Абстракция сетевого слоя с применением «стратегий» |
От всех моих предыдущих реализаций сетевого слоя осталось впечатление, что есть еще куда расти. Данная публикация ставит целью привести один из вариантов архитектурного решения по построению сетевого слоя приложения. Речь пойдет не об очередном способе использования очередного сетевого фреймворка.
Для начала из публикации 21 Amazing Open Source iOS Apps Written in Swift взято приложение Artsy. В нем используется популярный фреймворк Moya, на базе которого и построен весь сетевой слой. Отмечу ряд основных недостатков, которые встретил в данном проекте и часто встречаю в других приложениях и публикациях.
let endpoint: ArtsyAPI = ArtsyAPI.activeAuctions
provider.request(endpoint)
.filterSuccessfulStatusCodes()
.mapJSON()
.mapTo(arrayOf: Sale.self)Разработчик этим кодом обозначил некую логическую цепочку, в которой ответ на запрос activeAuctions преобразуется в массив объектов Sale. При повторном использовании этого запроса в других ViewModel или ViewController разработчику придется копировать запрос вместе с цепочкой преобразования ответа. Чтобы избежать копирования повторяющейся логики преобразования, запрос и ответ можно связать неким контрактом, который будет описан ровно один раз.
Часто для работы с сетью используются фреймворки Alamofire, Moya и др. В идеале приложение должно минимально зависеть от этих фреймворков. Если в поиске по репозитоию Artsy набрать import Moya, то можно увидеть десятки совпадений. Если вдруг проект решит отказаться от использования Moya — очень много кода придется рефакторить.
Не сложно оценить, на сколько каждый проект зависит от сетевого фреймворка, если убрать эту зависимость и попробовать доработать приложение до работоспособного состояния.
Возможным выходом из ситуации с зависимостями будет создание специального класса, который будет один знать о фреймворках и обо всех возможных способах получить данные из сети. Эти способы будут описаны функциями со строго типизированными входящими и исходящими параметрами, что в свою очередь будет являться контрактом, упомянутом выше, и поможет справиться с проблемой повторов цепочек преобразования ответа. Такой подход тоже достаточно часто встречается. Его применение на практике можно также найти в приложениях из списка 21 Amazing Open Source iOS Apps Written in Swift. Например, в приложении DesignerNewsApp. Выглядит такой класс следующим образом:
struct DesignerNewsService {
static func storiesForSection(..., response: ([Story]) -> ()) {
// parameters
Alamofire.request(...).response { _ in
// parsing
}
}
static func loginWithEmail(..., response: (token: String?) -> ()) {
// parameters
Alamofire.request(...).response { _ in
// parsing
}
}
}У такого подхода также есть минусы. Количество обязанностей, возложенных на этот класс больше, чем того требует принцип единственной ответственности. Его придется менять при смене способа выполнения запросов (замена Alamofire), при смене фреймворка для парсинга, при изменении параметров запроса. Кроме того, такой класс может перерасти в god object или использоваться как singleton со всеми вытекающими последствиями.
Вам знакомо то чувство уныния, когда нужно интегрировать проект с очередным RESTful API? Это когда в очередной раз нужно создавать какой-нибудь APIManager и наполнять его Alamofire запросами… (ссылка)
Учитывая все недостатки, описанные в 1-й части публикации, я сформулировал для себя ряд требований к будущему слою работы с сетью:
Что получилось в итоге:
Протокол ApiTarget определяет все данные, которые необходимы для формирования запроса (параметры, путь, метод… и др.)
protocol ApiTarget {
var parameters: [String : String] { get }
}Обобщенный протокол ApiResponseConvertible определяет способ преобразования полученного объекта (в данном случае Data) в объект связанного типа.
protocol ApiResponseConvertible {
associatedtype ResultType
func map(data: Data) throws -> ResultType
}Протокол ApiService определяет способ отправки запросов. Обычно функция, объявленная в протоколе, принимает замыкание содержащее объект ответа и возможные ошибки. В текущей реализации функция возвращает Observable — объект реактивного фреймворка RxSwift.
protocol ApiService: class {
func request(with target: T) -> Observable where T: ApiResponseConvertible, T: ApiTarget
} Стратегией я называю упомянутый в начале публикации контракт, который связывает между собой несколько типов данных. Стратегия является протоколом и выглядит в самом простом случае таким образом:
protocol Strategy {
associatedtype ObjectType
associatedtype ResultType
}Для нужд сетевого слоя стратегия должна уметь создавать объект, который можно передать в экземпляр класса, соответствующего протоколу ApiService. Добавим функцию создания объекта в протокол ApiStrategy.
protocol ApiStrategy {
associatedtype ObjectType
associatedtype ResultType
static func target(with object: ObjectType) -> AnyTarget
} Введение новой универсальной структуры AnyTarget обусловленно тем, что мы не можем использовать обобщенный протокол ApiResponseConvertible в качестве типа возвращаемого функцией объекта, потому что у протокола есть связанный тип.
struct AnyTarget: ApiResponseConvertible, ApiTarget {
private let _map: (Data) throws -> T
let parameters: [String : String]
init(with target: U) where U: ApiResponseConvertible, U: ApiTarget, U.ResultType == T {
_map = target.map
parameters = target.parameters
}
func map(data: Data) throws -> T {
return try _map(data)
}
} Вот так выглядит самая примитивная реализация стратегии:
struct SimpleStrategy: ApiStrategy {
typealias ObjectType = Int
typealias ResultType = String
static func target(with object: Int) -> AnyTarget {
let target = Target(value: object)
return AnyTarget(with: target)
}
}
private struct Target {
let value: Int
}
extension Target: ApiTarget {
var parameters: [String : String] {
return [:]
}
}
extension Target: ApiResponseConvertible {
public func map(data: Data) throws -> String {
return "\(value)" // map value from data
}
} Стоит отметить, что структура Target является приватной, т.к. за пределами файла использоваться она не будет. Она нужна лишь для инициализации универсальной структуры AnyTarget.
Преобразование объекта тоже происходит в рамках файла, поэтому ApiService не будет ничего знать об инструментах, используемых при парсинге.
let service: ApiService = ...
let target = SimpleStrategy.target(with: ...)
let request = service.request(with: target)Стратегия подскажет, какой объект нужен для осуществления запроса и какой объект будет на выходе. Все строго типизировано стратегией и не требуется указывать типы как в случае с универсальными функциями.
Как можно было заметить, в данном подходе сетевой фреймворк остался за пределами основной логики построения сервиса. На первых порах его можно не использовать совсем. Например, если в реализации функции map протокола ApiResponseConvertible возвращать mock-объект, то сервис может быть совсем примитивным классом:
class MockService: ApiService {
func request(with target: T) -> Observable where T : ApiResponseConvertible, T : ApiTarget {
return Observable
.just(Data())
.map({ [map = target.map] (data) -> T.ResultType in
return try map(data)
})
}
} Тестовую реализацию и применение протокола ApiService на базе реального сетевого фреймворка Moya можно посмотреть спойлере:
public extension Api {
public class Service {
public enum Kind {
case failing(Api.Error)
case normal
case test
}
let kind: Api.Service.Kind
let logs: Bool
fileprivate lazy var provider: MoyaProvider = self.getProvider()
public init(kind: Api.Service.Kind, logs: Bool) {
self.kind = kind
self.logs = logs
}
fileprivate func getProvider() -> MoyaProvider {
return MoyaProvider(
stubClosure: stubClosure,
plugins: plugins
)
}
private var plugins: [PluginType] {
return logs ? [RequestPluginType()] : []
}
private func stubClosure(_ target: Target) -> Moya.StubBehavior {
switch kind {
case .failing, .normal:
return Moya.StubBehavior.never
case .test:
return Moya.StubBehavior.immediate
}
}
}
}
extension Api.Service: ApiService {
public func dispose() {
//
}
public func request(headers: [Api.Header: String], scheduler: ImmediateSchedulerType, target: T) -> Observable where T: ApiResponseConvertible, T: ApiTarget {
switch kind {
case .failing(let error):
return Observable.error(error)
default:
return Observable
.just((), scheduler: scheduler)
.map({ [weak self] _ -> MoyaProvider? in
return self?.provider
})
.filterNil()
.flatMap({ [headers, target] provider -> Observable in
let api = Target(headers: headers, target: target)
return provider.rx
.request(api)
.asObservable()
})
.map({ [map = target.map] (response: Moya.Response) -> T.ResultType in
switch response.statusCode {
case 200:
return try map(response.data)
case 401:
throw Api.Error.invalidToken
case 404:
do {
let json: JSON = try response.data.materialize()
let message: String = try json["ErrorMessage"].materialize()
throw Api.Error.failedWithMessage(message)
} catch let error {
if case .some(let error) = error as? Api.Error, case .failedWithMessage = error {
throw error
} else {
throw Api.Error.failedWithMessage(nil)
}
}
case 500:
throw Api.Error.serverInteralError
case 501:
throw Api.Error.appUpdateRequired
default:
throw Api.Error.unknown(nil)
}
})
.catchError({ (error) -> Observable in
switch error as? Api.Error {
case .some(let error):
return Observable.error(error)
default:
let error = Api.Error.unknown(error)
return Observable.error(error)
}
})
}
}
} func observableRequest(_ observableCancel: Observable, _ observableTextPrepared: Observable) -> Observable> {
let factoryApiService = base.factoryApiService
let factoryIndicator = base.factoryIndicator
let factorySchedulerConcurrent = base.factorySchedulerConcurrent
return observableTextPrepared
.observeOn(base.factorySchedulerConcurrent())
.flatMapLatest(observableCancel: observableCancel, observableFactory: { (text) -> Observable> in
return Observable
.using(factoryApiService) { (service: Api.Service) -> Observable> in
let object = Api.Request.Categories.Name(text: text)
let target = Api.Strategy.Categories.Auto.target(with: object)
let headers = [Api.Header.authorization: ""]
let request = service
.request(headers: headers, scheduler: factorySchedulerConcurrent(), target: target)
.map({ Objects(text: text, manual: true, objects: $0) })
.map({ Result(value: $0) })
.shareReplayLatestWhileConnected()
switch factoryIndicator() {
case .some(let activityIndicator):
return request.trackActivity(activityIndicator)
default:
return request
}
}
.catchError({ (error) -> Observable> in
switch error as? Api.Error {
case .some(let error):
return Observable.just(Result(error: error))
default:
return Observable.just(Result(error: Api.Error.unknown(nil)))
}
})
})
.observeOn(base.factorySchedulerConcurrent())
.shareReplayLatestWhileConnected()
} Полученный сетевой слой сможет успешно существовать и без стратегий. Точно так же стратегии можно использовать для других целей и задач. Совместное же их использование сделало использование сетевого слоя удобным и понятным.
|
Метки: author iWheelBuy разработка под ios swift ios rxswift moya alamofire solid dry srp xcode |
Абстракция сетевого слоя с применением «стратегий» |
От всех моих предыдущих реализаций сетевого слоя осталось впечатление, что есть еще куда расти. Данная публикация ставит целью привести один из вариантов архитектурного решения по построению сетевого слоя приложения. Речь пойдет не об очередном способе использования очередного сетевого фреймворка.
Для начала из публикации 21 Amazing Open Source iOS Apps Written in Swift взято приложение Artsy. В нем используется популярный фреймворк Moya, на базе которого и построен весь сетевой слой. Отмечу ряд основных недостатков, которые встретил в данном проекте и часто встречаю в других приложениях и публикациях.
let endpoint: ArtsyAPI = ArtsyAPI.activeAuctions
provider.request(endpoint)
.filterSuccessfulStatusCodes()
.mapJSON()
.mapTo(arrayOf: Sale.self)Разработчик этим кодом обозначил некую логическую цепочку, в которой ответ на запрос activeAuctions преобразуется в массив объектов Sale. При повторном использовании этого запроса в других ViewModel или ViewController разработчику придется копировать запрос вместе с цепочкой преобразования ответа. Чтобы избежать копирования повторяющейся логики преобразования, запрос и ответ можно связать неким контрактом, который будет описан ровно один раз.
Часто для работы с сетью используются фреймворки Alamofire, Moya и др. В идеале приложение должно минимально зависеть от этих фреймворков. Если в поиске по репозитоию Artsy набрать import Moya, то можно увидеть десятки совпадений. Если вдруг проект решит отказаться от использования Moya — очень много кода придется рефакторить.
Не сложно оценить, на сколько каждый проект зависит от сетевого фреймворка, если убрать эту зависимость и попробовать доработать приложение до работоспособного состояния.
Возможным выходом из ситуации с зависимостями будет создание специального класса, который будет один знать о фреймворках и обо всех возможных способах получить данные из сети. Эти способы будут описаны функциями со строго типизированными входящими и исходящими параметрами, что в свою очередь будет являться контрактом, упомянутом выше, и поможет справиться с проблемой повторов цепочек преобразования ответа. Такой подход тоже достаточно часто встречается. Его применение на практике можно также найти в приложениях из списка 21 Amazing Open Source iOS Apps Written in Swift. Например, в приложении DesignerNewsApp. Выглядит такой класс следующим образом:
struct DesignerNewsService {
static func storiesForSection(..., response: ([Story]) -> ()) {
// parameters
Alamofire.request(...).response { _ in
// parsing
}
}
static func loginWithEmail(..., response: (token: String?) -> ()) {
// parameters
Alamofire.request(...).response { _ in
// parsing
}
}
}У такого подхода также есть минусы. Количество обязанностей, возложенных на этот класс больше, чем того требует принцип единственной ответственности. Его придется менять при смене способа выполнения запросов (замена Alamofire), при смене фреймворка для парсинга, при изменении параметров запроса. Кроме того, такой класс может перерасти в god object или использоваться как singleton со всеми вытекающими последствиями.
Вам знакомо то чувство уныния, когда нужно интегрировать проект с очередным RESTful API? Это когда в очередной раз нужно создавать какой-нибудь APIManager и наполнять его Alamofire запросами… (ссылка)
Учитывая все недостатки, описанные в 1-й части публикации, я сформулировал для себя ряд требований к будущему слою работы с сетью:
Что получилось в итоге:
Протокол ApiTarget определяет все данные, которые необходимы для формирования запроса (параметры, путь, метод… и др.)
protocol ApiTarget {
var parameters: [String : String] { get }
}Обобщенный протокол ApiResponseConvertible определяет способ преобразования полученного объекта (в данном случае Data) в объект связанного типа.
protocol ApiResponseConvertible {
associatedtype ResultType
func map(data: Data) throws -> ResultType
}Протокол ApiService определяет способ отправки запросов. Обычно функция, объявленная в протоколе, принимает замыкание содержащее объект ответа и возможные ошибки. В текущей реализации функция возвращает Observable — объект реактивного фреймворка RxSwift.
protocol ApiService: class {
func request(with target: T) -> Observable where T: ApiResponseConvertible, T: ApiTarget
} Стратегией я называю упомянутый в начале публикации контракт, который связывает между собой несколько типов данных. Стратегия является протоколом и выглядит в самом простом случае таким образом:
protocol Strategy {
associatedtype ObjectType
associatedtype ResultType
}Для нужд сетевого слоя стратегия должна уметь создавать объект, который можно передать в экземпляр класса, соответствующего протоколу ApiService. Добавим функцию создания объекта в протокол ApiStrategy.
protocol ApiStrategy {
associatedtype ObjectType
associatedtype ResultType
static func target(with object: ObjectType) -> AnyTarget
} Введение новой универсальной структуры AnyTarget обусловленно тем, что мы не можем использовать обобщенный протокол ApiResponseConvertible в качестве типа возвращаемого функцией объекта, потому что у протокола есть связанный тип.
struct AnyTarget: ApiResponseConvertible, ApiTarget {
private let _map: (Data) throws -> T
let parameters: [String : String]
init(with target: U) where U: ApiResponseConvertible, U: ApiTarget, U.ResultType == T {
_map = target.map
parameters = target.parameters
}
func map(data: Data) throws -> T {
return try _map(data)
}
} Вот так выглядит самая примитивная реализация стратегии:
struct SimpleStrategy: ApiStrategy {
typealias ObjectType = Int
typealias ResultType = String
static func target(with object: Int) -> AnyTarget {
let target = Target(value: object)
return AnyTarget(with: target)
}
}
private struct Target {
let value: Int
}
extension Target: ApiTarget {
var parameters: [String : String] {
return [:]
}
}
extension Target: ApiResponseConvertible {
public func map(data: Data) throws -> String {
return "\(value)" // map value from data
}
} Стоит отметить, что структура Target является приватной, т.к. за пределами файла использоваться она не будет. Она нужна лишь для инициализации универсальной структуры AnyTarget.
Преобразование объекта тоже происходит в рамках файла, поэтому ApiService не будет ничего знать об инструментах, используемых при парсинге.
let service: ApiService = ...
let target = SimpleStrategy.target(with: ...)
let request = service.request(with: target)Стратегия подскажет, какой объект нужен для осуществления запроса и какой объект будет на выходе. Все строго типизировано стратегией и не требуется указывать типы как в случае с универсальными функциями.
Как можно было заметить, в данном подходе сетевой фреймворк остался за пределами основной логики построения сервиса. На первых порах его можно не использовать совсем. Например, если в реализации функции map протокола ApiResponseConvertible возвращать mock-объект, то сервис может быть совсем примитивным классом:
class MockService: ApiService {
func request(with target: T) -> Observable where T : ApiResponseConvertible, T : ApiTarget {
return Observable
.just(Data())
.map({ [map = target.map] (data) -> T.ResultType in
return try map(data)
})
}
} Тестовую реализацию и применение протокола ApiService на базе реального сетевого фреймворка Moya можно посмотреть спойлере:
public extension Api {
public class Service {
public enum Kind {
case failing(Api.Error)
case normal
case test
}
let kind: Api.Service.Kind
let logs: Bool
fileprivate lazy var provider: MoyaProvider = self.getProvider()
public init(kind: Api.Service.Kind, logs: Bool) {
self.kind = kind
self.logs = logs
}
fileprivate func getProvider() -> MoyaProvider {
return MoyaProvider(
stubClosure: stubClosure,
plugins: plugins
)
}
private var plugins: [PluginType] {
return logs ? [RequestPluginType()] : []
}
private func stubClosure(_ target: Target) -> Moya.StubBehavior {
switch kind {
case .failing, .normal:
return Moya.StubBehavior.never
case .test:
return Moya.StubBehavior.immediate
}
}
}
}
extension Api.Service: ApiService {
public func dispose() {
//
}
public func request(headers: [Api.Header: String], scheduler: ImmediateSchedulerType, target: T) -> Observable where T: ApiResponseConvertible, T: ApiTarget {
switch kind {
case .failing(let error):
return Observable.error(error)
default:
return Observable
.just((), scheduler: scheduler)
.map({ [weak self] _ -> MoyaProvider? in
return self?.provider
})
.filterNil()
.flatMap({ [headers, target] provider -> Observable in
let api = Target(headers: headers, target: target)
return provider.rx
.request(api)
.asObservable()
})
.map({ [map = target.map] (response: Moya.Response) -> T.ResultType in
switch response.statusCode {
case 200:
return try map(response.data)
case 401:
throw Api.Error.invalidToken
case 404:
do {
let json: JSON = try response.data.materialize()
let message: String = try json["ErrorMessage"].materialize()
throw Api.Error.failedWithMessage(message)
} catch let error {
if case .some(let error) = error as? Api.Error, case .failedWithMessage = error {
throw error
} else {
throw Api.Error.failedWithMessage(nil)
}
}
case 500:
throw Api.Error.serverInteralError
case 501:
throw Api.Error.appUpdateRequired
default:
throw Api.Error.unknown(nil)
}
})
.catchError({ (error) -> Observable in
switch error as? Api.Error {
case .some(let error):
return Observable.error(error)
default:
let error = Api.Error.unknown(error)
return Observable.error(error)
}
})
}
}
} func observableRequest(_ observableCancel: Observable, _ observableTextPrepared: Observable) -> Observable> {
let factoryApiService = base.factoryApiService
let factoryIndicator = base.factoryIndicator
let factorySchedulerConcurrent = base.factorySchedulerConcurrent
return observableTextPrepared
.observeOn(base.factorySchedulerConcurrent())
.flatMapLatest(observableCancel: observableCancel, observableFactory: { (text) -> Observable> in
return Observable
.using(factoryApiService) { (service: Api.Service) -> Observable> in
let object = Api.Request.Categories.Name(text: text)
let target = Api.Strategy.Categories.Auto.target(with: object)
let headers = [Api.Header.authorization: ""]
let request = service
.request(headers: headers, scheduler: factorySchedulerConcurrent(), target: target)
.map({ Objects(text: text, manual: true, objects: $0) })
.map({ Result(value: $0) })
.shareReplayLatestWhileConnected()
switch factoryIndicator() {
case .some(let activityIndicator):
return request.trackActivity(activityIndicator)
default:
return request
}
}
.catchError({ (error) -> Observable> in
switch error as? Api.Error {
case .some(let error):
return Observable.just(Result(error: error))
default:
return Observable.just(Result(error: Api.Error.unknown(nil)))
}
})
})
.observeOn(base.factorySchedulerConcurrent())
.shareReplayLatestWhileConnected()
} Полученный сетевой слой сможет успешно существовать и без стратегий. Точно так же стратегии можно использовать для других целей и задач. Совместное же их использование сделало использование сетевого слоя удобным и понятным.
|
Метки: author iWheelBuy разработка под ios swift ios rxswift moya alamofire solid dry srp xcode |
learnopengl. Уроки 3.1(Assimp) + 3.2(класс Mesh) |

