Bill Walker: Replacing Google Image Charts with D3.js |
[When I'm not in the office, I'm often out birding and photographing birds. To keep track of my life list and bird photos I wrote a Ruby on Rails site hosted at birdwalker.com; you can see all the source on github. This post is about some recent improvements to that code]
When I first discovered Google Image Chart API, I had written little JS and was excited about how easily I could create decent-looking bar charts without including big libraries or writing a lot of code. I added a method in my Rails ApplicationHelper class to generate a URL for the Google Image Chart API by encoding my parameters and data values into the expected format:
def counts_by_month_image_tag(totals, width=370, height=150)
monthly_max = 10 * (totals[1..12].max / 10.0).ceil
stuff = {
:chco => 555555,
:chxt => "y",
:chxr => "0,0," + monthly_max.to_s,
:cht => "bvs",
:chd => "t:" + totals[1..12].join(","),
:chds => "0," + monthly_max.to_s,
:chs => width.to_s + "x" + height.to_s,
:chl => Date::ABBR_MONTHNAMES[1..12].join("|")
}
chartString = ("http://chart.googleapis.com/chart" + "?" +
stuff.collect { |x| x[0].to_s + "=" + x[1].to_s }.join("&")).html_safe
(" ").html_safe
end
").html_safe
end
I started using this helper from my various page templates and all was well. Time went by.
Eventually, I became disenchanted with this solution. I can develop and test the rest of the site locally on my laptop, but the external image URL’s like those aren’t reachable offline. The Google chart images are statically sized, so they’re ill-suited to responsive design frameworks like Twitter Bootstrap. And, rendering charts as images doesn’t allow for any interactivity. [note: Google addressed these deficiencies in a subsequent version of their Chart API, which does most of the work client-side, and adds a lot of scope for interactivity].
Meanwhile, I became more comfortable with JS and began to create more of birdwalker.com using it. After attending a conference talk about D3, I decided to copy a sample bar chart and adapt it for my purposes. I put the finished code in a Rails partial called _species_by_month.html.erb
D3.js code works by chaining many function calls together. Each call has a very specific purpose, and the calls can generally go in any order. By chaining them together, you get the overall behavior you want. For example, to create the bars in my bar graph I do this:
var bars = svg.selectAll("rect").remove().data(sightingData).enter()
.append("rect")
.attr("x", function(d, i) { return x(d.month); })
.attr("y", function(d, i) { return y(d.count);})
.attr("height", function(d, i) { return height - y(d.count); })
.attr("width", function(d, i) { return x.rangeBand(); })
.attr("class", "bargraph-bar"
The calls to attr() specify the location and size of an SVG rectangle and assign it a CSS style name. By calling data() you can iterate over an array of data; by calling enter() you can create new SVG nodes for each item in the array. In this case, we iterate over twelve numeric values representing birding activity during each month of the year and create twelve rectangles.
These new graphs resize nicely as elements within my Bootstrap layout. And I was able to create a tooltip when mousing over each bar like this:
svg.selectAll("rect").on("mouseover.tooltip", function(d){
d3.select("text#" + d.month).remove();
svg
.append("text")
.text(d.count)
.attr("x", x(d.month) + 10)
.attr("y", y(d.count) - 10)
.attr("id", d.month);
});
And remove the tooltip on mouse exit like this:
svg.selectAll("rect").on("mouseout.tooltip", function(d){
d3.select("text#" + d.month).remove();
});
The tooltips are styled with CSS just like the other graph elements.
So far, my experience with D3 has been really great. I now have graphs that work well in a responsive layout, don’t require external image links, and have some interactivity. Suggestions and code reviews welcome!
-Bill

http://softwarewalker.com/2014/01/31/replacing-google-image-charts-with-d3-js/
|
|
Ron Piovesan: Interview tip: Talk ideas, not resume |
At Hearsay Social we’re hiring like mad so I’ve been doing a lot of interviewing. As a result, I’ve also been asked for interview tips and feedback.
My number one reply is to make the interview about ideas, strategies and tactics and not about your experience.
