Data@Mozilla: This Week in Glean: Cross-Platform Language Binding Generation with Rust and “uniffi” |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
As the Glean SDK continues to expand its features and functionality, it has also continued to expand the number and types of consumers within the Mozilla ecosystem that rely on it for collection and transport of important metrics. On this particular adventure, I find myself once again working on one of these components that tie into the Glean ecosystem. In this case, it has been my work on the Nimbus SDK that has inspired this story.
Nimbus is our new take on a rapid experimentation platform, or a way to try out new features in our applications for subsets of the population of users in a way in which we can measure the impact. The idea is to find out what our users like and use so that we can focus our efforts on the features that matter to them. Like Glean, Nimbus is a cross-platform client SDK intended to be used on Android, iOS, and all flavors of Desktop OS that we support. Also like Glean, this presented us with all of the challenges that you would normally encounter when creating a cross-platform library. Unlike Glean, Nimbus was able to take advantage of some tooling that wasn’t available when we started Glean, namely: uniffi.
So what is uniffi? It’s a multi-language bindings generator for Rust. What exactly does that mean? Typically you would have to write something in Rust and create a hand-written Foreign Function Interface (FFI) layer also in Rust. On top of that, you also end up creating a hand-written wrapper in each and every language that is supported. Instead, uniffi does most of the work for us by generating the plumbing necessary to transport data across the FFI, including the specific language bindings, making it a little easier to write things once and a lot easier to maintain multiple supported languages. With uniffi we can write the code once in Rust, and then generate the code we need to be able to reuse these components in whatever language (currently supporting Kotlin, Swift and Python with C++ and JS coming soon) and on whatever platform we need.
So how does uniffi work? The magic of uniffi works through generating a cdylib crate from the Rust code. The interface is defined in a separate file through an Interface Description Language (IDL), specifically, a variant of WebIDL. Then, using the uniffi-bindgen tool, we can scaffold the Rust side of the FFI and build our Rust code as we normally would, producing a shared library. Back to uniffi-bindgen again to then scaffold the language bindings side of things, either Kotlin, Swift, or Python at the moment, with JS and C++ coming soon. This leaves us with platform specific libraries that we can include in applications that call through the FFI directly into the Rust code at the core of it all.
There are some limitations to what uniffi can accomplish, but for most purposes it handles the job quite well. In the case of Nimbus, it worked amazingly well because Nimbus was written keeping uniffi language binding generation in mind (and uniffi was written with Nimbus in mind). As part of playing around with uniffi, I also experimented with how we could leverage it in Glean. It looks promising for generating things like our metric types, but we still have some state in the language binding layer that probably needs to be moved into the Rust code before Glean could move to using uniffi. Cutting down on all of the handwritten code is a huge advantage because the Glean metric types require a lot of boilerplate code that is basically duplicated across all of the different languages we support. Being able to keep this down to just the Rust definitions and IDL, and then generating the language bindings would be a nice reduction in the burden of maintenance. Right now if we make a change to a metric type in Glean, we have to touch every single language binding: Rust, Kotlin, Swift, Python, C#, etc.
Looking back at Nimbus, uniffi does save a lot on overhead since we can write almost everything in Rust. We will have a little bit of functionality implemented at the language layer, namely a callback that is executed after receiving and processing the reply from the server, the threading implementation that ensures the networking is done in a background thread, and the integration with Glean (at least until the Glean Rust API is available). All of these are ultimately things that could be done in Rust as uniffi’s capabilities grow, making the language bindings basically just there to expose the API. Right now, Nimbus only has a Kotlin implementation in support of our first customer, Fenix, but when it comes time to start supporting iOS and desktop, it should be as simple as just generating the bindings for whatever language that we want (and that uniffi supports).
Having worked on cross-platform tools for the last two years now, I can really appreciate the awesome power of being able to leverage the same client SDK implementation across multiple platforms. Not only does this come as close as possible to giving you the same code driving the way something works across all platforms, it makes it a lot easier to trust that things like Glean collect data the same way across different apps and platforms and that Nimbus is performing randomization calculations the same across platforms and apps. I have worked with several cross-platform technologies in my career like Xamarin or Apache Cordova, but Rust really seems to work better for this without as much of the overhead. This is especially true with tools like uniffi to facilitate unlocking the cross-platform potential. So, in conclusion, if you are responsible for cross-platform applications or libraries or are interested in creating them, I strongly urge you to think about Rust (there’s no way I have time to go into all the cool things Rust does…) and tools like uniffi to make that easier for you. (If uniffi doesn’t support your platform/language yet, then I’m also happy to report that it is accepting contributions!)
|
|
The Mozilla Blog: Mozilla Reaction to U.S. v. Google |
Today the US Department of Justice (“DOJ”) filed an antitrust lawsuit against Google, alleging that it unlawfully maintains monopolies through anticompetitive and exclusionary practices in the search and search advertising markets. While we’re still examining the complaint our initial impressions are outlined below.
Like millions of everyday internet users, we share concerns about how Big Tech’s growing power can deter innovation and reduce consumer choice. We believe that scrutiny of these issues is healthy, and critical if we’re going to build a better internet. We also know from firsthand experience there is no overnight solution to these complex issues. Mozilla’s origins are closely tied to the last major antitrust case against Microsoft in the nineties.
In this new lawsuit, the DOJ referenced Google’s search agreement with Mozilla as one example of Google’s monopolization of the search engine market in the United States. Small and independent companies such as Mozilla thrive by innovating, disrupting and providing users with industry leading features and services in areas like search. The ultimate outcomes of an antitrust lawsuit should not cause collateral damage to the very organizations – like Mozilla – best positioned to drive competition and protect the interests of consumers on the web.
For the past 20 years, Mozilla has been leading the fight for competition, innovation and consumer choice in the browser market and beyond. We have a long track record of creating innovative products and services that respect the privacy and security of consumers, and have successfully pushed the market to follow suit.
Unintended harm to smaller innovators from enforcement actions will be detrimental to the system as a whole, without any meaningful benefit to consumers — and is not how anyone will fix Big Tech. Instead, remedies must look at the ecosystem in its entirety, and allow the flourishing of competition and choice to benefit consumers.
We’ll be sharing updates as this matter proceeds.
The post Mozilla Reaction to U.S. v. Google appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/10/20/mozilla-reaction-to-u-s-v-google/
|
|
Hacks.Mozilla.Org: Coming through with Firefox 82 |
As October ushers in the tail-end of the year, we are pushing Firefox 82 out the door. This time around we finally enable support for the Media Session API, provide some new CSS pseudo-selector behaviours, close some security loopholes involving the Window.name property, and provide inspection for server-sent events in our developer tools.
