Mozilla Reps Community: Celebrating 10 years of Reps |
Last week the Reps program celebrated its 10 years anniversary. To honor the event, a week of celebrations took place, with meetings in Zoom rooms and virtual hangouts in specially decorated Hubs rooms. During that week, current Reps and Reps alumni shared memories of the past years, talked about their current work, and discussed future plans and aspirations.
The Reps program was created with a simple narrative in the mind of its founders (William Quiviger and Pierros Papadeas), to bring structure to the regional communities and help them grow. Throughout the last years, the Reps have served their communities, by growing them and mentoring them, supporting all Mozilla’s big projects and launches, and pivoting to be able to help where the organization needed them the most. From the 1 million Mozillians initiative to the Firefox OS days, and from the Quantum launch to the recent foxfoooding campaign, Reps have always stepped up for the challenge, giving a helping hand, organizing thousands of events, and amplifying Mozilla’s work and mission. And is that spirit that we wanted to celebrate during the last week. A spirit of giving and helping.
Due to the pandemic, an event with physical attendance was not possible. However, that didn’t discourage the Reps. A full-week virtual event was organized instead (special kudos to Francesca Minelli for all the work on planning and coordinating it) that included virtual talks in Zoom rooms and hanging out time to two Hubs rooms. There was a dedicated Reps room and a room for communities. The first day we kicked off with a trip down memory lane. Reps alumni and longtime Reps were invited to talk about their experiences during the first days of the program. The day closed with a talk and Q&A with Mitchell Baker about the significance of the Reps program and how Reps can contribute to the future of Mozilla. The second day was dedicated to the current state of the program, where Reps had a chance to chat with the Reps council and its current work. The last 2 days were dedicated to the current work of Reps and how it is affecting the rest of the organization with talks from both staff and also volunteers presenting their communities. During the last days, we also focused on how Reps can improve, gathered feedback and suggestions for the future of the program.

Long time Reps and Reps alumni

Hanging out at the Hubs room
For the future we are focusing on 2 main pillars: 1) improving the mentorship program, so Reps can feel more supported and be able to do more 2) work more on how we can bring volunteers to product work. The last part is already happening via the campaigns. We want to work more on how we can bring volunteers earlier on product experience and ideation and nevertheless, spreading the word. A busy future is ahead for the Reps but we are ready for it. Reps onwards!
https://blog.mozilla.org/mozillareps/2021/06/22/celebrating-10-years-of-reps/
|
|
Karl Dubost: Today is my Mozilla 8 years anniversary |
Eight years ago, I have started working at Mozilla.

In my employment history, I have never tried to spread a large net to try to land a job, except probably for my first real job in 1995. I have always carefully chosen the company I wanted to work for. I probably applied ten times on the course of 10 years before landing a job at Mozilla.
When the Web Compatibility team was created, I applied to one of the positions available in 2013. In April 2013, from Montreal, I flew to Mountain View for a series of job interviews with different Mozilla employees. Most of the interviews were interesting but I remember one engineer was apparently not happy interviewing me and it didn't go very well. I don't remember who, but it left me with a bitter taste at the time. A couple of days later I was notified that I was not taken for the job. While disappointing, I was not surprised. I usually do not perform well during interviews, specifically when you have to demonstrate knowledge instead of articulating the way you work with knowledge. I find interviews a kind of theater.
But Mozilla came back to me and proposed me a 6 months contract, still in the Mozilla Web Compatibility team but for another role. It was not what I was initially interested by, but why not? It's when I met Lawrence Mandel, who would be my future manager if I landed the job. I liked the contact right away. I got an offer in June 2013. I signed.
Fast forward 8 years, I'm currently the manager of the Web Compatibility team.
The Web Compatibility team started with 3 persons: Mike Taylor, Hallvord R. M. Steen and myself and at its peak we were probably 10 persons, depending on how we count. We are currently 7 persons including myself. Talking about my 8 years anniversary doesn't make sense without mentioning the work of the team. My work is insignificant if we don't take the globability of what the team is achieving.

« Et par contre, si je communique `a mes hommes l’amour de la marche sur la mer, et que chacun d’eux soit ainsi en pente `a cause d’un poids dans le coeur, alors tu les verras bient^ot se diversifier selon leurs mille qualit'es particuli`eres. Celui-l`a tissera des toiles, l’autre dans la for^et par l’'eclair de sa hache couchera l’arbre. L’autre, encore, forgera des clous, et il en sera quelque part qui observeront les 'etoiles afin d’apprendre `a gouverner. Et tous cependant ne seront qu’un. Cr'eer le navire ce n’est point tisser les toiles, forger les clous, lire les astres, mais bien donner le go^ut de la mer qui est un, et `a la lumi`ere duquel il n’est plus rien qui soit contradictoire mais communaut'e dans l’amour. »
Antoine de Saint-Exup'ery. « Citadelle. »
Since the beginning of 2021,
Dennis has drastically reduced the number of old diagnosis that were on top (or at the bottom?) of our pile. He is also now the module owner for Site Interventions, which help Mozilla to hotfix websites. When a site is broken and the outreach is unlikely to be unsuccessful, this one of the ways we have to fix the website on the fly so the people can continue to enjoy using troubled websites.
James is the mind and the smooth operator behind Web Platform Tests at Mozilla. He is doing an amazing job at encouraging Mozilla engineers to develop more Web Platform tests. He makes sure that everything is synchronized with other vendors. Web Platform Tests are essential to be able to discover bugs in specifications and differences in implementations. He is also the core person for the work on BiDi at Mozilla. BiDi is another important part of the puzzle of Web Compatibility. Testing manually websites is costly. Webdriver comes here to make it possible for automating the tests of websites functionalities. If the cost is lower, web developers can test their websites in more than one browser and discover and fix their webcompatibility issues before we discover them.
Ksenia is the owner of webcompat.com and webcompat ML bot. The ML bot helps us to pre-filter the bug and determine if it's a valid webcompat issue. We receive around 700 and 800 bugs a week and that's a lot for our small team. We would not be able to manage without the bot. Tiredlessly she has improved the tools used for minimizing the boring part of the work we do and at the same time, found solutions for helping bug reporters to have a better experience.
Softvision team: Oana and Raul. I have a lot of respect for the people at Softvision helping Mozilla to do the triage of bugs. This task is sisyphean. Every week, 700 to 800 bugs come in. Luckily enough we have a bot for pre-triage, but when bugs are evaluated being valid. They decipher the old runes of bug reports to understand what the bug reporter suffered and they make it something more compelling for people who will be diagnosing. Previously, we had Ciprian and Sergiu.
Thomas is the architect of the Site Interventions. He is also making sure that sites continue to work when tracking protection is blocking things. He has implemented lately SmartBlock. Thomas is this giant person who can touch everything in the Webcompat team, but still super caregiver when we do not understand something. He explains what he does and this is gold. It means that people can grow, evolve and be a better part of themselves.
The project would be nothing without the contributors and interns who worked with us on making the site, the tools, the process better:
Abdul, Alexa, Beatriz, Carol, Deepthi, Guillaume, Kate, Mariana, mesha, Reinhart, and more…
And there are those who have been in the webcompat team and have been participants to its success: Mike, Adam, Eric, Hallvord, Ola. I could write a lot more about it.
« En ce qui concerne donc mon voisin, j’ai observ'e qu’il n’'etait point fertile d’examiner de son empire les faits, les 'etats de choses, les institutions, les objets, mais exclusivement les pentes. Car si tu examines mon empire tu t’en iras voir les forgerons et les trouveras forgeant des clous et se passionnant pour les clous et te chantant les cantiques de la clouterie. Puis tu t’en iras voir les b^ucherons et tu les trouveras abattant des arbres et se passionnant pour l’abattage d’arbres, et se remplissant d’une intense jubilation `a l’heure de la f^ete du b^ucheron, qui est du premier craquement, lorsque la majest'e de l’arbre commence de se prosterner. Et si tu vas voir les astronomes, tu les verras se passionnant pour les 'etoiles et n’'ecoutant plus que leur silence. Et en effet chacun s’imagine ^etre tel. Maintenant si je te demande : « Que se passe-t-il dans mon empire, que na^itra-t-il demain chez moi ? » tu me diras : « On forgera des clous, on abattra des arbres, on observera les 'etoiles et il y aura donc des r'eserves de clous, des r'eserves de bois et des observations d’'etoiles. » Car myope et le nez contre, tu n’as point[…] »
Antoine de Saint-Exup'ery. « Citadelle. »
When working long enough at a company that you like, it becomes easy to feel comfortable. So every couple of years, I put myself in the position of looking for another job, even eventually having job interviews with some companies. I try to limit these interviews to the strict necessary by carefully selecting the companies I apply to.
I want to be in a position where I have to choose in between staying at Mozilla and discovering a new area with interesting people and interesting areas of work. Sometimes areas that I have probably poor knowledge of. This is slightly tricky because many companies have a tendency to recruit people ready to fit in the machinery instead of people with an ability to work and learn.
So far I have been 8 years at Mozilla, but I want to continue to make Mozilla a choice to stay instead of a place which is comfortable. So I will continue to explore new opportunities as I have always done.
If you have more questions, things I may have missed, different take on them. Feel free to comment…. Be mindful.
Otsukare!
|
|
The Mozilla Blog: Gary Linden, legendary surfer & Firefox fan |
On the internet you are never alone, and because of that at Mozilla we know that we can’t work to build a better internet alone. We believe in and rely on our community — from our volunteers, to our staff, to our users and even the parent’s of our staff (who also happen to be some of our power users). For Father’s Day, Mozilla’s Natalie Linden sat down with her father, big wave surf legend and surfboard maker, Gary Linden to talk the ocean, the internet and where humanity goes from here.
We should probably start by telling people who we are. I am Natalie Linden, the Director of the Creative Studio in Mozilla marketing.
And I’m Gary Linden. I’m your father. That’s probably my best accomplishment.
Awww Dad.
I make surfboards, run surfing events and surf. I’m semi-retired. Sort of.

I don’t think you’re giving yourself enough credit. When I tell people I’m Gary Linden’s daughter, they always say “Gary Linden?! He’s a legend!”
You know, if you’re involved in something for all your life, and you do a reasonably good job, you’ll get old and then you’ll be the oldest one around. So of course you’ll be the legend!
One of the things you’re the oldest guy doing is paddling into really, really big waves.
Yeah I’m a big wave surfer, that’s been my passion. I wasn’t afraid of the ocean or of big waves, and that set me apart from most other surfers. So I got admission to a club that was pretty exclusive. And that was pretty cool. Then I started the Big Wave World Tour so younger surfers could have a career path to becoming a big wave rider. Big wave surfing takes more time and resources: you have to have the means to travel, the boards are more expensive. We weren’t seeing the younger people really be able to surf the big waves so we weren’t seeing what could be done in the peak athletic performance years. I’m pretty proud of that tour.
One of the questions I was going to ask you is why you do what you do, and I think you’re starting to answer that. The way you’ve always described it to me is that from the first time you rode a wave on a surfboard, you knew that’s what you wanted to do, and you’ve oriented your whole life around being able to surf as much as possible.
Yes. Even before I rode a surfboard, my father took me to the ocean and taught me to play in the waves, and about the currents, and body surfing. The freedom of it was like nothing else. I had asthma and hay fever, and when I was in the ocean I didn’t feel any of that. Whereas on land the pollens and the dryness just made being on the land kind of miserable. Like a fish out of water in a lot of ways. It was always rewarding for me to go into the ocean. It goes beyond just feeling good. It’s a state of mind as well.

