Doug Belshaw: What does working openly on the web mean in practice? [UK Web Focus] |
It’s Open Education Week. In addition to facilitating a discussion on behalf of Mozilla, I’ve got a guest post on Brian Kelly’s blog entitled What Does Working Openly on the Web Mean in Practice?
Here’s a preview:
Working open is not only in Mozilla’s DNA but leads to huge benefits for the project more broadly. While Mozilla has hundreds of paid contributors, they have tens of thousands of volunteer contributors — all working together to keep the web open and as a platform for innovation. Working open means Mozilla can draw on talent no matter where in the world someone happens to live. It means people with what Clay Shirky would call cognitive surplus can contribute as much or as little free time and labour to projects as they wish. Importantly, it also leads to a level of trust that users can have in Mozilla’s products. Not only can they inspect the source code used to build the product, but actually participate in discussions about its development.
Go and read the post in full. I’d be interested in your comments (over there – I’ve closed them here to encourage you!) ![]()
Bonus: The web is 25! Remix this
Image CC BY-NC Glen Scott
|
|
Geoffrey MacDougall: Infographic: Our 2013 Fundraising Success |
2013 was Mozilla’s most successful fundraising year ever. We grew our core operating grants and more than doubled the size of our donations campaign.
This is a shared, project-wide accomplishment. More than 40 Mozillians from across the foundation, corporation, and community pulled together to make it happen. And I’m proud of what we accomplished.
We still have a long way to go. We’re overly dependent on a few key funders and there’s a big gap between our current revenue and our goal of matching Wikimedia’s fundraising program.
But 2013 was an indication that we’re in good shape, with the right team, and a mission our community loves.


http://intangible.ca/2014/03/11/infographic-our-2013-fundraising-success/
|
|
Nick Cameron: Directory tiles, incentivisation, and indirection |
http://featherweightmusings.blogspot.com/2014/03/directory-tiles-incentivisation-and.html
|
|
Armen Zambrano Gasparnian: Debian packaging and deployment in Mozilla's Release Engineering setup |

cd puppet
hg up -r d6aac1ea887f #It has the 8.0.2 version checked-in
cd modules/packages/manifests
wget https://launchpad.net/ubuntu/+archive/primary/+files/mesa_8.0.2.orig.tar.gz
# The .deb files will appear under /tmp/mesa-precise-i386
puppetagain-build-deb precise amd64 mesa-debian
# The .deb files will appear under /tmp/mesa-precise-amd64
puppetagain-build-deb precise i386 mesa-debian
cp -r mesa-8.0.4/debian ~/puppet/modules/packages/manifests/mesa-debian
cd ~/puppet
hg addremove
hg diff
You can list the package names you compiled with something like this:
ls *deb | awk -F_ '{print $1}' | xargs
# copy the list of names and run the following on the target machine:
dpkg -l 2>/dev/null | grep ^ii | awk '{print $2}'
sudo su
rsync -av releng-puppet2.srv.releng.scl3.mozilla.com:/data/repos/apt/releng/ /data/repos/apt/releng/
rsync -av releng-puppet2.srv.releng.scl3.mozilla.com:/data/repos/apt/conf/ /data/repos/apt/conf/
rsync -av releng-puppet2.srv.releng.scl3.mozilla.com:/data/repos/apt/db/ /data/repos/apt/db/
cd /data/repos/apt
cp ~armenzg/tmp/mesa_8.0.4.orig.tar.gz releng/pool/main/m/mesa
reprepro -V --basedir . include precise ~armenzg/tmp/out64/*.changes
reprepro -V --basedir . includedeb precise ~armenzg/tmp/out32/*.deb
rsync -av /data/repos/apt/releng/ releng-puppet2.srv.releng.scl3.mozilla.com:/data/repos/apt/releng/
rsync -av /data/repos/apt/db/ releng-puppet2.srv.releng.scl3.mozilla.com:/data/repos/apt/db/
ssh root@releng-puppet2.srv.releng.scl3.mozilla.com
puppetmaster-fixperms
ssh armenzg@releng-puppet2.srv.releng.scl3.mozilla.com
cd /etc/puppet/environments/armenzg/env
hg pull -u && hg st
puppet agent --test --environment=armenzg --server=releng-puppet2.srv.releng.scl3.mozilla.com
puppet agent --test --environment=armenzg --server=releng-puppet2.srv.releng.scl3.mozilla.com

http://armenzg.blogspot.com/2014/03/debian-packaging-and-deployment-in.html
|
|
Andrea Marchesini: Audio volume and mute per window object |
I have finally found some time to finish a set of patches about a nice feature that will allow addon/firefox developers to control audio volumes for window object.
