Soledad Penades: Mozilla Brick 1.0 + Hacks post! |
![]()
Today two very exciting things happened:
I have worked in both things (more in Brick than in the article, which I just helped edit) so it’s naturally obvious that I’m excited they’re finally published. And also since the article is Chapter 1 (as mentioned in my post), that means that next week you get Chapter 2–i.e. my article.
Stay put, friends. It’s going to rock. Almost literally.
![]()
http://soledadpenades.com/2014/03/05/mozilla-brick-1-0-hacks-post/
|
|
David Ascher: Product Thinking |
I have a new job! Still with Mozilla, still doing a lot of what I’ve done in the past, just hopefully more/better/faster. The group I’m joining has a great culture of active blogging, so I’m hoping the peer pressure there will help me blog more often.
What’s the gig you ask? My new focus is to help the Mozilla Foundation make our products as adoptable as possible.
MoFo (as we affectionately call that part of the Mozilla organization) has a few main ways in which we’re hoping to change the world — some of those are programs, like Open News and the Science Lab, some are products. In a program, the change we’re hoping to effect happens by connecting brains together, either through fellowship programs, events, conferences, things like that. That work is the stuff of movement-building, and it’s fascinating to watch my very skilled colleagues at work — there is a distinctive talent required to attract autonomous humans to a project, get them excited about both what you’re doing and what they could do, and empowering them to help themselves and others.
Alongside these programmatic approaches, MoFo has for a while been building software whose use is itself impactful. Just like getting people to use Firefox was critical to opening up the web, we believe that using products like the Webmaker tools or BadgeKit will have direct impact and help create the internet the world needs.
And that’s where I come in! Over the last few years, various smart people have kept labeling me a “product person”, and I’ve only recently started to understand what they meant, and that indeed, they are right — “product” (although the word is loaded with problematic connotations) is central for me.
I’ll write a lot more about that over the coming months, but the short version is that I am particularly fascinated by the process that converts an idea or a pile of code into something that intelligent humans choose to use and love to use. That translation to me is attractive because it requires a variety of types of thinking: business modeling, design, consumer psychology, and creative application of technology. It is also compelling to me in three other aspects: it is subversive, it is humane, and it is required for impact.
It is subversive because I think if we do things right, we use the insights from billions of dollars worth of work by “greedy, evil, capitalist corporations” who have figured out how to get “eyeballs” to drive profit and repurpose those techniques for public benefit — to make it easy for people to learn what they want to learn, to allow people to connect with each other, to amplify the positive that emerges when people create. It is humane because I have never seen a great product emerge from teams that treat people as hyper-specialized workers, without recognizing the power of complex brains who are allowed to work creatively together. And it is required for impact because software in a repo or an idea in a notebook can be beautiful, but is inert. To get code or an idea to change the world, we need multitudes to use it; and the best way I know to get people to use software is to apply product thinking, and make something people love.
I am thrilled to say that I have as much to learn as I have to teach, and I hope to do much of both in public. I know I’ll learn a lot from my colleagues, but I’m hoping I’ll also get to learn on this blog.
I’m looking forward to this new phase, it fits my brain.
|
|
Rizky Ariestiyansyah: OpenX Quiz : Test your knowledge about Mozilla and Open Web |
http://oonlab.com/openx-quiz-test-your-knowledge-about-mozilla-and-open-web.onto
|
|
Brian Warner: Remote Entropy |
Running a system without enough entropy is like tolerating a toothache: something you’d really like to fix, but not quite bothersome enough to deal with.

I recently bought a Simtec EntropyKey to fix this locally: it’s a little USB dongle with avalanche-noise generation hardware and some firmware to test/whiten/deliver the resulting stream to the host. The dongle-to-host protocol is encrypted to protect against even USB man-in-the-middle attacks, which is pretty hardcore. I like it a lot. There’s a simple Debian package that continuously fills /dev/random with the results, giving you something more like this (which would look even better if Munin didn’t use entropy-consuming TCP connections just before each measurement):

But that’s on local hardware. What about virtual servers? I’ve got several remote VPS boxes, little Xen/KVM/VirtualBox slices running inside real computers, rented by the hour or the month. Like many “little” computers (including routers, printers, embedded systems), these systems are usually starved for entropy. They lack the sources that “big” computers usually have: spinning disk drives and keyboards/mice, both of which provide mechanical- or human- variable event timing. The EntropyKey is designed to bring good entropy to “little” machines. But I can’t plug a USB device into my remote virtual servers. So it’s pretty common to want to deliver the entropy from my (real) home computer to the (virtual) remote boxes. Can this be done safely?
Well, mostly nope: it depends upon how you define the threat model. First, let’s go over some background.
Remember that entropy is how you measure uncertainty, and it’s always relative to an observer who knows some things but not others. If I roll an 8-sided die on my desk right now, the entropy from your point of view is 3 bits. From my point of view it’s 0 bits: *I* know I just rolled a five. And now that *you* know that I rolled a five, it’s 0 bits from your POV too.
Computers use entropy to pick random numbers for cryptographic purposes: generating long-term SSH/GPG/TLS keys, creating ephemeral keys for Diffie-Hellman negotiation, unique nonces for DSA signatures, IVs, and TCP sequence numbers. Most of these uses are externally visible: the machine is constantly shedding clues as to its internal state. If the number of possible states is limited, and an eavesdropper can observe all (or most) of these clues, then they can deduce what that internal state is, and then predict what it will be next. The amount of computation Eve needs to do this depends upon how uncertain she is, and on the nature of the clues.
The most conservative model assumes that Eve sees every packet going into and out of the system, with perfect timing data, and that she knows the complete state of the system before the game begins (imagine that Eve creates a VM from the same EC2 AMI as you do). If she is truly omniscient, and the system is deterministic, then she will know the internal state of the system forever: all she has to do is feed her own clone the same input as your box receives, at the same time, and watch how its internal state evolves. She doesn’t even need to watch what your box outputs: it will always emit the same things as her clone.
If she misses a few bits (maybe she can’t measure the arrival time of a packet perfectly), or if there are hidden (nondeterministic) influences, then she needs to guess. For each guess, she needs to compare her subsequent observations against the predicted consequences of that guess, to determine which guess was correct. It’s as if she creates a new set of nearly-identical VMs for each bit of uncertainty, and then throws out most of them as new measurements rule them out.
There might be a lot of potential states, and it might take her a lot of CPU time to test each one. She might also not get a lot of observations, giving her fewer opportunities to discard the unknowns. Our goal is to make sure she can’t keep up: at any important moment (like when we create a GPG key), the number of possibilities must be so large that all keys are equally likely.
(In fact, our goal is to make sure she can’t retroactively catch up either. If we create a key, and then immediately reveal all the internal state, without going through some one-way function first, she can figure out what the state was *earlier*, and then figure out the key too. So the system also needs forward-security.)
To get out of this compromised Eve-knows-everything state, you have to feed it with enough entropy (which are bits that Eve doesn’t see) to exceed her ability to create and test guesses. But she’s watching the network. So you must feed entropy in locally (via the keyboard, locally-attached hardware, or non-deterministic execution).
Could you deliver entropy remotely if you encrypted it first? Sure, but you have to make sure Eve doesn’t know the key, otherwise she can see the data too, and then it isn’t entropy anymore. Encrypting it symmetrically (e.g. AES) means your remote random-number generator machine shares a secret key with the VM, but we already assumed that Eve knows the VM’s entire state, so it has no pre-existing secrets from her. To encrypt it asymmetrically (via a GPG public key) means the VM has a corresponding private key: again, Eve’s insider knowledge lets her decrypt it too.
Can you use authenticated Diffie-Hellman to build a secure connection *from* the VM to the remote entropy source? This would put a public key on the VM, not a private one, so Eve doesn’t learn anything from the key. But DH requires the creation of a random ephemeral key (the “x” in “g^x”), and Eve can still predict what the VM will do, so she can guess the ephemeral key (using the published g^x to test her guesses), determine the shared DH key, and decrypt the data.
So, in the most conservative model, there’s no way to get out of this compromised state using externally-supplied data. You *must* hide something from Eve, by delivering it over a channel that she can’t see.
The real world isn’t quite this bad, for a few reasons:
So in practice, once the kernel pool gets perhaps 128 or 256 bits of real
entropy, Eve’s job becomes impossible. This needs to happen before any
significant secrets are generated. How can we get to this point?
