Felipe Gomes: Hello 2014 |
Happy new year everyone! During the holidays I had been thinking about my goals for 2014, and I thought it’d be a good exercise to remember what I’ve done in the past year, the projects I worked on, etc. It’s nice to look back and see what was accomplished last year and think about how to improve it. So here’s my personal list; it doesn’t include everything but it includes the things I found most important:
Related to performance/removing main-thread-IO:
Related to hotfixes:
Related to electrolysis:
Other things:
Events attended:
And:
That’s it. Looking forward to a great 2014!

|
|
Gervase Markham: about:credits – Name Order and Non-ASCII Characters |
The Mozilla project credits those who have “made a significant investment of time, with useful results, into Mozilla project-governed activities”, and who apply for inclusion, in the about:credits list, which appears in every browser product Mozilla has ever made.
Historically, the system of scripts which I used to manage the list were not as internationalized as they could be. In particular, it did not support sorting on a name component other than the last-written one. Also, although I don’t know of technical reasons why this is so, many non-English names are present without the appropriate accents on the letters.
But I’m pleased to say that any issues here are now fixed. So, if your name is not rendered or sorted as you would like on about:credits (either due to name component ordering or lack of accents) please email me and I will correct it for you.
http://feedproxy.google.com/~r/HackingForChrist/~3/gjPhqSm9lzI/
|
|
Gervase Markham: How To Run a Productive Community Discussion |
I ran a session at the Mozilla Summit with the (wordy) title of “Building a Framework to Enable Mozilla to Effectively Communicate Across Our Community”.
The outcome of the Brussels session, cleaned up, was this document which explains how to run a useful and productive community consultation and discussion. So if you propose something to a colleague, they say “you should ask the community about that”, and a cold sweat breaks out on your forehead, this is the document for you.
Many thanks for Zach Beauvais for doing the initial wrangling of the session notes. Feedback on the current document is very welcome.
http://feedproxy.google.com/~r/HackingForChrist/~3/HjOh0SqVhr0/
|
|
Jess Klein: The Participatory Design Culture and Terms of Badges |

- As a badge issuer I might want people to:
- be able to use my badge 'as is' and re-issue it as their own.
- They can re-use the art
- They can re-use the metadata
- They can re-use the badge name
- They can re-use the badge criteria
- be able to 'fork' and modify my badge and re-issue it as their own.
- be able to tweak my badge's metadata
- be able to publicly issue my badge
- be able to only issue the badge privately
- use the badge artwork that I designed
- be able to issue this badge to <13 span="" users="">
- be able to issue this badge with age restrictions
- be able to issue this badge only to >13 users (etc)
- be able to localize the badge
The response from my colleague Michelle Thorne was so strong, I have to add it here: " Please, please, please don't make a new license! It will cause confusion and lack of interoperability. This is more restrictive than all rights reserved. Instead, consider a "badge licensing policy" which suggests how to license and attribute based on existing licensing standards, like Creative Commons."
http://jessicaklein.blogspot.com/2014/01/the-participatory-design-culture-and.html
|
|
Fr'ed'eric Buclin: Bugzilla 5.0 moved to HTML5 |
A quick note to let you know that starting with Bugzilla 4.5.2, which should be released soon (a few weeks at most), it now uses the HTML5 doctype instead of the HTML 4.01 Transitional one. This means that cool new features from HTML5 can now be implemented in the coming Bugzilla 5.0. A lot of cleanup has been required to remove all obsolete HTML elements and attributes, and to move all hardcoded styles into CSS files, and to replace many
http://lpsolit.wordpress.com/2014/01/09/bugzilla-5-0-moved-to-html5/
|
|
Michael Kaply: Can Firefox do this? |
A lot of what I’ve learned about customizing Firefox came from many different people asking me a question like – “Can you do this in Firefox?”
For instance:
Through the research I did into these types of questions, I learned a lot about how Firefox works and how to modify it to meet the needs of various people and organizations. And a lot of what I learned ended up in the new CCK2.
Have you ever asked the question “Can you do this in Firefox?”
What did you want to do?
|
|
Jonas Finnemann Jensen: Custom Telemetry Dashboards |
In the past quarter I’ve been working on analysis of telemetry pings for the telemetry dashboard, I previously outlined the analysis architecture here. Since then I’ve fixed bugs, ported scripts to C++, fixed more bugs and given the telemetry-dashboard a better user-interface with more features. There’s probably still a few bugs around, decent logging is still missing, but data aggregated is fairly stable and I don’t think we’re going to make major API changes anytime soon.
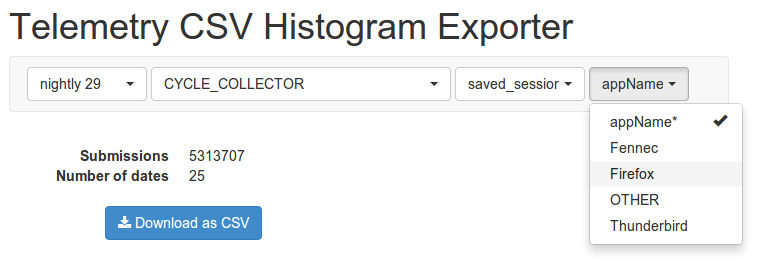
So I think it’s time to let others consume the aggregated histograms, enabling the creation of custom dashboard. In the following sections I’ll demonstrate how to get started with telemetry.js and build a custom filtered dashboard with CSV export.
telemetry.jsOn the server-side the aggregated histograms for a given channel, version and measure is stored in a single JSON file. To reduce storage overhead we use a few tricks, such as translating filter-paths to identifiers, appending statistical fields at the end of a histogram array and computing bucket offsets from specification. This makes the server-side JSON files rather hard to read. Furthermore, we would like the flexibility to change this format, move files to a different server or perhaps do a binary encoding of histograms. To facilitate this, data access is separated from data storage with telemetry.js. This is a Javascript library to be included from telemetry.mozilla.org/v1/telemetry.js. We promise that best efforts will be made to ensure API compatibility of the telemetry.js version hosted at telemetry.mozilla.org.
I’ve used telemetry.js to create the primary dashboard hosted at telemetry.mozilla.org, so the API grants access to the data used here. I ‘ve also written extensive documentation for telemetry.js. To get you started consuming the aggregates presented on the telemetry dashboard, I’ve posted the snippet below to a jsfiddle. The code initializes telemetry.js, then proceeds load the evolution of a measure over build dates. Once loaded the code prints a histogram for each build date of the 'CYCLE_COLLECTOR' measure within 'nightly/27'. Feel free to give it a try…
Telemetry.init(function() { Telemetry.loadEvolutionOverBuilds( 'nightly/28', // from Telemetry.versions() 'CYCLE_COLLECTOR', // From Telemetry.measures('nightly/28', callback) function(histogramEvolution) { histogramEvolution.each(function(date, histogram) { print("--------------------------------"); print("Date: " + date); print("Submissions: " + histogram.submissions()); histogram.each(function(count, start, end) { print(count + " hits between " + start + " and " + end); }); }); } ); });
Warning: the channel/version string and measure string shouldn’t be hardcoded. The list of channel/versions available is returned by Telemetry.versions() and Telemetry.measure('nightly/27', callback) invokes callback with a JSON object of measures available for the given version/channel (See documentation). I understand that it can be tempting to hardcode these values for some special dashboard, and while we don’t plan to remove data, it would be smart to test that the data is available and show a warning if not. Channel, version and measure names may be subject to change as they are changed in the repository.
telemetry.jquery.jsOne of the really boring and hard-to-get-right parts of the telemetry dashboard is the list of selectors used to filter histograms. Luckily, the user-interface logic for selecting channel, version, measure and applying filters is implemented as a reusable jQuery widget called telemetry.jquery.js. There’s no dependency on jQuery UI, just jquery.ui.widget.js which contains the jQuery widget factory. This library makes it very easy to write a custom dashboard if you just want write the part that presents a filtered histogram.
The snippet below shows how to create a histogramfilter widget and bind to the histogramfilterchange event, which is fired whenever the selected histogram is changed and loaded. With this setup you don’t need to worry about loading, filtering or maintaining state as the synchronizeStateWithHash option sets the filter-path as window.location.hash. If you want to have multiple instances of the histogramfilter widget, you might want to disable the synchronizeStateWithHash option, and read the state directly instead, see jQuery stateful plugins tutorial for how to get/set a option like state dynamically.
