Mozilla VR Blog: Your Privacy and Mozilla Hubs |

At Mozilla, we believe that privacy is fundamental to a healthy internet. We especially believe that this is the case in social VR platforms, which process and transmit large amounts of personal information. What happens in Hubs should stay in Hubs.
First, let’s discuss what your privacy expectations should be when you’re in a Hubs room. In general, anything transmitted in a room is available to everyone connected to that room. They can save anything that you send. This is why it’s so important to only give the Hubs link out to people you want to be in the room, or to use Discord authentication so only authorized users can access a room.
While some rooms may have audio falloff to declutter the audio in a room, users should still have the expectation that anyone in the room (or in the lobby) can hear what’s being said. Audio falloff is performed in the client, so anyone who modifies their client can hear you from anywhere in the room.
Other users in the room have the ability to create recordings. While recording, the camera tool will display a red icon, and your avatar will indicate to others with a red icon that you are filming and capturing audio. All users are notified when a photo or video has been taken. However, users should still be aware that others could use screen recorders to capture what happens in a Hubs room without their knowledge.
The only data we need to create an account for you is your email address, which we store hashed in an encrypted database. We don’t collect any additional personal information like birthdate, real name, or telephone numbers. Accounts aren’t required to use Hubs, and many features are available to users without accounts.
There’s a certain amount of information that we have to process in order to provide you with the Hubs experience. For example, we receive and send to others the name and likeness of your avatar, its position in the room, and your interactions with objects in the room. If you create an account, you can store custom avatars and their names.
We receive data about the virtual objects and avatars in a room in order to share that data with others in the room, but we don’t monitor the individual objects that are posted in a room. Users have the ability to permanently pin objects to a room, which will store them in the room until they’re deleted. Unpinned files are deleted from Mozilla’s servers after 72 hours.
We do collect basic metrics about how many rooms are being created and how many users are in those rooms, but we don’t tie that data to specific rooms or users. What we don’t do is collect or store any data without the user's explicit consent.
Hubs Cloud owners have the capability to implement additional server-side analytics. We provide Hubs Cloud instances with their own versions of Hubs, with minimal data collection and no user monitoring, which they can then modify to suit their needs. Unfortunately, this means that we can’t make any guarantees about what individual Hubs Cloud instances do, so you’ll need to consult with the instance owner if you have any privacy concerns.
We will never perform user monitoring or deep tracking, particularly using VR data sources like gaze-tracking. We will continue to minimize the personal data we collect, and when we do need to collect data, we will invest in privacy preserving solutions like differential privacy. For full details, see our privacy policy. Hubs is an open source project–to contribute to Hubs, visit https://github.com/mozilla/hubs.
|
|
The Rust Programming Language Blog: Call for 2021 Roadmap Blogs Ending Soon |
We will be closing the collection of blog posts on October 5th. As a reminder, we plan to close the survey on September 24th, later this week.
If you haven't written a post yet, read the initial announcement.
Looking forward, we are expecting the following:
We look forward to reading your posts!
https://blog.rust-lang.org/2020/09/21/Scheduling-2021-Roadmap.html
|
|
Cameron Kaiser: TenFourFox FPR27 available |
For our struggling Intel friends, if you are using Firefox on 10.9 through 10.11 Firefox ESR 78 is officially your last port of call, and support for these versions of the operating system will end by July 2021 when support for 78ESR does. The Intel version of TenFourFox may run on these machines, though it will be rather less advanced, and of course there is no official support for any Intel build of TenFourFox.
http://tenfourfox.blogspot.com/2020/09/tenfourfox-fpr27-available.html
|
|
Firefox Nightly: These Weeks in Firefox: Issue 79 |

An animated GIF shows a Picture-in-Picture toggle being moused over. When the mouse reaches the toggle, it extends, showing the text “Watch in Picture-in-Picture”

An animated GIF shows a Picture-in-Picture toggle being moused over. Text describing Picture-is-Picture is shown.
The WebRTC sharing indicator shows microphone, camera, and minimize buttons. The microphone button shows that it is muted.
Early skeleton UI displaying before the real UI shows up.
https://blog.nightly.mozilla.org/2020/09/19/these-weeks-in-firefox-issue-79/
|
|
Cameron Kaiser: Google, nobody asked to make the Blogger interface permanent |
Naturally, Google has removed the "return to legacy Blogger" button, but you can still get around that at least for the time being. On your main Blogger posts screen you will note a long multidigit number in the URL (perhaps that's why they're trying to hide URLs in Chrome). That's your blog ID. Copy that number and paste it in where the XXX is in this URL template (all one line):
https://www.blogger.com/blogger.g?blogID=XXX&useLegacyBlogger=true#allposts
Bookmark it and you're welcome. I look forward to some clever person making a Firefox extension to do this very thing very soon, and if you make one post it in the comments.
http://tenfourfox.blogspot.com/2020/09/google-nobody-asked-to-make-blogger.html
|
|
Daniel Stenberg: My first 15,000 curl commits |
I’ve long maintained that persistence is one of the main qualities you need in order to succeed with your (software) project. In order to manage to ship a product that truly conquers the world. By continuously and never-ending keeping at it: polishing away flaws and adding good features. On and on and on.
Today marks the day when I landed my 15,000th commit in the master branch in curl’s git repository – and we don’t do merge commits so this number doesn’t include such. Funnily enough, GitHub can’t count and shows a marginally lower number.

This is of course a totally meaningless number and I’m only mentioning it here because it’s even and an opportunity for me to celebrate something. To cross off an imaginary milestone. This is not even a year since we passed 25,000 total number of commits. Another meaningless number.
15,000 commits equals 57% of all commits done in curl so far and it makes me the only committer in the curl project with over 10% of the commits.