This blog post provides merely a set of highlights; for all the details, check out the following:
Server-sent events allow for an inversion of the traditional client-initiated web request model, with a server sending new data to a web page at any time by pushing messages. In this release we’ve added the ability to inspect server-sent events and their message contents using the Network Monitor.
You can go to the Network Monitor, select the file that is sending the server-sent events, and view the received messages in the Response tab on the right-hand panel.
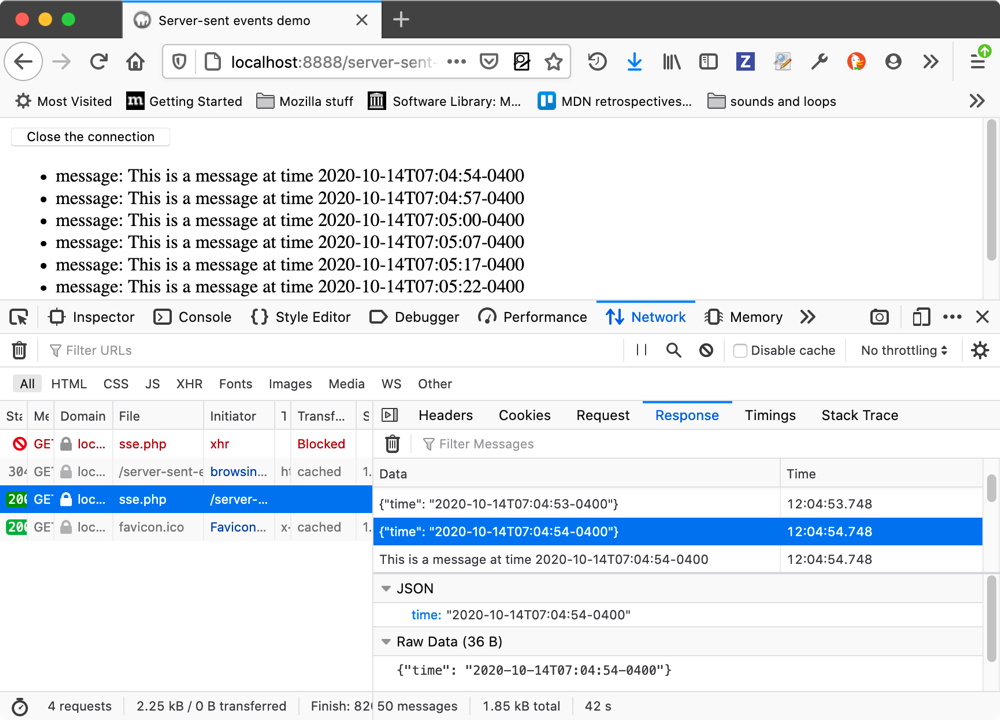
For more information, check out our Inspecting server-sent events guide.
Now let’s look at the web platform additions we’ve got in store in 82.
The Media Session API enables two main sets of functionality:
The code below provides an overview of both of these in action:
if ('mediaSession' in navigator) {
navigator.mediaSession.metadata = new MediaMetadata({
title: 'Unforgettable',
artist: 'Nat King Cole',
album: 'The Ultimate Collection (Remastered)',
artwork: [
{ src: 'https://dummyimage.com/96x96', sizes: '96x96', type: 'image/png' },
{ src: 'https://dummyimage.com/128x128', sizes: '128x128', type: 'image/png' },
{ src: 'https://dummyimage.com/192x192', sizes: '192x192', type: 'image/png' },
{ src: 'https://dummyimage.com/256x256', sizes: '256x256', type: 'image/png' },
{ src: 'https://dummyimage.com/384x384', sizes: '384x384', type: 'image/png' },
{ src: 'https://dummyimage.com/512x512', sizes: '512x512', type: 'image/png' },
]
});
navigator.mediaSession.setActionHandler('play', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('pause', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('seekbackward', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('seekforward', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('previoustrack', function() { /* Code excerpted. */ });
navigator.mediaSession.setActionHandler('nexttrack', function() { /* Code excerpted. */ });
}
Let’s consider what this could look like to a web user — say they are playing music through a web app like Spotify or YouTube. With the first block of code above we can provide metadata for the currently playing track that can be displayed on a system notification, on a lock screen, etc.
The second block of code illustrates that we can set special action handlers, which work the same way as event handlers but fire when the equivalent action is performed at the OS-level. This could include for example when a keyboard play button is pressed, or a skip button is pressed on a mobile lock screen.
The aim is to allow users to know what’s playing and to control it, without needing to open the specific web page that launched it.
This Window.name property is used to get or set the name of the window’s current browsing context — this is used primarily for setting targets for hyperlinks and forms. Previously one issue was that, when a page from a different domain was loaded into the same tab, it could access any information stored in Window.name, which could create a security problem if that information was sensitive.
To close this hole, Firefox 82 and other modern browsers will reset Window.name to an empty string if a tab loads a page from a different domain, and restore the name if the original page is reloaded (e.g. by selecting the “back” button).
This could potentially surface some issues — historically Window.name has also been used in some frameworks for providing cross-domain messaging (e.g. SessionVars and Dojo’s dojox.io.windowName) as a more secure alternative to JSONP. This is not the intended purpose of Window.name, however, and there are safer/better ways of sharing information between windows, such as Window.postMessage().
We’ve got a couple of interesting CSS additions in Firefox 82.
To start with, we’ve introduced the standard ::file-selector-button pseudo-element, which allows you to select and style the file selection button inside elements.
So something like this is now possible:
input[type=file]::file-selector-button {
border: 2px solid #6c5ce7;
padding: .2em .4em;
border-radius: .2em;
background-color: #a29bfe;
transition: 1s;
}
input[type=file]::file-selector-button:hover {
background-color: #81ecec;
border: 2px solid #00cec9;
}
Note that this was previously handled by the proprietary ::-webkit-file-upload-button pseudo, but all browsers should hopefully be following suit soon enough.
We also wanted to mention that the :is() and :where() pseudo-classes have been updated so that their error handling is more forgiving — a single invalid selector in the provided list of selectors will no longer make the whole rule invalid. It will just be ignored, and the rule will apply to all the valid selectors present.
Starting with Firefox 82, language packs will be updated in tandem with Firefox updates. Users with an active language pack will no longer have to deal with the hassle of defaulting back to English while the language pack update is pending delivery.
Take a look at the Add-ons Blog for more updates to the WebExtensions API in Firefox 82!
The post Coming through with Firefox 82 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/10/coming-through-with-firefox-82/
|
|
About:Community: New Contributors, Firefox 82 |
With Firefox 82 hot off the byte presses, we are pleased to welcome the developers whose first code contributions shipped in this release, 18 of whom were new volunteers! Please join us in thanking each of them for their persistence and enthusiasm, and take a look at their contributions:
https://blog.mozilla.org/community/2020/10/20/new-contributors-firefox-82/
|
|
Chris H-C: Five-Year Moziversary |
Wowee what a year that was. And I’m pretty sure the year to come will be even more so.
