Aki Sasaki: mozharness turns 5 |
Five years ago today, I landed the first mozharness commit in my user repo. (github)
starting something, or wasting my time. Log.py + a scratch trunk_nightly.json
The project had three initial goals:
Multi-locale Fennec became a reality, and then we started adding projects to mozharness, one by one.
As of last July, mozharness was the client-side engine for the majority of Mozilla's CI and release infrastructure. I still see plenty of activity in bugmail and IRC these days. I'll be the first to point out its shortcomings, but I think overall it has been a success.
Happy birthday, mozharness!
|
|
Air Mozilla: Mozilla Weekly Project Meeting |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20150525/
|
|
Nick Desaulniers: Interpreter, Compiler, JIT |
Interpreters and compilers are interesting programs, themselves used to run or translate other programs, respectively. Those other programs that might be interpreted might be languages like JavaScript, Ruby, Python, PHP, and Perl. The other programs that might be compiled are C, C++, and to some extent Java and C#.
Taking the time to do translation to native machine code ahead of time can result in better performance at runtime, but an interpreter can get to work right away without spending any time translating. There happens to be a sweet spot somewhere in between interpretation and compilation that combines the best of both worlds. Such a technique is called Just In Time (JIT) compiling. While interpreting, compiling, and JIT’ing code might sound radically different, they’re actually strikingly similar. In this post, I hope to show how similar by comparing the code for an interpreter, a compiler, and a JIT compiler for the language Brainfuck in around 100 lines of C code each.
All of the code in the post is up on GitHub.
Brainfuck is an interesting, if hard to read, language. It only has eight
operations it can perform > < + - . , [ ], yet is Turing complete. There’s nothing really to
lex; each character is a token, and if the token is not one of the eight
operators, it’s ignored. There’s also not much of a grammar to parse; the
forward jumping and backwards jumping operators should be matched for well
formed input, but that’s about it. In this post, we’ll skip over validating
input assuming well formed input so we can focus on the interpretation/code
generation. You can read more about it on the
Wikipedia page,
which we’ll be using as a reference throughout.
A Brainfuck program operates on a 30,000 element byte array initialized to all zeros. It starts off with an instruction pointer, that initially points to the first element in the data array or “tape.” In C code for an interpreter that might look like:
1 2 3 4 5 | |
Then, since we’re performing an operation for each character in the Brainfuck source, we can have a for loop over every character with a nested switch statement containing case statements for each operator.
The first two operators, > and < increment and decrement the data pointer.
1 2 | |
One thing that could be bad is that because the interpreter is written in C and we’re representing the tape as an array but we’re not validating our inputs, there’s potential for stack buffer overrun since we’re not performing bounds checks. Again, punting and assuming well formed input to keep the code and the point more precise.
Next up are the + and - operators, used for incrementing and decrementing
the cell pointed to by the data pointer by one.
1 2 | |
The operators . and , provide Brainfuck’s only means of input or output, by
writing the value pointed to by the instruction pointer to stdout as an ASCII
value, or reading one byte from stdin as an ASCII value and writing it to the
cell pointed to by the instruction pointer.
1 2 | |
Finally, our looping constructs, [ and ]. From the definition on Wikipedia
for [: if the byte at the data pointer is zero, then instead of moving the
instruction pointer forward to the next command, jump it forward to the command
after the matching ] command and for ]: if the byte at the data pointer is
nonzero, then instead of moving the instruction pointer forward to the next
command, jump it back to the command after the matching [ command.
I interpret that as:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Where the variable loop keeps track of open brackets for which we’ve not seen
a matching close bracket, aka our nested depth.
So we can see the interpreter is quite basic, in around 50 SLOC were able to read a byte, and immediately perform an action based on the operator. How we perform that operation might not be the fastest though.
How about if we want to compile the Brainfuck source code to native machine code? Well, we need to know a little bit about our host machine’s Instruction Set Architecture (ISA) and Application Binary Interface (ABI). The rest of the code in this post will not be as portable as the above C code, since it assumes an x86-64 ISA and UNIX ABI. Now would be a good time to take a detour and learn more about writing assembly for x86-64. The interpreter is even portable enough to build with Emscripten and run in a browser!
For our compiler, we’ll iterate over every character in the source file again, switching on the recognized operator. This time, instead of performing an action right away, we’ll print assembly instructions to stdout. Doing so requires running the compiler on an input file, redirecting stdout to a file, then running the system assembler and linker on that file. We’ll stick with just compiling and not assembling (though it’s not too difficult), and linking (for now).
First, we need to print a prologue for our compiled code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
During the linking phase, we’ll make sure to link in libc so we can call
memset. What we’re doing is backing up callee saved registers we’ll be using,
stack allocating the tape, realigning the stack (x86-64 ABI point #1), copying
the address of the only item on the stack into a register for our first
argument, setting the second argument to the constant 0, the third arg to
30000, then calling memset. Finally, we use the callee saved register %r12
as our instruction pointer, which is the address into a value on the stack.
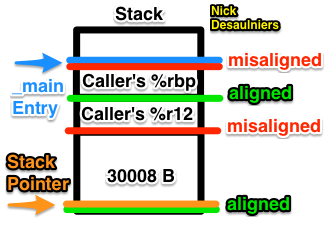
We can expect the call to memset to result in a segfault if simply subtract just 30000B, and not realign for the 2 registers (64 b each, 8 B each) we pushed on the stack. The first pushed register aligns the stack on a 16 B boundary, the second misaligns it; that’s why we allocate an additional 8 B on the stack (x86-64 ABI point #1). The stack is mis-aligned upon function entry in x86-64. 30000 is a multiple of 16.
Moving the instruction pointer (>, <) and modifying the pointed to value
(+, -) are straight-forward:
1 2 3 4 5 6 7 8 9 10 11 12 | |
For output, ., we need to copy the pointed to byte into the register for the
first argument to putchar. We
explicitly zero out the register before calling putchar, since it takes an int
(32 b), but we’re only copying a char (8 b) (Look up C’s type promotion rules for more info). x86-64 has an instruction that does both, movzXX, Where the first X is the source size (b, w) and the second is the destination size (w, l, q). Thus movzbl moves a byte (8 b) into a double word (32 b). %rdi and %edi are the same register, but %rdi is the full
64 b register, while %edi is the lowest (or least significant) 32 b.
1 2 3 4 5 6 | |
Input (,) is easy; call getchar, move the resulting lowest byte into the cell
pointed to by the instruction pointer. %al is the lowest 8 b of the 64 b %rax register.
1 2 3 4 | |
As usual, the looping constructs ([ & ]) are much more work. We have to
match up jumps to matching labels, but for an assembly program, labels must be
unique. One way we can solve for this is whenever we encounter an opening
brace, push a monotonically increasing number that represents the numbers of
opening brackets we’ve seen so far onto a stack like data structure. Then, we
do our comparison and jump to what will be the label that should be produced by
the matching close label. Next, we insert our starting label, and finally
increment the number of brackets seen.
