Mozilla Open Design Blog: Fine Tuning |
At the Brand New Conference in Nashville two weeks ago, we shared a snapshot of our progress and posted the designs here simultaneously. About 100 graphic designers and brand experts stayed after our presentation to share some snacks and their initial reactions.
Since then, we’ve continued to refine the work and started to gather feedback through quantitative testing, reflecting the great advice and counsel we’ve received online and in person. While we’ve continued to work on all four designs, Dino 2.0 and Flame show the most dramatic progress in response to feedback from conference attendees and Mozillians. We wanted to refine these designs prior to testing with broader audiences.
Meet Dino 2.1
Our early work on Dino 2.0 focused on communicating that Mozilla is opinionated, bold, and unafraid to be different. Embodying the optimism and quirkiness of our culture, the minimalist design of this dinosaur character needed to extend easily to express our wide array of programs, communities, events, and initiatives. Dino 2.0 met the challenge.
On the other hand, the character’s long jaw reminded some commenters of an alligator and others of a red stapler. Colleagues also pointed out that it’s playfulness might undermine serious topics and audiences. Would we be less believable showing up to testify about encryption with a dino logo smiling from our briefcases?
So the dinosaur has continued to evolve. A hand-cut font helps shorten the jaw while a rounder outline shifts the mis-perception that we sell office supplies. After much debate, we also decided to make the more serious Mozilla portion – the upper part of the jaw – the core mark.



Wait, does that doom the dino character? Not at all.
Since the bulk of our Mozilla brand expression occurs on screens, this shift would allow the animated dino to show an even wider range of emotions. Digitally, the core mark can come to life and look surprised, hungry, or annoyed as the situation warrants, without having those expressions show up on a printed report to Congress. And our communities would still have the complete Dino head to use as part of their own self expression.
Should Dino 2.1 end up as one of our finalists, we’ll continue to explore its expressions. Meanwhile, let us know what you think of this evolution.
Making Flame eternal.
The ink was still moist on Flame, our newest design direction, when we shared it in Nashville. We felt the flame metaphor was ideal for Mozilla, referencing being a torch-bearer for an equal, accessible internet, and offering a warm place for community to gather. Even so, would a newcomer seeing our name next to a traditional flame assume we were a religious organization? Or a gas company? We needed a flame that was more of the Web and more our own.
So we asked: what if our core mark was in constant motion — an eternal flame that represents and reinforces our purpose? Although we haven’t landed on the exact Flame or the precise font, we are on a better design path now.



Should the Flame make it into our final round, we will continue to explore different flame motions, shapes, and static resting states, along with a flexible design system. Tell us what you think so far.
What about Protocol 2.0 and Burst? We’ve shifted Protocol 2.0 from Lubalin to an open source font, Arvo Bold, to make it more readily available globally. We continue to experiment with Burst in smaller sizes (with reduced spokes) and as a means to visualize data. All four designs are still in the running.

Testing 1,2,3.
This week begins our quantitative consumer testing in five global markets. Respondents in our target audience will be asked to compare just one of the four designs to a series of brand attributes for Mozilla, including Unique, Innovative, Inclusive, and others. We have also shared a survey to all Mozillians with similar questions plus a specific ask to flag any cultural bias. And since web developers are a key audience for us, we’ve extended the survey through the Mozilla Developer Network as well.
This research phase will provide additional data to help us select our final recommendation. It will help us discern, for instance, which of these four pathways resonates best with which segment of our audience. The findings will not be the only factor in our decision-making. Comments from the blog and live crit sessions, our 5-year strategic goals as an organization, and other factors will weigh into the decision.
We’ll share our top-level research findings and our rationale for proceeding as we go. Continued refinement will be our next task for the route(s) selected in this next round, so your insights and opinions are still as valuable as ever.
Thanks again to everyone who has taken the time to be a part of this review process. Three cheers for Open Design!
|
|
Tarek Ziad'e: Lyme Disease & Running |
I am writing this blog post to share what happened to me, and make more people aware of that vicious illness.
If you don't know about Lyme, read up here: https://en.wikipedia.org/wiki/Lyme_disease
I am writing this blog post to share what happened to me, and make more people aware of that vicious illness. I've contracted the Lyme Disease a year ago and got gradually sick without knowing what was happening to me at first.
I am a avid runner and I live in a forest area. I do a lot of trail running and that exposes me to ticks. Winters are warmer these days and ticks are just craving to bite mammals.
On my case, I got bitten in the forest last summer by many ticks I've removed, and a week after, without making the link between the two events I got a full week of heavy fever. I did a bunch of tests back then including Lyme and we could not find what was happening. Just that my body was fighting something.
Then life went on and one month after that happened, I had a Erythema under the armpit that grew on half the torso.
I went back to the doctor, did some tests, and everything was negative again and life went on. The Erythema dissipated eventually.
About 3 months ago, I started to experience extreme eyes fatigue and muscle soreness. I blamed the short nights because of our new-born baby and I blamed over-training. But cutting the training down and sleeping more did not help.
This is where it gets interesting & vicious: for me, everything looked like my body was gradually reacting to over-training. I went to the osteopath and he started to tell me that I was simply doing too much, not stretching enough. etc. Every time I mentioned Lyme, people were skeptical. It's very weird how some doctors react when you tell them that it could be that.
This disease is not really known and since its symptoms are so different from one individual to the other due to its auto-immune behavior, some doctors will just end up saying you have psychosomatic reactions.
Yeah, doctors will end up telling you that it's all in your head just so they don't face their ignorance. Some Lyme victims turn nuts because of that. Suicides are happening in worst cases.
At some point, I felt like I simply broke my body with all those races I am doing. I felt 80 years old. Doing a simple 30 minutes endurance run would feel like doing a Marathon.
And I went to another doctor and did a new blood test to eventually discover I had late Lyme disease (probably phase 2) - that's when the borellia gets into your muscle/tendons/nerves.
I took me almost one year to get the confirmation. Right before I got that test result I really thought I had a cancer or something really bad. That is the worst: not knowing what's happening to you, and seeing your body degrading without being able to know what to do.
They gave me the usual 3 weeks of heavy antibiotics. I felt like crap the first week. Sometime raising my arm would be hard. But by the end of the 3 weeks, I felt much better and it looked like I was going to be ok.
After the 3 weeks ended, symptoms were back and I went to the hospital to see a neurologist that seemed to know a bit about Lyme. He said that I was probably having post Lyme symptoms, which is pretty common. e.g. your body continues to fight for something that's not there anymore. And that can last for months.
And the symptoms are indeed gradually fading out, like how they came.
I am just so worried about developing a chronic form. We'll see.
The main problem in my story is that my doctor did not give me some antibiotics when I had the Erythema. That was a huge mistake. Lyme is easy to get rid off when you catch it early. And it should be a no-brainer. Erythema == antibiotics.
Anyways, some pro tips so you don't catch that crap on trails:
|
|
QMO: Firefox 50 Beta 3 Testday Results |
Hello Mozillians!
As you may already know, last Friday – September 30th – we held a new Testday event, for Firefox 50 Beta 3.
Thank you all for helping us making Mozilla a better place – Julie Myers, Logicoma, Tayba Wasim, Nagaraj V, Suramya Shah, Iryna Thompson, Moin Shaikh, Dragota Rares, Dan Martin, P Avinash Sharma.
From Bangladesh: Hossain Al Ikram, Azmina Akter Papeya, Nazir Ahmed Sabbir, Saddam Hossain, Aminul Islam Alvi, Raihan Ali, Rezaul Huque Nayeem, Md. Rahimul Islam, Sayed Ibn Masud, Roman Syed, Maruf Rahman, Tovikur Rahman, Md. Rakibul Islam, Siful Islam Joy, Sufi Ahmed Hamim, Md Masudur-Rahman, Niaz Bhuiyan Asif, Akash Kishor Sarker, Mohammad Maruf Islam, MD Maksudur Rahman, M Eftekher Shuvo, Tariqul Islam Chowdhury, Abdullah Al Jaber Hridoy, Md Sajib Mullla, MD. Almas Hossain, Rezwana islam ria, Roy Ayers, Nzmul Hossain, Md. Nafis Fuad, Fahim.
From India: Vibhanshu Chaudhary, Subhrajyoti Sen, Bhuvana Meenakshi K, Paarttipaabhalaji, Nagaraj V, Surentharan.R.A, Rajesh . D, Pavithra.R.
A big thank you goes out to all our active moderators too!
Results:
https://quality.mozilla.org/2016/10/firefox-50-beta-3-testday-results/
|
|
This Week In Rust: This Week in Rust 150 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.

