Ryan Harter: Intentional Documentation |
Randy Au has a great post on documentation for data scientists here: Let's get intentional about documentation. Take a look, it's worth a read.
I've been able to find some decent guides for writing documentation but they're usually targeted at engineers. That's a shame. Data scientists have significantly different constraints …
|
|
Mozilla Addons Blog: More Recommended extensions added to Firefox for Android Nightly |
 As we mentioned recently, we’re adding Recommended extensions to Firefox for Android Nightly as a broader set of APIs become available to accommodate more add-on functionality. We just updated the collection with some new Recommended extensions, including…
As we mentioned recently, we’re adding Recommended extensions to Firefox for Android Nightly as a broader set of APIs become available to accommodate more add-on functionality. We just updated the collection with some new Recommended extensions, including…
Mobile favorites Video Background Play Fix (keeps videos playing in the background even when you switch tabs) and Google Search Fixer (mimics the Google search experience on Chrome) are now in the fold.
Privacy related extensions FoxyProxy (proxy management tool with advanced URL pattern matching) and Bitwarden (password manager) join popular ad blockers Ghostery and AdGuard.
Dig deeper into web content with Image Search Options (customizable reverse image search tool) and Web Archives (view archived web pages from an array of search engines). And if you end up wasting too much time exploring images and cached pages you can get your productivity back on track with Tomato Clock (timed work intervals) and LeechBlock NG (block time-wasting websites).
The new Recommended extensions will become available for Firefox for Android Nightly on 26 September, If you’re interested in exploring these new add-ons and others on your Android device, install Firefox Nightly and visit the Add-ons menu. Barring major issues while testing on Nightly, we expect these add-ons to be available in the release version of Firefox for Android in November.
The post More Recommended extensions added to Firefox for Android Nightly appeared first on Mozilla Add-ons Blog.
|
|
Data@Mozilla: Data Publishing @ Mozilla |
Mozilla’s history is steeped in openness and transparency – it’s simply core to what we do and how we see ourselves in the world. We are always looking for ways to bring our mission to life in ways that help create a healthy internet and support the Mozilla Manifesto. One of our commitments says “We are committed to an internet that elevates critical thinking, reasoned argument, shared knowledge, and verifiable facts”.
To this end, we have spent a good amount of time considering how we can publicly share our Mozilla telemetry data sets – it is one of the most simple and effective ways we can enable collaboration and share knowledge. But, only if it can be done safely and in a privacy protecting, principled way. We believe we’ve designed a way to do this and we are excited to outline our approach here.
Making data public not only allows us to be transparent about our data practices, but directly demonstrates how our work contributes to our mission. Having a publicly available methodology for vetting and sharing our data demonstrates our values as a company. It will also enable other research opportunities with trusted scientists, analysts, journalists, and policymakers in a way that furthers our efforts to shape an internet that benefits everyone.
We want our data publishing review process, as well as our review decisions to be public and understandable, similar to our Mozilla Data Collection program. To that end, our full dataset publishing policy and details about what considerations we look at before determining what is safe to publish can be found on our wiki here. Below is a summary of the critical pieces of that process.
The goal of our data publishing process is to:
Having a dataset published requires filling out a publicly available request on Bugzilla. Requesters will answer a series of questions, including information about aggregation levels, data collection categories, and dimensions or metrics that include sensitive data.
A data steward will review the bug request. They will help ensure the questions are correctly answered and determine if the data can be published or whether it requires review by our Trust & Security or Legal teams.
When a request is approved, our telemetry data engineering team will:
Finally, once the dataset is published, we’ll announce it on the Data @ Mozilla blog. It will also be added to https://public-data.telemetry.mozilla.org/
Questions? Contact us at publicdata@mozilla.com
https://blog.mozilla.org/data/2020/09/25/data-publishing-mozilla/
|
|
Data@Mozilla: This Week in Glean: glean-core to Wasm experiment |
(“This Week in Glean” is a series of blog posts that the Glean Team at Mozilla is using to try to communicate better about our work. They could be release notes, documentation, hopes, dreams, or whatever: so long as it is inspired by Glean.)
All “This Week in Glean” blog posts are listed in the TWiG index.
In the past week Alessio, Mike, Hamilton and I got together for the Glean.js workweek. Our purpose was to build a proof-of-concept of a Glean SDK that works on Javascript environments. You can expect a TWiG in the next few weeks about the outcome of that. Today I am going to talk about something that I tried out in preparation for that week: attempting to compile glean-core to Wasm.
The glean-core is the heart of the Glean SDK where most of the logic and functionality of Glean lives. It is written in Rust and communicates with the language bindings in C#, Java, Swift or Python through an FFI layer. For a comprehensive overview of the Glean SDKs architecture, please refer to Jan-Erik’s great blog post and talk on the subject.
From the WebAssembly website:
“WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server applications.”
Or, from Lin Clark’s “A cartoon intro to WebAssembly”:
“WebAssembly is a way of taking code written in programming languages other than JavaScript and running that code in the browser.”
On the Glean team we make an effort to move as much of the logic as possible to glean-core, so that we don’t have too much code duplication on the language bindings and guarantee standardized behaviour throughout all platforms.
Since that is the case, it was counterintuitive for me, that when we set out to build a version of Glean for the web, we wouldn’t rely on the same glean-core as all our other language bindings. The hypothesis was: let’s make JavaScript just another language binding, by making our Rust core compile to a target that runs on the browser.
Rust is notorious for making an effort to have a great Rust to Wasm experience, and the Rust and Webassembly working group has built awesome tools that make boilerplate for such projects much leaner.
Since this was my first try in doing anything Wasm, I started by following MDN’s guide “Compiling from Rust to WebAssembly”, but instead of using their example “Hello, World!” Rust project, I used glean-core.
From that guide I learned about wasm-pack, a tool that deals with the complexities of compiling a Rust crate to Wasm and wasm-bindgen a tool that exposes, among many other things, the #[wasm_bindgen] attribute which, when added to a function, will make that function accessible from Javascript.
The first thing that was obvious, was that it would be much harder to try and compile glean-core directly to Wasm. Passing complex types to it has many limitations and I was not able to add the #[wasm_bindgen] attribute to trait objects or structs that contain trait objects or lifetime annotations. I needed a simpler API surface to make the connection between Rust and Javascript. Fortunately, I had that in hand: glean-ffi.
Our FFI crate exposes functions that rely on a global Glean singleton and have relatively simple signatures. These functions are the ones accessed by our language bindings through a C FFI. Most of the Rust complex structures are hidden by this layer from the consumers.
Perfect! I proceeded to add the #[wasm_bindgen] attribute to one of our entrypoint functions: glean_initialize. This uncovered a limitation I didn’t know about: you can’t add this attribute to functions that are unsafe, which unfortunately this one is.
My assumption that I would be able to just expose the API of glean-ffi to Javascript by compiling it to Wasm without making any changes to it was not holding up. I would have to go through some refactoring to make that work. But until now, I hadn’t gotten to the actual compilation step, the error I was getting was a syntax error. I wanted to go through compilation and see if that completed before diving into any refactoring work. I just removed the #[wasm_bindgen] attribute for now and made a new attempt at compiling.
