Лог файлы Linux по порядку |
Невозможно представить себе пользователя и администратора сервера, или даже рабочей станции на основе Linux, который никогда не читал лог файлы. Операционная система и работающие приложения постоянно создают различные типы сообщений, которые регистрируются в различных файлах журналов. Умение определить нужный файл журнала и что искать в нем поможет существенно сэкономить время и быстрее устранить ошибку.

Журналирование является основным источником информации о работе системы и ее ошибках. В этом кратком руководстве рассмотрим основные аспекты журналирования операционной системы, структуру каталогов, программы для чтения и обзора логов.
Все файлы журналов, можно отнести к одной из следующих категорий:
Большинство же лог файлов содержится в директории /var/log.
--level= можно отфильтровать вывод по критерию значимости.Поддерживаемые уровни журналирования (приоритеты):
emerg - система неиспользуемая
alert - действие должно быть произведено немедленно
crit - условия критичности
err - условия ошибок
warn - условия предупреждений
notice - обычные, но значимые условия
info - информационный
debug - отладочные сообщения
(5:520)$ dmesg -l err
[1131424.604352] usb 1-1.1: 2:1: cannot get freq at ep 0x1
[1131424.666013] usb 1-1.1: 1:1: cannot get freq at ep 0x81
[1131424.749378] usb 1-1.1: 1:1: cannot get freq at ep 0x81update-alternatives, в котором находятся символические ссылки на команды или библиотеки по умолчанию.auditd.crond об исполняемых командах и сообщения от самих команд.faillog.Samba, который используется для доступа к общим папкам Windows и предоставления доступа пользователям Windows к общим папкам Linux.Для каждого дистрибутива будет отдельный журнал менеджера пакетов.
Yum в RedHat Linux.ebuild-ов установленных из Portage с помощью emerge в Gentoo Linux.dpkg в Debian Linux и всем семействе родственных дистрибутивах.И немного бинарных журналов учета пользовательских сессий.
last.pam_tally2.utmpdump.(5:535)$ sudo utmpdump /var/log/wtmp
[5] [02187] [l0 ] [ ] [4.0.5-gentoo ] [0.0.0.0 ] [Вт авг 11 16:50:07 2015]
[1] [00000] [~~ ] [shutdown] [4.0.5-gentoo ] [0.0.0.0 ] [Вт авг 11 16:50:08 2015]
[2] [00000] [~~ ] [reboot ] [3.18.12-gentoo ] [0.0.0.0 ] [Вт авг 11 16:50:57 2015]
[8] [00368] [rc ] [ ] [3.18.12-gentoo ] [0.0.0.0 ] [Вт авг 11 16:50:57 2015]
[1] [20019] [~~ ] [runlevel] [3.18.12-gentoo ] [0.0.0.0 ] [Вт авг 11 16:50:57 2015]Так как операционная система, даже такая замечательная как Linux, сама по себе никакой ощутимой пользы не несет в себе, то скорее всего на сервере или рабочей станции будет крутится база данных, веб сервер, разнообразные приложения. Каждое приложения или служба может иметь свой собственный файл или каталог журналов событий и ошибок. Всех их естественно невозможно перечислить, лишь некоторые.
access_log, а ошибки — в error_log.В домашнем каталоге пользователя могут находится журналы графических приложений, DE.
stderr графических приложений X11.Initializing "kcm_input" : "kcminit_mouse"
Initializing "kcm_access" : "kcminit_access"
Initializing "kcm_kgamma" : "kcminit_kgamma"
QXcbConnection: XCB error: 3 (BadWindow), sequence: 181, resource id: 10486050, major code: 20 (GetProperty), minor code: 0
kf5.kcoreaddons.kaboutdata: Could not initialize the equivalent properties of Q*Application: no instance (yet) existing.
QXcbConnection: XCB error: 3 (BadWindow), sequence: 181, resource id: 10486050, major code: 20 (GetProperty), minor code: 0
Qt: Session management error: networkIdsList argument is NULLПочти все знают об утилите less и команде tail -f. Также для этих целей сгодится редактор vim и файловый менеджер Midnight Commander. У всех есть свои недостатки: less неважно обрабатывает журналы с длинными строками, принимая их за бинарники. Midnight Commander годится только для беглого просмотра, когда нет необходимости искать по сложному шаблону и переходить помногу взад и вперед между совпадениями. Редактор vim понимает и подсвечивает синтаксис множества форматов, но если журнал часто обновляется, то появляются отвлекающие внимания сообщения об изменениях в файле. Впрочем это легко можно обойти с помощью <:view /path/to/file>.
Недавно я обнаружил еще одну годную и многообещающую, но слегка еще сыроватую, утилиту — lnav, в расшифровке Log File Navigator.
Установка пакета как обычно одной командой.
$ aptitude install lnav #Debian/Ubuntu/LinuxMint
$ yum install lnav #RedHat/CentOS
$ dnf install lnav #Fedora
$ emerge -av lnav #Gentoo, нужно добавить в файл package.accept_keywords
$ yaourt -S lnav #ArchНавигатор журналов lnav понимает ряд форматов файлов.
Что в данном случае означает понимание форматов файлов? Фокус в том, что lnav больше чем утилита для просмотра текстовых файлов. Программа умеет кое что еще. Можно открывать несколько файлов сразу и переключаться между ними.
(5:471)$ sudo lnav /var/log/pm-powersave.log /var/log/pm-suspend.logПрограмма умеет напрямую открывать архивный файл.
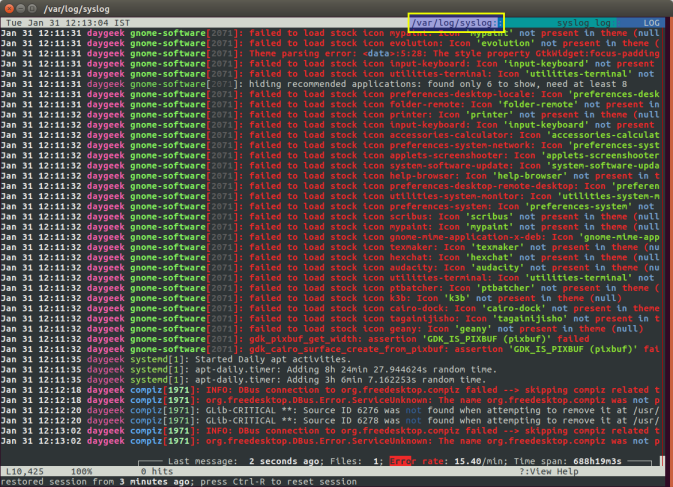
(5:471)$ lnav -r /var/log/Xorg.0.log.old.gzПоказывает гистограмму информативных сообщений, предупреждений и ошибок, если нажать клавишу . Это с моего syslog-а.
Mon May 02 20:25:00 123 normal 3 errors 0 warnings 0 marks
Mon May 02 22:40:00 2 normal 0 errors 0 warnings 0 marks
Mon May 02 23:25:00 10 normal 0 errors 0 warnings 0 marks
Tue May 03 07:25:00 96 normal 3 errors 0 warnings 0 marks
Tue May 03 23:50:00 10 normal 0 errors 0 warnings 0 marks
Wed May 04 07:40:00 96 normal 3 errors 0 warnings 0 marks
Wed May 04 08:30:00 2 normal 0 errors 0 warnings 0 marks
Wed May 04 10:40:00 10 normal 0 errors 0 warnings 0 marks
Wed May 04 11:50:00 126 normal 2 errors 1 warnings 0 marksКроме этого поддерживается подсветка синтаксиса, дополнение по табу и разные полезности в статусной строке. К недостаткам можно отнести нестабильность поведения и зависания. Надеюсь lnav будет активно развиваться, очень полезная программа на мой взгляд.
|
Метки: author temujin системное администрирование настройка linux *nix logs linux |
Забронируйте ваше место на БИТ-пикнике HPE |

|
Метки: author tonyafilonenko системное администрирование it- инфраструктура блог компании hewlett packard enterprise hpe мероприятие москва |
Семинар «Облака и реальность: кейсы, грабли, хорошие новости», 13 июля, Санкт-Петербург |

|
Метки: author 5000shazams виртуализация it- инфраструктура блог компании dataline виртуальные сервера облачные сервисы облако облачные технологии dataline даталайн |
[Перевод] Как создать билборд-текстуру растительности в Unreal Engine 4 |



float2 output;
output = atan2 (In.y,In.x);
return (output);



|
Метки: author Plarium работа с 3d-графикой компьютерная анимация дизайн игр cgi ( графика) блог компании plarium unreal engine 4 trees деревья игры создание графики |
Тюнинг типовых ролей Windows. Часть первая: Файлы и печать |

Начинаем небольшой цикл статей, посвященных тюнингу производительности сервера Windows и его типовых ролей. Материал будет полезен как при попытке выжать из старого сервера максимум (помимо покраски в красный цвет), так и при планировании новых высоконагруженных систем без покупки топовых серверов (как это советуют интеграторы).
Процессор - он как сердце сервера, поэтому от него зависит очень много в плане производительности. Благодаря маркетологам мы знаем - чем больше ядер и мегагерцев, тем круче. На самом деле всё не совсем так:
Выбирайте 64-битный процессор. Современные серверные Windows не поддерживают 32-битные процессоры, да и памяти он может адресовать намного больше.
Количество ядер не имеет большого значения. Не все приложения и сервисы могут использовать несколько ядер, и в общем случае одно ядро с большой частотой будет эффективнее, чем два с меньшей.
Hyperthreading - гиперпоточность - когда одно физическое ядро процессора определяется как два логических. Функция процессора позволяет обрабатывать два разных потока на одном ядре, что в общем случае увеличивает производительность. Но бывает, что производительность наоборот снижается из-за того, что кэш процессорного ядра один.
Кэш процессора. Тут все просто: чем он больше, тем лучше, и часто больший кэш дает большую производительность, чем частота процессора.
Не нужно сравнивать процессоры разных поколений и производителей по частоте: скорость обработки данных зависит и от многих других факторов вроде кэша и частоты шины.

Проверка процессора под требования Hyper-V.
С оперативной памятью все довольно просто: чем она больше и быстрее, тем лучше. Чуть интереснее становится, если оперативной памяти недостаточно и системе необходимо использовать файл подкачки. Тут можно ограничиться следующими рекомендациями:
файл подкачки стоит положить на отдельный физический диск. Чем он быстрее, тем лучше. Если такой возможности нет, то лучше разместить его на диске, к которому меньше файловых обращений;

Размещение файла подкачки на системном диске - не лучший вариант.
Теперь о сетевых адаптерах. Из интересных особенностей можно отметить:
Только адаптеры с поддержкой 64-разрядных систем имеют DMA (Direct Memory Access) - технологию прямого доступа к памяти по сети. Если нужна действительно быстрая сеть между нодами кластера - на это стоит обратить внимание.

