CodeSOD: Switched Requirements |
Code changes over time. Sometimes, it feels like gremlins sweep through the codebase and change it for us. Usually, though, we have changes to requirements, which drives changes to the code.
Thibaut was looking at some third party code to implement tooling to integrate with it, and found this C# switch statement:
if (effectID != 10)
{
switch (effectID)
{
case 21:
case 24:
case 27:
case 28:
case 29:
return true;
case 22:
case 23:
case 25:
case 26:
break;
default:
switch (effectID)
{
case 49:
case 50:
return true;
}
break;
}
return false;
}
return true;
I'm sure this statement didn't start this way. And I'm sure that, to each of the many developers who swung through to add their own little case to the switch their action made some sort of sense, and maybe they knew they should refactor, they need to get this functionality in and they need it now, and code cleanliness can wait. And wait. And wait.
Until Thibaut comes through, and replaces it with this:
switch (effectID)
{
case 10:
case 21:
case 24:
case 27:
case 28:
case 29:
case 49:
case 50:
return true;
}
return false;
|
Метки: CodeSOD |
CodeSOD: Imploded Code |
Cassi’s co-worker (previously) was writing some more PHP. This code needed to take a handful of arguments, like id and label and value, and generate HTML text inputs.
Well, that seems like a perfect use case for PHP. I can’t possibly see how this could go wrong.
echo $sep."\n";Now, PHP’s array_map is a beast of a function, and its documentation has some pretty atrocious examples. It’s not just a map, but also potentially a n-ary zip, but if you use it that way, then the function you’re passing needs to be able to handle the right number of arguments, and– sorry. Lost my train of thought there when checking the PHP docs. Back to the code.
In this case, we use array_map to make all our fields JavaScript safe by json_encodeing them. Then we use implode to mash them together into a comma separated string. Then we concatenate all that together into a CreateField call.
CreateField is a JavaScript function. Cassi didn’t supply the implementation, but lets us know that it uses document.write to output the input tag into the document body.
So, this is server side code which generates calls to client side code, where the client side code runs at page load to document.write HTML elements into the document… elements which the server side code could have easily supplied.
I’ll let Cassi summarize:
I spent 5 minutes staring at this trying to figure out what to say about it. I just… don’t know. What’s the worst part? json_encoding individual arguments and then imploding them? Capital HTML tags? A $sep variable that doesn’t need to exist? (Trust me on this one.) Maybe it’s that it’s a line of PHP outputting a Javascript function call that in turn uses document.write to output a text HTML input field? Yeah, it’s probably that one.
|
Метки: CodeSOD |
CodeSOD: A Poor Facsimile |
For every leftpad debacle, there are a thousand “utility belt” libraries for JavaScript. Whether it’s the “venerable” JQuery, or lodash, or maybe Google’s Closure library, there’s a pile of things that usually end up in a 50,000 line util.js file available for use, and packaged up a little more cleanly.
Dan B had a co-worker who really wanted to start using Closure. But they also wanted to be “abstract”, and “loosely coupled”, so that they could swap out implementations of these utility functions in the future.
This meant that they wrote a lot of code like:
initech.util.clamp = function(value, min, max) {
return goog.math.clamp(value, min, max);
}But it wasn’t enough to just write loads of functions like that. This co-worker “knew” they’d need to provide their own implementations for some methods, reflecting how the utility library couldn’t always meet their specific business needs.
Unfortunately, Dan noticed some of those “reimplementations” didn’t always behave correctly, for example:
initech.util.isDefAndNotNull(null); //returns trueLet’s look at the Google implementations of some methods, annotated by Dan:
goog.isDef = function(val) {
return val !== void 0; // tests for undefined
}
goog.isDefAndNotNull = function(val) {
return val != null; // Also catches undefined since ==/!= instead of ===/!== allows for implicit type conversion to satisfy the condition.
}Setting aside the problems of coercing vs. non-coercing comparison operators even being a thing, these both do the job they’re supposed to do. But Dan’s co-worker needed to reinvent this particular wheel.
initech.util.isDef = function (val) {
return val !== void 0;
}This code is useless, since we already have it in our library, but whatever. It’s fine and correct.
initech.util.isDefAndNotNull = initech.util.isDef; This developer is the kid who copied someone else’s homework and still somehow managed to get a failing grade. They had a working implementation they could have referenced to see what they needed to do. The names of the methods themselves should have probably provided a hint that they needed to be mildly different. There was no reason to write any of this code, and they still couldn’t get that right.
Dan adds:
Thankfully a lot of this [functionality] was recreated in C# for another project…. I’m looking to bring all that stuff back over… and just destroy this monstrosity we created. Goodbye JavaScript!
|
Метки: CodeSOD |
CodeSOD: Taking Your Chances |
A few months ago, Sean had some tasks around building a front-end for some dashboards. Someone on the team picked a UI library for managing their widgets. It had lovely features like handling flexible grid layouts, collapsing/expanding components, making components full screen and even drag-and-drop widget rearrangement.
