Chris McAvoy: Hand Crafted Open Badges Display |
Earning an Open Badge is easy, there’s plenty of places that offer them, with more issuers signing up every day. Once you’ve earned an open badge, you can push it to your backpack, but what if you want to include the badge on your blog, or your artisanal hand crafted web page?
You could download the baked open badge and host it on your site. You could tell people it’s a baked badge, but using that information isn’t super easy. Last year, Mike Larsson had a great idea to build a JS library that would discover open badges on a page, and make them dynamic so that a visitor to the page would know what they were, not just a simple graphic, but a full-blown recognition for a skill or achievement.
Since his original prototype, the process of baking a badge has changed, plus Atul Varma built a library to allow baking and unbaking in the browser. This summer, Joe Curlee and I took all these pieces, prototypes and ideas and pulled them together into a single JS library you can include in a page to make the open badges on that page more dynamic.
There’s a demo of the library in action on Curlee’s Github. It shows a baked badge on the page, when you click the unbake button, it takes the baked information from the image and makes the badge dynamic and clickable. We added the button to make it clear what was happening on the page, but in a normal scenario, you’d just let the library do it’s thing and transform the badges on the page automatically. You can grab the source for the library on Github, or download the compiled / minified library directly.
There’s lot’s more we can do with the library, I’ll be writing more about it soon.
http://chrismcavoy.org/2014/09/21/hand-crafted-open-badges-display/
|
|
John O'Duinn: San Francisco Car Culture: Unusual Jaguar XK8 paint job |
Found this earlier this month while on the way to work. The color scheme really threw me off, so at first I couldn’t even tell it was a Jaguar. I remain speechless.




http://oduinn.com/blog/2014/09/21/san-francisco-car-culture-jaguar-paint-job/
|
|
Mark Surman: You did it! (maker party) |
This past week marked the end of Maker Party 2014. The results are well beyond what we expected and what we did last year — 2,513 learning events in 86 countries. If you we’re one of the 5,000+ teachers, librarians, parents, Hivers, localizers, designers, engineers and marketing ninjas who contributed to Webmaker over the past few months, I want to say: Thank you! You did it! You really did it!

What did you do? You taught over 125,000 people how to make things on the web — which is the point of the program and an important end in itself. At the same time, you worked tirelessly to build out and expand Webmaker in meaningful ways. Some examples:
It’s important to say: these things add up to something. Something big. They add up to a better Webmaker — more curriculum, better tools, a larger network of contributors. These things are assets that we can build on as we move forward. And you made them.
You did one other thing this summer that I really want to call out — you demonstrated what the Mozilla community can be when it is at its best. So many of you took leadership and organized the people around you to do all the things I just listed above. I saw that online and as I traveled to meet with local communities this summer. And, as you did this, so many of you also reached out an mentored others new to this work.You did exactly what Mozilla needs to do more of: you demonstrated the kind of commitment, discipline and thoughtfulness that is needed to both grow and have impact at the same time. As I wrote in July, I believe we need simultaneously drive hard on both depth and scale if we want Webmaker to work. You showed that this was possible.

Celebrating at MozFest East Africa
So, if you were one of the 5000+ people who contributed to Webmaker during Maker Party: pat yourself on the back. You did something great! Also, consider: what do you want to do next? Webmaker doesn’t stop at the end of Maker Party. We’re planning a fall campaign with key partners and networks. We’re also moving quickly to expand our program for mentors and leaders, including thinking through ideas like Webmaker Clubs. These are all things that we need your help with as we build on the great work of the past few months.

http://commonspace.wordpress.com/2014/09/21/you-did-it-maker-party/
|
|
Arky: Noto Fonts Update |
Google Internationalization team released new update of Noto Fonts this week. The update brings numerous new features enhancements. Please read the project release notes for the full list of changes.
You can preview the fonts and download them at google.com/get/noto.

It is very simple to test the Noto fonts on a Firefox OS device. Just copy the the font files into /system/fonts folder and reboot the device. Don't forget to back-up the existing fonts on device first.
Am writing this blog post in Bangkok, So I am going to use Thai Noto fonts in these instructions. Connect your Firefox OS device to the computer with a USB cable. Make sure to turn on developer settings to enable debugging via USB.
# Backup the existing Thai font
$ adb pull /system/fonts/DroidSansThai.ttf
# Remount the /system partition as read-write
$ adb remount /system
# Remove the font on the device
$ adb shell rm /system/fonts/DroidSansThai
# Unzip the previously downloaded Thai font package
$ unzip NotoSansThai-hinted.zip
# Push to Firefox OS device
$ adb push NotoSansThai-Regular.ttf /system/fonts
# Reboot the phone. Test your localization by selecting your language
#in Language settings menu or navigating to local language webpage with browser app.
$ adb reboot
If you see square blocks (lovingly referred as Tofu) instead of characters, that means the font file for your language is missing. Please double check the steps, if everything fails restore the previously copy of your font file.

Happy Hacking!
