Tiger Oakes: How to replace onCommit, onActive, and onDispose in Jetpack Compose |
If you’re looking at some Jetpack Compose code or tutorials written last year, you might see the use of onCommit, onActive, and onDispose. However, these functions are no longer present in Android’s developer documentation. They were deprecated in version 1.0.0-alpha11 in favor of SideEffect and DisposableEffect. Here’s how to use those new functions and update your code.
Composables should be side-effect free and not handle use cases such as connecting with a HTTP API or showing a snackbar directly. You should use the side effect APIs in Jetpack Compose to ensure that these effects are run in a predictable way, rather than writing it alongside your UI rendering code.
onCommit with just a callbackThis simple use case has a simple update. Just use the new SideEffect function instead.
// Before
onCommit {
sideEffectRunEveryComposition()
}
// After
SideEffect {
sideEffectRunEveryComposition()
}
onCommit with keysIf you only want to run your side effect when keys are changed, then you should LaunchedEffect if you don’t call onDispose. (If you do, scroll down to the next section.)
// Before
onCommit(userId) {
searchUser(userId)
}
// After
LaunchedEffect(userId) {
searchUser(userId)
}
onCommit with onDisposeEffects using onDispose to clean up are now handled in a separate function called DisposableEffect.
// Before
onCommit(userId) {
val subscription = subscribeToUser(userId)
onDispose {
subscription.cleanup()
}
}
// After
DisposableEffect(userId) {
val subscription = subscribeToUser(userId)
onDispose {
subscription.cleanup()
}
}
onActiveRather than having a separate function for running an effect only on the first composition, this use cases is now handled by passing Unit as a key to LaunchedEffect or DisposableEffect. You can pass any static value as a key, including Unit or true.
// Before
onActive {
search()
}
// After
LaunchedEffect(Unit) {
search()
}
onActive with onDispose// Before
onActive {
val subscription = subscribe()
onDispose {
subscription.cleanup()
}
}
// After
DisposableEffect(Unit) {
val subscription = subscribe()
onDispose {
subscription.cleanup()
}
}
|
|
Cameron Kaiser: TenFourFox FPR31b1 available (now with site-specific user agent UI and Auto Reader View) |
However, there's still new stuff in this release. Olga T Park contributed a backport from later Firefox versions to fix saving passwords in private browsing, and I also finished fully exposing support for site specific user agents. This was quietly reimplemented in FPR17 for interested users, but now that it's getting more and more necessary on more and more sites, I have made the feature a visible and supported part of the browser interface. Instead of having to enter sites and strings manually into about:config, though you still can, you can now go to the TenFourFox preference pane,



I was also planning to do a Reader View update for this release, which will need a user interface of its own, but every new UI feature requires additional locale strings and I wanted to give our localizers (led by Chris) a chance to catch up on the new strings in time for the final release on March 22. However, I do have a not-yet-exposed feature's plumbing done, which is another enhancement to Reader View: auto Reader View.
Auto Reader View is different from sticky Reader View, which has been the default since FPR27. Sticky Reader View means that when you go into Reader View, links you click on also load in Reader View, until you quit it by clicking one of the exit buttons. Auto Reader View, however, allows you to tell the browser to automatically open pages from a domain in Reader View as soon as you click on any link to that domain from any page, in Reader View or not. Since front pages may not work as well, you can specify to do this just for "subpages" or for all pages.
An example is the Los Angeles Times, which is more or less my semi-local newspaper here in Southern California. Its article pages have a lot of irritating popup divs, so go into about:config, create a new string preference called tenfourfox.reader.auto.www.latimes.com and set it to the single letter s (for subpages; for all pages, use y for, um, "yes"). Now, visit the L.A. Times front page. It renders in the normal browser view, but if you click on any article, it immediately shifts to Reader View. Click the back button and you're back on the front page. If you decide you do want to see the article as intended, just click the Reader View icon in the address bar as usual, and the article will render in "full" form; links to subpages you click on from there will go back to Reader View.
As I've said many times, I think Reader View is an important way of making sites render faster and more usefully, especially on G3 and low-end G4 systems. It also cuts out a lot of crap, meaning it's back to only the columnists annoying me in the L.A. Times and not the popups. For FPR32 I will be updating the internal Reader View to the current version of Readability.js, adding a preference pane UI similar to site-specific user agents, and maybe also adding the current Firefox feature allowing you to adjust the gutter margins wider or narrower. But for now you can experiment with the feature and let me know how functional or useful it is to you. FPR31 final comes out on or around March 22, parallel with Firefox 78.9 and 87.
http://tenfourfox.blogspot.com/2021/03/tenfourfox-fpr31b1-available-now-with.html
|
|
Mozilla Addons Blog: Two-factor authentication required for extension developers |
At the end of 2019, we announced an upcoming requirement for extension developers to enable two-factor authentication (2FA) for their Firefox Accounts, which are used to log into addons.mozilla.org (AMO). This requirement is intended to protect add-on developers and users from malicious actors if they somehow get a hold of your login credentials, and it will go into effect starting March 15, 2021.
If you are an extension developer and have not enabled 2FA by this date, you will be directed to your Firefox Account settings to turn it on the next time you log into AMO.
Instructions for enabling 2FA for your Firefox Account can be found on support.mozilla.org. Once you’ve finished the set-up process, be sure to download or print your recovery codes and keep them in a safe place. If you ever lose access to your 2FA devices and get locked out of your account, you will need to provide one of your recovery codes to regain access. Misplacing these codes can lead to permanent loss of access to your account and your add-ons on AMO. Mozilla cannot restore your account if you have lost access to it.
If you only upload using the AMO external API, you can continue using your API keys and you will not be asked to provide the second factor.
The post Two-factor authentication required for extension developers appeared first on Mozilla Add-ons Blog.
|
|
The Firefox Frontier: Firefox’s Multiple Picture-in-Picture feature is the gametime assist you need for this month’s big games |
It has been a year since we were forced to stay home and recreate most of our life experiences with a screen between us. You may think you’ve reached peak … Read more
The post Firefox’s Multiple Picture-in-Picture feature is the gametime assist you need for this month’s big games appeared first on The Firefox Frontier.
|
|
Mozilla GFX: WebGPU progress |
WebGPU is a new standard for graphics and computing on the Web. Our team is actively involved in the design and specification process, while developing an implementation in Gecko. We’ve made a lot of progress since the last public update in Mozilla Hacks blog, and we’d like to share!

