Giorgos Logiotatidis: Takis - A util that blocks until a port is open. |
Over at Mozilla's Engagement Engineering we use Docker to ship our websites. We build the docker images in CI and then we run tests against them. Our tests usually need a database or a cache server which you can get it running simply with a single command:
docker run -d mariadb
The problem is that this container will take some time to initialize and become available to accept connections. Depending on what your test and how you run your tests this delay can cause a test failure to due database connection timeouts.
We used to wait on executing our tests with sleep command but that -besides
being an ugly hack- will not always work. For example you may set sleep timeout
to 10 seconds and due to CI server load database initialization takes 11
seconds. And nobody wants a non-deterministic test suite.
Meet Takis. Takis checks once per
second if a host:port is open. Once it's open, it just returns. It blocks the
execution of your pipeline until services become available. No messages or other
output to get in the way of your build logs. No complicated configuration
either: It reads CHECK_PORT and optionally CHECK_HOST environment variables,
waits and eventually returns.
Takis is build using Go and it's fully statically linked as Adriaan explains in this intriguing read. You can download it and directly use it in your scripts
~$ wget https://github.com/glogiotatidis/takis/raw/master/bin/takis ~$ chmod +x takis ~$ CHECK_PORT=3306 ./takis
or use it's super small Docker image
docker run -e CHECK_PORT=3306 -e CHECK_HOST=database.example.com giorgos/takis
For example here's how we use it to build Snippets Service in TravisCI:
script: - docker run -d --name mariadb -e MYSQL_ALLOW_EMPTY_PASSWORD=yes -e MYSQL_DATABASE=snippets mariadb:10.0 # Wait mariadb to initialize. - docker run --link mariadb:db -e CHECK_PORT=3306 -e CHECK_HOST=db giorgos/takis - docker run --env-file .env --link mariadb:db mozorg/snippets:latest coverage run ./manage.py test
My colleague Paul also build urlwait, a Python utility and library with similar functionality that can be nicely added to your docker-compose workflow to fight the same problem. Neat!
https://giorgos.sealabs.net/takis-a-util-that-blocks-until-a-port-is-open.html
|
|
Daniel Stenberg: curl user poll 2016 |
It is time for our annual survey on how you use curl and libcurl. Your chance to tell us how you think we’ve done and what we should do next. The survey will close on midnight (central European time) May 27th, 2016.
If you use curl or libcurl from time to time, please consider helping us out with providing your feedback and opinions on a few things:
http://goo.gl/forms/e4CoSDEKde
It’ll take you a couple of minutes and it’ll help us a lot when making decisions going forward. Thanks a lot!
The poll is hosted by Google and that short link above will take you to:
https://docs.google.com/forms/d/1JftlLZoOZLHRZ_UqigzUDD0AKrTBZqPMpnyOdF2UDic/viewform
|
|
Karl Dubost: [worklog] Make Web sites simpler. |
Not a song this week, but just a documentary to remind me that some sites are overly complicated and there are strong benefits and resilience in chosing a solid simple framework for working. Not that it makes easier the work. I think it's even the opposite, it's basically harder to make a solid simple Web site. But that the cost is beneficial on the longterm. Tune of the week: The Depth of simplicity in Ozu's movie.
Progress this week:
Today: 2016-05-16T10:12:01.879159 354 open issues ---------------------- needsinfo 3 needsdiagnosis 109 needscontact 30 contactready 55 sitewait 142 ----------------------
In my journey in getting the contactready and needscontact lower, we are making progress. You are welcome to participate
Reorganizing a bit the wiki so it better aligns with our current work. In Progress.
Good news on the front of appearance in CSS.
The CSSWG just resolved that
"appearance: none"should turn checkbox & radioelements into a normal non-replaced element.
Learning on how to do mozregression
We are looking at creating a mechanism similar to Opera browser.js into Firefox. Read and participate to the discussion.
(a selection of some of the bugs worked on this week).
Cache-Control: immutable. Good stuff.Vendor Prefixes are dead but with them mass author involvement in early stage specifications. The history of Grid shows that it is incredibly difficult to get people to do enough work to give helpful feedback with something they can’t use – even a little bit – in production.
widthOtsukare!
|
|
Nick Desaulniers: What's in a Word? |
Recently, there some was some confusion between myself and a coworker over the definition of a “word.” I’m currently working on a blog post about data alignment and figured it would be good to clarify some things now, that we can refer to later.
