The Mozilla Blog: Fall Plans vs. the Delta Variant, deciphering Gen Z’s use of emojis, Sarah Paulson as Linda Tripp, and more are on this week’s Top Shelf |
|
|
Aaron Klotz: All Good Things... |
Today is my final day as an employee of Mozilla Corporation.
My first patch landed in Firefox 19, and my final patch as an employee has landed in Nightly for Firefox 93.
I’ll be moving on to something new in a few weeks’ time, but for now, I’d just like to say this:
My time at Mozilla has made me into a better software developer, a better leader, and more importantly, a better person.
I’d like to thank all the Mozillians whom I have interacted with over the years for their contributions to making that happen.
I will continue to update this blog with catch-up posts describing my Mozilla work, though I am unsure what content I will be able to contribute beyond that. Time will tell!
Until next time…
|
|
Mozilla Thunderbird: Thunderbird 91 Available Now |
The newest stable release of Thunderbird, version 91, is available for download on our website now. Existing Thunderbird users will be updated to the newest version in the coming weeks.
Thunderbird 91 is our biggest release in years with a ton of new features, bug fixes and polish across the app. This past year had its challenges for the Thunderbird team, our community and our users. But in the midst of a global pandemic, the important role that email plays in our lives became even more obvious. Our team was blown away by the support we received in terms of donations and open source contributions and we extend a big thanks to everyone who helped out Thunderbird in the lead up to this release.
There are a ton of changes in the new Thunderbird, you can see them all in the release notes. In this post we’ll focus on the most notable and visible ones.
Thunderbird has gotten faster with multi-process support. The new multi-process Thunderbird takes better advantage of the processor in your computer by splitting up the application into multiple smaller processes instead of running as one large one. That’s a lot of geekspeak to say that Thunderbird 91 will feel like it got a speed boost.
One of the most noticeable changes for Thunderbird 91 is the new account setup wizard. The new wizard not only features a better look, but does auto-discovery of calendars and address books and allows most users to set them up with just a click. After setting up an account, the wizard also points users at additional (optional) things to do – such as adding a signature or setting up end-to-end encryption.

The New Account Setup Wizard
The attachments pane been moved to the bottom of the compose window for better visibility of filenames as well as being able to see many at once. We’ve also added an overlay that appears when you drag-and-drop a file into the compose window asking how you would like to handle the file in that email (such as putting a picture in-line in your message or simply attaching it to the email).

Compose window with bottom attachment pane.

The new attachment drag-and-drop overlay.
Thunderbird now has a built-in PDF viewer, which means you can read and even do some editing on PDFs sent to you as attachments. You can do all this without ever leaving Thunderbird, allowing you to return to your inbox without missing a beat.

The PDF Viewer in Thunderbird 91
Depending on how you use Thunderbird and whether you are using it on a large desktop monitor or a small laptop touchscreen, you may want the icons and text of the interface to be larger and more spread out or very compact. In Thunderbird 91 under the View -> Density in the menu, you can select the UI density for the entire application. Three options are available: compact – which puts everything closer together, normal – the experience you are accustomed to in Thunderbird, and touch – that makes icons bigger and separates elements.
Play around with this new level of control and find what works best for you!

UI density control options
Managing multiple calendars has been made easier with the calendar sidebar improvements in this release. There is a quick enable button for disabled calendars, as well as a show/hide icon for easily toggling what calendars are visible. There is also a lock indicator for read-only calendars. Additionally, although not a sidebar improvement, there are now better color accents to highlight the current day in the calendar.

Improved Calendar sidebar
Thunderbird’s Dark Theme got even better in this release. In the past some windows and dialogues looked a bit out of place if you had Thunderbird’s dark theme selected. Now almost every dialogue and window in Thunderbird is fully styled to respect the user’s color scheme preferences.

