The Rust Programming Language Blog: The Foundation Conversation |
In August, we on the Core Team announced our plans to create a Foundation by the end of the year. Since that time, we’ve been doing a lot of work but it has been difficult to share many details, and we know that a lot of you have questions.
This blog post announces the start of the “Foundation Conversation”. This is a week-long period in which we have planned a number of forums and opportunities where folks can ask questions about the Foundation and get answers from the Core team. It includes both text-based “question-and-answer” (Q&A) periods as well as live broadcasts. We’re also going to be coming to the Rust team’s meetings to have discussions. We hope that this will help us to share our vision for the Foundation and to get the community excited about what’s to come.
A secondary goal for the Foundation Conversation is to help us develop the Foundation FAQ. Most FAQs get written before anyone has ever really asked a question, but we really wanted to write a FAQ that responds honestly to the questions that people have. We’ve currently got a draft of the FAQ which is based both on questions we thought people would ask and questions that were raised by Rust team members thus far, but we would like to extend it to include questions raised by people in the broader community. That’s where you come in!
There are many ways to participate in the Foundation Conversation:
Read on for more details.
We have chosen to coordinate the Foundation Conversation using a GitHub repository called foundation-faq-2020. This repository contains the draft FAQ we’ve written so far, along with a series of issues representing the questions that people have. Last week we opened the repository for Rust team members, so you can see that we’ve already had quite a few questions raised (and answered). Once a new issue is opened, someone from the core team will come along and post an answer, and then label the question as “answered”.
We have scheduled a number of 3 hour periods in which the repository will be open for anyone to open new issues. Outside of these slots, the repository is generally “read only” unless you are a member of a Rust team. We are calling these slots the “Community Q&A” sessions, since it is a time for the broader community to open questions and get answers.
We’ve tried to stagger the times for the “Community Q&A” periods to be accessible from all time zones. During each slot, members of the core team will be standing by to monitor new questions and post answers. In some cases, if the question is complex, we may hold off on answering right away and instead take time to draft the response and post it later.
Here are the times that we’ve scheduled for folks to pose questions.
| PST US | EST US | UTC Europe/Africa | India | China | |
|---|---|---|---|---|---|
| Dec 7th (View in my timezone) | 3-6pm | 6-9pm | 23:00-2:00 | 4:30am-7:30am (Dec 8) | 7am-10am (Dec 8) |
| Dec 9th (View in my timezone) | 4-7am | 7-10am | 12:00-15:00 | 5:30-8:30pm | 8pm-11pm |
| Dec 11th (View in my timezone) | 10-1pm | 1-4pm | 18:00-21:00 | 11:30pm-2:30am | 2am-5am (Dec 12) |
In addition to the repository, we’ve scheduled two “live broadcasts”. These sessions will feature members of the core team discussing and responding to some of the questions that have been asked thus far. Naturally, even if you can’t catch the live broadcast, the video will be available for streaming afterwards. Here is the schedule for these broadcasts:
| PST US | EST US | UTC Europe/Africa | India | China | ||
|---|---|---|---|---|---|---|
| Dec 9th (View in my timezone) | Watch on YouTube | 3-4pm | 6-7pm | 23:00-24:00 | 4:30-5:30am (Dec 10) | 7-8am (Dec 10) |
| Dec 12th (View in my timezone) | Watch on YouTube | 4-5am | 7-8am | 12:00-13:00 | 5:30pm-6:30pm | 8-9pm |
These will be hosted on our YouTube channel.
We’re very excited about the progress on the Rust foundation and we’re looking forward to hearing from all of you.
https://blog.rust-lang.org/2020/12/07/the-foundation-conversation.html
|
|
Nicholas Nethercote: Farewell, Mozilla |
Today is my last day working for Mozilla. I will soon be starting a new job with Apple.
I have worked on a lot of different things over my twelve years at Mozilla. Some numbers:
Two areas of work stand out for me.
I have a lot of memories, and the ones relating to these two projects are at the forefront. Thank you to everyone I’ve worked with. It’s been a good time.
As I understand it, this blog will stay up in read-only mode indefinitely. I will make a copy of all the posts and if it ever goes down I will rehost them at my personal site.
All the best to everyone.
https://blog.mozilla.org/nnethercote/2020/12/04/farewell-mozilla/
|
|
Hacks.Mozilla.Org: Flying the Nest: WebThings Gateway 1.0 |
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla reacts to publication of the EU Democracy Action Plan |
The European Commission has just published its new EU Democracy Action Plan (EDAP). This is an important step forward in the efforts to better protect democracy in the digital age, and we’re happy to see the Commission take onboard many of our recommendations.
Reacting to the EDAP publication, Raegan MacDonald, Mozilla’s Head of Public Policy, said:
“Mozilla has been a leading advocate for the need for greater transparency in online political advertising. We haven’t seen adequate steps from the platforms to address these problems themselves, and it’s time for regulatory solutions. So we welcome the Commission’s signal of support for the need for broad disclosure of sponsored political content. We likewise welcome the EDAP’s acknowledgement of the risks associated with microtargeting of political content.
As a founding signatory to the EU Code of Practice on Disinformation we are encouraged that the Commission has adopted many of our recommendations for how the Code can be enhanced, particularly with respect to its implementation and its role within a more general EU policy approach to platform responsibility.
We look forward to working with the EU institutions to fine-tune the upcoming legislative proposals.”
The post Mozilla reacts to publication of the EU Democracy Action Plan appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2020/12/03/mozilla-statement-on-eu-democracy-action-plan/
|
|
Daniel Stenberg: Twitter lockout, again |
Status: 00:27 in the morning of December 4 my account was restored again. No words or explanations on how it happened – yet.
This morning (December 3rd, 2020) I woke up to find myself logged out from my Twitter account on the devices where I was previously logged in. Due to “suspicious activity” on my account. I don’t know the exact time this happened. I checked my phone at around 07:30 and then it has obviously already happened. So at time time over night.
Trying to log back in, I get prompted saying I need to update my password first. Trying that, it wants to send a confirmation email to an email address that isn’t mine! Someone has managed to modify the email address associated with my account.
It has only been two weeks since someone hijacked my account the last time and abused it for scams. When I got the account back, I made very sure I both set a good, long, password and activated 2FA on my account. 2FA with auth-app, not SMS.
The last time I wasn’t really sure about how good my account security was. This time I know I did it by the book. And yet this is what happened.
I was in touch with someone at Twitter security and provided lots of details of my systems , software, IP address etc while they researched their end about what happened. I was totally transparent and gave them all info I had that could shed some light.
I was contacted by a Sr. Director from Twitter (late Dec 4 my time). We have a communication established and I’ve been promised more details and information at some point next week. Stay tuned.
