Hacks.Mozilla.Org: How MDN’s autocomplete search works |
Last month, Gregor Weber and I added an autocomplete search to MDN Web Docs, that allows you to quickly jump straight to the document you’re looking for by typing parts of the document title. This is the story about how that’s implemented. If you stick around to the end, I’ll share an “easter egg” feature that, once you’ve learned it, will make you look really cool at dinner parties. Or, perhaps you just want to navigate MDN faster than mere mortals.
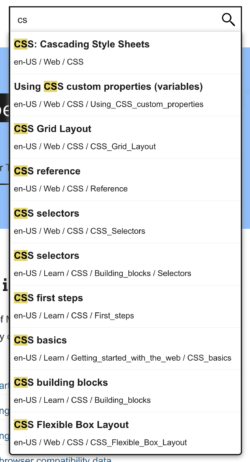
In its simplest form, the input field has an onkeypress event listener that filters through a complete list of every single document title (per locale). At the time of writing, there are 11,690 different document titles (and their URLs) for English US. You can see a preview by opening https://developer.mozilla.org/en-US/search-index.json. Yes, it’s huge, but it’s not too huge to load all into memory. After all, together with the code that does the searching, it’s only loaded when the user has indicated intent to type something. And speaking of size, because the file is compressed with Brotli, the file is only 144KB over the network.
By default, the only JavaScript code that’s loaded is a small shim that watches for onmouseover and onfocus for the search field. There’s also an event listener on the whole document that looks for a certain keystroke. Pressing / at any point, acts the same as if you had used your mouse cursor to put focus into the field. As soon as focus is triggered, the first thing it does is download two JavaScript bundles which turns the field into something much more advanced. In its simplest (pseudo) form, here’s how it works:
let started = false;
function startAutocomplete() {
if (started) {
return false;
}
const script = document.createElement("script");
script.src = "/static/js/autocomplete.js";
document.head.appendChild(script);
}Then it loads /static/js/autocomplete.js which is where the real magic happens. Let’s dig deeper with the pseudo code:
(async function() {
const response = await fetch('/en-US/search-index.json');
const documents = await response.json();
const inputValue = document.querySelector(
'input[type="search"]'
).value;
const flex = FlexSearch.create();
documents.forEach(({ title }, i) => {
flex.add(i, title);
});
const indexResults = flex.search(inputValue);
const foundDocuments = indexResults.map((index) => documents[index]);
displayFoundDocuments(foundDocuments.slice(0, 10));
})();As you can probably see, this is an oversimplification of how it actually works, but it’s not yet time to dig into the details. The next step is to display the matches. We use (TypeScript) React to do this, but the following pseudo code is easier to follow:
function displayFoundResults(documents) {
const container = document.createElement("ul");
documents.forEach(({url, title}) => {
const row = document.createElement("li");
const link = document.createElement("a");
link.href = url;
link.textContent = title;
row.appendChild(link);
container.appendChild(row);
});
document.querySelector('#search').appendChild(container);
}
Then with some CSS, we just display this as an overlay just beneath the field. For example, we highlight each title according to the inputValue and various keystroke event handlers take care of highlighting the relevant row when you navigate up and down.
We create the FlexSearch index just once and re-use it for every new keystroke. Because the user might type more while waiting for the network, it’s actually reactive so executes the actual search once all the JavaScript and the JSON XHR have arrived.
Before we dig into what this FlexSearch is, let’s talk about how the display actually works. For that we use a React library called downshift which handles all the interactions, displays, and makes sure the displayed search results are accessible. downshift is a mature library that handles a myriad of challenges with building a widget like that, especially the aspects of making it accessible.
So, what is this FlexSearch library? It’s another third party that makes sure that searching on titles is done with natural language in mind. It describes itself as the “Web’s fastest and most memory-flexible full-text search library with zero dependencies.” which is a lot more performant and accurate than attempting to simply look for one string in a long list of other strings.
In fairness, if the user types foreac, it’s not that hard to reduce a list of 10,000+ document titles down to only those that contain foreac in the title, then we decide which result to show first. The way we implement that is relying on pageview stats. We record, for every single MDN URL, which one gets the most pageviews as a form of determining “popularity”. The documents that most people decide to arrive on are most probably what the user was searching for.
Our build-process that generates the search-index.json file knows about each URLs number of pageviews. We actually don’t care about absolute numbers, but what we do care about is the relative differences. For example, we know that Array.prototype.forEach() (that’s one of the document titles) is a more popular page than TypedArray.prototype.forEach(), so we leverage that and sort the entries in search-index.json accordingly. Now, with FlexSearch doing the reduction, we use the “natural order” of the array as the trick that tries to give users the document they were probably looking for. It’s actually the same technique we use for Elasticsearch in our full site-search. More about that in: How MDN’s site-search works.
Actually, it’s not a whimsical easter egg, but a feature that came from the fact that this autocomplete needs to work for our content creators. You see, when you work on the content in MDN you start a local “preview server” which is a complete copy of all documents but all running locally, as a static site, under http://localhost:5000. There, you don’t want to rely on a server to do searches. Content authors need to quickly move between documents, so much of the reason why the autocomplete search is done entirely in the client is because of that.
Commonly implemented in tools like the VSCode and Atom IDEs, you can do “fuzzy searches” to find and open files simply by typing portions of the file path. For example, searching for whmlemvo should find the file files/web/html/element/video. You can do that with MDN’s autocomplete search too. The way you do it is by typing / as the first input character.
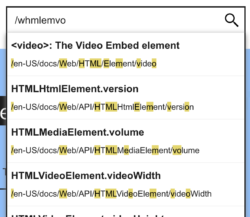
It makes it really quick to jump straight to a document if you know its URL but don’t want to spell it out exactly.
In fact, there’s another way to navigate and that is to first press / anywhere when browsing MDN, which activates the autocomplete search. Then you type / again, and you’re off to the races!
The code for all of this is in the Yari repo which is the project that builds and previews all of the MDN content. To find the exact code, click into the client/src/search.tsx source code and you’ll find all the code for lazy-loading, searching, preloading, and displaying autocomplete searches.
The post How MDN’s autocomplete search works appeared first on Mozilla Hacks - the Web developer blog.
|
|
Wladimir Palant: Data exfiltration in Keepa Price Tracker |
As readers of this blog might remember, shopping assistants aren’t exactly known for their respect of your privacy. They will typically use their privileged access to your browser in order to extract data. For them, this ability is a competitive advantage. You pay for a free product with a privacy hazard.
Usually, the vendor will claim to anonymize all data, a claim that can rarely be verified. Even if the anonymization actually happens, it’s really hard to do this right. If anonymization can be reversed and the data falls into the wrong hands, this can have severe consequences for a person’s life.
Today we will take a closer look at a browser extension called “Keepa – Amazon Price Tracker” which is used by at least two million users across different browsers. The extension is being brought out by a German company and the privacy policy is refreshingly short and concise, suggesting that no unexpected data collection is going on. The reality however is: not only will this extension extract data from your Amazon sessions, it will even use your bandwidth to load various Amazon pages in the background.
The Keepa extension keeps a persistent WebSocket connection open to its server dyn.keepa.com. The server parameters include your unique user identifier, stored both in the extension and as a cookie on keepa.com. As a result, this identifier will survive both clearing browse data and reinstalling the extension, you’d have to do both for it to be cleared. If you choose to register on keepa.com, this identifier will also be tied to your user name and email address.
