Byron Jones: renaming mozilla-corporation-confidential to mozilla-employee-confidential |
in the early days of bugzilla.mozilla.org there were three bugzilla security groups which covered all mozilla employees: mozilla-corporation-confidential (mozilla corporation employees), mozilla-foundation-confidential (mozilla foundation employees), and mozilla-confidential (both corporation and foundation). as is the way, things change. the mozilla-confidential group got deprecated and eventually disabled. mozilla-corporation-confidential’s usage within bugzilla has expanded and is now the default security group for a large number of products. mozilla itself has made efforts to remove the distinction between the foundation and the corporation.
this has resulted in bugs which should be visible to all employees but were not (see bug 941671).
late on wednesday the 22nd of feburary we will be renaming the mozilla-corporation-confidential group to mozilla-employee-confidential, and will update the group’s membership to include mozilla foundation staff.
discuss these changes on mozilla.tools.bmo.
|
|
Ron Piovesan: Vertical enterprise apps: Empowering the end user |
Just as (relatively) new and (at first) niche TV outlets like HBO or Netflix, brought new choices to consumers, so too will new, and at first niche, applications bring more functionality and utility to enterprise users.
OK, I’ll admit that the analogy made in this GigaOm article is a bit odd, but the point is well taken.
The enterprise is probably the most exciting market in disruption now.
As Hearsay Social investor and all around genius Jon Sakoda highlighted in an earlier talk, Silicon Valley left behind many key verticals in the 1990s. Sure, there are ton of great horizontal applications, most notably Salesforce, but few have attempted to go into a vertical, really understand the requirements and workflow, and come up with a new application just for them.
Happily, all that is changing and it is exciting stuff. The poster child is Veeva and how they are overhauling the life sciences industry.
Guidewire is not only vertically focused (insurance), but focused on a vertical within a vertical (property and casualty insurance.) Oh yeah, their market cap is $3.4 billion, thank you very much.
We’re seeing the same trend at Hearsay Social. We know there many various social media sales and marketing platforms out there but none really understand or serve the needs of the financial services market.
The financial services market is huge, complex, critical to the success of our economy, and yet so poorly understood by tech companies.
But being laser focused on that industry means we can help financial agents and advisers better understand social, better understand their customers, and help them turn social into as important a communications channel as the phone or email.
The financial services industry is dying to learn more about the crazy rapid changes in how consumers are accessing information.
Hearsay understands social, we understand financial services and because of our focus, we are the best in the market hands-down in bringing the two industries together.
The enterprise is going though massive disruption. We’re leading the way in financial services and it is great to see others adding unique, industry specific value, in other verticals.

http://ronpiovesan.com/2014/01/19/vertical-enterprise-apps-empowering-the-end-user/
|
|
Peter Bengtsson: Sorting mixed type lists in Python 3 |
Because this bit me harder than I was ready for, I thought I'd make a note of it for the next victim.
In Python 2, suppose you have this:
Python 2.7.5 >>> items = [(1, 'A number'), ('a', 'A letter'), (2, 'Another number')]
Sorting them, without specifying how, will automatically notice that it contains tuples:
Python 2.7.5 >>> sorted(items) [(1, 'A number'), (2, 'Another number'), ('a', 'A letter')]
This doesn't work in Python 3 because comparing integers and strings is not allowed. E.g.:
Python 3.3.3 >>> 1 < '1' Traceback (most recent call last): File "" , line 1, in <module> TypeError: unorderable types: int() < str()
You have to convert them to stings first.
Python 3.3.3 >>> sorted(items, key=lambda x: str(x[0])) [(1, 'A number'), (2, 'Another number'), ('a', 'A letter')]
If you really need to sort by 1 < '1' this won't work. Then you need a more complex key function. E.g.:
Python 3.3.3 >>> def keyfunction(x): ... v = x[0] ... if isinstance(v, int): v = '0%d' % v ... return v ... >>> sorted(items, key=keyfunction) [(1, 'A number'), (2, 'Another number'), ('1', 'Actually a string')]
That's really messy but the best I can come up with at past 4PM on Friday.
http://www.peterbe.com/plog/sorting-mixed-type-lists-in-python-3
|
|
Asa Dotzler: What’s Happening with Firefox OS (week ending 2014-01-17) |
This is the second of a weekly series of posts I’ll be doing to highlight the goings on in Firefox OS development.
