Karl Dubost: Capping User Agent String - followup meeting |
Web compatibility is about dealing with a constantly evolving biotope where things die slowly. And even when they disappear, they have contributed to the balance of the ecosystem and modified it in a way they keep their existence.

A couple of weeks ago, I mentionned the steps which have been taken about capping the User Agent String on macOS 11 for Web compatibility issues. Since then, Mozilla and Google organized a meeting to discuss the status and the issues related to this effort. We invited Apple but probably too late to find someone who could participate to the meeting (my bad). The minutes of the meeting are publicly accessible.
This is to preserve a copy of the minutes in case they are being defaced or changed.
Capping UA string
====
(Minutes will be public)
Present: Mike Taylor (Google), Karl Dubost (Mozilla), Chris Peterson (Mozilla), Aaron Tagliaboschi (Mozilla), Kenneth Russell (Google), Avi Drissman (Google), Tantek Celik (Mozilla)
### Background
* Karl’s summary/history of the issue so far on
https://www.otsukare.info/2021/02/15/capping-macos-user-agent
* What Apple/Safari currently does
Safari caps the UA string to 10.15.7.
* What is Mozilla status so far
Capped UA’s macOS version at 10.15 in Firefox 87 and soon ESR 78: https://bugzilla.mozilla.org/show_bug.cgi?id=1679929
Capped Windows version to 10 (so we can control when and how we bump Firefox's Windows OS version if Microsoft ever bumps Windows's version): https://bugzilla.mozilla.org/show_bug.cgi?id=1693295
### What is Google status so far
Ken: We have 3 LGTMs on blink-dev, but some folks had concerns. We know there's broad breakage because of this issue. It's not just Unity, and it's spread across a lot of other sites. I think we should land this. Apple has already made this change. Our CL is ready to land.
Avi: I have no specific concerns. It aligns with our future goals. It is unfortunate it brings us ahead of our understood schedule.
Mike: Moz is on board. Google seems to be on board.
Kenneth: If there are any objections from the Chromium side, there has been plenty of time to react.
Mike: Have there any breakage reports for Mozilla after landing?
Karl: Not yet. I've seen a lot of reports related to Cloudinary, etc, which are a larger concern for Apple. For Firefox, there was no breakage with regards to the thing that was released last week. It's not yet in release. There's still plenty of time to back it out if needed.
Chris: Was there an issue for Duo Mobile?
Karl: We didn't have any reports like this. But we saw a mention online... from what I understood. Apple had modified the UA string to be 10.15. Then the OS evolved to 10.16. Duo had an issue with the disparity between 10.15.7 in the OS and 10.15.6 in the browser. Since then, they modifed and there's no other issue.
Karl: On the Firefox side, if we have breakage, we still have possibility to do site-specific UA interventions.
Ken: did you (tantek) have concerns about this change? The review sat there for a while.
Tantek: I didn't have any problems with the freezing MacOS version per the comments in our bugzilla on that. My general philosophy is that the UA string has been abused for so long, freezing any part of it is a win. I don't even think we need a 1:1 replacement for everything that's in there today.
Chris: The long review time was unrelated to reservations, we were sorting out ownership of the module.
### macOS 11.0 compat issues:
Unity’s UA parsing issue
Cloudinary’s Safari WebP issue
Firefox and Chrome send “Accept: image/webp” header.
### Recurring sync on UA Reduction efforts
Which public arena should we have this discussion?
Mike: we do have public plans for UA reduction/freezing. These might evolve. It would be cool to be able to meet in the future with other vendors and discuss about the options.
Chris & Karl: Usual standards forums would be good. People have opinions on venues.
Otsukare!
https://www.otsukare.info/2021/03/02/capping-user-agent-string
|
|
The Mozilla Blog: Notes on Addressing Supply Chain Vulnerabilities |
|
|
Mozilla Accessibility: 2021 Firefox Accessibility Roadmap Update |
We’ve spent the last couple of months finalizing our plans for 2021 and we’re ready to share them. What follows is a copy of the Firefox Accessibility Roadmap taken from the Mozilla Accessibility wiki.
Mozilla’s mission is to ensure the Internet is a global public resource, open and accessible to all. An Internet that truly puts people first, where individuals can shape their own experience and are empowered, safe and independent.
People with disabilities can experience huge benefits from technology but can also find it frustrating or worse, downright unusable. Mozilla’s Firefox accessibility team is committed to delivering products and services that are not just usable for people with disabilities, but a delight to use.
The Firefox accessibility (a11y) team will be spending much of 2021 re-building major pieces of our accessibility engine, the part of Firefox that powers screen readers and other assistive technologies.
While the current Firefox a11y engine has served us well for many years, new directions in browser architectures and operating systems coupled with the increasing complexity of the modern web means that some of Firefox’s venerable a11y engine needs a rebuild.
