Matt Thompson: Building better user testing for Webmaker |
TLDR version:

Who are we most interested in testing with?
We’ve done user testing sessions for Webmaker in the past, and we’ve learned a lot from them. The goal now is to make them more regular, actionable, and community-powered.
“Watching real users can give you that eureka moment. It’s like travel: a broadening experience. You realize that the rest of the world doesn’t live and think the same way you do. This profoundly changes your relationship to users, making you a better developer, designer or manager.” –Steve Krug
To that end, Karen Smith and I have been working on a lightweight event model. Here’s the recipe we’re using for our prototype user testing event on Jan 24:
I just saw this bug and I am damn interested to help you out. Can I be told how to join you and help testing webmaker? (p.s. I am a peer in the webmaker task force of Bangladesh) –Tanha Islam, Mozilla Reps
The ultimate goal, of course, is to build off this prototype towards a community-driven system that scales. Since we first started working on this ticket, we’ve received requests from a number of community asking how they can get involved. There’s already big interest in hosting user testing events for Appmaker in Brazil, Webmaker tools in Bangladesh, and beyond.
We think the best approach is to write and localize a Webmaker User Testing Kit together. Like our current Webmaker event guides, but specifically geared towards user testing.

We haven’t started writing it, yet. So let’s get started on it now! If you’d like to get involved in building a Webmaker User Testing Kit, here’s how:
|
|
Luke Wagner: asm.js AOT compilation and startup performance |
With the recent announcement of a commercial game shipping using Emscripten and asm.js, I thought it’d be a good time to explain how asm.js is executed in Firefox and some of the load-time optimizations we’ve made since the initial landing of OdinMonkey in March. (OdinMonkey is an optimization module inside Mozilla’s JavaScript engine.) There have also been significant throughput optimizations as well, but I’ll stick to load time in this post.
Measuring the Epic Citadel demo (based on the same Unreal Engine 3 inside Monster Madness), I see a 2x improvement:
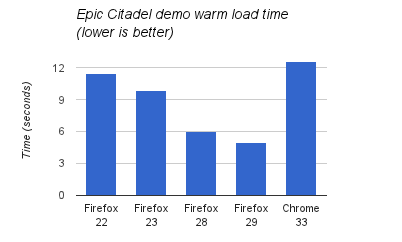
Times were measured with a simple stopwatch up to the first animation frame on a 16x2.4Ghz core Linux machine. (An IndexedDB bug in either the demo or Chrome causes level data not to be cached so time in “Downloading data” is explicitly subtracted from Chrome’s time.)
Cold load time improvements on the Citadel demo are harder to see since network latency plays a much larger part and adds considerable variance. Measuring the Nebula3 demos instead, which have a smaller initial download size and are compiled with both Emscripten and PNaCl, we can also see significantly better load times:
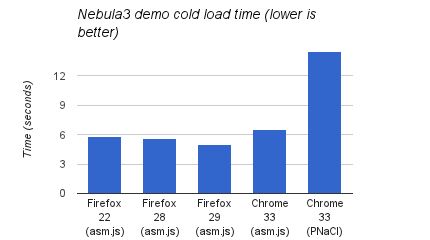
Times were again measured with a simple stopwatch up to first animation frame.
In this blog post I’ll explain the compilation strategy we use for asm.js, why we decided to try this strategy, how it’s been working, and 3 optimizations that have had a significant impact on load time.
The post is a bit long, so here’s the TL;DR:
Before getting into how we compile asm.js, let’s look at a diagram of the path taken by normal JavaScript in SpiderMonkey (Mozilla’s JavaScript engine). In this diagram, boxes are data structures and arrows represent algorithms which consume and/or generate these data structures:

In short, units of code (like functions, eval scripts, and global scripts) start as a bunch of characters in memory and gradually get compiled into forms that are able to execute more efficiently. While each unit of code starts the same way, different units of code will move along the arrows of this diagram at different times as they are run and judged hot enough. This compilation strategy is generally called Just-In-Time (JIT) compilation.
Going into a little more detail on the labels in the digram:
Given this whole process, it’s reasonable to ask: why do we need all these tiers of execution? To wit, V8 has two tiers, and Apple’s JSC has three and is experimenting with a fourth. Thus, this strategy is common (although people are always looking for something simpler). There are two main reasons we’ve found in SpiderMonkey for this tiered structure.
One reason is that SpiderMonkey has to run many different types of code and most code doesn’t run long enough to amortize the cost of compilation. In fact, most code doesn’t even run once which is why SpiderMonkey and other JS engines wait for a function to be run before even fully parsing it. Of code that is run, most doesn’t get warm enough to Baseline-compile and, similarly, most warm code doesn’t get hot enough to Ion-compile. Thus, each tier of execution services a distinct type of workload.
The other reason is that the Ion-build step actually depends on code having warmed up in Baseline so that the profiling metadata is likely representative of future execution. Ion compilation uses this metadata to specialize the types of values, objects, operations, etc which it could not do based on static analysis of the code alone.
What’s great about this design is that it has allowed continual progress by modern JavaScript engines on all kinds of JavaScript code. This progress continues today in all the major JS engines without signs of letting up.
As it became clear that Emscripten was a big deal (remember the H.264 decoder?), we started to try it out on bigger codes and talk with potential users. As we did this, one thing that became clear: if the web was going to be a serious porting target for large, computationally-intensive apps, we needed performance to be predictable. Now, even with native code, performance is never truly predictable due to things like dynamic scheduling and cache hierarchies. However, with Emscripten output, we were seeing some pretty violent fluctuations in startup and throughput on differnet codes and on different browsers.
Analyzing these fluctuations, we saw several causes:
Each of these problems can potentially be mitigated by adding new JIT compilation techniques and heuristics. Indeed, we’ve seen a lot of improvement along these lines in the V8 and SpiderMonkey JIT compilers in the last year and I expect to see more in the future. For example, in both JIT compilers, a few heuristic tweaks provided large throughput improvements on the asmjs-apps benchmarks on arewefastyet.com and background JIT compilation has helped to significantly reduce JIT compilation pauses.
However, the question is: to what extent can these problems be mitigated? Unfortunately, that’s hard to know a priori: you only really know when you’re done. Furthermore, as with any heuristic tuning problem, it’s easy to measure on workloads A, B and C only to find afterwards that the fixes don’t generalize to workloads D-Z.
In broader terms: with the proliferation of walled gardens and the consequent frustration of developers, the Web has a great opportunity to provide an open, portable alternative. But to really be an alternative for many types of applications, the web needs predictable, near-native performance. The time is ripe, so we don’t want to miss the opportunity by blocking on a Sufficiently Smart Compiler.
To attempt to solve the above problems, we started the OdinMonkey experiment. The basic idea behind the experiment was: Emscripten-generated code has enough type information preserved from the original statically-typed source language that we can avoid all the dynamic-language compilation infrastructure and use a simple Ahead-of-Time (AOT) compiler.
For example, given the following C code:
int function f(int i) {
return i + 1;
}Emscripten would output the following JS code:
function f(i) {
i = i|0;
return (i + 1)|0;
}The statement “i = i|0” effectively performs the JS spec ToInt32 on the input, ensuring that + always operates on an integer. If we can prove that all callers pass ints, then this coercion is a no-op. The expression “(i + 1)|0” exactly simulates 2s complement addition meaning that this JavaScript expression compiles to a single machine instruction — no type tests, no overflow checks.
