Mozilla Addons Blog: FAQ for extension support in new Firefox for Android |
The new Firefox for Android experience is currently available for early testing on the Firefox Preview Nightly and Firefox Preview production channels.
In February 2020, we will change which Firefox applications remain available in the Play store. Once we’ve completed this transition, Firefox Preview Nightly will no longer be available. New feature development will take place on what is currently Firefox Preview.
We encourage users who are eager to make use of extensions to stay on Firefox Preview. This will ensure you continue to receive updates while still being among the first to see new developments.
Support for one extension, uBlock Origin, has been enabled for Firefox Preview Nightly. Every two weeks, the code for Firefox Preview Nightly gets migrated to the production release of Firefox Preview. Users of Firefox Preview should be able to install uBlock Origin by mid-February 2020.
We expect to start transferring the code from the production release of Firefox Preview to the Firefox for Android Beta channel during the week of February 17.
We are rolling out the new Firefox for Android experience to our users in small increments to test for bugs and other unexpected surprises. Don’t worry — you should receive an update that will enable extension support soon!
No, in the near term you will need to install extensions from the Add-ons Manager on the new Firefox for Android. For the time being, you will not be able to install extensions directly from addons.mozilla.org.
Currently, uBlock Origin is the only supported extension for the new Firefox for Android. We are working on building support for other extensions in our Recommended Extensions program.
We want to ensure that the first add-ons supported in the new Firefox for Android provide an exceptional, secure mobile experience to our users. To this end, we are prioritizing Recommended Extensions that cover common mobile use cases and that are optimized for different screen sizes. For these reasons, it’s possible that not all the add-ons you have previously installed in Firefox for Android will be supported in the near future.
We would like to expand our support to other add-ons. At this time, we don’t have details on enabling support for extensions not part of the Recommended Extensions program in the new Firefox for Android. Please follow the Add-ons Blog for future updates.
GeckoView is Mozilla’s mobile browser engine. It takes Gecko, the engine that powers the desktop version of Firefox, and packages it as a reusable Android library. Rebuilding our Firefox for Android browser with GeckoView means we can leverage our Firefox expertise in creating safe and robust online experiences for mobile.
Support for uBlock Origin will be migrated for users currently on Firefox Nightly, Firefox Beta, and Firefox Production. All other add-ons will be disabled for now.
The post FAQ for extension support in new Firefox for Android appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/02/11/faq-for-extension-support-in-new-firefox-for-android/
|
|
Hacks.Mozilla.Org: Firefox 73 is upon us |
Another month, another new browser release! Today we’ve released Firefox 73, with useful additions that include CSS and JavaScript updates, and numerous DevTools improvements.
Read on for the highlights. To find the full list of additions, check out the following links:
Note: Until recently, this post mentioned the new form method requestSubmit() being enabled in Firefox 73. It has come to light that requestSubmit() is in fact currently behind a flag, and targetted for a release in Firefox 75. Apologies for the error. (Updated Friday, 14 February.)
Our latest Firefox offers a fair share of new web platform additions; let’s review the highlights now.
We’ve added to CSS logical properties, with overscroll-behavior-block and overscroll-behavior-inline.
These new properties provide a logical alternative to overscroll-behavior-x and overscroll-behavior-y, which allow you to control the browser’s behavior when the boundary of a scrolling area is reached.
The yearName and relatedYear fields are now available in the DateTimeFormat.prototype.formatToParts() method. This enables useful formatting options for CJK (Chinese, Japanese, Korean) calendars.
There are several interesting DevTools updates in this release. Upcoming features can be previewed now in Firefox DevEdition.
We continually survey DevTools users for input, often from our @FirefoxDevTools Twitter account. Many useful updates come about as a result. For example, thanks to your feedback on one of those surveys, it is now possible to copy cleaner CSS snippets out of the Inspector’s Changes panel. The + and - signs in the output are no longer part of the copied text.
The DevTools engineering work for this release focused on pushing performace forward. We made the process of collecting fast-firing requests in the Network panel a lot more lightweight, which made the UI snappier. In the same vein, large source-mapped scripts now load much, much faster in the Debugger and cause less strain on the Console as well.
Loading the right sources in the Debugger is not straightforward when the DevTools are opened on a loaded page. In fact, modern browsers are too good at purging original files when they are parsed, rendered, or executed, and no longer needed. Firefox 73 makes script loading a lot more reliable and ensures you get the right file to debug.
Console script authoring and logging gained some quality of life improvements. To date, CORS network errors have been shown as warnings, making them too easy to overlook when resources could not load. Now they are correctly reported as errors, not warnings, to give them the visibility they deserve.
Variables declared in the expression will now be included in the autocomplete. This change makes it easier to author longer snippets in the multi-line editor. Furthermore, the DevTools setting for auto-closing brackets is now working in the Console as well, bringing you closer to the experience of authoring in an IDE.
Did you know that console logs can be styled using backgrounds? For even more variety, you can add images, using data-uris. This feature is now working in Firefox, so don’t hesitate to get creative. For example, we tried this in one of our Fetch examples:
console.log('There has been a problem with your fetch operation: %c' +
e.message, 'color: red; padding: 2px 2px 2px 20px; background: yellow 3px no-repeat
url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAwAAAAMCAYAAABWdVznAAAACXBIWXMAAA
7EAAAOxAGVKw4bAAAApUlEQVQoz5WSwQ3DIBAE50wEEkWkABdBT+bhNqwoldBHJF58kzryIp+zgwiK5JX2w+
2xdwugMMZ4IAIZeCszELX2hYhcgQIkEQnOOe+c8yISgAQU1Rw3F2BdlmWig56tQNmdIpA68Qbcu6akWrJat7
gp27EDkCdgttY+uoaX8oBq5gsDiMgToNY6Kv+OZIzxfZT7SP+W3oZLj2JtHUaxnnu4s1/jA4NbNZ3AI9YEA
AAAAElFTkSuQmCC);');And got the following result:
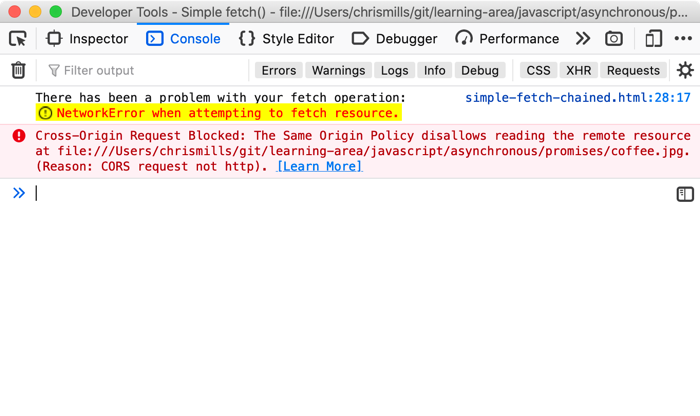
We’d like to thank Firefox DevTools contributor Edward Billington for the data-uri support!
We now show arguments by default. We believe this makes logging JavaScript functions a bit more intuitive.
And finally for this section, when you perform a text or regex search in the Console, you can negate a search item by prefixing it with ‘-’ (i.e. return results not including this term).
The WebSocket inspector that shipped in Firefox 71 now nicely prints WAMP-formatted messages (in JSON, MsgPack, and CBOR flavors).