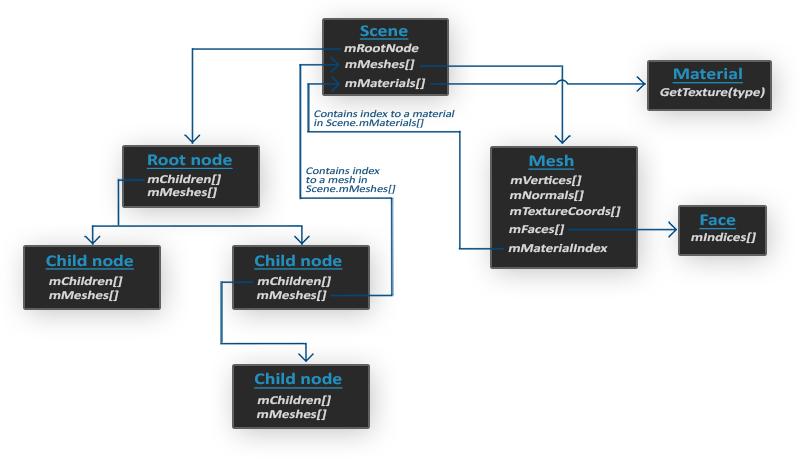
Mesh — набор вершин и треугольников
Одна сетка (Mesh) — это минимальный набор данных, необходимый для вывода средствами OpenGL(данные вершин, индексов, материала). Модель же, обычно, состоит из нескольких сеток. При моделировании объектов в специальных программах(Blender, 3D max), художники не создают целую модель из одной формы. Обычно, каждая модель имеет несколько под-моделей\форм, из которых она состоит. Подумайте о человеке, как о модели: художник обычно моделирует голову, конечности, одежду, оружие, все как отдельные компоненты, затем объединив все под-модели, получает исходную.
Если вы хотите использовать многопоточность для увеличения производительности, вы можете собрать Assimp с Boost. Полная инструкция находится здесь.
struct Vertex {
glm::vec3 Position;
glm::vec3 Normal;
glm::vec2 TexCoords;
};struct Texture {
unsigned int id;
string type;
}; class Mesh {
public:
/* Mesh Data */
vector vertices;
vector indices;
vector textures;
/* Functions */
Mesh(vector vertices, vector indices, vector textures);
void Draw(Shader shader);
private:
/* Render data */
unsigned int VAO, VBO, EBO;
/* Functions */
void setupMesh();
}; Mesh(vector vertices, vector indices, vector textures)
{
this->vertices = vertices;
this->indices = indices;
this->textures = textures;
setupMesh();
} void setupMesh()
{
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glGenBuffers(1, &EBO);
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, vertices.size() * sizeof(Vertex), &vertices[0], GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, indices.size() * sizeof(unsigned int),
&indices[0], GL_STATIC_DRAW);
// vertex positions
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)0);
// vertex normals
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Normal));
// vertex texture coords
glEnableVertexAttribArray(2);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, TexCoords));
glBindVertexArray(0);
} Vertex vertex;
vertex.Position = glm::vec3(0.2f, 0.4f, 0.6f);
vertex.Normal = glm::vec3(0.0f, 1.0f, 0.0f);
vertex.TexCoords = glm::vec2(1.0f, 0.0f);
// = [0.2f, 0.4f, 0.6f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f];glBufferData(GL_ARRAY_BUFFER, vertices.size() * sizeof(Vertex), vertices[0], GL_STATIC_DRAW);glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Normal));uniform sampler2D texture_diffuse1;
uniform sampler2D texture_diffuse2;
uniform sampler2D texture_diffuse3;
uniform sampler2D texture_specular1;
uniform sampler2D texture_specular2;Кроме этого решения, есть также много других, и если вам не нравится это, вы можете проявить свою творческую способность и придумать свое собственное решение.
void Draw(Shader shader)
{
unsigned int diffuseNr = 1;
unsigned int specularNr = 1;
for(unsigned int i = 0; i < textures.size(); i++)
{
glActiveTexture(GL_TEXTURE0 + i); // активируем текстурный блок, до привязки
// получаем номер текстуры
stringstream ss;
string number;
string name = textures[i].type;
if(name == "texture_diffuse")
ss << diffuseNr++; // передаем unsigned int в stream
else if(name == "texture_specular")
ss << specularNr++; // передаем unsigned int в stream
number = ss.str();
shader.setFloat(("material." + name + number).c_str(), i);
glBindTexture(GL_TEXTURE_2D, textures[i].id);
}
glActiveTexture(GL_TEXTURE0);
// отрисовывем полигональную сетку
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, indices.size(), GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
} Обратите внимание, что увеличив диффузные и бликовые счетчики, мы сразу передаем их в stringstream. Правый инкремент в C++ увеличивает значение на 1, но возвращает старое значение.
|
Метки: author dima19972525 разработка игр c++ перевод glsl opengl opengl 3 casters |
learnopengl. Уроки 3.1(Assimp) + 3.2(класс Mesh) |
Mesh — набор вершин и треугольников
Одна сетка (Mesh) — это минимальный набор данных, необходимый для вывода средствами OpenGL(данные вершин, индексов, материала). Модель же, обычно, состоит из нескольких сеток. При моделировании объектов в специальных программах(Blender, 3D max), художники не создают целую модель из одной формы. Обычно, каждая модель имеет несколько под-моделей\форм, из которых она состоит. Подумайте о человеке, как о модели: художник обычно моделирует голову, конечности, одежду, оружие, все как отдельные компоненты, затем объединив все под-модели, получает исходную.
Если вы хотите использовать многопоточность для увеличения производительности, вы можете собрать Assimp с Boost. Полная инструкция находится здесь.
struct Vertex {
glm::vec3 Position;
glm::vec3 Normal;
glm::vec2 TexCoords;
};struct Texture {
unsigned int id;
string type;
}; class Mesh {
public:
/* Mesh Data */
vector vertices;
vector indices;
vector textures;
/* Functions */
Mesh(vector vertices, vector indices, vector textures);
void Draw(Shader shader);
private:
/* Render data */
unsigned int VAO, VBO, EBO;
/* Functions */
void setupMesh();
}; Mesh(vector vertices, vector indices, vector textures)
{
this->vertices = vertices;
this->indices = indices;
this->textures = textures;
setupMesh();
} void setupMesh()
{
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glGenBuffers(1, &EBO);
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, vertices.size() * sizeof(Vertex), &vertices[0], GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, indices.size() * sizeof(unsigned int),
&indices[0], GL_STATIC_DRAW);
// vertex positions
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)0);
// vertex normals
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Normal));
// vertex texture coords
glEnableVertexAttribArray(2);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, TexCoords));
glBindVertexArray(0);
} Vertex vertex;
vertex.Position = glm::vec3(0.2f, 0.4f, 0.6f);
vertex.Normal = glm::vec3(0.0f, 1.0f, 0.0f);
vertex.TexCoords = glm::vec2(1.0f, 0.0f);
// = [0.2f, 0.4f, 0.6f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f];glBufferData(GL_ARRAY_BUFFER, vertices.size() * sizeof(Vertex), vertices[0], GL_STATIC_DRAW);glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Normal));uniform sampler2D texture_diffuse1;
uniform sampler2D texture_diffuse2;
uniform sampler2D texture_diffuse3;
uniform sampler2D texture_specular1;
uniform sampler2D texture_specular2;Кроме этого решения, есть также много других, и если вам не нравится это, вы можете проявить свою творческую способность и придумать свое собственное решение.
void Draw(Shader shader)
{
unsigned int diffuseNr = 1;
unsigned int specularNr = 1;
for(unsigned int i = 0; i < textures.size(); i++)
{
glActiveTexture(GL_TEXTURE0 + i); // активируем текстурный блок, до привязки
// получаем номер текстуры
stringstream ss;
string number;
string name = textures[i].type;
if(name == "texture_diffuse")
ss << diffuseNr++; // передаем unsigned int в stream
else if(name == "texture_specular")
ss << specularNr++; // передаем unsigned int в stream
number = ss.str();
shader.setFloat(("material." + name + number).c_str(), i);
glBindTexture(GL_TEXTURE_2D, textures[i].id);
}
glActiveTexture(GL_TEXTURE0);
// отрисовывем полигональную сетку
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, indices.size(), GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
} Обратите внимание, что увеличив диффузные и бликовые счетчики, мы сразу передаем их в stringstream. Правый инкремент в C++ увеличивает значение на 1, но возвращает старое значение.
|
Метки: author dima19972525 разработка игр c++ перевод glsl opengl opengl 3 casters |
День открытых дверей «Лаборатории Касперского»: закрываем данные от взлома, открываем новые возможности |
|
Метки: author megapost карьера в it-индустрии информационная безопасность касперский день открытых дверей |
День открытых дверей «Лаборатории Касперского»: закрываем данные от взлома, открываем новые возможности |
|
Метки: author megapost карьера в it-индустрии информационная безопасность касперский день открытых дверей |
День открытых дверей «Лаборатории Касперского»: закрываем данные от взлома, открываем новые возможности |
|
Метки: author megapost карьера в it-индустрии информационная безопасность касперский день открытых дверей |
День открытых дверей «Лаборатории Касперского»: закрываем данные от взлома, открываем новые возможности |
|
Метки: author megapost карьера в it-индустрии информационная безопасность касперский день открытых дверей |
Достижения в глубоком обучении за последний год |