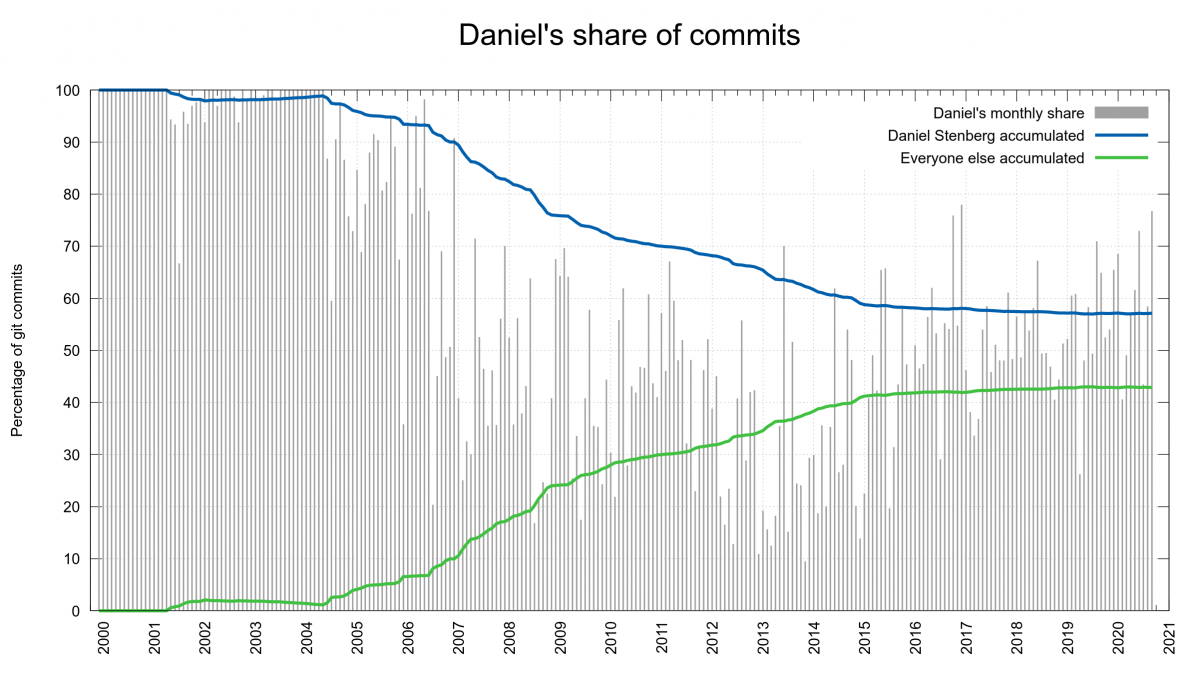
The curl git history starts on December 29 1999, so the first 19 months of commits from the early curl history are lost. 15,000 commits over this period equals a little less than 2 commits per day on average. I reached 10,000 commits in December 2011, so the latest 5,000 commits were done at a slower pace than the first 10,000.
I estimate that I’ve spent more than 15,000 hours working on curl over this period, so it would mean that I spend more than one hour of “curl time” per commit on average. According to gitstats, these 15,000 commits were done on 4,271 different days.
We also have other curl repositories that aren’t included in this commit number. For example, I have done over 4,400 commits in curl’s website repository.
With these my first 15,000 commits I’ve added 627,000 lines and removed 425,000, making an average commit adding 42 and removing 28 lines. (Feels pretty big but I figure the really large ones skew the average.)
The largest time gap ever between two of my commits in the curl tree is almost 35 days back in June 2000. If we limit the check to “modern times”, as in 2010 or later, there was a 19 day gap in July 2015. I do take vacations, but I usually keep up with the most important curl development even during those.
On average it is one commit done by me every 12.1 hours. Every 15.9 hours since 2010.
I’ve been working full time on curl since early 2019, up until then it was a spare time project only for me. Development with pull-requests and CI and things that verify a lot of the work before merge is a recent thing so one explanation for a slightly higher commit frequency in the past is that we then needed more “oops” commits to rectify mistakes. These days, most of them are done in the PR branches that are squashed when subsequently merged into master. Fewer commits with higher quality.
We have merged commits authored by over 833 authors into the curl master repository. Out of these, 537 landed only a single commit (so far).
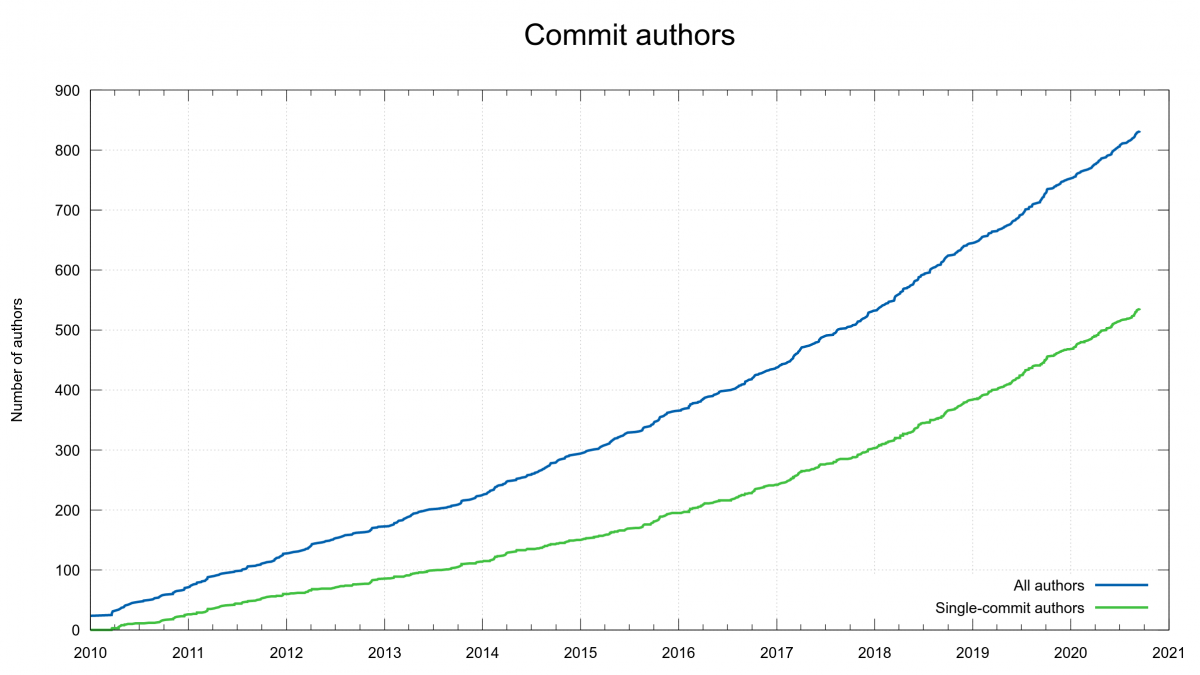
We are 48 authors who ever wrote 10 or more commits within the same year. 20 of us committed that amount of commits during more than one year.