You won’t needlessly wait for updates, as the Inspector now also indicates when a WebSocket connection is closed.
A big thanks to contributor Tobias Oberstein for implementing the WAMP support, and to saihemanth9019 for the WebSocket closed indicator!
We wanted to mention a couple of nice power user Preferences features dropping in Firefox 73.
First of all, the General tab in Preferences now has a Zoom tool. You can use this feature to set the magnification level applied to all pages you load. You can also specify whether all page contents should be enlarged, or only text. We know this is a hugely popular feature because of the number of extensions that offer this functionality. Selective zoom as a native feature is a huge boon to users.
The DNS over HTTPS control in the Network Settings tab includes a new provider option, NextDNS. Previously, Cloudflare was the only available option.
The post Firefox 73 is upon us appeared first on Mozilla Hacks - the Web developer blog.
|
|
Mozilla Privacy Blog: Mozilla Mornings on the EU Digital Services Act: Making responsibility a reality |
On 3 March, Mozilla will host the next installment of Mozilla Mornings – our regular breakfast series that brings together policy experts, policymakers and practitioners for insight and discussion on the latest EU digital policy developments.
In 2020 Mozilla Mornings is adopting a thematic focus, starting with a three-part series on the upcoming Digital Services Act. This first event on 3 March will focus on how content regulation laws and norms are shifting from mere liability frameworks to more comprehensive responsibility ones, and our panelists will discuss how the DSA should fit within this trend.
Siada El-Ramly
Director-General, EDiMA
Owen Bennett
EU Internet Policy Manager, Mozilla
Moderated by Jennifer Baker
EU Tech Journalist
The post Mozilla Mornings on the EU Digital Services Act: Making responsibility a reality appeared first on Open Policy & Advocacy.
|
|
Niko Matsakis: Async Interview #6: Eliza Weisman |
Hello! For the latest async interview, I spoke with Eliza Weisman (hawkw, mycoliza on twitter). Eliza first came to my attention as the author of the tracing crate, which is a nifty crate for doing application level tracing. However, she is also a core maintainer of tokio, and she works at Buoyant on the linkerd system. linkerd is one of a small set of large applications that were build using 0.1 futures – i.e., before async-await. This range of experience gives Eliza an interesting “overview” perspective on async-await and Rust more generally.
You can watch the video on YouTube. I’ve also embedded a copy here for your convenience:
Since I didn’t know Eliza as well, we started out talking a bit about
her background. She has been using Rust for 5 years, and I was amused
by how she characterized the state of Rust when she got started:
pre-“question mark” Rust. Indeed, the introduction of the ? operator
does feel one of those “turning points” in the history of Rust, and
I’m quite sure that async-await will feel similarly (at least for
some applications).
One interesting observation that Eliza made is that it feels like Rust has reached the point where there is nothing critically missing. This isn’t to say there aren’t things that need to be improved, but that the number of “rough edges” has dramatically decreased. I think this is true, and we should be proud of it – though we also shouldn’t relax too much. =) Getting to learn Rust is still a significant hurdle and there are still a number of things that are much harder than they need to be.
One interesting corrolary of this is that a number of the things that most affect Eliza when writing Async I/O code are not specific to async I/O. Rather, they are more general features or requirements that apply to a lot of different things.
We talked some about what tokio needs from async Rust. As Eliza said, many of the main points already came up in my conversation with Carl:
One thing we spent a fair while discusing is how to best communicate our stability story. This goes beyond “semver”. semver tells you when a breaking change has been made, of course, but it doesn’t tell whether a breaking change will be made in the future – or how long we plan to do backports, and the like.
The easiest way for us to communicate stability is to move things to the std library. That is a clear signal that breaking changes will never be made.
But there is room for us to set “intermediate” levels of stability.
One thing that might help is to make a public stability policy for
crates like futures. For example, we could declare that the futures
crate will maintain compatibility with the current Stream crate for
the next year, or two ears.
These kind of timelines would be helpful: for example, tokio plans to
maintain a stable interface for the next 5 years, and so if
they want to expose traits from the futures crate, they would want a
guarantee that those traits would be supported during that period (and
ideally that futures would not release a semver-incompatible version
of those traits).
When we talk about interoperability, we are often talking about core
traits like Future, Stream, and AsyncRead. But as we move up the
stack, there are other things where having a defined standard could be
really useful. My go to example for this is the http crate, which
defines a number of types for things like HTTP error codes. The types
are important because they are likely to find their way in the “public
interface” of libraries like hyper, as well as frameworks and things.
I would like to see a world where web frameworks can easily be
converted between frameworks or across HTTP implementations, but that
would be made easier if there is an agreed upon standard for
representing the details of a HTTP request. Maybe the http crate is
that already, or can become that – in any case, I’m not sure if the
stdlib is the right place for such a thing, or at least not for some
time. It’s something to think about. (I do suspect that it might be
useful to move such crates to the Rust org? But we’d have to have a
good story around maintainance.) Anyway, I’m getting beyond what was
in the interview I think.
We talked a fair amount about the tracing library. Tracing is one of those libraries that can do a large number of things, so it’s kind of hard to concisely summarize what it does. In short, it is a set of crates for collecting scoped, structured, and contextual diagnostic information in Rust programs. One of the simplest use cases is to collect logging information, but it can also be used for things like profiling and any number of other tasks.
I myself started to become interesting in tracing as a possible tool to help for debugging and analyzing programs like rustc and chalk, where the “chain” that leads to a bug can often be quite complex and involve numerous parts of the compiler. Right now I tend to just dump gigabytes of logs into files and traverse them with grep. In so doing, I lose all kinds of information (like hierarchical information about what happens during what) that would make my life easier. I’d love a tool that let me, for example, track “all the logs that pertain to a particular function” while also making it easy to find the context in which a particular log occurred.
The tracing library got its start as a structured replacement for
various hacky layers atop the log crate that were in use for
debugging linkerd. Like many async applications, debugging a
linkerd session involves correlating a lot of events that may be
taking place at distinct times – or even distinct machines – but
are still part of one conceptual “thread” of control.
tracing is actually a “front-end” built atop the “tracing-core” crate. tracing-core is a minimal crate that just stores a thread-local containing the current “event subscriber” (which processes the tracing events in some way). You don’t interact with tracing-core directly, but it’s important to the overall design, as we’ll see in a bit.
The tracing front-end contains a bunch of macros, rather like the
debug! and info! you may be used to from the log crate (and indeed
there are crates that let you use those debug! logs directly). The
major one is the span! macro, which lets you declare that a task is
happening. It works by putting a “placeholder” on the stack: when
that placeholder is dropped, the task is done:
let s: Span = span!(...); // create a span `s`
let _guard = s.enter(); // enter `s`, so that subsequent events take place "in" `s`
let t: Span = span!(...); // create a *subspan* of `s` called `t`
...
Under the hood, all of these macros forward to the “subscripber” we were talking about later. So they might receive events like “we entered this span” or “this log was generated”.
The idea is that events that happen inside of a span inherit the context of that span. So, to jump back to my compiler example, I might use a span to indicate which function is currently being type-checked, which would then be associated with any events that took place.
There are many different possible kinds of subscribers. A subscriber might, for example, dump things out in real time, or it might just collectevents and log them later. Crates like tracing-timing record inter-event timing and make histograms and flamegraphs.
It seems clear that tracing would work best if it is integrated with other libaries. I believe it is already integrated into tokio, but one could also imagine integrating tracing with rayon, which distributes tasks across worker threads to run in parallel. The goal there would be that we “link” the tasks so that events which occur in a parallel task inherit the context/span information from the task which spawned them, even though they’re running on another thread.
The idea here is not only that Rayon can link up your application
events, but that Rayon can add its own debugging information using
tracing in a non-obtrusive way. In the ‘bad old days’, tokio used to
have a bunch of debug! logs that would let you monitor what was
going on – but these logs were often confusing and really targeting
internal tokio developers.
With the tracing crate, the goal is that libraries can enrich the user’s diagnostics. For example, the hyper library might add metadata about the set of headers in a request, and tokio might add information about which thread-pool is in use. This information is all “attached” to your actual application logs, which have to do with your business logic. Ideally, you can ignore them most of the time, but if that sort of data becomes relevant – e.g., maybe you are confused about why a header doesn’t seem to be being detected by your appserver – you can dig in and get the full details.
Eliza emphasized that she would really like to see more interoperability amongst tracing libraries. The current tracing crate, for example, can be easily made to emit log records, making it interoperable with the log crate (there is also a “logger” that implements the tracing interface).
Having a distinct tracing-core crate means that it possible for there
to be multiple facades that build on tracing, potentially operating in
quite different ways, which all share the same underlying “subscriber”
infrastructure. (rayon uses the same trick; the rayon-core crate
defines the underlying scheduler, so that multiple versions of the
rayon ParallelIterator traits can co-exist without having multiple
global schedulers.) Eliza mentioned that – in her ideal world –
there’d be some alternative front-end that is so good it can replaces
the tracing crate altogether, so she no longer has to maintain the
macros. =)
