About:Community: Maker Party 2016: Stand Up for a Better Internet |
Cross post from: The Mozilla Blog.
Mozilla’s annual celebration of making online is challenging outdated copyright law in the EU. Here’s how you can participate.
It’s that time of year: Maker Party.
Each year, Mozilla hosts a global celebration to inspire learning and making online. Individuals from around the world are invited. It’s an opportunity for artists to connect with educators; for activists to trade ideas with coders; and for entrepreneurs to chat with makers.
This year, we’re coming together with that same spirit, and also with a mission: To challenge outdated copyright laws in the European Union. EU copyright laws are at odds with learning and making online. Their restrictive nature undermines creativity, imagination, and free expression across the continent. Mozilla’s Denelle Dixon-Thayer wrote about the details in her recent blog post.
By educating and inspiring more people to take action, we can update EU copyright law for the 21st century.
Over the past few months, everyday internet users have signed our petition and watched our videos to push for copyright reform. Now, we’re sharing copyright reform activities for your very own Maker Party.
Want to join in? Maker Party officially kicks-off today.
Here are activities for your own Maker Party:
Be a #cczero Hero
In addition to all the amazing live events you can host or attend, we wanted to create a way for our global digital community to participate.
We’re planning a global contribute-a-thon to unite Mozillians around the world and grow the number of images in the public domain. We want to showcase what the open internet movement is capable of. And we’re making a statement when we do it: Public domain content helps the open internet thrive.
Check out our #cczero hero event page and instructions on contributing. You should be the owner of the copyright in the work. It can be fun, serious, artistic — whatever you’d like. Get started.
For more information on how to submit your work to the public domain or to Creative Commons, click here.

Post Crimes
Mozilla has created an app to highlight the outdated nature of some of the EU’s copyright laws, like the absurdity that photos of public landmarks can be unlawful. Try the Post Crimes web app: Take a selfie in front of the Eiffel Tower’s night-time light display, or the Little Mermaid in Denmark.
Then, send your selfie as a postcard to your Member of the European Parliament (MEP). Show European policymakers how outdated copyright laws are, and encourage them to forge reform. Get started.
Meme School
It’s absurd, but it’s true: Making memes may be technically illegal in some parts of the EU. Why? Exceptions for parody or quotation are not uniformly required by the present Copyright Directive.
Help Mozilla stand up for creativity, wit, and whimsy through memes! In this Maker Party activity, you and your friends will learn and discuss how complicated copyright law can be. Get started.

We can’t wait to see what you create this Maker Party. When you participate, you’re standing up for copyright reform. You’re also standing up for innovation, creativity, and opportunity online.
https://blog.mozilla.org/community/2016/10/12/maker-party-2016-stand-up-for-a-better-internet/
|
|
Air Mozilla: [Monthly Speaker Series] Metadata is the new data… and why that matters, with Harlo Holmes. |
![[Monthly Speaker Series] Metadata is the new data… and why that matters, with Harlo Holmes.](https://air.cdn.mozilla.net/media/cache/5b/cb/5bcb94566ef574e7cd9c8fa2ad9d5313.jpg) Today's proliferation of mobile devices and platforms such as Google and Facebook has exacerbated an extensive, prolific sharing about users and their behaviors in ways...
Today's proliferation of mobile devices and platforms such as Google and Facebook has exacerbated an extensive, prolific sharing about users and their behaviors in ways...
https://air.mozilla.org/monthly-speaker-series-metadata-with-harlo-holmes-2016-10-12/
|
|
Air Mozilla: The Joy of Coding - Episode 75 |
 mconley livehacks on real Firefox bugs while thinking aloud.
mconley livehacks on real Firefox bugs while thinking aloud.
|
|
Air Mozilla: Weekly SUMO Community Meeting Oct. 12, 2016 |
 This is the sumo weekly call
This is the sumo weekly call
https://air.mozilla.org/weekly-sumo-community-meeting-oct-12-2016/
|
|
Armen Zambrano: Usability improvements for Firefox automation initiative - Status update #7 |

|
|
Doug Belshaw: 5 steps to creating a sustainable digital literacies curriculum |

The following is based on my doctoral thesis, my experience as Web Literacy Lead at the Mozilla Foundation, and the work that I’ve done as an independent consultant, identifying, developing, and credentialing digital skills and literacies.
To go into more depth on this topic, check out my book, The Essential Elements of Digital Literacies.
The quotation below, illustrated by Bryan Mathers, is an African proverb that I’ve learned to be true.

The easiest thing to do, especially if you’re short of time, is to take a definition - or even a whole curriculum / scheme of work - and use it off-the-shelf. This rarely works, for a couple of reasons.
First, every context is different. Everything can look great, but the devil really is in the details of translating even very practical resources into your particular situation.
Second, because the people within your organisation or programme haven’t been part of the definition, they’re not invested in it. Why should they do something that’s been imposed upon them?
I’m a fan of Helen Beetham’s work. The diagram below is from a collaboration with Rhona Sharpe, which illustrates an important point: any digital literacies curriculum should scaffold towards digital identity.
