Air Mozilla: Ignite View Source |
 Ignite opens the View Source Conference with an hour of Ignite talks. Ignite is a fast-paced geek event where speakers present 20 slides, each shown...
Ignite opens the View Source Conference with an hour of Ignite talks. Ignite is a fast-paced geek event where speakers present 20 slides, each shown...
|
|
Mozilla Open Policy & Advocacy Blog: Creating opportunities for Open Innovation through Patents |
In April, I wrote about the challenges the patent system presents to open source software development. I believed then that Mozilla needed to do more by leveraging our mission and position as an innovator. Today, I’m excited to announce the Mozilla Open Software Patent Initiative and Mozilla Open Software Patent License (“MOSPL”). This is our proposal for a first step towards improving the impact of patents on open source software development.
The MOSPL was born from a need to find practical solutions to the challenges to creating openness in the software space. Since its beginning, Mozilla has been bringing together software companies to encourage development and adoption of new, open, and royalty-free technological standards (such as the Opus audio codec and the next generation Daala video codec). We found that, without related patents of our own, it was extremely difficult to persuade companies (particularly large ones) to openly license their patents or adopt standards based on our developed technology. We ran into this problem repeatedly, especially in spaces that are more commonly patented. Obtaining a patent not only gave us leverage in these discussions, it also presented another benefit for open innovation by helping ensure that this work would not be overlooked by the patent office’s prior art searches (which typically might not include open source projects). Over time, this may even reduce the number of abstract, vague, and overbroad patents and the problems that arise from them.
However, once we obtained patents and licensed them openly for our standards work, we ran into another problem: because patents are a right to exclude, owning a patent means that others, from large companies to hackers, cannot use the technology embodied in the patent without a license from the owner. This is not a small problem for Mozilla – the whole point of creating open technology is to encourage use. How would we encourage open use of the ideas embodied within the patents that were outside of the standard? We realized that what we needed was a way to balance the benefit we received from patents with the negative effects of the right to exclude that they created.
As we struggled with this dilemma, we realized we weren’t alone. From Tesla, to Google, to individual developers, many patents are owned for purposes that aren’t at odds with innovation, such as preventing trolls from halting future development and preventing other aggressive incumbents abusing their patent portfolios to stifle competition. However, these owners also realized the broad right to exclude creates challenges for others whom they wanted to encourage to adopt or innovate upon their work. This led to many interesting solutions, from patent pledges, to statements of intent, and implied licenses.
The MOSPL v1 is Mozilla’s proposal to address this challenging issue. It grants everyone the right to use the innovations embodied in our patents in exchange for a guarantee that they won’t offensively accuse others’ software of infringing their own patents and that they will license their own patents out under royalty-free terms to all open source software projects. It represents our effort to address the harm caused by patents when applied to open source software. We are actively seeking feedback on it, so please help us by giving us your thoughts in the governance group.
We’d love to see more companies approach licensing their patents to maximize openness in a way that makes sense for them. If you’ve made the decision as a company or individual to consider open licensing for your patents, we’ve created an Open Patent Licensing Guide to help you understand some of the parameters we encountered through the process. We look forward to seeing more innovation in the open patent licensing space and are excited that even large companies are taking steps to help open innovation thrive, recognizing the importance that openness plays in creating the next generation of technology.
|
|
Karl Dubost: Many questions about Google's AMP (Accelerated Mobile Pages) |
During the last TPAC meetings (October 2015, Sapporo), Google convened during the unconference about AMP (Accelerated Mobile Pages), their new project. Jeremy Keith has a very good blog post about it.
Rather than creating a proprietary format from scratch, it mandates a subset of HTML …with some proprietary elements thrown in (or, to use the more diplomatic parlance of the extensible web, custom elements).
I have a similar feeling about it than Jeremy. Based on a nascent technology, custom elements, Google will probably have the leverage for forcing people into these new elements.
Basically Google is trying to get Publishers to have a set of limited elements for increasing performances on the Web and more specifically on mobile. A way to promote the static Web, but more on that later. Alex made a demo page on his Web site.
