Mozilla Security Blog: Preloading Intermediate CA Certificates into Firefox |
Throughout 2020, Firefox users have been seeing fewer secure connection errors while browsing the Web. We’ve been improving connection errors overall for some time, and a new feature called Intermediate Certificate Authority (CA) Preloading is our latest innovation. This technique reduces connection errors that users encounter when web servers forget to properly configure their TLS security.
In essence, Firefox pre-downloads all trusted Web Public Key Infrastructure (PKI) intermediate CA certificates into Firefox via Mozilla’s Remote Settings infrastructure. This way, Firefox users avoid seeing an error page for one of the most common server configuration problems: not specifying proper intermediate CA certificates.
For Intermediate CA Preloading to work, we need to be able to enumerate every intermediate CA certificate that is part of the trusted Web PKI. As a result of Mozilla’s leadership in the CA community, each CA in Mozilla’s Root Store Policy is required to disclose these intermediate CA certificates to the multi-browser Common CA Database (CCADB). Consequently, all of the relevant intermediate CA certificates are available via the CCADB reporting mechanisms. Given this information, we periodically synthesize a list of these intermediate CA certificates and place them into Remote Settings. Currently the list contains over two thousand entries.
When Firefox receives the list for the first time (or later receives updates to the list), it enumerates the entries in batches and downloads the corresponding intermediate CA certificates in the background. The list changes slowly, so once a copy of Firefox has completed the initial downloads, it’s easy to keep it up-to-date. The list can be examined directly using your favorite JSON tooling at this URL: https://firefox.settings.services.mozilla.com/v1/buckets/security-state/collections/intermediates/records
For details on processing the records, see the Kinto Attachment plugin for Kinto, used by Firefox Remote Settings.
Certificates provided via Intermediate CA Preloading are added to a local cache and are not imbued with trust. Trust is still derived from the standard Web PKI algorithms.
Our collected telemetry confirms that enabling Intermediate CA Preloading in Firefox 68 has led to a decrease of unknown issuers errors in the TLS Handshake.
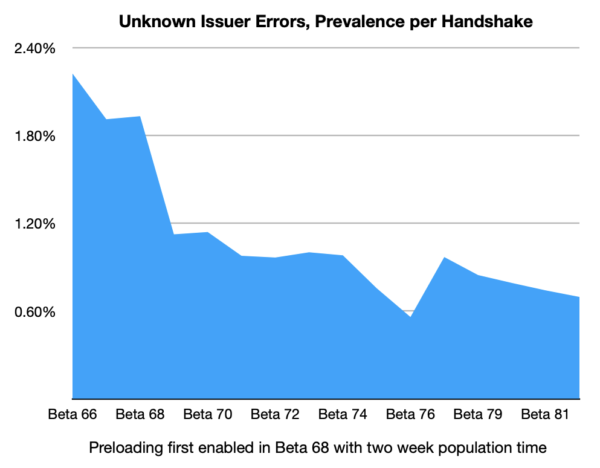
While there are other factors that affect the relative prevalence of this error, this data supports the conclusion that Intermediate CA Preloading is achieving the goal of avoiding these connection errors for Firefox users.
Intermediate CA Preloading is reducing errors today in Firefox for desktop users, and we’ll be working to roll it out to our mobile users in the future.
The post Preloading Intermediate CA Certificates into Firefox appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2020/11/13/preloading-intermediate-ca-certificates-into-firefox/
|
|
Daniel Stenberg: there is always a CURLOPT for it |

Embroidered and put on the kitchen wall, on a mug or just as words of wisdom to bring with you in life?
https://daniel.haxx.se/blog/2020/11/13/there-is-always-a-curlopt-for-it/
|
|
Hacks.Mozilla.Org: Warp: Improved JS performance in Firefox 83 |
We have enabled Warp, a significant update to SpiderMonkey, by default in Firefox 83. SpiderMonkey is the JavaScript engine used in the Firefox web browser.
With Warp (also called WarpBuilder) we’re making big changes to our JIT (just-in-time) compilers, resulting in improved responsiveness, faster page loads and better memory usage. The new architecture is also more maintainable and unlocks additional SpiderMonkey improvements.
This post explains how Warp works and how it made SpiderMonkey faster.
The first step when running JavaScript is to parse the source code into bytecode, a lower-level representation. Bytecode can be executed immediately using an interpreter or can be compiled to native code by a just-in-time (JIT) compiler. Modern JavaScript engines have multiple tiered execution engines.
JS functions may switch between tiers depending on the expected benefit of switching:
The optimizing JIT makes assumptions based on the profiling data collected by the other tiers. If these assumptions turn out to be wrong, the optimized code is discarded. When this happens the function resumes execution in the baseline tiers and has to warm-up again (this is called a bailout).
For SpiderMonkey it looks like this (simplified):
Our previous optimizing JIT, Ion, used two very different systems for gathering profiling information to guide JIT optimizations. The first is Type Inference (TI), which collects global information about the types of objects used in the JS code. The second is CacheIR, a simple linear bytecode format used by the Baseline Interpreter and the Baseline JIT as the fundamental optimization primitive. Ion mostly relied on TI, but occasionally used CacheIR information when TI data was unavailable.
With Warp, we’ve changed our optimizing JIT to rely solely on CacheIR data collected by the baseline tiers. Here’s what this looks like:
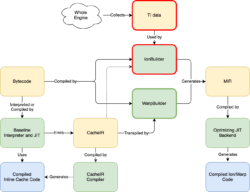
There’s a lot of information here, but the thing to note is that we’ve replaced the IonBuilder frontend (outlined in red) with the simpler WarpBuilder frontend (outlined in green). IonBuilder and WarpBuilder both produce Ion MIR, an intermediate representation used by the optimizing JIT backend.
Where IonBuilder used TI data gathered from the whole engine to generate MIR, WarpBuilder generates MIR using the same CacheIR that the Baseline Interpreter and Baseline JIT use to generate Inline Caches (ICs). As we’ll see below, the tighter integration between Warp and the lower tiers has several advantages.
Consider the following JS function:
function f(o) {
return o.x - 1;
}The Baseline Interpreter and Baseline JIT use two Inline Caches for this function: one for the property access (o.x), and one for the subtraction. That’s because we can’t optimize this function without knowing the types of o and o.x.
The IC for the property access, o.x, will be invoked with the value of o. It can then attach an IC stub (a small piece of machine code) to optimize this operation. In SpiderMonkey this works by first generating CacheIR (a simple linear bytecode format, you could think of it as an optimization recipe). For example, if o is an object and x is a simple data property, we generate this:
GuardToObject inputId 0 GuardShape objId 0, shapeOffset 0 LoadFixedSlotResult objId 0, offsetOffset 8 ReturnFromIC
Here we first guard the input (o) is an object, then we guard on the object’s shape (which determines the object’s properties and layout), and then we load the value of o.x from the object’s slots.
Note that the shape and the property’s index in the slots array are stored in a separate data section, not baked into the CacheIR or IC code itself. The CacheIR refers to the offsets of these fields with shapeOffset and offsetOffset. This allows many different IC stubs to share the same generated code, reducing compilation overhead.
The IC then compiles this CacheIR snippet to machine code. Now, the Baseline Interpreter and Baseline JIT can execute this operation quickly without calling into C++ code.
The subtraction IC works the same way. If o.x is an int32 value, the subtraction IC will be invoked with two int32 values and the IC will generate the following CacheIR to optimize that case:
GuardToInt32 inputId 0 GuardToInt32 inputId 1 Int32SubResult lhsId 0, rhsId 1 ReturnFromIC
This means we first guard the left-hand side is an int32 value, then we guard the right-hand side is an int32 value, and we can then perform the int32 subtraction and return the result from the IC stub to the function.
The CacheIR instructions capture everything we need to do to optimize an operation. We have a few hundred CacheIR instructions, defined in a YAML file. These are the building blocks for our JIT optimization pipeline.
If a JS function gets called many times, we want to compile it with the optimizing compiler. With Warp there are three steps:
The WarpOracle phase runs on the main thread and is very fast. The actual MIR building can be done on a background thread. This is an improvement over IonBuilder, where we had to do MIR building on the main thread because it relied on a lot of global data structures for Type Inference.
WarpBuilder has a transpiler to transpile CacheIR to MIR. This is a very mechanical process: for each CacheIR instruction, it just generates the corresponding MIR instruction(s).
Putting this all together we get the following picture (click for a larger version):

We’re very excited about this design: when we make changes to the CacheIR instructions, it automatically affects all of our JIT tiers (see the blue arrows in the picture above). Warp is simply weaving together the function’s bytecode and CacheIR instructions into a single MIR graph.
Our old MIR builder (IonBuilder) had a lot of complicated code that we don’t need in WarpBuilder because all the JS semantics are captured by the CacheIR data we also need for ICs.
Optimizing JavaScript JITs are able to inline JavaScript functions into the caller. With Warp we are taking this a step further: Warp is also able to specialize inlined functions based on the call site.
Consider our example function again:
function f(o) {
return o.x - 1;
}This function may be called from multiple places, each passing a different shape of object or different types for o.x. In this case, the inline caches will have polymorphic CacheIR IC stubs, even if each of the callers only passes a single type. If we inline the function in Warp, we won’t be able to optimize it as well as we want.
To solve this problem, we introduced a novel optimization called Trial Inlining. Every function has an ICScript, which stores the CacheIR and IC data for that function. Before we Warp-compile a function, we scan the Baseline ICs in that function to search for calls to inlinable functions. For each inlinable call site, we create a new ICScript for the callee function. Whenever we call the inlining candidate, instead of using the default ICScript for the callee, we pass in the new specialized ICScript. This means that the Baseline Interpreter, Baseline JIT, and Warp will now collect and use information specialized for that call site.
Trial inlining is very powerful because it works recursively. For example, consider the following JS code:
function callWithArg(fun, x) {
return fun(x);
}
function test(a) {
var b = callWithArg(x => x + 1, a);
var c = callWithArg(x => x - 1, a);
return b + c;
}
When we perform trial inlining for the test function, we will generate a specialized ICScript for each of the callWithArg calls. Later on, we attempt recursive trial inlining in those caller-specialized callWithArg functions, and we can then specialize the fun call based on the caller. This was not possible in IonBuilder.
When it’s time to Warp-compile the test function, we have the caller-specialized CacheIR data and can generate optimal code.
This means we build up the inlining graph before functions are Warp-compiled, by (recursively) specializing Baseline IC data at call sites. Warp then just inlines based on that without needing its own inlining heuristics.
IonBuilder was able to inline certain built-in functions directly. This is especially useful for things like Math.abs and Array.prototype.push, because we can implement them with a few machine instructions and that’s a lot faster than calling the function.
Because Warp is driven by CacheIR, we decided to generate optimized CacheIR for calls to these functions.
This means these built-ins are now also properly optimized with IC stubs in our Baseline Interpreter and JIT. The new design leads us to generate the right CacheIR instructions, which then benefits not just Warp but all of our JIT tiers.
For example, let’s look at a Math.pow call with two int32 arguments. We generate the following CacheIR:
LoadArgumentFixedSlot resultId 1, slotIndex 3 GuardToObject inputId 1 GuardSpecificFunction funId 1, expectedOffset 0, nargsAndFlagsOffset 8 LoadArgumentFixedSlot resultId 2, slotIndex 1 LoadArgumentFixedSlot resultId 3, slotIndex 0 GuardToInt32 inputId 2 GuardToInt32 inputId 3 Int32PowResult lhsId 2, rhsId 3 ReturnFromIC
First, we guard that the callee is the built-in pow function. Then we load the two arguments and guard they are int32 values. Then we perform the pow operation specialized for two int32 arguments and return the result of that from the IC stub.
Furthermore, the Int32PowResult CacheIR instruction is also used to optimize the JS exponentiation operator, x ** y. For that operator we might generate:
GuardToInt32 inputId 0 GuardToInt32 inputId 1 Int32PowResult lhsId 0, rhsId 1 ReturnFromIC
When we added Warp transpiler support for Int32PowResult, Warp was able to optimize both the exponentiation operator and Math.pow without additional changes. This is a nice example of CacheIR providing building blocks that can be used for optimizing different operations.
Warp is faster than Ion on many workloads. The picture below shows a couple examples: we had a 20% improvement on Google Docs load time, and we are about 10-12% faster on the Speedometer benchmark:

We’ve seen similar page load and responsiveness improvements on other JS-intensive websites such as Reddit and Netflix. Feedback from Nightly users has been positive as well.
The improvements are largely because basing Warp on CacheIR lets us remove the code throughout the engine that was required to track the global type inference data used by IonBuilder, resulting in speedups across the engine.
The old system required all functions to track type information that was only useful in very hot functions. With Warp, the profiling information (CacheIR) used to optimize Warp is also used to speed up code running in the Baseline Interpreter and Baseline JIT.
Warp is also able to do more work off-thread and requires fewer recompilations (the previous design often overspecialized, resulting in many bailouts).
Warp is currently slower than Ion on certain synthetic JS benchmarks such as Octane and Kraken. This isn’t too surprising because Warp has to compete with almost a decade of optimization work and tuning for those benchmarks specifically.
We believe these benchmarks are not representative of modern JS code (see also the V8 team’s blog post on this) and the regressions are outweighed by the large speedups and other improvements elsewhere.
That said, we will continue to optimize Warp the coming months and we expect to see improvements on all of these workloads going forward.
Removing the global type inference data also means we use less memory. For example the picture below shows JS code in Firefox uses 8% less memory when loading a number of websites (tp6):
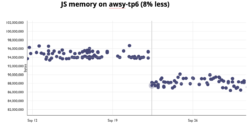
We expect this number to improve the coming months as we remove the old code and are able to simplify more data structures.
The type inference data also added a lot of overhead to garbage collection. We noticed some big improvements in our telemetry data for GC sweeping (one of the phases of our GC) when we enabled Warp by default in Firefox Nightly on September 23:

Because WarpBuilder is a lot more mechanical than IonBuilder, we’ve found the code to be much simpler, more compact, more maintainable and less error-prone. By using CacheIR everywhere, we can add new optimizations with much less code. This makes it easier for the team to improve performance and implement new features.
With Warp we have replaced the frontend (the MIR building phase) of the IonMonkey JIT. The next step is removing the old code and architecture. This will likely happen in Firefox 85. We expect additional performance and memory usage improvements from that.
We will also continue to incrementally simplify and optimize the backend of the IonMonkey JIT. We believe there’s still a lot of room for improvement for JS-intensive workloads.
Finally, because all of our JITs are now based on CacheIR data, we are working on a tool to let us (and web developers) explore the CacheIR data for a JS function. We hope this will help developers understand JS performance better.
Most of the work on Warp was done by Caroline Cullen, Iain Ireland, Jan de Mooij, and our amazing contributors Andr'e Bargull and Tom Schuster. The rest of the SpiderMonkey team provided us with a lot of feedback and ideas. Christian Holler and Gary Kwong reported various fuzz bugs.
Thanks to Ted Campbell, Caroline Cullen, Steven DeTar, Matthew Gaudet, Melissa Thermidor, and especially Iain Ireland for their great feedback and suggestions for this post.
The post Warp: Improved JS performance in Firefox 83 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/11/warp-improved-js-performance-in-firefox-83/
|
|
Mozilla Performance Blog: Using the Mach Perftest Notebook |
Using the Mach Perftest Notebook
In my previous blog post, I discussed an ETL (Extract-Transform-Load) implementation for doing local data analysis within Mozilla in a standardized way. That work provided us with a straightforward way of consuming data from various sources and standardizing it to conform to the expected structure for pre-built analysis scripts.
Today, not only are we using this ETL (called PerftestETL) locally, but also in our CI system! There, we have a tool called Perfherder which ingests data created by our tests in CI so that we can build up visualizations and dashboards like Are We Fast Yet (AWFY). The big benefit that this new ETL system provides here is that it greatly simplifies the path to getting from raw data to a Perfherder-formatted datum. This lets developers ignore the data pre-processing stage which isn’t important to them. All of this is currently available in our new performance testing framework MozPerftest.
One thing that I omitted from the last blog post is how we use this tool locally for analyzing our data. We had two students from Bishop’s University (:axew, and :yue) work on this tool for course credits during the 2020 Winter semester. Over the summer, they continued hacking with us on this project and finalized the work needed to do local analyses using this tool through MozPerftest.
Below you can see a recording of how this all works together when you run tests locally for comparisons.
There is no audio in the video so here’s a short summary of what’s happening:
With these pre-built analyses, we can help developers who are tracking metrics for a product over time, or simply checking how their changes affected performance without having to build their own scripts. This ensures that we have an organization-wide standardized approach for analyzing and viewing data locally. Otherwise, developers each start making their own report which (1) wastes their time, and more importantly, (2) requires consumers of these reports to familiarize themselves with the format.
That said, the real beauty in the MozPerftest integration is that we’ve decoupled the ETL from the notebook-specific code. This lets us expand the notebooks that we can open data in so we could add the capability for using R-Studio, Google Data Studio, or Jupyter Notebook in the future.
If you have any questions, feel free to reach out to us on Riot in #perftest.
https://blog.mozilla.org/performance/2020/11/12/using-the-mach-perftest-notebook/
|
|
Mozilla Performance Blog: Performance Sheriff Newsletter (October 2020) |
|
|
Benjamin Bouvier: Botzilla, a multi-purpose Matrix bot tuned for Mozilla |
|
|
Firefox UX: We’re Changing Our Name to Content Design |
Co-authored with Betsy Mikel

Photo by Brando Makes Branding on Unsplash
Hello. We’re the Firefox Content Design team. We’ve actually met before, but our name then was the Firefox Content Strategy team.
Why did we change our name to Content Design, you ask? Well, for a few (good) reasons.
We are designers, and our material is content. Content can be words, but it can be other things, too, like layout, hierarchy, iconography, and illustration. Words are one of the foundational elements in our design toolkit — similar to color or typography for visual designers — but it’s not always written words, and words aren’t created in a vacuum. Our practice is informed by research and an understanding of the holistic user journey. The type of content, and how content appears, is something we also create in close partnership with UX designers and researchers.
“Then, instead of saying ‘How shall I write this?’, you say, ‘What content will best meet this need?’ The answer might be words, but it might also be other things: pictures, diagrams, charts, links, calendars, a series of questions and answers, videos, addresses, maps […] and many more besides. When your job is to decide which of those, or which combination of several of them, meets the user’s need — that’s content design.”
— Sarah Richards defined the content design practice in her seminal work, Content Design
While content strategy accurately captures the full breadth of what we do, this descriptor is better understood by those doing content strategy work or very familiar with it. And, as we know from writing product copy, accuracy is not synonymous with clarity.
Strategy can also sound like something we create on our own and then lob over a fence. In contrast, design is understood as an immersive and collaborative practice, grounded in solving user problems and business goals together.
Content design is thus a clearer descriptor for a broader audience. When we collaborate cross-functionally (with product managers, engineers, marketing), it’s important they understand what to expect from our contributions, and how and when to engage us in the process. We often get asked: “When is the right time to bring in content? And the answer is: “The same time you’d bring in a designer.”
Content strategy is a job title often used by the much larger field of marketing content strategy or publishing. There are website content strategists, SEO content strategists, and social media content strategists, all who do different types of content-related work. Content design is a job title specific to product and user experience.
And, making this change is in keeping with where the field is going. Organizations like Slack, Netflix, Intuit, and IBM also use content design, and practice leaders Shopify and Facebook recently made the change, articulating reasons that we share and echo here.
Writing interface copy is about 10% of what we do. While we do write words that appear in the product, it’s often at the end of a thoughtful design process that we participate in or lead.
We’re still doing all the same things we did as content strategists, and we are still strategic in how we work (and shouldn’t everyone be strategic in how they work, anyway?) but we are choosing a title that better captures the unseen but equally important work we do to arrive at the words.
Job titles are tricky, especially for an emerging field like content design. The fact that titles are up for debate and actively evolving shows just how new our profession is. While there have been people creating product content experiences for a while, the field is really starting to now professionalize and expand. For example, we just got our first dedicated content design and UX writing conference this year with Button.
Content strategy can be a good umbrella term for the activities of content design and UX writing. Larger teams might choose to differentiate more, staffing specialized strategists, content designers, and UX writers. For now, content design is the best option for us, where we are, and the context and organization in which we work.
“There’s no ‘correct’ job title or description for this work. There’s not a single way you should contribute to your teams or help others understand what you do.”
— Metts & Welfle, Writing is Designing
We’re documenting our name change publicly because, as our fellow content designers know, words matter. They reflect but also shape reality.
We feel a bit self-conscious about this declaration, and maybe that’s because we are the newest guests at the UX party — so new that we are still writing, and rewriting, our name tag. So, hi, it’s nice to see you (again). We’re happy to be here.
Thank you to Michelle Heubusch, Gemma Petrie, and Katie Caldwell for reviewing this post.
https://blog.mozilla.org/ux/2020/11/were-changing-our-name-to-content-design/
|
|
Mike Hommey: Announcing git-cinnabar 0.5.6 |
Git-cinnabar is a git remote helper to interact with mercurial repositories. It allows to clone, pull and push from/to mercurial remote repositories, using git.
These release notes are also available on the git-cinnabar wiki.
git cinnabar git2hg and git cinnabar hg2git now have a --batch flag.git cinnabar download.|
|
Karl Dubost: Career Opportunities mean a lot of things |
When being asked
I believe there are good career opportunities for me at Company X
what do you understand? Some people will associate this directly to climbing the hierarchy ladder of the company. I have the feeling the reality is a lot more diverse. "career opportunities" mean different things to different people.
So I asked around me (friends, family, colleague) what was their take about it, outside of going higher in the hierarchy.
change of titles (role recognition).
This doesn't necessary imply climbing the hierarchy ladder, it can just mean you are recognized for a certain expertise.
change of salary/work status (money/time).
Sometimes, people don't want to change their status but want a better compensation, or a better working schedule (aka working 4 days a week with the same salary).
change of responsibilities (practical work being done in the team)
Some will see this as a possibility to learn new tricks, to diversify the work they do on a daily basis.
change of team (working on different things inside the company)
Working on a different team because you think they do something super interesting there is appealing.
being mentored (inside your own company)
It's a bit similar to the two previous one, but there's a framework inside the company where you are not helping and/or bringing your skills to the project, but you go partially in another team to learn the work of this team. Think about it as a kind of internal internship.
change of region/country
Working in a different country or region in the same country when it's your own choice. This flexibility is a gem for me. I did it a couple of times. When working at W3C, I moved from the office on the French Riviera to working from home in Montreal (Canada). And a bit later, I moved from Montreal to the W3C office in Japan. At Mozilla too, (after moving back to Montreal for a couple of years), I moved from Montreal to Japan again. There are career opportunities because they allow you to work in a different setting with different people and communities, and this in itself makes the life a lot richer.
Having dedicated/planned time for Conference or Courses
Being able to follow a class on a topic which helps the individual to grow is super useful. But for this to be successful, it has to be understood that it requires time. Time to follow the courses, time to do the homework of the course.
I'm pretty sure there are other possibilities. Thanks to everyone who shared their thoughts.
Otsukare!
|
|
Firefox UX: How to Write Microcopy That Improves the User Experience |

Photo by Amador Loureiro on Unsplash.
The small bits of copy you see sprinkled throughout apps and websites are called microcopy. As content designers, we think deeply about what each word communicates.
Microcopy is the tidiest of UI copy types. But do not let its crisp, contained presentation fool you: the process to get to those final, perfect words can be messy. Very messy. Multiple drafts messy, mired with business and technical constraints.
Here’s a secret about good writing that no one ever tells you: When you encounter clear UX content, it’s a result of editing and revision. The person who wrote those words likely had a dozen or more versions you’ll never see. They also probably had some business or technical constraints to consider, too.
If you’ve ever wondered what all goes into writing microcopy, pour yourself a micro-cup of espresso or a micro-brew and read on!

