Air Mozilla: Bugzilla Development Meeting, 28 Oct 2015 |
 Help define, plan, design, and implement Bugzilla's future!
Help define, plan, design, and implement Bugzilla's future!
https://air.mozilla.org/bugzilla-development-meeting-20151028/
|
|
Air Mozilla: London Web Components Meetup – Lightning Talks – 20151026 |
 Matteo Figus presents the OpenComponents framework, then Bram Product talks about Welvolver, the Platform for Open Source Hardware.
Matteo Figus presents the OpenComponents framework, then Bram Product talks about Welvolver, the Platform for Open Source Hardware.
https://air.mozilla.org/london-web-components-meetup-lightning-talks-20151026/
|
|
Air Mozilla: London Web Components Meetup – Wilson Page: Web Components in Firefox OS – 20151026 |
 Wilson Pages presents how Web Components are used in Gaia.
Wilson Pages presents how Web Components are used in Gaia.
|
|
Air Mozilla: London Web Components Meetup – Francesco Iovine: Practical Web Components – 20151026 |
 Francesco Iovine talks about Web Components today and his experience in using them.
Francesco Iovine talks about Web Components today and his experience in using them.
|
|
Air Mozilla: Martes mozilleros, 27 Oct 2015 |
 Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos.
Reuni'on bi-semanal para hablar sobre el estado de Mozilla, la comunidad y sus proyectos.
|
|
Mozilla WebDev Community: Eradicating those nasty .pyc files |
I recently acquired a new development laptop and moved a number of local Git repositories from my old machine to my new machine. In doing so I also changed the folder structure, and when trying to run some code I was presented with this Python error:
import file mismatch:
imported module 'tests.desktop.consumer_pages.test_details_page' has this __file__ attribute:
/Users/bsilverberg/gitRepos/marketplace-tests/tests/desktop/consumer_pages/test_details_page.py
which is not the same as the test file we want to collect:
/Users/bsilverberg/Documents/gitRepos/marketplace-tests/tests/desktop/consumer_pages/test_details_page.py
HINT: remove __pycache__ / .pyc files and/or use a unique basename for your test file modules
This was a symptom of the fact that Python creates .pyc files on my machine when it compiles code. This can result in other nastiness too, as well as cluttering up your machine, so I wanted to both delete all of these files and also prevent Python from doing it in the future. This post contains info on how to do both.
You can use the find command (on OS X and Linux) to locate all of the .pyc files, and then use its delete option to delete them.
The command to find all .pyc files in all folders, starting with the current one is:
find . -name '*.pyc'
If you want to delete all the files found, just add the -delete option:
find . -name '*.pyc' -delete
Obviously, this can be used for any file type that you wish to eradicate, not just .pyc files.
I don’t like having all of those extra files cluttering my machine, and, in addition to the error I mentioned above, I have from time to time seen other errors related to out of date .pyc files.
Another issue that .pyc files can cause is that they can be orphaned, for example if you remove a .py file from your project, but the .pyc file remains (which can happen as one often adds *.pyc to .gitignore). Python can then still pick up the module from the .pyc file via an import which can lead to difficult to diagnose bugs.
For these reasons I want to prevent Python from ever writing those files again. To do this all you have to do is set the environment variable PYTHONDONTWRITEBYTECODE to 1. You can ensure that that variable is set for any bash session that you start by adding the following to your .bash_profile or .bashrc:
export PYTHONDONTWRITEBYTECODE=1
https://blog.mozilla.org/webdev/2015/10/27/eradicating-those-nasty-pyc-files/
|
|
David Rajchenbach Teller: Designing the Firefox Performance Stats Monitor, part 1: Measuring time without killing battery or performance |
For a few versions, Firefox Nightly has been monitoring the performance of add-ons, thanks to the Performance Stats API. While we are waiting for the greenlight to let it graduate to Firefox Aurora, as well as investigating a few lingering false-positives, and while v2 is approaching steadily, it is time for a brain dump on this toolbox and its design.
The initial objective of this monitor is to be able to flag both add-ons and webpages that cause noticeable slowdowns, so as to let users disable/close whatever is making their use of Firefox miserable. We also envision more advanced uses that could let us find out if features of webpages cause slowdowns on specific OS/hardware combinations.
Firefox has long had a built-in profiler, that can be used to obtain detailed performance information about a specific webpage (through the DevTools), or about the entirety of Firefox (though a dedicated add-on). If you have not tried the Gecko Profiler, you really should. However, the Performance Stats API does not build upon this profiler. Let’s see why.
The Gecko Profiler is a Sampling Profiler. This means that it spawns a thread, which wakes up regularly (every ~1 millisecond by default) to capture the stack of the main thread and store it to memory. Once profiling is over, it examines the symbols in the captured stacks, and extrapolates that if a symbol appears in n% of the samples, it must also take n% of the CPU time. Also, it consolidates the stacks into a tree for easier visualisation.
This technique has several big advantages:
Also, the stack contains all the information needed to determine if the code being executed belongs to an add-on or a webpage, which means that the Gecko Profiler could theoretically be used as a back-end for the Performance Stats API.
Unfortunately, it also has a few major drawbacks:
It might be possible to partially mitigate point 1/ by ensuring that the sampling thread is stopped whenever the execution thread is not executing “interesting” code. The battery gains are not clear – especially since we do not have a good way to measure such costs – and, more importantly, this would make point 4/ much more complex and error-prone.
It is also likely that points 2/ and 3/ could be addressed by making sure that, for the sake of Performance Stats, we only extract simplified stacks containing solely information about the owner of the code, whether add-on, webpage or platform. To do this, we would need to hack relatively deep in both the profiler (to be able to extract and treat various kinds of data, and to be able to do it both after-the-fact and in real time), and the JavaScript VM (to annotate the stack with ownership information), as well as to introduce support code (to provide a mapping between stack ownership data and add-on identification/webpage identification). Interestingly, introducing these VM changes and the support code essentially amount to writing a form of Event Profiler, which would use the existing Sampling Profiler essentially as a form of high-resolution clock. Sadly, these changes would probably make the interaction between threads quite more complicated.
Finally, the only way to get rid of points 4/ would be to move entirely away from a Sampling Provider to an Event Profiler. So let’s see how we could design Performance Stats as a form of Event-based Profiler.
One of the main interests of Sampling Profilers is that they interfere with the code considerably less than most other kinds of profilers. However, we have an advantage that most profilers do not have: we need much, much fewer details. Indeed, knowing whether a statement or even a function takes time will not help us find out whether an add-on is slow. Rather, we are interested in knowing whether a Performance Groups take time – we’ll return later to a more precise definition of Group, but for the moment, let’s just assume that a Group is anything we want to monitor: an add-on, or a webpage including its frames, or a webpage without its frames, etc.
In other words, we are interested in two events:
If we can just implement a quick and reasonably accurate Stopwatch to measure the duration between these events, we have all the information we need.
Note that the structure is purely stack-based. So we can already start designing our Stopwatch API along the following lines:
class Stopwatch { // RAII
public:
explicit Stopwatch(JSRuntime*, Group*); // Start the measure.
~Stopwatch(); // Stop the measure.
};
Now, let’s look at the issues we may encounter with such a design:
Let’s start with issue 3/.
In terms of API, this means something along the lines of:
class Group {
public:
bool HasStopwatch();
void AttachStopwatch();
void DetachStopwatch();
};
This almost immediately gives us a design for issue 4/.
To avoid having to maintain long lists of current stopwatches in case we may need to invalidate them, and to avoid the linear cost of such invalidation, we alter the API to take into account an iteration number, which increases whenever we start processing an event:
class Stopwatch { // RAII
public:
explicit Stopwatch(JSRuntime*, Group*); // Start the measure. Record the current iteration.