In the last week, the Mozilla community fixed about 200 issues and features tracked in the Firefox OS Bugzilla product. Here are a few of the highlights.
Bug 855165 – Make message notifications work properly.
Bug 947234 – Improvements to launch speed of SMS app.
Bug 862870 – Responsiveness improvements for Email app.
Bug 950124 – Powersave filters now support WiFi
Bug 898354 – Notifications for Timer in Clock app.
Bug 956220 – Emergency Call UI.
Bug 875951 – Danish keyboard layout added.
Bug 946596 – Full resolutions screenshot support on higher resolution devices.
Bug 929388 – Incorporate a FxA Manager and FxA Client into the System app
Bug 958251 – Swipe from top of display to access Task Manager
I’ve tried to clean up the descriptions to make them a bit more obvious. I’m planning on adding some more commentary around important fixes in the future. I’ll also try to add some screenshots or other visuals.
Did I miss a big or interesting change? Let me know in the comments.
http://asadotzler.com/2014/01/17/whats-happening-with-firefox-os-week-ending-2014-01-17/
|
|
Doug Belshaw: Weeknote 03/2014 |
This week I’ve been:
Next week I’ll be with my wife in Gozo on Monday and Tuesday trying to find somewhere for us to move to for six months. I’ll also be celebrating my son’s birthday and then travelling down for BETT on Thursday and Friday.
Image CC BY-NC-SA Murray Head
|
|
Ben Hearsum: This week in Mozilla RelEng – January 17th, 2014 — new format! |
This week I’m going to try something new and try to report on in progress bugs in addition to completed ones. I finally got around to scripting this, too (at Catlee’s urging), and thus the categories have changed to match the Release Engineering Bugzilla components exactly. The code that generates this is available in a github repository for the curious:
In progress work (unresolved and not assigned to nobody):
Completed work (resolution is ‘FIXED’):
http://hearsum.ca/blog/this-week-in-mozilla-releng-january-17th-2014-new-format/
|
|
Nathan Froyd: packing structures for fun and profit |
When the DOM bindings code first started generating information for the JavaScript JIT about getters and setters, the generated information was rather sparse. JSJitInfo, the container for such information, looked like this:
struct JSJitInfo {
JSJitPropertyOp op;
uint32_t protoID;
uint32_t depth;
bool isInfallible;
bool isConstant;
};
On a 32-bit platform, sizeof(JSJitInfo) was 16. You could shrink some of the fields, and even pack things into bitfields, but there weren’t that many getters and setters, so it probably wasn’t worth it.
Of course, nothing ever gets smaller: the bindings code started generating these structures for methods, the amount of information the bindings code wanted to communicate to the JIT expanded, and some of the parallel JS work started using the structure for its own purposes. And a bunch more interfaces got converted to WebIDL, so many more of these “little” structures were generated. Eventually, we wound up with:
struct JSJitInfo {
enum OpType { ... };
enum AliasSet { ... };
union {
JSJitGetterOp getter;
JSJitSetterOp setter;
JSJitMethodOp method;
};
uint32_t protoID;
uint32_t depth;
OpType type;
bool isInfallible;
bool isMovable;
AliasSet aliasSet;
bool isInSlot;
size_t slotIndex;
JSValueType returnType;
const ArgType* const argTypes;
JSParallelNative parallelNative;
};
This structure has several issues:
This definition weighed in at 44 bytes on a 32-bit system. With 7k+ of these being generated by the bindings code, and more being added every release cycle, now seemed like a worthwhile time to slim these structures down.
