I'm Blue |
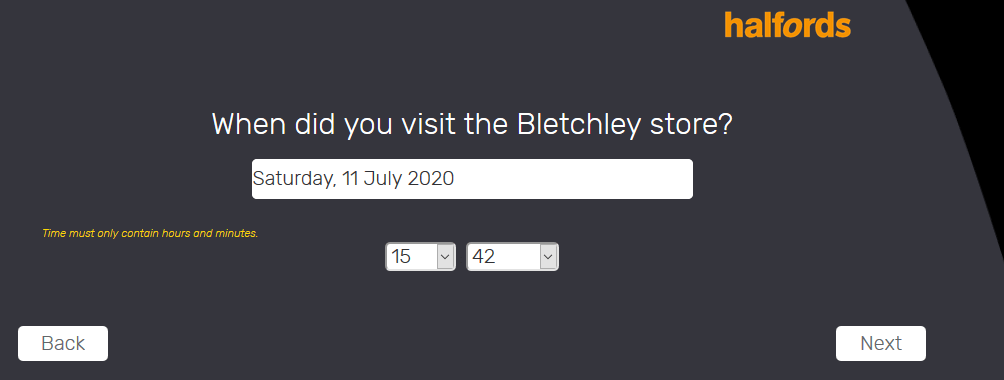
Designers are used to getting vague direction from clients. "It should have more pop!" or "Can you make the blue more blue?" But Kevin was a contractor who worked on embedded software, so he didn't really expect to have to deal with that, even if he did have to deal with colors a fair bit.
Kevin was taking over a contract from another developer to build software for a colorimeter, a device to measure color. When companies, like paint companies, care about color, they tend to really care about color, and need to be able to accurately observe a real-world color. Once you start diving deep into color theory, you start having to think about things like observers, and illuminants and tristimulus models and "perceptual color spaces".
The operating principle of the device was fairly simple. It had a bright light, of a well known color temperature. It had a brightness sensor. It had a set of colored filter gels that would pass in front of the sensor. Place the colorimeter against an object, and the bright light would reflect off the surface, through each of the filters in turn and record the brightness. With a little computation, you can determine, with a high degree of precision, what color something is.
Now, this is a scientific instrument, and that means that the code which runs it, even though it's proprietary, needs to be vetted by scientists. The device needs to be tested against known samples. Deviations need to be corrected for, and then carefully justified. There should be no "magic numbers" in the code that aren't well documented and explained. If, for example, the company gets its filter gels from a new vendor and they filter slightly different frequencies, the commit needs to link to the datasheets for those gels to explain the change. Similarly, if a sensor has a frequency response that means that the samples may be biased, you commit that with a link to the datasheet showing that to be the case.
Which is why Kevin was a little surprised by the commit by his predecessor. The message read: "Nathan wants the blue 'more blue'? Fine. the blue is more blue." Nathan was the product owner.
The corresponding change was a line which read:
blue += 20;
Well, Nathan got what he wanted. It's a good thing he didn't ask for it to "pop" though.
|
Метки: Feature Articles |
Error'd: All Natural Errors |
"I'm glad the asdf is vegan. I'm really thinking of going for the asasdfsadf, though. With a name like that, you know it's got to be 2 1/2 times as good for you," writes VJ.
Phil G. wrote, "Get games twice as fast with Epic's new multidimensional downloads!"
"But...it DOES!" Zed writes.
John M. wrote, "I appreciate the helpful suggestion, but I think I'll take a pass."
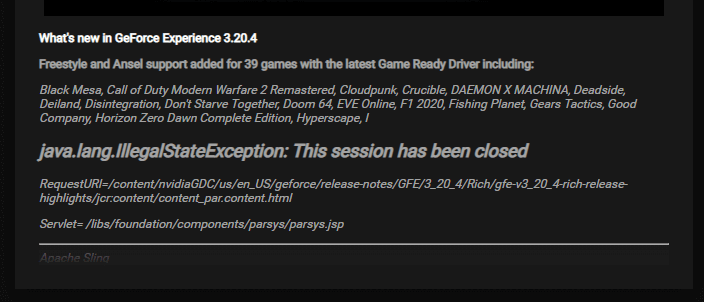
"java.lang.IllegalStateException...must be one of those edgy indie games! I just hope it's not actually illegal," writes Matthijs .
"For added flavor, I received this reminder two hours after I'd completed my checkout and purchased that very same item_name," Aaron K. writes.
|
Метки: Error'd |
CodeSOD: A Slow Moving Stream |
We’ve talked about Java’s streams in the past. It’s hardly a “new” feature at this point, but its blend of “being really useful” and “based on functional programming techniques” and “different than other APIs” means that we still have developers struggling to figure out how to use it.
Jeff H has a co-worker, Clarence, who is very “anti-stream”. “It creates too many copies of our objects, so it’s terrible for memory, and it’s so much slower. Don’t use streams unless you absolutely have to!” So in many a code review, Jeff submits some very simple, easy to read, and fast-performing bit of stream code, and Clarence objects. “It’s slow. It wastes memory.”
Sometimes, another team member goes to bat for Jeff’s code. Sometimes they don’t. But then, in a recent review, Clarence submitted his own bit of stream code.
schedules.stream().forEach(schedule -> visitors.stream().forEach(scheduleVisitor -> {
scheduleVisitor.visitSchedule(schedule);
if (schedule.getDays() != null && !schedule.getDays().isEmpty()) {
schedule.getDays().stream().forEach(day -> visitors.stream().forEach(dayVisitor -> {
dayVisitor.visitDay(schedule, day);
if (day.getSlots() != null && !day.getSlots().isEmpty()) {
day.getSlots().stream().forEach(slot -> visitors.stream().forEach(slotVisitor -> {
slotVisitor.visitSlot(schedule, day, slot);
}));
}
}));
}
}));That is six nested “for each” operations, and they’re structured so that we iterate across the same list multiple times. For each schedule, we look at each visitor on that schedule, then we look at each day for that schedule, and then we look at every visitor again, then we look at each day’s slots, and then we look at each visitor again.
Well, if nothing else, we understand why Clarence thinks the Java Streams API is slow. This code did not pass code review.
|
Метки: CodeSOD |
CodeSOD: A Private Code Review |
Jessica has worked with some cunning developers in the past. To help cope with some of that “cunning”, they’ve recently gone out searching for new developers.
Now, there were some problems with their job description and salary offer, specifically, they were asking for developers who do too much and get paid too little. Which is how Jessica started working with Blair. Jessica was hoping to staff up her team with some mid-level or junior developers with a background in web development. Instead, she got Blair, a 13+ year veteran who had just started doing web development in the past six months.
Now, veteran or not, there is a code review process, so everything Blair does goes through code review. And that catches some… annoying habits, but every once in awhile, something might sneak through. For example, he thinks static is a code smell, and thus removes the keyword any time he sees it. He’ll rewrite most of the code to work around it, except once the method was called from a cshtml template file, so no one discovered that it didn’t work until someone reported the error.
Blair also laments that with all the JavaScript and loosely typed languages, kids these days don’t understand the importance of separation of concerns and putting a barrier between interface and implementation. To prove his point, he submitted his MessageBL class. BL, of course, is to remind you that this class is “business logic”, which is easy to forget because it’s in an assembly called theappname.businesslogic.
