John Ford: Taskcluster Credential Derivation in EC2 using S/MIME, OpenSSL's C api and Node.js's N-API |
$ cat test-files/document
{
"accountId" : "692406183521",
"architecture" : "x86_64",
"availabilityZone" : "us-west-2a",
"billingProducts" : null,
"devpayProductCodes" : null,
"imageId" : "ami-6b8cef13",
"instanceId" : "i-0a30e04d85e6f8793",
"instanceType" : "t2.nano",
"kernelId" : null,
"marketplaceProductCodes" : null,
"pendingTime" : "2018-05-09T12:30:58Z",
"privateIp" : "172.31.46.215",
"ramdiskId" : null,
"region" : "us-west-2",
"version" : "2017-09-30"
}
child_process and temporary files to write out the documents and call the OpenSSL command line tool with the temporary files. This didn't work out because of the performance overhead as well as difficulty managing temporary files at runtime.apps/smime.c. After spending a lot of time tracing through the program, I found that the function that I needed was PKCS7_verify.{ Error: asn1 encoding routines ../deps/openssl/openssl/crypto/asn1/asn1_lib.c:101 ASN1_get_object header too long
at verify (/home/jhford/taskcluster/iid-verify/index.js:70:23)
errors:
[ 'PEM routines ../deps/openssl/openssl/crypto/pem/pem_oth.c:33 PEM_ASN1_read_bio ASN1 lib',
'asn1 encoding routines ../deps/openssl/openssl/crypto/asn1/tasn_dec.c:289 asn1_item_embed_d2i nested asn1 error',
'asn1 encoding routines ../deps/openssl/openssl/crypto/asn1/tasn_dec.c:1117 asn1_check_tlen bad object header',
'asn1 encoding routines ../deps/openssl/openssl/crypto/asn1/asn1_lib.c:101 ASN1_get_object header too long' ] }
http://blog.johnford.org/2018/08/taskcluster-credential-derivation-in.html
|
|
Mozilla Reps Community: Rep of the Month – August 2018 |
Please join us in congratulating Abhiram Ravikumar, our Rep of the Month for August 2018!
Abhiram Ravikumar is an amazing contributor from Bangalore India and a long time Mozillian contributing as a Rep since November 2015. He is the so-called backbone of the Bangalore community keeping activities going in and around the region.

He is also a Rust contributor helping the Rust team evangelize the programming language by speaking at events and organizing them. As a Tech Speaker, he speaks about Rust, Blockchain, Machine Learning, Git and Open Source at events and conferences.
Abhiram is a part of the Mozilla India Rust focus group helping volunteers getting started with Rust. Professionally he works as a machine learning fellow at SAP Labs. A great example of contributions with passion towards open source, Abhiram surely stands out with his contributions to the community.
Thanks Abhiram, keep rocking the Open Web! 
https://blog.mozilla.org/mozillareps/2018/08/27/rep-of-the-month-august-2018/
|
|
Support.Mozilla.Org: SUMO Days Firefox 62: you are invited! |
On September 5th, Firefox 62 will be updating for both Desktop and Android platforms. Please join the community for the following SUMO Days focusing on answering questions from Firefox users on Twitter and in the Support Forums:
On these days, Support contributors will be online answering questions live and hanging out. If you do not see anyone active online, please contact Rachel (username: guigs) or another Administrator or Operator in the #sumo IRC channel listed in the wiki.
There is also the two Telegram channels that are active for assignments of tweets and collaboration. You may need an account to participate, so just send a message to social Telegram group – there are guidelines on how to set up Tweetdeck for social if you would like your own workspace, or you can message guigs to add your trello account to the trello board with delegated tweets for the day.
If you do not like live chats, you can check out our forums with all the updates for both social and support forum dwellers to collaborate on: Firefox 62 SUMO Days MozWiki page
Like Twitter and we have not seen you in a while? That is OK!
Welcome back! Please say “hello”! We have some new friends answering questions, you can ask them for help on the live chat IRC channels #aoa or #sumo.
We also have updated Common Responses that you can use when replying with the #fxhelp tweet tag.
If you need a quick reminder of how things work, please use the guidelines to get started again. We can always use your help.
See you online real soon!
https://blog.mozilla.org/sumo/2018/08/27/sumo-day-firefox-62-you-are-invited/
|
|
Daniel Stenberg: Blessed curl builds for Windows |
The curl project is happy to introduce official and blessed curl builds for Windows for download on the curl web site.
This means we have a set of recommended curl packages that we advice users on Windows to download.
On Linux, macOS, cygwin and pretty much all the other alternatives you have out there, you don't need to go to random sites on the Internet and download a binary package provided by a (to you) unknown stranger to get curl for your system. Unfortunately that is basically what we have forced Windows users into doing for a few years since our previous maintainer of curl builds for Windows dropped off the project.
These new official curl builds for Windows are the same set of builds Viktor Szakats has been building and providing to the community for a long time already. Now just with the added twist that he feeds his builds and information about them to the main curl site so that users can get them from the same site and thus lean on the same trust they already have in the curl brand in general.
These builds are reproducible, provided with sha256 hashes and a link to the full build log. Everything is public and transparently done.
All the hard work to get these builds in this great shape was done by Viktor Szakats.
https://daniel.haxx.se/blog/2018/08/27/blessed-curl-builds-for-windows/
|
|
Cameron Kaiser: TenFourFox FPR9b3 available |
Of the security patches that landed in this version is a specific one for an issue that affects 10.5, but not 10.4. It's more of an information leak than anything else and wouldn't seem to be very common, but I was able to exploit it on the test network, so now it's worked around. Our implementation is completely different from Mozilla's largely for performance reasons since we only have two operating system flavours to worry about.
Watch for the final to emerge this weekend sometime, for public release next Tuesday (not Monday because of the US Labor Day holiday).
http://tenfourfox.blogspot.com/2018/08/tenfourfox-fpr9b3-available.html
|
|
Christopher Arnold: My 20 years of web |
 The amazing thing about the Internet is the creativity it brings out of the people who engage with it. Back when I started telling the story of the web to people, I realized I needed to have my own web page. So I needed to figure out what I wanted to amplify to the world. Because I admired folk percussion that I'd seen while I was living in Japan, I decided to make my website about the drums of the world. I used a web editor called Geocities to create this web page you see at right. I decided to leave in its original 1999 Geocities template design for posterity's sake. Since then my drum pursuits have expanded to include various other web projects including a YouTube channel dedicated to traditional folk percussion. A flickr channel dedicated to drum photos. Subsequently I launched a Soundcloud channel and a Mixcloud DJ channel for sharing music I'd composed or discovered over the decades.
The amazing thing about the Internet is the creativity it brings out of the people who engage with it. Back when I started telling the story of the web to people, I realized I needed to have my own web page. So I needed to figure out what I wanted to amplify to the world. Because I admired folk percussion that I'd seen while I was living in Japan, I decided to make my website about the drums of the world. I used a web editor called Geocities to create this web page you see at right. I decided to leave in its original 1999 Geocities template design for posterity's sake. Since then my drum pursuits have expanded to include various other web projects including a YouTube channel dedicated to traditional folk percussion. A flickr channel dedicated to drum photos. Subsequently I launched a Soundcloud channel and a Mixcloud DJ channel for sharing music I'd composed or discovered over the decades.https://ncubeeight.blogspot.com/2018/08/my-20-years-of-web.html
|
|
Support.Mozilla.Org: Support Localization – Top 20 Sprint and More |
|
|
Mozilla VR Blog: This Week in Mixed Reality: Issue 17, Hubs Edition |

As I do every week, I was going to say it's mostly be bug fixing. However this week the big news is our update to Hubs, Mozilla's VR chat system. You can now share any kind of media within Hubs: PDFs, images, music, and even Youtube videos.