Ironically, in an interview people don’t want to learn about you, they want to learn how you can help them and their company. (OK, maybe I’m overstating this a little… they want to learn about you also!)
But when you interview, try to put yourself in the interviewer’s place and understand their problems and challenges. Then be proactive in addressing those concerns.
I’m always impressed with people who make the effort to try to understand what my challenges are then use the interview time to talk me through how they would manage those challenges.
Sure, as you’re coming from the outside, some if it is guesswork and no one will ever expect someone to get the company’s challenges 100% correct. But if someone does their homework, make smart guesses about what the challenges are, and then comes up with reasoned approach to solve those challenges, they’ll immediately impress and make the conversation more about an exchange of ideas and tactics, rather than going point-by-point through a resume.
My goal when I’ve interviewed is to never have the interviewer refer to my resume. If they need to look at my resume and ask me about what is on it, I feel like I’ve lost because we’ve run out of things to talk about and have had to resort to a resume discussion.
Boring.
But if we spend the entire time talking about ideas, strategies and tactics, I feel like I’m making myself already part of the team. And that’s the ultimate goal.

http://ronpiovesan.com/2014/01/31/interview-tip-talk-ideas-not-resume/
|
|
Doug Belshaw: 3 things I’m looking forward to at the Webmaker workweek |
Tomorrow I’m heading off to the icy wastelands of Toronto for a Webmaker workweek. As with everything at Mozilla, we’ll be planning and working in the open. You can see what we’ll be up to on this wiki page.
I’m helping the multi-talented Kat Braybrooke wrangle the Web Literacy Content ‘scrum’, but here’s what I’m looking forward to more generally.
Working remotely is great, but virtual interactions differ markedly from embodied ones. I feel this acutely when I meet offline those I’ve only ever known online; it’s like two pieces of a jigsaw puzzle with one explaining the other.
We’ve quite a few new shipmates, but one I’m looking forward to meeting in particular is fellow Englishman Adam Lofting, our new Metrics Lead. We’re going to try and figure out (if and) how we can measure users’ development of web literacy. I think it will tie in nicely with the upcoming OpenHTML research project we’re doing with Drexel University.
Although this will mainly be led by the radiant Cassie McDaniel, I’m excited to see the ways we can weave the Web Literacy Map throughout the Webmaker site. Laura ‘super productive’ Hilliger has already produced an ‘if that then this’ demo, so I’m interested in how we can iterate towards a delightful UX for interest-based pathways to learning.
One thing I do think we need to do is to carefully consider the (visual and verbal) language we’re using. We’ve moved from Web Literacy ‘Standard’ to ‘Map’ and so we’ve got infinite scope for cartographic metaphors. ![]()
Webmaker (big ‘W’) is Mozilla’s offering in a wider webmaker (small ‘w’) ecosystem. Brett Gaylor‘s team has done a great job of creating innovative, open, stable tools; now we need to connect them more concretely to other people who are doing awesome stuff.
Happily, because Brett’s team has created a Make API this should be easier than it otherwise would have been. In practice, it means people can pull content out of Webmaker and we can pull in OERs and other openly-licensed content. Win.

My apologies, Kat. I take it back: Canada is not a frozen wasteland. ![]()
Main image CC BY Roland Tanglao
|
|
Mike Hommey: Ccache efficiency on Mozilla builders |
In the past two blog posts, I’ve detailed some results I got experimenting with a shared compilation cache. Today, I will be exploring in some more detail why ccache is not helping us as much as it should.
TL;DR conclusion: we need to be smarter about which build slaves build what.
Preliminary note: the stats below were gathered over a period of about 10 days after the holidays, on several hundred successful builds (failed builds were ignored ; this is skewed, but we don’t have ccache stats for those).
Try is a special repository. Developers push very different changes on it, based on more or less random points of mozilla-central history. But they’d also come back with different iterations of a patch set, and effectively rebuild mostly the same thing. One could expect cache hit rates to be rather low on those builds, and as we’ve seen in the past posts, they are.
