О дизайне в мобильных приложениях (глазами, умом и сердцем разработчика) |
Дизайн — это не то, как продукт выглядит и воспринимается. Дизайн — это то, как он работает. Steve Jobs
|
Метки: author AKhatmullin разработка под ios разработка мобильных приложений анализ и проектирование систем дизайн мобильных приложений проектирование мобильных приложений |
Getsploit: поиск и загрузка эксплойтов по агрегированной базе данных |
Когда я думал над дальнейшим вектором развития Vulners, я обратил внимание на наших старших братьев — базу данных Exploit-DB. Одной из основных утилит в их арсенале является searchsploit. Это консольная утилита, которая позволяет искать эксплойты по пользовательским поисковым запросам и сразу же получать их исходные коды. Она является базовой частью Kali Linux и оперирует данными по эксплойтам из базы Exploit-DB. Что самое "вкусное", что утилита умеет работать с локальной базой и ты можешь всегда взять ее с собой. Так чем же мы хуже? Мы собрали в Vulners не только коллекцию эксплойтов из Exploit-DB, но и Packet Storm, 0day.today, Seebug, Zero Science Lab и многих других. Что же, давайте изобретем новый велосипед с преферансом и поэтессами.
И видим внутри bash скрипт длиною 711 строчек. Он скачивает с публичного репозитария exploit-database копию данных и ищет уже по ней. Но где же Google-style синтаксис и прочие прелести современного поиска? Увы, в их подходе нашлись и плюсы и минусы. Плюсы оказались в том, что они способны находить эксплойты по критериям применимости. Минусы — довольно бедный функционал для неточного поиска. На этом идея интегрироваться с ним была отброшена и решение писать свой форк стала доминирующей.
Начнем с того, что определимся с функциональностью.
В итоге утилита была реализована на Python с совместимостью от Python 2.6 до Python 3.6. Основные ключи я постарался сохранить идентичными searchsploit для того, что бы не приходилось привыкать заново.
isox$ git clone https://github.com/vulnersCom/getsploit
isox$ cd getsploit
isox$ ./getsploit.py -h
usage: Exploit search and download utility [-h] [-t] [-j] [-m] [-c COUNT] [-l]
[-u]
[query [query ...]]
positional arguments:
query Exploit search query. See https://vulners.com/help for
the detailed manual.
optional arguments:
-h, --help show this help message and exit
-t, --title Search JUST the exploit title (Default is description
and source code).
-j, --json Show result in JSON format.
-m, --mirror Mirror (aka copies) search result exploit files to the
subdirectory with your search query name.
-c COUNT, --count COUNT
Search limit. Default 10.
-l, --local Perform search in the local database instead of
searching online.
-u, --update Update getsploit.db database. Will be downloaded in
the script path.Основная механика поиска строится на базе Vulners API. Таким образом вы всегда получите актуальные данные на момент "здесь и сейчас". Что же, поищем эксплойты под Wordpress?

Довольно неплохо, да? Попробуем теперь ограничить нас только коллекцией Packet Storm. Синтаксис выражений полностью совпадает с поисковой строкой сайта и его можно подглядеть на страничке help.
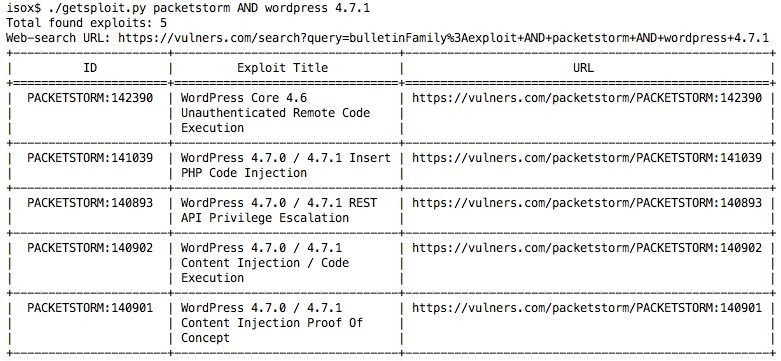
Так, нужные нам эксплойты найдены. Теперь их нужно сохранить для последующего использования. Для этого нужно использовать ключик "-m". После этого утилита создаст папку с вашим поиском и загрузит эксплойты туда.
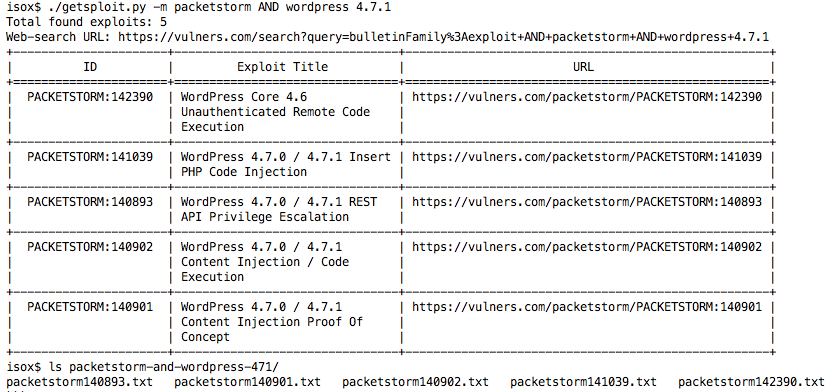
Но что же делать, если у нас нет онлайн подключения к интернету? Вспомнить об этом пока он еще доступен и сделать "--update"!
isox$ ./getsploit.py --update
Downloading getsploit database archive. Please wait, it may take time. Usually around 5-10 minutes.
219686398/219686398 [100.00%]
Unpacking database.
Database download complete. Now you may search exploits using --local key './getsploit.py -l wordpress 4.7'При таком запросе getsploit скачает SQLite базу данных со всей коллекцией эксплойтов. Это порядка 594 мегабайт данных на момент написания статьи.
Обратите внимание, что если у вас Python скомпилирован без поддержки sqlite3 (что в принципе редкость), то локальная база, увы, работать не будет.
Здесь пришлось пожертвовать совместимостью ради скорости работы и возможности полнотекстового поиска с FTS4 модулем SQLite.
Но все не так плохо, основная масса сборок Python по умолчанию идет с модулем sqlite3. Попробуем найти эксплойты локально?
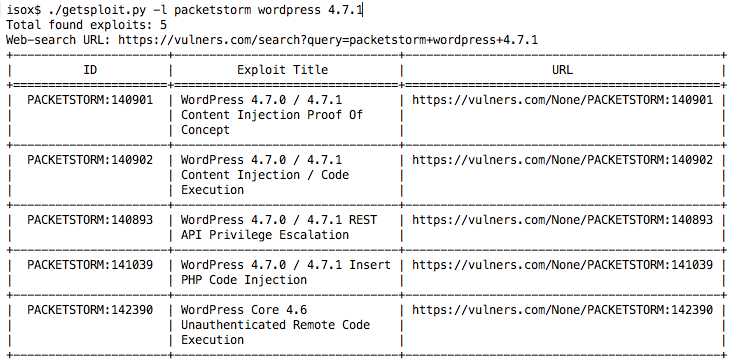
Отлично! Теперь можно взять с собой всю коллекцию эксплойтов с Vulners и использовать ее в оффлайне без регистрации и смс.
Ну и конечно же, исходные коды лежат на нашем GitHub.
Pull-request'ы крайне приветствуются.
|
Метки: author isox информационная безопасность python exploit exploitdb hacking |
Superjob PHP-meetup. Прямая трансляция |
|
|
Интеграция Oculus Rift в десктопное Direct3D приложение на примере Renga |
#define OVR_D3D_VERSION 11 // in case direct3d 11
#include "OVR_CAPI_D3D.h"
bool InitOculus()
{
ovrSession session = 0;
ovrGraphicsLuid luid = 0;
// Initializes LibOVR, and the Rift
ovrInitParams initParams = { ovrInit_RequestVersion, OVR_MINOR_VERSION, NULL, 0, 0 };
if (!OVR_SUCCESS(ovr_Initialize(&initParams)))
return false;
if (!OVR_SUCCESS(ovr_Create(&session, &luid)))
return false;
// FloorLevel will give tracking poses where the floor height is 0
if(!OVR_SUCCESS(ovr_SetTrackingOriginType(session, ovrTrackingOrigin_EyeLevel)))
return false;
return true;
}
struct EyeTexture
{
ovrSession Session;
ovrTextureSwapChain TextureChain;
std::vector TexRtv;
EyeTexture() :
Session(nullptr),
TextureChain(nullptr)
{
}
bool Create(ovrSession session, int sizeW, int sizeH)
{
Session = session;
ovrTextureSwapChainDesc desc = {};
desc.Type = ovrTexture_2D;
desc.ArraySize = 1;
desc.Format = OVR_FORMAT_R8G8B8A8_UNORM_SRGB;
desc.Width = sizeW;
desc.Height = sizeH;
desc.MipLevels = 1;
desc.SampleCount = 1;
desc.MiscFlags = ovrTextureMisc_DX_Typeless;
desc.BindFlags = ovrTextureBind_DX_RenderTarget;
desc.StaticImage = ovrFalse;
ovrResult result = ovr_CreateTextureSwapChainDX(Session, pDevice, &desc, &TextureChain);
if (!OVR_SUCCESS(result))
return false;
int textureCount = 0;
ovr_GetTextureSwapChainLength(Session, TextureChain, &textureCount);
for (int i = 0; i < textureCount; ++i)
{
ID3D11Texture2D* tex = nullptr;
ovr_GetTextureSwapChainBufferDX(Session, TextureChain, i, IID_PPV_ARGS(&tex));
D3D11_RENDER_TARGET_VIEW_DESC rtvd = {};
rtvd.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
rtvd.ViewDimension = D3D11_RTV_DIMENSION_TEXTURE2D;
ID3D11RenderTargetView* rtv;
DIRECTX.Device->CreateRenderTargetView(tex, &rtvd, &rtv);
TexRtv.push_back(rtv);
tex->Release();
}
return true;
}
~EyeTexture()
{
for (int i = 0; i < (int)TexRtv.size(); ++i)
{
Release(TexRtv[i]);
}
if (TextureChain)
{
ovr_DestroyTextureSwapChain(Session, TextureChain);
}
}
ID3D11RenderTargetView* GetRTV()
{
int index = 0;
ovr_GetTextureSwapChainCurrentIndex(Session, TextureChain, &index);
return TexRtv[index];
}
void Commit()
{
ovr_CommitTextureSwapChain(Session, TextureChain);
}
};
ovrHmdDesc hmdDesc = ovr_GetHmdDesc(session);
ovrSizei idealSize = ovr_GetFovTextureSize(session, (ovrEyeType)eye, hmdDesc.DefaultEyeFov[eye], 1.0f);
// Create a mirror to see on the monitor.
ovrMirrorTexture mirrorTexture = nullptr;
mirrorDesc.Format = OVR_FORMAT_R8G8B8A8_UNORM_SRGB;
mirrorDesc.Width = width;
mirrorDesc.Height =height;
ovr_CreateMirrorTextureDX(session, pDXDevice, &mirrorDesc, &mirrorTexture);
ovrHmdDesc hmdDesc = ovr_GetHmdDesc(session);
ovrEyeRenderDesc eyeRenderDesc[2];
eyeRenderDesc[0] = ovr_GetRenderDesc(session, ovrEye_Left, hmdDesc.DefaultEyeFov[0]);
eyeRenderDesc[1] = ovr_GetRenderDesc(session, ovrEye_Right, hmdDesc.DefaultEyeFov[1]);
// Get both eye poses simultaneously, with IPD offset already included.
ovrPosef EyeRenderPose[2];
ovrVector3f HmdToEyeOffset[2] = { eyeRenderDesc[0].HmdToEyeOffset,
eyeRenderDesc[1].HmdToEyeOffset };
double sensorSampleTime; // sensorSampleTime is fed into the layer later
ovr_GetEyePoses(session, frameIndex, ovrTrue, HmdToEyeOffset, EyeRenderPose, &sensorSampleTime);
OculusTexture * pEyeTexture[2] = { nullptr, nullptr };
// ...
// Draw into eye textures
// ...
// Initialize our single full screen Fov layer.
ovrLayerEyeFov ld = {};
ld.Header.Type = ovrLayerType_EyeFov;
ld.Header.Flags = 0;
for (int eye = 0; eye < 2; ++eye)
{
ld.ColorTexture[eye] = pEyeTexture[eye]->TextureChain;
ld.Viewport[eye] = eyeRenderViewport[eye];
ld.Fov[eye] = hmdDesc.DefaultEyeFov[eye];
ld.RenderPose[eye] = EyeRenderPose[eye];
ld.SensorSampleTime = sensorSampleTime;
}
ovrLayerHeader* layers = &ld.Header;
ovr_SubmitFrame(session, frameIndex, nullptr, &layers, 1);
ID3D11Texture2D* tex = nullptr;
ovr_GetMirrorTextureBufferDX(session, mirrorTexture, IID_PPV_ARGS(&tex));
pDXContext->CopyResource(backBufferTexture, tex);
|
|
[Из песочницы] Wi-Fi адаптер через OTG |

