[Перевод] Охота на вредоносные npm-пакеты |
|
Метки: author ru_vds node.js javascript блог компании ruvds.com npm безопасность |
DLP и Закон: как правильно оформить внедрение системы для защиты от утечек |

|
Метки: author SolarSecurity информационная безопасность блог компании solar security dlp юридические тонкости юридические вопросы защита информации защита от утечек |
DLP и Закон: как правильно оформить внедрение системы для защиты от утечек |
|
Метки: author SolarSecurity информационная безопасность блог компании solar security dlp юридические тонкости юридические вопросы защита информации защита от утечек |
[Из песочницы] Автоматизация рыбной ловли для World of Warcraft |
import pyscreenshot as ImageGrab
screen_size = None
screen_start_point = None
screen_end_point = None
# Сперва мы проверяем размер экрана и берём начальную и конечную точку для будущих скриншотов
def check_screen_size():
print "Checking screen size"
img = ImageGrab.grab()
# img.save('temp.png')
global screen_size
global screen_start_point
global screen_end_point
# я так и не смог найти упоминания о коэффициенте в методе grab с параметром bbox, но на моем макбуке коэффициент составляет 2. то есть при создании скриншота с координатами x1=100, y1=100, x2=200, y2=200), размер картинки будет 200х200 (sic!), поэтому делим на 2
coefficient = 2
screen_size = (img.size[0] / coefficient, img.size[1] / coefficient)
# берем примерно девятую часть экрана примерно посередине.
screen_start_point = (screen_size[0] * 0.35, screen_size[1] * 0.35)
screen_end_point = (screen_size[0] * 0.65, screen_size[1] * 0.65)
print ("Screen size is " + str(screen_size))
def make_screenshot():
print 'Capturing screen'
screenshot = ImageGrab.grab(bbox=(screen_start_point[0], screen_start_point[1], screen_end_point[0], screen_end_point[1]))
# сохраняем скриншот, чтобы потом скормить его в OpenCV
screenshot_name = 'var/fishing_session_' + str(int(time.time())) + '.png'
screenshot.save(screenshot_name)
return screenshot_name
def main():
check_screensize()
make_screenshot()









import cv2
import numpy as np
from matplotlib import pyplot as plt
def find_float(screenshot_name):
print 'Looking for a float'
for x in range(0, 7):
# загружаем шаблон
template = cv2.imread('var/fishing_float_' + str(x) + '.png', 0)
# загружаем скриншот и изменяем его на чернобелый
src_rgb = cv2.imread(screenshot_name)
src_gray = cv2.cvtColor(src_rgb, cv2.COLOR_BGR2GRAY)
# берем ширину и высоту шаблона
w, h = template.shape[::-1]
# магия OpenCV, которая и находит наш темплейт на картинке
res = cv2.matchTemplate(src_gray, template, cv2.TM_CCOEFF_NORMED)
# понижаем порог соответствия нашего шаблона с 0.8 до 0.6, ибо поплавок шатается и освещение в локациях иногда изменяет его цвета, но не советую ставить ниже, а то и рыба будет похожа на поплавок
threshold = 0.6
# numpy фильтрует наши результаты по порогу
loc = np.where( res >= threshold)
# выводим результаты на картинку
for pt in zip(*loc[::-1]):
cv2.rectangle(src_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
# и если результаты всё же есть, то возвращаем координаты и сохраняем картинку
if loc[0].any():
print 'Found float at ' + str(x)
cv2.imwrite('var/fishing_session_' + str(int(time.time())) + '_success.png', src_rgb)
return (loc[1][0] + w / 2) / 2, (loc[0][0] + h / 2) / 2 # опять мы ведь помним, что макбук играется с разрешениями? поэтому снова приходится делить на 2
def main():
check_screensize()
img_name = make_screenshot()
find_float(img_name)
import autopy
def move_mouse(place):
x,y = place[0], place[1]
print("Moving cursor to " + str(place))
autopy.mouse.smooth_move(int(screen_start_point[0]) + x , int(screen_start_point[1]) + y)
def main():
check_screensize()
img_name = make_screenshot()
cords = find_float(img_name)
move_mouse(cords)
import pyaudio
import wave
import audioop
from collections import deque
import time
import math
def listen():
print 'Listening for loud sounds...'
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 18000 # битрейт звука, который мы хотим слушать
THRESHOLD = 1200 # порог интенсивности звука, если интенсивность ниже, значит звук по нашим меркам слишком тихий
SILENCE_LIMIT = 1 # длительность тишины, если мы не слышим ничего это время, то начинаем слушать заново
# открываем стрим
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
# output=True, # на мак ос нет возможности слушать output, поэтому мне пришлось прибегнуть к использованию Soundflower, который умеет перенаправлять канал output в input, таким образом мы перехватываем звук игры будто это микрофон
input=True,
frames_per_buffer=CHUNK)
cur_data = ''
rel = RATE/CHUNK
slid_win = deque(maxlen=SILENCE_LIMIT * rel)
# начинаем слушать и по истечении 20 секунд (столько максимум длится каждый заброс поплавка), отменяем нашу слушалку.
success = False
listening_start_time = time.time()
while True:
try:
cur_data = stream.read(CHUNK)
slid_win.append(math.sqrt(abs(audioop.avg(cur_data, 4))))
if(sum([x > THRESHOLD for x in slid_win]) > 0):
print 'I heart something!'
success = True
break
if time.time() - listening_start_time > 20:
print 'I don't hear anything during 20 seconds!'
break
except IOError:
break
# обязательно закрываем стрим
stream.close()
p.terminate()
return success
def main():
check_screensize()
img_name = make_screenshot()
cords = find_float(img_name)
move_mouse(cords)
listen()
def snatch():
print('Snatching!')
autopy.mouse.click(autopy.mouse.RIGHT_BUTTON)
def main():
check_screensize()
img_name = make_screenshot()
cords = find_float(img_name)
move_mouse(cords)
if listen():
snatch()
|
Метки: author kio_tk python world of warcraft боты opencv |
[Из песочницы] Автоматизация рыбной ловли для World of Warcraft |
import pyscreenshot as ImageGrab
screen_size = None
screen_start_point = None
screen_end_point = None
# Сперва мы проверяем размер экрана и берём начальную и конечную точку для будущих скриншотов
def check_screen_size():
print "Checking screen size"
img = ImageGrab.grab()
# img.save('temp.png')
global screen_size
global screen_start_point
global screen_end_point
# я так и не смог найти упоминания о коэффициенте в методе grab с параметром bbox, но на моем макбуке коэффициент составляет 2. то есть при создании скриншота с координатами x1=100, y1=100, x2=200, y2=200), размер картинки будет 200х200 (sic!), поэтому делим на 2
coefficient = 2
screen_size = (img.size[0] / coefficient, img.size[1] / coefficient)
# берем примерно девятую часть экрана примерно посередине.
screen_start_point = (screen_size[0] * 0.35, screen_size[1] * 0.35)
screen_end_point = (screen_size[0] * 0.65, screen_size[1] * 0.65)
print ("Screen size is " + str(screen_size))
def make_screenshot():
print 'Capturing screen'
screenshot = ImageGrab.grab(bbox=(screen_start_point[0], screen_start_point[1], screen_end_point[0], screen_end_point[1]))
# сохраняем скриншот, чтобы потом скормить его в OpenCV
screenshot_name = 'var/fishing_session_' + str(int(time.time())) + '.png'
screenshot.save(screenshot_name)
return screenshot_name
def main():
check_screensize()
make_screenshot()
import cv2
import numpy as np
from matplotlib import pyplot as plt
def find_float(screenshot_name):
print 'Looking for a float'
for x in range(0, 7):
# загружаем шаблон
template = cv2.imread('var/fishing_float_' + str(x) + '.png', 0)
# загружаем скриншот и изменяем его на чернобелый
src_rgb = cv2.imread(screenshot_name)
src_gray = cv2.cvtColor(src_rgb, cv2.COLOR_BGR2GRAY)
# берем ширину и высоту шаблона
w, h = template.shape[::-1]
# магия OpenCV, которая и находит наш темплейт на картинке
res = cv2.matchTemplate(src_gray, template, cv2.TM_CCOEFF_NORMED)
# понижаем порог соответствия нашего шаблона с 0.8 до 0.6, ибо поплавок шатается и освещение в локациях иногда изменяет его цвета, но не советую ставить ниже, а то и рыба будет похожа на поплавок
threshold = 0.6
# numpy фильтрует наши результаты по порогу
loc = np.where( res >= threshold)
# выводим результаты на картинку
for pt in zip(*loc[::-1]):
cv2.rectangle(src_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
# и если результаты всё же есть, то возвращаем координаты и сохраняем картинку
if loc[0].any():
print 'Found float at ' + str(x)
cv2.imwrite('var/fishing_session_' + str(int(time.time())) + '_success.png', src_rgb)
return (loc[1][0] + w / 2) / 2, (loc[0][0] + h / 2) / 2 # опять мы ведь помним, что макбук играется с разрешениями? поэтому снова приходится делить на 2
def main():
check_screensize()
img_name = make_screenshot()
find_float(img_name)
import autopy
def move_mouse(place):
x,y = place[0], place[1]
print("Moving cursor to " + str(place))
autopy.mouse.smooth_move(int(screen_start_point[0]) + x , int(screen_start_point[1]) + y)
def main():
check_screensize()
img_name = make_screenshot()
cords = find_float(img_name)
move_mouse(cords)
import pyaudio
import wave
import audioop
from collections import deque
import time
import math
def listen():
print 'Listening for loud sounds...'
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 18000 # битрейт звука, который мы хотим слушать
THRESHOLD = 1200 # порог интенсивности звука, если интенсивность ниже, значит звук по нашим меркам слишком тихий
SILENCE_LIMIT = 1 # длительность тишины, если мы не слышим ничего это время, то начинаем слушать заново
# открываем стрим
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
# output=True, # на мак ос нет возможности слушать output, поэтому мне пришлось прибегнуть к использованию Soundflower, который умеет перенаправлять канал output в input, таким образом мы перехватываем звук игры будто это микрофон
input=True,
frames_per_buffer=CHUNK)
cur_data = ''
rel = RATE/CHUNK
slid_win = deque(maxlen=SILENCE_LIMIT * rel)
# начинаем слушать и по истечении 20 секунд (столько максимум длится каждый заброс поплавка), отменяем нашу слушалку.
success = False
listening_start_time = time.time()
while True:
try:
cur_data = stream.read(CHUNK)
slid_win.append(math.sqrt(abs(audioop.avg(cur_data, 4))))
if(sum([x > THRESHOLD for x in slid_win]) > 0):
print 'I heart something!'
success = True
break
if time.time() - listening_start_time > 20:
print 'I don't hear anything during 20 seconds!'
break
except IOError:
break
# обязательно закрываем стрим
stream.close()
p.terminate()
return success
def main():
check_screensize()
img_name = make_screenshot()
cords = find_float(img_name)
move_mouse(cords)
listen()
def snatch():
print('Snatching!')
autopy.mouse.click(autopy.mouse.RIGHT_BUTTON)
def main():
check_screensize()
img_name = make_screenshot()
cords = find_float(img_name)
move_mouse(cords)
if listen():
snatch()
|
Метки: author kio_tk python world of warcraft боты opencv |
Цифровая экономика и экосистема R |
Если смотреть прессу, словосочетание «цифровая экономика» ожидается одним из популярных в ближайшие несколько лет.
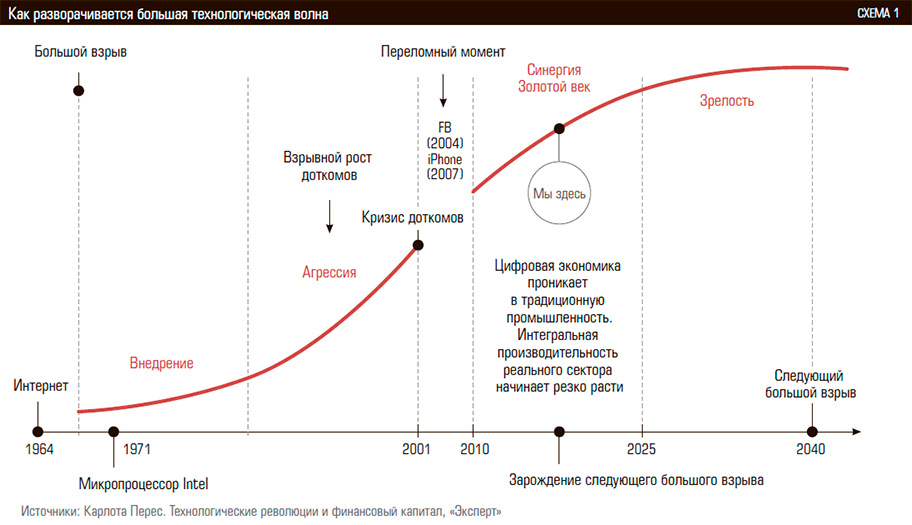
Но чтобы от перейти от слов к делу и действительно совершить цифровой скачок необходимо пересмотреть подходы и используемые инструменты. В рамках настоящей публикации, являющейся продолжением предыдущих публикаций, планирую кратко проиллюстрировать, тезис о том, что применение в бизнесе R экосистемы прекрасно вписывается в задачу перехода к цифровой экономике.
В эволюционного развития различных задач были пересмотрены различные методики и современные open-source средства. В результате сформировался достаточно универсальный стек общего назначения, общая архитектура которого выглядит следующим образом:

Ключевые компоненты решения
В зависимости от предметной области, типов и масштабов данных могут использоваться не все элементы стека. Но какая бы задачи ни была, аналитическим ядром, а также лицом системы с точки зрения пользователя остается R & Shiny соотвественно.
Как правило, большинство людей ожидают увидеть «отчеты», не детализируя, что именно они в это слово вкладывают. Экосистема R позволяет получать много больше типичных ожиданий:
Средой существования всех упомянутых типов отчетов и АРМ является Shiny Server\Connect Server. В платной или бесплатной редакции — зависит от требований, которые выходят за рамки аналитики и определяются требованиями по нагрузке, безопасности, централизованному управлению.
P.S.
Практика раз за разом показывает, что цифровые преобразования упираются отнюдь не в возможности инструментов (open-source), а в неготовность людей менять восприятие, изучать новое, мыслить стратегически или просто страх перемен.
Примером подобного типового пожелания является наличие «визуального» конструктора, так, чтобы только мышкой, без какого-либо программирования можно было получить результат неограниченной сложности. Однако, это красивое требование, культивируемое представителями BI визуализации, очень плохо сочетается с самим содержанием цифровых перемен которые ожидают человечество.
Парадокс этого требования вполне прозрачен. Повсеместно используя машины в качестве помощников крайне затруднительно общаться с ними с помощю ограниченного языка жестов или словаря Эллочки-людоедки. Даже из теории информации следует, что двумя-тремя кликами очень мало чего можно передать, если только это не код заранее досконально согласованного действия.
В цифровом мире язык програмимирования становится таким же важным знанием, как язык международного общения. Интересно, что в отдельных западных компаниях, воспринимавшихся ранее как классическое производство, программирование становится важным навыком даже для менеджеров. Прекрасный пример подобной трансформации — компания GE, подразделеие GE Digital. Ролик — Discover GE Digital: The Digital Industrial Company
|
Метки: author i_shutov data mining big data data science |
Новые инструменты Safari для отладки WebRTC |


|
Метки: author eyeofhell разработка веб-сайтов программирование safari javascript блог компании voximplant webrtc |
[Из песочницы] Chromebook для удаленной работы. Настраиваем VPN и RDP |

openvpn --mktun --dev tap0
openvpn --config /usr/local/vpn/openvpn.ovpn --dev tap0
openvpn --rmtun --dev tap0
|
Метки: author Zin4uk системное администрирование *nix cromebook remote linux vpn remmina rdp |
[Перевод] Погружение в F#. Пособие для C#-разработчиков |
Этот пост будет не о том, как «перевести» код с C# на F#: различные парадигмы делают каждый из этих языков лучшим для своего круга задач. Однако вы сможете оценить все достоинства функционального программирования быстрее, если не будете думать о переводе кода из одной парадигмы в другую. Настало время любопытных, пытливых и готовых изучать совершенно новые вещи. Давайте начнем!