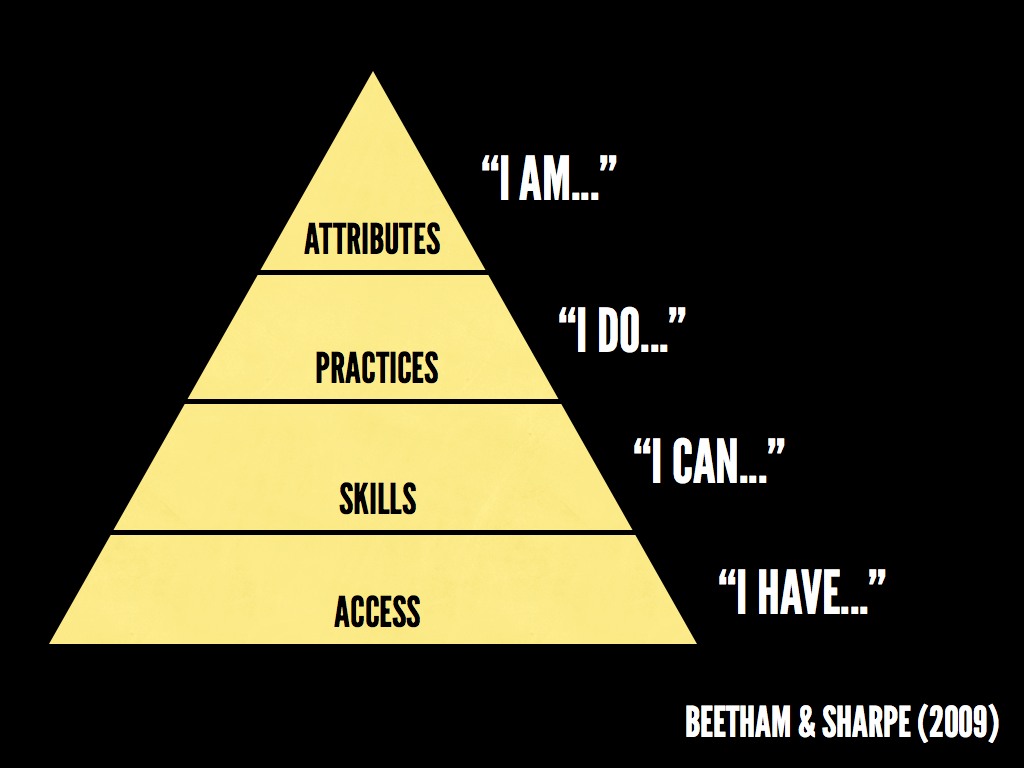
These days, we assume access (perhaps incorrectly?) and focus on skills and practices. What we need from any digital literacies curriculum is a way to develop learners’ identities.
There are obvious ways to do this - for example encourage students to create their own, independent, presence on the web. However, it’s also important to note that identities are multi-faceted, and so any digital literacies curriculum should encourage learners to develop identities in multiple places on the web. Interacting in various online communities involves different methods of expression.
We all have pressures and skillsets we need to develop immediately. Nevertheless, equally important when developing digital literacies are the mindsets behind these skillsets.
In my doctoral thesis and subsequent book I outlined eight ‘essential elements’ of digital literacies from the literature.

Whether you’re creating a course within a formal educational institution, attempting to improve the digital literacies of your colleagues in a corporate setting, or putting together a after-school programme for youth, the above skillsets and mindsets are equally applicable.
It’s all too-easy to focus on surface level skillsets without addressing underlying mindsets. Any curriculum should develop both, hand-in-hand. As for what the above elements mean, why not co-create the definitions with (representatives of) your target audience?
The stimulus for a new digital literacies curriculum can often be the recognition of an existing lack of skills. This often leads to a deficit model when it comes to developing the learning activities involved in the curriculum. In other words, the course undertaken by learners becomes just about them reaching a pre-defined standard, rather than developing their digital identity.
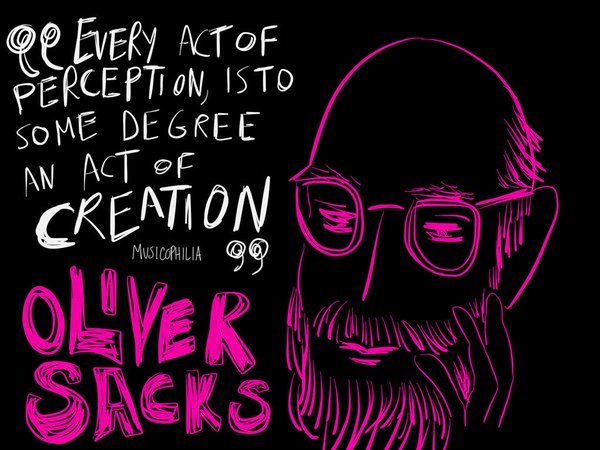
As Amy Burvall points out through the quotation in her image above, to create is to perceive the world in a different way.
If you’re developing a digital literacies curriculum and have the 'big stick’ of compliance hanging over you, then there’s ways in which you can have your carrot (and eat it, too!) By encouraging learners to create artefacts and connections as part of the learning activities, not only do you have something to demonstrate to show the success of your programme, but you are helping them become self-directed learners.
When individuals can point to something that they have created that resides online, then they move from 'elegant consumption’ to digital creation. This can be tremendously empowering.
Until recently, the most learners could expect from having completed a course on a particular subject was flimsy paper certificate, or perhaps a PDF of questionable value and validity.

All that has changed thanks to the power of the web, and Open Badges in particular. As you can discover in the Open Badges 101 course I put together with Bryan Mathers, there are many and varied ways in which you can scaffold learning.
Whether through complex game mechanics or more simple pathways, badges and microcredentialing work all the way from recognising that someone signed up for a course, through to completing it. In fact, some courses never finish, which means a never-ending way to show progression!