Привет, Хабр. В своей статье я расскажу вам, что интересного произошло в мире машинного обучения за последний год (в основном в Deep Learning). А произошло очень многое, поэтому я остановился на самых, на мой взгляд, зрелищных и/или значимых достижениях. Технические аспекты улучшения архитектур сетей в статье не приводятся. Расширяем кругозор!
Почти год назад Google анонсировала запуск новой модели для Google Translate. Компания подробно описала архитектуру сети — Recurrent Neural Network (RNN) — в своей статье.
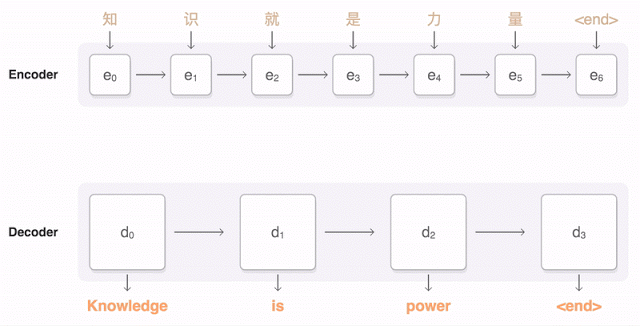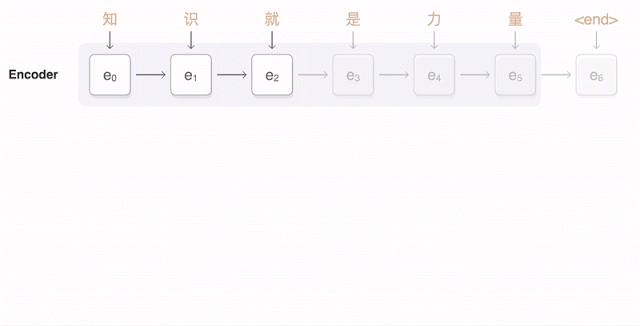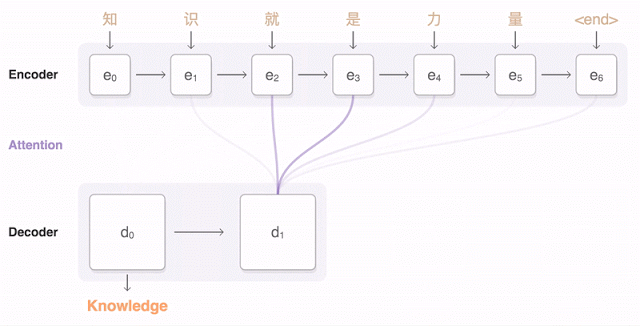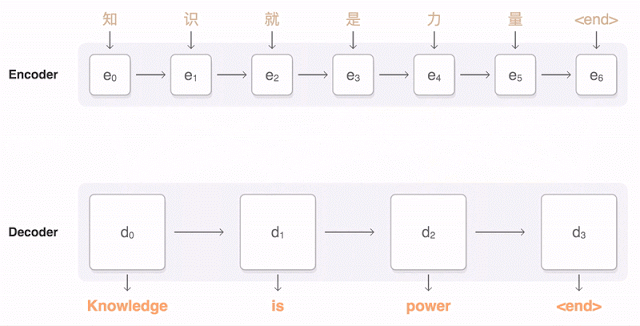
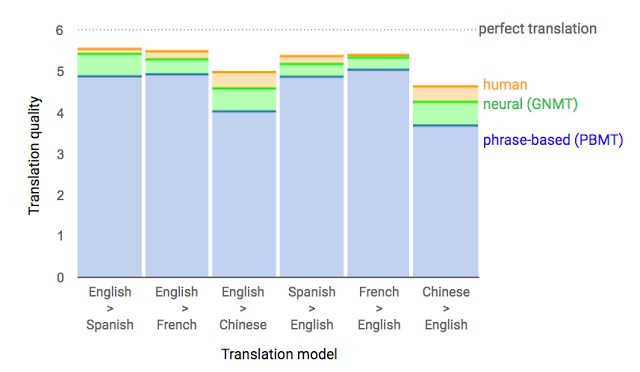
Основной результат: сокращение отставания от человека по точности перевода на 55—85 % (оценивали люди по 6-балльной шкале). Воспроизвести высокие результаты этой модели сложно без огромного датасета, который имеется у Google.
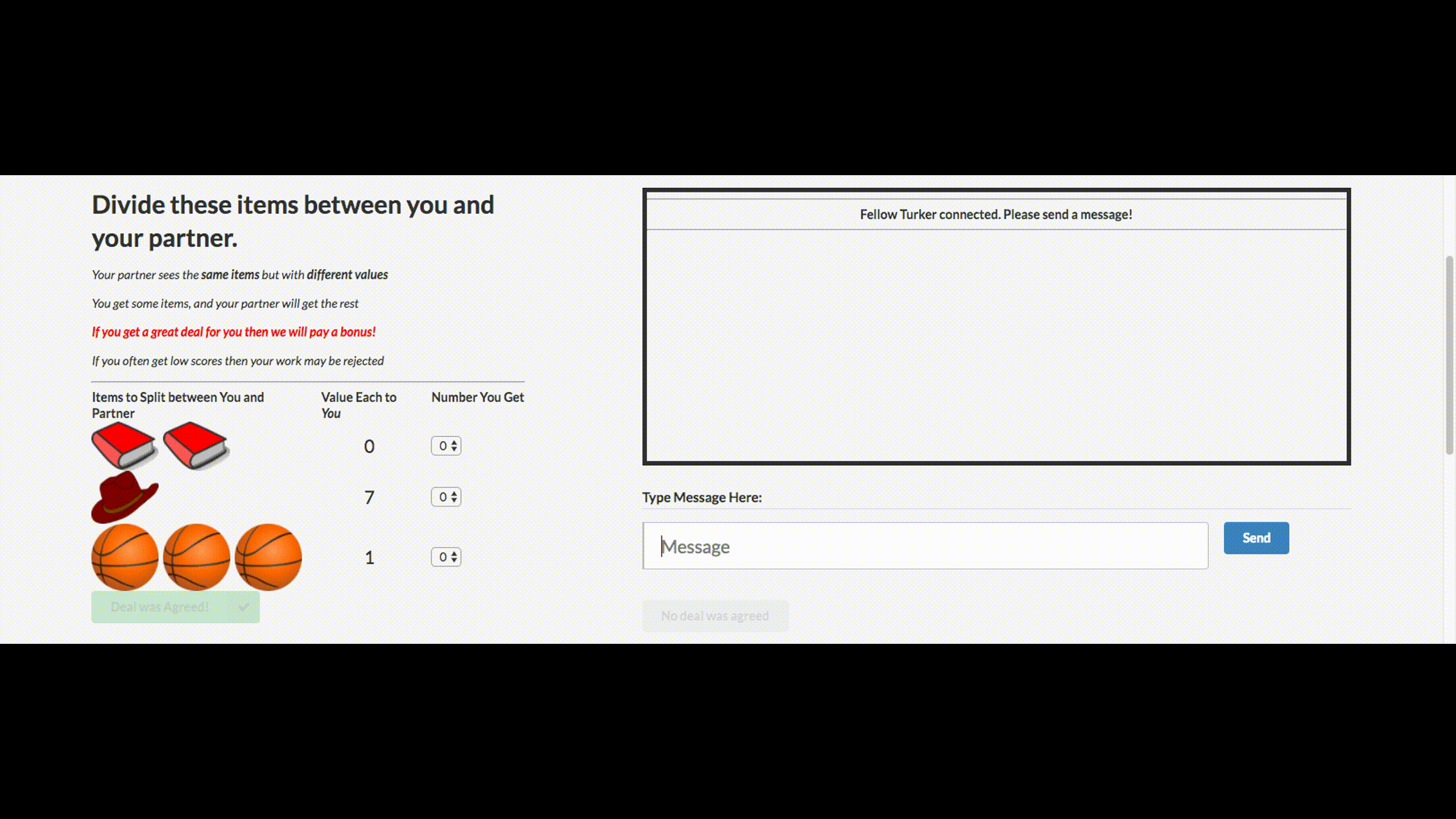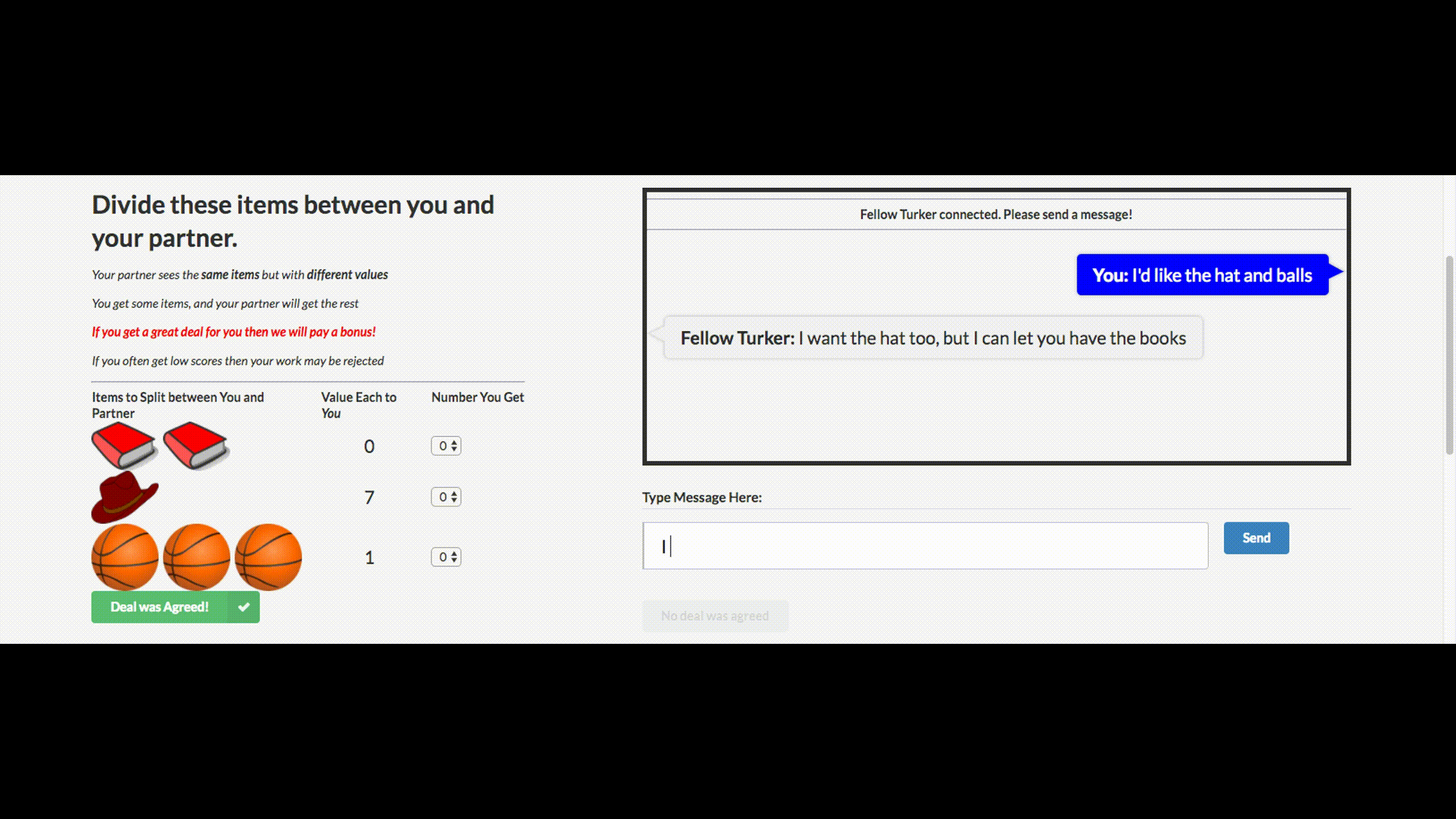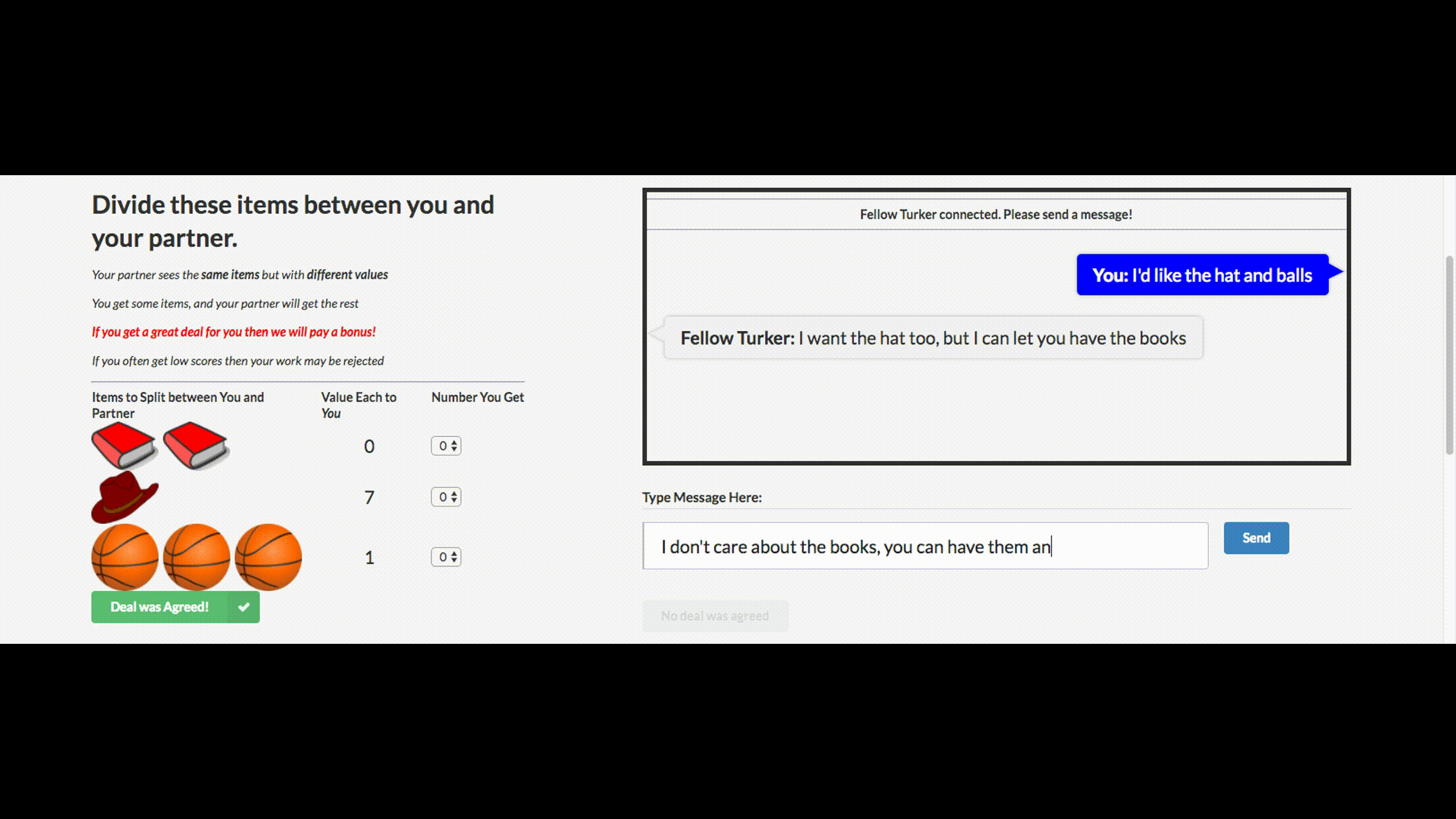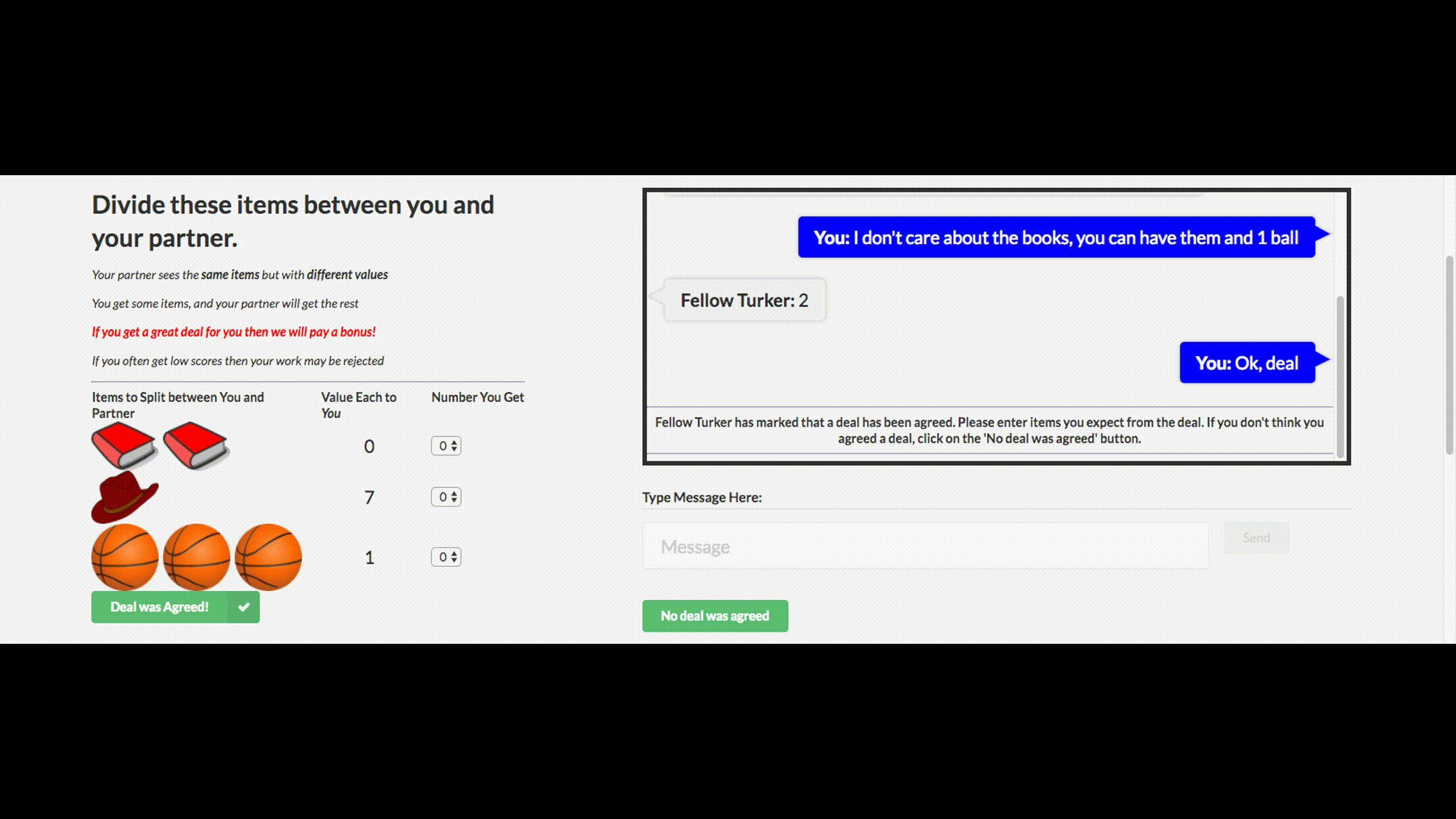
Вы могли слышать дурацкие новости о том, что Facebook выключила своего чат-бота, который вышел из-под контроля и выдумал свой язык. Этого чат-бота компания создала для переговоров. Его цель — вести текстовые переговоры с другим агентом и достичь сделки: как разделить на двоих предметы (книги, шляпы...). У каждого агента своя цель в переговорах, другой ее не знает. Просто уйти с переговоров без сделки нельзя.
Для обучения собрали датасет человеческих переговоров, обучили supervised рекуррентную сеть, далее уже обученного агента с помощью reinforcement learning (обучения с подкреплением) тренировали переговариваться с самим собой, поставив ограничение: похожесть языка на человеческий.
Бот научился одной из стратегий реальных переговоров — показывать поддельный интерес к некоторым аспектам сделки, чтобы потом по ним уступить, получив выгоду по своим настоящим целям. Это первая попытка создания подобного переговорного бота, и довольно удачная.
Подробности — в статье, код выложен в открытый доступ.
Разумеется, новость о том, что бот якобы придумал язык, раздули на пустом месте. При обучении (при переговорах с таким же агентом) отключили ограничение похожести текста на человеческий, и алгоритм модифицировал язык взаимодействия. Ничего необычного.
За последний год рекуррентные сети активно развивали и использовали во многих задачах и приложениях. Архитектуры рекуррентных сетей сильно усложнились, однако по некоторым направлениям похожих результатов достигают и простые feedforward-сети — DSSM. Например, Google для своей почтовой фичи Smart Reply достигла такого же качества, как и с LSTM до этого. А Яндекс запустил новый поисковый движок на основе таких сетей.
Сотрудники DeepMind (компания, известная своим ботом для игры в го, ныне принадлежащая Google) рассказали в своей статье про генерирование аудио.
Если коротко, то исследователи сделали авторегрессионную полносверточную модель WaveNet на основе предыдущих подходов к генерированию изображений (PixelRNN и PixelCNN).

Сеть обучалась end-to-end: на вход текст, на выход аудио. Результат превосходный, разница с человеком сократилась на 50 %.
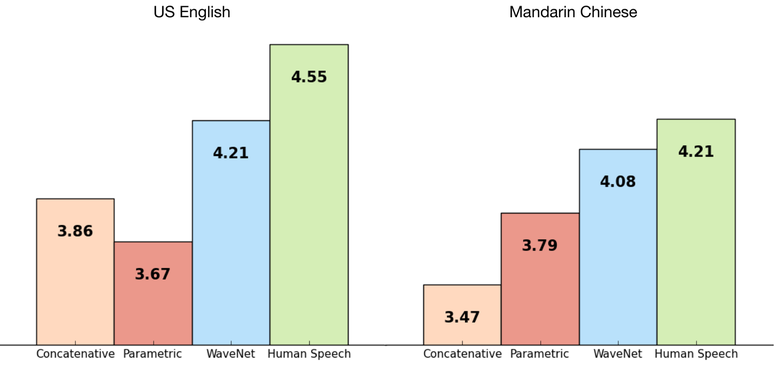
Основной недостаток сети — низкая производительность, потому что из-за авторегрессии звуки генерируются последовательно, на создание одной секунды аудио уходит около 1—2 минут.
Английский: пример
Если убрать зависимость сети от входного текста и оставить только зависимость от предыдущей сгенерированной фонемы, то сеть будет генерировать подобные человеческому языку фонемы, но бессмысленные.
Генерирование голоса: пример
Эту же модель можно применить не только к речи, но и, например, к созданию музыки. Пример аудио, сгенерированного моделью, которую обучили на датасете игры на пианино (опять же без всякой зависимости от входных данных).
Подробности — в статье.
Еще одна победа машинного обучения над человеком ;) На этот раз — в чтении по губам.
Google Deepmind в сотрудничестве с Оксфордским университетом рассказывают в статье «Lip Reading Sentences in the Wild», как их модель, обученная на телевизионном датасете, смогла превзойти профессионального lips reader’а c канала BBC.

В датасете 100 тыс. предложений с аудио и видео. Модель: LSTM на аудио, CNN + LSTM на видео, эти два state-вектора подаются в итоговую LSTM, которая генерирует результат (characters).
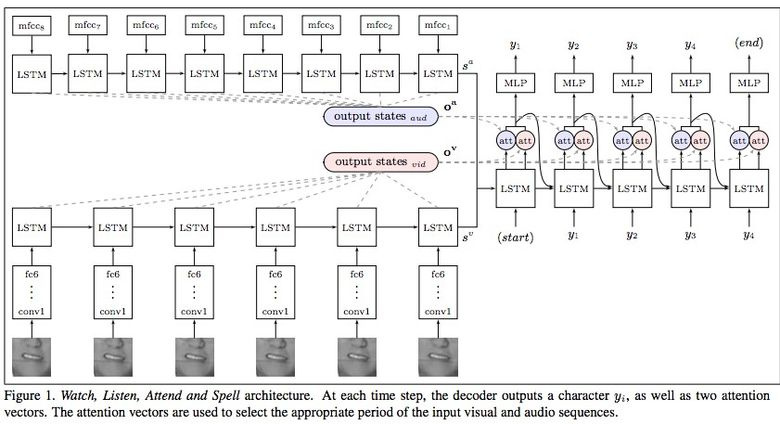
При обучении использовались разные варианты входных данных: аудио, видео, аудио + видео, то есть модель «омниканальна».
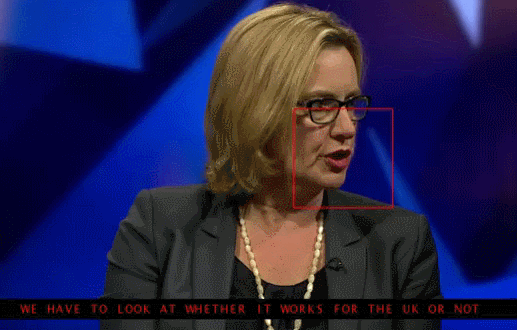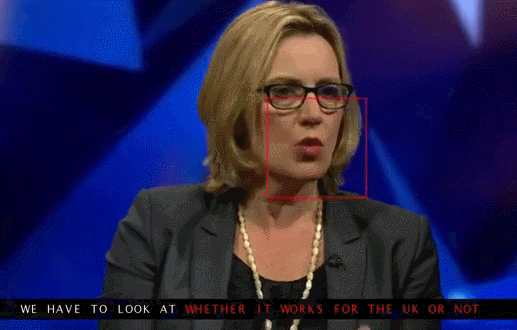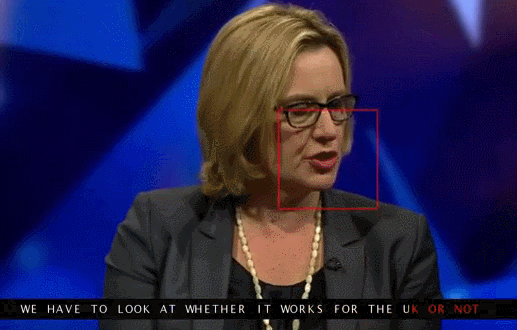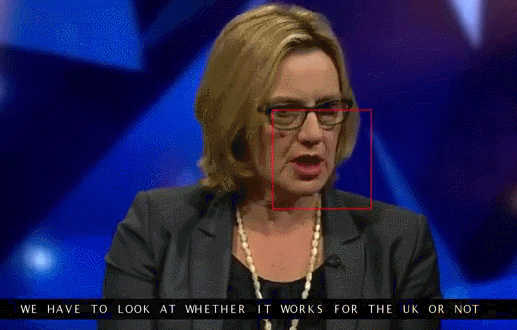
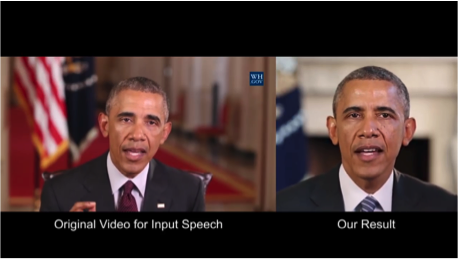
Университет Вашингтона проделал серьезную работу по генерированию движения губ бывшего президента США Обамы. Выбор пал на него в том числе из-за огромного количества записей его выступления в сети (17 часов HD-видео).
Одной сетью обойтись не удалось, получалось слишком много артефактов. Поэтому авторы статьи сделали несколько костылей (или трюков, если угодно) по улучшению текстуры и таймингам.
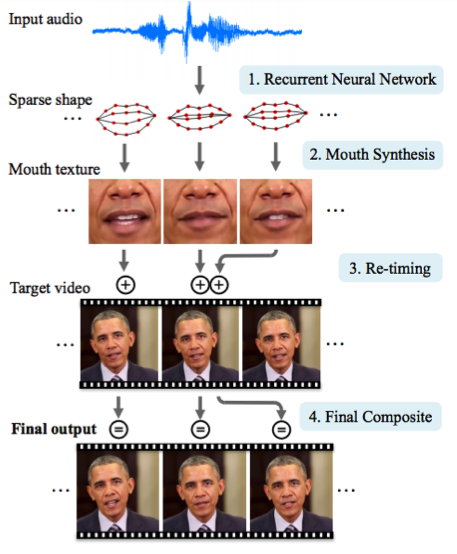
Результат впечатляет. Скоро нельзя будет верить даже видео с президентом ;)
В своих посте и статье команда Google Brain рассказывает, как внедрила в свои Карты новый движок OCR (Optical Character Recognition), с помощью которого распознаются указатели улиц и вывески магазинов.


