The Servo Blog: This Week In Servo 134 |
In the past week, we merged 69 PRs in the Servo organization’s repositories.
The latest nightly builds for common platforms are available at download.servo.org.
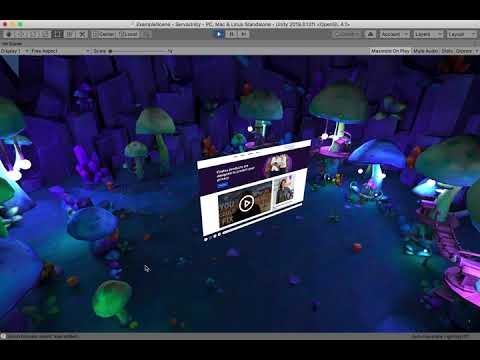
Servo has been successfully integrated into 3d Unity scenes as a 2d browser plugin.
Our macOS nightly builds last week panicked on launch due to missing shared libraries. That issue has been fixed.
Our roadmap is available online, including the team’s plans for 2020.
This week’s status updates are here.
fxrmin:// protocol to launch immersive mode immediately on document load.display: list-item in the Layout 2020 engine.Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
|
|
Karl Dubost: A-localized work or distributed work |
Jason Fried published Remote work is a platform. After a quick metaphor about the Web and how at the begining of any ecosystem change, he explains how we have a tendency to port what we knew from the old ecosystem into the new ones, before being able to develop its own grammar and language. The case here is work in offices.
In-person office work is a platform. It has its own advantages and disadvantages.
I wrote about the topic in This is not a remote work. While I hear Jason asking for people to create new techniques of working for the specific context of alocalized work (which I agree with), it probably goes deeper than just an « in-person office » versus « remote » work.
The key argument of the post is this one.
They’ll have discovered that remote work means more autonomy, more trust, more uninterrupted stretches of time, smaller teams, more independent, concurrent work (and less dependent, sequenced work).
Yes. Yes. Yes.
I would add a if the type of job allows it. You can not clean the floor of a building being away from it (except being in a SciFi style futuristic view of the future where offices are flawless… and humanless.)
The first steps for thinking about this « new platform » is
Otsukare!
|
|
Cameron Kaiser: TenFourFox FPR25 available |
For FPR26 there will be one additional change to DOM workers and I'm looking at some problem sites to see if there are some easy fixes. Still, the big issues continue to be the big issues and we'll just have to do things like the AppleScript workarounds to deal with them better in future. I'd like to see more people experimenting with AppleScript, too -- we have a whole page of documentation devoted to it and some examples which you can download if you don't want to type them in.
Meantime, did you know Apple had LocalTalk cards for the PC?
http://tenfourfox.blogspot.com/2020/07/tenfourfox-fpr25-available.html
|
|
Mozilla Addons Blog: Extensions in Firefox 79 |
We have a little more news this release: a new API method, a reminder about a recently announced change, a preview of some things to come, and a few interesting improvements. Let’s get started!
To optimize resource usage, render information on inactive tabs is discarded. When Firefox anticipates that a tab will be activated, the tab is “warmed up”. Switching to it then feels much more instantaneous. With the new tabs.warmup function, tab manager extensions will be able to benefit from the same perceived performance improvements. Note this API does not work on discarded tabs and does not need to be called immediately prior to switching tabs. It is merely a performance improvement when the tab switch can be anticipated, such as when hovering over a button that when clicked would switch to the tab.
We’ve blogged about this recently, but given this is part of Firefox 79 I wanted to make sure to remind you about the storage.sync changes we’ve been working on. Storage quotas for the storage.sync API are now being enforced as part of backend changes we’ve introduced for better scalability and performance.
There is no immediate action required if you don’t use the storage.sync API or are only storing small amounts of data. We encourage you to make your code resilient while your storage needs grow by checking for quota errors. Also, if you are getting support requests from users related to stored preferences you may want to keep this change in mind and support them in filing a bug as necessary.
For more information and how to file a bug in case you come across issues with this change, please see the blog post.
The Firefox platform team has been working on a new security architecture that isolates sites from each other, down to separating cross-origin iframes from the tab’s process. This new model, nicknamed Fission, is currently available for opt-in testing in Nightly. The platform team is planning to begin roll-out to Nightly and Beta users later this year.
So far, we have identified two changes with Fission enabled that will impact extensions:
moz-extension:// url) and accessing them directly via the contentWindow property will be incompatible with Fission, since that iframe will run in a different process. The recommended pattern, as always, is to use postMessage and extension messaging instead.drawWindow API will be deprecated, since it’s unable to draw out-of-process iframes. You should switch to the captureTab method, which we are looking to extend with more functionality to provide a sufficient replacement.If you are the developer of an extension that uses one of these features, we recommend that you update your extension in the coming months to avoid potential breakages.
We’re working to make the transition to Fission as smooth as possible for users and extension developers, so we need your help: please test your extensions with Fission enabled, and report any issues on Bugzilla as blocking the fission-webext meta bug. If you need help or have any questions, come find us on our community forum or Matrix.
We will continue to monitor changes that will require add-ons to be updated. We encourage you to subscribe to our blog to stay up to date on the latest developments. If more changes to add-ons are necessary we will reach out to developers individually or announce the changes here.
Special thanks in this release goes to community members Myeongjun Go, Sonia Singla, Deepika Karanji, Harsh Arora, and my friends at Mozilla that have put a lot of effort into making Firefox 79 successful. Also a special thanks to the Fission team for supporting us through the changes to the extension architecture. Stay tuned for next time!
The post Extensions in Firefox 79 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/07/24/extensions-in-firefox-79/
|
|
Mozilla Addons Blog: Extensions in Firefox 79 |
We have a little more news this release: a new API method, a reminder about a recently announced change, a preview of some things to come, and a few interesting improvements. Let’s get started!
To optimize resource usage, render information on inactive tabs is discarded. When Firefox anticipates that a tab will be activated, the tab is “warmed up”. Switching to it then feels much more instantaneous. With the new tabs.warmup function, tab manager extensions will be able to benefit from the same perceived performance improvements. Note this API does not work on discarded tabs and does not need to be called immediately prior to switching tabs. It is merely a performance improvement when the tab switch can be anticipated, such as when hovering over a button that when clicked would switch to the tab.
We’ve blogged about this recently, but given this is part of Firefox 79 I wanted to make sure to remind you about the storage.sync changes we’ve been working on. Storage quotas for the storage.sync API are now being enforced as part of backend changes we’ve introduced for better scalability and performance.
There is no immediate action required if you don’t use the storage.sync API or are only storing small amounts of data. We encourage you to make your code resilient while your storage needs grow by checking for quota errors. Also, if you are getting support requests from users related to stored preferences you may want to keep this change in mind and support them in filing a bug as necessary.
For more information and how to file a bug in case you come across issues with this change, please see the blog post.
The Firefox platform team has been working on a new security architecture that isolates sites from each other, down to separating cross-origin iframes from the tab’s process. This new model, nicknamed Fission, is currently available for opt-in testing in Nightly. The platform team is planning to begin roll-out to Nightly and Beta users later this year.
So far, we have identified two changes with Fission enabled that will impact extensions:
moz-extension:// url) and accessing them directly via the contentWindow property will be incompatible with Fission, since that iframe will run in a different process. The recommended pattern, as always, is to use postMessage and extension messaging instead.drawWindow API will be deprecated, since it’s unable to draw out-of-process iframes. You should switch to the captureTab method, which we are looking to extend with more functionality to provide a sufficient replacement.If you are the developer of an extension that uses one of these features, we recommend that you update your extension in the coming months to avoid potential breakages.
We’re working to make the transition to Fission as smooth as possible for users and extension developers, so we need your help: please test your extensions with Fission enabled, and report any issues on Bugzilla as blocking the fission-webext meta bug. If you need help or have any questions, come find us on our community forum or Matrix.
We will continue to monitor changes that will require add-ons to be updated. We encourage you to subscribe to our blog to stay up to date on the latest developments. If more changes to add-ons are necessary we will reach out to developers individually or announce the changes here.