The value of any digital literacies curriculum depends both on the depth it goes into regarding skillsets and mindsets, but also its currency. The zeitgeist is fast-paced and ever-changing online. As a result, learning activities are likely to need to be updated regularly.

Good practice when creating a curriculum for digital literacies, therefore, is to version your work. Ensure that people know when it was created, and the number of the latest iteration. This also makes it easier when creating digital credentials that align with it.
If you take nothing else away from this post, learn this: experiment. Be as inclusive as possible, bringing people along with you. Ask people what they thing. Try new things and jettison what doesn’t work. Ensure that what you do has 'exchange value’ for your learners. Celebrate developments in their mindsets as well as their skillsets!
Questions? Comments? I’m @dajbelshaw on Twitter, or you can email me: hello@dynamicskillset.com
|
|
The Mozilla Blog: Maker Party 2016: Stand Up for a Better Internet |
Mozilla’s annual celebration of making online is challenging outdated copyright law in the EU. Here’s how you can participate
It’s that time of year: Maker Party.
Each year, Mozilla hosts a global celebration to inspire learning and making online. Individuals from around the world are invited. It’s an opportunity for artists to connect with educators; for activists to trade ideas with coders; and for entrepreneurs to chat with makers.
This year, we’re coming together with that same spirit, and also with a mission: To challenge outdated copyright laws in the European Union. EU copyright laws are at odds with learning and making online. Their restrictive nature undermines creativity, imagination, and free expression across the continent. Mozilla’s Denelle Dixon-Thayer wrote about the details in her recent blog post.
By educating and inspiring more people to take action, we can update EU copyright law for the 21st century.
Over the past few months, everyday internet users have signed our petition and watched our videos to push for copyright reform. Now, we’re sharing copyright reform activities for your very own Maker Party.
Want to join in? Maker Party officially kicks-off today. Here are activities for your own Maker Party:
Be a #cczero Hero
In addition to all the amazing live events you can host or attend, we created a way for our global digital community to participate.
We’re planning a global contribute-a-thon to unite Mozillians around the world and grow the number of images in the public domain. We want to showcase what the open internet movement is capable of. And we’re making a statement when we do it: Public domain content helps the open internet thrive.
Check out our #cczero hero event page and instructions on contributing. You should be the owner of the copyright in the work. It can be fun, serious, artistic — whatever you’d like. Get started.
For more information on how to submit your work to the public domain or to Creative Commons, click here.

Post Crimes
Mozilla has created an app to highlight the outdated nature of some of the EU’s copyright laws, like the absurdity that photos of public landmarks can be unlawful. Try the Post Crimes web app: Take a selfie in front of the Eiffel Tower’s night-time light display, or the Little Mermaid in Denmark.
Then, send your selfie as a postcard to your Member of the European Parliament (MEP). Show European policymakers how outdated copyright laws are, and encourage them to forge reform. Get started.
Meme School
It’s absurd, but it’s true: Making memes may be technically illegal in some parts of the EU. Why? Exceptions for parody or quotation are not uniformly required by the present Copyright Directive.
Help Mozilla stand up for creativity, wit, and whimsy through memes! In this Maker Party activity, you and your friends will learn and discuss how complicated copyright law can be. Get started.

We can’t wait to see what you create this Maker Party. When you participate, you’re standing up for copyright reform. You’re also standing up for innovation, creativity, and opportunity online.
https://blog.mozilla.org/blog/2016/10/11/maker-party-2016-stand-up-for-a-better-internet/
|
|
Air Mozilla: TechWomen Emerging Leader Presentations (2016) |
 As part of the TechWomen program, Mozilla has had the fortunate opportunity to host five Emerging Leaders over the past month. Estelle Ndedi (Cameroon), Chioma...
As part of the TechWomen program, Mozilla has had the fortunate opportunity to host five Emerging Leaders over the past month. Estelle Ndedi (Cameroon), Chioma...
https://air.mozilla.org/techwomen-emerging-leader-presentations-2016/
|
|
Daniel Pocock: Outreachy and GSoC 2017 opportunities in Multimedia Real-Time Communication |
I've proposed Free Real-Time Communication as a topic in Outreachy this year. The topic will also be promoted as part of GSoC 2017.
If you are interested in helping as either an intern or mentor, please follow the instructions there to make contact.
Even if you can't participate, if you have the opportunity to promote the topic in a university or any other environment where potential interns will see it, please do so as this makes a big difference to the success of these programs.
The project could involve anything related to SIP, XMPP, WebRTC or peer-to-peer real-time communication, as long as it emphasizes a specific feature or benefit for the Debian community. If other Outreachy organizations would also like to have a Free RTC project for their community, then this could also be jointly mentored.
|
|
Air Mozilla: Martes Mozilleros, 11 Oct 2016 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
|
|
Firefox Nightly: Found a regression in Firefox? Give us details with mozregression! |
One of the most useful things you can do to help improve the quality for Firefox is to warn developers about regressions and give them all the details that will turn your issue into a useful actionable bug report.
This is actually the raison d’^etre of Nightly builds: parallelizing the work done by our communities of testers and developpers so as to catch regressions as early as possible and provide a feedback loop to developers in the early stages of development.
Complementary to nighly builds, we also have a nifty Python command line tool called mozregression (with an experimental GUI version but that will be for another post…) that allows a tester to easily find when a regression happened and what code changes are likely to have introduced the regression. This tool is largely the result of the awesome work of Julien Pag`es, William Lachance, Heather Arthur and Mike Ling!
tl;dr for people that do Python:
mozregression is a python package installable via pip, preferably in a virtualenv.
