ИТ против ИИ: отберут ли машины работу у своих создателей? |
 Читать дальше ->
Читать дальше ->
|
Метки: author itmo карьера в it-индустрии блог компании университет итмо университет итмо ии работа будущего |
ИТ против ИИ: отберут ли машины работу у своих создателей? |
Читать дальше ->
|
Метки: author itmo карьера в it-индустрии блог компании университет итмо университет итмо ии работа будущего |
ИТ против ИИ: отберут ли машины работу у своих создателей? |
Читать дальше ->
|
Метки: author itmo карьера в it-индустрии блог компании университет итмо университет итмо ии работа будущего |
ИТ против ИИ: отберут ли машины работу у своих создателей? |
Читать дальше ->
|
Метки: author itmo карьера в it-индустрии блог компании университет итмо университет итмо ии работа будущего |
Мультиформатные баннеры в Tinkoff.ru и подход к верстке адаптивных баннеров в Google AdWords |

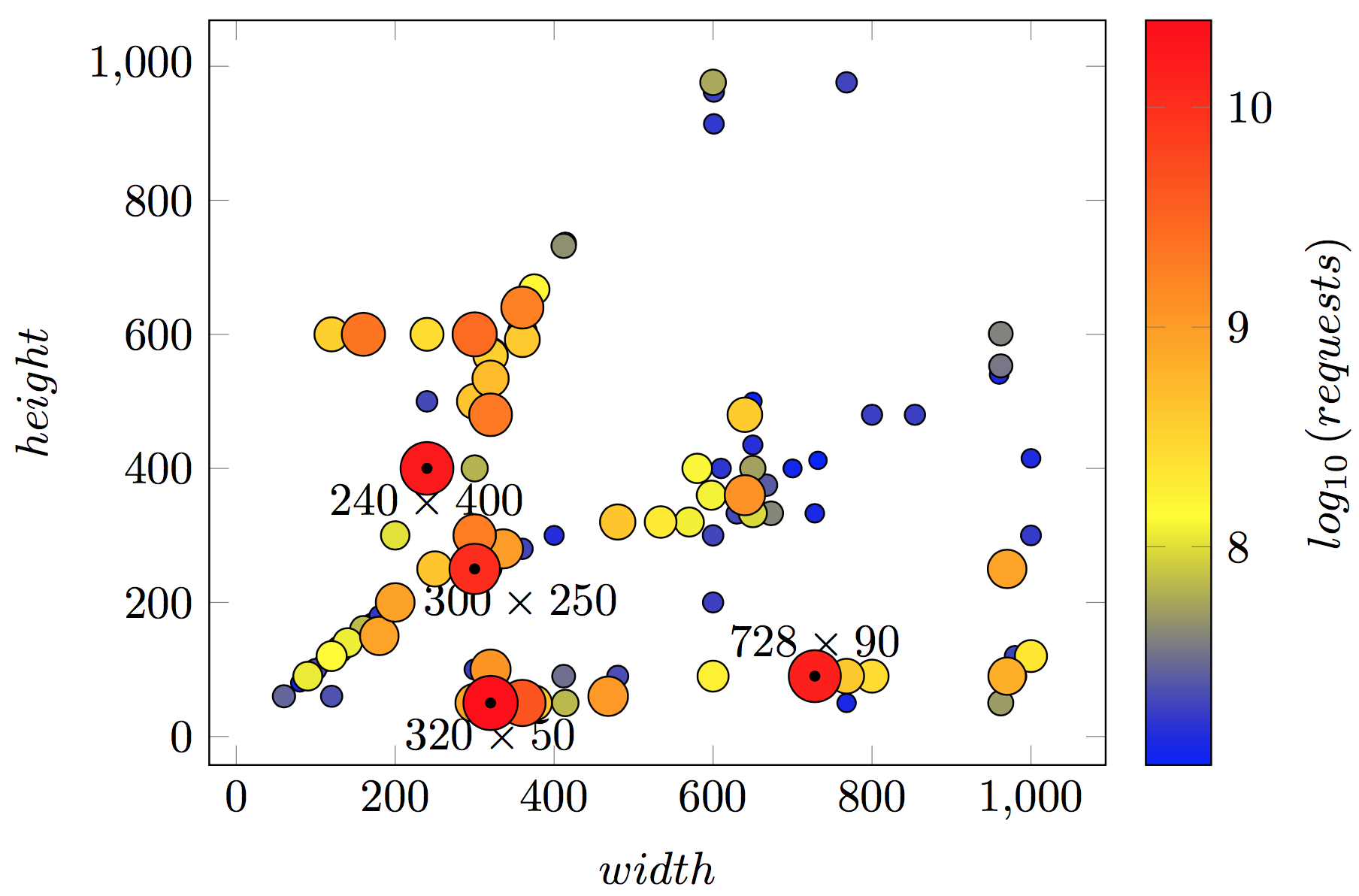
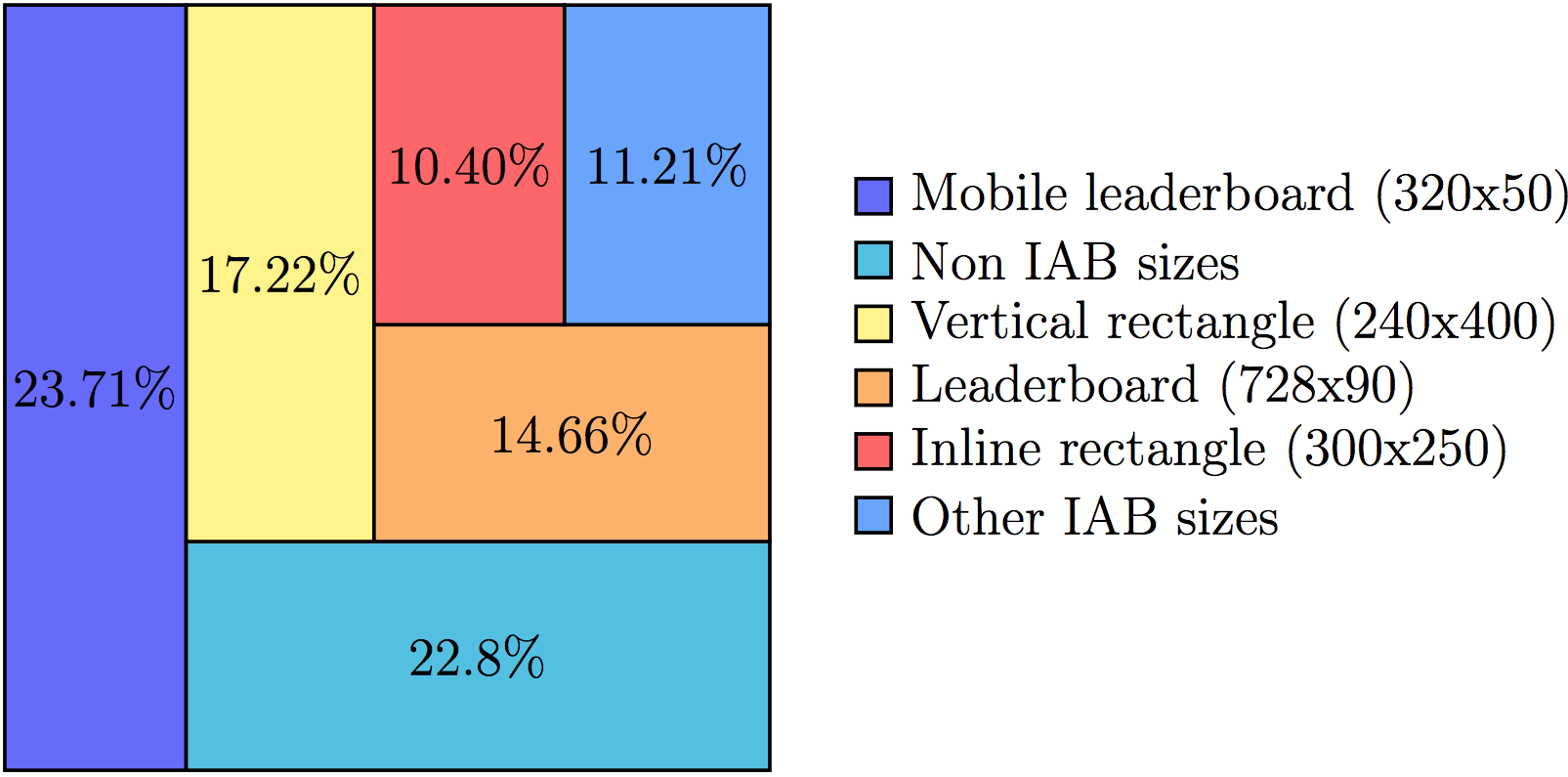
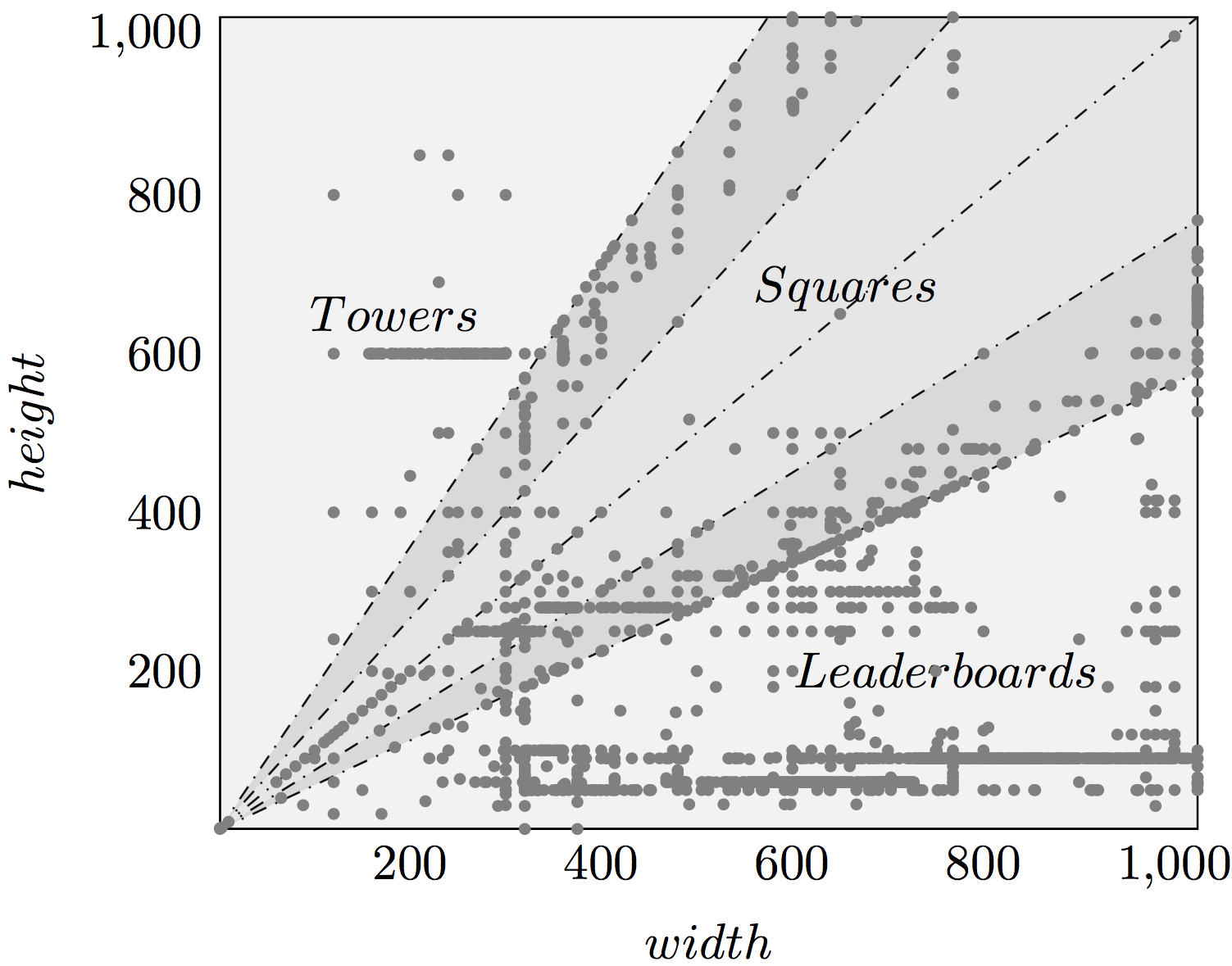
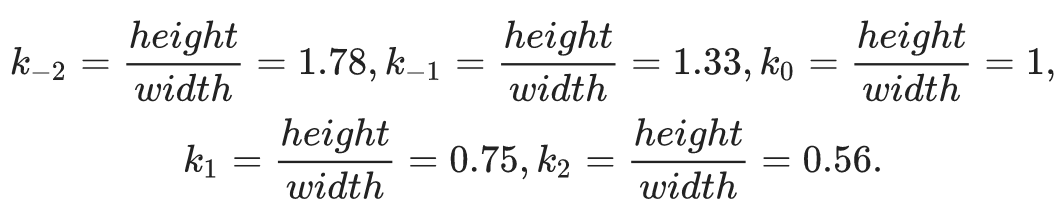
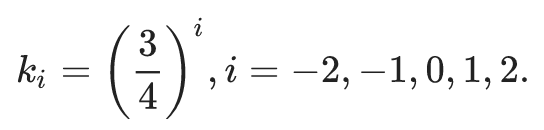
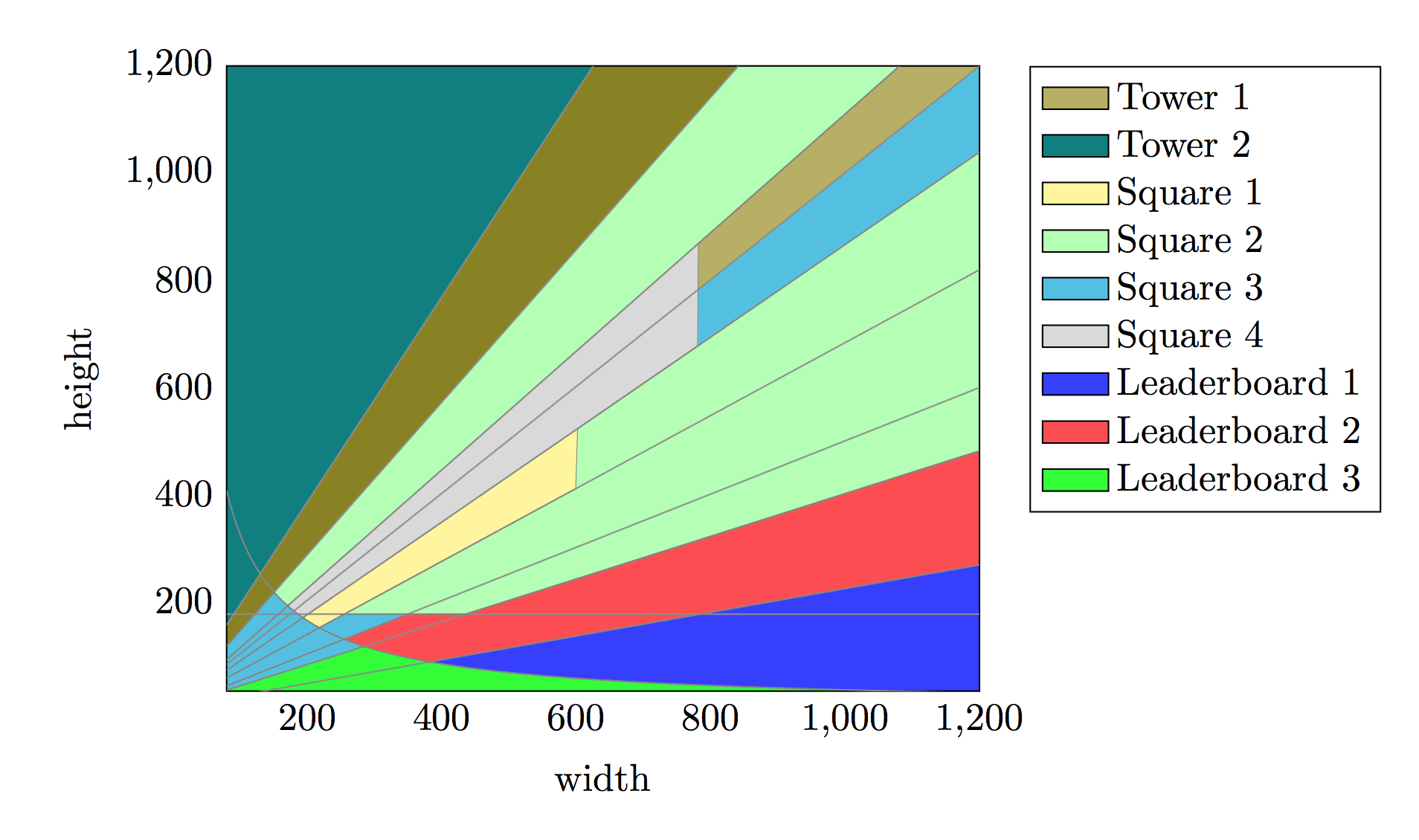

template_names = ['leaderboard1', 'leaderboard2', 'leaderboard3', 'square1', 'square2', 'square3', 'square4', 'tower1'];
function getTemplate(w, h) {
var wdh = w/h,
wh = w*h;
if (wdh >= 0.7000456) {
if (wdh >= 2.499373) {
if (wh >= 32399) {
if (wdh >= 4.501131) {
return template_names[0]; //leaderboard1 - bannerA
} else {
return template_names[1]; //leaderboard2 - bannerB
}
};
return template_names[2]; //leaderboard3 - smallBanner
} else {
if (wdh < 1.200121) {
if (wdh >= 0.8999545) {
if (w < 781.5) {
if (wh < 32399.5) {
return template_names[5];// "square3"; //smallSquare
} else {
return template_names[6];//"square4"; //square191
}
} else {
if (wdh >= 0.9995005) {
return template_names[5];//"square3"; //smallSquare
} else {
return template_names[7];//"tower1"; //towerB
}
}
} else {
if (wh < 32399) {
return template_names[5]; //"square3"; //smallSquare
} else {
return template_names[4]; //"square2"; //squareC
}
}
} else {
if (h< 174.5) {
if (wdh >= 2.002874 && wh >= 32392.5) {
return template_names[1];//"leaderboard2"; //bannerB
}
return template_names[5];//"square3"; //smallSquare
} else {
if (w < 601.5 && wdh < 1.531339) {
return template_names[3];//"square1"; //squareA
}
return template_names[4];//"square2"; //squareC
}
}
}
} else {
return template_names[7];//"tower1"; //towerA + towerB
}
}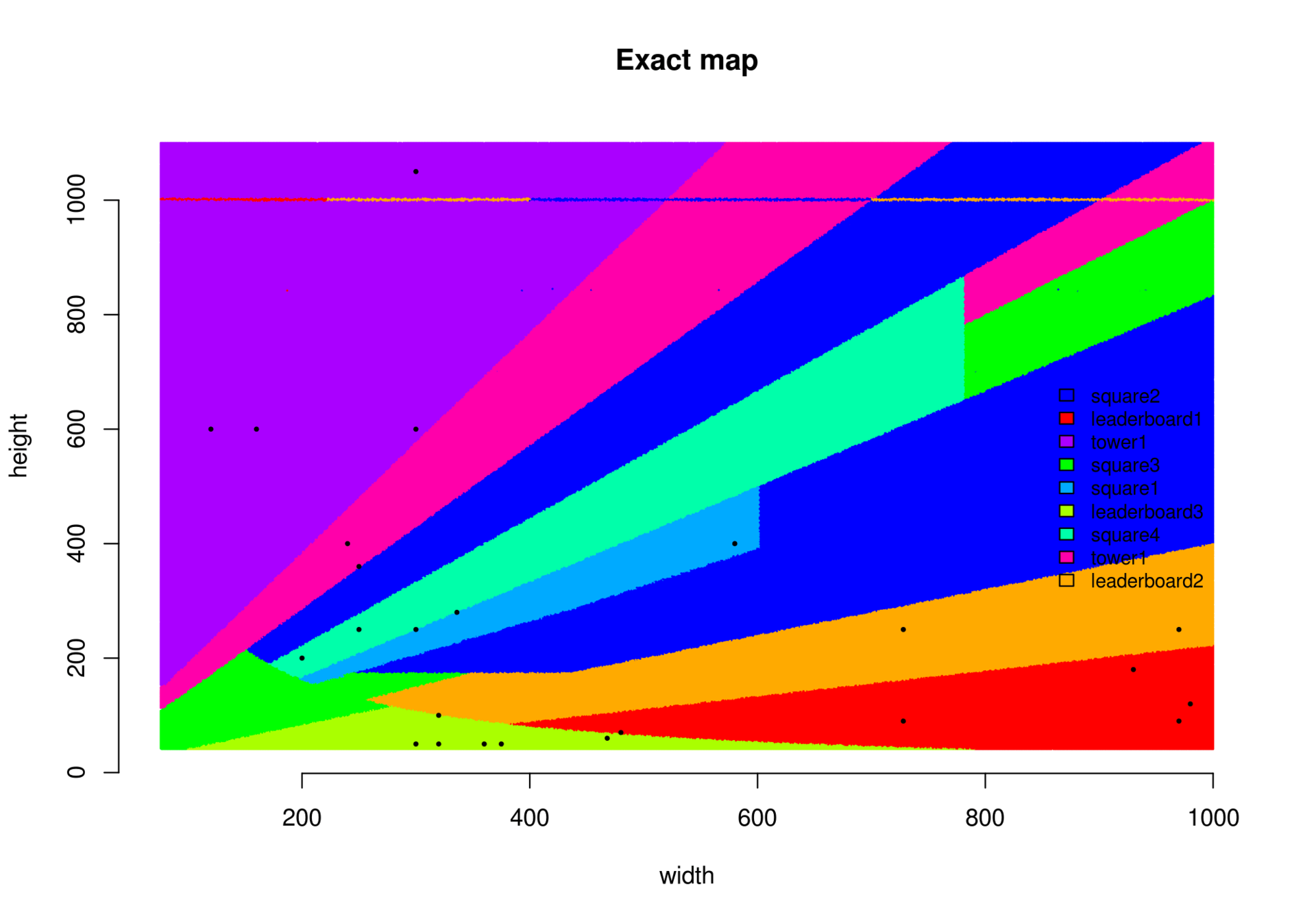
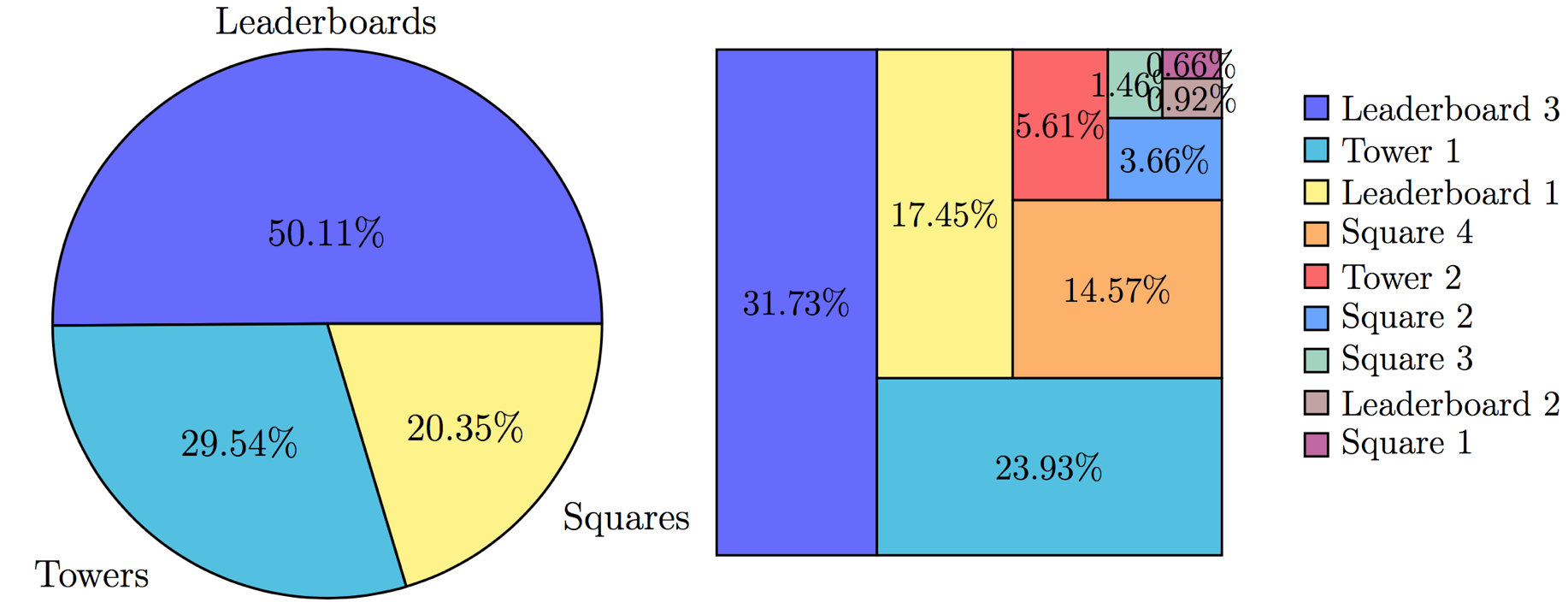
 |
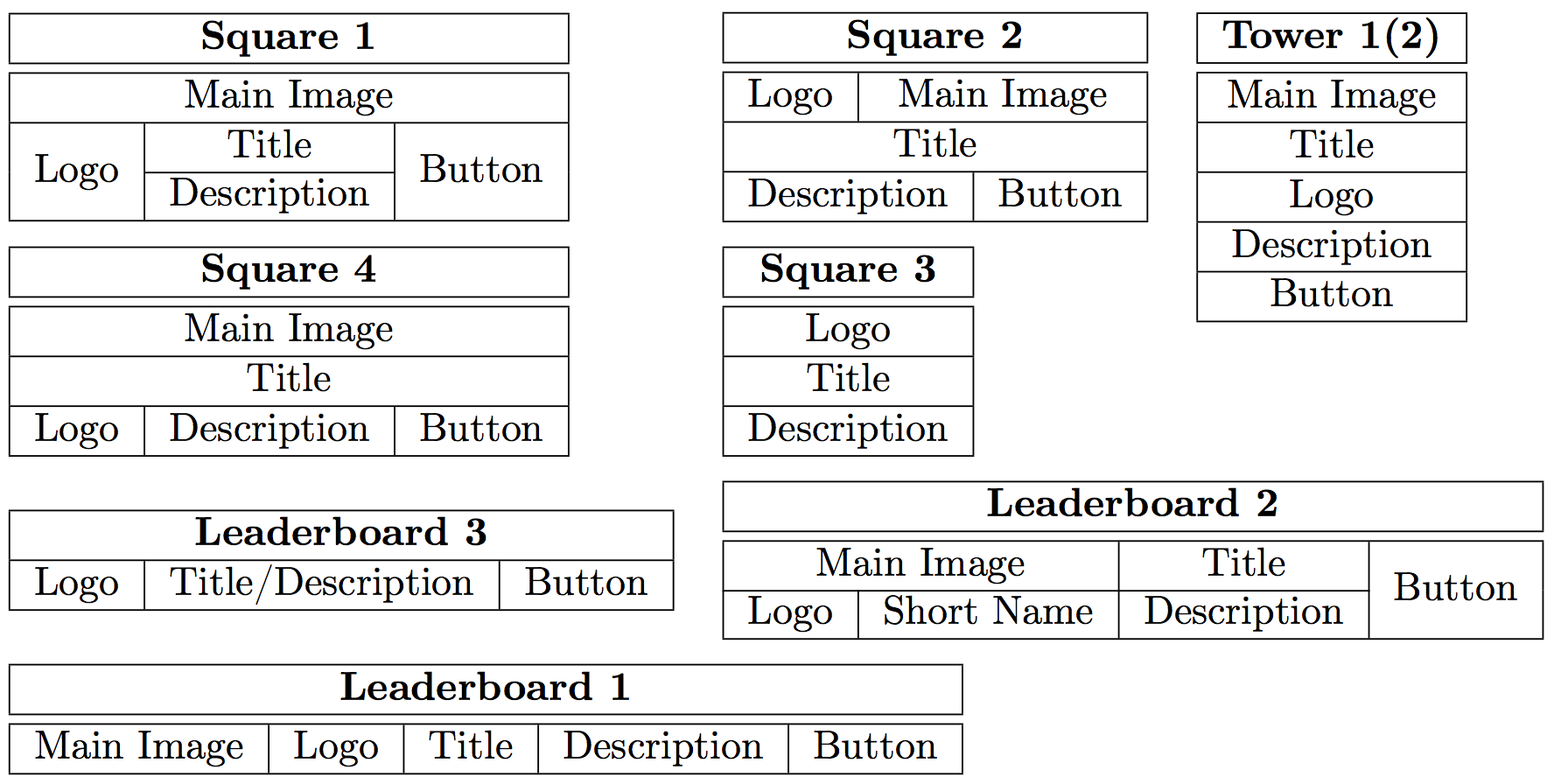
Leaderboard 1 для рекламного блока 480x70 |
 |
Leaderboard 2 для рекламного блока 400x125 |
 |
Leaderboard 3 для рекламного блока 400x100. Показан второй кадр с описанием |
 |
 |
 |
 |
| Square 1 для рекламного блока 300x300 |
Square 2 для рекламного блока 150x215 |
Square 3 для рекламного блока 215x250 |
Square 4 для рекламного блока 250x250 |
 |
 |
 |
| Реализации шаблона Tower |
||
|
Метки: author AndreyIvanoff медийная реклама интернет-маркетинг веб-аналитика блог компании tinkoff.ru баннеры реклама в интернете дизайн rtb- реклама rtb |
Мультиформатные баннеры в Tinkoff.ru и подход к верстке адаптивных баннеров в Google AdWords |
template_names = ['leaderboard1', 'leaderboard2', 'leaderboard3', 'square1', 'square2', 'square3', 'square4', 'tower1'];
function getTemplate(w, h) {
var wdh = w/h,
wh = w*h;
if (wdh >= 0.7000456) {
if (wdh >= 2.499373) {
if (wh >= 32399) {