Special thanks in this release goes to community members Myeongjun Go, Sonia Singla, Deepika Karanji, Harsh Arora, and my friends at Mozilla that have put a lot of effort into making Firefox 79 successful. Also a special thanks to the Fission team for supporting us through the changes to the extension architecture. Stay tuned for next time!
The post Extensions in Firefox 79 appeared first on Mozilla Add-ons Blog.
https://blog.mozilla.org/addons/2020/07/24/extensions-in-firefox-79/
|
|
Mozilla VR Blog: A browser plugin for Unity |
Unity's development tools and engine are far and away the most common way to build applications for VR and AR today. Previously, we've made it possible to export web-based experiences from Unity. Today, we're excited to show some early work addressing the other way that Unity developers want to use the web: as a component in their Unity-based virtual environments.
Building on our work porting a browser engine to many platforms and embedding scenarios, including as Firefox Reality AR for HoloLens 2, we have built a new Unity component based on Servo, a modern web engine written in the Rust language.
The Unity engine has a very adaptable multi-platform plugin system with a healthy ecosystem of third-party plugins, both open-source and proprietary. The plugin system allows us to run OS-native modules and connect them directly to components executing in the Unity scripting environment.
The goals of the experiments were to build a Unity native plugin and a set of Unity C# script components that would allow third parties to incorporate Servo browser windows into Unity scenes, and optionally, provide support for using the browser surface in VR and AR apps built in Unity.
Today, we’re releasing a fully-functional prototype of the Servo web browser running inside a Unity plugin. This is an early-stage look into our work, but we know excitement is high for this kind of solution, so we hope you’ll try out this prototype, provide your feedback, and join us in building things with it. The version released today targets the macOS platform, but we will add some of the other platforms supported by Servo very soon.
We’ve open-sourced the plugin, at https://github.com/MozillaReality/servo-unity. Head on over, click the star and fork the code, check it out to your local machine, and then open the project inside Unity.

Developer instructions are in the README file in the repository.
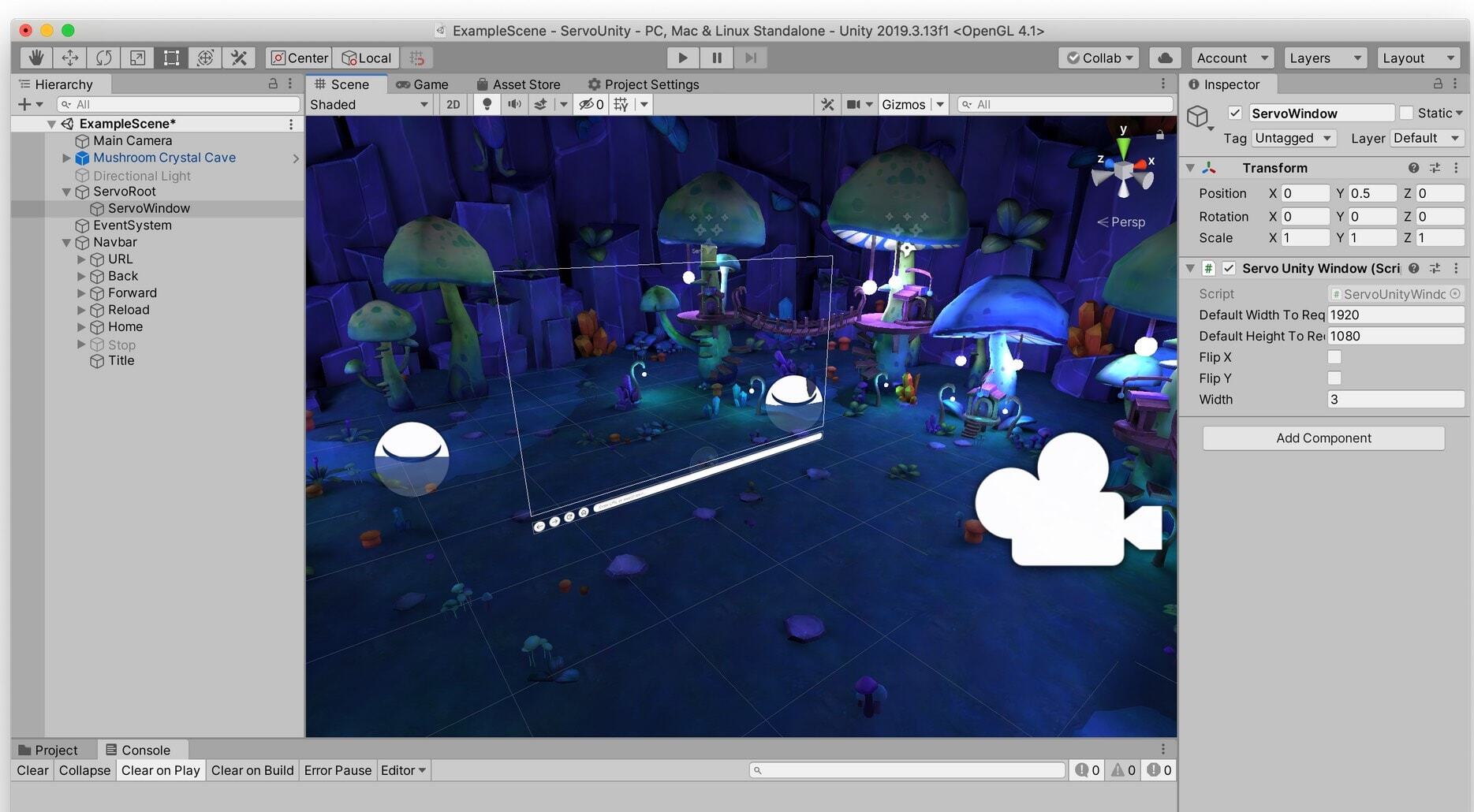
You can work directly with the browser window and controls inside the Unity Editor. Top-level config is on the ServoUnityController object. Other important objects in the scene include the ServoUnityWindow, ServoUnityNavbarController, and ServoUnityMousePointer.
The ServoUnityWindow can be positioned anywhere in a Unity scene. Here, we’ve dropped it into the Mozilla mushroom cave (familiar to users of Firefox Reality, by the amazing artist Jasmin Habezai-Fekri), and provided a camera manipulator that allows us to move around the scene and see that it is a 3D view of the browser content.
Servo has high-quality media playback via the GStreamer framework, including audio support. Here we’re viewing sample MPEG4 video, running inside a deployed Unity player build.
Customizable search is included in the plugin. A wide variety of web content is viewable with the current version of Servo, with greater web compatibility being actively worked on (more on that below). WebGL content works too.
Development in Unity uses a component-based architecture, where Unity executes user code attached to GameObjects, organised into scenes. Users customise GameObjects by attaching scripts which execute in a C# environment, either using the Mono runtime or the IL2CPP ahead-of-time compiler. The Unity event lifecycle is accessible to user scripts inheriting from the Unity C# class MonoBehaviour. User scripts can invoke native code in plugins (which are just OS-native dynamic shared objects) via the C# runtime’s P/Invoke mechanism. In fact, Unity’s core itself is implemented in C++ and provides native code in plugins with a second set of C/C++-accessible interfaces to assist in some low-level plugin tasks.
Servo is itself a complex piece of software. By design, most of its non user-facing functionality is compiled into a Rust library, libservo. For this first phase of the project, we make use of a simplified C-compatible interface in another Rust library named libsimpleservo2. This library exposes C-callable functions and callback hooks to control the browser and view its output. Around libsimpleservo2, we put in place native C++ abstractions that encapsulate the Unity model of threads and rendering, and expose a Unity-callable set of interfaces that are in turn operated by our C# script components.