Now I got a new error. Progress! If you clone the Glean repository, install wasm-pack, and run wasm-pack build inside the glean-core/ffi/ folder right now, you are bound to get this same error and here is one important excerpt of it:
<...> fatal error: 'sys/types.h' file not found cargo:warning=#includetypes.h> cargo:warning= ^~~~~~~~~~~~~ cargo:warning=1 error generated. exit code: 1 --- stderr error occurred: Command "clang" "-Os" "-ffunction-sections" "-fdata-sections" "-fPIC" "--target=wasm32-unknown-unknown" "-Wall" "-Wextra" "-DMDB_IDL_LOGN=16" "-o" "<...>/target/wasm32-unknown-unknown/release/build/lmdb-rkv-sys-5e7282bb8d9ba64e/out/mdb.o" "-c" "<...>/.cargo/registry/src/github.com-1ecc6299db9ec823/lmdb-rkv-sys-0.11.0/lmdb/libraries/liblmdb/mdb.c" with args "clang" did not execute successfully (status code exit code: 1)
One of glean-core’s dependencies is rkv a storage crate we use for persisting metrics before they are collected and sent in pings. This crate depends on LMDB which is written in C, thus the clang error.
I do not have extensive experience in writing C/C++ programs, so this was not familiar to me. I figured out that the file this error points to as “not found”,
Internet searching pointed me to wasi-libc, a libc for WebAssembly programs. Promising! With this, I retried compiling glean-ffi to Wasm. I just needed to run the build command with added flags:
CFLAGS="--sysroot=/path/to/the/newly/built/wasi-libc/sysroot" wasm-pack build
This didn’t work immediately and the error messages told me to add some extra flags to the command, which I did without thinking much and the final command is:
CFLAGS="--sysroot=/path/to/wasi-sdk/clone/share/wasi-sysroot -D_WASI_EMULATED_MMAN -D_WASI_EMULATED_SIGNAL" wasm-pack build
I would advise the reader now not to get too excited. This command still doesn’t work. It will return yet another set of errors and warnings, mostly related to “usage of undeclared identifiers” or “implicit declaration of functions”. Most of the identifiers that were erroing started with the pthread_ prefix, which reminded me of something that I read on the wasi-sdk, a toolkit for compiling C programs to WebAssembly that includes wasi-libc, README section:
“Specifically, WASI does not yet have an API for creating and managing threads yet, and WASI libc does not yet have pthread support”.
That was it. I was done with trying to approach the problem of compiling glean-core to Wasm “as is” and I decided to try another way. I could try to abstract away our usage of rkv so that depending on it didn’t block compilation to Wasm, but that is way too big a refactoring task that I considered it a blocker for this experiment.
After learning that it would require way too much refactoring of glean-core and glean-ffi to get them to compile to Wasm, I decided to try a different approach and just get a small self contained part of glean-core and compile that to Wasm.
Earlier this year I had a small taste of trying to rewrite part of glean-core in Javascript for the distribution simulators that we added to The Glean Book. To make the simulators work I essentially had to reimplement histograms code and part of the distribution metrics code in Javascript.
The histograms code is very self contained so it was a perfect candidate to try and single out for this experiment. I did just that and I was actually able to get it to not error fairly quickly as a standalone thing (you can check out the histogram code on the glean-to-wasm repo vs. the histogram code on the Glean repo).
After getting this to work I created three accumulation functions that would mimic how each one of the distribution metric types work. These functions would then be exposed to Javascript. The resulting API looks like this:
#[wasm_bindgen]
pub fn accumulate_samples_custom_distribution(
range_min: u32,
range_max: u32,
bucket_count: usize,
histogram_type: i32,
samples: Vec,
) -> String
#[wasm_bindgen]
pub fn accumulate_samples_timing_distribution(
time_unit: i32,
samples: Vec
) -> String
#[wasm_bindgen]
pub fn accumulate_samples_memory_distribution(
memory_unit: i32,
samples: Vec
) -> String
Each one of these functions creates a histogram, accumulates the given samples to this histogram and returns the resulting histogram as a JSON encoded string. I tried getting them to return HashMap at first, but that is not supported.
For this I was still following MDN’s guide “Compiling from Rust to WebAssembly”, which I can’t recommend enough, and after I got my Rust code to compile to Wasm it was fairly straightforward to call the functions imported from the Wasm module inside my Javascript code.
Here is a little taste of what that looked like:
import("glean-wasm").then(Glean => {
const data = JSON.parse(
Glean.accumulate_samples_memory_distribution(
unit, // A Number value between 0 - 3
values // A BigUint64Array with the sample values
)
)
// data>
})
The only hiccup I ran into was that I needed to change my code to use the BigInt number type instead of the default Number type from Javascript. That is necessary because, in Rust, my functions expect a u64 and BigInt is the type that maps to that from Javascript.
This code can be checked out at: https://github.com/brizental/glean-wasm-experiment
And there is a demo of it working in: https://glean-wasm.herokuapp.com/
This was a very fun experiment, but does it validate my initial hypothesis:
Should we compile glean-core to Wasm and have Javascript be just another language binding?
We definitely can do that. Even though my first try was not concluded, if we abstract away all the dependencies that we have that can’t be compiled to Wasm, refactor the unsafe functions out and all other possible roadblocks that we find other than these, we can do it. The effort that would take though, I believe is not worth it. It would take us much less time to rewrite glean-core’s code in Javascript. Spoiler alert for our upcoming TWiG about the Glean.js workweek, but in just a week we were able to get a functioning prototype of that.
Our requirements for a Glean software for the web are different from our requirements for a native version of Glean. Different enough that the burden of maintenance for two versions of glean-core, one in Rust and another in Javascript, is probably smaller than the amount of work and hacks it would take to build a single version that attends both platforms.
Another issue is compatibility, Wasm is very well supported but there are environments that still don’t have support for it. It would be suboptimal if we went through the trouble of changing glean-core for it to compile to Wasm and then still had to make a Javascript only version for compatibility reasons.
My conclusion is that although we can compile glean-core to Wasm, it doesn’t mean that we should do that. The advantages of having a single source of truth for the Glean SDK are very enticing, but at the moment it would be more practical to rewrite something specific for the web.
https://blog.mozilla.org/data/2020/09/25/this-week-in-glean-glean-core-to-wasm-experiment/
|
|
Jeff Klukas: The Nitty-Gritty of Moving Data with Apache Beam |
Summary of a talk delivered at Apache Beam Digital Summit on August 24, 2020.

In this session, you won’t learn about joins or windows or timers or any other advanced features of Beam. Instead, we will focus on the real-world complexity that comes from simply moving data from one system to another safely. How do we model data as it passes from one transform to another? How do we handle errors? How do we test the system? How do we organize the code to make the pipeline configurable for different source and destination systems?
We will explore how each of these questions are addressed in Mozilla’s open source codebase for ingesting telemetry data from Firefox clients. By the end of the session, you’ll be equipped to explore the codebase and documentation on your own to see how these concepts are composed together.
https://jeff.klukas.net/writing/2020-09-25-the-nitty-gritty-of-moving-data-with-apache-beam/
|
|
Karl Dubost: Week notes - 2020 w39 - worklog - A new era |
So the Mozilla Webcompat team is entering a new era. Mike Taylor (by the time this will be published) was the manager of the webcompat team at Mozilla since August 2015. He decided to leave. Monday, September 21 was his last day. We had to file an issue about this.