Trouble-shooting graphics issues can be tough without proper tools. In WebRender, we have the capture infrastructure that allows us to save the state of the rendering pipeline at any given moment to disk, and replayed independently in a standalone environment. In WebGPU, we integrated something similar, called API tracing. Instead of slicing through the state at any given time, it records every command executed by WebGPU implementation from the start. The produced traces are ultimately portable, they can be replayed in a standalone environment on a different system. This infrastructure helps us breeze through the issues, fixing them quickly and not letting them stall the progress.
Gecko implementation of WebGPU has to talk in multiple languages: WebIDL, in which the specification is written, C++ – the main language of Gecko, IPDL – the description of inter-process communication (IPC), and Rust, in which wgpu library (the core of WebGPU) is implemented. This variety caused a lot of friction when updating the WebIDL API to latest, it was easy to introduce bugs, which were hard to find later. This architectural problem has been mostly solved by making our IPC rely on Rust serde+bincode. This allows Rust logic on the content process side to communicate with Rust logic on the GPU process side with minimal friction. It was made possible by the change to Rust structures to use Cow types aggressively, which are flexible and efficient, even though we don’t use the “write” part of the copy-on-write semantics.
The API on the Web is required to be safe and portable, which is enforced by the validation logic. We’ve made a lot of progress in this area: wgpu now has a first-class concept of “error” objects, which is what normal objects become if their creation fails on the server side (the GPU process). We allow these error objects to be used by the content side, and at the same time it returns the errors to the GPU process C++ code, which routes them back to the content side. There, we are now properly triggering the “uncaptured error” events with actual error messages:
In a draw command, indexed:false indirect:false, caused by: vertex buffer 0 must be set
GPUValidationError
What this means for us, as well as the brave experimental users, is better robustness and safety, less annoying panics/crashes, and less time wasted on investigating issues. The validation logic is not yet comprehensive, there is a lot yet to be done, but the basic infrastructure is mostly in place. We validate the creation of buffers, textures, bind group layouts, pipelines, and we validate the encoded commands, including the compute and render pass operations. We also validate the shader interface, and we validate the basic properties of the shader (e.g. the types making sense). We even implement the logic to check the uniformity requirements of the control flow, ahead of the specification, although it’s new and fragile at the moment.
WebGPU Shading Language, or WGSL for short, is a new secure shading language for the Web, targeting SPIR-V, HLSL, and MSL on the native platforms. It’s exceptionally hard to support right now because of how young it is. The screenshot above was rendered with WGSL shaders in Firefox Nightly, you can get a feel of it by looking at the code.
Our recent update carried basic support for WGSL, using Naga library. The main code path in Gecko right now involves the following stages:
One of the areas of improvement here is related to SPIR-V. In the future, we don’t want to unconditionally route the shader translation through SPIR-V, and we don’t want to rely on SPIRV-Cross, which is currently a giant C++ dependency that is hard to secure. Instead, we want to generate the platform-specific shaders straight from Naga IR ourselves. This will drastically reduce the amount of code involved, cut down the dependencies, and make the shader generation faster and more robust, but it requires more work.
Another missing bit is shader sanitation. In order to allow shaders to execute safely on GPU, it’s not enough to enable the safety features of the underlying APIs. We also need to insert bound checks in the shader code, where we aren’t sure about resource bounds being respected. These changes will be very sensitive to performance of some of the heaviest GPU users, such as TFjs.
Most importantly, we need to start testing Gecko’s implementation on the conformance test suite (CTS) that is developed by WebGPU group. This would uncover most of the missing bits in the implementation, and will make it easier to avoid regressions in the near future. Hopefully, the API has stabilized enough today that we can all use the same tests.
There is a large community around the Rust projects involved in our implementation. We welcome anyone to join the fun, and are willing to mentor them. Please hop into a relevant Matrix room to chat:
https://mozillagfx.wordpress.com/2021/03/10/webgpu-progress/
|
|
Mozilla Attack & Defense: Insights into HTTPS-Only Mode |
In a recent academic publication titled HTTPS-Only: Upgrading all connections to https in Web Browsers (to appear at MadWeb – Measurements, Attacks, and Defenses for the Web) we present a new browser connection model which paves the way to an ‘https-by-default’ web. In this blogpost, we provide technical details about HTTPS-Only Mode’s upgrading mechanism and share data around the success rate of this feature. (Note that links to source code are perma-linked to a recent revision as of this blog post. More recent changes may have changed the location of the code in question.)
The fundamental security problem of the current browser practice of defaulting to use insecure http, instead of secure https, when initially connecting to a website, is that attackers can intercept the initial request to a website. Hijacking the initial request suffices for an attacker to perform a man-in-the-middle attack, which in turn allows the attacker to downgrade the connection, eavesdrop or modify data sent between client and server.
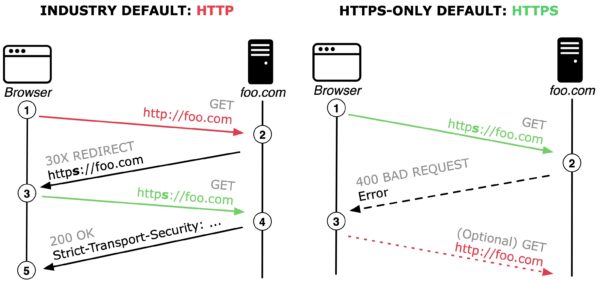
Left: The current standard behavior of browsers defaulting to http with a server reachable over https; Right: HTTPS-Only behaviour defaulting to https with fallback to http when a server is not reachable over https.
Industry-wide default Connection Model: Current best practice to counter the explained man-in-the-middle security risk primarily relies on HTTP Strict-Transport-Security (HSTS). However, HSTS does not solve the problems associated with performing the initial request in plain http. As illustrated in the above Figure (left), the current browser default is to first connect to foo.com using http (see 1). If the server follows best practice and implements HSTS, then the server responds with a redirect to the secure version of the website (see 2). After the next GET request (see 3) the server adds the HSTS response header (see 4), signalling that the server prefers https connections and the browser should always perform https requests to foo.com (see 5).
HTTPS-Only Connection Model: In contrast and as illustrated in the above Figure (right), the presented HTTPS-Only approach first tries to connect to the web server using https (see 1). Given that most popular websites support https, our upgrading algorithm commonly establishes a secure connection and starts loading content. In a minority of cases, connecting to the server using https fails and the server reports an error (see 2). The proposed HTTPS-Only Mode then prompts the user, explaining the security risk, to either abandon the request or to connect using http (see 3).