If you squint your eyes at the above code, you can view “i = i|0” as a parameter type declaration, “return (...)|0” as a return type declaration and binary + as taking two int types and returning a special type which requires coercion via ToInt32 or ToUint32 before use. This basic idea of viewing runtime coercions as types can be extended to all statements and expressions in Emscripten-generated code and the resulting type system is asm.js.
Given the asm.js type system, OdinMonkey is easily able to generate MIR from the AST. As an example, check out the CheckNot function in OdinMonkey (which checks the ! operator): as input it receives a ParseNode (an AST node) and, as output, it returns an MNot MIR node and the expression’s result type (which according to the spec is int). If any of the types fail to match, a type error message (like you’d expect from a C compiler) is output to the Web Console and OdinMonkey transparently falls back to normal JS compilation.
In terms of the previous JIT compilation diagram, OdinMonkey adds a single new arrow between AST and MIR:

Furthermore, after asm.js type checking succeeds (as well as the link-time check), it is not possible for the generated code to take the Bail edge: there are no dynamically-checked assumptions that can fail.
In addition to simplifying the compilation process, the asm.js type system also provides three broader benefits:
Despite all these advantages, AOT has a significant potential downside: it compiles everything using the most expensive compiler without knowing if the code being compiled is hot or cold. This would obviously be a problem if an app contained a lot of cold or dead asm.js code. Similarly, AOT would be a net loss for an app with a lot of code that runs in short bursts so that low tiers of execution and compilation stalls aren’t noticeable. Thus, the load-time performance of AOT relative to JIT depends on the kind of code being executed.
Another potential pitfall for AOT is pathologically-large functions since these can take a really long time to compile in the top-tier compiler. With JIT compilation, the usual heuristics ensure that the top-tier compiler is never used. With some work, OdinMonkey could be extended with heuristics do the same. In the meantime, Alon added an “outlining” option to Emscripten that automatically breaks up large functions and has been quite effective. By making functions smaller, outlining also improves performance of asm.js on non-OdinMonkey since it encourages the JIT to use the top-tier compiler.
One theoretical response to these load-time concerns is that the "use asm" directive required at the beginning of any asm.js module has no semantics and can simply be removed if AOT compilation is not beneficial. As such, "use asm" gives the developer more control over the compilation scheme used for their application. In theory (it’s difficult in practice at the moment due to lack of automated tooling), developers can exercise even finer-grain control by choosing which functions are inside the asm.js module (and thus receive AOT compilation) and which are outside (and thus receive JIT compilation). One can even imagine an Emscripten PGO pass that does this automatically for cold code.
In the end, though, it’s hard to predict what will happen in practice so we had to just try. (OdinMonkey was started as a experiment, after all.)
The results so far have been good. In addition to those reported at the beginning of the post, cold load times are also measured by the asmjs-apps-*-loadtime synthetic workloads on awfy:
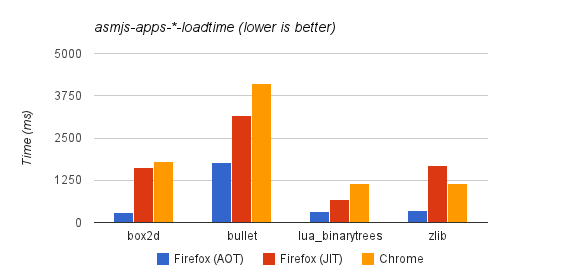
In this graph, Firefox (JIT) refers to Firefox’s performance with OdinMonkey disabled (by passing --no-asmjs to the JS shell or setting javascript.options.asmjs to false in about:config in the browser).
Another data point is the BananaBread benchmark which conveniently measures its own load time:
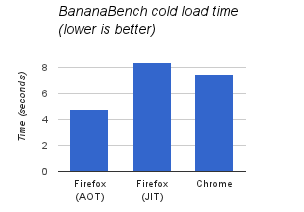
This graph reports the sum of the “preload” and “startup” times when the benchmark is run in headless mode with a cold cache.
Now let’s look at the major optimizations that AOT compilation allows.
With the intermediate JIT compilation steps avoided, the majority of AOT compilation time is in the Ion-compile step. For example, measuring the Citadel demo we can see the following breakdown of time:
Fortunately, the Ion-compile step is also the most parallelizable: each function in the asm.js module results in an independent Ion compilation and there are tens of thousands of functions in large apps. Even better, SpiderMonkey had already supported background Ion-compilation for a year before OdinMonkey, so we were able to add parallel compilation to OdinMonkey without much trouble.
After basic parallel compilation worked, we made an additional refinement to extract further parallelism. Originally, the entire asm.js module would be parsed into one big AST before being handed over to OdinMonkey. OdinMonkey would then simply recurse over the AST, firing off parallel Ion compilations as it went. This was suboptimal for two reasons:
The solution to both of these problems was to allow Odin-building and Ion-compiling to overlap parsing as illustrated in the following psuedo code:
while (not at end of asm.js module) {
ast = ParseFunction();
mir = CheckAndEmit(ast);
StartBackgroundIonCompilation(mir);
ReleaseMemory(ast)
}Since the time to Ion-compile a function is on average longer than the time to parse, the process looks something like this:

To measure the effect, first disable caching (set javascript.options.parallel_parsing to false) and then compare compile times with and without javascript.options.ion.parallel_compilation enabled. To get a more precise measure of compile time, look at the “total compilation time ___ms” part of the “Successfully compiled asm.js code” Web Console message.
On my machine, parallel compilation reduces compile time from 11s to 5s on the Citadel demo, but this improvement is obviously contigent on the number of cores. Measuring with 2 cores, the compile time is 9s, with 3 cores, 6s, and with 4 cores, 5s. Adding further cores doesn’t appear to help. The remaining gap between this and the theoretical minimum of 3s suggested above is largely due to a fixable implementation detail.
As described above, AOT compilation occurs when "use asm" is first encountered while parsing. This can be while parsing an inline
https://blog.mozilla.org/luke/2014/01/14/asm-js-aot-compilation-and-startup-performance/
|
|
Rebeccah Mullen: Work it, 2014! |
This blog post challenge is where me and my coworkers get the opportunity to employ a scrying glass (if we have one on hand) and liberally articulate our views on how the next 12 months should be – how we as a team can make the most of our skills and shared energies.
And luckily, we’re all here together in Vancouver – one of those deep, green, grounded places on the big blue ball that is full of magics. I am pretty delighted to have the Engagement & Communications Team workweek here, where it gets a little hippy in the good sorts of ways.
Also, now it won’t be surprising if I somehow reference Totem spirits and maybe Bowie somewhere in this thing.

I’m a specialist communications operations unit, with a diverse set of skills and a ton of experience that allows me to man the ship alone, or play a strong supporting role in the team.
Essentially, I am a social media satellite, orbiting both the Mozilla Home Planet and also the lunar outpost of Webmaker (currently in the process of being colonized by the early and brave – those who don’t quite need a glossy brochure to envision the shape of the terrain they wish to inhabit). This orbit of mine however, makes for a very sore neck as I strive to keep an eye on all directions in order to capture both the galactic republic and also the shipping news on a daily basis, 24/7/365.
If I should be more concrete about it – I’d tell you this about the work I do for our Comms team. In 2013 I have:
I also have a background in Google Analytics reporting for websites – and if you accused me of self improvement by sourcing my social links and tracking them to determine efficacy, I’d have to admit that I do that on a regular basis. The other work I’ve done at Mozilla with BSD data tracking, as well as previous experience with voter contact database integration and email campaign management in NGP VAN makes me well suited to play a support role there if ever needed – as well as someone who understands and respects the process and potential of that channel.
