Christian Heilmann: ChakraCore and Node musings at NodeConf London |
Yesterday morning I dragged myself to present at NodeConf London in the Barbican to present. Dragged not because I didn’t want to, but because I had 3 hours sleep coming back from Beyond Tellerand the day before.
 Photo by Adrian Alexa
Photo by Adrian AlexaI didn’t quite have time to prepare my talk, and I ended up finishing my slides 5 minutes before it. That’s why I was, to use a simple term, shit scared of my talk. I’m not that involved in the goings on in Node, and the impostor in me assumed the whole audience to be all experts and me making an utter berk of myself. However, this being a good starting point I just went with it and used the opportunity to speak to an audience that much in the know about something I want Node to be.
I see the Node environment and ecosystem as an excellent opportunity to test out new JavaScript features and ideas without the issue of browser interoperability and incompatibility.
The thing I never was at ease about it though is that *everything is based on on one JS engine&. This is not how you define and test out a standard. You need to have several runtimes to execute your code. Much like a browser monoculture was a terrible thing and gave us thousands of now unmaintainable and hard to use web sites, not opening ourselves to various engines can lead to terrible scripts and apps based on Node.
The talk video is already live and you can also see all the other talks in this playlist:
The slides are on Slideshare:
A screencast recording of the talk is on YouTube.
Resources I mentioned:
I was very happy to get amazing feedback from everyone I met, and that people thoroughly enjoyed my presentation. Goes to show that the voice in your head telling you that you’re not good enough often is just being a a dick.
https://www.christianheilmann.com/2016/05/12/chakracore-and-node-musings-at-nodeconf-london/
|
|
Karl Dubost: Schools Of Thoughts In Web Standards |
Last night, I had the pleasure of reading Daniel Stenberg's blog post about URL Standards. It led me to the discussion happening about the WHATWG URL spec about "It's not immediately clear that "URL syntax" and "URL parser" conflict". As you can expect, the debate is inflammatory on both sides, border line hypocrite at some occasions and with a lot of the arguments I have seen in the last 20 years I have followed discussions around the Web development.
This post has no intent to be the right way to talk about it. It's more a collection of impression I had when reading the thread with my baggage of ex-W3C staff, Web agency work and, ex-Opera and now-Mozilla Web Compatibility work.
"Le chat a bon dos". French expression to basically say we are in the blaming game in that thread. Maybe not that useful.
What is happening?
$BROWSER lord: In the discussion, the $BROWSER is Google's Chrome. A couple of years ago, it was IE. Again, saying Chrome has no specific responsibility is again an escapism. The same way that Safari has a lot of influences on the mobile Web, Chrome currently by its market share creates a tide which influences a lot the Web content and its patterns out there. I can guarantee that it's easier now for Chrome to be stricter with regards to syntax than it is for Edge or Firefox. Opera had to give up its rendering engine (Presto) because of this and switched to blink.There are different schools for the Web specifications:
I'm swaying in between these three schools all the time. I don't like the number 2 at all, but because of survival it is sometimes necessary. My preferred way it's 3, having a clear strict syntax for producing content, and a recovery parsing technique. And when possible I would prefer a sanitizer version of the Postel's law.
What did he say btw?
The implementation of a protocol must be robust. Each implementation must expect to interoperate with others created by different individuals. While the goal of this specification is to be explicit about the protocol there is the possibility of differing interpretations. In general, an implementation should be conservative in its sending behavior, and liberal in its receiving behavior. That is, it should be careful to send well-formed datagrams, but should accept any datagram that it can interpret (e.g., not object to technical errors where the meaning is still clear).
Then in RFC 1122: The 1.2.2 section, the Robustness Principle
At every layer of the protocols, there is a general rule whose application can lead to enormous benefits in robustness and interoperability [IP:1]:
"Be liberal in what you accept, and conservative in what you send"
Software should be written to deal with every conceivable error, no matter how unlikely; sooner or later a packet will come in with that particular combination of errors and attributes, and unless the software is prepared, chaos can ensue. In general, it is best to assume that the network is filled with malevolent entities that will send in packets designed to have the worst possible effect. This assumption will lead to suitable protective design, although the most serious problems in the Internet have been caused by unenvisaged mechanisms triggered by low-probability events; mere human malice would never have taken so devious a course!
Adaptability to change must be designed into all levels of Internet host software. As a simple example, consider a protocol specification that contains an enumeration of values for a particular header field -- e.g., a type field, a port number, or an error code; this enumeration must be assumed to be incomplete. Thus, if a protocol specification defines four possible error codes, the software must not break when a fifth code shows up. An undefined code might be logged (see below), but it must not cause a failure.
The second part of the principle is almost as important: software on other hosts may contain deficiencies that make it unwise to exploit legal but obscure protocol features. It is unwise to stray far from the obvious and simple, lest untoward effects result elsewhere. A corollary of this is "watch out for misbehaving hosts"; host software should be prepared, not just to survive other misbehaving hosts, but also to cooperate to limit the amount of disruption such hosts can cause to the shared communication facility.
The important point in the discussion of Postel's law is that he is talking about software behavior, not specifications. The new school of thoughts for Web standards is to create specification which are "software-driven", not "syntax-driven". And it's why you can read entrenched debates about the technology.
My sanitizer version of the Postel's law would be something along:
Basically when you receive something broken, and there is a clear path for fixing it, do it. Normalize it. In the debated version, about accepting http://////, it would be
http://////http:// and possibly with an optional notification it has been recovered. Otsukare!
http://www.otsukare.info/2016/05/12/web-standards-school-of-thoughts
|
|
The Mozilla Blog: Advance Disclosure Needed to Keep Users Secure |
User security is paramount. Vulnerabilities can weaken security and ultimately harm users. We want people who identify security vulnerabilities in our products to disclose them to us so we can fix them as soon as possible. That’s why we were one of the first companies to create a bug bounty program and that’s why we are taking action again – to get information that would allow us to fix a potential vulnerability before it is more widely disclosed.