http://playingwithsid.blogspot.com/2014/09/noto-fonts-update.html
|
|
Mozilla Release Management Team: Firefox 33 beta4 to beta5 |
| Extension | Occurrences |
| cpp | 21 |
| js | 10 |
| java | 10 |
| h | 6 |
| in | 3 |
| html | 3 |
| cc | 3 |
| xml | 2 |
| mozbuild | 2 |
| ini | 2 |
| txt | 1 |
| nsi | 1 |
| mn | 1 |
| list | 1 |
| jsm | 1 |
| css | 1 |
| Module | Occurrences |
| mobile | 16 |
| netwerk | 13 |
| layout | 7 |
| media | 6 |
| browser | 6 |
| gfx | 5 |
| toolkit | 4 |
| security | 3 |
| dom | 3 |
| js | 2 |
| widget | 1 |
| extensions | 1 |
| caps | 1 |
List of changesets:
| Sylvestre Ledru | Post Beta 4: disable EARLY_BETA_OR_EARLIER a=me - abf1c1e6b222 |
| Aaron Klotz | Bug 937306 - Improvements to WinUtils::WaitForMessage. r=jimm, a=sylvestre - 60aecc9d11ab |
| Richard Newman | Bug 1065523 - Part 1: locale picker screen displays short locale display name, not capitalized region-decorated name. r=nalexander, a=sledru - cea1db6ec4ac |
| Jason Duell | Bug 966713 - Intermittent test_cookies_read.js times out. r=mcmanus, a=test-only - bd8bbb683257 |
| Brian Hackett | Bug 1061600 - Fix PropertyWriteNeedsTypeBarrier. r=jandem, a=abillings - 025117f71163 |
| Bobby Holley | Bug 1066718 - Get sIOService before invoking ReadPrefs. r=bz, a=sledru - 262de5944a01 |
| Richard Newman | Bug 1045087 - Remove Product Announcements integration points from Fennec. r=mfinkle, a=sledru - c0ba357c4c89 |
| Richard Newman | Bug 1045085 - Remove main Product Announcements code. r=mcomella, a=lmandel - d5ed7dd8f996 |
| Oscar Patino | Bug 1064882 - Receive RTCP SR's on recvonly streams for A/V sync. r=jesup, a=sledru - e99eaafdbda1 |
| Matt Woodrow | Bug 1044129 - Don't crash if ContainerLayer temporary surface allocation fails. r=jrmuizel, a=sledru - 11e34dc2f591 |
| Eric Faust | Bug 1033873 - "Differential Testing: Different output message involving __proto__". r=jandem, a=sledru - 2dbe6d8a5c30 |
| Mo Zanaty | Bug 1054624 - Fix high-packet-loss problems with H.264 WebRTC calls. r=jesup, a=lmandel - 75eddbd6dc80 |
| Michal Novotny | Bug 1056919 - Crash in memcpy | mozilla::net::CacheFileChunk::OnDataRead(mozilla::net::CacheFileHandle*, char*, tag_nsresult). r=honzab, a=sledru - 62d020eff891 |
| Stephen Pohl | Bug 1065509: Bump maximum download size from 35 MB to 70 MB in stub installer. r=rstrong, a=lmandel - e85a6d689148 |
| Cameron McCormack | Bug 1041512 - Mark intrinsic widths dirty on a style change even if the frame hasn't had its first reflow yet. r=dbaron, a=abillings - dafe68644b45 |
| Andrea Marchesini | Bug 1064481 - URLSearchParams should encode % values correcty. r=ehsan, a=lmandel - f44f06112715 |
| Jonathan Watt | Bug 1067998 - Fix OOM crash in gfxAlphaBoxBlur::Init on large blur surface. r=Bas, a=sylvestre - 023a362fab21 |
| Matt Woodrow | Bug 1037226 - Don't crash when surface allocation fails in BasicCompositor. r=Bas, a=sledru - 9dd2e1834651 |
| Margaret Leibovic | Bug 996753 - Telemetry probes for settings pages. r=liuche, a=sledru - 8d7b3bfaf3ab |
| Margaret Leibovic | Bug 996753 - Telemetry probes for changing settings and hitting back. r=liuche, a=sledru - 3504f727e58c |
| Margaret Leibovic | Bug 1063128 - Make sure all preferences have keys. r=liuche, a=sledru - e981cc82a3e5 |
| Margaret Leibovic | Bug 1058813 - Add telemetry probe for clicking sync preference. r=liuche, a=sledru - 340bddec5bf5 |
| Honza Bambas | Bug 1065478 - POSTs are coming from offline application cache. r=jduell, a=sledru - 6c39ccb686a5 |
| Honza Bambas | Bug 1066726 - Concurrent HTTP cache read and write issues. r=michal, r=jduell, a=sledru - 8a1cffa4c130 |
| David Keeler | Bug 1066190 - Ensure that pinning checks are done for otherwise overridable errors. r=mmc, a=sledru - 1e3320340bd2 |
| Wes Johnston | Bug 1063896 - Loop over all url list, not just ones with metadata. r=lucasr, a=sledru - 792d0824a8f0 |
| Blair McBride | Bug 1039028 - Show license info for OpenH264 plugin. r=irving, a=sledru - 01411f43df67 |
| Drew Willcoxon | Bug 1066794 - Make the search suggestions popup on about:home/about:newtab more consistent with the main search bar's popup. r=MattN, a=sledru - 44cc9f25426d |
| Drew Willcoxon | Bug 1060888 - Autocomplete drop down list item should not be copied to the search fields when mouse over the list item. r=MattN, a=sledru - 6975bbd6c73a |
| Richard Newman | Bug 1057247 - Increase favicon refetch time to four hours. r=mfinkle, a=sledru - 515fa121e700 |
| Mats Palmgren | Bug 1067088 - Use aBorderArea when not skipping any sides (e.g. ::first-letter), not the joined border area. r=roc, a=sledru - af1dbe183e3d |
| Ryan VanderMeulen | Backed out changeset af1dbe183e3d (Bug 1067088) for bustage. - f5ba94d7170d |
| Honza Bambas | Bug 1000338 - nsICacheEntry.lastModified not properly implemented. r=michal, a=sledru - b88069789828 |
| Benjamin Smedberg | Bug 1063052 - In case a user ends up with unpacked chrome, on update use omni.ja again by removing chrome.manifest. r=rstrong, r=glandium, sr=dbaron, a=lmandel - 2dce6525ddfe |
| Mats Palmgren | Bug 1067088 - Use aBorderArea when not skipping any sides (e.g. ::first-letter), not the joined border area. r=roc a=sledru - 9f2dc7a2df34 |
| Nick Alexander | Bug 996753 - Workaround for Fx33 not having AppConstants.Versions. r=rnewman, a=bustage - 7cd3ae0255ec |
http://release.mozilla.org/statistics/33/2014/09/20/fx-34-b4-to-b5.html
|
|
Yunier Jos'e Sosa V'azquez: Mozilla lanza “Miniaturas” patrocinadas en Firefox |
Mozilla acaba de lanzar las miniaturas patrocinadas en Firefox Nightly. El mosaico con miniaturas son los recuadros con enlaces a p'aginas web, que aparecen cuando se abre una nueva pesta~na en Firefox. Estos se dividen en tres tipos:
Si te preocupa la privacidad, no te inquietes, pues s'olo la informaci'on de la miniatura en una p'agina de nueva pesta~na es recolectada, con el fin de ofrecer sitios mas interesantes a nuevos usuarios de Firefox y mejorar las recomendaciones a usuarios existentes. Toda esa informaci'on es recopilada y no incluye ninguna manera de distinguir al usuario, pues solo se recogen los datos necesarios para asegurarse que los recuadros env'ian valor a nuestros usuarios y socios comerciales.
Los datos son transmitidos directamente a Mozilla y 'esta es almacenada en los servidores de Mozilla. Para todo tipo de Miniaturas, Mozilla est'a compartiendo n'umeros a los socios como: cantidad de impresiones, clics, fijaciones y ocultamiento del contenido recibido.
Puedes desactivarlo haciendo clic en el 'icono del engranaje, ubicado en la esquina superior derecha de una p'agina de nueva pesta~na y seleccionando Cl'asico para mostrar las Miniaturas no mejoradas, o el modo Vac'io que desactiva esta caracter'istica por completo.