It was great, until one day it wasn't. As more and more people started using the front end, they kept getting more and more reports about broken dashboards, misrendering, duplicated widgets, and all sorts of other difficult to explain bugs. These were bugs which Sean and the other developers had a hard time replicating, and even on the rare occassions that they did replicate it, they couldn't do it twice in a row.
Stumped, Sean took a peek at the code. Each on-screen widget was assigned a unique ID. Except at those times when the screen broke- the IDs weren't unique. So clearly, something went wrong with the ID generation, which seemed unlikely. All the IDs were random-junk, like 7902699be4, so there shouldn't be a collision, right?
generateID() {
return sha256(Math.floor(Math.random() * 100)). substring(1, 10);
}
Good idea: feeding random values into a hash function to generate unique IDs. Bad idea: constraining your range of random values to integers between 0 and 99.
SHA256 will take inputs like 0, and output nice long, complex strings like "5feceb66ffc86f38d952786c6d696c79c2dbc239dd4e91b46729d73a27fb57e9". And a mildly different input will generate a wildly different output. This would be good for IDs, if you had a reasonable expectation that the values you're seeding are themselves unique. For this use case, Math.random() is probably good enough. Even after trimming to the first ten characters of the hash, I only hit two collisions for every million IDs in some quick tests. But Math.floor(Math.random() * 100) is going to give you a collision a lot more frequently. Even if you have a small number of widgets on the screen, a collision is probable. Just rare enough to be hard to replicate, but common enough to be a serious problem.
Sean did not share what they did with this library. Based on my experience, it was probably "nothing, we've already adopted it" and someone ginned up an ugly hack that patches the library at runtime to replace the method. Despite the library being open source, nobody in the organization wants to maintain a fork, and legal needs to get involved if you want to contribute back upstream, so just runtime patch the object to replace the method with one that works.
At least, that's a thing I've had to do in the past. No, I'm not bitter.
|
Метки: CodeSOD |
The Watchdog Hydra |
Ammar A uses Node to consume an HTTP API. The API uses cookies to track session information, and ensures those cookies expire, so clients need to periodically re-authenticate. How frequently?
That's an excellent question, and one that neither Ammar nor the docs for this API can answer. The documentation provides all the clarity and consistency of a religious document, which is to say you need to take it on faith that these seemingly random expirations happen for a good reason.
Ammar, not feeling particularly faithful, wrote a little "watchdog" function. Once you log in, every thirty seconds it tries to fetch a URL, hopefully keeping the session alive, or, if it times out, starts a new session.
That's what it was supposed to do, but Ammar made a mistake.
function login(cb) {
request.post({url: '/login', form:{username: config.username, password: config.password}, function(err, response) {
if (err) return cb(err)
if (response.statusCode != 200)
return cb(response.statusCode);
console.log("[+] Login succeeded");
setInterval(watchdog, 30000);
return cb();
})
}
function watchdog() {
// Random request to keep session alive
request.get({url: '/getObj', form:{id: 1}, (err, response)=>{
if (!err && response.statusCode == 200)
return console.log("[+] Watchdog ping succeeded");
console.error("[-] Watchdog encountered error, session may be dead");
login((err)=>{
if (err)
console.error("[-] Failed restarting session:",err);
})
})
}
login sends the credentials, and if we get a 200 status back, we setInterval to schedule a call to the watchdog every 30,000 milliseconds.
In the watchdog, we fetch a URL, and if it fails, we call login. Which attempts to login, and if it succeeds, schedules the watchdog every 30,000 milliseconds.
Late one night, Ammar got a call from the API vendor's security team. "You are attacking our servers, and not only have you already cut off access to most of our customers, you've caused database corruption! There will be consequences for this!"
Ammar checked, and sure enough, his code was sending hundreds of thousands of requests per second. It didn't take him long to figure out why: requests from the watchdog were failing with a 500 error, so it called the login method. The login method had been succeeding, so another watchdog got scheduled. Thirty seconds later, that failed, as did all the previously scheduled watchdogs, which all called login again. Which, on success, scheduled a fresh round of watchdogs. Every thirty seconds, the number of scheduled calls doubled. Before long, Ammar's code was DoSing the API.
In the aftermath, it turned out that Ammar hadn't caused any database corruption, to the contrary, it was an error in the database which caused all the watchdog calls to fail. The vendor corrupted their own database, without Ammar's help. Coupled with Ammar's careless setInterval management, that error became even more punishing.
Which raises the question: why wasn't the vendor better prepared for this? Ammar's code was bad, sure, a lurking timebomb, just waiting to go off. But any customer could have produced something like that. A hostile entity could easily have done something like that. And somehow, this vendor had nothing in place to deal with what appeared to be a denial-of-service attack, short of calling the customer responsible?
