Hacks.Mozilla.Org: AV1: next generation video – The Constrained Directional Enhancement Filter |

![]()
For those just joining us….
AV1 is a new general-purpose video codec developed by the Alliance for Open Media. The alliance began development of the new codec using Google’s VPX codecs, Cisco’s Thor codec, and Mozilla’s/Xiph.Org’s Daala codec as a starting point. AV1 leapfrogs the performance of VP9 and HEVC, making it a next-next-generation codec . The AV1 format is and will always be royalty-free with a permissive FOSS license.
This post was written originally as the second in an in-depth series of posts exploring AV1 and the underlying new technologies deployed for the first time in a production codec. An earlier post on the Xiph.org website looked at the Chroma from Luma prediction feature. Today we cover the Constrained Directional Enhancement Filter. If you’ve always wondered what goes into writing a codec, buckle your seat-belts, and prepare to be educated!
Virtually all video codecs use enhancement filters to improve subjective output quality.
By ‘enhancement filters’ I mean techniques that do not necessarily encode image information or improve objective coding efficiency, but make the output look better in some way. Enhancement filters must be used carefully because they tend to lose some information, and for that reason they’re occasionally dismissed as a deceptive cheat used to make the output quality look better than it really is.
But that’s not fair. Enhancement filters are designed to mitigate or eliminate specific artifacts to which objective metrics are blind, but are obvious to the human eye. And even if filtering is a form of cheating, a good video codec needs all the practical, effective cheats it can deploy.
Filters are divided into multiple categories. First, filters can be normative or non-normative. A normative filter is a required part of the codec; it’s not possible to decode the video correctly without it. A non-normative filter is optional.
Second, filters are divided according to where they’re applied. There are preprocessing filters, applied to the input before coding begins, postprocessing filters applied to the output after decoding is complete, and in-loop or just loop filters that are an integrated part of the encoding process in the encoding loop. Preprocessing and postprocessing filters are usually non-normative and external to a codec. Loop filters are normative almost by definition and part of the codec itself; they’re used in the coding optimization process, and applied to the reference frames stored or inter-frame coding.
 AV1 uses three normative enhancement filters in the coding loop. The first, the deblocking filter, does what it says; it removes obvious bordering artifacts at the edges of coded blocks. Although the DCT is relatively well suited to compacting energy in natural images, it still tends to concentrate error at block edges. Remember that eliminating this blocking tendency was a major reason Daala used a lapped transform, however AV1 is a more traditional codec with hard block edges. As a result, it needs a traditional deblocking filter to smooth the block edge artifacts away.
AV1 uses three normative enhancement filters in the coding loop. The first, the deblocking filter, does what it says; it removes obvious bordering artifacts at the edges of coded blocks. Although the DCT is relatively well suited to compacting energy in natural images, it still tends to concentrate error at block edges. Remember that eliminating this blocking tendency was a major reason Daala used a lapped transform, however AV1 is a more traditional codec with hard block edges. As a result, it needs a traditional deblocking filter to smooth the block edge artifacts away.

An example of blocking artifacts in a traditional DCT block-based codec. Errors at the edges of blocks are particularly noticeable as they form hard edges. Worse, the DCT (and other transforms in the DCT family) tend to concentrate error at block edges, compounding the problem.
The last of the three filters is the Loop Restoration filter. It consists of two configurable and switchable filters, a Wiener filter and a Self-Guided filter. Both are convolving filters that try to build a kernel to restore some lost quality of the original input image and are usually used for denoising and/or edge enhancement. For purposes of AV1, they’re effectively general-purpose denoising filters that remove DCT basis noise via a configurable amount of blurring.
The filter between the two, the Constrained Directional Enhancement Filter (CDEF) is the one we’re interested in here; like the loop restoration filter, it removes ringing and basis noise around sharp edges, but unlike the loop restoration filter, it’s directional. It can follow edges, as opposed to blindly filtering in all directions like most filters. This makes CDEF especially interesting; it’s the first practical and useful directional filter applied in video coding.
The CDEF story isn’t perfectly linear; it’s long and full of backtracks, asides, and dead ends. CDEF brings multiple research paths together, each providing an idea or an inspiration toward the final Constrained Directional Enhancement Filter in AV1. The ‘Directional’ aspect of CDEF is especially novel in implementation, but draws ideas and inspiration from several different places.
The whole point of transforming blocks of pixel data using the DCT and DCT-like transforms is to represent that block of pixels using fewer numbers. The DCT is pretty good at compacting the energy in most visual images, that is, it tends to collect spread out pixel patterns into just a few important output coefficients.
There are exceptions to the DCT’s compaction efficiency. To name the two most common examples, the DCT does not represent directional edges or patterns very well. If we plot the DCT output of a sharp diagonal edge, we find the output coefficients also form…. a sharp diagonal edge! The edge is different after transformation, but it’s still there and usually more complex than it started. Compaction defeated!

Sharp features are a traditional problem for DCT-based codecs as they do not compact well, if at all. Here we see a sharp edge (left) and its DCT transform coefficients (right). The energy of the original edge is spread through the DCT output in a directional rippling pattern.
Over the past two decades, video codec research has increasingly looked at transforms, filters, and prediction methods that are inherently directional as a way of better representing directional edges and patterns, and correcting this fundamental limitation of the DCT.
Directional intra prediction is probably one of the best known directional techniques used in modern video codecs. We’re all familiar with h.264’s and VP9’s directional prediction modes, where the codec predicts a directional pattern into a new block, based on the surrounding pixel pattern of already decoded blocks. The goal is to remove (or greatly reduce) the energy contained in hard, directional edges before transforming the block. By predicting and removing features that can’t be compacted, we improve the overall efficiency of the codec.

Illustration of directional prediction modes available in AVC/H.264 for 4x4 blocks. The predictor extends values taken from a one-pixel-wide strip of neighboring pixels into the predicted block in one of eight directions, plus an averaging mode for simple DC prediction.
Motion compensation, an even older idea, is also a form of directional prediction, though we seldom think of it that way. It displaces blocks in specific directions, again to predict and remove energy prior to the DCT. This block displacement is directional and filtered, and like directional intra-prediction, uses carefully constructed resampling filters when the displacement isn’t an integer number of pixels.
As noted earlier, video codecs make heavy use of filtering to remove blocking artifacts and basis noise. Although the filters work on a 2D plane, the filters themselves tend to be separable, that is, they’re usually 1D filters that are run horizontally and vertically in separate steps.
Directional filtering attempts to run filters in directions besides just horizontal and vertical. The technique is already common in image processing, where noise removal and special effects filters are often edge- and direction-aware. However, these directional filters are often based on filtering the output of directional transforms, for example, the [somewhat musty] image denoising filters I wrote based on dual-tree complex wavelets.
The directional filters in which we’re most interested for video coding need to work on pixels directly, following along a direction, rather than filtering the frequency-domain output of a directional transform. Once you try to design such a beast, you quickly hit the first Big Design Question: how do you ‘follow’ directions other than horizontal and vertical, when your filter tap positions no longer land squarely on pixels arranged in a grid?
One possibility is the classic approach used in high-quality image processing: transform the filter kernel and resample the pixel space as needed. One might even argue this is the only ‘correct’ or ‘complete’ answer. It’s used in subpel motion compensation, which cannot get good results without at least decent resampling, and in directional prediction which typically uses a fast approximation.
That said, even a fast approximation is expensive when you don’t need to do it, so avoiding the resampling step is a worthy goal if possible. The speed penalty is part of the reason we’ve not seen directional filtering in video coding practice.
Directional transforms attempt to fix the DCT’s edge compaction problems in the transform itself.
Experimental directional transforms fall into two categories. There are the transforms that use inherently directional bases, such as directional wavelets. These transforms tend to be oversampled/overcomplete, that is, they produce more output data than they take input data— usually massively more. That might seem like working backwards; you want to reduce the amount of data, not increase it! But these transforms still compact the energy, and the encoder still chooses some small subset of the output to encode, so it’s really no different from usual lossy DCT coding. That said, overcomplete transforms tend to be expensive in terms of memory and computation, and for this reason, they’ve not taken hold in mainstream video coding.
The second category of directional transform takes a regular, non-directional transform such as the DCT, and modifies it by altering the input or output. The alteration can be in the form of resampling, a matrix multiplication (which can be viewed as a specialized form of resampling), or juggling of the order of the input data.
It’s this last idea that’s the most powerful, because it’s fast. There’s no actual math to do when simply rearranging numbers.