Within that class, he implemented a bunch of data access methods, and this pair of methods lays out the pattern he followed.
public async Task GetLinkAndContentTrackingModelAndUpdate(int id, Msg msg)
{
return await GetLinkAndContentTrackingAndUpdate(id, msg);
}
///
/// LinkTrackingUpdateLinks
/// returns: HasAnalyticsConfig, LinkTracks, ContentTracks
///
///
///
private async Task GetLinkAndContentTrackingAndUpdate(int id, Msg msg)
{
//snip
} Here, we have one public method, and one private method. Their names, as you can see, are very similar. The public method does nothing but invoke the private method. This public method is, in fact, the only place the private method is invoked. The public method, in turn, is called only twice, from one controller.
This method also doesn’t ever need to be called, because the same block of code which constructs this object also fetches the relevant model objects. So instead of going back to the database with this thing, we could just use the already fetched objects.
But the real magic here is that Blair was veteran enough to know that he should put some “thorough” documentation using Visual Studio’s XML comment features. But he put the comments on the private method.
Jessica was not the one who reviewed this code, but adds:
I won’t blame the code reviewer for letting this through. There’s only so many times you can reject a peer review before you start questioning yourself. And sometimes, because Blair has been here so long, he checks code in without peer review as it’s a purely manual process.
|
Метки: CodeSOD |
A Massive Leak |
"Memory leaks are impossible in a garbage collected language!" is one of my favorite lies. It feels true, but it isn't. Sure, it's much harder to make them, and they're usually much easier to track down, but you can still create a memory leak. Most times, it's when you create objects, dump them into a data structure, and never empty that data structure. Usually, it's just a matter of finding out what object references are still being held. Usually.
A few months ago, I discovered a new variation on that theme. I was working on a C# application that was leaking memory faster than bad waterway engineering in the Imperial Valley.

I don't exactly work in the "enterprise" space anymore, though I still interact with corporate IT departments and get to see some serious internal WTFs. This is a chandelier we built for the Allegheny Health Network's Cancer Institute which recently opened in Pittsburgh. It's 15 meters tall, weighs about 450kg, and is broken up into 30 segments, each with hundreds of addressable LEDs in a grid. The software we were writing was built to make them blink pretty.
Each of those 30 segments is home to a single-board computer with their GPIO pins wired up to addressable LEDs. Each computer runs a UDP listener, and we blast them with packets containing RGB data, which they dump to the LEDs using a heavily tweaked version of LEDScape.
This is our standard approach to most of our lighting installations. We drop a Beaglebone onto a custom circuit board and let it drive the LEDs, then we have a render-box someplace which generates frame data and chops it up into UDP packets. Depending on the environment, we can drive anything from 30-120 frames per second this way (and probably faster, but that's rarely useful).
Apologies to the networking folks, but this works very well. Yes, we're blasting many megabytes of raw bitmap data across the network, but we're usually on our own dedicated network segment. We use UDP because, well, we don't care about the data that much. A dropped packet or an out of order packet isn't going to make too large a difference in most cases. We don't care if our destination Beaglebone is up or down, we just blast the packets out onto the network, and they get there reliably enough that the system works.
Now, normally, we do this from Python programs on Linux. For this particular installation, though, we have an interactive kiosk which provides details about cancer treatments and patient success stories, and lets the users interact with the chandelier in real time. We wanted to show them a 3D model of the chandelier on the screen, and show them an animation on the UI that was mirrored in the physical object. After considering our options, we decided this was a good case for Unity and C#. After a quick test of doing multitouch interactions, we also decided that we shouldn't deploy to Linux (Unity didn't really have good Linux multitouch support), so we would deploy a Windows kiosk. This meant we were doing most of our development on MacOS, but our final build would be for Windows.
Months go by. We worked on the software while building the physical pieces, which meant the actual testbed hardware wasn't available for most of the development cycle. Custom electronics were being refined and physical designs were changing as we iterated to the best possible outcome. This is normal for us, but it meant that we didn't start getting real end-to-end testing until very late in the process.
Once we started test-hanging chandelier pieces, we started basic developer testing. You know how it is: you push the run button, you test a feature, you push the stop button. Tweak the code, rinse, repeat. Eventually, though, we had about 2/3rds of the chandelier pieces plugged in, and started deploying to the kiosk computer, running Windows.
We left it running, and the next time someone walked by and decided to give the screen a tap… nothing happened. It was hung. Well, that could be anything. We rebooted and checked again, and everything seems fine, until a few minutes later, when it's hung… again. We checked the task manager- which hey, everything is really slow, and sure enough, RAM is full and the computer is so slow because it's constantly thrashing to disk.
We're only a few weeks before we actually have to ship this thing, and we've discovered a massive memory leak, and it's such a sudden discovery that it feels like the draining of Lake Agassiz. No problem, though, we go back to our dev machines, fire it up in the profiler, and start looking for the memory leak.
Which wasn't there. The memory leak only appeared in the Windows build, and never happened in the Mac or Linux builds. Clearly, there must be some different behavior, and it must be around object lifecycles. When you see a memory leak in a GCed language, you assume you're creating objects that the GC ends up thinking are in use. In the case of Unity, your assumption is that you're handing objects off to the game engine, and not telling it you're done with them. So that's what we checked, but we just couldn't find anything that fit the bill.
Well, we needed to create some relatively large arrays to use as framebuffers. Maybe that's where the problem lay? We keep digging through the traces, we added a bunch of profiling code, we spent days trying to dig into this memory leak…
… and then it just went away. Our memory leak just became a Heisenbug, our shipping deadline was even closer, and we officially knew less about what was going wrong than when we started. For bonus points, once this kiosk ships, it's not going to be connected to the Internet, so if we need to patch the software, someone is going to have to go onsite. And we aren't going to have a suitable test environment, because we're not exactly going to build two gigantic chandeliers.
The folks doing assembly had the whole chandelier built up, hanging in three sections (we don't have any 14m tall ceiling spaces), and all connected to the network for a smoke test. There wasn't any smoke, but they needed to do more work. Someone unplugged a third of the chandelier pieces from the network.
And the memory leak came back.
We use UDP because we don't care if our packet sends succeed or not. Frame-by-frame, we just want to dump the data on the network and hope for the best. On MacOS and Linux, our software usually uses a sender thread that just, at the end of the day, wraps around calls to the send system call. It's simple, it's dumb, and it works. We ignore errors.
In C#, though, we didn't do things exactly the same way. Instead, we used the .NET UdpClient object and it's SendAsync method. We assumed that it would do roughly the same thing.
We were wrong.
await client.SendAsync(packet, packet.Length, hostip, port);
Async operations in C# use Tasks, which are like promises or futures in other environments. It lets .NET manage background threads without the developer worrying about the details. The await keyword is syntactic sugar which lets .NET know that it can hand off control to another thread while we wait. While we await here, we don't actually await the results of the await, because again: we don't care about the results of the operation. Just send the packet, hope for the best.
We don't care- but Windows does. After a load of investigation, what we discovered is that Windows would first try and resolve the IP address. Which, if a host was down, obviously it couldn't. But Windows was friendly, Windows was smart, and Windows wasn't going to let us down: it kept the Task open and kept trying to resolve the address. It held the task open for 3 seconds before finally deciding that it couldn't reach the host and errored out.
An error which, as I stated before, we were ignoring, because we didn't care.
