It's a (focus) Trap |
|
Метки: author kashey javascript html aria a11y dom |
Sberbank In-Memory Computing Day |
|
Метки: author megapost высокая производительность сбер |
Sberbank In-Memory Computing Day |
|
Метки: author megapost высокая производительность сбер |
[Перевод] Создаём GTK-видеоплеер с использованием Haskell |

Когда мы в последний раз остановились на Movie Monad, мы создали десктопный видео-плеер, использующий все веб-технологии (HTML, CSS, JavaScript и Electron). Фокус был в том, что весь исходный код проекта был написан на Haskell.
Одним из ограничений нашего веб-подхода было то, что размер видео-файла не мог быть слишком большим, в противном случае приложение падало. Чтобы этого избежать, мы внедрили проверку размера файла и предупреждали пользователя о превышении ограничения.
Мы могли бы продолжить развивать наш подход с вебом, настроив бэкенд на стриминг видеофайла в HTML5-сервер, запустив параллельно сервер и Electron-приложение. Вместо этого мы откажемся от веб-технологий и обратимся к GTK+, Gstreamer и системе управления окнами X11.
Если вы используете другую систему управления окнами, например, Wayland, Quartz или WinAPI, то этот подход может быть адаптирован для работы с вашим GDK-бэкендом. Адаптация заключается во встраивании выходного видеосигнала GStreamer playbin в окно Movie Monad.
GDK — важный аспект портируемости GTK+. Поскольку Glib уже предоставляет низкоуровневую кроссплатформенную функциональность, то чтобы заставить GTK+ работать на других платформах вам нужно только портировать GDK на базовый графический уровень операционной системы. То есть именно GDK-порты на Windows API и Quartz позволяют приложениям GTK+ исполняться на Windows и macOS (источник).
Сначала нам нужно настроить машину для разработки Haskell-программ, а также настроить файлы и зависимости для директории проекта.
Если ваша машина ещё не готова к разработке Haskell-программ, то всё необходимое вы можете получить, скачав и установив платформу Haskell.
Если у вас ещё нет Stack, то обязательно установите его, прежде чем приступать к разработке. Но если вы уже пользовались платформой Haskell, то Stack у вас уже есть.
Прежде чем проигрывать видео в Movie Monad, нам нужно собрать кое-какую информацию о выбранном пользователем файле. Для этого воспользуемся ExifTool. Если вы работаете под Linux, то велик шанс, что у вас уже есть этот инструмент (which exiftool). ExifTool доступен для Windows, Mac и Linux.
Есть три способа получения файлов проекта.
wget https://github.com/lettier/movie-monad/archive/master.zip
unzip master.zip
mv movie-monad-master movie-monad
cd movie-monad/Можете скачать ZIP-архив и извлечь их.
git clone git@github.com:lettier/movie-monad.git
cd movie-monad/Можете сделать Git-клон с помощью SSH.
git clone https://github.com/lettier/movie-monad.git
cd movie-monad/Можете склонировать git через HTTPS.
haskell-gi умеет генерировать Haskell-привязки (bindings) к библиотекам, использующим связующее ПО для самодиагностики (introspection middleware) GObject. На момент написания статьи все необходимые привязки доступны на Hackage.
Теперь устанавливаем зависимости проекта.
cd movie-monad/
stack install --dependencies-onlyТеперь настраиваем внедрение Movie Monad. Вы можете удалить исходные файлы и создать их заново, или следовать указаниям.
Paths_movie_monad.hs используется для поиска файла Glade XML GUI во время runtime. Поскольку мы занимаемся разработкой, то будем использовать фиктивный модуль (dummy module) (movie-monad/src/dev/Paths_movie_monad.hs) для поиска файла movie-monad/src/data/gui.glade. После сборки/установки проекта реальный модуль Paths_movie_monad будет сгенерирован автоматически. Он предоставит нам функцию getDataFileName. Она присваивает своим выходным данным префикс в виде абсолютного пути, куда скопированы или установлены data-dir (movie-monad/src/) data-files.
{-# LANGUAGE OverloadedStrings #-}
module Paths_movie_monad where
dataDir :: String
dataDir = "./src/"
getDataFileName :: FilePath -> IO FilePath
getDataFileName a = do
putStrLn "You are using a fake Paths_movie_monad."
return (dataDir ++ "/" ++ a)Фиктивный модуль Paths_movie_monad.
{-# LANGUAGE CPP #-}
{-# OPTIONS_GHC -fno-warn-missing-import-lists #-}
{-# OPTIONS_GHC -fno-warn-implicit-prelude #-}
module Paths_movie_monad (
version,
getBinDir, getLibDir, getDynLibDir, getDataDir, getLibexecDir,
getDataFileName, getSysconfDir
) where
import qualified Control.Exception as Exception
import Data.Version (Version(..))
import System.Environment (getEnv)
import Prelude
#if defined(VERSION_base)
#if MIN_VERSION_base(4,0,0)
catchIO :: IO a -> (Exception.IOException -> IO a) -> IO a
#else
catchIO :: IO a -> (Exception.Exception -> IO a) -> IO a
#endif
#else
catchIO :: IO a -> (Exception.IOException -> IO a) -> IO a
#endif
catchIO = Exception.catch
version :: Version
version = Version [0,0,0,0] []
bindir, libdir, dynlibdir, datadir, libexecdir, sysconfdir :: FilePath
bindir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/bin"
libdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/lib/x86_64-linux-ghc-8.0.2/movie-monad-0.0.0.0"
dynlibdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/lib/x86_64-linux-ghc-8.0.2"
datadir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/share/x86_64-linux-ghc-8.0.2/movie-monad-0.0.0.0"
libexecdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/libexec"
sysconfdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/etc"
getBinDir, getLibDir, getDynLibDir, getDataDir, getLibexecDir, getSysconfDir :: IO FilePath
getBinDir = catchIO (getEnv "movie_monad_bindir") (\_ -> return bindir)
getLibDir = catchIO (getEnv "movie_monad_libdir") (\_ -> return libdir)
getDynLibDir = catchIO (getEnv "movie_monad_dynlibdir") (\_ -> return dynlibdir)
getDataDir = catchIO (getEnv "movie_monad_datadir") (\_ -> return datadir)
getLibexecDir = catchIO (getEnv "movie_monad_libexecdir") (\_ -> return libexecdir)
getSysconfDir = catchIO (getEnv "movie_monad_sysconfdir") (\_ -> return sysconfdir)
getDataFileName :: FilePath -> IO FilePath
getDataFileName name = do
dir <- getDataDir
return (dir ++ "/" ++ name) Автоматически сгенерированный модуль Paths_movie_monad.
Main.hs — это входная точка для Movie Monad. В этом файле мы настраиваем наше окно с разными виджетами, подключаем GStreamer, а когда пользователь выходит, мы сносим окно.
Прагмы (Pragmas)
Нам нужно сказать компилятору (GHC), что нам нужны перегруженные (overloaded) строковые и лексически входящие в область видимости (lexically scoped) переменные типов.
OverloadedStrings позволяет нам использовать строковые литералы ("Literal") там, где требуются String/[Char] или Text. ScopedTypeVariables позволяет нам использовать сигнатуру типа в паттерне параметра лямбда-функции, передаваемую для перехвата при вызове ExifTool.
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE ScopedTypeVariables #-}Импорты
module Main where
import Prelude
import Foreign.C.Types
import System.Process
import System.Exit
import Control.Monad
import Control.Exception
import Text.Read
import Data.IORef
import Data.Maybe
import Data.Int
import Data.Text
import Data.GI.Base
import Data.GI.Base.Signals
import Data.GI.Base.Properties
import GI.GLib
import GI.GObject
import qualified GI.Gtk
import GI.Gst
import GI.GstVideo
import GI.Gdk
import GI.GdkX11
import Paths_movie_monadПоскольку мы работает с привязками Си, нам понадобится работать с типами, уже существующими в этом языке. Немалую часть импортов составляют привязки, генерируемые haskell-gi.
IsVideoOverlay
GStreamer-видеопривязки (gi-gstvideo) содержат класс типа (интерфейс) IsVideoOverlay. GStreamer-привязки (gi-gst) содержат тип элемента. Чтобы использовать элемент playbin с функцией GI.GstVideo.videoOverlaySetWindowHandle, нам нужно объявить GI.Gst.Element — экземпляр типа (type instance) IsVideoOverlay. А на стороне Cи playbin реализует интерфейс VideoOverlay.
newtype GstElement = GstElement GI.Gst.Element
instance GI.GstVideo.IsVideoOverlay GstElementОбратите внимание, что мы обёртываем GI.Gst.Element в новый тип (newtype), чтобы избежать появления потерянного (orphaned) экземпляра, поскольку мы объявляем экземпляр вне привязок haskell-gi.
main
Main — наша самая большая функция. В ней мы инициализируем все GUI-виджеты и определяем коллбэк-процедуры на основе определённых событий.
main :: IO ()
main = doGI-инициализация
_ <- GI.Gst.init Nothing
_ <- GI.Gtk.init NothingЗдесь мы инициализировали GStreamer и GTK+.
Сборка GUI-виджетов
gladeFile <- getDataFileName "data/gui.glade"
builder <- GI.Gtk.builderNewFromFile (pack gladeFile)
window <- builderGetObject GI.Gtk.Window builder "window"
fileChooserButton <- builderGetObject GI.Gtk.FileChooserButton builder "file-chooser-button"
drawingArea <- builderGetObject GI.Gtk.Widget builder "drawing-area"
seekScale <- builderGetObject GI.Gtk.Scale builder "seek-scale"
onOffSwitch <- builderGetObject GI.Gtk.Switch builder "on-off-switch"
volumeButton <- builderGetObject GI.Gtk.VolumeButton builder "volume-button"
desiredVideoWidthComboBox <- builderGetObject GI.Gtk.ComboBoxText builder "desired-video-width-combo-box"
fullscreenButton <- builderGetObject GI.Gtk.Button builder "fullscreen-button"
errorMessageDialog <- builderGetObject GI.Gtk.MessageDialog builder "error-message-dialog"
aboutButton <- builderGetObject GI.Gtk.Button builder "about-button"
aboutDialog <- builderGetObject GI.Gtk.AboutDialog builder "about-dialog"Как уже было сказано, мы получаем абсолютный путь к XML-файлу data/gui.glade, который описывает все наши GUI-виджеты. Дальше создаём из этого файла конструктор и получаем свои виджеты. Если бы мы не использовали Glade, то их пришлось бы создавать вручную, что довольно утомительно.
Playbin
playbin <- fromJust <$> GI.Gst.elementFactoryMake "playbin" (Just "MultimediaPlayer")Здесь мы создаём GStreamer-конвейер playbin. Он предназначен для решения самых разных нужд и экономит нам время на создании собственного конвейера. Назовём этот элемент MultimediaPlayer.
Встраиванние выходных данных GStreamer
Чтобы GTK+ и GStreamer заработали вместе, нам нужно сказать GStreamer, куда именно нужно выводить видео. Если этого не сделать, то GStreamer создаст собственное окно, поскольку мы используем playbin.
_ <- GI.Gtk.onWidgetRealize drawingArea $ onDrawingAreaRealize drawingArea playbin fullscreenButton
-- ...
onDrawingAreaRealize ::
GI.Gtk.Widget ->
GI.Gst.Element ->
GI.Gtk.Button ->
GI.Gtk.WidgetRealizeCallback
onDrawingAreaRealize drawingArea playbin fullscreenButton = do
gdkWindow <- fromJust <$> GI.Gtk.widgetGetWindow drawingArea
x11Window <- GI.Gtk.unsafeCastTo GI.GdkX11.X11Window gdkWindow
xid <- GI.GdkX11.x11WindowGetXid x11Window
let xid' = fromIntegral xid :: CUIntPtr
GI.GstVideo.videoOverlaySetWindowHandle (GstElement playbin) xid'
GI.Gtk.widgetHide fullscreenButtonЗдесь вы видите настройку коллбэка по мере готовности виджета drawingArea. Именно в этом виджете GStreamer должен показывать видео. Мы получаем родительское GDK-окно для виджета области отрисовки. Затем получаем обработчик окна, или XID системы X11 нашего окна GTK+. Строка CUIntPtr преобразует ID из CULong в CUIntPtr, необходимый для videoOverlaySetWindowHandle. Получив правильный тип, мы уведомляем GStreamer, что с помощью обработчика xid' он может отрисовывать в нашем окне выходные данные playbin.
Из-за бага в Glade мы программно скрываем полноэкранный виджет, поскольку если в Glade снять галочку visible box, то виджет всё-равно не будет спрятан.
Обратите внимание, что здесь нужно адаптировать Movie Monad для работы с оконной системой, если вы используете не Х-систему, а какую-то другую.
Выбор файла
_ <- GI.Gtk.onFileChooserButtonFileSet fileChooserButton $
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
-- ...
onFileChooserButtonFileSet ::
GI.Gst.Element ->
GI.Gtk.FileChooserButton ->
GI.Gtk.VolumeButton ->
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Switch ->
GI.Gtk.Button ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
GI.Gtk.MessageDialog ->
GI.Gtk.FileChooserButtonFileSetCallback
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
= do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
filename <- fromJust <$> GI.Gtk.fileChooserGetFilename fileChooserButton
setPlaybinUriAndVolume playbin filename volumeButton
isWindowFullScreen <- readIORef isWindowFullScreenRef
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePaused
GI.Gtk.windowUnfullscreen window
GI.Gtk.switchSetActive onOffSwitch False
GI.Gtk.widgetHide fullscreenButton
GI.Gtk.widgetShow desiredVideoWidthComboBox
resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
_ <- GI.Gtk.onDialogResponse errorMessageDialog (\ _ -> GI.Gtk.widgetHide errorMessageDialog)
void $ GI.Gtk.dialogRun errorMessageDialog
Just (width, height) -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePlaying
GI.Gtk.switchSetActive onOffSwitch True
GI.Gtk.widgetShow fullscreenButton
unless isWindowFullScreen $ setWindowSize width height fileChooserButton drawingArea windowДля начала сессии проигрывания видео, пользователь должен иметь возможность выбрать видео-файл. После того, как файл выбран, нужно выполнить ряд обязательных действий, чтобы всё работало хорошо.
playbin, какой файл он должен воспроизвести.playbin.playbin на паузу.Пауза и воспроизведение
_ <- GI.Gtk.onSwitchStateSet onOffSwitch (onSwitchStateSet playbin)
-- ...
onSwitchStateSet ::
GI.Gst.Element ->
Bool ->
IO Bool
onSwitchStateSet playbin switchOn = do
if switchOn
then void $ GI.Gst.elementSetState playbin GI.Gst.StatePlaying
else void $ GI.Gst.elementSetState playbin GI.Gst.StatePaused
return switchOnВсё просто. Если переключатель в положении ”on”, то задаём элементу playbin состояние воспроизведения. В противном случае задаём ему состояние паузы.
Настройка громкости
_ <- GI.Gtk.onScaleButtonValueChanged volumeButton (onScaleButtonValueChanged playbin)
-- ...
onScaleButtonValueChanged ::
GI.Gst.Element ->
Double ->
IO ()
onScaleButtonValueChanged playbin volume =
void $ Data.GI.Base.Properties.setObjectPropertyDouble playbin "volume" volumeПри изменении уровня громкости в виджете мы передаём его значение в GStreamer, чтобы тот мог подстроить громкость воспроизведение.
Перемещение по видео
seekScaleHandlerId <- GI.Gtk.onRangeValueChanged seekScale (onRangeValueChanged playbin seekScale)
-- ...
onRangeValueChanged ::
GI.Gst.Element ->
GI.Gtk.Scale ->
IO ()
onRangeValueChanged playbin seekScale = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
when couldQueryDuration $ do
percentage' <- GI.Gtk.rangeGetValue seekScale
let percentage = percentage' / 100.0
let position = fromIntegral (round ((fromIntegral duration :: Double) * percentage) :: Int) :: Int64
void $ GI.Gst.elementSeekSimple playbin GI.Gst.FormatTime [ GI.Gst.SeekFlagsFlush ] positionВ Movie Monad есть шкала воспроизведения, в которой вы можете перемещать ползунок вперёд/назад, тем самым переходя по видеофреймам.
Шкала от 0 до 100% представляет общую длительность видео-файла. Если переместить ползунок, например, на 50, то мы перейдём к временной отметке, находящийся посередине между началом и окончанием. Можно было бы настроить шкалу от нуля до значения длительности видео, но описанный метод более универсален.
Обратите внимание, что для этого коллбэка мы используем сигнальный ID (seekScaleHandlerId), поскольку он понадобится нам позднее.
Обновление шкалы воспроизведения
_ <- GI.GLib.timeoutAddSeconds GI.GLib.PRIORITY_DEFAULT 1 (updateSeekScale playbin seekScale seekScaleHandlerId)
-- ...
updateSeekScale ::
GI.Gst.Element ->
GI.Gtk.Scale ->
Data.GI.Base.Signals.SignalHandlerId ->
IO Bool
updateSeekScale playbin seekScale seekScaleHandlerId = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
(couldQueryPosition, position) <- GI.Gst.elementQueryPosition playbin GI.Gst.FormatTime
let percentage =
if couldQueryDuration && couldQueryPosition && duration > 0
then 100.0 * (fromIntegral position / fromIntegral duration :: Double)
else 0.0
GI.GObject.signalHandlerBlock seekScale seekScaleHandlerId
GI.Gtk.rangeSetValue seekScale percentage
GI.GObject.signalHandlerUnblock seekScale seekScaleHandlerId
return TrueЧтобы синхронизировать шкалу и сам процесс воспроизведения видео, нужно передавать сообщения между GTK+ и GStreamer. Каждую секунду мы будем запрашивать текущую позицию воспроизведения и в соответствии с ней обновлять шкалу. Так мы показываем пользователю, какая часть файла уже показана, а ползунок всегда будет соответствовать реальной позиции воспроизведения.
Чтобы не инициировать настроенный ранее коллбэк, мы отключаем обработчик сигнала onRangeValueChanged при обновлении шкалы воспроизведения. Коллбэк onRangeValueChanged должен быть выполнен только если пользователь изменит положение ползунка.
Изменение размеров видео
_ <- GI.Gtk.onComboBoxChanged desiredVideoWidthComboBox $
onComboBoxChanged fileChooserButton desiredVideoWidthComboBox drawingArea window
-- ...
onComboBoxChanged ::
GI.Gtk.FileChooserButton ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
onComboBoxChanged
fileChooserButton
desiredVideoWidthComboBox
drawingArea
window
= do
filename' <- GI.Gtk.fileChooserGetFilename fileChooserButton
let filename = fromMaybe "" filename'
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
Just (width, height) -> setWindowSize width height fileChooserButton drawingArea windowЭтот виджет позволяет пользователю выбирать желаемую ширину видео. Высота будет подобрана автоматически на основе соотношения сторон видеофайла.
Полноэкранный режим
_ <- GI.Gtk.onWidgetButtonReleaseEvent fullscreenButton
(onFullscreenButtonRelease isWindowFullScreenRef desiredVideoWidthComboBox fileChooserButton window)
-- ...
onFullscreenButtonRelease ::
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Window ->
GI.Gdk.EventButton ->
IO Bool
onFullscreenButtonRelease
isWindowFullScreenRef
desiredVideoWidthComboBox
fileChooserButton
window
_
= do
isWindowFullScreen <- readIORef isWindowFullScreenRef
if isWindowFullScreen
then do
GI.Gtk.widgetShow desiredVideoWidthComboBox
GI.Gtk.widgetShow fileChooserButton
void $ GI.Gtk.windowUnfullscreen window
else do
GI.Gtk.widgetHide desiredVideoWidthComboBox
GI.Gtk.widgetHide fileChooserButton
void $ GI.Gtk.windowFullscreen window
return TrueКогда пользователь отпускает кнопку виджета полноэкранного режим, мы переключаем состояние полноэкранного режима окна, скрываем панель выбора файла и виджет выбора ширины видео. При выходе из полноэкранного режима мы восстанавливаем панель и виджет.
Обратите внимание, что мы не показываем виджет полноэкранного режима, если у нас нет видео.
_ <- GI.Gtk.onWidgetWindowStateEvent window (onWidgetWindowStateEvent isWindowFullScreenRef)
-- ...
onWidgetWindowStateEvent ::
IORef Bool ->
GI.Gdk.EventWindowState ->
IO Bool
onWidgetWindowStateEvent isWindowFullScreenRef eventWindowState = do
windowStates <- GI.Gdk.getEventWindowStateNewWindowState eventWindowState
let isWindowFullScreen = Prelude.foldl (\ acc x -> acc || GI.Gdk.WindowStateFullscreen == x) False windowStates
writeIORef isWindowFullScreenRef isWindowFullScreen
return TrueДля управления полноэкранным состоянием окна мы должны настроить коллбэк, чтобы он запускался при каждом изменении состояния окна. От информации о состоянии полноэкранности окна зависят различные коллбэки. В качестве помощи воспользуемся IORef, из которого будет читать каждая функция и в который будет писать коллбэк. Этот IORef является изменяемой (и общей) ссылкой. В идеале нам нужно запрашивать окно именно в то время, когда оно находится в полноэкранном режиме, но для этого не существует API. Поэтому будем использовать изменяемую ссылку.
Благодаря использованию в главном потоке выполнения единственного пишущего и кучи сигнальных коллбэков, мы избегаем возможных ловушек общего изменяемого состояния. Если бы нас заботила безопасность потока выполнения, то вместо этого мы могли бы использовать MVar, TVar или atomicModifyIORef.
О программе
_ <- GI.Gtk.onWidgetButtonReleaseEvent aboutButton (onAboutButtonRelease aboutDialog)
-- ...
onAboutButtonRelease ::
GI.Gtk.AboutDialog ->
GI.Gdk.EventButton ->
IO Bool
onAboutButtonRelease aboutDialog _ = do
_ <- GI.Gtk.onDialogResponse aboutDialog (\ _ -> GI.Gtk.widgetHide aboutDialog)
_ <- GI.Gtk.dialogRun aboutDialog
return TrueПоследний рассматриваемый виджет — диалоговое окно «О программе». Здесь мы связываем диалоговое окно с кнопкой «О программе», отображающейся в основном окне.
Закрытие окна
_ <- GI.Gtk.onWidgetDestroy window (onWindowDestroy playbin)
-- ...
onWindowDestroy ::
GI.Gst.Element ->
IO ()
onWindowDestroy playbin = do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
_ <- GI.Gst.objectUnref playbin
GI.Gtk.mainQuitКогда пользователь закрывает окно, мы уничтожаем конвейер playbin и выходим из основного цикла GTK.
Запуск
GI.Gtk.widgetShowAll window
GI.Gtk.mainНаконец, мы показываем или отрисовываем главное окно и запускаем основной цикл GTK+. Он блокируется до вызова mainQuit.
Полный файл Main.hs
Ниже приведён файл movie-monad/src/Main.hs. Не показаны разные вспомогательные функции, относящиеся к main.
