Kat Braybrooke: PhD Student Life at 30, Six Months In... |

Small updates about big things: Today I wrote this piece for Medium about what it’s been like leaving a job in the tech industry at 30, moving back to the United Kingdom and accepting a position as a PhD candiate at the University of Sussex. These thoughts had been building for a while (I still can’t believe six months have passed by already!), so it’s been great to so many friends and networks find it useful to them.
I also wrote this piece for the Guardian a few months ago entitled “Hacking Apple: Putting the Power of Tech Back into Our Hands” which was based on some of my early research into community makerspaces and sustainability here in the UK. This piece also got some great and thoughful responses. Overall, it’s been a really wonderful process to get long-brewing thoughts out into the wild at last!
|
|
Kat Braybrooke: Life as a PhD Student at 30, Six Months In I wrote a little... |

|
|
Jorge Villalobos: Some notes on WebExtensions discovery |
As I was preparing for my presentation at FOSDEM, I tried to approach WebExtensions from a beginner’s perspective and document the entire process. I wrote it all down on this Etherpad, if you’re interested in the raw notes. This blog post is about the first part of the notes: discovery.
We have a history with naming at Mozilla, where project codenames often end up taking over, project names are reused, and all sorts of confusion ensue. I wanted to see what showed up running various queries through the most popular search engines, and here’s what I found:
My main takeaway is that we have our SEO work cut out for the coming months. Maybe WebExtensions isn’t the best of names for this new technology, but it’s been out there long enough that there’s probably no turning back. And choosing names is hard anyway.
The complete results are in the Etherpad. Of course, your results may vary, since many search engines personalize rankings based on past searches, and I ran this experiment 3 weeks ago. The pad also has some notes about the documentation and how easy it was to port a relatively simple add-on to the new API. There’s also a good blog post about porting a Chrome extension to WebExtensions in the Mozilla Hacks blog, which I recommend you read next.
http://xulforge.com/blog/2016/02/some-notes-on-webextensions-discovery/
|
|
Air Mozilla: Web QA Weekly Meeting, 18 Feb 2016 |
 This is our weekly gathering of Mozilla'a Web QA team filled with discussion on our current and future projects, ideas, demos, and fun facts.
This is our weekly gathering of Mozilla'a Web QA team filled with discussion on our current and future projects, ideas, demos, and fun facts.
|
|
Air Mozilla: Reps weekly, 18 Feb 2016 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
Daniel Stenberg: HTTP redirects |
I find that many web minded people working client-side or even server-side have neglected to learn the subtle details of the redirects of today. Here’s my attempt at writing another text about it that the ones who should read it still won’t.
The “redirect” is a fundamental part of the HTTP protocol. The concept was present and is documented already in the first spec (RFC 1945), published in 1996, and it has remained well used ever since.
A redirect is exactly what it sounds like. It is the s erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.
erver sending back an instruction to the client – instead of giving back the contents the client wanted. The server basically says “go look over [here] instead for that thing you asked for“.
But not all redirects are alike. How permanent is the redirect? What request method should the client use in the next request?
All redirects also need to send back a Location: header with the new URI to ask for, which can be absolute or relative.
Is the redirect meant to last or just remain for now? If you want a GET to resource A permanently redirect users to resource B with another GET, send back a 301. It also means that the user-agent (browser) is meant to cache this and keep going to the new URI from now on when the original URI is requested.
The temporary alternative is 302. Right now the server wants the client to send a GET request to B, but it shouldn’t cache this but keep trying the original URI when directed to it.
Note that both 301 and 302 will make browsers do a GET in the next request, which possibly means changing method if it started with a POST (and only if POST). This changing of the HTTP method to GET for 301 and 302 responses is said to be “for historical reasons”, but that’s still what browsers do so most of the public web will behave this way.
In practice, the 303 code is very similar to 302. It will not be cached and it will make the client issue a GET in the next request. The differences between a 302 and 303 are subtle, but 303 seems to be more designed for an “indirect response” to the original request rather than just a redirect.
