[Из песочницы] Действия при приходе на работу — прием дел, актуализация, документирование, аудит |
|
Метки: author Scif_yar it- инфраструктура системное администрирование windows |
Какие языки наиболее востребованы в сфере финансов: мнения рекрутеров с Уолл-стрит |

|
Метки: author itinvest программирование блог компании itinvest языки программирования биржа финансы торговые роботы |
[Из песочницы] Flat Cubik (развертка кубика Рубика на плоскость) |

var Tnew = [
[[1, 1, 1], [1, 1, 1], [1, 1, 1]], // синий
[[2, 2, 2], [2, 2, 2], [2, 2, 2]], // белый
[[3, 3, 3], [3, 3, 3], [3, 3, 3]], // зеленый
[[4, 4, 4], [4, 4, 4], [4, 4, 4]], // желтый
[[5, 5, 5], [5, 5, 5], [5, 5, 5]], // оранжевый
[[6, 6, 6], [6, 6, 6], [6, 6, 6]] // красный
]var Tnew = [
[[5, 5, 5], [5, 5, 5], [5, 5, 5]], // оранжевый
[[3, 3, 3], [3, 3, 3], [3, 3, 3]], // зеленый
[[1, 1, 1], [1, 1, 1], [1, 1, 1]], // синий
[[4, 4, 4], [4, 4, 4], [4, 4, 4]], // желтый
[[2, 2, 2], [2, 2, 2], [2, 2, 2]], // белый
[[6, 6, 6], [6, 6, 6], [6, 6, 6]] // красный
]|
Метки: author abcdsash я пиарюсь flat cubik развертка кубика кубик рубика app store apple ios ipad iphone developing |
[Перевод] Увольнять, нанимать, повышать — культура вашей компании |
«Настоящие, а не фейковые ценности компании можно увидеть, посмотрев на то, кого повышают, награждают и с кем расстаются»
– Культура Netflix: Свобода и Ответственность
«Разрыв между вожделенными и практикуемыми ценностями показывает, насколько культура вашей компании нуждается в улучшении. Действия, которые вы предпринимаете для устранения этого разрыва, показывают, насколько это улучшение возможно»
«Несмотря на то что большинство сотрудников заморачивается о том, что думают о них лидеры компании, в реальности им важно то, как ведут себя лидеры, а не то, что они говорят»
«Сотрудники вашей компании практикуют то поведение, которое ценится в компании, а не ценности, в которые вы верите»
«Редиски могут легко замаскироваться во время интервью, но, что бы ни случилось, они не смогут маскироваться всю неделю. Не знаю почему, но за неделю все становится на свои места»
«Момент, в который лидеры компании начинают выбирать между тем, можно ли вести себя только согласно ценностям или нет, является моментом, в который ценности компрометируются»

«Как говорится в старой поговорке, что посеешь, то и пожнешь. Лидеры получают то поведение, которое они вознаграждают»
|
Метки: author Sherbinin управление проектами управление персоналом блог компании райффайзенбанк управление людьми культура сотрудники компании |
[Перевод] Постмортем Super Meat Boy |







|
Метки: author PatientZero разработка игр super meat boy team meat xbla игры для xbox игры для pc |
Определяем номера с помощью CallKit |

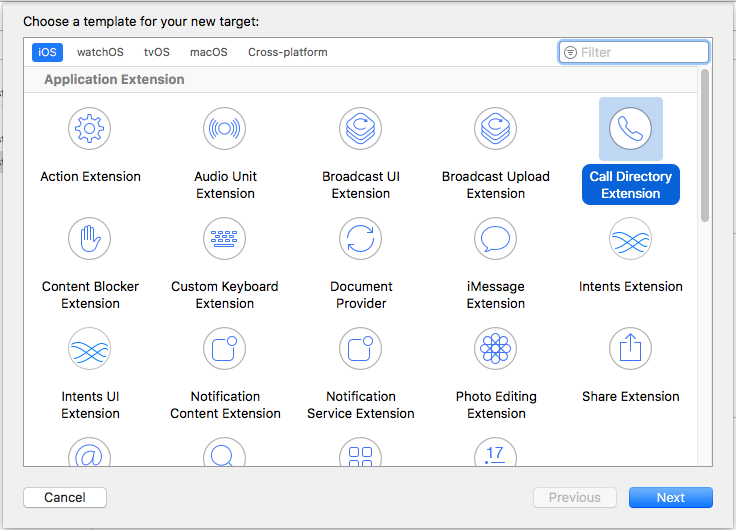
addIdentificationPhoneNumbers. Там вы увидите массивы phoneNumbers и labels. Удалите номера из phoneNumbers, впишите туда тестовый номер. Удалите содержимое массива labels, впишите туда «Test number».private func addIdentificationPhoneNumbers(to context: CXCallDirectoryExtensionContext) throws {
let phoneNumbers: [CXCallDirectoryPhoneNumber] = [ 79214203692 ]
let labels = [ "Test number" ]
for (phoneNumber, label) in zip(phoneNumbers, labels) {
context.addIdentificationEntry(withNextSequentialPhoneNumber: phoneNumber, label: label)
}
}typealias для Int64. Номер должен быть в формате 7XXXXXXXXXX, то есть сначала код страны (country calling code), потом сам номер. Код России +7, поэтому в данном случае пишем 7.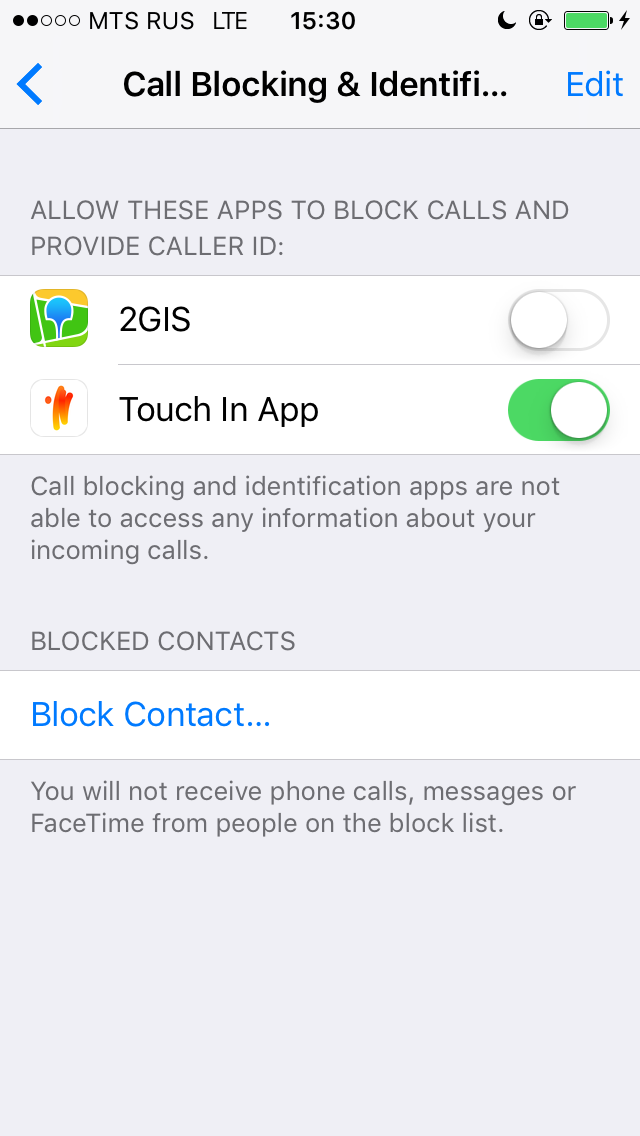
addIdentificationPhoneNumbers из ранее добавленного расширения и считывает оттуда контакты.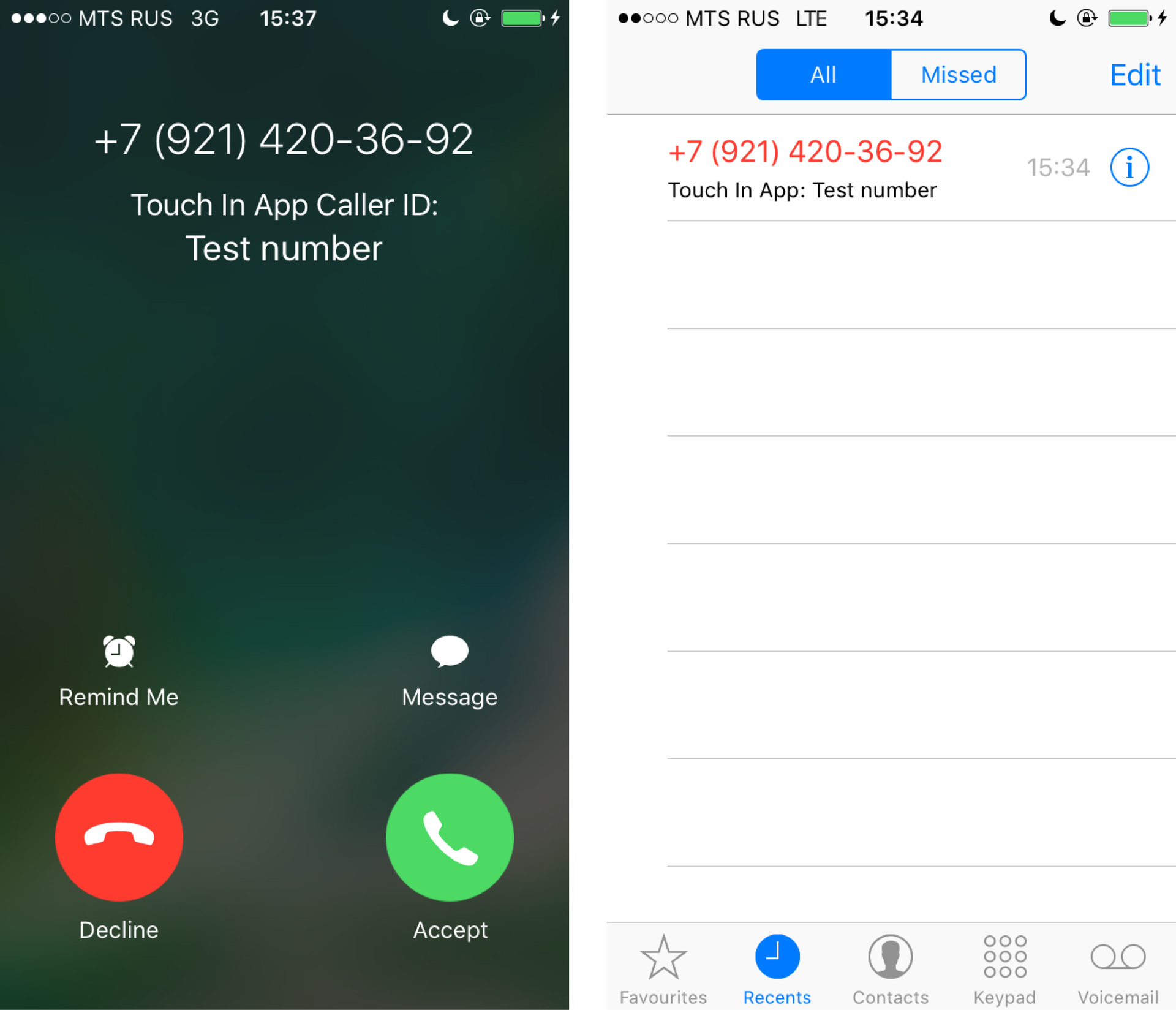
phoneNumbers и labels.reloadExtension, вызов которой приведет к вызову addIdentificationPhoneNumbers. О ней я расскажу чуть позже.
addIdentificationPhoneNumbers, вы наверняка заметили комментарии. Там говорится о том, что «Numbers must be provided in numerically ascending order.». Сортировка выборки из базы слишком ресурсоемка для расширения. Поэтому решение, использующее БД, нам не подходит.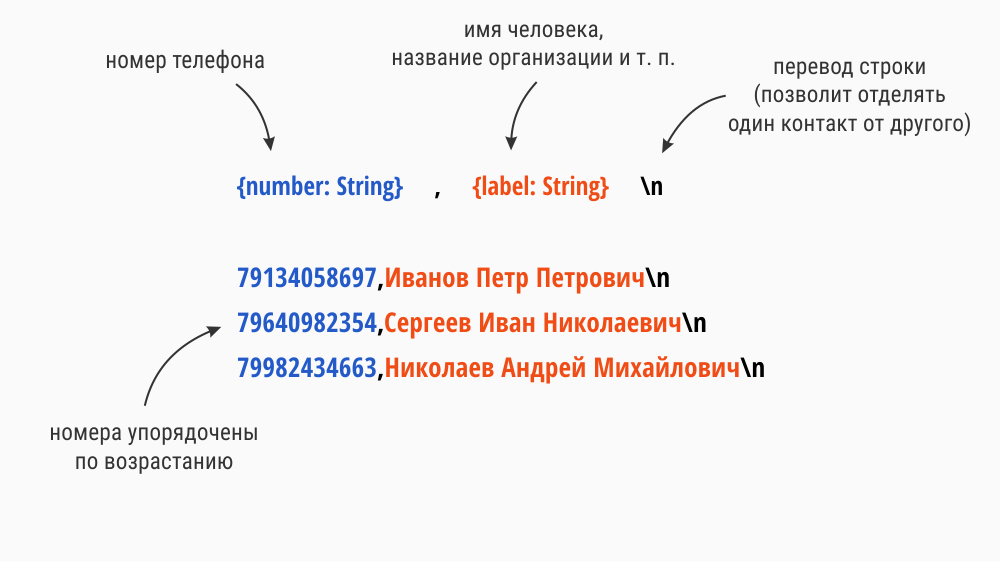

