Reeder (it_is_it) все записи автора
Reeder (it_is_it) все записи автора
Intel Core i7 пяти поколений в близком частотном диапазоне
Топовые процессоры трех последних поколений микроархитектур Intel мы тестировали уже и as is, и с дискретной видеокартой, однако эти два материала, как нам кажется, все еще недостаточны для полного раскрытия темы. Первым «тонким моментом» являются тактовые частоты — все-таки при выпуске Haswell Refresh компания уже разделила жестко линейку «обычных» Core i7 и «оверклокерских», фабрично разогнав последние (что было не так уж и сложно, поскольку таких процессоров вообще говоря требуется немного, так что отобрать необходимое количество нужных кристаллов несложно). Появление же Skylake положение дел не только сохранило, но и усугубило: Core i7-6700 и i7-6700K это вообще очень разные процессоры, различающиеся и уровнем TDP. Таким образом, даже при одинаковых частотах эти модели могли бы работать по-разному с точки зрения производительности, а ведь и частоты совсем не одинаковые. В общем, делать выводы по старшей модели опасно, но в основном-то как раз везде изучалась она и только она. «Младшая» (и более востребованная) до последнего времени вниманием тестовых лабораторий избалована не была.
А для чего это может быть нужно? Как раз для сравнения с «верхушками» предыдущих семейств, тем более что там обычно такого большого разброса частот не было. Иногда и вообще не было — например, пары 2600/2600K и 4771/4770К в плане процессорной части в штатном режиме идентичны. Понятно, что 6700 в большей степени является аналогом не названных моделей, а 2600S, 3770S, 4770S и 4790S, но... Важно это лишь с технической точки зрения, которая, в общем-то, мало кого интересует. В плане распространенности, легкости приобретения и других значимых (в отличие от технических деталей) характеристик это как раз «регулярное» семейство, к которому и будет присматриваться большинство владельцев «старых» Core i7. Или потенциальных владельцев — пока еще апгрейд временами остается чем-то полезным, большинство пользователей процессоров младших семейств процессоров при необходимости увеличения производительности присматривается в первую очередь к устройствам для уже имеющейся «на руках» платформы, а только потом уже рассматривает (или не рассматривает) идею ее замены. Правильный это подход или не очень — покажут тесты.
Конфигурация тестовых стендов
|
Процессор |
Intel Core i7-2700K |
Intel Core i7-3770 |
Intel Core i7-4770K |
Intel Core i7-5775C |
Intel Core i7-6700 |
|
Название ядра |
Sandy Bridge |
Ivy Bridge |
Haswell |
Broadwell |
Skylake |
|
Технология пр-ва |
32 нм |
22 нм |
22 нм |
14 нм |
14 нм |
|
Частота ядра std/max, ГГц |
3,5/3,9 |
3,4/3,9 |
3,5/3,9 |
3,3/3,7 |
3,4/4,0 |
|
Кол-во ядер/потоков |
4/8 |
4/8 |
4/8 |
4/8 |
4/8 |
|
Кэш L1 (сумм.), I/D, КБ |
128/128 |
128/128 |
128/128 |
128/128 |
128/128 |
|
Кэш L2, КБ |
4×256 |
4×256 |
4×256 |
4×256 |
4×256 |
|
Кэш L3 (L4), МиБ |
8 |
8 |
8 |
6 (128) |
8 |
|
Оперативная память |
2×DDR3-1333 |
2×DDR3-1600 |
2×DDR3-1600 |
2×DDR3-1600 |
2×DDR4-2133 |
|
TDP, Вт |
95 |
77 |
84 |
65 |
65 |
|
Графика |
HDG 3000 |
HDG 4000 |
HDG 4600 |
IPG 6200 |
HDG 530 |
|
Кол-во EU |
12 |
16 |
20 |
48 |
24 |
|
Частота std/max, МГц |
850/1350 |
650/1150 |
350/1250 |
300/1150 |
350/1150 |
|
Цена |
18747 руб. (4) |
26027 руб. (10) |
28440 руб. (158) |
30220 руб. (68) |
30990 руб. (51) |
Для пущей академичности имело бы смысл тестировать Core i7-2600 и i7-4790, а вовсе не 2700К и 4770К, но первый в наше время найти уже сложно, в то время как 2700К у нас под рукой в свое время нашелся и был протестирован. Равно как и 4770К тоже изучался, причем в «обычном» семействе он имеет полный (4771) и близкий (4770) аналоги, и вся упомянутая троица от 4790 отличается несущественно, так что возможностью минимизировать количество работы мы решили не пренебрегать. В итоге, кстати, процессоры Core второго, третьего и четвертого поколений оказались максимально близки друг к другу по официальному диапазону тактовых частот, да и 6700 отличается от них незначительно. Broadwell тоже можно было «подтянуть» к этому уровню, взяв результаты не i7-5775C, а Xeon E3-1285 v4, но только лишь подтянуть, а не полностью устранить различие. Именно поэтому мы решили воспользоваться более массовым (благо и большинство других участников такие же), а не экзотическим процессором.
