The Servo Blog: This Week In Servo 52 |
In the last week, we landed 72 PRs in the Servo organization’s repositories.
The biggest news from last week is that WebRender landed in Servo master! It is behind a flag right now (-w) and still has some bugs, but the move to shift more of Servo
into the GPU in the pursuit of 60 fps CSS animations continues! This was great work over many months by glennw and pcwalton. The first talk at the most recent Rust
meetup covered this, and there are additional details on the WebRender wiki.
Paul Rouget also made it possible to install Servo on OSX via Homebrew! Just do brew install --HEAD servo/servo/servo and wait 30 minutes for it to compile!
Nightly builds coming soon…
hasInstanceAttila Dusnoki (dati on IRC) from the University of Szeged has made great progress in getting Servo on embedded ARM Linux to connect up over Bluetooth (via Rust to dbus) with a Google Chromebook. IoT, here we come!
The meeting was canceled last week, due to US and Canadian Holidays.
|
|
Tarek Ziad'e: Kinto Work Week Recap |
We just had a work-week in London on Kinto our JSON storage project, and while heading back to France in the Eurostar, I figured I'd give a summary of where we're at in the project and what's next.

If you are not familiar with Kinto, it's an HTTP API that'll let you store (not so) arbitrary JSON content. Data is organized in collections, which are basically a list of timestamped records. As a client, you can query Kinto to get records filtered by dates or other fields. Kinto also provides neat features like a diff-based API to grab only the newest data, like how you would with a git client.
Kinto is the project designed to serve collections of data to Firefox in real-time, such as configurations.
Kinto stores arbitrary JSON because like some other storage systems, you don't really have to describe the data you are pushing in it like in a classical Database (you can if you want Kinto to control inputs).
Kinto stores not so arbitrary JSON because we're using some of the cool features Postgres has to index in specific fields the JSON mappings - and we are making the assumption that your data does follow a schema.
We were featured in Hackernews a couple of times already, and as you would expect, it sparked a lot of comparisons with other systems that exist. Things like "Are you the Parse killer?" "Why don't you use CouchDB already?" "You don't have everything Firebase provides!"
But frankly, for a HN thread, most of the feedback was really positive and useful for us. In particular it gave us a good hindsight on what things should be improved in the documentation. For instance, making it crystal clear that we are not building a product with a tight integration with the clients and the server API and a service we'd provide (our comparison table right now is a mixed bag of products and server-side frameworks, so that's confusing.)
We're building an HTTP API and we provide a JS client and working on some other clients -- that's it for now.
That said, we're sure hoping products and services will be built by the community with this "toolkit" at some point in the future.
But as far as 2016 is concerned, our main goal is to develop Kinto for our needs in Firefox.
For our daily work, the goal of Kinto is to be used in Firefox as the go-to service to grab data continuously from our servers without having to wait for the next release.
That's the Go Faster umbrella project.
We're going to use Kinto for:
Mark is driving the development of the client on behalf of the Firefox Security Team, and besides the obvious benefit of getting certificate revocations changes on-the-fly as diffs, he started to work with my team, Julien and Franziskus on a signing protocol that will allow the Kinto client to verify that the data that was sent by the server was not tampered with.
That work started a few months ago and the work week was a perfect time to give it a boost.
On the server-side, the signing is done with a micro-service Julien started, called autograph that will let a Kinto administrator sign the data before it's pushed into Kinto.
See https://github.com/mozilla-services/autograph
Kinto is interacting with the signer through a specialized plugin, that triggers the signing whenever some data is changed into Kinto, and that makes sure the data is published to clients once properly signed.
See https://github.com/mozilla-services/kinto-signer
The storage itself is pretty passive about this, as it just stores signed hashes of collections and let any client get them back.
The Kinto client can grab that signature and ask Firefox to verify it before applying data changes. The verification logic uses a custom PKI that Mark and Franziskus and building on top of NSS in the client.
Obviously, we should do this for all the data Kinto ever sends to Firefox, so going forward, all our Kinto deployments will integrate by default signatures capabilities.

The existing AMO blocklist client is already doing most of what we do in Kinto: it performs daily download of an XML file and applies changes in Firefox.
So what are the benefits of moving to Kinto for this ?
The biggest one will be the signing of the data, since this is not something the current client has. The second one will be to separate the feature from the current AMO Django website. Instead of having a dashboard within the Django admin to push data, the Addons administrator will be able to manage the whole dataset in a dedicated web admin.
We've built an admin app for Kinto that will be used for this.
See https://github.com/Kinto/kinto-admin
It's a static React-based app, and we're providing now a Kinto Distribution to let you have a full Kinto service that include among other things that web admin hooked into an /admin endpoint.
See https://github.com/Kinto/kinto-dist/
The last benefit is mostly a side-benefit, but quite important. Right now, the daily ping done by Firefox for the AMO blocklist is used for some metrics work. This is not related to the blocklist feature itself, but happened for historical reasons.
The plan (ongoing dicussion though) is to separate the two features in Firefox as they should, and make sure we have a dedicated ping mechanism for the metrics.
We'll end up with two clearly separated and identified features, that can be maintained and evolve separately.
Sebastian, from the Fennec team, has been working on the Fennec client to sync a list of assets into Kinto. The goal is to reduce the size of the Android package, and download those extra files in the background.
We've built for this a plugin to Kinto, to extend our API so files could be uploaded and downloaded.
Kinto stores files on disk or on Amazon S3 (or whatever backend you write the class for) and their metadata in a Kinto collection.
See https://github.com/Kinto/kinto-attachment/
From a client point of view, what you get is a MANIFEST you can browse and sync locally, of what files are available on the server.
Fennec is going to use this to let admins manage static file lists that will be made available to the mobile browser, and downloaded if they really need them.
They are tons and tons of other stuff happening in Kinto right now, but I wanted to give you an overview of the three major use cases we currently have for it at Mozilla.
If all goes according to ours plans, these are the Firefox versions they will land in:
Good times!
|
|
Mozilla Cloud Services Blog: WebPush’s New Requirement: TTL Header |
WebPush is a new service where web applications can receive notification messages from servers. WebPush is available in Firefox 45 and later and will be available in Firefox for Android soon. Since it’s a new technology, the WebPush specification continues to evolve. We’ve been rolling out the new service and we saw that many updates were not reaching their intended audience.
Each WebPush message has a TTL (Time To Live), which is the number of seconds that a message may be stored if the user is not immediately available. This value is specified as a TTL: header provided as part of the WebPush message sent to the push server. The original draft of specification stated that if the header is missing, the default TTL is zero (0) seconds. This means if the TTL header was omitted, and the corresponding recipient was not actively connected, the message was immediately discarded. This was probably not obvious to senders since the push server would return a 201 Success status code.
Immediately discarding the message if the user is offline is probably not what many developers expect to happen. The working group decided that it was better for the sender to explicitly state the length of time that the message should live. The Push Service may still limit this TTL to it’s own maximum. In any case, the Push Service server would return the actual TTL in the POST response.
You can still specify a TTL of zero, but it will be you setting it explicitly, rather than the server setting it implicitly. Likewise if you were to specify TTL: 10000000, and the Push Service only supports a maximum TTL of 5,184,000 seconds (about one month), then the Push Service would respond with a TTL:5184000
As an example,
curl -v -X POST https://updates.push.services.mozilla.com/push/LongStringOfStuff \
-H "encryption-key: keyid=p256dh;dh=..." \
-H "encryption: keyid=p256dh;salt=..." \
-H "content-encoding: aesgcm128" \
-H "TTL: 60" \
--data-binary @encrypted.data
> POST /push/LongStringOfStuff HTTP/1.1
> User-Agent: curl/7.35.0
> Host: updates.push.services.mozilla.com
> Accept: */*
> encryption-key: ...