let container = FileManager.default
.containerURL(forSecurityApplicationGroupIdentifier: "group.ru.touchin.TouchInApp")URL:guard let fileUrl = FileManager.default
.containerURL(forSecurityApplicationGroupIdentifier: "group.ru.touchin.TouchInApp")?
.appendingPathComponent("contacts") else { return }let numbers = ["79214203692",
"79640982354",
"79982434663"]
let labels = ["Иванов Петр Петрович",
"Сергеев Иван Николаевич",
"Николаев Андрей Михайлович"]var string = ""
for (number, label) in zip(numbers, labels) {
string += "\(number),\(label)\n"
}
try? string.write(to: fileUrl, atomically: true, encoding: .utf8)CXCallDirectoryManager.sharedInstance.reloadExtension(
withIdentifier: "ru.touchin.TouchInApp.TouchInCallExtension")@IBAction func addContacts(_ sender: Any) {
let numbers = ["79214203692",
"79640982354",
"79982434663"]
let labels = ["Иванов Петр Петрович",
"Сергеев Иван Николаевич",
"Николаев Андрей Михайлович"]
writeFileForCallDirectory(numbers: numbers, labels: labels)
}
private func writeFileForCallDirectory(numbers: [String], labels: [String]) {
guard let fileUrl = FileManager.default
.containerURL(forSecurityApplicationGroupIdentifier: "group.ru.touchin.TouchInApp")?
.appendingPathComponent("contacts") else { return }
var string = ""
for (number, label) in zip(numbers, labels) {
string += "\(number),\(label)\n"
}
try? string.write(to: fileUrl, atomically: true, encoding: .utf8)
CXCallDirectoryManager.sharedInstance.reloadExtension(
withIdentifier: "ru.touchin.TouchInApp.TouchInCallExtension")
}
LineReader вместе с расширением.LineReader путем к файлу. Читаем файл построчно и добавляем контакт за контактом.addIdentificationPhoneNumbers:private func addIdentificationPhoneNumbers(to context: CXCallDirectoryExtensionContext) throws {
guard let fileUrl = FileManager.default
.containerURL(forSecurityApplicationGroupIdentifier: "group.ru.touchin.TouchInApp")?
.appendingPathComponent("contacts") else { return }
guard let reader = LineReader(path: fileUrl.path) else { return }
for line in reader {
autoreleasepool {
// удаляем перевод строки в конце
let line = line.trimmingCharacters(in: .whitespacesAndNewlines)
// отделяем номер от имени
var components = line.components(separatedBy: ",")
// приводим номер к Int64
guard let phone = Int64(components[0]) else { return }
let name = components[1]
context.addIdentificationEntry(withNextSequentialPhoneNumber: phone, label: name)
}
}
}
autoreleasepool. Это позволит освобождать временные объекты и использовать меньше памяти.addContacts телефон будет способен определять номера из массива numbers.|
Метки: author ivan1911 разработка под ios разработка мобильных приложений программирование swift блог компании touch instinct callkit ios |
Android Architecture Components. Часть 3. LiveData |

public class NetworkLiveData extends LiveData {
private Context context;
private BroadcastReceiver broadcastReceiver;
private static NetworkLiveData instance;
public static NetworkLiveData getInstance(Context context){
if (instance==null){
instance = new NetworkLiveData(context.getApplicationContext());
}
return instance;
}
private NetworkLiveData(Context context) {
this.context = context;
}
private void prepareReceiver(Context context) {
IntentFilter filter = new IntentFilter();
filter.addAction("android.net.wifi.supplicant.CONNECTION_CHANGE");
filter.addAction("android.net.wifi.STATE_CHANGE");
broadcastReceiver = new BroadcastReceiver() {
@Override
public void onReceive(Context context, Intent intent) {
WifiManager wifiMgr = (WifiManager) context.getSystemService(Context.WIFI_SERVICE);
WifiInfo wifiInfo = wifiMgr.getConnectionInfo();
String name = wifiInfo.getSSID();
if (name.isEmpty()) {
setValue(null);
} else {
setValue(name);
}
}
};
context.registerReceiver(broadcastReceiver, filter);
}
@Override
protected void onActive() {
prepareReceiver(context);
}
@Override
protected void onInactive() {
context.unregisterReceiver(broadcastReceiver);
broadcastReceiver = null;
}
} public class MainActivity extends LifecycleActivity implements Observer {
private TextView networkName;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
networkName = (TextView) findViewById(R.id.network_name);
NetworkLiveData.getInstance(this).observe(this,this);
//NetworkLiveData.getInstance(this).observeForever(this);
}
@Override
public void onChanged(@Nullable String s) {
networkName.setText(s);
}
} void update(String someText){
ourMutableLiveData.setValue(String);
}
public class MobileNetworkLiveData extends LiveData {
private static MobileNetworkLiveData instance;
private Context context;
private MobileNetworkLiveData(Context context) {
this.context = context;
}
private MobileNetworkLiveData() {
}
@Override
protected void onActive() {
TelephonyManager telephonyManager = (TelephonyManager) context
.getSystemService(Context.TELEPHONY_SERVICE);
String networkOperator = telephonyManager.getNetworkOperatorName();
setValue(networkOperator);
}
public static MobileNetworkLiveData getInstance(Context context) {
if (instance == null) {
instance = new MobileNetworkLiveData(context);
}
return instance;
}
} public class MainActivity extends LifecycleActivity implements Observer {
private MediatorLiveData mediatorLiveData;
private TextView networkName;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
networkName = (TextView) findViewById(R.id.network_name);
mediatorLiveData = new MediatorLiveData<>();
init();
}
private void init() {
final LiveData network = NetworkLiveData.getInstance(this);
final LiveData mobileNetwork = MobileNetworkLiveData.getInstance(this);
Observer networkObserver = new Observer() {
@Override
public void onChanged(@Nullable String s) {
if (!TextUtils.isEmpty(s))
mediatorLiveData.setValue(s);
else
mediatorLiveData.setValue(mobileNetwork.getValue());
}
};
Observer mobileNetworkObserver = new Observer() {
@Override
public void onChanged(@Nullable String s) {
if (TextUtils.isEmpty(network.getValue())){
mediatorLiveData.setValue(s);
}
}
};
mediatorLiveData.addSource(network, networkObserver);
mediatorLiveData.addSource(mobileNetwork,mobileNetworkObserver);
mediatorLiveData.observe(this, this);
}
@Override
public void onChanged(@Nullable String s) {
networkName.setText(s);
}
}
, где T — это типизация входящей LiveData, а P желаемая типизация исходящей, по факту же каждый раз когда будет происходить изменения в входящей LiveData она будет нотифицировать нашу исходящую, а та в свою очередь будет нотифицировать подписчиков после того как переконвертирует тип с помощью нашей реализации Function. Весь этот механизм работает за счет того что по факту исходящая LiveData, является MediatiorLiveData.
LiveData location = ...;
LiveData locationString = Transformations.map(location, new Function() {
@Override
public String apply(Location input) {
return input.toString;
}
}); LiveData location = ...;
LiveData getPlace(Location location) = ...;
LiveData userName = Transformations.switchMap(location, new Function>() {
@Override
public LiveData apply(Location input) {
return getPlace(input);
}
});
|
|
Правила хорошего тона для API |
$out = '';
$module = "console";
$testRunner = new PHPUnit_TextUI_TestRunner();
$testPrinter = new ZeroTech_printer($out);
$testRunner->setPrinter($testPrinter);
$testSuite = new PHPUnit_Framework_TestSuite();
foreach (glob(U_PATH . "/tests/*test.php") as $filename)
{
$testSuite->addTestFile($filename);
}
$testRunner->doRun($testSuite, array("verbose" => true));

FORMAT: 1A
# Group User
## /user
### GET - Получение данных профиля пользователя [GET]
+ Response 200 (application/json)
+ Attributes
+ first_name: Иван (required, string) - Имя пользователя (только русские символы)
+ last_name: Иванов (required, string) - Фамилия пользователя (только русские символы)
+ dob: 1988-10-01 (required, string) - Дата рождения
+ sex: 1 (required, number) - Пол (0 - женский, 1 - мужской)
+ city: Москва (required, string) - Город
### POST - Создание нового пользователя [POST]
+ Request (application/json)
+ Attributes
+ first_name: Иван (required, string) - Имя пользователя (только русские символы)
+ last_name: Иванов (required, string) - Фамилия пользователя (только русские символы)
+ dob: 1988-10-01 (required, string) - Дата рождения
+ sex: 1 (required, number) - Пол (0 - женский, 1 - мужской)
+ city: Москва (required, string) - Город
+ Response 201
{
message: “Successfully created”,
id: 123
}

|
Метки: author ValeriaVG совершенный код проектирование и рефакторинг api блог компании zerotech phpunit php |
Security Week 29: Как взломать ICO, RCE-баг в десятках миллионах инсталляций, Nukebot пошел в народ |
 Взломать одностраничный сайт на Wordpress и украсть $7,7 млн – это теперь не сценарий безграмотного кино про хакеров, а состоявшаяся реальность. Технологии! Все же заметили повальное увлечение ICO? Это как IPO, когда компания впервые выпускает свои акции и продает их через биржу. Только не акции, а токены, не через биржу, а напрямую, и строго за криптовалюту.
Взломать одностраничный сайт на Wordpress и украсть $7,7 млн – это теперь не сценарий безграмотного кино про хакеров, а состоявшаяся реальность. Технологии! Все же заметили повальное увлечение ICO? Это как IPO, когда компания впервые выпускает свои акции и продает их через биржу. Только не акции, а токены, не через биржу, а напрямую, и строго за криптовалюту. 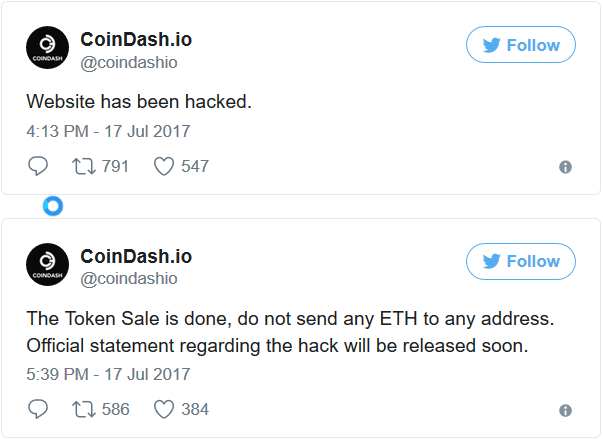
 Новость. Исследование. Вести из мира интернета вещей весьма однообразны, однако тренд прослеживается вполне апокалиптичный – чем дальше в лес, тем больше дыр. А все потому, что когда исследователю-безопаснику нечем заняться, он берет первый попавшийся IoT-девайс, за полчаса находит там уязвимость, прикидывает число проданных экземпляров, и вот на тебе, сценарий очередного роутеркалипсиса во всех профильных изданиях!
Новость. Исследование. Вести из мира интернета вещей весьма однообразны, однако тренд прослеживается вполне апокалиптичный – чем дальше в лес, тем больше дыр. А все потому, что когда исследователю-безопаснику нечем заняться, он берет первый попавшийся IoT-девайс, за полчаса находит там уязвимость, прикидывает число проданных экземпляров, и вот на тебе, сценарий очередного роутеркалипсиса во всех профильных изданиях!

|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw ico wordpress coindash iot nukebot |
RubyMine 2017.2: Docker Compose, автокоррекции RuboCop в редакторе, улучшенный VCS |