Having studied computer engineering and being quite fond of processor design, when I think of a “word,” I think of the number of bits wide a processor’s general purpose registers are (aka word size). This places hard requirements on the largest representable number and address space. A 64 bit processor can represent 264-1 (1.8x1019) as the largest unsigned long integer, and address up to 264-1 (16 EiB) different addresses in memory.
Further, word size limits the possible combinations of operations the processor can perform, length of immediate values used, inflates the size of binary files and memory needed to store pointers, and puts pressure on instruction caches.
Word size also has implications on loads and stores based on alignment, as we’ll see in a follow up post.
When I think of 8 bit computers, I think of my first microcontroller: an Arduino with an Atmel AVR processor. When I think of 16 bit computers, I think of my first game console, a Super Nintendo with a Ricoh 5A22. When I think of 32 bit computers, I think of my first desktop with Intel’s Pentium III. And when I think of 64 bit computers, I think modern smartphones with ARMv8 instruction sets. When someone mentions a particular word size, what are the machines that come to mind for you?
So to me, when someone’s talking about a 64b processor, to that machine (and me) a word is 64b. When we’re referring to a 8b processor, a word is 8b.
Now, some confusion.
Back in my previous blog posts about x86-64 assembly, JITs, or debugging, you might have seen me use instructions that have suffixes of b for byte (8b), w for word (16b), dw for double word (32b), and qw for quad word (64b) (since SSE2 there’s also double quadwords of 128b).
Wait a minute! How suddenly does a “word” refer to 16b on a 64b processor, as opposed to a 64b “word?”
In short, historical baggage. Intel’s first hit processor was the 4004, a 4b processor released in 1971. It wasn’t until 1979 that Intel created the 16b 8086 processor.
The 8086 was created to compete with other 16b processors that beat it to the market, like the Zilog Z80 (any Gameboy emulator fans out there? Yes, I know about the Sharp LR35902). The 8086 was the first design in the x86 family, and it allowed for the same assembly syntax from the earlier 8008, 8080, and 8085 to be reassembled for it. The 8086’s little brother (8088) would be used in IBM’s PC, and the rest is history. x86 would become one of the most successful ISAs in history.
For backwards compatibility, it seems that both Microsoft’s (whose success has tracked that of x86 since MS-DOS and IBM’s PC) and Intel’s documentation refers to words still as being 16b. This allowed 16b PE32+ executables to be run on 32b or even 64b newer versions of Windows, without requiring recompilation of source or source code modification.
This isn’t necessarily wrong to refer to a word based on backwards compatibility, it’s just important to understand the context in which the term “word” is being used, and that there might be some confusion if you have a background with x86 assembly, Windows API programming, or processor design.
So the next time someone asks: why does Intel’s documentation commonly refer to a “word” as 16b, you can tell them that the x86 and x86-64 ISAs have maintained the notion of a word being 16b since the first x86 processor, the 8086, which was a 16b processor.
Side Note: for an excellent historical perspective programming early x86 chips, I recommend Michael Abrash’s Graphics Programming Black Book. For instance he talks about 8086’s little brother, the 8088, being a 16b chip but only having an 8b bus with which to access memory. This caused a mysterious “cycle eater” to prevent fast access to 16b variables, though they were the processor’s natural size. Michael also alludes to alignment issues we’ll see in a follow up post.
http://nickdesaulniers.github.io/blog/2016/05/15/whats-in-a-word/
|
|
Mark C^ot'e: BMO's database takes a leap forward |
For historical reasons (or “hysterical raisins” as gps says) that elude me, the BMO database has been in (ughhh) Pacific Time since it was first created. This caused some weirdness on every daylight savings time switch (particularly in the fall when 2:00-3:00 am technically occurs twice), but not enough to justify the work in fixing it (it’s been this way for close to two decades, so that means lots of implicit assumptions in the code).
However, we’re planning to move BMO to AWS at some point, and their standard db solution (RDS) only supports UTC. Thus we finally had the excuse to do the work, and, after a bunch of planning, developing, and reviewing, the migration happened yesterday without issues. I am unreasonably excited by this and proud to have witnessed the correction of this egregious violation of standard db principles 18 years after BMO was originally deployed.