if (wdh >= 4.501131) {
return template_names[0]; //leaderboard1 - bannerA
} else {
return template_names[1]; //leaderboard2 - bannerB
}
};
return template_names[2]; //leaderboard3 - smallBanner
} else {
if (wdh < 1.200121) {
if (wdh >= 0.8999545) {
if (w < 781.5) {
if (wh < 32399.5) {
return template_names[5];// "square3"; //smallSquare
} else {
return template_names[6];//"square4"; //square191
}
} else {
if (wdh >= 0.9995005) {
return template_names[5];//"square3"; //smallSquare
} else {
return template_names[7];//"tower1"; //towerB
}
}
} else {
if (wh < 32399) {
return template_names[5]; //"square3"; //smallSquare
} else {
return template_names[4]; //"square2"; //squareC
}
}
} else {
if (h< 174.5) {
if (wdh >= 2.002874 && wh >= 32392.5) {
return template_names[1];//"leaderboard2"; //bannerB
}
return template_names[5];//"square3"; //smallSquare
} else {
if (w < 601.5 && wdh < 1.531339) {
return template_names[3];//"square1"; //squareA
}
return template_names[4];//"square2"; //squareC
}
}
}
} else {
return template_names[7];//"tower1"; //towerA + towerB
}
} |
Leaderboard 1 для рекламного блока 480x70 |
|
Leaderboard 2 для рекламного блока 400x125 |
|
Leaderboard 3 для рекламного блока 400x100. Показан второй кадр с описанием |
|
|
|
|
| Square 1 для рекламного блока 300x300 |
Square 2 для рекламного блока 150x215 |
Square 3 для рекламного блока 215x250 |
Square 4 для рекламного блока 250x250 |
|
|
|
| Реализации шаблона Tower |
||
|
Метки: author AndreyIvanoff медийная реклама интернет-маркетинг веб-аналитика блог компании tinkoff.ru баннеры реклама в интернете дизайн rtb- реклама rtb |
Мультиформатные баннеры в Tinkoff.ru и подход к верстке адаптивных баннеров в Google AdWords |
template_names = ['leaderboard1', 'leaderboard2', 'leaderboard3', 'square1', 'square2', 'square3', 'square4', 'tower1'];
function getTemplate(w, h) {
var wdh = w/h,
wh = w*h;
if (wdh >= 0.7000456) {
if (wdh >= 2.499373) {
if (wh >= 32399) {
if (wdh >= 4.501131) {
return template_names[0]; //leaderboard1 - bannerA
} else {
return template_names[1]; //leaderboard2 - bannerB
}
};
return template_names[2]; //leaderboard3 - smallBanner
} else {
if (wdh < 1.200121) {
if (wdh >= 0.8999545) {
if (w < 781.5) {
if (wh < 32399.5) {
return template_names[5];// "square3"; //smallSquare
} else {
return template_names[6];//"square4"; //square191
}
} else {
if (wdh >= 0.9995005) {
return template_names[5];//"square3"; //smallSquare
} else {
return template_names[7];//"tower1"; //towerB
}
}
} else {
if (wh < 32399) {
return template_names[5]; //"square3"; //smallSquare
} else {
return template_names[4]; //"square2"; //squareC
}
}
} else {
if (h< 174.5) {
if (wdh >= 2.002874 && wh >= 32392.5) {
return template_names[1];//"leaderboard2"; //bannerB
}
return template_names[5];//"square3"; //smallSquare
} else {
if (w < 601.5 && wdh < 1.531339) {
return template_names[3];//"square1"; //squareA
}
return template_names[4];//"square2"; //squareC
}
}
}
} else {
return template_names[7];//"tower1"; //towerA + towerB
}
} |
Leaderboard 1 для рекламного блока 480x70 |
|
Leaderboard 2 для рекламного блока 400x125 |
|
Leaderboard 3 для рекламного блока 400x100. Показан второй кадр с описанием |
|
|
|
|
| Square 1 для рекламного блока 300x300 |
Square 2 для рекламного блока 150x215 |
Square 3 для рекламного блока 215x250 |
Square 4 для рекламного блока 250x250 |
|
|
|
| Реализации шаблона Tower |
||
|