This work has gone on in bug 952777, bug 960653, and yet-to-be-landed bug 960109. After all of those bugs land, we’ll have something that looks like:
struct JSJitInfo {
union {
JSJitGetterOp getter;
JSJitSetterOp setter;
JSJitMethodOp method;
JSParallelNative parallelNative;
};
uint16_t protoID;
uint16_t depth;
uint32_t type_ : 4;
uint32_t aliasSet_ : 4;
uint32_t returnType_ : 8;
uint32_t isInfallible : 1;
uint32_t isMovable : 1;
uint32_t isInSlot : 1;
uint32_t isTypedMethod : 1;
uint32_t slotIndex : 12;
};
Compared to our earlier version, we’ve addressed every complaint:
It’s worth noting that several of these fields could be smaller, but there’s no reason for them to be currently, given that shrinking them wouldn’t make the overall structure smaller.
The final size of the structure is 12 bytes on 32-bit platforms, and 16 bytes on 64-bit platforms. With 7k+ JSJitInfo structures, that means we’ve saved ~220K of space in a 32-bit libxul. For a 32-bit libxul, this is almost 1% of the entire size of libxul, which is an extremely pleasant win for size optimizations. Smaller downloads, less space on your device, and less memory at runtime!
If you’re interested in examining how much space particular structures take up, you can use pahole for Linux or struct_layout for Mac. I’m not aware of any similar program for Windows, though I imagine such a beast does exist. These programs work by examining the debugging information generated by the compiler and displaying the structure layout, along with any “holes” in the structure. pahole will also tell you about cacheline boundaries, so that you can pack frequently-accessed members in the same cacheline to minimize cache misses.
Given the above (and that there have been other wins, somewhat less spectacular in nature), I’ve wondered if it isn’t worth adding some sort of annotations, either in-source or off to the side, about how big we expect certain structures to be or how much internal waste we expect them to have. Then people modifying those structures–and the reviewers as well–would be aware that they were modifying something space-critical, and take appropriate steps to minimize the space increase or even trim things down a bit.
https://blog.mozilla.org/nfroyd/2014/01/17/packing-structures-for-fun-and-profit/
|
|
Gregory Szorc: Things Mozilla Could Do with Mercurial |
As I've written before, Mercurial is a highly extensible version control system. You can do things with Mercurial you can't do in other version control systems.
In this post, I'll outline some of the cool things Mozilla could do with Mercurial. But first, I want to outline some features of Mercurial that many don't know exist.
The Mercurial wire protocol (how two Mercurial peer repositories talk to each other over a network) contains two very useful commands: pushkey and listkeys. These commands allow the storage and listing of arbitrary key-value pair metadata in the repository.
This generic storage mechanism is how Mercurial stores and synchronizes bookmarks and phases information, for example.
By implementing a Mercurial extension, you can have Mercurial store key-value data for any arbitrary data namespace. You can then write a simple extension that synchronizes this data as part of the push and pull operations.
For cases where you want to transmit arbitrary data to/from Mercurial servers and where the pushkey framework isn't robust enough, it's possible to implement custom commands in the Mercurial wire protocol.
A server installs an extension making the commands available. A client installs an extension knowing how to use the commands. Arbitrary data is transferred or custom actions are performed.
When it comes to custom commands, the sky is really the limit. You could do pretty much anything from transfer extra data types (this is how the largefiles extension works) to writing commands that interact with remote agents.
Mercurial offers a rich framework for querying repository data and for formatting data. The querying is called revision sets and the later templates. If you are unfamiliar with the feature, I encourage you to run hg help revset and hg help templates right now to discover the awesomeness.
As I've demonstrated, you can do some very nifty things with custom revision sets and templating!
Now that you know some ways Mercurial can be extended, let's talk about some cool use cases at Mozilla. I want to be clear that I'm not advocating we do these things, just that they are possible and maybe they are a little cool.
Mozilla records information about who pushed what changesets where and when in what's called the pushlog. The pushlog data is currently stored in a SQLite database inside the repository on the server. The data is made available via a HTTP+JSON API.
