William Lachance: Using BigQuery JavaScript UDFs to analyze Firefox telemetry for fun & profit |
For the last year, we’ve been gradually migrating our backend Telemetry systems from AWS to GCP. I’ve been helping out here and there with this effort, most recently porting a job we used to detect slow tab spinners in Firefox nightly, which produced a small dataset that feeds a small adhoc dashboard which Mike Conley maintains. This was a relatively small task as things go, but it highlighted some features and improvements which I think might be broadly interesting, so I decided to write up a small blog post about it.
Essentially all this dashboard tells you is what percentage of the Firefox nightly population saw a tab spinner over the past 6 months. And of those that did see a tab spinner, what was the severity? Essentially we’re just trying to make sure that there are no major regressions of user experience (and also that efforts to improve things bore fruit):
Pretty simple stuff, but getting the data necessary to produce this kind of dashboard used to be anything but trivial: while some common business/product questions could be answered by a quick query to clients_daily, getting engineering-specific metrics like this usually involved trawling through gigabytes of raw heka encoded blobs using an Apache Spark cluster and then extracting the relevant information out of the telemetry probe histograms (in this case, FX_TAB_SWITCH_SPINNER_VISIBLE_MS and FX_TAB_SWITCH_SPINNER_VISIBLE_LONG_MS) contained therein.
The code itself was rather complicated (take a look, if you dare) but even worse, running it could get very expensive. We had a 14 node cluster churning through this script daily, and it took on average about an hour and a half to run! I don’t have the exact cost figures on hand (and am not sure if I’d be authorized to share them if I did), but based on a back of the envelope sketch, this one single script was probably costing us somewhere on the order of $10-$40 a day (that works out to between $3650-$14600 a year).
With our move to BigQuery, things get a lot simpler! Thanks to the combined effort of my team and data operations[1], we now produce “stable” ping tables on a daily basis with all the relevant histogram data (stored as JSON blobs), queryable using relatively vanilla SQL. In this case, the data we care about is in telemetry.main (named after the main ping, appropriately enough). With the help of a small JavaScript UDF function, all of this data can easily be extracted into a table inside a single SQL query scheduled by sql.telemetry.mozilla.org.
CREATE TEMP FUNCTION
udf_js_json_extract_highest_long_spinner (input STRING)
RETURNS INT64
LANGUAGE js AS """
if (input == null) {
return 0;
}
var result = JSON.parse(input);
var valuesMap = result.values;
var highest = 0;
for (var key in valuesMap) {
var range = parseInt(key);
if (valuesMap[key]) {
highest = range > 0 ? range : 1;
}
}
return highest;
""";
SELECT build_id,
sum (case when highest >= 64000 then 1 else 0 end) as v_64000ms_or_higher,
sum (case when highest >= 27856 and highest < 64000 then 1 else 0 end) as v_27856ms_to_63999ms,
sum (case when highest >= 12124 and highest < 27856 then 1 else 0 end) as v_12124ms_to_27855ms,
sum (case when highest >= 5277 and highest < 12124 then 1 else 0 end) as v_5277ms_to_12123ms,
sum (case when highest >= 2297 and highest < 5277 then 1 else 0 end) as v_2297ms_to_5276ms,
sum (case when highest >= 1000 and highest < 2297 then 1 else 0 end) as v_1000ms_to_2296ms,
sum (case when highest > 0 and highest < 50 then 1 else 0 end) as v_0ms_to_49ms,
sum (case when highest >= 50 and highest < 100 then 1 else 0 end) as v_50ms_to_99ms,
sum (case when highest >= 100 and highest < 200 then 1 else 0 end) as v_100ms_to_199ms,
sum (case when highest >= 200 and highest < 400 then 1 else 0 end) as v_200ms_to_399ms,
sum (case when highest >= 400 and highest < 800 then 1 else 0 end) as v_400ms_to_799ms,
count(*) as count
from
(select build_id, client_id, max(greatest(highest_long, highest_short)) as highest
from
(SELECT
SUBSTR(application.build_id, 0, 8) as build_id,
client_id,
udf_js_json_extract_highest_long_spinner(payload.histograms.FX_TAB_SWITCH_SPINNER_VISIBLE_LONG_MS) AS highest_long,
udf_js_json_extract_highest_long_spinner(payload.histograms.FX_TAB_SWITCH_SPINNER_VISIBLE_MS) as highest_short
FROM telemetry.main
WHERE
application.channel='nightly'
AND normalized_os='Windows'
AND application.build_id > FORMAT_DATE("%Y%m%d", DATE_SUB(CURRENT_DATE(), INTERVAL 2 QUARTER))
AND DATE(submission_timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 QUARTER))
group by build_id, client_id) group by build_id;In addition to being much simpler, this new job is also way cheaper. The last run of it scanned just over 1 TB of data, meaning it cost us just over $5. Not as cheap as I might like, but considerably less expensive than before: I’ve also scheduled it to only run once every other day, since Mike tells me he doesn’t need this data any more often than that.
[1] I understand that Jeff Klukas, Frank Bertsch, Daniel Thorn, Anthony Miyaguchi, and Wesley Dawson are the principals involved - apologies if I’m forgetting someone.
|
|
Mozilla VR Blog: A Year with Spoke: Announcing the Architecture Kit |

Spoke, our 3D editor for creating environments for Hubs, is celebrating its first birthday with a major update. Last October, we released the first version of Spoke, a compositing tool for mixing 2D and 3D content to create immersive spaces. Over the past year, we’ve made a lot of improvements and added new features to make building scenes for VR easier than ever. Today, we’re excited to share the latest feature that adds to the power of Spoke: the Architecture Kit!
We first talked about the components of the Architecture Kit back in March. With the Architecture Kit, creators now have an additional way to build custom content for their 3D scenes without using an external tool. Specifically, we wanted to make it easier to take existing components that have already been optimized for VR and make it easy to configure those pieces to create original models and scenes. The Architecture Kit contains over 400 different pieces that are designed to be used together to create buildings - the kit includes wall, floor, ceiling, and roof pieces, as well as windows, trim, stairs, and doors.
Because Hubs runs across mobile, desktop, and VR devices and delivered through the browser, performance is a key consideration. The different components of the Architecture Kit were created in Blender so that each piece would align together to create seamless connections. By avoiding mesh overlap, which is a common challenge when building with pieces that were made separately, z-fighting between faces becomes less of a problem. Many of the Architecture Kit pieces were made single-sided, which reduces the number of faces that need to be rendered. This is incredibly useful when creating interior or exterior pieces where one side of a wall or ceiling piece will never be visible by a user.
We wanted the Architecture Kit to be configurable beyond just the meshes. Buildings exist in a variety of contexts, so different pieces of the Kit can have one or more material slots with unique textures and materials that can be applied. This allows you to customize a wall with a window trim to have, for example, a brick wall and a wood trim. You can choose from the built-in textures of the Architecture Kit pieces directly in Spoke, or download the entire kit from GitHub.