So you started making surfboards, too.
I started making surfboards because surfing went into a transitional period — we all had longboards and then in the 70s, some of the Australians started experimenting with boards that were a foot shorter. There was nobody in San Diego making them, so I got a blank and shaped a board. And then I started making them for my friends, and it just set me on a path. But I’ve always made surfboards so that I could have the boards I needed to surf. If somebody else wanted one, that was fine, but I wasn’t making it for them. I was making it for me. Because surfing — not surfboard making — was my primary focus.
How has the internet changed what you do?
Well first, the internet has made it incredibly easy to find out where the best waves of the day are. There are cameras all over the world now and you get surf reports. You don’t have to drive to the beach — you can live inland and plan ahead. And this year with the pandemic, live surfing competition was pretty much shut down. So a friend and I created a virtual surfing world tour called Surf Web Series, where we could take video clips of surfers who had gone out the prior year, take a little video of their best waves and then we’d put those in heats just like a regular event and judge them and take it all the way to a final like a surfing competition. That was a lot of fun because it filled the gaps for a lot of the kids who are surfing professionally but they couldn’t give anything back to their sponsors during the pandemic because they weren’t competing, they didn’t have a way to get exposure, they didn’t have a way to further their career. This gave them an opportunity to keep going in their career, and keep the world interested in the sport of surfing. It’s opened up another avenue for the sport.
I just focus on being in the best shape I possibly can, so I can surf. And I’m going to do it as long as I can. And when I can’t stand up anymore, I’ll be on a belly board. And when I can’t do that, I’ll jump in the waves.
One of the things I really admire about you, dad, is that you never stop having ideas. You set this intention of surfing for your life, and you keep finding new ways at it. You’re 71 and you’re still growing, you’re still changing, you’re still figuring out how to use the latest tools and culture to do the thing you set out to do. It inspires me every single day. It also helps that I see it up close, because we share an office!
Well you inspire me too, because of your energy and motivation. I don’t think you’re ever going to stop either, because you are inspired, you are motivated. That’s what surfing was for me: it gave me something to focus on 100%. I love it so much, and it’s so good for me, that I don’t go snowboarding, I don’t skateboard, I don’t play football, I don’t ride bicycles. I don’t want to get hurt doing anything else. I don’t drink, or stay out at night. I just focus on being in the best shape I possibly can, so I can surf. And I’m going to do it as long as I can. And when I can’t stand up anymore, I’ll be on a belly board. And when I can’t do that, I’ll jump in the waves. I don’t really care. I just like that original feeling of going in the ocean with my dad and feeling clean and involved with the earth. My connection with the earth is the ocean.
Speaking of staying in shape, how has your relationship with the internet changed since the pandemic?
You know the answer to this one, since we share a yoga room at our office. I started yoga about three years ago now because I wanted to be in better shape for surfing. I didn’t want to go at first because everyone was so young and as a beginner, it was intimidating. I couldn’t really keep up and felt awkward. But I found a geriatric yoga class, and it was really fun. I was getting better. Then with the pandemic, they started a zoom class. And now it’s actually even better. Because for older people, it’s still really intimidating. Now we can focus on the teacher and not feel self-conscious. It’s pretty awesome. Now you can do your work on the internet too — all the meetings and stuff. I mean, sometimes I wish the internet wasn’t there because you have to focus a lot more to stay grounded on the earth. Otherwise you’re just in that cloud. And that’s a really all-consuming place to be. I don’t think we were really made for that. So it’s another area where you have to find your balance. But you gotta find your balance in everything anyway. Even pigeon pose!

Is there something about technology that blows your mind?
Yeah, it doesn’t ever stop. It’s like watching science fiction happen in real life. It goes so fast. I’m fortunate enough that I was born before television, so I’ve seen a lot of stuff change. It’s so rapid. If you go back in history and think about evolution, it took so long for us not to be covered in hair, and to be able to talk, and now we’re talking about having chips in our bodies to help us heal, and artificial intelligence. If you dwell on it, it’s really overwhelming for someone my age. It can be scary. But there’s a lot of positive to it, so you’ve gotta stay on that side.
Speaking of positivity, what’s your favorite fun stuff to do online?
I like Facebook and Instagram because I get to have some kind of contact with people all over the world. I’ve got friends everywhere from my life of traveling, and when I post something, the person who comments could be someone I haven’t talked to for 50 years! I like going on Surfline to see the surf report. And I like to write and receive emails. Because it used to be such a lag! I used to write letters to my friends, and it would be a month between receipt. And you’d change in that month. But with email, you can keep the conversation going without interruption.
…it took so long for us not to be covered in hair, and to be able to talk, and now we’re talking about having chips in our bodies to help us heal, and artificial intelligence. If you dwell on it, it’s really overwhelming for someone my age. It can be scary. But there’s a lot of positive to it, so you’ve gotta stay on that side.
What’s your hope for how technology can change or improve the future? What do you want [your grandson] Nimo to be able to do?
I would like my grandson to be able to use the internet to feed and shelter the world. I don’t know how it’ll work, but you can already see… GoFundMe has helped the lives of a lot of my friends who got to my age or older, and just didn’t put anything away. Everybody throws a hundred bucks in, and all the sudden the guy’s at least got a chance to make it to hospice. That’s the kind of thing I hope we can do, that the communication will help us realize that it’s not just one person or one country versus another. It’s our world, and we have to all live together. I hope we get to the point that we see it’s a global economy, a global outcome. That we have to live as humans and not Americans or Chinese or Russians. I just think being able to communicate and see that we’re all the same, we all have the same needs. Food, shelter, companionship. If you get all that, you don’t really need anything else.
That’s exactly why I work at Mozilla: I believe our collective future will be decided on the internet. So we need to make sure it’s a place that can breed a positive outcome.
That’s right. And that’s the scary part we saw in the last election. All the junk that was online! So many lies! We didn’t know what was true, and what wasn’t true, and we had to decide for ourselves. We had to create our own filters. We had to choose the truth we wanted, the one that reflected the future of the world we want.
You’re my hero, Dad. Happy Father’s Day.

Natalie Linden and her dad,
Gary Linden
The post Gary Linden, legendary surfer & Firefox fan appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/products/firefox/gary-linden-big-wave-surfer/
|
|
The Mozilla Blog: What is the difference between the internet, browsers, search engines and websites? |
Real talk: this web stuff can get confusing. And it’s really important that we all understand how it works, so we can be as informed and empowered as possible. Let’s start by breaking down the differences between the internet, browsers, search engines and websites. Lots of us get these four things confused with each other and use them interchangeably, though they are different. In this case, the old “information superhighway” analogy comes in handy.

Let’s start by breaking down the differences between internet, search engine, and browser. Lots of us get these three things confused with each other.
In this case, the old “internet superhighway” analogy comes in handy.
The internet is the superhighway’s system of roads, bridges and tunnels. It is the technical network and infrastructure that connect all the computers and devices that are online together across the world. Being connected to the internet means devices, and whoever is using them, can communicate with each other and share information.
The browser is the car that gets you everywhere. You type a destination into the address bar and zoooom: your browser takes you anywhere on the internet. Firefox is a browser — one built specifically for people, not profit.
Search engines like Yahoo, Google, Bing and DuckDuckGo are the compass and the map. You tell a search engine an idea of where you want to go by typing your search terms, and it gives you some possible destinations. Search engines are websites, and they can also be apps. More on apps later.
Effectively, you drive along the internet highway, stopping at whatever towns, stores and roadside attractions catch your fancy, aka websites. Websites are the specific destinations you visit throughout the internet. This is the content — the webpages, websites, documents, social media, news, videos, images and so on that you view and experience via the internet. The “web” (which is short for “world wide web”, hence “www”) is the collection of all these websites.
Any program that you download and install on your device is an app. Browsers are apps. Some websites — like Facebook, YouTube, Spotify and The New York Times, for example — double up as apps, so you get the same or similar content on the app as you would on the corresponding website.
The key thing to remember about apps, especially social media apps, is that while they are accessed via a connection to the internet (the infrastructure), content on them does not represent the full web. It’s just a slice. In addition, not everything published in an app is necessarily publicly accessible on the web.
The web is the largest software platform ever, a great equalizer that works on any device, anywhere. By design, the web is open for anyone to participate in. Read more about Mozilla’s mission to keep the internet open and accessible to all.
Know someone who gets these things mixed up? It’s easy to do!
Pass this article along to share the knowledge.
The post What is the difference between the internet, browsers, search engines and websites? appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/internet-culture/mozilla-explains/internet-search-engine-browser/
|
|
The Rust Programming Language Blog: Announcing Rust 1.53.0 |
|
|
The Mozilla Blog: Celebrating our community: 10 years of the Reps Program |
Mozilla has always been about community and understanding that the internet is a better place when we work together. Ten years ago, Mozilla created the Reps program to add structure to our regional programs, further building off of our open source foundation. Over the last decade, the program has helped activate local communities in over 50 countries, tested Mozilla products and launches before they were released to the public, and collaborated on some of our biggest projects.
The last decade also has seen big shifts in technology, and it has only made us at Mozilla more thankful for our volunteers and more secure in our belief that community and collaboration are key to making a better internet.
“As the threats to a healthy internet persist, our network of collaborative communities and contributors continues to provide an essential role in helping us make it better,” said Mitchell Baker, CEO and Chairwoman of Mozilla. “These passionate Mozillians give up their time to educate, empower and mobilize others to support Mozilla’s mission and expand the impact of the open source ecosystem – a critical part of making the internet more accessible and better than how they found it.”
Ahead of our 10 year anniversary virtual celebration for the Reps Mozilla program, or ReMo for short, we connected with six of the 205 current reps to talk about their favorite parts of the internet, why community is so important, and where the Reps program can go from here.
Ioana Chiorean: I am the Reps Module Owner at this time. I am part of Mozilla Romania, but have always been involved in technical communities directly, like QA, Firefox OS and support. My latest roles have been more on the advocacy side as Tech Speaker and building the Reps community. I’ve been in the Reps program since 2011.
Irvin Chen: I’m a Mozilla Rep from Taipei, Taiwan. I’m representing the Mozilla Taiwan Community, one of the oldest Mozilla communities.
Lidya Christina: I’m a Mozilla Reps from Jakarta, Indonesia. I’ve been involved in the Reps program for more than two years now. I am also part of the review and resources team, provide operational support for the Mozilla community space in Jakarta, and a translator for the Mozilla localization project.
Michael Kohler: I have been part of the Reps program since 2012, and I am currently a Reps Peer helping out with strategy-related topics within the Reps program. After organizing events and building the community in Switzerland, I moved to Berlin in 2018 and started to help there. In the past 13 years I have worked on different Mozilla products such as Firefox, Firefox OS and Common Voice.
Pranshu Khanna: I’m Pranshu Khanna, a Reps Council Member for the current term and a Rep from Mozilla Gujarat. I started my journey as a Firefox Student Ambassador from an event in January 2016, where my first contribution was to introduce the world of Open Source to over 150 college students. Since then, I’ve spoken to thousands of people about privacy, open web and open source to people across the world and have been a part of hundreds of events, programs and initiatives.
Robert Sayles: Currently, I reside in Dallas, Texas, and I represent the North American community. I first joined the Mozilla Reps program in 2012, focusing mainly on my volunteer contribution to the Mozilla Festival Volunteer Coordinator 2013.