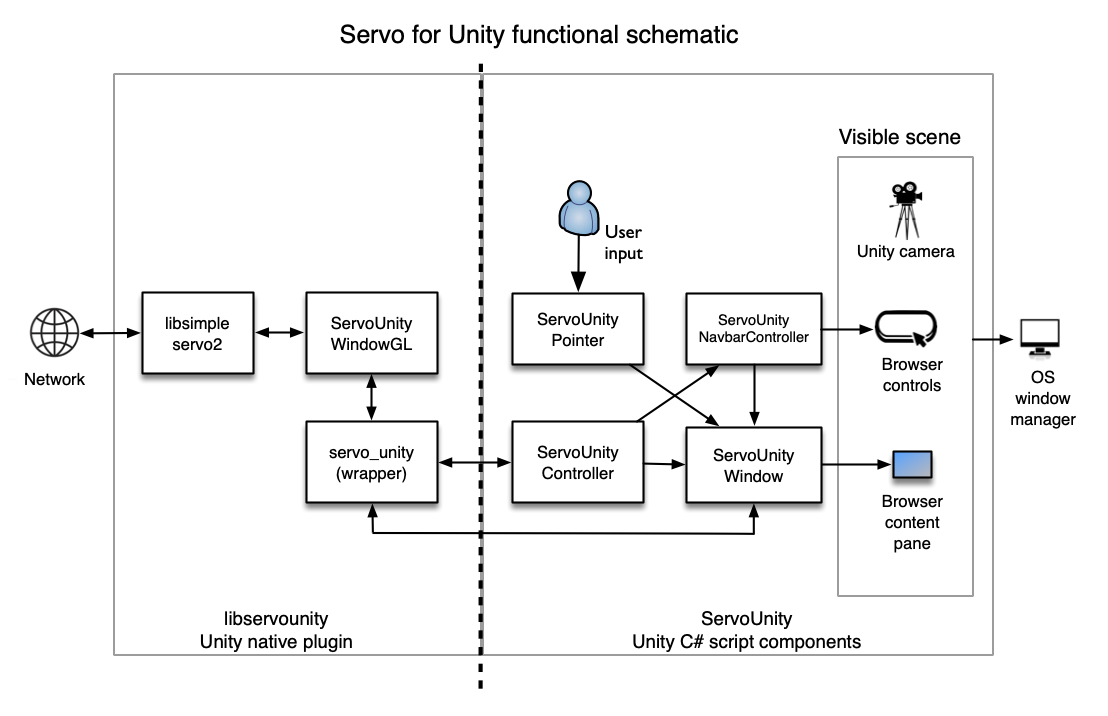
We create an object in Unity, an instance of ServoUnityWindow, to wrap an instance of Unity’s Texture2D class and treat it as a browser content pane. When using Unity’s OpenGL renderer, the Texture2D class is backed by a native OpenGL texture, and we pass the OpenGL texture “name” (i.e. an ID) to the plugin, which binds the texture to a framebuffer object which receives the final composited texture from Servo.
As we do not have control over the binding of the texture and the Unity context, the current design for updating this texture uses a blit (copy) via Servo’s surfman-chains API. Essentially, Servo’s WebRender writes to an OS-specific surface buffer on one thread, and then this surface buffer is bound read-only to Unity’s render thread and a texture copy is made using OpenGL APIs. In the initial macOS implementation for example, the surface buffer is an IOSurface which can be zero-cost moved between threads, allowing an efficient implementation where the browser compositor can write in a different thread to the thread displaying the texture in Unity.
Control and page meta-data is communicated separately, via a set of APIs that allow search and navigation to URLs, updating of page titles, and the usual back/forward/stop/home button set.
Because the browser content and controls are all ultimately Unity objects, the Unity application you’re building can position, style, or programmatically control these in any way you like.
Getting the project to this stage has not been without its challenges, some of which we are still addressing. Unity’s scripting environment runs largely single-threaded, with the exception of rendering operations which take place on a separate thread on a different cadence. Servo, however, spawns potentially dozens of lightweight threads for a variety of tasks. We have taken care to marshal returning work items from Servo back to the correct threads in Unity. There are some remaining optimizations to be made in deciding when to refresh the Unity texture. Currently, it just refreshes every frame, but we are adding an API to the embedding interface to allow finer-grained control.
As an incubator for browser technology, Servo is focused on developing new technologies. Notable tech that has moved from Servo to the Gecko engine powering Firefox include the GPU-based rendering engine WebRender, and the CSS engine Stylo. Those successes aside, full web compatibility is still an area where Servo has a significant gap, as we have focused primarily on big improvements for the user and specific experiences over the long tail of the web. A recent effort by the Servo community has seen great advances in Servo’s webcompat, so we expect the subset of the web browsable by Servo to continue to grow rapidly.
Supporting the full range of platforms currently supported by Servo is our first follow-up development priority, with Windows Win32 and Windows UWP support at the top of the list. Many of you have seen our Firefox Reality AR for HoloLens 2 app, and UWP support will allow you to build Servo into a your own AR apps for the HoloLens platform using the same underlying browser engine.
We’d also like to support a greater subset of the full browser capability. High on the list is multiple-window support. We’re currently working on graduating the plugin from the libsimpleservo2 interface to a new interface that will allow applications to instantiate multiple windows, tabs, and implement features like history, bookmarks and more.
This first release is focused on the web browsable through 2D web pages. Servo also supports the immersive web through the WebXR API, and we’re exploring connecting WebXR to Unity’s XR hardware support through the plugin interface. We’ll be starting with support for viewing 360° video, which we know from our Firefox Reality user base is a prime use case for the browser.
Whether it’s a media player, an in-game interface to the open web, browser-as-UI, bringing in specific web experiences, or the myriad of other possibilities, we can’t wait to see some of the imaginative ways developers will exploit Servo’s power and performance inside Unity-built apps.
|
|
Mozilla VR Blog: A browser plugin for Unity |
Unity's development tools and engine are far and away the most common way to build applications for VR and AR today. Previously, we've made it possible to export web-based experiences from Unity. Today, we're excited to show some early work addressing the other way that Unity developers want to use the web: as a component in their Unity-based virtual environments.
Building on our work porting a browser engine to many platforms and embedding scenarios, including as Firefox Reality AR for HoloLens 2, we have built a new Unity component based on Servo, a modern web engine written in the Rust language.
The Unity engine has a very adaptable multi-platform plugin system with a healthy ecosystem of third-party plugins, both open-source and proprietary. The plugin system allows us to run OS-native modules and connect them directly to components executing in the Unity scripting environment.
The goals of the experiments were to build a Unity native plugin and a set of Unity C# script components that would allow third parties to incorporate Servo browser windows into Unity scenes, and optionally, provide support for using the browser surface in VR and AR apps built in Unity.
Today, we’re releasing a fully-functional prototype of the Servo web browser running inside a Unity plugin. This is an early-stage look into our work, but we know excitement is high for this kind of solution, so we hope you’ll try out this prototype, provide your feedback, and join us in building things with it. The version released today targets the macOS platform, but we will add some of the other platforms supported by Servo very soon.
We’ve open-sourced the plugin, at https://github.com/MozillaReality/servo-unity. Head on over, click the star and fork the code, check it out to your local machine, and then open the project inside Unity.
Developer instructions are in the README file in the repository.
You can work directly with the browser window and controls inside the Unity Editor. Top-level config is on the ServoUnityController object. Other important objects in the scene include the ServoUnityWindow, ServoUnityNavbarController, and ServoUnityMousePointer.
The ServoUnityWindow can be positioned anywhere in a Unity scene. Here, we’ve dropped it into the Mozilla mushroom cave (familiar to users of Firefox Reality, by the amazing artist Jasmin Habezai-Fekri), and provided a camera manipulator that allows us to move around the scene and see that it is a 3D view of the browser content.
Servo has high-quality media playback via the GStreamer framework, including audio support. Here we’re viewing sample MPEG4 video, running inside a deployed Unity player build.
Customizable search is included in the plugin. A wide variety of web content is viewable with the current version of Servo, with greater web compatibility being actively worked on (more on that below). WebGL content works too.
Development in Unity uses a component-based architecture, where Unity executes user code attached to GameObjects, organised into scenes. Users customise GameObjects by attaching scripts which execute in a C# environment, either using the Mono runtime or the IL2CPP ahead-of-time compiler. The Unity event lifecycle is accessible to user scripts inheriting from the Unity C# class MonoBehaviour. User scripts can invoke native code in plugins (which are just OS-native dynamic shared objects) via the C# runtime’s P/Invoke mechanism. In fact, Unity’s core itself is implemented in C++ and provides native code in plugins with a second set of C/C++-accessible interfaces to assist in some low-level plugin tasks.