Blaise Pascal, translated from Lettres Provinciales
As a content designer, you should try to consider as many cases as possible up front. Work with Design and Engineering to test the limits of the container you’re writing for. What will copy look like when it’s really short? What will it look like when it’s really long? You might be surprised what you discover.
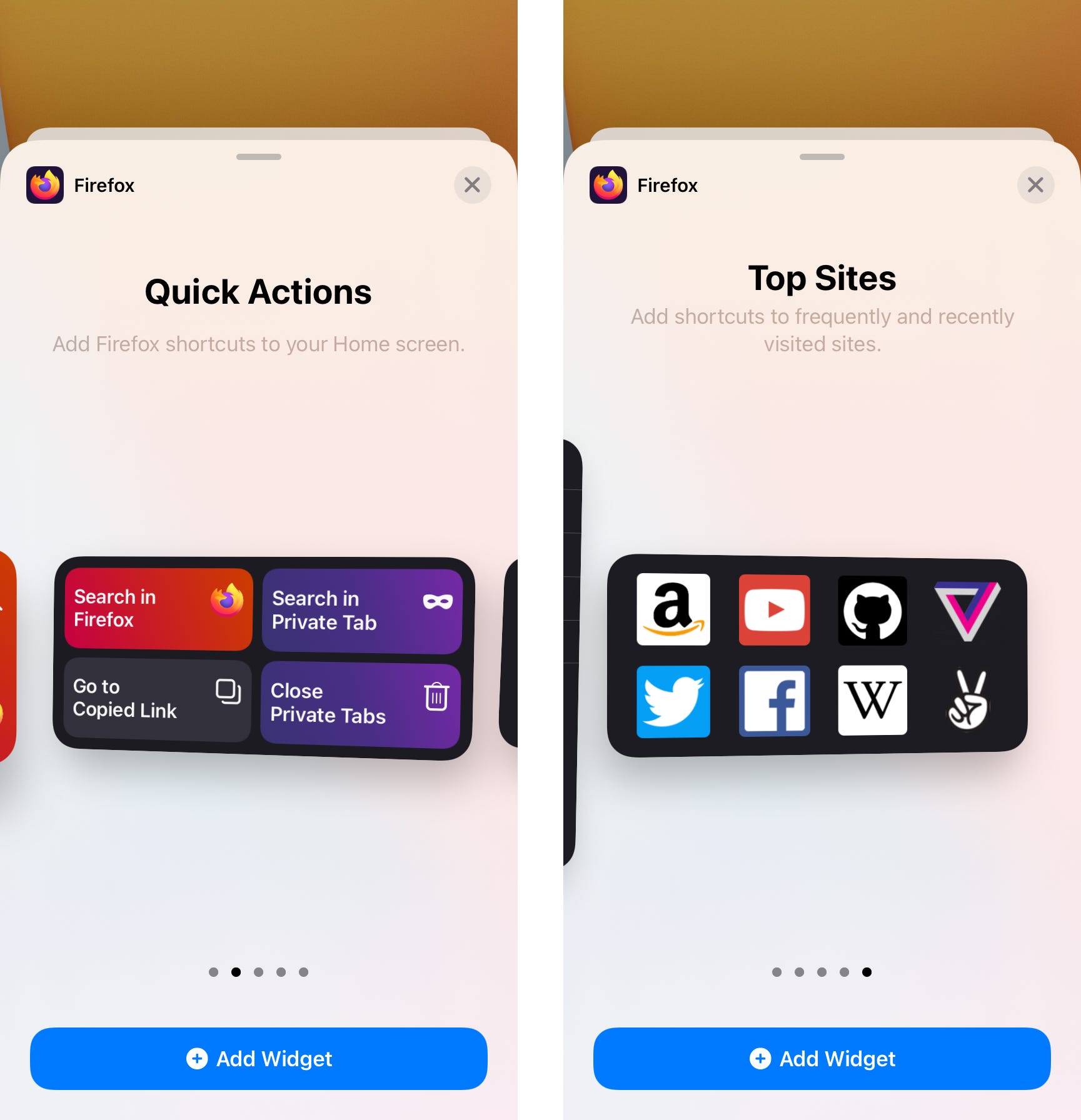
Before writing the microcopy for iOS widgets, I needed first to understand the component and how it worked.
Apple recently introduced a new component to the iOS ecosystem. You can now add widgets the Home Screen on your iPhone, iPad, or iPod touch. The Firefox widgets allow you to start a search, close your tabs, or open one of your top sites.
Before I sat down to write a single word of microcopy, I would need to know the following:
Because these widgets didn’t yet exist in the wild for me to interact with, I asked Engineering to help answer my questions. Engineering played with variations of character length in a testing environment to see how the UI might change.
Engineering tried variations of copy length in a testing environment. This helped us understand surprising behavior in the template itself.
We learned the template behaved in a peculiar way. The widget would shrink to accommodate a longer description. Then, the template would essentially lock to that size. Even if other widgets had shorter descriptions, the widgets themselves would appear teeny. You had to strain your eyes to read any text on the widget itself. Long story short, the descriptions needed to be as concise as possible. This would accommodate for localization and keep the widgets from shrinking.
First learning how the widgets behaved was a crucial step to writing effective microcopy. Build relationships with cross-functional peers so you can ask those questions and understand the limitations of the component you need to write for.

Mark Twain, The Wit and Wisdom of Mark Twain
Now that I understood my constraints, I was ready to start typing. I typically work through several versions in a Google Doc, wearing out my delete key as I keep reworking until I get it ‘right.’
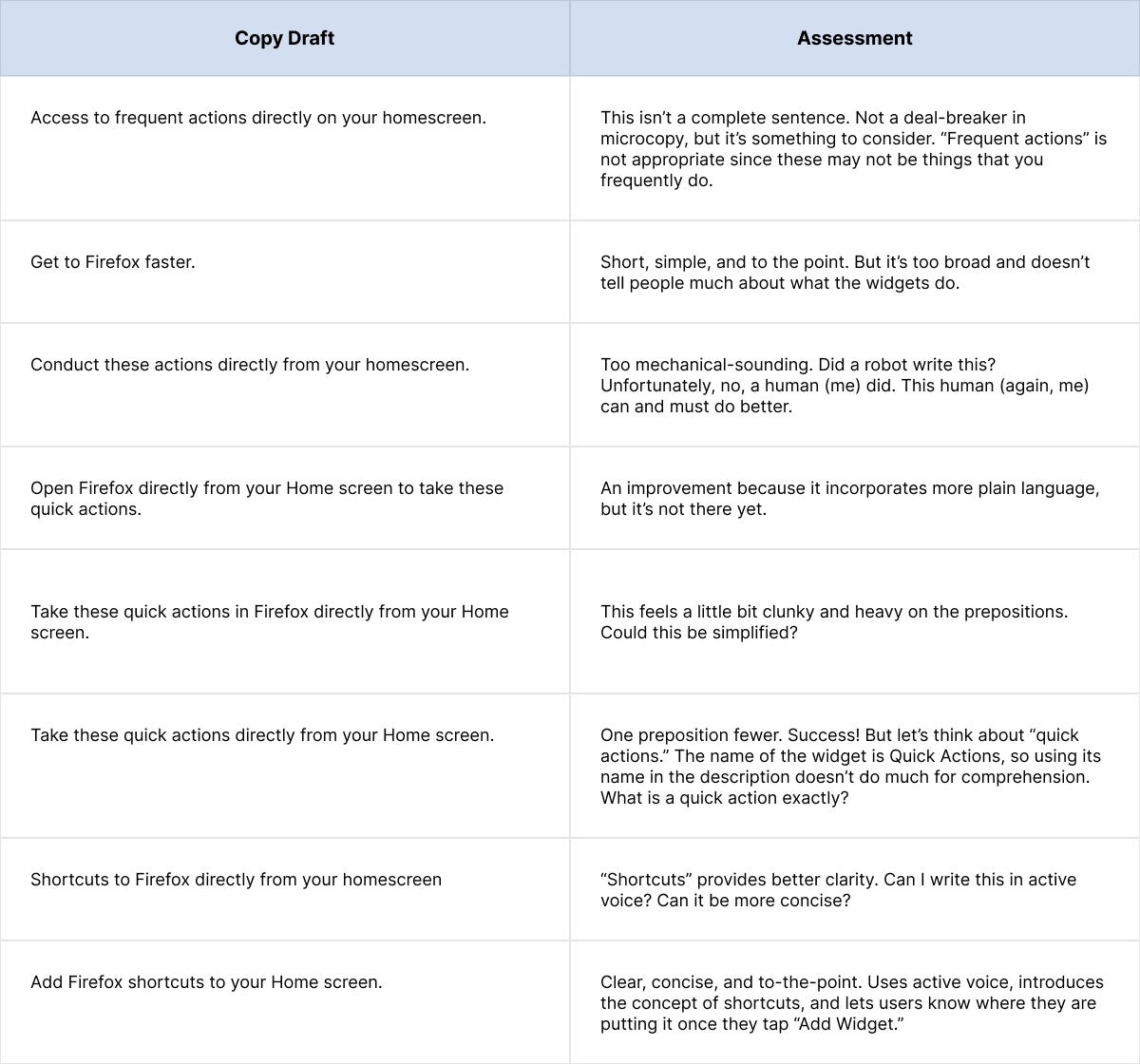
I wrote several iterations of the description for this widget to maximize the limited space and make the microcopy as useful as possible.
Microcopy strives to provide maximum clarity in a limited amount of space. Every word counts and has to work hard. It’s worth the effort to analyze each word and ask yourself if it’s serving you as well as it could. Consider tense, voice, and other words on the screen.
Before delivering final strings to Engineering, it’s always a good practice to get a second set of eyes from a fellow team member (this could be a content designer, UX designer, or researcher). Someone less familiar with the problem space can help spot confusing language or superfluous words.
In many cases, our team also runs copy by our localization team to understand if the language might be too US-centric. Sometimes we will add a note for our localizers to explain the context and intent of the message. We also do a legal review with in-house product counsel. These extra checks give us better confidence in the microcopy we ultimately ship.
Magical microcopy doesn’t shoot from our fingertips as we type (though we wish it did)! If we have any trade secrets to share, it’s only that first we seek to understand our constraints, then we revise, tweak, and rethink our words many times over. Ideally we bring in a partner to help us further refine and help us catch blind spots. This is why writing short can take time.
If you’re tasked with writing microcopy, first learn as much as you can about the component you are writing for, particularly its constraints. When you finally sit down to write, don’t worry about getting it right the first time. Get your thoughts on paper, reflect on what you can improve, then repeat. You’ll get crisper and cleaner with each draft.
Thank you to my editors Meridel Walkington and Sharon Bautista for your excellent notes and suggestions on this post. Thanks to Emanuela Damiani for the Figma help.
This post was originally published on Medium.
https://blog.mozilla.org/ux/2020/11/how-to-write-microcopy-that-improves-the-user-experience/
|
|
This Week In Rust: This Week in Rust 364 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's crate is postfix-macros, a clever hack to allow postfix macros in stable Rust.
Thanks to Willi Kappler for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
333 pull requests were merged in the last week
@std::io functions constPoll::is_ready and is_pending as consthint::spin_loopCell::get_mutStreamExt::cycleTryStreamExt::try_bufferedA mixed week with improvements still outweighing regressions. Perhaps the biggest highlight was the move to compiling rustc crates with the initial-exec TLS model which results in fewer calls to _tls_get_addr and thus faster compile times.
See the full report for more.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
No RFCs are currently in the final comment period.
bool to OptionIf you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
There are no bad programmers, only insufficiently advanced compilers
Thanks to Nixon Enraght-Moony for the suggestion.
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2020/11/11/this-week-in-rust-364/
|
|
William Lachance: iodide retrospective |
A bit belatedly, I thought I’d write a short retrospective on Iodide: an effort to create a compelling, client-centred scientific notebook environment.
Despite not writing a ton about it (the sole exception being this brief essay about my conservative choice for the server backend) Iodide took up a very large chunk of my mental energy from late 2018 through 2019. It was also essentially my only attempt at working on something that was on its way to being an actual product while at Mozilla: while I’ve led other projects that have been interesting and/or impactful in my 9 odd-years here (mozregression and perfherder being the biggest successes), they fall firmly into the “internal tools supporting another product” category.
At this point it’s probably safe to say that the project has wound down: no one is being paid to work on Iodide and it’s essentially in extreme maintenance mode. Before it’s put to bed altogether, I’d like to write a few notes about its approach, where I think it had big advantanges, and where it seems to fall short. I’ll conclude with some areas I’d like to explore (or would like to see others explore!). I’d like to emphasize that this is my opinion only: the rest of the Iodide core team no doubt have their own thoughts. That said, let’s jump in.
One thing that’s interesting about a product like Iodide is that people tend to project their hopes and dreams onto it: if you asked any given member of the Iodide team to give a 200 word description of the project, you’d probably get a slightly different answer emphasizing different things. That said, a fair initial approximation of the project vision would be “a scientific notebook like Jupyter, but running in the browser”.
What does this mean? First, let’s talk about what Jupyter does: at heart, it’s basically a Python “kernel” (read: interpreter), fronted by a webserver. You send snipits of the code to the interpreter via a web interface and they would faithfully be run on the backend (either on your local machine in a separate process or a server in the cloud). Results are then be returned back to the web interface and then rendered by the browser in one form or another.
Iodide’s model is quite similar, with one difference: instead of running the kernel in another process or somewhere in the cloud, all the heavy lifting happens in the browser itself, using the local JavaScript and/or WebAssembly runtime. The very first version of the product that Hamilton Ulmer and Brendan Colloran came up with was definitely in this category: it had no server-side component whatsoever.
Truth be told, even applications like Jupyter do a fair amount of computation on the client side to render a user interface and the results of computations: the distinction is not as clear cut as you might think. But in general I think the premise holds: if you load an iodide notebook today (still possible on alpha.iodide.io! no account required), the only thing that comes from the server is a little bit of static JavaScript and a flat file delivered as a JSON payload. All the “magic” of whatever computation you might come up with happens on the client.
Let’s take a quick look at the default tryit iodide notebook to give an idea of what I mean:
%% fetch
// load a js library and a csv file with a fetch cell
js: https://cdnjs.cloudflare.com/ajax/libs/d3/4.10.2/d3.js
text: csvDataString = https://data.sfgov.org/api/views/5cei-gny5/rows.csv?accessType=DOWNLOAD
%% js
// parse the data using the d3 library (and show the value in the console)
parsedData = d3.csvParse(csvDataString)
%% js
// replace the text in the report element "htmlInMd"
document.getElementById('htmlInMd').innerText = parsedData[0].Address
%% py
# use python to select some of the data
from js import parsedData
[x['Address'] for x in parsedData if x['Lead Remediation'] == 'true']The %% delimiters indicate individual cells. The fetch cell is an iodide-native cell with its own logic to load the specified resources into a JavaScript variables when evaluated. js and py cells direct the browser to interpret the code inside of them, which causes the DOM to mutate. From these building blocks (and a few others), you can build up an interactive report which can also be freely forked and edited by anyone who cares to.
In some ways, I think Iodide has more in common with services like Glitch or Codepen than with Jupyter. In effect, it’s mostly offering a way to build up a static web page (doing whatever) using web technologies— even if the user interface affordances and cell-based computation model might remind you more of a scientific notebook.
There’s a few nifty things that come from doing things this way:
I continue to be surprised and impressed with what people come up with in the Jupyter ecosystem so I don’t want to claim these are things that “only Iodide” (or other tools like it) can do— what I will say is that I haven’t seen many things that combine both the conciseness and expressiveness of iomd. The beauty of the web is that there is such an abundance of tutorials and resources to support creating interactive content: when building iodide notebooks, I would freely borrow from resources such as MDN and Stackoverflow, instead of being locked into what the authoring software thinks one should be able express.
Every silver lining has a cloud and (unfortunately) Iodide has a pretty big one. Depending on how you use Iodide, you will almost certainly run into the following problems:
The first, I (and most people?) can usually live with. Computers are quite powerful these days and most data tasks I’m interested in are easily within the range of capabilities of my laptop. In the cases where I need to do something larger scale, I’m quite happy to fire up a Jupyter Notebook, BigQuery Console, or
The second is much harder to deal with, since it means that the process of exploration that is so key to scientific computing. I’m quite happy to wait 5 seconds, 15 seconds, even a minute for a longer-running computation to complete but if I see the slow script dialog and everything about my environment grinds to a halt, it not only blocks my work but causes me to lose faith in the system. How do I know if it’s even going to finish?
This occurs way more often than you might think: even a simple notebook loading pandas (via pyodide) can cause Firefox to pop up the slow script dialog:

Why is this so? Aren’t browsers complex beasts which can do a million things in parallel these days? Only sort of: while the graphical and network portions of loading and using a web site are highly parallel, JavaScript and any changes to the DOM can only occur synchronously by default. Let’s break down a simple iodide example which trivially hangs the browser:
%% js
while (1) { true }link (but you really don’t want to)
What’s going on here? When you execute that cell, the web site’s sole thread is now devoted to running that infinite loop. No longer can any other JavaScript-based event handler be run, so for example the text editor (which uses Monaco under the hood) and menus are now completely unresponsive.
The iodide team was aware of this issue since I joined the project. There were no end of discussions about how to work around it, but they never really come to a satisfying conclusion. The most obvious solution is to move the cell’s computation to a web worker, but workers don’t have synchronous access to the DOM which is required for web content to work as you’d expect. While there are projects like ComLink that attempt to bridge this divide, they require both a fair amount of skill and code to use effectively. As mentioned above, one of the key differentiators between iodide and other notebook environments is that tools like jQuery, d3, etc. “just work”. That is, you can take a code snipit off the web and run it inside an iodide notebook: there’s no workaround I’ve been able to find which maintains that behaviour and ensures that the Iodide notebook environment is always responsive.
It took a while for this to really hit home, but having some separation from the project, I’ve come to realize that the problem is that the underlying technology isn’t designed for the task we were asking of it, nor is it likely to ever be in the near future. While the web (by which I mean not only the browser, but the ecosystem of popular tooling and libraries that has been built on top of it) has certainly grown in scope to things it was never envisioned to handle like games and office applications, it’s just not optimized for what I’d call “editable content”. That is, the situation where a web page offers affordances for manipulating its own representation.
While modern web browsers have evolved to (sort of) protect one errant site from bringing the whole thing down, they certainly haven’t evolved to protect a particular site against itself. And why would they? Web developers usually work in the terminal and text editor: the assumption is that if their test code misbehaves, they’ll just kill their tab and start all over again. Application state is persisted either on-disk or inside an external database, so nothing will really be lost.
Could this ever change? Possibly, but I think it would be a radical rethinking of what the web is, and I’m not really sure what would motivate it.
While working on iodide, we were fond of looking at this diagram, which was taken from this study of the data science workflow:

It describes how people typically perform computational inquiry: typically you would poke around with some raw data, run some transformations on it. Only after that process was complete would you start trying to build up a “presentation” of your results to your audience.
Looking back, it’s clear that Iodide’s strong suit was the explanation part of this workflow, rather than collaboration and exploration. My strong suspicion is that we actually want to use different tools for each one of these tasks. Coincidentally, this also maps to the bulk of my experience working with data at Mozilla, using iodide or not: my most successful front-end data visualization projects were typically the distilled result of a very large number of adhoc explorations (python scripts, SQL queries, Jupyter notebooks, …). The actual visualization itself contains very little computational meat: basically “just enough” to let the user engage with the data fruitfully.
Unfortunately much of my work in this area uses semi-sensitive internal Mozilla data so can’t be publicly shared, but here’s one example:

I built this dashboard in a single day to track our progress (resolved/open bugs) when we were migrating our data platform from AWS to GCP. It was useful: it let us quickly visualize which areas needed more attention and gave upper management more confidence that we were moving closer to our goal. However, there was little computation going on in the client: most of the backend work was happening in our Bugzilla instance: the iodide notebook just does a little bit of post-processing to visualize the results in a useful way.
Along these lines, I still think there is a place in the world for an interactive visualization environment built on principles similar to iodide: basically a markdown editor augmented with primitives oriented around data exploration (for example, charts and data tables), with allowances to bring in any JavaScript library you might want. However, any in-depth data processing would be assumed to have mostly been run elsewhere, in advance. The editing environment could either be the browser or a code editor running on your local machine, per user preference: in either case, there would not be any really important computational state running in the browser, so things like dynamic reloading (or just closing an errant tab) should not cause the user to lose any work.
This would give you the best of both worlds: you could easily create compelling visualizations that are easy to share and remix at minimal cost (because all the work happens in the browser), but you could also use whatever existing tools work best for your initial data exploration (whether that be JavaScript or the more traditional Python data science stack). And because the new tool has a reduced scope, I think building such an environment would be a much more tractable project for an individual or small group to pursue.
More on this in the future, I hope.
Many thanks to Teon Brooks and Devin Bayly for reviewing an early draft of this post
https://wlach.github.io/blog/2020/11/iodide-retrospective/?utm_source=Mozilla&utm_medium=RSS
|
|
Mozilla Attack & Defense: Firefox for Android: LAN-Based Intent Triggering |
This blog post is a guest blog post. We invite participants of our bug bounty program to write about bugs they’ve reported to us.
In its inception, Firefox for Desktop has been using one single process for all browsing tabs. Since Firefox Quantum, released in 2017, Firefox has been able to spin off multiple “content processes”. This revised architecture allowed for advances in security and performance due to sandboxing and parallelism. Unfortunately, Firefox for Android (code-named “Fennec”) could not instantly be built upon this new technology. Legacy architecture with a completely different user interface required Fennec to remain single-process. But in the fall of 2020, a Fenix rose: The latest version of Firefox for Android is supported by Android Components, a collection of independent libraries to make browsers and browser-like apps that bring latest rendering technologies to the Android ecosystem.
For this rewrite to succeed, most work on legacy Android product (“Fennec”) was paused and put into maintenance mode except for high-severity security vulnerabilities.
It was during this time, coinciding with the general availability of the new Firefox for Android, that Chris Moberly from GitLab’s Security Red Team reported the following security bug in the almost legacy browser.
Back in August, I found a nifty little bug in the Simple Service Discovery Protocol (SSDP) engine of Firefox for Android 68.11.0 and below. Basically, a malicious SSDP server could send Android Intent URIs to anyone on a local wireless network, forcing their Firefox app to launch activities without any user interaction. It was sort of like a magical ability to click links on other peoples’ phones without them knowing.
I disclosed this directly to Mozilla as part of their bug bounty program – you can read the original submission here.
I discovered the bug around the same time Mozilla was already switching over to a completely rebuilt version of Firefox that did not contain the vulnerability. The vulnerable version remained in the Google Play store only for a couple weeks after my initial private disclosure. As you can read in the Bugzilla issue linked above, the team at Mozilla did a thorough review to confirm that the vulnerability was not hiding somewhere in the new version and took steps to ensure that it would never be re-introduced.
Disclosing bugs can be a tricky process with some companies, but the Mozilla folks were an absolute pleasure to work with. I highly recommend checking out their bug bounty program and seeing what you can find!
I did a short technical write-up that is available in the exploit repository. I’ll include those technical details here too, but I’ll also take this opportunity to talk a bit more candidly about how I came across this particular bug and what I did when I found it.
I’m lucky enough to be paid to hack things at GitLab, but after a long hard day of hacking for work I like to kick back and unwind by… hacking other things! I’d recently come to the devastating conclusion that a bug I had been chasing for the past two years either didn’t exist or was simply beyond my reach, at least for now. I’d learned a lot along the way, but it was time to focus on something new.
A friend of mine had been doing some cool things with Android, and it sparked my interest. I ordered a paperback copy of “The Android Hacker’s Handbook” and started reading. When learning new things, I often order the big fat physical book and read it in chunks away from my computer screen. Everyone learns differently of course, but there is something about this method that helps break the routine for me.
Anyway, I’m reading through this book and taking notes on areas that I might want to explore. I spend a lot of time hacking in Linux, and Android is basically Linux with an abstraction layer. I’m hoping I can find something familiar and then tweak some of my old techniques to work in the mobile world.
I get to Chapter 2, where it introduces the concept of Android “Intents” and describes them as follows:
“These are message objects that contain information about an operation to be performed… Nearly all common actions – such as tapping a link in a mail message to launch the browser, notifying the messaging app that an SMS has arrived, and installing and removing applications – involve Intents being passed around the system.”
This really piqued my interest, as I’ve spent quite a lot of time looking into how applications pass messages to each other under Linux using things like Unix domain sockets and D-Bus. This sounded similar. I put the book down for a bit and did some more research online.
The Android developer documentation provides a great overview on Intents. Basically, developers can expose application functionality via an Intent. Then they create something called an “Intent filter” which is the application’s way of telling Android what types of message objects it is willing to receive.
For example, an application could offer to send an SMS to one of your contacts. Instead of including all of the code required actually to send an SMS, it could craft an Intent that included things like the recipient phone number and a message body and then send it off to the default messaging application to handle the tricky bits.
Something I found very interesting is that while Intents are often built in code via a complex function, they can also be expressed as URIs, or links. In the case of our text message example above, the Intent URI to send an SMS could look something like this:
sms://8675309?body=”hey%20there!”
In fact, if you click on that link while reading this on an Android phone, it should pop open your default SMS application with the phone number and message filled in. You just triggered an Intent.
It was at this point that I had my “Hmmm, I wonder what would happen if I…” moment. I don’t know how it is for everyone else, but that phrase pretty much sums up hacking for me.
You see, I’ve had a bit of success in forcing desktop applications to visit URIs and have used this in the past to find exploitable bugs in targets like Plex, Vuze, and even Microsoft Windows.
These previous bugs abused functionality in something called Simple Service Discovery Protocol (SSDP), which is used to advertise and discover services on a local network. In SSDP, an initiator will send a broadcast out over the local network asking for details on any available services, like a second-screen device or a networked speaker. Any system can respond back with details on the location of an XML file that describes their particular service. Then, the initiator will automatically go to that location to parse the XML to better understand the service offering.
And guess what that XML file location looks like…
… That’s right, a URI!
In my previous research on SSDP vulnerabilities, I had spent a lot of time running Wireshark on my home network. One of the things I had noticed was that my Android phone would send out SSDP discovery messages when using the Firefox mobile application. I tried attacking it with all of the techniques I could think of at that time, but I never observed any odd behavior.
But that was before I knew about Intents!
So, what would happen if we created a malicious SSDP server that advertised a service’s location as an Android Intent URI? Let’s find out!
First, let’s take a look at what I observed over the network prior to putting this all together. While running Wireshark on my laptop, I noticed repeated UDP packets originating from my Android phone when running Firefox. They were being sent to port 1900 of the UDP multicast address 239.255.255.250. This meant that any device on the local network could see these packets and respond if they chose to.
The packets looked like this:
M-SEARCH * HTTP/1.1HOST: 239.255.255.250:1900MAN: "ssdp:discover"MX: 2ST: roku:ecp
This is Firefox asking if there are any Roku devices on the network. It would actually ask for other device types as well, but the device type itself isn’t really relevant for this bug.
It looks like an HTTP request, right? It is… sort of. SSDP uses two forms of HTTP over UDP:
If we had a Roku on the network, it would immediately respond with a UDP uni-cast packet that looks something like this:
HTTP/1.1 200 OK CACHE-CONTROL: max-age=1800 DATE: Tue, 16 Oct 2018 20:17:12 GMT EXT: LOCATION: http://192.168.1.100/device-desc.xml OPT: "http://schemas.upnp.org/upnp/1/0/"; ns=01 01-NLS: uuid:7f7cc7e1-b631-86f0-ebb2-3f4504b58f5c SERVER: UPnP/1.0 ST: roku:ecp USN: uuid:7f7cc7e1-b631-86f0-ebb2-3f4504b58f5c::roku:ecp BOOTID.UPNP.ORG: 0 CONFIGID.UPNP.ORG: 1
Then, Firefox would query that URI in the LOCATION header (http://192.168.1.100/device-desc.xml), expecting to find an XML document that told it all about the Roku and how to interact with it.
This is where the experimenting started. What if, instead of http://192.168.1.100/device-desc.xml, I responded back with an Android Intent URI?
I grabbed my old SSDP research tool evil-ssdp, made some quick modifications, and replied with a packet like this:
HTTP/1.1 200 OK CACHE-CONTROL: max-age=1800 DATE: Tue, 16 Oct 2018 20:17:12 GMT EXT: LOCATION: tel://666 OPT: "http://schemas.upnp.org/upnp/1/0/"; ns=01 01-NLS: uuid:7f7cc7e1-b631-86f0-ebb2-3f4504b58f5c SERVER: UPnP/1.0 ST: upnp:rootdevice USN: uuid:7f7cc7e1-b631-86f0-ebb2-3f4504b58f5c::roku:ecp BOOTID.UPNP.ORG: 0 CONFIGID.UPNP.ORG: 1
Notice in the LOCATION header above we are now using the URI tel://666, which uses the URI scheme for Android’s default Phone Intent.
Guess what happened? The dialer on the Android device magically popped open, all on its own, with absolutely no interaction on the mobile device itself. It worked!