Through this new feature any window object has two new attributes: audioMuted and audioVolume (accessible from chrome code only using nsIDOMWindowUtils). The aim is to change the volume of any HTML5 media element and any WebAudio destination node (soon WebRTC and also FMRadio API). The control of the volumes works “on cascade” - if a window has an iframe, the iframe elements will be effected by the parent window audio attributes.
The code is just landed on m-c and it will be available on nightly in a few hours.
Also, in order to test this feature I wrote an addon. As you could see, the UI is not the best… I know, but it was just a proof of concept, I’m sure somebody else will do a better work! Download the addon.
This feature is currently disabled by default, but it’s easy to enable it by changing or creating a preference in about:config. Some instructions to do it: open ‘about:config’ in a new tab and add a new boolean preference called ‘media.useAudioChannelService' and set it to true. This property will enable the AudioChannelService for any HTMLMediaElement and any WebAudio destination node.
AudioChannelService is the audio policy controller of Firefox OS. You will know once you use it, that the AudioChannelService is enabled when, while changing tabs, media elements of invisible tabs will be muted. From now on, you can use the addon.
The addon UI can be open from Tools -> Web Developers -> Audio Test.
Here a screenshot:

From a code point of view, you can play with this audio feature from the nsIDOMWindowUtils interface. For instance:
var currentBrowser = tabbrowser.getBrowserAtIndex(0 /* an index */);
var utils = currentBrowser.contentWindow
.QueryInterface(Ci.nsIInterfaceRequestor)
.getInterface(Ci.nsIDOMWindowUtils);
dump("The default audioVolume should be 1.0: " + utils.audioVolume + "\n");
utils.audioVolume = 0.8;
dump("By default the window is not muted: " + utils.audioMuted + "\n");
utils.audioMuted = true;
(More info about tabbrowser object can be read from this page)
There is also a notification that is dispatched when a window starts and stops playing audio: media-playback. The value of this notification can be active or inactive. If you are interested about how to use them, there are a couple of tests on bug 923247.
What can we do with this new feature? Here some ideas:
Please, use this feature and let me know if you have problems, new ideas or needs. Good hack!
|
|
Lawrence Mandel: Stepping Down as Chair of the Engineering Meeting |
 As I previously shared, I have accepted a new role at Mozilla. As my responsibilities have changed, I am stepping down as the chair of the Engineering Meeting.
As I previously shared, I have accepted a new role at Mozilla. As my responsibilities have changed, I am stepping down as the chair of the Engineering Meeting.
Looking back over the last year or so of running this meeting, I am pleased by the positive reaction to the meeting reboot in June 2013, where we refocused on the needs of engineering, and by the successful follow on changes, such as including additional engineering teams and broadcasting and archiving the meeting on Air Mozilla.
I would like to thank everyone who took the time to provide feedback about the meeting. The changes to the meeting were a direct result of our conversations. I would also like to thank Richard Milewski and the Air Mozilla team for working out how to broadcast the meeting to our global audience each week.
I chaired my last meeting on Mar 5, 2014. You can watch my swan song on Air Mozilla.
Chris Peterson takes over as the chair of the Engineering Meeting effective this week.







http://lawrencemandel.com/2014/03/11/stepping-down-as-chair-of-the-engineering-meeting/
|
|
Sean McArthur: Persona is dead, long live Persona |
The transition period was really tough for me. It felt like we were killing Persona. But more like tying a rope around it and dragging it behind us as we road tripped to Firefox OS Land. I first argued against this. Then, eventually I said let’s at least be humane, and take off the rope, and put a slug in its head. Like an Angel of Death. That didn’t happen either. The end result is one where Persona fights on.
Persona is free open source software, and has built up a community who agree that decentralized authentication is needed o the Internet. I still think Persona is the best answer in that field, and the closest to becoming the answer. And it’s not going away. We’re asking that the Internet help us make the Internet better.