Servo is itself a complex piece of software. By design, most of its non user-facing functionality is compiled into a Rust library, libservo. For this first phase of the project, we make use of a simplified C-compatible interface in another Rust library named libsimpleservo2. This library exposes C-callable functions and callback hooks to control the browser and view its output. Around libsimpleservo2, we put in place native C++ abstractions that encapsulate the Unity model of threads and rendering, and expose a Unity-callable set of interfaces that are in turn operated by our C# script components.
We create an object in Unity, an instance of ServoUnityWindow, to wrap an instance of Unity’s Texture2D class and treat it as a browser content pane. When using Unity’s OpenGL renderer, the Texture2D class is backed by a native OpenGL texture, and we pass the OpenGL texture “name” (i.e. an ID) to the plugin, which binds the texture to a framebuffer object which receives the final composited texture from Servo.
As we do not have control over the binding of the texture and the Unity context, the current design for updating this texture uses a blit (copy) via Servo’s surfman-chains API. Essentially, Servo’s WebRender writes to an OS-specific surface buffer on one thread, and then this surface buffer is bound read-only to Unity’s render thread and a texture copy is made using OpenGL APIs. In the initial macOS implementation for example, the surface buffer is an IOSurface which can be zero-cost moved between threads, allowing an efficient implementation where the browser compositor can write in a different thread to the thread displaying the texture in Unity.
Control and page meta-data is communicated separately, via a set of APIs that allow search and navigation to URLs, updating of page titles, and the usual back/forward/stop/home button set.
Because the browser content and controls are all ultimately Unity objects, the Unity application you’re building can position, style, or programmatically control these in any way you like.
Getting the project to this stage has not been without its challenges, some of which we are still addressing. Unity’s scripting environment runs largely single-threaded, with the exception of rendering operations which take place on a separate thread on a different cadence. Servo, however, spawns potentially dozens of lightweight threads for a variety of tasks. We have taken care to marshal returning work items from Servo back to the correct threads in Unity. There are some remaining optimizations to be made in deciding when to refresh the Unity texture. Currently, it just refreshes every frame, but we are adding an API to the embedding interface to allow finer-grained control.
As an incubator for browser technology, Servo is focused on developing new technologies. Notable tech that has moved from Servo to the Gecko engine powering Firefox include the GPU-based rendering engine WebRender, and the CSS engine Stylo. Those successes aside, full web compatibility is still an area where Servo has a significant gap, as we have focused primarily on big improvements for the user and specific experiences over the long tail of the web. A recent effort by the Servo community has seen great advances in Servo’s webcompat, so we expect the subset of the web browsable by Servo to continue to grow rapidly.
Supporting the full range of platforms currently supported by Servo is our first follow-up development priority, with Windows Win32 and Windows UWP support at the top of the list. Many of you have seen our Firefox Reality AR for HoloLens 2 app, and UWP support will allow you to build Servo into a your own AR apps for the HoloLens platform using the same underlying browser engine.
We’d also like to support a greater subset of the full browser capability. High on the list is multiple-window support. We’re currently working on graduating the plugin from the libsimpleservo2 interface to a new interface that will allow applications to instantiate multiple windows, tabs, and implement features like history, bookmarks and more.
This first release is focused on the web browsable through 2D web pages. Servo also supports the immersive web through the WebXR API, and we’re exploring connecting WebXR to Unity’s XR hardware support through the plugin interface. We’ll be starting with support for viewing 360° video, which we know from our Firefox Reality user base is a prime use case for the browser.
Whether it’s a media player, an in-game interface to the open web, browser-as-UI, bringing in specific web experiences, or the myriad of other possibilities, we can’t wait to see some of the imaginative ways developers will exploit Servo’s power and performance inside Unity-built apps.
|
|
The Firefox Frontier: Use your voice to #StopHateForProfit |
Facebook is still a place where it’s too easy to find hate, bigotry, racism, antisemitism and calls to violence. Today, we are standing alongside our partners in the #StopHateForProfit coalition … Read more
The post Use your voice to #StopHateForProfit appeared first on The Firefox Frontier.
|
|
About:Community: Firefox 79 new contributors |
With the release of Firefox 79, we are pleased to welcome the 21 developers who contributed their first code change to Firefox in this release, 18 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/07/23/firefox-79-new-contributors/
|
|
About:Community: Firefox 79 new contributors |
With the release of Firefox 79, we are pleased to welcome the 21 developers who contributed their first code change to Firefox in this release, 18 of whom were brand new volunteers! Please join us in thanking each of these diligent and enthusiastic individuals, and take a look at their contributions:
https://blog.mozilla.org/community/2020/07/23/firefox-79-new-contributors/
|
|
The Mozilla Blog: Mozilla Joins New Partners to Fund Open Source Digital Infrastructure Research |
Today, Mozilla is pleased to announce that we’re joining the Ford Foundation, the Sloan Foundation, and the Open Society Foundations to launch a request for proposals (RFP) for research on open source digital infrastructure. To kick off this RFP, we’re joining with our philanthropic partners to host a webinar today at 9:30 AM Pacific. The Mozilla Open Source Support Program (MOSS) is contributing $25,000 to this effort.
Nearly everything in our modern society, from hospitals and banks to universities and social media platforms, runs on “digital infrastructure” – a foundation of open source code that is designed to solve common challenges. The benefits of digital infrastructure are numerous: it can reduce the cost of setting up new businesses, support data-driven discovery across research disciplines, enable complex technologies such as smartphones to talk to each other, and allow everyone to have access to important innovations like encryption that would otherwise be too expensive.
In joining with these partners for this funding effort, Mozilla hopes to propel further investigation into the sustainability of open source digital infrastructure. Selected researchers will help determine the role companies and other private institutions should play in maintaining a stable ecosystem of open source technology, the policy and regulatory considerations for the long-term sustainability of digital infrastructure, and much more. These aims align with Mozilla’s pledge for a healthy internet, and we’re confident that these projects will go a long way towards deepening a crucial collective understanding of the industrial maintenance of digital infrastructure.
We’re pleased to invite interested researchers to apply to the RFP, using the application found here. The application opened on July 20, 2020, and will close on September 4, 2020. Finalists will be notified in October, at which point full proposals will be requested. Final proposals will be selected in November.
More information about the RFP is available here.
The post Mozilla Joins New Partners to Fund Open Source Digital Infrastructure Research appeared first on The Mozilla Blog.
|
|
Hacks.Mozilla.Org: MDN Web Docs: 15 years young |
On July 23, MDN Web Docs turned 15 years old. From humble beginnings, rising out of the ashes of Netscape DevEdge, MDN has grown to be one of the best-respected web platform documentation sites out there. Our popularity is growing, and new content and features arrive just about every day.
When we turned 10, we had a similar celebration, talking about MDN Web Docs’ origins, history, and what we’d achieved up until then. Refer to MDN at ten if you want to go further back!
In the last five years, we’ve broken much more ground. These days, we can boast roughly 15 million views per month, a comprehensive browser compatibility database, an active beginner’s learning community, editable interactive examples, and many other exciting features that didn’t exist in 2015. An anniversary to be proud of! 
In this article, we present 15 sections highlighting our most significant achievements over the last five years. Read on and enjoy, and please let us know what MDN means to you in the comments section.
Launched earlier this year, the MDN Web Docs Store is the place to go to show your support for web standards documentation and get your MDN Web Docs merchandise. Whether it’s clothing, bags, or other accessories featuring your favorite dino head or MDN Web Docs logos, we’ve got something for you.
And, for a limited time only, you can pick up special 15th anniversary designs.
In 2015, MDN served 4.5 million users on a monthly basis. A year later, we launched a product strategy designed to better serve Web Developers and increase MDN’s reach. We improved the site’s performance significantly. Page load time has gone down from 5s to 3.5s for the slowest 90th percentile on MDN, in the last two years alone.