Browsers, including Firefox, once simple single process applications, have become complex multi-process systems that have to move lots of data between processes, which can cause performance slowdowns. In order to ensure the best performance and stability and to enable support for a growing, wider variety of accessibility tools in the future (such as Windows Narrator, Speech Recognition and Text Cursor Indicator), Firefox’s accessibility engine needs to be more robust and versatile. And where ATs used to spend significant resources ensuring a great experience across browsers, the dominance of one particular browser means less resources being committed to ensuring the ATs work well with Firefox. This changing landscape means that Firefox too must evolve significantly and that’s what we’re going to be doing in 2021.
The most important part of this rebuild of the Firefox accessibility engine is what we’re calling “cache the world”. Today, when an accessibility client wants to access web content, Firefox often has to send a request from its UI process to the web content process. Only a small amount of information is maintained in the UI process for faster response. Aside from the overhead of these requests, this can cause significant responsiveness problems, particularly if an accessibility client accesses many elements in the accessibility tree. The architecture we’re implementing this year will ameliorate these problems by sending the entire accessibility tree from the web content process to the UI process and keeping it up to date, ensuring that accessibility clients have the fastest possible response to their requests regardless of their complexity.
So that’s the biggest lift we’re planning for 2021 but that’s not all we’ll be doing. Firefox is always adding new features and adjusting existing features and the accessibility team will be spending significant effort ensuring that all of the Firefox changes are accessible. And we know we’re not perfect today so we’ll also be working through our backlog of defects, prioritizing and fixing the issues that cause the most severe problems for users with disabilities.
Firefox has a long history of providing great experiences for disabled people. To continue that legacy, we’re spending most of our resources this year on rebuilding core pieces of technology supporting those experiences. That means we won’t have the resources to tackle some issues we’d like to, but another piece of Firefox’s long history is that, through open source and open participation, you can help. This year, we can especially use your help identifying any new issues that take away from your experience as a disabled Firefox user, fixing high priority bugs that affect large numbers of disabled Firefox users, and spreading the word about the areas where Firefox excels as a browser for disabled users. Together, we can make 2021 a great year for Firefox accessibility.
The post 2021 Firefox Accessibility Roadmap Update appeared first on Mozilla Accessibility.
https://blog.mozilla.org/accessibility/2021-firefox-accessibility-roadmap-update/
|
|
Hacks.Mozilla.Org: Here’s what’s happening with the Firefox Nightly logo |
The internet was set on fire (pun intended) this week, by what I’m calling ‘fox gate’, and chances are you might have seen a meme or two about the Firefox logo. Many people were pulling up for a battle royale because they thought we had scrubbed fox imagery from our browser.
This is definitely not happening.
The logo causing all the stir is one we created a while ago with input from our users. Back in 2019, we updated the Firefox browser logo and added the parent brand logo.
What we really learned throughout this, is that many of our users aren’t actually using the browser because then they’d know (no shade) the beloved fox icon is alive and well in Firefox on your desktop.
Shameless plug – you can download the browser here

You can read more about how all this spiralled in the mini-case study on how the ‘fox gate’ misinformation spread online here.

Long story short, the fox is here to stay and for our Firefox Nightly users out there, we’re bringing back a very special version of an older logo, as a treat.
Our commitment to privacy and a safe and open web remains the same and we hope you enjoy the nightly version of the logo and take some time to read up on spotting misinformation and fake news.
The post Here’s what’s happening with the Firefox Nightly logo appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/heres-whats-happening-with-the-firefox-nightly-logo/
|
|
The Firefox Frontier: Remain Calm: the fox is still in the Firefox logo |
If you’ve been on the internet this week, chances are you might have seen a meme or two about the Firefox logo. And listen, that’s great news for us. Sure, … Read more
The post Remain Calm: the fox is still in the Firefox logo appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/the-fox-is-still-in-the-firefox-logo/
|
|
Patrick Cloke: django-querysetsequence 0.14 released! |
django-querysetsequence 0.14 has been released with support for Django 3.2 (and Python 3.9). django-querysetsequence is a Django package for treating multiple QuerySet instances as a single QuerySet, this can be useful for treating similar models as a single model. The QuerySetSequence class supports much of the API …
https://patrick.cloke.us/posts/2021/02/26/django-querysetsequence-0-14-released/
|
|
Spidermonkey Development Blog: SpiderMonkey Newsletter 9 (Firefox 86-87) |
|
|
Mozilla VR Blog: Behind-the-Scenes at Hubs Hack Week |

Earlier this month, the Hubs team spent a week working on an internal hackathon. We figured that the start of a new year is a great time to get our roadmap in order, do some investigations about possible new features to explore this year, and bring in some fresh perspectives on what we could accomplish. Plus, we figured that it wouldn’t hurt to have a little fun doing it! Our first hack week was a huge success, and today we’re sharing what we worked on this month so you can get a “behind the scenes” peek at what it’s like to work on Hubs.
As part of our work on Hubs, we think a lot about expression and identity. From the beginning, we've made it a priority to allow creators to develop their own avatar styles, which is why you might find yourself in a Hubs room with robots, humans, parrots, carrots, and everything in between.