~Stopwatch(); // Stop the measure. If the current iteration is not the one that was originally recorded, this Stopwatch is stale, don’t bother with a final measure, just drop everything.
};
class Group {
public:
bool HasStopwatch(uint64_t iteration); // Does the group have a stopwatch for the current event?
void AttachStopwatch(uint64_t iteration); // Attach a stopwatch for the current event.
void DetachStopwatch(uint64_t iteration); // Does nothing if `iteration` is stale.
};
Note that, had we chosen to base our profiler on sampling, we would still have needed to find solutions to issues 3/ and 4/, and the implementation would certainly have been similar.
Sampling profilers rely on a fixed rate system timer, which solves elegantly both the problem of clock imprecision (issue 1/) and that of the speed of actually reading the clock (issue 2/). Unfortunately, due to the issues mentioned in I., this is a solution that we could not adopt. Hence the need to find another mechanism to implement the Stopwatch. A mechanism that is both fast and reasonably accurate.
We experimented with various clocks and were disappointed in varying manners. After these experiments, we decided to go for a statistical design, in which each `Stopwatch` does not measure an actual time (which proved either slow or unreliable) but a number of CPU clock cycles, through the CPU’s built-in TimeStamp Counter and instruction RDTSC. In terms of performance, this instruction is a dream: on modern architectures, reading the TimeStamp Counter takes a few dozen CPU cycles, i.e. less than 10ns.
However, the value provided by RDTSC is neither a wall clock time, nor a CPU time. Indeed, RDTSC increases whenever code is executed on the CPU (or, on older architectures, on the Core), regardless of whether the code belongs to the current application, the kernel, or any other application.
In other words, we have the following issues:
If you recall, we have decided to use RDTSC instead of the usual OS-provided clocks because clocks were generally either not fine-grained enough to measure the time spent in a Group or too slow whenever we needed to switch between groups thousands of times per second. However, we can easily perform two (and exactly two) clock reads per event to measure the total CPU Time spent executing the event. This measure does not require a precision as high as we would have needed to measure the time spent in a group, nor does it need to be as fast. Once we have this measure, we can extrapolate: if n% of the cycles were spent executing Group A, then n% of the time spent in the event was spent executing Group A.
If n<0 or n>100 due to issues 2/ or 3/, we simply discard the measure.
Now that we have mapped clock cycles and wall time, we can revisit the issue of a computer going to sleep. Since the counter is reset to 0, we have n<0, hence the measure is discarded. Theoretically, if the computer goes to sleep many times in a row within the execution of the event loop, we could end up in an exotic case of n>=0 and n<=100, but the error would remain bounded to the total CPU cost of this event loop. In addition, I am unconvinced that a computer can physically go to sleep quite that fast.
In theory, this is the scariest issue. Fortunately, modern Operating Systems try to avoid this whenever possible, as this decreases overall cache performance, so we can hope that this will happen seldom.
Also, on platforms that support it (i.e. not MacOS/BSD), we only measure the number of cycles if we start and end execution of a group on the same CPU/core. While there is a small window (a few cycles) during which the thread can be migrated without us noticing, we expect that this will happen rarely enough that this won’t affect the statistics meaningfully.
On other platforms, but on modern architectures, if a thread jumps between cores during the execution of a Group, this has no effect, as cores of a single CPU have synchronized counters.
Even in the worst case scenario (MacOS/BSD, jump to a different CPU), statistics are with us. Assuming that the probability of jumping between CPUs/cores during a given (real) cycle is constant, and that the distribution of differences between clocks is even, the probability that the number of cycles reported by a measure is modified by X cycles should be a gaussian distribution, with groups with longer execution having a larger amplitude than groups with shorter execution. Since we discard measures that result in a negative number of cycles, this distribution is actually skewed towards over-estimating the number of cycles of groups that already have many cycles and under-estimating the number of cycles that already have fewer cycles.
Recall that this error is bounded by the total CPU time spent in the event. So if the total time spent in the event is low, the information will not contribute to us detecting a slow add-on or webpage, because the add-on or webpage is not slow in the first place. If the total time spent in the event in high, i.e. if something is slow in the first place, this will tend to make the slowest offenders appear even slower, something which we accept without difficulty.
Once again, this is an issue that cannot be solved in theory but that works nicely in practice. For once thing, recent architectures actually make sure that the mapping remains constant.
Moreover, even on older architectures, we suspect that the mapping between clock cycles and wall time will change rarely on a given thread during the execution of a single event. This may, of course, be less true in case of I/O on the thread.
Finally, even in the worst case, if we assume that the mapping between clock cycles and wall time is evenly distributed, we expect that this will eventually balance out between Groups.
Assuming that, within an iteration of the event loop, this happens uniformly over time, this will skew towards over-estimating the number of cycles of groups that already have many cycles and under-estimating the number of cycles that already have fewer cycles.
Again, for the same reason as issue 3/, this effect is bounded, and this is a bias that we accept without difficulty.
Once we have decided on the algorithm above, the design of the Stopwatch becomes mostly natural.
In followup blog entries, I plan to discuss Performance Groups, measuring the duration of cross-process blocking calls, collating data from processes, determining when an add-on is slow and more. Stay tuned

|
|
Yunier Jos'e Sosa V'azquez: Nilmar S'anchez: “Mozilla es sin'onimo de colaboraci'on y libertad” |
 Regresan las entrevistas a los miembros de Firefoxman'ia y lo hacemos con una persona que ha estado muy involucrado en el desarrollo de aplicaciones para Firefox OS y CRIAX SDK, me refiero a Nilmar S'anchez Muguercia.
Regresan las entrevistas a los miembros de Firefoxman'ia y lo hacemos con una persona que ha estado muy involucrado en el desarrollo de aplicaciones para Firefox OS y CRIAX SDK, me refiero a Nilmar S'anchez Muguercia.
!Conozcamos m'as acerca de Nilmar!
Pregunta:/ ?C'omo te llamas y a qu'e te dedicas?
Respuesta:/ Mi nombre es Nilmar S'anchez Muguercia, soy graduado de la UCI por el curso de trabajadores y trabajo como t'ecnico de laboratorio en el centro DATEC de la universidad. En mi tiempo libre me dedico a trabajar en proyectos personales donde la mayor'ia incluye aplicaciones para Firefox OS con CRIAX SDK.
P:/ ?Por qu'e te decidiste a colaborar con Mozilla/Firefoxman'ia?
R:/ Primeramente la web me encant'o desde que comenc'e en la inform'atica. Cuando conoc'i a Erick, la forma desinteresada en la que me ofreci'o participar en la comunidad me gust'o mucho, me di cuenta de que s'i ten'ia la disposici'on para ayudar de los miembros de la comunidad y que tambi'en podr'ia ayudar a otros. Mozilla es sin'onimo de colaboraci'on y libertad, la primera vez que vi Firefox me asombr'o y me llam'o tanto la atenci'on que fue el punto de partida para que le echara un ojo a Linux.
P:/ ?Actualmente qu'e labor desempe~nas en la Comunidad?
R:/ Actualmente aporto en el desarrollo de aplicaciones para Firefox OS, investigo los interiores de este SO y alguna que otra vez escribo alg'un art'iculo sobre el tema.Se siente muy bien tener un tel'efono y en un momento poder realizar “algo” sin que sea muy complicado para mejorar la experiencia para otras personas y uno mismo. Tambi'en trabajo en una plataforma que permita desarrollar aplicaciones para los dispositivos con Firefox OS y al mismo tiempo permita desarrollar aplicaciones de escritorio con tecnolog'ias web, CRIAX. A falta de Internet no meto las narices en mas nada.
P:/ Adem'as de tu trabajo y el aporte a la comunidad ?Tienes alg'un pasatiempo?