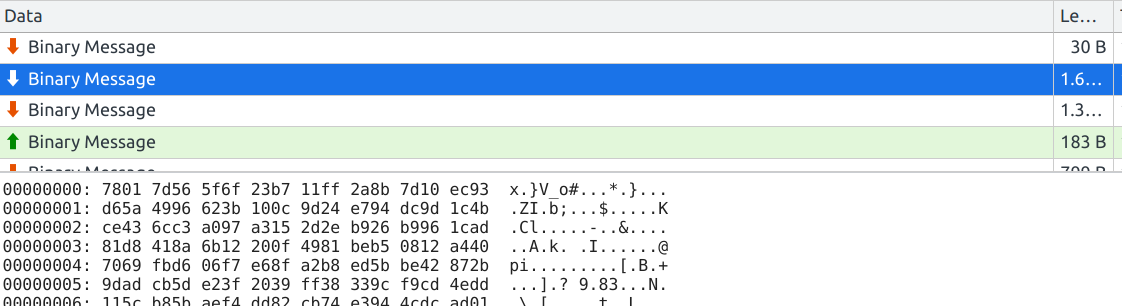
Looking at the messages being exchanged, you’ll see that these are binary data. But they aren’t encrypted, it’s merely deflate-compressed JSON-data.
You can see the original message contents by copying the message as a Base64 string, then running the following code in the context of the extension’s background page:
pako.inflate(atob("eAGrViouSSwpLVayMjSw0FFQylOyMjesBQBQGwZU"), {to: "string"});
This will display the initial message sent by the server:
{
"status": 108,
"n": 71
}Whenever I open an Amazon product page, a message like the following is sent to the Keepa server:
{
"payload": [null],
"scrapedData": {
"tld": "de"
},
"ratings": [{
"rating": "4,3",
"ratingCount": "2.924",
"asin": "B0719M4YZB"
}],
"key": "f1",
"domainId": 3
}This tells the server that I am using Amazon Germany (the value 3 in domainId stands for .de, 1 would have been .com). It also indicates the product I viewed (asin field) and how it was rated by Amazon users. Depending on the product, additional data like the sales rank might be present here. Also, the page scraping rules are determined by the server and can change any time to collect more sensitive data.
A similar message is sent when an Amazon search is performed. The only difference here is that ratings array contains multiple entries, one for each article in your search results. While the search string itself isn’t being transmitted (not with the current scraping rules at least), from the search results it’s trivial to deduce what you searched for.
That’s not the end of it however. The extension will also regularly receive instructions like the following from the server (shortened for clarity):
{
"key": "o1",
"url": "https://www.amazon.de/gp/aod/ajax/ref=aod_page_2?asin=B074DDJFTH&…",
"isAjax": true,
"httpMethod": 0,
"domainId": 3,
"timeout": 8000,
"scrapeFilters": [{
"sellerName": {
"name": "sellerName",
"selector": "#aod-offer-soldBy div.a-col-right > a:first-child",
"altSelector": "#aod-offer-soldBy .a-col-right span:first-child",
"attribute": "text",
"reGroup": 0,
"multiple": false,
"optional": true,
"isListSelector": false,
"parentList": "offers",
"keepBR": false
},
"rating": {
"name": "rating",
"selector": "#aod-offer-seller-rating",
"attribute": "text",
"regExp": "(\\d{1,3})\\s?%",
"reGroup": 1,
"multiple": false,
"optional": true,
"isListSelector": false,
"parentList": "offers",
"keepBR": false
},
…
}],
"l": [{
"path": ["chrome", "webRequest", "onBeforeSendHeaders", "addListener"],
"index": 1,
"a": {
"urls": [""],
"types": ["main_frame", "sub_frame", "stylesheet", "script", …]
},
"b": ["requestHeaders", "blocking", "extraHeaders"]
}, …, null],
"block": "(https?:)?\\/\\/.*?(\\.gif|\\.jpg|\\.png|\\.woff2?|\\.css|adsystem\\.)\\??"
}The address https://www.amazon.de/gp/aod/ajax/ref=aod_page_2?asin=B074DDJFTH belongs to an air compressor, not a product I’ve ever looked at but one that Keepa is apparently interested in. The extension will now attempt to extract data from this page despite me not navigating to it. Because of isAjax flag being set here, this address is loaded via XMLHttpRequest, after which the response text is being put into a frame of extensions’s background page. If isAjax flag weren’t set, this page would be loaded directly into another frame.
The scrapeFilters key sets the rules to be used for analyzing the page. This will extract ratings, prices, availability and any other information via CSS selectors and regular expressions. Here Keepa is also interested in the seller’s name, elsewhere in the shipping information and security tokens. There is also functionality here to read out contents of the Amazon cart, I didn’t look too closely at that however.
The l key is also interesting. It tells the extension’s background page to call a particular method with the given parameters, here chrome.webRequest.onBeforeSendHeaders.addListener method is being called. The index key determines which of the predefined listeners should be used. The purpose of the predefined listeners seems to be removing some security headers as well as making sure headers like Cookie are set correctly.
Let’s take a closer look at the privileges granted to the Keepa server here, these aren’t entirely obvious. Loading pages in the background isn’t meant to happen within the user’s usual session, there is some special cookie handling meant to produce a separate session for scraping only. This doesn’t appear to always work reliably, and I am fairly certain that the server can make pages load in the usual Amazon session, rendering it capable of impersonating the user towards Amazon. As the server can also extract arbitrary data, it is for example entirely possible to add a shipping address to the user’s Amazon account and to place an order that will be shipped there.
The l key is also worth taking a second look. At first the impact here seems limited by the fact that the first parameter will always be a function, one out of a few possible functions. But the server could use that functionality to call eval.call(function(){}, "alert(1)") in the context of the extension’s background page and execute arbitrary JavaScript code. Luckily, this call doesn’t succeed thanks to the extension’s default Content Security Policy.
But there are more possible calls, and some of these succeed. For example, the server could tell the extension to call chrome.tabs.executeScript.call(function(){}, {code: "alert(1)"}). This will execute arbitrary JavaScript code in the current tab if the extension has access to it (meaning any Amazon website). It would also be possible to specify a tab identifier in order to inject JavaScript into background tabs: chrome.tabs.executeScript.call(function(){}, 12, {code: "alert(1)"}). For this the server doesn’t need to know which tabs are open: tab identifiers are sequential, so it’s possible to find valid tab identifiers simply by trying out potential candidates.
Certainly, a browser extension collecting all this data will have a privacy policy to explain how this data is used? Here is the privacy policy of the German-based Keepa GmbH in full:
You can use all of our services without providing any personal information. However, if you do so we will not sell or trade your personal information under any circumstance. Setting up a tracking request on our site implies that you’d like us to contact you via the contact information you provided us. We will do our best to only do so if useful and necessary - we hate spam as much as you do. If you login/register using Social-Login or OpenID we will only save the username and/or email address of the provided data. Should you choose to subscribe to one of our fee-based subscriptions we will share your email and billing address with the chosen payment provider - solely for the purpose of payment related communication and authentication. You can delete all your information by deleting your account through the settings.
This doesn’t sound right. Despite being linked under “Privacy practices” in the Chrome Web Store, it appears to apply only to the Keepa website, not to any of the extension functionality. The privacy policy on the Mozilla Add-ons site is more specific despite also being remarkably short (formatting of the original preserved):
You can use this add-on without providing any personal information. If you do opt to share contact information, we will only use it to provide you updates relevant to your tracking requests. Under no circumstances will your personal information be made available to a third party. This add-on does not collect any personal data beyond the contact information provided by you.
Whenever you visit an Amazon product page the ASIN (Amazon Standard Identification Number) of that product is used to load its price history graph from Keepa.com. We do not log such requests.
The extension creates required functional cookies containing a session and your settings on Keepa.com, which is required for session management (storing settings and accessing your Keepa.com account, if you create one). No other (tracking, advertising) cookies are created.