Many people have proposed that the attacker must have come through my local machine to pull this off. If someone did, it has been a very polished job as there is no trace at all of that left anywhere on my machine. Also, to reset my password I would imagine the attacker would need to somehow hijack my twitter session, need the 2FA or trigger a password reset and intercept the email. I don’t receive emails on my machine so the attacker would then have had to (also?) manage to get into my email machine and removed that email – and not too many others because I receive a lot of email and I’ve kept on receiving a lot of email during this period.
I’m not ruling it out. I’m just thinking it seems unlikely.
If the attacker would’ve breached my phone and installed something nefarious on that, it would not have removed any reset emails and it seems like a pretty touch challenge to hijack a “live” session from the Twitter client or get the 2FA code from the authenticator app. Not unthinkable either, just unlikely.
As I have no insights into the other end I cannot really say which way I think is the most likely that the perpetrator used for this attack, but I will maintain that I have no traces of a local attack or breach and I know of no malicious browser add-ons or twitter apps on my devices.
Firefox version 83.0 on Debian Linux with Tweetdeck in a tab – a long-lived session started over a week ago (ie no recent 2FA codes used),
Browser extensions: Cisco Webex, Facebook container, multi-account containers, HTTPS Everywhere, test pilot and ublock origin.
I only use one “authorized app” with Twitter and that’s Tweetdeck.
On the Android phone, I run an updated Android with an auto-updated Twitter client. That session also started over a week ago. I used Google Authenticator for 2fa.
While this hijack took place I was asleep at home (I don’t know the exact time of it), on my WiFi, so all my most relevant machines would’ve been seen as originating from the same “NATed” IP address. This info was also relayed to Twitter security.
The actual restoration happens like this (and it was the exact same the last time): I just suddenly receive an email on how to reset my password for my account.
The email is a standard one without any specifics for this case. Just a template press the big button and it takes you to the Twitter site where I can set a new password for my account. There is nothing in the mail that indicates a human was involved in sending it. There is no text explaining what happened. Oh, right, the mail also include a bunch of standard security advice like “use a strong password”, “don’t share your password with others” and “activate two factor” etc as if I hadn’t done all that already…
It would be prudent of Twitter to explain how this happened, at least roughly and without revealing sensitive details. If it was my fault somehow, or if I just made it easier because of something in my end, I would really like to know so that I can do better in the future.
No tweets were sent. The name and profile picture remained intact. I’ve not seen any DMs sent or received from while the account was “kidnapped”. Given this, it seems possible that the attacker actually only managed to change the associated account email address.
https://daniel.haxx.se/blog/2020/12/03/twitter-lockout-again/
|
|
Dustin J. Mitchell: Taskcluster's DB (Part 3) - Online Migrations |
This is part 3 of a deep-dive into the implementation details of Taskcluster’s backend data stores. If you missed the first two, see part 1 and part 2 for the background, as we’ll jump right in here!
A few of the tables holding data for Taskcluster contain a tens or hundreds of millions of lines. That’s not what the cool kids mean when they say “Big Data”, but it’s big enough that migrations take a long time. Most changes to Postgres tables take a full lock on that table, preventing other operations from occurring while the change takes place. The duration of the operation depends on lots of factors, not just of the data already in the table, but on the kind of other operations going on at the same time.
The usual approach is to schedule a system downtime to perform time-consuming database migrations, and that’s just what we did in July. By running it a clone of the production database, we determined that we could perform the migration completely in six hours. It turned out to take a lot longer than that. Partly, this was because we missed some things when we shut the system down, and left some concurrent operations running on the database. But by the time we realized that things were moving too slowly, we were near the end of our migration window and had to roll back. The time-consuming migration was version 20 - migrate queue_tasks, and it had been estimated to take about 4.5 hours.
When we rolled back, the DB was at version 19, but the code running the Taskcluster services corresponded to version 12. Happily, we had planned for this situation, and the redefined stored functions described in part 2 bridged the gap with no issues.
Our options were limited: scheduling another extended outage would have been difficult. We didn’t solve all of the mysteries of the poor performance, either, so we weren’t confident in our prediction of the time required.
The path we chose was to perform an “online migration”. I wrote a custom migration script to accomplish this. Let’s look at how that worked.
The goal of the migration was to rewrite the queue_task_entities table into a tasks table, with a few hundred million rows.
The idea with the online migration was to create an empty tasks table (a very quick operation), then rewrite the stored functions to write to tasks, while reading from both tables.
Then a background task can move rows from the queue_task_entitites table to the tasks table without blocking concurrent operations.
Once the old table is empty, it can be removed and the stored functions rewritten to address only the tasks table.
A few things made this easier than it might have been.
Taskcluster’s tasks have a deadline after which they become immutable, typically within one week of the task’s creation.
That means that the task mutation functions can change the task in-place in whichever table they find it in.
The background task only moves tasks with deadlines in the past.
This eliminates any concerns about data corruption if a row is migrated while it is being modified.
A look at the script linked above shows that there were some complicating factors, too – notably, two more tables to manage – but those factors didn’t change the structure of the migration.
With this in place, we ran the replacement migration script, creating the new tables and updating the stored functions. Then a one-off JS script drove migration of post-deadline tasks with a rough ETA calculation. We figured this script would run for about a week, but in fact it was done in just a few days. Finally, we cleaned up the temporary functions, leaving the DB in precisely the state that the original migration script would have generated.
After this experience, we knew we would run into future situations where a “regular” migration would be too slow. Apart from that, we want users to be able to deploy Taskcluster without scheduling downtimes: requiring downtimes will encourage users to stay at old versions, missing features and bugfixes and increasing our maintenance burden.
We devised a system to support online migrations in any migration.
Its structure is pretty simple: after each migration script is complete, the harness that handles migrations calls a _batch stored function repeatedly until it signals that it is complete.
This process can be interrupted and restarted as necessary.
The “cleanup” portion (dropping unnecessary tables or columns and updating stored functions) must be performed in a subsequent DB version.
The harness is careful to call the previous version’s online-migration function before it starts a version’s upgrade, to ensure it is complete. As with the old “quick” migrations, all of this is also supported in reverse to perform a downgrade.
The _batch functions are passed a state parameter that they can use as a bookmark.
For example, a migration of the tasks might store the last taskId that it migrated in its state.
Then each batch can begin with select .. where task_id > last_task_id, allowing Postgres to use the index to quickly find the next task to be migrated.
When the _batch function indicates that it processed zero rows, the handler calls an _is_completed function.
If this function returns false, then the whole process starts over with an empty state.
This is useful for tables where more rows that were skipped during the migration, such as tasks with deadlines in the future.
An experienced engineer is, at this point, boggling at the number of ways this could go wrong! There are lots of points at which a migration might fail or be interrupted, and the operators might then begin a downgrade. Perhaps that downgrade is then interrupted, and the migration re-started! A stressful moment like this is the last time anyone wants surprises, but these are precisely the circumstances that are easily forgotten in testing.