You can discover the list of scripts to create the elements on the fly.
span>async custom-element="amp-audio" src="https://cdn.ampproject.org/v0/amp-audio-0.1.js">
span>async custom-element="amp-anim" src="https://cdn.ampproject.org/v0/amp-anim-0.1.js">
span>async custom-element="amp-carousel" src="https://cdn.ampproject.org/v0/amp-carousel-0.1.js">
span>async custom-element="amp-iframe" src="https://cdn.ampproject.org/v0/amp-iframe-0.1.js">
span>async custom-element="amp-image-lightbox" src="https://cdn.ampproject.org/v0/amp-image-lightbox-0.1.js">
span>async custom-element="amp-instagram" src="https://cdn.ampproject.org/v0/amp-instagram-0.1.js">
span>async custom-element="amp-fit-text" src="https://cdn.ampproject.org/v0/amp-fit-text-0.1.js">
span>async custom-element="amp-twitter" src="https://cdn.ampproject.org/v0/amp-twitter-0.1.js">
span>async custom-element="amp-youtube" src="https://cdn.ampproject.org/v0/amp-youtube-0.1.js">
span>async src="https://cdn.ampproject.org/v0.js">
And in the HTML Markup we can see things like:
span>-img src="https://www.ampproject.org/how-it-works/malte.jpg"
id="author-avatar" placeholder
height="50" width="50" alt="Malte Ubl">
</amp-img>
In return, it raises a lot of questions about the freedom for other people outside of Google of creating more elements. The answer given about the governance of what goes in and out of the list of elements has been avoided or more exactly Chris Wilson said:
Like any other project. Pull requests.
To the credits of Chris Wilson, Alex Russel and Dan Brickley (poor them), the project is not coming from them but from the Google Search team who was not here to defend their own project. I feel their pain in having to deal with this hot potato. You can read the archived minutes of the meeting.
Pull Requests are not governance. It's a geek curtain to avoid talking about the real issues. The governance comes into play when you know who decides to merge (or deny) the pull request and why it was done based on which criteria. So that would be very cool to clarify these aspects of the project. From the current governance rules:
In the event there are no Core Committers, Google Inc. will appoint one.
Interesting question here. What's happening if Chrome team starts to implement natively the elements sanctified by the Google's AMP Project? What does it mean for other browsers in forcing them to adopt the same elements? Vendor extensions circa 1995.
I asked:
What's in it for Google.
To which Chris replied:
Google wants the web to be fast.
This is true for everyone, every player on the Web. So I tried to ask again the question. This time, Dan Brickly answered:
When the web sucks we suck
Yeah… still true for everyone. So it's not really an answer. They said at the beginning it was coming from the Google Search team and they were targeting publishers. They also said during the meeting that it was not hard to convince Web developers about the performance issues, but Web developers didn't have enough power to change the mind of business people on not adding yet another tracker. As someone else said during the meeting, this is more of psychological event to help people move forward with optimization. This is indeed a possibility. What I foresee is that business people once they learn custom elements == performance, they will go back to their old habits and ask the developers to add custom elements trackers. And we go round again about the governance and the impact that Google has potentially on the project through deciding what is valid AMPed pages and how it affects their SEO.
And here maybe is the start of an answer. For the last couple of weeks, I have started to browse blocking everything by default with uBlock origin. Here is the rendering of the same page with blocking everything and not blocking anything in Firefox. An article in Fortune Magazine that Jeremy Keith talked about recently.
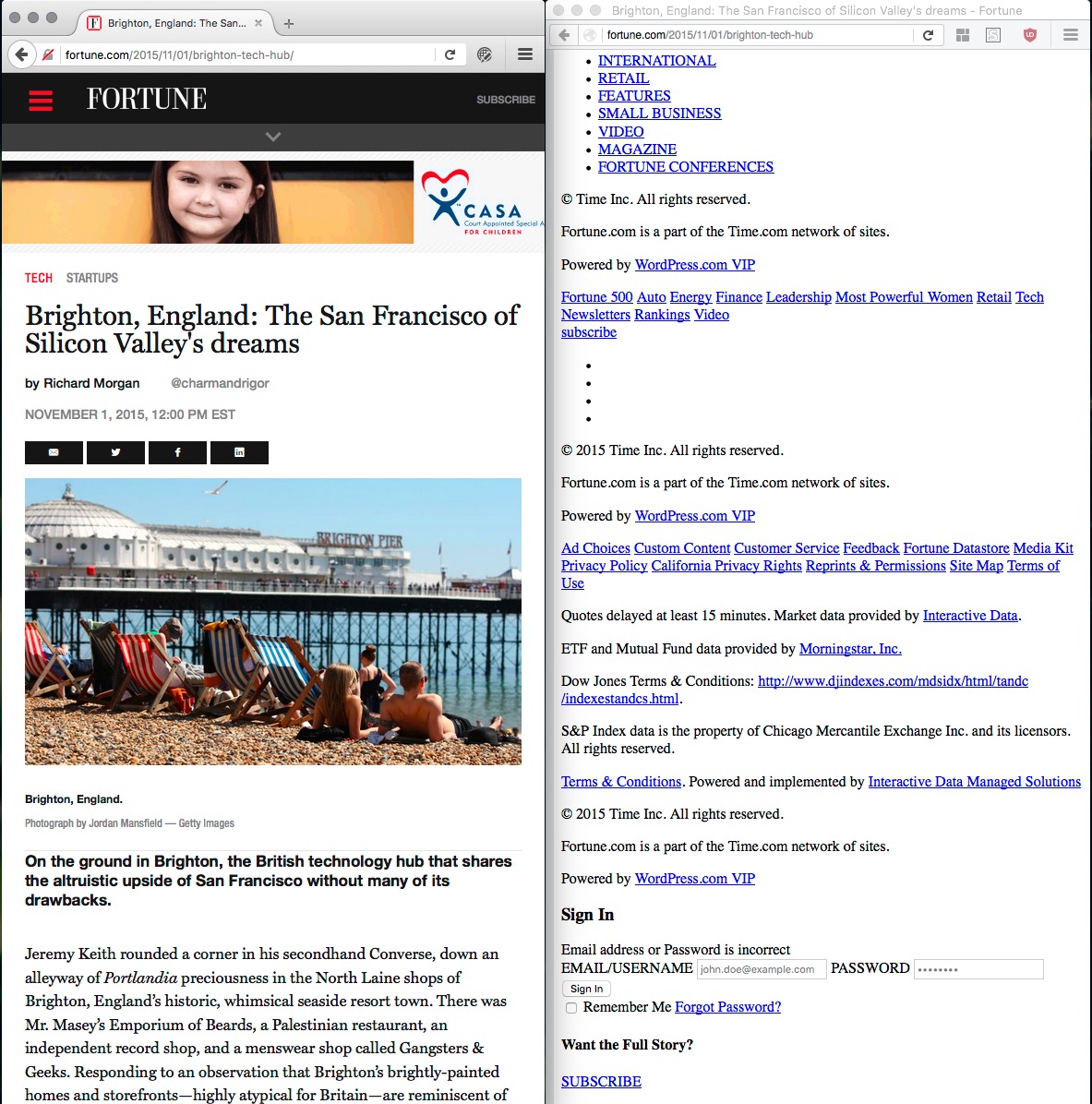
The main difference is not that much about the style, but about the content. Without JavaScript the content is simply not loaded and some links do not exist at all. It means that the content is very hard to both:
Remember AMP is coming from Google Search team. Heavy pages in JavaScript requires more CPU, more time, and a JS enabled bot to index pages. The more time you spend on one page, the less time for other pages and being able to index the full Web. The core business of Google is to know everything about everything so they can sell relevant ads. I imagine the decrease in performances of Web pages directly hinders the business model of Google.
This is all supposition. Nothing in the meeting minutes or discussions says so. So to take with a grain of salt.
After the meeting, I was still confused and I was wondering why the project was not brought to the W3C WebPlatform, so if there was really an issue to solve about Web Performance (and there is), the idea of doing that in cooperation with other people would be better.