Me, in last year’s moziversary post
Oof. I hate being right for the wrong reasons. And that’s all I’ll say about COVID-19 and the rest of the 2020 dumpster fire.
In team news, Georg’s short break turned into the neverending kind as he left Mozilla late last year. We gained Michael Droettboom as our new fearless leader, and from my perspective he seems to be doing quite well at the managery things. Bea and Travis, our two newer team members, have really stepped into their roles well, providing much needed bench depth on Rust and Mobile. And Jan-Erik has taken over leadership of the SDK, freeing up Alessio to think about data collection for Web Extensions.
2020 is indeed being the Year of Glean on the Desktop with several projects already embedding the now-successful Glean SDK, including our very own mach (Firefox Build Tooling Commandline) and mozregression (Firefox Bug Regression Window Finding Tool). Oh, and Jan-Erik and I’ve spent ten months planning and executing on Project FOG (Firefox on Glean) (maybe you’ve heard of it), on track (more or less) to be able to recommend it for all new data collections by the end of the year.
My blogging frequency has cratered. Though I have a mitt full of ideas, I’ve spent no time developing them into proper posts beyond taking my turn at This Week in Glean. In the hopper I have “Naming Your Kid Based on how you Yell At Them”, “Tools Externalize Costs to their Users”, “Writing Code for two Wolves: Computers and Developers”, “Glean is Frictionless”, “Distributed Teams: Proposals are Inclusive”, and whatever of the twelve (Twelve?!) drafts I have saved up in wordpress that have any life in them.
Progress on my resolutions to blog more, continue improving, and put Glean on Firefox? Well, I think I’ve done the latter two. And I think those resolutions are equally valid for the next year, though I may tweak “put Glean on Firefox” to “support migrating Firefox Telemetry to Glean” which is more or less the same thing.
:chutten
https://chuttenblog.wordpress.com/2020/10/20/five-year-moziversary/
|
|
Ryan Harter: Defining Data Intuition |
Last week, one of my peers asked me to explain what I meant by "Data Intuition", and I realized I really didn't have a good definition. That's a problem! I refer to data intuition all the time!
Data intuition is one of the three skills I interview new data scientists …
|
|
The Rust Programming Language Blog: Marking issues as regressions |
The Rust project gets many issues filed every day, and we need to keep track of them all to make sure we don't miss anything. To do that we use GitHub's issue labels feature, and we need your help to make sure we fix regressions as soon as possible!
We have many issue labels that help us organize our issues, and we have a few in particular that mark an issue as a regression. These labels will ping a Rust working group called the prioritization working group, whose members will work to determine the severity of an issue and then prioritize it. But, this won't happen unless someone marks the issue with one of those labels!
We recently had a case where a regression was not caught before a release because the issue was not marked with a regression label. So we have now added the ability for anyone to set regression labels on issues! This is all you have to do to mark an issue as a regression and it will automatically ping people to prioritize it:
@rustbot modify labels: regression-untriaged
Alternatively, if you are reporting a new regression, you can use the regression issue template. It will guide you through the process of reporting a regression and providing information that will help us fix the issue.
Finally, if you have an issue that is not a regression, but is still something that is important to be fixed, you can request prioritization with:
@rustbot prioritize
We really appreciate it if you mark all regressions with an appropriate label so we can track them and fix them as soon as possible!
https://blog.rust-lang.org/2020/10/20/regression-labels.html
|
|
Mozilla Privacy Blog: Mozilla Mornings on addressing online harms through advertising transparency |
On 29 October, Mozilla will host the next installment of Mozilla Mornings – our regular breakfast series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
A key focus of the upcoming Digital Services Act and European Democracy Action Plan initiatives is platform transparency – transparency about content curation, commercial practices, and data use to name a few. This installment of Mozilla Mornings will focus on transparency of online advertising, and in particular, how mechanisms for greater transparency of ad placement and ad targeting could mitigate the spread and impact of illegal and harmful content online.
As the European Commission prepares to unveil a series of transformative legislative proposals on these issues, the discussion promises to be timely and insightful.
Karolina Iwa'nska
Lawyer and Policy Analyst, Panoptykon Foundation
Sam Jeffers
Co-Founder and Executive Director, Who Targets Me
With opening remarks by Raegan MacDonald
Head of Public Policy, Mozilla Corporation
Moderated by Jennifer Baker
EU Tech Journalist
Logistical information
29 October, 2020
10:30-12:00 CET
Zoom Webinar (conferencing details to be provided on morning of event)
Register your attendance here
The post Mozilla Mornings on addressing online harms through advertising transparency appeared first on Open Policy & Advocacy.
|
|
Daniel Stenberg: Three years since the Polhem prize |
Today, exactly three years ago, I received flowers, money and a gold medal at a grand prize ceremony that will forever live on in my mind and memory. I was awarded the Polhem Prize for my decades of work on curl. The prize itself was handed over to me by no one else than the Swedish king himself. One of the absolute top honors I can imagine in my little home country.
In some aspects, my life is divided into the life before this event and the life after. The prize has even made little me being presented on a poster in the Technical Museum in Stockholm. The medal itself still sits on my work desk and if I just stop starring at my monitors for a moment and glance a little over to the left – I can see it. I think the prize made my surroundings, my family and friends get a slightly different view and realization of what I actually do all these hours in front of my screens.
In the tree years since I received the prize, we’ve increased the total number of contributors and authors in curl by 50%. We’ve done over 3,700 commits and 25 releases since then. Upwards and onward.
Life moved on. It was not “peak curl”. There was no “prize curse” that left us unable to keep up the pace and development. It was possibly a “peak life moment” there for me personally. As an open source maintainer, I can’t imagine many bigger honors or awards to come my way ever again, but I’m not complaining. I got the prize and I still smile when I think about it.

https://daniel.haxx.se/blog/2020/10/19/three-years-since-the-polhem-prize/
|
|
Cameron Kaiser: TenFourFox FPR28 available |
In the meantime, all the other improvements and upgrades planned for FPR28 have stuck, and this final release adds updated timezone data as well as all outstanding security updates. Assuming no issues, it will go live as usual on or around Monday, October 19 Pacific time.
http://tenfourfox.blogspot.com/2020/10/tenfourfox-fpr28-available.html
|
|
Mozilla Performance Blog: Performance Sheriff Newsletter (September 2020) |
|
|
Daniel Stenberg: curl 7.73.0 – more options |
In international curling competitions, each team is given 73 minutes to complete all of its throws. Welcome to curl 7.73.0.
the 195th release
9 changes
56 days (total: 8,2XX)
135 bug fixes (total: 6,462)
238 commits (total: 26,316)
3 new public libcurl function (total: 85)
1 new curl_easy_setopt() option (total: 278)
2 new curl command line option (total: 234)
63 contributors, 31 new (total: 2,270)
35 authors, 17 new (total: 836)
0 security fix (total: 95)
0 USD paid in Bug Bounties (total: 2,800 USD)
We have to look back almost two years to find a previous release packed with more new features than this! The nine changes we’re bringing to the world this time are…
--output-dirTell curl where to store the file when you use -o or -O! Requested by users for a long time. Now available!