I don't know what was going on with the vendor's operations team, but I suspect that the real WTF is somewhere in there.
|
Метки: Feature Articles |
Error'd: Where to go, Next? |
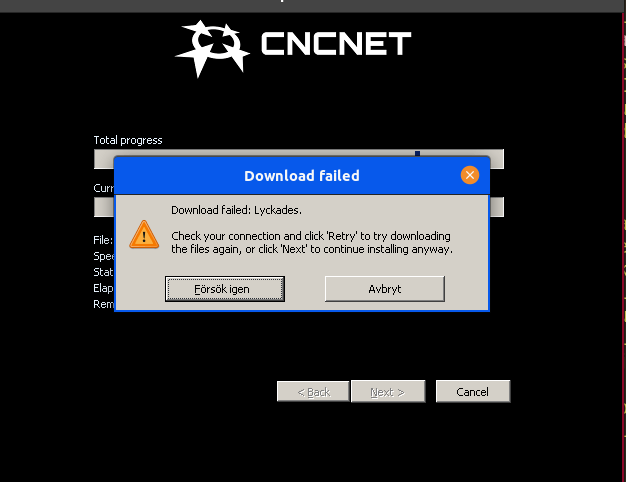
"In this screenshot, 'Lyckades' means 'Succeeded' and the buttons say 'Try again' and 'Cancel'. There is no 'Next' button," wrote Martin W.
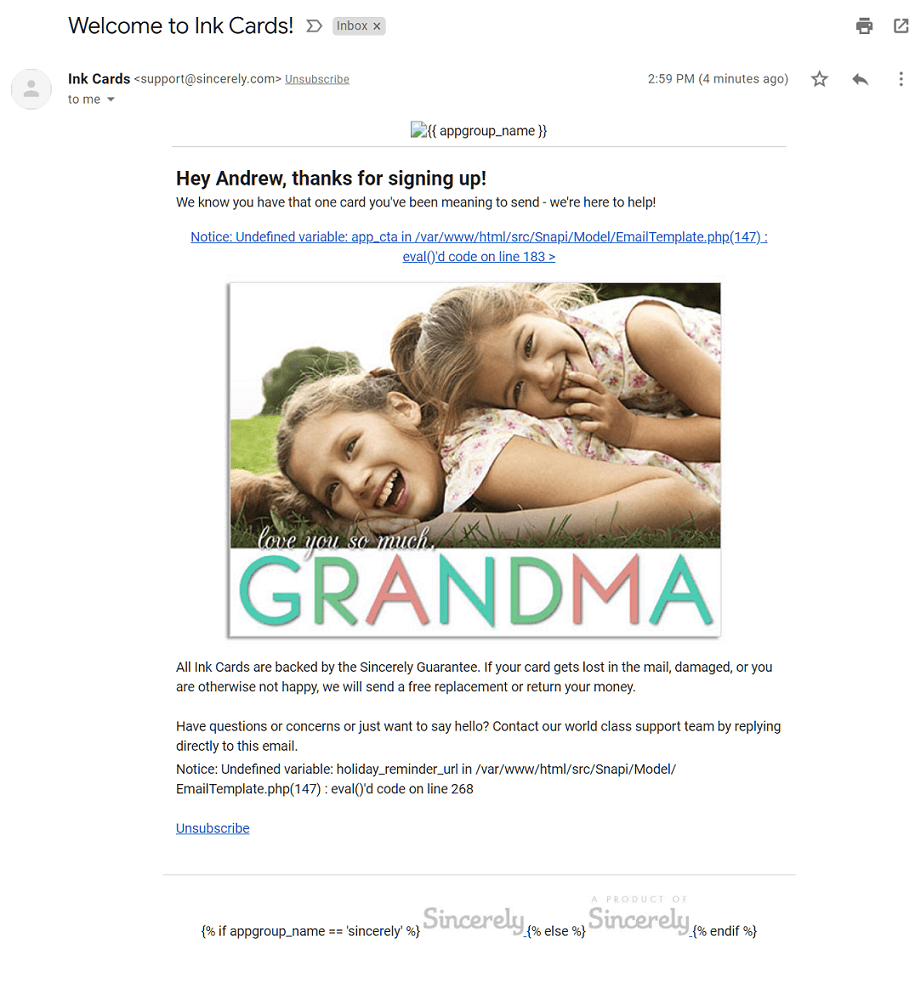
"I have been meaning to send a card, but I just wasn't planning on using PHP's eval() to send it," Andrew wrote.
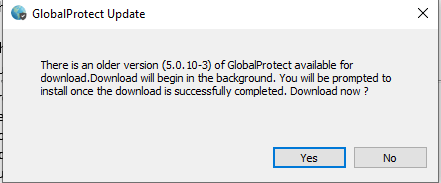
Martyn R. writes, "I was trying to connect to PA VPN and it seems they think that downgrading my client software will help."