Telemetry.init(function() { // Create histogram-filter from jquery.telemetry.js $('#filters').histogramfilter({ // Synchronize selected histogram with window.location.hash synchronizeStateWithHash: true, // This demo fetches histograms aggregated by build date evolutionOver: 'Builds' }); // Listen for histogram-filter changes $('#filters').bind('histogramfilterchange', function(event, data) { // Check if histogram is loaded if (data.histogram) { update(data.histogram); } else { // If data.histogram is null, then we're loading... } }); });
The options for histogramfilter is will documented in the source for telemetry.jquery.js. This file can be found in the telemetry-dashboard repository, but it should be distributed with custom dashboards, as backwards compatibility isn’t a priority for this library. There is a few extra features hidden in telemetry.jquery.js, which let’s you implement custom elements, choose useful defaults, change behavior, limit available histogram kinds and a few other things.
|
|
Gregory Szorc: Why do Projects Support old Python Releases |
I see a number of open source projects supporting old versions of Python. Mercurial supports 2.4, for example. I have to ask: why do projects continue to support old Python releases?
Consider:
Given these facts, I'm not sure why projects insist on supporting old and end-of-lifed Python releases.
I think maintainers of Python projects should seriously consider dropping support for Python 2.6 and below. Are there really that many people on systems that don't have Python 2.7 easily available? Why are we Python developers inflicting so much pain on ourselves to support antiquated Python releases?
As a data point, I successfully transitioned Firefox's build system from requiring Python 2.5+ to 2.7.3+ and it was relatively pain free. Sure, a few people complained. But as far as I know, not very many new developers are coming in and complaining about the requirement. If we can do it with a few thousand developers, I'm guessing your project can as well.
Update 2014-01-09 16:05:00 PST: This post is being discussed on Slashdot. A lot of the comments talk about Python 3. Python 3 is its own set of considerations. The intended focus of this post is strictly about dropping support for Python 2.6 and below. Python 3 is related in that porting Python 2.x to Python 3 is much easier the higher the Python 2.x version. This especially holds true when you want to write Python that works simultaneously in both 2.x and 3.x.
http://gregoryszorc.com/blog/2014/01/08/why-do-projects-support-old-python-releases
|
|
Fr'ed'eric Harper: Trace a line between the web, and your private life |

Creative Commons: http://j.mp/1cB9LKZ
People often tell me that I share a lot of things on the Web: it’s true. As weird as it seems to some people, I traced a line between my private life, and what I’m sharing online.
It’s important in today’s world to trace a line between your personal life, and the web itself. With services like Facebook, Twitter, Flickr, Instagram, and more, it has never been so easy to share every little moment of your life with friends, family, but also with strangers. I won’t talk about the privacy rights (or not) on these websites as I’m not an expert on this topic, but the truth is that mostly everything you put on the web, will probably live there forever (kind of), and someone, somewhere, will have access to it. Don’t get me wrong, I like the web, but I used to tell people that if you want something to stay private, just don’t put it on the web (even if you carefully set the privacy settings, and targeted who will see what you want to share).
My rule is quite simple as there are few things I don’t want to share online: I don’t want people to know where I’m living (neighborhood is ok), and I don’t want people to have my phone number (I hate this way of communicating, too intrusive for me). This is my line between privacy, and the web… what is yours?
--
Trace a line between the web, and your private life is a post on Out of Comfort Zone from Fr'ed'eric Harper
Related posts:
|
|
Selena Deckelmann: My nerd story: it ran in the family, but wasn’t inevitable |
This is about how I came to identify as a hacker. It was inspired by Crystal Beasley’s post. This is unfortunately also related to recent sexist comments from a Silicon Valley VC about the lack of women hackers. I won’t bother to hate-link, as others have covered his statements fully elsewhere.
I’ve written and talked about my path into the tech industry before, and my thoughts about how to get more women involved. But I didn’t really ever start the story where it probably should have been started: in my grandfather’s back yard.

I spent the first few years of my life in Libby, MT. Home of the Libby Dam, an asbestos mine and loggers. My grandfather, Bob, was a TV repairman in this very remote part of Montana. He was also a bit of a packrat.
I can still picture the backyard in my mind — a warren of pathways through busted up TVs, circuit boards, radios, transistors, metal scrap, wood and hundreds of discarded appliances that Grandpa would find broken and eventually would fix.
His garage was similarly cramped — filled with baby jars, coffee cans and bizarre containers of electronic stuff, carefully sorted. Grandpa was a Ham, so was my uncle and Grandma. I don’t remember exactly when it happened, but at some point my uncle taught me Morse code. I can remember writing notes full of dots and dashes and being incredibly excited to learn a code and to have the ability to write secret messages.
I remember soldering irons and magnifying lens attachments to glasses. We had welding equipment and so many tools. And tons of repaired gadgets, rescued from people who thought they were dead for good.
Later, we had a 286 and then a 386 in the house. KayPro, I think, was the model. I’d take off the case and peer at the dust bunnies and giant motherboard of that computer. I had no idea what the parts were back then, but it looked interesting, a lot like the TV boards I’d seen in piles when I was little.
I never really experimented with software or hardware and computers as a kid. I was an avid user of software. Which, is something of a prelude to my first 10 years of my professional life as a sysadmin. I’m a programmer now, but troubleshooting and dissecting other people’s software problems still feels the most natural.
Every floppy disk we had was explored. I played Dig Dug and Mad Libs on an Apple IIe like a champ. I mastered PrintShop and 8-in-1, the Office-equivalent suite we had at the time. And if something went wrong with our daisy wheel printer, I was on it – troubleshooting paper jams, ribbon outages and stuck keys.
My stepdad was a welder, and he tried to get me interested in mechanical things (learning how to change the oil in my car was a point of argument in our family). But, to be honest, I really wasn’t that into it beyond fixing paper jams so that I could get a huge banner printed out.
I was good at pretty much all subjects in school apart from spelling and gym class. I LOVED to read — spending all my spare time at the local library for many years, and then consuming books (sometimes two a day) in high school. My focus was: get excellent grades, get a scholarship, get out of Montana.
And there were obstacles. We moved around pretty often, and my new schools didn’t always believe that I’d taken certain classes, or that grades I’d gotten were legit. I had school counselors tell me that I shouldn’t take math unless I planned “to become a mathematician.” I was required to double up on math classes to “make up” algebra and pre-algebra I’d taken one and two years earlier. I gave and got a lot of shit from older kids in classes because I was immature and a smartass. I got beat up on buses, again because I was a smartass and had a limited sense of self-preservation.
The two kids I knew who were into computers in high school were really, really nerdy. I was awkward, in Orchestra, and didn’t wear the kind of cool girl clothes you need to make it socially. I wasn’t exactly at the bottom of the social heap, but I was pretty close for most of high school. And avoiding those kids who hung out after school in the computer lab was something I knew to do to save myself social torture.
Every time I hear people say that all we need to do is offer computer science classes to get more girls coding, I remember myself at that age, and exactly what I knew would happen to me socially if I openly showed an interest in computers.
I lucked out my first year in college. I met a guy in my dorm who introduced me to HTML and the web in 1994. He spent hours telling me story after story about kids hacking hotel software and stealing long distance. He introduced me to Phrack and 2600. He and his friends helped me build my first computer. I remember friends saying stuff to me like, “You really did that?” at the time. Putting things together seemed perfectly natural and fun, given my childhood spent around family doing exactly the same thing.
It took two more years before I decided that I wanted to learn how to program, and that I maybe wanted to get a job doing computer-related work after college. What I do now has everything to do with those first few months in 1994 when I just couldn’t tear myself away from the early web, or the friends I made who all did the same thing.
Jen posted an awesome chart of her nerd story. I made one sorta like it, but couldn’t manage to make it as terse.

Whether it was to try and pursue a music performance career after my violin teacher encouraged me, starting out as a chemistry major after a favorite science teacher in high school told me I should, or moving into computer science after several years of loving, mischievous fun with a little band of hackers; what made the difference in each of these major life decisions was mentorship and guidance from people I cared about.
Maybe that’s a no-brainer to people reading this. I say it because sometimes people think that we come to our decisions about what we do with our lives in a vacuum. That destiny or natural affinity are mostly at work. I’m one anecdata point against destiny being at work, and I have heard lots of stories like mine. Especially from new PyLadies.
Not everyone is like me, but I think plenty of people are. And those people who are like me — who could have picked one of many careers, who like computers but weren’t in love or obsessed with them at a young age — could really use role models, fun projects and social environments that are low-risk in middle school, high school and college. And as adults.
Making that happen isn’t easy, but it’s worth sharing our enthusiasm and creating spaces safe for all kinds of people to explore geeky stuff.
Thanks to an early childhood enjoyment of electronics and the thoughtfulness of a few young men in 1994, I became the open source hacker I am today.
|
|
Christian Heilmann: This developer wanted to create a language selector and asked for help on Twitter. You won’t believe what happened next! |
Hey, it works for Upworthy, right?
Yesterday in a weak moment Dhananjay Garg asked me on Twitter to help him with a coding issue and I had some time to do that. Here’s a quick write-up of what I created and why.
Dhananjay had posted his problem on StackOverflow and promptly got an answer that wasn’t really solving or explaining the issue, but at least linked to W3Schools to make matters worse (no, I am not bitter about the success of either resource).