HPE ProLiant DL360 Gen7 обладает изначально четырьмя сетевыми портами.
На этом закончу небольшую вводную и перейду непосредственно к оптимизации ролей сервера. Начнем с самого простого - с файлового сервера.
Обычно при установке и работе файлового сервера вопрос быстродействия не стоит. Но только до тех пор, пока на обычной файлопомойке на заводятся базы данных, чудовищные файлы Excel и им подобные «интересные» вещи. Расскажу про параметры, которые могут улучшить или ухудшить быстродействие SMB.
Отдельно отмечу вопрос быстродействия сервера, который обрабатывает не только клиентов внутри локальной сети, но и удаленных - например, по VPN. Лично я сталкивался с ситуацией, когда в сети на Windows XP\2003 начали появляться компьютеры на Windows 7\2008. Тогда мы столкнулись с тем, что быстродействие сети новых компьютеров оставляет желать лучшего при общении со старыми ОС. Начитавшись интернетов, выполнили на новых машинах следующий скрипт:
netsh int tcp set global autotuning=disabled
netsh int tcp set global autotuninglevel=disabled
netsh int tcp set global rss=disabled chimney=disabled
Сеть заработала, скрипт был добавлен в разворачиваемые образа систем.
И все было хорошо, пока в сети не появился удаленный сегмент с повышенным требованием к скорости работы сети. Файлы передавались по VPN не быстрее 2 Мб/с. Проблему локализовали: оказалось, что специально для работы в LAN\WAN сетях в новых операционных системах добавили функцию autotuning. С помощью нее системы определяют скорость соединения и договариваются о размерах кадра TCP для оптимального быстродействия. Чтобы VPN работала быстро, и сервера не тормозили при обращениях к WIndows 2003, достаточно было не отключать autotuning, а ограничить его командой:
netsh int tcp set global autotuninglevel=highlyrestricted
Но перейдем к более специализированным параметрам.
Помним, что изменения параметров реестра и настроек служб могут привести к чему угодно. Поэтому делаем все аккуратно.
Начнем с тюнинга клиентов файловых серверов. За подключение к серверу SMB отвечает служба LanmanWorkstation. Большинство параметров находятся в следующей ветке реестра:
HKLM\System\CurrentControlSet\Services\LanmanWorkstation\Parameters
В большинстве своем параметры имеют тип REG_DWORD. В современных Windows управление частью настроек возможно через командлет Set-SmbClientConfiguration. Просмотреть текущие значения - соответственно, Get-SmbClientConfiguration.
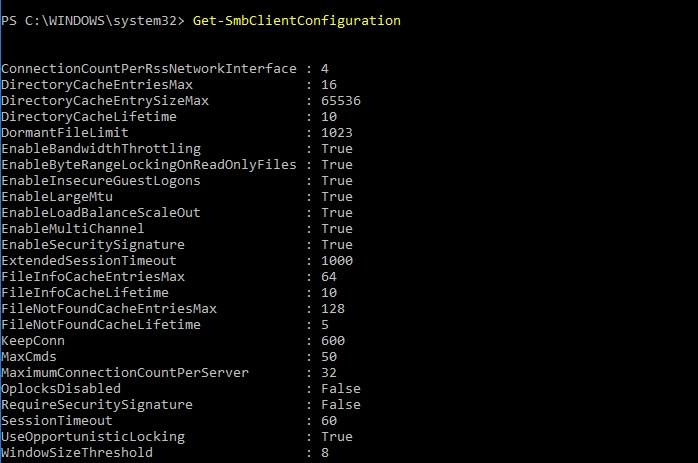
Значения параметров клиента SMB.
Параметры, на которые стоит обратить внимание в первую очередь при вопросах быстродействия:
| Имя параметра | Значение по умолчанию | Варианты значений | За что отвечает | Комментарий |
| DisableBandwidthThrottling | 0 | 0-1 | Включение - отключение троттлинга для сетей с высокой задержкой | Включение параметра может повысить пропускную способность сетей с высокой задержкой (WAN) |
| FileInfoCacheEntriesMax | 64 | 1-65536 | Максимальное количество значений в кэше метаданных файлов | Увеличение параметра уменьшает трафик и повышает пропускную способность сети при обращении к большому количеству файлов |
| DirectoryCacheEntrySizeMax | 64 | 1-65536 | Максимальный размер кэша для каталогов | Измеряется в килобайтах |
| FileNotFoundCacheEntriesMax | 128 | 1-65536 | Максимальное количество значений в кэше информации о файлах | Увеличение параметра уменьшает трафик и повышает пропускную способность сети при обращении к большому количеству файлов |
| MaxCmds | 50 | 1-65536 | Максимальное количество команд в сеансе | Увеличение параметра увеличит расход памяти, но поднимет быстродействие. Только для SMB v1 |
| DormantFileLimit | 1023 | 1-65536 | Максимальное количество файлов, которые могут быть открыты, после того как «отпущены» приложением | |
| ScavengerTimeLimit | 10 | 0-127 | Как часто запускается «мусорщик», очищающий кэш дескрипторов файлов | Измеряется в секундах, актуально для Windows XP\2003 |
В качестве примера тюнинга, можно привести следующие значения:
DisableBandwidthThrottling = 1;
FileInfoCacheEntriesMax = 32768;
DirectoryCacheEntriesMax = 4096;
FileNotFoundCacheEntriesMax = 32768;
MaxCmds = 32768;
DormantFileLimit = 32768;
Разумеется, конкретно эти значения - не панацея. Параметры должны подбираться индивидуально.
Параметры, настраиваемые через powershell и реестр:
| Имя параметра | Значение по умолчанию | Варианты значений | За что отвечает | Комментарий |
| ConnectionCountPerNetworkInterface | 1 | 1-16 | Максимальное количество подключений к серверу с интерфейсом без поддержки RSS | MS не рекомендует изменять значение по умолчанию |
| ConnectionCountPerRssNetworkInterface | 4 | 1-16 | Максимальное количество подключений к серверу с интерфейсом c поддержкой RSS | |
| ConnectionCountPerRdmaNetworkInterface | 2 | 1-16 | Максимальное количество подключений к серверу с интерфейсом с поддержкой RDMA | |
| MaximumConnectionCountPerServer | 32 | 1-64 | Максимальное количество подключений к одному серверу | |
| DormantDirectoryTimeout | 600 | Максимальное количество времени обработки каталога | Измеряется в секундах |
|
| FileInfoCacheLifetime | 10 | Время хранения информации о файле в кэше | ||
| DirectoryCacheLifetime | 10 | Время хранения метаданных каталога в кэше | ||
| FileNotFoundCacheLifetime | 5 | Время хранения кэша не найденных файлов | ||
| CacheFileTimeout | 10 | Время хранения кэша для файла, после того как файл «отпущен» приложением | ||
| DisableLargeMtu | 0 (Win8) | 0-1 | Включение-отключение большого размера MTU | С включенным параметром размер запроса ограничен 64 КБ, с включенным - 1 МБ. |
| RequireSecuritySignature | 0 | 0-1 | Включение-отключение обязательной подписи SMB | Включение этого параметра замедляет скорость работы, но повышает защиту от атаки MITM |
| DirectoryCacheEntriesMax | 16 | 1-4096 | Максимальное количество значений в кэше информации о каталогах | Увеличение параметра уменьшает трафик и повышает пропускную способность сети при обращении к большим каталогам |
| MaxCredits | 128 | Максимальное количество команд в сеансе | Тоже самое, что и MaxCmds, но для SMB v2 |
Параметры, настраиваемые через powershell:
| EnableMultiChannel | 1 | 0-1 | Включение-отключение использования нескольких физических адаптеров | |
| EnableByteRangeLockingOnReadOnlyFiles | True | True\False | Включение-отключение блокировки файлов «только для чтения» | |
| EnableInsecureGuestLogons | True | True\False | Включение-отключение гостевого входа на ресурс | Отключение не позволит заходить без авторизации на расшаренные для всех папки на недоменном сервере (NAS) |
| EnableLoadBalanceScaleOut | True | True\False | Включение-отключение поддержки распределения нагрузки при подключении к кластеру | |
| EnableSecuritySignature | True | True\False | Включение-отключение возможности подписи SMB | |
| ExtendedSessionTimeout | 1000 | Время ожидания ответа от сервера | Измеряется в секундах | |
| KeepConn | 600 | Время до закрытия неактивной сессии | Измеряется в секундах, применимо только к SMB v1 | |
| OplocksDisabled | False | True\False |
Переключается автоматически в зависимости от значения параметра UseOpportunisticLocking | |
| SessionTimeout | 60 | Время до закрытия неактивной сессии | Измеряется в секундах | |
| UseOpportunisticLocking | True | True\False | Включение-отключение режима гибких блокировок (oplock) файлов с их буферизацией | Включенный механизм сильно увеличивает быстродействие, но в ненадежных сетях может привести к повреждению файлов |
| WindowSizeThreshold | 1 для серверных систем, 8 для клиентских | Минимальный размер окна до включения режима Multichannel |
Если же говорить уже непосредственно про файловый сервер, то вот несколько общих рекомендаций:
Для лучшего быстродействия не используйте ненужные функции вроде мини-фильтров файловой системы, IPSec, шифрование и сжатие NTFS, шифрование SMB и другие. Включение антивируса может существенно подпортить быстродействие, и если периметр сети защищен, лучше его и не устанавливать.
Регулярно стоит проверять актуальность драйверов, особенно на сетевые карты. Встречались ситуации, когда из-за кривых драйверов сетевая карта стабильно работала только при принудительном выставлении сто мегабит. И только с выходом свежих драйверов удалось выжать полноценный гигабит.
Для оценки быстродействия работы протокола SMB можно использовать счетчики производительности, которые существуют как для сервера, так и для клиента.
Тут поможет утилита perfmon.exe. После запуска удобно переключить отображение в режим «отчет»:
Потом необходимо добавить нужные счетчики производительности. Для примера добавим счетчик «Общие ресурсы SMB сервера», нажав на зеленый плюс, выбрав нужный нам счетчик и общий ресурс:
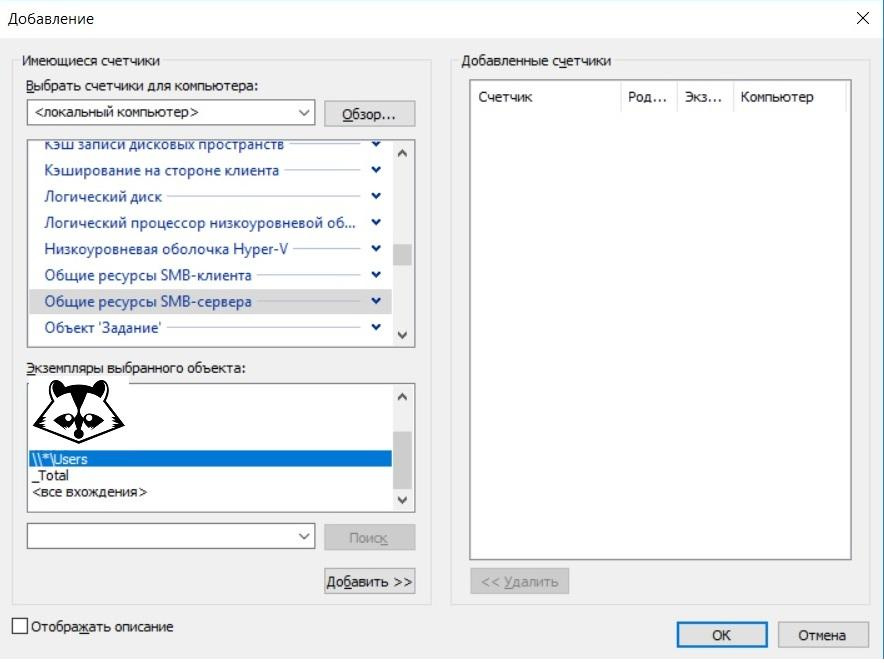
И наслаждаемся результатом:

Более полно с процедурой использования счетчиков производительности, сбора и анализа результата рекомендую ознакомиться в блоге Microsoft.
Перейдем к тюнингу. За работу сервера SMB отвечает служба Lanmanserver, поэтому часть параметров можно изменить в соответствующей ветке реестра:
HKLM\System\CurrentControlSet\Services\LanmanServer\Parameters.
Удобнее, конечно, использовать командлет Set-SmbServerConfiguration.
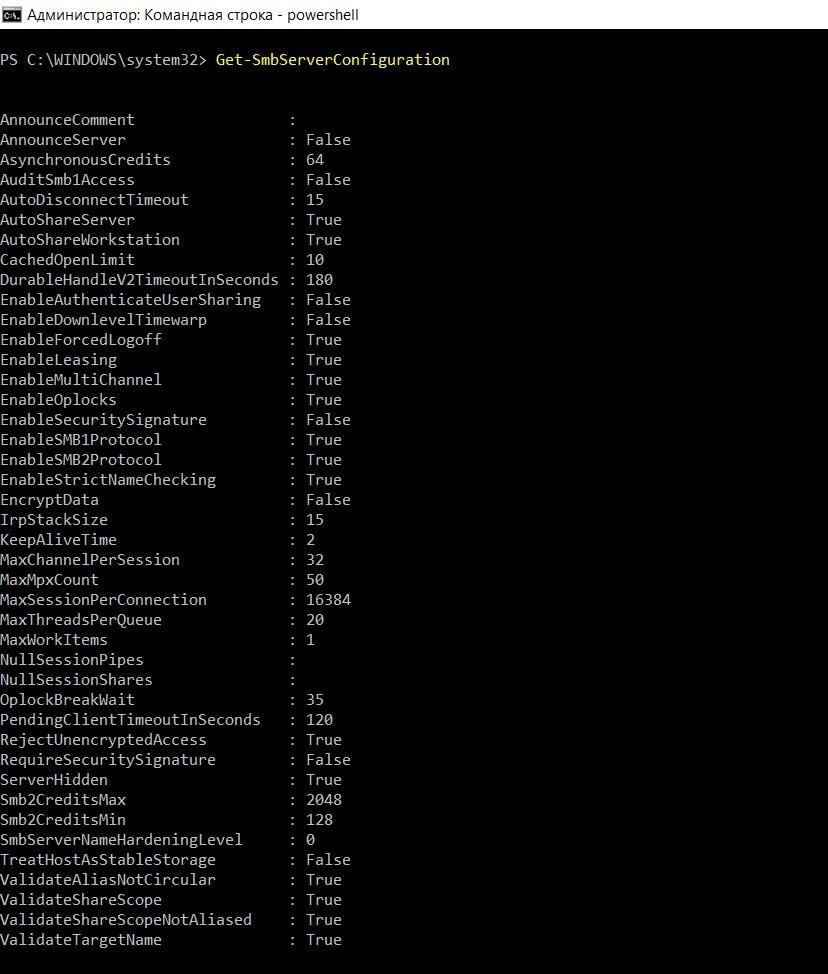
Вывод значений параметров с помощью командлета Get-SmbServerConfiguration.
Параметры, на которые стоит обратить внимание в первую очередь:
| Имя параметра | Значение по умолчанию | Тип параметра | За что отвечает | Комментарий |
| Smb2CreditsMax | 8192 | uint32 | Максимальное количество команд SMB v2 | Эти два параметра позволяют динамически распределять нагрузку. Иногда при использовании скоростных каналов с высокой задержкой (WAN) изменение этих параметров увеличит скорость. Посмотреть, есть ли проблемы, поможет счетчик производительности «Общие ресурсы SMBклиента - Задержек кредита/c» |
| Smb2CreditsMin | 512 | uint32 | Минимальное количество команд SMB v2 | |
| MaxThreadsPerQueue | 20 | unit32 | Максимальное количество потоков сервера при обработке одновременных запросов | Увеличение параметра влияет на аппаратную загрузку, но увеличивает производительность. Показателем к изменению параметра может служить значение счетчика производительности «Рабочие очереди сервера - Длина очереди - SMB2 NonBlocking» становится больше 100. |
| AsynchronousCredits | 512 | uint32 | Максимальное количество одновременных асинхронных команд в одной сессии | В ряде случаев, например, при использовании нагруженного веб-сервера, увеличение значения параметра увеличивает производительность |
| MaxMpxCt | 50 | uint32 | Максимальное количество невыполненных клиентских запросов для каждого клиента | Влияет только на клиентов SMB v1 |
Существует еще один параметр реестра, не контролируемый командлетом powershell:
путь: HKLM\System\CurrentControlSet\Control\Session Manager\Executive;
параметр: REG_DWORD c именем AdditionalCriticalWorkerThreads;
Этот параметр отвечает за дополнительные рабочие процессы, отвечающие за процедуры записи и чтения в системном кэше файловой системы. По умолчанию дополнительных процессов нет, и изменение этого параметра может существенно ускорить работу файлового сервера. Особенно при наличии многоядерных процессоров и производительной дисковой системы. Задумываться об увеличении этого параметра можно при росте счетчика производительности «Кэш - «Грязные» страницы».
В качестве примера тюнинга можно привести следующие значения параметров:
AdditionalCriticalWorkerThreads = 64;
MaxThreadsPerQueue = 64;
Значения также должны подбираться индивидуально.
| Имя параметра | Значение по умолчанию | Тип параметра | За что отвечает | Комментарий |
| AnnounceComment | null | string | Представление сервера | |
| AnnounceServer | False | boolean | Включение - отключение представления сервера | |
| AuditSmb1Access | False | boolean | Включение - отключение аудита доступа по протоколу SMB v1 | Параметр появился только в Windows 10\2016 |
| AutoDisconnectTimeout | 15 | uint32 | Время, после которого отключается неактивная сессия | |
| AutoShareServer | True | boolean | Включение - отключение сетевых ресурсов сервера по умолчанию | |
| AutoShareWorkstation | True | boolean | Включение - отключение сетевых ресурсов рабочей станции по умолчанию | |
| CachedOpenLimit | 10 | uint3 | Максимальное количество открытых файлов в кэше | |
| DurableHandleV2TimeoutInSeconds | 180 | uint32 | Время отключения неактивного дескриптора | |
| EnableAuthenticateUserSharing | False | boolean | Включение - отключение возможности общего доступа к соединению | |
| EnableDownlevelTimewarp | False | boolean | Включение - отключение низкоуровневого искажения времени | |
| EnableForcedLogoff | True | boolean | Включение - отключение принудительного выхода | |
| EnableLeasing | True | boolean | Включение - отключение аренды | |
| EnableMultiChannel | True | boolean | Включение - отключение использования нескольких физических адаптеров | |
| EnableOplocks | True | boolean | Включение - отключение гибких блокировок (oplock) | |
| EnableSecuritySignature | False | boolean | Включение - отключение возможности подписи SMB | |
| EnableSMB1Protocol | True | boolean | Включение - отключение протокола SMB v1 | |
| EnableSMB2Protocol | True | boolean | Включение - отключение протокола SMB v2+ | |
| EnableStrictNameChecking | True | boolean | Включение - отключение проверки имени входящего подключения | |
| EncryptData | False | boolean | Включение - отключение поддержки шифрования данных | |
| IrpStackSize | 15 | unit32 | Размер стека IRP (запросов ввода - вывода) | |
| KeepAliveTime | 2 | unit32 | Частота TCP запросов keepalive для подключения SMB | |
| MaxChannelPerSession | 32 | unit32 | Количество каналов в одной сессии | |
| MaxMpxCount | 50 | unit32 | Максимальное количество команд в сессии | Параметр должен быть настроен так же, как и параметр MaxCmds клиента |
| MaxSessionPerConnection | 16384 | unit32 | Максимальное количество сессий в одном соединении | |
| MaxWorkItems | 1 | uint32 | Максимальное количество рабочих элементов | Параметр влияет только на SMB v1 |
| NullSessionPipes | null | string | Каналы, доступные в нулевой сессии | |
| NullSessionShares | null | string | Сетевые ресурсы, доступные в нулевой сессии | |
| OplockBreakWait | 35 | uint32 | Время ожидания до прерывания блокировки | |
| PendingClientTimeoutInSeconds | 120 | uint32 | Время ожидания клиента | |
| RejectUnencryptedAccess | True | boolean | Включение - отключение незашифрованных запросов на доступ | |
| RequireSecuritySignature | False | boolean | Включение - отключение обязательной подписи SMB | Включение этого параметра замедляет скорость работы, но повышает защиту от атаки MITM |
| ServerHidden | True | boolean | Включение - отключение представления сервера | По умолчанию сервер не представляет себя |
| SmbServerNameHardeningLevel | 0 | uint32 | Уровень упрощения имени сервера | |
| TreatHostAsStableStorage | False | boolean | Включение - отключение надежного дискового хранилища | Включение этого параметра говорит серверу о надежности дискового хранилища, стоит включать его при работе с диском с энергонезависимым кэшем на запись. Тогда сервер не будет дожидаться подтверждения записи на диск, что ускорит быстродействие. |
| ValidateAliasNotCircular | True | boolean | Включение - отключение использования псевдонимов | |
| ValidateShareScope | True | boolean | Включение - отключение проверки имени ресурсов при создании нового ресурса | |
| ValidateShareScopeNotAliased | True | boolean | Включение - отключение проверки псевдонимов ресурсов при создании нового ресурса | |
| ValidateTargetName | True | boolean | Включение - отключение проверки имени целевого ресурса при создании псевдонима |
Повторюсь: изменение параметров может привести к неработоспособности сервера. Поэтому лучше сначала «потренироваться на кошках». Или хотя бы делать бэкапы.
Перейду к следующей, казалось бы, простой роли - сервер печати.
Помимо рекомендаций вида «быстрее, выше, сильнее» в плане аппаратной части, нужно отметить несколько других интересных моментов.
Перенос очереди печати на несистемный диск довольно сильно увеличит производительность сервера. Это делается в свойствах сервера печати, на вкладке «дополнительные параметры».
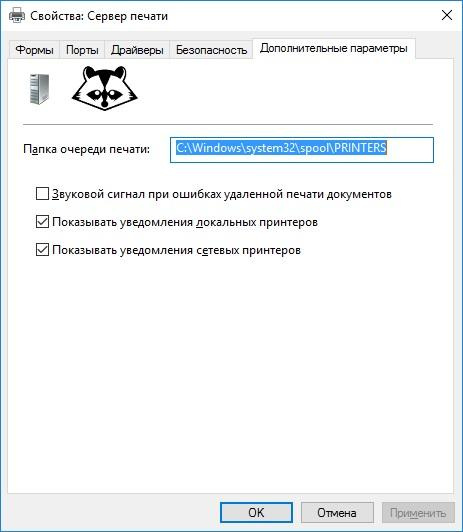
Настройка размещения очереди печати.
По возможности лучше отрисовывать задачи на клиенте. В таком случае клиент будет сам переводить документ в специальный формат для печати (PDL). Сервер же не будет тратить ресурсы на это преобразование.
По умолчанию эта возможность уже включена, включить-выключить можно групповой политикой для всех принтеров. Индивидуальную настройку принтеров можно провести с помощью команды
printui /Xs /n "printer" ClientSideRender disabled
Отключать отрисовку на клиенте имеет смысл при достаточном запасе производительности сервера печати для разгрузки клиентов.
Принтеры с поддержкой XPS (OpenXPS) меньше нагружают сервер, чем принтеры без нее. Принтеры с поддержкой PCL 6 и Postscript чуть менее эффективны из-за векторного формата. Поэтому при выборе принтера лучше подбирать с поддержкой XPS, и устанавливать соответствующий драйвер.
С выходом Windows 8\2012 появилась поддержка драйверов печати v4. Драйвера 4-й версии более производительны, но Windows 7 будет печатать на драйвере четвертого типа, отрисовывая задачи на клиенте. Поэтому если в сети еще встречаются старые Windows, стоит установить и драйвера третьего типа. Посмотреть на тип драйвера можно в свойствах сервера печати на вкладке «Драйверы»:

Окно установки дополнительных драйверов.
Если говорить о возможностях драйверов четвертого типа, то к ним можно отнести:
использование видеокарты для отрисовки задач печати. Да, теперь для повышения быстродействия при отрисовке задач на сервере можно установить в принтсервер видеокарту;
Заслуживает внимания и технология Branch Office. С ее помощью клиент работает с принтером напрямую, минуя какую-либо обработку на сервере печати. Правда, понадобятся принтеры с поддержкой TCP\IP или WSD. Подробнее ознакомиться с технологией можно на сайте Microsoft, а включить или отключить для конкретного принтера можно с помощью командлета powershell:
Set-Printer -name -ComputerName -RenderingMode BranchOffice
Технология не работает, если используется обработка печати на сервере.
Для диагностики узких мест при печати обратите внимание на три процесса:
Spoolsv.exe;
Printfilterpipelinesvc.exe;
А также смотрите на расход этими процессами памяти, процессора и нагрузки на жесткий диск. Для более тонкого поиска узких мест помогут специальные счетчики производительности.

Набор типовых счетчиков производительности подсистемы печати.
| Название | Описание |
| Всего заданий напечатано | Количество напечатанных заданий |
| Всего напечатано страниц | Количество напечатанных страниц |
| Вызовов добавления сетевого принтера | Количество подключений к расшаренному принтеру с момента последнего перезапуска службы |
| Заданий | Количество напечатанных заданий с момента последнего перезапуска службы |
| Заданий, обрабатываемых диспетчером печати | Текущее количество заданий в службе печати |
| Максимум заданий, обрабатываемых диспетчером | Максимальное количество заданий в службе печати |
| Максимум ссылок | Максимальное количество обращений к очереди печати |
| Ошибок заданий | Количество ошибок заданий |
| Ошибок «Отсутствует бумага» | Количество ошибок, вызванных отсутствием бумаги |
| Ошибок «Принтер не готов» | Количество ошибок принтера |
| Печатаемых байт/c | Скорость текущей печати в байтах, позволяет приблизительно оценить время занятости принтера |
| Ссылок | Текущее количество обращений к очереди печати |
В общем, подобрав параметры под конкретную ситуацию, можно повысить производительность этих простых ролей до 50%. А refurbished сервер еще даст прикурить современным монстрам с настройками «по умолчанию».
Расскажите в комментариях, про повышение быстродействия каких ролей Windows вам было бы интересно почитать. Приходилось ли вам заниматься тюнингом ролей и сервисов? Каких результатов достигли?
|
Метки: author Tri-Edge системное администрирование серверное администрирование серверная оптимизация блог компании сервер молл оптимизация windows производительность |
Как собрать базу данных для рассылок и не превратиться в спамера? |

