Margaret Leibovic: WIP: Home Page Customization in Firefox for Android |
In Firefox 26, we released a completely revamped version of the Firefox for Android Home screen, creating a centralized place to find all of your stuff. While this is certainly awesome, we’ve been working to make this new home screen customizable and extensible. Our goal is to give users control of what they see on their home screen, including interesting new content provided by add-ons. For the past two months, we’ve been making steady progress laying the ground work for this feature, but last week the team got together in San Francisco to bring all the pieces together for the first time.
Firefox for Android has a native Java UI that’s partially driven by JavaScript logic behind the scenes. To allow JavaScript add-ons to make their own home page panels, we came up with two sets of APIs for storing and displaying data:
During the first half of our hack week, we agreed on a working first version of these APIs, and we hooked up our native Java UI to HomeProvider data stored from JS. After that, we started to dig into the bugs necessary to flesh out a first version of this feature.

Many of these patches are still waiting to land, so unfortunately there’s nothing to show in Nightly yet. But stay tuned, exciting things are coming soon!
|
|
Swarnava Sengupta: New Firefox Sync has landed in Firefox Nightly |



http://blog.swarnava.in/2014/02/new-firefox-sync-has-landed-in-firefox.html
|
|
Anthony Hughes: Firefox 26, A Restrospective in Quality (Part II) |
A few days ago a wrote a post detailing a qualitative analysis of Firefox 26 using statistics from Bugzilla. In it I talked about regressions and the volume speaking to a “potential failure, something that was missed, not accounted for, or unable to be tested either by the engineer or by QA”. I’d like to modify that a little by incorporating post-release regressions.
Certainly one would expect the volume of regressions in pre-release to increase as QA, Engineers, or volunteers find and report more regressions. I realize now that simply measuring the volume of regressions might not be a clear indication of quality or a breakdown in process. Perhaps I painted this a bit too broadly.
I’ve just retooled this metric to take a look at pre-release versus post-release regression volume. I think looking at regressions in this way is a bit more telling. After all, a pre-release regression is something we technically knew about before release whereas a post-release regression is something that became known after we released. A high volume of post-release regressions would therefore imply a lower quality release and an opportunity for us to improve.
Just as a reminder, here is the chart comparing all regressions from a few days ago:

Here is the new chart incorporating regressions found post-release:

As you can see the volume of post-release regressions is fairly significant. Perhaps unsurprisingly chemspills seem to correlate to periods of more post-release regressions. Speaking of Firefox 26 specifically, it continues a downward trend marking the fourth release with fewer post-release regressions and fewer regressions overall.
Anyway, that’s all I wanted to call out for this release. I will be back in six weeks to talk about how things shaped up for Firefox 27. I’m hoping we can continue to see improvements through iterating on our process and working closer with other teams.
|
|
Eric Shepherd: First five “paper cuts” of 2014 |
A recent initiative for the development of the Kuma software powering the Mozilla Developer Network (MDN) site is that we are going to be maintaining a list of the top five “paper cut” bugs that we’d like the dev team to find time to fix. These won’t have a schedule attached to them, and will only be worked on when other, priority items are fixed, but will each have a huge impact on the site’s usability, functionality, or simple friendliness.
During the MDN writing staff meeting (about which I’ll be blogging over the next few days), we pored over the long list of pending MDN bugs and selected the five we’d like to see the development team try to tackle as time allows.
I think you’ll agree that each time one of these is fixed, there will be celebratory riots in the streets!
http://www.bitstampede.com/2014/02/03/first-five-paper-cuts-of-2014/
|
|
David Burns: Updated BrowserMob Proxy Python Documentation |
After much neglect I have finally put some effort into writing some documentation for the BrowserMob Proxy Python bindings however I am sure that they can be a lot better!