But while the previous posts were focusing on ccache vs. shared cache, let’s see how it goes for different platforms using ccache, namely linux64 and mac, for one type of build each:
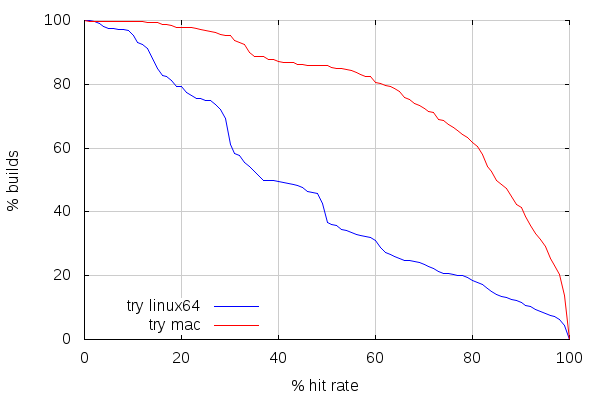
Here comes the surprise. Mac builds are getting a decent cache hit rate on try. Which is kind of surprising considering the usage pattern, but it’s not what’s the most interesting. Let’s focus on why mac slaves have better hit rates than linux slaves.
And here’s the main difference: there are way less mac slaves than there are linux slaves. The reason is that we do a lot of different build types on the linux slaves: linux 32 bits, 64 bits, android, ASAN, static rooting hazard analysis, valgrind, etc. We have 663 linux slaves and 23 mac slaves for try (arguably, a lot of the linux slaves are not running permanently, but you get the point), and they are all part of the same pool.
So let’s look how those try builds I’ve been getting stats for were spread across slaves:
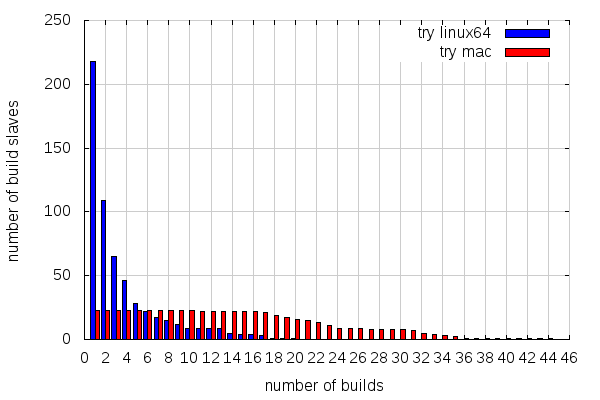
This is not the best graph in the world, but it shows how many slaves did x builds or more. So 218 linux slaves did one build or more, 109 did two builds or more, etc. And there comes the difference: half of the linux slaves have only done one linux64 opt build, while all the mac slaves involved have made at least 10 mac opt builds!
Overall, this is what it looks like:
Let’s now compare linux builds cache hit rates for slaves with 5 builds and more, and 10 builds and more:
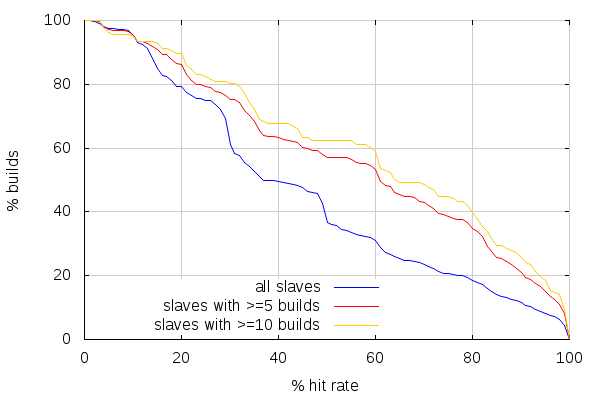
While the hit rates are better when looking at the slaves with more linux64 opt builds, they don’t come close to mac hit rates. But this has to do with the fact that I merely removed results from slaves that only did a few builds. That didn’t change how the builds were spread amongst slaves, and how more or less related those builds were in consequence: with fewer slaves to build on, slaves are more likely to build sources that look alike.