I was pretty excited at this point, but I needed to do some sanity checks and make sure that this could be reproduced reliably.
I toyed around with a couple different Android devices I had, including the official emulator. The behavior was consistent. Any device on the network running Firefox would repeatedly trigger whatever Intent I sent via the LOCATION header as long as the PoC script was running.
This was great, but for a good PoC we need to show some real impact. Popping the dialer may look like a big scary Remote Code Execution bug, but in this case it wasn’t. I needed to do better.
The first step was to write an exploit that was specifically designed for this bug and that provided the flexibility to dynamically provide an Intent at runtime. You can take a look at what I ended up with in this Python script.
The TL;DR of the exploit code is that it will listen on the network for SSDP “discovery” messages and respond back to them pretending to be exactly the type of device they are looking for. Instead of providing a link to an XML in the LOCATION header, I would pass in a user supplied argument, which can be an Android Intent. There’s some specifics here that matter and have to be formatted exactly right in order for the initiator to trust them. Luckily, I’d spent some quality time reading the IETF specs to figure that out in the past.
The next step was to find an Intent that would be meaningful in a demonstration of web browser exploitation. Targeting the browser itself seemed like a likely candidate. However, the developer docs were not very helpful here – the URI scheme to open a web browser is defined as http or https. However, the native SSDP code in Firefox mobile would handle those URLs on its own and not pass them off to the Intent system.
A bit of searching around and I learned that there was another way to build an Intent URI while specifying the actual app you would like to send it to. Here’s an example of an Intent URI to specifically launch Firefox and browse to example.com:
intent://example.com/#Intent;scheme=http;package=org.mozilla.firefox;endIf you’d like to try out the exploit yourself, you can grab an older version of Firefox for Android here.
To start, simply join an Android device running a vulnerable version of Firefox to a wireless network and make sure Firefox is running.
Then, on a device that is joined to the same wireless network, run the following command:
# Replace "wlan0" with the wireless device on your attacking machine. python3 ./ffssdp.py wlan0 -t "intent://example.com/#Intent;scheme=http;package=org.mozilla.firefox;end"
All Android devices on the network running Firefox will automatically browse to example.com.
If you’d like to see an example of using the exploit to launch another application, you can try something like the following, which will open the mail client with a pre-filled message:
# Replace "wlan0" with the wireless device on your attacking machine. python3 ./ffssdp.py wlps0 -t "mailto:itpeeps@work.com?subject=I've%20been%20hacked&body=OH%20NOES!!!"
These of course are harmless examples to demonstrate the exploit. A bad actor could send a victim to a malicious website, or directly to the location of a malicious browser extension and repeatedly prompt the user to install it.
It is possible that a higher impact exploit could be developed by looking deeper into the Intents offered inside Firefox or to target known-vulnerable Intents in other applications.
When disclosing vulnerabilities, I often feel a sense of urgency once I’ve found something new. I want to get it reported as quickly as possible, but I also try to make sure I’ve built a PoC that is meaningful enough to be taken seriously. I’m sure I don’t always get this balance right, but in this case I felt like I had enough to provide a solid report to Mozilla.
I worked out a public disclosure date with Mozilla, waited until that day, and then uploaded the exploit code with a short technical write-up and posted a link on Twitter.
To be perfectly honest, I thought the story would end there. I assumed I would get a few thumbs-up emojis from friends and it would then quickly fade away. Or worse, someone would call me out as a fraud and point out that I was completely wrong about the entire thing.
But, guess what? It caught on a bit. Apparently people are really into web browser bugs AND mobile bugs. I think probably it resonates as it is so close to home, affecting that little brick that we all carry in our pockets and share every intimate detail of our life with.
I have a Google “search alert” for my name, and it started pinging me a couple times a day with mentions in online tech articles all around the world, and I even heard from some old friends who came across my name in their news feeds. Pretty cool!
While I’ll be the first to admit that this isn’t some super-sophisticated, earth-shattering discovery, it did garner me a small bit of positive attention and in my line of work that’s pretty handy. I think this is one of the major benefits of disclosing bugs in open-source software to organizations that care – the experience is transparent and can be shared with the world.
Another POC video created by @LukasStefanko
This was the first significant discovery I’ve made both in a mobile application and in a web browser, and I certainly wouldn’t consider myself an expert in either. But here I am, writing a guest blog with Mozilla. Who’d have thought? I guess the lesson here is to try new things. Try old things in new ways. Try normal things in weird things. Basically, just try things.
Hacking, for me at least, is more of an exploration than a well-planned journey. I often chase after random things that look interesting, trying to understand exactly what is happening and why it is happening that way. Sometimes it pays off right away, but more often than not it’s an iterative process that provides benefits at unexpected times. This bug was a great example, where my past experience with SSDP came back to pay dividends with my new research into Android.
Also, read books! And while the book I mention above just happens to be about hacking, I honestly find just as much (maybe more) inspiration consuming information about how to design and build systems. Things are much easier to take apart if you understand how they are put together.
Finally, don’t avoid looking for bugs in major applications just because you may not be the globally renowned expert in that particular area. If I did that, I would never find any at all. The bugs are there, you just have to have curiosity and persistence.
If you read this far, thanks! I realize I went off on some personal tangents, but hopefully the experience will resonate with other hackers on their own explorations.
With that, back to you Freddy.
As one of the oldest Bug Bounty Programs out there, we really enjoy and encourage direct participation on Bugzilla. The direct communication with our developers and security engineers help you gain insight into browser development and allows us to gain new perspectives.
Furthermore, we will continue to have guest blog posts for interesting bugs here. If you want to learn more about our security internals, follow us on Twitter @attackndefense or subscribe to our RSS feed.
Finally, thanks to Chris for reporting this interesting bug!
|
|
Eric Shepherd: Amazon Wins Sheppy |
Following my departure from the MDN documentation team at Mozilla, I’ve joined the team at Amazon Web Services, documenting the AWS SDKs. Which specific SDKs I’ll be covering are still being finalized; we have some in mind but are determining who will prioritize which still, so I’ll hold off on being more specific.
Instead of going into details on my role on the AWS docs team, I thought I’d write a new post that provides a more in-depth introduction to myself than the little mini-bios strewn throughout my onboarding forms. Not that I know if anyone is interested, but just in case they are…
Now a bit about me. I was born in the Los Angeles area, but my family moved around a lot when I was a kid due to my dad’s work. By the time I left home for college at age 18, we had lived in California twice (where I began high school), Texas twice, Colorado twice, and Louisiana once (where I graduated high school). We also lived overseas once, near Pekanbaru, Riau Province on the island of Sumatra in Indonesia. It was a fun and wonderful place to live. Even though we lived in a company town called Rumbai, and were thus partially isolated from the local community, we still lived in a truly different place from the United States, and it was a great experience I cherish.
My wife, Sarah, and I have a teenage daughter, Sophie, who’s smarter than both of us combined. When she was in preschool and kindergarten, we started talking about science in pretty detailed ways. I would give her information and she would draw conclusions that were often right, thinking up things that essentially were black holes, the big bang, and so forth. It was fun and exciting to watch her little brain work. She’s in her “nothing is interesting but my 8-bit chiptunes, my game music, the games I like to play, and that’s about it” phase, and I can’t wait until she’s through that and becomes the person she will be in the long run. Nothing can bring you so much joy, pride, love, and total frustration as a teenage daughter.
I got my first taste of programming on a TI-99/4 computer bought by the Caltex American School there. We all were given a little bit of programming lesson just to get a taste of it, and I was captivated from the first day, when I got it to print a poem based on “Roses are red, violets are blue” to the screen. We were allowed to book time during recesses and before and after school to use the computer, and I took every opportunity I could to do so, learning more and more and writing tons of BASIC programs on it.
This included my masterpiece: a game called “Alligator!” in which you drove an alligator sprite around with the joystick, eating frogs that bounced around the screen while trying to avoid the dangerous bug that was chasing you. When I discovered that other kids were using their computer time to play it, I was permanently hooked.
I continued to learn and expand my skills over the years, moving on to various Apple II (and clone) computers, eventually learning 6502 and 65816 assembly, Pascal, C, dBase IV, and other languages.
During my last couple years of high school, I got a job at a computer and software store (which was creatively named “Computer and Software Store”) in Mandeville, Louisiana. In addition to doing grunt work and front-of-store sales, I also spent time doing programming for contract projects the store took on. My first was a simple customer contact management program for a real estate office. My most complex completed project was a three-store cash register system for a local chain of taverns and bars in the New Orleans area. I also built most of a custom inventory, quotation, and invoicing system for the store, though this was never finished due to my departure to start college.
The project about which I was most proud: a program for tracking information and progress of special education students and students with special needs for the St. Tammany Parish School District. This was built to run on an Apple IIe computer, and I was delighted to have the chance to build a real workplace application for my favorite platform.
I attended the University of California—Santa Barbara with a major in computer science. I went through the program and reached the point where I only needed 12 more units (three classes): one general education class under the subject area “literature originating in a foreign language” and two computer science electives. When I went to register for my final quarter, I discovered that none of the computer science classes offered that quarter were ones I could take to fulfill my requirements (I’d either already taken them or they were outside my focus area, and thus wouldn’t apply).
Thus I withdrew from school for a quarter with the plan that I would try again for the following quarter. During the interim, I became engaged to my wife and took my first gaming industry job (where they promised to allow me leave, with benefits, for the duration of my winter quarter back at school). As the winter approached, I drove up to UCSB to get a catalog and register in person. Upon arrival, I discovered that, once again, there were no computer science offerings that would fulfill my requirements.
At that point, I was due to marry in a few months (during the spring quarter), my job was getting more complicated due to the size and scope of the projects I was being assigned, and the meaningfulness of the degree was decreasing as I gained real work experience.
Thus, to this day, I remain just shy of my computer science degree. I have regrets at times, but never so much so that it makes sense to go back. Especially given the changed requirements and the amount of extra stuff I’d probably have to take. My experience at work now well outweighs the benefits of the degree.
Time to drop that other shoe. I have at least one, and possibly two, chronic medical conditions that complicate everything I do. If there are two such conditions, they’re similar enough that I generally treat them as one when communicating with non-doctors, so that’s what I’ll do here.
I was born with tibiae (lower leg bones) that were twisted outward abnormally. This led to me walking with feet that were pointed outward at about a 45° angle from normal. This, along with other less substantial issues with the structure of my legs, was always somewhat painful, especially when doing things which really required my feet to point forward, such as walking on a narrow beam, skating, or trying to water ski.
Over time, this pain became more constant, and began to change. I noticed numbness and tingling in my feet and ankles, along with sometimes mind-crippling levels of pain. In addition, I developed severe pain in my neck, shoulders, and both arms. Over time, I began to have spasms, in which it felt like I was being blasted by an electric shock, causing my arms or legs to jerk wildly. At times, I would find myself uncontrollably lifting my mouse off the desk and slamming it down, or even throwing it to the floor, due to these spasms.
Basically, my nervous system has run amok. Due, we think, to a lifetime of strain and pressure caused by my skeletal structure issues, the nerves have been worn and become permanently damaged in various places. This can’t be reversed, and the pain I feel every moment of every day will never go away.
I engage in various kinds of therapy, both physical and medicinal, and the pain is kept within the range of “ignorable” much of the time. But sometimes it spikes out of that range and becomes impossible to ignore, leading to me not being able to focus clearly on what I’m doing. Plus there are times when it becomes so intense, all I can do is curl up and ride it out. This can’t be changed, and I’ve accepted that. We do our best to manage it and I’m grateful to have access to the medical care I have.
This means, of course, that I have times during which I am less attentive than I would like to be, or have to take breaks to ride out pain spikes. On less frequent occasions, I have to write a day off entirely when I simply can’t shake the pain at all. I have to keep warm, too, since cold (even a mild chill or a slight cooling breeze) can trigger the pain to spike abruptly.
But I’ve worked out systems and skills that let me continue to do my work despite all this. The schedule can be odd, and I have to pause my work for a while a few times a week, but I get the job done.
I wrote a longer and more in-depth post about my condition and how it feels a few years ago, if you want to know more.
My very favorite thing to do in my free time is to write code for my good old Apple II computers. Or, barring that, to work on the Apple IIgs emulator for the Mac that I’m the current developer for. I dabble in Mac and iOS code and have done a few small projects for my own use. However, due to my medical condition, I don’t get to spend as much time doing that as I can.
With the rest of my free time, I love to watch movies and read books. So very, very many books. My favorite genres are science fiction and certain types of mysteries and crime thrillers, though I dabble in other areas as well. I probably read, on average, four to six novels per week.
I also love to play various types of video games. I have an Xbox One, but I don’t play on it much (I got it mostly to watch 4K Blu-Ray discs on it), though I do have a few titles for it. I’ve played and enjoyed the Diablo games as well as StarCraft, and have been captivated by many of the versions of Civilization over the years (especially the original and Civ II). I also, of course, play several mobile games.
My primary gaming focus has been World of Warcraft for years. I was a member of a fairly large guild for a few years, then joined a guild that split off from it, but that guild basically fell apart. Only a scant handful of us are left, and none of us really feel like hunting for another guild, and since we enjoy chatting while we play, we do fine. It’d be interesting, though, to find coworkers that play and spend some time with them.
I began my career as a software engineer for a small game development shop in Southern California. My work primarily revolved around porting games from other platforms to the Mac, though I did also do small amounts of Windows development at times. I ported a fair number of titles to Mac, most of which most people probably don’t remember—if they ever heard of them at all—but some of them were actually pretty good games. I led development of a Mac/Windows game for kids which only barely shipped due to changing business conditions with the publisher, and by then I was pretty much fed up with the stress of working in the games industry.
Over the years, I’ve picked or at least used up a number of languages, including C++ (though I’ve not written any in years now), JavaScript, Python, Perl, and others. I love trying out new languages, and have left out a lot of the ones I experimented with and abandoned over the years.
By that point, I was really intrigued by the Be Operating System, and started trying to get a job there. The only opening I wasn’t painfully under-qualified for was a technical writing position. It occurred to me that I’ve always written well (according to teachers and professors, at least), so I applied and eventually secured a junior writer job on the BeOS documentation team.
Within seven months, I was a senior technical writer and was deeply involved in writing the Be Developers Guide (more commonly known as the Be Book) and Be Advanced Topics (which are still the only two published books which contain anything I’ve written). Due to the timing of my arrival, very little for my work is in the Be Book, but broad sections of Be Advanced Topics were written by me.
Unfortunately, for various reasons, BeOS wasn’t able to secure a large enough chunk of the market to succeed, and our decline led to our acquisition by Palm, the manufacturers of the Palm series of handhelds. We were merged into the various teams there, with myself joining the writing team for Palm OS documentation.
Within just a handful of weeks, the software team, including those of us documenting the operating system, was spun off into a new company, PalmSource. There, I worked on documentation updates for Palm OS 5, as well as updated and brand-new documentation for Palm OS 6 and 6.1.
My most memorable work was done on the rewrites and updates of the Low-Level Communications Guide and the High-Level Communications Guide, as well as on various documents for licensees’ use only. I also wrote the Binder Guide for Palm OS 6, and various other things. It was fascinating work, though ultimately and tragically doomed due to the missteps with the Palm OS 6 launch and the arrival of the iPhone three years after my departure from PalmSource.
Unfortunately, neither the Palm OS 6 update and its follow up, version 6.1, saw significant use during my tenure due to the vast changes in the platform that were made in order to modernize the operating system for future devices. The OS was also sluggish in Palm OS 6, though 6.1 was quite peppy and really very nice. But the writing was on the wall there and, though I survived three or four rounds of layoffs, eventually I was cut loose.
After PalmSource let me go, I returned briefly to the games industry, finalizing the ports of a couple of games to the Mac for Reflexive Entertainment (now part of Amazon): Ricochet Lost Worlds and Big Kahuna Reef. I departed Reflexive shortly after completing those projects, deciding I wanted to return to technical writing, or at least something not in the game industry.
That’s why my friend Dave Miller, who was at the time on the Bugzilla team as well as working in IT for Mozilla, recommended me for a Mac programming job at Mozilla. When I arrived for my in-person interviews, I discovered that they had noticed my experience as a writer and had shunted me over to interview for a writing job instead. After a very long day of interviews and a great deal of phone and email tag, I was offered a job as a writer on the Mozilla Developer Center team.
And there I stayed for 14 years, through the changes in documentation platform (from MediaWiki to DekiWiki to our home-built Kuma platform), the rebrandings (to Mozilla Developer Network, then to simply MDN, then MDN Web Docs), and the growth of our team over time. I began as the sole full-time writer, and by our peak as a team we had five or six writers. The MDN team was fantastic to work with, and the work had enormous meaning. We became over time the de-facto official documentation site for web developers.
My work spanned a broad range of topics from basics of HTML and CSS to the depths of WebRTC, WebSockets, and other, more arcane topics. I loved doing the work, with the deep dives into the source code of the major browsers to ensure I understood how things work and why and reading the specifications for new APIs.
Knowing that my work was not only used by millions of developers around the world, but was being used by teachers, professors, and students, as well as others who just wanted to learn, was incredibly satisfying. I loved doing it and I’m sure I’ll always miss it.
But between the usual business pressures and the great pandemic of 2020, I found myself laid off by Mozilla in mid-2020. That leads me to my arrival at Amazon a few weeks later, where I started on October 26.
So here we are! I’m still onboarding, but soon enough, I’ll be getting down to work, making sure my parts of the AWS documentation are as good as they can possibly be. Looking forward to it!
|
|
Daniel Stenberg: a US visa in 937 days |
Here’s the complete timeline of events. From my first denial to travel to the US until I eventually received a tourist visa. And then I can’t go anyway.
I spent a week on Hawaii with Mozilla – my employer at the time. This was my 12th visit to the US over a period of 19 years. I went there on ESTA, the visa waiver program Swedish citizens can use. I’ve used it many times, there was nothing special this time. The typical procedure with ESTA is that we apply online: fill in a form, pay a 14 USD fee and get a confirmation within a few days that we’re good to go.