В процессе разработки технологии компания составила новый FSNS (French Street Name Signs), который содержит множество сложных кейсов.
Сеть использует для распознавания каждого знака до четырех его фотографий. С помощью CNN извлекаются фичи, взвешиваются с помощью spatial attention (учитываются пиксельные координаты), а результат подается в LSTM.
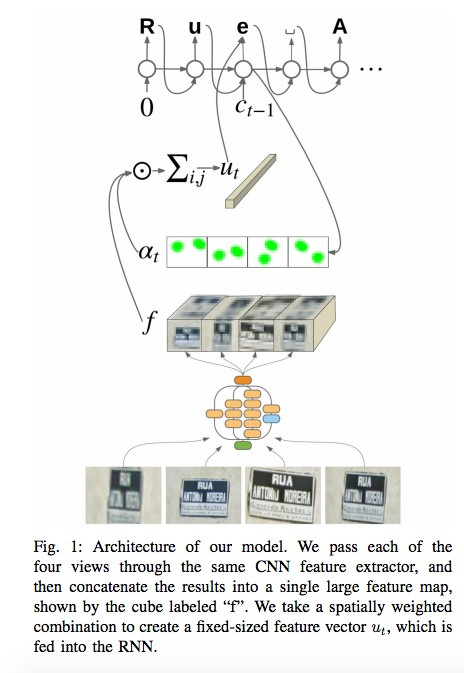
Тот же самый подход авторы применяют к задаче распознавания названий магазинов на вывесках (там может быть много «шумовых» данных, и сеть сама должна «фокусироваться» в нужных местах). Алгоритм применили к 80 млрд фотографий.
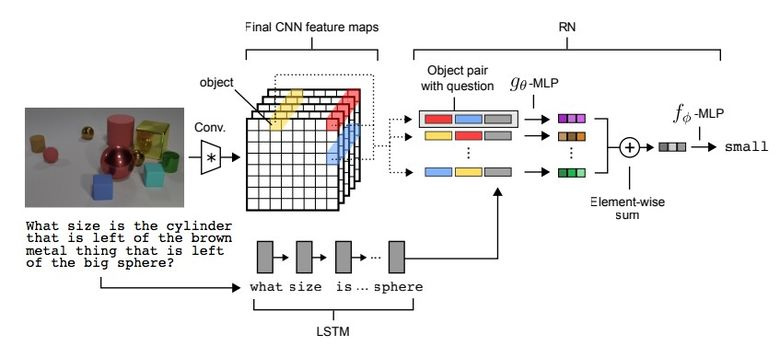
Существует такой тип задач, как Visual Reasoning, то есть нейросеть должна по фотографии ответить на какой-то вопрос. Например: «Есть ли на картинке резиновые вещи того же размера, что и желтый металлический цилиндр?» Вопрос и правда нетривиальный, и до недавнего времени задача решалась с точностью всего лишь 68,5 %.

И вновь прорыва добилась команда из Deepmind: на датасете CLEVR они достигли super-human точности в 95,5 %.
Архитектура сети весьма интересная:
Полученное представление прогоняем через еще одну feedforward-сеть, которая уже на софтмаксе выдает ответ.
Интересное применение нейросетям придумала компания Uizard: по скриншоту от дизайнера интерфейсов генерировать код верстки.

Крайне полезное применение нейросетей, которое может облегчить жизнь при разработке софта. Авторы утверждают, что получили 77 % точности. Понятно, что это пока исследовательская работа и о боевом применении речи не идет.
Кода и датасета в open source пока нет, но обещают выложить.
Возможно, вы видели страничку Quick, Draw! от Google с призывом нарисовать скетчи различных объектов за 20 секунд. Корпорация собирала этот датасет для того, чтобы обучить нейросеть рисовать, о чем Google рассказала в своем блоге и статье.

Собранный датасет состоит из 70 тыс. скетчей, он был в итоге выложен в открытый доступ. Скетчи представляют собой не картинки, а детализированные векторные представления рисунков (в какой точке пользователь нажал «карандаш», отпустил, куда провел линию и так далее).
Исследователи обучили Sequence-to-Sequence Variational Autoencoder (VAE) c использованием RNN в качестве механизма кодирования/декодирования.
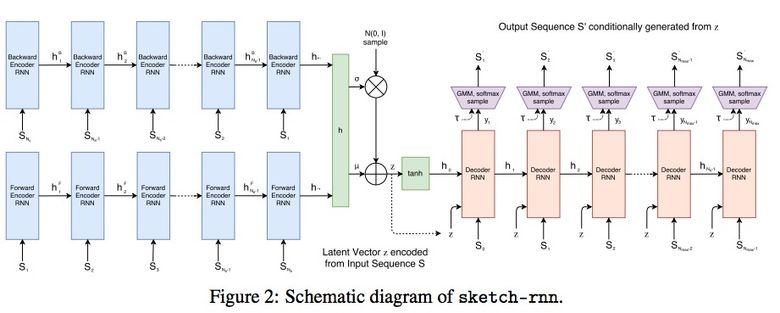
В итоге, как и положено автоенкодеру, модель получает латентный вектор, который характеризует исходную картинку.

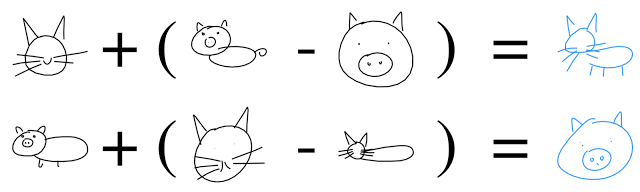
Поскольку декодер умеет извлекать из этого вектора рисунок, то можно его менять и получать новые скетчи.

И даже выполнять векторную арифметику, чтобы соорудить котосвина:
Одна из самых горячих тем в Deep Learning — Generative Adversarial Networks (GAN). Чаще всего эту идею используют для работы с изображениями, поэтому объясню концепцию именно на них.
Суть идеи состоит в соревновании двух сетей — Генератора и Дискриминатора. Первая сеть создает картинку, а вторая пытается понять, реальная это картинка или сгенерированная.
Схематично это выглядит так:
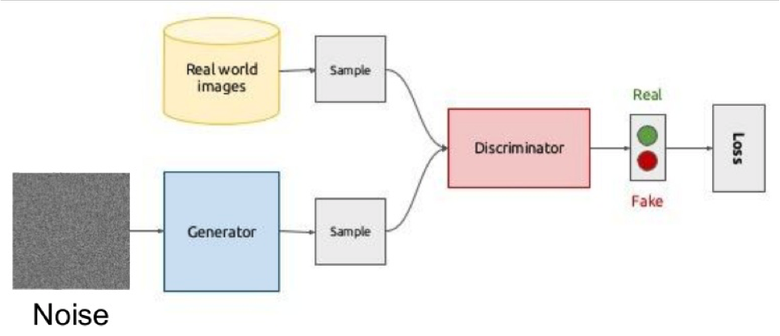
Во время обучения генератор из случайного вектора (шума) генерирует изображение и подает на вход дискриминатору, который говорит, фальшивка это или нет. Дискриминатору также подаются реальные изображения из датасета.
Обучать такую конструкцию часто тяжело из-за того, что трудно найти точку равновесия двух сетей, чаще всего дискриминатор побеждает и обучение стагнирует. Однако преимущество системы в том, что мы можем решать задачи, в которых нам тяжело задать loss-функцию (например, улучшение качества фотографии), мы это отдаем на откуп дискриминатору.
Классический пример результата обучения GAN — картинки спален или лиц.


Ранее мы рассматривали автокодировщики (Sketch-RNN), которые кодируют исходные данные в латентное представление. С генератором получается то же самое.
Очень наглядно идея генерирования изображения по вектору на примере лиц показана тут (можно изменять вектор и посмотреть, какие выходят лица).

Работает все та же арифметика над латентным пространством: «мужчина в очках» минус «мужчина» плюс «женщина» равно «женщина в очках».

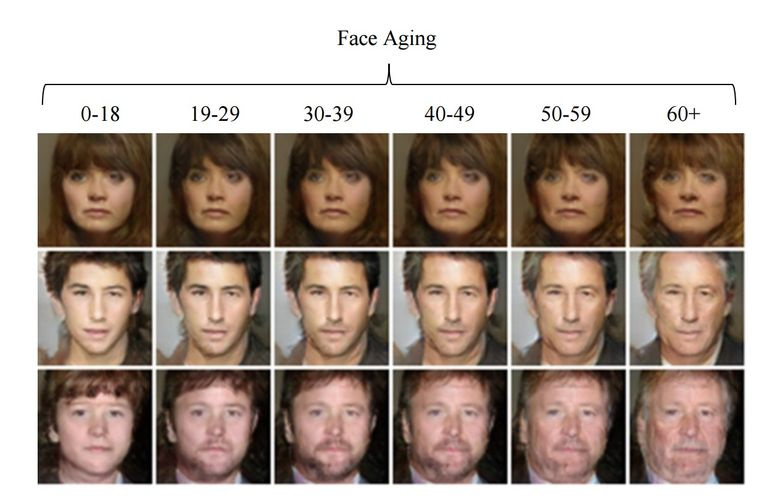
Если при обучении подсунуть в латентный вектор контролируемый параметр, то при генерировании его можно менять и так управлять нужным образом на картинке. Этот подход именуется Conditional GAN.
Так поступили авторы статьи «Face Aging With Conditional Generative Adversarial Networks». Обучив машину на датасете IMDB с известным возрастом актеров, исследователи получили возможность менять возраст лица.
В Google нашли еще одно интересное применение GAN — выбор и улучшение фотографий. GAN обучали на датасете профессиональных фотографий: генератор пытается улучшить плохие фотографии (профессионально снятые и ухудшенные с помощью специальных фильтров), а дискриминатор — различить «улучшенные» фотографии и реальные профессиональные.
Обученный алгоритм прошелся по панорамам Google Street View в поиске лучших композиций и получил некоторые снимки профессионального и полупрофессионального качества (по оценкам фотографов).


Впечатляющий пример использования GAN — генерирование картинок по тексту.

Авторы статьи предлагают подавать embedding текста на вход не только генератору (conditional GAN), но и дискриминатору, чтобы он проверял соответствие текста картинке. Чтобы дискриминатор научился выполнять свою функцию, дополнительно в обучение добавляли пары с неверным текстом для реальных картинок.
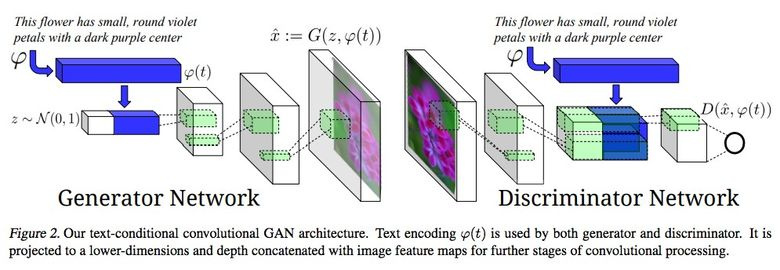
Одна из ярких статей конца 2016 года — «Image-to-Image Translation with Conditional Adversarial Networks» Berkeley AI Research (BAIR). Исследователи решали проблему image-to-image генерирования, когда, например, требуется по снимку со спутника создать карту или по наброску предметов — их реалистичную текстуру.
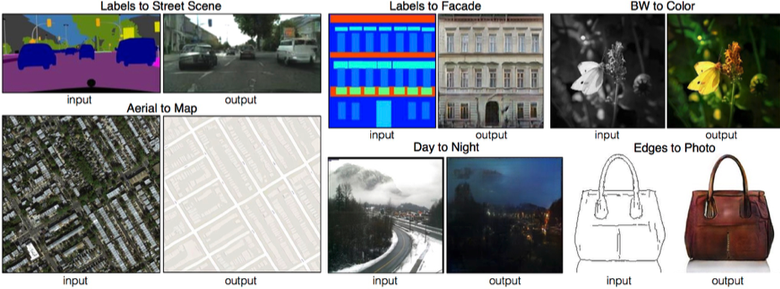
Это еще один пример успешной работы conditional GAN, в данном случае condition идет на целую картинку. В качестве архитектуры генератора использовалась UNet, популярная в сегментации изображений, а для борьбы с размытыми изображениями в качестве дискриминатора взяли новый классификатор PatchGAN (картинка нарезается на N патчей, и предсказание fake/real идет по каждому из них в отдельности).
Авторы выпустили онлайн-демо своих сетей, что вызвало огромный интерес у пользователей.
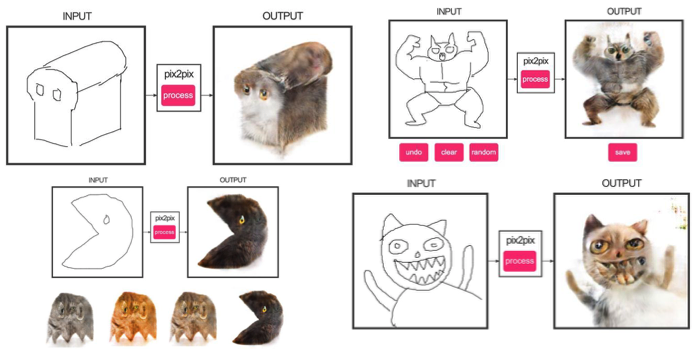
Чтобы применить Pix2Pix, требуется датасет с соответствующими парами картинок из разных доменов. В случае, например, с картами собрать такой датасет не проблема. Но если хочется сделать что-то более сложное вроде «трансфигурирования» объектов или стилизации, то пар объектов не найти в принципе. Поэтому авторы Pix2Pix решили развить свою идею и придумали CycleGAN для трансфера между разными доменами изображений без конкретных пар — Unpaired Image-to-Image Translation.

Идея состоит в следующем: мы учим две пары генератор-дискриминатор из одного домена в другой и обратно, при этом мы требуем cycle consistency — после последовательного применения генераторов должно получиться изображение, похожее на исходное по L1 loss’у. Цикличный loss требуется для того, чтобы генератор не начал просто транслировать картинки одного домена в совершенно не связанные с исходным изображением.
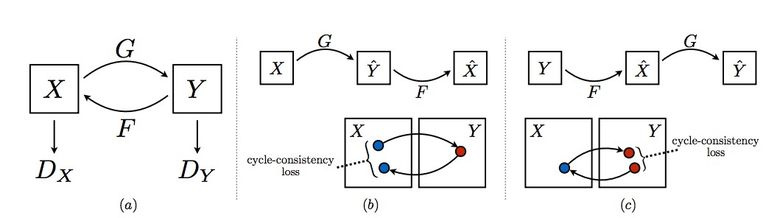
Такой подход позволяет выучить маппинг лошади –> зебры.

Такие трансформации работают нестабильно и часто создают неудачные варианты:

Машинное обучение сейчас приходит и в медицину. Помимо распознавания УЗИ, МРТ и диагностики его можно использовать для поиска новых лекарств для борьбы с раком.
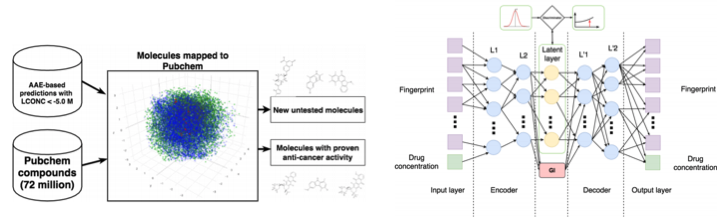
Мы уже подробно писали об этом исследовании тут, поэтому коротко: с помощью Adversarial Auto Encoder (AAE) можно выучить латентное представление молекул и дальше с его помощью искать новые. В результате нашли 69 молекул, половина из которых применяются для борьбы с раком, остальные имеют серьезный потенциал.
Сейчас активно исследуется тема с adversarial-атаками. Что это такое? Стандартные сети, обучаемые, например, на ImageNet, совершенно неустойчивы к добавлению специального шума к классифицируемой картинке. На примере ниже мы видим, что картинка с шумом для человеческого глаза практически не меняется, однако модель сходит с ума и предсказывает совершенно иной класс.

Устойчивость достигается с помощью, например, Fast Gradient Sign Method (FGSM): имея доступ к параметрам модели, можно сделать один или несколько градиентных шагов в сторону нужного класса и изменить исходную картинку.
Одна из задач на Kaggle к грядущему NIPS как раз связана с этим: участникам предлагается создать универсальные атаки/защиты, которые в итоге запускаются все против всех для определения лучших.
Зачем нам вообще исследовать эти атаки? Во-первых, если мы хотим защитить свои продукты, то можно добавлять к капче шум, чтобы мешать спамерам распознавать ее автоматом. Во-вторых, алгоритмы все больше и больше участвуют в нашей жизни — системы распознавания лиц, беспилотные автомобили. При этом злоумышленники могут использовать недостатки алгоритмов. Вот пример, когда специальные очки позволяют обмануть систему распознавания лиц и «представиться» другим человеком. Так что модели надо будет учить с учетом возможных атак.

Такие манипуляции со знаками тоже не позволяют правильно их распознать.