|
|
Рынок систем детекции и распознавания: Эмоции и «эмоциональные вычисления» |
 / Flickr / Britt Selvitelle / CC
/ Flickr / Britt Selvitelle / CC
|
Метки: author alinatestova машинное обучение блог компании neurodata lab neurodata lab affective computing edrs |
[Из песочницы] Почему мобильные приложения занимают все больше места |
Совсем недавно в интернете появилось несколько интересных инфографик, о том, что популярные приложения для телефонов за пару лет выросли в размере в 12 раз. В этой заметке делается попытка разъяснить некоторые неочевидные причины роста размера мобильных приложений.
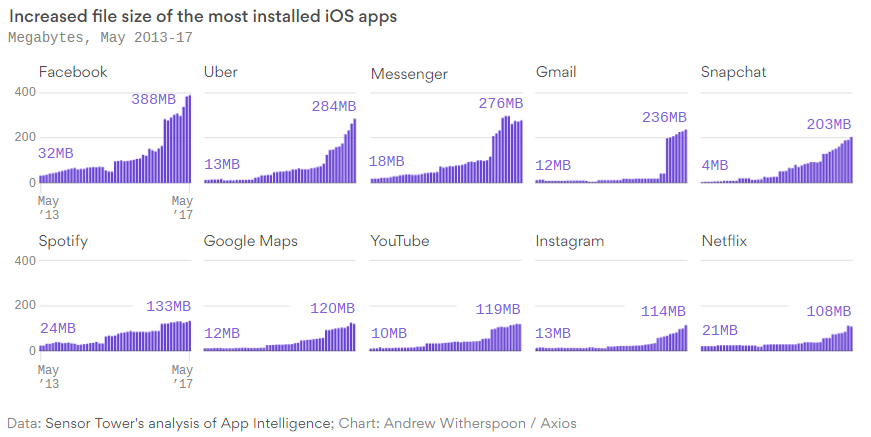
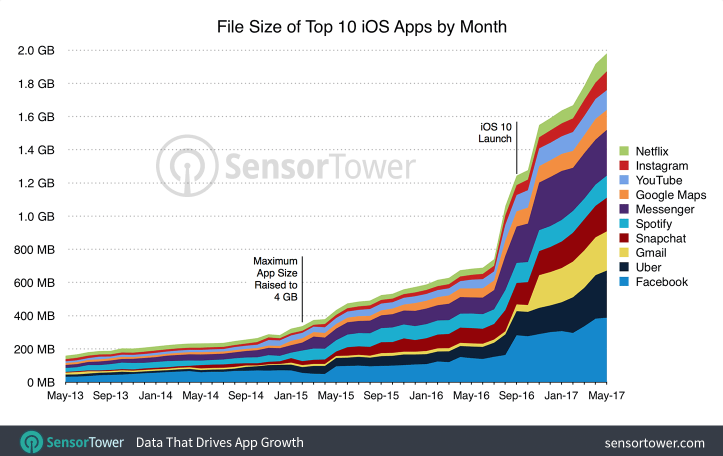
Авторы инфографик в оригинальных статьях выделяют две причины такого роста:
На мой взгляд, указанные тезисы являются только предпосылками и до конца не отвечают на вопрос "почему приложения становятся больше?".
Конечно, в первую очередь дело в добавлении новых функций. Развитие функциональности приложений требует большего размера.

Вот только размер приложений в отличие от их функциональности растет в десятки раз и обычно у этого роста совсем другие причины. Далее на базе разных источников с конкретными примерами я попробую систематизировать разные причины:
Как ни банально звучит, но в приложениях часто сохраняются одни и те же внутренние ресурсы (картинки, библиотеки, и так далее) по нескольку копий. Это происходит из-за того, что крупные приложения разрабатываются несколькими командами разработчиками, отвечающими за свой конкретный функционал программы. Бывает так, что команда тащит для своего модуля те же ресурсы, что и другая, вызывая задвоение.
В одной из статей автор решил детально разобрать внутреннее строение приложения Facebook для iOS после того, как оно увеличилось за полгода с 165 до 253 мегабайт. Он обнаружил, что в приложении содержалось свыше 40 мегабайт избыточных дублирующих данных. В основном это были картинки, но также были и абсолютно идентичные внутренние программные файлы. Таким образом, просто удалив дубликаты, можно было бы уменьшить размер приложения на 15% процентов. Что, кстати, Facebook впоследствии и сделал.
Распространенной практикой при разработке приложения является добавление новой функциональности и по умолчанию отключение ее. Это позволяет в дальнейшем постепенно включать ее для тестовых или пилотных групп и по необходимости корректировать или обратно выключать. Но даже по прошествии длительного времени, как правило, возможность отключить новый функционал и восстановить старый не убирается и все равно остается в приложении на всякий случай и для экономии времени.
В случае с приложениями под iOS переход с Objective-C на Swift может дать увеличение размера скомпилированного кода приложения в 3-4 раза. Это происходит из-за того, что ради удобства и скорости разработки новые языки могут:
Сюда же можно отнести переход приложений на новые фреймворки, которые тащат с собой много необходимых им файлов.
Одним из трендов мобильной разработки под несколько платформ является стремление минимизировать зависимость от конкретной операционной системы. У этого подхода есть свои плюсы. Во-первых, это позволяет не переписывать много кода при изменении внешних системных библиотек. Во-вторых, это позволяет удержать пользователя в своем приложении и обеспечить более консистентный пользовательский опыт (хотя часто бывает так, что своя реализация визуально не отличима от стандартной).
Среди наиболее популярных "велосипедов", заменяющих стандартные средства ОС, можно выделить:
По мере развития телефонов владельцы экосистем (Apple, Google) начинают предъявлять к программам новые требования по поддержке системных появляющихся возможностей телефонов, которые требуют больше места:
К слову в AppStore для борьбы с ростом размера приложений по таким требованиям потом была представлена технологий App thinning, по которой на конкретный телефон скачивается адаптированная версия приложения без избыточных ресурсов для других версий телефонов.
|
Метки: author OlegPyatakov исследования и прогнозы в it мобильные приложения мобильная разработка ios разработка app store google play |
Снимаем и вносим наличные в банкомате с помощью смартфона. Впервые в мире |





|
|
[Перевод] Исправляем баги в стиле 1988 года |



1780 MAAL=MAAL-1:IFMAAL=0THENGOTO18101810 POKECROSS+4096,1 :REM MARK EXIT ON THE MAP
1820 SYS16540 :REM COPY MAP TO SCREEN
1830 POKESID+11,0:POKE53248+21,0:REM STOP SOUND AND DISABLE SPRITES
1840 GOTO1840 :REM ENDLESS LOOPL40CB: LDA #$FF ; >-- инициализация --
STA $FB ; |
LDA #$6F ; |
STA $FC ; |
LDA #$F4 ; |
STA $FD ; |
LDA #$D7 ; |
STA $FE ; <--------------------
LDX #$04 ; >-- внешний цикл -----------------
L40DD: LDY #$FA ; >-- внутр. цикл I --- |
L40DF: LDA ($FB),Y ; (копирование байтов) | |
STA ($FD),Y ; | |
DEY ; | |
BNE L40DF ; <------------------- |
LDY #$FA ; >-- внутр. цикл II ----------- |
L40E8: INC $FB ; (обновление начальных адресов) | |
BNE L40EE ; | |
INC $FC ; | |
L40EE: INC $FD ; | |
BNE L40F4 ; | |
INC $FE ; | |
L40F4: DEY ; | |
BNE L40E8 ; <---------------------------- |
DEX ; |
BNE L40DD ; <------------------------------- LDX #$04
;
; внутренний цикл
;
DEX
BNE L40DDL40DD: LDY #$FA
L40DF: LDA ($FB),Y
STA ($FD),Y
DEY
BNE L40DF LDA ($FB),Y выполняется следующим образом:3670 DATA 252,169,244,133,253
|
Метки: author PatientZero ненормальное программирование basic commodore 64 commodore dossier |
Kubernetes & production — быть или не быть? |




Вообще идея 3-х слойной архитектуры и задач связанных с ней — это тема отдельной статьи. Но в свет она выйдет не раньше, чем этот самый чек-лист будет безукоризненно полон. Это может и не случиться никогда :)


Например, как делать проверку того, что один из объектов успешно установлен и можно продолжить выкатку других? Или как делать более тонкие настройки и установки контейнеров, которые уже работают, и нужно просто выполнить пару команд внутри их?
Эти и многие другие вопросы обязывают относиться к Helm как к простому шаблонизатору. Но зачем это?.. если Jinja2, входящая в состав Ansible, даст фору любому не профильному решению.

Небольшой пример.
Собирать логи внутри запущенного Docker контейнера нельзя. НО очень много систем и фреймворков не готовы к стримингу в `STDOUT`. Нужно заниматься `патчингом` и осознанной разработкой на системном уровне: писать в пайпы, заботиться о процессах и т.д. Немного времени и у нас есть Monolog Handler для `php`, который способен выдавать логи так, как их поймет Docker/k8s

Искушенный пользователь Kubernetes поспешит спросить о Kubernetes Ingress Resource, который предназначен именно для решения подобных задач. Все верно! Но мы требовали немного больше `фич`, как вы могли заметить, для нашего API Gateway чем есть в Ingress. Тем более, это всего лишь обертка для Nginx, с которым мы и так умеем работать.

Список отражает множество фактов, но опущенными остаются явные преимущества и приятные особенности Kubernetes как системы управления Docker процессами. Подробнее с этими вещами можно ознакомится на оффициальном сайте Kubernetes, в статьях на том же Хабре или Medium.
|
|
[Перевод] Создание движка для блога с помощью Phoenix и Elixir / Часть 9. Каналы |