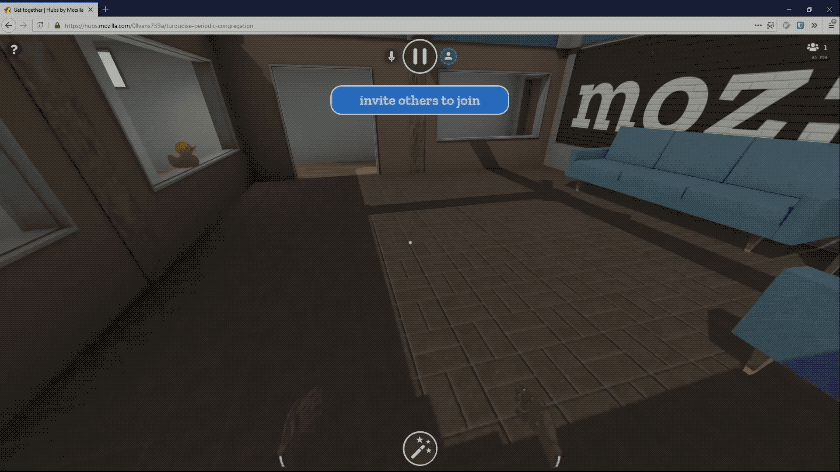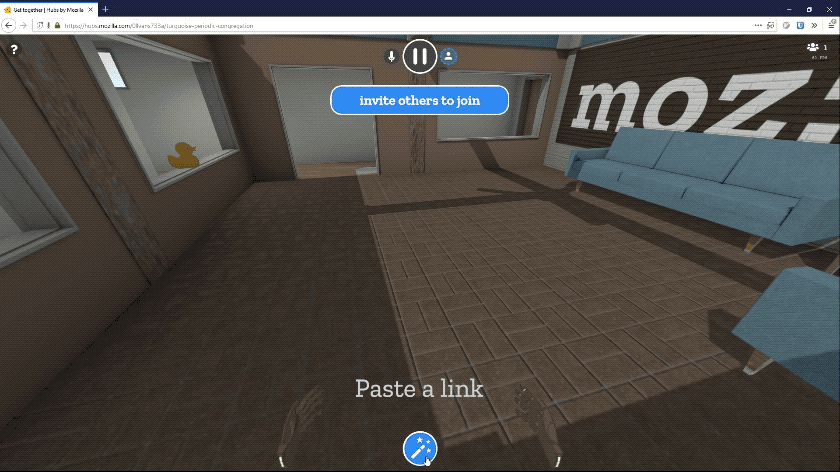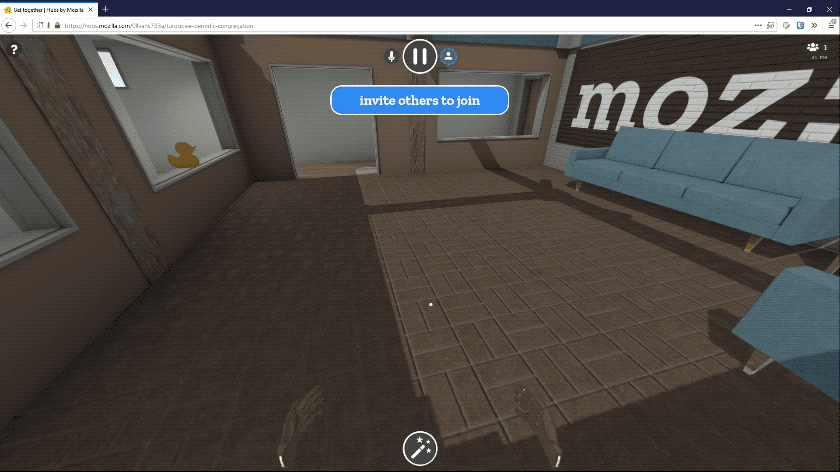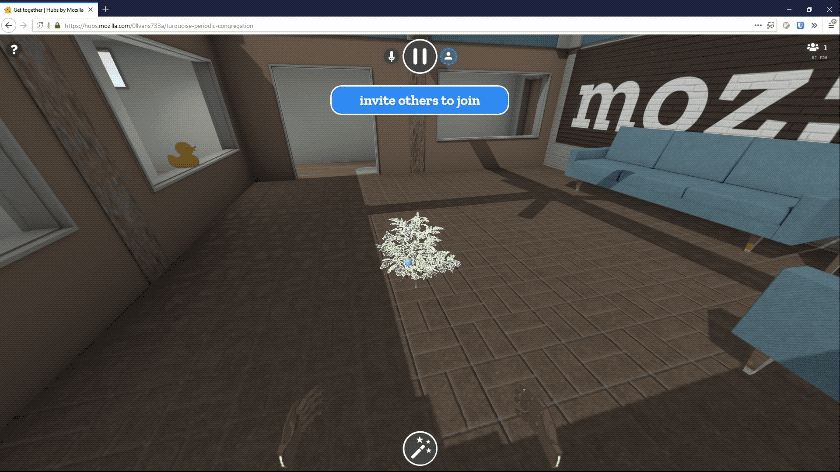
The Mixed Reality team has been working hard on this release for months. Being in VR is so much more immersive when you can bring other parts of the world with you. You could review 3D models with your co-workers, give a PDF presentation to your meetup group, or watch some funny YouTube clips with your friends. We think you will all find tons of unique new uses for Hubs now.
In other news (if Hubs just isn't enough for you), the Firefox Reality team is cleaning up the code and focusing on more bug fixes and performance, as well as getting the developer tools integration finished so you can debug VR easily from your desktop.
The Firefox Reality team has also been polishing the UI, such as adding a splashscreen, working on the icon, and tweaking the keyboard design.
The JS13KCompetion is going strong, with a new prize added: 10 copies of PyxelEdit, a wonderful desktop pixel editor. (I use it myself, actually).
Fernando Serrano demonstrated a multi-view extension for ThreeJS built by our team which promises to greatly speed up VR on the web.
I've also finished the next module in my opensource WebXR workshop series: GLTF and 3D Models. If you are interested in teaching WebXR, please let me know. This workshop series is specifically designed to help you do that.
Virtuleap announced the winners of their Global WebXR Hackathon. The top prize went to Crystalis VR, a unique take on the classic puzzler genre.
That's it for this week folks. Be sure to follow our Twitter account for the latest in WebXR development.
|
|
Firefox UX: Bias and Hiring: How We Hire UX Researchers |
This year, the Firefox User Research team is planning to add two new researchers to our group. The job posting went live last month, and after just a few weeks of accepting applications, we had over 900 people apply.
Current members of the Firefox User Research Team fielded dozens of messages from prospective applicants during this time, most asking for informational meetings to discuss the open role. We decided as a team to decline these requests across the board because we did not have the bandwidth for the number of meetings requested, and more importantly we have spent a significant amount of time this year working on minimizing bias in our hiring process.
We felt that meeting with candidates outside of the formal hiring process would give unfair advantage to some candidates and undermine our de-biasing work. At the same time, in alignment with Mozilla’s values and to build on Mozilla’s diversity and inclusion disclosures from earlier this year, we realized there was an opportunity to be more transparent about our hiring process for the benefit of future job applicants and teams inside and outside Mozilla thinking about how they can minimize bias in their own hiring.
Our Hiring Process Before This Year
Before this year, our hiring process consisted of a number of steps. First, a Mozilla recruiter would screen resumes for basic work requirements such as legal status to work in the regions where we were hiring and high-level relevant work experience. Applicants with resumes that passed the initial screen would then be screened by the recruiter over the phone. The purpose of the phone screen was to verify the HR requirements, the applicant’s requirements, work history, and most relevant experience.
If the applicant passed the screen with the recruiter, two members of the research team would conduct individual phone screens with the applicant to understand the applicant’s experience with different research methods and any work with distributed teams. Applicants who passed the screen with the researchers would be invited to a Mozilla office for a day of 1:1 in-person interviews with researchers and non-researchers and asked to present a research exercise prepared in advance of the office visit.

This hiring process served us well in several ways. It involved both researchers and roles that interact with researchers regularly, such as UX designers and product managers. Also, the mix of remote and in-person components reflected the ways we actually work at Mozilla. The process overall yielded hires — our current research team members — who have worked well together and with cross-functional teams.