So, in essence, I’d have to call me the Macguyver Totem of the Communications team: I can run around and play a rogue agent and be trusted to hit my marks, but when utilized in either crunch or strategic ways, solo or in group – I can always pull something out of the air using paperclips and bravado.

What can we do better this year?
This year it is crucial to know ourselves and drive hard towards concrete goals that we can measure and evaluate.
I would say that last year we had a challenging time with self-identity. At times, our projects diverged so wildly we weren’t sure the ‘teenaged’ versions of them could all live under the same roof – and it was hard to tell whether our goals and priorities were the same as they were when we first began these growth surges in the Badges, Webmaker, Open News, Games and Ignite spaces. I feel like we likely sacrificed too many opportunities to get real clarity on exactly who and where we wanted to be, and exactly what we wished to bring to each space – and gave that energy instead to building a high level of robustness into the tools.
We also focused on throwing large scale campaigns that sometimes didn’t synch with our main objectives – to drive *our* growth in particular.
For me, fuzzy goals tend to give fuzzy results, and so this year I’d like to use more traditional techniques and tools to enhance our game – looking at market research to help provide strategic direction, heavy user testing, niche identification, community profiling, competitor evaluation, tracking user opinion, and a building a very strong and clear engagement strategy for creating true evangelists for our products.

What should we make sure not to lose?
Working openly, regularly and in group settings keeps us honest – and offers the fastest download of quality groupthink.
One of my favorite things about Mozilla is that we get together and present ideas, break ground immediately, and are always willing to throw our resources – mental and physical – into gear in a social atmosphere. Community meetings, working meetings, and collaborations of all sorts are the breathing heartbeat of our group, and I am always amazed how quickly we are able to brainstorm a solution.
I also enjoy seeing us apply ourselves to the dogfooding process – I really can’t express just how valuable it was to me to learn to use the tools we make, so that I can better understand the needs of the people who are not at all coming from an intellectual place, but a true, functional, face-value place.
I’d say much about our process is worth striving to keep – peer-to-peer contact – in both our work and in what we’re building for others.

What do you most want to get out of the work week?
Ground Control to Major Replica.
I do sometimes feel like the lonely Russian left alone up there in space station orbit – I often have no real idea what’s percolating organization wide. I’d like to tap into Mozilla.Org’s creative calendar – and it very well could be as simple as that to cure some of the ’404' feeling I often get when trying to plan ahead. The Mozilla project is a different animal than much of what we’ll be discussing this week, and has its own audience needs and requirements. I’d very much like to find time to dig into the really awesome growth I’m building in this space and see how far and fast we can push these channels into true Mozillian-grabbing conversion engines of awesomeness.
I also have a sweet spot on the projects I saw grow from tadpoles to dragons, and so I’d like to continue to dig into potential audience leads, rewarding and mutually beneficial tactics for capturing ‘mentor market share’ and working on what it takes to truly onramp, and care and feed the community.
So, let us rock along the weirding way, zipline some fear into our spirits, and hang out at Dude Chilling Park as we work out how best to accomplish it all.
|
|
Rob Hawkes: 2013: All change |
This time last year I rounded up my 2012. I wrote that it was the craziest year of my life so far, and one that I won't forget. I obviously had no idea what 2013 had in store for me!
2013 was the year for massive change in my life, in every aspect. The funny thing is that none of the changes were planned or even desired, yet I'm glad each and every one happened as they taught me valuable lessons that I'll remember forever.
Back in December 2012 I announced my intentions to leave my role as a Technical Evangelist at Mozilla, arguably my dream job. I wrote about the reasoning behind this in a lot of detail. In short, I suffered a combination of burnout and a catastrophic demotivation in what Mozilla was doing and what my role was there.
As of the 25th of January 2013 I was no longer a Mozilla employee, something I never imagined myself saying.
Lessons learnt: Even the most perfect things in life have downsides and if you ignore them you'll pay for it in the long run. Focus on keeping yourself happy, otherwise you'll cause yourself long-term damage.
After 4 years together, Lizzy and I decided it was time to call it a day. It's quite surreal uttering a few disembodied words and subsequently ending a relationship with someone you've spent practically every day with for what feels like forever.
Yes, of course it sucked. But no, I don't regret it and it was definitely the right decision for the both of us. What I was most surprised about was how we both handled it; from sitting down, talking for a while, and deciding that we should split up, to sorting everything out afterward so neither of us got left in a difficult situation.
2013 has shown us both that we're better off because of it. That makes me happy.
Lessons learnt: Good things sometimes come to an end, and that isn't necessarily a bad thing. Remember the good times and make sure you learn something from the experience. Things do get better in time, you just need to make sure you allow them to.
Part of my decision to leave Mozilla was to take some time off to rest and work out what I wanted from life. What was planned to be 6 months out ended up turning into near-enough 10 months without firm commitment or income. I'm sure glad I saved while I was at Mozilla!
1 year on and, although much better, I'm still suffering from the burnout that I experienced while at Mozilla. Someday it'll fade into the background, though I've resided myself to the fact that it won't be any time soon, nor an obvious transition.
Lessons learnt: Take time off when you get the chance, it's a great healer. Don't force yourself to do something, it's nearly more valuable to do nothing and let your body tell you what it needs.
One of the general lessons I learnt from 2012 was that I had neglected my close friends. Part of 2013 was about fixing that, at least in a small way.
Over the year I spent much more time with my best friend of 10+ years, helping her through a tough and similar career problem, and generally looking out for each other. Although I don't need to see or talk to her often (the sign of a great friend), doing so has shown me how valuable my close friends are to me and how important that are to my happiness.
March was pretty special as I travelled to Wales to visit Matt and Sophie, two friends that I've known online for a long time but had never met before. I had a great time exploring their part of the world and being taught how to ride on Anubis, one of their (three!) horses.
Lessons learnt: Don't neglect your close friends. It sucks, and you'll look and feel like a dick because of it. You may not make things perfect but at least try your best to make an effort.
Soon after leaving Mozilla, Peter Smart and I decided to work on a seemingly innocuous project called ViziCities. Oh how naive we were!
 ViziCities
ViziCitiesNearly a year to the day since we first started ViziCities, we've come a hell of a long way and have learnt a huge amount about the power of a good idea, especially when implemented well. So much happened but I'll try my best to round up the key events:
As it stands, ViziCities is still being worked on, just at a slower pace due to Peter and I both recovering from big changes and events in our lives. It's too good an idea to let slide.
Lessons learnt: When you have a good idea, run with it. Don't ruin a good thing by taking it too seriously too quickly. Release early and worry about making it perfect later. Working on something purely for fun and the good of others is an incredible motivator, don't squander it.
Something I didn't really consider when leaving Mozilla was that I would need to do everything under my own steam from that point. No Mozilla to hide behind. No Mozilla to help me get events to speak at. No Mozilla to help with travel. Just little old me.
Fortunately I haven't found the desire to do much speaking of late, though I've had some great opportunities this year. Taking part in the real-time Web panel at EDGE in NYC is a particular favourite, as is speaking at FOWA in London toward the end of the year. Going on the stage as Robin Hawkes (of no affiliation) was quite a liberating and scary experience.
Most recently, I got to attend Mozilla Festival in London. This was lovely because I got to catch up with some of my old Mozilla friends and show them ViziCities. I don't think I've ever said so much to so many people in such a short period of time.