Still, if you can count and have a vague sense of the linear passage of time, you can see where this is going. We had 30 hosts. We sent each of the 30 packets every second. When one or more of those hosts were down, Windows would keep each of those packets "alive" for 3 seconds. By the time that one expired, 90 more had queued up behind it.
That was the source of our memory leak, and our Heisenbug. If every Beaglebone was up, we didn't have a memory leak. If only one of them was down, the leak was pretty slow. If ten or twenty were out, the leak was a waterfall.
I spent a lot of time reading up on Windows networking after this. Despite digging through the socket APIs, I honestly couldn't figure out how to defeat this behavior. I tried various timeout settings. I tried tracking each task myself and explicitly timing them out if they took longer than a few frames to send. I was never able to tell Windows, "just toss the packet and hope for the best".
Well, my co-worker was building health monitoring on the Beaglebones anyway. While the kiosk wasn't going to be on the Internet via a "real" Internet connection, we did have a cellular modem attached, which we could use to send health info, so getting pings that say "hey, one of the Beaglebones failed" is useful. So my co-worker hooked that into our network sending layer: don't send frames to Beaglebones which are down. Recheck the down Beaglebones every five minutes or so. Continue to hope for the best.
This solution worked. We shipped. The device looks stunning, and as patients and guests come to use it, I hope they find some useful information, a little joy, and maybe some hope while playing with it. And while there may or may not be some ugly little hacks still lurking in that code, this was the one thing which made me say: WTF.
|
Метки: Feature Articles |
CodeSOD: A Unique Choice |
There are many ways to mess up doing unique identifiers. It's a hard problem, and that's why we've sorta agreed on a few distinct ways to do it. First, we can just autonumber. Easy, but it doesn't always scale that well, especially in distributed systems. Second, we can use something like UUIDs: mix a few bits of real data in with a big pile of random data, and you can create a unique ID. Finally, there are some hashing-related options, where the data itself generates its ID.
Tiffanie was digging into some weird crashes in a database application, and discovered that their MODULES table couldn't decide which was correct, and opted for two: MODULE_ID, an autonumbered field, and MODULE_UUID, which one would assume, held a UUID. There were also the requsite MODULE_NAME and similar fields. A quick scan of the table looked like:
| MODULE_ID | MODULE_NAME | MODULE_UUID | MODULE_DESC |
|---|---|---|---|
| 0 | Defects | 8461aa9b-ba38-4201-a717-cee257b73af0 | Defects |
| 1 | Test Plan | 06fd18eb-8214-4431-aa66-e11ae2a6c9b3 | Test Plan |
Now, using both UUIDs and autonumbers is a bit suspicious, but there might be a good reason for that (the UUIDs might be used for tracking versions of installed modules, while the ID is the local database-reference for that, so the ID shouldn't change ever, but the UUID might). Still, given that MODULE_NAME and MODULE_DESC both contain exactly the same information in every case, I suspect that this table was designed by the Department of Redunancy Department.
Still, that's hardly the worst sin you could commit. What would be really bad would be using the wrong datatype for a column. This is a SQL Server database, and so we can safely expect that the MODULE_ID is numeric, the MODULE_NAME and MODULE_DESC must be text, and clearly the MODULE_UUID field should be the UNIQUEIDENTIFIER type, right?
Well, let's look at one more row from this table:
| MODULE_ID | MODULE_NAME | MODULE_UUID | MODULE_DESC |
|---|---|---|---|
| 11 | Releases | Releases does not have a UUID | Releases |
Oh, well. I think I have a hunch what was causing the problems. Sure enough, the program was expecting the UUID field to contain UUIDs, and was failing when a field contained something that couldn't be converted into a UUID.
|
Метки: CodeSOD |
Error'd: Please Reboot Faster, I Can't Wait Any Longer |
"Saw this at a German gas station along the highway. The reboot screen at the pedestal just kept animating the hourglass," writes Robin G.
"Somewhere, I imagine there's a large number of children asking why their new bean bag is making them feel hot and numb," Will N. wrote.
Joel B. writes, "I came across these 'deals' on the Microsoft Canada store. Normally I'd question it, but based on my experiences with Windows, I bet, to them, the math checks out."
Kyle H. wrote, "Truly, nothing but the best quality strip_zeroes will be accepted."
"My Nan is going to be thrilled at the special discount on these masks!" Paul R. wrote.
Paul G. writes, "I know it seemed like the hours were passing more slowly, and thanks to Apple, I now know why."
https://thedailywtf.com/articles/please-reboot-faster-i-can-t-wait-any-longer
|
Метки: Error'd |
CodeSOD: A Variation on Nulls |
Submitter “NotAThingThatHappens” stumbled across a “unique” way to check for nulls in C#.
Now, there are already a few perfectly good ways to check for nulls. variable is null, for example, or use nullable types specifically. But “NotAThingThatHappens” found approach:
if(((object)someObjThatMayBeNull) is var _)
{
//object is null, react somehow
}
else
{
UseTheObjectInAMethod(someObjThatMayBeNull);
}What I hate most about this is how cleverly it exploits the C# syntax to work.
Normally, the _ is a discard. It’s meant to be used for things like tuple unpacking, or in cases where you have an out parameter but don’t actually care about the output- foo(out _) just discards the output data.
But _ is also a perfectly valid identifier. So var _ creates a variable _, and the type of that variable is inferred from context- in this case, whatever type it’s being compared against in someObjThatMayBeNull. This variable is scoped to the if block, so we don’t have to worry about it leaking into our namespace, but since it’s never initialized, it’s going to choose the appropriate default value for its type- and for reference types, that default is null. By casting explicitly to object, we guarantee that our type is a reference type, so this makes sure that we don’t get weird behavior on value types, like integers.
So really, this is just an awkward way of saying objectCouldBeNull is null.
NotAThingThatHappens adds:
The code never made it to production… but I was surprised that the compiler allowed this.
It’s stupid, but it WORKS!
It’s definitely stupid, it definitely works, I’m definitely glad it’s not in your codebase.
|
Метки: CodeSOD |
CodeSOD: True if Documented |
“Comments are important,” is one of those good rules that often gets misapplied. No one wants to see a method called addOneToSet and a comment that tells us Adds one item to the set.
Still, a lot of our IDEs and other tooling encourage these kinds of comments. You drop a /// or /* before a method or member, and you get an autostubbed out comment that gives you a passable, if useless, comment.
Scott Curtis thinks that is where this particular comment originated, but over time it decayed into incoherent nonsense:
/// True to use quote value
///
/// True if false, false if not
private readonly bool _mUseQuoteValueTrue if false, false if not. Or, worded a little differently, documentation makes code less clear, clearer if not.
|
Метки: CodeSOD |
CodeSOD: Underscoring the Comma |
Andrea writes to confess some sins, though I'm not sure who the real sinner is. To understand the sins, we have to talk a little bit about C/C++ macros.
Andrea was working on some software to control a dot-matrix display from an embedded device. Send an array of bytes to it, and the correct bits on the display light up. Now, if you're building something like this, you want an easy way to "remember" the proper sequences. So you might want to do something like:
uint8_t glyph0[] = {'0', 0x0E, 0x11, 0x0E, 0};
uint8_t glyph1[] = {'1', 0x09, 0x1F, 0x01, 0};
And so on. And heck, you might want to go so far as to have a lookup array, so you might have a const uint8_t *const glyphs[] = {glyph0, glyph1…}. Now, you could just hardcode those definitions, but wouldn't it be cool to use macros to automate that a bit, as your definitions might change?
