Mozilla Open Policy & Advocacy Blog: Searching for sustainable and progressive policy solutions for illegal content in Europe |
As we’ve previously blogged, lawmakers in the European Union are reflecting intensively on the problem of illegal and harmful content on the internet, and whether the mechanisms that exist to tackle those phenomena are working well. In that context, we’ve just filed comment with the European Commission, where we address some of the key issues around how to efficiently tackle illegal content online within a rights and ecosystem-protective framework.
Our filing builds upon our response to the recent European Commission Inception Impact Assessment on illegal content online, and has four key messages:
Illegal content is symptomatic of an unhealthy internet ecosystem, and addressing it is something that we care deeply about. To combat an online environment in which harmful content and activity continue to persist, we recently adopted an addendum to our Manifesto, where we affirmed our commitment to an internet that promotes civil discourse, human dignity, and individual expression. The issue is also at the heart of our recently published Internet Health Report, though its dedicated section on digital inclusion.
As a mission-driven not-for-profit and the steward of a community of internet builders, we can bring a unique perspective into this debate. Indeed, our filing seeks to firmly root the fight against illegal content online within a framework that is both rights-protective and attune with the technical realities of the internet ecosystem.
This is a really challenging policy space, to which we are committed to advancing progressive and sustainable policy solutions.
Read more:
The post Searching for sustainable and progressive policy solutions for illegal content in Europe appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/07/11/sustainable-policy-solutions-for-illegal-content/
|
|
Daniel Stenberg: curl 7.61.0 |
Yet again we say hello to a new curl release that has been uploaded to the servers and sent off into the world. Version 7.61.0 (full changelog). It has been exactly eight weeks since 7.60.0 shipped.
the 175th release
7 changes
56 days (total: 7,419)
88 bug fixes (total: 4,538)
158 commits (total: 23,288)
3 new curl_easy_setopt() options (total: 258)
4 new curl command line option (total: 218)
55 contributors, 25 new (total: 1,766)
42 authors, 18 new (total: 596)
1 security fix (total: 81)
A stupid heap buffer overflow that can be triggered when the application asks curl to use a smaller download buffer than default and then sends a larger file - over SMTP. Details.
The trailing dot zero in the version number reveals that we added some news this time around - again.
More microsecond timersOver several recent releases we've introduced ways to extract timer information from libcurl that uses integers to return time information with microsecond resolution, as a complement to the ones we already offer using doubles. This gives a better precision and avoids forcing applications to use floating point math.
Bold headersThe curl tool now outputs header names using a bold typeface!
Bearer tokensThe auth support now allows applications to set the specific bearer tokens to pass on.
TLS 1.3 cipher suitesAs TLS 1.3 has a different set of suites, using different names, than previous TLS versions, an application that doesn't know if the server supports TLS 1.2 or TLS 1.3 can't set the ciphers in the single existing option since that would use names for 1.2 and not work for 1.3 . The new option for libcurl is called CURLOPT_TLS13_CIPHERS.
Disallow user name in URLThere's now a new option that can tell curl to not acknowledge and support user names in the URL. User names in URLs can brings some security issues since they're often sent or stored in plain text, plus if .netrc support is enabled a script accepting externally set URLs could risk getting exposing the privately set password.
Some of my favorites include...
Resolver local host names fasterWhen curl is built to use the threaded resolver, which is the default choice, it will now resolve locally available host names faster. Locally as present in /etc/hosts or in the OS cache etc.
Use latest PSL and refresh it periodicallycurl can now be built to use an external PSL (Public Suffix List) file so that it can get updated independently of the curl executable and thus better keep in sync with the list and the reality of the Internet.
Rumors say there are Linux distros that might start providing and updating the PSL file in separate package, much like they provide CA certificates already.
fnmatch: use the system one if availableThe somewhat rare FTP wildcard matching feature always had its own internal fnmatch implementation, but now we've finally ditched that in favour of the system fnmatch() function for platforms that have such a one. It shrinks footprint and removes an attack surface - we've had a fair share of tiresome fuzzing issues in the custom fnmatch code.
axTLS: not considered fit for useIn an effort to slowly increase our requirement on third party code that we might tell users to build curl to use, we've made curl fail to build if asked to use the axTLS backend. This since we have serious doubts about the quality and commitment of the code and that project. This is just step one. If no one yells and fights for axTLS' future in curl going forward, we will remove all traces of axTLS support from curl exactly six months after step one was merged. There are plenty of other and better TLS backends to use!
Detailed in our new DEPRECATE document.
TLS 1.3 used by defaultWhen negotiating TLS version in the TLS handshake, curl will now allow TLS 1.3 by default. Previously you needed to explicitly allow that. TLS 1.3 support is not yet present everywhere so it will depend on the TLS library and its version that your curl is using.
We have several changes and new features lined up for next release. Stay tuned!
First, we will however most probably schedule a patch release, as we have two rather nasty HTTP/2 bugs filed that we want fixed. Once we have them fixed in a way we like, I think we'd like to see those go out in a patch release before the next pending feature release.
|
|
Mozilla Addons Blog: New Site for Thunderbird and SeaMonkey Add-ons |
When Firefox Quantum (version 57) launched in November 2017, it exclusively supported add-ons built using WebExtensions APIs. addons.mozilla.org (AMO) has followed a parallel development path to Firefox and will soon only support WebExtensions-based add-ons.
As Thunderbird and SeaMonkey do not plan to fully switch over to the WebExtensions API in the near future, the Thunderbird Council has agreed to host and manage a new site for Thunderbird and SeaMonkey add-ons. This new site, addons.thunderbird.net, will go live in July 2018.
Starting on July 12th, all add-ons that support Thunderbird and SeaMonkey will be automatically ported to addons.thunderbird.net. The update URLs of these add-ons will be redirected from AMO to the new site and all users will continue to receive automatic updates. Developer accounts will also be ported and developers will be able to log in and manage their listings on the new site.
Thunderbird or SeaMonkey add-ons that also support Firefox or Firefox for Android will remain listed on AMO.
If you come across any issues or need support during the migration, please post to this thread in our community forum.
The post New Site for Thunderbird and SeaMonkey Add-ons appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/07/10/new-site-for-thunderbird-and-seamonkey-add-ons/
|
|
Mark C^ot'e: A Vision for Engineering Workflow at Mozilla (Part Three) |
This is the last post in a three-part series on A Vision for Engineering Workflow at Mozilla. The first post in this series provided some background, while the second introduced the first four points of our nine-point vision.
The Engineering Workflow team has spent a lot of time over the last few years on review tools, starting with Splinter, moving into MozReview, and now onto Phabricator. In particular, MozReview was a grand experiment; its time may be over, but we learned a lot from the project and are incorporating these lessons not just into our new tools but also into how we work.
There are a lot of aspects to the code-review process. First and foremost is, of course, the tool that is used to actually leave reviews. One important meta-aspect of review-tool choice is that there should only be one. Mozilla has suffered from the problems caused by multiple review tools for quite a long time. Even before MozReview, users had the choice of raw diffs versus Splinter. Admittedly, the difference there is fairly minimal, but if you look at reviews conducted with Splinter, you will see the effect of having two systems: initial reviews are done in Splinter, but follow ups are almost always done as comments left directly in the bug. The Splinter UI rarely shows any sort of conversation. We didn’t even use this simple tool entirely effectively.
Preferences for features and look and feel in review tools vary widely. One of the sole characteristics that is uncontroversial is that it should be fast—but of course even this is a trade off, as nothing is faster than commenting directly on a diff and pasting it as a comment into Bugzilla. However, at a minimum the chosen tool should not feel slow and cumbersome, regardless of features.
Other aspects that are more difficult but nice to have include
For the record, while not perfect, we believe Phabricator, our chosen review tool for the foreseeable future, fares pretty well against all of these requirements, while also being relatively intuitive and visually pleasing.
