boot.bin (0x440). Сказать о нём мне нечего, он содержит в себе информацию для debug режима.
Apploader
Данный блок, как понятно по название, отвечает за загрузку образа, парсинга FST, инициализацию модулей, запуска DOL файла. Рассказать о нём, как и о bi2.bin мне нечего, так что идём дальше.
FileStringTable, блок fst.bin
Вот мы и добрались до самого интересного, данный блок содержит в себе разметку всех файлов, находящихся в образе: имена файлов и папок, их смещение и размер. Начинается он с адреса gcmBoot>offsetFST и имеет размер gcmBoot>sizeFST.
Его структура такова:
class gcmFST
{
public byte flags; // 0: File; 1: Dir;
public uint offsetName;//Real size 3 byte
//if flags = 0
public uint fileOffset;
public uint fileSize;
//if flags = 1
public uint dirParent;
public uint dirNext;
}
Попробую разъяснить полегче:
1 байт предназначается для определения, идёт информация о файле или о папке. 3 остальных байта предназначаются для указателя на строку с именем файла или папки (указатель начинается с начало блока с именами файлов\папок, а не с начала блока FST).
Если первый байт равен 0 (файл), то следующие 8 байт значат:
4 байта – указатель на файл в образе
4 байта – размер файла
Если же первый байт равен 1 (папка), то следующие 8 байт значат:
4 байта – номер папки, в которой находится данная папка
4 байта – номер элемента, на котором заканчиваются элементы в данной папке
С файлами всё просто и понятно, а вот с папками не очень. Но, я здесь для того, чтобы вам всё объяснить. К примеру, папка находится в корне диска, имеет название habr, dirParent равен 0 (т.к. в корне диска), а вот dirNext имеет значение 6. Сама папка находится 3 элементом в блоке FST, следовательно, все последующие элементы ровно до 6 элемента будут находится в папке habr, то есть элемент 4 и 5.
Самое главное, о чём забыл сказать, так что 0 блок (то бишь первый) является ссылкой на корень диска, он не имеет имени в блоке с названиями элементов, хоть и имеет указатель. Это просто надо учитывать и ничего более.
Как видите, благодаря подобной структуре, она имеет очень малый размер (если сравнивать с ISO9660 и её модификациями).
DOL
Как говорится, сердце игры. Как у Windows – EXE, так и на GameCube – DOL. Блок с основным исполняемым файлом. Конечно, были и игры, где использовался иной исполняемый файл, хранимый с основными игровыми файлами, но, чаще, никто так не извращался, слава богу.
Ну что ж можно рассказать о нём? Простой исполняемый файл, разделённый на секции:
Семь TEXT секций (код)
Одиннадцать DATA секций (данные)
Основные данные
И последний блок, который свою суть рассказывает по названию. Это блок идёт до конца файла и содержит в себе все файлы, выровненные по 2048 байт. Ходит легенда, что для экономии места можно выровнять эти файлы не по 2048 байт, а по 4 байта. И даже работать будет, на эмуляторе так точно. А вот убить лазер таким способом Вам точно не составит труда.
Заключение
В данной теме я попытался раскрыть, как Nintendoпослала всех куда подальше и разработала простую, но всё же интересную и компактную файловую систему. Конечно, она не подойдёт для использования на домашних ПК из-за её особенностей хранения файлов. Данная файловая система не хранит в себе никаких флагов, кроме как File\Dir, не хранит время создания файла, EDC\ECC каждого сектора и т.п информацию, которая имеется в ISO9660. Но, она здесь и не нужна. Nintendo разработали такую компактную файловую систему, чтобы предоставить больше места для игровых данных. Ведь зачем диску с игровой системы хранить время создания файла и т.п.?
Спасибо за внимание.
Некоторое время назад я приобрёл для домашнего использования ноутбук FUJITSU LIFEBOOK E746, который позиционируется как рабочая лошадка для бизнеса. В основном, они продаются с предустановленным Windows 10; с трудом, но возможно найти экземпляры без предустановленной системы. Производитель поддерживает официально только Windows, в сети я находил информацию, что на нём заводится Ubuntu, но с оговорками. Так как переплачивать за операционную систему, которую я давно не использую и не планирую использовать (Windows 10), не особо хотелось, то я заказал его без системы и установил на нём Linux (Fedora 25). В этом небольшом обзоре я хочу поделиться с общественностью этим опытом. Целевая аудитория этой статьи — люди, которые интересуются недорогими, средними по производительность ноутбуками под Linux. Для остальных, скорее всего, особого интереса эта заметка предоставлять не будет.
Сразу отмечу, что это герой данной статьи — не самая актуальная машинка. Представленный в 2016 году, оснащённый процессором Intel Core 6-го поколения — это не писк моды. Зато соотношение цена/качество не может не радовать.
Немного об аппаратной составляющей
Характеристики приведены на официальном сайте, копировать эту информацию сюда особого смысла нет. В сети также есть обзоры этого ноутбука, например, тут.
Заказывал я его в Германии, в официальном магазине Фуджитсу. Мне достался экземпляр с английской (Великобритания) клавиатурой, базовой станций (т.н. порт-репликатор) в комплекте, двумя сетевыми адаптерами (один для самого ноутбука, второй для базовой станции). Процессор i5 (Intel Core i5-6200U @ 2.80 GHz), 8Гб памяти, DVD привод.
Так как клавиатура английская, русские буквы пришлось клеить самостоятельно
Единственное, что я хочу добавить к имеющимся обзорам и спецификациям — это большой набор стандартных портов (не говоря уже о базовой станции с 4 USB Type-A, 1 eSATA, 2 DisplayPort, LAN, 1 VGA, 1 DVI, Audio: line-in/out), а также возможность расширения памяти, и горячей замене DVD привода на дополнительный диск или второй аккумулятор:
Установка и настройка операционной системы (Fedora 25)
Теперь о программном обеспечении. У меня нет какого-либо неприятия того или иного дистрибутива линукса. Исторически сложилось, что в основном я использую Red Hat или Centos как для разработки, так и как платформу для установки клиентам. Поэтому выбор пал на Fedora 25: не такой консервативный, как Centos, более-менее стабильный в отличие от новейшей Fedora 26.
Дистрибутив в виде ISO, оптимизированный для сетевой установки, можно взять отсюда. Для того, чтобы было понятно конечное состояние ноутбука, расскажу про установку и настройку немного подробней.
Для начала, образ ISO нужно закинуть на флешку. Например, используя любой другой компьютер под линукс:
вставляем пустую флешку объёма большего, чем файл ISO. Тип файловой системы на ней не важен, главное, она не должна быть разбита на тома.
смотрим, как она смонтирована и какому устройству соответствует:
cat /proc/mounts
размонтируем это устройство, иначе в требуемом нам режиме оно будет недоступно:
umount /dev/NNN
переходим в режим root и переходим в каталог, где сохранен файл ISO.
В BIOS выбираем опцию загрузки по USB и загружаем инсталлятор. В сети есть красочная инструкция по установке (формально, для версии 26, но я не вижу в ней каких-либо отличий от версии 25). Следуя этой инструкции, необходимо:
Задать все параметры сетевой карты, к которой подключён кабель, чтобы работал доступ в интернет: ip, шлюз, dns, активировать адаптер, задать имя компьютера.
В окне настроек времени выбрать правильный часовой пояс и настроить время. Я лично всегда использую синхронизацию времени по сети.
Разбить диск на разделы. Обычно я использую схему разбивки по умолчанию, но значительно уменьшаю размер папки /home, так как все рабочие данные предпочитаю сохранять в папке /work
Выбрать ближайшее зеркало, откуда будут вытягиваться пакеты в процессе инсталляции.
После этого нажимаем на «Начать установку». Пока идёт скачивание и установка пакетов, имеется возможность задать пароль рута, а также добавить пользователей в систему. После завершения установки перезагрузка, после чего шаг второй — настройка окружения и ПО. Основной инструмент этого этапа — консоль. Естественно, все дальнейшие операции делаются из под рута:
Первое, что необходимо сделать на свежеустановленной системе — обновить её. В системе уже присутствует пакетный менеджер dnf. Также еще пока остался старый добрый yum, который вызывает соответствующие команды dnf. Я по привычке использую yum. Пакетные репозитории уже настроены по умолчанию, поэтому для обновления всей системы достаточно команды:
yum update
Добавляем полезные репозитории с ПО, которое не входит в дистрибутив. Установка ПО не напрямую, а из репозиторя имеет то преимущество, что потом, при появлении новых версий, оно будет автоматически обновляться (по команде yum update).
rpmfusion — для медиаплейера VLC, кодеков, Steam. Достаточно установить два небольших пакета, и репозиторий будет активирован
Если в качестве системной оболочки используется GNOME3, то для установки его расширений из Google Chrome нужна библиотека chrome-gnome-shell из репозитория region51-chrome-gnome-shell. Этот репозиторий также устанавливается вручную — находясь в папке /etc/yum.repos.d, необходимо его загрузить:
После чего одной командой можно установить всё прикладное ПО общего назначения (естественно, этот список — только пример того, что может понадобится в начале, я ни в коем случае его никому не навязываю):
где:
mc — терминальный файловый менеджер
gnome-commander — графический файловый менеджер
menulibre — утилита настройки системного меню
gnome-tweak-tool и dconf-editor — утилиты для тонкой настройки оболочки GNOME3
vlc — медиаплейер. Функциональный музыкальный плейер, Rhythmbox, уже установлен по-умолчанию
gimp — растровый графический редактор
inkscape — векторный графический редактор
gthumb — менеджер изображений, в чём-то похожий на старый добрый ACDSee
steam — да-да, тот самый Steam
lshw lshw-gui — утилита для просмотра детализированной информации о начинке ноутбука
brasero — запить CD, DVD дисков
audacity — аудио-редактор
thunderbird — почтовый клиент от Mozilla
unzip unrar google-chrome-stable java — ну тут все очевидно
Если vlc будет основным видеоплейером, то имеет смысл установить для него кодеки:
После установки расширений необходимо перелогироваться, после чего их можно активировать из утилиты Tweek Tools
Другие расширения устанавливаются из броузера. Библиотека расширений тут. Если используется Google Chrome, то для него нужно установить дополнительную библиотеку:
yum install chrome-gnome-shell
После всех этих и нескольких дополнительных настроек, у меня на рабочем столе стильный ноутбук с широким набором открытого прикладного ПО и стильным рабочим столом:
Производительность
Для измерения производительности я воспользовался программой Geekbench 4.1. В бесплатном варианте эта программа сгружает результаты замеров на сервер Geekbench (если не платить, то сам будешь товаром). После этого там можно посмотреть как результаты своего теста, так и сравнить с другими системами.
Если посмотреть на модели с тем же процессором (i5-6200U), то видно, что в многопоточном тесте E746 проигрывает достаточно многим моделям, также работающим под Linux (напр. Dell Latitude E5470, MacBook9,1, HP EliteBook 820). Несмотря на тот же самый процессор, что-то у E746 подтормаживает. С другой стороны, в однопоточном режиме от находостся наверху списка.
Также можно взглянуть на всю серию FUJITSU LIFEBOOK. В принципе, E746 не так уж и сильно уступает в этом тесте как старшим моделям серии, так и моделям с процессором i7. Опять же из этой выборки видно, что, за редким исключением, эти ноутбуки работают под управлением Windows, хотя, как показывает мой личный опыт, Fedora ведёт себя очень достойно на этом железе. Но об этом в следующем разделе.
Стабильность работы
Вот список оборудования, которое заработало сразу же после установки Fedora 25 без всяких дополнительных настроек: всё (за исключением дополнительной клавиши ECO).
То есть оба сетевых адаптера, камера, звук, изменение яркости экрана, дополнительная клавиша вкл./выкл. беспроводного адаптера, уход в спящий режим при закрытии крышки и пробуждение из него при открытии, прокрутка с тачпада заработали из коробки (на версии ядра линукс 4.11.10).
Температурный режим: вентилятор включается, но редко. Например, в момент подготовки этого документа (в фоне работает Rhythmbox), сенсоры показывают следующее:
Устойчивость: на данный момент 5 дней с момента последней перезагрузки, при этом многократная активация спящего режима, установка/съём с базовой станции (хотя это, по идее, чисто аппаратная процедура, прозрачная для операционки), переключение сети с проводного на беспроводной адаптер. Никаких помех и проблем не выявлено.