The installation steps detailed for mozregression on their documentation site are a bit short on details and tell you to install the tool with admin rights on linux/mac (sudo) which is not necessarily a good idea since we don’t want to potentially create conflicts with other python tools installed on your system and that may have different dependencies.
I would instead install mozregression in a virtualenv so as to isolate it from your OS, it works the same, avoids breaking something else on your OS and AFAIK, there is no advantage to having mozregression installed as a global package except of course having it available for all accounts on your system.
The installation steps in a terminal are those:
sudo apt install python-pip virtualenvwrapper
echo 'export WORKON_HOME=~/.virtualenvs' >> ~/.bashrc
source ~/.bashrc
mkvirtualenv mozreg
pip install mozregression
mozregression --write-config
Here are line by line explanations because understanding is always better than copy-pasting and you may want to adapt those steps with your own preferences:
sudo apt install python-pip virtualenvwrapper» Install the software needed to install python packages (pip) as well as the tool to create virtual environments for Python, the packae names here are for Debian-based distros.
echo 'export WORKON_HOME=~/.virtualenvs' >> ~/.bashrc» Add to your bash config (adapt the destination if you use another shell) an environment variable indicating where your virtualenvs are stored in your home.
source ~/.bashrc» Reload your updated .bashrc settings
mkvirtualenv mozreg» Create a virtualenv called mozreg in ~/.virtualenvs/mozreg/. Your terminal should get the name of this virtualenv prepended to your terminal prompt such as (mozreg) ~ $>, that means you are in this virtualenv now.
pip install mozregression» The previous step activated the mozreg virtualenv automatically, this step installs mozregression in ~/.virtualenvs/mozreg/lib/python2.7/site-packages/mozregression
mozregression --write-config» In this final installation step, we are creating a configuration file for mozregression, the defaults are fine and detailed here.
Now that mozregression is installed in a virtualenv, first you need to know how to activate/deactivate your virtualenv.
As said previously, if you are already in your virtualenv, your terminal prompt will have (mozreg) mentionned. If you want to exit your virtualenv, type:
deactivateIf you are not in your virtualenv, you can enter it with this command:
workon mozregYou can now use mozregression following the Quick Start steps in the documentation but basically it boils down to indicating a good and a bad date for Firefox and the bad date is optional, so if you found a regression in Nightly that you know didn’t exist in say Firefox 49, launching mozregression is as easy as:
mozregression --good 49 Then test the nightly builds that mozregression downloads for you and indicate in the terminal ‘good’ or ‘bad’ for every build you try until the regression is found and you will get a message such as:
INFO: Last good revision: e3cff5e3ae3cc1b20d4861e7934e54c9e407a750
INFO: First bad revision: 5194eeb6ca2d34b5fca72d2a78d6a9ec95a36763
INFO: Pushlog:
https://hg.mozilla.org/integration/autoland/pushloghtml?fromchange=e3cff5e3ae3cc1b20d4861e7934e54c9e407a750&tochange=5194eeb6ca2d34b5fca72d2a78d6a9ec95a36763
INFO: Looks like the following bug has the changes which introduced the regression:
https://bugzilla.mozilla.org/show_bug.cgi?id=1296280The above text is what you should paste in the bug (for the record, this specific example is copied from bug 1307060), this is the information that will make your bug report actionable by a developer.
Mozregression is a tool that allows power-users with no development skills to participate actively in the development of Firefox.
Providing such information to developers saves them a lot of time and most importantly, it allows bugzilla triagers to put the right developers in copy of the bug (“Hey Anne, it seems your patch in Bug XXX caused the regression described in this bug, could you have a look please?”)
Being a developer is not the only way you can help Firefox being a better browser, any advanced user able to use a terminal on his machine can participate, so don’t hesitate, file bugs and become a regression range finder!
|
|
Air Mozilla: Mozilla Curriculum Workshop: Ada Lovelace Day |
 Join us for this special Ada Lovelace Day webcast of the Mozilla Curriculum Workshop as we recognize the challenges, work and contributions of women leaders...
Join us for this special Ada Lovelace Day webcast of the Mozilla Curriculum Workshop as we recognize the challenges, work and contributions of women leaders...
https://air.mozilla.org/mozilla-curriculum-workshop-ada-lovelace-day-2016-10-11/
|
|
Daniel Stenberg: poll on mac 10.12 is broken |
When Mac OS X first launched they did so without an existing poll function. They later added poll() in Mac OS X 10.3, but we quickly discovered that it was broken (it returned a non-zero value when asked to wait for nothing) so in the curl project we added a check in configure for that and subsequently avoided using poll() in all OS X versions to and including Mac OS 10.8 (Darwin 12). The code would instead switch to the alternative solution based on select() for these platforms.
With the release of Mac OS X 10.9 “Mavericks” in October 2013, Apple had fixed their poll() implementation and we’ve built libcurl to use it since with no issues at all. The configure script picks the correct underlying function to use.
Enter macOS 10.12 (yeah, its not called OS X anymore) “Sierra”, released in September 2016. Quickly we discovered that poll() once against did not act like it should and we are back to disabling the use of it in preference to the backup solution using select().
The new error looks similar to the old problem: when there’s nothing to wait for and we ask poll() to wait N milliseconds, the 10.12 version of poll() returns immediately without waiting. Causing busy-loops. The problem has been reported to Apple and its Radar number is 28372390. (There has been no news from them on how they plan to act on this.)
poll() is defined by POSIX and The Single Unix Specification it specifically says:
If none of the defined events have occurred on any selected file descriptor, poll() waits at least timeout milliseconds for an event to occur on any of the selected file descriptors.