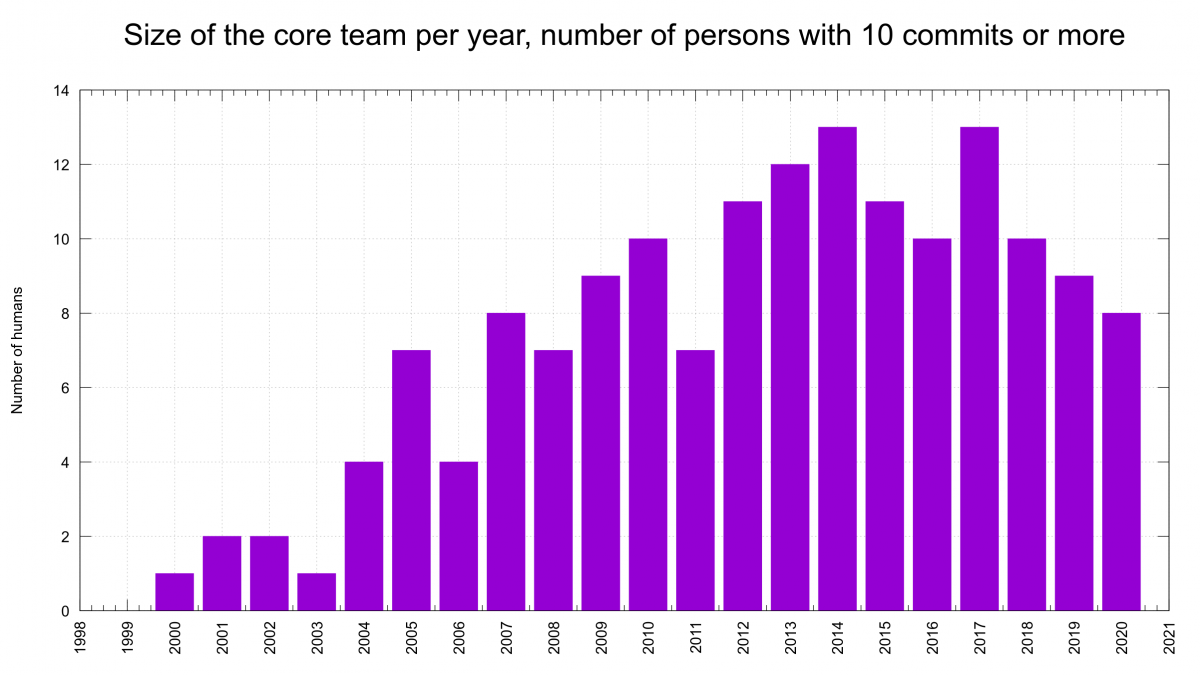
We are 9 authors who wrote more than 1% of the commits each.
We are 5 authors who ever wrote 10 or more commits within the same year in 10 or more years.
Our second-most committer (by commit count) has not merged a commit for over seven years.
To reach curl’s top-100 committers list right now, you only need to land 6 commits.
I intend to stick around in the curl project going forward as well. If things just are this great and life remains fine, I hope that I will be maintaining roughly this commit speed for years to come. My prediction is therefore that it will take longer than another twenty years to reach 30,000 commits.
I’ve worked on curl and its precursors for almost twenty-four years. In another twenty-four years I will be well into my retirement years. At some point I will probably not be fit to shoulder this job anymore!
I have never planned long ahead before and I won’t start now. I will instead keep focused on keeping curl top quality, an exemplary open source project and a welcoming environment for newcomers and oldies alike. I will continue to make sure the project is able to function totally independently if I’m present or not.
So what exactly did I change in the project when I merged my 15,000th ever change into the branch?
It was a pretty boring and non-spectacular one. I removed a document (RESOURCES) from the docs/ folder as that has been a bit forgotten and now is just completely outdated. There’s a much better page for this provided on the web site: https://curl.haxx.se/rfc/
I of coursed asked my twitter friends a few days ago on how this occasion is best celebrated:
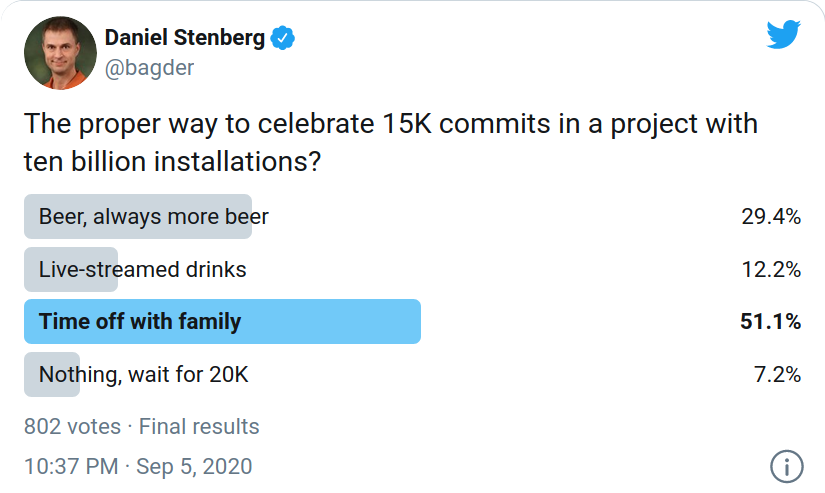
I showed these results to my wife. She approved.
https://daniel.haxx.se/blog/2020/09/18/my-first-15000-curl-commits/
|
|
Mike Taylor: Upcoming US Holidays (for Mike Taylor) |
This is a copy of the email I sent a few days ago to all of Mozilla. I just realized that I'm possibly not the only person with a mail filter to auto-delete company-wide "Upcoming $COUNTRY Holidays" emails, so I'm reposting here.
Maybe I'll blog later about my experience at Mozilla.
Subject: Upcoming US Holidays (for Mike Taylor)
Howdy all,
This is my last full week at Mozilla, with my last day being Monday, September 21. It’s been just over 7 years since I joined (some of them were really great, and others were fine, I guess).
I’m grateful to have met and worked with so many kind and smart people across the company.
I’m especially grateful for Karl Dubost inviting me to apply to Mozilla 7 years ago, and for getting to know and become friends with the people who joined our team after (Cipri, Dennis, James, Ksenia, Oana, Tom, Guillaume, Kate, et al). I believe they’ve made Firefox a significantly better browser for our users and will continue to unbreak the web.
Anyways, you can find me on the internet in all the usual places. Don’t be a stranger.
Blog: https://miketaylr.com/posts/ Twitter: https://twitter.com/miketaylr Facebook: https://fishbrain.com/anglers/miketaylr LinkedIn: https://www.linkedin.com/in/mike-taylor-7a09163/ Email: (redacted, stalkers. also it's TOTALLY unguessable don't even try)
Later,
-- Mike Taylor Web Compat, Mozilla
https://miketaylr.com/posts/2020/09/upcoming-us-holidays-for-mike-taylor.html
|
|
The Mozilla Blog: Update on Firefox Send and Firefox Notes |
As Mozilla tightens and refines its product focus in 2020, today we are announcing the end of life for two legacy services that grew out of the Firefox Test Pilot program: Firefox Send and Firefox Notes. Both services are being decommissioned and will no longer be a part of our product family. Details and timelines are discussed below.
Firefox Send was a promising tool for encrypted file sharing. Send garnered good reach, a loyal audience, and real signs of value throughout its life. Unfortunately, some abusive users were beginning to use Send to ship malware and conduct spear phishing attacks. This summer we took Firefox Send offline to address this challenge.
In the intervening period, as we weighed the cost of our overall portfolio and strategic focus, we made the decision not to relaunch the service. Because the service is already offline, no major changes in status are expected. You can read more here.