The new interim manager is… well… myself.
So last week and this week will be a lot about:
Hence these notes restarting. I will try to keep a track of what I do and what I learn both for the public, but mostly for my team mates.
Currently the Mozilla webcompat team is composed of these wonderful people:
A lot of reading, a lot of thinking around management (probably more about that later).
I always said to Mike (and previous managers) in the past, that I was not interested in management position. But I deeply care about the webcompat project, and I want it to thrive as much as possible. I never associated management with a sense of promotion or career growth. I'm very careful about the issues that positions of power create both ways: from the manager toward the people being managed and from the people toward their manager. Power is a often tool of corruption and abuse and makes some people abandon their sense of autonomy and responsibility. The interim word in the title here is quite important. If someone more qualified wants to jump into the job, please reach out to Lonnen or Andrew Overholt. If anyone from the webcompat team is not satisfied, I will happily step down.
Last but not least, Thanks to Mike to have done this job for the last couple of years. Mike has a talent for being human and in touch with people. I wish a bright journey on his new endeavors.
Rachel Tublitz asked to give an update about ETP workarounds for site breakage for the What's New with Firefox 82 for the SUMO team. She's doing an amazing job at compiling information for the sumo team to be prepared in advance of the release and be able to support users.
Thomas delivered on it two months ago. Add support for shimming resources blocked by Tracking Protection. The progress is tracked on the webcompat OKR board. Latest update from Thomas is
We're likely to slip the release of ETP shims slip into the 83 release instead of 82, due to the UX team wanting some more time to think through the way the ETP "blocked content" interfaces interact with shims. In that case they will continue to be a nightly-only feature during the 82 release cycle.
Congrats on Dennis for releasing AC Report Site Issue improvements. This is done.
WPT stands for Web Platform Tests. The code was in python 2 and it has been fully ported to Python 3 by James. This created a major sync issue at a point that James recovered these last couple of days and started to implement safe guards for it to not happen again.
Ksenia has been on a tool for generating outreach templates to contact people with regards to web compatibility issues. She has been using Svelte and the work seems to be in a pretty good shape. Mike and Guillaume have been helping with the review.
Oana and Ciprian have tiredlessly triaged all the incoming issues of webcompat. And more specifically starting to test some JavaScript frameworks to detect webcompat issues. The JS frameworks were installed by Guillaume.
How do define the priority on bugs causing webcompat issues?
Otsukare!
|
|
Mozilla Localization (L10N): L10n Report: September 2020 Edition |
New localizers
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
As part of the effort to streamline and rationalize the localization infrastructure, following the recent lay-offs, we have decided to decommission Elmo. Elmo is the project name of what has been the backbone of our localization infrastructure for over 10 years, and its public facing part was hosted on l10n.mozilla.org (el as in “el-10-en (l10n)”, m(ozilla), o(rg) = elmo).
The practical consequences of this change are:
Upcoming deadlines:
As you might have noticed, the number of new strings in Firefox has significantly decreased, with DevTools becoming less actively developed. Now more than ever it’s a good time to:
This last month, as announced – and as you have probably noticed – we have been reducing the number, and priority, of mobile products to localize. We are now focusing much more on Firefox for Android and Firefox for iOS – our original flagship products for mobile. Please thus refer to the “star” metric on Pontoon to prioritize your work for mobile.
The Firefox for Android schedule from now on should give two weeks out of four for localization work – as it did for Focus. This means strings will be landing during two weeks in Pontoon – and then you will have two weeks to work on those strings so they can make it into the next version. Check the deadline section in Pontoon to know when the l10n deadline for the next release is.
Concerning iOS: with iOS 14 we can now set Firefox as default! Thanks to everyone who has helped localize the new strings that will enable globally this functionality.
The support will continue with reduced staff. Though there won’t be new features introduced in the next six months, the team is still committed to fixing high priority bugs, adding newly requested languages, and releasing updated dataset. It will take longer to implement than before. Please follow the project’s latest update on Discourse.
The project is being spun out of Mozilla as an independent open source project. It will be renamed from Mozilla WebThings to WebThings and will be moved to a new home at webthings.io. For other FAQ, please check out here. When the transition is complete, we will update everyone as soon as it becomes available.
It would be great to get the following articles localized in Indonesian in the upcoming release for Firefox for iOS:

Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2020/09/25/l10n-report-september-2020-edition/
|
|
Mozilla VR Blog: Firefox Reality 12 |

The latest version of Firefox Reality for standalone VR headsets brings a host of long-awaited features we're excited to reveal, as well as improved stability and performance.
Firefox Reality is the first and only browser to bring add-on support to the immersive web. Now you can download powerful extensions that help you take control of your VR browsing experience. We started with favorites like uBlock, Dark Reader, and Privacy Badger.
Ever get tired of typing your passwords in the browser? This can be tedious, especially using VR headset controllers. Now, your browser can do the work of remembering and entering your passwords and other frequent form text with our autofill feature.
We’ve completely redesigned and streamlined our library and simplified our status bar. You can also find additional information on the status bar, including indicators for the battery levels of controllers and the headset, as well as time/date info.