We could go a step further and make the pushlog data available via listkeys so Mercurial clients could download pushlog data with the same channel used to pull core repository data. (Currently, we have to open a new TCP connection and talk to the HTTP+JSON API.) This would make fetching of pushlog data faster, especially for clients on slow connections.
I concede this is an iterative improvement and adds little value beyond what we currently have. But if I were designing pushlog storage from scratch, this is how I'd do it.
The pushkey framework could be used to mark specific changesets as passing automation. When release automation or a sheriff determines that a changeset/push is green, they could issue an authenticated pushkey command to the Mercurial server stating such. Clients could then easily obtain a list of all changesets that are green.
Why stop there? We could also record automation failures in Mercurial as well. Depending on how complex this gets, we may outgrow pushkey and require a separate command. But that's all doable.
Anyway, clients could download automation results for a specific changeset as part of the repository data. The same extension that pulls down that data could also monkeypatch the bisection algorithm used by hg bisect to automatically skip over changesets that didn't pass automation. You'll never bisect a backed out changeset again!
If this automation data were stored on the Try repository, the autoland tool would just need to query the Mercurial repo to see which changesets are candidates for merging into mainline - there would be no need for a separate database and web service!
Currently, Mozilla's review procedure is very patch and Bugzilla centric. But it doesn't have to be that way. (I argue it shouldn't be that way.)
Imagine a world where code review is initiated by pushing changesets to a special server, kind of like how Try magically turns pushes into automation jobs.
In this world, reviews could be initiated by issuing a pushkey or custom command to the server. This could even initiate server-side static analysis that would hold off publishing the review unless static analysis checks passed!
Granted review could be recorded by having someone issue a pushkey command to mark a changeset as reviewed. The channel to the Mercurial server is authenticated via SSH, so the user behind the current SSH key is the reviewer. The Mercurial server could store this username as part of the repository data. The autoland tool could then pull down the reviewer data and only consider changesets that have an appropriate reviewer.
It might also be possible to integrate crypto magic into this workflow so reviewers could digitally sign a changeset as reviewed. This could help with the verification of the Firefox source code that Brendan Eich recently outlined.
Like the automation data above, no separate database would be required: all data would be part of the repository. All you need to build is a Mercurial extension.
Mozillians have written a handful of useful Mercurial extensions to help people become more productive. We have also noticed that many developers are still (unknowingly?) running old, slow, and buggy Mercurial releases. We want people to have the best experience possible. How do we do that?
One idea is to install an extension on the server that strongly recommands or even requires users follow best practices (minimal HG version, installed extensions, etc).
I have developed a proof-of-concept that does just this.
When you start putting more metadata into Mercurial (or at least write Mercurial extensions to aggregate this metadata), all kinds of interesting query opportunities open up. Using revsets and templates, you can do an awful lot to use Mercurial as a database of sorts to extract useful reports.
I dare say reports like John O'duinn's Monthly Infrastructure Load posts could be completely derived from Mercurial. I've demonstrated this ability previously. That's only the tip of the iceburg.
We could enable a lot of new and useful scenarios by extending Mercurial. We could accomplish this without introducing new services and tools into our already complicated infrastructure and workflows.
The possibilities I've suggested are by no means exhaustive. I encourage others to dream up new and interesting ideas. Who knows, maybe some of them may actually happen.
http://gregoryszorc.com/blog/2014/01/17/things-mozilla-could-do-with-mercurial
|
|
Mike Hommey: Shared compilation cache experiment, part 2 |
I spent some more time this week on the shared compilation cache experiment, in order to get it in a shape we can actually put in production.
As I wrote in the comments to previous post, the original prototype worked similarly to ccache with CCACHE_NODIRECT and CCACHE_CPP2. Which means it didn’t support ccache’s direct mode, and didn’t avoid a second preprocessor invocation on cache misses. While I left the former for (much) later improvements, I implemented the latter, thinking it would improve build times. And it did, but only marginally: 36 seconds on a ~31 minutes build with 100% cache misses (and no caching at all, more on that below). I was kind of hoping for more (on the other hand, with unified sources, we now have less preprocessing and more compilation…).