You’d probably think you ought to encrypt these network requests, but as described above it’s not really clear what this buys you. The best hope is that it increases the cost of Eve’s guess-testing. You might not bother with authenticating this link: if the RNG is well-designed, then it can’t hurt to add more data, even attacker-controlled data (but note that entropy counters could be incorrectly incremented, which means it can hurt to *rely* on attacker-controlled data).
Continuing this analysis, you might not even bother decrypting the data before adding it to the pool, since that doesn’t increase the entropy by more than the size of the decryption key, so you can get the same effect by just writing the key into the pool too. (But it might be more expensive for Eve if her guess-testing function must include the decryption work).
And if you don’t bother decrypting it, then clearly there’s no point to encrypting it in the first place (since encrypted random data is indistinguishable from unencrypted random data). Which suggests that really you’re just piping /dev/urandom from one box into netcat, plus maybe some timestamps, and just have to hope that Eve misses a packet or two.
What about entropy counters, and the difference between /dev/random and /dev/urandom? They’re trying to provide two different things. The first is to protect you against using the RNG before it’s really ready, which makes a lot of sense (see Mining Your Ps and Qs for evidence of failures here). The second is to protect you against attackers who have infinite computational resources, by attempting to distinguish between computational “randomness” and information-theoretic randomness. This latter distinction is kind of silly, in my mind. Like other folks, I think there should be one kernel source of entropy, it should start in the “off” mode (return errors) until someone tells it that it is ready, and switch to the “on” mode forevermore (never return errors or block).
But I’ll have to cover that in another post. The upshot is that it isn’t safe to make this startup-time off-to-on mode switch unless you have some confidence that the data you’ve added to the kernel’s entropy pool is actually entropy, so attacker-supplied data shouldn’t count. But after you’ve reached the initial threshold, when (in my opinion) you don’t bother counting entropy any more, then it doesn’t hurt to throw anything and everything into the pool.
(cross-posted to my personal blog)
|
|
Armen Zambrano Gasparnian: Planet Release Engineering |


http://armenzg.blogspot.com/2014/03/planet-release-engineering.html
|
|
Patrick McManus: On the Application of STRINT to HTTP/2 |
http://bitsup.blogspot.com/2014/03/on-application-of-strint-to-http2.html
|
|
Joel Maher: Where did all the good first bugs go? |
As this is the short time window of Google Summer of Code applications, I have seen a lot of requests for mochitest related bugs to work on. Normally, we look for new bugs on the bugs ahoy! tool. Most of these have been picked through, so I spent some time going through a bunch of mochitest/automation related bugs. Many of the bugs I found were outdated, duplicates of other things, or didn’t apply to the tools today.
Here is my short list of bugs to get more familiar with automation while fixing bugs which solve real problems for us:
I have added the appropriate tags to those bugs to make them good first bugs. Please take time to look over the bug and ask questions in the bug to get a full understanding of what needs to be done and how to test it.
Happy hacking!

http://elvis314.wordpress.com/2014/03/04/where-did-all-the-good-first-bugs-go/
|
|
Nick Fitzgerald: Memory Tooling In Firefox Developer Tools In 2014 |
A big push for the Firefox Developer Tools team this year is performance tools. Jim Blandy and I are collaborating on the memory half of performance tooling. What follows is a broad overview of our plans.
ubi::Node: An abstract base class that provides a generic
nodes-and-edges view of any sort of heap object. Not just the JavaScript
world, but also XPCOM and the DOM!
Category: A key/value pair with which we can tag an individual
ubi::Node. Some categories are simple booleans, such as whether a DOM node
is orphaned from its document. Others may have a value, for example an object
may be categorized by its prototype and constructor. ubi::Nodes can have to
many categories!
Census: A semi-lightweight traversal of the heap that provides accurate category counts without saving the full heap state. It gives us totals, but not the specifics of individuals.
Snapshot: A heavyweight traversal of the heap. It saves the full heap state for later inspection by creating a core dump.
Core dump: A binary blob containing the full serialized heap state at a past instant in time.
As we build the infrastructure and lay the foundation for the memory panel, we
will expose utility and testing functions developers can use now. Generally, the
console object will expose these functions.
The benefit of this approach is two-fold. First, it enables developers to cash in on our work quickly. Second, it gives us a larger testing population; helping us catch and fix bugs as soon as possible.
If x dominates y, then any path from the global window to y
must pass through x. We can use this information in two practical ways:
If you nullify all references to x, every y such that x dominates y
will also become unreachable and will eventually be garbage collected.
We can calculate the retained size of x. That is, the amount of memory
that will be reclaimed if x (and therefore also every y such that x
dominates y) were to be garbage collected.
We can expose this information to developers with console.retainedSize(obj).
By doing a BFS in the heap graph from the global window to an object, we find
the shortest retaining path for that object. We can use this path to construct
a developer-friendly label for that object. Often the label we provide will be a
snippet of JavaScript that can be evaluated in the console. For example:
"window.MyApp.WidgetView.element". Other times, we will be forced to display
labels that cannot be evaluated in the console:
"window.[[requestAnimationFrame renderLoop]].[[ closure environment ]].player.sprite".
This can be exposed to developers as a useful little pair of methods on
console. If you expect an object to be reclaimed by GC, you will be able to
tag it with console.expectGarbageCollected(obj). Next, you would perform
whatever actions are supposed to trigger the clean up of that object. Finally,
you could call console.logRetained() to log the retaining path of any objects
that you tagged via console.expectGarbageCollected that have not been garbage
collected. I realize these aren't the greatest method names;
please tweet me your suggestions!
We will track the allocation site of every object in the heap. Allocation sites come into play in a few ways.
First, if you interact with one component of your app, and notice that an unrelated component is allocating or retaining objects, you most likely have an opportunity to reduce memory consumption. Perhaps that unrelated component can lazily delay any allocations it needs, thereby lowering your app's memory usage when that component isn't active.
Second, once developers know which objects are using their precious memory, the next info they need is where the objects were allocated. That leads to why they were allocated, and finally how to reduce those allocations. We can hack this workflow and group objects by allocation site then sort them for developers to effectively make the first step (which objects) redundant.
I'm not sure what the best way to expose this information to developers before
the complete memory panel is ready. Tracking allocations isn't lightweight; we
can't do it all the time, you have to turn the mode on. We could expose
console.startTrackingAllocationSites() and
console.stopTrackingAllocationSites(), and then allow calls to
console.allocationSite(obj) if obj was allocated while we were tracking
allocation sites. Or, we could expose console.startLoggingAllocationSites()
and console.stopLoggingAllocationSites(), which could just dump every
allocation site to the console as it occurs. Tweet at me if you have
an opinion about the best API from which to expose this data.
The memory panel will feature a live-updating graph. To construct this graph we will frequently poll the recent categorized allocations, and the total, non-granular heap size. This gives us a fuzzy, slightly inaccurate picture of the heap over time, but it should be efficient enough for us to do at a high frequency. At a less frequent interval, we will take a census. This will be a reality check of sorts that gives us precise numbers for each category of objects in the heap.
You will be able to click on the graph to get a shallow view into the heap at that past moment in time. Alternatively, you will be able to select a region of the graph to view the difference in memory consumption between the start and end points of your selection.
If you need to deep dive into the full heap state, you'll be able to take snapshots, which are too heavy for us to automatically collect on an interval. These can be compared with other snapshots down to each individual object, so you will be able to see exactly what has been allocated and reclaimed in the time between when each snapshot was taken. They will also be exportable and importable as core dumps, so you could attach them to bug tickets, send to other developers, etc.
Darrin Henein has created a beautiful mockup of the memory panel. Caveat: despite said beauty, the mockup is still very much a work in progress, it is far from complete, and what we ship might look very different!
You can follow along with our work by watching the bugs in this bugzilla dependency graph.
2014 will be an exciting year for memory tooling in Firefox Developer Tools!
|
|
Paul Rouget: My Firefox OS homescreen |
I'm having fun building my own homescreen for Firefox OS. I call it "riverscreen". Code's on github. Totally WIP. Barely functional.