In the early morning one day by the check-in counter at Arlanda airport in Sweden, I was refused to board my flight. Completely unexpected and out of the blue! I thought I was going to San Francisco via London with British Airways, but instead I had to turn around and go back home – slightly shocked. According to the lady behind the counter there was “something wrong with my ESTA”. I used the same ESTA and passport as I used just fine back in December 2016. They’re made to last two years and it had not expired.
People engaged by Mozilla to help us out could not figure out or get answers about what the problem was (questions and investigations were attempted both in the US and in Sweden), so we put our hopes on that it was a human mistake somewhere and decided to just try again next time.
I missed the following meeting (in December 2017) for other reasons but in the summer of 2018 another Mozilla all-hands meeting was coming up (in Texas, USA this time) so I went ahead and applied for a new ESTA in good time before the event – as I was a bit afraid there was going to be problems. I was right and I got denied ESTA very quickly. “Travel Not Authorized”.

Gaaah. It meant it was no mistake last year, they actually mean this. I switched approach and instead applied for a tourist visa. I paid 160 USD, filled in a ridiculous amount of information about me and my past travels over the last 15 years and I visited the US embassy for an in-person interview and fingerprinting.
This is day 0 in the visa process, 296 days after I was first stopped at Arlanda.
I missed the all-hands meeting in San Francisco when I didn’t get the visa in time.
I quit Mozilla, so I then had no more reasons to go to their company all-hands…
A year passed. “someone is working on it” the embassy email person claimed when I asked about progress.
I emailed the embassy to query about the process

The reply came back quickly:
Dear Sir,
All applications are processed in the most expeditious manner possible. While we understand your frustration, we are required to follow immigration law regarding visa issuances. This process cannot be expedited or circumvented. Rest assured that we will contact you as soon as the administrative processing is concluded.
Another year had passed and I had given up all hope. Now it turned into a betting game and science project. How long can they actually drag out this process without saying either yes or no?
A friend of mine, a US citizen, contacted his Congressman – Gerry Connolly – about my situation and asked for help. His office then subsequently sent a question to the US embassy in Stockholm asking about my case. While the response that arrived on September 17 was rather negative…
your case is currently undergoing necessary administrative processing and regrettably it is not possible to predict when this processing will be completed.
… I think the following turn of events indicates it had an effect. It unclogged something.
After 889 days since my interview on the embassy (only five days after the answer to the congressman), the embassy contacted me over email. For the first time since that April day in 2018.
Your visa application is still in administrative processing. However, we regret to inform you that because you have missed your travel plans, we will require updated travel plans from you.
My travel plans – that had been out of date for the last 800 days or so – suddenly needed to be updated! As I was already so long into this process and since I feared that giving up now would force me back to square one if I would stop now and re-attempt this again at a later time, I decided to arrange myself some updated travel plans. After all, I work for an American company and I have a friend or two there.
I replied to the call for travel plan details with an official invitation letter attached, inviting me to go visit my colleagues at wolfSSL signed by our CEO, Larry. I really want to do this at some point, as I’ve never met most of them so it wasn’t a made up reason. I could possibly even get some other friends to invite me to get the process going but I figured this invite should be enough to keep the ball rolling.
I got another email. Now at 910 days since the interview. The embassy asked for my passport “for further processing”.
I posted my passport to the US embassy in Stockholm. I also ordered and paid for “return postage” as instructed so that they would ship it back to me in a safe way.
At 10:30 in the morning my phone lit up and showed me a text telling me that there’s an incoming parcel being delivered to me, shipped from “the Embassy of the United State” (bonus points for the typo).