Irvin: For me, the most exciting thing about the internet is that no matter who you are or where you are located, you can always find and make some friends on the internet. For example, apart from each other, we could still collaborate online and successfully host the release party of Firefox in early 2000. Mozilla gives us, the local community contributors, the opportunity to participate, contribute and learn from each other on a global scale.
Michael: Nyan Cat is probably the part of the internet that I get most joy from. Kidding aside, for me the best part of the internet is probably the possibility to learn new astonishing facts about things I otherwise would never have looked up. All the knowledge is a few clicks away.
Pranshu: The most joyful moments from the internet have always come from being connected to people. It was 2006, and the ability to be on chat boards on a dial-up modem on 256Kbps to connect with people about anything, and scraping people on Orkut (remember that?). It’s been a ride, and now I speak to my mother everyday through FaceTime who is thousands of miles away and to my colleagues across the world. I would have been a kid in a small town in India who would not have imagined a world this big without the internet. It helped me embrace the idea of open knowledge and learn so much.

Lidya: I started in 2016, when I attended an offline localization event at the Mozilla community space in Jakarta for the first time. I have continued to be involved in localization (L10N) events since then, and I also joined the Mozilla Indonesia community to help manage events and the community space in Jakarta.
What makes me really engage with the community is that I appreciate that it is a supportive environment where the opportunities to learn (locally and globally) are wide.
Michael: When I was in high school one of my teachers was a Firefox contributor. At some point he showed us what he is working on and that got me hooked into Mozilla. Already back then I had a big interest in open source, however it hadn’t occurred to me to contribute until that moment. I was mostly impressed by the kindness and willingness to help volunteers to contribute to Mozilla’s mission and products. I didn’t have much in-person contact with the community for the first three years, but the more I got to know many more Mozillians all around the world, the more I felt like I belonged in this community. I have found friends from all over the world due to my involvement with Mozilla!
Pranshu: Roots. Mozilla has its roots in activism since the time the internet was born, and my connection with the Mozilla manifesto was instant. I realized that it wasn’t just marketing fluff since this is a community built with passion like the company is, from a small community of developers working to build not just a browser, but user’s freedom of choice. Mozilla’s community is important to how it started and where it’s being taken, and — if you’re committed to be a part of the journey — shape the future of the internet. I have been a part of protesting Aadhaar for user privacy, building India’s National Privacy Law, mentor Open Source Leaders, and much much more. I’m so grateful for being a part of this family that genuinely wants to help people fall in love with what they are doing.

Lidya: Beside the browser, my top favorite project/product are Pontoon (localization tool) and Firefox Monitor to get notified if my account was part of a data breach or not.
Michael: My favorite Mozilla product got to be Firefox. I’ve been a Firefox user for a long time and since 2008 I’ve been using Firefox Nightly (appropriately called “Minefield” back then). Since then I have been an avid advocate for Firefox and suggested Firefox to everyone who wasn’t already using Firefox. Thanks to Firefox my software engineering knowledge grew over time and up to this day has helped me in my career. And all that of course apart from being the window to the online world!
Pranshu: I love Common Voice! If I could use emojis, this would be filled with hearts. Common Voice is such a noble project to help people around the world give a voice. The beauty of the project is how it democratizes locales and gives people across all demographics a voice in the binary technological world.
Robert: I enjoyed working with Firefox Flicks many moons ago; as a Mozilla Rep, I had the privilege of interacting with the many talented creators and exploring how they were able to express themselves; I thought it was fantastic.

Ioana: For me, it literally means the people. Especially those that dedicate their free time to help others, to volunteer. It is the place I grew up as a professional and learned so much about different cultures worldwide.
Pranshu: The Mozilla community is my family. I’ve met so many people across the world who passionately believe in the open web. This is a very different ecosystem than what the world considers a community, we are really close to each other. After all, doing good is a part of all of our code.
Robert: Mozilla community means everyone brings something different to the table; I have witnessed a powerful movement over the years. When everyone gets together and brings their knowledge to the table, we can make a difference in the world.

Irvin: The Reps program had played an important role in connecting the isolated local communities. With regular meetups and events, we can meet with each other, receive regular updates from various projects, and collaborate on different efforts. As a community with years of history, we can extend our help beyond local users to foreign Mozillians by sharing our experience, such as experiences on community building, planning events, setting up the local website…etc.
Michael: In the past years Reps continued to provide important knowledge about their regions, such as organizing bug hunting events to test local websites to make sure they work for Firefox Quantum. There would have been quite a few bugs without the volunteers testing local websites that Mozilla employees wouldn’t have been able to test themselves. Additionally, Reps have always been great at coordinating communities and helping out with conflicts in the community.
I see a bright future for the Reps program. Mozilla can do so much more with the help of volunteers. Mozilla Reps is the perfect program to help coordinate, find and grow communities to advance Mozilla’s vision and mission over the coming years to come.
Pranshu: In the last decade the ReMo program has evolved from helping people to read, write and build on the internet to making the ecosystem better through creating leaders and helping users focus on their privacy. The program is headed to create pillars in the society that are committed to catalyse collaboration amongst diverse communities together for the common good, destroying silos that divide people. ReMo has Reps across the world, and I can imagine the community building great things together.

The post Celebrating our community: 10 years of the Reps Program appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/mozilla/news/reps-mozilla-community-10-year-celebration/
|
|
Daniel Stenberg: What goes into curl? |

curl is a command line tool and library for doing Internet data transfers. It has been around for a loooong time (over 23 years) but there is still a flood of new things being added to it and development being made, to take it further and to keep it relevant today and in the future.
I’m the lead developer and head maintainer of the curl project.
How do we decide what goes into curl? And perhaps more importantly, what does not get accepted into curl?
Let’s look how this works in the curl factory.
curl has come this far by being reliable, trusted and familiar. We don’t rock the boat: curl does Internet transfers specified as URLs and it doesn’t parse or understand the content it transfers. That goes for libcurl too.
Whatever we add should stick to these constraints and core principles, at least. Then of course there are more things to consider.
I personally usually have a shortlist of a few features I personally want to work on in the coming months and maybe half year. Items I can grab when other things are slow or if I need a change or fun thing to work on a rainy day. These items are laid out in the ROADMAP document – which also tends to be updated a little too infrequently…
There’s also the TODO document that lists things we consider could be good to do and KNOWN_BUGS that lists known shortcomings we want to address.
I’m the lead developer of the curl project but I also offer commercial support and curl services to allow me to work on curl full-time. This means that paying customers can get a “priority lane” into landing new features or bug-fixes in future releases of curl. They still need to suit the project though, we don’t abandon our principles even for money. (Contact me to learn how I can help you get your proposed changes done!)
All changes and improvements that help curl keep up with and follow where the Internet protocol community is moving, are considered good and necessary changes. The curl project has always been on the front-lines of protocols and that is where we want to remain. It takes a serious effort.
Every year around the May time frame we do a “user survey” that we try to get as many users as possible to respond to. It asks about user patterns, what’s missing and how things are working.
The results from that work provide good feedback on areas to improve and help us identify features our community think curl lacks etc. (The 2020 survey analysis)
Even outside of the annual survey, discussions on the mailing list is a good way for getting direct feedback on questions and ideas and users very often bring up their ideas and suggestions using those channels.
Actually implementing and providing a feature is a lot harder than just providing an idea. We almost drown among all the good ideas people propose we might or could do one day. What someone might think is a great idea may therefore still not be implemented very soon. Because of the complexity of implementing it or because of lack of time or energy etc.
But at the same time: oftentimes, someone needs to bring the idea or crack the suggestion for it to happen.
Related to the previous section. Code and changes that exist, that are provided are of course much more likely to actually end up in curl than abstract ideas. If a pull-request comes to curl and the change adheres to our standards and meet the requirements mentioned in this post, then the chances are very good that it will be accepted and merged.
As I am currently the only one working on curl professionally (ie I get paid to do it). I can rarely count on or assume work submissions from other team members. They usually show up more or less by surprise, which of course is awesome in itself but also makes such work and features very hard to plan for ahead of time. Sometimes people bring new features. Then we deal with them!
A decent amount of all pull requests submitted to the project never get merged because they aren’t good enough and the person who submitted them doesn’t respond to feedback and improvement requests properly so that they never become good enough. Things like documentation and tests are typically just as important as the functionality itself.
Pull requests that are abandoned by the author can of course also get taken over by someone else but it cannot be expected or relied upon. A person giving up on the pull request is also a strong sign to the rest of us that obviously the desire to get that specific change landed wasn’t that big and that tells us something.
We don’t accept and merge partial changes that for example lack a crucial part like tests or documentation because we’ve learned the hard way many times over the years that it is just too common that the author then vanishes before completing the work – forcing others to do that work or we have to rip the change out again.
At times people suggest we support new protocols or experiments for new things. While that can be considered fun and useful, we typically want both the protocol and the associated URL syntax to already be in use and be somewhat established and preferably even standardized and properly documented in specifications. One of the fundamental core ideas with URLs is that they should mean the same thing for more than one application.
Most changes are in line with what we already do and how the products work so no major considerations are necessary. Only once in a while do we get requests or suggestions that actually challenge the direction or forces us to consider what is the right and the wrong way.
If the reason and motivation provided is valid and holds up, then we might agree and go in that direction, If we don’t, we discuss the topic and see if we perhaps can change someone’s mind or “wiggle” the concepts and ideas to see whether we can change the suggestion or perhaps see it from n a different angle to reconsider. Sometimes we just have to decline and say no: that’s not something we think is in line with curl.
curl is not a democracy, we don’t vote about decisions or what to accept etc.
curl is also not a strict dictatorship where a single leader dictates all truths and facts from above for all subjects to accept and obey.
We’re somewhere in between. We discuss and try to find consensus of what and how to do things. The persons who bring the code or experience the actual problems of course will have more to say. Experienced and long-term maintainers’ opinions have more weight in discussions and they’re free and allowed to merge pull-requests they think are good.
I retain the right to veto stuff, but I very rarely exercise that right.
curl is still a small project. You’ll notice that you’ll quickly recognize the same handful of maintainers in all pull-requests and long tail of others chipping in here and there. There’s no massive crowd anywhere. That’s also the explanation why sometimes your pull-requests might not get reviewed instantly but you must rather wait for a while until you get someone’s attention.
If you’re curious to learn how the project is governed in more detail, then check out the governance docs.
I’ve done a previous presentation on how to work with the project get your code landed in curl. Check it out!
Listening to what users want, miss and think are needed when going forward is very important to us. Even if it sometimes is hard to react immediately and often we have to bounce things a little back and forth before they can become “curl material”. So, please don’t expect us to immediately implement what you suggest, but please don’t let that stop you from bringing your grand ideas.
And bring your code. We love your code.
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla joins call for fifth FCC Commissioner appointment |
In a letter sent to the White House on Friday, June 11, 2021, Mozilla joined over 50 advocacy groups and unions asking President Biden and Vice President Harris to appoint the fifth FCC Commissioner. Without a full team of appointed Commissioners, the Federal Communications Commission (FCC) is limited in its ability to move forward on crucial tech agenda items such as net neutrality and on addressing the country’s digital divide.
“Net neutrality preserves the environment that creates room for new businesses and new ideas to emerge and flourish, and where internet users can choose freely the companies, products, and services that they want to interact with and use. In a marketplace where consumers frequently do not have access to more than one internet service provider (ISP), these rules ensure that data is treated equally across the network by gatekeepers. We are committed to restoring the protections people deserve and will continue to fight for net neutrality,” said Amy Keating, Mozilla’s Chief Legal Officer.
In March 2021, we sent a joint letter to the FCC asking for the Commission to reinstate net neutrality as soon as it is in working order. Mozilla has been one of the leading voices in the fight for net neutrality for almost a decade, together with other advocacy groups. Mozilla has defended user access to the internet, in the US and around the world. Our work to preserve net neutrality has been a critical part of that effort, including our lawsuit against the FCC to keep these protections in place for users in the US.
The post Mozilla joins call for fifth FCC Commissioner appointment appeared first on Open Policy & Advocacy.
|
|
Daniel Stenberg: Bye bye Travis CI |
In the afternoon of October 17, 2013 we merged the first config file ever that would use Travis CI for the curl project using the nifty integration at GitHub. This was the actual introduction of the entire concept of building and testing the project on every commit and pull request for the curl project. Before this merge happened, we only had our autobuilds. They are systems run by volunteers that update the code from git maybe once per day, build and run the tests and then upload all the logs.
Don’t take this wrong: the autobuilds are awesome and have helped us make curl what it is. But they rely on individuals to host and admin the machines and to setup the specific configs that are tested.
With the introduction of “proper” CI, the configs that are tested are now also hosted in git and allows the project members to better control and adjust the tests and configs, plus that we can run them on already on pull-requests so that we can verify code before merge instead of having to first merge the code to master before the changes can get verified.
Travis provided a free service with a great promise.