> encryption: ...
> content-encoding: aesgcm128
> TTL: 60
> Content-Length: 36
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 36 out of 36 bytes
< HTTP/1.1 201 Created
< Access-Control-Allow-Headers: content-encoding,encryption,...
< Access-Control-Allow-Methods: POST,PUT
< Access-Control-Allow-Origin: *
< Access-Control-Expose-Headers: location,www-authenticate
< Content-Type: text/html; charset=UTF-8
< Date: Thu, 18 Feb 2016 20:33:55 GMT
< Location: https://updates.push.services.mozilla.com...
< TTL: 60
< Content-Length: 0
< Connection: keep-alive
In this example, the message would be held for up to 60 seconds before either the recipient reconnected, or the message was discarded.
If you fail to include a TTL header, the server will respond with an HTTP status code of 400. The result will be similar to:
< HTTP/1.1 400 Bad Request
< Access-Control-Allow-Headers: content-encoding,encryption,...
< Access-Control-Allow-Methods: POST,PUT
< Access-Control-Allow-Origin: *
< Access-Control-Expose-Headers: location,www-authenticate
< Content-Type: application/json
< Date: Fri, 19 Feb 2016 00:46:43 GMT
< Content-Length: 84
< Connection: keep-alive
<
{"errno": 111, "message": "Missing TTL header", "code": 400, "error": "Bad Request"}
The returned error will contain a JSON block that describes what went wrong. Refer to our list of error codes for more detail.
We understand that the change to require the TTL header may have not reached everyone, and we apologize about that. We’re going to be “softening” the requirement soon. The server will return a 400 only if the remote client is not immediately connected, otherwise we will accept the WebPush with the usual 201. Please understand that this relaxation of the spec is temporary and we will return to full specification compliance in the near future.
We’re starting up a Twitter account, @MozillaWebPush, where we’ll post announcements, status, and other important information related to our implementation of WebPush. We encourage you to follow that account.
https://blog.mozilla.org/services/2016/02/20/webpushs-new-requirement-ttl-header/
|
|
Benoit Girard: Using RecordReplay to investigate intermittent oranges, bug #2 |
This is a follow up from my previous blog entry. I wanted to see if I could debug faster with the previous lessons learned. I managed to reproduced the #2 intermittent reftest (#1 which was recently fixed).
This bug was nicer because I had a single replay that had a passing and a failling run in the same trace. This means that I could jump around my replay and compare an expected execution vs. a failing a execution simply by running ‘run 343663’ and ‘run 344535’ (from the reftest TEST-START event log).
Step 1. Compare the frame tree
$ (rr) run 343651
$ (rr) goto-snapshot
$ (rr) next-display-list
Image p=0x20187201a1a0 f=0x7f1261051d38(ImageFrame(img)(0)
(rr) print *((nsIFrame*)0x7f1261051d38)->mImage.mRawPtr
$26 = (mozilla::image::OrientedImage) {
….
rotation = mozilla::image::Angle::D90
vs.
$ (rr) run 344535
$ (rr) goto-snapshot
$ (rr) next-display-list
Image p=0x210a130a89a0 f=0x30f01d0acd38(ImageFrame(img)(0) class:shrinkToFit)
(rr) print *((nsIFrame*)0x30f01d0acd38)->mImage.mRawPtr
$24 = (mozilla::image::OrientedImage) {
…
rotation = mozilla::image::Angle::D0,
step 2. Trace the mismatched value
Alright so this means that when the intermittent failure occurs the rotation field is incorrectly set incorrectly in the ImageFrame. It’s hard to find out why a field isn’t being set so let’s focus on finding out what is setting D90 in the correct case.
$ (rr) watch -l ((nsIFrame*)0x7f1261051d38)->mImage.mRawPtr->mOrientation.rotation
$ (rr) reverse-continue
(…) We see the rotation is provided from StyleVisibility()->mImageOrientation
mImage = nsLayoutUtils::OrientImage(image, StyleVisibility()->mImageOrientation);
Another reverse continue step and we see that it’s being from mozilla::image::RasterImage::SetMetadata. This is called in both the good and bad test with D90 and D0 respectively.
Another step backwards to ‘mozilla::image::Decoder::PostSize(int, int, mozilla::image::Orientation)’. Again the mismatch is seen.
Digging further brought me to the code in ‘mozilla::image::EXIFParser::ParseOrientation’. Both are trying to read at position 24 of the Exif buffer of the same length.
(rr) x/30x mStart
0x1b807e4201e0: 0x66697845 0x4d4d0000 0x00002a00 0x07000800
0x1b807e4201f0: 0x03001201 0x01000000 0x00000600
vs
0x49394230e1e0: 0x66697845 0x4d4d0000 0x00002a00 0x07000800
0x49394230e1f0: 0x03001201 0x01000000 0x00000100
My original theory was a race in getting the data from the decoder and displaying the frame but at this point it looks like something entirely different. We can see here that the Exif data is the same except for the single rotation byte that we want to read.