Thanks to the BMO team and the DBAs!
https://mrcote.info/blog/2016/05/15/bmos-database-takes-a-leap-forward/
|
|
David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/05/14/happy-bmo-push-day-18/
|
|
Emma Humphries: Readable Bug Statuses For Bugzilla: Update |
First, thank you for your interest in this project. Over 100 npm users have downloaded the package this week!
Second, I've been making updates:
npm script bundle and create a browserify'ed version of the module to include on web pages. Make sure you're using the latest version, and if you have a feature request, find a bug, or want to make an improvement, submit it to the GitHub repo.
|
|
Yunier Jos'e Sosa V'azquez: Mozilla abre su programa de ayuda al software libre a todos los proyectos |
El a~no pasado Mozilla lanz'o MOSS (por sus siglas en ingl'es de Mozilla Open Source Support), un programa para ayudar econ'omicamente a proyectos de c'odigo abierto. En sus inicios, MOSS estuvo dirigido principalmente a los proyectos que Mozilla emplea a diario. Ahora, con la adici'on de “Mozilla Partners” cualquier proyecto que est'a realizando actividades relacionadas con la Misi'on de Mozilla podr'a acceder a 'el.
Nuestra misi'on, tal como se plasma en nuestro Manifiesto, es garantizar que Internet permanezca siendo un recurso p'ublico global, abierto y accesible a todos. Una Internet que realmente ponga a las personas de primero. Sabemos que muchos otros proyectos de software comparten estas metas con nosotros, y queremos utilizar nuestros recursos para ayudar y animar a otros a trabajar hacia ellos.
Si usted piensa que su proyecto califica, le recomendamos que env'ie su solicitud llenando este formulario. Los criterios de selecci'on en que se basa el comit'e encargado de elegir los proyectos que apliquen puedes leerlos en la Wiki. El presupuesto para este a~no es de aproximadamente 1,25 millones de d'olares estadounidenses (USD).
El plazo para recibir solicitudes para la etapa inicial cerrar'a el jueves 31 de mayo a las 11:59 PM (hora del pac'ifico). Los primeros premiados ser'an dados a conocer a mediados de junio en Londres durante el evento Mozilla All Hands. Es v'alido mencionar que las solicitudes permanecer'an abiertas.
Si deseas unirte a la lista de discusi'on o mantenerte informado del avance del programa, puedes hacerlo mediante las siguientes v'ias:
Fuente: The Mozilla Blog
|
|
Matt Thompson: Our network is full of stories |
Our network is full of stories, impact and qualitative data. Colleagues and community members discover and use these narratives daily across a broad range — from communications and social media, to metrics and evaluation, to grant-writing, curriculum case studies, and grist for new outlets like the State of the Web.
Our challenge is: how do we capture and analyze these stories and qualitative data in a more systematic and rigorous way?
Can we design a unified “Story Engine” that serves multiple customers and use cases simultaneously — in ways that knit together much of our existing work? That’s the challenge we undertook in our first “Story Engine 0.1” sprint: document the goals, interview colleagues, a develop personae. Then design a process, ship a baby prototype, and test it out using some real data.

Here’s what we shipped in our first 3-day sprint:

http://mzl.la/story is now a thing! It packages what we’ve done so far. Plus a work-bench for ongoing work. It includes:

What happens when a story tip gets filed? Who does what? Where are the decision points? We mapped some of this initial process, including things like: assess the lead, notify the right staff, conduct follow-up interviews, generate writing/ artefacts, share via social, code and analyze the story, then package and use findings.

Our colleagues in the “Insights and Impact” team recently conducted their first survey of the network. These survey responses are rich in potential stories, evidence narratives, and qualitative data that can help test and refine our value proposition.
We tested the first piece of our baby story engine by pulling from the network survey and mapping data we just gathered.
This proved to be rich. It proved that our network surveys are not only great ways to gather quantitative data and map network relationships — they also provide rich leads for our grants / comms / M&E / strategy teams to follow up on.
(Anonymous for privacy reasons):
These are examples of leads that may be worth following up on to help flesh out theory of change, analyze trends, and tell a story about impact. Some of the leads we gathered also include critique or ways we need to do better — combined with explicit offers to help.