Набор статей от организаторов конкурса.
Уже написанные библиотеки для атак: cleverhans и foolbox.
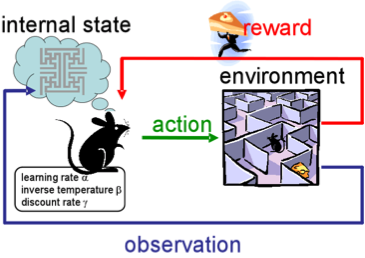
Reinforcement learning (RL), или обучение с подкреплением, — также сейчас одна из интереснейших и активно развивающихся тем в машинном обучении.
Суть подхода заключается в выучивании успешного поведения агента в среде, которая при взаимодействии дает обратную связь (reward). В общем, через опыт — так же, как учатся люди в течение жизни.
RL активно применяют в играх, роботах, управлении системами (трафиком, например).
Разумеется, все слышали о победах AlphaGo от DeepMind в игре го над лучшими профессионалами. Статья авторов была опубликована в Nature «Mastering the game of Go». При обучении разработчики использовали RL: бот играл сам с собой для совершенствования своих стратегий.
В предыдущие годы DeepMind научился с помощью DQN играть в аркадные игры лучше человека. Сейчас алгоритмы учат играть в более сложные игры типа Doom.
Много внимания уделено ускорению обучения, потому что наработка опыта агента во взаимодействии со средой требует многих часов обучения на современных GPU.
Deepmind в своем блоге рассказывает о том, что введение дополнительных loss’ов (auxiliary tasks, вспомогательных задач), таких как предсказание изменения кадра (pixel control), чтобы агент лучше понимал последствия действий, существенно ускоряет обучение.
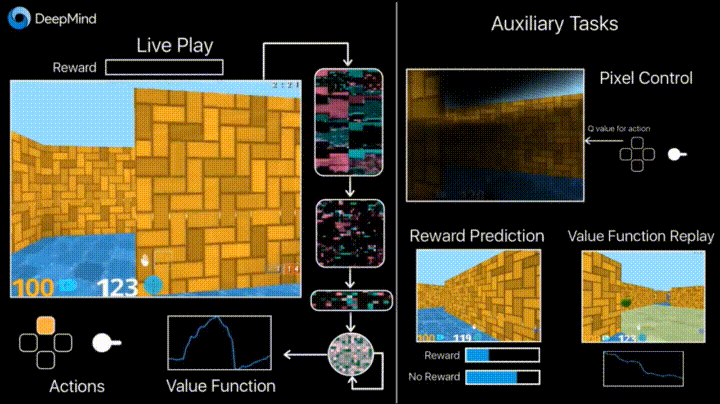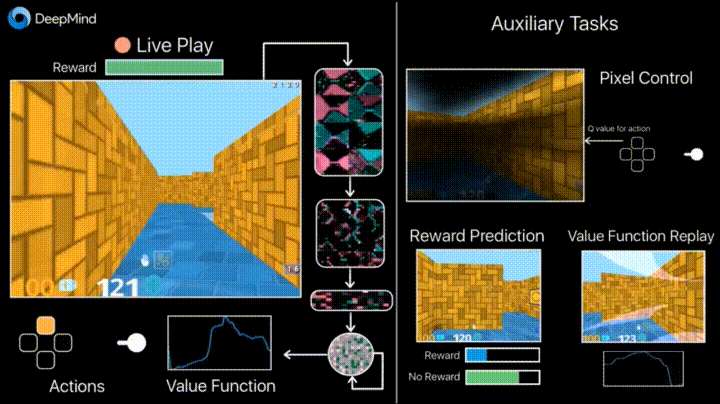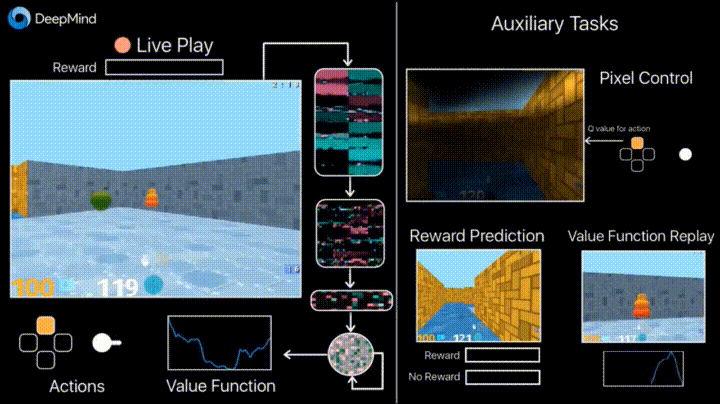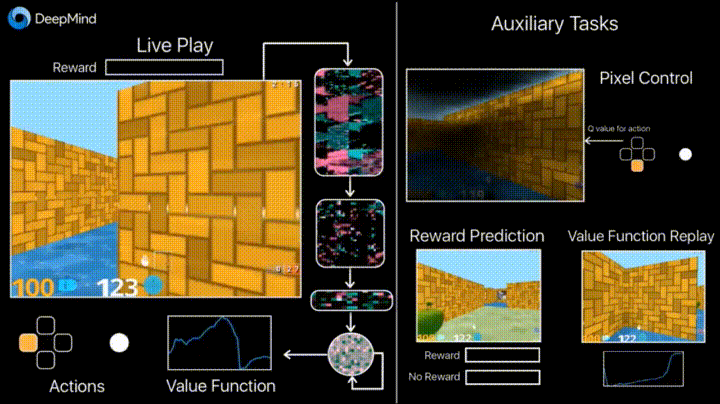
Результаты обучения:
В OpenAI активно исследуют обучение человеком агента в виртуальной среде, что более безопасно для экспериментов, чем в реальной жизни ;)
В одном из исследований команда показала, что one-shot learning возможно: человек показывает в VR, как выполнить определенную задачу, и алгоритму достаточно одной демонстрации, чтобы выучить ее и далее воспроизвести в реальных условиях.

Эх, если бы с людьми было так просто ;)
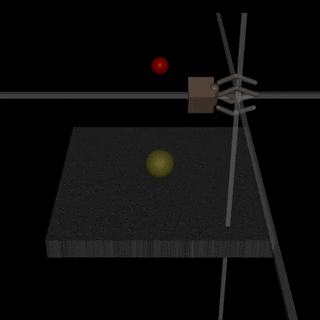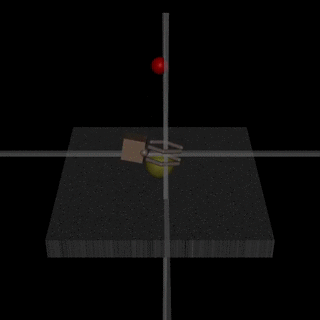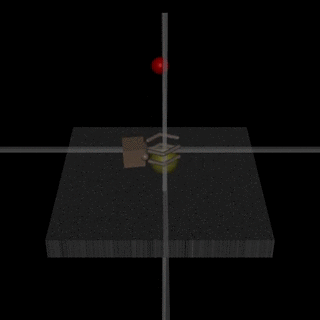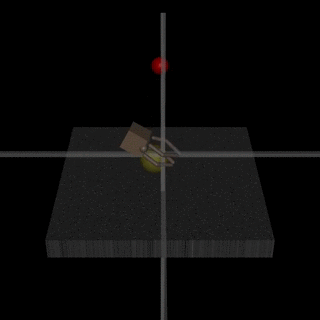
Работа OpenAI и DeepMind на ту же тему. Суть состоит в следующем: у агента есть некая задача, алгоритм предоставляет на суд человеку два возможных варианта решения, и человек указывает, какой лучше. Процесс повторяется итеративно, и алгоритм за 900 бит обратной связи (бинарной разметки) от человека выучился решать задачу.


Как всегда, человеку надо быть осторожным и думать, чему он учит машину. Например, оценщик решил, что алгоритм действительно хотел взять объект, но на самом деле тот лишь имитировал это действие.
Еще одно исследование от DeepMind. Чтобы научить робота сложному поведению (ходить/прыгать/...), да еще и похожему на человеческое, нужно сильно заморочиться с выбором функции потерь, которая будет поощрять нужное поведение. Но хотелось бы, чтобы алгоритм сам выучивал сложное поведение, опираясь на простые reward.
Исследователям удалось этого добиться: они научили агентов (эмуляторы тел) совершать сложные действия с помощью конструирования сложной среды с препятствиями и с простым reward за прогресс в передвижении.

Впечатляющее видео с результатами. Но оно гораздо забавнее с наложенным звуком ;)
Напоследок дам ссылку на опубликованные недавно алгоритмы обучения RL от OpenAI. Теперь можно использовать более современные решения, чем уже ставший стандартным DQN.
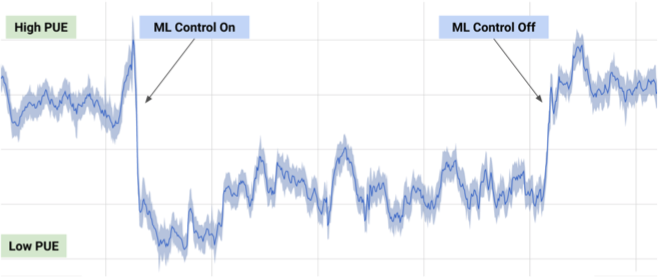
В июле 2017-го Google рассказала, что воспользовалась разработками DeepMind в машинном обучении, чтобы сократить энергозатраты своего дата-центра.
На основе информации с тысяч датчиков в дата-центре разработчики Google натренировали ансамбль нейросетей для предсказания PUE (Power Usage Effectiveness) и более эффективного управления дата-центром. Это впечатляющий и значимый пример практического применения ML.
Как вы знаете, обученные модели плохо переносятся от задачи к задаче, под каждую задачу приходится обучать/дообучать специфичную модель. Небольшой шаг в сторону универсальности моделей сделала Google Brain в своей статье «One Model To Learn Them All».
Исследователи обучили модель, которая выполняет восемь задач из разных доменов (текст, речь, изображения). Например, перевод с разных языков, парсинг текста, распознавание изображений и звука.
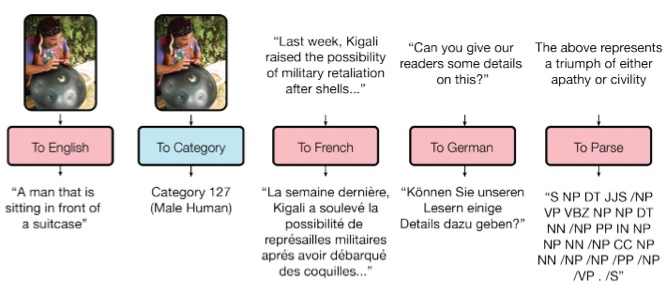
Для достижения этой цели сделали сложную архитектуру сети с различными блоками для обработки разных входных данных и генерирования результата. Блоки для encoder/decoder делятся на три типа: сверточные, attention, gated mixture of experts (MoE).
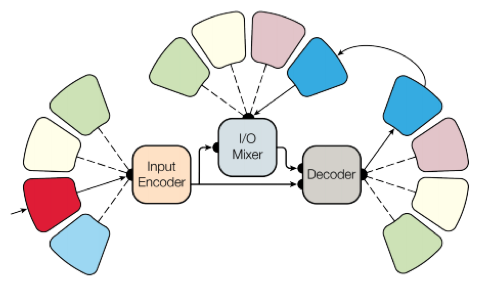
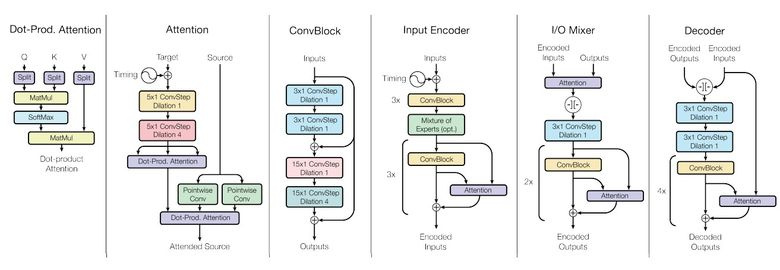
Основные итоги обучения:
Кстати, эта модель есть в tensor2tensor.
В своем посте сотрудники Facebook рассказали, как их инженеры смогли добиться обучения модели Resnet-50 на Imagenet всего за один час. Правда, для этого потребовался кластер из 256 GPU (Tesla P100).
Для распределенного обучения использовали Gloo и Caffe2. Чтобы процесс шел эффективно, пришлось адаптировать стратегию обучения при огромном батче (8192 элемента): усреднение градиентов, фаза прогрева, специальные learning rate и тому подобное. Подробнее в статье.
В итоге удалось добиться эффективности 90% при масштабировании от 8 к 256 GPU. Теперь исследователи из Facebook могут экспериментировать еще быстрее, в отличие от простых смертных без такого кластера ;)
Сфера беспилотных автомобилей интенсивно развивается, и машины активно тестируют в боевых условиях. Из относительно недавних событий можно отметить покупку Intel’ом MobilEye, скандал вокруг Uber и украденных экс-сотрудником Google технологий, первую смерть при работе автопилота и многое другое.
Отмечу один момент: Google Waymo запускает бета-программу. Google — пионер в этой области, и предполагается, что их технология очень хороша, ведь машины наездили уже более 3 млн миль.
Также совсем недавно беспилотным автомобилям разрешили колесить по всем штатам США.
Как я уже говорил, современный ML начинает внедряться в медицину. Например, Google сотрудничает с медицинским центром для помощи диагностам.
Deepmind создал даже отдельное подразделение.

В этом году в рамках Data Science Bowl был проведен конкурс по предсказанию рака легких через год на основе подробных снимков, призовой фонд — один миллион долларов.
Сейчас много и усердно инвестируют в ML, как до этого — в BigData.
КНР вкладывает 150 млрд долларов в AI, чтобы стать мировым лидером индустрии.
Для сравнения, в Baidu Research работает 1300 человек, а в том же FAIR (Facebook) — 80. На последнем KDD сотрудники Alibaba рассказывали про свой parameter server KungPeng, который работает на 100 миллиардных выборках при триллионе параметров, что «становится обычной задачей» (с).