We fixed many issues that made it harder to surface MDN results in search engines, from removing spam to removing hundreds of thousands of pages from indexing. We listened to users to address an under-served audience on MDN: action-oriented developers, those who like actionable information right away. You can read below about some of the specific changes we made to better serve this audience.
With over 3,000 new articles in the last 3 years, 260,000 article edits, and all the other goodness you can read about here, MDN has grown in double-digit percentages, year over year, every year — since 2015. Today MDN is serving more than 15 million web developers on a monthly basis. And, it’s serving them better than ever before.
When we first started tracking task completion and satisfaction on MDN Web Docs 4 years ago, we were thrilled to see that more than 78% of MDN users were either satisfied or very satisfied with MDN, and 87% of MDN users reported that they were able to complete the task that brought them to the site.
Since then it has been our goal to address a larger share of the developer audience while still maintaining these levels of satisfaction and task completion. Today, even though we have tripled our audience size, the share of people satisfied or very satisfied with MDN has gone up to 80%. Task completion has increased to a phenomenal 92%.
Around the middle of 2015, the writers’ team began to act on user feedback that MDN wasn’t very beginner-friendly. We heard from novice web developers that MDN had been recommended as a good source of documentation. However, when they went to check out the site, they found it too advanced for their needs.

In response to this feedback, we started the Learn Web Development section, informally known as the learning area. This area initially covered a variety of beginner’s topics ranging from what tools you need and how to get content on the web, to the very basics of web languages like HTML, CSS, and JavaScript. Getting started with the web was the first fully-fledged learning module to be published. It paved the way nicely for what was to come.
From simple beginnings, Learn Web Development has grown to over 330 articles covering all the essentials for aspiring web developers. We serve over 3 million page views per month (a little under 10% of all monthly MDN views). And you’ll find an active learner community over on our discourse forums.
By 2019, the learning area was doing well, but we felt that something was still missing. There is a huge demand for training material on client-side JavaScript frameworks, and structured learning pathways. Serious students tend to learn with a goal in a mind such as becoming a front-end developer.
Here’s what happened next:
Some folks have expressed concern over MDN’s framework-oriented content. MDN is supposed to be the neutral docs site, and focus purely on the standards! We understand this concern. And yet, the learning area has been created from a very pragmatic standpoint. Today’s web development jobs demand knowledge of frameworks and other modern tooling, and to pretend that these don’t exist would be bad for the resource (and its users).
Instead, we aim to strike a balance, providing framework coverage as a neutral observer, offering opinions on when to use frameworks and when not to, and introducing them atop a solid grounding of standards and best practices. We show you how to use frameworks while adhering to essential best practices like accessibility.
The 2016 MDN product strategy highlighted an opportunity to add interactive examples to our reference docs. From user feedback, we knew that users value easy availability of simple code examples to copy, paste, and experiment with. It is a feature of documentation resources they care deeply about, and we certainly weren’t going to disappoint.
So between 2017 and 2019, a small team of writers and developers designed and refined editors for interactive examples. They wrote hundreds of examples for our JavaScript, CSS, and HTML reference pages, which you can now find at the top of most of the reference pages in those areas. See Bringing interactive examples to MDN for more details.

The most significant recent change to this system was a contribution from @ikarasz. We now run ESLint on our JavaScript examples, so we can guarantee a consistent code style.
In the future, we’d love to add interactive examples for some of the Web API reference documentation.
In 2017, the team started a project to completely redo MDN Web Docs’ compatibility data tables. The wiki had hand-maintained compat sections on about 6,000 pages, and these differed greatly in terms of quality, style, and completeness.
Given that the biggest web developer pain point is dealing with browser compatibility and interoperability, our compat sections needed to become a lot more reliable.
Throughout 2017 and 2018, the MDN community cleaned up the data. Over the course of many sprints, such as Hack on MDN: Building useful tools with browser compatibility data, compatibility information moved from the wiki tables into a structured JSON format in a GitHub repository.
About half-way through the project we saw the first fruits of this work. Read MDN browser compatibility data: Taking the guesswork out of web compatibility for more details of what we’d achieved by early 2018.
It took until the end of 2018 to finish the migration. Today more than 8,000 English pages show compat data from our BCD repo – a place where all major browser vendors come together to maintain compatibility information.

Over time, other projects have become interested in using the data as well. MDN compat data is now shown in VS Code, webhint, and other tools besides. And even the premier site about compat info — caniuse.com — has switched to use MDN compat data, as announced in 2019. (Read Caniuse and MDN compatibility data collaboration.)
Soon compat info about CSS will also ship in Firefox Devtools, giving web developers even more insights into potential compatibility breakages. This feature is currently in beta in Firefox Developer Edition.
In 2015 Mozilla announced plans to introduce a new browser extension system that would eventually replace the existing ones. This system is based on, and largely compatible with, Chrome’s extension APIs. Over the next couple of years, as the Add-ons team worked on the WebExtensions APIs, we documented their work, writing hundreds of pages of API reference documentation, guides, tutorials, and how-to pages. (See the Browser Extensions docs landing page to start exploring.)
We also wrote dozens of example extensions, illustrating how to use the APIs. Then we prototyped a new way to represent browser compatibility data as JSON, which enabled us to publish a single page showing the complete compat status of the APIs. In fact, this work helped inspire and form the basis of what became the browser compat data project (see above).
On MDN Web Docs, we’ve always collaborated and shared goals with standards bodies, browser vendors, and other interested parties. Around three years ago, we started making such collaborations more official with the MDN Product Advisory Board (PAB), a group of individuals and representatives from various organizations that meet regularly to discuss MDN-related issues and projects. This helps us recognise problems earlier, prioritize content creation, and find collaborators to speed up our work.

The PAB as it existed in early 2019. From left to right — Chris Mills (Mozilla), Kadir Topal (Mozilla), Patrick Kettner (Microsoft), Dominique Hazael-Massieux (W3C), Meggin Kearney (Google), Dan Applequist (Samsung), Jory Burson (Bocoup), Ali Spivak (Mozilla), and Robert Nyman (Google).
Under normal circumstances, we tend to have around 4 meetings per year — a combination of face-to-face and virtual meetups. This year, since the 2020 pandemic, we’ve started to have shorter, more regular virtual meetups. You can find the PAB meeting minutes on GitHub, if you are interested in seeing our discussions.
Usually MDN Web Docs is there for you when you search for an API or a problem you need help solving. Most of MDN’s traffic is from search engines. In 2016, we thought about ways in which our content could come closer to you. When a JavaScript error appears in the console, we know that you need help, so we created [Learn more] links in the console that point to JavaScript error docs on MDN. These provide more information to help you debug your code. You can read more about this effort in Helping web developers with JavaScript errors.
We’ve also provided error documentation for other error types, such as CORS errors.
For some time, MDN Web Docs’ layout had a basic level of responsiveness, but the experience on mobile was not very satisfying. The jump menu and breadcrumb trail took up too much space, and the result just wasn’t very readable.
In 2020, our dev team decided to do something about this, and the result is much nicer. The jump menu is now collapsed by default, and expands only when you need it. And the breadcrumb trail only shows the “previous page” breadcrumb, not the entire trail.

Please have a look at MDN on your mobile device, and let us know what you think! And please be aware that this represents the first step towards MDN Web Docs rolling out a fully-fledged design system to enforce consistency and quality of its UI elements.
In 2016, we drafted a plan to create HTTP docs. Traditionally, MDN has been very much focused on the client-side, but more recently developers have been called upon to understand new network APIs like Fetch, and more and more HTTP headers. In addition, HTTP is another key building block of the web. So, we decided to create an entire new docs section to cover it.
Today, MDN documents more than 100 HTTP headers, provides in-depth information about CSP and CORS, and helps web developers to secure their sites — together with the Mozilla Observatory.
We would be remiss not to mention our wonderful contributor community in this post. Our community of volunteers has made us what we are. They have created significantly more content on MDN over the years than our paid staff, jumped into action to help with new initiatives (such as interactive examples and browser compat data), evangelised MDN Web Docs far and wide, and generally made the site a more diverse, more fun, and brighter place to be around.