Как отмечается во всех обзорах, которые я читал, E746 — это не игровой ноутбук. Да и игр, кроме HalfLife 2, у меня нет. Но ради теста я таки запустил HL2. На максимальных настройках графики игра прекрасно себя чувствует, видеоряд совершенно плавный, без задержек. Хотя я и сам понимаю, что игра почти 15-летней давности так и должна вести себя на современном железе:
Немного истории
Некоторое (продолжительное) время я использовал LIFEBOOK E8110, выпущенный в 2006. Пара фотографий этого дедушки, предшественника E746 у меня сохранилась. Не могу удержаться и прикреплю одну:
На этом завершусь. Спасибо всем, кто дочитал до конца.
Цитата из комментариев к предыдущей статье: «Вот, к сожалению, данные, адреса и любые операции над ними не годятся для графового представления. Если придумаете как это сделать — будет революция. А без данных, адресов и арифметики, лучшее что можно сделать асинхронным (с помощью графового метода) — машину Тьюринга. Но никак не процессор, к примеру. Поэтому тематика и заброшена, уже 20 лет как.» В компетенции автора сомневаться не приходится, все-таки доктор наук. А я вот попробую сделать революцию.
Как видно из цитаты проблема состоит из двух частей: операции над данными и операции над адресами. С адресами разберусь в следующей статье, а сейчас — данные.
Для примера попробую сделать схему разряда регистра, выполняющего две операции. Почему две? Потому что две, три операции или десять — принципиальной разницы нет. От увеличения количества операций увеличивается только объем вычислений при синтезе схемы. Главное, чтобы таких операций было более одной. В качестве операций выберу копирование из буфера и сложение с содержимым другого регистра. Итак, попробую нарисовать поведение разряда такого регистра. Как понимаю, проблема описания поведения объекта (носителя информации) заключается в том, что он взаимодействует с другими объектами (носителями информации). И эти связанные объекты могут изменять свои значения произвольно (относительно описываемого объекта). Если связанных объектов 2, 3 и более, то описывать все возможные изменения таких объектов на языке STG занятие бессмысленное. Но есть выход. Достаточно ввести в STG три новых типа событий:
f? — с этого момента значение сигнала f не определено,
f/ — с этого момента значение сигнала f определено, и оно равно 1,
f\ — с этого момента значение сигнала f определено, и оно равно 0.
Очередность типов событий для одного сигнала такая:
после "+" — "-" или "?",
после "-" — "+" или "?",
после "?" — "/" или "\",
после "/" — "?" или "-",
после "\" — "?" или "+".
Используя новые типы событий можно описать поведение разряда регистра.
Входные сигналы:
a — команда на операцию прибавления значения второго регистра;
c — команда на операцию копирования из буфера;
r0 — значение соответствующего разряда второго регистра;
b — значение соответствующего разряда буфера;
y0 — сигнал переноса из младшего разряда при операции сложения;
n0 — сигнал отказа от переноса из младшего разряда при операции сложения.
Выходные сигналы:
r — значение разряда описываемого регистра;
t — сигнал завершения операции сложения;
t0 — сигнал завершения операции копирования;
y — сигнал переноса в старший разряд при операции сложения;
n — сигнал отказа от переноса в старший разряд при операции сложения.
Процесс исполнения команд по шагам выглядит так:
Копирование.
1. Внешняя управляющая схема (ВУС) вырабатывает сигнал c+. К этому моменту сигнал b устанавливается в одном из состояний (0 или 1).
2. Схема разряда регистра (СРР) вырабатывает сигнал t0+ для ВУС.
3. ВУС вырабатывает сигнал c-.
4. Если это необходимо, СРР меняет значение сигнала r на противоположное.
5. СРР вырабатывает сигнал завершения операции t0-. После этого ВУС может изменять значение сигнала b.
Сложение.
1. ВУС вырабатывает сигнал a+. К этому моменту сигнал r0 устанавливается в одном из состояний (0 или 1).
2. Если это возможно без использования информации о переносе из младшего разряда, СРР вырабатывает сигнал y+ или n+ для старшего разряда.
3. СРР дожидается из младшего разряда сигнал y0+ или n0+.
4. СРР вырабатывает для старшего разряда сигнал y+ или n+, если он еще не был сформирован.
5. СРР вырабатывает сигнал t+ для ВУС.
6. ВУС, собрав сигналы t+ со всех разрядов, вырабатывает сигнал a-.
7. СРР вырабатывает сигнал y- или n- для старшего разряда.
8. СРР дожидается сигнала y0- или n0- из младшего разряда.
9. Если это необходимо, СРР меняет значение сигнала r на противоположное.
10. СРР вырабатывает сигнал завершения операции t-. После этого ВУС может изменять значение сигнала r0.
Взаимодействие с младшим разрядом осуществляется опосредованно через ВУС. Введение прямого ответного сигнала для младшего разряда позволило бы запараллелить взаимодействие с ВУС и с соседними разрядами. Но для этой статьи я решил выбрать исходное задание попроще.
Казалось бы, задание составлено, можно приступать к синтезу схемы. Но не все так просто. Ни один из известных методов не способен для данного типа поведений синтезировать SI схему (даже если адаптирует новые типы событий). Более того, на мой взгляд ни один из методов не сможет это задание втиснуть в более менее приемлемую элементную базу.
Но, к счастью есть мой метод, который позволяет эти проблемы решить. Процесс корректировки исходного задания я здесь приводить не буду. Покажу лишь конечный результат. Для удобства восприятия покажу его на четырех отдельных картинках.
Копирование когда r=1.
Копирование когда r=0.
Сложение когда r=1.
Сложение когда r=0.
А теперь логические функции.
Как видно, схема синтезирована в базисе 2И-НЕ, 2ИЛИ-НЕ Задачу ограничения нагрузок на выходы элементов я не ставил. Но если каждый выход элемента ограничить двумя нагрузками, то схема увеличится процента на 2-3 (по моей оценке). А вот если ограничить входы схемы двумя нагрузками, то это задача посложнее. Тут я ожидаю увеличения схемы процентов на 25.
Zimbra — это комплексное решение для обмена электронными сообщениями, а также организации совместной работы с календарями и задачами. Но сегодня поговорим не о почте, а о тех возможностях программного комплекса, которые помогают организовать продуктивную работу в любой организации.
В Zimbra встроен мощный функционал для работы с почтой, но адресная книга, календарь, задачи и управление документами также очень хорошо развиты и представляют возможность эффективной и интуитивной совместной работы в команде. С общими почтовыми ящиками, файлами и документами, расписаниями и контактами, разграничением полномочий, а также публикациями в общие и ограниченные группы можно дать возможность работать пользователям с максимальной эффективностью.
Гибкий веб-интерфейс Zimbra подстраивается под размеры дисплеев устройств, что обеспечивает качественное взаимодействие пользователя с инструментами. Возможна синхронизация с мобильными устройствами и совместимость с MS Exchange. Zimbra имеет простую и развитую систему Администрирования, которая позволяет гибко настраивать политики, классы обслуживания, управлять хранилищем, а также обладает интегрированным антиспамом и антивирусом.
Возможности же по подключению к сервисам Zimbra во многом превосходят ближайших конкурентов. Работать по сети можно через любой привычный пользователю браузер (Chrome, Firefox, IE, Safari) и с помощью программ для работы с электронной почтой (MS Outlook, Thunderbird и т. д.). Zimbra обладает широким функционалом. Особенно стоит отметить режим диалога и теги, быстрый поиск по содержимому и вложениям, кросс-платформенность, оффлайн доступ и т.д…
Всё-таки, почему стоит выбрать Zimbra для работы? Причин несколько. Самая обычная почта, как средство отправки и получения электронной корреспонденции, сейчас почти никого не устраивает. Любой компании нужен общий календарь с возможностью задавать и пересылать задачи, а также контролировать ход их выполнения. Также крайне желательно наличие удобного веб-интерфейса, поддерживающего работу мобильных устройств, для сотрудников находящихся вне офиса. И это — необходимый минимум. Сегодня даже бесплатные почтовые службы готовы предложить многое из перечисленного.
Но бесплатные почтовые службы не обладают сразу всем функционалом или часто не безопасны. Zimbra же позволяет развернуть почтовый сервер со всеми инструментами для работы в команде на ваших серверах. Разберём возможности Zimbra подробнее.
Ежедневник
Ежедневник — удобный инструмент для создания личного наглядного расписания, информацией о котором вы можете делиться с другими пользователями. Создать новую встречу можно, нажав на кнопку «Создать» в верхнем меню Zimbra и выбрав пункт «Встреча». В открывшемся окне вы сможете задать название для встречи, добавить других пользователей и направить им уведомление о встрече, выбрать время и место и добавить описание. В самом Ежедневнике Zimbra можно отслеживать расписание ваших встреч и редактировать их на свое усмотрение.
Задачи
Задачи в Zimbra — удобный инструмент для структурирования и отслеживания текущих дел. Вы можете создавать как личные папки задач, которые необходимо выполнить, так и общие с другими пользователями (например, с коллегами), чтобы они могли вносить свои правки и предложения, а также видеть объем уже выполненных задач. Вы можете выставить приоритет текущей задачи (низкий, средний, высокий), дату начала и окончания, настроить напоминание о задаче и статус её готовности.
Список задач удобен тем, что вы можете структурировать свои задачи по темам/месту/срокам и так далее. Например, Вы можете создать список рабочих задач (позвонить/сделать рассылку/подготовить) и домашних (прикрутить полку/съездить к тёще/купить веник).
Портфель
Портфель — это внутреннее хранилище файлов в Zimbra. Этот инструмент удобен для тех, кто часто добавляет одни и те же файлы в свои письма. В своем портфеле вы можете создать несколько тематических папок (например, «Договора», «Заявления»). Вы сможете добавлять эти файлы в ваше письмо непосредственно из портфеля, а не путём загрузки с жесткого диска компьютера. Кроме того, можно создать общедоступные папки портфеля, файлы которых смогут просматривать и загружать другие пользователи. Рекомендуем структурировать ваши файлы по папкам портфеля Zimbra, например, в одной папке хранить рабочие, часто отсылаемые файлы, а в другой — Ваши личные.
Не рекомендуется хранить в портфеле важные файлы, нежелательные для просмотра третьими лицами. Кроме того, всегда имейте копии ваших файлов на ином носителе данных во избежание их потери.
Контакты
Контакты всех людей, с которыми вы ведете переписку, автоматически сохраняются в список «Отправленные по электронной почте контакты». Иногда письмо нужно отправить нескольким адресатам, а иногда это нужно делать ещё и часто. Чтобы каждый раз не вбивать в поле «Кому» по несколько человек, существует удобный инструмент «Папка контактов». Стоит один раз создать эту папку, чтобы в будущем сэкономить много времени. Также папки контактов можно сделать общими и поделиться ими с коллегами.
Также вы можете просто создать контакт, заполнив форму:
Документы
Zimbra включает в себя также сервис мгновенного обмена сообщениями (Jabber), систему обмена документами с полноценным WYSIWYG редактором Zimbra Document. Последний поддерживает форматы RTF, HTML, работу с буфером обмена, и что особенно важно, редактор понимает кириллические шрифты. Предусмотрена возможность вставки таблиц и изображений, поэтому Zimbra Document может удовлетворить потребности большинства пользователей, без необходимости дополнительной установки офисного пакета. Проблем с набором или чтением документов у пользователя точно не будет. Любой документ можно расшарить, чтобы к нему могли получить доступ другие участники (для доступа нужно знать URL). Адрес документа можно отправить по e-mail или публиковать в виде RSS/Atom.
Zimbra даже в бесплатной версии предоставляет все то, что нужно корпоративным клиентам и, к тому же, весьма прост в установке и использовании.
Все IT-руководители фактически преследуют одни и те же цели – снижение затрат, повышение производительности конечных пользователей, соответствие IT-операций бизнес-целям организации. Ясно, что любые технологии, которые способствуют выполнению этих целей, должны быть внимательно рассмотрены. К ним относятся и те, которые разрабатывает Extreme Networks в области беспроводных сетей.
