EBU R128/BS.1770-3: Пакетная нормализация громкости аудио/видео файлов, ч2 |
[\\host\path\]
destination=\\host\path\
bak=\\host\path\
stmp=tmp\
tmp1=tmp\
tmp2=tmp\
otmp=tmp\
destinationExtension=.avi
threads=16
prepare_ffmpeg_cmd=-flags +ilme+ildct -deinterlace -c:v copy -c:a copy
ffmpeg_cmd=-flags +ilme+ildct -deinterlace -c:v copy -c:a copy
sox_cmd=compand 0.1,0.3 -90,-90,-70,-55,-50,-35,-31,-31,-21,-21,0,-20 0 0 0.1
$sFile = $stmp & $tempFile & $sExtension$audioInputSox = $tmp1 & $tempFile & "_sox.wav"
$audioOutput = $tmp1 & $tempFile & "_norm.wav"$audioInput = $tmp2 & $tempFile & ".wav"$outFile = $otmp & $tempFile & "_out" & $destinationExtensionffmpeg -y -ss 0:0:0.0 -r 25 -i [bak] [prepare_ffmpeg_cmd] [stmp]ffmpeg -i [stmp(video)] -i [tmp1(normalized -23LUFS audio)] [ffmpeg_cmd] -map 0:v -map 1:a -threads [threads] [otmp] -ysox [tmp2] [tmp1] [sox_cmd]#Region ;**** Directives created by AutoIt3Wrapper_GUI ****
#AutoIt3Wrapper_Icon=C:\Program Files (x86)\AutoIt3\Icons\MyAutoIt3_Blue.ico
#AutoIt3Wrapper_Compile_Both=y
#AutoIt3Wrapper_UseX64=y
#EndRegion ;**** Directives created by AutoIt3Wrapper_GUI ****
#include
#include
Func randomString($digits)
Local $pwd = ""
Local $aSpace[3]
For $i = 1 To $digits
$aSpace[0] = Chr(Random(65, 90, 1)) ;A-Z
$aSpace[1] = Chr(Random(97, 122, 1)) ;a-z
$aSpace[2] = Chr(Random(48, 57, 1)) ;0-9
$pwd &= $aSpace[Random(0, 2, 1)]
Next
Return $pwd
EndFunc
$iniFile = "watch.ini"
Dim $run[0][2]
Dim $newRun[0]
Func TerminateChilds()
For $i = 0 to UBound($run) - 1
ProcessClose($run[$i][0])
Next
EndFunc
Local $source
If $CmdLine[0] == 0 Then
Local $i, $j, $exists, $pid
OnAutoItExitRegister ( "TerminateChilds" )
While 1
$source = IniReadSectionNames($iniFile)
For $i = 0 To UBound($run) - 1
$exists = False
For $j = 1 To $source[0]
If $source[$j] == $run[$i][1] Then $exists = True
Next
If Not $exists Then
ProcessClose($run[$i][0])
_ArrayDelete($run, $i)
ContinueLoop
EndIf
Next
For $i = 1 To $source[0]
$exists = False
For $j = 0 To UBound($run) - 1
If $source[$i] == $run[$j][1] Then $exists = True
Next
If Not $exists Then
$pid = Run(@ScriptName & " """ & $source[$i] & """")
Dim $temp[1][2] = [[$pid, $source[$i]]]
_ArrayAdd($run, $temp)
ContinueLoop
EndIf
Next
For $i = 0 To UBound($run) - 1
If ProcessExists($run[$i][0]) == 0 Then
$pid = Run(@ScriptName & " """ & $run[$i][1] & """")
$run[$i][0] = $pid
ContinueLoop
EndIf
Next
Sleep(1000)
WEnd
EndIf
MsgBox($MB_SYSTEMMODAL, $CmdLine[1], "I am started " & @CRLF & $CmdLine[1], 10)
Func Terminated()
MsgBox($MB_SYSTEMMODAL, $CmdLine[1], "I am terminated " & @CRLF & $CmdLine[1], 10)
EndFunc
OnAutoItExitRegister ( "Terminated" )
TraySetToolTip($CmdLine[1])
$tools = "bs1770gain-tools\"
Local $source = $CmdLine[1]
Local $destination = IniRead($iniFile, $source, "destination", Null)
Local $bak = IniRead($iniFile, $source, "bak", Null)
Local $stmp = IniRead($iniFile, $source, "stmp", Null)
Local $tmp1 = IniRead($iniFile, $source, "tmp1", Null)
Local $tmp2 = IniRead($iniFile, $source, "tmp2", Null)
Local $otmp = IniRead($iniFile, $source, "otmp", Null)
Local $ffmpeg_cmd = IniRead($iniFile, $source, "ffmpeg_cmd", Null)
Local $destinationExtension = IniRead($iniFile, $source, "destinationExtension", Null)
Local $threads = IniRead($iniFile, $source, "threads", Null)
Local $sox_cmd = IniRead($iniFile, $source, "sox_cmd", Null)
If Not FileExists($source) Then DirCreate($source)
If Not FileExists($bak) Then DirCreate($bak)
If Not FileExists($destination) Then DirCreate($destination)
If Not FileExists($stmp) Then DirCreate($stmp)
If Not FileExists($tmp1) Then DirCreate($tmp1)
If Not FileExists($tmp2) Then DirCreate($tmp2)
If Not FileExists($otmp) Then DirCreate($otmp)
Local $tempFile
Local $sFile
Local $descriptionFile
Local $audioInput
Local $audioOutput
Local $outFile
Local $sTitr
Local $eTitr
While 1
Local $files = _FileListToArray($source, "*", $FLTA_FILES, False)
Local $i = 1
For $i = 1 To Ubound($files) - 1
Local $f = $files[$i]
Local $sDrive = "", $sDir = "", $sFileName = "", $sExtension = ""
Local $aPathSplit = _PathSplit($f, $sDrive, $sDir, $sFileName, $sExtension)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
Sleep(50)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
Sleep(50)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
Sleep(50)
Local $h = FileOpen($source & $sFileName & $sExtension, $FO_APPEND)
If $h == -1 Then ContinueLoop
FileClose($h)
$bak = IniRead($iniFile, $source, "bak", Null)
$destination = IniRead($iniFile, $source, "destination", Null)
$stmp = IniRead($iniFile, $source, "stmp", Null)
$tmp1 = IniRead($iniFile, $source, "tmp1", Null)
$tmp2 = IniRead($iniFile, $source, "tmp2", Null)
$otmp = IniRead($iniFile, $source, "otmp", Null)
$ffmpeg_cmd = IniRead($iniFile, $source, "ffmpeg_cmd", Null)
$destinationExtension = IniRead($iniFile, $source, "destinationExtension", Null)
$threads = IniRead($iniFile, $source, "threads", Null)
$sox_cmd = IniRead($iniFile, $source, "sox_cmd", Null)
$pre_cmd = IniRead($iniFile, $source, "prepare_ffmpeg_cmd", Null)
$tempFile = randomString(8)
$bak &= $sFileName & $sExtension
$sFile = $stmp & $tempFile & $sExtension
$descriptionFile = $tmp1 & $tempFile & $sExtension & ".ini"
$audioInput = $tmp2 & $tempFile & ".wav"
$audioInputSox = $tmp1 & $tempFile & "_sox.wav"
$audioOutput = $tmp1 & $tempFile & "_norm.wav"
$outFile = $otmp & $tempFile & "_out" & $destinationExtension
If FileMove($source & $sFileName & $sExtension, $bak, $FC_OVERWRITE) == 0 Then ContinueLoop
If Not $pre_cmd Then
If FileCopy($bak, $sFile, $FC_OVERWRITE) == 0 Then ContinueLoop
Else
$cmd_pre = $tools & "ffmpeg -y -ss 0:0:0.0 -r 25 -i """ & $bak & """ " & $pre_cmd & " " & $sFile
RunWait($cmd_pre)
EndIf
Sleep(100)
;$log = FileOpen($tempFile & ".bat", $FO_OVERWRITE + $FO_UTF8 + $FO_CREATEPATH)
$cmd_info = "cmd /c """ & $tools & "ffprobe -v quiet -print_format ini -show_format -show_streams " & $sFile & " > """ & $descriptionFile & """"
;FileWriteLine($log, $cmd_info)
RunWait($cmd_info)
$dur = Number(IniRead($descriptionFile, "streams.stream.0", "duration", Null))
$cmd_AudioInput = $tools & "ffmpeg -ss 0:0:0 -i " & $sFile & " -t " & $dur & " -vn -c:a pcm_s16le -af ""pan=stereo| FL < FL + 0.5*FC + 0.6*BL + 0.6*SL | FR < FR + 0.5*FC + 0.6*BR + 0.6*SR"" -ac 2 " & $audioInput & " -y -threads " & $threads
;FileWriteLine($log, $cmd_AudioInput)
RunWait($cmd_AudioInput)
Sleep(100)
$audioOutput = "tmp\" & $tempFile & ".flac"
If IsString($sox_cmd) And $sox_cmd <> "" Then
$audioOutput = "tmp\" & $tempFile & "_sox.flac"
$cmd_Sox = $tools & "sox " & $audioInput & " " & $audioInputSox & " " & $sox_cmd
;FileWriteLine($log, $cmd_Sox)
RunWait($cmd_Sox)
$audioInput = $audioInputSox
EndIf
$cmd_BS1770gain = "bs1770gain --ebu """ & $audioInput & """ -ao ""tmp"""
;FileWriteLine($log, $cmd_BS1770gain)
RunWait($cmd_BS1770gain)
Sleep(100)
$a = StringRegExp($sFileName, "^.+{(\d{2}) (\d{2}) (\d{2}) (\d{2}) (\d{2})}$", $STR_REGEXPARRAYGLOBALMATCH)
If @error Then
$cmd_Output = $tools & "ffmpeg -i " & $sFile & " -i " & $audioOutput & " " & $ffmpeg_cmd & " -map 0:v -map 1:a -threads " & $threads & " " & $outFile & " -y"
;FileWriteLine($log, $cmd_Output)
RunWait($cmd_Output)
Else
$titr_h = Number($a[0])
$titr_m = Number($a[1])
$titr_s = Number($a[2])
$dur_m = Number($a[3])
$dur_s = Number($a[4])
$dur = $dur - ($titr_h*60*60 + $titr_m*60 + $titr_s)
$dstDur = $dur_m*60 + $dur_s
$outDur = $titr_h*60*60 + $titr_m*60 + $titr_s + $dur_m*60 + $dur_s
$speed = $dstDur / $dur
$codec = IniRead($descriptionFile, "streams.stream.0", "codec_name", Null)
$sTitr = $tmp1 & $tempFile & "_stitr" & $sExtension
$eTitr = $tmp1 & $tempFile & "_etitr" & $sExtension
$cmd_ETirt = $tools & "ffmpeg -y -ss " & $titr_h & ":" & $titr_m & ":" & $titr_s & " -i " & $sFile & " -filter:v ""setpts=" & $speed & "*PTS"" -t 00:" & $dur_m & ":" & $dur_s & " -c:v " & $codec & " -qscale:v 0 -flags +ilme+ildct -deinterlace -an " & $eTitr
$cmd_STitr = $tools & "ffmpeg -y -ss 0:0:0 -i " & $sFile & " -t " & $titr_h & ":" & $titr_m & ":" & $titr_s & " -c:v copy -an " & $sTitr
$cmd_Output = $tools & "ffmpeg -y -i concat:""" & $sTitr & "|" & $eTitr & """ -i " & $audioOutput & " -t " & $outDur & " " & $ffmpeg_cmd & " -map 0:v -map 1:a -threads " & $threads & " " & $outFile
;FileWriteLine($log, $cmd_ETirt)
;FileWriteLine($log, $cmd_STitr)
;FileWriteLine($log, $cmd_Output)
RunWait($cmd_ETirt)
RunWait($cmd_STitr)
RunWait($cmd_Output)
EndIf
;FileClose($log)
FileMove($outFile, $destination & $sFileName & $destinationExtension, $FC_OVERWRITE)
Sleep(100)
FileDelete($sFile)
FileDelete($descriptionFile)
FileDelete($sTitr)
FileDelete($eTitr)
FileDelete($tmp2 & $tempFile & ".wav")
FileDelete($tmp1 & $tempFile & "_sox.wav")
FileDelete($tmp1 & $tempFile & "_norm.wav")
FileDelete($audioOutput)
;Exit
Next
Sleep(1000)
WEnd|
Метки: author AntonCheloshkin обработка изображений занимательные задачки open source ebu r128 bs.1770-3 bs1770gain sox ffmpeg |
Программисты-коммунисты всех стран, соединяйтесь |