In the meantime I’ll be working on our Firefox Accounts system, which understandably could not rely entirely on Persona1. We need to keep Firefox competitive, since it’s what pays for us to do all the other awesomizing we do. Plus, as the Internet becomes more mobile and more multi-device, we need to make sure there is an alternative that puts users first. A goal of Firefox Accounts is to be pluggable, and to integrate with other services on the Web. Why should your OS demand you use their siloed services? If you want to use Box instead of iCloud, we want you to use it.
How does this affect Persona? We’re actually using browserid assertions within our account system, since it’s a solved problem that works well. We’ll need to work on a way to get all sorts of services working with your FxAccount, and it might include proliferating browserid assertions everywhere2. As we learn, and grow the service so that millions of Firefox users have accounts, we can explore easing them into easily and automatically being Persona users. This solves part of the chicken-egg problem of Persona, by having millions of users ready to go.
I’d definitely rather this have ended up differently, but I can also think of far worse endings. The upside is, Persona still exists, and could take off more so with the help of Firefox. Persona is dead, long live Persona!
|
|
Planet Mozilla Interns: Michael Sullivan: Inline threading for TraceMonkey slides |
Here are the slides from my end of summer brown-bag presentation: http://www.msully.net/~sully/files/inline_slides.pdf.
http://www.msully.net/blog/2009/08/16/inline-threading-slide/
|
|
Melissa Romaine: Make Things Do Stuff |

 With solid research in hand, Nesta, Nominet Trust (a funder for socially-minded tech solutions), and Mozilla (a socially-minded engineering organization) banded together to create Make Things Do Stuff. This relationship works not only because we have robust research, funding and tools, but also because we all recognize the importance of bringing together other organizations in the making space, and know that the collaborative effort is greater than the sum of its parts.
With solid research in hand, Nesta, Nominet Trust (a funder for socially-minded tech solutions), and Mozilla (a socially-minded engineering organization) banded together to create Make Things Do Stuff. This relationship works not only because we have robust research, funding and tools, but also because we all recognize the importance of bringing together other organizations in the making space, and know that the collaborative effort is greater than the sum of its parts. Audience: We work with organizations, not schools, so a lot of young people we see are already highly motivated to learn through making. While it’s great that we’re reaching them through their passions and building on them, I wonder about the young people we’re not reaching. To mitigate this, we try to attend a variety of events – everything from the nationwide Big Bang Fair with 65,000 young people getting their digital hands dirty over 4 days, to small-scale workshops where 25 school children made robots out of plastic cups, remixed our Keep Calm And…Thimble make, and created circuits out of play-dough at an event hosted by the new Children’s Museum at MozLDN. (Some fun remixes: Live long and Prosper, Freak Out and Throw Stuff, Eat Sleep Rave Repeat.)
Audience: We work with organizations, not schools, so a lot of young people we see are already highly motivated to learn through making. While it’s great that we’re reaching them through their passions and building on them, I wonder about the young people we’re not reaching. To mitigate this, we try to attend a variety of events – everything from the nationwide Big Bang Fair with 65,000 young people getting their digital hands dirty over 4 days, to small-scale workshops where 25 school children made robots out of plastic cups, remixed our Keep Calm And…Thimble make, and created circuits out of play-dough at an event hosted by the new Children’s Museum at MozLDN. (Some fun remixes: Live long and Prosper, Freak Out and Throw Stuff, Eat Sleep Rave Repeat.) 
http://londonlearnin.blogspot.com/2014/03/make-things-do-stuff.html
|
|
Gervase Markham: The Necessity of Management |
Getting people to agree on what a project needs, and to work together to achieve it, requires more than just a genial atmosphere and a lack of obvious dysfunction. It requires someone, or several someones, consciously managing all the people involved. Managing volunteers may not be a technical craft in the same sense as computer programming, but it is a craft in the sense that it can be improved through study and practice.
– Karl Fogel, Producing Open Source Software
http://feedproxy.google.com/~r/HackingForChrist/~3/42x2_reTePU/
|
|
William Duyck: Open Education and the Open Web – Day 2 |
Today is day 2 of the open education week, and an interested question has been asked.