{-
Movie Monad
(C) 2017 David lettier
lettier.com
-}
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE ScopedTypeVariables #-}
module Main where
import Prelude
import Foreign.C.Types
import System.Process
import System.Exit
import Control.Monad
import Control.Exception
import Text.Read
import Data.IORef
import Data.Maybe
import Data.Int
import Data.Text
import Data.GI.Base
import Data.GI.Base.Signals
import Data.GI.Base.Properties
import GI.GLib
import GI.GObject
import qualified GI.Gtk
import GI.Gst
import GI.GstVideo
import GI.Gdk
import GI.GdkX11
import Paths_movie_monad
-- Declare Element a type instance of IsVideoOverlay via a newtype wrapper
-- Our GStreamer element is playbin
-- Playbin implements the GStreamer VideoOverlay interface
newtype GstElement = GstElement GI.Gst.Element
instance GI.GstVideo.IsVideoOverlay GstElement
main :: IO ()
main = do
_ <- GI.Gst.init Nothing
_ <- GI.Gtk.init Nothing
gladeFile <- getDataFileName "data/gui.glade"
builder <- GI.Gtk.builderNewFromFile (pack gladeFile)
window <- builderGetObject GI.Gtk.Window builder "window"
fileChooserButton <- builderGetObject GI.Gtk.FileChooserButton builder "file-chooser-button"
drawingArea <- builderGetObject GI.Gtk.Widget builder "drawing-area"
seekScale <- builderGetObject GI.Gtk.Scale builder "seek-scale"
onOffSwitch <- builderGetObject GI.Gtk.Switch builder "on-off-switch"
volumeButton <- builderGetObject GI.Gtk.VolumeButton builder "volume-button"
desiredVideoWidthComboBox <- builderGetObject GI.Gtk.ComboBoxText builder "desired-video-width-combo-box"
fullscreenButton <- builderGetObject GI.Gtk.Button builder "fullscreen-button"
errorMessageDialog <- builderGetObject GI.Gtk.MessageDialog builder "error-message-dialog"
aboutButton <- builderGetObject GI.Gtk.Button builder "about-button"
aboutDialog <- builderGetObject GI.Gtk.AboutDialog builder "about-dialog"
playbin <- fromJust <$> GI.Gst.elementFactoryMake "playbin" (Just "MultimediaPlayer")
isWindowFullScreenRef <- newIORef False
_ <- GI.Gtk.onWidgetRealize drawingArea $ onDrawingAreaRealize drawingArea playbin fullscreenButton
_ <- GI.Gtk.onFileChooserButtonFileSet fileChooserButton $
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
_ <- GI.Gtk.onSwitchStateSet onOffSwitch (onSwitchStateSet playbin)
_ <- GI.Gtk.onScaleButtonValueChanged volumeButton (onScaleButtonValueChanged playbin)
seekScaleHandlerId <- GI.Gtk.onRangeValueChanged seekScale (onRangeValueChanged playbin seekScale)
_ <- GI.GLib.timeoutAddSeconds GI.GLib.PRIORITY_DEFAULT 1 (updateSeekScale playbin seekScale seekScaleHandlerId)
_ <- GI.Gtk.onComboBoxChanged desiredVideoWidthComboBox $
onComboBoxChanged fileChooserButton desiredVideoWidthComboBox drawingArea window
_ <- GI.Gtk.onWidgetButtonReleaseEvent fullscreenButton
(onFullscreenButtonRelease isWindowFullScreenRef desiredVideoWidthComboBox fileChooserButton window)
_ <- GI.Gtk.onWidgetWindowStateEvent window (onWidgetWindowStateEvent isWindowFullScreenRef)
_ <- GI.Gtk.onWidgetButtonReleaseEvent aboutButton (onAboutButtonRelease aboutDialog)
_ <- GI.Gtk.onWidgetDestroy window (onWindowDestroy playbin)
GI.Gtk.widgetShowAll window
GI.Gtk.main
builderGetObject ::
(GI.GObject.GObject b, GI.Gtk.IsBuilder a) =>
(Data.GI.Base.ManagedPtr b -> b) ->
a ->
Prelude.String ->
IO b
builderGetObject objectTypeClass builder objectId =
fromJust <$> GI.Gtk.builderGetObject builder (pack objectId) >>=
GI.Gtk.unsafeCastTo objectTypeClass
onDrawingAreaRealize ::
GI.Gtk.Widget ->
GI.Gst.Element ->
GI.Gtk.Button ->
GI.Gtk.WidgetRealizeCallback
onDrawingAreaRealize drawingArea playbin fullscreenButton = do
gdkWindow <- fromJust <$> GI.Gtk.widgetGetWindow drawingArea
x11Window <- GI.Gtk.unsafeCastTo GI.GdkX11.X11Window gdkWindow
xid <- GI.GdkX11.x11WindowGetXid x11Window
let xid' = fromIntegral xid :: CUIntPtr
GI.GstVideo.videoOverlaySetWindowHandle (GstElement playbin) xid'
GI.Gtk.widgetHide fullscreenButton
onFileChooserButtonFileSet ::
GI.Gst.Element ->
GI.Gtk.FileChooserButton ->
GI.Gtk.VolumeButton ->
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Switch ->
GI.Gtk.Button ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
GI.Gtk.MessageDialog ->
GI.Gtk.FileChooserButtonFileSetCallback
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
= do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
filename <- fromJust <$> GI.Gtk.fileChooserGetFilename fileChooserButton
setPlaybinUriAndVolume playbin filename volumeButton
isWindowFullScreen <- readIORef isWindowFullScreenRef
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePaused
GI.Gtk.windowUnfullscreen window
GI.Gtk.switchSetActive onOffSwitch False
GI.Gtk.widgetHide fullscreenButton
GI.Gtk.widgetShow desiredVideoWidthComboBox
resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
_ <- GI.Gtk.onDialogResponse errorMessageDialog (\ _ -> GI.Gtk.widgetHide errorMessageDialog)
void $ GI.Gtk.dialogRun errorMessageDialog
Just (width, height) -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePlaying
GI.Gtk.switchSetActive onOffSwitch True
GI.Gtk.widgetShow fullscreenButton
unless isWindowFullScreen $ setWindowSize width height fileChooserButton drawingArea window
onSwitchStateSet ::
GI.Gst.Element ->
Bool ->
IO Bool
onSwitchStateSet playbin switchOn = do
if switchOn
then void $ GI.Gst.elementSetState playbin GI.Gst.StatePlaying
else void $ GI.Gst.elementSetState playbin GI.Gst.StatePaused
return switchOn
onScaleButtonValueChanged ::
GI.Gst.Element ->
Double ->
IO ()
onScaleButtonValueChanged playbin volume =
void $ Data.GI.Base.Properties.setObjectPropertyDouble playbin "volume" volume
onRangeValueChanged ::
GI.Gst.Element ->
GI.Gtk.Scale ->
IO ()
onRangeValueChanged playbin seekScale = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
when couldQueryDuration $ do
percentage' <- GI.Gtk.rangeGetValue seekScale
let percentage = percentage' / 100.0
let position = fromIntegral (round ((fromIntegral duration :: Double) * percentage) :: Int) :: Int64
void $ GI.Gst.elementSeekSimple playbin GI.Gst.FormatTime [ GI.Gst.SeekFlagsFlush ] position
updateSeekScale ::
GI.Gst.Element ->
GI.Gtk.Scale ->
Data.GI.Base.Signals.SignalHandlerId ->
IO Bool
updateSeekScale playbin seekScale seekScaleHandlerId = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
(couldQueryPosition, position) <- GI.Gst.elementQueryPosition playbin GI.Gst.FormatTime
let percentage =
if couldQueryDuration && couldQueryPosition && duration > 0
then 100.0 * (fromIntegral position / fromIntegral duration :: Double)
else 0.0
GI.GObject.signalHandlerBlock seekScale seekScaleHandlerId
GI.Gtk.rangeSetValue seekScale percentage
GI.GObject.signalHandlerUnblock seekScale seekScaleHandlerId
return True
onComboBoxChanged ::
GI.Gtk.FileChooserButton ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
onComboBoxChanged
fileChooserButton
desiredVideoWidthComboBox
drawingArea
window
= do
filename' <- GI.Gtk.fileChooserGetFilename fileChooserButton
let filename = fromMaybe "" filename'
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
Just (width, height) -> setWindowSize width height fileChooserButton drawingArea window
onFullscreenButtonRelease ::
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Window ->
GI.Gdk.EventButton ->
IO Bool
onFullscreenButtonRelease
isWindowFullScreenRef
desiredVideoWidthComboBox
fileChooserButton
window
_
= do
isWindowFullScreen <- readIORef isWindowFullScreenRef
if isWindowFullScreen
then do
GI.Gtk.widgetShow desiredVideoWidthComboBox
GI.Gtk.widgetShow fileChooserButton
void $ GI.Gtk.windowUnfullscreen window
else do
GI.Gtk.widgetHide desiredVideoWidthComboBox
GI.Gtk.widgetHide fileChooserButton
void $ GI.Gtk.windowFullscreen window
return True
onWidgetWindowStateEvent ::
IORef Bool ->
GI.Gdk.EventWindowState ->
IO Bool
onWidgetWindowStateEvent isWindowFullScreenRef eventWindowState = do
windowStates <- GI.Gdk.getEventWindowStateNewWindowState eventWindowState
let isWindowFullScreen = Prelude.foldl (\ acc x -> acc || GI.Gdk.WindowStateFullscreen == x) False windowStates
writeIORef isWindowFullScreenRef isWindowFullScreen
return True
onAboutButtonRelease ::
GI.Gtk.AboutDialog ->
GI.Gdk.EventButton ->
IO Bool
onAboutButtonRelease aboutDialog _ = do
_ <- GI.Gtk.onDialogResponse aboutDialog (\ _ -> GI.Gtk.widgetHide aboutDialog)
_ <- GI.Gtk.dialogRun aboutDialog
return True
onWindowDestroy ::
GI.Gst.Element ->
IO ()
onWindowDestroy playbin = do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
_ <- GI.Gst.objectUnref playbin
GI.Gtk.mainQuit
setPlaybinUriAndVolume ::
GI.Gst.Element ->
Prelude.String ->
GI.Gtk.VolumeButton ->
IO ()
setPlaybinUriAndVolume playbin filename volumeButton = do
let uri = "file://" ++ filename
volume <- GI.Gtk.scaleButtonGetValue volumeButton
Data.GI.Base.Properties.setObjectPropertyDouble playbin "volume" volume
Data.GI.Base.Properties.setObjectPropertyString playbin "uri" (Just $ pack uri)
getVideoInfo :: Prelude.String -> Prelude.String -> IO (Maybe Prelude.String)
getVideoInfo flag filename = do
(code, out, _) <- catch (
readProcessWithExitCode
"exiftool"
[flag, "-s", "-S", filename]
""
) (\ (_ :: Control.Exception.IOException) -> return (ExitFailure 1, "", ""))
if code == System.Exit.ExitSuccess
then return (Just out)
else return Nothing
isVideo :: Prelude.String -> IO Bool
isVideo filename = do
maybeOut <- getVideoInfo "-MIMEType" filename
case maybeOut of
Nothing -> return False
Just out -> return ("video" `isInfixOf` pack out)
getWindowSize :: Int -> Prelude.String -> IO (Maybe (Int32, Int32))
getWindowSize desiredVideoWidth filename =
isVideo filename >>=
getWidthHeightString >>=
splitWidthHeightString >>=
widthHeightToDouble >>=
ratio >>=
windowSize
where
getWidthHeightString :: Bool -> IO (Maybe Prelude.String)
getWidthHeightString False = return Nothing
getWidthHeightString True = getVideoInfo "-ImageSize" filename
splitWidthHeightString :: Maybe Prelude.String -> IO (Maybe [Text])
splitWidthHeightString Nothing = return Nothing
splitWidthHeightString (Just string) = return (Just (Data.Text.splitOn "x" (pack string)))
widthHeightToDouble :: Maybe [Text] -> IO (Maybe Double, Maybe Double)
widthHeightToDouble (Just (x:y:_)) = return (readMaybe (unpack x) :: Maybe Double, readMaybe (unpack y) :: Maybe Double)
widthHeightToDouble _ = return (Nothing, Nothing)
ratio :: (Maybe Double, Maybe Double) -> IO (Maybe Double)
ratio (Just width, Just height) =
if width <= 0.0 then return Nothing else return (Just (height / width))
ratio _ = return Nothing
windowSize :: Maybe Double -> IO (Maybe (Int32, Int32))
windowSize Nothing = return Nothing
windowSize (Just ratio') =
return (Just (fromIntegral desiredVideoWidth :: Int32, round ((fromIntegral desiredVideoWidth :: Double) * ratio') :: Int32))
getDesiredVideoWidth :: GI.Gtk.ComboBoxText -> IO Int
getDesiredVideoWidth = fmap (\ x -> read (Data.Text.unpack x) :: Int) . GI.Gtk.comboBoxTextGetActiveText
setWindowSize ::
Int32 ->
Int32 ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
setWindowSize width height fileChooserButton drawingArea window = do
GI.Gtk.setWidgetWidthRequest fileChooserButton width
GI.Gtk.setWidgetWidthRequest drawingArea width
GI.Gtk.setWidgetHeightRequest drawingArea height
GI.Gtk.setWidgetWidthRequest window width
GI.Gtk.setWidgetHeightRequest window height
GI.Gtk.windowResize window width (if height <= 0 then 1 else height)
resetWindowSize ::
(Integral a) =>
a ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
resetWindowSize width' fileChooserButton drawingArea window = do
let width = fromIntegral width' :: Int32
GI.Gtk.widgetQueueDraw drawingArea
setWindowSize width 0 fileChooserButton drawingArea windowМы настроили наше сборочное окружение и подготовили весь исходный код, можно собирать Movie Monad и запускать исполняемый файл.
cd movie-monad/
stack clean
stack install
stack exec -- movie-monad
# Or just `movie-monad` if `stack path | grep local-bin-path` is in your `echo $PATH`Если всё в порядке, то Movie Monad должен запуститься.
Пересмотрев проект Movie Monad, мы заново сделали приложение с помощью программных библиотек GTK+ и GStreamer. Благодаря им приложение осталось таким же портируемым, как и Electron-версия. Movie Monad теперь может обрабатывать большие видеофайлы и имеет все стандартные элементы управления.
Другим преимуществом использования GTK+ стало уменьшение потребления памяти. Если сравнивать резидентный размер в памяти при старте, то версия GTK+ занимает ~50 Мб, а версия Electron — ~300 Мб (500%-ное увеличение).
Наконец, вариант с GTK+ имеет меньше ограничений и требует меньше программирования. Для обеспечения такой же функциональности, вариант с Electron требует использования громоздкой клиент-серверной архитектуры. Но благодаря прекрасным сборкам haskell-gi мы смогли избежать решения на базе веба.
Если хотите посмотреть другие приложения, построенные с помощью GTK+ и Haskell, то обратите внимание на Gifcurry. Оно умеет брать видеофайлы и на их основе создавать гифки с наложенным текстом.
|
Метки: author AloneCoder программирование высокая производительность haskell gtk+ блог компании mail.ru group gtk video player никто не читает теги |
[Перевод] Создаём GTK-видеоплеер с использованием Haskell |
Когда мы в последний раз остановились на Movie Monad, мы создали десктопный видео-плеер, использующий все веб-технологии (HTML, CSS, JavaScript и Electron). Фокус был в том, что весь исходный код проекта был написан на Haskell.
Одним из ограничений нашего веб-подхода было то, что размер видео-файла не мог быть слишком большим, в противном случае приложение падало. Чтобы этого избежать, мы внедрили проверку размера файла и предупреждали пользователя о превышении ограничения.
Мы могли бы продолжить развивать наш подход с вебом, настроив бэкенд на стриминг видеофайла в HTML5-сервер, запустив параллельно сервер и Electron-приложение. Вместо этого мы откажемся от веб-технологий и обратимся к GTK+, Gstreamer и системе управления окнами X11.
Если вы используете другую систему управления окнами, например, Wayland, Quartz или WinAPI, то этот подход может быть адаптирован для работы с вашим GDK-бэкендом. Адаптация заключается во встраивании выходного видеосигнала GStreamer playbin в окно Movie Monad.
GDK — важный аспект портируемости GTK+. Поскольку Glib уже предоставляет низкоуровневую кроссплатформенную функциональность, то чтобы заставить GTK+ работать на других платформах вам нужно только портировать GDK на базовый графический уровень операционной системы. То есть именно GDK-порты на Windows API и Quartz позволяют приложениям GTK+ исполняться на Windows и macOS (источник).
Сначала нам нужно настроить машину для разработки Haskell-программ, а также настроить файлы и зависимости для директории проекта.
Если ваша машина ещё не готова к разработке Haskell-программ, то всё необходимое вы можете получить, скачав и установив платформу Haskell.
Если у вас ещё нет Stack, то обязательно установите его, прежде чем приступать к разработке. Но если вы уже пользовались платформой Haskell, то Stack у вас уже есть.
Прежде чем проигрывать видео в Movie Monad, нам нужно собрать кое-какую информацию о выбранном пользователем файле. Для этого воспользуемся ExifTool. Если вы работаете под Linux, то велик шанс, что у вас уже есть этот инструмент (which exiftool). ExifTool доступен для Windows, Mac и Linux.
Есть три способа получения файлов проекта.
wget https://github.com/lettier/movie-monad/archive/master.zip
unzip master.zip
mv movie-monad-master movie-monad
cd movie-monad/Можете скачать ZIP-архив и извлечь их.
git clone git@github.com:lettier/movie-monad.git
cd movie-monad/Можете сделать Git-клон с помощью SSH.
git clone https://github.com/lettier/movie-monad.git
cd movie-monad/Можете склонировать git через HTTPS.
haskell-gi умеет генерировать Haskell-привязки (bindings) к библиотекам, использующим связующее ПО для самодиагностики (introspection middleware) GObject. На момент написания статьи все необходимые привязки доступны на Hackage.
Теперь устанавливаем зависимости проекта.
cd movie-monad/
stack install --dependencies-onlyТеперь настраиваем внедрение Movie Monad. Вы можете удалить исходные файлы и создать их заново, или следовать указаниям.
Paths_movie_monad.hs используется для поиска файла Glade XML GUI во время runtime. Поскольку мы занимаемся разработкой, то будем использовать фиктивный модуль (dummy module) (movie-monad/src/dev/Paths_movie_monad.hs) для поиска файла movie-monad/src/data/gui.glade. После сборки/установки проекта реальный модуль Paths_movie_monad будет сгенерирован автоматически. Он предоставит нам функцию getDataFileName. Она присваивает своим выходным данным префикс в виде абсолютного пути, куда скопированы или установлены data-dir (movie-monad/src/) data-files.
{-# LANGUAGE OverloadedStrings #-}
module Paths_movie_monad where
dataDir :: String
dataDir = "./src/"
getDataFileName :: FilePath -> IO FilePath
getDataFileName a = do
putStrLn "You are using a fake Paths_movie_monad."
return (dataDir ++ "/" ++ a)Фиктивный модуль Paths_movie_monad.
{-# LANGUAGE CPP #-}
{-# OPTIONS_GHC -fno-warn-missing-import-lists #-}
{-# OPTIONS_GHC -fno-warn-implicit-prelude #-}
module Paths_movie_monad (
version,
getBinDir, getLibDir, getDynLibDir, getDataDir, getLibexecDir,
getDataFileName, getSysconfDir
) where
import qualified Control.Exception as Exception
import Data.Version (Version(..))
import System.Environment (getEnv)
import Prelude
#if defined(VERSION_base)
#if MIN_VERSION_base(4,0,0)
catchIO :: IO a -> (Exception.IOException -> IO a) -> IO a
#else
catchIO :: IO a -> (Exception.Exception -> IO a) -> IO a
#endif
#else
catchIO :: IO a -> (Exception.IOException -> IO a) -> IO a
#endif
catchIO = Exception.catch
version :: Version
version = Version [0,0,0,0] []
bindir, libdir, dynlibdir, datadir, libexecdir, sysconfdir :: FilePath
bindir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/bin"
libdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/lib/x86_64-linux-ghc-8.0.2/movie-monad-0.0.0.0"
dynlibdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/lib/x86_64-linux-ghc-8.0.2"
datadir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/share/x86_64-linux-ghc-8.0.2/movie-monad-0.0.0.0"
libexecdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/libexec"
sysconfdir = "/home//.stack-work/install/x86_64-linux-nopie/lts-9.1/8.0.2/etc"
getBinDir, getLibDir, getDynLibDir, getDataDir, getLibexecDir, getSysconfDir :: IO FilePath
getBinDir = catchIO (getEnv "movie_monad_bindir") (\_ -> return bindir)
getLibDir = catchIO (getEnv "movie_monad_libdir") (\_ -> return libdir)
getDynLibDir = catchIO (getEnv "movie_monad_dynlibdir") (\_ -> return dynlibdir)
getDataDir = catchIO (getEnv "movie_monad_datadir") (\_ -> return datadir)
getLibexecDir = catchIO (getEnv "movie_monad_libexecdir") (\_ -> return libexecdir)
getSysconfDir = catchIO (getEnv "movie_monad_sysconfdir") (\_ -> return sysconfdir)
getDataFileName :: FilePath -> IO FilePath
getDataFileName name = do
dir <- getDataDir
return (dir ++ "/" ++ name) Автоматически сгенерированный модуль Paths_movie_monad.
Main.hs — это входная точка для Movie Monad. В этом файле мы настраиваем наше окно с разными виджетами, подключаем GStreamer, а когда пользователь выходит, мы сносим окно.
Прагмы (Pragmas)
Нам нужно сказать компилятору (GHC), что нам нужны перегруженные (overloaded) строковые и лексически входящие в область видимости (lexically scoped) переменные типов.
OverloadedStrings позволяет нам использовать строковые литералы ("Literal") там, где требуются String/[Char] или Text. ScopedTypeVariables позволяет нам использовать сигнатуру типа в паттерне параметра лямбда-функции, передаваемую для перехвата при вызове ExifTool.
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE ScopedTypeVariables #-}Импорты
module Main where
import Prelude
import Foreign.C.Types
import System.Process
import System.Exit
import Control.Monad
import Control.Exception
import Text.Read
import Data.IORef
import Data.Maybe
import Data.Int
import Data.Text
import Data.GI.Base
import Data.GI.Base.Signals
import Data.GI.Base.Properties
import GI.GLib
import GI.GObject
import qualified GI.Gtk
import GI.Gst
import GI.GstVideo
import GI.Gdk
import GI.GdkX11
import Paths_movie_monadПоскольку мы работает с привязками Си, нам понадобится работать с типами, уже существующими в этом языке. Немалую часть импортов составляют привязки, генерируемые haskell-gi.
IsVideoOverlay
GStreamer-видеопривязки (gi-gstvideo) содержат класс типа (интерфейс) IsVideoOverlay. GStreamer-привязки (gi-gst) содержат тип элемента. Чтобы использовать элемент playbin с функцией GI.GstVideo.videoOverlaySetWindowHandle, нам нужно объявить GI.Gst.Element — экземпляр типа (type instance) IsVideoOverlay. А на стороне Cи playbin реализует интерфейс VideoOverlay.
newtype GstElement = GstElement GI.Gst.Element
instance GI.GstVideo.IsVideoOverlay GstElementОбратите внимание, что мы обёртываем GI.Gst.Element в новый тип (newtype), чтобы избежать появления потерянного (orphaned) экземпляра, поскольку мы объявляем экземпляр вне привязок haskell-gi.
main
Main — наша самая большая функция. В ней мы инициализируем все GUI-виджеты и определяем коллбэк-процедуры на основе определённых событий.
main :: IO ()
main = doGI-инициализация
_ <- GI.Gst.init Nothing
_ <- GI.Gtk.init NothingЗдесь мы инициализировали GStreamer и GTK+.
Сборка GUI-виджетов
gladeFile <- getDataFileName "data/gui.glade"
builder <- GI.Gtk.builderNewFromFile (pack gladeFile)
window <- builderGetObject GI.Gtk.Window builder "window"
fileChooserButton <- builderGetObject GI.Gtk.FileChooserButton builder "file-chooser-button"
drawingArea <- builderGetObject GI.Gtk.Widget builder "drawing-area"
seekScale <- builderGetObject GI.Gtk.Scale builder "seek-scale"
onOffSwitch <- builderGetObject GI.Gtk.Switch builder "on-off-switch"
volumeButton <- builderGetObject GI.Gtk.VolumeButton builder "volume-button"
desiredVideoWidthComboBox <- builderGetObject GI.Gtk.ComboBoxText builder "desired-video-width-combo-box"
fullscreenButton <- builderGetObject GI.Gtk.Button builder "fullscreen-button"
errorMessageDialog <- builderGetObject GI.Gtk.MessageDialog builder "error-message-dialog"
aboutButton <- builderGetObject GI.Gtk.Button builder "about-button"
aboutDialog <- builderGetObject GI.Gtk.AboutDialog builder "about-dialog"Как уже было сказано, мы получаем абсолютный путь к XML-файлу data/gui.glade, который описывает все наши GUI-виджеты. Дальше создаём из этого файла конструктор и получаем свои виджеты. Если бы мы не использовали Glade, то их пришлось бы создавать вручную, что довольно утомительно.
Playbin
playbin <- fromJust <$> GI.Gst.elementFactoryMake "playbin" (Just "MultimediaPlayer")Здесь мы создаём GStreamer-конвейер playbin. Он предназначен для решения самых разных нужд и экономит нам время на создании собственного конвейера. Назовём этот элемент MultimediaPlayer.
Встраиванние выходных данных GStreamer
Чтобы GTK+ и GStreamer заработали вместе, нам нужно сказать GStreamer, куда именно нужно выводить видео. Если этого не сделать, то GStreamer создаст собственное окно, поскольку мы используем playbin.
_ <- GI.Gtk.onWidgetRealize drawingArea $ onDrawingAreaRealize drawingArea playbin fullscreenButton
-- ...
onDrawingAreaRealize ::
GI.Gtk.Widget ->
GI.Gst.Element ->
GI.Gtk.Button ->
GI.Gtk.WidgetRealizeCallback
onDrawingAreaRealize drawingArea playbin fullscreenButton = do
gdkWindow <- fromJust <$> GI.Gtk.widgetGetWindow drawingArea
x11Window <- GI.Gtk.unsafeCastTo GI.GdkX11.X11Window gdkWindow
xid <- GI.GdkX11.x11WindowGetXid x11Window
let xid' = fromIntegral xid :: CUIntPtr
GI.GstVideo.videoOverlaySetWindowHandle (GstElement playbin) xid'
GI.Gtk.widgetHide fullscreenButtonЗдесь вы видите настройку коллбэка по мере готовности виджета drawingArea. Именно в этом виджете GStreamer должен показывать видео. Мы получаем родительское GDK-окно для виджета области отрисовки. Затем получаем обработчик окна, или XID системы X11 нашего окна GTK+. Строка CUIntPtr преобразует ID из CULong в CUIntPtr, необходимый для videoOverlaySetWindowHandle. Получив правильный тип, мы уведомляем GStreamer, что с помощью обработчика xid' он может отрисовывать в нашем окне выходные данные playbin.
Из-за бага в Glade мы программно скрываем полноэкранный виджет, поскольку если в Glade снять галочку visible box, то виджет всё-равно не будет спрятан.
Обратите внимание, что здесь нужно адаптировать Movie Monad для работы с оконной системой, если вы используете не Х-систему, а какую-то другую.
Выбор файла
_ <- GI.Gtk.onFileChooserButtonFileSet fileChooserButton $
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
-- ...
onFileChooserButtonFileSet ::
GI.Gst.Element ->
GI.Gtk.FileChooserButton ->
GI.Gtk.VolumeButton ->
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Switch ->
GI.Gtk.Button ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
GI.Gtk.MessageDialog ->
GI.Gtk.FileChooserButtonFileSetCallback
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
= do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
filename <- fromJust <$> GI.Gtk.fileChooserGetFilename fileChooserButton
setPlaybinUriAndVolume playbin filename volumeButton
isWindowFullScreen <- readIORef isWindowFullScreenRef
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePaused
GI.Gtk.windowUnfullscreen window
GI.Gtk.switchSetActive onOffSwitch False
GI.Gtk.widgetHide fullscreenButton
GI.Gtk.widgetShow desiredVideoWidthComboBox
resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
_ <- GI.Gtk.onDialogResponse errorMessageDialog (\ _ -> GI.Gtk.widgetHide errorMessageDialog)
void $ GI.Gtk.dialogRun errorMessageDialog
Just (width, height) -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePlaying
GI.Gtk.switchSetActive onOffSwitch True
GI.Gtk.widgetShow fullscreenButton
unless isWindowFullScreen $ setWindowSize width height fileChooserButton drawingArea windowДля начала сессии проигрывания видео, пользователь должен иметь возможность выбрать видео-файл. После того, как файл выбран, нужно выполнить ряд обязательных действий, чтобы всё работало хорошо.
playbin, какой файл он должен воспроизвести.playbin.playbin на паузу.Пауза и воспроизведение
_ <- GI.Gtk.onSwitchStateSet onOffSwitch (onSwitchStateSet playbin)
-- ...
onSwitchStateSet ::
GI.Gst.Element ->
Bool ->
IO Bool
onSwitchStateSet playbin switchOn = do
if switchOn
then void $ GI.Gst.elementSetState playbin GI.Gst.StatePlaying
else void $ GI.Gst.elementSetState playbin GI.Gst.StatePaused
return switchOnВсё просто. Если переключатель в положении ”on”, то задаём элементу playbin состояние воспроизведения. В противном случае задаём ему состояние паузы.