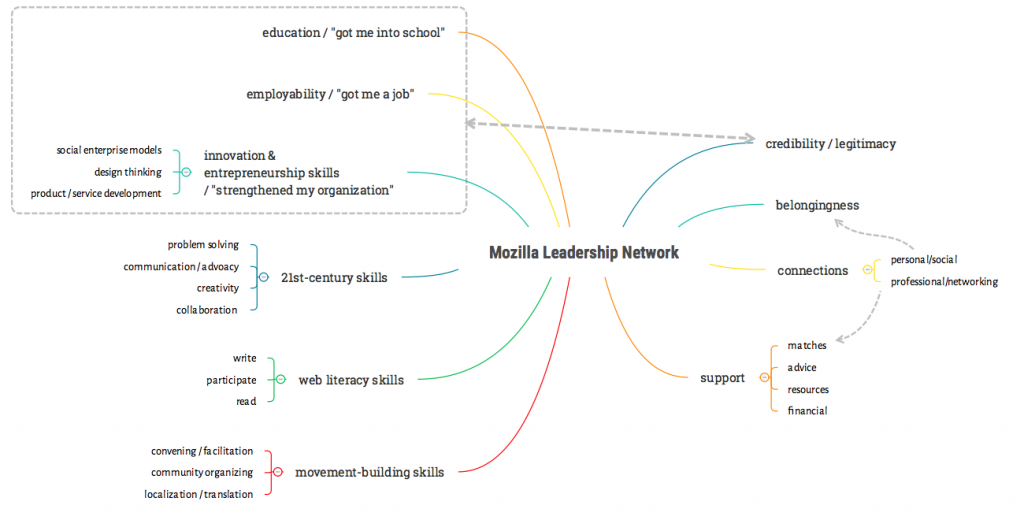
One of our goals is to combine the power of both qualitative and quantitative data. Out of this can come tagging and codes around the benefit / value the network is providing to members. Some early patterns in the benefits network members are reporting:
Imagine these as simple tags we could apply to story tickets in a repo. This will help colleagues sift, sort and follow up on specific evidence narratives that matter to them. Plus allow us to spot patterns, develop claims, and test assumptions over time.

Some of our “a ha!” moments from this first sprint:
This is a key muscle we want to strengthen in MoFo’s culture and systems: the ability to empathize with our members’ aspirations, challenges and benefits.
Regularly exposing staff and community to these stories from our network can ground our strategy, boost motivation, aid our change management process, and regularly spark “a ha” moments.
Feedback on the network survey process:
Open-ended questions like: “what’s the value or benefit you get from the network” generate great material.
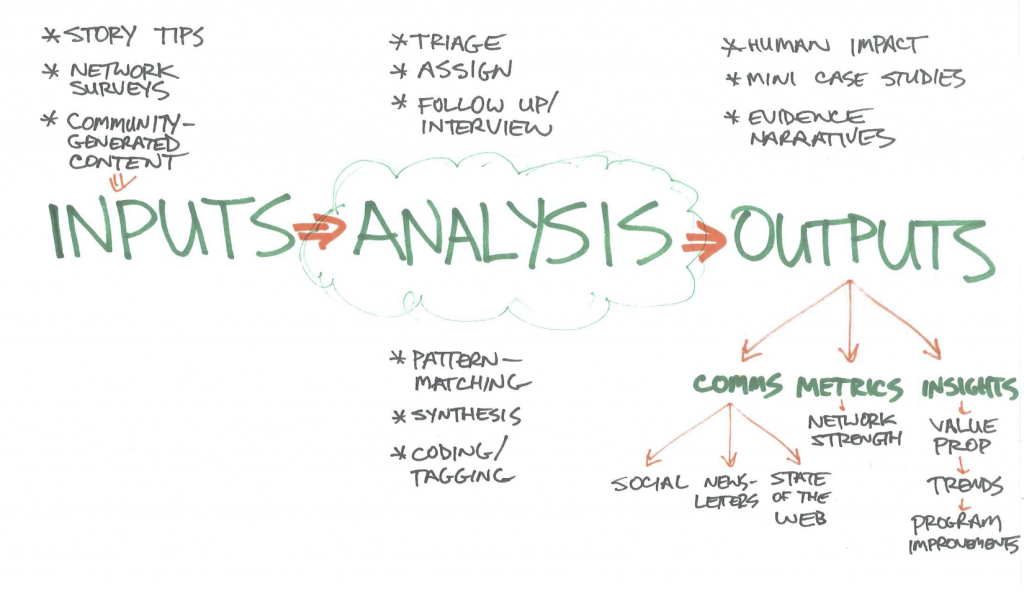
We’ve documented our next steps here. Over the last three days, we’ve dug into how to better capture the impact of what we do. We’ve launched the first discovery phase of a design thinking process centred around: “How might we create stories that are also data?”