These three codes were the only redirect codes in the HTTP/1.0 spec.
All three of these response codes, 301 and 302/303, will assume that the client sends a GET to get the new URI, even if the client might’ve sent a POST in the first request. This is very important, at least if you do something that doesn’t use GET.
If the server instead wants to redirect the client to a new URI and wants it to send the same method in the second request as it did in the first, like if it first sent POST it’d like it to send POST again in the next request, the server would use different response codes.
To tell the client “the URI you sent a POST to, is permanently redirected to B where you should instead send your POST now and in the future”, the server responds with a 308. And to complicate matters, the 308 code is only recently defined (the spec was published in June 2014) so older clients may not treat it correctly! If so, then the only response code left for you is…
The (older) response code to tell a client to send a POST also in the next request but temporarily is 307. This redirect will not be cached by the client though so it’ll again post to A if requested to. The 307 code was introduced in HTTP/1.1.
Oh, and redirects work the exact same way in HTTP/2 as they do in HTTP/1.1.
| Permanent | Temporary | |
|---|---|---|
| Switch to GET | 301 | 302 and 303 |
| Keep original method | 308 | 307 |
Yes. The 304, 305, and 306 codes are not used for redirects at all.
I decided to simplify the explanation above. In all places where it says POST above, you can replace it with any non-GET method. They’re just slightly less common on the browser centric web.
I couldn’t write a text like this without spicing it up with some curl details!
First, curl and libcurl don’t follow redirects by default. You need to ask curl to do it with -L (or –location) or libcurl with CURLOPT_FOLLOWLOCATION.
It turns out that there are web services out there in the world that want a POST sent, are responding with HTTP redirects that use a 301, 302 or 303 response code and still want the HTTP client to send the next request as a POST. As explained above, browsers won’t do that and neither will curl – by default.
Since these setups exist, and they’re actually not terribly rare, curl offers options to alter its behavior.
You can tell curl to not change the non-GET request method to GET after a 30x response by using the dedicated options for that:
–post301, –post302 and –post303. If you are instead writing a libcurl based application, you control that behavior with the CURLOPT_POSTREDIR option.
Here’s how a simple HTTP/1.1 redirect can look like. Note the 301, this is “permanent”:
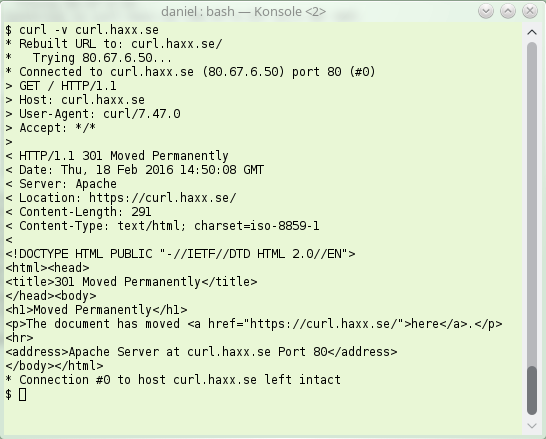
|
|
The Mozilla Blog: Firefox for iOS is Faster with 3D Touch and More |
We recently released the first version of Firefox for iOS. It’s a great browser and we’re excited to bring you more new features today. The latest release of Firefox for iOS brings improvements to make browsing simpler and more fun by taking advantage of the latest iOS hardware and software features.
Firefox for iOS on iPhone 6S and 6S Plus now offers 3D Touch to help you access commonly used features faster than ever before. Simply press the Firefox app icon to open the Quick Access menu which has shortcuts to Open Last Bookmark, open a New Private Tab or a New Tab.