This refers to some pieces of the Keepa functionality but it once again completely omits the data collection outlined here. It’s reassuring to know that they don’t log product identifiers when showing product history, but they don’t need to if on another channel their extension sends far more detailed data to the server. This makes the first sentence, formatted as bold text, a clear lie. Unless of course you don’t consider the information collected here personal. I’m not a lawyer, maybe in the legal sense it isn’t.
I’m fairly certain however that this privacy policy doesn’t meet the legal requirements of the GDPR. To be compliant it would need to mention the data being collected, explain the legal grounds for doing so, how it is being used, how long it is being kept and who it is shared with.
That said, this isn’t the only regulation violated by Keepa. As a German company, they are obliged to publish a legal note (in German: Impressum) on their website so that visitors can immediately recognize the party responsible. Keepa hides both this information and the privacy policy in a submenu (one has to click “Information” first) under the misleading name “Disclaimer.” The legal requirements are for both pages to be reachable with one click, and the link title needs to be unambiguous.
Keepa extension is equipped to collect any information about your Amazon visits. Currently it will collect information about the products you look at and the ones you search for, all that tied to a unique and persistent user identifier. Even without you choosing to register on the Keepa website, there is considerable potential for the collected data to be deanonymized.
Some sloppy programming had the (likely unintended) consequence of making the server even more powerful, essentially granting it full control over any Amazon page you visit. Luckily, the extension’s privileges don’t give it access to any websites beyond Amazon.
The company behind the extension fails to comply with its legal obligations. The privacy policy is misleading in claiming that no personal data is being collected. It fails to explain how the data is being used and who it is shared with. There are certainly companies interested in buying detailed online shopping profiles, and a usable privacy policy needs to at least exclude the possibility of the data being sold.
https://palant.info/2021/08/02/data-exfiltration-in-keepa-price-tracker/
|
|
Cameron Kaiser: And now for something completely different: "Upgrading" your Quad G5 LCS |
The Quad G5 is one of the better ones in this regard and most of the ones that would have suffered early deaths already have, but it still requires service due to evaporative losses and sediment, and any Quad on its original processors is by now almost certainly a windtunnel under load. An ailing LCS, even an intact one, runs the real risk of an unexpected shutdown if the CPU it can no longer cool effectively ends up exceeding its internal thermal limits; you'll see a red OVERTEMP light illuminate on the logic board when this is imminent, followed by a CHECKSTOP. Like an automotive radiator it is possible to open the LCS up and flush the coolant (and potentially service the pumps), but this is not a trivial process. Additionally, those instructions are for the single-pump Delphi version 1 assembly, which is the more reliable of the two; the less reliable double-pump Cooligy version 2 assemblies are even harder to work on.
Unfortunately our current employment situation requires I downsize, so I've been starting on consolidating or finding homes for excess spare systems. I had several spare Quad G5 systems in storage in various states, all version 2 Cooligy LCSes, but the only LCS assemblies I have in stock (and the LCS in my original Quad G5) are version 1. These LCSes were bought Apple Certified Refurbished, so they were known to be in good condition and ready to go; as the spare Quads were all on their original marginal LCSes and processors, I figured I would simply "upgrade" the best-condition v2 G5 with a v1 assembly. The G5 service manual doesn't say anything about this, though it has nothing in it indicating that they aren't interchangeable, or that they need different logic boards or ROMs, and now having done it I can attest that it "just works." So here's a few things to watch out for.
Both the v1 and the v2 assemblies have multiple sets of screws: four "captive" (not really) float plate screws, six processor mount screws, four terminal assembly screws (all of which require a 3mm flathead hex driver), and four captive ballheads (4mm ballhead hex). Here's the v1, again:




Once installed, the grey inlet frame used in the v2 doesn't grip the v1:

The fan and pump connector cable is also the same between v1 and v2, though you may need to move the cable around a bit to get the halves to connect if it was in a wacky location.
Now run thermal calibration, and enjoy your renewed Apple PowerPC tank.
http://tenfourfox.blogspot.com/2021/07/and-now-for-something-completely.html
|
|
Firefox Add-on Reviews: Supercharge your productivity with a browser extension |
With more work and education happening online (and at home) you may find yourself needing new ways to juice your productivity. From time management to organizational tools and more, the right browser extension can give you an edge in the art of efficiency.
Capture, save, and share anything you find on the web. Gyazo is a great tool for personal or collaborative record keeping and research.
Clip entire pages or just pertinent portions. Save images or take screenshots. Gyazo makes it easy to perform any type of web clipping action by either right-clicking on the page element you want to save or using the extension’s toolbar button. Everything gets saved to your Gyazo account, making it accessible across devices and collaborative teams.
On your Gyazo homepage you can easily browse and sort everything you’ve clipped; and organize everything into shareable topics or collections.
Similar to Gyazo, Evernote Web Clipper offers a kindred feature set—clip, save, and share web content—albeit with some nice user interface distinctions.
Evernote places emphasis on making it easy to annotate images and articles for collaborative purposes. It also has a strong internal search feature, allowing you to search for specific words or phrases that might appear across scattered groupings of clipped content. Evernote also automatically strips out ads and social widgets on your saved pages.
Anti-distraction extensions can be a major boon for online workers and students…
Do you struggle avoiding certain time-wasting, productivity-sucking websites? With Block Site you can enforce restrictions on sites that tempt you away from good work habits.
Just list the websites you want to avoid for specified periods of time (certain hours of the day or some days entirely, etc.) and Block Site won’t let you access them until you’re out of the focus zone. There’s also a fun redirection feature where you’re automatically redirected to a more productive website anytime you try to visit a time waster
Very similar in function to Block Site, LeechBlock NG offers a few intriguing twists beyond standard site-blocking features.
In addition to blocking sites during specified times, LeechBlock NG offers an array of granular, website-specific blocking abilities—like blocking just portions of websites (e.g. you can’t access the YouTube homepage but you can see video pages) to setting restrictions on predetermined days (e.g. no Twitter on weekends) to 60-second delayed access to certain websites to give you time to reconsider that potentially productivity killing decision.
A simple but highly effective time management tool, Tomato Clock (based on the Pomodoro technique) helps you stay on task by tracking short, focused work intervals.
The premise is simple: it assumes everyone’s productive attention span is limited, so break up your work into manageable “tomato” chunks. Let’s say you work best in 40-minute bursts. Set Tomato Clock and your browser will notify you when it’s break time (which is also time customizable). It’s a great way to stay focused via short sprints of productivity. The extension also keeps track of your completed tomato intervals so you can track your achieved results over time.
Imagine a world wide web where everything but the words are stripped away—no more distracting images, ads, tempting links to related stories, nothing—just the words you’re there to read. That’s Tranquility Reader.
Simply hit the toolbar button and instantly streamline any web page. Tranquility Reader offers quite a few other nifty features as well, like the ability to save content offline for later reading, customizable font size and colors, add annotations to saved pages, and more.
We hope some of these great extensions will give your productivity a serious boost! Fact is there are a vast number of extensions out there that could possibly help your productivity—everything from ways to organize tons of open tabs to translation tools to bookmark managers and more.
https://addons.mozilla.org/blog/supercharge-your-productivity-with-a-browser-extension/
|
|
The Mozilla Blog: 2021: The year privacy went mainstream |
It’s been a hell of a year so far for data privacy. Apple has been launching broadsides at the ad-tech industry with each new big privacy feature unveiling. Google is playing catch-up, promising that Android users will also soon be able to stop apps from tracking them across the internet. Then there’s WhatsApp, going on a global PR offensive after changes to its privacy policy elicited consumer backlash.