Firefox Notes was initially developed to experiment with new methods of encrypted data syncing. Having served that purpose, we kept the product as a little utility tool For Firefox and Android users. In early November, we will decommission the Android Notes app and syncing service. The Firefox Notes desktop browser extension will remain available for existing installs and we will include an option to export all notes, however it will no longer be maintained by Mozilla and will no longer be installable. You can learn more about how to export your notes here.
Thank you for your patience as we’ve refined our product strategy and portfolio over the course of 2020. While saying goodbye is never easy, this decision allows us to sharpen our focus on experiences like Mozilla VPN, Firefox Monitor, and Firefox Private Network.
The post Update on Firefox Send and Firefox Notes appeared first on The Mozilla Blog.
https://blog.mozilla.org/blog/2020/09/17/update-on-firefox-send-and-firefox-notes/
|
|
Mozilla Addons Blog: Download Statistics Update |
In June, we announced that we were making changes to add-on usage statistics on addons.mozilla.org (AMO). Now, we’re making a similar change to add-on download statistics. These statistics are aggregated from the AMO server logs, do not contain any personally identifiable information, and are only available to add-ons developers via the Developer Hub.
Just like with usage stats, the new download stats will be less expensive to process and will be based on Firefox telemetry data. As users can opt out of telemetry reporting, the new download numbers will be generally lower than those reported from the server logs. Additionally, the download numbers are based on new telemetry introduced in Firefox 80, so they will be lower at first and increase as users update their Firefox. As before, we will only count downloads originating from AMO.
The good news is that it’ll be easier now to track attribution for downloads. The old download stats were based on a custom src parameter in the URL. The new ones will break down sources with the more standard UTM parameters, making it easier to measure the effect of social media and other online campaigns.
Here’s a preview of what the new downloads dashboard will look like:

We expect to turn on the new downloads data on October 8. Make sure to export your current download numbers if you’re interested in preserving them.
The post Download Statistics Update appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/09/17/download-statistics-update/
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla files comments with the European Commission on safeguarding democracy in the digital age |
As in many parts of the world, EU lawmakers are eager to get greater insight into the ways in which digital technologies and online discourse can serve to both enhance and create friction in democratic processes. In context of its recent ‘Democracy Action Plan’ (EDAP), we’ve just filed comments with the European Commission, with the aim of informing thoughtful and effective EU policy responses to key issues surrounding democracy and digital technologies.
Our submission complements our recent EU Digital Services Act filing, and focuses on four key areas:
A high-level overview of our filing can be read here, and the substantive questionnaire response can be read here.
We look forward to working alongside policymakers in the European Commission to give practical meaning to the political ambition expressed in the EDAP and the EU Code of Practice on Disinformation. This, as well as our work on the EU Digital Services Act will be a key focus of our public policy engagement in Europe in the coming months.
The post Mozilla files comments with the European Commission on safeguarding democracy in the digital age appeared first on Open Policy & Advocacy.
|
|
This Week In Rust: This Week in Rust 356 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
No newsletters this week.
The Rust Core Team wants input from the community! If you haven't already, read the official blog and submit a blog post - it will show up here! Here are the wonderful submissions since the call for blog posts:
This week's crate is gitoxide, an idiomatic, modern, lean, fast, safe & pure Rust implementation of git.
Thanks again to Vlad Frolov for the suggestion!
Submit your suggestions and votes for next week!
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
No issues were proposed for CfP.
If you are a Rust project owner and are looking for contributors, please submit tasks here.
336 pull requests were merged in the last week
SyntaxContextconst_item_mutation lint&mut of a non-ZST everSimplifyArmIdentity MIR optimization at mir-opt-level=1doc_aliascore::future::{pending,ready}Durationslice::array_chunks_mutDrop impl for RcBTreeMap mutable iterators should not take any reference to visited nodes during iterationBTreeMap: move up reference to map's root from NodeRefdrain_filter method to HashMap and HashSetMaybeUninit::assume_init_dropMaybeUninit::UNINITA few small compile-time regressions this week. The first was
#70793, which added some
specializations to the standard library in order to increase runtime
performance. The second was
#73996, which adds an option to
the diagnostics code to print only the names of types and traits when they are
unique instead of the whole path. The third was
#75200, which refactored part
of BTreeMap to avoid aliasing mutable references.
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
[T; N]: TryFrom> (insta-stable)If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Tweet us at @ThisWeekInRust to get your job offers listed here!
When you have a lifetime
<'a>on a struct, that lifetime denotes references to values stored outside of the struct. If you try to store a reference that points inside the struct rather than outside, you will run into a compiler error when the compiler notices you lied to it.
Thanks to Tom Phinney for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, and cdmistman.
https://this-week-in-rust.org/blog/2020/09/16/this-week-in-rust-356/
|
|
The Firefox Frontier: Make Firefox your default browser on iOS (finally!) |
With iOS 14, Apple users will finally have the power to choose any default browser on iPhones and iPads. And now that there’s a choice, make it count with Firefox! … Read more
The post Make Firefox your default browser on iOS (finally!) appeared first on The Firefox Frontier.
|
|
Mozilla Cloud Services Blog: The Future of Sync |
There’s a new Sync back-end! The past year or so has been a year of a lot of changes and some of those changes broke things. Our group reorganized, we moved from IRC to Matrix, and a few other things caught us off guard and needed to be addressed. None of those should be excuses for why we kinda stopped keeping you up to date about Sync. We did write a lot of stuff about what we were going to do, but we forgot to share it outside of mozilla. Again, not an excuse, but just letting you know why we felt like we had talked about all of this, even though we absolutely had not.
So, allow me to introduce you to the four person “Services Engineering” team whose job it is to keep a bunch of back-end services running, including Push Notifications and Sync back-end, and a few other miscellaneous services.
For now, let’s focus on Sync.
Sync probably didn’t do what you thought it did.
Sync’s job is to make sure that the bookmarks, passwords, history, extensions and other bits you want to synchronize between one copy of Firefox gets to your other copies of Firefox. Those different copies of Firefox could be different profiles, or be on different devices. Not all of your copies of Firefox may be online or accessible all the time, though, so sync has to do is keep a temporary, encrypted copy on some backend servers which it can use to coordinate later. Since it’s encrypted, Mozilla can’t read that data, we just know it belongs to you. A side effect is that adding a new instance of Firefox (by installing and signing in on a new device, or uninstalling and reinstalling on the same device, or creating a new Firefox profile you then sign in to), just adds another copy of Firefox to Sync’s list of things to synchronize. It might be a bit confusing, but this is true even if you only had one copy of Firefox. If you “lost” a copy of Firefox because you uninstalled it, or your computer’s disc crashed, or your dog buried your phone in the backyard, when you re-installed Firefox, you add another copy of Firefox to your account. Sync would then synchronize your data to that new copy. Sync would just never get an update from the “old” version of Firefox you lost. Sync would just try to rebuild your data from the temporary echoes of the encrypted data that was still on our servers.