 Announcing Rust 1.12.
Announcing Rust 1.12. No crate was selected for CotW.
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
181(!) pull requests were merged in the last week.
#[may_dangle].ExactSizeIterator from RangeInclusive<{u,i}{32,size}>. Breaking-change for some nightly users.Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
loop { ... } expression return a value via break my_value;.If you are running a Rust event please add it to the calendar to get it mentioned here. Email the Rust Community Team for access.
No jobs listed for this week.
Tweet us at @ThisWeekInRust to get your job offers listed here!
Our community likes to recognize people who have made outstanding contributions to the Rust Project, its ecosystem, and its community. These people are 'friends of the forest'.
This week's friends of the forest are:
I'd like to nominate Veedrac for his awesome contributions to various performance-related endeavors.
I'd like to highlight tomaka for his numerous projects (glium, vulkano, glutin). I know he's also involved in some other crates I take for granted, like gl_generator.
I like to play with gamedev, but I am a newcomer to OpenGL things and I have been very grateful for projects like glium and gl_generator that not only give me a good starting point, but through various documentation has informed me of OpenGL pitfalls.
He recently wrote a post-mortem for glium, which I think is good as a matter of reflection, but I'm still very impressed with that project, and the others he is tirelessly contributing to.
Well done!
Submit your Friends-of-the-Forest nominations for next week!
My favorite new double-meaning programming phrase: "my c++ is a little rusty"
Thanks to Zachary Dremann for the suggestion.
Submit your quotes for next week!
This Week in Rust is edited by: nasa42, llogiq, and brson.
https://this-week-in-rust.org/blog/2016/10/04/this-week-in-rust-150/
|
|
The Mozilla Blog: MOSS supports four more open source projects in Q3 2016 with $300k |

If you have worked with data at Mozilla you have likely seen a data dashboard built with it. Re:dash is enabling Mozilla to become a truly data driven organization.
— Roberto Vitillo, Mozilla
In the third quarter, the Mozilla Open Source Support (MOSS) program has made awards to a number of “plumbing” projects – unobtrusive but essential initiatives which are part of the foundation for building software, building businesses and improving accessibility. This quarter, we awarded over $300k to four projects – three on Track 1 Foundational Technology for projects Mozilla already uses or deploys, and one on Track 2 Mission Partners for projects doing work aligned with our mission.
On the Foundational Technology track, we awarded $100,000 to Redash, a tool for building visualizations of data for better decision-making within organizations, and $50,000 to Review Board, software for doing web-based source code review. Both of these pieces of software are in heavy use at Mozilla. We also awarded $100,000 to Kea, the successor to the venerable ISC DHCP codebase, which deals with allocation of IP addresses on a network. Mozilla uses ISC DHCP, which makes funding its replacement a natural move even though we haven’t deployed it yet.

On the Mission Partners track, we awarded $56,000 to Speech Rule Engine, a code library which converts mathematical markup into vocalised form (speech) for the sight-impaired, allowing them to fully appreciate mathematical and scientific content on the web.
In addition to all that, we have completed another two MOSS Track 3 Secure Open Source audits, and have more in the pipeline. The first was for the dnsmasq project. Dnsmasq is another piece of Internet plumbing – an embedded server for the DNS and DHCP protocols, used in all mainstream Linux distros, Android, OpenStack, open router projects like openWRT and DD-WRT, and many commercial routers. We’re pleased to say only four issues were found, none of them severe. The second was for the venerable zlib project, a widely-used compression library, which also passed with flying colors.
Applications for Foundational Technology and Mission Partners remain open, with the next batch deadline being the end of November 2016. Please consider whether a project you know could benefit from a MOSS award, and encourage them to apply. You can also submit a suggestion for a project which might benefit from an SOS audit.
https://blog.mozilla.org/blog/2016/10/03/moss-supports-four-more-open-source-projects-with-300k/
|
|
Air Mozilla: Brownbag: Brand Identity |
 A presentation of the next round of refined designs for the Mozilla brand identity and a Q & A session about the Open Design process...
A presentation of the next round of refined designs for the Mozilla brand identity and a Q & A session about the Open Design process...
|
|
Robert Kaiser: The Neverending Question of Login Systems |
http://home.kairo.at/blog/2016-10/the_neverending_question_of_login_system
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 03 Oct 2016 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20161003/
|
|
Air Mozilla: View Source Wrap Up |
 Summary of View Source 2016 in Berlin
Summary of View Source 2016 in Berlin
|
|
Chris Finke: Interpr.it Will Be Shutting Down |
Interpr.it is a platform for translating browser extensions that I launched five years ago; it will be shutting down on September 1, 2017. I no longer have the time to maintain it, and since I stopped writing Firefox extensions, I don’t have any skin in the game either.
I’ve notified everyone that uploaded an extension so that they have ample time to download any translations (333 days). It was not a large Bcc list; although nearly six thousand users created an account during the last five years, only about two dozen of those users uploaded an extension. Eight hundred of those six thousand contributed a translation of at least one string.
For anyone interested in improving the browser extension translation process, I’d suggest writing a GlotPress plugin to add support for Firefox and Chrome-style locale files. It’s been on my todo list for so long that I’m sure I will never get to it.
http://www.chrisfinke.com/2016/10/03/interprit-shutting-down/
|
|
Daniel Stenberg: screenshotted curl credits |
If you have more or better screenshots, please share!