In 2017 we surpassed 10 jobs per commit, all still on Travis.
In early 2019 we reached 30 jobs per commit, and at that time we started to use and spread out the work on more CI services. Travis would still remain as the one we’d lean on the heaviest. It was there and we had custom-written a bunch of jobs for it and it performed well.
Travis even turned some levers for us so that we got more parallel processing powers than on the regular open source tier, and we listed them as sponsors of the curl project for their gracious help. This may or may not be related to the fact that I met Josh Kalderimis (co-founder of travis) in 2019 and we talked about curl’s use of it and they possibly helping us more.
This year, 2021, the curl project runs around 100 CI jobs per commit and PR. 33 of them ran on Travis when we were finally pushed over from travis-ci.org to their new travis-ci.com domain. A transition they’d been advertising for a while but wasn’t very clearly explained or motivated in my eyes.
The new domain also implied new rules and new tiers, we quickly learned. Now we would have to apply to be recognized as an open source project (after 7.5 years of using their services as an open source project). But also, in order to get to take advantage of their free tier being an open source project was no longer enough. Among the new requirements on the project was this:
Project must not be sponsored by a commercial company or
organization (monetary or with employees paid to work on the project)
We’re a small independent open source project, but yes I work on curl full-time thanks to companies paying for curl support. I’m paid to work on curl and therefore we cannot meet that requirement.
I’m not sure why, but apparently we still got free “credits” for running CI on Travis. The CI jobs kept working and I think maybe I sighed a little from relief – of course I did it prematurely as it only took us a few days into the month of June until we had run out of the free credits. There’s no automatic refill but we can apparently ask for more. We asked, but many days after having asked we still had no more credits and no CI jobs could run on Travis anymore. CI on Travis at the same level as before would cost more than 249 USD/month. Maybe not so much “it will always be free”.
The 33 jobs on Travis were there for a purpose. They’re prerequisites for us to develop and ship a quality product. Without the CI jobs running, we risk landing bad code. This was not a sustainable situation.
We looked for alternative services and we quickly got several offers of help and assistance.
Friends from both Zuul CI and Circle CI stepped up and helped us started to get CI jobs transitioned over from Travis over to their new homes.
At June 14th 2021, we officially had no more jobs running on Travis.
Visualized as a graph, we can see the Travis jobs “falling off a cliff” with Zuul rising to the challenge:

Services come and go. There’s no need to get hung up on that fact but instead keep moving forward with our eyes fixed on the horizon.
Thank you Travis CI for all those years of excellent service!
Lots of people have commented and think I’m “whining” about Travis CI charging for something that is useful and that I should rather just pay up. I could probably have gone with that but I dislike their broken promise and that they don’t consider us Open source anymore and I feel I have a responsibility to use the funds we get from gracious donors as wisely and economically as possible, and that includes using no-cost or cheap services rather than services charging thousands of dollars per year.
If there really were no other available and viable options, then paying could’ve been an alternative. Now, moving on to something else was the right choice for us.
Image by Gerd Altmann from Pixabay
|
|
Niko Matsakis: CTCFT 2021-06-21 Agenda |
 The second “Cross Team Collaboration Fun Times” (CTCFT) meeting will take place one week from today, on 2021-06-21 (in your time zone)! This post describes the main agenda items for the meeting; you’ll find the full details (along with a calendar event, zoom details, etc) on the CTCFT website.
The second “Cross Team Collaboration Fun Times” (CTCFT) meeting will take place one week from today, on 2021-06-21 (in your time zone)! This post describes the main agenda items for the meeting; you’ll find the full details (along with a calendar event, zoom details, etc) on the CTCFT website.
After the CTCFT this week, we are going to try an experimental social hour. The hour will be coordinated in the #ctcft stream of the rust-lang Zulip. The idea is to create breakout rooms where people can gather to talk, hack together, or just chill.
Presented by: pnkfelix and Eliza (hawkw)
Rust programs are known for being performant and correct – but what about when that’s not true? Unfortunately, the state of the art for Rust tooling today can often be a bit difficult. This is particularly true for Async Rust, where users need insights into the state of the async runtime so that they can resolve deadlocks and tune performance. This talk discuss what top-notch debugging and tooling for Rust might look like. One particularly exciting project in this area is tokio-console, which lets users visualize the state of projects build on the tokio library.
Presented by: nikomatsakis
As Rust grows, we need to ensure that it retains a coherent design. Establishing a set of “guiding principles” is one mechanism for doing that. Each principle captures a goal that Rust aims to achieve, such as ensuring correctness, or efficiency. The principles give us a shared vocabulary to use when discussing designs, and they are ordered so as to give guidance in resolving tradeoffs. This talk will walk through a draft set of guiding principles for Rust that nikomatsakis has been working on, along with examples of how they those principles are enacted through Rust’s language, library, and tooling.
http://smallcultfollowing.com/babysteps/blog/2021/06/14/ctcft-2021-06-21-agenda/
|
|
Francois Marier: How to get a direct WebRTC connections between two computers |
WebRTC is a standard real-time communication protocol built directly into modern web browsers. It enables the creation of video conferencing services which do not require participants to download additional software. Many services make use of it and it almost always works out of the box.
The reason it just works is that it uses a protocol called ICE to establish a connection regardless of the network environment. What that means however is that in some cases, your video/audio connection will need to be relayed (using end-to-end encryption) to the other person via third-party TURN server. In addition to adding extra network latency to your call that relay server might overloaded at some point and drop or delay packets coming through.
Here's how to tell whether or not your WebRTC calls are being relayed, and how to ensure you get a direct connection to the other host.
Before you place a real call, I suggest using the official test page which will test your camera, microphone and network connectivity.
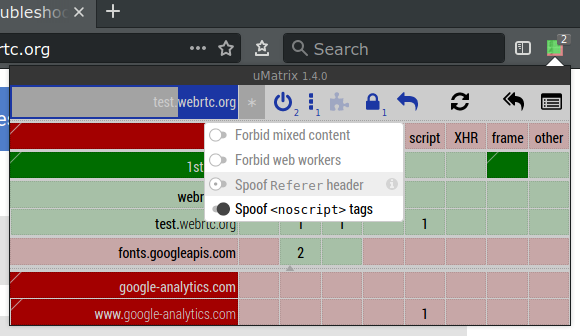
Note that this test page makes use of a Google TURN server which is locked to particular HTTP referrers and so you'll need to disable privacy features that might interfere with this:
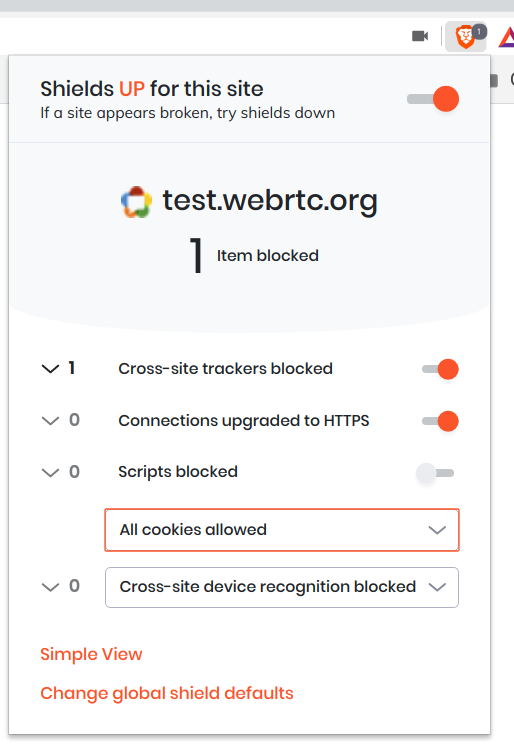
Firefox: Ensure that http.network.referer.spoofSource is set to false
in about:config, which it is by default.
uMatrix: The "Spoof Referer
header" option needs to be turned off for that site.
Once you know that WebRTC is working in your browser, it's time to establish a connection and look at the network configuration that the two peers agreed on.
My favorite service at the moment is Whereby (formerly Appear.in), so I'm going to use that to connect from two different computers:
canada is a laptop behind a regular home router without any port
forwarding.siberia is a desktop computer in a remote location that is also behind a
home router, but in this case its internal IP address (192.168.1.2) is
set as the DMZ
host.For all Chromium-based browsers, such as Brave, Chrome, Edge, Opera and
Vivaldi, the debugging page you'll need to open is called
chrome://webrtc-internals.
Look for RTCIceCandidatePair lines and expand them one at a time until you
find the one which says:
state: succeeded (or state: in-progress)nominated: truewritable: true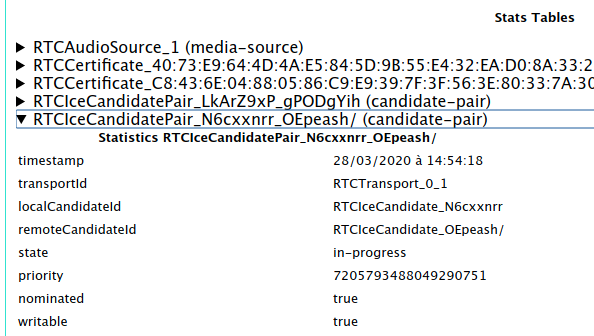
Then from the name of that pair (N6cxxnrr_OEpeash in the above example)
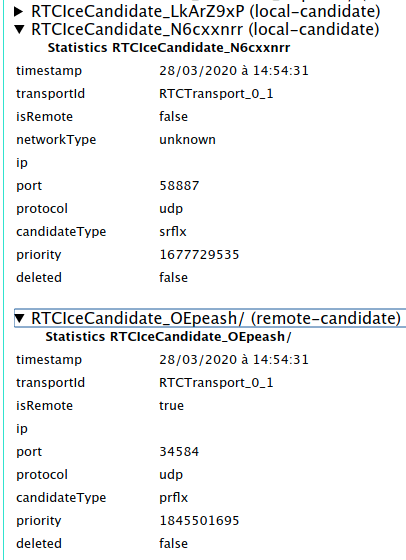
find the two matching RTCIceCandidate lines (one local-candidate and one
remote-candidate) and expand them.
In the case of a direct connection, I saw the following on the
remote-candidate:
ip shows the external IP address of siberiaport shows a random number between 1024 and 65535candidateType: srflxand the following on local-candidate:
ip shows the external IP address of canadaport shows a random number between 1024 and 65535candidateType: prflxThese candidate types indicate that a STUN server was used to determine the public-facing IP address and port for each computer, but the actual connection between the peers is direct.
On the other hand, for a relayed/proxied connection, I saw the following
on the remote-candidate side:
ip shows an IP address belonging to the TURN servercandidateType: relayand the same information as before on the local-candidate.
If you are using Firefox, the debugging page you want to look at is
about:webrtc.
Expand the top entry under "Session Statistics" and look for the line (should be the first one) which says the following in green:
ICE State: succeededNominated: trueSelected: truethen look in the "Local Candidate" and "Remote Candidate" sections to find the candidate type in brackets.
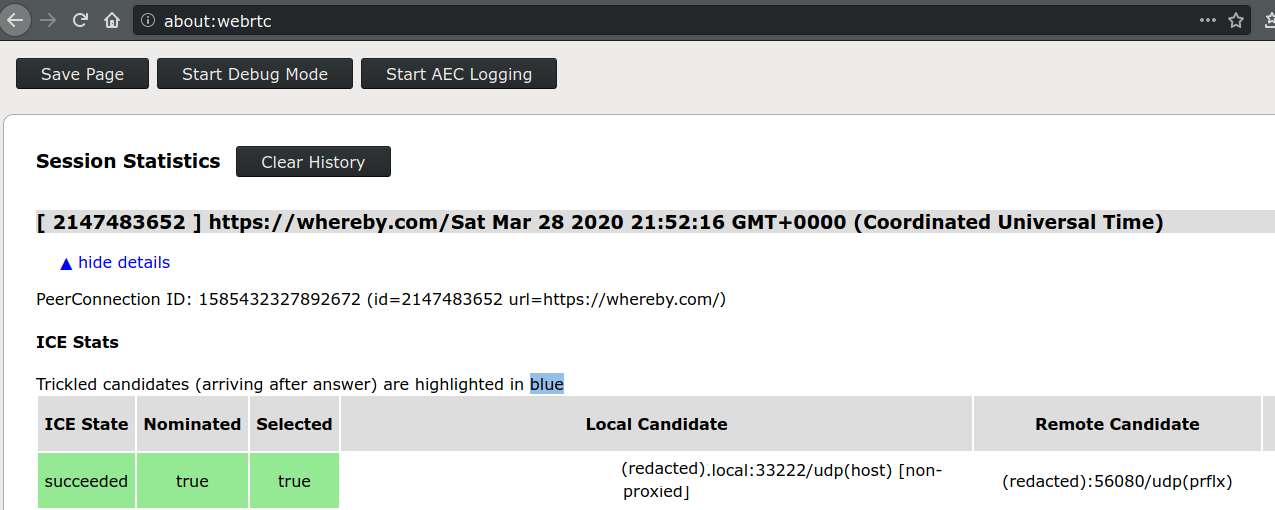
In order to get a direct connection to the other WebRTC peer, one of the
two computers (in my case, siberia) needs to open all inbound UDP
ports since there doesn't appear to be a way to restrict Chromium or
Firefox to a smaller port range for incoming WebRTC connections.
This isn't great and so I decided to tighten that up in two ways by:
siberia's ISP, andsiberia.To get the IP range, start with the external IP address of the machine (I'll
use the IP address of my blog in this example: 66.228.46.55) and pass it
to the whois command:
$ whois 66.228.46.55 | grep CIDR
CIDR: 66.228.32.0/19
To get the list of open UDP ports on siberia, I sshed into it and ran
nmap:
$ sudo nmap -sU localhost
Starting Nmap 7.60 ( https://nmap.org ) at 2020-03-28 15:55 PDT
Nmap scan report for localhost (127.0.0.1)
Host is up (0.000015s latency).
Not shown: 994 closed ports
PORT STATE SERVICE
631/udp open|filtered ipp
5060/udp open|filtered sip
5353/udp open zeroconf
Nmap done: 1 IP address (1 host up) scanned in 190.25 seconds
I ended up with the following in my /etc/network/iptables.up.rules (ports
below 1024 are denied by the default rule and don't need to be included
here):
# Deny all known-open high UDP ports before enabling WebRTC for canada
-A INPUT -p udp --dport 5060 -j DROP
-A INPUT -p udp --dport 5353 -j DROP
-A INPUT -s 66.228.32.0/19 -p udp --dport 1024:65535 -j ACCEPT
https://feeding.cloud.geek.nz/posts/how-to-get-direct-webrtc-connection-between-computers/
|
|
Patrick Cloke: Converting Twisted’s inlineCallbacks to async |
Almost a year ago we had a push at Element to convert the remaining instances of Twisted’s inlineCallbacks to use native async/await syntax from Python [1]. Eventually this work got covered by issue #7988 (which is the original basis for this blogpost).
Note that Twisted itself gained some …
https://patrick.cloke.us/posts/2021/06/11/converting-twisteds-inlinecallbacks-to-async/
|
|
Mozilla Localization (L10N): L10n Report: June 2021 Edition |
Please note some of the information provided in this report may be subject to change as we are sometimes sharing information about projects that are still in early stages and are not final yet.
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
On June 1st, Mozilla released Firefox 89. That was a major milestone for Firefox, and a lot of work went into this release (internally called MR1, which stands for Major Release 1). If this new update was well received — see for example this recent article from ZDNet — it’s also thanks to the amazing work done by our localization community.
For the first time in over a decade, we looked at Firefox holistically, making changes across the board to improve messages, establish a more consistent tone, and modernize some dialogs. This inevitably generated a lot of new content to localize.
Between November 2020 and May 2021, we added 1637 strings (6798 words). To get a point of reference, that’s almost 14% of the entire browser. What’s amazing is that the completion levels didn’t fall drastically:
The completion level across all locales is lower, but that’s mostly due to locales that are completely unmaintained, and that we’ll likely need to drop from release later this year. If we exclude those 7 locales, overall completion increased by 0.10% (to 89.84%).
Once again, thanks to all the volunteers who contributed to this successful release of Firefox.
These are the important deadlines for Firefox 90, currently in Beta:
Keep in mind that Firefox 91 is also going to be the next ESR version. Once that moves to release, it won’t generally be possible to update translations for that specific version.
Talking about Firefox 91, we’re planning to add a new locale: Scots. Congratulations to the team for making it so quickly to release!
On a final note, expect to see more updates to the Firefox L10n Newsletter, since this has proved to be an important tool to provide more context to localizers, and help them with testing.
Next l10n deadlines for mobile projects:
Once more, we want to thank all the localizers who worked hard for the MR1 (Proton) mobile release. We really appreciate the time and effort spent on helping ensure all these products are available globally (and of course, also on desktop). THANK YOU!
There are a few strings exposed to Pontoon that do not require translation. Only Mozilla staff in the admin role to the product would be able to see them. The developer for the feature will add a comment of “no need to translate” or context to the string at a later time. We don’t know when this will be added. For the time being, please ignore them. Most of the strings with a source string ID of src/olympia/scanners/templates/admin/* can be ignored. However, there are still a handful of strings that fall out of the category.
The project continues to be on hold in Pontoon. The product repository doesn’t pick up any changes made in Pontoon, so fr, ja, zh-CN, and zh-TW are now read-only for now. The MDN site, however, is still maintaining the articles localized in these languages plus ko, pt-BR, and ru.
The websites in ar, hi-IN, id, ja, and ms languages are now fully localized through vendor service since our last report. Communities of these languages are encouraged to help promote the sites through various social media platforms to increase download, conversion and create new profiles.
Lots of exciting things happening in SUMO in Q2. Here’s a recap of what’s happening:
As always, feel free to join SUMO Matrix room to discuss or just say hi to the rest of the community.
Since May, we’ve been running experiments in Pontoon to increase the number of users reading notifications. For example, as part of this campaign, you might have seen a banner encouraging you to install the Pontoon Add-on — which you really should do — or noticed a slightly different notification icon in the top right corner of the window.
 Recently, we also sent an email to all Pontoon accounts active in the past 2 years, with a link to a survey specifically about further improving notifications. If you haven’t completed the survey yet, or haven’t received the email, you can still take the survey here (until June 20th).