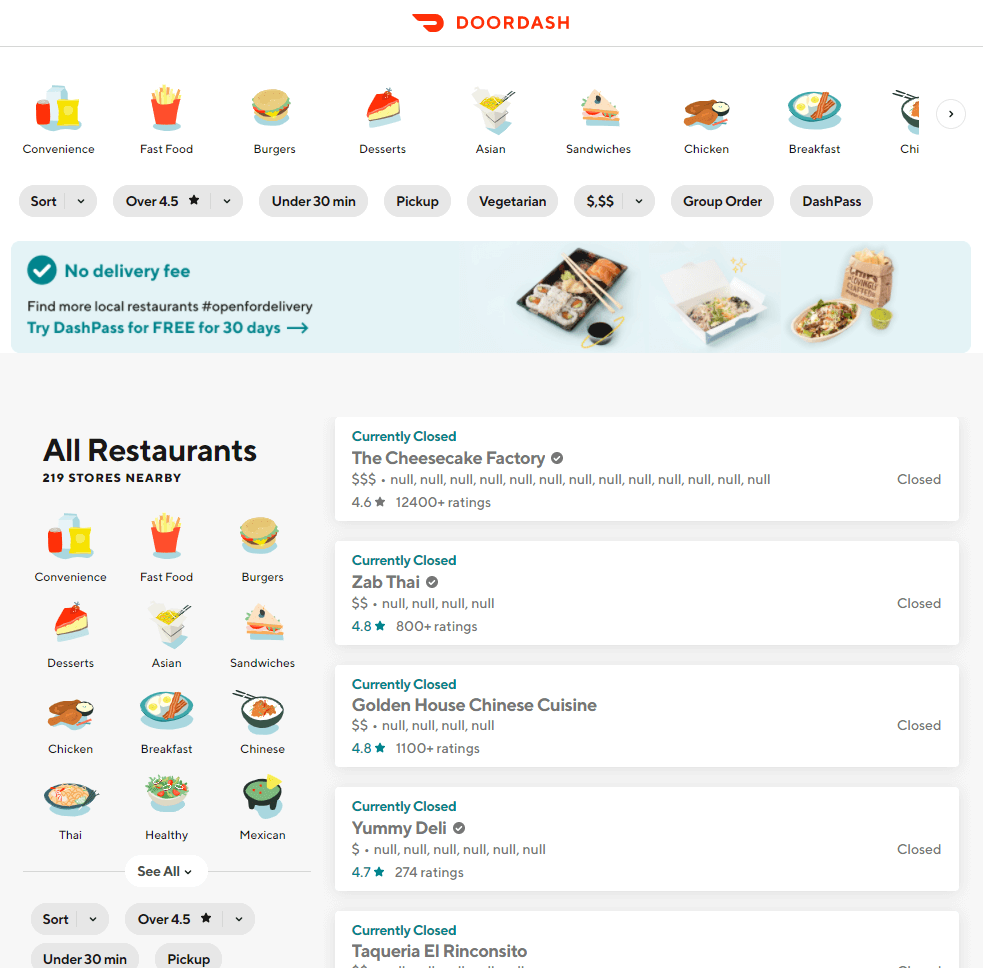
"What the heck, Doordash? I was expecting a little more variety from you guys...but, to be honest, I gotta wonder what 'null' flavored cheesecake is like," Joshua M. writes.
Nicolas wrote, "NaN exclusive posts? I'm already on the inside loop. After all, I love my grandma!"
|
Метки: Error'd |
CodeSOD: A Generic Comment |
To my mind, code comments are important to explain why the code what it does, not so much what it does. Ideally, the what is clear enough from the code that you don’t have to. Today, we have no code, but we have some comments.
Chris recently was reviewing some C# code from 2016, and found a little conversation in the comments, which may or may not explain whats or whys. Line numbers included for, ahem context.
4550: //A bit funky, but entirely understandable: Something that is a C# generic on the storage side gets
4551: //represented on the client side as an array. Why? A C# generic is rather specific, i.e., Java
4552: //doesn't have, for example, a Generic List class. So we're messing with arrays. No biggie.Now, honestly, I’m more confused than I probably would have been just from the code. Presumably as we’re sending things to a client, we’re going to serialize it to an intermediate representation, so like, sure, arrays. The comment probably tells me why, but it’s hardly a necessary explanation here. And what does Java have to do with anything? And also, Java absolutely does support generics, so even if the Java trivia were relevant, it’s not accurate.
I’m not the only one who had some… questions. The comment continues:
4553: //
4554: //WTF does that have to do with anything? Who wrote this inane, stupid comment,
4555: //but decided not to put comments on anything useful?Not to sound judgmental, but if you’re having flamewars in your code comments, you may not be on a healthy, well-functioning team.
Then again, if this is someplace in the middle of your file, and you’re on line 4550, you probably have some other problems going on.
|
Метки: CodeSOD |
CodeSOD: A Random While |
A bit ago, Aurelia shared with us a backwards for loop. Code which wasn’t wrong, but was just… weird. Well, now we’ve got some code which is just plain wrong, in a number of ways.
The goal of the following Java code is to generate some number of random numbers between 1 and 9, and pass them off to a space-separated file.
