Были представлены новейшие аудио- и видеотехнологии для создания как мобильных роботов, так и стационарной робототехники. В частности, для создания виртуальных референтов была предложена технология, являющая собой сочетание распознавания русской речи, русско-английского перевода и синтеза английской речи. Компьютер теперь способен переводить речь с русского языка на английский и произносить перевод. Кроме того, создан способ сочетания распознавания русской речи с личностью говорящего. Система осуществляет распознавание произносимой фразы с идентификацией личности говорящего после 1–2 минут обучения; на вход системы при этом поступают произвольные фразы. Пока что система оперирует с ограниченным набором предложений: несколько вопросов и последовательность числительных.
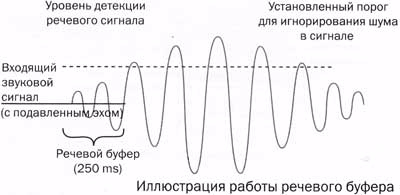
Существенный прогресс в создании виртуальных референтов становится возможен благодаря технологии непрерывной обработки речевого сигнала CSP (ContinuousSpeech Рrосеssing), разработанной и реализованной Intel для высокопроизводительных систем распознавания речи (материал на эту тему подготовила фирма Comptek). Важнейшее интеллектуальное свойство CSР — функция bаrge-in, которая даёт возможность перебивать виртуального референта, не дожидаясь окончания произнесения им приветствий и/или дежурной информации, что позволяет клиенту не тратить время на прослушивание всего меню, а вступать в диалог сразу. Выделенная референтом ключевая фраза этoro вступления клиента с речевым буфером (см. рис.) отправляются на хост-процессор модуля распознавания, который распознаёт фразу и даёт команду на исполнение.
Технология работы CSP исходит из того, что когда клиент произносит что-то, входящий сигнал представляет собой смесь из голосового сигнала, эха от воспроизведения и шума в линии (если речь идёт о применении технологии в телефонных автоинформаторах). Для обработки такого сигнала требуется большая вычислительная мощность. CSP берёт эти функции на себя, выполняя их на DSP-процессорах плат Dialogic, и, таким образом, разгружая хост-процессор компьютера. Проводя предварительную обработку сигнала, CSP отпpaвляет модулю распознавания, выполняемому на хост-процессоре компьютера, «чистый» речевой фрагмент, готовый к распознаванию. Это позволяет значительно повысить общую производительность системы и увеличить размер распознаваемых словарей. Фактически, CSP — это набор функций бортового программного обеспечения firmware плат Intel Dialogic, отвечающих за обработку звукового сигнала. Функции CSP в режиме реального времени определяют, что данный звуковой сигнал представляет собой человеческую речь, производят предварительную его обработку и передают на хост-процeccop компьютера в удобном для модуля распознавания виде. CSP firmware обеспечивает выполнение DSP-процессором платы следующих функций: полнодуплексный режим (позволяющий одновременно воспроизводить и записывать звук на каждом из каналов), эхоподавление, определение начала звукового сигнала в линии, речевой буфер (облегчающий проблему «рваной речи»).
Технология Intel ContinuousSpeech Рrосеssing поддерживается в действующем продукте SpeechPearl, осуществляющем распознавание речи в телефонии и базирующемся на русских фонемах. SpeechPearl обеспечивает дикторонезависимое распознавание без необходимости настройки на голос, распознавание непрерывной речи, поддержку 45 языков, включая русский (но при необходимости возможен и дикторозависимый режим работы и режим настройки на голос). Словарь распознаваемых слов — произвольный, составляется разработчиком приложения самостоятельно. Максимальный размер возможного словаря в одном приложении — 1,5 млн распознаваемых слов.
То есть, SpeechPearl — это интегрированная среда разработки приложений с распознаванием речи. В состав этой среды входит набор инструментов, оптимизированных для создания, тестирования и настройки приложений распознавания речи. Встроенный графический интерфейс способствует созданию, настройке и тестированию грамматик и языковых ресурсов. После того, как разработчик приложения создал диалоги и определил задачи распознавания, SpeechPearl предоставляет соответствующий инструмент для создания и оптимизации грамматик и языковых ресурсов. В состав основных компонентов SpeechPearl входит инструмент, позволяющий проверить, покрывается ли слово, сказанное клиентом, соответствующей грамматикой, а также инструмент, позволяющий создавать «тренируемые» языковые модели. А. П. Барсуков, журнал "ТКТ", № 1, 2004 г.
В дополнение к теме
Тема электронного слуха на VI Международной конференции «Цифровая обработка сигналов и её применение» (по материалам РНТОРЭС им. А. С. Попова).
Явления основного тона (Авиационный научно-технический комплекс «Антонов»). В современных устройствах цифровых звукотехнических систем требуются акустические кодеры, обеспечивающие кодирование звукового сигнала с минимальным информационным объёмом без потери качества. Первоначально этого можно достичь при параметрическом кодировании звукового сигнала. Опыт показывает, что для успешного лечения этой проблемы, а также для создания многоязычных «естественных» речевых интерфейсов, не требующих специальной подготовки пользователей, настройки оборудования при их смене и работающих в реальной акустической среде, необходимо определение слуховых параметров звукового сигнала - то есть, физических параметров звукового сигнала, кодируемых слуховой системой. В докладе рассмотрены результаты психоакустических экспериментов по восприятию характерных представителей сложных звуков, давшие в литературе названия таким явлениям, как унисон и явление остатка.
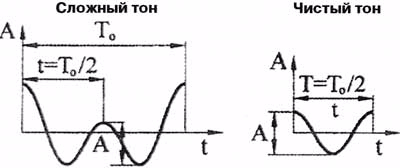
С физической точки зрения, при унисоне еще до улитки происходит сложение чистых тонов в пределах периода основного тона, что приводит к образованию сложного тона, который интегрально характеризуется своим временным профилем. С психологической точки зрения звуки унисона воспринимаются слитно.