Ранее, в посте «Почему вам следует использовать F#», мы рассказали, почему F# стоит попробовать прямо сейчас. Теперь мы разберем основы, необходимые для его успешного применения. Пост предназначен для людей, знакомых с C#, Java или другими объектно-ориентированными языками. Если вы уже пишете на F#, эти понятия должны быть вам хорошо знакомы.
Перед тем, как приступить к изучению понятий функционального программирования, давайте посмотрим на небольшой пример и определим, в чем F# отличается от C#. Это базовый пример с двумя функциями и выводом результата на экран:
let square x = x * x
let sumOfSquares n =
[1..n] // Создадим список с элементами от 1 до n
|> List.map square // Возведем в квадрат каждый элемент
|> List.sum // Просуммируем их!
printfn "Сумма квадратов первых 5 натуральных чисел равна %d" (sumOfSquares 5)Обратите внимание, что здесь нет явного указания типов, отсутствуют точки с запятой или фигурные скобки. Скобки используются в единственном месте: для вызова функции sumOfSquares с числом 5 в качестве входного значения и последующего вывода результата на экран. Конвейерный оператор |> (pipeline operator) используется так же, как конвейеры (каналы, pipes) в Unix. square — это функция, которая напрямую передается в функцию List.map как параметр (функции в F# рассматриваются как значения, first-class functions).
Хотя различий на самом деле еще много, сперва стоит разобраться с фундаментальными вещами, поскольку они — ключ к пониманию F#.
Следующая таблица показывает соответствия между некоторыми ключевыми понятиями C# и F#. Это умышленно короткое и неполное описание, но так его проще запомнить в начале изучения F#.
| C# и Объектно-Ориентированное Программирование | F# и Функциональное Программирование |
|---|---|
| Переменные | Неизменяемые значения |
| Инструкции | Выражения |
| Объекты с методами | Типы и функции |
Быстрая шпаргалка по некоторым терминам:
Переменные — это значения, которые могут меняться. Это следует из их названия!
Неизменяемые значения — это значения, которые не могут быть изменены после присваивания.
Инструкции — это команды, исполняемые после запуска программы.
Выражения — это фрагменты кода, которые можно вычислить и получить значения.
Стоит отметить, что все указанное в столбце C# так же возможно в F# (и довольно легко реализуется). В столбце F# также есть вещи, которые можно сделать в C#, хотя и намного сложнее. Следует упомянуть, что элементы в левом столбце не являются "плохими" в F#, и наоборот. Объекты с методами отлично подходят для использования в F# и часто являются лучшим решением в зависимости от вашей ситуации.
Одним из наиболее непривычных понятий в функциональном программировании является неизменяемость (иммутабельность, immutability). Ему часто уделяют недостаточно внимания в сообществе любителей функционального программирования. Но если вы никогда не использовали язык, в котором значения неизменяемы по умолчанию, это часто является первым и наиболее значимым препятствием для дальнейшего изучения. Неизменяемость является фундаментальным понятием практически во всех функциональных языках.
let x = 1В предыдущем выражении значение 1 связано с именем x. В течение всего времени существования имя x теперь ссылается на значение 1 и не может быть изменено. Например, следующий код не может переназначить значение x:
let x = 1
x = x + 1 // Это выражение ничего не присваивает!Вместо этого, вторая строка является сравнением, определяющим, является ли x равным x + 1. Хотя существует способ изменить (мутировать, mutate) x с помощью использования оператора <- и модификатора mutable (см. подробности в Mutable Variables), вы быстро поймете, что проще думать о решении задач без переприсвоения значений. Если не рассматривать F# как еще один императивный язык программирования, вы сможете использовать его самые сильные стороны.
Неизменяемость существенным образом преобразует ваши привычные подходы к решению задач. Например, циклы for и другие базовые операции императивного программирования не так часто используются в F#.
Рассмотрим более конкретный пример: вы хотите возвести в квадрат числа из входного списка. Вот как это можно сделать в F#:
// Определим функцию, которая вычисляет квадрат значения
let square x = x * x
let getSquares items =
items |> List.map square
let lst = [ 1; 2; 3; 4; 5 ] // Создать список в F#
printfn "Квадрат числа %A равен %A" lst (getSquares lst)Заметим, что в этом примере нет цикла for. На концептуальном уровне это сильно отличается от императивного кода. Мы не возводим в квадрат каждый элемент списка. Мы применяем функцию square к входному списку и получаем значения, возведенные в квадрат. Это очень тонкое различие, но на практике оно может приводить к значительно отличающемуся коду. Прежде всего, функция getSquares на самом деле создает полностью новый список.
Неизменяемость — это гораздо более широкая концепция, чем просто иной способ управления данными в списках. Понятие ссылочной прозрачности (Referential Transparency) естественно для F#, и оказывает значительное влияние, как на разработку систем, так и на то, как части этих систем сочетаются. Функциональные характеристики системы становятся более предсказуемыми, когда значения не изменяются, если вы этого не ожидаете.
Более того, когда значения неизменяемы, конкурентное программирование становится проще. Некоторые сложные проблемы, возникающие в С# из-за изменяемого состояния, в F# не встречаются вообще. F# не может волшебным образом решить все ваши проблемы с многопоточностью и асинхронностью, однако он сделает многие вещи проще.
Как было упомянуто ранее, F# использует выражения (expressions). Это контрастирует с C#, где практически для всего используются инструкции (statements). Различие между ними может казаться на первый взгляд незначительным, однако есть одна вещь, о которой следует помнить: выражения производят значения. Инструкции — нет.
// 'getMessage' -- это функция, и `name` - ее входной параметр.
let getMessage name =
if name = "Phillip" then // 'if' - это выражение.
"Hello, Phillip!" // Эта строка тоже является выражением. Оно возвращает значение
else
"Hello, other person!" // То же самое с этой строкой.
let phillipMessage = getMessage "Phillip" // getMessage, при вызове, является выражением. Его значение связано с именем 'phillipMessage'.
let alfMessage = getMessage "Alf" // Это выражение связано с именем 'alfMessage'!В предыдущем примере вы можете увидеть несколько моментов, которые отличают F# от императивных языков вроде C#:
if...then...else — это выражение, а не инструкция.if возвращает значение, которое в данном случае будет являться возвращаемым значением функции getMessage.getMessage — это выражение, которое принимает строку и возвращает строку.Этот подход сильно отличается от C#, но скорее всего он покажется вам естественным при написании кода на F#.
Если копнуть немного глубже, в F# даже инструкции описываются с помощью выражений. Такие выражения возвращают значение типа unit. unit немного похож на void в C#:
let names = [ "Alf"; "Vasily"; "Shreyans"; "Jin Sun"; "Moulaye" ]
// Цикл `for`. Ключевое слово 'do' указывает, что выражение их внутренней области видимости должно иметь тип `unit`.
// Если это не так, то результат выражения неявно игнорируется.
for name in names do
printfn "My name is %s" name // printfn возвращает unit.В предыдущем примере с циклом for всё имеет тип unit. Выражения типа unit — это выражения, которые не имеют возвращаемого значения.
Предыдущие примеры кода использовали массивы и списки F#. В данном разделе разъясняются некоторые подробности.
F# предоставляет несколько типов коллекций и самые распространенные из них — это массивы, списки и последовательности.
IEnumerable. Они вычисляются лениво.Массивы, списки и последовательности в F# также имеют особый синтаксис для выражений. Это очень удобно для различных задач, когда нужно генерировать данные программно.
// Создадим список квадратов первых 100 натуральных чисел
let first100Squares = [ for x in 1..100 -> x * x ]
// То же самое, но массив!
let first100SquaresArray = [| for x in 1..100 -> x * x |]
// Функция, которая генерирует бесконечную последовательность нечетных чисел
//
// Вызывать вместе с Seq.take!
let odds =
let rec loop x = // Использует рекурсивную локальную функцию
seq { yield x
yield! loop (x + 2) }
loop 1
printfn "Первые 3 нечетных числа: %A" (Seq.take 3 odds)
// Вывод: "Первые 3 нечетных числа: seq [1; 3; 5]Если вы знакомы с методами LINQ, следующая таблица поможет вам понять аналогичные функции в F#.
| LINQ | F# функция |
|---|---|
Where |
filter |
Select |
map |
GroupBy |
groupBy |
SelectMany |
collect |
Aggregate |
fold или reduce |
Sum |
sum |
Вы также можете заметить, что такой же набор функций существует для модулей Seq, List и Array. Функции модуля Seq могут быть использованы для последовательностей, списков или массивов. Функции для массивов и списков могут быть использованы только для массивов и списков в F# соответственно. Также последовательности в F# ленивые, а списки и массивы — энергичные. Использование функций модуля Seq на списках или массивах влечет за собой ленивое вычисление, а тип возвращаемого значения будет последовательностью.
Предыдущий раздел содержит в себе довольно много информации, но по мере написания программ на F# она станет интуитивно понятной.
Вы могли заметить, что оператор |> используется в предыдущих примерах кода. Он очень похож на конвейеры в unix: принимает что-то слева от себя и передает на вход чему-то справа. Этот оператор (называется «pipe» или «pipeline») используется для создания функциональных конвейеров. Вот пример:
let square x = x * x
let isOdd x = x % 2 <> 0
let getOddSquares items =
items
|> Seq.filter isOdd
|> Seq.map squareВ данном примере сначала items передается на вход функции Seq.filter. Затем возвращаемое значение Seq.filter (последовательность) передается на вход функции Seq.map. Результат выполнения Seq.map является выходным значением функции getOddSquares.
Конвейерный оператор очень удобно использовать, поэтому редко кто обходится без него. Возможно, это одна из самых любимых возможностей F#!
Поскольку F# — язык платформы .NET, в нем существуют те же примитивные типы, что и C#: string, int и так далее. Он использует объекты .NET и поддерживает четыре основных столпа объектно-ориентированного программирования. F# предоставляет кортежи (tuples), а также два основных типа, которые отсутствуют в C#: записи (records) и размеченные объединения (discriminated unions).
Запись — это группа упорядоченных именованных значений, которая автоматически реализует операцию сравнения — в самом буквальном смысле. Не нужно задумываться о том, как происходит сравнение: через равенство ссылок или с помощью пользовательского определения равенства между двумя объектами. Записи — это значения, а значения можно сравнивать. Они являются типами-произведениями, если говорить на языке теории категорий. У них есть множество применений, однако одно из самых очевидных — их можно использовать в качестве POCO или POJO.
open System
// Вот так вы можете определить тип-запись.
// Можно располагать метки на новых строках
type Person =
{ Name: string
Age: int
Birth: DateTime }
// Создать новую запись `Person` можно примерно так.
// Если метки расположены на одной строке, они разделяются точкой с запятой
let p1 = { Name="Charles"; Age=27; Birth=DateTime(1990, 1, 1) }
// Или же можно располагать метки на новых строках
let p2 =
{ Name="Moulaye"
Age=22
Birth=DateTime(1995, 1, 1) }
// Записи можно сравнивать на равенство. Не нужно определять метод Equals() и GetHasCode().
printfn "Они равны? %b" (p1 = p2) // Это выведет `false`, потому что они не равны.Другой основной тип в F# — это размеченные объединения, или РО, или DU в англоязычной литературе. РО — это типы, представляющие некоторое количество именованных вариантов. На языке теории категорий это называется типом-суммой. Они также могут быть определены рекурсивно, что значительно упрощает описание иерархических данных.
// Определим обобщенное бинарное дерево поиска.
//
// Заметим, что обобщенный тип-параметр имеет ' в начале.
type BST<'T> =
| Empty
| Node of 'T * BST<'T> * BST<'T> // Каждый узел имеет левый и правый BST<'T>
// Развернем BST с помощью сопоставления с образцом!
let rec flip bst =
match bst with
| Empty -> bst
| Node(item, left, right) -> Node(item, flip right, flip left)
// Определим пример BST
let tree =
Node(10,
Node(3,
Empty,
Node(6,
Empty,
Empty)),
Node(55,
Node(16,
Empty,
Empty),
Empty))
// Развернем его!
printfn "%A" (flip tree)Тадам! Вооружившись мощью размеченных объединений и F#, вы можете пройти любое собеседование, в котором требуется развернуть бинарное дерево поиска.
Наверняка вы увидели странный синтаксис в определении варианта Node. Это на самом деле сигнатура кортежа. Это означает, что определенное нами BST может быть или пустым, или являться кортежем (значение, левое поддерево, правое поддерево). Более подробно про это написано в разделе о сигнатурах.
Следующий пример кода представлен с разрешения Скотта Влашина, героя сообщества F#, написавшего этот прекрасный обзор F# синтаксиса. Вы прочтете его примерно за минуту. Пример был немного отредактирован.
// Данный код представлен с разрешения автора, Скотта Влашина. Он был немного модифицирован.
// Для однострочных комментариев используется двойной слеш.
(*
Многострочные комментарии можно сделать вот так (хотя обычно используют двойной слеш).
*)
// ======== "Переменные" (на самом деле нет) ==========
// Ключевое слово "let" определяет неизменяемое (иммутабельное) значение
let myInt = 5
let myFloat = 3.14
let myString = "привет" // обратите внимание - указывать тип не нужно
// ======== Списки ============
let twoToFive = [ 2; 3; 4; 5 ] // Списки создаются с помощью квадратных скобок,
// для разделения значений используются точки с запятой.
let oneToFive = 1 :: twoToFive // оператор :: создает список с новым первым элементом
// Результат: [1; 2; 3; 4; 5]
let zeroToFive = [0;1] @ twoToFive // оператор @ объединяет два списка
// ВАЖНО: запятые никогда не используются для разделения значений, только точки с запятой!
// ======== Функции ========
// Ключевое слово "let" также определяет именованную функцию.
let square x = x * x // Обратите внимание - скобки не используются.
square 3 // А сейчас вызовем функцию. Снова никаких скобок.
let add x y = x + y // не используйте add (x,y)! Это означает
// совершенно другую вещь.
add 2 3 // Вызовем фукнкцию.
// чтобы определить многострочную функцию, просто используйте отступы.
// Точки с запятой не требуются.
let evens list =
let isEven x = x % 2 = 0 // Определет "isEven" как внутреннюю ("вложенную") функцию
List.filter isEven list // List.filter - это библиотечная функция
// с двумя параметрами: предикат
// и список, которые требуется отфильтровать
evens oneToFive // Вызовем функцию
// Вы можете использовать скобки, чтобы уточнить приоритет.
// В данном примере, сначала используем "map" с двумя аргументами,
// а потом вызываем "sum" для результата.
// Без скобок "List.map" была бы передана как аргумент в "List.sum"
let sumOfSquaresTo100 =
List.sum (List.map square [ 1 .. 100 ])
// Вы можете передать результат одной функции в следующую с помощью "|>"
// Вот та же самая функция sumOfSquares, переписанная с помощью конвейера
let sumOfSquaresTo100piped =
[ 1 .. 100 ] |> List.map square |> List.sum // "square" определена раньше
// вы можете определять лямбда-функции (анонимные функции)
// с помощью ключевого слова "fun"
let sumOfSquaresTo100withFun =
[ 1 .. 100 ] |> List.map (fun x -> x * x) |> List.sum
// В F# значения возвращаются неявно - ключевое слово "return" не используется
// Функция всегда возвращает значение последнего выражения в ее теле
// ======== Сопоставление с образцом ========
// Match..with.. - это case/switch инструкции "на стероидах".
let x = "a"
match x with
| "a" -> printfn "x - это a"
| "b" -> printfn "x - это b"
| _ -> printfn "x - это что-то другое" // подчеркивание соответствует "чему угодно"
// Some(..) и None приблизительно соответствуют оберткам Nullable
let validValue = Some(99)
let invalidValue = None
// В данном примере match..with сравнивает с "Some" и "None"
// и в то же время распаковывает значение в "Some".
let optionPatternMatch input =
match input with
| Some i -> printfn "целое число %d" i
| None -> printfn "входное значение отсутствует"
optionPatternMatch validValue
optionPatternMatch invalidValue
// ========= Сложные типы данных =========
// Кортежи - это пары, тройки значений и так далее.
// Кортежи используют запятые.
let twoTuple = (1, 2)
let threeTuple = ("a", 2, true)
// Записи имеют именованные поля. Точки с запятой являются разделителями.
type Person = { First: string; Last: string }
let person1 = { First="John"; Last="Doe" }
// Вы можете также использовать переносы на новую строку
// вместо точек с запятой.
let person2 =
{ First="Jane"
Last="Doe" }
// Объединения представляют варианты. Разделитель - вертикальная черта.
type Temp =
| DegreesC of float
| DegreesF of float
let temp = DegreesF 98.6
// Типы можно комбинировать рекурсивно различными путями.
// Например, вот тип-объединение, который содержит список
// элементов того же типа:
type Employee =
| Worker of Person
| Manager of Employee list
let jdoe = { First="John"; Last="Doe" }
let worker = Worker jdoe
// ========= Вывод на экран =========
// Функции printf/printfn схожи с функциями Console.Write/WriteLine из C#.
printfn "Вывод на экран значений типа int %i, float %f, bool %b" 1 2.0 true
printfn "Строка %s, и что-то обобщенное %A" "hello" [ 1; 2; 3; 4 ]
// все сложные типы имеют встроенный красивый вывод
printfn "twoTuple=%A,\nPerson=%A,\nTemp=%A,\nEmployee=%A"
twoTuple person1 temp worker В дополнение, в нашей официальной документации для .NET и поддерживаемых языков есть материал «Тур по F#».
Всё описанное в данном посте — лишь поверхностные возможности F#. Мы надеемся, что после прочтения этой статьи вы сможете погрузиться в F# и функциональное программирование. Вот несколько примеров того, что можно написать в качестве упражнения для дальнейшего изучения F#:
Есть очень много других задач, для которых можно использовать F#; предыдущий список ни в коем случае не является исчерпывающим. F# используется в различных приложениях: от простых скриптов для сборки до бэкенда интернет-магазинов с миллиардной выручкой. Нет никаких ограничений по проектам, для которых вы можете использовать F#.
Для F# существует множество самоучителей, включая материалы для тех, кто пришел с опытом C# или Java. Следующие ссылки могут быть полезными по мере того, как вы будете глубже изучать F#:
Также описаны еще несколько способов, как начать изучение F#.
И наконец, сообщество F# очень дружелюбно к начинающим. Есть очень активный чат в Slack, поддерживаемый F# Software Foundation, с комнатами для начинающих, к которым вы можете свободно присоединиться. Рекомендуем вам это сделать!
Не забудьте посетить сайт русскоязычного сообщества F#! Если у вас возникнут вопросы по изучению языка, мы будем рады обсудить их в чатах:
#ru_general в Slack-чате F# Software Foundation Статья переведена усилиями русскоязычного сообщества F#-разработчиков.
Статья переведена усилиями русскоязычного сообщества F#-разработчиков.
Мы также благодарим @schvepsss за подготовку данной статьи к публикации.
|
Метки: author Schvepsss программирование mono и moonlight c# .net блог компании microsoft microsoft f# fsharplangru microsoft research |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №275 (7 — 13 августа 2017) |