Компания Extreme Networks разрабатывает и поставляет управляемые сетевые решения, которые помогают IT-подразделениям организаций улучшать итоговые бизнес-результаты за счет более тесных связей между клиентами, партнерами и сотрудниками.
В течение последних пяти лет стоимость акций Extreme Networks не претерпевала значительных изменений, а в последний год, с появлением Wave 2, стабильно растет
Сегодня Wi-Fi является лучшей в технологическом отношении и наиболее удобной возможностью соединения для пользователей, - в любой организации и практически для всех мобильных устройств и приложений. Поэтому высокая заинтересованность заказчиков в решениях, основанных на стандарте 802.11ac Wave 2, не удивляет.
Улучшения в беспроводных технологиях, радиоконструировании, построении точек доступа, а также практика внедрений за последние два десятилетия породили уже несколько сетевых поколений: 10 Мбит/с, 100 Мбит/с, и теперь с 802.11ac - 1 Гбит/с. Фактически, 802.11ac Wave 2 достигает пропускной способности 1,733 Гбит/с.
Важно, что 802.11ac Wave 2 обеспечивает не только высокую пропускную способность, но и позволяет использовать едва ли не любое устройство и транспортное соединение с большей производительностью и меньшей стоимостью, чем когда-либо прежде.
Увеличение производительности Wi-Fi за последние 20 лет
IT-менеджеры сегодня вынуждены работать с сокращенными бюджетами при одновременном требовании обеспечения все большей эффективности. В связи с этим на первый план выходит поиск аргументов для оправдания новых инвестиций с точки зрения бизнеса.
Ниже рассматриваются пять ключевых составляющих экономического обоснования использования Wave 2.
1. Понимание выгоды использования Advanced Wireless Technologies
При обсуждении беспроводных решений привычно говорят об их пропускной способности. Однако она уже не является основной проблемой Wi-Fi, тем более, что речь сегодня идет о поколении Wave 2 с 1,7 Гбит/с. Этого вполне достаточно для решения большинства современных корпоративных задач.
Гораздо более важная проблема - обеспечение поддержки большого и все растущего числа пользователей, устройств и приложений, многие из которых используют воспроизведение звука в реальном времени и потоковое видео.
Даже при 33%-м улучшением пиковой пропускной способности по сравнению с Wave 1, технологии Wave 2 скорее эволюционны, чем революционны. Они основываются на инновациях 802.11n и не слишком принципиально отличаются по сравнению с 802.11ac Wave 1.
Улучшения включают большую спектральную эффективность (меньшее число ошибок) и MIMO (Multiple Input/Multiple Output) - способность использовать пространство, а не только частоту и время, что значительно повышает пропускную способность.
Дополнительное новшество, которое получило название «beamforming», также является частью стандарта 802.11ac. В упрощенном изложении, beamforming - это способность сосредоточить радиопередачи в направлении, оптимальном для связей между данной точкой доступа и клиентом в любой момент времени, а также внести корректировки в реальном времени, чтобы обеспечить компенсацию перемещений и других условий радиосреды.
До настоящего времени все, кроме очень немногих продуктов на 802.11ac, обеспечивали самое большее три потока MIMO, каждый с максимальной пропускной способностью 433,3 Мбит/с при оптимальных условиях. Wave 2 работает с четырьмя потоками, обеспечивая 1,733 Гбит/с.
Интересно, что стандарт 802.11ac фактически определяет до восьми потоков. Однако продукты, осуществляющие это на практике, вряд ли станут распространенными из-за их сложности и стоимости (по крайней мере, в обозримом будущем). Кроме того, сегодня большинство устройств на стороне клиента поддерживает только один (реже два) потока.
Технология Vawe 2 Multi-User MIMO позволяет многочисленным пользователям принять передачу, уникальную для каждого клиента при единственной передаче от данной точки доступа. То есть нет необходимости ждать, пока будут обслужены другие пользователи и впустую тратить потенциальную полосу пропускания. В результате эффективность резко повышается наряду с производительностью конечного пользователя.
Схематическое представление работы Multi-User MIMO 2. Максимальное использование капитальных вложений
Капитальные вложения (Capital Expense, CapEx) ограничены в IT-бюджетах практически всех компаний, начиная со спада в 2008 г. В то же время непрерывный поток инноваций в IT продолжает влиять и на инфраструктуру, и на циклы замены оборудования, хотя и в несколько более медленном темпе, чем это было в прошлом. И, конечно, внимательное рассмотрение и абсолютных расходов, и особенно ROI, должны сегодня быть частью всех решений о капитальных вложениях.
Как было отмечено, для беспроводных LAN соотношение цена/производительность улучшается с каждым новым поколением продуктов. Но, собственно, это происходит за счет увеличения их пропускной способности, - в то время как цены на определенное оборудование (точки доступа и др.) остаются неизменными или немного снижаются.
Продукты 802.11ac Wave 2 полностью обратно совместимы с Wave 1 (и даже с 802.11n). Они лучше работают по сравнению со своими предшественниками, поскольку имеют более совершенные системную архитектуру и firmware. Улучшения коснулись и их инсталляции в корпоративной среде, которая типично становится бесшовной и стабильной.
Такое улучшение соотношения цена/производительность с минимальными инсталляционными расходами поднимает важный вопрос - действительно ли пора заменять существующие решения Wi-Fi на Wave 2. Здесь нет однозначного ответа. Каждая организация должна оценить покупку с точки зрения своих циклов амортизации, доступных финансовых ресурсов и сочетания со всей IT-инфраструктурой и IT-стратегией предприятия.
Вместе с тем очевидно, что любые 802.11g (или более ранние) решения определенно созрели для замены, поскольку слишком многое изменилось к настоящему времени с точки зрения технических возможностей и ценности WLAN. Действующие системы на 802.11n будут испытывать все увеличивающееся давление со стороны Wave 2, особенно если есть смысл использовать в своих интересах преимущества MU-MIMO.
3. Уменьшение эксплуатационных расходов
По определению, CapEx плюс OpEx составляют совокупную стоимость владения (Total Cost of Ownership, TCO). Это - ключевая метрика в определении коэффициента возврата инвестиций (Return on Investment, ROI) и оценке капитальных затрат в течение долгого времени.
Структура Total Costof Ownership (TCO)
В то время как составляющая капитальных затрат 802.11ac Wave 2 достаточно понятна, эксплуатационные расходы (Operating Eexpense, OpEx) - несколько более сложный предмет для рассмотрения. Причина этого состоит в том, что OpEx состоят из таких аспектов, как мониторинг, управление, поддержка, поиск неисправностей и др. Они требуют внимания квалифицированных IT-специалистов.
В отличие от CapEx, показатель OpEx склонен увеличиваться с течением времени - люди становятся более дорогими благодаря инфляции и соревнованию за особые навыки. С этой проблемой предприятия зачастую справляются, повышая производительность IT-персонала.
Поэтому именно внедрение Wave 2 обещает существенное повышение производительности сотрудников IT-департаментов. Прежде всего улучшенная работа WLAN (пропускная способность, емкость и поддержка ограниченных временем коммуникаций, - таких, как голос и видео) приведет к меньшему количеству обращений к техническому персоналу. Кроме того, Wave 2 даст улучшенное управление и аналитику, видимость результатов и меньшее время устранения проблем.
И, наконец, независмо от того, как реализуется Wave 2, - как новое развертывание или как модернизация, - гибкая, стабильная и дешевая бесшовная масштабируемость является неотъемлемой частью Wave 2. Таким образом, любые расходы IT-персонала, связанные с развертыванием Wave 2, также минимизированы.
4. Повышение производительности конечных пользователей
Любая сетевая стратегия лучше всего оценивается с точки зрения повышения производительности работы конечных пользователей, обслуживаемых сетью. Как было отмечено выше, количество пользователей беспроводных сетей постоянно растет, - и не только с точки зрения числа персонала компаний.
Распространение тенденции Bring Your Own Device (BYOD) вызвало больший, чем когда либо ранее, спрос на сервисы от пользователей с несколькими одновременно активными устройствами. Сегодня зачастую можно встретить пользователей, одновременно подключенных к беспроводной сети двумя устройствами (смартфон и планшет). Не редкостью является и одновременное использование трех-четырех устройств.
Ни одно из этих устройств (как и сами пользователи) не любят сети, которые являются медленными, недоступными в определенных местоположениях, ненадежными или не отвечающими возрастающим потребностям, включая поддержку потоковых медиа, телефонии в реальном времени и других «тяжелых» коммуникаций.
Новые приложения для Internet of Things (IoT) также выдвигают дополнительные требования к беспроводным сетям. Конечно, многие IoT решения будут по-прежнему оперировать относительно небольшим трафиком. Однако существуют и достаточно тяжелые сервисы - такие, например, как видеонаблюдение и процессы в реальном времени. Это означает, что сеть Wi-Fi, в которой они работают, будет иметь потребности на уровне Wave 2.
Чем надежнее и доступнее беспроводная LAN, тем выше производительность конечных пользователей. Поэтому для распространения беспроводных сервисов практически в любой организации требуется все больше потоков MIMO и MU-MIMO.
Практический результат Wave 2 в том, что относительно небольшие инвестиции в новые технологии могут уже сегодня обеспечить значительное уменьшение эксплуатационных расходов за счет максимизирования производительности, и, соответственно, уменьшения TCO и увеличения ROI.
5. Сопутствующие сетевые технологии
Продукты, основанные на 802.11ac Wave 2, воплощают последние достижения в особенностях и технологиях для оптимизации всей цепочки создания беспроводных сетей. Это относится к мобильным клиентам, точкам доступа, контроллерам, свитчам и маршрутизаторам, системам управления и т. д.
Wave 2 является технологической основой для современных беспроводных LAN. Сетевая инфраструктура будет все больше зависеть от новых и возможностей, реализованных в продуктах, основанных на Wave 2. Вот основные из них.
— Коммутация (Switchihg). Wave 2 потребует, чтобы технология питания через Ethernet PoE+ реализовала свой полный потенциал.
— Управление (Management). Эта функция включает управляемый контекстом мониторинг, предупреждения и тревожные сообщения, построение отчетов, аудит и др.
— Аналитика. Определяется как набор способностей, разработанных для исследования больших объемов данных в условиях неопределенности, - т.е., когда трудно точно определить предмет поиска.
— Продвинутая безопасность (Advanced security). Безопасность всегда является одним из ключевых элементов в любой сети. Все меньше для этого используется функция WPA2 Wi-Fi (которая, конечно, остается важной). Все больше безопасность зависит от других средств сети, которые основаны на идентификации, политиках доступа, контексте, фильтрации контента и др.
— Облако. Ключевая тенденция сегодняшнего дня в развертывании и проводных, и беспроводных сетей - управление и связанные с ним функции в облаке. Главные преимущества основанного на облаке управления - легкое внедрение «под ключ», простая масштабируемость, отказоустойчивость и повышенная безопасность. Выгода в стоимости такого подхода также существенна, поскольку капитальные вложения предприятия CapEx при этом преобразуются в очень экономичный вариант OpEx.
— SDN. Программно-определяемые сети будут играть намного большую роль и в проводных, и в беспроводных сетях в последующие годы. Использование SDN повышает сетевую безопасность, целостность решения, упрощает внедрение, обеспечивает более всестороннее и качественное управление и аналитику, чем традиционные решения.
Учитывая непрерывный поток инноваций в технологиях и системах Wi-Fi, возникает еще один вопрос - как скоро появится следующая технология, которая будет способна вытеснить Wave 2?
Действительно, IEEE 802 Standards Committee работает над новыми, еще более высокими стандартами, но они ожидаются только через три года, и пройдет как минимум пять лет, прежде чем любой из них станет господствующей тенденцией на практике. Таким образом, период окупаемости для Wave 2 будет достаточно длительным, с хорошим экономическим обоснованием.
Примеры использования Wave 2
В данном разделе рассматриваются преимущества использования решений Wave 2 в общественных местах, образовании, условиях промышленного производства, корпоративных офисных сетях и здравоохранении.