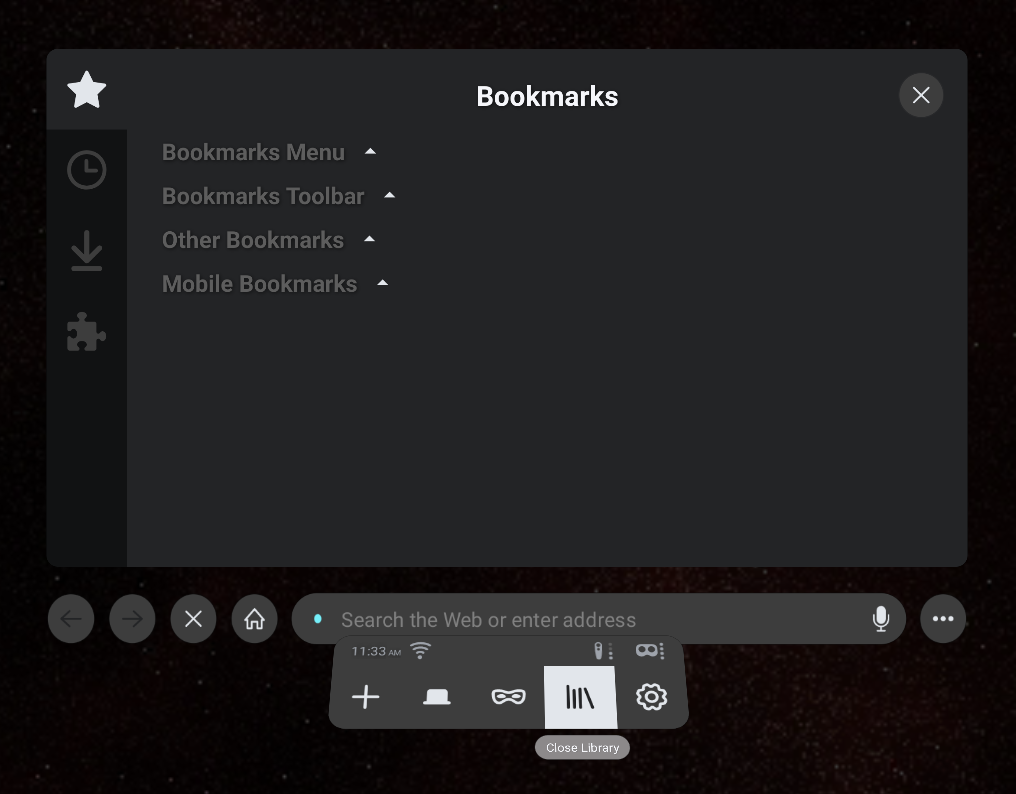
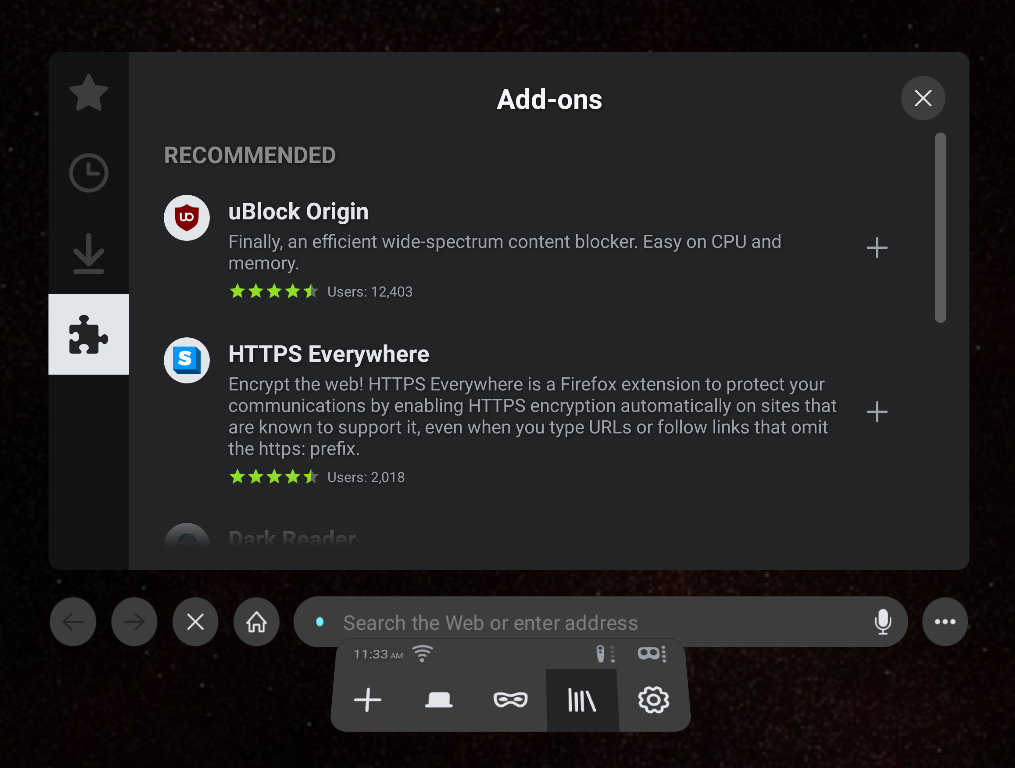
We’ve also redesigned our content feed for ease of navigation and discovery of related content organized by the categories in the left menu. Stay tuned for this change rolling out to your platform of choice soon.
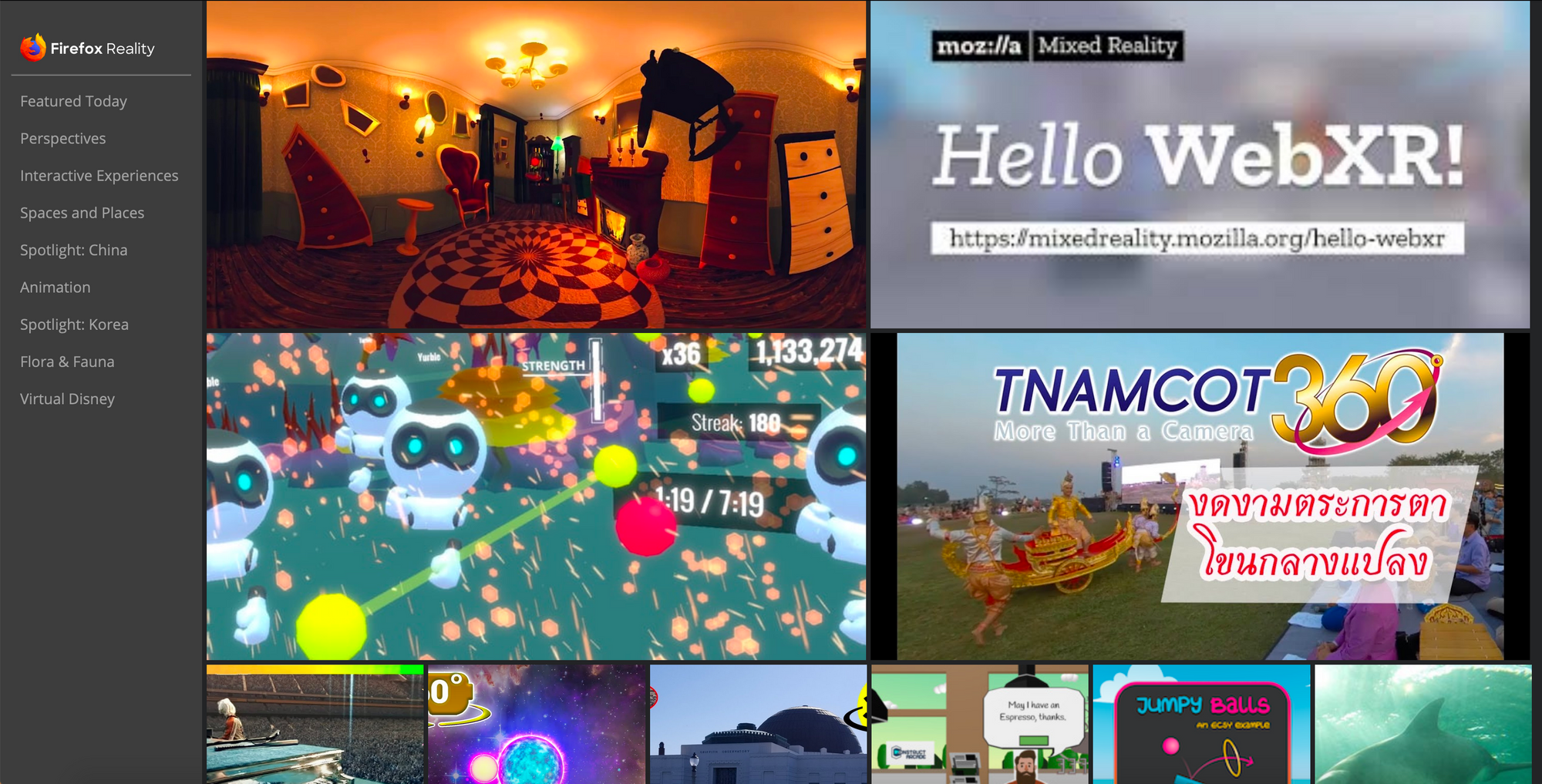
Look for Firefox Reality 12 available now in the HTC, Pico and Oculus stores. This feature-packed release of Firefox Reality will be the last major feature release for a while as we gear up for a deeper investment in Hubs. But not to worry! Firefox Reality will still be well supported and maintained on your favorite standalone VR platform.