| Медиа |
| Веб-разработка |
| CSS |
| Javascript |
| Браузеры |
| Занимательное |
 Медиа
Медиа Подкаст «Веб-стандарты», Выпуск №80 : Firefox 55, Samsung есть, Safari виднее, алгоритмы и паттерны, прозрачный JPG, Телеграм, приоритеты загрузки, фокусы, модули в Node.js. Подкаст «Пятиминутка React» #30 : setState и организация кода Подкаст «Пятиминутка Angular» #1 : Angular 5 Beta 3, Angular CLI 1.3, CreateAngularComponents Подкаст «Фронтенд Юность (18+)» #14: Все секреты производительности фронтенда Подкаст «devschacht», Выпуск №6: Готовим с фронтендером: одна часть Node.js, одна часть CSS-in-JS, густо приправить ФРП, добавить щепотку корутин и чайную ложечку зелёных тредов. Подкаст «Drinkcast» #3: «Раньше дивы были зеленее»
Подкаст «Веб-стандарты», Выпуск №80 : Firefox 55, Samsung есть, Safari виднее, алгоритмы и паттерны, прозрачный JPG, Телеграм, приоритеты загрузки, фокусы, модули в Node.js. Подкаст «Пятиминутка React» #30 : setState и организация кода Подкаст «Пятиминутка Angular» #1 : Angular 5 Beta 3, Angular CLI 1.3, CreateAngularComponents Подкаст «Фронтенд Юность (18+)» #14: Все секреты производительности фронтенда Подкаст «devschacht», Выпуск №6: Готовим с фронтендером: одна часть Node.js, одна часть CSS-in-JS, густо приправить ФРП, добавить щепотку корутин и чайную ложечку зелёных тредов. Подкаст «Drinkcast» #3: «Раньше дивы были зеленее» Нужно ли фронтендеру знать алгоритмы и паттерны проектирования?. Игорь Алексеенко в HTML Шортах Totally Tooling Tips: Webpack Tips. Регулярное шоу от разработчиков Google Chrome, в этом выпуске советы по Webpack
Нужно ли фронтендеру знать алгоритмы и паттерны проектирования?. Игорь Алексеенко в HTML Шортах Totally Tooling Tips: Webpack Tips. Регулярное шоу от разработчиков Google Chrome, в этом выпуске советы по Webpack Веб Разработка
Веб Разработка О чем всегда стоит помнить при локализации веб-сайта, чтобы потом не было стыдно Ускорьте ваш сайт с помощью машинного обучения
О чем всегда стоит помнить при локализации веб-сайта, чтобы потом не было стыдно Ускорьте ваш сайт с помощью машинного обучения Календарь событий по фронтенду. Конференции, встречи и другие события по фронтенду во всём мире в одном календаре.
Календарь событий по фронтенду. Конференции, встречи и другие события по фронтенду во всём мире в одном календаре. .NET и WebAssembly — это будущее фронтенда?
.NET и WebAssembly — это будущее фронтенда?  Какие функции Progressive Web App будет поддерживать Apple? JavaScript и SEO: разница между Crawling и Indexing Разработчик из Shuvayatra делится опытом внедрения Progressive Web App в контексте SEO Вредоносный код в npm-пакетах и борьба с ним Официальный релиз Bootstrap 4 beta наконец состоялся. Переход с Bootstrap 4 Alpha 6 на Beta
Какие функции Progressive Web App будет поддерживать Apple? JavaScript и SEO: разница между Crawling и Indexing Разработчик из Shuvayatra делится опытом внедрения Progressive Web App в контексте SEO Вредоносный код в npm-пакетах и борьба с ним Официальный релиз Bootstrap 4 beta наконец состоялся. Переход с Bootstrap 4 Alpha 6 на Beta  JPNG.svg — прозрачный PNG с JPEG компрессией Transitions with JavaScript: коллекция небольших Chrome-only демок от Ana Tudor (CSS переменные плюс немного JS) Производительные веб-анимации и интерактив: достигаем 60 FPS Креативные переходы между страницами с эффектом морфинга Руководство по покадровой анимации с помощью CSS и JavaScript
JPNG.svg — прозрачный PNG с JPEG компрессией Transitions with JavaScript: коллекция небольших Chrome-only демок от Ana Tudor (CSS переменные плюс немного JS) Производительные веб-анимации и интерактив: достигаем 60 FPS Креативные переходы между страницами с эффектом морфинга Руководство по покадровой анимации с помощью CSS и JavaScript CSS Практическое руководство по использованию CSS Modules в React приложениях Изоляция css стилей с помощью компонентного подхода Развенчание мифов о Hex цветах в CSS Font-size: неожиданно сложное CSS-свойство Shadow DOM: Быстрые и инкапсулированные стили Веб-шрифты: когда вы нуждаетесь в них, а когда нет Наследование в CSS: введение Лучший способ сделать “Wrapper”-обертку на CSS Flex Grow и Flex Basis: адаптивная раскладка страниц Разница между явными и неявными сетками Простые Sass миксины для улучшения браузерной совместимости для CSS Grid Layouts Изменения в спецификации Grid и использование многоколоночного макета Создание графиков на CSS с помощью гридов и пользовательских свойств chrome-css-grid-highlighter — Chrome-расширение для подсветки CSS Grid Layout
CSS Практическое руководство по использованию CSS Modules в React приложениях Изоляция css стилей с помощью компонентного подхода Развенчание мифов о Hex цветах в CSS Font-size: неожиданно сложное CSS-свойство Shadow DOM: Быстрые и инкапсулированные стили Веб-шрифты: когда вы нуждаетесь в них, а когда нет Наследование в CSS: введение Лучший способ сделать “Wrapper”-обертку на CSS Flex Grow и Flex Basis: адаптивная раскладка страниц Разница между явными и неявными сетками Простые Sass миксины для улучшения браузерной совместимости для CSS Grid Layouts Изменения в спецификации Grid и использование многоколоночного макета Создание графиков на CSS с помощью гридов и пользовательских свойств chrome-css-grid-highlighter — Chrome-расширение для подсветки CSS Grid Layout JavaScript ES Modules в Node уже сегодня. Анонс нового загрузчика standard/esm JavaScript для людей, которые ненавидят JavaScript Машинное обучение в Javascript. Слайды с обзором возможностей JavaScript паттерны: паттерн Observer Как все время быть в теме экосистемы JavaScript? Как на самом деле работает JavaScript: часть 1 Ленивая загрузка изображений с помощью Intersection Observer Бинарный поиск в JavaScript. Практический пример Как мы создали наше первое full-stack JavaScript приложение за три недели. Простое пошаговое руководство от идеи до запуска Улучшаем разговоры с помощью Perspective API Как создать UI поиска по GitHub за 60 минут
JavaScript ES Modules в Node уже сегодня. Анонс нового загрузчика standard/esm JavaScript для людей, которые ненавидят JavaScript Машинное обучение в Javascript. Слайды с обзором возможностей JavaScript паттерны: паттерн Observer Как все время быть в теме экосистемы JavaScript? Как на самом деле работает JavaScript: часть 1 Ленивая загрузка изображений с помощью Intersection Observer Бинарный поиск в JavaScript. Практический пример Как мы создали наше первое full-stack JavaScript приложение за три недели. Простое пошаговое руководство от идеи до запуска Улучшаем разговоры с помощью Perspective API Как создать UI поиска по GitHub за 60 минут VueJS: Лучшие мобильные компоненты для PWA в VueJs React + Webpack: замешательство, фрустрация и как Vue.js может помочь Компонент Yandex Maps для VueJS
VueJS: Лучшие мобильные компоненты для PWA в VueJs React + Webpack: замешательство, фрустрация и как Vue.js может помочь Компонент Yandex Maps для VueJS React: Почему React лучше, чем Vue.js. И когда. React Progressive Web Apps — часть Part 1 Получение данных из API с React.JS Использование Create React App с Relay Modern react-beautiful-dnd — доступные drag and drop для списков с React.js
React: Почему React лучше, чем Vue.js. И когда. React Progressive Web Apps — часть Part 1 Получение данных из API с React.JS Использование Create React App с Relay Modern react-beautiful-dnd — доступные drag and drop для списков с React.js Angular: Как Angular защищает нас от XSS атак? MEAN Stack: разработка приложения с помощью Angular 2+ и Angular CLI Избегайте общих проблем с модулями в Angular js-meter — инструмент для измерения производительности времени выполнения, CPU, RAM и кучи javascript кода posterus — компонуемые асинхронные примитивы (futures) с реальной отменой, управлением расписанием и корутинами nanoid — крошечный генератор уникальных ID, дружественный к URL react-simple-maps — SVG карты с d3-geo и topojson DisplayJS — быстрый и простой JS фреймворк для создания амбициозных UI, местами похожий на jQuery
Angular: Как Angular защищает нас от XSS атак? MEAN Stack: разработка приложения с помощью Angular 2+ и Angular CLI Избегайте общих проблем с модулями в Angular js-meter — инструмент для измерения производительности времени выполнения, CPU, RAM и кучи javascript кода posterus — компонуемые асинхронные примитивы (futures) с реальной отменой, управлением расписанием и корутинами nanoid — крошечный генератор уникальных ID, дружественный к URL react-simple-maps — SVG карты с d3-geo и topojson DisplayJS — быстрый и простой JS фреймворк для создания амбициозных UI, местами похожий на jQuery Браузеры
Браузеры У Mozilla есть план, как победить Chrome. Встречайте Firefox 57 и боевую лисичку в броне Релиз Firefox 55, разбор деталей от Марата Таналина Firefox 55: first desktop browser to support WebVR
У Mozilla есть план, как победить Chrome. Встречайте Firefox 57 и боевую лисичку в броне Релиз Firefox 55, разбор деталей от Марата Таналина Firefox 55: first desktop browser to support WebVR Фишеры уже два месяца «охотятся» на разработчиков расширений для Chrome Релиз Safari Technology Preview Release 37
Фишеры уже два месяца «охотятся» на разработчиков расширений для Chrome Релиз Safari Technology Preview Release 37 Занимательное Алгоритмы компрессии — введение с хорошей визуализацией Руководство по участию в Open Source
Занимательное Алгоритмы компрессии — введение с хорошей визуализацией Руководство по участию в Open Source Просим прощения за возможные опечатки или неработающие/дублирующиеся ссылки. Если вы заметили проблему — напишите пожалуйста в личку, мы стараемся оперативно их исправлять.
|
Метки: author alexzfort разработка веб-сайтов javascript html css дайджест фронтенд js es6 vue react angular html5 браузеры ссылки |
Цифровая экономика должна быть цифровой |

Источник
«Экономика должна быть экономной – таково требование времени»
Л.И.Брежнев (из отчетного доклада на XXVI съезде КПСС, 1981 г.)
Требования к экономике у каждого времени свои, и поднявшаяся в XXI веке до невероятных высот информатизация внесла в них свои серьезные коррективы. Появившаяся на мировой сцене, так называемая, цифровая экономика – это система экономических, социальных и культурных отношений, основанных на использовании цифровых информационно-коммуникационных технологий. Поговорим сегодня о приметах цифровой экономики, чего в ней на сегодняшний день не хватает, о вовлеченности в процесс перехода на «цифру» государства и его граждан и, конечно же, о последствиях цифровой трансформации.
Презентации конкретных решений и продуктов, относящихся к различным категориям экосистемы цифровой экономики производятся в наше время регулярно, и уже многие участники как мирового, так и отечественного рынка имеют ежедневный опыт создания элементов и продуктов онлайн-экономики. И потому нет ничего удивительного, что согласно опубликованному рейтингу самых дорогих брендов мира The BrandZ Global Top 100, на первом месте в нем расположилась компания Google со стоимостью бренда 245,6 млрд долларов США, а вслед за ней — еще четыре представителя Кремниевой долины: Apple, Microsoft, Amazon и Facebook. Российских брендов в сотне самых дорогих, правда, не оказалось. Это все интернет-гиганты, которые построены на мощных и инновационных платформах. Что касается пятерки лидеров, то за год она претерпела лишь одно изменение: теперь на четвертой строчке располагается не телекоммуникационный гигант AT&T, а крупнейший в мире онлайн-ритейлер Amazon. Что касается цифрового бизнеса, то это новая модель бизнеса, охватывающая людей/бизнес/вещи, масштабируемая глобально для всего мира за счет использования информационных технологий, интернета, и всех их свойств, предполагающая эффективное персональное обслуживание всех, везде, всегда.
В целом так называемый Data Driven бизнес или же, говоря простым языком, — бизнес, основной движущей силой которого являются данные, сегодня становится общей практикой для множества предприятий самых разных отраслей. А управление данными лежит в основе набирающей популярность цифровой трансформации бизнеса. По оценкам экспертов к 2020 г. объем данных, ежегодно обрабатываемых ЦОДами (центрами обработки данных), достигнет отметки 15,3 Зб (зетабайт), количество бизнес-пользователей превысит 325 млн., количество подключенных к Интернету устройств достигнет 20 млрд., заметно расширится спектр типов данных, 92% трафика данных в ЦОДах придется на «облачные вычисления», а на помощь миллиарду работников придет искусственный интеллект.
В декабре прошлого года регулятор развития транспортной инфраструктуры США объявил, что все новые автомобили в стране, выпуск которых начнется в 2023 году, должны быть оснащены системами обмена данными стандарта V2V (vehicle-to-vehicle, "автомобиль-автомобиль"), который предполагает обмен данными о маршрутах и скорости движения между всеми машинами на дороге, что должно принципиально снизить аварийность на дорогах.