We designed HTTPS-Only Mode following the principle of Secure by Default which means that by default, our approach will upgrade all outgoing connections from http to https. Following this principle allows us to provide a future-proof implementation where exceptions to the rule require explicit annotation by setting the flag HTTPS_ONLY_EXEMPT.
Our proposed security-enhancing feature internally upgrades (a) top-level document loads as well as (b) all subresource loads (images, stylesheets, scripts) within a secure website by rewriting the scheme of a URL from http to https. Internally this upgrading algorithm is realized by consulting the function nsHTTPSOnlyUtils::ShouldUpgradeRequest().
Upgrading a top-level (document) request with HTTPS-Only entails uncertainties about the response that the browser needs to handle. For example, a non-responding firewall or a misconfigured or outdated server that fails to send a response can result in long timeouts. To mitigate this degradation of a users browsing experience, HTTPS-Only first sends a top-level request for https, and after a three second delay, if no response is received, sends an additional http background request by calling the function nsHTTPSOnlyUtils::PotentiallyFireHttpRequestToShortenTimout(). If the background http connection is established prior to the https connection, then this signal is a strong indicator that the https request will result in a timeout. In this case, the https request is canceled and the user is shown the HTTPS-Only Mode exception page.
In addition to comprehensively enforcing https for sub-resources, HTTPS-Only also accounts for WebSockets by consulting the function nsHTTPSOnlyUtils::ShouldUpgradeWebSocket().
Ultimately, HTTPS-Only also needs full integration with two critical browser security mechanisms related to subresource loads: (a) Mixed Content Blocker, and (b) Cross-Origin Resource Sharing (CORS). We adapt both security mechanisms by consulting nsHTTPSOnlyUtils::IsSafeToAcceptCORSOrMixedContent().
The HTTPS-Only approach specifically aims to ensure connections use the secure https protocol, where browsers traditionally would connect using the http protocol. To target this data set, we record information when HTTPS-Only Mode is able to upgrade a connection by rewriting the scheme of a URL from http to https and a load succeeds.
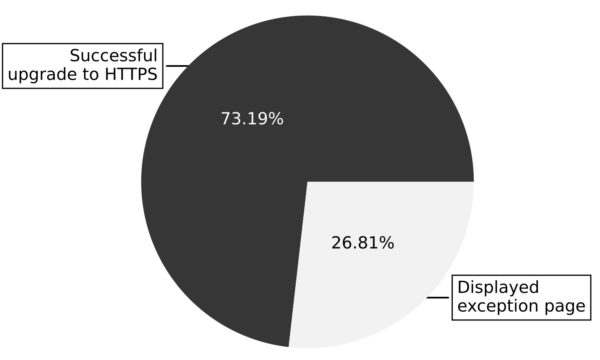
Attempts to upgrade top-level (document) legacy addresses from http to https via HTTPS-Only (data collected between Nov 17th and Dec. 17th 2020).
As illustrated in the Figure above, the HTTPS-Only mechanism successfully upgrades top-level (document) loads from http to https for more than 73% of legacy addresses. These 73% of successful upgrades originate from the user clicking legacy http links, or entering http (or even scheme-less) URLs in the address-bar, where the target website, fortunately, supports https.
Our observation that HTTPS-Only can successfully upgrade seven out of ten of top-level loads from http to https reflects a general migration of websites supporting https. At the same time, this fraction of successful upgrades of legacy addresses also confirms that web pages still contain a multitude of http-based URLs where browsers would traditionally establish an insecure connection.

Use of https for top-level (document) loads when HTTPS-Only is enabled (data collected between Nov 17th and Dec. 17th 2020).
As illustrated in the Figure above, our collected information shows that in 92.8% of cases the top-level URL is already https without any need to upgrade. We further see that HTTPS-Only users experienced a successful upgrade from http to https in 3.5% of the loads, such that, overall, 96.3% of page loads are secure. The remaining 3.7% of page loads are insecure, on websites for which the user has explicitly opted to allow insecure connections. Note that the total number of insecure top-level loads observed depends on how many pages a user visited on the website or websites they had exempted from HTTPS-Only.
Providing architectural insights into the security design of a system is crucial for truly working in the open. We hope that sharing technical details and the collected upgrading information allows contributors, hackers, and researchers to verify our claims or even build new research models on top of the provided insights.
https://blog.mozilla.org/attack-and-defense/2021/03/10/insights-into-https-only-mode/
|
|
Mike Hommey: 5 years ago, Firefox (re)entered Debian |
5 years ago today, I was declaring Iceweasel dead, and Firefox was making a come back in Debian. I hadn’t planned to make this post, and in fact, I thought it had been much longer. But coincidentally, I was binge-watching Mr. Robot recently, which prominently featured Iceweasel.
Mr. Robot is set in the year 2015, and I was surprised that Iceweasel was being used, which led me to search for that post where I announced Firefox was back… and realizing that we were close to the 5 years mark. Well, we are at the 5 years mark now.
I’d normally say time flies, but it turns out it hasn’t flown as much as I thought it did. I wonder if the interminable pandemic is to blame for that.
|
|
The Firefox Frontier: How one woman fired up her online business during the pandemic |
Sophia Keys started her ceramics business, Apricity Ceramics, five years ago. But it wasn’t until a global pandemic forced everyone to sign on at home and Screen Time Report Scaries … Read more
The post How one woman fired up her online business during the pandemic appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/sophia-keys-apricity-ceramics-woman-owned-online-business/
|
|
Mozilla Performance Blog: Performance Sheriff Newsletter (February 2021) |
|
|
Wladimir Palant: How Amazon Assistant lets Amazon track your every move on the web |
I recently noticed that Amazon is promoting their Amazon Assistant extension quite aggressively. With success: while not all browsers vendors provide usable extension statistics, it would appear that this extension has beyond 10 million users across Firefox, Chrome, Opera and Edge. Reason enough to look into what this extension is doing and how.
Here I must say that the privacy expectations for shopping assistants aren’t very high to start with. Still, I was astonished to discover that Amazon built the perfect machinery to let them track any Amazon Assistant user or all of them: what they view and for how long, what they search on the web, what accounts they are logged into and more. Amazon could also mess with the web experience at will and for example hijack competitors’ web shops.