dmesg. Нахожу:...
[ 256.815266] usbcore: registered new interface driver ath9k_htc
...apt-get install android-tools-adbexport ARCH=arm
export CROSS_COMPILE=~/тот самый произвольный путь/arm-eabi-4.4.3/bin/arm-eabi-make help и получаю тучу информации, среди которой нужно найти нечто, заканчивающееся на _defconfig, у меня это:...
android_espresso10_omap4430_r02_user_defconfig - Build for android_espresso10_omap4430_r02_user
...make android_espresso10_omap4430_r02_user_defconfigmake menuconfig
CFLAGS_MODULE = -fno-picСохраняю. Возвращаюсь в терминал, а если вы его закрыли, то в и каталог с исходниками тоже, и выполняю сначала
make modules_prepare, а следом просто make. Результат потребует ожидания. Мой итоговый набор:MODPOST 8 modules
CC drivers/net/wireless/ath/ath.mod.o
LD [M] drivers/net/wireless/ath/ath.ko
CC drivers/net/wireless/ath/ath9k/ath9k_common.mod.o
LD [M] drivers/net/wireless/ath/ath9k/ath9k_common.ko
CC drivers/net/wireless/ath/ath9k/ath9k_htc.mod.o
LD [M] drivers/net/wireless/ath/ath9k/ath9k_htc.ko
CC drivers/net/wireless/ath/ath9k/ath9k_hw.mod.o
LD [M] drivers/net/wireless/ath/ath9k/ath9k_hw.ko
CC drivers/net/wireless/bcmdhd/dhd.mod.o
LD [M] drivers/net/wireless/bcmdhd/dhd.ko
CC drivers/scsi/scsi_wait_scan.mod.o
LD [M] drivers/scsi/scsi_wait_scan.ko
CC net/mac80211/mac80211.mod.o
LD [M] net/mac80211/mac80211.ko
CC net/wireless/cfg80211.mod.o
LD [M] net/wireless/cfg80211.ko
adb start-server
adb shell
sulsmod и выгружаю их все, если это возможно, командой rmmod имямодуляcd /sdcard/ваш путь/ls. a@ubuntu:~/Kernel$ adb start-server
* daemon not running. starting it now on port 5037 *
* daemon started successfully *
a@ubuntu:~/Kernel$ adb shell
shell@android:/ $ su
root@android:/ # cd /sdcard/temp
root@android:/sdcard/temp # ls
ath.ko
ath9k_common.ko
ath9k_htc.ko
ath9k_hw.ko
mac80211.ko
insmod имямодуля в такой и только такой последовательности (иначе просто не загрузится, выдавая ошибку):insmod ath.koinsmod: init_module 'ath.ko' failed (Exec format error)dmesg:... ath: version magic '3.0.31 SMP preempt mod_unload modversions ARMv7 p2v8' should be '3.0.31-1919150 SMP preempt mod_unload modversions ARMv7 p2v8'VERSION = 3Дописываю к EXTRAVERSION = недостающий кусок версии -1919150 так, чтобы получилось:
PATCHLEVEL = 0
SUBLEVEL = 31
EXTRAVERSION =
NAME = Sneaky Weasel
VERSION = 3И сохраняю.
PATCHLEVEL = 0
SUBLEVEL = 31
EXTRAVERSION = -1919150
NAME = Sneaky Weasel
make modules_prepare, make и далее по предыдущему пункту.dmesg скажет следующее:<4>[ 3491.160949] C1 [ insmod] mac80211: Unknown symbol ewma_add (err 0)
<4>[ 3491.161865] C1 [ insmod] mac80211: Unknown symbol ewma_init (err 0)