To do this I am going to need your help! If there are specific pieces of information, or examples, that you would like in the documentation please either raise an issue or even better create a pull request with the information, or example, that you would like to see in the documentation.
http://www.theautomatedtester.co.uk/blog/2014/updated-browsermob-proxy-python-documentation.html
|
|
Tristan Nitot: I'm a Mozillian |
Today, in San Francisco, a Mozilla Monument is officially unveiled. I took pictures of it when I was in California a few weeks ago:

My contribution to Mozilla started 16 years ago, in January 1998, a few weeks before the Mozilla project was launched, and event that has changed my life in many ways. A colleague of mine (I'm looking at you, Barry!) asked me a couple of questions on email, and I'd like to share the answers publicly:
I was a Netscape employee in Paris back in January 1998, and my job title was "Product PR manager". Trained as an engineer, my role was to explain to the media what this Internet thing was about. Best. Job. Ever. Then Netscape announced that due to competitive pressure, it was making its Web browser (Netscape Communicator 4.x at the time) free. This was easy to understand for most. But there was something else to be announced: its source code was going to be released in the open, for people to contribute to it, the Open Source way. Most people stopped understanding that sentence right when reading "source code". No kidding. Nobody had an idea what it meant. And for those who knew, "Open Source" did not ring a bell. It happened that I had some background in Open Source or, more precisely, Free Software. I had met with Richard Stallman in the past and was a long-time user of Emacs ten years earlier.
For many people around me at Netscape, often salespeople or marketing people, this Open Source/Free Software thing was nonsense: it was too technical to be understood and the bottom line was that... it did not contribute to the bottom line.
For me, it was the possibility to invent a revolutionary new future, to build a piece of the Internet, to create a new way to work, to help make the world a better place. It immediately fell in love. This love is still growing strong today.
So many Mozillians inspire me. In November 2011 at Mozcamp Berlin, I gave a talk that started like this: "You are my heroes". I meant it back then and I still mean it today. So instead of giving one name, let me list a handful of people, even if the three of them will probably hate me for naming them:
My life would not be what is is today without Mozilla. I just can't imagine my life without Mozilla!

|
|
Melissa Romaine: Earning Bett(er) Badges |
http://londonlearnin.blogspot.com/2014/02/earning-better-badges.html
|
|
Jesse Ruderman: Fuzzers love assertions |
Fuzzers make things go wrong.
Assertions make sure we find out.
Assertions can improve code quality in many ways, but they truly shine when combined with fuzzing. Fuzzing is normally limited to finding obvious symptoms like crashes, because it's rare to be able to tell correct behavior from incorrect behavior when the input is generated randomly. Assertions expand the scope of fuzzing to include everything they check.
Assertions can even help find crash bugs: some bugs are relatively easy for fuzzers to trigger, but only lead to crashes when additional conditions are met. A well-placed assertion can let us know every time we trigger the bug.
Fuzzing JS and DOM has found about 4000 assertion bugs, including about 300 security bugs.
Assertions in widely-used data structures can find bugs in many callers.
get method takes a key and a closure for computing values in the case of a cache miss, debug builds can check whether the cached values are still correct. This is effectively a form of differential testing that notices bugs in cache-invalidation logic.When an entire module must maintain an invariant, a single assertion can catch dozens of bugs.
Gecko's CSS box objects, called "frames", are created and destroyed manually. They are allocated within an arena to reduce malloc overhead and fragmentation. The arena also made it possible to reduce the risk associated with manual memory management. A combination of assertions (in debug builds) and runtime mitigations (in all builds) mitigates dangling pointer bugs that involve frames.
Please add assertions, especially when:
Also consider:
http://www.squarefree.com/2014/02/03/fuzzers-love-assertions/
|
|
Lloyd Hilaiel: Leaving Mozilla |
My first day at Mozilla was August 16th 2010, my last will be February 14th 2014.
My first day as a Mozillian was either in November 2004, or it might have been around January 2008. I will not have a last day as a Mozillian.
|
|
Soledad Penades: What have I been working on? (2014/01) |
January is over, what have I done with it?
Well, to start with I’ve been working with the fantastic people from Firefox DevTools. We’re preparing a new feature for the App Manager and I’m really thrilled to be a part of this. I’m not going to disclose what it is yet until I have something to show (it’s my way to make you all download a Nightly build, tee hee), but I believe it’s going to be GREAT.
Then I’ve also been lending my brain to other projects. First, localForage, our library for storing data using the same interface from localStorage, but asynchronously and with better performance (by using IndexedDB or WebSQL if available). Or just falling back to localStorage otherwise (sad face, sad face).
