Mike Conley: Things I’ve Learned This Week (May 25 – May 29, 2015) |
Up until recently, anytime you pushed a patch series to MozReview, a single attachment would be created on the bug associated with the push.
That single attachment would link to the “parent” or “root” review request, which contains the folded diff of all commits.
We noticed a lot of MozReview users were (rightfully) confused about this mapping from Bugzilla to MozReview. It was not at all obvious that Ship It on the parent review request would cause the attachment on Bugzilla to be r+’d. Consequently, reviewers used a number of workarounds, including, but not limited to:
Anyhow, this model wasn’t great, and caused a lot of confusion.
So it’s changed! Now, when you push to MozReview, there’s one attachment created for every commit in the push. That means that when different reviewers are set for different commits, that’s reflected in the Bugzilla attachments, and when those reviewers mark “Ship It” on a child commit, that’s also reflected in an r+ on the associated Bugzilla attachment!
I think this makes quite a bit more sense. Hopefully you do too!
See gps’s blog post for the nitty gritty details, and some other cool MozReview announcements!
http://mikeconley.ca/blog/2015/06/01/things-ive-learned-this-week-may-25-may-29-2015/
|
|
Nick Cameron: My Git and GitHub work flow |
http://featherweightmusings.blogspot.com/2015/06/my-git-and-github-work-flow.html
|
|
Karl Dubost: What a Web developer should know about cross compatibility? |
This morning on reddit I discovered the following question:
What big cross browser compatibility issues (old and new) should we know about as web developers?
followed by the summary:
I am a relative noob to web dev and have my first interview for my first front end dev role coming up. Cross browser compatibility isn't a strong point of mine. What issues should I (and any developers) know about and cater for?
Any links to articles so I can do some further reading would be awesome sauce. Thanks!
When talking about compatibility, I usually prefer Web Compatibility to cross browser compatibility. It's not that much but there is a turn into it which focus less on browsers and more on the Web as used by people.
First of all, there's no magic bullet. Browsers evolve, devices and networks change, Web development practices and tooling are emerging at a pace which is difficult to follow. Your knowledge will always be outdated. There's no curriculum which once known will guarantee that all Web development practices will be flawless. It leads me to a first rule.
Web Compatibility is a practice.
Read blogs around, look at Stackoverflow, understand the issues that some people have with their Web development. But more than blindly copying a quick solution, understand your choices and the impact on users. Often your users are in a blind spot. You can't see them because your Web development prevent them to access the content you have created. One of the quick answers we receive when contacting for Web Compatibility issues is: "This browser is not part of our targets list, because it's not visible in our stats." As a matter of fact, indeed, a browser Z is not visible in their stats, because… the Web site is not usable at all with this browser. There's no chance it will ever appear in the stats. Worse. The browsers have to lie about which they are to be able to get the site working, inflating the stats of the targeted list. Another strategy is to make your Web site resilient enough that you do not have to question yourselves about Web Compatibility.
Web Compatibility is about being resilient.
All of these you may find on Planet WebCompat
Before I would have told you on each browser bug reporting systems. But now we have a place for this:
There are some people who you should read absolutely about the Web in general and why it's important to be inclusive in the Web development. They do not necessary talk often about Web Compatibility per se, but they approach the Web with a more 30,000 meters view of the Web. A more humane Web. This list is open ended, but I would start with:
Otsukare!
http://www.otsukare.info/2015/06/01/webdev-cross-compatibility-101
|
|
Kartikaya Gupta: Management, TRIBE, and other thoughts |
At the start of 2014, I became a "manager". At least in the sense that I had a couple of people reporting to me. Like most developers-turned-managers I was unsure if management was something I wanted to do but I figured it was worth trying at least. Somebody recommended the book First, Break All The Rules to me as a good book on management, so I picked up a copy and read it.
The book is based on data from many thousands of interviews and surveys that the Gallup organization did, across all sorts of organizations. There were lots of interesting points in the book, but the main takeaway relevant here was that people who build on their strengths instead of trying to correct their weaknesses are generally happier and more successful. This leads to some obvious follow-up questions: how do you know what your strengths are? What does it mean to "build on your strengths"?
To answer the first question I got the sequel, Now, Discover Your Strengths, which includes a single-use code for the online StrengthsFinder assessment. I read the book, took the assessment, and got a list of my top 5 strengths. While interesting, the list was kind of disappointing, mostly because I didn't really know what to do with it. Perhaps the next book in the series, Go Put Your Strengths To Work, would have explained but at this point I was disillusioned and didn't bother reading it.
Fast-forward to a month ago, when I finally got to attend the first TRIBE session. I'd heard good things about it, without really knowing anything specific about what it was about. Shortly before it started though, they sent us a copy of Strengths Based Leadership, which is a book based on the same Gallup data as the aforementioned books, and includes a code to the 2.0 version of the same online StrengthsFinder assessment. I read the book and took the new assessment (3 of the 5 strengths I got matched my initial results; the variance is explained on their FAQ page) but didn't really end up with much more information than I had before.