There’s no doubt about it, digital privacy is shaping up as the key tech battleground in 2021 and the years ahead. But how did this happen? Wasn’t digital privacy supposed to be dead and buried by now? After all, many tech CEOs and commentators have told us that a zero-privacy world was inevitable and that everyone should just get used to it. Until recently, it would have been tough to argue that they were wrong.
Over the last 18 months, events have conspired to accelerate this shift in public attitudes towards privacy from a niche concern to something much more fundamental and mainstream. In the process, more people also began to see how privacy and security are inextricably linked.
The abrupt shift to remote working prompted by COVID-19 “stay at home” orders globally was the first crank of the engine. Many of us have had to use personal devices and work in less-than-secure home environments, exposing vast swathes of corporate data to greater risk.
The result has been something of a crash course in cybersecurity for all involved. Workers have had to navigate VPNs in order to access their company networks and learn how to keep their employer’s data safe. Those that didn’t suffered the consequences. In August 2020, MalwareBytes reported that 20% of organizations had had a data breach due to remote working.
With home working here to stay in some form at least, employees must now be kept updated on cybersecurity best practice to ensure their networks stay protected. This should seep into people’s own online habits, prompting them to be more cautious and to adopt better everyday security hygiene.
Then there was the COVID-19 public health response, with contact tracing apps and vaccine passports putting health privacy front of mind. Their introduction raised thorny questions about how to balance managing the spread of the virus with respecting data privacy. In the UK, privacy fears forced the government to scrap the original version of its contact tracing app and switch to a decentralized operating model.
As mass vaccinations roll out, attention has since turned to vaccine passport apps. In New York, the Excelsior Pass controversially uses private blockchain technology leading to criticism that developer IBM and the state government are hiding behind the blockchain gimmick rather than genuinely earning the trust of the public to protect their information. As a result, the Linux Foundation is now working to develop a set of standards that protects our privacy when we use these apps. This is a significant step forward and provides a baseline for digital privacy protections that could be referenced in the development of other apps.
It’s not just the pandemic that has opened more eyes to privacy issues. Over a tumultuous summer, law enforcement agencies across the U.S. flaunted surveillance powers that brought home just how flimsy our privacy protections truly are.
At the peak of the Black Lives Matter protests, authorities were able to identify protestors via facial recognition tech and track them down using phone location data. To combat this, major news outlets like Time and human rights organizations such as Amnesty International published articles on how we can protect our digital privacy while protesting. The encrypted messaging app Signal even developed an anti-facial recognition mask which they distributed to Black Lives Matter protesters for free.
Finally, moves from Apple over the past year have really hammered home the growing demand for protecting our personal data. The introduction of privacy labels to the App Store means we can now get an idea of an app’s privacy practices before we download it. The iOS 14.5 update also made app tracking opt-in only. A whopping 96% of U.S. users chose not to opt-in, showing just how much consumer behaviour is changing. Needless to say Google has followed suit in some regards, announcing its own version of privacy labels to come next year for Android owners.
This last point is important. Big tech companies have the power to force each other’s hands and shape our lives. If they continue seeing that digital privacy can be profitable, then there’s a great chance it’s here to stay.
Looking back to 2018 when the Cambridge Analytica / Facebook scandal broke, digital privacy was on life support, hanging on by a thread. That shocking moment proved to be the tipping point when many people looked up to see a less private and less secure reality, one which they didn’t want. Since then, many tech companies have found themselves firmly in the sights of a Congress looking to take them down a peg or two. States, led by California, began enacting consumer privacy legislation. Meanwhile in Europe, the introduction of GDPR has been an opening salvo for what strong international consumer privacy protections can look like. Countries like India and Kenya have also begun to consider a data protection law, impacting the privacy of over a billion users on the internet.
But what can we do to demand more for our digital privacy? A good place to start is by using alternatives to big tech platforms like Google, Facebook and Amazon. Switching from Google Chrome to a privacy-focused browser like Mozilla Firefox is a good first step, and maybe it’s time you considered deleting Facebook for good. Until these platforms clean up their act, we can take action by avoiding them all together. We can also ask our local senators and representatives to vote for legislation that will safeguard us online, such as the Fourth Amendment is Not for Sale Act. The Electronic Frontier Foundation runs numerous campaigns online to help us do this and you can get involved via their Action Center.
It’s the combination of companies protecting their bottom lines, pressure from regulators, and extraordinary societal moments where we are seeing a turning point in favor of consumer privacy, and there is no going back. As consumers of technology, we must never take these privacy gains for granted and continue pressing for more.
Callum Tennent is a guest opinion columnist for Mozilla’s Distilled blog. He is Site Editor of Top10VPN and a consumer technology journalist as well as a former product testing professional at Which? Magazine. You can find more information about him here and follow him on Twitter at @TennentCallum.
The post 2021: The year privacy went mainstream appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/internet-culture/deep-dives/2021-the-year-privacy-went-mainstream/
|
|
Mozilla Addons Blog: New tagging feature for add-ons on AMO |
There are multiple ways to find great add-ons on addons.mozilla.org (AMO). You can browse the content featured on the homepage, use the top navigation to drill down into add-on types and categories, or search for specific add-ons or functionality. Now, we’re adding another layer of classification and opportunities for discovery by bringing back a feature called tags.
We introduced tagging long ago, but ended up discontinuing it because the way we implemented it wasn’t as useful as we thought. Part of the problem was that it was too open-ended, and anyone could tag any add-on however they wanted. This led to spamming, over-tagging, and general inconsistencies that made it hard for users to get helpful results.
Now we’re bringing tags back, but in a different form. Instead of free-form tags, we’ll provide a set of predefined tags that developers can pick from. We’re starting with a small set of tags based on what we’ve noticed users looking for, so it’s possible many add-ons don’t match any of them. We will expand the list of tags if this feature performs well.
The tags will be displayed on the listing page of the add-on. We also plan to display tagged add-ons in the AMO homepage.

Example of a tag shelf in the AMO homepage
We’re only just starting to roll this feature out, so we might be making some changes to it as we learn more about how it’s used. For now, add-on developers should visit the Developer Hub and set any relevant tags for their add-ons. Any tags that had been set prior to July 22, 2021 were removed when the feature was retooled.
The post New tagging feature for add-ons on AMO appeared first on Mozilla Add-ons Community Blog.
https://blog.mozilla.org/addons/2021/07/29/new-tagging-feature-for-add-ons-on-amo/
|
|
The Rust Programming Language Blog: Announcing Rust 1.54.0 |
|
|
Mozilla Security Blog: Making Client Certificates Available By Default in Firefox 90 |
Starting with version 90, Firefox will automatically find and offer to use client authentication certificates provided by the operating system on macOS and Windows. This security and usability improvement has been available in Firefox since version 75, but previously end users had to manually enable it.
When a web browser negotiates a secure connection with a website, the web server sends a certificate to the browser to prove its identity. Some websites (most commonly corporate authentication systems) request that the browser sends a certificate back to it as well, so that the website visitor can prove their identity to the website (similar to logging in with a username and password). This is sometimes called “mutual authentication”.
Starting with Firefox version 90, when you connect to a website that requests a client authentication certificate, Firefox will automatically query the operating system for such certificates and give you the option to use one of them. This feature will be particularly beneficial when relying on a client certificate stored on a hardware token, since you do not have to import the certificate into Firefox or load a third-party module to communicate with the token on behalf of Firefox. No manual task or preconfiguration will be necessary when communicating with your corporate authentication system.
If you are a Firefox user, you don’t have to do anything to benefit from this usability and security improvement to load client certificates. As soon as your Firefox auto-updates to version 90, you can simply select your client certificate when prompted by a website. If you aren’t a Firefox user yet, you can download the latest version here to start benefiting from all the ways that Firefox works to protect you when browsing the web.