Lessons learnt: Doing things on your own is scary but ultimately liberating and rewarding. Don't shun opportunities to do things as you. Stay grounded — it's what you're talking about that's the important thing, not you.
After spending what feels like most of my adult life living in Bournemouth, recent events gave me the perfect opportunity to up sticks and move back to London. I never thought I'd move back to London, or any city, but after travelling the world I can safely say that London is by far my favourite city in the world. There's something special about it.
I originally moved back with family, which was meant to be temporary but ended up lasting for about 4 months while I sorted my shit out. While slightly embarrassing as a 27-year-old, it was really nice to spend more time with my Dad.
Just before the end of the year I finally got the opportunity to move out and get my independence back. I absolutely hate moving but it's totally been worth it. Having a place that I can call my own is immensely good for my happiness and wellbeing. It also helps that the place I live is beautiful (right alongside the Thames).
Lessons learnt: It's easy to settle and get scared of change. Not having independence can really, really suck. Finding and moving house is incredibly stressful, but worth it in the long run. Make sure you find somewhere that makes you happy, even if it costs a little extra.
In October I decided to do something that I've wanted to do for a very long time; I changed my name back to the one I was born with.
 My name in full
My name in fullFor near-enough 16 years I've referred to myself as Rob Hawkes, completely shunning my full name because of bullying earlier in life and general habit since then. Changing back to Robin Hawkes has quite literally felt like a weight has been lifted from my shoulders. I feel like the real me is back again.
The feedback since changing my name has quite honestly been overwhelming; I never knew how much my friends preferred my birth-name!
Lessons learnt: Personal identity is something I should have taken more seriously. It doesn't matter how well you pronounce 'Robin', people in Starbucks will still write 'Robert'.
In November I decided that it was time to get serious and get a proper job, in a real office and everything. A few weeks later I started at Pusher as Head of Developer Relations.
It's been a couple months now and I've absolutely loved my time here so far — everyone at Pusher is amazingly friendly and good at what they do. I'm looking forward to working somewhere and actually making a difference.
Lesson learnt: Sometimes the obvious solution is the best one. Commuting can suck, but it can be solved (by moving house). Being part of something small(er) is an awesome feeling.
In general, this year has taught me to look after myself and listen to what my body is trying to tell me (it's usually right).
Some of the things I've done this year include:
All in all, I feel much better about myself after doing these relatively minor things. Even just the regular exercise has had a huge effect on my energy levels, which I've noticed decreasing since I stopped cycling recently (due to winter and moving house).
Lessons learnt: Routine is easy, until you stop it. You don't have to cook crazy meals to eat well. Getting a good night's sleep is so, so important. Taking time off seriously will pay off in the long run. Burnout sucks.
At the beginning of last year I outlined a few wishes for the following 12 months. Let's see how they did…
My wish…
Right now, Rawkes is purely a personal blog containing information about me and the things that I'm currently thinking about. In 2013 I want to explore the idea of turning Rawkes into a much larger content platform, revolving around technology and development. I'd also like to see more authors contributing to Rawkes.
Fail. I completely neglected Rawkes in 2013, mostly due to taking time off and working on ViziCities.
My wish…
The next 6 months are going to be spent working out how to fund time to continue experimenting and learning new things. I'm keen to find a way to do this without the act of earning money being my primary focus.
Half-success. I didn't need to fund myself in the end as I sustained myself long enough on savings to last me until I got a proper job. I still got to work on my personal projects.
My wish…
More often than not, the projects I work on are targeted mainly to the developer community. I'm keen to work on some projects this year that are also of use to the general public, or at least to the wider Internet community.
Massive success. While accidental, ViziCities proved to be incredibly valuable to the general public!
I don't do resolutions so instead here are my overall wishes for the coming year.
Even if not the full feature-set that we envisaged, I want to make sure ViziCities can actually be used by people. It's too good an idea to let it sit and gather dust.
While perhaps not completely up to me, I think I'm ready to write another book.
I've done enough crazy stuff in the past few years to last me for a while. I'd be happy for 2014 to be spent taking things relatively easy and keeping myself happy instead.
As always, I'll end this round-up with a few facts and figures about the previous year with comparisons to last year in grey.

I find these retrospectives incredibly useful to me personally, especially when you have a few years-worth to look back on. I'd recommend you try doing them! So how was your 2013? Post it online and send me the link on Twitter.
http://feedproxy.google.com/~r/rawkes/~3/btqik9aTHxA/2013-in-review
|
|
Planet Mozilla Interns: Mihnea Dobrescu-Balaur: Switching browser tabs by number in Windows |
I always loved the Linux/OS X shortcut that allows you to go to any tab between
1 and 8 by using ALT + number (or CMD + number). However, I couldn't get
it to work on Windows. Recently, out of pure luck, I stumbled across the
working key combination - you just have to use CTRL instead!
So, next time you're browsing the Web on a Windows box, go ahead and switch
between tabs using CTRL + number!
P.S.: 9 refers to the last tab. And if you really use tabs and find yourself
having lots of them open all the time, I suggest you try out
Tree Style Tab
for Firefox.
http://www.mihneadb.net/post/switching-browser-tabs-by-number-in-windows
|
|
Alexander Surkov: Accessible Mozilla: tech overview of Firefox 26 and Firefox 27 |
http://asurkov.blogspot.com/2014/01/accessible-mozilla-tech-overview-of.html
|
|
Matt Thompson: Celebrating Webmakers as “Friends of Mozilla” |
Who would *you* nominate for next week’s “Friends of Mozilla?”
Every week, the Mozilla All Hands meeting has a “Friends of Mozilla” section. These are community members who deserve some extra love and recognition for a special contribution or extra effort they made that week. (Here’s an example from a recent meeting.)
You can suggest members of the Webmaker community you think deserve special recognition each week. (Or Open Badges, Open News, Science Lab, or anywhere across Mozilla.)
That way, they can get love and respect from the rest of Mozilla, have their name read out by the meeting’s MC (the fabulous Potch), and get 15 seconds of fame in the Mozilla universe! ![]()
Not sure how to participate in the Monday All Hands? Here’s a handy guide: http://mzl.la/Mozilla_All_Hands
|
|
Christian Heilmann: Myth busting mythbusted |
Today CSS tricks features an article on JavaScript animations vs. CSS animations entitled Myth Busting: CSS Animations vs. JavaScript guest-written by Jack Doyle, one of the people behind the Greensock animation platform. Not surprisingly, Jack debunks the blanket statement that CSS animations are always better for performance and functionality than JavaScript animations.
 Mythbusters parody by Sephie-monster
Mythbusters parody by Sephie-monsterJack is doing a great job arguing his point that CSS animations are not always better than JavaScript animations. The issue is that all this does is debunking a blanket statement that was flawed from the very beginning and distilled down to a sound bite. An argument like “CSS animations are better than JavaScript animations for performance” is not a technical argument. It is damage control. You need to know a lot to make a JavaScript animation perform well, and you can do a lot of damage. If you use a CSS animation the only source of error is the browser. Thus, you prevent a lot of people writing even more badly optimised code for the web.
These kind of articles are lots of research but easy to write: you take a “common practice truth” and you debunk it by collecting counter arguments. Extra points go to having lots of performance benchmarks or demos that can not be done with the technology you debunk.
Personally, I have no problem when libraries, frameworks or software solutions are getting debunked but I have a real problem when solutions built into browsers and defined in standards are being painted as inadequate for the sake of a yet another library or – in a lot of cases of articles of this kind – your own product.