This shot is taken from the ending sequence of the PC version of the game Grand Theft Auto V. 44 minutes in! See the youtube version.

Sky HD is a satellite TV box.

This is a Philips TV. The added use of c-ares I consider a bonus!

The infotainment display of a BMW car.

Playstation 4 lists open source products it uses.

This is a screenshot from an Iphone open source license view. The iOS 10 screen however, looks like this:

curl in iOS 10 with an older year span than in the much older screenshot?

Instagram on an Iphone.

Spotify on an Iphone.

Virtualbox (thanks to Anders Nilsson)

Battle.net (thanks Anders Nilsson)

Freebox (thanks Alexis La Goutte)

The Youtube app on Android. (Thanks Ray Satiro)

The Youtube app on iOS (Thanks Anthony Bryan)
https://daniel.haxx.se/blog/2016/10/03/screenshotted-curl-credits/
|
|
Tarek Ziad'e: Web Services Best Practices |
The other day I've stumbled on a reddit comment on Twitter about micro-services. It really nailed down the best practices around building web services, and I wanted to use it as a basis to write down a blog post. So all the credits go to rdsubhas for this post :)
The notion of micro-service rose in the past 5 years, to describe the fact that our applications are getting splitted into smaller pieces that need to interact to provide the same service that what we use to do with monolothic apps.
Splitting an app in smaller micro services is not always the best design decision in particular when you own all the pieces. Adding more interactions to serve a request just makes things more complex and when something goes wrong you're just dealing with a more complex system.
Peope often think that it's easier to scale an app built with smaller blocks, but it's often not the case, and sometimes you just end up with a slower, over-engineered solution.
So why are we building micro-services ?
What really happened I think is that most people moved their apps to cloud providers and started to use the provider services, like centralized loggers, distributed databases and all the fancy services that you can use in Amazon, Rackspace or other places.
In the LAMP architecture, we're now building just one piece of the P and configuring up to 20 services that interact with it.
A good chunk of our daily jobs now is to figure out how to deploy apps, and even if some tools like Kubertenes gives us the promise of an abstraction on the top of cloud providers, the reality is that you have to learn how AWS or another provider works to built something that works well.
Understanding how multi-zone replication works in RDS is mandatory to make sure you control your application behavior.
Because no matter how fancy and reliable, all those services are, the quality of your application will be tighted to its ability to deal with problems like network splits or timeouts etc.
That's where the shift in bests practices is: when something goes wrong, it's harder just to tail your postgres logs and your Python app and see what's going on. You have to deal with many parts.
I can't find the original post on Reddit, so I am just going to copy it here and curate it with my own opinions and with the tools we use at Mozilla. I've also removed what I see as redundant tips.
Basic monitoring, instrumentation, health check
We use statsd everywhere and services like Datadog to see what's going on in our services.
We also have two standard heartbeat endpoints that are used to monitor the services. One is a simple round trip where the service just sends back a 200, and one is more of a smoke test, where the service tries to use all of its own backends to make sure it can reach them and read/write into them.
We're doing this distinction because the simple round trip health check is being hit very often, and the one that calls all the services the service use, less often to avoid doing too much traffic and load.
Distributed logging, tracing
Most of our apps are in Python, and we use Sentry to collect tracebacks and sometimes New Relic to detect problems we could not reproduce in a dev environment.
Isolation of the whole build+test+package+promote for every service.
We use Travis-CI to trigger most of our builds, tests and packages. Having reproducible steps made in an isolated environment like a CI gives us good confidence on the fact that the service is not spaghetti-ed with other services.
The bottom line is that "gill pull & make test" should work in Travis no matter what, without calling an external service. The travis YML file, the Makefile and all the mocks in the tests are rhoughly our 3 gates to the outside world. That's as far as we go in term of build standards.
Maintain backward compatibility as much as possible
The initial tip included forward compatibility. I've removed it, because I don't think it's really a thing when you build web services. Forward compatibility means that an older version of your service can accept requests from newer version of the client side. But I think it should just be a deployment issue and an error management on the client side, so you don't bend your data design just so it works with older service versions.
For backward compatibility though, I think it's mandatory to make sure that you know how to interact with older clients, whatever happens. Depending on your protocol, older clients could get an update triggered, partially work, or just work fine -- but you have to get this story right even before the first version of your service is published.
But if your design has dramatically changed, maybe you need to accept the fact that your are building something different, and just treat it as a new service (with all the pain that brings if you need to migrate data.)
Firefox Sync was one complex service to migrate from its first version to its latest version because we got a new authentication service along the way.
Ready to do more TDD
I just want to comment on this tip. Doing more TDD imply that it's cool to do less TDD when you build software that's not a service.
I think this is a bad advice. You should simply do TDD right. Not less or more, but right.
Doing TDD right in my opinion is :
Have engineering methodologies and process-tools to split down features and develop/track/release them across multiple services (xp, pivotal, scrum)
That's a good tip. Trying to reproduce what has worked when building a service, to build the next one is a great idea.
However, this will only work if the services are built by the same team, because the whole engineering methodology is adopted and adapted by people. You don't stick into people's face the SCRUM methodology and make the assumption that everyone will work as described in the book. This never happens. What usually happens is that every member of the team brings their own recipes on how things should be done, which tracker to use, what part of XP makes sense to them, and the team creates its own custom methodology out of this. And it takes time.
Start a service with a new team, and that whole phase starts again.
|
|
Mozilla Reps Community: Introducing Regional Coaches |
As a way to amplify the Participation’s team focused support to communities, we have created a project called Regional Coaches.
Reps Regional coaches project aims to bring support to all Mozilla local communities around the world thanks to a group of excellent core contributors who will be talking with these communities and coordinating with the Reps program and the Participation team.
We divided the world into 10 regions, and selected 2 regional coaches to take care of the countries in these regions.
These regional coaches are not a power structure nor a decision maker, they are there to listen to the communities and establish a 2-way communication to:
We want communities to be better integrated with the rest of the org, not just to be aligned with the current organizational needs but also to allow them to be more involved in shaping the strategy and vision for Mozilla and work together with staff as a team, as One Mozilla.
We would like to ask all Reps and mozillians to support our Regional Coaches, helping them to meet communities and work with them. This project is key for bringing support to everyone, amplifying the strategy, vision and work that we have been doing from the Reps program and the Participation team.
 We have on-boarded 18 regional coaches to bring support to 87 countries (wow!) around the world. Currently they have started to contact local communities and hold video meetings with all of them.
We have on-boarded 18 regional coaches to bring support to 87 countries (wow!) around the world. Currently they have started to contact local communities and hold video meetings with all of them.
What have we learned so far?
Mozilla communities are very diverse, and their structure and activity status is very different. Also, there is a need for alignment with the current projects and focus activities around Mozilla and work to encourage mozillians to get involved in shaping the future.
In region 1, there are no big formal communities and mozillians are working as individuals or city-level groups. The challenge here is to get everyone together.
In region 2 there are a lot of communities, some of them currently re-inventing themselves to align better with focus initiatives. There is a huge potential here.
Region 3 is where the oldest communities started, and there is big difference between the old and the emerging ones. The challenge is to get the old ones to the same level of diverse activity and alignment as the new ones.
In region 4 the challenge is to re-activate or start communities in small countries.
Region 5 has been active for a long time, focused mainly in localization. How to align with new emerging focus areas is the main challenge here.
Region 6 and 7 are also very diverse, huge potential, a lot of energy. Getting mozillians supercharged again after Firefox OS era is the big challenge.
Region 8 has some big and active communities (like Bangladesh and Taiwan) and a lot of individuals working as small groups in other countries. The challenge is to bring alignment and get the groups together.
In region 9 the challenge is to bring the huge activity and re-organization Indian communities are doing to nearby countries. Specially the ones who are not fully aligned with the new environment Mozilla is in today.
Region 10 has a couple of big active communities. The challenge is how to expand this to other countries where Mozilla has never had community presence or communities are no longer active.
Comments, feedback? We want to hear from you on Mozilla’s discourse forum.
https://blog.mozilla.org/mozillareps/2016/10/03/introducing-regional-coaches/
|
|
Rub'en Mart'in: Amplifying our support to communities with Reps Regional Coaches |
In my previous post, I explained how the Participation staff team was going to work with a clear focus, and today I want to explain how we are going to amplify this support to all local communities thanks to a project inside the Reps program called Regional Coaches.
Reps Regional coaches project aims to bring support to all Mozilla local communities around the world thanks to a group of excellent core contributors who will be talking with these communities and coordinating with the Reps program and the Participation team.
We divided the world into 10 regions, and selected 2 regional coaches to take care of the countries in these regions.
These regional coaches are not a power structure nor a decision maker, they are there to listen to the communities and establish a 2-way communication to:
We want communities to be better integrated with the rest of the org, not just to be aligned with the current organizational needs but also to allow them to be more involved in shaping the strategy and vision for Mozilla and work together with staff as a team, as One Mozilla.
I would like to ask all mozillians to support our Regional Coaches, helping them to meet communities and work with them. This project is key for bringing support to everyone, amplifying the strategy, vision and work that we have been doing from the Reps program and the Participation team.