Andrea went with a style known as X macros, which let you specify one pattern of data which can be re-used by redefining X. So, for example, I could do something like:
#define MY_ITEMS \
X(a, 5) \
X(b, 6) \
X(c, 7)
#define X(name, value) int name = value;
MY_ITEMS
#undef X
This would generate:
int a = 5;
int b = 6;
int c = 7;
But I could re-use this, later:
#define X(name, data) name,
int items[] = { MY_ITEMS nullptr};
#undef X
This would generate, in theory, something like: int items[] = {a,b,c,nullptr};
We are recycling the MY_ITEMS macro, and we're changing its behavior by altering the X macro that it invokes. This can, in practice, result in much more readable and maintainable code, especially code where you need to have parallel lists of items. It's also one of those things that the first time you see it, it's… surprising.
Now, this is all great, and it means that Andrea could potentially have a nice little macro system for defining arrays of bytes and a lookup array pointing to those arrays. There's just one problem.
Specifically, if you tried to write a macro like this:
#define GLYPH_DEFS \
X(glyph0, {'0', 0x0E, 0x11, 0x0E, 0})
It wouldn't work. It doesn't matter what you actually define X to do, the preprocessor isn't aware of the C/C++ syntax. So it doesn't say "oh, that second comma is inside of an array initalizer, I'll ignore it", it says, "Oh, they're trying to pass more than two parameters to the macro X."
So, you need some way to define an array initializer that doesn't use commas. If macros got you into this situation, macros can get you right back out. Here is Andrea's solution:
#define _ , // Sorry.
#define GLYPH_DEFS \
X(glyph0, { '0' _ 0x0E _ 0x11 _ 0x0E _ 0 } ) \
X(glyph1, { '1' _ 0x09 _ 0x1F _ 0x01 _ 0 }) \
X(glyph2, { '2' _ 0x13 _ 0x15 _ 0x09 _ 0 }) \
X(glyph3, { '3' _ 0x15 _ 0x15 _ 0x0A _ 0 }) \
X(glyph4, { '4' _ 0x18 _ 0x04 _ 0x1F _ 0 }) \
X(glyph5, { '5' _ 0x1D _ 0x15 _ 0x12 _ 0 }) \
X(glyph6, { '6' _ 0x0E _ 0x15 _ 0x03 _ 0 }) \
X(glyph7, { '7' _ 0x10 _ 0x13 _ 0x0C _ 0 }) \
X(glyph8, { '8' _ 0x0A _ 0x15 _ 0x0A _ 0 }) \
X(glyph9, { '9' _ 0x08 _ 0x14 _ 0x0F _ 0 }) \
X(glyphA, { 'A' _ 0x0F _ 0x14 _ 0x0F _ 0 }) \
X(glyphB, { 'B' _ 0x1F _ 0x15 _ 0x0A _ 0 }) \
X(glyphC, { 'C' _ 0x0E _ 0x11 _ 0x11 _ 0 }) \
X(glyphD, { 'D' _ 0x1F _ 0x11 _ 0x0E _ 0 }) \
X(glyphE, { 'E' _ 0x1F _ 0x15 _ 0x15 _ 0 }) \
X(glyphF, { 'F' _ 0x1F _ 0x14 _ 0x14 _ 0 }) \
#define X(name, data) const uint8_t name [] = data ;
GLYPH_DEFS
#undef X
#define X(name, data) name _
const uint8_t *const glyphs[] = { GLYPH_DEFS nullptr };
#undef X
#undef _
So, when processing the X macro, we pass it a pile of _s, which aren't commas, so it doesn't complain. Then we expand the _ macro and voila: we have syntactically valid array initalizers. If Andrea ever changes the list of glyphs, adding or removing any, the macro will automatically sync the declaration of the individual arrays and their pointers over in the glyphs array.
Andrea adds:
The scope of this definition is limited to this data structure, in which the X macros are used, and it is #undef'd just after that. However, with all the stories of #define abuse on this site, I feel I still need to atone.
The testing sketch works perfectly.
Honestly, all sins are forgiven. There isn't a true WTF here, beyond "the C preprocessor is TRWTF". It's a weird, clever hack, and it's interesting to see this technique in use.
That said, as you might note: this was a testing sketch, just to prove a concept. Instead of getting clever with macros, your disposable testing code should probably just get to proving your concept as quickly as possible. You can worry about code maintainability later. So, if there are any sins by Andrea, it's the sin of overengineering a disposable test program.
|
Метки: CodeSOD |
Ultrabase |
After a few transfers across departments at IniTech, Lydia found herself as a senior developer on an internal web team. They built intranet applications which covered everything from home-grown HR tools to home-grown supply chain tools, to home-grown CMSes, to home-grown "we really should have purchased something but the approval process is so onerous and the budgeting is so constrained that it looks cheaper to carry an IT team despite actually being much more expensive".
A new feature request came in, and it seemed extremely easy. There was a stored procedure that was normally invoked by a scheduled job. The admin users in one of the applications wanted to be able to invoke it on demand. Now, Lydia might be "senior", but she was new to the team, so she popped over to Desmond's cube to see what he thought.
"Oh, sure, we can do that, but it'll take about a week."
"A week?" Lydia asked. "A week? To add a button that invokes a stored procedure. It doesn't even take any parameters or return any results you'd need to display."
"Well, roughly 40 hours of effort, yeah. I can't promise it'd be a calendar week."
"I guess, with testing, and approvals, I could see it taking that long," Lydia said.
"Oh, no, that's just development time," Desmond said. "You're new to the team, so it's time you learned about Ultrabase."
Wyatt was the team lead. Lydia had met him briefly during her onboarding with the team, but had mostly been interacting with the other developers on the team. Wyatt, as it turned out, was a Certified Super Genius™, and was so smart that he recognized that most of their applications were, functionally, quite the same. CRUD apps, mostly. So Wyatt had "automated" the process, with his Ultrabase solution.
First, there was a configuration database. Every table, every stored procedure, every view or query, needed to be entered into the configuration database. Now, Wyatt, Certified Super Genius™, knew that he couldn't define a simple schema which would cover all the possible cases, so he didn't. He defined a fiendishly complicated schema with opaque and inconsistent validity rules. Once you had entered the data for all of your database objects, hopefully correctly, you could then execute the Data program.
The Data program would read through the configuration database, and through the glories of string concatenation generate a C# solution containing the definitions of your data model objects. The Data program itself was very fault tolerant, so fault tolerant that if anything went wrong, it still just output C# code, just not syntactically correct C# code. If the C# code couldn't compile, you needed to go back to the configuration database and figure out what was wrong.
Eventually, once you had a theoretically working data model library, you pushed the solution to the build server. That would build and sign the library with a corporate key, and publish it to their official internal software repository. This could take days or weeks to snake its way through all the various approval steps.
Once you had the official release of the datamodel, you could fire up the Data Access Layer tool, which would then pull down the signed version in the repository, and using reflection and the config database, the Data Access Layer program would generate a DAL. Assuming everything worked, you would push that to the build server, and then wait for that to wind its way through the plumbing of approvals.
Then the Business Logic Layer. Then the "Core" layer. The "UI Adapter Layer". The "Front End" layer.
Each layer required the previous layer to be in the corporate repository before you could generate it. Each layer also needed to check the config database. It was trivial to make an error that wouldn't be discovered until you tried to generate the front end layer, and if that happened, you needed to go all the way back to the beginning.