Firefox for iOS also supports Peek and Pop which lets you preview a tab and take actions on it such as Add to Reading List, Copy URL or Close Tab with fewer steps. You no longer have to tap on the page, wait for it to load and then tap again to use these popular features. Instead, you can preview content by lightly pressing on a tab in the tab menu then swipe up to access these shortcuts. This is especially useful when you’re organizing many tabs and will help you sort them faster.

To speed up searches in open tabs, Firefox for iOS lets you type your search query directly into the Spotlight Search Bar on your iPhone, iPad or iPod touch. You can also search for text in a Web page with ‘Find in Page’ by long-pressing on a text item or from the ‘Share’ menu. Managing your saved Logins with Firefox for iOS is easier too. You can search, filter, view and edit your saved Logins in Settings, whether they’re stored locally or synced through Firefox Accounts.
Finally, when you open the latest version of Firefox for iOS, you’ll see a page listing all the updates we’ve made. We hope you enjoy the latest, faster Firefox for iOS.
![]()
More information:
https://blog.mozilla.org/blog/2016/02/17/firefox-for-ios-is-faster-with-3d-touch-and-more-2/
|
|
Tantek Celik: Going Silo-Private to Prefer the IndieWeb, Leave Silo Publics, and Pioneer Privacy on the Independent Web |
I changed my silo (social media) profiles to private today to:
In that last respect, this is just one of many private vs. public experiments I will be conducting, including with my own website and posts, to gain real world experience of the privacy design challenges and opportunities for individual or small group independent web sites, inspired but not burdened by existing silo designs.
Starting in 2010-2011 we the IndieWeb community pioneered and documented details and best practices of how to POSSE (Publish on your Own Site, Syndicate Elsewhere) by doing so live on our own sites to various silos like Twitter.
By 2015, POSSE had grown far beyond the indieweb community and became an accepted open independent web practice, with many others reconceptulaizing or redeveloping it, e.g. POSSE to Medium by “Creating Medium stories via RSS”.
It’s now 2016, and just as 2010 felt like the right time to develop and show POSSE (and outdo silos at & with it), now feels like the right time for those of us with our own indieweb sites to take steps with those sites to pioneer, develop, document, and show how the independent web can do better at private accounts & posts, improving upon silos both technically, and more importantly, with better user experiences.
Read more at IndieWebCamp.com, and join the discussion at #indiewebcamp.
Thanks to Ben Werdm"uller for reviewing and providing feedback on this post.
http://tantek.com/2016/048/b1/going-silo-private-prefer-indieweb
|
|
Air Mozilla: UI Telemetry in Firefox |
 Jullie Utsch, Outreachy Participant from Brazil, talks about her project on UI Telemetry for Round 11 of the Outreachy project.
Jullie Utsch, Outreachy Participant from Brazil, talks about her project on UI Telemetry for Round 11 of the Outreachy project.
|
|
Air Mozilla: Rust Berlin - Machine Learning: Leaf and Collenchyma |
 MJ and Max will talk about Leaf and Collenchyma: We will show that Machine Learning, including the promising subfield of Deep Learning, are based on...
MJ and Max will talk about Leaf and Collenchyma: We will show that Machine Learning, including the promising subfield of Deep Learning, are based on...
https://air.mozilla.org/rust-berlin-machine-learning-leaf-and-collenchyma/
|
|
Air Mozilla: The Joy of Coding - Episode 45 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Mozilla Addons Blog: Add-ons Update – Week of 2016/02/17 |
I post these updates every 3 weeks to inform add-on developers about the status of the review queues, add-on compatibility, and other happenings in the add-ons world.
In the past 3 weeks, 1197 add-ons were reviewed:
There are 90 listed add-ons awaiting review.
Thanks to our volunteer team, and the addition of Philipp Kewisch as a new admin reviewer, the review queues are looking great and have a good shot of staying that way.
If you’re an add-on developer and are looking for contribution opportunities, please consider joining us. Add-on reviewers get invited to Mozilla events and earn cool gear with their work. Visit our wiki page for more information.