Today, we filed a brief in an ongoing criminal case asking the court to ensure that, if our code is implicated in a security vulnerability, that the government must disclose the vulnerability to us before it is disclosed to any other party. We aren’t taking sides in the case, but we are on the side of the hundreds of millions of users who could benefit from timely disclosure.
The relevant issue in this case relates to a vulnerability allegedly exploited by the government in the Tor Browser. The Tor Browser is partially based on our Firefox browser code. Some have speculated, including members of the defense team, that the vulnerability might exist in the portion of the Firefox browser code relied on by the Tor Browser. At this point, no one (including us) outside the government knows what vulnerability was exploited and whether it resides in any of our code base. The judge in this case ordered the government to disclose the vulnerability to the defense team but not to any of the entities that could actually fix the vulnerability. We don’t believe that this makes sense because it doesn’t allow the vulnerability to be fixed before it is more widely disclosed.
Court ordered disclosure of vulnerabilities should follow the best practice of advance disclosure that is standard in the security research community. In this instance, the judge should require the government to disclose the vulnerability to the affected technology companies first, so it can be patched quickly.
Governments and technology companies both have a role to play in ensuring people’s security online. Disclosing vulnerabilities to technology companies first, allows us to do our job to prevent users from being harmed and to make the Web more secure.
https://blog.mozilla.org/blog/2016/05/11/advanced-disclosure-needed-to-keep-users-secure/
|
|
Selena Deckelmann: TaskCluster Platform Team: Q1 retrospective |
TaskCluster Platform team did a lot of foundational work in Q1, to set the stage for some aggressive goals in Q2 around landing new OS support and migrating as fast as we can out of Buildbot.
The two big categories of work we had were “Moving Forward” — things that move TaskCluster forward in terms of developing our team and adding cool features, and “Paying debt” — upgrading infra, improving security, cleaning up code, improving existing interfaces and spinning out code into separate libraries where we can.
As you’ll see, there’s quite a lot of maintenance that goes into our services at this point. There’s probably some overlap of features in the “paying debt” section. Despite a little bit of fuzzyness in the definitions, I think this is an interesting way to examine our work, and a way for us to prioritize features that eliminate certain classes of unpleasant debt paying work. I’m planning to do a similar retrospective for Q2 in July.
I’m quite proud of the foundational work we did on taskcluster-worker, and it’s already paying off in rapid progress with OS X support on hardware in Q2. We’re making fairly good progress on Windows in AWS as well, but we had to pay down years of technical debt around Windows configuration to get our builds running in TaskCluster. Making a choice on our monitoring systems was also a huge win, paying off in much better dashboarding and attention to metrics across services. We’re also excited to have shipped the “Big Graph Scheduler”, which enables cross-graph dependencies and arbitrarily large task graphs (previous graphs were limited to about 1300 tasks). Our team also grew by 2 people – we added Dustin Mitchell, who will continue to do all kinds of work around our systems, focus on security-related issues and will ship a new intree configuration in Q2, and Eli Perelman, who will focus on front end concerns.
The TaskCluster Platform team put the following list together at the start of Q2.
Moving forward:
Paying debt:
http://www.chesnok.com/daily/2016/05/11/taskcluster-platform-team-q1-retrospective/
|
|
Mozilla Addons Blog: Add-ons Update – Week of 2016/05/11 |
I post these updates every 3 weeks to inform add-on developers about the status of the review queues, add-on compatibility, and other happenings in the add-ons world.
In the past 3 weeks, 1387 listed add-ons were reviewed:
There are 67 listed add-ons awaiting review.
You can read about the recent improvements in the review queues here.
If you’re an add-on developer and are looking for contribution opportunities, please consider joining us. Add-on reviewers get invited to Mozilla events and earn cool gear with their work. Visit our wiki page for more information.
Most of you should have received an email from us about the future compatibility of your add-ons. You can use the compatibility tool to enter your add-on ID and get some info on what we think is the best path forward for your add-on. This tool only works for listed add-ons.
To ensure long-term compatibility, we suggest you start looking into WebExtensions, or use the Add-ons SDK and try to stick to the high-level APIs. There are many XUL add-ons that require APIs that aren’t available in either of these options, which is why we ran a survey so we know which APIs we should look into adding to WebExtensions. You can read about the survey results here.
We’re holding regular office hours for Multiprocess Firefox compatibility, to help you work on your add-ons, so please drop in on Tuesdays and chat with us!
The compatibility blog post for 47 is up and the bulk validation has been run.
The compatibility blog post for Firefox 48 is coming up soon.
As always, we recommend that you test your add-ons on Beta and Firefox Developer Edition to make sure that they continue to work correctly. End users can install the Add-on Compatibility Reporter to identify and report any add-ons that aren’t working anymore.
The wiki page on Extension Signing has information about the timeline, as well as responses to some frequently asked questions. The current plan is to remove the signing override preference in Firefox 47.
The preference was actually removed recently in the beta channel (future Firefox 47), though this was done before the unbranded builds were available for testing. We’re trying to get those builds out as soon as possible to avoid more disruption. For now I suggest you use Developer Edition for testing or, if your add-on is restartless, you can also use the temporary load option.
https://blog.mozilla.org/addons/2016/05/11/add-ons-update-81/
|
|
The Mozilla Blog: Mozilla Open Source Support (MOSS): Now Open To All Projects |
Last year, we launched the Mozilla Open Source Support Program (MOSS) – an award program specifically focused on supporting open source and free software. The first track within MOSS (“Foundational Technology”) provides support for open source and free software projects that Mozilla uses or relies on. We are now adding a second track. “Mission Partners” is open to any open source project in the world which is undertaking an activity that meaningfully furthers Mozilla’s mission.
Our mission, as embodied in our Manifesto, is to ensure the Internet is a global public resource, open and accessible to all. An Internet that truly puts people first, where individuals can shape their own experience and are empowered, safe and independent. We know that many other software projects around the world share these goals with us, and we want to use our resources to help and encourage others to work towards them.
So if you think your project qualifies, we encourage you to apply. Applications for the Mission Partners track are open as of today. (Applications for Foundational Technology also remain open.) You can read more about our selection criteria and committee on the wiki. The budget for this track for 2016 is approximately US$1.25 million.