Так как одинаковые звуки различных октав при одновременном звучании воспринимаются слитно, то с целью исследования восприятия звуков унисона, при раздельном их бинауральном предъявлении, были проведены психоакустические эксперименты с использованием метода дихотической стимуляции. Этот метод позволяет раздельно варьировать сигналы в двух головных телефонах, вводя межушную разницу стимуляции по интенсивности, частоте, фазе и их комбинациям.
Уровень сигнала чистого тона при слуховом унисоне:
То – период основного тона
t – временная координата тона высшей октавы
Т – период чистого тона
А – уровень тона высшей октавы
Результаты эксперимента показали, что подача на одно ухо сигнала сложного тона, состоящего из двух одинаковых звуков различных октав, а на второе – сигнала чистого тона с частотой звука высшей октавы в сложном тоне и уровнем, указанным на рисунке, вызывает ощущения слуховых образов «отфильтрованного» звука низшей октавы в ухе, на которое подаётся сложный тон, и слухового унисона звука высшей октавы в созвучии с чистым тоном в виде слитного звукового образа, латерализованного внутри головы в верхней центральной её части. Таким образом, слуховой унисон в приведённом случае – это латерализация двух одинаковых звуков высшей октавы. На основании этого можно утверждать, что слуховыми параметрами тона высшей октавы в приведённом сложном тоне является временная координата пика и его уровень во временном профиле периода основного тона (см. рис.).
Синтетический слуховой образ, вызываемый одновременным звучанием верхних частот и имеющий высоту, равную высоте основной частоты, Схоутен назвал остатком. Предположение Схоутена и Ликляйдера о том, что физическим признаком резидуального тона является период временной огибающей сложного звука, а также опровержение Де Буром этой гипотезы было проверено в психоакустических экспериментах с использованием слухового унисона (т. е. восприятия звуков унисона при раздельном их предъявлении с помощью двух головных телефонов). Эксперименты показали, что восприятие основного тона, частота которого отсутствует в физическом стимуле, происходит при условии, что ряд частот в физическом стимуле являются арифметической прогрессией, разность которой равна наибольшему общему делителю её членов. При таком условии высота остатка равна высоте основного тона, период которого равен интервалу между главными пиками во временном профиле сложного звука. Восприятие резидуального тона при прослушивании такого сложного звука в докладе предложено назвать «явлением основного тона» (ЯОТ).
Показательно ЯОТ демонстрируется благодаря феномену латерализации, например, в слуховом унисоне стереосигнала сложного тона (360 + 450 + 540) Гц в одном канале и его основного тона 90 Гц в другом канале с уровнем 30% от уровня сигнала сложного тона. ЯОТ, наряду с другими, подтверждает предположение о том, что слуховая система отслеживает временную периодичность звукового сигнала, использует этот параметр для кодирования и формирования его высоты. Это явление однозначно определяет слуховой параметр высоты основного тона, период которого является интервалом кодирования слуховых параметров звукового сигнала. А. Барсуков, журнал "ТКТ", № 10, 2004 г.
Санкт-Петербург, 19 октября 2011 г. Компания PROMT приняла участие в ежегодной конференции TAUS (Translation Automaton User Society, ассоциация пользователей автоматизированного перевода), прошедшей 6-7 октября 2011 г. в Калифорнии.
На этом мероприятии традиционно обсуждаются актуальные вопросы автоматизации перевода, инновационные технологии в сфере локализации, а также вопросы сотрудничества разработчиков автоматического перевода, бюро переводов, локализационных агентств и компаний-клиентов. В программный комитет конференции входят представители таких компаний, как Oracle, Intel, Symantec, Adobe, Microsoft, McAfee и других, а среди участников этого года были сотрудники AsiaOnline, Cisco, Caterpillar, Dell, eBay, Lionbridge, MultiCorpora, Siemens.
PROMT участвовал в совместной презентации с крупнейшей системой электронных платежей PayPal, поставщиком решений по машинному переводу Safaba Translation Solutions и международной локализационной компанией Welocalize. Представитель PROMT рассказал об участии компании в проекте по внедрению решений по автоматическому переводу в компании PayPal.
PayPal работает на рынке многих стран, и для компании имеет существенное значение быстрый перевод на национальные языки контента разного типа, включая пользовательские интерфейсы, онлайн-справку, часто задаваемые вопросы, сообщения об ошибках, типовые письма службы поддержки, руководства пользователя, электронную почту.
В рамках совместного проекта PROMT создал уникальную интеграционную платформу по машинному переводу для локализационных целей. Эта платформа уже сейчас поддерживает 10 направлений перевода, позволяет интегрировать решения по машинному переводу сторонних разработчиков, полностью интегрируется в локализационный процесс, использующий решение на базе Translation Memory – WorldServer (Idiom), обеспечивает сохранение метаданных и другой форматной информации, которыми традиционно насыщены тексты по программному обеспечению.
Это решение работает на базе PROMT Translation Server – серверного решения PROMT с большими возможностями интеграции в документооборот и информационные процессы компании-клиента.
«Мы все живем в эпоху интернета, когда люди годами могут вместе работать над одним проектом и ни разу не встречаться, – рассказывает Юлия Епифанцева, директор по развитию PROMT. – А конференции TAUS дают нам такую возможность. Разработчики и поставщики решений по машинному переводу могут, наконец, лично увидеть своих коллег и клиентов, познакомиться с разработками других компаний и услышать о проблемах и насущных задачах по локализации, возникающих у компаний разного типа. Это помогает нам идти вперед».