However, there were also a lot of limitations to our former hiring process. Each Mozilla staff person involved determined their own questions for the phone and in-person components. We had a living document of questions team members liked to ask, but staff were free to draw on this list as little or as much as they wanted. Moreover, while each staff person had to enter notes into our applicant tracking system after a phone screen or interview with an applicant, we had no explicit expectations about how these notes were to be structured. We were also inconsistent in how we referred to notes during the hiring team debrief meetings where final decisions about applicants were typically made.
Our New Hiring Process: What We’ve Done
Our new hiring process is a work in progress. We want to share the strides we have made and also what we would still like to do. Our first step in trying to reduce bias in our hiring process was to document our current hiring process, which was not documented comprehensively anywhere, and to try and identify areas for improvement. Simultaneously, we set out to learn as much as we could about bias in hiring in general. We consulted members of Mozilla’s Diversity and Inclusion team, dug into materials from Stanford’s Clayman Institute for Gender Research, and talked with several managers in other parts of Mozilla who had undertaken de-biasing efforts for their own hiring. This “discovery” period helped us identify a number of critical steps.
First, we needed to develop a list of essential and desired criteria for job candidates. The researcher job description we had been using reflected many of the criteria we ultimately kept, but the exercise of distilling essential and desired criteria allowed current research team members to make much that was implicit, explicit.
Team members were able to ask questions about the criteria, challenge assumptions, and in the end build a shared understanding of expectations for members of our team. For example, we previously sought out candidates with 1–3 years of work experience. With this criteria, we were receiving applications from some candidates who only had experience within academia. It was through discussing how each of our criteria relates to ways we actually work at Mozilla that we determined that what was even more essential than 1–3 years of any user research experience was that much experience specifically working in industry. The task of distilling our hiring criteria was not necessarily difficult, but it took several hours of synchronous and asynchronous discussion — time we all acknowledged was well-spent because our new hiring process would be built from these agreed-upon criteria.
Next, we wrote phone screen and interview questions that aligned with the essential and desired criteria. We completed this step mostly asynchronously, with each team member contributing and reviewing questions. We also asked UX designers, content strategists, and product managers that we work with to contribute questions, also aligned with our essential and desired criteria, that they would like to ask researcher candidates.
The next big piece was to develop a rubric for grading answers to the questions we had just written. For each question, again mostly asynchronously, research team members detailed what they thought were “excellent,” “acceptable,” and “poor answers,” with the goal of producing a rubric that was self-evident enough that it could be used by hiring team members other than ourselves. Like the exercise of crafting criteria, this step required as much research team discussion time as writing time. We then took our completed draft of a rubric and determined at which phase of the hiring process each question would be asked.
Additionally, we revisited the research exercise that we have candidates complete to make its purpose and the exercise constraints more explicit. Like we did for the phone screen and interview questions, we developed a detailed rubric for the research exercise based on our essential and desirable hiring criteria.
Most recently, we have turned our new questions and rubrics into worksheets, which Mozilla staff will use to document applicants’ answers. These worksheets will also allow staff to document any additional questions they pose to applicants and the corresponding answers, as well as questions applicants ask us. Completed worksheets will be linked to our applicant tracking system and be used to structure the hiring team debrief meetings where final decisions about leading applicants will be made.
From the work we have done to our hiring process, we anticipate a number of benefits, including:
Next Steps
Our Mozilla recruiter and members of the research team have started going through the 900+ resumes we have received to determine which candidates will be screened by phone. We fully expect to learn a lot and make changes to our hiring process after this first attempt at putting it into practice. There are also several other resource-intensive steps we would like to take in the near future to mitigate bias further, including:
Teams who are interested in trying out some of the exercises we carried out to improve our hiring process are welcome to use the template we developed for our purposes. We are also interested in learning how other teams have tackled bias in hiring and welcome suggestions, in particular, for blinding when hiring people from around the world.
We are looking forward to learning from this work and welcoming new research team members who can help us advance our efforts.
Thank you to Gemma Petrie and Mozilla’s Diversity & Inclusion Team for reviewing an early draft of this post.
Bias and Hiring: How We Hire UX Researchers was originally published in Firefox User Experience on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
The Firefox Frontier: Let Firefox’s Side-View extension give you an edge for fantasy football, basketball, hockey and all the other sportsballs |
It’s that time of year again. When we find ourselves pouring over player rosters, reading frustratingly vague injury reports and trying to shake down our friends and colleagues to reveal … Read more
The post Let Firefox’s Side-View extension give you an edge for fantasy football, basketball, hockey and all the other sportsballs appeared first on The Firefox Frontier.
|
|
Hacks.Mozilla.Org: Share your favorite images and videos in VR with Mozilla Hubs |
Last April we released Mozilla Hubs, a VR chat system that lets you walk and talk in VR with your friends, no matter where in the world they are. Now we have a game changing new feature: you can share virtually any kind of media with everyone in your Hubs room by just pasting in a URL. Anything you share becomes a virtual object that everyone can interact with. From images to videos to 3D models, Hubs is the best way to collaborate across devices (laptops, phones, headsets) and OSes. Let’s look at a few details.
Hubs supports the common image formats: PNG, JPG, and even animated GIFs.

Hubs also supports streaming media files like MP3s and MP4s, as well as 3D models in GLB format (the compact binary form of GLTF). And finally, Hubs has special support for content from certain websites.
If you paste in a URL to a model on Sketchfab (an online community and marketplace of 3D artists and makers), Hubs will fetch the model and import it into the room, no extra work required. As long as the model is less than 100MB and marked as downloadable, the Hubs server will process the webpage to find the link to the actual 3D model and import only that. Hubs can also perform this same trick with URLs from Giphy, Imgur, Google Poly (only objects made in Blocks, not panoramas), and even YouTube videos. The media is cached into the Hubs server before sending to Hubs clients.
Yes. When someone in your Hubs room pastes in a URL it does not immediately go to every client logged into the room. Instead the URL is processed by the Hubs server which hosts the encrypted media, sending only the validated data to the other clients. This helps to protect from XSS attacks as well.
The Hubs server will host all content for up to 48 hours after the last time it is accessed, so once everyone is done interacting with it, the media file will eventually disappear. It is never copied anywhere else. The server also encrypts the data, so only clients in your Hubs room can see it. Additionally, Hubs does not track logins, so content has no user-identifiable data that could be used for tracking.
You can pick up any kind of content object then move it, throw it, or leave it stuck in one place by holding still for a moment before releasing. If you have a 6DoF controller then you can also resize the object.
For audio and video you can click to play and pause the media stream. For PDFs you can advance one page at a time, making Hubs the best way to share presentations in VR, or just join your friends for some YouTube binging.
Nope. Any content you have on the web you can share. Since the server acts as a proxy you don’t need to worry about CORS. If the content you want to share is not web accessible then you can upload the file directly to Hubs, which will then host and share it automatically. You can even use content from your public Dropbox folder. It all just works.
If you have content that you want to ensure users can share within Hubs, then just make it publicly accessible from the web in one of the file formats we support (as listed above). For data you don’t want to stay public permanently, you can serve up a randomly generated URL which expires after 10 minutes. Once the data is imported into the Hubs server it no longer needs to be accessible on the web.
Play with it. Join your friends in a room to hang out, work on a presentation, or just watch some videos. All with real-time voice communication as well. As always, Hubs will work on any device with a browser, from 2D desktop to standalone VR headset to smartphone. Hubs will adapt to the device you have available. Just share a link to your room and go.
https://hacks.mozilla.org/2018/08/share-your-favorite-images-and-videos-in-vr-with-mozilla-hubs/
|
|
Firefox Nightly: Screenshots from the Console |
Firefox DevTools has now added a screenshot command, so you can take screenshots directly from the Console (bug #1464461).
To access the command, open the Web Console via Tools -> Web Developer -> Console, type in :screenshot and press ENTER. A screenshot of the current document will be downloaded to your downloads directory.