However, the TRIBE session changed that. It was during the session that I learned the answer to my earlier question about what it means to "build on strengths". If you're familiar with the 4 stages of competence, that TRIBE session took me from "unconscious incompetence" to "conscious incompetence" with regard to using my strengths - it made me aware of when I'm using my strengths and when I'm not, and to be more purposeful about when to use them. (Two asides: (1) the TRIBE session also included other useful things, so I do recommend attending and (2) being able to give something a name is incredibly powerful, but perhaps that's worth a whole 'nother blog post).
At this point, I'm still not 100% sure if being a manager is really for me. On the one hand, the strengths I have are not really aligned with the strengths needed to be a good manager. On the other hand, the Strengths Based Leadership book does provide some useful tips on how to leverage whatever strengths you do have to help you fulfill the basic leadership functions. I'm also not really sold on the idea that your strengths are roughly constant over your lifetime. Having read about neuroplasticity I think your strengths might change over time just based on how you live and view your life. That's not really a case for or against being a manager or leader, it just means that you'd have to be ready to adapt to an evolving set of strengths.
Thankfully, at Mozilla, unlike many other companies, it is possible to "grow" without getting pushed into management. The Mozilla staff engineer level descriptions provide two tracks - one as an individual contributor and one as a manager (assuming these descriptions are still current - and since the page was last touched almost 2 years ago it might very well not be!). At many companies this is not even an option.
For now I'm going to try to level up to "conscious competence" with respect to using my strengths and see where that gets me. Probably by then the path ahead will be more clear.
|
|
Andy McKay: Docker in development (part 2) |
Tips for developing with Docker.
You are developing an app, so it will go wrong. It will go wrong a lot, that's fine. But at the beginning you will have a cycle that goes like this: container starts up, container starts your app, app fails and exits, container stops. What went wrong with your app? You've got no idea.
Because the container died, you lost the logs and if you start the container up again, the same thing happens.
If you store the critical logs of your app outside your container, then you can see the problems after it exits. If you use a process runner like supervisord then you'll find that docker logs contains your process runner.
You can do a few things here, like move your logs into the process runner logs, or just write your logs to a location that allows you to save them. There's lots of ways to do that, but since we use supervisord and docker-compose, for us its a matter of making sure supervisord writes its logs out to a volume.
See also part 1.
http://www.agmweb.ca/2015-05-31-docker-in-development-part-2/
|
|
Christian Heilmann: That one tweet… |
One simple tweet made me feel terrible. One simple tweet made me doubt myself. One simple tweet – hopefully not meant to be mean – had a devastating effect on me. Here’s how and why, and a reminder that you should not be the person that with one simple tweet causes anguish like that.

As readers of this blog, you know that the last weeks have been hectic for me:
I bounced from conference to conference, delivering a new talk at each of them, making my slides available for the public. I do it because I care about people who can not get to the conference and for those I coach about speaking so they can re-use the decks if they wanted to. I also do a recording of my talks and publish them on YouTube so people can listen. Mostly I do these for myself, so I can get better at what I do. This is a trick I explained in the developer evangelism handbook – another service I provide for free.
Publishing on the go is damn hard:
The format of your slides are irellevant to these issues. HTML, Powerpoint, Keynote – lots of images means lots of bytes.
Presenting and traveling is both stressful and taxing. Many people ask me how I do it and my answer is simply that: the positive feedback I get and seeing people improve when they get my advice is a great reward and keeps me going. The last few weeks have been especially taxing as I also need to move out of my flat. I keep getting calls by my estate agent that I need to wire money or be somewhere I can not. I also haven’t seen my partner more than a few hours because we are both busy.
I love my job. I still get excited to go to conferences, hear other presenters, listen to people’s feedback and help them out. A large part of my career is based on professional relationships that formed at events.

Being a public speaker means you don’t spend much time for yourself. At the event you sleep on average 4-5 hours as you don’t want to be the rockstar presenter that arrives, delivers a canned talk and leaves. You are there for the attendees, so you sacrifice your personal time. That’s something to prepare for. If you make promises, you also need to deliver them immediately. Any promise of you to look into something or contact someone you don’t follow up as soon as you can piles up to a large backlog you have a hard time remembering what it is you wanted to find out.
It also can make you feel very lonely. I’ve had many conversations with other presenters who feel very down as you are not with the people you care about, in the place you call home or in an environment you understand and feel comfortable in. Sure, hotels, airports and conference venues are all lush and have a “jet set” feel to them. They are also very nondescript and make you feel like a stranger.
I care deeply about progressive enhancement. To me, it means you care more for the users of your products than you care about development convenience. It is a fundamental principal of the web, and – to me – the start of caring about accessibility.
In the last few weeks progressive enhancement was a hot topic in our little world and I wanted to chime in many a time. After all, I wrote training materials on this 11 years ago, published a few books on it and keep banging that drum. But, I was busy with the other events on my backlog and the agreed topics I would cover.
That’s why I was very happy when “at the frontend” came up as a speaking opportunity and I submitted a talk about progressive enhancement. In this talk, I explain in detail that it is not about the JavaScript on or off case. I give out a lot of information and insight into why progressive enhancement is much more than that.