This release, which focuses on classic architectural styles and interior building tools, is just the beginning. As part of building the architecture kit, we’ve built a Blender add-on that will allow 3D artists to create their own kits. Creators will be able to specify individual collections of pieces and set an array of different materials that can be applied to the models to provide variation for different meshes. If you’re an artist interested in contributing to Spoke and Hubs by making a kit, drop us a line at hubs@mozilla.com.

In addition to the Architecture Kit, Spoke has had some other major improvements over the course of its first year. Recent changes to object placement have made it easier when laying out scene objects, and an update last week introduced the ability to edit multiple objects at one time. We added particle systems over the summer, enabling more dynamic elements to be placed in your rooms. It’s also easier to visualize different components of your scene with a render mode toggle that allows you to swap between wireframe, normals, and shadows. The Asset Panel got a makeover, multi-select and edit was added, and we fixed a huge list of bugs when we made Spoke available as a fully hosted web app.
Looking ahead to next year, we’re planning on adding features that will give creators more control over interactivity within their scenes. While the complete design and feature set for this isn’t yet fully scoped, we’ve gotten great feedback from Spoke creators that they want to add custom behaviors, so we’re beginning to think about what it will look like to experiment with scripting or programmed behavior on elements in a scene. If you’re interested in providing feedback and following along with the planning, we encourage you to join the Hubs community Discord server, and keep an eye on the Spoke channel. You can also follow development of Spoke on GitHub.
There has never been a better time to start creating 3D content for the web. With new tools and features being added to Spoke all the time, we want your feedback in and we’d love to see what you’re building! Show off your creations and tag us on Twitter @ByHubs, or join us in the Hubs community Discord and meet other users, chat with the team, and stay up to date with the latest in Mozilla Social VR.
|
|
Mozilla Open Policy & Advocacy Blog: A Year in Review: Fighting Online Disinformation |
A year ago, Mozilla signed the first ever Code of Practice on Disinformation, brokered in Europe as part of our commitment to an internet that elevates critical thinking, reasoned argument, shared knowledge, and verifiable facts. The Code set a wide range of commitments for all the signatories, from transparency in political advertising to the closure of fake accounts, to address the spread of disinformation online. And we were hopeful that the Code would help to drive change in the platform and advertising sectors.
Since then, we’ve taken proactive steps to help tackle this issue, and today our self assessment of this work was published by the European Commission. Our assessment covers the work we’ve been doing at Mozilla to build tools within the Firefox browser to fight misinformation, empower users with educational resources, support research on disinformation and lead advocacy efforts to push the ecosystem to live up to their own commitments within the Code of Practice.
Most recently, we’ve rolled-out enhanced security features in the default setting of Firefox that safeguards our users from the pervasive tracking and collection of personal data by ad networks and tech companies by blocking all third-party cookies by default. As purveyors of disinformation feed off of information that can be revealed about an individual’s browsing behavior, we expect this protection to reduce the exposure of users to the risks of being targeted by disinformation campaigns.
We are proud of the steps we’ve taken during the last year, but it’s clear that the platforms and online advertising sectors need to do more – e.g. protection against online tracking, meaningful transparency of political ads and support of the research community – to fully tackle online disinformation and truly empower individuals. In fact, recent studies have highlighted the fact that disinformation is not going away – rather, it is becoming a “pervasive and ubiquitous part of everyday life”.
The Code of Practice represents a positive shift in the fight to counter misinformation, and today’s self assessments are proof of progress. However, this work has only just begun and we must make sure that the objectives of the Code are fully realized. At Mozilla, we remain committed to further this agenda to counter disinformation online.
The post A Year in Review: Fighting Online Disinformation appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2019/10/29/a-year-in-review-fighting-online-disinformation/
|
|
Cameron Kaiser: SourceForge download issues (and Github issues issues) |
The first one is that the hack we use to relax JavaScript syntax to get Github working (somewhat) is now causing the browser to go into an infinite error loop on Github issue reports and certain other Github pages, presumably due to changes in code on their end. Unfortunately we use Github heavily for the wiki and issues tracker, so this is a major problem. The temporary workaround is, of course, a hack to relax JavaScript syntax even further. This hack is disgusting and breaks a lot of tests but is simple and does seem to work, so if I can't come up with something better it will be in FPR17. Most regular users won't be affected by this.
However, the one that is now starting to bite people is that SourceForge has upgraded its cipher suite to require a new cipher variant TenFourFox doesn't support. Unfortunately all that happens is links to download TenFourFox don't work; there is no error message, no warning and no explanation. That is a bug in and of itself but this leaves people dead in the water being pinged to install an update they can't access directly.
Naturally you can download the browser on another computer but this doesn't help users who only have a Power Mac. Fortunately, the good old TenFourFox Downloader works fine. As a temporary measure I have started offering the Downloader to all users from the TenFourFox main page, or you can get it from this Tenderapp issue. I will be restricting it to only Power Mac users regardless of browser very soon because it's not small and serves no purpose on Intel Macs (we don't support them) or other current browsers (they don't need it), but I want to test that the download gate works properly first and I'm not at my G5 right this second, so this will at least unblock people for the time being.
For regression and stability reasons I don't want to do a full NSPR/NSS update but I think I can hack this cipher in as we did with another one earlier. I will be speeding up my timetable for FPR17 so that people can test the changes (including some other site compatibility updates), but beta users are forewarned that you will need to use another computer to download the beta. Sorry about that.
http://tenfourfox.blogspot.com/2019/10/sourceforge-download-issues-and-github.html
|
|
The Firefox Frontier: Password dos and don’ts |
So many accounts, so many passwords. That’s online life. The average person with a typical online presence is estimated to have close to 100 online accounts, and that figure is … Read more
The post Password dos and don’ts appeared first on The Firefox Frontier.
|
|
Hacks.Mozilla.Org: Auditing For Accessibility Problems With Firefox Developer Tools |
Since its debut in Firefox 61, the Accessibility Inspector in the Firefox Developer Tools has evolved from a low-level tool showing the accessibility structure of a page. In Firefox 70, the Inspector has become an auditing facility to help identify and fix many common mistakes and practices that reduce site accessibility. In this post, I will offer an overview of what is available in this latest release.
First, select the Accessibility Inspector from the Developer Toolbox. Turn on the accessibility engine by clicking “Turn On Accessibility Features.” You’ll see a full representation of the current foreground tab as assistive technologies see it. The left pane shows the hierarchy of accessible objects. When you select an element there, the right pane fills to show the common properties of the selected object such as name, role, states, description, and more. To learn more about how the accessibility tree informs assistive technologies, read this post by Hidde de Vries.

The DOM Node property is a special case. You can double-click or press ENTER to jump straight to the element in the Page Inspector that generates a specific accessible object. Likewise, when the accessibility engine is enabled, open the context menu of any HTML element in the Page Inspector to inspect any associated accessible object. Note that not all DOM elements have an accessible object. Firefox will filter out elements that assistive technologies do not need. Thus, the accessibility tree is always a subset of the DOM tree.
In addition to the above functionality, the inspector will also display any issues that the selected object might have. We will discuss these in more detail below.