We are keen to enable applications from groups not currently connected with Mozilla and from communities outside the English-speaking free software world. Therefore, applications for Mission Partners do not require a Mozillian to support them. Instead, they must be endorsed by a well-known and respected figure from the wider software community of which the project is a part.
The deadline for applications for the initial batch of Mission Partners awards is Tuesday, May 31 at 11:59pm Pacific Time. The first awardees will be announced at the Mozilla All Hands in London in the middle of June. After that time, applications will continue to be accepted and will be considered on an ongoing basis.
If you want to be kept informed of updates to the MOSS program, please join our discussion forum and read our updates on the Mozilla blog.
We look forward to considering the applications.
https://blog.mozilla.org/blog/2016/05/11/mozilla-open-source-support-moss-now-open-to-all-projects/
|
|
The Mozilla Blog: Firefox for iOS Makes it Faster and Easier to Use the Mobile Web the Way You Want |
We’re always focused on making the best Firefox experience we can offer. We want to give you complete control over your web experience, while also making sure to protect your privacy and security the best we can. Today, we’re pleased to share an update to Firefox for iOS that gives you a more streamlined experience and that allows for more control over your mobile browsing experience.
What’s New in Firefox for iOS?
iOS Today Widget: We know that getting to what you need on the Web fast is important, especially on your mobile, so you can access Firefox through the iOS Today widget to quickly open a new tab, a new private tab or a recently copied URL.
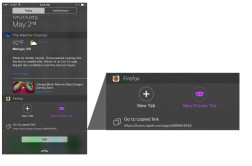
iOS Today Widget in Firefox for iOS
Awesomebar: Firefox for iOS allows you to search your bookmarks and history within the smart URL bar, making it easier to quickly access your favorite websites.
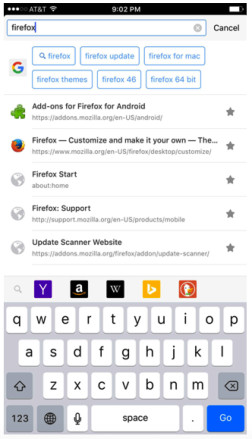
Search bookmarks in Firefox for iOS
Manage Security: By default, Firefox helps to ensure your security by warning you when a website’s connection is not secure. When you attempt to access an unsafe website, you’ll see an error message stating that the connection is untrusted, and you are prevented from accessing that site. With iOS, you can now temporarily ignore these error messages for websites you have deemed as “safe”, but that might register as potentially unsafe by Firefox.
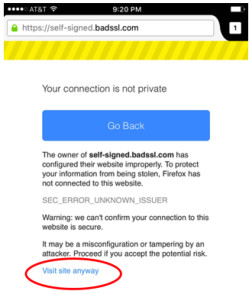
Over-ride certificate errors in Firefox for iOS
To experience the newest features and use the latest version of Firefox for iOS, download the update and let us know what you think.
![]()
|
|
Robert O'Callahan: Data On x86-64 Register Usage |
I looked into the frequency of register usage in x86-64. I disassembled optimized and debug builds of Firefox's libxul.so and counted, for each general-purpose register, the number of instructions referencing that register. The graph below shows those results, normalized to a fraction of the total number of instructions in each binary.

These results severely undercount the actual usage of rsp, since it's implicitly used in every push, pop, call and ret instruction, but otherwise should be accurate. 8, 16 and 32-bit registers were counted as the 64-bit register they belong to.
Observations:
http://robert.ocallahan.org/2016/05/data-on-x86-64-register-usage.html
|
|
Daniel Stenberg: My URL isn’t your URL |

When I started the precursor to the curl project, httpget, back in 1996, I wrote my first URL parser. Back then, the universal address was still called URL: Uniform Resource Locators. That spec was published by the IETF in 1994. The term “URL” was then used as source for inspiration when naming the tool and project curl.
The term URL was later effectively changed to become URI, Uniform Resource Identifiers (published in 2005) but the basic point remained: a syntax for a string to specify a resource online and which protocol to use to get it. We claim curl accepts “URLs” as defined by this spec, the RFC 3986. I’ll explain below why it isn’t strictly true.
There was also a companion RFC posted for IRI: Internationalized Resource Identifiers. They are basically URIs but allowing non-ascii characters to be used.
The WHATWG consortium later produced their own URL spec, basically mixing formats and ideas from URIs and IRIs with a (not surprisingly) strong focus on browsers. One of their expressed goals is to “Align RFC 3986 and RFC 3987 with contemporary implementations and obsolete them in the process“. They want to go back and use the term “URL” as they rightfully state, the terms URI and IRI are just confusing and no humans ever really understood them (or often even knew they exist).
The WHATWG spec follows the good old browser mantra of being very liberal in what it accepts and trying to guess what the users mean and bending backwards trying to fulfill. (Even though we all know by now that Postel’s Law is the wrong way to go about this.) It means it’ll handle too many slashes, embedded white space as well as non-ASCII characters.
From my point of view, the spec is also very hard to read and follow due to it not describing the syntax or format very much but focuses far too much on mandating a parsing algorithm. To test my claim: figure out what their spec says about a trailing dot after the host name in a URL.
On top of all these standards and specs, browsers offer an “address bar” (a piece of UI that often goes under other names) that allows users to enter all sorts of fun strings and they get converted over to a URL. If you enter “http://localhost/%41” in the address bar, it’ll convert the percent encoded part to an ‘A’ there for you (since 41 in hex is a capital A in ASCII) but if you type “http://localhost/A A” it’ll actually send “/A%20A” (with a percent encoded space) in the outgoing HTTP GET request. I’m mentioning this since people will often think of what you can enter there as a “URL”.
The above is basically my (skewed) perspective of what specs and standards we have so far to work with. Now we add reality and let’s take a look at what sort of problems we get when my URL isn’t your URL.
Or more specifically, how do we write them. What syntax do we use.