От переводчика: «Elixir и Phoenix — прекрасный пример того, куда движется современная веб-разработка. Уже сейчас эти инструменты предоставляют качественный доступ к технологиям реального времени для веб-приложений. Сайты с повышенной интерактивностью, многопользовательские браузерные игры, микросервисы — те направления, в которых данные технологии сослужат хорошую службу. Далее представлен перевод серии из 11 статей, подробно описывающих аспекты разработки на фреймворке Феникс казалось бы такой тривиальной вещи, как блоговый движок. Но не спешите кукситься, будет действительно интересно, особенно если статьи побудят вас обратить внимание на Эликсир либо стать его последователями.
В этой части мы воспользуемся каналами из Phoenix для того, чтобы оживить комментарии.
На данный момент наше приложение основано на:
В прошлый раз было полностью покончено с комментариями! Теперь, когда все функции готовы, давайте сделаем блог по-настоящему классным, воспользовавшись возможностями, которые Elixir и Phoenix предоставляют прямо из коробки. Превратим систему комментариев в систему «живых» комментариев с помощью каналов из Phoenix. Честно признаёмся: в этой части ОЧЕНЬ много тяжёлого джаваскрипта.
Пойдём тем же путём, что и раньше: спроектируем новую функцию до начала её реализации. К системе живых комментариев предъявляются следующие требования:
Первым шагом при реализации любого канала в Phoenix является работа с файлом web/channels/user_socket.ex. Изменим закомментированную строку, находящуюся под ## Channels, на следующее:
channel "comments:*", Pxblog.CommentChannelА затем создадим сам канал, с которым будем работать. Для этого воспользуемся генератором Phoenix:
$ mix phoenix.gen.channel Comment
* creating web/channels/comment_channel.ex
* creating test/channels/comment_channel_test.exs
Add the channel to your `web/channels/user_socket.ex` handler, for example:
channel "comment:lobby", Pxblog.CommentChannelОсновываясь на требованиях, мы будем создавать отдельный канал комментариев для каждого post_id.
Начнём с простейшей реализации и пойдём в обратном направлении для добавления безопасности, поэтому сначала у нас будет авторизованный канал, видимый всем. Нам также нужно определить события, которые будем транслировать.
Для авторизованных пользователей:
Для всех:
Для начала нам нужно настроить некоторые базовые вещи. Добавим jQuery к приложению, чтобы легче взаимодействовать с DOM.
Начнём с установки jQuery через NPM.
npm install --save-dev jqueryА затем перезагрузим сервер Phoenix и проверим, что jQuery успешно установился. Откройте файл web/static/js/app.js и добавьте вниз следующий код:
import $ from "jquery"
if ($("body")) {
console.log("jquery works!")
}Если вы увидели сообщение «jquery works!» в Developer Console браузера, то можете удалять эти строчки и переходить к следующему шагу.
Первым делом вернёмся к файлу web/static/js/app.js и раскомментируем оператор импорта сокета.
Затем откроем файл web/static/js/socket.js и внесём несколько небольших правок:
// For right now, just hardcode this to whatever post id you're working with
const postId = 2;
const channel = socket.channel(`comments:${postId}`, {});
channel.join()
.receive("ok", resp => { console.log("Joined successfully", resp) })
.receive("error", resp => { console.log("Unable to join", resp) });Обратимся к описанию сокета, чтобы понять какие сообщения нужно слушать/транслировать. Будем использовать «CREATED_COMMENT» для свежесозданных комментариев, «APPROVED_COMMENT» для одобренных комментариев и «DELETED_COMMENT» для удалённых. Добавим их в качестве констант в файл socket.js:
const CREATED_COMMENT = "CREATED_COMMENT"
const APPROVED_COMMENT = "APPROVED_COMMENT"
const DELETED_COMMENT = "DELETED_COMMENT"Затем приступим к добавлению обработчиков событий в канале для каждого из этих действий.
channel.on(CREATED_COMMENT, (payload) => {
console.log("Created comment", payload)
});
channel.on(APPROVED_COMMENT, (payload) => {
console.log("Approved comment", payload)
});
channel.on(DELETED_COMMENT, (payload) => {
console.log("Deleted comment", payload)
});И наконец, изменим кнопку Submit, чтобы вместо отправки комментария создавать «фальшивое» событие:
$("input[type=submit]").on("click", (event) => {
event.preventDefault()
channel.push(CREATED_COMMENT, { author: "test", body: "body" })
})Если попробовать протестировать в браузере, приложение упадёт. Вы получите сообщение об ошибке наподобие этого:
[error] GenServer #PID<0.1250.0> terminating
** (FunctionClauseError) no function clause matching in Pxblog.CommentChannel.handle_in/3
(pxblog) web/channels/comment_channel.ex:14: Pxblog.CommentChannel.handle_in(“CREATED_COMMENT”, %{“author” => “test”, “body” => “body”}, %Phoenix.Socket{assigns: %{}, channel: Pxblog.CommentChannel, channel_pid: #PID<0.1250.0>, endpoint: Pxblog.Endpoint, handler: Pxblog.UserSocket, id: nil, joined: true, pubsub_server: Pxblog.PubSub, ref: “2”, serializer: Phoenix.Transports.WebSocketSerializer, topic: “comments:2”, transport: Phoenix.Transports.WebSocket, transport_name: :websocket, transport_pid: #PID<0.1247.0>})
(phoenix) lib/phoenix/channel/server.ex:229: Phoenix.Channel.Server.handle_info/2
(stdlib) gen_server.erl:615: :gen_server.try_dispatch/4
(stdlib) gen_server.erl:681: :gen_server.handle_msg/5
(stdlib) proc_lib.erl:240: :proc_lib.init_p_do_apply/3
Last message: %Phoenix.Socket.Message{event: “CREATED_COMMENT”, payload: %{“author” => “test”, “body” => “body”}, ref: “2”, topic: “comments:2”}
State: %Phoenix.Socket{assigns: %{}, channel: Pxblog.CommentChannel, channel_pid: #PID<0.1250.0>, endpoint: Pxblog.Endpoint, handler: Pxblog.UserSocket, id: nil, joined: true, pubsub_server: Pxblog.PubSub, ref: nil, serializer: Phoenix.Transports.WebSocketSerializer, topic: “comments:2”, transport: Phoenix.Transports.WebSocket, transport_name: :websocket, transport_pid: #PID<0.1247.0>}Прямо сейчас у нас нет функциии для обработки сообщений внутри канала. Откройте файл web/channels/comment_channel.ex и давайте сделаем так, чтобы функция handle_in транслировала сообщения подписчикам, вместо того, чтобы молча наблюдать. Нам также нужно изменить стандартную функцию join вверху:
def join("comments:" <> _comment_id, payload, socket) do
if authorized?(payload) do
{:ok, socket}
else
{:error, %{reason: "unauthorized"}}
end
end
# ...
# It is also common to receive messages from the client and
# broadcast to everyone in the current topic (comments:lobby).
def handle_in("CREATED_COMMENT", payload, socket) do
broadcast socket, "CREATED_COMMENT", payload
{:noreply, socket}
endТеперь мы можем добавить сходный код для двух другим сообщений, которые мы предполагаем «слушать».
def handle_in("APPROVED_COMMENT", payload, socket) do
broadcast socket, "APPROVED_COMMENT", payload
{:noreply, socket}
end
def handle_in("DELETED_COMMENT", payload, socket) do
broadcast socket, "DELETED_COMMENT", payload
{:noreply, socket}
endНам также нужно внести несколько правок в шаблоны. Необходимо знать с каким постом мы работаем и кем является текущий пользователь. Таким образом, добавим наверх файла web/templates/post/show.html.eex следующий код:
Затем откройте файл web/templates/comment/comment.html.eex и измените открывающий div:
Теперь, когда всё, связанное с комментариями, обрабатывается через Javascript, нам нужно удалить некоторый написанный ранее код для кнопок Approve/Reject. Изменим весь блок, чтобы он выглядел похожим на это:
Также, внутри тегов div, где выводятся автор и текст комментария, измените тег strong, чтобы у них появились классы .comment-author and .comment-body, соответственно.
...
Наконец, нужно убедиться, что мы можем подходящим образом обращаться к автору и тексту комментария, так что откроем файл web/templates/comment/form.html.eex и убедимся, что поле ввода комментария и кнопка отправки выглядят так:
Сейчас необходимо реализовать каждую из возможностей транслирования должным образом, так что вернёмся на «поле джаваскрипта» и продолжим!
Нам понадобится способ для проверки, является ли пользователь тем, за кого себя выдаёт и имеет ли он доступ к изменению данных комментария. Чтобы сделать это, мы воспользуемся встроенным в Phoenix модулем Phoenix.Token.
Начнём с проставления пользовательского токена в шаблон приложения. Это достаточно удобно, ведь вероятно мы захотим отображать его везде. В файле web/templates/layout/app.html.eex добавьте следующее к остальным мета-тегам:
Здесь мы говорим, что хотим подписанный токен, который указывает на идентификатор пользователя (конечно, если пользователь вошёл в систему). Это даст нам прекрасный способ для проверки user_id пользователя через Javascript без необходимости доверять скрытым полям ввода или пользоваться другими странными способами.
Далее в файле web/static/js/socket.js, внесите несколько изменений в код соединения сокета:
// Grab the user's token from the meta tag
const userToken = $("meta[name='channel_token']").attr("content")
// And make sure we're connecting with the user's token to persist the user id to the session
const socket = new Socket("/socket", {params: {token: userToken}})
// And then connect to our socket
socket.connect()Теперь передадим валидный токен обратно в код Phoenix. На этот раз нам нужен файл web/channels/user_socket.ex, в котором изменим функцию connect для проверки токена пользователя:
def connect(%{"token" => token}, socket) do
case Phoenix.Token.verify(socket, "user", token, max_age: 1209600) do
{:ok, user_id} ->
{:ok, assign(socket, :user, user_id)}
{:error, reason} ->
{:ok, socket}
end
endИтак, мы вызываем функцию verify из модуля Phoenix.Token и передаём в неё сокет, значение для проверки, сам токен и значение max_age (максимальное время жизни токена, например, две недели).
Если верификация прошла успешно, то отправим обратно кортеж {:ok, [значение, извлечённое из токена]}, которым в нашем случае является user_id. Затем поддержим соединение со значением user_id, сохранённым в сокете (подобно сохранению значения в сессии или conn).
Если верифицировать соединение не удалось, это тоже нормально. Так как мы по-прежнему хотим, чтобы неавторизованные пользователи так же могли получать обновления без верифицированного user_id, то не будем ничего присваивать, а просто вернём {:ok, socket}.
Нам понадобится тонна Javascript-кода для поддержки всего задуманного. Рассмотрим задачи подробнее:
А я предупреждал вас, что здесь будет полно джаваскрипта :) Давайте не будем терять времени и сразу же приступим к написанию каждой из этих функций. Комментарии в данном куске кода описывают каждое из требований соответственно.
// Import the socket library
import {Socket} from "phoenix"
// And import jquery for DOM manipulation
import $ from "jquery"
// Grab the user's token from the meta tag
const userToken = $("meta[name='channel_token']").attr("content")
// And make sure we're connecting with the user's token to persist the user id to the session
const socket = new Socket("/socket", {params: {token: userToken}})
// And connect out
socket.connect()
// Our actions to listen for
const CREATED_COMMENT = "CREATED_COMMENT"
const APPROVED_COMMENT = "APPROVED_COMMENT"
const DELETED_COMMENT = "DELETED_COMMENT"
// REQ 1: Grab the current post's id from a hidden input on the page
const postId = $("#post-id").val()
const channel = socket.channel(`comments:${postId}`, {})
channel.join()
.receive("ok", resp => { console.log("Joined successfully", resp) })
.receive("error", resp => { console.log("Unable to join", resp) })
// REQ 2: Based on a payload, return to us an HTML template for a comment
// Consider this a poor version of JSX
const createComment = (payload) => `
${payload.author}
${payload.insertedAt}
${ userToken ? ' ' : '' }
${payload.body}
`
// REQ 3: Provide the comment's author from the form
const getCommentAuthor = () => $("#comment_author").val()
// REQ 4: Provide the comment's body from the form
const getCommentBody = () => $("#comment_body").val()
// REQ 5: Based on something being clicked, find the parent comment id
const getTargetCommentId = (target) => $(target).parents(".comment").data("comment-id")
// REQ 6: Reset the input fields to blank
const resetFields = () => {