Data is still wrong in save_marker at tree/media/libjpeg/jdmarker.c:811. reverse-continue from here leads to me:
#0 __memcpy_avx_unaligned () at ../sysdeps/x86_64/multiarch/memcpy-avx-unaligned.S:238
#1 0x00007b605468563a in mozilla::image::SourceBuffer::Append (this=0x344b09866e20, aData=0x21b203e9e000 “\377\330\377”,
#2 0x00007b60546859d3 in mozilla::image::AppendToSourceBuffer (aClosure=0x344b09866e20, aFromRawSegment=0x21b203e9e000 “\377\330\377”,
#3 0x00007b6052fe40d1 in nsPipeInputStream::ReadSegments (this=0x21b203e8d980, aWriter=0x7b6054685996 , aClosure=0x344b09866e20, aCount=90700, aReadCount=0x7ffcab77bc20) at /home/bgirard/mozilla-central/tree/xpcom/io/nsPipe3.cpp:1283
#4 0x00007b6054685a3f in mozilla::image::SourceBuffer::AppendFromInputStream (this=0x344b09866e20, aInputStream=0x21b203e8d980, aCount=90700) at /home/bgirard/mozilla-central/tree/image/SourceBuffer.cpp:385
#5 0x00007b605463d893 in mozilla::image::RasterImage::OnImageDataAvailable (this=0x21b203e9abc0, aInputStream=0x21b203e8d980, aCount=90700) at /home/bgirard/mozilla-central/tree/image/RasterImage.cpp:1072
#6 0x00007b605465fc72 in imgRequest::OnDataAvailable (this=0x57a03547860, aRequest=0x4f7d247b7950, aContext=0x0, aInStr=0x21b203e8d980, aOffset=0, aCount=90700) at /home/bgirard/mozilla-central/tree/image/imgRequest.cpp:1106
and for the base case:
#0 __memcpy_avx_unaligned () at ../sysdeps/x86_64/multiarch/memcpy-avx-unaligned.S:238
#1 0x00007b6054684c66 in mozilla::image::SourceBuffer::Compact (this=0xe95558cee70) at /home/bgirard/mozilla-central/tree/image/SourceBuffer.cpp:153
#2 0x00007b6054685f7d in mozilla::image::SourceBuffer::OnIteratorRelease (this=0xe95558cee70) at /home/bgirard/mozilla-central/tree/image/SourceBuffer.cpp:478
#3 0x00007b6054684414 in mozilla::image::SourceBufferIterator::~SourceBufferIterator (this=0x6c1e7a56a0b8, __in_chrg=
#4 0x00007b60546803b4 in mozilla::Maybe::reset (this=0x6c1e7a56a0b0) at /home/bgirard/mozilla-central/tree/obj-x86_64-unknown-linux-gnu/dist/include/mozilla/Maybe.h:373
#5 0x00007b605467e8e4 in mozilla::Maybe::~Maybe (this=0x6c1e7a56a0b0, __in_chrg=
#6 0x00007b605466bc74 in mozilla::image::Decoder::~Decoder (this=0x6c1e7a56a000, __in_chrg=
#7 0x00007b60546ad304 in mozilla::image::nsJPEGDecoder::~nsJPEGDecoder (this=0x6c1e7a56a000, __in_chrg=
#8 0x00007b60546ad33c in mozilla::image::nsJPEGDecoder::~nsJPEGDecoder (this=0x6c1e7a56a000, __in_chrg=
#9 0x00007b605467b357 in mozilla::image::Decoder::Release (this=0x6c1e7a56a000) at /home/bgirard/mozilla-central/tree/image/Decoder.h:91
#10 0x00007b6054644e55 in RefPtr::AddRefTraitsReleaseHelper (aPtr=0x6c1e7a56a000) at /home/bgirard/mozilla-central/tree/obj-x86_64-unknown-linux-gnu/dist/include/mozilla/RefPtr.h:362
#11 0x00007b605464467c in RefPtr::AddRefTraits::Release (aPtr=0x6c1e7a56a000) at /home/bgirard/mozilla-central/tree/obj-x86_64-unknown-linux-gnu/dist/include/mozilla/RefPtr.h:372
#12 0x00007b605464322f in RefPtr::~RefPtr (this=0x344b09865598, __in_chrg=
#13 0x00007b60546816e2 in mozilla::image::NotifyDecodeCompleteWorker::~NotifyDecodeCompleteWorker (this=0x344b09865580, __in_chrg=
#14 0x00007b6054681726 in mozilla::image::NotifyDecodeCompleteWorker::~NotifyDecodeCompleteWorker (this=0x344b09865580, __in_chrg=
Assuming there’s no mistake above it means were getting the wrong data from the input stream. However it would be odd that the single byte for orientation would get corrupted. Something is fishy here! I’ll continue this debugging session and blog post next week!

|
|
J.C. Jones: Early Impacts of Let's Encrypt |
During the months I worked in Let's Encrypt's operations team I got fairly used to being the go-to man for any question that a database query could solve. I also threw together the code for the Let's Encrypt Stats page. All said, I'd gotten quite attached to being able to query the Let's Encrypt data set. Now, however, I don't have any access to the datacenters, or the databases within. But I do have access to Certificate Transparency logs, as well as other data sources like Censys.io.
I've been coding up a Golang tool called ct-sql that imports CT and Censys.io certificate exports into a MariaDB Database to help me perform population statistics on the state of TLS on the public Internet.
With this tool I imported the Google Pilot, Certly.io, and Izenpe.com certificate transparency logs into a local MariaDB database:
go get -u github.com/jcjones/ct-sql
ct-sql -dbConnect "mysql+tcp://ctsql@localhost:3306/ctdb" -log "https://log.certly.io"
ct-sql -dbConnect "mysql+tcp://ctsql@localhost:3306/ctdb" -log "https://ct.izenpe.com"
ct-sql -dbConnect "mysql+tcp://ctsql@localhost:3306/ctdb" -log "https://ct.googleapis.com/pilot"
# Create the views from https://gist.github.com/jcjones/f140919a4d2d41216bee
curl "https://gist.githubusercontent.com/jcjones/f140919a4d2d41216bee/raw/86a284f3b659834f11e936debc635df204def30f/letsencrypt-ct-sql-views.sql" > letsencrypt-ct-sql-views.sql
mysql < letsencrypt-ct-sql-views.sql
I've been really interested in one question since we started opening up the private beta at IETF94 last November:
Is Let's Encrypt prompting people to secure domains which had not been secure before, or are people changing from their existing CA?
Since I was first introduced to the Let's Encrypt concept in 2014, I had a feeling free and automated certificates would primarily be added to new sites, and for the most part existing properties would stay with their status quo.
Using my tools, I did some analysis and posted some of the results to Twitter, which has gotten a lot of positive response; particularly this chart from Certificate Transparency data showing how many of the domain names in Let's Encrypt's certificates have not appeared in Certificate Transparency before. Certificate Transparency logs are a limited data set, and Ryan Hurst rightly called me out on that:
@vtlynch @jamespugjones @Cryptoki @letsencrypt yes crawler gets a lot, but not all, censys and log overlap isnt as big as assumed
— Ryan Hurst (@rmhrisk) February 16, 2016
@jamespugjones @Cryptoki @letsencrypt best you can do today would be union of censys and ct.
— Ryan Hurst (@rmhrisk) February 16, 2016
At his recommendation, I patched ct-sql to understand the Censys.io certificate JSON export format, and then expanded my data set by importing the 92.4GB export from 2016-02-16 (free account required). This took about a day, given the speed of iSCSI on my LAN.
ct-sql -dbConnect "mysql+tcp://ctsql@localhost:3306/ctdb" -censysJson "/mnt/nas/certificates.20160216T112902.json"
I set up a couple of useful SQL views to simplify queries and then got started. First, I wanted to find out how big the overlap actually is between Censys.io and CT.
--
-- Determine the quantity of certificates which are
-- in Censys but not in CT, CT but not in Censys, or
-- in both. Do this by using LEFT JOINs and counting the
-- combinations of NULL fields.
--
SELECT
DATE_FORMAT(c.notBefore, "%Y-%m") AS issueMonth,
SUM(ct.certID IS NOT NULL
AND censys.certID IS NULL) AS onlyCT,
SUM(censys.certID IS NOT NULL
AND ct.logID IS NULL) AS onlyCensys,
SUM(ct.logId IS NOT NULL
AND censys.certID IS NOT NULL) AS inBoth
FROM
unexpired_certificate AS c
LEFT JOIN
censysentry AS censys ON censys.certID = c.certID
LEFT JOIN
ctlogentry AS ct ON ct.certID = c.certID
GROUP BY issueMonth;
The output is here: CertsInCTversusCensys.tsv.
With the data, summed over those months, it turns out while Censys.io has a larger data set, 82% of their crawled certificates have already been imported into at least one of those CT logs.

This is useful to anyone doing analysis on CT, whether it's via tools like mine, or via Rob Stradling's fabuluous crt.sh. Generally speaking, most certs are in CT, and it won't be very difficult to back-fill the million certs which aren't yet. (Maybe next week...)
So that leads to an opportunity to use this additional data to re-examine the first question: is Let's Encrypt being used to secure new domains, or as a cost-saving replacement CA for existing domains?
--
-- For every domain name on every cert issued by
-- Let's Encrypt, find how many trusted issuers have
-- previously issued certificates with that name.