Wave 2 в общественных местах. Беспроводный трафик быстро растет в гостиничном хозяйстве, на спортивных состязаниях, в местах развлечений. Все они характеризуются высокой плотностью пользователей и устройств. Это мотивирует спрос на Wave 2 802.11ac.
И проблемы, и решения для беспроводных LAN часто определяются именно с точки зрения плотности. Требования, в конце концов, только растут с течением времени. Пример - IoT со своими многими новыми потребительскими устройствами, сервисами и другими приложениями.
Wave 2 в образовании. Сфера образования всегда была одним из основных потребителей беспроводных LAN. В конце концов, кто потребляет большую полосу пропускания, чем студенты, - особенно по мере увеличения доли потокового видео в учебном процессе? И кто захотел бы учиться в школе, где не было бы Wi-Fi?
Но все же бюджетные ограничения часто вынуждают многих IT-менеджеров учебных заведений использовать устаревшие системы. Wave 2 является большим шагом вперед в решении этой проблемы, обеспечивая большую полосу пропускания и являясь более рентабельным, чем какое-либо предыдущее поколение Wi-Fi.
Кроме того, избыточные возможности Wave 2 означают, что срок службы этих сетей будет достаточно длительным. В довольно консервативной образовательной окружающей IT среде это является важным фактором.
Wave 2 на производстве. Производственная среда, как правило, довольно сложна для настройки Wi-Fi сервисов. Надежность - самый важный элемент для беспроводных решений в цехах и центрах дистрибуции, поскольку они связаны с управлением непрерывными потоками и бизнес-процессами. Здесь могут иметь место неблагоприятные климатические условия и радиочастотные помехи. В этом отношении Wave 2 идеально подходят для условий производства, обеспечивая непрерывность и гибкость работы производства в любой среде.
Корпоративные Wave 2. Почти каждое предприятие сегодня, как и большинство правительственных организаций, зависит от Wi-Fi как основной коммуникации. В таких условиях Wave 2 является основой, на который будут строится корпоративные беспроводные сетевые решения еще довольно длительное время.
Wave 2 в здравоохранении. Нет IT-среды более требовательной, чем в здравоохранении. Здесь главным требованием является надежность в медицинских информационных системах для решений, связанных с жизнью человека…
Поэтому многое зависит от беспроводной LAN, предоставляющей лучшие защиту, возможности и надежность для коммуникаций и телеметрии пациентов, так же как доступа с малым временем ожидания к большим (и часто очень большим) объемам данных, производимых устройствами компьютерной томографии (Computed Tomography, CT) и магниторезонансной томографии (Magnetic Resonance Imaging, MRI). Wave 2 сегодня является в этом отношении лучшей технологией для отрасли здравоохранения.
Ассортимент Wave 2 Extreme Networks
Сегодня компания предлагает разнообразные точки доступа, в том числе защищенные от климатических воздействий наружные устройства, контроллеры для беспроводных сетей, а также управляющее ПО.
Точки доступа ExtremeWireless
Точки доступа ExtremeWireless обеспечивают производительность современных проводных сетей для окружающей сетевой среды высокой плотности. Smart Access Points одинаково хорошо подходят как для распределенных, так и для централизованных моделей развертывания.
Оборудование для беспроводных сетей ExtremeWireless
Характеристики предлагаемых сегодня компанией точек доступа ExtremeWireless
Наружные точки доступа (Outdoor Access Points)
Семейство точек доступа разработано для наружного развертывания в непостоянной климатической среде – например, для массовых мероприятий под открытым небом и т. п. Они также обеспечивают бесшовный роуминг в множественных кампусных подсетях без потребности в тяжелом клиентском ПО.
Наружная точка доступа AP3965
Характеристики предлагаемых компанией наружных точек доступа
Контроллеры (ExtremeWireless Controllers)
Контроллеры ExtremeWireless просты в развертывании и управлении. Они обеспечивают высокую функциональность, позволяя организациям определять, как будет обрабатываться беспроводный трафик, аудио- и видео-данные без архитектурных ограничений и в соответствии с потребностями организации.
Контроллер ExtremeWireless C35
Характеристики предлагаемых сегодня компанией контроллеров
ExtremeManagement
Единый инструмент управления - информационный центр для мобильных устройств
ExtremeManagement держит все под контролем, используя ролевые средства управления доступом и единую панель управления. При этом при управлении сетью с помощью ExtremeManagement одним кликом можно совершать целый ряд действий.
Заключение
Конечно, экономическое обоснование нового решения для каждой организации уникально, но совершенно ясно, что Wave 2 уже здесь и предлагает реальную выгоду для любой организации, использующей IT. Такие особенности, как совокупная пропускная способность 1,7 Гбит/с и многопользовательский MIMO не доступны ни в каком другом поколении продуктов Wi-Fi.
Отличное соотношение цена/производительность и возможность бесшовной интеграции в корпоративную IT-инфраструктуру снимают все вопросы относительно капитальных затрат. Резкое повышение производительности - как для IT-персонала, так и для конечных пользователей - снижает эксплуатационные расходы, минимизируя TCO и максимизируя ROI. Дополнительные сетевые способности в коммутации, управлении, аналитике, безопасности и SDN естественно работают с Wave 2, составляя вместе достаточное экономическое обоснование.
Другими словами, время для внедрения и использования 802.11ac Wave 2 уже наступило.
Группа компаний Bluetooth SIG, контролирующая развитие Bluetooth-технологий, 18 июля объявила, что стандарт Bluetooth с этого момента поддерживает функциональность mesh-сетей. Эта новость особенно тепло была принята энтузиастами концепции IoT.
Актуальной версией стандарта Bluetooth, более 10 лет известного в качестве ведущей технологии беспроводной связи с низким энергопотреблением, на сегодняшний день является Bluetooth 5.0. По сравнению со своей предшественницей — 4.2 — она предоставляет в четыре раза больший охват, удвоенную скорость и увеличенную в восемь раз ширину канала связи.
И теперь, когда Bluetooth способен связывать устройства в целом здании, стандарт обзавелся новым способом осуществления соединения. Mesh-сети, или иначе ячеистые сети, — это децентрализованные сети, основанные на ряде соединяющихся друг с другом устройств. Каждый из узлов в них выступает коммутатором. В основе концепции лежит форма ретрансляции сообщений, готовая к масштабируемости за счет добавления новых узлов — устройств.
Такой подход используются технологией Google Wi-Fi, которая выстраивает mesh-сеть в масштабах здания. Чтобы охватить области, которые остаются вне действия традиционного Wi-Fi, единственный маршрутизатор в сети заменяется несколькими точками, действующими как маршрутизаторы. Если говорить о стандарте Bluetooth, такими точками выступают подключенные устройства.
Mesh-сети Bluetooth работают на основе протокола Bluetooth Low Energy (LE) и совместимы с устройствами, поддерживающими базовые спецификации версии 4.0 и выше.
Чтобы создавать сетевые продукты с поддержкой Bluetooth, потребуется совместимое оборудование и программное обеспечение. Иначе говоря, любое устройство (в том числе смартфоны и планшеты), которое поддерживает Bluetooth LE, скорее всего, сможет использоваться в ячеистой сети после обновления программного обеспечения. Для процесса, называемого инициализацией, потребуется приложение, работающее на смартфоне, планшете или компьютере с поддержкой Bluetooth. Новые устройства, будь то бытовые девайсы, промышленные датчики или камеры безопасности, должны будут загружать ключи шифрования, чтобы присоединиться к сети в качестве узла.
Касательно конкретных устройств, способных поучаствовать в развертывании mesh-сетей по протоколу Bluetooth, уже известно, что ими станут девайсы, оснащенные всеми микропроцессорами будущих поколений Qualcomm, которые поддерживают Bluetooth LE, начиная с QCA4020 и QCA4024. Об этом стало известно из официального заявления производителя Qualcomm в день анонса от Bluetooth SIG. QCA4020 и QCA4024 используются для создания интеллектуальных домашних или промышленных устройств: дронов, роботов и так далее.
Mesh-сети Bluetooth и Internet of Things
Известно, что mesh-функциональность изначально закладывалась в стандарт Bluetooth 5.0 в качестве платформы для развертывания масштабируемых умных систем. В бытовом сценарии концепция может быть применима следующим образом: когда пользователь входит в дом, данные с датчиков на входе передаются одновременно для включения источников света и системы отопления.
Эта же модель подходит для автоматизации зданий и других решений в сфере IoT, где десятки, сотни или тысячи устройств должны надежно взаимодействовать друг с другом.
Mesh-сети для IoT позволяют устройствам совместно использовать общие данные в масштабах предприятия. Например, система безопасности может взаимодействовать с пожарным датчиком или камерой напрямую с помощью Bluetooth без необходимости обмениваться данными по проводному или Wi-Fi-соединению через центральный маршрутизатор.
«Добавление ячеистой топологии к стандарту Bluetooth откроет значительные возможности для автоматизации зданий и принесет с собой новую волну инноваций во множестве IoT-приложений», — прокомментировал нововведение Боб Моррис (Bob Morris), вице-президент по маркетингу в Wireless Business Unit, ARM.
Особенную роль mesh-сети Bluetooth смогут сыграть в сегменте промышленного IoT (IIoT). Такие устройства, как роботы и подключенные девайсы, оснащенные датчиками, производят огромное количество данных, и их сложно передать посредством стандартов и протоколов по типу LoRaWan или Narrowband-IoT. В то же время Bluetooth может обрабатывать больше данных, чем эти протоколы, и теперь, когда сеть можно расширить дополнительными узлами, решение может стать инструментом для объединения, к примеру, всего оборудования на конкретном производстве.
В свете участившихся атак на IoT-устройства Bluetooth SIG пришлось также сделать акцент на безопасности mesh-сетей, что также позволяет рассматривать их в качестве основной платформы умных городов. Все сообщения, отправленные через Bluetooth-сети, будут зашифрованы и аутентифицированы с использованием трех типов ключей.
Одним из важных достоинств новых сетей Bluetooth SIG называют проверенную глобальную функциональную совместимость, которая обеспечивает совместную работу продуктов разных поставщиков.
По словам Эндрю Зиньяни (Andrew Zignani), старшего аналитика ABI Research, внедрение mesh-сети поможет Bluetooth преодолеть ряд существующих ограничений по диапазону и размеру сети.
«Ячеистая топология представляет собой новый этап в развитии Bluetooth и станет важным фактором перехода от персональной сети и технологии сопряжения к более масштабируемому, надежному и энергоэффективному IoT-соединению с возможностью подключения к вещам вокруг нас», — считает он.
Важно, что внедрение mesh-функциональности в Bluetooth-сети происходит в момент значительного роста отрасли — ABI Research ожидают, что к 2021 году будет установлено 48 млрд совместимых с IoT устройств, из которых почти треть будет поддерживать Bluetooth. В BI Intelligence считают, что международные производители потратят $267 млрд на решения IoT к 2020 году и установят свыше 24 млрд устройств IoT.
О группе Bluetooth SIG
Bluetooth Special Interest Group была основана в 1998 году. В неё вошли компании Ericsson, IBM, Intel, Toshiba и Nokia. Позднее список участников пополнился такими компаниями, как Lenovo, Microsoft и Apple. Bluetooth SIG занимается надзором за разработкой Bluetooth-стандартов и лицензированием технологий и торговых марок производителей.
В последние два года мы широко используем Docker как для разработки, так и для выполнения систем в производственной среде, и все текущие продукты для наших клиентов разрабатываются именно с учетом данной системы контейнеризации. Стоит отметить, что Docker достаточно сильно изменяется от версии к версии, добавляя как дополнительные возможности (Swarm, Compose), так и дополнительные инструменты повышения защищенности и контроля приложений.
Так с большим удивлением мы недавно обнаружили, что контейнер, который был разработан и протестирован некоторое время назад, не работает в текущей версии Docker. Дело в том, что контейнер был не совсем типовым и внутри него использовалась утилита strace для анализа поведения процесса. Про данное применение утилиты мы ранее подробно писали на Habrahabr.