|
|
Mike Hommey: Linux and Android try builds, now up to twice as fast |
(Taras told me to use sensationalist titles to draw more attention, so here we are)
Last week, I brought up the observable build times improvements on Linux try builds with the use of shared cache. I want to revisit those results now there have been more builds, and to look at the first results of the switch for Android try builds, which are now also using the shared cache.
Here is a comparison between the repartition of build times from last time (about ten days of try pushes, starting from the moment shared cache was enabled) vs. build times for the past ten days (which, almost, start at the point the previous data set stopped)):
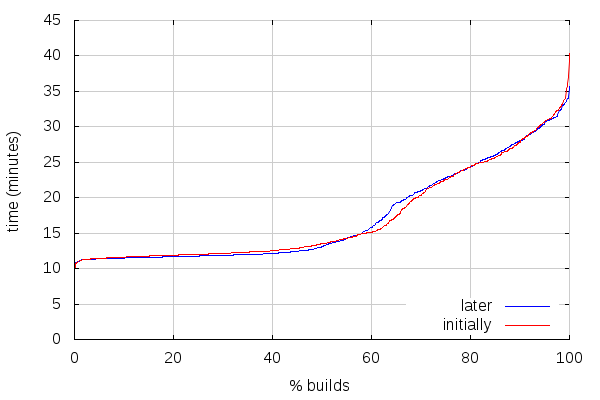
As expected, the build times are still improving overall thanks to the cache being fuller. The slowest build times are now slightly lower than the slowest build times we were getting without the shared cache. There is a small “regression” in the number of builds taking between 15 and 20 minutes, but that’s likely related to changes in the tree creating more cache misses. To summarize the before/after:
| Unified | Non-unified | |||||
|---|---|---|---|---|---|---|
| shared after 10 days | shared initially | ccache | shared after 10 days | shared initially | ccache | |
| Average | 17:11 | 17:11 | 29:19 | 31:00 | 30:58 | 57:08 |
| Median | 13:03 | 13:30 | 30:10 | 22:07 | 22:27 | 60:57 |
[Note I'm not providing graphs for non-unified builds, they are boringly similar, with different values, which average and median values should give a grasp on]
Android try builds also got faster with shared cache. The situation looks pretty similar to what we observed after the first ten days of Linux try shared cache builds:
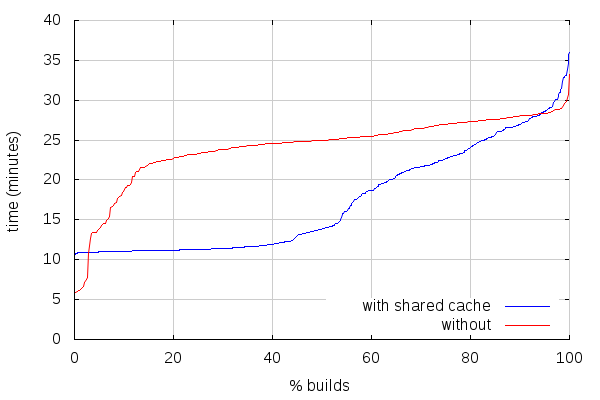
[Note I removed two builds without shared cache from those stats, both of which were taking more than an hour for some reason I haven't investigated]
The fastest shared cache builds are, like for Linux builds, slower than the fastest ccache builds, and the slowest builds too, but as we can see above, those slowest builds get faster as the cache fills up. And as I wrote last week, work is under way to make the fastest builds faster.
This is what the average and median look like for Android try builds:
| Unified | Non-unified | |||
|---|---|---|---|---|
| shared | ccache | shared | ccache | |
| Average | 17:14 | 24:08 | 27:49 | 43:00 |
| Median | 13:52 | 24:57 | 20:35 | 47:17 |
|
|
Yunier Jos'e Sosa V'azquez: Deshabilita la carga de las im'agenes a la antigua con Disable Load Images |
Si eres de los que se enfad'o con la llegada de Firefox 23 al ver que hab'ian quitado la opci'on de cargar o no las im'agenes autom'aticamente, ya no tendr'as que sentirte as'i porque puedes tener esta funcionalidad de vuelta con Disable Load Images. Ya una vez estuvimos comentando el tema por aqu'i pero esta vez se trata de otra alternativa.
Sin 'animo de justificar, es bueno que todos sepan la raz'on por la que se quit'o esta opci'on de Firefox. Resulta ser que en Bugzilla (la plataforma de Mozilla para reporte de bugs) hay muchas peticiones relacionado con este tema y la principal queja es el alto consumo de recursos cuando cargar im'agenes esta deshabilitada en algunos sitios. Los desarrolladores investigaron al respecto pero dieron con la soluci'on y en los reportes de salud en Firefox esta opci'on no era desactivada por muchos usuarios.
Pero bueno, vayamos al grano y hablemos del complemento.
Disable Load Images esta siendo desarrollado por Yaicel Torres y por m'i, con el asesoramiento de Jorge Villalobos (Mozilla). Se encuentra en su versi'on 0.3 y con 'el podr'as habilitar o deshabilitar la opci'on de cargar im'agenes autom'aticamente y cuenta con una interfaz donde se podr'a:
Adem'as, tiene soporte para los idiomas espa~nol e ingl'es.

Interfaz Disable Load Images
A continuaci'on, un video de como utilizar esta extensi'on:
Instalar Disable Load Images.
Si deseas colaborar o ver el c'odigo puedes acceder a la direcci'on del proyecto en el GitLab de las comunidades. En pr'oximas versiones se espera adaptar el dise~no de la “ventana” al sistema operativo.
!Espero que les guste Disable Load Images! ![]()
|
|
Margaret Leibovic: Dare 2B Digital 2014: Remix the Web! |
Dare 2B Digital is an annual South Bay conference that brings 300 young women ages 12-16 together to encourage them to consider STEM fields in college by coming together for a full day of inspiring talks and workshops showcasing women’s work and relevance in technology. For the past four conferences, Lukas has signed Mozilla up as a sponsor and created a workshop that is run 3 times that day and reaches about 80-100 attendees. Last year, Lukas and I created a workshop to teach these girls how to create mobile HTML5 games. This year, Lukas couldn’t make it to the conference because she was busy organizing another great outreach event, so I volunteered to organize our workshop, and I recruited Katie and Heather to help me.
I really love Webmaker, a Mozilla project dedicated to helping people learn how to create amazing things on the web, so I decided to create a workshop to teach the girls how to use some of the Webmaker tools. My goal was to teach the girls how to use these tools to understand the basic building blocks of the web, as well as show them how easy it is to make their own web content. To prepare for the conference, I gathered 20 loaner laptops, ordered some swag, and remixed an existing Webmaker teaching kit to create an outline for the workshop.
We started off each workshop with a brief overview of how the web works (Katie used her teacher skills to create some nice whiteboard diagrams), and then we jumped right into using the Webmaker tools. We started by walking the girls through using the X-Ray Goggles to inspect webpages, and taught them that they can modify what they see in their browsers. We definitely heard lots of “This is so cool!!!” when we showed them how to change text and images on any webpage.
Once they felt comfortable with X-Ray Goggles, we pointed them to a gallery of existing Webmaker projects, and showed them how to use Thimble to remix those projects into their own. At this point, we let them loose to start working on their own remixes, and there was lots of enthusiasm and laughter as they started working on their own projects. We also felt thoroughly out of touch with youth culture when they started filling their projects with images of young male celebrities we had never even heard of.
Unfortunately, we only had an hour and 15 minutes for each workshop, which flew by, but we encouraged the girls to make their own Webmaker accounts to continue working on their remixes at home. They were definitely really excited to learn that all of these resources are available to them at home, and that they only need a web browser to get started!
|
|
Ian Bicking: Towards a Next Level of Collaboration |
With TogetherJS we’ve been trying to make a usable tool for the web we have, and the browsers we have, and the web apps we have. But we’re also accepting a lot of limitations.
For a particular scope the limitations in TogetherJS are reasonable, but my own goals have been more far-reaching. I am interested in collaboration with as broad a scope as the web itself. (But no broader than the web because I’m kind of biased.) “Collaboration” isn’t quite the right term — it implies a kind of active engagement in creation, but there’s more ways to work together than collaboration. TogetherJS was previously called TowTruck, but we wanted to rename it to something more meaningful. While brainstorming we kept coming back to names that included some form of “collaboration” but I strongly resisted it because it’s such a mush-mouthed term with too much baggage and too many preconceptions.