Настройка громкости
_ <- GI.Gtk.onScaleButtonValueChanged volumeButton (onScaleButtonValueChanged playbin)
-- ...
onScaleButtonValueChanged ::
GI.Gst.Element ->
Double ->
IO ()
onScaleButtonValueChanged playbin volume =
void $ Data.GI.Base.Properties.setObjectPropertyDouble playbin "volume" volumeПри изменении уровня громкости в виджете мы передаём его значение в GStreamer, чтобы тот мог подстроить громкость воспроизведение.
Перемещение по видео
seekScaleHandlerId <- GI.Gtk.onRangeValueChanged seekScale (onRangeValueChanged playbin seekScale)
-- ...
onRangeValueChanged ::
GI.Gst.Element ->
GI.Gtk.Scale ->
IO ()
onRangeValueChanged playbin seekScale = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
when couldQueryDuration $ do
percentage' <- GI.Gtk.rangeGetValue seekScale
let percentage = percentage' / 100.0
let position = fromIntegral (round ((fromIntegral duration :: Double) * percentage) :: Int) :: Int64
void $ GI.Gst.elementSeekSimple playbin GI.Gst.FormatTime [ GI.Gst.SeekFlagsFlush ] positionВ Movie Monad есть шкала воспроизведения, в которой вы можете перемещать ползунок вперёд/назад, тем самым переходя по видеофреймам.
Шкала от 0 до 100% представляет общую длительность видео-файла. Если переместить ползунок, например, на 50, то мы перейдём к временной отметке, находящийся посередине между началом и окончанием. Можно было бы настроить шкалу от нуля до значения длительности видео, но описанный метод более универсален.
Обратите внимание, что для этого коллбэка мы используем сигнальный ID (seekScaleHandlerId), поскольку он понадобится нам позднее.
Обновление шкалы воспроизведения
_ <- GI.GLib.timeoutAddSeconds GI.GLib.PRIORITY_DEFAULT 1 (updateSeekScale playbin seekScale seekScaleHandlerId)
-- ...
updateSeekScale ::
GI.Gst.Element ->
GI.Gtk.Scale ->
Data.GI.Base.Signals.SignalHandlerId ->
IO Bool
updateSeekScale playbin seekScale seekScaleHandlerId = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
(couldQueryPosition, position) <- GI.Gst.elementQueryPosition playbin GI.Gst.FormatTime
let percentage =
if couldQueryDuration && couldQueryPosition && duration > 0
then 100.0 * (fromIntegral position / fromIntegral duration :: Double)
else 0.0
GI.GObject.signalHandlerBlock seekScale seekScaleHandlerId
GI.Gtk.rangeSetValue seekScale percentage
GI.GObject.signalHandlerUnblock seekScale seekScaleHandlerId
return TrueЧтобы синхронизировать шкалу и сам процесс воспроизведения видео, нужно передавать сообщения между GTK+ и GStreamer. Каждую секунду мы будем запрашивать текущую позицию воспроизведения и в соответствии с ней обновлять шкалу. Так мы показываем пользователю, какая часть файла уже показана, а ползунок всегда будет соответствовать реальной позиции воспроизведения.
Чтобы не инициировать настроенный ранее коллбэк, мы отключаем обработчик сигнала onRangeValueChanged при обновлении шкалы воспроизведения. Коллбэк onRangeValueChanged должен быть выполнен только если пользователь изменит положение ползунка.
Изменение размеров видео
_ <- GI.Gtk.onComboBoxChanged desiredVideoWidthComboBox $
onComboBoxChanged fileChooserButton desiredVideoWidthComboBox drawingArea window
-- ...
onComboBoxChanged ::
GI.Gtk.FileChooserButton ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
onComboBoxChanged
fileChooserButton
desiredVideoWidthComboBox
drawingArea
window
= do
filename' <- GI.Gtk.fileChooserGetFilename fileChooserButton
let filename = fromMaybe "" filename'
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
Just (width, height) -> setWindowSize width height fileChooserButton drawingArea windowЭтот виджет позволяет пользователю выбирать желаемую ширину видео. Высота будет подобрана автоматически на основе соотношения сторон видеофайла.
Полноэкранный режим
_ <- GI.Gtk.onWidgetButtonReleaseEvent fullscreenButton
(onFullscreenButtonRelease isWindowFullScreenRef desiredVideoWidthComboBox fileChooserButton window)
-- ...
onFullscreenButtonRelease ::
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Window ->
GI.Gdk.EventButton ->
IO Bool
onFullscreenButtonRelease
isWindowFullScreenRef
desiredVideoWidthComboBox
fileChooserButton
window
_
= do
isWindowFullScreen <- readIORef isWindowFullScreenRef
if isWindowFullScreen
then do
GI.Gtk.widgetShow desiredVideoWidthComboBox
GI.Gtk.widgetShow fileChooserButton
void $ GI.Gtk.windowUnfullscreen window
else do
GI.Gtk.widgetHide desiredVideoWidthComboBox
GI.Gtk.widgetHide fileChooserButton
void $ GI.Gtk.windowFullscreen window
return TrueКогда пользователь отпускает кнопку виджета полноэкранного режим, мы переключаем состояние полноэкранного режима окна, скрываем панель выбора файла и виджет выбора ширины видео. При выходе из полноэкранного режима мы восстанавливаем панель и виджет.
Обратите внимание, что мы не показываем виджет полноэкранного режима, если у нас нет видео.
_ <- GI.Gtk.onWidgetWindowStateEvent window (onWidgetWindowStateEvent isWindowFullScreenRef)
-- ...
onWidgetWindowStateEvent ::
IORef Bool ->
GI.Gdk.EventWindowState ->
IO Bool
onWidgetWindowStateEvent isWindowFullScreenRef eventWindowState = do
windowStates <- GI.Gdk.getEventWindowStateNewWindowState eventWindowState
let isWindowFullScreen = Prelude.foldl (\ acc x -> acc || GI.Gdk.WindowStateFullscreen == x) False windowStates
writeIORef isWindowFullScreenRef isWindowFullScreen
return TrueДля управления полноэкранным состоянием окна мы должны настроить коллбэк, чтобы он запускался при каждом изменении состояния окна. От информации о состоянии полноэкранности окна зависят различные коллбэки. В качестве помощи воспользуемся IORef, из которого будет читать каждая функция и в который будет писать коллбэк. Этот IORef является изменяемой (и общей) ссылкой. В идеале нам нужно запрашивать окно именно в то время, когда оно находится в полноэкранном режиме, но для этого не существует API. Поэтому будем использовать изменяемую ссылку.
Благодаря использованию в главном потоке выполнения единственного пишущего и кучи сигнальных коллбэков, мы избегаем возможных ловушек общего изменяемого состояния. Если бы нас заботила безопасность потока выполнения, то вместо этого мы могли бы использовать MVar, TVar или atomicModifyIORef.
О программе
_ <- GI.Gtk.onWidgetButtonReleaseEvent aboutButton (onAboutButtonRelease aboutDialog)
-- ...
onAboutButtonRelease ::
GI.Gtk.AboutDialog ->
GI.Gdk.EventButton ->
IO Bool
onAboutButtonRelease aboutDialog _ = do
_ <- GI.Gtk.onDialogResponse aboutDialog (\ _ -> GI.Gtk.widgetHide aboutDialog)
_ <- GI.Gtk.dialogRun aboutDialog
return TrueПоследний рассматриваемый виджет — диалоговое окно «О программе». Здесь мы связываем диалоговое окно с кнопкой «О программе», отображающейся в основном окне.
Закрытие окна
_ <- GI.Gtk.onWidgetDestroy window (onWindowDestroy playbin)
-- ...
onWindowDestroy ::
GI.Gst.Element ->
IO ()
onWindowDestroy playbin = do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
_ <- GI.Gst.objectUnref playbin
GI.Gtk.mainQuitКогда пользователь закрывает окно, мы уничтожаем конвейер playbin и выходим из основного цикла GTK.
Запуск
GI.Gtk.widgetShowAll window
GI.Gtk.mainНаконец, мы показываем или отрисовываем главное окно и запускаем основной цикл GTK+. Он блокируется до вызова mainQuit.
Полный файл Main.hs
Ниже приведён файл movie-monad/src/Main.hs. Не показаны разные вспомогательные функции, относящиеся к main.
{-
Movie Monad
(C) 2017 David lettier
lettier.com
-}
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE ScopedTypeVariables #-}
module Main where
import Prelude
import Foreign.C.Types
import System.Process
import System.Exit
import Control.Monad
import Control.Exception
import Text.Read
import Data.IORef
import Data.Maybe
import Data.Int
import Data.Text
import Data.GI.Base
import Data.GI.Base.Signals
import Data.GI.Base.Properties
import GI.GLib
import GI.GObject
import qualified GI.Gtk
import GI.Gst
import GI.GstVideo
import GI.Gdk
import GI.GdkX11
import Paths_movie_monad
-- Declare Element a type instance of IsVideoOverlay via a newtype wrapper
-- Our GStreamer element is playbin
-- Playbin implements the GStreamer VideoOverlay interface
newtype GstElement = GstElement GI.Gst.Element
instance GI.GstVideo.IsVideoOverlay GstElement
main :: IO ()
main = do
_ <- GI.Gst.init Nothing
_ <- GI.Gtk.init Nothing
gladeFile <- getDataFileName "data/gui.glade"
builder <- GI.Gtk.builderNewFromFile (pack gladeFile)
window <- builderGetObject GI.Gtk.Window builder "window"
fileChooserButton <- builderGetObject GI.Gtk.FileChooserButton builder "file-chooser-button"
drawingArea <- builderGetObject GI.Gtk.Widget builder "drawing-area"
seekScale <- builderGetObject GI.Gtk.Scale builder "seek-scale"
onOffSwitch <- builderGetObject GI.Gtk.Switch builder "on-off-switch"
volumeButton <- builderGetObject GI.Gtk.VolumeButton builder "volume-button"
desiredVideoWidthComboBox <- builderGetObject GI.Gtk.ComboBoxText builder "desired-video-width-combo-box"
fullscreenButton <- builderGetObject GI.Gtk.Button builder "fullscreen-button"
errorMessageDialog <- builderGetObject GI.Gtk.MessageDialog builder "error-message-dialog"
aboutButton <- builderGetObject GI.Gtk.Button builder "about-button"
aboutDialog <- builderGetObject GI.Gtk.AboutDialog builder "about-dialog"
playbin <- fromJust <$> GI.Gst.elementFactoryMake "playbin" (Just "MultimediaPlayer")
isWindowFullScreenRef <- newIORef False
_ <- GI.Gtk.onWidgetRealize drawingArea $ onDrawingAreaRealize drawingArea playbin fullscreenButton
_ <- GI.Gtk.onFileChooserButtonFileSet fileChooserButton $
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
_ <- GI.Gtk.onSwitchStateSet onOffSwitch (onSwitchStateSet playbin)
_ <- GI.Gtk.onScaleButtonValueChanged volumeButton (onScaleButtonValueChanged playbin)
seekScaleHandlerId <- GI.Gtk.onRangeValueChanged seekScale (onRangeValueChanged playbin seekScale)
_ <- GI.GLib.timeoutAddSeconds GI.GLib.PRIORITY_DEFAULT 1 (updateSeekScale playbin seekScale seekScaleHandlerId)
_ <- GI.Gtk.onComboBoxChanged desiredVideoWidthComboBox $
onComboBoxChanged fileChooserButton desiredVideoWidthComboBox drawingArea window
_ <- GI.Gtk.onWidgetButtonReleaseEvent fullscreenButton
(onFullscreenButtonRelease isWindowFullScreenRef desiredVideoWidthComboBox fileChooserButton window)
_ <- GI.Gtk.onWidgetWindowStateEvent window (onWidgetWindowStateEvent isWindowFullScreenRef)
_ <- GI.Gtk.onWidgetButtonReleaseEvent aboutButton (onAboutButtonRelease aboutDialog)
_ <- GI.Gtk.onWidgetDestroy window (onWindowDestroy playbin)
GI.Gtk.widgetShowAll window
GI.Gtk.main
builderGetObject ::
(GI.GObject.GObject b, GI.Gtk.IsBuilder a) =>
(Data.GI.Base.ManagedPtr b -> b) ->
a ->
Prelude.String ->
IO b
builderGetObject objectTypeClass builder objectId =
fromJust <$> GI.Gtk.builderGetObject builder (pack objectId) >>=
GI.Gtk.unsafeCastTo objectTypeClass
onDrawingAreaRealize ::
GI.Gtk.Widget ->
GI.Gst.Element ->
GI.Gtk.Button ->
GI.Gtk.WidgetRealizeCallback
onDrawingAreaRealize drawingArea playbin fullscreenButton = do
gdkWindow <- fromJust <$> GI.Gtk.widgetGetWindow drawingArea
x11Window <- GI.Gtk.unsafeCastTo GI.GdkX11.X11Window gdkWindow
xid <- GI.GdkX11.x11WindowGetXid x11Window
let xid' = fromIntegral xid :: CUIntPtr
GI.GstVideo.videoOverlaySetWindowHandle (GstElement playbin) xid'
GI.Gtk.widgetHide fullscreenButton
onFileChooserButtonFileSet ::
GI.Gst.Element ->
GI.Gtk.FileChooserButton ->
GI.Gtk.VolumeButton ->
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Switch ->
GI.Gtk.Button ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
GI.Gtk.MessageDialog ->
GI.Gtk.FileChooserButtonFileSetCallback
onFileChooserButtonFileSet
playbin
fileChooserButton
volumeButton
isWindowFullScreenRef
desiredVideoWidthComboBox
onOffSwitch
fullscreenButton
drawingArea
window
errorMessageDialog
= do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
filename <- fromJust <$> GI.Gtk.fileChooserGetFilename fileChooserButton
setPlaybinUriAndVolume playbin filename volumeButton
isWindowFullScreen <- readIORef isWindowFullScreenRef
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePaused
GI.Gtk.windowUnfullscreen window
GI.Gtk.switchSetActive onOffSwitch False
GI.Gtk.widgetHide fullscreenButton
GI.Gtk.widgetShow desiredVideoWidthComboBox
resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
_ <- GI.Gtk.onDialogResponse errorMessageDialog (\ _ -> GI.Gtk.widgetHide errorMessageDialog)
void $ GI.Gtk.dialogRun errorMessageDialog
Just (width, height) -> do
_ <- GI.Gst.elementSetState playbin GI.Gst.StatePlaying
GI.Gtk.switchSetActive onOffSwitch True
GI.Gtk.widgetShow fullscreenButton
unless isWindowFullScreen $ setWindowSize width height fileChooserButton drawingArea window
onSwitchStateSet ::
GI.Gst.Element ->
Bool ->
IO Bool
onSwitchStateSet playbin switchOn = do
if switchOn
then void $ GI.Gst.elementSetState playbin GI.Gst.StatePlaying
else void $ GI.Gst.elementSetState playbin GI.Gst.StatePaused
return switchOn
onScaleButtonValueChanged ::
GI.Gst.Element ->
Double ->
IO ()
onScaleButtonValueChanged playbin volume =
void $ Data.GI.Base.Properties.setObjectPropertyDouble playbin "volume" volume
onRangeValueChanged ::
GI.Gst.Element ->
GI.Gtk.Scale ->
IO ()
onRangeValueChanged playbin seekScale = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
when couldQueryDuration $ do
percentage' <- GI.Gtk.rangeGetValue seekScale
let percentage = percentage' / 100.0
let position = fromIntegral (round ((fromIntegral duration :: Double) * percentage) :: Int) :: Int64
void $ GI.Gst.elementSeekSimple playbin GI.Gst.FormatTime [ GI.Gst.SeekFlagsFlush ] position
updateSeekScale ::
GI.Gst.Element ->
GI.Gtk.Scale ->
Data.GI.Base.Signals.SignalHandlerId ->
IO Bool
updateSeekScale playbin seekScale seekScaleHandlerId = do
(couldQueryDuration, duration) <- GI.Gst.elementQueryDuration playbin GI.Gst.FormatTime
(couldQueryPosition, position) <- GI.Gst.elementQueryPosition playbin GI.Gst.FormatTime
let percentage =
if couldQueryDuration && couldQueryPosition && duration > 0
then 100.0 * (fromIntegral position / fromIntegral duration :: Double)
else 0.0
GI.GObject.signalHandlerBlock seekScale seekScaleHandlerId
GI.Gtk.rangeSetValue seekScale percentage
GI.GObject.signalHandlerUnblock seekScale seekScaleHandlerId
return True
onComboBoxChanged ::
GI.Gtk.FileChooserButton ->
GI.Gtk.ComboBoxText ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
onComboBoxChanged
fileChooserButton
desiredVideoWidthComboBox
drawingArea
window
= do
filename' <- GI.Gtk.fileChooserGetFilename fileChooserButton
let filename = fromMaybe "" filename'
desiredVideoWidth <- getDesiredVideoWidth desiredVideoWidthComboBox
maybeWindowSize <- getWindowSize desiredVideoWidth filename
case maybeWindowSize of
Nothing -> resetWindowSize desiredVideoWidth fileChooserButton drawingArea window
Just (width, height) -> setWindowSize width height fileChooserButton drawingArea window
onFullscreenButtonRelease ::
IORef Bool ->
GI.Gtk.ComboBoxText ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Window ->
GI.Gdk.EventButton ->
IO Bool
onFullscreenButtonRelease
isWindowFullScreenRef
desiredVideoWidthComboBox
fileChooserButton
window
_
= do
isWindowFullScreen <- readIORef isWindowFullScreenRef
if isWindowFullScreen
then do
GI.Gtk.widgetShow desiredVideoWidthComboBox
GI.Gtk.widgetShow fileChooserButton
void $ GI.Gtk.windowUnfullscreen window
else do
GI.Gtk.widgetHide desiredVideoWidthComboBox
GI.Gtk.widgetHide fileChooserButton
void $ GI.Gtk.windowFullscreen window
return True
onWidgetWindowStateEvent ::
IORef Bool ->
GI.Gdk.EventWindowState ->
IO Bool
onWidgetWindowStateEvent isWindowFullScreenRef eventWindowState = do
windowStates <- GI.Gdk.getEventWindowStateNewWindowState eventWindowState
let isWindowFullScreen = Prelude.foldl (\ acc x -> acc || GI.Gdk.WindowStateFullscreen == x) False windowStates
writeIORef isWindowFullScreenRef isWindowFullScreen
return True
onAboutButtonRelease ::
GI.Gtk.AboutDialog ->
GI.Gdk.EventButton ->
IO Bool
onAboutButtonRelease aboutDialog _ = do
_ <- GI.Gtk.onDialogResponse aboutDialog (\ _ -> GI.Gtk.widgetHide aboutDialog)
_ <- GI.Gtk.dialogRun aboutDialog
return True
onWindowDestroy ::
GI.Gst.Element ->
IO ()
onWindowDestroy playbin = do
_ <- GI.Gst.elementSetState playbin GI.Gst.StateNull
_ <- GI.Gst.objectUnref playbin
GI.Gtk.mainQuit
setPlaybinUriAndVolume ::
GI.Gst.Element ->
Prelude.String ->
GI.Gtk.VolumeButton ->
IO ()
setPlaybinUriAndVolume playbin filename volumeButton = do
let uri = "file://" ++ filename
volume <- GI.Gtk.scaleButtonGetValue volumeButton
Data.GI.Base.Properties.setObjectPropertyDouble playbin "volume" volume
Data.GI.Base.Properties.setObjectPropertyString playbin "uri" (Just $ pack uri)
getVideoInfo :: Prelude.String -> Prelude.String -> IO (Maybe Prelude.String)
getVideoInfo flag filename = do
(code, out, _) <- catch (
readProcessWithExitCode
"exiftool"
[flag, "-s", "-S", filename]
""
) (\ (_ :: Control.Exception.IOException) -> return (ExitFailure 1, "", ""))
if code == System.Exit.ExitSuccess
then return (Just out)
else return Nothing
isVideo :: Prelude.String -> IO Bool
isVideo filename = do
maybeOut <- getVideoInfo "-MIMEType" filename
case maybeOut of
Nothing -> return False
Just out -> return ("video" `isInfixOf` pack out)
getWindowSize :: Int -> Prelude.String -> IO (Maybe (Int32, Int32))
getWindowSize desiredVideoWidth filename =
isVideo filename >>=
getWidthHeightString >>=
splitWidthHeightString >>=
widthHeightToDouble >>=
ratio >>=
windowSize
where
getWidthHeightString :: Bool -> IO (Maybe Prelude.String)
getWidthHeightString False = return Nothing
getWidthHeightString True = getVideoInfo "-ImageSize" filename
splitWidthHeightString :: Maybe Prelude.String -> IO (Maybe [Text])
splitWidthHeightString Nothing = return Nothing
splitWidthHeightString (Just string) = return (Just (Data.Text.splitOn "x" (pack string)))
widthHeightToDouble :: Maybe [Text] -> IO (Maybe Double, Maybe Double)
widthHeightToDouble (Just (x:y:_)) = return (readMaybe (unpack x) :: Maybe Double, readMaybe (unpack y) :: Maybe Double)
widthHeightToDouble _ = return (Nothing, Nothing)
ratio :: (Maybe Double, Maybe Double) -> IO (Maybe Double)
ratio (Just width, Just height) =
if width <= 0.0 then return Nothing else return (Just (height / width))
ratio _ = return Nothing
windowSize :: Maybe Double -> IO (Maybe (Int32, Int32))
windowSize Nothing = return Nothing
windowSize (Just ratio') =
return (Just (fromIntegral desiredVideoWidth :: Int32, round ((fromIntegral desiredVideoWidth :: Double) * ratio') :: Int32))
getDesiredVideoWidth :: GI.Gtk.ComboBoxText -> IO Int
getDesiredVideoWidth = fmap (\ x -> read (Data.Text.unpack x) :: Int) . GI.Gtk.comboBoxTextGetActiveText
setWindowSize ::
Int32 ->
Int32 ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
setWindowSize width height fileChooserButton drawingArea window = do
GI.Gtk.setWidgetWidthRequest fileChooserButton width
GI.Gtk.setWidgetWidthRequest drawingArea width
GI.Gtk.setWidgetHeightRequest drawingArea height
GI.Gtk.setWidgetWidthRequest window width
GI.Gtk.setWidgetHeightRequest window height
GI.Gtk.windowResize window width (if height <= 0 then 1 else height)
resetWindowSize ::
(Integral a) =>
a ->
GI.Gtk.FileChooserButton ->
GI.Gtk.Widget ->
GI.Gtk.Window ->
IO ()
resetWindowSize width' fileChooserButton drawingArea window = do
let width = fromIntegral width' :: Int32
GI.Gtk.widgetQueueDraw drawingArea
setWindowSize width 0 fileChooserButton drawingArea windowМы настроили наше сборочное окружение и подготовили весь исходный код, можно собирать Movie Monad и запускать исполняемый файл.
cd movie-monad/
stack clean
stack install
stack exec -- movie-monad
# Or just `movie-monad` if `stack path | grep local-bin-path` is in your `echo $PATH`Если всё в порядке, то Movie Monad должен запуститься.
Пересмотрев проект Movie Monad, мы заново сделали приложение с помощью программных библиотек GTK+ и GStreamer. Благодаря им приложение осталось таким же портируемым, как и Electron-версия. Movie Monad теперь может обрабатывать большие видеофайлы и имеет все стандартные элементы управления.
Другим преимуществом использования GTK+ стало уменьшение потребления памяти. Если сравнивать резидентный размер в памяти при старте, то версия GTK+ занимает ~50 Мб, а версия Electron — ~300 Мб (500%-ное увеличение).
Наконец, вариант с GTK+ имеет меньше ограничений и требует меньше программирования. Для обеспечения такой же функциональности, вариант с Electron требует использования громоздкой клиент-серверной архитектуры. Но благодаря прекрасным сборкам haskell-gi мы смогли избежать решения на базе веба.