We have on-boarded 18 regional coaches to bring support to 87 countries (wow!) around the world. Currently they have started to contact local communities and hold video meetings with all of them.
What have we learned so far?
Mozilla communities are very diverse, and their structure and activity status is very different. Also, there is a need for alignment with the current projects and focus activities around Mozilla and work to encourage mozillians to get involved in shaping the future.
In region 1, there are no big formal communities and mozillians are working as individuals or city-level groups. The challenge here is to get everyone together.
In region 2 there are a lot of communities, some of them currently re-inventing themselves to align better with focus initiatives. There is a huge potential here.
Region 3 is where the oldest communities started, and there is big difference between the old and the emerging ones. The challenge is to get the old ones to the same level of diverse activity and alignment as the new ones.
In region 4 the challenge is to re-activate or start communities in small countries.
Region 5 has been active for a long time, focused mainly in localization. How to align with new emerging focus areas is the main challenge here.
Region 6 and 7 are also very diverse, huge potential, a lot of energy. Getting mozillians supercharged again after Firefox OS era is the big challenge.
Region 8 has some big and active communities (like Bangladesh and Taiwan) and a lot of individuals working as small groups in other countries. The challenge is to bring alignment and get the groups together.
In region 9 the challenge is to bring the huge activity and re-organization Indian communities are doing to nearby countries. Specially the ones who are not fully aligned with the new environment Mozilla is in today.
Region 10 has a couple of big active communities. The challenge is how to expand this to other countries where Mozilla has never had community presence or communities are no longer active.
Comments, feedback? We want to hear from you on Mozilla’s discourse forum.
|
|
Firefox Nightly: These Weeks in Firefox: Issue 2 |
As is fortnightly tradition, the Firefox Desktop team rallied together last Tuesday to share notes and ramblings on things that are going on. Here are some hand-picked, artisinal updates from your friendly neighbourhood Firefox team:
Here are the raw meeting notes that were used to derive this list.
Want to help us build Firefox? Get started here!
Here’s a tool to find some mentored, good first bugs to hack on.
https://blog.nightly.mozilla.org/2016/10/03/these-weeks-in-firefox-issue-2/
|
|
Robert O'Callahan: rr Paper: "Lightweight User-Space Record And Replay" |
Earlier this year we submitted the paper Lightweight User-Space Record And Replay to an academic conference. Reviews were all over the map, but ultimately the paper was rejected, mainly on the contention that most of the key techniques have (individually) been presented in other papers. Anyway, it's probably the best introduction to how rr works and how it performs that we currently have, so I want to make it available now in the hope that it's interesting to people.
http://robert.ocallahan.org/2016/10/rr-paper-lightweight-user-space-record.html
|
|
Niko Matsakis: Observational equivalence and unsafe code |
I spent a really interesting day last week at Northeastern University.
First, I saw a fun talk by Philip Haller covering LaCasa, which is a
set of extensions to Scala that enable it to track ownership. Many of
the techniques reminded me very much of Rust (e.g., the use of
spores
, which are closures that can limit the types of things they
close over); if I have time, I’ll try to write up a more detailed
comparison in some later post.
Next, I met with Amal Ahmed and her group to discuss the process of crafting unsafe code guidelines for Rust. This is one very impressive group. It’s this last meeting that I wanted to write about now. The conversation helped me quite a bit to more cleanly separate two distinct concepts in my mind.
The TL;DR of this post is that I think we can limit the capabilities
of unsafe code to be things you could have written using the safe
code plus a core set of unsafe abstractions
(ignoring the fact that
the safe implementation would be unusably slow or consume ridiculous
amounts of memory). This is a helpful and important thing to be able
to nail down.
One of the things that we talked about was observational
equivalence and how it relates to the unsafe code guidelines. The
notion of observational equivalence is really pretty simple: basically
it means two bits of code do the same thing, as far as you can tell
.
I think it’s easiest to think of it in terms of an API. So, for
example, consider the HashMap and BTreeMap types in the Rust
standard library. Imagine I have some code using a HashMap
that only invokes the basic map operations – e.g., new, get, and
insert. I would expect to be able to change that code to use a
BTreeMap and have it keep working. This is because HashMap
and BTreeMap, at least with respect to i32 keys and
new/get/insert, are observationally equivalent.
If I expand the set of API routines that I use, however, this
equivalence goes away. For example, if I iterate over the map, then a
BTreeMap gives me an ordering guarantee, whereas HashMap doesn’t.
Note that the speed and memory use will definitely change as I shift
from one to the other, but I still consider them observationally
equivalent. This is because I consider such changes unobservable
, at
least in this setting (crypto code might beg to differ).
One thing that I’ve been kind of wrestling with in the unsafe code
guidelines is how to break it up. A lot of the attention has gone into
thinking about some very low-level decisions: for example, if I make a
*mut pointer and an &mut reference, when can they legally alias?
But there are some bigger picture questions that are also equally
interesting: what kinds of things can unsafe code even do in the
first place, whatever types it uses?
One example that I often give has to do with the infamous
setjmp/longjmp in C. These are some routines that let you
implement a poor man’s exception handling. You call setjmp at one
stack frame and then, down the stack, you call longjmp. This will
cause all the intermediate stack frames to be popped (with no
unwinding or other cleanup) and control to resume from the point where
you called setjmp. You can use this to model exceptions (a la
Objective C),
build coroutines, and of
course – this is C – to shoot yourself in the foot (for example,
by invoking longjmp when the stack frame that called setjmp has
already returned).
So you can imagine someone writing a Rust wrapper for
setjmp/longjmp. You could easily guarantee that people use the API
in a correct way: e.g., that you when you call longjmp, the setjmp
frame is still on the stack, but does that make it safe?
One concern is that setjmp/longjmp do not do any form of
unwinding. This means that all of the intermediate stack frames are
going to be popped and none of the destructors for their local
variables will run. This certainly means that memory will leak, but it
can have much worse effects if you try to combine it with other unsafe abstractions. Imagine
for example that you are using Rayon: Rayon relies on running
destructors in order to join its worker threads. So if a user of the
setjmp/longjmp API wrote something like this, that would be very
bad:
1 2 3 4 5 | |
What is happening here is that we are first calling setjmp using our
safe
wrapper. I’m imagining that this takes a closure and supplies
it some handle j that can be used to longjmp
back to the setjmp
call (basically like break on steroids). Now we call rayon::join
to (potentially) spin off another thread. The way that join works is
that the first closure executes on the current thread, but the second
closure may get stolen and execute on another thread – in that case,
the other thread will be joined before join returns. But here we are
calling j.longjmp() in the first closure. This will skip right over
the destructor that would have been used to join the second thread.
So now potentially we have some other thread executing, accessing
stack data and raising all kinds of mischief.