1 2 3 4 5 6 | |
For close brackets, we pop the number of brackets seen (or rather, number of pending open brackets which we have yet to see a matching close bracket) off of the stack, do our comparison, jump to the matching start label, and finally place our end label.
1 2 3 4 5 6 | |
So for sequential loops ([][]) we can expect the relevant assembly to look
like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
and for nested loops ([[]]), we can expect assembly like the following (note
the difference in the order of numbered start and end labels):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Finally, we need an epilogue to clean up the stack and callee saved registers after ourselves.
1 2 3 4 5 6 | |
The compiler is a pain when modifying and running a Brainfuck program; it takes a couple extra commands to compile the Brainfuck program to assembly, assemble the assembly into an object file, link it into an executable, and run it whereas with the interpreter we can just run it. The trade off is that the compiled version is quite a bit faster. How much faster? Let’s save that for later.
Wouldn’t it be nice if there was a translation & execution technique that didn’t force us to compile our code every time we changed it and wanted to run it, but also performance closer to that of compiled code? That’s where a JIT compiler comes in!
For the basics of JITing code, make sure you read my previous article on the basics of JITing code in C. We’re going to follow the same technique of creating executable memory, copying bytes into that memory, casting it to a function pointer, then calling it. Just like the interpreter and the compiler, we’re going to do a unique action for each recognized token. What’s different is that for each operator, we’re going to push opcodes into a dynamic array, that way it can grow based on our sequential reading of input and will simplify our calculation of relative offsets for branching operations.
The other special thing we’re going to do it that we’re going to pass the address of our libc functions (memset, putchar, and getchar) into our JIT’ed function at runtime. This avoids those kooky stub functions you might see in a disassembled executable. That means we’ll be invoking our JIT’ed function like:
1 2 3 4 5 | |
Where mem is our mmap’ed executable memory with our opcodes copied into it, and the typedef’s are for the respective function signatures for our function pointers we’ll be passing to our JIT’ed code. We’re kind of getting ahead of ourselves, but knowing how we will invoke the dynamically created executable code will give us an idea of how the code itself will work.
The prologue is quite a bit involved, so we’ll take it step at a time. First, we have the usual prologue:
1 2 3 | |
Then we want to back up our callee saved registers that we’ll be using. Expect horrific and difficult to debug bugs if you forget to do this.
1 2 3 | |
At this point, %rdi will contain the address of memset, %rsi will contain the address of putchar, and %rdx will contain the address of getchar, see x86-64 ABI point #2. We want to store these in callee saved registers before calling any of them, else they may clobber %rdi, %rsi, or %rdx since they’re not “callee saved,” rather “call clobbered.” See x86-64 ABI point #4.
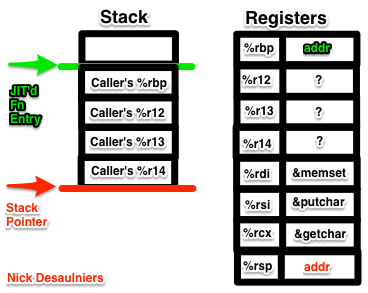
1 2 3 | |
At this point, %r12 will contain the address of memset, %r13 will contain the address of putchar, and %r14 will contain the address of getchar.
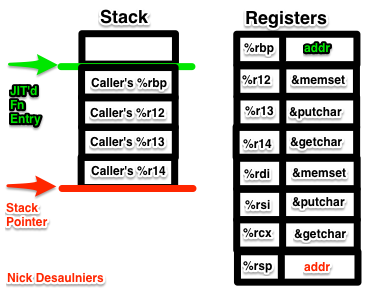
Next up is allocating 30008 B on the stack:
1
| |
This is our first hint at how numbers, whose value is larger than the maximum
representable value in a byte, are represented on x86-64. Where in this
instruction is the value 30008? The answer is the 4 byte sequence
0x38, 0x75, 0x00, 0x00. The x86-64 architecture is “Little Endian,” which
means that the least significant bit (LSB) is first and the most significant
bit (MSB) is last. When humans do math, they typically represent numbers the
other way, or “Big Endian.” Thus we write decimal ten as “10” and not “01.”
So that means that 0x38, 0x75, 0x00, 0x00 in Little Endian is
0x00, 0x00, 0x75, 0x38 in Big Endian, which then is
7*16^3+5*16^2+3*16^1+8*16^0
which is 30008 in decimal, the amount of bytes we want to subtract from the
stack. We’re allocating an additional 8 B on the stack for alignment
requirements, similar to the compiler. By pushing even numbers of 64 b
registers, we need to realign our stack pointer.
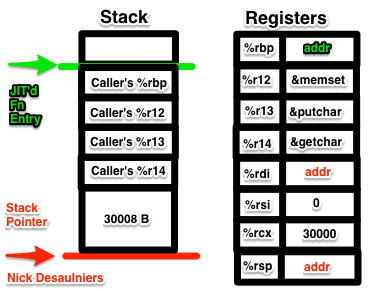
Next in the prologue, we set up and call memset:
1 2 3 4 5 6 7 8 | |
After invoking memset, %rdi, %rsi, & %rcx will contain garbage values since they are “call clobbered” registers. At this point we no longer need memset, so we now use %r12 as our instruction pointer. %rsp will point to the top (technically the bottom) of the stack, which is the beginning of our memset’ed tape. That’s the end of our prologue.
1 2 | |
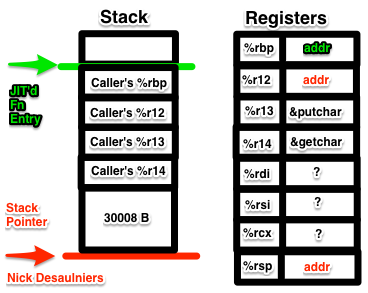
We can then push our prologue into our dynamic array implementation:
1
| |
Now we iterate over our Brainfuck program and switch on the operations again. For pointer increment and decrement, we just nudge %r12.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
That extra fun block in the switch statement is because in C/C++, we can’t define variables in the branches of switch statements.
Pointer deref then increment/decrement are equally uninspiring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
I/O might be interesting, but in x86-64 we have an opcode for calling the function at the end of a pointer. %r13 contains the address of putchar while %r14 contains the address of getchar.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Now with our looping constructs, we get to the fun part. With the compiler, we deferred the concept of “relocation” to the assembler. We simply emitted labels, that the assembler turned into relative offsets (jumps by values relative to the last byte in the jump instruction). We’ve found ourselves in a Catch-22 though: how many bytes forward do we jump to the matching close bracket that we haven’t seen yet?