--
SELECT
COUNT(*),
(SELECT
COUNT(DISTINCT issuerID)
FROM
name AS n2
JOIN
certificate AS c2 ON n2.certID = c2.certID
WHERE
n2.name = n.name) AS numIssuers
FROM
le_certificate AS c
JOIN
name AS n ON c.certID = n.certID
GROUP BY numIssuers;
The output is here: NamesIssuedElsewhere.tsv.
This query takes about 4 hours on my home server: The name table has over 97 million rows, and the certificate table another almost 14 million rows. This is the same query I ran to produce the tweeted graph, but here's the new one including one more CT Log (Izenpe) and the Censys.io export:

As Ryan expected, with a larger dataset of certificates, we did find some more instances of sites changing from another CA to Let's Encrypt. Overall, the percent of sites which have only had a publicly-trusted certificate issued by Let's Encrypt went from 94.3% down to 93.9%.
There are still some caveats:
nss_valid=true, so upstream provided the filtering as to which certificates from that dataset were publicly trusted. This is also true for CT, as each log restricts what issuers are permitted to be entered. ct-sql tool throws away certificates which do not parse in Golang's x509 code. Some old certificates are discriminated against due to this, though the total number of affected certs is < 1000. ct-sql tool enforces a database constraint that for a given Issuer, certificate serial numbers should be unique. This is also in the Baseline Requirements, but I had ~100 issuer/serial collisions during the imports, again mostly from old certificates.All said, I believe Ryan Hurst is correct that this is about the most complete data set we can readily obtain. In the first quarter of its' operation then, Let's Encrypt has far and away been used more to secure previously-unsecured (or at least untrusted) websites than simply as a cost-savings measure.
One last question I often get asked is:
How large is Let's Encrypt compared to other Certificate Authorities?
How you ask this question is important. Most Certificate Authorities issue a lot of TLS certificates for corporations' internal use, not to mention email and code-signing certificates. Also, there have been two decades of SSL/TLS, so we'll need to limit this to unexpired certificates.
If we stick with just unexpired certificates observed on the Web (via Certificate Transparency and Censys.io), we can figure that out pretty readily:
--
-- For each known issuer, count the number of unexpired
-- certificates issued by the issuer.
--
SELECT
i.issuerID,
i.commonName,
(SELECT
COUNT(1)
FROM
unexpired_certificate AS c
WHERE
c.issuerID = i.issuerID) AS numCerts
FROM
issuer AS i
ORDER BY numCerts DESC;
The output is here: UnexpiredCertsByIssuer.tsv.
This is a relatively fast query, as my database contains only 2,383 unique issuing certificates.
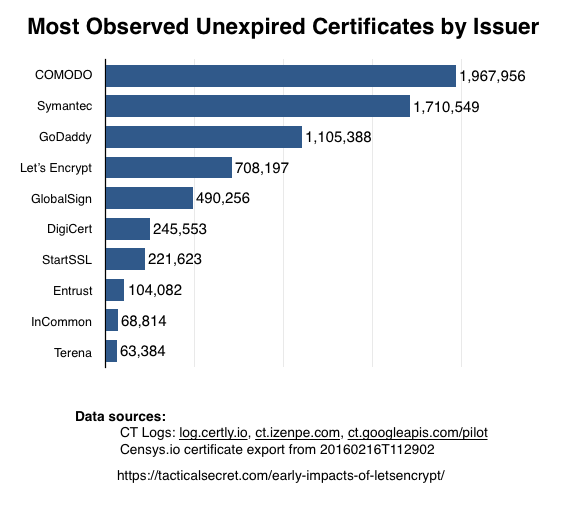
I took a best effort at grouping all the various intermediate issuers to match with the actual organization that operates the Certificate Authority. You can see the grouping I used here: UnexpiredCertsGroupedByCA.tsv. I apologize in advance if I made mistakes; I'm going to be adding that information on a per-issuer basis into my tables to make this a little easier, and will (of course) publish the list.
As I write this, I'm importing WoSign, Symmantec, DigiCert, Venafi, and Google's other logs into the database. There's always more ways to pull out data.
If you have some questions you think my database can answer, feel free to suggest them to me via Twitter.
|
|
Chris Cooper: RelEng & RelOps Weekly Highlights - February 19, 2016 |
A quieter week than last in terms of meetings and releases, but a glibc stack overflow exploit made things “fun” from an operational standpoint this week.
Improve CI Pipeline:
Dustin deployed a change to the TaskCluster login service to allow logins by people who have LDAP accounts (e.g,. for try pushes) but do not have access to the company’s single-sign-on provider. This closes a gap that excluded some of our most productive contributors from access to TaskCluster. With this change, anyone who has a Mozillians account or an LDAP account can connect to TaskCluster and have appropriate access based on group membership.
Ben wrote a blog post about using the Balrog agent to streamline the throttled rollout of Firefox releases. This is one of the few remaining interactive activities in the Firefox release process. Being able to automate it will eliminate some email hand-offs, leading to faster turnaround.
Release:
As opposed to last week’s congestion, this week had a rather normal pace. Various releases have been shipped or are still in-flight:
As always, you can find more specific release details in our post-mortem minutes: https://wiki.mozilla.org/Releases:Release_Post_Mortem:2016-02-17 and https://wiki.mozilla.org/Releases:Release_Post_Mortem:2016-02-24
Next week a handful of the people working on “Release Promotion” will be in Vancouver to try and sprint our way to the finish line. Among them are Jlund, Rail, Kmoir, and Mtabara. Callek won’t be able to make it in person, but will be joining them remotely.
Operational:
Over the course of the week, Jake, Hal, and Amy have worked to patch and reboot our infrastructure to make it safe against the glibc gethostinfo exploit.
Many people from various different teams pitched in to diagnose a bug that was causing our Windows 7 test pool to shut down. Special thanks to philor who finally tracked it down to a Firefox graphics problem. The patch was backed out, and operations are back to normal. (https://bugzil.la/1248347)
Alin landed changes to make the pending counts alerts more granular on a per platform basis (https://bugzil.la/1204970)
Outreach:
Aki wrote a blog post this week about how releng should get better about providing generically packaged tools. Not only would this make our own internal testing story better, but would make easier for contributors outside of releng to hack and help.
See you next week!
|
|
Adam Roach: Laziness in the Digital Age: Law Enforcement Has Forgotten How To Do Their Jobs |
http://sporadicdispatches.blogspot.com/2016/02/laziness-in-digital-age-law-enforcement.html
|
|
Air Mozilla: Webdev Beer and Tell: February 2016 |
 Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on in...
Once a month web developers across the Mozilla community get together (in person and virtually) to share what cool stuff we've been working on in...
|
|
Joel Maher: QoC.2 – Iterations and thoughts |
Quite a few weeks ago now, the Second official Quarter of Contribution wrapped up. We had advertised 4 projects and found awesome contributors for all 4. While all hackers gave a good effort, sometimes plans change and life gets in the way. In the end we had 2 projects with very active contributors.
We had two projects with a lot of activity throughout the project:
First off, this 2nd round of QoC wouldn’t have been possible without the Mentors creating projects and mentoring, nor without the great contributors volunteering their time to build great tools and features.
I really like to look at what worked and what didn’t, let me try to summarize some thoughts.
What worked well:
What I would like to see changed for QoC.3:
As it stands now, we are pushing on submitting Outreachy and GSoC project proposals, assuming that those programs pick up our projects, we will look at QoC.3 more into September or November.