.curlrc in $XDG_CONFIG_HOMEIf this environment variable is set and there’s a .curlrc in there, it will now be used in preference to the other places curl will look for it.
--help has categoriesThe huge wall of text that --help previously gave us is now history. “curl --help” will now only show a few important options and the rest is provided if you tell curl which category you want to list help for. Requested by users for a long time.
With three new functions, libcurl now provides an API for getting meta-data and information about all existing easy options that an application (possibly via a binding) can set for a transfer in libcurl.
We’ve introduced a new error code, and what makes this a little extra note-worthy besides just being a new way to signal a particular error, is that applications that receive this error code can also query libcurl for extended error information about what exactly in the proxy use or handshake that failed. The extended explanation is extracted with the new CURLINFO_PROXY_ERROR.
This is the first curl release where MQTT support is enabled by default. We’ve had it marked experimental for a while, which had the effect that virtually nobody actually used it, tried it or even knew it existed. I’m very eager to get some actual feedback on this…
The “quote” functionality in curl which can sends custom commands to the SFTP server to perform various instructions now also supports atime and mtime for setting the access and modification times of a remote file.
The “known hosts” feature is a SSH “thing” that lets an application get told if libcurl connects to a host that isn’t already listed in the known hosts file and what to do about it. This new feature lets the application return CURLKHSTAT_FINE_REPLACE which makes libcurl treat the host as “fine” and it will then replace the host key for that host in the known hosts file.
Assuming you use the supported backend, you can now select which curves libcurl should use in the TLS handshake, with CURLOPT_SSL_EC_CURVES for libcurl applications and with --curves for the command line tool.
As always, here follows a small selection of the many bug-fixes done this cycle.
Born in May 2001, this script was introduced to build configure etc so that you can run configure etc, when you’re building code straight from git (even if it was CVS back in 2001).
Starting now, the script just runs ‘autoreconf -fi‘ and no extra custom magic is needed.
Our homegrown code style checker got better and now also verifies:
do { } while“if(!true) expressions// comments are not allowed even on column 0The text that was previously output, saying that the cmake build has glitches has been removed. Not really because it has gotten much better, but to not scare people away, let them proceed and use cmake and then report problems and submit pull requests that fix them!
The libcurl internal system for doing “dynamic buffers” (strings) is now also used by the curl tool and a lot of custom realloc logic has been converted over.
The --retry option didn’t work when doing parallel transfers, and when fixed, the retry delay option didn’t work either so that was also fixed!
We changed the handling of saving and loading etags a little bit, so that it now stores and loads the full etag contents and not just the bytes between double quotes. This has the added benefit that the etag functionality now also works with weak etags and when working with servers that don’t really follow the syntax rules for etags.
Getting a 550 response back from a SIZE command will now make curl return at once saying the file is missing. Previously it would put that into the generic “SIZE doesn’t work” pool of errors, but that could lead to some inconsistent return codes.
Turns out that when uploading data to an FTP server, there’s a dedicated response code for the server to tell the client when the disk system is full (there was not room enough to store the file) and since there was also an existing libcurl return code for it, this new mapping thus made perfect sense…
The FTP code would previously wrongly consider a HTTPS proxy to euqal *using TLS” as if it was using TLS for its control channel, which made it wrongly use commands that are reserved for TLS connections.
Some adjustments were necessary to make sure the SCP and SFTP work when spoken over an HTTPS proxy. Also note that this fix is only done for the libssh2 backend (primarily because I didn’t find out to do it in the others when I did a quick check).
I blogged about this malloc reducing adventure separately. The command sending function in curl for FTP, IMAP, POP3 and SMTP now reuses the same memory buffer much better over a transfer’s lifetime.
One of the really nice benefits of “preprocessing” the text files and generate another file that is actually used for running tests, is that we now can provide meta-instructions to generate content when the test starts up. For example, we had tests that had a megabyte or several hundred kilobytes of text for test purposes, and how we can replace those with just a single %repeat% instruction. Makes test cases much smaller and much easier to read. %hex% can generate binary output given a hex string.
The test suite now knows which version of curl it tests, which means it can properly verify the User-Agent: headers in curl’s outgoing HTTP requests. We’ve previously had a filter system that would filter out such headers before comparing. Yours truly then got the pleasure of updating no less than 619 test cases to longer filter off that header for the comparison and instead use %VERSION!
Apparently version 2 has been supported in Windows since Windows 95…
Unless we’ve screwed up somewhere, the next release will be 7.74.0 and ship on December 9, 2020. We have several pending pull-requests already in the queue with new features and changes!
https://daniel.haxx.se/blog/2020/10/14/curl-7-73-0-more-options/
|
|
Karl Dubost: Browser Wish List - Native Video Controls Features |
Firefox PiP (Picture in Picture) is a wondeful feature of the native video html element. But we could probably do better.
Here a very simple video element that you can copy and paste in your URL bar.
data:text/html,span> controls>span> src="https://interactive-examples.mdn.mozilla.net/media/cc0-videos/flower.mp4" type="video/mp4">
But these are a couple of things I wish were accessible natively.
Otsukare!
|
|
Ryan Harter: Follow up: Intentional Documentation |
Last week I presented the idea of Intentional Documentation to Mozilla's data science team. Here's a link to the slides.
The rest of this post is a transcription of what I shared with the team (give or take).
In Q4, I'm trying to build a set of trainings to help …
|
|
Marco Zehe: 25 years of Help Tech and Me |
There are many experiences in a person's life that in some way more or less strongly influence their course of life. However, there are some such events whose impact is so lasting that they can rightly be described as a key experience.
I had such an experience in the autumn of 1995. I visited a small exhibition of assistive technology products for the blind, which took place at the Hamburg-Farmsen Vocational Promotion Agency. At that time I had just started my studies in business informatics at the University of Applied Sciences Wedel and needed a notebook with a refreshable Braille display. Up to that point, I had already visited some exhibitions and Hamburg-based representatives of assistive technology vendors, but by then I had not found anything that I had been really convinced of. Either there was no mobile solution at all, or the systems on offer were so unwieldy that they were simply too heavy to carry around. I had to go by public transit for an hour each direction, from the place where I lived to the place I was studying at. Weight was therefore a key factor for me.