The problem was solved, yes (assignment instead of comparison – = instead of === ) but the code was still far from efficient or easily maintainable which was something he asked about.
The thing Dhananjay wanted to achieve was to have a language selector for a web site that would redirect to documents in different languages and store the currently selected one in localStorage to redirect automatically on subsequent visits. The example posted has lots and lots of repetition in it:
function english() { if(typeof(Storage)!=="undefined") { localStorage.clear(); localStorage.language="English"; window.location.reload(); } } function french() { if(typeof(Storage)!=="undefined") { localStorage.clear(); localStorage.language="French"; window.location.href = "french.html"; } } window.onload = function() { if (localStorage.language === "Language") { window.location.href = "language.html"; } else if (localStorage.language === "English") { window.location.href = "eng.html"; } else if (localStorage.language === "French") { window.location.href = "french.html"; } else if (localStorage.language === "Spanish") { window.location.href = "spanish.html"; } |
This would be done for 12 languages, meaning you’ll have 12 functions all doing the same with different values assigned to the same property. That’s the first issue here, we have parameters on functions to avoid this. Instead of having a function for each language, you write a generic one:
function setLanguage(language, url) { localStorage.clear(); localStorage.language = language; window.location.href = url; } } |
Then you could call for example setLanguage(‘French’, ‘french.html’) to set the language to French and do a redirect. However, it seems dangerous to clear the whole of localStorage every time when you simply redefine one of its properties.
The onload handler reading from localStorage and redirecting accordingly is again riddled with repetition. The main issue I see here is that both the language values and the URLs to redirect to are hard-coded and a repetition of what has been defined in the functions setting the respective languages. This would make it easy to make a mistake as you repeat values.
Assuming we really want to do this in JavaScript (I’d probably do a .htaccess re-write on a GET parameter and use a cookie) here’s the solution I came up with.
First of all, text links to set a language seem odd as a choice and do take up a lot of space. This is why I decided to go with a select box instead. As our functionality is dependent on JavaScript to work, I do not create any static HTML at all but just use a placeholder form in the document to add our language selector to:
span> id="languageselect">> |
Instead of repeating the same information in the part of setting the language and reading out which one has been set onload, I store the information in one singular object:
var locales = { 'us': {label: 'English',location:'english.html'}, 'de': {label: 'German',location: 'german.html'}, 'fr': {label: 'Francais',location: 'french.html'}, 'nl': {label: 'Nederlands',location: 'dutch.html'} }; |
I also create locale strings instead of using the name of the language as the condition. This makes it much easier to later on change the label of the language.
This is generally always a good plan. If you find yourself doing lots of “if – else if” in your code use an object instead. That way to get to the information all you need to do is test if the property exists in your object. In this case:
if (locales['de']) { // or locales.de - the bracket allows for spaces console.log(locales.de.label) // -> "German" } |
The rest is then all about using that data to populate the select box options and to create an accessible form. I explained in the comments what is going on:
// let's not leave globals (function(){ // when the browser knows about local storage… if ('localStorage' in window) { // Define a single object to hold all the locale // information - notice that it is a good idea // to go for a language code as the key instead of // the text that is displayed to allow for spaces // and all kind of special characters var locales = { 'us': {label: 'English',location:'english.html'}, 'de': {label: 'German',location: 'german.html'}, 'fr': {label: 'Francais',location: 'french.html'}, 'nl': {label: 'Nederlands',location: 'dutch.html'} }; // get the current locale. If nothing is stored in // localStorage, preset it to 'en' var currentlocale = window.localStorage.locale || 'en'; // Grab the form element var selectorContainer = document.querySelector('#languageselect'); // Add a label for the select box - this is important // for accessibility selectorContainer.innerHTML = '+ 'Select Language'; // Create a select box var selector = document.createElement('select'); selector.name = 'language'; selector.id = 'languageselectdd'; var html = ''; // Loop over all the locales and put the right data into // the options. If the locale matches the current one, // add a selected attribute to the option for (var i in locales) { var selected = (i === currentlocale) ? 'selected' : ''; html += 'i+'" '+selected+'>'+ locales[i].label+''; } // Set the options of the select box and add it to the // form selector.innerHTML = html; selectorContainer.appendChild(selector); // Finish the form HTML with a submit button selectorContainer.innerHTML += ''; // When the form gets submitted… selectorContainer.addEventListener('submit', function(ev) { // grab the currently selected option's value var currentlocale = this.querySelector('select').value; // Store it in local storage as 'locale' window.localStorage.locale = currentlocale; // …and redirect to the document defined in the locale object alert('Redirect to: '+locales[currentlocale].location); //window.location = locales[currentlocale].location; // don't send the form ev.preventDefault(); }, false); } })(); |
Surely there are different ways to achieve the same, but the important part here is that an object is a great way to store information like this and simplify the whole process. If you want to add a language now, all you need to do is to modify the locales object. Everything is maintained in one place.
|
|
Robert Nyman: Geek Meet January 2014 with Ade Oshineye |
All seats have been taken. Please write a comment to be put on a waiting list, there are always a number of cancellations, so there’s still a chance.
It’s finally time for another Geek Meet! Man, it’s been a while, but now it’s actually happening again!
I’m proud to introduce Ade Oshineye (Twitter, Google+), Developer Advocate at Google. I’ve had the pleasure of seeing Ade present and to learn from him, and happy to have him come to Stockholm and talk at Geek Meet.
He works on the stack of protocols, standards and APIs that power the social web, which in practice means looking after the Google+ APIs and +1 button with a focus on Europe, Middle East and Africa (EMEA). He’s also the co-author of O’Reilly’s “Apprenticeship Patterns: Guidance for the aspiring software craftsman” and part of the small team behind http://developerexperience.org/, which is an attempt to successfully apply the techniques of user experience professionals to products and tools for developers.
Ade will give two presentations during the evening:
In this talk he will explore the problem of cross-context user journeys. These are user journeys which cross devices (imagine starting your shopping list on your home machine and finishing it on your work computer), contexts (for example desktop to mobile or app to web site) and platforms (a user with an Android phone and an iPad).
He’ll show you how:
In this talk he’ll show you how to use Youtube watch history and the Freebase ontology to build a simple recommendation system. We’ll walk through the code for the system and talk about how you can build similar things using these datasets and datasets you already own.
This Geek Meet will be sponsored by Creuna, and will take place January 30th at 18:00 in their office at Kungsholmsgatan 23 in Stockholm. Creuna will also provide beer/wine and pizza to every attendee, all free of charge.
Please sign up with a comment below. Please only sign up if you know you can attend. There are 150 seats available, and you can only sign up yourself. Please use a valid name and e-mail address, since this will be used to identify you at the event to get in.
Geek Meet is available in a number of channels:
The hash tag used is #geekmeetsthlm.
All seats have been taken. Please write a comment to be put on a waiting list, there are always a number of cancellations, so there’s still a chance.
|
|
James Long: Stop Writing JavaScript Compilers! Make Macros Instead |
The past several years have been kind to JavaScript. What was once a mediocre language plagued with political stagnation is now thriving with an incredible platform, a massive and passionate community, and a working standardization process that moves quickly. The web is the main reason for this, but node.js certainly has played its part.
ES6, or Harmony, is the next batch of improvements to JavaScript. It is near finalization, meaning that all interested parties have mostly agreed on what is accepted. It's more than just a new standard; Chrome and Firefox have already implemented a lot of ES6 like generators, let declarations, and more. It really is happening, and the process that ES6 has gone through will pave the way for quicker, smaller improvements to JavaScript in the future.
There is much to be excited about in ES6. But the thing I am most excited about is not in ES6 at all. It is a humble little library called sweet.js.
Sweet.js implements macros for JavaScript. Stay with me here. Macros are widely abused or badly implemented so many of you may be in shock right now. Is this really a good idea?
Yes, it is, and I hope this post explains why.
There are lots of different notions of "macros" so let's get that out of the way first. When I say macro I mean the ability to define small things that can syntactically parse and transform code around them.
C calls these strange things that look like #define foo 5 macros, but they really aren't macros like we want. It's a bastardized system that essentially opens up a text file, does a search-and-replace, and saves. It completely ignores the actual structure of the code so they are pointless except for a few trivial things. Many languages copy this feature and claim to have "macros" but they are extremely difficult and limiting to work with.
Real macros were born from Lisp in the 1970's with defmacro (and these were based on decades of previous research, but Lisp popularized the concept). It's shocking how often good ideas have roots back into papers from the 70s and 80s, and even specifically from Lisp itself. It was a natural step for Lisp because Lisp code has exactly the same syntax as its data structures. This means it's easy to throw data and code around and change its meaning.
Lisp went on to prove that macros fundamentally change the ecosystem of the language, and it's no surprise that newer languages have worked hard to include them.