Improving the performance of the Web is a good goal, but I still don't have the feeling that AMP, as it is proposed today, is a good way to achieve this in a collegial and cooperative way. Google has too much power already (IBM or Microsoft of the past). So any projects of this nature should be carefully handled.
Thanks to Alex, Chris and Dan for answering the question to the best they could.
Otsukare!
|
|
Mozilla Addons Blog: Join the Featured Add-ons Community Board |
All the add-ons featured on addons.mozilla.org (AMO) are selected by a board of community members. Each board consists of 5-7 members who nominate and select featured add-ons once a month for six months…and the time has come to assemble a new board!
Featured add-ons help users discover what’s new and useful, and downloads increase drastically in the months they are featured, so your participation really makes an impact.
Anyone from the add-ons community is welcome to apply: power users, theme designers, developers, and evangelists. Priority will be given to applicants who have not served on the board before, followed by those from previous boards, and finally from the outgoing board. This page provides more information on the duties of a board member.
To be considered, please email us at amo-featured@mozilla.org with your name, and tell us how you’re involved with AMO. The deadline is Monday, Nov 9, 2015 at 23:59 PDT. The new board will be announced about a week after.
We look forward to hearing from you!
https://blog.mozilla.org/addons/2015/11/02/join-the-featured-add-ons-community-board-2/
|
|
Mozilla Addons Blog: November 2015 Featured Add-ons |
by nobzol
Translate any text to your own language with one click or hot-key. You can either translate the selected text (the translated text will overwrite the original selected text), or you can translate a full page.
“I was tired of copying and pasting small messages, like tweets, or Facebook comments to understand what they were saying so it was very nice to find an add-on to do this.”
by Linder
Quickly and easily switch between popular user-agent strings. The User Agent is a string that the browser sends to websites to identify itself. This allows websites to serve different content depending on the browser, platform, and other factors. User-Agent Switcher lets you change the User Agent string so you can have your Firefox impersonate a Chrome browser, Safari on iOS, and so on, to see the content those browsers get.
Featured add-ons are selected by a community board made up of add-on developers, users, and fans. Board members change every six months, so there’s always an opportunity to participate. Stayed tuned to this blog for the next call for applications.
If you’d like to nominate an add-on for featuring, please send it to amo-featured@mozilla.org for the board’s consideration. We welcome you to submit your own add-on!
https://blog.mozilla.org/addons/2015/11/02/november-2015-featured-add-ons/
|
|
Air Mozilla: Mozilla Weekly Project Meeting, 02 Nov 2015 |
 The Monday Project Meeting
The Monday Project Meeting
https://air.mozilla.org/mozilla-weekly-project-meeting-20151102/
|
|
Mozilla Release Management Team: Firefox 42 rc1 to rc2 |
| Extension | Occurrences |
| cpp | 10 |
| py | 1 |
| mm | 1 |
| js | 1 |
| ini | 1 |
| h | 1 |
| Module | Occurrences |
| dom | 11 |
| testing | 2 |
| widget | 1 |
| modules | 1 |
List of changesets:
| Wes Kocher | Merge beta to m-r a=merge - a09f90a74e72 |
| Wes Kocher | Merge beta to m-r a=merge - 7c0672cba1de |
| Rail Aliiev | Bug 1218914 - Add win64 bouncer configs. r=nthomas DONTBUILD on a CLOSED TREE a=lizzard - e59a1a631240 |
| Steven Michaud | Bug 1187613 - Error: cannot initialize a variable of type 'const CGEventField' with an rvalue of type 'int' if build with 10.11 SDK. r=spohl a=sylvestre - 5aecc34603af |
| Jean-Yves Avenard | Bug 1218157: Only ever read from cached data in NotifyDataArrived. r=cpearce a=sylvestre - 2216fd8a49fe |
| Ryan VanderMeulen | Merge beta to m-r. a=merge - 68048d187998 |
| Chris Pearce | Bug 1205083 - Don't enable low latency WMF video decoding as it crashes sometimes. r=jya, a=sylvestre - 4661413507b3 |
http://release.mozilla.org/statistics/42/2015/11/02/fx-42-rc-to-rc2.html
|
|
Yunier Jos'e Sosa V'azquez: 85.04 nuevo r'ecord para el uso de Firefox en Cuba |
Hace casi 3 a~nos publicamos aqu'i el 'ultimo art'iculo relacionado con las estad'isticas del uso de Firefox en Cuba y para nuestra alegr'ia, hoy lo volvemos a hacer. Si en aquel momento 74,37 % parec'ia una cifra enorme, esta vez el 85,04 % alcanzado nos parece de pel'icula.
Este hecho es posible gracias a todas las personas que eligen Firefox y son fieles al navegador m'as transparente y protector de la privacidad de sus usuarios. Este hecho nos llena de alegr'ia, orgullo y nos alienta a seguir trabajando a'un m'as para ustedes. Si te interesa colaborar con nosotros, por favor llena este formulario.
Y es que a nosotros los cubanos nos encanta Firefox, incluso, por encima de otras buenas soluciones que existen en el mercado. Firefox a logrado en Cuba lo que Chrome, Opera, Safari, IE y otros no han podido hacer, la facilidad para obtener sus versiones y extensiones que lo hacen tan especial mediante diferentes v'ias, sumando el apoyo que recibe de centros e instituciones, hacen posible que nuestro panda rojo goce de una excelente adopci'on en el pa'is.