Fuente: Mozilla Hispano
http://firefoxmania.uci.cu/mozilla-lanza-miniaturas-patrocinadas-en-firefox/
|
|
Ben Hearsum: New update server has been rolled out to Firefox/Thunderbird Beta users |
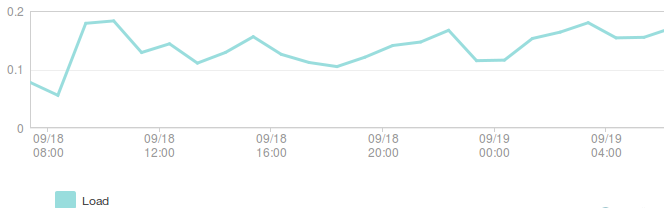
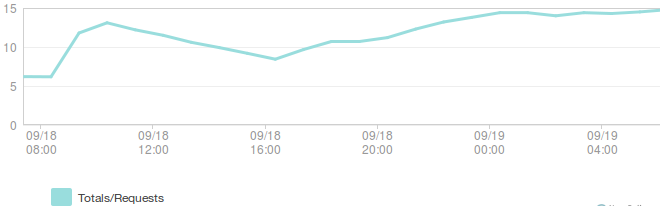
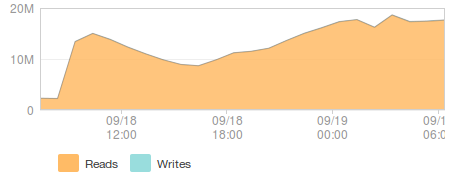
Yesterday marked a big milestone for the Balrog project when we made it live for Firefox and Thunderbird Beta users. Those with a good long term memory may recall that we switched Nightly and Aurora users over almost a year ago. Since then, we’ve been working on and off to get Balrog ready to serve Beta updates, which are quite a bit more complex than our Nightly ones. Earlier this week we finally got the last blocker closed and we flipped it live yesterday morning, pacific time. We have significantly (~10x) more Beta users than Nightly+Aurora, so it’s no surprise that we immediately saw a spike in traffic and load, but our systems stood up to it well. If you’re into this sort of thing, here are some graphs with spikey lines:
The load average on 1 (of 4) backend nodes:
The rate of requests to 1 backend node (requests/second):
Database operations (operations/second):

And network traffic to the database (MB/sec):
Despite hitting a few new edge cases (mostly around better error handling), the deployment went very smoothly – it took less than 15 minutes to be confident that everything was working fine.
While Nick and I are the primary developers of Balrog, we couldn’t have gotten to this point without the help of many others. Big thanks to Chris and Sheeri for making the IT infrastructure so solid, to Anthony, Tracy, and Henrik for all the testing they did, and to Rail, Massimo, Chris, and Aki for the patches and reviews they contributed to Balrog itself. With this big milestone accomplished we’re significantly closer to Balrog being ready for Release and ESR users, and retiring the old AUS2/3 servers.
http://hearsum.ca/blog/new-update-server-has-been-rolled-out-to-beta-users/
|
|
Soledad Penades: Extensible Web Summit Berlin 2014: my lightning talk on Web Components |
I was invited to join and give a lightning talk at the Extensible Web Summit that was held in Berlin past week, as part of the whole JSFest.berlin series of events.
The structure of the event consisted in having a series of introductory lightning talks to “set the tone” and then the rest would be a sort of unconference where people would suggest topics to talk about and then we would build a timetable collaboratively.
The topic for my talk was… Web Components. Which was quite interesting because I have been working/fighting with them and various implementations in various levels of completeness at the same time lately, so I definitely had some things to add!
I didn’t want people to get distracted by slides (including myself) so I didn’t have any. Exciting! Also challenging.
These are the notes I more or less followed for my minitalk:
The question I’m asked 99% of the time is “why, when I can do the same with divs? with jQuery even? what is the point?”
fine, this seems amazing, but what can it do for me and why should I use any of this in my projects?
With thanks to all the people whose brain I’ve been picking lately on the subject of Web Components: Angelina, Wilson, Francisco, Les, Potch, Fred and Christian.
![]()
|
|
Daniel Stenberg: Using APIs without reading docs |
This morning, my debug session was interrupted for a brief moment when two friends independently of each other pinged me to inform me about a talk at the current SEC-T conference going on here in Stockholm right now. It was yet again time to bring up the good old fun called libcurl API bashing. Again from the angle that users who don’t read the API docs might end up using it wrong.
I managed to see the talk off the live youtube feed, but it isn’t a stable url/video so I can’t link to it here now, but I will update this post with a link as soon as I have one!
The specific libcurl topic at hand once again mostly had the CURLOPT_VERIFYHOST option in focus, with basically is the same argument that was thrown at us two years ago when libcurl was said to be dangerous. It is not a boolean. It is an option that takes (or took) three different values, where 2 is the secure level and 0 is disabled.

(This picture is a screengrab from the live stream off youtube, I don’t have any link to a stored version of it yet. Click it for slightly higher resolution.)
Speaker Meredith L. Patterson actually spoke for quite a long time about curl and its options to verify server certificates. While I will agree that she has a few good points, it was still riddled with errors and I think she deliberately phrased things in a manner to make the talk good and snappy rather than to be factually correct and trying to understand why things are like they are.
The VERIFYHOST option apparently sounds as if it takes a boolean (accordingly), but it doesn’t. She says verifying a certificate has to be a Yes/No question so obviously it is a boolean. First, let’s be really technical: the libcurl options that take numerical values always accept a ‘long’ and all documentation specify which values you can pass in. None of them are boolean, not by actual type in the C language and not described like that in the man pages. There are however language bindings running on top of libcurl that may use booleans for the values that take 0 or 1, but there’s no guarantee we won’t add more values in a future to numerical options.
I wrote down a few quotes from her that I’d like to address.
“In order for it to do anything useful, the value actually has to be set to two”
I get it, she wants a fun presentation that makes the audience listen and grin cheerfully. But this is highly inaccurate. libcurl has it set to verify by default. An application doesn’t have to set it to anything. The only reason to set this value is if you’re not happy with checking the cert unconditionally, and then you’ve already wondered off the secure route.
“All it does when set to to two is to check that the common name in the cert matches the host name in the URL. That’s literally all it does.”
No, it’s not. It “only” verifies the host name curl connects to against the name hints in the server cert, yes, but that’s a lot more than just the common name field.
“there’s been 10 versions and they haven’t fixed this yet [...] the docs still say they’re gonna fix this eventually [...] I wanna know when eventually is”
Qualified BS and ignorance of details. Let’s see the actual code first: it ignores the 1 value and returns an error and thus leaves the internal default 2, Alas, code that sets 1 or 2 gets the same effect == verified certificate. Why is this a problem?
Then, she says she really wants to know when “eventually” is. (The docs say “Future versions will…”) So if she was so curious you’d think she would’ve tried to ask us? We’re an accessible bunch, on mailing lists, on IRC and on twitter. No she didn’t ask.
But perhaps most importantly: did she really consider why it returns an error for 1? Since libcurl silently accepted 1 as a value for something like 10 years, there are a lot of old installations “out there” in the wild, and by returning an error for 1 we try to make applications notice and adjust. By silently accepting 1 without errors, there would be no notice and people will keep using 1 in new applications as well and thus when running such an newly written application with an older libcurl – you’d be back to having the security problem again. So, we have the error there to improve the situation.
“a peer is someone like you [...] a host is a server”
I’m a networking guy since 20+ years and I’m not used to people having a hard time to understand these terms. While perhaps there are rookies out in the world who don’t immediately understand some terms in the curl option names, should we really be criticized for that? I find that a hilarious critique. Also, these names were picked 13 years ago and we have them around for compatibility and API stability.