Firefox Reality is an open source project. We love hearing from and collaborating with our developer community. Check out Firefox Reality on GitHub and help build the open immersive web
|
|
Daniel Stenberg: everything curl five years |
The first content to the book Everything curl was committed on September 24, 2015 but I didn’t blog about it until several months later in December 2015: Everything curl – work in progress.

At the time of that blog post, the book was already at 13,000 words and 115 written subsections. I still had that naive hope that I would have it nearly “complete” by the summer of 2016. Always the optimist.
Today, the book is at over 72,000 words with content in 600 subsections – with just 21 subtitles noted “TBD” to signal that there’s still content to add there. The PDF version of it now clocks in at over 400 pages.
I’ve come to realize and accept that it will never be “complete” and that we will just keep on working on it indefinitely since curl itself keeps changing and we keep improving and expanding texts in the book.
Right now, we have 21 sections marked as not done, but then we’ve also added features through these five years that we haven’t described in the book yet. And there are probably other areas still missing too that would benefit the book to add. There’s no hurry, we’ll just add more content when we get around to it.
Everything curl is quite clearly the most complete book and resource about curl, libcurl, the project and how all of it works. We have merged contributions from 39 different authors and we’re always interested in getting more help!
We’ve printed two editions of the book. The 2017 and the 2018 versions. As of 2020, the latest edition is out of print. If you really want one, email Dan Fandrich as mention on the web page this link takes you to. Maybe we can make another edition reality again.
The book was always meant to remain open and free, we only sell the printed version because it costs actual money to produce it.
For a long time we also offered e-book versions of everything curl, but sadly gitbooks removed those options in a site upgrade a while ago so now unfortunately we only offer a web version and a PDF version.
There are many books that mention curl and that have sections or parts devoted to various aspects of curl but there are not many books about just curl. curl programming (by Dan Gookin) is one of those rare ones.
https://daniel.haxx.se/blog/2020/09/24/everything-curl-five-years/
|
|
Daniel Stenberg: Reducing mallocs for fun |
Everyone needs something fun to do in their spare time. And digging deep into curl internals is mighty fun!
One of the things I do in curl every now and then is to run a few typical command lines and count how much memory is allocated and how many memory allocation calls that are made. This is good project hygiene and is a basic check that we didn’t accidentally slip in a malloc/free sequence in the transfer path or something.
We have extensive memory checks for leaks etc in the test suite so I’m not worried about that. Those things we detect and fix immediately, even when the leaks occur in error paths – thanks to our fancy “torture tests” that do error injections.
The amount of memory needed or number of mallocs used is more of a boiling frog problem. We add one now, then another months later and a third the following year. Each added malloc call is motivated within the scope of that particular change. But taken all together, does the pattern of memory use make sense? Can we make it better?
Now this is easy because when we build curl debug enabled, we have a fancy logging system (we call it memdebug) that logs all calls to “fallible” system functions so after the test is completed we can just easily grep for them and count. It also logs the exact source code and line number.
cd tests ./runtests -n [number] egrep -c 'alloc|strdup' log/memdump
Let me start out with a look at the history and how many allocations (calloc, malloc, realloc or strdup) we do to complete test 103. The reason I picked 103 is somewhat random, but I wanted to look at FTP and this test happens to do an “active” transfer of content and makes a total of 10 FTP commands in the process.
The reason I decided to take a closer look at FTP this time is because I fixed an issue in the main ftp source code file the other day and that made me remember the Curl_pp_send() function we have. It is the function that sends FTP commands (and IMAP, SMTP and POP3 commands too, the family of protocols we refer to as the “ping pong protocols” internally because of their command-response nature and that’s why it has “pp” in the name).
When I reviewed the function now with my malloc police hat on, I noticed how it made two calls to aprintf(). Our printf version that returns a freshly malloced area – which can even cause several reallocs in the worst case. But this meant at least two mallocs per issued command. That’s a bit unnecessary, isn’t it?
I picked a few random older versions, checked them out from git, built them and counted the number of allocs they did for test 103:
7.52.1: 141
7.68.0: 134
7.70.0: 137
7.72.0: 123
It’s been up but it has gone down too. Nothing alarming, Is that a good amount or a bad amount? We shall see…
The function gets printf style arguments and sends them to the server. The sent command also needs to append CRLF to the data. It was easy to make sure the CRLF appending wouldn’t need an extra malloc. That was just sloppy of us to have there in the first place. Instead of mallocing the new printf format string with CRLF appended, it could use one in a stack based buffer. I landed that as a first commit.
This trimmed off 10 mallocs for test 103.
The remaining malloc allocated the memory block for protocol content to send. It can be up to several kilobytes but is usually just a few bytes. It gets allocated in case it needs to be held on to if the entire thing cannot be sent off over the wire immediately. Remember, curl is non-blocking internally so it cannot just sit waiting for the data to get transferred.
I switched the malloc’ed buffer to instead use a ‘dynbuf’. That’s our internal “dynamic buffer” system that was introduced earlier this year and that we’re gradually switching all internals over to use instead of doing “custom” buffer management in various places. The internal API for dynbuf is documented here.
The internal API Curl_dyn_addf() adds a printf()-style string at the end of a “dynbuf”, and it seemed perfectly suitable to use here. I only needed to provide a vprintf() alternative since the printf() format was already received by Curl_pp_sendf()… I created Curl_dyn_vaddf() for this.
This single dynbuf is kept for the entire transfer so that it can be reused for subsequent commands and grow only if needed. Usually the initial 32 bytes malloc should be sufficient for all commands.
It didn’t help!
Counting the mallocs showed me with brutal clarity that my job wasn’t done there. Having dug this deep already I wasn’t ready to give this up just yet…
Why? Because Curl_dyn_addf() was still doing a separate alloc of the printf string that it then appended to the dynamic buffer. But okay, having our own printf() implementation in the code has its perks.
Back in May 2020 when I introduced this dynbuf thing, I converted the aprintf() code over to use dynbuf to truly unify our use of dynamically growing buffers. That was a main point with it after all.
As all the separate individual pieces I needed for this next step were already there, all I had to do was to add a new entry point to the printf() code that would accept a dynbuf as input and write directly into that (and grow it if needed), and then use that new function (Curl_dyn_vprintf) from the Curl_dyn_addf().
Phew. Now let’s see what we get…
There are 10 FTP commands that previously did 2 mallocs each: 20 mallocs were spent in this function when test 103 was executed. Now we are down to the ideal case of one alloc in there for the entire transfer.
The code right now in master (to eventually get released as 7.73.0 in a few weeks), now shows a total of 104 allocations. Down from 123 in the previous release, which not entirely surprising is 19 fewer and thus perfectly matching the logic above.
All tests and CI ran fine. I merged it. This is a change that benefits all transfers done with any of the “ping pong protocols”. And it also makes the code easier to understand!
Compared to curl 7.52.1, this is a 26% reduction in number of allocation; pretty good, but even compared to 7.72.0 it is still a 15% reduction.