Делайте выводы, изучайте ML. Так или иначе со временем все разработчики будут использовать машинное обучение, что станет одной из компетенций, как сегодня — умение работать с базами данных.
|
Метки: author EdT машинное обучение алгоритмы big data блог компании mail.ru group deep learning machine learning |
Достижения в глубоком обучении за последний год |
Привет, Хабр. В своей статье я расскажу вам, что интересного произошло в мире машинного обучения за последний год (в основном в Deep Learning). А произошло очень многое, поэтому я остановился на самых, на мой взгляд, зрелищных и/или значимых достижениях. Технические аспекты улучшения архитектур сетей в статье не приводятся. Расширяем кругозор!
Почти год назад Google анонсировала запуск новой модели для Google Translate. Компания подробно описала архитектуру сети — Recurrent Neural Network (RNN) — в своей статье.
Основной результат: сокращение отставания от человека по точности перевода на 55—85 % (оценивали люди по 6-балльной шкале). Воспроизвести высокие результаты этой модели сложно без огромного датасета, который имеется у Google.
Вы могли слышать дурацкие новости о том, что Facebook выключила своего чат-бота, который вышел из-под контроля и выдумал свой язык. Этого чат-бота компания создала для переговоров. Его цель — вести текстовые переговоры с другим агентом и достичь сделки: как разделить на двоих предметы (книги, шляпы...). У каждого агента своя цель в переговорах, другой ее не знает. Просто уйти с переговоров без сделки нельзя.
Для обучения собрали датасет человеческих переговоров, обучили supervised рекуррентную сеть, далее уже обученного агента с помощью reinforcement learning (обучения с подкреплением) тренировали переговариваться с самим собой, поставив ограничение: похожесть языка на человеческий.
Бот научился одной из стратегий реальных переговоров — показывать поддельный интерес к некоторым аспектам сделки, чтобы потом по ним уступить, получив выгоду по своим настоящим целям. Это первая попытка создания подобного переговорного бота, и довольно удачная.
Подробности — в статье, код выложен в открытый доступ.
Разумеется, новость о том, что бот якобы придумал язык, раздули на пустом месте. При обучении (при переговорах с таким же агентом) отключили ограничение похожести текста на человеческий, и алгоритм модифицировал язык взаимодействия. Ничего необычного.
За последний год рекуррентные сети активно развивали и использовали во многих задачах и приложениях. Архитектуры рекуррентных сетей сильно усложнились, однако по некоторым направлениям похожих результатов достигают и простые feedforward-сети — DSSM. Например, Google для своей почтовой фичи Smart Reply достигла такого же качества, как и с LSTM до этого. А Яндекс запустил новый поисковый движок на основе таких сетей.
Сотрудники DeepMind (компания, известная своим ботом для игры в го, ныне принадлежащая Google) рассказали в своей статье про генерирование аудио.
Если коротко, то исследователи сделали авторегрессионную полносверточную модель WaveNet на основе предыдущих подходов к генерированию изображений (PixelRNN и PixelCNN).
Сеть обучалась end-to-end: на вход текст, на выход аудио. Результат превосходный, разница с человеком сократилась на 50 %.
Основной недостаток сети — низкая производительность, потому что из-за авторегрессии звуки генерируются последовательно, на создание одной секунды аудио уходит около 1—2 минут.
Английский: пример
Если убрать зависимость сети от входного текста и оставить только зависимость от предыдущей сгенерированной фонемы, то сеть будет генерировать подобные человеческому языку фонемы, но бессмысленные.
Генерирование голоса: пример
Эту же модель можно применить не только к речи, но и, например, к созданию музыки. Пример аудио, сгенерированного моделью, которую обучили на датасете игры на пианино (опять же без всякой зависимости от входных данных).
Подробности — в статье.
Еще одна победа машинного обучения над человеком ;) На этот раз — в чтении по губам.
Google Deepmind в сотрудничестве с Оксфордским университетом рассказывают в статье «Lip Reading Sentences in the Wild», как их модель, обученная на телевизионном датасете, смогла превзойти профессионального lips reader’а c канала BBC.
В датасете 100 тыс. предложений с аудио и видео. Модель: LSTM на аудио, CNN + LSTM на видео, эти два state-вектора подаются в итоговую LSTM, которая генерирует результат (characters).
При обучении использовались разные варианты входных данных: аудио, видео, аудио + видео, то есть модель «омниканальна».
Университет Вашингтона проделал серьезную работу по генерированию движения губ бывшего президента США Обамы. Выбор пал на него в том числе из-за огромного количества записей его выступления в сети (17 часов HD-видео).
Одной сетью обойтись не удалось, получалось слишком много артефактов. Поэтому авторы статьи сделали несколько костылей (или трюков, если угодно) по улучшению текстуры и таймингам.
Результат впечатляет. Скоро нельзя будет верить даже видео с президентом ;)
В своих посте и статье команда Google Brain рассказывает, как внедрила в свои Карты новый движок OCR (Optical Character Recognition), с помощью которого распознаются указатели улиц и вывески магазинов.
В процессе разработки технологии компания составила новый FSNS (French Street Name Signs), который содержит множество сложных кейсов.
Сеть использует для распознавания каждого знака до четырех его фотографий. С помощью CNN извлекаются фичи, взвешиваются с помощью spatial attention (учитываются пиксельные координаты), а результат подается в LSTM.
Тот же самый подход авторы применяют к задаче распознавания названий магазинов на вывесках (там может быть много «шумовых» данных, и сеть сама должна «фокусироваться» в нужных местах). Алгоритм применили к 80 млрд фотографий.
Существует такой тип задач, как Visual Reasoning, то есть нейросеть должна по фотографии ответить на какой-то вопрос. Например: «Есть ли на картинке резиновые вещи того же размера, что и желтый металлический цилиндр?» Вопрос и правда нетривиальный, и до недавнего времени задача решалась с точностью всего лишь 68,5 %.
И вновь прорыва добилась команда из Deepmind: на датасете CLEVR они достигли super-human точности в 95,5 %.
Архитектура сети весьма интересная:
Полученное представление прогоняем через еще одну feedforward-сеть, которая уже на софтмаксе выдает ответ.
Интересное применение нейросетям придумала компания Uizard: по скриншоту от дизайнера интерфейсов генерировать код верстки.
Крайне полезное применение нейросетей, которое может облегчить жизнь при разработке софта. Авторы утверждают, что получили 77 % точности. Понятно, что это пока исследовательская работа и о боевом применении речи не идет.
Кода и датасета в open source пока нет, но обещают выложить.
Возможно, вы видели страничку Quick, Draw! от Google с призывом нарисовать скетчи различных объектов за 20 секунд. Корпорация собирала этот датасет для того, чтобы обучить нейросеть рисовать, о чем Google рассказала в своем блоге и статье.
Собранный датасет состоит из 70 тыс. скетчей, он был в итоге выложен в открытый доступ. Скетчи представляют собой не картинки, а детализированные векторные представления рисунков (в какой точке пользователь нажал «карандаш», отпустил, куда провел линию и так далее).
Исследователи обучили Sequence-to-Sequence Variational Autoencoder (VAE) c использованием RNN в качестве механизма кодирования/декодирования.
В итоге, как и положено автоенкодеру, модель получает латентный вектор, который характеризует исходную картинку.
Поскольку декодер умеет извлекать из этого вектора рисунок, то можно его менять и получать новые скетчи.
И даже выполнять векторную арифметику, чтобы соорудить котосвина:
Одна из самых горячих тем в Deep Learning — Generative Adversarial Networks (GAN). Чаще всего эту идею используют для работы с изображениями, поэтому объясню концепцию именно на них.
Суть идеи состоит в соревновании двух сетей — Генератора и Дискриминатора. Первая сеть создает картинку, а вторая пытается понять, реальная это картинка или сгенерированная.
Схематично это выглядит так:
Во время обучения генератор из случайного вектора (шума) генерирует изображение и подает на вход дискриминатору, который говорит, фальшивка это или нет. Дискриминатору также подаются реальные изображения из датасета.
Обучать такую конструкцию часто тяжело из-за того, что трудно найти точку равновесия двух сетей, чаще всего дискриминатор побеждает и обучение стагнирует. Однако преимущество системы в том, что мы можем решать задачи, в которых нам тяжело задать loss-функцию (например, улучшение качества фотографии), мы это отдаем на откуп дискриминатору.
Классический пример результата обучения GAN — картинки спален или лиц.
Ранее мы рассматривали автокодировщики (Sketch-RNN), которые кодируют исходные данные в латентное представление. С генератором получается то же самое.
Очень наглядно идея генерирования изображения по вектору на примере лиц показана тут (можно изменять вектор и посмотреть, какие выходят лица).
Работает все та же арифметика над латентным пространством: «мужчина в очках» минус «мужчина» плюс «женщина» равно «женщина в очках».
Если при обучении подсунуть в латентный вектор контролируемый параметр, то при генерировании его можно менять и так управлять нужным образом на картинке. Этот подход именуется Conditional GAN.
Так поступили авторы статьи «Face Aging With Conditional Generative Adversarial Networks». Обучив машину на датасете IMDB с известным возрастом актеров, исследователи получили возможность менять возраст лица.
В Google нашли еще одно интересное применение GAN — выбор и улучшение фотографий. GAN обучали на датасете профессиональных фотографий: генератор пытается улучшить плохие фотографии (профессионально снятые и ухудшенные с помощью специальных фильтров), а дискриминатор — различить «улучшенные» фотографии и реальные профессиональные.
Обученный алгоритм прошелся по панорамам Google Street View в поиске лучших композиций и получил некоторые снимки профессионального и полупрофессионального качества (по оценкам фотографов).
Впечатляющий пример использования GAN — генерирование картинок по тексту.
Авторы статьи предлагают подавать embedding текста на вход не только генератору (conditional GAN), но и дискриминатору, чтобы он проверял соответствие текста картинке. Чтобы дискриминатор научился выполнять свою функцию, дополнительно в обучение добавляли пары с неверным текстом для реальных картинок.
Одна из ярких статей конца 2016 года — «Image-to-Image Translation with Conditional Adversarial Networks» Berkeley AI Research (BAIR). Исследователи решали проблему image-to-image генерирования, когда, например, требуется по снимку со спутника создать карту или по наброску предметов — их реалистичную текстуру.
Это еще один пример успешной работы conditional GAN, в данном случае condition идет на целую картинку. В качестве архитектуры генератора использовалась UNet, популярная в сегментации изображений, а для борьбы с размытыми изображениями в качестве дискриминатора взяли новый классификатор PatchGAN (картинка нарезается на N патчей, и предсказание fake/real идет по каждому из них в отдельности).
Авторы выпустили онлайн-демо своих сетей, что вызвало огромный интерес у пользователей.
Чтобы применить Pix2Pix, требуется датасет с соответствующими парами картинок из разных доменов. В случае, например, с картами собрать такой датасет не проблема. Но если хочется сделать что-то более сложное вроде «трансфигурирования» объектов или стилизации, то пар объектов не найти в принципе. Поэтому авторы Pix2Pix решили развить свою идею и придумали CycleGAN для трансфера между разными доменами изображений без конкретных пар — Unpaired Image-to-Image Translation.
Идея состоит в следующем: мы учим две пары генератор-дискриминатор из одного домена в другой и обратно, при этом мы требуем cycle consistency — после последовательного применения генераторов должно получиться изображение, похожее на исходное по L1 loss’у. Цикличный loss требуется для того, чтобы генератор не начал просто транслировать картинки одного домена в совершенно не связанные с исходным изображением.
Такой подход позволяет выучить маппинг лошади –> зебры.
Такие трансформации работают нестабильно и часто создают неудачные варианты:
Машинное обучение сейчас приходит и в медицину. Помимо распознавания УЗИ, МРТ и диагностики его можно использовать для поиска новых лекарств для борьбы с раком.
Мы уже подробно писали об этом исследовании тут, поэтому коротко: с помощью Adversarial Auto Encoder (AAE) можно выучить латентное представление молекул и дальше с его помощью искать новые. В результате нашли 69 молекул, половина из которых применяются для борьбы с раком, остальные имеют серьезный потенциал.
Сейчас активно исследуется тема с adversarial-атаками. Что это такое? Стандартные сети, обучаемые, например, на ImageNet, совершенно неустойчивы к добавлению специального шума к классифицируемой картинке. На примере ниже мы видим, что картинка с шумом для человеческого глаза практически не меняется, однако модель сходит с ума и предсказывает совершенно иной класс.
Устойчивость достигается с помощью, например, Fast Gradient Sign Method (FGSM): имея доступ к параметрам модели, можно сделать один или несколько градиентных шагов в сторону нужного класса и изменить исходную картинку.
Одна из задач на Kaggle к грядущему NIPS как раз связана с этим: участникам предлагается создать универсальные атаки/защиты, которые в итоге запускаются все против всех для определения лучших.
Зачем нам вообще исследовать эти атаки? Во-первых, если мы хотим защитить свои продукты, то можно добавлять к капче шум, чтобы мешать спамерам распознавать ее автоматом. Во-вторых, алгоритмы все больше и больше участвуют в нашей жизни — системы распознавания лиц, беспилотные автомобили. При этом злоумышленники могут использовать недостатки алгоритмов. Вот пример, когда специальные очки позволяют обмануть систему распознавания лиц и «представиться» другим человеком. Так что модели надо будет учить с учетом возможных атак.
Такие манипуляции со знаками тоже не позволяют правильно их распознать.
Набор статей от организаторов конкурса.
Уже написанные библиотеки для атак: cleverhans и foolbox.
Reinforcement learning (RL), или обучение с подкреплением, — также сейчас одна из интереснейших и активно развивающихся тем в машинном обучении.
Суть подхода заключается в выучивании успешного поведения агента в среде, которая при взаимодействии дает обратную связь (reward). В общем, через опыт — так же, как учатся люди в течение жизни.
RL активно применяют в играх, роботах, управлении системами (трафиком, например).
Разумеется, все слышали о победах AlphaGo от DeepMind в игре го над лучшими профессионалами. Статья авторов была опубликована в Nature «Mastering the game of Go». При обучении разработчики использовали RL: бот играл сам с собой для совершенствования своих стратегий.
В предыдущие годы DeepMind научился с помощью DQN играть в аркадные игры лучше человека. Сейчас алгоритмы учат играть в более сложные игры типа Doom.
Много внимания уделено ускорению обучения, потому что наработка опыта агента во взаимодействии со средой требует многих часов обучения на современных GPU.
Deepmind в своем блоге рассказывает о том, что введение дополнительных loss’ов (auxiliary tasks, вспомогательных задач), таких как предсказание изменения кадра (pixel control), чтобы агент лучше понимал последствия действий, существенно ускоряет обучение.
Результаты обучения:
В OpenAI активно исследуют обучение человеком агента в виртуальной среде, что более безопасно для экспериментов, чем в реальной жизни ;)
В одном из исследований команда показала, что one-shot learning возможно: человек показывает в VR, как выполнить определенную задачу, и алгоритму достаточно одной демонстрации, чтобы выучить ее и далее воспроизвести в реальных условиях.
Эх, если бы с людьми было так просто ;)
Работа OpenAI и DeepMind на ту же тему. Суть состоит в следующем: у агента есть некая задача, алгоритм предоставляет на суд человеку два возможных варианта решения, и человек указывает, какой лучше. Процесс повторяется итеративно, и алгоритм за 900 бит обратной связи (бинарной разметки) от человека выучился решать задачу.
Как всегда, человеку надо быть осторожным и думать, чему он учит машину. Например, оценщик решил, что алгоритм действительно хотел взять объект, но на самом деле тот лишь имитировал это действие.
Еще одно исследование от DeepMind. Чтобы научить робота сложному поведению (ходить/прыгать/...), да еще и похожему на человеческое, нужно сильно заморочиться с выбором функции потерь, которая будет поощрять нужное поведение. Но хотелось бы, чтобы алгоритм сам выучивал сложное поведение, опираясь на простые reward.
Исследователям удалось этого добиться: они научили агентов (эмуляторы тел) совершать сложные действия с помощью конструирования сложной среды с препятствиями и с простым reward за прогресс в передвижении.
Впечатляющее видео с результатами. Но оно гораздо забавнее с наложенным звуком ;)
Напоследок дам ссылку на опубликованные недавно алгоритмы обучения RL от OpenAI. Теперь можно использовать более современные решения, чем уже ставший стандартным DQN.
В июле 2017-го Google рассказала, что воспользовалась разработками DeepMind в машинном обучении, чтобы сократить энергозатраты своего дата-центра.
На основе информации с тысяч датчиков в дата-центре разработчики Google натренировали ансамбль нейросетей для предсказания PUE (Power Usage Effectiveness) и более эффективного управления дата-центром. Это впечатляющий и значимый пример практического применения ML.
Как вы знаете, обученные модели плохо переносятся от задачи к задаче, под каждую задачу приходится обучать/дообучать специфичную модель. Небольшой шаг в сторону универсальности моделей сделала Google Brain в своей статье «One Model To Learn Them All».
Исследователи обучили модель, которая выполняет восемь задач из разных доменов (текст, речь, изображения). Например, перевод с разных языков, парсинг текста, распознавание изображений и звука.
Для достижения этой цели сделали сложную архитектуру сети с различными блоками для обработки разных входных данных и генерирования результата. Блоки для encoder/decoder делятся на три типа: сверточные, attention, gated mixture of experts (MoE).
Основные итоги обучения:
Кстати, эта модель есть в tensor2tensor.
В своем посте сотрудники Facebook рассказали, как их инженеры смогли добиться обучения модели Resnet-50 на Imagenet всего за один час. Правда, для этого потребовался кластер из 256 GPU (Tesla P100).
Для распределенного обучения использовали Gloo и Caffe2. Чтобы процесс шел эффективно, пришлось адаптировать стратегию обучения при огромном батче (8192 элемента): усреднение градиентов, фаза прогрева, специальные learning rate и тому подобное. Подробнее в статье.
В итоге удалось добиться эффективности 90% при масштабировании от 8 к 256 GPU. Теперь исследователи из Facebook могут экспериментировать еще быстрее, в отличие от простых смертных без такого кластера ;)
Сфера беспилотных автомобилей интенсивно развивается, и машины активно тестируют в боевых условиях. Из относительно недавних событий можно отметить покупку Intel’ом MobilEye, скандал вокруг Uber и украденных экс-сотрудником Google технологий, первую смерть при работе автопилота и многое другое.
Отмечу один момент: Google Waymo запускает бета-программу. Google — пионер в этой области, и предполагается, что их технология очень хороша, ведь машины наездили уже более 3 млн миль.
Также совсем недавно беспилотным автомобилям разрешили колесить по всем штатам США.
Как я уже говорил, современный ML начинает внедряться в медицину. Например, Google сотрудничает с медицинским центром для помощи диагностам.
Deepmind создал даже отдельное подразделение.
В этом году в рамках Data Science Bowl был проведен конкурс по предсказанию рака легких через год на основе подробных снимков, призовой фонд — один миллион долларов.
Сейчас много и усердно инвестируют в ML, как до этого — в BigData.
КНР вкладывает 150 млрд долларов в AI, чтобы стать мировым лидером индустрии.
Для сравнения, в Baidu Research работает 1300 человек, а в том же FAIR (Facebook) — 80. На последнем KDD сотрудники Alibaba рассказывали про свой parameter server KungPeng, который работает на 100 миллиардных выборках при триллионе параметров, что «становится обычной задачей» (с).
Делайте выводы, изучайте ML. Так или иначе со временем все разработчики будут использовать машинное обучение, что станет одной из компетенций, как сегодня — умение работать с базами данных.
|
Метки: author EdT машинное обучение алгоритмы big data блог компании mail.ru group deep learning machine learning |
Достижения в глубоком обучении за последний год |
Привет, Хабр. В своей статье я расскажу вам, что интересного произошло в мире машинного обучения за последний год (в основном в Deep Learning). А произошло очень многое, поэтому я остановился на самых, на мой взгляд, зрелищных и/или значимых достижениях. Технические аспекты улучшения архитектур сетей в статье не приводятся. Расширяем кругозор!
Почти год назад Google анонсировала запуск новой модели для Google Translate. Компания подробно описала архитектуру сети — Recurrent Neural Network (RNN) — в своей статье.
Основной результат: сокращение отставания от человека по точности перевода на 55—85 % (оценивали люди по 6-балльной шкале). Воспроизвести высокие результаты этой модели сложно без огромного датасета, который имеется у Google.
Вы могли слышать дурацкие новости о том, что Facebook выключила своего чат-бота, который вышел из-под контроля и выдумал свой язык. Этого чат-бота компания создала для переговоров. Его цель — вести текстовые переговоры с другим агентом и достичь сделки: как разделить на двоих предметы (книги, шляпы...). У каждого агента своя цель в переговорах, другой ее не знает. Просто уйти с переговоров без сделки нельзя.
Для обучения собрали датасет человеческих переговоров, обучили supervised рекуррентную сеть, далее уже обученного агента с помощью reinforcement learning (обучения с подкреплением) тренировали переговариваться с самим собой, поставив ограничение: похожесть языка на человеческий.
Бот научился одной из стратегий реальных переговоров — показывать поддельный интерес к некоторым аспектам сделки, чтобы потом по ним уступить, получив выгоду по своим настоящим целям. Это первая попытка создания подобного переговорного бота, и довольно удачная.
Подробности — в статье, код выложен в открытый доступ.
Разумеется, новость о том, что бот якобы придумал язык, раздули на пустом месте. При обучении (при переговорах с таким же агентом) отключили ограничение похожести текста на человеческий, и алгоритм модифицировал язык взаимодействия. Ничего необычного.
За последний год рекуррентные сети активно развивали и использовали во многих задачах и приложениях. Архитектуры рекуррентных сетей сильно усложнились, однако по некоторым направлениям похожих результатов достигают и простые feedforward-сети — DSSM. Например, Google для своей почтовой фичи Smart Reply достигла такого же качества, как и с LSTM до этого. А Яндекс запустил новый поисковый движок на основе таких сетей.
Сотрудники DeepMind (компания, известная своим ботом для игры в го, ныне принадлежащая Google) рассказали в своей статье про генерирование аудио.
Если коротко, то исследователи сделали авторегрессионную полносверточную модель WaveNet на основе предыдущих подходов к генерированию изображений (PixelRNN и PixelCNN).
Сеть обучалась end-to-end: на вход текст, на выход аудио. Результат превосходный, разница с человеком сократилась на 50 %.
Основной недостаток сети — низкая производительность, потому что из-за авторегрессии звуки генерируются последовательно, на создание одной секунды аудио уходит около 1—2 минут.
Английский: пример
Если убрать зависимость сети от входного текста и оставить только зависимость от предыдущей сгенерированной фонемы, то сеть будет генерировать подобные человеческому языку фонемы, но бессмысленные.
Генерирование голоса: пример
Эту же модель можно применить не только к речи, но и, например, к созданию музыки. Пример аудио, сгенерированного моделью, которую обучили на датасете игры на пианино (опять же без всякой зависимости от входных данных).
Подробности — в статье.
Еще одна победа машинного обучения над человеком ;) На этот раз — в чтении по губам.
Google Deepmind в сотрудничестве с Оксфордским университетом рассказывают в статье «Lip Reading Sentences in the Wild», как их модель, обученная на телевизионном датасете, смогла превзойти профессионального lips reader’а c канала BBC.
В датасете 100 тыс. предложений с аудио и видео. Модель: LSTM на аудио, CNN + LSTM на видео, эти два state-вектора подаются в итоговую LSTM, которая генерирует результат (characters).
При обучении использовались разные варианты входных данных: аудио, видео, аудио + видео, то есть модель «омниканальна».
Университет Вашингтона проделал серьезную работу по генерированию движения губ бывшего президента США Обамы. Выбор пал на него в том числе из-за огромного количества записей его выступления в сети (17 часов HD-видео).
Одной сетью обойтись не удалось, получалось слишком много артефактов. Поэтому авторы статьи сделали несколько костылей (или трюков, если угодно) по улучшению текстуры и таймингам.
Результат впечатляет. Скоро нельзя будет верить даже видео с президентом ;)
В своих посте и статье команда Google Brain рассказывает, как внедрила в свои Карты новый движок OCR (Optical Character Recognition), с помощью которого распознаются указатели улиц и вывески магазинов.
В процессе разработки технологии компания составила новый FSNS (French Street Name Signs), который содержит множество сложных кейсов.
Сеть использует для распознавания каждого знака до четырех его фотографий. С помощью CNN извлекаются фичи, взвешиваются с помощью spatial attention (учитываются пиксельные координаты), а результат подается в LSTM.
Тот же самый подход авторы применяют к задаче распознавания названий магазинов на вывесках (там может быть много «шумовых» данных, и сеть сама должна «фокусироваться» в нужных местах). Алгоритм применили к 80 млрд фотографий.
Существует такой тип задач, как Visual Reasoning, то есть нейросеть должна по фотографии ответить на какой-то вопрос. Например: «Есть ли на картинке резиновые вещи того же размера, что и желтый металлический цилиндр?» Вопрос и правда нетривиальный, и до недавнего времени задача решалась с точностью всего лишь 68,5 %.
И вновь прорыва добилась команда из Deepmind: на датасете CLEVR они достигли super-human точности в 95,5 %.
Архитектура сети весьма интересная:
Полученное представление прогоняем через еще одну feedforward-сеть, которая уже на софтмаксе выдает ответ.
Интересное применение нейросетям придумала компания Uizard: по скриншоту от дизайнера интерфейсов генерировать код верстки.
Крайне полезное применение нейросетей, которое может облегчить жизнь при разработке софта. Авторы утверждают, что получили 77 % точности. Понятно, что это пока исследовательская работа и о боевом применении речи не идет.
Кода и датасета в open source пока нет, но обещают выложить.
Возможно, вы видели страничку Quick, Draw! от Google с призывом нарисовать скетчи различных объектов за 20 секунд. Корпорация собирала этот датасет для того, чтобы обучить нейросеть рисовать, о чем Google рассказала в своем блоге и статье.
Собранный датасет состоит из 70 тыс. скетчей, он был в итоге выложен в открытый доступ. Скетчи представляют собой не картинки, а детализированные векторные представления рисунков (в какой точке пользователь нажал «карандаш», отпустил, куда провел линию и так далее).
Исследователи обучили Sequence-to-Sequence Variational Autoencoder (VAE) c использованием RNN в качестве механизма кодирования/декодирования.
В итоге, как и положено автоенкодеру, модель получает латентный вектор, который характеризует исходную картинку.
Поскольку декодер умеет извлекать из этого вектора рисунок, то можно его менять и получать новые скетчи.
И даже выполнять векторную арифметику, чтобы соорудить котосвина:
Одна из самых горячих тем в Deep Learning — Generative Adversarial Networks (GAN). Чаще всего эту идею используют для работы с изображениями, поэтому объясню концепцию именно на них.
Суть идеи состоит в соревновании двух сетей — Генератора и Дискриминатора. Первая сеть создает картинку, а вторая пытается понять, реальная это картинка или сгенерированная.
Схематично это выглядит так:
Во время обучения генератор из случайного вектора (шума) генерирует изображение и подает на вход дискриминатору, который говорит, фальшивка это или нет. Дискриминатору также подаются реальные изображения из датасета.
Обучать такую конструкцию часто тяжело из-за того, что трудно найти точку равновесия двух сетей, чаще всего дискриминатор побеждает и обучение стагнирует. Однако преимущество системы в том, что мы можем решать задачи, в которых нам тяжело задать loss-функцию (например, улучшение качества фотографии), мы это отдаем на откуп дискриминатору.
Классический пример результата обучения GAN — картинки спален или лиц.
Ранее мы рассматривали автокодировщики (Sketch-RNN), которые кодируют исходные данные в латентное представление. С генератором получается то же самое.
Очень наглядно идея генерирования изображения по вектору на примере лиц показана тут (можно изменять вектор и посмотреть, какие выходят лица).
Работает все та же арифметика над латентным пространством: «мужчина в очках» минус «мужчина» плюс «женщина» равно «женщина в очках».
Если при обучении подсунуть в латентный вектор контролируемый параметр, то при генерировании его можно менять и так управлять нужным образом на картинке. Этот подход именуется Conditional GAN.
Так поступили авторы статьи «Face Aging With Conditional Generative Adversarial Networks». Обучив машину на датасете IMDB с известным возрастом актеров, исследователи получили возможность менять возраст лица.
В Google нашли еще одно интересное применение GAN — выбор и улучшение фотографий. GAN обучали на датасете профессиональных фотографий: генератор пытается улучшить плохие фотографии (профессионально снятые и ухудшенные с помощью специальных фильтров), а дискриминатор — различить «улучшенные» фотографии и реальные профессиональные.
Обученный алгоритм прошелся по панорамам Google Street View в поиске лучших композиций и получил некоторые снимки профессионального и полупрофессионального качества (по оценкам фотографов).
Впечатляющий пример использования GAN — генерирование картинок по тексту.
Авторы статьи предлагают подавать embedding текста на вход не только генератору (conditional GAN), но и дискриминатору, чтобы он проверял соответствие текста картинке. Чтобы дискриминатор научился выполнять свою функцию, дополнительно в обучение добавляли пары с неверным текстом для реальных картинок.