Normally, an assembler might have a data structure known as a “relocation table.” It keeps track of the first byte after a label and jumps, rewriting jumps-to-labels (which aren’t kept around in the resulting binary executable) to relative jumps. Spidermonkey, Firefox’s JavaScript Virtual Machine has two classes for this, MacroAssembler and Label. Spidermonkey embeds a linked list in the opcodes it generates for jumps with which it’s yet to see a label for. Once it finds the label, it walks the linked list (which itself is embedded in the emitted instruction stream) patching up these locations as it goes.
For Brainfuck, we don’t have to anything quite as fancy since each label only ends up having one jump site. Instead, we can use a stack of integers that are offsets into our dynamic array, and do the relocation once we know where exactly we’re jumping to.
1 2 3 4 5 6 7 8 9 10 11 | |
First we push the compare and jump opcodes, but for now we leave the relative offset blank (four zero bytes). We will come back and patch it up later. Then, we push the current length of dynamic array, which just so happens to be the offset into the instruction stream of the next instruction.
All of the relocation magic happens in the case for the closing bracket.
1 2 3 4 5 6 7 8 9 10 | |
First, we push our comparison and jump instructions into the dynamic array. We should know the relative offset we need to jump back to at this point, and thus don’t need to push four empty bytes, but it makes the following math a little simpler, as were not done yet with this case.
1 2 3 4 | |
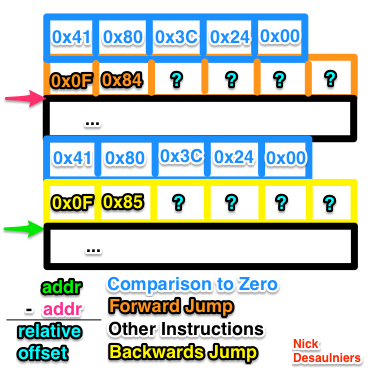
We pop the matching offset into the dynamic array (from the matching open bracket), and calculate the difference from the current size of the instruction stream to the matching offset to get our relative offset. What’s interesting is that this offset is equal in magnitude for the forward and backwards jumps that we now need to patch up. We simply go back in our instruction stream 4 B, and write that relative offset negated as a 32 b LE number (patching our backwards jump), then go back to the site of our forward jump minus 4 B and write that relative offset as a 32 b LE number (patching our forwards jump).
1 2 3 4 | |
Thus, when writing a JIT, one must worry about manual relocation. From the Intel 64 and IA-32 Architectures Software Developer’s Manual Volume 2 (2A, 2B & 2C): Instruction Set Reference, A-Z “A relative offset (rel8, rel16, or rel32) is generally specified as a label in assembly code, but at the machine code level, it is encoded as a signed, 8-bit or 32-bit immediate value, which is added to the instruction pointer.”
The last thing we push onto our instruction stream is clean up code in the epilogue.
1 2 3 4 5 6 7 8 9 10 | |
A dynamic array of bytes isn’t really useful, so we need to create executable memory the size of the current instruction stream and copy all of the machine opcodes into it, cast it to a function pointer, call it, and finally clean up:
1 2 3 4 5 6 7 | |
Note: we could have used the instruction stream rewinding technique to move the address of memset, putchar, and getchar as 64 b immediate values into %r12-%r14, which would have simplified our JIT’d function’s type signature.
Compile that, and we now have a function that will JIT compile and execute Brainfuck in roughly 141 SLOC. And, we can make changes to our Brainfuck program and not have to recompile it like we did with the Brainfuck compiler.
Hopefully it’s becoming apparent how similar an interpreter, compiler, and JIT
behave. In the interpreter, we immediately execute some operation. In the
compiler, we emit the equivalent text based assembly instructions corresponding
to what the higher level language might get translated to in the interpreter.
In the JIT, we emit the binary opcodes into executable memory and manually
perform relocation, where the binary opcodes are equivalent to the text based
assembly we might emit in the compiler. A production ready JIT would probably have macros for each operation in the JIT would perform, so the code would look more like the compiler rather than raw arrays of bytes (though the preprocessor would translate those macros into such). The entire process is basically disassembling C code with gobjdump -S -M suffix a.out, and punching in hex like one would a Gameshark.
Compare pointer incrementing from the three:
Interpreter:
1
| |
Compiler:
1 2 3 | |
JIT:
1 2 3 4 5 6 7 8 | |
Or compare the full sources of the the interpreter, the compiler, and the JIT. Each at ~100 lines of code should be fairly easy to digest.
Let’s now examine the performance of these three. One of the longer running Brainfuck programs I can find is one that prints the Mandelbrot set as ASCII art to stdout.
Running the UNIX command time on the interpreter, compiled
result, and the JIT, we should expect numbers similar to:
1 2 3 4 5 6 7 8 | |
The interpreter is an order of magnitude slower than the compiled result or run of the JIT. Then again, the interpreter isn’t able to jump back and forth as efficiently as the compiler or JIT, since it scans back and forth for matching brackets O(N), while the other two can jump to where they need to go in a few instructions O(1). A production interpreter would probably translate the higher level language to a byte code, and thus be able to calculate the offsets used for jumps directly, rather than scanning back and forth.
The interpreter bounces back and forth between looking up an operation, then doing something based on the operation, then lookup, etc.. The compiler and JIT preform the translation first, then the execution, not interleaving the two.
The compiled result is the fastest, as expected, since it doesn’t have the overhead the JIT does of having to read the input file or build up the instructions to execute at runtime. The compiler has read and translated the input file ahead of time.
What if we take into account the time it takes to compile the source code, and run it?
1 2 | |
Including the time it takes to compile the code then run it, the compiled results are now slightly slower than the JIT (though I bet the multiple processes we start up are suspect), but with the JIT we pay the price to compile each and every time we run our code. With the compiler, we pay that tax once. When compilation time is cheap, as is the case with our Brainfuck compiler & JIT, it makes sense to prefer the JIT; it allows us to quickly make changes to our code and re-run it. When compilation is expensive, we might only want to pay the compilation tax once, especially if we plan on running the program repeatedly.
JIT’s are neat but compared to compilers can be more complex to implement. They also repeatedly re-parse input files and re-build instruction streams at runtime. Where they can shine is bridging the gap for dynamically typed languages where the runtime itself is much more dynamic, and thus harder (if not, impossible) to optimize ahead of time. Being able to jump into JIT’d native code from an interpreter and back gives you the best of both (interpreted and compiled) worlds.
http://nickdesaulniers.github.io/blog/2015/05/25/interpreter-compiler-jit/
|
|
Nathan Froyd: white space as unused advertising space |
I picked up Matthew Crawford’s The World Outside Your Head this weekend. The introduction, subtitled “Attention as a Cultural Problem”, opens with these words:
The idea of writing this book gained strength one day when I swiped my bank card to pay for groceries. I watched the screen intently, waiting for it to prompt me to do the next step. During the following seconds it became clear that some genius had realized that a person in this situation is a captive audience. During those intervals between swiping my card, confirming the amount, and entering my PIN, I was shown advertisements. The intervals themselves, which I had previously assumed were a mere artifact of the communication technology, now seemed to be something more deliberately calibrated. These haltings now served somebody’s interest.