The accessibility tree refers to the full tree generated from the HTML, JavaScript, and certain bits of CSS from the web site or application. However, to find issues more easily, you can filter the left pane to only show elements with current accessibility issues.
To filter the tree, select one of the auditing filters from the “Check for issues” drop-down in the toolbar at the top of the inspector window. Firefox will then reduce the left pane to the problems in your selected category or categories. The items in the drop-down are check boxes — you can check for both text labels and focus issues. Alternatively, you can run all the checks at once if you wish. Or, return the tree to its full state by selecting None.
Once you select an item from the list of problems, the right pane fills with more detailed information. This includes an MDN link to explain more about the issue, along with suggestions for fixing the problem. You can go into the page inspector and apply changes temporarily to see immediate results in the accessibility inspector. Firefox will update Accessibility information dynamically as you make changes in the page inspector. You gain instant feedback on whether your approach will solve the problem.
Since Firefox 69, you have the ability to filter the list of accessibility objectss to only display those that are not properly labeled. In accessibility jargon, these are items that have no names. The name is the primary source of information that assistive technologies, such as screen readers, use to inform a user about what a particular element does. For example, a proper button label informs the user what action will occur when the button is activated.
The check for text labels goes through the whole document and flags all the issues it knows about. Among other things, it finds missing alt-text (alternative text) on images, missing titles on iframes or embeds, missing labels for form elements such as inputs or selects, and missing text in a heading element.

Keyboard navigation and visual focus are common sources of accessibility issues for various types of users. To help debug these more easily, Firefox 70 contains a checker for many common keyboard and focus problems. This auditing tool detects elements that are actionable or have interactive semantics. It can also detect if focus styling has been applied. However, there is high variability in the way controls are styled. In some cases, this results in false positives. If possible, we would like to hear from you about these false positives, with an example that we can reproduce.
For more information about focus problems and how to fix them, don’t miss Hidde’s post on indicating focus.

Firefox includes a full-page color contrast checker that checks for all three types of color contrast issues identified by the Web Content Accessibility Guidelines 2.1 (WCAG 2.1):
In addition, the color contrast checker provides information on the triple-A success criteria contrast ratio. You can see immediately whether your page meets this advanced standard.
Are you using a gradient background or a background with other forms of varying colors? In this case, the contrast checker (and accessibility element picker) indicates which parts of the gradient meet the minimum requirements for color contrast ratios.
Firefox 70 contains a new tool that simulates seven types of color vision deficiencies, a.k.a. color blindness. It shows a close approximation of how a person with one of these conditions would see your page. In addition, it informs you if you’ve colored something that would not be viewable by a colorblind user. Have you provided an alternative? For example, someone who has Protanomaly (low red) or Protanopia (no red) color perception would be unable to view an error message colored in red.
As with all vision deficiencies, no two users have exactly the same perception. The low red, low green, low blue, no red, no green, and no blue deficiencies are genetic and affect about 8 percent of men, and 0.5 percent of women worldwide. However, contrast sensitivity loss is usually caused by other kinds of mutations to the retina. These may be age-related, caused by an injury, or via genetic predisposition.
Note: The color vision deficiency simulator is only available if you have WebRender enabled. If it isn’t enabled by default, you can toggle the gfx.webrender.all property to True in about:config.

As a mouse user, you can also quickly audit elements on your page using the accessibility picker. Like the DOM element picker, it highlights the element you selected and displays its properties. Additionally, as you hover the mouse over elements, Firefox displays an information bar that shows the name, role, and states, as well as color contrast ratio for the element you picked.
First, click the Accessibility Picker icon. Then click on an element to show its properties. Want to quickly check multiple elements in rapid succession? Click the picker, then hold the shift key to click on multiple items one after another to view their properties.

Since its release back in June 2018, the Accessibility Inspector has become a valuable helper in identifying many common accessibility issues. You can rely on it to assist in designing your color palette. Use it to ensure you always offer good contrast and color choices. We build a11y features into the DevTools that you’ve come to depend on, so you do not need to download or search for external services or extensions first.
The post Auditing For Accessibility Problems With Firefox Developer Tools appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2019/10/auditing-for-accessibility-problems-with-firefox-developer-tools/
|
|
Tantek Celik: #Redecentralize 2019 Session: IndieWeb Decentralized Standards and Methods |
Kevin Marks started the session by having me bring up the tabs that I’d shown in my lightning talk earlier, digging into the specifications, tools, and services linked therein. Participants asked questions and Kevin & I answered, demonstrating additional resources as necessary.
One of the first questions was about how do people represent themselves on the IndieWeb, in a way that is discoverable and expresses various properties.
Kevin described how the h-card standard works and is used to express a person’s name, their logo or photo, and other bits of optional information. He showed his own site kevinmarks.com and asked me to Show View Source to illustrate the markup.
Next we showed indiewebify.me which has a form to check your h-card, show what it found and suggest properties you could add to your profile on your home page.
From the consuming code perspective, we demonstrated the microformats2 parser at microformats.io using Kevin’s site again. We went through the standard parser JSON output with clear values for the name, photo, and other properties.
Similarly we took a look at one of my posts parsed by microformats.io as an examle of parsing an h-entry and seeing the author, content etc. properties in the JSON output.
Next we walked through the overview of IndieWeb specifications that I’d quickly mentioned by name in my lightning talk but had not explicitly described. We explained each of these building block standards, its features, and what user functionality each provides when implemented.
In particular we spent some time on the Micropub living standard for client software and websites to post and update content. The living standard editor’s draft has errata and updates from the official W3C Micropub Recommendation which itself was finished using the Micropub.rocks test suite & implementation results used to demonstrate that each feature was interoperably implementable, by several implementations.
Lastly we noted that many more Micropub clients & servers have been interoperably developed since then using the test suite, and the importance of test suites for longterm interopability and dependable standards in general.
Kevin used his mobile phone to post an Indie RSVP post in response to the Indie Event post that I’d shown in my talk. He had me bring it up again to show that this time it had an RSVP from him.
Clicking it took us to Kevin’s Known site which he’d used to post the RSVP from his mobile. I had to enable JavaScript for the “Filter Content” dropdown navigation menu to work (It really should work without JS, via CSS using googleable well established techniques). Choosing RSVP showed a list of recent RSVPs, at the top the one he’d just posted: RSVP No: But I do miss it.
We viewed the source of the RSVP post and walked through the markup, identifying the
p-rsvp property that was used along with the no value. Additionaly we ran it through
microformats.io to show the resulting JSON with
the "p-rsvp" property and "no" value.
As had been implied so far, the IndieWeb built upon the widely existing practice of using personal domain names for identity. While initially we had used OpenID, early usage & implementation frustrations (from confusing markup to out of date PHP libraries etc.) led us down the path of using the XFN rel=me value to authenticate using providers that allowed linking back to your site. We mentioned RelMeAuth and Web Sign-in accordingly.
We used yet another form on
indiewebify.me
to check the rel=me markup on KevinMarks.com and my own site tantek.com.
As a demonstration I signed out of
indieweb.org
and click sign-in in the top right corner.