There are other parts of code review that can be automated to ease the whole process. Given that they are fairly specific to the way Mozilla works, they will likely need to be custom solutions, but the work and maintenance involved should easily be paid off in terms of efficiency gains. These include
This last point segues into the next item in the vision.
Mozilla has had an autoland feature as part of MozReview for about 2.5 years now, and we recently launched Lando as our new automatic-landing tool integrated with Phabricator. Lando has incorporated some of the lessons we learned from MozReview (not the least of which is “don’t build your custom tools directly into your third-party tools”), but there is much we can do past our simple click-to-land system.
One feature that will unlock a lot of improvements is purely automatic landings, that is, landings that are initiated automatically after the necessary reviews are granted. This relies on the system understanding which reviews are necessary (see above), but beyond that it needs just a simple checkbox to signal the author’s intent to land (so we avoid accidentally landing patches that are works in progress). Further, as opposed to Try runs for testing, developers don’t tend to care too much about the time to land a completed patch as long as a whole series lands together, so this feature could be used to schedule landings over time to better distribute load on the CI systems.
Automatic landings also provide opportunities to reduce manual involvement in other processes, including backouts, uplifts, and merges. Using a single tool also provides a central place for record-keeping, to both generate metrics and follow how patches move through the trains. More on this in future sections.
Particularly at Mozilla, bug tracking is a huge topic, greater than code review. For better or worse, Bugzilla has been a major part of the central nervous system of Mozilla engineering since its earliest days; indeed, Bugzilla turns 20 in just a couple months! Discussing Bugzilla’s past, present, and future roles at Mozilla would take many blog posts, if not a book, so I’ll be a bit broad in my comments here.
First, and probably most obviously, Mozilla’s bug tracker should prioritize usability and user experience (yes they’re different). Mozilla engages not just full-time engineer employees but also a very large community with diverse backgrounds and skill sets. Allowing an engineer to be productive while encouraging users without technical backgrounds to submit bug reports is quite a challenge, and one that most high-tech organizations never have to face.
Another topic that has come up in the past is search functionality. Developers frequently need to find bugs they’ve seen previously, or want to find possible duplicates of recently filed bugs. The ideal search feature would be fast, of course, but also accurate and relevant. I think about these two aspects are slightly differently: accuracy pertains to finding a specific bug, whereas relevancy is important when searching for a class of bugs matching some given attributes.
Over the past couple years we have been trying to move certain use cases out of Bugzilla, so that we can focus specifically on engineering. This is part of a grander effort to consolidate workflows, which has a host of benefits ranging from simpler, more intuitive interfaces to reduced maintenance burden. However this means we need to understand specific use cases within engineering and implement features to support them, in addition to the more general concerns above. A recent example is the refinement of triage processes, which is helped along by specific improvements to Bugzilla.
The value of data about one’s products and processes is not something that needs much justification today. Mozilla has already invested heavily in a data-driven approach to developing Firefox and other applications. The Engineering Workflow team is starting to do the same, thanks to infrastructure built for Firefox telemetry.
The list of data we could benefit from collecting is endless, but a few examples include * backout rates and causes * build times * test-run times * patch-review times * tool adoption
We’re already gathering and visualizing some of these stats:

Naturally such data is even more valuable if shared so other teams can analyze it for their benefit.
This item builds on the former. It is the most nebulous, but to me it is one of the most interesting.
Code changes (patches, commits, changesets, whatever you want to call them) have a life cycle:
A developer writes one or more patches to solve a problem. Sometimes the patches are in response to a bug report; sometimes a bug report is filed just for tracking.
The patches are often sent to Try for testing, sometimes multiple times.
The patches are reviewed by one or more developers, sometimes through multiple cycles.
The patches are landed, usually on an integration branch, then merged to mozilla-central.
Occasionally, the patches are backed out, in which case flow returns to step 1.
The patches are periodically merged to the next channel branch, or occasionally uplifted directly to one or more branches.
The patches are included in a specific channel build.
Repeat 6. and 7. until the patch ends up in the mozilla-release branch and is included in a Release build.
There’s currently no way to easily follow a code change through these stages, and thus no metrics on how flow is affected by the various aspects of a change (size, area of code, author, reviewer(s), etc.). Further, tracking this information could provide clear indicators of flow problems, such as commits that are ready to land but have merge conflicts, or commits that have been waiting on review for an extended period. Collecting and visualizing this information could help improve various engineering processes, as well as just the simple thrill of literally watching your change progress to release.
This is a grand idea that needs a lot more thought, but many of the previous items feed naturally into it.
This vision is just a starting point. We’re building a road map for short-to-medium-term map, while we think about a larger 2-to-3-year plan. Figuring out how to prioritize by a combination of impact, feasibility, risk, and effort is no small feat, and something that we’ll likely have to course-correct over time. Overall, the creation of this vision has been inspiring for my team, as we can now envision a better world for Mozilla engineering and understand our part in it. I hope the window this provides into the work of the Engineering Workflow team is valuable to other teams both within and outside of Mozilla.
https://mrcote.info/blog/2018/07/10/a-vision-for-engineering-workflow-at-mozilla-part-three/
|
|
Firefox Test Pilot: Notes is available on Android |
Today we are releasing Test Pilot Notes on Android. This new app allows you to access all your notes from the Firefox sidebar on your Android device.

The mobile companion application supports the same multi-note and end-to-end encryption features as the WebExtension. After you sign in into the app, it will sync all your existing notes from Firefox desktop, so you can access them on the go. You can also use the app standalone, but we suggest you pair it with the WebExtension for maximum efficiency.
Please provide any feedback and share your experience using the “Feedback” button in the app drawer. This is one of the first mobile Test Pilot experiments and we would like to hear from you and understand your expectations for future Test Pilot mobile applications.
We have also released a new update to WebExtension version of Notes.