Что касается прочих условий тестирования, то они были равными, но не одинаковыми: частота работы оперативной памяти была максимальной поддерживаемой по спецификациям. А вот ее объем (8 ГБ) и системный накопитель (Toshiba THNSNH256GMCT емкостью 256 ГБ) были одинаковыми для всех испытуемых.
Методика тестирования
Для оценки производительности мы использовали нашу методику измерения производительности с применением бенчмарков iXBT Application Benchmark 2015 и iXBT Game Benchmark 2015. Все результаты тестирования в первом бенчмарке мы нормировали относительно результатов референсной системы, которая в этом году будет одинаковой и для ноутбуков, и для всех остальных компьютеров, что призвано облегчить читателям нелегкий труд сравнения и выбора:
|
Процессор |
Intel Core i5-3317U |
|
Чипсет |
Intel HM77 Express |
|
Память |
4 ГБ DDR3-1600 (двухканальный режим) |
|
Графическая подсистема |
Intel HD Graphics 4000 |
|
Накопитель |
SSD 128 ГБ Crucial M4-CT128M4SSD1 |
|
Операционная система |
Windows 8 (64-битная) |
|
Версия видеодрайвера графического ядра Intel |
9.18.10.3186 |
iXBT Application Benchmark 2015
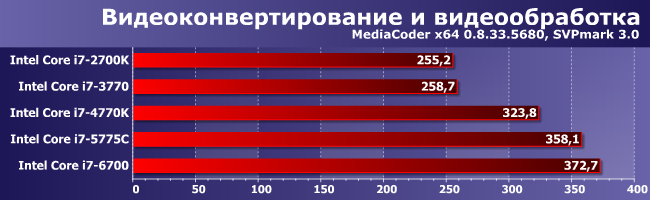
Как мы уже не раз писали, в этой группе немалое значение имеет видеоядро. Однако далеко не все так просто, как можно было бы предположить только лишь по техническим характеристикам — например, i7-5775C все же медленнее, чем i7-6700, хотя у первого как раз GPU намного мощнее. Впрочем, еще более показательно тут сравнение 2700К и 3770, которые в плане исполнения OpenCL-кода различаются принципиально — первый задействовать для этого GPU вообще не способен. Второй — способен. Но делает это настолько медленно, что никаких преимуществ перед предшественником не имеет. С другой стороны, наделение такими способностями «самого массового GPU на рынке» привело к тому, что их начали понемногу использовать производители программного обеспечения, что проявилось уже к моменту выхода на рынок следующих поколений Core. И наряду с небольшими улучшениями и процессорных ядер способно привести к достаточно заметному эффекту.
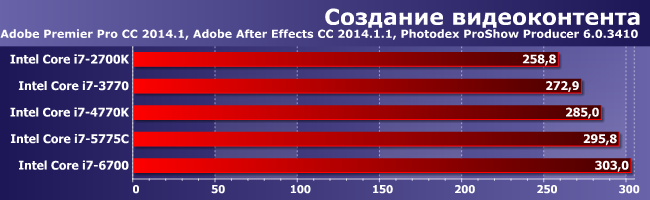
Однако не везде — вот как раз случай, когда прирост от поколения к поколению совсем не заметен. Впрочем, он есть, но такой, что проще не обращать на него внимания. Интересным тут является разве что то, что прошедший год позволил совместить такое увеличение производительности с существенно менее жесткими требованиями к системе охлаждения (что открывает обычным настольным Core i7 и сегмент компактных систем), однако не во всех случаях это актуально.