https://elvis314.wordpress.com/2016/02/19/qoc-2-iterations-and-thoughts/
|
|
Air Mozilla: Foundation Demos February 19 2016 |
 Mozilla Foundation Demos February 19 2016
Mozilla Foundation Demos February 19 2016
|
|
Joel Maher: QoC.2 – WPT Results Viewer – wrapping up |
Quite a few weeks ago now, the Second official Quarter of Contribution wrapped up. We had advertised 4 projects and found awesome contributors for all 4. While all hackers gave a good effort, sometimes plans change and life gets in the way. In the end we had 2 projects with very active contributors.
This post, I want to talk about WPT Results Viewer. You can find the code on github, and still find the team on irc in #ateam. As this finished up, I reached out to :martianwars to learn what his experience was like, here are his own words:
What interested you in QoC?
So I’d been contributing to Mozilla for sometime fixing random bugs here and there. I was looking for something larger and more interesting. I think that was the major motivation behind QoC, besides Manishearth’s recommendation to work on the Web Platform Test Viewer. I guess I’m really happy that QoC came around the right time!
What challenges did you encounter while working on your project? How did you solve them?
I guess the major issue while working on wptview was the lack of Javascript knowledge and the lack of help online when it came to Lovefield. But like every project, I doubt I would have enjoyed much had I known everything required right from the start. I’m glad I got jgraham as a mentor, who made sure I worked my way up the learning curve as we made steady progress.
What are some things you learned?
So I definitely learnt some Javascript, code styling, the importance of code reviews, but there was a lot more to this project. I think the most important thing that I learnt was patience. I generally tend to search for StackOverflow answers when it I need to perform a programming task I’m unaware of. With Lovefield being a relatively new project, I was compelled to patiently read and understand the documentation and sample programs. I also learnt a bit on how a large open source community functions, and I feel excited being a part of it! A bit irrelevant to the question, but I think I’ve made some friends in #ateam :) The IRC is like my second home, and helps me escape life’s never ending stress, to a wonderland of ideas and excitement!
If you were to give advice to students looking at doing a QoC, what would you tell them?
Well the first thing I would advice them is not to be afraid, especially of asking the so called “stupid” questions on the IRC. The second thing would be to make sure they give the project a decent amount of time, not with the aim of completing it or something, but to learn as much as they can :) Showing enthusiasm is the best way to ensure one has a worthwhile QoC :) Lastly, I’ve tried my level best to get a few newcomers into wptview. I think spreading the knowledge one learns is important, and one should try to motivate others to join open source :)
If you were to give advice to mentors wanting to mentor a project, what would you tell them?
I think jgraham has set a great example of what an ideal mentor should be like. Like I mentioned earlier, James helped me learn while we made steady progress. I especially appreciate the way he had (has rather) planned this project. Every feature was slowly built upon and in the right order, and he ensured the project continued to progress while I was away. He would give me a sufficient insight into each feature, and leave the technical aspects to me, correcting my fallacies after the first commit. I think this is the right approach. Lastly, a quality every mentor MUST have, is to be awake at 1am on a weekend night reviewing PRs ;)
Personally I have really enjoyed getting to know :martianwars and seeing the great progress he has made.

https://elvis314.wordpress.com/2016/02/19/qoc-2-wpt-results-viewer-wrapping-up/
|
|
Ben Hearsum: Streamlining throttled rollout of Firefox releases |
When we ship new versions of Firefox we do our best to avoid introducing new bugs or crashes, especially those that affect large numbers of users. One of the strategies we use to accomplish this is to ship new versions to a subset of people before shipping to everyone. We call this a "throttled rollout", and it's something we've been doing for many years. The tricky part of this is getting the new version to enough users to have a representative sample size without overshooting our target.
Our current process for doing this is as follows:
The rate and time period has been tuned over time, but it's still a very fragile process. Sometimes we get more or fewer update requests than expected during the 24h window. Sometimes we forget to set the rate back down to 0%. A process that's driven manually and dependent on guesswork has a lot of things that can go wrong. We can do better here. What if we could schedule rate changes to avoid forgetting to make them? What if we could monitor real-time uptake information to eliminate the guesswork? Nick and I have come up with a plan that allows Balrog to do these things, and I'm excited to share it.
The Balrog Agent will be a new component of the system that can be configured to enact changes to update rules at specific times or when certain conditions are met. We will allow users to schedule changes through Admin UI, the Agent will watch for their condition(s) to be hit, and then enact the requested change. For now the only condition we will support is uptake of a specific version on a specific channel, which we will soon be able to get from Telemetry. This diagram shows where the Agent fits into the system:
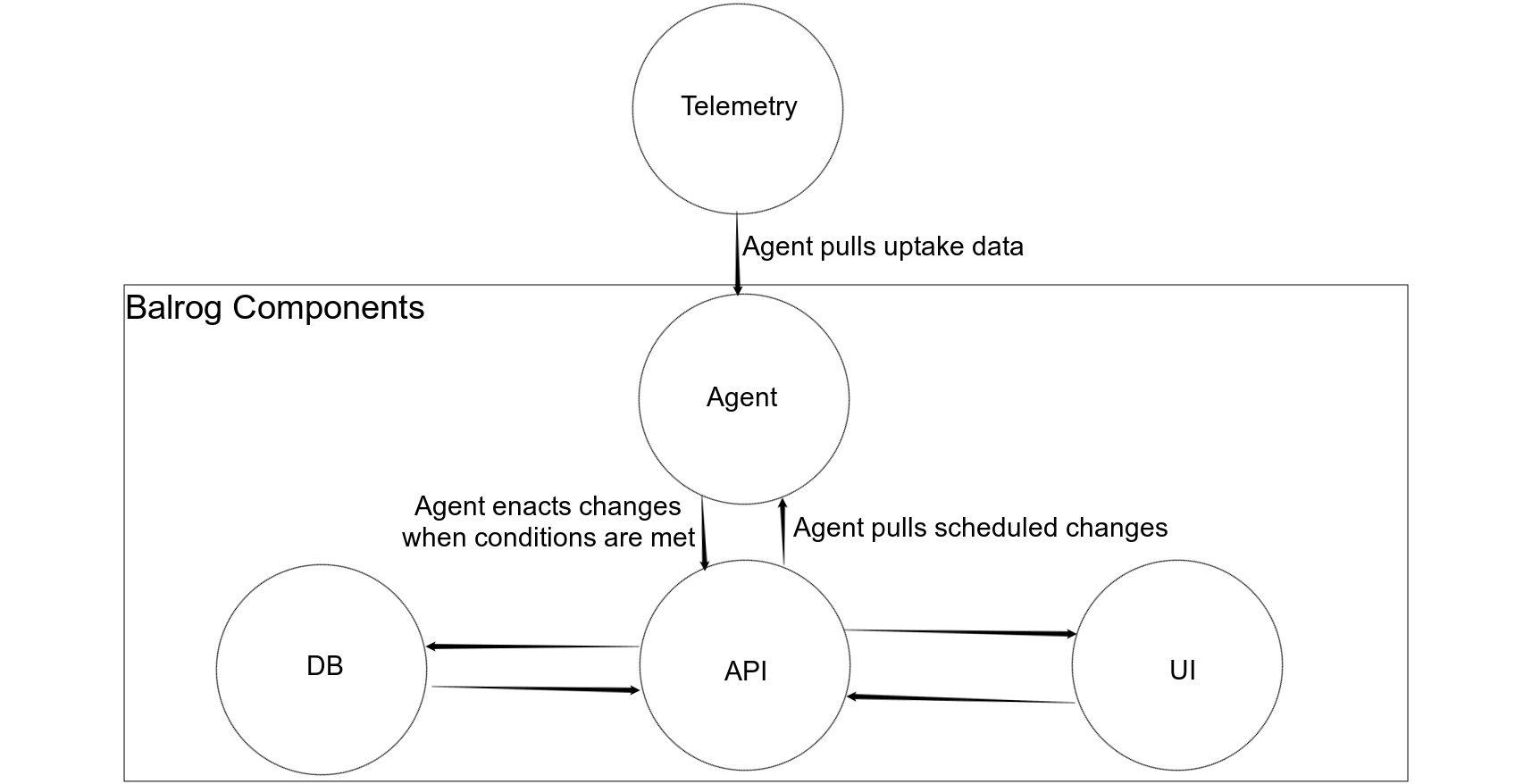
Once implemented, our new process could look something like:
Unlike the manual changes in our current process, the creation of both scheduled changes is not time sensitive - it can be done at any point prior to release day. This means that humans don't have to be around and/or remember to flip bits at certain times, nor do we have to worry about tweaking the time windows as our uptake rate changes. It Just Works (tm).