I think one of the biggest mistakes the WHATWG spec has made (and why you will find me argue against their spec in its current form with fierce conviction that they are wrong), is that they seem to believe that URLs are theirs to define and work with and they limit their view of URLs for browsers, HTML and their address bars. Sure, they are the big companies behind the browsers almost everyone uses and URLs are widely used by browsers, but URLs are still much bigger than so.
The WHATWG view of a URL is not widely adopted outside of browsers.
If we ask users, ordinary people with no particular protocol or web expertise, what a URL is what would they answer? While it was probably more notable years ago when the browsers displayed it more prominently, the :// (colon-slash-slash) sequence will be high on the list. Seeing that marks the string as a URL.
Heck, going beyond users, there are email clients, terminal emulators, text editors, perl scripts and a bazillion other things out there in the world already that detects URLs for us and allows operations on that. It could be to open that URL in a browser, to convert it to a clickable link in generated HTML and more. A vast amount of said scripts and programs will use the colon-slash-slash sequence as a trigger.
The WHATWG spec says it has to be one slash and that a parser must accept an indefinite amount of slashes. “http:/example.com” and “http:////////////////////////////////////example.com” are both equally fine. RFC 3986 and many others would disagree. Heck, most people I’ve confronted the last few days, even people working with the web, seem to say, think and believe that a URL has two slashes. Just look closer at the google picture search screen shot at the top of this article, which shows the top images for “URL” google gave me.
We just know a URL has two slashes there (and yeah, file: URLs most have three but lets ignore that for now). Not one. Not three. Two. But the WHATWG doesn’t agree.
“Is there really any reason for accepting more than two slashes for non-file: URLs?” (my annoyed question to the WHATWG)
“The fact that all browsers do.”
The spec says so because browsers have implemented the spec.
No better explanation has been provided, not even after I pointed out that the statement is wrong and far from all browsers do. You may find reading that thread educational.
In the curl project, we’ve just recently started debating how to deal with “URLs” having another amount of slashes than two because it turns out there are servers sending back such URLs in Location: headers, and some browsers are happy to oblige. curl is not and neither is a lot of other libraries and command line tools. Who do we stand up for?
A space character (the ASCII code 32, 0x20 in hex) cannot be part of a URL. If you want it sent, you percent encode it like you do with any other illegal character you want to be part of the URL. Percent encoding is the byte value in hexadecimal with a percent sign in front of it. %20 thus means space. It also means that a parser that for example scans for URLs in a text knows that it reaches the end of the URL when the parser encounters a character that isn’t allowed. Like space.
Browsers typically show the address in their address bars with all %20 instances converted to space for appearance. If you copy the address there into your clipboard and then paste it again in your text editor you still normally get the spaces as %20 like you want them.
I’m not sure if that is the reason, but browsers also accept spaces as part of URLs when for example receiving a redirect in a HTTP response. That’s passed from a server to a client using a Location: header with the URL in it. The browsers happily allow spaces in that URL, encode them as %20 and send out the next request. This forced curl into accepting spaces in redirected “URLs”.
Making URLs support non-ASCII languages is of course important, especially for non-western societies and I’ve understood that the IRI spec was never good enough. I personally am far from an expert on these internationalization (i18n) issues so I just go by what I’ve heard from others. But of course users of non-latin alphabets and typing systems need to be able to write their “internet addresses” to resources and use as links as well.
In an ideal world, we would have the i18n version shown to users and there would be the encoded ASCII based version below, to get sent over the wire.
For international domain names, the name gets converted over to “punycode” so that it can be resolved using the normal system name resolvers that know nothing about non-ascii names. URIs have no IDN names, IRIs do and WHATWG URLs do. curl supports IDN host names.
WHATWG states that URLs are specified as UTF-8 while URIs are just ASCII. curl gets confused by non-ASCII letters in the path part but percent encodes such byte values in the outgoing requests – which causes “interesting” side-effects when the non-ASCII characters are provided in other encodings than UTF-8 which for example is standard on Windows…
Similar to what I’ve written above, this leads to servers passing back non-ASCII byte codes in HTTP headers that browsers gladly accept, and non-browsers need to deal with…
I’ve not tried to write a conclusive list of problems or differences, just a bunch of things I’ve fallen over recently. A “URL” given in one place is certainly not certain to be accepted or understood as a “URL” in another place.
Not even curl follows any published spec very closely these days, as we’re slowly digressing for the sake of “web compatibility”.
There’s no unified URL standard and there’s no work in progress towards that. I don’t count WHATWG’s spec as a real effort either, as it is written by a closed group with no real attempts to get the wider community involved.
I’m employed by Mozilla and Mozilla is a member of WHATWG and I have colleagues working on the WHATWG URL spec and other work items of theirs but it makes absolutely no difference to what I’ve written here. I also participate in the IETF and I consider myself friends with authors of RFC 1738, RFC 3986 and others but that doesn’t matter here either. My opinions are my own and this is my personal blog.
https://daniel.haxx.se/blog/2016/05/11/my-url-isnt-your-url/
|
|
Air Mozilla: Firefox Test Pilot: Suit up and take experimental features for a test flight |
 Be the first to try experimental Firefox features. Join Test Pilot to unlock access to our rainbow launchers, teleportation devices, security sphinxes, invisibility cloaks –...
Be the first to try experimental Firefox features. Join Test Pilot to unlock access to our rainbow launchers, teleportation devices, security sphinxes, invisibility cloaks –...
https://air.mozilla.org/firefox-test-pilot-suit-up-and-take-experimental-features-for-a-test-flight/
|
|
Mozilla WebDev Community: Extravaganza – May 2016 |
Once a month, web developers from across Mozilla get together to talk about the work that we’ve shipped, share the libraries we’re working on, meet new folks, and talk about whatever else is on our minds. It’s the Webdev Extravaganza! The meeting is open to the public; you should stop by!
You can check out the wiki page that we use to organize the meeting, or view a recording of the meeting in Air Mozilla. Or just read on for a summary!
The shipping celebration is for anything we finished and deployed in the past month, whether it be a brand new site, an upgrade to an existing one, or even a release of a library.