А вот пример, когда на GPU уже удалось переложить немалую часть нагрузки. Единственное, что может «спасти» в этом случае старые Core i7 это дискретная видеокарта, однако пересылки данных по шине эффект портят, так что i7-2700K и в этом случае не обязательно догонит i7-6700, а 3770 на это способен, но вот угнаться ни за 4790К или 6700К, ни за 5775С с любым видео уже не может. Собственно, ответ на иногда возникающий у части пользователей недоуменный вопрос — зачем в Intel уделяют столько внимания интегрированной графике, если для игр ее все равно мало, а для других целей давно достаточно? Как видим, не слишком-то и «достаточно», если самым быстрым иногда способен (как здесь) оказаться процессор с далеко не самой мощной «процессорной» частью. И уже заранее интересно — что мы сможем получить от Skylake в модификации GT4e ;)
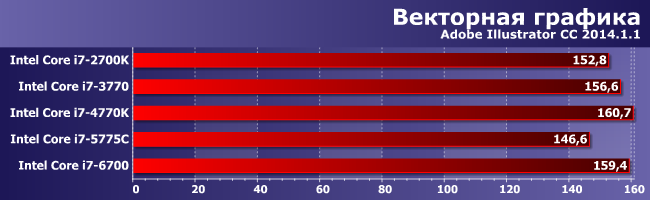
Поразительное единодушье, обеспеченное тем, что этой программе не требуются ни новые наборы инструкций, ни какие-то чудеса на ниве увеличения многопоточной производительности. Небольшая разница между поколениями процессоров, все же, есть. Но выискивать ее можно разве что при в точности идентичной тактовой частоте. А когда таковая различается существенно (что мы имеем в исполнении i7-5775С, в однопоточном режиме отстающем от всех на 10%) — можно и не искать :)
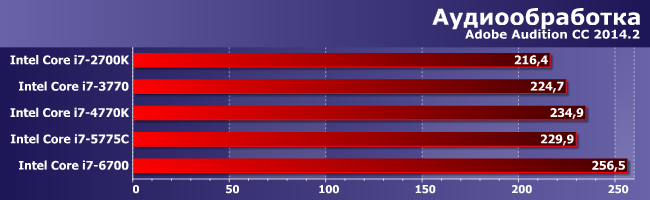
Audition «умеет» более-менее все. Разве что к дополнительным потокам вычисления довольно равнодушен, но использовать их умеет. Причем, судя по результатам, на Skylake делает это лучше, чем было свойственно предыдущим архитектурам: преимущество 4770К над 4690К составляет порядка 15%, а вот 6700 обходит 6600К уже на 20% (при том, что частоты у всех примерно равные). В общем, скорее всего, в новой архитектуре будет ждать нас еще немало открытий. Небольших, но иногда дающих кумулятивный эффект.
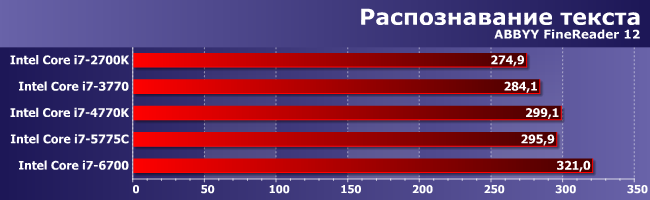
Как и в случае распознавания текста, где именно 6700 отрывается от предшественников наиболее «резво». Хоть в абсолютном итоге и незначительно, но ждать на относительно старых и хорошо «вылизанных» алгоритмах такого прироста при учете того, что, по сути, перед нами энергоэффективный процессор (кстати — 6700К действительно намного быстрее справляется с этой задачей) априори было бы слишком оптимистично. Мы и не ждали. А практика оказалась интереснее априорных предположений :)
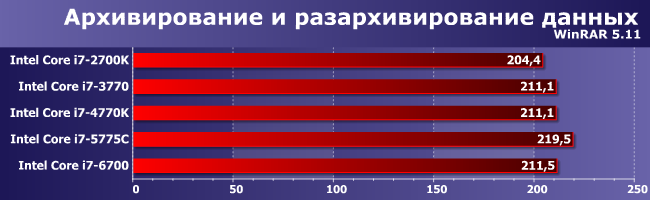
С архиваторами все топовые процессоры справляются очень хорошо независимо от поколения. Во многом, как нам кажется, потому, что для них-то эта задача уж очень уже простая. Собственно, счет уже идет на секунды, так что что-то здесь радикально улучшить практически невозможно. Если только ускорить работу системы памяти, но DDR4 имеет более высокие задержки, нежели DDR3, так что гарантированный результат дает разве что увеличение кэшей. Поэтому самым быстрым оказался единственный среди протестированных процессор с GPU GT3e — кэш-память четвертого уровня используется не только видеоядром. С другой стороны, не так уж и велик прирост от дополнительного кристалла, так что архиваторы просто та нагрузка, на которую в случае заведомо быстрых систем (а не каких-нибудь мини-ПК) можно уже не обращать внимания.