Two examples implementing a directional transforms in different directions using pixel and coefficient reshuffling, rather than a resampling filter. This example is from An Overview of Directional Transforms in Image Coding, by Xu, Zeng, and Wu.
A few practical complications make implementation tricky. Rearranging a square to make a diagonal edge into a [mostly] vertical or horizontal line results in a non-square matrix of numbers as an input. Conceptually, that’s not a problem; the 2D DCT is separable, and since we can run the row and column transforms independently, we can simply use different sized 1D DCTs for each length row and column, as in the figure above. In practice this means we’d need a different DCT factorization for every possible column length, and shortly after realizing that, the hardware team throws you out a window.
There are also other ways of handling the non-squareness of a rearrangement, or coming up with resampling schemes that keep the input square or only operate on the output. Most of the directional transform papers mentioned below are concerned with the various schemes for doing so.
But here’s where the story of directional transforms mostly ends for now. Once you work around the various complications of directional transforms and deploy something practical, they don’t work well in a modern codec for an unexpected reason: They compete with variable blocksize for gains. That is, in a codec with a fixed blocksize, adding directional transforms alone gets impressive efficiency gains. Adding variable blocksize alone gets even better gains. Combining variable blocksize and directional transforms gets no benefit over variable blocksize alone. Variable blocksize has already effectively eliminated the same redundancies exploited by directional transforms, at least the ones we currently have, and done a better job of it.
Nathan Egge and I both experimented extensively with directional transforms during Daala research. I approached the problem from both the input and output side, using sparse matrix multiplications to transform the outputs of diagonal edges into a vertical/horizontal arrangement. Nathan ran tests on mainstream directional approaches with rearranged inputs. We came to the same conclusion: there was no objective or subjective gain to be had for the additional complexity.
Directional transforms may have been a failure in Daala (and other codecs), but the research happened to address a question posed earlier: How to filter quickly along edges without a costly resampling step? The answer: don’t resample. Approximate the angle by moving along the nearest whole pixel. Approximate the transformed kernel by literally or conceptually rearranging pixels. This approach introduces some aliasing, but it works well enough, and it’s fast enough.
The Daala side of the CDEF story began while trying to do something entirely different: normal, boring, directional intra-prediction. Or at least what passed for normal in the Daala codec.
I wrote about Daala’s frequency-domain intra prediction scheme at the time we were just beginning to work on it. The math behind the scheme works; there was never any concern about that. However, a naive implementation requires an enormous matrix multiplication that was far too expensive for a production codec. We hoped that sparsifying— eliminating matrix elements that didn’t contribute much to the prediction— could reduce the computational cost to a few percent of the full multiply.
Sparsification didn’t work as hoped. At least as we implemented it, sparsification simply lost too much information for the technique to be practical.
Of course, Daala still needed some form of intra-prediction, and Jean-Marc Valin had a new idea: A stand-alone prediction codec, one that worked in the spatial domain, layered onto the frequency-domain Daala codec. As a kind of symbiont that worked in tandem with but had no dependencies on the Daala codec, it was not constrained by Daala’s lapping and frequency domain requirements. This became Intra Paint.

An example of the Intra Paint prediction algorithm as applied to a photograph of Sydney Harbor. The visual output is clearly directional and follows the edges and features in the original image well, producing a pleasing (if somewhat odd) result with crisp edges.
The way intra paint worked was also novel; it coded 1-dimensional vectors along only the edges of blocks, then swept the pattern along the selected direction. It was much like squirting down a line of colored paint dots, then sweeping the paint in different directions across the open areas.
Intra paint was promising and produced some stunningly beautiful results on its own, but again wasn’t efficient enough to work as a standard intra predictor. It simply didn’t gain back enough bits over the bits it had to use to code its own information.

Difference between the original Sydney Harbor photo and the Intra Paint result. Despite the visually pleasing output of Intra Paint, we see that it is not an objectively super-precise predictor. The difference between the original photo and the intra-paint result is fairly high, even along many edges that it appeared to reproduce well.
The intra paint ‘failure’ again planted the seed of a different idea; although the painting may not be objectively precise enough for a predictor, much of its output looked subjectively quite good. Perhaps the paint technique could be used as a post-processing filter to improve subjective visual quality? Intra paint follows strong edges very well, and so could potentially be used to eliminate basis noise that tends to be strongest along the strongest edges. This is the idea behind the original Daala paint-deringing filter, which eventually leads to CDEF itself.
There’s one more interesting mention on the topic of directional prediction, although it too is currently a dead-end for video coding. David Schleef implemented an interesting edge/direction aware resampling filter called Edge-Directed Interpolation (EDI). Other codecs (such as the VPx series and for a while AV1) have experimented with downsampled reference frames, transmitting the reference in a downsampled state to save coding bits, and then upsampling the reference for use at full resolution. We’d hoped that much-improved upsampling/interpolation provided by EDI would improve the technique to the point it was useful. We also hoped to use EDI as an improved subpel interpolation filter for motion compensation. Sadly, those ideas remain an unfulfilled dream.
At this point, I’ve described all the major background needed to approach CDEF, but chronologically the story involves some further wandering in the desert. Intra paint gave rise to the original Daala paint-dering filter, which reimplemented the intra-paint algorithm to perform deringing as a post-filter. Paint-dering proved to be far too slow to use in production.
As a result, we packed up the lessons we learned from intra paint and finally abandoned the line of experimentation. Daala imported Thor’s CLPF for a time, and then Jean-Marc built a second, much faster Daala deringing filter based on the intra-paint edge direction search (which was fast and worked well) and a Conditional Replacement Filter. The CRF is inspired somewhat by a median filter and produces results similar to a bilateral filter, but is inherently highly vectorizable and therefore much faster.

Demonstration of a 7-tap linear filter vs the constrained replacement filter as applied to a noisy 1-dimensional signal, where the noise is intended to simulate the effects of quantization on the original signal.
The final Daala deringing filter used two 1-dimensional CRF filters, a 7-tap filter run in the direction of the edge, and a weaker 5-tap filter run across it. Both filters operate on whole pixels only, performing no resampling. At that point, the Daala deringing filter began to look a lot like what we now know as CDEF.
We’d recently submitted Daala to AOM as an input codec, and this intermediate filter became the AV1 daala_dering experiment. Cisco also submitted their own deringing filter, the Constrained Low-Pass Filter (CLPF) from the Thor codec. For some time the two deringing filters coexisted in the AV1 experimental codebase where they could be individually enabled, and even run together. This led both to noticing useful synergies in their operation, as well as additional similarities in various stages of the filters.
And so, we finally arrive at CDEF: The merging of Cisco’s CLPF filter and the second version of the Daala deringing filter into a single, high-performance, direction-aware deringing filter.
The CDEF filter is simple and bears a deep resemblance to our preceding filters. It is built out of three pieces (directional search, the constrained replacement/lowpass filter, and integer-pixel tap placement) that we’ve used before. Given the lengthy background preamble to this point, you might almost look at the finished CDEF and think, “Is that it? Where’s the rest?” CDEF is an example of gains available by getting the details of a filter exactly right as opposed to just making it more and more complex. Simple and effective is a good place to be.
CDEF operates in a specific direction, and so it is necessary to determine that direction. The search algorithm used is the same as from intra paint and paint-dering, and there are eight possible directions.

The eight possible filtering directions of the current CDEF filter. The numbered lines in each directional block correspond to the ‘k’ parameter within the direction search.
We determine the filter direction by making “directional” variants of the input block, one for each direction, where all of the pixels along a line in the chosen direction are forced to have the same value. Then we pick the direction where the result most closely matches the original block. That is, for each direction d, we first find the average value of the pixels in each line k, and then sum, along each line, the squared error between a given pixel value and the average value of that pixel line.

An example process of selecting the direction d that best matches the input block. First we determine the average pixel value for each line of operation k for each direction. This is illustrated above by setting each pixel of a given line k to that average value. Then, we sum the error for a given direction, pixel by pixel, by subtracting the input value from the average value. The direction with the lowest error/variance is selected as the best direction.
This gives us the total squared error, and the lowest total squared error is the direction we choose. Though the pictured example above does so, there’s no reason to convert the squared error to variance; each direction considers the same number of pixels, so both will choose the same answer. Save the extra division!
This is the intuitive, long-way-around to compute the directional error. We can simplify the mechanical process down to the following equation:  In this equation, E is the error, p is a pixel, xp is the value of a pixel, k is one of the numbered lines in the directional diagram above, and Nd,k is the cardinality of (the number of pixels in) the line k for direction d. This equation can be simplified in practice; for example the first term is the same for each given d. In the end, the AV1 implementation of CDEF currently requires 5.875 additions and 1.9375 multiplications per pixel and can be deeply vectorized, resulting in a total cost less than an 8x8 DCT.
In this equation, E is the error, p is a pixel, xp is the value of a pixel, k is one of the numbered lines in the directional diagram above, and Nd,k is the cardinality of (the number of pixels in) the line k for direction d. This equation can be simplified in practice; for example the first term is the same for each given d. In the end, the AV1 implementation of CDEF currently requires 5.875 additions and 1.9375 multiplications per pixel and can be deeply vectorized, resulting in a total cost less than an 8x8 DCT.
The CDEF filter works pixel-by-pixel across a full block. The direction d selects the specific directional filter to be used, each consisting of a set of filter taps (that is, input pixel locations) and tap weights.
CDEF conceptually builds a directional filter out of two 1-dimensional filters. A primary filter is run along the chosen direction, like in the Daala deringing filter. The secondary filter is run twice in a cross-pattern, at 45° angles to the primary filter, like in Thor’s CLPF.