Uso de navegadores en Cuba desde 2012
Con este nuevo r'ecord alcanzado nuestro pa'is se reafirma como el que m'as aboga por el uso de Firefox.
Aunque desde hace algunos a~nos en el resto del mundo la tendencia respecto a los navegadores es otra, y pr'acticamente Chrome impulsado por Google es el principal competidor como lo era IE hace a~nos atr'as. A los seguidores de Firefox nos alegra saber que por estos lares se ama al zorro de fuego.

Uso de navegadores en el mundo desde 2012
Por 'ultimo, te pido que compartas esta noticia en tus redes sociales utilizando el hashtag #FirefoxUnoCuba y referenciando, si es posible a: @ffxmania, @mozilla y @firefox. Ay'udanos para que m'as personas sepan que en Cuba, Firefox es el n'umero 1.
85,04 nuevo r'ecord para uso de @Firefox en Cuba #FirefoxUnoCuba @ffxmania @mozilla http://firefoxmania.uci.cu/85-04-nuevo-record-para-el-uso-de-firefox-en-cuba/
http://firefoxmania.uci.cu/85-04-nuevo-record-para-el-uso-de-firefox-en-cuba/
|
|
QMO: Firefox 43.0 Aurora Testday Results |
Hi everyone!
Last Friday, October 30th, we held Firefox 43.0 Aurora Testday. It was a successful event (please see the results section below) so a big Thank You goes to everyone involved.
First of all, many thanks to our active contributors: Hossain Al Ikram, Nazir Ahmed Sabbir, Rezaul Huque Nayeem, Bolaram Paul, Mohammed Adam, Muktasib Un Nur, Fahmida Noor, Adnan Sabbir, Hasin Raihan, Abdullah Umar Nasib, Rayhna Rashid, K.M.Mahmudul Monir, Md.Mazidul Hasan, Azmina Akter Papeya, Md. Asif Bin Khaled, Ashikul Alam Chowdhury, Amitabha Dey, Pranjal Chakraborty, Mohammad Samman Hossain, M M Shaifur Rahman, Yasin Ahmed, Khalid Syfullah Zaman, Mahfuzur Rahman, Humayun Kabir, B M Abir, Hasna Hena, Rashedul Hoque Arif, Mahir Labib Chowdhury, Raihan Ali, Habiba Bint Obaid, Ahmed Tareque, Md.Tarikul Islam Oashi, Mostafa Kamal Ornab, Anna Mary Mondol, Afia Anjum Preety, Md.Imrul Kaesh, MD. Nazmus Shakib, Mahfuza Humayra Mohona, Tahsan Chowdhury Akash, MD. Ehsanul Hassan, Md. Badiuzzaman Pranto, Mohammad Maruf Islam, Sajedul Islam, Mubina Jerin, Md. Rahimul Islam, Md. Asiful Kabir, T.M. Sazzad Hossain, Md. Almas Hossain, Tasmia Tanjum, Kamil Pawelec, Naina Razafindrabiby, Jakub Kulik, Michal Graczyk, Anna Wesolowska, Robert Weclawski, Dawid Kostrzewski, Krzysztof Kosek, Radoslaw Kobus, Marcin Kowalczyk, Moin Shaikh, gaby2300, Alex Bakcht, Aleksej.
Secondly, a big thank you to all our active moderators.
Results:
We hope to see you all in our next events, all the details will be posted on QMO!
https://quality.mozilla.org/2015/11/firefox-43-0-aurora-testday-results/
|
|
Daniel Pocock: FOSDEM 2016 Real-Time Communications dev-room and lounge |
FOSDEM is one of the world's premier meetings of free software developers, with over five thousand people attending each year. FOSDEM 2016 takes place 30-31 January 2016 in Brussels, Belgium.
This call-for-participation contains information about:
The Real-Time dev-room and Real-Time lounge is about all things involving real-time communication, including: XMPP, SIP, WebRTC, telephony, mobile VoIP, codecs, privacy and encryption. The dev-room is a successor to the previous XMPP and telephony dev-rooms. We are looking for speakers for the dev-room and volunteers and participants for the tables in the Real-Time lounge.
The dev-room is only on Saturday, 30 January 2016 in room K.3.401. The lounge will be present for both days in building K.
To discuss the dev-room and lounge, please join the FSFE-sponsored Free RTC mailing list.
Note: if you used Pentabarf before, please use the same account/username
Main track: the deadline for main track presentations was midnight on 30 October. Leading developers in the Real-Time Communications field are encouraged to consider submitting a presentation to the main track.
Real-Time Communications dev-room: deadline 27 November. Please also use the Pentabarf system to submit a talk proposal for the dev-room. On the "General" tab, please look for the "Track" option and choose "Real-Time devroom".
Other dev-rooms: some speakers may find their topic is in the scope of more than one dev-room. It is permitted to apply to more than one dev-room but please be kind enough to tell us if you do this. See the full list of dev-rooms.
Lightning talks: deadline 27 November. The lightning talks are an excellent opportunity to introduce a wider audience to your project. Given that dev-rooms are becoming increasingly busy, all speakers are encouraged to consider applying for a lightning talk as well as a slot in the dev-room. Pentabarf system to submit a lightning talk proposal. On the "General" tab, please look for the "Track" option and choose "Lightning Talks".
FOSDEM dev-rooms are a welcoming environment for people who have never given a talk before. Please feel free to contact the dev-room administrators personally if you would like to ask any questions about it.
The Pentabarf system will ask for many of the essential details. Please remember to re-use your account from previous years if you have one.
In the "Submission notes", please tell us about:
You can use HTML in your bio, abstract and description.
If you maintain a blog, please consider providing us with the URL of a feed with posts tagged for your RTC-related work.
We will be looking for relevance to the conference and dev-room themes, presentations aimed at developers of free and open source software about RTC-related topics.
Please feel free to suggest a duration between 20 minutes and 55 minutes but note that the final decision on talk durations will be made by the dev-room administrators. As the two previous dev-rooms have been combined into one, we may decide to give shorter slots than in previous years so that more speakers can participate.
Please note FOSDEM aims to record and live-stream all talks. The CC-BY license is used.
For any questions, please join the FSFE-sponsored Free RTC mailing list.
To make the dev-room and lounge run successfully, we are looking for volunteers:
FOSDEM is made possible by volunteers and if you have time to contribute, please feel free to get involved.
The XMPP Standards Foundation (XSF) has traditionally held a summit in the days before FOSDEM. There is discussion about a similar summit taking place on 28 and 29 January 2016. Please see the XSF Summit 19 wiki and join the mailing list to discuss.
We are also considering a more general RTC or telephony summit, potentially on 29 January. Please join the Free-RTC mailing list and send an email if you would be interested in participating, sponsoring or hosting such an event.
The traditional FOSDEM beer night occurs on Friday, 29 January
On Saturday night, there are usually dinners associated with each of the dev-rooms. Most restaurants in Brussels are not so large so these dinners have space constraints. Please subscribe to the Free-RTC mailing list for further details about the Saturday night dinner options and how you can register for a seat.
If you know of any mailing lists where this CfP would be relevant, please forward this email. If this dev-room excites you, please blog or microblog about it, especially if you are submitting a talk.
If you regularly blog about RTC topics, please send details about your blog to the planet site administrators:
| http://planet.jabber.org | ralphm@ik.nu |
| http://planet.sip5060.net | daniel@pocock.pro |
| http://planet.opentelecoms.org | daniel@pocock.pro |
Please also link to the Planet sites from your own blog or web site.
For discussion and queries, please subscribe to the Free-RTC mailing list.
The dev-room administration team:
http://danielpocock.com/fosdem-2016-free-rtc-dev-room-and-lounge
|
|
Nick Fitzgerald: Back To The Futu-Rr-E: Deterministic Debugging With Rr |
What follows is an embloggified version of an introduction to the rr
debugger that I gave at a local Linux Users Group meet up on October 6th, 2015.