|
|
[Из песочницы] Создание Angular 2+ компонентов с возможностью переключения темы |
.my-button {
padding: 10px;
font-size: 14px;
color: midnightblue;
border: 1px solid mdnightblue;
background: white;
cursor: pointer;
}
my-button:disabled {
pointer-events: none;
cursor: default;
color: grey;
border: 1px solid grey;
}
.my-button {
padding: 10px;
font-size: 14px;
color: lightblue;
border: 1px solid lightblue;
background: midnightblue;
cursor: pointer;
}
.my-button:disabled {
pointer-events: none;
cursor: default;
background: grey;
color: lightgrey;
border: 1px solid lightgrey;
}
.my-button {
padding: 10px;
font-size: 14px;
cursor: pointer;
}
.my-button:disabled {
pointer-events: none;
cursor: default;
}
.my-button {
color: midnightblue;
border: 1px solid mdnightblue;
background: white;
}
my-button:disabled {
color: grey;
border: 1px solid grey;
}
.my-button {
color: lightblue;
border: 1px solid lightblue;
background: midnightblue;
}
.my-button:disabled {
background: grey;
color: lightgrey;
border: 1px solid lightgrey;
}
@import 'button-core.css'
@import 'button-light.css'
@import 'button-dark.css'
:host-context(.parent-component:hover) .child-component {
background: lightcoral;
}
:host-context(.light-theme) .my-button {
color: midnightblue;
border: 1px solid mdnightblue;
background: white;
}
:host-context(.light-theme) my-button:disabled {
color: grey;
border: 1px solid grey;
}
[ngClass]="{'light-theme': theme === 'light', 'dark-theme': theme === 'dark'}".|
Метки: author sunnywhale css angularjs angular2 angular angular4 component theme |
Делаем приложения с поиском на Go |
Однажды в рассылке Golang Weekly мне попался проект Bleve. Это полнотекстовый поиск, который написан на Go. Проект интересный, и появилось бешеное желание получить с ним опыт работы.
import "github.com/blevesearch/bleve"
func main() {
// Откроем новый индекс
mapping := bleve.NewIndexMapping()
index, err := bleve.New("example.bleve", mapping)
// Положим не много данных
err = index.Index(identifier, your_data)
// Найдем что-нибудь
query := bleve.NewMatchQuery("text")
search := bleve.NewSearchRequest(query)
searchResults, err := index.Search(search)
}Все просто и понятно. Но выглядит оно не с реального мира. Чтобы быть ближе к реальному миру, сделаем бота для Slack, который будет хранить историю.
Сервис для работы со slack;
Сервис индекс. Для хранения и поиска сообщений.
Со слаком все просто и пример по сути будет чуть сложнее, чем пример из репо
Единственное, что нам потребуется — два метода, чтобы проверить, адресовано ли боту сообщение и очистить его от имени бота
import "strings"
func isToMe(message string) bool {
return strings.Contains(message, fmt.Sprintf("<@%s>", ss.me))
}
func cleanMessage(message string) string {
return strings.Replace(message, fmt.Sprintf("<@%s> ", ss.me), "", -1)
}Учитывая то, что я люблю использовать goleveldb как встраиваемую БД для своих проектов. В этом проекте решил использовать ее же.
Хранить в Bleve будем данные посложнее в виде:
type IndexData struct {
ID string `json:"id"`
Username string `json:"username"`
Message string `json:"message"`
Channel string `json:"channel"`
Timestamp string `json:"timestamp"`
}Создадим индекс с Goleveldb в качестве БД:
import (
"github.com/blevesearch/bleve"
"github.com/blevesearch/bleve/index/store/goleveldb"
)
func createIndex() (bleve.Index, error) {
indexName := "history.bleve"
index, err := bleve.Open(indexName)
if err == bleve.ErrorIndexPathDoesNotExist {
mapping := buildMapping()
kvStore := goleveldb.Name
kvConfig := map[string]interface{}{
"create_if_missing": true,
}
index, err = bleve.NewUsing(indexName, mapping, "upside_down", kvStore, kvConfig)
}
if err != nil {
return err
}
}и метод buildMapping, который создаст нам mapping для хранения:
func (ss *SearchService) buildMapping() *bleve.IndexMapping {
ruFieldMapping := bleve.NewTextFieldMapping()
ruFieldMapping.Analyzer = ru.AnalyzerName
eventMapping := bleve.NewDocumentMapping()
eventMapping.AddFieldMappingsAt("message", ruFieldMapping)
mapping := bleve.NewIndexMapping()
mapping.DefaultMapping = eventMapping
mapping.DefaultAnalyzer = ru.AnalyzerName
return mapping
}С поиском все чуть сложнее:
func (ss *SearchService) Search(query, channel string) (*bleve.SearchResult, error) {
stringQuery := fmt.Sprintf("/.*%s.*/", query)
// NewTermQuery создает Query для нахождения значений в индексе, которые строго совпадают с запросом
ch := bleve.NewTermQuery(channel)
// Создаем Query для совпадений фраз в индексе. Анализатор выбирается по полю. Ввод анализируется этим анализатором. Токенезированные выражения от анализа используются для посторения поисковой фразы. Результирующие документы должны совпадать с этой фразой.
mq := bleve.NewMatchPhraseQuery(query)
// Создаем Query для поиска значений в индексе по регулярному выражению
rq := bleve.NewRegexpQuery(query)
// Создаем Query для поиска документов, результаты которого удовлетворят поисковой строке.
qsq := bleve.NewQueryStringQuery(stringQuery)
// Создаем составную Query Результат должен удовлетворять хотя бы одной Query.
q := bleve.NewDisjunctionQuery([]bleve.Query{ch, mq, rq, qsq})
search := bleve.NewSearchRequest(q)
search.Fields = []string{"username", "message", "channel", "timestamp"}
return ss.index.Search(search)
}Соединив все вместе, мы получим бота, который сохраняет историю и может искать по ней без тяжеловесной жавы на примерах ElasticSearch, Solr.
Полный код проекта доступен на Github
|
Метки: author Gen1us2k поисковые технологии go пщ bleve поиск blevesearch bleve search |
А ну-ка, девушки! Аде Лавлейс посвящается |








Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author IrinaB управление разработкой блог компании гк ланит женщины разработка ланит кадры профессия |
[Перевод] Что нового в Swift 4.0 |
struct Language: Codable {
var name: String
var version: Int
}
let swift = Language(name: "Swift", version: 4)
let php = Language(name: "PHP", version: 7)
let perl = Language(name: "Perl", version: 6)
let encoder = JSONEncoder()
if let encoded = try? encoder.encode(swift) {
// сохраняем `encoded` где-нибудь
}
if let encoded = try? encoder.encode(swift) {
if let json = String(data: encoded, encoding: .utf8) {
print(json)
}
let decoder = JSONDecoder()
if let decoded = try? decoder.decode(Language.self, from: encoded) {
print(decoded.name)
}
}
let longString = """
When you write a string that spans multiple
lines make sure you start its content on a
line all of its own, and end it with three
quotes also on a line of their own.
Multi-line strings also let you write "quote marks"
freely inside your strings, which is great!
"""
// структура для примера
struct Crew {
var name: String
var rank: String
}
// другая структура, в этот раз с методом
struct Starship {
var name: String
var maxWarp: Double
var captain: Crew
func goToMaximumWarp() {
print("\(name) is now travelling at warp \(maxWarp)")
}
}
// создаем экземпляры наших структур
let janeway = Crew(name: "Kathryn Janeway", rank: "Captain")
let voyager = Starship(name: "Voyager", maxWarp: 9.975, captain: janeway)
// захватываем ссылку на `goToMaximumWarp()` метод
let enterWarp = voyager.goToMaximumWarp
// вызываем ссылку
enterWarp()
let nameKeyPath = \Starship.name
let maxWarpKeyPath = \Starship.maxWarp
let captainName = \Starship.captain.name
let starshipName = voyager[keyPath: nameKeyPath]
let starshipMaxWarp = voyager[keyPath: maxWarpKeyPath]
let starshipCaptain = voyager[keyPath: captainName]
let cities = ["Shanghai": 24_256_800, "Karachi": 23_500_000, "Beijing": 21_516_000, "Seoul": 9_995_000];
let massiveCities = cities.filter { $0.value > 10_000_000 }
massiveCities["Shanghai"]massiveCities[0].valuelet populations = cities.map { $0.value * 2 }
let groupedCities = Dictionary(grouping: cities.keys) { $0.characters.first! }
print(groupedCities)
["B": ["Beijing"], "S": ["Shanghai", "Seoul"], "K": ["Karachi"]]
let groupedCities = Dictionary(grouping: cities.keys) { $0.count }
print(groupedCities)
[5: ["Seoul"], 7: ["Karachi", "Beijing"], 8: ["Shanghai"]]
let person = ["name": "Taylor", "city": "Nashville"]
let name = person["name", default: "Anonymous"]
let name = person["name"] ?? "Anonymous"
var favoriteTVShows = ["Red Dwarf", "Blackadder", "Fawlty Towers", "Red Dwarf"]
var favoriteCounts = [String: Int]()
for show in favoriteTVShows {
favoriteCounts[show, default: 0] += 1
}
let quote = "It is a truth universally acknowledged that new Swift versions bring new features."
let reversed = quote.reversed()
for letter in quote {
print(letter)
}
let characters = ["Dr Horrible", "Captain Hammer", "Penny", "Bad Horse", "Moist"]
let bigParts = characters[..<3]
let smallParts = characters[3...]
print(bigParts)
print(smallParts)
["Dr Horrible", "Captain Hammer", "Penny"]
["Bad Horse", "Moist"]
|
Метки: author AKhatmullin разработка под ios swift swift 4 ios разработка ios development |
[Перевод] K-sort: новый алгоритм, превосходящий пирамидальную при n <= 7 000 000 |
|
Метки: author stranger777 алгоритмы внутренняя сортировка равномерное распределение средняя временная сложность статистический анализ статистическая оценка |
[Из песочницы] 3D Блокчейн. Доказательство на лицо (PoF) |
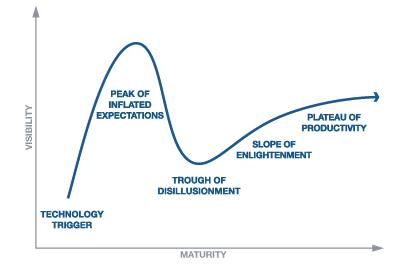 Моя склонность — всё подвергать сомнению и блокчейн[1] не оказался исключением. Давайте взглянем на Цикл зрелости технологии (Gartner Hype Cycles). Где по Вашему находится Блокчейн? Естественно каждый для себя определит своё нахождение на том или ином цикле, которое свойственно проекту на каком-то из стадий разработки. Кто-то во всю развивает бизнес приложение и видит будущие горизонты, а кто-то только начинает знакомство. Но если взглянуть шире? Блокчейн неоспоримо засел в мысли и показал большой потенциал по трансформации многих сегментов взаимоотношения людей. Но у меня остаётся доля сомнения в отношении некоторых текущих принципов его работы. В итоге, я вижу эту стадию где-то на уровне пика завышенных ожиданий (Peak of inflated expectations) — общественный ажиотаж с чрезмерным энтузиазмом и нереалистичными ожиданиями. Что означает, впереди ещё ждать такие циклы как: Избавление от иллюзий, Преодоление недостатков, Плато продуктивности.
Моя склонность — всё подвергать сомнению и блокчейн[1] не оказался исключением. Давайте взглянем на Цикл зрелости технологии (Gartner Hype Cycles). Где по Вашему находится Блокчейн? Естественно каждый для себя определит своё нахождение на том или ином цикле, которое свойственно проекту на каком-то из стадий разработки. Кто-то во всю развивает бизнес приложение и видит будущие горизонты, а кто-то только начинает знакомство. Но если взглянуть шире? Блокчейн неоспоримо засел в мысли и показал большой потенциал по трансформации многих сегментов взаимоотношения людей. Но у меня остаётся доля сомнения в отношении некоторых текущих принципов его работы. В итоге, я вижу эту стадию где-то на уровне пика завышенных ожиданий (Peak of inflated expectations) — общественный ажиотаж с чрезмерным энтузиазмом и нереалистичными ожиданиями. Что означает, впереди ещё ждать такие циклы как: Избавление от иллюзий, Преодоление недостатков, Плато продуктивности. 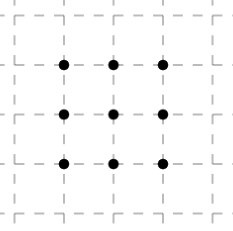 Взгляните на рисунок, это задача. Необходимо соединить все 9 точек четырьмя линиями, идущими непрерывно друг за другом. Данная задача демонстрирует принципы выхода за рамки мышления. Быть может и к блокчейну это применимо и не отталкиваться от старых парадигм в виду его выхода за рамки денежных транзакций? Поскольку в блокчейн не нужно доказывать всем о его необходимости, потенциале и он уже давно дистанцировался от обычных транзакций, и предоставил такие возможности как распределённый реестр данных, осуществление смарт-контрактов, децентрализованных приложений, а также проведение ICO. Тогда возможен ли блокчейн без майнеров обеспечивающих надежность? И без основной криптовалюты, которая необходима прежде всего для стимулирования обеспечения этой надежности? Сама то криптовалюта конечно необходима для осуществления денежных транзакций, просто сам блокчейн будет от неё независим, и иные действия не связанные с денежными транзакциями будут протекать обособленно. В таком случае, кто будет обеспечивать надёжность системы? У кого уже есть стимул делать это безвозмездно, но с той же степенью защиты?
Взгляните на рисунок, это задача. Необходимо соединить все 9 точек четырьмя линиями, идущими непрерывно друг за другом. Данная задача демонстрирует принципы выхода за рамки мышления. Быть может и к блокчейну это применимо и не отталкиваться от старых парадигм в виду его выхода за рамки денежных транзакций? Поскольку в блокчейн не нужно доказывать всем о его необходимости, потенциале и он уже давно дистанцировался от обычных транзакций, и предоставил такие возможности как распределённый реестр данных, осуществление смарт-контрактов, децентрализованных приложений, а также проведение ICO. Тогда возможен ли блокчейн без майнеров обеспечивающих надежность? И без основной криптовалюты, которая необходима прежде всего для стимулирования обеспечения этой надежности? Сама то криптовалюта конечно необходима для осуществления денежных транзакций, просто сам блокчейн будет от неё независим, и иные действия не связанные с денежными транзакциями будут протекать обособленно. В таком случае, кто будет обеспечивать надёжность системы? У кого уже есть стимул делать это безвозмездно, но с той же степенью защиты?
 Теперь представим данный блокчейн графически. У нас есть различные сервисы (ось X) на блокчейне (разные криптовалюты — государственные или нет, платформы смарт-контрактов, приложения и т.п.) предоставляющие тем самым возможности (услуги и продукты) клиентам (ось Y), которыми являются как физ. лица, так и юр. лица. А также транзакции клиентов (ось Z). В итоге получается, что у одного лица в разных сервисах свой блокчейн, но при этом связан воедино с остальными. Иными словами Если пользователь Б зарегистрировался в сервисе 1 (например, криптовалюта ЦБ), то все транзакции порождённые пользователем Б в данном сервисе будут записываться последовательно цепочкой в его (пользователя) блокчейне, относящийся к данному сервису. При этом сервис 1 также будет вести последовательность цепочки, но чередуя транзакции от всех пользователей сервиса (т.е. своеобразно будет нодой, последовательно записывающая блоки порождённые пользователями данного сервиса), но при этом не является основным хранителем цепочки, а лишь представляется резервом. Это обусловлено тем, что исходя из схемы формирования блока, каждая транзакция порождённая пользователем Б также записывается в блоки иных шестерых участников (в их блокчейн), это принимающий транзакцию (пользователь С) и пять валидаторов (Та, Тх, Тв, Тг, Тд каждая из которых могла быть осуществлена в ином сервисе). Удивительно, это совпало с теорией шести рукопожатий. Если верить которой, то совершая все участники транзакции будут условно соединены друг с другом как одно целое. Это значит, если кото-то захочет изменить информацию в своём блоке, то данному лицу потребуется подговорить изменить её ещё у шестерых участников, те в свою очередь у своих и далее до конца.
Теперь представим данный блокчейн графически. У нас есть различные сервисы (ось X) на блокчейне (разные криптовалюты — государственные или нет, платформы смарт-контрактов, приложения и т.п.) предоставляющие тем самым возможности (услуги и продукты) клиентам (ось Y), которыми являются как физ. лица, так и юр. лица. А также транзакции клиентов (ось Z). В итоге получается, что у одного лица в разных сервисах свой блокчейн, но при этом связан воедино с остальными. Иными словами Если пользователь Б зарегистрировался в сервисе 1 (например, криптовалюта ЦБ), то все транзакции порождённые пользователем Б в данном сервисе будут записываться последовательно цепочкой в его (пользователя) блокчейне, относящийся к данному сервису. При этом сервис 1 также будет вести последовательность цепочки, но чередуя транзакции от всех пользователей сервиса (т.е. своеобразно будет нодой, последовательно записывающая блоки порождённые пользователями данного сервиса), но при этом не является основным хранителем цепочки, а лишь представляется резервом. Это обусловлено тем, что исходя из схемы формирования блока, каждая транзакция порождённая пользователем Б также записывается в блоки иных шестерых участников (в их блокчейн), это принимающий транзакцию (пользователь С) и пять валидаторов (Та, Тх, Тв, Тг, Тд каждая из которых могла быть осуществлена в ином сервисе). Удивительно, это совпало с теорией шести рукопожатий. Если верить которой, то совершая все участники транзакции будут условно соединены друг с другом как одно целое. Это значит, если кото-то захочет изменить информацию в своём блоке, то данному лицу потребуется подговорить изменить её ещё у шестерых участников, те в свою очередь у своих и далее до конца.|
|
От репозитория до CI/CD-инфраструктуры в продакшене за неделю |