The other project I’m involved with is chatspaces, “a snazzy chat app”. I’ve done some (yet unfinished) work with implementing push notifications using Simple Push, and I’m also working on outputting better GIFs (i.e. smaller but with same perceived quality). If you’re up for a slightly bumpy ride, you can try out chatspaces today.
“Generating better GIFs” means that I’m spending quite a bit of time in Animated_GIF, a library for creating animated GIFs in the browser. I implemented a couple of features like dithering and custom palettes past week and I’m pretty happy with the results you can get. I still have some more work to do before it’s a totally awesome library from README to code to examples, but it’s already used in somewhat popular places like chat.meatspac.es which you might have heard about ;-)
And I’ve also written an article for Mozilla Hacks. If you liked my previous article on unprefixed Web Audio code, I think you might like this one too. It should be published some time soon (fingers crossed).
There are more things that I’ve been doing this month like attending LNUG’s meetup, helping people with their Firefox OS apps, improving documentation for X-Tag, and finding+filing a bunch of bugs… all of which make me terribly happy as I feel like I’m making an impact. Yay! :-)
![]()
http://soledadpenades.com/2014/02/02/what-have-i-been-working-on-201401/
|
|
Christian Heilmann: Why “just use Adblock” should never be a professional answer |

Ahh, ads. The turd in the punchbowl of the internet party. Slow, annoying things full of dark interaction patterns and security issues. Good thing they are only for the gullible and not really our issue as we are clever; we use browsers that blocked popups for years and we use an ad blocker!

Hang on a second. Whether we like it or not, ads are what makes the current internet work. They are what ensures the “free” we crave and benefit from, and if you dig deep enough you will find that nobody working in web development or design is not in one way or another paid by income stemming from ad sales on the web. Thus, us pretending that ads are for other people is sheer arrogance. I’ve had discussions about this a few times and so far the pinnacle to me still was an answer I got on Twitter to posting an article that 40 percent of mobile ad clicks are fraud or accidents:
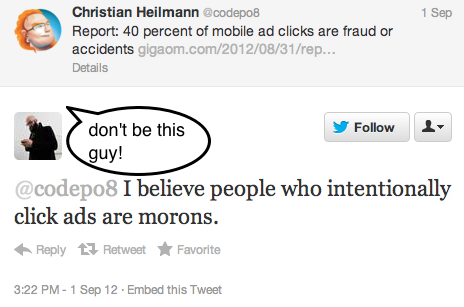
I believe people who intentionally click ads are morons
Don’t get me wrong: ads as a whole are terrible. In many cases they have the grace of a drunk guy kicking you in the shin before asking you to buy him a beer. They are very much to blame for our users being conditioned to things behaving in weird ways on the web, thus opening the door for the bad guys to phish and clickjack them. Ads may also be the thing that drives many of our users to preferring apps instead. Which is kind of ironic as an app in many cases is a mixture of a bit of highly catered functionality wrapped in an interactive ad.
So what does that make us? Not the intelligent people who know how to game the system, but people not owning the platform we work for and are reliant on. As people in the know, it should be our job to ensure ads we publish or include in our project are not counterproductive to the optimisation efforts we put into our work. We also should have a stake in the kind of ads that are being displayed, making sure they don’t soil the messages we try to convey with our content.
This is uncomfortable, it is extra work and it feels like we are depriving ourselves of an expert shortcut. The problem with blocking ads ourselves is though that we are not experiencing what our end users experience. We get the first class treatment of the web with comfortable computers and less interruptions whilst our users are stuck in a low cost carrier where they get asked every few seconds if they don’t want to buy something and pay extra if they forgot to bring the printout of their ticket.
By blocking all the ads and advocating for “clever web users” to do the same we perpetuate a model of only the most aggressive and horrible ads to get through. We treat each ad the same, the “find sexy singles in your IP range” and the actual useful ones: we just block them all. Yes, I’ve had some deals by clicking an ad. Yes, I found things I really use and am happy to have now by clicking an ad. I could have never done that with an ad blocker. What it does though is cut into the views of ads and thus force ad companies to play dirty to get the figures they are used to and use to negotiate payments to the people who display their ads. In essence, we are creating the terrible ads we hate as we don’t allow the good ones to even show up. It’s like stopping people swearing by not allowing anyone to speak. Or trying to block adult content by filtering for the word “sex”.