Just before my talk, I uploaded and tweeted my deck, in case people are interested. And then I get this tweet as an answer:
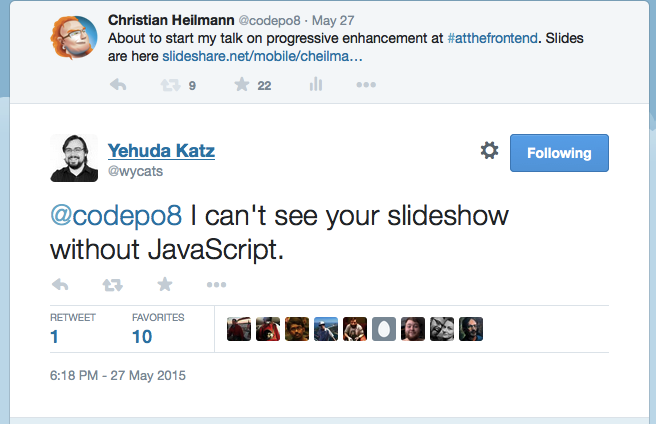
It made me angry – a few minutes before my talk. It made me angry because of a few things:
I posted the Zeldman article as an answer to the tweet and got reprimanded for not using any of the dozens available HTML slide deck versions that are progressively enhancing a document. Never mind that using keynote makes me more effective and helps me with re-use. I have betrayed the cause and should do better and feel bad for being such a terrible slide-creator. OK then. I shrugged this off before, and will again. But, this time, I was vulnerable and it hurt more.
I addition to me having lot of respect of what Yehuda achieved other people started favouriting the tweet. People I look up to, people I care about:
And that’s when my anger turned inward and the ugly voice of impostor syndrome reared its head. Here is what it told me:
I felt devastated, I doubted everything I did. When I delivered the talk I had so looked forward to and many people thanked me for my insights I felt even worse:
Eventually, I did what I always do and what all of you should: tell the impostor syndrome voice in your head to fuck off and let my voice of experience ratify what I am doing. I know my stuff, I did this for a long time and I have a great job working on excellent products.
I didn’t have any time to dwell more on this, as I went to the next conference. A wonderful place where every presentation was full of personal stories, warmth and advice how to be better in communicating with another. A place with people from 37 countries coming together to celebrate their love for a product that brings them closer. A place where people brought their families and children although it was a geek event.
I’m not looking for pity here. I am not harbouring a grudge against Yehuda and I don’t want anyone to reprimand him. My insecurities and how they manifest themselves when I am vulnerable and tired are my problem. There are many other people out there with worse issues and they are being attacked and taken advantage of and scared. These are the ones we need to help.
What I want though is to make you aware that everything you do online has an effect. And I want you to think next time before you post the “ha-ha you are wrong” tweet or favourite and amplify it. I want you to consider to:
Social media was meant to make media more social. Not to make it easier to attack and shut people up or tell them what you think they should do without asking about the how and why.
I’m happy. Help others to be the same.
|
|
Patrick Cloke: New Position in Cyber Security at Percipient Networks |
Note
If you’re hitting this from planet mozilla, this doesn’t mean I’m leaving the Mozilla Community since I’m not (nor was I ever) a Mozilla employee.
After working for The MITRE Corporation for a bit over four years, I left a few weeks ago to begin work at a cyber security start-up: Percipient Networks. Currently our main product is STRONGARM: an intelligent DNS blackhole. Usually DNS blackholes are set-up to block known bad domains by sending requests for those domains to a non-routable or localhost. STRONGARM redirects that traffic for identification and analysis. You could give it a try and let us know of any feedback you might have! Much of my involvement has been in the design and creation of the blackhole, including writing protocol parsers for both standard protocols and malware.
So far, I’ve been greatly enjoying my new position. There’s been a renewed focus on technical work, while being in a position to greatly influence both SRTONGARM and Percipient Networks. My average day involves many more activities now, including technical work: reverse engineering, reviewing/writing code, or reading RFCs; as well as other work: mentoring [1], user support, writing documentation, and putting desks together [2]. I’ve been thoroughly enjoying the varied activities!
Shifting software stacks has also been nice. I’m now writing mostly Python code, instead of mostly MATLAB, Java and C/C++ [3]. It has been great how many ready to use packages are available for Python! I’ve been very impressed with the ecosystem, and been encouraged to feed back into the open-source community, where appropriate.
| [1] | We currently have four interns, so there’s always some mentoring to do! |
| [2] | We got a delivery of 10 desks a couple of weeks ago and spent the evening putting them together. |
| [3] | I originally titled this post "xx days since my last semi-colon!", since that has gone from being a common key press of mine to a rare one. Although now I just get confused when switching between Python and JavaScript. Since semicolons are optional in both, but encouraged in JavaScript and discouraged in Python… |
http://patrick.cloke.us/posts/2015/05/30/new-position-in-cyber-security-at-percipient-networks/
|
|
Niko Matsakis: Virtual Structs Part 2: Classes strike back |
This is the second post summarizing my current thoughts about ideas related to “virtual structs”. In the last post, I described how, when coding C++, I find myself missing Rust’s enum type. In this post, I want to turn it around. I’m going to describe why the class model can be great, and something that’s actually kind of missing from Rust. In the next post, I’ll talk about how I think we can get the best of both worlds for Rust. As in the first post, I’m focusing here primarily on the data layout side of the equation; I’ll discuss virtual dispatch afterwards.