(Note: the current signature of join would probably prohibit this,
since it does not reflect the fact that the first closure is known to
execute in the original thread, and hence requires that it close over
only sendable data, but I’ve contemplated changing that.)
So what went wrong here? We tried to combine two things that independently seemed safe but wound up with a broken system. How did that happen? The problem is that when you write unsafe code, you are not only thinking about what your code does, you’re thinking about what the outside world can do. And in particular you are modeling the potential actions of the outside world using the limits of safe code.
In this case, Rayon was making the assumption that when we call a closure, that closure will do one of four things:
This is true of all safe code – unless that safe code has access to
setjmp/longjmp.
This illustrates the power of unsafe abstractions. They can extend the very vocabulary with which safe code speaks. (Sorry, I know that was ludicrously flowery, but I can’t bring myself to delete it.) Unsafe abstractions can extend the capabilities of safe code. This is very cool, but also – as we see here – potentially dangerous. Clearly, we need some guidelines to decide what kinds of capabilities it is ok to add and which are not.
But how can we decide what capabilities to permit and which to deny? This is where we get back to this notion of observational equivalence. After all, both Rayon and setjmp/longjmp give the user some new powers:
But these two capabilities are qualitiatively different. For the most part, Rayon’s superpower is observationally equivalent to safe Rust. That is, I could implement Rayon without using threads at all and you as a safe code author couldn’t tell the difference, except for the fact that your code runs slower (this is a slight simplification; I’ll elaborate below). In contrast, I cannot implement setjmp/longjmp using safe code.
But wait
, you say, Just what do you mean by ‘safe code’?
OK,
That last paragraph was really sloppy. I keep saying things like you
could do this in safe Rust
, but of course we’ve already seen that the
very notion of what safe Rust
can do is something that unsafe code
can extend. So let me try to make this more precise. Instead of
talking about Safe Rust as it was a monolithic entity, we’ll
gradually build up more expressive versions of Rust by taking a safe
code and adding unsafe capabilities. Then we can talk more precisely
about things.
Let’s start with Rust0, which corresponds to what you can do without
using any unsafe code at all, anywhere. Rust0 is a remarkably
incapable language. The most obvious limitation is that you have no
access to the heap (Box and Vec are unsafely implemented
libraries), so you are limited to local variables. You can still do
quite a lot of interesting things: you have arrays and slices,
closures, enums, and so forth. But everything must live on the stack
and hence ultimately follow a stack discipline. Essentially, you can
never return anything from a function whose size is not statically
known. We can’t even use static variables to stash stuff, since those
are inherently shared and hence immutable unless you have some unsafe
code in the mix (e.g., Mutex).
Vec)So now let’s consider Rust1, which is Rust0 but with access to Vec.
We don’t have to worry about how Vec is implemented. Instead, we can
just think of Vec as if it were part of Rust itself (much like how
~[T] used to be, in the bad old days). Suddenly our capabilities are
much increased!
For example, one thing we can do is to implement the Box type
(Box is basically a Vec whose length is always 1, after
all). We can also implement something that acts identically to
HashMap and BTreeMap in pure safe code (obviously the performance
characteristics will be different).
(At first, I thought that giving access to Box would be enough, but
you can’t really simulate Vec just by using Box. Go ahead and try
and you’ll see what I mean.)
Rc, Arc)This is sort of an interesting one. Even if you have Vec, you still
cannot implement Rc or Arc in Rust1. At first, I thought perhaps we could
fake it by cloning data – so, for example, if you want a Rc, you
could (behind the scenes) make a Box. Then when you clone the
Rc you just clone the box. Since we don’t yet have Cell or
RefCell, I reasoned, you wouldn’t be ablle to tell that the data had
been cloned. But of course that won’t work, because you can use a
Rc for any T, not just T that implement Clone.
That brings us to another fundamental capability. Cell and RefCell
permit mutation when data is shared. This can’t be modeled with just
Rc, Box, or Vec, all of which maintain the invariant that
mutable data is uniquely reachable.
This is an interesting level. Here we add the ability to spawn a
thread, as described in std::thread (note that this thread runs
asynchronously and cannot access data on the parent’s stack frame). At
first, I thought that threading didn’t add expressive power
since we
lacked the ability to share mutable data across threads (we can
share immutable data with Arc).
After all, you could implement std::thread in safe code by having it
queue up the closure to run and then, when the current thread
finishes, have it execute. This isn’t really correct for a number
of reasons (what is this scheduler that overarches the safe code?
Where do you queue up the data?), but it seems almost true.
But there is another way that adding std::thread is important. It
means that safe code can observe memory in an asynchronous thread,
which affects the kinds of unsafe code that we might write. After
all, the whole purpose of this exercise is to figure out the limits of
what safe code can do, so that unsafe code knows what it has to be
wary of. So long as safe code did not have access to std::thread,
one could imagine writing an unsafe function like this:
1 2 3 4 5 6 | |
This function takes a shared i32 and temporarily increments and
then decrements it. The important point here is that the invariant
that the Arc is immutable is broken, but it is restored before
foo returns. Without threads, safe code can’t tell the difference
between foo(&my_arc) and a no-op. But with threads, foo() might
trigger a data-race. (This is all leaving aside the question of
compiler optimization and aliasing rules, of course.)
(Hat tip to Alan Jeffreys for pointing this out to me.)
The next level I think are abstractions that enable threads to
communiate with one another. This includes both within a process
(e.g., AtomicU32) and across processes (e.g., I/O).
This is an interesting level to me because I think it represents the point where the effects of a library like rayon becomes observable to safe code. Until this point, the only data that could be shared across Rayon threads was immutable, and hence I think the precise interleavings could also be simulated. But once you throws atomics into the mix, and in particular the fact that atomics give you control over the memory model (i.e., they do not require sequential consistency), then you can definitely observe whether threading is truly in use. The same is true for I/O and so forth.
So this is the level that shows that what I wrote earlier, that
Rayon’s superpower is observationally equivalent to safe Rust
is
actually false. I think it is observationally equivalent to safe
Rust4
, but not Rust5. Basically Rayon serves as a kind of Rust6
, in
which we grow Rust5 by adding scoped threads, that allow sharing data
on stack frames.
We can keep going with this exercise, which I actually think is quite
valuable, but I’ll stop here for now. What I’d like to do
asynchronously is to go over the standard library and interesting
third-party packages and try to nail down the core unsafe
abstractions
that you need to build Rust, as well as the
dependencies
between them.
But I want to bring this back to the core point: the focus in the
unsafe code guidelines has been on exploring what unsafe code can do
in the small
. Basically, what types it ought to use to achieve
certain kinds of aliasing and so forth. But I think it’s also very
important to nail down what unsafe code can do in the large
. How
do we know whether (say)
abomonation,
deque, and so forth represent legal