"Wyatt is working on a 'config validation tool' which he says will avoid some of these errors," Desmond said. "So we've got that to look forward to. Anyway, that's our process. Glad to have you on the team!"
Lydia was significantly less glad to be on the team, now that Desmond had given her a clearer picture of how it actually worked.
|
Метки: Feature Articles |
Error'd: Free Coff...Wait! |
"Hey! I like free coffee! Let me just go ahead and...um...hold on a second..." writes Adam R.
"I know I have a lot of online meetings these days but I don't remember signing up for this one," Ged M. wrote.
Peter G. writes, "The $60 off this $1M nylon bag?! What a deal! I should buy three of them!"
"So, because it's free, it's null, so I guess that's how Starbucks' app logic works?" James wrote.
Graham K. wrote, "How very 'zen' of National Savings to give me this particular error when I went to change my address."
"I'm not sure I trust "scenem3.com" with their marketing services, if they send out unsolicited template messages. (Muster is German for template, Max Muster is our equivalent of John Doe.)" Lukas G. wrote.
|
Метки: Error'd |
CodeSOD: A Step too Var |
Astor works for a company that provides software for research surveys. Someone needed a method to return a single control object from a list of control objects, so they wrote this C# code:
private ResearchControl GetResearchControlFromListOfResearchControls(int theIndex,
List researchControls)
{
var result = new ResearchControl();
result = researchControls[theIndex];
return result;
} Astor has a theory: “I can only guess the author was planning to return some default value in some case…”
I’m sorry, Astor, but you are mistaken. Honestly, if that were the case, I wouldn’t consider this much of a WTF at all, but here we have a subtle hint about deeper levels of ignorance, and it’s all encoded in that little var.
C# is strongly typed, but declaring the type for every variable is a pain, and in many cases, it’s redundant information. So C# lets you declare a variable with var, which does type interpolation. A var variable has a type, just instead of saying what it is, we just ask the compiler to figure it out from context.
But you have to give it that context, which means you have to declare and assign to the variable in a single step.
So, imagine you’re a developer who doesn’t know C# very well. Maybe you know some JavaScript, and you’re just trying to muddle through.
“Okay, I need a variable to hold the result. I’ll type var result. Hmm. Syntax error. Why?”
The developer skims through the code, looking for similar statements, and sees a var / new construct, and thinks, “Ah, that must be what I need to do!” So var result = new ResearchControl() appears, and the syntax error goes away.
Now, that doesn’t explain all of this code. There are still more questions, like: why not just return researchControls[index] or realize that, wait, you’re just indexing an array, so why not just not write a function at all? Maybe someone had some thoughts about adding exception handling, or returning a default value in cases where there wasn’t a valid entry in the array, but none of that ever happened. Instead, we just get this little artifact of someone who didn’t know better, and who wasn’t given any direction on how to do better.
|
Метки: CodeSOD |
Science Is Science |

Bruce worked for a small engineering consultant firm providing custom software solutions for companies in the industrial sector. His project for CompanyX involved data consolidation for a new oil well monitoring system. It was a two-phased approach: Phase 1 was to get the raw instrument data into the cloud, and Phase 2 was to aggregate that data into a useful format.
Phase 1 was completed successfully. When it came time to write the business logic for aggregating the data, CompanyX politely informed Bruce's team that their new in-house software team would take over from here.
Bruce and his team smelled trouble. They did everything they could think of to persuade CompanyX not to go it alone when all the expertise rested on their side. However, CompanyX was confident they could handle the job, parting ways with handshakes and smiles.
Although Phase 2 was officially no longer on his plate, Bruce had a suspicion borne from experience that this wasn't the last he'd hear from CompanyX. Sure enough, a month later he received an urgent support request via email from Rick, an electrical engineer.
We're having issues with our aggregated data not making it into the database. Please help!!
Rick Smith
LEAD SOFTWARE ENGINEER
"Lead Software Engineer!" Bruce couldn't help repeating out loud. Sadly, he'd seen this scenario before with other clients. In a bid to save money, their management would find the most sciency people on their payroll and would put them in charge of IT or, worse, programming.
Stifling a cringe, Bruce dug deeper into the email. Rick had written a Python script to read the raw instrument data, aggregate it in memory, and re-insert it into a table he'd added to the database. Said script was loaded with un-parameterized queries, filters on non-indexed fields, and SELECT * FROM queries. The aggregation logic was nothing to write home about, either. It was messy, slow, and a slight breeze could take it out. Bruce fired up the SQL profiler and found a bigger issue: a certain query was failing every time, throwing the error Cannot insert the value NULL into column 'requests', table 'hEvents'; column does not allow nulls. INSERT fails.
Well, that seemed straightforward enough. Bruce replied to Rick's email, asking if he knew about the error.
Rick's reply came quickly, and included someone new on the email chain. Yes, but we couldn't figure it out, so we were hoping you could help us. Aaron is our SQL expert and even he's stumped.
Product support was part of Bruce's job responsibilities. He helpfully pointed out the specific query that was failing and described how to use the SQL profiler to pinpoint future issues.
Unfortunately, CompanyX's crack new in-house software team took this opportunity to unload every single problem they were having on Bruce, most of them just as basic or even more basic than the first. The back-and-forth email chain grew to epic proportions, and had less to do with product support than with programming education. When Bruce's patience finally gave out, he sent Rick and Aaron a link to the W3 schools SQL tutorial page. Then he talked to his manager. Agreeing that things had gotten out of hand, Bruce's manager arranged for a BA to contact CompanyX to offer more formal assistance. A teleconference was scheduled for the next week, which Bruce and his manager would also be attending.
When the day of the meeting came, Bruce and his associates dialed in—but no one from CompanyX did. After some digging, they learned that the majority of CompanyX's software team had been fired or reassigned. Apparently, the CompanyX project manager had been BCC'd on Bruce's entire email chain with Rick and Aaron. Said PM had decided a new new software team was in order. The last Bruce heard, the team was still "getting organized." The fate of Phase 2 remains unknown.
|
Метки: Feature Articles |
CodeSOD: A Dropped Pass |
A charitable description of Java is that it’s a strict language, at least in terms of how it expects you to interact with types and definitions. That strictness can create conflict when you’re interacting with less strict systems, like JSON data.
Tessie produces data as a JSON API that wraps around sensing devices which report a numerical value. These sensors, as far as we care for this example, come in two flavors: ones that report a maximum recorded value, and ones which don’t. Something like:
{
dataNoMax: [
{name: "sensor1", value: 20, max: 0}
],
dataWithMax: [
{name: "sensor2", value: 25, max: 50 }
]
}By convention, the API would report max: 0 for all the devices which didn’t have a max.
With that in mind, they designed their POJOs like this:
class Data {
String name;
int value;
int max;
}
class Readings {
List dataNoMax;
List dataWithMax;
}These POJOs would be used both on the side producing the data, and in the client libraries for consuming the data.
Of course, by JSON convention, including a field that doesn’t actually hold a meaningful value is a bad idea- max: 0 should either be max: null, or better yet, just excluded from the output entirely.
So one of Tessie’s co-workers hacked some code into the JSON serializer to conditionally include the max field in the output.
QA needed to validate that this change was correct, so they needed to implement some automated tests. And this is where the problems started to crop up. The developer hadn’t changed the implementation of the POJOs, and they were using int.