Illustration of primary and secondary 1-D filter directionality in relation to selected direction d. The primary filter runs along the selected filter direction, the secondary filters run across the selected direction at a 45° angle. Every pixel in the block is filtered identically.
The filters run at angles that often place the ideal tap locations between pixels. Rather than resampling, we choose the nearest exact pixel location, taking care to build a symmetric filter kernel.
Each tap in a filter also has a fixed weight. The filtering process takes the input value at each tap, applies the constraint function, multiplies the result by the tap’s fixed weight, and then adds this output value to the pixel being filtered.

Primary and secondary tap locations and fixed weights (w) by filter direction. For primary taps and even Strengths a = 2 and b = 4, whereas for odd Strengths a = 3 and b = 3. The filtered pixel in shown in gray.
In practice, the primary and secondary filters are not run separately, but combined into a single filter kernel that’s run in one step.
CDEF uses a constrained low-pass filter in which the value of each filter tap is first processed through a constraint function parameterized by the difference between the tap value and pixel being filtered d, the filter strength S, and the filter damping parameter D:  The constraint function is designed to deemphasize or outright reject consideration of pixels that are too different from the pixel being filtered. Tap value differences within a certain range from the center pixel value (as set by the Strength parameter S) are wholly considered. Value differences that fall between the Strength and Damping parameters are deemphasized. Finally, tap value differences beyond the Damping parameter are ignored.
The constraint function is designed to deemphasize or outright reject consideration of pixels that are too different from the pixel being filtered. Tap value differences within a certain range from the center pixel value (as set by the Strength parameter S) are wholly considered. Value differences that fall between the Strength and Damping parameters are deemphasized. Finally, tap value differences beyond the Damping parameter are ignored.

An illustration of the constraint function. In both figures, the difference (d) between the center pixel and the tap pixel being considered is along the x axis. The output value of the constraint function is along y. The figure on the left illustrates the effect of varying the Strength (S) parameter. The figure on the right demonstrates the effect of varying Damping (D).
The output value of the constraint function is then multiplied by the fixed weight associated with each tap position relative to the center pixel. Finally the resulting values (one for each tap) are added to the center filtered pixel, giving us the final, filtered pixel value. It all rolls up into: …where the introduced (p) and (s) mark values for the primary and secondary sets of taps.
…where the introduced (p) and (s) mark values for the primary and secondary sets of taps.
There are a few additional implementation details regarding rounding and clipping not needed for understanding; if you’re intending to implement CDEF they can of course be found in the full CDEF paper.
CDEF is intended to remove or reduce basis noise and ringing around hard edges in an image without blurring or damaging the edge. As used in AV1 right now, the effect is subtle but consistent. It may be possible to lean more heavily on CDEF in the future.

An example of ringing/basis noise reduction in an encode of the image Fruits. The first inset closeup shows the area without processing by CDEF, the second inset shows the same area after CDEF.
The quantitative value of any enhancement filter must be determined via subjective testing. Better objective metrics numbers as well wouldn’t exactly be shocking, but the kind of visual improvements that motivate CDEF are mostly outside the evaluation ability of primitive objective testing tools such as PSNR or SSIM.
As such, we conducted multiple rounds of subjective testing, first during the development of CDEF (when Daala dering and Thor CLPF were still technically competitors) and then more extensive testing of the merged CDEF filter. Because CDEF is a new filter that isn’t present at all in previous generations of codecs, testing primarily consisted of AV1 with CDEF enabled, vs AV1 without CDEF.

Subjective A-B comparison results (with ties) for CDEF vs. no CDEF for the high-latency configuration.
Subjective results show a statistically significant (p<.05) improvement for 3 out of 6 clips. This normally corresponds to a 5-10% improvement in coding efficiency, a fairly large gain for a single tool added to an otherwise mature codec.
Objective testing, as expected, shows more modest improvements of approximately 1%, however objective testing is primarily useful only insofar as it agrees with subjective results. Subjective testing is the gold standard, and the subjective results are clear.
Testing also shows that CDEF performs better when encoding with fewer codec ‘tools’; like directional transforms, CDEF is competing for coding gains with other, more-complex techniques within AV1. As CDEF is simple, small, and fast, it may provide future means to reduce the complexity of AV1 encoders. In terms of decoder complexity, CDEF represents between 3% and 10% of the AV1 decoder depending on the configuration.
|
|
Onno Ekker: Garbage |
No, I didn’t put Mozilla out with the garbage.

I only put my Mozilla stickers out on the garbage, so I can more easily recognize my trash bin when recollecting it after dark…

|
|
Gervase Markham: We Win |
Mozilla has been making a big effort in the past few years to make privacy and data (ab)use a first-class concern in the public consciousness. I think we can safely say that when a staid company like Barclays Bank is using dancing vegetables on national broadcast TV in a privacy-focussed advert, we have won that battle…
http://feedproxy.google.com/~r/HackingForChrist/~3/in1l5Qj1Swg/
|
|
Firefox Nightly: Protecting Your Privacy in Firefox Pre-Release |
As a matter of principle, we’ve built Firefox to work without collecting information about the people who use it and their browsing habits. Operating in this way is the right thing to do, but it makes it hard to infer what Firefox users do and want so that we can make improvements to the browser and its features. We need this information to compete effectively, but we have to do it in a way that respects our users’ privacy. That is why experimentation in our pre-release channels like Nightly, Beta and Developer Edition is so critical.
One outcome of the unified telemetry project that we finished last September was to streamline data collection as it takes place in the different channels of Firefox. As part of that project, we created four categories of data: Category 1 “technical data”, Category 2 “interaction data”, Category 3 “web activity data”, and Category 4 “highly sensitive data” which includes information that can identify a person. These categories apply to all Firefox data collection including telemetry (data that Firefox sends Mozilla by default) and Shield Studies (a Mozilla program to test rough features and ideas on small numbers of Firefox users).
The release channel of Firefox that hundreds of millions of people use sends us Category 1 and 2 technical and interaction data by default. The latter is especially useful so that we can understand how people interact with menus, prompts, features, and core browser functions. Because this telemetry data is limited, it is not enough to make fully informed decisions about product changes.
This is why we rely on our pre-release channels to collect, when necessary, additional Category 3 web activity data or run studies on particular features with unique privacy properties. Gathering this information is critical so that we can understand the real-world impact of new ideas and technologies on a limited audience before deploying to all Firefox users.
Any new Firefox data collection must go through a rigorous process. The lean data practices that we follow mean that we minimize collection, secure data, limit data sharing, clearly explain what we’re doing, and provide user controls. For example, Shield Studies are controlled weekly Firefox studies that answer specific questions using the minimum amount of data needed on the smallest relevant sample size. Every study is reviewed and signed off by a data scientist, a QA engineer, and a Firefox Peer. The majority of studies stay within Category 1 and Category 2 data; for anything sensitive, even in pre-release, additional sign-off by our Legal and Trust teams are required.
We don’t compromise our principles when we work with partners. Privacy and security threats on the web are evolving and so are we to protect our users. This includes partnering with others to provide expertise that we don’t have. We require partners who works with us to uphold the same privacy and accountability standards we’ve set for ourselves.
The Firefox Privacy Notice has always said that pre-release has different privacy characteristics, but we are going to update this to clarify what that means. We’ll do the same on the landing pages for pre-release, because anyone who is uncomfortable with additional data collection or sharing should instead download the release version of Firefox.
We are deeply grateful to our community of pre-release users who put up with unstable builds, report issues, and contribute much needed data. Ultimately, it is the insights from our most passionate users and advocates in pre-release that allow us to offer a better product to all users, with less data collection in the long run.
https://blog.nightly.mozilla.org/2018/06/27/protecting-your-privacy-in-firefox-pre-release/
|
|
Ryan Harter: If you can't do it in a day, you can't do it |
I was talking with Mark Reid about some of the problems with Coding in a GUI. He nailed part of the problem with soundbite too good not to share:
"If you can't do it in a day, you can't do it."
This is a persistent problem with tools that make you code in a GUI. These tools are great for working on bite-sized problems, but the workflow becomes painful when the problem needs to be broken into pieces and attacked separately.
Part of the problem is that I can't test the code. That means I need to understand how each change will affect the entire code base. It's impossible to compartmentalize.
GUI's also make it difficult to split a problem across people. If I can't track changes easily it's impossible to tell whether my changes conflict with a peer's changes.
So look out, bad tools are insidious! If you find yourself abandoning an analysis because it's hard to refactor, consider choosing a different toolchain next time. Especially if it's because there's no easy way to move your code out of a GUI!
|
|
Armen Zambrano: Workshop experience at Smashing Conf |
This week I attended Toronto’s first Smashing Conf.