There is one feature request for async-await that arises from the tracing library. I mentioned that tracing uses a guard to track the “current span”:
let s: Span = span!(...); // create a span `s`
let _guard = s.enter(); // enter `s`, so that subsequent events take place "in" `s`
...
The way this works is that the guard returned by s.enter() adds some
info into the thread-local state and, when it is dropped, that info is
withdrawn. Any logs that occur while the _guard is still live are
then decorated with this extra span information. The problem is that
this mechanism doesn’t work with async-await.
As explained in the tracing README, the problem is that if an
async await function yields during an await, then it is removed from
the current thread and suspended. It will later be resumed, but
potentially on another thread altogether. However, the _guard
variable is not notified of these events, so (a) the thread-local info
remains set on the original thread, where it may not longer belong and
(b) the destructor which goes to remove the info will run on the wrong
thread.
One way to solve this would be to have some sort of callback that
_guard can receive to indicate that it is being yielded, along with
another callback for when an async fn resumes. This would probably
wind up being optional methods of the Drop trait. This is basically
another feature request to making RAII work well in an async
environment (in addition to the existing problems with async drop that boats
described here).
I asked Eliza to think for a second about what priorities she would set for the Rust org while wearing her “linkerd hacker” hat – in other words, when acting not as a library designer, but as the author of an that relies on Async I/O. Most of the feedback here though had more to do with general Rust features than async-await specifically.
Eliza pointed out that linkerd hasn’t yet fully upgraded to use async-await, and that the vast majority of pain points she’s encountered thus far stem from having to use the older futures model, which didn’t integrate well with rust borrows.
The other main pain point is the compilation time costs imposes by the deep trait hierarchies created by tower’s service and layer traits. She mentioned hitting a type error that was so long it actually crashed her terminal. I’ve heard of others hitting similar problems with this sort of setup. I’m not sure yet how this is best addressed.
Another major feature request would be to put more work into
procedural macros, especially in expression position. Right now
proc-macro-hack is the tool of choice but – as the name suggests –
it doesn’t seem ideal.
The other major point is that support for cargo feature flags in tooling is pretty minimal. It’s very easy to have code with feature flags that “accidentally” works – i.e., I depend on feature flag X, but I don’t specify it; it just gets enabled via some other dependency of mine. This also makes testing of feature flags hard. rustdoc integration could be better. All true, all challenging. =)
There is a thread on the Rust users forum for this series.
http://smallcultfollowing.com/babysteps/blog/2020/02/11/async-interview-6-eliza-weisman/
|
|
The Firefox Frontier: The 7 best things about the new Firefox browser for Android |
The biggest ever update to Firefox browser for Android is on its way. Later this spring, everyone using the Firefox browser on their Android phones and tablets will get the … Read more
The post The 7 best things about the new Firefox browser for Android appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-android-new-features/
|
|
Mozilla Addons Blog: Extensions in Firefox 73 |
As promised, the update on changes in Firefox 73 is short: There is a new sidebarAction.toggle API that will allow you to open and close the sidebar. It requires being called from a user action, such as a context menu or click handler. The sidebar toggle was brought to you by M'elanie Chauvel. Thanks for your contribution, M'elanie!
On the backend, we fixed a bug that caused tabs.onCreated and tabs.onUpdated events to be fired out-of-order.
We have also added more more documentation on changing preferences for managing settings values with experimental WebExtensions APIs. As a quick note, you will need to set the preference extensions.experiments.enabled to true to enable experimental WebExtensions APIs starting with Firefox 74.
That’s all there is to see for Firefox 73. We’ll be back in a few weeks to highlight changes in Firefox 74.
The post Extensions in Firefox 73 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/02/10/extensions-in-firefox-73/
|
|
Daniel Stenberg: curl ootw: –keepalive-time |
(previously blogged about options are listed here.)
This option is named --keepalive-time even if the title above ruins the double-dash (thanks for that WordPress!). This command line option was introduced in curl 7.18.0 back in early 2008. There’s no short version of it.
The option takes a numerical argument; number of seconds.
What’s implied in the option name and not spelled out is that the particular thing you ask to keep alive is a TCP connection. When the keepalive feature is not used, TCP connections typically don’t send anything at all if no data is transmitted.
Silent TCP connections typically cause the two primary issues:
TCP stacks then typically implement a low-level feature where they can send a “ping” frame over the connection if it has been idle for a certain amount of time. This is the keepalive packet.
--keepalive-time therefor sets the interval. After this many seconds of “silence” on the connection, there will be a keepalive packet sent. The packet is totally invisible to the applications on both sides but will maintain the connection through NATs better and if the connection is broken, this packet will make curl detect it.
To complicate issues even further, there are also devices out there that will still close down connections if they only send TCP keepalive packets and no data for certain period. Several protocols on top of TCP have their own keepalive alternatives (sometimes called ping) for this and other reasons.
This aggressive style of closing connections without actual traffic TCP traffic typically hurts long-going FTP transfers. This, because FTP sets up two connections for a transfer, but the first one is the “control connection” and while a transfer is being delivered on the “data connection”, nothing happens over the first one. This can then result in the control connection being “dead” by the time the data transfer completes!
The default keepalive time is 60 seconds. You can also disable keepalive completely with the --no-keepalive option.
The default time has been selected to be fairly low because many NAT routers out there in the wild are fairly aggressively and close idle connections already after two minutes (120) seconds.
This works for all TCP-based protocols, which is what most protocols curl speaks use. The only exception right now is TFTP. (See also QUIC below.)
Change the interval to 3 minutes:
curl --keepalive-time 180 https://example.com/
A related functionality is the --speed-limit amd --speed-time options that will cancel a transfer if the transfer speed drops below a given speed for a certain time. Or just the --max-time that sets a global timeout for an entire operation.
Soon we will see QUIC getting used instead of TCP for some protocols: HTTP/3 being the first in line for that. We will have to see what exactly we do with this option when QUIC starts to get used and what the proper mapping and behavior shall be.
https://daniel.haxx.se/blog/2020/02/10/curl-ootw-keepalive-time/
|
|
Cameron Kaiser: TenFourFox FPR19 available |
Since the new NSS is sticking nicely, FPR20 will probably be an attempt at enabling TLS 1.3, and just in time, too.
http://tenfourfox.blogspot.com/2020/02/due-to-busy-work-schedule-and-reallife.html
|
|
About:Community: Firefox 73 new contributors |
With the release of Firefox 73, we are pleased to welcome the 19 developers who contributed their first code change to Firefox in this release, 18 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/02/09/firefox-73-new-contributors/
|
|
Daniel Stenberg: Rockbox services transition |
Remember Rockbox? It is a free software firmware replacement for mp3 players. I co-founded the project back in 2001 together with Bj"orn and Linus. I officially left the project back in 2014.
The project is still alive today, even of course many of us can’t hardly remember the concept of a separate portable music player and can’t figure out why that’s a good idea when we carry around a powerful phone all days anyway that can do the job – better.
Already when the project took off, we at Haxx hosted the web site and related services. Heck, if you don’t run your own server to add fun toy projects to, then what kind of lame hacker are you?
None of us in Haxx no longer participates in the project and we haven’t done so for several years. We host the web site, we run the mailing lists, we take care of the DNS, etc.
Most of the time it’s no biggie. The server hosts a bunch of other things anyway for other project so what is a few extra services after all?
Then there are times when things stop working or when we get a refreshed bot attack or web crawler abuse against the site and we get reminded that here we are more than eighteen years later hosting things and doing work for a project we don’t care much for anymore.
It doesn’t seem right anymore. We’re pulling the plug on all services for Rockbox that occasionally gives us work and annoyances. We’re offering to keep hosting DNS and the mailing lists – but if active project members rather do those too, feel free. It never was a life-time offer and the time has come for us.
If people still care for the project, it is much better if those people will also care for these things for the project’s sake. And today there are more options than ever for an open source project to get hosting, bug tracking, CI systems etc setup for free with quality. There’s no need for us ex-Rockboxers to keep doing this job that we don’t want to do.
I created a wiki page to detail The Transition. We will close down the specified services on January 1st 2021 but I strongly urge existing Rockboxers to get the transition going as soon as possible.
I’ve also announced this on the rockbox-dev mailing list, and I’ve mentioned it in the Rockbox IRC.
https://daniel.haxx.se/blog/2020/02/08/rockbox-services-transition/
|
|
Mozilla VR Blog: Visual Development in Hello WebXR! |
This is a post that tries to cover many aspects of the visual design of our recently released demo Hello WebXR! (more information in the introductory post), targeting those who can create basic 3D scenes but want to find more tricks and more ways to build things, or simply are curious about how the demo was made visually. Therefore this is not intended to be a detailed tutorial or a dogmatic guide, but just a write-up of our decisions. End of the disclaimer :)
Here it comes a mash-up of many different topics presented in a brief way:
From the beginning, our idea was to make a simple, down-paced, easy to use experience that gathered many different interactions and mini-experiences that introduces VR newcomers to the medium, and also showcased the recently released WebXR API. It would run on almost any VR device but our main target device was the Oculus Quest, so we thought that we could have some mini-experiences that could share the same physical space, but other experiences should have to be moved to a different scene (room), either for performance reasons and also due its own nature.
We started by gathering references and making concept art, to figure out how the "main hall" would look like:

Then, we used Blender to start sketching the hall and test it on VR to see how it feels. It should have to be welcoming and nice, and kind of neutral to be suitable for all audiences.



3D models were exported to glTF format (Blender now comes with an exporter, and three.js provides a loader), and for textures PNG was used almost all the time, although on a late stage in the development of the demo all textures were manually optimized to drastically reduce the size of the assets. Some textures were preserved in PNG (handles transparency), others were converted to JPG, and the bigger ones were converted to BASIS using the basisu command line program. Ada Rose Cannon’s article introducing the format and how to use it is a great read for those interested.
glTF files were exported without materials, since they were created manually by code and assigned to the specific objects at load time to make sure we had the exact material we wanted and that we could also tweak easily.
In general, the pipeline was pretty traditional and simple. Textures were painted or tweaked using Photoshop. Meshes and lightmaps were created using Blender and exported to glTF and PNG.
For creating the lightmap UVs, and before unwrapping, carefully picked edges were marked as seams and then the objects were unwrapped using the default unwrapper, in the majority of cases. Finally, UVs were optimized with UVPackMaster 2 PRO.
Draco compression was also used in the case of the photogrammetry object, which reduced the size of the asset from 1.41MB to 683KB, less than a half.
Some custom shaders were created for achieving special effects:
This was achieved offseting the texture along one axis and rendered in additive mode:

The texture is a simple gradient. Since it is rendered in additive mode, black turns transparent (does not add), and dark blue adds blue without saturating to white:

And the ray target is a curved mesh. The top cylinder and the bottom disk are seamlessly joined, but their faces and UVs go in opposite directions.
This is for the star field effect in the doors. The inward feeling is achieved by pushing the mesh from the center, and scaling it in Z when it is hovered by the controller’s ray:

This is the texture that is rendered in the shader using polar coordinates and added to a base blue color that changes in time:

Used in the deformation (in shape and color) of the panorama balls.

The halo effect is just a special texture summed to the landscape thumbnail, which is previously modified by shifting red channel to the left and blue channel to the right:

Used in the zoom effect for the paintings, showing only a portion of the texture and also a white circular halo. The geometry is a simple plane, and the shader gets the UV coordinates of the raycast intersection to calculate the amount of texture to show in the zoom.

Text rendering was done using the Troika library, which turned out to be quite handy because it is able to render SDF text using only a url pointing to a TTF file, without having to generate a texture.
Oculus Quest is a device with mobile performance, and that requires a special approach when dealing with polygon count, complexity of materials and textures; different from what you could do for desktop or high end devices. We wanted the demo to perform smoothly and be indistinguishable from native or desktop apps, and these are some of the techniques and decisions we took to achieve that:



Each sound in the sound room is accompanied by a visual hint. These little animations are simple meshes animated using regular keyframes on position/rotation/scale transforms.
The first idea for the vertigo room was to build a low-poly but convincing city and put the user on top of a skyscraper. After some days of Blender work:

We tried this in VR, and to our surprise it did not produce vertigo! We tested different alternatives and modifications to the initial design without success. Apparently, you need more than just lifting the user to 500m to produce vertigo. Texture scale is crucial for this and we made sure they were at a correct scale, but there is more needed. Vertigo is about being in a situation of risk, and there were some factors in this scene that did not make you feel unsafe. Our bet is that the position and scale of the other buildings compared to the player situation make them feel less present, less physical, less tangible. Also, unrealistic lighting and texture may have influenced the lack of vertigo.
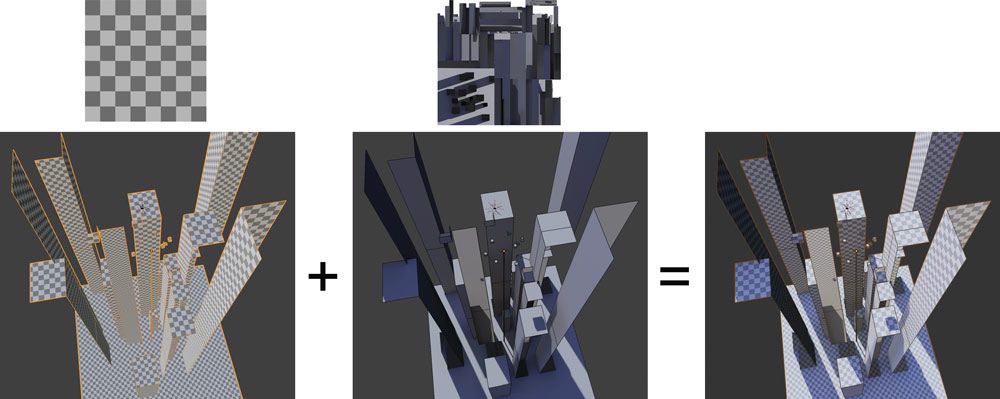
So we started another scene for the vertigo, focusing on the position and scale of the buildings, simplifying the texture to a simple checkerboard, and adding the user in a really unsafe situation.

The scene is comprised of only two meshes: the buildings and the teleport door. Since the range of movements of the user in this scene is very limited, we could remove all those sides of the buildings that face away from the center of the scene. It is a constant material with a repeated checkerboard texture to give sense of scale, and a lightmap texture that provides lighting and volume.
Things that did not go very well:
Things we like how it turned out:
We uploaded the Blender files to the Hello WebXR repository.
If you want to know the specifics of something, do not hesitate to contact me at @feiss or the whole team at @mozillareality.
Thanks for reading!
|
|
Support.Mozilla.Org: Brrrlin 2020: a SUMO journal from All Hands |
Hello, SUMO Nation!
Berlin 2020 has been my first All Hands and I am still experiencing the excitement the whole week gave me.

The intensity an event of this scale is able to build is slightly overwhelming (I suppose all the introverts reading this can easily get me), but the gratification and insights everyone of us has taken home are priceless.
The week started last Monday, on January 27th, when everyone landed in Berlin from all over the world. An amazing group of contributors, plus every colleague I had always only seen on a small screen, was there, in front of me, flesh and bones. I was both excited and scared by the number of people that suddenly were inhabiting the corridors of our conference/dorm/workspace.
The schedule for the SUMO team and SUMO contributors was a little tight, but we managed to make it work: Kiki and I decided to share our meetings between the days and I am happy about how we balanced the work/life energy.
On Tuesday we opened the week by having a conversation over the past, the current state and the future of SUMO. The community meeting was a really good way to break the ice, the whole SUMO team was there and gave updates from the leadership, products, as well as the platform team. This meeting was necessary also to lay down the foundations for the priorities of the week and develop an open conversation.
On Wednesday, Kiki and I were fully in the game. We decided to have two parallel sessions: one regarding the Forum and Social support and one focusing on the KB localization. The smaller groups were both really vibrant and lively. We highlighted pain points, things that are working and issues that we as community managers could focus more on at this time. In the afternoon, we had a face to face meeting between the community and the Respond Tool team. It was a feedback-based discussion on features and bugs.
Thursday was ON FIRE. In the morning we had the pleasure to host Vesta Zare, the Product Manager of Fenix, and we had a session focusing on Firefox Preview and its next steps. Vesta was thrilled to meet the SUMO community, excited to share information, and happy to answer questions. After the session, we had a 2-hour-long brainstorming workshop organized by Kiki and me for the community to help us build a priority pipeline for the Community plan we have been working on in the last few months. The session was long but incredibly helpful and everyone who participated was active and rich in insights. The day was still running at a fast pace and the platform team had an Ask-Me-Anything session with the contributors. Madalina and Tasos were great and they both set real expectations while leaving the community open doors to get involved.
On Friday the community members were free to follow their own schedule, while the SUMO team had the last meetings to run up to. The week was closing up with one of the most incredible parties I have ever experienced, and that was a great opportunity to finally collect the last feedback and friendly connections we lost along the way of this really busy week.
Here is a recollection of the pain points we got from the meetings with contributors:
We have also highlighted the many successes that we have from last year:
As you’ve probably heard before, we’re currently working with an external agency called Context Partners on the community strategy project. The result from that collaboration is a set of recommendations on 3 areas that we managed to discuss during the all hands.