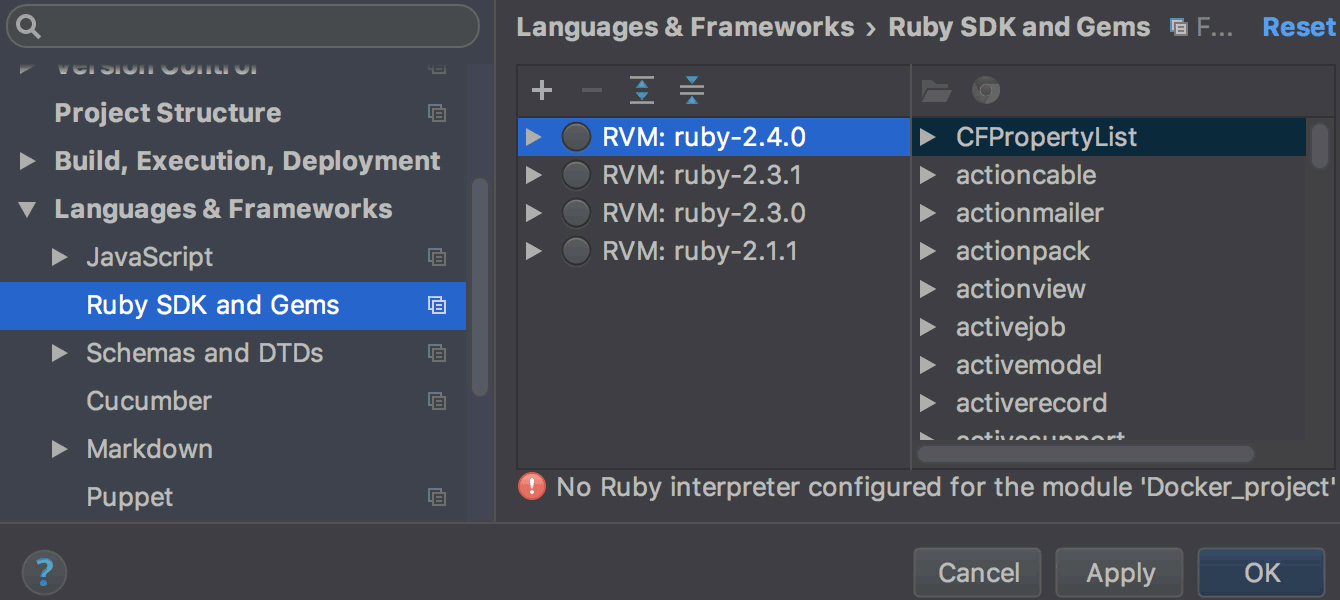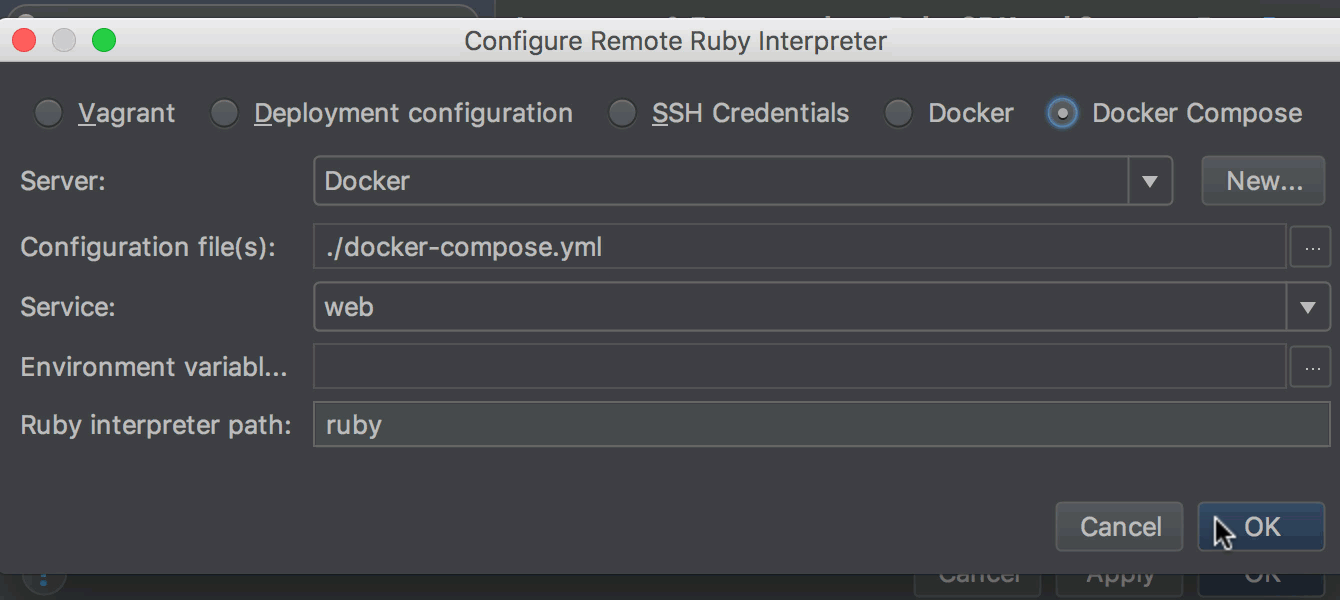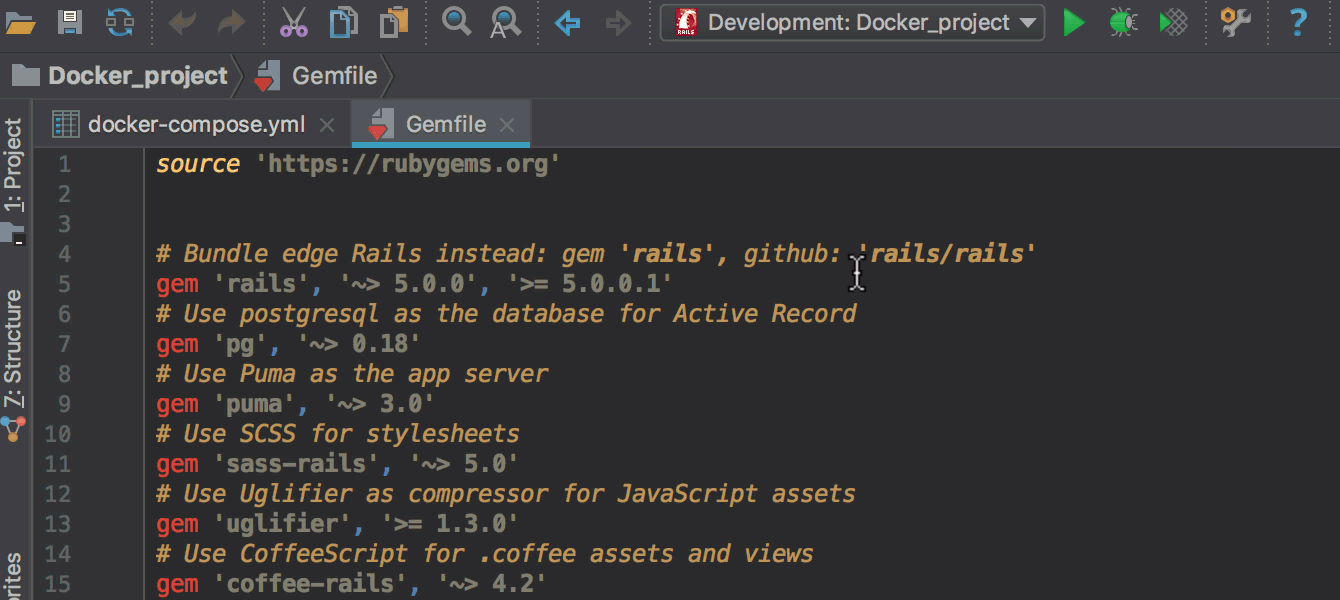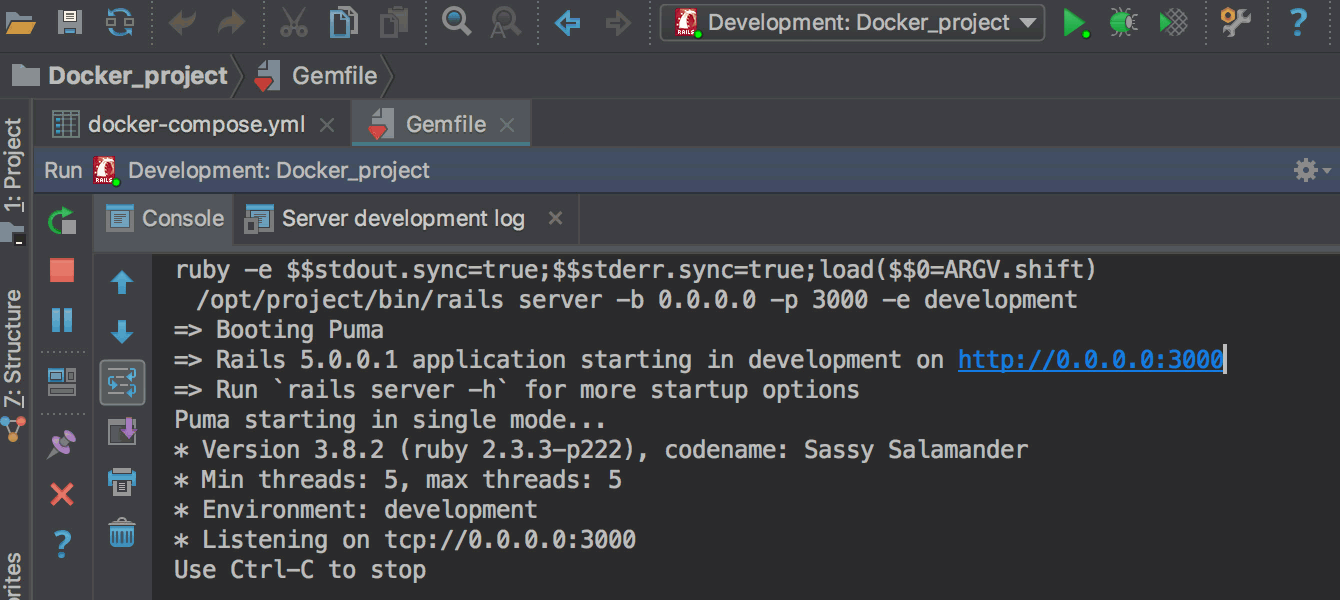
Gemfile нужно добавить гемы ruby-debug-ide и debase и установить их через команду docker-compose build, запускаемую прямо из редактора Gemfile вместо bundle install. Об этом также подробнее в блоге.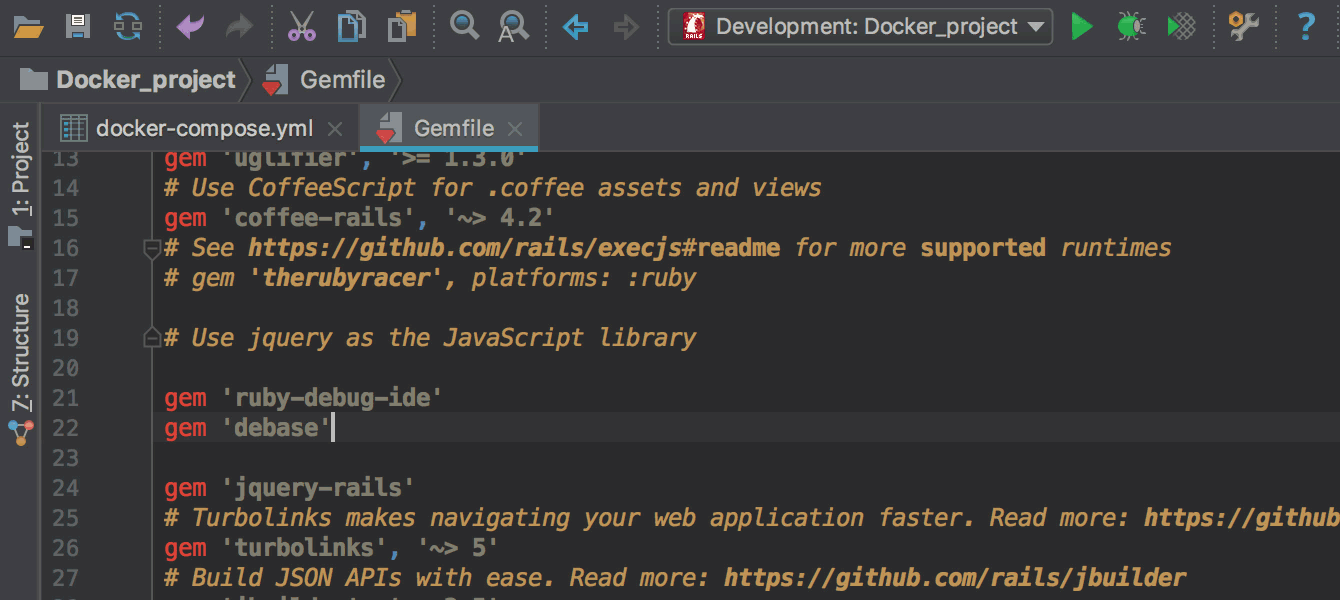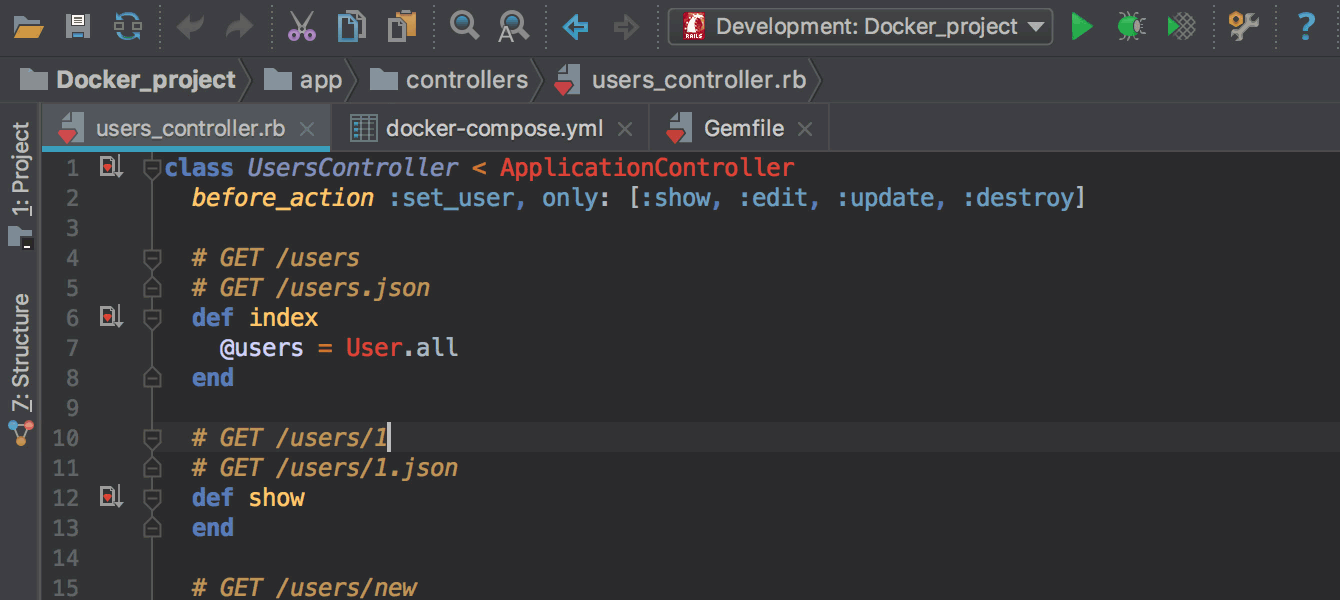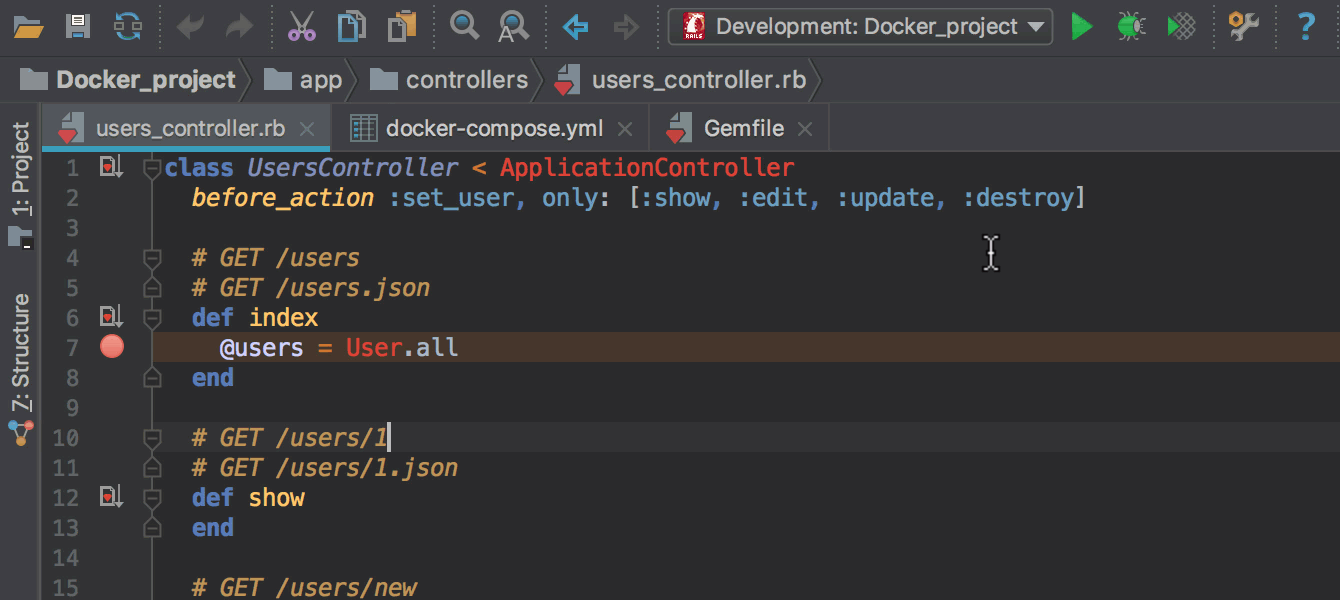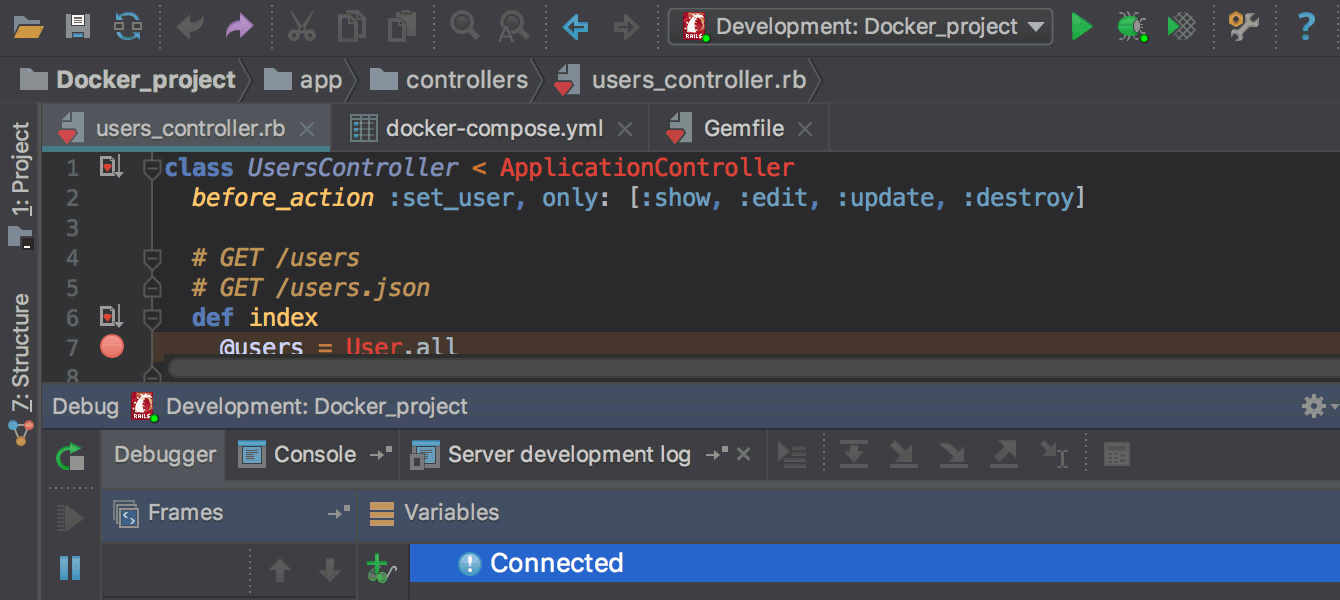