Interestingly, we can get a sense of how much builds done by a given slave are related by looking at direct mode cache hits.
The direct mode is a feature introduced in ccache 3 that avoids preprocessor calls by looking directly at sources files and their dependencies. When you have an empty cache, ccache will use the preprocessor as usual, but it will also store information about all the files that were used to preprocess the given source. That information, as well as the hash of the preprocessed source, is stored with a key corresponding, essentially, to a hash of the source file, unpreprocessed. So the next time the same source file is compiled, ccache will look at that dependency information (manifest), and check if all the dependent files are unchanged.
If they are, then it knows the hash of the preprocessed source without running the preprocessor, and can thus get the corresponding object file. If they aren’t, then ccache runs the preprocessor, and does a lookup based on the preprocessed source. So the more direct mode cache hits there are compared to overall cache hits, the more slaves tended to build similar trees.
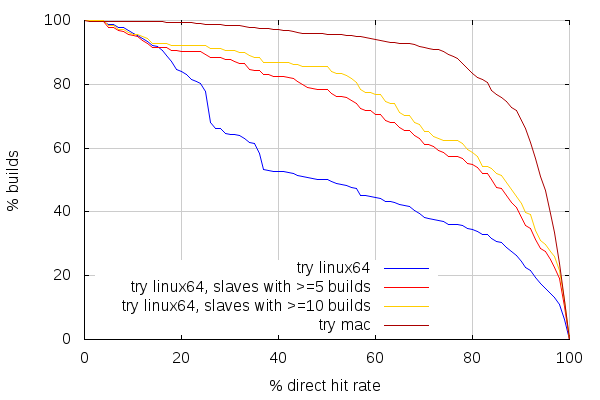
And again, looking at linux slaves with 5 or more builds, and 10 or more builds, shows the general trend that the more related builds a slave does, the more efficient the cache is (News at 11).
The problem is that we don’t let them be efficient with the current pooling of slaves. Shared caching would conveniently wallpaper around that scheduling inefficiency. But the latency due to network access for the shared cache makes it necessary, for further build times improvements, to still have a local cache, which means we should still address that inefficiency.
Inbound is, nowadays, the branch where most things happen. It is the most active landing branch, which makes it the place where most of future Firefox code lands first. Continuous integration of that branch relies on a different pool of build slaves than those used for try, but it uses the same pool of slaves as other project branches such as mozilla-central, b2g-inbound, fx-team, aurora, etc. or disposable branches. There are 573 linux slaves (like for try, not necessarily all running) and 63 mac slaves for all those branches.
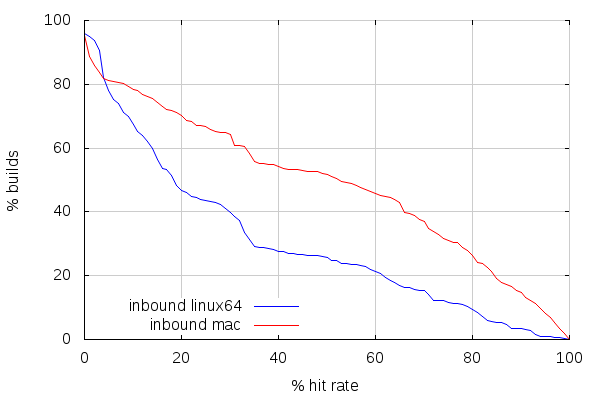
The first thing to realize here is that there are between 4 and 5% of those builds with absolutely no cache hit. I haven’t researched why that is. Maybe we’re starting with an empty cache on some slaves. Or maybe we recently landed something that invalidates the cache completely (build flags changes would tend to do that).
The second thing is that cache hit rate on inbound is lower than it is on try. Direct mode cache hit rates, below, show, however, a tendency for better similarity between builds than on try. Which is pretty much expected, considering inbound only takes incremental changes, compared to try, which takes random patch sets based on more or less randomly old mozilla-central changesets.