Mind you, I’m not saying that Amazon is currently doing any of this. While I’m not done analyzing the code, so far everything suggests that Amazon Assistant is only transferring domain names of the web pages you visit rather than full addresses. And all website manipulations seem in line with the extension’s purpose. But since all extension privileges are delegated to Amazon web services, it’s impossible to make sure that it always works like this. If for some Amazon Assistant users the “hoover up all data” mode is switched on, nobody will notice.
On the first glance, Amazon Assistant is just the panel showing up when you click the extension icon. It will show you current Amazon deals, let you track your orders and manage lists of items to buy. So far very much confined to Amazon itself.
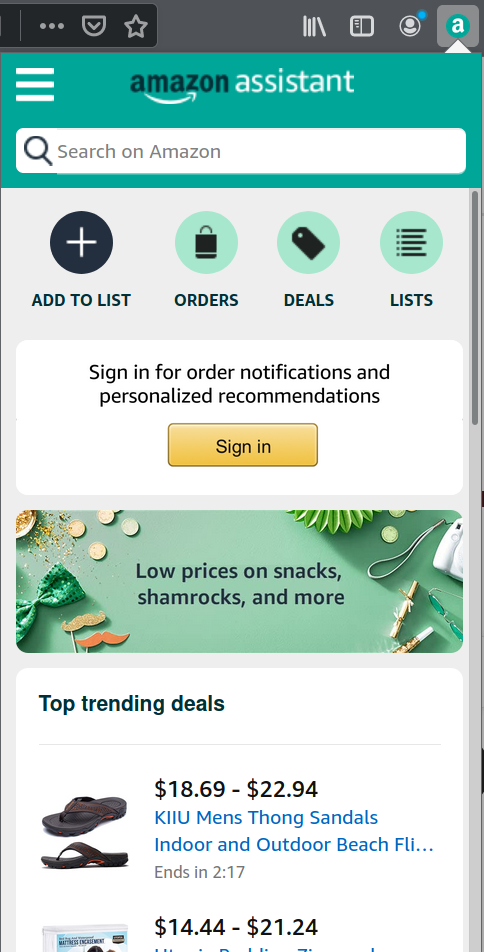
What’s not quite obvious: “Add to list” will attempt to recognize what product is displayed in the current browser tab. And that will work not only on Amazon properties. Clicking this button while on some other web shop will embed an Amazon Assistant into that web page and offer you to add this item to your Amazon wishlist.
But Amazon Assistant will become active on its own as well. Are you searching for “playstation” on Google? Amazon Assistant will show its message right on top of Google’s ads, because you might want to buy that on Amazon.
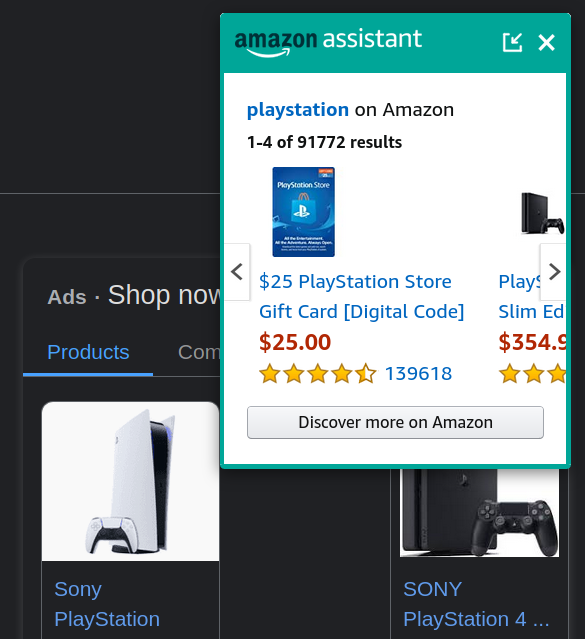
You will see similar messages when searching on eBay or other online shops.
So you can already guess that Amazon Assistant will ask Amazon web services what to do on any particular website: how to recognize searches, how to extract product information. There are just too many shops to keep all this information in the extension. As a side-effect that is certainly beneficial to Amazon’s business, Amazon will learn which websites you visit and what you search there. That’s your unavoidable privacy cost of this extension. But it doesn’t stop here.
Let’s first take a look at what this extension is allowed to do. That’s the permissions entry in the extension’s manifest.json file:
"permissions": [
"tabs",
"storage",
"http://*/*",
"https://*/*",
"notifications",
"management",
"contextMenus",
"cookies",This is really lots of privileges. First note http://*/* and https://*/*: the extension has access to each and every website (I cut off the long list of Amazon properties here which is irrelevant then). This is necessary if it wants to inject its content there. The tabs permission then allows recognizing when tabs are created or removed, and when a new page loads into a tab.
The storage permission allows the extension to keep persistent settings. One of these settings is called ubpv2.Identity.installationId and contains (you guessed it) a unique identifier for this Amazon Assistant installation. Even if you log out of Amazon and clear your cookies, this identifier will persist and allow Amazon to connect your activity to your identity.
Two other permissions are also unsurprising. The notifications permission presumably lets the extension display a desktop notification to keep you updated about your order status. The contextMenus permission lets it add an “Add to Amazon Lists” item to the browser’s context menu.
The cookies permission is unusual however. In principle, it allows the extension to access cookies on any website. Yet it is currently only used to access Amazon cookies in order to recognize when the user logs in. The same could be achieved without this privilege, merely by accessing document.cookie on an Amazon website (which is how the extension in fact does it in one case).
Even weirder is the management permission which is only requested by the Firefox extension but not the Chrome one. This permission gives an extension access to other browser extension and even allows uninstalling them. Requesting it is highly unusual and raises suspicions. Yet there is only code to call management.uninstallSelf() and management.getSelf(), the two function that don’t require this permission! And even this code appears to be unused.
Now it’s not unusual for extensions to request wide reaching privileges. It’s not even unusual to request privileges that aren’t currently used, prompting Google to explicity forbid this in their Chrome Web Store policy. The unusual part here is how almost all of these capabilities are transferred to Amazon web properties.