Разработчики из Университета штата Огайо недавно получили правительственный грант на создание "умного" шоссе на 56-километровом участке трассы в пригороде Колумбуса, столицы штата. Речь идет о трассе стандарта V2I (vehicle-to-infrastructure, "автомобиль-инфраструктура"), который предусматривает обмен данными между объектами дорожной инфраструктуры (дорожными знаками, светофорами и различными датчиками) и движущимися автомобилями. Вдоль шоссе будет проложена волоконно-оптическая линия связи, которая соединит приемопередатчики, расположенные через каждые 600 метров. Благодаря полученной информации от дороги автомобиль сможет, к примеру, предупредить водителя о заторе по маршруту движения, просчитать объезд, а также спрогнозировать время простоя на светофоре.
Или вот настоящая «звезда блокчейна», любимец банкиров и журналистов, Виталий Бутерин, создавший Ethereum — платформу для создания децентрализованных интернет-сервисов (dapps), работающих на базе умных контрактов. Платформа запустилась 30 июля 2015 года. В марте этого года рыночная капитализация Ethereum превысила 1 млрд долларов США, а созданная на ее базе криптовалюта Ether заняла второе место после биткоина. В ходе недавнего Петербургского экономического форума (ПМЭФ) президент РФ Владимир Путин встречался и с основателем Ethereum, а первый вице-премьер российского правительства Игорь Шувалов в ходе панельной сессии на ПМЭФ заявил о том, что в России в настоящее время уже работают над тремя направлениями развития технологии блокчейн. По его словам, среди задач, требующих оперативного решения — обеспечение «цифровой прослеживаемости товаров», создание общей платформы на основе блокчейна для идентификации личности и электронная защита титула собственника.
Мобильное приложение «Помощник Москвы», позволяющее направлять фото неправильно запаркованных авто «куда надо», работает с середины 2015 г. и только за первый год работы позволило выписать около 25 тыс. штрафов. В масштабах Москвы, конечно, немного, но процесс запущен. Использование краудфандинга и различных мобильных приложений для исполнения некоторых публичных функций сегодня модно во всем мире. Поэтому нарушения правил парковки могут фиксировать не только дорожные полицейские, зарплату которым в каждом государстве, кстати, платят граждане, но и сами граждане, вооруженные смартфоном со специальным приложением. Мотивацию сознательных граждан можно стимулировать переводом на банковскую карточку процентами с оплаченных штрафов. Можно и «геймифицировать» процесс, чтобы подросткам стало интересным фиксировать нарушителей из спортивного интереса.
В целом же подобных примеров из сегодняшней жизни можно привести множество. Экономика, как процесс создания материальных и духовных ценностей, несомненно, получает с цифровой трансформацией дополнительный импульс, поставляя новые виды контента и программных продуктов. Экономика в прямом смысле также получает свой импульс, позволяя получать несоизмеримо больше информации обо всех процессах, что крайне полезно при формировании систем мониторинга и управления, а также повышении эффективности самих процессов. Информационный обмен, на котором стоит весь бизнес и все государственное управление, обеспечивается с помощью цифровых каналов передачи данных, во многом беспроводных, а также электронным документооборотом, что открывает новые просторы для дальнейшего совершенствования бизнес-моделей и бизнес-процессов. Финансы начинают присматриваться к цифровым валютам. Социальная часть «сидит» в социальных сетях, подчас занимая все свободное и даже несвободное время граждан. Зрелища представлены не только новыми видами контента, но и играми, трафик от которых уже конкурирует с другими видами трафика.
Вовлечение граждан в управление государством также упрощается в эпоху цифровой экономики. Считается, что к 2024 году в сфере инфраструктуры в России будет устранено цифровое неравенство, во всех труднодоступных районах страны появится связь. К 2024 году в России должна быть сформирована основа для развития цифровой экономики. В ключевых отраслях в результате трансформации должны возникнуть национальные лидеры в своей области, которые станут операторами цифровых платформ. На базе этих платформ будет формироваться определенная система взаимодействия участников. Бизнес и государство должны будут пересмотреть правила и форматы онлайн-взаимодействия с гражданами. В рамках платформы участники не будут ограничены в создании новых способов взаимодействия друг с другом, в создании добавленной стоимости. Казалось бы, «цифра» везде, и вот она, цифровая экономика.
Хотя нет, из известной формулы «хлеба и зрелищ» в цифровой экономике не хватает именно хлеба. То есть поучаствовать в приобретении, хранении, выращивании, сборе и переработке зерна, а также в поставке и продаже готового продукта она может. Теоретически может даже создать цифровую очередь за хлебом в интернет-магазине, но вот сотворить из данных непосредственно хлеб ей пока не под силу. Цифры нельзя кушать, цифру на себя не наденешь и на цифре не поедешь. И это оставляет шансы всем религиям мира, где Господь умеет-таки создавать все сущее, в том числе и хлеб.

То есть углубить и улучшить бизнес-процессы, это — пожалуйста, но вот создать полезные ископаемые, биосферу и пр. и пр. цифровая экономика не может. Поэтому, как считают некоторые специалисты, целесообразно было бы говорить не о цифровой экономике, а об экономике знаний, креаномике. И вкладывать деньги в науку и научно-технические проекты на чем, в частности, серьезно поднялся Китай. Причем сами по себе высокие технологии – не товар. Их еще нужно применить в реальном производстве, каковое все-таки должно быть в стране. От текстильной до космической.
Впрочем, возможно, что бурно развивающиеся биотехнологии со временем позволят синтезировать пищу по заказу, о чем полвека назад популярно рассказал Илья Варшавский в рассказе «Молекулярное кафе». Может быть, со временем получится и что-то более продвинутое, о чем рассказывалось, к примеру, в «Трудно быть Богом» Стругацких:
«Хрустя каблуками по битому стеклу, Румата пробрался в дальний угол и включил электрический фонарик. Там под грудой хлама стоял в прочном силикетовом сейфе малогабаритный полевой синтезатор «Мидас». Румата разбросал хлам, набрал на диске комбинацию цифр и поднял крышку сейфа. Даже в белом электрическом свете синтезатор выглядел странно среди развороченного мусора. Румата бросил в приемную воронку несколько лопат опилок, и синтезатор тихонько запел, автоматически включив индикаторную панель. Румата носком ботфорта придвинул к выходному желобу ржавое ведро. И сейчас же — дзинь, дзинь, дзинь! — посыпались на мятое жестяное дно золотые кружочки с аристократическим профилем Пица Шестого, короля Арканарского».
Правда, братья Стругацкие забыли уточнить, что «Мидас» был цифровым, но мы-то с вами уже понимаем, в чем там дело. Таким образом, пока человечество не научится делать золото хотя бы из опилок, говорить о полной победе цифровой экономики несколько преждевременно. Но о бизнес-моделях и бизнес-процессах поговорить стоит.
Не стоит также забывать, что введение «цифры» должно всесторонне улучшать бизнес-процессы с помощью оперативности доставки, прозрачности и достоверности данных. Собственно, именно поэтому цифровая экономика и призвана быть именно цифровой. С оперативностью, вроде бы, понятно, а что с прозрачностью и достоверностью? Вернее, насколько это всем понравится?
К примеру, даже если польза вовлечения сограждан в различные процессы контроля над общественным порядком очевидна, само это вовлечение во многом зависит от доверия граждан государству. На граждан можно переложить значительную часть функций по контролю за соблюдением общественного порядка, многие вопросы пожарного надзора, контроля безопасности строительства и многих других видов контроля. С одной стороны, лишние деньги не помешают, а, с другой, — ябедничать нехорошо.

Еще и ябеду отыщут по IP-адресам с неизвестными для него, но весьма прогнозируемыми последствиями. Любое государство, существующее по роду своему как институт принуждения, объективно заинтересовано во все большем обладании информацией о своих гражданах, но гражданам это перестает нравиться, если, к примеру, эта информация плохо защищена. Говорят, что лишь десятилетия разумного и последовательного поведения очень постепенно формируют в обществе доверие к тому, что полученная информация будет использована властью во благо, а не во вред. Если же граждане воспринимают государство как нечто учрежденное самими гражданами для защиты собственных прав и интересов, то для них логично помогать этому государству и приветствовать подобную помощь от других членов сообщества. И если государство исполнит свои функции хорошо, то выиграют все за исключением злостных нарушителей.
Возможности цифровой экономики становятся тем шире, чем более честно ведет себя само общество, и эта честность имеет с цифровой экономикой положительную обратную связь. Именно благодаря научно-техническому прогрессу мир будет становиться все более и более прозрачным. Если этот тренд сохранится, человечеству откроются многие тайны. В дополнение ожидается, что в ближайшие годы у человечества появятся чисто технические возможности для вскрытия лжи и идентификации честного поведения, для чего сегодня существует много государственных институтов вроде юристов и пр. Сто лет назад скрыть правду было гораздо проще. К примеру, даже массовые преступления можно было замолчать или оттянуть правду о них на годы. И потому возможности вмешаться и противодействовать практически не было. Сегодня все совсем по-другому, и мир узнает о подобных и других событиях почти мгновенно. Впрочем, и эту информацию теперь можно сфальсифицировать.

Несмотря на обилие реальных и потенциальных преимуществ цифровая экономика подтачивается изнутри не менее широкими возможностями цифровых преступлений, фальсификации данных и коррупцией. Воровство финансовых средств и интеллектуальной собственности, шантаж, вымогательство, взлом информационных хранилищ, получение несанкционированного доступа к чужим персональным данным для нарушений закона – далеко не полный перечень известных преступлений из мира цифровой экономики. По вполне объективным причинам любое государство не в состоянии защитить граждан от всего перечисленного хотя бы потому, что нападение всегда на шаг впереди защиты.
Еще лет десять назад политики и военные представить не могли, что тысячи страниц секретных материалов могут быть обнародованы вместе с их откровенными частными беседами. Сейчас подобные утечки стали обыденным делом. Взять хотя бы длящуюся уже давно истерику в США по части якобы хакерского взлома у них чего-либо. Простите, ребята, а разве это не вы в течение десятилетий гордились наличием у себя системы «Эшелон», «стригущей» любую информацию на планете, позже привлекали для этого интернет-ресурсы, создавали кибервойска и пр.? Большего саморазоблачения творцов, в том числе и цифровой экономики, и придумать сложно. Либо это ложь во спасение каких-то своих политических целей, потому что не в традициях разведок столь публично заявлять о своих провалах, либо настоящее бессилие перед выпущенным из бутылки джинном. Причем и то, и другое не внушает оптимизма по поводу перспектив цифровой экономики.
Именно поэтому, в частности, среди населения растет популярность мессенджеров. «Конфиденциальность и безопасность заложены в нашей ДНК… — говорится на официальном сайте мессенджера WhatsApp. — Сквозное шифрование обеспечивает защиту ваших сообщений и звонков. Таким образом, только вы и человек, с которым вы общаетесь, можете прочитать или прослушать содержимое, и никто другой». Именно поэтому мессенжеры вызывают закономерное беспокойство спецслужб, которым по роду деятельности нужно не только ловить преступников, террористов и т.п., но и предупреждать подобные преступления.
Одним из последствий новой цифровой трансформации будет, в частности, более глубокое видение того, что люди делают в компаниях. Это важно, поскольку сейчас люди составляют половину активов компаний. Активы типичной компании сейчас на 25% состоят из физических активов, на 50% из сотрудников и на 25% из стоимости бренда и других нематериальных активов. Специалисты отмечают, что при цифровой экономике обязательно будут проигравшие и среди простых граждан. Какие-то специальности станут ненужными, кого-то заменит искусственный интеллект. «Новый уклад разрушает многие традиционные сектора, растут отрицательные эмоции среди тех, кто там работал. Цифровые технологии могут усугублять социально-экономическое неравенство», – признают даже во Всемирном банке.
А теперь представим, что вожделенная «цифра» победила, и каждый член общества, каждый представитель бизнеса, каждый чиновник, каждый супруг, каждый член коллектива имеет полный доступ к любой информации, которая может его касаться. Впрочем, и о другой тоже. И все тайное вдруг станет явным. Все узнают, кто, где, когда и сколько украл, кого обманул, какие интриги плел, кого подставил, засадил в тюрьму или даже убил… Трудно представить, что будет с бизнесом, с финансовыми взаимоотношениями и, конечно, с политиками. Искусство возможного чаще всего конфликтует с честностью. Катастрофические последствия всеобщего прозрения ощутят на себе не только политики и чиновники, бизнесмены и банкиры, но и самые простые граждане.
Кто-то считает, что подобное развитие событий может стать реальным уже в ближайшем будущем и окажется сродни тому, что принято называть Апокалипсисом. К сведению любителей теорий катастроф в переводе с греческого Апокалипсис — это «открытие, снятие покрова, разоблачение». Иначе — всеобщее прозрение. И что самое забавное, к этому прозрению человечество толкает банальное развитие цифровой экономики, а отнюдь не только вдруг снизошедшая откуда-то способность к телепатии. Указанный перелом в истории человечества предсказан не только лишь Иисусом Христом, который, кстати, и обещал, что однажды «все тайное станет явным», но и многими пророками, которые видели приход «Золотого века» и появление нового, более честного и справедливого общества. Американский Университет Сингулярности, созданный NASA и Google, опубликовал недавно «Предсказания человечеству на следующие 20 лет», где его эксперты утверждают, что до 2020 года появятся интернет-приложения, способные с высокой вероятностью распознавать правду и ложь. И очень даже может быть, что уже через пять-семь лет такие мини-детекторы лжи начнут входить в стандартный набор функций многих смартфонов.

Сегодня ложь пронизывает все сферы бытия, начиная от политики и кончая отношениями в семье. В связи с этим ожидается, что человечество в целом и каждая страна в отдельности совершат грандиозный рывок в своем развитии, как только люди перестанут лгать и воровать, что, как мы видели выше, может стать «станцией назначения» поезда цифровой экономики. Но подобное развитие цифровой экономики нанесло бы удар по огромному количеству богатых, влиятельных, прекрасно себя чувствующих людей, вызвав с их стороны логичное противодействие. Интересно, подозревают ли об этом те, кто собирается на всем этом заработать?
По материалам: tass.ru, ng.ru, cnews.ru, helionews.ru, pcweek.ru, forum-msk.org, nplus1.ru, dic.academic.ru, mk.ru, arb.ru, 3rm.info
Автор публикации:
Александр ГОЛЫШКО, системный аналитик ГК «Техносерв»
|
Метки: author TS_Telecom законодательство и it-бизнес блог компании техносерв цифровая экономика цифровая трансформация техносерв |
Рынок источников бесперебойного питания вырос впервые за четыре года |
 / Flickr / Torkild Retvedt / CC
/ Flickr / Torkild Retvedt / CC / Flickr / Paradox Wolf / CC
/ Flickr / Paradox Wolf / CC|
Метки: author 1cloud it- инфраструктура блог компании 1cloud.ru 1cloud ибп рынок |
Построение рекомендаций для сайта вакансий. Лекция в Яндексе |