Одна из ярких статей конца 2016 года — «Image-to-Image Translation with Conditional Adversarial Networks» Berkeley AI Research (BAIR). Исследователи решали проблему image-to-image генерирования, когда, например, требуется по снимку со спутника создать карту или по наброску предметов — их реалистичную текстуру.
Это еще один пример успешной работы conditional GAN, в данном случае condition идет на целую картинку. В качестве архитектуры генератора использовалась UNet, популярная в сегментации изображений, а для борьбы с размытыми изображениями в качестве дискриминатора взяли новый классификатор PatchGAN (картинка нарезается на N патчей, и предсказание fake/real идет по каждому из них в отдельности).
Авторы выпустили онлайн-демо своих сетей, что вызвало огромный интерес у пользователей.
Чтобы применить Pix2Pix, требуется датасет с соответствующими парами картинок из разных доменов. В случае, например, с картами собрать такой датасет не проблема. Но если хочется сделать что-то более сложное вроде «трансфигурирования» объектов или стилизации, то пар объектов не найти в принципе. Поэтому авторы Pix2Pix решили развить свою идею и придумали CycleGAN для трансфера между разными доменами изображений без конкретных пар — Unpaired Image-to-Image Translation.
Идея состоит в следующем: мы учим две пары генератор-дискриминатор из одного домена в другой и обратно, при этом мы требуем cycle consistency — после последовательного применения генераторов должно получиться изображение, похожее на исходное по L1 loss’у. Цикличный loss требуется для того, чтобы генератор не начал просто транслировать картинки одного домена в совершенно не связанные с исходным изображением.
Такой подход позволяет выучить маппинг лошади –> зебры.
Такие трансформации работают нестабильно и часто создают неудачные варианты:
Машинное обучение сейчас приходит и в медицину. Помимо распознавания УЗИ, МРТ и диагностики его можно использовать для поиска новых лекарств для борьбы с раком.
Мы уже подробно писали об этом исследовании тут, поэтому коротко: с помощью Adversarial Auto Encoder (AAE) можно выучить латентное представление молекул и дальше с его помощью искать новые. В результате нашли 69 молекул, половина из которых применяются для борьбы с раком, остальные имеют серьезный потенциал.
Сейчас активно исследуется тема с adversarial-атаками. Что это такое? Стандартные сети, обучаемые, например, на ImageNet, совершенно неустойчивы к добавлению специального шума к классифицируемой картинке. На примере ниже мы видим, что картинка с шумом для человеческого глаза практически не меняется, однако модель сходит с ума и предсказывает совершенно иной класс.
Устойчивость достигается с помощью, например, Fast Gradient Sign Method (FGSM): имея доступ к параметрам модели, можно сделать один или несколько градиентных шагов в сторону нужного класса и изменить исходную картинку.
Одна из задач на Kaggle к грядущему NIPS как раз связана с этим: участникам предлагается создать универсальные атаки/защиты, которые в итоге запускаются все против всех для определения лучших.
Зачем нам вообще исследовать эти атаки? Во-первых, если мы хотим защитить свои продукты, то можно добавлять к капче шум, чтобы мешать спамерам распознавать ее автоматом. Во-вторых, алгоритмы все больше и больше участвуют в нашей жизни — системы распознавания лиц, беспилотные автомобили. При этом злоумышленники могут использовать недостатки алгоритмов. Вот пример, когда специальные очки позволяют обмануть систему распознавания лиц и «представиться» другим человеком. Так что модели надо будет учить с учетом возможных атак.
Такие манипуляции со знаками тоже не позволяют правильно их распознать.
Набор статей от организаторов конкурса.
Уже написанные библиотеки для атак: cleverhans и foolbox.
Reinforcement learning (RL), или обучение с подкреплением, — также сейчас одна из интереснейших и активно развивающихся тем в машинном обучении.
Суть подхода заключается в выучивании успешного поведения агента в среде, которая при взаимодействии дает обратную связь (reward). В общем, через опыт — так же, как учатся люди в течение жизни.
RL активно применяют в играх, роботах, управлении системами (трафиком, например).
Разумеется, все слышали о победах AlphaGo от DeepMind в игре го над лучшими профессионалами. Статья авторов была опубликована в Nature «Mastering the game of Go». При обучении разработчики использовали RL: бот играл сам с собой для совершенствования своих стратегий.
В предыдущие годы DeepMind научился с помощью DQN играть в аркадные игры лучше человека. Сейчас алгоритмы учат играть в более сложные игры типа Doom.
Много внимания уделено ускорению обучения, потому что наработка опыта агента во взаимодействии со средой требует многих часов обучения на современных GPU.
Deepmind в своем блоге рассказывает о том, что введение дополнительных loss’ов (auxiliary tasks, вспомогательных задач), таких как предсказание изменения кадра (pixel control), чтобы агент лучше понимал последствия действий, существенно ускоряет обучение.
Результаты обучения:
В OpenAI активно исследуют обучение человеком агента в виртуальной среде, что более безопасно для экспериментов, чем в реальной жизни ;)
В одном из исследований команда показала, что one-shot learning возможно: человек показывает в VR, как выполнить определенную задачу, и алгоритму достаточно одной демонстрации, чтобы выучить ее и далее воспроизвести в реальных условиях.
Эх, если бы с людьми было так просто ;)
Работа OpenAI и DeepMind на ту же тему. Суть состоит в следующем: у агента есть некая задача, алгоритм предоставляет на суд человеку два возможных варианта решения, и человек указывает, какой лучше. Процесс повторяется итеративно, и алгоритм за 900 бит обратной связи (бинарной разметки) от человека выучился решать задачу.
Как всегда, человеку надо быть осторожным и думать, чему он учит машину. Например, оценщик решил, что алгоритм действительно хотел взять объект, но на самом деле тот лишь имитировал это действие.
Еще одно исследование от DeepMind. Чтобы научить робота сложному поведению (ходить/прыгать/...), да еще и похожему на человеческое, нужно сильно заморочиться с выбором функции потерь, которая будет поощрять нужное поведение. Но хотелось бы, чтобы алгоритм сам выучивал сложное поведение, опираясь на простые reward.
Исследователям удалось этого добиться: они научили агентов (эмуляторы тел) совершать сложные действия с помощью конструирования сложной среды с препятствиями и с простым reward за прогресс в передвижении.
Впечатляющее видео с результатами. Но оно гораздо забавнее с наложенным звуком ;)
Напоследок дам ссылку на опубликованные недавно алгоритмы обучения RL от OpenAI. Теперь можно использовать более современные решения, чем уже ставший стандартным DQN.
В июле 2017-го Google рассказала, что воспользовалась разработками DeepMind в машинном обучении, чтобы сократить энергозатраты своего дата-центра.
На основе информации с тысяч датчиков в дата-центре разработчики Google натренировали ансамбль нейросетей для предсказания PUE (Power Usage Effectiveness) и более эффективного управления дата-центром. Это впечатляющий и значимый пример практического применения ML.
Как вы знаете, обученные модели плохо переносятся от задачи к задаче, под каждую задачу приходится обучать/дообучать специфичную модель. Небольшой шаг в сторону универсальности моделей сделала Google Brain в своей статье «One Model To Learn Them All».
Исследователи обучили модель, которая выполняет восемь задач из разных доменов (текст, речь, изображения). Например, перевод с разных языков, парсинг текста, распознавание изображений и звука.
Для достижения этой цели сделали сложную архитектуру сети с различными блоками для обработки разных входных данных и генерирования результата. Блоки для encoder/decoder делятся на три типа: сверточные, attention, gated mixture of experts (MoE).
Основные итоги обучения:
Кстати, эта модель есть в tensor2tensor.
В своем посте сотрудники Facebook рассказали, как их инженеры смогли добиться обучения модели Resnet-50 на Imagenet всего за один час. Правда, для этого потребовался кластер из 256 GPU (Tesla P100).
Для распределенного обучения использовали Gloo и Caffe2. Чтобы процесс шел эффективно, пришлось адаптировать стратегию обучения при огромном батче (8192 элемента): усреднение градиентов, фаза прогрева, специальные learning rate и тому подобное. Подробнее в статье.
В итоге удалось добиться эффективности 90% при масштабировании от 8 к 256 GPU. Теперь исследователи из Facebook могут экспериментировать еще быстрее, в отличие от простых смертных без такого кластера ;)
Сфера беспилотных автомобилей интенсивно развивается, и машины активно тестируют в боевых условиях. Из относительно недавних событий можно отметить покупку Intel’ом MobilEye, скандал вокруг Uber и украденных экс-сотрудником Google технологий, первую смерть при работе автопилота и многое другое.
Отмечу один момент: Google Waymo запускает бета-программу. Google — пионер в этой области, и предполагается, что их технология очень хороша, ведь машины наездили уже более 3 млн миль.
Также совсем недавно беспилотным автомобилям разрешили колесить по всем штатам США.
Как я уже говорил, современный ML начинает внедряться в медицину. Например, Google сотрудничает с медицинским центром для помощи диагностам.
Deepmind создал даже отдельное подразделение.
В этом году в рамках Data Science Bowl был проведен конкурс по предсказанию рака легких через год на основе подробных снимков, призовой фонд — один миллион долларов.
Сейчас много и усердно инвестируют в ML, как до этого — в BigData.
КНР вкладывает 150 млрд долларов в AI, чтобы стать мировым лидером индустрии.
Для сравнения, в Baidu Research работает 1300 человек, а в том же FAIR (Facebook) — 80. На последнем KDD сотрудники Alibaba рассказывали про свой parameter server KungPeng, который работает на 100 миллиардных выборках при триллионе параметров, что «становится обычной задачей» (с).
Делайте выводы, изучайте ML. Так или иначе со временем все разработчики будут использовать машинное обучение, что станет одной из компетенций, как сегодня — умение работать с базами данных.
|
Метки: author EdT машинное обучение алгоритмы big data блог компании mail.ru group deep learning machine learning |
Достижения в глубоком обучении за последний год |
Привет, Хабр. В своей статье я расскажу вам, что интересного произошло в мире машинного обучения за последний год (в основном в Deep Learning). А произошло очень многое, поэтому я остановился на самых, на мой взгляд, зрелищных и/или значимых достижениях. Технические аспекты улучшения архитектур сетей в статье не приводятся. Расширяем кругозор!
Почти год назад Google анонсировала запуск новой модели для Google Translate. Компания подробно описала архитектуру сети — Recurrent Neural Network (RNN) — в своей статье.
Основной результат: сокращение отставания от человека по точности перевода на 55—85 % (оценивали люди по 6-балльной шкале). Воспроизвести высокие результаты этой модели сложно без огромного датасета, который имеется у Google.
Вы могли слышать дурацкие новости о том, что Facebook выключила своего чат-бота, который вышел из-под контроля и выдумал свой язык. Этого чат-бота компания создала для переговоров. Его цель — вести текстовые переговоры с другим агентом и достичь сделки: как разделить на двоих предметы (книги, шляпы...). У каждого агента своя цель в переговорах, другой ее не знает. Просто уйти с переговоров без сделки нельзя.
Для обучения собрали датасет человеческих переговоров, обучили supervised рекуррентную сеть, далее уже обученного агента с помощью reinforcement learning (обучения с подкреплением) тренировали переговариваться с самим собой, поставив ограничение: похожесть языка на человеческий.
Бот научился одной из стратегий реальных переговоров — показывать поддельный интерес к некоторым аспектам сделки, чтобы потом по ним уступить, получив выгоду по своим настоящим целям. Это первая попытка создания подобного переговорного бота, и довольно удачная.
Подробности — в статье, код выложен в открытый доступ.
Разумеется, новость о том, что бот якобы придумал язык, раздули на пустом месте. При обучении (при переговорах с таким же агентом) отключили ограничение похожести текста на человеческий, и алгоритм модифицировал язык взаимодействия. Ничего необычного.
За последний год рекуррентные сети активно развивали и использовали во многих задачах и приложениях. Архитектуры рекуррентных сетей сильно усложнились, однако по некоторым направлениям похожих результатов достигают и простые feedforward-сети — DSSM. Например, Google для своей почтовой фичи Smart Reply достигла такого же качества, как и с LSTM до этого. А Яндекс запустил новый поисковый движок на основе таких сетей.
Сотрудники DeepMind (компания, известная своим ботом для игры в го, ныне принадлежащая Google) рассказали в своей статье про генерирование аудио.
Если коротко, то исследователи сделали авторегрессионную полносверточную модель WaveNet на основе предыдущих подходов к генерированию изображений (PixelRNN и PixelCNN).
Сеть обучалась end-to-end: на вход текст, на выход аудио. Результат превосходный, разница с человеком сократилась на 50 %.
Основной недостаток сети — низкая производительность, потому что из-за авторегрессии звуки генерируются последовательно, на создание одной секунды аудио уходит около 1—2 минут.
Английский: пример
Если убрать зависимость сети от входного текста и оставить только зависимость от предыдущей сгенерированной фонемы, то сеть будет генерировать подобные человеческому языку фонемы, но бессмысленные.
Генерирование голоса: пример
Эту же модель можно применить не только к речи, но и, например, к созданию музыки. Пример аудио, сгенерированного моделью, которую обучили на датасете игры на пианино (опять же без всякой зависимости от входных данных).
Подробности — в статье.
Еще одна победа машинного обучения над человеком ;) На этот раз — в чтении по губам.
Google Deepmind в сотрудничестве с Оксфордским университетом рассказывают в статье «Lip Reading Sentences in the Wild», как их модель, обученная на телевизионном датасете, смогла превзойти профессионального lips reader’а c канала BBC.
В датасете 100 тыс. предложений с аудио и видео. Модель: LSTM на аудио, CNN + LSTM на видео, эти два state-вектора подаются в итоговую LSTM, которая генерирует результат (characters).
При обучении использовались разные варианты входных данных: аудио, видео, аудио + видео, то есть модель «омниканальна».
Университет Вашингтона проделал серьезную работу по генерированию движения губ бывшего президента США Обамы. Выбор пал на него в том числе из-за огромного количества записей его выступления в сети (17 часов HD-видео).
Одной сетью обойтись не удалось, получалось слишком много артефактов. Поэтому авторы статьи сделали несколько костылей (или трюков, если угодно) по улучшению текстуры и таймингам.
Результат впечатляет. Скоро нельзя будет верить даже видео с президентом ;)
В своих посте и статье команда Google Brain рассказывает, как внедрила в свои Карты новый движок OCR (Optical Character Recognition), с помощью которого распознаются указатели улиц и вывески магазинов.
В процессе разработки технологии компания составила новый FSNS (French Street Name Signs), который содержит множество сложных кейсов.
Сеть использует для распознавания каждого знака до четырех его фотографий. С помощью CNN извлекаются фичи, взвешиваются с помощью spatial attention (учитываются пиксельные координаты), а результат подается в LSTM.
Тот же самый подход авторы применяют к задаче распознавания названий магазинов на вывесках (там может быть много «шумовых» данных, и сеть сама должна «фокусироваться» в нужных местах). Алгоритм применили к 80 млрд фотографий.
Существует такой тип задач, как Visual Reasoning, то есть нейросеть должна по фотографии ответить на какой-то вопрос. Например: «Есть ли на картинке резиновые вещи того же размера, что и желтый металлический цилиндр?» Вопрос и правда нетривиальный, и до недавнего времени задача решалась с точностью всего лишь 68,5 %.
И вновь прорыва добилась команда из Deepmind: на датасете CLEVR они достигли super-human точности в 95,5 %.
Архитектура сети весьма интересная:
Полученное представление прогоняем через еще одну feedforward-сеть, которая уже на софтмаксе выдает ответ.
Интересное применение нейросетям придумала компания Uizard: по скриншоту от дизайнера интерфейсов генерировать код верстки.
Крайне полезное применение нейросетей, которое может облегчить жизнь при разработке софта. Авторы утверждают, что получили 77 % точности. Понятно, что это пока исследовательская работа и о боевом применении речи не идет.
Кода и датасета в open source пока нет, но обещают выложить.
Возможно, вы видели страничку Quick, Draw! от Google с призывом нарисовать скетчи различных объектов за 20 секунд. Корпорация собирала этот датасет для того, чтобы обучить нейросеть рисовать, о чем Google рассказала в своем блоге и статье.
Собранный датасет состоит из 70 тыс. скетчей, он был в итоге выложен в открытый доступ. Скетчи представляют собой не картинки, а детализированные векторные представления рисунков (в какой точке пользователь нажал «карандаш», отпустил, куда провел линию и так далее).
Исследователи обучили Sequence-to-Sequence Variational Autoencoder (VAE) c использованием RNN в качестве механизма кодирования/декодирования.
В итоге, как и положено автоенкодеру, модель получает латентный вектор, который характеризует исходную картинку.
Поскольку декодер умеет извлекать из этого вектора рисунок, то можно его менять и получать новые скетчи.
И даже выполнять векторную арифметику, чтобы соорудить котосвина:
Одна из самых горячих тем в Deep Learning — Generative Adversarial Networks (GAN). Чаще всего эту идею используют для работы с изображениями, поэтому объясню концепцию именно на них.
Суть идеи состоит в соревновании двух сетей — Генератора и Дискриминатора. Первая сеть создает картинку, а вторая пытается понять, реальная это картинка или сгенерированная.
Схематично это выглядит так:
Во время обучения генератор из случайного вектора (шума) генерирует изображение и подает на вход дискриминатору, который говорит, фальшивка это или нет. Дискриминатору также подаются реальные изображения из датасета.
Обучать такую конструкцию часто тяжело из-за того, что трудно найти точку равновесия двух сетей, чаще всего дискриминатор побеждает и обучение стагнирует. Однако преимущество системы в том, что мы можем решать задачи, в которых нам тяжело задать loss-функцию (например, улучшение качества фотографии), мы это отдаем на откуп дискриминатору.
Классический пример результата обучения GAN — картинки спален или лиц.
Ранее мы рассматривали автокодировщики (Sketch-RNN), которые кодируют исходные данные в латентное представление. С генератором получается то же самое.
Очень наглядно идея генерирования изображения по вектору на примере лиц показана тут (можно изменять вектор и посмотреть, какие выходят лица).
Работает все та же арифметика над латентным пространством: «мужчина в очках» минус «мужчина» плюс «женщина» равно «женщина в очках».
Если при обучении подсунуть в латентный вектор контролируемый параметр, то при генерировании его можно менять и так управлять нужным образом на картинке. Этот подход именуется Conditional GAN.
Так поступили авторы статьи «Face Aging With Conditional Generative Adversarial Networks». Обучив машину на датасете IMDB с известным возрастом актеров, исследователи получили возможность менять возраст лица.
В Google нашли еще одно интересное применение GAN — выбор и улучшение фотографий. GAN обучали на датасете профессиональных фотографий: генератор пытается улучшить плохие фотографии (профессионально снятые и ухудшенные с помощью специальных фильтров), а дискриминатор — различить «улучшенные» фотографии и реальные профессиональные.
Обученный алгоритм прошелся по панорамам Google Street View в поиске лучших композиций и получил некоторые снимки профессионального и полупрофессионального качества (по оценкам фотографов).
Впечатляющий пример использования GAN — генерирование картинок по тексту.
Авторы статьи предлагают подавать embedding текста на вход не только генератору (conditional GAN), но и дискриминатору, чтобы он проверял соответствие текста картинке. Чтобы дискриминатор научился выполнять свою функцию, дополнительно в обучение добавляли пары с неверным текстом для реальных картинок.
Одна из ярких статей конца 2016 года — «Image-to-Image Translation with Conditional Adversarial Networks» Berkeley AI Research (BAIR). Исследователи решали проблему image-to-image генерирования, когда, например, требуется по снимку со спутника создать карту или по наброску предметов — их реалистичную текстуру.
Это еще один пример успешной работы conditional GAN, в данном случае condition идет на целую картинку. В качестве архитектуры генератора использовалась UNet, популярная в сегментации изображений, а для борьбы с размытыми изображениями в качестве дискриминатора взяли новый классификатор PatchGAN (картинка нарезается на N патчей, и предсказание fake/real идет по каждому из них в отдельности).
Авторы выпустили онлайн-демо своих сетей, что вызвало огромный интерес у пользователей.
Чтобы применить Pix2Pix, требуется датасет с соответствующими парами картинок из разных доменов. В случае, например, с картами собрать такой датасет не проблема. Но если хочется сделать что-то более сложное вроде «трансфигурирования» объектов или стилизации, то пар объектов не найти в принципе. Поэтому авторы Pix2Pix решили развить свою идею и придумали CycleGAN для трансфера между разными доменами изображений без конкретных пар — Unpaired Image-to-Image Translation.
Идея состоит в следующем: мы учим две пары генератор-дискриминатор из одного домена в другой и обратно, при этом мы требуем cycle consistency — после последовательного применения генераторов должно получиться изображение, похожее на исходное по L1 loss’у. Цикличный loss требуется для того, чтобы генератор не начал просто транслировать картинки одного домена в совершенно не связанные с исходным изображением.
Такой подход позволяет выучить маппинг лошади –> зебры.
Такие трансформации работают нестабильно и часто создают неудачные варианты:
Машинное обучение сейчас приходит и в медицину. Помимо распознавания УЗИ, МРТ и диагностики его можно использовать для поиска новых лекарств для борьбы с раком.
Мы уже подробно писали об этом исследовании тут, поэтому коротко: с помощью Adversarial Auto Encoder (AAE) можно выучить латентное представление молекул и дальше с его помощью искать новые. В результате нашли 69 молекул, половина из которых применяются для борьбы с раком, остальные имеют серьезный потенциал.
Сейчас активно исследуется тема с adversarial-атаками. Что это такое? Стандартные сети, обучаемые, например, на ImageNet, совершенно неустойчивы к добавлению специального шума к классифицируемой картинке. На примере ниже мы видим, что картинка с шумом для человеческого глаза практически не меняется, однако модель сходит с ума и предсказывает совершенно иной класс.
Устойчивость достигается с помощью, например, Fast Gradient Sign Method (FGSM): имея доступ к параметрам модели, можно сделать один или несколько градиентных шагов в сторону нужного класса и изменить исходную картинку.
Одна из задач на Kaggle к грядущему NIPS как раз связана с этим: участникам предлагается создать универсальные атаки/защиты, которые в итоге запускаются все против всех для определения лучших.
Зачем нам вообще исследовать эти атаки? Во-первых, если мы хотим защитить свои продукты, то можно добавлять к капче шум, чтобы мешать спамерам распознавать ее автоматом. Во-вторых, алгоритмы все больше и больше участвуют в нашей жизни — системы распознавания лиц, беспилотные автомобили. При этом злоумышленники могут использовать недостатки алгоритмов. Вот пример, когда специальные очки позволяют обмануть систему распознавания лиц и «представиться» другим человеком. Так что модели надо будет учить с учетом возможных атак.
Такие манипуляции со знаками тоже не позволяют правильно их распознать.
Набор статей от организаторов конкурса.
Уже написанные библиотеки для атак: cleverhans и foolbox.
Reinforcement learning (RL), или обучение с подкреплением, — также сейчас одна из интереснейших и активно развивающихся тем в машинном обучении.
Суть подхода заключается в выучивании успешного поведения агента в среде, которая при взаимодействии дает обратную связь (reward). В общем, через опыт — так же, как учатся люди в течение жизни.
RL активно применяют в играх, роботах, управлении системами (трафиком, например).
Разумеется, все слышали о победах AlphaGo от DeepMind в игре го над лучшими профессионалами. Статья авторов была опубликована в Nature «Mastering the game of Go». При обучении разработчики использовали RL: бот играл сам с собой для совершенствования своих стратегий.
В предыдущие годы DeepMind научился с помощью DQN играть в аркадные игры лучше человека. Сейчас алгоритмы учат играть в более сложные игры типа Doom.
Много внимания уделено ускорению обучения, потому что наработка опыта агента во взаимодействии со средой требует многих часов обучения на современных GPU.
Deepmind в своем блоге рассказывает о том, что введение дополнительных loss’ов (auxiliary tasks, вспомогательных задач), таких как предсказание изменения кадра (pixel control), чтобы агент лучше понимал последствия действий, существенно ускоряет обучение.
Результаты обучения:
В OpenAI активно исследуют обучение человеком агента в виртуальной среде, что более безопасно для экспериментов, чем в реальной жизни ;)
В одном из исследований команда показала, что one-shot learning возможно: человек показывает в VR, как выполнить определенную задачу, и алгоритму достаточно одной демонстрации, чтобы выучить ее и далее воспроизвести в реальных условиях.
Эх, если бы с людьми было так просто ;)
Работа OpenAI и DeepMind на ту же тему. Суть состоит в следующем: у агента есть некая задача, алгоритм предоставляет на суд человеку два возможных варианта решения, и человек указывает, какой лучше. Процесс повторяется итеративно, и алгоритм за 900 бит обратной связи (бинарной разметки) от человека выучился решать задачу.
Как всегда, человеку надо быть осторожным и думать, чему он учит машину. Например, оценщик решил, что алгоритм действительно хотел взять объект, но на самом деле тот лишь имитировал это действие.
Еще одно исследование от DeepMind. Чтобы научить робота сложному поведению (ходить/прыгать/...), да еще и похожему на человеческое, нужно сильно заморочиться с выбором функции потерь, которая будет поощрять нужное поведение. Но хотелось бы, чтобы алгоритм сам выучивал сложное поведение, опираясь на простые reward.
Исследователям удалось этого добиться: они научили агентов (эмуляторы тел) совершать сложные действия с помощью конструирования сложной среды с препятствиями и с простым reward за прогресс в передвижении.
Впечатляющее видео с результатами. Но оно гораздо забавнее с наложенным звуком ;)
Напоследок дам ссылку на опубликованные недавно алгоритмы обучения RL от OpenAI. Теперь можно использовать более современные решения, чем уже ставший стандартным DQN.
В июле 2017-го Google рассказала, что воспользовалась разработками DeepMind в машинном обучении, чтобы сократить энергозатраты своего дата-центра.
На основе информации с тысяч датчиков в дата-центре разработчики Google натренировали ансамбль нейросетей для предсказания PUE (Power Usage Effectiveness) и более эффективного управления дата-центром. Это впечатляющий и значимый пример практического применения ML.
Как вы знаете, обученные модели плохо переносятся от задачи к задаче, под каждую задачу приходится обучать/дообучать специфичную модель. Небольшой шаг в сторону универсальности моделей сделала Google Brain в своей статье «One Model To Learn Them All».
Исследователи обучили модель, которая выполняет восемь задач из разных доменов (текст, речь, изображения). Например, перевод с разных языков, парсинг текста, распознавание изображений и звука.
Для достижения этой цели сделали сложную архитектуру сети с различными блоками для обработки разных входных данных и генерирования результата. Блоки для encoder/decoder делятся на три типа: сверточные, attention, gated mixture of experts (MoE).
Основные итоги обучения:
Кстати, эта модель есть в tensor2tensor.
В своем посте сотрудники Facebook рассказали, как их инженеры смогли добиться обучения модели Resnet-50 на Imagenet всего за один час. Правда, для этого потребовался кластер из 256 GPU (Tesla P100).
Для распределенного обучения использовали Gloo и Caffe2. Чтобы процесс шел эффективно, пришлось адаптировать стратегию обучения при огромном батче (8192 элемента): усреднение градиентов, фаза прогрева, специальные learning rate и тому подобное. Подробнее в статье.
В итоге удалось добиться эффективности 90% при масштабировании от 8 к 256 GPU. Теперь исследователи из Facebook могут экспериментировать еще быстрее, в отличие от простых смертных без такого кластера ;)
Сфера беспилотных автомобилей интенсивно развивается, и машины активно тестируют в боевых условиях. Из относительно недавних событий можно отметить покупку Intel’ом MobilEye, скандал вокруг Uber и украденных экс-сотрудником Google технологий, первую смерть при работе автопилота и многое другое.
Отмечу один момент: Google Waymo запускает бета-программу. Google — пионер в этой области, и предполагается, что их технология очень хороша, ведь машины наездили уже более 3 млн миль.
Также совсем недавно беспилотным автомобилям разрешили колесить по всем штатам США.
Как я уже говорил, современный ML начинает внедряться в медицину. Например, Google сотрудничает с медицинским центром для помощи диагностам.
Deepmind создал даже отдельное подразделение.
В этом году в рамках Data Science Bowl был проведен конкурс по предсказанию рака легких через год на основе подробных снимков, призовой фонд — один миллион долларов.
Сейчас много и усердно инвестируют в ML, как до этого — в BigData.
КНР вкладывает 150 млрд долларов в AI, чтобы стать мировым лидером индустрии.
Для сравнения, в Baidu Research работает 1300 человек, а в том же FAIR (Facebook) — 80. На последнем KDD сотрудники Alibaba рассказывали про свой parameter server KungPeng, который работает на 100 миллиардных выборках при триллионе параметров, что «становится обычной задачей» (с).
Делайте выводы, изучайте ML. Так или иначе со временем все разработчики будут использовать машинное обучение, что станет одной из компетенций, как сегодня — умение работать с базами данных.
|
Метки: author EdT машинное обучение алгоритмы big data блог компании mail.ru group deep learning machine learning |
Uptime day 2: российские ИТ-компании расскажут о том, как справляются с катастрофами |