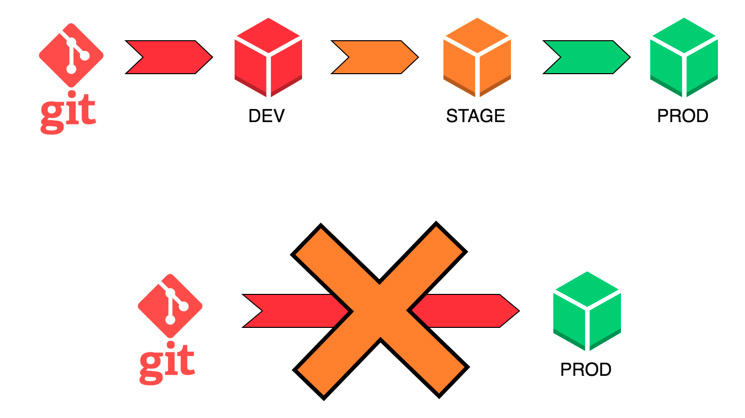

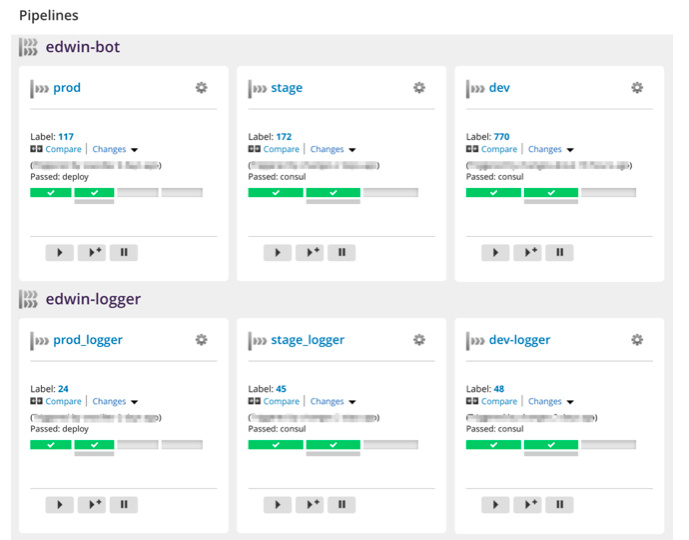

|
Метки: author 4umak it- инфраструктура devops *nix блог компании itsumma docker ci cd aws consul gocd |
Корпоративное управление: как юридически строится управление в компании |
|
Метки: author Roman_Yankovskiy законодательство и it-бизнес венчурные инвестиции корпорации управление компанией юридические вопросы закон стартапа |
Галактический хакатон: как убедить молодых разработчиков перейти на свою сторону |