The editor has been updated to the latest CKEditor 5 release. This brings improvements to Chinese, Japanese and Korean inputs into Notes. Other important fixes include:
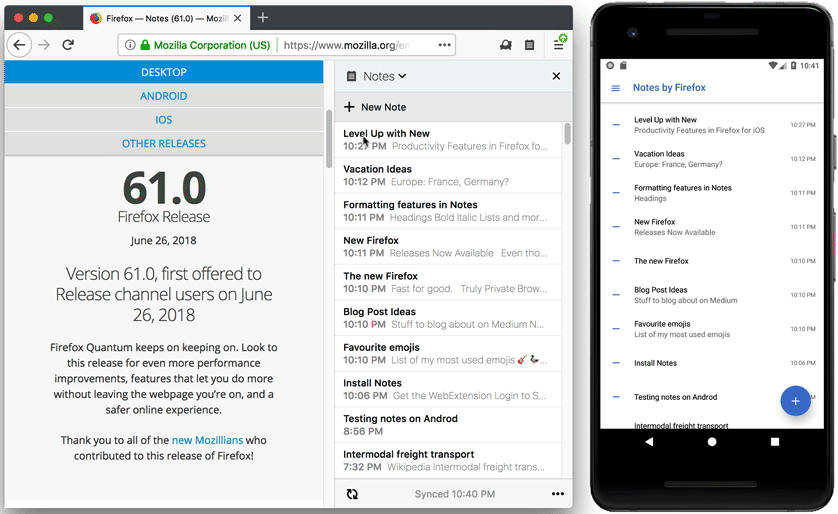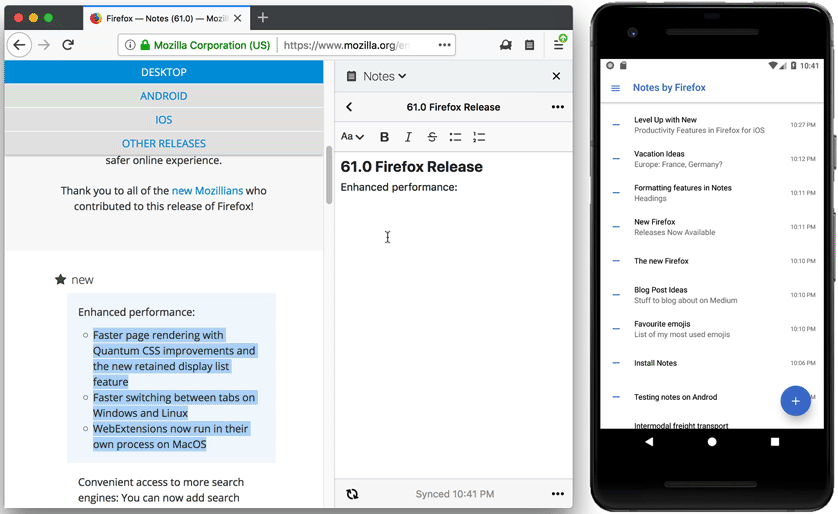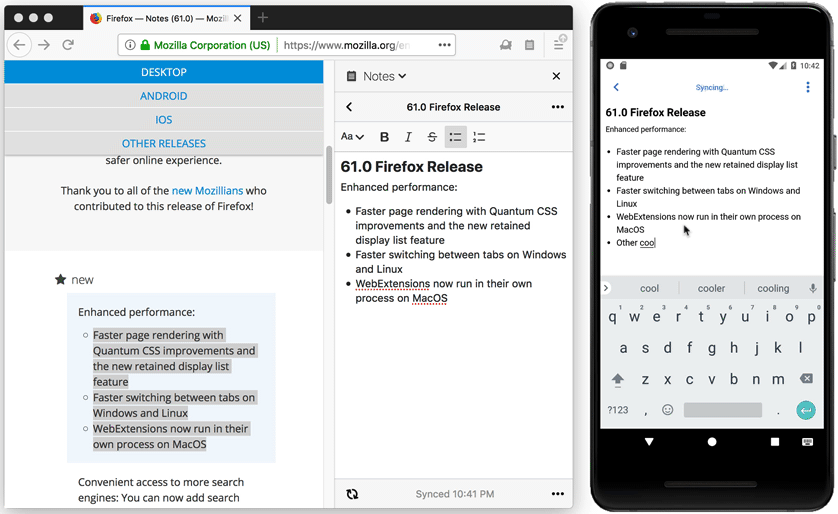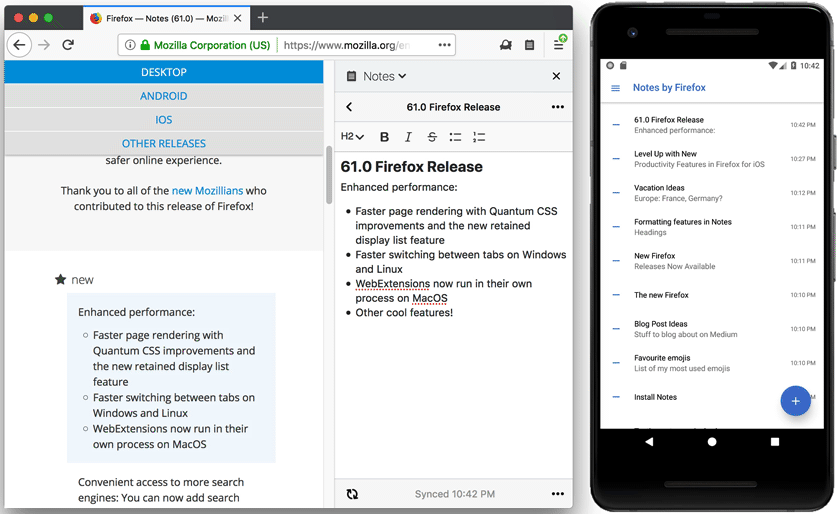
Big thanks to CKEditor development team and our SoftVision QA team for making these releases happen! We would also like to extend our gratitude to our language localisation contributors, release manager Sylvestre Ledru, and open source contributors - S'ebastien Barbier and R'emy Hubscher.
Notes is available on Android was originally published in Firefox Test Pilot on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
Firefox Test Pilot: Take your passwords everywhere with Firefox Lockbox |

Firefox users, you can now easily access the passwords you save in the browser in a lightweight iOS app!
Download Firefox Lockbox from the App Store. Sign in with your Firefox Account, and your saved usernames and passwords will securely sync to your device using 256-bit encryption, giving you convenient access to your apps and websites, wherever you are. Find out more about the experiment on Firefox Test Pilot.
We have so many online accounts, and it’s hard to keep track of them all. The browser can save them, but they’re not always easy to find or access later, especially when trying to get into the same account on mobile. The Firefox Lockbox iOS app is our first experiment to help you find and use your passwords everywhere.
Take back control of your digital life with Firefox Lockbox.
Take your passwords everywhere with Firefox Lockbox was originally published in Firefox Test Pilot on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
The Mozilla Blog: Introducing Firefox’s First Mobile Test Pilot Experiments: Lockbox and Notes |
This summer, the Test Pilot team has been heads down working on experiments for our Firefox users. On the heels of our most recent and successful desktop Test Pilot experiments, Firefox Color and Side View, it was inevitable that the Test Pilot Program would expand to mobile.
Today, we’re excited to announce the first Test Pilot experiments for your mobile devices. With these two experiences, we are pushing beyond the boundaries of the desktop browser and into mobile apps. We’re taking the first steps toward bringing Mozilla’s mission of privacy, security and control to mobile apps beyond the browser.
Are you having a tough time keeping track of all the different passwords you’ve made for your online accounts? How many times have you had to reset a password you forgot? What do you do when you’ve saved a password on your desktop but have no way to access that online account on your mobile device? Look no further, we’ve created a simple app to take your passwords anywhere you go.
With Firefox Lockbox, iOS users will be able to seamlessly access Firefox saved passwords. This means you can use any password you’ve saved in the browser to log into any online account like your Twitter or Instagram app. No need to open a web page. It’s that seamless and simple. Plus, you can also use Face ID and Fingerprint touch to unlock the app, so you can safely access your accounts.
Jotting down quick notes is something many of us do everyday to keep track of our busy lives. Whether you’re on your desktop at home or at the office, or on the go with your mobile device, we want to make sure you’re able to access those notes wherever you are.
Notes by Firefox is a simple, secure place to take and store notes across your devices – desktop AND mobile. Now Firefox account users have the option to sync notes from any Firefox browser on any Android smartphone or tablet. Plus, your files are encrypted from end-to-end,, which means that only you can read them.

Sync notes from any Firefox browser on any Android smartphone or tablet
The Test Pilot program is open to all Firefox users and helps us test and evaluate a variety of potential Firefox features. To activate the new Lockbox and Notes extensions, you must have a Firefox Account and Firefox Sync for full functionality.
If you’re familiar with Test Pilot then you know all our projects are experimental, so we’ve made it easy to give us feedback or disable features at any time from testpilot.firefox.com.
We’re committed to making your web browsing experience more efficient, and are excited for the even bigger mobile experiments still ahead.
Check out the new Firefox Lockbox and Notes by Firefox extensions and help us decide which new features to build into future versions of Firefox.
The post Introducing Firefox’s First Mobile Test Pilot Experiments: Lockbox and Notes appeared first on The Mozilla Blog.
|
|
Don Marti: Bug futures: business models |
Recent question about futures markets on software bugs: what's the business model?
As far as I can tell, there are several available models, just as there are multiple kinds of companies that can participate in any securities or commodities market.

Oracle operator: Read bug tracker state, write futures contract state, profit. This business would take an agreed-upon share of any contract in exchange for acting as a referee. The market won't work without the oracle operator, which is needed in order to assign the correct resolution to each contract, but it's possible that a single market could trade contracts resolved by multiple oracles.
Actively managed fund: Invest in many bug futures in order to incentivize a high-level outcome, such as support for a particular use case, platform, or performance target.
Bot fund: An actively managed fund that trades automatically, using open source metrics and other metadata.
Analytics provider: Report to clients on the quality of software projects, and the market-predicted likelihood that the projects will meet the client's maintenance and improvement requirements in the future.