15.05.2013. Статистический перевод PROMT представят на AINL
На второй конференции «AINL: Искусственный интеллект и естественный язык» руководитель группы статистических исследований PROMT Александр Молчанов выступит с докладом «Статистические методы в машинном переводе: проблемы роста».
Компания PROMT, которая занимается этой темой с 2009 года, сейчас разрабатывает статистические системы для финского, казахского, китайского, японского и других языков, а также гибридные системы для еще нескольких языков. Первые статистические и гибридные системы уже сданы заказчикам и успешно работают, однако в ходе дальнейших исследований разработчики сталкиваются с рядом типичных проблем.
Во-первых, это объем и качество исходных данных. Для «обучения» систем необходимы большие объемы сопоставимых текстов на двух языках, которые не всегда легко найти, кроме того, нужно обработать тексты перед использованием.
Вторая группа задач связана с обработкой результатов машинного перевода, которую также необходимо автоматизировать.
Наконец, третья группа задач, характерная для машинного перевода в целом, – это создание оптимальной системы оценки качества.
О том, что делают для решения этих проблем исследователи PROMT, можно будет узнать в ходе конференции AINL. Она пройдет 17-18 мая 2013 в Санкт-Петербурге и будет посвящена распознаванию и синтезу речи, искусственному интеллекту, извлечению данных, data mining и другим вопросам.
Язык кур. «Глупая курица» — так назвал свою книгу западногерманский ученый Эрих Баемер, хотя его глубокое убеждение состоит именно в том, что курица — птица умная и в высшей степени дипломатичная.
В течение пятидесяти лет Эрих Баемер, член научно-исследовательского института Макса Планка, внимательно наблюдал поведение кур и пришел к выводу, что у них есть свой язык, более того: все породы кур разговаривают на одном и том же языке. Доктору Баемеру удалось установить, что словарь куриного языка состоит из 35 «предложений», которые выражают самые разные эмоции кур в зависимости от обстоятельств.
К этой своеобразной куриной энциклопедии Баемер приложил коллекцию звукозаписей с различными сигналами, которые куры подают в минуту опасности. Он установил, что есть четыре или пять видов сигналов, предупреждающих о серьезной или отдаленной опасности с воздуха или с земли.
Доктор Баемер утверждает, что куры разных пород отлично понимают друг друга и все же в их «языке» наблюдаются различные акценты. К тому же, по его мнению, есть куры разговорчивые и есть .молчаливые. Журнал "Знание-сила" времён СССР
Интерпретатор текста (Академия ФАПСИ) обеспечивает анализ массивов текстовой информации в следующих аспектах: классификация документов по смыслу (рубрицирование), выделение основных тем (масштабируемое реферирование), визуальный анализ количественных данных, входящих в текст. Входными текстами для системы являются русскоязычные текстовые файлы форматов rtf, txt. Тип текстов - повествование, описание. Стиль - публицистический. Тип предложений - простое, повествовательное, двухсоставное. Интерпретатор основан на: рекурсивной модели поддержки принятия решений; семантико-прагматической модели анализа текстов; продукционно-фреймовой модели представления знаний; технологии OLAP-текст, объединяющей методы компьютерной лингвистики с методами визуального анализа хранилищ данных.
Психолингвистическая экспертная система "ВААЛ" осуществляет анализ текста, оценку воздействия агитационных материалов, выступлений и рекламы на подсознание, составление текстов с заданными параметрами воздействия, генерацию новых слов (например, названий фирм и торговых марок) тонкую настройку текста на целевую аудиторию. Особенности системы: оценка неосознаваемого фонетического воздействия текстов и отдельных слов, генерирование слов с заданными фоносемантическими характеристиками, редактирование текстов до достижения указанных характеристик воздействия, корректировка текстов с использованием встроенного словаря синонимов, настройка на различные социальные и профессиональные группы людей, оценка уровня агрессивности текстов, оценка уровня архетипичности текстов, оценка сексуальных характеристик текстов, оценка психологической акцентуации автора текста, определение используемых в текстах метапрограмм, оценка звуко-цветовых характеристик текстов, оценка ритмических характеристик текстов, конструирование новых фоносемантических шкал и подключение их к системе, факторный анализ данных.
SpeechPearl — интегрированная среда разработки телефонных приложений с распознаванием речи. В состав входит набор инструментов, оптимизированных для создания, тестирования и настройки приложений распознавания речи. Встроенный графический интерфейс предоставляет дружественный интерфейс для создания, настройки и тестирования грамматик и языковых ресурсов. После того, как разработчик приложения создал диалоги и определил задачи распознавания, SpeechPearl предоставляет соответствующий инструмент для создания и оптимизации грамматик и языковых ресурсов.