You could say that people who expect everything to be free don’t deserve better. This would hold water if the paid experiences of the web without ads were better or even available. In many cases, they are not. You can not pay for Facebook to get rid of ads. Many providers are so comfortable in the horrible model of “plaster everything with ads and create as much traffic as possible” that trying a subscription model instead bears too much danger and extra effort in comparison.
A sign of this is the horrible viral bullshit world we live in right now. Creators of original content are not the ones who make the most money with it; instead it is the ones who put it in “this kid did one weird trick, the result will amaze you” headlined posts with lots of ads and social media sharing buttons. This is killing the web. We allowed the most important invention for publishing since the printing press brought literacy to the masses to become a glossy lifestyle magazine that spies on its readers.
It should be up to us to show better ways, to create more engaging interfaces, to play with the technology and break conventions. It is sad to see that all we have to show for about 16 years of web innovation is that we keep some parts of our designs blank where other people can paste in ads using code we don’t even know or trust or care to understand. This isn’t innovative; this is lazy.
There’s more to come here and some great stuff brewing in Mozilla Labs. It is time to be grown-up about this: ads happen, let’s make them worth-while for everyone involved.
http://christianheilmann.com/2014/02/02/why-just-use-adblock-should-never-be-a-professional-answer/
|
|
Nick Cameron: Changing roles |
http://featherweightmusings.blogspot.com/2014/02/changing-roles.html
|
|
Selena Deckelmann: PyLadies Meeting notes from “Negotiating the job market: a panel discussion” |
Flora Worley organized a fantastic PyLadies PDX meeting called “Negotiating the job market: a panel discussion“.
The meeting was organized in three parts:
We kicked things off by asking people to get into groups of four and talk to each other about why they came and what they were hoping to get out of the meeting.
Some of the comments from the meeting and feedback after included:
Below are my notes from the first panel, anonymized and edited a bit.
How did you find your first job in the industry and know it was the right place for you?
At what point do you say you “know” a programming language?
What was your interview like?
Were there classes or resources that prepared you for interviewing?
What if your coding style is really different than other people’s? How do you handle that?
What kinds of positions can you get? And where do you want to go?
Do you find that as a woman you communicate differently and you are interpreted differently?
|
|
Priyanka Nag: Campus Konnect II |

http://priyankaivy.blogspot.com/2014/02/campus-konnect-ii.html
|
|
Shane Tomlinson: v0.49 Release of the Persona WordPress Plugin |
Today I released v0.49 of the Persona WordPress plugin. This release fixes an issue with Strict Standards warnings on the admin page.
Thank you Jason D. Moss for the fix!
https://shanetomlinson.com/2014/persona-browserid-wordpress-plugin-49/
|
|
Joshua Cranmer: Why email is hard, part 5: mail headers |
Back in my first post, Ludovic kindly posted, in a comment, a link to a talk of someone else's email rant. And the best place to start this post is with a quote from that talk: "If you want to see an email programmer's face turn red, ask him about CFWS." CFWS is an acronym that stands for "comments and folded whitespace," and I can attest that the mere mention of CFWS is enough for me to start ranting. Comments in email headers are spans of text wrapped in parentheses, and the folding of whitespace refers to the ability to continue headers on multiple lines by inserting a newline before (but not in lieu of) a space.
I'll start by pointing out that there is little advantage to adding in free-form data to headers which are not going to be manually read in the vast majority of cases. In practice, I have seen comments used for only three headers on a reliable basis. One of these is the Date header, where a human-readable name of the timezone is sometimes included. The other two are the Received and Authentication-Results headers, where some debugging aids are thrown in. There would be no great loss in omitting any of this information; if information is really important, appending an X- header with that information is still a viable option (that's where most spam filtration notes get added, for example).