Hello, everyone! My name is Nick Fitzgerald and I'm here to talk about a
(relatively) new kid on the block: the rr debugger. rr is built by some
super folks working at Mozilla, and I work at Mozilla too, but not with them and
I haven't contributed to rr (yet!) — I'm just a very happy customer!
At Mozilla, I am a member of the Firefox Developer Tools team. I've done a good amount of thinking about bugs, where they come from, the process of debugging, and the tools we use in the process. I like to think that I am a fairly savvy toolsmith.
These days, I'm doing less of building the devtools directly and more of baking APIs into Gecko (Firefox's browser engine) and SpiderMonkey (Firefox's JavaScript engine) that sit underneath and support the devtools. That means I'm writing a lot of C++.
And rr has quickly become the number one tool I reach for when debugging
complicated C++ code. rr only runs on Linux and I don't even use Linux as my
day-to-day operating system! But rr provides such a great debugging
experience, and gives me such a huge productivity boost, that I will reboot
into Fedora just to use rr for all but the most trivial bugs. Take note of
that, Linux advocates.
But before we dive into rr and why it is so awesome, I'd like to step back and
talk a bit about the anatomy of a bug and the process of debugging.

A bug has a symptom, for example the program crashes or something that was supposed to happen didn't, and it has an origin where things first started going wrong or misbehaving. Between the origin and the symptom is a cause and effect chain. The cause and effect chain begins with the bug's origin and ends with the symptom you've observed.

Initially, the cause and effect chain and the origin are hidden from us. When first investigating a bug, we only know its final symptoms.

But what we really want to know is the root cause or origin of the bug, because that is where we need to apply a fix and resolve the bug. To get there, we have to reason backwards through the cause and effect chain. The process of debugging is the process of reasoning backwards through the cause and effect chain from the bug's symptom to its origin.
It follows that all debugging is "reverse debugging", but not all debuggers support reverse execution. And even among those debuggers that do support reverse execution, going backwards and forwards repeatedly can give you different results due to nondeterminism in the program.

Let's take a look at the ergonomics of walking backwards through the cause and effect chain in a traditional stepping debugger without reverse execution.

With a traditional debugger, we are slowly reasoning our way backwards, while the program executes forwards and we end up in a loop that looks something like this:
Pause or break at the point in the program's execution where things start to go wrong. "The program is crashing at D, let's pause at that point."
Poke around, inspect variables, frames on the stack, etc. and discover the immediate cause of the effect you have observed. "Oh, I see: D is being passed a null pointer because of C!"
But we get to the point where in order to find the next immediate cause, we need to either go backwards in time or restart the program's execution. Since the former is not an option in traditional debuggers, we are forced to restart the program. "But what conditions led to C giving out a null pointer? I'll set this breakpoint and restart the program."
Re-execute the program until you hit the breakpoint. Hopefully there aren't many false positives; conditional breakpoints can help cut down on them.
Loop back to (2) until we've found the origin of the bug.
I really hope we can reliably and consistently reproduce this bug, or else (4) will involve re-running the program many times! If the cause and effect chain is long, that means we are re-running the program many, many, many times! This productivity drain is compounded by false positives and manual, non-automatable steps-to-reproducing the bug. Not a good look.
 where d = distance between origin and symptom, r = inverse reproducibility (ie, reproduces 1/r program executions)")
If we shoehorn the debugging process afforded by a traditional debugger into big-O notation, we get O(d•r) where d is the length of the cause and effect chain, and r is the inverse reproducibility, meaning that we need to execute the program about r times to reproduce the bug once.
When both d and r are very small, discovering the bug's origin is trivial. We aren't interested in this class of bugs; a traditional debugger will already serve just fine. When d or r grow larger, we quickly spend more and more time debugging and our productivity slows to a crawl. When both d and r are large, bugs can feel (and in practice be) impossible to resolve. It can even be so impractical that it's not worth spending time on and makes more business sense to let the bug live on! It's a sad situation to be in.
These really difficult to diagnose and fix bugs are the type we are interested in. If we can better debug this class of bug, we increase our productivity and can even fix bugs that were impossible or impractical to fix before. This results in better, more reliable software that is delivered faster.

rr provides a fundamentally better debugging process than traditional
debuggers and lives up to the promise of making seemingly impossible to fix bugs
into simply difficult. It untangles reproducing a bug from investigating the
cause effect chain by splitting the debugging process into two phases: recording
a program's execution and then replaying and debugging that recording
deterministically.
Using rr is kind of like investigating a theft at a corner store. The store
has a CCTV system that is recording everything going on inside. If you want to
solve the store's security problem, you could hire someone to watch the CCTV
feed in real time 24 hours a day and try and spot a thief in action but that is
expensive, manual, and time consuming. Alternatively, you could save that time
and money spent on watching the live video feed and wait until you've captured a
thief on camera. At that point, you can watch that recording at your leisure and
rewind, replay, fast forward, and enhance to determine who the thief is, and how
to make that theft impossible in the future. rr is the same way: you keep
recording until you've captured an occurrence of your bug and then you go back
and replay the recording to determine the origin of why that bug happened.

Photo credits: https://flic.kr/p/mYvfNr and https://flic.kr/p/7zrdKz
With rr, the first phase is recording an execution of your program that
reproduces the bug in question. The recording must include everything needed to
replay the program execution exactly. The key observation that rr leverages is
that most of a program's execution is deterministic. Therefore, if you record
all of the nondeterministic parts, then the rest of the program (the
deterministic parts) will by definition always yield the same results. This also
turns out to have less recording overhead than alternative techniques.
Examples of nondeterminism that rr records:
SIGINT, SIGSEGV, …read(fd, buf, size), …getrandom(buf, size, flags), …For system calls, ptrace is used to wrap the call, note its occurrence and
return value in the recording, and let the call return.
Concurrency and parallelism is a little trickier. True parallelism with shared
memory can't be recorded efficiently with today's hardware. Instead, rr only
supports concurrency and all threads are pinned to a single core. rr counts
the number of instructions executed between preemptions so it can recreate them
exactly in the replay phase. Unfortunately, this means that very parallel
programs will run much slower under rr than they otherwise would.