Основные компоненты SpeechPearl: SpeechXpert — графическая среда для разработки, компиляции и оптимизации грамматических и лексических блоков распознавания, проверки и редактирования лексиконов и конфигурирования серверов SpeechPearl; Transcription Station — позволяет протоколировать диалоги из работающего приложения в виде, удобном для оценки качества распознавания и подстройки системы; SPEval (SpeechPearl Evaluation) — инструмент оценки качества работы системы; позволяет проверить, покрывается ли слово, сказанное абонентом, соответствующей грамматикой, устанавливать точки останова на разных уровнях в соответствии с разными режимами оценок, находит оптимальные "уровни уверенности" и измеряет производительность для различных наборов параметров распознавания; SPTrain — позволяет создавать "тренируемые" языковые модели, что повышает производительность и ускоряет сам процесс распознавания; SpeechPath — контроллер распределенных ресурсов
Разработка крупных многорежимных систем с распознаванием речи требует интеллектуального управления распределенной архитектурой речевых серверов. Это необходимо для надежности, масштабируемости и эффективности использования ресурсов. SpeechPath — это контроллер ресурсов. Это программный модуль, выполненный в клиент"серверной TCP/IP архитектуре. Модуль может распределять множество параллельных запросов различных типов, что позволяет осуществлять прозрачную интеграцию различных ПО распознавания речи
CSP (Continuous Speech Processing) — технология непрерывной обработки речевого сигнала, разработанная и реализованная Intel для высокопроизводительных систем распознавания речи. CSP предоставляет разработчикам речевых приложений следующие преимущества: Масштабируемость — делает возможным поэтапный переход от малых систем к крупным; Емкость — позволяет строить системы с большим числом портов
Ключевым функциональным преимуществом, которое дает CSP, является barge-in — возможность перебивать систему, произнося команды, не дожидаясь окончания проигрывания приветствий и/или меню. Это позволяет абонентам, уже знакомым с системой, не тратить время на прослушивание всех проигрываемых пунктов меню, а произносить командынемедленно. Поэтому с такой системой значительно приятней общаться, не говоря уже о том, что это экономит время звонящего и позволяет системе обслужить большее количество абонентов.
Технология непрерывной обработки речи CSP
Обычно, когда абонент произносит что"то во время воспроизведения, входящий сигнал представляет собой смесь из голосового сигнала, эха от воспроизведения и шума в линии. Для обработки такого сигнала требуется большая вычислительная мощность. CSP берет эти функции на себя, выполняя их на DSP-процессорах плат Dialogic и таким образом разгружая хост"процессор компьютера. Проводя предварительную обработку сигнала, CSP отправляет модулю распознавания, выполняемому на хост"процессоре компьютера, "чистый" речевой фрагмент, готовый к распознаванию. Это позволяет значительно повысить общую производительность системы, увеличить размер распознаваемых словарей и существенно повысить емкость решения.
CSP — это набор функций бортового программного обеспечения firmware плат Intel Dialogic, отвечающих за обработку звукового сигнала. Функции CSP в режиме реального времени определяют, что данный звуковой сигнал представляет собой человеческую речь, производит предварительную его обработку и передает на хост-процессор компьютера в "удобном" для модуля распознавания виде.
Такой подход позволяет существенным образом разгрузить хост-процессор компьютера. Без использования CSP хост-процессор непрерывно получает данные от DSP-платы Dialogic со всех ее телефонных портов, получая тем самым серьезную загрузку. Кроме того, этот получаемый от DSP-сигнал никак не обработан, и хост-процессору нужно самостоятельно обрабатывать его еще до того, как отдать на вход модулю распознавания (например, определять, представляет ли этот сигнал человеческую речь или посторонний звук). Все это дает лишнюю нагрузку на хост, ухудшает производительность и качество распознавания, снижает возможную емкость системы и заставляет устанавливать более мощные и дорогостоящие процессорные ресурсы. Всего этого удается избежать при использовании плат с firmware CSP. CSP firmware обеспечивает выполнение DSP-процессорам платы следующих функций:
Полнодуплексный режим работы — позволяет одновременно проигрывать и записывать звук на каждом из каналов
Эхоподавление — до 16 ms
VAD — Voice Activity Detection определяет начало звукового сигнала в линии
Речевой буфер — существенно облегчает проблему "рваной речи" и повышает качество распознавания
Сигнализация голосового события — работая совместно с VAD, позволяет CSP firmware посылать сообщения хост"приложению
Voice_activated streaming/recording — отправляет поток голосовых данных на хост только при определении голосовой энергии в канале
Система эхоподавления и VAD позволяют реализовывать функции barge-in, что предоставляет возможность звонящему начинать говорить, не дожидаясь окончания проигрывания приветствия или меню. Функция barge-in аппаратно прерывает проигрывание, чтобы не мешать говорить абоненту. В то же время возможны сценарии, когда система должна реагировать только на конкретное слово звонящего, поэтому можно отключить автоматическое прерывание воспроизведения, чтобы оно не прерывалось, пока не будет распознана конкретная команда абонента. По материалам Comptec
"Голосовое управление для мобильных устройств" (ЗАО "Титан информационный сервис") - проект, победивший в номинации "Лучший инновационный проект" Конкурса Русских Инноваций. Это система распознавания голоса, независимая от диктора (не требует предварительной настройки на голос владельца). Разработчики утверждают, что средний уровень безошибочности средней коммерческой системы распознавания составляет 70%, немногим удалось достичь уровня 90%, а их система в тестах показала уровень 95%.
Система распознавания речи, разработанная компанией "Сакрамент" (г. Минск) не зависит от языка, имеет точность распознавания около 98%. Размер словаря виртуально не ограничен. Распознавание - в реальном времени с использованием активных словарей. Также разработана система идентификации голоса, предназначенная для автоматического сравнения неизвестного голоса с фонотекой известных голосов. Не зависит от языка, обеспечивает уровень ложного пропуска FAR=0,01, уровень ложной тревоги FRR=0,28%, уровень равных ошибок ложного пропуска и ложной тревоги EER=1,2%.
"Шепот" - автоматизированная система оценки защищенности выделенных помещений по виброакустическому каналу, разработанная фирмой "Маском". Система предназначена для полностью автоматического измерения акустических и виброакустических параметров ограждающих и инженерных конструкций выделенных помещений и расчета параметров защищенности в соответствии с действующими нормативно-методическими документами. Система может быть построена на базе прецизионных интегрирующих шумомеров фирмы Larson&Davis модели 812, 824 или Brul&Kjaer, дополненного оригинальными элементами и оборудованием, обеспечивающими проведение всего комплекса измерений в автоматическом режиме.