I have had a similar experience: the gas station down the road from me has begun playing loud “news media” clips on the digital display of the gas pump while your car is being refueled, cleverly exploiting the driver as a captive audience. Despite this gas station being somewhat closer to my house and cheaper than the alternatives, I have not been back since I discovered this practice.
Crawford continues, describing how a recent airline trip bombarded him with advertisements in “unused” (“unmonetized”?) spaces: on the fold-down tray table in his airplane seat, the moving handrail on the escalator in the airport, on the key card (!) for his hotel room. The logic of filling up unused space reaches even to airport security:
But in the last few years, I have found I have to be careful at the far end of [going through airport security], because the bottoms of the gray trays that you place your items in for X-ray screening are now papered with advertisements, and their visual clutter makes it very easy to miss a pinky-sized flash memory stick against a picture of fanned-out L’Or'eal lipstick colors…
Somehow L’Or'eal has the Transportation Security Administration on its side. Who made the decision to pimp out the security trays with these advertisements? The answer, of course, is that Nobody decided on behalf of the public. Someone made a suggestion, and Nobody responded in the only way that seemed reasonable: here is an “inefficient” use of space that could instead be used to “inform” the public of “opportunities.” Justifications of this flavor are so much a part of the taken-for-granted field of public discourse that they may override our immediate experience and render it unintelligible to us. Our annoyance dissipates into vague impotence because we have no public language in which to articulate it, and we search instead for a diagnosis of ourselves: Why am I so angry? It may be time to adjust the meds.
Reading the introduction seemed especially pertinent to me in light of last week’s announcement about Suggested Tiles. The snippets in about:home featuring Mozilla properties or efforts, or even co-opting tiles on about:newtab for similar purposes feels qualitatively different than using those same tiles for advertisements from third parties bound only to Mozilla through the exchange of money. I have at least consented to the former, I think, by downloading Firefox and participating in that ecosystem, similar to how Chrome might ask you to sign into your Google account when the browser opens. The same logic is decidedly not true in the advertising case.
People’s attention is a scarce resource. We should be treating it as such in Firefox, not by “informing” them of “opportunities” from third parties unrelated to Mozilla’s mission, even if we act with the utmost concern for their privacy. Like the gas station near my house, people are not going to come to Firefox because it shows them advertisements in “inefficiently” used space. At best, they will tolerate the advertisements (maybe even taking steps to turn them off); at worst, they’ll use a different web browser and they won’t come back.
https://blog.mozilla.org/nfroyd/2015/05/25/white-space-as-unused-advertising-space/
|
|
Mike Hommey: Dogfooding Firefox GTK+3 |
Thanks to Lee Salzman, the state of GTK+3 support in Firefox got better. Unit tests went from looking like this:

To looking like this:

There’s obviously some work left to make those look even better, but we’ve come a long way.
Ludovic Hirlimann recently asked if there were builds to dogfood and that prompted me to attempt making the builds from the elm branch auto-update. Which, after several attempts, I managed to get working with gross (but small) hacks of the build system.
So here we are, if you want to dogfood GTK+3 Firefox, here is what you can do::
about:config and create the following string preferences (right-click, New, String):
app.update.url.override” with the value “https://ftp.mozilla.org/pub/mozilla.org/firefox/tinderbox-builds/elm-linux/latest/update.xml” for 32-bits builds, or “https://ftp.mozilla.org/pub/mozilla.org/firefox/tinderbox-builds/elm-linux64/latest/update.xml” for 64-bits builds,app.update.certs.3.issuerName” with the value “CN=DigiCert SHA2 Secure Server CA,O=DigiCert Inc,C=US“,app.update.certs.3.commonName” with the value “ftp.mozilla.org“.Alternatively, you can just download and install the elm builds directly (32-bits, 64-bits).
If for some reason, you want to go back to a normal GTK+2 nightly, go to about:config, find the “app.update.url.override” preference and set it to an empty value. Triggering the update from “About Nightly” won’t, however, work until the next nightly is available, so give it a day.
As mentioned in my previous post about GTK+3, if you’re interested in making those builds work better, you are welcome to help:
|
|
John O'Duinn: “RelEng as a Force Multiplier” at RelEng Conf 2015 |
Last week, I was honored to give the closing talk at RelEng Conf 2015, here in Florence, Italy.
I’ve used this same title in previous presentations; the mindset it portrays still feels important to me. Every time I give this presentation, I am invigorated by the enthusiastic response, and work to improve further, so I re-write it again. This most recent presentation at RelEngConf2015 was almost a complete re-write; only a couple of slides remain from the original. Click on the thumbnail to get the slides 
The main focus of this talk was:
1) Release Engineers build pipelines, while developers build products. When done correctly, this pipeline makes the entire company more effective. By contrast, done incorrectly, broken pipelines will hamper a company – sometimes fatally. This different perspective and career focus is important to keep in mind when hiring to solve company infrastructure problems.
2) Release Engineers routinely talk and listen with developers and testers, typically about the current project-in-progress. Thats good – we obviously need to keep doing that. However, I believe that Release Engineers also need to spend time talking to and listening with people who have a very different perspective – people who care about the fate of the *company*, as opposed to a specific project, and have a very different longer-term perspective. Typically, these people have titles like Founder/CxO/VP but every company has different cultural leaders and uses slightly different titles, so some detective work is in order. The important point here is to talk with people who care about the fate of the company, as opposed to the fate of a specific project – and keep that perspective in mind when building a pipeline that helps *all* your customers.
3) To illustrate these points, I then went into detail on some technical, and culture change, projects which highlighted the strategic importance of those points.
 As usual, it was a lively presentation with lots of active Q+A during the talk, as well as the following break-out session. Afterwards, 25 of us managed to find a great dinner (without a reservation!) in a nearby restaurant where the geek talk continued at full force for several more hours.
As usual, it was a lively presentation with lots of active Q+A during the talk, as well as the following break-out session. Afterwards, 25 of us managed to find a great dinner (without a reservation!) in a nearby restaurant where the geek talk continued at full force for several more hours.
All in all, a wonderful day.
It was also great to meet up with catlee in person again. We both had lots to catch up on, in work and in life.