When we came up with “together” it immediately seemed right. Admittedly the word feels a little cheesy (it’s a web built out of hugs and holding hands!) but it covers the broad set of activities we want to enable.
With the experience from TogetherJS in mind I want to spend some time thinking about what a less limited tool would look like. Much of this has become manifest in Hotdish, and the notes below have informed its design.
Intense collaboration is cool, but it’s not comprehensive. I don’t want to always be watching over your shoulder. What will first come to mind is privacy, but that’s not interesting to me. I would rather address privacy by helping you scope your actions, let you interact with your peers or not and act appropriately with that in mind. I don’t want to engage with my collaborators all the time because it’s boring and unproductive and my eyes glaze over. I want to engage with other people appropriately: with all the intensity called for given the circumstances, but also all the passivity that is also sometimes called for.
I’ve started to think in terms of categories of collaboration:
This includes email of course, but also issue trackers, planning tools, any notification system. If you search for “collaboration software” this is most of what you find, and much of the innovation is in representing and organizing the messages.
I don’t think I have any particularly new ideas in this well-explored area. That’s not to say there aren’t lots of important ideas, but the work I want to do is in complementing these tools rather than competing with them. But I do want to note that they exist on this continuum.
This is the awareness of a person’s presence and activity. We have a degree of this with Instant Messaging and chat rooms (IRC, Campfire, etc). But they don’t show what we are actively doing, just our presence or absence, and in the case of group discussions some of what we’re discussing with other people.
Many tools that indicate presence also include status messages which would purport to summarize a person’s current state and work. I’ve never worked with people who keep those status messages updated. It’s a very explicit approach. At best it devolves into a record of what you had been doing.
A more interesting tool to make people’s presence more present is Sqwiggle, a kind of always-on video conference. It’s not exactly always-on, there is a low-fidelity video with no audio until you start a conversation with someone and it goes to full video and audio. This way you know not only if someone is actually sitting at the computer, but also if they are eating lunch, if they have the furrowed brows of careful concentration, or are frustrated or distracted. Unfortunately most people’s faces only show that they are looking at a screen, with the slightly studious but mostly passive facial expressions that we have when looking at screens.
Instant messaging has grown to include an additional the presence indicator: I am currently typing a response. A better fidelity version of this would indicate if I am typing right now, or if I forgot I started typing and switched tabs but left text in the input box, or if I am trying hard to compose my thoughts (typing and deleting), or if I’m pasting something, or if I am about to deliver a soliloquy in the form of a giant message. (Imagine a typing indicator that gives a sense of the number of words you have typed but not sent.)
I like that instant messaging detects your state automatically, using something that you are already engaged with (the text input box). Sqwiggle has a problem here: because you aren’t trying to project any emotions to your computer screen, Sqwiggle catches expressions that don’t mean anything. We can engage with our computers in different ways, there’s something there to express, it’s just not revealed on our faces.
I’d like to add to the activity indicators we have. Like the pages (and web apps) you are looking at (or some privacy-aware subset). I’d like to show how you are interacting with those pages. Are you flopping between tabs? Are you skimming? Scrolling through in a way that shows you are studying the page? Typing? Clicking controls?
I want to show something like the body language of how you are interacting with the computer. First I wondered if we could interpret your actions and show them as things like “reading”, “composing”, “being pissed off with your computer”, etc. But then I thought more about body language. When I am angry there’s no “angry” note that shows up above my head. A furrowed brow isn’t a message, or at least mostly not a message. Body language is what we read from cues that aren’t explicit. And so we might be able to show what a person is doing, and let the person watching figure out why.
This is where both people (or more than 2 people) are actively working on the same thing, same project, same goal, but aren’t directly supporting each other at every moment.
When you’ve entered into this level of collaboration you’ve both agreed that you are working together — you’re probably actively talking through tasks, and may regularly be relying on each other (“does what I wrote sound right?” or “did you realize this test is failing” etc). A good working meeting will be like this. A bad meeting would probably have been better if you could have stuck to ambient awareness and promoted it to a more intense level of collaboration only as needed.
This is where you are both locked on a single task. When I write something and say “does what I wrote sound right?” we have to enter this mode: you have to look at exactly what I’m talking about. In some sense “close parallel” may mean “prepared to work directly”.
I have found that video calls are better than audio-only calls, more than I would have expected. It’s not because the video content is interesting. But the video makes you work directly, while being slightly uncomfortable so you are encouraged to acknowledge when you should end the call. In a way you want your senses filled. Or maybe that’s my propensity to distraction.
There’s a lot more to video calls than this (like the previously mentioned body language). But in each feature I suspect there are parallels in collaborative work. Working directly together should show some of the things that video shows when we are focused on a conversation, but can’t show when we are focusing on work.
This is common for instruction and teaching, but that shouldn’t be the only case we consider. In Hotdish we have often called it “presenting” and “viewing”. In this mode someone is the driver/presenter, and someone is the passenger/viewer. When the presenter focuses on something, you want the viewer to be aware of that and follow along. The presenter also wants to be confident that the viewer is following along. Maybe we want something like how you might say “uh huh” when someone is talking to you — if a listener says nothing it will throw off the talker, and these meaningless indications of active listening are important.
Demonstration could just be a combination of direct work and social convention. Does it need to be specially mediated by tools? I’m not sure. Do we need a talking stick? Can I take the talking stick? Are these interactions like a conversation, where sometimes one person enters into a kind of monologue, but the rhythm of the conversation will shift? If we focus on the demonstration tools we could miss the social interactions we are trying to support.
Between each of these styles of interaction I think there must be some kind of positive action. A natural promotion of demotion of your interaction with someone should be mutual. (A counter example would be the dangling IM conversation, where you are never sure it’s over.)
At the same time, the movement between modes also builds your shared context and your relationship with the other person. You might be proofing an article with another person, and you say: “clearly this paragraph isn’t making sense, let me just rewrite it, one minute” — now you know you are leaving active collaboration, but you also both know you’ll be reentering it soon. You shouldn’t have to record that expectation with the tool.
I’m reluctant to put boundaries up between these modes, I’d rather tools simply inform people that modes are changing and not ask if they can change. This is part of the principles behind Defaulting To Together.
At least in the context of computers we often have strong notions of ownership. Maybe we don’t have to — maybe it’s because we have to hand off work explicitly, and maybe we have to hand off work explicitly because we lack fluid ways to interact, cooperate, delegate.
With good tools in hand I see “ownership” being exchanged more regularly:
I find some documentation, then show it to you, and now it’s yours to make use of.
I am working through a process, get stuck, and need your skills to finish it up. Now it’s yours. But you might hand it back when you unstick me.
You are working through something, but are not permitted to complete the operation, you have to hand it over to me for me to complete the last step.
Layered on this we have the normal notions of ownership and control — the login accounts and permissions of the applications we are using. Whether these are in opposition to cooperation or maybe complementary I have not decided.
Perhaps a technical aside, but when dealing with real-time collaboration (not asynchronous) there are two distinct approaches.
Screensharing means one person (and one computer) is “running” the session — that one person is logged in, their page or app is “live”, everyone else sees what they see.
Screensharing doesn’t mean other people can’t interact with the screen, but any interaction has to go through the owner’s computer. In the case of a web page we can share the DOM (the current visual state of the page) with another person, but we can’t share the Javascript handlers and state, cookies, etc., so most interactions have to go back through the original browser. Any side effects have to make a round trip. Latency is a problem.
It’s hard to figure out exactly what interactivity to implement in a screensharing situation. Doing a view-only interaction is not too hard. There are a few things you can add after that — maybe you let someone touch a form control, suggest that you follow a link, send clicks across the wire — but there’s no clear line to stop at. Worse, there’s no clear line to express. You can implement certain mechanisms (like a click), but these don’t always map to what the user thinks they are doing — something like a drag might involve a mousedown/mousemove/mouseup event, or it might be implemented directly as dragging. Implementing one of those interactions is a lot easier than the other, but the distinction means nothing to the user.
When you implement incomplete interactions you are setting up a situation where a person can do something in the original application that viewers can’t do, even though it looks like the real live application. An uncanny valley of collaboration.