First up was Osmose (that’s me!), sharing the news that Normandy has shipped! Normandy is a service that will eventually power several Firefox features that involve interacting with users and testing changes to Firefox quickly and safely, such as recommending features that may be useful to users or offering opportunities to try out changes. Right now the service is powering Heartbeat surveys being sent to release users.
Big thanks to the User Advocacy and Web Engineering teams for working on the project!
Next was shobson who talked about MDN‘s Safe Draft feature. When editing an MDN article, the site autosaves your edits to localStorage (if it’s available). Then, when you revisit the editing interface later, the site offers to let you restore or discard the draft, disabling autosave until a decision is made. Future improvements may include previewing drafts and notifying users when an article has changed since their draft was saved.
peterbe stopped by to talk about Air Mozilla‘s chapters feature, which allows users to mark and link to segments in a video. The site now auto-generates thumbnails for chapters to help preview what the chapter is about.
The Roundtable is the home for discussions that don’t fit anywhere else.
Last up was jgmize, who asked about use of Docker for easy development environments. The general consensus was that most of the developers present had tried using Dockerized development environments, but tended towards using it only for deployed services or not at all.
Some of the interesting projects brought up for using Docker for development or deployment were:
Check ’em out!
If you’re interested in web development at Mozilla, or want to attend next month’s Extravaganza, subscribe to the dev-webdev@lists.mozilla.org mailing list to be notified of the next meeting, and maybe send a message introducing yourself. We’d love to meet you!
See you next month!
https://blog.mozilla.org/webdev/2016/05/10/extravaganza-may-2016/
|
|
Emma Humphries: Readable Bug Statuses For Bugzilla |
Bugs in bugzilla.mozilla.org have a lot of metadata, and it's often not immediately obvious what the state of a bug is. To help with that, I've written an opinionated module for npm that looks at the bug's metadata and returns a readable status message.
I've published the first version of it on npmjs.org and encourage you to install it and try it out.
It's opinionated in the metadata it considers important to a bug's status: the regression keyword, status flags, and release flags.
The module also has a strong opinion about the meaning of the priority field, and uses it to describe the decision of what to do with bugs that haven't been nominated by the release team.
There's a GitHub repo for the module for pull requests, and of course a bugzilla bug, #1271685.
|
|
Air Mozilla: Connected Devices Weekly Program Update, 10 May 2016 |
 Weekly project updates from the Mozilla Connected Devices team.
Weekly project updates from the Mozilla Connected Devices team.
https://air.mozilla.org/connected-devices-weekly-program-update-20160510/
|
|
Mike Hommey: Using git to access mercurial repositories, without mercurial |
If you’ve been following this blog, you know I’ve been working on a git remote helper that gives access to mercurial repositories, named git-cinnabar. So far, it has been using libraries from mercurial itself in order to talk to local or remote repositories.
That is, until today. The current master branch now has experimental support for direct access to remote mercurial repositories, without mercurial.
|
|
Air Mozilla: Martes mozilleros, 10 May 2016 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos. Bi-weekly meeting to talk (in Spanish) about Mozilla status, community and...
|
|
David Lawrence: Happy BMO Push Day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.

https://dlawrence.wordpress.com/2016/05/10/happy-bmo-push-day-17/
|
|
The Mozilla Blog: You Can Help Build the Future of Firefox with the New Test Pilot Program |
When building features for hundreds of millions of Firefox users worldwide, it’s important to get them right. To help figure out which features should ship and how they should work, we created the new Test Pilot program. Test Pilot is a way for you to try out experimental features and let us know what you think. You can turn them on and off at any time, and you’ll always know what information you’re sharing to help us understand how these features are used. Of course, you can also use Test Pilot to provide feedback and suggestions to the teams behind each new feature.
As you’re experimenting with new features, you might experience some bugs or lose some of the polish from the general Firefox release, so Test Pilot allows you to easily enable or disable features at any time.
Feedback and data from Test Pilot will help determine which features ultimately end up in a Firefox release for all to enjoy.
What New Experimental Features Can You Test?
Activity Stream: This experiment will make it easier to navigate through browsing history to find important websites and content faster. Activity stream helps you rediscover the things you love the most on the web. Each time you open a new tab, you’ll see your top sites along with highlights from your bookmarks and history. Simply browse the visual timeline to find what you want.
Tab Center: Display tabs vertically along the side of the screen instead of horizontally along the top of the browser to give you a new way to experience tabbed browsing.
Universal search: Combines the Awesome Bar history with the Firefox Search drop down menu to give you the best recommendations so you can spend less time sifting through search results and more time enjoying the web. You’ll notice that search suggestions look different. If you have been to a site before, you will see it clearly highlighted as a search suggestion. Recommended results will include more information about the site suggestion, like top stories on the news page or featured content.
How do I get started?
Test Pilot experiments are currently available in English only and we will add more languages later this year. To download Test Pilot and help us build the future of Firefox, visit https://testpilot.firefox.com/
|
|
Wil Clouser: Test Pilot launches today! |

Check out Test Pilot or read the official announcement.
I joined the Test Pilot team in January and am pleased to be a part of launching our experiment platform today on testpilot.firefox.com! Our goal is to provide a portal where you can easily browse and play with experimental features in Firefox.
We're starting out with three new experiments so people can get a feel for what the program is like and we'll be rotating new experiments in as previous ones graduate from the program.
Behind the scenes is a pretty comprehensive pipeline to rocket an idea from the back of a napkin to being used by users in a short period of time. If you have an idea (bonus points if it's already an add-on) and would like to get in the program let us know, look us up in #testpilot on irc.mozilla.org, or get in touch with me directly.
|
|
Niko Matsakis: Non-lexical lifetimes: adding the outlives relation |
This is the third post in my series on non-lexical lifetimes. Here I want to dive into Problem Case #3 from the introduction. This is an interesting case because exploring it is what led me to move away from the continuous lifetimes proposed as part of RFC 396.
As a reminder, problem case #3 was the following fragment:
1 2 3 4 5 6 7 8 9 10 11 12 | |
What makes this example interesting is that it crosses functions. In
particular, when we call get_mut the first time, if we get back a
Some value, we plan to return the point, and hence the value must
last until the end of the lifetime 'm (that is, until some point in
the caller). However, if we get back a None value, we wish to
release the loan immediately, because there is no reference to return.