Bram Adams, Christian, Foutse, Kim and Stephany Bellomo all deserve ongoing credit for continuing to make this unusual and very educational conference come to life, as well as for curating the openness that is the hallmark of this event. As usual, I love the mix of academic researchers and industry practitioners, with talks alternating between industry and academic speakers all day long. The different perspectives, and the eagerness of everyone to have fully honest “what worked, what didnt work” conversations with others from very different backgrounds is truly refreshing… and was very informative for everyone. I’m already looking forward to the next RelEngConf!!
http://oduinn.com/blog/2015/05/24/releng-as-a-force-multiplier-releng-conf-2015/
|
|
Christian Heilmann: The Ryanair approach to progressive enhancement |
I fly – a lot. I spend more time in airports, in the air, hotel rooms and conferences than at home. As I am a natural recording and analysing device, I take in a lot of things on my travels. People at airports are stressed, confused, don’t pay attention to things, eat badly and are not always feeling good. They are tired, they feel rushed and they want just to get things over with and get where they want to go. Others – those new to travel – are overly excited about everything and want to things right, making mistakes because they are too eager. Exactly what users on the web are like. I found that companies who use technology for the benefit of their users are those people love and support. That’s what progressive enhancement means to me. But let’s start at the beginning.
Getting somewhere by plane is pretty simple. You buy a ticket and you get a booking confirmation number, an airport you leave from, a time and a destination airport. To claim all this and get on the flight, you also need to prove that you are you. You can do this in domestic flights with the credit card you booked the flight with, a driving license or your passport. For international travels, the latter is always the safest option.
The main thing you have to fear about flying is delays that make you miss your plane. Delays can be natural problems, technical failures with the plane or the airport. They could also be issues with air traffic control. It is busy up in the blue yonder, as this gorgeous visualisation shows. Another big issue is getting to the airport in time as all kind of traffic problems can delay you.
You can’t do much about that – you just have to take it in stride. I plan 3 hours from my house to sitting on the plane.
One thing you want to avoid is queues. The longer the queue, the more likely you are to miss your plane. Every single person in that queue and their problems become yours.
Airlines understand that and over the years have put improvements in place that make it easier for you to get up in the air.
In essence, what you need to get in exchange of your information is a boarding pass. It is the proof that all is well and you are good to go.
The fool-proof way of doing that is having check-in counters. These have people with computers and you go there, tell them your information and you get your boarding pass. You can also drop off your luggage and you get up-to-date information from them on delays, gates and – if you are lucky – upgrades. Be nice to them – they have a tough job and they can mess up your travels if you give them a tough time.
Manned check-in counters are also the most time consuming and expensive way. They also don’t scale to hundreds of customers – hence the queues.

The first step to improve this was self-check-in terminals. If you allow people to type in their booking confirmation and scan their passport, a machine can issue the boarding pass. You can then have a special check-in counter only for those who need to drop off luggage. Those without luggage, move on to the next level without having to interact with a person behind the counter and take up a space in the queue. Those who don’t know how to use the machine or who forgot some information or encounter a technical failure can still go to a manned check-in counter.

Nowadays this is even better. We have online check-in that allows us to check in at home and print out our own boarding passes. As printer ink is expensive and boarding passes tend to be A4 and littered with ads, you can also use apps on smartphones.
Of course, every airline has their own app and all work different and – at times – in mysterious ways. But let’s not dwell on that.
Apps are incredible – they show you when your flight happens, delays, and you don’t need to print out anything. You get this uplifting feeling that you’re part of a technical elite and that you know your stuff.
Of course, as soon as you go high-tech, things also break:
Despite all that, you are still safe. When things go wrong, there are the fallbacks of the machines or the manned counter to go back to.
This, is progressive enhancement.
You make it easier for users who are frequently using your product. That’s why I get access to fast-track security lanes and lounges. I get a reward for saving the company time and money and allowing them to cater to more users.
You almost never meet people in these lounges who have bad things to say about the airline. Of course they are stressed – everybody at an airport is – but there is a trust in the company they chose and good experiences means having a good relationship. You can check in 24 hours before your flight and all you bring to the airport is your phone and your passport. If you fail to do so, or you feel like it, you can still go to the counter. You feel like James Bond or Tony Stark.
Then there is Ryanair and other budget airlines. You will be hard pushed to find anyone who loves them. The mood ranges from “meh, it is convenient, as I can afford it” to “necessary evil” and ends in “spawn of satan and bane of my existence”. Why is that?
Well, budget airlines try to save and make money wherever they can. They have less ground staff and check-in counters. They have online check-in and expect you to bring a printout of your boarding pass. They have draconic measures when it comes to the size and weight of your luggage. They are less concerned when it comes to your available space on the plane or happy to charge extra for it. Instead of using a service it feels like you have to game it. You need to be on your toes, or you pay extra. You feel like you have to work for what you already paid for and you feel not empowered, but stupid when you forgot to have one thing the company requests you to have – things others don’t bother with.
They also have apps. And pretty ones at that. When everything goes right, these are cool. Yet, these come with silly limitations. These companies chose to offer apps so they can cut down on ground staff and less check-in counters. They are not an improvement or convenience, but become a necessity.
The other day I was in Italy flying to Germany with Ryanair. I have no Italian data connection and roaming is expensive. I also had no wireless in the hotel or the convention I was at. Ryanair allows me to check-in online with a browser 24 hours before the flight. I couldn’t. When you use the app is even more draconic: you can only check in two hours before the flight. If you remember, I add a my 3 hour trip cushion to the airport to my travels. Which means I am on the road which in London means I am underground without a connection when I need to check in.
I grumpily queued up at the hot, packed airport in a massive queue full of screaming kids and drunk tourists. Others were people standing over half-unpacked luggage as their passports were missing. When I arrived at the counter, the clerk told me that as I needed to print out my boarding pass or check in with the app. As I failed to do so, I now need to pay 45 Euro for my boarding pass if he were to print it for me.
This was almost the price of the ticket. I told him that because of the 2 hour period and me not having connectivity, I couldn’t do that. All I got was “this is our policy”.
I ground my teeth, and connected my roaming data on my phone, trying to check in with the app. Instead of asking for my name and booking confirmation it asked for all kind of extra information. I guess the reason was that I hadn’t booked the ticket but someone had booked it for me. The necessary information included entering a lot of dates with a confusing date picker. In the end, I was one minute late and the app told me there is no way I can check in without going to a counter. I queued up again, and the clerk told me that I can not pay at his counter. Instead I needed to go to the other side of the airport to the ticketing counter, pay there and bring back a printout that I did pay. Of course, there was another queue. Coming back, I ended up in yet another queue, this time for another flight. I barely made it to my plane.
Guess what my attitude towards future business with this airline is. Right – they have a bleak future with me.
And this is when you use progressive enhancement the wrong way. Yes, an app is an improvement over queuing up or printing out. But you shouldn’t add arbitrary rules or punish those who can’t use it. Progressive enhancement is for the benefit of the end user. We also benefit a lot from it. Unlike the physical world of airport we can enhance without extra overhead. We don’t need to hire extra ground staff or put up hardware to read passports. All we need to do is to analyse:
The latter is the main thing: you don’t rely on any of those. Instead you test if they can be applied and apply them as needed.