R:/ S'i, la lectura y las artes marciales principalmente, tambi'en reunirme con mis amistades y ver filmes de la Marvel.
P:/ ?Qu'e es lo que m'as valoras o es lo m'as positivo de Mozilla / la Comunidad? ?Qu'e te aporta a ti Mozilla / la Comunidad?
R:/ Lo que m'as valoro es el ideal y la fidelidad de Mozilla para contribuir a la libertad y el poder de elecci'on de los usuarios. Mozilla me ha aportado muchas cosas, pero las m'as destacadas son las ansias de investigaci'on e innovaci'on, de superarme cada d'ia y los conocimientos frescos de la actualidad internacional en torno a los avances de la web. Firefoxman'ia en particular, la oportunidad de llevar a cabo mi granito de arena en el aporte a la web, un espacio. He conocido personas excelentes y he hecho muy buenas amistades. Me siento orgulloso de pertenecer a la comunidad y 'util por dem'as.
P:/ Ya has desarrollado varias aplicaciones para Firefox OS y desarrollas CRIAX SDK, podr'ias decirme las nuevas aplicaciones que nos traer'as?
R:/ Las aplicaciones que hay en camino realmente no son tan nuevas, primero se migrar'a las ya realizadas hacia la nueva interfaz y estructura que propone CRIAX para su versi'on 1.4. Quisiera destacar que el nuevo *99 vendr'a muy completo pues unir'a todos los servicios de las diferentes aplicaciones que utilizan servicios de Cubacell, adem'as de nuevas facilidades. Otra idea que se est'a planteando en estos momentos es dar la posibilidad de interacci'on entre las aplicaciones, por ejemplo, cuando se necesite una contrase~na, un servicio de PasswordCreator la genere en segundo plano.
P:/ ?C'omo crees que ser'a Mozilla en el futuro?
R:/ Una comunidad que seguir'a creciendo con muchas ganas de hacer y promover una web abierta con muchos proyectos nuevos y a la vanguardia.
P:/ En pocas palabras ?Qu'e es Firefoxman'ia para ti?
R:/ La familia que me acogi'o con los brazos abiertos cuando no sab'ia donde colocar mis ideas, la comunidad que me ense~na cada d'ia mas.
P:/ Unas palabras para las personas que desean unirse a la Comunidad?
R:/ Simplemente no lo piensen mas, hay todo un mundo nuevo, si est'an interesados en la web y la libertad y privacidad del usuario en la web entonces Mozilla es su casa. Si los necesitamos y mucho y no solo nosotros por muy grande que pueda parecer la comunidad completa de Mozilla, esta te necesita no importa lo peque~no que creas que es tu aporte una vez aqu'i veras que se vuelve inmenso que es un grano de arena que ayuda a completar toda una labor, una idea, un producto. No te limites a decirnos por ah'i como podemos mejorar, que podemos hacer, ven llevalo a cabo por ti mismo en vivo y en directo.
Muchas gracias Nilmar por acceder a la entrevista.
http://firefoxmania.uci.cu/nilmar-sanchez-mozilla-es-sinonimo-de-colaboracion-y-libertad/
|
|
Christian Heilmann: Testing out node and express without a local install or editor |
Node.js and Express.js based web apps are getting a lot of attention these days. Setting up the environment is not rocket science, but might be too much effort if all you want to kick the tires of this technology stack.
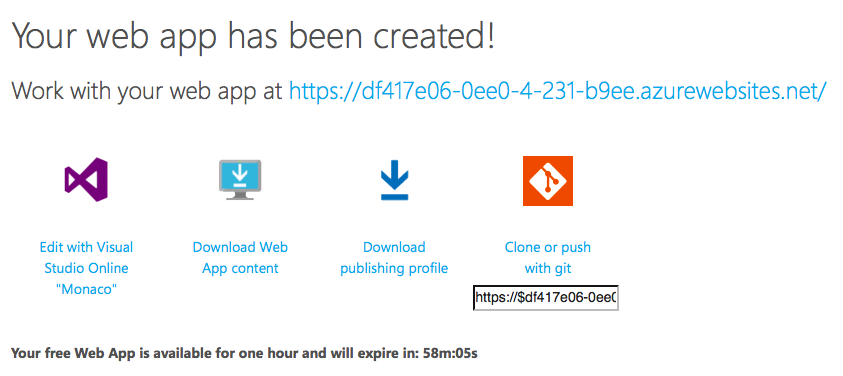
Here’s a simple way to play with both for an hour without having to install anything on your computer or even having access to an editor. This is a great opportunity for showcases, hackathons or a quick proof of concept.
The trick is to use a one-hour trial server of Azure. You don’t need to sign in for anything other than an authentication and you can use Facebook, Google or a Microsoft account for that. You can edit your site right in the browser or by using Git and you can export your efforts for re-use after you discarded the trial server.
Here’s the short process to start playing:
* This is a prevention measure to avoid people spawning lots of bots with this service. Your information isn’t stored, you won’t be contacted and you don’t need to provide any payment details.
You can also clone the site, edit it locally and push to the server with Git. The server is available for an hour and will expire after that. In addition to Git you can also download the app or it’s publishing profile.
There is a quick video of me showing setting up a trial server on YouTube.
Hello I am Chris Heilmann and I want to quickly show you how to set up a
node and Express.js server without having to install anything on your computer. This is a good way to try these technologies out without having to mess with your settings, without having to have an editor. Or if you want to show something to a client who don’t know what node and express do for them.
What you do is you go to a website that allows you to try out Microsoft Azure without having to do anything like buying it, or signing up for it or something like that.
Everything happens in the browser. You go to tryappwebservice.azure.com and then you say you want to start an application. I say I want to have a web application and if I click Next I have a choice of saying I want an asp.net page or whatever. But now I just want to have an Express.js page here right now. I click this one, I say
create and then it can sign in with any of these settings. We only do that so spammers don’t create lots and lots of files and lots and lots of servers.
There’s no billing going on there is no recording going on. You can sign out again afterwards. You can log in with Facebook, log in with Google or you can login with Microsoft. In this case let’s sign in with Google – it’s just my account here – and I sign in with it.
Then I can select what kind of application I want. So now it’s churning in the background and setting up a machine for me on Azure that I will have for one hour. It has a node install and Express.js install and also gives me an online editor so I can play with the information without having to use my own editor or having an editor on my computer.
This takes about a minute up to two minutes depending on how how much traffic we have on the servers but I’ve never waited more than five minutes.
So there you go – your free web app is available for one hour and will expire in in 58 minutes. So you got that much time to play with the express and Node server. After that, you can download the app content, you can download a publishing profile (in case you want to stay on Azure and do something there). Or you can clone or push with git so you can have it on your local machine or you put it on another server afterwards.
What you also have is that you can edit with Visual Studio “Monaco”. So if I click on that one, I get Visual Studio in my browser. I don’t have to download anything, I don’t have to install anything – I can start playing with the application.
The URL is up here so I just click on that one. This is of course not a pretty URL but it’s just for one hour so it’s a throwaway URL anyways. So now I have “express” and “welcome to express” here and if I go to my www root and I start editing in my views and start editing the index.jade file I can say “high at” instead of “welcome to”. It automatically saved it for me in the background so if I now reload the page it should tell me “hi at express” here. I can also go through all the views and all the functionality and the routes – the things that Express.js gives me. If I edit index.js here and instead of “express” I say Azure it again saves automatically for me. I don’t have to do anything else; I just reload the page and instead of “express” it says “Azure”.
If you’re done with it you can just download it or you can download the publishing profile or you can just let it go away. If you say for example you want to have a previous session it will ask you to delete the one that you have right now.