We pushed a configure check for this in curl, to be part of the upcoming 7.51.0 release. I’ll also show you a small snippet you can use stand-alone below.
Apple is hardly alone in the broken-poll department. Remember how Windows’ WSApoll is broken?
Here’s a little code snippet that can detect the 10.12 breakage:
#include
#include
#include https://daniel.haxx.se/blog/2016/10/11/poll-on-mac-10-12-is-broken/
|
|
Hannes Verschore: Performance improvements to tracelogger |
Tracelogger is a tool to create traces of the JS engine to investigate or visualize performance issues in SpiderMonkey. Steve Fink has recently been using it to dive into google docs performance and has been hitting some road blocks. The UI became unresponsive and crashing the browser wasn’t uncommon. This is unacceptable and it urged me to improve the performance!

I looked at the generated log files which were not unacceptable large. The log itself contained 3 million logged items, while I was able to visualize 12 million logged items. The cheer number of logged items was not the cause. I knew that creating the fancy graphs were also not the problem. They have been optimized quite heavily already. That only left the overview as a possible problem.
The overview pane gives an overview of the engines / sub parts we spend time in. Beneath it we see the same, but for the scripts. The computation of this runs in a web worker to not make the browser unresponsive. Once in a while the worker gives back the partial result which the browser renders.
The issue was in the rendering of the partial result. We update this table every time the worker has finished a chunk. Generating the table is generally fast for the workloads I was testing, since there weren’t a lot of different scripts. Though running the full browser gave a lot of different scripts. As a result updating the table became a big overhead. Also you need to know this could happen every 1ms.
The first fix was to make sure we only update this table every 100ms. This is a nice trade-off between seeing the newest information and not making the browser unresponsive. This resulted in far fewer calls to update the table. Up to 100x less.
The next thing I did was to delay the creation of the table. Instead of creating a table it now shows a textual representation of the data. Only upon when the computation is complete it will show the sortable table. This was 10x to 100x faster.

In most cases the UI is now possible to generate the temporary view in 1ms. Though I didn’t want to take any chances. As a result if generating the temporary view takes longer than 100ms it will stop live updating the temporary view and only show the result when finished.
Lastly I also fixed a memory issue. A tracelog log is a tree of where time is spend. This is parsed breadth-first. That is better since it will give a quite good representation quite quickly, even if all the small logged items are not processed yet. But this means the UI needs to keep track of which items will get processed in the next round. This list of items could get unwieldy large. This is now solved by switching to dept-first traversal when that happens. Dept-first traversal needs no additional state to traverse the tree. In my testcase it previously went to 2gb and crashed. With this change the maximum needed memory I saw was 1.2gb and no crash.
Everything has landed in the github repo. Everybody using the tracelogger is advised to pull the newest version and experience the improved performance. As always feel free to report new issues or to contribute in making tracelogger even better.
|
|
Wil Clouser: testpilot.firefox.com just got a lot easier to work on |
We originally built Test Pilot on top of Django and some JS libraries to fulfill our product requirements as well as keep us flexible enough to evolve quickly since we were a brand new site.
As the site has grown, we've dropped a few requirements, and realized that we were using APIs from our engagement team to collect newsletter sign ups, APIs from our measurement team for our metrics, and everything else on the site was essentially HTML and JS. We used the Django scaffolding for updating the experiments, but there was no reason we needed to.
I'm happy to highlight that as of today testpilot.firefox.com is served 100% statically. Moving to flat files means:
Easier to deploy. All we do is copy files to an S3 bucket. No more SQL migrations or strange half-pushed states.
More secure. With just flat files we have way less surface area to attack.
Easier to participate in. You'll no longer need to set up Docker or a
database. Just check out the files, run npm install and you're done.
(disclaimer: we just pushed this today, so we actually still need to update
the documentation)
Excellent change control. Instead of using an admin panel on the site, we now use GitHub to manage our static content. This means all changes are tracked for free, we already have a process in place for reviewing pull requests, and it's easy to roll back or manipulate the data because it's all in the repository already.
If you want to get involved with Test Pilot, come join us in #testpilot (or webchat)!
http://micropipes.com/blog//2016/10/11/test-pilot-just-got-easier-to-work-on/
|
|
Shing Lyu: Mutation Testing in JavaScript Using Stryker |
Earlier this year, I wrote a blog post introducing Mutation Testing in JavaScript using the Grunt Mutation Testing framework. But as their NPM README said,
We will be working on (gradually) migrating the majority of the code base to the Stryker.
So I’ll update my post to use the latest Stryker framework. The following will be the updated post with all the code example migrated to the Stryker framework:
Last November (2015) I attended the EuroStar Software Testing Conference, and was introduced to a interesting idea called mutation testing. Ask yourself: “How do I ensure my (automated) unit test suite is good enough?”. Did you miss any important test? Is your test always passing so it didn’t catch anything? Is there anything un-testable in your code such that your test suite can never catch it?
Mutation testing tries to “test your tests” by deliberately inject faults (called “mutants”) into your program under test. If we re-run the tests on the crippled program, our test suite should catch it (i.e. some test should fail.) If you missed some test, the error might slip through and the test will pass. Borrowing terms from Genetics, if the test fails, we say the mutant is “killed” by the test suite; on the opposite, if the tests passes, we say the mutant survived.
The goal of mutation testing is to kill all mutants by enhancing the test suite. Although 100% kill is usually impossible for even small programs, any progress on increasing the number can still benefit your test a lot.