To address this, and to make such testing easier, we developed a test framework that defines a suite of tests for all manner of circumstances. In each case, it uses callbacks to verify proper functionality at every step of the way. It tests both the “happy path” of a successful migration and the “unhappy paths” involving failed migrations and downgrades.
The impetus to actually implement support for online migrations came from some work that Alex Lopez has been doing to change the representation of worker pools in the queue.
This requires rewriting the tasks table to transform the provisioner_id and worker_type columns into a single, slash-separated task_queue_id column.
The pull request is still in progress as I write this, but already serves as a great practical example of an online migration (and online dowgrade, and tests).
As we’ve seen in this three-part series, Taskcluster’s data backend has undergone a radical transformation this year, from a relatively simple NoSQL service to a full Postgres database with sophisticated support for ongoing changes to the structure of that DB.
In some respects, Taskcluster is no different from countless other web services abstracting over a data-storage backend. Indeed, Django provides robust support for database migrations, as do many other application frameworks. One factor that sets Taskcluster apart is that it is a “shipped” product, with semantically-versioned releases which users can deploy on their own schedule. Unlike for a typical web application, we – the software engineers – are not “around” for the deployment process, aside from the Mozilla deployments. So, we must make sure that the migrations are well-tested and will work properly in a variety of circumstances.
We did all of this with minimal downtime and no data loss or corruption. This involved thousands of lines of new code written, tested, and reviewed; a new language (SQL) for most of us; and lots of close work with the Cloud Operations team to perform dry runs, evaluate performance, and debug issues. It couldn’t have happened without the hard work and close collaboration of the whole Taskcluster team. Thanks to the team, and thanks to you for reading this short series!
|
|
Data@Mozilla: This Week in Glean: Glean is Frictionless Data Collection |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
So you want to collect data in your project? Okay, it’s pretty straightforward.
stop() before start(). Your networking code will encounter the weirdness of the full Internet. Your storage will get full. You need some way to communicate the health of your data collection system to yourself (the owner who needs to adjust scheduling and persistence and other stuff to decrease errors) and to others (devs who need to fix their instrumentation, analysts who should be told if there’s a problem with the data, QA so they can write tests for these corner cases).You get all that? Thread safety. File formats. Networking protocols. Scheduling using real wall-clock time. Schema validation. Open ports on the Internet. At scale. User-facing tools and documentation. All tested and verified.
Look, I said it’d be straightforward, not that it’d be easy. I’m sure it’ll only take you a few years and a couple tries to get it right.
Or, y’know, if you’re a Mozilla project you could just use Glean which already has all of these things…
Glean takes this incredibly complex problem, breaks it into pieces, solves each piece individually, then puts the solution together in a way that makes it greater than the sum of its parts.
All you need is to follow the six steps to integrate the Glean SDK and notify the Ecosystem that your project exists, and then your responsibilities shrink to just instrumentation and analysis.
If that isn’t frictionless data collection, I don’t know what is.
:chutten
(( If you’re not a Mozilla project, and thus don’t by default get to use the Data Platform (numbers 6-10) for your project, come find us on the #glean channel on Matrix and we’ll see what help we can get you. ))
(( This post was syndicated from its original location. ))
https://blog.mozilla.org/data/2020/12/01/this-week-in-glean-glean-is-frictionless-data-collection/
|
|
Mozilla Security Blog: Design of the CRLite Infrastructure |
Firefox is the only major browser that still evaluates every website it connects to whether the certificate used has been reported as revoked. Firefox users are notified of all connections involving untrustworthy certificates, regardless the popularity of the site. Inconveniently, checking certificate status sometimes slows down the connection to websites. Worse, the check reveals cleartext information about the website you’re visiting to network observers.
We’re now testing a technology named CRLite which provides Firefox users with the confidence that the revocations in the Web PKI are enforced by the browser without this privacy compromise. This is a part of our goal to use encryption everywhere. (See also: Encrypted SNI and DNS-over-HTTPS)
The first three posts in this series are about the newly-added CRLite technology and provide background that will be useful for following along with this post:
This blog post discusses the back-end infrastructure that produces the data which Firefox uses for CRLite. To begin with, we’ll trace that data in reverse, starting from what Firefox needs to use for CRLite’s algorithms, back to the inputs derived from monitoring the whole Web PKI via Certificate Transparency.
Individual copies of Firefox maintain in their profiles a CRLite database which is periodically updated via Firefox’s Remote Settings. Those updates come in the form of CRLite filters and “stashes”.
The general mechanism for how the filters work is explained in Figure 3 of The End-to-End Design of CRLite.
Introduced in this post is the concept of CRLite stashes. These are lists of certificate issuers and the certificate serial numbers that those issuers revoked, which the CRLite infrastructure distributes to Firefox users in lieu of a whole new filter. If a certificate’s identity is contained within any of the issued stashes, then that certificate is invalid.
Combining stashes with the CRLite filters produces an algorithm which, in simplified terms, proceeds like this:

Figure 1: Simplified CRLite Decision Tree
Every time the CRLite infrastructure updates its dataset, it produces both a new filter and a stash containing all of the new revocations (compared with the previous run). Firefox’s CRLite is up-to-date if it has a filter and all issued stashes for that filter.
To produce the filters and stashes, CRLite needs as input:
These bits of data are the basis of the CRLite decision-making.
The enrolled issuers are communicated to Firefox clients as updates within the existing Intermediate Preloading feature, while the certificate sets are compressed into the CRLite filters and stashes. Whether a certificate issuer is enrolled or not is directly related to obtaining the list of their revoked certificates.
To obtain all the revoked certificates for a given issuer, the CRLite infrastructure reads the Certificate Revocation List (CRL) Distribution Point extension out of all that issuer’s unexpired certificates and filters the list down to those CRLs which are available over HTTP/HTTPS. Then, every URL in that list is downloaded and verified: Does it have a valid, trusted signature? Is it up-to-date? If any could not be downloaded, do we have a cached copy which is still both valid and up-to-date?
For issuers which are considered enrolled, all of the entries in the CRLs are collected and saved as a complete list of all revoked certificates for that issuer.
The lists of currently-valid certificates and unexpired-but-revoked certificates have to be calculated, as the data sources that CRLite uses consist of:
By policy now, Certificate Transparency (CT) Logs, in aggregate, are assumed to provide a complete list of all certificates in the public Web PKI. CRLite then filters the complete CT dataset down to certificates which haven’t yet reached their expiration date, but which have been issued by certificate authorities trusted by Firefox.
Filtering CT data down to a list of unexpired certificates allows CRLite to derive the needed data sets using set math:
The CT data simply comes from a continual monitoring of the Certificate Transparency ecosystem. Every known CT log is monitored by Mozilla’s infrastructure, and every certificate added to the ecosystem is processed.