In the previous post, I described how one can setup a class hierarchy in C++ (or Java, Scala, etc) with a base class and one subclass for every variant:
1 2 3 | |
This winds up being very similar to a Rust enum:
1 2 3 4 | |
However, there are are some important differences. Chief among them is
that the Rust enum has a size equal to the size of its largest
variant, which means that Rust enums can be passed “by value” rather
than using a box. This winds up being absolutely crucial to Rust: it’s
what allows us to use Option<&T>, for example, as a zero-cost
nullable pointer. It’s what allows us to make arrays of enums (rather
than arrays of boxed enums). It’s what allows us to overwrite one enum
value with another, e.g. to change from None to Some(_). And so
forth.
There are a lot of use cases, however, where having a size equal to the largest variant is actually a handicap. Consider, for example, the way the rustc compiler represents Rust types (this is actually a cleaned up and simplified version of the real thing).
The type Ty represents a rust type:
1 2 | |
As you can see, it is in fact a reference to a TypeStructure (this
is called sty in the Rust compiler, which isn’t completely up to
date with modern Rust conventions). The lifetime 'tcx here
represents the lifetime of the arena in which we allocate all of our
type information. So when you see a type like &'tcx, it represents
interned information allocated in an arena. (As an aside, we
added the arena back before we even had lifetimes at all, and
used to use unsafe pointers here. The fact that we use proper
lifetimes here is thanks to the awesome eddyb and his super duper
safe-ty branch. What a guy.)
So, here is the first observation: in practice, we are already boxing
all the instances of TypeStructure (you may recall that the fact
that classes forced us to box was a downside before). We have to,
because types are recursively structured. In this case, the ‘box’ is
an arena allocation, but still the point remains that we always pass
types by reference. And, moreover, once we create a Ty, it is
immutable – we never switch a type from one variant to another.
The actual TypeStructure enum is defined something like this:
1 2 3 4 5 6 7 8 | |
You can see that, in addition to the types themselves, we also intern
a lot of the data in the variants themselves. For example, the
BareFn variant takes a &'tcx BareFnData<'tcx>. The reason we do
this is because otherwise the size of the TypeStructure type
balloons very quickly. This is because some variants, like BareFn,
have a lot of associated data (e.g., the ABI, the types of all the
arguments, etc). In contrast, types like structs or references have
relatively little associated data. Nonetheless, the size of the
TypeStructure type is determined by the largest variant, so it
doesn’t matter if all the variants are small but one: the enum is
still large. To fix this, Huon
spent quite a bit of time analyzing the size of each variant
and introducing indirection and interning to bring it down.
Consider what would have happened if we had used classes instead. In that case, the type structure might look like:
1 2 3 4 5 6 7 | |
In this case, whenever we allocated a Reference from the arena, we
would allocate precisely the amount of memory that a Reference
needs. Similarly, if we allocated a BareFn type, we’d use more
memory for that particular instance, but it wouldn’t affect the other
kinds of types. Nice.
The definition for Ty that I gave in the previous section was
actually somewhat simplified compared to what we really do in rustc.
The actual definition looks more like:
1 2 3 4 5 6 7 8 9 | |
As you can see, Ty is in fact a reference not to a TypeStructure
directly but to a struct wrapper, TypeData. This wrapper defines a
few fields that are common to all types, such as a unique integer id
and a set of flags. We could put those fields into the variants of
TypeStructure, but it’d be repetitive, annoying, and inefficient.
Nonetheless, introducing this wrapper struct feels a bit indirect. If we are using classes, it would be natural for these fields to live on the base class:
1 2 3 4 5 6 7 8 9 10 11 | |
In fact, we could go further. There are many variants that share common bits of data. For example, structs and enums are both just a kind of nominal type (“named” type). Almost always, in fact, we wish to treat them the same. So we could refine the hierarchy a bit to reflect this:
1 2 3 4 5 6 7 8 | |
Now code that wants to work uniformly on either a struct or enum could
just take a Nominal*.
Note that while it’s relatively easy in Rust to handle the case where
all variants have common fields, it’s a lot more awkward to handle a
case like Struct or Enum, where only some of the variants have
common fields.
Rust differs from purely OO languages in that it does not have special constructors. An instance of a struct in Rust is constructed by supplying values for all of its fields. One great thing about this approach is that “partially initialized” struct instances are never exposed. However, the Rust approach has a downside, particularly when we consider code where you have lots of variants with common fields: there is no way to write a fn that initializes only the common fields.