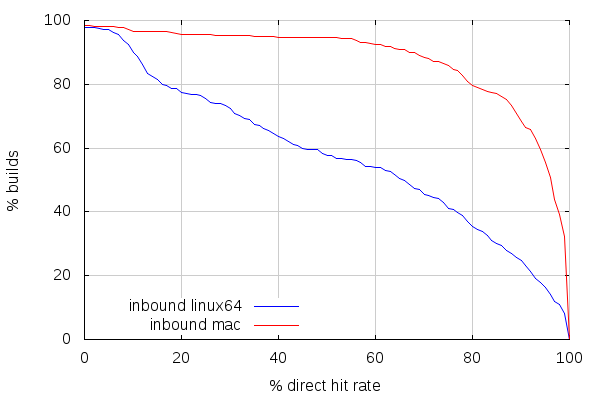
But here’s the deal: builds are even more spread across slaves than on try.
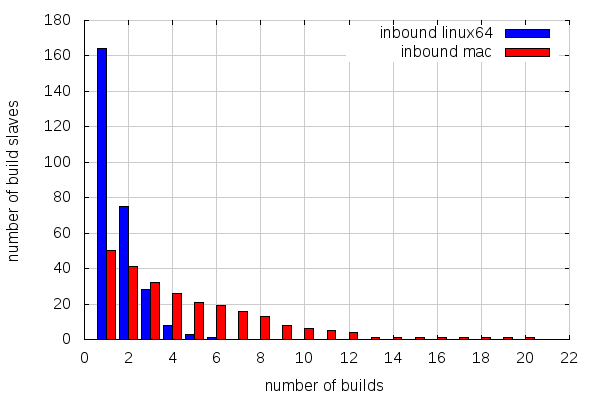
There are also less builds than on try overall, but there are more slaves involved in proportion (repeating the numbers for try for better comparison):
Contrary to try, where all builds start from scratch (clobber builds), builds for inbound may start from a previous build state from an older changeset. We sometimes force clobber builds on inbound, but the expectation is that most builds should not be clobber builds. The fact that so few builds run on a same slave over a period of 10 days undermines that and likely makes us mostly do near clobber builds all the time. But this will be the subject of next post. Stay tuned.
Note: CCACHE_BASEDIR makes things a bit more complicated, since the same slaves are used for various branches and CCACHE_BASEDIR might help getting better hit rates across branches, but since inbound is the place where most things land first, it shouldn’t influence too much the above analysis.
Although, there is a concern that the number of different unrelated branches and different build types occurring on a same slave might be helping cache entries being evicted because the cache has a finite size. There are around 200k files in ccache on slaves, and a clobber build will fill about 8k. It only takes about 25 completely unrelated builds (think different build flags, etc.) to throw an older build’s cache away. I haven’t analyzed this part of the problem, but it surely influences cache hit rate in the wrong direction.
Anyways, for all these reasons, and again, while shared cache will wallpaper over it, we need to address the build scheduling inefficiencies somehow.
|
|
Paul Rouget: MDN JSON API |
Did you know that MDN has a JSON API? Documentation of the API is here: https://developer.mozilla.org/en-US/docs/Project:MDN/Contributing/Advanced_search.
2 examples:
Some more fun here.
Kudos to the MDN team!
|
|
Daniel Glazman: CSS Regions |
If there is one and only article you should read about CSS Regions, that's this one. And the conclusion is quite clear and I agree with it:
CSS Regions give us the ability to do a lot of things that are otherwise not possible without them
http://www.glazman.org/weblog/dotclear/index.php?post/2014/01/31/CSS-Regions
|
|
Selena Deckelmann: Everyday Postgres: Describing an “ideal” Postgres Operational Environment |
I spent some time thinking about what things in the Postgres environment (and specifically for crash-stats.mozilla.com) make me happy, and which things bother me so much that I feel like something is pretty wrong until they are fixed or monitored.
I’m planning to go through each of these items and talk about how we address them in the Web Engineering team, and that will include implementing some new things over the next couple of quarters that we haven’t had in the past.