I’ve experimented with DOM-based screen sharing in Browser Mirror, and you can see this approach in a tool like Surfly. As I write this a minimal version of this is available in Hotdish.
In peer-to-peer collaboration both people are viewing their own version of the live page. Everything works exactly like in the non-collaborative environment. Both people are logged in as themselves. This is the model TogetherJS uses, and is also present as a separate mode in Hotdish.
This has a lot of obvious advantages over the problems identified above for screensharing. The big disadvantage is that hardly anything is collaborative by default in this model.
In the context of the web the building blocks we do have are:
URLs. Insofar as a URL defines the exact interface you look at, then putting both people at the same URL gives a consistent experience. This works great for applications that use lots of server-side logic. Amazon is pretty great, for example, or Wikipedia. It falls down when content is substantially customized for each person, like the Facebook frontpage or a flight search result.
Event echoing: events aren’t based on any internal logic of the program, they are something initiated by the user. So if the user can do something, a remote user can do something. Form fields are the best example of this, as there’s a clear protocol for doing form changes (change the value, fire a change event).
But we don’t have:
Consistent event results: events aren’t state changes, and transferring events about doesn’t necessarily lead to a consistent experience. Consider the modest toggle control, where a click on the toggler element shows or hides some other element. If our hidden states are out of sync (e.g., my toggleable element is hidden, yours is shown), sending the click event between the clients keeps them consistently and perfectly out of sync.
Consistent underlying object models. In a single-page app of some sort, or a whatever fancy Javascript-driven webapp, a lot of what we see is based on Javascript state and models that are not necessarily consistent across peers. This is in contrast to old-school server-side apps, where there’s a good chance the URL contains enough information to keep everything consistent, and ultimately the “state” is held on a single server or database that both peers are connecting to. But we can’t sync the client’s object models, as they are not built to support arbitrary modification from the outside. Apps that use a real-time database work well.
To make this work the application usually has to support peer-to-peer collaboration to some degree. A messy approach can help, but can never be enough, not complete enough, not robust enough.
So peer-to-peer collaboration offers potentially more powerful and flexible kinds of collaboration, but only with work on the part of each application. We can try to make it as easy as possible, and maybe integrate with tools or libraries that support the kinds of higher-level synchronization we would want, but it’s never reliably easy.
Another question: what kind of experiences do we want to create?
The most obvious real-time experience is: everything sees the same thing. Everything is fully synchronized. In the screensharing model this is what you always get and what you have to get.
The obvious experience is probably a good starting point, but shouldn’t be the end of our thinking.
The trivial example here is the cursor point. We can both be editing content and viewing each other’s edits (close to full sync), but we don’t have to be at exactly the same place. (This is something traditional screensharing has a hard time with, as you are sharing a screen of pixels instead of a DOM.)
But other more subtle examples exist. Maybe only one person has the permission to save a change. A collaboration-aware application might allow both people to edit, while still only allowing one person to save. (Currently editors will usually be denied to people who don’t have permission to save.)
I think there’s fruit in playing with the timing of actions. We don’t have to replay remote actions exactly how they occurred. For example, in a Demonstration context we might detect that when the driver clicks a link the page will change. To the person doing the click the order of events is: find the link, focus attention on the link, move cursor to the link, click. To the viewer the order of events is: cursor moves, maybe a short click indicator, and boom you are at a new page. There’s much less context given to the viewer. But we don’t have to display those events with the original timing for instance we could let the mouse hover over its target for a more extended amount of time on the viewer.
High-level (application-specific) representation of actions could be available. Instead of trying to express what the other person is doing through every click and scroll and twiddling of a form, you might just say “Bob created a new calendar event”.
In the context of something like a bug tracker, you might not want to synchronize the comment field. Instead you might want to show individual fields for all participants on a page/bug. Then I can see the other person’s in-progress comment, even add to it, but I can also compose my own comment as myself.
This is where the peer-to-peer model has advantages, as it will (by necessity) keep the application in the loop. It does not demand that collaboration take one form, but it gives the application an environment in which to build a domain-specific form of collaboration.
We can imagine moving from screenshare to peer-to-peer through a series of enhancements. The first might be: let applications opt-in to peer-to-peer collaboration, or implement a kind of transparent-to-the-application screensharing, and from there tweak. Maybe you indicate some scripts should run on the viewer’s side, and some compound UI components can be manipulated. I can imagine with a component system like Brick where you could identify safe ways to run rich components, avoiding latency.
Given tools and interactions, what is the actual context for collaboration?
TogetherJS has a model of a persistent session, and you invite people to that session. Only for technical reasons the session is bound to a specific domain, but not a specific page.
In Hotdish we’ve used a group approach: you join a group, and your work clearly happens in the group context or not.
One of the interesting things I’ve noticed when getting feedback about TogetherJS is that people are most interested in controlling and adding to how the sessions are setup. While, as an implementor, I find myself drawn to the tooling and specific experiences of collaboration, there’s just as much value in allowing new and interesting groupings of people. Ways to introduce people, ways to start and end collaboration, ways to connect to people by role instead of identity, and so on.
Should this collaboration be a conversation or an environment? When it is a conversation you lead off with the introduction, the “hello” the “so why did you call?” and finish with “talk to you later” — when it is an environment you enter the environment and any coparticipants are just there, you don’t preestablish any specific reason to collaborate.
I’m still developing these ideas. And for each idea the real test is if we can create a useful experience. For instance, I’m pretty sure there’s some ambient information we want to show, but I haven’t figured out what.
Experience has shown that simple history (as in an activity stream) seems too noisy. And is history shown by group or person?
In the past I unintentionally exposed all tab focus and unfocus in TogetherJS, and it felt weird to both expose my own distracted state and my collaborator’s distraction. But part of why it was weird was that in some cases it was simply distraction, but in other cases it was useful multitasking (like researching a question in another tab). Was tab focus too much information or too little?
I am still in the process of figuring out how and where I can explore these questions, build the next thing, and the next thing after that — the tooling I envision doesn’t feel impossibly far away, but still more than one iteration of work yet to be done, maybe many more than one but I can only see to the next peak.
Who else is thinking about these things? And thinking about how to build these things? If you are, or you know someone who is, please get in contact — I’m eager to talk specifics with people who have been thinking about it too, but I’m not sure how to find these people.
http://www.ianbicking.org/blog/3014/03/towards-next-level-of-collaboration.html
|
|
Ian Bicking: Towards a Next Level of Collaboration |
With TogetherJS we’ve been trying to make a usable tool for the web we have, and the browsers we have, and the web apps we have. But we’re also accepting a lot of limitations.
For a particular scope the limitations in TogetherJS are reasonable, but my own goals have been more far-reaching. I am interested in collaboration with as broad a scope as the web itself. (But no broader than the web because I’m kind of biased.) “Collaboration” isn’t quite the right term — it implies a kind of active engagement in creation, but there’s more ways to work together than collaboration. TogetherJS was previously called TowTruck, but we wanted to rename it to something more meaningful. While brainstorming we kept coming back to names that included some form of “collaboration” but I strongly resisted it because it’s such a mush-mouthed term with too much baggage and too many preconceptions.
When we came up with “together” it immediately seemed right. Admittedly the word feels a little cheesy (it’s a web built out of hugs and holding hands!) but it covers the broad set of activities we want to enable.
With the experience from TogetherJS in mind I want to spend some time thinking about what a less limited tool would look like. Much of this has become manifest in Hotdish, and the notes below have informed its design.
Intense collaboration is cool, but it’s not comprehensive. I don’t want to always be watching over your shoulder. What will first come to mind is privacy, but that’s not interesting to me. I would rather address privacy by helping you scope your actions, let you interact with your peers or not and act appropriately with that in mind. I don’t want to engage with my collaborators all the time because it’s boring and unproductive and my eyes glaze over. I want to engage with other people appropriately: with all the intensity called for given the circumstances, but also all the passivity that is also sometimes called for.
I’ve started to think in terms of categories of collaboration:
This includes email of course, but also issue trackers, planning tools, any notification system. If you search for “collaboration software” this is most of what you find, and much of the innovation is in representing and organizing the messages.
I don’t think I have any particularly new ideas in this well-explored area. That’s not to say there aren’t lots of important ideas, but the work I want to do is in complementing these tools rather than competing with them. But I do want to note that they exist on this continuum.