To give you an idea of our community’s significance, have a look at the Mozilla & the Rebel Alliance report 2020, in which MDN is shown to be the largest community cluster in Mozilla, after Firefox.

A graphical representation of the size of Mozilla community contributions. MDN is on the bottom-right.
And we’d also like to give the browser compat data repo an honourable mention as one of the most active GitHub repos in the overall Mozilla GitHub presence.
Our community members are too numerous to thank individually, but we’d like to extend our warmest regards and heartfelt thanks to you all! You know who you are.
It’s hard to believe that at the beginning of 2016, MDN Web Docs was served from a fixed set of servers in our old Santa Clara data center. Those servers were managed by a separate team, and modifications had to be coordinated far in advance. There was no way to quickly grow our server capacity to meet increasing demand. Deployments of new code always generated undue anxiety, and infrastructure-related problems were often difficult to diagnose, involving engineers from multiple teams.
Fast-forward to today, and so much has changed for the better. We’re serving MDN via a CDN backed by multiple services running within an AWS EKS Kubernetes cluster — with both cluster and pod auto-scaling. This is a huge step forward. We can not only grow our capacity automatically to meet increasing demand and deploy new code more reliably, but we can manage the infrastructure ourselves, in the open. You can visit the MDN Infra repo today. You’ll see that the infrastructure itself is defined as a set of files, and evolves in the open just like any other public repository on GitHub.
This transition was a huge, complex effort, involving many collaborators, and it was all accomplished without any significant disruption in service. We’ve placed MDN on a solid foundation, but we’re not resting. We’ll continue to evolve the foundation to meet the demands of an even brighter future!
In 2019, we were thinking about how to gain more insight into web developer problems, in order to make our content better address their needs. In the end, we decided to invest in an in-depth survey to highlight web developer pain points, in collaboration with the other members of the MDN PAB (see above). This effort was termed the Web Developer Needs Assessment (or Web DNA).

The survey results were widely publicized (download the 2019 Web DNA report (PDF)), and proved popular and influential. MDN Web docs and many other projects and organizations used the results to help shape their future strategies.
And the good news is that we have secured funding to run a new Web DNA in 2020! Later on this year we’ll have updated findings to publish, so watch this space.
That’s the story up to now, but it doesn’t end here. MDN Web Docs will carry on improving. Our next major move is a significant platform and content update to simplify our architecture and make MDN usage and contribution quicker and more effective. This also includes reinventing our content storage as structured data on GitHub. This approach has many advantages over our current storage in a MySQL database — including easier mass updates and linting, better consistency, improved community and contribution workflow, and more besides.
We hope you enjoyed reading. Stay tuned for more Web Docs excitement. And please don’t forget to share your thoughts and feedback below.
The post MDN Web Docs: 15 years young appeared first on Mozilla Hacks - the Web developer blog.
https://hacks.mozilla.org/2020/07/mdn-web-docs-15-years-young/
|
|
Mozilla Localization (L10N): L10n Report: July 2020 Edition |
New localizers
Welcome Prasanta Hembram, Cloud-Prakash and Chakulu Hembram, from the newly created Santali community! They are currently localizing Firefox for iOS in Santali Ol Chiki script.
Are you a locale leader and want us to include new members in our upcoming reports? Contact us!
Santali (Ol-Chiki script “sat-Olck”) has been added to Pontoon.
Upcoming deadlines:
As explained in a recent email to dev-l10n, we’re in the process of removing English terms that make direct or indirect references to racial oppression and discrimination.
In terms of impact on localization, that mainly involves the Master Password feature, which is now called Primary Password, starting from Firefox 80.
A Primary Password is a password that unlocks the other passwords saved locally in Firefox. Primary passwords are not synced between profiles or devices.
We ask all localizers to keep these implications in mind when translating, and to evaluate the translations previously used for “Master Password” in this light. If you identify other terms in your localizations or in the en-US version of our products that you feel are racially-charged, please raise the issue in Bugzilla and CC any of the l10n-drivers.
Most string changes regarding this update already landed in the last few days, and are available for translation in Pontoon. There is also going to be an alert in Firefox 80, to warn the users about the change:
 If your translations for “Master Password” and “Primary Password” are identical, you can leave that string empty, otherwise you should translate “Formerly known as Master Password” accordingly, so that the warning is displayed. The string should be exposed in Pontoon shortly after this l10n report is published.
If your translations for “Master Password” and “Primary Password” are identical, you can leave that string empty, otherwise you should translate “Formerly known as Master Password” accordingly, so that the warning is displayed. The string should be exposed in Pontoon shortly after this l10n report is published.
Make sure to test the new about:welcome in Nightly. As usual, it’s a good idea to test this type of changes in a new profile.
Note that a few more string updates and changes are expected to land this week, before Firefox 80 moves to beta.

Firefox 80 has a new Experiments section in Preferences (about:preferences#experimental). By the end of this Nightly cycle, there should be about 20 experiments listed there, generating a sizable content to translate, and often quite technical.
These are experiments that existed in Firefox for a while (since Firefox 70), but could only be manually enabled in about:config before this UI existed. Once the initial landing is complete, this feature will not require such a large amount of translation on a regular basis.
Most of these experiments will be available only in Nightly, and will be hidden in more stable versions, so it’s important – as always – to test your translations in Nightly. Given this, you should also prioritize translation for these strings accordingly, and focus on more visible parts first (always check the priority assigned to files in Pontoon).
As many are already aware, the l10n deadline for getting strings into the Fenix release version was this past Saturday July 18th. Out of the 90 locales working on Fenix on Pontoon, 85 made it to release! Congratulations to everyone for their hard work and dedication in trying to keep the same mobile experience to all our global users! This was a very critical step in the adventure of our new Android mobile browser.
Since we are now past string freeze, we have exposed new strings for the upcoming release. More details on the l10n timeline will come soon, so stay tuned.
There will also be a new version of Firefox for iOS (v28) soon: the l10n deadline to complete strings – as well as testing – is today, Wednesday July 22nd (PDT, end of day).
We have screenshots in Taskcluster now so that you can test your work (vs Google Drive): feel free to send me feedback about those. A big thank you to the iOS team (especially Isabel Rios and Johan Lorenzo from RelEng) for getting these ready and updated regularly!
The web team continues making progress in migrating files to Fluent. Please take some time to review the files. Here are a few things to pay attention to:
String with a warning: It is important to check the strings with warnings first. They are usually caused by brands and product names not converted correctly because the names were translated. As long as these strings contain warnings, they can’t be activated at string level on production. Localized string with a warning will fallback to the English string. Since page activation threshold is at 80% completion, this means a page that was fully localized in the old format, if containing a warning, will appear to mix with English text.
String with error but no warning: All migrated pages need a thorough review. Even when a page doesn’t have warnings, it may contain errors that a script can’t detect. Here is an example:
Testing on staging: Other than a few files that are “shared” or for forms, meaning the content in the file is not page specific, most files have a page specific URL for review. Here is an example to figure out how to test Firefox/enterprise.ftl:
Keeping track of Machinery translations.
Pontoon now stores Machinery source(s) of translations copied from the Machinery panel. The feature will help us evaluate performance of each Machinery source and make improvements in the future.
It should also help reviewers, who can instantly see if and which Machinery source was used while suggesting a translation. If it was, a “Copy” icon will appear over the author’s avatar and the Machinery sources will be revealed on hover.

We have a new locale available in Nightly for Firefox desktop: Silesian (szl). In less than 5 months, they managed to get over 60% completion, with most of the high priority parts close to 100%. Kudos to Rafal and Grzegorz for the great work.
Know someone in your l10n community who’s been doing a great job and should appear here? Contact one of the l10n-drivers and we’ll make sure they get a shout-out (see list at the bottom)!