<4>[ 2435.271636] C1 [ insmod] mac80211: Unknown symbol led_trigger_unregister (err 0)
<4>[ 2435.271820] C1 [ insmod] mac80211: Unknown symbol led_brightness_set (err 0)
<4>[ 2435.271972] C1 [ insmod] mac80211: Unknown symbol led_blink_set (err 0)
<4>[ 2435.272033] C1 [ insmod] mac80211: Unknown symbol led_trigger_register (err 0)
<4>[ 2435.272155] C1 [ insmod] mac80211: Unknown symbol led_trigger_event (err 0)
<4>[ 2709.396392] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_start_tx_ba_cb_irqsafe (err 0)
<4>[ 2709.396972] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_free_hw (err 0)
<4>[ 2709.397155] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_alloc_hw (err 0)
<4>[ 2709.397216] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_start_tx_ba_session (err 0)
<4>[ 2709.397369] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_register_hw (err 0)
<4>[ 2709.397430] C1 [ insmod] ath9k_htc: Unknown symbol led_classdev_unregister (err 0)
<4>[ 2709.397491] C1 [ insmod] ath9k_htc: Unknown symbol __ieee80211_create_tpt_led_trigger (err 0)
<4>[ 2709.397766] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_get_buffered_bc (err 0)
<4>[ 2709.397827] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_find_sta (err 0)
<4>[ 2709.398284] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_stop_tx_ba_cb_irqsafe (err 0)
<4>[ 2709.398376] C1 [ insmod] ath9k_htc: Unknown symbol wiphy_to_ieee80211_hw (err 0)
<4>[ 2709.398498] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_queue_delayed_work (err 0)
<4>[ 2709.398712] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_rx (err 0)
<4>[ 2709.398895] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_wake_queues (err 0)
<4>[ 2709.399230] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_tx_status (err 0)
<4>[ 2709.399291] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_stop_queues (err 0)
<4>[ 2709.399505] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_iterate_active_interfaces_atomic (err 0)
<4>[ 2709.399597] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_unregister_hw (err 0)
<4>[ 2709.399749] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_beacon_get_tim (err 0)
<4>[ 2709.399871] C1 [ insmod] ath9k_htc: Unknown symbol led_classdev_register (err 0)
<4>[ 2709.399932] C1 [ insmod] ath9k_htc: Unknown symbol ieee80211_queue_work (err 0)

Defined at drivers/leds/KconfigА значит все настройки хранятся в данном файле. Долго я мучал Kconfig в /drivers/leds/ пока не додумался посмотреть такой же файл в своем /drivers/net/wireless/ath/ath9k, где нашел ответ на свой вопрос:
…Сходу удаляю строки, включающие страшное слово LED, получаю
config ATH9K_HTC
tristate «Atheros HTC based wireless cards support»
depends on USB && MAC80211
select ATH9K_HW
select MAC80211_LEDS
select LEDS_CLASS
select NEW_LEDS
select ATH9K_COMMON
...
…и сохраняю. Теперь можно снимать галочки:
config ATH9K_HTC
tristate «Atheros HTC based wireless cards support»
depends on USB && MAC80211
select ATH9K_HW
select ATH9K_COMMON
...


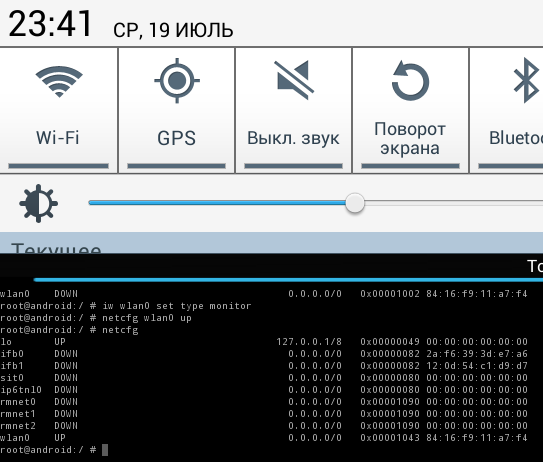
netcfg, то на помощь приходит все тот же dmesg. …
[ 7582.477874] C0 [ khubd] ath9k_htc 1-1:1.0: ath9k_htc: Please upgrade to FW version 1.3
...



|
Метки: author Rechnoy разработка под android android wifi otg monitor |
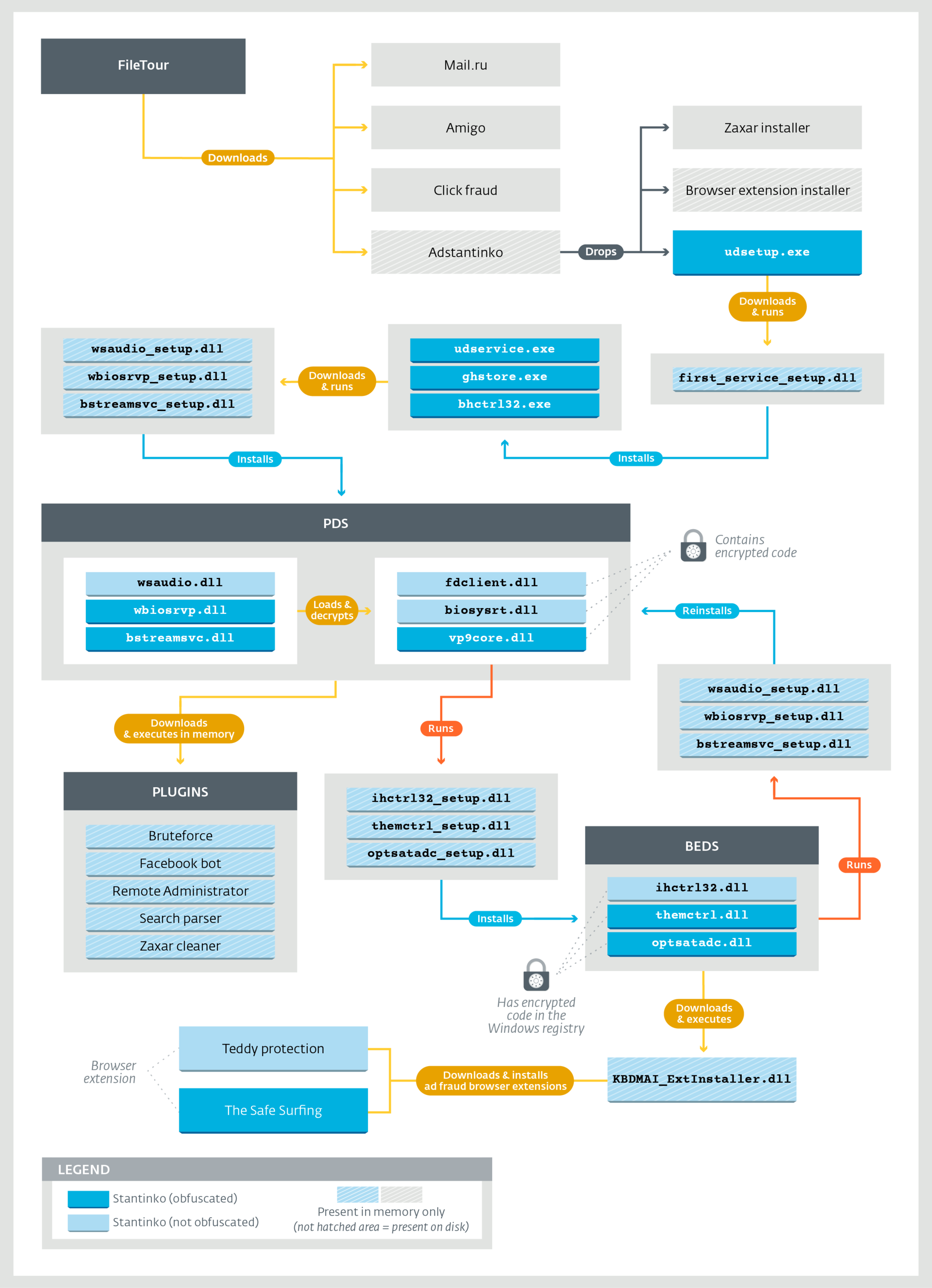
Stantinko: масштабная adware-кампания, действующая с 2012 года |






|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 stantinko adware сlick fraud |
Компания HPE начала продажи новых серверов HPE ProLiant Gen10 |