Сегодня у наших разработчиков наконец-то дошли руки до внедрения данного проблемного контейнера в приложение и они обнаружили, что он больше не работает. Начав разбираться в чем причина такого поведения, мы увидели, что strace, а конкретно ptrace, не может присоединяться к процессам и выдает ошибку вида:
strace: attach: ptrace(PTRACE_ATTACH, ...): Operation not permitted Could not attach to process. If your uid matches the uid of the target process, check the setting of /proc/sys/kernel/yama/ptrace_scope, or try again as the root user. For more details, see /etc/sysctl.d/10-ptrace.conf
Случай довольно редкий, и решение легко не идентифицируется коллективным разумом разработчиков, хотя разных подсказок разбросано достаточно много. Итак, в чем же было дело?
Подсистема Seccomp
В новых ядрах ОС Linux новый Docker использует функцию ядра seccomp, которая позволяет блокировать системные вызовы внутри контейнера. Документация Docker по поводу данной возможности находится здесь. Ptrace находится среди заблокированных системных вызовов. Тонкая настройка механизма осуществляется с помощью аргумента Docker run --security-opt seccomp=/path/to/file.json, который позволяет указать файл, в котором описывается что разрешено, а что нет. Поскольку наш контейнер работает в защищенной среде, то мы отключаем данную возможность полностью: --security-opt seccomp=unconfined.
Поведение Ptrace
Strace выдала нам подсказку о том, что есть некий псевдофайл /proc/sys/kernel/yama/ptrace_scope, в котором тоже описываются ограничения ptrace. Смотрим в документацию ядра и узнаем, что не все так просто, как было раньше. Значения 0-3, находящиеся в данном псевдофайле существенно меняют поведение ptrace:
0 — UID трассирующего процесса должен совпадать с UID трассируемого или быть 0 (поведение как было раньше);
1 — ограниченный ptrace, процессы должны быть родственными, трассируемый процесс должен быть потомком
трассирующего или трассирующий процесс должен иметь UID=0;
2 — для трассирующего процесса должен быть установлен флаг CAP_SYS_PTRACE или потомок устанавливает себе флаг PTRACE_TRACEME;
мы обнаружили, что в файле установлено значение 1, соответственно, не будучи родственным процессом, strace не мог подключиться к трассируемому процессу. При этом, попытка установить в /proc/sys/kernel/yama/ptrace_scope значение 0 не увенчалась успехом, было получено сообщение о том, что "/proc is read only".
Привилегированный запуск контейнера
Преодолеть данное ограничение нам помог флаг Docker, разрешающий в привилегированное исполнение: --privileged, а в инициализацию приложения мы добавили установку значения "0" в псевдофайл /proc/sys/kernel/yama/ptrace_scope.
echo 0 > /proc/sys/kernel/yama/ptrace_scope
В итоге проблема была успешно решена. Пример решения и аргументы для запуска контейнера можно найти в нашем GitHub репозитории для web ssh прокси.
Было интересно заметить, что ядро Linux получает существенные улучшения безопасности и дополнительные инструменты управления настройками безопасности, о которых достаточно трудно узнать, если не держать постоянно руку "на пульсе" и работать в рамках приложений, которые развиваются в рамках продолжительных жизненных циклов в стабильных средах. В один прекрасный день обнаруживаешь новый удивительный мир улучшений, которые "внезапно" проявили себя благодаря вот такому досадному случаю.
Привет, Хабр! Лето в этом году местами подкачало (у команды CLion в Питере уж точно), а вот новый релиз CLion 2017.2, мы надеемся, удался! В этом посте мы хотим рассказать про новые возможности, важные баг-фиксы, и дать Вам возможность задать вопросы или поинтересоваться какими-то конкретными планами в комментариях.
Если коротко, то релиз CLion 2017.2 посвящен:
Расширению возможностей анализатора кода (это касается как встроенного, так и стороннего инструмента – CLang-Tidy)
C++17 в мастере создания нового проекта
Поддержке PCH для MSVC (мы ниже обязательно расшифруем все аббревиатуры!)
Force Step Into в отладчике
Автоматическому созданию Google Test конфигураций для таргетов, слинкованных с gmock
Отменяемым асинхронным действиям навигации и загрузки CMake
Общим улучшения производительности
И еще многому другому!
Готовы попробовать уже сейчас? Скачивайте бесплатную 30-дневную версию с нашего сайта и вперед!
Нужно больше подробностей? Детали ниже. Кстати, попробовать все новые возможности можно на небольшом демо-проекте, который мы специально подготовили для этих целей.
Анализатор кода
Новые quick-fixes и улучшения корректности парсера
Quick-fixes в CLion позволяют исправлять потенциальные проблемы в коде в одно нажатие Alt+Enter. В этом релизе мы улучшили некоторые из них.
Так, например, ранее можно было только удалить неиспользуемую переменную. Но, если конструктор у такой переменной нетривиальный, то это может быть не вполне корректное исправление. Теперь CLion предлагает два варианта – просто удалить переменную или удалить переменную и оставить инициализацию для сохранения семантики кода:
Другое улучшение связано с приведением типов. CLion активно указывает на ситуации, где явное приведение типов необходимо. Но если раньше quick-fixes использовали только приведение типов в стиле языка C, то теперь на вооружение взяты и варианты приведения типов из C++ – static_cast, dynamic_cast, reinterpret_cast, const_cast:
В течение всего этого релизного цикла мы активно занимались исправлением багов в парсере / резолве / анализаторе кода. Изменений много и они расположены в самых разнообразных областях:
это и более корректный анализ кода в случае std::enable_if,
и поддержка va_* макросов (анализатор раньше ошибочно помечал переменные, используемые только в этих макросах, как неиспользуемые),
и более правильная работа с функциями, которые принимают пакет параметров и еще не-шаблонные аргументы,
и корректная работа с вложенными шаблонными типами в STL контейнерах для GCC 5 / 6,
и многое-многое другое.
Тут сразу стоит оговориться, что на следующий релиз план немного другой. Мы планируем вместо точечных исправлений переписать целый пласт кода внутри нашей языковой поддержки.
Не буду вдаваться сильно в подробности, но лишь скажу, что мы, основываясь на предыдущем опыте, проанализировали, где больше всего проблем, отсортировали эти области снизу вверх и выбрали те проблемные области, которые лежат в основе остальных. Ими и будем заниматься. Кстати, год назад мы уже занимались такой переделкой в overload resolution, и отзывы пользователей были очень позитивные.
Интеграция с Clang-Tidy
Помимо улучшений во встроенном анализаторе кода, мы решили увеличить количество разнообразных проверок и quick-fixes за счет популярного и быстро развивающегося сейчас инструмента на базе Clang – Clang-Tidy. Самым большим аргументом в его пользу является частичная поддержка проверок из C++ Core Guidelines, которые сейчас активно продвигают в сообществе C++ разработчиков Бьерн Страуструп и Херб Саттер. Но это не единственное его достоинство!
Важным аргументом является возможность писать свои собственные проверки и добавлять их в Clang-Tidy.
Что же из себя представляет интеграция Clang-Tidy в CLion? Для пользователя IDE проверки из Clang-Tidy выглядят так же, как и проверки встроенного анализатора кода:
То есть ошибки подсвечиваются на лету в редакторе, по Alt+Enter для некоторых проверок доступны исправления (quick-fixes).
По умолчанию мы включили не все проверки из Clang-Tidy. Какие именно включены, а какие выключены, можно посмотреть на нашей страничке на confluence. Чтобы изменить конфигурацию, нужно пойти в настройки в Settings/Preferences | Editor | Inspections | C/C++ | General | Clang-Tidy и там воспользоваться настройкой опций в формате командной строки:
Для тех, кто уже использовал Clang-Tidy на своих проектах, строка будет очень знакомой – это тот список включенных/выключенных проверок, который передается Clang-Tidy при запуске из командной строки. Так, например, для включения только проверок из C++ Core Guidelines надо написать -*,cppcoreguidelines-*.
А как насчет своих собственных проверок? Точно так же! Добавляйте их в Clang-Tidy, который используется в CLion, и они автоматически появятся в редакторе CLion. Правда, если быть честными до конца, сейчас есть пара тонкостей, которые надо учитывать:
Clang-Tidy необходимо брать из нашего репозитория, где лежит версия с нашими изменениями для корректной работы с CLion. Как только наши патчи примут в LLVM (они сейчас на ревью) и изменения попадут в мастер, можно будет использовать основную ветку LLVM. Подробнее о том, где искать наш репозиторий и какие именно патчи, можно почитать в блоге.
В релиз не успела попасть настройка UI для смены Clang-Tidy, так что пока надо заменять бинарник встроенного Clang-Tidy. Но это будет поправлено, мы надеемся, в одном из ближайших обновлений.
C++17 в мастере создания нового проекта
История этого изменения началась с того, что мы. включили CMake 3.8 в CLion 2017.2. А именно в этой версии CMake появилась возможность привычным образом указывать версию стандарта языка в CMake файлах – set(CMAKE_CXX_STANDARD 17) — такую строчку генерирует CLion при создании нового проекта. И теперь в мастере создания нового проекта в выпадающем списке стандартов C++ появился дополнительный пункт – C++17.
PCH для MSVC
Как я и обещала, расшифровываю использованные аббревиатуры. Поддержка precompiled headers в CLion (то есть корректный резолв символов из таких файлов и их правильная подсветка в редакторе) появилась еще в прошлом релизе. Но это касается не всех компиляторов, а только для GCC и Clang. Microsoft Visual C++ compiler (MSVC) поддерживается в CLion в экспериментальном режиме также с прошлого релиза. Но именно в случае с MSVC необходимо и широко распространено использование PCH. Так что мы добавили эту поддержку и для данного случая. Некоторые тонкости и ограничения описаны в запросе в трекере.
Отладчик
У нас поистине наполеоновские планы в области отладки в CLion, но в этом релизе нашей целью были исправления ошибок и доработки текущей функциональности.
Так, после релиза CLion 2017.1 стало понятно, что не очень удобно использовать обычное действие Step Into для того, чтобы попадать на код на дизассемблере при отладке. Зачастую пользователям хочется, чтобы при обычных шагах в отладчике CLion пропускал все фреймы, для которых нет исходного кода. Так что теперь Step Into (F7) работает именно так; а чтобы попасть на код на дизассемблере, следует использовать Force Step Into (Shift+Alt+F7).
Еще одно важное изменение в отладчике — это дополнительная опция в Registry для просмотров массивов во время отладки. Дело в том, что для улучшения производительности CLion подгружает и показывает не весь массив сразу, а только некоторое количество элементов. По умолчанию это 50 элементов. Чтобы посмотреть следующие 50, надо нажать Expand. И так каждые 50 элементов.
Теперь в Registry доступна опция cidr.debugger.value.maxChildren, равная по умолчанию 50 и определяющая количество элементов, которые необходимо подгружать с каждым нажатием Expand:
С этой опцией стоит быть осторожным, так как слишком большое значение может привести к задержкам при вычислении значений при отладке.
Gmock и Google Test конфигурации
CLion поддерживает Google Test и Catch фреймворки для модульного тестирования. Поддержка включает в себя встроенное специальное окно с выводом результатов тестов (test runner). Для того, чтобы туда попадали результаты тестов, необходимо использовать специальную конфигурацию Google Test или Catch при запуске тестов. Для Google Test она создается автоматически для любого таргета в CMake, слинкованного с gtest. А теперь еще и для любого, слинкованного с gmock.
Отменяемые действия навигации и загрузки CMake
В фокусе этого релиза была производительность IDE. Например, мы уменьшили время индексации за счет более оптимальной обработки компиляторных макросов (compiler-predefined macros). Были и другие улучшения в этом направлении.
Помимо обычной работы над производительностью IDE, мы решили передать больше возможностей управления в руки пользователей. Для этого мы начали некоторые действия в IDE делать асинхронными и отменяемыми, чтобы пользователь мог не ждать действия, которые по каким-то причинам выполняется очень долго, а быстро и безболезненно отменить его.
Первыми такими действиями стали – перезагрузка CMake и действия навигации (Go to subclass и Go to overridden functions). В случае CMake в соответствующем инструментальном окне добавилась кнопка отмены работающей команды CMake:
Чтобы по выводу результата выполнения команды CMake в этом окне можно было легко понять завершена команда успешно или же отменена, соответствующий текст автоматически добавляется в конец лога ([Finished], [Reloading canceled]).