Dark Theme
You really have to scroll through the release notes as there are a lot of little changes that make Thunderbird 91 feel really polished. Some other notable mentions are:
https://blog.thunderbird.net/2021/08/thunderbird-91-available-now/
|
|
The Talospace Project: Firefox 91 on POWER fur the fowk |
Anyway, Firefox 91 builds oot o the kist oa, er, Firefox 91 builds out of the box on OpenPOWER using the same .mozconfigs for Firefox 90; I made a wee change to the PGO-LTO patch since I messed up the diff the last time and didn't notice. The crypto issues in Fx90 are fixed in this release.
Meanwhile, the OpenPOWER JIT is now passing all but a handful of the basic tests in Baseline Interpreter mode, and some amount of Wasm, though this isn't nearly as far along. Ye kin hulp.
https://www.talospace.com/2021/08/firefox-91-on-power-fur-fowk.html
|
|
Hacks.Mozilla.Org: Hopping on Firefox 91 |
August is already here, which means so is Firefox 91! This release has a Scottish locale added and, if the ‘increased contrast’ setting is checked, auto enables High Contrast mode on macOS.
Private browsing windows have an HTTPS-first policy and will automatically attempt to make all connections to websites secure. Connections will fall back to HTTP if the website does not support HTTPS.
For developers Firefox 91 supports the Visual Viewport API and adds some more additions to the Intl.DateTimeFormat object.
This blog post provides merely a set of highlights; for all the details, check out the following:
Implemented back in Firefox 63, the Visual Viewport API was behind the pref dom.visualviewport.enabled in the desktop release. It is now no longer behind that pref and enabled by default, meaning the API is now supported in all major browsers.
There are two viewports on the mobile web, the layout viewport and the visual viewport. The layout viewport covers all the elements on a page and the visual viewport represents what is actually visible on screen. If a keyboard appears on screen, the visual viewport dimensions will shrink, but the layout viewport will remain the same.
This API gives you information about the size, offset and scale of the visual viewport and allows you to listen for resize and scroll events. You access it via the visualViewport property of the window interface.
In this simple example the resize event is listened for and when a user zooms in, hides an element in the layout, so as not to clutter the interface.
const elToHide = document.getElementById('to-hide');
var viewport = window.visualViewport;
function resizeHandler() {
if (viewport.scale > 1.3)
elToHide.style.display = "none";
else
elToHide.style.display = "block";
}
window.visualViewport.addEventListener('resize', resizeHandler);
A couple of updates to the Intl.DateTimeFormat object include new timeZoneName options for formatting how a timezone is displayed. These include the localized GMT formats shortOffset and longOffset, and generic non-location formats shortGeneric and longGeneric. The below code shows all the different options for the timeZoneName and their format.
var date = Date.UTC(2021, 11, 17, 3, 0, 42);
const timezoneNames = ['short', 'long', 'shortOffset', 'longOffset', 'shortGeneric', 'longGeneric']
for (const zoneName of timezoneNames) {
// Do something with currentValue
var formatter = new Intl.DateTimeFormat('en-US', {
timeZone: 'America/Los_Angeles',
timeZoneName: zoneName,
});
console.log(zoneName + ": " + formatter.format(date) );
}
// expected output:
// > "short: 12/16/2021, PST"
// > "long: 12/16/2021, Pacific Standard Time"
// > "shortOffset: 12/16/2021, GMT-8"
// > "longOffset: 12/16/2021, GMT-08:00"
// > "shortGeneric: 12/16/2021, PT"
// > "longGeneric: 12/16/2021, Pacific Time"You can now format date ranges as well with the new formatRange() and formatRangeToParts() methods. The former returns a localized and formatted string for the range between two Date objects:
const options = { weekday: 'long', year: 'numeric', month: 'long', day: 'numeric' };
const startDate = new Date(Date.UTC(2007, 0, 10, 10, 0, 0));
const endDate = new Date(Date.UTC(2008, 0, 10, 11, 0, 0));
const dateTimeFormat = new Intl.DateTimeFormat('en', options1);
console.log(dateTimeFormat.formatRange(startDate, endDate));
// expected output: Wednesday, January 10, 2007 – Thursday, January 10, 2008And the latter returns an array containing the locale-specific parts of a date range:
const startDate = new Date(Date.UTC(2007, 0, 10, 10, 0, 0)); // > 'Wed, 10 Jan 2007 10:00:00 GMT'
const endDate = new Date(Date.UTC(2007, 0, 10, 11, 0, 0)); // > 'Wed, 10 Jan 2007 11:00:00 GMT'
const dateTimeFormat = new Intl.DateTimeFormat('en', {
hour: 'numeric',
minute: 'numeric'
});
const parts = dateTimeFormat.formatRangeToParts(startDate, endDate);
for (const part of parts) {
console.log(part);
}
// expected output (in GMT timezone):
// Object { type: "hour", value: "2", source: "startRange" }
// Object { type: "literal", value: ":", source: "startRange" }
// Object { type: "minute", value: "00", source: "startRange" }
// Object { type: "literal", value: " – ", source: "shared" }
// Object { type: "hour", value: "3", source: "endRange" }
// Object { type: "literal", value: ":", source: "endRange" }
// Object { type: "minute", value: "00", source: "endRange" }
// Object { type: "literal", value: " ", source: "shared" }
// Object { type: "dayPeriod", value: "AM", source: "shared" }
There have been a few updates to the Gamepad API to fall in line with the spec. It is now only available in secure contexts (HTTPS) and is protected by Feature Policy: gamepad. If access to gamepads is disallowed, calls to Navigator.getGamepads() will throw an error and the gamepadconnected and gamepaddisconnected events will not fire.
The post Hopping on Firefox 91 appeared first on Mozilla Hacks - the Web developer blog.
|
|
Mozilla Security Blog: Firefox 91 Introduces Enhanced Cookie Clearing |
We are pleased to announce a new, major privacy enhancement to Firefox’s cookie handling that lets you fully erase your browser history for any website. Today’s new version of Firefox Strict Mode lets you easily delete all cookies and supercookies that were stored on your computer by a website or by any trackers embedded in it.
Building on Total Cookie Protection, Firefox 91’s new approach to deleting cookies prevents hidden privacy violations and makes it easy for you to see which websites are storing information on your computer.
When you decide to tell Firefox to forget about a website, Firefox will automatically throw away all cookies, supercookies and other data stored in that website’s “cookie jar”. This “Enhanced Cookie Clearing” makes it easy to delete all traces of a website in your browser without the possibility of sneaky third-party cookies sticking around.
Browsing the web leaves data behind in your browser. A site may set cookies to keep you logged in, or store preferences in your browser. There are also less obvious kinds of site data, such as caches that improve performance, or offline data which allows web applications to work without an internet connection. Firefox itself also stores data safely on your computer about sites you have visited, including your browsing history or site-specific settings and permissions.
Firefox allows you to clear all cookies and other site data for individual websites. Data clearing can be used to hide your identity from a site by deleting all data that is accessible to the site. In addition, it can be used to wipe any trace of having visited the site from your browsing history.
To make matters more complicated, the websites that you visit can embed content, such as images, videos and scripts, from other websites. This “cross-site” content can also read and write cookies and other site data.
Let’s say you have visited facebook.com, comfypants.com and mealkit.com. All of these sites store data in Firefox and leave traces on your computer. This data includes typical storage like cookies and localStorage, but also site settings and cached data, such as the HTTP cache. Additionally, comfypants.com and mealkit.com embed a like button from facebook.com.
Firefox Strict Mode includes Total Cookie Protection, where the cookies and data stored by each website on your computer are confined to a separate cookie jar. In Firefox 91, Enhanced Cookie Clearing lets you delete all the cookies and data for any website by emptying that cookie jar. Illustration: Megan Newell and Michael Ham.
Embedded third-party resources complicate data clearing. Before Enhanced Cookie Clearing, Firefox cleared data only for the domain that was specified by the user. That meant that if you were to clear storage for comfypants.com, Firefox deleted the storage of comfypants.com and left the storage of any sites embedded on it (facebook.com) behind. Keeping the embedded storage of facebook.com meant that it could identify and track you again the next time you visited comfypants.com.
Total Cookie Protection, built into Firefox, makes sure that facebook.com can’t use cookies to track you across websites. It does this by partitioning data storage into one cookie jar per website, rather than using one big jar for all of facebook.com’s storage. With Enhanced Cookie Clearing, if you clear site data for comfypants.com, the entire cookie jar is emptied, including any data facebook.com set while embedded in comfypants.com.
Now, if you click on Settings > Privacy and Security > Cookies and Site Data > Manage Data, Firefox no longer shows individual domains that store data. Instead, Firefox lists a cookie jar for each website you have visited. That means you can easily recognize and remove all data a website has stored on your computer, without having to worry about leftover data from third parties embedded in that website. Here is how it looks:

In Firefox’s Privacy and Security Settings, you can manage cookies and other site data stored on your computer. In Firefox 91 ETP Strict Mode, Enhanced Cookie Clearing ensures that all data for any site you choose has been completely removed.
In order for Enhanced Cookie Clearing to work, you need to have Strict Tracking Protection enabled. Once enabled, Enhanced Cookie Clearing will be used whenever you clear data for specific websites. For example, when using “Clear cookies and site data” in the identity panel (lock icon) or in the Firefox preferences. Find out how to clear site data in Firefox.
If you not only want to remove a site’s cookies and caches, but want to delete it from history along with any data Firefox has stored about it, you can use the “Forget About This Site” option in the History menu:

Firefox’s History menu lets you clear all history from your computer of any site you have visited. Starting in Firefox 91 in ETP Strict Mode, Enhanced Cookie Clearing ensures that third-party cookies that were stored when you visited that site are deleted as well.
We would like to thank the many people at Mozilla who helped and supported the development and deployment of Enhanced Cookie Clearing, including Steven Englehardt, Stefan Zabka, Tim Huang, Prangya Basu, Michael Ham, Mei Loo, Alice Fleischmann, Tanvi Vyas, Ethan Tseng, Mikal Lewis, and Selena Deckelmann.
The post Firefox 91 Introduces Enhanced Cookie Clearing appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2021/08/10/firefox-91-introduces-enhanced-cookie-clearing/
|
|
Mozilla Security Blog: Firefox 91 introduces HTTPS by Default in Private Browsing |
We are excited to announce that, starting in Firefox 91, Private Browsing Windows will favor secure connections to the web by default. For every website you visit, Firefox will automatically establish a secure, encrypted connection over HTTPS whenever possible.
The Hypertext Transfer Protocol (HTTP) is a key protocol through which web browsers and websites communicate. However, data transferred by the traditional HTTP protocol is unprotected and transferred in clear text, such that attackers are able to view, steal, or even tamper with the transmitted data. The introduction of HTTP over TLS (HTTPS) fixed this privacy and security shortcoming by allowing the creation of secure, encrypted connections between your browser and the websites that support it.
In the early days of the web, the use of HTTP was dominant. But, since the introduction of its secure successor HTTPS, and further with the availability of free, simple website certificates, the large majority of websites now support HTTPS. While there remain many websites that don’t use HTTPS by default, a large fraction of those sites do support the optional use of HTTPS. In such cases, Firefox Private Browsing Windows now automatically opt into HTTPS for the best available security and privacy.
Firefox’s new HTTPS by Default policy in Private Browsing Windows represents a major improvement in the way the browser handles insecure web page addresses. As illustrated in the Figure below, whenever you enter an insecure (HTTP) URL in Firefox’s address bar, or you click on an insecure link on a web page, Firefox will now first try to establish a secure, encrypted HTTPS connection to the website. In the cases where the website does not support HTTPS, Firefox will automatically fall back and establish a connection using the legacy HTTP protocol instead:

If you enter an insecure URL in the Firefox address bar, or if you click an insecure link on a web page, Firefox Private Browsing Windows checks if the destination website supports HTTPS. If YES: Firefox upgrades the connection and establishes a secure, encrypted HTTPS connection. If NO: Firefox falls back to using an insecure HTTP connection.
(Note that this new HTTPS by Default policy in Firefox Private Browsing Windows is not directly applied to the loading of in-page components like images, styles, or scripts in the website you are visiting; it only ensures that the page itself is loaded securely if possible. However, loading a page over HTTPS will, in the majority of cases, also cause those in-page components to load over HTTPS.)
We expect that HTTPS by Default will expand beyond Private Windows in the coming months. Stay tuned for more updates!
As a Firefox user, you can benefit from the additionally provided security mechanism as soon as your Firefox auto-updates to version 91 and you start browsing in a Private Browsing Window. If you aren’t a Firefox user yet, you can download the latest version here to start benefiting from all the ways that Firefox works to protect you when browsing the internet.
We are thankful for the support of our colleagues at Mozilla including Neha Kochar, Andrew Overholt, Joe Walker, Selena Deckelmann, Mikal Lewis, Gijs Kruitbosch, Andrew Halberstadt and everyone who is passionate about building the web we want: free, independent and secure!
The post Firefox 91 introduces HTTPS by Default in Private Browsing appeared first on Mozilla Security Blog.
|
|
Firefox Add-on Reviews: Find that font! I must have that font! |
You’re probably a digital designer or work in some publishing capacity (otherwise it would be pretty strange to have a fascination with fonts); and you appreciate the aesthetic power of exceptional typography.
So what do you do when you encounter a wonderful font in the wild that you might want to use in your own design work? Well, if you have a font finder browser extension you can learn all about it within a couple mouse clicks. Here are some of our favorite font discovery extensions…
Striking a balance between simple functionality and nuanced features, Font Finder (revived) delivers about everything you’d want in a font inspector.
The extension provides three main functions:
If you just want to know the name of any font you find and not much else, WhatFont is the ideal tool.
See an interesting font? Just click the WhatFont toolbar button and mouseover any text on the page to see its font. If you want a bit more info, click the text and a pop-up will show font size, color, and family.
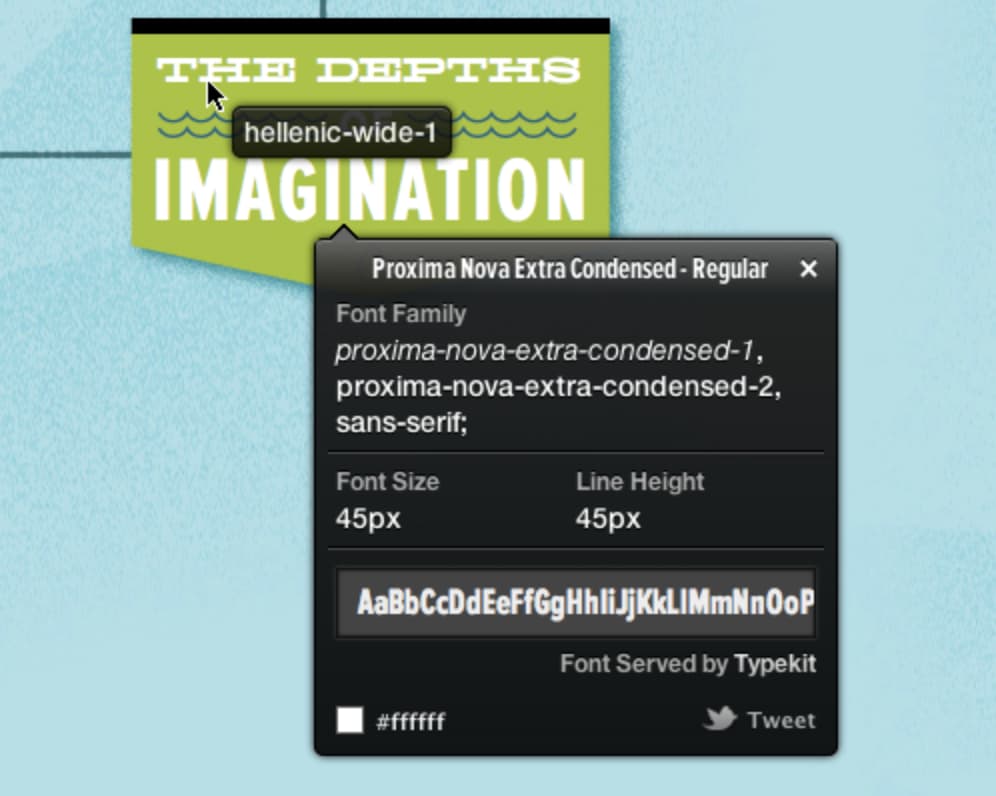
With a few distinct features, FontsNinja is great if you’re doing a lot of font finding and organization.
The extension really shines when you encounter a page loaded with a bunch of different fonts you want to learn about. Click the toolbar button and Fonts Ninja will analyze the entire page and display info for every single font found. Then, when you mouseover text on the page you’ll see which font it is and its CSS properties.
We hope these extensions help in your search for amazing fonts! Explore more visual customization extensions on addons.mozilla.org.
https://addons.mozilla.org/blog/find-that-font-i-must-have-that-font/
|
|
Cameron Kaiser: TenFourFox FPR32 SPR3 available |
http://tenfourfox.blogspot.com/2021/08/tenfourfox-fpr32-spr3-available.html
|
|
Cameron Kaiser: And now for something completely different: Australia needs to cut the crap with expats |

I am an Australian-American dual citizen (via my mother, who is Australian, but is resident in the United States), and my wife of five years is Australian. She is legimately a resident of Australia because she was completing her master's degree there and had to teach in the Australian system to get an unrestricted credential. All this happened when the borders closed. Anyone normally resident in Australia must obtain an exemption to leave the country and cite good cause, except to a handful of countries like New Zealand (who only makes the perfectly reasonable requirement that its residents have a spot in quarantine for when they return).
It was already difficult to exit Australia before, which is why, for the six weeks that I've gotten to see my wife since January 2020, it was me traveling to Australia. Here again many thanks to Air New Zealand, who were very understanding on rescheduling (twice) and even let us keep our Star Alliance Gold status even though we weren't flying much, I did my two weeks of quarantine, got my two negative tests, and was released into the hinterlands of regional New South Wales to visit that side of the family. Upon return to Sydney Airport, it was a simple matter to leave the country, since it was already obvious in the immigration records that I don't normally reside in it.