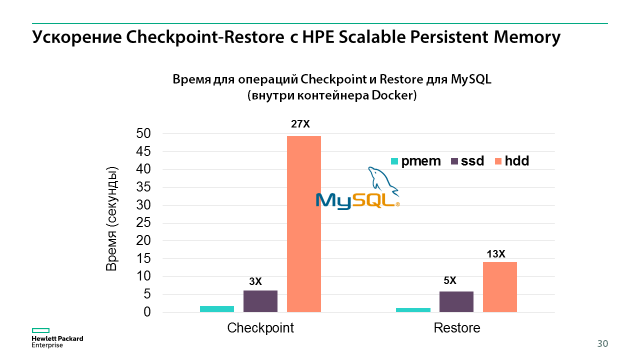

 Зачем эта технология? Во-первых, прошивка компонента может повредиться в процессе обновления вручную или просто из-за сбоя в микросхеме. Во-вторых, аналитики угроз ИБ с каждым годом обнаруживают все больше уязвимостей в прошивках и другом низкоуровневом коде серверов. Последний громкий пример – найденная уязвимость в патчах для прошивок серверов SuperMicro, которые закупила себе компания Apple (ссылка: arstechnica.com/information-technology/2017/02/apple-axed-supermicro-servers-from-datacenters-because-of-bad-firmware-update). Этот уровень практически не контролируется привычными антивирусами, поэтому и угроза там скрывается значительная.
Зачем эта технология? Во-первых, прошивка компонента может повредиться в процессе обновления вручную или просто из-за сбоя в микросхеме. Во-вторых, аналитики угроз ИБ с каждым годом обнаруживают все больше уязвимостей в прошивках и другом низкоуровневом коде серверов. Последний громкий пример – найденная уязвимость в патчах для прошивок серверов SuperMicro, которые закупила себе компания Apple (ссылка: arstechnica.com/information-technology/2017/02/apple-axed-supermicro-servers-from-datacenters-because-of-bad-firmware-update). Этот уровень практически не контролируется привычными антивирусами, поэтому и угроза там скрывается значительная.
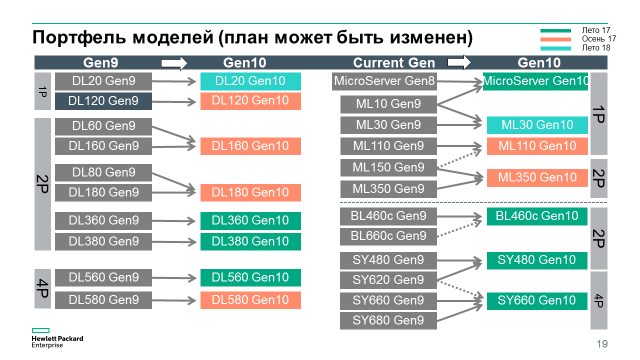











|
|
[Из песочницы] Система электронной очереди в банковском бизнесе |
|
Метки: author TehnologiiBudushego финансы в it электронная очередь банковский бизнес it в финансовой сфере |
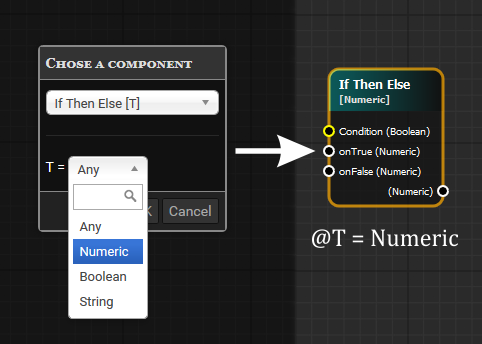
VAX — инструмент для визуального программирования, или как написать SQL мышкой |
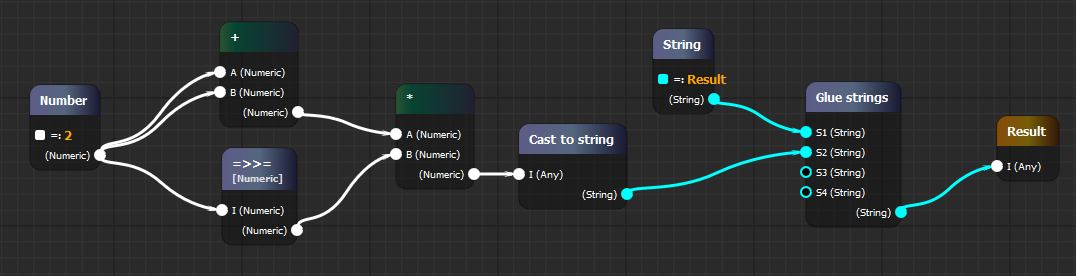

types:
# Всегда есть тип Any, который супер-родитель всех типов
Scalar:
Numeric:
extends: Scalar
String:
extends: Scalar
List:
typeParams: [A]
IfThenElse:
typeParams: [T]
in:
C: Boolean
out:
onTrue: @T
onFalse: @T
types:
# Всегда есть тип Any, который супер-родитель всех типов
Numeric:
color: "#fff"
components:
Literal: # Название компонента
attrs: # Атрибуты
V: Numeric
out: # Исходящие сокеты
O: Numeric
Plus:
in: # Входящие сокеты
A: Numeric
B: Numeric
out:
O: Numeric
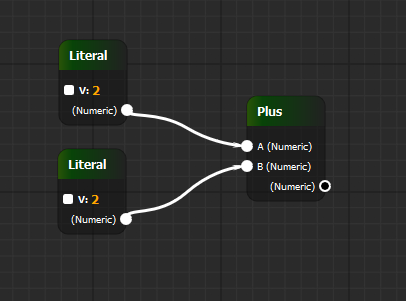
[
{
"id": 8,
"c": "Plus",
"links": {
"A": {
"id": 2,
"c": "Literal",
"a": {
"V": "2"
},
"links": {},
"out": "O"
},
"B": {
"id": 5,
"c": "Literal",
"a": {
"V": "2"
},
"links": {},
"out": "O"
}
}
}
]function walk(node) {
switch (node.c) {
case 'Literal':
return parseFloat(node.a.V);
case 'Plus':
return walk(node.links.A) + walk(node.links.B);
default:
throw new Error("Unsupported node component: " + node.component);
}
}
walk(tree);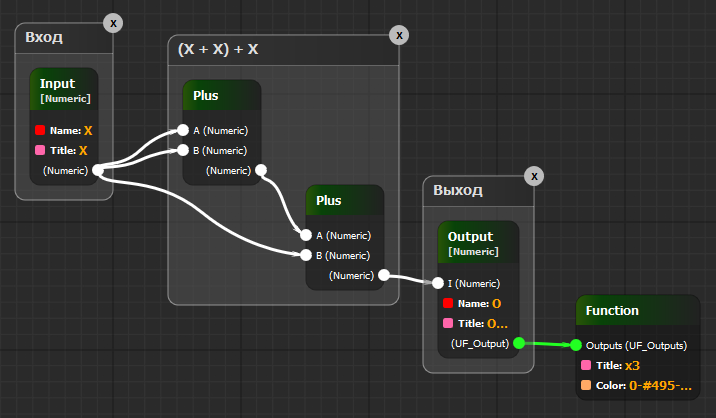