StringBuffer buffer = new StringBuffer();
long count = 0;
long numResults = GetNumResults();
while (count < numResults)
{
ArrayList numbers = new ArrayList();
while (numbers.size() < 1)
{
int randInt = random.nextInt(10);
long randLong = randInt & 0xffffffffL;
if (!numbers.contains(new BigDecimal(randLong)) && (randLong != 0))
{
buffer.append(randLong);
buffer.append(" ");
numbers.add(new BigDecimal(randLong));
}
System.out.println("Random Integer: " + randInt + ", Long Integer: " + randLong);
}
outFile.writeLine(buffer.toString());
buffer = new StringBuffer();
count++;
} Pretty quickly, we get a sense that something is up, with the while (count < numResults)- this begs to be a for loop. It’s not wrong to while this, but it’s suspicious.
Then, right away, we create an ArrayList. There is no reasonable purpose to using a BigDecimal to hold a value between 1 and 9. But the rails don’t really start to come off until we get into the inner loop.
while (numbers.size() < 1)
{
int randInt = random.nextInt(10);
long randLong = randInt & 0xffffffffL;
if (!numbers.contains(new BigDecimal(randLong)) && (randLong != 0))
…This loop condition guarantees that we’ll only ever have one element in the list, which means our numbers.contains check doesn’t mean much, does it?
But honestly, that doesn’t hold a candle to the promotion of randInt to randLong, complete with an & 0xffffffffL, which guarantees… well, nothing. It’s completely unnecessary here. We might do that sort of thing when we’re bitshifting and need to mask out for certain bytes, but here it does nothing.
Also note the (randLong != 0) check. Because they use random.nextInt(10), that generates a number in the range 0–9, but we want 1 through 9, so if we draw a zero, we need to re-roll. A simple, and common solution to this would be to do random.nextInt(9) + 1, but at least we now understand the purpose of the while (numbers.size() < 1) loop- we keep trying until we get a non-zero value.
And honestly, I should probably point out that they include a println to make sure that both the int and the long versions match, but how could they not?
Nothing here is necessary. None of this code has to be this way. You don’t need the StringBuffer. You don’t need nested while loops. You don’t need the ArrayList, you don’t need the conversion between integer types. You don’t need the debugging println.
|
Метки: CodeSOD |
CodeSOD: A Cutt Above |
We just discussed ViewState last week, and that may have inspired Russell F to share with us this little snippet.
private ConcurrentQueue lstAppointmentCuttOff
{
get
{
object o = ViewState["lstAppointmentCuttOff"];
if (o == null)
return null;
else
return (ConcurrentQueue)o;
}
set
{
ViewState["lstAppointmentCuttOff"] = value;
}
}
This pattern is used for pretty much all of the ViewState data that this code interacts with, and if you look at the null check, you can see that it's unnecessary. Our code checks for a null, and if we have one… returns null. The entire get block could just be: return (ConcurrentQueue
The bigger glitch here is the data-type. While there are a queue of appointments, that queue is never accessed across threads, so there's no need for a threadsafe ConcurrentQueue.
But I really love the name of the variable we store in ViewState. We have Hungarian notation, which calls it a lst, which isn't technically correct, though it is iterable, so maybe that's what they meant, but if the point of Hungarian notation is to make the code more clear, this isn't helping.
But what I really love is that these are CuttOffs, which just sounds like some retail brand attempting to sell uncomfortably short denim. It'll be next year's summer trend, mark my words!
|
Метки: CodeSOD |
CodeSOD: Exceptional Standards Compliance |
When we're laying out code standards and policies, we are, in many ways, relying on "policing by consent". We are trying to establish standards for behavior among our developers, but we can only do this with their consent. This means our standards have to have clear value, have to be applied fairly and equally. The systems we build to enforce those standards are meant to reduce conflict and de-escalate disagreements, not create them.
But that doesn't mean there won't always be developers who resist following the agreed upon standards. Take, for example, Daniel's co-worker. Their CI process also runs a static analysis step against their C# code, which lets them enforce a variety of coding standards.
One of those standards is: "Catch specific exceptions. Don't catch the generic Exception type unless explicitly necessary." If it is explicitly necessary, their CI system attaches "Comments" (not code comments) to the commit, so all you need to do is click the "resolve" button and provide a brief explanation of why it was necessary.
This wouldn't be an… exceptional standard. Specific is always better than vague, and in this case, the rule isn't hard and fast: you're allowed to violate it if you can explain why.
But explaining yourself sounds like a lot of work. Wouldn't it be easier to try and fool the static analysis tool?
try
{
{...}
}
catch (Exception ex) when (ex is Exception exception)
{
{...}
}
C#'s catch block supports a when operator, which is meant to filter based on properties of the exception. The ex is Exception exception is a pattern match and also a cast: it's true if the type of ex is Exception, and also cast it to Exception and store the cast in exception.
Or to word it another way, we catch the exception if it is of the type Exception but only when the type is Exception in which case we cast the exception which we know is an Exception to Exception and store it in exception, and I take exception to all of that.
Presumably, they'll change the rule in the CI system to exclude these, but hopefully they'll also have a talk with the developer responsible about the purpose of standards. Maybe they'll get some "standards by consent", or maybe somebody'll be looking for a new job.
https://thedailywtf.com/articles/exceptional-standards-compliance
|
Метки: CodeSOD |
Error'd: Just a Trial Run |
"How does Netflix save money when making their original series? It's simple. They just use trial versions of VFX software," Nick L. wrote.