For this feature of questionable utility in the first place, the impact it has on parsing message headers is enormous. RFC 822 is specified in a manner that is familiar to anyone who reads language specifications: there is a low-level lexical scanning phase which feeds tokens into a secondary parsing phase. Like programming languages, comments and white space are semantically meaningless [1]. Unlike programming languages, however, comments can be nested—and therefore lexing an email header is not regular [2]. The problems of folding (a necessary evil thanks to the line length limit I keep complaining about) pale in comparison to comments, but it's extra complexity that makes machine-readability more difficult.
Fortunately, RFC 2822 made a drastic change to the specification that greatly limited where CFWS could be inserted into headers. For example, in the Date header, comments are allowed only following the timezone offset (and whitespace in a few specific places); in addressing headers, CFWS is not allowed within the email address itself [3]. One unanticipated downside is that it makes reading the other RFCs that specify mail headers more difficult: any version that predates RFC 2822 uses the syntax assumptions of RFC 822 (in particular, CFWS may occur between any listed tokens), whereas RFC 2822 and its descendants all explicitly enumerate where CFWS may occur.
Beyond the issues with CFWS, though, syntax is still problematic. The separation of distinct lexing and parsing phases means that you almost see what may be a hint of uniformity which turns out to be an ephemeral illusion. For example, the header parameters define in RFC 2045 for Content-Type and Content-Disposition set a tradition of ;-separated param=value attributes, which has been picked up by, say, the DKIM-Signature or Authentication-Results headers. Except a close look indicates that Authenticatin-Results allows two param=value pairs between semicolons. Another side effect was pointed out in my second post: you can't turn a generic 8-bit header into a 7-bit compatible header, since you can't tell without knowing the syntax of the header which parts can be specified as 2047 encoded-words and which ones can't.
There's more to headers than their syntax, though. Email headers are structured as a somewhat-unordered list of headers; this genericity gives rise to a very large number of headers, and that's just the list of official headers. There are unofficial headers whose use is generally agreed upon, such as X-Face, X-No-Archive, or X-Priority; other unofficial headers are used for internal tracking such as Mailman's X-BeenThere or Mozilla's X-Mozilla-Status headers. Choosing how to semantically interpret these headers (or even which headers to interpret!) can therefore be extremely daunting.
Some of the headers are specified in ways that would seem surprising to most users. For example, the venerable From header can represent anywhere between 0 mailboxes [4] to an arbitrarily large number—but most clients assume that only one exists. It's also worth noting that the Sender header is (if present) a better indication of message origin as far as tracing is concerned [5], but its relative rarity likely results in filtering applications not taking it into account. The suite of Resent-* headers also experiences similar issues.
Another impact of email headers is the degree to which they can be trusted. RFC 5322 gives some nice-sounding platitudes to how headers are supposed to be defined, but many of those interpretations turn out to be difficult to verify in practice. For example, Message-IDs are supposed to be globally unique, but they turn out to be extremely lousy UUIDs for emails on a local system, even if you allow for minor differences like adding trace headers [6].
More serious are the spam, phishing, etc. messages that lie as much as possible so as to be seen by end-users. Assuming that a message is hostile, the only header that can be actually guaranteed to be correct is the first Received header, which is added by the final user's mailserver [7]. Every other header, including the Date and From headers most notably, can be a complete and total lie. There's no real way to authenticate the headers or hide them from snoopers—this has critical consequences for both spam detection and email security.
There's more I could say on this topic (especially CFWS), but I don't think it's worth dwelling on. This is more of a preparatory post for the next entry in the series than a full compilation of complaints. Speaking of my next post, I don't think I'll be able to keep up my entirely-unintentional rate of posting one entry this series a month. I've exhausted the topics in email that I am intimately familiar with and thus have to move on to the ones I'm only familiar with.
[1] Some people attempt to be to zealous in following RFCs and ignore the distinction between syntax and semantics, as I complained about in part 4 when discussing the syntax of email addresses.
[2] I mean this in the theoretical sense of the definition. The proof that balanced parentheses is not a regular language is a standard exercise in use of the pumping lemma.
[3] Unless domain literals are involved. But domain literals are their own special category.
[4] Strictly speaking, the 0 value is intended to be used only when the email has been downgraded and the email address cannot be downgraded. Whether or not these will actually occur in practice is an unresolved question.