Если хотите посмотреть другие приложения, построенные с помощью GTK+ и Haskell, то обратите внимание на Gifcurry. Оно умеет брать видеофайлы и на их основе создавать гифки с наложенным текстом.
|
Метки: author AloneCoder программирование высокая производительность haskell gtk+ блог компании mail.ru group gtk video player никто не читает теги |
Как увеличить показатели сервиса в 7 раз за три месяца с помощью HADI-циклов и приоритизации гипотез |



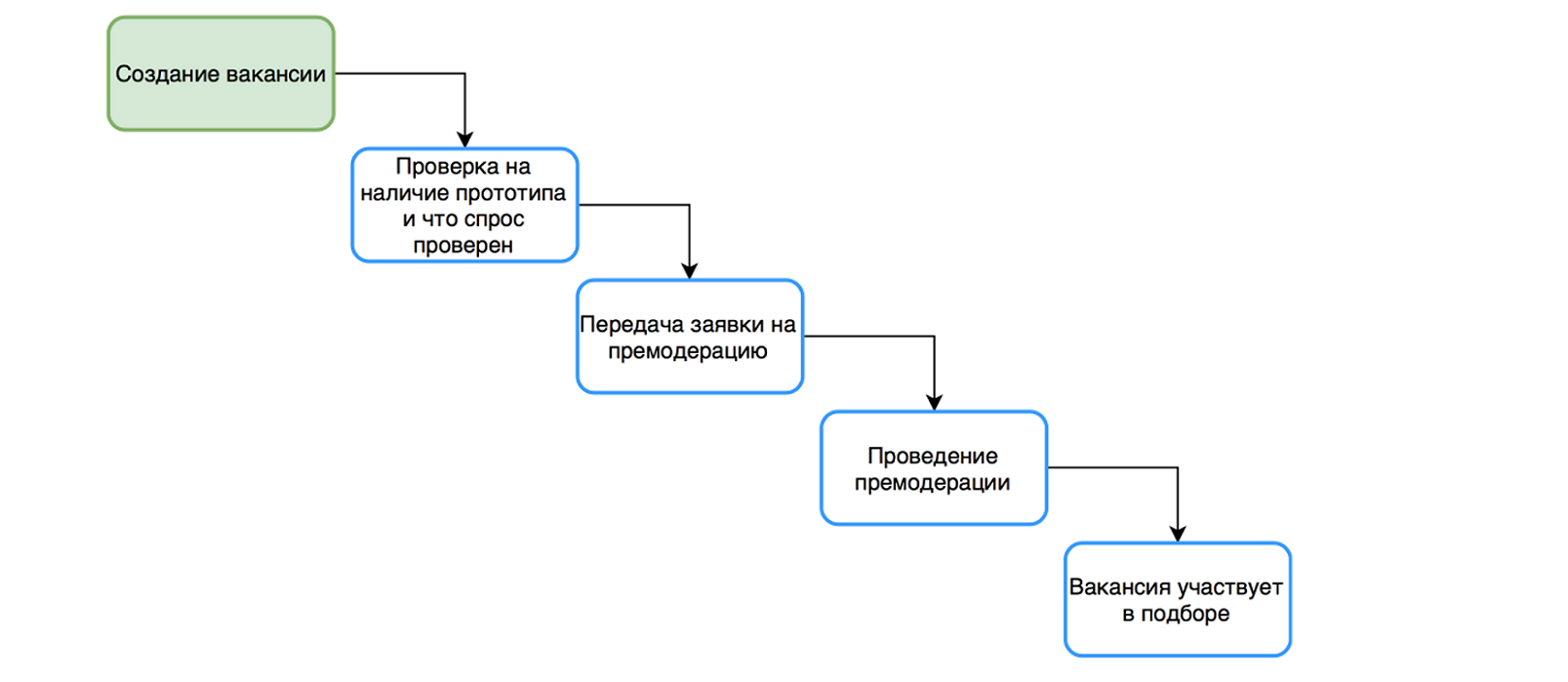
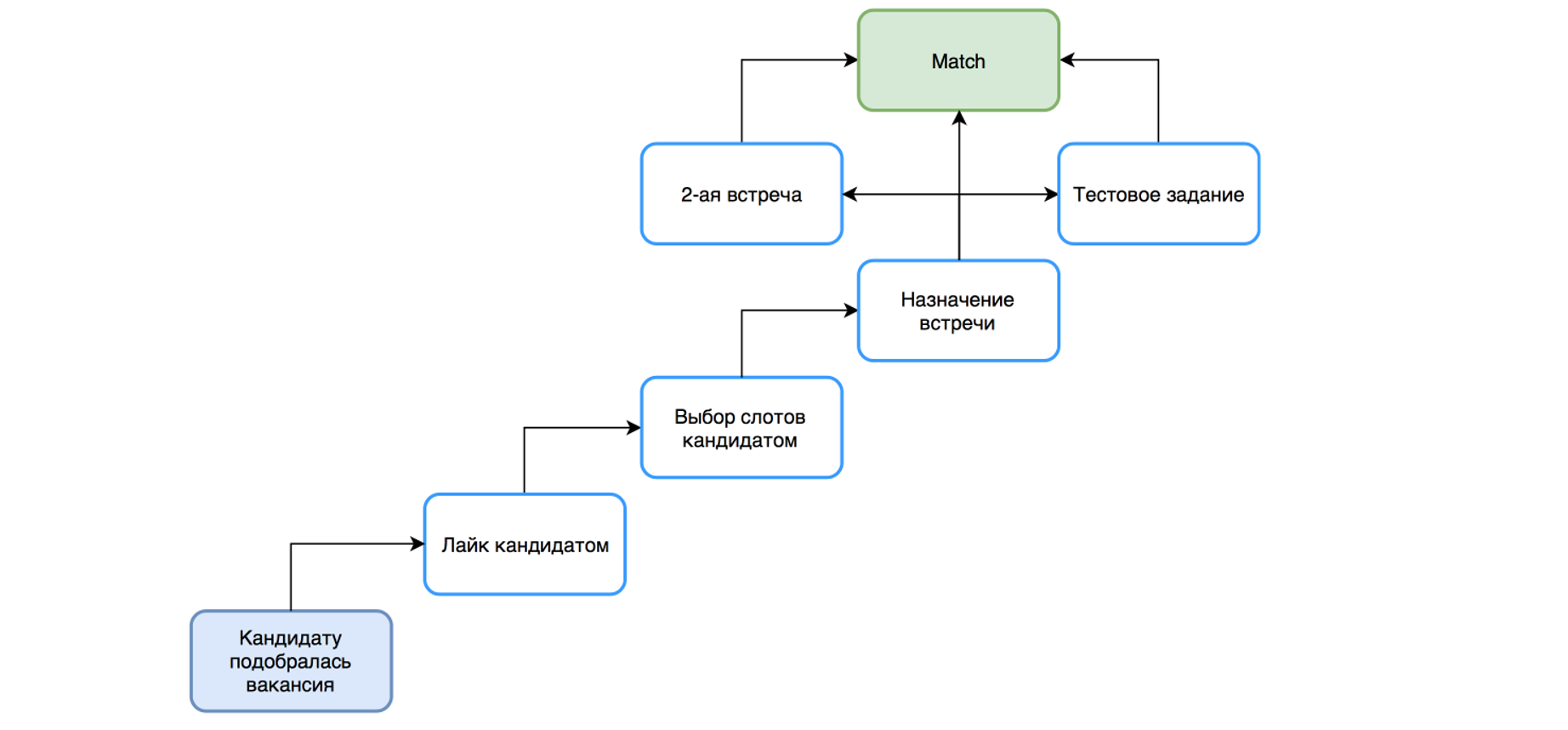
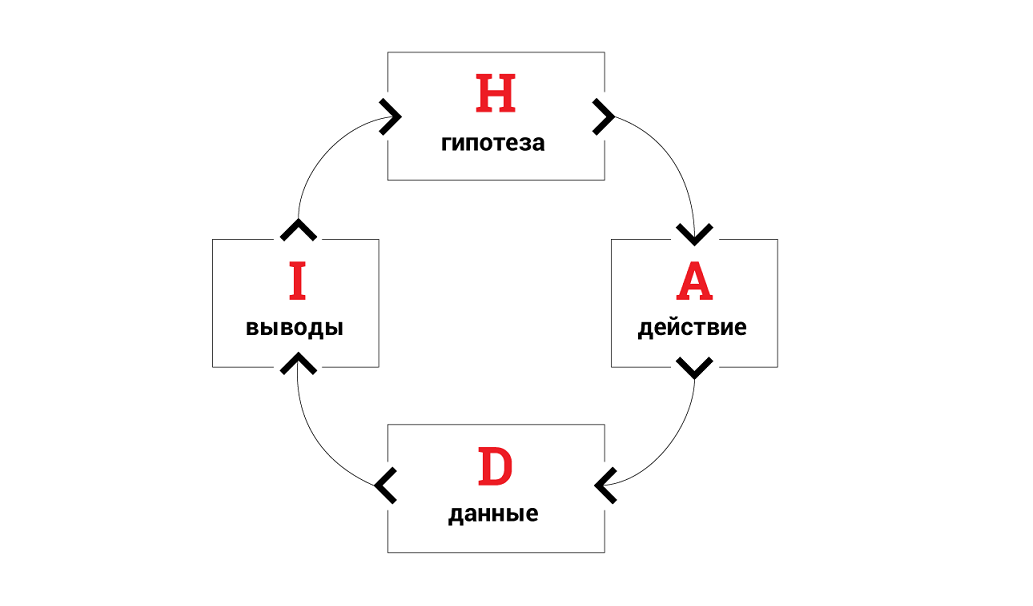
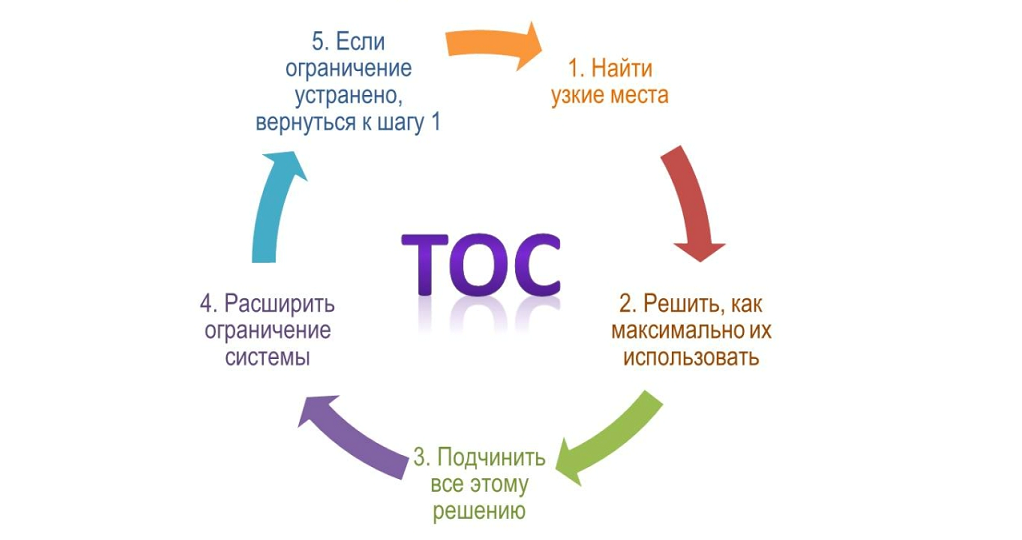
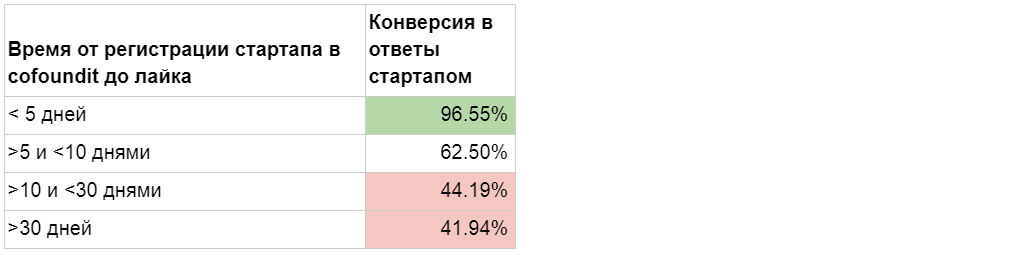



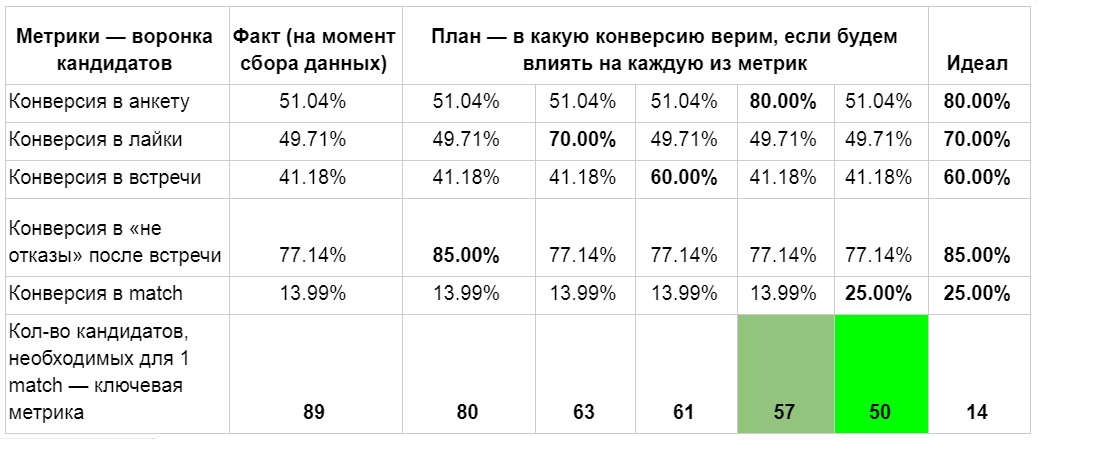
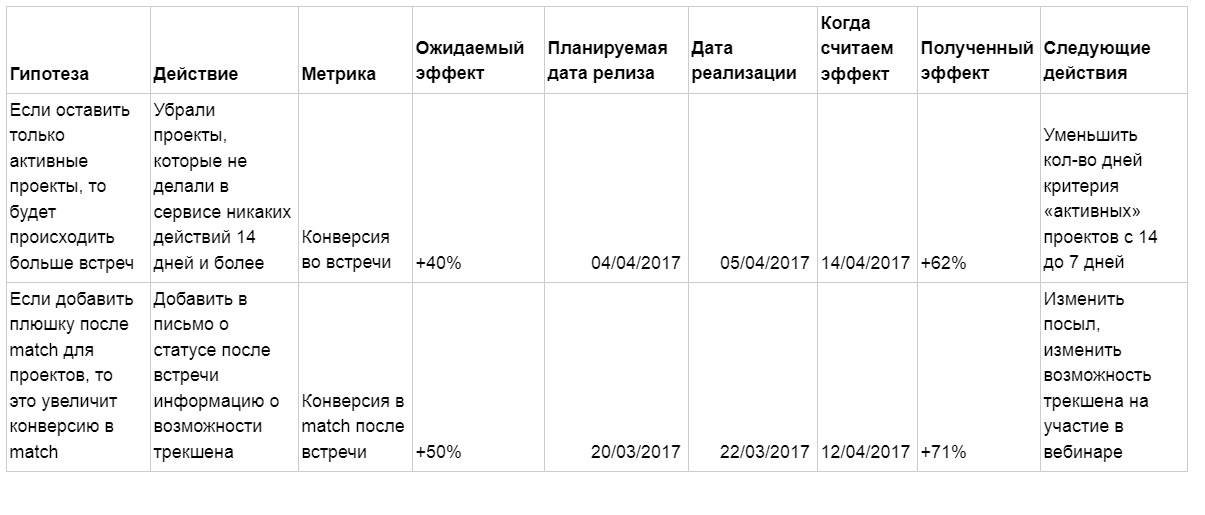
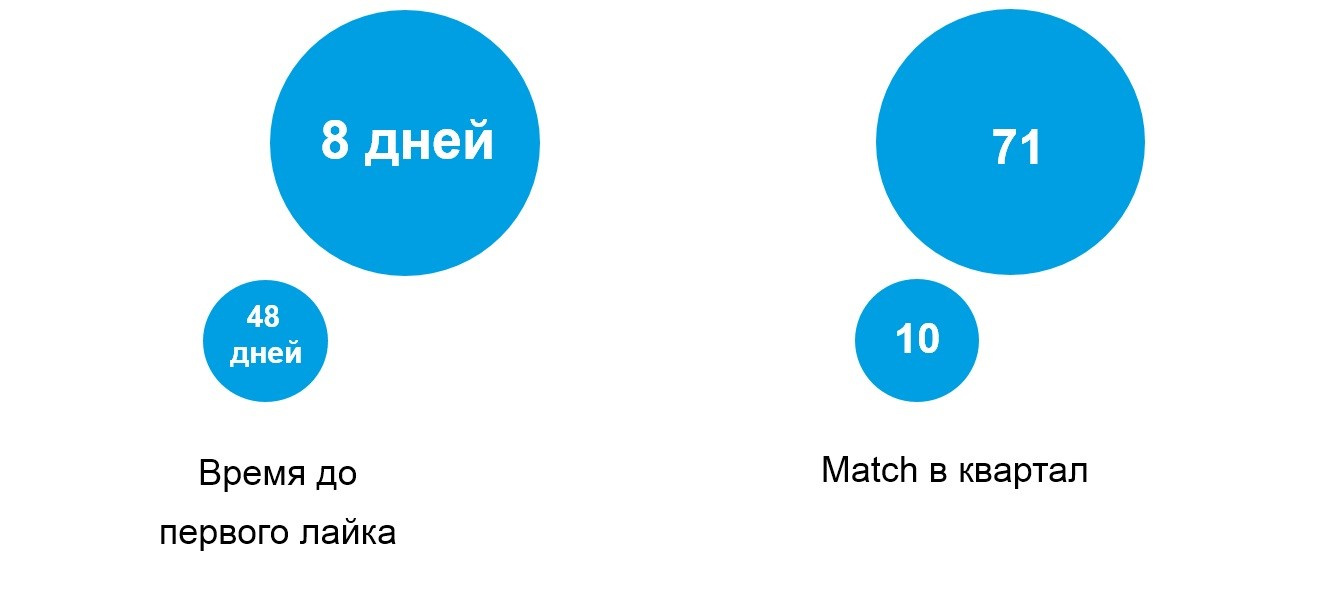
|
|
Как увеличить показатели сервиса в 7 раз за три месяца с помощью HADI-циклов и приоритизации гипотез |
|
|
Parrot Security OS — альтернатива Kali Linux |

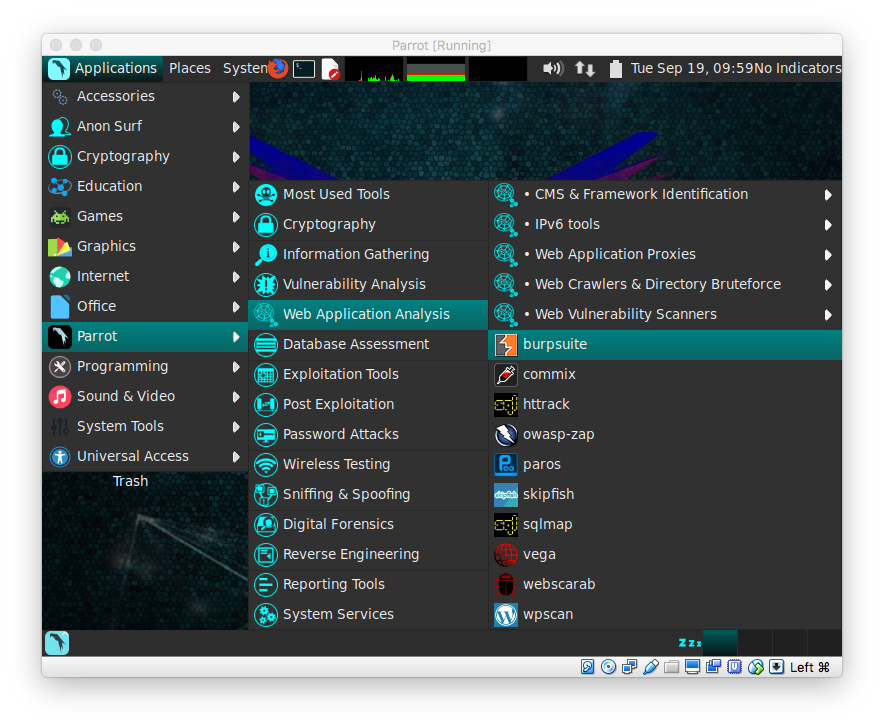
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit parrot security os |
Parrot Security OS — альтернатива Kali Linux |
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit parrot security os |
[Из песочницы] Из хирурга в разработчики: как в 40 лет сменить профессию? |

Привет! Меня зовут Алексей, я тимлид в крупной IT-компании. Сейчас мне 43, только в 40 лет я стал разработчиком, а до этого 15 лет был практикующим врачом-хирургом. Делюсь с вами, как в середине жизни я поменял профессию, о страхах, рисках и планах с этим связанных.
Возможно мой опыт пригодится тем, кто хочет изменить свою жизнь, но боится или сомневается. Сейчас могу сказать, что рисков в этом деле, действительно, хватает, но и результат может превзойти все ожидания. И возраст или другие обстоятельства не должны стать причиной НЕ пробовать и НЕ пытаться.
В 1998 году я закончил Самарский государственный медицинский университет, в 2000 – ординатуру по специальности «Хирургия» и одновременно защитил кандидатскую диссертацию. Переехал в г. Усинск (Республика Коми), где 8 лет проработал хирургом, потом был г. Ханты-Мансийск (Югра), где я продолжил трудиться по специальности.
Хирургия – интересная область, работа, которая одновременно очень увлекает и изрядно выматывает. Я выполнял в основном торакоабдоминальные операции, а также неотложку. В районах приходилось делать от трепанаций до ампутаций. Хотя для районного хирурга – это обычная практика, без многопрофильности никуда.
За время работы повышал профессиональный уровень с помощью дополнительных специализаций, в том числе в больницах и госпиталях Франции, Чехии и США.
В целом моя карьера складывалась удачно, были профессиональные перспективы, но были и сложности. В России врач – это призвание. Не в том смысле, чтобы любить свое дело и посвящать ему себя полностью. Этого хватало. Несмотря на то, что ты ежедневно отвечаешь за жизнь и здоровье людей, тебе и твоей семье при этом приходится практически выживать. На севере (Республика Коми, ХМАО) еще можно получать хорошую зарплату врача, но в средней полосе ситуация крайне сложная. Туда мне предстояло вернуться: на малой родине (г. Пенза) остались родители, которым нужно помогать и поддерживать.
А в этом регионе с зарплатами совсем туго. Чтобы не оказаться без денег после очередного переезда, нужно было позаботиться о будущем заранее. Помогло хобби. В свободное время я выручал знакомых – настраивал программное обеспечение. Даже одно время подрабатывал программистом в пожарной части в Усинске. Начальник пожарной части был у меня пациентом, а потом предложил дополнительный заработок. В основном делал внешние отчеты и дорабатывал конфигурацию 1С Предприятия под их организацию. В общем пришлось освоить нехитрый язык 1С. Помимо этого написал и поддерживал систему учета в пожарной части на FireBird & Delphi.
Я был самоучкой, специальных знаний не имел, мне просто нравилось программирование само по себе. Решил, что дополнительная профессия не помешает, а станет моей подстраховкой. Потому в 2011 году поступил на заочное отделение в Томский государственный университет систем управления и радиоэлектроники по специальности «Программное обеспечение вычислительных систем и автоматизированных комплексов». Закончил его экстерном в 2014 году.
Было очень непросто совмещать хирургию, семью и обучение по новой специальности. Однако я понимал, что базовые знания для дальнейшего развития необходимы. Знаю, что есть самоучки, но это более сложный и запутанный путь.
В том же 2014 году я с семьей переехал в Поволжье. Во всех городах средней полосы ситуация с зарплатами плачевная. На 20 тысяч докторской з/п, что мне предложили в Пензе, невозможно обеспечить достойную жизни для себя и семьи. Предстояло решить, что делать дальше. С одной стороны, привычная жизнь, профессиональные успехи, но критично низкая зарплата и грустная перспектива – в финансовом отношении ждать изменений не приходилось. С другой стороны, стартовая позиция в новой профессии и не факт, что «выстрелит» и я в возрасте «далеко за 30» чего-то достигну. Однако надежда поднять уровень жизни семьи и хорошо зарабатывать в будущем перевесила страхи.
К тому моменту, как я уволился и стал искать работу по специальности разработчика, у меня были небольшие накопления. Этой подушки безопасности должно было хватить на год, если, конечно, жить скромно, не на широкую ногу. Еще одна подстраховка – я понимал, что могу в любой момент вернуться на прежнюю работу, если что-то пойдет не так или я передумаю. Об абсолютной безрассудности в моих обстоятельствах говорить не приходится: содержание семьи, детей и помощь родителям никто не отменял. К тому же решение о смене профессии совпало с декретным отпуском жены. Мы ждали второго сына. В каком-то смысле это послужило дополнительным стимулом для изменений.
Первое место, куда я устроился на стартовую позицию Delphi-разработчика была компания, которая специализируется на разработке электронного оборудования. Тогда-то я и ощутил, что значит быть разработчиком на деле. В течение года, я жил в режиме нон-стоп: работа – учеба – сон – учеба – работа без выходных и праздников. Это было напряженное время, ведь по сути мне нужно было за короткий срок дотянуть свой уровень до более-менее хорошего, чтобы расти профессионально и рассчитывать на более высокую позицию. Но этого того стоило: освоил С/С++ и Delphi.
В нынешней компании я оказался случайно. Жена увидела открытую вакансию, мы обсудили и решили: а почему бы не попробовать? Тогда я сомневался: крупная компания, серьезный продукт, у меня мало опыта, совсем не был уверен, что из этого что-то выйдет. Но на вакансию откликнулся, решил, что попытаться стоит. Выполнил тестовое, меня пригласили на собеседование в головной офис. Волновался, но все прошло гладко и меня взяли на испытательный срок на 2 месяца.
Плюсы, которые, я сразу оценил: хорошая зарплата, крутая команда, возможность работать удаленно и перспективы роста. Начал с позиции рядового разработчика, за 1,5 года дорос до тимлида. Сейчас практически все мое рабочее время занимает SIEM: подготовка кандидат-релизов, написание коннекторов, разработка дальнейшей функциональности. Иногда исправляю старые «баги», доставшиеся мне по наследству от коллег по работе, участвую в разработке общего для всех продуктов SDK взаимодействия между компонентами (REST). Задачи интересные, команда сильная.