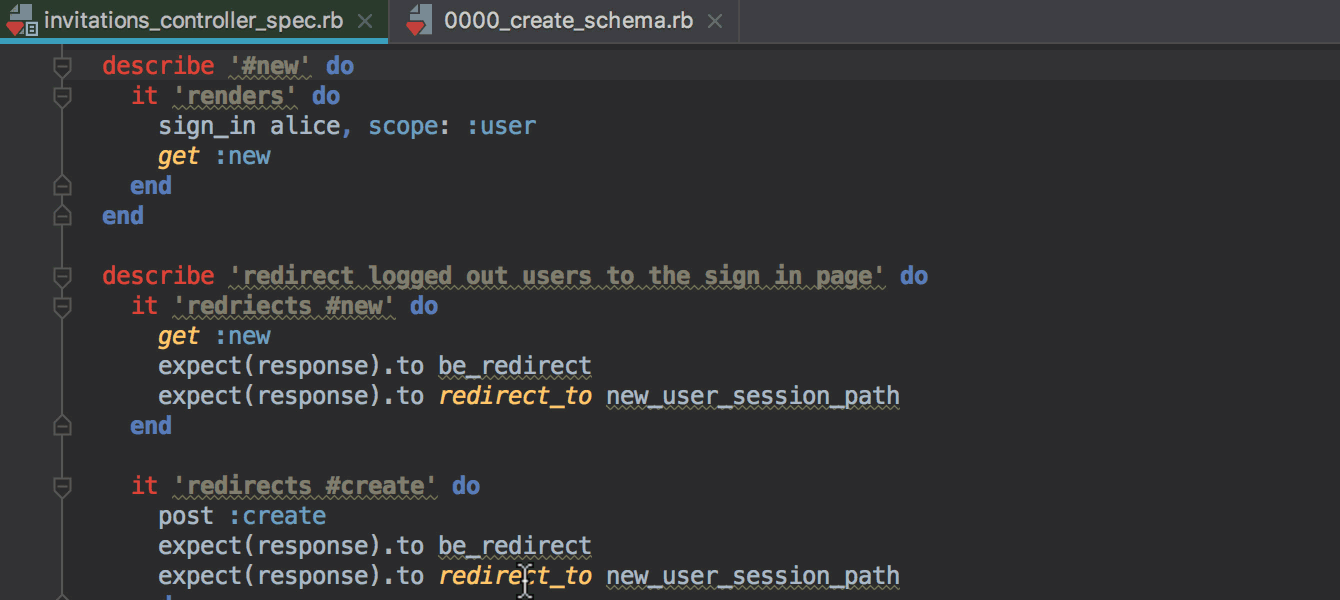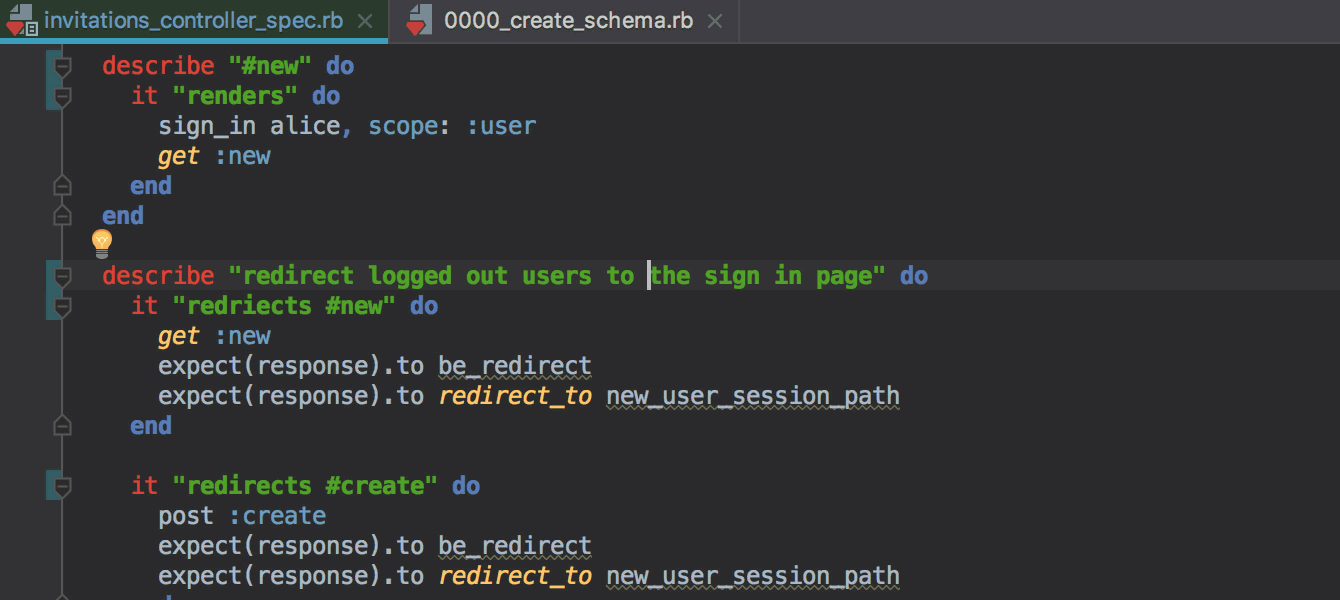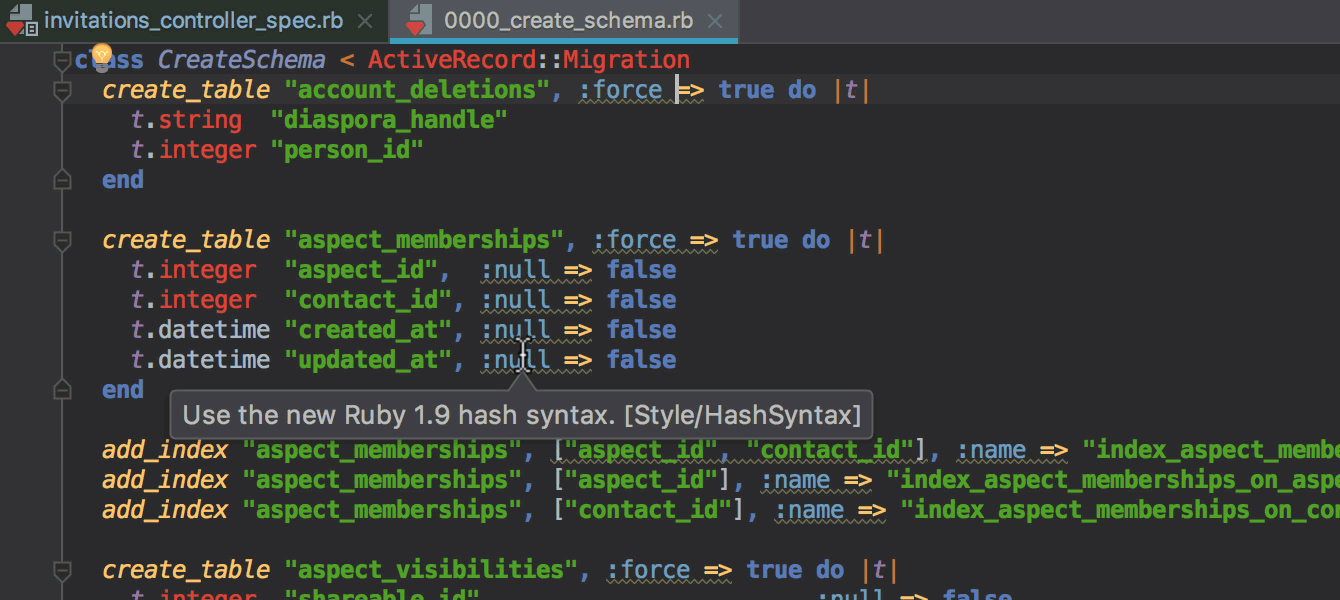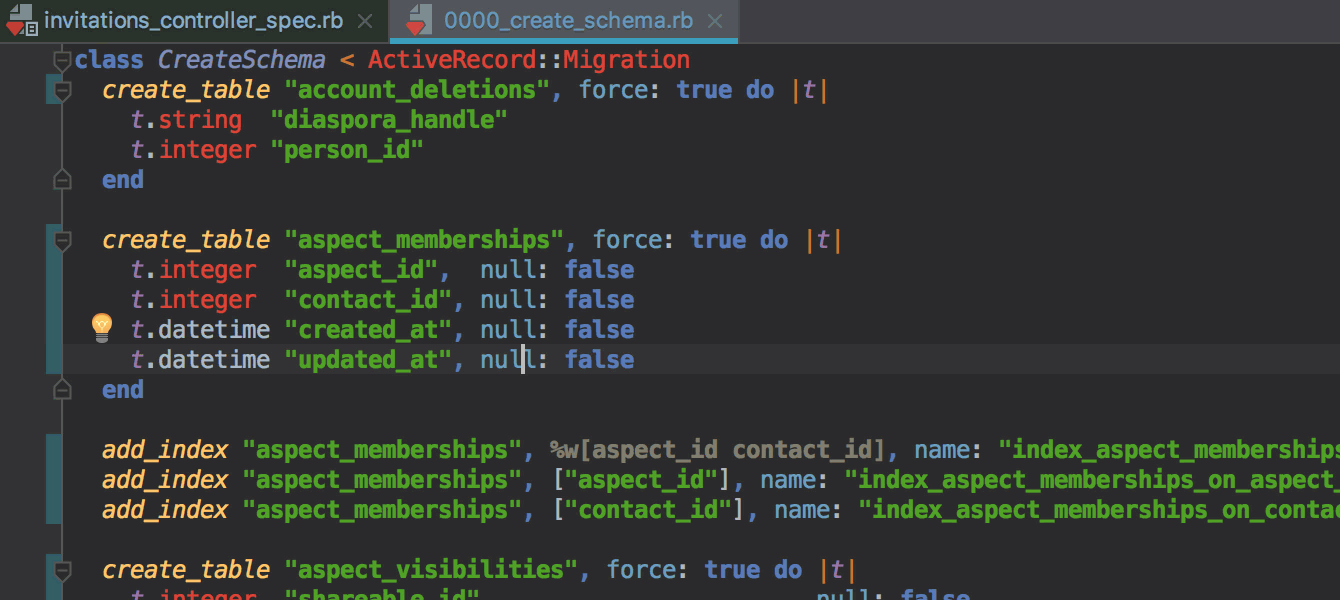
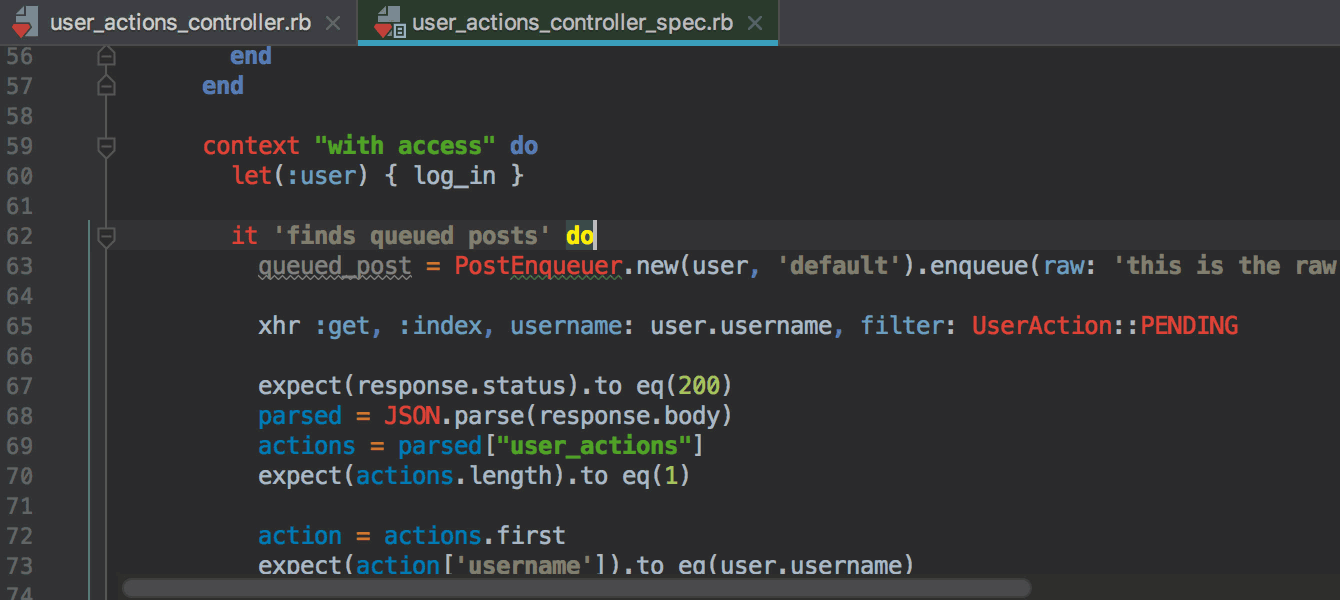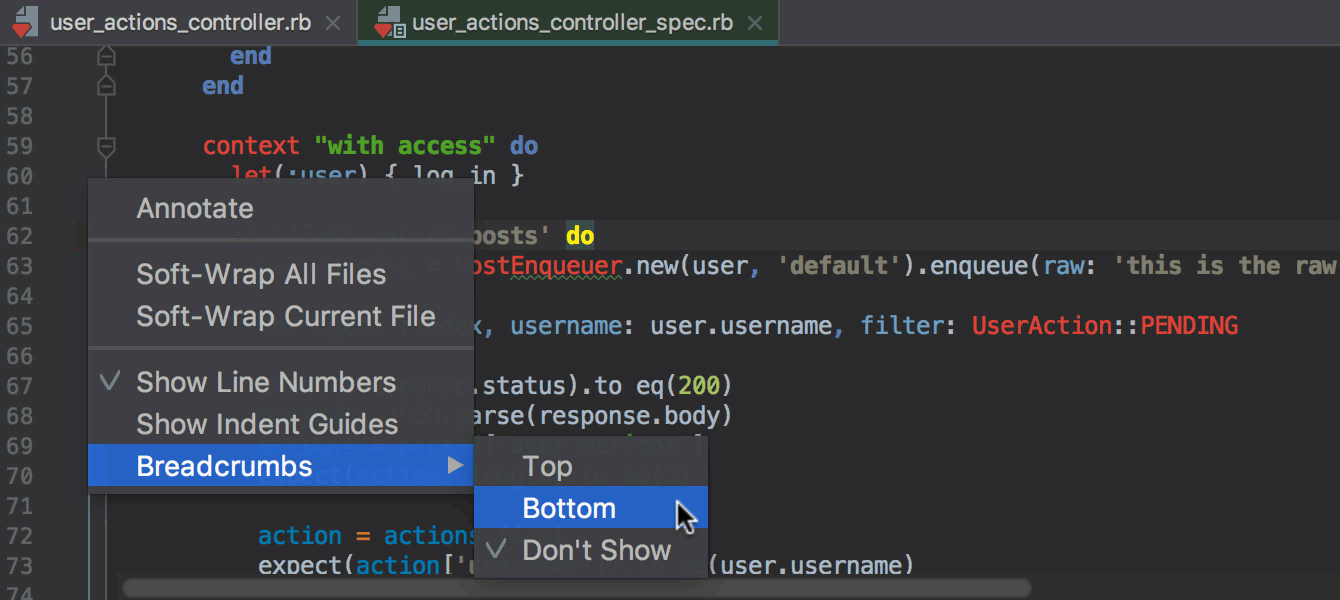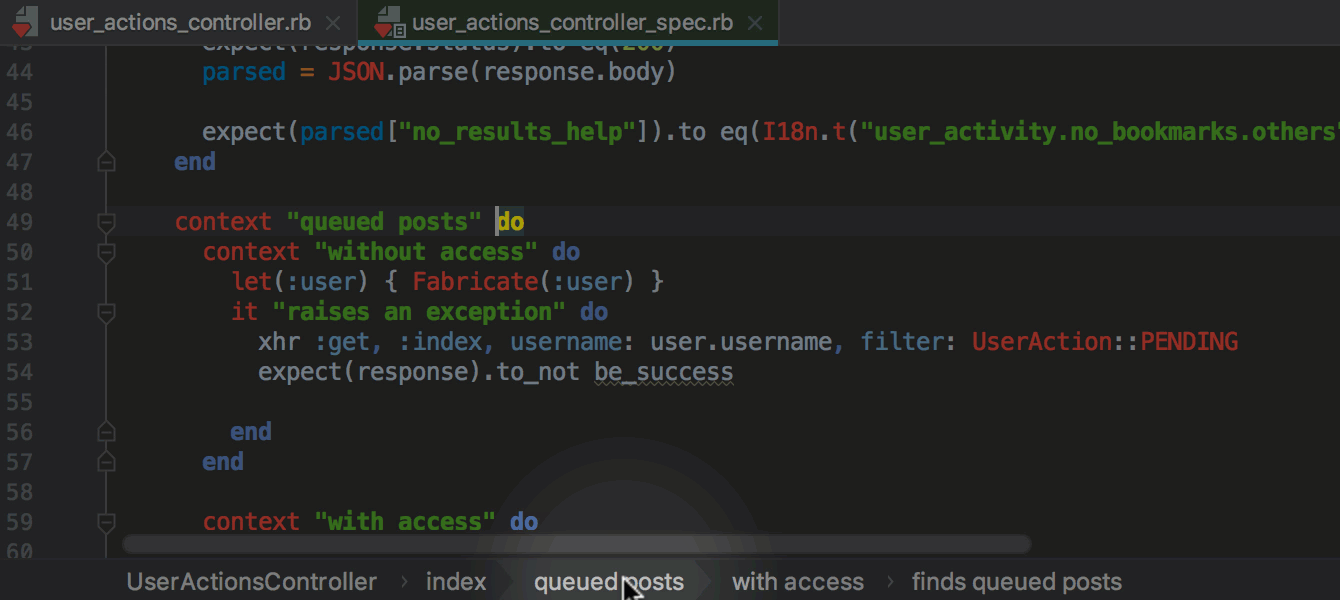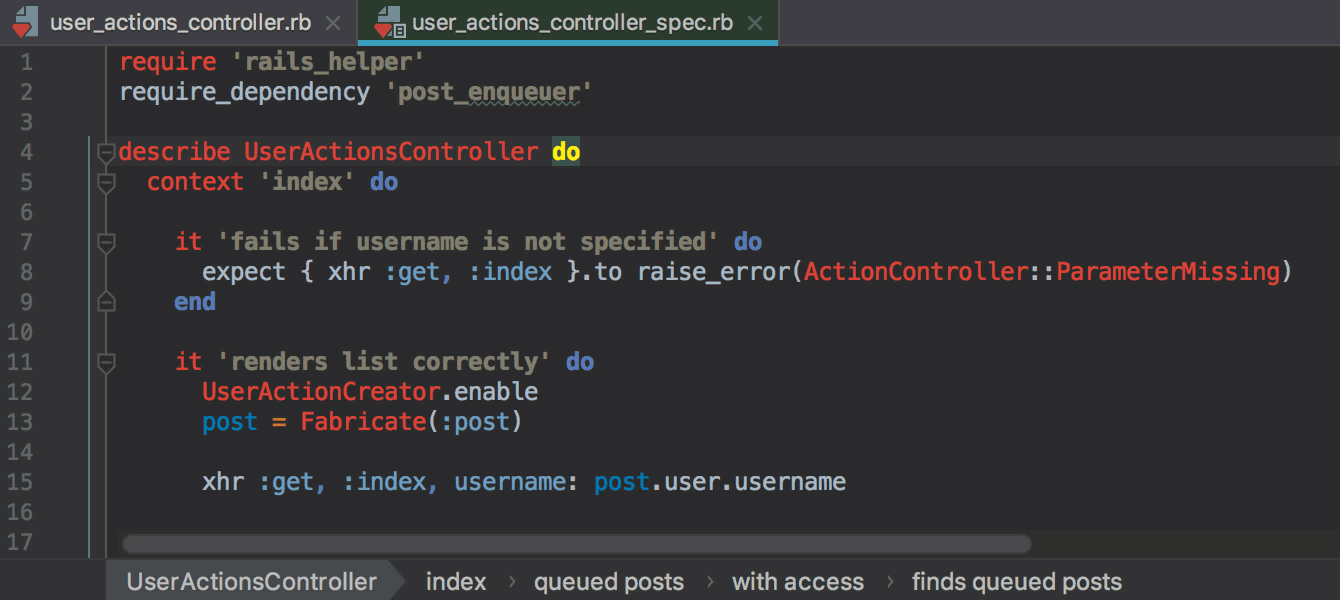
webpack.config.js..eslintrc в настройки форматирования в IDE и будет применять их автоматически при форматировании.git revert в IDE, позволяющая сделать Revert выбранных комитов. 