However, it's a whole lot harder to do that kind of stuff in other languages that have a lot more syntax (like JavaScript). The naive approach would make a function that takes an AST, but ASTs are really cumbersome to work with, and at that point you might as well just write a compiler. Luckily, a lot of research recently has solved this problem and real Lisp-style macros have been included in newer languages like julia and rust.
And now, JavaScript.
This post is not a tutorial on JavaScript macros. This post intends to explain how they could radically improve JavaScript's evolution. But I think I need to provide a little meat first for people who have never seen macros before.
Macros for languages that have a lot of special syntax take advantage of pattern matching. The idea is that you define a macro with a name and a list of patterns. Whenever that name is invoked, at compile-time the code is matched and expanded.
macro define {
rule { $x } => {
var $x
}
rule { $x = $expr } => {
var $x = $expr
}
}
define y;
define y = 5;
The above code expands to:
var y;
var y = 5;
when run through the sweet.js compiler.
When the compiler hits define, it invokes the macro and runs each rule against the code after it. When a pattern is matched, it returns the code within the rule. You can bind identifiers & expressions within the matching pattern and use them within the code (typically prefixed with $) and sweet.js will replace them with whatever was matched in the original pattern.
We could have written a lot more code within the rule for more advanced macros. However, you start to see a problem when you actually use this: if you introduce new variables in the expanded code, it's easy to clobber existing ones. For example:
macro swap {
rule { ($x, $y) } => {
var tmp = $x;
$x = $y;
$y = tmp;
}
}
var foo = 5;
var tmp = 6;
swap(foo, tmp);
swap looks like a function call but note how the macro actually matches on the parentheses and 2 arguments. It might be expanded into this:
var foo = 5;
var tmp = 6;
var tmp = foo;
foo = tmp;
tmp = tmp;
The tmp created from the macro collides with my local tmp. This is a serious problem, but macros solve this by implementing hygiene. Basically they track the scope of variables during expansion and rename them to maintain the correct scope. Sweet.js fully implements hygiene so it never generates the code you see above. It would actually generate this:
var foo = 5;
var tmp$1 = 6;
var tmp$2 = foo;
foo = tmp$1;
tmp$1 = tmp$2;
It looks a little ugly, but notice how two different tmp variables are created. This makes it extremely powerful to create complex macros elegantly.
But what if you want to intentionally break hygiene? Or what you want to process certain forms of code that are too difficult for pattern matching? This is rare, but you can do this with something called case macros. With these macros, actual JavaScript code is run at expand-time and you can do anything you want.
macro rand {
case { _ $x } => {
var r = Math.random();
letstx $r = [makeValue(r)];
return #{ var $x = $r }
}
}
rand x;
The above would expand to:
var x$246 = 0.8367501533161177;
Of course, it would expand to a different random number every time. With case macros, you use case instead of rule and code within the case is run at expand-time and you use #{} to create "templates" that construct code just like the rule in the other macros. I'm not going to go deeper into this now, but I will be posting tutorials in the future so follow my blog if you want to here more about how to write these.
These examples are trivial but hopefully show that you can hook into the compilation phase easily and do really powerful things.
One thing I like about the JavaScript community is that they aren't afraid of compilers. There are a wealth of libraries for parsing, inspecting, and transforming JavaScript, and people are doing awesome things with them.
Except that doesn't really work for extending JavaScript.
Here's why: it splits the community. If project A implements an extension to JavaScript and project B implements a different extension, I have to choose between them. If I use project A's compiler to try to parse code from project B, it will error.
Additionally, each project will have a completely different build process and having to learn a new one every time I want to try out a new extension is terrible (the result is that fewer people try out cool projects, and fewer cool projects are written). I use Grunt, so every damn time I need to write a grunt task for a project if one doesn't exist already.
For example, traceur is a really cool project that compiles a lot of ES6 features into simple ES5. However, it only has limited support for generators. Let's say I wanted to use regenerator instead, since it's much more awesome at compiling yield expressions.
I can't reliably do that because traceur might implement ES6 features that regenerator's compiler doesn't know about.
Now, for ES6 features we kind of get lucky because it is a standard and compilers like esprima have included support for the new syntax, so lots of projects will recognize it. But passing code through multiple compilers is just not a good idea. Not only is it slower, it's not reliable and the toolchain is incredibly complicated.
The process looks like this:
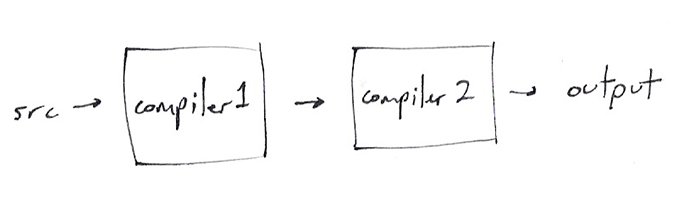
I don't think anyone is actually doing this because it doesn't compose. The result is that we have big monolothic compilers and we're forced to choose between them.
Using macros, it would look more like this:
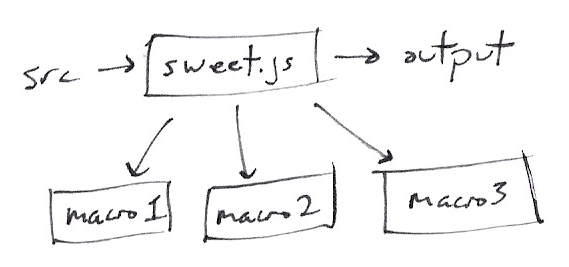
There's only one build step, and we tell sweet.js which modules to load and in what order. sweet.js registers all of the loaded macros and expands your code with all them.
You can setup an ideal workflow for your project. This is my current setup: I configure grunt to run sweet.js on all my server-side and client-side js (see my gruntfile). I run grunt watch whenever I want to develop, and whenever a change is made grunt compiles that file automatically with sourcemaps. If I see a cool new macro somebody wrote, I just npm install it and tell sweet.js to load it in my gruntfile, and it's available. Note that for all macros, good sourcemaps are generated, so debugging works naturally.
Think about that. Imagine being able to pull in extensions to JavaScript that easily. What if TC39 actually introduced future JavaScript enhancements as macros? What if JavaScript actually adopted macros natively so that we never even had to run the build step?
This could potentially loosen the shackles of JavaScript to legacy codebases and a slow standardization process. If you can opt-in to language features piecemeal, you give the community a lot of power to be a part of the conversation since they can make those features.
Speaking of which, ES6 is a great place to start. Features like destructuring and classes are purely syntactical improvements, but are far from widely implemented. I am working on a es6-macros project which implements a lot of ES6 features as macros. You can pick and choose which features you want and start using ES6 today, as well as any other macros like Nate Faubion's execellent pattern matching library.
A good example of this is in Clojure, the core.async library offers a few operators that are actually macros. When a go block is hit, a macro is invoked that completely transforms the code to a state machine. They were able to implement something similar to generators, which lets you pause and resume code, as a library because of macros (the core language doesn't know anything about it).
Of course, not everything can be a macro. The ECMA standardization process will always be needed and certain things require native implementations to expose complex functionality. But I would argue that a large part of improvements to JavaScript that people want could easily be implemented as macros.
That's why I'm excited about sweet.js. Keep in mind it is still in early stages but it is actively being worked on. I will teach you how to write macros in the next few blog posts, so please follow my blog if you are interested.
(Thanks to Tim Disney and Nate Faubion for reviewing this)
http://jlongster.com/Stop-Writing-JavaScript-Compilers--Make-Macros-Instead
|
|
Mike Hommey: Shared compilation cache experiment |
One known way to make compilation faster is to use ccache. Mozilla release engineering builds use it. In many cases, though, it’s not very helpful on developer local builds. As usual, your mileage may vary.
Anyways, one of the sad realizations on release engineering builds is that the ccache hit rate is awfully low for most Linux builds. Much lower than for Mac builds. According to data I gathered a couple months ago on mozilla-inbound, only about a quarter of the Linux builds have a ccache hit rate greater than 50% while more than half the Mac builds have such a hit rate.
A plausible hypothesis for most of this problem is that the number of build slaves being greater on Linux, a build is less likely to occur on a slave that has a recent build in cache. And while better, the Mac cache hit rates were not really great either. That’s due to the fact that consecutive pushes, that share like > 99% code in common, are most usually not built on the same slave.
With this in mind, at Taras’s request, I started experimenting, before the holiday break, with sharing the ccache contents. Since a lot of our builds are running on Amazon Web Services (AWS), it made sense to run the experiment with S3.
After setting up some AWS instances as custom builders (more on this in a subsequent post) with specs similar to what we use for build slaves, I took past try pushes and replayed them on my builder instances, with a proof of concept, crude implementation of ccache-like compilation caching on S3. Both the build times and cache hit rate looked very promising. Unfortunately, I didn’t get the corresponding try build stats at the time, and it turns out the logs are now gone from the FTP server, so I had to rerun the experiment yesterday, against what was available, which is the try logs from the past two weeks.