Now, there is the distinct possibility that if I can land a ticket to visit my wife, and if I can get space in hotel quarantine (at A$3000, plus greatly inflated airfares), despite being fully vaccinated, I may not be able to leave. Trying to get my credentials approved in Australia has been hung up for months so I wouldn't be able to have a job there in my current employ, and with my father currently on chemo, if he were to take a turn for the worse there are plenty of horror stories of Australians being unable to see terminally ill family members due to refused exemptions (or, adding insult to injury, being approved when they actually died).
I realize as (technically) an expat there isn't much of a constituency to join, but even given we're in the middle of a pandemic this crap has to stop. Restricting entries is heavyhanded, but understandable. Reminding those exiting that they're responsible for hotel or camp quarantine upon return is onerous (and should be reexamined at minimum for those who have indeed gotten the jab), but defensible. Preventing Australian citizens from leaving altogether, especially those with family, is unconscionable and the arbitrary nature of the exemption process is a foul joke.
If Premier Palaszczuk can strike a pose at the International Olympic Committee and Prime Minster Morrison can go gallivanting with randos in English pubs, those of us who are vaccinated and following the law should have that same freedom. I should be able to visit my wife and she should be able to visit me.
http://tenfourfox.blogspot.com/2021/08/and-now-for-something-completely.html
|
|
The Mozilla Blog: Perseid meteor shower on your mind? Check out these online resources for newbie astronomers plus 6 Firefox themes for daytime stargazing. |
Every summer I say I’m going to go watch the meteor showers, but life always seems to get in the way. This year, however, I scored a last minute midweek campsite on the Washington coast so I can take in the Perseid meteor shower away from city lights. While the Perseids are ongoing from mid-July to the end of August, they are expected to peak on the night of August 11 all around the world. This year’s Perseid event is predicted to be extra special due to the waxing crescent moon, which is to say, the moon will be a mere sliver in the sky. Less moonlight means the sky is darker, which means meteor showers appear brighter.
Interested in learning more? Here are some internet resources for newbie astronomers out there:

If you work at a computer all day, a fun thing about Firefox is that you can style your browser with a colorful theme. Keep the Perseid inspiration going all day at the keyboard with a free space-themed skin for Firefox. Browser themes are easy to install and change any time you’re in the mood.






The post Perseid meteor shower on your mind? Check out these online resources for newbie astronomers plus 6 Firefox themes for daytime stargazing. appeared first on The Mozilla Blog.
|
|
Data@Mozilla: This Week in Glean: Building a Mobile Acquisition Dashboard in Looker |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.) All “This Week in Glean” blog posts are listed in the TWiG index (and on the Mozilla Data blog).
As part of the DUET (Data User Engagement Team) working group, some of my day-to-day work involves building dashboards for visualizing user engagement aspects of the Firefox product. At Mozilla, we recently decided to use Looker to create dashboards and interactive views on our datasets. It’s a new system to learn but provides a flexible model for exploring data. In this post, I’ll walk through the development of several mobile acquisition funnels built in Looker. The most familiar form of engagement modeling is probably through funnel analysis — measuring engagement by capturing a cohort of users as they flow through various acquisition channels into the product. Typically, you’d visualize the flow as a Sankey or funnel plot, counting retained users at every step. The chart can help build intuition about bottlenecks or the performance of campaigns.
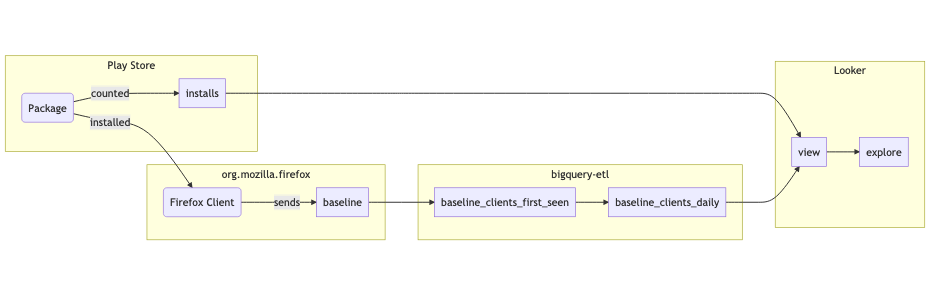
Mozilla owns a few mobile products; there is Firefox for Android, Firefox for iOS, and then Firefox Focus on both operating systems (also known as Klar in certain regions). We use Glean to instrument these products. The foremost benefit of Glean is that it encapsulates many best practices from years of instrumenting browsers; as such, all of the tables that capture anonymized behavior activity are consistent across the products. One valuable idea from this setup is that writing a query for a single product should allow it to extend to others without too much extra work. In addition, we pull in data from both the Google Play Store and Apple App Store to analyze the acquisition numbers. Looker allows us to take advantage of similar schemas with the ability to templatize queries.
The pipeline brings all of the data into BigQuery so it can be referenced in a derived table within Looker.
Before jumping off into implementing a dashboard, it’s essential to discuss the quality of the data sources. For one, Mozilla and the app stores count users differently, which leads to subtle inconsistencies.
For example, there is no way for Mozilla to tie a Glean client back to the Play Store installation event in the Play Store. Each Glean client is assigned a new identifier for each device, whereas the Play Store only counts new installs by account (which may have several devices). We can’t track a single user across this boundary, and instead have to rely on the relative proportions over time. There are even more complications when trying to compare numbers between Android and iOS. Whereas the Play Store may show the number of accounts that have visited a page, the Apple App Store shows the total number of page visits instead. Apple also only reports users that have opted into data collection, which under-represents the total number of users.
These differences can be confusing to people who are not intimately familiar with the peculiarities of these different systems. Therefore, an essential part of putting together this view is documenting and educating the dashboard users to understand the data better.
There are three components to building a Looker dashboard: a view, an explore, and a dashboard. These files are written in a markup called LookML. In this project, we consider three files:
The view is the bulk of data modeling work. Here, there are a few fields that are particularly important to keep in mind. First, there is a derived table alongside parameters, dimensions, and measures.
The derived table section allows us to specify the shape of the data that is visible to Looker. We can either refer to a table or view directly from a supported database (e.g., BigQuery) or write a query against that database. Looker will automatically re-run the derived table as necessary. We can also template the query in the view for a dynamic view into the data.
derived_table: { sql: with period as (SELECT ...), play_store_retained as ( SELECT Date AS submission_date, COALESCE(IF(country = "Other", null, country), "OTHER") as country, SUM(Store_Listing_visitors) AS first_time_visitor_count, SUM(Installers) AS first_time_installs FROM `moz-fx-data-marketing-prod.google_play_store.Retained_installers_country_v1` CROSS JOIN period WHERE Date between start_date and end_date AND Package_name IN ('org.mozilla.{% parameter.app_id %}') GROUP BY 1, 2 ), ... ;;} |
Above is the derived table section for the Android query. Here, we’re looking at the play_store_retained statement inside the common table expression (CTE). Inside of this SQL block, we have access to everything available to BigQuery in addition to view parameters.
# Allow swapping between various applications in the datasetparameter: app_id { description: "The name of the application in the `org.mozilla` namespace." type: unquoted default_value: "fenix" allowed_value: { value: "firefox" } allowed_value: { value: "firefox_beta" } allowed_value: { value: "fenix" } allowed_value: { value: "focus" } allowed_value: { value: "klar" }} |
View parameters trigger updates to the view when changed. These are referenced using the liquid templating syntax:
AND Package_name IN (‘org.mozilla.{% parameter.app_id %}’)
For Looker to be aware of the shape of the final query result, we must define dimensions and metrics corresponding to columns in the result. Here is the final statement in the CTE from above:
SELECT submission_date, country, max(play_store_updated) AS play_store_updated, max(latest_date) AS latest_date, sum(first_time_visitor_count) AS first_time_visitor_count, ... sum(activated) AS activatedFROM play_store_retainedFULL JOIN play_store_installsUSING (submission_date, country)FULL JOIN last_seenUSING (submission_date, country)CROSS JOIN periodWHERE submission_date BETWEEN start_date AND end_dateGROUP BY 1, 2ORDER BY 1, 2 |
Generally, in an aggregate query like this, the grouping columns will become dimensions while the aggregate values become metrics. A dimension is a column that we can filter or drill down into to get a different slice of the data model:
dimension: country { description: "The country code of the aggregates. The set is limited by those reported in the play store." type: string sql: ${TABLE}.country ;;} |
Note that we can refer to the derived table using the ${TABLE} variable (not unlike interpolating a variable in a bash script).
A measure is a column that represents a metric. This value is typically dependent on the dimensions.
measure: first_time_visitor_count { description: "The number of first time visitors to the play store." type: sum sql: ${TABLE}.first_time_visitor_count ;;} |
We must ensure that all dimensions and columns are declared to make them available to explores. Looker provides a few ways to create these fields automatically. For example, if you create a view directly from a table, Looker can autogenerate these from the schema. Likewise, the SQL editor has options to generate a view file directly. Whatever the method may be, some manual modification will be necessary to build a clean data model for use.
One of the more compelling features of Looker is the ability for folks to drill down into data models without the need to write SQL. They provide an interface where the dimensions and measures can be manipulated and plotted in an easy-to-use graphical interface. To do this, we need to declare which view to use. Often, just declaring the explore is sufficient:
include: "../views/*.view.lkml"
|
We include the view from a location relative to the explore file. Then we name an explore that shares the same name as the view. Once committed, the explore is available to explore in a drop-down menu in the main UI.
The explore can join multiple views and provide default parameters. In this project, we utilize a country view that we can use to group countries into various buckets. For example, we may have a group for North American countries, another for European countries, and so forth.
explore: mobile_android_country { join: country_buckets { type: inner relationship: many_to_one sql_on: ${country_buckets.code} = ${mobile_android_country.country} ;; } always_filter: { filters: [ country_buckets.bucket: "Overall" ] }} |
Finally, the explore is also the place where Looker will materialize certain portions of the view. Materialization is only relevant when copying the materialized segments from the exported dashboard code. An example of what this looks like follows:
aggregate_table: rollup__submission_date__0 { query: { dimensions: [ # "app_id" is filtered on in the dashboard. # Uncomment to allow all possible filters to work with aggregate awareness. # app_id, # "country_buckets.bucket" is filtered on in the dashboard. # Uncomment to allow all possible filters to work with aggregate awareness. # country_buckets.bucket, # "history_days" is filtered on in the dashboard. # Uncomment to allow all possible filters to work with aggregate awareness. # history_days, submission_date ] measures: [activated, event_installs, first_seen, first_time_visitor_count] filters: [ # "country_buckets.bucket" is filtered on by the dashboard. The filter # value below may not optimize with other filter values. country_buckets.bucket: "tier-1", # "mobile_android_country.app_id" is filtered on by the dashboard. The filter # value below may not optimize with other filter values. mobile_android_country.app_id: "firefox", # "mobile_android_country.history_days" is filtered on by the dashboard. The filter # value below may not optimize with other filter values. mobile_android_country.history_days: "7" ] } # Please specify a datagroup_trigger or sql_trigger_value # See https://looker.com/docs/r/lookml/types/aggregate_table/materialization materialization: { sql_trigger_value: SELECT CURRENT_DATE();; }} |
Looker provides the tooling to build interactive dashboards that are more than the sum of its parts. Often, the purpose is to present easily digestible information that has been vetted and reviewed by peers. To build a dashboard, you start by adding charts and tables from various explores. Looker provides widgets for filters and for markdown text used to annotate charts. It’s an intuitive process that can be somewhat tedious, depending on how complex the information you’re trying to present.