You can also use the flags, as you could with the old screenshot command that was part of the GCLI. Here is a quick list, generated with screenshot --help
:screenshot --fullpage // take a screenshot of the whole page
:screenshot --selector “.some-class”// take a screenshot of an element on the page
:screenshot --clipboard --fullpage // take a screenshot of the full page and add it to your clipboard
You may have noticed the new colon syntax used for the screenshot command. We are using this to represent commands that are not part of the web environment, that can be accessed from the console. Moving screenshot to the console is part of the work we are doing to unship GCLI, you can learn more about this here. The GCLI used a UNIX style input grammar, and after some discussion we decided to keep it. The command is not part of the JavaScript language, or web APIs, and could potentially be confusing. This is why we use the : character to prefix commands. If this is something that works well, we may expand it to include other commands. For example, you can also try out :help to get the same result as help().
If there are other commands that you would like to see available in this format, let us know. If you are working on a web extension and would like to be able to implement your own web commands, let us know about that too, so we can work on getting you what you need.
If you start typing a command prefixed by the : symbol in the console, you will see an autocomplete menu for commands (done in bug #1473923). At the moment it only contains the two available commands, :screenshot, and :help. We do not yet have support for the flags, but this may be added in a future iteration.
We have deprecated the “Upload to imgur” functionality with the new screenshot feature. In a future iteration, we plan to allow uploading to Firefox Screenshots directly, and be able to share them from your profile (you can read more about this feature here).
At present, the screenshot feature can be used from the browser console as well, but it will only capture the chrome of the browser and not the content window. This is planned for a future iteration (see bug #1474006)
We have a couple of known bugs which can be found under this metabug. If you come across something that isn’t working as expected and hasn’t been listed, feel free to open a new issue.
https://blog.nightly.mozilla.org/2018/08/23/screenshots-from-the-console/
|
|
Nick Cameron: More on the RLS and a 1.0 release |
In my last post, I announced a release candidate for the RLS 1.0. There has been a lot of feedback (and quite a lot of that was negative on the general idea), so I wanted to expand on what 1.0 means for the RLS, and why I think it is ready. I also want to share some of my vision for the future of the RLS, in particular changes that might warrant a major version release.
The general thrust of a lot of the feedback was that the RLS is not ready for a 1.0 release. Where a specific reason was given it was usually regarding code completion. I'll drill deeper in a minute. There were also a few comments along the lines of the RLS architecture being wrong. I'm not going to argue against that one, certainly if we started over I would do some things differently (hindsight is great). However, I don't think that at this point changing the architecture (which basically means starting again from scratch) is going to get us to an excellent product any quicker than continuing with the current architecture. I'm also confident that the current design can evolve over time.
What does 1.0 mean for the RLS?
There is no backwards compatibility guarantee for the RLS, and no obvious quality cut-off. This is what I meant by "arbitrary" in my last post.
The way I have been thinking of 1.0 is as a signal that the RLS is worth using for a majority of users. It is that signal which is much more important than the 1.0 label. The Rust roadmap has 'a high quality IDE experience' as a key goal, and that is what I want to deliver, regardless of the version number. In terms of "ticking things off on a Powerpoint presentation", it is the 'high quality IDE experience' we're going for, not the 1.0 label.
I believe that for the RLS, quality can be measured along four axes: stability - how often does the RLS crash, fail to respond, or give incorrect results; completeness - how many cases are covered (e.g., code completion not working for some types, type info missing for macro-generated identifiers, etc.); features - what can do the RLS do (e.g., code completion, refactoring); and performance.
I have mainly been thinking in terms of stability for 1.0 - it is essential that for nearly all users, crashes and incorrect results are rare. I believe that we have achieved that (or that we can achieve that by the end of the 'release candidate' phase). Most of the negative feedback around the RC announcement focused on completeness. Features and performance can always be improved; my opinion is that there is minimum core that is required for 1.0 and we have that, though of course there is plenty of room for improvement.
Code completion is powered by Racer. Long-term we'd like to drive code completion with the compiler, but that is a long way off. Racer needs to be able to determine the type of the expression with fairly limited input. Given the type, it can be pretty smart about finding implemented traits and providing methods. However, this is not perfect.
There are two ways that code completion is incomplete: we can't give any suggestions where we can't find the type, and even if we can find the type, then sometimes we do not suggest all the things that we should. One could consider incomplete suggestions for a type to be incorrect as well as incomplete; I think that depends on how suggestions are used. Although I haven't observed it, I believe Racer can rarely make incorrect suggestions.
The RLS has three kinds of information source: the compiler, Racer, and external tools (Rustfmt, Clippy, etc.). The latter are not really relevant here. The compiler processes a program semantically, i.e., it knows what the program means. It takes a long time to do that. Racer processes a program syntactically, it only knows what a program looks like. It runs quickly. We use the compiler for 'goto def', showing types and documentation, etc. We use Racer mostly for code completion.
There are some fundamental limitations. The compiler has to be able to build your program, which prevents it working with individual files and some very complex systems like the Rust project. For large programs, it is only feasible to use it 'on save', rather than 'live' as the user types. We can make this better, but it is a very long-term process. In particular, getting the compiler fast enough to do code completion will take at least a year, probably more.
Racer cannot understand every expression in a program. We can't hope for Racer to have perfect completion for all expressions.
Fully complete (i.e., compiler-powered) code completion will take years. Even when completion is powered by the compiler, there will be work to do to understand macros and so forth. Excluding the most complex cases, we're still looking at more than a year for complete code completion.
On the compiler side, there are a few things which could improve things, but none are trivial. My opinion is that here we have a 'good enough' base and we can incrementally improve that.
One new idea is to pass data from the compiler to Racer, to improve Racer's completeness. This is a promising angle to investigate, and might get us some big wins to the completeness of code completion.
Rolling back the 1.0 RC is definitely an option at this stage. I do believe that although the RLS is lacking in completeness, for most users, the cost/benefit ratio is favourable and therefore it should be widely recommended (if you use the RLS and don't agree, I'd be keen to hear why). One question is how to signal that.
For how to handle the RC and 1.0 release, some options I see (I'd be happy to hear more ideas):
foo in foo::bar). RC again when ready. Estimated 1.0 release: mid 2019.When thinking about the quality requirement for a 1.0 it is good to consider some other examples. Rust itself set a pretty high bar for it's 1.0 release. However, there was plenty which was missing, incomplete, or imperfect; the focus was on backwards compatibility. Other IDEs have been around a long time and have seen a lot of improvement (e.g., IntelliJ was first released in 2001), I would avoid comparing VSCode and the RLS to IntelliJ or similar tools for that reason.
In the wider Rust ecosystem, there are a lot of crates which have yet to announce a 1.0 release. However, the feeling among the core and library teams is that the community is often over-conservative here; that the ecosystem would be better served by announcing 1.0 releases and not being so keen to avoid a major version increment (in particular, the current situation can give the impression that Rust is 'not ready').
There are a lot of things that could be added or improved in the RLS. I'll try and list some of the more significant things here, in particular things that might warrant a major version increment.
For each work item, I've indicated the priority (further discussion about priorities in particular is needed), status, and sometimes an expected version. A status of "-" means that it could be started straight away, but hasn't been started yet. A status of "planning" means that we need to work out how the feature will be implemented. A version number indicates that the feature should block the given version (assuming 1.0 RC becomes 1.0).
Tell me!
http://www.ncameron.org/blog/more-on-the-rls-and-a-1-0-release/
|
|
Firefox Test Pilot: Notes now uses Rust & Android components |
Today we shipped Notes by Firefox 1.1 for Android, all existing users will get the updated version via Google Play.
After our initial testing in version 1.0, we identified several issues with the Android’s “Custom Tab” login features. To fix those problems the new version has switched to using the newly developed Firefox Accounts Android component. This component should resolve the issues that the users experienced while signing in to Notes.