“why would you ever want to …”
Welcome to the real world. Why would an application author ever want to have these options to something else than just full check and no check? Because people and software development is a large world with many different desires and use case scenarios and curl is more widely used and abused than what many people consider. Lots of people have wanted something else than just a Yes/No to server cert verification. In fact, I’ve had many users ask for even more switches and fine-grained ways to fiddle with verification. Yes/No is a lay mans simplified view of certificate verification.

(This picture is the slide from the above picture, just zoomed and straightened out a bit.)
We started working on libcurl in spring 1999, we added the CURLOPT_SSL_VERIFYPEER option in October 2000 and we added CURLOPT_SSL_VERIFYHOST in August 2001. All that quite a long time ago.
Then add thousands of hours, hundreds of hackers, thousands of applications, a user count that probably surpasses one billion users by now. Then also add the fact that option names are sticky in the way we write docs, examples pop up all over the internet and everyone who’s close to the project learns them by name and spirit and we quite simply grow attached to them and the way they work. Changing the name of an option is really painful and cause of a lot of confusion.
I’ve instead tried to more and more emphasize the functionality in the docs, to stress what the options do and how to do server cert verifications with curl the safe way.
I can’t force users to read docs. I can’t forbid users to blindly assume something and I’m not in control of, nor do I want to affect, the large population of third party bindings that exist for using on top of libcurl to cater for every imaginable programming language – and some of them may of course themselves have documentation problems and what not.
Would I change some of the APIs and names for options we have in libcurl if I would redo them today? Yes I would.
I think this is the only really interesting question to take from all this. Everyone wants stable APIs. Everyone wants sensible and easy to understand APIs and as we can see they should also basically be possible to figure out without reading any documentation. And yet the API has to be powerful and flexible enough to be really useful for all those different applications.
At this point where we have these options that we do, when you’ve done your mud slinging and the finger of blame is firmly pointed at us. How exactly do you suggest we move forward to fix these claimed problems?
Before anyone tells me to not take it personally: curl is my biggest hobby and a project I’ve spent many years and thousands of hours on. Of course I take it personally, otherwise I would’ve stopped working in the project a long time ago. This is personal to me. I give it my loving care and personal energy and then someone comes here and throw ill-founded and badly researched criticisms at me. I think criticizers of open source projects should learn to discuss the matters with the projects as their primary way instead of using it to make their conference presentations become more feisty.
http://daniel.haxx.se/blog/2014/09/18/using-apis-without-reading-docs/
|
|
Luke Wagner: asm.js on status.modern.ie |
I was excited to see that asm.js has been added to status.modern.ie as “Under Consideration”. Since asm.js isn’t a JS language extension like, say, Generators, what this means is that Microsoft is currently considering adding optimizations to Chakra for the asm.js subset of JS. (As explained in my previous post, explicitly recognizing asm.js allows an engine to do a lot of exciting things.)
Going forward, we are hopeful that, after consideration, Microsoft will switch to “Under Development” and we are quite happy to collaborate with them and any other JS engine vendors on the future evolution of asm.js.
On a more general note, it’s exciting to see that there has been across-the-board improvements on asm.js workloads in the last 6 months. You can see this on arewefastyet.com or by loading up the Dead Trigger 2 demo on Firefox, Chrome or (beta) Safari. Furthermore, with the recent release of iOS8, WebGL is now shipping in all modern browsers. The future of gaming and high-performance applications on the web is looking good!
https://blog.mozilla.org/luke/2014/09/18/asm-js-on-status-modern-ie/
|
|
Kartikaya Gupta: Maker Party shout-out |
I've blogged before about the power of web scale; about how important it is to ensure that everybody can use the web and to keep it as level of a playing field as possible. That's why I love hearing about announcements like this one: 127K Makers, 2513 Events, 86 Countries, and One Party That Just Won't Quit. Getting more people all around the world to learn about how the web works and keeping that playing field level is one of the reasons I love working at Mozilla. Even though I'm not directly involved in Maker Party, it's great to see projects like this having such a huge impact!
|
|
Henrik Skupin: Memchaser 0.6 has been released |
The Firefox Automation team would like to announce the release of memchaser 0.6. After nearly a year of no real feature updates, but also some weeks of not being able to run Memchaser in Firefox Aurora (34.0a2) at all (due to a regression), we decided to release the current state of development as a public release. We are aware that we still do not fully support the default Australis theme since Firefox 29.0, but that’s an issue, which takes some more time to finish up.
For all the details about the 0.6 release please check our issue tracker on Github.
http://www.hskupin.info/2014/09/18/memchaser-0-6-has-been-released/
|
|
Matt Brubeck: Let's build a browser engine! Part 6: Block layout |
Welcome back to my series on building a toy HTML rendering engine:
- Part 1: Getting started
- Part 2: HTML
- Part 3: CSS
- Part 4: Style
- Part 5: Boxes
- Part 6: Block layout
This article will continue the layout module that we started in Part 5. This time, we’ll add the ability to lay out block boxes. These are boxes that are stack vertically, such as headings and paragraphs.
To keep things simple, this code implements only normal flow: no floats, no absolute positioning, and no fixed positioning.
The entry point to this code is the layout function, which takes a takes a
LayoutBox and calculates its dimensions. We’ll break this function into three
cases, and implement only one of them for now:
impl LayoutBox {
/// Lay out a box and its descendants.
fn layout(&mut self, containing_block: Dimensions) {
match self.box_type {
BlockNode(_) => self.layout_block(containing_block),
InlineNode(_) => {} // TODO
AnonymousBlock => {} // TODO
}
}
// ...
}A block’s layout depends on the dimensions of its containing block. For block boxes in normal flow, this is just the box’s parent. For the root element, it’s the size of the browser window (or “viewport”).
You may remember from the previous article that a block’s width depends on its parent, while its height depends on its children. This means that our code needs to traverse the tree top-down while calculating widths, so it can lay out the children after their parent’s width is known, and traverse bottom-up to calculate heights, so that a parent’s height is calculated after its children’s.
fn layout_block(&mut self, containing_block: Dimensions) {
// Child width can depend on parent width, so we need to calculate
// this box's width before laying out its children.
self.calculate_block_width(containing_block);
// Determine where the box is located within its container.
self.calculate_block_position(containing_block);
// Recursively lay out the children of this box.
self.layout_block_children();
// Parent height can depend on child height, so `calculate_height`
// must be called *after* the children are laid out.
self.calculate_block_height();
}This function performs a single traversal of the layout tree, doing width calculations on the way down and height calculations on the way back up. A real layout engine might perform several tree traversals, some top-down and some bottom-up.
The width calculation is the first step in the block layout function, and also
the most complicated. I’ll walk through it step by step. To start, we need
the values of the CSS width property and all the left and right edge sizes:
fn calculate_block_width(&mut self, containing_block: Dimensions) {
let style = self.get_style_node();
// `width` has initial value `auto`.
let auto = Keyword("auto".to_string());
let mut width = style.value("width").unwrap_or(auto.clone());
// margin, border, and padding have initial value 0.
let zero = Length(0.0, Px);
let mut margin_left = style.lookup("margin-left", "margin", &zero);
let mut margin_right = style.lookup("margin-right", "margin", &zero);
let border_left = style.lookup("border-left-width", "border-width", &zero);
let border_right = style.lookup("border-right-width", "border-width", &zero);
let padding_left = style.lookup("padding-left", "padding", &zero);
let padding_right = style.lookup("padding-right", "padding", &zero);
// ...