Obviously, we wouldn’t be able to do all of them, so we need your help.
Which recommendation do you believe would provide the greatest benefit to the SUMO community?
Is there a recommendation you would make that is missing from this list?
Your input would be very valuable for us since the community is all about you. We will collect all of your feedback with us to be discussed in our final meeting with the Context Partner team in Toronto in mid-February. We’ll appreciate any additional feedback that we can gather before the end of next week (02/14/2020).
Please read carefully and think about the questions above. Kiki and I have opened a Discourse post and Contributor Forum thread to collect feedbacks on this. You can also reach out directly to us with your questions or feedbacks.
I feel lucky to be part of this amazing community and to work alongside passionate and lively people I can look up to everyday. Remember that SUMO is made by you and you should be proud to identify yourself as part of this incredible group of people who honestly enjoy helping others.
As a celebration of the All Hands and the SUMO community, I would like to share the poem that Seburo kindly shared with us:
It is now over six months since Mozilla convened last,
and All Hands is now coming up so fast.
From whatever country, nation or state they currently be in,
Many MoCo and MoFo staff, interns and contributors are converging on Berlin.
Twenty Nineteen was a busy year,
Much is going on with Firefox Voice, so I hear.
The new Fenix is closer to release,
the GeckoView team’s efforts will not cease.
MoFo is riding high after an amazing and emotional MozFest,
For advice on how to make the web better, they are the best.
I hope that the gift guide was well read,
Next up is putting concerns about AI to bed…?
Please don’t forget contributors who are supporting the mission from wide and far,
Writing code, building communities and looking to Mozilla’s north star.
The SUMO team worked very hard during the add-on apocalypse,
And will not stop helping users with useful advice and tips.
I guess I should end with an attempt at a witty one liner.
So here it is.
For one week in January 2020,
Mozillianer sind Berliner.
Thank you for being part of SUMO,
See you soon!
Giulia
|
|
Mozilla Addons Blog: uBlock Origin available soon in new Firefox for Android Nightly |
Last fall, we announced our intention to support add-ons in Mozilla’s reinvented Firefox for Android browser. This new, high-performance browser for Android has been rebuilt from the ground up using GeckoView, Mozilla’s mobile browser engine and has been available for early testing as Firefox Preview. A few weeks ago, Firefox Preview moved into the Firefox for Android Nightly pre-release channel, starting a new chapter of the Firefox experience on Android.
In the next few weeks, uBlock Origin will be the first add-on to become available in the new Firefox for Android. It is currently available on Firefox Preview Nightly and will soon be available on Firefox for Android Nightly. As one of the most popular extensions in our Recommended Extensions program, uBlock Origin helps millions of users gain control of their web experience by blocking intrusive ads and improving page load times.
As GeckoView builds more support for WebExtensions APIs, we will continue to enable other Recommended Extensions to work in the new Firefox for Android.
We want to ensure that any add-on supported in the new Firefox for Android provides an exceptional, secure mobile experience to our users. To this end, we are prioritizing Recommended Extensions that are optimized for different screen sizes and cover common mobile use cases. For these reasons, it’s possible that not all the add-ons you have previously installed in Firefox for Android will be supported in the near future. When an add-on you previously installed becomes supported, we will notify you.
When we have more information about how we plan to support add-ons in Firefox for Android beyond our near-term goals, we will post them on this blog. We hope you stay tuned!
The post uBlock Origin available soon in new Firefox for Android Nightly appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/02/06/ublock-origin-for-firefox-android-nightly/
|
|
Jan-Erik Rediger: "Edit this file on GitHub" |
At work I help with maintaining two large documentation books:
Back in 2018 I migrated dtmo from gitbook to mdbook (see the pull request). mdbook is maintained by the Rust project and hosts the Rust book as well as a multitude of other community projects. It provided all we need, plus a way to extend it with some small things, I blogged about ToC and mermaid before.
During the Mozilla All Hands last week my colleague Mike casually asked why we don't have links to quickly edit the documentation. When someone discovers a mistake or inaccuracy in the book the current process involves finding the repository of the book, then finding the right file, then edit that file (through the GitHub UI or by cloning the repository), then push changes, open a pull request, wait for review and finally get it merged and deployed.
I immediately set out to build this feature.
I present to you: mdbook-open-on-gh
It's another preprocessor for mdbook, that adds a link to the edit dialog on GitHub (if your book is actually hosted on GitHub). And that's how it looks:

It's already deployed on dtmo and the Glean SDK book and simplifies the workflow to: click the link, edit the file on GitHub, commit and open a PR, get a review and merge it to deploy.
If you want to use this preprocessor, install it:
cargo install mdbook-open-on-gh
Add it as a preprocessor to your book.toml:
[preprocessor.open-on-gh]
command = "mdbook-open-on-gh"
renderer = ["html"]
Add a repository URL to use as a base in your book.toml:
[output.html]
git-repository-url = "https://github.com/mozilla/glean"
To style the footer add a custom CSS file for your HTML output:
[output.html]
additional-css = ["open-in.css"]
And in open-in.css style the element or directly the CSS element id open-on-gh:
footer { font-size: 0.8em; text-align: center; border-top: 1px solid black; padding: 5px 0; }
This code block shrinks the text size, center-aligns it under the rest of the content and adds a small horizontal bar above the text to separate it from the page content.
Finally, build your book as normal:
mdbook path/to/book
|
|
Hacks.Mozilla.Org: It’s the Boot for TLS 1.0 and TLS 1.1 |
The Transport Layer Security (TLS) protocol is the de facto means for establishing security on the Web. The protocol has a long and colourful history, starting with its inception as the Secure Sockets Layer (SSL) protocol in the early 1990s, right up until the recent release of the jazzier (read faster and safer) TLS 1.3. The need for a new version of the protocol was born out of a desire to improve efficiency and to remedy the flaws and weaknesses present in earlier versions, specifically in TLS 1.0 and TLS 1.1. See the BEAST, CRIME and POODLE attacks, for example.
With limited support for newer, more robust cryptographic primitives and cipher suites, it doesn’t look good for TLS 1.0 and TLS 1.1. With the safer TLS 1.2 and TLS 1.3 at our disposal to adequately project web traffic, it’s time to move the TLS ecosystem into a new era, namely one which doesn’t support weak versions of TLS by default. This has been the abiding sentiment of browser vendors – Mozilla, Google, Apple and Microsoft have committed to disabling TLS 1.0 and TLS 1.1 as default options for secure connections. In other words, browser clients will aim to establish a connection using TLS 1.2 or higher. For more on the rationale behind this decision, see our earlier blog post on the subject.
We deployed this in Firefox Nightly, the experimental version of our browser, towards the end of 2019. It is now also available in Firefox Beta 73. In Firefox, this means that the minimum TLS version allowable by default is TLS 1.2. This has been executed in code by setting security.tls.version.min=3, a preference indicating the minimum TLS version supported. Previously, this value was set to 1. If you’re connecting to sites that support TLS 1.2 and up, you shouldn’t notice any connection errors caused by TLS version mismatches.
In cases where only lower versions of TLS are supported, i.e., when the more secure TLS 1.2 and TLS 1.3 versions cannot be negotiated, we allow for a fallback to TLS 1.0 or TLS 1.1 via an override button. As a Firefox user, if you find yourself in this position, you’ll see this:

As a user, you will have to actively initiate this override. But the override button offers you a choice. You can, of course, choose not to connect to sites that don’t offer you the best possible security.
This isn’t ideal for website operators. We would like to encourage operators to upgrade their servers so as to offer users a secure experience on the Web. We announced our plans regarding TLS 1.0 and TLS 1.1 deprecation over a year ago, in October 2018, and now the time has come to make this change. Let’s work together to move the TLS ecosystem forward.
We plan to monitor telemetry over two Firefox Beta cycles, and then we’re going to let this change ride to Firefox Release. So, expect Firefox 74 to offer TLS 1.2 as its minimum version for secure connections when it ships on 10 March 2020. We plan to keep the override button for now; the telemetry we’re collecting will tell us more about how often this button is used. These results will then inform our decision regarding when to remove the button entirely. It’s unlikely that the button will stick around for long. We’re committed to completely eradicating weak versions of TLS because at Mozilla we believe that user security should not be treated as optional.
Again, we would like to stress the importance of upgrading web servers over the coming months, as we bid farewell to TLS 1.0 and TLS 1.1. R.I.P, you’ve served us well.
The post It’s the Boot for TLS 1.0 and TLS 1.1 appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/02/its-the-boot-for-tls-1-0-and-tls-1-1/
|
|
Robert Kaiser: FOSDEM, and All Those 20's |
|
|
Ludovic Hirlimann: Fosdem turns 20 |
I've been attending Fosdem since 2004 when I was involved with Camino. I got enticed to come by a post of Tristan. On that particular year I got enrolled by Gerv to check a few mac things. I met Patrick who was working on enigmail, and we became friends. I was hooked - and have only missed Fosdem 2015. Over the years I gave talks. I met new people, made friends. 3 years ago I became a volunteer, by accident and ran the PGP key signing party. I enjoyed being a volunteer, it was fun and gave me an orange T-shirt to grow my collection. So the year after I signed up on volunteers.fosdem.org to help clean up on the Sunday evening. It was my first time attending the fosdem fringe (CentOS dojo and Configuration Management Camp).
2020 was very special: I helped organize the Mozilla dev room (thank you, Anthony and Jean-Yves for letting me be part of that). A few things happened that shortened the number of Volunteers this year. I Managed the room and had the pleasure to introduce speakers and talks. It was very smooth because Robert was directing people to the door where space was available in the auditorium. My two favorites were:
Once the talks were over, I attended the last two talks in the main auditorium Janson. The closing talk and the one remembering 20 year of conference. This later was a hell of a great show thanks MarquisdeGeek (Video is not ready yet).
https://www.hirlimann.net/Ludovic/carnet/?post/2020/02/06/Fosdem-turns-20
|
|
Tantek Celik: Local First, Undo Redo, JS-Optional, Create Edit Publish |
For a while I have brainstormed designs for a user experience (UX) to create, edit, and publish notes and other types of posts, that is fully undoable (like Gmail’s "Undo Send" yet generalized to all user actions) and redoable, works local first, and lastly, uses progressive enhancement to work without scripts in the extreme fallback case of not being installed, and scripts not loading.
I’d like to be able to construct an entire post on a mobile device, like a photo post with caption, people tags, location tag etc. all locally, offline, without any need to access a network.
This is like how old email applications used to work. You could be completely offline, open your email application (there was no need to login to it!), create a message, add attachments, edit it etc., click "Send" and then forget about it. Eventually it synced to the network but you didn’t worry or care about when that step would happen, you just knew it would eventually work without you having to tend to it or watch it.
I want to approach this from user-experience-first design perspective, rather than a bottom-up protocol/technology/backend first perspective. For one, I don’t know if any existing protocols actually have the necessary features to support such a UX.
Micropub has a lot of what’s needed, and I won’t know what else is needed until I build the user flows I want, and then use those to drive any necessary Micropub feature additions. I absolutely do not want to limit my UX by what an existing protocol can or cannot do (essentially the software design version of the tail wags dog problem).
I wrote up a brief stub article on the IndieWeb wiki on local first. I see local first as an essential aspect of an authoring experience that is maximally responsive to user input, and avoids any and all unnecessary ties to other services.
I want a 100% local first offline capable creating / editing / posting workflow which then “auto-syncs” once the network shows up. The presence / absence of internet access should not affect user flow at all. Network presence or absence should only be a status indicator (e.g. whether / how much a post has been sent to the internet or not, any edits / updates etc.). It should never block any user actions. I’ll say it again for emphasis:
The absence or presence of network access must not block any user actions. Ever. Any changes should be effective locally immediately, with zero data loss.
Nearly no one actually builds apps like that today. Even typical mobile “native” apps fail without network access (a few counter-examples are the iOS built-in Notes & Photos apps, as well as the independent maps.me 100% offline mapping program). Some “offline first” apps get close. But even those, especially on mobile, fail in both predictable (like requiring logging into a website or network service, just to edit a local text document) and strange ways.
Every such user action should be undoable and redoable, again, without waiting for the network (it’s reasonable to apply some time limits for some actions, e.g. Gmail Undo can be configured to work for 30 seconds). Now imagine that for any user action, especially any user action that creates, edits, or deletes content or any aspects thereof (like name, tags, location etc.).
In the case where a web application has not yet been installed, I also want it to be 100% capable without depending on loading any external scripts. This JS-Optional approach is more broadly known as progressive enhancement, which does require that you have at least some connection, enough for a browser to submit form requests and retrieve static HTML (and preferably though not required, static CSS and image files too).
Once you are connected and are running at least a Service Worker for the site, local first requires execution of some scripts, though even then dependencies on any external scripts should be minimized and preferably eliminated.
I believe aspects of this experience can be built and deployed incrementally, iterating over time until the full system is built.
I’ve got a handful of paper sketches of local-first undoable/redoable user flows. I have a Service Worker deployed on my site that allows offline browsing of previously visited pages, and I have a form submission user interface that handles part of publishing. There are many more aspects to design & implement. As I think of them I’m capturing them in part of my “Working On” list on the IndieWeb Wiki, iteratively reprioritizing and making incremental progress at IndieWebCamps.
One building block at a time, collaboratively.
Thanks to J. Gregory McVerry, Grant Richmond, and Kevin Marks for reviewing drafts of this post.
https://tantek.com/2020/037/b2/local-first-undo-redo-create-edit-publish
|
|
Mike Hommey: Announcing git-cinnabar 0.5.4 |
Git-cinnabar is a git remote helper to interact with mercurial repositories. It allows to clone, pull and push from/to mercurial remote repositories, using git.
These release notes are also available on the git-cinnabar wiki.
git cinnabar fsck would not skip files it was meant to skip and failed as a result.|
|
Karl Dubost: Week notes - 2020 w05 - worklog - Mozilla All Hands Berlin |
Left home in between 5:30 AM and 6:00 AM. All geared up for the coronavirus outbreak just in case. Japan is not yet heavily affected. 3 cases at the time of this writing and all coming from Chinese traveling in Japan. Taking the train to Narita Airport. Then the plane to Brussels, and finally Brussels to Berlin.