Метки: author AndreyIvanoff медийная реклама интернет-маркетинг веб-аналитика блог компании tinkoff.ru баннеры реклама в интернете дизайн rtb- реклама rtb |
Мультиформатные баннеры в Tinkoff.ru и подход к верстке адаптивных баннеров в Google AdWords |
template_names = ['leaderboard1', 'leaderboard2', 'leaderboard3', 'square1', 'square2', 'square3', 'square4', 'tower1'];
function getTemplate(w, h) {
var wdh = w/h,
wh = w*h;
if (wdh >= 0.7000456) {
if (wdh >= 2.499373) {
if (wh >= 32399) {
if (wdh >= 4.501131) {
return template_names[0]; //leaderboard1 - bannerA
} else {
return template_names[1]; //leaderboard2 - bannerB
}
};
return template_names[2]; //leaderboard3 - smallBanner
} else {
if (wdh < 1.200121) {
if (wdh >= 0.8999545) {
if (w < 781.5) {
if (wh < 32399.5) {
return template_names[5];// "square3"; //smallSquare
} else {
return template_names[6];//"square4"; //square191
}
} else {
if (wdh >= 0.9995005) {
return template_names[5];//"square3"; //smallSquare
} else {
return template_names[7];//"tower1"; //towerB
}
}
} else {
if (wh < 32399) {
return template_names[5]; //"square3"; //smallSquare
} else {
return template_names[4]; //"square2"; //squareC
}
}
} else {
if (h< 174.5) {
if (wdh >= 2.002874 && wh >= 32392.5) {
return template_names[1];//"leaderboard2"; //bannerB
}
return template_names[5];//"square3"; //smallSquare
} else {
if (w < 601.5 && wdh < 1.531339) {
return template_names[3];//"square1"; //squareA
}
return template_names[4];//"square2"; //squareC
}
}
}
} else {
return template_names[7];//"tower1"; //towerA + towerB
}
} |
Leaderboard 1 для рекламного блока 480x70 |
|
Leaderboard 2 для рекламного блока 400x125 |
|
Leaderboard 3 для рекламного блока 400x100. Показан второй кадр с описанием |
|
|
|
|
| Square 1 для рекламного блока 300x300 |
Square 2 для рекламного блока 150x215 |
Square 3 для рекламного блока 215x250 |
Square 4 для рекламного блока 250x250 |
|
|
|
| Реализации шаблона Tower |
||
|
Метки: author AndreyIvanoff медийная реклама интернет-маркетинг веб-аналитика блог компании tinkoff.ru баннеры реклама в интернете дизайн rtb- реклама rtb |
[Из песочницы] Продажа электронных подписей и сопутствующих услуг |
Осуществление предпринимательской деятельности без специального разрешения (лицензии), если такое разрешение (такая лицензия) обязательно (обязательна), — влечет наложение административного штрафа:
- на граждан в размере от двух тысяч до двух тысяч пятисот рублей с конфискацией изготовленной продукции, орудий производства и сырья или без таковой;
- на должностных лиц — от четырех тысяч до пяти тысяч рублей с конфискацией изготовленной продукции, орудий производства и сырья или без таковой;
- на юридических лиц — от четырехсот до пятисот минимальных размеров оплаты труда с конфискацией изготовленной продукции, орудий производства и сырья или без таковой.
Постановление Правительства РФ от 16.04.2012 N 313 (ред. от 18.05.2017)
21. Передача шифровальных (криптографических) средств, за исключением шифровальных (криптографических) средств защиты фискальных данных, разработанных для применения в составе контрольно-кассовой техники, сертифицированных Федеральной службой безопасности Российской Федерации.
(п. 21 в ред. Постановления Правительства РФ от 18.05.2017 N 596)
(см. текст в предыдущей редакции)
22. Передача защищенных с использованием шифровальных (криптографических) средств информационных систем.
23. Передача защищенных с использованием шифровальных (криптографических) средств телекоммуникационных систем.