This is not helping us having a professional platform. If there are issues with performance or functionality of a standard, we should get them fixed on browser and spec level. Yes, this takes longer and we can not be the hero to the rescue that built the quick library that fixes all these problems. But we also fix it for everyone and not just for the moment as inevitably following one of these articles will be another one a few months later showing that the solution of the first one has issues.
And thus, the cycle restarts. We discuss things, we create performance tests, we find proof in a certain environment and we give once again the message that everything on the web is broken and needs people to fix it with JavaScript.
Here are a few truths about web development:
All of this would not be an issue if people looked at the source of the article, the date of it and see it as a problem solution in a certain environment and time frame. What we do though is keep quoting them out of context and as gospel. Until someone else will take that argument without context and writes a mythbusting article about it.
http://christianheilmann.com/2014/01/13/myth-busting-mythbusted/
|
|
Doug Belshaw: The web is the platform (or, the perils of esoteric setups) |
At Mozilla we say that “the web is the platform”. It’s almost like a mantra. By that we mean that, as the world’s largest public resource, the web is big enough, fast enough, and open enough for everyone to use on a full-time basis.
To prove this, we made FirefoxOS, a mobile operating system comprised entirely of web-native technologies. But FirefoxOS devices aren’t the only ones that lean heavily on the web for their functionality. Google Chromebooks have a stripped-down version of Linux that boots directly into Google’s Chrome web browser.
The meme over the last few years seems to have been that Chromebooks (and by extension, I guess, FirefoxOS devices) are for other people – you know, the type that “just do a little bit of web browsing here and there.” They’re not for us power users.
Here, for example, is Andrew Cunningham from Ars Technica talking about covering CES 2014 on a Chromebook:
Even if you can do everything you need to be able to do on a Chromebook, switching from any operating system to any other operating system is going to cause some friction. I use OS X to get most of my work done because it’s got a bunch of built-in features and applications that I like. I use Full Screen Mode to keep my laptop’s display organized and uncluttered. I like Limechat because it’s got a bunch of preferences and settings that lets me change the way it looks and works. I like Messages because it lets me connect to our XMPP server and Google Talk and iMessage, all within one client.
That’s what bothers me the most about Chrome OS. It’s not that you can’t do a lot with a Chromebook. It’s not even about getting used to different tools. It’s just that the operating system works so differently from established desktop operating systems that you’ll have to alter many of your normal workflows. No one’s saying it’s impossible to do, but for people used to something else it can be a laborious process.
Don’t get me wrong: there’s nothing wrong with native apps. I really like Scrivener, Notational Velocity, and others. But unless you’ve got unusual requirements I reckon that in 2014 you should have a workflow that can use the web as the platform. In other words, being away from your own machine and ‘perfect setup’ shouldn’t dent your productivity too much.
One blocker to all this, of course, is other people. For example, it’s very difficult to move away from using Skype (which doesn’t have a web client) because it’s the de facto standard for business VoIP communication. That is only likely to change when there’s a critical mass of people familiar enough with different technologies to be able to switch to them quickly and easily. Hopefully WebRTC will expedite this process!
So, in conclusion, if you’ve got a workflow that depends upon a particular native app, perhaps it’s time to look for an alternative?* Then, at the minimum you’ve got that alternative up your sleeve in a pinch, and at best you may find you want to switch to it full time.**
Image CC BY Robert S. Donovan
*For example, I’ve recently moved from Evernote to Simplenote and from Adium to IRCcloud.
**If you want to simultaneously focus on privacy/security, look at the newly-revamped PRISM Break site.
http://dougbelshaw.com/blog/2014/01/13/the-web-is-the-platform-or-the-perils-of-esoteric-setups/
|
|
Carla Casilli: Badge System Design: ideas to build on |
Hey there, happy new year! I hope that the new year is going well and continues to go well for everyone. Over the holidays—and for quite some time actually—I’ve been meditating on some thoughts about badges and systems. And in the interest of starting 2014 off right, I have decided to throw them out here for discussion. Some of the ideas I’m pretty committed to and others are drifting in a bit more of a nebulous state. Still, overall there’s good content in here worth discussing, content I plan to build on throughout the year.
So how about a bit of context for this content? Last year saw me working closely with Radhika Tandon on ideas for illustrating and communicating badge system design tenets. Her innovative thinking led me to rethink some of my own proposed concepts and continue to explore others. What you’ll find below in the first set is a distillation of some ideas previously expressed in the (still fledgling) white paper about a the framework—previously principles—of a complex adaptive badge system. You’ll note that I’m now intentionally including the “complex adaptive” descriptor. Why? Because it’s a mistake to call an effective badge system a simple system. Indeed, a truly functional system is one that grows, changes, and evolves. It is one that adapts and eventually produces emergent qualities. I’m hoping that we can begin talking about and seeing some emergent qualities emanating from complex adaptive badge systems this year. (Suggestions welcome!)
Outline / framework for badge design
A quick explanation of the list: it began with enumerating a set of single words that encapsulated a primary, defining idea for badge system design. The second word came into being when I began to try to explain the first word from a slightly different perspective. Interestingly enough, the second word performed more of a conceptual rounding out than I had anticipated. Additionally, the second words provided new ideological possibilities because the first and second words began to create sets. In other words, they had a multiplying effect that resulted in sums greater than their parts.
I’m listing these quickly here in an effort to get them out there so we can begin talking about them in detail. Obviously, they’re somewhat stripped of their context—that will come! Even so, I’d love to hear your response to these basic structural tenets. No doubt the third one will invite a lot of discussion. I certainly hope so. But, here they are.
7 aspects of roadmapping + resource management
This set of ideas sprang from our MOOC on badges. In addition to building the badge system for the MOOC, I also ran two labs; one about badge system design and one about badge system roadmapping. What you see below is the streamlined view of the latter lab. I truly enjoyed this lab: it stretched my capabilities in thinking about and expressing tangential yet vital aspects of developing a complex adaptive badge system. The order is not necessarily pointing toward any deep meaning; however, some of the enumerated points may be contingent upon others.
I hope to dive into this list this year. There are many ideas here that deserve their own discussion. For example, Funding appears to be a continuing concern for many badge creators. This concern might possibly be mitigated by developing partnerships between organizations. In my discussions and research, this has not been a typical finding. Okay, so take a gander at these, we’ll be visiting them again this year.
2014 is going to be an exciting year for the open badges ecosystem and I’m looking forward to discussing it with you here, during MOOCs, on blogs, and during the Mozilla Open Badges Research / System Design call.
—
Much more soon.

http://carlacasilli.wordpress.com/2014/01/13/badge-system-design-ideas-to-build-on/
|
|
Nick Fitzgerald: Hiding Implementation Details With Ecmascript 6 Weakmaps |
WeakMaps are a new feature in ECMAScript 6 that, among many other things, gives us a new technique to hide private implementation data and methods from consumers of the public API we choose to expose.
Here is what the basics look like:
const privates = new WeakMap();
function Public() {
const me = {
// Private data goes here
};
privates.set(this, me);
}
Public.prototype.method = function () {
const me = privates.get(this);
// Do stuff with private data in `me`...
};
module.exports = Public;
Two things to take note of:
Private data and methods belong inside the object stored in the privates
WeakMap.
Everything exposed on the instance and prototype is public; everything else
is inaccessible from the outside world because privates isn't exported from the
module.