For all that Java has a reputation as “everything’s an object”, a few things explicitly aren’t: primitive types. int is a primitive integer, while Integer is an object integer. Integers are references. ints are not. An Integer could be null, but an int cannot ever be null.
This meant if QA tried to write a test assertion that looked like this:
assertThat(readings.dataNoMax[0].getMax()).isNull()it wouldn’t work. max could never be null.
There are a few different ways to solve this. One could make the POJO support nullable types, which is probably a better way to represent an object which may not have a value for certain fields. An int in Java that isn’t initialized to a value will default to zero, so they probably could have left their last unit test unchanged and it still would have passed. But this was a code change, and a code change needs to have a test change to prove the code change was correct.
Let’s compare versions. Here was their original test:
/** Should display max */
assertEquals("sensor2", readings.dataWithMax[0].getName())
assertEquals(50, readings.dataWithMax[0].getMax());
assertEquals(25, readings.dataWithMax[0].getValue());
/** Should not display max */
assertEquals("sensor1", readings.dataNoMax[0].getName())
assertEquals(0, readings.dataNoMax[0].getMax());
assertEquals(20, readings.dataNoMax[0].getValue());And, since the code changed, and they needed to verify that change, this is their new test:
/** Should display max */
assertEquals("sensor2", readings.dataWithMax[0].getName())
assertThat(readings.dataWithMax[0].getMax()).isNotNull()
assertEquals(25, readings.dataWithMax[0].getValue());
/** Should not display max */
assertEquals("sensor1", readings.dataNoMax[0].getName())
//assertThat(readings.dataNoMax[0].getMax()).isNull();
assertEquals(20, readings.dataNoMax[0].getValue());So, their original test compared strictly against values. When they needed to test if values were present, they switched to using an isNotNull comparison. On the side with a max, this test will always pass- it can’t possibly fail, because an int can’t possibly be null. When they tried to do an isNull check, on the other value, that always failed, because again- it can’t possibly be null.
So they commented it out.
Test is green. Clearly, this code is ready to ship.
Tessie adds:
[This] is starting to explain why our git history is filled with commits that “fix failing test” by removing all the asserts.
|
Метки: CodeSOD |
Mega-Agile |
A long time ago, way back in 2009, Bruce W worked for the Mega-Bureaucracy. It was a slog of endless forms, endless meetings, endless projects that just never hit a final ship date. The Mega-Bureaucracy felt that the organization which manages best manages the most, and ensured that there were six tons of management overhead attached to the smallest project.
After eight years in that position, Bruce finally left for another division in the same company.
But during those eight years, Bruce learned a few things about dealing with the Mega-Bureaucracy. His division was a small division, and while Bruce needed to interface with the Mega-Bureaucracy, he could shield the other developers on his team from it, as much as possible. This let them get embedded into the business unit, working closely with the end users, revising requirements on the fly based on rapid feedback and a quick release cycle. It was, in a word, "Agile", in the most realistic version of the term: focus on delivering value to your users, and build processes which support that. They were a small team, and there were many layers of management above them, which served to blunt and filter some of the mandates of the Mega-Bureaucracy, and that let them stay Agile.
Nothing, however, protects against management excess than a track record of success. While they had a reputation for being dangerous heretics: they released to test continuously and releasing to production once a month, they changed requirements as needs changed, meaning what they delivered was almost never what they specced, but it was what their users needed, and worst of all, their software defeated all the key Mega-Bureaucracy metrics. It performed better, it had fewer reported defects, it return-on-investment metrics their software saved the division millions of dollars in operating costs.
The Mega-Bureaucracy seethed at these heretics, but the C-level of the company just saw a high functioning team. There was nothing that the Bureaucracy could do to bring them in line-
-at least until someone opened up a trade magazine, skimmed the buzzwords, and said, "Maybe our processes are too cumbersome. We should do Agile. Company wide, let's lay out an Agile Process."
There's a huge difference between the "agile" created by a self-organizing team, that grows based on learning what works best for the team and their users, and the kind of "agile" that's imposed from the corporate overlords.
First, you couldn't do Agile without adopting the Agile Process, which in Mega-Bureaucracy-speak meant "we're doing a very specific flavor of scrum". This meant morning standups were mandated. You needed a scrum-master on the team, which would be a resource drawn from the project management office, and well, they'd also pull double duty as the project manager. The word "requirements" was forbidden, you had to write User Stories, and then estimate those User Stories as taking a certain number of hours. Then you could hold your Sprint Planning meeting, where you gathered a bucket of stories that would fit within your next sprint, which would be a 4-week cadence, but that was just the sprint planning cadence. Releases to production would happen only quarterly. Once user stories were written, they were never to be changed, just potentially replaced with a new story, but once a story was added to a sprint, you were expected to implement it, as written. No changes based on user feedback. At the end of the sprint, you'd have a whopping big sprint retrospective, and since this was a new process, instead of letting the team self-evaluate in private and make adjustments, management from all levels of the company would sit in on the retrospectives to be "informed" about the "challenges" in adopting the new process.
The resulting changes pleased nearly no one. The developers hated it, the users, especially in Bruce's division, hated it, management hated it. But the Mega-Bureaucracy had won; the dangerous heretics who didn't follow the process now were following the process. They were Agile.
That is what motivated Bruce to transfer to a new position.
Two years later, he attended an all-IT webcast. The CIO announced that they'd spun up a new pilot development team. This new team would get embedded into the business unit, work closely with the end user, revise requirements on the fly based on rapid feedback and a continuous release cycle. "This is something brand new for our company, and we're excited to see where it goes!"
|
Метки: Feature Articles |
Error'd: Not Applicable |
"Why yes, I have always pictured myself as not applicable," Olivia T. wrote.
"Hey Amazon, now I'm no doctor, but you may need to reconsider your 'Choice' of Acetaminophen as a 'stool softener'," writes Peter.
Ivan K. wrote, "Initially, I balked at the price of my new broadband plan, but the speed is just so good that sometimes it's so fast that the reply packets arrive before I even send a request!"
"I wanted to check if a site was being slow and, well, I figured it was good time to go read a book," Tero P. writes.
Robin L. writes, "I just can't wait to try Edge!"
"Yeah, one car stays in the garage, the other is out there tailgating Starman," Keith wrote.
|
Метки: Error'd |
CodeSOD: Because of the Implication |
Even when you’re using TypeScript, you’re still bound by JavaScript’s type system. You’re also stuck with its object system, which means that each object is really just a dict, and there’s no guarantee that any object has any given key at runtime.
Madison sends us some TypeScript code that is, perhaps not strictly bad, in and of itself, though it certainly contains some badness. It is more of a symptom. It implies a WTF.
private _filterEmptyValues(value: any): any {
const filteredValue = {};
Object.keys(value)
.filter(key => {
const v = value[key];
if (v === null) {
return false;
}
if (v.von !== undefined || v.bis !== undefined) {
return (v.von !== null && v.von !== 'undefined' && v.von !== '') ||
(v.bis !== null && v.bis !== 'undefined' && v.bis !== '');
}
return (v !== 'undefined' && v !== '');
}).forEach(key => {
filteredValue[key] = value[key];
});
return filteredValue;
}At a guess, this code is meant to be used as part of prepping objects for being part of a request: clean out unused keys before sending or storing them. And as a core methodology, it’s not wrong, and it’s pretty similar to your standard StackOverflow solution to the problem. It’s just… forcing me to ask some questions.