Chris A. writes, "Why get low quality pixelated tickets when you can have these?"
"Better make room! This USB disk enclosure is ready for supper and som really mega-bytes!" wrote Stuart L.
Scott writes, "Go Boncos!"
"With rewards like these, I can't believe more people don't pledge on Patreon!" writes Chris A.
|
Метки: Error'd |
Configuration Errors |
Automation and tooling, especially around continuous integration and continuous deployment is standard on applications, large and small.
Paramdeep Singh Jubbal works on a larger one, with a larger team, and all the management overhead such a team brings. It needs to interact with a REST API, and as you might expect, the URL for that API is different in production and test environments. This is all handled by the CI pipeline, so long as you remember to properly configure which URLs map to which environments.
Paramdeep mistyped one of the URLs when configuring a build for a new environment. The application passed all the CI checks, and when it was released to the new environment, it crashed and burned. Their error handling system detected the failure, automatically filed a bug ticket, Paramdeep saw the mistake, fixed it, and everything was back to the way it was supposed to be within five minutes.
But a ticket had been opened. For a bug. And the team lead, Emmett, saw it. And so, in their next team meeting, Emmett launched with, “We should talk about Bug 264.”
“Ah, that’s already resolved,” Paramdeep said.
“Is it? I didn’t see a commit containing a unit test attached to the ticket,” Emmett said.
“I didn’t write one,” Paramdeep said, getting a little confused at this point. “It was just a misconfiguration.”
“Right, so there should be a test to ensure that the correct URL is configured before we deploy to the environment.” That was, in fact, the policy: any bug ticket which was closed was supposed to have an associated unit test which would protect against regressions.
“You… want a unit test which confirms that the environment URLs are configured correctly?”
“Yes,” Emmett said. “There should never be a case where the application connects to an incorrect URL.”
“But it gets that URL from the configuration.”
“And it should check that configuration is correct. Honestly,” Emmett said, “I know I’m not the most technical person on this team, but that just sounds like common sense to me.”
“It’s just…” Paramdeep considered how to phrase this. “How does the unit test tell which are the correct or incorrect URLs?”
Emmett huffed. “I don’t understand why I’m explaining this to a developer. But the URLs have a pattern. URLs which match the pattern are valid, and they pass the test. URLs which don’t fail the test, and we should fallback to a known-good URL for that environment.”
“And… ah… how do we know what the known-good URL is?”
“From the configuration!”
“So you want me to write a unit test which checks the configuration to see if the URLs are valid, and if they’re not, it uses a valid URL from the configuration?”
“Yes!” Emmett said, fury finally boiling over. “Why is that so hard?”
Paramdeep thought the question explained why it was so hard, but after another moment’s thought, there was an even better reason that Emmett might actually understand.
“Because the configuration files are available during the release step, and the unit tests are run after the build step, which is before the release step.”
Emmett blinked and considered how their CI pipeline worked. “Right, fair enough, we’ll put a pin in that then, and come back to it in a future meeting.”
“Well,” Paramdeep thought, “that didn’t accomplish anything, but it was a good waste of 15 minutes.”
|
Метки: Feature Articles |
CodeSOD: Get My Switch |
You know how it is. The team is swamped, so you’ve pulled on some junior devs, given them the bare minimum of mentorship, and then turned them loose. Oh, sure, there are code reviews, but it’s like, you just glance at it, because you’re already so far behind on your own development tasks and you’re sure it’s fine.
And then months later, if you’re like Richard, the requirements have changed, and now you’ve got to revisit the junior’s TypeScript code to make some changes.
switch (false) {
case (this.fooIsConfigured() === false && this.barIsConfigured() === false):
this.contactAdministratorText = 'Foo & Bar';
break;
case this.fooIsConfigured():
this.contactAdministratorText = 'Bar';
break;
case this.barIsConfigured():
this.contactAdministratorText = 'Foo';
break;
}We’ve seen more positive versions of this pattern before, where we switch on true. We’ve even seen the false version of this switch before.
What makes this one interesting, to me, is just how dedicated it is to this inverted approach to logic: if it’s false that “foo” is false and “bar” is false, then obviously they’re all true, thus we output a message to that effect. If one of those is false, we need to figure out which one that is, and then do the opposite, because if “foo” is false, then clearly “bar” must be true, so we output that.
Richard was able to remove this code, and then politely suggest that maybe they should be more diligent in their code reviews.
|
Метки: CodeSOD |
CodeSOD: //article title here |
Menno was reading through some PHP code and was happy to see that it was thoroughly commented:
function degToRad ($value)
{
return $value * (pi()/180); // convert excel timestamp to php date
}
Today's code is probably best explained in meme format:

As Menno summarizes: "It's a function that has the right name, does the right thing, in the right way. But I'm not sure how that comment came to be."
|
Метки: CodeSOD |
CodeSOD: A Nice Save |
Since HTTP is fundamentally stateless, developers have found a million ways to hack state into web applications. One of my "favorites" was the ASP.NET ViewState approach.