Questions: What do you see as the link between Open Education and the Open Web? Does the former depend on the latter?
I took the time to answer this over on my Year In Industry blog, so go and take a nose… OR join the discussion over on Google +.
The tl;dr for me is that an Open Education does not require the use of the Open Web. But it helps.
http://blog.wduyck.com/2014/03/open-education-and-the-open-web-day-2/
|
|
Doug Belshaw: On the link between Open Education and the Open Web |
I’m currently moderating a discussion as part of Open Education Week on behalf of Mozilla. In today’s discussion prompt I asked:
What do you see as the link between Open Education and the Open Web? Does the former depend on the latter?
It’s a question that depends on several things, not least your definition of the two terms under consideration. Yesterday, in answer to the first discussion prompt, I used Mozilla Thimble to make this:

The above would be my current (brief) definition of Open Education. But what about the Open Web? Here I’m going to lean on Mark Surman’s definition from 2010:
Open web = freedom, participation, decentralization and generativity.
That last word, ‘generativity’ is an interesting one. Here’s part of the definition from Wikipedia:
Generativity in essence describes a self-contained system from which its user draws an independent ability to create, generate, or produce new content unique to that system without additional help or input from the system’s original creators.
As an educator, I believe that the role of teachers is to make themselves progressively redundant. That is to say, the learner should take on more and more responsibility for their own learning. Both teachers and learners can work together within an Open Educational Ecosystem (OEE) that is more than the sum of its parts.
The more I think about it, this is how the Open Web is similar to Open Education. Both are trying to participate in a generative ecosystem benefitting humankind. It’s about busting silos. It’s about collaborating and sharing.
Does Open Education depend upon the Open Web? No, I wouldn’t say it that strongly. Open Education can happen without technology; you can share ideas and resources without the web. However, the Open Web significantly accelerates the kind of sharing and collaboration that can happen within an OEE. In other words, the Open Web serves as a significant catalyst for Open Education.
What do you think? What’s the relationship between Open Education and the Open Web?
http://dougbelshaw.com/blog/2014/03/11/on-the-link-between-open-education-and-the-open-web/
|
|
Marco Zehe: Easy ARIA Tip #7: Use “listbox” and “option” roles when constructing AutoComplete lists |
One question that comes up quite frequently is the one of which roles to use for an auto-complete widget, or more precisely, for the container and the individual auto-complete items. Here’s my take on it: Let’s assume the following rough scenario (note that the auto-complete you have developed may or may not work in the same, but a similar way):
Say your auto-complete consists of a textbox or textarea that, when typing, has some auto-complete logic in it. When auto-complete results appear, the following happens:
Note: If your widget does not support keyboard navigation yet, go back to it and add that. Without that, you’re leaving a considerable amount of users out on the advantages you want to provide. This does not only apply to screen reader users.
The question now is: Which roles should the container and individual items get from WAI-ARIA?Some think it’s a list, others think it’s a menu with menu items. There may be more cases, but those are probably the two most common ones.
My advice: use the listbox role for the container, and option for the individual auto-complete items the user can choose. The roles menubar, menu, and menuitem plus related menuitemcheckbox and menuitemradio roles should be reserved for real menu bar/dropdown menu, or context menu scenarios. But why, you may ask?
The short version: Menus on Windows are a hell of a mess, and that’s historically rooted in the chaos that is the Win32 API. Take my word for it and stay out of that mess and the debugging hell that may come with it.
The long version: Windows has always known a so-called menu mode. That mode is in effect once a menu bar, a drop-down menu, or a context menu become active. This has been the case for as long as Windows 3.1/3.11 days, possibly even longer. To communicate the menu mode state to screen readers, Windows, or more precisely, Microsoft Active Accessibility, uses four events:
These events have to arrive in this exact order. Screen readers like JAWS or Window-Eyes rely heavily on the even order to be correct, and they ignore everything that happens outside the menus once the menu mode is active. And even NVDA, although it has no menu mode that is as strict as that of other “older” screen readers, relies on the SystemMenuStart and SystemMenuPopupStart events to recognize when a menu gained focus. Because the menu opening does not automatically focus any item by default. An exception is JAWS, which auto-selects the first item it can once it detects a context or start menu opening.