Recently, we also sent an email to all Pontoon accounts active in the past 2 years, with a link to a survey specifically about further improving notifications. If you haven’t completed the survey yet, or haven’t received the email, you can still take the survey here (until June 20th).
When a source string includes line breaks, Pontoon will show a pilcrow character (¶) where the line break happens.
 This is how the Fluent file looks like:
This is how the Fluent file looks like:
onboarding-multistage-theme-tooltip-automatic-2 =
.title =
Inherit the appearance of your operating
system for buttons, menus, and windows.
While in most cases the line break is not relevant — it’s just used to make the source file more readable — double check the resource comment: if the line break is relevant, it will be pointed out explicitly.
 If they’re not relevant, you can just put your translation on one line.
If they’re not relevant, you can just put your translation on one line.
If you want to preserve the line breaks in your translation, you have a few options:
Do not select the text with your mouse, and copy it in the translation field. That will copy the literal character in the translation, and it will be displayed in the final product, causing bugs.
If you see the ¶ character in the translation field (see red arrow in the image below), it will also appear in the product you are translating, which is most likely not what you want. On the other hand, it’s expected to see the ¶ character in the list of translations under the translation field (green arrow), as it is in the source string and the string list.
 Events
EventsKnow someone in your l10n community who’s been doing a great job and should appear here? Contact one of the l10n-drivers and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2021/06/10/l10n-report-june-2021-edition/
|
|
The Mozilla Blog: Privacy analysis of FLoC |
In a previous post, I wrote about a new set of technologies “Privacy Preserving Advertising”, which are intended to allow for advertising without compromising privacy. This post discusses one of those proposals–Federated Learning of Cohorts (FLoC)–which Chrome is currently testing. The idea behind FLoC is to make it possible to target ads based on the interests of users without revealing their browsing history to advertisers. We have conducted a detailed analysis of FLoC privacy. This post provides a summary of our findings.
In the current web, trackers (and hence advertisers) associate a cookie with each user. Whenever a user visits a website that has an embedded tracker, the tracker gets the cookie and can thus build up a list of the sites that a user visits. Advertisers can use the information gained from tracking browsing history to target ads that are potentially relevant to a given user’s interests. The obvious problem here is that it involves advertisers learning everywhere you go.
FLoC replaces this cookie with a new “cohort” identifier which represents not a single user but a group of users with similar interests. Advertisers can then build a list of the sites that all the users in a cohort visit, but not the history of any individual user. If the interests of users in a cohort are truly similar, this cohort identifier can be used for ad targeting. Google has run an experiment with FLoC; from that they’ve stated that FLoC provides 95% of the per-dollar conversion rate when compared to interest-based ad targeting using tracking cookies.
Our analysis shows several privacy issues that we believe need to be addressed:
Although any given cohort is going to be relatively large (the exact size is still under discussion, but these groups will probably consist of thousands of users), that doesn’t mean that they cannot be used for tracking. Because only a few thousand people will share a given cohort ID, if trackers have any significant amount of additional information, they can narrow down the set of users very quickly. There are a number of possible ways this could happen:
Not all browsers are the same. For instance, some people use Chrome and some use Firefox; some people are on Windows and others are on Mac; some people speak English and others speak French. Each piece of user-specific variation can be used to distinguish between users. When combined with a FLoC cohort that only has a few thousand users, a relatively small amount of information is required to identify an individual person or at least narrow the FLoC cohort down to a few people. Let’s give an example using some numbers that are plausible. Imagine you have a fingerprinting technique which divides people up into about 8000 groups (each group here is somewhat bigger than a ZIP code). This isn’t enough to identify people individually, but if it’s combined with FLoC using cohort sizes of about 10000, then the number of people in each fingerprinting group/FLoC cohort pair is going to be very small, potentially as small as one. Though there might be larger groups that can’t be identified this way, that is not the same as having a system that is free from individual targeting.
People’s interests aren’t constant and neither are their FLoC IDs. Currently, FLoC IDs seem to be recomputed every week or so. This means that if a tracker is able to use other information to link up user visits over time, they can use the combination of FLoC IDs in week 1, week 2, etc. to distinguish individual users. This is a particular concern because it works even with modern anti-tracking mechanisms such as Firefox’s Total Cookie Protection (TCP). TCP is intended to prevent trackers from correlating visits across sites but not multiple visits to one site. FLoC restores cross-site tracking even if users have TCP enabled.
With cookie-based tracking, the amount of information a tracker gets is determined by the number of sites it is embedded on. Moreover, a site which wants to learn about user interests must itself participate in tracking the user across a large number of sites, work with some reasonably large tracker, or work with other trackers. Under a permissive cookie policy, this type of tracking is straightforward using third-party cookies and cookie syncing. However, when third-party cookies are blocked (or isolated by site in TCP) it’s much more difficult for trackers to collect and share information about a user’s interests across sites.
FLoC undermines these more restrictive cookie policies: because FLoC IDs are the same across all sites, they become a shared key to which trackers can associate data from external sources. For example, it’s possible for a tracker with a significant amount of first-party interest data to operate a service which just answers questions about the interests of a given FLoC ID. E.g., “Do people who have this cohort ID like cars?”. All a site needs to do is call the FLoC APIs to get the cohort ID and then use it to look up information in the service. In addition, the ID can be combined with fingerprinting data to ask “Do people who live in France, have Macs, run Firefox, and have this ID like cars?” The end result here is that any site will be able to learn a lot about you with far less effort than they would need to expend today.
Google has proposed several mechanisms to address these issues.
First, sites have the option of whether or not to participate in FLoC. In the current experiment that Chrome is conducting, sites are included in the FLoC computation if they do ads-type stuff, either “load ads-related resources” or call the FLoC APIs. It’s not clear what the eventual inclusion criteria are, but it seems likely that any site which includes advertising will be included in the computation by default. Sites can also opt-out of FLoC entirely using the Permissions-Policy HTTP header but it seems likely that many sites will not do so.
Second, Google itself will suppress FLoC cohorts which it thinks are too closely correlated with “sensitive” topics. Google provides the details in this whitepaper, but the basic idea is that they will look to see if the users in a given cohort are significantly more likely to visit a set of sites associated with sensitive categories, and if so they will just return an empty cohort ID for that cohort. Similarly, they say they will remove sites which they think are sensitive from the FLoC computation. These defenses seem like they are going to be very difficult to execute in practice for several reasons: (1) the list of sensitive categories may be incomplete or people may not agree on what categories are sensitive, (2) there may be other sites which correlate to sensitive sites but are not themselves sensitive, and (3) clever trackers may be able to learn sensitive information despite these controls. For instance: it might be the case that English-speaking users with FLoC ID X are no more likely to visit sensitive site type A, but French-speaking users are.
While these mitigations seem useful, they seem to mostly be improvements at the margins, and don’t address the basic issues described above, which we believe require further study by the community.
FLoC is premised on a compelling idea: enable ad targeting without exposing users to risk. But the current design has a number of privacy properties that could create significant risks if it were to be widely deployed in its current form. It is possible that these properties can be fixed or mitigated — we suggest a number of potential avenues in our analysis — further work on FLoC should be focused on addressing these issues.
For more on this:
Building a more privacy-preserving ads-based ecosystem
The post Privacy analysis of FLoC appeared first on The Mozilla Blog.
https://blog.mozilla.org/en/mozilla/privacy-analysis-of-floc/
|
|
Mozilla Privacy Blog: Working in the open: Enhancing privacy and security in the DNS |
In 2018, we started pioneering work on securing one of the oldest parts of the Internet, one that had till then remained largely untouched by efforts to make the web safer and more private: the Domain Name System (DNS). We passed a key milestone in that endeavor last year, when we rolled out DNS-over-HTTPS (DoH) technology by default in the United States, thus improving privacy and security for millions of people. Given the transformative nature of this technology and in line with our mission commitment to transparency and collaboration, we have consistently sought to implement DoH thoughtfully and inclusively. Today we’re sharing our latest update on that continued effort.
Between November 2020 and January 2021 we ran a public comment period, to give the broader community who care about the DNS – including human rights defenders; technologists; and DNS service providers – the opportunity to provide recommendations for our future DoH work. Specifically, we canvassed input on our Trusted Recursive Resolver (TRR) policies, the set of privacy, security, and integrity commitments that DNS recursive resolvers must adhere to in order to be considered as default partner resolvers for Mozilla’s DoH roll-out.
We received rich feedback from stakeholders across the world, and we continue to reflect on how it can inform our future DoH work and our TRR policies. As we continue that reflection, we’re today publishing the input we received during the comment period – acting on a commitment to transparency that we made at the outset of the process. You can read the comments here.
During the comment period and prior, we received substantial input on the blocklist publication requirement of our TRR policies. This requirement means that resolvers in our TRR programme must publicly release the list of domains that they block access to. This blocking could be the result of either legal requirements that the resolver is subject to, or because a user has explicitly consented to certain forms of DNS blocking. We are aware of the downsides associated with blocklist publication in certain contexts, and one of the primary reasons for undertaking our comment period was to solicit constructive feedback and suggestions on how to best ensure meaningful transparency when DNS blocking takes place. Therefore, while we reflect on the input regarding our TRR policies and solutions for blocking transparency, we will relax this blocklist publication requirement. As such, current or prospective TRR partners will not be required to mandatorily publish DNS blocklists from here on out.
DoH is a transformative technology. It is relatively new and, as such, is of interest to a variety of stakeholders around the world. As we bring the privacy and security benefits of DoH to more Firefox users, we will continue our proactive engagement with internet service providers, civil society organisations, and everyone who cares about privacy and security in the internet ecosystem.
We look forward to this collaborative work. Stay tuned for more updates in the coming months.
The post Working in the open: Enhancing privacy and security in the DNS appeared first on Open Policy & Advocacy.
|
|
Firefox UX: Content design considerations for the new Firefox |