24. Передача средств изготовления ключевых документов.
|
Метки: author ninadinastiia управление проектами законодательство и it-бизнес организация бизнеса информационная безопасность защита информации лицензирование |
RAIF-Challenge 2017: онлайн-чемпионат по искусственному интеллекту. Применяем ML/AI на практике |
|
|
RAIF-Challenge 2017: онлайн-чемпионат по искусственному интеллекту. Применяем ML/AI на практике |
|
|
RAIF-Challenge 2017: онлайн-чемпионат по искусственному интеллекту. Применяем ML/AI на практике |
|
|
RAIF-Challenge 2017: онлайн-чемпионат по искусственному интеллекту. Применяем ML/AI на практике |
|
|
Zabbix 3.4: Массовый сбор данных на примерах счетчика Меркурий и smartmontools |

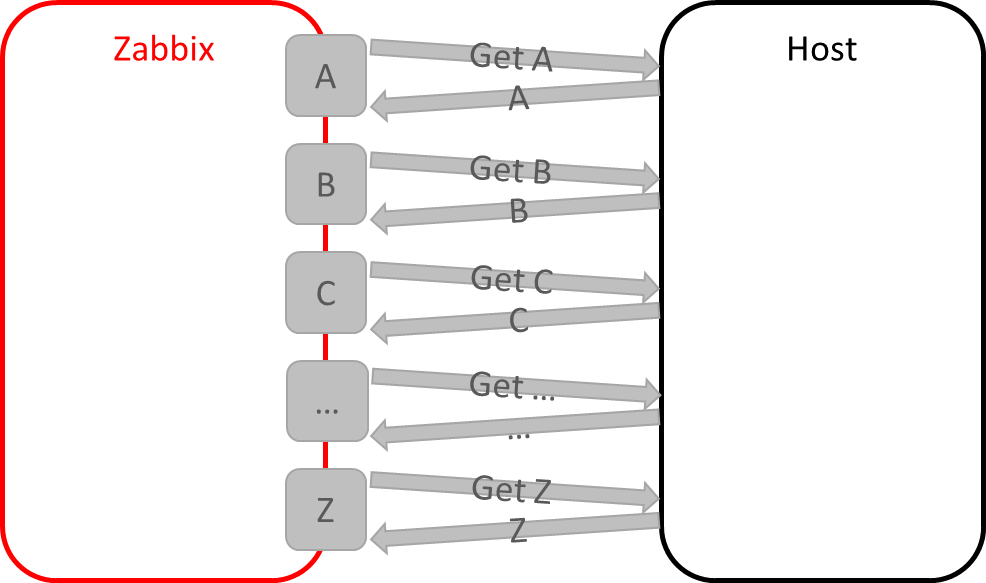
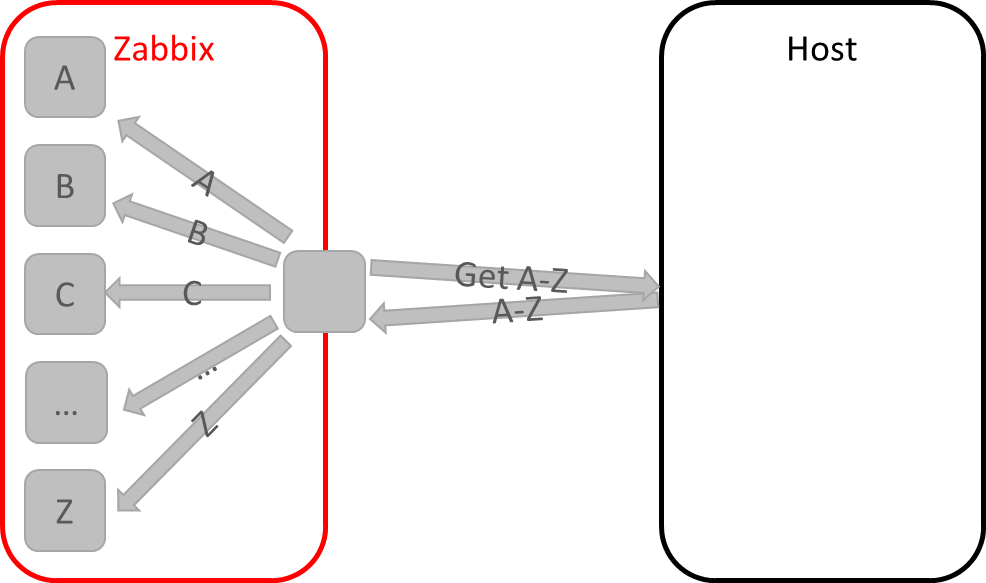

git clone https://github.com/Shden/mercury236.git
cd mercury236
make
./mercury236 /dev/ttyS0 --help
Usage: mercury236 RS485 [OPTIONS] ...
RS485 address of RS485 dongle (e.g. /dev/ttyUSB0), required
--debug to print extra debug info
--testRun dry run to see output sample, no hardware required
Output formatting:
....
--help prints this screen
{
"U": {