That’s great for short term things, but kinda terrible if you, say, shut down Firefox while you go on walk-about only to come back months later to a bad hard drive. You reinstall, try to set up sync, and due to an unexpected Sync server crash we wound up losing your data echos.
That was part of the problem. If we lost a server, we’d basically tell all the copies of Firefox that were using that server, “Whoops, go talk to this new server” and your copy of Firefox would then re-upload what it had. Sometimes this might result in you losing a line of history, sometimes you’d get a duplicate bookmark, but generally, Sync would tend to recover OK and you’d be none the wiser. If that happens when there are no other active copies of Firefox for your account , however, all bets were off and you’d probably lose everything since there were no other copies of your data anywhere.
A lot of folks expected it to be a Backup service. The good news is, now it is a backup service. Sync is more reliable now. We use a distributed database to store your data securely, so we no longer lose databases (or your data echos). There’s a lot of benefit for us as well. We were able to rewrite the service in Rust, a more efficient programming language that lets us run on less machines.
Of course, there are a few challenges we face when standing up a service like this.
Sync needs to run with new versions of Firefox, as well as older ones. In some cases, very old ones, which had some interesting “quirks”. It needs to continue to be at least as secure as before while hopefully giving devs a chance to fix some of the existing weirdness as well as add new features. Oh, and switching folks to the new service should be as transparent as possible.
It’s a long, complicated list of requirements.
First off we had to decide a few things. Like what data store were we going to use. We picked Google Cloud’s Spanner database for its own pile of reasons, some technical, some non-technical. Spanner provides a SQL like database which means that we don’t have to radically change existing MySQL based code. This means that we can provide some level of abstraction allowing for those who want to self-host without radically altering internal data structures. In addition, Spanner provides us an overall cost savings in running our servers. It’s a SQL like database that should be able to handle what we need to do.
We then picked Rust as our development platform and Actix as the web base because we had pretty good experience with moving other Python projects to them. It’s not been magically easy, and there have been plenty of pain points we’ve hit, but by-and-large we’re confident in the code and it’s proven to be easy enough to work with. Rust has also allowed us to reduce the number of servers we have to run in order to provide the service at the scale we need to offer it, which also helps us reduce costs.
For folks interested in following our progress, we’re working with the syncstorage-rs repo on Github. We also are tracking a bunch of the other issues at the services engineering repo.
Because Rust is ever evolving, often massively useful features roll out on different schedules. For instance, we HEAVILY use the async/await code, which landed in late December of 2019, and is taking a bit to percolate through all the libraries. As those libraries update, we’re going to need to rebuild bits of our server to take advantage of them.
Right now, all we can ask is some patience, and possibly help with some of our Good First Bugs. Google released a “stand-alone” spanner emulator that may help you work with our new sync server if you want to play with that part, or you can help us work on the traditional, MySQL stand alone side. That should let you start experimenting with the server and help us find bugs and issues.
To be honest, our initial focus was more on the Spanner integration work than the stand-alone SQL side. We have a number of existing unit tests that exercise both halves and there are a few of us who are very vocal about making sure we support stand-alone SQL databases, but we can use your help testing in more “real world” environments.
For now, folks interested in running the old python 2.7 syncserver still can while we continue to improve stand-alone support inside of syncstorage-rs.
Some folks who run stand-alone servers are well aware that Python 2.7 officially reached “end of life”, meaning no further updates or support is coming from the Python developers, however, we have a bit of leeway here. The Pypy group has said that they plan on offering some support for Python 2.7 for a while longer. Unfortunately, the libraries that we use continue to progress or get abandoned for python3. We’re trying to lock down versions as much as possible, but it’s not sustainable.
We finally have rust based sync storage working with our durable back end running and hosting users. Our goal is to now focus on the “stand-alone” version, and we’re making fairly good progress.
I’m sorry that things have been too quiet here. While we’ve been putting together lots of internal documents explaining how we’re going to do this move, we’ve not shared them publicly. Hopefully we can clean them up and do that.
We’re excited to offer a new version of Sync and look forward to telling you more about what’s coming up. Stay tuned!
https://blog.mozilla.org/services/2020/09/15/the-future-of-sync/
|
|
Mozilla Privacy Blog: Mozilla announces partnership to explore new technology ideas in the Africa Region |
Mozilla and AfriLabs – a Pan-African community and connector of African tech hubs with over 225 technology innovation hubs spread across 47 countries – have partnered to convene a series of roundtable discussions with African startups, entrepreneurs, developers and innovators to better understand the tech ecosystem and identify new product ideas – to spur the next generation of open innovation.
This strategic partnership will help develop more relevant, sustainable support for African innovators and entrepreneurs to build scalable resilient products while leveraging honest and candid discussions to identify areas of common interest. There is no shortage of innovators and creative talents across the African continent, diverse stakeholders coming together to form new ecosystems to solve social, economic problems that are unique to the region.
“Mozilla is pleased to be partnering with AfriLabs to learn more about the intersection of African product needs and capacity gaps and to co-create value with local entrepreneurs,” said Alice Munyua, Director of the Africa Innovation Program.
Mozilla is committed to supporting communities of technologists by putting people first while strengthening the knowledge-base. This partnership is part of Mozilla’s efforts to reinvest within the African tech ecosystem and support local innovators with scalable ideas that have the potential to impact across the continent.
The post Mozilla announces partnership to explore new technology ideas in the Africa Region appeared first on Open Policy & Advocacy.
|
|
Mozilla Attack & Defense: Inspecting Just-in-Time Compiled JavaScript |
The security implications of Just-in-Time (JIT) Compilers in browsers have been getting attention for the past decade and the references to more recent resources is too great to enumerate. While it’s not the only class of flaw in a browser, it is a common one; and diving deeply into it has a higher barrier to entry than, say, UXSS injection in the UI. This post is about lowering that barrier to entry.
If you want to understand what is happening under the hood in the JIT engine, you can read the source. But that’s kind of a tall order given that the folder js/ contains 500,000+ lines of code. Sometimes it’s easier to treat a target as a black box until you find something you want to dig into deeper. To aid in that endeavor, we’ve landed a feature in the js shell that allows you to get the assembly output of a Javascript function the JIT has processed. Disassembly is supported with the zydis disassembly library (our in-tree version).
To use the new feature; you’ll need to run the js interpreter. You can download the jsshell for any Nightly version of Firefox from our FTP server – for example here’s the latest Linux x64 jsshell. Helpfully, these links always point to the latest version available, historical versions can also be downloaded.