Сейчас я пишу на Delphi, Go, немного поработал с C#. В качестве БД на хорошем уровне изучил MSSQL и MongoDB. Теперь я могу жить и работать в том регионе, где мне удобно, заниматься делом, которое мне по душе, и при этом не быть ущемленным финансово.
Как говорится, жизнь разделилась на «до» и «после», хотя круг общения сильно не изменился и состоит из бывших коллег, медицинских работников. Общаюсь с ними и вижу, что проблемы в этой сфере те же. Какой-то ностальгии по бывшей профессии не испытываю, просто очень жаль, что сама медицинская отрасль болеет одними и теми же «болезнями» из года в год. Понимаю, как не просто моим бывшим коллегам, потому ни разу не пожалел о своем решении и о смене рода деятельности.
Теперь оглядываясь назад, вижу, что можно было бы сделать лучше и что стоит сделать обязательно, если вы также решите сменить профессию:
Решение уйти из медицины было одним из самых сложных в моей жизни. Еще и потому, что среди знакомых-врачей очень много не просто талантливых людей, но людей с совершенно особой судьбой. Каждая история – сценарий для фильма. Рад, что, покинув профессию, удалось сохранить отношения со старыми друзьями.
Могло показаться, что я решился на авантюру, уйдя из профессии, но на самом деле, 80% успеха зависит от того, как вы спланируете перемены. Конечно, я понимал, что при должной подготовке могу рассчитывать и на хорошую должность, и на хороший доход, и на интересные задачи в крупном проекте. Так и вышло. Но повторюсь, что это результат не столько удачи и везения, сколько здравой оценки ситуации и планирования своих действий.
|
Метки: author alxpotapov учебный процесс в it работа саморазвитие обучение программированию первые шаги смена работы профессиональный рост |
[Из песочницы] Из хирурга в разработчики: как в 40 лет сменить профессию? |
Привет! Меня зовут Алексей, я тимлид в крупной IT-компании. Сейчас мне 43, только в 40 лет я стал разработчиком, а до этого 15 лет был практикующим врачом-хирургом. Делюсь с вами, как в середине жизни я поменял профессию, о страхах, рисках и планах с этим связанных.
Возможно мой опыт пригодится тем, кто хочет изменить свою жизнь, но боится или сомневается. Сейчас могу сказать, что рисков в этом деле, действительно, хватает, но и результат может превзойти все ожидания. И возраст или другие обстоятельства не должны стать причиной НЕ пробовать и НЕ пытаться.
В 1998 году я закончил Самарский государственный медицинский университет, в 2000 – ординатуру по специальности «Хирургия» и одновременно защитил кандидатскую диссертацию. Переехал в г. Усинск (Республика Коми), где 8 лет проработал хирургом, потом был г. Ханты-Мансийск (Югра), где я продолжил трудиться по специальности.
Хирургия – интересная область, работа, которая одновременно очень увлекает и изрядно выматывает. Я выполнял в основном торакоабдоминальные операции, а также неотложку. В районах приходилось делать от трепанаций до ампутаций. Хотя для районного хирурга – это обычная практика, без многопрофильности никуда.
За время работы повышал профессиональный уровень с помощью дополнительных специализаций, в том числе в больницах и госпиталях Франции, Чехии и США.
В целом моя карьера складывалась удачно, были профессиональные перспективы, но были и сложности. В России врач – это призвание. Не в том смысле, чтобы любить свое дело и посвящать ему себя полностью. Этого хватало. Несмотря на то, что ты ежедневно отвечаешь за жизнь и здоровье людей, тебе и твоей семье при этом приходится практически выживать. На севере (Республика Коми, ХМАО) еще можно получать хорошую зарплату врача, но в средней полосе ситуация крайне сложная. Туда мне предстояло вернуться: на малой родине (г. Пенза) остались родители, которым нужно помогать и поддерживать.
А в этом регионе с зарплатами совсем туго. Чтобы не оказаться без денег после очередного переезда, нужно было позаботиться о будущем заранее. Помогло хобби. В свободное время я выручал знакомых – настраивал программное обеспечение. Даже одно время подрабатывал программистом в пожарной части в Усинске. Начальник пожарной части был у меня пациентом, а потом предложил дополнительный заработок. В основном делал внешние отчеты и дорабатывал конфигурацию 1С Предприятия под их организацию. В общем пришлось освоить нехитрый язык 1С. Помимо этого написал и поддерживал систему учета в пожарной части на FireBird & Delphi.
Я был самоучкой, специальных знаний не имел, мне просто нравилось программирование само по себе. Решил, что дополнительная профессия не помешает, а станет моей подстраховкой. Потому в 2011 году поступил на заочное отделение в Томский государственный университет систем управления и радиоэлектроники по специальности «Программное обеспечение вычислительных систем и автоматизированных комплексов». Закончил его экстерном в 2014 году.
Было очень непросто совмещать хирургию, семью и обучение по новой специальности. Однако я понимал, что базовые знания для дальнейшего развития необходимы. Знаю, что есть самоучки, но это более сложный и запутанный путь.
В том же 2014 году я с семьей переехал в Поволжье. Во всех городах средней полосы ситуация с зарплатами плачевная. На 20 тысяч докторской з/п, что мне предложили в Пензе, невозможно обеспечить достойную жизни для себя и семьи. Предстояло решить, что делать дальше. С одной стороны, привычная жизнь, профессиональные успехи, но критично низкая зарплата и грустная перспектива – в финансовом отношении ждать изменений не приходилось. С другой стороны, стартовая позиция в новой профессии и не факт, что «выстрелит» и я в возрасте «далеко за 30» чего-то достигну. Однако надежда поднять уровень жизни семьи и хорошо зарабатывать в будущем перевесила страхи.
К тому моменту, как я уволился и стал искать работу по специальности разработчика, у меня были небольшие накопления. Этой подушки безопасности должно было хватить на год, если, конечно, жить скромно, не на широкую ногу. Еще одна подстраховка – я понимал, что могу в любой момент вернуться на прежнюю работу, если что-то пойдет не так или я передумаю. Об абсолютной безрассудности в моих обстоятельствах говорить не приходится: содержание семьи, детей и помощь родителям никто не отменял. К тому же решение о смене профессии совпало с декретным отпуском жены. Мы ждали второго сына. В каком-то смысле это послужило дополнительным стимулом для изменений.
Первое место, куда я устроился на стартовую позицию Delphi-разработчика была компания, которая специализируется на разработке электронного оборудования. Тогда-то я и ощутил, что значит быть разработчиком на деле. В течение года, я жил в режиме нон-стоп: работа – учеба – сон – учеба – работа без выходных и праздников. Это было напряженное время, ведь по сути мне нужно было за короткий срок дотянуть свой уровень до более-менее хорошего, чтобы расти профессионально и рассчитывать на более высокую позицию. Но этого того стоило: освоил С/С++ и Delphi.
В нынешней компании я оказался случайно. Жена увидела открытую вакансию, мы обсудили и решили: а почему бы не попробовать? Тогда я сомневался: крупная компания, серьезный продукт, у меня мало опыта, совсем не был уверен, что из этого что-то выйдет. Но на вакансию откликнулся, решил, что попытаться стоит. Выполнил тестовое, меня пригласили на собеседование в головной офис. Волновался, но все прошло гладко и меня взяли на испытательный срок на 2 месяца.
Плюсы, которые, я сразу оценил: хорошая зарплата, крутая команда, возможность работать удаленно и перспективы роста. Начал с позиции рядового разработчика, за 1,5 года дорос до тимлида. Сейчас практически все мое рабочее время занимает SIEM: подготовка кандидат-релизов, написание коннекторов, разработка дальнейшей функциональности. Иногда исправляю старые «баги», доставшиеся мне по наследству от коллег по работе, участвую в разработке общего для всех продуктов SDK взаимодействия между компонентами (REST). Задачи интересные, команда сильная.
Сейчас я пишу на Delphi, Go, немного поработал с C#. В качестве БД на хорошем уровне изучил MSSQL и MongoDB. Теперь я могу жить и работать в том регионе, где мне удобно, заниматься делом, которое мне по душе, и при этом не быть ущемленным финансово.
Как говорится, жизнь разделилась на «до» и «после», хотя круг общения сильно не изменился и состоит из бывших коллег, медицинских работников. Общаюсь с ними и вижу, что проблемы в этой сфере те же. Какой-то ностальгии по бывшей профессии не испытываю, просто очень жаль, что сама медицинская отрасль болеет одними и теми же «болезнями» из года в год. Понимаю, как не просто моим бывшим коллегам, потому ни разу не пожалел о своем решении и о смене рода деятельности.
Теперь оглядываясь назад, вижу, что можно было бы сделать лучше и что стоит сделать обязательно, если вы также решите сменить профессию:
Решение уйти из медицины было одним из самых сложных в моей жизни. Еще и потому, что среди знакомых-врачей очень много не просто талантливых людей, но людей с совершенно особой судьбой. Каждая история – сценарий для фильма. Рад, что, покинув профессию, удалось сохранить отношения со старыми друзьями.
Могло показаться, что я решился на авантюру, уйдя из профессии, но на самом деле, 80% успеха зависит от того, как вы спланируете перемены. Конечно, я понимал, что при должной подготовке могу рассчитывать и на хорошую должность, и на хороший доход, и на интересные задачи в крупном проекте. Так и вышло. Но повторюсь, что это результат не столько удачи и везения, сколько здравой оценки ситуации и планирования своих действий.
|
Метки: author alxpotapov учебный процесс в it работа саморазвитие обучение программированию первые шаги смена работы профессиональный рост |
[Перевод] Оптимизация веб-серверов для повышения пропускной способности и уменьшения задержки |
Привет! Меня зовут Макс Матюхин, я работаю в SRV-команде Badoo. Мы в Badoo не только активно пишем посты в свой блог, но и внимательно читаем блоги наших коллег из других компаний. Недавно ребята из Dropbox опубликовали шикарный пост о различных способах оптимизации серверных приложений: начиная с железа и заканчивая уровнем приложения. Его автор – Алексей Иванов – дал огромное количество советов и ссылок на дополнительные источники информации. К сожалению, у Dropbox нет блога на Хабре, поэтому я решил перевести этот пост для наших читателей.
Это расширенная версия моего выступления на nginx.conf 2017 в сентябре этого года. В качестве старшего инженера по контролю качестве (SRE) в команде Dropbox Traffic я отвечаю за нашу сеть Edge: её надёжность, производительность и эффективность. Это proxy-tier-сеть, построенная на базе nginx и предназначенная как для обработки чувствительных к задержке метаданных, так и для передачи данных с высокой пропускной способностью. В системе, обрабатывающей десятки гигабитов в секунду и одновременно – десятки тысяч транзакций, чувствительных к задержкам, используются различные оптимизации эффективности и производительности: начиная с драйверов и прерываний, сквозь ядро и TCP/ IP-стек, и заканчивая библиотеками и настройками уровня приложения.
В этом посте мы рассмотрим многочисленные способы настройки веб-серверов и прокси. Пожалуйста, не занимайтесь карго-культом. Подходите к этому с позиции науки, применяйте оптимизации по одной, измеряйте эффект и принимайте решение, действительно ли они полезны для вашей работы.
Это не пост о производительности Linux (хотя я и буду часто ссылаться на bcc, eBPF и perf) и не исчерпывающее руководство по использованию инструментов профилирования производительности (если вы хотите узнать о них больше, почитайте блог Брендана Грегга).
Это также не пост о производительности браузеров. Я буду упоминать о клиентской производительности применительно к оптимизациям задержек, но очень коротко. Хотите узнать больше – прочитайте статью High Performance Browser Networking Ильи Григорика.
И это не компиляция на тему лучших методик TLS. Хотя я и буду упоминать TLS-библиотеки и их настройки, вы и ваша команда обеспечения безопасности должны самостоятельно оценивать их производительность и влияние на безопасность. Чтобы узнать, насколько ваши серверы отвечают набору лучших методик, можете воспользоваться Qualys SSL Test. Если хотите узнать больше о TLS в целом, подпишитесь на рассылку Feisty Duck Bulletproof TLS Newsletter.
Мы рассмотрим оптимизации эффективности/ производительности на разных уровнях системы. Начнём с самого нижнего, аппаратно-драйверного, уровня: эти настройки можно применить практически к любому высоконагруженному серверу. Затем я перейду к ядру Linux и его TCP/IP-стеку: можете покрутить эти ручки на своих ящиках, активно использующих TCP. Наконец, мы обсудим настройки на уровне библиотек и приложений, которые по большей части применимы ко многим веб-серверам и в частности к nginx.
По каждой области оптимизаций я постараюсь дать пояснения касательно компромиссов в отношении задержки/ пропускной способности (если они будут), а также дам советы по мониторингу и предложения по настройкам для разных уровней рабочей нагрузки.
Для хорошей производительности асимметричного RSA/EC выбирайте процессоры как минимум с поддержкой AVX2 (avx2 в /proc/cpuinfo) и желательно подходящие для вычислений с большими целыми числами (bmi и adx). Для симметричного шифрования выбирайте AES-NI для AES-шифров и AVX-512 – для ChaCha+Poly. У Intel есть сравнение производительности разных поколений процессоров с OpenSSL 1.0.2, где рассматривается влияние этих аппаратных оптимизаций.
Для задач, где важен уровень задержки, вроде роутинга рекомендуется уменьшить количество NUMA-узлов и отключить Hyper-Threading. Задачи, требующие высокой пропускной способности, эффективнее выполняются при большем количестве ядер с использованием Hyper-Threading (если только нет привязки к кэшу), и в целом NUMA не играет для них особой роли.
Если выбираете среди продукции Intel, то смотрите на процессоры с архитектурой Haswell/ Broadwell, а лучше Skylake. У AMD впечатляющую производительность демонстрируют EPYC-модели.
Вам нужно как минимум 10 Гбит, а лучше – 25 Гбит. Если хотите передавать через один сервер с TLS ещё больше, то описанных здесь настроек может быть недостаточно – возможно, придётся сдвинуть TLS-фрейминг на уровень ядра (FreeBSD, Linux).
Что касается программного уровня, поищите open-source-драйверы с активными списками рассылки и сообществами. Это будет очень важным фактором, если (скорее «когда») вы будете заниматься решением проблем, связанных с драйверами.
Эмпирическое правило: задачи, чувствительные к задержке, требуют более быстрой памяти; задачи, чувствительные к пропускной способности, требуют больше памяти.
Всё зависит от ваших требований к буферизации/кэшированию. Если вам нужно много буферизировать или кэшировать, то лучше выбрать SSD-диски. Некоторые даже устанавливают заточенные под флеш файловые системы (обычно log-structured), но они не всегда показывают более высокую производительность по сравнению с обычными ext4/ xfs.
В любом случае не сгубите свои флеш-накопители, забыв включить TRIM или обновить прошивку.
Используйте свежие прошивки, чтобы избежать долгого и болезненного выявления сбоев. Старайтесь поддерживать актуальные прошивки для процессора, материнской платы, сетевых карт и SSD-накопителей. Это не значит, что нужно всегда использовать самые последние версии — рекомендуется брать предпоследние, если в них нет критически важных багов, которые устранены в последних версиях.
Здесь можно дать тот же совет, что и в отношении прошивки: по возможности используйте свежие версии, но не последние. Старайтесь разделить апгрейды ядра и обновления драйверов. Например, можете упаковать драйверы с помощью DKMS или предварительно скомпилировать их для всех версий ядра, которые вы используете. Благодаря этому, если после обновления ядра что-то пойдёт не так, вы быстрее поймёте, в чём проблема.
Ваш лучший друг — репозиторий ядра (и инструменты, поставляемые с ним). В Ubuntu/ Debian вы можете установить пакет linux-tools с набором утилит, но в этом посте мы будем использовать только cpupower, turbostat и x86_energy_perf_policy. Для проверки связанных с процессором оптимизаций вы можете провести стресс-тестирование своего ПО с помощью любимого генератора нагрузки (например, Yandex.Tank). Вот презентация о лучших методиках нагрузочного тестирования от разработчиков nginx: NGINX Performance testing.
$ cpupower frequency-info
...
driver: intel_pstate
...
available cpufreq governors: performance powersave
...
The governor "performance" may decide which speed to use
...
boost state support:
Supported: yes
Active: yesПроверьте, включён ли Turbo Boost, а если у вас процессор Intel, удостоверьтесь, что система работает с intel_pstate, а не с acpi-cpufreq или pcc-cpufreq. Если вы всё ещё используете acpi-cpufreq, обновите ядро. Если это невозможно, используйте режим performance. При работе с intel_pstate даже режим powersave должен выполняться с хорошей производительностью, но вам придётся проверить это самостоятельно.
Что касается простоя, чтобы посмотреть, что реально происходит с вашим процессором, вы можете с помощью turbostat напрямую заглянуть в процессорные MSR и извлечь информацию о питании, частоте и так называемых Idle States:
# turbostat --debug -P
... Avg_MHz Busy% ... CPU%c1 CPU%c3 CPU%c6 ... Pkg%pc2 Pkg%pc3 Pkg%pc6 ...Здесь вы видите реальную частоту процессора (да, /proc/cpuinfo вам врёт), а также текущее состояние ядра/набора ядер.
Если даже с драйвером intel_pstate процессор тратит на простой больше времени, чем вы думали, вы можете:
x86_energy_perf_policy. А для очень чувствительных к задержке задач можно:
/dev/cpu_dma_latency; Узнать больше об управлении питанием процессора в целом и P-состояниями в частности можно из презентации Balancing Power and Performance in the Linux Kernel с LinuxCon Europe 2015.
Можно ещё больше уменьшить задержку, привязав поток или процесс к CPU. Например, в nginx есть директива worker_cpu_affinity, которая автоматически привязывает каждый процесс веб-сервера к конкретному ядру. Это позволяет исключить миграцию процесса / потока на другое ядро, уменьшить количество промахов кэша и ошибок страниц памяти, а также слегка увеличить количество инструкций в цикле. Всё это можно проверить через perf stat.
Но процессорная привязка негативно влияет на производительность, поскольку процессам дольше приходится ждать освобождения процессора. Это можно отслеживать с помощь запуска runqlat на одном из ваших PID nginx-воркера:
usecs : count distribution
0 -> 1 : 819 | |
2 -> 3 : 58888 |****************************** |
4 -> 7 : 77984 |****************************************|
8 -> 15 : 10529 |***** |
16 -> 31 : 4853 |** |
...
4096 -> 8191 : 34 | |
8192 -> 16383 : 39 | |
16384 -> 32767 : 17 | |Если заметите длинные хвосты на много миллисекунд, то, вероятно, на серверах выполняется слишком много всего, помимо nginx, и привязка увеличит задержку, а не уменьшит её.
Все настройки Memory Management обычно сильно зависят от рабочего процесса, так что могу дать лишь такие рекомендации:
madvise и включайте их, только когда уверены в их пользе, иначе можете сильно замедлить работу, стремясь к 20%-ному уменьшению задержки; vm.zone_reclaim_mode в 0.Современные процессоры представляют собой несколько отдельных процессоров, связанных очень быстрой шиной и совместно использующих различные ресурсы, начиная с кэша L1 на HT-ядрах и заканчивая кэшем L3 применительно к пакетам, памятью и PCIe-соединениями в рамках сокетов. Это и есть NUMA: многочисленные модули исполнения и хранения с быстрой шиной обмена данными.
Исчерпывающее описание NUMA и её применения содержится в статье Фрэнка Деннемана NUMA Deep Dive Series.
Короче, вы можете:
numactl --interleave=all (так вы получите посредственную, но достаточно стабильную производительность); Давайте рассмотрим третий вариант, поскольку в двух остальных не требуется много оптимизировать.
Для правильного использования NUMA вам нужно рассматривать каждый её узел в качестве отдельного сервера. Проверьте топологию с помощью numactl --hardware:
$ numactl --hardware
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 16 17 18 19
node 0 size: 32149 MB
node 1 cpus: 4 5 6 7 20 21 22 23
node 1 size: 32213 MB
node 2 cpus: 8 9 10 11 24 25 26 27
node 2 size: 0 MB
node 3 cpus: 12 13 14 15 28 29 30 31
node 3 size: 0 MB
node distances:
node 0 1 2 3
0: 10 16 16 16
1: 16 10 16 16
2: 16 16 10 16
3: 16 16 16 10Что нужно проверять:
Это очень плохой пример, поскольку здесь четыре узла, и к тому же прикреплены узлы без памяти. Здесь нельзя использовать каждый узел как отдельный сервер без потери половины ядер.
Это можно проверить с помощью numastat:
$ numastat -n -c
Node 0 Node 1 Node 2 Node 3 Total
-------- -------- ------ ------ --------
Numa_Hit 26833500 11885723 0 0 38719223
Numa_Miss 18672 8561876 0 0 8580548
Numa_Foreign 8561876 18672 0 0 8580548
Interleave_Hit 392066 553771 0 0 945836
Local_Node 8222745 11507968 0 0 19730712
Other_Node 18629427 8939632 0 0 27569060Также с помощью numastat можно получить статистику использования памяти по каждому узлу в формате /proc/meminfo:
$ numastat -m -c
Node 0 Node 1 Node 2 Node 3 Total
------ ------ ------ ------ -----
MemTotal 32150 32214 0 0 64363
MemFree 462 5793 0 0 6255
MemUsed 31688 26421 0 0 58109
Active 16021 8588 0 0 24608
Inactive 13436 16121 0 0 29557
Active(anon) 1193 970 0 0 2163
Inactive(anon) 121 108 0 0 229
Active(file) 14828 7618 0 0 22446
Inactive(file) 13315 16013 0 0 29327
...
FilePages 28498 23957 0 0 52454
Mapped 131 130 0 0 261
AnonPages 962 757 0 0 1718
Shmem 355 323 0 0 678
KernelStack 10 5 0 0 16Теперь рассмотрим пример более простой топологии.
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 46967 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 48355 MBПоскольку узлы по большей части симметричны, мы можем привязать экземпляр нашего приложения к каждому NUMA-узлу с помощью numactl --cpunodebind=X --membind=X, а затем открыть его на другом порте. Пропускная способность увеличится благодаря использованию обоих узлов и уменьшению задержки за счёт сохранения локальности памяти.
Проверить эффективность размещения NUMA можно по задержке операций в памяти. Например, с помощью funclatency в BCC измерьте задержку операции, активно использующей память, допустим, memmove.
Наблюдать за эффективностью на стороне ядра можно с помощью perf stat, отслеживая соответствующие события памяти и планировщика:
# perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p PID
...
1 sched:sched_stick_numa
3 sched:sched_move_numa
41 sched:sched_swap_numa
5,239 migrate:mm_migrate_pages
50,161 minor-faultsПоследняя порция связанных с NUMA оптимизаций для сетевых нагрузок с активным использованием сети продиктована тем фактом, что сетевая карта — это PCIe-устройство, а каждое устройство привязано к своему NUMA-узлу; следовательно, у каких-то процессоров задержка при обращении к сети будет меньше. Возможные оптимизации мы обсудим в главе, где будет рассматриваться привязка сетевая карта -> процессор, а пока перейдём к PCI Express.
Обычно нет нужды углубляться в решение проблем с PCIe, если только не возникает какой-то аппаратный сбой. Однако стоит хотя бы просто создать для своих PCIe-устройств «ширину шины», «скорость шины» и предупреждения RxErr/BadTLP. Это должно сэкономить вам часы на отладку из повреждённого железа или сбойного PCIe-согласования. Для этого можете воспользоваться lspci:
# lspci -s 0a:00.0 -vvv
...
LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM L1, Exit Latency L0s <2us, L1 <16us
LnkSta: Speed 8GT/s, Width x8, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
...
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- ...
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+PCIe может стать узким местом, если у вас несколько высокоскоростных устройств, конкурирующих за ширину канала (например, при комбинации быстрой сети с быстрым хранилищем), так что вам может понадобиться физически шардить свои PCIe-устройства среди процессоров, чтобы получить максимальную пропускную способность.

Также советую прочитть статью Understanding PCIe Configuration for Maximum Performance, в ней подробнее рассматривается конфигурация PCIe, что может быть полезно при высоких скоростях, когда происходит потеря пакетов между картой и ОС.
Intel предполагает, что иногда управление питанием PCIe (ASPM) может приводить к большим задержкам, а значит, и к потере большего количества пакетов. Эту функцию можно отключить, введя pcie_aspm=off в командной строке ядра.
Прежде чем мы начнём, стоит упомянуть, что Intel и Mellanox предлагают собственные руководства по настройке производительности, и вне зависимости от выбранного вами вендора стоит прочитать оба материала. Кроме того, драйверы обычно идут с собственными README и наборами полезных утилит.
Также можете поискать руководства для вашей ОС. Например, в руководстве по настройке сетевой производительности в Linux от Red Hat Enterprise объясняются многие из упомянутых выше оптимизаций. У Cloudflare тоже есть хорошая статья о настройке этой части сетевого стека, хотя по большей части она посвящена ситуациям, когда нужна низкая задержка.
В ходе оптимизации вашим лучшим другом будет ethtool.
Примечание: если вы используете достаточно свежее ядро (а вам следует это сделать!), то вы также столкнётесь с некоторыми аспектами вашего пользовательского пространства. Например, для сетевых операций вы, вероятно, захотите использовать более свежие версии пакетов ethtool, iproute2 и, быть может, iptables/nftables.
Получить ценные сведения о том, что происходит с вашей сетевой картой, можно с помощью ethtool -S:
$ ethtool -S eth0 | egrep 'miss|over|drop|lost|fifo'
rx_dropped: 0
tx_dropped: 0
port.rx_dropped: 0
port.tx_dropped_link_down: 0
port.rx_oversize: 0
port.arq_overflows: 0Проконсультируйтесь с производителем вашей сетевой карты относительно подробного описания статистики. Например, у Mellanox есть отдельная Wiki-статья об этом.