On Monday I attended one of the pre-conference workshops by Dan Mall’s “Design workflow for a multi-device world”. Dan guided us through the process of defining a problem, brainstorming objectives and key results (aka OKRs) and made us work together to build some of what we decided to tackle. We divided the whole classroom into five or six teams with 5 to 7 members each. Each team had various skillsets (e.g. designers and coders).
In my team, the “bike shed” team, we decided to rewrite TTC’s trip planning feature. We did not manage to finish the product, however, we managed to build one of the three objectives and partially complete another. The team had two people who did compositions, two people who could code and one person helping us collaborate and coordinate.
This exercise included few new things to me. For instance, I worked within a team context to create a product rather than building a feature by myself.

It was also a new experience for me to work closely with a designer. We chose to build a multi-option toggle feature to mix transit methods. The process started with writing on paper what he had in mind. I tried building a prototype from scratch to see if I understood what he wanted. I did not get it quite right the first time so wedecided to search in codepen to find similar. Once we found something we liked I started iterating on the code while he started preparing the icons for me to use. By the end of it we had something that worked but did not have enough time to complete. This is the codepen I forked and this is the unfinished feature where I left it at.

This exercise was a very humbling experience as I felt the pressure to produce something for a designer (Scott from Motorola services) that was right there beside me and I was “the coding expert”. I quote coding expert as I barely have a year of frontend experience. I started from a forked pen that had roughly what Scott wanted, however, I knew I was going to face a very difficult time not before long. The codepen had been written using few non-standard languages (pugjs and SCSS) instead of writing standard HTML & CSS. Another difficulty I knew I was going to face was that I did not have experience turning an image into a toggle button. The forked pen only had text inside the buttons. I deferred solving it by only dealing with text labels at first, instead I addressed other issues before integrating the icons which would require some extra research.
It was also the first time working with another coder (Sheneille Patil) on a fast paced environment. We needed to quickly figure our own development culture. Creating a GitHub repository was not an option as she was not comfortable with it. We decided to turn to codepen.io and to build features that would not conflict with each other. The final plan was to collect our different pieces of code and merge them in a single pen. We did not have enough time to get to this.
I hope you found something interesting out of this post. It’s not my tipical programming related post. I’m very grateful to SmashingConf for having lined up such great speakers and very practical workshops and for Mozilla to support my learning.
|
|
Mozilla Localization (L10N): L10N Report: June Edition |
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
New localizers
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
Firefox 61 has been released on June 26th. This also means that Firefox 62 is in Beta, while 63 is on Nightly, and that’s where you should focus your work for localization and testing.
This development cycle will be a little longer than usual, to account for Summer holidays in the Northern hemisphere: the deadline to provide your localization for Beta is August 21st, with Firefox 62 planned for release on September 5th.That’s a Wednesday and not a Tuesday, which is the common release day for Mozilla products, because September 3rd is a public holiday in US (Labor Day).
Now, diving into updates and new content. There are several new in-product pages:
One important note about Activity Stream (about:newtab and about:welcome): unlike other strings in Firefox, once translated they are not used directly in the following Nightly, they need a new build of Activity Stream (for now). That normally happens once a week. For this reason, if you’re targeting Beta, make sure to prioritize localization of activity-stream/newtab.properties.
Two new Test Pilot experiments were published on the website about 3 weeks ago: Color and Side View. While the experiments themselves were not localized, new content was added to the website. Unfortunately, that happened with poor timing, resulting in English content being displayed on the website. The following cycle is longer than usual (normally they are 2 weeks long), because most people were traveling for the bi-annual Mozilla All Hands, making things worse.
We realize that this is less than ideal, and we are trying to set up a system to avoid repeating these mistakes in the future.
As mentioned in the section about Firefox desktop, Firefox 61 has been released on June 26th, which means that Firefox for Android 61 updates will start rolling out to users progressively. Please refer to the section about Firefox desktop above since the Firefox for Android release cycle is the same, and the comments concerning localization apply as well.
We’ve also recently decided to stop updating the What’s New content for Firefox Android (due to low visibility and interest in localizing this section, and the fact that it does not affect the number of downloads – amongst other things). This means the locales that were supported by the Play Store will no longer need to localize the updated version for Beta each time we are releasing a new version. Instead, we’ve opted for displaying a generic message.
On the Firefox iOS front, English from Canada (en-CA) was added to the ever-growing list of shipping locales with the new v12. Congratulations on that! Next update (and so, new strings) is slowly creeping up, so stay tuned for more.
Focus Android locales are also continuously growing, with Afrikaans (af), Pai-pai (pai), Punjabi (pa-IN), Quechua Chanka (quy) and Aymara (ay) teams having started to localize. Note that there are public Nightlies available on the Play Store that you can test your work on. Instructions on how to do that are here.
And finally, after months of silence localization-wise, Focus iOS will get new strings soon! However at the moment, we are not opening the project back up to new locales as there is no clearly defined schedule, and we cannot guarantee by when new locales can be added once completed.
Legal documentation:
Common Voice:
Copyright campaign! The battle to fix copyright has started a few days ago, and while we were disappointed by the JURI Committee vote, we’re now mobilizing citizens to ask a larger group of MEPs to reject Article 13 during the EU Parliament plenary on July 5th. We can still win!
In the second half of 2018, the Advocacy team will have a bigger focus on both Europe and company misbehavior around data, so we can expect more campaigns being localized. It’s also an opportunity to mobilize internal resources to plan and build localization support on the new foundation website.
If you would like to learn more, you can watch Jon Lloyd, Advocacy Campaigns Manager, during the Foundation All-Hands in Toronto talk briefly about the recent campaign wins and the strategy for the next 6 month:
On fundraising, the current plan for the coming month is to communicate an update to existing donors, do various testing around it, then send a broader fundraising ask towards end of July/beginning of August. The donate website will soon get a makeover that will fix some layout issues with currencies, and generally provide more space for localization. Which is good news!
Several foundation website will also soon get a unified navigation header to match the one on foundation.mozilla.org.
Reviewing pending suggestions regularly is important and making them discoverable is the first step to get there. That’s why we got rid of the misleading Suggested count, which didn’t include suggestions to Translated strings, and started exposing Unreviewed suggestions in a new sortable column in dashboards. It’s represented by a lightbulb, which is painted blue if unreviewed suggestions are present.

To help you prioritize your work, we rolled out Tags. The idea is pretty simple: we define a set of tags with set priority, which are then assigned to translation resources (files). Effectively, that assigns priority to each string. Currently, tags are only enabled for Firefox, which you’ll notice by the Tags tab available in the Firefox localization dashboard and filters.

Pontoon Tools is a must-have add-on for all Pontoon users, which allows you to stay up-to-date with localization activity even when you don’t use Pontoon. Michal Stanke just released a new version, which is now also available for Chrome and Chromium-based browsers. Additionally, it also brings support for the aforementioned Unreviewed state and enables system notifications by default.
Extensions for Firefox are built using the WebExtensions API, a cross-browser system for developing extensions. The WebExtensions API has a rather handy module available for internationalizing extensions – i18n. It stores translations in messages.json files, which are now supported in Pontoon. For more technical details on internationalizing WebExtensions, see this MDN page.
As mentioned in the last month’s report, Pramit Singhi is working on Pontoon homepage redesign as part of the Google Summer of Code project. Based on the impressive amount of feedback collected during the research among Pontoon users, he came up with a proposal of the new homepage and would like to hear your thoughts. Please consider the proposal a wireframe, so he’s more interested in hearing what you think about the overall page structure and content and less so how you like fonts and colors.