We don’t make assumptions about how you want to look on a given day with a specific group of people. That's why when an artist on the team built a series of components for a modular avatar system, we built a standalone editor instead of integrating one directly into Hubs itself.
Over the past year, we’ve been delighted to see avatar editors popping up for Hubs, like Rhiannan’s editor and Ready Player Me. For hack week, we added one more to the collection for you the community to play with, tinker on, and modify to your liking!

To get started, head to the hack week avatar maker website. The avatar you see when you first arrive is made out of a random combination of kit components. Use the drop down menus on the left hand side of the screen to pick your favorite features and accessories.
To import your avatar into Hubs, click the “Export Avatar” button to save it to your local computer, and follow these steps to upload it into Hubs.
Social distancing can be tough! While Hubs is built for avatar-based communication, sometimes it’s nice to see a friendly face. We’ve gotten lots of feedback from community members asking for new ways to share their webcams in Hubs. We took that feedback to heart, and set off to see what we could do.
Our team philosophy tends to fall on the side of giving people different options, so we took on two different projects: one that would explore having camera feeds as part of the 2D user interface, and one that put them onto avatars.

Avatar-based chat apps can be a lot to take in if you’re new to 3D, so we experimented with a video feed layer that would sit on top of the Hubs world. While this is still just in a prototype stage, there’s a lot of potential here. We’re looking at doing a deeper dive into this type of feature later in the year when we can devote some time to figuring out how this could tie into the spatial audio in Hubs and our upcoming explorations into navigation in general.

While we’re probably still a ways off from having true holograms, we did figure out that we could get some virtual holograms in a Hubs room using some new billboard techniques and a couple of filters. These video avatars allow you to use your webcam to represent you in a Hubs space, and shares your video with the room such that it sticks to you as you move. When you’re wearing a video avatar, a new option will appear to share your webcam onto the video texture component specified. We are extremely excited to see what the community comes up with using these avatar screens.
Our first iteration of the video avatars is shipping with the webcam as-is in the near future, but as you can see in the photo above, we’re experimenting with filters (hello, green screen!) to make video avatars even more personalized. Using filters remains in the prototype stage, and we will continue how we can explore how we can incorporate it into Hubs over the coming year. Keep an eye out for featured video avatars landing on hubs.mozilla.com soon!
A long-term goal of ours with Hubs is to make the platform easily extensible, so that more types of content can be shared in a 3D space. We had two hack week projects explore this in more detail, one specifically focused on the experience of calling into a Zoom room from Hubs and one that focused more on providing a general-purpose solution for sharing 2D web content. Extensibility is also the reason we’re able to build features like bloom (thanks, glTF!) so you can get an effect like the one pictured on the robot’s eyes below.

Video conferencing + Hubs

One of our goals with the recent redesign was to make it easier to use Hubs from different devices - to meet people where they are. We took this a step further by extending that mindset to meeting people where they were meeting: Zoom! While some of our team members have played around with using external tools to make a Hubs window show up as a virtual camera feed for video calls, one engineer took it a step further and brought Zoom directly into Hubs by implementing a 2-way portal between apps. Pretty cool! While we probably won’t get around to shipping this project in the next few weeks, we’d love to hear your feedback about it to get a better sense of how you might use it with Hubs.
Embedding 2D Web Content with 3D CSS iFrames
We have a lot of interest in supporting general web content in Hubs, but (for good reason!) there are a lot of security considerations for websites having some limitations about what that looks like. One avenue that we’re exploring to do this is by using CSS to draw an iFrame window “in” the 3D space, and it shows a lot of promise. Using iFrames means that each client resolves the web content on its own, which has security benefits but comes with some tradeoffs. Applications that are already networked (like Google Docs or collaboration tools such as Figma or Miro) work great using this method, but there’s some additional work that has to be done to synchronize non-networked content.
Sometimes progress isn’t always visible, but that doesn’t mean that it’s not worth celebrating! In addition to some of the features that are easy to see, we also had the opportunity to dig into some server-side developments. One of these projects explored the possibility of streaming from Hubs directly to a third-party service by adding a new server-side feature to encode from a camera stream, and another tested out some alternative audio processing codecs. Both of these projects provided some great insight into the capabilities of the code base, and prompted some good ideas for future projects down the line.
|
|
The Rust Programming Language Blog: Const generics MVP hits beta! |
After more than 3 years since the original RFC for const generics was accepted, the first version of const generics is now available in the Rust beta channel! It will be available in the 1.51 release, which is expected to be released on March 25th, 2021. Const generics is one of the most highly anticipated features coming to Rust, and we're excited for people to start taking advantage of the increased power of the language following this addition.
Even if you don't know what const generics are (in which case, read on!), you've likely been benefitting from them: const generics are already employed in the Rust standard library to improve the ergonomics of arrays and diagnostics; more on that below.
With const generics hitting beta, let's take a quick look over what's actually being stabilized, what this means practically, and what's next.