One thing that didn’t surprise me about this list was how much documentation is needed to keep environments running smoothly. By smoothly, I mean that other people on the team can jump in and fix things, not just a single domain expert.
Sometimes docs come in the form of scripts or code. However, some prose and explanation of the thinking behind the way things works is often also necessary. I frequently underestimate how much domain knowledge I have that I really aught to be sharing for the sake of my team.
|
|
Laura Thomson: My nerd story |
I was born to be a nerd.
My dad was an engineer and pilot in the RAF. We come from a long line of engineers, all the way back to Napier, the dude that figured out logarithms.
As a kid I wanted to learn everything about everything. I read every book I could lay my hands on, and I took things apart to see how they worked, notably, an alarm clock that never went back together right. (Why is there always a spring left over? The clock still worked, so I guess you could call it refactoring.)
I first programmed when I was in the fourth grade. I was eight. A school near me had an Apple II, and they set up a program to bring in kids who were good at math to learn to program. Everybody else was in the seventh or eighth grades, but my school knew I was bored, so they sent me. We learned LOGO, a Lisp.
In the seventh grade my school got BBC Bs. I typed in games in Basic from magazines (Computer and Video Games, anyone?) and modified them. I worked out how to put them on the file server so everybody could play. The teacher could not figure out how to get rid of them.
I saved up money from many odd jobs and bought myself a Commodore 64, and wrote code for that. All through this, I still wanted to be a lawyer/veterinarian/secret agent/journalist. I don’t think I ever considered being a programmer at that stage. I don’t think I knew it was a job, as such.
At the start of my final year of high school, I had a disagreement with my parents and moved out of home, and dropped out of school. After a short aborted career as a bicycle courier, I applied for and got a job working for the government as a trainee, a program where you worked three days a week and went to TAFE (community college) for two. They called and said, we have a new program which is on a technology track. Is that interesting? I said yes, and that was my first tech job.
I went from there to another courier firm where I did things with dBase, and worked in the evenings at a Laser Tag place. One night, at a party, I started talking to these guys who were doing stuff with recorded information services over POTS. They had the first NeXTs in Australia, and I really wanted to get my hands on them.
They offered me a job, and I was suddenly Operations Controller, leading a team of four people. Still not really sure how that happened.
The bottom fell out of that industry, and I went back to school, finished high school, and went to college. Best decision I ever made career wise was my choice of program. I studied Computer Science and Computer Systems Engineering at RMIT. I was the only woman in the combined program. It was intense: you took basically all the courses needed for both of those programs (one three years, one four years) in a five year period. We took more courses in a single semester than most people did in a year. I loved it. I had found my tribe.
One day, I went to the 24 hour lab and I saw a friend, Rosemary Waghorn, with something on her terminal I had never seen before. “What’s that?” I asked. “It’s called Mosaic,” she said. “This is the world wide web.”
I sat down. I was hooked. I knew right away that *this* was what I wanted to do.
That was twenty-one years ago, and now I work at Mozilla.
|
|
Bas Schouten: FOSDEM 2014 |
https://fosdem.org/2014/schedule/event/graphics_in_gecko/
To those that have not given up on reading my blog, I will be giving a talk at FOSDEM 2014 this year about utilizing GPUs to accelerate 2D graphics. It will be at 16:30 in the Mozilla Developer room and it will be fairly technical! For those of you that have enjoyed my other posts on here you might find this interesting as well.
My shortest post ever! Not even any pictures!
Original post blogged on b2evolution.
|
|
Planet Mozilla Interns: Mihnea Dobrescu-Balaur: Liking Light Table |
If you haven't done so already, you should check out Light Table. It's a great new IDE that is trying to approach the way we go about programming in a different manner, kind of like what Bret Victor suggests.
Leaving the philosophical aspects aside, Light Table is also interesting from a technology perspective. First of all, its architecture allows for plugins to be "first class citizens", able to do anything within the IDE, as if their code was part of the editor's core. Second, LT is a packaged webapp. It's written in ClojureScript and packaged with node-webkit, so it's pushing both ClojureScript's development and the Web forward.