So, I ran 629 new linux64 opt builds using between 30 and 60 builders. Which ended up being too much because the corresponding try pushes didn’t all trigger linux64 opt builds. Only 311 of them did. I didn’t start this run with a fresh compilation cache, but obviously, so do try builders, so it’s fair game. Of my 629 builds, 50 failed. Most of those failures were due to problems in the corresponding try pushes. But a few were problems with S3 that I didn’t handle in the PoC (sometimes downloading from S3 fails for some reason, and that would break the build instead of falling back to compiling locally), or with something fishy happening with the way I set things up.
Of the 311 builds on try, 23 failed. Of those 288 successful builds, 8 lack ccache stats, because in some cases (like a failure during “make check”) the ccache stats are not printed. Interestingly, only 81 of the successful builds ran on AWS, while 207 ran on Mozilla-owned machines. This unfortunately makes build time comparisons harder.
With that being said, here is how cache hit rates compare between non-AWS build slaves using ccache, AWS build slaves using ccache and my AWS builders using shared cache:
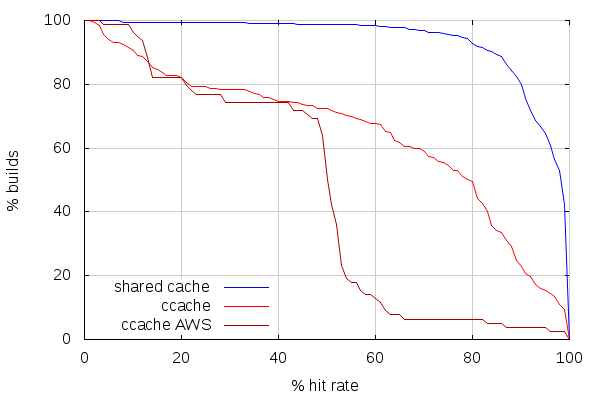
The first thing to note here is that this quite doesn’t match my observations from a few months ago on mozilla-inbound. But that could very be related to the fact that try and mozilla-inbound pushes have different patterns.
The second thing to note is how few builds have more than 50% hit rate on AWS build slaves. A possible explanation is that AWS instances are started with a prefilled but old ccache (because looking at the complete stats shows the ccache storage is almost full), and that a lot of those AWS slaves are new (we recently switched to using spot instances). It would be worth checking the stats again after a week of try builds.
While better, non-AWS slaves are still far from efficient. But the crude shared cache PoC shows very good hit rates. In fact, it turns out most if not all builds with less than 50% hit rate are PGO or non-unified builds. As most builds are neither, the cache hit rate for the first few of those is low.
This shows another advantage of the shared cache: a new slave doesn’t have to do slow builds before doing faster builds. It gets the same cache hit rate as slaves that have been running for longer. Which, on AWS, means we could actually shutdown slaves during low activity periods, without worrying about losing the cache data on ephemeral storage.
With such good hit rates, we can expect good build times. Sadly, the low number of high ccache hit rate builds on AWS slaves makes the comparison hard. Again, coming back with new stats in a week or two should make for better numbers to compare against.
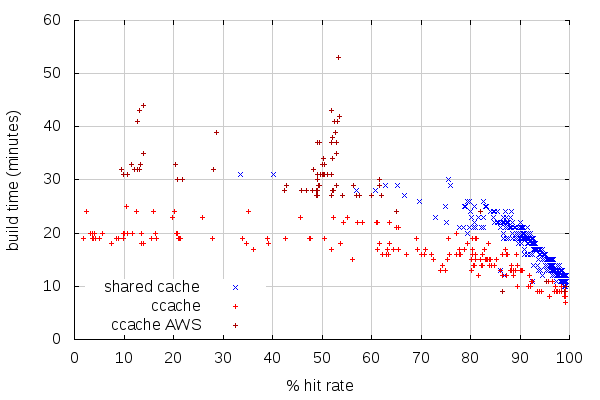
(Note that I removed, from this graph, non-unified and PGO builds, which have very different build times)
At first glance, it would seem builds with the shared cache are slower, but there are a number of factors to take into account:
This is reflected on average build times: with shared cache, it is 14:20, while it is 15:27 with ccache on non-AWS slaves. And the average build time for AWS slaves with ccache is… 31:35. Overall, the average build time on try, with AWS and non-AWS build slaves, is 20:03. So on average, shared cache is a win over any setup we’re currently using.
Now, I need to mention that when I say the shared cache implementation I used is crude, I do mean it. For instance, it doesn’t re-emit warnings like ccache does. But more importantly, it’s not compressing anything, which makes its bandwidth use very high, likely making things slower than they could be.
I’ll follow-up with hopefully better stats in the coming weeks. I may gather stats for inbound, as well. I’ll also likely test the same approach with Windows builds some time soon.
|
|
Jeff Griffiths: (de) centralization |

I'm a big fan of Zombie movies and comics. I suspect I am not alone in this, Zombies have never been more popular than they are right now. One of my favourite parts about these movies is how they typically end: a small group of survivors in a post-apocalyptic wasteland, scrappily starting to build a new civilization amongst the rubble of the old.
Being a nerd, it's a fun thought experiment to wonder how a world in this state would use the technology all around them and communicate, re-build the internet, re-connect with each other. What would the web look like?
This low-power future implies a lot about the devices we'd be using. Low power mobile devices might be the only thing we could run - all these data centers running Twitter & Facebook would go dark after a few weeks. Imagine this scene: a small encampment of survivors generating power using improvised hydroelectric from a small river, charging deep cycle marine batteries and using power inverters to power a minimum number of AC devices.
The good news is that as a survivor you wouldn't be short on entertainment. Just raid a nearby Walmart / Bestbuy and you've have all the movies you'd want. Power any laptop or tablet from your dodgy bicycle-powered generators or batteries, and you've got movie night to keep you sane in a world gone mad!
Communications would be much harder. All the equipment required to run our modern mobile data networks is completely dependant on high-power infrastructure. Like with power we would need to improvise, fall back on sneakernet meetups, shortwave radio for voice communications, eventually longer range wireless tech like WiMAX. We'd need software that's just as home being offline as it is syncing local changes to remote data.
Interestingly enough, this idea of 'offline first' apps and eventually consistent data is exacly what we need for mobile web apps right now. The toolset you would need to provide service with relatively unreliable infrastructure is basically what's described by the 'offline first' project:
It strikes me that the conditions we imagine for ourselves in a post-apocalyptic world aren't that different than thouse that exist right now in 3rd and 2nd world countries, after a natural disaster or even on certain networks in the heart of Silicon Valley ( I'm looking at you AT&T ). The tools we deliver to these environments would be no different, and having our apps and data handle bad networks just makes sense given how bad networks can be even when there isn't a disaster happening.
|
|
Gregory Szorc: On Multiple Patches in Bugs |
There is a common practice at Mozilla for developing patches with multiple parts. Nothing wrong with that. In fact, I think it's a best practice:
There are some downsides to multiple, smaller patches:
Anyway, the prevailing practice at Mozilla seems to be that multiple patches related to the same logical change are attached to the same bug. I would like to challenge the effectiveness of this practice.
Given:
I therefore argue that attaching multiple reviews to a single Bugzilla bug is not a best practice and it should be avoided if possible. If that means filing separate bugs for each patch, so be it. That process can be automated. Tools like bzexport already do it. Alternatively (and even better IMO), we ditch Bugzilla's code review interface (Splinter) and integrate something like ReviewBoard instead. We limit Bugzilla to tracking, high-level discussion, and metadata aggregation. Code review happens elsewhere, without all the clutter and chaos that Bugzilla brings to the table.
Thoughts?
http://gregoryszorc.com/blog/2014/01/07/on-multiple-patches-in-bugs
|
|
Christian Heilmann: Finding real happiness in our jobs |
Want to comment? There are threads on Google+ and Facebook
It is 2014 and you are reading a post that will be talk at a web development conference. We’re lucky. We are super lucky. We are part of an elite group of people who are in a market where companies come to court us. We are in a position to say no to some contracts and we are so tainted by now that we complain when companies we work for have lesser variety in the free lunches – things that proverbially don’t exist – than the other companies we hear about.

I’ve talked about this before in my “Reasons to be cheerful” and “The prestige of being a web developer” presentations and I stand by my word: there is nothing more exciting in IT than being a web developer. It is the only platform that has the openness, the decentralisation and the ever constant evolution that is necessary to meet the demands of people out there when it comes to interacting with computers. All of this, however, relies on things we seem to have forgotten about: longevity, reaching who we work for and constantly improving the platform we are dependent on.