All these functions are orchestrated as four Kubernetes pods with the descriptive names Fetch, Generate, Publish, and Sign-off.
Fetch is a Kubernetes deployment, or always-on task, which constantly monitors Certificate Transparency data from all Certificate Transparency logs. Certificates that aren’t expired are inserted into a Redis database, configured so that certificates are expunged automatically when they reach their expiration time. This way, whenever the CRLite infrastructure requires a list of all unexpired certificates known to Certificate Transparency, it can iterate through all of the certificates in the Redis database. The actual data stored in Redis is described in our FAQ.

Figure 2: The Fetch task reads from Certificate Transparency and stores data in a Redis database
The Generate pod is a periodic task, which currently runs four times a day. This task reads all known unexpired certificates from the Redis database, downloads and validates all CRLs from the issuing certificate authorities, and synthesizes a filter and a stash from those data sources. The resulting filters and stashes are uploaded into a Google Cloud Storage bucket, along with all the source input data, for both public audit and distribution.

Figure 3: The Generate task reads from a Redis database and the Internet, and writes its results to Google Cloud Storage
The Publish task is also a periodic task, running often. It looks for new filters and stashes in the Google Cloud Storage bucket, and stages either a new filter or a stash to Firefox’s Remote Settings when the Generate task finishes producing one.

Figure 4: The Publish job reads from Google Cloud Storage and writes to Remote Settings
Finally, a separate Sign-Off task runs periodically, also often. When there is an updated filter or stash staged at Firefox’s Remote Settings, the sign-off task downloads the staged data and tests it, looking for coherency and to make sure that CRLite does not accidentally include revocations that could break Firefox. If all the tests pass, the Sign-Off task approves the new CRLite data for distribution, which triggers Megaphone to push the update to Firefox users that are online.

Figure 5: The Sign-Off task interacts with both Remote Settings and the public Internet
We recently announced in the mozilla.dev.platform mailing list that Firefox Nightly users on Desktop are relying on CRLite, after collecting encouraging performance measurements for most of 2020. We’re working on plans to begin tests for Firefox Beta users soon. If you want to try using CRLite, you can use Firefox Nightly, or for the more adventurous reader, interact with the CRLite data directly.
Our final blog post in this series, Part 5, will reflect on the collaboration between Mozilla Security Engineering and the several research teams that designed and have analyzed CRLite to produce this impressive system.
The post Design of the CRLite Infrastructure appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/12/01/crlite-part-4-infrastructure-design/
|
|
J.C. Jones: Design of the CRLite Infrastructure |
Firefox is the only major browser that still evaluates every website it connects to whether the certificate used has been reported as revoked. Firefox users are notified of all connections involving untrustworthy certificates, regardless the popularity of the site. Inconveniently, checking certificate status sometimes slows down the connection to websites. Worse, the check reveals cleartext information about the website you’re visiting to network observers.
We’re now testing a technology named CRLite which provides Firefox users with the confidence that the revocations in the Web PKI are enforced by the browser without this privacy compromise. This is a part of our goal to use encryption everywhere. (See also: Encrypted SNI and DNS-over-HTTPS)
The first three posts in this series are about the newly-added CRLite technology and provide background that will be useful for following along with this post:
This blog post discusses the back-end infrastructure that produces the data which Firefox uses for CRLite. To begin with, we’ll trace that data in reverse, starting from what Firefox needs to use for CRLite’s algorithms, back to the inputs derived from monitoring the whole Web PKI via Certificate Transparency.
Individual copies of Firefox maintain in their profiles a CRLite database which is periodically updated via Firefox’s Remote Settings. Those updates come in the form of CRLite filters and “stashes”.
The general mechanism for how the filters work is explained in Figure 3 of The End-to-End Design of CRLite.
Introduced in this post is the concept of CRLite stashes. These are lists of certificate issuers and the certificate serial numbers that those issuers revoked, which the CRLite infrastructure distributes to Firefox users in lieu of a whole new filter. If a certificate’s identity is contained within any of the issued stashes, then that certificate is invalid.
Combining stashes with the CRLite filters produces an algorithm which, in simplified terms, proceeds like this:

Every time the CRLite infrastructure updates its dataset, it produces both a new filter and a stash containing all of the new revocations (compared with the previous run). Firefox’s CRLite is up-to-date if it has a filter and all issued stashes for that filter.
To produce the filters and stashes, CRLite needs as input:
These bits of data are the basis of the CRLite decision-making.
The enrolled issuers are communicated to Firefox clients as updates within the existing Intermediate Preloading feature, while the certificate sets are compressed into the CRLite filters and stashes. Whether a certificate issuer is enrolled or not is directly related to obtaining the list of their revoked certificates.
To obtain all the revoked certificates for a given issuer, the CRLite infrastructure reads the Certificate Revocation List (CRL) Distribution Point extension out of all that issuer’s unexpired certificates and filters the list down to those CRLs which are available over HTTP/HTTPS. Then, every URL in that list is downloaded and verified: Does it have a valid, trusted signature? Is it up-to-date? If any could not be downloaded, do we have a cached copy which is still both valid and up-to-date?
For issuers which are considered enrolled, all of the entries in the CRLs are collected and saved as a complete list of all revoked certificates for that issuer.
The lists of currently-valid certificates and unexpired-but-revoked certificates have to be calculated, as the data sources that CRLite uses consist of:
By policy now, Certificate Transparency (CT) Logs, in aggregate, are assumed to provide a complete list of all certificates in the public Web PKI. CRLite then filters the complete CT dataset down to certificates which haven’t yet reached their expiration date, but which have been issued by certificate authorities trusted by Firefox.
Filtering CT data down to a list of unexpired certificates allows CRLite to derive the needed data sets using set math:
The CT data simply comes from a continual monitoring of the Certificate Transparency ecosystem. Every known CT log is monitored by Mozilla’s infrastructure, and every certificate added to the ecosystem is processed.
All these functions are orchestrated as four Kubernetes pods with the descriptive names Fetch, Generate, Publish, and Sign-off.
Fetch is a Kubernetes deployment, or always-on task, which constantly monitors Certificate Transparency data from all Certificate Transparency logs. Certificates that aren’t expired are inserted into a Redis database, configured so that certificates are expunged automatically when they reach their expiration time. This way, whenever the CRLite infrastructure requires a list of all unexpired certificates known to Certificate Transparency, it can iterate through all of the certificates in the Redis database. The actual data stored in Redis is described in our FAQ.

The Generate pod is a periodic task, which currently runs four times a day. This task reads all known unexpired certificates from the Redis database, downloads and validates all CRLs from the issuing certificate authorities, and synthesizes a filter and a stash from those data sources. The resulting filters and stashes are uploaded into a Google Cloud Storage bucket, along with all the source input data, for both public audit and distribution.