|
Метки: author artysark ruby on rails ruby блог компании jetbrains rubymine javascript web- разработка программирование docker docker-compose rubocop |
Что читать о нейросетях |

Нейросети переживают второй Ренессанс. Сначала еще казалось, что сообщество, решив несколько прикладных задач, быстро переключится на другую модную тему. Сейчас очевидно, что спада интереса к нейросетям в ближайшем будущем не предвидится. Исследователи находят новые способы применения технологий, а следом появляются стартапы, использующие в продукте нейронные сети.
Стоит ли изучать нейросети не специалистам в области машинного обучения? Каждый для себя ответит на этот вопрос сам. Мы же посмотрим на ситуацию с другой стороны — что делать разработчикам (и всем остальным), которые хотят больше знать про методы распознавания образов, дискриминантный анализ, методы кластеризации и другие занимательные вещи, но не хотят расходовать на эту задачу лишние ресурсы.
Ставить перед собой амбициозную цель, с головой бросаться в онлайн-курсы — значит потратить много времени на изучение предмета, который, возможно, вам нужен лишь для общего развития. Есть один проверенный (ретроградный) способ, занимающий по полчаса в день. Книга — офлайновый источник информации. Книга не может похвастаться актуальностью, но за ограниченный период времени даст вам фундаментальное понимание технологии и способов ее возможной реализации под ваши задачи.

Если у вас уже есть базовые знания в области машинного обучения, и вы хотите двигаться дальше, то авторы «Neural Network Toolbox для MATLAB» предложат вам четкое и подробное погружение в фундаментальные основы архитектуры нейронных сетей и методов обучения. Методы обучения приводятся как для нейронных сетей прямого распространения (включая многослойные и радиальные сети), так и для рекуррентных сетей. Дополнительно к книге можно получить иллюстрации и код для примеров (сайт).

Священная книга сверточных нейронных сетей и глубокого обучения — без шуток, это действительно очень важная книга, которую рекомендуют многие успешные разработчики… и не только они. «Написанная тремя экспертами, "Deep Learning" является единственной всеобъемлющей книгой в этой области», — так сказал Илон Маск, и если вы верите в надежность автопилота Tesla и перспективы проекта OpenAI, то ему можно верить. :)
Книга предлагает математический инструментарий и фундаментальные основы, охватывающие линейную алгебру, теории вероятностей и теории информации, численные методы и непосредственно машинное обучение. В «Deep Learning» описываются методы глубокого обучения, используемые специалистами-практиками в промышленности, в том числе глубокие сети прямого распространения, алгоритмы оптимизации, сверточные сети, методы Монте-Карло, построение сетевой модели и т.д. Кроме того, вы узнаете много интересного про обработку естественного языка, распознавание речи, компьютерное зрение, системы рекомендаций, биоинформатику и даже игры. Проще сказать, чего в этой книге нет… хотя и это сложно — если вы чего-то не найдете на 800 страницах, есть еще сайт к книге с дополнительными материалами.
P.S. Электронная версия книги выложена в открытый доступ.

Классика жанра, фундаментальный труд 1996 года из эры до глубокого обучения. Если вы хотите не только познакомиться с предметом машинного обучения, но и стать специалистом в этой области, стоит познакомиться и с таким взглядом на проблематику. В книге меньше (по сравнению с другими в этой подборке) чистой математики, вместо этого делается попытка дать читателю интуитивное понимание концепции нейронных сетей. Делается это за счет глубины подхода — нет попыток сходу написать свою сеть; автор сначала предлагает изучить теоретические законы и модели на примере биологии. Не будем забывать, что каждый человек обладает своей собственной нейронной сетью. На простых примерах показывается, как изменяются свойства моделей, когда вводятся общие вычислительные элементы и сетевые топологии.

Если вам понравится предыдущая книга из подборки, то можете усилить знания схожим по концепции изданием 2006 года. «Распознавание образов и машинное обучение» стал первым учебником по распознаванию образов, представляющим Байесовский метод (хотя сама формула Байеса была опубликована аж в 1763 году). В книге представлены алгоритмы вывода, которые позволяют быстро найти ответы в ситуациях, когда точные ответы невозможны. Автор Кристофер Бишоп, директор лаборатории Microsoft Research Cambridge, первым дал пояснение графическим моделям для описания вероятностных распределений.
P.S. В 2013 году подразделение Microsoft Research выпустила в открытый доступ отдельную книгу Deep Learning.

Одна из лучших книг по основам машинного обучения (в связке с Python), написанная за несколько лет до того, как нейросети обрели культовый статус. Но возраст ей не помеха — методы коллаборативной фильтрации, байесовская фильтрация, метод опорных векторов сохраняют актуальность. Затрагиваются принципы работы поисковых систем (поисковые роботы, индексы, механизмы запросов и алгоритм PageRank), алгоритмы оптимизации, неотрицательная матричная факторизация и другие темы.

Пошаговое путешествие по математике нейронных сетей к созданию собственных сеток с помощью Python. Большой плюс книги — заниженные требования к объему знаний читателя. В области математики потребуются лишь школьные знания (без глубокого погружения). Авторы поставили себе цель дать представление о нейросетях самому широкому кругу читателей. Похвально, учитывая, как много книг написано для продвинутых специалистов.
После прочтения вы сможете сделать главное: писать код на Python, создавать свои собственные нейронные сети, обучая их распознавать различные изображения, и даже создавать решения на базе Raspberry Pi. Математика в книге тоже есть, но она не заставит кричать от ужаса (что возможно, если область вашей деятельности сильно далека от алгоритмов) — математические идеи, лежащие в основе нейронных сетей, даются с большим количеством иллюстраций и примеров.
P.S. Если вы заинтересовались, но не можете заниматься по книге, рекомендуем одноименный блог с большим количеством полезных статей.