[5] Semantically speaking, Sender is the person who typed the message up and actually sent it out. From is the person who dictated the message. If the two headers would be the same, then Sender is omitted.
[6] Take a message that's cross-posted to two mailing lists. Each mailing list will generate copies of the message which end up being submitted back into the mail system and will typically avoid touching the Message-ID.
[7] Well, this assumes you trust your email provider. However, your email provider can do far worse to your messages than lie about the Received header…
http://quetzalcoatal.blogspot.com/2014/01/why-email-is-hard-part-5-mail-headers.html
|
|
Asa Dotzler: Firefox OS Happenings: week ending 2014-01-31 |
In the last week, at least 96 Mozillians fixed about 200 bugs and features tracked in Product:Firefox OS and OS:Gonk.
These are a few of those that caught my eye:
[Rocketbar][meta] Get rocketbar patches landed in master This is a significant part of the Haida Firefox OS UX update that’s happening right now. Rocket Bar is the system-wide search and addressing feature that lots of other Haida UX is built around. Very exciting stuff.
B2G Wifi: Support Wifi Direct gives us the DOM API and related implementation for Wi-FI Direct in Firefox OS. Wi-Fi Direct, earlier called Wi-Fi P2P, is used to easily connect devices with each other without requiring a wireless access point.
We got a couple more good tablet fixes:
[Flatfish] make Context menu not fill fullscreen
[Flatfish] Add pathmap to support Bluez on android 4.2.2
A few nice usability wins:
[B2G][Settings] Developer settings are too hard to access
[Search] Add ‘Install’ text before Marketplace Title
Provide a way to fetch the message threads in reverse order
[Browser] It’s not possible to move the cursor to the last character in the URL bar
And here’s a sampling of the performance and memory improvements.
Rewrite net worker in C++
[1.3] Launch latency of SMS app needs to be improved
Reading objects from datastore has serious performance and memory consumption problems
[b2g] convert all vorbis files to opus to improve memory usage
Bluetooth leaks every blob
We’re also getting closer to the launch of the Firefox OS Tablet Contribution Program. Stay tuned to this site and hacks.mozilla.org for updates and the application form. Once again, it’d be useful for you to have your Mozillians profile already filled out and a Bugzilla account established.
http://asadotzler.com/2014/01/31/firefox-os-happenings-week-ending-2014-01-31/
|
|
Anthony Hughes: Firefox 26, A Retrospective in Quality |
[Edit: @ttaubert informed me the charts weren't loading so I've uploaded new images instead of linking directly to my document]
The release of Firefox 27 is imminently upon us, next week will mark the end of life for Firefox 26. As such I thought it’d be a good time to look back on Firefox 26 from a Quality Assurance (QA) perspective. It’s kind of hard to measure the impact QA has on a per release basis and whether our strategies are working. Currently, the best data source we have to go on is statistics from Bugzilla. It may not be a foolproof but I don’t think that necessarily devalues the assumptions I’m about to make; particularly when put in the context of data going back to Firefox 5.
Before I begin, let me state that this data is not indicative of any one team’s successes or failures. In large part this data is limited to the scope of bugs flagged with various values of the status-firefox26 flag. This means that there are a large amount of bugs that are not being counted (not every bug has the flag accurately set or set at all) and the flag itself is not necessarily indicative of any one product. For example, this flag could be applied to Desktop, Android, Metro, or some combination with no way easy way to statistically separate the two. Of course one could with some more detailed Bugzilla querying and reporting, but I’ve personally not yet reached a point where I’m able or willing to dig that deep.
Unconfirmed bugs are an indication of our ability to deal with the steady flow of incoming bug reports. For the most part these bugs are reported from our users (trusted Bugzilla accounts are automatically bumped up to NEW). The goal is to be able to get down to 0 UNCONFIRMED bugs before we release a product.

What this data tells us is that we’ve held pretty steady over the months, in spite of the ever increasing volume, but things have slipped somewhat in Firefox 26. In raw terms, Firefox 26 was released with 412 of the 785 reported bugs being confirmed. The net result is a 52% confirmation rate of new bug reports.