When you start looking into how the extension uses its privileges, it’s hard to overlook the fact that it appears to be an empty shell. Yes, there is a fair amount of code. But all of it is just glue code. Neither the extension’s user interface nor any of its logic is to be found anywhere. What’s going on? It gets clearer if you inspect the extension’s background page in Developer Tools:
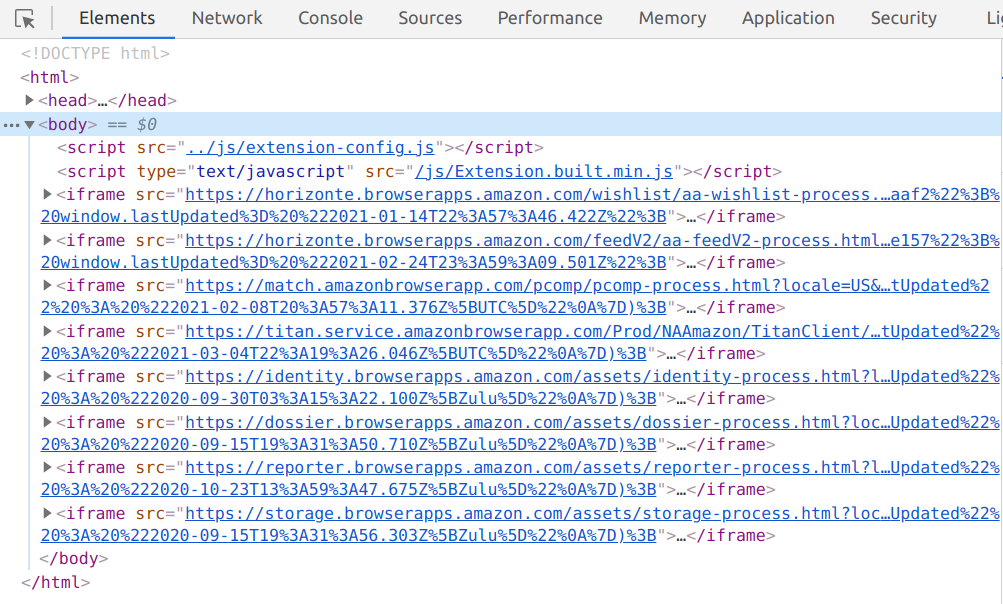
Yes, that’s eight remote frames loaded into the extension’s background page, all pointing to Amazon domains. And the ninth remote frame loads when you click the extension icon, it contains the user interface of the panel shown above. All these panels communicate with each other and the extension via Amazon’s internal UBP protocol, exchanging messages via window.postMessage().
How does the extension know what page to load in the frames and what these should be allowed to do? It doesn’t, this information is downloaded as FeatureManifest.js from an Amazon server. This file defines a number of “processes,” each with its list of provided and consumed APIs and events. And while the extension code makes sure that processes only access what they are allowed to access, this file on an Amazon web service sets the rules.
Here is what this file currently has to say about AAWishlistProcess, a particularly powerful process:
"AAWishlistProcess" : {
"manifestVersion" : "2015-03-26",
"manifest" : {
"name" : "AAWishlistProcess",
"version" : {"major" : 1, "minor" : 1, "build" : 1, "revision" : 1},
"enabled" : true,
"processType" : "Remote",
"configuration" : {
"url" : "https://horizonte.browserapps.amazon.com/wishlist/aa-wishlist-process.html",
"assetTag" : "window.eTag = \"e19e28ac-784e-4e22-8e2b-6d36a9d3aaf2\"; window.lastUpdated= \"2021-01-14T22:57:46.422Z\";"
},
"consumedAPIs" : {
"Identity" : [ "getAllWeblabTreatments", "getCustomerPreferences" ],
"Dossier" : [ "buildURLs" ],
"Platform" : [
"getPlatformInfo", "getUWLItem", "getActiveTabInfo", "createElement",
"createSandbox", "createSandboxById", "createLocalSandbox", "modifySandbox",
"showSandbox", "sendMessageToSandbox", "destroySandbox", "scrape",
"listenerSpecificationScrape", "applyStyle", "resetStyle", "registerAction",
"deregisterAction", "createContextMenuItem", "deleteAllContextMenuItems",
"deleteContextMenuItemById", "getCookieInfo", "bulkGetCookieInfo",
"getStorageValue", "putStorageValue", "deleteStorageValue", "publish"
],
"Reporter" : [ "appendMetricData" ],
"Storage" : [ "get", "put", "putIfAbsent", "delete" ]
},
"consumedEvents" : [
"Tabs.PageTurn", "Tabs.onRemoved", "Sandbox.Message.UBPSandboxMessage",
"Action.Message", "Platform.PlatformDataUpdate",
"Contextmenu.ItemClicked.AAWishlistProcess", "Identity.CustomerPreferencesUpdate",
"Gateway.AddToListClick"
],
"providedAPIs" : {
},
"providedEvents" : [ "Wishlist.update", "Storage.onChange.*", "Storage.onChange.*.*", "Storage.onChange.*.*.*", "Storage.onChange.*.*.*.*", "Storage.onChange.*.*.*.*.*", "Storage.onDelete.*", "Storage.onDelete.*.*", "Storage.onDelete.*.*.*", "Storage.onDelete.*.*.*.*", "Storage.onDelete.*.*.*.*.*" ],
"CTI" : {
"Category" : "AmazonAssistant",
"Type" : "Engagement",
"Item" : "Wishlist"
}
}
},The interesting consumed APIs are the ones belonging to Platform: that “process” is provided by the extension. So the extension lets this website among other things request information on the active tab, create context menu items, retrieve cookies and access extension’s storage.
We don’t have to speculate, it’s easy to try things out that this website is allowed to do. For this, change to the Console tab in Developer Tools and make sure aa-wishlist-process.html is selected as context rather than top. Now enter the following command making sure incoming messages are logged:
window.onmessage = event => console.log(JSON.stringify(event.data, undefined, 2));
Note: For me, console.log() didn’t work inside a background page’s frame on Firefox, so I had to do this on Chrome.
Now let’s subscribe to the Tabs.PageTurn event:
parent.postMessage({
mType: 0,
source: "AAWishlistProcess",
payload: {
msgId: "test",
mType: "rpcSendAndReceive",
payload: {
header: {
messageType: 2,
name: "subscribe",
namespace: "PlatformHub"
},
data: {
args: {
eventName: "Tabs.PageTurn"
}
}
}
}
}, "*");
A message from PlatformHub comes in indicating that the call was successful ("error": null). Good, if we now open https://example.com/ in a new tab… Three messages come in, first one indicating that the page is loading, second that its title is now known and finally the third one indicating that the page loaded:
{
"mType": 0,
"source": "PlatformHub",
"payload": {
"msgId": "3eee7d9b-ee2b-4f1d-be92-693119b5654c",
"mType": "rpcSend",
"payload": {
"header": {
"messageType": 2,
"name": "publish",
"namespace": "PlatformHub",
"sourceProcessName": "Platform",
"extensionStage": "prod"
},
"data": {
"args": {
"eventName": "Tabs.PageTurn",
"eventArgs": {
"tabId": "31",
"url": "http://example.com/",
"status": "complete",
"title": "Example Domain"
}
}
}
}
}
}Yes, that’s essentially the tabs.onUpdated extension API exposed to a web page. The Tabs.onRemoved event works similarly, that’s tabs.onRemoved extension API exposed.