Let’s trace through it. We start by doing an Object.keys to get all the fields on the object. We then filter to remove the “empty” ones.
First, if the value is null, that’s empty. That makes sense.
Then, if the value is an object which contains a von or bis property, we’ll do some more checks. This is a weird definition of “empty”, but fine. We’ll check that they’re both non-null, not an empty string, and not… 'undefined'.
Uh oh.
We then do a similar check on the value itself, to ensure it’s not an empty string, and not 'undefined'.
What this is telling me is that somewhere in processing, sometimes, the actual string “undefined” can be stored, and it’s meant to be treated as JavaScript’s type undefined. That probably shouldn’t be happening, and implies a WTF somewhere else.
Similarly, the von and bis check has to raise a few eyebrows. If an object contains these fields, these fields must contain a value to pass this check. Why? I have no idea.
In the end, this code isn’t the WTF itself, it’s all the questions that it raises that tell me the shape of the WTF. It’s like looking at a black hole: I can’t see the object itself, I can only see the effect it has on the space around it.
|
Метки: CodeSOD |
CodeSOD: Dates by the Dozen |
Before our regularly scheduled programming, Code & Supply, a developer community group we've collaborated with in the past, is running a salary survey, to gauge the state of the industry. More responses are always helpful, so I encourage you to take a few minutes and pitch in.
Cid was recently combing through an inherited Java codebase, and it predates Java 8. That’s a fancy way of saying “there were no good date builtins, just a mess of cruddy APIs”. That’s not to say that there weren’t date builtins prior to Java 8- they were just bad.
Bad, but better than this. Cid sent along a lot of code, and instead of going through it all, let’s get to some of the “highlights”. Much of this is stuff we’ve seen variations on before, but have been combined in ways to really elevate the badness. There are dozens of these methods, which we are only going to look at a sample of.
Let’s start with the String getLocalDate() method, which attempts to construct a timestamp in the form yyyyMMdd. As you can already predict, it does a bunch of string munging to get there, with blocks like:
switch (calendar.get(Calendar.MONTH)){
case Calendar.JANUARY:
sb.append("01");
break;
case Calendar.FEBRUARY:
sb.append("02");
break;
…
}Plus, we get the added bonus of one of those delightful “how do I pad an integer out to two digits?” blocks:
if (calendar.get(Calendar.DAY_OF_MONTH) < 10) {
sb.append("0" + calendar.get(Calendar.DAY_OF_MONTH));
}
else {
sb.append(calendar.get(Calendar.DAY_OF_MONTH));
}Elsewhere, they expect a timestamp to be in the form yyyyMMddHHmmssZ, so they wrote a handy void checkTimestamp method. Wait, void you say? Shouldn’t it be boolean?
Well here’s the full signature:
public static void checkTimestamp(String timestamp, String name)
throws IOExceptionWhy return a boolean when you can throw an exception on bad input? Unless the bad input is a null, in which case:
if (timestamp == null) {
return;
}Nulls are valid timestamps, which is useful to know. We next get a lovely block of checking each character to ensure that they’re digits, and a second check to ensure that the last is the letter Z, which turns out to be double work, since the very next step is:
int year = Integer.parseInt(timestamp.substring(0,4));
int month = Integer.parseInt(timestamp.substring(4,6));
int day = Integer.parseInt(timestamp.substring(6,8));
int hour = Integer.parseInt(timestamp.substring(8,10));
int minute = Integer.parseInt(timestamp.substring(10,12));
int second = Integer.parseInt(timestamp.substring(12,14));Followed by a validation check for day and month:
if (day < 1) {
throw new IOException(msg);
}
if ((month < 1) || (month > 12)) {
throw new IOException(msg);
}
if (month == 2) {
if ((year %4 == 0 && year%100 != 0) || year%400 == 0) {
if (day > 29) {
throw new IOException(msg);
}
}
else {
if (day > 28) {
throw new IOException(msg);
}
}
}
if (month == 1 || month == 3 || month == 5 || month == 7
|| month == 8 || month == 10 || month == 12) {
if (day > 31) {
throw new IOException(msg);
}
}
if (month == 4 || month == 6 || month == 9 || month == 11) {
if (day > 30) {
throw new IOException(msg);
}
"The upshot is they at least got the logic right.
What’s fun about this is that the original developer never once considered “maybe I need an intermediate data structure beside a string to manipulate dates”. Nope, we’re just gonna munge that string all day. And that is our entire plan for all date operations, which brings us to the real exciting part, where this transcends from “just regular old bad date code” into full on WTF territory.
Would you like to see how they handle adding units of time? Like days?
public static String additionOfDays(String timestamp, int intervall) {
int year = Integer.parseInt(timestamp.substring(0,4));
int month = Integer.parseInt(timestamp.substring(4,6));
int day = Integer.parseInt(timestamp.substring(6,8));
int len = timestamp.length();
String timestamp_rest = timestamp.substring(8, len);
int lastDayOfMonth = 31;
int current_intervall = intervall;
while (current_intervall > 0) {
lastDayOfMonth = getDaysOfMonth(year, month);
if (day + current_intervall > lastDayOfMonth) {
current_intervall = current_intervall - (lastDayOfMonth - day);
if (month < 12) {
month++;
}
else {
year++;
month = 1;
}
day = 0;
}
else {
day = day + current_intervall;
current_intervall = 0;
}
}
String new_year = "" + year + "";
String new_month = null;
if (month < 10) {
new_month = "0" + month + "";
}
else {
new_month = "" + month + "";
}
String new_day = null;
if (day < 10) {
new_day = "0" + day + "";
}
else {
new_day = "" + day + "";
}
return new String(new_year + new_month + new_day + timestamp_rest);
}The only thing I can say is that here they realized that “hey, wait, maybe I can modularize” and figured out how to stuff their “how many days are in a month” logic into getDaysOfMonth, which you can see invoked above.
Beyond that, they manually handle carrying, and never once pause to think, “hey, maybe there’s a better way”.
And speaking of repeating code, guess what- there’s also a public static String additionOfSeconds(String timestamp, int intervall) method, too.
There are dozens of similar methods, Cid has only provided us a sample. Cid adds:
This particular developer didn’t trust in too fine modularization and code reusing (DRY!). So for every of this dozen of methods, he has implemented these date parsing/formatting algorithms again and again! And no, not just copy/paste; every time it is a real wheel-reinvention. The code blocks and the position of single code lines look different for every method.
Once Cid got too frustrated by this code, they went and reimplemented it in modern Java date APIs, shrinking the codebase by hundreds of lines.