Other than preprocessing, one of the operations every invocation of the cache script for compilation does is to hash various data together (including the preprocessed source) to get a unique id for a given (preprocessed) source, compiler and command line combination. I originally used MD4, like ccache, as hash algorithm. While unlikely, I figured there would be even less risks of collisions with SHA1, so I tried that. And it didn’t change the build times much: 6 seconds build time regression on a ~31 minutes build with 100% cache misses.
As emptying the cache on S3 is slow, I tested the above changes with a modified script that still checks the cache for existing results, but doesn’t upload anything new to the cache. The interesting thing to note is that this got me faster build times: down to 31:15 from 34:46. So there is some overhead in pushing data to S3, even though the script uploads in the background (that is, the script compiles, then forks another process to do the actual upload, while the main script returns so that make can spawn new builds). Fortunately, cache hit rates are normally high, so it shouldn’t be a big concern.
Another thing that was missing is compression, making S3 transfers and storage huge. While the necessary bandwidth went down with compression implemented, build times didn’t move. The time spent on compression probably compensates for the saved bandwidth.
To summarize, following are the build times I got, on the same changeset, on the same host, with different setups, from fastest to slowest:
For reference, the following are build times on the same host with the same changeset, with ccache:
This means the shared cache script has more overhead than ccache has (also, that SSDs with ccache do wonders with high cache hit rates, but, disclaimer, both ccache builds were run one after the other, there may have not been much I/O on the 99.9% cache hit build). On the other hand, 99.9% hit rate is barely attained with ccache, and 100% cache miss rarely obtained with shared cache. Overall, I’d expect average build times to be better with shared cache, even with its current overhead, than they are with ccache.
The previous post had ccache stats which didn’t look very good, and it could have been related to both the recent switch to AWS spot instances and the holiday break. So I re-ran builds with the shared cache on the same setup as before, replaying the 10 past days or so of try builds after the holiday break, and compared again with what happened on try.
The resulting stats account for 587 linux64 opt builds on try, 356 of which ran on AWS slaves, vs. 231 on non-AWS slaves (so, much more builds ran on AWS, in proportion, compared to last time).
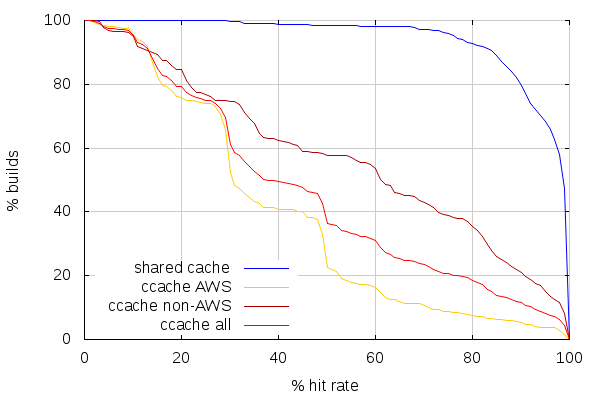
(Note this time I added a line combining both AWS and non-AWS ccache stats)
The first observation to make is that the line for shared cache looks identical. Which is not surprising, but comforting. The next observation is that ccache hit rates got worse on non-AWS slaves, and got slightly better on AWS slaves above 50% hit rate, but worse below. This still places ccache hit rates very far from what can be achieved with a shared cache.
The comparison between build times and hit rates, on the other hand, looks very similar to last time on both ends.