You can possibly imagine what happens if the events get out of order, or are not all fired in a complete cycle. Those screen readers that rely on the order get confused, stay in a menu mode state even when the menus have all closed etc.
So, when a web developer uses one of the menu roles, they set this whole mechanism in motion, too. Because it is assumed a menu system like a Windows desktop app is being implemented, browsers that implement WAI-ARIA have to also send these events to communicate the state of a menu, drop-down or context or sub menu.
So, what happens in the case of our auto-complete example if you were to use the role menu on the container, and menuitem on the individual items? Let’s go back to our sequence from the beginning of the post:
The consequences of this event are rather devastating to the user. Because you just popped up the list of items, you didn’t even set focus to one of its items yet. So technically and visually, focus is still in your text field, the cursor is blinking away merrily.
But for a screen reader user, the context just changed completely. Because of the SystemMenuPopupStart event that got fired, screen readers now have to assume that focus went to a menu, and that just no item is selected yet. Worse, in the case of JAWS, the first item may even get selected automatically, producing potentially undesired side effects!
Moreover, the user may continue typing, even use the left and right arrow keys to check their spelling, but the screen reader will no longer read this to them, because their screen reader thinks it’s in menu mode and ignores all happenings outside the “menu”. And one last thing: Because you technically didn’t set focus to your list of auto-complete items, there is no easy way to dismiss that menu any more.
On the other hand, if you use listbox and option roles as I suggested, none of these problems occur. The list will be displayed, but because it doesn’t get focus yet, it doesn’t disturb the interaction with the text field. When focus gets into the list of items, by means of DownArrow, the transition will be clearly communicated, and when it is transitioning back to the text field, even when the list remains open, that will be recognized properly, too.
So even when you sighted web developers think that this is visually similar to a context menu or a popup menu or whatever you may want to call it, from a user interaction point of view it is much more like a list than a menu. A menu system should really be confined to an actual menu system, like the one you see in Google Docs. The side effects of the menu related roles on Windows are just too severe for scenarios like auto-completes. And the reason for that lies in over 20 years of Windows legacy.
Some final notes: You can spice up your widget by letting the user know that auto-complete results are available via a text that gets automatically spoken if you add it in a text element that is moved outside the viewport, but apply an attribute aria-live=”polite” to it. In addition, you can use aria-expanded=”true” if you just popped up the list, and aria-expanded=”false” if it is not there, both applied to your input or textarea element. And the showing and hiding of the auto-complete list should be done via display:none; or visibility:hidden; and their counterparts, or they will appear somewhere in the user’s virtual buffer and cause confusion.
A great example of all of this can be seen in the Tweet composition ContentEditable on twitter.com.
I also sent a proposal for an addition to the Protocols and Formatting Working Group at the W3C, because the example in the WAI-ARIA authoring practices for an auto-complete doesn’t cover most advanced scenarios, like the one on Twitter and others I’ve come across over time. Hope the powers that may be follow my reasoning and make explicit recommendations regarding the use of roles that should and shouldn’t be used for auto-completes!
![]()
|
|
Daniel Stenberg: http2 in curl |
While the first traces of http2 support in curl was added already back in September 2013 it hasn’t been until recently it actually was made useful. There’s been a lot of http2 related activities in the curl team recently and in the late January 2014 we could run our first command line inter-op tests against public http2 (draft-09) servers on the Internet.
There’s a lot to be said about http2 for those not into its nitty gritty details, but I’ll focus on the curl side of this universe in this blog post. I’ll do separate posts and presentations on http2 “internals” later.
http2 (without the minor version, as per what the IETF work group has decided on) is a binary protocol that allows many logical streams multiplexed over the same physical TCP connection, it features compressed headers in both directions and it has stream priorities and more. It is being designed to maintain the user concepts and paradigms from HTTP 1.1 so web sites don’t have to change contents and web authors won’t need to relearn a lot. The web will not break because of http2, it will just magically work a little better, a little smoother and a little faster.
In libcurl we build http2 support with the help of the excellent library called nghttp2, which takes care of all the binary protocol details for us. You’ll also have to build it with a new enough version of the SSL library of your choice, as http2 over TLS will require use of some fairly recent TLS extensions that not many older releases have and several TLS libraries still completely lack!