I entered my domain https://tantek.com/ and the site redirected to Indie Login authentication screen where it found one confirmed provider, GitHub, and showed a green button accordingly. Clicking the green button briefly redirected to GitHub for authentication (I was already signed into GitHub) and then returned back through the flow to IndieWeb.org which now showed that I was logged-in in the top right corner with tantek.com.
To setup your own domain to sign-into IndieWeb.org, we showed the
setup instructions for the IndieLogin service,
noting in addition to rel=me to an OAuth-based identity provider like GitHub, you could use a PGP public key. If you choose PGP at the confirmed provider screen, IndieLogin provides challenge text for you to encrypt with your private key and submit, and it decrypts with your public key that you’ve provided to confirm your identity.
Popping up a level, we noted that the IndieLogin service works by implementing the IndieAuth protocol as a provider, that IndieWeb.org uses as a default authentication provider (sites can specify their own authetication providers, naturally).
Andre (Soapdog) asked:
How do I add a new way to authenticate, like SecureScuttleButt (SSB)?
The answer is to make an IndieAuth provider that handles SSB authentication. See the IndieAuth specification for reference, however, first read Aaron Parecki's article on "OAuth for the Open Web"
Another asked:
How does reading work on the IndieWeb?
From the longterm experience with classic Feed Readers (RSS Readers), the IndieWeb community figured out that there was a need to modularize readers. In particular there was a clear difference in developer expertise and incentive models of serverside feed aggregators and clientside feed readers that would be better served by independent development, with a standard protocol for communicating between the two.
The Microsub standard was designed from this experience and these identified needs. In the past couple of years, several Microsub clients and a few servers have been developed, listed in the section on Social Readers.
Social Readers also build upon the IndieAuth authentication standard for signing-in, and then associate your information with your domain accordingly. I demonstrated this by signing into the Aperture feed aggregator (and Microsub server) with my own domain name, and it listed my channels and feeds therein.
I demonstarted adding another feed to aggregate in my "IndieWeb" channel by entering Kevin Marks’s Known, choosing its microformats h-feed, which then resulted in 200+ new unread items!
I signed-into the Monocle social reader which showed notifications by default and a list of channels. Selecting the IndieWeb channel showed the unread items from Kevin’s site.
In short, yes. The IndieWeb works great with static sites.
One of the most common questions we get in the IndieWeb community is whether or not any one partcular standard or technique works with static sites and static site generator setups.
During the many years on the W3C Social Web Working group, many different approaches were presented for solving various social web use-cases. So many of these approaches had strong dynamic assumptions that they outright rejected static sites as a use-case. It was kind of shocking to be honest, as if the folks behind those particular approaches had not actually encountered the real world diversity of web site developers and techniques that were out there.
Fortunately we were able to uphold static sites as a legitimate use-case for the majority of specifications, and thus at least all the W3C Recommendations which were the result of incubations and contributions by the IndieWeb community were designed to support static sites.
There are couple of great reference pages on the IndieWeb wiki for static site setups:
In addition, there are IndieWeb pages for any particular static site system with particular recommendations and setup steps for adding support for various IndieWeb standards.
Kevin also pointed out that his home page kevinmarks.com is simple static HTML page that uses the Heroku Webmention service to display comments, likes, and mentions of his home page in the footer.
As we got the 2 minute warning that our session time was almost up we wrapped up the session with how to keep the conversation going. We encouraged everyone to join the online IndieWeb Chat which is available via IRC (Freenode #indieweb), Slack, Matrix, Discourse, and of course the web.
See: chat.indieweb.org to view today’s chats, and links to join from Slack, Matrix, etc.
Lastly we announced the next two IndieWebCamps coming up!
We encouraged all the Europeans to sign-up for IndieWebCamp Berlin, while encouraging folks from the US to sign-up for San Francisco.
With that we thanked everyone for their participation, excellent questions & discussion and look forward to seeing them online and meeting up in person!
https://tantek.com/2019/301/b1/redecentralize-indieweb-standards-methods
|
|
Firefox Nightly: These Weeks in Firefox: Issue 67 |
|
|
Mozilla Addons Blog: Add-on Policies Update: Newtab and Search |
As part of our ongoing work to make add-ons safer for Firefox users, we are updating our Add-on Policies to add clarification and guidance for developers regarding data collection. The following is a summary of the changes, which will go into effect on December 2, 2019.
You can preview the policies and ensure your extensions abide by them to avoid any disruption. If you have questions about these updated policies or would like to provide feedback, please post to this forum thread.
The post Add-on Policies Update: Newtab and Search appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2019/10/28/add-on-policies-update-newtab-and-search/
|
|
Nathan Froyd: evaluating bazel for building firefox, part 1 |
After the Whistler All-Hands this past summer, I started seriously looking at whether Firefox should switch to using Bazel for its build system.
The motivation behind switching build systems was twofold. The first motivation was that build times are one of the most visible developer-facing aspects of the build system and everybody appreciates faster builds. What’s less obvious, but equally important, is that making builds faster improves automation: less time waiting for try builds, more flexibility to adjust infrastructure spending, and less turnaround time with automated reviews on patches submitted for review. The second motivation was that our build system is used by exactly one project (ok, two projects), so there’s a lot of onboarding cost both in terms of developers who use the build system and in terms of developers who need to develop the build system. If we could switch to something more off-the-shelf, we could improve the onboarding experience and benefit from work that other parties do with our chosen build system.
You may have several candidates that we should have evaluated instead. We did look at other candidates (although perhaps none so deeply as Bazel), and all of them have various issues that make them unsuitable for a switch. The reasons for rejecting other possibilities fall into two broad categories: not enough platform support (read: Windows support) and unlikely to deliver on making builds faster and/or improving the onboarding/development experience. I’ll cover the projects we looked at in a separate post.
With that in mind, why Bazel?
Bazel advertises itself with the tagline “{Fast, Correct} – Choose two”. What’s sitting behind that tagline is that when building software via, say, Make, it’s very easy to write Makefiles in such a way that builds are fast, but occasionally (or not-so-occasionally) fail because somebody forgot to specify “to build thing X, you need to have built thing Y”. The build doesn’t usually fail because thing Y is built before thing X: maybe the scheduling algorithm for parallel execution in make chooses to build Y first 99.9% of the time, and 99% of those times, building Y finishes prior to even starting to build X.
The typical solution is to become more conservative in how you build things such that you can be sure that Y is always built before X…but typically by making the dependency implicit by, say, ordering the build commands Just So, and not by actually making the dependency explicit to make itself. Maybe specifying the explicit dependency is rather difficult, or maybe somebody just wants to make things work. After several rounds of these kind of fixes, you wind up with Makefiles that are (probably) correct, but probably not as fast as it could be, because you’ve likely serialized build steps that could have been executed in parallel. And untangling such systems to the point that you can properly parallelize things and that you don’t regress correctness can be…challenging.
(I’ve used make in the above example because it’s a lowest-common denominator piece of software and because having a concrete example makes differentiating between “the software that runs the build” and “the specification of the build” easier. Saying “the build system” can refer to either one and sometimes it’s not clear from context which is in view. But you should not assume that the problems described above are necessarily specific to make; the problems can happen no matter what software you rely on.)