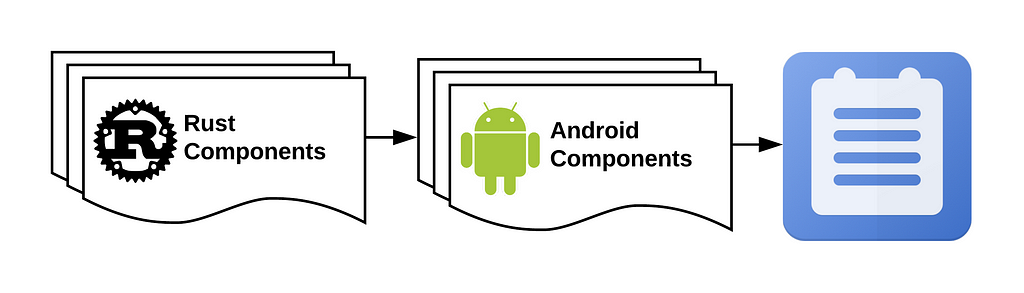
The Android component in Notes uses one of our Rust components in the background to perform authentication actions for Firefox Accounts. The Rust components can be cross-compiled for different environments such as Android, iOS and desktop operating systems. This way we don’t have to rewrite and maintain several copies of the same authentication logic in different languages. There are other reasons why we chose Rust to develop low-level components, such as memory safety, no data races, performance, and more. We hope to bring these new components into our other apps in the near future.
If you are interested in this component architecture and want to contribute, please check out the following links below:

Big thanks to our SoftVision QA, Mozilla Mobile and Mozilla Application Services teams for helping with this release!
Notes now uses Rust & Android components was originally published in Firefox Test Pilot on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Dustin J. Mitchell: Introducing CI-Admin |
A major focus of recent developments in Firefox CI has been putting control of the CI process in the hands of the engineers working on the project. For the most part, that means putting configuration in the source tree. However, some kinds of configuration don’t fit well in the tree. Notably, configuration of the trees themselves must reside somewhere else.
This information is collected in the ci-configuration repository.
This is a code-free library containing YAML files describing various aspects of the configuration – currently the available repositories (projects.yml) and actions.
This repository is designed to be easy to modify by anyone who needs to modify it, through the usual review processes. It is even Phabricator-enabled!
Historically, we’ve managed this sort of configuration by clicking around in the Taskcluster Tools. The situation is analogous to clicking around in the AWS console to set up a cloud deployment – it works, and it’s quick and flexible. But it gets harder as the configuration becomes more complex, it’s easy to make a mistake, and it’s hard to fix that mistake. Not to mention, the tools UI shows a pretty low-level view of the situation that does not make common questions (“Is this scope available to cron jobs on the larch repo?”) easy to answer.
The devops world has faced down this sort of problem, and the preferred approach is embodied in tools like Puppet or Terraform:
This “desired state” approach means that the tool examines the current configuration, compares it to the configuration expressed in the text files, and makes the necessary API calls to bring the current configuration into line with the text files. Typically, there are utilities to show the differences, partially apply the changes, and so on.
The ci-configuration repository contains those human-parsable text files.
The tool to enforce that state is ci-admin.
It has some generic resource-manipulation support, along with some very Firefox-CI-specific code to do weird things like hashing .taskcluster.yml.
The current process for making changes is a little cumbersome. In part, that’s intentional: this tool controls the security boundaries we use to separate try from release, so its application needs to be carefully controlled and subject to significant human review. But there’s also some work to do to make it easier (see below).
The process is this:
ci-admin apply for you (probably the reviewer can do this)We are in the process of setting up some automation around these repositories. This includes Phabricator, Lando, and Treeherder integration, along with automatic unit test runs on push.
More specific to this project, we also need to check that the current and expected configurations match.
This needs to happen on any push to either repo, but also in between pushes: someone might make a change “manually”, or some of the external data sources (such as the Hg access-control levels for a repo) might change without a commit to the ci-configuration repo.
We will do this via a Hook that runs ci-admin diff periodically, notifying relevant people when a difference is found.
These results, too, will appear in Treeherder.
One of the most intricate and confusing aspects of configuration for Firefox CI is the assignment of scopes to various jobs.
The current implementation uses a cascade of role inheritance and * suffixes which, frankly, no human can comprehend.
The new plan is to “grant” scopes to particular targets in a file in ci-configuration.
Each grant will have a clear purpose, with accompanying comments if necessary.
Then, ci-admin will gather all of the grants and combine them into the appropriate role definitions.
At the moment, the configuration of, say, aws-provsioner-v1/gecko-t-large is a bit of a mystery.
It’s visible to some people in the AWS-provisioner tool, if you know to look there.
But that definition also contains some secret data, so it is not publicly visible like roles or hooks are.
In the future, we’d like to generate these configurations based on ci-configuration.
That both makes it clear how a particular worker type is configured (instance type, capacity configuration, regions, disk space, etc.), and allows anyone to propose a modification to that configuration – perhaps to try a new instance type.
As noted above, ci-admin is fairly specific to the needs of Firefox CI.
Other users of Taskcluster would probably want something similar, although perhaps a bit simpler.
Terraform is already a popular tool for configuring cloud services, and supports plug-in “providers”.
It would not be terribly difficult to write a terraform-provider-taskcluster that can create roles, hooks, clients, and so on.
This is left as an exercise for the motivated user!
|
|
Hacks.Mozilla.Org: Dweb: Serving the Web from the Browser with Beaker |
In this series we are covering projects that explore what is possible when the web becomes decentralized or distributed. These projects aren’t affiliated with Mozilla, and some of them rewrite the rules of how we think about a web browser. What they have in common: These projects are open source, and open for participation, and share Mozilla’s mission to keep the web open and accessible for all.
So far we’ve covered distributed social feeds and sharing files in a decentralized way with some new tools for developers. Today we’d like to introduce something a bit different: Imagine what an entire browser experience would be like if the web was distributed… Beaker browser does exactly this! Beaker is a big vision from a team who are proving out the distributed web from top to bottom. Please enjoy this post from Beaker co-creator Tara Vancil. – Dietrich Ayala
We’re Blue Link Labs, a team of three working to improve the Web with the Dat protocol and an experimental peer-to-peer browser called Beaker.

We work on Beaker because publishing and sharing is core to the Web’s ethos, yet to publish your own website or even just share a document, you need to know how to run a server, or be able to pay someone to do it for you.
So we asked ourselves, “What if you could share a website directly from your browser?”
Peer-to-peer protocols like dat:// make it possible for regular user devices to host content, so we use dat:// in Beaker to enable publishing from the browser, where instead of using a server, a website’s author and its visitors help host its files. It’s kind of like BitTorrent, but for websites!
Beaker uses a distributed peer-to-peer network to publish websites and datasets (sometimes we call them “dats”).
dat:// websites are addressed with a public key as the URL, and each piece of
data added to a dat:// website is appended to a signed log. Visitors to a dat://
website find each other with a tracker or DHT, then sync the data between each other, acting both as downloaders and uploaders, and checking that the data hasn’t been tampered with in transit.

At its core, a dat:// website isn’t much different than an https:// website — it’s a collection of files and folders that a browser interprets according to Web standards. But dat:// websites are special in Beaker because we’ve added peer-to-peer Web APIs so developers can do things like read, write, and watch dat:// files and build peer-to-peer Web apps.
Beaker makes it easy for anyone to create a new dat:// website with one click (see our tour). If you’re familiar with HTML, CSS, or JavaScript (even just a little bit!) then you’re ready to publish your first dat:// website.
Developers can get started by checking out our API documentation or reading through our guides.
This example shows a website editing itself to create and save a new JSON file. While this example is contrived, it demonstrates a common pattern for storing data, user profiles, etc. in a dat:// website—instead of application data being sent away to a server, it can be stored in the website itself!
// index.html
Submit message
// index.js
// first get an instance of the website's files
var files = new DatArchive(window.location)
document.getElementById('create-json-button').addEventListener('click', saveMessage)
async function saveMessage () {
var timestamp = Date.now()
var filename = timestamp + '.json'
var content = {
timestamp,
message: document.getElementById('message').value
}
// write the message to a JSON file
// this file can be read later using the DatArchive.readFile API
await files.writeFile(filename, JSON.stringify(content))
}
We’re always excited to see what people build with dat:// and Beaker. We especially love seeing when someone builds a personal site or blog, or when they experiment with Beaker’s APIs to build an app.