As always, security was a concern when designing the Balrog Agent. We don't want it to have root-like access to the Balrog database, we just want it to be able to make the specific changes that users have already set-up. To satisify this requirement, we'll be adding a special endpoint to the Admin API (something like /rules/scheduled_changes) which can only enact changes that users have previously scheduled. When users schedule new changes through the UI, Balrog will ensure that they have permission to make the change they're scheduling. The Agent will use the new endpoint to enact changes, which prevents it from making changes that a user didn't explicitly request. As with other parts of Balrog's database, the history of scheduled changes and when they were enacted will be kept to ensure that they are auditable.
Because this is the first time we'll have an automated system making changes to update rules at unpredictible times, another concern that came up was making sure that humans are not surprised when it happens. It's going to feel weird at first to have the release channel update rate managed by automation. To minimize the surprise and confusion of this we're planning to have the Agent send out e-mail before making changes. This serves as a heads up us humans and gives us time to react if the Agent is about to make a change that may not be desired anymore.
We know from past experience that it's impossible for us to predict the interesting ways and conditions we'll want to offer updates. One of the things I really like about this design is that the only limit to what we can do is the data that the Agent has available. While it's starting off with uptake data, we can enhance it later to look at Socorro or other key systems. Wouldn't it be pretty cool if we automatically shut off updates if we hit a major crash spike? I think so.
If you're interested in the nitty-gritty details of this project there's a lot more information in the bug. If you're interested in Balrog in general, I encourage you to check out the wiki or come chat with us on IRC.
http://hearsum.ca/blog/streamlining-throttled-rollout-of-firefox-releases.html
|
|
Air Mozilla: Learning JavaScript Algorithms: Cryptography |
 This month's algorithm challenge is cryptography, which will be presented by Katy Moe. After we've walked through the challenge there will be time to pair...
This month's algorithm challenge is cryptography, which will be presented by Katy Moe. After we've walked through the challenge there will be time to pair...
https://air.mozilla.org/learning-javascript-algorithms-cryptography/
|
|
Niko Matsakis: Parallel Iterators Part 1: Foundations |
Since giving a talk about Rayon at the Bay Area Rust meetup, I’ve been working off and on on the support for parallel iterators. The basic idea of a parallel iterator is that I should be able to take an existing iterator chain, which operates sequentially, and easily convert it to work in parallel. As a simple example, consider this bit of code that computes the dot-product of two vectors:
1 2 3 4 | |
Using parallel iterators, all I have to do to make this run in
parallel is change the iter calls into par_iter:
1 2 3 4 | |
This new iterator chain is now using Rayon’s parallel iterators instead of the standard Rust ones. Of course, implementing this simple idea turns out to be rather complicated in practice. I’ve had to iterate on the design many times as I tried to add new combinators. I wanted to document the design, but it’s too much for just one blog post. Therefore, I’m writing up a little series of blog posts that cover the design in pieces:
Before we get to parallel iterators, let’s start by covering how
Rust’s sequential iterators work. The basic idea is that iterators
are lazy, in the sense that constructing an iterator chain does not
actually do anything until you execute
that iterator, either with
a for loop or with a method like sum. In the example above, that
means that the chain vec1.iter().zip(...).map(...) are all
operations that just build up a iterator, without actually doing
anything. Only when we call sum do we start actually doing work.
In sequential iterators, the key to this is
the Iterator trait. This trait is actually very simple; it
basically contains two members of interest:
1 2 3 4 | |
The idea is that, for each collection, we have a method that will
return some kind of iterator type which implements this Iterator
trait. So let’s walk through all the pieces of our example iterator
chain one by one (I’ve highlighted the steps in comments below):
1 2 3 4 | |
The very start of our iterator chain was a call vec1.iter(). Here
vec1 is a slice of integers, so it has a type like &[i32]. (A
slice is a subportion of a vector or array.) But the iter() method
(and the iterator it returns) is defined generically for slices of any
type T. The method looks something like this (because this method
applies to all slices in every crate, you can only write an impl like
this in the standard library):
1 2 3 4 5 | |
It creates and returns a value of the struct SliceIter, which is the
type of the slice iterator (in the standard library, this type is
std::slice::Iter, though it’s implemented somewhat
differently). The definition of SliceIter looks something like this:
1 2 3 | |
The SliceIter type has only one field, slice, which stores the
slice we are iterating over. Each time we produce a new item, we will
update this field to contain a subslice with just the remaining items.
If you’re wondering what the 'iter notation means, it represents the
lifetime of the slice, meaning the span of the code where that
reference is in use. In general, references can be elided within
function signatures and bodies, but they must be made explicit in type
definitions. In any case, without going into too much detail here, the
net effect of this annotation is to ensure that the iterator does not
outlive the slice that it is iterating over.
Now, to use SliceIter as an iterator, we must implement the
Iterator trait. We want to yield up a reference &T to each item in
the slice in turn. The idea is that each time we call next, we will
peel off a reference to the first item in self.slice, and then
adjust self.slice to contain only the remaining items. That looks
something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Ok, so let’s return to our example iterator chain:
1 2 3 4 | |
We’ve now seen how vec1.iter() and vec2.iter() work, but what
about zip? The zip iterator is an adapter that takes two
other iterators and walks over them in lockstep. The return type
of zip then is going to be a type ZipIter that just stores
two other iterators:
1 2 3 4 | |
Here the generic types A and B represent the types of the
iterators being zipped up. Each iterator chain has its own type that
determines exactly how it works. In this example we are going to zip
up two slice iterators, so the full type of our zip iterator will be
ZipIter, SliceIter<'b, i32>> (but we never have
to write that down, it’s all fully inferred by the compiler).
When implementing the Iterator trait for ZipIter, we just want the
next method to draw the next item from a and b and pair them up,
stopping when either is empty:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
The next step in our example iterator chain is the call to map:
1 2 3 4 | |
Map is another iterator adapter, this time one that applies a function
to each item we are iterating, and then yields the result of that
function call. The MapIter type winds up with three generic types:
ITER, the type of the base iterator;MAP_OP, the type of the closure that we will apply at each step (in
Rust, closures each have their own unique type);RET, the return type of that closure, which will be the type of the
items that we yield on each step.The definition looks like this:
1 2 3 4 5 6 7 | |
(As an aside, here I’ve switched to using a where clause to write out the constraints on the various parameters. This is just a stylistic choice: I find it easier to read if they are separated out.)