What do I mean by that? Well, I am disappointed. When the web came about and became widely available – even at a 56k connection – it was a revolution. It blew everything that came before it away:
It was a shock to the system, a world-wide distribution platform and everybody was invited. It scared the hell out of old-school publishers and it still scares the hell out of governments and other people who’d like to keep information controlled and maybe even hidden. Much like the printing press scared the powers in charge when it was invented as it brought literacy to the people who otherwise weren’t allowed to be literate.
In Renaissance Europe, the arrival of mechanical movable type printing introduced the era of mass communication which permanently altered the structure of society. The relatively unrestricted circulation of information and (revolutionary) ideas transcended borders, captured the masses in the Reformation and threatened the power of political and religious authorities; the sharp increase in literacy broke the monopoly of the literate elite on education and learning and bolstered the emerging middle class.
The web is all that; and more. If we allow it to blossom and change and not turn into TV on steroids where people go to consume and forget about creation.
But enough about history, let’s fast forward through a period of abundance and ridiculous projects for us: the first Dotcom bubble, the current entrepreneurial avalanche and move on to the now.
The web was good to all of us – damn good – and it is slipping away from us. When the president of the United States of America declares that people should learn to “code” and not to “make”, I get worried (code is only a small part of building product to help humans, you also need interfaces and data). When schools get iPads instead of computers with editors I get worried. When we measure what we do by comparing us with the success of software products built for closed environments and in a fixed state then we have a real problem with our self-image.
The web replaced a large amount of desktop apps of old and made them hardware and location independent. Now we go back full cycle to a world where consuming web content means downloading and installing an app on your device – if it is available for yours, that is. This is not innovation – it is staying safe in an old monetization model of controlling the consumption and being able to make the consumption environment become outdated so people have to buy the newer, shinier, more expensive one. Giving up control is still anathema for many of our clients – but this is actually what the web is about. You give up control and trade it for lots more users and very simple software update cycles. The same way we have to finally get it into our heads that the user controls the experience and we can not force them into a certain resolution, hardware or browser. Then we reach the most users.
However, there is a problem: the larger part of the web still runs on outdated ideas and practices and therefore easily can be seen as inferior to native apps.
When was the last time you saw a product used by millions and making a real difference to people being built with the things we all are excited about? I am not talking about the things that keep us busy – the Instagrams, the Twitters, the Imgurs – these are time sinks and escapism. I am talking about the things that keep the world moving. The banking sites, the booking systems, the email systems, the travel sites, government web sites, educational institutions. The solutions we promised when the web boomed to replace the clunky old desktop software, phone numbers and faxes.
Case in point: check out the beauty of the ESTA Visa waiver web site where you need to fill in your personal information if you want to travel to the States. Still, it beats the Indian counterpart which only works in Chrome or IE8, and from time to time has no working SSL certificate.

How come there is a big gap between what universities teach and what we do – we who are seen as magicians by people who just use the web? Of course universities are not there to teach the most current, unstable, state of affairs, but it has been over 15 years and a lot of coursework is still stuck with pre-CSS practices.
One main issue I see is a massive disconnect between the people who pay us and what they care about and our wants and needs. This becomes painfully obvious when you contract, build something and a few months later have to remove it from your portfolio as the maintenance crew completely changed or messed up the product.
Many times our clients don’t get excited about the things we get excited about. All they really want is to have the product delivered on budget, on time and in a state that does the job. I call this the “good enough” problem. Reaching a milestone in the product cycle is more important than the quality of the product. How many times have you heard a sentence like “yes, this is not up to our standard but it needs to get out the door. We’ll plan for a cleanup later”. That cleanup never happens though. And that frustrates us.
So what do we do when we get frustrated? We look for other ways to get excited; quick wins and things that sound innovative and great. This is a very natural survival instinct – we deserve to be happy and if what we are asked to do doesn’t make us happy, we find other ways.

If the people who caused our frustration don’t understand what we do, we find solace in talking to those who do, namely us. We blog on design blogs, we create quick scripts and tools that are almost the same as another one we use (but not quite) and we get a warm fuzzy feeling when people applaud, upvote and tweet what we did for a day. We keep solving the same issues that have been solved, but this time we do it in node.js and python and ruby and not in PHP (just as an example). We run in circles but every year we get better and shinier shoes to run with. We keep busy.
This has become an epidemic. We are not fixing projects, we are not really communicating with the people who mess up all of our good intentions. We don’t even talk to the people who build the software platforms our work is dependent on. Instead, we come up with more and more plugins, build scripts, pre-processors and other abstractions that sound amazing and promise to make us more effective. This is navel gazing, it is escapism, and it won’t help us a bit in our quest to build great products with the web. The straw-man we erected is that our platform isn’t good, our workflow is broken and that standards are not evolving fast enough and that browsers always lag behind. Has this not always been the case? And how did we get here if everything is so terrible and in need of replacement? Is live reloading really that much of a lifesaver or is switching with cmd+tab and hitting cmd+r not something that could become muscle memory, like handling all the gears and pedals when driving a car?
Ironically we solve the problem of the people who we blame not to care about our work – we concentrate on delivering more in a shorter amount of time with lesser able developers. We’re heading toward an assembly line mentality where products are built by putting together things we don’t understand to create other things that can be shipped in vast numbers and lacking individual touches.
What it boils down to is motivation and sincere happiness. There is an excellent TED talk out there by Dan Ariely called “What makes us feel good about our work?” and it contains some very interesting concepts.
As part of his research, Dan conducted an experiment: people in a study were asked to look at sheets of paper and count letters that are double. They are told that they get paid a certain amount of money for each sheet they work through. Every time they finish with a page the interviewers renegotiated the money people get, giving less and less with each sheet. The idea was to test when people say “no, that is not worth my time”.
The study tested three scenarios:
This lead to some very interesting findings. First of all, although people saw their papers being shredded without being looked at, they still did not cheat, although it’d be easy money. Secondly there was not much of a gap between the minimum viable price per sheet in the scenario where the paper was shredded to the one that was not looked at.
The most important part was not what happened to the paper or if money would still flow – it was adding a sense of ownership by adding a name and being recognised for having done the work. Validation was the most important part that kept people going.
The other study was asking people to fold origami objects with or without detailed explanations. Instead of just paying people to do that, the supervisor afterwards asked people for how much these should be sold. Other participants were asked how much they would pay for the final products, not knowing how much work went into them. Not surprisingly the creators of the origami structures valued them much higher than the ones who were asked to buy them. The origami structures done without detailed explanations were of lesser visual quality, which lead the prospective buyers to value them even less, whereas the makers ranked them higher, as more work went into them.
Dan calls this the IKEA principle – if you make people assemble something with very simple instructions but that still needed some extra work people value it much more. The other example he showed that explained this were ready-made cake bake mixtures. These were not a big seller, although they promised homemakers to save a lot of time. They became much more successful when the company making them removed the egg powder and asked people to add an egg. This meant people customised the cake – if only a bit – and got a feeling that they achieved something when they bake a cake. Furthermore, adding fresh eggs made for higher quality cakes at the same time.
This all sounds amazingly familiar, doesn’t it?
There is a reason I am so happy to be a web developer: I fought for it. I didn’t start in a time where advice I got was to “use build script X and library Y and you are done”. I didn’t start in a time where browsers had developer tools built in. I did start in a time where browsers were not even remotely rendering the same and there was no predictable way to tell why things went wrong. That’s why I can enjoy what we have. That’s why I can marvel at the fact that I could do a button with rounded corners, drop shadows and a gradient in a few lines of CSS now and make it smoothly transition to another state without a single line of script.
This is happiness we don’t allow newcomers into our market to find these days as we force-feed them quick solutions that make us more effective but to them are just tools to put together. Instead of explaining outlines and brush strokes and pens we give them a paint-by-number template and wonder when there is not much excitement once they finished painting it out. We don’t allow people to feel ownership, to discover on their own terms how to do things, and thus we get a new generation of developers who see the web as a half-baked development environment compared to others. We don’t make newcomers happy by keeping them from making mistakes or find out about bugs. We bore them instead as we don’t challenge them.
Instead of creating a weekly abstraction to a problem and declaring it better than anything the W3C agrees on maybe it is time for us “in the know” to take our ideas elsewhere. It is time to make the whole web better, not the shiny echosphere we work in. This means we should talk more to product managers, project managers, CEOs, CMS creators, framework people, enterprise software developers – all the people that we see as not caring for what we care for and we’ve been ignoring as being boring.
These are the people who build the enterprise solutions we are baffled by. These are the people who need to deal with compliance and certifcations before they can work. And for that, they need standards, not awesomesauce.js or amazingstuff.io.
We chickened out having these hard and tiring conversations for too long. But they are worth having. Only when people realise just how much a labour of love a working, progressively enhancing interface that works across devices is we will get the recognition we deserve. We will not have our papers shredded in front of us, but get the nod instead. Right now we are being paid ridiculous amounts of money to do something other people do not want to care about. This is cushy, but leaves us empty and unappreciated on a intellectual level.