Const generics are generic arguments that range over constant values, rather than types or lifetimes. This allows, for instance, types to be parameterized by integers. In fact, there has been one example of const generic types since early on in Rust's development: the array types [T; N], for some type T and N: usize. However, there has previously been no way to abstract over arrays of an arbitrary size: if you wanted to implement a trait for arrays of any size, you would have to do so manually for each possible value. For a long time, even the standard library methods for arrays were limited to arrays of length at most 32 due to this problem. This restriction was finally lifted in Rust 1.47 - a change that was made possible by const generics.
Here's an example of a type and implementation making use of const generics: a type wrapping a pair of arrays of the same size.
struct ArrayPair {
left: [T; N],
right: [T; N],
}
impl Debug for ArrayPair {
// ...
}
The first iteration of const generics has been deliberately constrained: in other words, this version is the MVP (minimal viable product) for const generics. This decision is motivated both by the additional complexity of general const generics (the implementation for general const generics is not yet complete, but we feel const generics in 1.51 are already very useful), as well as by the desire to introduce a large feature gradually, to gain experience with any potential shortcomings and difficulties. We intend to lift these in future versions of Rust: see what's next.
For now, the only types that may be used as the type of a const generic argument are the types of integers (i.e. signed and unsigned integers, including isize and usize) as well as char and bool. This covers a primary use case of const, namely abstracting over arrays. In the future, this restriction will be lifted to allow more complex types, such as &str and user-defined types.
Currently, const parameters may only be instantiated by const arguments of the following forms:
{}), involving no generic parameters.For example:
fn foo() {}
fn bar() {
foo::(); // ok: `M` is a const parameter
foo::<2021>(); // ok: `2021` is a literal
foo::<{20 * 100 + 20 * 10 + 1}>(); // ok: const expression contains no generic parameters
foo::<{ M + 1 }>(); // error: const expression contains the generic parameter `M`
foo::<{ std::mem::size_of::() }>(); // error: const expression contains the generic parameter `T`
let _: [u8; M]; // ok: `M` is a const parameter
let _: [u8; std::mem::size_of::()]; // error: const expression contains the generic parameter `T`
}
In addition to the language changes described above, we've also started adding methods to the standard library taking advantage of const generics. While most are not yet ready for stabilization in this version, there is one method that has been stabilized. array::IntoIter allows arrays to be iterated by value, rather than by reference, addressing a significant shortcoming. There is ongoing discussion about the possibility of implementing IntoIterator directly for arrays, though there are backwards-compatibility concerns that still have to be addressed. IntoIter::new acts as an interim solution that makes working with arrays significantly simpler.
use std::array;
fn needs_vec(v: Vec) {
// ...
}
let arr = [vec![0, 1], vec![1, 2, 3], vec![3]];
for elem in array::IntoIter::new(arr) {
needs_vec(elem);
}
Generic parameters must currently come in a specific order: lifetimes, types, consts. However, this causes difficulties when one attempts to use default arguments alongside const parameters. For the compiler to know which generic argument is which, any default arguments need to be placed last. These two constraints - "types come before consts", and "defaults come last" - conflict with each other for definitions that have default type arguments and const parameters.
The solution to this is to relax the ordering constraint so that const parameters may precede type arguments. However, there turn out to be subtleties involved in implementing this change, because the Rust compiler currently makes assumptions about parameter ordering that require some delicacy to remove.
In light of similar design questions around defaults for const arguments, these are also currently not supported in version 1.51. However, fixing the parameter ordering issues above will also unblock const defaults.
For a type to be valid, in theory, as the type of a const parameter, we must be able to compare values of that type at compile-time. Furthermore, equality of values should be well-behaved (namely, it should be deterministic, reflexive, symmetric, and transitive). To guarantee these properties, the concept of structural equality was introduced in the const generics RFC: essentially this includes any type with #[derive(PartialEq, Eq)] whose members also satisfy structural equality.
There are still some questions concerning precisely how structural equality should behave, and prerequisites for implementation. Primitive types are significantly simpler, which has allowed us to stabilize const generics for these types before more general types.
There are several complexities involved in supporting complex expressions. A feature flag, feature(const_evaluatable_checked), is available in the Nightly channel, which enables a version of complex expression support for const generics.
One difficulty lies in the necessity of having some way to compare unevaluated constants, as the compiler does not automatically know that two syntactically identical expressions are actually equal. This involves a kind of symbolic reasoning about expressions, which is a complex problem in general.
// The two expressions `N + 1` and `N + 1` are distinct
// entities in the compiler, so we need a way to check
// if they should be considered equal.
fn foo() -> [u8; N + 1] {
[0; N + 1]
}
We also want a way to deal with potential errors when evaluating generic operations.
fn split_first(arr: [T; N]) -> (T, [T; N - 1]) {
// ...
}
fn generic_function(arr: [i32; M]) {
// ...
let (head, tail) = split_first(arr);
// ...