The post Making Client Certificates Available By Default in Firefox 90 appeared first on Mozilla Security Blog.
|
|
The Mozilla Blog: Lalo Luevano, restaurateur and co-founder of Bodega wine bar |
On the internet you are never alone, and because of that at Mozilla we know that we can’t work to build a better internet alone. We believe in and rely on our community — from our volunteers, to our staff, to our users, fans and friends. Meet Lalo Luevano, partner and co-founder of Bodega, a natural wine bar in the North Beach neighborhood of San Francisco.
Tell me a little about yourself.
I was born and raised in Santa Cruz, California. It’s a little surf town, very tight knit, very laid back. I think it rubbed off on me a lot because I’m a laid back sort of person. I’m from a Mexican background. My parents always loved having big barbecues and having lots of friends over. They were involved with fundraisers for my baseball team or my sister’s soccer teams. I always wanted to be part of the production side, getting involved in what we were serving and in the cooking. My dad also loves to cook. He’d be on the grill and I was very much into manning the grill any chance I got. Cooking has been a big part of my family upbringing.
What do you love about cooking?
It’s like my therapy, essentially. I definitely get into a meditative state when cooking. I can just kind of zero in and focus on something and that’s really important to me when I’m doing it.

How long have you been involved in the restaurant scene?
Right out of college, I went into engineering, working for a defense contractor for about six to eight years. I was living in Santa Clara and I found myself coming to San Francisco quite a bit to indulge in the live music scene, the food and the bars, but never really considered it as a profession or a lifestyle. It just seemed very daunting. Everybody hears the horror stories of restaurants and the failure rate.
By becoming friends with restaurateurs and owners of different places, I started getting the idea that maybe this is something I can do. I met somebody who was a trained chef who invited me to get involved in a pop-up so I could understand how a restaurant works behind the scenes. It was so successful the first time that we ended up doing it seasonally.
We walked away with a good chunk of change that we weren’t really looking for. The pop-up was just a way to do something fun and have a bunch of friends and feed strangers, and such, but we would still walk away with a good amount of cash, at which point, I think that’s what really gave me the confidence of like saying hey, we can actually open up a spot.

And that led you to Bodega?
Yeah, this space in North Beach in San Francisco just happened to fall on our laps. I caught wind from a friend that this woman was considering selling her business, so I went and checked it out with my business partner, and it was just an amazing location right next to Washington Square Park. We’ve been doing this now for six years, and I’m proud to say, I think we were probably one of the first natural wine bars in the city. We have a really nice curated list of wines and a menu that rotates frequently but it’s really fresh and it’s inventive. It’s a really fun and energetic atmosphere.
What do you enjoy most about being a restaurateur?
The creativity of it. Like creating the concept itself. I really enjoy how the menu coincides with the wine list and the music. I just love the entire production of it. I feel like I picked the right profession because it’s where I get to have a good time and explore the fun side of my personality. I really enjoy being a curator.
Who inspires you?
Throughout the pandemic, I was very inspired by — like I’m sure a lot of people were — what David Chang was doing. Here’s a guy who owns some of the best restaurants in the U.S. And he’s posting videos during complete lockdowns on how to keep your scallions going after you’ve used them down to the end. He was doing stuff in the microwave. Or showing how to reuse stuff. I was like this guy’s amazing!
I’m always looking for inspiration. It’s honestly a constant thing. I guess this goes back to my indie sort of roots. I’m a mixtape sort of person. I’m always trying to look a little bit further and deeper. For me it’s not usually on the surface. I really have to dig in to find a pop-up or a chef or something that somebody’s talking about that I have to go through multiple channels in order to find out more. But I enjoy that.
What’s your favorite fun stuff to do online?
I’m a business tech nerd. I’m very much in tune with what’s going on in the valley. That’s still very ingrained in me just being here. I want to know what’s happening and who the movers and shakers are at the moment, or what’s the latest unicorn. That’s always been very fascinating to me.
The restaurant and service industries were hit especially hard during the pandemic, and we’re still in bumpy times. How did things go for you?
We didn’t know what to expect early on, obviously I don’t think anybody did. At that point we thought it was just going to be a two month thing, and we were prepared for that. We started to realize that a lot of restaurants and places were allowed to do window service. But there was no joy in it. Honestly it was hard to find joy during those times.
The way we looked at it was that there are so many restaurants and so many concepts that we’ve been inspired by through the years or even places overseas that just do a window and they still bring a lot of joy. That inspired us to just open up the windows, play some music, have a good time with it. We started experimenting with some with some dishes that we were doing. We were doing everything from TV dinner nights with Salisbury steak and potatoes, Jamaican jerk night with chicken, burger night, taco Tuesdays and just being really just creative and fun with the dishes.
We’d have the music going and have safety in mind with the six foot tape and wear your mask. We could still be playing punk rock or hip hop and you know say hi to people and just have a great time with it. We would post everything the day before to be aligned. I don’t know if it would have been possible without the social media aspect.

The internet has touched restaurants in so many ways, like social media, third party delivery services, review sites and even maintaining a website. How have any of these touched restaurant life for you?
I’ve always had mixed feelings about that. I like that Bodega is the little sexy wine bar on the corner that only so many people know about but we’re always super busy. I’ve always thought that it adds to the mysteriousness of it. I’d rather have people just come in the doors and experience it themselves. Maybe that’s part of the magic that we create.
If budget, time and location were not issues, where would you go for a meal and why?
St. John in London. I’ve never been, but I’ve followed them closely. It just looks like a place I want to go and spend hours just drinking wine and having a good conversation. It looks like they care very much about the details, and I can expect to have a really, really nice dish.
This interview has been edited for length and clarity.
The post Lalo Luevano, restaurateur and co-founder of Bodega wine bar appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/products/firefox/sidebar-lalo-luevano-restauranteur-bodega/
|
|
The Mozilla Blog: Celebrating Mozilla VPN: How we’re keeping your data safe for you |
A year goes by so quickly, and we have good reason to celebrate. Since our launch last year, Mozilla VPN, our fast and easy-to-use Virtual Private Network service, has expanded to seven countries including Austria, Belgium, France, Germany, Italy, Spain and Switzerland adding to 13 countries where Mozilla VPN is available. We also expanded our VPN service offerings and it’s now available on Windows, Mac, Linux, Android and iOS platforms. We have also given you more payment choices from credit card, paypal or through Apple in-app purchases. Lastly, our list of languages that we support continues to grow, and to date we support 28 languages. Thousands of people have signed up to subscribe to our Mozilla VPN, which provides encryption and device-level protection of your connection and information when you are on the Web.
Developed by Mozilla, a mission-driven company with a 20-year track record of fighting for online privacy and a healthier internet, we are committed to innovate and bring new features to the Mozilla VPN through feedback from our community. This year, the team has been working on additional security and customization features which will soon be available to our users.
Today, we’re launching a new feature, one that’s been requested by many users called split tunneling. This allows you to divide your internet traffic and choose which apps you want to secure through an encrypted VPN tunnel, and which apps you want to connect to an open network. Additionally, we recently released the captive portal feature which allows you to join public Wi-Fi networks securely. We continue to add new features to offer you the flexibility to use Mozilla VPN wherever you go.
Today, we’re launching the split tunneling feature so you can choose which apps that you want to use the Mozilla VPN and which ones you want to go through an open network. This allows you to prioritize and choose the internet connections on the apps that you want to continue to be kept safe with the Mozilla VPN. This feature is available on Windows, Linux and Android.