It’s a great way to test things out and you don’t have to install anything on your computer. So if you always wanted to play with node.js and express but you were too timid to go to the command line or to mess up your computer and to have your own editor this is a great way to show people the power of node and express without having to have any server. So, have fun and play with that.
|
|
John O'Duinn: Looking for a job in a “remote friendly” company? |
Last week, I was looped into a discussion around “what companies are remote-friendly”, “how to find a job when you are a remotie” and “what companies have a good remote culture?”. These questions are trickier than one might expect – after all, everyone will have their own definition of “good”.
My metric for deciding if a company has a good remote culture is a variation of the Net Promoter Score:
If you don’t find a remote job by word-of-mouth referral from a friend, how can you find a job in a remote friendly company? I have been accumulating a few useful sites for remote job seekers, avoiding all the “make $$$ working from home” spam out there. After last week’s discussion, I realized I haven’t seen this list posted in any one place, so thought it worthwhile to post here. Without further ado, in no particular order, here goes:
Some sites seemed more focused on freelancer / short term positions, which were less of interest to me at this time, so I’ve skipped most of those, and only listed a couple here for completeness:
Some of these sites are better then others in terms of how you search for “remote” jobs – for example, I think this needs a little UX love.  But something is better then nothing. As I said in my presentation at Cultivate NYC, for job-listings posted on your own company website, simply having “remote welcome” in the job description is a great quick-and-easy start.
But something is better then nothing. As I said in my presentation at Cultivate NYC, for job-listings posted on your own company website, simply having “remote welcome” in the job description is a great quick-and-easy start.
Hopefully, people find this list useful. Of course, if there’s any forums / job boards listing remote jobs that you see missing from here, please let me know.
(Thanks to @laurelatoreilly, @jessicard, @qethanm and @hwine for last week’s discussion.)
John.
http://oduinn.com/blog/2015/10/27/looking-for-job-in-remote-friendly-company/
|
|
The Servo Blog: This Week In Servo 39 |
In the last week, we landed 88 PRs in the Servo organization’s repositories.
We have TWO new reviewers this week! Eli Friedman has been doing fantastic work reviewing some DOM/Content-related PRs and we’re looking forward to burdening them with even more in the future!
Michael Wu, the originator of our Gonk port (aka, Boot2Servo) and frequent hacker on our SpiderMonkey integration, has also been granted reviewer priviledges.
webkitMatchesSelectorwhitespace: pre-wrap and whitespace: pre-lineAt last week’s meeting, we discussed Are We Fast Yet support, DOM feature breakdowns, and iframe regressions.
|
|
Mark Surman: Fueling a movement |
Mozilla was born from the free and open source software movement. And, as a part of this larger movement, Mozilla helped make open mainstream. We toppled a monopoly, got the web back on an open track, and put open source software into the hands of hundreds of millions of people.
It’s time for us to do this again. Which brings me to this blog’s topic: where should Mozilla Foundation focus its effort over the next five years?

If you’ve been following my blog, you’ll know the answer we gave to this question back in June was ‘web literacy’. We dug deep into this thinking over the summer and early fall. As we did, we realized: we need to think more broadly. We need to champion web literacy, but we also need to champion privacy and tinkering and the health of the public internet. We need to fully embrace the movement of people who are trying to make open mainstream again, and add fuel to it. Building on a Mozilla strategy town hall talk I gave last week (see: video and slides), this post describes how we came to this conclusion and where we’re headed with our thinking.
Part of ‘digging deep’ into our strategy was taking another look at the world around us. We saw what we already knew: things are getting worse on the web. Monopolies. Silos. Surveillance. Fear. Insecurity. Public apathy. All are growing. However, we also noticed a flip side: there is a new wave of open afoot. Makers. Open data. Internet activism. Hackable connected devices. Open education. This new wave of open is gaining steam, even more so than we already knew.
This sparked our first big insight: Mozilla needs to actively engage on both sides. We need to tackle big challenges like monopolies and walled gardens, but we also need to add fuel and energy to the next wave of open. This is how we had an impact the first time around with Firefox. It’s what we need to do again.
As the Mozilla project overall, there are a number of things we should do to this end. We should build out from the base we already have with Firefox, reigniting our mojo as a populist challenger brand and developer platform. We should build our values and vision into areas like connected devices and online advertising, pushing ourselves to innovate until we find a new product beachhead. And, we should also back leaders and rally citizens to grow the movement of people who are building a digital world that is open, hackable and ours. As our colleagues at Mozilla Corporation drive on the first two fronts, the Mozilla Foundation can lead the way on the third.
Which brings us to the second place we explored over the summer: what we’ve achieved and built in the last five years. In 2010, we kicked off a new era for Mozilla Foundation with the Drumbeat Festival in Barcelona. At the time, we had half a dozen staff and $250k/year in outside revenue. Since then, we’ve grown to 80 staff, $12M/year in outside revenue and 5,000 active community leaders and contributors. We’ve rallied 1.7M supporters and brought in $40M in grants. More importantly: we have built a vibrant network of friends and allies who share our vision of the internet as a global public resource that belongs to all of us.

As we looked back, we had a second insight: we have built two very powerful new capabilities into Mozilla. They are:
1. A leadership network: Mozilla has gotten good at gathering and connecting people — from executives to young community leaders — who share our cause. We get people working on projects where they teach, organize and hack with peers, helping them learn about open source and become stronger leaders along the way. The now-annual Mozilla Festival in London provides a snapshot of this network in action.
2. An advocacy engine: we’ve become good at rallying activists and citizens to take action for the open internet. This includes everything from attending local ‘teach-ins’ to signing a petition to donating to our shared cause. Our grassroots Maker Party learning campaign and our mass mobilization around issues like net neutrality are examples of this in action.
If our aim is to fuel the movement that’s driving the next wave of open, these capabilities can be incredibly powerful. They give us a way to support and connect the leaders of that movement. And they give us a way to join in common cause with others in incredibly powerful ways.
In the end, this led us to a very simple strategy that the Mozilla Foundation team will focus on over the coming years:
1. Build and connect leaders (leadership network)
+
2. Rally citizens to our common cause (advocacy engine)
=
3. Fuel the movement (to drive the next wave of open)
This strategy is about doubling down on the strengths we’ve built, strengthening the leadership side and investing significantly more on the advocacy side. The Mozilla Foundation board and team have all expressed strong support for this approach. Over the coming week we’re taking this strategy into an operational planning phase that will wrap up in December.
One important note as we dive into detailed planning: it will be critical that we’re concrete and focused on what ‘hills’ we want to take. Web literacy is definitely one of them. Privacy, walled gardens and the economics of the public internet are also on the list. The final list needs to be short (less than five) and, ideally, aligned with where we are aiming Mozilla’s product and innovation efforts. One of our top tasks for 2016 will be to develop a research and thought leadership program across Mozilla that will set a very specific public agenda, defining which topics we will focus our efforts on.
If you’ve been following my blog, you know this is a significant evolution in our strategic thinking. We’ve broadened our focus from web literacy to fueling the movement of which we are part. Universal web literacy is still central to this — both as a challenge that leaders in our network will tackle and as a goal that our large scale advocacy will focus on. However, looking at the world around us, the capabilities we’ve developed and the work we already have in play, I believe this broader approach is the right one. It adds a powerful and focused prong to Mozilla’s efforts to build and protect the internet as a public resource. Which, in the end, is why we’re here.
As always, comments on this post and the larger strategy are very welcome. Please post them here or email me directly.
Also, PS, here are the video and slide links again if you want more detail.
The post Fueling a movement appeared first on Mark Surman.
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 26 Oct 2015 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20151026/
|
|
Nick Cameron: Macros in Rust pt1 |
In the last blog post I introduced macros and some general issues. In this post I want to describe macros (and other syntactic tools) in Rust. In the next instalment, I'll go into hygiene and implementation issues in more detail, and cover some areas for improvement in Rust.