Для верификации голоса фирма SPIRIT Corp. разработала систему, которая, при среднем количестве парольных фраз, равном 2, удостоверяет голос с вероятностью принять чужого за своего равной 0,01%, а отвергнуть своего - 0,1%. Кроме того, разработан дикторонезависимый распознаватель речевых команд, работающий при ухудшении соотношения с/ш до 6 дБ и обеспечивающий надёжность 99%. Создан прототип и текстонезависимой системы, который, в отсутствие сильных помех (с/ш>20 дБ), с вероятностью до 99% идентифицирует по голосу человека в группе из 10-15 людей при условии, что перед этим был обучен данным человеком в результате произнесения им произвольной фразы продолжительностью до 60 с.
Записи радиопереговоров военных лётчиков в критические моменты рассматриваются в качестве речевых баз данных для анализа стрессовых характеристик человека, когда изменяются параметры формант, тона, пауз. Этот анализ должен помочь для идентификации состояния разбалансированности человека, возникающего, когда он вынужден говорить неправду.
Машинное распознавание речи примерно на 25% лучше человека распознаёт иноязычную для него речь, поскольку человек "тормозит" на поисках семантической связи между незнакомыми сочетаниями слогов и отдельных фонем.
Сканер-сонар высокого разрешения помог фирме Advanced Digital Communications обнаружить неподалёку от берегов Кубы объекты, похожие на объекты архитектуры. Впоследствии искусственный характер происхождения этих объектов был подтверждён видеосъёмкой подводного робота. Распознавание изображения и речи - теперь функция микросхемы фирмы STMicroelectronics, хранящей данные во флеш-памяти со скоростью их считывания 1,2 ГБайт/с.
Распознавание речи на Макинтош. Фирма MacSpeech Inc. выпустила новую версию iListen. iListen - это программа для распознавания речи, которая использует технологию "TalkAnywhere", позволяющую диктовать текст практически в любом приложении. Программа переводит речь в напечатанный текст. iListen настраивается под конкретного пользователя. Это значит, что вы должны потратить некоторое время, "обучая" iListen узнавать ваш голос. iListen работает в Mac OS 9 и Mac OS X. В версии 1.6.4 исправлено несколько ошибок. Кроме того, в нее добавлена возможность обращения к пунктам меню Mac OS X Services и поддержка иерархических меню в Script Editor.
Система "Речевой портал", созданная фирмой "Светец", обладает функцией распознавания речи, позволяющей реализовать сценарии услуг, приближенные к сценариям обслуживания с помощью оператора.
До 180 голосовых команд способна понимать киберсобака AIBO благодаря записанной на флеш-карте программе AIBO Mind.
Центр Речевых Технологий стал победителем в номинации "Лучшее техническое решение для ввода звука" на международной выставке-конференции Speech TEK 2003. В числе разработок ЦРТ - двухканальная встраиваемая плата (50 х 40 х 6 мм) шумоочистки речевых сигналов в каналах передачи звуковой информации. Плата имеет двухканальный аналоговый вход/выход, линейный вход, вход для динамических и электретных микрофонов (1,5 В), линейный выход, выход на головные телефоны; частота дискретизации - до 22050 Гц. Алгоритмы шумоочистки - адаптивная фильтрация широкополосных шумов (подавление широкополосных, гармонических и импульсных шумов и помех в одном или одновременно двух каналах) и стереофильтрация (подавление шумов и помех любого типа при наличии опорного канала). Кроме того, разработан набор аппаратных и программных средств для изменения параметров шумоочистки и установки новых алгоритмов обработки с помощью ПЭВМ.
Акустический микроскоп для визуализации с высоким пространственным разрешением микроструктур в объёме исследуемого образца и на его поверхности разработан в Институте биохимической физики им. Н. М. Эмануэля. Прибор основан на растровом принципе получения изображений с помощью фокусированного ультразвукового пучка. Посредством механического перемещения акустического объектива таким пучком сканируют исследуемый объект и регистрируют отраженные эхо-сигналы. По накопленным данным компьютер восстанавливает изображение указанной оператором области объекта.
Речевой идентификатор разработан в Центре защищенных технологий. Система осуществляет регистрацию аудиосигналов и телефонных сообщений с целью получения индивидуальных "отпечатков голоса". Получение индивидуальных "отпечатков голоса" (цифровых сонограмм) достигается путём использования технологии вейвлет-анализа. Для обработки аудиозаписей используется пакет программ "Речевой микроскоп".
Речевой микроскоп разработан в МГТУ им. Н. Э. Баумана. В приборе используется математический аппарат вейвлет-анализа. Особенности прибора – повышенное разрешение при построении изображений «видимая речь» или сонограмм, а также адаптация под структуру сигнала «тон»-«шум»-«пауза» путём выбора «материнского» вейвлета.
Услуги по распознаванию и синтезу русской речи предложила фирма Cayo communications. Программно-аппаратный комплекс выполняет следующие операции:
- Распознавание русского языка (Automatic Speech Recognition - ASR).
- Автоматизированная обработка запросов со всех телефонов, включая поддерживающие импульсный набор, наиболее естественным для человека образом (например: ТЯ хочу заказать билет на самолёт из Москвы в Челябинск") Помимо русского языка поддерживаются ещё более 30 языков, включая английский, немецкий, французский, испанский и др.
- Русскоязычный синтез речи (Text-to-Speech - TTS ). Поддерживает все SAPI5-совместимые модули синтеза речи (Elan, AT&T, Sakrament и другие). Используется для озвучивания динамически меняющейся информации.
- Русскоязычный IVR.