«Машинное обучение на Python» это сборник полезных советов для начинающих специалистов по машинному обучению. Почему Python? Так автор захотел, просто ему язык нравится. Себастьян Рашка объясняет самые общие концепции, дополняет их необходимым математическим аппаратом для понимания темы на внутрисистемном уровне, приводит примеры и объясняет способы реализации. Также есть репозиторий на GitHub с общей информацией и примерами кода. Планируется перевод книги на русский язык.

Эта книга кратко познакомит вас с миром машинного обучения. Кроме того, читателям предоставляется бесплатный доступ к онлайн-главам, которые постоянно обновляются в соответствии с тенденциями в области машинного обучения. Это книга рекомендуется тем, кто только-только начал знакомиться с предметом и не понимает, что значит высказывание «обучение на массиве данных».
Авторы соблюдают баланс между теоретической и практической частью машинного обучения. Эта книга используется в качестве учебного пособия в Калифорнийском технологическом институте, Политехническом институте Ренсселера (США) и Национальном университете Тайваня. Авторы также активно консультируются с финансовыми и коммерческими компаниями по приложениям, использующим машинное обучение.

Популярная книга от известных авторов Stuart Russell и Peter Norvig, которая пережила уже третье издание. Полное, современное введение в теорию и практику искусственного интеллекта, предназначенное для учащихся первых курсов вуза. Книга используется в качестве введения в тему на огромном количестве курсов по Data science и ИИ. Если вас интересует применение нейросетей именно для создания искусственного интеллекта, с нее можно начать путь в этой увлекательной и очень сложной области.
Artificial Intelligence: A Modern Approach есть в открытом доступе.

Эта «книга» не совсем книга — у нее даже обложки нет. Но перед вами действительно полноценное издание, выложенное в открытый доступ (по ссылке выше). Майкл Нильсен дает отличное введение в нейронные сети в серии пошаговых примеров, посвященных проблемам распознавания рукописных цифр. Книга хорошо подходит для тех, у кого уже есть опыт машинного обучения, и хочется глубже вникнуть в нейронные сети.
Теперь даже программисты, которые почти ничего не знают о технологии глубокого машинного обучения, могут использовать простые и эффективные инструменты для создания самообучающихся программ.
Что касается книг по нейросетям на русском, то отзывы о них противоречивые. «Нейронные сети. Полный курс» Саймона Хайкина отличается повышенной сложностью и неоднозначным переводом (но если вас не пугает, можете ознакомиться). Найти книгу, которая была бы на таком же уровне качества, как и другие издания в подборке, нам так и не удалось. Если вы можете что-то порекомендовать, напишите в комментариях.
|
Метки: author randall профессиональная литература программирование обработка изображений машинное обучение блог компании mail.ru group книги нейросеть глубокое обучение ии |
[Перевод] Сети Docker изнутри: как Docker использует iptables и интерфейсы Linux |
Я познакомился с Docker довольно давно и, как и большинство его пользователей, был мгновенно очарован его мощью и простотой использования. Простота является основным столпом, на котором основывается Docker, чья сила кроется в легких CLI-командах. Когда я изучал Docker, я захотел выяснить, что происходит у него в бэкграунде, как вообще все происходит, особенно что касается работы с сетью (для меня это одна из самых интересных областей).
Я нашел много разной документации о том, как создавать контейнерные сети и управлять ими, но в отношении того, как именно они работают, материалов намного меньше. Docker широко использует Linux iptables и bridge-интерфейсы для создания контейнерных сетей, и в этой статье я хочу подробно рассмотреть именно этот аспект. Информацию я почерпнул, в основном, из комментариев на github-е, разных презентаций, ну и из моего собственного опыта. В конце статьи можно найти список полезных ресурсов.
Я использовал Docker версии 1.12.3 для примеров в этой статье. Я не ставил своей целью дать исчерпывающее описание Docker-сетей или написать полное введение в эту тему. Я надеюсь, что этот материал будет полезен для пользователей, и я буду рад, если вы в комментариях оставите обратную связь, укажете на ошибки или скажете, чего недостает.
Сеть Docker построена на Container Network Model (CNM), которая позволяет кому угодно создать свой собственный сетевой драйвер. Таким образом, у контейнеров есть доступ к разным типам сетей и они могут подключаться к нескольким сетям одновременно. Помимо различных сторонних сетевых драйверов, у самого Docker-а есть 4 встроенных:
Сетевые драйвера Bridge и Overlay, возможно, используются чаще всего, поэтому в этой статье я буду больше уделять им внимание.
По умолчанию для контейнеров используется bridge. При первом запуске контейнера Docker создает дефолтную bridge-сеть с одноименным названием. Эту сеть можно увидеть в общем списке по команде docker network ls:
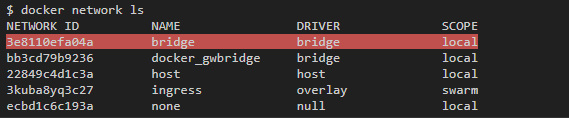
Чтобы проинспектировать ее свойства, запустим команду docker network inspect bridge:
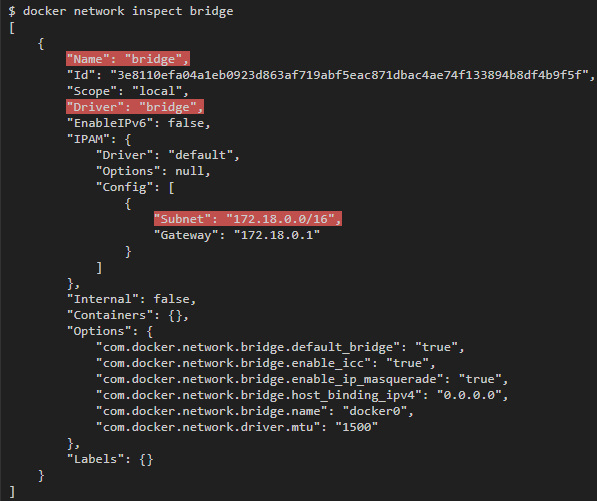
Вы также можете создать свои собственные bridge-сети при помощи команды docker network create, указав опцию --driver bridge.
Например, команда docker network create --driver bridge --subnet 192.168.100.0/24 --ip-range 192.168.100.0/24 my-bridge-network создает еще одну bridge-сеть с именем “my-bridge-network” и подсетью 192.168.100.0/24.
Каждая bridge-сеть имеет свое представление в виде интерфейса на хосте. С сетью “bridge”, которая стоит по умолчанию, обычно ассоциируется интерфейс docker0, и с каждой новой сетью, которая создается при помощи команды docker network create, будет ассоциироваться свой собственный новый интерфейс.
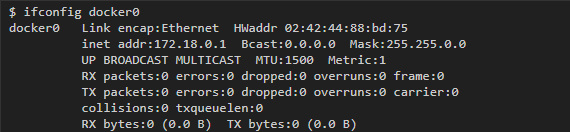
Чтобы найти интерфейс, который ассоциируется с сетью, которую вы создали, введите команду ifconfig, чтобы вывести все интерфейсы, а затем найти тот интерфейс, который относится к созданной вами подсети. Например, если нам надо найти интерфейс для сети my-bridge-network, которую мы только что создали, то можно запустить такую команду:

Bridge-интерфейсы Linux похожи на свичи тем, что они присоединяют несколько интерфесов к одной подсети и перенаправляют трафик на основе MAC-адресов. Как будет видно ниже, у каждого контейнера, привязанного к bridge-сети, будет свой собственный виртуальный интерфейс на хосте, и все контейнеры в одной сети будут привязаны к одному интерфейсу, что позволит им передавать друг другу данные. Можно получить больше данных о статусе моста при помощи утилиты brctl:

Как только мы запустим контейнеры и привяжем их к этой сети, интерфейс каждого из этих контейнеров будет выведен в списке в отдельной колонке. А если включить захват трафика в bridge-интерфейсе, то можно увидеть, как передаются данные между контейнерами в одной подсети.
Container Networking Model дает каждому контейнеру свое собственное сетевое пространство. Если запустить команду ifconfig внутри контейнера, то можно увидеть его интерфейсы такими, какими их видит сам контейнер:
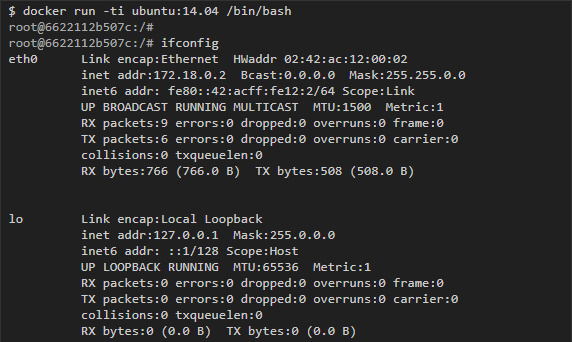
Впрочем, eth0, который представлен в этом примере, можно увидеть только изнутри контейнера, а снаружи, на хосте, Docker создает соответствующую копию виртуального интерфейса, которая служит связью с внешним миром. Затем эти виртуальные интерфейсы соединяются с bridge-интерфейсами, о которых мы говорили выше, чтобы легче установить связь между разными контейнерами в одной подсети.
Чтобы рассмотреть этот процесс, для начала запустим два контейнера, связанных с дефолтной bridge-сетью, а затем посмотрим на конфигурацию интерфейса хоста.
До запуска каких-либо контейнеров у bridge-интерфейса docker0 нет никаких других присоединенных интерфейсов:

Затем я запустил два контейнера на образе ubuntu:14.04:

Сразу стало видно, что два интерфейса присоединены к bridge-интерфейсу docker0 (по одному на каждый контейнер):

Если начать пинговать Google с одного из контейнеров, то захват трафика с хоста на виртуальном интерфейсе контейнера покажет нам трафик контейнеров:
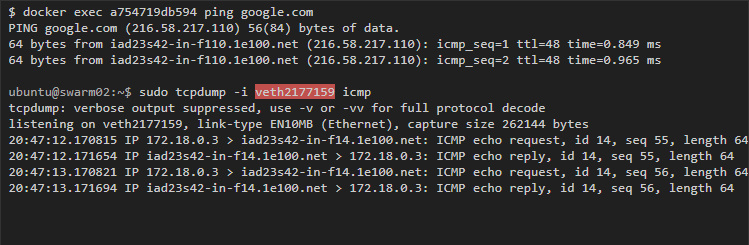
Аналогично можно выполнить пинг от одного контейнера к другому.
Во-первых, надо получить IP-адрес контейнера. Это можно сделать либо при помощи команды ifconfig, либо при помощи docker inspect, что позволяет проинспектировать контейнер:

Затем начинаем пинг от одного контейнера к другому:

Чтобы увидеть трафик с хоста, мы можем сделать захват на любом из виртуальных интерфейсов, которые соотносятся с контейнерами, либо на bridge-интерфейсе (в данном случае docker0), что покажет нам все коммуникации внутри контейнеров данной подсети:

Если вы хотите узнать, какой veth-интерфейс хоста привязан к интерфейсу внутри контейнера, то простого способа вы не найдете. Однако, есть несколько методов, которые можно найти на разных форумах и в обсуждениях на github. Самый простой, на мой взгляд, способ я почерпнул из этого обсуждения на github, немного его изменив. Он зависит от того, присутствует ли ethtool в контейнере.
Например, у меня в системе запущены 3 контейнера:

Для начала, я выполняю следующую команду в контейнере и получаю номер peer_ifindex:

Затем на хосте я использую peer_ifindex, чтобы узнать имя интерфейса:

В данном случае интерфейс называется veth7bd3604.
Docker использует linux iptables, чтобы контролировать коммуникации между интерфейсами и сетями, которые он создает. Linux iptables состоят из разных таблиц, но нам в первую очередь интересны только две из них: filter и nat. Таблица filter содержит правила безопасности, которые решают, допускать ли трафик к IP-адресам или портам. С помощью таблицы nat Docker дает контейнерам в bridge-сетях связываться с адресатами, которые находятся снаружи хоста (иначе пришлось бы добавлять маршруты к контейнерным сетям в сети хоста).
Таблицы в iptables состоят из различных цепочек, которые соответствуют разным состояниям или стадиям обработки пакета на хосте. По умолчанию, у таблицы filter есть 3 цепочки:
Input для обработки входящих пакетов, предназначенных для того же хоста, на который они приходят;
Output для пакетов, возникающих на хосте, предназначенных для внешнего адресата;
Forward для обработки входящих пакетов, предназначенных для внешнего адресата.
Каждая цепочка включает в себя правила, которые определяют, какие действия и при каких условиях надо применить к пакету (например, отклонить или принять его). Правила обрабатываются последовательно, пока не будет найдено соответствие, иначе применяются дефолтные правила цепочки. Также в таблице можно задать кастомные цепочки.
Чтобы увидеть текущие правила цепочки и дефолтные установки в таблице filter, запустите команду iptables -t filter -L или iptables -L, если таблица filter используется по умолчанию и не указана никакая другая таблица:

Жирным выделены разные цепочки и дефолтные установки для каждой из них (у кастомных цепочек дефолтных установок нет). Также видно, что Docker добавил две кастомные цепочки: Docker и Docker-Isolation, также добавил правила в цепочку Forward, целью которых являются эти две новые цепочки.
Docker-isolation содержит правила, которые ограничивают доступ между разными сетями. Чтобы узнать подробности, добавляйте -v, когда запускаете iptables:
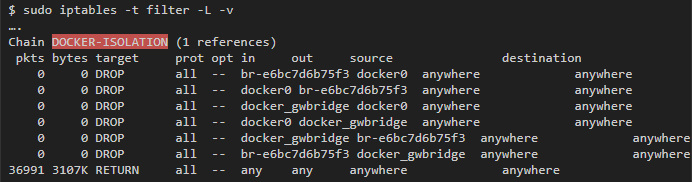
Можно увидеть несколько правил DROP, которые блокируют трафик между всеми bridge-интерфейсами, которые создал Docker, и таким образом не дают сетям обмениваться данными.
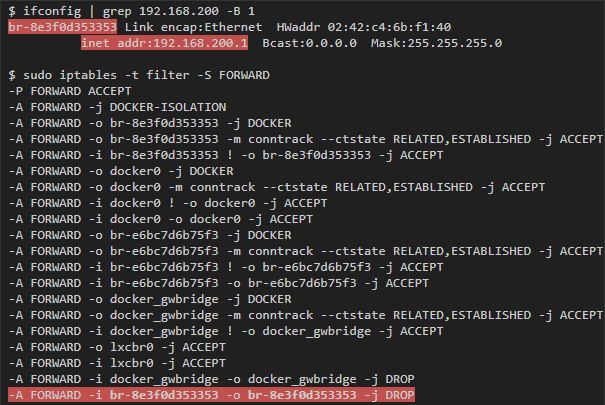
Одна из опций, которую можно передать команде docker network create, — это опция, которая отвечает за передачу данных внутри контейнера: com.docker.network.bridge.enable_icc. Если задать ей значение false, то передача данных между контейнерами внутри одной сети будет заблокирована. Для этого нужно добавить DROP-правило в цепочку forward, которое соответствует пакетам, приходящим от bridge-интерфейса, связанного с сетью для данного интерфейса.
Например, если создать новую сеть при помощи команды docker network create --driver bridge --subnet 192.168.200.0/24 --ip-range 192.168.200.0/24 -o "com.docker.network.bridge.enable_icc"="false" no-icc-network, то мы получим следующее:
С помощью nat можно поменять IP-адрес или порт пакета. В данном случае он используется, чтобы за IP-адресом хоста спрятать адреса источников пакетов, которые приходят от bridge-сетей (например, хосты в подсети 172.18.0.0/24) и направлены во внешний мир. Эта фича контролируется опцией com.docker.network.bridge.enable_ip_masquerade, которую можно передать docker network create (если не задать ничего специфического, то по умолчанию будет значение true).
Результат этой команды можно увидеть в таблице nat:

В этой цепочке postrouting можно увидеть все сети, которые созданы под действием masquerade, которое применяется, когда они передают данные любому хосту вне своей собственной сети.
|
Метки: author r-moiseev системное администрирование сетевые технологии devops docker docker swarm iptables |
[recovery mode] Openstack. Детективная история или куда пропадает связь? Часть третья |

Какой адрес у маршрутизатора должен быть по-умолчанию в сети – это большой вопрос. На самом деле ничто не мешает ему быть любым адресом из подсети. И сочинители OpenStack тоже решили – давайте будет первый, что мучиться?
В итоге ты опомниться не успеваешь, как всё падает. Почему? Потому что неожиданно для всех default gw оказывается не на роутере, как ему положено, а на твоём опенстеке. Клиенты звонят, шеф лютует. А ты ищешь очередную причину падения. Просто коллега отцепил существующий адрес с целью замены, а опенстек оказался хитрее…
В некоторых случаях проблема возникает сразу, в некоторых – нет. Напомню: старая проблема состояла в том, что периодически начинались пропадания части IP-пакетов.
Попытаюсь немного оправдаться. – часто наши проблемы совпадали с наличием внешних атак. При этом во многих случаях казалось, что проблемы именно в перегруженных каналах. В каких-то случаях мы превышали лимит каналов и пакеты действительно дропались. Это усугублялось наличием заражённых машин в платформе, которые генерировали неимоверный объём внутреннего трафика. Плюс неисправности сетевого оборудования, в котором, из-за ошибок программистов тоже убивались не те пакеты. Кроме того, конфигурационные файлы просто огромны.
Я не робот и не волшебник – понять функционал опций можно при вдумчивом чтении, но нужны ли они в конкретном контексте – было совершенно не ясно. Пришлось интуитивно угадывать, проверяя самые разумные предположения на практике.
Поэтому мне с коллегами сложно было отделить и выявить проблему. Хуже того – в созданной вновь ферме проблема не возникала. Мы сгенерировали триста машин, и всё работало, как часы. Конечно мы тут же мы стали готовить её в «продакшн». Это подразумевало введение «рваных» диапазонов ip адресов. Мы очистили ферму, убрав эти самые триста машин. И вдруг, при наличии всего трёх тестовых виртуальных машин случилось то же, что и на старой ферме – стали пропадать пакеты, в большом количестве. Так мы определились, что проблема где-то в глубине OpenStack.
В старой ферме мы нашли относительно простой способ эту проблему обходить. Это делалось отрыванием внутреннего IP адреса и назначением его из другой подсети – нам при этом приходилось часто добавлять новые подсети. Проблема на какое-то время уходила. Часть машин при этом работала хорошо.
В ходе долго расследования, прерываемые на проектные работы, отвлекаемые проблемами от VIPов, мы всё-таки смогли выявить несколько ошибок. Кроме того, эти самые файлы различаются, если вы используете контроллер в качестве вычислительного узла, и если не используете. В одной из первых удачных конфигураций, мы его использовали. Затем от этого отказались. Часть настроек –осталась. Таким образом в двух из девяти машин были неправильные настройки (на вычислительные узлы попал параметр не dvr, а dvr-snat). В конце концов я нашёл правильный параметр и поставил на место.
Без понимания того, как работает виртуальный роутер – где же он берёт настройки, пришлось настраивать и его. Он, по идее, должен быть с одним адресом и, соответственно, с одним мак-адресом. Логично? Мы так рассуждали и соответственно настраивали с коллегой.
В какой-то момент при расследовании проблем с DHCP (см. часть 2) я нашёл задваивающиеся мак-адреса. Не один, два, а гораздо больше. Вот это номер!
Было принято решение сменить параметры настройки base_mac и dvr_base_mac. Теперь в каждой вычислительной машине и в каждом контроллере эти параметры разные.
Мы с самого начала ещё не включили l2population – ну просто руки не доходили. А в новой ферме включили. И гляди, после всех таких изменений – заработало! Мало того – пинги перестали пропадать от слова «вообще»! Раньше нет-нет, да и пропадёт пакетик просто так – 0,1% и мы считали, что это вообще неплохо. Потому что гораздо хуже, когда пропадала четверть, а то и половина.
Сутки терпеливо выждав (а ведь хотелось бегать, с криками «всё заработало!»), мы применили подобные изменения и в старой ферме. Вторая неделя – полёт нормальный.
Вывод: конечно же, всего этого не случилось бы, если бы мы настраивали не вручную, а через автоматизированный инсталлятор. Однако полученный опыт бесценен.
|
Метки: author JohnSelfiedarum серверное администрирование облачные вычисления виртуализация *nix openstack linux neutron |
Разработка мобильных приложений с помощью SAP Cloud Platform SDK для iOS, часть 1 |

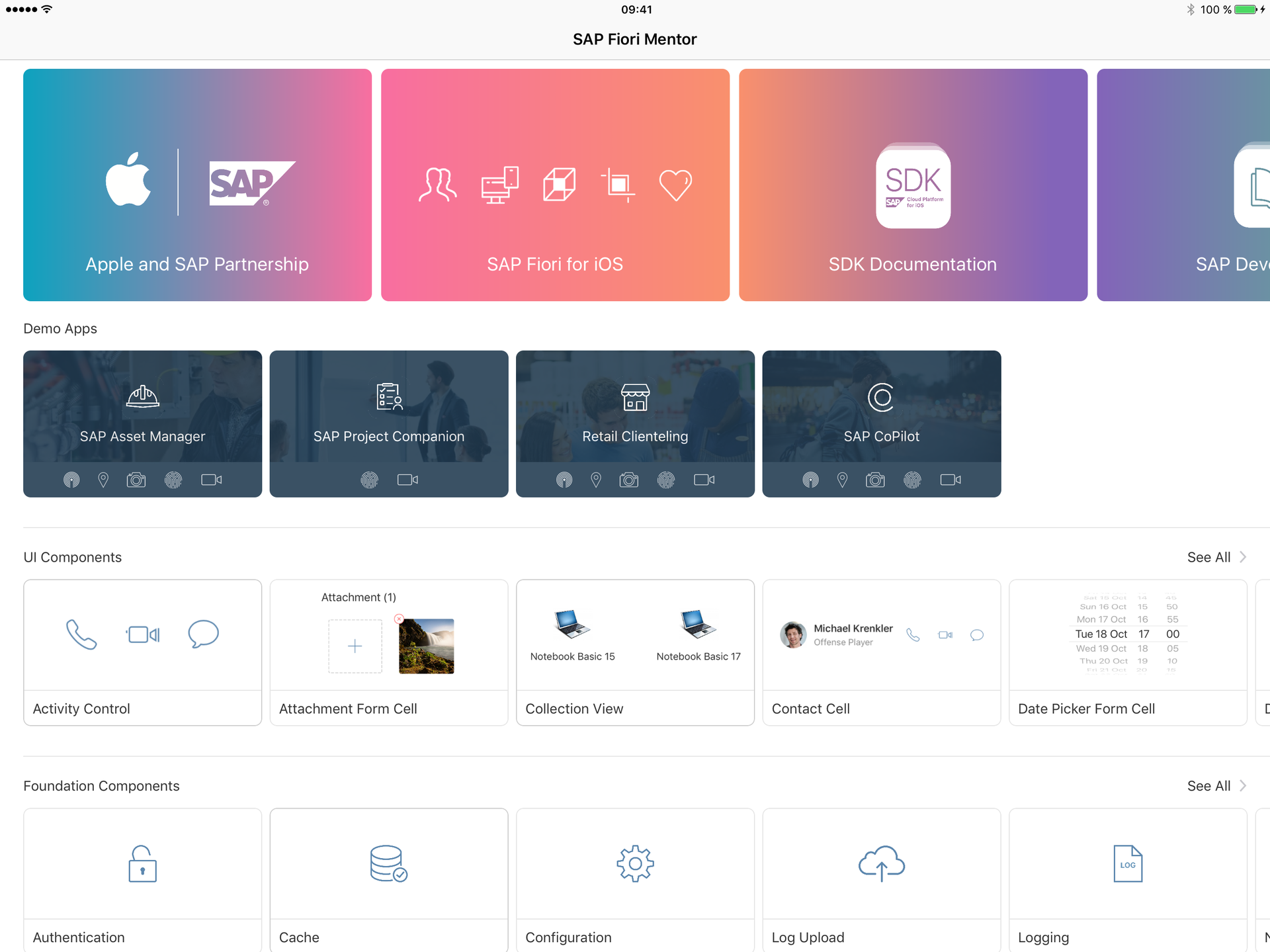
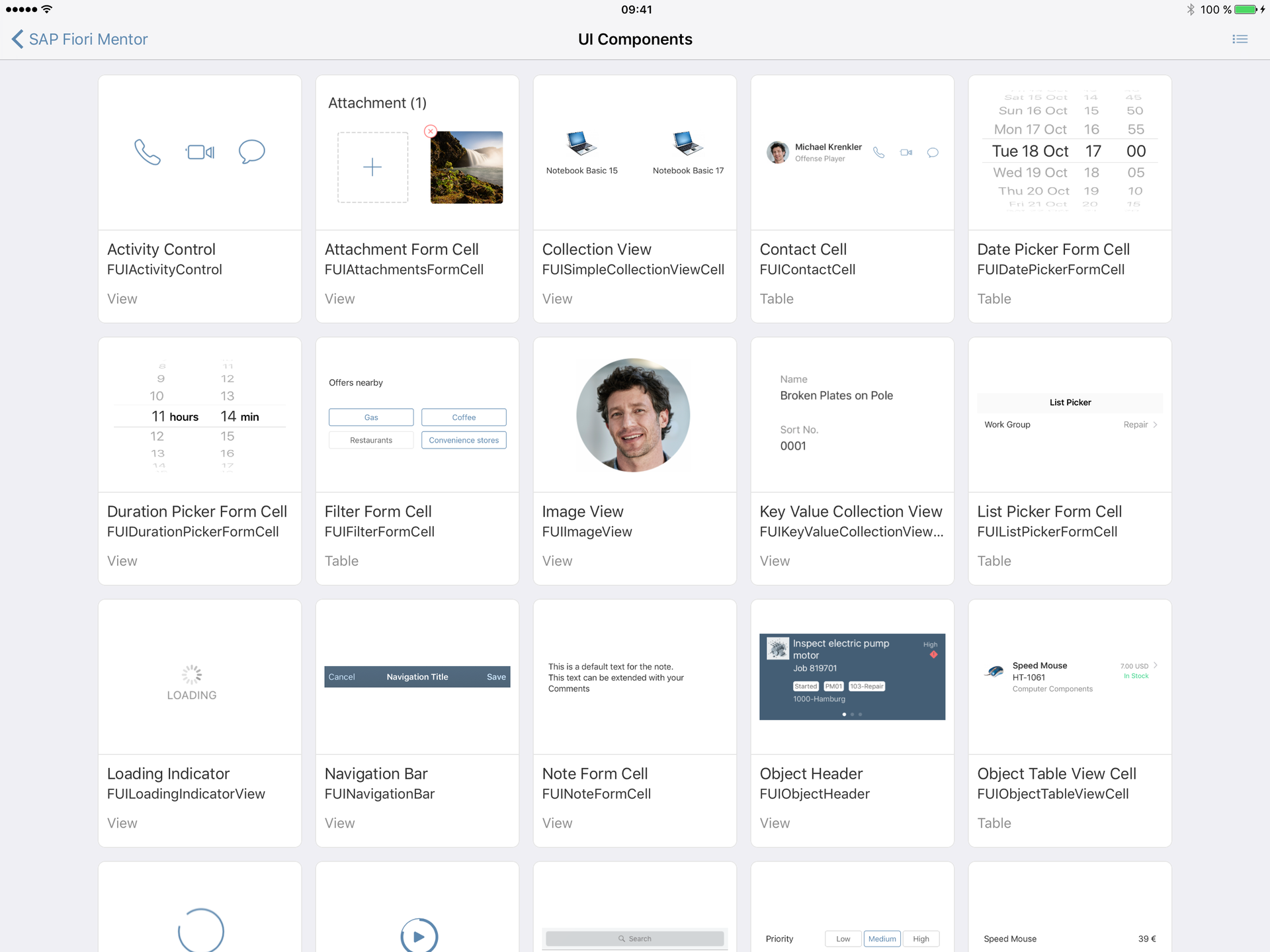
|
|
[Из песочницы] Red Architecture — красная кнопка помощи для сложных и запутанных систем |


using System;
using System.Collections.Generic;
using System.Collections.ObjectModel;
namespace Common
{
public enum k {OnMessageEdit, MessageEdit, MessageReply, Unused, MessageSendProgress, OnMessageSendProgress, OnIsTyping, IsTyping, MessageSend, JoinRoom, OnMessageReceived, OnlineStatus, OnUpdateUserOnlineStatus }
public class v : ObservableCollection >
{
static v i;
static v sharedInstance()
{
if (i == null)
i = new v();
return i;
}
public static void h(System.Collections.Specialized.NotifyCollectionChangedEventHandler handler)
{
i.CollectionChanged += handler;
}
public static void m(System.Collections.Specialized.NotifyCollectionChangedEventHandler handler)
{
i.CollectionChanged -= handler;
}
public static void Add(k key, object o)
{
i.OnCollectionChanged(new System.Collections.Specialized.NotifyCollectionChangedEventArgs(System.Collections.Specialized.NotifyCollectionChangedAction.Add,
new List>(new KeyValuePair[] { new KeyValuePair(key, o) })));
}
protected v()
{
}
}
}
void OnEvent(object sener, NotifyCollectionChangedEventArgs e)
{
if (e.Action == NotifyCollectionChangedAction.Add)
{
var newItem = (KeyValuePair)e.NewItems[0];
if (newItem.Key == k.OnMessageSendProgress)
{
var d = (Dictionary)newItem.Value;
if ((string)d["guid"] == _guid && (ChatMessage.Status)d["status"] == ChatMessage.Status.Deleted)
{
Device.BeginInvokeOnMainThread(() =>
{
FindViewById(Resource.Id.message).Text = "";
});
}
}
else if (newItem.Key == k.OnMessageEdit)
{
var d = (Dictionary)newItem.Value;
if ((string)d["guid"] == _guid)
{
Device.BeginInvokeOnMainThread(() =>
{
FindViewById(Resource.Id.message).Text = (string)d["message"];
});
}
}
}
}
var newItem = (KeyValuePair)e.NewItems[0];
if (newItem.Key == k.OnMessageSendProgress)
Device.BeginInvokeOnMainThread(() =>
{
FindViewById(Resource.Id.message).Text = "";
});
FindViewById(Resource.Id.message).Text = "";
string s = Response.ResponseObject["success"].ToString();
success = Convert.ToBoolean(s);
if (success)
{
var r = Response.ResponseObject["data"].ToString();
if(r.Contains("status")) // response not empty
{
Dictionary retVal = JsonConvert.DeserializeObject>(r);
// convert status from web to internal type
retVal["status"] = (ChatMessage.Status)Enum.ToObject(typeof(ChatMessage.Status), retVal["status"]);
await PersistanceService.GetCacheMessagePersistance().UpdateItemAsync(retVal);
v.Add(k.OnMessageSendProgress, retVal);
}
}
|
Метки: author anagovitsyn проектирование и рефакторинг c# xamarin red architecture архитектура clean architecture mobile development мобильная разработка |
Жизнь разработчика на Кипре |




|
Метки: author t13s карьера в it-индустрии кипр солнце воздух и вода иммиграция |
Отчет с Science Slam Digital 7 июля |