Introducing the redesigned Firefox browser, featuring the Alpenglow them
We just launched a major redesign of the Firefox desktop browser to 240 million users. The effort was so large that we put our full content design team — all two of us — on the case. Over the course of the project, we updated nearly 1,000 strings, re-architected our menus, standardized content patterns, established new principles, and cleaned up content debt.
The primary goal of the redesign was to make Firefox feel modern. We needed to concretize that term to guide the design and content decisions, as well as to make the measurement of visual aesthetics more objective and actionable.
To do this, we used the Microsoft Desirability Toolkit, which measures people’s attitudes towards a UI with a controlled vocabulary test. Content design worked with our UX director to identify adjectives that could embody what “modern” meant for our product. The UX team used those words for early visual explorations, which we then tested in a qualitative usertesting.com study.
Based on the results, we had an early idea of where the designs were meeting goals and where we could make adjustments.

Sampling of qualitative feedback from the visual appeal test with word cloud and participant comments.
Over time, our application menu had grown unwieldy. Sub-menus proliferated like dandelions. It was difficult to scan, resulting in high cognitive load. Grouping of items were not intuitive. By re-organizing the items, prioritizing high-value actions, using clear language, and removing icons, the new menu better supports people’s ability to move quickly and efficiently in the Firefox browser.
To finalize the menu’s information architecture, we leveraged a variety of inputs. We studied usage data, reviewed past user research, and referenced external sources like the Nielsen Norman Group for menu design best practices. We also consulted with product managers to understand the historical context of prior decisions.
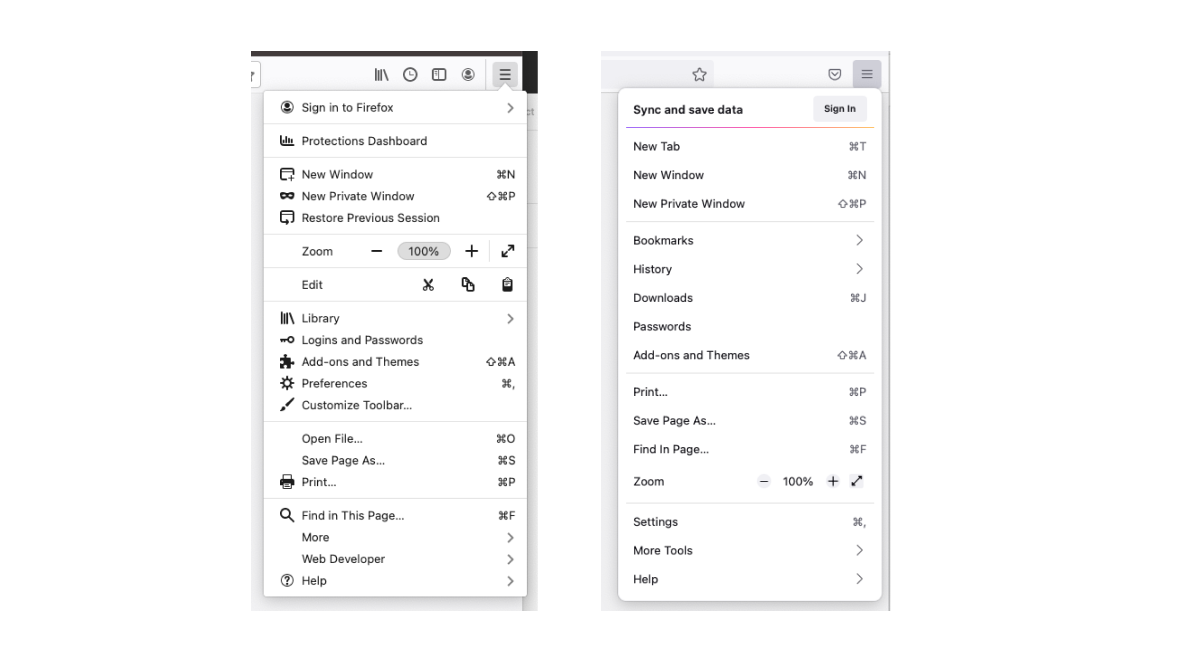
The Firefox application menu, before and after the information architecture redesign.
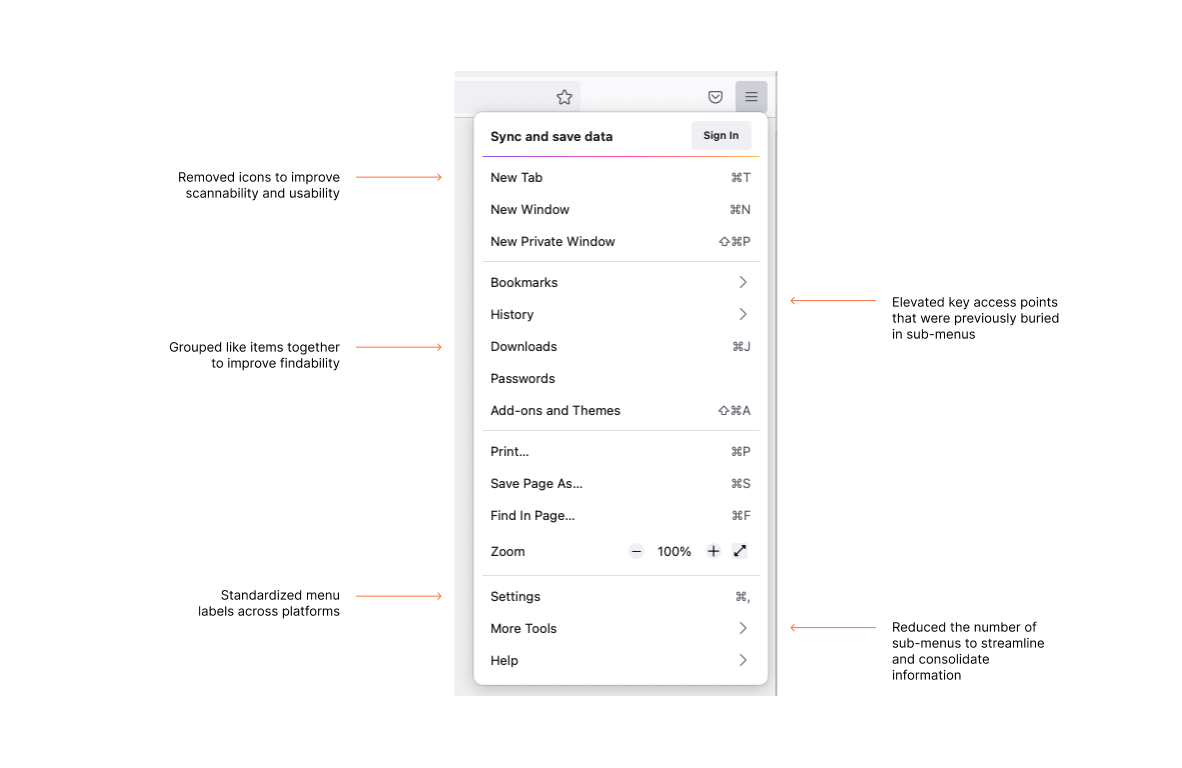
Changes made to the Firefox application menu include removing icons, grouping like items together, and reducing the number of sub-menus.
As a final step, we created principles to document the rationale behind the menu redesign so a consistent approach could be applied to other menu-related decisions across the product and platforms.