Что касается ядра, то нужно смотреть /proc/interrupts, /proc/softirqs и /proc/net/softnet_stat. Здесь есть два полезных BCC-инструмента: hardirqs и softirqs. Цель вашей оптимизации сети заключается в такой настройке системы, чтобы процессор использовался минимально, а пакеты не терялись.
Обычно настройки здесь начинаются с распределения прерываний по процессорам. Как именно это делать, зависит от вашей рабочей нагрузки:
ethtool -L). Как правило, для этого вендоры предоставляют скрипты. Например, у Intel это set_irq_affinity.
Сетевым картам нужно обмениваться информацией с ядром. Обычно это делается через структуру данных, называющуюся «кольцо». Текущий/ максимальный размер этого кольца можно посмотреть с помощью ethtool -g:
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
TX: 4096
Current hardware settings:
RX: 4096
TX: 4096С помощью -G можно настраивать значения в рамках предварительно заданных экстремумов. Обычно чем больше, тем лучше (особенно если вы используете объединение прерываний), поскольку это даёт вам лучшую защиту от пиков и каких-то проблем в ядре, а значит, уменьшает количество дропнутых пакетов из-за нехватки места в буфере или пропущенного прерывания. Но есть пара предостережений:
в более старых ядрах или драйверах без поддержки BQL высокие значения могут относиться к более высокому bufferbloat на TX-стороне;
Этот механизм обеспечивает задержку уведомления ядра о новых событиях за счёт объединения нескольких сообщений в одно прерывание. Текущие настройки можно посмотреть с помощью ethtool -c:
$ ethtool -c eth0
Coalesce parameters for eth0:
...
rx-usecs: 50
tx-usecs: 50Также вы можете придерживаться статичных пределов (static limits), жёстко ограничив максимальное количество прерываний в секунду на одно ядро, или положиться на автоматическую аппаратную подстройку частоты прерываний в зависимости от пропускной способности.
Включение объединения (-C) увеличит задержку и, вероятно, приведёт к потере пакетов, так что эту функцию не рекомендуется использовать для задач, чувствительных к уровню задержки. Но с другой стороны, её полное отключение может привести к троттлингу прерываний, а следовательно, ограничению производительности.
Современные сетевые карты довольно умны и могут разгружать немалую часть работы посредством железа либо эмулировать разгрузку в самих драйверах.
Все возможные разгрузки можно просмотреть с помощью ethtool -k:
$ ethtool -k eth0
Features for eth0:
...
tcp-segmentation-offload: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]Все ненастраиваемые разгрузки помечены суффиксом [fixed]. О них можно долго рассказывать, но я только приведу несколько эмпирических правил:
Все современные сетевые карты оптимизированы под многопроцессорные системы, поэтому они распределяют пакеты по виртуальным очередям (обычно по одной на процессор). Когда это выполняется аппаратно, то называется RSS; когда за балансировку пакетов между процессорами отвечает ОС, это называется RPS (TX-эквивалент называется XPS). Если ОС пытается регулировать потоки к процессорам, которые в данный момент обрабатывают этот сокет, это называется RFS. А когда этим занимается железо, это называется «ускоренный RFS» или aRFS.
Вот несколько хороших методик:
1) у вас больше процессоров, чем аппаратных очередей, и вы хотите пожертвовать задержкой в пользу пропускной способности;
2) вы используете внутреннее туннелирование (например, GRE/ IPinIP), при котором сетевая карта не может применять RSS;
Включённый Flow Director (или fdir в терминологии Intel) по умолчанию оперирует в режиме Application Targeting Routing, при котором реализуется aRFS посредством семплирования пакетов и регулирования потоков в процессорное ядро, где они, по-видимому, обрабатываются. Статистику можно посмотреть с помощью ethtool -S:$ ethtool -S eth0 | egrep ‘fdir’ port.fdir_flush_cnt: 0 …
Хотя Intel заявляет, что fdir в некоторых случаях увеличивает производительность, результаты одного исследования говорят о том, что это может также привести к переупорядочиванию 1% пакетов, что может довольно негативно сказаться на производительности TCP. Поэтому протестируйте самостоятельно и посмотрите, будет ли Flow Director полезен при вашей рабочей нагрузке, проверяя счётчик TCPOFOQueue.
Существует огромное количество книг, видео и руководств по настройке сетевого стека Linux, в которых растиражирован «карго-культ sysctl.conf». И хотя свежие версии ядра уже не требуют такого объёма настройки, как десять лет назад, а большинство новых TCP/ IP-свойств по умолчанию включены и хорошо настроены, люди продолжают копипастить свои старые sysctls.conf, которые они использовали для настройки ядер версий 2.6.18/ 2.6.32.
Для проверки эффективности сетевых оптимизаций сделайте следующее:
/proc/net/snmp and /proc/net/netstat соберите TCP-метрики в рамках системы; ss -n --extended --info или при вызове внутри сервера getsockopt(``[TCP_INFO]``)/getsockopt(``[TCP_CC_INFO]``); В качестве источников информации о сетевых оптимизациях я обычно использую выступления специалистов по CDN, потому что, как правило, они знают, что делают. Например, Fastly on LinuxCon Australia. Полезно также послушать, что говорят разработчики ядра Linux, к примеру, на NetDevConf и Netconf.
Также стоит упомянуть про подробные материалы от PackageCloud по сетевому стеку Linux, особенно в свете того, что они сделали акцент на мониторинг, а не на «слепую» настройку:
И позвольте дать совет напоследок: обновите ядро ОС! Существует множество новых сетевых улучшений, и я говорю даже не об IW10 (который 2010) – я говорю о таких новинках, как автоматический выбор размера TSO, FQ, pacing, TLP и RACK. В качестве бонуса от апгрейда вы получите ряд улучшений масштабируемости, например, убранный кэш рутинга, неблокирующие сокеты прослушивания, SO_REUSEPORT и многое другое.
Из недавних документов по работе с сетью в Linux особенно выделяется Making Linux TCP Fast. В нём на четырёх страницах собраны улучшения в ядре ОС за много лет. TCP-стек на стороне отправителя разбит на функциональные части:

Fair queueing отвечает за соблюдение «справедливости» и уменьшает блокировку очереди между TCP-потоками, что положительно сказывается на частоте отбрасывания пакетов. Pacing, в свою очередь, равномерно распределяет пакеты во времени с частотой, определяемой Congestion Control, что ещё больше уменьшает долю потерянных пакетов, тем самым увеличивая пропускную способность.
Попутно хочу заметить, что fair queueing и pacing доступны в Linux посредством fq qdisc. Обе фичи требуются для BBR (впрочем, уже нет), но их можно использовать и с CUBIC, добиваясь 15–20%-ного снижения потери пакетов, а значит, и повышения пропускной способности в алгоритмах управления перегрузками (loss-based CCs). Только не используйте их на старых ядрах (<3.19), поскольку вы станете регулировать обычные ACKs и сломаете аплоад/ RPCs.
Обе функции отвечают за ограничение буферизации внутри TCP-стека, а следовательно, и за уменьшение задержки без ухудшения пропускной способности.
CC-алгоритмы сами по себе – объёмная тема, и в последние годы о них было много разговоров. Что-то из этого вылилось в код: tcp_cdg (CAIA), tcp_nv (Facebook) и tcp_bbr (Google). Мы не будем углубляться в их устройство, скажу лишь, что индикация о перегрузке во всех них основана больше на увеличении отсрочки (delay), чем на отбрасывании пакетов.
BBR – один из наиболее задокументированных, протестированных и практичных из всех новых алгоритмов управления перегрузками. На основании доли доставленных пакетов создаётся модель сетевого пути, а затем для увеличения ширины пропускания и минимизации RTT выполняются управляющие циклы. Это именно то, что мы ищем в нашем прокси-стеке.
Предварительные результаты экспериментов с BBR на наших Edge PoP показали увеличение скорости скачивания файлов:

Шестичасовой эксперимент с TCP BBR в Tokyo PoP: ось x — время, ось y — скорость скачивания на клиенте
Увеличение скорости наблюдалось по всем перцентилям. При изменениях бэкенда такого не происходит — обычно положительный результат наблюдается только p90+ пользователей (у которых самое быстрое интернет-подключение), поскольку мы считаем, что у всех остальных уже ограничена полоса пропускания. Настройки на сетевом уровне вроде изменения управления перегрузками или включения FQ/ pacing демонстрируют, что у пользователей ограничена не полоса пропускания, а, я бы сказал, присутствует «ограниченность TCP».
Если вы хотите больше узнать о BBR, то у APNIC есть хороший обзор для новичков (и сравнение с loss-based-управлением перегрузками). Более глубокую информацию можно извлечь из архивов почтовой рассылки bbr-dev (там сверху закреплено множество полезных ссылок). Если вас в целом интересует тема управления перегрузками, то можете понаблюдать за активностью Internet Congestion Control Research Group.
Теперь поговорим об обнаружении пропадания пакетов (loss detection). Снова упомяну про важность использования свежей версии ядра ОС. В TCP постоянно добавляются новые эвристики вроде TLP и RACK, а старые (наподобие FACK и ER) убираются. Нововведения работают по умолчанию, так что вам не придётся настраивать систему после апгрейда.
API сокета пользовательского пространства (userspace socket API) предоставляют механизм явной буферизации, и после отправки чанков их уже невозможно перегруппировать. Поэтому при использовании мультиплексирования (например, в HTTP/2) это может привести к Head-of-Line блокировке и инверсии h2-приоритетов. Для решения этой проблемы были разработаны опция сокета и соответствующая опция sysctl net.ipv4.tcp_notsent_lowat. Они позволяют настраивать границы, в пределах которых сокет считает себя доступным для записи (то есть epoll в вашем приложении будет врать). Это может решить проблемы с HTTP/2-приоритизацией, но при этом плохо повлиять на пропускную способность, так что рекомендую проверить самостоятельно.
Непросто говорить об оптимизации работы с сетью, не упомянув про необходимость настройки sysctls. Но сначала рассмотрим, что вам трогать точно не следует:
net.ipv4.tcp_tw_recycle=1: не используйте это — для пользователей за NAT это всё уже сломано, а если вы обновите ядро, то сломаете у всех; net.ipv4.tcp_timestamps=0: не отключайте как минимум до тех пор, пока не будете знать обо всех побочных эффектах. Например, одним из неочевидных последствия является то, что вы лишитесь оконного масштабирования и SACK-опций в syncookie.Лучше сделайте вот что:
net.ipv4.tcp_slow_start_after_idle=0: главная проблема с медленным стартом (slow start) после простоя заключается в том, что «простой» определяется как один RTO, а этого слишком мало; net.ipv4.tcp_mtu_probing=1: полезно при наличии ICMP-«чёрных дыр» между вами и клиентами (наверняка они есть ); net.ipv4.tcp_rmem, net.ipv4.tcp_wmem: нужно настроить так, чтобы подходило к BDP; только не забудьте, что больше – не значит лучше; echo 2 > /sys/module/tcp_cubic/parameters/hystart_detect: если вы используете FQ+CUBIC, то это может помочь решить проблему слишком раннего выхода tcp_cubic из медленного старта. Стоит упомянуть, что существует RFC-черновик (хотя и подзаброшенный) от Дэниела Штенберга, автора curl, под названием TCP Tuning for HTTP, в котором сделана попытка собрать все системные настройки, которые могут быть полезны для HTTP.
Как и в случае с ядром ОС, пользовательское пространство крайне важно актуализировать. Начните с обновления своего инструментария, например, можете упаковать более свежие версии perf, bcc и так далее.
После этого можно приступать к настройке и отслеживанию поведения системы. В этой части поста мы будем по большей части опираться на профилирование процессора с помощью perf top, on-CPU flame-графики и ad hoc-гистрограммы из funclatency в bcc.
Если вы хотите сделать аппаратно-оптимизированную сборку, то необходимо обзавестись современными инструментами для компилирования, представленных во многих библиотеках, широко используемых в веб-серверах.
Помимо производительности, новые компиляторы могут похвастаться и новыми свойствами обеспечения безопасности (например, -fstack-protector-strong или SafeStack). Также современный инструментарий будет полезен, если вы хотите прогонять тесты через бинарные файлы, скомпилированные с использованием санитайзеров (например, AddressSanitizer и других).
Рекомендую обновить системные библиотеки вроде glibc, иначе вы можете не получить свежих оптимизаций низкоуровневых функций из -lc, -lm, -lrt и так далее. Стандартное предупреждение: тестируйте самостоятельно, поскольку могут встречаться неожиданные регрессии.
Обычно за компрессию отвечает веб-сервер. В зависимости от объёма данных, проходящих через прокси, вы можете встретить упоминание zlib в perf top, например:
# perf top
...
8.88% nginx [.] longest_match
8.29% nginx [.] deflate_slow
1.90% nginx [.] compress_blockЭто можно оптимизировать на самом низком уровне: Intel и Cloudflare, как и отдельный проект zlib-ng, имеют собственные zlib-форки, обеспечивающие более высокую производительность за счёт использования новых наборов инструкций.
При обсуждении оптимизаций до этого момента мы по большей части ориентировались на процессор. Теперь же поговорим о памяти. Если вы активно используете Lua с FFI или тяжёлые сторонние модули, которые самостоятельно управляют памятью, то могли заметить рост потребления памяти из-за фрагментации. Эту проблему можно попытаться решить переключением на jemalloc или tcmalloc.
Использование кастомного malloc даёт следующие преимущества:
Если в конфигурации nginx вы используете многочисленные сложные регулярные выражения или активно применяете Lua, то могли встретить в perf top упоминание PCRE. Это можно оптимизировать, скомпилировав PCRE с JIT, а также включив её в nginx посредством pcre_jit on;.
Результат оптимизации можно проверить на flame-графиках или с помощью funclatency:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_http_regex_exec -u
...
usecs : count distribution
0 -> 1 : 1159 |********** |
2 -> 3 : 4468 |****************************************|
4 -> 7 : 622 |***** |
8 -> 15 : 610 |***** |
16 -> 31 : 209 |* |
32 -> 63 : 91 | |Если вы прерываете TLS не на границе с CDN, то TLS-оптимизации могут сыграть важную роль. При обсуждении настроек мы будем по большей части говорить об их эффективности на стороне сервера.
Сегодня первое, что вам нужно решить, — какую TLS-библиотеку вы будете использовать: Vanilla OpenSSL, OpenBSD’s LibreSSL или BoringSSL от Google. Определившись, вам нужно правильно её собрать: к примеру, у OpenSSL есть куча сборочных эвристик, позволяющих использовать оптимизации на базе сборочного окружения; у BoringSSL есть детерминистские сборки, но они более консервативны и по умолчанию просто отключают некоторые оптимизации. В любом случае, здесь вы наконец-то ощутите выгоду от выбора современного процессора: большинство TLS-библиотек могут использовать всё, от AES-NI и SSE до ADX и AVX-512. Можете воспользоваться встроенными тестами производительности. Например, в случае с BoringSSL это bssl speed.
Производительность по большей части зависит не от вашего железа, а от наборов шифров, которые вы собираетесь использовать, так что оптимизируйте их с осторожностью. Также знайте, что изменения в данном случае повлияют на безопасность вашего веб-сервера — самые быстрые наборы не обязательно лучшие. Если не знаете, какое шифрование использовать, можете начать с Mozilla SSL Configuration Generator.
Если у вас “front”-сервис (сервис к которому пользователи подключаются напрямую), то вы могли столкнуться со значительным количеством TLS-«рукопожатий», а значит, немалая доля ресурсов вашего процессора тратится на асимметричное шифрование, которое необходимо оптимизировать.
Для оптимизации использования серверного процессора можете переключиться на сертификаты ECDSA, которые в десять раз быстрее, чем RSA. К тому же они значительно меньше, что может ускорить «рукопожатия» при наличии потерь пакетов. Но ECDSA сильно зависят от качества генератора случайных чисел в вашей системе, так что если вы используете OpenSSL, то удостоверьтесь, что у вас достаточно энтропии (в случае с BoringSSL об этом можно не волноваться).
И ещё раз напоминаю, что больше – не значит лучше, то есть использование сертификатов 4096 RSA ухудшит производительность в десять раз:
$ bssl speed
Did 1517 RSA 2048 signing ... (1507.3 ops/sec)
Did 160 RSA 4096 signing ... (153.4 ops/sec)Но меньше тоже не значит лучше: при использовании малораспространённого поля p-224 для ECDSA вы получите 60%-ное снижение производительности по сравнению с обычным p-256:
$ bssl speed
Did 7056 ECDSA P-224 signing ... (6831.1 ops/sec)
Did 17000 ECDSA P-256 signing ... (16885.3 ops/sec)Эмпирическое правило: самое распространённое шифрование обычно самое оптимизированное.
При запуске правильно оптимизированной библиотеки на основе OpenTLS, использующей сертификаты RSA, в своём perf top вы должны увидеть следующие трейсы: процессоры, использующие AVX2, а не ADX (например, с архитектурой Haswell), должны использовать кодовый путь AVX2:
6.42% nginx [.] rsaz_1024_sqr_avx2
1.61% nginx [.] rsaz_1024_mul_avx2Более новые модели должны использовать обычный алгоритм Монтгомери с кодовым путём ADX:
7.08% nginx [.] sqrx8x_internal
2.30% nginx [.] mulx4x_internalЕсли у вас много массовых передач данных вроде видео, фото и прочих файлов, то можете начать отслеживать в данных профилировщика упоминания о симметричном шифровании. Тогда просто удостоверьтесь, что ваш процессор поддерживает AES-NI и что вы настроили на сервере применение шифров AES-GCM. При правильно настроенном оборудовании в perf top должно выдаваться:
8.47% nginx [.] aesni_ctr32_ghash_6xНо заниматься шифрованием/ дешифрованием будут не только ваши серверы, но и клиенты, причём у них априори гораздо более слабые процессоры. Без аппаратного ускорения это может быть достаточно сложной операцией, поэтому позаботьтесь о выборе алгоритма, который работает быстро без аппаратных технологий ускорения работы с шифрованием, например, ChaCha20-Poly1305. Это снизит TTLB для части мобильных клиентов.
В BoringSSL из коробки поддерживается ChaCha20-Poly1305, а в OpenSSL 1.0.2 можете использовать патчи Cloudflare. BoringSSL также поддерживает «шифрогруппы равного предпочтения», так что можете использовать следующую конфигурацию, которая позволит клиентам решать, какие шифры использовать, отталкиваясь от своих аппаратных возможностей (бесстыдно украдено из cloudflare/sslconfig):
ssl_ciphers '[ECDHE-ECDSA-AES128-GCM-SHA256|ECDHE-ECDSA-CHACHA20-POLY1305|ECDHE-RSA-AES128-GCM-SHA256|ECDHE-RSA-CHACHA20-POLY1305]:ECDHE+AES128:RSA+AES128:ECDHE+AES256:RSA+AES256:ECDHE+3DES:RSA+3DES';
ssl_prefer_server_ciphers on;Для анализа эффективности ваших оптимизаций на этом уровне вам нужно собирать RUM-данные. В браузерах можно применять API Navigation Timing и Resource Timing. Ваши главные метрики — TTFB и TTV/ TTI. Вам сильно упростит итерирование, если эти данные будут представлены в форматах, удобных для составления запросов и графиков.
В nginx компрессия начинается с файла mime.types, определяющего соответствие между расширением файла и MIME-типом. Затем вам нужно определить, какой тип вы хотите передавать компрессору, с, например, gzip_types. Если хотите завершить этот список, то для автоматического генерирования mime.types с добавлением compressible == true to gzip_types можете воспользоваться mime-db.
Включая gzip, имейте в виду:
gzip_buffers); gzip_no_buffer).Отмечу, что HTTP-компрессия не ограничивается одним gzip: в nginx есть сторонний модуль ngx_brotli, который способен сжимать на 30% лучше, чем gzip.
Что касается настроек сжатия, давайте рассмотрим два отдельных случая: статичные и динамические данные.
В случае со статичными данными можно архивировать коэффициенты сжатия с помощью предварительной компрессии статичных ресурсов, сделав эту процедуру частью процесса сборки. Для gzip и brotli это подробно рассмотрено в посте Deploying Brotli for static content.
В случае с динамическими данными вам нужно выполнять осторожную балансировку полного цикла: время на сжатие данных + время на их передачу + время на распаковку. Поэтому может быть нецелесообразно устанавливать самую высокую степень сжатия не только с точки зрения потребления ресурсов процессора, но и с точки зрения TTFB.
Буферизация внутри прокси может сильно влиять на производительность веб-сервера, особенно с учётом задержки. В прокси-модуле nginx есть разные настройки буферизации, которые можно регулировать в зависимости от местонахождения буферов и каждая из которых полезна в определённых случаях. С помощью proxy_request_buffering и proxy_buffering можно отдельно управлять буферизацией в обоих направлениях. Если включена буферизация, то верхняя граница потребления памяти определяется с помощью client_body_buffer_size и proxy_buffers, и по достижении этой границы запрос/ ответ будут буферизоваться на диске. Для ответов это можно отключить, присвоив proxy_max_temp_file_size значение 0.
Наиболее распространённые примеры использования:
X-Accel-Buffering можно реализовать управляемую приложением буферизацию ответов. Что бы вы ни выбрали, не забудьте протестировать это на TTFB и TTLB. Как уже упоминалось, буферизация может повлиять на количество операций ввода/ вывода и даже использование бэкенда, так что отслеживайте и эти моменты.
Теперь поговорим о высокоуровневых аспектах TLS и уменьшения задержки, которые можно реализовать с помощью правильной конфигурации nginx. Большинство оптимизаций, которые я буду упоминать, описаны в разделе Optimizing for TLS High Performance Browser Networking и в выступлении Making HTTPS Fast(er) на nginx.conf 2014. Настройки, описываемые в этой части поста, повлияют на производительность и безопасность вашего веб-сервера, так что, если вы в них не уверены, обратитесь к руководству Mozilla’s Server Side TLS Guide и/ или проконсультируйтесь со своими коллегами, отвечающими за безопасность.
Для проверки результатов оптимизаций можно использовать:
Как любят говорить DBA, «самый быстрый запрос – тот, который вы не делали». Это касается и TLS: можно уменьшить задержку с помощью одного RTT, если вы кэшируете результаты «рукопожатия». Это можно сделать двумя способами:
ssl_session_tickets. Это не приводит к потреблению памяти на сервере, но имеет ряд недостатков: 1) понадобится инфраструктура для создания, ротации и распределения случайных ключей шифрования/ подписи для TLS-сессий. Помните, что не следует: 1) использовать управление ресурсами для хранения тикет-ключей; 2) генерировать эти ключи на основе каких-то неэфемерных вещей вроде даты или сертификата;
2) PFS будет зависеть не от конкретной сессии, а от TLS-тикет-ключа, так что если злоумышленник завладеет тикет-ключом, то сможет расшифровать любой перехваченный трафик в течение всего действия тикета;
3) ваше шифрование будет ограничено размером тикет-ключа. Не имеет смысла использовать AES-256, если вы применяете 128-битный тикет-ключ. Nginx поддерживает 128-битные и 256-битные ключи;
4) не все клиенты поддерживают тикет-ключи (хотя они поддерживаются всеми современными браузерами);
1) они потребляют на сервере ~256 байтов памяти на каждую сессию, так что вы не сможете хранить слишком много ключей слишком долго;
2) нет простого способа использовать их одновременно несколькими серверами. Так что вам понадобится ещё и балансировщик нагрузки, который будет отправлять тот же клиент на тот же сервер, чтобы сохранить локальн
|
Метки: author max_m системное администрирование серверное администрирование серверная оптимизация настройка linux блог компании badoo linux nginx высокая производительность dropbox |
[Перевод] Оптимизация веб-серверов для повышения пропускной способности и уменьшения задержки |
Привет! Меня зовут Макс Матюхин, я работаю в SRV-команде Badoo. Мы в Badoo не только активно пишем посты в свой блог, но и внимательно читаем блоги наших коллег из других компаний. Недавно ребята из Dropbox опубликовали шикарный пост о различных способах оптимизации серверных приложений: начиная с железа и заканчивая уровнем приложения. Его автор – Алексей Иванов – дал огромное количество советов и ссылок на дополнительные источники информации. К сожалению, у Dropbox нет блога на Хабре, поэтому я решил перевести этот пост для наших читателей.
Это расширенная версия моего выступления на nginx.conf 2017 в сентябре этого года. В качестве старшего инженера по контролю качестве (SRE) в команде Dropbox Traffic я отвечаю за нашу сеть Edge: её надёжность, производительность и эффективность. Это proxy-tier-сеть, построенная на базе nginx и предназначенная как для обработки чувствительных к задержке метаданных, так и для передачи данных с высокой пропускной способностью. В системе, обрабатывающей десятки гигабитов в секунду и одновременно – десятки тысяч транзакций, чувствительных к задержкам, используются различные оптимизации эффективности и производительности: начиная с драйверов и прерываний, сквозь ядро и TCP/ IP-стек, и заканчивая библиотеками и настройками уровня приложения.
В этом посте мы рассмотрим многочисленные способы настройки веб-серверов и прокси. Пожалуйста, не занимайтесь карго-культом. Подходите к этому с позиции науки, применяйте оптимизации по одной, измеряйте эффект и принимайте решение, действительно ли они полезны для вашей работы.
Это не пост о производительности Linux (хотя я и буду часто ссылаться на bcc, eBPF и perf) и не исчерпывающее руководство по использованию инструментов профилирования производительности (если вы хотите узнать о них больше, почитайте блог Брендана Грегга).
Это также не пост о производительности браузеров. Я буду упоминать о клиентской производительности применительно к оптимизациям задержек, но очень коротко. Хотите узнать больше – прочитайте статью High Performance Browser Networking Ильи Григорика.