We’re listening, reviewing existing thinking, digging into people’s needs and context — asking “what if?” Based on the Mozilla Foundation strategy, we’ve created personas, thought about claims they might want to make, pulled from the results of a first round of surveys on network impacts (New York Hive, Open Science Lab, Mozilla Clubs), and created a prototype workflow and tip sheet. Next up: more digging, listening, and prototyping.
What would you focus on next?
If we consider what we’ve done above as version 0.1, what would you prioritize or focus on for version 0.2? Let us know!
https://openmatt.org/2016/05/13/our-network-is-full-of-stories/
|
|
Tim Taubert: Six Months as a Security Engineer |
It’s been a little more than six months since I officially switched to the Security Engineering team here at Mozilla to work on NSS and related code. I thought this might be a good time to share what I’ve been up to in a short status update:
NSS contained quite a lot of SSLv2-specific code that was waiting to be removed. It was not compiled by default so there was no way to enable it in Firefox even if you wanted to. The removal was rather straightforward as the protocol changed significantly with v3 and most of the code was well separated. Good riddance.
Adam Langley submitted a patch to bring ChaCha20/Poly1305 cipher suites to NSS already two years ago but at that time we likely didn’t have enough resources to polish and land it. I picked up where he left and updated it to conform to the slightly updated specification. Firefox 47 will ship with two new ECDHE/ChaCha20 cipher suites enabled.
Ryan Sleevi, also a while ago, implemented RSA-PSS in freebl, the lower
cryptographic layer of NSS. I hooked it up to some more APIs so Firefox can
support RSA-PSS signatures in its WebCrypto API implementation. In NSS itself
we need it to support new handshake signatures in our experimental TLS v1.3
code.
Kai Engert from RedHat is currently doing a hell of a job maintaining quite a few buildbots that run all of our NSS tests whenever someone pushes a new changeset. Unfortunately the current setup doesn’t scale too well and the machines are old and slow.
Similar to e.g. Travis CI, Mozilla maintains its own continuous integration and release infrastructure, called TaskCluster. Using TaskCluster we now have an experimental Docker image that builds NSS/NSPR and runs all of our 17 (so far) test suites. The turnaround time is already very promising. This is an ongoing effort, there are lots of things left to do.
I’ve been working on the Firefox WebCrypto API implementation for a while, long before I switched to the Security Engineering team, and so it made sense to join the working group to help finalize the specification. I’m unfortunately still struggling to carve out more time for involvement with the WG than just attending meetings and representing Mozilla.
The main reason the WebCrypto API in Firefox did not support HKDF until recently is that no one found the time to implement it. I finally did find some time and brought it to Firefox 46. It is fully compatible to Chrome’s implementation (RFC 5869), the WebCrypto specification still needs to be updated to reflect those changes.
Since we shipped the first early version of the WebCrypto API, SHA-1 was the only available PRF to be used with PBKDF2. We now support PBKDF2 with SHA-2 PRFs as well.
Our initial implementation of the WebCrypto API would naively spawn a new thread
every time a crypto.subtle.* method was called. We now use a thread pool per
process that is able to handle all incoming API calls much faster.
After working on this on and off for more than six months, so even before I officially joined the security engineering team, I managed to finally get it landed, with a lot of help from Boris Zbarsky who had to adapt our WebIDL code generation quite a bit. The WebCrypto API can now finally be used from (Service)Workers.
In the near future I’ll be working further on improving our continuous integration infrastructure for NSS, and clean up the library and its tests. I will hopefully find the time to write more about it as we progress.
https://timtaubert.de/blog/2016/05/six-months-as-a-security-engineer/
|
|
Kim Moir: Welcome Mozilla Releng summer interns |
 |
| Kim, Francis, Connor and Rail |

http://relengofthenerds.blogspot.com/2016/05/welcome-mozilla-releng-summer-interns.html
|
|
QMO: Firefox 47 Beta 7 Testday, May 20th |
Hey y’all!