You can also build the js shell from source (which can be done separately from building Firefox, but doing the full browser build can also create the shell.) If building from source, in your .mozconfig, you’ll want to following to get the tools and output you want but also emulate the shell as the Javascript engine is released to users:
ac_add_options --enable-application=js
ac_add_options --enable-js-shell
ac_add_options --enable-jitspew
ac_add_options --disable-debug
ac_add_options --enable-optimize
# If you want to experiment with the debug and optimize flags,
# you can build Firefox to different object directories
# (and avoid an entire recompilation)
mk_add_options MOZ_OBJDIR=@TOPSRCDIR@/obj-nodebug-opt
# mk_add_options MOZ_OBJDIR=@TOPSRCDIR@/obj-debug-noopt
After building the shell or Firefox, fire up `obj-dir/dist/bin/js[.exe]` and try the following script:
function add(x, y) { x = 0+x; y = 0+y; return x+y; }
for(i=0; i<500; i++) { add(2, i); }
print(disnative(add))

You’ll be greeted by an initial line indicating which backend is being used. The possible values and their meanings are:
0 The WASM function itself might be Baseline WASM or compiled with an optimizing compiler Cranelift on Nightly; Ion otherwise – it’s not easily enumerated which the assembly function is, but identifying baseline or not becomes easier once you’ve looked at the assembly output a few times.
After running a function 100 times, we will trigger the Baseline compiler; after 1000 times we will trigger Ion, and after 100,000 times the full, more expensive, Ion compilation.
For more information about the differences and internals of the JIT Engines, we can point to the following articles:
Let’s dive into the output we just generated. Here’s the output of the above script:
; backend=baseline
00000000 jmp 0x0000000000000028
00000005 mov $0x7F8A23923000, %rcx
0000000F movq 0x170(%rcx), %rcx
00000016 movq %rsp, 0xD0(%rcx)
0000001D movq $0x00, 0xD8(%rcx)
00000028 push %rbp
00000029 mov %rsp, %rbp |
0000002C sub $0x48, %rsp | Allocating & initializing
00000030 movl $0x00, -0x10(%rbp) | BaselineFrame structure on
00000037 movq 0x18(%rbp), %rcx | stack.
0000003B and $-0x04, %rcx | (BaselineCompilerCodeGen::
0000003F movq 0x28(%rcx), %rcx | emitInitFrameFields)
00000043 movq %rcx, -0x30(%rbp) |
00000047 mov $0x7F8A239237E0, %r11 |
00000051 cmpq %rsp, (%r11) |
00000054 jbe 0x000000000000006C |
0000005A mov %rbp, %rbx | Stackoverflow check
0000005D sub $0x48, %rbx | (BaselineCodeGen::
00000061 push %rbx | emitStackCheck)
00000062 push $0x5821 |
00000067 call 0xFFFFFFFFFFFE1680 |
0000006C mov $0x7F8A226CE0D8, %r11
00000076 addq $0x01, (%r11)
0000007A mov $0x7F8A227F6E00, %rax |
00000084 movl 0xC0(%rax), %ecx |
0000008A add $0x01, %ecx |
0000008D movl %ecx, 0xC0(%rax) |
00000093 cmp $0x3E8, %ecx |
00000099 jl 0x00000000000000CC | Check if we should tier up to
0000009F movq 0x88(%rax), %rax | Ion code. 0x38 (1000) is the
000000A6 cmp $0x02, %rax | threshold. After that check,
000000AA jz 0x00000000000000CC | it checks 'are we already
000000B0 cmp $0x01, %rax | compiling' and 'is Ion
000000B4 jz 0x00000000000000CC | compilation impossible'
000000BA mov %rbp, %rcx |
000000BD sub $0x48, %rcx |
000000C1 push %rcx |
000000C2 push $0x5821 |
000000C7 call 0xFFFFFFFFFFFE34B0 |
000000CC movq 0x28(%rbp), %rcx |
000000D0 mov $0x7F8A227F6ED0, %r11 |
000000DA movq (%r11), %rdi |
000000DD callq (%rdi) |
000000DF movq 0x30(%rbp), %rcx | Type Inference Type Monitors
000000E3 mov $0x7F8A227F6EE0, %r11 | for |this| and each arg.
000000ED movq (%r11), %rdi | (This overhead is one of the
000000F0 callq (%rdi) | reasons we're doing
000000F2 movq 0x38(%rbp), %rcx | WARP - see below.)
000000F6 mov $0x7F8A227F6EF0, %r11 |
00000100 movq (%r11), %rdi |
00000103 callq (%rdi) |
00000105 movq 0x30(%rbp), %rbx |
00000109 mov $0xFFF8800000000000, %rcx |
00000113 mov $0x7F8A227F6F00, %r11 | Load Int32Value(0) + arg1 and
0000011D movq (%r11), %rdi | calling an Inline Cache stub
00000120 callq (%rdi) |
00000122 movq %rcx, 0x30(%rbp) |
00000126 movq 0x38(%rbp), %rbx |
0000012A mov $0xFFF8800000000000, %rcx | Load Int32Value(0) + arg2 and
00000134 mov $0x7F8A227F6F10, %r11 | calling an Inline Cache stub
0000013E movq (%r11), %rdi |
00000141 callq (%rdi) |
00000143 movq %rcx, 0x38(%rbp) |
00000147 movq 0x38(%rbp), %rbx |
0000014B movq 0x30(%rbp), %rcx |
0000014F mov $0x7F8A227F6F20, %r11 |
00000159 movq (%r11), %rdi | Final Add Inline Cache call
0000015C callq (%rdi) | followed by epilogue code and
0000015E jmp 0x0000000000000163 | return
00000163 mov %rbp, %rsp |
00000166 pop %rbp |
00000167 jmp 0x0000000000000171 |
0000016C jmp 0xFFFFFFFFFFFE69E0
00000171 ret
00000172 ud2
So that’s the Baseline code. It’s the more simplistic JIT in Firefox. What about IonMonkey – its faster, more aggressive big brother?