"p1": 0.35,
"p2": 0.35,
"p3": 226.86
},
"I": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.39
},
"CosF": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.60,
"sum": 0.60
},
"F": 50.00,
"A": {
"p1": 41943.03,
"p2": 41943.03,
"p3": 41943.03
},
"P": {
"p1": 0.00,
"p2": 0.00,
"p3": 53.45,
"sum": 53.45
},
"S": {
"p1": 0.00,
"p2": 0.00,
"p3": 89.83,
"sum": 89.83
},
"PR": {
"ap": 120.51
},
"PR-day": {
"ap": 86.00
},
"PR-night": {
"ap": 34.51
},
"PY": {
"ap": 0.00
},
"PT": {
"ap": 0.04
}
}sudo cp mercury236 /etc/zabbix/scripts
cd /etc/zabbix/scripts
chmod +x mercury236
sudo usermod -G dialout zabbix
UserParameter=mercury236[],/etc/zabbix/scripts/mercury236 $1 $2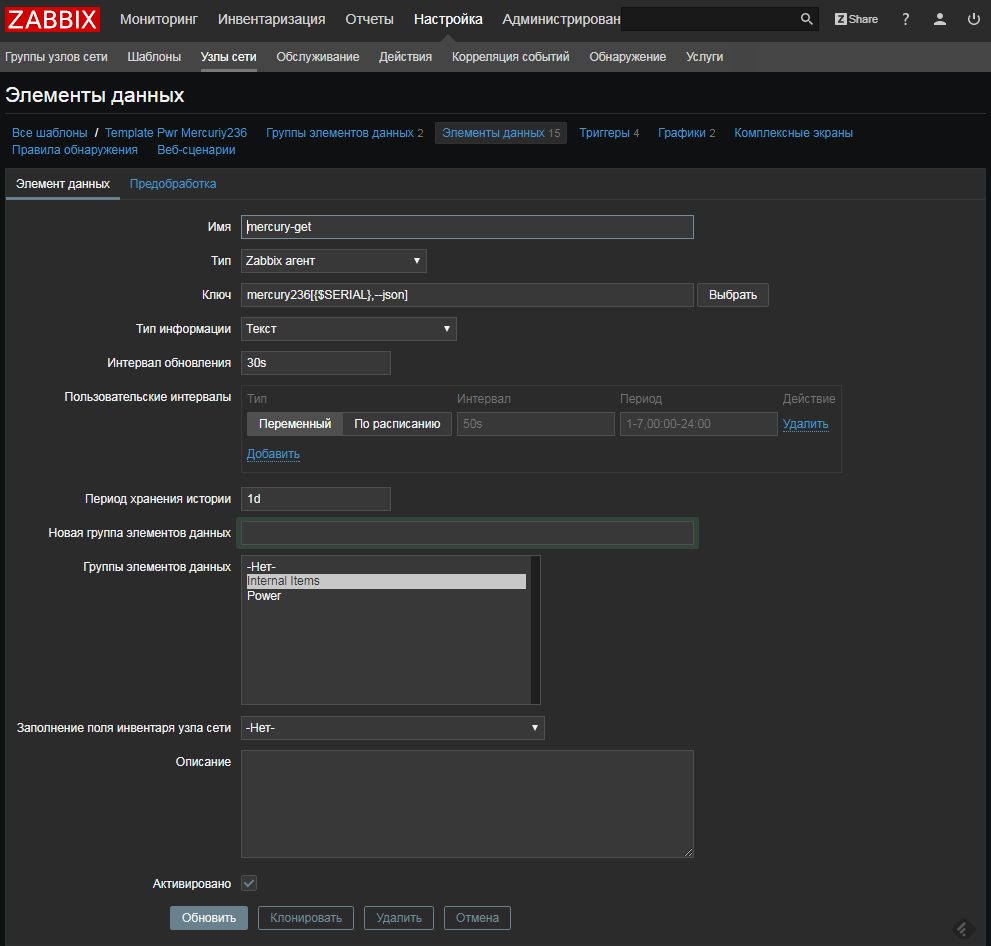
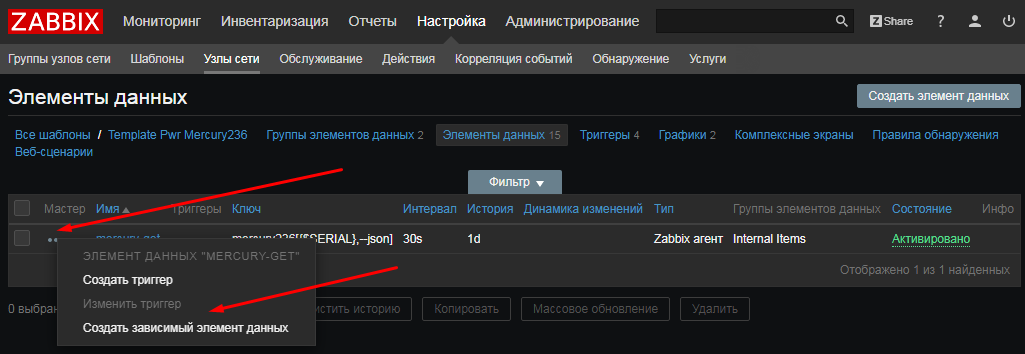
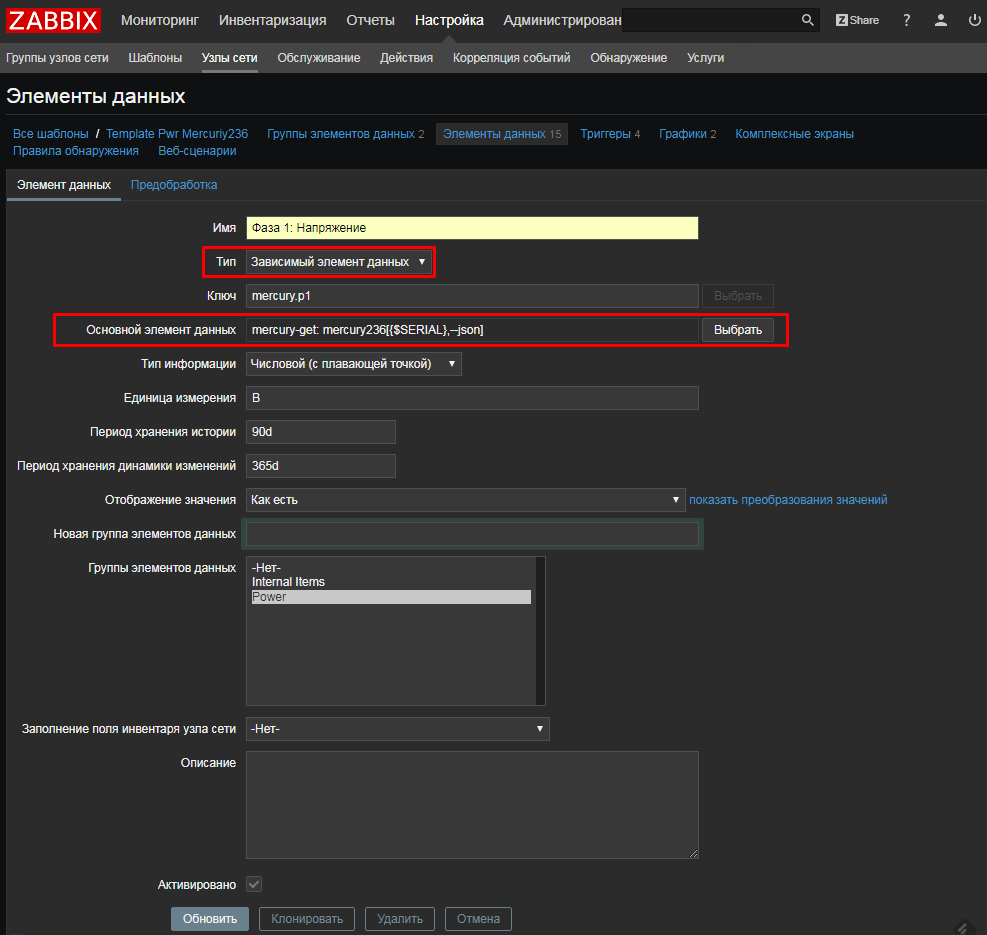

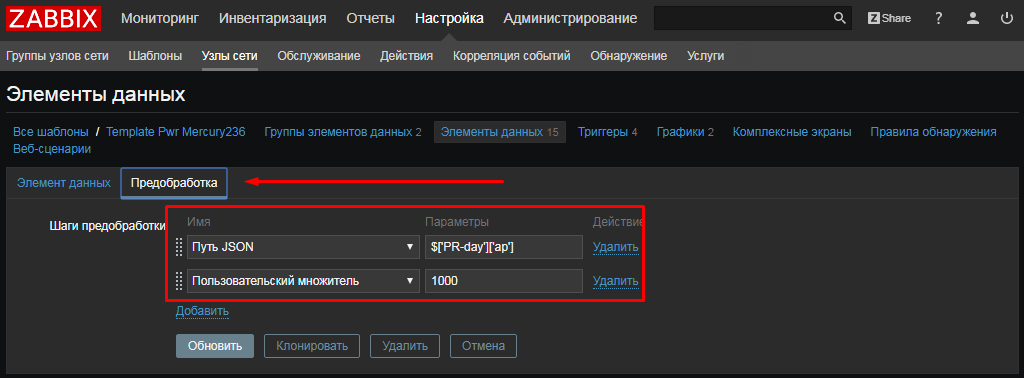
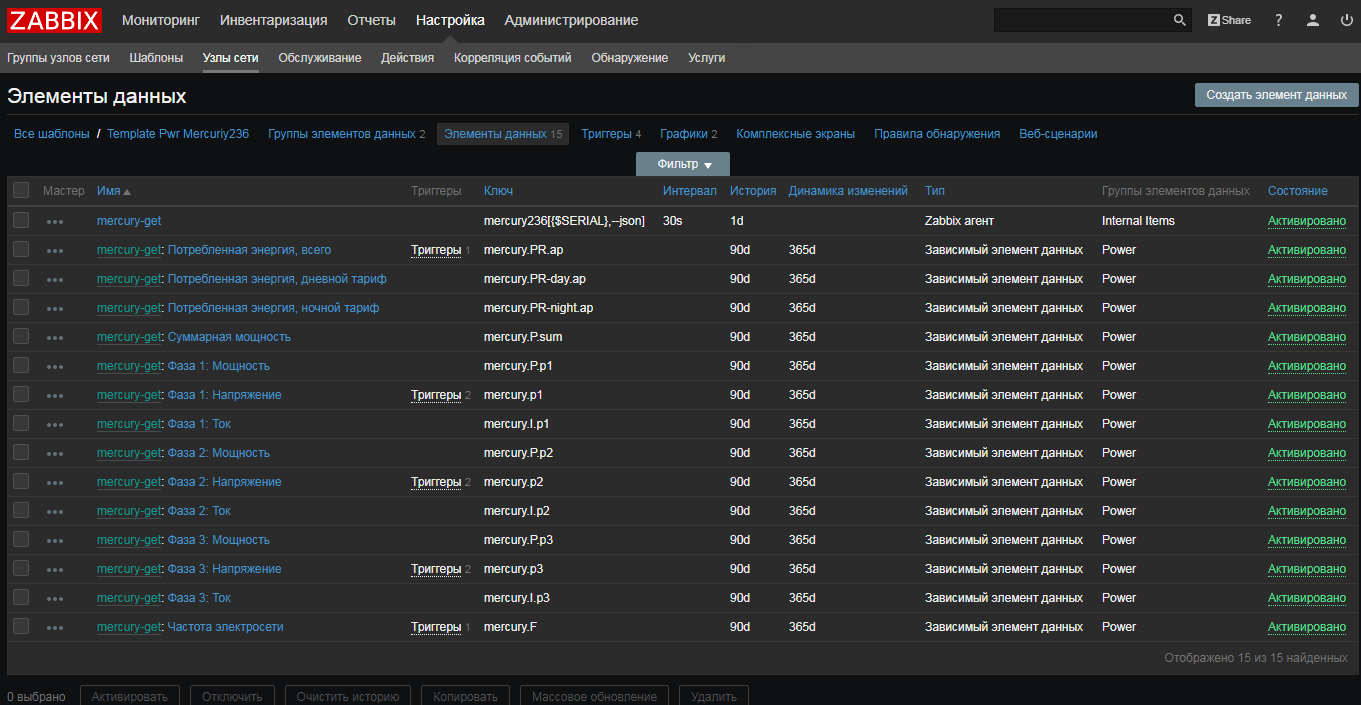
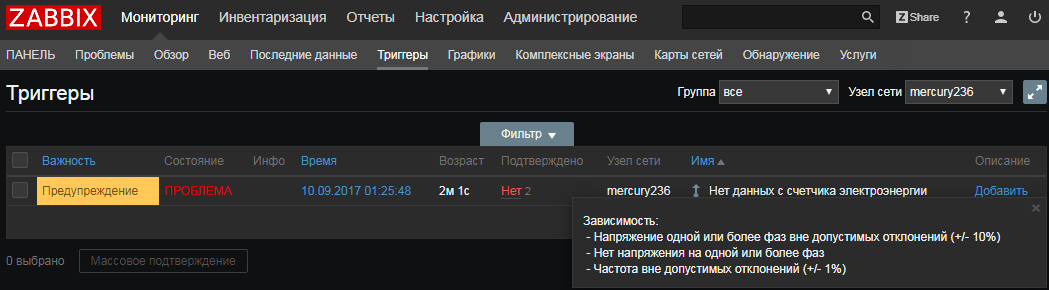

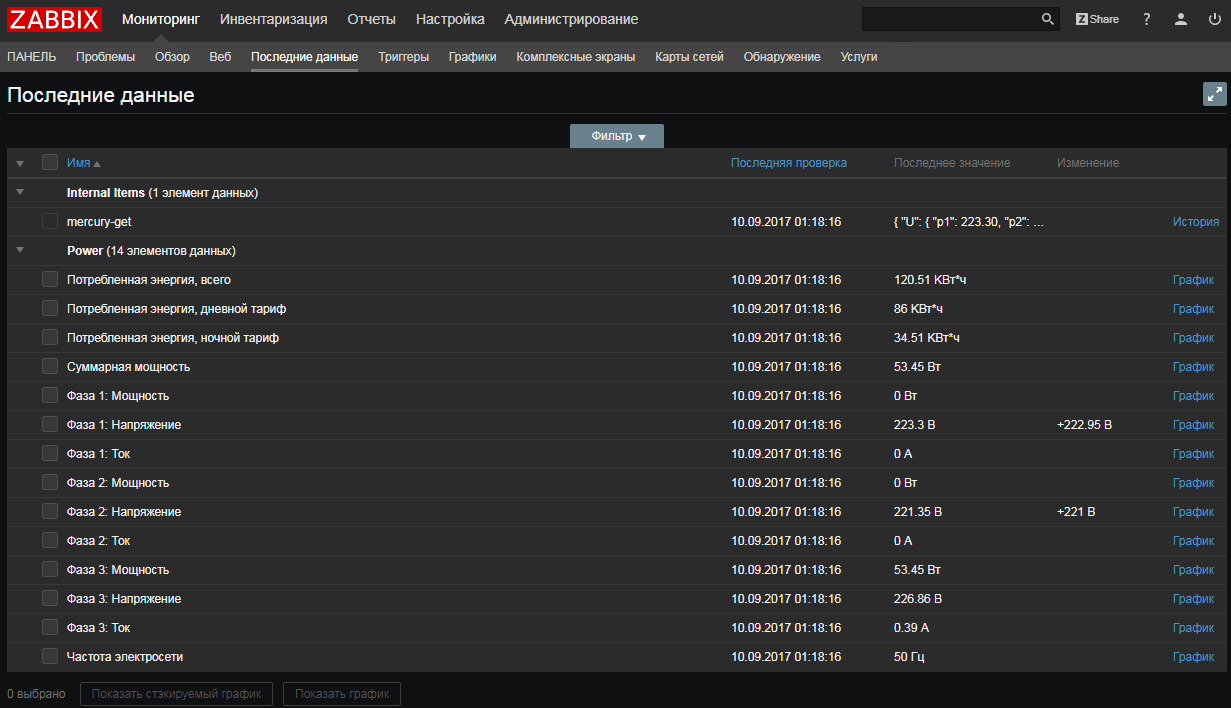

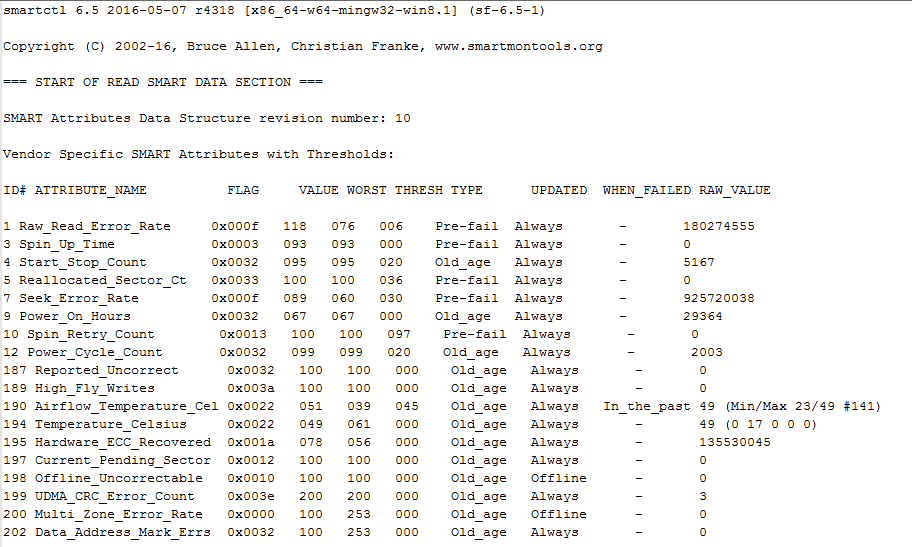
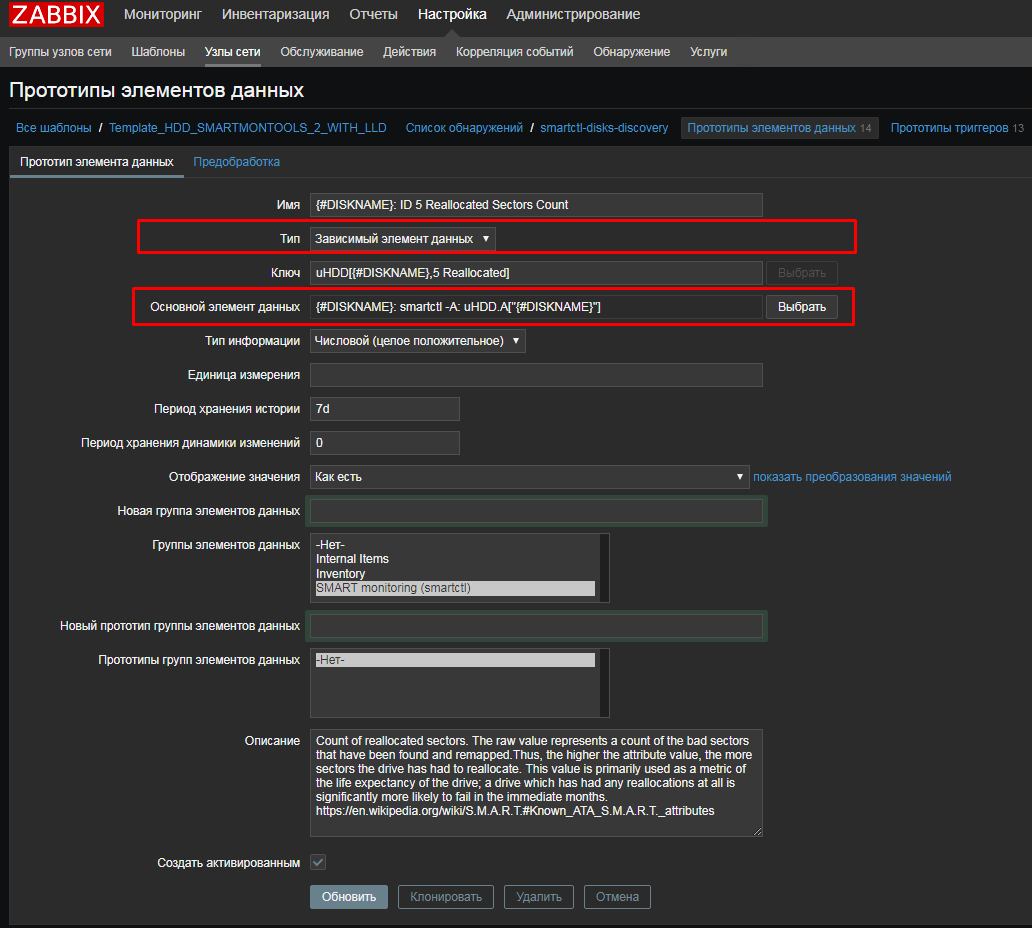
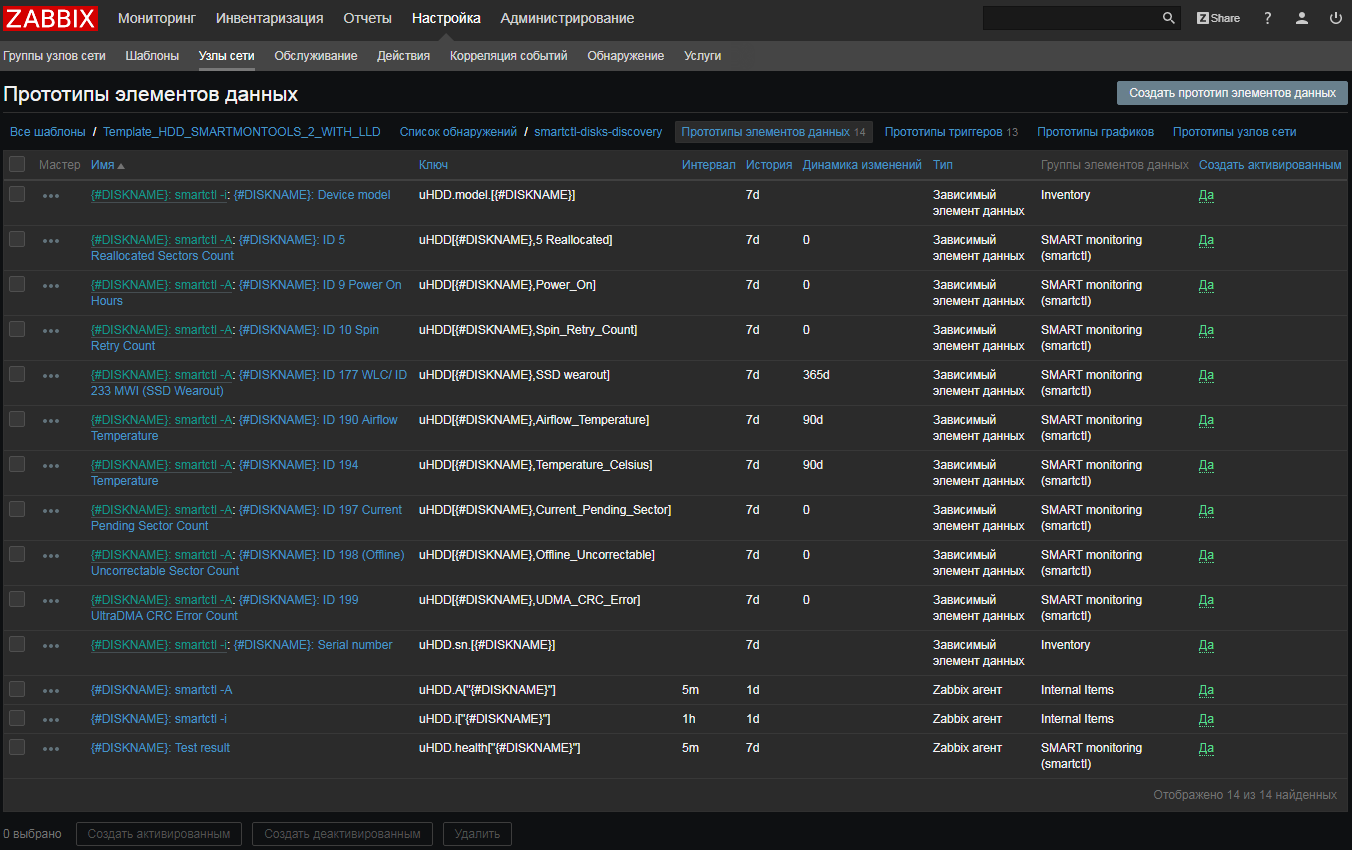
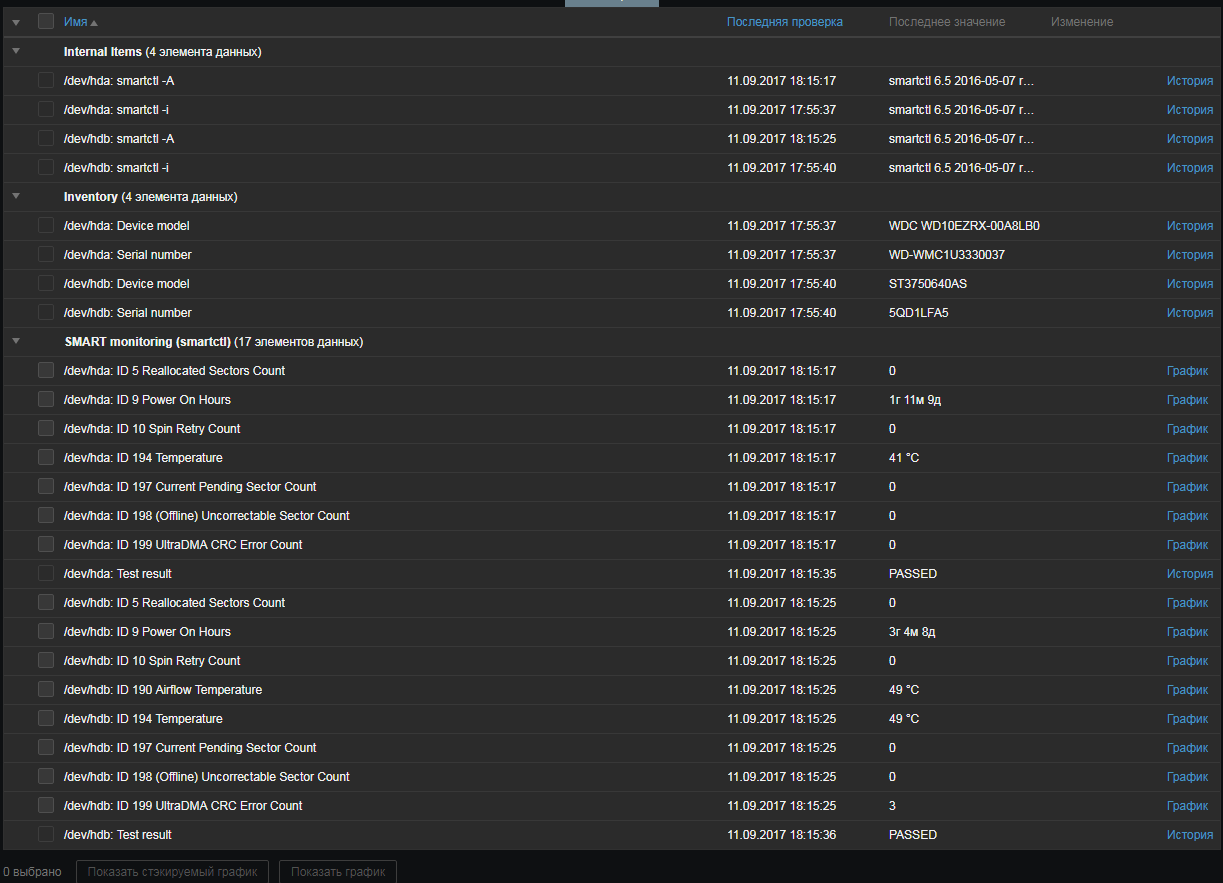