libraries?
As I left the meeting with Amal’s group, she posed this question to me. Is there something where all three of these things are true:
reasonablething to do.
Whenever the answer is yes, that’s a candidate for growing another
Rust level. We already saw one yes
answer in this blog post, right
at the end: scoped threads, which enable threading with access to
stack contents. Beyond that, most of the potential answers I’ve come
up with are access to various kernel capabilities:
What’s a bit interesting about these is that they seem to be mostly
about the operating system itself. They don’t feel fundamental
in
the same way as scoped threads: in other words, you could imagine
simulating the O/S itself in safe code, and then you could build these
things. Not quite how to think about that yet.
In any case, I’d be interested to hear about other fundamental
abstractions
that you can think of.
Oh, one last thing. It might seem like defining all these language levels is a bit academic. But it can be very useful to pick them apart. For example, imagine you are targeting a processor that has no preemption and always uses cooperative multithreading. In that case, the concerns I talked about in Rust4 may not apply, and you may be able to do more aggressive things in your unsafe code.
Please leave comments in this thread on the Rust internals forum.
http://smallcultfollowing.com/babysteps/blog/2016/10/02/observational-equivalence-and-unsafe-code/
|
|
Chris McDonald: i-can-manage-it Weekly Update 3 |
Weekly post already? But it seems like the last one was just the other day! It’s true, it has been less than a week since the last one, but I feel like the weekend is a good time for me to write these so you’re getting another update. This post is going to be very tech heavy. So I’m going to put the less tech heavy stuff in the next couple paragraph or so, then I’m going to explain my implementation for educational purposes.
I’m currently reading Game Engine Architecture by Jason Gregory and one of the early chapters focused on development tools and how important they are. My previous full time job was building development tools for web developers so I’ve already developed an appreciation for having them. Also, you may remember my last post where I talked about debugging tools I’ve added to my game.
Games require a lot of thought and consideration to the performance of the code that is written and one of the primary metrics that the game industry uses is FPS, or Frames Per Second. This is the number of times the full screen is rendered to the screen per second. A common standard for this is 60FPS which is what most “high definition” monitors and TVs can produce. Because the frames need to be roughly evenly spaced it means that each frame gets about 16.6 milliseconds to be fully calculated and rendered.
So, I built a tool to let me analyze the amount of time each frame took to render. I knew I’d want to graph the data, and I didn’t have the ability to make graphs using my game engine. I don’t even have the ability to display text. So I went with a setup called Electron to let me use the sort of code and techniques I use for web development and am very familiar with. And this screenshot is the results:
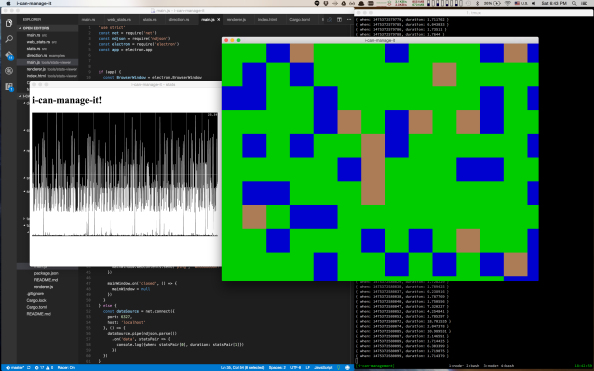
In the background is my text editor with some code, and a bunch of debug information in my terminal. On the right with the pretty colors is my game. It is over there rendering about 400-450 FPS on my mac. On the left in the black and white is my stats viewer. Right now it just shows the duration of every frame. The graph dynamically sizes itself, but at the moment it was showing 2ms-25ms range. Interesting things to note is that I’m averaging 400FPS but I have spikes that take over 16.6ms, so the frames are not evenly spaced and it looks like ~58FPS.
Ok, that’s the tool I built and a brief explanation. Next, I’m going to go into the socket server I wrote to have the apps communicate. This is the very tech heavy part so friends just reading along because they want to see what I’m up to, but aren’t programmers, this is the time to hit the eject button if you find that stuff boring and you kinda wish I’d just shut up sometimes.
To start with, this gist has the full code that I’ll be talking about here. I’m going to try to use snippets cut up with text from that, so you can refer to that gist for context if needed. This is a very simple socket server I wrote to export a few numbers out of my engine. I expect to expand this and make it more featureful as well as bidirectional so I can opt in or out of debugging stuff or tweak settings.
Lets first look at the imports, I say as if that’s interesting, but one thing to note is I’m not using anything outside of std for my stats collection and socket server. Keep in mind this is a proof of concept, not something that will need to work for hundreds of thousands of users per second or anything.
use std::io::Write;
use std::net::TcpListener;
use std::sync::mpsc::{channel, Receiver, Sender};
use std::thread;
I’ve pulled in the Write trait from std::io so I can write to the sockets that connect. Next up is TcpListener which is the way in the standard library to listen for new socket connections. Then we have channels for communicating across threads easily. Speaking of threads, I pull in that module as well.
Ok, so now that we know the pieces we’re working with, lets talk design. I wanted to have my stats display work by a single initializing call, then sending data over a channel to a stats collection thread. Because channels in rust are MPSC channels, or Multiple Producer Single Consumer channels, they can have many areas sending data, but only 1 thing consuming data. This is what lead to the interesting design of the initializing function seen below:
pub fn run_stats_server () -> Sender{ let (stats_tx, stats_rx) = channel(); thread::Builder::new() .name("Stats:Collector".into()) .spawn(move || { let new_socket_rx = stats_socket_server(); let mut outputs = vec![]; while let Ok(stats) = stats_rx.recv() { while let Ok(new_output) = new_socket_rx.try_recv() { outputs.push(new_output); } let mut dead_ones = vec![]; for (number, output) in outputs.iter().enumerate() { if let Err(_) = output.send(stats) { dead_ones.push(number); } } for dead in dead_ones.into_iter() { outputs.remove(dead); } } }) .unwrap(); stats_tx }
Let’s work our way through this. At the start we have our function signature,
run_stats_server is the name of our function, it takes no arguments and returns a Sender channel that sends Stats objects. That channel is how we’ll export data from the engine to the stats collector. Next we create a channel, using common rust naming of tx or “transmit” for the Sender and rx for Receiver sides of the channel. These will send and receive stats objects so we’ll name them as such.
Next, we start building up the thread that will house our stats collection. We make sure to give it a name so stack traces, profilers, and other development tools will be able to help us identify what we are seeing. In this case, Stats:Collector. We spawn the thread and hand it a special type of function called a closure, specifying that values it uses from the function creating the closure, should become owned by the closure via the move flag.
We’re going to skip the implementation of stats_socket_server() for now, except to note that it returns a Receiver> which the receiving side of a channel that will contain the sending side of a channel containing stats objects. Oooph a mouthful! Remember the “interesting” design, this is the heart of it. Because, I could have any number of clients connect to the socket over the life of the app, I needed to be able to receive from a single channel on multiple threads. But if you recall above, channels are single consumer. This means I have to spread the messages across multiple channels myself. Part of that design means anytime a new connection comes in, the stats collection service gets another channel to send to.