Many people lack intuition for named lifetime parameters. To help get
some better intuition for what a named lifetime parameter represents,
imagine some caller of get_default:
1 2 3 4 5 6 7 8 9 | |
Here we can see that we first create a reference to map called
map_ref (I pulled this reference into a variable for purposes of
exposition). This variable is passed into get_default, which returns
a reference into the map called value. The important point here is
that the signature of get_default indicates that value is a
reference into the map as well, so that means that the lifetime of
map_ref will also include any uses of value. Therefore, the
lifetime 'm winds up extending from the creation of map_ref until
after the call to use(value).
Although ostensibly problem case #3 is about cross-function use, it
turns out that – for the purposes of this blog post – we can create
an equally interesting test case by inlining get_default into the
caller. This will produce the following combined example, which will
be the running example for this post. I’ve also taken the liberty of
desugaring
the method calls to get_mut a bit, which helps with
explaining what’s going on:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Written this way, we can see that there are two loans: map_ref1 and
map_ref2. Both loans are passed to get_mut and the resulting
reference must last until after the call to use(value) has finished.
I’ve depicted the lifetime of the two loans here (and denoted them
'm1 and 'm2).
Note that, for this fragment to type-check, 'm1 must exclude the
None arm of the match. I’ve denoted this by using a . for that
part of the line. This area must be excluded because, otherwise, the
calls to insert and get_mut, both of which require mutable borrows
of map, would be in conflict with map_ref1.
But if 'm1 excludes the None part of the match, that means that
control can flow out of the region 'm1 (into the None arm) and
then back in again (in the use(value)).
At this point, it’s worth revisiting RFC 396. RFC 396 was based on
the very clever notion of defining lifetimes based on the dominator
tree. The idea (in my own words here) was that a lifetime consists of
a dominator node (the entry point H) along with a series of of
tails
T. The lifetime then consisted of all nodes that were
dominated by H but which dominated one of the tails T. Moreover,
you have as a consistency condition, that for every edge V -> W in
the CFG, if W != H is in the lifetime, then V is in the lifetime.
The RFC’s definition is somewhat different but (I believe) equivalent. It defines a non-lexical lifetime as a set R of vertifes in the CFG, such that:
V -> W is an edge in the CFG
such that V doesn’t strictly dominate W, then V is in R.In the case of our example above, the dominator tree looks like this (I’m labeling the nodes as well):
let mut map = HashMap::new();
let key = ...;let map_ref1 = &mut map
map_ref1.get_mut(&key)Some(value) => valuemap.insert(key.clone(), V::default())
let map_ref2 = &mut mapmap_ref2.get_mut(&key).unwrap()use(value)Here the lifetime 'm1 would be a set containing at least {D, E, I}, because the value in
question is used in those places. But then there is an edge in the CFG from H to I,
and thus by rule #2, H must be in 'm1 as well. But then rule 1 will require that F and G
are in the set, and hence the resulting lifetime will be {D, E, F, G, H, I}. This implies
then that the calls to insert and get_mut are disallowed.
In my previous post, I defined a lifetime as simply a set of
points in the control-flow graph and showed how we can use liveness to
ensure that references are valid at each point where they are
used. But that is not the full set of constraints we must consider. We
must also consider the 'a: 'b constraints that arise as a result of
type-checking as well as where clauses.
The constraint 'a: 'b means the lifetime `‘a` outlives `'b`
. It
basically means that 'a corresponds to something at least as long
as 'b (note that the outlives relation, like many other relations
such as dominators and subtyping, is reflexive – so it’s ok for 'a
and 'b to be equally big). The intuition here is that, if you a
reference with lifetime 'a, it is ok to approximate that lifetime to
something shorter. This corresponds to a subtyping rule like:
'a: 'b
----------------------
&'a mut T <: &'b mut T
In English, you can approximate a mutable reference of type &'a mut
T to a mutable reference of type &'b mut T so long as the new
lifetime 'b is shorter than 'a (there is a similar, though
different in one particular, rule governing shared references).
We’re going to see that for the type system to work most smoothly, we really want this subtyping relation to be extended to take into account the point P in the control-flow graph where it must hold. So we might write a rule like this instead:
('a: 'b) at P
--------------
(&'a mut T <: &'b mut T) at P
However, let’s ignore that for a second and stick to the simpler version of the subtyping rules that I showed at first. This is sufficient for the running example. Once we’ve fully explored that I’ll come back and show a second example where we run into a spot of trouble.
Before we go any further, let’s transform our running example into a
more MIR-like form, based on a control-flow graph. I will use the
convention that each basic block ia assigned a letter (e.g., A) and
individual statements (or the terminator, in MIR speak) in the basic
block are named via the block and an index. So A/0 is the call to
HashMap::new() and B/2 is the goto terminator.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Let’s assume that the types of all these variables are as follows (I’m simplifying in various respects from what the real MIR would do, just to keep the number of temporaries and so forth under control):
map: HashMapkey: Kmap_ref: &'m1 mut HashMaptmp: Option<&'v1 mut V>v1: &'v1 mut Vvalue: &'v0 mut Vmap_ref2: &'m2 mut HashMapv2: &'v2 mut VIf we type-check the MIR, we will derive (at least) the following outlives relationships between these lifetimes (these fall out from the rules on subtyping above; if you’re not sure on that point, I have an explanation below of how it works listed under appendix):
'm1: 'v1 – because of B/1'm2: 'v2 – because of D/2'v1: 'v0 – because of C/2'v2: 'v0 – beacuse of D/5In addition, the liveness rules will add some inclusion constraints
as well. In particular, the constraints on 'v0 (the lifetime of the value
reference) will be as follows:
'v0: E/0 – value is live here'v0: C/2 – value is live here'v0: D/4 – value is live hereFor now, let’s just treat the outlives relation as a superset
relation. So 'm1: 'v1, for example, requires that 'm1 be a
superset of 'v1. In turn, 'v0: E/0 can be written 'v0: {E/0}.