The Publish task is also a periodic task, running often. It looks for new filters and stashes in the Google Cloud Storage bucket, and stages either a new filter or a stash to Firefox’s Remote Settings when the Generate task finishes producing one.

Finally, a separate Sign-Off task runs periodically, also often. When there is an updated filter or stash staged at Firefox’s Remote Settings, the sign-off task downloads the staged data and tests it, looking for coherency and to make sure that CRLite does not accidentally include revocations that could break Firefox. If all the tests pass, the Sign-Off task approves the new CRLite data for distribution, which triggers Megaphone to push the update to Firefox users that are online.

We recently announced in the mozilla.dev.platform mailing list that Firefox Nightly users on Desktop are relying on CRLite, after collecting encouraging performance measurements for most of 2020. We’re working on plans to begin tests for Firefox Beta users soon. If you want to try using CRLite, you can use Firefox Nightly, or for the more adventurous reader, interact with the CRLite data directly.
Our final blog post in this series, Part 5, will reflect on the collaboration between Mozilla Security Engineering and the several research teams that designed and have analyzed CRLite to produce this impressive system.
https://insufficient.coffee/2020/12/01/crlite-part-4-infrastructure-design/
|
|
Patrick Cloke: celery-batches 0.4 released! |
Earlier today I released a version 0.4 of celery-batches with support for Celery 5.0. As part of this release support for Python < 3.6 was dropped and support for Celery < 4.4 was dropped.
celery-batches is a small library that allows you process multiple calls to a Celery …
https://patrick.cloke.us/posts/2020/11/30/celery-batches-0.4-released/
|
|
Chris H-C: This Week in Glean: Glean is Frictionless Data Collection |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
So you want to collect data in your project? Okay, it’s pretty straightforward.
stop() before start(). Your networking code will encounter the weirdness of the full Internet. Your storage will get full. You need some way to communicate the health of your data collection system to yourself (the owner who needs to adjust scheduling and persistence and other stuff to decrease errors) and to others (devs who need to fix their instrumentation, analysts who should be told if there’s a problem with the data, QA so they can write tests for these corner cases).You get all that? Thread safety. File formats. Networking protocols. Scheduling using real wall-clock time. Schema validation. Open ports on the Internet. At scale. User-facing tools and documentation. All tested and verified.
Look, I said it’d be straightforward, not that it’d be easy. I’m sure it’ll only take you a few years and a couple tries to get it right.
Or, y’know, if you’re a Mozilla project you could just use Glean which already has all of these things…
Glean takes this incredibly complex problem, breaks it into pieces, solves each piece individually, then puts the solution together in a way that makes it greater than the sum of its parts.
All you need is to follow the six steps to integrate the Glean SDK and notify the Ecosystem that your project exists, and then your responsibilities shrink to just instrumentation and analysis.
If that isn’t frictionless data collection, I don’t know what is.
:chutten
(( If you’re not a Mozilla project, and thus don’t by default get to use the Data Platform (numbers 6-10) for your project, come find us on the #glean channel on Matrix and we’ll see what help we can get you. ))
|
|
Daniel Stenberg: I am an 80 column purist |
I write and prefer code that fits within 80 columns in curl and other projects – and there are reasons for it. I’m a little bored by the people who respond and say that they have 400 inch monitors already and they can use them.
I too have multiple large high resolution screens – but writing wide code is still a bad idea! So I decided I’ll write down my reasoning once and for all!
There’s a reason newspapers and magazines have used narrow texts for centuries and in fact even books aren’t using long lines. For most humans, it is simply easier on the eyes and brain to read texts that aren’t using really long lines. This has been known for a very long time.
Easy-to-read code is easier to follow and understand which leads to fewer bugs and faster debugging.
I never run windows full sized on my screens for anything except watching movies. I frequently have two or more editor windows next to each other, sometimes also with one or two extra terminal/debugger windows next to those. To make this feasible and still have the code readable, it needs to fit “wrapless” in those windows.
Sometimes reading a code diff is easier side-by-side and then too it is important that the two can fit next to each other nicely.
Having code grow vertically rather than horizontally is beneficial for diff, git and other tools that work on changes to files. It reduces the risk of merge conflicts and it makes the merge conflicts that still happen easier to deal with.
A side effect by strictly not allowing anything beyond column 80 is that it becomes really hard to use those terribly annoying 30+ letters java-style names on functions and identifiers. A function name, and especially local ones, should be short. Having long names make them really hard to read and makes it really hard to spot the difference between the other functions with similarly long names where just a sub-word within is changed.
I know especially Java people object to this as they’re trained in a different culture and say that a method name should rather include a lot of details of the functionality “to help the user”, but to me that’s a weak argument as all non-trivial functions will have more functionality than what can be expressed in the name and thus the user needs to know how the function works anyway.
I don’t mean 2-letter names. I mean long enough to make sense but not be ridiculous lengths. Usually within 15 letters or so.
To make this work, and yet allow a few indent levels, the code basically have to have small indent-levels, so I prefer to have it set to two spaces per level.
If you do a lot of indent levels it gets really hard to write code that still fits within the 80 column limit. That’s a subtle way to suggest that you should not write functions that needs or uses that many indent levels. It should then rather be split out into multiple smaller functions, where then each function won’t need that many levels!
Once upon the time it was of course because terminals had that limit and these days the exact number 80 is not a must. I just happen to think that the limit has worked fine in the past and I haven’t found any compelling reason to change it since.
It also has to be a hard and fixed limit as if we allow a few places to go beyond the limit we end up on a slippery slope and code slowly grow wider over time – I’ve seen it happen in many projects with “soft enforcement” on code column limits.
In curl, we have ‘checksrc’ which will yell errors at any user trying to build code with a too long line present. This is good because then we don’t have to “waste” human efforts to point this out to contributors who offer pull requests. The tool will point out such mistakes with ruthless accuracy.
Image by piotr kurpaska from Pixabay
https://daniel.haxx.se/blog/2020/11/30/i-am-an-80-column-purist/
|
|
J.C. Jones: Auditing the CRLs in CRLite |
Since Firefox Nightly is now using CRLite to determine if enrolled websites’ certificates are revoked, it’s useful to dig into the data to answer why a given certificate issuer gets enrolled or not.
Ultimately this is a matter of whether the CRLs for a given issuer are available to CRLite, and are valid, but the Internet is a messy place, and sometimes things don’t work as planned. If an issuing CA is not enrolled in CRLite, the Mozilla infrastructure emits enough information to figure out what went wrong.
Mozilla’s infrastructure publishes not only the filters and stashes that define the CRLite state-of-the-WebPKI, it also publishes all the intermediate datasets that can be used to both reproduce the filters, and validate them.