Progressive enhancement is not about adding more work to your product. It is about protecting the main use case of your product and then enhance it with new functionality as it becomes available. Google is a great example of that. Turn off JavaScript and you still get a form to enter information in and you get a search result page with ads on it. This is how you find things and Google makes money. Anything else they added over time makes it more convenient for you but is not needed. It also offers them more opportunities to show you more ads and point at other services.
Use progressive enhancement as a means to reward your users. Don’t expect them to do things for you just to use your product. If the tools you use means your users have to have a “modern” browser and load a lot of script you share your problems with them. You can only get away with that if you offer them a cheaper version of what others offer but that’s a risky race to take part in. You can win their current business, but never their hearts or support. You become a necessary evil, not something they tell others about.
http://christianheilmann.com/2015/05/24/the-ryanair-approach-to-progressive-enhancement/
|
|
Mozilla Release Management Team: Firefox 38.0.5b3 to 38.0.5 RC |
Ready for the release! This RC was mainly about fixing the last pocket bugs and some stability fixes.
| Extension | Occurrences |
| html | 13 |
| cpp | 6 |
| js | 3 |
| sh | 2 |
| properties | 2 |
| ini | 2 |
| py | 1 |
| mn | 1 |
| json | 1 |
| jsm | 1 |
| java | 1 |
| h | 1 |
| Module | Occurrences |
| dom | 16 |
| mobile | 15 |
| browser | 7 |
| toolkit | 2 |
| testing | 2 |
| js | 2 |
| gfx | 2 |
| layout | 1 |
List of changesets:
| Jean-Yves Avenard | Bug 1154881 - Disable test. r=karlt, a=test-only - 573c47bc1bf2 |
| Nick Alexander | Bug 1151619 - Add Adjust SDK license. r=gerv, a=NPOTB - 62e7fffff542 |
| Ryan VanderMeulen | Bug 1164866 - Bump mozharness.json to rev 6f91445be987. a=test-only - f2ef3e1dadaf |
| Jared Wein | Bug 1166240 - Add pocket.svg to aero section of toolkit's windows/jar.mn. r=Gijs, a=gavin - 58d8fb9fc5e3 |
| James Willcox | Bug 1163841 - Always call eglInitialize(), but kill the preloading hack (which was crashing before). r=nchen, a=sledru - daa1f205525a |
| Benjamin Chen | Bug 1149842 - Release the mutex for NS_OpenAnonymousTemporaryFile to prevent the deadlock. r=roc, a=sledru - 06bdddc6463d |
| Chris Manchester | Bug 978846 - Add a file to the tree to tell mozharness what arguments from try are acceptable to pass on to the harness process. r=ahal, a=test-only - cda517b321ee |
| Alexandre Lissy | Bug 960762 - Fix intermittence of Notification mochitests. r=mhenretty, a=test-only - fe2c942655ec |
| Aaron Klotz | Bug 1158761 - Part 1: Make CheckPluginStopEvent run asynchronously. r=bholley, a=sledru - c163f5453215 |
| Aaron Klotz | Bug 1158761 - Part 2: Update checks for plugin stop event in tests. r=jimm, a=sledru - aa884d29e93c |
| tbirdbld | Automated checkin: version bump for thunderbird 38.0b6 release. DONTBUILD CLOSED TREE a=release - 7f925ad5b331 |
| Justin Dolske | Bug 1164649 - More late string changes in Pocket. r=jaws a=Sylvestre - 36b60a224d01 |
| Geoff Brown | Bug 1073761 - Increase timeout for test_value_storage. r=dholbert, a=test-only - 1266331d5bc7 |
| Kyle Machulis | Bug 1166870 - Fix permissions on settings event tests. a=test-only - 9e473441cbd9 |
| Albert Crespell | Bug 849642 - Intermittent test_networkstats_enabled_perm.html. r=ettseng, a=test-only - bee6825f6c92 |
| Albert Crespell | Bug 958689 - Fix intermittent errors in networkstats tests. r=ettseng, a=test-only - ad098fdd6f81 |
| Milan Sreckovic | Bug 1156058 - Null pointer check. r=jgilbert, a=sledru - 013da2859c88 |
| Nicholas Nethercote | Bug 1103375 - Fix some crashes triggered from about:memory. r=mrbkap, a=sledru - b90caf52b6e2 |
| Gijs Kruitbosch | Bug 1166771 - Force isArticle to false on pushstate on non-article pages. r=margaret, a=sledru - 17169e355c59 |
| Jeff Muizelaar | Bug 1165732 - Block WARP when using the built-in VGA driver. r=bas, a=sledru - a297bd71b81a |
| Gijs Kruitbosch | Bug 1167096 - Flip introductory prefs if there's no saved state. r=jaws, a=sledru - 3ef925962765 |
| Nick Thomas | Backout rev 27bacb9dff64 to make mozilla-release ready to do release builds again, ra=release DONTBUILD - 79f9cd31b4b1 |
http://release.mozilla.org/statistics/38_0/2015/05/24/fx-38.0.5b3-to-rc.html
|
|
Mike Conley: Things I’ve Learned This Week (May 18 – May 22, 2015) |
You might have noticed that I had no “Things I’ve Learned This Week” post last week. Sorry about that – by the end of the week, I looked at my Evernote of “lessons from the week”, and it was empty. I’m certain I’d learned stuff, but I just failed to write it down. So I guess the lesson I learned last week was, always write down what you learn.
I like Mercurial. I also like Git, but recently, I’ve gotten pretty used to Mercurial.
One complaint I hear over and over (and I’m guilty of it myself sometimes), is that “Mercurial is slow”. I’ve even experienced that slowness during some of my Joy of Coding episodes.
This past week, I was helping my awesome new intern get set up to tear into some e10s bugs, and at some point we went through this document to get her .hgrc all set up.
This document did not exist when I first started working with Mercurial – back then, I was using mq or sometimes pbranch, and grumbling about how I missed Git.
But there is some gold in this document.
gps has been doing some killer work documenting best practices with Mercurial, and this document is one of the results of his labour.
The part that’s really made the difference for me is the hgwatchman bit.
watchman is a tool that some folks at Facebook wrote to monitor changes in a folder. hgwatchman is an extension for Mercurial that takes advantage of watchman for a repository, smartly precomputing a bunch of stuff when the folder changes so that when you fire a command, like
hg status
It takes a fraction of the time it’d take without hgwatchman. A fraction.
Here’s how I set hgwatchman up on my MacBook (though you should probably go by the Mercurial for Mozillians doc as the official reference):
brew install watchman
hg clone https://bitbucket.org/facebook/hgwatchman cd hgwatchman make local
[extensions] hgwatchman = cloned-in-dir/hgwatchman/hgwatchman
hg help extensions
[watchman] mode = on
Congratulations, hg should feel snappier now!