Rust offers an array of macro-like features: macro_rules macros, procedural macros, and built-in macros (like println! and asm!, #[cfg], and #[derive()]) (I feel like I'm missing something). I was going to cover them all in this post, but it's already huge, so I'll just cover macro_rules, more later...
macro_rules! lets you write syntactic macros based on pattern matching. They are often described as 'macros by example' since you write pretty much the Rust code you would expect them to expand to.
They are defined using the macro_rules! built-in macro, and are used in a function like style: foo!(a, b, c), the ! distinguishes a macro from a regular function. For example, a very simple (and pointless) macro:
macro_rules! hello {
() => { println!("hello world"); }
}
fn main() {
hello!();
}
This simple program defines a single macro called hello and calls it once from within the main function. After a round of expansion, this will turn into:
fn main() {
println!("hello world");
}
This is dead simple, the only interesting thing being that we use a macro inside the macro definition. As the compiler further process the program, that macro (println!) will be expanded into regular Rust code.
The syntax of macro definitions looks a bit verbose at this stage, because we only have a single rule and we don't take any arguments, this is very rare in real life.
As in a match expression, => indicates matching a pattern (in this case ()) to a body (in this case println!(...);). Since our use of the macro matches the single pattern (hello!() has no arguments), we expand into the given body.
The next example has some arguments, but still a single rule for matching:
macro_rules! my_print {
($i: ident, $e: expr) => {
let $i = {
let a = $e;
println!("{}", a);
a
};
}
}
fn main() {
my_print!(x, 30 + 12);
println!("and again {}", x);
}
This is somewhat contrived, partly to demonstrate a few features at once and partly because some of the details of Rust's macro implementation are a little odd.
The macro this time takes two arguments. Macro arguments must be prefixed with a $, the formal arguments are $i and $e. The 'types' of macro arguments are different to proper Rust types. An ident is the name of an identifier (we pass in x), expr is an expression (we pass 30 + 12). When the macro is expanded, these values are substituted into the macro body. Note that (as opposed to function evaluation in Rust), expressions are not evaluated, so the compiler actually does substitute 30 + 12, not 42.
Note what is happening with x in the example: the macro declares a new variable called x and we can refer to it outside the macro. This is hygienic (technically, you could have an interesting argument about hygiene here, but lets not) because we pass x in to the macro, so it 'belongs' to the caller's scope. If instead we had used let x = { ... in the macro, referring to x would be an error, because the x belongs to the scope of the macro.
The last example introduces proper pattern matching:
macro_rules! my_print {
(foo <> $e: expr) => { println!("FOOOOOOOOOOOOoooooooooooooooooooo!! {}", $e); };
($e: expr) => { println!("{}", $e); };
($i: ident, $e: expr) => {
let $i = {
let a = $e;
println!("{}", a);
a
};
};
}
fn main() {
my_print!(x, 30 + 12);
my_print!("hello!");
my_print!(foo <> "hello!");
}
OK, the example is getting really silly now, but hopefully it is illustrative. We now have three patterns to match, in reverse order, we have: the same pattern as before (an ident and an expression), a pattern which takes just an expression, and a pattern which requires some literal tokens and an expression. Depending on the pattern matched by the arguments, my_print! will expand into one of the three possible bodies. Note that we separate arms of the pattern match with ;s.
Where exactly can macros be used? It's not quite anywhere - the reason is that the AST needs an entry for everywhere it is allowed to use a macro, for example there is ExprMac for a macro use in expression position. Macros can be used anywhere that an expression, statement, item, type, pattern, or impl item could be used. That means there are a few places you can't use a macro - as a trait item or a field, for example.
Macros can be used with different kinds of bracket too - foo!(...) is function-like and the most common. Foo {...} is item-like and foo[...] is array-like, used for initialising vectors (vec![...]), for example. What kind of bracket you use doesn't make much difference. The only subtlety is that item-like macros don't need a semi-colon in item position.
It's also possible to take a variable number of arguments (as is done in println!) by using repetition in macro patterns and bodies. $(...)* will match many instances of .... You can use tokens outside the parentheses as a separator, so $($x:expr),* will match a, b, c or or a (but not a, b, c,), whereas $($x:expr,)* will match a, b, c, or or a, (but not a, b, c). You can also use + rather than * to match at least one instance.
I'll delay discussion of scoping/modularisation until later.
For more details on macros, see the guide or The Little Book of Macros.
|
|
This Week In Rust: This Week in Rust 102 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us an email! Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's edition was edited by: nasa42, brson, and llogiq.
try!.struct data type constructor, and the basics of Rust's "ownership" concept and "borrowing" and "moving".enum) types, pattern matching, and meaningful return values.101 pull requests were merged in the last week.
See the subteam report for 2015-10-23 for details.
cargo install.VecDeque.#[derive(Show)].Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week!
Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
libc crate from the nursery.OsString and OsStr.If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
No jobs listed for this week. Tweet us at @ThisWeekInRust to get your job offers listed here!
This week's Crate of the Week is winapi-rs. Thanks to DanielKeep for the suggestion. Submit your suggestions for next week!
@retep998 has, by and large, taken it upon himself to try and bind the Windows API using the sadistically horrible official
windows.hheader. By hand.Having chipped away at the surface myself, let me tell you some of the horrors I've seen.
windows.hcontains sub-headers that implicitly depend on other headers having been imported in a particular order. Get the order wrong, and the definitions change. This makes isolating anything, let alone defining where it canonically is supposed to come from a Sisyphean task. It contains symbols that are deliberately defined multiple times. Sometimes, with different types. Sometimes, with different values. Becausewindows.hwas written by shambling horrors from beyond time and space. That's not even touching the titanic, C'thuloid mass of brain-twisting agony that is the conditional compilation definitions and annotations sprinkled throughout like some kind of virulent pox. There are obscure conditional flags that change or omit functions based on bizarre edge cases buried in some obscure file which is included three different ways by paths so obtuse you could make a credible argument for a satellite map of the damn thing except it'd have to be a six dimensional monstrosity that would drive you mad just from looking at it. Then there's the vast tracts of API surface that are exposed via COM which Rust does absolutely jack toward making in any way usable so you have to write the damn vtables by hand and heaven help you if you run into an interface with multiple base interfaces because at that point you might as well give up and just use C because at least that has an IDL generator for it. That's even before you realise that LLVM's code generation isn't even correct on Windows, and this whole time, it's been silently generating bad code for stdcall methods which you'd think would be just like functions but nooo that's now how Visual C++ works, so methods with particular return types are incompatible at the binary level, unless you know about this and manually correct for it by fudging the type signatures in the Rust binding code and really it's no wonder he's a rabbit because a human would have been driven so deep into madness they'd need be halfway to the Earth's firey core.To put it another way: I think it'd be kinda nice to give him a proverbial pat on the back for his herculean efforts thus far.
Submit your quotes for next week!
http://this-week-in-rust.org/blog/2015/10/26/this-week-in-rust-102/
|
|
Mozilla Release Management Team: Firefox 42 beta8 to beta9 |
For once, we released beta 9 for mobile. We tried to address a bug in dalvik and a graphic glitch.