Once you’ve built the dashboard, Looker provides a button to get a YAML representation to check into version control. The configuration file contains all the relevant information for constructing the dashboard and could even be written by hand with enough patience.
Now that I’ve gone through building a dashboard end-to-end, here are a few points summarizing my experience and the take-aways from putting together this dashboard.
I worked with Glean-instrumented data in another project by parameterizing SQL queries using Jinja2 and running queries multiple times. Looker effectively brings this process closer to runtime and allows the ETL and visualization to live on the same platform. I’m impressed by how well it works in practice. The combination of consistent data models in bigquery-etl (e.g. clients_first_seen) and the ability to parameterize based on app-id was surprisingly straightforward. The dashboard can switch between Firefox for Android and Focus for Android without a hitch, even though they are two separate products with two separate datasets in BigQuery.
I can envision many places where we may not want to precompute all results ahead of time but instead just a subset of columns or dates on-demand. The costs of precomputing and materializing data is non-negligible, especially for large expensive queries that are viewed once in a blue moon or dimensions that fall in the long tail. Templating and parameters provide a great way to build these into the data model without having to resort to manually written SQL.
While Looker appeals to the non-technical crowd, it also affords many conveniences for the data practitioners who are familiar with the software development practices.
Changes to LookML files are version controlled (e.g., git). Being able to create branches and work on multiple features in parallel has been handy at times. It’s relieving to have the ability to make changes in my instance of the Looker files when trying out something new without having to lose my place. In addition, the ability to configure LookML views, explores, and dashboards in code allow for the process of creating new dashboards to incorporate many best practices like code review.
In addition, it’s nice to be able to use a real editor for mass revision. I was able to create a new dashboard for iOS data that paralleled the Android dashboard by copying over files, modifying the SQL in the view, and making a few edits to the dashboard code directly.
While there are many upsides to having LookML explores and dashboards in code, there are several pain points while working with the Looker interface.
In particular, the workflow for editing a Dashboard goes something like this. First, you copy the dashboard into a personal folder that you can edit. Next, you make whatever modifications to that dashboard using the UI. Afterward, you export the result and copy-paste it into the dashboard code. While not ideal, this prevents the Dashboard from going out of sync from the one that you’re editing directly (since there won’t be conflicts between the UI and the code in version control). However, it would be nice if it were possible to edit the dashboard directly instead of making a copy with Looker performing any conflict resolution internally.
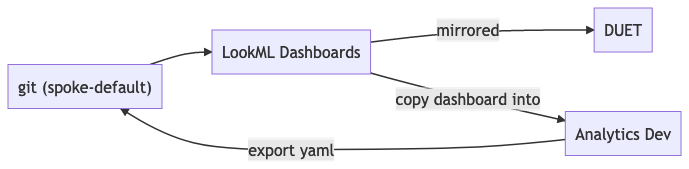
There have been moments where I’ve had to fight with the built-in git interface built into Looker’s development mode. Reverting a commit to a particular branch or dealing with merge conflicts can be an absolute nightmare. Suppose you do happen to pull the project in a local environment. In that case, you aren’t able to validate your changes locally (you’ll need to push, pull into Looker, and then validate and fix anything). Finally, the formatting option is stuck behind a keyboard shortcut while the browser is already using the keyboard shortcut.
Simply building a dashboard is not enough to demonstrate that it has value. It’s important to gather feedback from peers and stakeholders to determine the best path forward. Some things benefit from having a concrete implementation, though; there are differences between different platforms and inconsistencies in the data that may only appear after putting together an initial draft of a project.
While hitting goals of making data across app stores and our user populations visible, the funnel dashboard has room for improvement. Having this dashboard located in Looker makes the process of iterating that much easier, though. In addition, the feedback cycle of changing the query to seeing the results is relatively low and is easy to roll back. The tool is promising, and I look forward to seeing how it transforms the data landscape at Mozilla.
|
|
Mozilla Addons Blog: Thank you, Recommended Extensions Community Board! |
Given the broad visibility of Recommended extensions across addons.mozilla.org (AMO), the Firefox Add-ons Manager, and other places we promote extensions, we believe our curatorial process should include a wide range of perspectives from our global community of contributors. That’s why we have the Recommended Extensions Advisory Board—an ongoing project that involves a rotating group of contributors to help identify and evaluate new extension candidates for the program.
Our most recent community board just completed their six-month project and I’d like to take a moment to thank Sylvain Giroux, Jyotsna Gupta, Chandan Baba, Juraj M"asiar, and Pranjal Vyas for sharing their time, passion, and knowledge of extensions. Their insights helped usher a wave of new extensions into the Recommended program, including really compelling content like I Don’t Care About Cookies (A+ cookie manager), Tab Stash (highly original take on tab management), Custom Scrollbars (neon colored scrollbar? Yes please!), PocketTube (great way to organize a bunch of YouTube subscriptions), and many more.
On behalf of the entire Add-ons staff, thank you and all!
Now we’ll turn our attention to forming the next community board for another six-month project dedicated to evaluating new Recommended candidates. If you have a passion for browser extensions and you think you could make an impact contributing your insights to our curatorial process, we’d love to hear from you by Monday, 30 August. Just drop us an email at amo-featured [at] mozilla.org along with a brief note letting us know a bit about your experience with extensions—whether as a developer, user, or both—and why you’d like to participate on the next Recommended Extensions Community Advisory Board.
The post Thank you, Recommended Extensions Community Board! appeared first on Mozilla Add-ons Community Blog.
https://blog.mozilla.org/addons/2021/08/05/thank-you-recommended-extensions-community-board/
|
|
Mozilla Performance Blog: Performance in progress |
In the last six months the Firefox performance team has implemented changes to improve startup, responsiveness, security (Fission), and web standards.
Doug Thayer and Emma Malysz implemented work to improve the perceived startup of Firefox on Windows using a concept called the skeleton UI. Users on Windows may click the Firefox icon and not get visual feedback in the timeline they expect that Firefox is starting. So they click the icon again. And again. And then their screen looks like this.
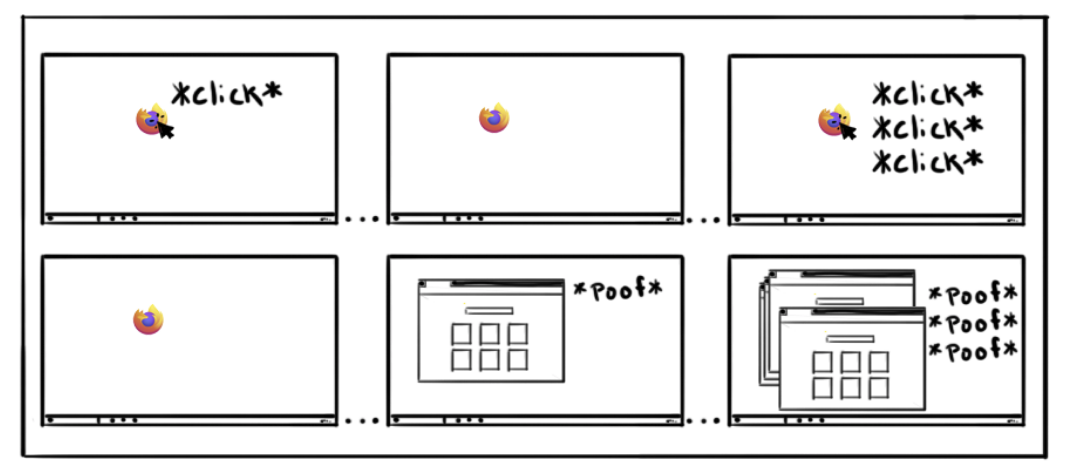
The reason that startup takes a long time is that many things need to happen before Firefox starts.
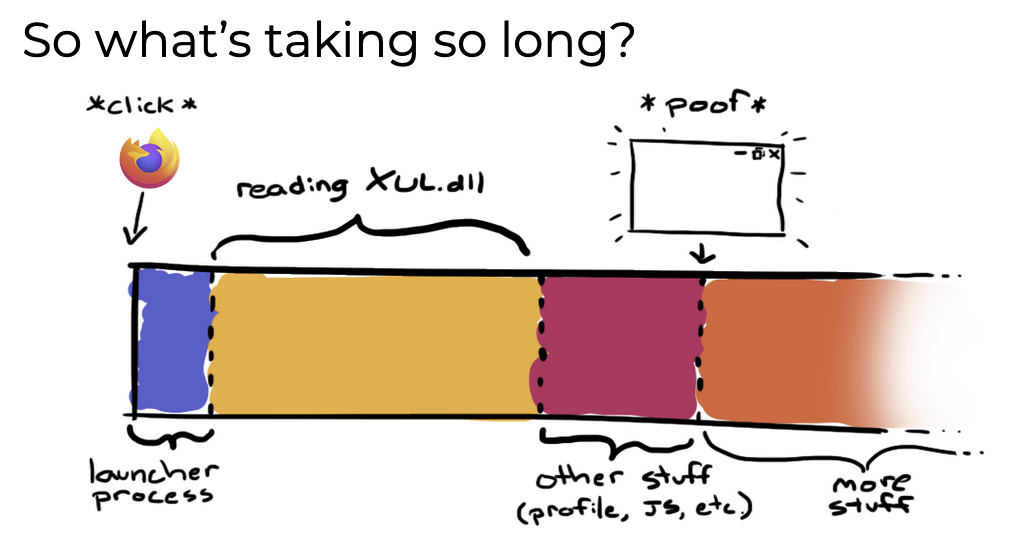
As part of startup, we need to start the JS engine, load the profile to get the size and position of the window. We also need to load a large library called XUL.dll which takes a lot of time to read from disk, especially if your computer is slow.
So what changes did the skeleton UI implement? Basically after the icon is clicked, we immediately show a window to indicate that Firefox is starting.