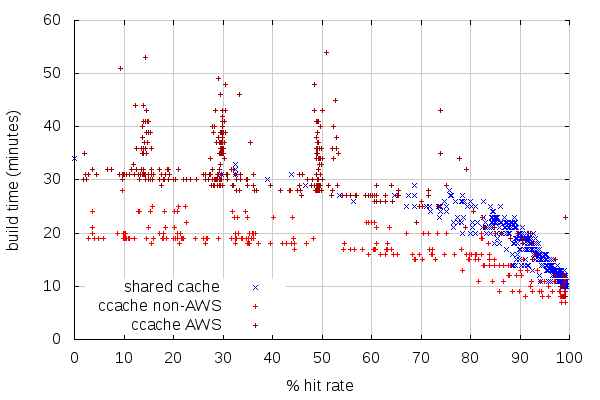
One interesting phenomenon is the three spikes of spread build times. Considering the previous graphs, one of the reason for the spikes is because there are many builds with about the same hit rate (which in itself is interesting), but the strange thing is how different the build times can be at those rates. The origin of this might be the use of EBS which may not have the same performance on all AWS instances. The builders for shared cache, on the other hand, were using ephemeral SSD storage for the build.
While the graphs look similar, let’s see how average build times evolved:
This matches the observation from the first graph: cache hits regressed on try build slaves, but stays the same on custom builders with shared cache. And with the now different usage between AWS and non-AWS, the overall build time average on try went up significantly: from 20:03 to 26:15. This might mean we should build more on non-AWS slaves, but we don’t have the capacity (which is why we’re using AWS in the first place). But it means AWS slave builds are currently slower than non-AWS, and that hurts. And that we need to address that.
(Note those figures only include build time, not any of the preparation steps (which can be long for different reasons), or any of the post-build steps (make package, make check, etc.))
One of the figures that wasn’t present in the previous post, though, to put those averages in perspective, is standard deviation. And this is what it looks like:
Again, the non-AWS build slaves are better here, but shared cache may help us for AWS build slaves. Test is currently undergoing to see how shared cache performs with those AWS slaves. Stay tuned.
|
|
Lloyd Hilaiel: Evolving BrowserID Data Formats |
After a couple years of experience, we (the identity community that supports Persona) have amassed a small collection of changes to the data formats which underly the BrowserID protocol. This post will informally present the desired set of changes to BrowserID data representation to help identity providers and maintainers of client implementations migrate to the new formats.
|
|
Asa Dotzler: Firefox OS Tablet Program: First Device Specs |
The first device for the Firefox OS tablet program has these specs:
Brand/Model: InFocus New tab F1, Wi-Fi
Processor: A31 (ARM Cortex A7) Quad-Core 1.0GHz w/ PowerVR SGX544MP2 GPU
Memory: 2GB DDR3
Hard Disk: 16GB Flash
Screen: 10.1 IPS capacitive multi-touch @ 1280x800
Camera: Dual cameras, 2MP/5MP
Wireless Network: 802.11b/g/n
Ports: Micro SD, Micro USB, headphone
Other: GPS, Bluetooth, Gyroscope
Battery:7000mAh
And its dimensions are:

If you missed it, here’s a photo of the tablet running the latest nightly build of Firefox OS.

First device for the Firefox OS Tablet Contributor Program
http://asadotzler.com/2014/01/16/firefox-os-tablet-program-first-device-specs/
|
|
Jeff Griffiths: Running multiple versions of Firefox (update) |
Back on the old blog I posted about how I run multiple version / profile pairs of Firefox on OS X using a mix of shell script and AppleScript with a dash of yak shaving.
I still use this all the time, but it continues to be a problem for others so here's an update on the various third-party options out there for making this easier:
There are in fact a LOT of blog posts about this, mainly targeted at the power user / web developer audience. Mozilla has not made any changes in this area for years, although it has been discussed a lot. As a Product Manager for Firefox Developer Tools I care a lot about this issue, and as Dave mentions here making it easier for developers to use the latest tools is a very high priority for us in 2014.
http://canuckistani.ca/running-multiple-versions-of-firefox-update/
|
|
Gervase Markham: UK Centralized Health Records: Opt-Out |
If you live in the UK, and would rather your medical information were not stored in a central database (no, not the Summary Care Record database, yet another central database) and given, in a possibly-anonymized-but-no-guarantees form, to researchers and companies, then you need to actively opt out. Yes, really.