The ViewState is essentially a dictionary, where you can store any arbitrary state values you might want to track between requests. When the server outputs HTML to send to the browser, the contents of ViewState are serialized, hashed, and base-64 encoded and dumped into an element. When the next request comes in, the server unpacks the hidden field and deserializes the dictionary. You can store most objects in it, if you'd like. The goal of this, and all the other WebForm state stuff was to make handling web forms more like handling forms in traditional Windows applications.
It's "great". It's extra great when its default behavior is to ensure that the full state for every UI widget on the page. The incident which inpsired Remy's Law of Requirements Gathering was a case where our users wanted like 500 text boxes on a page, and we blew out our allowed request sizes due to gigundous ViewState because, at the time, we didn't know about that "helpful" feature.
Ryan N inherited some code which uses this, and shockingly, ViewState isn't the biggest WTF here:
protected void ValidateForm(object sender, EventArgs e)
{
bool Save = true;
if (sInstructions == string.Empty)
{
sInstructions = string.Empty;
}
else
{
Save = false;
}
if (Save)
{...}
}
Let me just repeat part of that:
if (sInstructions == string.Empty)
{
sInstructions = string.Empty;
}
If sInstructions is empty, set it to be empty. If sInstructions is not empty, then we set… Save to false? Reading this code, it implies if we have instructions we shouldn't save? What the heck is this sInstructions field anyway?
Well, Ryan explains: "sInstructions is a ViewState string variable, it holds error messages."
I had to spend a moment thinking "wait, why is it called 'instructions'?" But the method name is called ValidateForm, which explains it. It's because it's user instructions, as in, "please supply a valid email address". Honestly, I'm more worried about the fact that this approach is starting to make sense to me, than anything else.
|
Метки: CodeSOD |
Error'd: This Could Break the Bank! |
"Sure, free for the first six months is great, but what exactly does happen when I hit month seven?" Stuart L. wrote.
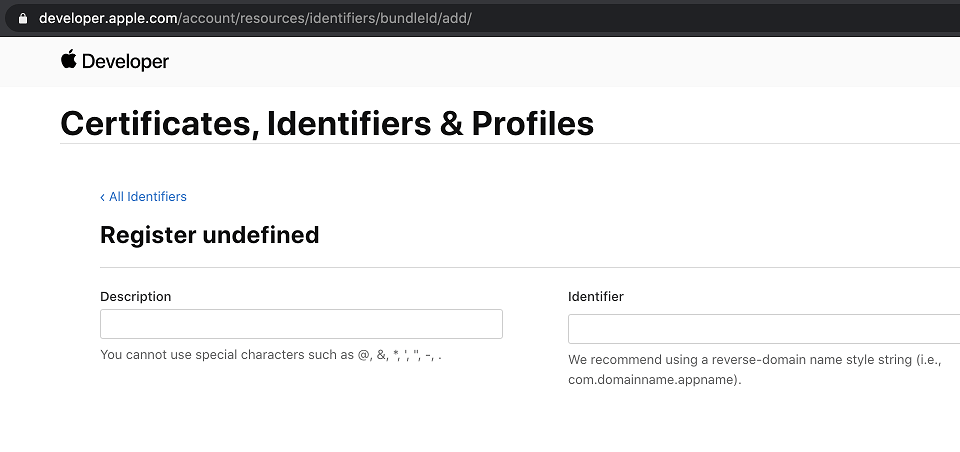
"In order to add an app on the App Store Connect dashboard, you need to 'Register a new bundle ID in Certificates, Identifiers & Profiles'," writes Quentin, "Open the link, you have a nice 'register undefined' and cannot type anything in the identifier input field!"
"I was taught to keep money amounts as pennies rather than fractional dollars, but I guess I'm an old-fashioned guy!" writes Paul F.
Anthony C. wrote, "I was looking for headphones on Walmart.com and well, I guess they figured I'd like to look at something else for a change?"
"Build an office chair using only a spork, a napkin, and a coffee stirrer? Sounds like a job for McGuyver!"
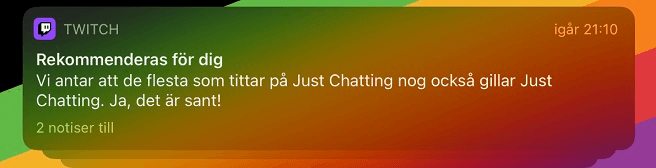
"Translation from Swedish, 'We assume that most people who watch Just Chatting probably also like Just Chatting.' Yes, I bet it's true!," Bill W. writes.
|
Метки: Error'd |
CodeSOD: Put a Dent in Your Logfiles |
Valencia made a few contributions to a large C++ project run by Harvey. Specifically, there were some pass-by-value uses of a large data structure, and changing those to pass-by-reference fixed a number of performance problems, especially on certain compilers.