Ранним утром 20 мая мы, команда организаторов первого в истории CUSTIS хакатона, радовались разгоравшемуся теплому дню (что для весны 2017 — эксклюзив). Каждый думал о своем: админы изучали графики нагруженности Wi-Fi-диапазона, девушки из PR- и HR-отделов сверлили взглядом списки участников, кураторы из департамента разработки почему-то вспоминали Макаренко и лучшие навыки управления распределенными командами. Антикафе во «Флаконе», где мы должны проводить хакатон, еще закрыто, узкие проезды между лофтами еще не наполнились густым туманом от вейпов и гулом гироскутеров. Мы были уверены в том, что все готово, но легкое волнение нас не покидало.
Это было утро перед Битвой. Спустя 15 часов мы, усталые, но довольные, прощались на том же месте, вспоминали яркие моменты, благодарили участников и друг друга и точно знали, как нужно проводить хакатоны. Спокойствие и чувство выполненного долга.
Этот пост для тех, кто испытывает трепет при мысли о том, что предстоит организовать подобное мероприятие без многомиллионных бюджетов силами команды в 20 человек, или раздумывает, стоит ли оно того.
Никакой магии не существует: крутые идеи всегда появляются из самых острых потребностей. Нашим проектам, как в любой растущей компании, стало сильно не хватать молодых разработчиков, а HR- и PR-службам — классических способов выстроить доверительные коммуникации с потенциальными сотрудниками.
Что мы практиковали раньше:
Представьте, что сразу несколько ключевых проектов компании выходят в стадию продакшена с высокими темпами отгрузок функционала. Открытых вакансий — пара десятков, основные технологии — Java и С#. Аутсорсинговыми командами утолить ресурсный голод нельзя, так как люди нужны в ядро проектной команды. И нужны классные разработчики: со светлой головой, большим добрым сердцем и огнем в глазах, пусть с маленьким опытом в суровой промышленной разработке. А еще необходимо то, чего не даст ни одно интервью с эйчаром и решение тестовых задачек на собеседовании: в короткие сроки проверить, что молодой разработчик действительно талантливый, а мы действительно интересны ему как команда. Мы твердо решили, что друзья познаются в бою.
Для решения этих задач идеально подошел формат хакатона: мероприятие можно компактно упаковать в одни земные сутки и уже к концу дня пригласить на работу как можно больше участников.
Хакатоны внутри команды мы проводим не первый год. Для нас это не только фан или форма тимбилдинга, это творческий процесс, когда мы знакомимся друг с другом, открываем общие интересы к каким-то технологиям и делаем полезные штуки, до которых не доходят руки в рабочее время. Год назад мы за день уничтожили недельную норму пиццы и сделали красивую утилитку для мониторинга боевых серверов клиента, а в этом году прикрутили Телеграм-бота к корпоративному багтрекеру и wiki-порталу, чтобы лишний раз не открывать массивные страницы в нашей подсети.
Неудивительно, что за подготовку первого внешнего хакатона взялись заядлые участники и вдохновители хакатонов внутренних.
Нет ничего проще, чем объявить хакатон на тему, актуальную для отрасли или конкретной компании. Как показывает скроллинг выдачи в Гугле, хакатон можно устроить практически по любому поводу, была бы в основе идея, которая будоражит отрасль или отдельных ее игроков: алгоритмы machine learning, нейросети и компьютерное зрение, банковские микросервисы, социальные и благотворительные проекты и даже целые технологические стартапы с TTM в 48 часов.
Что нам нравилось в формате:
Что мы хотели привнести от себя:
Идея «Битвы технологий» оказалась настолько привлекательной, что мы твердо решили: устроим айтишный турнир! Там не будет жюри и экспертных комиссий, не потребуется защищать свой проект перед переодетыми в инвесторов пиэмами, не нужно даже участвовать в конкурсе красоты кода. Все просто — как в гонках или в бизнесе — нужно что-то построить, испытать и выставить на одну арену с соперником. И пусть победит сильнейший!
За генерацию взялись глава департамента разработки, предводитель HR-подразделения и группа энтузиастов — несколько ведущих разработчиков от каждого техстека. Мы генерили идеи внутри команды, спрашивали у коллег и знакомых, не заснули бы они на таком хакатоне, создавали темы на форумах разработчиков и пытались опробовать игровую механику на себе.
Проектировать в мире идей — клево! Перед глазами встают сцены азартного и захватывающего турнира, безграничных вариантов воплощения игровых алгоритмов. Но идеи витают в воздухе, а реализация требует немалых усилий, даже если в основу турнира мы положим простую игру. В итоге мы остановились на морском бое: игра достаточно динамичная, алгоритмически постижимая и не требует слишком большого времени на реализацию работоспособного бота.
Когда эксперты пришли к консенсусу по поводу игровой механики и даже начали делать первые наброски сервер-сайда, мы содрогнулись еще раз: остался всего месяц на подготовку.
Мы проектировали формат около месяца, после чего настало время зафиксировать основные детали мероприятия. Финальный вердикт выглядел так:
Когда мы определились с игровой платформой, стало ясно, что для успешного продвижения нашей идеи в массы нужно что-то более оригинальное, чем предложение сыграть в морской бой. И достойный замысел родился там же, в недрах нашего департамента разработки: «Айтишники всех поколений искренне любят вселенную „Звездных войн“. Так почему бы не назвать наш турнир галактической битвой, а весь антураж — от интерфейсов серверной части приложения до оформления площадки — адаптировать под эту концепцию?». Морской бой не в тренде — да здравствует космический бой!
Чтобы обеспечить всех участников главным орудием пролетариата 21 века — настроенной средой разработки и удобными компьютерами, наши админы тщательно выбрали и арендовали 26 ноутбуков. На них были развернуты Visual Studio и IDEA, а на площадку мы привезли и подключили к локальной сети резервный сервер (его роль блистательно сыграл мощный десктоп) на случай, если удаленный будет недоступен.
Мы реализовали игровой сервер, доступ к которому выдавали командам в ходе соревнования. Архитектурно он состоит из двух частей: сервер RabbitMQ и, собственно, сервер приложения. RabbitMQ выполняет функцию связи между сервером и ботами, а также между админкой и сервером. Он был выбран в силу своей легкости, быстроты и распространенности.
Чтобы не заморачиваться с реализацией своей системы безопасности, мы решили использовать авторизацию и аутентификацию RabbitMQ. Это сделано так: если пользователь имеет права на отправку сообщений в какой-то канал, значит, он имеет права на все действия, привязанные к этому каналу. Если он имеет права на получение данных из какого-то канала, значит, он имеет право на их чтение. Таким образом сервер приложения получился свободным от логики безопасности.
Сервер приложения устроен очень просто и не требует какого-либо контейнера (обычное standalone java-приложение). Он подключается ко всем очередям в RabbitMQ и слушает их. В этом плане технологически сервер похож на клиентские приложения. Можно сказать, что все боты и сервер образуют микросервисы, перевязанные каналами RabbitMQ. Сложность здесь только в том, что сервер хранит множество информации: текущие и прошедшие игры, статистику и т. д. Чтобы это не вызвало проблем, для всех таких данных есть лимиты по количеству, то есть старые сведения забываются и запоминаются новые.
Написан сервер на Kotlin, но никакой особой котлинской магии не используется — в основном функциональщина и extension-методы.
Подробнее о том, как строится взаимодействие ботов с сервером, а также о техническом задании для команд можно почитать в мануале, который мы раздавали участникам перед стартом турнира.
Параллельно мы стартовали трек поиска площадки, подходящей по техническим и эстетическим параметрам.
Мы хотели:
Мы чуть было не вернулись к концепции морского боя, потому что ресторанов, лофтов и галерей, оформленных в «подводном» стиле, — море (простите за каламбур). А вот подобрать подходящую площадку на тему «Звездных войн» оказалось сложнее.
В итоге мы все-таки нашли несколько аутентичных мест, в которых сам старина Вейдер почувствовал бы себя как дома. Большое их преимущество — готовый тематический декор и, конечно же, управляющие, хорошо знакомые не только со «Звездными войнами», но и с IT (в лице гик-культуры, как правило).
Наш шорт-лист выглядел так:
Мы остановили свой выбор на антикафе. Это была любовь с первого взгляда, которой мы легко простили все недостатки.
Как только внутри нашей команды воцарилось согласие о том, что backend мероприятия полностью готов к бою, мы принялись за активную работу над «клиентской частью» турнира.
Мы представляли себе портрет потенциального участника (и сотрудника) так:
Нам предстояло:
Перед тем как начать регистрацию на турнир, мы завели гуглоформу, в которой постарались отразить все, что хотели узнать о ребятах. Форма оказалась удобной, чтобы сводить воедино, хранить и обрабатывать данные, а также большой командой параллельно работать с участниками.
Чтобы анонсировать регистрацию на Битву, в ход пошли все доступные инструменты диджитал-маркетинга, которые мы своими силами и с помощью партнеров смогли в короткое время мобилизовать. Мы даже почти устроили тотализатор на тему «Сколько нужно времени, сил и охваченных аудиторий, чтобы 24 разработчика пришли на хакатон?».
Первыми в бой были брошены e-mail’ы. Текст приглашения участников был оформлен в стилистике мероприятия. Мы сделали две рассылки по партнерским базам и две — по своим. Рассылки проводились в несколько этапов. Охват: 10 000 человек. Результат: 29 регистраций (конверсия = 0,29).
Затем мы подключили SMM-артиллерию и порекламировались в группах «Типичный программист» и «Программирование ITmozg» Вконтакте. О нас узнали 42 000 и 12 000 человек соответственно. Результат: 10 регистраций (конверсия = 0,02) и 5 регистраций (конверсия = 0,04) соответственно.
Еще несколько тысяч человек удалось охватить с помощью корпоративного профиля на Фейсбуке и репостов коллег, партизанского маркетинга в сообществах ВК и тематических каналах в Телеграме. Наше сообщество CUSTIS Young ВК не принесло нам новых регистраций, но стало хорошей точкой оперативного взаимодействия с ребятами, у которых были оргвопросы.
На выходе форма регистрации показала занимательную статистику:
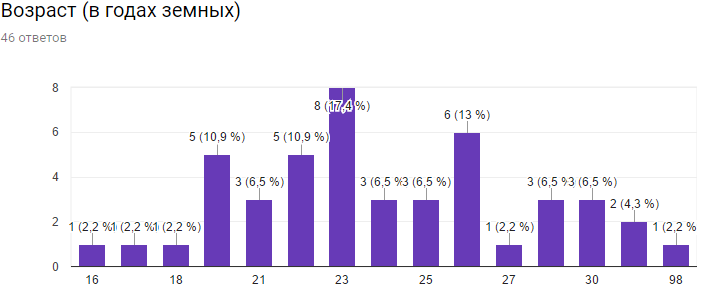
Приятно было наблюдать, что IT все возрасты покорны и молодыми разработчиками ощущают себя ребята 16 лет и старше. Сильно старше.
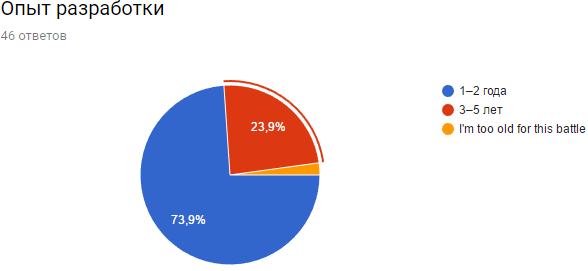
Примерно та же картина с опытом наших конкурсантов. Большого разрыва в опыте разработки не получилось, а значит, всем должно быть интересно.
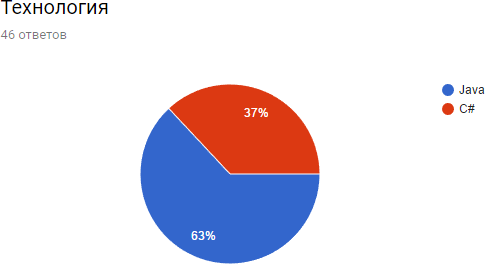
А вот эта диаграмма хорошо отражает рыночные тренды.
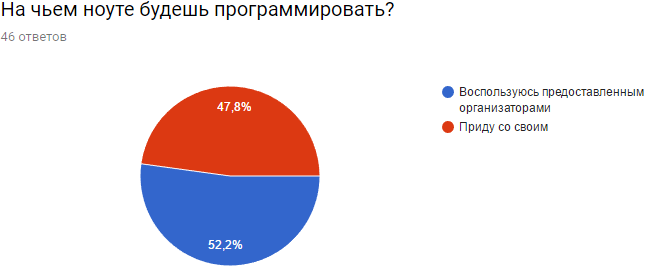
Несмотря на все опасения, что разработчики — люди, признающие уют и кастомизацию только собственных ноутбуков, мы не прогадали. Арендованные ноуты пришлись очень кстати.
Графу анкеты «Расскажи о себе» мы придумали, чтобы ребята могли поделиться коротким резюме о своем опыте и задать вопросы организаторам. Помимо обстоятельных рассказов о достижениях и ожиданиях участников (а таких было большинство) мы получили нетривиальное собрание занимательных фактов:
Во время сбора заявок наши эйчары оперативно связывались с участниками и проводили терапевтические беседы, предлагая еще раз поделиться информацией о своем опыте, уточняли детали участия и отвечали на все вопросы о нашем турнире.
В последний день перед хакатоном мы подвели финальную статистику:
Параллельно с регистрацией шла закупка призов. По ряду причин мы отказались от денежных подарков. Мы приобрели:
В ночь перед турниром мы привезли на площадку все оборудование (ноутбуки, сервер, призы), еще раз протестировали интернет-соединение, проектор и акустику. Все шло отлично до тех пор, пока мы не решили расположить диванчики и столы так, чтобы в основной части кафе разместились все восемь команд. Мы прибегали к фен-шую и 3D-визуализации, меняли местами столы и пуфы, но идеальной рассадки так и не получили. В некотором смятении, но с надеждой, что в итоге всем командам будет одинаково удобно, мы отправились по домам.
Ранним утром 20 мая мы, команда организаторов… Стоп, мы уже об этом рассказывали. Если отвлечься от субъективных переживаний, мы предпринимали вот что:
Мы встречали ребят, клеили именной бэйдж, вручали брошюрку с правилами турнира, которая впервые приоткрывала завесу тайны над тем, каких именно ботов придется создавать. Участники завтракали на веранде, изучали инструкции и морально готовились к предстоящей битве. В антикафе их уже встречали наши админы, которые выдавали ноутбуки, помогали подключаться к сети и настраивать инфраструктуру.