}This uses a helper function called lookup, which just tries a
series of values in sequence. If the first property isn’t set, it tries the
second one. If that’s not set either, it returns the given default value.
This provides an incomplete (but simple) implementation of shorthand
properties and initial values.
Note: This is similar to the following code in, say, JavaScript or Ruby:
margin_left = style["margin-left"] || style["margin"] || zero;
Since a child can’t change its parent’s width, it needs to make sure its own width fits the parent’s. The CSS spec expresses this as a set of constraints and an algorithm for solving them. The following code implements that algorithm.
First we add up the margin, padding, border, and content widths. The
to_px helper method converts lengths to their numerical values. If
a property is set to 'auto', it returns 0 so it doesn’t affect the sum.
let total = [&margin_left, &margin_right, &border_left, &border_right,
&padding_left, &padding_right, &width].iter().map(|v| v.to_px()).sum();This is the minimum horizontal space needed for the box. If this isn’t equal to the container width, we’ll need to adjust something to make it equal.
If the width or margins are set to 'auto', they can expand or contract to
fit the available space. Following the spec, we first check if the box is too
big. If so, we set any expandable margins to zero.
// If width is not auto and the total is wider than the container, treat auto margins as 0.
if width != auto && total > containing_block.width {
if margin_left == auto {
margin_left = Length(0.0, Px);
}
if margin_right == auto {
margin_right = Length(0.0, Px);
}
}If the box is too large for its container, it overflows the container. If it’s too small, it will underflow, leaving extra space. We’ll calculate the underflow—the amount of extra space left in the container. (If this number is negative, it is actually an overflow.)
let underflow = containing_block.width - total;We now follow the spec’s algorithm for eliminating any
overflow or underflow by adjusting the expandable dimensions. If there are no
'auto' dimensions, we adjust the right margin. (Yes, this means the
margin may be negative in the case of an overflow!)
match (width == auto, margin_left == auto, margin_right == auto) {
// If the values are overconstrained, calculate margin_right.
(false, false, false) => {
margin_right = Length(margin_right.to_px() + underflow, Px);
}
// If exactly one size is auto, its used value follows from the equality.
(false, false, true) => { margin_right = Length(underflow, Px); }
(false, true, false) => { margin_left = Length(underflow, Px); }
// If width is set to auto, any other auto values become 0.
(true, _, _) => {
if margin_left == auto { margin_left = Length(0.0, Px); }
if margin_right == auto { margin_right = Length(0.0, Px); }
if underflow >= 0.0 {
// Expand width to fill the underflow.
width = Length(underflow, Px);
} else {
// Width can't be negative. Adjust the right margin instead.
width = Length(0.0, Px);
margin_right = Length(margin_right.to_px() + underflow, Px);
}
}
// If margin-left and margin-right are both auto, their used values are equal.
(false, true, true) => {
margin_left = Length(underflow / 2.0, Px);
margin_right = Length(underflow / 2.0, Px);
}
}At this point, the constraints are met and any 'auto' values have been
converted to lengths. The results are the the used values for
the horizontal box dimensions, which we will store in the layout tree. You
can see the final code in layout.rs.
The next step is simpler. This function looks up the remanining margin/padding/border styles, and uses these along with the containing block dimensions to determine this block’s position on the page.
fn calculate_block_position(&mut self, containing_block: Dimensions) {
let style = self.get_style_node();
let d = &mut self.dimensions;
// margin, border, and padding have initial value 0.
let zero = Length(0.0, Px);
// If margin-top or margin-bottom is `auto`, the used value is zero.
d.margin.top = style.lookup("margin-top", "margin", &zero).to_px();
d.margin.bottom = style.lookup("margin-bottom", "margin", &zero).to_px();
d.border.top = style.lookup("border-top-width", "border-width", &zero).to_px();
d.border.bottom = style.lookup("border-bottom-width", "border-width", &zero).to_px();
d.padding.top = style.lookup("padding-top", "padding", &zero).to_px();
d.padding.bottom = style.lookup("padding-bottom", "padding", &zero).to_px();
// Position the box below all the previous boxes in the container.
d.x = containing_block.x +
d.margin.left + d.border.left + d.padding.left;
d.y = containing_block.y + containing_block.height +
d.margin.top + d.border.top + d.padding.top;
}Take a close look at that last statement, which sets the y position. This
is what gives block layout its distinctive vertical stacking behavior. For
this to work, we’ll need to make sure the parent’s height is updated after
laying out each child.
Here’s the code that recursively lays out the box’s contents. As it loops through the child boxes, it keeps track of the total content height. This is used by the positioning code (above) to find the vertical position of the next child.
fn layout_block_children(&mut self) {
let d = &mut self.dimensions;
for child in self.children.mut_iter() {
child.layout(*d);
// Track the height so each child is laid out below the previous content.
d.height = d.height + child.dimensions.margin_box_height();
}
}The total vertical space taken up by each child is the height of its margin box, which we calculate just by adding all up the vertical dimensions.
impl Dimensions {
/// Total height of a box including its margins, border, and padding.
fn margin_box_height(&self) -> f32 {
self.height + self.padding.top + self.padding.bottom
+ self.border.top + self.border.bottom
+ self.margin.top + self.margin.bottom
}
}For simplicity, this does not implement margin collapsing. A real layout engine would allow the bottom margin of one box to overlap the top margin of the next box, rather than placing each margin box completely below the previous one.
By default, the box’s height is equal to the height of its contents. But if
the 'height' property is set to an explicit length, we’ll use that instead:
fn calculate_block_height(&mut self) {
// If the height is set to an explicit length, use that exact length.
match self.get_style_node().value("height") {
Some(Length(h, Px)) => { self.dimensions.height = h; }
_ => {}
}
}And that concludes the block layout algorithm. You can now call layout() on
a styled HTML document, and it will spit out a bunch of rectangles with
widths, heights, margins, etc. Cool, right?
Some extra ideas for the ambitious implementer:
Collapsing vertical margins.
Parallelize the layout process, and measure the effect on performance.
If you try the parallelization project, you may want to separate the width
calculation and the height calculation into two distinct passes. The top-down
traversal for width is easy to parallelize just by spawning a separate task
for each child. The height calculation is a little trickier, since you need
to go back and adjust the y position of each child after its siblings are
laid out.
Thank you to everyone who’s followed along this far!
These articles are taking longer and longer to write, as I journey further into unfamiliar areas of layout and rendering. There will be a longer hiatus before the next part as I experiment with font and graphics code, but I’ll resume the series as soon as I can.
http://limpet.net/mbrubeck/2014/09/17/toy-layout-engine-6-block.html
|
|
James Long: Transducers.js: A JavaScript Library for Transformation of Data |
If you didn't grab a few cups of coffee for my last post, you're going to want to for this one. While writing my last post about js-csp, a port of Clojure's core.async, they announced transducers which solves a key problem when working with transformation of data. The technique works particularly well with channels (exactly what js-csp uses), so I dug into it.