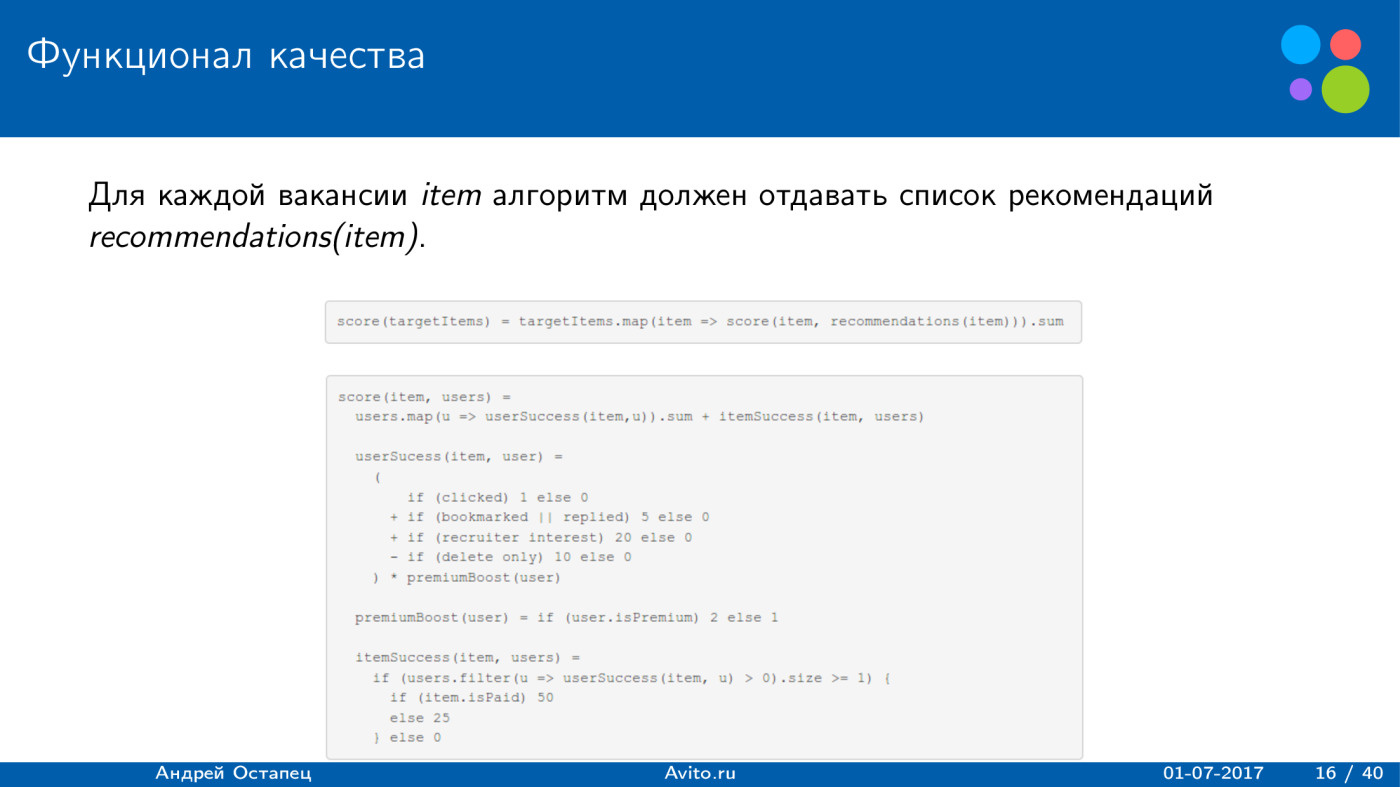
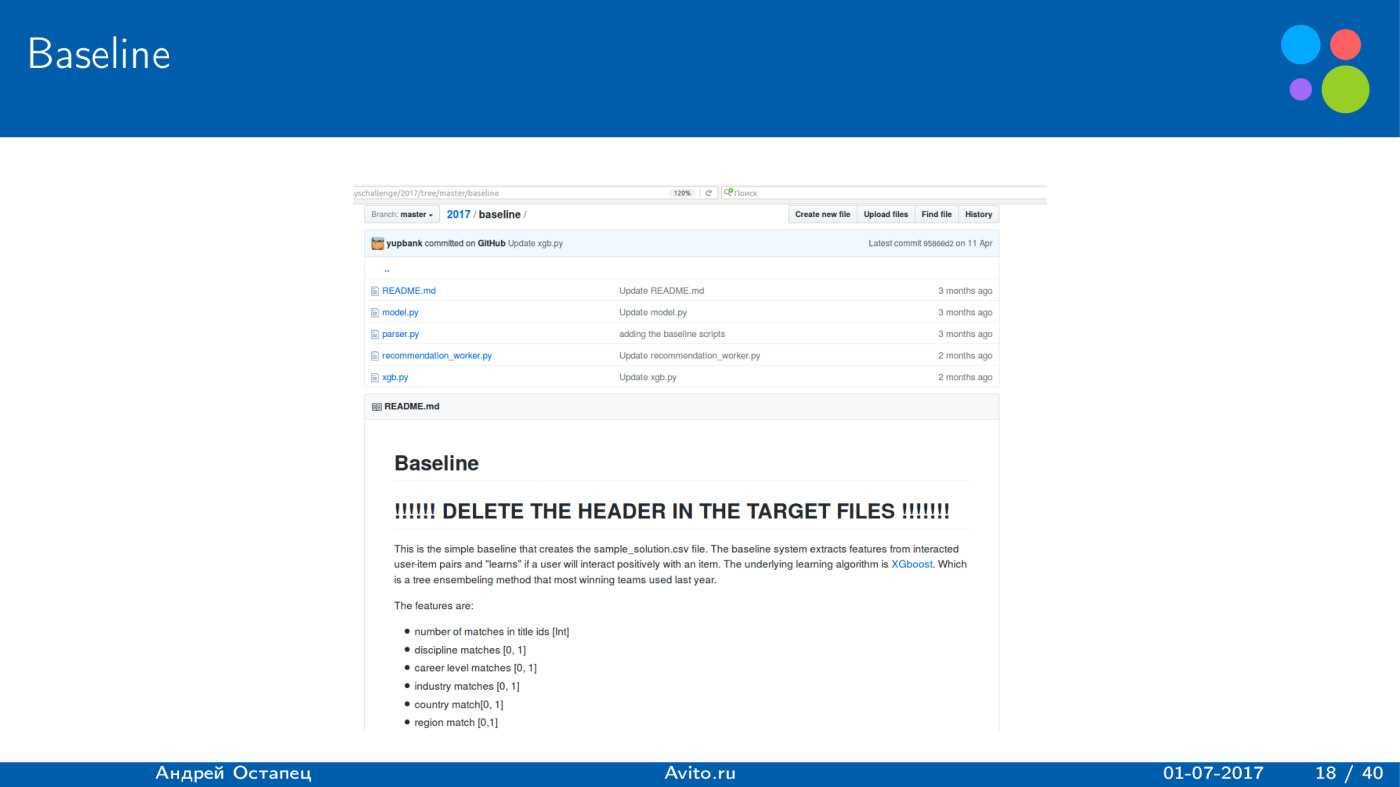

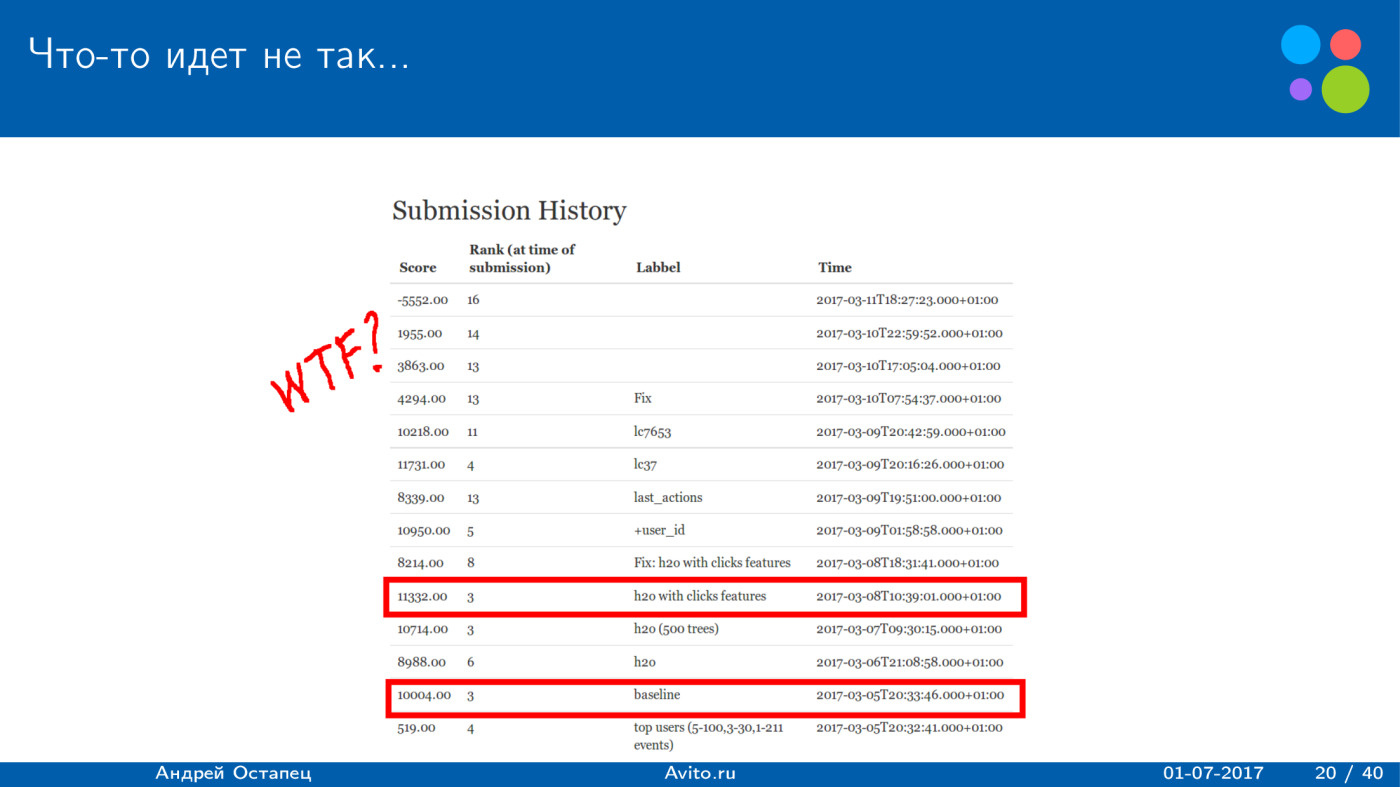





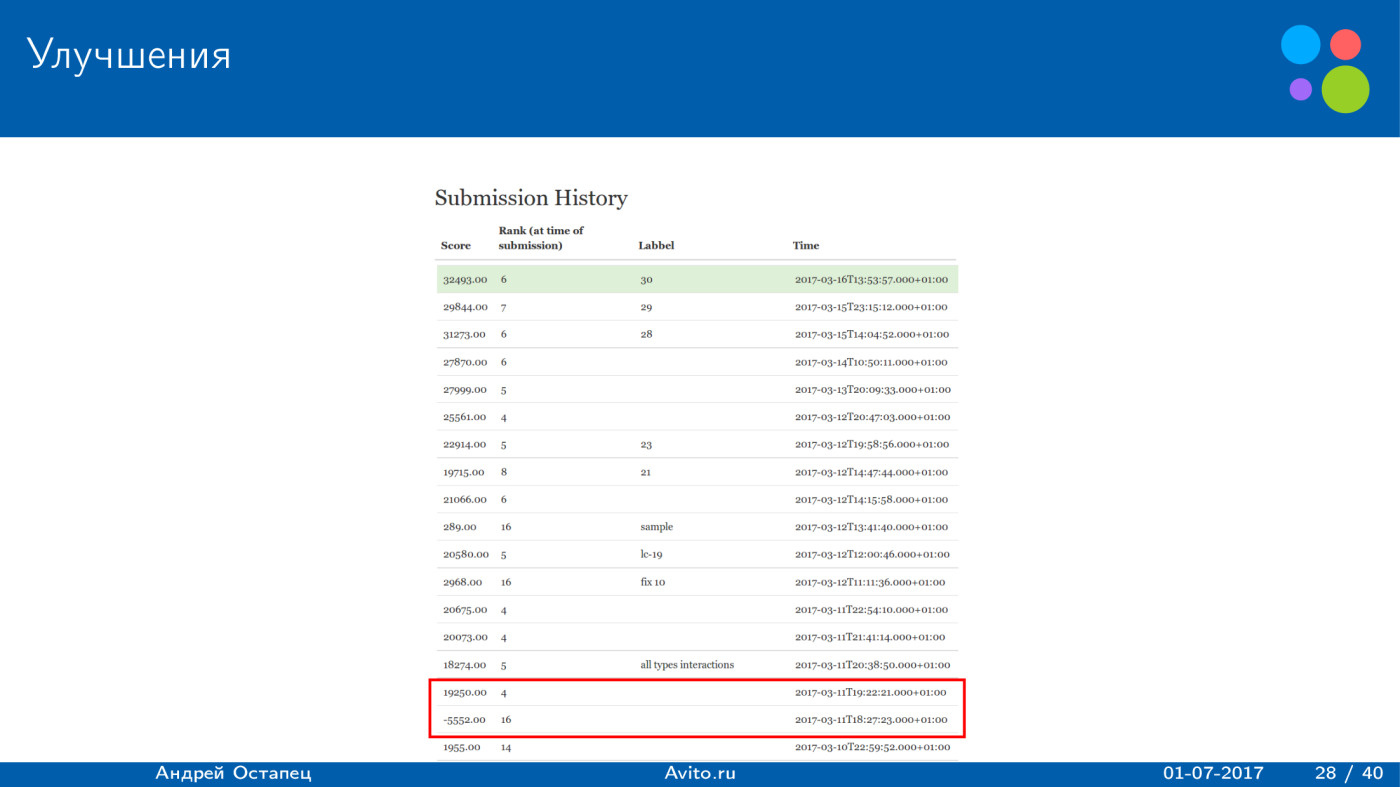
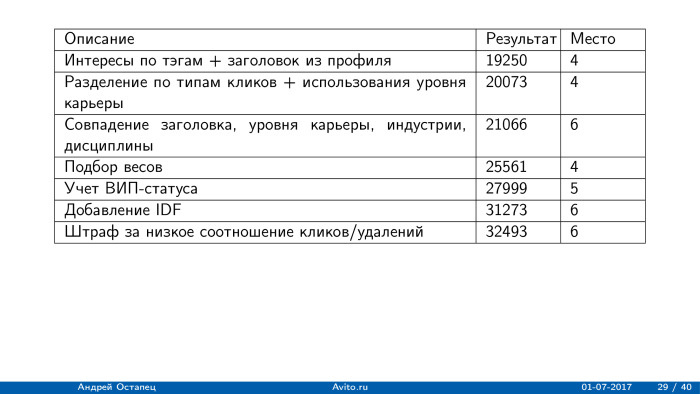