Что такое реальная конверсия, мы поняли за полчаса до старта турнира. Несмотря на активный утренний follow up, уговоры, торг с аргументами про печеньки, к началу битвы пришли только 14 из 31 заявившихся участников. Нужно было заранее опираться на отраслевую статистику и понимать, что до большинства бесплатных мероприятий доходит около 50% «подтвердившихся» участников.
В 11:05 было принято волевое решение начинать битву. Те, кто в это утро смог победить сон, трудности навигации по «Флакону» и плотный кофе-брейк, уже были достойны приза организаторских симпатий. И, руководствуясь принципом «четырнадцать смелых шестнадцать спящих не ждут», мы объявили начало турнира. Мы представили себя и компанию, рассказали о наших кураторах. После этого разбили участников на пять команд по технологиям (слепой жребий и цветные бейджи помогли нам) и комфортно разместили на площадке (нет худа без добра!).

После выступления организаторов на сцену взошли наши кураторы, которые с азартом рассказали гораздо больше того, что было написано в мануалах, пояснили регламент и правила битвы.
Перед тем как начать разрабатывать ботов, участникам нужно было подключиться к общему репозиторию турнира на GitHub. Как оказалось, не у всех был там «живой» аккаунт, поэтому значительную часть утреннего этапа мы потратили на их создание и настройку инфраструктуры. Нам стоило бы заранее предупредить участников, чтобы не терять драгоценное время.
Поскольку до обеда удалось только установить контакт с репозиторием, настроить подключение к серверу и наладить распределение ролей в командах, было решено не углубляться в кодинг и немедленно покушать.
После обеда стартовала активная фаза разработки и отладки ботов. Кураторы были нарасхват, а бои с серверными ботами разных уровней сложности происходили все чаще. Но между собой команды состязаться еще были не готовы. Они писали код, выводили на экран визуализацию боев с сервером и, поняв, что бота по имени Йода не удалось одолеть, отправлялись отлаживать алгоритмы своих творений.

В отличие от других командных массовых мероприятий, на хакатоне часовая тишина, повисшая на площадке, — вовсе не признак всеобщего уныния и неизбывной тоски. Это периоды сосредоточенной работы, когда попытки растормошить участников только отвлекут их и выбьют из потока. Незримый азарт этой деятельности всегда внутри команд.
Солнце клонилось к горизонту, и мы решили провести первый чемпионат. Для этого команды прервали бесконечный процесс совершенствования кода и выставили своих ботов на общую арену. Когда все команды сыграли установленное количество игр по круговой системе и посмотрели визуализацию самых успешных боев, мы составили первый рейтинг. Из него стало ясно, что уровень команд, участвующих в битве, сильно (хотя и не критично) отличается. Но поскольку девиз битвы требовал победы сильнейшего, мы решили это во внимание не принимать.

Наличие в турнире фаворитов не отбивает соревновательный дух. У участников появляется зримый ориентир, которого нужно достичь, чтобы побороться за победу.
Мы понимали, что в означенный вначале тайминг не укладываемся. К финалу очередного этапа оптимизации одна из команд одолела главного босса сервера — Йоду. Остальные команды тоже почувствовали себя уверенно перед финалом, одной из них даже удалось «положить» сервер в очередной жаркой битве.
В плей-офф вышли четыре лучшие команды и по турнирной системе сыграли заключительные игры. В режиме «финал» сервер сразу же включал визуализацию боя, и мы на большом экране наблюдали взлеты и падения топовых ботов наших участников. Это было похоже на просмотр финала Лиги чемпионов и других подобных ивентов: все собрались перед экраном проектора и оживленно болели за своих ботов. Попытки оптимизировать ботов предпринимались даже в коротких перерывах между битвами.

Турнир закончился около полуночи. Мы наградили победителей и команды, занявшие второе и третье место. Остальные участники получили классные сувениры и толстовки. Также мы снабдили ребят ланчбоксами с бургерами и капкейками в дорогу.

Ребята благодарили кураторов и друг друга за отлично проведенный день, продолжали бурно обсуждать итоги битвы и даже делились призами с другими командами. В половине первого ночи, загрузив все оборудование в машину, мы снова стояли у входа в антикафе. Усталые, но довольные тем, что ивент удался.
После турнира мы получали отзывы и вопросы от участников и собирали воедино фидбек. Кураторы пристальнее просмотрели код, созданный участниками, и оценили общий уровень команд. Эйчары продолжали общаться с ребятами и получали вопросы о возможности присоединиться к нашей команде.
В целом мы получили благодарные отзывы: участники были довольны проделанной работой, многие просили оставить доступ на сервер, чтобы совершенствовать ботов уже после битвы и однажды устроить Йоде и другим ботам реванш.
На момент написания поста мы поддерживаем связь с большинством ребят. Пятеро из них (в том числе победители битвы) выразили интерес к сотрудничеству и сейчас проходят собеседования с нашими эйчарами и руководителями производственных подразделений. Хотя наш хакатон собрал мало участников, мы считаем его успешным, так как:
Чем в итоге оказался крут хакатон (справедливо для участников и организаторов):
С какими вызовами нам пришлось столкнуться:
Мы с удовольствием поделились историей о нашем «хэндмейдовом» хакатоне, постарались акцентировать внимание на деталях и нюансах, которые почти невозможно учесть, делая такое мероприятие в первый раз. Не хотим громко заявлять, что этот текст претендует на гордое имя мануала DIY-хакатоностроения. Каждая компания уникальна в своей организационной культуре и ищет свой особый путь к сердцам молодых специалистов. Все вольны выбирать свои инструменты работы с HR-брендом.
Но мы можем с уверенностью заявить, что формат хакатона, каким бы тривиальным и избитым он ни казался «снаружи», наполнен особой магией, позволяющей по-новому взглянуть на мотивацию участников и организаторов, на процесс и практический результат всего мероприятия. Суть в том, что в течение целого дня (а то и пары дней) вы будете наблюдать динамично меняющийся рабочий поток, ситуации взаимного обучения и самомотивации (это касается не только участников, но и организаторов), построение оптимальной командной тактики. Все события происходят в сжатые сроки и в ограниченном пространстве, поэтому вы сможете в режиме реального времени увидеть скилы и компетенции, на раскрытие которых в привычном рабочем режиме уходят недели.
|
Метки: author CUSTIS хакатоны блог компании custis custis hr-brand хакатон star wars c# java молодые специалисты |
Как EA усложнили нам жизнь, или как мы чинили баг 12-летней давности |


#include
#include
#include
#include
#include
#define REPEATS 1000 // Количество проверок
#define ESCAPE 27 // Код клавиши ESCAPE
#define TEST_TIME 2 // Время, проведенное на трассе
#define START_TIME 0 // Изначальное значение внутриигрового таймиера
void main( )
{
time_t t;
srand( time( &t ) );
while ( true )
{
float diffs[ REPEATS ];
int frame_diffs[ REPEATS ]; // Сторэйдж разниц
for ( int i = 0; i < REPEATS; i++ )
{
int limit = rand( ) % TEST_TIME + 1;// Генерируем случайное кол-во времени,
// +1 не даст нам сгенерировать 0
limit *= 60; // Минуты в секунды
limit += (START_TIME * 60); // Выравниваем конечное время
float t = 0.0f + (START_TIME*60); // Выравниваем начальное время
float step = 1.0f / 60.0f; // И лочим все на 60 фпс
int steps = 0;
while ( t < limit )
{
steps++;
t += step;
}
// Считаем ожидания и выводим их на экран
double expectation = (double)(limit - START_TIME*60)/ ( 1.0 / 60.0 );
printf("%f\n", t );
printf("Difference = %f; steps = %d\n", t - limit, steps );
printf( "Expected steps = %f; frames dropped = %d\n",
expectation, (int)expectation - (int)steps );
diffs[i] = fabs( t - limit );
frame_diffs[ i ] = (int)expectation - (int)steps;
}
// Считаем среднее и статистику
float sum = 0;
int frame_sum = 0;
for ( int j = 0; j < REPEATS; j++ )
{
sum += diffs[ j ];
frame_sum += frame_diffs[ j ];
}
printf( "Avg. time difference = %f, avg. frame difference = %d\n",
sum / REPEATS, frame_sum / REPEATS );
// В случае "any key" продолжаем, в случае "ESCAPE" выходим
printf( "Press any key to continue, press esc to quit\n" );
if ( getch() == ESCAPE )
break;
}
}