Now let’s try calling Platform.getCookieInfo:
parent.postMessage({
mType: 0,
source: "AAWishlistProcess",
payload: {
msgId: "test",
mType: "rpcSendAndReceive",
payload: {
header: {
messageType: 1,
name: "getCookieInfo",
namespace: "Platform"
},
data: {
args: {
url: "https://www.google.com/",
cookieName: "CONSENT"
}
}
}
}
}, "*");
A response comes in:
{
"mType": 0,
"source": "PlatformHub",
"payload": {
"msgId": "fefc2939-70c3-4138-8bb6-a6120b57e563",
"mType": "rpcReply",
"payload": {
"cookieFound": true,
"cookieInfo": {
"name": "CONSENT",
"domain": ".google.com",
"value": "PENDING+376",
"path": "/",
"session": false,
"expirationDate": 2145916800.121322
}
},
"t": 1615035509370,
"rMsgId": "test",
"error": null
}
}Yes, that’s the CONSENT cookie I have on google.com. So that’s pretty much cookies.get() extension API available to this page.
Here are the Platform APIs that the extension allows Amazon web services to call:
| Call name | Purpose |
|---|---|
| getPlatformInfo getFeatureList |
Retrieves information about the extension and supported functionality |
| openNewTab | Opens a page in a new tab, not subject to the pop-up blocker |
| removeTab | Closes a given tab |
| getCookieInfo bulkGetCookieInfo |
Retrieves cookies for any website |
| createDesktopNotification | Displays a desktop notification |
| createContextMenuItem deleteAllContextMenuItems deleteContextMenuItemById |
Manages extension’s context menu items |
| renderButtonText | Displays a “badge” on the extension’s icon (typically a number indicating unread messages) |
| getStorageValue putStorageValue deleteStorageValue setPlatformCoreInfo clearPlatformInfoCache updatePlatformLocale isTOUAccepted acceptTermsOfUse setSmileMode setLocale handleLegacyExternalMessage |
Accesses extension storage/settings |
| getActiveTabInfo | Retrieves information about the current tab (tab ID, title, address) |
| createSandbox createLocalSandbox createSandboxById modifySandbox showSandbox sendMessageToSandbox instrumentSandbox getSandboxAttribute destroySandbox |
Injects a frame (any address) into any tab and communicates with it |
| scrape listenerSpecificationScrape getPageReferrer getPagePerformanceTimingData getPageLocationData getPageDimensionData getUWLItem |
Extracts data from any tab using various methods |
| registerAction deregisterAction |
Listens to an event on a particular element in any tab |
| applyStyle resetStyle |
Sets CSS styles on a particular element in any tab |
| instrumentWebpage | Queries information about the page in any tab, clicks elements, sends input and keydown events |
| createElement | Creates an element in any tab with given ID, class and styles |
| closePanel | Closes the extension’s drop-down panel |
| reloadExtension | Reloads the extension, installing any pending updates |
And here are the interesting events it provides:
| Event name | Purpose |
|---|---|
| Tabs.PageTurn | Triggered on tab changes, contains tab ID, address, loading status, title |
| Tabs.onRemoved | Triggered when a tab is closed, contains tab ID |
| WebRequest.onBeforeRequest WebRequest.onBeforeSendHeaders WebRequest.onCompleted |
Correspond to webRequest API listeners (this functionality is currently inactive, the extension has no webRequest permission) |
Given extension’s privileges, not much is missing here. The management permission is unused as I mentioned before, so listing installed extensions isn’t possible. Cookie access is read-only, setting cookies isn’t possible. And general webpage access appears to stop short of arbitrary code execution. But does it?
The createSandbox call can be used with any frame address, no checks performed. This means that a javascript: address is possible as well. So if we run the following code in the context of aa-wishlist-process.html:
parent.postMessage({
mType: 0,
source: "AAWishlistProcess",
payload: {
msgId: "test",
mType: "rpcSendAndReceive",
payload: {
header: {
messageType: 1,
name: "createSandbox",
namespace: "Platform"
},
data: {
args: {
tabId: 31,
sandboxSpecification: {
proxy: "javascript:alert(document.domain)//",
url: "test",
sandboxCSSSpecification: "none"
}
}
}
}
}
}, "*");
Yes, a message pops up indicating that this successfully executed JavaScript code in the context of the example.com domain. So there is at least one way for Amazon services to do anything with the web pages you visit. This particular attack worked only on Chrome however, not on Firefox.
As I already pointed out in a previous article, it’s hard to build a shopping assistant that wouldn’t receive all its configuration from some server. This makes shopping assistants generally a privacy hazard. So maybe this privacy and security disaster was unavoidable?
No, for most part this isn’t the case. Amazon’s remote “processes” aren’t some server-side magic. They are merely static JavaScript files running in a frame. Putting these JavaScript files into the extension would have been possible with almost no code changes. And it would open up considerable potential for code simplification and performance improvements if Amazon is interested.
This design was probably justified with “we need this to deploy changes faster.” But is it really necessary? The FeatureManifest.js file mentioned above happens to contain update times of the components. Out of nine components, five had their last update five or six months ago. One was updated two months ago, another a month ago. Only two were updated recently (four and twelve days ago).
It seems that these components are maintained by different teams who work on different release schedules. But even if Amazon cannot align the release schedules here, this doesn’t look like packaging all the code with the extension would result in unreasonably frequent releases.
Why does it make a difference where this code is located? It’s the same code doing the same things, whether it is immediately bundled with the extension or whether the extension merely downloads it from the web and gives it access to the necessary APIs, right?
Except: there is no way of knowing that it is always the same code. For example, there isn’t actually a single FeatureManifest.js file on the web but rather 15 of them, depending on your language. Similarly, there are 15 versions of the JavaScript files it references. Presumably, this is merely about adjusting download servers to the ones closer to you. The logic in all these files should be exactly identical. But I don’t have the resources to verify this, and maybe Amazon is extracting way more data for users in Brazil for example.