Image by Elio Qoshi
Francis who speaks many languages, joined the l10n community not long ago, thanks to the Common Voice project. He has been actively involved in bringing new contributors and introduce new localization communities to Mozilla. He also makes sure the new contributors have a simple onboarding process so they can contribute right away and see the fruit of their work quickly. Additionally, Francis files issues and fixes bugs through the project on GitHub. Thank you!
Know someone in your l10n community who’s been doing a great job and should appear here? Contact one of the l10n-drivers and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2018/06/27/l10n-report-june-edition/
|
|
Chris H-C: When, Exactly, does a Firefox User Update, Anyway? |
There’s a brand new Firefox version coming. There always is, since we adopted the Rapid Release scheme way back in 2011 for Firefox 5. Every 6-8 weeks we instantly update every Firefox user in the wild with the latest security and performance…
Well, no. Not every Firefox user. We have a dashboard telling us only about 90% of Firefox users are presently up-to-date. And “up-to-date” here means any user within two versions of the latest:

Why two versions? Shouldn’t “Up to date” mean up-to-date?
Say it’s June 26, 2018, and Firefox 61 is ready to go. The first code new to this version landed March 13, and it has spent the past three months under intense development and scrutiny. During its time as Firefox Nightly 61.0a1 it had features added, performance and security improvements layered in, and some rearranging of home page settings. While it was known as Firefox Beta 61.0b{1-14} it has stabilized, with progressively fewer code changes accepted as we prepare it for our broadest population.
So we put Firefox 61.0 up on the server, ring the bell and yell “Come and get it~!”?
No.
Despite our best efforts, our Firefox Beta-running population is not as diverse as our release population. The release population has thousands of gpu+driver combinations 61 has never run on before. Some users will use it for kiosks and internet cafes in areas of the world we have no beta users. Other users will have combinations of addons and settings that are unique to them alone… and we’ll be shipping a fresh browsing experience to each and every one of them.
So maybe we shouldn’t send it to everyone at once in case it breaks something for those users whose configurations we haven’t had an opportunity to test.
As a result, our update servers will, upon being asked by your Firefox instance if there is an update available, determine whether or not to lie. Our release managers will chose to turn the release dial to, say, 10% to begin. So when your Firefox asks if there is an update, nine out of ten times we will lie and say “No, try again later.” And that random response is cached so that everyone else trying for the next one or two minutes will get the same response you did.
At 10% roughly one out of every ten 1-2min periods will tell the truth: “Yes, there is an update and you can find it here:
Eventually, after a couple of days or maybe up to a week, we will turn the dial up to 100% and everyone will be able to receive the update and in a matter of hours the entire population will be up-to-date and…
No.
When does a Firefox instance ask for an update? We “only” release a new update every six-to-eight weeks, it would be wasteful to be asking all the time. When -should- we ask?
If you’ve ever listened to a programmer complain about time, you might have an inkling of the complexity involved in simply trying to figure out when to ask if there’s an update available.
The simplest two cases of Firefox instances asking for updates are: “When the user tells it to”, and “If the Firefox instance was released more than 63 days ago.”
For the first of these two cases, you can at any time open Help > About Firefox and it will check to see if your Firefox is up-to-date. There is also a button labeled “Check for Updates” in Preferences/Options.
For the second, we have a check during application startup that compares the date we built your Firefox to the date your computer thinks it is. If they differ by more than 63 days, we will ask for an update.
We can’t rely on users to know how to check for updates, and we don’t want our users to wait over two -more- months to benefit from all of our hard work.
Maybe we should check twice a day or so. That seems like a decent compromise. So that’s what we do for Firefox release users: we check every 12 hours or so. If the user isn’t running Firefox for more than 12 hours, then when they start it up again we check against the client’s clock to see if it’s been 12 hours since our last check.
Putting this all together:
Firefox must be running. It must have been at least 12 hours since the last time we checked for updates. If we are still throttling updates to, say, 10% we (or the client who asked previously within the past 1-2min) must be lucky to be told the truth that there is an update available. Firefox must be able to download the entire update (which can be interrupted if the user closes Firefox before the download is complete). Firefox must be able to apply the update. The user must restart Firefox to start running the new version.
And then, and only then, is that one Firefox user running the updated Firefox.
How does this look like for an entire population of Firefox users whose configurations and usage behaviours I already mentioned are the most diverse of all of our user populations?
That’ll have to wait for another time, as it sure isn’t a simpler story than this one. For now, you can enjoy looking at some graphs I used to explore a similar topic, earlier.
:chutten
https://chuttenblog.wordpress.com/2018/06/27/when-exactly-does-a-firefox-user-update-anyway/
|
|
Mozilla Open Policy & Advocacy Blog: Privacy Progress and Protections for California |
Update: “We’re pleased to see California passed a sweeping privacy law to protect your data and right to choose how it’s used. It’s still not perfect, but we’re not letting perfect be the enemy of good – and Mozilla will work with legislators in California to strengthen it.” – Denelle Dixon, Chief Operating Officer
People in California are in midst of an important discussion around improving privacy protections. This comes in the wake of Cambridge Analytica and the European GDPR going into effect – but it’s a discussion that has been a long time in the making. We are excited to see the potential for progress.
Californians are considering two competing approaches; a narrow ballot initiative on privacy and a broader privacy bill, the California Consumer Privacy Act or CalCPA, currently moving quickly through the legislature. Today, Mozilla is weighing in to endorse the broader bill. While we are also supportive of the ballot initiative, we believe the bill is the better option for Californians.
The ballot initiative would allow anyone to know what kinds of data a company collects and would require an opt-out for data selling to third parties. These are important first steps. The bill takes bigger steps forward, giving consumers rights more in line with the GDPR, like access to your data and correction or deletion of your data.
The bill is moving through the legislature quickly and still has flaws. Mozilla has suggested substantive changes that could clarify its requirements and better protect Californians’ privacy. But overall the bill is a very positive move that offers huge potential to advance the privacy conversation in the United States, as other states look to these concepts and even apply them at the national level.
Mozilla stands with Californians – and our community globally – to support positive progress in protecting user privacy. We look forward to working with policymakers to ensure that the draft puts users first.
The post Privacy Progress and Protections for California appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/06/26/privacy-progress-and-protections-for-california/
|
|
The Mozilla Blog: Supreme Court’s Decision to Uphold Trump’s Travel Ban is a Disappointment |
We are deeply disappointed by today’s Supreme Court 5-4 ruling which provides a legal basis for the Trump Administration to prohibit individuals from Libya, Iran, Somalia, Syria, Yemen, North Korea and Venezuela from entering the United States. We agree with the four dissenting Justices that the majority ignored key facts that overwhelmingly showed that this is a religious ban that “masquerades behind a facade of national-security concerns.”
At issue is the Trump Administration’s third Executive Order on immigration, which differed from the original January 2017 and March 2017 orders by the removal of Iraq and Sudan, and the addition of three non-muslim majority countries. Five Justices held that the President has broad discretion to protect national security, and irrespective of Trump’s personal beliefs or statements, his action was justified because he consulted with other agencies and officials on whether people from certain countries posed security risks.
This was harshly criticized in the two dissenting opinions as a highly abridged account that ignores:
Cumulatively, the dissenting justices believed there was enough evidence to hold the Executive Order unlawful. Unfortunately, history will not reflect that. Since Trump issued his first travel ban, Mozilla and 100+ tech companies filed several “friend of the court” briefs warning against its adverse consequences and reminding the Court of the importance of diversity.
The internet is built, maintained, and governed through a myriad of global civil society, private sector, government, academic, and developer communities. Travel across borders is central for their cooperation and exchange of ideas and information. It is also necessary for a global workforce that reflects the diversity of the internet itself.
Today’s opinion turns “a blind eye to the pain and suffering the Proclamation inflicts upon countless families and individuals.” We will continue our fight to protect the internet. Countries may arbitrarily close their borders, but the internet must remain open and accessible to everyone.
The post Supreme Court’s Decision to Uphold Trump’s Travel Ban is a Disappointment appeared first on The Mozilla Blog.
|
|
Ryan Harter: Planning Data Science is hard: EDA |
Data science is weird. It looks a lot like software engineering but in practice the two are very different. I've been trying to pin down where these differences come from.
Michael Kaminsky hit on a couple of key points in his series on Agile Management for Data Science on Locally Optimistic. In Part II Michael notes that Exploratory Data Analyses (EDA) are difficult to plan for: "The nature of exploratory data analysis means that the objectives of the analysis may change as you do the work." - Bingo!
I've run into this problem a bunch of times when trying to set OKRs for major analyses. It's nearly impossible to scope a project if I haven't already done some exploratory analysis. I didn't have this problem when I was doing engineering work. If I had a rough idea of what pieces I needed to stitch together, I could at least come up with an order-of-magnitude estimate of how long a project would take to complete. Not so with Data Science: I have a hard time differentiating between analyses that are going to take two weeks and analyses that are going to take two quarters.
That's all. No deep insight. Just a +1 and a pointer to the folks who got there first.
|
|
Mozilla Open Innovation Team: Cracking the Code — how Mozilla is helping university students contribute to Open Source |
After a year of research, Mozilla’s Open Source Student Network (OSSN), is launching a pilot program to tackle the challenges around how Open Source projects effectively support university students as they work towards their first code contribution.
Despite an abundance of evidence that the most valuable contributions to a project often come from people under the age of 30, Open Source projects often struggle to onboard and maintain university students as new code contributors.
Students who have expressed interest in contributing often feel intimidated, that they don’t have the appropriate skills or aren’t able to find a project, to begin with.
Based on our recent research, we identified that more than 50% of university students within our network who had tried to contribute code to an Open Source project had been unable to make a successful contribution because of issues they encountered during their contribution journey.
From identifying a project to work on, exploring the codebase, setting up the development environment, writing code and even when trying merge their code, students faced issues which drove them away from the project before they completed their first contribution.
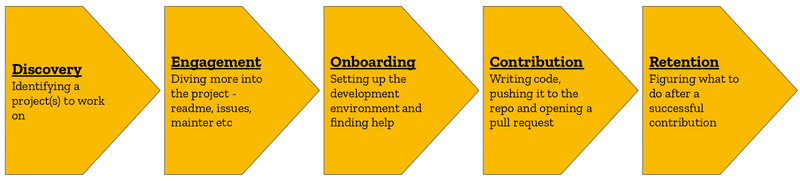
Our research uncovered a series of questions related to each portion of the user journey.
We’re designing a series of pilots, each of which aims to answer specific questions, connected to different parts of the typical user’s journey, such as:
As part of the pilots and in collaboration with Mozilla projects like Common Voice, Devtools, Firefox Focus for Android and external organizations like the GNOME Foundation, the Linux Foundation and Wikimedia the OSSN is building new ways for students to discover, interact and engage with Open Source projects.
An example of one of these pilots is the “Project Overview Pilot”. The aim of this particular pilot is to answer a question from the “discovery” portion of the user journey: how do students evaluate whether they want to contribute to a project?
Based on a survey we released at the beginning of the year, we discovered that students care equally for the mission of the project as well as the technical skills required for contribution. Here are the top four criteria for project selection:
While the mission and the technical requirements of a project are often well presented and visible, we can argue that the other two criteria are not properly surfaced.
Our assumption for our pilot is that by surfacing this information, students will identify the right project for them to contribute to and hence will contribute code with more confidence, less effort and in a shorter time.
In order to validate our assumption, we created the following platform for showcasing all the relevant information students care about at a glance for a broad set of diverse, healthy, active and inclusive Open Source projects.
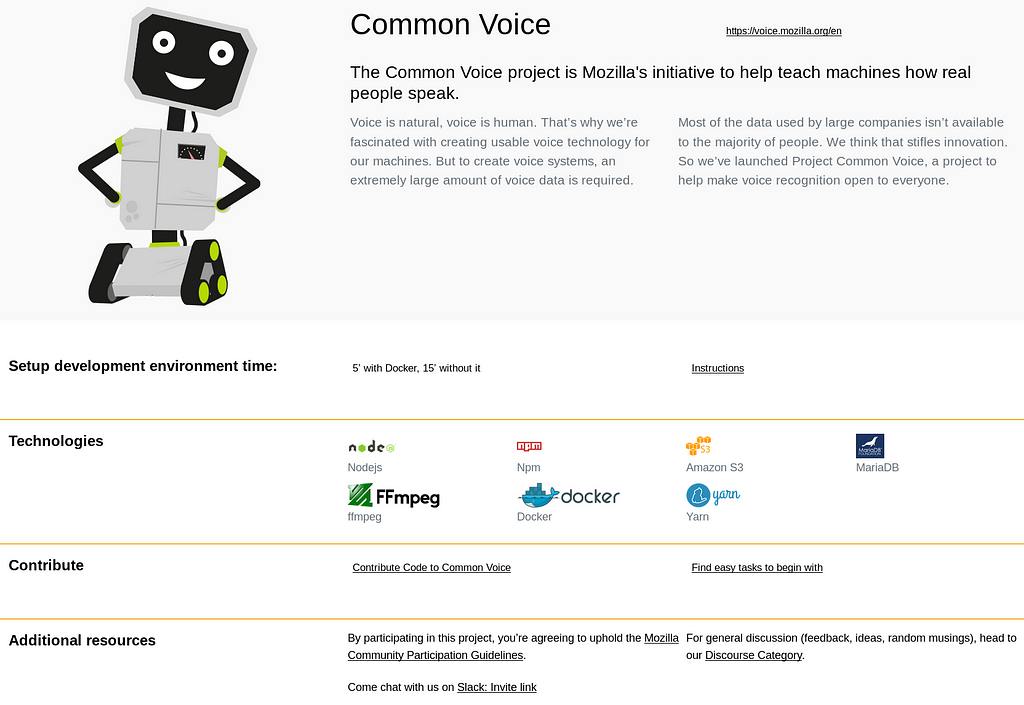
From now until October 2018, along with our key collaborators, we will continue building and providing pilots for our students to help them contribute code to their favorite projects while growing their skills around a diverse set of technologies. Furthermore, throughout these pilots, students will be helping the network by providing useful insights and metrics, which will be used to refine the onboarding experience of projects in the future.
If you are a student from an American and/or a Canadian post-secondary institution or you know students who might be interested participating in this initiative, please share this link with them.
If you are an organization or project interested in supporting our initiative by having us surface your project’s contribution opportunities within our network, please reach out at christos AT mozilla DOT com.
Cracking the Code — how Mozilla is helping university students contribute to Open Source was originally published in Mozilla Open Innovation on Medium, where people are continuing the conversation by highlighting and responding to this story.
|
|
The Mozilla Blog: New Firefox Releases Now Available |
Even though summer is here in the northern hemisphere, we’re not taking any breaks. Firefox continues our focus on making a browser that is smarter and faster than any other, so you can get stuff done before you take that much needed outdoor stroll.
For additional information on developer news in today’s update, visit here. For more details on all of today’s news, you can review our release notes here.
Check out and download the latest version of Firefox Quantum available here.
The post New Firefox Releases Now Available appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2018/06/26/new-firefox-releases-now-available-2/
|
|
Hacks.Mozilla.Org: Firefox 61 – Quantum of Solstice |
Summertime1, and the browser is speedy! Firefox 61 is now available, and with it come new performance improvements that make the fox faster than ever! Let’s take a short tour of the highlights:

Quantum CSS boosted our style system by calculating computed styles in parallel. Firefox 61 adds even more power to Quantum CSS by also parallelizing the parsing step! The extra horsepower pays real dividends on sites with large stylesheets and complex layouts.
One of the final steps before a page is painted onto the screen is building a list of everything that is going to be drawn, from lowest z-order to highest (“back to front”). In Firefox, this is called the display list, and it’s the final chance to determine what’s on screen before painting begins. The display list contains backgrounds, borders, box shadows, text, everything that’s about to be pixels on the screen.
Historically, the entire display list was computed prior to every new paint. This meant that if a 60fps animation was running, the display list would be computed 60 times a second. For complex pages, this gets to be costly and can lead to reduced script execution budget and, in severe cases, dropped frames. Firefox 61 enables “retained” display lists, which, as the name would suggest, are retained from paint to paint. If only a small amount of the page has changed, the renderer may only have to recompute a small portion of the display list. With retained display lists enabled, the graphics team has observed a near 40% reduction in dropped frames due to list building! We’ve decided to pass those savings on to you, and are enabling the initial work in Firefox 61.
You can dive deeper into display lists in Matt Woodrow’s recent post here on Hacks.
Pretty snazzy stuff, but there’s more than just engine improvements! Here are few other new things to check out in this release:
A great website is one that works for everyone! The web platform has accessibility features baked right in that let users with assistive technologies make use of web content. Just as the JS engine can see and interact with a tree of elements on a page, there is a separate “accessibility tree” that is available to assistive technologies so they can better describe and understand the structure and UI of a website. Firefox 61 ships with an Accessibility Inspector that lets developers view the computed accessibility tree and better understand which aspects of their site are friendly to assistive technologies and spot areas where accessible markup is needed. Useful for spotting poorly-labeled buttons and for debugging advanced interactions annotated with ARIA.
You can learn more about how to use the Accessibility Inspector in Marco Zehe’s introductory blog post.
One of the most popular uses of browser extensions is to help users better hoard manage their open tabs. Firefox 61 ships with new extension APIs to help power users use tabs more powerfully! Extensions with the tabs permission can now hide and restore tabs on the browser’s tab bar. The hidden tabs are still loaded, they’re simply not shown. Extensions for productivity and organization can now swap out groups of tabs based on task or context. Firefox also includes an always-available menu that lists all open tabs regardless of their hidden state.
Curious about everything that’s new or changed in Firefox 61? You can view the Release Notes or see the full platform changelog on MDN Web Docs.
Have A Great Summer!
1. In the Northern hemisphere, that is. I mean, I hope the Southern hemisphere has a great summer too- it’s just a ways off.
https://hacks.mozilla.org/2018/06/firefox-61-quantum-of-solstice/
|
|
Mozilla Future Releases Blog: Testing Firefox Monitor, a New Security Tool |
From shopping to social media, the average online user will have hundreds of accounts requiring passwords. At the same time, the number of user data breaches occurring each year continues to rise dramatically. Understandably, people are now more worried about internet-related crimes involving personal and financial information theft than conventional crimes. In order to help keep personal information and accounts safe, we will be testing user interest in a security tool that lets users check if one of their accounts has been compromised in a data breach.
 We decided to address a growing need for account security by developing Firefox Monitor, a proposed security tool that is designed for everyone, but offers additional features for Firefox users. Visitors to the Firefox Monitor website will be able to check (by entering an email address) to see if their accounts were included in known data breaches, with details on sites and other sources of breaches and the types of personal data exposed in each breach. The site will offer recommendations on what to do in the case of a data breach, and how to help secure all accounts. We are also considering a service to notify people when new breaches include their personal data.
We decided to address a growing need for account security by developing Firefox Monitor, a proposed security tool that is designed for everyone, but offers additional features for Firefox users. Visitors to the Firefox Monitor website will be able to check (by entering an email address) to see if their accounts were included in known data breaches, with details on sites and other sources of breaches and the types of personal data exposed in each breach. The site will offer recommendations on what to do in the case of a data breach, and how to help secure all accounts. We are also considering a service to notify people when new breaches include their personal data.
Partnership with HaveIBeenPwned.com
In order to create Firefox Monitor, we have partnered with HaveIBeenPwned.com (HIBP). HIBP is a valuable service, operated by Troy Hunt, one of the most renowned and respected security experts and bloggers in the world. Troy is best known for the HIBP service, which includes a database of email addresses that are known to have been compromised in data breaches. Through our partnership, Firefox is able to check your email address against the HIBP database in a private-by-design way. You can find Troy’s blog post on the partnership here.
How does it work?
It is important that we not violate our users’ privacy expectations with respect to the handling of their email address. As such, we’ve worked closely with HIBP and Cloudflare to create a method of anonymized data sharing for Firefox Monitor, which never sends your full email address to a third party, outside of Mozilla. You can read the full details of the solution here.
What will we be testing?
At this stage, we are testing initial designs of the Firefox Monitor tool in order to refine it. Beginning next week, we expect to invite approximately 250,000 users (mainly in the US) to try out the feature.
What to expect next
Once we’re satisfied with user testing, we will work on making the service available to all Firefox users. Once a release schedule has been established, it will be announced in a follow-up blog post.
In the meantime, check out and download the latest version of Firefox Quantum for the desktop in order to use the Firefox Monitor feature when it becomes available.
Download Firefox for Windows, Mac, Linux
The post Testing Firefox Monitor, a New Security Tool appeared first on Future Releases.
https://blog.mozilla.org/futurereleases/2018/06/25/testing-firefox-monitor-a-new-security-tool/
|
|
Mozilla Security Blog: Scanning for breached accounts with k-Anonymity |
The new Firefox Monitor service will use anonymized range query API endpoints from Have I Been Pwned (HIBP). This new Firefox feature allows users to check for compromised online accounts while preserving their privacy.
An API request can reveal subject identifiers like cookies, IP address, etc.
Operations like ‘search’ often need plaintext, or simply-hashed data. But, as Cloudflare has described in their own HIBP integration, searching with plain account data introduces privacy & security risks that allow an adversary, or even the service itself, to use the data to breach the searched account.
As an alternative, a user search client could download an entire set of data. Unfortunately this practice discloses all the service data to the client, which could abuse the data of all other users.
To mitigate these risks, Mozilla is working with Troy Hunt – creator and maintainer of HIBP – to use new hash range query API endpoints for breached account data in the Firefox Monitor project.
Hash range queries add k-Anonymity to the data that Mozilla exchanges with HIBP. Data with k-Anonymity protects individuals who are the subjects of the data from re-identification while preserving the utility of the data.
When a user submits their email address to Firefox Monitor, it hashes the plaintext value and sends the first 6 characters to the HIBP API. For example, the value “test@example.com” hashes to 567159d622ffbb50b11b0efd307be358624a26ee. We send this hash prefix to the API endpoint:
GET https://haveibeenpwned.com/api/breachedaccount/range/567159
The API responds with many suffixes and the list of breaches that include the full value:
[
{
"HashSuffix": "D622FFBB50B11B0EFD307BE358624A26EE",
"Websites": [
"LinkedIn"
]
},
{
"HashSuffix": "0000000000000000000000000000000000",
"Websites": [
"Dropbox"
]
},
{
"HashSuffix": "1111111111111111111111111111111111",
"Websites": [
"Adobe",
"Plex"
]
}
]
When Firefox Monitor receives this response, it loops thru the objects to find which (if any) prefix and breached account HashSuffix equals the the user-submitted hash value. The following pseudo code describes the algorithm in more detail:
if (fullUserHash === userHashPrefix + breachedAccount.HashSuffix)
Using the running example from above, for the first HashSuffix, the expression evaluates to:
if (‘567159D622FFBB50B11B0EFD307BE358624A26EE’ ===
‘567159’+‘D622FFBB50B11B0EFD307BE358624A26EE’)
Firefox Monitor discovers that “test@example.com” appears in the LinkedIn breach, but does not disclose plaintext or even hashes of sensitive user data. Further, HIBP does not disclose its entire set of hashes, which allows Firefox users to maintain their privacy, and protects breached users from further exposure.
Hashed data is still vulnerable to brute-force attacks. An adversary could still loop thru a dictionary of email addresses to find the plaintext of all the range query results. To reduce this attack surface, Firefox Monitor does not store the range queries nor any results in its database. Instead, it caches a user’s results in an encrypted client session. We also monitor our scan endpoint to prevent abuse by an adversary attempting a brute force breached-account enumeration attack against our service.
HIBP contains billions of records of email addresses. Troy has done an outstanding job to raise awareness and educate users about breaches globally. Breached sites embrace HIBP, even self-submitting their breached data. HIBP is there to help victims of data breaches after things go wrong, and Firefox Monitor is extending that help to more people.
The post Scanning for breached accounts with k-Anonymity appeared first on Mozilla Security Blog.
https://blog.mozilla.org/security/2018/06/25/scanning-breached-accounts-k-anonymity/
|
|
Hacks.Mozilla.Org: Retained Display Lists for improved page performance |
Continuing Firefox Quantum’s investment in a high-performance engine, the Firefox 61 release will boost responsiveness of modern interfaces with an optimization that we call Retained Display Lists. Similar to Quantum’s Stylo and WebRender features, developers don’t need to change anything on their sites to reap the benefits of these improvements.
I wrote about this feature on the Mozilla Graphics Team blog back in January, when it was first implemented in Nightly. Now it’s ready to ship with Firefox 61. If you’re already familiar with retained display lists and how this feature optimizes painting performance, you might want to skip ahead to read about the results of our efforts and the future work we’re planning.
Display list building is the process in which we collect the set of high-level items to display on screen (borders, backgrounds, text and much more), and then sort the list according to CSS painting rules into the correct back-to-front order. It’s at this point that we figure out which parts of the page are already visible on screen.
Currently, whenever we want to update what’s on the screen, we build a full new display list from scratch and then we use it to paint everything on the screen. This is great for simplicity: we don’t have to worry about figuring out which bits changed or went away. Unfortunately, the process can take a really long time. This has always been a performance problem, but as websites have become more complex and more users have access to higher resolution monitors, the problem has been magnified.
The solution is to retain the display list between paints—we build a new display list only for the parts of the page that changed since we last painted and then merge the new list into the old to get an updated list. This adds a lot more complexity, since we need to figure out which items to remove from the old list, and where to insert new items. The upside is that, in many cases, the new list can be significantly smaller than the full list. This creates the opportunity to improve perceived performance and save significant amounts of time.
As part of the lead up to the release of Firefox Quantum, we added new telemetry to Firefox to help us measure painting performance, which therefore enabled us to make more informed decisions as to where to direct our efforts. One of these measurements defined a minimum threshold for a ‘slow’ paint (16ms), and recorded percentages of time spent in various paint stages when it occurred. We expected display list building to be significant, but were still surprised with the results: On average, display list building was consuming more than 40% of the total paint time, for work that was often almost identical to the previous frame. We’d long been planning to overhaul how we built and managed display lists, but with this new data we decided to make it a top priority for our Painting team.
Once we had everything working, the next step was to see how much of an effect we’d made on performance! We had the feature enabled for the first half of the Beta 60 cycle, and compared the results with and without it enabled.
The first and most significant change: The median amount of time spent painting (the full pipeline, not just display list building) dropped by more than 33%!