The concept of mutation testing has been around for quite a while, but it didn’t get very popular because of the following reasons: first, it is slow. The number of possible mutations are just too much, re-compiling (e.g. C++) and re-run the test will take too long. Various methods has been proposed to lower the number of tests we need to run without sacrifice the chance of finding problems. The second is the “equivalent mutation” problem, which we’ll discuss in more detail in the examples.
There are many existing mutation testing framework. But most of them are for languages like Java, C++ or C#. Since my job is mainly about JavaScript (both in browser and Node.js), I wanted to run mutation testing in JavaScript.
I have found a few mutation testing frameworks for JavaScript, but they are either non-open-source or very academic. The most mature one I can find so far is the Stryker framework, which is released under Apache 2.0 license.
This framework supports mutants like changing the math operators, changing logic operators or even removing conditionals and block statements. You can find a full list of mutations with examples here.
You can follow the quickstart guide to install everything you need. The guide has a nice interactive menu so you can choose your favorite build system, test runner, test framework and reporting format. In this blog post I’ll demonstrate with my favorite combination: Vanilla NPM + Mocha + Mocha + clear-text.
You’ll need node and npm installed. (I recommended using nvm).
There are a few Node packages you need to install,
sudo npm install -g --save-dev mocha
npm install --save-dev stryker styker-api stryker-mocha-runnerHere are the list of packaged that I’ve installed:
"devDependencies": {
"mocha": "^2.5.3",
"stryker": "^0.4.3",
"stryker-api": "^0.2.0",
"stryker-mocha-runner": "^0.1.0"
}I created a simple program in src/calculator.js, which has two functions:
// ===== calculator.js =====
function substractPositive(num1, num2){
if (num1 > 0){
return num1 - num2;
}
else {
return 0
}
}
function add(num1, num2){
if (num1 == num2){
return num1 + num2;
}
else if (num1 num2){
return num1 + num2;
}
else {
return num1 + num2;
}
}
module.exports.substractPositive = substractPositive
module.exports.add = add;The first function is called substractPositive, it substract num2 from num1 if num1 is a positive number. If num1 is not positive, it will return 0 instead. It doesn’t make much sense, but it’s just for demonstrative purpose.
The second is a simple add function that adds two numbers. It has a unnecessary if...else... statement, which is also used to demonstrate the power of mutation testing.
The two functions are tested using test/test_calculator.js:
var assert = require("assert");
var cal = require("../src/calculator.js")
describe("Calculator", function(){
it("substractPositive", function(){
assert.equal("2", cal.substractPositive(1, -1));
});
it("add", function(){
assert.equal("2", cal.add(1, 1));
});
})This is a test file running using mocha, The first verifies substractPositive(1, -1) returns 2. The second tests add(1,1) produces 2. If you run mocha in your commandline, you’ll see both the test passes. If you run mocha in the commandline you’ll see the output:
% mocha
Calculator
https://shinglyu.github.io/testing/2016/10/11/Mutation_Testing_in_JavaScript_Using_Stryker.html
|
|
Nick Cameron: Macros (and syntax extensions and compiler plugins) - where are we at? |
Procedural macros are one of the main reasons Rust programmers use nightly rather than stable Rust, and one of the few areas still causing breaking changes. Recently, part of the story around procedural macros has been coming together and here I'll explain what you can do today, and where we're going in the future.
TL;DR: as a procedural macro author, you're now able to write custom derive implementations which are on a fast track to stabilisation, and to experiment with the beginnings of our long-term plan for general purpose procedural macros. As a user of procedural macros, you'll soon be saying goodbye to bustage in procedural macro libraries caused by changes to compiler internals.
Macros are an important part of Rust. They facilitate convenient and safe functionality used by all Rust programmers, such as println! and assert!; they reduce boilerplate, and make implementing traits trivial via derive. They also allow libraries to provide interesting and unusual abstractions.
However, macros are a rough corner - declarative macros (macro_rules macros) have their own system for modularisation, a fiddly syntax for declarations, and some odd rules around hygiene. Procedural macros (aka syntax extensions, compiler plugins) are unstable and painful to use. Despite that, they are used to implement some core parts of the ecosystem, including serialisation, and this causes a great deal of friction for Rust users who have to use nightly Rust or clunky build systems, and either way get hit with regular upstream breakage.
We strongly want to improve this situation. Our current priority is procedural macros, and in particular the parts of the procedural macro system which force Rust users onto nightly or cause recurring upstream errors.
Our goal is an expressive, powerful, and well-designed system that is as stable as the rest of the language. Design work is ongoing in the RFC process. We have accepted RFCs on naming and custom derive/macros 1.1, there are open RFCs on the overall design of procedural macros, attributes, etc., and probably several more to come, in particular about the libraries available to macro authors.
One of the core innovations to the procedural macro system is to base our macros on tokens rather than AST nodes. The AST is a compiler-internal data structure; it must change whenever we add new syntax to the compiler, and often changes even when we don't due to refactoring, etc. That means that macros based on the AST break whenever the compiler changes, i.e., with every new version. In contrast, tokens are mostly stable, and even when they must change, that change can easily be abstracted over.
We have begun the implementation of token-based macros and today you can experiment with them in two ways: by writing custom derive implementations using macros 1.1, and within the existing syntax extension framework. At the moment these two features are quite different, but as part of the stabilisation process they should become more similar to use, and share more of their implementations.
Even better for many users, popular macro-based libraries such as Serde are moving to the new macro system, and crates using these libraries should see fewer errors due to changes to the compiler. Soon, users should be able to use these libraries from stable Rust.