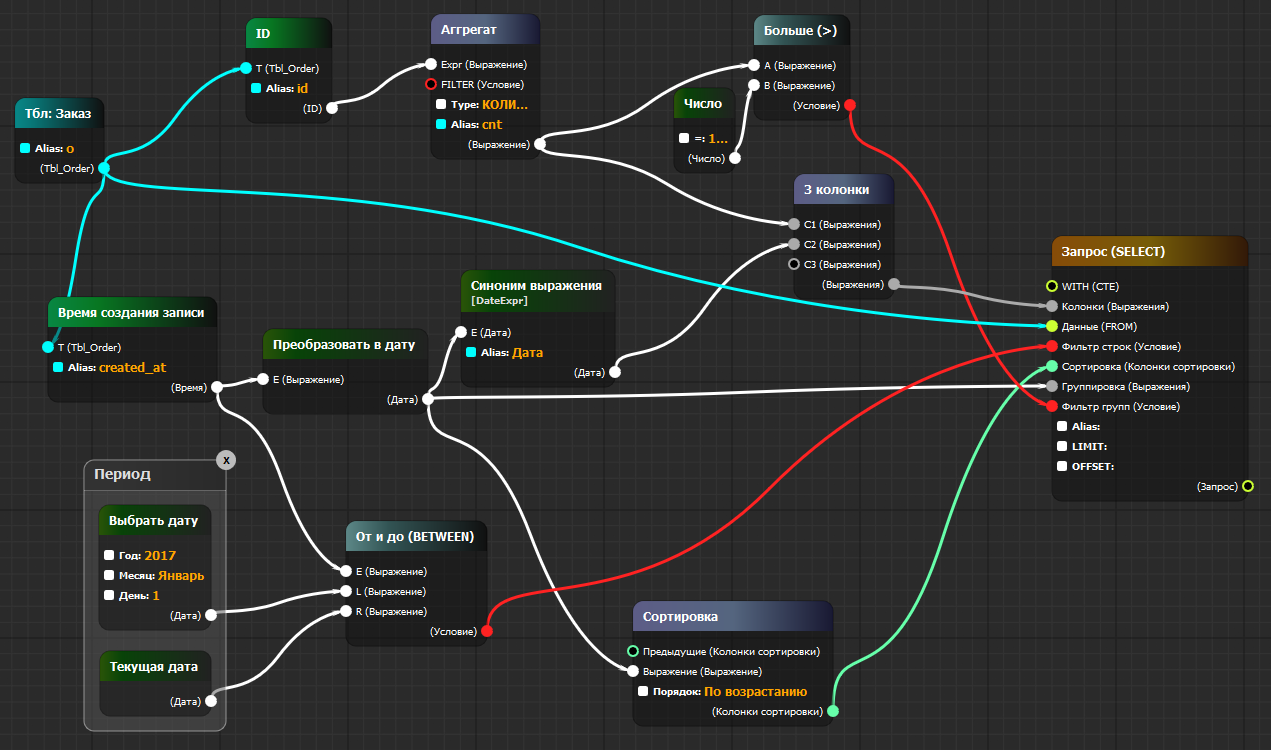
localStorage.clear()SELECT
COUNT(o.id) AS cnt
, (o.created_at)::DATE AS "Дата"
FROM tbl_order AS o
WHERE o.created_at BETWEEN '2017-1-1'::DATE AND CURRENT_DATE
GROUP BY (o.created_at)::DATE
HAVING ( COUNT(o.id) ) > ( 100 )
ORDER BY (o.created_at)::DATE ASCPlus:
typeParams: [T]
typeBounds: {T: {<: Expr}} # Параметризованный тип 'T' ограничен сверху типом 'Expr',
# что означает, что нам надо сюда передать наследник типа 'Expr'
in:
A: @T
B: @T
out:
O: @T
def Plus[T <: Expr](A: T, B: T): T = A + B|
Метки: author aveic программирование анализ и проектирование систем sql javascript визуальное программирование я пиарюсь raphael.js vax все взять и обобщить |
Как перейти от КЛАДР к ФИАС и ничего себе не сломать |
Дисклеймер:
Если вы совсем не поняли, что означают эти наборы букв, ничего страшного. Ниже мы расскажем о реалиях работы с адресами в России. Если вам это неинтересно, почитайте про топографические каламбуры.
Как вы думаете, какой государственный орган наиболее заинтересован в том, чтобы вы получали от него письма? Правильно! Налоговая. Поэтому ФНС России много лет разрабатывает и поддерживает ведомственные общероссийские классификаторы адресов. И так как более полных справочников нет, их стали использовать повсеместно.
Сначала был КЛАДР, и было в нем 6 уровней:
Регион -> Район -> Город -> Населенный пункт -> Улица -> Дом со строениями и корпусами
С 2012 года в эксплуатацию ввели новый классификатор — ФИАС. Про основные отличия мы писали три года назад в статье «ФИАС или КЛАДР: выбираем справочник адресов». В ФНС к разработке нового классификатора подошли основательнее и постарались учесть все грабли минусы КЛАДР. Из интересного добавили дату начала и окончания записи, ввели фиксированный ID для каждого дома (предполагается, что он не будет меняться).
До сих пор продолжают обновляться оба классификатора, но поддерживать совместимость становится сложнее. В прошлом году в ФИАС начали добавлять новые уровни. Например, планировочные структуры — это всякие дачные товарищества и микрорайоны, в классификаторе их уже больше 81 000. В конечном итоге в ФНС приняли логичное решение прекратить поддержку КЛАДР и удалить его в конце 2017 года.
То есть задача миграции сводится к тому, чтобы перевести код или текстовый адрес в формате КЛАДР в код ФИАС.
Классификационные коды выглядят так:
- КЛАДР: СС+РРР+ГГГ+ППП+УУУУ+ДДДД;
- ФИАС: СС+РРР+ГГГ+ППП+СССС+УУУУ+ДДДД (или ЗЗЗЗ)+ОООО.
| № | Уровень | Пример | код ФИАС | код КЛАДР |
| 1 | Регион | Ленинградская область | СС: 47 | СС: 47 |
| 2 | Автономный округ | |||
| 3 | Район | Всеволожский р-н | РРР: 005 | РРР: 005 |
| 4 | Город | ГГГ: 000 | ГГГ: 000 | |
| 5 | Внутригородская территория | |||
| 6 | Населенный пункт | деревня Кудрово | ||
| 65 | Планировочная структура | мкр Новый Оккервиль | ||
| 7 | Улица | УУУУ | УУУУ: 0023 | |
| 75 | Земельный участок | ЗЗЗЗ | ||
| 8 | Здание, сооружение, объект незавершенного строительства | ДДДД | ДДДД | |
| 9 | Помещение в пределах здания, сооружения | ОООО | ||
| 90 | Дополнительная территория | |||
| 91 | Подчинённые дополнительных территорий |

Будем использовать следующие колонки:
- код КЛАДР (PlainCode);
- наименование и тип текстом (FormalName и ShortName);
- актуальность объекта (CurrStatus);
- почтовый индекс (PostalCode);
- собственный и родительский идентификатор ФИАС (AoGuid и ParentGuid);
- уровень (AoLevel).
Шаг 1. Выделяем из кода КЛАДР код до улицы, то есть берем первые 15 цифр: 77000000000151900.
Шаг 2. Ищем код КЛАДР в поле PlainCode. Если нашлась одна запись, то сохраняем значение поля AoGuid и пропускаем следующий пункт. Но по нашему коду 770000000001519 находится три записи, нужна дополнительная проверка.
Шаг 3. Находим актуальную запись. Значение поля CurrStatus = 0 означает, что запись актуальна. Выбираем ее и сохраняем значение поля AoGuid. Идентификационный код ФИАС найден!
Но можно поступить еще проще и воспользоваться готовым сервисом. DaData.ru умеет подсказывать адреса в конкретных регионах, районах, городах и населенных пунктах. Понимает названия («Петергоф»), коды КЛАДР («7800000800000») и ФИАС («8f238984-812b-4bb1-850b-49749fb5c56d»).
Если адреса у вас хранятся одной строкой, вроде этой:
г Москва, улица Большая Коммунистическая, дом 3,то поздравляем, это самая интересная задача. Нужно писать свой адресный парсер, который будет разделять строку в формате КЛАДР на части, искать каждый ее компонент в ФИАС с учетом опечаток, сокращений, исторических названий и определять по ним ФИАС-код. Легче это сделать уже готовым адресным парсером. Как выбрать алгоритм для адресного фильтра, мы рассказывали раньше.
| Тип региона | Название региона | Тип улицы | Название улицы | Тип дома | Номер дома |
| г | Москва | улица | Коммунистическая Б. | дом | 3 |
Шаг 1. Берем название региона и ищем его в поле FormalName таблицы ADDROBJ.
FormalName = Москва ->
AoGuid = 0c5b2444-70a0-4932-980c-b4dc0d3f02b5
Шаг 2. Идем дальше по уровням вниз и ищем по FormalName с фиксированным родителем — найденным AoGuid на предыдущем шаге. В нашем случае уровни «город» и «населенный пункт» пустые, а следующий непустой уровень — улица.
ParentGuid = 0c5b2444-70a0-4932-980c-b4dc0d3f02b5,
FormalName = Коммунистическая Б. -> AoGuid=f77948dc-7bc8-42cb-979e-2c958d162d63
Шаг 3. Если дошли до улицы, то можно найти и дом. Для этого в таблице HOUSE ищем номер дома с фиксированным AoGuid улицы. ФИАС не полон домами, поэтому не расстраивайтесь, если нужный номер не найдется.
AoGuid = f77948dc-7bc8-42cb-979e-2c958d162d63,
дом номер 3 ->
HouseGuid = bce8be1f-f2f7-4cce-836e-08daac0b931e
| LEVEL | SCNAME | SOCRNAME | KOD_T_ST |
| 7 | тракт | Тракт | 727 |
| 7 | туп | Тупик | 728 |
| 7 | ул | Улица | 729 |
| 7 | уч-к | Участок | 730 |
| 7 | ф/х | Фермерское хозяйство | 789 |
| 7 | ферма | Ферма | 769 |
| 7 | х | Хутор | 758 |
| 7 | ш | Шоссе | 731 |
|
|
[Из песочницы] Asterisk func_odbc или странный ael |
[cid]
dsn=asterisk
readsql=SELECT cid FROM sipusers WHERE username = ${ARG1}
dsn=asterisk — Параметр DSN отвечает за подключение Asterisk к базе данных, указанной в файле /etc/odbc.ini. readsql=SELECT cid FROM sipusers WHERE username = ${ARG1} — нужный вам запрос sql, но с переменной._89. => {
Set(cid=${ODBC_cid(${CALLERID(num)})});
SET(CALLERID(num)=${cid});
SET(CALLERID(name)=${cid});
......
}
Set(cid=${ODBC_cid(${CALLERID(num)})}); - собственно это SELECT cid FROM sipusers WHERE username = ${CALLERID(num)})} , думаю пояснения излишни.
SET(CALLERID(num)=${cid}) - устанавливаем CALLERID(num)
SET(CALLERID(name)=${cid}) - CALLERID(name)[forward]
dsn=asterisk
readsql=SELECT numforward, `type` FROM call_forwarding WHERE number = ${ARG1} macro redirect(number, from){
Set(ARRAY(forward,type)=${ODBC_forward(${number})});
}
if (${EXISTS(${forward})}) {
switch(${type}) {
case all:
....
case noanswer:
....
case noanswer-worktime:
....
break;
default:
break;
}
hangup;
}
return;
};
Set(ARRAY(forward,type)=${ODBC_forward(${number})}); — мы получаем от запроса два параметра, следовательно, нам нужно использовать массив. if (${EXISTS(${forward})}) — если существует номер переадресации, то действуем дальше… switch(${type}) — определяем тип переадресации и в зависимости от нужного типа, делаем условия пере адресации. |
Метки: author agic asterisk odbc asterisk |
Сортировка пузырьком в коде Qualcomm |
#ifndef ABS
#define ABS(x) (((x) < 0) ? -(x) : (x))
#endif
/*==============================================================================
* Function: bubblesort
*
* Description: Subroutine for sorting 1-D array elements
*
* Parameters: double *x ---> input one-dimensional array
* int n ---> size of input array
* int *m ---> indices of sorted elements
*============================================================================*/
void bubblesort(double *x, int n, int *m)
{
int i, j, t1;
double t2;
for(i = 0; i < n; i++)
m[i] = i;
for(i = 0; i < n; i++) {
for(j = 0; j * bubblesort */
/*==============================================================================
* Function: absmax
*
* Description:
*
* Parameters: double *x ---> input one-dimensional array
* int n ---> size of input array
*============================================================================*/
double absmax(double *x, int n)
{
int j, *l;
int index = 0;
double *y;
l = (int *)malloc(n * sizeof(int));
if (NULL == l) {
CDBG("%s: Error mem alloc for l.\n", __func__);
return -1;
}
y = (double *)malloc(n * sizeof(double));
if (NULL == y) {
free(l);
CDBG("%s: Error mem alloc for y.\n", __func__);
return -1;
}
for(j = 0; j < n; j++)
y[j] = ABS(x[j]);
bubblesort(y, n, l);
index = l[0];
free(l);
free(y);
return ABS(x[index]);
}|
Метки: author HotWaterMusic программирование алгоритмы qualcomm qualcomm snapdragon пузырьковая сортировка |
A!Hack Summer — хакатон Альфа-Банка 5 и 6 августа 2017 |