C++ and Java take a different approach to initialization based on constructors. The idea of a constructor is that you first allocate the complete structure you are going to create, and then execute a routine which fills in the fields. This approach to constructos has a lot of problems – some of which I’ll detail below – and I would not advocate for adding it to Rust. However, it does make it convenient to separately abstract over the initialization of base class fields from subclass fields:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Here, the constructor for TypeStructure initializes the
TypeStructure fields, and the Bool constructor initializes the
Bool fields. Imagine we were to add a field to TypeStructure that
is always 0, such as some sort of counter. We could do this without
changing any of the subclasses:
1 2 3 4 5 6 7 8 9 | |
If you have a lot of variants, being able to extract the common initialization code into a function of some kind is pretty important.
Now, I promised a critique of constructors, so here we go. The biggest
reason we do not have them in Rust is that constructors rely on
exposing a partially initialized this pointer. This raises the
question of what value the fields of that this pointer have before
the constructor finishes: in C++, the answer is just undefined
behavior. Java at least guarantees that everything is zeroed. But
since Rust lacks the idea of a “universal null” – which is an
important safety guarantee! – we don’t have such a convenient option.
And there are other weird things to consider: what happens if you call
a virtual function during the base type constructor, for example? (The
answer here again varies by language.)
So, I don’t want to add OO-style constructors to Rust, but I do want some way to pull out the initialization code for common fields into a subroutine that can be shared and reused. This is tricky.
Related to the last point, Rust currently lacks a way to “refine” the
type of an enum to indicate the set of variants that it might be. It
would be great to be able to say not just “this is a TypeStructure”,
but also things like “this is a TypeStructure that corresponds to
some nominal type (i.e., a struct or an enum), though I don’t know
precisely which kind”. As you’ve probably surmised, making each
variant its own type – as you would in the classes approach – gives
you a simple form of refinement types for free.
To see what I mean, consider the class hierarchy we built for TypeStructure:
1 2 3 4 5 6 7 8 | |
Now, I can pass around a TypeStructure* to indicate “any sort of
type”, or a Nominal* to indicate “a struct or an enum”, or a
BareFn* to mean “a bare fn type”, and so forth.
If we limit ourselves to single inheritance, that means one can construct an arbitrary tree of refinements. Certainly one can imagine wanting arbitrary refinements, though in my own investigations I have always found a tree to be sufficient. In C++ and Scala, of course, one can use multiple inheritance to create arbitrary refinements, and I think one can imagine doing something similar in Rust with traits.
As an aside, the right way to handle ‘datasort refinements’ has been a topic of discussion in Rust for some time; I’ve posted a different proposal in the past, and, somewhat amusingly, my very first post on this blog was on this topic as well. I personally find that building on a variant hierarchy, as above, is a very appealing solution to this problem, because it avoids introducing a “new concept” for refinements: it just leverages the same structure that is giving you common fields and letting you control layout.
So we’ve seen that there also advantages to the approach of using
subclasses to model variants. I showed this using the TypeStructure
example, but there are lots of cases where this arises. In the
compiler alone, I would say that the abstract syntax tree, the borrow
checker’s LoanPath, the memory categorization cmt types, and
probably a bunch of other cases would benefit from a more class-like
approach. Servo developers have long been requesting something more
class-like for use in the DOM. I feel quite confident that there are
many other crates at large that could similarly benefit.
Interestingly, Rust can gain a lot of the benefits of the subclass approach—namely, common fields and refinement types—just by making enum variants into types. There have been proposals along these lines before, and I think that’s an important ingredient for the final plan.
Perhaps the biggest difference between the two approaches is the size
of the “base type”. That is, in Rust’s current enum model, the base
type (TypeStructure) is the size of the maximal variant. In the
subclass model, the base class has an indeterminate size, and so must
be referenced by pointer. Neither of these are an “expressiveness”
distinction—we’ve seen that you can model anything in either
approach. But it has a big effect on how easy it is to write code.
One interesting question is whether we can concisely state conditions in which one would prefer to have “precise variant sizes” (class-like) vs “largest variant” (enum). I think the “precise sizes” approach is better when the following apply:
The fact that this is really a kind of efficiency tuning is an important insight. Hopefully our final design can make it relatively easy to change between the ‘maximal size’ and the ‘unknown size’ variants, since it may not be obvious from the get go which is better.
The next post will describe a scheme in which we could wed together enums and structs, gaining the advantages of both. I don’t plan to touch virtual dispatch yet, but intead just keep focusing on concrete types.
http://smallcultfollowing.com/babysteps/blog/2015/05/29/classes-strike-back/
|
|
Adam Munter: “The” Problem With “The” Perimeter |
“It’s secure, we transmit it over over SSL to a cluster behind a firewall in a restricted vlan.”

“But my PCI QSA said I had to do it this way to be compliant.”
This study by Gemalto discusses interesting survey results about perceptions of security perimeters such as that 64% of IT decision makers are looking to increase spend on perimeter security within the next 6 months and that 1/3 of those polled believe that unauthorized users have access to their information assets. It also revealed that only 8% of data affected by breaches was protected by encryption.