Recently, we added the option to join public Wi-Fi networks securely. It’s a feature to make sure you can easily use our trustworthy Mozilla VPN service to protect your device and data when you are on a public WiFi network. If your VPN is on and you first connect to the cafe’s public Wi-Fi network, you may be blocked from seeing the cafe or public Wi-Fi’s landing or login page, known as the captive portal. Mozilla VPN will recognize this, and provide a notification to turn off the Mozilla VPN so you can connect through the public Wi-Fi’s landing or login page. Then, once you’re logged in, you’ll receive a notification to click to connect to our Mozilla VPN. This feature is available on Windows, Linux and Android.
Recently, we changed our prices after we heard from consumers who wanted more flexibility and different plan options at different price points. As a token of our appreciation to the users who signed up when we first launched last year, we will continue to honor the $4.99 monthly subscription to users in those six countries – the United States, Canada, the United Kingdom, Singapore, Malaysia, and New Zealand. For new customers in those six countries that subscribe after July 14, 2021, they can get the same low cost by signing up for a 12 month subscription.
We know that it’s more important than ever for you to be safe, and for you to know that what you do online is your own business. By subscribing to Mozilla VPN, users support both Mozilla’s product development and our mission to build a better web for all. Check out the Mozilla VPN and subscribe today from our website.
The post Celebrating Mozilla VPN: How we’re keeping your data safe for you appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/mozilla/celebrating-mozilla-vpn-how-were-keeping-your-data-safe-for-you/
|
|
The Mozilla Blog: Celebrating Mozilla VPN: How we’re keeping your data safe for you |
A year goes by so quickly, and we have good reason to celebrate. Since our launch last year, Mozilla VPN, our fast and easy-to-use Virtual Private Network service, has expanded to seven countries including Austria, Belgium, France, Germany, Italy, Spain and Switzerland adding to 13 countries where Mozilla VPN is available. We also expanded our VPN service offerings and it’s now available on Windows, Mac, Linux, Android and iOS platforms. We have also given you more payment choices from credit card, paypal or through Apple in-app purchases. Lastly, our list of languages that we support continues to grow, and to date we support 28 languages. Thousands of people have signed up to subscribe to our Mozilla VPN, which provides encryption and device-level protection of your connection and information when you are on the Web.
Developed by Mozilla, a mission-driven company with a 20-year track record of fighting for online privacy and a healthier internet, we are committed to innovate and bring new features to the Mozilla VPN through feedback from our community. This year, the team has been working on additional security and customization features which will soon be available to our users.
Today, we’re launching a new feature, one that’s been requested by many users called split tunneling. This allows you to divide your internet traffic and choose which apps you want to secure through an encrypted VPN tunnel, and which apps you want to connect to an open network. Additionally, we recently released the captive portal feature which allows you to join public Wi-Fi networks securely. We continue to add new features to offer you the flexibility to use Mozilla VPN wherever you go.
Today, we’re launching the split tunneling feature so you can choose which apps that you want to use the Mozilla VPN and which ones you want to go through an open network. This allows you to prioritize and choose the internet connections on the apps that you want to continue to be kept safe with the Mozilla VPN. This feature is available on Windows, Linux and Android.
Recently, we added the option to join public Wi-Fi networks securely. It’s a feature to make sure you can easily use our trustworthy Mozilla VPN service to protect your device and data when you are on a public WiFi network. If your VPN is on and you first connect to the cafe’s public Wi-Fi network, you may be blocked from seeing the cafe or public Wi-Fi’s landing or login page, known as the captive portal. Mozilla VPN will recognize this, and provide a notification to turn off the Mozilla VPN so you can connect through the public Wi-Fi’s landing or login page. Then, once you’re logged in, you’ll receive a notification to click to connect to our Mozilla VPN. This feature is available on Windows, Linux and Android.
Recently, we changed our prices after we heard from consumers who wanted more flexibility and different plan options at different price points. As a token of our appreciation to the users who signed up when we first launched last year, we will continue to honor the $4.99 monthly subscription to users in those six countries – the United States, Canada, the United Kingdom, Singapore, Malaysia, and New Zealand. For new customers in those six countries that subscribe after July 14, 2021, they can get the same low cost by signing up for a 12 month subscription.
We know that it’s more important than ever for you to be safe, and for you to know that what you do online is your own business. By subscribing to Mozilla VPN, users support both Mozilla’s product development and our mission to build a better web for all. Check out the Mozilla VPN and subscribe today from our website.
The post Celebrating Mozilla VPN: How we’re keeping your data safe for you appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/mozilla/celebrating-mozilla-vpn-how-were-keeping-your-data-safe-for-you/
|
|
Firefox Add-on Reviews: Tweak Twitch—BetterTTV and other extensions for Twitch customization |
Customize chat, optimize your video player, auto-collect channel points, and much much more. Explore some of the ways you can radically transform your Twitch experience with a browser extension…
One of the most feature rich and popular Twitch extensions out there, BetterTTV has everything from fun new emoticons to advanced content filtering.
Key features:
While this extension’s focus is on video player customization, Alternate Player for Twitch.tv packs a bunch of other great features unrelated to video streaming.
Let’s start with the video player. Some of its best tweaks include:
Alternate Player for Twitch.tv also appears to run live streams at even smoother rates than Twitch’s default player. You can further optimize your stream by adjusting the extension’s bandwidth settings to better suit your internet speed. Audio Only mode is really great for saving bandwidth if you’re just tuning in for music or discussion.
Our favorite feature is the ability to customize the size and location of the chat interface while in full-screen mode. Make the chat small and tuck it away in a corner or expand it to consume most of the screen; or remove chat altogether if the side conversation is a mood killer.
This is the best way to channel surf. Just hover over a stream icon in the sidebar and Twitch Previews will display its live video in a tiny player.
No more clicking away from the thing you’re watching just to check out other streams. Additional features we love include the ability to customize the video size and volume of the previews, a sidebar auto-extender (to more easily see all live streamers), and full-screen mode with chat.
Do you keep seeing the same channels over and over again that you’re not interested in? Unwanted Twitch wipes them from your experience.
Not only block specific channels you don’t want, but you can even hide entire categories (I’m done with dub step!) or specific tags (my #Minecraft days are behind me). Other niche “hide” features include the ability to block reruns and streams with certain words appearing in their title.
What a neat idea. Twitch Chat Pronouns lets you add gender pronouns to usernames.
The pronouns will display next to Twitch usernames. You’ll need to enter a pronoun for yourself if you want one to appear to other extension users.
We hope your Twitch experience has been improved with a browser extension! Find more media enhancing extensions on addons.mozilla.org.
|
|
Data@Mozilla: This Week in Glean: Shipping Glean with GeckoView |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.) All “This Week in Glean” blog posts are listed in the TWiG index (and on the Mozilla Data blog).
The Glean SDK is Mozilla’s telemetry library, used in most mobile products and now for Firefox Desktop as well. By now it has grown to a sizable code base with a lot of functionality beyond just storing some metric data. Since its first release as a Rust crate in 2019 we managed to move more and more logic from the language SDKs (previously also known as “language bindings”) into the core Rust crate. This allows us to maintain business logic only once and can easily share that across different implementations and platforms. The Rust core is shipped precompiled for multiple target platforms, with the language SDK distributed through the respective package manager.
I talked about how this all works in more detail last year, this year and blogged about it in a previous TWiG.
GeckoView is Mozilla’s alternative implementation for WebViews on Android, based on Gecko, the web engine that also powers Firefox Desktop. It is used as the engine behind Firefox for Android (also called Fenix). The visible parts of what makes up Firefox for Android is written in Kotlin, but it all delegates to the underlying Gecko engine, written in a combination of C++, Rust & JavaScript.
The GeckoView code resides in the mozilla-central repository, next to all the other Gecko code. From there releases are pushed to Mozilla’s own Maven repository.