 Первый хакатон мы делали в ноябре 2013-го, тогда еще само слово «Хакатон» не вошло в обиход и многим казалось смешным. В банковской среде практически не было культуры хакатонов, которую мы можем наблюдать сейчас.
Первый хакатон мы делали в ноябре 2013-го, тогда еще само слово «Хакатон» не вошло в обиход и многим казалось смешным. В банковской среде практически не было культуры хакатонов, которую мы можем наблюдать сейчас.|
|
Как работать с UX-подрядчиками? Опыт мессенджера «Ответ» |
|
Метки: author rebraining блог компании собака павлова прототипирование интерфейсы usability совместная работа подрядчики ux- команда ux |
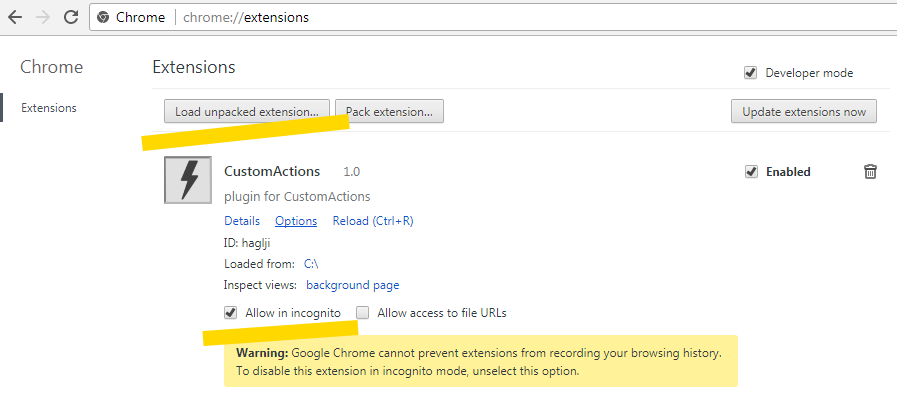
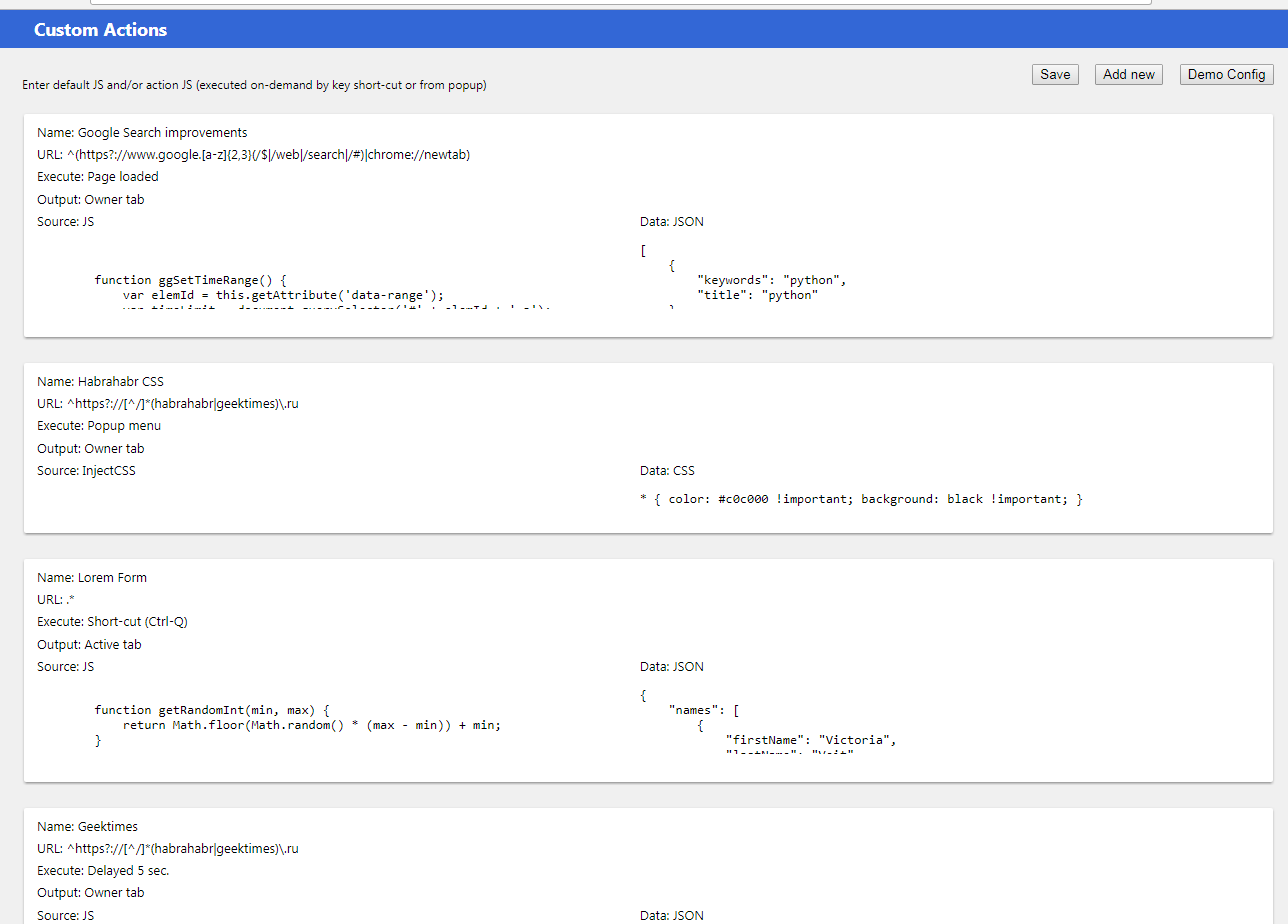
[Из песочницы] Пусть интернет прогнётся под нас |