}
Without a way to restrict the possible values of M here, calling generic_function::<0>() would cause an error when evaluating 0 - 1 that is not caught at declaration time and so may unexpectedly fail for downstream users.
There are design questions about how exactly to express these kinds of bounds, which need to be addressed before stabilising complex const arguments.
With such a major new feature, there are likely to be a few rough edges. If you encounter any problems, even if it's as minor as a confusing error message, please open an issue! We want the user experience to be the best it can possibly be - and any issues now are likely to be even more important for the next iterations of const generics.
https://blog.rust-lang.org/2021/02/26/const-generics-mvp-beta.html
|
|
Will Kahn-Greene: Data Org Working Groups: retrospective (2020) |
1 month
established cross organization groups as a tool for grouping people
Data Org architects, builds, and maintains a data ingestion system and the ecosystem of pieces around it. It covers a swath of engineering and data science disciplines and problem domains. Many of us are generalists and have expertise and interests in multiple areas. Many projects cut across disciplines, problem domains, and organizational structures. Some projects, disciplines, and problem domains benefit from participation of other stakeholders who aren't in Data Org.
In order to succeed in tackling the projects of tomorrow, we need to formalize creating, maintaining, and disbanding groups composed of interested stakeholders focusing on specific missions. Further, we need a set of best practices to help make these groups successful.
Read more… (7 min remaining to read)
https://bluesock.org/~willkg/blog/mozilla/do_working_groups.html
|
|
The Talospace Project: Firefox 86 on POWER |
Our .mozconfigs are mostly the same except for purging a couple iffy options. Here's Optimized:
And here's Debug:
export CC=/usr/bin/gcc
export CXX=/usr/bin/g++
mk_add_options MOZ_MAKE_FLAGS="-j24"
ac_add_options --enable-application=browser
ac_add_options --enable-optimize="-O3 -mcpu=power9"
ac_add_options --enable-release
ac_add_options --enable-linker=bfd
ac_add_options --enable-lto=full
ac_add_options MOZ_PGO=1
# uncomment if you have it
#export GN=/home/censored/bin/gn
export CC=/usr/bin/gcc
export CXX=/usr/bin/g++
mk_add_options MOZ_MAKE_FLAGS="-j24"
ac_add_options --enable-application=browser
ac_add_options --enable-optimize="-Og -mcpu=power9"
ac_add_options --enable-debug
ac_add_options --enable-linker=bfd
# uncomment if you have it
#export GN=/home/censored/bin/gn
|
|
Aaron Klotz: 2018 Roundup: H2 |
This is the fifth post in my “2018 Roundup” series. For an index of all entries, please see my blog entry for Q1.
Yes, you are reading the dates correctly: I am posting this over two years after I began this series. I am trying to get caught up on documenting my past work!
Given that the launcher process completely changes how our Win32 Firefox builds start, I needed to update both our CI harnesses, as well as the launcher process itself. I didn’t do much that was particularly noteworthy from a technical standpoint, but I will mention some important points:
During normal use, the launcher process usually exits immediately after the browser process is confirmed to have started. This was a deliberate design decision that I made. Having the launcher process wait for the browser process to terminate would not do any harm, however I did not want the launcher process hanging around in Task Manager and being misunderstood by users who are checking their browser’s resource usage.
On the other hand, such a design completely breaks scripts that expect to start
Firefox and be able to synchronously wait for the browser to exit before
continuing! Clearly I needed to provide an opt-in for the latter case, so I added
the --wait-for-browser command-line option. The launcher process also implicitly
enables this mode under a few other scenarios.
Secondly, there is the issue of debugging. Developers were previously used to
attaching to the first firefox.exe process they see and expecting to be debugging
the browser process. With the launcher process enabled by default, this is no
longer the case.
There are few options here:
-o command-line flag,
or use the Debug child processes also checkbox in the GUI;MOZ_DEBUG_BROWSER_PAUSE environment variable, which
allows developers to set a timeout (in seconds) for the browser process to
print its pid to stdout and wait for a debugger attachment.As I have alluded to in previous posts, I needed to measure the effect of adding
an additional process to the critical path of Firefox startup. Since in-process
testing will not work in this case, I needed to use something that could provide
a holistic view across both launcher and browser processes. I decided to enhance
our existing xperf suite in Talos to support my use case.
I already had prior experience with xperf; I spent a significant part of 2013
working with Joel Maher to put the xperf Talos suite into production. I also
knew that the existing code was not sufficiently generic to be able to handle my
use case.
I threw together a rudimentary analysis framework
for working with CSV-exported xperf data. Then, after Joel’s review, I vendored
it into mozilla-central and used it to construct an analysis for startup time.
[While a more thorough discussion of this framework is definitely warranted, I
also feel that it is tangential to the discussion at hand; I’ll write a dedicated
blog entry about this topic in the future. – Aaron]
In essence, the analysis considers the following facts when processing an xperf recording:
firefox.exe process that runs;For our analysis, we needed to do the following:
firefox.exe process being created;This block of code demonstrates how that analysis is specified using my analyzer framework.