I had heard that Help Tech, which at that time was still called Handy Tech, would be present at this exhibition. Handy Tech had just emerged from another company called Blista-EHG a year earlier. In addition, the company had no representative in Hamburg, so I had not yet been able to try their products. According to the announcement, they would exhibit their new innovative line of Braille displays, combined with a first version of the screen reader JAWS for Windows. That definitely piqued my curiosity.
I arrived at the exhibition place and found the exhibit hall right away. An employee showed me the table where Handy Tech had set up a Braille display connected to a desktop computer. The Handy Tech representative was in conversation with another interested party at that moment. I just sat in front of the display and started exploring what was in front of me.
And what can I say? It was love on first touch, so to speak! The Braille display that stood in front of me was a model called "Braille Window Modular 84". Unlike all the other displays I had looked at, it had no flat, but cells that were curved inwards, with an upward tilt towards the user. These felt very gentle under my fingertips. The hand automatically fell into a slightly curved posture, similar to what is ideal for pianists to play the most relaxed. The dot caps were pleasantly round, and the fingers glided over the displayed information effortlessly in this natural hand posture.
The keyboard mounted on the display had clearly noticeable dots on the common keys, so that orientation was a breeze. The PC was open to MS Word in a document in which someone had written the mandatory "This is a test". I started writing something into the document to see how the keyboard felt, then opened the menu bar using the Alt key, then flipped through other applications and the program manager of Windows 3.11 with Alt-Tab. Surprised, I found that I was just using Windows all the time, and the Braille display always showed me the current location. I didn't have to learn awkwardly complicated keyboard shortcuts. In contrast to many other screen reader experiments at the time JAWS followed a different philosophy. Right from the start, JAWS had the aim of not standing in the way of the user, but to put the usage of Windows and its programs at the forefront.
At that moment I knew I wanted this system for my studies. The Handy Tech employee had since ended his conversation and turned to me. He was blind himself, which pleased me very much. This meant that he would probably be able to answer some more in-depth questions, which had caused stuttering, long faces, and other signs of lack of knowledge in mostly sighted representatives from other AT vendors before.
The conversation was indeed very constructive, informative and illuminating. We discussed my requirements, he noted down my details, and a few weeks later, they made me an offer. At that time, however, I needed the mobile version of the system, i.e. the little sibling display "Modular 44". Using an auxiliary construction, I could connect this display to a suitable notebook in a way that it formed a stable unit. Just as easily, however, the notebook could be undocked, and the keyboard and the corresponding number pad could then be clipped on. I could then use the display comfortably with the stationary PC at home.
Just in time for the 2nd semester at the beginning of 1996, I had mastered the administrative procedures and received the system along with my first JAWS version. A few weeks later I programmed my first Windows application in Borland Delphi. I reported on my experience in the Henter-Joyce Forum on CompuServe, and how I managed to make the development environment itself more accessible using configuration adjustments and JAWS macros.
In July, I received a surprising call that I was being invited to a workshop, which would take place in a lovely remote hotel somewhere in the Black Forest, in the south-west of Germany. This workshop was jointly hosted by Handy Tech and the European importer of JAWS. During the first day, I spontaneously took over the guidance of the Macro Beginner group because I was already familiar with macro programming. In August, in parallel with my studies, I started working as a translator for JAWS. Together with another colleague, I translated the user interface, macros and help into German. The rest, as they say, is history.
In conclusion, this contact with Handy Tech not only got me my first Braille display, but also my first job. I worked at Freedom Scientific, makers of JAWS, until 2007.
Through my work at the JAWS vendor, I also made my first appearance at Reha (later RehaCare) trade show in D"usseldorf in 1997. Handy Tech had announced a world premier for this occasion: A Braille reader for the trouser or vest pocket. I had always been a passionate reader of Braille books, so I was naturally very curious. I went to D"usseldorf and experienced a real surprise.
When Sigi Kipke, the managing director, showed me the bookworm for the first time, it was like a revelation. The bookworm was a box with eight concave Braille modules that I had come to love and rely on heavily on my Braille display. The box was as wide as one hand's spread, Right and left buttons were inserted to the left and right of the modules to scroll forward and backward, and above were an Escape and Enter key. The modules were protected by a movable lid. The battery-powered device switched on the moment the lid was pulled back to reveal the Braille cells. The case almost snuggled into the palm of my hand. One used the index finger to read the displayed information. You could scroll back or forward with the other hand or leave the scrolling to the auto-advance feature, which was incorporated into the software and which you could adjust quite well to your reading speed.
The data was uploaded to the bookworm from an MS-DOS-based software called BWCom. This was later replaced by the Windows version HTCom, which is still part of the Handy Tech Braille systems until now. The software converted TXT or HTML files and translated them into Grade 2 if desired. The resulting files had not only paragraphs, but also a heading structure. The bookworm actually had a multi-level heading navigation facility, making scrolling even in large files easy.
Unfortunately, this heading navigation was lost in their later Braille notetakers, so you have to make do with the search function of the editor to find the next heading. But it was precisely this heading navigation that showed how much the bookworm was ahead of its time. Screen readers received the ability to navigate by headings on websites only two to three years later. And the development of the digital audiobook format DAISY, which also has the ability to navigate by different heading levels, was still in its early iterations at the time.
Many criticized that eight Braille modules were too few to read sensibly and fluently. However, I found that the high level of mobility outweighed this argument, at least for me. In any case, by saving up, and receiving a subsidy from my parents as a gift, I made sure that I got one of the first market-ready Bookworm devices for my 25th birthday in April 1998. Over the course of the following years, on many long transit and train journeys as well as long-haul flights, it kept me good company and helped kill time.

In 2000, a small German newspaper called Taz was one of the first newspapers in Germany to offer digital subscriptions, not only in the mostly inaccessible PDF format, but also in HTML and plain text formats. The HTML version was a bit too bloated to be easily consumed by the bookworm software. So, I wrote a small program in Delphi that converted the plain text version of an edition into a simple HTML framework so that BWCom could structure it and load it into the bookworm. I could then navigate from main to main part on the first, between departments on the second, and between articles at the third heading level. I very often took the daily edition of the Taz with me when going on longer trips or lying on the couch and browsed it like others could skim the daily newspaper. In the same year, Der Spiegel also offered its weekly edition in a format that BWCom could process and make accessible to the bookworm. Here, too, navigation at different heading levels was possible.
Even my first guide dog Falko liked the bookworm: One morning during the acclimatization phase, he grabbed it from the bedside table and chewed on it slightly. I had gone to take a shower and had carelessly left the bookworm lying there. Handy Tech kindly built a new, again hand-flattering, housing around the interior later.