However, if we look at these numbers in the historical context it tells us that we’ve slipped by 10% confirmation rate in Firefox 26 while the volume of incoming bugs has increased by 64%. A part of me sees this as acceptable but a large part of me sees a huge opportunity for improvement.
The lesson here is that we need to put more focus on ensuring day to day attention is paid to incoming bugs, particularly since many of them could end up being serious regressions.
Regressions are those bugs which are a direct result of some other bug being resolved. Usually this is caused by an unforeseen consequence of a particular code change. Regressions are not always immediately known and can exist in hiding until a third-party (hardware, software, plug-in, website, etc) makes a change that exposes a Firefox regression. These bugs tend to be harder to investigate as we need to track down the fix which ultimately caused the regression. If we’re lucky the offending change was a recent one as we’ll have builds at our disposal. However, in rare cases there are regressions that go far enough back that we don’t have the builds needed to test. This makes it a much more involved process as we have to begin bisecting changesets and rebuilding Firefox.
The number of regressions speaks to a potential failure, something that was missed, not accounted for, or unable to be tested either by the engineer or by QA. In a perfect world a patch would be tested taking into account all potential edge cases. This is just not feasible in reality due to the time and resources it would take to cover all known edge cases; and that’s to say nothing of the unknown edge cases. But that’s how open source works: we release software we think is ready, users report issues, and we fix them as fast and as through as we reasonably can.
In the case of Firefox 26 we’ve seen a continued trend of a reduction in known regressions. I think this is due to QA taking a more focused approach to feature testing and bug verifications. Starting with Firefox 24 we brought on a third QA release driver (the person responsible for coordinating testing of and ultimately signing-off on a release) and shifted toward a more surgical approach to bug testing. In other words we are trying to spend more time doing deeper and exploratory testing of bug fixes which are more risky. We are also continuing to hone our processes and work closer with developers and release managers. I think these efforts are paying off.
The numbers certainly seem to support this theory. Firefox 26 saw a reduction of regressions by 20% over Firefox 25, 25% over Firefox 24, and 57% better than Firefox 17 (our worst release for regressions).
Stability bugs are a reflection of how frequently our users are encountering crashes. In bugzilla these are indicated using the crash keyword. The most serious crashes are given the topcrash designation. The more crash bugs we ship in a particular release does not necessarily translate for more crashes per user, but it is indicative of more scenarios under which a user may crash. Many of these bugs are considered a subset of the regression bugs discussed earlier as these mostly come about by changes we have made or that a third-party has exposed.
In Firefox 26 we again see a downward trend in the number of crash bugs known to affect the release. I believe this speaks to the success of educating more people in the skills necessary to participate in reviewing the data in crash-stats dashboard, converting that into bugs, and getting the necessary testing done so developers can fix the issues. Before Firefox 24 was on the train the desktop QA really only had one or two people doing day to day triage of the dashboards and crash bugs. Now we have four people looking at the data and escalating bug reports on a daily basis.

The numbers above indicate that Firefox 26 saw 12% less crash bugs that Firefox 25, 41% less than Firefox 24, and 59% less than Firefox 15, our most unstable release.
Reopened bugs are those bugs which developers have landed a fix for but the issue was proven not to have been resolved in testing. These bugs are a little bit different than regressions in that the core functionality the patch was meant to address still remains at issue (resulting in the bug being reopened), whereas a regression is typically indicative of an unforeseen edge case or user experience (resulting in a new bug being filed to block the parent bug).
That said, a high volume of reopened bugs is not necessarily an indication of poor QA; in fact it could mean the exact opposite. You might expect there to be a higher volume of reopened bugs if QA was doing their due diligence and found many bugs needing follow up work. However, this could also be an indication of feature work (and by consequence a release) that is of higher risk to regression.

As you can see with Firefox 26 we’re still pretty high in terms of the number of reopened bugs. We’re only 5% better than Firefox 23, our worst release in terms of reopened bugs. I believe this to be a side-effect of us doing more focused feature testing as indicated earlier. However it could also be indicative of problems somewhere else in the chain. I think it warrants looking at more closely and is something I will be raising in future discussions with my peers.