Firefox Accounts is now live on AMO. Next time you log in, you’ll be prompted to migrate your account. If you have any problems with this process, please post in the forum thread.
This compatibility blog post is up. The bulk compatibility validation will be run in the coming weeks.
As always, we recommend that you test your add-ons on Beta and Firefox Developer Edition to make sure that they continue to work correctly. End users can install the Add-on Compatibility Reporter to identify and report any add-ons that aren’t working anymore.
The wiki page on Extension Signing has information about the timeline, as well as responses to some frequently asked questions. The current plan is to remove the signing override preference in Firefox 46 (updated from the previous deadline of Firefox 44).
Electrolysis, also known as e10s, is the next major compatibility change coming to Firefox. Firefox will run on multiple processes now, running content code in a different process than browser code.
This is the time to test your add-ons and make sure they continue working in Firefox. We’re holding regular office hours to help you work on your add-ons, so please drop in on Tuesdays and chat with us!
We’re working on the new WebExtensions API, and we recommend that you start looking into it for your add-ons. You can track progress of its development in http://www.arewewebextensionsyet.com/.
https://blog.mozilla.org/addons/2016/02/17/add-ons-update-77/
|
|
Mark Surman: Help Us Spread the Word: Encryption Matters |
Today, the Internet is one of our most important global public resources. It’s open, free and essential to our daily lives. It’s where we chat, play, bank and shop. It’s also where we create, learn and organize.
All of this is made possible by a set of core principles. Like the belief that individual security and privacy on the Internet is fundamental.
Mozilla is devoted to standing up for these principles and keeping the Internet a global public resource. That means watching for threats. And recently, one of these threats to the open Internet has started to grow: efforts to undermine encryption.
Encryption is key to a healthy Internet. It’s the encoding of data so that only people with a special key can unlock it, such as the sender and the intended receiver of a message. Internet users depend on encryption everyday, often without realizing it, and it enables amazing things. It safeguards our emails and search queries, and medical data. It allows us to safely shop and bank online. And it protects journalists and their sources, human rights activists and whistleblowers.
Encryption isn’t a luxury — it’s a necessity. This is why Mozilla has always taken encryption seriously: it’s part of our commitment to protecting the Internet as a public resource that is open and accessible to all.
Government agencies and law enforcement officials across the globe are proposing policies that will harm user security through weakening encryption. The justification for these policies is often that strong encryption helps bad actors. In truth, strong encryption is essential for everyone who uses the Internet. We respect the concerns of law enforcement officials, but we believe that proposals to weaken encryption — especially requirements for backdoors — would seriously harm the security of all users of the Internet.
At Mozilla, we continue to push the envelope with projects like Let’s Encrypt, a free, automated Web certificate authority dedicated to making it easy for anyone to run an encrypted website. Developed in collaboration with the Electronic Frontier Foundation, Cisco, Akamai and many other technology organizations, Let’s Encrypt is an example of how Mozilla uses technology to make sure we’re all more secure on the Internet.
However, as more and more governments propose tactics like backdoors, technology alone will not be enough. We will also need to get Mozilla’s community — and the broader public — involved. We will need them to tell their elected officials that individual privacy and security online cannot be treated as optional. We can play a critical role if we get this message across.
We know this is a tough road. Most people don’t even know what encryption is. Or, they feel there isn’t much they can do about online privacy. Or, both.
This is why we are starting a public education campaign run with the support of our community around the world. In the coming weeks, Mozilla will release videos, blogs and activities designed to raise awareness about encryption. You can watch our first video today — it shows why controlling our personal information is so key. More importantly, you can use this video to start a conversation with friends and family to get them thinking more about privacy and security online.
If we can educate millions of Internet users about the basics of encryption and its connection to our everyday lives, we’ll be in a good position to ask people to stand up when the time comes. We believe that time is coming soon in many countries around the world. You can pitch in simply by watching, sharing and having conversations about the videos we’ll post over the coming weeks.