The final version of the skeleton UI looks at the user’s past sessions and creates a window with the theme, window dimensions, toolbar content and positions. You can see what it looks like in this video where the right hand side starts up with the skeleton UI in place. These changes are now available on Firefox 92 beta and riding the trails to release!
In other impactful work to address startup, last summer, Keefer Rourke, an intern on the performance team wrote a simplified API for file IO called IOUtils for use with privileged JavaScript. Emma Malysz and Barret Rennie, along with contributors migrated the existing startup code to IOUtils to improve startup performance.
Previously, when a Firefox user encountered a page that had a script that ran over a certain timing threshold, you would see a warning message that looked as follows:

For many people, this warning showed up too often, the cause was unclear and the options or next steps were confusing.
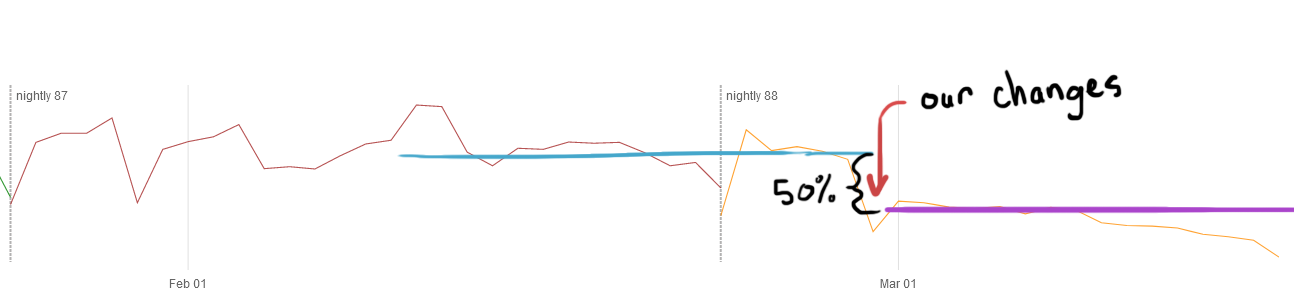
Doug Thayer and Emma Malysz embarked on work in early 2021 to reduce the proportion of users who experience the slow script warning. The solution that was implemented changed the user experience so the warning would only show if a user interacted with a hung page. They also added code to blame the page that’s causing the hang and remove the confusing “wait button”.