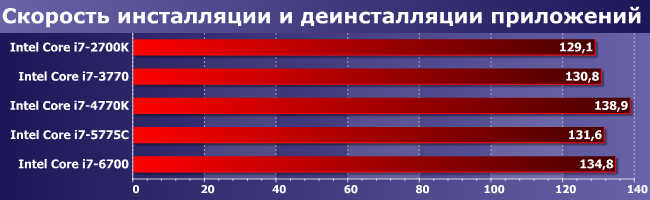
Плюс-минус пол-лаптя от Солнца, что, в общем, тоже подтверждает, что все топовые процессоры справляются с такими задачами одинаково, контроллеры в чипсетах трех серий примерно идентичные, так что существенная разница может быть обусловлена только накопителем.
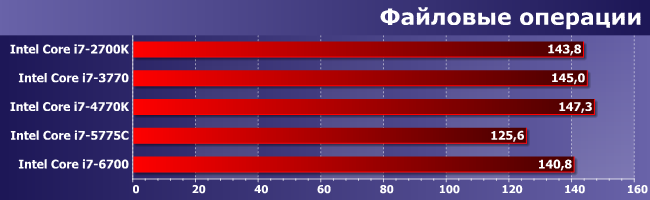
А вот в таком банальном сценарии, как простое копирование файлов, еще и теплопакетом: модели с пониженным «разгоняются» достаточно вяло (благо формально и не за чем), что приводит к чуть более низким результатам, чем могло бы. Но в целом тоже не тот случай, ради которого может возникнуть желание менять платформу.
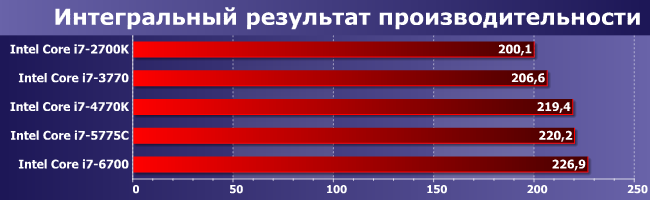
Что получаем в итоге? Все процессоры примерно идентичны друг другу. Да, конечно, разница между лучшим и худшим превышает 10%, но не стоит забывать о том, что это различия, накопившиеся за три с лишним года (а возьми мы i7-2600, так было бы 15% почти за пять). Таким образом, практического смысла в замене одной платформы на другую нет, пока старая работает. Естественно, если речь идет о LGA1155 и ее последователях — как мы уже убедились«перепад» между LGA1156 и LGA1155 куда более заметный, причем не только в плане производительности. На последних на данный момент платформах Intel что-то можно «выжать» использованием «стероидных» Core i7 (если уж все равно ориентироваться именно на это недешевое семейство), но не так и много: по интегральной производительности i7-6700K обгоняет i7-6700 на 15%, так что и его отрыв от какого-нибудь i7-2700K увеличивается почти до 30%, что уже более весомо, но все равно еще не принципиально.
Игровые приложения
По понятным причинам, для компьютерных систем такого уровня мы ограничиваемся режимом минимального качества, причем не только в «полном» разрешении, но и с его уменьшением до 1366×768: Несмотря на очевидный прогресс в области интегрированной графики, она пока не способна удовлетворить требовательного к качеству картинки геймера. А 2700К мы решили и вовсе на стандартном игровом наборе не проверять: очевидно, что тех его владельцев, кто использует именно интегрированное видеоядро, игры не интересуют от слова совсем. Кого интересуют хоть как-то, те уж точно как минимум какую-нибудь «затычку для слота» в закромах нашли и установили, благо наше тестирование по предыдущей версии методикипоказало, что HD Graphics 3000 не лучше, чем даже Radeon HD 6450, причем обоих практически ни на что не хватает. Вот HDG 4000 и более новые IGP уже какой-никакой интерес собой представляют.
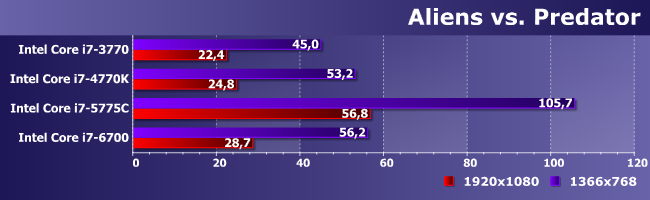
Вот, например, в Aliens vs. Predator можно поиграть на любом из изучаемых процессоре, но только снизив разрешение. Для FHD же подходит только GT3e, причем неважно какой — просто в сокетном исполнении такая конфигурация на данный момент доступна лишь для Broadwell со всеми вытекающими.