See medconfidential.org for how to do it.
http://feedproxy.google.com/~r/HackingForChrist/~3/Xog5Vox65uI/
|
|
Aki Sasaki: hg-git part xii: we're live; mapfiles |
This is a long overdue blost post to say that gecko-dev and gecko-projects are fully live and cut over (and renamed, for those who have been looking at the now-defunct links in my previous blog posts).
Gecko-dev is on git.mozilla.org and on github; gecko-projects is on github only until it's clear that we won't need regular branch and repo resets. We have retired the following github repos, which we will probably remove after a period of time:
The mapfiles are still in http://people.mozilla.org/~asasaki/vcs2vcs/, which is not the final location. There's a combined mapfile in here for convenience, but the gecko-mapfile is the canonical mapfile.
I've been working on a db-based mapper app, which, given a git or hg sha, would allow us to query for the corresponding sha. It also allows for downloading the full mapfile for a repo (gecko.git, gecko-dev, gecko-projects) or the combined full mapfile of two or more of those repos. It also allows for downloading the shas inserted since a particular datetime. Screenshots of my development instance are here.
Bear with me; I've got lots on my plate and not enough time. Mapper is in the works, however, and I think this should smooth over some of the rough edges when dealing with both hg and git. Additional eyeballs and/or patience would be appreciated!
My db-based mapper repo is here.
The db-based mapper bug is here.
The permanent upload location bug is here.
|
|
Doug Belshaw: The Web Literacy Standard is dead (long live the Web Literacy Map!) |
I spent a good chunk of 2013 working with colleagues and a community of stakeholders creating a Web Literacy Standard. The result is testament to the way Mozilla, as a global non-profit, can innovate on behalf of users. I’m delighted with what we created.
Until recently, the literature and language in the field of Web Literacy has been relatively undeveloped. This is important, because although it doesn’t always seem like it, words are hard:
This seems to be a problem for anyone trying to explain the unfamiliar. If you invent new words, few people will know what you’re talking about, but if you make analogies using existing words, you bring along all their context, whether you want to or not.
In early 2013 we wanted to avoid creating just another ‘framework’. Why? Although we wanted to be more descriptive than prescriptive, we still didn’t want people to just pick-and-choose the bits they liked. Instead, we wanted to co-create something more holistic. That’s we chose to call what we were creating a ‘Standard’. The idea was for the community to come together to build something they felt they could align with.
And that’s exactly what we did. We created something that, while not perfect, we can feel a justifiable pride about.
A problem we’ve encountered is that because words are hard and dependent upon context, ‘Standard’ can have negative connotations – especially in North America. So after announcing the first version of the Standard at MozFest we, as a community, started to have a discussion as to whether ‘Standard’ was a word we wanted to keep.
The result of that consultation is that we’ve decided to move away from ‘Standard’ to describe what we’re doing here. While we could fight a valiant crusade on behalf of the term, it doesn’t seem like a battle that’s worth our time and effort. It’s better to focus on winning the war. In this case, that’s ensuring the newly re-titled Web Literacy Map underpins the work we do around Mozilla Webmaker. After all, we want 2014 to be the year we move beyond the ‘learn to code’ movement and focus on a more holistic understanding of web literacy.
We decided on Web Literacy ‘Map’ because we found that most of the language we used to describe what we’re doing was cartographic in nature. Also, it means that our designers have a lot more scope around visual metaphors! It’s going to be (and, importantly, look) – amazing!
|
|
Ludovic Hirlimann: For those of you attending FOSDEM |
In a a few weeks it will be Fosdem week-end. Something I’ve been attending since 2004.
This year I’d like to tell people that care about email privacy that fosdem has the biggest pgp key signing party in Europe. If you use pgp, or gnupg you might want to join the party.
To do so you’ll need to register before the 30th of January and follow the detailed instructions at https://fosdem.org/2014/keysigning/ .
update: People are sending plenty of keys it’s going to be a great event.
|
|
Nick Cameron: A rough guide to DXR |
http://featherweightmusings.blogspot.com/2014/01/a-rough-guide-to-dxr.html
|
|
Mark Surman: MoFo 2014 plans |
I’m excited about 2014 at Mozilla. Building on last fall’s Mozilla Summit, it feels like people across the project are re-energized by Mitchell’s reminder that we are a global community with a common cause. Right now, this community is sharply focused on making sure the web wins on mobile and on teaching the world how the web works. I’m optimistic that we’re going to make some breakthroughs in these areas in the year ahead.