Stake provider: A developer participant in a bug futures market must invest to acquire a position on the fixed side of a contract. The stake provider enables low-budget developers to profit from larger contracts, by lending or by investing alongside them.
Arbitrageur: Helps to re-focus development efforts by buying the fixed side of one contract and the unfixed side of another. For example, an arbitrageur might buy the fixed side of several user-facing contracts and the unfixed side of the contract on a deeper issue whose resolution will result in a fix for them.
Arbitrageurs could also connect bug futures to other kinds of markets, such as subscriptions, token systems, or bug bounties.
Smart futures contracts on software issues talk, and bullshit walks?
Some ways that bug futures markets differ from prediction markets
Some ways that bug futures markets differ from open source bounties
A trading market to incentivize secure software: Malvika Rao, Georg Link, Don Marti, Andy Leak & Rich Bodo (PDF) (presented at WEIS 2018)
Corporate Prediction Markets: Evidence from Google, Ford, and Firm X (PDF) by Bo Cowgill and Eric Zitzewitz.
Despite theoretically adverse conditions, we find these markets are relatively efficient, and improve upon the forecasts of experts at all three firms by as much as a 25% reduction in mean squared error.
(This paper covers a related market type, not bug futures. However some of the material about interactions of market data and corporate management could also turn out to be relevant to bug futures markets.)
Pipeline monument in Cushing, Oklahoma: photo by Roy Luck for Wikimedia Commons. This file is licensed under the Creative Commons Attribution 2.0 Generic license.
|
|
Kartikaya Gupta: Howto: FEMP stack on Amazon EC2 |
I recently migrated a bunch of stuff (including this website) to Amazon EC2, running on a FEMP (FreeBSD, nginx, MySQL, PHP) stack. I had to fiddle with a few things to get it running smoothly, and wanted to document the steps in case anybody else is trying to do this (or I need to do it again later). This assumes you have an Amazon AWS account and some familiarity with how to use it.
Before you start
Ensure you know what region and instance type you want. I used the Canada (Central) region but it should work the same in any other region. And I used a t2.micro instance type because I have a bunch of stuff running on the instance, but presumably you could use a t2.nano type if you wanted to go even lighter. Also, I'm using Amazon Route53 to handle the DNS, but if you have DNS managed separately that's fine too.
Upload your SSH public key
In the EC2 dashboard, select "Key Pairs" under the "Network and Security" section in the left pane. Click on "Import Key pair" and provide the public half of your SSH keypair. This will get installed into the instance so that you can SSH in to the instance when it boots up.
Create the instance
Select "Instances" in the EC2 dashboard, and start the launch wizard by clicking "Launch Instance". You'll find the FreeBSD images under "Community AMIs" if you search for FreeBSD using the search. Generally you want to grab the most recent FreeBSD release you can find (note: the search results are not sorted by recency). If you want to make sure you're getting an official image, head over to the freebsd-announce mailing list, and look for the most recent release announcement email. As of this writing it is 11.2-RELEASE. The email should contain AMI identifiers for all the different EC2 regions; for example the Canada AMI for 11.2-RELEASE is ami-a2f97bc6. Searching for that in the launch wizard finds it easily.
Next step is to select the instance type. Select one that's appropriate for your needs (I'm using t2.micro). The next step is to configure instance details. Unless you have specific changes you want to make here you can leave this with the default settings. Next you have to choose the root volume size. With my instances I like using a 10 GB root volume for the system and swap, and using a separate EBS volume for the "user data" (home folders and whatnot). For reference my 10G root volume is currently 54% full with the base system, extra packages, and a 2G swap file.
After that you can add tags if you want, change the security groups, and finally review everything. I just go with the defaults for the security groups, since it allows external SSH access and you can always change it later. Finally, time to launch! In the launch dialog you select the keypair from the previous step and you're off to the races.
Logging in
Once the instance is up, the EC2 console should display the public IP address. You'll need to log in with the user ec2-user at that IP address, using the keypair you selected previously. If you're paranoid about security (and you should be), you can verify the host key that SSH shows you by selecting the instance in the EC2 console, going to Actions -- Instance Settings -- Get Instance Screenshot. The screenshot should display the host keys as shown on the instance itself, and you can compare it to what SSH is showing to ensure you're not getting MITM'd.
Initial housekeeping
This part is sort of optional, but I like having a reasonable hostname and shell installed before I get to work. I'm going to use jasken.example.com as the hostname and I like using bash as my default shell. To do this, run the following commands:
su # switch to root shell sysrc hostname="jasken.example.com" # this modifies /etc/rc.conf pkg update # update package manager pkg install -y vim bash # install useful packages chsh -s /usr/local/bin/bash root # change shell to bash for root and ec2-user chsh -s /usr/local/bin/bash ec2-user
At this point I also like to reboot the machine (pretty much the only time I ever have to) because I've found that not everything picks up the hostname change if you change it via the hostname command while the instance is running. So run reboot and log back in once the instance is back up. The rest of the steps need root access so go ahead and su to root once you're back in.
IPv6 configuration
While you're rebooting, you can also set up IPv6 support. FreeBSD has everything built-in, you just need to fiddle with the VPC settings in AWS to get an IP address assigned. Note the VPC ID and Subnet ID in your instance's details, and then go to the VPC dashboard (it's a separate AWS service, not inside EC2). Find the VPC your instance is in, then go to Actions -- Edit CIDRs. Click on the "Add IPv6 CIDR" button and then "Close". Still in the VPC dashboard, select "Subnets" from the left panel and select the subnet of your instance. Here again, go to Actions -- Edit IPv6 CIDRs, and then click on "Add IPv6 CIDR". Put "00" in the box that appears to fill in the IPv6 subnet and hit ok.
Next, go to the "Route Tables" section of the VPC dashboard, and select the route table for the VPC. In the Routes tab, add a new route with destination ::/0 and the same gateway as the 0.0.0.0/0 entry. This ensures that outbound IPv6 connections will use the external network gateway.
Finally, go back to the EC2 dashboard, select your instance, and go to Actions -- Networking -- Manage IP addresses. Under IPv6 addresses, click "Assign new IP" and "Yes, Update" to auto-assign a new IPv6 address. That's it! If you SSH in to the instance you should be able to ping6 google.com successfully for example. It might take a minute or so for the connection to start working properly.
Installing packages
For the "EMP" part of the FEMP stack, we need to install nginx, mysql, and php. Also because we're not barbarians we're going to make sure our webserver is TLS-enabled with a Let's Encrypt certificate that renews automatically, for which we want certbot. So:
pkg install -y nginx mysql56-server php56 php56-mysql php56-mysqli php56-gd php56-json php56-xml php56-dom php56-openssl py36-certbot
Note that the set of PHP modules you need may vary; I'm just listing the ones that I needed, but you can always install/uninstall more later if you need to.