The bookworm accompanied me for a long time until a few years ago, when it fell victim to a leaked battery, which irreparably damaged its electronic parts. Today, it found a worthy successor in an Actilino. I will write about this one in a later article. However, I still miss the heading navigation, and may I say, dearly.
In 1999, my workplace, now converted into a full-time job, was upgraded with both a Braille Window Modular 84 and a notebook display called Braille Top. This was slightly smaller and more handy than the Modular 44 and accompanied me on many national and international trips over the next few years. It was the only Help Tech display I ever owned that had no concave modules.

In 2007, the displays were sold and found new homes with nice people, who certainly made good use of them for a few more years. I got both a Modular Evolution 88, the first display that had ATC technology, and a notebook display called Braille Star 40. The former now lives with a lady near Potsdam because I only work with notebooks nowadays and simply have no use for large desktop-line displays anymore. The Braille Star still works theoretically, but is now old and has age-related failure symptoms. I hope to replace it soon with its successor, the Active Star.
But even aside from the devices I used myself, I kept an eye on the development at Handy Tech, which was renamed Help Tech in 2018. For example, several times during visits or exhibitions, I played with the Braillino, the first 20-cell Braille display they made. At the time, the Braillino was pretty much tailored to the Nokia Communicator, one of the first accessible smartphones. It is the precursor of the already mentioned Actilino, which I use as a reader and for note-taking.
I also saw the Braille Wave first at the fair where it was debuting. It was released a year after the bookworm and was their first display with built-in smart functions. This included not only a notepad and calculator, but also a scheduler and other useful functions that could be used when away from a computer. The functions introduced at that time have been continuously developed further and are still part of many Braille systems from Help Tech. The key difference was that, unlike other notetakers, Help Tech's Braille Wave was Braille first, not Speech first with Braille developed as an add-on.
I even got a chance to test the successor to the Braille Wave, the Active Braille, for a few weeks, when hardly anyone knew yet that it had been released. I got to try the music Braille feature. This is a feature where one can enter musical notes in Braille and immediately hear the note played back. This feature is also available in Actilino and Active star.
In general, Actilino and its bigger sibling, Active Braille, are the most exciting Braille systems Help Tech is currently offering. This is because of their features and portability. Reading without ATC Is really starting to bother me when I am using other Braille displays. ATC means that the Braille display automatically recognizes the position of my finger. When it reaches the last displayed character, the display automatically pans to the next segment. This means that I'm no longer bound to a fixed time interval when reading one Braille display segment, as is the case in virtually all Braille auto-advance features in screen readers and was also the case in the Bookworm. If there is a term or name somewhere that I want or need to inspect more closely, I have all the time in the world. When I am ready to continue, I swipe to the end of the cells. ATC recognizes the movement of my finger and advances the display. I move my hand back to the left and continue reading. On the Actilino I can read for hours without getting tired. The natural hand posture, which I have already described above, does the rest.
Well, there are several reasons for this. It's not like I hadn't worked with other Braille displays, for a time, even for a living. I was using displays made by my former employer, such as the Focus or PAC Mate displays. So, I was in fact working a lot with displays that weren't from Handy Tech. This included noticing the differences during day-to-day productive use. But when I had the choice, I kept coming back to Handy Tech displays time and again.
On the one hand, it is not only the displays themselves that are really cleverly thought out. The Braille Top included a backpack with all sorts of useful compartments, which matched exactly the display and an accompanying notebook. The bookworm's carrying case contained a rain cape. You could pull a rain protection from the side pocket so that all surfaces were protected from water, including those parts of the Bookworm that were left exposed when it was in the case.
Ergonomics is unparalleled, not only because of the concave modules, but also because of the arrangement of the braille keys. The controls always have exactly the right pressure point-for my fingers. The housings are also very robust, due to their design, but still very pleasant to the touch. Nothing wobbles or slags at the buttons. And in my case, the concave modules are even a real health factor: I have found that when I work on a braille display with flat modules for longer, I get a pain in the finger joints and the palm of my hand when doing extensive reading or working with code. If I stop reading on such a display and return to one with concave modules, the pain disappears, and I can read for hours, as I already mentioned.
On the other hand, there are the features of the Braille systems themselves. They are simple enough for beginners, but also have features for real power users like me. We can squeeze a lot out of the editor or other parts. They even offer learning and training opportunities, for example via the drivers for JAWS or within Music Braille, especially when displays that have ATC are used. I will cover more details about that in the article about Actilino. And with every function, I have the feeling that it was carefully developed and actually designed by people who would use something like this themselves, from users for users.
I hope that Help Tech will remain true to this philosophy when developing future products as well. There are enough experiments to develop Braille notetakers with an Android base, which always feel rather half-baked or inconsistent to me, as if not all parts want to fit together. This is particularly noticeable when, in addition to the proprietary blindness-specific functions, there are parts of the operating system that use the screen reader integrated into Android and the BrailleBack component. The differences are often so profound that it almost bites one in the fingers. With Help Tech systems, everything feels like a very consistent and coherent piece, no matter what the task at hand may be.
Another point is the superb documentation. The manuals are extensive. I still vividly remember the two thick volumes for the DOS screen reader Braille Window Pro, which was included with my first Braille display. I think because I was a programmer myself, e.g. using Turbo Pascal for DOS, and other not every-day programs, I already got a lot out of this DOS screen reader. These manuals were definitely a great help.
Even for current braille systems, the manuals are very well-structured and describe all functions in detail without bloating the text unnecessarily. For manuals, this is almost a form of art, describing functions of a product exhaustively without getting into a shamble.
But if there is a problem, I haven't seen any other company that is so committed to the interests of its customers. There is no attempt to sugarcoat bugs, to sweep current problems under the carpet or to pass on the "guilt" of the malfunction to the user. The problem is methodically recorded, analyzed and then determined where it is stuck: on the hardware, the software or indeed a user error, or quite simply the fact that the user has tried something that no one has ever thought of. Or an opportunity for a new function is detected and then possibly even implemented in a later version of the device software. As a customer, I feel that I am being taken seriously and treated with honesty and respect. And there are companies, even in the assistive technology industry, where I have had to experience this not to be the case. This kind of thing creates lasting trust, and when trust is there, I like to come back as a customer.
And one more point is crucial: At Help Tech, blind and visually impaired people work on the company's products in various key areas (development, support, sales) that blind people are supposed to use afterwards. One simply notices. It makes a difference whether blindness-specific products are being developed for the blind by sighted people who believe they know what a blind user might need, or whether devices and functions are being developed by the blind for the blind.
Therefore, my choice will always fall on Help Tech products in the future. They are exactly what I need in the Braille space.
I am not an employee of Help Tech and have never been one. I am just an avid customer who wrote an article on the occasion of the 25th anniversary of his first encounter with these extraordinary braille displays.