There’s lots to explore on the peer-to-peer Web!
https://hacks.mozilla.org/2018/08/dweb-serving-the-web-from-the-browser-with-beaker/
|
|
Mozilla VR Blog: New in Hubs: Images, Videos, and 3D Models |
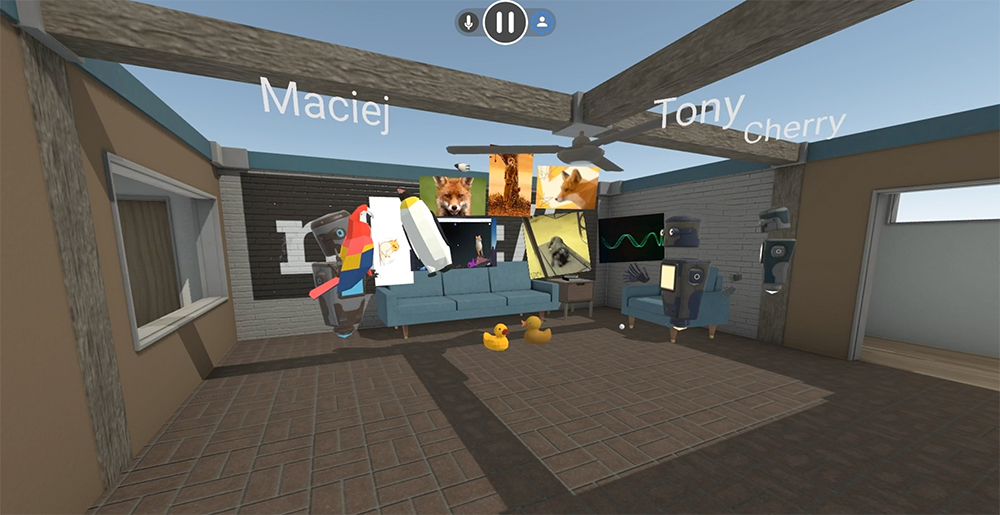
A few months ago, we announced an early preview release of Hubs by Mozilla, an experiment to bring Social Mixed Reality to the browser. Since then, we’ve made major strides in improving usability, performance, and support for standalone devices like the Oculus Go. Today, we’re excited to share our first big feature update to Hubs: the ability bring your videos, images, documents, and even 3D models into Hubs by simply pasting a link.
The progress we’ve made over the last several months has strengthened our view that the open web is the best platform for getting together in Mixed Reality. Today, you can join a room in Hubs using any VR device on the market, as well as your phone or PC. It is so easy to use, our team has switched to using Hubs for our regular VR standup meetings!
Utilizing the browser helps us create features that are easy to understand, because people are already familiar with how the web works. You can invite people into a room on Hubs by simply sharing a link - and now, you can bring your favorite content into the room by pasting a link to anything on the web!
If you want to share a video on YouTube, hop into a Hubs room on your PC or phone and paste the URL to the video. It’s that simple! The video will appear in the space and start playing, and can be moved around or thrown up on a wall.
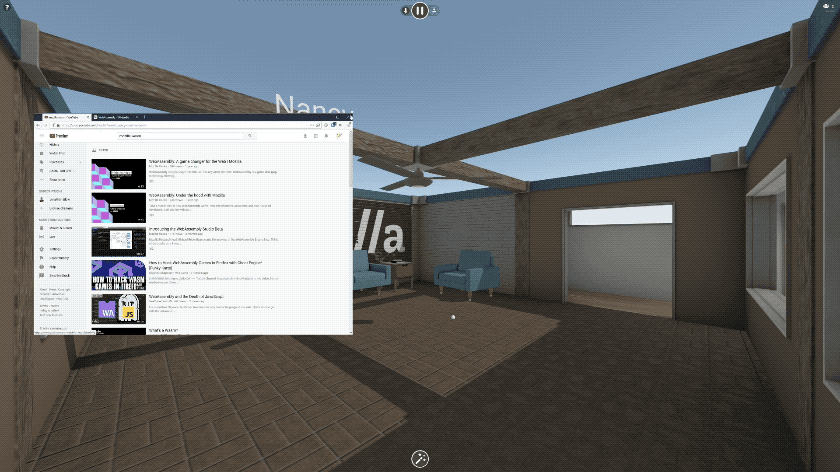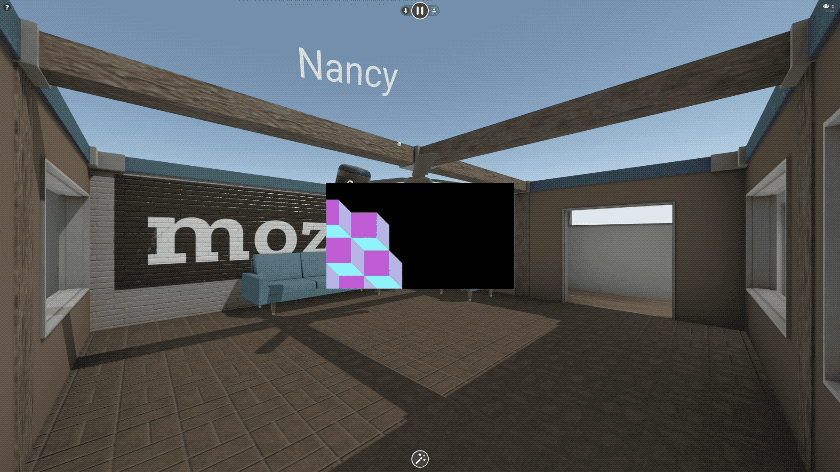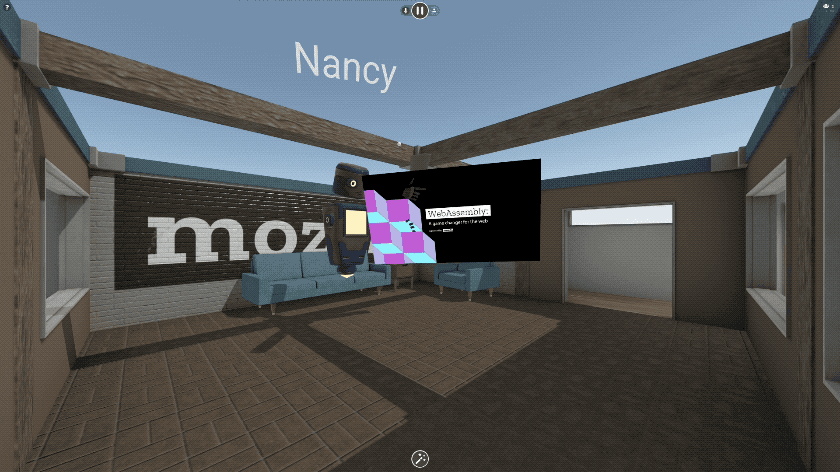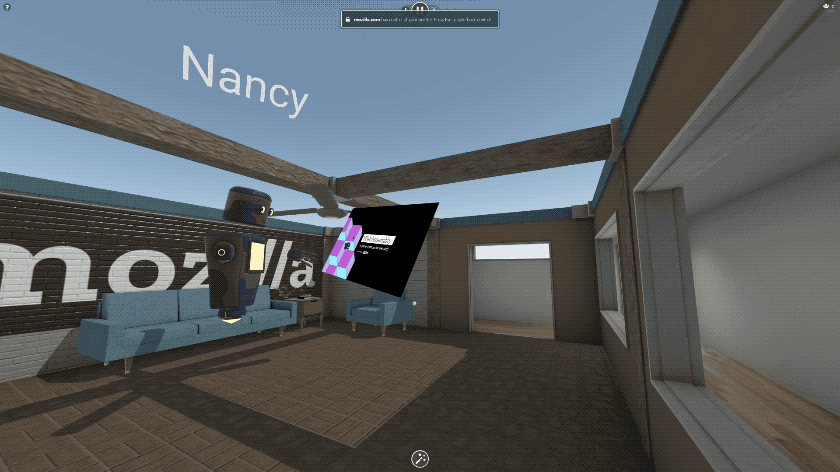
Being able to share a video with friends in VR so easily is transformative, but that’s just the beginning!
You can paste the URL to any image on the web, and we’ve added first-class support for all of your favorite image sites like imgur and Giphy. 3D content also works - you can paste links to 3D models on Sketchfab or Poly, or to any GLTF scene. It’s magical.