enum ProcessSizes
{
MW13 = 0x00678e4e
}
public void Refresh()
{
if(!process.IsOpen)
{
// In cases when the process is not open, but the game exists
// The process had either crashed, either was exited on purpose
if(game != null)
Console.WriteLine("Process lost (quit?)");
game = null;
return;
}
if(isUnknown) // If we couldn't determine game version, do nothing
{
return;
}
// If process is opened, but the game doesn't exist, we need to create it
if(process.IsOpen && game == null)
{
Console.WriteLine("Opened process, size = 0x{0:X}", process.ImageSize);
switch((ProcessSizes)process.ImageSize) // Guessing version
{
case ProcessSizes.MW13:
game = new MW.MW13(process);
break;
default:
Console.WriteLine("Unknown game type");
isUnknown = false;
break;
}
}
// At last, update game
game.Update();
}
public abstract class Game
{
private float lastTime;
private GameProcess game;
///
/// Synch-timer's address
///
protected int raceIgtAddress;
///
/// Timer-to-sync address
///
protected int globalIgtAddress;
private void ResetTime()
{
byte[] data = { 0, 0, 0, 0 };
game.WriteMemory(globalIgtAddress, data);
}
public void Update()
{
float tmp = game.ReadFloat(raceIgtAddress);
if (tmp < lastTime)
{
ResetTime();
Console.WriteLine("Timer reset");
}
lastTime = tmp;
}
public Game(GameProcess proc)
{
game = proc;
lastTime = -2; // Why not anyway
}
}
class Program
{
static void Run(object proc)
{
GameHolder holder = new GameHolder((string)proc);
while (true)
{
Thread.Sleep(100);
holder.Refresh();
}
}
static void Main(string[] args)
{
Thread t = new Thread(new ParameterizedThreadStart(Run));
t.Start(args[0]);
Console.WriteLine("Press any key at any time to close");
Console.ReadKey();
t.Abort();
}
}

|
Метки: author GrimMaple реверс-инжиниринг c# reverse engineering reverse-engineering debug отладка bugfix |
[Из песочницы] Дженерики и конвертеры в Nim |

proc plusOne(arg: int): int =
return arg + 1
echo plusOne(5) # Выведет 6
proc tryLen[T](something: T) =
when compiles(something.len): # something.len это тоже самое, что len(something)
echo something.len
else:
echo "У этого типа не объявлена процедура `len`"
# Объявим тип нового объекта, у которого не будет процедуры `len` (так как мы её не объявляли)
type MyObject = object
# Создадим сам объект
let myObj = MyObject()
tryLen([1, 2, 3]) # Выведет 3
tryLen("Hello world!") # Выведет 12
tryLen(myObj) # Выведет "У этого типа не объявлена процедура `len`"
type MyObject = object
let myObj = MyObject()
# Если процедура или конвертер маленькие, то можно сразу написать возвращаемое значение без return
# Имя конвертера не играет какой-либо особенной роли
converter toInt(b: MyObject): int = 1
# Конвертер можно вызвать явно (однако в этом случае лучше сделать обычную процедуру)
echo myObj.toInt + 1 # Выведет 2
# Или он сам может вызываться неявно:
echo myObj + 1 # Тоже выведет 2, так как toInt неявно конвертировал myObj в число 1
converter toBool[T](arg: T): bool =
# Если для данного типа аргумента имеется процедура len
when compiles(arg.len):
arg.len > 0
# Если аргумент можно сложить с числом того же типа T
# T(0) используется для того, чтобы условие одновременно совпадало
# со всеми числовыми типами (т.е мы конвертируем 0 в данный тип)
elif compiles(arg + T(0)):
arg > 0
if [1, 2, 3]: # Длина массива
echo "True!"
if @[1, 2, 3]: # Длина последовательности
echo "True too!"
if "": # Пустая строка
echo "No :("
if 5: # Integer
echo "Nice number!"
if 0.0001: # Float
echo "Floats are nice too!"
|
Метки: author Tiberiumk программирование nim metaprogramming generics converters метапрограммирование дженерики |
Черты великого продакт-менеджера |







|
Метки: author SmirkinDA управление разработкой управление персоналом развитие стартапа карьера в it-индустрии блог компании parallels parallels product management pmm management |
npm link на стероидах |