We make some storage for the channels we’ll be getting back from the socket server, then launch into our loop. A reader may notice that the pattern while let Ok(value) = chan_rx.recv() {} is littered all over my code. I just learned of this and it is terribly useful for working with channels. You see, that stats_rx.recv() call in the code above? That blocks the thread until something is written to stats_tx. When it does return a value, that value is a result that could be Ok where T is the type of the channel, or Err where E is some error type.
Channels will return an Err when you try to read or write to them and the other side of the channel has been closed. Generally when this channel fails it is because I’ve started shutting down the main thread and the Stats:Collector thread hasn’t shut down yet. So as long as the channel is still open, the server will keep running.
Once we get past this while let we have a new Stats object to work with. We check to see if any new connections have come in and add them to the outputs vector. We do it in this order because new connections only matter if there is new data to send to them. We aren’t sending any history. Notice how this loop uses try_recv() instead of recv()to get messages from the channel. This is because we don’t want to wait for a message if there isn’t any, we just want to check and keep going instead. The try version of the function will immediately return an Err if there are no messages ready.
We make a vector to hold onto the indices of the dead channels as we try to send the stats payload to each of them. Since channels return errors when the other side has closed, we close the socket’s side of the channel when the socket closes, letting it cascade the error to here. We then collect the index so we can remove it later. We can’t remove it now since we’re accessing the vector, and rust ensures that while something is reading the data, nothing can write to it. Also, a note, when you use a channel’s send function it takes ownership of the object you are sending. Since my stats objects are pretty small and simple I made them copiable and rust is automatically creating a copy for each outgoing channel.
In the last part of the loop, we do a quick pass to clean up any dead channels. The only other things of note in this function are that the thread creation uses .unwrap() as a deliberate choice because thread creation should never fail, if it does, the application is in some state we didn’t account for and should crash, probably low memory or too many threads. Then finally it returns the stats_tx we made at the top.
Now we get to the other function that makes up this stats collector and server. The goal of this function is to listen for new socket connections and return channels to send to them. Without further adieu here it is:
fn stats_socket_server() -> Receiver> {
let (new_socket_tx, new_socket_rx) = channel();
thread::Builder::new()
.name("Stats:SocketServer".into())
.spawn(move || {
let server = TcpListener::bind("127.0.0.1:6327").unwrap();
let mut connection_id = 0;
for stream in server.incoming() {
if let Ok(mut stream) = stream {
let (tx, rx): (_, Receiver) = channel();
new_socket_tx.send(tx).unwrap();
thread::Builder::new()
.name(format!("Stats:SocketServer:Socket:{}",
connection_id))
.spawn(move || {
while let Ok(stats) = rx.recv() {
let message = format!("[{},{}]\n",
stats.when,
stats.duration)
.into_bytes();
if let Err(_) = stream.write(&message) {
// Connection died;
break;
}
}
})
.unwrap();
connection_id += 1;
}
}
})
.unwrap();
new_socket_rx
}
We’ve already discussed the function signature above, but now we’ll get to see the usage of the Sender side of at channel sending channel. Like our first function, we immediately create a channel, one side of which new_socket_rx is returned at the bottom of the function. The other we’ll use soon.
Also familiar is the thread building. This time we name it Stats:SocketServer as that is what will be running in this thread. Moving on, we see TcpListener show up. We create a new TcpListener bound to localhost on port 6327 and unwrap the value. We create a counter we’ll use to uniquely track the socket threads.
We use the .incoming() function much the same way as we use the .recv() function on channels. It will return an Ok on successful connect or Err when an error happens. We ignore the errors for now and grab the stream in the success case. Each stream will get its own channel so we create channels, simply named tx and rx. We send tx to over new_socket_tx which is connected to the channel sending channel we return.
We build yet another thread, 1 thread per connection would be wasteful if I planned on having a lot of connections, but since I’ll typically only have 0-1 connection, I feel like using a thread for each isn’t too expensive. This is where we used that connection_id counter to uniquely name the thread. Because we may have multiple of these at the same time, we make sure they are named so we can tell them apart.
Inside the thread, we use the now familiar pattern of using .recv() to block and wait for messages. Once we get one, we format it as a 2 element JSON array with a newline on the end. I didn’t want to worry about escaping or using a full JSON serialization library, so I just wrote the values to a string and sent that. The reason for the newline is so the receiving side of the socket can treat it as a “newline delimited JSON stream” which is a convenient way to speak across languages. We note if there is an error trying to write to the socket, and if so, break out of our loop.
The rest is just a little bookkeeping for tracking the connection_id and returning the channel sending channel. While this description has gotten pretty long, the implementation is relatively simple. Speaking of things to build out with time, the last bit of code we’ve not discussed for there rust side of this. The Stats struct.
#[derive(Clone, Copy, Debug)]
pub struct Stats {
pub when: u64,
pub duration: u64
}
The reason I didn’t mention it sooner, is it is pretty boring. It holds onto two u64 which are unsigned 64bit integers, or whole positive numbers, that I send over the wire. With time this will certainly grow larger, not sure in what ways though. I could have used a 2-tuple to hold my stats like (u64, u64) instead of a struct. As far as I know they are just as memory efficient. The reason I went with a struct though was for two attributes. First it is a name that I can change the contents of without having to change code everywhere it passes through, just where the struct is created or accessed. If I add another u64 to the tuple above, the function signatures and the points where the data is created and accessed need to change.
The other reason is proper use of the type system. There are many reasons to create a (u64, u64) that have nothing to do with stats, by creating a type we force the API user to be specific about what their data is. Both that the positions of the data are correct by referencing them by name, and because they are in a container with a very specific name. Granted, I’m the API user as well as implementer, but in 6 months, it may as well been implemented by you, for how familiar it’ll be to me.
The electron side of this is actually pretty boring. Because JS is built to work well with events, and this data comes in as a series of events, I basically just propagate them from the socket connection to electron’s IPC, or Inter Process Communication, layer which is one of the first things folks learn when making electron apps. For the graph I used Smoothie and basically just copied their example code and replaced their call to Math.random() with my data.
This project was meant to be the start of development tools for my game engine. A proof of concept for having those tools be external but hooked up via a socket. Next steps will be making the data presentation nicer, possibly making it two way so I can see what debugging tools are enabled and change those settings from this tool, and many other things.
I really hope that this explanation of some rust code was fun and helpful. If you have questions, feel free to ask. Keep in mind this tool and code are not meant to be a bullet proof production used by many people thing, but more just an exploration of a brain worm I had. While I’m keeping most of my source private, all the source shown here should be considered under the ISC license which basically says do whatever with it and don’t blame me if it turns out to be terrible.