If we preface our script with setJitCompilerOption("ion.warmup.trigger", 4); then we will induce the Ion compiler to trigger earlier instead of the aforementioned 1000 invocations. You can also set setJitCompilerOption("ion.full.warmup.trigger", 4); to trigger the more aggressive tier for Ion compilation that otherwise kicks in after 100,000 invocations. After triggering the ‘full’ layer, the output will look like:
; backend=ion 00000000 movq 0x20(%rsp), %rax | 00000005 shr $0x2F, %rax | 00000009 cmp $0x1FFF3, %eax | 0000000E jnz 0x0000000000000078 | 00000014 movq 0x28(%rsp), %rax | 00000019 shr $0x2F, %rax | Type Guards 0000001D cmp $0x1FFF1, %eax | for this variable, 00000022 jnz 0x0000000000000078 | arg1, & arg2 00000028 movq 0x30(%rsp), %rax | 0000002D shr $0x2F, %rax | 00000031 cmp $0x1FFF1, %eax | 00000036 jnz 0x0000000000000078 | 0000003C jmp 0x0000000000000041 | 00000041 movl 0x28(%rsp), %eax | 00000045 movl 0x30(%rsp), %ecx | Addition 00000049 add %ecx, %eax | 0000004B jo 0x000000000000007F | Overflow Check 00000051 mov $0xFFF8800000000000, %rcx | Box int32 into 0000005B or %rax, %rcx | Int32Value 0000005E ret 0000005F nop 00000060 nop 00000061 nop 00000062 nop 00000063 nop 00000064 nop 00000065 nop 00000066 nop 00000067 mov $0x7F8A23903FC0, %r11 | 00000071 push %r11 | 00000073 jmp 0xFFFFFFFFFFFDED40 | 00000078 push $0x00 | 0000007A jmp 0x000000000000008D | 0000007F sub %ecx, %eax | Out-of-line 00000081 jmp 0x0000000000000086 | error handling 00000086 push $0x0D | code 00000088 jmp 0x000000000000008D | 0000008D push $0x00 | 0000008F jmp 0xFFFFFFFFFFFDEC60 | 00000094 ud2 |
There are some other things worth noting.
You can control the behavior of the JITs using environment variables, such as JIT_OPTION_fullDebugChecks=false (this will avoid running all the debug checks even in the debug build.) The full list of JIT Options with documentation is available in JitOptions.cpp.
There are also a variety of command-line flags that can be used in place of environment variables or setJitCompilerOption. For instance --baseline-eager and --ion-eager will trigger JIT compilation immediately instead of requiring multiple compilations. (ion-eager triggers ‘full’ compilation, so avoid it if you want the non-full behavior.) --no-threads or --ion-offthread-compile=off will disable off-thread compilation that can make it harder to write reliable tests because it adds non-determinism. no-threads turns off all the background threads and implies ion-offthread-compile=off.
Finally, we have a new in-development frontend for Ion: WarpBuilder. You can learn more about WarpBuilder over in the spidermonkey newsletter or the Bugzilla bug. Enabling warp (by passing --warp to the js shell executable) significantly reduces the assembly generated, partly because we’re simplifying how type information is collected and updated.
If you’ve got other tricks or techniques you use to help you navigate our JIT(s), be sure to reply to our tweet so others can find them!
https://blog.mozilla.org/attack-and-defense/2020/09/15/inspecting-just-in-time-compiled-javascript/
|
|
Mozilla Addons Blog: Extensions in Firefox 81 |
In Firefox 81, we have improved error messages for extension developers and updated user-facing notifications to provide more information on how extensions are modifying their settings.
For developers, the menus.create API now provides more meaningful error messages when supplying invalid match or url patterns. This updated message should make it easier for developers to quickly identify and fix the error. In addition, webNavigation.getAllFrames and webNavigation.getFrame will return a promise resolved with null in case the tab is discarded, which is how these APIs behave in Chrome.
For users, we’ve added a notification when an add-on is controlling the “Ask to save logins and passwords for websites” setting, using the privacy.services.passwordSavingEnabled settings API. Users can see this notification in their preferences or by navigating to about:preferences#privacy.
Thank you Deepika Karanji for improving the error messages, and our WebExtensions and security engineering teams for making these changes possible. We’re looking forward to seeing what is next for Firefox 82.
The post Extensions in Firefox 81 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/09/14/extensions-in-firefox-81/
|
|
Mozilla Open Policy & Advocacy Blog: Mozilla applauds TRAI for maintaining the status quo on OTT regulation, upholding a key aspect of net neutrality in India |
Mozilla applauds the Telecom Regulatory Authority of India (TRAI) for its decision to maintain the existing regulatory framework for OTT services in India. The regulation of OTT services sparked the fight for net neutrality in India in 2015, leading to over a million Indians asking TRAI to #SaveTheInternet and over time becoming one of the most successful grassroots campaigns in the history of digital activism. Mozilla’s CEO, Mitchell Baker, wrote an open letter to Prime Minister Modi at the time stating: “We stand firm in the belief that all users should be able to experience the full diversity of the Web. For this to be possible, Internet Service Providers must treat all content transmitted over the Internet equally, regardless of the sender or the receiver.”
Since then, as we have stated in public consultations in both 2015 and 2019, we believe that imposing a new uniform regulatory framework for OTT services, akin to how telecom operators are governed, would irredeemably harm the internet ecosystem in India. It would create legal uncertainty, chill innovation, undermine security best practices, and eventually, hurt the promise of Digital India. TRAI’s thoughtful and considered approach to the topic sets an example for regulators across the world and helps mitigate many of these concerns. It is a historical step for a country which already has among the strongest net neutrality regulations in the world. We look forward to continuing to work with TRAI to create a progressive regulatory framework for the internet ecosystem in India.
The post Mozilla applauds TRAI for maintaining the status quo on OTT regulation, upholding a key aspect of net neutrality in India appeared first on Open Policy & Advocacy.
|
|
The Rust Programming Language Blog: A call for contributors from the WG-prioritization team |
Are you looking for opportunities to contribute to the Rust community? Have some spare time to donate? And maybe learn something interesting along the way?
The WG-prioritization can be the right place for you: we are looking for new contributors!
The Prioritization WG is a compiler Working Group dedicated to handling the most important bugs found in the Rust compiler (rustc), to ensure that they are resolved. We stand at the frontline of the Github Rust issue tracker and our job is to do triaging, mainly deciding which bugs are critical (potential release blockers) and prepare the weekly agenda for the Compiler Team with the most pressing issues to be taken care of.
Here is a bit more comprehensive description. How we work is detailed on the Rust Forge.
Our tooling is mainly the triagebot, a trustful messenger that helps us by sending notification to our Zulip stream when an issue on Github is labelled.
We also have a repository with some issues and meta-issues, where we basically note down how we would like our workflow to evolve. Contributions to these issues are welcome, but a bit more context about the workflow of this Working Group is probably necessary.
Documentation is also a fundamental part of the onboarding package that we provide to newcomers. As we basically "organize and sort stuff", a lot happens without writing a single line of code but rather applying procedures to optimize triaging and issues prioritization.
This requires our workflow to be as efficient and well documented as possible. As such, we are always open to contributions to clarify the documentation (and fresh eyeballs are especially precious for that!).
Our week starts on Thursday/Friday after the Rust Compiler Team meeting (one of the cool teams that keep that beast at bay) by preparing a new agenda for the following meeting, leaving placeholders to be filled during the week.
In the following days the WG-prioritization and other teams will asynchronously monitor the issue tracker - everyone at their own pace, when time allows - trying to assign a priority to new issues. This greatly helps the compiler team to sort and prioritize their work.
If the issue priority is not immediately clear, it will be tagged with a temporary label and briefly discussed on Zulip by the WG-prioritization: is this issue critical? Is it clear? Does it need a minimal reproducible example (often abbreviated in MCVE) or even better a bisect to find a regression (we love contributors bisecting code)? We then assign the priority by choosing a value in a range from P-low to P-critical. The rationale behind the priority levels is detailed in our guide.