If you want to get involved or learn more about Mozilla’s encryption education campaign, visit mzl.la/encrypt. We hope you’ll join us to learn about and support encryption.
[This blog post originally appeared on blog.mozilla.org on February 16, 2016]
The post Help Us Spread the Word: Encryption Matters appeared first on Mark Surman.
http://marksurman.commons.ca/2016/02/17/help-us-spread-the-word-encryption-matters/
|
|
Matthew Ruttley: Extending MongoDB findOne() functionality to findAnother() |
Given a new MongoDB instance to work with, its often difficult to understand the structure since, unlike SQL, the database is inherently schema-less. A popular initial tool is Variety.js, which finds all possible fields and tells you the types, occurrences and percentages of them in the db.
However, it is often useful to see the contents of the fields as well. For this, you can use findOne(), which grabs what seems to be the last inserted record from the collection and pretty-prints it to the terminal. This is great, but sometimes you want to see more than one record to get a better feel for field contents. In this post I’ll show you how I extended Mongo to do this.
(Assuming you’ve already installed mongo and git – I use
brew install mongofrom the homebrew package manager and git came with XCode on my Mac)
First off, let’s get a copy of mongo’s code:
mruttley$ cd ~/Documents mruttley$ git clone https://github.com/mongodb/mongo.git
This will have created a folder in your Documents, so let’s inspect it:
mruttley$ cd mongo mruttley$ ls APACHE-2.0.txt GNU-AGPL-3.0.txt SConstruct buildscripts distsrc etc rpm src CONTRIBUTING.rst README build debian docs jstests site_scons
There’s quite a lot of files there, it will take a while to find where the findOne() function is located. Github’s repository search returns far too many results so let’s use a unix file search instead. MongoDB is written in JavaScript (and compiled) so we need to look for a function definition like
findOne = function(or
function findOne(. Try this search:
mruttley$ grep -lR "findOne = function(" .
./build/opt/mongo/mongo
./build/opt/mongo/shell/mongo.cpp
./build/opt/mongo/shell/mongo.o
./src/mongo/shell/collection.jsThe two flags here are
-l(lowercase L) which shows filenames, and
Rwhich searches all subdirectories. The fullstop at the end means to search the current directory. You can see it found a javascript file there, “collection.js”. If you open it up in a text editor, the findOne() function is listed:
DBCollection.prototype.findOne = function( query , fields, options, readConcern ){
var cursor = this.find(query, fields, -1 /* limit */, 0 /* skip*/,
0 /* batchSize */, options);
if ( readConcern ) {
cursor = cursor.readConcern(readConcern);
}
if ( ! cursor.hasNext() )
return null;
var ret = cursor.next();
if ( cursor.hasNext() ) throw Error( "findOne has more than 1 result!" );
if ( ret.$err )
throw _getErrorWithCode(ret, "error " + tojson(ret));
return ret;
};This code can also be found here on the mongodb github page: https://github.com/mongodb/mongo/blob/master/src/mongo/shell/collection.js#L207
Our function is going to extend findOne instead to find another record. This can be implemented by doing a “find” using exactly the same code, but then skipping a random number of records ahead. The skip amount has to be less than the number of records listed which unfortunately means we have to run the query twice. First to count the number of results, and second to actually skip some amount.
Copy the findOne function and rename it to findAnother, with these lines at the top instead:
DBCollection.prototype.findAnother = function( query , fields, options, readConcern ){
// Similar to findOne but returns a different record each time
// Have to make the query twice as we need to know the count before being able to
// apply a random skip
var total_records = this.find(query, fields, -1, 0, 0, options).count();
// random number generation from: http://stackoverflow.com/a/7228322
var randomNumber = Math.floor(Math.random()*(total_records+1)+1);
var cursor = this.find(query, fields, -1, randomNumber, 0, options);
if ( readConcern ) {
cursor = cursor.readConcern(readConcern);
}
if ( ! cursor.hasNext() )
return null;
var ret = cursor.next();
if ( cursor.hasNext() ) throw Error( "findAnother has more than 1 result!" );
if ( ret.$err )
throw _getErrorWithCode(ret, "error " + tojson(ret));
return ret;
};
Generating random numbers in a range is a little obscure in JavaScript but I found a helpful tip on StackOverflow to do it: http://stackoverflow.com/a/7228322 in one line. I’m used to Python’s ultra simple random.randrange().