In that case, if we turn the crank and compute some minimal lifetimes
that satisfy the various constraints, we wind up with the following
values for each lifetime:
'v0 = {C/2, D/4, E/0}'v1 = {C/*, D/4, E/0}'m1 = {B/*, C/*, E/0, D/4}'v2 = {C/2, D/{3,4}, E/0}'m2 = {C/2, D/{2,3,4}, E/0}This turns out not to yield any errors, but you can see some kind of
surprising results. For example, the lifetime assigned to v1 (the
value from the Some arm) includes some points that are in the None
arm – e.g., D/5. This is because 'v1: 'v0 (subtyping from the
assignment in C/2) and 'v0: {D/5} (liveness). It turns out you can
craft examples where these extra blocks
pose a problem.
To see where these extra blocks start to get us into trouble, consider
this example (here I have annotated the types of some variables, as
well as various lifetimes, inline). This is a variation on the
previous theme in which there are two maps. This time, along one
branch, v0 will equal this reference v1 pointing into map1, but
in the in the else branch, we assign v0 from a reference v2
pointing into map2. After that assignment, we try to insert into
map1. (This might arise for example if map1 represents a cache
against some larger map2.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Let’s view this in CFG form::
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
The types of the interesting variables are as follows:
v0: &'v0 mut Vmap_ref1: &'m1 mut HashMapv1: Option<&'v1 mut V>map_ref2: &'m2 mut HashMapv2: Option<&'v2 mut V>The outlives relations that result from type-checking this fragment are as follows:
'm1: 'v1 from A/4 'v1: 'v0 from B/0'm2: 'v2 from C/1'v2: 'v0 from C/2'v0: {B/1, C/3, C/4, D/0} from liveness of v0'm1: {A/3, A/4} from liveness of map_ref1'v1: {A/5, B/0} from liveness of v1'm2: {C/0, C/1} from liveness of map_ref2'v2: {C/2} from liveness of v2Following the simple “outlives is superset rules we’ve covered so far,
this in turn implies the lifetime 'm1 would be {A/3, A/4, B/*, C/3,
C/4, D/0}. Note that this includes C/3, precisely where we would
call map1.insert, which means we will get an error at this point.
What I propose as a solution is to have the outlives relationship take
into account the current position. As I sketched above, the rough idea
is that the 'a: 'b relationship becomes ('a: 'b) at P – meaning
that 'a must outlive 'b at the point P. We can define this
relation as follows:
'b reachable from P,
'b'b is the mutual dominator of all points in 'b'a is a superset of S,('a: 'b) at PBasically, the idea is that ('a: 'b) at P means that, given that we
have arrived at point P, any points that we can reach from here that
are still in 'b are also in 'a.
If we apply this new definition to the outlives constraints from the
previous section, we see a key difference in the result. In
particular, the assignment v0 = v1.unwrap() in B/0 generates the
constraint ('v1: 'v0) at B/0. 'v0 is {B/1, C/3, C/4, D/0}.
Before, this meant that 'v1 must include C/3 and C/4, but now we
can screen those out because they are not reachable from B/0 (at
least, not without calling the enclosing function again). Therefore,
the result is that 'v1 becomes {A/5, B/0, B/1, D/0}, and hence
'm1 becomes {A/3, A/4, A/5, B/0, B/1, D/0} – notably, it no
longer includes C/3, and hence no error is reported.
This post dug in some detail into how we can define the outlives
relationship between lifetimes. Interestingly, in order to support the
examples we want to support, when we move to NLL, we have to be able
to support gaps in lifetimes. In all the examples in this post, the
key idea was that we want to exit the lifetime when we enter one
branch of a conditional, but then re-enter
it afterwards when we
join control-flow after the conditional. This works out ok because we
know that, when we exit the first-time, all references with that
lifetime are dead (or else the lifetime would have to include that
exit point).
There is another way to view it: one can view a lifetime as a set of
paths through the control-flow graph, in which case the points after
the match or after the if would appear on only on paths that
happened to pass through the right arm of the match. They are
conditionally included
, in other words, depending on how
control-flow proceeded.
One downside of this approach is that it requires augmenting the subtyping relationship with a location. I don’t see this causing a problem, but it’s not something I’ve seen before. We’ll have to see as we go. It might e.g. affect caching.
Please comment on this internals thread.
There is another alternative to lifetimes with gaps that we might
consider. We might also consider allow variables to have multiple
types. I explored this a bit by using an SSA-like renaming, where
each verson assignment to a variable yielded a fresh type. However, I
thought that in the end it felt more complicated than just allowing
lifetimes to have gaps; for one thing, it complicates determining
whether two paths overlap in the borrow checker (different versions of
the same variable are still stored in the same lvalue), and it doesn’t
interact as well with the notion of fragments that I talked about in
the previous post (though one can use variants of SSA that
operate on fragments, I suppose). Still, it may be worth exploring –
and there more precedent for that in the literature, to be sure. One
advantage of that approach is that one can use continuous lifetimes
,
I think, which may be easier to represent in a compact fashion – on
the other hand, you have a lot more lifetime variables, so that may
not be a win. (Also, I think you still need the outlives relationship
to be location-dependent.)
Given the definition of the get_mut method, the compiler is able to
see that the reference which gets returned is reborrowed from the
self argument. That is, the compiler can see that as long as you are using
the return value, you are (indirectly) using the self reference
as well. This is indicated by the named lifetime parameter 'v that
appears in the definition of get_mut:
1
| |
There are various ways to think of this signature, and in particular
the named lifetime parameter 'v. The most intuitive explanation is
this parameter indicates that the return value is borrowed from
the
self argument (because they share the same lifetime 'v). Hence we
could conclude that when we call tmp = map_ref1.get_mut(&key), the
lifetime of the input ('m1) must outlive the lifetime of the output
('v1). Written using outlives notation, that would be that this call
requires that 'm1: 'v1. This is the right conclusion, but it may be
worth digging a bit more into how the type system actually works
internally.