PHP setup
To use PHP over CGI with nginx we're going to use the php-fpm service. Instead of having the service listen over a network socket, we'll have it listen over a file socket, and make sure PHP and nginx are in agreement about the info passed back and forth. The sed commands below do just that.
cd /usr/local/etc/ sed -i "" -e "s#listen = 127.0.0.1:9000#listen = /var/run/php-fpm.sock#" php-fpm.conf sed -i "" -e "s#;listen.owner#listen.owner#" php-fpm.conf sed -i "" -e "s#;listen.group#listen.group#" php-fpm.conf sed -i "" -e "s#;listen.mode#listen.mode#" php-fpm.conf sed -e "s#;cgi.fix_pathinfo=1#cgi.fix_pathinfo=0#" php.ini-production > php.ini sysrc php_fpm_enable="YES" service php-fpm start
MySQL setup
This is really easy to set up. The hard part is optimizing the database for your workload, but that's outside the scope of my knowledge and of this tutorial.
sysrc mysql_enable="YES" service mysql-server start mysql_secure_installation # this is interactive, you'll want to set a root password service mysql-server restart
Swap space
MySQL can eat up a bunch of memory, and it's good to have some swap set up. Without this you might find, as I did, that weekly periodic tasks such as rebuilding the locate database can result in OOM situations and take down your database. On a t2.micro instance which has 1GB of memory, a 2GB swap file works well for me:
# Make a 2GB (2048 1-meg blocks) swap file at /usr/swap0 dd if=/dev/zero of=/usr/swap0 bs=1m count=2048 chmod 0600 /usr/swap0 # Install the swap filesystem echo 'md99 none swap sw,file=/usr/swap0,late 0 0' >> /etc/fstab # and enable it swapon -aL
You can verify the swap is enabled by using the swapinfo command.
nginx setup
Because the nginx config can get complicated, specially if you're hosting multiple websites, it pays to break it up into manageable pieces. I like having an includes/ folder which contains snippets of reusable configuration (error pages, PHP stuff, SSL stuff), and a sites-enabled/ folder that has a configuration per website you're hosting. Also, we want to generate some Diffie-Hellman parameters for TLS purposes. So:
cd /usr/local/etc/nginx/
openssl dhparam -out dhparam.pem 4096
mkdir includes
cd includes/
# This creates an error.inc file with error handling snippet
cat >error.inc <<'END'
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/www/nginx-dist;
}
END
# PHP snippet
cat >php.inc <<'END'
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php-fpm.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $request_filename;
include fastcgi_params;
}
END
# SSL snippet
cat >ssl.inc <<'END'
ssl on;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
ssl_dhparam /usr/local/etc/nginx/dhparam.pem;
ssl_ciphers 'ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:AES:CAMELLIA:DES-CBC3-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!MD5:!PSK:!aECDH:!EDH-DSS-DES-CBC3-SHA:!EDH-RSA-DES-CBC3-SHA:!KRB5-DES-CBC3-SHA';
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_stapling on;
ssl_stapling_verify on;
END
If you want to fiddle with the above, feel free. I'm not a security expert so I don't know what a lot of the stuff in the ssl.inc does, but based on the Qualys SSL test it seems to provide a good security/compatibility tradeoff. I mostly cobbled it together from various recommendations on the Internet.
Finally, we set up the server entry (assuming we're serving up the website "example.com") and start nginx:
cd /usr/local/etc/nginx/
cat >nginx.conf <<'END'
user www;
worker_processes 1;
error_log /var/log/nginx/error.log info;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
resolver 127.0.0.1;
include sites-enabled/example;
}
END
mkdir sites-enabled
cd sites-enabled/
cat >example <<'END'
server {
listen [::]:80;
listen 80;
server_name example.com;
root /usr/local/www/nginx;
index index.php index.html index.htm;
include includes/php.inc;
location / {
try_files $uri $uri/ =404;
}
include includes/error.inc;
}
END
sysrc nginx_enable="YES"
service nginx start
Open up ports
The nginx setup above is sufficient to host an insecure server on port 80, which is what we need in order to get the certificate that we need to enable TLS. So at this point go to your DNS manager, wherever that is, and point the A and AAAA records for "example.com" (or whatever site you're hosting) to the public IP addresses for your instance. Also, go to the "Security Groups" pane in the EC2 dashboard and edit the "Inbound" tab for your instance's security group to allow HTTP traffic on TCP port 80 from source 0.0.0.0/0, ::/0, and the same for HTTPS traffic on TCP port 443.
After you've done that and the DNS changes have propagated, you should be able to go to http://example.com in your browser and get the nginx welcome page, served from your very own /usr/local/www/nginx folder.
TLS
Now it's time to get a TLS certificate for your example.com webserver. This is almost laughably easy once you have regular HTTP working:
certbot-3.6 certonly --webroot -n --agree-tos --email 'admin@example.com' -w /usr/local/www/nginx -d example.com crontab <(echo '0 0 1,15 * * certbot-3.6 renew --post-hook "service nginx restart"')
Make sure to replace the email address and domain above as appropriate. This will use certbot's webroot plugin to get a Let's Encrypt TLS cert and install it into /usr/local/etc/letsencrypt/live/. It also installs a cron job to automatically attempt renewal of the cert twice a month. This does nothing if the cert isn't about to expire, but otherwise renews it using the same options as the initial request. The final step is updating the sites-enabled/example config to redirect all HTTP requests to HTTPS, and use the aforementioned TLS cert.
cd /usr/local/etc/nginx/sites-enabled/
cat >example <<'END'
server {
listen [::]:80;
listen 80;
server_name example.com;
return 301 https://$host$request_uri;
}
server {
listen [::]:443;
listen 443;
server_name example.com;
root /usr/local/www/nginx;
index index.php index.html index.htm;
include includes/ssl.inc;
ssl_certificate /usr/local/etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /usr/local/etc/letsencrypt/live/example.com/privkey.pem;
include includes/php.inc;
location / {
try_files $uri $uri/ =404;
}
include includes/error.inc;
}
END
service nginx restart
And that's all, folks!
Parting words
The above commands set things up so that they persist across reboots. That is, if you stop and restart the EC2 instance, everything should come back up enabled. The only problem is that if you stop and restart the instance, the IP address changes so you'll have to update your DNS entry.
If there's commands above you're unfamiliar with, you should use the man pages to read up on them. In general copying and pasting commands from some random website into a command prompt is a bad idea unless you know what those commands are doing.
One thing I didn't cover in this blog post is how to deal with the daily emails that FreeBSD will send to the root user. I also run a full blown mail gateway with postfix and I plan to cover that in another post.
|
|
Cameron Kaiser: Pro tip: sleep's good for your Power Mac |
But sleeping the G5 has unquestionably been a good thing. Not only does it prolong its life by reducing heat (another plus in summer) as well as saving a substantial amount of energy (around 20W sleeping versus 200-250W running), but sleeping also can speed up TenFourFox. If you have lots of tabs open and those tabs are refreshing their data or otherwise running active content, then this contributes to a greater need for garbage collection and this will slow down your user experience as this overhead accumulates. (This is why running TenFourFox from a "fresh" start is much faster than when it's been chugging away for awhile.) It's possible to "pause" TenFourFox to a certain extent but the browser really isn't tested this way and may not behave properly when this is done. Sleeping the Power Mac pauses everything, so the cruft in memory that garbage collection has to clean out doesn't pile up while you're not using the machine, and everything comes back up in sync.
A whole lot of stuff has landed for TenFourFox FPR9. More about that when the beta is out, which I'm hoping to do by the middle-end of July.
http://tenfourfox.blogspot.com/2018/07/pro-tip-sleeps-good-for-your-power-mac.html
|
|
The Mozilla Blog: Welcoming Sunil Abraham – Mozilla Foundation’s New VP, Leadership Programs |
I’m thrilled to welcome Sunil Abraham as Mozilla Foundation’s new VP, Leadership Programs. Sunil joins us from The Centre for Internet and Society, the most recent chapter in a 20 year career of developing free and open source software and an open internet agenda.
During our search we stated a goal of finding someone with “deep experience working on some aspect of internet health; and a proven track record building high impact organizations and teams.” In Sunil we have managed to find just that. An engineer by training, much of Sunil’s research and policy work has deep technical grounding. For example one of his current projects is doing a human rights review of various Internet Engineering Task Force (IETF) standards with Article 19. He has also founded and run two organizations: Mahiti, a non-profit software development shop; and The Centre for Internet and Society, a policy and technology think tank in Bangalore. Sunil is truly ‘of the movement’ and is perfectly positioned to help us build a strong cadre of internet health leaders all around the world.
Our global community is the linchpin in our strategy to grow a movement to create a healthier digital world. In this role, Sunil will head up the programs that bring people from around the world into our work — the Internet Health Report, MozFest, our fellowships and awards — with the aim of supporting people who want to take a leadership role in this community. In addition to a great passion for Mozilla’s mission and issues, Sunil also brings a tremendous amount of experience working on this kind of leadership development. He’s worked closely with Ashoka and the Open Society Foundation in developing leaders for many years. And, notably, the Centre for Internet and Society has been a home for many of the key players in India’s open internet space.