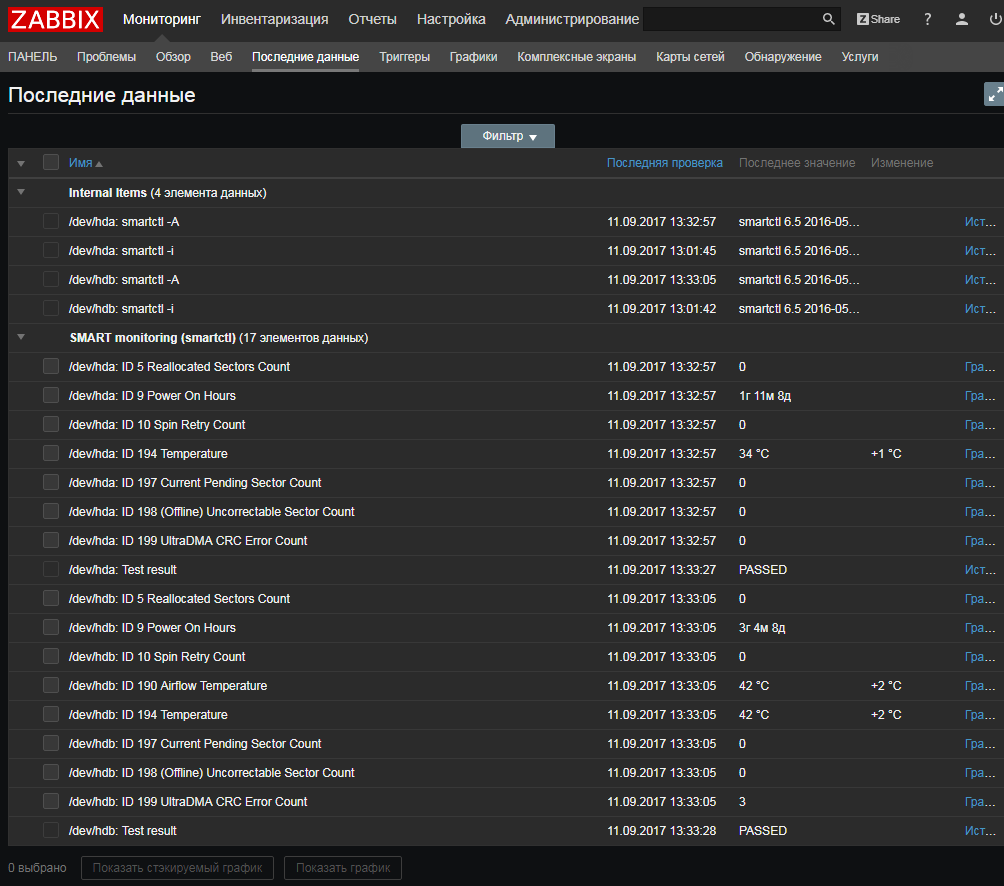
UserParameter=uHDD[], sudo smartctl -A $1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' '
UserParameter=uHDD.model.[],sudo smartctl -i $1 |grep -i "Device Model"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.sn.[],sudo smartctl -i $1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.health.[],sudo smartctl -H $1 |grep -i "test"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.errorlog.[],sudo smartctl -l error $1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
UserParameter=uHDD.A[],sudo smartctl -A $1
UserParameter=uHDD.i[],sudo smartctl -i $1
UserParameter=uHDD.health[],sudo smartctl -H $1
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
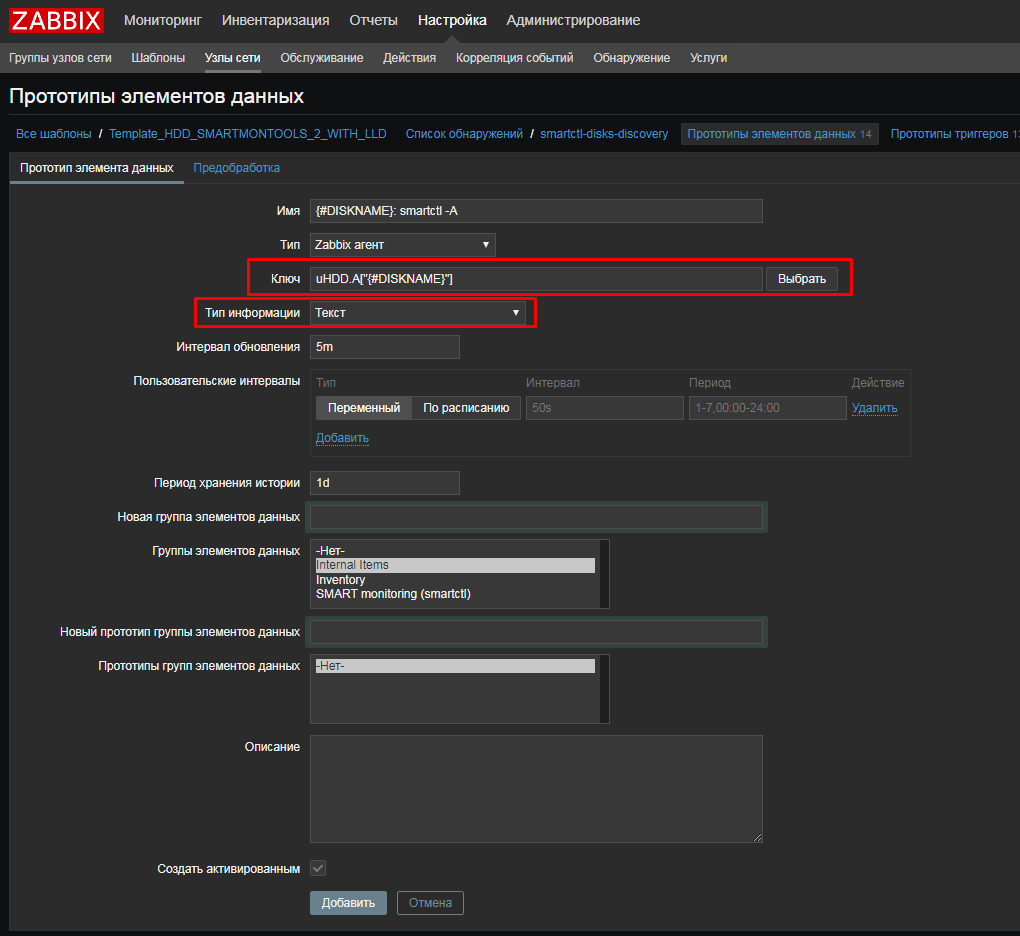

|
Метки: author wabbit системное администрирование сетевые технологии серверное администрирование блог компании zabbix monitoring мониторинг меркурий230 smartmontools opensource |
Zabbix 3.4: Массовый сбор данных на примерах счетчика Меркурий и smartmontools |
git clone https://github.com/Shden/mercury236.git
cd mercury236
make
./mercury236 /dev/ttyS0 --help
Usage: mercury236 RS485 [OPTIONS] ...