The result is a 50% reduction in slow script notification submissions!
Sean Feng implemented changes to make user interaction more strictly aligned with when the next frame is going to be presented on the screen. This makes Firefox feel more responsive by making sure a Frame always contains the result of all pending user interactions. On mobile Sean also implemented changes for better responsiveness on mobile devices. Sean landed code to allow the coalescing of more touchmove events to generate the events more efficiently.
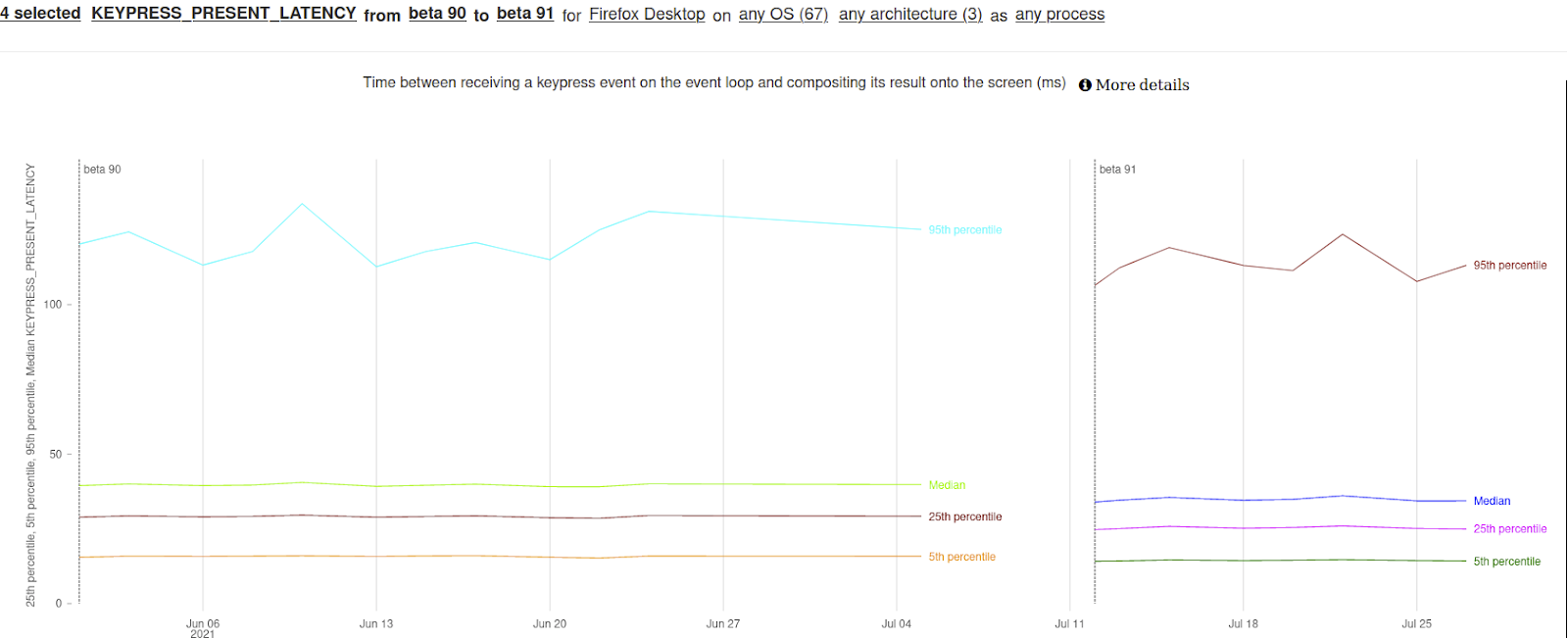
The impact of Sean’s work plus Matt Woodrow’s vsync work in bug is reflected in the graph above. To read more about other responsiveness changes in Firefox, Bas Schouten’s blog post provides more details.
Fission is site isolation in Firefox. If you want to learn more, read this detailed and thorough blog post by Anny Gakhokidz and Neha Kochar to learn about the implementation and rollout of Fission in Firefox.
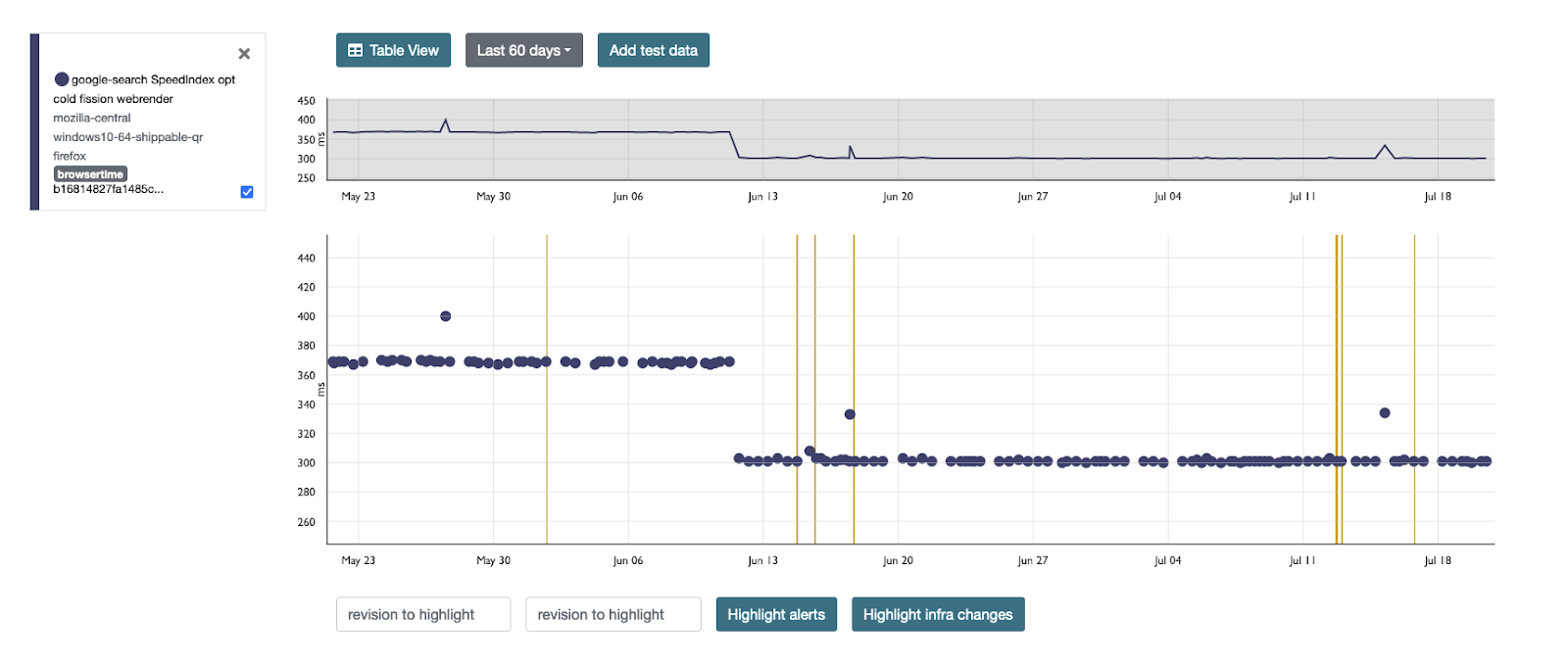
Sean Feng and Randell Jesup landed changes to improve process switches related to NSS initialization and http accept setup in process preallocation for Fission. There are improvements on several pages on Windows (~9% for google search, 5% for bing, around 3-4% for gmail, 2-3% for Microsoft); This should cut process-switch times by 6-8ms, perhaps as high as 10. Previously, we were seeing 20-40ms of time attributable to switching processes.
The Performance Event Timing API was enabled in Firefox 89 by Sean Feng on all platforms. This API provides web page authors with insights into the latency of certain events triggered by user interactions which is a prerequisite for Web Vitals. To learn more read 1667836 – Prototype PerformanceEventTiming, the announcement and the specification.
The performance team would like to thank everyone who contributed to this work
Markus Jaritz, Eric Smyth, Adam Gashlin, Molly Howell, Chris Martin, Jim Mathies, Aaron Klotz, Florian Qu`eze, Gijs Kruitbosch, Mike Conley, Markus Stange, Emma Malysz, Doug Thayer, Denis Palmerio, Sean Feng, Andrew Creskey, Barret Rennie, Benjamin De Kosnik, Bas Schouten Marc Leclair and Mike Comella. A special thanks to Doug Thayer for the artwork to display the changes in the skeleton UI and slow script work!
https://blog.mozilla.org/performance/2021/08/05/performance-in-progress/
|
|
The Mozilla Blog: An update from Firefox |
The post An update from Firefox appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/products/firefox/an-update-from-firefox/
|
|
Firefox Add-on Reviews: Read EPUB e-books right in your browser |
For many online readers you simply can’t beat the convenience and clarity of reading e-books in EPUB form (i.e. “electronic publication”). EPUB literature adjusts nicely to any screen size or device, but if you want to read EPUBs in your browser, you’ll need an extension to open their distinct files. Here are a few extensions to help turn your browser into an awesome digital bookshelf.
Extremely popular and easy to use, EPUBReader can take care of all your e-reading needs in one extension.
Whenever you encounter a website that offers EPUB, the extension automatically loads the ebook for you.
Access features by clicking EPUBReader’s toolbar icon, which launches a hub for all your EPUB activity. Here you’ll find all of your saved EPUB files (plus a portal for discovering new, free ebooks), as well as manage your layout settings like text font, size, colors, backgrounds, and more.