What I discovered is mind-blowing. So I also ported it to JavaScript, and today I'm announcing transducers.js, a library to build transformations of data and apply it to any data type you could imagine.
Woha, what did I just say? Let's take a step back for a second. If you haven't heard of transducers before, you can read about their history in Clojure's announcement. Additionally, there's an awesome post that explores these ideas in JavaScript and walks you through them from start to finish. I give a similar (but brief) walkthrough at the end of this post.
The word transduce is just a combination of transform and reduce. The reduce function is the base transformation; any other transformation can be expressed in terms of it (map, filter, etc).
var arr = [1, 2, 3, 4];
arr.reduce(function(result, x) {
result.push(x + 1);
return result;
}, []);
// -> [ 2, 3, 4, 5 ]
The function passed to reduce is a reducing function. It takes a result and an input and returns a new result. Transducers abstract this out so that you can compose transformations completely independent of the data structure. Here's the same call but with transduce:
function append(result, x) {
result.push(x);
return result;
}
transduce(map(x => x + 1), append, [], arr);
We created append to make it easier to work with arrays, and are using ES6 arrow functions (you really should too, they are easy to cross-compile). The main difference is that the push call on the array is now moved out of the transformation. In JavaScript we always couple transformation with specific data structures, and we've got to stop doing that. We can reuse transformations across all data structures, even streams.
There are three main concerns here that reduce needs to work. First is to iterate over the source data structure. Second is to transform each value. Third is to build up a new result.
![]()
These are completely separate concerns, and yet most transformations in JavaScript are tightly coupled with specific data structures. Transducers decouples this and you can apply all the available transformations on any data structure.
We have a small amount of transformations that will solve most of your needs like map, filter, dedupe, and more. Here's an example of composing transformations:
sequence(
compose(
cat,
map(x => x + 1),
dedupe(),
drop(3)
),
[[1, 2], [3, 4], [4, 5]]
)
// -> [ 5, 6 ]
The compose function combines transformations, and sequence just creates a new collection of the same type and runs the transformations. Note that nothing within the transformations assume anything about the data structure from where it comes or where it's going.
Most of the transformations that transducers.js provides can also simply take a collection, and it will immediately run the transformation over the collection and return a new collection of the same type. This lets you do simple transformations the familiar way:
map(x => x + 1, [1, 2, 3, 4]);
filter(x => x % 2 === 0, [1, 2, 3, 4])
These functions are highly optimized for the builtin types like arrays, so the above map literally just runs a while loop and applies your function over each value.
These transformations aren't useful unless you can actually apply them. We figured out the transform concern, but what about iterate and build?
First lets take a look at the available functions for applying transducers:
sequence(xform, coll) - get a collection of the same type and fill it with the results of applying xform over each item in colltransduce(xform, f, init, coll) - reduce a collection starting with the initial value init, applying xform to each value and running the reducing function finto(to, xform, from) - apply xform to each value in the collection from and append it to the collection toEach of these has different levels of assumptions. transduce is the lowest-level in that it iterates over coll but lets you build up the result. into assumes the result is a collection and automatically appends to it. Finally, sequence assumes you want a collection of the same type so it creates it and fills it with the results of the transformation.
Ideally our library wouldn't care about the details of iteration or building either, otherwise it kind of kills the point of generic transformations. Luckily ES6 has an iteration protocol, so we can use that for iteration.
But what about building? Unfortunately there is no protocol for that, so we need to create our own. transducers.js looks for @@append and @@empty methods on a collection for adding to it and creating new collections. (Of course, it works out of the box for native arrays and objects).
Let's drive this point home with an example. Say you wanted to use the immutable-js library. It already supports iteration, so you can automatically do this:
into([],
compose(
map(x => x * 2),
filter(x => x > 5)
),
Immutable.Vector(1, 2, 3, 4));
// -> [ 6, 8 ]
We really want to use immutable vectors all the way through, so let's augment the vector type to support "building":
Immutable.Vector.prototype['@@append'] = function(x) {
return this.push(x);
};
Immutable.Vector.prototype['@@empty'] = function(x) {
return Immutable.Vector();
};
Now we can just use sequence, and we get an immutable vector back:
sequence(compose(
map(x => x * 2),
filter(x => x > 5)
),
Immutable.Vector(1, 2, 3, 4));
// -> Immutable.Vector(6, 8)
This is experimental, so I would wait a little while before using this in production, but so far this gives a surprising amount of power for a 500-line JavaScript library.
Let's play around with all the kinds of data structures we can use now. A type must at least be iterable to use with into or transduce, but if it is also buildable then it can also be used with sequence or the target collection of into.
var xform = compose(map(x => x * 2),
filter(x => x > 5));
// arrays (iterable & buildable)
sequence(xform, [1, 2, 3, 4]);
// -> [ 6, 8 ]
// objects (iterable & buildable)
into([],
compose(map(kv => kv[1]), xform),
{ x: 1, y: 2, z: 3, w: 4 })
// -> [ 6, 8 ]
sequence(map(kv => [kv[0], kv[1] + 1]),
{ x: 1, y: 2, z: 3, w: 4 })
// -> { x: 2, y: 3, z: 4, w: 5 }
// generators (iterable)
function *data() {
yield 1;
yield 2;
yield 3;
yield 4;
}
into([], xform, data())
// -> [ 6, 8 ]
// Sets and Maps (iterable)
into([], xform, new Set([1, 2, 3, 3]))
// -> [ 6 ]
into({}, map(kv => [kv[0], kv[1] * 2], new Map([['x', 1], ['y', 2]])))
// -> { x: 2, y: 4 }
// or make it buildable
Map.prototype['@@append'] = Map.prototype.add;
Map.prototype['@@empty'] = function() { return new Map(); };
Set.prototype['@@append'] = Set.prototype.add;
Set.prototype['@@empty'] = function() { return new Set(); };
sequence(xform, new Set([1, 2, 3, 2]))
sequence(xform, new Map([['x', 1], ['y', 2]]));
// node lists (iterable)
into([], map(x => x.className), document.querySelectorAll('div'));
// custom types (iterable & buildable)
into([], xform, Immutable.Vector(1, 2, 3, 4));
into(MyCustomType(), xform, Immutable.Vector(1, 2, 3, 4));
// if implemented append and empty:
sequence(xform, Immutable.Vector(1, 2, 3, 4));
// channels
var ch = chan(1, xform);
go(function*() {
yield put(ch, 1);
yield put(ch, 2);
yield put(ch, 3);
yield put(ch, 4);
});
go(function*() {
while(!ch.closed) {
console.log(yield take(ch));
}
});
// output: 6 8
Now that we've decoupled the data that comes in, how it's transformed, and what comes out, we have an insane amount of power. And with a pretty simple API as well.