Думаю многие из вас уже сталкивались с локальной разработкой npm-пакетов. Обычно никаких трудностей это не вызывает: создаём папку, запускаем npm init, пишем тесты, дальше используем npm link (либо просто симлинк) и «шлифуем» api до полной готовности.
Звучит просто… только если вы не используете Babel, Rollup, Webpack и т.п. Иными словами, всё хорошо, пока проект не нужно собрать перед публикацией, да ещё с модификацией исходного кода. Кроме того, одновременно разрабатываемых пакетов может быть больше чем один, что в разы усложняет «жизнь». Чтобы исправить эту ситуацию, пришлось сделать маленькую утилиту npmy, под катом небольшая статья с описанием тех. процесса работы и пример использования.
Итак, как я уже говорил, основная проблема локальной разработки — это использование scripts/хуков (prepublish, prepublishOnly и т.д.), именно по этой причине npm link не подходит, ведь по сути — это банальный симлинк, да ещё по завершению разработки нужно не забывать про npm unlink.
Поэтому я принялся за свое решение, которое:
Первой мыслью было добавить правила прямо в package.json, но это неправильно, ведь это именно локальная разработка, поэтому правила было решено размещать в .npmyrc, который без труда можно добавить в .gitignore.
Сам файл — ни что иное, как простой JSON-объект, у которого:
key — название зависимости из package.json;value — локальный путь до разрабатываемого пакета (относительный или абсолютный).Всё, на этом конфигурация закончена.
Заходим в папку с .npmyrc и запускаем npmy, который:
.npmrc..npmrc.Это самое интересное, ради чего всё и затевалось. Для начала вспомним, как это работает в оригинальном npm.
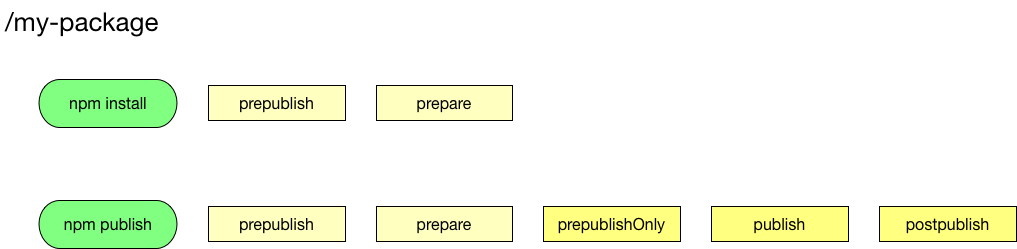
Как видите, тут нас ждет сюрприз, prepublish и prepare выполняются как на npm publish, так и на npm install (без аргументов). Поэтому если вам нужна сборка проекта перед публикацией, используйте prepublishOnly, но только начиная с 5 версии. Хоть этот хук и добавили в 4, работает он неправильно, и вместо собранного пакета уедет не пойми что, увы.
В моём процессе перед запуском всех хуков есть ещё одно звено, а именно создание копии проекта (вместе с node_modules):
rsync в темповую папку.package.json, из которого убирается npm test, чтобы не тормозить процесс псевдо-публикации.files.Вуаля, теперь мы имеем версию пакета, которую бы вы получили при установки из npm. Также при каждом изменении исходников, ПОВ будет обновлена автоматом.
Кроме этого, npmy не забывает про секцию bin в package.json и корректно создаёт симлинки на объявленные там скрипты.
npm install -g npmy.npmrc в проекте npmyСпасибо за внимание, надеюсь утилита будет полезна не только мне. :]
P.S. Инструмент новый, так что не стесняйтесь писать о проблемах.
|
Метки: author RubaXa разработка веб-сайтов node.js javascript блог компании mail.ru group npm link npm |
Система управления складом с использованием CQRS и Event Sourcing. Проектирование |
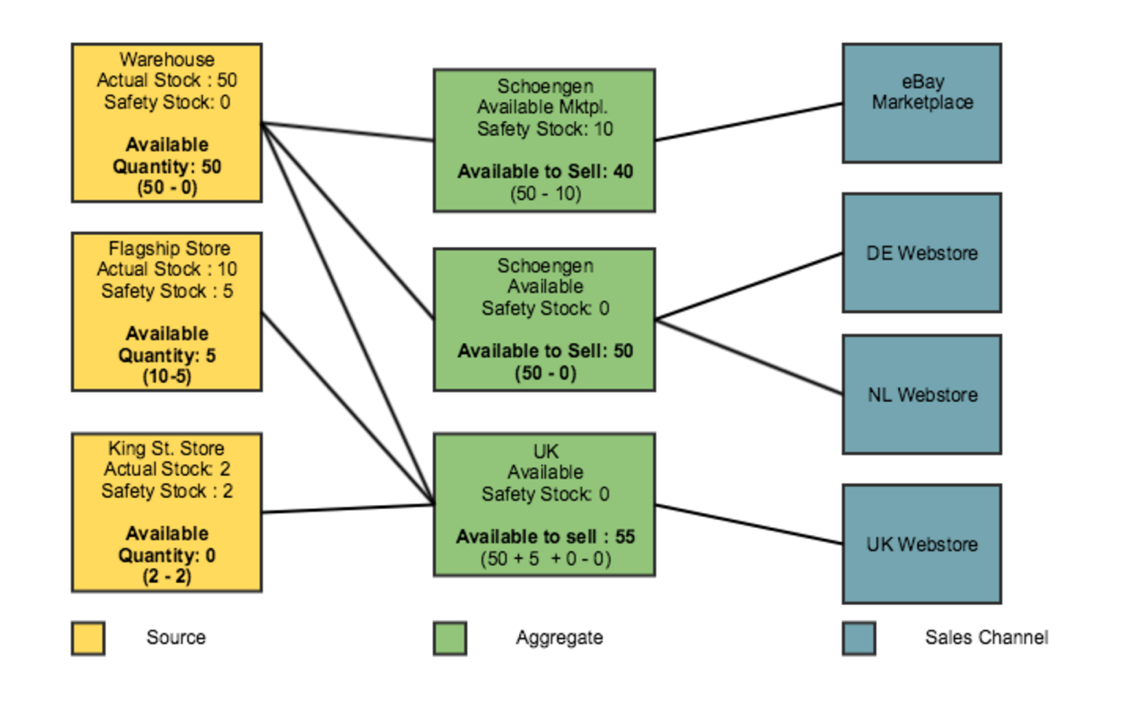
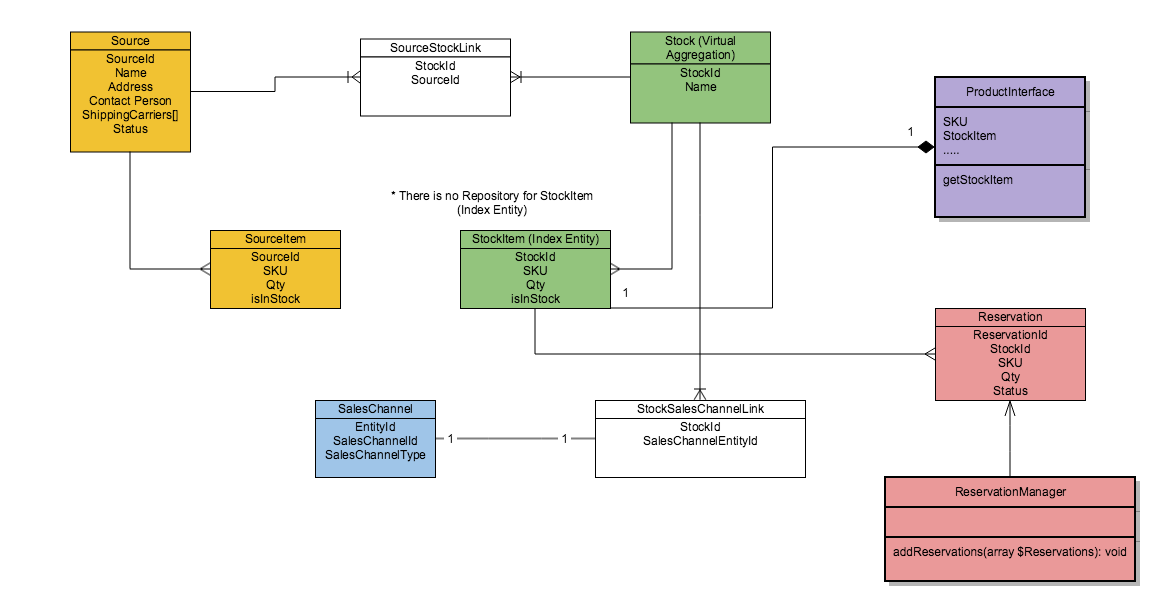
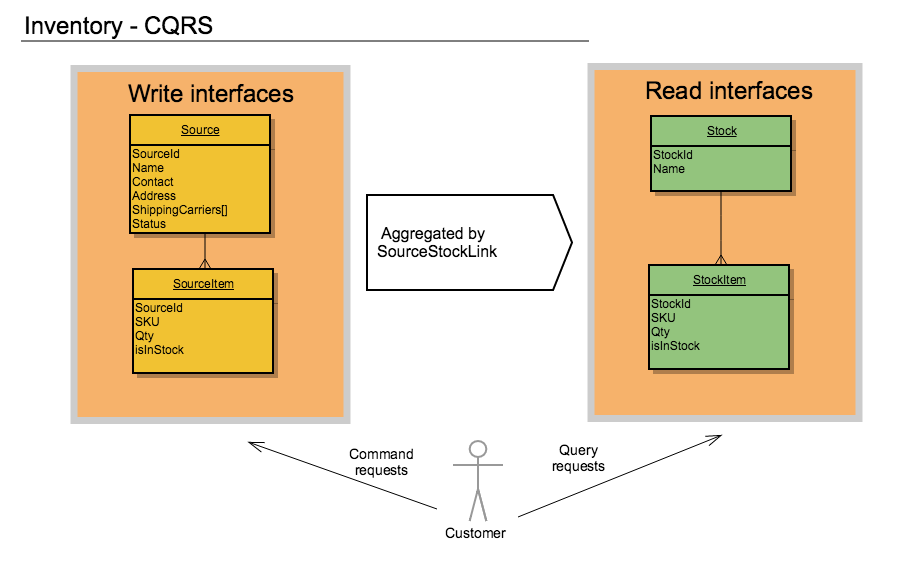
|
|
Продолжаем изучать Tizen: C# компоненты оказались высокого качества |


internal BluetoothLeDevice(BluetoothLeScanData scanData)
{
_scanData = new BluetoothLeScanData ();
_scanData = scanData;
....
}internal class BluetoothLeScanData
{
internal string RemoteAddress { get; set; }
internal BluetoothLeDeviceAddressType AddressType { get; set; }
internal int Rssi { get; set; }
internal int AdvDataLength { get; set; }
internal byte[] AdvData { get; set; }
internal int ScanDataLength { get; set; }
internal byte[] ScanData { get; set; }
}private int OnCreate(....)
{
WidgetBase b = Activator.CreateInstance(ClassType) as WidgetBase;
....
if (b == null)
return 0;
....
return 0;
}private int OnCreate(....)
{
WidgetBase b = Activator.CreateInstance(ClassType) as WidgetBase;
....
if (b == null)
return 0;
....
return 1;
}private TEdge ProcessBound(TEdge E, bool LeftBoundIsForward)
{
....
if (LeftBoundIsForward)
{
....
if (!LeftBoundIsForward) Result = Horz.Prev;
....
}
else
{
....
if (!LeftBoundIsForward) Result = Horz.Next;
....
}
....
}private void DoMaxima(TEdge e)
{
....
if(....)
{
....
} else if( e.OutIdx >= 0 && eMaxPair.OutIdx >= 0 )
{
if (e.OutIdx >= 0) AddLocalMaxPoly(e, eMaxPair, e.Top);
....
}
....
}public ToolbarItem InsertBefore(ToolbarItem before, string label)
{
return InsertBefore(before, label);
}public ToolbarItem InsertBefore(ToolbarItem before, string label,
string icon)
{
....
}internal XamlServiceProvider(INode node, HydratationContext context)
{
....
if (node != null && node.Parent != null
&& context.Values.TryGetValue(node.Parent, // <=
out targetObject))
IProvideValueTarget = new XamlValueTargetProvider(....);
if (context != null) // <=
IRootObjectProvider =
new XamlRootObjectProvider(context.RootElement);
....
}public INode Parse(....)
{
....
var xmltype = new XmlType(namespaceuri, type.Name, null); // <=
if (type == null)
throw new NotSupportedException();
....
}void OnProxyCollectionChanged(....)
{
....
if (e.NewStartingIndex >= 0 && e.NewItems != null) // <=
maxindex = Math.Max(maxindex, e.NewStartingIndex +
e.NewItems.Count);
....
for (int i = e.NewStartingIndex; i < _templatedObjects.Count; i++)
SetIndex(_templatedObjects[i], i + e.NewItems.Count); // <=
....
}


|
Метки: author n0mo разработка под tizen блог компании pvs-studio c# .net pvs-studio open source tizen static code analysis visual studio |
Официально представляем dapp — DevOps-утилиту для сопровождения CI/CD |

Dappfile) позволяют выполнять сборку образов быстро и эффективно:before_install, install, before_setup, setup), результаты выполнения которых кэшируются (даёт значительный рост в скорости повторных сборок образа);git patch apply) при новых сборках и кэширующая содержимое этих патчей;backend.yaml, frontend.yaml, cron.yaml в специальном каталоге .kube/).kubectl, которая разворачивает описанную в них инфраструктуру в нужном кластере Kubernetes (опять же, кластеры могут быть разными для каждого контура).dapp kube deploy (см. документацию), которая по своей сути является обёрткой к менеджеру пакетов Kubernetes — Helm, позволяя:Dappfile, в Helm (имеет helper для составления имени образа).|
|
Вы ни черта не понимаете в цветах |





Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Meklon графический дизайн usability цвет hsl этот мир сошел с ума лососевое пальто |