The pictures used in this article were thankfully provided to me by Help Tech and are for illustration purposes only.
|
|
Mozilla Attack & Defense: Guest Blog Post: Rollback Attack |
This blog post is the first of several guest blog posts we’ll be publishing, where we invite participants of our bug bounty program to write about bugs they’ve reported to us.
This blog post is about a vulnerability I found in the Mozilla Maintenance Service on Windows that allows an attacker to elevate privileges from a standard user account to SYSTEM. While the specific vulnerability only works on Windows, this is not really because of any Windows-specific issue but rather about how Mozilla validated trust in files it operated on with privileged components. This vulnerability is assigned CVE-2020-15663. It was reported on Mozilla Bugzilla Bug 1643199.
One day I read the “Mozilla Foundation Security Advisory 2019-25,” and one bug caught my attention: “CVE-2019-11753: Privilege escalation with Mozilla Maintenance Service in custom Firefox installation location.” The description mentioned that a privilege escalation was caused “due to a lack of integrity checks.” My past experience taught me that maybe the fix was to check digital signatures only. If that’s the case, then a version rollback attack may be used to bypass the fix. So, I decided to check that, and it worked.
Firefox’s Windows installer allows users to customize the Firefox installation directory. If Firefox is installed to a non-standard location, and not the typical C:\Program Files\Mozilla Firefox\, the Firefox installation path may be user-writable. If that is the case, then a local attacker with a standard account can replace any files in the installation path. If the attacker has permission to do this, they can already execute arbitrary code as the user – but they are interested in elevating privileges to SYSTEM.
The Mozilla Maintenance Service is a Windows service, installed by default. This service runs with SYSTEM privilege. One of its tasks is to launch the Firefox updater with SYSTEM privilege, so that it can update write-protected files under C:\Program Files\Mozilla Firefox without showing UAC prompts. The Mozilla Maintenance Service can be started by standard users, but its files are in C:\Program Files (x86)\Mozilla Maintenance Service\ and not writable by standard users.
However, the Maintenance Service copies files from the Firefox installation and then runs them with SYSTEM privileges: those files are updater.exe and updater.ini. Although the Maintenance Service checks if updater.exe contains an identity string and is signed by Mozilla, it doesn’t check the file version. Thus, an attacker can replace the currently installed updater.exe with an old and vulnerable version of updater.exe. Then the Maintenance Service copies the old updater.exe and updater.ini to C:\Program Files (x86)\Mozilla Maintenance Service\update\, and runs the updater.exe in this update directory with SYSTEM privilege.
This type of bug is a classic rollback attack (sometimes called a replay attack). Most search results for this attack are focused on network protocols (especially TLS), but it’s also applicable to software updates. It was described for Linux package managers at least ten years ago. The general fix for this type of bug is to include in the signed metadata for a file when it should no longer be trusted. Debian uses a Valid-Until date in the metadata for the entire package repository; and The Update Framework is a specification for doing this in a more generic way.
Another example of a software rollback attack is a Steam Service privilege escalation vulnerability, CVE-2019-15315, which I discovered last year. The Steam Service vulnerability was also caused by only verifying digital signatures but not the file version.
I looked for old bugs that may allow me to exploit this issue by searching “Mozilla updater privilege escalation” on MITRE. Luckily, there were two matches: CVE-2017-7766 and CVE-2017-7760. The description of CVE-2017-7766 is “an attack using manipulation of ‘updater.ini’ contents, used by the Mozilla Windows Updater, and privilege escalation through the Mozilla Maintenance Service to allow for arbitrary file execution and deletion by the Maintenance Service, which has privileged access.” This looked very promising to me, because it only required manipulation of updater.ini contents, which standard users can fully control in our bug, so I decided to try this one.
CVE-2017-7766 corresponds to Bug 1342742 on Mozilla Bugzilla. Bug 1342742 is a combination of two bugs: the first is an arbitrary file execution by manipulating “updater.ini”; the second is arbitrary file overwriting with partially attacker controlled data.
The idea of CVE-2017-7766 is that they use the second bug to overwrite “updater.ini” in a way that can trigger the first bug to achieve arbitrary file execution. In our exploitation, we don’t need the arbitrary file overwriting bug, because our “updater.ini” is copied from the Firefox installation directory, which a standard user can already modify.
To exploit the first bug, we first need to change the value of “ExeRelPath” in updater.ini. The “ExeRelPath” is the path of an executable that will be launched after updater.exe successfully applies an update. According to the comments, “ExeRelPath” must be “in the same directory or a sub-directory of the directory of the application executable that initiated the software update.” However, the author of Bug 1342742 discovered that updater.exe accepts any file path, as long as we specify its absolute path. This executable file still needs be signed by Mozilla though, but we can overcome this restriction by using the DLL hijacking.
First, we create a new directory in the root of C:, e.g. C:\poc. (Standard users can create new directories under C:\, but not new files.) Then copy a Mozilla-signed exe file, such as crashreporter.exe, and the DLL we wish to inject to C:\poc. It can be any other Mozilla-signed executable, as long as its Import Directory contains some library that is not a known DLL. Known DLLs are listed in Registry key HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\KnownDLLs. As far as I know, only installers of Mozilla products guarantee that they only load known DLLs at executable’s loading time, to prevent DLL hijacking in the Downloads folder.
To recap, the whole exploitation process is: a standard user starts the Mozilla Maintenance Service -> the Mozilla Maintenance Service runs old updater.exe -> the old updater.exe executes the file specified in ExeRelPath as SYSTEM e.g. crashreporter.exe -> crashreporter.exe loads the hijacked DLL located in the same directory. Thus, the local attacker can successfully escalate the privilege from standard user to SYSTEM.
The Mozilla team fixed this vulnerability by only allowing the Mozilla Maintenance Service to update files under C:\Program Files and C:\Program Files (x86). In the ExecuteServiceCommand function, the function now tests if the install directory path, passed to the Maintenance Service as argv[5], is a Program Files path. Since files under Program Files are protected from standard users, they can no longer downgrade the updater.exe.
I want to thank the Mozilla security team for investigating and fixing this vulnerability and for the bug bounty. A special thank goes to Tom Ritter from Mozilla for his help with the bug bounty process, and for his help with this article. I also thank Holger Fuhrmannek, the reporter of CVE-2019-11753, and Seb Patane, the reporter of CVE-2017-7766, where I borrowed the idea for the exploitation.
https://blog.mozilla.org/attack-and-defense/2020/10/12/guest-blog-post-rollback-attack/
|
|
Hacks.Mozilla.Org: A New Backend for Cranelift, Part 1: Instruction Selection |
|
|
Daniel Stenberg: rust in curl with hyper |
tldr: work has started to make Hyper work as a backend in curl for HTTP.
curl and its data transfer core, libcurl, is all written in C. The language C is known and infamous for not being memory safe and for being easy to mess up and as a result accidentally cause security problems.