We were planning to disable async plugin init but the patch only landed in time for rc.
| Extension | Occurrences |
| cpp | 21 |
| h | 7 |
| py | 3 |
| js | 3 |
| java | 3 |
| ini | 2 |
| xul | 1 |
| xml | 1 |
| webidl | 1 |
| txt | 1 |
| inc | 1 |
| idl | 1 |
| html | 1 |
| css | 1 |
| c | 1 |
| Module | Occurrences |
| dom | 9 |
| mozglue | 7 |
| netwerk | 5 |
| mobile | 5 |
| gfx | 5 |
| testing | 4 |
| browser | 4 |
| media | 3 |
| widget | 2 |
| ipc | 2 |
| modules | 1 |
| layout | 1 |
List of changesets:
| Steve Fink | Bug 1211402 - Disable hazard upload to reopen the CLOSED TREE, r=pleasework, a=test-only - 27209127fa19 |
| Margaret Leibovic | Bug 1216265 - Only record tracking protection telemetry in non-private tabs. r=mfinkle, a=sylvestre - 7239727fb9d7 |
| Mark Finkle | Bug 1216265 - Remove any UI telemetry probes that reveal a user has entered private browsing. r=margaret, a=sylvestre - 504f0544d601 |
| Valentin Gosu | Bug 1215944 - Return false if string is empty. r=mcmanus, a=sylvestre - 50213377c223 |
| Cameron McCormack | Bug 1203610 - Don't load on-demand non-SVG UA sheets during static document clone. r=jwatt, a=sylvestre - c480e12985af |
| Jonas Sicking | Bug 1215745 - Safer implemetation of nsJarChannel::AsyncOpen2. r=ckerschb, a=sylvestre - 1fd5bf9d2f18 |
| Dan Glastonbury | Bug 1193614 - Schedule State Machine when VideoQueue() is low. r=cpearce, a=sylvestre - 849483c937b8 |
| Andrea Marchesini | Bug 1160890, r=smaug a=sylvestre - 451d4a04dae4 |
| Jim Chen | Bug 1207642 - Work around Dalvik bug by realigning stack on JNI entry; r=snorp, a=sylvestre - fbd30c48f6ec |
| Gerald Squelart | Bug 1204580 - p2: Check box ranges. r=rillian, a=al - 4cebb6ab9288 |
| Dragana Damjanovic | Bug 1214122 - Check if addon ProtocolHandler actually provide nsHttpChannel. r=sicking,mayhemer,ba=sylvestre - e1261e250e85 |
| Aaron Klotz | Bug 1213567 - Prevent neutering from occurring during CreateWindow(Ex) calls; r=jimm, a=sylvestre - aac4b4aaa5f4 |
| Carsten "Tomcat" Book | Backed out changeset aac4b4aaa5f4 (Bug 1213567) for bustage - f2ec86a8b1a8 |
| Gerald Squelart | Bug 1187067 - Null-check mLastTrack before dereferencing it - r=rillian, a=sylvestre - 1721db97f72e |
| Gerald Squelart | Bug 1156505 - p2: Null-check sampleTable before use. r=rillian, a=sylvestre - 6b8a2f0f4e2e |
| Matthew Noorenberghe | Bug 1212610 - Fix sorting permissions by site due a legacy property name being referenced. r=jaws, a=sylvestre - f23031e5a290 |
| Jamie Nicol | Bug 1210444 - Set DEALLOCATE_CLIENT flag for EGLImage SharedSurfaceTextureClients. r=nical, a=sylvestre - e7061d4d10fd |
| Xidorn Quan | Bug 1203089 - Override perspective property of fullscreen ancestors to initial. r=dholbert, a=sylvestre - 2c672ff8f3fb |
| Marco Bonardo | Bug 1192505 - location bar suggestions disappear if mouse moves. r=adw a=sylvestre - 28e133a79f2e |
| Aaron Klotz | Bug 1213567 - Prevent neutering from occurring during CreateWindow(Ex) calls; r=jimm, a=sylvestre - 45ab7cdffbb4 |
| Jan-Ivar Bruaroey | Bug 1216758 - change %ld to %lld for int64 printf argument to fix invalid memory access. r=rjesup, a=sylvestre - 807268f4e3c5 |
| Martin Thomson | Bug 1215519 - Switch to DOMTimeStamp for RTCCertificate. r=bz, a=sylvestre - e91b6fcbc1bb |
| Byron Campen [:bwc] | Bug 1214279: Fix the same infinite loop from Bug 957236 in a different place. r=drno a=sylvestre - 894bc1fcf2a9 |
http://release.mozilla.org/statistics/42/2015/10/25/fx-42-b8-to-b9.html
|
|
Cameron Kaiser: And now for something completely different: El Crapitan sucks (or why SIP will make me go Linux if they keep this crap up) |
Yes, I confess I actually do own two Intel Macs, an old 2007 Core 2 Duo Mac mini running 10.6 which mostly serves as a test machine, and a 2014 i7 MacBook Air which I use for taxes and Master's program homework. The MBA reminds me regularly of why I preferred the New World Power Mac days, and why my daily drivers are still all Tiger PowerPC. Lately every year when Apple issues their annual update I get a bit nervous because their quality assurance seems to have gone right down the pot -- I think the beta testers just twiddle a couple buttons and call it good for golden master, and never mind when everyone's machines explode because they might actually have customized it a bit, or something similarly empowering that Apple doesn't want you doing with your overpriced appliances. (More on that when we get to my overall gripe at the end.)
Part of what makes my trepidation more acute is that I actually do write software that can run on a current Intel Mac from time to time, despite my reputation as a Power Mac-clinging troglodyte. Now, this software is still truly Universal in the strictest sense of the term -- I build on my G5 against the 10.4 universal SDK to make applications that generally run on any Mac OS from 10.4 till now, on any Power Mac and on any Intel Mac, and I even found a version of SDL 1.2 (1.2.14) that happily runs in the same environments on all systems without tripping any deprecation warnings so far. I'll be talking about one particular app in the very near future because not only is it Universal ppc/i386, it also includes AltiVec support, so it's actually 750/7400/i386. Keep an eye out for that column. Fortunately El Capitan didn't break the ones I write based on that environment.
Next, I turned to GopherVR and Mosaic-CK, my rebuilds of two venerable Motif-based X11 applications (the GopherVR client, allowing you to view gopherspace graphically, and an updated port of NCSA Mosaic that doesn't immediately barf on newer pages). These use a special launcher program to install a Dock icon and transfer control to the binary under X11. They both crashed immediately. I looked in the console and found that they were unable to run OpenMotif, which they should have detected, but I said no problem and got out my installer of IST OpenMotif 10.5+ which worked perfectly in Yosemite. On El Cap, it wouldn't install.
Why? Blame the new System Integrity Protection, which amongst other things blocks write access to certain directories, in this case /usr, even if you're root ("rootless protection"). OpenMotif expects to install itself to (more or less) /usr/OpenMotif. El Crap won't let it.
Now, you can keep your superior security snark out of my comments, thanks. I get why SIP exists, because users are stupid, and SIP saves them (somewhat) from themselves. At least so far, unless some gaping kernel hole is discovered, it looks pretty hard to toast an SIP-locked installation other than via hardware failure, and yes, if you're willing to jump through a couple hoops, you can turn it off. But you don't have to be particularly clairvoyant to realize Apple won't let you do that forever, and even now it's mostly all or nothing unless you turn SIP off and tinker with its configuration file. Frankly, making users go to all that trouble isn't a good way to distribute software.
So the first thing I did was patch OpenMotif to run from /Applications, which isn't protected (yes, /Library might be more appropriate, but I had to patch a couple paths embedded in the libraries in place and the length matched better), by changing all the linkages to the new path with a Perl script I dashed off and doing a couple direct binary changes. It looked sane, so I put it in /Applications/OpenMotif21 and rebuilt the apps on the G5 to link against that. It worked fine on 10.4 and 10.6, but on the 10.11 MBA they still crashed.
This time, the OpenMotif libraries could be found, but they were linking against /usr/X11R6, because that's where the universal X11 libraries are in the 10.4 universal SDK and every version of OS X from 10.5 to 10.10 had a symlink to /usr/X11 so it all just worked. Guess what new version of OS X doesn't? And guess what version prevents you from modifying /usr to add that link because of SIP?