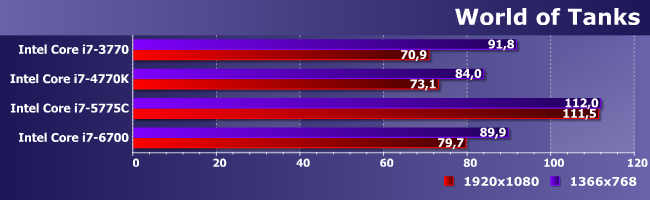
Зато «танчики» на минималках уже на всем «бегают» столь хорошо, что стройная картина только в высоком разрешении и «вытанцовывается»: в низком даже непонятно — кто лучше, а кто хуже.
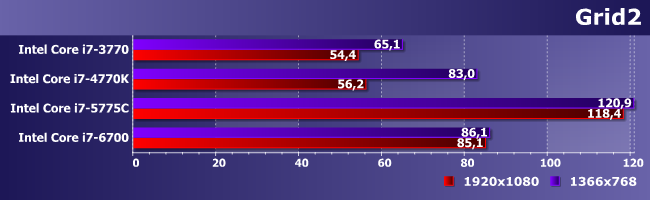
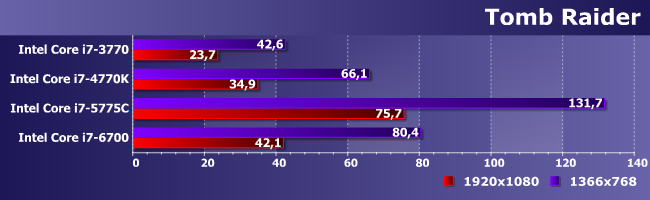
Grid2 при всей своей слабой требовательности к видеочасти все еще ставит процессоры строго по ранжиру. Но особенно хорошо это видно опять в FHD, где и пропускная способность памяти уже имеет значение. В итоге на i7-6700 уже можно разрешение не снижать. На i7-5775C тем более, причем и абсолютные результаты намного выше, так что если данная сфера применения интересует, а использование дискретной видеокарты по каким-либо причинам нежелательно, альтернатив этой линейке процессоров по-прежнему нет. В чем нет и ничего нового.
Лишь старшие Haswell «вытягивают» игру хотя бы в низком разрешении, а Skylake делает это уже без оговорок. Broadwell не комментируем — это не архитектурное, а, скажем так, количественное превосходство.
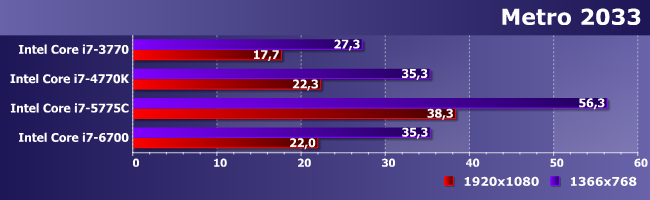
Более старая игра серии на первый взгляд аналогична, но тут уже и между Haswell и Skylake даже количественных отличий не наблюдается.
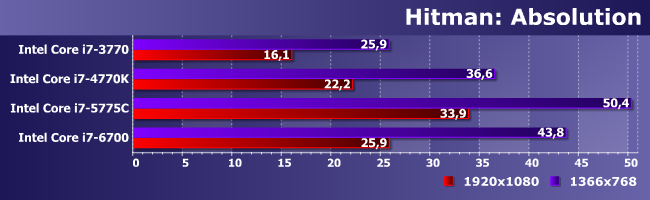
В Hitman — наблюдаются и заметные, но перехода количества в качество по-прежнему нет.
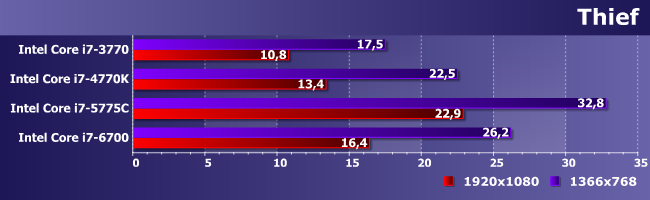
Как и здесь, где даже режим низкого разрешения может «вытянуть» только процессор с GT3e. У остальных — весомый, но все еще недостаточный даже для таких «подвигов» прогресс.