“It’s a simple typo,” Valencia thought. “Anyone could have done that.” But they kept digging…
The original code-base was indented with spaces, but Harvey just used tabs. That was a mild annoyance, but Harvey used a lot of tabs, as his code style was “nest as many blocks as deeply as possible”. In addition to loads of magic numbers that should be enums, Harvey also had a stance that “never use an int type when you can store your number as a double”.
Then, for example, what if you have a char and you want to turn the char into a string? Do you just use the std::string() constructor that accepts a char parameter? Not if you’re Harvey!
std::string ToString(char c)
{
std::stringstream ss;
std::string out = "";
ss << c;
ss >> out;
return out;
}What if you wanted to cache some data in memory? A map would be a good place to start. How many times do you want to access a single key while updating a cache entry? How does “four times” work for you? It works for Harvey!
void WriteCache(std::string key, std::string value)
{
Setting setting = mvCache["cache_"+key];
if (!setting.initialized)
{
setting.initialized=true;
setting.data = "";
mvCache.insert(std::map::value_type("cache_"+key,setting));
mvCache["cache_"+key]=setting;
}
setting.data = value;
mvCache["cache_"+key]=setting;
}And I don’t know exactly what they are trying to communicate with the mv prefix, but people have invented all sorts of horrible ways to abuse Hungarian notation. Fortunately, Valencia clarifies: “Harvey used an incorrect Hungarian notation prefix while they were at it.”
That’s the easy stuff. Ugly, bad code, sure, but nothing that leaves you staring, stunned into speechlessness.
Let’s say you added a lot of logging messages, and you wanted to control how many logging messages appeared. You’ve heard of “logging levels”, and that gives you an inspiration for how to solve this problem:
bool LogLess(int iMaxLevel)
{
int verboseLevel = rand() % 1000;
if (verboseLevel < iMaxLevel) return true;
return false;
}
//how it's used:
if(LogLess(500))
log.debug("I appear half of the time");Normally, I’d point out something about how they don’t need to return true or return false when they could just return the boolean expression, but what’d be the point? They’ve created probabilistic log levels. It’s certainly one way to solve the “too many log messages” problem: just randomly throw some of them away.
Valencia gives us a happy ending:
Needless to say, this has since been rewritten… the end result builds faster, uses less memory and is several orders of magnitude faster.
https://thedailywtf.com/articles/put-a-dent-in-your-logfiles
|
Метки: CodeSOD |
Web Server Installation |

Once upon a time, there lived a man named Eric. Eric was a programmer working for the online development team of a company called The Company. The Company produced Media; their headquarters were located on The Continent where Eric happily resided. Life was simple. Straightforward. Uncomplicated. Until one fateful day, The Company decided to outsource their infrastructure to The Service Provider on Another Continent for a series of complicated reasons that ultimately benefited The Budget.
Part of Eric's job was to set up web servers for clients so that they could migrate their websites to The Platform. Previously, Eric would have provisioned the hardware himself. Under the new rules, however, he had to request that The Service Provider do the heavy lifting instead.
On Day 0 of our story, Eric received a server request from Isaac, a representative of The Client. On Day 1, Eric asked for the specifications for said server, which were delivered on Day 2. Day 2 being just before a long weekend, it was Day 6 before the specs were delivered to The Service Provider. The contact at The Service Provider, Thomas, asked if there was a deadline for this migration. Eric replied with the hard cutover date almost two months hence.
This, of course, would prove to be a fatal mistake. The following story is true; only the names have been changed to protect the guilty. (You might want some required listening for this ... )
Day 6
Day 7
Day 8
Day 9
Day 16
Day 19
Day 20
Day 22
Day 23
Day 28
Day 29
Day 30
Day 33
Day 35
Day 36
Day 37
Day 40
Day 41
Day 42
Day 47
Day 48
Day 51
Day 54
Day 55
Day 56
Day 57
Day 58
Day 61
Day 62
Day 63
Day 64
|
Метки: Feature Articles |
CodeSOD: Sleep on It |
If you're fetching data from a remote source, "retry until a timeout is hit" is a pretty standard pattern. And with that in mind, this C++ code from Auburus doesn't look like much of a WTF.
bool receiveData(uint8_t** data, std::chrono::milliseconds timeToWait) {
start = now();
while ((now() - start) < timeToWait) {
if (/* successfully receive data */) {
return true;
}
std::this_thread::sleep_for(100ms);
}
return false;
}
Track the start time. While the difference between the current time and the start is less than our timeout, try and get the data. If you don't, sleep for 100ms, then retry.
This all seems pretty reasonable, at first glance. We could come up with better ways, certainly, but that code isn't quite a WTF.
This code is:
// The ONLY call to that function
receiveData(&dataPtr, 100ms);
By calling this with a 100ms timeout, and because we hard-coded in a 100ms sleep, we've guaranteed that we will never retry. That may or not be intentional, and that's what really bugs me about this code. Maybe they meant to do that (because they originally retried, and found it caused other bugs?). Maybe they didn't. But they didn't document it, either in the code or as a commit comment, so we'll never know.
|
Метки: CodeSOD |