There is always more to do, but there’s also a question of diminishing returns. I will continue to look at curl’s memory use going forward too and make sure everything is motivated and reasonable. At least every once in a while.
I have some additional ideas for further improvements in the memory use area to look into. We’ll see if they pan out…
Don’t count on me to blog about every such finding with this level of detail! If you want to make sure you don’t miss any of these fine-tunes in the future, follow the curl github repo.
Image by Julio C'esar Vel'asquez Mej'ia from Pixabay
https://daniel.haxx.se/blog/2020/09/24/reducing-mallocs-for-fun/
|
|
The Talospace Project: Firefox 81 on POWER |
This release heralds the first official change in our standard POWER9 .mozconfig since Fx67. Link-time optimization continues to work well (and in 81 the LTO-enhanced build I'm using now benches about 6% faster than standard -O3 -mcpu=power9), so I'm now making it a standard part of my regular builds with a minor tweak we have to make due to bug 1644409. Build time still about doubles on this dual-8 Talos II and it peaks out at almost 84% of its 64GB RAM during LTO, but the result is worth it.
Unfortunately PGO (profile-guided optimization) still doesn't work right, probably due to bug 1601903. The build system does appear to generate a profile properly, i.e., a controlled browser instance pops up, runs some JavaScript code, does some browser operations and so forth, and I see gcc created .gcda files with all the proper count information, but then the build system can't seem to find them to actually tune the executable. This needs a little more hacking which I might work on as I have free time™. I'd also like to eliminate ac_add_options --disable-release as I suspect it is no longer necessary but I need to do some more thorough testing first.
In any event, reliable LTO at least with the current Fedora 32 toolchain is still continuous progress. I've heard concerns that some distributions are not making functional builds of Firefox for ppc64le (let alone ppc64, which has its own problems), though Fedora is not one of them. Still, if you have issues with your distribution's build and you are not able to build it for yourself, if there is interest I may put up a repo or a download spot for the binaries I use since I consider them reliable. Without further ado, here are the current .mozconfigs that I attest as functional.
Optimized Configuration
Debug Configuration
export CC=/usr/bin/gcc
export CXX=/usr/bin/g++
mk_add_options MOZ_MAKE_FLAGS="-j24"
ac_add_options --enable-application=browser
ac_add_options --enable-optimize="-O3 -mcpu=power9"
ac_add_options --disable-release
ac_add_options --enable-linker=bfd
ac_add_options --enable-lto=full
#export GN=/uncomment/and/set/path/if/you/haz
export RUSTC_OPT_LEVEL=2
export CC=/usr/bin/gcc
export CXX=/usr/bin/g++
mk_add_options MOZ_MAKE_FLAGS="-j24"
ac_add_options --enable-application=browser
ac_add_options --enable-optimize="-Og -mcpu=power9"
ac_add_options --enable-debug
ac_add_options --disable-release
ac_add_options --enable-linker=bfd
#export GN=/uncomment/and/set/path/if/you/haz
export RUSTC_OPT_LEVEL=0
|
|
About:Community: Contributors to Firefox 81 (and 80, whoops) |
Errata: In our release notes for Firefox 80, we forgot to mention all the developers who contributed their first code change to Firefox in this release, 10 of whom were brand new volunteers! We’re grateful for their efforts, and apologize for not giving them the recognition they’re due on time. Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
As well, with the release of Firefox 81 we are once again honoured to welcome the developers who contributed their first code change to Firefox with this release, 18 of whom were brand new volunteers. Again, please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/09/23/contributors-to-firefox-81-and-80-whoops/
|
|
The Mozilla Blog: Launching the European AI Fund |
Right now, we’re in the early stages of the next phase of computing: AI. First we had the desktop. Then the internet. And smartphones. Increasingly, we’re living in a world where computing is built around vast troves of data and the algorithms that parse them. They power everything from the social platforms and smart speakers we use everyday, to the digital machinery of our governments and economies.
In parallel, we’re entering a new phase of how we think about, deploy, and regulate technology. Will the AI era be defined by individual privacy and transparency into how these systems work? Or, will the worst parts of our current internet ecosystem — invasive data collection, monopoly, opaque systems — continue to be the norm?
A year ago, a group of funders came together at Mozilla’s Berlin office to talk about just this: how we, as a collective, could help shape the direction of AI in Europe. We agreed on the importance of a landscape where European public interest and civil society organisations — and not just big tech companies — have a real say in shaping policy and technology. The next phase of computing needs input from a diversity of actors that represent society as a whole.
Over the course of several months and with dozens of organizations around the table, we came up with the idea of a European AI Fund — a project we’re excited to launch this week.
The fund is supported by the Charles Stewart Mott Foundation, King Baudouin Foundation, Luminate, Mozilla, Oak Foundation, Open Society Foundations and Stiftung Mercator. We are a group of national, regional and international foundations in Europe that are dedicated to using our resources — financial and otherwise — to strengthen civil society. We seek to deepen the pool of experts across Europe who have the tools, capacity and know-how to catalogue and monitor the social and political impact of AI and data driven interventions — and hold them to account. The European AI Fund is hosted by the Network of European Foundations. I can’t imagine a better group to be around the table with.
Over the next five years, the European Commission and national governments across Europe will forge a plan for Europe’s digital transformation, including AI. But without a strong civil society taking part in the debate, Europe — and the world — risk missing critical opportunities and could face fundamental harms.
At Mozilla, we’ve seen first-hand the expertise that civil society can provide when it comes to the intersection of AI and consumer rights, racial justice, and economic justice. We’ve collaborated closely over the years with partners like European Digital Rights, Access Now Algorithm Watch and Digital Freedom Fund. Alternatively, we’ve seen what can go wrong when diverse voices like these aren’t part of important conversations: AI systems that discriminate, surveil, radicalize.
At Mozilla, we believe that philanthropy has a key role to play in Europe’s digital transformation and in keeping AI trustworthy, as we’ve laid out in our trustworthy AI theory of change. We’re honoured to be working alongside this group of funders in an effort to strengthen civil society’s capacity to contribute to these tech policy discussions.
In its first step, the fund will launch with a 1,000,000 € open call for funding, open until November 1. Our aim is to build the capacity of those who already work on AI and Automated Decision Making (ADM). At the same time, we want to bring in new civil society actors to the debate, especially those who haven’t worked on issues relating to AI yet, but whose domain of work is affected by AI.
To learn more about the European AI Fund visit http://europeanaifund.org/
The post Launching the European AI Fund appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/09/23/launching-the-european-ai-fund/
|
|
The Firefox Frontier: How to spot (and do something) about real fake news |
Think you can spot fake news when you see it? You might be surprised even the most digitally savvy folks can (at times) be fooled into believing a headline or … Read more
The post How to spot (and do something) about real fake news appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/how-to-spot-real-fake-news/
|
|
Daniel Stenberg: a Google grant for libcurl work |
Earlier this year I was the recipient of a monetary Google patch grant with the expressed purpose of improving security in libcurl.
This was an upfront payout under this Google program describing itself as “an experimental program that rewards proactive security improvements to select open-source projects”.