In any case, I want to focus on the second where clause for a second:
1
| |
There’s a lot packed in here. First, we said that MAP_OP was the
type of the closure that we are going to be mapping over: FnMut is
one of Rust’s standard closure traits;
it indicates a function that will be called repeatedly in a sequential
fashion (notice I said sequential; we’ll have to adjust this later
when we want to generalize to parallel execution). It’s called FnMut
because it takes an &mut self reference to its environment, and thus
it can mutate data from the enclosing scope.
The where clause also indicates the argument and return type of the
closure. MAP_OP will take one argument, ITER::Item – this it the
type of item that our base iterator produces – and it will return
values of type RET.
OK, now let’s write the iterator itself:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
The final step is the actual summation. This turns out to be fairly
straightforward. The actual sum method is designed to work over any
kind of type that can be added in a generic way, but in the interest
of simplicity, let me just give you a version of sum that works on
integers (I’ll also write it as a free-function rather than a method):
1 2 3 4 5 6 7 | |
Here we take in some iterator of type ITER. We don’t care what kind
of iterator it is, but it must produce integers, which is what the
Iterator bound means. Next we repeatedly call next to
draw all the items out of the iterator; at each step, we add them up.
There is one last piece of the iterator puzzle that I would like to
cover, because I make use of it in the parallel iterator design. In my
example, I created iterators explicitly by calling iter:
1 2 3 4 | |
But you may have noticed that in idiomatic Rust code, this explicit call to
iter can sometimes be elided. For example, if I were actually writing
that iterator chain, I wouldn’t call iter() from within the call to zip:
1 2 3 4 | |
Similarly, if you are writing a simple for loop that just goes over a
container or slice, you can often elide the call to iter:
1 2 3 | |
So what is going on here? The answer is that we have another trait
called IntoIterator, which defines what types can be converted
into iterators:
1 2 3 4 5 6 7 8 9 10 | |
Naturally, anything which is itself an iterator implements
IntoIterator automatically – it just gets converted
into itself,
since it is already an iterator. Container types also implement
IntoIterator. The usual convention is that the container type itself
implements IntoIterator so as to give ownership of its contents:
e.g., converting Vec into an iterator takes ownership of the
vector and gives back an iterator yielding ownership of its T
elements. However, converting a reference to a vector (e.g.,
`&Vec) gives back references to the elements &T. Similarly,
converting a borrowed slice like &[T] into an iterator also gives
back references to the elements (&T). We can implement
IntoIterator for &[T] like so:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Finally, the zip helper method uses IntoIterator to convert its
argument into an iterator:
1 2 3 4 5 6 7 8 | |
Now that we’ve covered the whole iterator chain, let’s take a moment
to reflect on some interesting properties of this whole setup. First,
notice that as we create our iterator chain, nothing actually
happens until we call sum. That is, you might expect that calling
vec1.iter().zip(vec2.iter()) would go and allocate a new vector that
contains pairs from both slices, but, as we’ve seen, it does not. It
just creates a ZipIter that holds references to both slices. In
fact, no vector of pairs is ever created (unless you ask for one by
calling collect). Thus iteration can be described as lazy, since
the various effects described by an iterator take place at the last
possible time.
The other neat thing is that while all of this code looks very
abstract, it actually optimizes to something very efficient. This is a
side effect of all those generic types that we saw before. They
basically ensure that the resulting iterator has a type that describes
precisely what it is going to do. The compiler will then generate a
custom copy of each iterator function tailored to that particular
type. So, for example, we wind up with a custom copy of ZipIter that
is specific to iterating over slices, and a custom copy of MapIter
that is specific to multiplying the results of that particular
ZipIter. These copies can then be optimized independently. The end
result is that our dot-product iteration chain winds up being
optimized into some very tight assembly; in fact, it even gets
vectorized. You can verify this yourself by
looking at this example on play and clicking
the ASM
button (but don’t forget to select Release
mode). Here is
the inner loop you will see:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Neat.
So let’s review the criticial points of sequential iterators:
next, and then the iterator
does the minimal amount of work it can to produce a result.collect, which accumulates the iterator’s items into a vector
or other data structure, building that data structure will require
allocating memory.So in summary, you get to write really high-level, convenient code with really low-level, efficient performance.
http://smallcultfollowing.com/babysteps/blog/2016/02/19/parallel-iterators-part-1-foundations/
|
|
Karl Dubost: [worklog] closing bugs like the smell of spring |
The sun is coming back. The temperature is going up on the shore of Shonan. There was a pretty strong storm in the night of Saturday to Sunday. I can't wait the time where I will unroll the sudare for getting shadows. Tune for this week: Happy from Shonan (Japan) - Pharrell Williams
zoom property in CSS, which is an IE-ism, which was then implemented in WebKit, then in Blink, then in Edge, but which is not in Gecko and create WebCompat issues. It's a very similar story than innerText except that it is maybe less used. Also refined the code example.You are welcome to participate
11 status-needsinfo 135 status-needsdiagnosis 102 status-needscontact 80 status-contactready 102 status-sitewait
(a selection of some of the bugs worked on this week).
app.js takes in between 1 to 3 min to download?-$pref-border-image and -$pref-appearance are annoyances coming in multiple bugs. I need to publish a blog post about this. Let's put this on my todo list.appearance issuesborder-image issueswidthOtsukare!
|
|
Emily Dunham: Buildbot WithProperties |
Today, I copied an existing command from a Buildbot configuration and then modified it to print a date into a file.:
... if "cargo" in component: cargo_date_cmd = "echo `date +'%Y-%m-%d'` > " + final_dist_dir + "/cargo-build-date.txt" f.addStep(MasterShellCommand(name="Write date to cargo-build-date.txt", command=["sh", "-c", WithProperties(cargo_date_cmd)] )) ...
It broke:
Failure: twisted.internet.defer.FirstError: FirstError[#8, [Failure instance: Traceback (failure with no frames):: FirstError[#2, [Failure instance: Traceback: : unsupported format character 'Y' (0x59) at index 14
Why? WithProperties.
It turns out that WithProperties should only be used when you need to interpolate strings into an argument, using either %s, %d, or %(propertyname)s syntax in the string.
The lesson here is Buildbot will happily accept WithProperties("echo 'this command uses no interpolation'") in a command argument, and then blow up at you if you ever change the command to have a % in it.
|
|
Air Mozilla: Bay Area Rust Meetup February 2016 |
 Bay Area Rust Meetup for February 2016. Topics TBD.
Bay Area Rust Meetup for February 2016. Topics TBD.
|
|
Aki Sasaki: generically packaged tools |
One of the reasons I'm back at Mozilla is to work in-depth with some exciting new tools and infrastructure, at scale. However, I wish these tools could be used equally well by employees and non-employees. I see some efforts to improve this. But if this is really important to us, we need to make it a point of emphasis.
If we do this, we can benefit from a healthier, extended community. There are also internal benefits to making our tools packaged in a generic way. I'll go into these in the next section.
I did start to contact some tool maintainers, and so far the response is good. I'll continue doing so. Hopefully I can write a followup blog post about how efforts are under way to make generically packaged tools a reality.