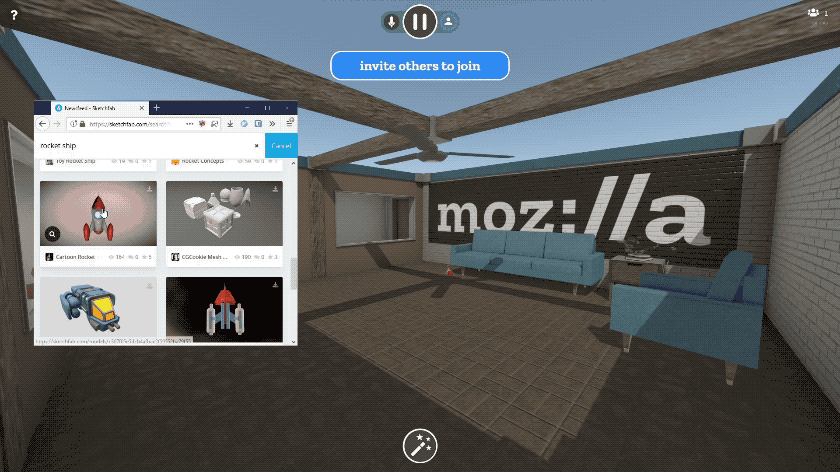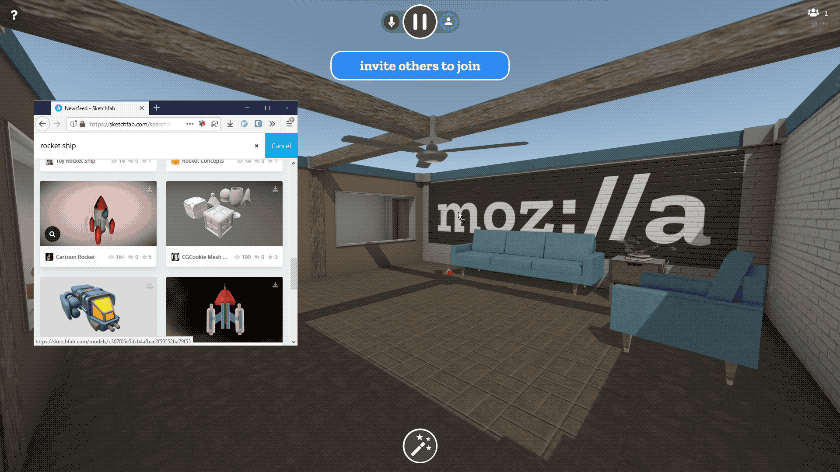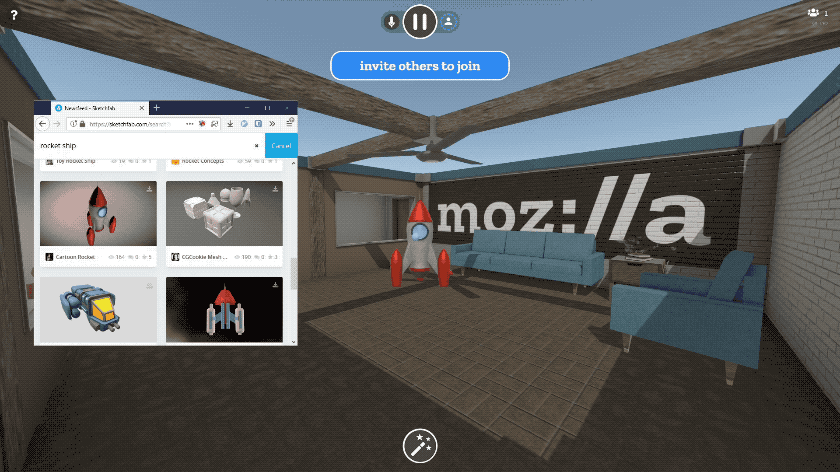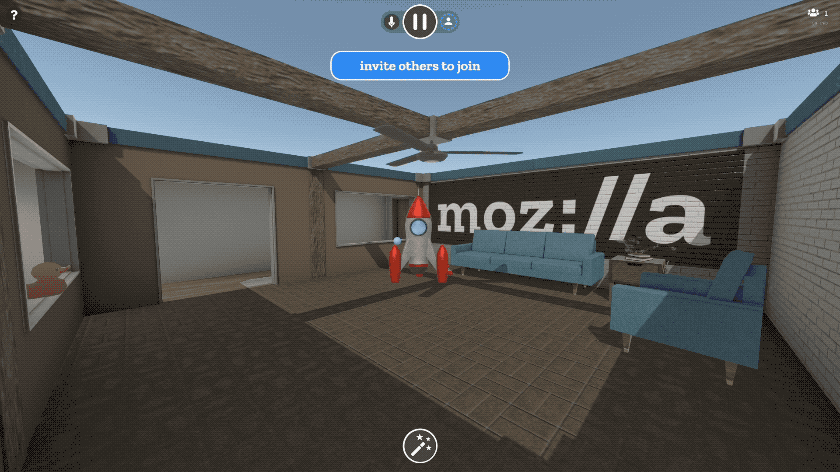
We didn’t stop there. We know that some things you’d like to share, like photos and documents, may be saved on your phone or PC. You can upload files, drag and drop files, or even paste content out of your clipboard right into Hubs. Upload a slide deck as a PDF, and you can flip through it together in VR. Export a 3D model to GLTF and drag it into the browser and everyone else will see it in 3D. Upload a few photos from your phone and everyone can arrange them together into a gallery. Take a screenshot, copy it to your clipboard, and paste it right into the room.
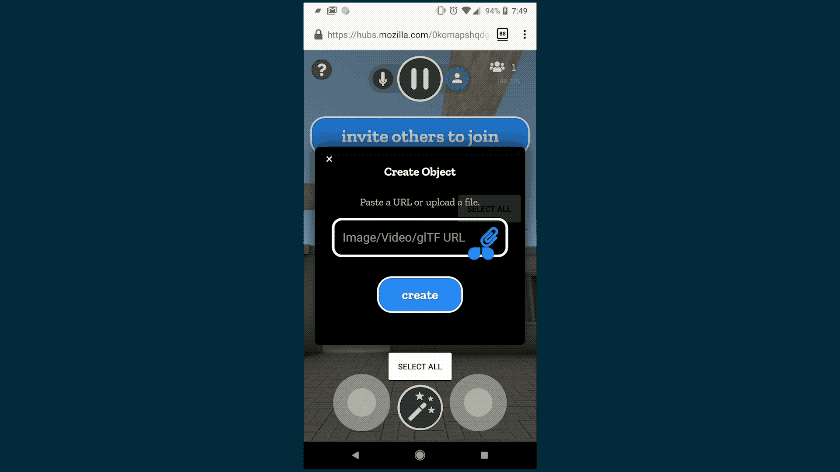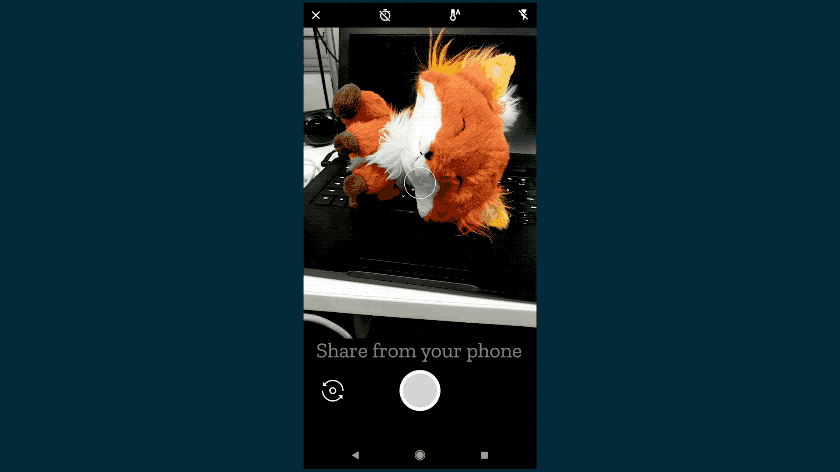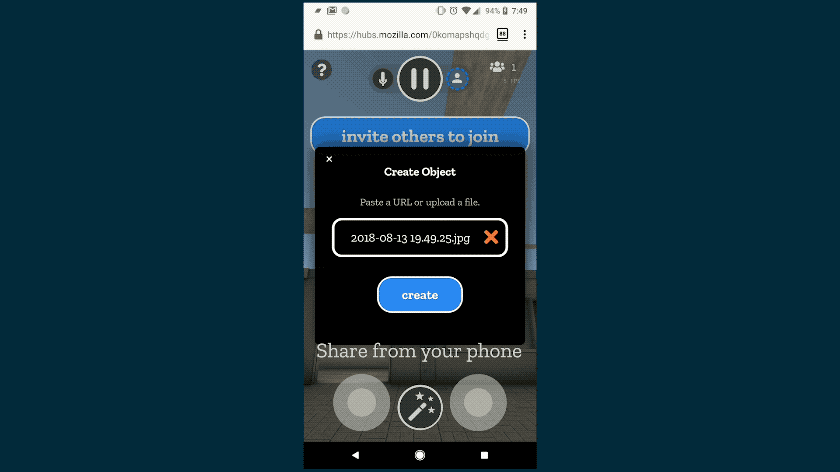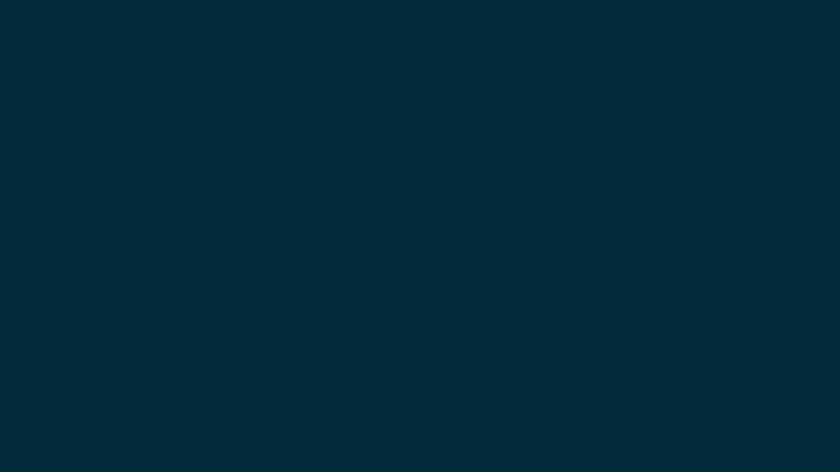