Что касается действий навигации Go to subclass и Go to overridden functions, они теперь работают асинхронно, а чтобы отменить их, достаточно просто кликнуть мышкой в любую область за пределами всплывающего окна с результатами:
Интерфейс Find in Path, улучшения поддержки систем контроля версий и другое
CLion – это продукт на основе платформы IntelliJ, а значит, на него распространяются следующие изменения:
Улучшенный пользовательский интерфейс поиска Find in Path
Новые возможности встроенной VCS поддержки, такие как Git Revert, Reword и настройки редактирования commit messages
Улучшения в поддержке мониторов с высоким разрешением (HiDPI)
Демонстрация новых возможностей CLion 2017.2 на английском языке от нашего девелопер-адвоката (автора того самого Catch фреймворка):
Если вам стало интересно, скачайте 30-дневную бесплатную пробную версию с официального сайта компании, где в разделе цен можно также узнать о стоимости подписки.
Следите также за статьями и обновлениями в нашем англоязычном блоге. Мы будем рады ответить на любые ваши вопросы в комментариях.
 В книге рассмотрены все важнейшие навыки работы с JavaScript, HTML5 и CSS3, требующиеся разработчику, чтобы преуспеть в создании современного клиентского кода. Изучая эту книгу, вы напишете четыре веб-приложения. Каждому приложению посвящена отдельная часть книги, а каждая глава добавляет в создаваемое приложение новые функциональные возможности. Создание этих четырех веб-приложений даст вам возможность изучить все технологии, требуемые для создания клиентской части.
В книге рассмотрены все важнейшие навыки работы с JavaScript, HTML5 и CSS3, требующиеся разработчику, чтобы преуспеть в создании современного клиентского кода. Изучая эту книгу, вы напишете четыре веб-приложения. Каждому приложению посвящена отдельная часть книги, а каждая глава добавляет в создаваемое приложение новые функциональные возможности. Создание этих четырех веб-приложений даст вам возможность изучить все технологии, требуемые для создания клиентской части. 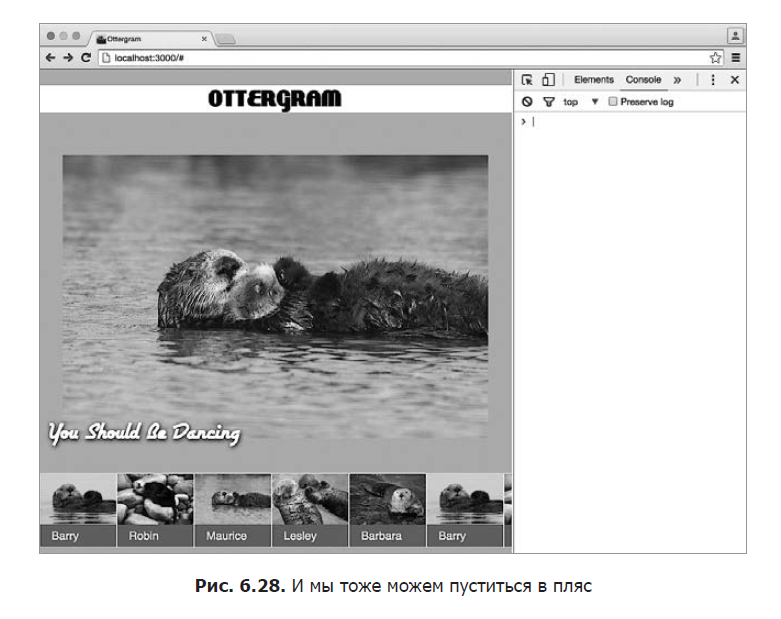