I received my passport. Inside, there’s a US visa that is valid for ten years, until November 2030.

As a bonus, the visa also comes with a NIE (National Interest
Exception) that allows me a single entry to the US during the PP (Presidential Proclamations) – which is restricting travels to the US from the European Schengen zone. In other words: I am actually allowed to travel right away!
The timing is fascinating. The last time I was in the US, Trump hadn’t taken office yet and I get the approved visa in my hands just days after Biden has been announced as the next president of the US.
Covid-19 is still over us and there’s no end in sight of the pandemic. I will of course not travel to the US or any other country until it can be deemed safe and sensible.
When the pandemic is under control and traveling becomes viable, I am sure there will be opportunities. Hopefully the situation will improve before the visa expires.
All my family and friends, in the US and elsewhere who have supported me and cheered me up through this entire process. Thanks for keeping inviting me to fun things in the US even though I’ve not been able to participate. Thanks for pushing for events to get organized outside of the US! I’m sorry I’ve missed social gatherings, a friend’s marriage and several conference speaking opportunities. Thanks for all the moral support throughout this long journey of madness.
A special thanks go to David (you know who you are) for contacting Gerry Connolly’s office. I honestly think this was the key event that finally made things move in this process.
https://daniel.haxx.se/blog/2020/11/09/a-us-visa-in-937-days/
|
|
Wladimir Palant: Adding DKIM support to OpenSMTPD with custom filters |
If you, like me, are running your own mail server, you might have looked at OpenSMTPD. There are very compelling reasons for that, most important being the configuration simplicity. The following is a working base configuration handling both mail delivery on port 25 as well as mail submissions on port 587:
pki default cert "/etc/mail/default.pem"
pki default key "/etc/mail/default.key"
table local_domains {"example.com", "example.org"}
listen on eth0 tls pki default
listen on eth0 port 587 tls-require pki default auth
action "local" maildir
action "outbound" relay
match from any for domain action "local"
match for local action "local"
match auth from any for any action "outbound"
match from local for any action "outbound"You might want to add virtual user lists, aliases, SRS support, but it really doesn’t get much more complicated than this. The best practices are all there: no authentication over unencrypted connections, no relaying of mails by unauthorized parties, all of that being very obvious in the configuration. Compare that to Postfix configuration with its multitude of complicated configuration files where I was very much afraid of making a configuration mistake and inadvertently turning my mail server into an open relay.
There is no DKIM support out of the box however, you have to add filters for that. The documentation suggests using opensmtpd-filter-dkimsign that most platforms don’t have prebuilt packages for. So you have to get the source code from some Dutch web server, presumably run by the OpenBSD developer Martijn van Duren. And what you get is a very simplistic DKIM signer, not even capable of supporting multiple domains.
The documentation suggests opensmtpd-filter-rspamd as an alternative which can indeed both sign and verify DKIM signatures. It relies on rspamd however, an anti-spam solution introducing a fair deal of complexity and clearly overdimensioned in my case.
So I went for writing custom filters. With dkimpy implementing all the necessary functionality in Python, how hard could it be?
You can see the complete code along with installation instructions here. It consists of two filters: dkimsign.py should be applied to outgoing mail and will add a DKIM signature, dkimverify.py should be applied to incoming mail and will add an Authentication-Results header indicating whether DKIM and SPF checks were successful. SPF checks are optional and will only be performed if the pyspf module is installed. Both filters rely on the opensmtpd.py module providing a generic filter server implementation.
I have no time to maintain this code beyond what I need myself. This means in particular that I will not test it with any OpenSMTPD versions but the one I run myself (currently 6.6.4). So while it should work with OpenSMTPD 6.7.1, I haven’t actually tested it. Anybody willing to maintain this code is welcome to do so, and I will happily link to their repository.
The DKIM mechanism allows recipients to verify that the email was really sent from the domain listed in the From field, thus helping combat spam and phishing mails. The goals are similar to Sender Policy Framework (SPF), and it’s indeed recommended to use both mechanisms. A positive side-effect: implementing these mechanisms should reduce the likelihood of mails from your server being falsely categorized as spam.
DKIM stands for DomainKeys Identified Mail and relies on public-key cryptography. The domain owner generates a signing key and stores its public part in a special DNS entry for the domain. The private part of the key is then used to sign the body and a subset of headers for each email. The resulting signature is added as DKIM-Signature: header to the email before it is sent out. The receiving mail server can look up the DNS entry and validate the signature.
The protocol used by OpenSMTPD to communicate with its filters is described in the smtpd-filters(7) man page. It is text-based and fairly straightforward: report events and filter requests come in on stdin, filter responses go out on stdout.
So my FilterServer class will read the initial messages from stdin (OpenSMTPD configuration) when it is created. Then the register_handler() method should be called any number of times, which sends out a registration request for a report event or a filter request. And the serve_forever() method will tell OpenSMTD that the filter is ready, read anything coming in on stdin and call the previously registered handlers.
So far very simple, if it weren’t for a tiny complication: when I tried this initially, mail delivery would hang up. Eventually I realized that OpenSMTD didn’t recognize the filter’s response, so it kept waiting for one. Debugging output wasn’t helpful, so it took me a while to figure this one out. A filter response is supposed to contain a session identifier and some opaque token for OpenSMTPD to match it to the correct request. According to documentation, session identifier goes first, but guess what: my slightly older OpenSMTPD version expects the token to go first.
The documentation doesn’t bother mentioning things that used to be different in previous versions of the protocol, a practice that OpenSMTPD developers will hopefully reconsider. And OpenSMTPD doesn’t bother logging filter responses with what it considers an unknown session identifier, as there are apparently legitimate scenarios where a session is removed before the corresponding filter response comes in.
This isn’t the only case where OpenSMTPD flipped parameter order recently. The parameters of the tx-mail report event are listed as message-id result address, yet the order was message-id address result in previous versions apparently. Sadly, not having documentation for the protocol history makes it impossible to tell whether your filter will work correctly with any OpenSMTPD version but the one you tested it with.
If one wants to look at the message body, the way to go is registering a handler for the data-line filter. This one will be called for every individual line however. So the handler would have to store previously received lines somewhere until it receives a single dot indicating the end of the message. Complication: this single dot might never come, e.g. if the other side disconnects without finishing the transfer. How does one avoid leaking memory in this case? The previously stored lines have to be removed somehow.
The answer is listening to the link-disconnect report event and clearing out any data associated with the session when it is received. And since all my handlers needed this logic, I added it to the FilterServer class implementation. Calling track_context() during registration phase will register link-connect and link-disconnect handlers, managing session context objects for all handlers. Instead of merely receiving a session identifier, the handlers will receive a context object that they can add more data to as needed.
This doesn’t change the fact that data-line filters will typically keep collecting lines until they have a complete message. So I added a register_message_filter() method to FilterServer that will encapsulate this logic. The handler registered here will always be called with a complete list of lines for the message. This method also makes sure that errors during processing won’t prevent the filter from generating a response, the message is rather properly rejected in this case.
Altogether this means that the DKIM signer now looks like this (logic slightly modified here for clarity):
def sign(context, lines):
message = email.message_from_string('\n'.join(lines))
domain = extract_sender_domain(message)
if domain in config:
signature = dkim_sign(
'\n'.join(lines).encode('utf-8'),
config[domain]['selector'],
domain,
config[domain]['keydata']
)
add_signature(message, signature)
lines = message.as_string().splitlines(False)
return lines
server = FilterServer()
server.register_message_filter(sign)
server.serve_forever()The DKIM verifier is just as simple if you omit the SPF validation logic:
def verify(context, lines):
dkim_result = 'unknown'
if 'dkim-signature' in message:
if dkim_verify('\n'.join(lines).encode('utf-8')):
dkim_result = 'pass'
else:
dkim_result = 'fail'
message = email.message_from_string('\n'.join(lines))
if 'authentication-results' in message:
del message['authentication-results']
message['Authentication-Results'] = 'localhost; dkim=' + dkim_result
return message.as_string().splitlines(False)
server = FilterServer()
server.register_message_filter(verify)
server.serve_forever()This solution isn’t meant for high-volume servers. It has at least one significant issue: all processing happens sequentially. So while DKIM/SPF checks are being performed (25 seconds for DNS requests in the worst-case scenario) no other mails will be processed. This could be solved by running message filters on a separate thread, but the added complexity simply wasn’t worth the effort for my scenario.
https://palant.info/2020/11/09/adding-dkim-support-to-opensmtpd-with-custom-filters/
|
|
Daniel Stenberg: This is how I git |
Every now and then I get questions on how to work with git in a smooth way when developing, bug-fixing or extending curl – or how I do it. After all, I work on open source full time which means I have very frequent interactions with git (and GitHub). Simply put, I work with git all day long. Ordinary days, I issue git commands several hundred times.
I have a very simple approach and way of working with git in curl. This is how it works.
I use git almost exclusively from the command line in a terminal. To help me see which branch I’m working in, I have this little bash helper script.
brname () {
a=$(git rev-parse --abbrev-ref HEAD 2>/dev/null)
if [ -n "$a" ]; then
echo " [$a]"
else
echo ""
fi
}
PS1="\u@\h:\w\$(brname)$ "
That gives me a prompt that shows username, host name, the current working directory and the current checked out git branch.
In addition: I use Debian’s bash command line completion for git which is also really handy. It allows me to use tab to complete things like git commands and branch names.
I of course also have my customized ~/.gitconfig file to provide me with some convenient aliases and settings. My most commonly used git aliases are:
st = status --short -uno
ci = commit
ca = commit --amend
caa = commit -a --amend
br = branch
co = checkout
df = diff
lg = log -p --pretty=fuller --abbrev-commit
lgg = log --pretty=fuller --abbrev-commit --stat
up = pull --rebase
latest = log @^{/RELEASE-NOTES:.synced}..
The ‘latest’ one is for listing all changes done to curl since the most recent RELEASE-NOTES “sync”. The others should hopefully be rather self-explanatory.
The config also sets gpgsign = true, enables mailmap and a few other things.
The main curl development is done in the single curl/curl git repository (primarily hosted on GitHub). We keep the master branch the bleeding edge development tree and we work hard to always keep that working and functional. We do our releases off the master branch when that day comes (every eight weeks) and we provide “daily snapshots” from that branch, put together – yeah – daily.
When merging fixes and features into master, we avoid merge commits and use rebases and fast-forward as much as possible. This makes the branch very easy to browse, understand and work with – as it is 100% linear.
When I start something new, like work on a bug or trying out someone’s patch or similar, I first create a local branch off master and work in that. That is, I don’t work directly in the master branch. Branches are easy and quick to do and there’s no reason to shy away from having loads of them!
I typically name the branch prefixed with my GitHub user name, so that when I push them to the server it is noticeable who is the creator (and I can use the same branch name locally as I do remotely).
$ git checkout -b bagder/my-new-stuff-or-bugfix
Once I’ve reached somewhere, I commit to the branch. It can then end up one or more commits before I consider myself “done for now” with what I was set out to do.
I try not to leave the tree with any uncommitted changes – like if I take off for the day or even just leave for food or an extended break. This puts the repository in a state that allows me to easily switch over to another branch when I get back – should I feel the need to. Plus, it’s better to commit and explain the change before the break rather than having to recall the details again when coming back.
“git stash” is therefore not a command I ever use. I rather create a new branch and commit the (temporary?) work in there as a potential new line of work.
Yes I am the lead developer of the project but I still maintain the same work flow as everyone else. All changes, except the most minuscule ones, are done as pull requests on GitHub.
When I’m happy with the functionality in my local branch. When the bug seems to be fixed or the feature seems to be doing what it’s supposed to do and the test suite runs fine locally.
I then clean up the commit series with “git rebase -i” (or if it is a single commit I can instead use just “git commit --amend“).
The commit series should be a set of logical changes that are related to this change and not any more than necessary, but kept separate if they are separate. Each commit also gets its own proper commit message. Unrelated changes should be split out into its own separate branch and subsequent separate pull request.
git push origin bagder/my-new-stuff-or-bugfix
On GitHub, I then make the newly pushed branch into a pull request (aka “a PR”). It will then become visible in the list of pull requests on the site for the curl source repository, it will be announced in the #curl IRC channel and everyone who follows the repository on GitHub will be notified accordingly.
Perhaps most importantly, a pull request kicks of a flood of CI jobs that will build and test the code in numerous different combinations and on several platforms, and the results of those tests will trickle in over the coming hours. When I write this, we have around 90 different CI jobs – per pull request – and something like 8 different code analyzers will scrutinize the change to see if there’s any obvious flaws in there.