Photo credit: https://flic.kr/p/7JH3T3
The second phase is replaying the recording. Mostly, this phase is just running
the program again and letting the deterministic majority of it recompute the
same things it originally did. That is what lets rr's overhead stay low when
replaying.
The nondeterministic parts of the program's execution are emulated from the
original execution's recording in a couple different ways. System calls are
intercepted and the corresponding value from the recording is returned instead
of continuing with the actual system call. To emulate the exact preemptions
between context switches between threads, rr implements its own scheduler and
uses hardware performance counters to interrupt after the desired number of
instructions (that were previously noted in the recording) have been
executed. rr's scheduler then handles the interrupt and switches
contexts. Replaying signals is handled similarly.
If you want more implementation details,
this slide deck is a great deep dive into rr's internals for potential contributors. It
is from April, 2014, so a little dated, but my understanding is that rr is
just more featureful and hasn't been fundamentally re-architected since then.
")
By splitting out reproducing a failure from investigating the cause and effect
chain, rr's debugging process is O(r+d). This is the time spent reproducing
the bug once while we are recording, plus the time spent deducing the cause and
effect chain. We don't need to continually reproduce the bug anymore! Only once
ever! This is a huge improvement over traditional debuggers, and if we can
automate recording the steps to reproduce until the bug occurs with a script,
then it is only O(d) of our personal time!

This is treeherder. All of Firefox, Gecko, and SpiderMonkey live inside the big mozilla-central repository. Everyday, there are hundreds of commits (from both paid Mozilla employees and volunteer contributors) landing on mozilla-central, one of its integration repositories (mozilla-inbound for platform changes and fx-team for frontend changes), or the Try testing repository. Every one of these commits gets tested with our continuous integration testing. Treeherder displays these test results. Green is a test suite that passed, orange means that one or more tests in that suite failed.
We have a lot of tests in mozilla-central. Some quick and dirty shell scripting yielded just under 30,000 test files and I'm sure that it wasn't exhaustive. Because we're all human, we write tests with bugs and they intermittently fail. If a test is failing consistently it is usually pretty easy to fix. But if a test only fails one out of a thousand times, it is very hard to debug. Still, it has a real impact: because of the sheer number of commits on and tests within mozilla-central, we still get many intermittent failures on every test run. These failures are a drag on developer time when developers have to check if it is a "real" failure or not, and while often they are poorly written tests that contain race conditions only in the test code, sometimes they will be real bugs that down the line are affecting real users.
rr puts these bugs that are seemingly impossible to debug within
reach. Mozilla infrastructure folks are investigating what is required to
optionally run these test suites under rr during our integration tests and
throw away the recording if an intermittent failure doesn't occur, but if it
does then save the recording for developers to debug at their leisure.

Wow! Hopefully you're convinced that rr is worth using. Most of the familiar
commands from gdb are still present since it uses gdb as a frontend. You
should definitely read the wiki page on
rr's usage. Here are a few tips
and tricks so you can hit the ground running.

These are the same as the normal stepping commands but go backwards instead of forwards in the execution. Go backwards one instruction, expression, line, or even frame. What's really neat about this is that going backwards and forwards repeatedly is deterministic and you'll always get the same results.
Step backwards through the cause and effect chain directly, rather than piecing it back together with repeated forward execution!

Here is a real example I had a couple months ago where reverse stepping really
saved me a ton of time. I was implementing an extension to the structured
cloning algorithm to handle my SavedFrame stack objects so
that they could be sent between WebWorkers. The function in question returns
nullptr on failure, and it does a lot of potentially fallible
operations. Twelve to be exact (see the lines highlighted with an arrow in the
screencap). I had a test that was failing. This function was called many times
and usually it would succeed, but one time it would fail and return nullptr
because one of its fallible operations was failing but I had no idea which one
or why. With a traditional debugger, my options were to set twelve breakpoints,
one on every return nullptr;, or break on every entry of the function (which
is called many times and usually succeeds) and then step through line by
line. Both options were tedious. With rr, I just set a conditional breakpoint
for when my call to the function returned nulltpr and then did a single
reverse-step command. I was taken directly to the failing operation, and from
there the origin of the bug quickly became apparent.
In the end, it turned out to be embarrassingly simple. I was doing this:
result = fallibleOperation();
if (result)
return nullptr;
instead of this:
result = fallibleOperation();
if (!result)
return nullptr;
Note the ! in the latter code snippet.

This is the Holy Grail of debuggers. If you could most directly translate "reasoning backwards through the cause and effect chain" into a debugger command, it would be this. When a value has become corrupted, or an instance's member has an unexpected value, we can set a hardware watchpoint on the value or member and then reverse continue directly to the last point in the program's execution when the given value was modified.
This also works with breakpoints and conditional breakpoints in addition to watchpoints.
A few months ago, I was doing a little refactoring of the way that
SpiderMonkey's Debugger API objects interact with the garbage
collector. When SpiderMonkey finishes its final shutdown GC, it asserts that
every Debugger API object has been reclaimed. Somehow, my changes broke that
invariant. I couldn't use the memory tools we have been building to help find
retainers because this was the middle of shutdown and those APIs weren't
designed with that constraint. Additionally,
the core marking loop of the GC is very, very hot and is implemented as a bunch of gotos.
Using a traditional debugger and setting a conditional breakpoint for when my
"leaking" Debugger API object was processed in the marking loop was useless;
it gave no clue as to why it was being marked or who was retaining it and
why they were retained in turn. Using rr, I did set a conditional breakpoint
for when my Debugger API object was pushed on the "to-mark" stack, but then I
reverse stepped to find what object was being marked and queueing my Debugger
API object for marking in turn. Using the combination of conditional breakpoints
and rr's reverse execution, I was able to walk the retaining path backwards
through the GC's marking loop to figure out why my Debugger API object was
sticking around and not getting reclaimed. It turned out that my refactoring
marked a global's Debugger API objects unconditionally, when they should only
be marked if the global was still live.