I toyed with a couple solutions, but the simplest was to lipo a second i386 binary from the main one (since all Power Macs will run the original binary pointing to /usr/X11R6 fine) at the time the app package is built and rewrite all its linkages to /usr/X11 instead. Then, when the launcher starts, it figures out which binary to run depending if /usr/X11R6 exists or not, and transfers control to that. It's ugly and it bloats the app by about 25%, but it's transparent to the user, at least, and it doesn't require the user to have developer tools installed or I'd just have the launcher do the stripping and rewriting on the fly.
After that, I fixed a couple more bugs (including the original one where I had a short-circuit in the prerequisites detector) and packed everything up for distribution, and now you can use GopherVR and Mosaic-CK once again. Make sure you have X11 or XQuartz installed first, and then grab my patched OpenMotif from SourceForge (choose the 10.4 package for Tiger, or the 10.5 package for Leopard through El Capitan). Just drag the folder to /Applications without changing the name or any of the contents, and then run either GopherVR and Mosaic-CK's launcher app, and it should "just work" on any 10.4+ Mac just as it did before.
Why does SIP annoy me most, though, aside from making my binaries more complex and my headache larger? Simply put, I don't like the feeling I don't own my computer, and I'm getting that feeling more and more from Apple. I feel this much less on my Tiger boxes because I can patch them up manually and improve their security and functionality, or alter the way the OS is laid out to suit my taste and needs and how things are installed and activated, and I'm quite sure Apple has great concerns about allowing that on what they consider to be an "appliance." In fact, the irrepressible cynic in me suspects part of SIP's purpose is not just security -- it also has the (to Apple) desirable side effect of forcing most systems to exist in a specific uniform state so that installations and upgrades are more deterministic instead of allowing a (dangerously?) clueful user to muck about at will. While predictions that Gatekeeper would become locked in stone and unsigned apps would be never be allowed to run even by request have not yet come to pass, a lot fewer people will be inconvenienced by SIP than by Gatekeeper except for nutbag tinkerers and hackers like me, and Apple has little downside to making it permanent in a future version of OS X. That means one day you may not be able to change the OS at all except through those changes Apple authorizes, and that would really suck. It would also drive me to Linux on commodity hardware, because if system limitations mean I can't find a way to run my custom apps on a current Mac that run just fine on my G5 daily driver, then why have a current Mac? As it turns out, I'm not the only one thinking about that. What's Apple going to break next year, my legs?
Geez, Tim.
http://tenfourfox.blogspot.com/2015/10/and-now-for-something-completely_24.html
|
|
Wladimir Palant: Mozilla: What constitutes "open source"? |
I became a Mozillian more than twelve years ago. I’m not sure whether the term “Mozillian” was even being used back then, I definitely didn’t hear it. Also, I didn’t actually realize what happened — to me it was simply a fascinating piece of software, one that allowed me to do a lot more than merely consume it passively. I implemented changes to scratch my own itch, yet these changes had an enormous impact at times. I got more and more involved in the project, and I could see it grow and evolve over time.
Not all of the changes were positive in my eyes, so this blog post hit a nerve with me: is Mozilla still an open source project? How is Mozilla different from Google or Microsoft who also produce open source software? See Android for example: while being technically open source, the project around it is completely dominated by Google. Want to contribute? Apply at Google!
In my opinion, making the source code accessible is a necessary requirement for an open source project, but clearly not the only one. It should be possible for people to get involved and make a difference. I could identify the following contributing factors:
This sounds trivial but it isn’t, particularly with a project the size of Mozilla. Finding the Firefox source code is fairly easy, but it already gets more complicated if you need the build configuration of the Firefox release builds. And when you start looking into web services that Firefox relies on things get really tricky, with the source code hidden under cryptic codenames and distributed more or less randomly between hg.mozilla.org and various GitHub organizations. Even if you find the source code, chances are that setting up your own test environment will be hard to impossible.
There is also another aspect here: seeing a piece of code often isn’t enough, you need to see the reasoning behind it. That’s why the information contained in the revision history is so important. Unfortunately, I’m getting the impression that this aspect is increasingly getting neglected. I frequently see changes linking to bugs without any description whatsoever, or where the description is so cryptic that it is only understandable to some inner circle of developers. It also seems that Mozilla no longer has a consistent policy of opening up security-relevant bugs after they have been fixed. So the context of these changes stays hidden for a very long time.
Contribution processes have always been a sore spot with Mozilla. Finding corresponding documentation has always been too hard and the process in general too complicated. Contributors had to deal with depressingly long review times and lack of mentors. This is a tough topic, and finding the right balance between “just do it yourself” and “help somebody else do it” is hard. However, I’ve had the impression that Mozilla got too comfortable hiring people to do the job and neglected making contribution easier.
This might be the most disappointing aspect of all of them: that you can contribute your effort but have no way of making your voice heard or even understanding the direction in which the project is heading. I think the Australis project was one of the positive examples here: the goals and each step of the project were documented, feedback requested during various stages of the project, and the result was released when it was really ready. Sure, you cannot make everybody happy and lots of people ended up opposing Australis for whatever reasons. It’s a fact: when you ask your existing user base then typically most people will either be indifferent or oppose a change, simply due to self-selection bias. But I did have the impression that feedback was taken seriously on this one.
Sadly, that’s not always the case. I seem to recognize a tendency within Mozilla to delay public discussion until late stages of a project in order to avoid negative press. This is very unfortunate because people outside Mozilla cannot contribute until all the major decisions are already done (occasionally this even seems to apply to key figures within Mozilla). Contributors feel excluded and complain about Mozilla’s lack of transparency.
There are more issues here of course. There is the sheer amount of information, and the fact that it’s very non-obvious which information sources to follow for each particular topic — is X being discussed on Planet Mozilla or Google Groups? Bugzilla? Discourse? Air Mozilla? Something else?
There are also unclear hierarchies and responsibilities within Mozilla. Do you still remember those press articles citing a person with an impressive title who wasn’t actually qualified to speak for the project in question? Yes, journalists are very confused by this, and so are contributors. Already figuring out who is in charge of which project is a non-trivial task. I guess that this wiki page is the way to go but it isn’t easy to find and it doesn’t seem terribly up-to-date either.
And then there are people making strange statements on the Mozilla blog which seem to be very hard to justify, yet these are announced as new Mozilla policies without any obvious way to comment. How come that they are speaking for the entire Mozilla project? They definitely didn’t ask for community input, and I am unable to recognize relevant contributions to the project either (that’s assuming that Mozilla is still a meritocracy).
Don’t get me wrong, Mozilla is still a fascinating and unique project. Building up a large open source project and creating the right balance between contributors and paid employees is a very complex problem, and there is a lot to be learned from Mozilla here. However, I have the impression that the balance is increasingly shifting towards paid employees, and that the people at Mozilla understanding why this is a problem are getting fewer. I would love to have somebody prove me wrong.
https://palant.de/2015/10/24/mozilla-what-constitutes-open-source
|
|
Mozilla Open Policy & Advocacy Blog: Net neutrality amendments and final vote in the EU |
UPDATE:
Today, a bitter-sweet victory for net neutrality in Europe: the European Parliament voted on the Telecoms Single Market Regulation (TSM), which will bring some protections for the open internet in Europe. Regrettably, the European Parliament voted against amendments that would have brought clarity and strength to the proposed rules.
As voted, the proposal generally bans discrimination, but falls short in a few areas, including tightening the definition of “specialised services,” disallowing the discrimination of different types of traffic (see more in our analysis below).
The rules will enter into force as soon as the legislation is published in the Official Diary (which could be as early as November, though not yet confirmed).