Next step is to try out this chg thing – though I’m having some issues still.
http://mikeconley.ca/blog/2015/05/23/things-ive-learned-this-week-may-18-may-22-2015/
|
|
Mike Conley: The Joy of Coding (Ep. 15): OS X Printing Returns |
In Episode 15, we kept working on the same bug as the last two episodes – proxying the printing dialog on OS X to the parent process from the content process. At the end of Episode 14, we’d finished the serialization bits, and put in the infrastructure for deserialization. In this episode, we did the rest of the deserialization work.
And then we attempted to print a test page. And it worked!
We did it!

Then, we cleaned up the patches and posted them up for review. I had a lot of questions about my Objective-C++ stuff, specifically with regards to memory management (it seems as if some things in Objective-C++ are memory managed, and it’s not immediately obvious what that applies to). So I’ve requested review, and I hope to hear back from someone more experienced soon!
I also plugged a new show that’s starting up! If you’re a designer, and want to see how a designer at Mozilla does their work, you’ll love The Design Hour, by Ricardo Vazquez. His design chops are formidable, and he shows you exactly how he operates. It’s great!
Finally, I failed to mention that I’m on holiday next week, so I can’t stream live. I have, however, pre-recorded a shorter Episode 16, which should air at the right time slot next week. The show must go on!
Bug 1091112 – Print dialog doesn’t get focus automatically, if e10s is enabled – Notes
http://mikeconley.ca/blog/2015/05/23/the-joy-of-coding-ep-15-osx-printing-returns/
|
|
Air Mozilla: Mozilla Balkans Meetup |
 The Balkans Inter-Community meet-up 2015 will take place in Bucharest, Romania, on May 22-24th. Lead contributors from Balkan communities will be invited and sponsored by...
The Balkans Inter-Community meet-up 2015 will take place in Bucharest, Romania, on May 22-24th. Lead contributors from Balkan communities will be invited and sponsored by...
|
|
Robert O'Callahan: rr Performance Update |
It's been a while (March 2014 to be precise) since I gathered meaningful rr performance numbers. I'm preparing a talk for the TCE 2015 conference and as part of that I ran some new benchmarks with mozilla-central Firefox. It turned out that numbers had regressed --- unsurprisingly, since we don't have continuous performance tests for rr, and a lot has changed since March 2014. In particular, Firefox has evolved a lot, our tests have changed, we're using x86-64 now instead of x86-32, and rr has changed a lot. Over the last few days I studied the regressions and fixed a number of issues: in particular, during the transition to x86-64 some of the optimizations related to syscall-buffering were lost because we weren't patching some important syscall callsites and we weren't handling the recvfrom syscall, which is common in 64-bit Firefox. I also realized that in some cases we were flushing much more data from the syscallbuf to the trace file than we'd actually recorded in the buffer, massively bloating the traces, and fixed that.

There are still some regressions evident since last March. Octane overhead has increased significantly. Forcing Octane to run on a single core without rr shows a similar overhead; in particular that alone causes one test (Mandreel) to regress by a factor of 10! My guess is that Spidermonkey is using multiple cores much more aggressively that it did last year and because it's carefully tuned for Octane, going back to a single core really hurts performance. Replay overhead on the HTML mochitests has also increased significantly; I think this is partly because we changed rr to disable syscall buffering on writes to standard output. This improves the debugging experience but it results in a lot more overhead during replay.
Overall though, I remain very happy with rr performance, especially recording performance, which is critical when you're trying to capture a test failure under rr. Replay performance is becoming more important since it impacts the debugging experience, especially reverse execution; but doing a lot of work to improve raw replay performance is low priority since I think there are projects that could provide a better improvement in the debugging experience for less work (e.g. the ability to take a checkpoint during a recording and start debugging from there, and implement support for gdb's evaluate-in-target conditional breakpoints).
http://robert.ocallahan.org/2015/05/rr-performance-update.html
|
|
Mozilla Reps Community: Reps Weekly Call – May 21th 2015 |
Last Thursday we had our weekly call about the Reps program, where we talk about what’s going on in the program and what Reps have been doing during the last week.

Shoutouts to Alex Wafula, African Reps, @konstantina, @Ioana and @lshapiro
Michelle joined the call to talk about webmaker and Mozilla Learning projects.
Blog post about Webmaker changes.
Have a question? Ask on discourse.
Elio share his experience on how they set up a Club and what does it look like. More about how to set up a club. Also we have create a topic to share your experience or ask questions about clubs.
Patrick joined the call to update Reps about suggested Tiles in Firefox.
This week is going to be announced that it’s landing in beta starting with US users.
Firefox will use locally use the history to suggest interesting tiles for the user and it’s going to be super easy to opt-out or hide tiles you are not interested in. Firefox is the one deciding which tiles to show, not the partners.
Reps can be involved with this projects in two ways:
Patrick will work with the Reps team to open this opportunity and to improve localization around this announcement and the technical details.
We have opened a discourse topic to ask any questions you might have.
These are some events that have happened or are happening this week.
Staff onboarding
@george would love to know if a few volunteers would be excited to help out with new staff onboarding.
Requires availability at 17:15 UTC on Mondays for a 15min presentation, the benefit is that we would provide public speaking/presentation training and coaching and you will talk to new hires about the community and how awesome it is.
Business card generator
@helios needs help with the business card generator, which is written in nodejs.
Firefox e10s
@lshapiro needs help to test multiprocess in Firefox Developer Edition and add-ons.
We are only one month to the workweek and there might be some questions about how to help volunteers that need reimbursements.
Reps will be reached out from Mozillians for reimbursement, so help them as better as possible to make the reimbursement smooth.
There will be an event created on reps portal to use on the budget form, otherwise add the mozillians page URL as event in the request form (or Reps profile URL).
Contact your mentor if you have doubts about reimbursing without an event, other questions reach out to @franc.
The next online meetup of ReMo SEA will be on Fri 22 MAY 2015 at 1200Z (UTC)
This is a monthly meet-up held by @bobreyes. Reps based in nearby countries (i.e. China [including Hong Kong], Taiwan, Japan and Korea) are also welcome to attend the online meetup, even people from Europe/Americas are invited to join!
They will share more details once the meet-up is over.
Don’t forget to comment about this call on Discourse and we hope to see you next week!
https://blog.mozilla.org/mozillareps/2015/05/22/reps-weekly-call-may-21th-2015/
|
|
Robert O'Callahan: BlinkOn 4 |
Last week I went to BlinkOn 4 in Sydney, having been invited by a Google developer. It was a lot of fun and I'm glad I was able to go. A few impressions:
It was good to hear talk about acting responsibly for the Web platform. My views about Google are a matter of public record, but the Blink developers I talked to have good intentions.
The talks were generally good, but there wasn't as much audience interaction as I'd expected. In my experience interaction makes most talks a lot better, and the BlinkOn environment is well-suited to interaction, so I'd encourage BlinkOn speakers and audiences to be a bit more interactive next time. I admit I didn't ask as many questions during talks as I usually do, because I felt the time belonged to actual Blink developers.