Sunil is starting out immediately as an advisor to Mozilla’s executive team and directors, working a few hours per week. He will move to Berlin and start full time in his new role in January 2019. We will be planning a community town hall to welcome Sunil to our community and give everyone a chance to connect with him. Look for more in September.
The post Welcoming Sunil Abraham – Mozilla Foundation’s New VP, Leadership Programs appeared first on The Mozilla Blog.
|
|
Chris Ilias: Firefox now supports the macOS share menu |
Firefox 61 has a great new feature on macOS, and I don’t think it’s getting enough attention. Maybe it’s not a big deal for most other users, but it is for me!
Firefox now supports the macOS share menu. This means you can send the current page you are viewing to another application. For instance, you can add a link to your Things 3 or Omnifocus inbox, add a page to Apple Notes, send a link to Evernote, send a link to someone using messages, or share a link to a social network.
To share a page in Firefox, open the Page Actions menu (aka. the three dots), and go to the Share menu.

http://ilias.ca/blog/2018/07/firefox-now-supports-the-macos-share-menu/
|
|
QMO: Firefox 62 Beta 8 Testday, July 13th |
Greetings Mozillians!
We are happy to let you know that Friday, July 13th, we are organizing Firefox 62 Beta 8 Testday. We’ll be focusing our testing on 3-Pane Inspector and React animation inspector features.
Check out the detailed instructions via this etherpad.
No previous testing experience is required, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
See you on Friday!
https://quality.mozilla.org/2018/07/firefox-62-beta-8-testday-july-13th/
|
|
Wladimir Palant: Is your LastPass data really safe in the encrypted online vault? |
Disclaimer: I created PfP: Pain-free Passwords as a hobby, it could be considered a LastPass competitor in the widest sense. I am genuinely interested in the security of password managers which is the reason both for my own password manager and for this blog post on LastPass shortcomings.
TL;DR: LastPass fanboys often claim that a breach of the LastPass server isn’t a big deal because all data is encrypted. As I show below, that’s not actually the case and somebody able to compromise the LastPass server will likely gain access to the decrypted data as well.
A while back I stated in an analysis of the LastPass security architecture:
So much for the general architecture, it has its weak spots but all in all it is pretty solid and your passwords are unlikely to be compromised at this level.
That was really stupid of me, I couldn’t have been more wrong. Turned out, I relied too much on the wishful thinking dominating LastPass documentation. January this year I took a closer look at the LastPass client/server interaction and found a number of unpleasant surprises. Some of the issues went very deep and it took LastPass a while to get them fixed, which is why I am writing about this only now. A bunch of less critical issues remain unresolved as of this writing, so that I cannot disclose their details yet.
In 2015, LastPass suffered a security breach. The attackers were able to extract some data from the server yet LastPass was confident:
We are confident that our encryption measures are sufficient to protect the vast majority of users. LastPass strengthens the authentication hash with a random salt and 100,000 rounds of server-side PBKDF2-SHA256, in addition to the rounds performed client-side. This additional strengthening makes it difficult to attack the stolen hashes with any significant speed.
What this means: anybody who gets access to your LastPass data on the server will have to guess your master password. The master password isn’t merely necessary to authenticate against your LastPass account, it also allows encrypting your data locally before sending it to the server. The encryption key here is derived from the master password, and neither is known to the LastPass server. So attackers who managed to compromise this server will have to guess your master password. And LastPass uses PBKDF2 algorithm with a high number of iterations (LastPass prefers calling them “rounds”) to slow down verifying guesses. For each guess one has to derive the local encryption key with 5,000 PBKDF2 iterations, hash it, then apply another 100,000 PBKDF2 iterations which are normally added by the LastPass server. Only then can the result be compared to the authentication hash stored on the server.
So far all good: 100,000 PBKDF2 iterations should be ok, and it is in fact the number used by the competitor 1Password. But that protection only works if the attackers are stupid enough to verify their master password guesses via the authentication hash. As mentioned above, the local encryption key is derived from your master password with merely 5,000 PBKDF2 iterations. And it is used to encrypt various pieces of data: passwords, private RSA keys, OTPs etc. The LastPass server stores these encrypted pieces of data without any additional protection. So a clever attacker would guess your master password by deriving the local encryption key from a guess and trying to decrypt some data. Worked? Great, the guess is correct. Didn’t work? Try another guess. This approach speeds up guessing master passwords by factor 21.
So, what kind of protection do 5,000 PBKDF2 iterations offer? Judging by these numbers, a single GeForce GTX 1080 Ti graphics card (cost factor: less than $1000) can be used to test 346,000 guesses per second. That’s enough to go through the database with over a billion passwords known from various website leaks in barely more than one hour. And even if you don’t use any of the common passwords, it is estimated that the average password strength is around 40 bits. So on average an attacker would need to try out half of 240 passwords before hitting the right one, this can be achieved in roughly 18 days. Depending on who you are, spending that much time (or adding more graphics cards) might be worth it. Of course, more typical approach would be for the attackers to test guesses on all accounts in parallel, so that the accounts with weaker passwords would be compromised first.
We have increased the number of PBKDF2 iterations we use to generate the vault encryption key to 100,100. The default for new users was changed in February 2018 and we are in the process of automatically migrating all existing LastPass users to the new default. We continue to recommend that users do not reuse their master password anywhere and follow our guidance to use a strong master password that is going to be difficult to brute-force.
Somebody extracting data from the LastPass server sounds too far fetched? This turned out easier than I expected. When I tried to understand the LastPas login sequence, I noticed the script https://lastpass.com/newvault/websiteBackgroundScript.php being loaded. That script contained some data on the logged in user’s account, in particular the user name and a piece of encrypted data (private RSA key). Any website could load that script, only protection in place was based on the Referer header which was trivial to circumvent. So when you visited any website, that website could get enough data on your LastPass account to start guessing your master password (only weak client-side protection applied here of course). And as if that wasn’t enough, the script also contained a valid CSRF token, which allowed this website to change your account settings for example. Ouch…
To me, the most surprising thing about this vulnerability is that no security researcher found it so far. Maybe nobody expected that a script request receiving a CSRF token doesn’t actually validate this token? Or have they been confused by the inept protection used here? Beats me. Either way, I’d consider the likeliness of some blackhat having discovered this vulnerability independently rather high. It’s up to LastPass to check whether it was being exploited already, this is an attack that would leave traces in their logs.
The script can now only be loaded when supplying a valid CSRF token, so 3rd-parties cannot gain access to the data. We also removed the RSA sharing keys from the scripts generated output.
LastPass consistently calls its data storage the “encrypted vault.” Most people assume, like I did originally myself, that the server stores your data as an AES-encrypted blob. A look at https://lastpass.com/getaccts.php output (you have to be logged in to see it) quickly proves this assumption to be incorrect however. While some data pieces like account names or passwords are indeed encrypted, others like the corresponding URL are merely hex encoded. This 2015 presentation already pointed out that the incomplete encryption is a weakness (page 66 and the following ones). While LastPass decided to encrypt more data since then, they still don’t encrypt everything.
The same presentation points out that using ECB as block cipher mode for encryption is a bad idea. One issue in particular is that while passwords are encrypted, with ECB it is still possible to tell which of them are identical. LastPass mostly migrated to CBC since that publication and a look at getaccts.php shouldn’t show more than a few pieces of ECB-encrypted data (you can tell them apart because ECB is encoded as a single base64 blob like dGVzdHRlc3R0ZXN0dGVzdA== whereas CBC is two base64 blobs starting with an exclamation mark like !dGVzdHRlc3R0ZXN0dGVzdA==|dGVzdHRlc3R0ZXN0dGVzdA==). It’s remarkable that ECB is still used for some (albeit less critical) data however. Also, encryption of older credentials isn’t being “upgraded” it seems, if they were encrypted with AES-ECB originally they stay this way.