I have a tool, crlite-status, which barely sticks a toe into the water of these datasets.
crlite-status is distributed as a Python package that can be installed via a simple invocation of pip:
pip install crlite-status
It downloads data directly from the Google Cloud Storage buckets for the production and staging environments, and parses out some of the useful statistics. For a simple example, asking for the last four runs out of the default production environment:

It gets more exciting when enabling CRL auditing, as CRLs dermine whether an issuer is “enrolled” in CRLite or not:

For just the most recent run, we can see which issuers were excluded from CRLite due to CRL issues, marked with a red X. There are actually six of them.
Even more details to trace this information is available with the --crl-details command line option. I’ve posted one output from 20201126-0 as an example. Using that 20201126-0, one can see that all three CertCloud issuers are not enrolled as their CRLs are returning a status 403 Forbidden, while the Actalis URL is giving a 404 Not Found. TeleSec’s CRL is hosted at a domain that is down entirely. Starfield and Secom both had recoverable warnings, though the Starfield root failed to recover and details would have to be harvested from the crls and logs directory, while the Secom issuer remained enrolled on the basis of the already-cached CRL still being valid.
Lots of the CRLite CRL auditing is manual, still. Since the whole state of the generation task gets uploaded to the Google Cloud Filestore, it’s always possible to determine what state existed for CRLite at the time it made its enrollment decisions, certainly better tools would make it a simpler process.
https://insufficient.coffee/2020/11/27/auditing-crls-of-crlite/
|
|
The Rust Programming Language Blog: Announcing Rustup 1.23.0 |
The rustup working group is happy to announce the release of rustup version 1.23.0. Rustup is the recommended tool to install Rust, a programming language that is empowering everyone to build reliable and efficient software.
If you have a previous version of rustup installed, getting rustup 1.23.0 is as easy as closing your IDE and running:
rustup self update
Rustup will also automatically update itself at the end of a normal toolchain update:
rustup update
If you don't have it already, you can get rustup from the appropriate page on our website.
Rustup is now natively available for the new Apple M1 devices, allowing you to install it on the new Macs the same way you'd install it on other platforms!
Note that at the time of writing this blog post the aarch64-apple-darwin compiler is at Tier 2 target: precompiled binaries are available starting from Rust 1.49 (currently in the beta channel), but no automated tests are executed on them.
You can follow issue #73908 to track the work needed to bring Apple Silicon support to Tier 1.
The Rust team releases a new version every six weeks, bringing new features and bugfixes on a regular basis. Sometimes a regression slips into a stable release, and the team releases a "point release" containing fixes for that regression. For example, 1.45.1 and 1.45.2 were point releases of Rust 1.45.0, while 1.46.0 and 1.47.0 both had no point releases.
With rustup 1.22.1 or earlier if you wanted to use a stable release you were able to either install stable (which automatically updates to the latest one) or a specific version number, such as 1.48.0, 1.45.0 or 1.45.2. Starting from this release of rustup (1.23.0) you can also install a minor version without specifying the patch version, like 1.48 or 1.45. These "virtual" releases will always point to the latest patch release of that cycle, so rustup toolchain install 1.45 will get you a 1.45.2 toolchain.
rust-toolchainThe rustup 1.5.0 release introduced the rust-toolchain file, allowing you to choose the default toolchain for a project. When the file is present rustup ensures the toolchain specified in it is installed on the local system, and it will use that version when calling rustc or cargo:
$ cat rust-toolchain
nightly-2020-07-10
$ cargo --version
cargo 1.46.0-nightly (fede83ccf 2020-07-02)
The file works great for projects wanting to use a specific nightly version, but didn't allow to add extra components (like clippy) or compilation targets. Rustup 1.23.0 introduces a new, optional TOML syntax for the file, with support for specifying components and targets:
[toolchain]
channel = "nightly-2020-07-10"
components = ["rustfmt", "clippy"]
targets = ["wasm32-unknown-unknown"]
The new syntax doesn't replace the old one, and both will continue to work. You can learn more about overriding the default toolchain in the "Overrides" chapter of the rustup book.
There are more changes in rustup 1.23.0: check them out in the changelog! Rustup's documentation is also available in the rustup book starting from this release.
Thanks to all the contributors who made rustup 1.23.0 possible!
|
|
Cameron Kaiser: TenFourFox FPR30b1 available |
A few people got bitten by not noticing the locale update, so let me remind everyone that FPR29 needs new locales if you are using a custom langpack. They're linked from the main TenFourFox page and all of them are on SourceForge except for the separately-maintained Japanese version, which I noticed has also been updated to FPR29. If you get a weird error starting TenFourFox and you have a langpack installed, quit the browser and run the new langpack installer and it should fix itself.
Finally, in case you missed it, with the right browser and a side-car TLS 1.2 proxy, you can get A/UX, Power MachTen (on any classic MacOS supporting it) and pre-Tiger Mac OS X able to access modern web pages again. The key advance here is that the same machine can also run the proxy all by itself: no cheating with a second system! Sadly, this does not work as-is with all browsers, including with Classilla, which is something I'll think about allowing as a down payment on proper in-browser support at some future date.
http://tenfourfox.blogspot.com/2020/11/tenfourfox-fpr30b1-available.html
|
|
The Talospace Project: Firefox 83 on POWER |
Dan Hor'ak has filed three bugs (1679271, 1679272 and 1679273) for build failures related to the internal profiler, which is still not supported on ppc64, ppc64le or s390x (or, for that matter, 32-bit PowerPC). These targetted fixes should be landing well before release, but perhaps we should be thinking about how to get it working on OpenPOWER rather than having to play emergency games of whack-a-mole whenever the build blows up.
|
|
This Week In Rust: This Week in Rust 366 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is cargo-intraconv, a cargo subcommand to convert links in rust documentation to the newly stable intra-doc-links format.
Thanks to Alexis Bourget for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
345 pull requests were merged in the last week
Vecslice::to_vec to not use extend_from_slicestd::sys::unix::weak::Weak#[cold] attribute to std::process::abort and alloc::alloc::handle_alloc_errorDefault for PhantomPinnedtrailing_zeros and leading_zeros to non zero typesf{32, 64}::is_subnormalcore::slice::fill_withIndex and IndexMut for arraysas{_mut,}_slice on array::IntoIter publicrefcell_takeclampthenIpAddr::is_ipv4 and is_ipv6 as constalloc::Layout const functionsrdpmc)This week saw landing of #79237 which by itself provides no wins but opens the door to support for split debuginfo on macOS. This'll eventually show huge wins as we can likely avoid re-collecting debuginfo while retaining support for lldb and Rust backtraces. #79361 tracks the stabilization of the rustc flag, but the precise rollout to stable users is not yet 100% clear.
Triage done by @jyn514 and @simulacrum.
4 regressions, 4 improvements, 2 mixed results. 5 of them in rollups.