And this is merely what’s visible from the outside. What if some US government agency asks Amazon for the data of a particular user? Theoretically, Amazon can serve up a modified FeatureManifest.js file for that user only, one that gives them way more access. And this attack wouldn’t leave any traces whatsoever. No extension release where malicious code could theoretically be discovered. Nothing.
That’s the issue here: Amazon Assistant is an extension with very extensive privileges. How are these being used? If all logic were contained in the extension, we could analyze it. As things are right now however, all we can do is assuming that everybody gets the same logic. But that’s really at Amazon’s sole discretion.
There is another aspect here. Even the regular functionality of Amazon Assistant is rather invasive, with the extension letting Amazon know of every website you visit as well as some of your search queries. In theory, the extension has settings to disable this functionality. In practice, it’s impossible to verify that the extension will always respect these settings.
If we are talking about legal boundaries such as GDPR, Amazon provides a privacy policy for Amazon Assistant. I’m no expert, but my understanding is that this meets the legal requirements, as long as what Amazon does matches this policy. For the law, it doesn’t matter what Amazon could do.
That’s different for browser vendors however who have an interest in keeping their extensions platform secure. Things are most straightforward for Mozilla, their add-on policies state:
Add-ons must be self-contained and not load remote code for execution
While, technically speaking, no remote code is being executed in extension context here, delegating all extension privileges to remote code makes no difference in practice. So Amazon Assistant clearly violates Mozilla’s policies, and we can expect Mozilla to enforce their policies here. With Honey, another shopping assistant violating this rule the enforcement process is already in its fifth month, and the extension is still available on Mozilla Add-ons without any changes. Well, maybe at some point…
With Chrome Web Store things are rather fuzzy. The recently added policy states:
Your extension should avoid using remote code except where absolutely necessary. Extensions that use remote code will need extra scrutiny, resulting in longer review times. Extensions that call remote code and do not declare and justify it using the field shown above will be rejected.
This isn’t a real ban on remote code. Rather, remote code can be used where “absolutely necessary.” Extension authors then need to declare and justify remote code. So in case of Amazon Assistant there are two possibilities: either the developers declared this usage of remote code and Google accepted it. Or they didn’t declare it, and Google didn’t notice remote code being loaded here. There is no way for us to know which is true, and so no way of knowing whether Google’s policies are being violated. This in turn means that there is no policy violation to be reported, we can only hope for Google to detect a policy violation on their own, something that couldn’t really be relied upon in the past.
Opera again is very clear in their Acceptance Criteria:
No external JavaScript is allowed. All JavaScript code must be contained in the extension. External APIs are ok.
Arguably, what we have here is way more than “external APIs.” So Amazon Assistant violates Opera’s policies as well and we can expect enforcement action here.
Finally, there is Microsoft Edge. The only related statement I could find in their policies reads:
For example, your extension should not download a remote script and subsequently run that script in a manner that is not consistent with the described functionality.
What exactly is consistent with the described functionality? Is Amazon Assistant delegating its privileges to remote scripts consistent with its description? I have really no idea. Not that there is a working way of reporting policy violations to Microsoft, so this is largely a theoretical discussion.
Amazon Assistant extension requests a wide range of privileges in your browser. This in itself is neither untypical nor unjustified (for most part). However, it then provides access to these privileges to several Amazon web services. In the worst case, this allows Amazon to get full information on the user’s browsing behavior, extract information about accounts they are logged into and even manipulate websites in an almost arbitrary way.
Amazon doesn’t appear to make use of these possibilities beyond what’s necessary for the extension functionality and covered by their privacy policy. With web content being dynamic, there is no way of ensuring this however. If Amazon is spying on a subgroup of their users (be it out of their accord or on behalf of some government agency), this attack would be almost impossible to detect.
That’s the reason why the rules for Mozilla Add-ons and Opera Add-ons websites explicitly prohibit such extension design. It’s possible that Chrome Web Store and Microsoft Store policies are violated as well here. We’ll have to see which browser vendors take action.
https://palant.info/2021/03/08/how-amazon-assistant-lets-amazon-track-your-every-move-on-the-web/
|
|
Tantek Celik: One Year Since The #IndieWeb Homebrew Website Club Met In Person And Other Last Times |
A year ago yesterday (2020-03-04) we hosted the last in-person Homebrew Website Club meetups in Nottingham (by Jamie Tanna in a caf'e) and San Francisco (by me at Mozilla).
Normally I go into the office on Wednesdays but I had worked from home that morning. I took the bus (#5736) inbound to work in the afternoon, the last time I rode a bus. I setup a laptop on the podium in the main community room to show demos on the displays as usual.
Around 17:34 we kicked off our local Homebrew Website Club meetup with four of us which grew to seven before we took a photo. As usual we took turns taking notes in IRC during the meetup as participants demonstrated their websites, something new they had gotten working, ideas being developed, or inspiring independent websites they’d found.
Can you see the joy (maybe with a little goofiness, a little seriousness) in our faces?

We wrapped up the meeting, and as usual a few (or in this case two) of us decided to grab a bite and keep chatting. I did not even consider the possibility that it would be the last time I would see my office for over a year (still haven’t been back), and left my desk upstairs in whatever condition it happened to be. I remember thinking I’d likely be back in a couple days.
We walked a few blocks to Super Duper Burgers on Mission near Spear. That would be the last time I went to that Super Duper Burgers. Glad I decided to indulge in a chocolate milkshake.

Afterwards Katherine and I went to the Embarcadero MUNI station and took the outbound MUNI N-Judah light rail. I distinctly remember noticing people were quieter than usual on the train. There was a palpable sense of increased anxiety.

Instinctually I felt compelled to put on my mask, despite only two cases of Covid having been reported in San Francisco (of course now we know that it was already spreading, especially by the asymptomatic, undetected in the community). Later that night the total reported would be 6.
Yes I was carrying a mask in March of 2020. Since the previous 2+ years of seasonal fires and subsequent unpredictable days of unbreathable smoke in the Bay Area, I’ve traveled with a compact N-95 respirator in my backpack.
Side note: the CDC had yet to recommend that people wear masks. However I had been reading and watching enough global media to know that the accepted practice and recommendation in the East was quite different. It seemed people in Taiwan, China, and Hong Kong were already regularly wearing masks (including N95 respirators) in close public quarters such as transit. Since SARS had hit those regions much harder than the U.S. I figured they had learned from the experience and thus it made sense to follow their lead, not the CDC (which was already under pressure from a criminally incompetent neglectful administration to not scare people). Turned out my instinct (and analysis and conclusions based on watching & reading global behaviors) was more correct than the U.S. CDC at the time (they eventually got there).