$("#comment_author").val("")
$("#comment_body").val("")
}
// REQ 7: Push the CREATED_COMMENT event to the socket with the appropriate author/body
$(".create-comment").on("click", (event) => {
event.preventDefault()
channel.push(CREATED_COMMENT, { author: getCommentAuthor(), body: getCommentBody(), postId })
resetFields()
})
// REQ 8: Push the APPROVED_COMMENT event to the socket with the appropriate author/body/comment id
$(".comments").on("click", ".approve", (event) => {
event.preventDefault()
const commentId = getTargetCommentId(event.currentTarget)
// Pull the approved comment author
const author = $(`#comment-${commentId} .comment-author`).text().trim()
// Pull the approved comment body
const body = $(`#comment-${commentId} .comment-body`).text().trim()
channel.push(APPROVED_COMMENT, { author, body, commentId, postId })
})
// REQ 9: Push the DELETED_COMMENT event to the socket but only pass the comment id (that's all we need)
$(".comments").on("click", ".delete", (event) => {
event.preventDefault()
const commentId = getTargetCommentId(event.currentTarget)
channel.push(DELETED_COMMENT, { commentId, postId })
})
// REQ 10: Handle receiving the CREATED_COMMENT event
channel.on(CREATED_COMMENT, (payload) => {
// Don't append the comment if it hasn't been approved
if (!userToken && !payload.approved) { return; }
// Add it to the DOM using our handy template function
$(".comments h2").after(
createComment(payload)
)
})
// REQ 11: Handle receiving the APPROVED_COMMENT event
channel.on(APPROVED_COMMENT, (payload) => {
// If we don't already have the right comment, then add it to the DOM
if ($(`#comment-${payload.commentId}`).length === 0) {
$(".comments h2").after(
createComment(payload)
)
}
// And then remove the "Approve" button since we know it has been approved
$(`#comment-${payload.commentId} .approve`).remove()
})
// REQ 12: Handle receiving the DELETED_COMMENT event
channel.on(DELETED_COMMENT, (payload) => {
// Just delete the comment from the DOM
$(`#comment-${payload.commentId}`).remove()
})
export default socketПожалуй, достаточно с джаваскриптом. Сейчас у нас есть рабочая функциональность, но без какой-либо защиты. Давайте добавим её в нашем Elixir-коде с помощью создания вспомогательной функции для добавления, одобрения и удаления комментариев.
С нашим Javascript-кодом всё отлично, так что, вероятно, добавить вспомогательные функции нужно на стороне бэкенда. Начнём с создания нового модуля, который станет рабочей лошадкой наших взаимодействий с базой данных для создания/одобрения/удаления комментариев. Так что создадим файл web/channels/comment_helper.ex:
defmodule Pxblog.CommentHelper do
alias Pxblog.Comment
alias Pxblog.Post
alias Pxblog.User
alias Pxblog.Repo
import Ecto, only: [build_assoc: 2]
def create(%{"postId" => post_id, "body" => body, "author" => author}, _socket) do
post = get_post(post_id)
changeset = post
|> build_assoc(:comments)
|> Comment.changeset(%{body: body, author: author})
Repo.insert(changeset)
end
def approve(%{"postId" => post_id, "commentId" => comment_id}, %{assigns: %{user: user_id}}) do
authorize_and_perform(post_id, user_id, fn ->
comment = Repo.get!(Comment, comment_id)
changeset = Comment.changeset(comment, %{approved: true})
Repo.update(changeset)
end)
end
def delete(%{"postId" => post_id, "commentId" => comment_id}, %{assigns: %{user: user_id}}) do
authorize_and_perform(post_id, user_id, fn ->
comment = Repo.get!(Comment, comment_id)
Repo.delete(comment)
end)
end
defp authorize_and_perform(post_id, user_id, action) do
post = get_post(post_id)
user = get_user(user_id)
if is_authorized_user?(user, post) do
action.()
else
{:error, "User is not authorized"}
end
end
defp get_user(user_id) do
Repo.get!(User, user_id)
end
defp get_post(post_id) do
Repo.get!(Post, post_id) |> Repo.preload([:user, :comments])
end
defp is_authorized_user?(user, post) do
(user && (user.id == post.user_id || Pxblog.RoleChecker.is_admin?(user)))
end
endНачнём сверху. Мы будем часто обращаться к модулям Comment/Post/User/Repo, так что для чистоты кода, правильно будет добавить для них алиасы. Нам также нужно импортировать функцию build_assoc из Ecto, но только версию арности 2.
Далее мы переходим сразу к созданию поста. Мы по привычке передаём в функцию socket, но он нам не всегда нужнен. Например, в данном случае, ведь комментарий добавить может любой. Мы сопоставляем с образцом значения post_id, body и author в аргументах, чтобы с ними можно было работать внутри функции.
def create(%{"postId" => post_id, "body" => body, "author" => author}, _socket) do
post = get_post(post_id)
changeset = post
|> build_assoc(:comments)
|> Comment.changeset(%{body: body, author: author})
Repo.insert(changeset)
endМы получаем пост через функцию get_post , которую пока не написали. Это будет приватная функция чуть ниже. We then build a changeset off the post to build an associated comment with the body and author we supplied.
Затем создаём ченджсет из поста для создания связанного комментария. В конце вернём результат функции Repo.insert. Это абсолютно простой и стандарный код на Ecto, так что здесь никаких сюрпризов возникнуть не должно. Тоже самое можно сказать и обо всех остальных функциях. Далее взглянем на функцию approve:
def approve(%{"postId" => post_id, "commentId" => comment_id}, %{assigns: %{user: user_id}}) do
authorize_and_perform(post_id, user_id, fn ->
comment = Repo.get!(Comment, comment_id)
changeset = Comment.changeset(comment, %{approved: true})
Repo.update(changeset)
end)
endЗдесь снова сопоставляются с образцом необходимые значения — post_id и comment_id из первого аргумента и проверенный user_id из сокета, переданного вторым. Далее мы вызываем вспомогательную функцию authorize_and_perform и передаём в неё анонимную функцию, которая получает комментарий, обновляет флаг approved в true через ченджсет и затем отправляет обновление в Repo. Довольно стандартный код, но эта функция authorize_and_perform выглядит загадочной, так что давайте отвлечёмся на её разбор:
defp authorize_and_perform(post_id, user_id, action) do
post = get_post(post_id)
user = get_user(user_id)
if is_authorized_user?(user, post) do
action.()
else
{:error, "User is not authorized"}
end
endВ неё передаются post_id и user_id, так как оба этих значения требуются для правильной авторизации действий с комментарием. Затем вызывается другая вспомогательная функция is_authorized_user?, которая, получая пользователя и пост, возвращает true или false. Если всё хорошо, то вызывается анонимная функция action. Обратите внимание на точку между названием и скобками. Иначе возвращается кортеж {:error, «User is not authorized»}, который мы можем перехватить далее, если захотим вывести красивое сообщение об ошибке.
Авторизация совершается внутри функции, а затем исполняются действия, переданные с помощью блока fn -> ... end. Это хороший образец, когда дублируется много логики.
С функции authorize_and_perform достаточно. Перейдём к функции delete:
def delete(%{"postId" => post_id, "commentId" => comment_id}, %{assigns: %{user: user_id}}) do
authorize_and_perform(post_id, user_id, fn ->
comment = Repo.get!(Comment, comment_id)
Repo.delete(comment)
end)
endЗдесь тот же подход. Получаем необходимые значения через сопоставление с образцом, авторизуем действие, затем получаем комментарий и удаляем его. Всё просто!
Наконец, взглянем на вспомогательные функции поменьше.
defp get_user(user_id) do
Repo.get!(User, user_id)
end
defp get_post(post_id) do
Repo.get!(Post, post_id) |> Repo.preload([:user, :comments])
end
defp is_authorized_user?(user, post) do
(user && (user.id == post.user_id || Pxblog.RoleChecker.is_admin?(user)))
endПолучение пользователя, получение поста и проверка авторизации пользователя (код, взятый из PostController). Со вспомогательными функциями покончено. Добавим их в CommentChannel.
Все, что нам нужно — заменить первоначальный код с сообщениями CREATED/APPROVED/DELETED на вспомогательные функции. Откройте файл web/channels/comment_channel.ex:
alias Pxblog.CommentHelper
# It is also common to receive messages from the client and
# broadcast to everyone in the current topic (comments:lobby).
def handle_in("CREATED_COMMENT", payload, socket) do
case CommentHelper.create(payload, socket) do
{:ok, comment} ->
broadcast socket, "CREATED_COMMENT", Map.merge(payload, %{insertedAt: comment.inserted_at, commentId: comment.id, approved: comment.approved})
{:noreply, socket}
{:error, _} ->
{:noreply, socket}
end
end
def handle_in("APPROVED_COMMENT", payload, socket) do
case CommentHelper.approve(payload, socket) do
{:ok, comment} ->
broadcast socket, "APPROVED_COMMENT", Map.merge(payload, %{insertedAt: comment.inserted_at, commentId: comment.id})
{:noreply, socket}
{:error, _} ->
{:noreply, socket}
end
end
def handle_in("DELETED_COMMENT", payload, socket) do
case CommentHelper.delete(payload, socket) do
{:ok, _} ->
broadcast socket, "DELETED_COMMENT", payload
{:noreply, socket}
{:error, _} ->
{:noreply, socket}
end
endПринципы схожи во всех трёх вызовах, так что разберём только create:
# It is also common to receive messages from the client and
# broadcast to everyone in the current topic (comments:lobby).
def handle_in("CREATED_COMMENT", payload, socket) do
case CommentHelper.create(payload, socket) do
{:ok, comment} ->
broadcast socket, "CREATED_COMMENT", Map.merge(payload, %{insertedAt: comment.inserted_at, commentId: comment.id, approved: comment.approved})
{:noreply, socket}
{:error, _} ->
{:noreply, socket}
end
endСигнатура функции не изменилась, так что оставим её в покое. Первое, что мы делаем — добавляем оператор case для функции CommentHelper.create и передаём в неё payload и socket (вспомните про сопоставление с образцом, которое мы делали). Если приходит :ok вместе с созданным комментарием, мы транслируем в сокет сообщение CREATED_COMMENT вместе с некоторыми данными из базы, которых нет у Javascript. Если произошла ошибка, то не нужно ничего транслировать, просто возвращаем сокет и беззаботно идём дальше.
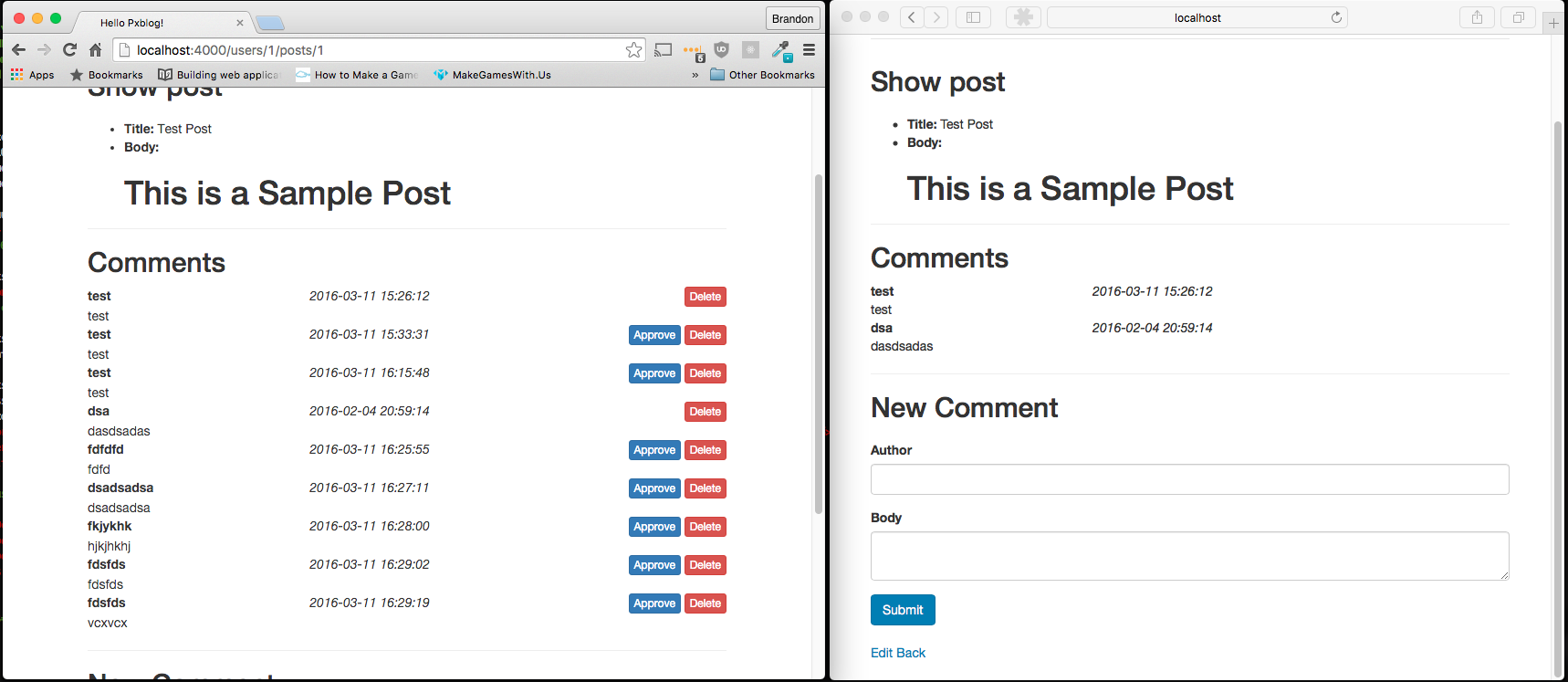
Теперь у блога есть потрясающая система комментариев в реальном времени. Также мы очень глубоко нырнули в изучение каналов и токенов в Phoenix И узнали как совместить их для повышения уровня безопасности. В этом плане пример, конечно, не идеален — мы по-прежнему транслируем все комментарии, но не все добавляем в div. Так что кто-то может увидеть все добавленные комментарии, даже неодобренные. Дальше это можно улучшить с помощью создания отдельных аутентифицированных и неаутентифицированных каналов и транлировать сообщения только в необходимый. Учитывая, что фильтрация комментариев лишь помогает избежать спам, то повышение защищённости в этом случае не так важно. Но этот приём может пригодиться в будущем. Также мы забыли про тесты. Лучше стараться так не делать, но эта часть получается больно длинной, так что закончим с тестами в следующей. Это позволит оставить уровень покрытия кода высоким и удалить некоторый ненужный код.
Дизайн по-прежнему плох, так что нужно заняться и им. Для этого добавим Zurb Foundation 6 и создадим чистый внешний вид нашей блоговой платформы!
Ребята! Ещё три десятка статей по Elixir на русском ждут вас на сайте нашего проекта под названием Вунш. Там же можно подписаться на прикольную рассылку и получать самые интересные новости по Эликсиру вместе с эксклюзивными статьями. Приглашаю вас также присоединиться к работе над переводом документации. А если появились вопросы, то подключайтесь к нашему чату и каналу в Телеграм.
|
Метки: author jarosluv функциональное программирование ruby on rails ruby erlang/otp elixir/phoenix elixir phoenix wunsh |
Автоматное программирование – новая веха или миф? Часть 2 |
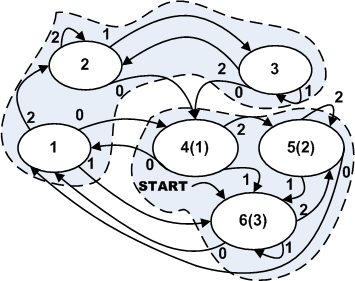
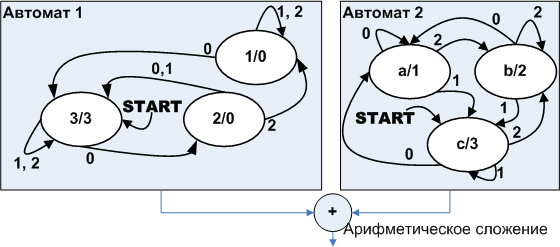
«Человеческий разум устроен так, что ему проще понимать алгоритмы, которым скармливают данные на входе и получают данные на выходе, и результат зависит только от входа, но не от внутреннего состояния. Такие «чистые функции» (назовём их аналитические прим.авт.) проще понимать, тестировать и использовать повторно».
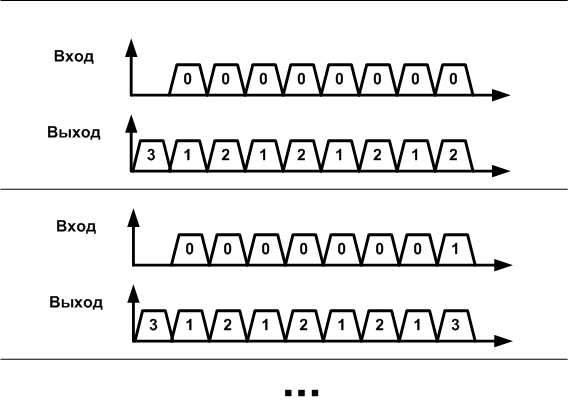