Let’s test this out first. You’ll notice that all code can be returned in mongo’s javascript shell:
mruttley$ mongo 127.0.0.1
MongoDB shell version: 3.3.1-217-gdfaa843
connecting to: localhost
>
> use my_db
switched to db my_db
> db.coll.findOne
function ( query , fields, options, readConcern ){
var cursor = this.find(query, fields, -1 /* limit */, 0 /* skip*/,
0 /* batchSize */, options);
...etcYou can actually replace this code live in the terminal, though it won’t be saved once you close it. Try first replacing findOne with a Hello World:
> db.coll.findOne = function(){return 'Hello World'}
function (){return 'Hello World'}
> db.coll.findOne()
Hello WorldYou can test out our new function first in the terminal by copying everything after the first equals. Open a mongoDB shell to your favourite db and type
db.my_collection.findOne =then paste in the function. Try calling it and it should return different results each time.
Let’s patch mongodb now with our function. We have to compile mongo from the source we just downloaded.
brew install gcc
scons -j4 mongoand press enter. The
4here is the number of cores I have, and seriously speeds things up.
sconsis a program that handles compilation, and putting
mongoat the end of this specifies that we only want to patch mongo’s client.
You’ll see a huge amount of green text as scons checks everything, and then:
mruttley$ scons -j4 mongo scons: Reading SConscript files ... scons version: 2.4.1 (blah blah...) Checking for C header file x86intrin.h... (cached) yes scons: done reading SConscript files. scons: Building targets ... Install file: "build/opt/mongo/mongo" as "mongo" scons: done building targets. mruttley$
Its compiled! We now have to replace the existing mongo application with our modified version. Let’s do a unix find:
mruttley$ sudo find / -name "mongo" Password: find: /dev/fd/3: Not a directory find: /dev/fd/4: Not a directory /usr/local/bin/mongo /usr/local/Cellar/mongodb/3.2.0/bin/mongo /usr/local/Library/Aliases/mongo /Volumes/Data/Users/mruttley/Documents/code/mongo /Volumes/Data/Users/mruttley/Documents/code/mongo/build/opt/mongo /Volumes/Data/Users/mruttley/Documents/code/mongo/build/opt/mongo/mongo /Volumes/Data/Users/mruttley/Documents/code/mongo/mongo /Volumes/Data/Users/mruttley/Documents/code/mongo/src/mongo
We want to replace the mongo application in /usr/local/Cellar/ (where brew installed it to). Let’s back it up then copy across:
mruttley$ cp /usr/local/Cellar/mongodb/3.2.0/bin/mongo /usr/local/Cellar/mongodb/3.2.0/bin/mongo_backup mruttley$ cp mongo /usr/local/Cellar/mongodb/3.2.0/bin/
Now, open up a MongoDB shell to your favourite DB:
mruttley$ mongo 127.0.0.1
MongoDB shell version: 3.3.1-217-gdfaa843
connecting to: localhost
> use my_db
> my_db.coll.findAnother()
{
"_id" : ObjectId("...
etc...Caveats:
Improvements
|
|
David Rajchenbach Teller: Dreaming the Internet of Things |
One of these days, using the Cloud of OpaqueCompany ™, I will be able to set the colour of my lightbulbs by talking to my TV. Somewhere along the way, my house will become a little bit more energy hungry and a little bit more dependent on the Cloud of OpaqueCompany(tm) . That’s the promise of the Internet of Things. Isn’t that neat? Isn’t that exciting?