But it’s not over yet. BEREC, the association of telecoms regulators in Europe, will devise guidelines during a 9 month consultation period that could clarify the interpretation of the rules. We hope that BEREC finishes what the EU institutions started and enacts real net neutrality in the European Union.
ORIGINAL POST:
We’re days away from the vote for adoption of the Telecoms Single Market (TSM), a proposed EU Regulation that would enshrine net neutrality across the continent. The TSM contains rules which would specify the equal treatment of traffic and ban blocking, throttling, and the establishment of fast lanes, although a handful of key amendments are still needed to bring clarity and strength to the proposed rules. There’s still time to take action – find out more about possible amendments and contact members of the European Parliament through a campaign platform launched by European civil society at: https://savetheinternet.eu/.
Net neutrality is central to the Mozilla mission and to the openness of the Internet. As a global community of technologists, thinkers, and makers, we want to build an Internet that is open and enables creativity and collaboration. This is why we have taken a strong stance in favour of real net neutrality around the world. Net neutrality preserves the disruptive and collaborative nature of the Internet, and benefits competition, innovation, and creativity online.
The TSM was proposed in September 2013, and originally contained a number of semi-related issues, from consumer rights, spectrum management, and roaming, to net neutrality. Over the course of negotiations, the text was cut down to contain a reform of roaming charges and net neutrality rules. Since March, the TSM has been in the final stages of negotiation called the “trialogue,” where the three EU institutions (European Parliament, Commission, and the Council) agree on a common approach. The Parliament will get the final say in the Plenary vote in Strasbourg next Tuesday (27 October).
The current text of the TSM would bring a much needed improvement in the EU for protections against blocking, throttling, and prioritisation of online traffic. Still, there are areas where the text needs to be clarified and strengthened, and we hope these changes can be made over the next few days. Here are two we believe to be of critical importance:
Prohibiting the discrimination of different types of traffic. The current text allows ISPs opportunities to prioritize or throttle some “types of traffic” without violating net neutrality. Such type-based discrimination permits ISPs to slow down or speed up entire types of traffic, resulting in severe harm to net neutrality. For example, an application considered to be “chat” type might include video capabilities, or might be text-only; throttling the latter might have no impact, yet might cripple user experience for the former. Furthermore, the technical characteristics of a “type” of application today may not be the same in the future, as the technologies evolve and add new functionality, so even treatment for a “type” that seems reasonable today may not be tomorrow. Other loopholes are possible as well. Network operators may discriminate against encrypted traffic if unable to determine the “type,” or may create unique “types” of traffic for certain preferred classes, even if there are no inherent distinctions – artificially separating their own preferred or partner traffic from their competitors in order to work around the rules. An amendment that reinforces equal treatment across data types would help close these loopholes.
Tightening the definition of “specialised services” to prevent discrimination. Specialised services – or “services other than Internet access services” – represent a complex and unresolved set of market practices, including very few current ones and many speculative future possibilities. While there is certainly potential for real value in these services, the criteria defining these services should be refined to prohibit discrimination that harms open Internet access services.
The European Parliament will have an opportunity to vote on amendments before considering the final text, so there’s still time to let them know about these valuable improvements. The final outcome of this process will set a strong standard for the open Internet in the European Union and beyond. It’s therefore more important than ever to ensure that the rules are clear, comprehensive and enforceable. Take action today – find out more about the amendments and contact members of the European Parliament at: https://savetheinternet.eu/.
Raegan MacDonald, Senior Policy Manager, EU Principal
Jochai Ben-Avie, Senior Global Policy Manager
Chris Riley, Head of Public Policy
https://blog.mozilla.org/netpolicy/2015/10/24/net-neutrality-amendments-and-final-vote-in-the-eu/
|
|
William Lachance: The new old Perfherder data model |
I spent a good chunk of time last quarter redesigning how Perfherder stores its data internally. Here are some notes on this change, for posterity.
Perfherder’s data model is based around two concepts:
When it was first written, Perfherder stored the second type of data as a JSON-encoded series in a relational (MySQL) database. That is, instead of storing each datum as a row in the database, we would store sequences of them. The assumption was that for the common case (getting a bunch of data to plot on a graph), this would be faster than fetching a bunch of rows and then encoding them as JSON. Unfortunately this wasn’t really true, and it had some serious drawbacks besides.
First, the approach’s performance was awful when it came time to add new data. To avoid needing to decode or download the full stored series when you wanted to render only a small subset of it, we stored the same series multiple times over various time intervals. For example, we stored the series data for one day, one week… all the way up to one year. You can probably see the problem already: you have to decode and re-encode the same data structure many times for each time interval for every new performance datum you were inserting into the database. The pseudo code looked something like this for each push:
for each platform we're testing talos on:
for each talos job for the platform:
for each test suite in the talos job:
for each subtest in the test suite:
for each time interval in one year, 90 days, 60 days, ...:
fetch and decode json series for that time interval from db
add datapoint to end of series
re-encode series as json and store in db
Consider that we have some 6 platforms (android, linux64, osx, winxp, win7, win8), 20ish test suites with potentially dozens of subtests… and you can see where the problems begin.
In addition to being slow to write, this was also a pig in terms of disk space consumption. The overhead of JSON (“{, }” characters, object properties) really starts to add up when you’re storing millions of performance measurements. We got around this (sort of) by gzipping the contents of these series, but that still left us with gigantic mysql replay logs as we stored the complete “transaction” of replacing each of these series rows thousands of times per day. At one point, we completely ran out of disk space on the treeherder staging instance due to this issue.
Read performance was also often terrible for many common use cases. The original assumption I mentioned above was wrong: rendering points on a graph is only one use case a system like Perfherder has to handle. We also want to be able to get the set of series values associated with two result sets (to render comparison views) or to look up the data associated with a particular job. We were essentially indexing the performance data only on one single dimension (time) which made these other types of operations unnecessarily complex and slow — especially as the data you want to look up ages. For example, to look up a two week old comparison between two pushes, you’d also have to fetch the data for every subsequent push. That’s a lot of unnecessary overhead when you’re rendering a comparison view with 100 or so different performance tests:

So what’s the alternative? It’s actually the most obvious thing: just encode one database row per performance series value and create indexes on each of the properties that we might want to search on (repository, timestamp, job id, push id). Yes, this is a lot of rows (the new database stands at 48 million rows of performance data, and counting) but you know what? MySQL is designed to handle that sort of load. The current performance data table looks like this:
+----------------+------------------+ | Field | Type | +----------------+------------------+ | id | int(11) | | job_id | int(10) unsigned | | result_set_id | int(10) unsigned | | value | double | | push_timestamp | datetime(6) | | repository_id | int(11) | | signature_id | int(11) | +----------------+------------------+
MySQL can store each of these structures very efficiently, I haven’t done the exact calculations, but this is well under 50 bytes per row. Including indexes, the complete set of performance data going back to last year clocks in at 15 gigs. Not bad. And we can examine this data structure across any combination of dimensions we like (push, job, timestamp, repository) making common queries to perfherder very fast.
What about the initial assumption, that it would be faster to get a series out of the database if it’s already pre-encoded? Nope, not really. If you have a good index and you’re only fetching the data you need, the overhead of encoding a bunch of database rows to JSON is pretty minor. From my (remote) location in Toronto, I can fetch 30 days of tcheck2 data in 250 ms. Almost certainly most of that is network latency. If the original implementation was faster, it’s not by a significant amount.

Lesson: Sometimes using ancient technologies (SQL) in the most obvious way is the right thing to do. DoTheSimplestThingThatCouldPossiblyWork
http://wrla.ch/blog/2015/10/the-new-old-perfherder-data-model/
|
|