Content design developed these principles to help establish a consistent approach for other menus in the product.
Firefox surfaces a number of messages to users while they use the product. Those messages had dated visuals, inconsistent presentation, and clunky copy.
We partnered with our UX and visual designers to redesign those message types using a content-first approach. By approaching the redesign this way, we better ensured the resulting components supported the message needs. Along the way, we were able to make some improvements to the existing copy and establish guidelines so future modals, infobars, and panels would be higher quality.
A modal sits on top of the main content of a webpage. It’s a highly intrusive message that disables background content and requires user interaction. By redesigning it we made one of the most interruptive browsing moments smoother and more cohesive.
Before and after images of a redesigned Firefox modal dialog. Content decisions are highlighted.
Annotated example of the content decisions in a redesigned Firefox modal dialog.
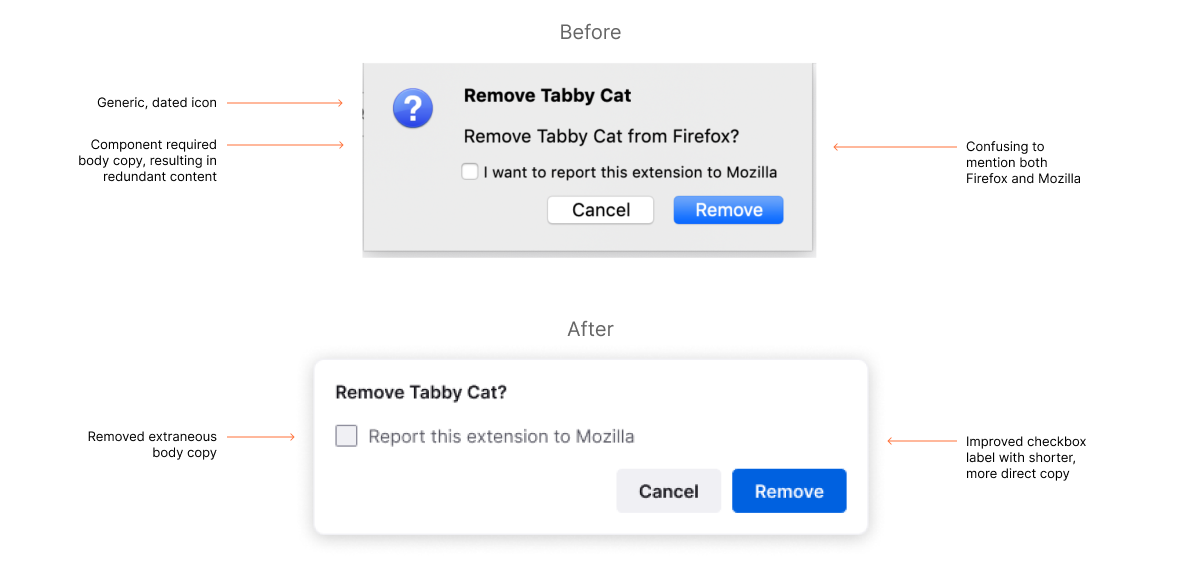
Annotated example of the content decisions in a redesigned Firefox modal dialog
Permissions panels get triggered when you visit certain websites. For example, a website may request to send you notifications, know your location, or gain access to your camera and microphone. We addressed inconsistencies and standardized content patterns to reduce visual clutter. The redesigned panels are cleaner and more concise.
Before and after images of a redesigned Firefox permissions panel. Content decisions are highlighted.
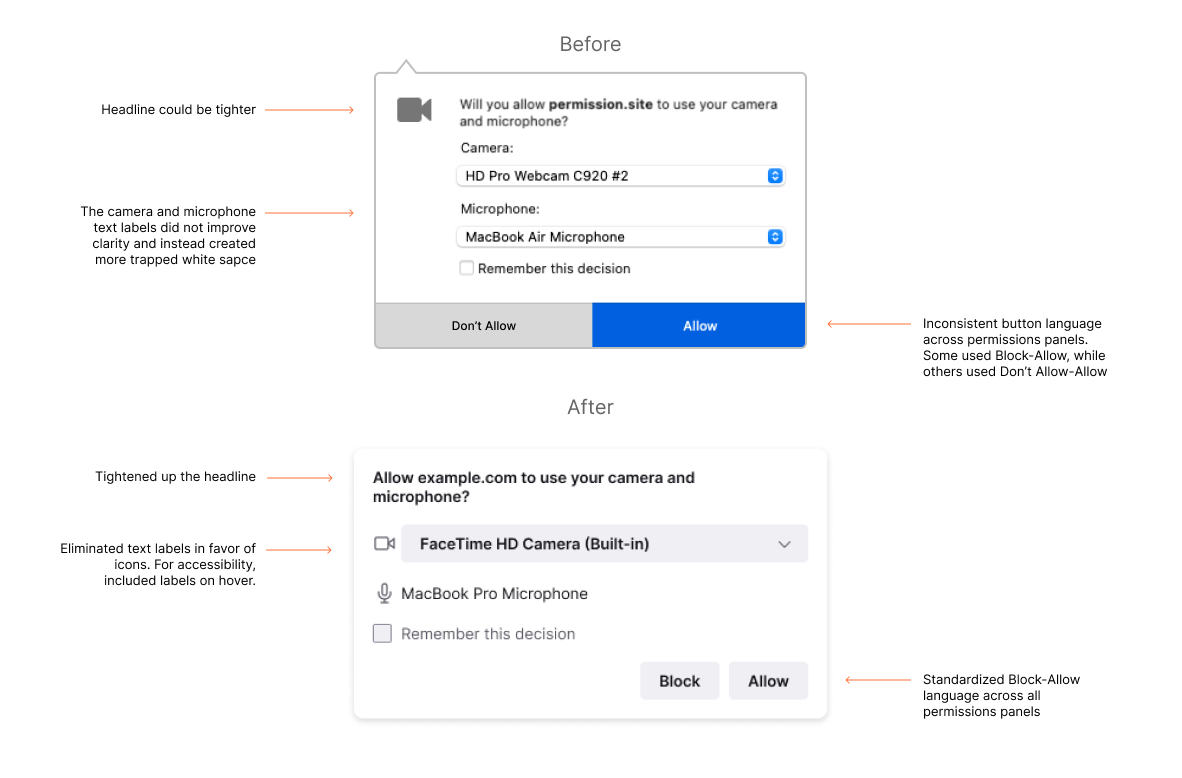
Annotated example of the content decisions in a redesigned Firefox permissions panel.
This major refresh appears simple and somewhat effortless, which was the goal. A large amount of work happened behind the scenes to make that end result possible — a whole lot of auditing, iteration, communication, collaboration, and reviews. As usual, the lion’s share of content design happened before we put ‘pen to paper.’
Like any major renovation project, we navigated big dreams, challenging constraints, tough compromises, and a whole lot of dust. Software is never ‘done,’ but we cleared significant content weeds and co-created a future-forward design experience.
As anyone who has contributed to a major redesign knows, this involved months of collaboration between our user experience team, engineers, and product managers, as well as our partners in localization, accessibility, and quality assurance. We were fortunate to work with such a smart, hard-working group.
This post was originally published on Medium.
https://blog.mozilla.org/ux/2021/06/content-design-considerations-for-the-new-firefox/
|
|
Mozilla Attack & Defense: Eliminating Data Races in Firefox – A Technical Report |
We successfully deployed ThreadSanitizer in the Firefox project to eliminate data races in our remaining C/C++ components. In the process, we found several impactful bugs and can safely say that data races are often underestimated in terms of their impact on program correctness. We recommend that all multithreaded C/C++ projects adopt the ThreadSanitizer tool to enhance code quality.
ThreadSanitizer (TSan) is compile-time instrumentation to detect data races according to the C/C++ memory model on Linux. It is important to note that these data races are considered undefined behavior within the C/C++ specification. As such, the compiler is free to assume that data races do not happen and perform optimizations under that assumption. Detecting bugs resulting from such optimizations can be hard, and data races often have an intermittent nature due to thread scheduling.
Without a tool like ThreadSanitizer, even the most experienced developers can spend hours on locating such a bug. With ThreadSanitizer, you get a comprehensive data race report that often contains all of the information needed to fix the problem.
 ThreadSanitizer Output for this example program (shortened for article)
ThreadSanitizer Output for this example program (shortened for article)
One important property of TSan is that, when properly deployed, the data race detection does not produce false positives. This is incredibly important for tool adoption, as developers quickly lose faith in tools that produce uncertain results.
Like other sanitizers, TSan is built into Clang and can be used with any recent Clang/LLVM toolchain. If your C/C++ project already uses e.g. AddressSanitizer (which we also highly recommend), deploying ThreadSanitizer will be very straightforward from a toolchain perspective.
Despite ThreadSanitizer being a very well designed tool, we had to overcome a variety of challenges at Mozilla during the deployment phase. The most significant issue we faced was that it is really difficult to prove that data races are actually harmful at all and that they impact the everyday use of Firefox. In particular, the term “benign” came up often. Benign data races acknowledge that a particular data race is actually a race, but assume that it does not have any negative side effects.
While benign data races do exist, we found (in agreement with previous work on this subject [1] [2]) that data races are very easily misclassified as benign. The reasons for this are clear: It is hard to reason about what compilers can and will optimize, and confirmation for certain “benign” data races requires you to look at the assembler code that the compiler finally produces.
Needless to say, this procedure is often much more time consuming than fixing the actual data race and also not future-proof. As a result, we decided that the ultimate goal should be a “no data races” policy that declares even benign data races as undesirable due to their risk of misclassification, the required time for investigation and the potential risk from future compilers (with better optimizations) or future platforms (e.g. ARM).
However, it was clear that establishing such a policy would require a lot of work, both on the technical side as well as in convincing developers and management. In particular, we could not expect a large amount of resources to be dedicated to fixing data races with no clear product impact. This is where TSan’s suppression list came in handy:
We knew we had to stop the influx of new data races but at the same time get the tool usable without fixing all legacy issues. The suppression list (in particular the version compiled into Firefox) allowed us to temporarily ignore data races once we had them on file and ultimately bring up a TSan build of Firefox in CI that would automatically avoid further regressions. Of course, security bugs required specialized handling, but were usually easy to recognize (e.g. racing on non-thread safe pointers) and were fixed quickly without suppressions.
To help us understand the impact of our work, we maintained an internal list of all the most serious races that TSan detected (ones that had side-effects or could cause crashes). This data helped convince developers that the tool was making their lives easier while also clearly justifying the work to management.
In addition to this qualitative data, we also decided for a more quantitative approach: We looked at all the bugs we found over a year and how they were classified. Of the 64 bugs we looked at, 34% were classified as “benign” and 22% were “impactful” (the rest hadn’t been classified).
We knew there was a certain amount of misclassified benign issues to be expected, but what we really wanted to know was: Do benign issues pose a risk to the project? Assuming that all of these issues truly had no impact on the product, are we wasting a lot of resources on fixing them? Thankfully, we found that the majority of these fixes were trivial and/or improved code quality.
The trivial fixes were mostly turning non-atomic variables into atomics (20%), adding permanent suppressions for upstream issues that we couldn’t address immediately (15%), or removing overly complicated code (20%). Only 45% of the benign fixes actually required some sort of more elaborate patch (as in, the diff was larger than just a few lines of code and did not just remove code).
We concluded that the risk of benign issues being a major resource sink was not an issue and well acceptable for the overall gains that the project provided.
As mentioned in the beginning, TSan does not produce false positive data race reports when properly deployed, which includes instrumenting all code that is loaded into the process and avoiding primitives that TSan doesn’t understand (such as atomic fences). For most projects these conditions are trivial, but larger projects like Firefox require a bit more work. Thankfully this work largely amounted to a few lines in TSan’s robust suppression system.
Instrumenting all code in Firefox isn’t currently possible because it needs to use shared system libraries like GTK and X11. Fortunately, TSan offers the “called_from_lib” feature that can be used in the suppression list to ignore any calls originating from those shared libraries. Our other major source of uninstrumented code was build flags not being properly passed around, which was especially problematic for Rust code (see the Rust section below).
As for unsupported primitives, the only issue we ran into was the lack of support for fences. Most fences were the result of a standard atomic reference counting idiom which could be trivially replaced with an atomic load in TSan builds. Unfortunately, fences are fundamental to the design of the crossbeam crate (a foundational concurrency library in Rust), and the only solution for this was a suppression.
We also found that there is a (well known) false positive in deadlock detection that is however very easy to spot and also does not affect data race detection/reporting at all. In a nutshell, any deadlock report that only involves a single thread is likely this false positive.
The only true false positive we found so far turned out to be a rare bug in TSan and was fixed in the tool itself. However, developers claimed on various occasions that a particular report must be a false positive. In all of these cases, it turned out that TSan was indeed right and the problem was just very subtle and hard to understand. This is again confirming that we need tools like TSan to help us eliminate this class of bugs.
Currently, the TSan bug-o-rama contains around 20 bugs. We’re still working on fixes for some of these bugs and would like to point out several particularly interesting/impactful ones.
Bitfields are a handy little convenience to save space for storing lots of different small values. For instance, rather than having 30 bools taking up 240 bytes, they can all be packed into 4 bytes. For the most part this works fine, but it has one nasty consequence: different pieces of data now alias. This means that accessing “neighboring” bitfields is actually accessing the same memory, and therefore a potential data race.
In practical terms, this means that if two threads are writing to two neighboring bitfields, one of the writes can get lost, as both of those writes are actually read-modify-write operations of all the bitfields:
If you’re familiar with bitfields and actively thinking about them, this might be obvious, but when you’re just saying myVal.isInitialized = true you may not think about or even realize that you’re accessing a bitfield.
We have had many instances of this problem, but let’s look at bug 1601940 and its (trimmed) race report:
When we first saw this report, it was puzzling because the two threads in question touch different fields (mAsyncTransformAppliedToContent vs. mTestAttributeAppliers). However, as it turns out, these two fields are both adjacent bitfields in the class.
This was causing intermittent failures in our CI and cost a maintainer of this code valuable time. We find this bug particularly interesting because it demonstrates how hard it is to diagnose data races without appropriate tooling and we found more instances of this type of bug (racy bitfield write/write) in our codebase. One of the other instances even had the potential to cause network loads to supply invalid cache content, another hard-to-debug situation, especially when it is intermittent and therefore not easily reproducible.
We encountered this enough that we eventually introduced a MOZ_ATOMIC_BITFIELDS macro that generates bitfields with atomic load/store methods. This allowed us to quickly fix problematic bitfields for the maintainers of each component without having to redesign their types.
We also found several instances of components which were explicitly designed to be single-threaded accidentally being used by multiple threads, such as bug 1681950:
The race itself here is rather simple, we are racing on the same file through stat64 and understanding the report was not the problem this time. However, as can be seen from frame 10, this call originates from the PreferencesWriter, which is responsible for writing changes to the prefs.js file, the central storage for Firefox preferences.
It was never intended for this to be called on multiple threads at the same time and we believe that this had the potential to corrupt the prefs.js file. As a result, during the next startup the file would fail to load and be discarded (reset to default prefs). Over the years, we’ve had quite a few bug reports related to this file magically losing its custom preferences but we were never able to find the root cause. We now believe that this bug is at least partially responsible for these losses.
We think this is a particularly good example of a failure for two reasons: it was a race that had more harmful effects than just a crash, and it caught a larger logic error of something being used outside of its original design parameters.
On several occasions we encountered a pattern that lies on the boundary of benign that we think merits some extra attention: intentionally racily reading a value, but then later doing checks that properly validate it. For instance, code like:
See for example, this instance we encountered in SQLite.
Please Don’t Do This. These patterns are really fragile and they’re ultimately undefined behavior, even if they generally work right. Just write proper atomic code — you’ll usually find that the performance is perfectly fine.
Another difficulty that we had to solve during TSan deployment was due to part of our codebase now being written in Rust, which has much less mature support for sanitizers. This meant that we spent a significant portion of our bringup with all Rust code suppressed while that tooling was still being developed.
We weren’t particularly concerned with our Rust code having a lot of races, but rather races in C++ code being obfuscated by passing through Rust. In fact, we strongly recommend writing new projects entirely in Rust to avoid data races altogether.
The hardest part in particular is the need to rebuild the Rust standard library with TSan instrumentation. On nightly there is an unstable feature, -Zbuild-std, that lets us do exactly that, but it still has a lot of rough edges.
Our biggest hurdle with build-std was that it’s currently incompatible with vendored build environments, which Firefox uses. Fixing this isn’t simple because cargo’s tools for patching in dependencies aren’t designed for affecting only a subgraph (i.e. just std and not your own code). So far, we have mitigated this by maintaining a small set of patches on top of rustc/cargo which implement this well-enough for Firefox but need further work to go upstream.
But with build-std hacked into working for us we were able to instrument our Rust code and were happy to find that there were very few problems! Most of the things we discovered were C++ races that happened to pass through some Rust code and had therefore been hidden by our blanket suppressions.
We did however find two pure Rust races:
The first was bug 1674770, which was a bug in the parking_lot library. This Rust library provides synchronization primitives and other concurrency tools and is written and maintained by experts. We did not investigate the impact but the issue was a couple atomic orderings being too weak and was fixed quickly by the authors. This is yet another example that proves how difficult it is to write bug-free concurrent code.
The second was bug 1686158, which was some code in WebRender’s software OpenGL shim. They were maintaining some hand-rolled shared-mutable state using raw atomics for part of the implementation but forgot to make one of the fields atomic. This was easy enough to fix.
Overall Rust appears to be fulfilling one of its original design goals: allowing us to write more concurrent code safely. Both WebRender and Stylo are very large and pervasively multi-threaded, but have had minimal threading issues. What issues we did find were mistakes in the implementations of low-level and explicitly unsafe multithreading abstractions — and those mistakes were simple to fix.
This is in contrast to many of our C++ races, which often involved things being randomly accessed on different threads with unclear semantics, necessitating non-trivial refactorings of the code.
Data races are an underestimated problem. Due to their complexity and intermittency, we often struggle to identify them, locate their cause and judge their impact correctly. In many cases, this is also a time-consuming process, wasting valuable resources. ThreadSanitizer has proven to be not just effective in locating data races and providing adequate debug information, but also to be practical even on a project as large as Firefox.
We would like to thank the authors of ThreadSanitizer for providing the tool and in particular Dmitry Vyukov (Google) for helping us with some complex, Firefox-specific edge cases during deployment.
|
|