- Приветствие и выбор услуги: автоматизированное приветствие и выбор вида запроса (продажи, тех. поддержка, клиентская служба). Используется для выбора наиболее квалифицированной группы агентов.
- Ожидание в очереди – исключаются "потерянные" вызовы: если все агенты заняты, клиент удерживается на линии, прослушивая музыку, рекламную информацию, прерываемую сообщениями о среднем времени ожидания.
- Обслуживание во внерабочие часы – клиентам сообщается соответствующая информация и вызовы направляются на речевую почту (по желанию).
- Заранее предустановленные шаблоны – варианты организации речевого меню, словари фраз для озвучивания времени, цифр, состояния счёта, прогноза погоды и т.д.
- Контроль нагрузки – на случай непредвиденной пиковой нагрузки, одна или две входящие линии резервируются для произнесения сообщения вида "Все входные линии заняты. Пожалуйста, перезвоните позднее" – вежливый ответ всегда лучше сигнала "занято".
Робот-переводчик с собачьего языка разработан фирмой Takara. Программа, записанная на карте памяти, работающей с сотовым телефоном, способна анализировать собачий лай на расстоянии до 40 м.
ТРАЛ - автоматизированный комплекс распознавания дикторов в телефонном канале. Процедура идентификации заключается в автоматическом попарном сравнении «дикторских карточек», в которых закодированы индивидуальные характеристики голоса и речи говорящего. Основные характеристики: показатели надежности при идентификации «дальнего» диктора:
91% при сравнении пары речевых сигналов длительностью не менее 96 с каждый;
85% при сравнении пары речевых сигналов длительностью 16 с и 96 с соответственно;
не менее 90% при сравнении пары речевых сигналов длительностью 16 с и 96 с, передаваемых по одному и тому же каналу связи;
- время создания одной «дикторской карточки» - 3-4 с;
- время сравнения одной пары «дикторских карточек» (принятия решения о принадлежности голоса и речи конкретному лицу) - не более 0.7 с (при использовании ПК на базе Реntium III/1 ГГц);
- максимальное количество эталонов («дикторских карточек») для проведения автоматического сравнения - 100000.
Требования к сигналу:
- формат сигнала - ИКМ 16 бит;
- частота дискретизации 8 000 или 11 025 Гц;
- полоса частот сигнала - не хуже 300-3400 Гц;
- соотношение сигнал/шум - не менее 10 дБ;
- продолжительность сигналов при попарном сравнении - не менее 16 и 96 с.
ТЕРРИТОРИЯ - автоматизированная система диагностики акцентов и диалектов русской устной речи. Позволяет оперативно установить принадлежность говорящего к той или иной акцентно-диалектной группе и указать географический регион (регионы), где диктор получал начальное и школьное образование, или в котором проживал длительное время. Краткая характеристика системы: описывает и диагностирует 64 акцентно-диалектных зоны русского языка; 9 акцентов основных мировых языков (английский, арабский, итальянский, испанский, китайский, немецкий, французский, шведский, японский); 14 акцентов языков республик бывшего СССР; 33 региональных диалекта русского языка Российской Федерации; 6 региональных диалектов русского языка на Украине; по 2 региональных диалекта русского языка в Белоруссии, Литве и Грузии. Состав системы: мультимедийный справочник по акцентам и диалектам русской устной речи; модуль заполнения «дикторской карточки», содержащей набор установочных данных, список лингвистических особенностей и ссылку на звуковой файл с записью речи неизвестного диктора; модуль диагностики, производящий сравнение «дикторской карточки» с материалами справочника и формирующий текстовый отчет о результатах диагностики; специализированный сигнальный редактор; база данных эталонов звучания особенностей речи для отдельных вариантов акцентов и диалектов русского языка, содержащая около 9000 примеров (более 400 различных дикторов). Требования к сигналу: формат сигнала - ИКМ 8 или 16 бит; частота дискретизации - 8000-22050 Гц; полоса частот сигнала - не хуже 300-3400 Гц; соотношение сигнал/шум - не менее 15 дБ; продолжительность - не менее 200 с.При соблюдении данных требований и описании сигнала не менее, чем 10 признаками, надежность диагностики диалектной принадлежности диктора составляет не менее 75%.
ИКАР Лаб - Инструментальный комплекс криминалистического исследования фонограмм речи. Области применения: идентификация дикторов по фонограммам речи; шумоочистка и текстовая расшифровка низкокачественных фонограмм речи; диагностика личности говорящего; установление подлинности фонограмм речи и выявление следов монтажа; установление дословного содержания низкокачественных фонограмм речи. Состав: программный пакет ввода, визуализации и анализа звуковых сигналов Wawe Assistant Pro; программный комплекс шумоочистки и повышения качества звуковых сигналов в реальном масштабе времени Sоund Сlеаnеr; программа ввода и ускоренной текстовой расшифровки речевых сигналов "Транскрайбер"; внешнее устройство ввода/вывода звуковых сигналов SТС-Н216 или SТС-Н246 в комплекте с головными телефонами.
В инфразвуковом диапазоне работать способен прибор «ШИ-01В». Это универсальный прибор (интегрирующий шумомер – анализатор спектра – виброметр) I класса точности для измерения параметров шума, инфразвука и вибрации. Соответственно, в комплект поставки прибора входят микрофон с предусилителем и вибропреобразователь с адаптером. Технические характеристики прибора в режиме шумомера: диапазон измерений уровней звука, дБ – 20-140; диапазон частот, Гц – 2-20000; частотные характеристики – A, C, Lin; октавный и третьоктавный спектральный анализ; эквивалентный и текущие (F, S, I) уровни звука и звукового давления; максимальные и минимальные значения за время измерения. В режиме виброметра: диапазон измерений уровней виброускорения, дБ – 70-180; диапазон частот, Гц – 0,8-1400; частотная характеристика – Lin; октавный и третьоктавный спектральный анализ; эквивалентный и текущие уровни виброускорения; корректированные Wh, Wd и Wk уровни; максимальные и минимальные значения за время измерения.