Минимальный режим настроек в этой игре относится очень щадящим образом ко всем слабосильным GPU, хотя HDG 4000 еще «хватало» лишь на HD, но не FHD.
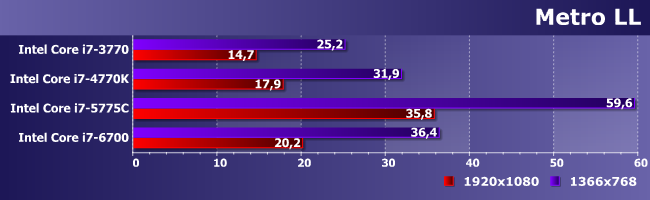
И снова тяжелый случай. Менее «тяжелый», чем Thief, но достаточный для того, чтобы продемонстрировать наглядно, что никакая интегрированная графика не может считаться игровым решением.
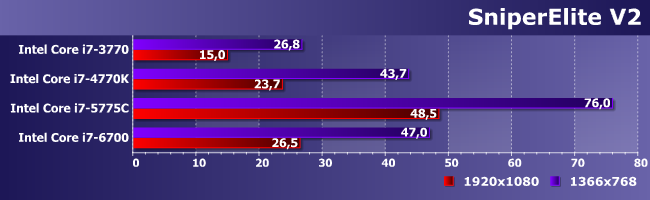
Хотя в некоторые игры может позволить поиграть и с относительным комфортом. Впрочем, ощутимым только если усложнять IGP и количественно наращивать все функциональные блоки. Собственно, как раз в легких режимах прогресс в области GPU Intel наиболее заметен — примерно два раза за три года (более старые-то разработки вообще уже нет смысла рассматривать серьезно). Но из этого не следует, что со временем интегрированная графика сможет легко и непринужденно догнать дискретную сравнимого возраста. Скорее всего, «паритет» будет установлен с другой стороны — имея в виду огромную базу инсталлированных решений невысокой производительности, производители тех же игр на нее и будут ориентироваться. Почему раньше этого не делали? Вообще говоря, делали — если рассматривать не только 3D-игры, а вообще рынок, огромное количество весьма популярных игровых проектов было предназначено как раз для того, чтобы нормально работать и на достаточно архаичных платформах. Но определенный сегмент программ, «двигавших рынок» был всегда, причем именно он и привлекал максимум внимания со стороны прессы и не только. Сейчас же процесс явно близок к точке насыщения, поскольку, во-первых, парк разнообразной компьютерной техники уже очень велик, и желающих заниматься перманентным апгрейдом все меньше. А во-вторых, «мультиплатформенность» нынче подразумевает под собой не только специализированные игровые консоли, но и разнообразные планшеты-смартфоны, где, очевидно, с производительностью все еще хуже, чем у «взрослых» компьютеров, независимо от степени интегрированности платформ последних. Но для того, чтобы данная тенденция стала преобладающей, нужно, все же, как нам кажется достигнуть определенного уровня гарантированной производительности. Чего пока нет. Но над проблемой все производители работают более чем активно и Intel тут исключением не является.
Итого
Что же мы видим в конечном итоге? В принципе, как не раз было сказано, последнее существенное изменение в процессорных ядрах семейства Core состоялось почти пять лет назад. На этом этапе уже удалось достичь такого уровня, «атаковать» который напрямую никто из конкурентов не может. Поэтому основной задачей Intel является улучшение положения в, скажем так, сопутствующих областях, а также наращивание количественных (но не качественных) показателей там, где это имеет смысл. Тем более, что серьезное влияние на массовый рынок оказывает растущая популярность портативных компьютеров, давно обогнавших по этому показателю настольные и становящихся все более портативными (несколько лет назад, например, ноутбук массой 2 кг еще считался «условно легким», а сейчас активно растут продажи трансформеров, в случае которых большая масса убивает весь смысл их существования). В общем, разработка компьютерных платформ давно идет не по пути наилучшего удовлетворения потребностей покупателей больших настольных компьютеров. В лучшем случае — не в ущерб им. Поэтому то, что в целом в этом сегменте производительность систем не снижается, а даже немного растет, уже повод для радости — могло быть и хуже :) Плохо только то, что из-за изменений в периферийной функциональности приходится постоянно менять и сами платформы: это сильно подкашивает такое традиционное преимущество модульных компьютеров, как ремонтопригодность, но здесь ничего не попишешь — попытки сохранять совместимость любой ценой до добра тем более не доводят (сомневающиеся могут посмотреть на, к примеру, AMD AM3+).