Thanks for bearing with me! I hope some of my excitement for rr has been
transferred to you. I definitely feel like I can debug more challenging problems
than I otherwise would be able to.
Go forth and use rr! Happy debugging!
That was everything I presented to the Linux Users Group, but since I gave that
presentation I've accumulated one more good rr debugging anecdote:
We (the devtools team) use a series of protobuf messages to serialize and deserialize heap snapshots to and from core dump files. While we are only just building a frontend to this functionality in the devtools, the APIs for saving and reading heap snapshots have existed for a while and have pretty good test coverage. In the process of testing out the new frontend we would seemingly randomly get errors originating from within the protobuf library when reading heap snapshots.
I don't know the protobuf internals, it's a black box to me and on top of that
a lot of it is machine generated by the protoc compiler. But, I rebooted into
Fedora, fired up rr and reproduced the bug. Starting from where the protobuf
message parsing API was returning false to denote a parse failure (no kind of
message or error code explaining why message parsing failed) I started
stepping backwards. It quickly became apparent that I was repeatedly stepping
backwards through frames belonging to the same handful of mutually recursive
functions (clue #1) that were unwinding the stack and returning false along
the way. So I set a breakpoint on the return false; statements I was
repeatedly stepping through and then used gdb's breakpoint commands
to help automate my debugging process.
(rr) commands
Type commands for when breakpoint is hit, one per line.
End with a line saying just "end".
>reverse-finish
>end
(rr)
After I added this command to each breakpoint, I kicked the process off with a
single reverse-finish which triggered a cascading series of breakpoint hits
followed by another reverse-finish from the automated breakpoint commands. In
a few seconds, I re-wound a couple hundred mutually recursive stack
frames. I ended up on this line within the protobuf library:
if (!input->IncrementRecursionDepth()) return false;
It turns out that the protobuf library protects against malicious, deeply
nested messages from blowing the stack by implementing a recursion limit for how
deep messages can nest. Thanks! (Although, I still wish it gave some indication
of why it was failing…) Our core dump protobuf message format was designed
so that we use a lot of individual messages rather than one big nested
structure, but there was one case where we were hitting the limit and that led
to this bug. Luckily, it was pretty easy to fix. I can only
imagine how hard it would have been to debug this without rr!
|
|
This Week In Rust: This Week in Rust 103 |
Hello and welcome to another issue of This Week in Rust! Rust is a systems language pursuing the trifecta: safety, concurrency, and speed. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us an email! Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
This week's edition was edited by: nasa42, brson, and llogiq.

 Announcing Rust 1.4.
Announcing Rust 1.4. rustc build process.94 pull requests were merged in the last week.
See the subteam report for 2015-10-31 for details.
RawVec::reserve.Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
libc crate from the nursery.OsString and OsStr.Every week the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now. This week's FCPs are:
#[deprecated] for Everyone.If you are running a Rust event please add it to the calendar to get it mentioned here. Email Erick Tryzelaar or Brian Anderson for access.
No jobs listed for this week. Tweet us at @ThisWeekInRust to get your job offers listed here!
This week's Crate of the Week is alias by Huon W. Thanks go to Reddit user notriddle for the suggestion. Submit your suggestions for next week!
alias allows mutably aliasing values – which seems to actually be safe, somewhat surprisingly. Honestly, I'm a bit shocked about it myself.
Submit your quotes for next week!
http://this-week-in-rust.org/blog/2015/11/02/this-week-in-rust-103/
|
|
Planet Mozilla Interns: Nguyen Ngoc Trung: radne pantalone prodaja |
|
|
Julien Pag`es: mozregression 1.1.0 release |
New release of mozregression, with some goodies!
See http://mozilla.github.io/mozregression/news.html#1.1.0-release for more details and the full changelog.

https://parkouss.wordpress.com/2015/10/31/mozregression-1-1-0-release/
|
|
Cameron Kaiser: TenFourFox 38.4.0 available |
As always, barring major issues, the browser will be released officially late Monday Pacific time, along with unveiling the new El Spoofistan design for the main page.
In other ecosystem news, I am incredibly delighted to see Tenfourbird 38.3 from our anonymous builder in the land of the Rising Sun, and it works great -- I use it for (appropriately enough) reading news.mozilla.org. Try it. You'll like it.
http://tenfourfox.blogspot.com/2015/10/tenfourfox-3840-available.html
|
|
Hannah Kane: A much needed update |
It’s been a minute. Here’s some of what we’ve been working on (with anagrams, since I haven’t done those in awhile!)
Thimble Dashboard {Anagram: Oh, medal birdbaths!}
Luke has been working on an awesome dashboard that will allow us to see what people are up to, discover trends, get inspiration for new curriculum modules, and do some of the necessary work for eventually displaying metrics to users (e.g. # of Remixes of my project).




 Curriculum Template {Anagram: Met crucial plum. True!}
Curriculum Template {Anagram: Met crucial plum. True!}
Luke also worked on comps for a new curriculum template—we focused on making the content more digestible by adding a sidebar nav to chunk the content better.

MozFest Schedule App {Anagram: A zestful pop schemed}
Mavis has been working with Ryan from Open News to adapt the SRCCON schedule app for MozFest purposes. It’s looking great, and offers several different views for browsing MozFest sessions. Users can also “favorite” sessions to create their own personal agenda.

Goggles FTU Experience {Anagram: Super Fox: Telegenic Egg}
Pomax and Kristina have been working together to create a much-improved first time use experience for Goggles users. Check out this fun animal mash-up activity! This is a great way to introduce new users to the magic of Goggles.

Web Literacy Map Feedback {Anagram: Play back if a wet December}
Sabrina has been working with An-Me to design an interactive session at MozFest to solicit input on the skills, design, and applications of the Web Literacy Map. Imagine this wall full of input from our community:

It’s been amazing watching this team work over the past month. They are on fire.