The need for an extension is because with speaking TLS over port 443 which HTTPS implies, the current and former web infrastructure assumes that we will speak HTTP 1.1 over that, while we now want to be able to instead say we want to talk http2. When Google introduced SPDY then pushed for a new extension called NPN to do this, which when taken through the standardization in IETF has been forked, changed and renamed to ALPN with roughly the same characteristics (I don’t know the specific internals so I’ll stick to how they appear from the outside).
So, NPN and especially ALPN are fairly recent TLS extensions so you need a modern enough SSL library to get that support. OpenSSL and NSS both support NPN and ALPN with a recent enough version, while GnuTLS only supports ALPN. You can build libcurl to use any of these threes libraries to get it to talk http2 over TLS.
(This still describes what’s in curl’s git repository, the first release to have this level of http2 support is the upcoming 7.36.0 release.)
Users of libcurl who want to enable http2 support will only have to set CURLOPT_HTTP_VERSION to CURL_HTTP_VERSION_2_0 and that’s it. It will make libcurl try to use http2 for the HTTP requests you do with that handle.
For HTTP URLs, this will make libcurl send a normal HTTP 1.1 request with an offer to the server to upgrade the connection to version 2 instead. If it does, libcurl will continue using http2 in the clear on the connection and if it doesn’t, it’ll continue using HTTP 1.1 on it. This mode is what Firefox and Chrome will not support.
For HTTPS URLs, libcurl will use NPN and ALPN as explained above and offer to speak http2 and if the server supports it. there will be http2 sweetness from than point onwards. Or it selects HTTP 1.1 and then that’s what will be used. The latter is also what will be picked if the server doesn’t support ALPN and NPN.
Alt-Svc and ALTSVC are new things planned to show up in time for http2 draft-11 so we haven’t really thought through how to best support them and provide their features in the libcurl API. Suggestions (and patches!) are of course welcome!
Hardly surprising, the curl command line tool also has this power. You use the –http2 command line option to switch on the libcurl behavior as described above.
To reduce transition pains and problems and to work with the rest of the world to the highest possible degree, libcurl will (decompress and) translate received http2 headers into http 1.1 style headers so that applications and users will get a stream of headers that look very much the way you’re used to and it will produce an initial response line that says HTTP 2.0 blabla.
See the README.http2 file in the lib/ directory.
I just want to make this perfectly clear: http2 is not out “for real” yet. We have tried our http2 support somewhat at the draft-09 level and Tatsuhiro has worked on the draft-10 support in nghttp2. I expect there to be at least one more draft, but perhaps even more, before http2 becomes an official RFC. We hope to be able to stay on the frontier of http2 and deliver support for the most recent draft going forward.
PS. If you try any of this and experience any sort of problems, please speak to us on the curl-library mailing list and help us smoothen out whatever problem you got!

|
|
Tantek Celik: Mockups For People Focused Mobile Communication |
I've been iterating on mockups for people focused mobile communication for a while on the IndieWebCamp wiki for my own publishing tool Falcon, but the mockups deserve a blog post of their own.
Going back to the original people focused mobile communication experience, we've already figured out how to add a personal icon to your site so that visitors can choose "Add to Home Screen" (or similar menu option) to add icons of people (represented by their site) directly to their mobile home screens where they normally organize their apps.
![]()
The next step is to mockup what happens when they select an icon of a person and it launches their website.
I started with a mockup for how I could present communication options on my home page when viewed on an iOS7 mobile device, figuring if I can create a seamless experience there, adapting it to other mobile devices, desktop etc. would be fairly straightforward.
Thus when someone selects an icon of a person and it launches their website, they might see a home page view like this:
![]()
This is a hybrid approach, providing a look and feel familiar to the user from their "native" environment (smooth, seamless, confidence invoking), with very simply styled web content right below it so if that's all they want, they get it immediately.
Continuing with the user flow, since they want to contact you, they select the "Contact" folder, which opens up accordingly. From there the user selects which "app" they want and it launches automatically into a new message/connection, skipping any distracting inboxes.