Not really. At least, not for me. But, for some reason, whenever I read about that Internet of Things, it is about expensive gadgets that, to me, sounds like Christmas commercials: marginally useful, designed by marketers for spoilt westerners to be consumed then forgotten before the next Christmas shopping spree.
But this doesn’t have to be.
I have spent a little time scratching the surface and trying to determine whether there was something more to this Internet of Things, beside the shopping list. I came back convinced that, once you forget the marketing, this Internet of Things can become a revolution as big as the Personal Computer or the World Wide Web – at least if we let it fall into the right hands.
Say you are the owner or manager of a small commerce, say a restaurant. Chances are that you need a burglar alarm, either because you fear that you are going to be burglarised, or because your insurance requires one. You have two solutions. Either you go to a store and buy some off-the-shelf product, or you contract a company, draw a list of requirements and pay for a custom setup. In either case, you are a consumer, and you are stuck with what you paid for. But needs change. Perhaps the insurance policies now requires you to have an alarm that can call the police automatically. Perhaps neighbours complained about the noise of the alarm and you need to turn it into a silent alarm that rings your cellphone. Perhaps the insurance has changed their policy and now requires you to take pictures of the burglary. Perhaps you have had work done and the small window in the bathroom is now large enough that it could be used to break in. Or water damage has destroyed one of your sensors and you need to replace it, but the model doesn’t exist anymore. Or you are tired of triggering the alarm when you take out the garbage and need to refine the policy. Of your product was linked to a subscription, to call the police on your behalf, but the provider has stopped this service. In any of these cases, you are probably stuck. Because your needs have made you a consumer and you are served only as long as there is a market for your specific need.
Now, consider an alternate universe, in which you just need to walk or drive to the nearest store, buy a few off-the-shelf motion detectors, for the price of a few dollars and simply attach them in your restaurant, where you see fit. They use open standards, so you can install an app to get them to work together, or even better, use your cellphone to script them visually into doing what you need. Do you need to add one or ten, or replace them with different models, or add door-lock sensors? It’s just as easy. Do you need to add a camera? Well, place it and use your cellphone to add that camera to your script. Use your cellphone again and customise the effect, to call the police, or ring your cellphone, or deactivate a single alarm between 11pm and 11.30pm, because that’s when you take out the trash. And if your product is linked to a subscription, because it uses open standards, you can switch provider as needed. In this universe, the Internet of Things has put you in control – not a Cloud, not a silo – and drastically cut your costs and your dependencies.
A few months ago, Mozilla has started pivoting from SmartPhones to the Web of Things – that’s the name we give to Internet of Things done right, with open standards, you in charge, rather than silos and Opaque Cloud ™. I can make no promise that we are going to succeed, but I believe in the huge potential of this Web of Things.
By the way, it doesn’t stop at restaurants. The exact same open standards can help you guard against fires in your house or humidity in your server room. Or crowdsourcing flood detection in cities exposed to flash floods or automating experiments in a physics lab. Or watching your heartbeat or listening to your snores. Or determining which part of the village farm needs to be irrigated in priority or which part of the sewers need most attention.
Some of these problems already have commercial solutions. But what about your next problem, the one that hasn’t attracted the attention of any company large enough to produce devices specifically for you?
Here is to the Web of Things. Let’s make sure that it falls into the right hands.

https://dutherenverseauborddelatable.wordpress.com/2016/02/17/dreaming-the-internet-of-things/
|
|
Mozilla Addons Blog: Style Refresh for addons.mozilla.org (AMO) |
AMO is the central hub for developers to distribute their add-ons, and for users to discover them. It’s a workhorse of a site, serving as a publishing platform, online community, and marketplace where over 1 million add-ons are downloaded each month.
The current design has been in place since September 2011, with only minor design changes since. We’ve begun overhauling the entire site to modernize it and make it more reliable, but in the meantime we’ve done a quick visual refresh to bridge the gap until we finish the transformation.