At the same time, C compilers are very widely used and available and you can compile C programs for virtually every operating system and CPU out there. A C program can be made far more portable than code written in just about any other programming language.
curl is a piece of “insecure” C code installed in some ten billion installations world-wide. I’m saying insecure within quotes because I don’t think curl is insecure. We have our share of security vulnerabilities of course, even if I think the rate of them getting found has been drastically reduced over the last few years, but we have never had a critical one and with the help of busloads of tools and humans we find and fix most issues in the code before they ever land in the hands of users. (And “memory safety” is not the single explanation for getting security issues.)
I believe that curl and libcurl will remain in wide use for a long time ahead: curl is an established component and companion in scripts and setups everywhere. libcurl is almost a de facto standard in places for doing internet transfers.
A rewrite of curl to another language is not considered. Porting an old, established and well-used code base such as libcurl, which to a far degree has gained its popularity and spread due to a stable API, not breaking the ABI and not changing behavior of existing functionality, is a massive and daunting task. To the degree that so far it hasn’t been attempted seriously and even giant corporations who have considered it, have backpedaled such ideas.
This preface above might make it seem like we’re stuck with exactly what we have for as long as curl and libcurl are used. But fear not: things are more complicated, or perhaps brighter, than it first seems.
What’s important to users of libcurl needs to be kept intact. We keep the API, the ABI, the behavior and all the documented options and features remain. We also need to continuously add stuff and keep up with the world going forward.
But we can change the internals! Refactor as the kids say.
Already today, you can build libcurl to use different “backends” for TLS, SSH, name resolving, LDAP, IDN, GSSAPI and HTTP/3.
A “backend” in this context is a piece of code in curl that lets you use a particular solution, often involving a specific third party library, for a certain libcurl functionality. Using this setup you can, for example, opt to build libcurl with one or more out of thirteen different TLS libraries. You simply pick the one(s) you prefer when you build it. The libcurl API remains the same to users, it’s just that some features and functionality might differ a bit. The number of TLS backends is of course also fluid over time as we add support for more libraries in the future, or even drop support for old ones as they fade away.
When building curl, you can right now make it use up to 33 different third party libraries for different functions. Many of them of course mutually exclusive, so no single build can use all 33.
Said differently: you can improve your curl and libcurl binaries without changing any code, by simply rebuilding it to use another backend combination.

With an extensive set of backends that use third party libraries, the job of libcurl to a large extent becomes to act as a switch between the provided stable external API and the particular third party library that does the heavy lifting.
API <=> glue code in C <=> backend library
libcurl as the rock, with a door and the entry rules written in stone. The backends can come and go, change and improve, but the applications outside the entrance won’t notice that. They get a stable API and ABI that they know and trust.
This setup provides a foundation and infrastructure to offer backends written in other languages as part of the package. As long as those libraries have APIs that are accessible to libcurl, libraries used by the backends can be written in any language – but since we’re talking about memory safety in this blog post the most obvious choices would probably be one of the modern and safe languages. For example Rust.
With a backend library written in Rust , libcurl would lean on such a component to do low level protocol work and presumably, by doing this it increases the chances of the implementations to be safe and secure.
Two of the already supported third party libraries in the world map image above are written in Rust: quiche and Mesalink.
Hyper is a HTTP library written in Rust. It is meant to be fast, accurate and safe, and it supports both HTTP/1 and HTTP/2.

As another step into this world of an ever-growing number of backends to libcurl, work has begun to make sure curl (optionally) can get built to use Hyper.
This work is gracefully funded by ISRG, perhaps mostly known as the organization behind Let’s Encrypt. Thanks!
I want to emphasize that this is early days. We know what we want to do, we know basically how to do it but from there to actually getting it done and providing it in source code to the world is a little bit of work that hasn’t been done. I’m set out to do it.
Hyper didn’t have a C API, they’re working on making one so that C based applications such as curl can actually use it. I do my best at providing feedback from my point of view, but as I’m not really into Rust much I can’t assist much with the implementation parts there.
Once there’s an early/alpha version of the API to try out, I will first make sure curl can get built to use Hyper, and then start poking on the code to start using it.
In that work I expect me to have to go back to the API with questions, feedback and perhaps documentation suggestions. I also anticipate challenges in switching libcurl internals to using this. Mostly small ones, but possibly also larger ones.
I have created a git branch and make my work on this public and accessible early on to let everyone who wants to, to keep up with the development. A first milestone will be the ability to run a single curl test case (any test case) successfully – unmodified. The branch is here: https://github.com/curl/curl/tree/bagder/hyper – beware that it will be rebased frequently.
There’s no deadline for this project and I don’t yet have any guesses as when there will be anything to test.
This project is truly ground work for future developers to build upon as some of the issues dealt with in here should benefit others as well down the road. For example it immediately became obvious that Rust in general encourages to abort on out-of-memory issues, while this is a big nono when the code is used in a system library (such as curl).
I’m a bit vague on the details here because it’s not my expertise, but Rust itself can’t even properly clean up its memory and just returns error when it hits such a condition. Clearly something to fix before a libcurl with hyper could claim identical behavior and never to leak memory.
Will Hyper be used by default in a future curl build near you?
We’re going to work on the project to make that future a possibility with the mindset that it could benefit users.
If it truly happens involve many different factors (for example maturity, feature set, memory footprint, performance, portability and on-disk footprint…) and in particular it will depend a lot on the people that build and ship the curl packages you use – which isn’t the curl project itself as we only ship source code. I’m thinking of Linux and operating system distributions etc.
When it might happen we can’t tell yet as we’re still much too early in this process.
This is not converting curl to Rust.
Don’t be fooled into believing that we are getting rid of C in curl by taking this step. With the introduction of a Hyper powered backend, we will certainly reduce the share of C code that is executed in a typical HTTP transfer by a measurable amount (for those builds), but curl is much more than that.
It’s not even a given that the Hyper backend will “win” the competition for users against the C implementation on the platforms you care about. The future is not set.
Sure, why not? There are efforts to provide more backends written in Rust. Gradually, we might move into a future where less and less of the final curl and libcurl executable code was compiled from C.
How and if that will happen will of course depend on a lot of factors – in particular funding of the necessary work.
Can we drive the development in this direction even further? I think it is much too early to speculate on that. Let’s first see how these first few episodes into the coming decades turn out.
ISRG’s blog post: Memory Safe ‘curl’ for a More Secure Internet and the hacker news discussion.
https://daniel.haxx.se/blog/2020/10/09/rust-in-curl-with-hyper/
|
|