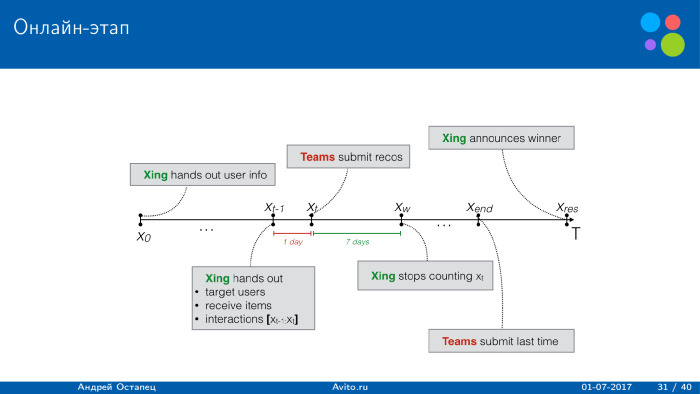




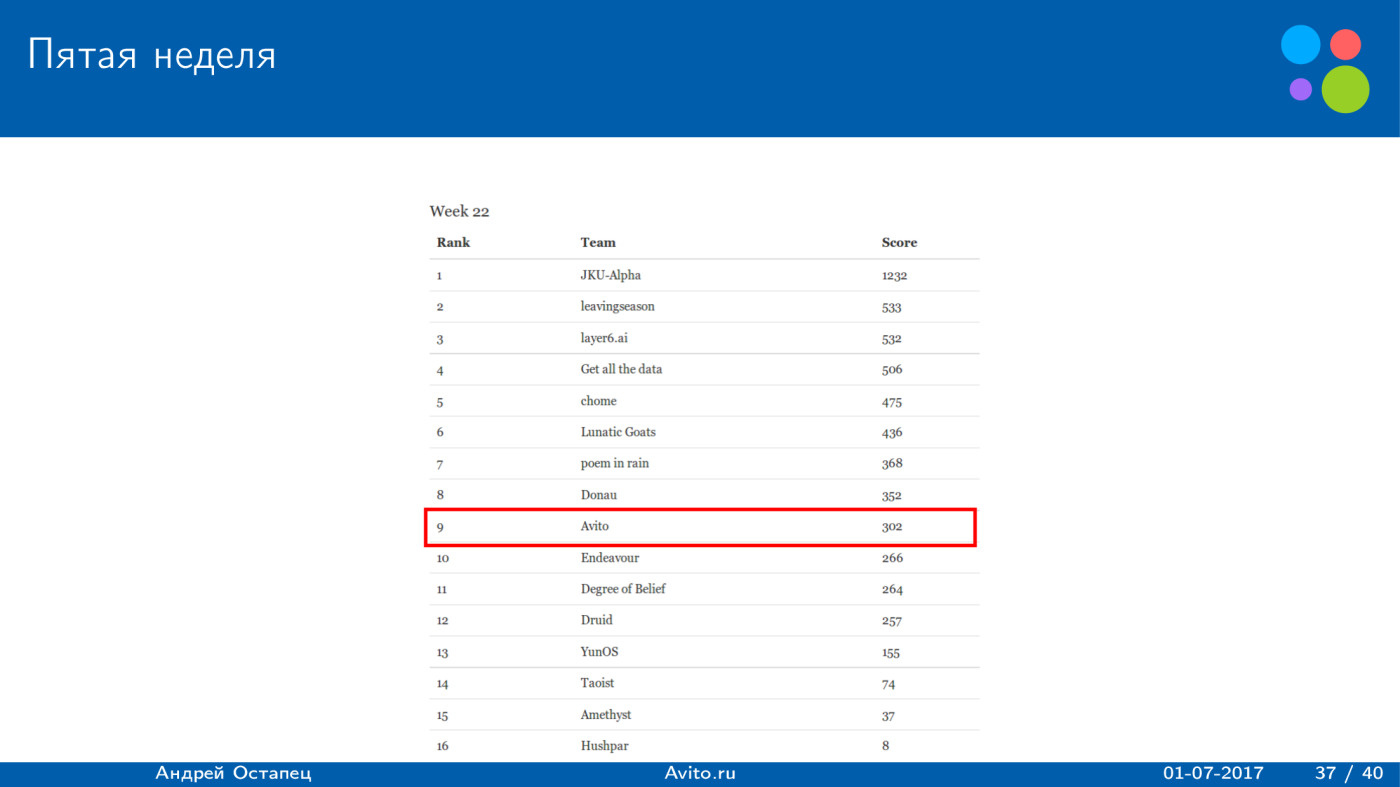
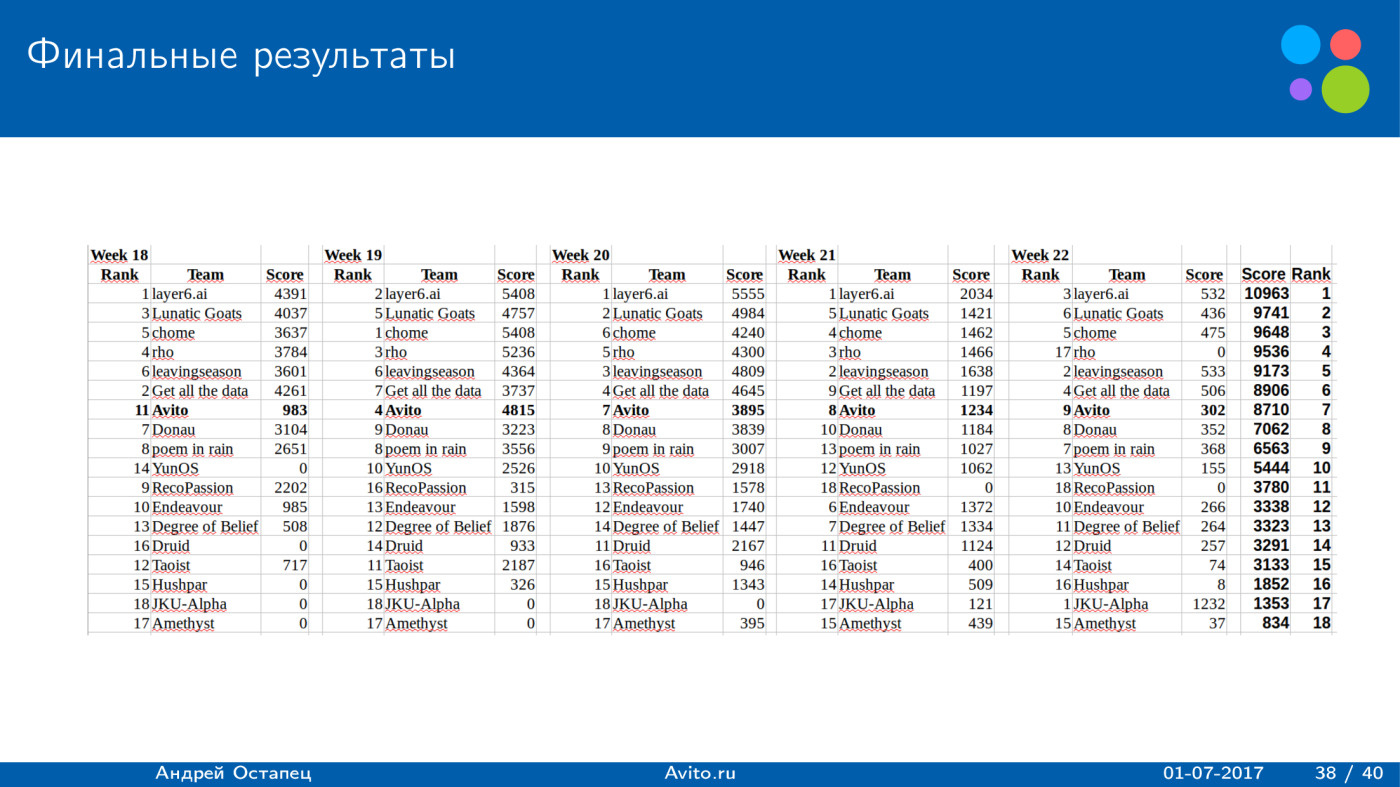
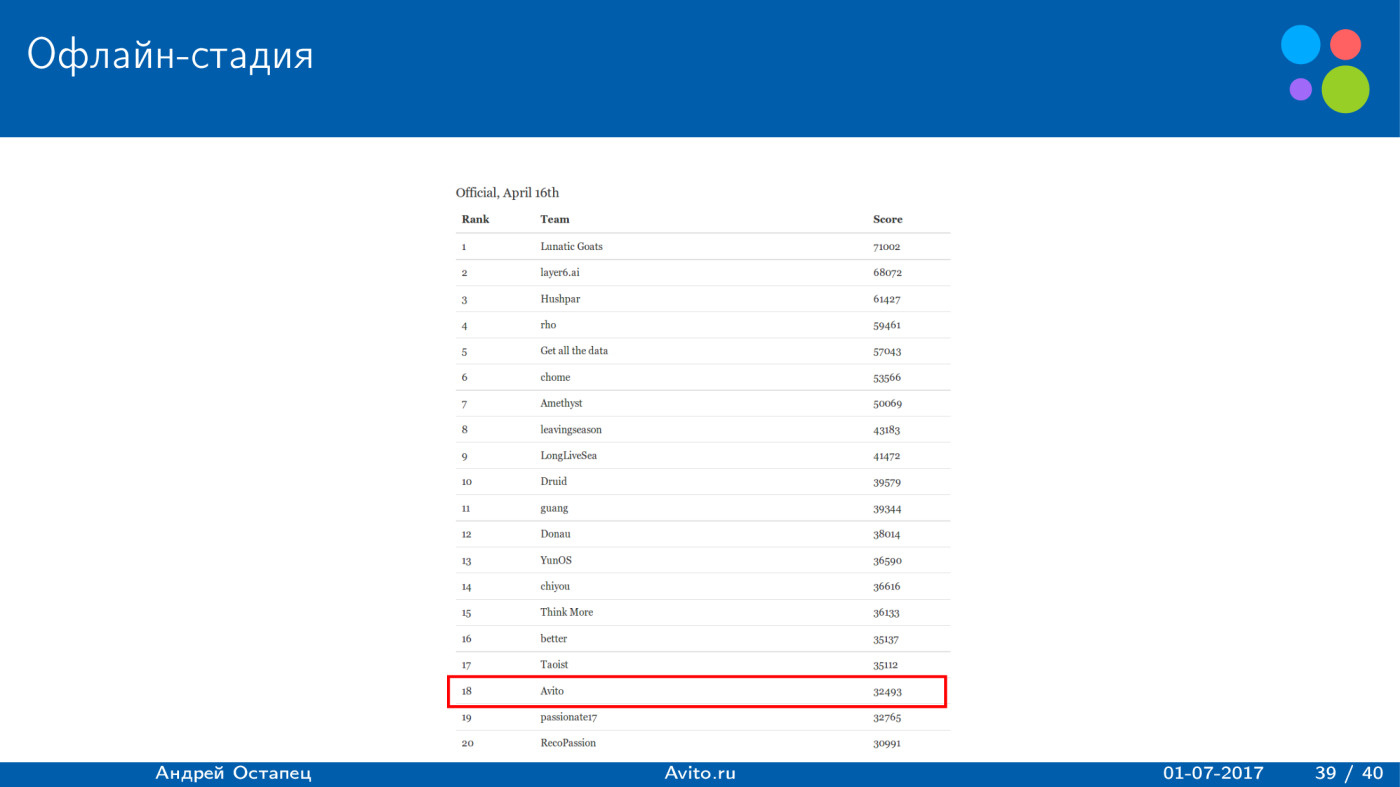
|
|
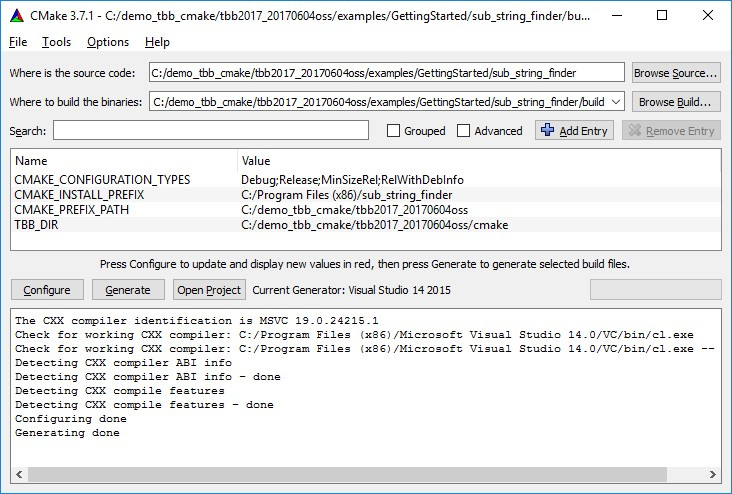
Интеграция Intel Threading Building Blocks в ваш CMake проект |
| TBB_FOUND |
флаг успешности поиска Intel TBB |
| TBB_ |
флаг успешности поиска отдельного компонента |
| TBB_IMPORTED_TARGETS |
все созданные импортированные цели |
| TBB_VERSION |
версия Intel TBB (формат: |
| TBB_INTERFACE_VERSION |
версия интерфейса Intel TBB |
| TBB_ROOT |
путь до корневой папки бибилотеки, которую нужно собрать |
| CONFIG_DIR |
переменная, в которую запишется полный путь к папке с созданными конфигурационными файлами; значение |
| MAKE_ARGS |
настраиваемые аргументы для make-команды; следующие аргументы определяются и передаются автоматически, если они не переопределены в :
|
include(/TBBBuild.cmake)
tbb_build(TBB_ROOT CONFIG_DIR TBB_DIR)
find_package(TBB ) | TBB_ROOT |
переменная, в которую будет записан полный путь к корневой папке скачанного и распакованного пакета; значение |
| RELEASE_TAG |LATEST |
тег релиза для скачивания; по умолчанию используется значение LATEST |
| SAVE_TO |
путь для распаковки скачанного пакета; по умолчанию используется ${CMAKE_CURRENT_BINARY_DIR}/tbb_downloaded |
| SYSTEM_NAME Linux|Windows|Darwin |
ОС, для которой необходимо скачать бинарный пакет; по умолчанию используется значение переменной CMAKE_SYSTEM_NAME |
| CONFIG_DIR |
переменная, в которую будет записан полный путь до конфигурационных файлов; параметр игнорируется, если указан флаг SOURCE_CODE |
| SOURCE_CODE |
флаг, сигнализирующий о необходимости скачивания пакета с исходным кодом вместо бинарного пакета |
include(/TBBGet.cmake)
tbb_get(TBB_ROOT tbb_root CONFIG_DIR TBB_DIR)
find_package(TBB ) include(/TBBGet.cmake)
include(/TBBBuild.cmake)
tbb_get(TBB_ROOT tbb_root SOURCE_CODE)
tbb_build(TBB_ROOT ${tbb_root} CONFIG_DIR TBB_DIR)
find_package(TBB )
cmake_minimum_required(VERSION 3.0.0 FATAL_ERROR)
project(sub_string_finder CXX)
add_executable(sub_string_finder sub_string_finder.cpp)
# Функция find_package ищет TBBConfig, используя переменные
# CMAKE_PREFIX_PATH и TBB_DIR.
find_package(TBB REQUIRED tbb)
# "TBB::tbb" можно использовать вместо "${TBB_IMPORTED_TARGETS}"
target_link_libraries(sub_string_finder ${TBB_IMPORTED_TARGETS})
mkdir ~/demo_tbb_cmake
cd ~/demo_tbb_cmake
git clone https://github.com/01org/tbb.git
cmake_minimum_required(VERSION 3.0.0 FATAL_ERROR)
project(sub_string_finder CXX)
add_executable(sub_string_finder sub_string_finder.cpp)
include(${TBB_ROOT}/cmake/TBBBuild.cmake)
# Строим Intel TBB с включенными Community Preview Features (CPF).
tbb_build(TBB_ROOT ${TBB_ROOT} CONFIG_DIR TBB_DIR MAKE_ARGS tbb_cpf=1)
find_package(TBB REQUIRED tbb_preview)
# "TBB::tbb_preview" можно использовать вместо "${TBB_IMPORTED_TARGETS}".
target_link_libraries(sub_string_finder ${TBB_IMPORTED_TARGETS})
mkdir ~/demo_tbb_cmake/tbb/examples/GettingStarted/sub_string_finder/build
cd ~/demo_tbb_cmake/tbb/examples/GettingStarted/sub_string_finder/buildcmake -DTBB_ROOT=${HOME}/demo_tbb_cmake/tbb ..make
./sub_string_finder
|
Метки: author moslex программирование c++ блог компании intel intel tbb intel open source cmake integration |
Comedy. Встречайте акторы в Node.JS |
Привет, хабравчане!
В этой статье я познакомлю вас с фреймворком Comedy — реализацией акторов в Node.JS.
Акторы позволяют масштабировать отдельные модули вашего Node.JS приложения без изменения кода.
Хотя модель акторов довольно популярна сегодня, не все про неё знают. Несмотря на несколько устрашающую статью в Википедии, акторы — это очень просто.
Что такое актор? Это такая штука, которая умеет:

Единственный способ что-либо сделать с актором — это отправить ему сообщение. Внутренне состояние актора полностью изолировано от внешнего мира. Благодаря этому актор является универсальной единицей масштабирования приложения. А его способность порождать дочерние акторы позволяет сформировать понятную структуру модулей с чётким разделением обязанностей.
Понимаю, звучит несколько абстрактно. Чуть ниже мы разберём на конкретном живом примере, как происходит работа с акторами и Comedy. Но сперва...
… сперва мотивация.
Все, кто программируют на Node.JS (ваш покорный среди них) прекрасно знают, что Node.JS — однопоточный. С одной стороны, это хорошо, поскольку избавляет нас от целого класса очень стрёмных и трудновоспроизводимых багов — многопоточных багов. В наших приложениях таких багов быть принципиально не может, и это сильно удешевляет и ускоряет разработку.
С другой стороны, это ограничивает область применимости Node.JS. Он отлично подходит для network-intensive приложений с относительно небольшой вычислительной нагрузкой, а вот для CPU-intensive приложений подходит плохо, поскольку интенсивные вычисления блокируют наш драгоценный единственный поток, и всё встаёт колом. Мы это прекрасно знаем.
Знаем мы также и то, что любое реальное приложение какое-то количество CPU всё равно потребляет (даже если у нас совсем нет бизнес-логики, нам нужно обрабатывать сетевой трафик на уровне приложения — HTTP там, протоколы баз данных и прочее). И по мере роста нагрузки мы всё равно рано или поздно приходим к ситуации, когда наш единственный поток потребляет 100% мощности ядра. А что происходит в этом случае? Мы не успеваем обрабатывать сообщения, очередь задач накапливается, время отклика растёт, а потом бац! — out of memory.
И тут мы приходим к ситуации, когда нам нужно отмасштабировать наше приложение уже на несколько ядер CPU. И в идеале, мы не хотим себя ограничивать ядрами только на одной машине — нам может потребоваться несколько машин. И при этом мы хотим как можно меньше переписывать наше приложение. Здорово, если приложение будет масштабироваться простым изменением конфигурации. А ещё лучше — автоматически, в зависимости от нагрузки.
И вот тут нам на помощь приходят акторы.
Для того, чтобы продемонстрировать, как работает Comedy, я набросал небольшой пример: микросервис, который находит простые числа. Доступ к сервису осуществляется через REST API.
Конечно, поиск простых чисел — это в чистом виде CPU-intensive задача. Если бы мы в реальной жизни проектировали такой сервис, нам бы стоило десять раз подумать, прежде чем выбрать Node.JS. Но в данном случае, мы как раз намеренно выбрали вычислительную задачу, чтобы было проще воспроизвести ситуацию, когда одного ядра не хватает.
Итак. Давайте начнём с самой сути нашего сервиса — реализуем актор, находящий простые числа. Вот его код:
/**
* Actor that finds prime numbers.
*/
class PrimeFinderActor {
/**
* Finds next prime, starting from a given number (not inclusive).
*
* @param {Number} n Positive number to start from.
* @returns {Number} Prime number next to n.
*/
nextPrime(n) {
if (n < 1) throw new Error('Illegal input');
const n0 = n + 1;
if (this._isPrime(n0)) return n0;
return this.nextPrime(n0);
}
/**
* Checks if a given number is prime.
*
* @param {Number} x Number to check.
* @returns {Boolean} True if number is prime, false otherwise.
* @private
*/
_isPrime(x) {
for (let i = 2; i < x; i++) {
if (x % i === 0) return false;
}
return true;
}
}Метод nextPrime() находит простое число, следующее за указанным (не обязательно простым). В методе используется хвостовая рекурсия, которая точно поддерживается в Node.JS 8 (для запуска примера нужно будет взять Node.JS не ниже 8 версии, поскольку там ещё async-await будет). В методе используется вспомогательный метод _isPrime(), проверяющий число на простоту. Это не самый оптимальный алгоритм подобной проверки, но для нашего примера это только лучше.
То, что мы видим в коде выше, с одной стороны — обычный класс. С другой стороны, для нас, это, так называемое, определение актора, то есть описание поведения актора. Класс описывает, какие сообщения актор может принимать (каждый метод — обработчик сообщения с одноимённым топиком), что он делает, приняв эти сообщения (реализация метода) и какой выдаёт результат (возвращаемое значение).
При этом, поскольку это обычный класс, мы можем написать на него unit-тест и легко протестировать корректность его реализации.
describe('PrimeFinderActor', () => {
it('should correctly find next prime', () => {
const pf = new PrimeFinderActor();
expect(pf.nextPrime(1)).to.be.equal(2);
expect(pf.nextPrime(2)).to.be.equal(3);
expect(pf.nextPrime(3)).to.be.equal(5);
expect(pf.nextPrime(30)).to.be.equal(31);
});
it('should only accept positive numbers', () => {
const pf = new PrimeFinderActor();
expect(() => pf.nextPrime(0)).to.throw();
expect(() => pf.nextPrime(-1)).to.throw();
});
});Теперь у нас есть актор-искатель простых чисел.
Наш следующий шаг — реализовать актор REST-сервера. Вот как будет выглядеть его определение:
const restify = require('restify');
const restifyErrors = require('restify-errors');
const P = require('bluebird');
/**
* Prime numbers REST server actor.
*/
class RestServerActor {
/**
* Actor initialization hook.
*
* @param {Actor} selfActor Self actor instance.
* @returns {Promise} Initialization promise.
*/
async initialize(selfActor) {
this.log = selfActor.getLog();
this.primeFinder = await selfActor.createChild(PrimeFinderActor);
return this._initializeServer();
}
/**
* Initializes REST server.
*
* @returns {Promise} Initialization promise.
* @private
*/
_initializeServer() {
const server = restify.createServer({
name: 'prime-finder'
});
// Set 10 minutes response timeout.
server.server.setTimeout(60000 * 10);
// Define REST method for prime number search.
server.get('/next-prime/:n', (req, res, next) => {
this.log.info(`Handling next-prime request for number ${req.params.n}`);
this.primeFinder.sendAndReceive('nextPrime', parseInt(req.params.n))
.then(result => {
this.log.info(`Handled next-prime request for number ${req.params.n}, result: ${result}`);
res.header('Content-Type', 'text/plain');
res.send(200, result.toString());
})
.catch(err => {
this.log.error(`Failed to handle next-prime request for number ${req.params.n}`, err);
next(new restifyErrors.InternalError(err));
});
});
return P.fromCallback(cb => {
server.listen(8080, cb);
});
}
}Что в нём происходит? Главное и единственное — в нём есть метод initialize(). Этот метод будет вызван Comedy при инициализации актора. В него передаётся экземпляр актора. Это та самая штука, в которую можно передавать сообщения. У экземпляра есть ещё ряд полезный методов. getLog() возвращает логгер для актора (он нам пригодится), а с помощью метода createChild() мы создаём дочерний актор — тот самый PrimeFinderActor, который мы реализовали в самом начале. В createChild() мы передаём определение актора, а получаем в ответ промис, который разрешится, как только дочерний актор будет проинициализирован, и выдаст нам экземпляр созданного дочернего актора.
Как вы заметили, инициализация актора — асинхронная операция. Наш метод initialize() тоже асинхронный (он возвращает промис). Соответственно наш RestServerActor будет считаться инициализированным только тогда, когда зарезолвится промис (ну не писать же "выполниться обещание"), отданный методом initialize().
Окей, мы создали дочерний PrimeFinderActor, дождались его инициализации и присвоили ссылку на экземпляр полю primeFinder. Осталась мелочёвка — сконфигурировать REST-сервер. Мы это делаем в методе _initializeServer() (он тоже асинхронный), используя библиотеку Restify.
Мы создаём один-единственный обработчик запроса ("ручку") — для метода GET /next-prime/:n, который вычисляет следующее за указанным целое число, отправляя сообщение дочернему PrimeFinderActor актору и получая от него ответ. Сообщение мы отправляем с помощью метода sendAndReceive(), первым параметром идёт название топика (nextPrime, по имени метода) следующим параметром — сообщение. В данном случае сообщением является просто число, но там может быть и строка, и объект с данными, и массив. Метод sendAndReceive() асинхронный, возвращает промис с результатом.
Почти готово. Нам осталась ещё одна мелочь: запустить всё это. Мы добавляем в наш пример ещё пару строк:
const actors = require('comedy');
actors({ root: RestServerActor });Здесь мы создаём систему акторов. В качестве параметров мы указываем определение корневого (самого родительского) актора. Им у нас является RestServerActor.
Получается вот такая иерархия:
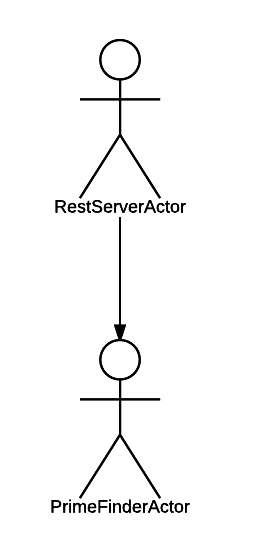
С иерархией нам повезло, она довольно простая!
Ну что, запускаем приложение и тестируем?
$ nodejs prime-finder.js
Mon Aug 07 2017 15:34:37 GMT+0300 (MSK) - info: Resulting actor configuration: {}$ curl http://localhost:8080/next-prime/30; echo
31Работает! Давайте ещё поэкспериментируем:
$ time curl http://localhost:8080/next-prime/30
31
real 0m0.015s
user 0m0.004s
sys 0m0.000s
$ time curl http://localhost:8080/next-prime/3000000
3000017
real 0m0.045s
user 0m0.008s
sys 0m0.000s
$ time curl http://localhost:8080/next-prime/300000000
300000007
real 0m2.395s
user 0m0.004s
sys 0m0.004s
$ time curl http://localhost:8080/next-prime/3000000000
3000000019
real 5m11.817s
user 0m0.016s
sys 0m0.000sПо мере возрастания стартового числа время обработки запроса растёт. Особенно впечатляет переход с трёхсот миллионов до трёх миллиардов. Давайте попробуем параллельные запросы:
$ curl http://localhost:8080/next-prime/3000000000 &
[1] 32440
$ curl http://localhost:8080/next-prime/3000000000 &
[2] 32442В top-е видим, что одно ядро полностью занято.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32401 weekens 20 0 955664 55588 20956 R 100,0 0,7 1:45.19 node В логе сервера видим:
Mon Aug 07 2017 16:05:45 GMT+0300 (MSK) - info: InMemoryActor(5988659a897e307e91fbc2a5, RestServerActor): Handling next-prime request for number 3000000000То есть первый запрос выполняется, а второй просто ждёт.
$ jobs
[1]- Выполняется curl http://localhost:8080/next-prime/3000000000 &
[2]+ Выполняется curl http://localhost:8080/next-prime/3000000000 &Это в точности та ситуация, которая и была описана: нам не хватает одного ядра. Нам нужно больше ядер!
Итак, настало время мастшабироваться. Все наши дальнейшие действия не потребуют модификации кода.
Давайте вначале выделим PrimeFinderActor в отдельный подпроцесс. Само по себе это действие довольно бесполезно, но хочется вводить вас в курс дела постепенно.
Мы создаём в корневой директории проекта файл actors.json вот с таким содержимым:
{
"PrimeFinderActor": {
"mode": "forked"
}
}И перезапускаем пример. Что произошло? Смотрим в список процессов:
$ ps ax | grep nodejs
12917 pts/19 Sl+ 0:00 nodejs prime-finder.js
12927 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
$ pstree -a -p 12917
nodejs,12917 prime-finder.js
+-nodejs,12927 /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
| +-{V8 WorkerThread},12928
| +-{V8 WorkerThread},12929
| +-{V8 WorkerThread},12930
| +-{V8 WorkerThread},12931
| +-{nodejs},12932
+-{V8 WorkerThread},12918
+-{V8 WorkerThread},12919
+-{V8 WorkerThread},12920
+-{V8 WorkerThread},12921
+-{nodejs},12922
+-{nodejs},12923
+-{nodejs},12924
+-{nodejs},12925
+-{nodejs},12926Мы видим, что процессов теперь два. Один — наш главный, "пусковой" процесс. Второй — дочерний процесс, в котором теперь крутится PrimeFinderActor, поскольку он теперь работает в режиме "forked". Мы это сконфигурировали с помощью файла actors.json, ничего не меняя в коде.
Получилась вот такая картина:
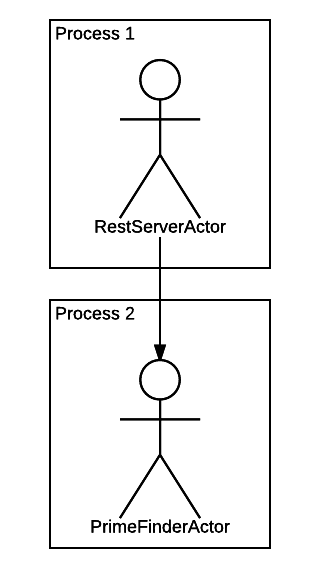
Запускаем тест снова:
$ curl http://localhost:8080/next-prime/3000000000 &
[1] 13240
$ curl http://localhost:8080/next-prime/3000000000 &
[2] 13242Смотрим лог:
Tue Aug 08 2017 08:54:41 GMT+0300 (MSK) - info: InMemoryActor(5989504694b4a23275ba5d29, RestServerActor): Handling next-prime request for number 3000000000
Tue Aug 08 2017 08:54:43 GMT+0300 (MSK) - info: InMemoryActor(5989504694b4a23275ba5d29, RestServerActor): Handling next-prime request for number 3000000000Хорошая новость: всё по-прежнему работает. Плохая новость: всё работает, почти как и раньше. Ядро по-прежнему не справляется, и запросы встают в очередь. Только теперь ядро нагружено нашим дочерним процессом (обратите внимание на PID):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12927 weekens 20 0 907160 40892 20816 R 100,0 0,5 0:20.05 nodejs Давайте сделаем больше процессов: кластеризуем PrimeFinderActor до 4-х экземпляров. Меняем actors.json:
{
"PrimeFinderActor": {
"mode": "forked",
"clusterSize": 4
}
}Перезапускаем сервис. Что видим?
$ ps ax | grep nodejs
15943 pts/19 Sl+ 0:01 nodejs prime-finder.js
15953 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
15958 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
15963 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
15968 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActorДочерних процессов стало 4. Всё как мы и хотели. Простым изменением конфигурации мы поменяли иерархию, которая теперь выглядит так:
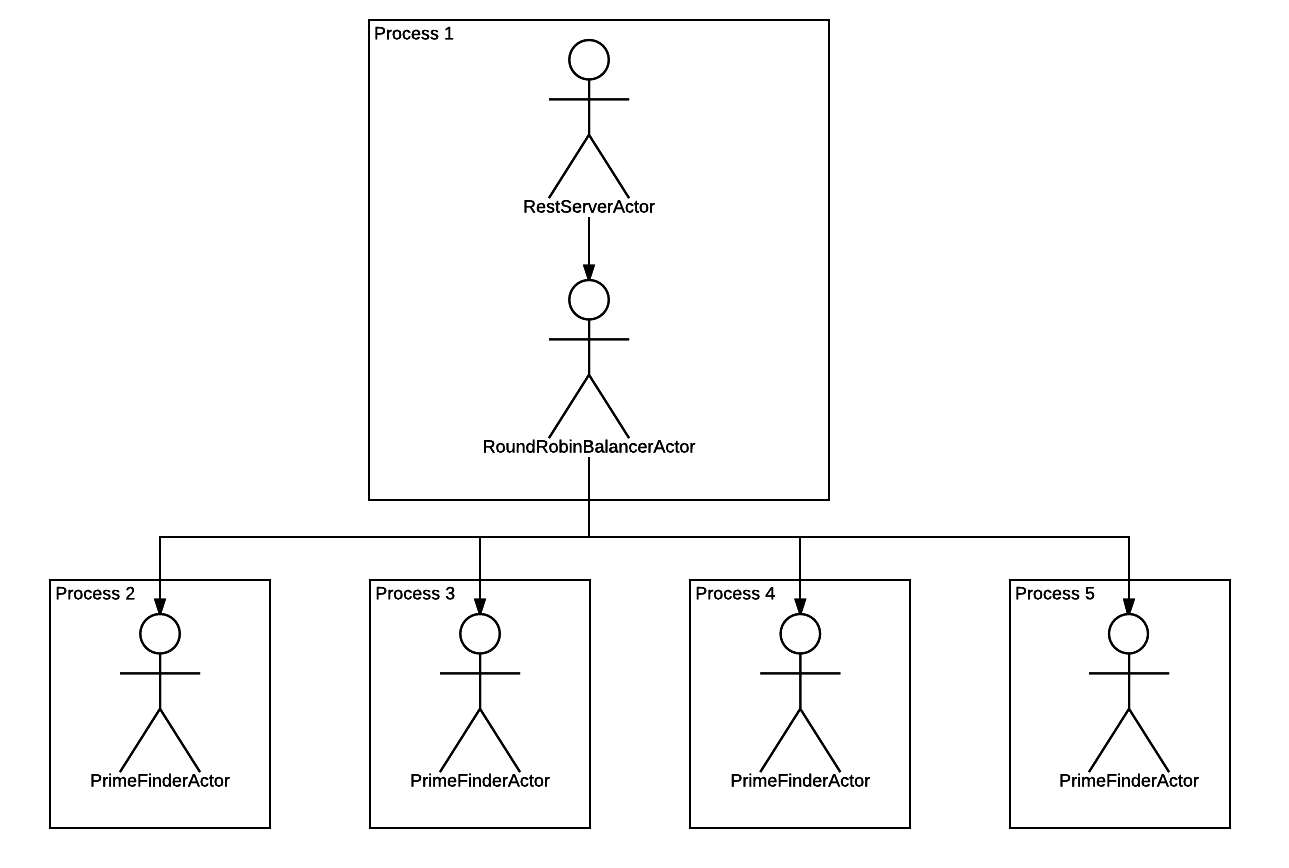
То есть Comedy размножил PrimeFinderActor до количества 4-х штук, каждый запустил в отдельном процессе, и между этими акторами и родительским RestServerActor-ом воткнул промежуточный актор, который будет раскидывать запросы по дочерним акторам раунд-робином.
Запускаем тест:
$ curl http://localhost:8080/next-prime/3000000000 &
[1] 20076
$ curl http://localhost:8080/next-prime/3000000000 &
[2] 20078И видим, что теперь занято два ядра:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
15953 weekens 20 0 909096 38336 20980 R 100,0 0,5 0:13.52 nodejs
15958 weekens 20 0 909004 38200 21044 R 100,0 0,5 0:12.75 nodejs В логе приложения видим два параллельно обрабатывающихся запроса:
Tue Aug 08 2017 11:51:51 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handling next-prime request for number 3000000000
Tue Aug 08 2017 11:51:52 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handling next-prime request for number 3000000000
Tue Aug 08 2017 11:57:24 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handled next-prime request for number 3000000000, result: 3000000019
Tue Aug 08 2017 11:57:24 GMT+0300 (MSK) - info: InMemoryActor(5989590ef554453e4798e965, RestServerActor): Handled next-prime request for number 3000000000, result: 3000000019Масштабирование работает!
Наш сервис сейчас может обрабатывать параллельно 4 запроса на нахождение простого числа. Остальные запросы встают в очередь. На моей машине всего 4 ядра. Если я хочу обрабатывать больше параллельных запросов, мне надо масштабироваться на соседние машины. Давайте сделаем это!
Вначале немного теории. В прошлом примере мы перевели PrimeFinderActor в режим "forked". Каждый актор может находиться в одном из трёх режимов:
"in-memory" (по-умолчанию): актор работает в том же процессе, что и создавший его код. Отправка сообщений такому актору сводится к вызову его методов. Накладные расходы на коммуникацию с "in-memory" актором нулевые (или близкие к нулевым);"forked": актор запускается в отдельном процессе на той же машине, где работает создавший его код. Коммуникация с актором осуществляется через IPC (Unix pipes в Unix-е, named pipes в Windows)."remote": актор запускается в отдельном процессе на удалённой машине. Коммуникация с актором осуществляется через TCP/IP.Как вы поняли, теперь нам нужно перевести PrimeFinderActor из "forked" режима в "remote". Мы хотим получить такую схему:
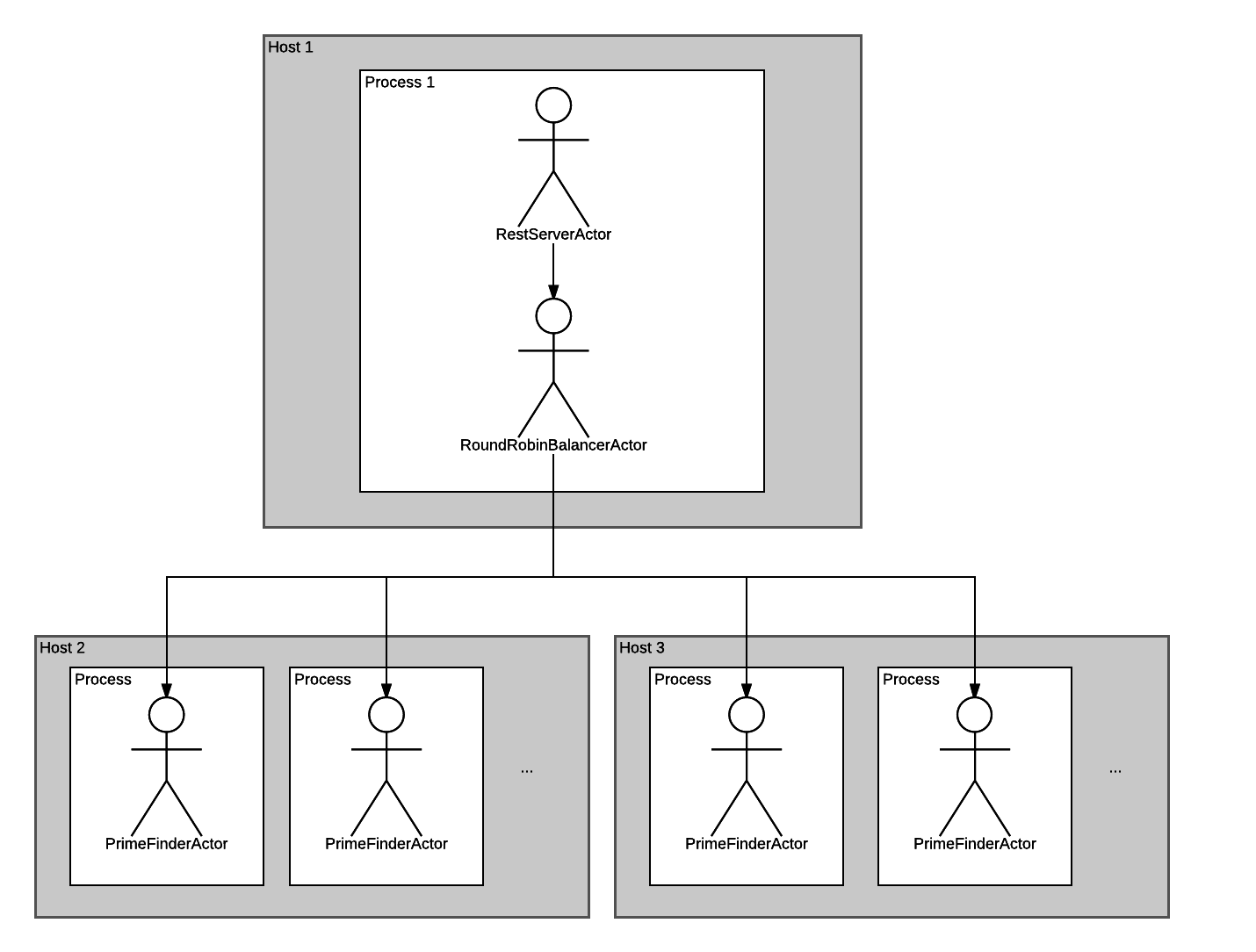
Давайте отредактируем файл actors.json. Просто указать режим "remote" в данном случае недостаточно: нужно ещё указать хост, на котором мы хотим запустить актор. У меня есть по соседству машинка с адресом 192.168.1.101. Её я и использую:
{
"PrimeFinderActor": {
"mode": "remote",
"host": "192.168.1.101",
"clusterSize": 4
}
}Только вот беда: эта самая соседняя машинка не знает ничего про Comedy. Нам нужно запустить на ней специальный процесс слушатель на известном порту. Делается это так:
$ ssh weekens@192.168.1.101
...
weekens@192.168.1.101 $ mkdir comedy
weekens@192.168.1.101 $ cd comedy
weekens@192.168.1.101 $ npm install comedy
...
weekens@192.168.1.101 $ node_modules/.bin/comedy-node
Thu Aug 10 2017 19:29:51 GMT+0300 (MSK) - info: Listening on :::6161Теперь процесс-слушатель готов принимать запросы на создание акторов по известному порту 6161. Пробуем:
$ nodejs prime-finder.js$ curl http://localhost:8080/next-prime/3000000000 &
$ curl http://localhost:8080/next-prime/3000000000 &Смотрим top на локальной машине. Никакой активности (если не считать Chromium):
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25247 weekens 20 0 1978768 167464 51652 S 13,6 2,2 32:34.70 chromium-browse Смотрим на удалённой машине:
weekens@192.168.1.101 $ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
27956 weekens 20 0 908612 40764 21072 R 100,1 0,1 0:14.97 nodejs
27961 weekens 20 0 908612 40724 21020 R 100,1 0,1 0:11.59 nodejs Идёт вычисление целых чисел, всё как мы и хотели.
Остался лишь один маленький штрих: использовать ядра и на локальной, и на удалённой машине. Это очень просто: мы указываем в actors.json не один хост, а несколько:
{
"PrimeFinderActor": {
"mode": "remote",
"host": ["127.0.0.1", "192.168.1.101"],
"clusterSize": 4
}
}Comedy распределит акторы равномерно между указанными хостами и будет раздавать им сообщения round robin-ом. Давайте проверим.
Сперва запустим процесс слушатель дополнительно на локальной машине:
$ node_modules/.bin/comedy-node
Fri Aug 11 2017 15:37:26 GMT+0300 (MSK) - info: Listening on :::6161Теперь запустим пример:
$ nodejs prime-finder.jsПосмотрим список процессов на локальной машине:
$ ps ax | grep nodejs
22869 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
22874 pts/19 Sl+ 0:00 /usr/bin/nodejs /home/weekens/workspace/comedy-examples/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActorИ на удалённой машине:
192.168.1.101 $ ps ax | grep node
5925 pts/4 Sl+ 0:00 /usr/bin/nodejs /home/weekens/comedy/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActor
5930 pts/4 Sl+ 0:00 /usr/bin/nodejs /home/weekens/comedy/node_modules/comedy/lib/forked-actor-worker.js PrimeFinderActorПо два на каждой, как и хотели (понадобится больше — увеличим clusterSize). Отправляем запросы:
$ curl http://localhost:8080/next-prime/3000000000 &
[1] 23000
$ curl http://localhost:8080/next-prime/3000000000 &
[2] 23002Смотрим загрузку на локальной машине:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
22869 weekens 20 0 908080 40344 21724 R 106,7 0,5 0:07.40 nodejs Смотрим загрузку на удалённой машине:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5925 weekens 20 0 909000 40912 21044 R 100,2 0,1 0:14.17 nodejs Загружено по одному ядру на каждой машине. То есть мы теперь распределяем нагрузку равномерно по обоим машинам. Заметьте, мы добились этого, не поменяв ни одной строчки кода. И нам помог в этом Comedy и модель акторов.
Мы рассмотрели пример гибкого масштабирования приложения с помощью модели акторов и её реализации в Node.JS — Comedy. Алгоритм наших действий выглядел следующим образом:
Как описывать приложение в терминах акторов? Это аналог вопроса "Как описать приложение в терминах объектов и классов?". Программирование на акторах очень похоже на ООП. Можно сказать, что это ООП++. В ООП есть различные устоявшиеся и успешные паттерны проектирования. Аналогичным образом, и для модели акторов есть свои паттерны. Вот книга по ним. Эти паттерны можно использовать, и они вам наверняка помогут, но, если вы уже владеете ООП, у вас точно не будет с акторами проблем.
Что если ваше приложение уже написано? Нужно ли "переписывать его на акторы"? Конечно, модификация кода в этом случае потребуется. Но не обязательно делать масштабный рефакторинг. Можно выделить несколько основных, "крупных" акторов, и после этого вы уже можете масштабироваться. "Крупные" акторы можно со временем раздробить на более мелкие. Опять же, если ваше приложение уже описано в терминах ООП, переход на акторы будет, скорее всего, безболезненным. Единственный момент, с которым, возможно, придётся поработать: акторы полностью изолированы друг от друга, в отличие от простых объектов.
Насчёт зрелости фреймворка. Первая рабочая версия Comedy была разработана внутри проекта SAYMON в июне 2016 года. Фреймворк с самой первой версии работал в продакшене в боевых условиях. В апреле 2017 года библиотека была выпущена в Open Source под Eclipse Public License. Comedy при этом продолжает быть частью SAYMON и используется для масштабирования системы и обеспечения её отказоустойчивости.
Список планируемых фич здесь.
В этой статье я не упомянул о целом ряде функциональный возможностей Comedy: о fault tolerance ("respawn" акторов), об инъекции ресурсов в акторы, об именованных кластерах, о маршаллинге пользовательских классов, о поддержке TypeScript. Но большую часть вышеперечисленного вы найдёте в документации, а то, что в ней ещё не описано — в тестах и примерах. Плюс, возможно, я напишу ещё статьи о Comedy и акторах в Node.JS, если тема пойдёт в массы.
Используйте Comedy! Создавайте issues! Жду ваших комментариев!
|
Метки: author weekens node.js акторы масштабирование |
[Перевод] Как на самом деле работает планировщик Kubernetes? |
while True:
pods = get_all_pods()
for pod in pods:
if pod.node == nil:
assignNode(pod)cronjob — единственный компонент Kubernetes, код которого был мною прочитан. Контроллер cronjob перебирает все cron-задания, проверяет, что ни для одного из них не надо ничего делать, ожидает 10 секунд и бесконечно повторяет этот цикл. Очень просто!Pending (когда узел не назначен на под). При перезагрузке планировщика под выходил из этого состояния (вот тикет).go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)sched.scheduleOne». А что происходит там?func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
// do all the scheduler stuff for `pod`
}NextPod()? Откуда растут ноги?func (f *ConfigFactory) getNextPod() *v1.Pod {
for {
pod := cache.Pop(f.podQueue).(*v1.Pod)
if f.ResponsibleForPod(pod) {
glog.V(4).Infof("About to try and schedule pod %v", pod.Name)
return pod
}
}
}podQueue), и следующие поды приходят из неё.podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
if err := c.podQueue.Add(obj); err != nil {
runtime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
},host, err := sched.config.Algorithm.Schedule(pod, sched.config.NodeLister)
if err != nil {
glog.V(1).Infof("Failed to schedule pod: %v/%v", pod.Namespace, pod.Name)
sched.config.Error(pod, err)sched.config.Error снова добавляет под в очередь, поэтому для него всё-таки будет предпринята повторная попытка обработки.Error не всегда вызывалась, когда реально происходила ошибка. Мы сделали патч (патч был опубликован в том же issue — прим. перев.), чтобы вызывать её корректно, после чего восстановление стало происходить правильно. Класс!while True:
pods = get_all_pods()
for pod in pods:
if pod.node == nil:
assignNode(pod)cronjob). Очень здорово!ИспользуйтеSharedInformers.SharedInformersпредлагают хуки для получения уведомлений о добавлении, изменении или удалении конкретного ресурса. Также они предлагают удобные функции для доступа к разделяемым кэшам и для определения, где кэш применим.
informer (например, pod informer), который отвечает за:cronjob не использует информаторов (работа с ними всё усложняет, а в данном случае, думаю, ещё не стоит вопрос производительности), однако многие другие (большинство?) — используют. В частности, планировщик так делает. Настройку его информаторов можно найти в этом коде.Для надёжного повторного помещения в очередь выносите ошибки на верхний уровень. Для простой реализации с разумным откатом естьworkqueue.RateLimitingInterface.
Главная функция контроллера должна возвращать ошибку, когда необходимо повторное помещение в очередь. Когда его нет, используйтеutilruntime.HandleErrorи возвращайтеnil. Это значительно упрощает изучение случаев обработки ошибок и гарантирует, что контроллер ничего не потеряет, когда это необходимо.
Watches и Informers будут «синхронизироваться». Периодически они доставляют вашему методуUpdateкаждый подходящий объект в кластере. Хорошо для случаев, когда может потребоваться выполнить дополнительное действие с объектом, хотя это может быть нужно и не всегда.
В случаях, когда вы уверены, что повторное помещение в очередь элементов не требуется и новых изменений нет, можно сравнить версию ресурса у нового и старого объектов. Если они идентичны, можете пропустить повторное помещение в очередь. Будьте осторожны. Если повторное помещение элемента будет пропущено при каких-либо ошибках, он может потеряться (никогда не попасть в очередь повторно).
informerFactory := informers.NewSharedInformerFactory(kubecli, 0)
// cache only non-terminal pods
podInformer := factory.NewPodInformer(kubecli, 0)@brendandburns — что здесь планируется исправить? Я действительно против таких маленьких периодов повторной синхронизации, потому что они значительно скажутся на производительности.
Согласен с @wojtek-t. Если resync вообще когда-либо и может решить проблему, это означает, что где-то в коде есть баг, который мы пытаемся спрятать. Не думаю, что resync — правильное решение.
|
Метки: author shurup системное администрирование devops *nix блог компании флант kubernetes go |
Pygest #15. Релизы, статьи, интересные проекты из мира Python [01 августа 2017 — 14 августа 2017] |
 Всем привет! Это уже пятнадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже пятнадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python. |
Метки: author andrewnester разработка веб-сайтов программирование машинное обучение python django digest pygest machine learning flask дайджест web deep learning |
Как распознать scam ICO? Часть II. Зрим |