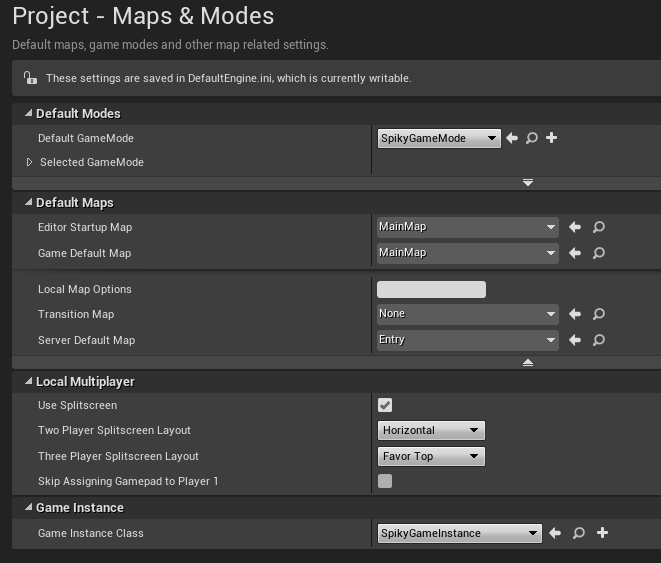

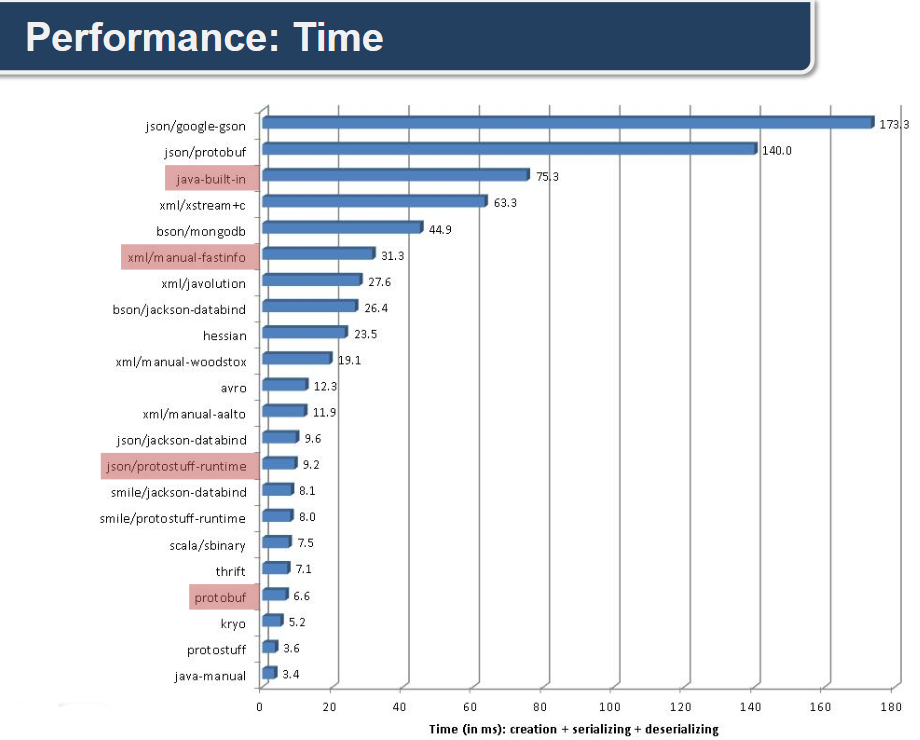




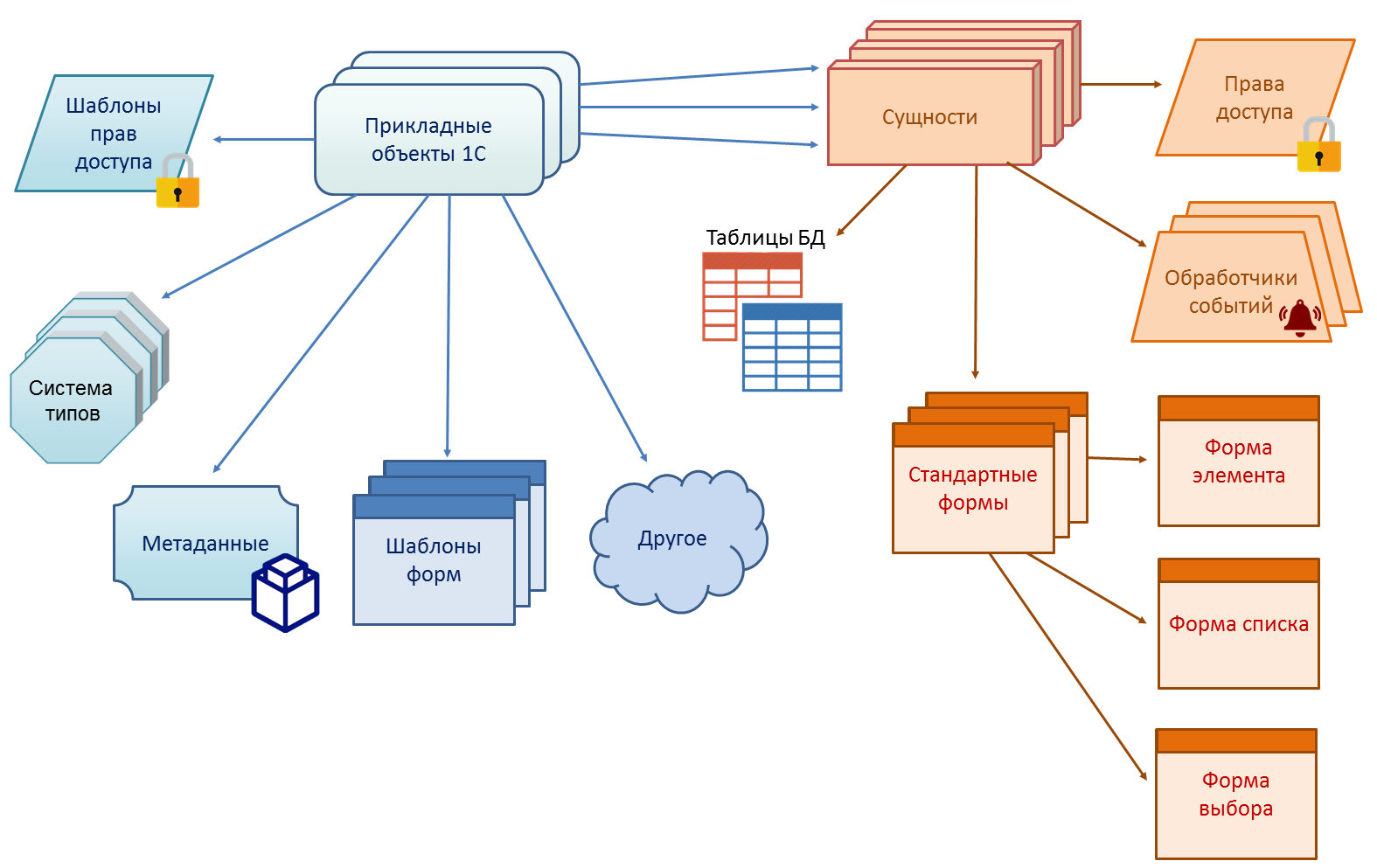
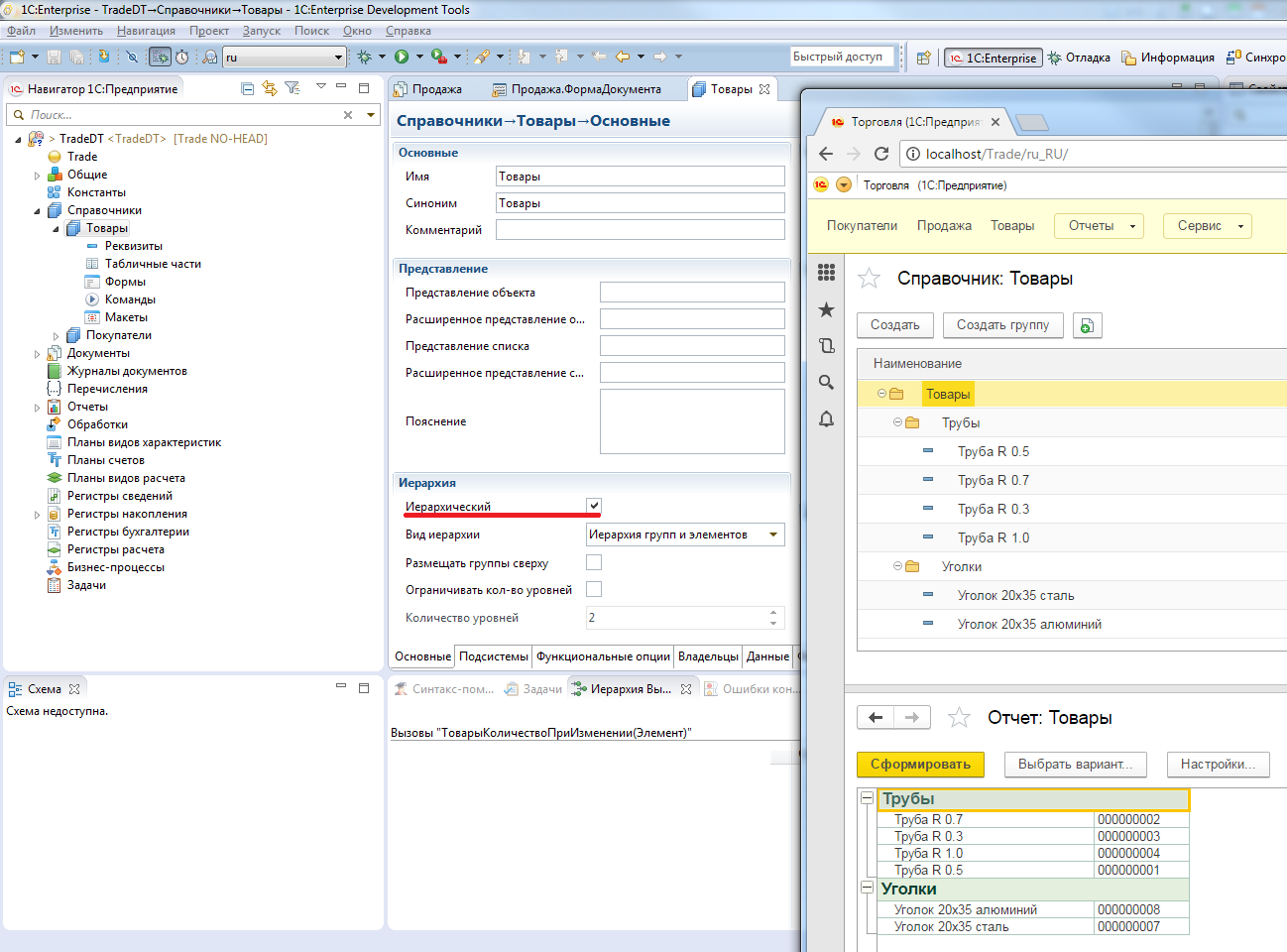
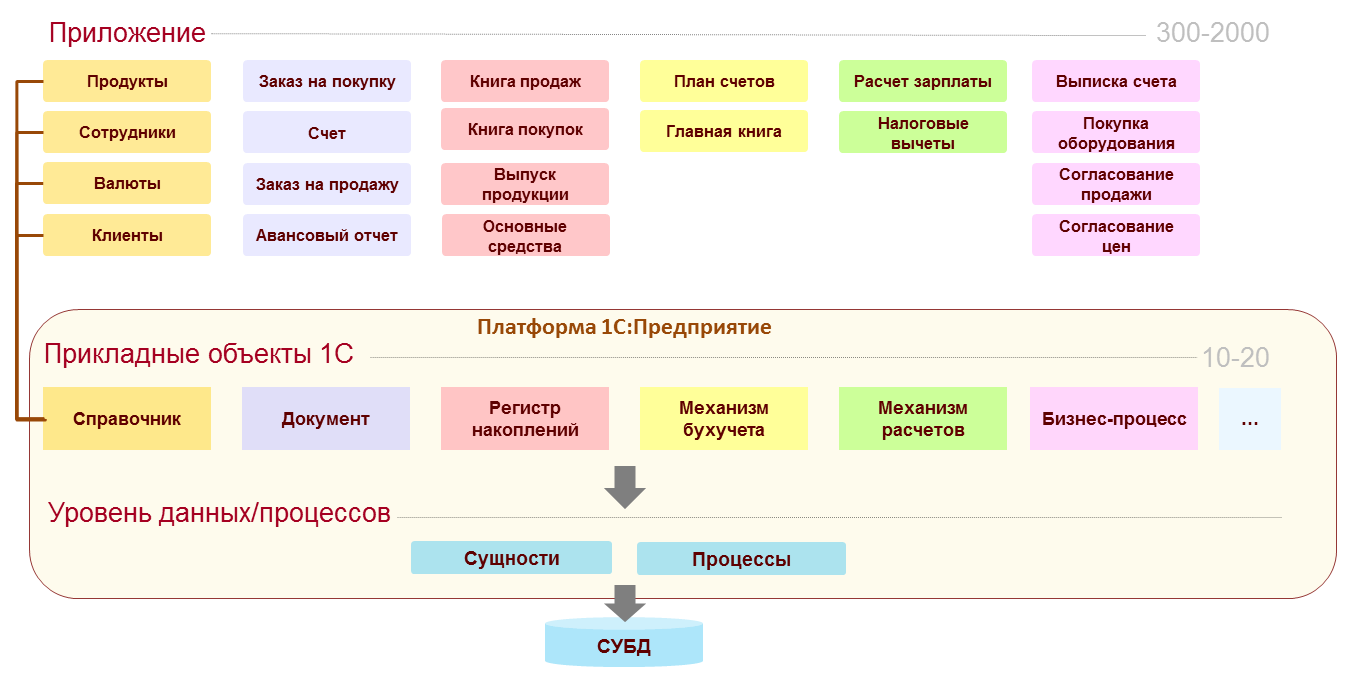 На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.
На основе типа «Справочник» разработчик строит справочники продуктов, сотрудников, валют, клиентов; на основе типа «Документ» — документы «Заказ на покупку», «Счет», «Заказ на продажу» и т.д.






























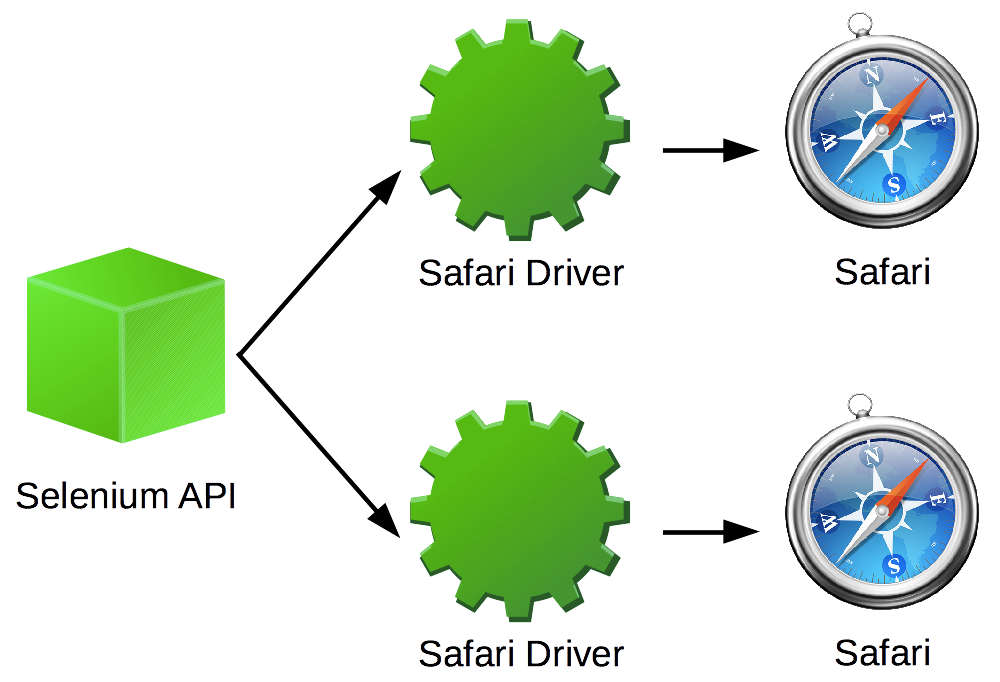



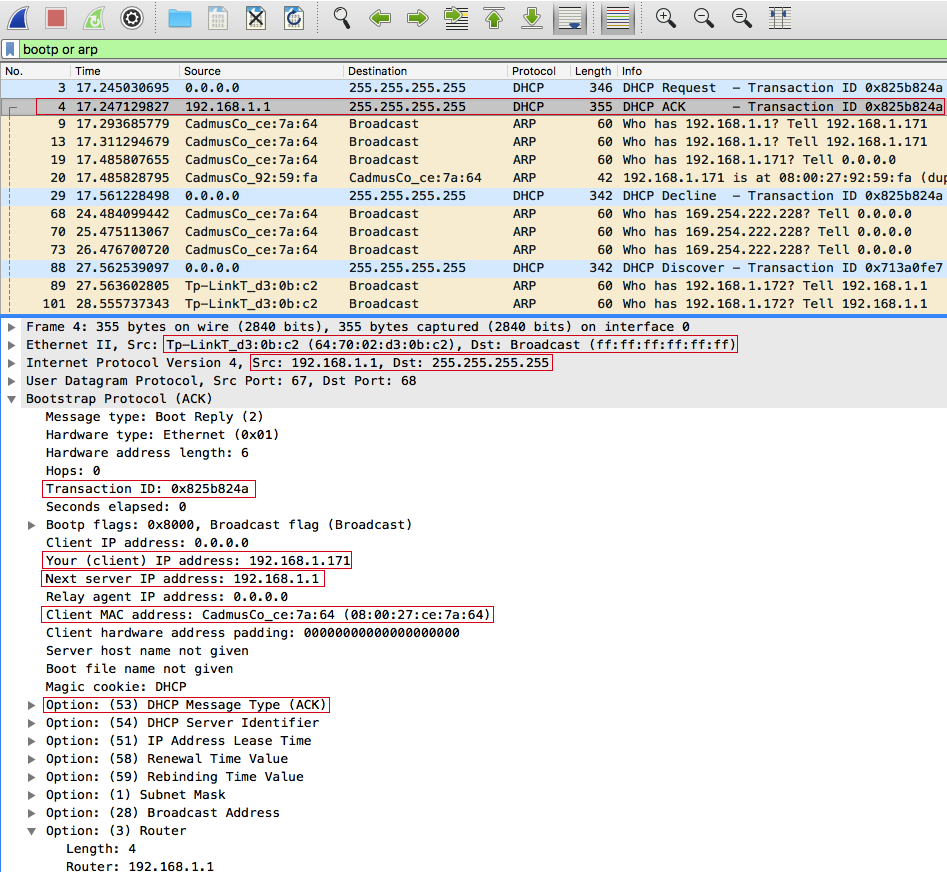









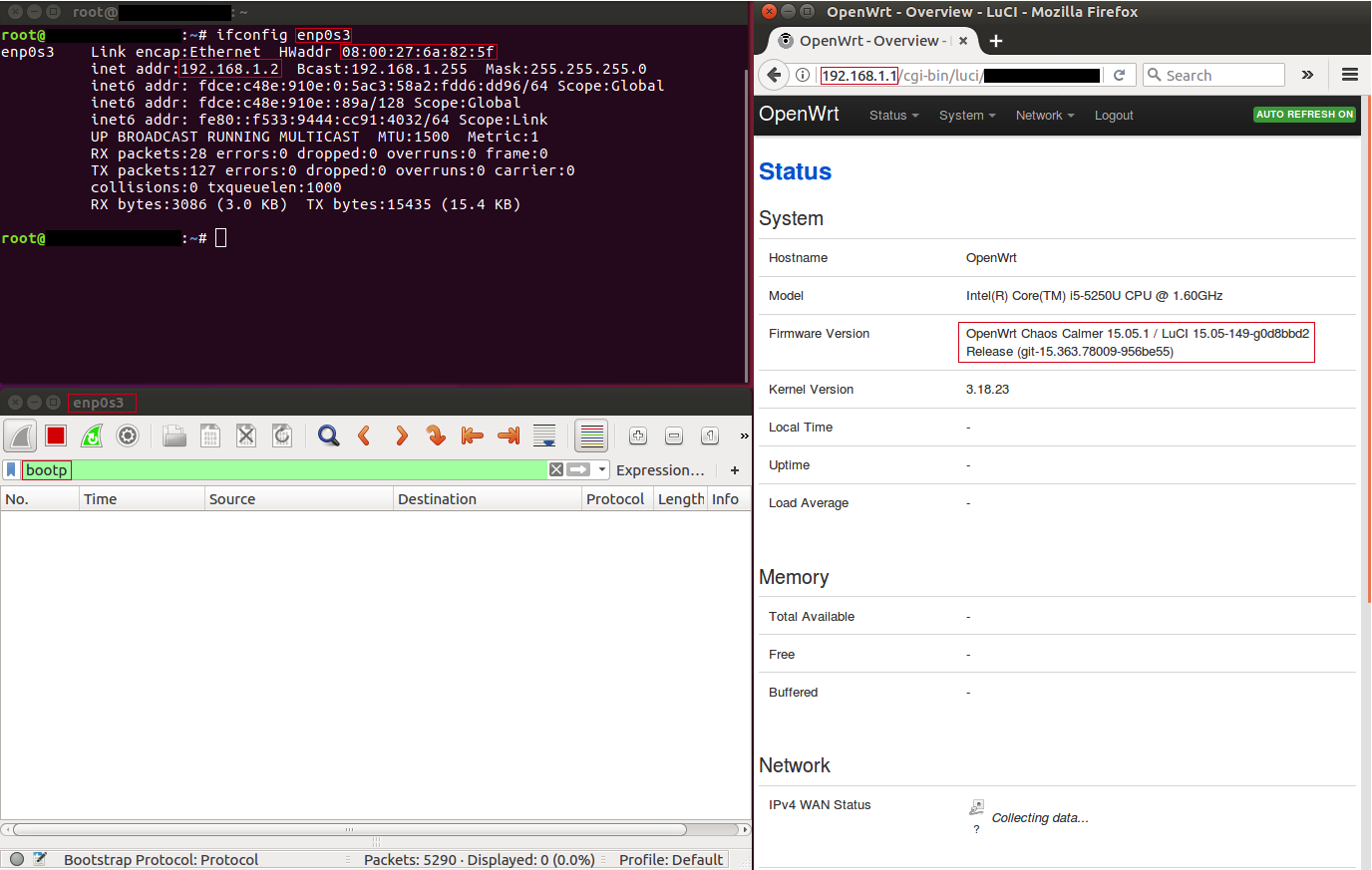



















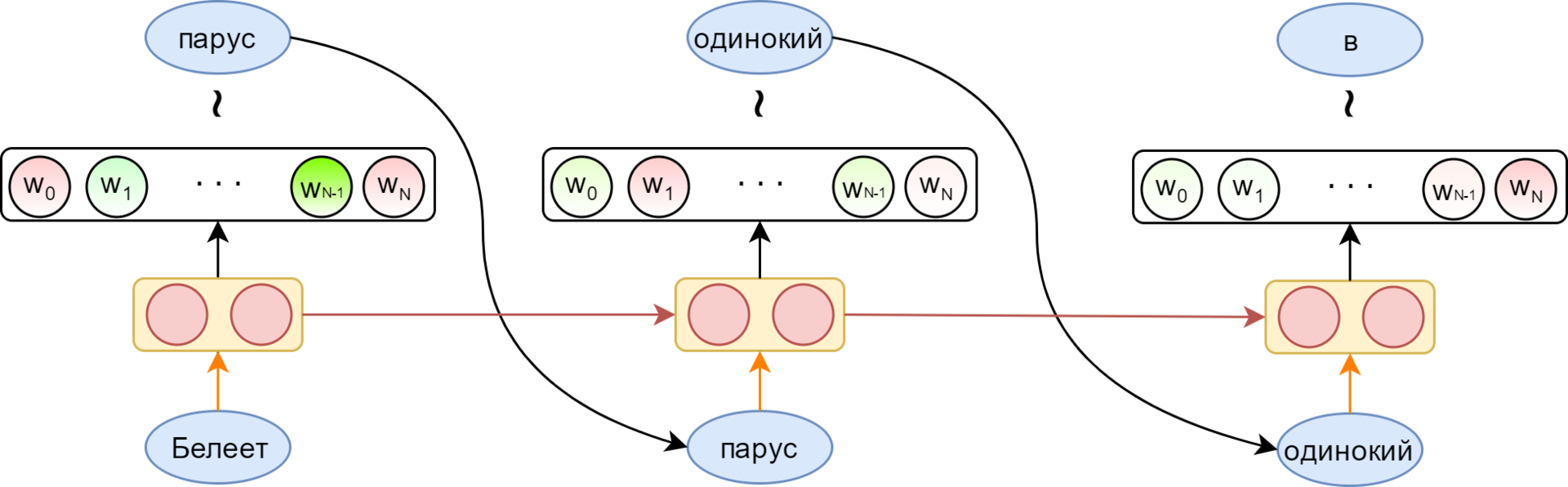

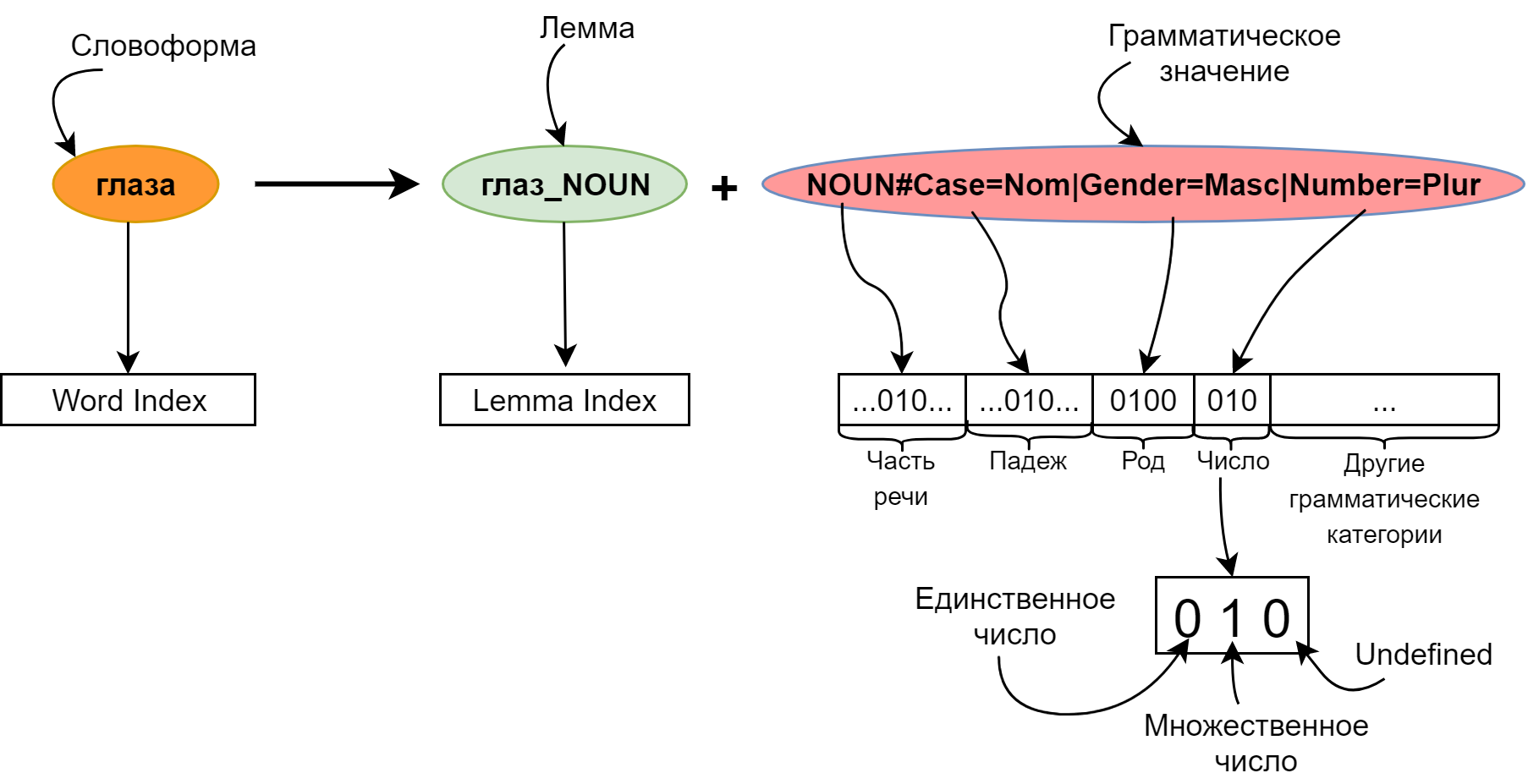









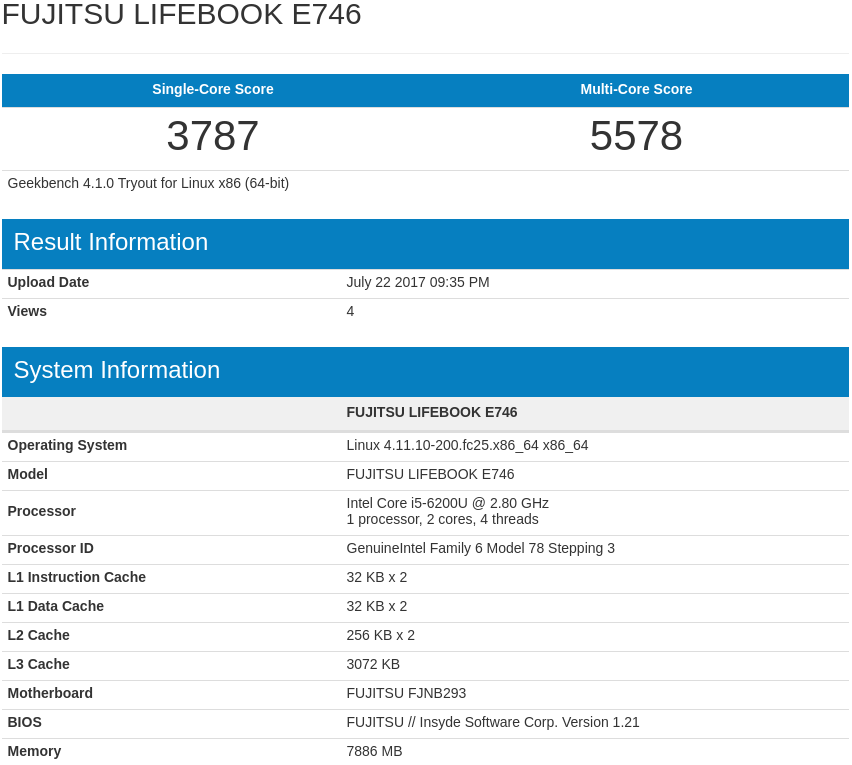













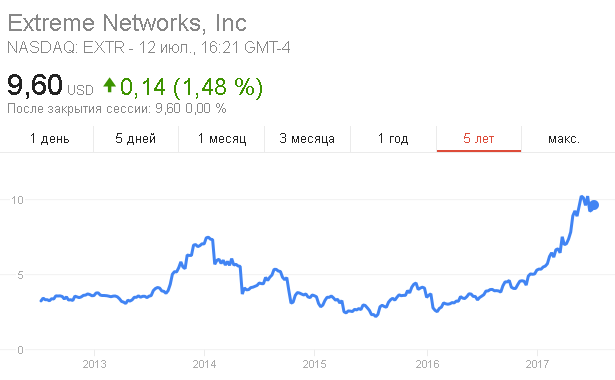







 / Flickr / JCT 600 / CC
/ Flickr / JCT 600 / CC / Flickr / skys the limit2 / CC
/ Flickr / skys the limit2 / CC