This is not the time to feel important about ourselves. This is not the time to make us more effective without people knowing what we do. This is the time to be experts who care for the platform that enabled us to be who we are. Each and everyone of you has it in you to make sure that what we do right now will continue to be good to us. This is the time to bring that out and use it.
Want to comment? There are threads on Google+ and Facebook
http://christianheilmann.com/2014/01/07/finding-real-happiness-in-our-jobs/
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/01/07/happy-bmo-push-day-78/
|
|
Robert Nyman: Looking at 2013 |
Now 2013 is over, 2014 has started, and it’s a new year with new possibilities, challenges and experiences. I thought I’d take a look back at what 2013 was like for me.
Thinking about all the things that happened in 2013, it’s hard to fathom just how many things one can experience in one year, places to see and things to do.
I never really got to write a post about my 2012, but I was quite happy with my my Summing up 2011 post. This time around, I contemplated what I wanted to cover and share, and came to the conclusion to focus on travel and places.
One thing that I also realized is that I’ve been blogging far too little this year, and rather just sharing small stories and anecdotes on Facebook (and some of the stories below are taken/inspired from those posts, marked as quotes). In 2014 I really want to get going with writing more here, and I hope I’ll live up to it!
Since I started to keep track a few years back of how much and far I travel, 2013 was the year with most travel days and kilometers so far: 99 travel days, 211,074 km covered, visiting 27 cities. A big amount of that was covered in the fall, which was packed with lots of interesting trips and experiences.
I’ve spent the last days categorizing and gathering my pictures from 2013 in a good structure, and all photos are available on Flickr – there you’ll find both all travel pics as well as those from other things I did throughout the year.
When it comes to speaking, I became Lanyrd’s most well-traveled speaker, with having given presentations in 27 countries at 66 events. That number has now gone up to 29 countries and 72 events; I really look forward to my 30th country I will speak in! Any takers? ![]()
Also, all the slides and videos from my talks are available on Lanyrd.
Let’s go through my trips in 2013:
Starting the year in a good travel fashion, I had to get up at dawn January 1st to fly to San Francisco, and then go down to Mountain View. We were giving our very first Firefox OS workshop to invited developers, teaching and hacking away.
Checking into a US hotel (in Mountain View now):
- Turn off the air condition, to avoid room temperature below freezing.
- Unplug the fridge, since it sounds like a hippo is trying to make love to it.
- Try and act grateful to the receptionist for the makeup remover (and thinking of asking for a hair brush as well…).
I also managed to squeeze in some time in San Francisco:
Best quote in San Francisco today:
A clerk in a store couldn’t believe Apple products are much cheaper in the US than Europe, since “Europe is so much closer to China than the US”…
[All pictures from San Francisco in January]
A couple of weeks later, it was time for our second workshop, this time on London. It was a good event, and also one where we learned a lot about the platform from people in the Mozilla community, such as Luca Greco, and I finally got to meet him in person.
Hotel gym offers Very Personal Trainers. I don’t want to know what that means…
Flight home cancelled. Heathrow doesn’t seem to like snow. Will hopefully get home tomorrow! (great help from British Airways, though!)
“…around 260 flights are due to be cancelled on Sunday after 2-6cm of snow was forecast”
2-6 centimeters? This really sounds like a joke for Swedes…
[All pictures from London in January]
In the end of February, I went down to Barcelona for Mobile World Congress, which is a massive event within the mobile sector. I believe there was around 90,000 visitors and the halls were enormous.
About to fly to Barcelona for Mobile World Congress. We’re on Vueling airlines, and Patrick Finch has already made jokes about them re-vueling the plane. It’s gonna be a long flight…
We worked day and night for about a week, talking till we were blue in the face. To me it was really great to be there, to meet all kinds of people with very different backgrounds, and talk to them about Firefox OS and the Open Web, the possibilities and implications for the future.
I also got to give a presentation together with Brendan Eich – it’s pretty cool to be a JavaScript developer, and then have the inventor of the language as your CTO and then also co-present with him. ![]()
The day before it all started I got up early and had a nice look around in Barcelona, together with F'abio Magnoni: Park G"uell, Sagrada Fam'ilia and more.
Mozilla, Ubuntu and Opera at Mobile World Congress, in the shape of me, Bruce Lawson and Stuart Langridge.
[All pictures from Mobile World Congress Barcelona in February]
[All pictures from Barcelona city in February]
Traveled to Edinburgh to speak at the Whisky Web Conference, Great fun!
I’m in Scotland.
And yes, of course I ate Haggis last night.
Morning rainbow over Edinburgh
What working remotely is like
[All pictures from Edinburgh in April]
I wrote more extensively about this trip in Tidbits from my trip to San Francisco and Bogot'a, Colombia
Dinner with Mozilla, Google, Opera and Microsoft in the shape of Bruce Lawson, Rey Bango, Sam Dutton, Ali Spivak, me + Adam DuVander and more!
Surreal party at Google I/O with Billy Idol playing:
[All pictures from San Francisco & Google I/O in May]
I wrote a lot more detailed about this trip in Tidbits from my trip to San Francisco and Bogot'a, Colombia
My life. It’s currently about 7 in the morning local time in Miami, where I’m sitting with my manager Mark Coggins waiting our next flight to Bogot'a, Colombia. One day ago I was in San Francisco watching Billy Idol and Steve Aoki playing at a Google Party.
We’ve flown five hours overnight, and the two people sitting next to me got into a fight twice over encroaching each other’s space – once during take-off… Naturally the Swede tried to mediate the situation. The result was of course that the guy sitting in the middle got our shared armrest and some of my space…
I managed to get some sleep in a weird position and now my body hurts everywhere. After we had landed I got to see a new first: someone flossing in the restroom. The high life of a traveler…
We’re now in a lounge, which was nice to have access to, but the “coffee” being offered looked like a horse had had diarrhea, so I managed to find a Cuban restaurant where they only spoke Spanish, where I could get a proper espresso.
Our current discussion is about Colombia, our assigned bodyguards and the sort of surreal lives we lead. That’s my life.
[All pictures from Bogot'a in May]
Gave a presentation today at the Web Rebels conference about life choices, how to approach challenges and opportunities and how to move forward in life.
No code, no programming. Great fun and very liberating!
It was filmed: What are you going to do with your life? by Robert Nyman
[All pictures from Oslo in May]
A few days vacation over Midsummer, with some nice beach weather and swimming.
[All pictures from Jurmala in June]
After having worked with it for a few years, it was a fantastic experience to be there for the first Firefox OS launch in the world!
I wrote a long story about the history and my takes in The launch of Firefox OS – my thoughts and some history.
Conference lunch in Madrid – dipping churros in chocolate!
Just gave a presentation in Madrid about Firefox OS. Had a great time and quite enjoyed it! This is some of the feedback – I think I did well!
“@robertnyman congrats, one of the best styles i’ve seen on stage
Love @robertnyman’s humor sense. Great speaker. #spainjs #mozilla
Listening to @robertnyman speak always reminds me how awesome mozilla is (with good humour to boot) #spainjs
FirefoxOS is now my preferred platform for mobile apps dev.Love the idea of improving the world. Thanks @robertnyman.
@robertnyman rocks as presenter #spainjs
It was a terrific talk indeed, best one for now imho. Congrats @robertnyman!
I think i should buy a firefox os phone and after listening @robertnyman talk”
[All pictures from the Firefox OS release in Madrid in July]
[All pictures from Madrid in July]
A vacation in Croatia, a country I’ve really started to love. Great nice people and beautiful surroundings!
Belive it or not, this picture was taken with a mobile phone, in action!
[All pictures from Baska Voda in July]
Family vacation, and celebrating my oldest daughter’s birthday by going on a dolphin safari, where we got to see tons of them and a turtle as well!
Quick work days as the beginning of a longer trip.
Night woes. I had a noisy fridge in my room, preventing me from sleeping, waking me up all the time. Eventually I decided that enough is enough.
I got out of bed to unplug it, but realized that the space between the cupboard it was standing on and the wall was to small to fit my arm. I really tried, but couldn’t reach the outlet. And the cupboard was far too heavy and big to move further away from the wall.
Then I tried with a hanger, but at 2 in the morning, really drowsy, I quickly came to the conclusion that playing with a metal hanger around an outlet probably wasn’t a good idea.
After a while, I managed to see there was a small hole in the cupboard, where the cable went from the fridge out to the outlet. Success!, I thought and managed to squeeze in my arm, reach the cord, and gently unplug it. However…
When I tried to pull my arm out again, I was stuck. Really stuck. By the elbow. I couldn’t budge the fridge, I couldn’t find a good angle to ease my arm out again. Like a trapped animal I tried to pull harder and harder, really hurting myself.