Bazel advertises a way out of the quagmire of probably correct specifications for building your software. It does this—at least so far as I understand things, and I’m sure the Internet will come to correct me if I’m wrong—by asking you to explicitly specify dependencies up front. Build commands can then be checked for correctness by executing the commands in a “sandbox” containing only those files specified as dependencies: if you forgot to specify something that was actually needed, the build will fail because the file(s) in question aren’t present.
Having a complete picture of the dependency graph enables faster builds in three different ways. The first is that you can maximally parallelize work across the build. The second is that Bazel comes with built-in facilities for farming out build tasks to remote machines. Note that all build tasks can be distributed, not just C/C++/Rust compilation as via sccache. So even if you don’t have a particularly powerful development machine, you can still pretend that you have a large multi-core system at your disposal. The third is that Bazel also comes with built-in facilities for aggressive caching of build artifacts. Again, like remote execution, this caching applies across all build tasks, not just C/C++/Rust compilation. In Firefox development terms, this is Firefox artifact builds done “correctly”: given appropriate setup, your local build would simply download whatever was appropriate for the changes in your current local tree and rebuild the rest.
Having a complete picture of the dependency graph enables a number of other nifty features. Bazel comes with a query language for the dependency graph, enabling you to ask questions like “what jobs need to run given that these files changed?” This sort of query would be valuable for determining what jobs to run in automation; we have a half-hearted (and hand-updated) version of this in things like files-changed in Taskcluster job specifications. But things like “run $OS tests for $OS-only changes” or “run just the mochitest chunk that contains the changed mochitest” become easy.
It’s worth noting here that we could indeed work towards having the entire build graph available all at once in the current Firefox build system. And we have remote execution and caching abilities via sccache, even moreso now that sccache-dist is being deployed in Mozilla offices. We think we have a reasonable idea of what it would take to work towards Bazel-esque capabilities with our current system; the question at hand is how a switch to Bazel compares to that and whether a switch would be more worthwhile for the health of the Firefox build system over the long term. Future posts are going to explore that question in more detail.
https://blog.mozilla.org/nfroyd/2019/10/28/evaluating-bazel-for-building-firefox-part-1/
|
|
Firefox UX: Prototyping Firefox With CSS Grid |
Prototyping with HTML and CSS grid is really helpful for understanding flexibility models. I was able to understand how my design works in a way that was completely different than doing it in a static design program.
Links:
Transcript:
So I’m working on a design of the new address bar in Firefox. Our code name for it is the QuantumBar. There’s a lot of pieces to this. But one of the things that I’ve been trying to figure out is how it fits into the Firefox toolbar and how it collapses and expands, the squishiness of the toolbar, and trying to kinda rethink that by just building it in code. So I have this sort of prototype here where I’ve recreated the Firefox top toolbar here in HTML, and you can see how it like collapses and things go away and expands as I grow and shrink this here.
I’ve used CSS Grid to do a lot of this layout. And here I’ve turned on the grid lines just for this section of the toolbar. It’s one of the many grids that I have here. But I wanna point out these like flexible spaces over here, and then this part here, the actual QuantumBar piece, right? So you can see I’ve played around with some different choices about how big things can be at this giant window size here. And I was inspired by my friend, Jen Simmons, who’s been talking about Grid for a long time, and she was explaining how figuring out whether to use minmax or auto or fr units. It’s something that is, you can only really figure out by coding it up and a little trial and error here. And it allowed me to understand better how the toolbar works as you squish it and maybe come up with some better ways of making it work.
Yeah, as we squish it down, maybe here we wanna prioritize the width of this because this is where the results are gonna show up in here, and we let these flexible spaces squish a little sooner and a little faster. And that’s something that you can do with Grid and some media queries like at this point let’s have it squished this way, at this point let’s have it squished another way. Yeah, and I also wanted to see how it would work then if your toolbar was full of lots of icons and you have the other search bar and no spacers, how does that work? And can we prioritize maybe the size of the address bar a little more so that because you’ll notice on the top is the real Firefox, we can get in weird situations where this, it’s just not even usable anymore. And maybe we should stop it from getting that small and still have it usable.
Anyway it’s a thing I’ve been playing with and what I’ve found was that using HTML and CSS to mock this up had me understand it in a way that was way better than doing it in some sort of static design program.
https://blog.mozilla.org/ux/2019/10/prototyping-firefox-with-css-grid/
|
|
Wladimir Palant: Avast Online Security and Avast Secure Browser are spying on you |
Are you one of the allegedly 400 million users of Avast antivirus products? Then I have bad news for you: you are likely being spied upon. The culprit is the Avast Online Security extension that these products urge you to install in your browser for maximum protection.
But even if you didn’t install Avast Online Security yourself, it doesn’t mean that you aren’t affected. This isn’t obvious but Avast Secure Browser has Avast Online Security installed by default. It is hidden from the extension listing and cannot be uninstalled by regular means, its functionality apparently considered an integral part of the browser. Avast products promote this browser heavily, and it will also be used automatically in “Banking Mode.” Given that Avast bought AVG a few years ago, there is also a mostly identical AVG Secure Browser with the built-in AVG Online Security extension.

When Avast Online Security extension is active, it will request information about your visited websites from an Avast server. In the process, it will transmit data that allows reconstructing your entire web browsing history and much of your browsing behavior. The amount of data being sent goes far beyond what’s necessary for the extension to function, especially if you compare to competing solutions such as Google Safe Browsing.
Avast Privacy Policy covers this functionality and claims that it is necessary to provide the service. Storing the data is considered unproblematic due to anonymization (I disagree), and Avast doesn’t make any statements explaining just how long it holds on to it.
Using browser’s developer tools you can look at an extension’s network traffic. If you do it with Avast Online Security, you will see a request to https://uib.ff.avast.com/v5/urlinfo whenever a new page loads in a tab:
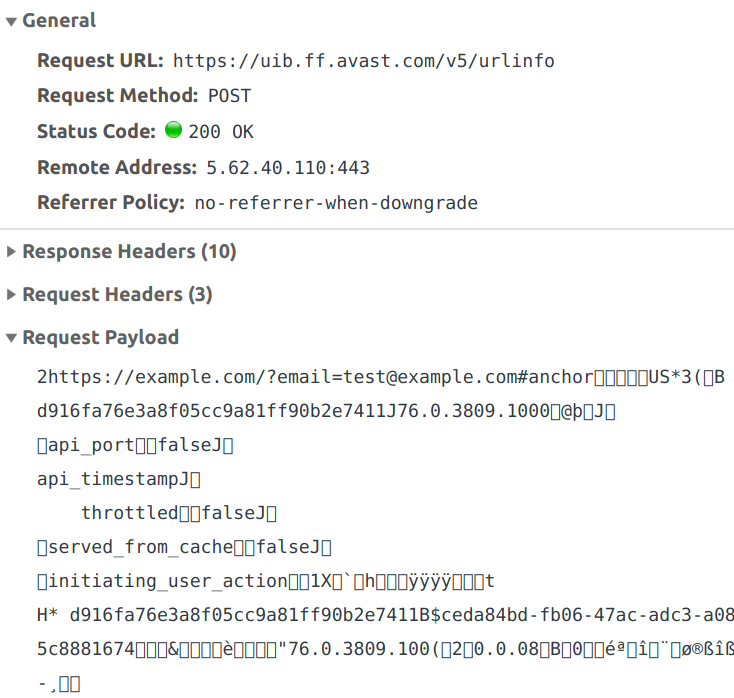
So the extension sends some binary data and in return gets information on whether the page is malicious or not. The response is then translated into the extension icon to be displayed for the page. You can clearly see the full address of the page in the binary data, including query part and anchor. The rest of the data is somewhat harder to interpret, I’ll get to it soon.