Initially Firefox for Android was the only user of the Glean SDK. Up until today it consumes Glean through its release as part of Android Components, a collection of libraries to build browser-like applications.
But the Glean SDK is also available outside of Android Components, as its own package. And additionally it’s available for other languages and platforms too, including a Rust crate. Over the past year we’ve been busy getting Gecko to use Glean through the Rust crate to build its own telemetry on top.
With the Glean SDK used in all these applications we’re in a difficult position: There’s a Glean in Firefox for Android that’s reporting data. Firefox for Android is using Gecko to render the web. And Gecko is starting to use Glean to report data.
That’s one Glean too many if we want coherent data from the full application.
Of course we knew about this scenario for a long time. It’s been one of the goals of Project FOG to transparently collect data from Gecko and the embedding application!
We set out to find a solution so that we can connect both sides and have only one Glean be responsible for the data collection & sending.
We started with more detailed planning all the way back in August of last year and agreed on a design in October. Due to changed priorities & availability of people we didn’t get into the implementation phase until earlier this year.
By February I had a first rough prototype in place. When Gecko was shipped as part of GeckoView it would automatically look up the Glean library that is shipped as a dynamic library with the Android application. All function calls to record data from within Gecko would thus ultimately land in the Glean instance that is controlled by Fenix. Glean and the abstraction layer within Gecko would do the heavy work, but users of the Glean API would notice no difference, except their data would now show up in pings sent from Fenix.
This integration was brittle. It required finding the right dynamic library, looking up symbols at runtime as well as reimplementing all metric types to switch to the FFI API in a GeckoView build. We abandoned this approach and started looking for a better one.
After the first failed approach the issue was acknowledged by other teams, including the GeckoView and Android teams.
Glean is not the only Rust project shipped for mobile, the application-services team is also shipping components written in Rust. They bundle all components into a single library, dubbed the megazord. This reduces its size (dependencies & the Rust standard library are only linked once) and simplifies shipping, because there’s only one library to ship. We always talked about pulling in Glean as well into such a megazord, but ultimately didn’t do it (except for iOS builds).
With that in mind we decided it’s now the time to design a solution, so that eventually we can bundle multiple Rust components in a single build. We came up with the following plan:
glean-native package, that only exists to ship the compiled Rust library, and a glean package, that contains the Kotlin code and has a dependency on glean-native.libxul library (that’s “Gecko”) will bundle the Glean Rust library and export the C-compatible FFI symbols, that are used by the Glean Kotlin SDK to call into Glean core.glean-native package with itself (this is actually handle by the Glean Gradle plugin).Consumers such as Fenix will depend on both GeckoView and Glean. At build time the Glean Gradle plugin will detect this and will ensure the glean-native package, and thus the Glean library, is not part of the build. Instead it assumes libxul from GeckoView will take that role.
This has some advantages. First off everything is compiled together into one big library. Rust code gets linked together and even Rust consumers within Gecko can directly use the Glean Rust API. Next up we can ensure that the version of the Glean core library matches the Glean Kotlin package used by the final application. It is important that the code matches, otherwise calling native functions could lead to memory or safety issues.
Glean is running ahead here, paving the way for more components to be shipped the same way. Eventually the experimentation SDK called Nimbus and other application-services components will start using the Rust API of Glean. This will require compiling Glean alongside them and that’s the exact case that is handled in mozilla-central for GeckoView then.
Now the unfortunate truth is: these changes have not landed yet. It’s been implemented for both the Glean SDK and mozilla-central, but also requires changes for the build system of mozilla-central. Initially that looked like simple changes to adopt the new bundling, but it turned into bigger changes across the board. Some of the infrastructure used to build and test Android code from mozilla-central was untouched for years and thus is very outdated and not easy to change. With everything else going on for Firefox it’s been a slow process to update the infrastructure, prepare the remaining changes and finally getting this landed.
But we’re close now!
Big thanks to Agi for connecting the right people, driving the initial design and helping me with the GeckoView changes. He also took on the challenge of changing the build system. And also thanks to chutten for his reviews and input. He’s driving the FOG work forward and thus really really needs us to ship GeckoView support.
https://blog.mozilla.org/data/2021/07/26/this-week-in-glean-shipping-glean-with-geckoview/
|
|
Jan-Erik Rediger: This Week in Glean: Shipping Glean with GeckoView |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.) All "This Week in Glean" blog posts are listed in the TWiG index (and on the Mozilla Data blog). This article is cross-posted on the Mozilla Data blog.
The Glean SDK is Mozilla's telemetry library, used in most mobile products and now for Firefox Desktop as well. By now it has grown to a sizable code base with a lot of functionality beyond just storing some metric data. Since its first release as a Rust crate in 2019 we managed to move more and more logic from the language SDKs (previously also known as "language bindings") into the core Rust crate. This allows us to maintain business logic only once and can easily share that across different implementations and platforms. The Rust core is shipped precompiled for multiple target platforms, with the language SDK distributed through the respective package manager.
I talked about how this all works in more detail last year, this year and blogged about it in a previous TWiG.
GeckoView is Mozilla's alternative implementation for WebViews on Android, based on Gecko, the web engine that also powers Firefox Desktop. It is used as the engine behind Firefox for Android (also called Fenix). The visible parts of what makes up Firefox for Android is written in Kotlin, but it all delegates to the underlying Gecko engine, written in a combination of C++, Rust & JavaScript.
The GeckoView code resides in the mozilla-central repository, next to all the other Gecko code. From there releases are pushed to Mozilla's own Maven repository.
Initially Firefox for Android was the only user of the Glean SDK. Up until today it consumes Glean through its release as part of Android Components, a collection of libraries to build browser-like applications.
But the Glean SDK is also available outside of Android Components, as its own package. And additionally it's available for other languages and platforms too, including a Rust crate. Over the past year we've been busy getting Gecko to use Glean through the Rust crate to build its own telemetry on top.
With the Glean SDK used in all these applications we're in a difficult position: There's a Glean in Firefox for Android that's reporting data. Firefox for Android is using Gecko to render the web. And Gecko is starting to use Glean to report data.
That's one Glean too many if we want coherent data from the full application.
Of course we knew about this scenario for a long time. It's been one of the goals of Project FOG to transparently collect data from Gecko and the embedding application!
We set out to find a solution so that we can connect both sides and have only one Glean be responsible for the data collection & sending.
We started with more detailed planning all the way back in August of last year and agreed on a design in October. Due to changed priorities & availability of people we didn't get into the implementation phase until earlier this year.
By February I had a first rough prototype in place. When Gecko was shipped as part of GeckoView it would automatically look up the Glean library that is shipped as a dynamic library with the Android application. All function calls to record data from within Gecko would thus ultimately land in the Glean instance that is controlled by Fenix. Glean and the abstraction layer within Gecko would do the heavy work, but users of the Glean API would notice no difference, except their data would now show up in pings sent from Fenix.
This integration was brittle. It required finding the right dynamic library, looking up symbols at runtime as well as reimplementing all metric types to switch to the FFI API in a GeckoView build. We abandoned this approach and started looking for a better one.
After the first failed approach the issue was acknowledged by other teams, including the GeckoView and Android teams.
Glean is not the only Rust project shipped for mobile, the application-services team is also shipping components written in Rust. They bundle all components into a single library, dubbed the megazord. This reduces its size (dependencies & the Rust standard library are only linked once) and simplifies shipping, because there's only one library to ship. We always talked about pulling in Glean as well into such a megazord, but ultimately didn't do it (except for iOS builds).