This is the awareness of a person’s presence and activity. We have a degree of this with Instant Messaging and chat rooms (IRC, Campfire, etc). But they don’t show what we are actively doing, just our presence or absence, and in the case of group discussions some of what we’re discussing with other people.
Many tools that indicate presence also include status messages which would purport to summarize a person’s current state and work. I’ve never worked with people who keep those status messages updated. It’s a very explicit approach. At best it devolves into a record of what you had been doing.
A more interesting tool to make people’s presence more present is Sqwiggle, a kind of always-on video conference. It’s not exactly always-on, there is a low-fidelity video with no audio until you start a conversation with someone and it goes to full video and audio. This way you know not only if someone is actually sitting at the computer, but also if they are eating lunch, if they have the furrowed brows of careful concentration, or are frustrated or distracted. Unfortunately most people’s faces only show that they are looking at a screen, with the slightly studious but mostly passive facial expressions that we have when looking at screens.
Instant messaging has grown to include an additional the presence indicator: I am currently typing a response. A better fidelity version of this would indicate if I am typing right now, or if I forgot I started typing and switched tabs but left text in the input box, or if I am trying hard to compose my thoughts (typing and deleting), or if I’m pasting something, or if I am about to deliver a soliloquy in the form of a giant message. (Imagine a typing indicator that gives a sense of the number of words you have typed but not sent.)
I like that instant messaging detects your state automatically, using something that you are already engaged with (the text input box). Sqwiggle has a problem here: because you aren’t trying to project any emotions to your computer screen, Sqwiggle catches expressions that don’t mean anything. We can engage with our computers in different ways, there’s something there to express, it’s just not revealed on our faces.
I’d like to add to the activity indicators we have. Like the pages (and web apps) you are looking at (or some privacy-aware subset). I’d like to show how you are interacting with those pages. Are you flopping between tabs? Are you skimming? Scrolling through in a way that shows you are studying the page? Typing? Clicking controls?
I want to show something like the body language of how you are interacting with the computer. First I wondered if we could interpret your actions and show them as things like “reading”, “composing”, “being pissed off with your computer”, etc. But then I thought more about body language. When I am angry there’s no “angry” note that shows up above my head. A furrowed brow isn’t a message, or at least mostly not a message. Body language is what we read from cues that aren’t explicit. And so we might be able to show what a person is doing, and let the person watching figure out why.
This is where both people (or more than 2 people) are actively working on the same thing, same project, same goal, but aren’t directly supporting each other at every moment.
When you’ve entered into this level of collaboration you’ve both agreed that you are working together — you’re probably actively talking through tasks, and may regularly be relying on each other (“does what I wrote sound right?” or “did you realize this test is failing” etc). A good working meeting will be like this. A bad meeting would probably have been better if you could have stuck to ambient awareness and promoted it to a more intense level of collaboration only as needed.
This is where you are both locked on a single task. When I write something and say “does what I wrote sound right?” we have to enter this mode: you have to look at exactly what I’m talking about. In some sense “close parallel” may mean “prepared to work directly”.
I have found that video calls are better than audio-only calls, more than I would have expected. It’s not because the video content is interesting. But the video makes you work directly, while being slightly uncomfortable so you are encouraged to acknowledge when you should end the call. In a way you want your senses filled. Or maybe that’s my propensity to distraction.
There’s a lot more to video calls than this (like the previously mentioned body language). But in each feature I suspect there are parallels in collaborative work. Working directly together should show some of the things that video shows when we are focused on a conversation, but can’t show when we are focusing on work.
This is common for instruction and teaching, but that shouldn’t be the only case we consider. In Hotdish we have often called it “presenting” and “viewing”. In this mode someone is the driver/presenter, and someone is the passenger/viewer. When the presenter focuses on something, you want the viewer to be aware of that and follow along. The presenter also wants to be confident that the viewer is following along. Maybe we want something like how you might say “uh huh” when someone is talking to you — if a listener says nothing it will throw off the talker, and these meaningless indications of active listening are important.
Demonstration could just be a combination of direct work and social convention. Does it need to be specially mediated by tools? I’m not sure. Do we need a talking stick? Can I take the talking stick? Are these interactions like a conversation, where sometimes one person enters into a kind of monologue, but the rhythm of the conversation will shift? If we focus on the demonstration tools we could miss the social interactions we are trying to support.
Between each of these styles of interaction I think there must be some kind of positive action. A natural promotion of demotion of your interaction with someone should be mutual. (A counter example would be the dangling IM conversation, where you are never sure it’s over.)
At the same time, the movement between modes also builds your shared context and your relationship with the other person. You might be proofing an article with another person, and you say: “clearly this paragraph isn’t making sense, let me just rewrite it, one minute” — now you know you are leaving active collaboration, but you also both know you’ll be reentering it soon. You shouldn’t have to record that expectation with the tool.
I’m reluctant to put boundaries up between these modes, I’d rather tools simply inform people that modes are changing and not ask if they can change. This is part of the principles behind Defaulting To Together.
At least in the context of computers we often have strong notions of ownership. Maybe we don’t have to — maybe it’s because we have to hand off work explicitly, and maybe we have to hand off work explicitly because we lack fluid ways to interact, cooperate, delegate.
With good tools in hand I see “ownership” being exchanged more regularly:
I find some documentation, then show it to you, and now it’s yours to make use of.
I am working through a process, get stuck, and need your skills to finish it up. Now it’s yours. But you might hand it back when you unstick me.
You are working through something, but are not permitted to complete the operation, you have to hand it over to me for me to complete the last step.
Layered on this we have the normal notions of ownership and control — the login accounts and permissions of the applications we are using. Whether these are in opposition to cooperation or maybe complementary I have not decided.
Perhaps a technical aside, but when dealing with real-time collaboration (not asynchronous) there are two distinct approaches.
Screensharing means one person (and one computer) is “running” the session — that one person is logged in, their page or app is “live”, everyone else sees what they see.
Screensharing doesn’t mean other people can’t interact with the screen, but any interaction has to go through the owner’s computer. In the case of a web page we can share the DOM (the current visual state of the page) with another person, but we can’t share the Javascript handlers and state, cookies, etc., so most interactions have to go back through the original browser. Any side effects have to make a round trip. Latency is a problem.
It’s hard to figure out exactly what interactivity to implement in a screensharing situation. Doing a view-only interaction is not too hard. There are a few things you can add after that — maybe you let someone touch a form control, suggest that you follow a link, send clicks across the wire — but there’s no clear line to stop at. Worse, there’s no clear line to express. You can implement certain mechanisms (like a click), but these don’t always map to what the user thinks they are doing — something like a drag might involve a mousedown/mousemove/mouseup event, or it might be implemented directly as dragging. Implementing one of those interactions is a lot easier than the other, but the distinction means nothing to the user.
When you implement incomplete interactions you are setting up a situation where a person can do something in the original application that viewers can’t do, even though it looks like the real live application. An uncanny valley of collaboration.
I’ve experimented with DOM-based screen sharing in Browser Mirror, and you can see this approach in a tool like Surfly. As I write this a minimal version of this is available in Hotdish.
In peer-to-peer collaboration both people are viewing their own version of the live page. Everything works exactly like in the non-collaborative environment. Both people are logged in as themselves. This is the model TogetherJS uses, and is also present as a separate mode in Hotdish.
This has a lot of obvious advantages over the problems identified above for screensharing. The big disadvantage is that hardly anything is collaborative by default in this model.
In the context of the web the building blocks we do have are:
URLs. Insofar as a URL defines the exact interface you look at, then putting both people at the same URL gives a consistent experience. This works great for applications that use lots of server-side logic. Amazon is pretty great, for example, or Wikipedia. It falls down when content is substantially customized for each person, like the Facebook frontpage or a flight search result.
Event echoing: events aren’t based on any internal logic of the program, they are something initiated by the user. So if the user can do something, a remote user can do something. Form fields are the best example of this, as there’s a clear protocol for doing form changes (change the value, fire a change event).
But we don’t have:
Consistent event results: events aren’t state changes, and transferring events about doesn’t necessarily lead to a consistent experience. Consider the modest toggle control, where a click on the toggler element shows or hides some other element. If our hidden states are out of sync (e.g., my toggleable element is hidden, yours is shown), sending the click event between the clients keeps them consistently and perfectly out of sync.