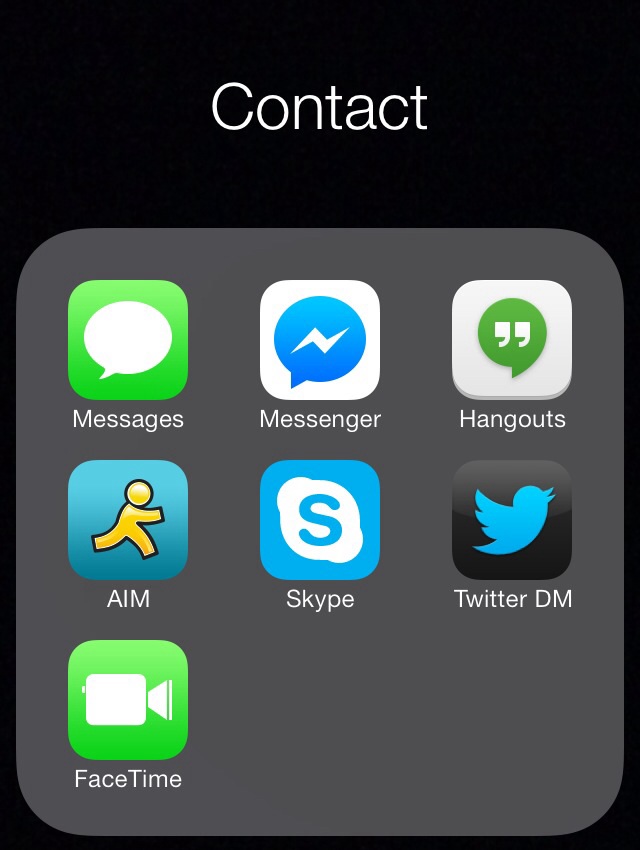
The various contact options are presented in preference order of the contactee.
Each of these can be optionally hidden based on presence status / availability, or time of day.
A subset of these could also be presented publicly, with others (e.g. perhaps Facetime and Skype) only shown when the visitor identifies themselves (e.g. with IndieAuth). The non-public options could either be hidden, or perhaps shown disabled, and selecting them would be discoverable way to request the visitor identify themselves.
This is enough of a mockup to get started with the other building blocks so I'm going to stop there.
I've started a wiki page on "communication" and will be iterating on the mockups there.
Got other thoughts? Upload your mockups to indiewebcamp.com and add them to the communication page as well. Let's build on each other's ideas in a spirit of open source design.
http://tantek.com/2014/067/b2/mockups-people-focused-mobile-communication
|
|
K Lars Lohn: Redneck Broadband - fixed! |
http://www.twobraids.com/2014/02/redneck-broadband-fixed.html
|
|
Tantek Celik: Building Blocks For People Focused Mobile Communication |
I'm at IndieWebCampSF and today, day 2, is "hack" or "create" day so I'm working on prototyping people focused mobile communication on my own website.
A few months ago I wrote about my frustrations with distracting app-centric communication interfaces, and how a people-focused mobile communication experience could not only solve that problem, but provide numerous other advantages as well.
Yesterday I led a discussion & brainstorming session on the subject, hashtagged #indiecomms, and it became clear that there were several pieces we needed to figure out:
So that's what I'm working on and will blog each building block as I get figure it out and create it.
http://tantek.com/2014/067/b1/building-blocks-people-focused-mobile-communication
|
|
Daniel Stenberg: HTTPbis design team meeting London |
I’m writing this just hours after the HTTPbis design team meeting in London 2014 has ended.
Around 30 people attended the meeting i Mozilla’s central London office. The fridge was filled up with drinks, the shelves were full of snacks and goodies. The day could begin. This is the Saturday after the IETF89 week so most people attending had already spent the whole or parts of the week before here in London doing other HTTP and network related work. The HTTPbis sessions at the IETF itself were productive and had already pushed us forward.
We started at 9:30 and we quickly got to work. Mark Nottingham guided us through the day with usual efficiency.