Recently, the code was open sourced and the plugin infrastructure was made available. It's been less than a month and the community has already added support for Ruby, Haskell, Markdown, LaTeX and more, in addition to the "standard" Clojure and Python.
Since the project was open sourced, I contributed with a few bug fixes and enhancements, and I even wrote my own plugin. I have to say, hacking on Light Table is pretty easy, thanks to the nicely written codebase and to the Behavior Object Tag architecture. As for plugins, there's a template that gets you up and running in no time.
So if you are looking for a new IDE to try, or a young open source project with a friendly community to contribute to, I suggest you take a look at Light Table!
|
|
Pete Moore: Weekly review 2014-01-30 |
That is the current status: now a bit about the strategy:
|
|
Christian Heilmann: Quick Hack: The Mozilla Monument Name Finder |
Outside the Mozilla office in San Francisco stands a beautiful monument thanking all the people who did work with Mozilla to keep the web open, secure, inviting and beautiful.

Overall, this is 4536 names on four sides with two panels, which means your name might be hard to find. Fret not, for Chris More released a dataset with the names and their locations on the document. Using this dataset and some CSS 3D transformations, I am now happy to give you the Mozilla Monument Name Finder.
You can see how it works in this screencast.
If you want to see the real images, here is another hack using the original images!
Again, a huge thanks to all the people who helped Mozilla become what it is! Here’s to you!
http://christianheilmann.com/2014/01/30/quick-hack-the-mozilla-monument-name-finder/
|
|
Byron Jones: happy bmo push day! |
the following changes have been pushed to bugzilla.mozilla.org:
the changes to quicksearch are worth highlighting:
the default operator, colon (:), has always performed a substring match of the value. the following operators are now also supported:
discuss these changes on mozilla.tools.bmo.
http://globau.wordpress.com/2014/01/30/happy-bmo-push-day-80/
|
|
Nathan Froyd: space saving miscellany |
Yesterday’s post on space saving techniques generated a few comments. It seemed worthwhile to highlight a few of the comments for a wider audience.
https://blog.mozilla.org/nfroyd/2014/01/29/space-saving-miscellany/
|
|
Armen Zambrano Gasparnian: How to create a new version of mozpoolclient |


http://armenzg.blogspot.com/2014/01/notes-on-how-to-create-new-version-of.html
|
|
Ron Piovesan: Content partnerships as a BD goal? |
I lead the strategic alliances team at Hearsay, which means my day-to-day is all about creating business partnerships with other companies in complimentary markets.
Business partnerships…. but what about content partnerships. Interesting idea. This article got me thinking.
Creating content partnerships seems to be the evolution of co-marketing agreements, maybe with less overhead.
“We’re a company that is very focused on the women and health spaces,” Bloom said. “We choose brands and organizations that align with our goals — widespread menstruation education and the destigmatization of women’s health taboo. Often, these brands are media properties or non-profits. It’s not uncommon for HelloFlo to promote content created by these other brands, and vice versa. It not only creates lasting partnerships, but also visibility and shared traffic.”
Content Partnerships Fuel Startup Growth | The Content Strategist.

http://ronpiovesan.com/2014/01/29/content-partnerships-as-a-bd-goal/
|
|
Swarnava Sengupta: New version of Firefox complete with the Social API |

http://blog.swarnava.in/2012/11/new-version-of-firefox-complete-with.html
|
|
Swarnava Sengupta: Firefox 17 launches with click-to-play plugin blocks for old AdobeReader, Flash, and Silverlight |


http://blog.swarnava.in/2012/11/firefox-17-launches-with-click-to-play.html
|
|
Swarnava Sengupta: WebRTC makes Social API even more social |
http://blog.swarnava.in/2012/12/webrtc-makes-social-api-even-more-social.html
|
|
Swarnava Sengupta: Stub Installer in Firefox Nightly – Try it out, Give feedback, and Testit! |
http://blog.swarnava.in/2012/10/stub-installer-in-firefox-nightly-try.html
|
|