Most contributors who would work on curl would not do like me and make the branch in the curl repository itself, but would rather do them in their own forked version instead. The difference isn’t that big and I could of course also do it that way.
As it will take some time to get the full CI results from the PR to come in (generally a few hours), I switch over to the next branch with work on my agenda. On a normal work-day I can easily move over ten different branches, polish them and submit updates in their respective pull-requests.
I can go back to the master branch again with ‘git checkout master‘ and there I can “git pull” to get everything from upstream – like when my fellow developers have pushed stuff in the mean time.
If a reviewer or a CI job find a mistake in one of my PRs, that becomes visible on GitHub and I get to work to handle it. To either fix the bug or discuss with the reviewer what the better approach might be.
Unfortunately, flaky CI jobs is a part of life so very often there ends up one or two red markers in the list of CI jobs that can be ignored as the test failures in them are there due to problems in the setup and not because of actual mistakes in the PR…
To get back to my branch for that PR again, I “git checkout bagder/my-new-stuff-or-bugfix“, and fix the issues.
I normally start out by doing follow-up commits that repair the immediate mistake and push them on the branch:
git push origin bagder/my-new-stuff-or-bugfix
If the number of fixup commits gets large, or if the follow-up fixes aren’t small, I usually end up doing a squash to reduce the number of commits into a smaller, simpler set, and then force-push them to the branch.
The reason for that is to make the patch series easy to review, read and understand. When a commit series has too many commits that changes the previous commits, it becomes hard to review.
When the pull request is ripe for merging (independently of who authored it), I switch over to the master branch again and I merge the pull request’s commits into it. In special cases I cherry-pick specific commits from the branch instead. When all the stuff has been yanked into master properly that should be there, I push the changes to the remote.
Usually, and especially if the pull request wasn’t done by me, I also go over the commit messages and polish them somewhat before I push everything. Commit messages should follow our style and mention not only which PR that it closes but also which issue it fixes and properly give credit to the bug reporter and all the helpers – using the right syntax so that our automatic tools can pick them up correctly!
As already mentioned above, I merge fast-forward or rebased into master. No merge commits.
There’s a button GitHub that says “rebase and merge” that could theoretically be used for merging pull requests. I never use that (and if I could, I’d disable/hide it). The reasons are simply:
The downside with not using the merge button is that the message in the PR says “closed by [hash]” instead of “merged in…” which causes confusion to a fair amount of users who don’t realize it means that it actually means the same thing! I consider this is a (long-standing) GitHub UX flaw.
If the branch has nothing to be kept around more, I delete the local branch again with “git branch -d [name]” and I remove it remotely too since it was completely merged there’s no reason to keep the work version left.
At any given point in time, I have some 20-30 different local branches alive using this approach so things I work on over time all live in their own branches and also submissions from various people that haven’t been merged into master yet exist in branches of various maturity levels. Out of those local branches, the number of concurrent pull requests I have in progress can be somewhere between just a few up to ten, twelve something.
Not strictly related, but in order to keep interested people informed about what’s happening in the tree, we sync the RELEASE-NOTES file every once in a while. Maybe every 5-7 days or so. It thus becomes a file that explains what we’ve worked on since the previous release and it makes it well-maintained and ready by the time the release day comes.
To sync it, all I need to do is:
$ ./scripts/release-notes.pl
Which makes the script add suggested updates to it, so I then load the file into my editor, remove the separation marker and all entries that don’t actually belong there (as the script adds all commits as entries as it can’t judge the importance).
When it looks okay, I run a cleanup round to make it sort it and remove unused references from the file…
$ ./scripts/release-notes.pl cleanup
Then I make sure to get a fresh list of contributors…
$ ./scripts/contributors.sh
… and paste that updated list into the RELEASE-NOTES. Finally, I get refreshed counters for the numbers at the top of the file by running
$ ./scripts/delta
Then I commit the update (which needs to have the commit message RELEASE-NOTES: synced“) and push it to master. Done!
The most up-to-date version of RELEASE-NOTES is then always made available on https://curl.se/dev/release-notes.html
Picture by me, taken from the passenger seat on a helicopter tour in 2011.
|
|
Chris H-C: Data Science is Hard: ALSA in Firefox |
(( We’re overdue for another episode in this series on how Data Science is Hard. Today is a story from 2016 which I think illustrates many important things to do with data. ))
It’s story time. Gather ’round.
In July of 2016, Anthony Jones made the case that the Mozilla-built Firefox for Linux should stop supporting the ALSA backend (and also the WinXP WinMM backend) so that we could innovate on features for more modern audio backends.
(( You don’t need to know what an audio backend is to understand this story. ))
The code supporting ALSA would remain in tree for any Linux distribution who wished to maintain the backend and build it for themselves, but Mozilla would stop shipping Firefox with that code in it.
But how could we ensure the number of Firefoxen relying on this backend was small enough that we wouldn’t be removing something our users desperately needed? Luckily :padenot had just added an audio backend measurement to Telemetry. “We’ll have data soon,” he wrote.
By the end of August we’d heard from Firefox Nightly and Firefox Developer Edition that only 3.5% and 2% (respectively) of Linux subsessions with audio used ALSA. This was small enough to for the removal to move ahead.
Fast-forward to March of 2017. Seven months have passed. The removal has wound its way through Nightly, Developer Edition, Beta, and now into the stable Release channel. Linux users following this update channel update their Firefox and… suddenly the web grows silent for a large number of users.
Bugs are filed (thirteen of them). The mailing list thread with Anthony’s original proposal is revived with some very angry language. It seems as though far more than just a fraction of a fraction of users were using ALSA. There were entire Linux distributions that didn’t ship anything besides ALSA. How did Telemetry miss them?
It turns out that many of those same ALSA-only Linux distributions also turned off Telemetry when they repackaged Firefox for their users. And for any that shipped with Telemetry at all, many users disabled it themselves. Those users’ Firefoxen had no way to phone home to tell Mozilla how important ALSA was to them… and now it was too late.
Those Linux distributions started building ALSA support into their distributed Firefox builds… and hopefully began reporting Telemetry by default to prevent this from happening again. I don’t know if they did for sure (we don’t collect fine-grained information like that because we don’t need it).
But it serves as a cautionary tale: Mozilla can only support a finite number of things. Far fewer now than we did back in 2016. We prioritize what we support based on its simplicity and its reach. That first one we can see for ourselves, and for the second we rely on data collection like Telemetry to tell us.
Counting things is harder than it looks. Counting things that are invisible is damn near impossible. So if you want to be counted: turn Telemetry on (it’s in the Preferences) and leave it on.
:chutten
https://chuttenblog.wordpress.com/2020/11/05/data-science-is-hard-alsa-in-firefox/
|
|
Cameron Kaiser: TenFourFox FPR29b1 available |
The December release may be an SPR only due to the holidays and my work schedule. More about that a little later.
http://tenfourfox.blogspot.com/2020/11/tenfourfox-fpr29b1-available.html
|
|
Daniel Stenberg: The journey to a curl domain |
Good things come to those who wait?
When I created and started hosting the first websites for curl I didn’t care about the URL or domain names used for them, but after a few years I started to think that maybe it would be cool to register a curl domain for its home. By then it was too late to find an available name under a “sensible” top-level domain and since then I’ve been on the lookout for one.
So yes, I’ve administrated every machine that has ever hosted the curl web site going all the way back to the time before we called the tool curl. I’m also doing most of the edits and polish of the web content, even though I’m crap at web stuff like CSS and design. So yeah, I consider it my job to care for the site and make sure it runs smooth and that it has a proper (domain) name.
The first ever curl web page was hosted on “www.fts.frontec.se/~dast/curl” in the late 1990s (snapshot). I worked for the company with that domain name at the time and ~dast was the location for my own personal web content.
The curl website moved to its first “own home”, with curl.haxx.nu in August 1999 (snapshot) when we registered our first domain and the .nu top-level domain was available to us when .se wasn’t.
We switched from curl.haxx.nu to curl.haxx.se in the summer of 2000 (when finally were allowed to register our name in the .se TLD) (snapshot).
The name “haxx” in the domain has been the reason for many discussions and occasional concerns from users and overzealous blocking-scripts over the years. I’ve kept the curl site on that domain since it is the name of one of the primary curl sponsors and partly because I want to teach the world that a particular word in a domain is not a marker for badness or something like that. And of course because we have not bought or been provided a better alternative.
Haxx is still the name of the company I co-founded back in 1997 so I’m also the admin of the domain.
I’ve looked for and contacted owners of curl under many different TLDs over the years but most have never responded and none has been open for giving up their domains. I’ve always had an extra attention put on curl.se because it is in the Swedish TLD, the same one we have for Haxx and where I live.
The first record on archive.org of anyone using the domain curl.se for web content is dated August 2003 when the Swedish curling team “H"arn"osands CK” used it. They used the domain and website for a few years under this name. It can be noted that it was team Anette Norberg, which subsequently won two Olympic gold medals in the sport.
In September 2007 the site was renamed, still being about the sport curling but with the name “the curling girls” in Swedish (curlingtjejerna) which remained there for just 1.5 years until it changed again. “curling team Folksam” then populated the site with contents about the sport and that team until they let the domain expire in 2012. (Out of these three different curling oriented sites, the first one is the only one that still seems to be around but now of course on another domain.)
In early August 2012 the domain was registered to a new owner. I can’t remember why, but I missed the chance to get the domain then.
August 28 2012 marks the first date when curl.se is recorded to suddenly host a bunch of links to casino, bingo and gambling sites. It seems that whoever bought the domain wanted to surf on the good name and possible incoming links built up from the previous owners. For several years this crap was what the website showed. I doubt very many users ever were charmed by the content nor clicked on many links. It was ugly and over-packed with no real content but links and ads.
The last archive.org capture of the ad-filled site was done on October 2nd 2016. Since then, there’s been no web content on the domain that I’ve found. But the domain registration kept getting renewed.
In August 2019, I noticed that the domain was about to expire, and I figured it could be a sign that the owner was not too interested in keeping it anymore. I contacted the owner via a registrar and offered to buy it. The single only response I ever got was that my monetary offer was “too low”. I tried to up my bid, but I never got any further responses from the owner and then after a while I noticed that the domain registration was again renewed for another year. I went back to waiting.
In September 2020 the domain was again up for expiration and I contacted the owner again, this time asking for a price for which they would be willing to sell the domain. Again no response, but this time the domain actually went all the way to expiry and deletion, which eventually made it available “on the market” for everyone interested to compete for the purchase.
I entered the race with the help of a registrar that would attempt to buy the name when it got released. When this happens, when a domain name is “released”, it becomes a race between all the potential buyers who want the domain. It is a 4-letter domain that is an English word and easy pronounceable. I knew there was a big risk others would also be trying to get it.
In the early morning of October 19th 2020, the curl.se domain was released and in the race of getting the purchase… I lost. Someone else got the domain before me. I was sad. For a while, until I got the good news…
It turned out my friend Bartek Tatkowski had snatched the domain! After getting all the administrative things in order, Bartek graciously donated the domain to me and 15:00 on October 30 2020 I could enter my own name servers into the dedicated inputs fields for the domain, and configure it properly in our master and secondary DNS servers.
Starting on November 4, 2020 curl.se is the new official home site for the curl project. The curl.haxx.se name will of course remain working for a long time more and I figure we can basically never shut it down as there are so many references to it spread out over the world. I intend to eventually provide redirects for most things from the old name to the new.
What about a www prefix? The jury is still out how or if we should use that or not. The initial update of the site (November 4) uses a www.curl.se host name in links but I’ve not done any automatic redirects to or from that. As the site is CDNed, and we can’t use CNAMEs on the apex domain (curl.se), we instead use anycast IPs for it – the net difference to users should be zero. (Fastly is a generous sponsor of the curl project.)
I also happen to own libcurl.se since a few years back and I’ll make sure using this name also takes you to the right place.
People repeatedly ask me. Names in the .dev domains are expensive. Registering curl.dev goes for 400 USD right now. curl.se costs 10 USD/year. I see little to no reason to participate in that business and I don’t think spending donated money on such a venture is a responsible use of our funds.
Image by truthseeker08 from Pixabay. Domain by Bartek Tatkowski.
https://daniel.haxx.se/blog/2020/11/04/the-journey-to-a-curl-domain/
|
|