Besides the strengthened community, there are other internal benefits.
Once installation is packaged and automated, an upgrade to a service might be:
This entire process can be fully automated. Once this process is smooth enough, upgrading a service can be seamless and relatively worry free.
If a service is only installable manually, a disaster recovery scenario might involve people working around the clock to reinstall a service.
Once the installation is automated and configurable, this changes. A cold backup solution might be similar to the above upgrade scenario. If disaster strikes, have someone install a new one from the automation, or have a backup instance already installed, ready for someone to switch over.
A hot backup solution might involve having multiple load balanced services running across regions, with automatic failovers. The automated install helps guarantee that each node in the cluster is configured correctly, without human error.
(or intern projects, or GSOC projects, or...)
The more special-snowflake and Mozilla-specific our tools are, the more likely the tool will be tied closely to other Mozilla-specific services, so a seemingly simple change might require touching many different codebases. These types of tools are also more likely to require VPN or special LDAP access that present barriers to new contributors.
If a new contributor is able to install tools locally, that guarantees that they can work on standalone bugs/projects involving those tools. And successful good first bugs and intern/GSOC type projects directly lead to a stronger contributor base.
At various team work weeks years past, we brainstormed being able to launch entire chunks of infrastructure up in self-contained units. These could handle project branch type work. When the code was merged back into trunk, we could archive the data and shut down the instances used.
This concept also works for special projects: things that don't fit within the standard workflow.
If we can spin up services in a separate, network isolated area, riskier or special-requirement work (whether in terms of access control, user permissions, partner secrets, etc) could happen there without affecting production.
Installing the package from scratch is the test for the generic packaging feature. The more we install it, the smaller the window of changes we need to inspect for installation bustage. This is the same as any other software feature.
Having an install test for each tool gives us reassurances that the next time we need to install the service (upgrade, disaster recovery, etc.) it'll work.
In 2000, a developer asked me to install tinderbox, a continuous integration tool written and used at Netscape. It would allow us see the state of the tree, and minimize bustage.
One of the first things I saw was this disclaimer:
This is not very well packaged code. It's not packaged at all. Don't come here expecting something you plop in a directory, twiddle a few things, and you're off and using it. Much work has to be done to get there. We'd like to get there, but it wasn't clear when that would be, and so we decided to let people see it first. Don't believe for a minute that you can use this stuff without first understanding most of the code.
I managed to slog through the steps and get a working tinderbox/bonsai/mxr install up and running. However, since then, I've met a number of other people who had tried and given up.
I ended up joining Netscape in 2001. (My history with tinderbox helped me in my interview.) An external contributor visited and presented tinderbox2 to the engineering team. It was configurable. It was modular. It removed Netscape-centric hardcodes.
However, it didn't fully support all tinderbox1 features, and certain default behaviors were changed by design. Beyond that, Netscape employees already had fully functional, well maintained instances that worked well for us. Rather than sinking time into extending tinderbox2 to cover our needs, we ended up staying with the disclaimered, unpackaged tinderbox1. And that was the version running at tinderbox.mozilla.org, until its death in May 2014.
For a company focused primarily on shipping a browser, shipping the tools used to build that browser isn't necessarily a priority. However, there were some opportunity costs:
In my previous stint at Mozilla, I wrote mozharness, which is a python framework for scripts.
I intentionally kept mozilla-specific code under mozharness.mozilla and generic mozharness code under mozharness.base. The idea was to make it easier for external users to grab a copy of mozharness and write their own scripts and modules for a non-Mozilla project. (By "non-Mozilla" and "external user", I mean anyone who wants to automate software anywhere.)
However, after I left Mozilla, I didn't use mozharness for anything. Why not?
mozharness.base module.
mozharness.base via review. However, this would have been more successful with either an external contributer speaking up before we broke their usage model, or automated tests, or both.
So even with the best intentions in mind, I had ended up putting roadblocks in the way of external users. I didn't realize their scope until I was fully in the mindset of an external user myself.
I wrote scriptharness to try to address these problems (among others):
After I left Mozilla, on several occasions we wanted to use other Mozilla tools in a non-Mozilla environment. As a general rule, this didn't work.
We had multiple Jenkins servers, each with a partial picture of our set of build+test jobs. Figuring out the state of the code base was complex and a specialized skill. Why couldn't we have one dashboard showing a complete view?
I took a look at Treeherder. It has improved upon the original TBPL, but is designed to work specifically with Mozilla's services and workflows. I found it difficult to set up outside of a Mozilla environment.
We were investigating other open source CI solutions. There are many solutions for server-side apps, or linux-only solutions, or cross-platform at small- to medium- scale. TaskCluster is the only one I know of that's cross-platform at massive scale.
When we looked, all the tutorials and docs had to do with using the existing Mozilla production instance, which required a mozilla.com email address at the time. There are no docs for setting up TaskCluster itself.
(Spoiler: I hear it may be a 2H project :D :D :D )
An open source, trusted SSO solution sounded like a good thing to implement.
However, we found out Persona has been EOL'd. We didn't look too closely at the implementation details after that.
(These are just the tools I tried to use in my 1 1/2 years away from Mozilla. There are more tools that might be useful to the outside world. I'll go into those in the next section.)
There are reasons behind each of these, and they may make a lot of sense internally. I'm not trying to place any blame or point fingers. I'm only raising the question of whether our future plans include packaging our tools for outside use, and if not, why not?
We're facing a similar decision to Netscape's. What's important? We can say we're a company that ships a browser, and the tools only exist for that purpose. Or we can put efforts towards making these tools useful in many environments. Generically packaged, with documentation that doesn't start with a disclaimer about how difficult they are to set up.
It's easy to say we'd like to, but we're too busy with ______. That's the gist of the tinderbox disclaimer. There are costs to designing and maintaining tools for use outside of one's subset of needs. But as long as packaging tools for outside use is not a point of emphasis, we'll maintain the status quo.
The above were just the tools that we tried to install. I asked around and built a list of Mozilla tools that might be useful to the outside world. I'm not sure if I have all the details correct; please correct me if I'm wrong!
So we already have some success here. I'd love to see it extended -- more tools, and more use cases, e.g. supporting bugzilla or jira as the bug db backend when applicable.
I don't know how much demand there will be, if we do end up packaging these tools in a way that others can use them. But if we don't package them, we may never know. And I do know that there are entire companies built around shipping tools like these. We don't have to drop any existing goals on the floor to chase this dream, but I think it's worth pursuing in the future.
|
|
Air Mozilla: Firefox Quality Initiatives - 2016 |
 Benjamin Smedberg will present a brownbag talk describing several focus areas and initiatives to improve Firefox quality over the coming year. These initiatives include: *...
Benjamin Smedberg will present a brownbag talk describing several focus areas and initiatives to improve Firefox quality over the coming year. These initiatives include: *...
|
|
Support.Mozilla.Org: What’s up with SUMO – 18th February |
Hello, SUMO Nation!
Another week, another blog post – and it’s me again… Aren’t you getting a bit bored with that? We hope to shake things up soon with some guest posts. Can you guess who will be our first guest writer this year? Let us know in the comments!
We salute you!
What’s your next voyage? I should be heading out to the (hopefully not so) rainy Emerald Isle to meet old friends and hang out with the leprechauns ;-) I hope to see you here next week!
https://blog.mozilla.org/sumo/2016/02/18/whats-up-with-sumo-18th-february/
|
|