Set_position(6,0);
Line_to (1,0); Line_to (1,1); Line_to (-1,2); Line_to (4,0);
Line_to (1,-3); Line_to (3,0); Line_to (0,6); Line_to (-11,0);
Line_to (-1,1); Line_to (-2,0); Line_to (3,-2); Line_to (0,-2);
Line_to (1,2); Line_to (2,0); Line_to (-1,-2); Line_to (1,-1);


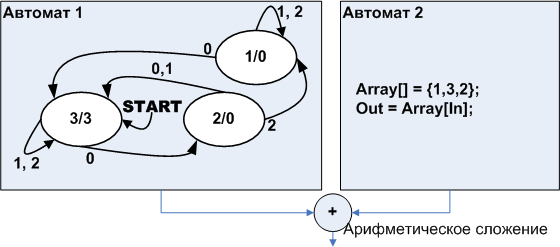
|
|
[Перевод] Защищаем сайт с помощью ZIP-бомб |
 [Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так?
[Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так? grep 'authentication failures' /var/log/auth.log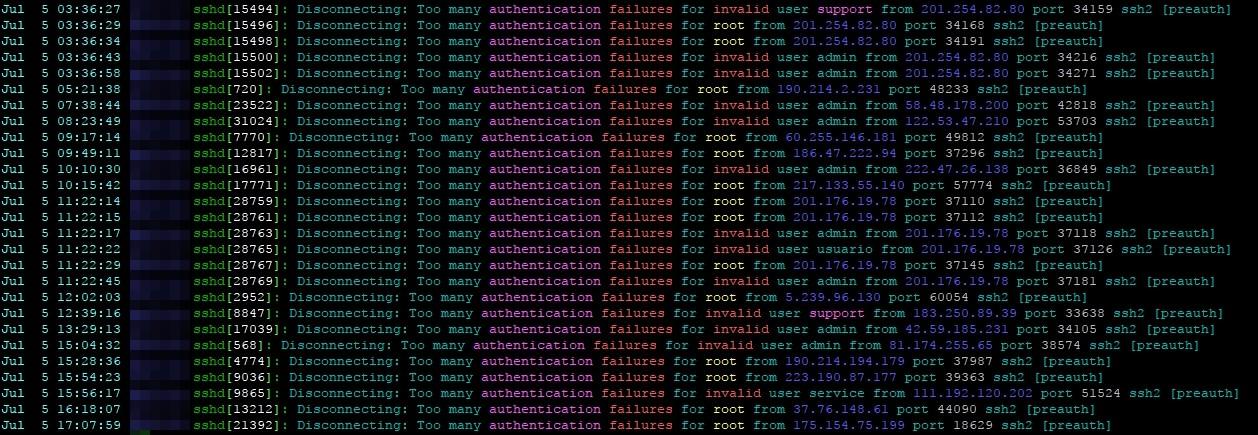
wp-admin и непропатченные плагины.
dd if=/dev/zero bs=1M count=10240 | gzip > 10G.gzip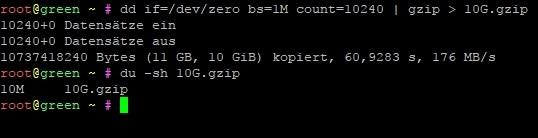
|
Метки: author m1rko разработка веб-сайтов информационная безопасность nikto wordpress уязвимости сканер zip- бомбы zip gzip |
[Перевод] Правда ли уже пора использовать CSS Grid Layout? |
Я учусь пилотировать легкие самолеты. Это отвлекает меня от компьютеров. Недавно мне никак не удавалось удержать Сессну-150 на малой высоте, когда мы приближались к аэропорту Бристоля. Меня буквально засосало в облако восходящим потоком. Мой летный инструктор сказал: «Это не ваша вина, но ваша проблема». Он имел в виду, что я обязана была удерживать высоту, пусть даже что-то работало против меня. Мне нужно было узнать, что бывает такая ситуация, и научиться справляться с ней при пилотировании.
Уже после приземления я подумала, что фраза «это не ваша вина, но ваша проблема» отлично подходит практически к любым ситуациям. В этой статье я раскрываю тему поддержки старых браузеров при использовании новых технологий наподобие CSS Grid Layout. Мы, разработчики, часто робеем при обсуждении браузерной поддержки с заказчиками и коллегами, как будто это мы виноваты в том, что сайты не выглядят в IE9 в точности так же, как в новейших Firefox или Chrome. Пора нам уже принять, что это не наша вина. Но обязанность справиться с этим как следует, с пользой для каждого — во многом наша проблема.
CSS Grid Layout уже работает в Chrome, Firefox, Opera и Safari с марта этого года. Microsoft Edge недавно выпустил предварительную сборку с гридами за флагом. На момент выхода статьи Can I Use показывает, что глобальная поддержка CSS Grid Layout составляет 65.64%, или 70.75%, если добавить версию с префиксом из IE10-11 и теперешнего Edge. До сих пор мы не видали, чтобы настолько грандиозная новинка внедрялась так быстро. Неудивительно, что люди не осознают, у какого множества посетителей поддержка будет.
Не стоило об этом и упоминать, но я всё равно скажу, что у вас цифры могут быть больше или меньше в зависимости от аудитории вашего сайта. Но если вы прямо сейчас делаете новый сайт, есть хорошая возможность воспользоваться преимуществами CSS Grid Layout.
Как я объясняла в предыдущей статье, CSS Grid Layout дает возможность делать двумерную раскладку без дополнительной разметки для оборачивания рядов. Поскольку раскладка двумерная, элементы в ней могут охватывать несколько рядов, надежным и предсказуемым образом.
Можно добиться некоторых приятных дизайнерских эффектов. Например, чтобы элементы в дизайне были как минимум определенной высоты, но растягивались при более высоком контенте — как в этом примере.
Можно легко чередовать элементы фиксированной ширины с гибкими элементами, с помощью единицы fr в гриде. Благодаря этому проще иметь дело с элементами макета, которые должны сохранять фиксированный размер.
Можно переопределять раскладку на уровне контейнера, что делает отзывчивый дизайн элементарной задачей, и настраивать дизайн индивидуально при различных размерах окна.
Можно накладывать элементы друг на друга, они подчиняются свойству z-index, так что разные элементы можно помещать в одни и те же грид-ячейки, что дает массу простора для творчества.
В CSS есть для вас решение. Во-первых, в спецификациях гридов и флексбоксов уже точно определено, как эти спецификации переопределяют старые методы раскладки.
Таким образом, если вы хотите использовать флоаты, инлайн-блоки, многоколоночную раскладку, флексбоксы или даже display: table в качестве фолбэка для своей раскладки на гридах, в спецификации уже всё предусмотрено. Можете переопределять эти методы надежным и предсказуемым способом. Я сделала шпаргалку с пояснением фолбэков. О некоторых из них говорится в моем докладе, записанном на конференции Render ранее в этом году.
В CSS также есть проверка наличия возможностей. У нее поистине замечательная поддержка браузерами, и что особенно радует в связи с ней, вам не нужно беспокоиться о браузерах без ее поддержки. Не бывает браузеров, поддерживающих гриды и не поддерживающих supports. Вот всё, что нужно вам в CSS-файле:
Все браузеры поймут стили для фолбэка. Те, что не поддерживают гриды, на этом и остановятся. А те, что поддерживают, будут использовать стили для гридов, и благодаря правилам, которые описаны в спецификации и поясняются в моей шпаргалке, многое в фолбэчном поведении обнулится.
Как правило, в стилях фолбэка у вас останется что-то, что «просочится» в раскладку на гридах. Часто это бывает ширина элементов, поскольку в старых раскладках приходится задавать им ширину, чтобы имитировать что-то похожее на грид. Поэтому мы используем простую директиву supports, проверяем поддержку гридов, и в ней, может быть, возвращаем ширине значение auto. Вообще там можно делать для грид-версии что угодно, не опасаясь, что это увидят старые браузеры.
Мы пишем CSS с помощью CSS. Никаких полифилов, никаких хаков. Всё строго по спецификации.
Это верно лишь если вы в своей работе исходите из того, что сайты должны одинаково выглядеть во всех браузерах. И знаете что? Это ни к чему.
Вот статья, которую я написала в 2002 г. В 2002-м люди боялись изучать верстку на CSS, потому что это значило бы, что их сайты не будут «одинаково отображаться» во всех браузерах. Но я верстала сайты с помощью CSS, стараясь выяснить, как это можно сделать наилучшим образом, и учила других людей тому, что узнавала сама. С самого открытия собственной фирмы, делая сайты для клиентов, требующих, чтоб всё работало в Netscape 4. Я занимаюсь этим на протяжении всей своей карьеры. Я разбираюсь с проблемами совместимости уже 20 лет. Сейчас я делаю продукт с интерфейсом, который должен работать вплоть до IE9. Не моя вина, что эти старые браузеры существовали, но моя проблема и моя работа все эти годы как раз в том и состояла, чтобы справляться с ними.
Если ваш сайт действительно должен выглядеть одинаково во всех браузерах (что бы это для вас ни значило), вы не сможете использовать ничего, что можно сделать только гридами. В таком случае не используйте гриды! Используйте Grid Layout, если хотите добиться чего-то, чего никак не сделать нормально старыми технологиями. Затем делайте фолбэк, которым можно будет пользоваться в менее продвинутых браузерах, и не беспокойтесь о том, чтобы сделать в точности так же. Мощь гридов в том, что с ними можно делать такое, что раньше было невозможным. Используйте их для этого, а не для воссоздания своих старых дизайнов.
Если глобально подпереть полифилом весь макет, для пользователей это будет кошмаром. Если реализовать то, что делают гриды, средствами JS, это всё будет жутко тормозить. Загрузка страницы в итоге будет выглядеть ужасно «дерганой». Гораздо лучше дать этим старым браузерам вариант попроще, адаптированный к их возможностям, чем пытаться насильно впихнуть в них грид-раскладку скриптами.
Попытки сделать полифил могут существенно затянуть вам сроки разработки и тестирования, причем для меньшей группы пользователей. Опять же, если одинаковый вид для всех — идеал для вашего сайта, я бы не советовала использовать гриды прямо сейчас. Вам придется принять, что все те пользователи, которые могли бы насладиться грид-раскладкой, будут ее лишены из-за наличия в мире старых браузеров.
Работа в вебе немыслима без вещей, у которых еще нет полной поддержки. Такова природа той отрасли, в которой мы работаем. Ваша работа состоит в том, чтобы нащупать неизбежный технологический компромисс для каждого проекта.
Ваша работа состоит в том, чтобы изучать новое и советовать своему клиенту или руководству, как наилучшим способом реализовать их бизнес-цели при помощи всех доступных технологий. А для этого вы должны сначала сами изучить эти новинки. Тогда вы сможете советовать им, на какие именно компромиссы пойти стоит. Гарантировать единообразный дизайн ценой добавочной разметки, лишнего времени на разработку или вынужденного ограничения удобства для всех браузеров? Или упрощенный макет для IE9, что позволит сократить время разработки, и более быстрый сайт благодаря новым технологиям в итоге? Если вы понимаете плюсы и минусы каждого варианта, вы сможете отстоять свои аргументы.
Если использование новой технологии не дает абсолютно никаких преимуществ, то и не используйте ее. Но если ваш клиент хочет чего-то такого, что есть смысл делать только на новых технологиях типа гридов, или что на гридах можно сделать быстро, а без них придется долго мучиться, у вас есть куча способов объяснить возможные компромиссы, их выгоду и цену.
Объясняйте их тем, сколько времени на разработку, сейчас и в будущем, можно будет сэкономить благодаря меньшей сложности.
Объясняйте их тем, что дизайнеры создали потрясающий дизайн, который просто невозможно надежно сверстать без гридов.
Объясняйте их быстродействием, во многих случаях этот аргумент сработает, потому что можно будет избавиться от громоздкого фреймворка, без которого иначе было бы не обойтись.
Всё это мы получим в обмен на требование отдавать упрощенный макет старым браузерам. Но это не значит «никакого макета». Будьте готовы объяснить и то, что внедрение гридов в браузеры не похоже на внедрение чего бы то ни было в CSS, что мы видели прежде. Реализации уже совместимы как никогда. Edge уже обновил гриды за флагом в предварительной сборке. Браузеры без поддержки исчезают намного быстрее, чем можно было бы ожидать по прошлому опыту.
Когда вы вооружены всей нужной информацией о цене вопроса, дискуссия становится очень простой. То, что старые браузеры существуют — не ваша вина. Не начинайте этих дискуссий так, как будто это вы провалили задание добиться, чтобы сайт выглядел одинаково во всех браузерах, выпущенных за последние 10 лет, используя при этом технологию, которой нет и года. Это не ваша вина, но ваша проблема. Ваша проблема, ваша обязанность как веб-профессионала, поставить себя в такие условия, в которых вы сможете выбирать правильный курс действий для каждого проекта.
Переход от табличной верстки к CSS изменил облик веба. Он увел нас от попиксельно нарезанных картинок к чему-то более гибкому, с текстом в основе, менее похожему на печатный дизайн. Последние 15 лет облик веба диктовался техническими ограничениями CSS. Думаю, что наши новые раскладочные методы — гриды, флексбоксы и штуки вроде веб-фигур — изменят его облик снова. Но мы должны дать этому случиться, нам надо позволить себе экспериментировать, учиться и творить новое.
Мы сможем сделать это, только если готовы показывать преимущества этих методов тем людям, для которых мы делаем сайты и приложения. Мы можем сделать это, только если отбросим наши предрассудки о вебе, браузерах и темпах внедрения хотя бы до тех пор, пока не изучим все эти штуки. Только тогда мы сможем принимать правильное решение для каждого проекта. Никогда не будет четкого «или — или», всегда будут компромиссы. Наша работа — справляться с этим, как и всегда.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author psywalker разработка веб-сайтов html css веб-разработка grid layout css grid layout |
Moya — как перестать беспокоиться о сетевой части и начать жить |