options.html
options.js
popup.html
popup.js
background.js
manifest.json
icon.png
images
images\icon128.png
images\icon16.png
images\icon48.png
{
"name": "CustomActions",
"description": "plugin for CustomActions",
"version": "1.0",
"background" : {
"scripts": ["background.js"]
},
"icons":
{
"128": "images/icon128.png",
"16": "images/icon16.png",
"48": "images/icon48.png"
},
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'",
"permissions": [
"webRequest", "tabs", "activeTab", "http://*/*", "https://*/*", "storage", "unlimitedStorage", "contextMenus", ""
],
"browser_action": {
"default_title": "Custom Actions Injection plugin",
"default_icon": "icon.png",
"default_popup": "popup.html"
},
"commands": {
"cmd-exec-1": {
"suggested_key": {
"default": "Ctrl+Q"
},
"description": "Custom Action #1"
},
"cmd-exec-2": {
"suggested_key": {
"default": "Ctrl+B"
},
"description": "Custom Action #2"
},
"cmd-exec-3": {
"suggested_key": {
"default": "Ctrl+Y"
},
"description": "Custom Action #3"
}
},
"options_page": "options.html",
"manifest_version": 2
}
"content_security_policy": "script-src 'self' 'unsafe-eval'; object-src 'self'"
chrome.storage.local.set(items, function () {
self.status('Items saved.');
setTimeout(function () { self.status(''); }, 750);
});
chrome.storage.local.set(items, function () {
self.status('Items saved.');
setTimeout(function () { self.status(''); }, 750);
chrome.runtime.sendMessage({ command: 'refreshConfig' });
});
chrome.runtime.onMessage.addListener(
function (request, sender, sendResponse) {
onCommand(request.command);
});
chrome.tabs.onUpdated.addListener(function (tabId, changeInfo, tab) {
var url = '';
if (changeInfo && changeInfo.url)
url = changeInfo.url.toLowerCase();
else if (tab && tab.url)
url = tab.url.toLowerCase();
// . . .
});
if (item.sourceType == 'InjectCSS')
chrome.tabs.insertCSS(item.output == 'Owner tab' ? tabId : null, { code: item.data });
else
chrome.tabs.executeScript(item.output == 'Owner tab' ? tabId : null, { code: item.source });
chrome.contextMenus.create({ id: item.id,
contexts: ["page", "frame", "selection"],
title: item.name,
onclick: function (info, tab) {
onCommand(info.menuItemId);
}
});
"commands": {
"cmd-exec-1": {
"suggested_key": {
"default": "Ctrl+Q"
},
"description": "Custom Action #1"
}
}
chrome.commands.onCommand.addListener(onCommand);

var loremDemoData = {
names: [
{ firstName: "Victoria", lastName: "Veit", email: "Victoria.Veit@noreply.ru" },
{ firstName: "Gisele", lastName: "Gillard", email: "Gisele.Gillard@noreply.ru" },
{ firstName: "Edmund", lastName: "Edelson", email: "Edmund.Edelson@noreply.ru" },
{ firstName: "Joey", lastName: "Janelle", email: "Joey.Janelle@noreply.ru" }
],
lorem: [
"Orem ipsum dolor sit amet, consectetur adipiscing elit. Etiam sit amet purus condimentum, porta nulla sed, consequat felis. Phasellus quis condimentum odio. Maecenas scelerisque vehicula leo, sit amet tristique tellus molestie sed. Aenean lacus lorem, feugiat semper imperdiet a, vehicula ac orci. Pellentesque ac nisi commodo, pellentesque lorem quis, fringilla tellus. Fusce bibendum erat sit amet libero maximus rutrum. Integer dictum nibh sodales efficitur congue. Mauris nulla libero, hendrerit eget dictum nec, aliquam eu mi. Donec ipsum nisi, bibendum et consequat eu, imperdiet eget nisl. Duis tincidunt nibh et nibh tempor, quis mattis mi vulputate.",
"Suspendisse quis eleifend lectus. Sed nec vehicula elit. Praesent ac sollicitudin diam. Nam at venenatis lectus. Fusce condimentum tortor nec augue vestibulum tempus. Nullam faucibus vehicula lorem, et mollis justo dapibus a. Proin sagittis velit in lectus vehicula, id eleifend urna hendrerit. Integer rhoncus dui sed enim sollicitudin, a finibus magna fermentum.",
"Fusce at urna vitae magna semper scelerisque id volutpat tellus. Pellentesque habitant morbi tristique senectus et netus et malesuada fames ac turpis egestas. Sed ut elit nisl. Duis sit amet ante accumsan nibh ultricies pharetra at vitae purus. Donec a felis eget ipsum euismod tempus. Donec elementum vel tortor vel efficitur. Nunc tristique, magna hendrerit sagittis placerat, odio sem commodo ligula, eu aliquam arcu elit sit amet diam. Etiam ultrices vehicula auctor."
],
loremShort: [
"Morbi nec sollicitudin augue.",
"Suspendisse sagittis fringilla aliquam.",
"Curabitur malesuada dolor.",
"Praesent quis lacus neque. Duis vitae vehicula felis"
]
};
function getRandomInt(min, max) {
return Math.floor(Math.random() * (max - min)) + min;
}
var name = data.names[getRandomInt(0, data.names.length)];
var hadEmail = false;
var t = document.querySelectorAll('input[type=text], textarea');
for (var i = 0, l = t.length; i < l; i++) {
var e = t[i];
var ro = e.getAttribute('readonly');
if (e.disabled || ro === '' || ro === 'true' || ro == '1')
continue;
var loremTxt = data.lorem[getRandomInt(0, data.lorem.length)];
var loremShort = data.loremShort[getRandomInt(0, data.loremShort.length)];
var na = ('' + e.name).toLowerCase();
var ia = ('' + e.id).toLowerCase();
if (na == 'firstname' || ia == 'firstname' || na == 'fname' || ia == 'fname')
e.value = name.firstName;
else if (na == 'lastname' || ia == 'lastname' || na == 'lname' || ia == 'lname')
e.value = name.lastName;
else if (!hadEmail && (na.indexOf('email') >= 0 || ia.indexOf('email') >= 0)) {
e.value = name.email;
hadEmail = true;
} else {
e.value = (e.tagName == 'TEXTAREA' ? loremTxt : loremShort);
}
}
{
"showCompanies": [
"yandex",
"mosigra"
],
"hideCompanies": [
"hashflare"
],
"hideHubs": [
"lib"
]
}
function hideParent(el) {
if (el.classList && el.classList.contains('post_teaser'))
el.style.display = 'none';
else if (el.parentElement)
hideParent(el.parentElement);
}
function sanitizeParent(el) {
if (el.classList && el.classList.contains('post_teaser')) {
el.querySelectorAll('img').forEach(function (img) { img.style.display = 'none'; });
el.querySelectorAll('.post__body_crop').forEach(function (chld) {
chld.style.maxHeight = '4em';
chld.style.overflow = 'hidden';
el.addEventListener('mouseover', function () {
chld.style.maxHeight = "inherit"; chl
d.querySelectorAll('img').forEach(function (img) {
img.style.display = 'block';
});
}, false);
el.addEventListener('mouseout', function () {
chld.style.maxHeight = "4em";
chld.querySelectorAll('img').forEach(function (img) {
img.style.display = 'none';
});
}, false);
});
el.querySelectorAll('.post__title a').forEach(function (titl) { titl.style.color = '#707040'; });
} else if (el.parentElement)
sanitizeParent(el.parentElement);
}
document.querySelectorAll('a[href*="https://geektimes.ru/hub/"]').forEach(function (el) {
var hub = el.getAttribute('href').replace(/^.*\.ru\/hub\//, '').replace(/\/.*$/, '');
if (data && data.hideHubs && data.hideHubs.indexOf(hub) >= 0)
hideParent(el);
});
document.querySelectorAll('a[href*="https://geektimes.ru/company/"], a[href*="https://habrahabr.ru/company/"]').forEach(function (el) {
var company = el.getAttribute('href').replace(/^.*\.ru\/company\//, '').replace(/\/.*$/, '');
if (data) {
if (data.hideCompanies && data.hideCompanies.indexOf(company) >= 0) {
hideParent(el);
return;
} else if (data.showCompanies && data.showCompanies.indexOf(company) >= 0)
return;
}
sanitizeParent(el);
});
var googleDemoData = [
{ "keywords": "python", "title": "python" },
{ "keywords": "javascript", "title": "javascript" },
{ "keywords": "php", "title": "php" },
{ "keywords": "mysql", "title": "mysql" },
{ "keywords": "site:stackoverflow.com", "title": "at stackoverflow.com" },
{ "keywords": "site:developer.mozilla.org", "title": "at developer.mozilla.org" },
{ "keywords": "site:developer.chrome.com", "title": "at developer.chrome.com" },
{ "keywords": "site:habrahabr.ru", "title": "at habrahabr.ru" }
];
function ggSetTimeRange() {
var elemId = this.getAttribute('data-range');
var timeLimit = document.querySelector('#' + elemId + ' a');
if (timeLimit)
timeLimit.click();
}
function ggReplaceAndSearch() {
var kw = this.getAttribute('data-search');
if (document.location.href.indexOf('chrome-search://') == 0 || document.location.href.indexOf('https://www.google.com/_/chrome/newtab?') == 0) {
document.location.href = "https://www.google.com/search?q=" + encodeURIComponent(kw);
return;
}
var inputText = document.querySelector('input[name="q"]');
if (inputText) {
setTimeout(function () {
var keyword = '' + inputText.value;
if (kw.indexOf('site:') >= 0 && keyword.indexOf('site:') >= 0) {
keyword = keyword.replace(/ *site:[^ ]+/, '');
}
else if (keyword.indexOf(kw) >= 0)
return;
kw = ' ' + kw;
if (kw.indexOf('site:') >= 0) {
inputText.value = keyword + ' ' + kw;
setTimeout(function () {
var btn = document.querySelector('form[action="/search"]');
if (btn) {
btn.submit();
} else {
btn = document.querySelector('button[name="btnK"]');
if (btn) {
btn.click();
}
}
}, 100);
}
else {
inputText.value = kw + ' ' + keyword;
var strLength = ('' + inputText.value).length;
inputText.setSelectionRange(strLength, strLength);
}
}, 200);
setTimeout(function () {
inputText.focus();
}, 100);
};
};
var ggHelper = document.getElementById('ggHelper');
if (!ggHelper) {
var helperHtml = '' +
'';
data.forEach(function(dataItem ) {
helperHtml += '- ' + dataItem.title + '
';
});
helperHtml += '
- ' +
'week :: ' +
'month :: ' +
'year :: ' +
'any
';
helperHtml += '
';
var bodyTag = document.querySelector('body');
if (bodyTag) {
var e = document.createElement('div');
e.innerHTML = helperHtml;
bodyTag.appendChild(e.firstChild);
document.querySelectorAll('#ggHelper .gg-keyword').forEach(function (el) {
el.addEventListener('click', ggReplaceAndSearch);
});
document.querySelectorAll('#ggHelper .gg-range').forEach(function (el) {
el.addEventListener('click', ggSetTimeRange);
});
}
}
|
Метки: author ntpetrova javascript google chrome плагин браузеры интернет |
Особенности национальной SMS-авторизации |