The derive attribute lets programmers implement common traits with minimal boilerplate, typically generating an impl based on the annotated data type. This can be used with Eq, Copy, Debug, and many other traits. These implementations of derive are built in to the compiler.
It would be useful for library authors to provide their own, custom derive implementations. This was previously facilitated by the custom_derive feature, however, that is unstable and the implementation is hacky. We now offer a new solution based on procedural macros (often called 'macros 1.1', RFC, tracking issue) which we hope will be on a fast path to stabilisation.
The macros 1.1 solution offers the core token-based framework for declaring and using procedural macros (including a new crate type), but only a bare-bones set of features. In particular, even the access to tokens is limited: the only stable API is one providing conversion to and from strings. Keeping the API surface small allows us to make a minimal commitment as we continue iterating on the design. Modularization and hygiene are not covered, nevertheless, we believe that this API surface is sufficient for custom derive (as evidenced by the fact that Serde was easily ported over).
To write a macros 1.1 custom derive, you need only a function which takes and returns a proc_macro::TokenStream, you then annotate this function with an attribute containing the name of the derive. E.g., #[proc_macro_derive(Foo)] will enable #[derive(Foo)]. To convert between TokenStreams and strings, you use the to_string and parse functions.
There is a new kind of crate (alongside dylib, rlib, etc.) - a proc-macro crate. All macros 1.1 implementations must be in such a crate.
To use, you import the crate in the usual way using extern crate, and annotate that statement with #[macro_use]. You can then use the derive name in derive attributes.
(These examples will need a pretty recent nightly compiler).
Macro crate (b.rs):
#![feature(proc_macro, proc_macro_lib)]
#![crate_type = "proc-macro"]
extern crate proc_macro;
use proc_macro::TokenStream;
#[proc_macro_derive(B)]
pub fn derive(input: TokenStream) -> TokenStream {
let input = input.to_string();
format!("{}\n impl B for A {{ fn b(&self) {{}} }}", input).parse().unwrap()
}
Client crate (client.rs):
#![feature(proc_macro)]
#[macro_use]
extern crate b;
trait B {
fn b(&self);
}
#[derive(B)]
struct A;
fn main() {
let a = A;
a.b();
}
To build:
rustc b.rs && rustc client.rs -L .
When building with Cargo, the macro crate must include proc-macro = true in its Cargo.toml.
Note that token-based procedural macros are a lower-level feature than the old syntax extensions. The expectation is that authors will not manipulate the tokens directly (as we do in the examples, to keep things short), but use third-party libraries such as Syn or Aster. It is early days for library support as well as language support, so there might be some wrinkles to iron out.
To see more complete examples, check out derive(new) or serde-derive.
As mentioned above, we intend for macros 1.1 custom derive to become stable as quickly as possible. We have just entered FCP on the tracking issue, so this feature could be in the stable compiler in as little as 12 weeks. Of course we want to make sure we get enough experience of the feature in libraries, and to fix some bugs and rough edges, before stabilisation. You can track progress in the tracking issue. The old custom derive feature is in FCP for deprecation and will be removed in the near-ish future.
If you are already a procedural macro author using the syntax extension mechanism, you might be interested to try out token-based syntax extensions. These are new-style procedural macros with a tokens -> tokens signature, but which use the existing syntax extension infrastructure for declaring and using the macro. This will allow you to experiment with implementing procedural macros without changing the way your macros are used. It is very early days for this kind of macro (the RFC hasn't even been accepted yet) and there will be a lot of evolution from the current feature to the final one. Experimenting now will give you a chance to get a taste for the changes and to influence the long-term design.
To write such a macro, you must use crates which are part of the compiler and thus will always be unstable, eventually you won't have to do this and we'll be on the path to stabilisation.
Procedural macros are functions and return a TokenStream just like macros 1.1 custom derive (note that it's actually a different TokenStream implementation, but that will change). Function-like macros have a single TokenStream as input and attribute-like macros take two (one for the annotated item and one for the arguments to the macro). Macro functions must be registered with a plugin_registrar.
To use a macro, you use #![plugin(foo)] to import a macro crate called foo. You can then use the macros using #[bar] or bar!(...) syntax.
Macro crate (foo.rs):
#![feature(plugin, plugin_registrar, rustc_private)]
#![crate_type = "dylib"]
extern crate proc_macro_plugin;
extern crate rustc_plugin;
extern crate syntax;
use proc_macro_plugin::prelude::*;
use syntax::ext::proc_macro_shim::prelude::*;
use rustc_plugin::Registry;
use syntax::ext::base::SyntaxExtension;
#[plugin_registrar]
pub fn plugin_registrar(reg: &mut Registry) {
reg.register_syntax_extension(token::intern("foo"),
SyntaxExtension::AttrProcMacro(Box::new(foo_impl)));
reg.register_syntax_extension(token::intern("bar"),
SyntaxExtension::ProcMacro(Box::new(bar)));
}
fn foo_impl(_attr: TokenStream, item: TokenStream) -> TokenStream {
let _source = item.to_string();
lex("fn f() { println!(\"Good bye!\"); }")
}
fn bar(_args: TokenStream) -> TokenStream {
lex("println!(\"Hello!\");")
}
Client crate (client.rs):
#![feature(plugin, custom_attribute)]
#![plugin(foo)]
#[foo]
fn f() {
println!("Hello world!");
}
fn main() {
f();
bar!();
}
To build:
rustc foo.rs && rustc client.rs -L .