After calming down and trying to carefully asses the situation, I managed to achieve a successful combination between arm angle and pulling hard. I was free!
Liberated, with a very aching arm, I went to bed and feel asleep.
[All pictures from Toronto in August]
I wrote in much detail about what happened during this trip in BrazilJS conference and a very interesting night in Brazil – a really recommended read, with great pics and videos too!
At the BrazilJS conference, getting ready to speak to close to 1000 people later today. Slightly intimidating and very exciting at the same time!
[All pictures from Porto Alegre in August]
Hello Copacabana!
Great day in Rio de Janeiro! F'abio and I went to the Sugarloaf Mountain, a most outstanding part! We took the cable car all the way to the top, watching all of Rio, Christ the Redeemer and the sun setting behind it.
I’ve been lucky to see many places in the world, but I have to say that the coastline here in Rio is one of the most beautiful I’ve ever seen!
[All pictures from Rio de Janeiro in August]
Went to India for workshps and giving a keynote at the JSFoo conference. It also led me to expressing my feelings on travel in Why I travel.
[All pictures from Bangalore in September]
When I got into JavaScript a good number of years ago, Douglas Crockford was a huge inspiration to me. Then, in one of my first major talks – about JavaScript nonetheless! – he was in the audience. We made friends, he liked my talk (!) and we have met on and off during the years since.
Today I got to meet him again, and I have to be honest and say that it is a special feeling of accomplishment, when he seeks me out after his talk to sit down and talk about it, and a lot of other things.
[All pictures from Aarhus in September]
Arrived in Lisbon, Portugal. As a nice surprise, the conference organizers had an offer to speakers and attendees to go surfing in the Atlantic this afternoon! Of course I had to take them up on that, and together we were five brave souls: me, James from England, David and John from Ireland and Matthew from Slovakia, and we were helped by the excellent surf teacher Luis.
We had wetsuits and the water was about 20 centigrade – not cold at all, to be honest. It’s been a LONG time since I surfed last, and it was such a great time doing it again! You do get a good beating by the water, but when you manage to stand up it’s all worth it!
I was also reminded that when you surf and get thrown in the water a lot, you swallow a lot of air, since you hold it in. So on a regular basis you need to burp; I felt like I sounded like I was calling seals at times…
Checked into the hotel, where I got the Charlie and the Chocolate Factory room. Now time to go to a pre-conference party! That is, after a very long shower to get warm.
[All pictures from Lisbon in October]
Good day in Toronto with the Mozilla Summit, bringing together employees and community members from all over the world. Got to hang out with my dear friends Stuart Colville and Chris Mills, pose with a fantastic ice Firefox and see a… well, unparalleled… karaoke version of Bohemian Rhapsody.
Wow! Last night Mozilla had organized for us to play an ice hockey game in the historical Maple Leaf Gardens here in Toronto, the venue for Toronto Maple Leafs between 1931 to 1999. About 22 years ago I came to Canada to play ice hockey for two weeks, playing games against a number of local teams.
What was special back then was that I got to go and see a NHL game in the Maple Leaf Gardens. So to come back now and be able to play a game myself on that ice was a fantastic moment! I used to play ice hockey for about ten years when I was young but I have only skated a handful times since I was 18.
Skating came back to me fast, though, but I’d say that the puck handling wasn’t as good as I wanted it to be. Also managed to get a hard tackle/hit, so I’m a bit sore today, but it was great fun!
Great day yesterday in Toronto with fantastic friends! We went on a full-day excursion of the city, naturally including a visit to the CN Tower (which was the highest in the world for 34 years!).
[All pictures from Toronto in October]
Guess who spoke just next-doors to the Apple keynote this morning?
Great evening after the last day of the HTML5DevConf in San Francisco. Hanging out with really nice, down to earth and inspiring people – the best kind!
Wonderful time at the Mozilla office in San Francisco with the fantastic Shezmeen Prasad and Luciana Viana! Bubbles and oysters for lunch!
Then the mandatory picture from the Mozilla patio overlooking the Bay Bridge, Halloween feel at the office and some nice cars.
[All pictures from San Francisco in October]
Nice day yesterday here in Guadalajara, Mexico, being guided through the city by Jorge and Paulina! Eating local food, getting the authentic Mexican experience! Some things spicy, some interesting beer mixes and lots more!
Happy to have done a great Firefox OS workshop yesterday in Guadalajara, Mexico!
Then we went out with the attendees and organizers in the evening, having a good time and the necessary tequila when in Mexico (only one for me, thank you).
The evening also included recreating the Evolution of Man chart and ending up in prison…
Also got the chance to have my Walter White/Breaking Bad moment!
[All pictures from Guadalajara in October]
Being a massive fan of pyramids, one of the places I’ve wanted to visit is the Teotihuacan area in Mexico City. Thanks to Miriam Leon and Jorge Diaz I finally got to do that yesterday!
They were kind enough to spend their entire day taking me there, and patient enough to watch me climb a lot of pyramids – I do like climbing stuff. Walking down the Avenue of the Dead, and got to get up on top of the Pyramid of the Sun and as far as was possible on Pyramid of the Moon.
I did, however, have an experience I’ve never had before…
Jorge and I walked for about an hour to a massive local market, packed with people. I was the only non-Mexican for miles, and not sure I’d gone there on my own. Then he looked up this medicinal place where I was to get a “Limpia” – a “spiritual cleansing, used to cleanse the body, mind and soul of negativity”.
When they do that, the person performing it and the one being cleansed have to be alone in the room, so I walked up these VERY small stairs into a back room, where I was alone with a guy speaking only Spanish (and while I love speaking Spanish, my level leaves a bit to desire). I can confess that I was just slightly worried…
Then he used raw eggs and some what I believe to be small branches with leaves from a tree to cleanse me, mumbling words and trying to explaining things to me (suffice to say, I didn’t understand).
Afterwards, he let Jorge in and explained his impressions of me. It was an interesting conversation about dealing with things that I have on my mind, envy in the world, me always getting up again when I’m down and more.
Got a new job in Mexico.
[All pictures from Mexico City in October]
Mozilla Developer Engagement Leads work week in Boulder, Colorado. Discussing goals for next year, possibilities, metrics, defending the Open Web.
After a long day of meetings yesterday, I blame/thank Luke Crouch for taking us to the local Avery Brewery here in Boulder, Colorado. We had a few tasters and some of them were really good!
The 16% Mephistopheles Stout, though, was good but at the same time almost like drinking tar.
Went on a lovely hike today in the Rocky Mountains, just outside of Boulder, Colorado. It was -7 Celsius, so quite a refreshing walk.
It took me to the Settlers Park and the Red Rocks Trail, where people came in the 1850s, looking for gold. I also saw a lot of squirrels and one woodpecker, but none of them were unfortunately interested nor kind enough to pose for a few pictures.
Boulder is a nice little town with about 80,000 people, and it has a few historical buildings and places to look at as well.
Luckily I got upgraded (again) on the Denver to London flight – an early Christmas present from British Airways, I guess – so I could lie down and have a proper sleep.
Also, the lobster starter was excellent!
[All pictures from Boulder in December]
My biggest gratitude and thank you to all the amazing people I met in 2014, the great times we had and the experiences we shared!
Here’s to a fantastic 2014!
|
|
Eric Shepherd: Ramping up for Dev Docs in 2014! |
Getting back to work after a long break is always odd. It’s especially strange this time, since all of Mozilla was closed for two weeks. Takes a while to get a big ship moving again after being in dry dock for a while.
Looking forward to a very crazy busy and productive month: a couple weeks of catch-up work and work on the MDN user guide materials, then on-site writer staff meetup for 2014 planning (I expect to do some video meetings too, for community involvement). Then a couple days visiting family before returning to the SF office to hang with a multi-team dev work week for a couple days, to give insights on the writing process and ways devs can help make docs processes go better.
My personal goals for MDN, content-wise, for the coming year revolve largely around ease-of-use: improving documentation about how to use MDN, guiding the development team toward making MDN easier to use, fixing site organization problems, and encouraging more developers and development teams to be more actively engaged with the documentation process.
I also hope to do more blogging about working in documentation as a field, how to be a technical writer, and the like. I feel that I have insights there that might be useful, and that I should try to share them.
It’s going to be a great year for MDN — I fully expect that people are going to be really impressed with, and excited by, all the improvements we’ll continue to make over the coming months.
On a personal note, my ability to get back up to speed is being seriously impacted by my being at a high point in my pain cycle. It also doesn’t help that my pain goes up faster the more I type. Next week, I will be seeing an orthopedic surgeon to investigate the possibility of a structural problem of some kind in my shoulder. That would be lovely, to have that on top of the existing nervous system problems, but it would at least be something that can probably be fixed!
http://www.bitstampede.com/2014/01/06/ramping-up-for-dev-docs-in-2014/
|
|