To protect your privacy, we’ve made sure any content you upload is only available to others in the room. It’s encrypted and removed when no longer needed. As always, the code is open source, so you can see how it works for yourself.
We’re beyond excited to see the browser already letting us experience Social Mixed Reality in whole new ways. We think there are endless ways people can use these new features, and we’ll be publishing some short video tutorials to help spark your creativity. We’ll be continually adding more and more supported content types and methods for bringing more media into Hubs. If you have ideas, feedback, or suggestions, please join us in the #social channel on the WebVR Slack or file a Github Issue.
We hope you enjoy this update!
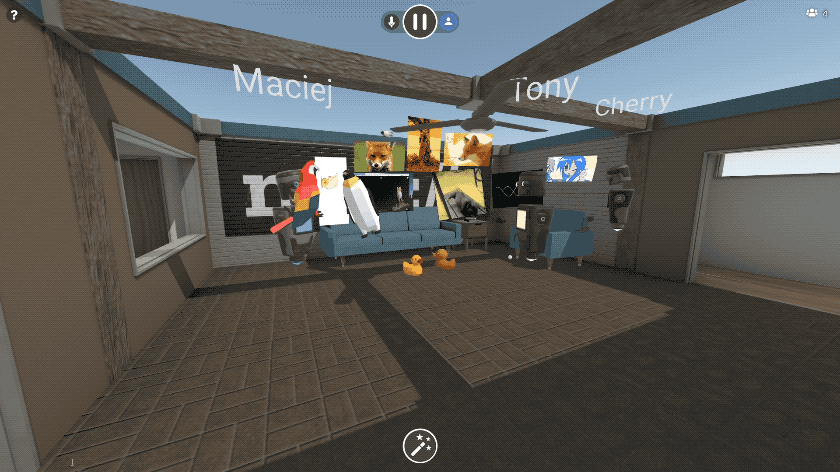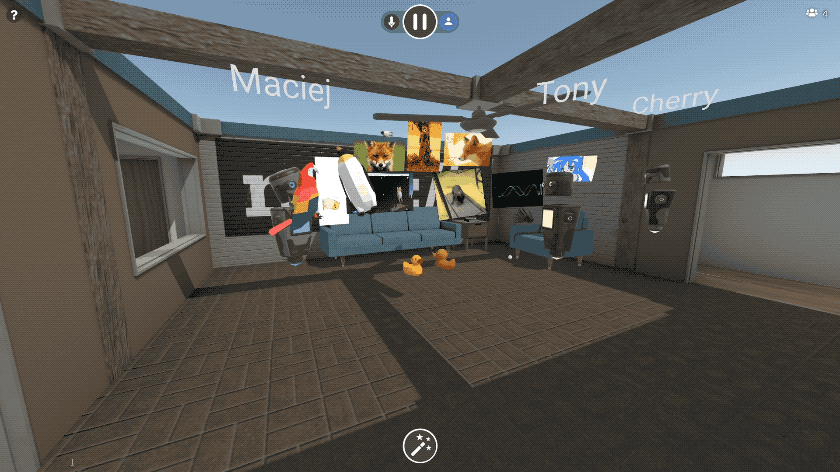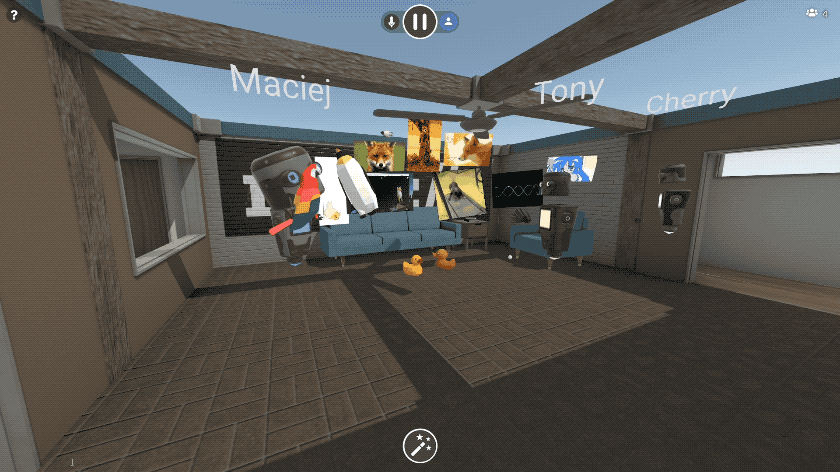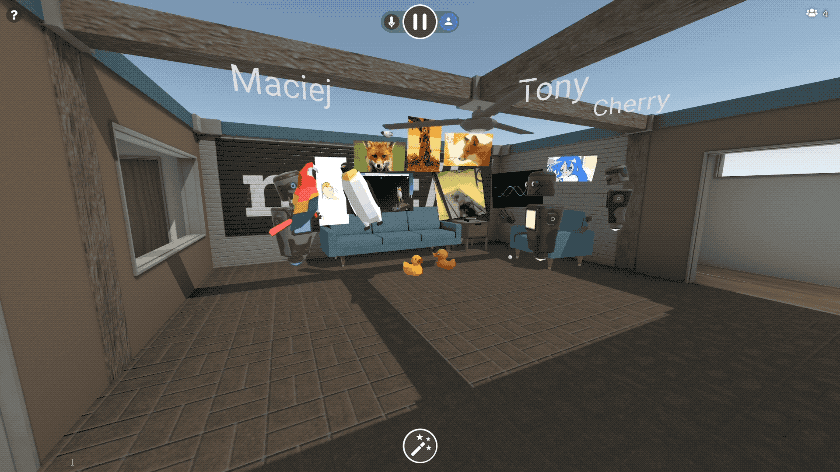
https://blog.mozvr.com/new-in-hubs-images-videos-and-3d-models/
|
|