The full blob of code Cid sent in follows, for your “enjoyment”:
public static String getLocalDate() {
TimeZone tz = TimeZone.getDefault();
GregorianCalendar calendar = new GregorianCalendar(tz);
calendar.setTime(new Date());
StringBuffer sb = new StringBuffer();
sb.append(calendar.get(Calendar.YEAR));
switch (calendar.get(Calendar.MONTH)){
case Calendar.JANUARY:
sb.append("01");
break;
case Calendar.FEBRUARY:
sb.append("02");
break;
case Calendar.MARCH:
sb.append("03");
break;
case Calendar.APRIL:
sb.append("04");
break;
case Calendar.MAY:
sb.append("05");
break;
case Calendar.JUNE:
sb.append("06");
break;
case Calendar.JULY:
sb.append("07");
break;
case Calendar.AUGUST:
sb.append("08");
break;
case Calendar.SEPTEMBER:
sb.append("09");
break;
case Calendar.OCTOBER:
sb.append("10");
break;
case Calendar.NOVEMBER:
sb.append("11");
break;
case Calendar.DECEMBER:
sb.append("12");
break;
}
if (calendar.get(Calendar.DAY_OF_MONTH) < 10) {
sb.append("0" + calendar.get(Calendar.DAY_OF_MONTH));
}
else {
sb.append(calendar.get(Calendar.DAY_OF_MONTH));
}
return sb.toString();
}
public static void checkTimestamp(String timestamp, String name)
throws IOException {
if (timestamp == null) {
return;
}
String msg = new String(
"Wrong date or time. (" + name + "=\"" + timestamp + "\")");
int len = timestamp.length();
if (len != 15) {
throw new IOException(msg);
}
for (int i = 0; i < (len - 1); i++) {
if (! Character.isDigit(timestamp.charAt(i))) {
throw new IOException(msg);
}
}
if (timestamp.charAt(len - 1) != 'Z') {
throw new IOException(msg);
}
int year = Integer.parseInt(timestamp.substring(0,4));
int month = Integer.parseInt(timestamp.substring(4,6));
int day = Integer.parseInt(timestamp.substring(6,8));
int hour = Integer.parseInt(timestamp.substring(8,10));
int minute = Integer.parseInt(timestamp.substring(10,12));
int second = Integer.parseInt(timestamp.substring(12,14));
if (day < 1) {
throw new IOException(msg);
}
if ((month < 1) || (month > 12)) {
throw new IOException(msg);
}
if (month == 2) {
if ((year %4 == 0 && year%100 != 0) || year%400 == 0) {
if (day > 29) {
throw new IOException(msg);
}
}
else {
if (day > 28) {
throw new IOException(msg);
}
}
}
if (month == 1 || month == 3 || month == 5 || month == 7
|| month == 8 || month == 10 || month == 12) {
if (day > 31) {
throw new IOException(msg);
}
}
if (month == 4 || month == 6 || month == 9 || month == 11) {
if (day > 30) {
throw new IOException(msg);
}
}
if ((hour < 0) || (hour > 24)) {
throw new IOException(msg);
}
if ((minute < 0) || (minute > 59)) {
throw new IOException(msg);
}
if ((second < 0) || (second > 59)) {
throw new IOException(msg);
}
}
public static String additionOfDays(String timestamp, int intervall) {
int year = Integer.parseInt(timestamp.substring(0,4));
int month = Integer.parseInt(timestamp.substring(4,6));
int day = Integer.parseInt(timestamp.substring(6,8));
int len = timestamp.length();
String timestamp_rest = timestamp.substring(8, len);
int lastDayOfMonth = 31;
int current_intervall = intervall;
while (current_intervall > 0) {
lastDayOfMonth = getDaysOfMonth(year, month);
if (day + current_intervall > lastDayOfMonth) {
current_intervall = current_intervall - (lastDayOfMonth - day);
if (month < 12) {
month++;
}
else {
year++;
month = 1;
}
day = 0;
}
else {
day = day + current_intervall;
current_intervall = 0;
}
}
String new_year = "" + year + "";
String new_month = null;
if (month < 10) {
new_month = "0" + month + "";
}
else {
new_month = "" + month + "";
}
String new_day = null;
if (day < 10) {
new_day = "0" + day + "";
}
else {
new_day = "" + day + "";
}
return new String(new_year + new_month + new_day + timestamp_rest);
}
public static String additionOfSeconds(String timestamp, int intervall) {
int hour = Integer.parseInt(timestamp.substring(8,10));
int minute = Integer.parseInt(timestamp.substring(10,12));
int second = Integer.parseInt(timestamp.substring(12,14));
int new_second = (second + intervall) % 60;
int minute_intervall = (second + intervall) / 60;
int new_minute = (minute + minute_intervall) % 60;
int hour_intervall = (minute + minute_intervall) / 60;
int new_hour = (hour + hour_intervall) % 24;
int day_intervall = (hour + hour_intervall) / 24;
StringBuffer new_time = new StringBuffer();
if (new_hour < 10) {
new_time.append("0" + new_hour + "");
}
else {
new_time.append("" + new_hour + "");
}
if (new_minute < 10) {
new_time.append("0" + new_minute + "");
}
else {
new_time.append("" + new_minute + "");
}
if (new_second < 10) {
new_time.append("0" + new_second + "");
}
else {
new_time.append("" + new_second + "");
}
if (day_intervall > 0) {
return additionOfDays(timestamp.substring(0,8) + new_time.toString() + "Z", day_intervall);
}
else {
return (timestamp.substring(0,8) + new_time.toString() + "Z");
}
}
public static int getDaysOfMonth(int year, int month) {
int lastDayOfMonth = 31;
switch (month) {
case 1: case 3: case 5: case 7: case 8: case 10: case 12:
lastDayOfMonth = 31;
break;
case 2:
if ((year % 4 == 0 && year % 100 != 0) || year %400 == 0) {
lastDayOfMonth = 29;
}
else {
lastDayOfMonth = 28;
}
break;
case 4: case 6: case 9: case 11:
lastDayOfMonth = 30;
break;
}
return lastDayOfMonth;
}|
Метки: CodeSOD |
Representative Line: An Exceptional Leader |
IniTech’s IniTest division makes a number of hardware products, like a protocol analyzer which you can plug into a network and use to monitor data in transport. As you can imagine, it involves a fair bit of software, and it involves a fair bit of hardware. Since it’s a testing and debugging tool, reliability, accuracy, and stability are the watchwords of the day.
Which is why the software development process was overseen by Russel. Russel was the “Alpha Geek”, blessed by the C-level to make sure that the software was up to snuff. This lead to some conflict- Russel had a bad habit of shoulder-surfing his fellow developers and telling them what to type- but otherwise worked very well. Foibles aside, Russel was technically competent, knew the problem domain well, and had a clean, precise, and readable coding style which all the other developers tried to imitate.
It was that last bit which got Ashleigh’s attention. Because, scattered throughout the entire C# codebase, there are exception handlers which look like this:
try
{
// some code, doesn't matter what
// ...
}
catch (Exception ex)
{
ex = ex;
}This isn’t the sort of thing which one developer did. Nearly everyone on the team had a commit like that, and when Ashleigh asked about it, she was told “It’s just a best practice. We’re following Russel’s lead. It’s for debugging.”
Ashleigh asked Russel about it, but he just grumbled and had no interest in talking about it beyond, “Just… do it if it makes sense to you, or ignore it. It’s not necessary.”
If it wasn’t necessary, why was it so common in the codebase? Why was everyone “following Russel’s lead”?
Ashleigh tracked down the original commit which started this pattern. It was made by Russel, but the exception handler had one tiny, important difference:
catch (Exception ex)
{
ex = ex; //putting this here to set a breakpoint
}Yes, this was just a bit of debugging code. It was never meant to be committed. Russel pushed it into the main history by accident, and the other developers saw it, and thought to themselves, “If Russel does it, it must be the right thing to do,” and started copying him.
By the time Russel noticed what was going on, it was too late. The standard had been set while he wasn’t looking, and whether it was ego or cowardice, Russel just could never get the team to follow his lead away from the pointless pattern.
|
Метки: Representative Line |