Overall, these test results were quite positive. We saw a very slight but imperceptible increase in startup time on machines with solid-state drives, however the security benefits from the launcher process outweigh this very small regression.
Most interestingly, we saw a signficant improvement in startup time on Windows
10 machines with magnetic hard disks! As I mentioned in Q2 Part 3, I believe
this improvement is due to reduced hard disk seeking thanks to the launcher
process forcing \windows\system32 to the front of the dynamic linker’s search
path.
By Q3 I had the launcher process in a state where it was built by default into Firefox, but it was still opt-in. As I have written previously, we needed the launcher process to gracefully fail even without having the benefit of various Gecko services such as preferences and the crash reporter.
First of call, I created a new class, WindowsError,
that encapsulates all types of Windows error codes. As an aside, I would strongly
encourage all Gecko developers who are writing new code that invokes Windows APIs
to use this class in your error handling.
WindowsError is currently able to store Win32 DWORD error codes, NTSTATUS
error codes, and HRESULT error codes. Internally the code is stored as an
HRESULT, since that type has encodings to support the other two. WindowsError
also provides a method to convert its error code to a localized string for
human-readable output.
As for the launcher process itself, nearly every function in the launcher
process returns a mozilla::Result-based type. In case of error, we return a
LauncherResult, which [as of 2018; this has changed more recently – Aaron]
is a structure containing the error’s source file, line number, and WindowsError
describing the failure.
While all Results in the launcher process may be indicating a successful
start, we may not yet be out of the woods! Consider the possibility that the
various interventions taken by the launcher process might have somehow impaired
the browser process’s ability to start!
The launcher process and the browser process share code that tracks whether both processes successfully started in sequence.
When the launcher process is started, it checks information recorded about the previous run. If the browser process previously failed to start correctly, the launcher process disables itself and proceeds to start the browser process without any of its typical interventions.
Once the browser has successfully started, it reflects the launcher process
state into telemetry, preferences, and about:support.
Future attempts to start Firefox will bypass the launcher process until the next time the installation’s binaries are updated, at which point we reset and attempt once again to start with the launcher process. We do this in the hope that whatever was failing in version n might be fixed in version n + 1.
Note that this update behaviour implies that there is no way to forcibly and permanently disable the launcher process. This is by design: the error detection feature is designed to prevent the browser from becoming unusable, not to provide configurability. The launcher process is a security feature and not something that we should want users adjusting any more than we would want users to be disabling the capability system or some other important security mitigation. In fact, my original roadmap for InjectEject called for eventually removing the failure detection code if the launcher failure rate ever reached zero.
The pref reflection built into the failure detection system is bi-directional. This allowed us to ship a release where we ran a study with a fraction of users running with the launcher process enabled by default.
Once we rolled out the launcher process at 100%, this pref also served as a useful “emergency kill switch” that we could have flipped if necessary.
Fortunately our experiments were successful and we rolled the launcher process out to release at 100% without ever needing the kill switch!
At this point, this pref should probably be removed, as we no longer need nor want to control launcher process deployment in this way.
When telemetry is enabled, the launcher process is able to convert its
LauncherResult into a ping which is sent in the background by ping-sender.
When telemetry is disabled, we perform a last-ditch effort to surface the error
by logging details about the LauncherResult failure in the Windows Event Log.
Thanks for reading! This concludes my 2018 Roundup series! There is so much more work from 2018 that I did for this project that I wish I could discuss, but for security reasons I must refrain. Nonetheless, I hope you enjoyed this series. Stay tuned for more roundups in the future!
|
|
Data@Mozilla: This Week in Glean: Boring Monitoring |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.)
All “This Week in Glean” blog posts are listed in the TWiG index (and on the Mozilla Data blog).
Every Monday the Glean has its weekly Glean SDK meeting. This meeting is used for 2 main parts: First discussing the features and bugs the team is currently investigating or that were requested by outside stakeholders. And second bug triage & monitoring of data that Glean reports in the wild.
Most of the time looking at our monitoring is boring and that’s a good thing.
From the beginning the Glean SDK supported extensive error reporting on data collected by the framework inside end-user applications. Errors are produced when the application tries to record invalid values. That could be a negative value for a counter that should only ever go up or stopping a timer that was never started. Sometimes this comes down to a simple bug in the code logic and should be fixed in the implementation. But often this is due to unexpected and surprising behavior of the application the developers definitely didn’t think about. Do you know all the ways that your Android application can be started? There’s a whole lot of events that can launch it, even in the background, and you might miss instrumenting all the right parts sometimes. Of course this should then also be fixed in the implementation.
For our weekly monitoring we look at one application in particular: Firefox for Android. Because errors are reported in the same way as other metrics we are able to query our database, aggregate the data by specific metrics and errors, generate graphs from it and create dashboards on our instance of Redash.