I accepted this grant for the curl project and I intend to keep working fiercely on securing curl. I recognize the importance of curl security as curl remains one of the most widely used software components in the world, and even one that is doing network data transfers which typically is a risky business. curl is responsible for a measurable share of all Internet transfers done over the Internet an average day. My job is to make sure those transfers are done as safe and secure as possible. It isn’t my only responsibility of course, as I have other tasks to attend to as well, but still.
Security is already and always a top priority in the curl project and for myself personally. This grant will of course further my efforts to strengthen curl and by association, all the many users of it.
When security comes up in relation to curl, some people like to mention and propagate for other programming languages, But curl will not be rewritten in another language. Instead we will increase our efforts in writing good C and detecting problems in our code earlier and better.
Things we have done lately and working on to enforce everywhere:
String and buffer size limits – all string inputs and all buffers in libcurl that are allowed to grow now have a maximum allowed size, that makes sense. This stops malicious uses that could make things grow out of control and it helps detecting programming mistakes that would lead to the same problems. Also, by making sure strings and buffers are never ridiculously large, we avoid a whole class of integer overflow risks better.
Unified dynamic buffer functions – by reducing the number of different implementations that handle “growing buffers” we reduce the risk of a bug in one of them, even if it is used rarely or the spot is hard to reach with and “exercise” by the fuzzers. The “dynbuf” internal API first shipped in curl 7.71.0 (June 2020).
Realloc buffer growth unification – pretty much the same point as the previous, but we have earlier in our history had several issues when we had silly realloc() treatment that could lead to bad things. By limiting string sizes and unifying the buffer functions, we have reduced the number of places we use realloc and thus we reduce the number of places risking new realloc mistakes. The realloc mistakes were usually in combination with integer overflows.
Code style – we’ve gradually improved our code style checker (checksrc.pl) over time and we’ve also gradually made our code style more strict, leading to less variations in code, in white spacing and in naming. I’m a firm believer this makes the code look more coherent and therefore become more readable which leads to fewer bugs and easier to debug code. It also makes it easier to grep and search for code as you have fewer variations to scan for.
More code analyzers – we run every commit and PR through a large number of code analyzers to help us catch mistakes early, and we always remove detected problems. Analyzers used at the time of this writing: lgtm.com, Codacy, Deepcode AI, Monocle AI, clang tidy, scan-build, CodeQL, Muse and Coverity. That’s of course in addition to the regular run-time tools such as valgrind and sanitizer builds that run the entire test suite.
Memory-safe components – curl already supports getting built with a plethora of different libraries and “backends” to cater for users’ needs and desires. By properly supporting and offering users to build with components that are written in for example rust – or other languages that help developers avoid pitfalls – future curl and libcurl builds could potentially avoid a whole section of risks. (Stay tuned for more on this topic in a near future.)
Recognizing that whatever we do and however tight ship we run, we will continue to slip every once in a while, is important and we should make sure we find and fix such slip-ups as good and early as possible.
Raising bounty rewards. While not directly fixing things, offering more money in our bug-bounty program helps us get more attention from security researchers. Our ambition is to gently drive up the reward amounts progressively to perhaps multi-thousand dollars per flaw, as long as we have funds to pay for them and we mange keep the security vulnerabilities at a reasonably low frequency.
More fuzzing. I’ve said it before but let me say it again: fuzzing is really the top method to find problems in curl once we’ve fixed all flaws that the static analyzers we use have pointed out. The primary fuzzing for curl is done by OSS-Fuzz, that tirelessly keeps hammering on the most recent curl code.
Good fuzzing needs a certain degree of “hand-holding” to allow it to really test all the APIs and dig into the dustiest corners, and we should work on adding more “probes” and entry-points into libcurl for the fuzzer to make it exercise more code paths to potentially detect more mistakes.
See also my presentation testing curl for security.
https://daniel.haxx.se/blog/2020/09/23/a-google-grant-for-libcurl-work/
|
|
Mike Taylor: Seven Platform Updates from the Golden Era of Computing |
Back in the Golden Era of Computing (which is what the industry has collectively agreed to call the years 2016 and 2017) I was giving semi-regular updates at the Mozilla Weekly Meeting.
Now this was also back when Potch was the Weekly Project All Hands Meeting module owner. If that sounds like a scary amount of power to entrust to that guy, well, that’s because it was.
(This doesn’t have anything to do with the point of this post, I’m just trying to game SEO with these outbound links.)
So anyways, the point of these updates was to improve communication between Firefox and Platform teams which were more siloed than you would expect, and generally just let people know about interesting Platform work other teams were doing. I don’t even remember how that task fell upon me, I think it was just cause I just showed up to do it.
Rumor has it that Chris Beard wanted to switch to Blink back then but was moved by my artwork, and that’s why Gecko still exists to this day.
(Full disclosure: I just made up this rumor, but please quote me as “Anonymous Source” and link back to here if anyone wants to run with it.)







https://miketaylr.com/posts/2020/09/seven-platform-updates.html
|
|
Firefox UX: From a Feature to a Habit: Why are People Watching Videos in Picture-in-Picture? |
At the end of 2019, if you were using Firefox to watch a video, you saw a new blue control with a simple label: “Picture-in-Picture.” Even after observing and carefully crafting the feature with feedback from in-progress versions of Firefox (Nightly and Beta), our Firefox team wasn’t really sure how people would react to it. So we were thrilled when we saw signals that the response was positive.
Firefox’s Picture-in-Picture allows you to watch videos in a floating window (always on top of other windows) so you can keep an eye on what you’re watching while interacting with other sites, or applications.
About 6 months after PiP’s release, we started to see some trends from our data. We know from our internal data that people use Firefox to watch video. In fact, some people watch video over 60% of the time when they’re using Firefox. And, some of these people use PiP to do that. Further, our data shows that people who use Picture-in-Picture open more PiP windows over time. In short, we see that not everyone uses PiP, but those who do seem to be forming a habit with it.
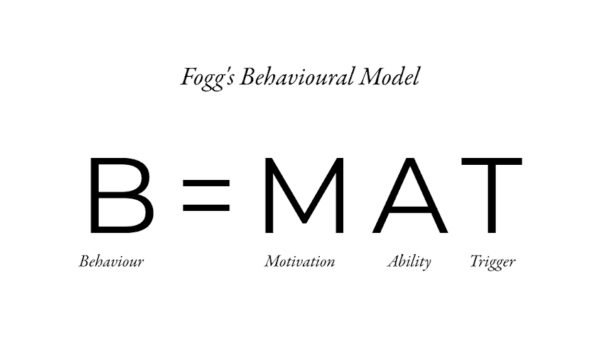
A habit is a behaviour “done with little or no conscious thought.” So we asked ourselves:
Fogg’s Behavior Model describes habits and how they form. We already knew two parts of this equation: Behavior and Ability. But we didn’t know Motivation and Trigger.
Fogg’s Behavior Model.
To get at these “why” questions, we conducted qualitative research with people who use PiP. We conducted interviews with 11 people to learn more about how they discovered PiP and how they use it in their everyday browsing. We were even able to observe these people using PiP in action. It’s always a privilege to speak directly to people who are using the product. Talking to and observing peoples’ actions is an indispensable part of making something people find useful.
Now we’ll talk about the Motivation part of the habit equation by sharing how the people we interviewed use PiP.