The perimeter is dead, long live the perimeter! The Jericho Forum started discussing “de-perimeterization” in 2003. If you hung out with pentesters, you already knew the the concept of ‘perimeter’ was built on shaky foundations. The growth of mobile, web API, and Internet of Things have only served to drive the point home. Yet, there is an entire industry of VC-funded product companies and armies of consultants who are still operating from the mental model of there being “a perimeter.”[0]
In discussion about “the perimeter,” it’s not the concept of “perimeter” that is most problematic, it’s the word “the.”
There is not only “a” perimeter, there are many possible logical perimeters, depending on the viewpoint of the actor you are considering. There are an unquantifiable number of theoretical overlaid perimeters based on the perspective of the actors you’re considering and their motivation, time and resources, what they can interact with or observe, what each of those components can interact with, including humans and their processes and automated data processing systems, authentication and authorization systems, all the software, libraries, and hardware dependencies going down to the firmware, the interaction between different systems that might interpret the same data to mean different things, and all execution paths, known and unknown, etc, etc.
The best CSOs know they are working on a problem that has no solution endpoint, and that thinking so isn’t even the right mindset or model. They know they are living in a world of resource scarcity and have a problem of potentially unlimited size and start by asset classification, threat modeling[1] and inventorying. Without that it’s impossible to even have a rough idea of the shape and size of the problem. They know that their actual perimeter isn’t what’s drawn inside an arbitrary theoretical border in a diagram. It’s based on the attackable surface area seen by an potential attacker, the value of the resource to the attacker, and the many possible paths that could be taken to reach it in a way that is useful to the attacker, not some imaginary mental model of logical border control.
You’ve deployed anti-malware and anti-APT products, Network and web app firewalls, endpoint protection and database encryption. Fully PCI compliant! All useful when applied with knowledge of what you’re protecting, how, from whom, and why. But if you don’t consider what you’re protecting and from whom as you design and build systems, not so useful. Imagine the following scenario: All of these perimeter protection technologies allow SSL traffic through port 443 to your webserver’s REST API listeners. The listening application has permission to access the encrypted database to read or modify data. And when the attacker finds a logic vulnerability that lets them access data which their user id should not be able to see, it looks looks like normal application traffic to your IDS/IPS and web app firewall. As requested, the application uses its credentials to retrieve decrypted data and present it to the user.
Footnotes
0. I’m already skeptical about the usefulness of studies that aggregate data in this way. N percent of respondents think that y% is the correct amount to spend on security technology categories A, B, C. Who cares? The increasing yoy numbers of attacks are the result of the distribution of knowledge during the time surveyed and in any event these numbers aggregate a huge variety of industries, business histories, risk tolerance, and other tastes and preferences.
1. Threat modeling doesn’t mean technical decomposition to identify possible attacks, that’s attack modeling, through the two are often confused, even in many books and articles. The “threat” is “customer data exposed to unauthorized individuals.” The business “risk” is “Data exposure would lead to headline risk(bad press) and loss of data worth approx $N dollars.” The technical risk is “Application was built using inline SQL queries and is vulnerable to SQL injection” and “Database is encrypted but the application’s credentials let it retrieve cleartext data” and probably a bunch of other things.
https://adammuntner.wordpress.com/2015/05/29/the-problem-with-the-perimeter/
|
|
Air Mozilla: World Wide Haxe Conference 2015 |
 Fifth International Conference in English about the Haxe programming language
Fifth International Conference in English about the Haxe programming language
|
|
Mozilla Open Policy & Advocacy Blog: Copyright reform in the European Union |
The European Union is considering broad reform of copyright regulations as part of a “Digital Single Market” reform agenda. Review of the current Copyright Directive, passed in 2001, began with a report by MEP Julia Reda. The European Parliament will vote on that report and a number of amendments this summer, and the process will continue with a legislative proposal from the European Commission in the autumn. Over the next few months we plan to add our voice to this debate; in some cases supporting existing ideas, in other cases raising new issues.
This post lays out some of the improvements we’d like to see in the EU’s copyright regime – to preserve and protect the Web, and to better advance the innovation and competition principles of the Mozilla Manifesto. Most of the objectives we identify are actively being discussed today as part of copyright reform. Our advocacy is intended to highlight these, and characterize positions on them. We also offer a proposed exception for interoperability to push the conversation in a slightly new direction. We believe an explicit exception for interoperability would directly advance the goal of promoting innovation and competition through copyright law.
Promoting innovation and competition
“The effectiveness of the Internet as a public resource depends upon interoperability (protocols, data formats, content), innovation and decentralized participation worldwide.” – Mozilla Manifesto Principle #6
Clarity, consistency, and new exceptions are needed to ensure that Europe’s new copyright system encourages innovation and competition instead of stifling it. If new and creative uses of copyrighted content can be shut down unconditionally, innovation suffers. If copyright is used to unduly restrict new businesses from adding value to existing data or software, competition suffers.
Open norm: Implement a new, general exception to copyright allowing actions which pass the 3-step test of the Berne Convention. That test says that any exception to copyright must be a special case, that it should not conflict with a normal exploitation of the work, and it should not unreasonably prejudice the legitimate interests of the author. The idea of an “open norm” is to capture a natural balance for innovation and competition, allowing the copyright holder to retain normal exclusionary rights but not exceptional restrictive capabilities with regards to potential future innovative or competing technologies.