Did you notice that last example with channels? That's right, a js-csp channel which I introduced in my last post now can take a transducer to apply over each item that passes through the channel. This easily lets us do Rx-style (reactive) code by simple reusing all the same transformations.
A channel is basically just a stream. You can reuse all of your familiar transformations on streams. That's huge!
This is possible because transducers work differently in that instead of applying each transformation to a collection one at a time (and creating multiple intermediate collections), they take each value separately and fire them through the whole transformation pipeline. That's leads us to the next point, in which there are...
Not only do we have a super generic way of transforming data, we get good performance on large arrays. This is because transducers create no intermediate collections. If you want to apply several transformations, usually each one is performed in order, creating a new collection each time.
Transducers, however, take one item off the collection at a time and fire it through the whole transformation pipeline. So it doesn't need any intermediate collections; each value runs through the pipeline separately.
Think of it as favoring a computational burden over a memory burden. Since each value runs through the pipeline, there are several function calls per item but no allocations, instead of 1 function call per item but an allocation per transformation. For small arrays there is a small difference, but for large arrays the computation burden easily wins out over the memory burden.
To be frank, early benchmarks show that this doesn't win anything in V8 until you reach a size of around 100,000 items (after that this really wins out). So it only matters for very large arrays. It's too early to post benchmarks.
If you are interested in walking through how transducers generalize reduce into what you see above, read the following. Feel free to skip this part though, or read this post which also does a great job of that.
The reduce function is the base transformation; any other transformation can be expressed in terms of it (map, filter, etc), so let's start with that. Here's an example call to reduce, which is available on native JS arrays:
var arr = [1, 2, 3, 4];
arr.reduce(function(result, x) { return result + x; }, 0);
// -> 10
This sums up all numbers in arr. Pretty simple, right? Hm, let's try and implement map in terms of reduce:
function map(f, coll) {
return coll.reduce(function(result, x) {
result.push(f(x));
return result;
}, []);
}
map(function(x) { return x + 1; }, arr);
// -> [2, 3, 4, 5]
That works. But our map only works with native JS arrays. It assumes a lot of knowledge about how to reduce, how to append an item, and what kind of collection to create. Shouldn't our map only be concerned with mapping? We've got to stop coupling transformations with data; every single collection is forced to completely re-implement map, filter, take, and all the collection operations, with varying incompatible properties!
But how is that possible? Well, let's start with something simple: the mapping function that we meant to create. It's only concernced with mapping. The key is that reduce will always be at the bottom of our transformation, but there's nothing stopping us from abstracting the function we pass to reduce:
function mapper(f) {
return function(result, x) {
result.push(f(x));
return result;
}
}
That looks better. We would use this by doing arr.reduce(mapper(function(x) { return x + 1; }), []). Note that now mapper has no idea how the reduction is actually done, or how the initial value is created. Unfortunately, it still has result.push embedded so it still only works with arrays. Let's abstract that out:
function mapper(f) {
return function(combine) {
return function(result, x) {
return combine(result, f(x));
}
}
}
That looks crazy, but now we have a mapper function that is literally only concerned about mapping. It calls f with x before passing it to combine. The above function may look daunting, but it's simple to use:
function append(arr, x) {
arr.push(x);
return arr;
}
arr.reduce(mapper(function(x) { return x + 1; })(append),
[]);
// -> [ 2, 3, 4, 5 ]
We create append to make it easy to functionally append to arrays. So that's about it, now we can just make this a little easi-- hold on, doesn't combine look a little like a reducer function?
If the result of applying append to the result of mapper creates a reducer function, can't we apply that itself to mapper?
arr.reduce(
mapper(function(x) { return x * 2; })(
mapper(function(x) { return x + 1; })(append)
),
[]
);
// -> [ 3, 5, 7, 9 ]
Wow! So now we can compose these super generic transformation functions. For example, let's create a filterer. You wouldn't normally apply two maps right next to each other, but you would certainly map and filter!
function filterer(f) {
return function(combine) {
return function(result, x) {
return f(x) ? combine(result, x) : result;
}
}
}
arr.reduce(
filterer(function(x) { return x > 2; })(
mapper(function(x) { return x * 2; })(append)
),
[]
);
// -> [ 6, 8 ]
Nobody wants to write code like that though. Let's make one more function compose which makes it easy to compose these, that's right, transducers. You just wrote transducers without even knowing it.
// All this does is it transforms
// `compose(x(), y(), z())(val)` into x(y(z(val)))`
function compose() {
var funcs = Array.prototype.slice.call(arguments);
return function(r) {
var value = r;
for(var i=funcs.length-1; i>=0; i--) {
value = funcs[i](value);
}
return value;
}
}
arr.reduce(
compose(
filterer(function(x) { return x > 2; }),
mapper(function(x) { return x * 2; })
)(append),
[]
);
// -> [ 6, 8 ]
Now we can write really clean sequential-looking transformations! Hm, there's still that awkward syntax to pass in append. How about we make our own reduce function?
function transduce(xform, f, init, coll) {
return coll.reduce(xform(f), init);
}
transduce(
compose(
filterer(function(x) { return x > 2; }),
mapper(function(x) { return x * 2; })
),
append,
[],
arr
);
// -> [ 6, 8 ]
Voila, you have transduce. Given a transformation, a function for appending data, an initial value, and a collection, run the whole process and return the final result from whatever append is. Each of those arguments are distinct pieces of information that shouldn't care at all about the others. You could easily apply the same transformation to any data structure you can imagine, as you will see below.
This transduce is not completely correct in that it should not care how the collection reduces itself.
You might think that this is sort of lazy evaluation, but that's not true. If you want lazy sequences, you will still have to explicitly build a lazy sequence type that handles those semantics. This just makes transformations first-class values, but you still always have to eagerly apply them. Lazy sequences are something I think should be added to transducers.js in the future. (edit: well, this paragraph isn't exactly true, but we'll have to explain laziness more in the future)
Some of the examples my also feel similar to ES6 comprehensions, and while true comprehensions don't give you the ability to control what type is built up. You can only get a generator or an array back. They also aren't composable; you will still need to solve the problem of building up transformations that can be reused.
When you correctly separate concerns in a program, it breeds super simple APIs that allow you build up all sorts of complex programs. This is a simple 500-line JavaScript library that, in my opinion, radically changes how I interact with data, and all with just a few methods.
transducers.js is still early work and it will be improved a lot. Let me know if you find any bugs (or if it blows your mind).
http://jlongster.com/Transducers.js--A-JavaScript-Library-for-Transformation-of-Data
|
|
Paul Rouget: (video) DevTools Timeline and Firefox OS |
Just thought I'd share that (if you're a Firefox OS hacker, you want to read this).
youtube videoWe recently landed a very basic timeline in the Firefox DevTools (enable it in the devtools options. Firefox and B2G nightly both required). It is basic. But already useful, especially to debug Firefox OS apps. For example today, we were looking at the System App and realized that the main thread was never idle. Looking at the timeline, we realized that a restyle was triggered many many times per seconds, even if nothing was happening on the screen. By tweaking the DOM with the inspector, we figured it was coming from a CSS animation that was display:none (see bug 962594).