I wonder whether the authors of this presentation got their security bug bounty retroactively now that LastPass has a bug bounty program. They uncovered some important flaws there, many of which still exist to some degree. This work deserves to be rewarded.
The fix for this issue is being deployed as part of the migration to the higher iteration count in the earlier mentioned report.
People losing access to their accounts is apparently an issue with LastPass, which is why they have been adding backdoors. These backdoors go under the name “One-Time Passwords” (OTPs) and can be created on demand. Good news: LastPass doesn’t know your OTPs, they are encrypted on the server side. So far all fine, as long as you keep the OTPs you created in a safe place.
There is a catch however: one OTP is being created implicitly by the LastPass extension to aid account recovery. This OTP is stored on your computer and retrieved by the LastPass website when you ask for account recovery. This means however that whenever LastPass needs to access your data (e.g. because US authorities requested it), they can always instruct their website to silently ask LastPass extension for that OTP and you won’t even notice.
Another consequence here: anybody with access to both your device and your email can gain access to your LastPass account. This is a known issue:
It is important to note that if an attacker is able to obtain your locally stored OTP (and decrypt it while on your pc) and gain access to your email account, they can compromise your data if this option is turned on. We feel this threat is low enough that we recommend the average user not to disable this setting.
I disagree on the assessment that the threat here is low. Many people had their co-workers play a prank on them because they left their computer unlocked. Next time one these co-workers might not send a mail in your name but rather use account recovery to gain access to your LastPass account and change your master password.
This is an optional feature that enables account recovery in case of a forgotten master password. After reviewing the bug report, we’ve added further security checks to prevent silent scripted attacks.
As this high-level overview demonstrates: if the LastPass server is compromised, you cannot expect your data to stay safe. While in theory you shouldn’t have to worry about the integrity of the LastPass server, in practice I found a number of architectural flaws that allow a compromised server to gain access to your data. Some of these flaws have been fixed but more exist. One of the more obvious flaws is the Account Settings dialog that belongs to the lastpass.com website even if you are using the extension. That’s something to keep in mind whenever that dialog asks you for your master password: there is no way to know that your master password won’t be sent to the server without applying PBKDF2 protection to it first. In the end, the LastPass extension depends on the server in many non-obvious ways, too many for it to stay secure in case of a server compromise.
We greatly appreciate Wladimir’s responsible disclosure and for working with our team to ensure the right fixes are put in place, making LastPass stronger for our users. As stated in our blog post, we’re in the process of addressing each report, and are rolling out fixes to all LastPass users. We’re in the business of password management; security is always our top priority. We welcome and incentivize contributions from the security research community through our bug bounty program because we value their cyber security knowledge. With their help, we’ve put LastPass to the test and made it more resilient in the process.
https://palant.de/2018/07/09/is-your-lastpass-data-really-safe-in-the-encrypted-online-vault
|
|
Rabimba: FirefoxOS, A keyboard and prediction: Story of my first contribution |

WordFrequency
the 222
of 214
and 212
in 210
a 208
to 208
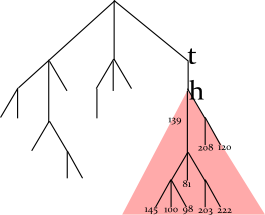
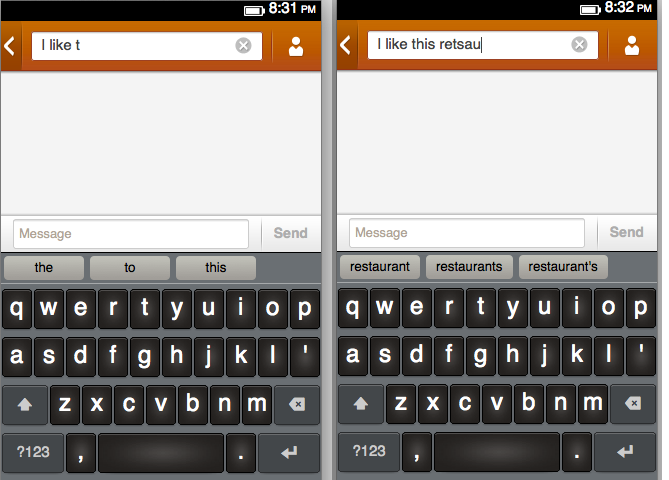
Words: tap ten the to
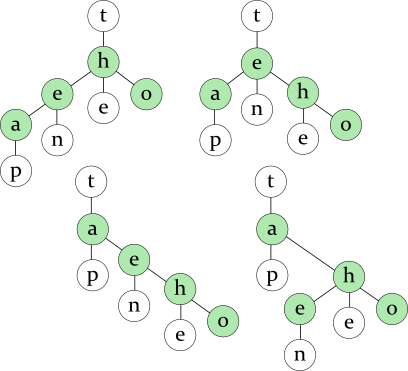
the 222thou 100ten 145to 208 tens 110voices 118voice 139
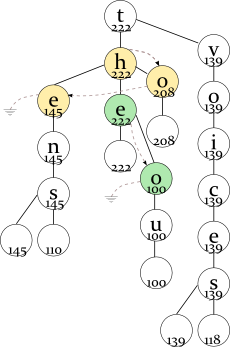
tho 100to 208
and find that TO, not THO is a prefix of the second most frequent word.
tho 100te 145
the 222thou 100ten 145to 208 tens 110voices 118voice 139
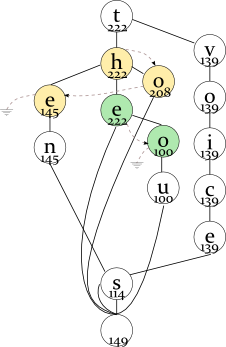
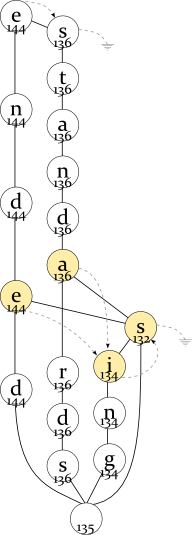
ended 144ending 135standards 136ends 130 standing 134stands 133
https://blog.rabimba.com/2017/02/firefoxos-keyboard-and-prediction-story.html
|
|
Mozilla Addons Blog: Extensions in Firefox 62 |
Last week Firefox 62 moved into the Beta channel. This version has fewer additions and changes to the WebExtensions API than the last several releases. Part of that is due to the maturing nature of the API as we get farther away from the WebExtension API cutover back in release 57, now over seven months ago. Part of it was a focus on cleaning up some internal features — code changes that increase the maintainability of Firefox but are not visible to external developers. And, let’s be honest, part of it is the arrival of summer in the Northern hemisphere, resulting in happy people taking time to enjoy life outside of browser development.
Extensions with a toolbar button (browser action) can now be managed directly from the context menu of the button. This is very similar to the behavior with page actions – simply right click on the toolbar button for an extension and select Manage Extension from the context menu. This will take you to the extension’s page in about:addons.
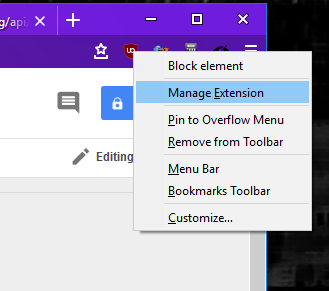
You can now manage hidden tabs, introduced in Firefox 61, via a down-arrow that is added to the end of the tab strip. When clicked, this icon will show all of your tabs, hidden and visible. Firefox 62 introduces a new way get to that same menu via the History item on the menu bar. If you have hidden tabs and select the History menu, it will display a submenu item called “Hidden Tabs.” Selecting that will take you to the normal hidden tabs menu panel.