I am writing to let you know that next week on Friday (May 20th) we are organizing Firefox 47 Beta 7 Testday. The main focus will be on APZ feature and plugin compatibility. Check out all the details via this etherpad.
No previous testing experience is needed, so feel free to join us on #qa IRC channel where our moderators will offer you guidance and answer your questions.
Join us and help us make Firefox better!
https://quality.mozilla.org/2016/05/firefox-47-beta-7-testday-may-20th/
|
|
Pascal Chevrel: MozFR Transvision Reloaded: 1 year later |
Just one year ago, the French Mozilla community was living times of major changes: several key historical contributors were leaving the project, our various community portals were no longer updates or broken, our tools were no longer maintained. At the same time a few new contributors were also popping in our IRC channel asking for ways to get involved in the French Mozilla community.
As a result, Kaze decided to organize the first ever community meetup for the French-speaking community in the Paris office (and we will repeat this meetup in June in the brand new Paris office!) .

This resulted in a major and successful community reboot. Leaving contributors passed on the torch to other members of the community, newer contributors were meeting in real life for the first time. This is how Clarista officially became our events organizer, this is how Th'eo replaced C'edric as the main Firefox localizer and this is how I became the new developer for Transvision! 
What is Transvision? Transvision is a web application created by Philippe Dessantes which was helping the French team finding localized/localizable strings in Mozilla repositories.
Summarized like that, it doesn't sound that great, but believe me, it is! Mozilla applications have big gigantic repos, there are tens of thousands of strings in our mercurial repositories, some of them we have translated like a decade ago, when you decide to change a verb for a better one for example, it is important to be able to find all occurrences of this verb you have used in the past to see if they need update too. When somebody spots a typo or a clumsy wording, it's good to be able to check if you didn't make the same translation mistakes in other parts of the Mozilla applications several years ago and of course, it's good to be able to check that in just a few seconds. Basically, Phillippe had built the QA/assistive technology for our localization process that best fitted our team needs and we just couldn't let it die.
During the MozFR meetup, Philippe showed to me how the application worked and we created a github repository where we put the currently running version of the code. I tagged that code as version 1.0.
Over the summer, I familiarized myself with the code which was mostly procedural PHP, several Bash scripts to maintain copies of our mercurial repos and a Python script used to extract the strings. Quickly, I decided that I would follow the old Open Source strategy of Release early, release often
. Since I was doing that on the sidelines of my job at Mozilla, I needed the changes to be small but frequent incremental steps as I didn't know how much time I could devote to this project. Basically, having frequent releases means that I always have the codebase in mind which is good since I can implement an idea quickly, without having to dive into the code to remember it.
One year and 15 releases later, we are now at version 2.5, so here are the features and achievements I am most proud of:
A quick recap of what we have done, feature-wise, in the last 12 months:
The above list is of course just a highlight of the main features, you can get more details on the changelog.
If you use Transvision, I hope you enjoy it and that it is useful oo you. If you don't use Transvision (yet), give it a try, it may help you in your translation process, especially if your localization process is similar to the French one (targets Firefox Nighty builds first, work directly on the mercurial repo, focus on QA).
This was the first year of the rebirth of Transvision, I hope that the year to come will be just as good as this one. I learnt a lot with this project and I am happy to see it grow both in terms of usage and community, I am also happy that one tool that was created by a specific localization team is now used by so many other teams in the world
|
|
Yunier Jos'e Sosa V'azquez: Ay'udanos a construir el futuro de Firefox con el nuevo programa Test Pilot |
El programa Test Pilot de Mozilla tiene una nueva cara y sitio web, as'i nos los ha mostrado Mozilla en un art'iculo publicado en su blog por Nick Nguyen, Vice Presidente de Firefox. Test Pilot representa la posibilidad de probar las funcionalidades experimentales que ser'an incorporadas a Firefox y decir lo que te parece, que deber'ia ser cambiado o nuevas ideas a trav'es de la retroalimentaci'on con cada nueva caracter'istica.
En el video que te mostramos a continuaci'on podr'as ver r'apidamente los experimentos disponibles.
|
|
Air Mozilla: Bay Area Rust Meetup May 2016 |
 Bay Area Rust Meetup for May 2016.
Bay Area Rust Meetup for May 2016.
|
|
Mozilla Addons Blog: AMO technical architecture |
addons.mozilla.org (AMO) has been around for more than 12 years, making it one of the oldest websites at Mozilla. It celebrated its 10th anniversary a couple of years ago, as Wil blogged about.