See the full report for more.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No RFCs are currently in the final comment period.
No Tracking Issues or PRs are currently in the final comment period.
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
I know noting about the compiler internals but it looks to me as if 90% of the time is spent pretty-printing LayoutError.
Thanks to mmmmib for the suggestion.
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2020/11/25/this-week-in-rust-366/
|
|
Allen Wirfs-Brock: Software Diagrams Aren’t Always Correct and That’s OK |
This morning I saw an interesting twitter thread:
Sorry, this makes no sense. Most valuable architectural depictions are high-level and abstract and can't be auto-generated from code, for example; hence they're manually created.
— Andrei Pacurariu (@AndreiPacurariu) November 23, 2020
Tudor is the driving-force behind gtoolkit.com, a modern and innovative programming environment that builds upon and extends classic Smalltalk development concepts. Tudor is someone worth listening to, but his tweet was something that I really couldn’t agree with. I found myself more in agreement with Andrei Pacurariu’s reply.
I started to tweet a response but quickly found that my thoughts were too complex to make a good tweet stream. Instead, I wrote the following mini essay.
Concretely, software is just bits in electronic storage that control and/or are manipulated by processors. Abstractions are the building blocks that enable humans to design and build complex software systems out of bits. Abstractions are products of out minds—they allow us to assign meaning to clusters (some large, some small) of bits. They allow us to build software systems without thinking about billions of bits or how processors work.
We manifest some useful and generally simple abstractions (instructions, statements, functions, classes, modules, etc.) as “code” using other abstractions we call “languages.” Languages give us a common vocabulary for us to communicate about those abstract building blocks and to produce the corresponding bits. There are many useful tools that can and should be created to help us understand the code-level operation of a system.
But most systems we build today are too complex to be fully understood at the level of code. In designing them we must use higher-level abstractions to conceptualize, compose, and organize code. Abstract machines, frameworks, patterns, roles, stereotypes, heuristics, constraints, etc. are examples of such higher-level abstractions.
The languages we commonly use provide few, if any, mechanisms for directly identifying such higher-level abstractions. These abstractions may manifest as naming or other coding conventions but recognizing them as such depends upon a pre-existing shared understanding between the writer and readers of the code.
If such conventions have been adequately formalized and followed, a tool may be able to assist a human identify and display the usage of higher-level abstractions within a code base. But traditionally, such tools are rare and often unreliable. One problem is that abstractions can overlap. So we (or the tools) not only need to identify and classify abstractions but also identify the clustering and organization of abstractions. Sometimes this results in multiple views that can provide totally different conceptions of the operation of the code we are looking at.
Software designers/architects often use informal diagrams to capture their conceptualization of the structure and interactions of the higher-level abstractions of their designs. Such diagrams can serve as maps that help developers understand the territory of the code.
But developers are often skeptical of such diagrams. Experience (and folklore) has taught them that design diagrams likely do not accurately reflect the actual state of a code base. So, how do we familiarize ourselves with a new software code base that we wish to modify or extend? Most commonly we just try to reverse engineer its architecture/design by examining the code. We tell ourselves that the code provides the ground truth and that we or our tools can generate truthful design docs from the code because the code doesn’t lie. When humans read code we can easily miss or misinterpret the higher-level abstractions that are lurking among and above the code. It’s a real challenge to imagine a tool that can do better.
Lacking design documents or even a good sense of a system’s overall design we then often make local code changes without correctly understanding the design context within which that code operates. Such local changes may “work” to solve some immediate problem. But as they accumulate over long periods such changes erode the design integrity of the overall system. And they contribute to the invalidation of any pre-existing design documents and diagrams that may have at one point in time provided an accurate map of the system.
We definitely need better tools for integrating higher-level system architecture/design abstraction with code—or at least for integrating documentation. But don’t tell me that creating such documents are a waste of time or that any such documents should be ignored. I’ve spent too many decades trying to guess how a complex program was intended to work by trying to use the code to get into the mind of the original designers and developers. Any design documentation is useful documentation. It will probably need to be verified against the current state of the code but even when the documents are no longer the truth they often provide insights that help our understanding of the system. When I asked Rebecca Wirfs-Brock to review this little essay, she had an experience to relate:
I remember doing a code/architecture review for a company that built software to perform high reliability backups…and I was happy that the architectural documents were say 70% accurate as they gave me a good look into the mind of the architect who engineered these frameworks. And I didn’t think it worthwhile to update it to reflect truth. As it was a snapshot in time. Sometimes updating may be worthwhile, but as in archeological digs, you’ve gotta be careful about this.
Diagrams and other design documents probably won’t be up to date when somebody reads them in the future. But that’s not an excuse to not create them. If you care about the design integrity of you software system you need to provide future developers (including yourself) a map of your abstract design as you currently know it.
|
|
Daniel Stenberg: The curl web infrastructure |
The purpose of the curl web site is to inform the world about what curl and libcurl are and provide as much information as possible about the project, the products and everything related to that.
The web site has existed in some form for as long as the project has, but it has of course developed and changed over time.
The curl project is completely independent and stands free from influence from any parent or umbrella organization or company. It is not even a legal entity, just a bunch of random people cooperating over the Internet. And a bunch of awesome sponsors to help us.
This means that we have no one that provides the infrastructure or marketing for us. We need to provide, run and care for our own servers and anything else we think we should offer our users.
I still do a lot of the work in curl and the curl web site and I work full time on curl, for wolfSSL. This might of course “taint” my opinions and views on matters, but doesn’t imply ownership or control. I’m sure we’re all colored by where we work and where we are in our lives right now.
Most of the web site is static content: generated HTML pages. They are served super-fast and very lightweight by any web server software.
The web site source exists in the curl-www repository (hosted on GitHub) and the web site syncs itself with the latest repository changes several times per hour. The parts of the site that aren’t static are mostly consisting of smaller scripts that run either on demand at the time of a request or on an interval in a cronjob in the background. That is part of the reason why pushing an update to the web site’s repository can take a little while until it shows up on the live site.
There’s a deliberate effort at not duplicating information so a lot of the web pages you can find on the web site are files that are converted and “HTMLified” from the source code git repository.
Some people say the curl web site is “retro”, others that it is plain ugly. My main focus with the site is to provide and offer all the info, and have it be accurate and accessible. The look and the design of the web site is a constant battle, as nobody who’s involved in editing or polishing the web site is really interested in or particularly good at design, looks or UX. I personally have done most of the editing of it, including CSS etc and I can tell you that I’m not good at it and I don’t enjoy it. I do it because I feel I have to.
I get occasional offers to “redesign” the web site, but the general problem is that those offers almost always involve rebuilding the entire thing using some current web framework, not just fixing the looks, layout or hierarchy. By replacing everything like that we’d get a lot of problems to get the existing information in there – and again, the information is more important than the looks.