Funny story about the mask. In Japan and many parts of Asia, wearing a mask is fairly common. You do it for mainly 3 reasons:
My mask has been unnoticeable in the eyes of anyone until I arrive… Brussels airport. First I was the only one wearing one. Second people were giving me a inquisitive look. I think some were worried.
I then walked from the Berlin airport to the hotel. It's something I do time to time to better understand the fabric of a city and how it changes from its periphery to its core. Walking is the best pace for thinking. It was only a 1 hour 45 minutes walk. It was night. First time for me doing it at night. The exit of Berlin airport on foot is not complicated, but the mood is a bit spooky for about 2 km with the motorway on one side and the forest on the other side.
I had a quick dinner with Kate that I bumped into at the registration desk. And then I didn't try to catch up with anyone and went directly to bed after 22 hours of trip.
Japan has now 6 cases of coronavirus, including one person infected through transmission, a bus driver who drove around a Chinese tour group.
This is a very special All Hands. It's happening just two weeks after the layoffs. So this was in the mind and talk of everyone. The catharsis may help and we need to rebuild our forces, hopes, and tackles some of the issues of the Web. When I think about Mozilla as a place for working, I still think it is one of the best places to work on the open web issues.
I had written something about the controversial tweet of the week, but i decided to give it a separate article, because it was starting to be longer. So it will be published soon on this blog.
During one of our discussions, someone wondered if Mozilla should enter the search space by providing a search engine.
Mozilla doesn't need to create a new search engine, but there is definitely a place for privacy-focused search engine. Currently there are solutions for people looking for information such as DuckDuckGo. But DuckDuckGo just use the index of Google, and a couple of other sources to give results. They do not have their own indexer. So as a site owner if you are blocking most of the search engines, because you do not want your website to appear in an environment full of ads, there is no possibility for you to provide this information to their users/readers.
I would love to see a indexer which is on-demand that would build an index for people who don't want to be for example on Google Search or Bing, but would still be willing to be on DuckDuckGo. Another consequence of this would be to have a leverage to improve the indexing of the information with better structured content. As the mission is not to index the web, but to catalog people who are requesting it. I even wonder if site owners would be ready to pay this as a service. What would be the cost of running such a thing? Would DuckDuckGo be interested?
Should Mozilla help with this? Create a deal with DuckDuckGo?
I want to be able to browse the Web keeping the history of some of the sites I visited. Basically keep a records of some targeted websites. When I go to let's say NY times homepage, I want to be able to save this page. If I go a couple of days later, the browser would remember I already visited this site and I would be able to access the previous instances as layers of timestamped-information of my previous visits. A kind of personal webarchive.
Mozilla AI plenary session was a good wake up call. A couple of speakers gave examples on the policies, the instrumentalization of ai to maximize profits (and not knowledge). I wish these talks were video recorded for public consumptions.
All-Hands are a great opportunity to re-think about what we are and what we do. I started to take notes on my laptop about the webcompat agencies.
Breakfast discussions around service workers, Web standards and balance of powers.
A walk, in the evening, along some stretches of the wall. Graffitis and holes in an agency which was once a divider in a city. The first time, I came to Berlin, was in 1988, during a school trip (I was 19 at the time). We traveled by train from France to Berlin, crossing East Germany in a fenced corridor until we reached Berlin. Then we visited different parts of Berlin west during the trip. We had a special day though. We crossed checkpoint charlie and for one afternoon, we stayed in East Berlin. The contrast with the luxurious west part of the city was stunning. The quietness of the street we could see from the bus was stunning. A few trabant here and there. I think I remember that we went to visit the Pergamon museum, which was in East Berlin at this time. It was not imaginable that the wall would fall one year later.
Friday was the concept map day where we drew what webcompat activity meant for the Web and Mozilla. It was pretty cool to see everyone pitching in. I will redraw it properly later, but here an incomplete draft.
I published the meeting minutes we had during the week. These often doesn't take into all the little brain storming, here and there. The breakfast discussions which matter. The meeting in person for the first time someone else from Mozilla giving the opportunity to thank them directly about something they did in the past year that helped you a lot.
Also for everyone landing here through twitter or because they are following the Mozilla Planet feed, just publish simple work thoughts, codes, cool things you are working on.
It's not about being oustanding to your peers or appealing to your boss, it's about helping people who are less knowledgeable than you. We all learn from people who had the grace to share their own knowledge and help us to grow as a person or as a better professional. You can do exactly the same for people who are not at the same level than you.
Tomorrow long flight back from Berlin to Tokyo (via Zurich).
Otsukare!
|
|