This request isn’t merely sent when you navigate to a page, it also happens whenever you switch tabs. And there is an additional request if you are on a search page. This one will send every single link found on this page, be it a search result or an internal link of the search engine.
The binary UrlInfoRequest data structure used here can be seen in the extension source code. It is rather extensive however, with a number of fields being nested types. Also, some fields appear to be unused, and the purpose of others isn’t obvious. Finally, there are “custom values” there as well which are a completely arbitrary key/value collection. That’s why I decided to stop the extension in the debugger and have a look at the data before it is turned into binary. If you want to do it yourself, you need to find this.message() call in scripts/background.js and look at this.request after this method is called.
The interesting fields were:
| Field | Contents |
|---|---|
| uri | The full address of the page you are on. |
| title | Page title if available. |
| referer | Address of the page that you got here from, if any. |
| windowNum tabNum |
Identifier of the window and tab that the page loaded into. |
| initiating_user_action windowEvent |
How exactly you got to the page, e.g. by entering the address directly, using a bookmark or clicking a link. |
| visited | Whether you visited this page before. |
| locale | Your country code, which seems to be guessed from the browser locale. This will be “US” for US English. |
| userid | A unique user identifier generated by the extension (the one visible twice in the screenshot above, starting with “d916”). For some reason this one wasn’t set for me when Avast Antivirus was installed. |
| plugin_guid | Seems to be another unique user identifier, the one starting with “ceda” in the screenshot above. Also not set for me when Avast Antivirus was installed. |
| browserType browserVersion |
Type (e.g. Chrome or Firefox) and version number of your browser. |
| os osVersion |
Your operating system and exact version number (the latter only known to the extension if Avast Antivirus is installed). |
And that’s merely the fields which were set. The data structure also contains fields for your IP address and a hardware identifier but in my tests these stayed unused. It also seems that for paying Avast customers the identifier of the Avast account would be transmitted as well.
The data collected here goes far beyond merely exposing the sites that you visit and your search history. Tracking tab and window identifiers as well as your actions allows Avast to create a nearly precise reconstruction of your browsing behavior: how many tabs do you have open, what websites do you visit and when, how much time do you spend reading/watching the contents, what do you click there and when do you switch to another tab. All that is connected to a number of attributes allowing Avast to recognize you reliably, even a unique user identifier.
If you now think “but they still don’t know who I am” – think again. Even assuming that none of the website addresses you visited expose your identity directly, you likely have a social media account. There has been a number of publications showing that, given a browsing history, the corresponding social media account can be identified in most cases. For example, this 2017 study concludes:
Of the 374 people who confirmed the accuracy of our de-anonymization attempt, 268 (72%) were the top candidate generated by the MLE, and 303 participants (81%) were among the top 15 candidates. Consistent with our simulation results, we were able to successfully de-anonymize a substantial proportion of users who contributed their web browsing histories.
With the Avast data being far more extensive, it should allow identifying users with an even higher precision.
No, the data collection is definitely unnecessary to this extent. You can see this by looking at how Google Safe Browsing works, the current approach being largely unchanged compared to how it was integrated in Firefox 2.0 back in 2006. Rather than asking a web server for each and every website, Safe Browsing downloads lists regularly so that malicious websites can be recognized locally.
No information about you or the sites you visit is communicated during list updates. […] Before blocking the site, Firefox will request a double-check to ensure that the reported site has not been removed from the list since your last update. This request does not include the address of the visited site, it only contains partial information derived from the address.
I’ve seen a bunch of similar extensions by antivirus vendors, and so far all of them provided this functionality by asking the antivirus app. Presumably, the antivirus has all the required data locally and doesn’t need to consult the web service every time. In fact, I could see Avast Online Security also consult the antivirus application for the websites you visit if this application is installed. It’s an additional request however, the request to the web service goes out regardless. Update (2019-10-29): I understand this logic better now, and the requests made to the antivirus application have a different purpose.
Wait, but Avast Antivirus isn’t always installed! And maybe the storage requirements for the full database exceed what browser extensions are allowed to store. In this case the browser extension has no choice but to ask the Avast web server about every website visited. But even then, this isn’t a new problem. For example, the Mozilla community had a discussion roughly a decade ago about whether security extensions really need to collect every website address. The decision here was: no, sending merely the host name (or even a hash of it) is sufficient. If higher precision is required, the extension could send the full address only if a potential match is detected.
But Avast has a privacy policy. They surely explained there what they need this data for and how they handle it. There will most certainly be guarantees in there that they don’t keep any of this data, right?
Let’s have a look. The privacy policy is quite long and applies to all Avast products and websites. The relevant information doesn’t come until the middle of it:
We may collect information about the computer or device you are using, our products and services running on it, and, depending on the type of device it is, what operating systems you are using, device settings, application identifiers (AI), hardware identifiers or universally unique identifiers (UUID), software identifiers, IP Address, location data, cookie IDs, and crash data (through the use of either our own analytical tools or tolls provided by third parties, such as Crashlytics or Firebase). Device and network data is connected to the installation GUID.
We collect device and network data from all users. We collect and retain only the data we need to provide functionality, monitor product and service performance, conduct research, diagnose and repair crashes, detect bugs, and fix vulnerabilities in security or operations (in other words, fulfil our contract with you to provision the service).
Unfortunately, after reading this passage I still don’t know whether they retain this data for me. I mean, “conduct research” for example is a very wide term and who knows what data they need to do it? Let’s look further.
Our AntiVirus and Internet security products require the collection of usage data to be fully functional. Some of the usage data we collect include:
[…]
- information about where our products and services are used, including approximate location, zip code, area code, time zone, the URL and information related to the URL of sites you visit online
[…]
We use this Clickstream Data to provide you malware detection and protection. We also use the Clickstream Data for security research into threats. We pseudonymize and anonymize the Clickstream Data and re-use it for cross-product direct marketing, cross-product development and third party trend analytics.
And that seems to be all of it. In other words, Avast will keep your data and they don’t feel like they need your approval for that. They also reserve the right to use it in pretty much any way they like, including giving it to unnamed third parties for “trend analytics.” That is, as long as the data is considered anonymized. Which it probably is, given that technically the unique user identifier is not tied to you as a person. That your identity can still be deduced from the data – well, bad luck for you.