We all basically hang out in a huge room, some in chairs, some in sofas and a bunch of people on the floor or just standing up. We had mikes passed around and the http2 discussions were flowing back and forth depending on the topics and what people felt about them. Some of the issues that were nailed down this time and will end up detailed in the upcoming draft-11 are (strictly speaking, we only discussed the things and formed opinions, as by IETF guidelines we can’t decide things on an offline meeting like this):
 o the same content on the same server. This will allow for what is popularly known as “opportunistic encryption” or at least one sort of that. In short, you can do “plain-text” HTTP over a TLS connection using this…
o the same content on the same server. This will allow for what is popularly known as “opportunistic encryption” or at least one sort of that. In short, you can do “plain-text” HTTP over a TLS connection using this…There were some other things too handled, but I believe those are the main changes. When the afternoon started to turn long, beers and other beverages were brought out and we did enjoy a relaxing social finale of the day before we split up in smaller groups and headed out in the busy London night to get dinner…
Thanks everyone for a great day. I also appreciated meeting several people in real-life I never met before, only discussed with and read emails from online and of course some old friends I hadn’t seen in a long time!
Oh, there’s also a new rough time frame for http2 going forward. Nearest in time would be the draft-11 at the end of March and another interim in the beginning of June (Boston?).
As a reminder, here’s what was happened for draft-10, and here is http2 draft-10.
Out of all people present today, I believe Mozilla was the company with the largest team (8 attendees) – funnily enough none of us Mozillians there actually work in this office or even in this country.
http://daniel.haxx.se/blog/2014/03/08/httpbis-design-team-meeting-london/
|
|
Konstantinos Antonakoglou: A Creative Commons music video made out of other CC videos |
Hello! Let’s go straight to the point. Here is the video:
…and here are the videos that were used having the Creative Commons Attribution licence: http://wonkydollandtheecho.com/thanks.html. They are downloadable via Vimeo, of course.
Videos available from NASA and the ALMA observatory were also used.
The video (not audio) is under the Creative Commons BY-NC-SA licence, which I think is quite reasonable since every scene used from the source videos (ok, almost every scene) has lyrics/graphics embedded on it.
I hope you like it! I didn’t have a lot of time to make this video but I like the result. The tools I used are not open source unfortunately, because the learning curve for these tools is quite steap. I will definitely try them in the future. Actually, I really haven’t come across any alternative to Adobe After Effects. You might say Blender…but is it really an alternative? Any thoughts?
PS. More news soon for the Sopler project (a web application for making to-do lists) and other things I’ve been working on lately (like MQTT-SN).

http://antonakoglou.com/2014/03/08/creative-commons-music-video-made-of-cc-videos/
|
|
Brendan Eich: MWC 2014, Firefox OS Success, and Yet More Web API Evolution |
Just over a week ago, I left Barcelona and Mobile World Congress 2014, where Mozilla had a huge third year with Firefox OS.

We announced the $25 Firefox OS smartphone with Spreadtrum Communications, targeting retail channels in emerging markets, and attracting operator interest to boot. This is an upgrade for those channels at about the same price as the feature phones selling there today. (Yes, $25 is the target end-user price.)

We showed the Firefox OS smartphone portfolio growing upward too, with more and higher-end devices from existing and new OEM partners. Peter Bright’s piece for Ars Technica is excellent and has nice pictures of all the new devices.
We also were pleased to relay the good news about official PhoneGap/Cordova support for Firefox OS.
We were above the fold for the third year in a row in Monday’s MWC daily.
(Check out the whole MWC 2014 photo set on MozillaEU’s Flickr.)
As I’ve noted before, our success in attracting partners is due in part to our ability to innovate and standardize the heretofore-missing APIs needed to build fully-capable smartphones and other devices purely from web standards. To uphold tradition, here is another update to my progress reports from last year and from 2012.
First, and not yet a historical curiosity: the still-open tracking bug asking for “New” Web APIs, filed at the dawn of B2G by Andreas Gal.
Next, links for “Really-New” APIs, most making progress in standards bodies:
getUserMedia support
Yet more APIs, some new enough that they are not ready for standardization:
Finally, the lists of new APIs in Firefox OS 1.1, 1.2, and 1.3:
This is how the web evolves: by implementors championing and testing extensions, with emerging consensus if at all possible, else in a pref-enabled or certified-app sandbox if there’s no better way. We thank colleagues at W3C and elsewhere who are collaborating with us to uplift the Web to include APIs for all the modern mobile device sensors and features. We invite all parties working on similar systems not yet aligned with the emerging standards to join us.
/be
https://brendaneich.com/2014/03/mwc-2014-firefox-os-success-and-yet-more-web-api-evolution/
|
|