In the Firefox Developer Tools, Anton Kovalyov used this pattern in our editor module. We use CodeMirror as the underlying implementation for our editor, but do not want to expose it directly to consumers of the editor API. Not exposing CodeMirror allows us to upgrade it when there are backwards incompatible releases or even replace CodeMirror with a different editor without the fear of breaking third party addons that have come to depend on older CodeMirror versions.
const editors = new WeakMap();
// ...
Editor.prototype = {
// ...
/**
* Mark a range of text inside the two {line, ch} bounds. Since the range may
* be modified, for example, when typing text, this method returns a function
* that can be used to remove the mark.
*/
markText: function(from, to, className = "marked-text") {
let cm = editors.get(this);
let text = cm.getRange(from, to);
let span = cm.getWrapperElement().ownerDocument.createElement("span");
span.className = className;
span.textContent = text;
let mark = cm.markText(from, to, { replacedWith: span });
return {
anchor: span,
clear: () => mark.clear()
};
},
// ...
};
module.exports = Editor;
In the editor module, editors is the WeakMap mapping public Editor instances
to private CodeMirror instances.
WeakMaps are used instead of normal Maps or the combination of instance IDs and a plain object so that we neither hold onto references and leak memory nor need to introduce manual object lifetime management. For more information, see the "Why WeakMaps?" section of the MDN documentation for WeakMaps.
This habit comes from the world of Python, but is pretty well spread through JS land.
function Public() {
this._private = "foo";
}
Public.prototype.method = function () {
// Do stuff with `this._private`...
};
It works just fine when you can trust that the consumers of your API will respect your wishes and ignore the "private" methods that are prefixed by an underscore. For example, this works peachy when the only people consuming your API are also on your team, hacking on a different part of the same app.
It completely breaks down when third parties are consuming your API and you want to move quickly and refactor without fear.
Alternatively, you can close over private data in your constructor or just define functions which return objects with function members that close over private variables.
function Public() {
const closedOverPrivate = "foo";
this.method = function () {
// Do stuff with `closedOverPrivate`...
};
}
// Or
function makePublic() {
const closedOverPrivate = "foo";
return {
method: function () {
// Do stuff with `closedOverPrivate`...
}
};
}
This works perfectly as far as information hiding goes: the private data is inaccessible to API consumers.
However, you are creating new copies of every method for each instance that you create. This can balloon your memory footprint if you are instantiating many instances, which can lead to noticeable GC pauses or even your app's process getting killed on mobile platforms.
Another language feature coming in ECMAScript 6 is the Symbol primitive type and it is designed for the kind of information hiding we have been discussing.
const privateFoo = Symbol("foo");
function Public() {
this[privateFoo] = "bar";
}
Public.prototype.method = function () {
// Do stuff with `this[privateFoo]`...
};
module.exports = Public;
Unfortunately, Symbols are only implemented in V8 (behind the --harmony or
--harmony_symbols flags) at the time of writing, but this is temporary.
More problematic is the fact that you can enumerate the Symbols in an object
with the Object.getOwnPropertySymbols and
Object.getOwnPropertyKeys functions. Because you can enumerate the
Symbols in an object, a determined third party could still access your private
implementation.
The WeakMap privates pattern is the best choice when you really need to hide private implementation details from public API consumers.
Brandon Benvie uses this WeakMap technique to create JavaScript Classes with private, protected, and super
|
|
Fr'ed'eric Wang: Improvements to Mathematics on Wikipedia |
As mentioned during the Mozilla Summit and recent MathML meetings, progress has recently be made to the way mathematical equations are handled on Wikipedia. This work has mainly be done by the volunteer contributor Moritz Schubotz (alias Physikerwelt), Wikimedia Foundation's developer Gabriel Wicke as well as members of MathJax. Moritz has been particularly involved in that project and he even travelled from Germany to San Francisco in order to meet MediaWiki developers and spend one month to do volunteer work on this project. Although the solution is essentially ready for a couple of months, the review of the patches is progressing slowly. If you wish to speed up the integration of what is probably the most important improvements to MediaWiki Math to happen, please read how you can help below.
The approach that has been used on Wikipedia so far is the following:
Native MathML is the appropriate way to fix all the issues regarding the display of mathematical formulas in browsers. However, the language is still not perfectly implemented in Web rendering engines, so some fallback is necessary. The new approach will thus be:
Most of the features above have already been approved and integrated in the development branch or are undergoing review process.
The main point is that everybody can review the patches on Gerrit. If you know about Javascript and/or PHP, if you are interested in math typesetting and wish to get involved in an important Open Source project such as Wikipedia then it is definitely the right time to help the MediaWiki Math project. The article How to become a MediaWiki hacker is a very good introduction.
When getting involved in a new open source project one of the most
important step is to set up the development environment. There are
various ways to setup a local installation of MediaWiki but
using
MediaWiki-Vagrant might be the simplest one: just follow the
Quick Start Guide and use
vagrant enable-role math to
enable the Math Extension.
The second step is to create a WikiTech account and to set up the appropriate SSH keys on your MediaWiki-Vagrant virtual machine. Then you can check the Open Changes, test & review them. The Gerrit code review guide may helpful, here.
If you need more information, you can ask
Moritz
or try to reach people on the
#mediawiki (freenode) or #mathml (mozilla) channels. Thanks in advance for your help!
|
|
Asa Dotzler: What’s Happening with Firefox OS |
This is the first of a weekly series of posts I’ll be doing to highlight the goings on in Firefox OS development. I’m going to start simple, with some recently fixed/implemented bugs/features and we’ll see where it goes from there.
Bug 898354 – [User Story] Timer Notification
Bug 903250 – [Gaia] Support sharing of URLs
Bug 909877 – (gaia-apzc) [meta] Turn on APZC for all of gaia
Bug 929388 – Incorporate a FxA Manager and FxA Client into the System app
Bug 934429 – [Messages] Optimizing the app’s startup path
Bug 935059 – Implement a FOTA update solution for Buri devices
Bug 937713 – [B2G] Display does not respond or responds too slowly to device rotation
Bug 944287 – [UITest] add share URL activity
Bug 944289 – [UITest] add compose Email activity
Bug 947094 – [Calendar] Update tool bar and tab bar designs
Bug 947095 – [Email] Update to new light 1.3 tool bar design
Bug 947097 – [Clock] Update tabs to use the new 1.3 designs
Bug 947099 – [Dialer] Update tab bar to new 1.3 visual designs
Bug 947104 – [Music] Update to new 1.3 tab bar visual design
Bug 947106 – [Browser] Update toolbar in browser to updated 1.3 visual designs
What else would you all like to see in a weekly update?
http://asadotzler.com/2014/01/10/whats-happening-with-firefox-os/
|
|
Julien Vehent: SSL/TLS analysis of the Internet's top 1,000,000 websites |
 It seems that evaluating different SSL/TLS configurations has become a hobby of mine. After publishing Server Side TLS back in October, my participation in discussions around ciphers preferences, key sizes, elliptic curves security etc...has significantly increased (ironically so, since the initial, naive, goal of "Server Side TLS" was to reduce the amount of discussion on this very topic).
It seems that evaluating different SSL/TLS configurations has become a hobby of mine. After publishing Server Side TLS back in October, my participation in discussions around ciphers preferences, key sizes, elliptic curves security etc...has significantly increased (ironically so, since the initial, naive, goal of "Server Side TLS" was to reduce the amount of discussion on this very topic).