Edit (2019-10-29): I got a hint that Avast acquired Jumpshot a bunch of years ago. And if you take a look at the Jumpshot website, they list “clickstream data from 100 million global online shoppers and 20 million global app users” as their product. So you now have a pretty good guess as to where your data is going.
Avast Online Security collecting personal data of their users is not an oversight and not necessary for the extension functionality either. The extension attempts to collect as much context data as possible, and it does so on purpose. The Avast privacy policy shows that Avast is aware of the privacy implications here. However, they do not provide any clear retention policy for this data. They rather appear to hold on to the data forever, feeling that they can do anything with it as long as the data is anonymized. The fact that browsing data can usually be deanonymized doesn’t instill much confidence however.
This is rather ironic given that all modern browsers have phishing and malware protection built in that does essentially the same thing but with a much smaller privacy impact. In principle, Avast Secure Browser has this feature as well, it being Chromium-based. However, all Google services have been disabled and removed from the settings page – the browser won’t let you send any data to Google, sending way more data to Avast instead.
Update (2019-10-28): Somehow I didn’t find existing articles on the topic when I searched initially. This article mentions the same issue in passing, it was published in January 2015 already. The screenshot there shows pretty much the same request, merely with less data.
https://palant.de/2019/10/28/avast-online-security-and-avast-secure-browser-are-spying-on-you/
|
|
IRL (podcast): “The Weird Kids at the Big Tech Party” from ZigZag |
Season 4 of ZigZag is about examining the current culture of business and work, figuring out what needs to change, and experimenting with new ways to do it. Sign up for their newsletter and subscribe to the podcast for free wherever you get your podcasts.
https://irl.simplecast.com/episodes/bonus-from-zigzag-h6exysMb
|
|
Robert O'Callahan: Pernosco Demo Video |
Over the last few years we have kept our work on the Pernosco debugger mostly under wraps, but finally it's time to show the world what we've been working on! So, without further ado, here's an introductory demo video showing Pernosco debugging a real-life bug:
This demo is based on a great gdb tutorial created by Brendan Gregg. If you read his blog post, you'll get more background and be able to compare Pernosco to the gdb experience.
Pernosco makes developers more productive by providing scalable omniscient debugging — accelerating existing debugging strategies and enabling entirely new strategies and features — and by integrating that experience into cloud-based workflows. The latter includes capturing test failures occurring in CI so developers can jump into a debugging session with one click on a URL, separating failure reproduction from debugging so QA staff can record test failures and send debugger URLs to developers, and letting developers collaborate on debugging sessions.
Over the next few weeks we plan to say a lot more about Pernosco and how it benefits software developers, including a detailed breakdown of its approach and features. To see those updates, follow @_pernosco_ or me on Twitter. We're opening up now because we feel ready to serve more customers and we're keen to talk to people who think they might benefit from Pernosco; if that's you, get in touch. (Full disclosure: Pernosco uses rr so for now we're limited x86-64 Linux, and statically compiled languages like C/C++/Rust.)
http://robert.ocallahan.org/2019/10/pernosco-demo-video.html
|
|
The Mozilla Blog: Longtime Mozilla board member Bob Lisbonne moves from Foundation to Corporate Board; Outgoing CEO Chris Beard Corporate Board Term Ends |
Today, Mozilla Co-Founder and Chairwoman Mitchell Baker announced that Mozilla Foundation Board member Bob Lisbonne has moved to the Mozilla Corporation Board; and as part of a planned, phased transition, Mozilla Corporation’s departing CEO Chris Beard has stepped down from his role as a Mozilla Corporation board member.
“We are in debt to Chris for his myriad contributions to Mozilla,” said Mozilla Chairwoman and Co-Founder Mitchell Baker. “We’re fortunate to have Bob make this shift at a time when his expertise is so well matched for Mozilla Corporation’s current needs.”
Bob has been a member of the Mozilla Foundation Board since 2006, but his contributions to the organization began with Mozilla’s founding. Bob played an important role in converting the earlier Netscape code into open source code and was part of the team that launched the Mozilla project in 1998.
“I’m incredibly fortunate to have been involved with Mozilla for over two decades,” said Bob Lisbonne. “Creating awesome products and services that advance the Mozilla mission remains as important as ever. In this new role, I’m eager to contribute my expertise and help advance the Internet as a global public resource, open and accessible to all.”
During his tenure on the Mozilla Foundation board, Bob has been a significant creative force in building both the Foundation’s programs — in particular the programs that led to MozFest — and the strength of the board. As he moves to the Mozilla Corporation Board, Bob will join the other Mozilla Corporation Board members in selecting, onboarding, and supporting a new CEO for Mozilla Corporation. Bob’s experience across innovation, investment, strategy and execution in the startup and technology arenas are particularly well suited to Mozilla Corporation’s setting.
Bob’s technology career spans 25 years, during which he played key roles as entrepreneur, venture capitalist, and executive. He was CEO of internet startup Luminate, and a General Partner with Matrix Partners. He has served on the Boards of companies which IPO’ed and were acquired by Cisco, HP, IBM, and Yahoo, among others. For the last five years, Bob has been teaching at Stanford University’s Graduate School of Business.
With Bob’s move and Chris’ departure, the Mozilla Corporation board will include: Mitchell Baker, Karim Lakhani, Julie Hanna, and Bob Lisbonne. The remaining Mozilla Foundation board members are: Mitchell Baker, Brian Behlendorf, Ronaldo Lemos, Helen Turvey, Nicole Wong and Mohamed Nanabhay.
The Mozilla Foundation board will begin taking steps to fill the vacancy created by Bob’s move. At the same time, the Mozilla Corporation board’s efforts to expand its make-up will continue.
Founded as a community open source project in 1998, Mozilla currently consists of two organizations: the 501(c)3 Mozilla Foundation, which backs emerging leaders and mobilizes citizens to create a global movement for the health of the internet; and its wholly owned subsidiary, the Mozilla Corporation, which creates products, advances public policy and explores new technologies that give people more control over their lives online, and shapes the future of the internet platform for the public good. Each is governed by a separate board of directors. The two organizations work in concert with each other and a global community of tens of thousands of volunteers under the single banner: Mozilla.
Because of its unique structure, Mozilla stands apart from its peers in the technology and social enterprise sectors globally as one of the most impactful and successful social enterprises in the world.
The post Longtime Mozilla board member Bob Lisbonne moves from Foundation to Corporate Board; Outgoing CEO Chris Beard Corporate Board Term Ends appeared first on The Mozilla Blog.
|
|
The Firefox Frontier: Firefox Extension Spotlight: Enhancer for YouTube |
“I wanted to offer a useful extension people can trust,” explains Maxime RF, creator of Enhancer for YouTube, a browser extension providing a broad assortment of customization options so you … Read more
The post Firefox Extension Spotlight: Enhancer for YouTube appeared first on The Firefox Frontier.
|
|
Jan-Erik Rediger: This Week in Glean: A Release |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.)
Last week's blog post: This Week in Glean: Glean on Desktop (Project FOG) by chutten.
Back in June when Firefox Preview shipped, it also shipped with Glean, our new Telemetry library, initially targeting mobile platforms. Georg recently blogged about the design principles of Glean in Introducing Glean — Telemetry for humans.