A few enhancements to the WebExtensions API are now available in Firefox 62, including:
A couple of changes to the WebExtensions theme API landed in this release:
A few noticeable bug fixes landed in Firefox release 62, including:
A total of 48 features and improvements landed as part of Firefox 62. As always, a sincere thank you to every contributor for this release, especially our community volunteers including Tim Nguyen, J"org Knobloch, Oriol Brufau, and Tomislav Jovanovic. It is only through the combined efforts of Mozilla and our amazing community that we can ensure continued access to the open web. If you are interested in contributing to the WebExtensions ecosystem, please take a look at our wiki.
The post Extensions in Firefox 62 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2018/07/05/extensions-in-firefox-62/
|
|
Mark C^ot'e: A Vision for Engineering Workflow at Mozilla (Part Two) |
In my last post I touched on the history and mission of the Engineering Workflow team, and I went into some of the challenges the team faces, which informed the creation of the team’s vision. In this post I’ll go into the vision itself.
First, a bit of a preamble to set context and expectations.
Members of the Engineering Workflow team have had many conversations with Firefox engineers, managers, and leaders across many years. The results of these conversations have led to various product decisions, but generally without a well-defined overarching direction. Over the last year we took a step back to get a more comprehensive understanding of the needs and inefficiencies in Firefox engineering. This enables us to lay out a map of where Engineering Workflow could go over the course of years, rather than our previous short-term approaches.
As I mentioned earlier, I couldn’t find much in the way of examples of tooling strategies to work from. However, there are many projects out there that have developed tooling and automation ecosystems that can provide ideas for us to incorporate into our vision. A notable example is the Chromium project, the open-source core of the Chrome browser. Aspects of their engineering processes and systems have made their way into what follows.
It is very important to understand that this vision, if not vision statements in general, is aspirational. I deliberately crafted it such that it could take many engineer-years to achieve even a large part of it. It should be something we can reference to guide our work for the foreseeable future. To ensure it was as comprehensive as possible, it was constructed without attention given to feasibility nor, therefore, the priority of its individual pieces. A road map for how to best approach the implementation of the vision for the most impact is a necessary next step.
The resulting vision is nine points laying out the ideal world from an Engineering Workflow standpoint. I’ll go through them one by one up to point four in this post, with the remaining five to follow.
The repository necessary for building and testing Firefox, mozilla-central, is massive. Cloning and updating the repo takes quite a while even for engineers located close by the central hg.mozilla.org servers; the experience for more distant contributors can be much worse. Furthermore, this affects our CI systems, which are constantly cloning the source to execute builds and tests. Thus there is a big benefit to making cloning and updating the Firefox source as fast as possible.
There are various ways to tackle this problem. We are currently working on geo-distributed mirrors of the source code that are at least read-only to minimize the distance the data has to travel to get onto your local machine. There is also work we can do to reduce the amount of data that needs to be fetched, by determining what data is actually required for a given task and using that to allow shallow and/or narrow clones.
There are other issues in the VCS space that hamper the productivity of both product and tooling engineers. One is our approach to branching. The various train, feature, and testing branches are in fact separate repositories altogether, stemming from the early days of the switch to Mercurial. This nonstandard approach is both confusing and inefficient. There are also multiple integration “branches”, in particular autoland and mozilla-inbound, which require regular merging which in turn complicates history.
Supporting multiple VCSes also has a cost. Although Mercurial is the core VCS for Firefox development, the rise of Git led to the development of git-cinnabar as an alternate avenue to interacting with Firefox source. If not a completely de juror solution, it has enough users to warrant support from our tools, which means extra work. Furthermore, it is still sufficiently different from Git, in terms of installation at least, to trip some contributors up. Ideally, we would have a single VCS in use throughout Firefox engineering, or at least a well-defined pipeline for contributions that allows smooth use of vanilla Git even if the core is still kept in Mercurial.
To continue from the previous point, the vast size of the Firefox codebase means that it can be quite tricky for even experienced engineers, let alone new contributors, to find their way around. To reduce this burden, we can both improve the way the source is laid out and support tools to make sense of the whole.
One confusing aspect of mozilla-central is the lack of organization and discoverability of the many third-party libraries and applications that are mirrored in. It is difficult to even figure out what is externally sourced, let alone how and how often our versions are updated. We have started a plan to provide metadata and reorganize the tree to make this more discoverable, with the eventual goal to automate some of the manual processes for updating third-party code.
Mozilla also has not just one but two tools for digging deep into Firefox source code: dxr and searchfox. Neither of these tools are well maintained at the moment. We need to critically examine these, and perhaps other, tools and choose a single solution, again improving discoverability and maintainability.
Over the years Mozilla engineers have developed solutions to simplify the installation of all the applications and libraries necessary to build Firefox that aren’t bundled into its codebase. Although they work relatively well, there are many improvements that can be made.
The rise of Docker and other container solutions has resulted in an appreciation of the benefits of isolating applications from the underlying system. Especially given the low cost of disk space today, a Firefox build and test environment should be completely isolated from the rest of the host system, preventing unwanted interactions between other versions of dependent apps and libraries that may already be installed on the system, and other such cross-contamination.
We can also continue down the path that was started with mach and encapsulate other common tasks in simple commands. Contributors should not have to be familiar with the intricacies of all of our tools, in-house and third-party, to perform standard actions like building, running tests, submitting code reviews, and landing patches.
Building Firefox is a task that individual developers perform all the time, and our CI systems spend a large part of their time doing the same. It should be pretty obvious that reducing the time to build Firefox with a code change anywhere in the tree has a serious impact.
There are myriad ways our builds can be made faster. We have already done a lot of work to abstract build definitions in order to experiment with different build systems, and it looks like tup may allow us to have lightning-fast incremental builds. Also, the strategy we used to isolate platform components written in C++ and Rust from the front-end JavaScript pieces, which dramatically lowered build times for people working on the latter, could similarly be applied to isolate the building of system add-ons, such as devtools, from the rest of Firefox. We should do a comprehensive evaluation of places existing processes can be tightened up and continue to look for where we can make larger changes.
Stay tuned for the final part of this series of posts.
https://mrcote.info/blog/2018/07/05/a-vision-for-engineering-workflow-at-mozilla-part-two/
|
|
Cameron Kaiser: Another one bites the Rust |
As Herwig Bauernfeind from Bitwise Works made clear in his presentation he gave at Warpstock 2018 Toronto, Firefox for OS/2 is on its way out for OS/2 after version 52 ESR. The primary reason is because Firefox is switching to RUST. Rust is a general purpose programming language sponsored by Mozilla Research. It is unlikely that RUST will ever be ported to OS/2.
Rust was the primary reason we dropped source parity for TenFourFox also (though there were plenty of other reasons such as changes to the graphics stack, the hard requirement for Skia, Electrolysis and changes to ICU; all of this could have been worked around, but with substantial difficulty, and likely with severe compromises). Now that Firefox 52ESR, the last ESR to not require Rust support, is on its last legs, this marks the final end of "Warpzilla" and Firefox on OS/2. SPARC (and apparently Solaris in general) doesn't have rustc or cargo support either, so this is likely the end of Firefox on any version of Solaris as well. Yes, I use Firefox on my Sun Ultra-3 laptop with Solaris 10. There are probably other minor platforms just hanging on that will wink out and disappear which I haven't yet discovered.
Every platform that dies is a loss to the technical diversity of the Mozilla community, no matter how you choose to put a happy face on it.
If you were trying to get a web browser up on a new platform these days, much as it makes me sick to say it, you'd probably be better off with WebKit rather than wrestle with Rust. Or NetSurf, despite its significant limitations, though I love the fact the project even exists. At least there's Rust for the various forms of PowerPC on Linux, including 64-bit and little-endian, so the Talos II can still run Firefox.
With FPR9 TenFourFox will switch to backporting security updates from Firefox 60ESR, though any last-minute chemspills to 52ESR will of course be reviewed promptly.
UPDATE 7/5: Someone in the discussion on Hacker News found that at least $12,650 was raised by the OS/2 community, and they're going to port a Qt based browser, which means ... WebKit. I told you so.
http://tenfourfox.blogspot.com/2018/07/another-one-bites-rust.html
|
|