RS485 address of RS485 dongle (e.g. /dev/ttyUSB0), required
--debug to print extra debug info
--testRun dry run to see output sample, no hardware required
Output formatting:
....
--help prints this screen
{
"U": {
"p1": 0.35,
"p2": 0.35,
"p3": 226.86
},
"I": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.39
},
"CosF": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.60,
"sum": 0.60
},
"F": 50.00,
"A": {
"p1": 41943.03,
"p2": 41943.03,
"p3": 41943.03
},
"P": {
"p1": 0.00,
"p2": 0.00,
"p3": 53.45,
"sum": 53.45
},
"S": {
"p1": 0.00,
"p2": 0.00,
"p3": 89.83,
"sum": 89.83
},
"PR": {
"ap": 120.51
},
"PR-day": {
"ap": 86.00
},
"PR-night": {
"ap": 34.51
},
"PY": {
"ap": 0.00
},
"PT": {
"ap": 0.04
}
}sudo cp mercury236 /etc/zabbix/scripts
cd /etc/zabbix/scripts
chmod +x mercury236
sudo usermod -G dialout zabbix
UserParameter=mercury236[],/etc/zabbix/scripts/mercury236 $1 $2UserParameter=uHDD[], sudo smartctl -A $1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' '
UserParameter=uHDD.model.[],sudo smartctl -i $1 |grep -i "Device Model"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.sn.[],sudo smartctl -i $1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.health.[],sudo smartctl -H $1 |grep -i "test"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.errorlog.[],sudo smartctl -l error $1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
UserParameter=uHDD.A[],sudo smartctl -A $1
UserParameter=uHDD.i[],sudo smartctl -i $1
UserParameter=uHDD.health[],sudo smartctl -H $1
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
|
Метки: author wabbit системное администрирование сетевые технологии серверное администрирование блог компании zabbix monitoring мониторинг меркурий230 smartmontools opensource |
Zabbix 3.4: Массовый сбор данных на примерах счетчика Меркурий и smartmontools |
git clone https://github.com/Shden/mercury236.git
cd mercury236
make
./mercury236 /dev/ttyS0 --help
Usage: mercury236 RS485 [OPTIONS] ...
RS485 address of RS485 dongle (e.g. /dev/ttyUSB0), required
--debug to print extra debug info
--testRun dry run to see output sample, no hardware required
Output formatting:
....
--help prints this screen
{
"U": {
"p1": 0.35,
"p2": 0.35,
"p3": 226.86
},
"I": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.39
},
"CosF": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.60,
"sum": 0.60
},
"F": 50.00,
"A": {
"p1": 41943.03,
"p2": 41943.03,
"p3": 41943.03
},
"P": {
"p1": 0.00,
"p2": 0.00,
"p3": 53.45,
"sum": 53.45
},
"S": {
"p1": 0.00,
"p2": 0.00,
"p3": 89.83,
"sum": 89.83
},
"PR": {
"ap": 120.51
},
"PR-day": {
"ap": 86.00
},
"PR-night": {
"ap": 34.51
},
"PY": {
"ap": 0.00
},
"PT": {
"ap": 0.04
}
}sudo cp mercury236 /etc/zabbix/scripts
cd /etc/zabbix/scripts
chmod +x mercury236
sudo usermod -G dialout zabbix
UserParameter=mercury236[],/etc/zabbix/scripts/mercury236 $1 $2UserParameter=uHDD[], sudo smartctl -A $1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' '
UserParameter=uHDD.model.[],sudo smartctl -i $1 |grep -i "Device Model"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.sn.[],sudo smartctl -i $1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.health.[],sudo smartctl -H $1 |grep -i "test"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.errorlog.[],sudo smartctl -l error $1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
UserParameter=uHDD.A[],sudo smartctl -A $1
UserParameter=uHDD.i[],sudo smartctl -i $1
UserParameter=uHDD.health[],sudo smartctl -H $1
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
|
Метки: author wabbit системное администрирование сетевые технологии серверное администрирование блог компании zabbix monitoring мониторинг меркурий230 smartmontools opensource |
Zabbix 3.4: Массовый сбор данных на примерах счетчика Меркурий и smartmontools |
git clone https://github.com/Shden/mercury236.git
cd mercury236
make
./mercury236 /dev/ttyS0 --help
Usage: mercury236 RS485 [OPTIONS] ...
RS485 address of RS485 dongle (e.g. /dev/ttyUSB0), required
--debug to print extra debug info
--testRun dry run to see output sample, no hardware required
Output formatting:
....
--help prints this screen
{
"U": {
"p1": 0.35,
"p2": 0.35,
"p3": 226.86
},
"I": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.39
},
"CosF": {
"p1": 0.00,
"p2": 0.00,
"p3": 0.60,
"sum": 0.60
},
"F": 50.00,
"A": {
"p1": 41943.03,
"p2": 41943.03,
"p3": 41943.03
},
"P": {
"p1": 0.00,
"p2": 0.00,
"p3": 53.45,
"sum": 53.45
},
"S": {
"p1": 0.00,
"p2": 0.00,
"p3": 89.83,
"sum": 89.83
},
"PR": {
"ap": 120.51
},
"PR-day": {
"ap": 86.00
},
"PR-night": {
"ap": 34.51
},
"PY": {
"ap": 0.00
},
"PT": {
"ap": 0.04
}
}sudo cp mercury236 /etc/zabbix/scripts
cd /etc/zabbix/scripts
chmod +x mercury236
sudo usermod -G dialout zabbix
UserParameter=mercury236[],/etc/zabbix/scripts/mercury236 $1 $2UserParameter=uHDD[], sudo smartctl -A $1| grep -i "$2"| tail -1| cut -c 88-|cut -f1 -d' '
UserParameter=uHDD.model.[],sudo smartctl -i $1 |grep -i "Device Model"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.sn.[],sudo smartctl -i $1 |grep -i "Serial Number"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.health.[],sudo smartctl -H $1 |grep -i "test"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.errorlog.[],sudo smartctl -l error $1 |grep -i "ATA Error Count"| cut -f2 -d: |tr -d " "
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
UserParameter=uHDD.A[],sudo smartctl -A $1
UserParameter=uHDD.i[],sudo smartctl -i $1
UserParameter=uHDD.health[],sudo smartctl -H $1
UserParameter=uHDD.discovery,sudo /etc/zabbix/scripts/smartctl-disks-discovery.pl
|
Метки: author wabbit системное администрирование сетевые технологии серверное администрирование блог компании zabbix monitoring мониторинг меркурий230 smartmontools opensource |
LibGDX. Практические вопросы и ответы |
 Привет хабр!
Привет хабр!import com.badlogic.gdx.Gdx;
public class GdxLog {
public static boolean DEBUG;
@SuppressWarnings("all")
public static void print(String tag, String message) {
if (DEBUG) {
Gdx.app.log(tag, message);
}
}
@SuppressWarnings("all")
public static void d(String tag, String message, Integer...values) {
if (DEBUG) {
Gdx.app.log(tag, String.format(message, values));
}
}
@SuppressWarnings("all")
public static void f(String tag, String message, Float...values) {
if (DEBUG) {
Gdx.app.log(tag, String.format(message.replaceAll("%f", "%.0f"), values));
}
}
}
//... вызов
GdxLog.d(TAG, "worldWidth: %d", worldWidth);
Gdx.app.postRunnable(new Runnable() {
@Override
public void run() {
// Здесь выполняется в самом потоке
}
});
// null may be only String params
public void postRunnable(final String name, final Object...params) {
Gdx.app.postRunnable(new Runnable() {
@Override
public void run() {
Method method = null;
Class[] classes = new Class[params.length];
for (int i = 0; i < params.length; i++) {
classes[i] = params[i] == null ? String.class : params[i].getClass();
}
try {
method = World.class.getMethod(name, classes);
} catch (SecurityException e) {
GdxLog.print(TAG, e.toString());
} catch (NoSuchMethodException e) {
GdxLog.print(TAG, e.toString());
}
if (method == null) {
return;
}
try {
method.invoke(WorldAdapter.this, params);
} catch (IllegalArgumentException e) {
GdxLog.print(TAG, e.toString());
} catch (IllegalAccessException e) {
GdxLog.print(TAG, e.toString());
} catch (InvocationTargetException e) {
GdxLog.print(TAG, e.toString());
}
}
});
}
public class ActivityMain extends AppCompatActivity
implements AndroidFragmentApplication.Callbacks {
protected FragmentWorld fragmentWorld;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// ...
getSupportFragmentManager()
.beginTransaction()
.add(R.id.world, fragmentWorld, FragmentWorld.class.getSimpleName())
.commitAllowingStateLoss();
}
@Override
public void exit() {}
public class FragmentWorld extends AndroidFragmentApplication {
public World world;
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
int worldWidth = getResources().getDimensionPixelSize(R.dimen.world_width);
int worldHeight = getResources().getDimensionPixelSize(R.dimen.world_height);
world = new World(BuildConfig.DEBUG, worldWidth, worldHeight);
return initializeForView(world);
}
}
final Pixmap pixmap = getScreenshot();
Observable.fromCallable(new Callable () {
@Override
public Boolean call() throws Exception {
PixmapIO.PNG writer = new PixmapIO.PNG((int)(pixmap.getWidth() * pixmap.getHeight() * 1.5 f));
writer.setFlipY(false);
ByteArrayOutputStream output = new ByteArrayOutputStream();
try {
writer.write(output, pixmap);
} finally {
StreamUtils.closeQuietly(output);
writer.dispose();
pixmap.dispose();
}
byte[] bytes = output.toByteArray();
Bitmap bitmap = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
return true;
}
}).subscribeOn(Schedulers.io()).subscribe();
protected Color parseColor(String hex) {
String s1 = hex.substring(0, 2);
int v1 = Integer.parseInt(s1, 16);
float f1 = 1 f * v1 / 255 f;
String s2 = hex.substring(2, 4);
int v2 = Integer.parseInt(s2, 16);
float f2 = 1 f * v2 / 255 f;
String s3 = hex.substring(4, 6);
int v3 = Integer.parseInt(s3, 16);
float f3 = 1 f * v3 / 255 f;
return new Color(f1, f2, f3, 1 f);
}
Sticker sticker = (Sticker) stickersStage.hit(coordinates.x, coordinates.y, false);
@Override
public boolean pinch(Vector2 initialPointer1, Vector2 initialPointer2, Vector2 pointer1,
Vector2 pointer2) {
// initialPointer doesn't change
// all vectors contains device coordinates
Sticker sticker = getCurrentSticker();
if (sticker == null) {
return false;
}
Vector2 startVector = new Vector2(initialPointer1).sub(initialPointer2);
Vector2 currentVector = new Vector2(pointer1).sub(pointer2);
sticker.setScale(sticker.startScale * currentVector.len() / startVector.len());
float startAngle = (float) Math.toDegrees(Math.atan2(startVector.x, startVector.y));
float endAngle = (float) Math.toDegrees(Math.atan2(currentVector.x, currentVector.y));
sticker.setRotation(sticker.startRotation + endAngle - startAngle);
return false;
}
@Override
public boolean touchDown(float x, float y, int pointer, int button) {
if (pointer == FIRST_FINGER) {
Vector2 coordinates = stickersStage.screenToStageCoordinates(new Vector2(x, y));
Sticker sticker = (Sticker) stickersStage.hit(coordinates.x, coordinates.y, false);
if (sticker != null) {
// здесь
sticker.setPinchStarts();
currentSticker = sticker.index;
}
}
return false;
}
@Override
public void pinchStop() {
Sticker sticker = getCurrentSticker();
if (sticker != null) {
// здесь
sticker.setPinchStarts();
}
}
spriteBatch.begin();
stickersStage.act();
stickersStage.getRoot().draw(spriteBatch, 1);
spriteBatch.end();
gradientTopLeftColor = parseColor(topLeftColor);
gradientBottomRightColor = parseColor(bottomRightColor);
gradientBlendedColor = new Color(gradientTopLeftColor).add(gradientBottomRightColor);
@Override
public boolean pan(float x, float y, float deltaX, float deltaY) {
if (currentSticker != Sticker.INDEX_NONE) {
Sticker sticker = getCurrentSticker();
if (sticker != null) {
sticker.moveBy(deltaX * worldDensity, -deltaY * worldDensity);
}
}
return false;
}
@Override
public void resize(int width, int height) {
if (height > width) {
worldDensity = 1f * worldWidth / width;
} else {
worldDensity = 1f * worldHeight / height;
}
viewport.update(width, height, true);
}
public void onAppear() {
ScaleToAction scaleToAction = scaleToPool.obtain();
scaleToAction.setPool(scaleToPool);
scaleToAction.setScale(startScale);
scaleToAction.setDuration(ANIMATION_TIME_APPEAR);
addAction(scaleToAction);
}
|
Метки: author mr-cpp разработка под android разработка игр libgdx android |
LibGDX. Практические вопросы и ответы |
Привет хабр!import com.badlogic.gdx.Gdx;
public class GdxLog {
public static boolean DEBUG;
@SuppressWarnings("all")
public static void print(String tag, String message) {
if (DEBUG) {
Gdx.app.log(tag, message);
}
}
@SuppressWarnings("all")
public static void d(String tag, String message, Integer...values) {
if (DEBUG) {
Gdx.app.log(tag, String.format(message, values));
}
}
@SuppressWarnings("all")
public static void f(String tag, String message, Float...values) {
if (DEBUG) {
Gdx.app.log(tag, String.format(message.replaceAll("%f", "%.0f"), values));
}
}
}
//... вызов
GdxLog.d(TAG, "worldWidth: %d", worldWidth);
Gdx.app.postRunnable(new Runnable() {
@Override
public void run() {
// Здесь выполняется в самом потоке
}
});
// null may be only String params
public void postRunnable(final String name, final Object...params) {
Gdx.app.postRunnable(new Runnable() {
@Override
public void run() {
Method method = null;
Class[] classes = new Class[params.length];
for (int i = 0; i < params.length; i++) {
classes[i] = params[i] == null ? String.class : params[i].getClass();
}
try {
method = World.class.getMethod(name, classes);
} catch (SecurityException e) {
GdxLog.print(TAG, e.toString());
} catch (NoSuchMethodException e) {
GdxLog.print(TAG, e.toString());
}
if (method == null) {
return;
}
try {
method.invoke(WorldAdapter.this, params);
} catch (IllegalArgumentException e) {
GdxLog.print(TAG, e.toString());
} catch (IllegalAccessException e) {
GdxLog.print(TAG, e.toString());
} catch (InvocationTargetException e) {
GdxLog.print(TAG, e.toString());
}
}
});
}
public class ActivityMain extends AppCompatActivity
implements AndroidFragmentApplication.Callbacks {
protected FragmentWorld fragmentWorld;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// ...