The curl logo is designed by a proper designer however (Adrian Burcea).
If you want to help out designing and improving the web site, you’d be most welcome!
I’ve already touched on it: the web site is mostly available in git so “anyone” can submit issues and pull-requests to improve it, and we are around twenty persons who have push rights that can then make a change on the live site. In reality of course we are not that many who work on the site any ordinary month, or even year. During the last twelve month period, 10 persons authored commits in the web repository and I did 90% of those.
Technically, we build the site with traditional makefiles and we generate the web contents mostly by preprocessing files using a C-like preprocessor called fcpp. This is an old and rather crude setup that we’ve used for over twenty years but it’s functional and it allows us to have a mostly static web site that is also fairly easy to build locally so that we can work out and check improvements before we push them to the git repository and then out to the world.
The web site is of course only available over HTTPS.
The curl web site is hosted on an origin VPS server in Sweden. The machine is maintained by primarily by me and is paid for by Haxx. The exact hosting is not terribly important because users don’t really interact with our server directly… (Also, as they’re not sponsors we’re just ordinary customers so I won’t mention their name here.)
A few years ago we experienced repeated server outages simply because our own infrastructure did not handle the load very well, and in particular not the traffic spikes that could occur when I would post a blog post that would suddenly reach a wide audience.
Enter Fastly. Now, when you go to curl.se (or daniel.haxx.se) you don’t actually reach the origin server we admin, you will instead reach one of Fastly’s servers that are distributed across the world. They then fetch the web contents from our origin, cache it on their edge servers and send it to you when you browse the site. This way, your client speaks to a server that is likely (much) closer to you than the origin server is and you’ll get the content faster and experience a “snappier” web site. And our server only gets a tiny fraction of the load.
Technically, this is achieved by the name curl.se resolving to a number of IP addresses that are anycasted. Right now, that’s 4 IPv4 addresses and 4 IPv6 addresses.
The fact that the CDN servers cache content “a while” is another explanation to why updated contents take a little while to “take effect” for all visitors.
When we just recently switched the site over to curl.se, we also adjusted how we handle DNS.

I run our own main DNS server where I control and admin the zone and the contents of it. We then have four secondary servers to help us really up our reliability. Out of those four secondaries, three are sponsored by Kirei and are anycasted. They should be both fast and reliable for most of the world.
With the help of fabulous friends like Fastly and Kirei, we hope that the curl web site and services shall remain stable and available.
DNS enthusiasts have remarked that we don’t do DNSSEC or registry-lock on the curl.se domain. I think we have reason to consider and possibly remedy that going forward.
The curl web site is just the home of our little open source project. Most users out there in the world who run and use curl or libcurl will not download it from us. Most curl users get their software installation from their Linux distribution or operating system provider. The git repository and all issues and pull-requests are done on GitHub.
Relevant here is that we have no logging and we run no ads or any analytics. We do this for maximum user privacy and partly because of laziness, since handling logging from the CDN system is work. Therefore, I only have aggregated statistics.
In this autumn of 2020, over a normal 30 day period, the web site serves almost 11 TB of data to 360 million HTTP requests. The traffic volume is up from 3.5 TB the same time last year. 11 terabytes per 30 days equals about 4 megabytes per second on average.
Without logs we cannot know what people are downloading – but we can guess! We know that the CA cert bundle is popular and we also know that in today’s world of containers and CI systems, a lot of things out there will download the same packages repeatedly. Otherwise the web site is mostly consisting of text and very small images.
One interesting specific pattern on the server load that’s been going on for months: every morning at 05:30 UTC, the site gets over 50,000 requests within that single minute, during which 10 gigabytes of data is downloaded. The clients are distributed world wide as I see the same pattern on access points all over. The minute before and the minute after, the average traffic rate remains at 200MB/minute. It makes for a fun graph:
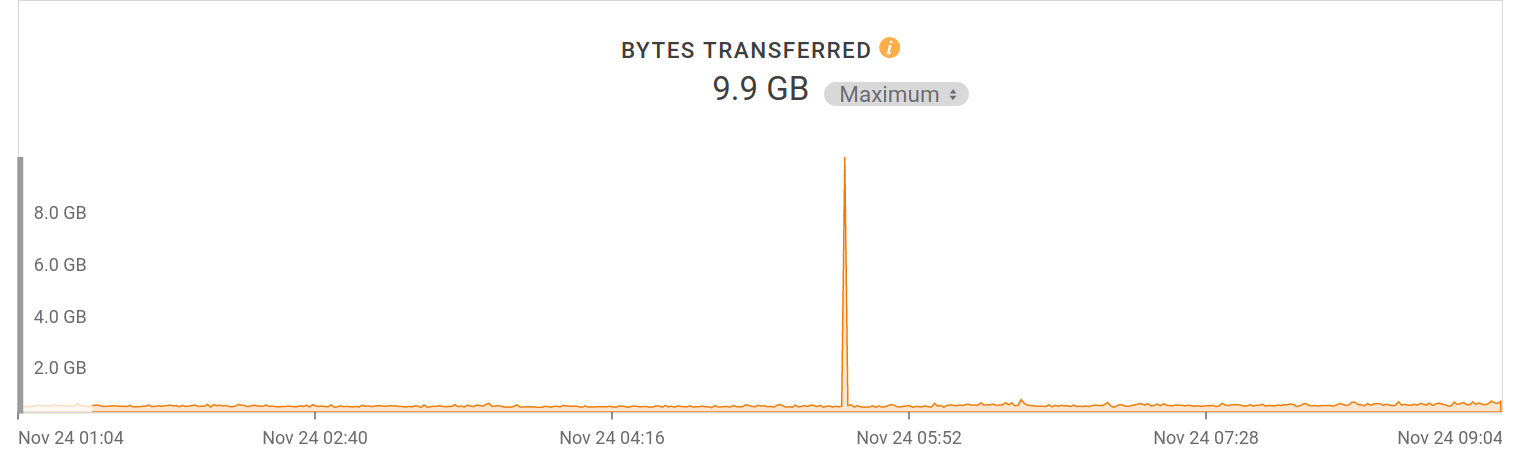
Our servers suffer somewhat from being the target of weird clients like qqgamehall that continuously “hammer” the site with requests at a high frequency many months after we started always returning error to them. An effect they have is that they make the admin dashboard to constantly show a very high error rate.
The origin server runs Debian Linux and Apache httpd. It has a reverse proxy based on nginx. The DNS server is bind. The entire web site is built with free and open source. Primarily: fcpp, make, roffit, perl, curl, hypermail and enscript.
If you curl the curl site, you can see in response headers that Fastly uses Varnish.
https://daniel.haxx.se/blog/2020/11/24/the-curl-web-infrastructure/
|
|