Consistent underlying object models. In a single-page app of some sort, or a whatever fancy Javascript-driven webapp, a lot of what we see is based on Javascript state and models that are not necessarily consistent across peers. This is in contrast to old-school server-side apps, where there’s a good chance the URL contains enough information to keep everything consistent, and ultimately the “state” is held on a single server or database that both peers are connecting to. But we can’t sync the client’s object models, as they are not built to support arbitrary modification from the outside. Apps that use a real-time database work well.
To make this work the application usually has to support peer-to-peer collaboration to some degree. A messy approach can help, but can never be enough, not complete enough, not robust enough.
So peer-to-peer collaboration offers potentially more powerful and flexible kinds of collaboration, but only with work on the part of each application. We can try to make it as easy as possible, and maybe integrate with tools or libraries that support the kinds of higher-level synchronization we would want, but it’s never reliably easy.
Another question: what kind of experiences do we want to create?
The most obvious real-time experience is: everything sees the same thing. Everything is fully synchronized. In the screensharing model this is what you always get and what you have to get.
The obvious experience is probably a good starting point, but shouldn’t be the end of our thinking.
The trivial example here is the cursor point. We can both be editing content and viewing each other’s edits (close to full sync), but we don’t have to be at exactly the same place. (This is something traditional screensharing has a hard time with, as you are sharing a screen of pixels instead of a DOM.)
But other more subtle examples exist. Maybe only one person has the permission to save a change. A collaboration-aware application might allow both people to edit, while still only allowing one person to save. (Currently editors will usually be denied to people who don’t have permission to save.)
I think there’s fruit in playing with the timing of actions. We don’t have to replay remote actions exactly how they occurred. For example, in a Demonstration context we might detect that when the driver clicks a link the page will change. To the person doing the click the order of events is: find the link, focus attention on the link, move cursor to the link, click. To the viewer the order of events is: cursor moves, maybe a short click indicator, and boom you are at a new page. There’s much less context given to the viewer. But we don’t have to display those events with the original timing for instance we could let the mouse hover over its target for a more extended amount of time on the viewer.
High-level (application-specific) representation of actions could be available. Instead of trying to express what the other person is doing through every click and scroll and twiddling of a form, you might just say “Bob created a new calendar event”.
In the context of something like a bug tracker, you might not want to synchronize the comment field. Instead you might want to show individual fields for all participants on a page/bug. Then I can see the other person’s in-progress comment, even add to it, but I can also compose my own comment as myself.
This is where the peer-to-peer model has advantages, as it will (by necessity) keep the application in the loop. It does not demand that collaboration take one form, but it gives the application an environment in which to build a domain-specific form of collaboration.
We can imagine moving from screenshare to peer-to-peer through a series of enhancements. The first might be: let applications opt-in to peer-to-peer collaboration, or implement a kind of transparent-to-the-application screensharing, and from there tweak. Maybe you indicate some scripts should run on the viewer’s side, and some compound UI components can be manipulated. I can imagine with a component system like Brick where you could identify safe ways to run rich components, avoiding latency.
Given tools and interactions, what is the actual context for collaboration?
TogetherJS has a model of a persistent session, and you invite people to that session. Only for technical reasons the session is bound to a specific domain, but not a specific page.
In Hotdish we’ve used a group approach: you join a group, and your work clearly happens in the group context or not.
One of the interesting things I’ve noticed when getting feedback about TogetherJS is that people are most interested in controlling and adding to how the sessions are setup. While, as an implementor, I find myself drawn to the tooling and specific experiences of collaboration, there’s just as much value in allowing new and interesting groupings of people. Ways to introduce people, ways to start and end collaboration, ways to connect to people by role instead of identity, and so on.
Should this collaboration be a conversation or an environment? When it is a conversation you lead off with the introduction, the “hello” the “so why did you call?” and finish with “talk to you later” — when it is an environment you enter the environment and any coparticipants are just there, you don’t preestablish any specific reason to collaborate.
I’m still developing these ideas. And for each idea the real test is if we can create a useful experience. For instance, I’m pretty sure there’s some ambient information we want to show, but I haven’t figured out what.
Experience has shown that simple history (as in an activity stream) seems too noisy. And is history shown by group or person?
In the past I unintentionally exposed all tab focus and unfocus in TogetherJS, and it felt weird to both expose my own distracted state and my collaborator’s distraction. But part of why it was weird was that in some cases it was simply distraction, but in other cases it was useful multitasking (like researching a question in another tab). Was tab focus too much information or too little?
I am still in the process of figuring out how and where I can explore these questions, build the next thing, and the next thing after that — the tooling I envision doesn’t feel impossibly far away, but still more than one iteration of work yet to be done, maybe many more than one but I can only see to the next peak.
Who else is thinking about these things? And thinking about how to build these things? If you are, or you know someone who is, please get in contact — I’m eager to talk specifics with people who have been thinking about it too, but I’m not sure how to find these people.
http://www.ianbicking.org/blog/2014/03/towards-next-level-of-collaboration.html
|
|
Lukas Blakk: I’m looking at you, Gift Horse |
 I have to avoid this. All. Day. Which turns into “avoid the office”.
I have to avoid this. All. Day. Which turns into “avoid the office”.I’m going to say something that might be controversial, or hard to understand for some folks but it’s getting to the point where I’m starting to stay away from the office more than I’d like to so here goes:
The snacks. The never-ending supply that I would *never* eat otherwise. That I would not go to a corner store and purchase. I really wish they were gone. I wish that we, people who all make salaries above that needed for living decently, were accountable for buying and bringing in our own snacks as we chose. Keep them at your desk, share with nearby co-workers, I would love to see this. It would be so much better for me if the only things we had in the kitchen were fruit and veg. Milk for coffee, sure.
When I first started working for Mozilla, as a working class grew up broke kid, I was floored by all the free stuff & free food. I lived off it as an intern to save money. I appreciated it. It made me feel cared for. Now it’s like a trap. A constant test of my ability to make “good” decisions for myself 250 times a day. Often I fail. Failure makes me stay away from the office as an attempt to cope. Staying away from the office causes loss of connection with you all.
I suspect there might be feelings of being ‘punished’ if the snacks were less abundant (or even gone) because we’re used to all these ‘perks’ in our tech offices. It’s not something most offices (outside of tech industry) have and I would encourage a perspective shift towards accountability, recognizing the privileges we *already* have even without free all-day snacks, and thinking about what it means if some people have to choose to stay away. Considering the origin of these snacks is from a startup mentality where workers were expected to be pulling really long hours without getting up, out, or going home. Is that really what we want to promote and call a perk?
|
|
Andrew Halberstadt: A Workflow for using Mach with multiple Object Directories |
Mach is an amazing tool which facilitates a large number of common user stories in the mozilla source tree. You can perform initial setup, execute a build, run tests, examine diagnostics, even search Google. Many of these things require an object directory. This can potentially lead to some confusion if you typically have more than one object directory at any given time. How does mach know which object directory to operate on?
It turns out that mach is pretty smart. It takes a very good guess at which object directory you want. Here is a simplification of the steps in order:
The cool thing about this is that there are tons of different workflows that fit nicely into this model. For example, many people put the mach binary on their $PATH and then always make sure to 'cd' into their objdirs before invoking related mach commands.
It turns out that mach works really well with a tool I had written quite awhile back called mozconfigwrapper. I won't go into details about mozconfigwrapper here. For more info, see my previous post on it. Now for the sake of example, let's say we have a regular and debug build called 'regular' and 'debug' respectively. Now let's say I wanted to run the 'mochitest-plain' test suite on each build, one after the other. My workflow would be (from any directory other than an objdir):
$ buildwith regular $ mach mochitest-plain $ buildwith debug $ mach mochitest-plain
How does this work? Very simply, mozconfigwrapper is exporting the $MOZCONFIG environment variable under the hood anytime you call 'buildwith'. Mach will then pick up on this due to the second step listed above.
Your second question might be why bother installing mozconfigwrapper when you can just export MOZCONFIG directly? This is a matter of personal preference, but one big reason for me is the buildwith command has full tab completion, so it is easy to see which mozconfigs you have available to choose from. Also, since they are hidden away in your home directory, you don't need to memorize any paths. There are other advantages as well which you can see in the mozconfigwrapper readme.