|
Метки: author Menaskop финансы в it учебный процесс в it исследования и прогнозы в it ico scam скамы оценка ico (ito tge) it- юрист |
Как распознать scam ICO? Часть II. Зрим |
|
Метки: author Menaskop финансы в it учебный процесс в it исследования и прогнозы в it ico scam скамы оценка ico (ito tge) it- юрист |
PHP-Дайджест № 114 – свежие новости, материалы и инструменты (1 – 14 августа 2017) |

Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.2.0 Beta 2, об истории и безопасности unserialize(), старт PSR HTTP Client, StackOverflow Driven Development, видео с конференций и митапов, и многое другое.
Приятного чтения!
 Доклад Тейлора на Laracon US 2017
Доклад Тейлора на Laracon US 2017 Laracon 2017 — краткий обзор и куча полезных ссылок Laravel — экосистема, а не просто PHP-фреймворк Как скрестить ежа с ужом. Используем GridView из Yii 2 в проекте на Laravel
Laracon 2017 — краткий обзор и куча полезных ссылок Laravel — экосистема, а не просто PHP-фреймворк Как скрестить ежа с ужом. Используем GridView из Yii 2 в проекте на LaravelPSA: Don't use unserialize() on untrusted input (see https://t.co/8GZb1xqE1u)
— Nikita Popov (@nikita_ppv) August 10, 2017
PHP will no longer treat unserialize() bugs are security bugs.
Распознать и обезвредить. Поиск неортодоксальных бэкдоров Оптимизация шаблонов представления в Codeigniter Framework при помощи AST трансформаций Microservices и Модель Акторов (Actor Model) Пишем расширения для PHP 7 на C++ Расчет приоритета комбинаций в техасском холдеме (покере) на PHP PHP Serbia Conference 2017 Интервью с Nils Adermann (Composer) о приватном Packagist Видео с PHP of BY #23: Как начать контрибьютить в PHP, PHP: generics, строгая типизация массивов и ...
Видео с PHP of BY #23: Как начать контрибьютить в PHP, PHP: generics, строгая типизация массивов и ...StackOverflowBuddy::substringBetweenTwoStrings('platypus', 'pl', 'us');
// atyp

Спасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в личку.
Вопросы и предложения пишите на почту или в твиттер.
Прислать ссылку
Быстрый поиск по всем дайджестам
<- Предыдущий выпуск: PHP-Дайджест № 113
|
Метки: author pronskiy разработка веб-сайтов php дайджест php- ссылки symfony yii laravel zend reactphp psr |