platform :ios, '9.0'
def app_pods
pod 'ObjectMapper', '~> 2.2'
pod 'Moya'
pod 'Moya-ObjectMapper'
end
target 'MoyaExample' do
use_frameworks!
app_pods
# Pods for MoyaExample
target 'MoyaExampleTests' do
inherit! :search_paths
app_pods
end
end
import Moya
enum MoyaExampleService {
case getRestaurants(page: Int?, perPage: Int?)
}
extension MoyaExampleService: TargetType {
var baseURL: URL { return URL(string: "http://moya-example.svyatoslav-reshetnikov.ru")! }
var path: String {
switch self {
case .getRestaurants:
return "/restaurants.json"
}
var method: Moya.Method {
return .get
}
var parameters: [String: Any]? {
return nil
}
var parameterEncoding: ParameterEncoding {
return URLEncoding.default
}
var sampleData: Data {
return Data()
}
var task: Task {
return .request
}
}
TargetType. Давайте рассмотрим подробней содержание этого протокола:var baseURL — это адрес сервера, на котором лежит RESTful API.var path — это роуты запросов.var method — это метод, который мы хотим послать. Moya ничего не придумывает и берёт все методы из Alamofire.var parameters — это параметры запроса. На данном этапе библиотеку не волнует будут ли эти параметры в теле запроса (POST) или в url (GET), эти нюансы определяются позже. Пока просто пишем параметры, которые мы хотим передать в запросе.var parameterEncoding — это кодировка параметров, также берётся из Alamofire. Можно сделать их как json, можно как url, можно как property list.var sampleData — это так называемые stubs, используются для тестирования. Можно взять стандартный ответ от сервера, сохранить его в проекте в формате JSON и затем использовать в unit тестах.var task — это задача, которую мы будем выполнять. Их всего 3 — request, download и upload.let provider = MoyaProvider() provider.request(.getRestaurants()) { result in
switch result {
case .success(let response):
let restaurantsResponse = try? response.mapObject(RestaurantsResponse.self)
// Do something with restaurantsResponse
case .failure(let error):
print(error.errorDescription ?? "Unknown error")
}
}
let provider = RxMoyaProvider()
provider.request(.getRestaurants())
.mapObject(RestaurantsResponse.self)
.catchError { error in
// Do something with error
return Observable.error(error)
}
.subscribe(
onNext: { response in
self.restaurants = response.data
}
)
.addDisposableTo(disposeBag)
let requestClosure = { (endpoint: Endpoint, done: MoyaProvider.RequestResultClosure) in
var request = endpoint.urlRequest
request?.setValue("set_your_token", forHTTPHeaderField: "XAuthToken")
done(.success(request!))
}
let provider = RxMoyaProvider(requestClosure: requestClosure)
let provider = RxMoyaProvider(plugins: [NetworkLoggerPlugin(verbose: true)])
import Quick
import Nimble
import RxSwift
import Moya
@testable import MoyaExample
class NetworkTests: QuickSpec {
override func spec() {
var testProvider: RxMoyaProvider!
let disposeBag = DisposeBag()
beforeSuite {
testProvider = RxMoyaProvider(stubClosure: MoyaProvider.immediatelyStub)
}
describe("testProvider") {
it("should be not nil") {
expect(testProvider).toNot(beNil())
}
}
describe("getRestaurants") {
it("should return not nil RestaurantsResponse object") {
testProvider.request(.getRestaurants())
.mapObject(RestaurantsResponse.self)
.subscribe(
onNext: { response in
expect(response).toNot(beNil())
}
)
.addDisposableTo(disposeBag)
}
}
}
}
|
Метки: author svyat_reshetnikov разработка под ios swift ios development moya unit testing |
Работа с API КОМПАС-3D -> Урок 3 -> Корректное подключение к КОМПАС |

KompasObjectPtr kompas;
kompas.ActiveInstance(L"KOMPAS.Application.5");
//Делаем КОМПАС видимым
kompas->Visible = true;
kompas.Unbind();


try{
KompasObjectPtr kompas;
kompas.ActiveInstance(L"KOMPAS.Application.5");
//Делаем КОМПАС видимым
kompas->Visible = true;
kompas.Unbind();
}catch(...){}
//Функция обратного вызова для поиска окна
bool CALLBACK EnumWindowsProc(HWND hwnd, LPARAM lParam)
{
//Получаем размер заголовка окна
unsigned int size;
size = GetWindowTextLength(hwnd);
if(!size) return true;
//Подготавливаем буфер под заголовок окна
wchar_t* pbuffer;
pbuffer = (wchar_t*)malloc(sizeof(wchar_t)*(size+1));
//Читаем заголовок окна
GetWindowTextW(hwnd, pbuffer, size-1);
//Ищем подстроку
wchar_t *p;
p = wcsstr(pbuffer, L"КОМПАС-3D");
//освобождаем память
free(pbuffer);
if(!p) return true;
//Окно найдено, сохраняем результат и останавливаем поиск
bool *pres;
pres = (bool*)lParam;
*pres = true;
return false;
}
//Функция проверки запущен ли КОМПАС?
bool IsKOMPASRun()
{
bool res = false;
EnumWindows((WNDENUMPROC)EnumWindowsProc, (LPARAM)(&res));
return res;
}
if(IsKOMPASRun())
ShowMessage("КОМПАС запущен");
else
ShowMessage("КОМПАС не запущен");
bool IsKOMPASRun()
{
//Имя исполняемого файла, который мы ищем
char ExeName[] = "kompas.exe";
size_t lenName = strlen(ExeName);
//Делаем снимок системы
HANDLE hSnapshot;
hSnapshot = CreateToolhelp32Snapshot(TH32CS_SNAPPROCESS, 0);
//Перечисляем процессы
PROCESSENTRY32 entry;
entry.dwSize = sizeof(PROCESSENTRY32);
Process32First(hSnapshot, &entry);
size_t len;
bool res = false;
do{
//Сравниваем наименования исполняемых файлов
len = strlen(entry.szExeFile);
if(len != lenName) continue;
if(!strnicmp(entry.szExeFile, ExeName, len))
{
res = true;
break;
}
}while(Process32Next(hSnapshot, &entry));
CloseHandle(hSnapshot);
return res;
}
bool IsKOMPASRun()
{
wchar_t ObjectName[] = L"KOMPAS.Application.5";
//Инициализируем библиотеку Ole32.dll
CoInitialize(NULL);
CLSID clsid;
//Получаем clsid объекта
CLSIDFromProgID(ObjectName, &clsid);
//Пытаемся подключиться
HRESULT res;
IUnknown *pIUnknown;
res = GetActiveObject(clsid, NULL, &pIUnknown);
if(res == S_OK)
{
pIUnknown->Release();
return true;
}
return false;
}
bool IsKOMPASInstalled()
{
wchar_t ObjectName[] = L"KOMPAS.Application.5";
//Инициализируем библиотеку Ole32.dll
CoInitialize(NULL);
CLSID clsid;
//Получаем clsid объекта
HRESULT res;
res = CLSIDFromProgID(ObjectName, &clsid);
return (res == S_OK);
}
wchar_t ObjectName[] = L"KOMPAS.Application.5";
……………………………………………………………
if(! IsKOMPASInstalled())
{
ShowMessage("КОМПАС не установлен");
return;
}
KompasObjectPtr kompas;
if(IsKOMPASRun())
kompas.ActiveInstance(ObjectName);
else
kompas.CreateInstance(ObjectName);
kompas->Visible = true;
kompas.Unbind();
 Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».
Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».
|
Метки: author kompas_3d разработка под windows cad/cam c++ api блог компании аскон компас 3d компас компас-3d приложения библиотеки |
Веб-разработка: как распознать проблемного клиента на старте |
 Моя компания НеВсем давно уже прочно обосновалась на первых местах по запросам, связанным с аудитом сайтов во многих городах Поволжья. Вот уже несколько лет мы делаем их все больше и больше, поэтому о качестве веб-сайтов и о том, как ведется разработка и подготовительный этап, знаем очень хорошо. И со стороны клиента и со стороны студии.
Моя компания НеВсем давно уже прочно обосновалась на первых местах по запросам, связанным с аудитом сайтов во многих городах Поволжья. Вот уже несколько лет мы делаем их все больше и больше, поэтому о качестве веб-сайтов и о том, как ведется разработка и подготовительный этап, знаем очень хорошо. И со стороны клиента и со стороны студии.|
Метки: author wilelf я пиарюсь разработка сайтов web- разработка веб-дизайн веб-студия |
Android Architecture Components. Часть 1. Введение |

class MyActivity extends LifecycleActivity {
private PlayerWrapper mPlayerWrapper;
public void onCreate(…) {
mPlayerWrapper = new PlayerWrapper (this, getLifecycle());
}
}
class PlayerWrapper implements LifecycleObserver {
private PlayerController mController;
public MyLocationListener(Context context, Lifecycle lifecycle) {
//init controller
}
@OnLifecycleEvent(Lifecycle.Event.ON_START)
void start() {
mController.play();
}
@OnLifecycleEvent(Lifecycle.Event.ON_PAUSE)
void stop() {
mController.stop();
}
}
class ChatLiveDataHolder extends LiveData{
private static ChatLiveDataHolder sInstance;
private ChatManager mChatManager;
private ChatListener mChatListener = new ChatListener(){
@Override
public void newMessage(Message message){
setValue(message);
}
}
public static ChatLiveDataHolder get() {
if (sInstance == null) {
sInstance = new ChatLiveDataHolder();
}
return sInstance;
}
private ChatLiveDataHolder(){
//init mChatManager and set listener
}
@Override
protected void onActive() {
mChatManager.start();
}
@Override
protected void onInactive() {
mChatManager.stop();
}
}
public class OurModel extends ViewModel {
private List userList;
public List getUserList() {
return userList;
}
public void setUserList(List list) {
this.userList = list;
}
}
@Override
protected void onCreate(Bundle savedInstanceState){
// init UI etc.
OurModel model = ViewModelProviders.of(this).get(OurModel.class);
If (model.getUserList()==null){
downloadData();
} else {
showData();
}
}
@Entity(tableName = «book»)
class Book{
@PrimaryKey
private int id;
@ColumnInfo(name = «title»)
private String title;
@ColumnInfo(name = «author_id»)
private int authorId;
…
//Get and set for fields
}
@Dao
public interface OurDao {
@Insert
public void insertBook(Book book);
@Update
public void updateBook(Book book);
@Delete
public void deleteBook(Book book);
@Query(«SELECT * FROM book»)
public Book[] loadAllBooks();
}
@Database(entities = {User.class}, version = 1)
public abstract class AppDatabase extends RoomDatabase {
public abstract OurDao ourDao();
}
AppDatabase db = Room.databaseBuilder(getApplicationContext(), AppDatabase.class, «database-name»).build();

|
Метки: author kb2fty7 разработка под android android architecture android architecture components development андроид разработка приложений |
Фреймворк для UI-тестирования JDI: как и зачем использовать |


|
Метки: author AliceMir тестирование мобильных приложений тестирование веб-сервисов блог компании epam тестирование ui epam systems jdi |