The above graph displays error counts for different metrics. Each line is a specific metric and error (such as Invalid Value or Invalid State). The exact numbers are not important. What we’re interested in is the general trend. Are the errors per metrics stable or are there sudden jumps? Upward jumps indicate a problem, downward jumps probably means the underlying bug got fixed and is finally rolled out in an update to users.

We have another graph that doesn’t take the raw number of errors, but averages it across the entire population. A sharp increase in error counts sometimes comes from a small number of clients, whereas the errors for others stay at the same low-level. That’s still a concern for us, but knowing that a potential bug is limited to a small number of clients may help with finding and fixing it. And sometimes it’s really just bogus client data we get and can dismiss fully.
Most of the time these graphs stay rather flat and boring and we can quickly continue with other work. Sometimes though we can catch potential issues in the first days after a rollout.

In this graph from the nightly release of Firefox for Android two metrics started reporting a number of errors that’s far above any other error we see. We can then quickly find the implementation of these metrics and report that to the responsible team (Filed bug, and the remediation PR).
It probably can! But it requires more work than throwing together a dashboard with graphs. It’s also not as easy to define thresholds on these changes and when to report them. There’s work underway that hopefully enables us to more quickly build up these dashboards for any product using the Glean SDK, which we can then also extend to do more reporting automated. The final goal should be that the product teams themselves are responsible for monitoring their data.
https://blog.mozilla.org/data/2021/02/24/this-week-in-glean-boring-monitoring/
|
|
William Lachance: Community @ Mozilla: People First, Open Source Second |
|
|
Jan-Erik Rediger: This Week in Glean: Boring Monitoring |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.)
All "This Week in Glean" blog posts are listed in the TWiG index (and on the Mozilla Data blog). This article is cross-posted on the Mozilla Data blog.
Every Monday the Glean has its weekly Glean SDK meeting. This meeting is used for 2 main parts: First discussing the features and bugs the team is currently investigating or that were requested by outside stakeholders. And second bug triage & monitoring of data that Glean reports in the wild.
Most of the time looking at our monitoring is boring and that's a good thing.
From the beginning the Glean SDK supported extensive error reporting on data collected by the framework inside end-user applications. Errors are produced when the application tries to record invalid values. That could be a negative value for a counter that should only ever go up or stopping a timer that was never started. Sometimes this comes down to a simple bug in the code logic and should be fixed in the implementation. But often this is due to unexpected and surprising behavior of the application the developers definitely didn't think about. Do you know all the ways that your Android application can be started? There's a whole lot of events that can launch it, even in the background, and you might miss instrumenting all the right parts sometimes. Of course this should then also be fixed in the implementation.
For our weekly monitoring we look at one application in particular: Firefox for Android. Because errors are reported in the same way as other metrics we are able to query our database, aggregate the data by specific metrics and errors, generate graphs from it and create dashboards on our instance of Redash.
The above graph displays error counts for different metrics. Each line is a specific metric and error (such as Invalid Value or Invalid State).
The exact numbers are not important.
What we're interested in is the general trend.
Are the errors per metrics stable or are there sudden jumps?
Upward jumps indicate a problem, downward jumps probably means the underlying bug got fixed and is finally rolled out in an update to users.
We have another graph that doesn't take the raw number of errors, but averages it across the entire population. A sharp increase in error counts sometimes comes from a small number of clients, whereas the errors for others stay at the same low-level. That's still a concern for us, but knowing that a potential bug is limited to a small number of clients may help with finding and fixing it. And sometimes it's really just bogus client data we get and can dismiss fully.
Most of the time these graphs stay rather flat and boring and we can quickly continue with other work. Sometimes though we can catch potential issues in the first days after a rollout.
In this graph from the nightly release of Firefox for Android two metrics started reporting a number of errors that's far above any other error we see. We can then quickly find the implementation of these metrics and report that to the responsible team (Filed bug, and the remediation PR).
It probably can! But it requires more work than throwing together a dashboard with graphs. It's also not as easy to define thresholds on these changes and when to report them. There's work underway that hopefully enables us to more quickly build up these dashboards for any product using the Glean SDK, which we can then also extend to do more reporting automated. The final goal should be that the product teams themselves are responsible for monitoring their data.
|
|
Karl Dubost: The Benefits Of Code Review For The Reviewer |
Code Review is an essential part of the process of publishing code. We often talk about the benefits of code review for projects and for people writing the code. I want to talk about the benefits for the person actually reviewing the code.

When doing code review, we don't necessarily have a good understanding of the project, or at least the same level of understanding than the person who has written the code.
Reviewing is a good way to piece together all the parts that makes this project work.
A lot of the reviews I have been have involved with taught me on how to become a better developer. Nobody has full knowledge of a language, an algorithm construct, a data structure. When reviewing we learn as much as we help. For things, which seem unclear, we dive into the documentation to better understand the intent. We can put into competition the existing knowledge with the one brought by the developer.
We might bring a new solution to the table that we didn't know existed. A review is not only discovering errors or weaknesses of a code, it's how to improve the code by exchanging ideas with the developer.