The following design is scheduled to debut in Firefox 48, and will remain in place until the larger overhaul is complete:

Screenshot of the AMO Style Refresh – coming soon
We started this project by tweaking the existing CSS using the Firefox Page Inspector. This is quite easy and got us visible results for every adjustment we made. Every change we liked was then recorded in a userstyle using Stylish. Adapting style-elements from the Firefox for iOS website, this resulted in AMO looking more modern within hours.

Comparison of AMO style in 2011 and January 2016
This is the first of many improvements that we will bring to the user experience of the add-on ecosystem. Many of them will take some time to be created and implemented, but they will all have a strong focus on its users—both the developers of add-ons and the people using them.
For a preview of the new look, you can install this userstyle.
https://blog.mozilla.org/addons/2016/02/17/amo-style-refresh/
|
|
Air Mozilla: The Hard Way |
 Mozilla's own Caitlin Galimidi is a singer and song-writer with a band called Love, Isabel. Here's their entry into NPR's 2016 Tiny Desk Contest, performed...
Mozilla's own Caitlin Galimidi is a singer and song-writer with a band called Love, Isabel. Here's their entry into NPR's 2016 Tiny Desk Contest, performed...
|
|
Daniel Pocock: FOSSASIA 2016, pgDay Asia 2016 and MiniDebConf Singapore |
The FOSSASIA 2016 conference is taking place next month, 18-20 March at the Science Centre Singapore. The FOSSASIA community has also offered to host a MiniDebConf Singapore 2016 and pgDay Asia 2016. With sufficient interest from volunteers and participants, these events could do a lot to raise the profile of free software in the region.
Applications from speakers and exhibition tables are still possible using the form.
We are currently discussing a Real-time lounge and demo area for FOSSASIA, hopefully with a live linkup to the FSF's LibrePlanet 2016 in Boston.
FOSSASIA have invited a number of developers to speak about SIP, XMPP, WebRTC and peer-to-peer communications solutions. Hopefully exact attendance and scheduling can be publicised soon.
Bringing leading free software developers to Singapore is not easy and further sponsorship is needed to ensure all the speakers who would like to participate can get there. If you or your organization can help with funding or accommodation please email me.
If you want to be selected for Google Summer of Code 2016 and you live in Singapore or a neighbouring country, FOSSASIA could be a great opportunity to meet potential mentors, hack on things together and talk about project ideas. Free software development is a community activity and the more you engage with the community, the more confident mentors are likely to be about selecting you.
For general questions about FOSSASIA 2016 and Singapore, please ask the FOSSASIA mailing list. For questions about the MiniDebConf, see debconf-discuss and for pgDay Asia, please join the pgday-asia mailing list or otherwise try pgsql-general or the seasiapug regional list.
http://danielpocock.com/fossasia-2016-pgday-asia-minidebconf-singapore
|
|
QMO: Firefox 45.0 Beta 7 Testday, February 19th |
Greetings Mozillians,
We are happy to announce that this Friday, February 19th, we are organizing Firefox 45.0 Beta 7 Testday, event focused on WebGL games :-).
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Looking forward to see you on Friday!
https://quality.mozilla.org/2016/02/firefox-45-0-beta-7-testday-february-19th/
|
|
Fr'ed'eric Harper: Open for new contracts |

After a couple of weeks off, I’m back! Actually, it’s been two weeks that I’m working with customers, but I’m now ready to take more. Yes, that mean I decided to do some freelance work right now and have some opening.
Taking in consideration my experience, and my passion, my offering is divided in three focus:
In the coming days, I’ll add detail on what that means for you and why we should work together. I also need to spare some time to work on my business site. Yes, no lion is born king is the name, because in the end, I want to help you be the king of your jungle…
Looking forward to working with you!
http://feedproxy.google.com/~r/outofcomfortzonenet/~3/T7fUB5VlVBY/
|
|