As you can see in the graph, the median time spent painting is around 3ms when retained display lists are enabled. Once the feature was disabled on April 18th, the paint time jumped up to 4.5ms. That frees up lots of extra time for the browser to spend on running JavaScript, doing layout, and responding to input events.
Another important improvement is in the frequency at which slow paints occurred. With retained display lists disabled, we miss the 16ms deadline around 7.8% of the time. With it enabled, this drops to 4.7%, an almost 40% reduction in frequency. We can see that we’re not just making fast paints faster, but we’re also having a significant impact on the slow cases.
As mentioned above, we aren’t always able to retain the display list. We’ve spent time working out which parts of the page have changed; when our analysis shows that most of the page has changed, then we still have to rebuild the full display list and time spent on the analysis is time wasted. Work is ongoing to try detect this as early as possible, but it’s unlikely that we’ll be able to entirely prevent it. We’re also actively working to minimize how long the preparation work takes, so that we can make the most of opportunities for a partial update.
Retaining the display list also doesn’t help for the first time we paint a webpage when it loads. The first paint always has to build the full list from scratch, so in the future we’ll be looking at ways to make that faster across the board.
Thanks to everyone who has helped make this possible, including: Miko Mynttinen, Jet Villegas, Timothy Nikkel, Markus Stange, David Anderson, Ethan Lin, and Jonathan Watt.
|
|
Shing Lyu: How to Unit Test WebExtensions |
We all know that unit-testing is a good software engineering practice, but sometimes the hassle of setting up the testing environment will keep us from doing it in the first place. After Firefox 57, WebExtension has become the new standard for writing add-ons for Firefox. How do you set up everything to start testing your WebExtension-based add-ons?
In the earlier format of the Firefox add-ons, namely the Add-on SDK (a.k.a. Jetpack), there is a built-in command for unit-test (jpm test). But for WebExtension, as far as I know, doesn’t have such thing built in. Luckily all the technology used in WebExtension is still standard web technology, so we can use off-the-shelf JavaScript unit-testing frameworks.
I want to keep my tests as simple as possible, so I made some assumptions:
We will be using Mocha test framework and expect.js assertion library, but you can use any test framework that supports running in browsers. We’ll be using the browser version of Mocha. You need to create an HTML file like this:
<html>
<head>
<meta charset="utf-8">
<title>Unit Tests (by Mocha)</title>
<link href="https://cdn.rawgit.com/mochajs/mocha/2.2.5/mocha.css" rel="stylesheet" />
</head>
<body>
<div id="mocha"></div>
<script src="https://cdn.rawgit.com/Automattic/expect.js/0.3.1/index.js"></script>
<script src="https://cdn.rawgit.com/mochajs/mocha/2.2.5/mocha.js"></script>
<script>mocha.setup('bdd')</script>
<script src="calculator.js"></script>
<script src="test.calculator.js"></script>
<script>
mocha.checkLeaks();
mocha.run();
</script>
</body>
</html>
In the file you can see that we imported the Mocha library and expect.js library from CDN, so we don’t need to install anything locally. We’ll be testing a imaginary calculator library used in our extension. The test cases are written in the test.calculator.js file. The classes and functions under tested are placed in the calculator.js file. We load the module under test and the test case in the file as well
The way to run it is to simply open this file in a Firefox, if everything goes well you should see the following screen:

I usually put the main logic and code that interacts with extension APIs in a file named background.js. Any other business and utility functions goes into separate JS files, which are test using the above unit testing framework. They are all load together with background.js as background scripts. To do so, you need to add all of them to manifest.json like so:
{
"name": "Calculator Add-on",
...
"background": {
"scripts": [
"background.js",
"calculator.js"
]
},
...
}
Now we can write more tests like so in test.calculator.js:
describe('My calculator', function() {
it('can add 1 and 1 and get 2', function() {
var result = my_add(1, 1); // my_add is definied in calculator.js
expect(result).to.eql(2);
});
});
Run the page again, and you should see it failing, because you haven’t defined my_add yet.

Now, write your my_add in calculator.js:
function my_add(x, y) {
return x + y;
}
Run the page once again, and your test now passes.

Many WebExtension APIs return promises so you can write functions that receives and returns promises so you can chain them. The problem is that if you have and error in the Promise chain, the error will be consumed by the promise, so the test framework will not catch it, resulting in an always-passing test. Let’s say you want to write a function that counts how many times you’ve visited Facebook, you can use the browser.hisotry.getVisits() API, which returns a promise. So first we write a test for the count_visits() function we are about to write.
describe('Facebook counter', function() {
it('can count', function() {
var mock_getVisits = new Promise(function(resolve, reject) {
// Simulate the getVisits API that returns 3 results
resolve([new Object(), new Object(), new Object()]);
});
mock_getVisits
.then(count_visits)
.then(function(count){
expect(count).to.eql(3);
});
});
});
Then we implement the count_visits(), but we made a typo by writing length as legnht
function count_visits(history_items) {
return history_items.legnht;
}
In this case, the function will always return undefined, because there is no such thing as legnht for arrays. But if you run the test, you’ll find the test still passing. If you open the developer, you’ll see the actual error. But seems the test framework didn’t catch it.

The latest Mocha library already have built in promise support, you only need to make sure you return the promise so the error can be captured.
describe('Facebook counter', function() {
it('can count', function() {
var mock_getVisits = function() {
return new Promise(function(resolve, reject) {
// Simulate the getVisits API that returns 3 results
resolve([new Object(), new Object(), new Object()]);
});
};
// vvvvvv Notice the "return" here
return mock_getVisits()
.then(count_visits)
.then(function(count){
expect(count).to.eql(3);
});
});
});
Now the test fails as expected:

Another way is to use async/await to make your async function looks sync. Mocha can easily handle that as usual synchronous functions.
describe('Facebook counter', function() {
// Notice the async here vvvvv
it('can count using async/await', async function() {
var mock_getVisits = function() {
return new Promise(function(resolve, reject) {
// Simulate the getVisits API that returns 3 results
resolve([new Object(), new Object(), new Object()]);
});
}
// and await here vvvvv
var visits = await mock_getVisits();
expect(count_visits(visits)).to.eql(3)
});
});
Writing test WebExtension it’s not as hard as you might think. Simply copying and pasting the HTML and you’re ready to go. You don’t need to install anything or set up complex Node.js compiling pipeline. Start testing your WebExtension code now, it saved me many hours of debugging time, and I believe it will help you as well.
https://shinglyu.github.io/web/2018/06/24/how-to-unit-test-webextensions.html
|
|
Cameron Kaiser: TenFourFox FPR8 available |
http://tenfourfox.blogspot.com/2018/06/tenfourfox-fpr8-available-plus-scsi2sd.html
|
|
Mozilla Open Policy & Advocacy Blog: The Supreme Court Scores a Win for Privacy |
Today, in a 5-to-4 vote, the Supreme Court held that the government must get a warrant to obtain records of where someone’s cell phone has been. This might seem obvious, but it wasn’t obvious to the four Supreme Court Justices who voted against today’s decision. And, it wasn’t obvious to the Sixth Circuit Court of Appeals, whose opinion claimed that people cannot expect the general location of their cell phones to remain private because they must know cell phone companies have this data.
That’s why we submitted an amicus brief last year to encourage the Supreme Court to recognize that it no longer makes sense to assume that people give up their expectation of privacy when third parties handle their data. Today’s Supreme Court’s decision in Carpenter v. United States sets the record straight and helps the Fourth Amendment keep up to date with the realities of our modern, internet-connected lives.
For the majority of Americans, a cell phone and internet access are necessities, not options. “ The Supreme Court recognized that “[c]ell phones . . . [are] indispensable to participation in modern society.” It also held that it makes no sense to pretend that people “voluntarily” give their location to cell phone companies when cell tower location information is increasingly vast, increasingly precise, and inherent to the way cell networks function. This is especially important “[b]ecause location information is continually logged for all of the 400 million devices in the United States–not just those belonging to persons who might happen to come under investigation.”
We hope Carpenter v. United States will have implications beyond just location data. The Supreme Court described it’s decision as “a narrow one,” refusing to extend its rule to other forms of data. Still, this decision sets the stage for other courts to recognize that people have privacy expectations in the vast amounts of data that third-parties handle. And further, that the government needs to meet the higher standard of review required by a warrant in order to access this data.
At Mozilla, we understand that the Internet is an integral part of modern life, and that individuals’ online privacy should be fundamental, not optional. People rely on internet technology companies to facilitate the practical necessities of modern life, and Mozilla and many other technology companies actively work to preserve the privacy of user data. We applaud the Supreme Court’s decision to respect these efforts and keep the Fourth Amendment working for today’s digital world[1].
[1] Bonus legal history: There are a few seminal cases which have brought the Fourth Amendment into the digital age. In U.S. v. Jones (2012), the Court decided it was unconstitutional to track a person’s car with a GPS device without a warrant. Then, in Riley v. California (2014), the Court held police could not search the data on a cellphone during an arrest without a warrant. This ruling recognizes that the government needs a warrant to get the whereabouts of an individual’s location based on cell phones records.
By Michael Feldman, Product Counsel
The post The Supreme Court Scores a Win for Privacy appeared first on Open Policy & Advocacy.
https://blog.mozilla.org/netpolicy/2018/06/22/the-supreme-court-scores-a-win-for-privacy/
|
|