Я не уверен, что там применяется фильтрация. Возможно речь идёт о том, что это т.н. A2P-сообщения, по которым заключается межоператорское соглашение. Если такого прямого контракта между сервисом и оператором нет, или нет соглашения с SMS-агрегатором, или контракт прекратил действие, то оператор может не пропускать такие сообщения. Это как один из вариантов. Чтобы СМС как-то фильтровались — таких данных у меня нет. Но если есть подтверждение от оператора, что смс отправлено на другого оператора, то можно отследить шлейф. Должна быть транзакция отправки смс на СМС-Центр.
Полагаю, правильнее всего составить техническую заявку, приложить данные исходящего оператора об СМС и запросить решения от оператора. Оператор либо подтвердит, что не пропускает по какой-то причине, либо скажет, что смс не приходила. Тогда только вариант искать по шлейфу.

Отказ лица, осуществляющего предпринимательскую или иную приносящую доход деятельность, от заключения публичного договора при наличии возможности предоставить потребителю соответствующие товары, услуги, выполнить для него соответствующие работы не допускается.Но потом я вспомнил, что у меня имеется то самое соглашение, оформленное в 2015 году, в котором черным по белому прописано обязательство сервиса отправлять SMS-пароли на тот самый номер. Разумеется, в том же соглашении был прописан и ряд исключений, включая наличие форс-мажорных обстоятельств, но, на мой взгляд, самодурство подрядчика на форс-мажор как-то не тянуло.
|
Метки: author pragmatik тестирование веб-сервисов тестирование it-систем информационная безопасность анализ и проектирование систем sms sms- сервис сервисы авторизация |
Выбранный UI-фреймворк – вред. Архитектурные требования – профит |



|
Метки: author dnovozhilov программирование reactjs javascript angularjs блог компании netcracker netcracker ui framework архитектура web- разработка |
Быстрое восстановление данных. Схема бабочки для регенерирующих кодов |
|
|
Автоматическое создание миграций Liquibase для PostgreSQL |

$ mkdir /tmp/migration
$ cd /tmp/migration/
$ createdb dbdev
$ createdb dbprod
$ wget https://jdbc.postgresql.org/download/postgresql-42.1.3.jar
$ wget https://github.com/liquibase/liquibase/releases/download/liquibase-parent-3.4.2/liquibase-3.4.2-bin.tar.gz
$ wget http://pgcodekeeper.ru/cli/release/pgCodeKeeper-cli-3.11.4.201707170702.zip
$ tar xzvf liquibase-3.4.2-bin.tar.gz
$ unzip pgCodeKeeper-cli-3.11.4.201707170702.zip
driver: org.postgresql.Driver
classpath: ./postgresql-42.1.3.jar
url: jdbc:postgresql:dbprod
username: user
password: topsecret
changeLogFile: db.changelog.xml
$ ./liquibase status
ags@jdbc:postgresql:dbprod is up to date
Liquibase 'status' Successful
$ ./pgcodekeeper-cli.sh jdbc:postgresql:dbdev jdbc:postgresql:dbprod[ags@saushkin-ag:/tmp/migration] $ psql dbdev
psql (9.6.3, сервер 9.5.7)
Введите "help", чтобы получить справку.
(ags@[local]:5432) 16:08:43 [dbdev] =# create table users (id serial primary key, name text);
CREATE TABLE
Время: 20,708 мс
(ags@[local]:5432) 16:09:16 [dbdev] * =# commit;
COMMIT
Время: 6,913 мс
$ ./pgcodekeeper-cli.sh jdbc:postgresql:dbdev jdbc:postgresql:dbprod
CREATE SEQUENCE users_id_seq
START WITH 1
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
ALTER SEQUENCE users_id_seq OWNER TO ags;
CREATE TABLE users (
id integer DEFAULT nextval('users_id_seq'::regclass) NOT NULL,
name text
);
ALTER TABLE users OWNER TO ags;
ALTER TABLE users
ADD CONSTRAINT users_pkey PRIMARY KEY (id);
ALTER SEQUENCE users_id_seq
OWNED BY users.id;
#!/bin/bash
FILENAME=${1:-changeset.sql}
# Заголовок файла миграции
echo "--liquibase formatted sql" > $FILENAME
echo "--changeset $USER:$FILENAME" >> $FILENAME
echo "" >> $FILENAME
# Создаем секцию наката
./pgcodekeeper-cli.sh jdbc:postgresql:dbdev jdbc:postgresql:dbprod >> $FILENAME
echo "" >> $FILENAME
# Создаем секцию отката (базы данных идут в обратном порядке)
./pgcodekeeper-cli.sh jdbc:postgresql:dbprod jdbc:postgresql:dbdev | sed -e 's/^/--rollback /' >> $FILENAME
./pgcodekeeper-cli.sh jdbc:postgresql:dbdev jdbc:postgresql:dbprod >> $FILENAME./pgcodekeeper-cli.sh jdbc:postgresql:dbprod jdbc:postgresql:dbdev | sed -e 's/^/--rollback /' >> $FILENAME
$ chmod +x ./migrate.sh
$ ./migrate.sh /dev/stdout
--liquibase formatted sql
--changeset ags:/dev/stdout
CREATE SEQUENCE users_id_seq
START WITH 1
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
ALTER SEQUENCE users_id_seq OWNER TO ags;
CREATE TABLE users (
id integer DEFAULT nextval('users_id_seq'::regclass) NOT NULL,
name text
);
ALTER TABLE users OWNER TO ags;
ALTER TABLE users
ADD CONSTRAINT users_pkey PRIMARY KEY (id);
ALTER SEQUENCE users_id_seq
OWNED BY users.id;
--rollback ALTER TABLE users
--rollback DROP CONSTRAINT users_pkey;
--rollback
--rollback DROP TABLE users;
--rollback
$ ./migrate.sh 001_users.sql
$ ./liquibase tag 001_before_users
Successfully tagged ags@jdbc:postgresql:dbprod
Liquibase 'tag' Successful
$ ./liquibase migrate
Liquibase Update Successful
$ ./liquibase status
ags@jdbc:postgresql:dbprod is up to date
Liquibase 'status' Successful
$ ./liquibase rollback 001_before_users
Liquibase Rollback Successful
$ ./liquibase status
1 change sets have not been applied to ags@jdbc:postgresql:dbprod
Liquibase 'status' Successful
$ ./liquibase migrate
Liquibase Update Successful
$ ./pgcodekeeper-cli.sh jdbc:postgresql:dbdev jdbc:postgresql:dbprod
ALTER TABLE databasechangeloglock
DROP CONSTRAINT pk_databasechangeloglock;
DROP TABLE databasechangeloglock;
DROP TABLE databasechangelog;
$ cat .pgcodekeeperignore
SHOW ALL
HIDE REGEX "databasechangelog.*"$ ./pgcodekeeper-cli.sh -I .pgcodekeeperignore jdbc:postgresql:dbdev jdbc:postgresql:dbprod|
Метки: author asaushkin sql postgresql базы данных continuous delivery liquibase pgcodekeeper |
Google планирует представить облачный сервис для квантовых вычислений |
 / фото Spiros Vathis CC
/ фото Spiros Vathis CC|
Метки: author it_man высокая производительность блог компании ит-град ит-град квантовые вычисления google |