Did you enjoy reading this report? Let us know how we can improve by reaching out to any one of the l10n-drivers listed above.
https://blog.mozilla.org/l10n/2020/07/22/l10n-report-july-2020-edition/
|
|
The Firefox Frontier: Extension Spotlight: SponsorBlock for YouTube |
Have you ever been engrossed in music or a great video when YouTube suddenly interrupts your experience to inject an ad? It’s jarring and ruins the mood of any moment. … Read more
The post Extension Spotlight: SponsorBlock for YouTube appeared first on The Firefox Frontier.
https://blog.mozilla.org/firefox/firefox-extension-sponsorblock/
|
|
The Mozilla Blog: A look at password security, Part III: More secure login protocols |
|
|
Marco Zehe: How to use Element and Matrix with a screen reader |
On December 19, 2019, Mozilla announced that it will switch to Matrix and Riot as the main synchronous communication platform, replacing IRC. In July 2020, Riot was renamed to Element, along with some other rebranding that happened around the software and services. This post is aimed to give you an introduction to using Element, the most popular Matrix client, with a screen reader.
Matrix itself is an open standard protocol that defines how a chat client, such as Element, talks to a server, such as Synapse, and how servers communicate to each other to exchange messages in shared, or as is the jargon, federated, rooms. In the Matrix network, rooms can be federated across the whole network, so no matter which server you choose as your home server, you’ll get the messages in rooms you join no matter where they originated from.
You can imagine this as if you were signing up to a particular e-mail or news server, and then getting messages from other servers depending on which newsgroups you subscribe to or e-mail lists you joined.
IRC, on the other hand, is pretty self-contained. You have to connect to a particular server to join a particular network. And federation was not built into the platform. There are a few non-standard ways for servers to communicate with one another to share the load on any single network, but as this is non-standard, it is also error-prone. Ever heard of net splits? Pretty not pretty.
But one thing both networks have in common is the fact that there are client choices available. There are clients for mobile platforms, the command line, the web, and first native offerings are also in the works. Check out this non-exhaustive list of clients for inspiration.
The client most people will, however, probably come in contact with initially is Element, the client primarily developed by Element Matrix Services, a company behind many Matrix offerings. Element for web/desktop, iOS, and Android are all open-source, with repositories on Github. Filing issues or submitting pull requests is therefore possible for anyone who wants to improve them.
Initially, accessibility was terrible across the board. And there are still a number of issues open for the web client. But things have improved massively since the one-month trial Mozilla did in September and October 2019.
But the team didn’t stop there and is improving accessibility, with also some help by yours truly, until now and beyond. So by the time you read this, there may already be more things working than described here.
The web client, once you signed up and logged in, consists of a top part that has a header, a Communities button which currently doesn’t do much, and a User sub menu button. That sub menu, when opened, has shortcuts to notifications, privacy, and all settings, feedback and Logout options.
The Settings, when opened, come up in a modal dialog. The buttons at the top are actually kind of tabs, just not exposed that way yet. They control various settings which then appear below. The settings apply once you change them. Some screens offer a Save button at the bottom. To close the dialog, choose the Close button at the top.
Back in the main UI, following the top bar is the left side bar. You first get a Search field. This is to filter your active rooms shown in the room list below. You can press DownArrow to move straight from the search field to the room list. This is arranged as a tree view. The top-level nodes are direct messages and rooms, and sometimes system alerts. Below those, when expanded, are the actual persons, rooms, and bots that sent those alerts. Use standard navigation like in Explorer’s folder tree to navigate.
Direct messages are private messages. They can be one-on-one, or small groups of people. You can focus the edit field for search, then tab forward once and use the arrow keys to navigate. Press Enter to switch to the selected room. You can also invoke a context menu by usual means to access more options. You can also start a new chat when in the People group, or create your own room when within the Rooms group.
If from the search field, you press Tab instead, you land on an Explore button. This allows you to explore other rooms on the server or the whole Matrix network. Type in a phrase you want to search for, and below, you will get a table of found rooms that you can either preview or join. Matrix usually keeps a history of what was being said, so if you are allowed to view the contents as a non-member, you will get a list showing recent messages. Otherwise, you can also join the room either from the table or the preview.
Press tab again, and depending on your settings, you may reach a toolbar of recently visited rooms. Use left and right arrows to navigate in this toolbar, Space to jump to that room, or tab to move to the room list that was described above.
If you are in a room, the main area, also denoted by a landmark, contains the room view. At the top, there is the name and topic, a Room Settings button, a means to manage Integrations, such as Github or other bots you have connected, or perform a Search.
Below that, you will find a set of tabs like Members List, Files, and Notifications. These pertain to the landmark right below them. Initially, no tab is selected, so the complementary landmark may not be there yet. Select one of the tabs to make it appear.
Below those tabs is that landmark with the side bar content in it. Visually, this side bar is displayed to the right of the main chat area. This can contain either the list of members in this room, files, or your Notifications. This depends on which tab is selected above.
If the room member list is displayed, you can invite others to the room as well if you know their handle. You can jump from button to button for each member. If you press Enter or Space, you’ll get more info about that member below the list. You can also bring up a context menu to get more options. You do this via regular shift+F10 or Applications Key. There is also a search facility available.
The Files tab contains files shared within this room.
Once that landmark ends, the main chat area begins. The first two elements are either a Jump To First Unread button, or one that is labeled Jump To The Latest Message. The other may or may not be there, and is labeled Mark Channel As Read. The Jump To the Latest Message button will often mark the whole room as read as well. Only if you haven’t visited a room in a long time and there are many unread messages, the Mark Channel As Read button, or hitting Escape while focused in the message composer, will mark all messages as read.
So, to get to the first unread messages, press the „Go To First Unread message „button. This will scroll the message list up. The list of messages is a live region, which means your screen reader will speak updates as they come in. After pressing the button, once your screen reader starts speaking, press s (in JAWS or NVDA) to move to the first separator. That is then usually the beginning of new messages.
Tip: The new messages separator disappears after 3 seconds, or 3,000 milliseconds, when the room is being displayed, by default. In the Settings dialog, on the tab also named Settings, you can change this threshold to a larger value, for example 15,000. This will give you much more time to actually jump to that separator, depending on how fast your screen reader is speaking. I found this to work much more reliably, too, when coming back to a room, and the new messages separator is being displayed right on the screen I arrive at. Adjusting this setting makes keeping up with channels regularly over the course of a day much more efficient.
Below those buttons, the main list of messages is shown. It is dynamically updating, so when you get close to either edge, new messages are pulled in. A separator marks where each new day begins, and also is the unread marker in case you have viewed this room before. You navigate either using the virtual cursor arrow keys, or by skipping between list items. In NVDA and JAWS, you press i and shift+i quick navigation keys, for example. Refer to your screen reader documentation on how this is done.
Once focused within a message, action items become available following the message, like adding a reaction, replying, or more options. If you are on your own message, you can also edit that, to correct typos, for example. Those are all labeled buttons. These appear either on mouse hover or when focus is within the message container. However, due to some browser quirks, sometimes things may disappear still, so if things aren’t working as you expect them to, route the mouse there to hover. Also, these buttons are contained within a toolbar, which responds to the usual pattern that arrow keys on the keyboard move between buttons, and tab moves out of the container to the next element. That is, if you are using a keyboard, or your screen reader is in focus or forms mode.
Full keyboard support for the message list, similar to what Slack is offering, for example, is planned, but not implemented yet. For screen reader users, it is best to rely on browse or virtual cursor mode to navigate around.
Below the messages, outside the list, is the composition area for new messages or replies if you chose to reply to a message. You can type as usual, use Markdown, and autocomplete people starting with an @ sign, or emojis starting with a colon. These auto-completes are accessible, although right now, you should complete with Space, not Enter or Tab yet. This is being worked on to meet expectations and comply with the WAI-ARIA authoring practices, but as of this writing, isn’t in a release yet.
Below that compose area, there are buttons to add files, start an audio or video call, and add stickers.
Apart from the problem that the messages list cannot yet be navigated with the keyboard, there are a few other things that don’t work so well yet, but which are in the works of getting improved. One of them is the members list itself. It should be easier to navigate with the keyboard.
One other area that is currently problematic is adding a reaction to a message. The emoji picker for that is not keyboard accessible yet, and the screen reader list has only menu items. Using NVDA, I can indeed add a reaction reliably, by using character or word navigation when in virtual mode inside the list, but it isn’t pretty.