EPUBReader also works very well in tandem with…
Think of Read Aloud: text to speech voice reader as an audio version of a traditional text-based e-reader. Sit back and let it read the web to you.
Key features:
Optimized for offline reading, EpubPress lets you easily download and organize web pages into a “book” for offline reading. Use it to compile an actual long read book, or utilize it for saving news articles and other short form reading lists.
Very intuitive to operate. Once you have all the pages you want to collate opened in separate tabs, just order them how you want them to appear in your book. Ads and other distracting widgets are automatically removed from your saved pages.
We hope these extensions bring you great browser reading joy! Explore more reading extensions on addons.mozilla.org.
https://addons.mozilla.org/blog/read-epub-e-books-right-in-your-browser/
|
|
The Mozilla Blog: Why Facebook’s claims about the Ad Observer are wrong |
Recently the Surgeon General of the United States weighed in on the spread of disinformation on major platforms and its effects on people and society. He echoed the calls of researchers, activists and organizations, like Mozilla, for the major platforms to release more data, and to provide access to researchers in order to analyze the spread and impact of misinformation.
Yet Facebook has again taken steps to shut down this exact kind of research on its platform, a troubling pattern we have witnessed from Facebook including sidelining their own Crowdtangle and killing a suite of tools from Propublica and Mozilla in 2019.
Most recently, Facebook has terminated the accounts of New York University researchers that built Ad Observer, an extension dedicated to bringing greater transparency to political advertising that was critical for researchers and journalists during the presidential election.
Facebook claims the accounts were shut down due to privacy problems with the Ad Observer. In our view, those claims simply do not hold water. We know this, because before encouraging users to contribute data to the Ad Observer, which we’ve done repeatedly, we reviewed the code ourselves. And in this blog post, we want to explain why we believe people can contribute to this important research without sacrificing their privacy.
Anytime you give your data to another party, whether Facebook or Mozilla or researchers at New York University, it is important that you know whether that party is trustworthy, what data will be collected, and what will be done with that data. Those are critical things to consider before you potentially grant access to your data. And those are also key factors for Mozilla when we consider recommending an extension.
Before Mozilla decided to recommend Ad Observer, we reviewed it twice, conducting both a code review and examining the consent flow to ensure users will understand exactly what they are installing. In both cases the team responsible for this add-on responded quickly to our feedback, made changes to their code, and demonstrated a commitment to the privacy of their users. We also conducted an in-depth design review of Ad Observer, the results of which can be found here.
We decided to recommend Ad Observer because our reviews assured us that it respects user privacy and supports transparency. It collects ads, targeting parameters and metadata associated with the ads. It does not collect personal posts or information about your friends. And it does not compile a user profile on its servers. The extension also allows you to see what data has been collected by visiting the “My Archive” tab. It gives you the choice to opt in to sharing additional demographic information to aid research into how specific groups are being targeted, but even that is off by default.
You don’t have to take our word for it. Ad Observer is open source, so anybody can see the code and confirm it is designed properly and doing what it purports to do.
Of course, companies like Facebook need to be proactive about third-parties that might be collecting data on their platform and putting their users at risk. Figuring out what third-parties to allow under what circumstances is certainly not an easy task. But in this case, the application of its policy is counterproductive. This is why Mozilla makes exceptions for good-faith security research in our own products and why we have been supportive of calls for Facebook to create safe harbors for public-interest research.
The truth is that major platforms continue to be a safe haven for disinformation and extremism — wreaking havoc on people, our elections and society. We actually launched Mozilla Rally to take back control of research from unresponsive platforms like Facebook. Telling the truth about misinformation needs consent, clarity and community, and businesses built on people’s data shouldn’t be scared of telling us what that data is used for. We’ve also pushed the industry through the EU’s Code of Practice on Disinformation, encouraged the European Commission to mandate disclosure of all advertisements on major platforms and encouraged users to contribute their data to Ad Observer. We need tools like Ad Observer to help us shine a light on the darkest corners of the web. And rather than standing in the way of efforts to hold platforms accountable, we all need to work together to support and improve these tools.
The post Why Facebook’s claims about the Ad Observer are wrong appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/mozilla/news/why-facebooks-claims-about-the-ad-observer-are-wrong/
|
|
The Mozilla Blog: Privacy analysis of SWAN.community and United ID 2.0 |
Earlier this summer, we started a series of blog posts analyzing the technical merits of the various privacy-preserving advertising proposals out there. Our goal is to advance the debate and help break down this complex topic. In this new addition to this series, we look at the SWAN.community and United ID 2.0 proposals. We have conducted a detailed analysis and this post provides a summary.
The conclusion of our analysis is that, from a purely technical standpoint, these proposals are a regression in privacy in that they allow tracking of users who are presently protected against tracking.
Advertising is central to the internet economy. But it is very intrusive. It is powered by ubiquitous surveillance and it is often used in ways that harm individuals and society. As a browser maker and as a nonprofit-backed organization driven by a clear mission, we want to ensure that the interests of users are represented and that privacy is a priority.
With the current debate on privacy-preserving advertising, we have a real opportunity now to challenge the status quo and improve the privacy properties of online advertising—an industry that hasn’t seen privacy improvement in years. Attempts by the advertising industry to improve privacy through voluntary and policy-based initiatives have demonstrably failed. These proposals rely on those same failed mechanisms.
As we continue to explore privacy preserving advertising proposals, our plan in the Firefox browser is to ratchet up the privacy and security protections we offer, with the goal of eliminating cross-site tracking from the browser entirely. That is the work we started with the launch of Enhanced Tracking Protection in 2019 and that work will continue.
Check out our analysis of SWAN and Unified ID 2.0.
For more on this:
Building a more privacy-preserving ads-based ecosystem
Mozilla responds to the UK CMA consultation on google’s commitments on the Chrome Privacy Sandbox
The post Privacy analysis of SWAN.community and United ID 2.0 appeared first on The Mozilla Blog.
|
|