With that in mind we decided it's now the time to design a solution, so that eventually we can bundle multiple Rust components in a single build. We came up with the following plan:
glean-native package, that only exists to ship the compiled Rust library, and a glean package,
that contains the Kotlin code and has a dependency on glean-native.libxul library (that's "Gecko") will bundle the Glean Rust library and export the C-compatible FFI symbols,
that are used by the Glean Kotlin SDK to call into Glean core.glean-native package with itself (this is actually handle by the Glean Gradle plugin).Consumers such as Fenix will depend on both GeckoView and Glean.
At build time the Glean Gradle plugin will detect this and will ensure the glean-native package, and thus the Glean library, is not part of the build.
Instead it assumes libxul from GeckoView will take that role.
This has some advantages. First off everything is compiled together into one big library. Rust code gets linked together and even Rust consumers within Gecko can directly use the Glean Rust API. Next up we can ensure that the version of the Glean core library matches the Glean Kotlin package used by the final application. It is important that the code matches, otherwise calling native functions could lead to memory or safety issues.
Glean is running ahead here, paving the way for more components to be shipped the same way. Eventually the experimentation SDK called Nimbus and other application-services components will start using the Rust API of Glean. This will require compiling Glean alongside them and that's the exact case that is handled in mozilla-central for GeckoView then.
Now the unfortunate truth is: these changes have not landed yet. It's been implemented for both the Glean SDK and mozilla-central, but also requires changes for the build system of mozilla-central. Initially that looked like simple changes to adopt the new bundling, but it turned into bigger changes across the board. Some of the infrastructure used to build and test Android code from mozilla-central was untouched for years and thus is very outdated and not easy to change. With everything else going on for Firefox it's been a slow process to update the infrastructure, prepare the remaining changes and finally getting this landed.
But we're close now!
Big thanks to Agi for connecting the right people, driving the initial design and helping me with the GeckoView changes. He also took on the challenge of changing the build system. And also thanks to chutten for his reviews and input. He's driving the FOG work forward and thus really really needs us to ship GeckoView support.
|
|
The Mozilla Blog: Space Cowboy, Guardians of Cleveland, and Tony Award winner Ellen Barkin considers a Subtack – here is this week’s Top Shelf. |
|
|
Mozilla Performance Blog: Performance Sheriff Newsletter (June 2021) |
|
|
Data@Mozilla: This Week in Glean: Firefox Telemetry is to Glean as C++ is to Rust |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
I had this goofy idea that, like Rust, the Glean SDKs (and Ecosystem) aim to bring safety and higher-level thought to their domain. This is in comparison to how, like C++, Firefox Telemetry is built out of flexible primitives that assume you very much know what you’re doing and cannot (will not?) provide any clues in its design as to how to do things properly.
I have these goofy thoughts a lot. I’m a goofy guy. But the more I thought about it, the more the comparison seemed apt.
In Glean wherever we can we intentionally forbid behaviour we cannot guarantee is safe (e.g. we forbid non-commutative operations in FOG IPC, we forbid decrementing counters). And in situations where we need to permit perhaps-unsafe data practices, we do it in tightly-scoped areas that are identified as unsafe (e.g. if a timing_distribution uses accumulate_raw_samples_nanos you know to look at its data with more skepticism).
In Glean we encourage instrumentors to think at a higher level (e.g. memory_distribution instead of a Histogram of unknown buckets and samples) thereby permitting Glean to identify errors early (e.g. you can’t start a timespan twice) and allowing Glean to do clever things about it (e.g. in our tooling we know counter metrics are interesting when summed, but quantity metrics are not). Speaking of those errors, we are able to forbid error-prone behaviour through design and use of language features (e.g. In languages with type systems we can prevent you from collecting the wrong type of data) and when the error is only detectable at runtime we can report it with a high degree of specificity to make it easier to diagnose.
There are more analogues, but the metaphor gets strained. (( I mean, I guess a timing_distribution’s `TimerId` is kinda the closest thing to a borrow checker we have? Maybe? )) So I should probably stop here.
Now, those of you paying attention might have already seen this relationship. After all, as we all know, glean-core (which underpins most of the Glean SDKs regardless of language) is actually written in Rust whereas Firefox Telemetry’s core of Histograms, Scalars, and Events is written in C++. Maybe we shouldn’t be too surprised when the language the system is written in happens to be reflected in the top-level design.
But! glean-core was (for a long time) written in Kotlin from stem to stern. So maybe it’s not due to language determinism and is more to do with thoughtful design, careful change processes, and a list of principles we hold to firmly as the number of supported languages and metric types continues to grow.
I certainly don’t know. I’m just goofing around.
:chutten
(( This is a syndicated copy of the original blog post. ))
|
|
Chris H-C: This Week in Glean: Firefox Telemetry is to Glean as C++ is to Rust |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean. You can find an index of all TWiG posts online.)
I had this goofy idea that, like Rust, the Glean SDKs (and Ecosystem) aim to bring safety and higher-level thought to their domain. This is in comparison to how, like C++, Firefox Telemetry is built out of flexible primitives that assume you very much know what you’re doing and cannot (will not?) provide any clues in its design as to how to do things properly.
I have these goofy thoughts a lot. I’m a goofy guy. But the more I thought about it, the more the comparison seemed apt.
In Glean wherever we can we intentionally forbid behaviour we cannot guarantee is safe (e.g. we forbid non-commutative operations in FOG IPC, we forbid decrementing counters). And in situations where we need to permit perhaps-unsafe data practices, we do it in tightly-scoped areas that are identified as unsafe (e.g. if a timing_distribution uses accumulate_raw_samples_nanos you know to look at its data with more skepticism).
In Glean we encourage instrumentors to think at a higher level (e.g. memory_distribution instead of a Histogram of unknown buckets and samples) thereby permitting Glean to identify errors early (e.g. you can’t start a timespan twice) and allowing Glean to do clever things about it (e.g. in our tooling we know counter metrics are interesting when summed, but quantity metrics are not). Speaking of those errors, we are able to forbid error-prone behaviour through design and use of language features (e.g. In languages with type systems we can prevent you from collecting the wrong type of data) and when the error is only detectable at runtime we can report it with a high degree of specificity to make it easier to diagnose.
There are more analogues, but the metaphor gets strained. (( I mean, I guess a timing_distribution’s `TimerId` is kinda the closest thing to a borrow checker we have? Maybe? )) So I should probably stop here.
Now, those of you paying attention might have already seen this relationship. After all, as we all know, glean-core (which underpins most of the Glean SDKs regardless of language) is actually written in Rust whereas Firefox Telemetry’s core of Histograms, Scalars, and Events is written in C++. Maybe we shouldn’t be too surprised when the language the system is written in happens to be reflected in the top-level design.
But! glean-core was (for a long time) written in Kotlin from stem to stern. So maybe it’s not due to language determinism and is more to do with thoughtful design, careful change processes, and a list of principles we hold to firmly as the number of supported languages and metric types continues to grow.
I certainly don’t know. I’m just goofing around.
:chutten
|
|
Support.Mozilla.Org: Introducing Joseph Cuevas |
Hey folks,
Please join me to welcome Joseph Cuevas (Joe) as part of the Customer Experience team and the broader SUMO family. Joe is going to be working as an Operations Manager specifically to build a premium customer experience for current and future Mozilla’s paid products.
Here’s a brief introduction from Joe:
Hi everyone! My name is Joe and I am the new User Support Operations Manager joining the Customer Experience Team. I’ll be working with my team to build a premium customer support experience for Mozilla VPN. I’m looking forward to working alongside and getting to know my fellow Mozillians. I just know we’re going to have a great time!
Welcome, Joe!
https://blog.mozilla.org/sumo/2021/07/21/introducing-joseph-cuevas/
|
|