Also, the fact that things you can do with a message are not as reliable as desired can pose some problems still. It is far better than it was, but the true solution will come with the work that makes the whole thing fully keyboard accessible. So, sometimes, for the messages list, you will need your screen reader’s mouse emulation commands to pull the mouse somewhere in order for certain controls to appear. But use this as a last resort if, for some reason, you get stuck.
Both Element for iOS and Element (formerly RiotX) for Android, the newer of the two flavours that are on the Google Play Store, have received accessibility improvements and are much more usable than they were a few months ago.
On iOS, I suggest ignoring the Home tab for now, since that doesn’t work at all with VoiceOver. Instead, use the Direct Messages and Rooms tabs to navigate your messages and room chats. You can also add some to favourites, which is the second tab, which also works. Communities are in the same “in development” state as they are on the web. Inside chats, double-tap and hold or use the context menu gesture to interact with elements. There is a button in the top middle below the header that allows you to jump to the first unread message. From there, you can swipe to the right to read through your chat log. Sometimes, if something in the room changes, the position may shift slightly, and you may lose position. This also happens to sighted people and is nothing VoiceOver specific.
On Android, the former Riot app has been deprecated, and people are migrated over to Element. This is also the only app that gets the attention and is a continuation of the former app named RiotX. That also gets the new TalkBack enhancements when there are some. I must admit I haven’t used it myself, since all this started when I already had switched back to iOS, but I hear good things from others in the #element-accessibility:matrix.org channel.
I must say I share the excitement the Matrix team expressed in their announcement of the collaboration with Mozilla. It is an open standard, with open-source software, with choices for clients to use, and the possibility to improve the accessibility by reporting issues or fixing bugs. New Element versions are released frequently, so those fixes also will get deployed to the Mozilla instance and other hosted Matrix offerings which also use Element as their front-end.
I hope this guide helps you find your way around Element and the Matrix Eco system more easily. It still has issues, but so have proprietary offerings like Slack or the like. And as we all know, accessibility is a process of constant improvement.
I would personally like to thank my colleagues for making accessibility one of the deciding factors for choosing the replacement. Big thanks also go out to the members of the Matrix and Element teams who were super responsive to accessibility concerns, and have kept the momentum going even after the trial was over and nobody knew if Matrix would be chosen in the end. It is a pleasure working with you all!
See you in the Matrix!
https://www.marcozehe.de/how-to-use-element-and-matrix-with-a-screen-reader/
|
|
The Servo Blog: This Week In Servo 133 |
In the past week, we merged 62 PRs in the Servo organization’s repositories.
The latest nightly builds for common platforms are available at download.servo.org.
We now have a collection of tips & tricks for using Firefox Reality on the HoloLens 2.
Our roadmap is available online, including the team’s plans for 2020.
This week’s status updates are here.
relList DOM attribute for HTMLFormElement.Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
|
|
Dzmitry Malyshau: wgpu API tracing infrastructure |
wgpu is a native WebGPU implementation in Rust, developed by gfx-rs community with help of Mozilla. It’s still an emerging technology, and it has many users:
Given the diversity of platforms and configurations it runs, and the variety of users, the questions of reproducing issues, debugging, and testing the implementation were critical to resolve.
Fortunately, I had some success in the past rolling out serialization-based infrastructures for capturing and testing complex pipelines.
First, it was Warden test framework in gfx-rs. It defined serializable types for all of gfx-rs commands, and also allowed describing different scenes, test-cases, and expectations. All the data was hand-written in RON format, which by the time was quite young, and not used anywhere seriously. The ability to test gfx-rs without code was very exciting to us, and in general it worked out OK. In the end, we haven’t written too many tests, mostly because we aggressively tested with Vulkan CTS (over gfx-portability) instead, which was enormous. The separation of scenes and workloads also ended up with a few gotchas and a less-than-elegant implementation. It was also a bit awkward to write the implicit synchronization code in Warden for grabbing back the results, or re-initializing the state between tests.
The other related project was done in WebRender: the capturing infrastructure. The purpose of this one was different: assist in reproducing and debugging issues. It serialized the pipeline at two different stages to disk, allowing the capture to be transferred to a different computer and reproduced in a simple standalone tool we called Wrench. The beauty of it is that we’d mess with the RON files by hands: remove items, or whole files, change values, just playing around and seeing how the problem reacts. Even if something goes off-rails, and your capture fails to replay, it was often possible to tweak it into a working state.
Overall, it was a huge success, and it became an indispensable tool in the arsenal of Firefox graphics team. Reproducing a bug in Firefox was half the problem, debugging it within Firefox was another half. The capturing infra solved both. However, I wanted to do more with it: I wanted to have a “portable” representation of a WR scene defined with a conversion to the regular WR scene. With this, we’d be able to route all the reftests through it, replacing the hand-parsed YAML format. This part of the story never happened - there were (and still are) more important things to do.
Now, wgpu is fresh from the oven, and I wanted to roll in something as the best of both worlds.
First problem was the incoming flow of bugs reported by users of wgpu-rs, users of Python API, users of Gecko, on different platforms, with closed source code, and so on. Reproducing these issues and debugging them was quite challenging. We figured that wgpu was the place where all the roads met, and we needed to serialize everything that reaches that intersection, to be replayed independently, on a different machine. We defined a serialization format that we’d save all the incoming commands into at device timeline. We introduced a standalone “player” tool to replay the traces, which once again were stored as RON files.
With this in, all we needed from a bug reporter was a zipped API trace attached to an issue, and a git revision of the code they used. WebGPU is truly a portable GPU API, so the captures are easy to replay on a different machine. This is very unlike low-level traces, such as Vulkan traces, or Metal GPU captures - replaying them mostly did not work (your hardware has different limits, different memory types, features, etc). And there was nothing to do if it failed, unlike with our API traces, where you could just look at RON itself and nudge it to work. All in all, working with bugs became joyful, but we didn’t stop there.
Another glaring problem was that wgpu repository didn’t have any means to test itself. Originally, all of wgpu, wgpu-core, and wgpu-native were a part of the same repository, so we had the examples to check if the changes were sane. But when it was time to integrate into Gecko, we wanted to minimize the code that mozilla-central needs to vendor, so we moved everything but the core logic out into separate repositories. Rust does wonders with “if it compiles, it works” motto, but riding without any tests was still an insane idea. Requiring the developers to coordinate patches with multiple repositories, just so they can prove the changes still work, started hurting our productivity.
To resolve this, we implemented a Rust integration test with a simple description of tests and expectations. With just a little bit of magic, we made it so cargo test casually enumerates the supported GPU backends on the developer’s machine, and runs the tests through it. The tests are described in the same RON format as API traces: they are basically sequences of actions, be it resource creation, or command submission. I call it “player-based GPU testing”, or “playtest” for short. I don’t know how far we are going to go with them, given that WebGPU API is being developed with it’s own CTS (which we’ll be able to run via browsers or NodeJS bindings to wgpu-native). At the very least, we’d want to cover the features in wgpu-rs example matrix, to allow developers feel safe when landing patches in wgpu.
Personally, I’m hugely excited for this wgpu infrastructure for tracing and playtesting. It’s very powerful, and it covers a lot of ground. However, it’s still early days, and there is a few rough corners and limitations.
One of the most annoying thing about the serialization format is bitflags. We use them aggressively in both wgpu and gfx-rs. Today, we have to use numerical representations of them, e.g. usage: (bits: 0x41), which is neither readable or writable. I hacked a small wrapper around bitflags a while ago to serialize it nicely, e.g. [VERTEX | MAP_READ]. Still trying to figuring out the best way to approach this (upstream issue)…
Another interesting feature could be to test for exact errors. WebGPU group decided to not require the implementations to report specified errors (and instead, just throw more generic errors with a string description), based on experience with WebGL where this introduced unnecessary complexity. We want stronger guarantees in wgpu though, so being able to test the exact error variants would totally make sense even in the presence of upstream CTS.
We are looking forward to use this technology more :)
http://kvark.github.io/wgpu/debug/test/ron/2020/07/18/wgpu-api-tracing.html
|
|