Голову совы венчают две покрытые перьями кисточки. Перья напоминают уши, но только напоминают: в действительности ушей не видно. А если бы было видно, многие удивились бы: уши совы не только разные по размеру, они отличаются по форме и расположению на голове. Тем не менее, именно эти уши позволяют ей охотиться в полной темноте, ориентируясь только по звукам: сова способна слышать передвижения мыши на расстоянии 800 м. Правое ухо совы находится ниже и направлено вверх, чтобы она могла слышать звуки сверху. Левое ухо совы находится выше и направлено вниз, чтобы улавливать звуки снизу. Такое расположение ушей помогает сове пеленговать звуки, определяя место расположения источника звука с большой точностью. Это природное явление составляет суть звукового эффекта, известного любителям музыки под названием sorround sound («звук вокруг»). Что же касается вышеупомянутых кисточек, они хотя и не улучшают слух, но указывают, какое у совы настроение, когда они вытянуты, либо приглажены. Комментарий: Туристу под видом попугая продали сову. Через полгода приятель спрашивает его: - Ну, как твой попугай? Научился говорить? - Еще нет. Но ты бы видел, как внимательно он слушает!
Робот, имеющий два слуховых сенсора (микрофона), обеспечивающих дальность работы 5-10 м, точность акустического пеленга 1-10°, рабочий частотный диапазон 200-2000 Гц. Назначение: акустическая пеленгация и локализация объектов-источников звука, сбор и передача акустической информации об окружающей среде, функции телеприсутствия, поддержка речевых команд управления роботом.
Шумомеры CENTER – измерители уровня шума. Приборы выполнены в портативных корпусах и используют в качестве измерительного датчика электретный микрофон.
Профессиональные услуги по переводу текста. Бюро переводов оказывает профессиональные услуги по переводу текста со многих языков мира любой сложности и тематики в самые сжатые сроки. Никаких наценок за срочность и выполнение перевода "трудной" тематики. Гарантия, что перевод будет точным, полным и читабельным. На каждую тематику имеется свой специалист, на каждый язык - носитель этого языка. Индивидуальный подход к каждому клиенту. Апостиль и нотариальное заверение, курьерская служба, online-заказы наличный и безналичный расчет. Cтоимость перевода от 190 рублей (англ-рус, нем-рус, фр-рус за 1800 символов с пробелами)
ВЫУЧИТЬ АНГЛИЙСКИЙ ЯЗЫК! На курсах английского языка English Lingua Centre разгар сезона. Интенсивная программа подходит для восстановления забытого лексического и грамматического материала за счет непрерывности учебного процесса и эффекта погружения в англоязычную среду. Акцент делается на разговорной практике и тренинге общения на английском языке.
Знание английского – это открытые двери в целый мир! Подарите себе новую жизнь - жизнь со свободным общением! Это новый прорыв технологий! Изучение иностранных языков уже стало гораздо быстрее, чем мы привыкли. Найдено достойное применение эффекту 25-го кадра, и теперь он служит людям. Лексика, преподносимая компьютерной программой на высокой частоте, запоминается супер эффективно. Вы просто смотрите на свой монитор, и уже через неделю Ваш словарный запас позволяет понимать песни и фильмы на английском. А уж через месяц!
...Главным источником успехов в решении фундаментальных проблем распознавания и синтеза речи профессор С. Фуруи считает исследования человеческого мозга.
В докладе Ю. Косарева, председателя оргкомитета SPECOM, обсуждается проблема устойчивого понимания речи как ключевая для развития перспективных диалоговых и других речевых систем. Отмечена недостаточная точность современных систем, даны оценки потенциальных резервов речевых и неречевых знаний, которые могут позволить сократить число ошибок в 10-30 раз, и сделать эти системы действительно полезными и комфортными для пользователя в реальных условиях эксплуатации. Как главное направление прогресса, предложено моделирование феномена «инсайт» (сквозное понимание) — способность человека угадывать, предсказывать, устранять неопределенность на основе комплексного использования разнообразных видов априорной и входной информации. Приведены результаты использования данного подхода в некоторых прикладных областях...
Г. Ниеманн (руководитель крупного исследовательского центра языка и речи, университет Эрланген, Германия) рассматривает в своем докладе возможности и подходы к использованию просодической информации в диалоговых системах. Важность этого аспекта хорошо видна в известной двусмысленности «казнить нельзя помиловать». Учет смысловых ударений и пауз снял бы эту проблему. Предложена классификация просодических образов, детализируется, как эти просодические явления проявляются в речевом сигнале, то есть какие акустические признаки являются важными для данной цели. Предложены статистические рамки, позволяющие надежно определять, например, границы фраз, акцент и др. Другие важные приложения просодии — это сегментация при предварительном лингвистическом анализе, выявление эмоций и др...
С. Краувер (координатор Европейской Ассоциации по языку и речи, Нидерланды), в своем докладе отмечает необычайную сложность проблемы перевода текста и речи и предлагает не пытаться имитировать человека-переводчика, а ставить задачи более узко за счет урезания коммуникационных ситуаций, использования языков-посредников и других искусственных приемов.
В докладе профессора Г. Риголла (университет г. Дьюзбург, Германия) представлено введение в технику гибридного моделирования распознавания речи. Это комбинация «скрытого марковского моделирования» и нейронных сетей, чтобы использовать достижения этих двух направлений для улучшения распознавания речи. Приводится обзор нескольких гибридных подходов, уделяется значительное внимание определению отношений между этими и традиционными технологиями распознавания речи. По мнению автора, эти гибридные технологии будут играть важную роль в будущих исследованиях по распознаванию речи.