|
|
Chris Cooper: RelEng & RelOps Weekly Highlights - October 30, 2015 |
Much of Q4 is spent planning and budgeting for the next year, so there’s been lots of discussion about which efforts will need support next year and which things we can accommodate with existing resources and which will need additional resources.
And if planning and budgeting doesn’t scare some Hallowe'en spirit into you, I don’t know what will.
Modernize infrastructure: Q got most of the automated installation of w10 working and is now focusing on making sure that jobs run.
Improve CI pipeline: Andrew (with help from Dustin) will be running a bunch of test suites in TaskCluster (based on TaskCluster-built binaries) at Tier 2.
Release: Callek built v1.5 of the OpenH264 Plugin, and pushed it out to the testing audience. Expecting to go live to our users in the next few weeks.
Callek managed to get “final verify” (an update test with all live urls) working on taskcluster in support of the “release promotion” project.
Firefox 42, our big moment-in-time release for the second half of 2015, gets released to the general public next week. Fingers are crossed.
Operational: Kim and Amy decommissioned about 50% of the remaining panda infrastructure (physical mobile testing boards) after shifting the load to AWS.
We repurposed 30 of our Linux64 talos machines for Windows 7 testing in preparation for turning on some e10s tests.
Kim turned off WinXP tests off by default on try to try to reduce some of our windows backlog (https://bugzil.la/1219434).
Kim implemented some changes to SETA which would allow us to configure the SETA parameters on a per platform basis (https://bugzil.la/1175568).
Rail performed the mozilla-central train uplifts a week early when the Release Management plans shifted, turning Nightly into Gecko 45. FirefoxOS v2.5 branch based on Gecko 44 has been created as a part of the uplift.
Callek investigated a few hours of nothing being scheduled on try on Tuesday, to learn there was an issue with a unicode character in the commit message which broke JSON importing of pushlog. And then did work to reschedule all those jobs (https://bugzil.la/1218943).
Industry News: In addition to the work we do at Mozilla, a number of our people are leaders in industry and help organize, teach, and speak. These are some of the upcoming events people are involved with:
SUntil next week, remember: don’t take candy from strangers!
|
|
Christie Koehler: Life After Mozilla, or My Next Adventure |
An audio version of this post is also available. You can subscribe to audio updates with this url.
 Portland in Fall. It’s my favorite season here.
Portland in Fall. It’s my favorite season here.It’s been 2 months since my last day at Mozilla. Hard to believe that much time has past and yet it feels like it’s gone by so quickly. Rainy, gloomy weather has arrived here in Portland, for which I’m very grateful after such a long, hot summer. My plan for my first weeks away from Mozilla, most of September, was to spend as little time on the computer as possible and to intentionally not think about my next career steps. I give myself a B at following this plan. At first I did great. I did a lot of work around our house, mostly in the form of tidying and organizing. I made a bookshelf from scratch and am very happy with how it turned out. I played a lot of Civilization. I read. I slept in. I played with the dogs and took photos.
 Bertie is always around to remind me of the value of play.
Bertie is always around to remind me of the value of play.And then I started reading & responding to my email.
More that a few of you were interested in how I was doing, what I was planning to do next and maybe I might be interested in this or that. It’s been amazing to hear from you, to know you value my skills and experience and want to be a part of helping me find what’s next. Not only amazing, but unexpected. Often I struggle with recognizing my own value and how I contribute to others and so explicit feedback is really helpful. Thank you everyone who’s reached out. (And know I’m still working on replying to you all.)
As good as it was to hear from everyone, it also meant that I started thinking about “what next” much sooner and in greater detail than I was ready for. I started having some conversations about projects that were exciting, but also left me agitated and unsettled.
Earlier this month I had a follow-up with my doctor that left me feeling down and depleted. It wasn’t a bad visit and was actually rather uneventful except that I left with an even longer list of asthma-related tasks to do. Pull up the carpet in our daylight basement (where my office is), have the air ducts cleaned, make the bedroom as sparse as possible, do this breathing training program, etc. And my blood pressure is a tad on the high side (in the right arm, but not the left?).
As my lack of accomplishment and I left the doctor’s I decided to stop by Powell’s as a way to cheer myself up. (I almost always want to browse books and it nearly always cheers me up.) I did a quick scan of the ‘careers’ section — which is a bit of gamble because there is so much there that’s either irrelevant (“You’ve just graduated, now what?”) or cheesy (literally, “Who Moved my Cheese?”) or just not applicable (there’s no “The Tech Industry Burned Me Out but Then I Found This Awesome, Life-Fullfilling Vocation and Here’s How You Can Too!”).
I did notice a copy of The Joy of Not Working. Huh, I thought, that sounds nice and bought it after scanning through the first couple of pages. I continued reading at home and finished that day.
Reading this and getting ideas. #uncareerplanning pic.twitter.com/kqKciWsj1o
— Christie Koehler (@christi3k) October 14, 2015
What I got from the book was less factual information and more inspiration and permission to pursue the kind of work that would allow me the time to do lots of other things that I’m interested in and care about. The book’s primary audience are retirees and others who suddenly have time on their hands due to lack of employment (voluntary or otherwise). Zelinsky emphasizes the importance of cultivating many interests and community connections, not just ones associated with work. He explores just how much there is to experience in life and how much of that experience we sacrifice when we prioritize the 40+ hour workweek and how unnecessary it is to do so. Reading The Joy of Not Working made me realize a couple of things:
Sounds nice, how to put this into practice? First, I identified the work projects that I would stay committed to: Stumptown Syndicate, Recompiler podcast, and whatever “working for myself” turns out to be. I’m either in the process of wrapping up or have already wrapped up my commitments to other projects. I’m not going to continue as a volunteer in any capacity for Mozilla (many feels about that, all for another blog post). Second, I’ve been making the space and doing the work to figure out what shape “working for myself” will take. I’ve thought a lot about what I’m good at and what I love doing and here’s what I’ve figured out:
At some point I realized, “this is what consultants do!” And so I’ve been reading every book about consulting I can get my hands on. And things are clicking. I find myself saying, “I can do this. I should do this. I will do this.”
I have a name picked out. I have a marketing plan and continue to improve it as I learn more and more about marketing. I have a launch plan. I’m figuring out how to make the finances work while I drum up business. It might involve some crowdfunding. I’ll be reaching out to a lot of you for support, in whatever capacity you can provide it (hugs, referrals, a loan/gift/investment of equipment or cash, etc.). If you know someone doing this kind of work and think they would be willing to chat with me about their experience, please introduce us.
If we’ve worked together, or you know of my work so far, I hope you’re excited. I am certainly am. I’m excited about bringing the same kind of energy, vision and integrity to this new practice as I have to other projects. I’m excited at the opportunity to partner with all kinds of organizations do their work better, more prosperously.
If you want to know for sure when I launch, subscribe to my TinyLetter.
Meanwhile, I’ll be sure to keep making time for rest and for taking awesome photos of Bertie, Dora and the rest of the critter cadre.

http://subfictional.com/2015/10/30/life-after-mozilla-or-my-next-adventure/
|
|
Mitchell Baker: Mozilla Open Source Support Program: Applications are Open |
http://blog.lizardwrangler.com/2015/10/30/mozilla-open-source-support-program-applications-are-open/
|
|