AMO started as a PHP site that grew and grew as new pieces of functionality were bolted on. In October 2009 the rewrite from PHP to Python began. New features were added, the site grew ever larger, and now a few cracks are starting to appear. These are merely the result of a site that has lots of features and functionality and has been around for a long time.
The site architecture is currently something like below, but please note this simplifies the site and ignores the complexities of AWS, the CDN and other parts of the site.

Basically, all the code is one repository and the main application (a Django app) is responsible for generating everything—from HTML, to emails, to APIs, and it all gets deployed at the same time. There’s a few problems with this:
We are moving towards a new model similar to the one used for Firefox Marketplace. Whereas Marketplace built its own front-end framework, we are going to be using React on the front end.
The end result will start look something like this:

A separate version of the site is rendered for the different use cases, for example developers or users. In this case a request comes in hits one of the appropriate front-end stacks. That will render the site using React universal in node.js on the server. It will access the data store by calling the appropriate Python REST APIs.
In this scenario, the legacy Python code will migrate to being a REST API that manages storage, transactions, workflow, permissions and the like. All the front-facing user interface work will be done in React and be independent from each other as much as possible.
It’s not quite micro services, but the breaking of a larger site into smaller independent pieces. The first part of this is happening with the “discovery pane” (accessible at about:addons). This is our first project using this infrastructure, which features a new streamlined way to install add-ons with a new technical architecture to serve it to users.
As we roll out this new architecture we’ll be doing more blog posts, so if you’d like to get involved then join our mailing list or check out our repositories on Github.
https://blog.mozilla.org/addons/2016/05/12/amo-technical-architecture/
|
|
Support.Mozilla.Org: What’s Up with SUMO – 12th May |
Hello, SUMO Nation!
Yes, we know, Friday the 13th is upon us… Fear not, in good company even the most unlucky days can turn into something special ;-) Pet a black cat, find a four leaf clover, smile and enjoy what the weekend brings!
As for SUMO, we have a few updates coming your way. Here they are!
We salute you!
Thanks for your attention and see you around SUMO, soon!
https://blog.mozilla.org/sumo/2016/05/12/whats-up-with-sumo-12th-may/
|
|
Air Mozilla: Web QA Team Meeting, 12 May 2016 |
 Weekly Web QA team meeting - please feel free and encouraged to join us for status updates, interesting testing challenges, cool technologies, and perhaps a...
Weekly Web QA team meeting - please feel free and encouraged to join us for status updates, interesting testing challenges, cool technologies, and perhaps a...
|
|
Air Mozilla: Reps weekly, 12 May 2016 |
 This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
This is a weekly call with some of the Reps to discuss all matters about/affecting Reps and invite Reps to share their work with everyone.
|
|
Daniel Glazman: BlueGriffon 2.0 approaching... |
BlueGriffon 2.0 is approaching, a major revamp of my cross-platform Wysiwyg Gecko-based editor. You can find previews here for OSX, Windows and Ubuntu 16.04 (64 bits).
Warnings:
Changes:
- major revamp, you won't even recognize the app- based on a very recent version of Gecko, that was a HUGE work. - no more floating panels, too hacky and expensive to maintain - rendering engine support added for Blink, Servo, Vivliostyle and Weasyprint! - tons of debugging in *all* areas of the app - BlueGriffon now uses the native colorpicker on OSX. Yay!!! The native colorpicker of Windows is so weak and ugly we just can't use it (it can't even deal with opacity...) and decided to stick to our own implementation. On Linux, the situation is more complicated, the colorpicker is not as ugly as the Windows' one, but it's unfortunately too weak compared to what our own offers. - more CSS properties handled - helper link from each CSS property in the UI to MDN - better templates handling - auto-reload of html documents if modified outside of BlueGriffon - better Markdown support - zoom in Source View - tech changes for future improvements: support for :active and other dynamic pseudo-classes, support for ::before and ::after pseudo-elements in CSS Properties; rely on Gecko's CSS lexer instead of our own. We're also working on cool new features on the CSS side like CSS Variables and even much cooler than that
http://www.glazman.org/weblog/dotclear/index.php?post/2016/05/12/BlueGriffon-2.0-approaching...
|
|