There is a lot of work still to do, stabilisation is going to be a long haul. Declaring and importing macros should end up very similar to custom derive with macros 1.1 - no plugin registrar. We expect to support full modularisation too. We need to provide, and then iterate on, the library functionality that is available to macro authors from the compiler. We need to implement a comprehensive hygiene scheme. We then need to gain experience and confidence with the system, and probably write some more RFCs.
However! The basic concept of tokens -> tokens macros will remain. So even though the infrastructure for building and declaring macros will change, the macro definitions themselves should be relatively future proof. Mostly, macros will just get easier to write (so less reliance on external libraries, or those libraries can get more efficient) and potentially more powerful.
We intend to deprecate and remove the MultiModifier and MultiDecorator forms of syntax extension. It is likely there will be a long-ish deprecation period to give macro authors opportunity to move to the new system.
This post has been focused on procedural macros, but we also have plans for declarative macros. However, since these are stable and mostly work, these plans are lower priority and longer-term. The current idea is that there will be new kind of declarative macro (possibly declared using macro! rather than macro_rules!); macro_rules macros will continue working with no breaking changes. The new declarative macros will be different, but we hope to keep them mostly backwards compatible with existing macros. Expect improvements to naming and modularisation, hygiene, and declaration syntax.
Thanks to Alex Crichton for driving, designing, and implementing (which, in his usual fashion, was done with eye-watering speed) the macros 1.1 system; Jeffrey Seyfried for making some huge improvements to the compiler and macro system to facilitate the new macro designs; Cameron Swords for implementing a bunch of the TokenStream and procedural macros work; Erick Tryzelaar, David Tolnay, and Sean Griffin for updating Serde and Diesel to use custom derive, and providing valuable feedback on the designs; and to everyone who has contributed feedback and experience as the designs have progressed.
This post was also posted on users.r-l.o, if you want to comment or discuss, please do so there.
http://www.ncameron.org/blog/macros-and-syntax-extensions-and-compiler-plugins-where-are-we-at/
|
|
Daniel Pocock: DVD-based Clean Room for PGP and PKI |
There is increasing interest in computer security these days and more and more people are using some form of PKI, whether it is signing Git tags, signing packages for a GNU/Linux distribution or just signing your emails.
There are also more home networks and small offices who require their own in-house Certificate Authority (CA) to issue TLS certificates for VPN users (e.g. StrongSWAN) or IP telephony.
Back in April, I started discussing the PGP Clean Room idea (debian-devel discussion and gnupg-users discussion), created a wiki page and started development of a script to build the clean room ISO using live-build on Debian.
Keeping the master keys completely offline and putting subkeys onto smart cards and other devices dramatically lowers the risk of mistakes and security breaches. Using a read-only DVD to operate the clean-room makes it convenient and harder to tamper with.
It is fairly easy to clone the Git repository, run the script to create the ISO and boot it in VirtualBox to see what is inside:
At the moment, it contains a number of packages likely to be useful in a PKI clean room, including GnuPG, smartcard drivers, the lightweight pki utility from StrongSWAN and OpenSSL.
I've been trying it out with an SPR-532, one of the GnuPG-supported smartcard readers with a pin-pad and the OpenPGP card.

More confident users will be able to build the ISO and use it immediately by operating all the utilities from the command line. For example, you should be able to fully configure PGP smart cards by following this blog from Simon Josefsson.
The ISO includes some useful scripts, for example, create-raid will quickly partition and RAID a set of SD cards to store your master key-pair offline.
To make PGP accessible to a wider user-base and more convenient for those who don't use GnuPG frequently enough to remember all the command line options, it would be interesting to create a GUI, possibly using python-newt to create a similar look-and-feel to popular text-based installer and system administration tools.
If you are keen on this project and would like to discuss it further, please come and join the new pki-clean-room mailing list and feel free to ask questions or share your thoughts about it.
One way to proceed may be to recruit an Outreachy or GSoC intern to develop the UI. Before they can get started, it would be necessary to more thoroughly document workflow requirements.
https://danielpocock.com/dvd-based-clean-room-for-pgp-and-pki
|
|
Joel Maher: Working towards a productive definition of “intermittent orange” |
Intermittent Oranges (tests which fail sometimes and pass other times) are an ever increasing problem with test automation at Mozilla.
While there are many common causes for failures (bad tests, the environment/infrastructure we run on, and bugs in the product)
we still do not have a clear definition of what we view as intermittent. Some common statements I have heard:
These are imply much different definitions of what is intermittent, a definition will need to:
Given the fact that I wanted to have a clear definition of what we are working with, I looked over 6 months (2016-04-01 to 2016-10-01) of OrangeFactor data (7330 bugs, 250,000 failures) to find patterns and trends. I was surprised at how many bugs had <10 instances reported (3310 bugs, 45.1%). Likewise, I was surprised at how such a small number (1236) of bugs account for >80% of the failures. It made sense to look at things daily, weekly, monthly, and every 6 weeks (our typical release cycle). After much slicing and dicing, I have come up with 4 buckets:
Alternatively, we could simplify our definitions and use:
Does defining these buckets about the number of failures in a given time window help us with what we are trying to solve with the definition?
One other way to look at this is what does gets put in bugs (war on orange bugzilla robot). There are simple rules:
Lastly I would like to cover some exceptions and how some might see this flawed:
I do not believe adjusting a definition will fix the above issues- possibly different tools or methods to run the tests would reduce the concerns there.

|
|
Air Mozilla: Mozilla Weekly Project Meeting, 10 Oct 2016 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20161010/
|
|