Blink project leaders felt that there wasn't enough long-term code ownership, so they formed subteams to own specific areas. It's a tricky balance between strong ownership, agile migration to areas of need, and giving people the flexibility to work on what excites them. I think Mozilla has a good balance right now.
The Blink event scheduling work is probably the only engine work I saw at BlinkOn that I thought was really important and that we're not currently working on in Gecko. We need to get going on that.
Another nice thing that Blink has that Gecko needs is the ability to do A/B performance testing on users in the field, i.e. switch on a new code path for N% of users and see how that affects performance telemetry.
On the other hand, we're doing some cool stuff that Blink doesn't have people working on --- e.g. image downscaling during decode, and compositor-driven video frame selection.
I spent a lot of time talking to Google staff working on the Blink "slimming paint" project. Their design is similar to some of what Gecko does, so I had information for them, but I also learned a fair bit by talking to their people. I think their design can be improved on, but we'll have to see about that.
Perhaps the best part of the conference was swapping war stories, realizing that we all struggle with basically the same set of problems, and remembering that the grass is definitely not all green on anyone's side of the fence. For example, Blink struggles with flaky tests just as we do, and deals with them the same way (by disabling them!).
It would be cool to have a browser implementors' workshop after some TPAC; a venue to swap war stories and share knowledge about how to implement all the specs we agreed on at TPAC :-).
|
|
Monica Chew: Tracking Protection for Firefox at Web 2.0 Security and Privacy 2015 |
http://monica-at-mozilla.blogspot.com/2015/05/tracking-protection-for-firefox-at-web.html
|
|
Daniel Stenberg: status update: http2 multiplexed uploads |
I wrote a previous update about my work on multiplexing in curl. This is a follow-up to describe the status as of today.
I’ve successfully used the http2-upload.c code to upload 600 parallel streams to the test server and they were all sent off fine and the responses received were stored fine. MAX_CONCURRENT_STREAMS on the server was set to 100.
This is using curl git master as of right now (thus scheduled for inclusion in the pending curl 7.43.0 release). I’m not celebrating just yet, but it is looking pretty good. I’ll continue testing.
Commit b0143a2a3 was crucial for this, as I realized we didn’t store and use the read callback in the easy handle but in the connection struct which is completely wrong when many easy handles are using the same connection! I don’t recall the exact reason why I put the data in that struct (I went back and read the commit messages etc) but I think this setup is correct conceptually and code-wise, so if this leads to some side-effects I think we need to just fix it.
Next up: more testing, and then taking on the concept of server push to make libcurl able to support it. It will certainly be a subject for future blog posts…

http://daniel.haxx.se/blog/2015/05/21/status-update-http2-multiplexed-uploads/
|
|
Mozilla Security Blog: MozDef: The Mozilla Defense Platform v1.9 |
At Mozilla we’ve been using The Mozilla Defense Platform (lovingly referred to as MozDef) for almost two years now and we are happy to release v1.9. If you are unfamiliar, MozDef is a Security Information and Event Management (SIEM) overlay for ElasticSearch.
MozDef aims to bring real-time incident response and investigation to the defensive tool kits of security operations groups in the same way that Metasploit, LAIR and Armitage have revolutionized the capabilities of attackers.
We use MozDef to ingest security events, alert us to security issues, investigate suspicious activities, handle security incidents and to visualize and categorize threat actors. The real-time capabilities allow our security personnel all over the world to work collaboratively even though we may not sit in the same room together and see changes as they occur. The integration plugins allow us to have the system automatically respond to attacks in a preplanned fashion to mitigate threats as they occur.
We’ve been on a monthly release cycle since the launch, adding features and squashing bugs as we find them. You can find the release notes for this version here.
Notable changes include:
Using the Myo armband in a TLS environment may require some tweaking to allow the browser to connect to the local Myo agent. Look for a how-to in the docs section soon.
Feel free to take it for a spin on the demo site. You can login by creating any test email/password combination you like. The demo site is rebuilt occasionally so don’t expect anything you put there to live for more than a couple days but feel free to test it out.
Development for the project takes place at mozdef.com and report any issues using the github issue tracker.
https://blog.mozilla.org/security/2015/05/20/mozdef-the-mozilla-defense-platform-v1-9/
|
|
Air Mozilla: Kids' Vision - Mentorship Series |
 Mozilla hosts Kids Vision Bay Area Mentor Series
Mozilla hosts Kids Vision Bay Area Mentor Series
https://air.mozilla.org/kids-vision-mentorship-series-20150520/
|
|
Mozilla Addons Blog: Add-ons Update – Week of 2015/05/20 |
I post these updates every 3 weeks to inform add-on developers about the status of the review queues, add-on compatibility, and other happenings in the add-ons world.
If you’re an add-on developer and would like to see add-ons reviewed faster, please consider joining us. Add-on reviewers get invited to Mozilla events and earn cool gear with their work. Visit our wiki page for more information.
The Firefox 38 compatibility blog post is up. The automatic AMO validation was already run. There’s a second blog post covering the upcoming 38.0.5 release and in-content preferences, which were an oversight in the first post.
The Firefox 39 compatibility blog post is up. I don’t know when the compatibility validation will be run yet.
As always, we recommend that you test your add-ons on Beta and Firefox Developer Edition (formerly known as Aurora) to make sure that they continue to work correctly. End users can install the Add-on Compatibility Reporter to identify and report any add-ons that aren’t working anymore.
We announced that we will require extensions to be signed in order for them to continue to work in release and beta versions of Firefox. A followup post was published recently, addressing some of the reasons behind this initiative.
A couple notable things are happening related to signing:
Electrolysis, also known as e10s, is the next major compatibility change coming to Firefox. In a nutshell, Firefox will run on multiple processes now, running each content tab in a different one. This should improve responsiveness and overall stability, but it also means many add-ons will need to be updated to support this.
We will be talking more about these changes in this blog in the future. For now we recommend you start looking at the available documentation.
https://blog.mozilla.org/addons/2015/05/20/add-ons-update-65/
|
|
Jim Chen: Post Fennec logs to Pastebin with LogView add-on |
The LogView add-on for Fennec now lets you copy the logcat to clipboard or post the logcat to pastebin.mozilla.org. Simply go to the about:logs page from Menu -> Tools -> Logs and tap on “Copy” or “Pastebin”. This feature is very useful if you encounter a bug and need the logs, but you are not next to a computer or don't have the Android SDK installed.



Last modified: 2015/05/20 15:49
http://www.jnchen.com/blog/2015/05/post-fennec-logs-to-pastebin-with-logview-add-on
|
|







 Photo by James Emery
Photo by James Emery Photo by mroach
Photo by mroach