When we started to look at PiP, we were worried that the feature would bring some unintended consequences in peoples’ lives. Could PiP diminish their productivity by increasing distractibility? Surprisingly, from what we observed in these interviews, PiP helped some participants do their task, as opposed to being needlessly distracting. People are using PiP as a study tool, to improve their focus, or to motivate them to complete certain tasks.
One of our participants was a student. He used Picture-in-Picture to watch lecture videos and take notes while doing his homework. PiP helped him complete and enhance a task.
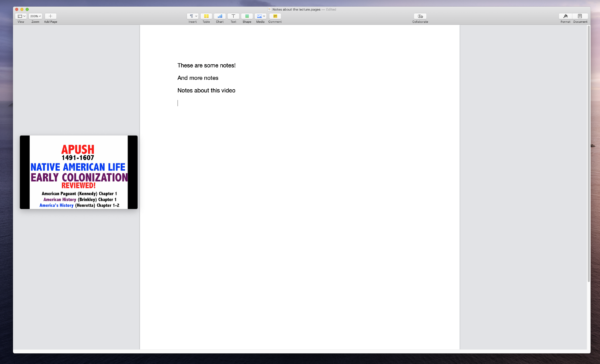
Taking notes in a native desktop application while watching a lecture video in picture-in-picture. (Recreation of what a participant did during an interview)
You might have this experience: listening to music or a podcast helps you “get in the zone” while you’re exercising or perhaps doing chores. It helps you lose yourself in the task, and make mundane tasks more bearable. Picture-in-Picture does the same for some people while they are at work, to avoid the surrounding silence.
“I just kind of like not having dead silence… I find it kind of motivating and I don’t know, it just makes the day seem less, less long.” — Executive Assistant to a Real Estate Developer
Multiple people told us they watch videos in PiP to calm themselves down. If they are reading a difficult article for work or study, or doing some art, watching ASMR or trance-like videos feels therapeutic. Not only does this calm people down, they said it can help them focus.

Reading an article in a native Desktop application while watching a soothing video of people running in picture-in-picture. (Recreation of what a participant did during an interview)
And finally, some people use Picture-in-Picture for pure and simple entertainment. One person watches a comedic YouTuber talk about reptiles while playing a dragon-related browser game. Another person watches a friend’s live streaming gaming while playing a game themself.
Playing a browser game while watching a funny YouTube video. (Recreation of what a participant showed us during an interview)
Some people have habits with PiP for the reasons listed above, and we also learned there’s nothing gravely wrong with PiP to prevent habit-forming. Therefore, our impact is related to PiP’s strategy: Do not make “habit-forming” a measure of PiP’s success. Instead, better support what people already do with PiP. Particularly, PiP is getting more controls, for example, changing the volume.
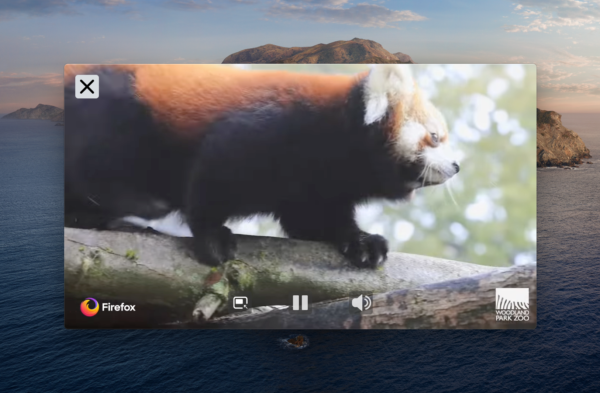
You don’t have to stop reading to watch this cute red panda in Picture-in-Picture
While conducting these interviews, we also prepared an experiment to test different versions of Picture-in-Picture, with the goal of increasing the number of people who discover it. We’ll talk more on that soon!
In the meantime, we’d like to hear even more stories. Are you using Picture-in-Picture in Firefox? Are you finding it useful? Please share your stories in the comments below, or send us a tweet @firefoxUX with a screenshot. We’d love to hear from you.
Thank you to Betsy Mikel for editing our blog post.
This post was originally published on Medium.
|
|
Mozilla VR Blog: Your Security and Mozilla Hubs |

Mozilla and the Hubs team takes internet security seriously. We do our best to follow best practices for web security and securing data. This post will provide an overview of how we secure access to your rooms and your data.
In the most basic scenario, only people who know the URL of your room can access your room. We use randomly generated strings in the URLs to obfuscate the URLs. If you need more security in your room, then you can limit your room to only allow users with Hubs accounts to join (usually, anyone can join regardless of account status). This is a server-wide setting, so you have to run your own Hubs Cloud instance to enable this setting.
You can also make rooms “invite only” which generates an additional key that needs to be used on the link to allow access. While the room ID can’t be changed, an “invite only” key can be revoked and regenerated, allowing you to revoke access to certain users.
Alternatively, users can create a room via the Hubs Discord bot, and the room becomes bound to the security context of that Discord. In this scenario, a user’s identity is tied to their identity in Discord, and they only have access to rooms that are tied to channels they have access to. Users with “modify channel” permissions in Discord get corresponding “room owner” permissions in Hubs, which allows them to change room settings and kick users out of the room. For example, if I am a member of the private channel #standup, and there is a room tied to that channel, only members of that channel (including me) are allowed in the associated room. Anyone attempting to access the room will first need to authenticate via Discord.
We collect minimal data on users. For any data that we do collect, all database data and backups are encrypted at rest. Additionally, we don’t store raw emails in our database--this means we can’t retrieve your email, we can only check to see if the email you enter for log in is in our database. All data is stored on a private subnet and is not accessible via the internet.
For example, let’s go through what happens when a user uploads a file inside a room. First, the user uploads a personal photo to the room to share with others. This generates a URL via a unique key, which is passed to all other users inside the room. Even if others find the URL of the file, they cannot decrypt the photo without this key (including the server operator!). The photo owner can choose to pin the photo to the room, which saves the encryption key in a database with the encrypted file. When you visit the room again, you can access the file, because the key is shared with room visitors. However, if the file owner leaves the room without pinning the photo, then the photo is considered ‘abandoned data’ and the key is erased. This means that no users can access the file anymore, and the data is erased within 72 hours.
All data is encrypted in transit via TLS. We do not currently support end-to-end encryption.
When you deploy your own Hubs Cloud instance, you have full control over the instance and its data via AWS or DigitalOcean infrastructure--Mozilla simply provides the template and automatic updates. Therefore, you can integrate your own security measures and technology as you like. Everyone’s use case is different. Hubs cloud is an as-is product, and we’re unable to predict the performance as you make changes to the template.
Server access is limited by SSH and sometimes two-factor authentication. For additional security, you can set stack template rules to restrict which IP addresses can SSH into the server.
We automatically update packages for security updates, and update our version in a monthly cadence, but if there’s a security issue exposed (either in our software or third party software), we can immediately update all stacks. We inherit our network architecture from AWS, which includes load balancing and DDoS protection.
Your security on the web is non-negotiable. Between maintaining security updates, authenticating users, and encrypting data at rest and in transit, we prioritize our users security needs. For any additional questions, please reach out to us. To contribute to Hubs, visit https://github.com/mozilla/hubs.
|
|