Доклад А. Вайбела (один из руководителей известного немецкого национального проекта «Вербмобиль», посвященного устному переводу с помощью компактных электронных устройств) рассматривает проблему и подходы к исправлению ошибок для современных прикладных систем типа «автоматическая стенографистка». При этом ошибки могут быть определены автоматически по оценкам правдоподобия, или корректором при окончательной обработке введенного голосом текста. Коррекция может вестись как с клавиатуры, так и голосом... Юрий Косарев, Рафаэль Юсупов, газета "Компьютер-Инфо", 7-20 мая 1999 г.
Образец создан изначально для охраны нефтепроводов: система Sentri с датчиками обоняния, которые реагируют на взрывчатые вещества. Затем система была дооборудования для целей безопасности и иными датчиками, в том числе – датчиками определения местоположения источника звука, например, выстрела. В основе работы системы – также тренировка на соответствующие шаблоны. Чтобы робот мог эффективно действовать, сенсоров у него должно быть как можно больше – хотя бы как у человека: два глаза и два уха. По многосенсорному принципу действует и система Sentri с целью определить местонахождение звука (выстрела, но её можно обучить на идентификацию и других звуков) и нацелить на его источник средства аудио- и видеорегистрации, чтобы соответствующие службы могли точнее разобраться в обстановке. Каковы алгоритмы, лежащие в основе данной системы? Анализируя модели традиционной искусственной нервной сети и динамичной синансовой нервной сети (DSNN), можно заметить определенные преимущества последней. В традиционной искусственной нервной сети работоспособность системы обеспечивает только единый синанс (соединяющая точка), а в динамичной - многократные синансы, увеличивающие скорость и приумножающие интеллект «мозга». Кроме того, в динамичной синансовой нервной сети звуковое распознавание работает совместно с другими сенсорами.
Серия сообщений "Машинное обучение":Обучение компьютерных систем. Компьютерное зрение.
Часть 1 - Тема электронного слуха на VI Международной конференции «Цифровая обработка сигналов и её применение» (по материалам РНТОРЭС им. А. С. Попова)
Часть 2 - Технологии Intel на Форуме IDF в Москве
Часть 3 - Примеры применения нейронных сетей в задачах распознавания
Часть 4 - Суперкомпьютер IBM Watson: создан прототип «умного робота»
...
Часть 47 - Внешность какой киноактрисы предпочтительнее для женщины-робота?
Часть 48 - Тест Тьюринга и робототехника
Часть 49 - О роботизации сбора грибов
 Были представлены новейшие аудио- и видеотехнологии для создания как мобильных роботов, так и стационарной робототехники. В частности, для создания виртуальных референтов была предложена технология, являющая собой сочетание распознавания русской речи, русско-английского перевода и синтеза английской речи. Компьютер теперь способен переводить речь с русского языка на английский и произносить перевод. Кроме того, создан способ сочетания распознавания русской речи с личностью говорящего. Система осуществляет распознавание произносимой фразы с идентификацией личности говорящего после 1–2 минут обучения; на вход системы при этом поступают произвольные фразы. Пока что система оперирует с ограниченным набором предложений: несколько вопросов и последовательность числительных.
Были представлены новейшие аудио- и видеотехнологии для создания как мобильных роботов, так и стационарной робототехники. В частности, для создания виртуальных референтов была предложена технология, являющая собой сочетание распознавания русской речи, русско-английского перевода и синтеза английской речи. Компьютер теперь способен переводить речь с русского языка на английский и произносить перевод. Кроме того, создан способ сочетания распознавания русской речи с личностью говорящего. Система осуществляет распознавание произносимой фразы с идентификацией личности говорящего после 1–2 минут обучения; на вход системы при этом поступают произвольные фразы. Пока что система оперирует с ограниченным набором предложений: несколько вопросов и последовательность числительных. Явления основного тона (Авиационный научно-технический комплекс «Антонов»). В современных устройствах цифровых звукотехнических систем требуются акустические кодеры, обеспечивающие кодирование звукового сигнала с минимальным информационным объёмом без потери качества. Первоначально этого можно достичь при параметрическом кодировании звукового сигнала. Опыт показывает, что для успешного лечения этой проблемы, а также для создания многоязычных «естественных» речевых интерфейсов, не требующих специальной подготовки пользователей, настройки оборудования при их смене и работающих в реальной акустической среде, необходимо определение слуховых параметров звукового сигнала - то есть, физических параметров звукового сигнала, кодируемых слуховой системой. В докладе рассмотрены результаты психоакустических экспериментов по восприятию характерных представителей сложных звуков, давшие в литературе названия таким явлениям, как унисон и явление остатка.
Явления основного тона (Авиационный научно-технический комплекс «Антонов»). В современных устройствах цифровых звукотехнических систем требуются акустические кодеры, обеспечивающие кодирование звукового сигнала с минимальным информационным объёмом без потери качества. Первоначально этого можно достичь при параметрическом кодировании звукового сигнала. Опыт показывает, что для успешного лечения этой проблемы, а также для создания многоязычных «естественных» речевых интерфейсов, не требующих специальной подготовки пользователей, настройки оборудования при их смене и работающих в реальной акустической среде, необходимо определение слуховых параметров звукового сигнала - то есть, физических параметров звукового сигнала, кодируемых слуховой системой. В докладе рассмотрены результаты психоакустических экспериментов по восприятию характерных представителей сложных звуков, давшие в литературе названия таким явлениям, как унисон и явление остатка.