We are working hard to build new Firefox performance tools. Expect to see better tools coming in the coming months. More info about this new timeline tool here.
|
|
David Boswell: Learning more about the Mozilla community |
We’ve learned a lot this year as we’ve been working on enabling communities that have impact. We discovered there is a high contributor churn rate, scaling the size of the community doesn’t meet the needs of all teams and there is a need to make community building more reliable and predictable.
There are still many more questions than answers right now though and there is much more to learn. A contributor audit was done in 2011 that had useful findings and recommendations, but it has now been 3 years since that research was completed. It is time to do more.

Research has provided other community-driven organizations with lessons that help them be more successful. For example, Lego has an active community and research has helped them develop a set of principles that promote successful interactions that provide value for both community members and the Lego organization.
We’ll be kicking off a new research project soon and we’d love to get your help. This will involve creating a survey to send out to Mozillians and will also dive into the contributor data we’ve started collecting. This won’t answer all the questions we have, but this will give us some insight and can provide a starting point for other research projects.

Some specific asks for helping with the survey include thinking about what questions we want to ask and thinking about the audience of people we want to reach out to. For the data analysis part, please comment here or contact me if you’re interested in helping.

http://davidwboswell.wordpress.com/2014/09/17/learning-more-about-the-mozilla-community/
|
|
Henrik Skupin: mozdownload 1.12 has been released |
The Firefox Automation team would like to announce the release of mozdownload 1.12. Without any other release of our universal download tool in the last 7 months, a couple of nice new features and bug fixes will make this release even more useful. You can upgrade your installation easily via pip, or by downloading it from PyPI.
http://www.hskupin.info/2014/09/18/mozdownload-1-12-has-been-released/
|
|
Henrik Skupin: Mozmill 2.0.7 and 2.0.8 have been released |
The Firefox Automation team would like to announce the release of Mozmill 2.0.7 and Mozmill 2.0.8. Both versions had to be released in such a short time frame to ensure continuing support for Firefox. Some latest changes done for Firefox Nightly broke Mozmill, or at least made it misbehaving. If you run tests with Mozmill ensure to upgrade to the latest version. You can do this via PyPI, or simply download the already pre-configured environment.
Please keep in mind that Mozmill 2.0 does not support electrolysis (e10s) builds of Firefox yet. We are working hard to get full support for e10s added, and hope it will be done until the next version bump mid of October.
Thanks everyone who was helping with those releases!
http://www.hskupin.info/2014/09/18/mozmill-2-0-7-and-2-0-8-have-been-released/
|
|
Sean Martell: Mozilla ID Project: Palette Explorations |
Churning along with out explorations into the Mozilla brand, we’ve been looking at nailing down an expanded base color palette to bring more choice and a bolder feel. We’ve injected the colors used in the Firefox color palette – derived from the logo itself – and added a few more previously missed hues, such as greens and pinks.
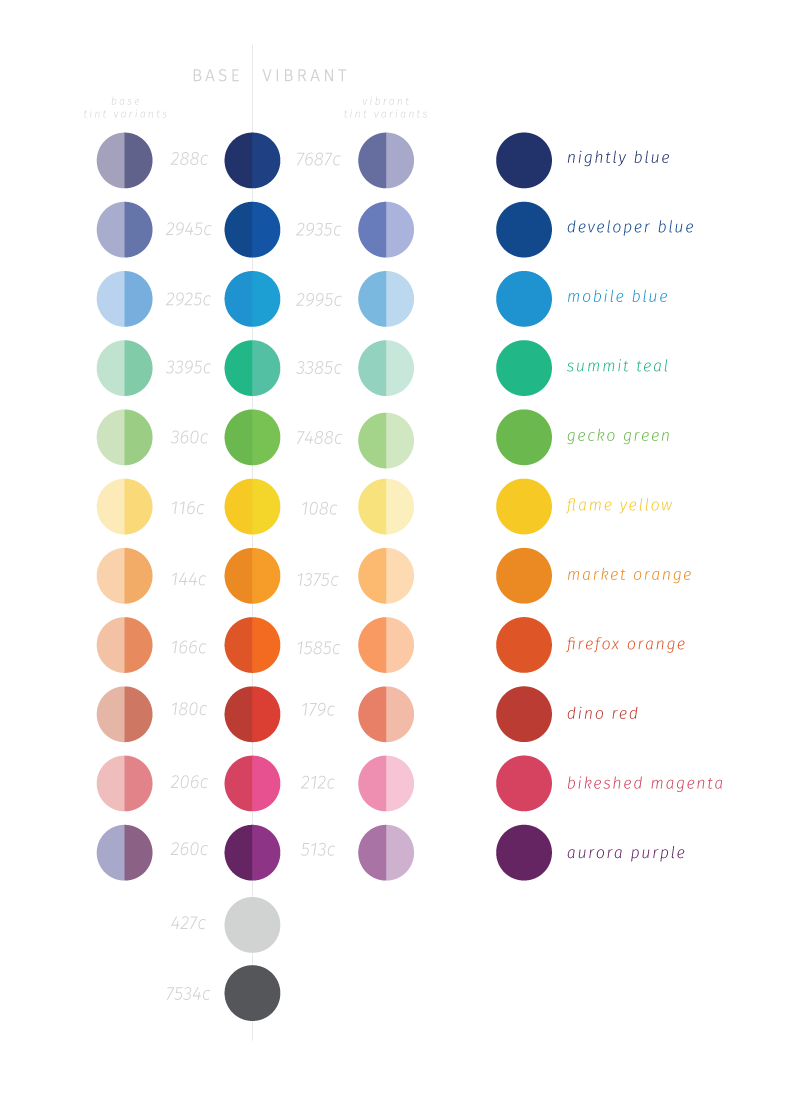
Along with the straight expansion of a single set, we’ve picked a vibrant set to compliment the base. With the two sets we then chose two stepped-down variants for each. This makes 6 variants for each of the named colors within the set.
All this is still in the works and not fully locked down, but we thought we’d share the thinking around this and offer a glimpse at where we’re going. We’re also updating the names of the base colors and adding a few fun labels in the process. Again, the labels aren’t finalized yet either, but thought we’d share. More to come on color and usage scenarios later!
http://blog.seanmartell.com/2014/09/17/mozilla-id-project-palette-explorations/
|
|
Byron Jones: we’re changing the default search settings for advanced search |
at the end of this week we will change the default search settings on bugzilla.mozilla.org’s advanced search page:

the resolution DUPLICATE will no longer be selected by default – only open bugs will be searched if the resolution field is left unmodified.
this change will not impact any existing saved searches or queries.
DUPLICATE has been a part of our default query for as long as i can remember, and was included to accommodate using that form to search for existing bugs.
since the addition of “possible duplicates” to the bug creation workflow, the importance of searching duplicates has lessened, and returning duplicates by default to advanced users is more of a hindrance than a help. the data reflects this – the logs indicate that over august less than 4% of advanced queries included DUPLICATE as a resolution.
this change is being tracked in bug 1068648.
|
|