https://wraithan.net/2016/10/02/i-can-manage-it-weekly-update-3/
|
|
Andy McKay: Your own AMO |
Back when I started on addons.mozilla.org (AMO) there was a suggestion lurking in the background... "what if I wanted to run my own copy of addons.mozilla.org"?
I'm never been quite sure if that would be something someone would actually want to do, but people kept mentioning it. I think for a while for some associated Mozilla projects might have tried it, but in the six years of the project I've seen zero bugs about anyone actually doing it. Just some talk of "well if you wanted to do it...".
I think we can finally lay to rest that while AMO is an open source project (and long may it stay it that way) and running your own version is technically possible, it's not something Mozilla should worry about or support.
This decision is bolstered by a couple of things that happened in the add-ons community recently: add-on signing, which means that Mozilla can be the only one to sign add-ons for Firefox and the use of Firefox Accounts for authentication.
These are things you can work around or re-purpose, but in the end you'll probably find that these things are not worth the effort when it comes down to it.
From a contribution point of view AMO is very easy to set up and install these days. Pull down the docker containers, run them and you are going. You'll have a setup that is really similar to production in a few minutes. As an aside: development and production actually use slightly different docker containers, but that will be merged in the future.
From a development point of view, knowing that AMO is only ever deployed in one way makes life so very much easier. We don't have to support multiple OS's, environments or combinations that will never happen in production.
Recently we've started to move to API driven site and that means that all the data in AMO is now exposed through an API. So if you want to do something with AMO data, the best thing to do is start playing with the API to grab some data and remix that add-on data as much as you'd like (example).
So AMO is still open source and remain so, it just won't support every single option in its development and I think that's a good thing.
|
|
Robert O'Callahan: rr 4.4.0 Released |
I just pushed out the release of rr 4.4.0. It's mostly the usual reliability and syscall coverage improvements. There are a few highlights:
|
|