Specifically, the way the type system works, is that when get_mut is
called, to find the signature at that particular callsite, we replace
the lifetime parameter 'v is replaced with a new inference variable
(let’s call it '0). So at the point where tmp = map_ref1.get_mut(&key)
is called, the signature of get_mut is effectively:
fn(self: &'0 mut HashMap,
key: &'1 K)
-> Option<&'0 mut V>
Here you can see that the self parameter is treated like any other
explicit argument, and that the lifetime of the key reference (now
made explicit as '1) is an independent variable from the lifetime of
the self reference. Next we would require that the type of each
supplied argument must be a subtype of what appears in the signature.
In particular, for the self argument, that results in this
requirement:
&'m1 mut HashMap <: &'0 mut HashMap
from which we can conclude that 'm1: '0 must hold. Finally, we
require that the declared return type of the function must be a
subtype of the type of the variable where the return value is stored,
and hence:
Option<&'0 mut V> <: Option<&'v1 mut V>
implies: &'0 mut V <: &'v1 mut V
implies: '0: 'v1
So the end result from all of these subtype operations is that we have two outlives relations:
'm1: '0
'0: 'v
These in turn imply an indirect relationship between 'm1 and 'v:
`'m1: 'v1`
This final relationship is, of course, precisely what our intuition led us to in the first place: the lifetime of the reference to the map must outlive the lifetime of the returned value.
|
|
Matt Thompson: Stories as Data |
Our network is full of stories. Correctly applied, they can help us illustrate how the Mozilla Leadership Network acts as a magnet, training ground and recharge station for innovators and leaders protecting the web.
The challenge: right now, these stories are not captured in a systematic way across the network. That makes them hard to gather, understand and use to inform strategy. So…
How can we systematically aggregate, analyze and act on this qualitative data and raw material?

Design a prototype story engine
Essentially: an MVP system to collect evidence narratives. These structured stories can serve as qualitative data, raw material for outreach and fundraising, feed into our various comms channels, and strengthen our network.
First step: do a 3-day design sprint. Build a quick and dirty prototype. Then test it with a handful of key customer segments.
Why? To increase and measure our network strength. And continually highlight the human stories behind it.
We want the best of both worlds: the human power of stories combined with methodological rigour. Learning from other organizations (Greenpeace, Upwell) and building on tested approaches (Utilization Focused Evaluation, Outcome Mapping, Most Significant Change).
Who? In this initial sprint the team is my colleague Chris Lawrence, longtime Mozilla contributor Christine Prefontaine and OpenMatt. This was an intentionally small group to help us get to some MVP process and prototype to discuss and test with provide a surface area for further iteration and conversation.
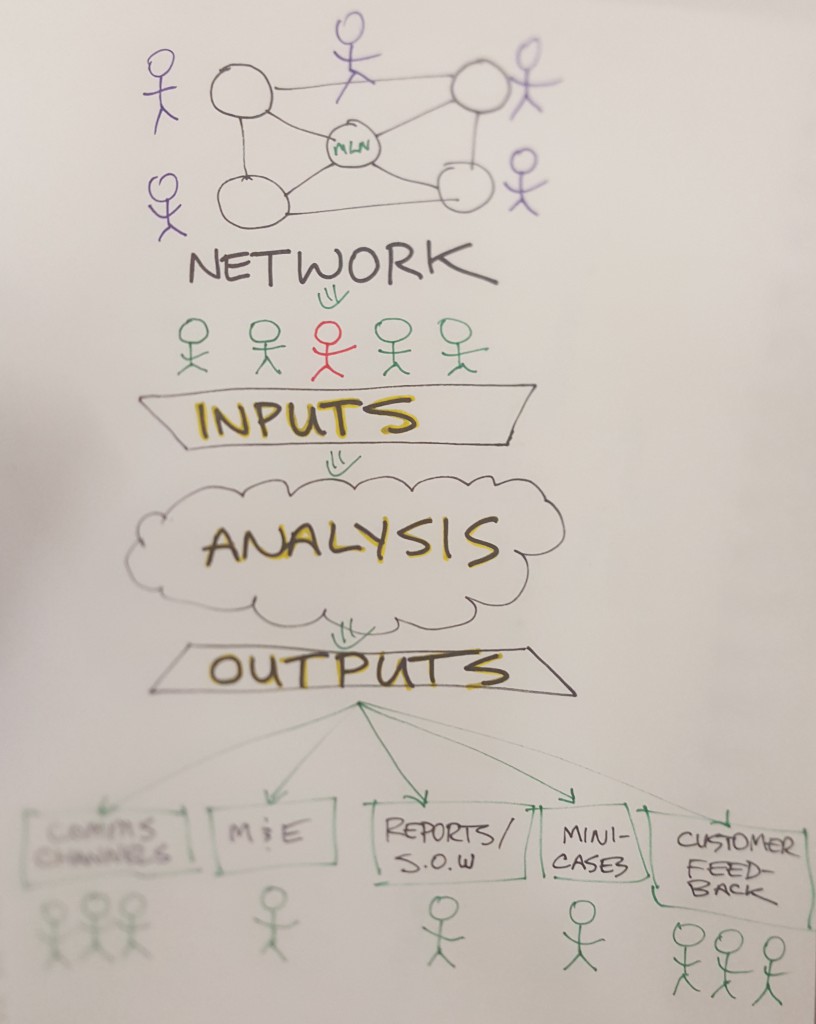
This project will touch on and potentially serve a bunch of different projects and initiatives already underway:
Alignment around our issues. What are network members doing / planning / thinking about our core issues? (e.g., web literacy, privacy / security / inclusion). And: why it matters. Inspire us and others about why these issues matter.
maps to: network alignment, communications
Alignment around working open / open leadership / tech-savvy collaboration.
How are you working on those issues? Open leadership / working open in action. Emerging best practises / inspiring examples of collaboration / lifehacker for work.
maps to: curriculum
Testing and refining our Value Proposition. How can we serve our members better? How do we learn more about what network members / customers want? How do we get better market / customer data? Stories and data they help us make our programs and inititaives / products better.
maps to: Membership / value proposition
What does distributed winning look like?
maps to: Network Influence, communications
|
|