Quotation: Expand existing protections for text quotations to all media and a wider range of uses. An exception of this type is fundamental not only for free expression and democratic dialogue, but also to promote innovation when the quoter is adding value through technology (such as a website which displays and combines excerpts of other pages to meet a new user need).
Interoperability: An exception for acts necessary to enable ongoing interoperability with an existing computer program, protocol, or data format. This would directly enable competition and technology innovation. Such interoperation is also necessary for full accessibility for the disabled (who are often not appropriately catered for in standard programs), and to allow citizens to benefit fully from other exceptions to copyright.
Not breaking the Internet
“The Internet is a global public resource that must remain open and accessible.” – Mozilla Manifesto Principle #2
The Internet has numerous technical and policy features which have combined, sometimes by happy coincidence, to make it what it is today. Clear legislation to preserve and protect these core capabilities would be a powerful assurance, and avoid creating chilling risk and uncertainty.
Hyperlinking: hyperlinking should not be considered as any form of “communication to a public”. A recent Court of Justice of the EU ruling stated that hyperlinking was generally legal, as it does not consist of communication to a “new public.” A stronger and more common-sense rule would be a legislative determination that linking, in and of itself, does not constitute communicating the linked content to a public under copyright law. The acts of communicating and making content available are done by the person who placed the content on the target server, not by those making links to content.
Robust protections for intermediaries: a requirement for due legal process before intermediaries are compelled to take down content. While it makes sense for content hosters to be asked to remove copyright-infringing material within their control, a mandatory requirement to do so should not be triggered by mere assertion, but only after appropriate legal process. The existing waiver for liability for intermediaries should thus be strengthened with an improved definition of “actual knowledge” that requires such process, and (relatedly) to allow minor, reasonable modifications to data (e.g. for network management) without loss of protection.
We look forward to working with European policymakers to build consensus on the best ways to protect and promote innovation and competition on the Internet.
Chris Riley
Gervase Markham
Jochai Ben-Avie
https://blog.mozilla.org/netpolicy/2015/05/28/copyright-reform-in-the-european-union/
|
|
The Servo Blog: This Week In Servo 33 |
In the past two weeks, we merged 73 pull requests.
We have a new member on our team. Please welcome Emily Dunham! Emily will be the DevOps engineer for both Servo and Rust. She has a post about her ideas regarding open infrastructure which is worth reading.
Josh discussed Servo and Rust at a programming talk show hosted by Alexander Putilin.
We have an impending upgrade of the SpiderMonkey Javascript engine by Michael Wu. This moves us from a very old spidermonkey to a recent-ish one. Naturally, the team is quite excited about the prospect of getting rid of all the old bugs and getting shiny new ones in their place.
rust-url using afl.rs, a fuzzer for Rust by Keegan. It’s had quite a few success stories so far, try it out on your own project!fetch modulebackground-origin, background-clip, padding-box and box-sizingRootedVec
This shows off the CSS direction property. RTL text still needs some work
|
|
Mike Conley: The Joy of Coding (Ep. 16): Wacky Morning DJ |
I’m on vacation this week, but the show must go on! So I pre-recorded a shorter episode of The Joy of Coding last Friday.
In this episode1, I focused on a tool I wrote that I alluded to in the last episode, which is a soundboard to use during Joy of Coding episodes.
I demo the tool, and then I explain how it works. After I finished the episode, I pushed to repository to GitHub, and you can check that out right here.
So I’ll see you next week with a full length episode! Take care!
http://mikeconley.ca/blog/2015/05/27/the-joy-of-coding-ep-16-wacky-morning-dj/
|
|
Air Mozilla: Kids' Vision - Mentorship Series |
 Mozilla hosts Kids Vision Bay Area Mentor Series
Mozilla hosts Kids Vision Bay Area Mentor Series
https://air.mozilla.org/kids-vision-mentorship-series-20150527/
|
|
Air Mozilla: Quality Team (QA) Public Meeting |
 This is the meeting where all the Mozilla quality teams meet, swap ideas, exchange notes on what is upcoming, and strategize around community building and...
This is the meeting where all the Mozilla quality teams meet, swap ideas, exchange notes on what is upcoming, and strategize around community building and...
https://air.mozilla.org/quality-team-qa-public-meeting-20150527/
|
|
Benjamin Smedberg: Yak Shaving |
Yak shaving tends to be looked down on. I don’t necessarily see it that way. It can be a way to pay down technical debt, or learn a new skill. In many ways I consider it a sign of broad engineering skill if somebody is capable of solving a multi-part problem.
It started so innocently. My team has been working on unifying the Firefox Health Report and Telemetry data collection systems, and there was a bug that I thought I could knock off pretty easily: “FHR data migration: org.mozilla.crashes”. Below are the roadblocks, mishaps, and sideshows that resulted, and I’m not even done yet:
nsCSubstringTuple str = str1 + str2; Fn(str);
Experiences like this are frustrating, but as long as it’s possible to keep the final goal in sight, fixing unrelated bugs along the way might be the best thing for everyone involved. It will certainly save context-switches from other experts to help out. And doing the Android build and debugging was a useful learning experience.