Shortly after the train doors closed I donned my mask and checked the seals. The other useful advantage of a properly fitted N95 is that it won’t (shouldn’t) let in any funky public transit smells (perfume, patchouli, or worse), like none of it. No one blinked at seeing someone put on a mask.
We reached our disembarkation stop and stepped off. I put my mask away. We hugged and said our goodbyes. Didn’t think it would be the last time I’d ride MUNI light rail. Or hug a friend without a second thought.
https://tantek.com/2021/064/b1/one-year-since-homebrew-website-club
|
|
The Firefox Frontier: Firefox B!tch to Boss extension takes the sting out of hostile comments directed at women online |
A great swathe of the internet is positive, a place where people come together to collaborate on ideas, discuss news and share moments of levity and sorrow, too. But there’s … Read more
The post Firefox B!tch to Boss extension takes the sting out of hostile comments directed at women online appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-b-tch-to-boss-extension/
|
|
Robert Kaiser: Mozilla History Talk @ FOSDEM |
https://home.kairo.at/blog/2021-03/mozilla_history_talk_fosdem
|
|
This Week In Rust: This Week in Rust 380 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
No newsletters this week.
impl blocks are kinda like macros...This week's crate is camino, a library with UTF-8 coded paths mimicking std::os::Path's API.
Thanks to piegames for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No calls for participation this week
If you are a Rust project owner and are looking for contributors, please submit tasks here.
402 pull requests were merged in the last week
returning tail expressions that match return typeRefCells from DocContextError on Arcptr::write constchar and u8 methods constchar::to_ascii_lowercasestr_split_onceslice::fill with Copy type and u8/i8/boolfuture::SelectAll::into_innerfutures_util::stream::SelectAll::push should use &selfCARGO_TARGET_DIR is an empty string[env] section in .cargo/config.tomlQuiet week, a couple regressions and several nice improvements.
Triage done by @simulacrum. Revision range: 301ad8..edeee
2 Regressions, 3 Improvements, 0 Mixed
0 of them in rollups
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
doc(include)If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Crown
Polymath
Tweede golf
Tweet us at @ThisWeekInRust to get your job offers listed here!
It's a great example of the different attitudes of C/C++ and Rust: In C/C++ something is correct when someone can use it correctly, but in Rust something is correct when someone can't use it incorrectly.
Thanks to Vlad Frolov for the suggestion.
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2021/03/03/this-week-in-rust-380/
|
|
Andrew Halberstadt: DevOps at Mozilla |
I first joined Mozilla as an intern in 2010 for the “Tools and Automation Team” (colloquially called the “A-Team”). I always had a bit of difficulty describing our role. We work on tests. But not the tests themselves, the the thing that runs the tests. Also we make sure the tests run when code lands. Also we have this dashboard to view results, oh and also we do a bunch of miscellaneous developer productivity kind of things. Oh and sometimes we have to do other operational type things as well, but it varies.
Over the years the team grew to a peak of around 25 people and the A-Team’s responsibilities expanded to include things like the build system, version control, review tools and more. Combined with Release Engineering (RelEng), this covered almost all of the software development pipeline. The A-Team was eventually split up into many smaller teams. Over time those smaller teams were re-org’ed, split up further, merged and renamed over and over again. Many labels were applied to the departments that tended to contain those teams. Labels like “Developer Productivity”, “Platform Operations”, “Product Integrity” and “Engineering Effectiveness”.
Interestingly, from 2010 to present, one label that has never been applied to any of these teams is “DevOps”.
|
|
Andrew Halberstadt: A Better Terminal for Mozilla Build |
If you’re working with mozilla-central on Windows and followed the official
documentation, there’s a good
chance the MozillaBuild shell is running in the default cmd.exe console. If you’ve spent any
amount of time in this console you’ve also likely noticed it leaves a bit to be desired. Standard
terminal features such as tabs, splits and themes are missing. More importantly, it doesn’t render
unicode characters (at least out of the box).
Luckily Microsoft has developed a modern terminal that can replace cmd.exe, and getting it set up with MozillaBuild shell is simple.
|
|
Mozilla Privacy Blog: India’s new intermediary liability and digital media regulations will harm the open internet |
Last week, in a sudden move that will have disastrous consequences for the open internet, the Indian government notified a new regime for intermediary liability and digital media regulation. Intermediary liability (or “safe harbor”) protections have been fundamental to growth and innovation on the internet as an open and secure medium of communication and commerce. By expanding the “due diligence” obligations that intermediaries will have to follow to avail safe harbor, these rules will harm end to end encryption, substantially increase surveillance, promote automated filtering and prompt a fragmentation of the internet that would harm users while failing to empower Indians. While many of the most onerous provisions only apply to “significant social media intermediaries” (a new classification scheme), the ripple effects of these provisions will have a devastating impact on freedom of expression, privacy and security.
As we explain below, the current rules are not fit-for-purpose and will have a series of unintended consequences on the health of the internet as a whole:
The final rules do contain some improvements from the 2011 original law and the 2018 draft such as limiting the scope of some provisions to significant social media intermediaries, user and public transparency requirements, due process checks and balances around traceability requests, limiting the automated filtering provision and an explicit recognition of the “good samaritan” principle for voluntary enforcement of platform guidelines. In their overall scope, however, they are a dangerous precedent for internet regulation and need urgent reform.
Ultimately, illegal and harmful content on the web, the lack of sufficient accountability and substandard responses to it undermine the overall health of the internet and as such, are a core concern for Mozilla. We have been at the forefront of these conversations globally (such as the UK, EU and even the 2018 version of this draft in India), pushing for approaches that manage the harms of illegal content online within a rights-protective framework. The regulation of speech online necessarily calls into play numerous fundamental rights and freedoms guaranteed by the Indian constitution (freedom of speech, right to privacy, due process, etc), as well as crucial technical considerations (‘does the architecture of the internet render this type of measure possible or not’, etc). This is a delicate and critical balance, and not one that should be approached with blunt policy proposals.
These rules are already binding law, with the provisions for significant social media intermediaries coming into force 3 months from now (approximately late May 2021). Given the many new provisions in these rules, we recommend that they should be withdrawn and be accompanied by wide ranging and participatory consultations with all relevant stakeholders prior to notification.
The post India’s new intermediary liability and digital media regulations will harm the open internet appeared first on Open Policy & Advocacy.
|
|