7 июля Science Slam Digital собрал в нашем офисе более 600 зрителей, а число просмотров трансляции в соцсетях Одноклассники и ВКонтакте превысило 420 тысяч. Формат Science Slam зародился в Германии семь лет назад для популяризации научных достижений среди простых обывателей. Он состоит из серии научных лекций, которые читают молодые ученые. Доклад участника должен быть коротким (10 минут), доступным и информативным. Победителя слема определяют с помощью определения громкости аплодисментов зрителей шумометром.
Нам очень понравился этот формат, и мы захотели провести свой Science Slam, только цифровой, чтобы рассказать о технологиях просто и понятно. О том, что происходит внутри компании и чем занимаются сотрудники. Шесть разработчиков рассказали гостям и зрителям трансляции, что можно определить по почте, не открывая самих писем; как выяснить возраст человека в социальных сетях, даже если он не указан; какие тренды в медиапотреблении можно выделить уже сейчас и как они влияют на восприятие информации; как модифицировать социальную сеть, которой пользуются 100 миллионов человек, чтобы у них ничего не сломалось. Как это у нас получилось, вы можете посмотреть по нашим докладам.
Ян Романихин (руководитель команды машинного обучения Почты Mail.Ru): «Когда умрет электронная почта? Не сегодня»
Борис Ребров (руководитель разработки клиентской части в группе frontend-разработки медиапроектов): «Как технологии меняют медиа»
Вячеслав Шебанов (старший разработчик ВКонтакте): «Как менять сервис, которым пользуются 100 миллионов человек»
Виталий Худобахшов (разработчик отдела дата-майнинга Одноклассников): «Как узнать возраст человека в социальной сети, даже если он не указан»
Дмитрий Суконовалов (руководитель направления аналитики):«Как вернуть ушедшего пользователя»
Алексей Петров (директор по качеству в отделе тестирования Почты Mail.Ru): «Баги есть? А если найду?»
Записи видеотрансляций доступны во ВКонтакте и Одноклассниках. А здесь можно найти фотоотчет с мероприятия и видеоотчет. В ноябре у нас состоится новый Science Slam Digital, но на этот раз он будет межкорпоративным. Встретимся осенью!
|
Метки: author mary_arti программирование big data блог компании mail.ru group science slam digital mail.ru одноклассники вконтакте |
Чёрная Лямбда ефрейтора Волкова: новое направление и гранты на летнюю школу |
|
|
Bitfury Group провела 1-ю транзакцию в Lightning Network c использованием биткойн-протокола |
 / изображение Vadim Kurland CC
/ изображение Vadim Kurland CC«Это крупное достижение нашей технической команды и важный шаг на пути к росту сети Lightning и биткойна, — говорит Валерий Вавилов, CEO Bitfury Group. — Lightning Network способна решить проблему масштабирования биткойн-блокчейна и предоставить функциональность мгновенных платежей. Продемонстрировав состоятельность LN-концепции, мы проложили путь дальнейшему развитию биткойна»Программное обеспечение, написанное разработчиками Bitfury, базируется на протоколе LND (Lightning Network Daemon), разрабатываемом Lightning Labs. Модифицированный код можно найти по ссылке на GitHub.
d8dc019280a8531fdcf26e350874fe3100c06925306f002d85c943d9c215609e 8a4bf5481b12ee572639454939bef0d5e5b1a92bb3892db431ebb88f944e3f90
5e1ddeb8ebdc1a8603e6294546858da3e432af532f2b71ba0fc2214a9ecafd0c 00843a49178ba5304d1940945312d66e066dc59f96a006d04c21adbb4f074656
|
Метки: author alinatestova платежные системы блог компании bitfury group bitfury блокчейн биткойн lightning network |
[Перевод] MVC на чистом JavaScript |


PenguinController занимается обработкой событий и служит посредником между представлением и моделью. Он выясняет, что произошло, когда пользователь выполняет некое действие (например, щёлкает по кнопке или нажимает клавишу на клавиатуре). Логика клиентских приложений может быть реализована в контроллере. В более крупных системах, в которых нужно обрабатывать множество событий, этот элемент можно разбить на несколько модулей. Контроллер является входной точкой для событий и единственным посредником между представлением и данными.PenguinView взаимодействует с DOM. DOM — это API браузера, с помощью которого работают с HTML. В MVC только представление отвечает за изменения DOM. Представление может выполнять подключение обработчиков событий пользовательского интерфейса, но обработка событий — прерогатива контроллера. Основная задача, решаемая представлением — управлять тем, что пользователь видит на экране. В нашем проекте представление будет выполнять манипуляции с DOM, используя JavaScript.PenguinModel отвечает за работу с данными. В клиентском JS это означает выполнение Ajax-операций. Одно из преимуществ шаблона MVC заключается в том, что всё взаимодействие с источником данных, например — с сервером, сосредоточено в одном месте. Такой подход помогает программистам, которые не знакомы с проектом, разобраться в нём. Модель в этом шаблоне проектирования занята исключительно работой с JSON или объектами, которые поступают с сервера.
var PenguinController = function PenguinController(penguinView, penguinModel) {
this.penguinView = penguinView;
this.penguinModel = penguinModel;
};PenguinController.prototype.initialize = function initialize() {
this.penguinView.onClickGetPenguin = this.onClickGetPenguin.bind(this);
};
PenguinController.prototype.onClickGetPenguin = function onClickGetPenguin(e) {
var target = e.currentTarget;
var index = parseInt(target.dataset.penguinIndex, 10);
this.penguinModel.getPenguin(index, this.showPenguin.bind(this));
};this.showPenguin():PenguinController.prototype.showPenguin = function showPenguin(penguinModelData) {
var penguinViewModel = {
name: penguinModelData.name,
imageUrl: penguinModelData.imageUrl,
size: penguinModelData.size,
favoriteFood: penguinModelData.favoriteFood
};
penguinViewModel.previousIndex = penguinModelData.index - 1;
penguinViewModel.nextIndex = penguinModelData.index + 1;
if (penguinModelData.index === 0) {
penguinViewModel.previousIndex = penguinModelData.count - 1;
}
if (penguinModelData.index === penguinModelData.count - 1) {
penguinViewModel.nextIndex = 0;
}
this.penguinView.render(penguinViewModel);
};var PenguinViewMock = function PenguinViewMock() {
this.calledRenderWith = null;
};
PenguinViewMock.prototype.render = function render(penguinViewModel) {
this.calledRenderWith = penguinViewModel;
};
// Arrange
var penguinViewMock = new PenguinViewMock();
var controller = new PenguinController(penguinViewMock, null);
var penguinModelData = {
name: 'Chinstrap',
imageUrl: 'http://chinstrapl.jpg',
size: '5.0kg (m), 4.8kg (f)',
favoriteFood: 'krill',
index: 2,
count: 5
};
// Act
controller.showPenguin(penguinModelData);
// Assert
assert.strictEqual(penguinViewMock.calledRenderWith.name, 'Chinstrap');
assert.strictEqual(penguinViewMock.calledRenderWith.imageUrl, 'http://chinstrapl.jpg');
assert.strictEqual(penguinViewMock.calledRenderWith.size, '5.0kg (m), 4.8kg (f)');
assert.strictEqual(penguinViewMock.calledRenderWith.favoriteFood, 'krill');
assert.strictEqual(penguinViewMock.calledRenderWith.previousIndex, 1);
assert.strictEqual(penguinViewMock.calledRenderWith.nextIndex, 3);PenguinViewMock реализует тот же контракт, что и реальный модуль представления. Это позволяет писать модульные тесты и проверять, в блоке Assert, всё ли работает так, как нужно.assert взят из Node.js, но можно воспользоваться аналогичным объектом из библиотеки Chai. Это позволяет писать тесты, которые можно выполнять и на сервере, и в браузере.this.render(). Именно такого подхода необходимо придерживаться для написания чистого кода. Контроллер, при таком подходе, может доверить компоненту выполнение тех задач, о возможности выполнения которых заявил этот компонент. Это делает структуру проекта прозрачной, что улучшает читаемость кода.var PenguinView = function PenguinView(element) {
this.element = element;
this.onClickGetPenguin = null;
};PenguinView.prototype.render = function render(viewModel) {
this.element.innerHTML = '' + viewModel.name + '
' +
' ' +
'
' +
'Size: ' + viewModel.size + '
' +
'Favorite food: ' + viewModel.favoriteFood + '
' +
'Previous ' +
'Next';
this.previousIndex = viewModel.previousIndex;
this.nextIndex = viewModel.nextIndex;
// Подключение обработчиков событий щелчков по кнопкам и передача задачи обработки событий контроллеру
var previousPenguin = this.element.querySelector('#previousPenguin');
previousPenguin.addEventListener('click', this.onClickGetPenguin);
var nextPenguin = this.element.querySelector('#nextPenguin');
nextPenguin.addEventListener('click', this.onClickGetPenguin);
nextPenguin.focus();
}var ElementMock = function ElementMock() {
this.innerHTML = null;
};
// Функции-заглушки, необходимые для того, чтобы провести тестирование
ElementMock.prototype.querySelector = function querySelector() { };
ElementMock.prototype.addEventListener = function addEventListener() { };
ElementMock.prototype.focus = function focus() { };
// Arrange
var elementMock = new ElementMock();
var view = new PenguinView(elementMock);
var viewModel = {
name: 'Chinstrap',
imageUrl: 'http://chinstrap1.jpg',
size: '5.0kg (m), 4.8kg (f)',
favoriteFood: 'krill',
previousIndex: 1,
nextIndex: 2
};
// Act
view.render(viewModel);
// Assert
assert(elementMock.innerHTML.indexOf(viewModel.name) > 0);
assert(elementMock.innerHTML.indexOf(viewModel.imageUrl) > 0);
assert(elementMock.innerHTML.indexOf(viewModel.size) > 0);
assert(elementMock.innerHTML.indexOf(viewModel.favoriteFood) > 0);
assert(elementMock.innerHTML.indexOf(viewModel.previousIndex) > 0);
assert(elementMock.innerHTML.indexOf(viewModel.nextIndex) > 0);var PenguinModel = function PenguinModel(XMLHttpRequest) {
this.XMLHttpRequest = XMLHttpRequest;
};XMLHttpRequest внедрён в конструктор модели. Это, кроме прочего, подсказка для других программистов касательно компонентов, необходимых модели. Если модель нуждается в различных способах работы с данными, в неё можно внедрить и другие модули. Так же, как и в рассмотренных выше случаях, для модели можно подготовить модульные тесты.PenguinModel.prototype.getPenguin = function getPenguin(index, fn) {
var oReq = new this.XMLHttpRequest();
oReq.onload = function onLoad(e) {
var ajaxResponse = JSON.parse(e.currentTarget.responseText);
// Индекс должен быть целым числом, иначе это работать не будет
var penguin = ajaxResponse[index];
penguin.index = index;
penguin.count = ajaxResponse.length;
fn(penguin);
};
oReq.open('GET', 'https://codepen.io/beautifulcoder/pen/vmOOLr.js', true);
oReq.send();
};var LIST_OF_PENGUINS = '[{"name":"Emperor","imageUrl":"http://imageUrl",' +
'"size":"36.7kg (m), 28.4kg (f)","favoriteFood":"fish and squid"}]';
var XMLHttpRequestMock = function XMLHttpRequestMock() {
// Для целей тестирования нужно это установить, иначе тест не удастся
this.onload = null;
};
XMLHttpRequestMock.prototype.open = function open(method, url, async) {
// Внутренние проверки, система должна иметь конечные точки method и url
assert(method);
assert(url);
// Если Ajax не асинхронен, значит наша реализация весьма неудачна :-)
assert.strictEqual(async, true);
};
XMLHttpRequestMock.prototype.send = function send() {
// Функция обратного вызова симулирует Ajax-запрос
this.onload({ currentTarget: { responseText: LIST_OF_PENGUINS } });
};
// Arrange
var penguinModel = new PenguinModel(XMLHttpRequestMock);
// Act
penguinModel.getPenguin(0, function onPenguinData(penguinData) {
// Assert
assert.strictEqual(penguinData.name, 'Emperor');
assert(penguinData.imageUrl);
assert.strictEqual(penguinData.size, '36.7kg (m), 28.4kg (f)');
assert.strictEqual(penguinData.favoriteFood, 'fish and squid');
assert.strictEqual(penguinData.index, 0);
assert.strictEqual(penguinData.count, 1);
});|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com mvc разработка шаблоны проектирования |