Landings are those changes which land on mozilla-central (our development branch) and ride the trains up to release following the 6-week cadence. Uplifts are those fixes which are deemed either important enough or low enough risk that it warrants releasing the fix earlier. In these cases the fix is landed on the mozilla-aurora and/or mozilla-beta branches. In discussions I had last year with my peers I raised concerns about the volume of uplifts happening and the lack of transparency in the selection criteria. Since then QA has been working closer with Release Management to address these concerns.

I don’t yet have a complete picture to compare Firefox 26 to a broad set of historical data (I’ve only plotted data back to Firefox 24 so far). However, I think the data I’ve collected so far shows that Firefox 26 seemed far more “controlled” than previous releases. For one, the volume of uplifts to Beta was 29% less than Firefox 25 and there were 42% less uplifts across the entire Firefox 26 cycle compared to Firefox 25. It was also good to see that uplifts trailed off significantly as we moved through the Aurora cycle into Beta.
However, this does show a recent history of crash-landings (landing a crash late in a cycle) around the Nightly -> Aurora merge. The problem there is that something that lands on the last day of a Nightly cycle does not get the benefit of Nightly user feedback, nor does it get much, if any, time for QA to verify the fix before it is uplifted. This is something else I believe needs to be mitigated in the future if we are to move to higher quality releases.
The final metric I’d like to share with you today is purely to showcase the volume of bugs. In particular how much the volume of bugs we deal with on a release-by-release basis has grown significantly over time. Again, I preface these numbers with the fact that these are only those bugs which have a status flag set. There are likely thousands of bugs that are not counted here because they don’t have a status flag set. A part of the reason for that is because the process for tracking bugs is not always strictly followed; this is particularly true as we go farther back in history.

As you can see above, the trend of ever increasing bug volume continues. Firefox 26 saw a 21% increase in tracked bugs over Firefox 25, and a 183% increase since we started tracking this data.
So there we have it. I think Firefox 26 was an incremental success over it’s predecessors. In spite of an ever increasing volume of bugs to triage we shipped less regressions and less crashes than previous releases. This is not just a QA success but is also a success borne of other teams like development and release management. It speaks to the success of implementing smarter strategies and stronger collaboration. We still have a lot of room to improve, in particular focusing more on incoming bugs, dealing with crash landings in a responsible way, and investigating the root cause of bugs that are reopened.
If we continue to identify problems, have open discussions, and make small iterative changes, I’m confident that we’ll be able to look back on 2014 as a year of success.
I will be back in six weeks to report on Firefox 27.
|
|
Wil Clouser: Splitting AMO and the Marketplace |
Years ago someone asked me what the fastest way to stand up an App Marketplace was. After considering that we already had several Add-on Types in AMO I replied that it would be to create another Add-on Type for apps, use the AMO infrastructure as a foundation for logins/reviews/etc. and do whatever minor visual tweaks were needed. This was a pretty quick solution but the plan evolved and “minor visual tweaks” turned into “major visual changes” and soon a completely different interface. Fast forward a few years and we have two separate sites (addons.mozilla.org and marketplace.firefox.com) running out of the same code repository but with different code. Much of the code is crudely separated (apps/ vs mkt/), but there are also many shared files, libraries, and utilities, both front and backend. The two sites run on the same servers but employ separate settings files.
There has been talk about combining the two sites so that the Firefox Marketplace was the one stop shop for all our apps/add-ons/themes/etc. but there was reluctance to move down that path due to the different user expectations and interfaces – for example, getting an app for your phone is a lot different flow than putting a theme on Firefox. While the debate has simmered with no great options the consequences of inaction continue to grow. Today’s world:
The best way to relieve the stress points above is complete separation of addons.mozilla.org and marketplace.firefox.com. Read the full (evolving) proposal. Feedback welcomed.
http://micropipes.com/blog/2014/01/31/splitting-amo-and-the-marketplace/
|
|
Ben Hearsum: This week in Mozilla RelEng – January 31st, 2014 |
Completed work (resolution is ‘FIXED’):
In progress work (unresolved and not assigned to nobody):
http://hearsum.ca/blog/this-week-in-mozilla-releng-january-31st-2014/
|
|