|
Метки: author eapotapov системное администрирование серверное администрирование блог компании itsumma uptime конференции |
Uptime day 2: российские ИТ-компании расскажут о том, как справляются с катастрофами |
|
Метки: author eapotapov системное администрирование серверное администрирование блог компании itsumma uptime конференции |
Uptime day 2: российские ИТ-компании расскажут о том, как справляются с катастрофами |
|
Метки: author eapotapov системное администрирование серверное администрирование блог компании itsumma uptime конференции |
Uptime day 2: российские ИТ-компании расскажут о том, как справляются с катастрофами |
|
Метки: author eapotapov системное администрирование серверное администрирование блог компании itsumma uptime конференции |
Jenkins Pipeline Shared Libraries |
@Grab(group = 'org.apache.commons', module = 'commons-lang3', version = '3.6')
import org.apache.commons.lang3.StringUtils
class Deployer {
int tries = 0
Script script
def run() {
while (tries < 10) {
Thread.sleep(1000)
tries++
script.echo("tries is numeric: " + StringUtils.isAlphanumeric("" + tries))
}
}
}
@Grab.#!/usr/bin/env groovy
def call(body) {
echo "Start Deploy"
new Deployer(script:this).run()
echo "Deployed"
currentBuild.result = 'SUCCESS' //FAILURE to fail
return this
}
currentBuild.result = 'FAILURE';env. Например, env.param1.
@Library('jenkins-pipeline-shared-lib-sample')_
stage('Print Build Info') {
printBuildinfo {
name = "Sample Name"
}
} stage('Disable balancer') {
disableBalancerUtils()
} stage('Deploy') {
deploy()
} stage('Enable balancer') {
enableBalancerUtils()
} stage('Check Status') {
checkStatus()
}
@Library('jenkins-pipeline-shared-lib-sample')_ (не забываем добавить _ в конце) и вызываем наши функции по имени скриптов, например deploy.|
Метки: author Andrey_V_Markelov it- инфраструктура devops jenkins ci continuous deployment pipelines развертывание deployment tools |
Jenkins Pipeline Shared Libraries |
@Grab(group = 'org.apache.commons', module = 'commons-lang3', version = '3.6')
import org.apache.commons.lang3.StringUtils
class Deployer {
int tries = 0
Script script
def run() {
while (tries < 10) {
Thread.sleep(1000)
tries++
script.echo("tries is numeric: " + StringUtils.isAlphanumeric("" + tries))
}
}
}
@Grab.#!/usr/bin/env groovy
def call(body) {
echo "Start Deploy"
new Deployer(script:this).run()
echo "Deployed"
currentBuild.result = 'SUCCESS' //FAILURE to fail
return this
}
currentBuild.result = 'FAILURE';env. Например, env.param1.@Library('jenkins-pipeline-shared-lib-sample')_
stage('Print Build Info') {
printBuildinfo {
name = "Sample Name"
}
} stage('Disable balancer') {
disableBalancerUtils()
} stage('Deploy') {
deploy()
} stage('Enable balancer') {
enableBalancerUtils()
} stage('Check Status') {
checkStatus()
}
@Library('jenkins-pipeline-shared-lib-sample')_ (не забываем добавить _ в конце) и вызываем наши функции по имени скриптов, например deploy.|
Метки: author Andrey_V_Markelov it- инфраструктура devops jenkins ci continuous deployment pipelines развертывание deployment tools |
Jenkins Pipeline Shared Libraries |
@Grab(group = 'org.apache.commons', module = 'commons-lang3', version = '3.6')
import org.apache.commons.lang3.StringUtils
class Deployer {
int tries = 0
Script script
def run() {
while (tries < 10) {
Thread.sleep(1000)
tries++
script.echo("tries is numeric: " + StringUtils.isAlphanumeric("" + tries))
}
}
}
@Grab.#!/usr/bin/env groovy
def call(body) {
echo "Start Deploy"
new Deployer(script:this).run()
echo "Deployed"
currentBuild.result = 'SUCCESS' //FAILURE to fail
return this
}
currentBuild.result = 'FAILURE';env. Например, env.param1.@Library('jenkins-pipeline-shared-lib-sample')_
stage('Print Build Info') {
printBuildinfo {
name = "Sample Name"
}
} stage('Disable balancer') {
disableBalancerUtils()
} stage('Deploy') {
deploy()
} stage('Enable balancer') {
enableBalancerUtils()
} stage('Check Status') {
checkStatus()
}
@Library('jenkins-pipeline-shared-lib-sample')_ (не забываем добавить _ в конце) и вызываем наши функции по имени скриптов, например deploy.|
Метки: author Andrey_V_Markelov it- инфраструктура devops jenkins ci continuous deployment pipelines развертывание deployment tools |
Jenkins Pipeline Shared Libraries |
@Grab(group = 'org.apache.commons', module = 'commons-lang3', version = '3.6')
import org.apache.commons.lang3.StringUtils
class Deployer {
int tries = 0
Script script
def run() {
while (tries < 10) {
Thread.sleep(1000)
tries++
script.echo("tries is numeric: " + StringUtils.isAlphanumeric("" + tries))
}
}
}
@Grab.#!/usr/bin/env groovy
def call(body) {
echo "Start Deploy"
new Deployer(script:this).run()
echo "Deployed"
currentBuild.result = 'SUCCESS' //FAILURE to fail
return this
}
currentBuild.result = 'FAILURE';env. Например, env.param1.@Library('jenkins-pipeline-shared-lib-sample')_
stage('Print Build Info') {
printBuildinfo {
name = "Sample Name"
}
} stage('Disable balancer') {
disableBalancerUtils()
} stage('Deploy') {
deploy()
} stage('Enable balancer') {
enableBalancerUtils()
} stage('Check Status') {
checkStatus()
}
@Library('jenkins-pipeline-shared-lib-sample')_ (не забываем добавить _ в конце) и вызываем наши функции по имени скриптов, например deploy.|
Метки: author Andrey_V_Markelov it- инфраструктура devops jenkins ci continuous deployment pipelines развертывание deployment tools |