More guides are being written on configuring SSL/TLS server side. One that is quickly gaining traction is Better Crypto, which we discussed quite a bit on the dev-tech-crypto mailing list.
People are often passionate about these discussions (and I am no exception). But one item that keeps coming back, is the will to kill deprecated ciphers as fast as possible, even if that means breaking connectivity for some users. I am absolutely against that, and still believe that it is best to keep backward compatibility to all users, even at the cost of maintaining RC4 or 3DES or 1024 DHE keys in our TLS servers.
One question that came up recently, on dev-tech-crypto, is "can we remove RC4 from Firefox entirely ?". One would think that, since Firefox supports all of these other ciphers (AES, AES-GCM, 3DES, Camellia, ...), surely we can remove RC4 without impacting users. But without numbers, it is not an easy decision to make.
Challenge accepted: I took my cipherscan arsenal for a spin, and decided to scan the Internet.
The scanning scripts are on github at https://github.com/jvehent/cipherscan/tree/master/top1m. The results dataset is here: http://4u.1nw.eu/cipherscan_top_1m_alexa_results.tar.xz. Uncompressed, the dataset is around 1.2GB, but XZ does an impressive job at compressing that to a 17MB archive.
I use Alexa's list of top 1,000,000 websites as a source. The script called "testtop1m.sh" scans targets in parallel, with some throttling to limit the numbers of simultaneous scans around 100, and writes the results into the "results" directory. Each target's results are stored in a json file named after the target. Another script named "parse_results.py", walks through the results directory and computes the stats. It's quite basic, really.
It took a little more than 36 hours to run the entire scan. A total of 451,470 websites have been found to have TLS enabled. Out of 1,000,000, that's a 45% ratio.
While not a comprehensive view of the Internet, it carries enough data to estimate the state of SSL/TLS in the real world.
Cipherscan retrieves all supported ciphers on a target server. The listing below shows which ciphers are typically supported, and which ciphers are only supported by some websites. This last item is the most interesting, as it appears that 1.23% of websites only accept 3DES, and 1.56% of websites only accept RC4. This is important data for developers who are considering dropping support for 3DES and RC4.
Noteworthy: there are two people, out there, who, for whatever reason, decided to only enable Camellia on their sites. To you, Sirs, I raise my glass.
The battery of unusual ciphers, prefixed with a 'z' to be listed at the bottom, is quite impressive. The fact that 28% of websites support DES-CBC-SHA clearly outlines the need for better TLS documentation and education.
Supported Ciphers Count Percent -------------------------+---------+------- 3DES 422845 93.6596 3DES Only 5554 1.2302 AES 411990 91.2552 AES Only 404 0.0895 CAMELLIA 170600 37.7877 CAMELLIA Only 2 0.0004 RC4 403683 89.4152 RC4 Only 7042 1.5598 z:ADH-DES-CBC-SHA 918 0.2033 z:ADH-SEED-SHA 633 0.1402 z:AECDH-NULL-SHA 3 0.0007 z:DES-CBC-MD5 55824 12.3649 z:DES-CBC-SHA 125630 27.8269 z:DHE-DSS-SEED-SHA 1 0.0002 z:DHE-RSA-SEED-SHA 77930 17.2614 z:ECDHE-RSA-NULL-SHA 3 0.0007 z:EDH-DSS-DES-CBC-SHA 11 0.0024 z:EDH-RSA-DES-CBC-SHA 118684 26.2883 z:EXP-ADH-DES-CBC-SHA 611 0.1353 z:EXP-DES-CBC-SHA 98680 21.8575 z:EXP-EDH-DSS-DES-CBC-SHA 11 0.0024 z:EXP-EDH-RSA-DES-CBC-SHA 87490 19.3789 z:EXP-RC2-CBC-MD5 105780 23.4301 z:IDEA-CBC-MD5 7300 1.6169 z:IDEA-CBC-SHA 53981 11.9567 z:NULL-MD5 379 0.0839 z:NULL-SHA 377 0.0835 z:NULL-SHA256 9 0.002 z:RC2-CBC-MD5 63510 14.0674 z:SEED-SHA 93993 20.8193
A pleasant surprise, is the percentage of deployment of ECDHE. 21% is not a victory, but an encouraging number for an algorithm that will hopefully replace RSA soon (at least for key negotiation).
DHE, supported since SSLv3, is closed to 60% deployment. We need to bump that number up to 100%, and soon !
Supported Handshakes Count Percent -------------------------+---------+------- DHE 267507 59.2524 ECDHE 97570 21.6116
Perfect Forward Secrecy is all the rage, so evaluating its deployment is most interesting. I am actually triple checking my results to make sure that the percentage below, 75% of websites supporting PFS, is accurate, because it seems so large to me. Even more surprising, is the fact that 61% of tested websites, either prefer, or let the client prefer, a PFS key exchange (DHE or ECDHE) to other ciphers.
As expected, the immense majority, 98%, of DHE keys are 1024 bits. Several reasons to this:
So, while everyone agrees that requiring a RSA modulus of 2048 bits, but using 1024 bits DHE keys, effectively reduces TLS security, there is no solution to this problem right now, other than breaking backward compatibility with old clients.
On ECDHE's side, handshakes almost always use the P-256 curve. Again, this makes sense, since Internet Explorer, Chrome and Firefox only support P256 at the moment. But according to recent research published by DJB & Lange, this might not be the safest choice.
The curve stats below are to take with a grain of salt: Cipherscan uses OpenSSL under the hood, and I am not certain of how OpenSSL elects the curve during the Handshake. This is an area of cipherscan that needs improvement, so don't run away with these numbers just yet.
Supported PFS Count Percent PFS Percent -------------------------+---------+--------+----------- Support PFS 342725 75.9131 Prefer PFS 279430 61.8934 DH,1024bits 262561 58.1569 98.1511 DH,1539bits 1 0.0002 0.0004 DH,2048bits 3899 0.8636 1.4575 DH,3072bits 2 0.0004 0.0007 DH,3248bits 2 0.0004 0.0007 DH,4096bits 144 0.0319 0.0538 DH,512bits 76 0.0168 0.0284 DH,768bits 825 0.1827 0.3084 ECDH,P-256,256bits 96738 21.4273 99.1473 ECDH,B-163,163bits 37 0.0082 0.0379 ECDH,B-233,233bits 295 0.0653 0.3023 ECDH,B-283,282bits 1 0.0002 0.001 ECDH,B-571,570bits 329 0.0729 0.3372 ECDH,P-224,224bits 4 0.0009 0.0041 ECDH,P-384,384bits 108 0.0239 0.1107 ECDH,P-521,521bits 118 0.0261 0.1209
A few surprises in the Protocol scanning: there is still 18.7% of websites that support SSLv2! Seriously, guys, we've been repeating it for years: SSLv2 is severely broken, don't use it!
I particularly appreciate the 38 websites that only accept SSLv2. Nice job.
Also of interest, is the 2.6% of websites that support TLSv1.2, but not TLSv1.1. This would make sense, if the number of TLSv1.2 websites was actually larger than 2.6%, but it isn't (0.001%). So I can only imagine that, for some reason, websites use TLSv1 and TLSv1.2, but not 1.1.