There is a feel good opportunity when doing good code reviews. Specifically, when the review helped to improve both the code and the developer. Nothing better than the last comment of a developer being happy of having the code merged and the feeling of improving skills.
Otsukare!
|
|
Support.Mozilla.Org: Introducing Fabiola Lopez |
Hi everyone,
Please join us in welcoming Fabiola Lopez (Fabi) to the team. Fabi will be helping us with support content in English and Spanish, so you’ll see her in both locales. Here’s a little more about Fabi:
Hi, everyone! I’m Fabi, and I am a content writer and a translator. I will be working with you to create content for all our users. You will surely find me writing, proofreading, editing and localizing articles. If you have any ideas to help make our content more user-friendly, please reach out to me. Thanks to your help, we make this possible.
Also, Angela’s contract was ended last week. We’d like to thank Angela for her support for the past year.
https://blog.mozilla.org/sumo/2021/02/24/introducing-fabiola-lopez/
|
|
Hacks.Mozilla.Org: A Fabulous February Firefox — 86! |
Looking into the near distance, we can see the end of February loitering on the horizon, threatening to give way to March at any moment. To keep you engaged until then, we’d like to introduce you to Firefox 86. The new version features some interesting and fun new goodies including support for the Intl.DisplayNames object, the :autofill pseudo-class, and a much better inspection feature in DevTools.
This blog post provides merely a set of highlights; for all the details, check out the following:
The Firefox web console used to include a cd() helper command that enabled developers to change the DevTools’ context to inspect a specific present on the page. This helper has been removed in favor of the iframe context picker, which is much easier to use.
When inspecting a page with s present, the DevTools will show the iframe context picker button.
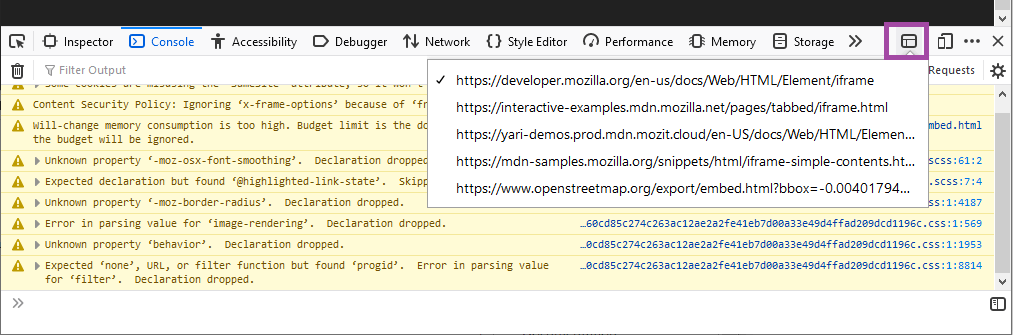
When pressed, it will display a drop-down menu listing all the URLs of content embedded in the page inside s. Choose one of these, and the inspector, console, debugger, and all other developer tools will then target that , essentially behaving as if the rest of the page does not exist.
The :autofill CSS pseudo-class matches when an element has had its value auto-filled by the browser. The class stops matching as soon as the user edits the field.
For example:
input:-webkit-autofill {
border: 3px solid blue;
}
input:autofill {
border: 3px solid blue;
}Firefox 86 supports the unprefixed version with the -webkit-prefixed version also supported as an alias. Most other browsers just support the prefixed version, so you should provide both for maximum browser support.
The Intl.DisplayNames built-in object has been enabled by default in Firefox 86. This enables the consistent translation of language, region, and script display names. A simple example looks like so:
// Get English currency code display names
let currencyNames = new Intl.DisplayNames(['en'], {type: 'currency'});
// Get currency names
currencyNames.of('USD'); // "US Dollar"
currencyNames.of('EUR'); // "Euro"The image-set() CSS function lets the browser pick the most appropriate CSS image from a provided set. This is useful for implementing responsive images in CSS, respecting the fact that resolution and bandwidth differ by device and network access.
The syntax looks like so:
background-image: image-set("cat.png" 1x,
"cat-2x.png" 2x,
"cat-print.png" 600dpi);Given the set of options, the browser will choose the most appropriate one for the current device’s resolution — users of lower-resolution devices will appreciate not having to download a large hi-res image that they don’t need, which users of more modern devices will be happy to receive a sharper, crisper image that looks better on their device.
As part of our work on Manifest V3, we have landed an experimental base content security policy (CSP) behind a preference in Firefox 86. The new CSP disallows remote code execution. This restriction only applies to extensions using manifest_version 3, which is not currently supported in Firefox (currently, only manifest_version 2 is supported).
If you would like to test the new CSP for extension pages and content scripts, you must change your extension’s manifest_version to 3 and set extensions.manifestv3.enabled to true in about:config. Because this is a highly experimental and evolving feature, we want developers to be aware that extensions that work with the new CSP may break as more changes are implemented.
The post A Fabulous February Firefox — 86! appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2021/02/a-fabulous-february-firefox-86/
|
|