И это не компиляция на тему лучших методик TLS. Хотя я и буду упоминать TLS-библиотеки и их настройки, вы и ваша команда обеспечения безопасности должны самостоятельно оценивать их производительность и влияние на безопасность. Чтобы узнать, насколько ваши серверы отвечают набору лучших методик, можете воспользоваться Qualys SSL Test. Если хотите узнать больше о TLS в целом, подпишитесь на рассылку Feisty Duck Bulletproof TLS Newsletter.
Мы рассмотрим оптимизации эффективности/ производительности на разных уровнях системы. Начнём с самого нижнего, аппаратно-драйверного, уровня: эти настройки можно применить практически к любому высоконагруженному серверу. Затем я перейду к ядру Linux и его TCP/IP-стеку: можете покрутить эти ручки на своих ящиках, активно использующих TCP. Наконец, мы обсудим настройки на уровне библиотек и приложений, которые по большей части применимы ко многим веб-серверам и в частности к nginx.
По каждой области оптимизаций я постараюсь дать пояснения касательно компромиссов в отношении задержки/ пропускной способности (если они будут), а также дам советы по мониторингу и предложения по настройкам для разных уровней рабочей нагрузки.
Для хорошей производительности асимметричного RSA/EC выбирайте процессоры как минимум с поддержкой AVX2 (avx2 в /proc/cpuinfo) и желательно подходящие для вычислений с большими целыми числами (bmi и adx). Для симметричного шифрования выбирайте AES-NI для AES-шифров и AVX-512 – для ChaCha+Poly. У Intel есть сравнение производительности разных поколений процессоров с OpenSSL 1.0.2, где рассматривается влияние этих аппаратных оптимизаций.
Для задач, где важен уровень задержки, вроде роутинга рекомендуется уменьшить количество NUMA-узлов и отключить Hyper-Threading. Задачи, требующие высокой пропускной способности, эффективнее выполняются при большем количестве ядер с использованием Hyper-Threading (если только нет привязки к кэшу), и в целом NUMA не играет для них особой роли.
Если выбираете среди продукции Intel, то смотрите на процессоры с архитектурой Haswell/ Broadwell, а лучше Skylake. У AMD впечатляющую производительность демонстрируют EPYC-модели.
Вам нужно как минимум 10 Гбит, а лучше – 25 Гбит. Если хотите передавать через один сервер с TLS ещё больше, то описанных здесь настроек может быть недостаточно – возможно, придётся сдвинуть TLS-фрейминг на уровень ядра (FreeBSD, Linux).
Что касается программного уровня, поищите open-source-драйверы с активными списками рассылки и сообществами. Это будет очень важным фактором, если (скорее «когда») вы будете заниматься решением проблем, связанных с драйверами.
Эмпирическое правило: задачи, чувствительные к задержке, требуют более быстрой памяти; задачи, чувствительные к пропускной способности, требуют больше памяти.
Всё зависит от ваших требований к буферизации/кэшированию. Если вам нужно много буферизировать или кэшировать, то лучше выбрать SSD-диски. Некоторые даже устанавливают заточенные под флеш файловые системы (обычно log-structured), но они не всегда показывают более высокую производительность по сравнению с обычными ext4/ xfs.
В любом случае не сгубите свои флеш-накопители, забыв включить TRIM или обновить прошивку.
Используйте свежие прошивки, чтобы избежать долгого и болезненного выявления сбоев. Старайтесь поддерживать актуальные прошивки для процессора, материнской платы, сетевых карт и SSD-накопителей. Это не значит, что нужно всегда использовать самые последние версии — рекомендуется брать предпоследние, если в них нет критически важных багов, которые устранены в последних версиях.
Здесь можно дать тот же совет, что и в отношении прошивки: по возможности используйте свежие версии, но не последние. Старайтесь разделить апгрейды ядра и обновления драйверов. Например, можете упаковать драйверы с помощью DKMS или предварительно скомпилировать их для всех версий ядра, которые вы используете. Благодаря этому, если после обновления ядра что-то пойдёт не так, вы быстрее поймёте, в чём проблема.
Ваш лучший друг — репозиторий ядра (и инструменты, поставляемые с ним). В Ubuntu/ Debian вы можете установить пакет linux-tools с набором утилит, но в этом посте мы будем использовать только cpupower, turbostat и x86_energy_perf_policy. Для проверки связанных с процессором оптимизаций вы можете провести стресс-тестирование своего ПО с помощью любимого генератора нагрузки (например, Yandex.Tank). Вот презентация о лучших методиках нагрузочного тестирования от разработчиков nginx: NGINX Performance testing.
$ cpupower frequency-info
...
driver: intel_pstate
...
available cpufreq governors: performance powersave
...
The governor "performance" may decide which speed to use
...
boost state support:
Supported: yes
Active: yesПроверьте, включён ли Turbo Boost, а если у вас процессор Intel, удостоверьтесь, что система работает с intel_pstate, а не с acpi-cpufreq или pcc-cpufreq. Если вы всё ещё используете acpi-cpufreq, обновите ядро. Если это невозможно, используйте режим performance. При работе с intel_pstate даже режим powersave должен выполняться с хорошей производительностью, но вам придётся проверить это самостоятельно.
Что касается простоя, чтобы посмотреть, что реально происходит с вашим процессором, вы можете с помощью turbostat напрямую заглянуть в процессорные MSR и извлечь информацию о питании, частоте и так называемых Idle States:
# turbostat --debug -P
... Avg_MHz Busy% ... CPU%c1 CPU%c3 CPU%c6 ... Pkg%pc2 Pkg%pc3 Pkg%pc6 ...Здесь вы видите реальную частоту процессора (да, /proc/cpuinfo вам врёт), а также текущее состояние ядра/набора ядер.
Если даже с драйвером intel_pstate процессор тратит на простой больше времени, чем вы думали, вы можете:
x86_energy_perf_policy. А для очень чувствительных к задержке задач можно:
/dev/cpu_dma_latency; Узнать больше об управлении питанием процессора в целом и P-состояниями в частности можно из презентации Balancing Power and Performance in the Linux Kernel с LinuxCon Europe 2015.
Можно ещё больше уменьшить задержку, привязав поток или процесс к CPU. Например, в nginx есть директива worker_cpu_affinity, которая автоматически привязывает каждый процесс веб-сервера к конкретному ядру. Это позволяет исключить миграцию процесса / потока на другое ядро, уменьшить количество промахов кэша и ошибок страниц памяти, а также слегка увеличить количество инструкций в цикле. Всё это можно проверить через perf stat.
Но процессорная привязка негативно влияет на производительность, поскольку процессам дольше приходится ждать освобождения процессора. Это можно отслеживать с помощь запуска runqlat на одном из ваших PID nginx-воркера:
usecs : count distribution
0 -> 1 : 819 | |
2 -> 3 : 58888 |****************************** |
4 -> 7 : 77984 |****************************************|
8 -> 15 : 10529 |***** |
16 -> 31 : 4853 |** |
...
4096 -> 8191 : 34 | |
8192 -> 16383 : 39 | |
16384 -> 32767 : 17 | |Если заметите длинные хвосты на много миллисекунд, то, вероятно, на серверах выполняется слишком много всего, помимо nginx, и привязка увеличит задержку, а не уменьшит её.
Все настройки Memory Management обычно сильно зависят от рабочего процесса, так что могу дать лишь такие рекомендации:
madvise и включайте их, только когда уверены в их пользе, иначе можете сильно замедлить работу, стремясь к 20%-ному уменьшению задержки; vm.zone_reclaim_mode в 0.Современные процессоры представляют собой несколько отдельных процессоров, связанных очень быстрой шиной и совместно использующих различные ресурсы, начиная с кэша L1 на HT-ядрах и заканчивая кэшем L3 применительно к пакетам, памятью и PCIe-соединениями в рамках сокетов. Это и есть NUMA: многочисленные модули исполнения и хранения с быстрой шиной обмена данными.
Исчерпывающее описание NUMA и её применения содержится в статье Фрэнка Деннемана NUMA Deep Dive Series.
Короче, вы можете:
numactl --interleave=all (так вы получите посредственную, но достаточно стабильную производительность); Давайте рассмотрим третий вариант, поскольку в двух остальных не требуется много оптимизировать.
Для правильного использования NUMA вам нужно рассматривать каждый её узел в качестве отдельного сервера. Проверьте топологию с помощью numactl --hardware:
$ numactl --hardware
available: 4 nodes (0-3)
node 0 cpus: 0 1 2 3 16 17 18 19
node 0 size: 32149 MB
node 1 cpus: 4 5 6 7 20 21 22 23
node 1 size: 32213 MB
node 2 cpus: 8 9 10 11 24 25 26 27
node 2 size: 0 MB
node 3 cpus: 12 13 14 15 28 29 30 31
node 3 size: 0 MB
node distances:
node 0 1 2 3
0: 10 16 16 16
1: 16 10 16 16
2: 16 16 10 16
3: 16 16 16 10Что нужно проверять:
Это очень плохой пример, поскольку здесь четыре узла, и к тому же прикреплены узлы без памяти. Здесь нельзя использовать каждый узел как отдельный сервер без потери половины ядер.
Это можно проверить с помощью numastat:
$ numastat -n -c
Node 0 Node 1 Node 2 Node 3 Total
-------- -------- ------ ------ --------
Numa_Hit 26833500 11885723 0 0 38719223
Numa_Miss 18672 8561876 0 0 8580548
Numa_Foreign 8561876 18672 0 0 8580548
Interleave_Hit 392066 553771 0 0 945836
Local_Node 8222745 11507968 0 0 19730712
Other_Node 18629427 8939632 0 0 27569060Также с помощью numastat можно получить статистику использования памяти по каждому узлу в формате /proc/meminfo:
$ numastat -m -c
Node 0 Node 1 Node 2 Node 3 Total
------ ------ ------ ------ -----
MemTotal 32150 32214 0 0 64363
MemFree 462 5793 0 0 6255
MemUsed 31688 26421 0 0 58109
Active 16021 8588 0 0 24608
Inactive 13436 16121 0 0 29557
Active(anon) 1193 970 0 0 2163
Inactive(anon) 121 108 0 0 229
Active(file) 14828 7618 0 0 22446
Inactive(file) 13315 16013 0 0 29327
...
FilePages 28498 23957 0 0 52454
Mapped 131 130 0 0 261
AnonPages 962 757 0 0 1718
Shmem 355 323 0 0 678
KernelStack 10 5 0 0 16Теперь рассмотрим пример более простой топологии.
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
node 0 size: 46967 MB
node 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
node 1 size: 48355 MBПоскольку узлы по большей части симметричны, мы можем привязать экземпляр нашего приложения к каждому NUMA-узлу с помощью numactl --cpunodebind=X --membind=X, а затем открыть его на другом порте. Пропускная способность увеличится благодаря использованию обоих узлов и уменьшению задержки за счёт сохранения локальности памяти.
Проверить эффективность размещения NUMA можно по задержке операций в памяти. Например, с помощью funclatency в BCC измерьте задержку операции, активно использующей память, допустим, memmove.
Наблюдать за эффективностью на стороне ядра можно с помощью perf stat, отслеживая соответствующие события памяти и планировщика:
# perf stat -e sched:sched_stick_numa,sched:sched_move_numa,sched:sched_swap_numa,migrate:mm_migrate_pages,minor-faults -p PID
...
1 sched:sched_stick_numa
3 sched:sched_move_numa
41 sched:sched_swap_numa
5,239 migrate:mm_migrate_pages
50,161 minor-faultsПоследняя порция связанных с NUMA оптимизаций для сетевых нагрузок с активным использованием сети продиктована тем фактом, что сетевая карта — это PCIe-устройство, а каждое устройство привязано к своему NUMA-узлу; следовательно, у каких-то процессоров задержка при обращении к сети будет меньше. Возможные оптимизации мы обсудим в главе, где будет рассматриваться привязка сетевая карта -> процессор, а пока перейдём к PCI Express.
Обычно нет нужды углубляться в решение проблем с PCIe, если только не возникает какой-то аппаратный сбой. Однако стоит хотя бы просто создать для своих PCIe-устройств «ширину шины», «скорость шины» и предупреждения RxErr/BadTLP. Это должно сэкономить вам часы на отладку из повреждённого железа или сбойного PCIe-согласования. Для этого можете воспользоваться lspci:
# lspci -s 0a:00.0 -vvv
...
LnkCap: Port #0, Speed 8GT/s, Width x8, ASPM L1, Exit Latency L0s <2us, L1 <16us
LnkSta: Speed 8GT/s, Width x8, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
...
Capabilities: [100 v2] Advanced Error Reporting
UESta: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UEMsk: DLP- SDES- TLP- FCP- CmpltTO- CmpltAbrt- ...
UESvrt: DLP+ SDES+ TLP- FCP+ CmpltTO- CmpltAbrt- ...
CESta: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr-
CEMsk: RxErr- BadTLP- BadDLLP- Rollover- Timeout- NonFatalErr+PCIe может стать узким местом, если у вас несколько высокоскоростных устройств, конкурирующих за ширину канала (например, при комбинации быстрой сети с быстрым хранилищем), так что вам может понадобиться физически шардить свои PCIe-устройства среди процессоров, чтобы получить максимальную пропускную способность.
Также советую прочитть статью Understanding PCIe Configuration for Maximum Performance, в ней подробнее рассматривается конфигурация PCIe, что может быть полезно при высоких скоростях, когда происходит потеря пакетов между картой и ОС.
Intel предполагает, что иногда управление питанием PCIe (ASPM) может приводить к большим задержкам, а значит, и к потере большего количества пакетов. Эту функцию можно отключить, введя pcie_aspm=off в командной строке ядра.
Прежде чем мы начнём, стоит упомянуть, что Intel и Mellanox предлагают собственные руководства по настройке производительности, и вне зависимости от выбранного вами вендора стоит прочитать оба материала. Кроме того, драйверы обычно идут с собственными README и наборами полезных утилит.
Также можете поискать руководства для вашей ОС. Например, в руководстве по настройке сетевой производительности в Linux от Red Hat Enterprise объясняются многие из упомянутых выше оптимизаций. У Cloudflare тоже есть хорошая статья о настройке этой части сетевого стека, хотя по большей части она посвящена ситуациям, когда нужна низкая задержка.
В ходе оптимизации вашим лучшим другом будет ethtool.
Примечание: если вы используете достаточно свежее ядро (а вам следует это сделать!), то вы также столкнётесь с некоторыми аспектами вашего пользовательского пространства. Например, для сетевых операций вы, вероятно, захотите использовать более свежие версии пакетов ethtool, iproute2 и, быть может, iptables/nftables.
Получить ценные сведения о том, что происходит с вашей сетевой картой, можно с помощью ethtool -S:
$ ethtool -S eth0 | egrep 'miss|over|drop|lost|fifo'
rx_dropped: 0
tx_dropped: 0
port.rx_dropped: 0
port.tx_dropped_link_down: 0
port.rx_oversize: 0
port.arq_overflows: 0Проконсультируйтесь с производителем вашей сетевой карты относительно подробного описания статистики. Например, у Mellanox есть отдельная Wiki-статья об этом.
Что касается ядра, то нужно смотреть /proc/interrupts, /proc/softirqs и /proc/net/softnet_stat. Здесь есть два полезных BCC-инструмента: hardirqs и softirqs. Цель вашей оптимизации сети заключается в такой настройке системы, чтобы процессор использовался минимально, а пакеты не терялись.
Обычно настройки здесь начинаются с распределения прерываний по процессорам. Как именно это делать, зависит от вашей рабочей нагрузки:
ethtool -L). Как правило, для этого вендоры предоставляют скрипты. Например, у Intel это set_irq_affinity.
Сетевым картам нужно обмениваться информацией с ядром. Обычно это делается через структуру данных, называющуюся «кольцо». Текущий/ максимальный размер этого кольца можно посмотреть с помощью ethtool -g:
$ ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
TX: 4096
Current hardware settings:
RX: 4096
TX: 4096С помощью -G можно настраивать значения в рамках предварительно заданных экстремумов. Обычно чем больше, тем лучше (особенно если вы используете объединение прерываний), поскольку это даёт вам лучшую защиту от пиков и каких-то проблем в ядре, а значит, уменьшает количество дропнутых пакетов из-за нехватки места в буфере или пропущенного прерывания. Но есть пара предостережений:
в более старых ядрах или драйверах без поддержки BQL высокие значения могут относиться к более высокому bufferbloat на TX-стороне;
Этот механизм обеспечивает задержку уведомления ядра о новых событиях за счёт объединения нескольких сообщений в одно прерывание. Текущие настройки можно посмотреть с помощью ethtool -c:
$ ethtool -c eth0
Coalesce parameters for eth0:
...
rx-usecs: 50
tx-usecs: 50Также вы можете придерживаться статичных пределов (static limits), жёстко ограничив максимальное количество прерываний в секунду на одно ядро, или положиться на автоматическую аппаратную подстройку частоты прерываний в зависимости от пропускной способности.
Включение объединения (-C) увеличит задержку и, вероятно, приведёт к потере пакетов, так что эту функцию не рекомендуется использовать для задач, чувствительных к уровню задержки. Но с другой стороны, её полное отключение может привести к троттлингу прерываний, а следовательно, ограничению производительности.
Современные сетевые карты довольно умны и могут разгружать немалую часть работы посредством железа либо эмулировать разгрузку в самих драйверах.
Все возможные разгрузки можно просмотреть с помощью ethtool -k:
$ ethtool -k eth0
Features for eth0:
...
tcp-segmentation-offload: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]Все ненастраиваемые разгрузки помечены суффиксом [fixed]. О них можно долго рассказывать, но я только приведу несколько эмпирических правил:
Все современные сетевые карты оптимизированы под многопроцессорные системы, поэтому они распределяют пакеты по виртуальным очередям (обычно по одной на процессор). Когда это выполняется аппаратно, то называется RSS; когда за балансировку пакетов между процессорами отвечает ОС, это называется RPS (TX-эквивалент называется XPS). Если ОС пытается регулировать потоки к процессорам, которые в данный момент обрабатывают этот сокет, это называется RFS. А когда этим занимается железо, это называется «ускоренный RFS» или aRFS.
Вот несколько хороших методик:
1) у вас больше процессоров, чем аппаратных очередей, и вы хотите пожертвовать задержкой в пользу пропускной способности;
2) вы используете внутреннее туннелирование (например, GRE/ IPinIP), при котором сетевая карта не может применять RSS;
Включённый Flow Director (или fdir в терминологии Intel) по умолчанию оперирует в режиме Application Targeting Routing, при котором реализуется aRFS посредством семплирования пакетов и регулирования потоков в процессорное ядро, где они, по-видимому, обрабатываются. Статистику можно посмотреть с помощью ethtool -S:$ ethtool -S eth0 | egrep ‘fdir’ port.fdir_flush_cnt: 0 …
Хотя Intel заявляет, что fdir в некоторых случаях увеличивает производительность, результаты одного исследования говорят о том, что это может также привести к переупорядочиванию 1% пакетов, что может довольно негативно сказаться на производительности TCP. Поэтому протестируйте самостоятельно и посмотрите, будет ли Flow Director полезен при вашей рабочей нагрузке, проверяя счётчик TCPOFOQueue.
Существует огромное количество книг, видео и руководств по настройке сетевого стека Linux, в которых растиражирован «карго-культ sysctl.conf». И хотя свежие версии ядра уже не требуют такого объёма настройки, как десять лет назад, а большинство новых TCP/ IP-свойств по умолчанию включены и хорошо настроены, люди продолжают копипастить свои старые sysctls.conf, которые они использовали для настройки ядер версий 2.6.18/ 2.6.32.
Для проверки эффективности сетевых оптимизаций сделайте следующее:
/proc/net/snmp and /proc/net/netstat соберите TCP-метрики в рамках системы; ss -n --extended --info или при вызове внутри сервера getsockopt(``[TCP_INFO]``)/getsockopt(``[TCP_CC_INFO]``); В качестве источников информации о сетевых оптимизациях я обычно использую выступления специалистов по CDN, потому что, как правило, они знают, что делают. Например, Fastly on LinuxCon Australia. Полезно также послушать, что говорят разработчики ядра Linux, к примеру, на NetDevConf и Netconf.
Также стоит упомянуть про подробные материалы от PackageCloud по сетевому стеку Linux, особенно в свете того, что они сделали акцент на мониторинг, а не на «слепую» настройку:
И позвольте дать совет напоследок: обновите ядро ОС! Существует множество новых сетевых улучшений, и я говорю даже не об IW10 (который 2010) – я говорю о таких новинках, как автоматический выбор размера TSO, FQ, pacing, TLP и RACK. В качестве бонуса от апгрейда вы получите ряд улучшений масштабируемости, например, убранный кэш рутинга, неблокирующие сокеты прослушивания, SO_REUSEPORT и многое другое.
Из недавних документов по работе с сетью в Linux особенно выделяется Making Linux TCP Fast. В нём на четырёх страницах собраны улучшения в ядре ОС за много лет. TCP-стек на стороне отправителя разбит на функциональные части:
Fair queueing отвечает за соблюдение «справедливости» и уменьшает блокировку очереди между TCP-потоками, что положительно сказывается на частоте отбрасывания пакетов. Pacing, в свою очередь, равномерно распределяет пакеты во времени с частотой, определяемой Congestion Control, что ещё больше уменьшает долю потерянных пакетов, тем самым увеличивая пропускную способность.
Попутно хочу заметить, что fair queueing и pacing доступны в Linux посредством fq qdisc. Обе фичи требуются для BBR (впрочем, уже нет), но их можно использовать и с CUBIC, добиваясь 15–20%-ного снижения потери пакетов, а значит, и повышения пропускной способности в алгоритмах управления перегрузками (loss-based CCs). Только не используйте их на старых ядрах (<3.19), поскольку вы станете регулировать обычные ACKs и сломаете аплоад/ RPCs.
Обе функции отвечают за ограничение буферизации внутри TCP-стека, а следовательно, и за уменьшение задержки без ухудшения пропускной способности.
CC-алгоритмы сами по себе – объёмная тема, и в последние годы о них было много разговоров. Что-то из этого вылилось в код: tcp_cdg (CAIA), tcp_nv (Facebook) и tcp_bbr (Google). Мы не будем углубляться в их устройство, скажу лишь, что индикация о перегрузке во всех них основана больше на увеличении отсрочки (delay), чем на отбрасывании пакетов.
BBR – один из наиболее задокументированных, протестированных и практичных из всех новых алгоритмов управления перегрузками. На основании доли доставленных пакетов создаётся модель сетевого пути, а затем для увеличения ширины пропускания и минимизации RTT выполняются управляющие циклы. Это именно то, что мы ищем в нашем прокси-стеке.
Предварительные результаты экспериментов с BBR на наших Edge PoP показали увеличение скорости скачивания файлов:
Шестичасовой эксперимент с TCP BBR в Tokyo PoP: ось x — время, ось y — скорость скачивания на клиенте
Увеличение скорости наблюдалось по всем перцентилям. При изменениях бэкенда такого не происходит — обычно положительный результат наблюдается только p90+ пользователей (у которых самое быстрое интернет-подключение), поскольку мы считаем, что у всех остальных уже ограничена полоса пропускания. Настройки на сетевом уровне вроде изменения управления перегрузками или включения FQ/ pacing демонстрируют, что у пользователей ограничена не полоса пропускания, а, я бы сказал, присутствует «ограниченность TCP».
Если вы хотите больше узнать о BBR, то у APNIC есть хороший обзор для новичков (и сравнение с loss-based-управлением перегрузками). Более глубокую информацию можно извлечь из архивов почтовой рассылки bbr-dev (там сверху закреплено множество полезных ссылок). Если вас в целом интересует тема управления перегрузками, то можете понаблюдать за активностью Internet Congestion Control Research Group.
Теперь поговорим об обнаружении пропадания пакетов (loss detection). Снова упомяну про важность использования свежей версии ядра ОС. В TCP постоянно добавляются новые эвристики вроде TLP и RACK, а старые (наподобие FACK и ER) убираются. Нововведения работают по умолчанию, так что вам не придётся настраивать систему после апгрейда.
API сокета пользовательского пространства (userspace socket API) предоставляют механизм явной буферизации, и после отправки чанков их уже невозможно перегруппировать. Поэтому при использовании мультиплексирования (например, в HTTP/2) это может привести к Head-of-Line блокировке и инверсии h2-приоритетов. Для решения этой проблемы были разработаны опция сокета и соответствующая опция sysctl net.ipv4.tcp_notsent_lowat. Они позволяют настраивать границы, в пределах которых сокет считает себя доступным для записи (то есть epoll в вашем приложении будет врать). Это может решить проблемы с HTTP/2-приоритизацией, но при этом плохо повлиять на пропускную способность, так что рекомендую проверить самостоятельно.
Непросто говорить об оптимизации работы с сетью, не упомянув про необходимость настройки sysctls. Но сначала рассмотрим, что вам трогать точно не следует:
net.ipv4.tcp_tw_recycle=1: не используйте это — для пользователей за NAT это всё уже сломано, а если вы обновите ядро, то сломаете у всех; net.ipv4.tcp_timestamps=0: не отключайте как минимум до тех пор, пока не будете знать обо всех побочных эффектах. Например, одним из неочевидных последствия является то, что вы лишитесь оконного масштабирования и SACK-опций в syncookie.Лучше сделайте вот что:
net.ipv4.tcp_slow_start_after_idle=0: главная проблема с медленным стартом (slow start) после простоя заключается в том, что «простой» определяется как один RTO, а этого слишком мало; net.ipv4.tcp_mtu_probing=1: полезно при наличии ICMP-«чёрных дыр» между вами и клиентами (наверняка они есть ); net.ipv4.tcp_rmem, net.ipv4.tcp_wmem: нужно настроить так, чтобы подходило к BDP; только не забудьте, что больше – не значит лучше; echo 2 > /sys/module/tcp_cubic/parameters/hystart_detect: если вы используете FQ+CUBIC, то это может помочь решить проблему слишком раннего выхода tcp_cubic из медленного старта. Стоит упомянуть, что существует RFC-черновик (хотя и подзаброшенный) от Дэниела Штенберга, автора curl, под названием TCP Tuning for HTTP, в котором сделана попытка собрать все системные настройки, которые могут быть полезны для HTTP.