Update: ''harshreality'', on HN, dug up a changelog in OpenSSL that could explain this behavior:
Changes between 1.0.1a and 1.0.1b 26 Apr 2012
- OpenSSL 1.0.0 sets SSL_OP_ALL to 0x80000FFFL and OpenSSL 1.0.1 and 1.0.1a set SSL_OP_NO_TLSv1_1 to 0x00000400L which would unfortunately mean any application compiled against OpenSSL 1.0.0 headers setting SSL_OP_ALL would also set SSL_OP_NO_TLSv1_1, unintentionally disablng TLS 1.1 also. Fix this by changing the value of SSL_OP_NO_TLSv1_1 to 0x10000000L Any application which was previously compiled against OpenSSL 1.0.1 or 1.0.1a headers and which cares about SSL_OP_NO_TLSv1_1 will need to be recompiled as a result.
Unsurprisingly, however, the immense majority supports SSLv3 and TLSv1. Respectively 99.6% and 98.7%. The small percentage of websites that support TLSv1.1 and 1.2 is worrisome, but not surprising.
Systems administrators are hardly to blame, considering the poor support of recent TLS versions in commercial products. Vendors could definitely use a push, so before you renew your next contract, make sure to add TLSv1.2 to your wishlist.
Supported Protocols Count Percent -------------------------+---------+------- SSL2 85447 18.9264 SSL2 Only 38 0.0084 SSL3 449864 99.6443 SSL3 Only 4443 0.9841 TLS1 446575 98.9158 TLS1 Only 736 0.163 TLS1.1 145266 32.1762 TLS1.1 Only 1 0.0002 TLS1.2 149921 33.2073 TLS1.2 Only 5 0.0011 TLS1.2 but not 1.1 11888 2.6332
This is not a comprehensive test. RSA key sizes are not evaluated. Nor are TLS extensions, OCSP Stapling support, and a bunch of features that could be interesting to loop at. Maybe next time.
If this little experiment showed something, it is that old ciphers and protocols are far from dead. Sure, you can decide to kill RC4 and 3DES in your client today, but be aware that a small percentage of the internet will be unreachable to you, and your users.
 What can we do about it? Education is key: TLS is a complex subject, and most administrators and website owners don't have the time and knowledge to dig through dozens of mailing lists and blog posts to find the best configuration choices.
What can we do about it? Education is key: TLS is a complex subject, and most administrators and website owners don't have the time and knowledge to dig through dozens of mailing lists and blog posts to find the best configuration choices.
It is the primary motivation for documents such as Server Side TLS and Better Crypto. Some of us are working on improving these documents. But we need an army to broadcast the message, teach administrators in conferences, mailing lists and user groups, and push websites owners to apply more secure configuration to their websites.
We could use some help: go out there and teach TLS !
|
|
Ben Hearsum: This week (and a half) in Mozilla RelEng – January 10th, 2014 |
http://hearsum.ca/blog/this-week-and-a-half-in-mozilla-releng-january-10th-2014/
|
|
Gervase Markham: Living Flash Free: Part 2 |
I’m trying to live Flash-free on my desktop. In Part 1, I got YouTube and Vimeo working (although the addon I use to make YouTube work seems to make the player bigger than the video sometimes).
The Flash-based Vidyo doesn’t work, of course. When using Vidyo (which Mozilla uses quite a lot), I need to use the Vidyo client. This is not free software, so I’m trying to avoid installing that on my main machine too. Instead, at home, I have a tablet which I use almost exclusively for Vidyo. That’s fine (and also allows me to see and type on my main machine at the same time), but it doesn’t work when I’m on the road, as I was quite a bit in December. So I had to scramble to find some other machine or room with Vidyo support.
I can’t watch Air Mozilla streams live very easily. There are rumours of changes in the works, but for now AirMo live streaming requires Flash. And Flash seems not to be working in Firefox or the stock browser on my tablet, although it is installed. The only workaround is (ironically) if it’s also connected to a Vidyo room, when I can join that. But because Vidyo have not yet implemented our long-open feature request to allow rooms to have participants muted automatically when joining, doing that leads to everyone hearing a “ping!” and getting a brief flash of my face. Which is not ideal.
Some things, I can watch later – AirMo’s archived streaming uses HTML5. But if I want to interact with the presenter or the audience, that’s not an option.
Video doesn’t work on the BBC either, and I’ve not figured out how to make that work yet. The mobile site does UA sniffing to keep out desktop browsers; if you spoof, you can see it, but video won’t play (perhaps it’s using some mobile-OS-specific mechanism). Any ideas welcome.
http://feedproxy.google.com/~r/HackingForChrist/~3/nTnzDW2TsW8/
|
|
Doug Belshaw: Weeknote 02/2014 |
This week I’ve been:
Next week is my only full week left living at our current house, I reckon. I’ve got so much to do (both Mozilla and non-Mozilla stuff) during that time it’s unreal.
Image CC BY-NC-SA Armando G Alonso
|
|
Asa Dotzler: Firefox OS Tablet Contribution Program |
As many of you have heard, we’re launching a developer program to bring Firefox OS up to speed on tablets.
Working with Foxconn, we have first round tablet hardware to develop against, a 10'' device running at 1280x800 resolution with 2GB RAM and b/g/n wireless.

First device for the Firefox OS Tablet Contributor Program
I will have more details on the device and the developer program in the coming days but the big picture is this:
We’ve got a new form factor with a whole range of new challenges, from design to implementation and from the top to the bottom of the software stack.
By making hardware available early and broadly as possible to our global community of contributors, we can tackle those challenges in Mozilla distributed and accelerated fashion.
This program will be looking for help from all of you, with an early focus on the core of the OS (Gecko/GFX, Gaia, UX, Productivity and System Apps) localization, and testing.
Keep your eye on the Hacks blog, and m.d.b2g and m.d.gaia for program news, and most importantly, instructions on how to apply for hardware!
http://asadotzler.com/2014/01/09/firefox-os-tablet-contribution-program/
|
|
William Reynolds: How the Mozilla Reps Portal grew in 2013 |
The Reps Portal, a platform used by our 400 Mozilla Reps to organize and measure activities, continued to be a critical piece to the success of the program in 2013. Here are some of the highlights.
We focused 2013 on preparing the Reps Portal to scale in impact. We built two key features (voting and continuous reporting) to that helped us streamline a slow process and better measure activities. The project made progress towards continuous delivery, which will speed up our development cycles in the future. Technical debt was repaid by upgrading frameworks and libraries and also by refactoring a huge number of tests. We spent a lot of time mentoring people contributing code to the portal. Much planning was also done during our UX Sessions in August, the Remo Camp in September and recent work with the Council to set 2014 development priorities.
The Reps Portal is in a position to become more valuable to Reps and all Mozillians in 2014. More people are contributing to the project, our development cycle is getting faster and we have clear priorities. Technical debt has reduced substantially, and we know where we can continue to improve on the technical side.
http://dailycavalier.com/2014/01/how-the-mozilla-reps-portal-grew-in-2013/
|
|
Fr'ed'eric Harper: Firefox OS love in Toronto |

Yesterday, I was in Toronto to share some Firefox OS love with my Canadian friends. I was invited to speak at a joint meetup with Mobile Startups Toronto, and HTML Toronto. The demo god wasn’t with me as mostly everything went wrong at the beginning, but fortunately, the rest of the presentation has been great, and I was surprised but the number, and the quality of the questions.
As usual, here are my slides:
Thanks to Matthew Potter, my presentation has been recorded.
It’s always a pleasure to come in Toronto, and even more to talk about this amazing OS. Remember, if you build a Firefox OS application or plan to port an actual web application to this platform, please let me know.
--
Firefox OS love in Toronto is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|