getSupportFragmentManager()
.beginTransaction()
.add(R.id.world, fragmentWorld, FragmentWorld.class.getSimpleName())
.commitAllowingStateLoss();
}
@Override
public void exit() {}
public class FragmentWorld extends AndroidFragmentApplication {
public World world;
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
int worldWidth = getResources().getDimensionPixelSize(R.dimen.world_width);
int worldHeight = getResources().getDimensionPixelSize(R.dimen.world_height);
world = new World(BuildConfig.DEBUG, worldWidth, worldHeight);
return initializeForView(world);
}
}
final Pixmap pixmap = getScreenshot();
Observable.fromCallable(new Callable () {
@Override
public Boolean call() throws Exception {
PixmapIO.PNG writer = new PixmapIO.PNG((int)(pixmap.getWidth() * pixmap.getHeight() * 1.5 f));
writer.setFlipY(false);
ByteArrayOutputStream output = new ByteArrayOutputStream();
try {
writer.write(output, pixmap);
} finally {
StreamUtils.closeQuietly(output);
writer.dispose();
pixmap.dispose();
}
byte[] bytes = output.toByteArray();
Bitmap bitmap = BitmapFactory.decodeByteArray(bytes, 0, bytes.length);
return true;
}
}).subscribeOn(Schedulers.io()).subscribe();
protected Color parseColor(String hex) {
String s1 = hex.substring(0, 2);
int v1 = Integer.parseInt(s1, 16);
float f1 = 1 f * v1 / 255 f;
String s2 = hex.substring(2, 4);
int v2 = Integer.parseInt(s2, 16);
float f2 = 1 f * v2 / 255 f;
String s3 = hex.substring(4, 6);
int v3 = Integer.parseInt(s3, 16);
float f3 = 1 f * v3 / 255 f;
return new Color(f1, f2, f3, 1 f);
}
Sticker sticker = (Sticker) stickersStage.hit(coordinates.x, coordinates.y, false);
@Override
public boolean pinch(Vector2 initialPointer1, Vector2 initialPointer2, Vector2 pointer1,
Vector2 pointer2) {
// initialPointer doesn't change
// all vectors contains device coordinates
Sticker sticker = getCurrentSticker();
if (sticker == null) {
return false;
}
Vector2 startVector = new Vector2(initialPointer1).sub(initialPointer2);
Vector2 currentVector = new Vector2(pointer1).sub(pointer2);
sticker.setScale(sticker.startScale * currentVector.len() / startVector.len());
float startAngle = (float) Math.toDegrees(Math.atan2(startVector.x, startVector.y));
float endAngle = (float) Math.toDegrees(Math.atan2(currentVector.x, currentVector.y));
sticker.setRotation(sticker.startRotation + endAngle - startAngle);
return false;
}
@Override
public boolean touchDown(float x, float y, int pointer, int button) {
if (pointer == FIRST_FINGER) {
Vector2 coordinates = stickersStage.screenToStageCoordinates(new Vector2(x, y));
Sticker sticker = (Sticker) stickersStage.hit(coordinates.x, coordinates.y, false);
if (sticker != null) {
// здесь
sticker.setPinchStarts();
currentSticker = sticker.index;
}
}
return false;
}
@Override
public void pinchStop() {
Sticker sticker = getCurrentSticker();
if (sticker != null) {
// здесь
sticker.setPinchStarts();
}
}
spriteBatch.begin();
stickersStage.act();
stickersStage.getRoot().draw(spriteBatch, 1);
spriteBatch.end();
gradientTopLeftColor = parseColor(topLeftColor);
gradientBottomRightColor = parseColor(bottomRightColor);
gradientBlendedColor = new Color(gradientTopLeftColor).add(gradientBottomRightColor);
@Override
public boolean pan(float x, float y, float deltaX, float deltaY) {
if (currentSticker != Sticker.INDEX_NONE) {
Sticker sticker = getCurrentSticker();
if (sticker != null) {
sticker.moveBy(deltaX * worldDensity, -deltaY * worldDensity);
}
}
return false;
}
@Override
public void resize(int width, int height) {
if (height > width) {
worldDensity = 1f * worldWidth / width;
} else {
worldDensity = 1f * worldHeight / height;
}
viewport.update(width, height, true);
}
public void onAppear() {
ScaleToAction scaleToAction = scaleToPool.obtain();
scaleToAction.setPool(scaleToPool);
scaleToAction.setScale(startScale);
scaleToAction.setDuration(ANIMATION_TIME_APPEAR);
addAction(scaleToAction);
}
|
Метки: author mr-cpp разработка под android разработка игр libgdx android |
Обзор GUI-интерфейсов для управления Docker-контейнерами |

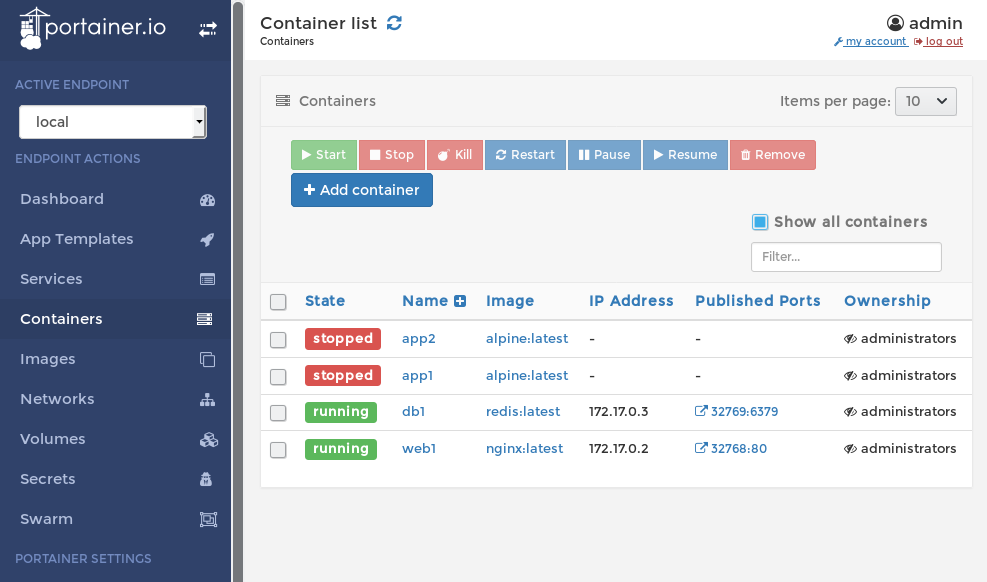



docker run в формат Docker Compose. Работает с Docker 1.10.0+ (Linux) и 1.12.0 (Mac + Windows), Docker Compose 1.6.0+.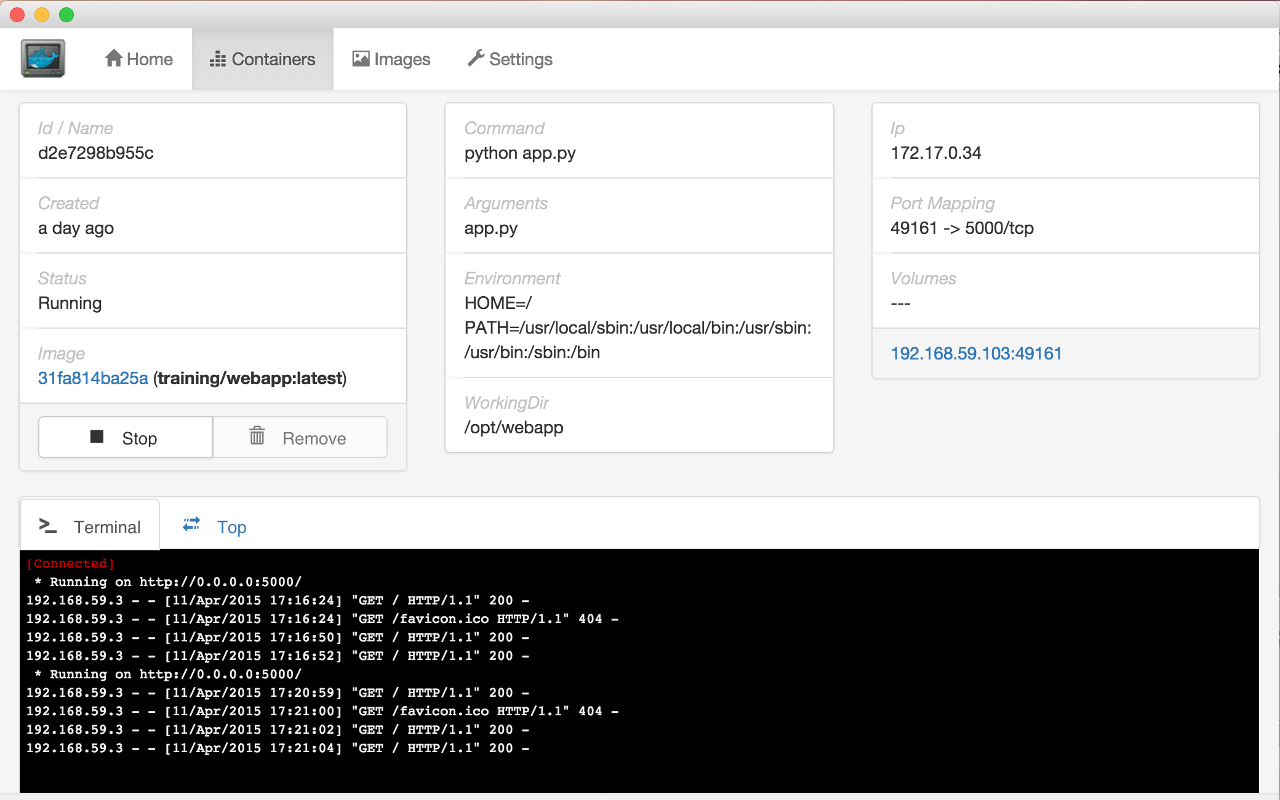
|
Метки: author shurup системное администрирование серверное администрирование devops блог компании флант docker контейнеры |