I've specially found this workflow useful when building several platforms at once (e.g firefox and b2g desktop) and switching back and forth between them with a high frequency. In the end, to each their own and this is just one possible workflow out of many. If you have a different workflow please feel free to share it in the comments.
|
|
Michael Kaply: New Features for CCK2 |
I realize it's been quite a while since I've posted any updates. I've been heads down on some projects, as well as dealing with some personal issues.
I have been working on the CCK2, though, and I have a new version to share.
This version adds some requested features, including custom JavaScript in the AutoConfig file as well as better backup of your configurations. It also migrates configurations from the original CCK Wizard.
I've also changed the versioning to make it clear that this version is newer than the CCK Wizard.
My plan is to deprecate and remove the old CCK Wizard in the next few weeks, so please take some time to make sure the new CCK2 works for you.
And if the CCK2 is useful to your organization, please consider purchasing a support plan.
|
|
Doug Belshaw: What’s new with Open Badges? |
Those keeping track will know that last year I moved teams within the Mozilla Foundation. I moved away from the Open Badges team to focus on (what is now) the Web Literacy Map. Despite this, I still have close ties to the Open Badges team. In fact, I’m currently helping design Webmaker and Web Literacy badges.
The big news at the start of 2014 on the Open Badges front is that there’s a new Badge Alliance to grow and develop the wider ecosystem. The Badge Alliance is a non-profit organisation to be led by Erin Knight, co-founder of the Open Badges Infrastructure (OBI). Over the next few months she’ll be joined at the Badge Alliance with a few members of the current Open Badges team. There’s more detail in Erin’s blog post.
Happily, Mozilla will continue to develop and nurture the open source technical stack behind the OBI. The next milestone is the release of BadgeKit in the next few months. This should remove any remaining friction from issuing Open Badges. For more on BadgeKit be sure to follow the blogs of Sunny Lee and Chris McAvoy. And, as ever, you should also follow Carla Casilli’s posts on badge system design.
If you want to keep up with what’s going on with Open Badges in general, the easiest thing to do is to keep tabs on the Open Badges blog. The weekly ‘Badger Beats’ in particular is a useful round-up of news from the world of badges. There’s also a good deal of conversation within the Open Badges discussion group. This is a friendly forum for those planning to dip their toes into the water for the first time.
Having joined Mozilla in 2012 to work both on the Open Badges project and (what’s grown into) the Web Literacy Map. I’m delighted that the former has been incubated with such success. I’m also pleased that the latter is to underpin both the next iteration of Webmaker and Mozilla’s aims to create a more web literate planet.
If you’d like to get involved with Mozilla’s work to create a better web then we’d love to have you onboard! The easiest way to get involved with the two projects I’ve mentioned is to join their respective weekly calls. The Open Badges community call is every Wednesday, and you can join us for the new #TeachTheWeb community call every Thursday.
Questions? I’ll do my best to respond to them in the comments below.
Image CC BY-NC-SA RSC Scotland
http://dougbelshaw.com/blog/2014/03/03/whats-new-with-open-badges/
|
|
Tobias Markus: Atypical Confessions of an atypical contributor |
I, your favorite hypocrite, traitor or whatever people might call me, thought about writing this for a long time. Just to give a different perspective on things. I have been a contributor for a rather long time (5 years to be exact). I confess that I am not a regular contributor. These things are mostly thoughts that I have, and I am going to be blunt about them. If people can’t deal with it, so be it. And this is not gonna be about Directory Tiles, even though I am eager to write my thoughts about them, but, no, not this time.
#1 – I hate the word ‘Mozillians’.
The word “Mozillians” suggest that people contributing to the Mozilla project are all the same. All one kind. It takes the focus away from potential differences in personality or culture. In my opinion, these differences need to be valued. For we are all different. And the fact that we contribute doesn’t take that difference away.
There’s another reason why I hate that word: “Mozillian” seems like “Human”. A status that, once acquired, lasts forever and cannot be taken away. However, what if I don’t want to be part of that group anymore? I think the term “contributor” is much more suited for that. It still gives some means of escape from the whole thing.
#2 – Products mean nothing to me.
Given there’s so much focus on products nowadays: I don’t like that. Products mean nothing to me. It’s just a name for what? Bunch of code? Initiatives? Philosophical thoughts? Honestly, do we need a name for everything? If we think about it, our product is not so different from other products. The browser is written in some programming language and evolved over years. Same for other products. That doesn’t make it ‘awesome’. That just means it’s evolved. Product names are just for identification, and that’s marketing. I don’t have anything to do with marketing reasons. I have my own mind.
Are we humans awesome? You’d assume it depends on the point of view. And YES: IT DOES!
#3 – I don’t like direction.
I am someone who values individuality. I don’t like direction. Giving direction means potentially saying “I know more than you do” or “I am better than you”, therefore I tell you what to do, and I will never accept that. Not when it comes to a such diverse group of people as the contributor base.
#4 – Good things take time
I don’t like for things being rushed. That’s not how I work. There have been so many things in the past years that have been rushed and then improved and improved or abandoned for reasons. Why not improve them and release them when ready? Unfinished projects do not make us more popular with the userbase.
#5 – Controversial discussions are good discussions
On a related note: In order for discussions to get most healthy, it’s important for them to be vivid. Vivid discussions means that any stand point is accepted. It might get a little heated from time to time, but that way we can ensure that there are a lot of thoughts covered in the discussion. I hate it when community doesn’t even have a say in what gets decided.
#6 – I hate the “1 million mozillians” initiative.
It’s hard to manage 1 million people. And frankly, I doubt Mozilla can do this. Let’s think about this: People are people, they have their own mind, their own ideals, their own hobbies, their own opinion. You can find more potential reasons in my comment here: http://hoosteeno.com/2013/12/17/a-new-mozillians-org-signup-process/#comment-159
What do they need 1 million contributors for? Hint: It’s not to benefit the people themselves.

http://mozillatobbi.wordpress.com/2014/03/02/atypical-confessions-of-an-atypical-contributor/
|
|
Jeff Griffiths: How I (quickly) write Firefox Extensions |
Over the last 2 or so years I've written a lot of add-ons and in particular a lot of very very simple add-ons that are either quick examples to show someone how to do something, or to try to reproduce a bug in Firefox or the SDK. And because I'm lazy, I've automated a lot of the tedious parts of this. Here's how I do it.
I use OS X and a lot of this assumes having a reasonable UNIX shell environment. If you're on Windows and don't have bash, some parts of this will not work for you. Thankfully, node.js 'jus works' everywhere.
The cfx tool does this already, but it creates a skeletal add-onwith example code and I almost never want that. So I use this quick shell script called jpinit:
#!/bin/bash
_PWD=`pwd`
mkdir -p "$_PWD/$1" && cd "$_PWD/$1" && cfx init
echo "" > lib/main.js && echo "" > doc/main.md && echo "" > test/test-main.js && echo "" > ./README.md
Put this on your path too, I tend to put scripts like this in $HOME/usr/local/bin or similar.
Once I've got a blank project going, I get to the fun part of actually implementing features. Whenenver I want to test my code, all I need to do is run this scipt and it will build and install my add-on in Firefox:
https://gist.github.com/canuckistani/9301061
Under the hood it's just using node's child_process module to first run cfx xpi, then wget to upload the xpi file to Firefox.
How does this even work? That's the magic of the 'Extension Auto-Installer' extension, how it works is it runs a local web server inside Firefox that listens on a port for xpi file uploads. If it gets an xpi file, it tries to install or reload it.
I primarily use Sublime Text. The slightly tricky thing about using ST for add-on development is that internal Firefox and add-on code is able to use more advanced JS features. To convince ST that things like the let and yield keywords are okay, you need to do the following:
.jshintrc fileHere's a quick screencast to show you how quickly this can get you hacking:
When you consider how time-consuming this has been in the past, I'm pretty happy with it, in particular if I just need to hack on something to answer a question on Stack Overflow or from IRC. The time consuming part becomes writing code, and that's the way it should be.
I do expect this all to change soon; the Jetpack team has been working on some new features that will provide everyone with an even more streamlined process without the need for extra extensions or shell scripts, as well as an advanced debugger specifically for add-ons. For a glimpse of just how awesome you really need to check out Erik's post from last week.
|
|