Как и в случае с ядром ОС, пользовательское пространство крайне важно актуализировать. Начните с обновления своего инструментария, например, можете упаковать более свежие версии perf, bcc и так далее.
После этого можно приступать к настройке и отслеживанию поведения системы. В этой части поста мы будем по большей части опираться на профилирование процессора с помощью perf top, on-CPU flame-графики и ad hoc-гистрограммы из funclatency в bcc.
Если вы хотите сделать аппаратно-оптимизированную сборку, то необходимо обзавестись современными инструментами для компилирования, представленных во многих библиотеках, широко используемых в веб-серверах.
Помимо производительности, новые компиляторы могут похвастаться и новыми свойствами обеспечения безопасности (например, -fstack-protector-strong или SafeStack). Также современный инструментарий будет полезен, если вы хотите прогонять тесты через бинарные файлы, скомпилированные с использованием санитайзеров (например, AddressSanitizer и других).
Рекомендую обновить системные библиотеки вроде glibc, иначе вы можете не получить свежих оптимизаций низкоуровневых функций из -lc, -lm, -lrt и так далее. Стандартное предупреждение: тестируйте самостоятельно, поскольку могут встречаться неожиданные регрессии.
Обычно за компрессию отвечает веб-сервер. В зависимости от объёма данных, проходящих через прокси, вы можете встретить упоминание zlib в perf top, например:
# perf top
...
8.88% nginx [.] longest_match
8.29% nginx [.] deflate_slow
1.90% nginx [.] compress_blockЭто можно оптимизировать на самом низком уровне: Intel и Cloudflare, как и отдельный проект zlib-ng, имеют собственные zlib-форки, обеспечивающие более высокую производительность за счёт использования новых наборов инструкций.
При обсуждении оптимизаций до этого момента мы по большей части ориентировались на процессор. Теперь же поговорим о памяти. Если вы активно используете Lua с FFI или тяжёлые сторонние модули, которые самостоятельно управляют памятью, то могли заметить рост потребления памяти из-за фрагментации. Эту проблему можно попытаться решить переключением на jemalloc или tcmalloc.
Использование кастомного malloc даёт следующие преимущества:
Если в конфигурации nginx вы используете многочисленные сложные регулярные выражения или активно применяете Lua, то могли встретить в perf top упоминание PCRE. Это можно оптимизировать, скомпилировав PCRE с JIT, а также включив её в nginx посредством pcre_jit on;.
Результат оптимизации можно проверить на flame-графиках или с помощью funclatency:
# funclatency /srv/nginx-bazel/sbin/nginx:ngx_http_regex_exec -u
...
usecs : count distribution
0 -> 1 : 1159 |********** |
2 -> 3 : 4468 |****************************************|
4 -> 7 : 622 |***** |
8 -> 15 : 610 |***** |
16 -> 31 : 209 |* |
32 -> 63 : 91 | |Если вы прерываете TLS не на границе с CDN, то TLS-оптимизации могут сыграть важную роль. При обсуждении настроек мы будем по большей части говорить об их эффективности на стороне сервера.
Сегодня первое, что вам нужно решить, — какую TLS-библиотеку вы будете использовать: Vanilla OpenSSL, OpenBSD’s LibreSSL или BoringSSL от Google. Определившись, вам нужно правильно её собрать: к примеру, у OpenSSL есть куча сборочных эвристик, позволяющих использовать оптимизации на базе сборочного окружения; у BoringSSL есть детерминистские сборки, но они более консервативны и по умолчанию просто отключают некоторые оптимизации. В любом случае, здесь вы наконец-то ощутите выгоду от выбора современного процессора: большинство TLS-библиотек могут использовать всё, от AES-NI и SSE до ADX и AVX-512. Можете воспользоваться встроенными тестами производительности. Например, в случае с BoringSSL это bssl speed.
Производительность по большей части зависит не от вашего железа, а от наборов шифров, которые вы собираетесь использовать, так что оптимизируйте их с осторожностью. Также знайте, что изменения в данном случае повлияют на безопасность вашего веб-сервера — самые быстрые наборы не обязательно лучшие. Если не знаете, какое шифрование использовать, можете начать с Mozilla SSL Configuration Generator.
Если у вас “front”-сервис (сервис к которому пользователи подключаются напрямую), то вы могли столкнуться со значительным количеством TLS-«рукопожатий», а значит, немалая доля ресурсов вашего процессора тратится на асимметричное шифрование, которое необходимо оптимизировать.
Для оптимизации использования серверного процессора можете переключиться на сертификаты ECDSA, которые в десять раз быстрее, чем RSA. К тому же они значительно меньше, что может ускорить «рукопожатия» при наличии потерь пакетов. Но ECDSA сильно зависят от качества генератора случайных чисел в вашей системе, так что если вы используете OpenSSL, то удостоверьтесь, что у вас достаточно энтропии (в случае с BoringSSL об этом можно не волноваться).
И ещё раз напоминаю, что больше – не значит лучше, то есть использование сертификатов 4096 RSA ухудшит производительность в десять раз:
$ bssl speed
Did 1517 RSA 2048 signing ... (1507.3 ops/sec)
Did 160 RSA 4096 signing ... (153.4 ops/sec)Но меньше тоже не значит лучше: при использовании малораспространённого поля p-224 для ECDSA вы получите 60%-ное снижение производительности по сравнению с обычным p-256:
$ bssl speed
Did 7056 ECDSA P-224 signing ... (6831.1 ops/sec)
Did 17000 ECDSA P-256 signing ... (16885.3 ops/sec)Эмпирическое правило: самое распространённое шифрование обычно самое оптимизированное.
При запуске правильно оптимизированной библиотеки на основе OpenTLS, использующей сертификаты RSA, в своём perf top вы должны увидеть следующие трейсы: процессоры, использующие AVX2, а не ADX (например, с архитектурой Haswell), должны использовать кодовый путь AVX2:
6.42% nginx [.] rsaz_1024_sqr_avx2
1.61% nginx [.] rsaz_1024_mul_avx2Более новые модели должны использовать обычный алгоритм Монтгомери с кодовым путём ADX:
7.08% nginx [.] sqrx8x_internal
2.30% nginx [.] mulx4x_internalЕсли у вас много массовых передач данных вроде видео, фото и прочих файлов, то можете начать отслеживать в данных профилировщика упоминания о симметричном шифровании. Тогда просто удостоверьтесь, что ваш процессор поддерживает AES-NI и что вы настроили на сервере применение шифров AES-GCM. При правильно настроенном оборудовании в perf top должно выдаваться:
8.47% nginx [.] aesni_ctr32_ghash_6xНо заниматься шифрованием/ дешифрованием будут не только ваши серверы, но и клиенты, причём у них априори гораздо более слабые процессоры. Без аппаратного ускорения это может быть достаточно сложной операцией, поэтому позаботьтесь о выборе алгоритма, который работает быстро без аппаратных технологий ускорения работы с шифрованием, например, ChaCha20-Poly1305. Это снизит TTLB для части мобильных клиентов.
В BoringSSL из коробки поддерживается ChaCha20-Poly1305, а в OpenSSL 1.0.2 можете использовать патчи Cloudflare. BoringSSL также поддерживает «шифрогруппы равного предпочтения», так что можете использовать следующую конфигурацию, которая позволит клиентам решать, какие шифры использовать, отталкиваясь от своих аппаратных возможностей (бесстыдно украдено из cloudflare/sslconfig):
ssl_ciphers '[ECDHE-ECDSA-AES128-GCM-SHA256|ECDHE-ECDSA-CHACHA20-POLY1305|ECDHE-RSA-AES128-GCM-SHA256|ECDHE-RSA-CHACHA20-POLY1305]:ECDHE+AES128:RSA+AES128:ECDHE+AES256:RSA+AES256:ECDHE+3DES:RSA+3DES';
ssl_prefer_server_ciphers on;Для анализа эффективности ваших оптимизаций на этом уровне вам нужно собирать RUM-данные. В браузерах можно применять API Navigation Timing и Resource Timing. Ваши главные метрики — TTFB и TTV/ TTI. Вам сильно упростит итерирование, если эти данные будут представлены в форматах, удобных для составления запросов и графиков.
В nginx компрессия начинается с файла mime.types, определяющего соответствие между расширением файла и MIME-типом. Затем вам нужно определить, какой тип вы хотите передавать компрессору, с, например, gzip_types. Если хотите завершить этот список, то для автоматического генерирования mime.types с добавлением compressible == true to gzip_types можете воспользоваться mime-db.
Включая gzip, имейте в виду:
gzip_buffers); gzip_no_buffer).Отмечу, что HTTP-компрессия не ограничивается одним gzip: в nginx есть сторонний модуль ngx_brotli, который способен сжимать на 30% лучше, чем gzip.
Что касается настроек сжатия, давайте рассмотрим два отдельных случая: статичные и динамические данные.
В случае со статичными данными можно архивировать коэффициенты сжатия с помощью предварительной компрессии статичных ресурсов, сделав эту процедуру частью процесса сборки. Для gzip и brotli это подробно рассмотрено в посте Deploying Brotli for static content.
В случае с динамическими данными вам нужно выполнять осторожную балансировку полного цикла: время на сжатие данных + время на их передачу + время на распаковку. Поэтому может быть нецелесообразно устанавливать самую высокую степень сжатия не только с точки зрения потребления ресурсов процессора, но и с точки зрения TTFB.
Буферизация внутри прокси может сильно влиять на производительность веб-сервера, особенно с учётом задержки. В прокси-модуле nginx есть разные настройки буферизации, которые можно регулировать в зависимости от местонахождения буферов и каждая из которых полезна в определённых случаях. С помощью proxy_request_buffering и proxy_buffering можно отдельно управлять буферизацией в обоих направлениях. Если включена буферизация, то верхняя граница потребления памяти определяется с помощью client_body_buffer_size и proxy_buffers, и по достижении этой границы запрос/ ответ будут буферизоваться на диске. Для ответов это можно отключить, присвоив proxy_max_temp_file_size значение 0.
Наиболее распространённые примеры использования:
X-Accel-Buffering можно реализовать управляемую приложением буферизацию ответов. Что бы вы ни выбрали, не забудьте протестировать это на TTFB и TTLB. Как уже упоминалось, буферизация может повлиять на количество операций ввода/ вывода и даже использование бэкенда, так что отслеживайте и эти моменты.
Теперь поговорим о высокоуровневых аспектах TLS и уменьшения задержки, которые можно реализовать с помощью правильной конфигурации nginx. Большинство оптимизаций, которые я буду упоминать, описаны в разделе Optimizing for TLS High Performance Browser Networking и в выступлении Making HTTPS Fast(er) на nginx.conf 2014. Настройки, описываемые в этой части поста, повлияют на производительность и безопасность вашего веб-сервера, так что, если вы в них не уверены, обратитесь к руководству Mozilla’s Server Side TLS Guide и/ или проконсультируйтесь со своими коллегами, отвечающими за безопасность.
Для проверки результатов оптимизаций можно использовать:
Как любят говорить DBA, «самый быстрый запрос – тот, который вы не делали». Это касается и TLS: можно уменьшить задержку с помощью одного RTT, если вы кэшируете результаты «рукопожатия». Это можно сделать двумя способами:
ssl_session_tickets. Это не приводит к потреблению памяти на сервере, но имеет ряд недостатков: 1) понадобится инфраструктура для создания, ротации и распределения случайных ключей шифрования/ подписи для TLS-сессий. Помните, что не следует: 1) использовать управление ресурсами для хранения тикет-ключей; 2) генерировать эти ключи на основе каких-то неэфемерных вещей вроде даты или сертификата;
2) PFS будет зависеть не от конкретной сессии, а от TLS-тикет-ключа, так что если злоумышленник завладеет тикет-ключом, то сможет расшифровать любой перехваченный трафик в течение всего действия тикета;
3) ваше шифрование будет ограничено размером тикет-ключа. Не имеет смысла использовать AES-256, если вы применяете 128-битный тикет-ключ. Nginx поддерживает 128-битные и 256-битные ключи;
4) не все клиенты поддерживают тикет-ключи (хотя они поддерживаются всеми современными браузерами);
1) они потребляют на сервере ~256 байтов памяти на каждую сессию, так что вы не сможете хранить слишком много ключей слишком долго;
2) нет простого способа использовать их одновременно несколькими серверами. Так что вам понадобится ещё и балансировщик нагрузки, который будет отправлять тот же клиент на тот же сервер, чтобы сохранить локальн
|
Метки: author max_m системное администрирование серверное администрирование серверная оптимизация настройка linux блог компании badoo linux nginx высокая производительность dropbox |
Тайминговая атака на Node.js — когда время работает против вас |
|
Метки: author serpentcross информационная безопасность node.js javascript блог компании «альфа-банк» уязвимость атака тайминговая атака |
Тайминговая атака на Node.js — когда время работает против вас |
|
Метки: author serpentcross информационная безопасность node.js javascript блог компании «альфа-банк» уязвимость атака тайминговая атака |
Трюки в Chrome DevTools |
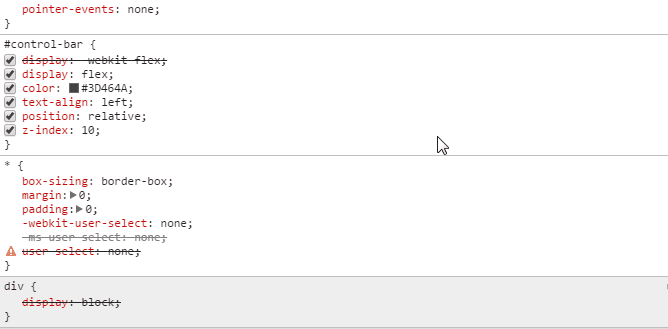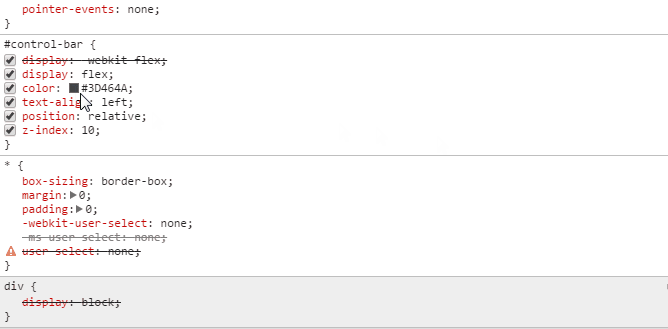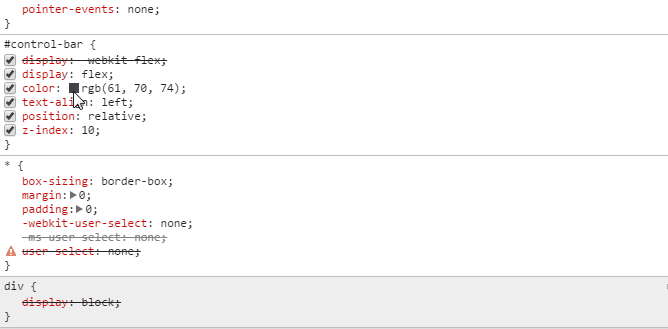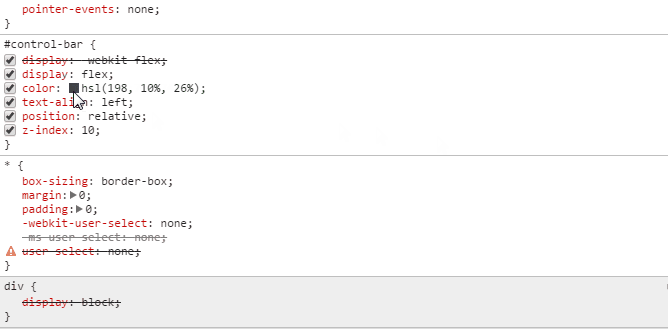
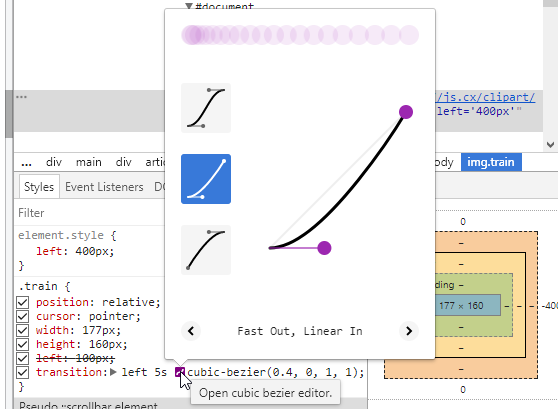
function name(obj) {
console.group('name');
console.log('first: ', obj.first);
console.log('middle: ', obj.middle);
console.log('last: ', obj.last);
console.groupEnd();
}
name({"first":"Wile","middle":"E","last":"Coyote"});

function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
var family = {};
family.mother = new Person("Jane", "Smith");
family.father = new Person("John", "Smith");
family.daughter = new Person("Emily", "Smith");
console.table(family);


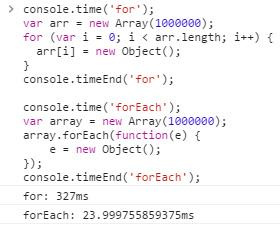
console.profile();
// Some code to execute
console.profileEnd();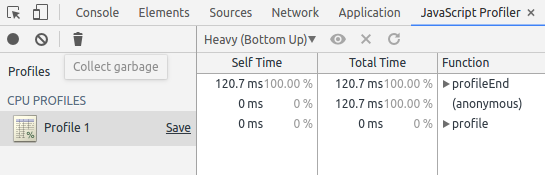
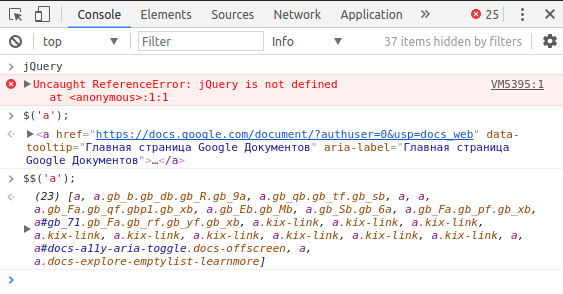

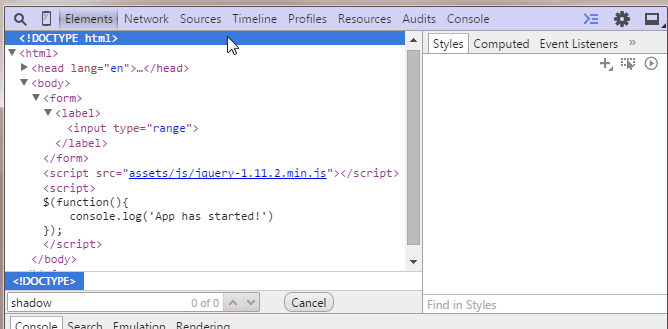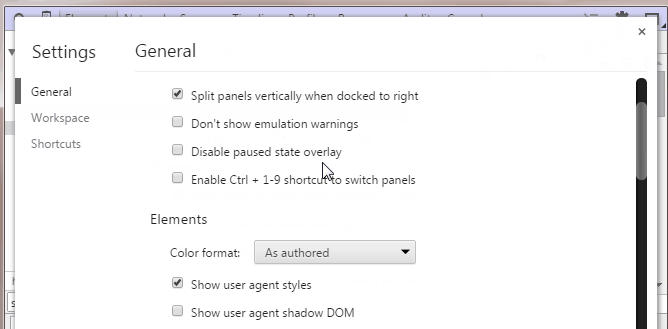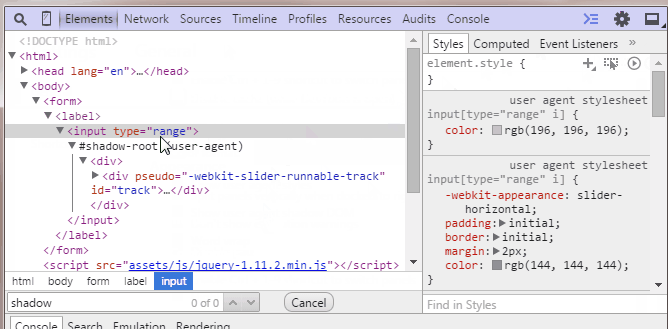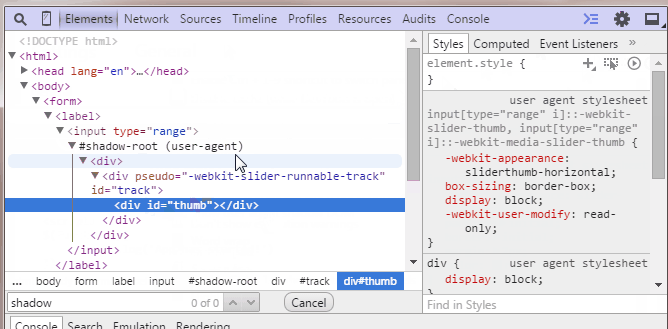

|
Метки: author SSul google chrome блог компании simbirsoft |
Трюки в Chrome DevTools |
function name(obj) {
console.group('name');
console.log('first: ', obj.first);
console.log('middle: ', obj.middle);
console.log('last: ', obj.last);
console.groupEnd();
}
name({"first":"Wile","middle":"E","last":"Coyote"});
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
var family = {};
family.mother = new Person("Jane", "Smith");
family.father = new Person("John", "Smith");
family.daughter = new Person("Emily", "Smith");
console.table(family);
console.profile();
// Some code to execute
console.profileEnd();|
Метки: author SSul google chrome блог компании simbirsoft |
Точка Б: как мы обучали приложение Яндекс.Такси предсказывать пункт назначения |

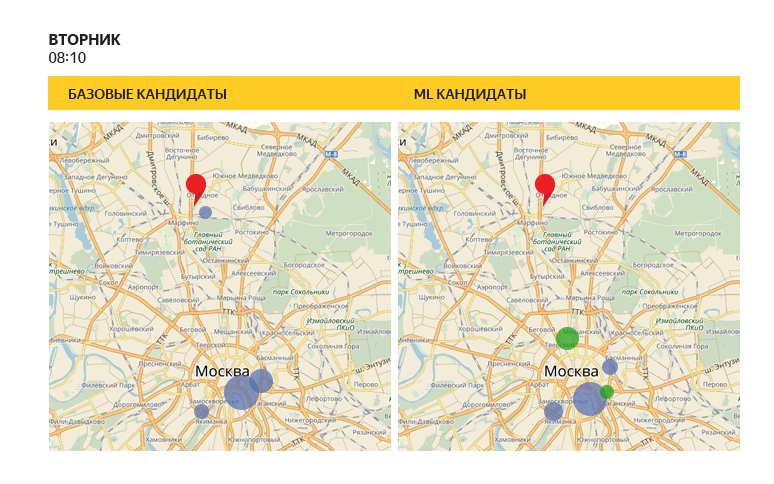
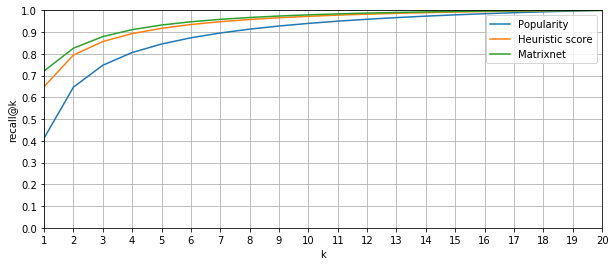
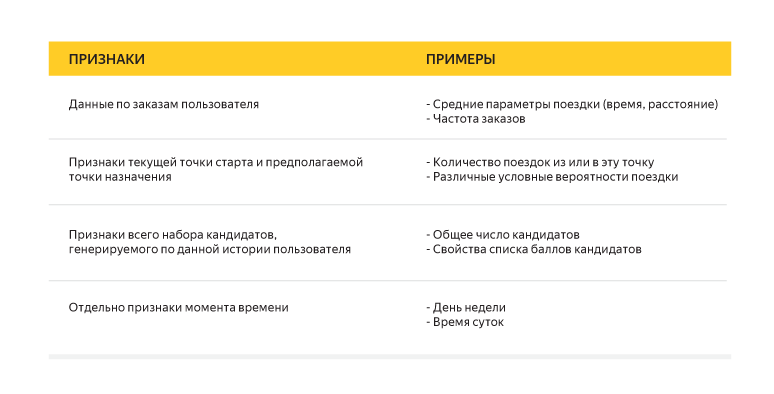

|
Метки: author vkantor машинное обучение алгоритмы data mining big data блог компании яндекс яндекс.такси анализ данных machine learning |
Философия статического анализа кода: три простых шага |
 Философия статического анализа кода очень проста. Чем раньше будет найдена ошибка, тем дешевле ее исправление. Инструменты статического анализа реализуют эту философию в три шага.
Философия статического анализа кода очень проста. Чем раньше будет найдена ошибка, тем дешевле ее исправление. Инструменты статического анализа реализуют эту философию в три шага.|
Метки: author EvgeniyRyzhkov управление разработкой управление проектами управление продуктом блог компании pvs-studio статический анализ кода c++ c# java |
Философия статического анализа кода: три простых шага |
Философия статического анализа кода очень проста. Чем раньше будет найдена ошибка, тем дешевле ее исправление. Инструменты статического анализа реализуют эту философию в три шага.|
Метки: author EvgeniyRyzhkov управление разработкой управление проектами управление продуктом блог компании pvs-studio статический анализ кода c++ c# java |