Perhaps, though, I’ll go back to my primary job of being a manager.
|
|
Air Mozilla: Security Services / MDN Update |
 An update on the roadmap and plan for Minion and some new MDN projects coming up in Q3 and the rest of 2015
An update on the roadmap and plan for Minion and some new MDN projects coming up in Q3 and the rest of 2015
|
|
Air Mozilla: Product Coordination Meeting |
 Duration: 10 minutes This is a weekly status meeting, every Wednesday, that helps coordinate the shipping of our products (across 4 release channels) in order...
Duration: 10 minutes This is a weekly status meeting, every Wednesday, that helps coordinate the shipping of our products (across 4 release channels) in order...
https://air.mozilla.org/product-coordination-meeting-20150527/
|
|
Armen Zambrano: Welcome adusca! |
Hi! I’m Alice. I studied Mathematics in college. I was doing a Master’s degree in Mathematical Economics before getting serious about programming.She is also a graduate from Hacker's School.

http://feedproxy.google.com/~r/armenzg_mozilla/~3/PV4N6y2VOos/welcome-adusca.html
|
|
Mark Surman: Mozilla Academy Strategy Update |
One of MoFo’s main goals for 2015 is to come up with an ambitious learning and community strategy. The codename for this is ‘Mozilla Academy’. As a way to get the process rolling, I wrote a long post in March outlining what we might include in that strategy. Since then, I’ve been putting together a team to dig into the strategy work formally.
This post is an update on that process in FAQ form. More substance and meat is coming in future posts. Also, there is lots of info on the wiki.
Our main goal is alignment: to get everyone working on Mozilla’s learning and leadership development programs pointed in the same direction. The three main places we need to align are:
At the end of the year, we will have a unified strategy that connects Mozilla’s learning and leadership development offerings (Webmaker, Hive, Open News, etc.). Right now, we do good work in these areas, but they’re a bit fragmented. We need to fix that by creating a coherent story and common approaches that will increase the impact these programs can have on the world.
That’s what we’re trying to figure out. At the very least, Mozilla Academy will be a clearly packaged and branded harmonization of Mozilla’s learning and leadership programs. People will be able to clearly understand what we’re doing and which parts are for them. Mozilla Academy may also include a common set of web literacy skills, curriculum format and learning approaches that we use across programs. We are also reviewing the possibility of a shared set of credentials or roles for people participating in Mozilla Academy.
Over the past few weeks, we’ve started to look at who we’re trying to serve with our existing programs (blog post on this soon). Using the ‘scale vs depth’ graph in the Mozilla Learning plan as a framework, we see three main audiences:
A big part of the strategy process is getting clear on these audiences. From there we can start to ask questions like: who can Mozilla best serve?; where can we have the most impact?; can people in one group serve or support people in another? Once we have the answers to these questions we can decide where to place our biggest bets (we need to do this!). And we can start raising more money to support our ambitious plans.
We want to accomplish a few things as a result of this process. A. A way to clearly communicate the ‘what and why’ of Mozilla’s learning and leadership efforts. B. A framework for designing new programs, adjusting program designs and fundraising for program growth. C. Common approaches and platforms we can use across programs. These things are important if we want Mozilla to stay in learning and leadership for the long haul, which we do.
There are a number of places where we do similar work in different ways. For example, Mozilla Clubs, Hive, Mozilla Developer Network, Open News and Mozilla Science Lab are all working on curriculum but do not yet have a shared curriculum model or repository. Similarly, Mozilla runs four fellowship programs but does not have a shared definition of a ‘Mozilla Fellow’. Common approaches could help here.
That’s not our goal. We like most of the work we’re doing now. As outlined in the 2015 Mozilla Learning Plan, our aim is to keep building on the strongest elements of our work and then connect these elements where it makes sense. We may modify, add or cut program elements in the future, but that’s not our main focus.
It’s pretty unlikely that we will use that name. Many people hate it. However, we needed a moniker to use during the strategy process. For better or for worse, that’s the one we chose.
We will have a basic alignment framework around ‘purpose, process and poetry’ by the end of June. We’ll work with the team at the Mozilla All Hands in Whistler. We will develop specific program designs, engage in a broad conversation and run experiments. By October, we will have an updated version of the Mozilla Learning plan, which will lay out our work for 2016+.
—
As indicated above, the aim of this post is to give a process update. There is much more info on the process, who’s running it and what all the pieces are in the Mozilla Learning strategy wiki FAQ. The wiki also has info on how to get involved. If you have additional questions, ask them here. I’ll respond to the comments and also add my answers to the wiki.
In terms of substance, I’m planning a number of posts in coming weeks on topics like the essence of web literacy, who our audiences are and how we think about learning. People leading Mozilla Academy working groups will also be posting on substantive topics like our evolving thinking around the web literacy map and fellows programs. And, of course, the wiki will be growing with substantive strategy documents covering many of the topics above.

https://commonspace.wordpress.com/2015/05/27/mozilla-academy-strategy-update/
|
|