Last month, I sat down with our board to talk about where we want to focus the Mozilla Foundation’s education and community program efforts in 2014. We agreed that two things should be our main priorities this year: 1. getting more people to use our learning tools and 2. growing our community of contributors. I’ve posted the board slides (pdf) and a screencast for people who want a detailed overview of our plans. Here is the screencast:
If you are just looking for a quick overview, here are some of the main points from the slides:
In addition to these slides, you can also find detailed workplans for Webmaker, Open Badges, Open News and other MoFo initiatives on the Mozilla Wiki.
At the Mozilla Summit, we imagined a bold future 10 years from now: one where the values of the web are built into all aspects of our connected lives and where the broad majority of people are literate in the ways of the web. In this world, Mozilla is a strong global movement with over a million active contributors.
We move towards this world by building real things: a widely used mobile operating system based on the web; new ways to store and protect personal information online; content and tools for teaching web literacy. I’m excited working on the education and community sides of all this in 2014 — I think we can make some breakthroughs.
As always, I’d love to hear your thoughts on our plans and the year ahead, either as comments here or by email.

http://commonspace.wordpress.com/2014/01/14/mofo-2014-plans/
|
|
Selena Deckelmann: Everyday Postgres: Specifying all your INSERT columns |
Postgres has so many convenient features, including the ability to not provide a list of columns to an INSERT.
For example:
CREATE TABLE temp_product_versions ( LIKE product_versions );
INSERT INTO temp_product_versions ( SELECT * from product_versions );
That’s pretty badass.
However, you may encounter trouble in paradise later if you use this kind of shortcut in production code.
See if you can spot the error in this code sample below.
Here’s the error message:
ERROR: column "is_rapid_beta" is of type boolean but expression is of type citext
LINE 10: repository
^
HINT: You will need to rewrite or cast the expression.
QUERY: INSERT INTO releases_recent
SELECT 'MetroFirefox',
version,
beta_number,
build_id
update_channel,
platform,
is_rapid,
is_rapid_beta,
repository
FROM releases_recent
JOIN products
ON products.product_name = 'MetroFirefox'
WHERE releases_recent.product_name = 'Firefox'
AND major_version_sort(releases_recent.version)
>= major_version_sort(products.rapid_release_version)
CONTEXT: PL/pgSQL function update_product_versions(integer) line 102 at SQL statement
And here’s the code (long!)
I’m sure quite a few of you found the problem right away. For the rest of us…
Here’s the error message you get if you specify the columns for the INSERT:
ERROR: INSERT has more target columns than expressions
LINE 10: repository
^
QUERY: INSERT INTO releases_recent (
product_name,
version,
beta_number,
build_id,
update_channel,
platform,
is_rapid,
is_rapid_beta,
repository
)
SELECT 'MetroFirefox',
version,
beta_number,
build_id
update_channel,
platform,
is_rapid,
is_rapid_beta,
repository
FROM releases_recent
JOIN products
ON products.product_name = 'MetroFirefox'
WHERE releases_recent.product_name = 'Firefox'
AND major_version_sort(releases_recent.version)
>= major_version_sort(products.rapid_release_version)
CONTEXT: PL/pgSQL function update_product_versions(integer) line 112 at SQL statement
Now, it should be completely obvious. There’s a missing comma after build_id.
Implicit columns for INSERT are a convenient feature when you’re getting work done quickly, they are definitely not a best practice when writing production code. If you know of a linting tool for plpgsql that calls this kind of thing out, I’d love to hear about it and use it.
|
|
Melissa Romaine: Engaging in 2014 |
http://londonlearnin.blogspot.com/2014/01/engaging-in-2014.html
|
|