The day before the meeting the agenda is filled and handed to the Compiler Team.
Someone from the WG-Prioritization will attend the meeting and provide some support (if needed).
Rinse and repeat for the next meeting.
Everything is described in excruciating detail on Rust Forge. Feel free to have a look there to learn more. The quantity of information there can be a bit overwhelming at first (there is quite a bit of lingo we use), but things will become clearer.
I-prioritize (issues that need a brief discussion before assigning a priority) but also P-critical and P-high (issues that need attention during the compiler meeting). All this is required for our next task:Yes, you are! There will always be one or more members available to explain, mentor and clarify things. Don't be shy and do not refrain from asking questions. You will very quickly be able to give a helpful opinion in our discussions.
Everyone can contribute on their capacity and availability. The reward is the warm feeling to do something concrete to ensure that the Rust compiler, one of the cornerstone of the project, stays in good shape and improves continuously. Moreover, you will be exposed to a continuous stream of new bugs and seeing how they are evaluated and managed is pretty educational.
One of the great things of the Rust governance is its openness. Join our stream #t-compiler/wg-prioritization, peek at how we work and if you want, also keep an eye to the weekly Team Compiler official meetings on #t-compiler/meetings. Have a question? Don't hesitate to open a new topic in our stream!
You can even simply just hang out on our Zulip stream, see how things work and then get involved where you feel able.
We keep a separate substream #t-compiler/wg-prioritization/alerts where all the issues nominated for discussion will receive their own topic. Subscription to this stream is optional for the members of the Working Group as it has a non-negligible volume of notifications (it is public and freely accessible anyway).
The main contact points for this Working Group are Santiago Pastorino (@Santiago Pastorino on Zulip) and Wesley Wiser (@Wesley Wiser on Zulip).
See you there!
https://blog.rust-lang.org/2020/09/14/wg-prio-call-for-contributors.html
|
|
Henri Sivonen: Rust 2021 |
It is again the time of year when the Rust team is calling for blog post as input to the next annual roadmap. This is my contribution.
I wish either the Rust Foundation itself or at least a sibling organization formed at the same time was domiciled in the EU. Within the EU, Germany looks like the appropriate member state.
Instead of simply treating the United States as the default jurisdiction for the Rust Foundation, I wish a look is taken at the relative benefits of other jurisdictions. The Document Foundation appears to be precedent of Germany recognizing Free Software development as having a public benefit purpose.
Even if the main Foundation ends up in the United States, I still think a sibling organization in the EU would be worthwhile. A substantial part of the Rust community is in Europe and in Germany specifically. Things can get problematic when the person doing the work resides in Europe but entity with the money is in the United States. It would be good to have a Rust Foundation-ish entity that can act as an European Economic Area-based employer.
Also, being domiciled in the European Union has the benefit of access to EU money. Notably, Eclipse Foundation is in the process of relocating from Canada to Belgium.
My technical wishes are a re-run of 2018, 2019, and 2020. Most of the text below is actual copypaste.
packed_simd to std::simdRust has had awesome portable (i.e. cross-ISA) SIMD since 2015—first in the form of the simd crate and now in the form of the packed_simd crate. Yet, it’s still a nightly-only feature.
As a developer working on a product that treats x86_64, aarch64, ARMv7+NEON, and x86 as tier-1, I wish packed_simd gets promoted to std::simd (on stable) in 2021. There now appears to be forward motion on this.
At this point, people tend to say: “SIMD is already stable.” No, not portable SIMD. What got promoted was vendor intrinsics for x86 and x86_64. This is the same non-portable feature that is available in C. Especially with Apple Silicon coming up, it’s bad if the most performant Rust code is built for x86_64 while aarch64 is left as a mere TODO item (not to mention less popular architectures). The longer Rust has vendor intrinsics on stable without portable SIMD on stable, the more the crate ecosystem becomes dependent on x86_64 intrinsics and the harder it becomes to restructure the crates to use portable SIMD where portable SIMD works and to confine vendor intrinsics only to specific operations.
The library support for the cargo bench feature has been in the state “basically, the design is problematic, but we haven’t had anyone work through those issues yet” since 2015. It’s a useful feature nonetheless. Like I said a year ago, the year before, and the year before that, it’s time to let go of the possibility of tweaking it for elegance and just let users use it on non-nighly Rust.
As a developer writing performance-sensitive inner loops, I wish rustc/LLVM did better integer range analysis for bound check elision. See my Rust 2019 post.
likely() and unlikely() for Plain if Branch Prediction HintsAlso, as a developer writing performance-sensitive inner loops, I wish likely() and unlikely() were available on stable Rust. Like benchmarking, likely() and unlikely() are a simple feature that works but has stalled due to concerns about lack of perfection. Let’s have it for plain if and address match and if let once there actually is a workable design for those.
Rust has successfully delivered on “stability without stagnation” to the point that Red Hat delivers Rust updates for RHEL on a 3-month frequency instead of Rust getting stuck for the duration of the lifecycle of a RHEL version. That is, contrary to popular belief, the “stability” part works without an LTS. At this point, doing an LTS would be a stategic blunder that would jeopardize the “without stagnation” part.
|
|
Mozilla Privacy Blog: India’s ambitious non personal data report should put privacy first, for both individuals and communities |
After almost a year’s worth of deliberation, the Kris Gopalakrishnan Committee released its draft report on non-personal data regulation in India in July 2020. The report is one of the first comprehensive articulations of how non-personal data should be regulated by any country and breaks new ground in interesting ways. While seemingly well intentioned, many of the report’s recommendations leave much to be desired in both clarity and feasibility of implementation. In Mozilla’s response to the public consultation, we have argued for a consultative and rights respecting approach to non-personal data regulation that benefits communities, individuals and businesses alike while upholding their privacy and autonomy.
We welcome the consultation, and believe the concept of non-personal data will benefit from a robust public discussion. Such a process is essential to creating a rights-respecting law compatible with the Indian Constitution and its fundamental rights of equality, liberty and privacy.
The key issues outlined in our submission are:
The goal of data-driven innovation oriented towards societal benefit is a valuable one. However, any community-oriented data models must be predicated on a legal framework that secures the individual’s rights to their data, as affirmed by the Indian Constitution. As we’ve argued extensively to MeitY and the Justice Srikrishna Committee, such a law has the opportunity to build on the globally standard of data protection set by Europe, and position India as a leader in internet regulation.
We look forward to engaging with the Indian government as it deliberates how to regulate non-personal data over the coming years.
Our full submission can be found here.
The post India’s ambitious non personal data report should put privacy first, for both individuals and communities appeared first on Open Policy & Advocacy.
|
|