Plans for improving mobile telemetry for Mozilla go back as as far as December 2017. The first implementation of the Glean SDK was started around August 2018, all written in Kotlin (though back then it was mostly ideas in a bunch of text documents). This implementation shipped in Firefox Preview and was used up until now.
On March 18th I created an initial Rust workspace. This kicked of a rewrite of Glean using Rust to become a cross-platform telemetry SDK to be used on Android, iOS and eventually coming back to desktop platforms again.
1382 commits later1 I tagged v19.0.02.
Obviously that doesn't make people use it right away, but given all consumers of Glean right now are Mozilla products, it's up on us to get them to use it. So Alessio did just that by upgrading Android Components, a collection of Android libraries to build browsers or browser-like applications, to this new version.
This will soon roll out to nightly releases of Firefox Preview and, given we don't hit any larger bugs, hit the release channel in about 2 weeks. Additionally, that finally unblocks the Glean team to work on new features, ironing out some sharp edges and bringing Glean to Firefox on Desktop. Oh, and of course we still need to actually release it for iOS.
Glean in Rust is the project I've been constantly working on since March. But getting it to a release was a team effort with help from a multitude of people and teams.
Thanks to everyone on the Glean SDK team:
Thanks to Frank Bertsch for a ton of backend work as well as the larger Glean pipeline team led by Mark Reid, to ensure we can handle the incoming telemetry data and also reliably analyse it. Thanks to the Data Engineering team led by Katie Parlante. Thanks to Mihai Tabara, the Release Engineering team and the Cloud Operations team, to help us with the release on short notice. Thanks to the Application Services team for paving the way of developing mobile libraries with Rust and to the Android Components team for constant help with Android development.
Not all of which are just code for the Android version. There's a lot of documentation too.
This is the first released version. This is just the version number that follows after the Kotlin implementation. Version numbers are cheap.
|
|
Hacks.Mozilla.Org: From js13kGames to MozFest Arcade: A game dev Web Monetization story |
This is a short story of how js13kGames, an online “code golf” competition for web game developers, tried out Web Monetization this year. And ended up at the Mozilla Festival, happening this week in London, where we’re showcasing some of our winning entries.

The js13kGames online competition for HTML5 game developers is constantly evolving. We started in 2012, and we run every year from August 13th to September 13th. In 2017, we added a new A-Frame category.
You still had to build web games that would fit within the 13 kilobytes zipped package as before, but the new category added the A-Frame framework “for free”, so it wasn’t counted towards the size limit. The new category resulted in some really cool entries.
Fast forward twelve months to 2018 – the category changed its name to WebXR. We added Babylon.js as a second option. In 2019, the VR category was extended again, with Three.js as the third library of choice. Thanks to the Mozilla Mixed Reality team we were able to give away three Oculus Quest devices to the winning entries.

The process for judging js13kGames entries has also evolved. At the beginning, about 60 games were submitted each year. Judges could play all the games to judge them fairly. In recent years, we’ve received nearly 250 entries. It’s really hard to play all of them, especially since judges tend to be busy people. And then, how can you be sure you scored fairly?
That’s why we introduced a new voting system. The role of judges changed: they became experts focused on giving constructive feedback, rather than scoring. Expert feedback is valued highly by participants, as one of the most important benefits in the competition.
At the same time, Community Awards became the official results. We upgraded the voting system with the new mechanism of “1 on 1 battles.” By comparing two games at once, you can focus and judge them fairly, and then move on to vote on another pair.
Voters compared the games based on consistent criteria: gameplay, graphics, theme, etc. This made “Community” votes valuable to developers as a feedback mechanism also. Developers could learn what their game was good at, and where they could improve. Many voting participants also wrote in constructive feedback, similar to what the experts provided. This feedback was accurate and eventually valuable for future improvements.

This year we introduced the Web Monetization category in partnership with Coil. The challenge to developers was to integrate Web Monetization API concepts within their js13kGames entries. Out of 245 games submitted overall, 48 entries (including WebXR ones) had implemented the Web Monetization API. It wasn’t that difficult.
Basically, you add a special monetization meta tag to index.html:
// ...
And then you need to add code to detect if a visitor is a paid subscriber (to Coil or any other similar service available in the future):
if(document.monetization && document.monetization.state === 'started') {
// do something
}You can do this detection via an event too:
function startEventHandler(event){
// do something
}
document.monetization.addEventListener('monetizationstart', startEventHandler);If the monetization event starts, that means the visitor has been identified as a paying subscriber. Then they can receive extra or special content: be it more coins, better weapons, shorter cooldown, extra level, or any other perk for the player.
It’s that simple to implement web monetization! No more bloated, ever changing SDKs to place advertisements into the games. No more waiting months for reports to see if spending time on this was even worth it.
The Web Monetization API gives game developers and content creators a way to monetize their creative work, without compromising their values or the user experience. As developers, we don’t have to depend on annoying in-game ads that interrupt the player. We can get rid of tracking scripts invading player privacy. That’s why Enclave Games creations never have any ads. Instead, we’ve implemented the Web Monetization API. We now offer extra content and bonuses to subscribers.
This all leads to London for the 2019 Mozilla Festival. Working with Grant for the Web, we’ve prepared something special: MozFest Arcade.
If you’re attending Mozfest, check out our special booth with game stations, gamepads, virtual reality headsets, and more. You will be able to play Enclave Games creations and js13kGames entries that are web-monetized! You can see for yourself how it all works under the hood.

Grant for the Web is a $100M fund to boost open, fair, and inclusive standards and innovation in web monetization. It is funded and led by Coil, working in collaboration with founding collaborators Mozilla and Creative Commons. (Additional collaborators may be added in the future.) A program team, led by Loup Design & Innovation, manages the day-to-day operations of the program.
It aims to distribute grants to web creators who would like to try web monetization as their business model, to earn revenue, and offer real competition to intrusive advertising, paywalls, and closed marketplaces.
If you’re in London, please join us at the Friday’s Science Fair at MozFest House. You can learn more about Web Monetization, Grant for the Web, while playing cool games. Also, you can get a free Coil subscription in the process. Join us through the weekend at the Indie Games Arcade at Ravensbourne University!
The post From js13kGames to MozFest Arcade: A game dev Web Monetization story appeared first on Mozilla Hacks - the Web developer blog.
|
|
Mike Hoye: The State Of Mozilla, 2019 |
As I’ve done in previous years, here’s The State Of Mozilla, as observed by me and presented by me to our local Linux user group.
Presentation:[ https://www.youtube.com/embed/RkvDnIGbv4w ]
And Q&A: [ https://www.youtube.com/embed/jHeNnSX6GcQ ]
Nothing tectonic in there – I dodged a few questions, because I didn’t want to undercut the work that was leading up to the release of Firefox 70, but mostly harmless stuff.
Can’t be that I’m getting stockier, though. Must be the shirt that’s unflattering. That’s it.
http://exple.tive.org/blarg/2019/10/23/the-state-of-mozilla-2019/
|
|






